You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
I thought that DATASET_DIR is referring to the directory that contain 3 text files (test_final.txt, train_final.txt, val_final.txt) along with directory that contain obj files along with the directory that contain vox files. In my case, it is ModelResource_RigNetv1_preproccessed directory inside the working directory (RigNet-master directory).
Here is the way I have set up for the training which I have added the debugging code to countercheck with my working directory as wizdir/RigNet-master:
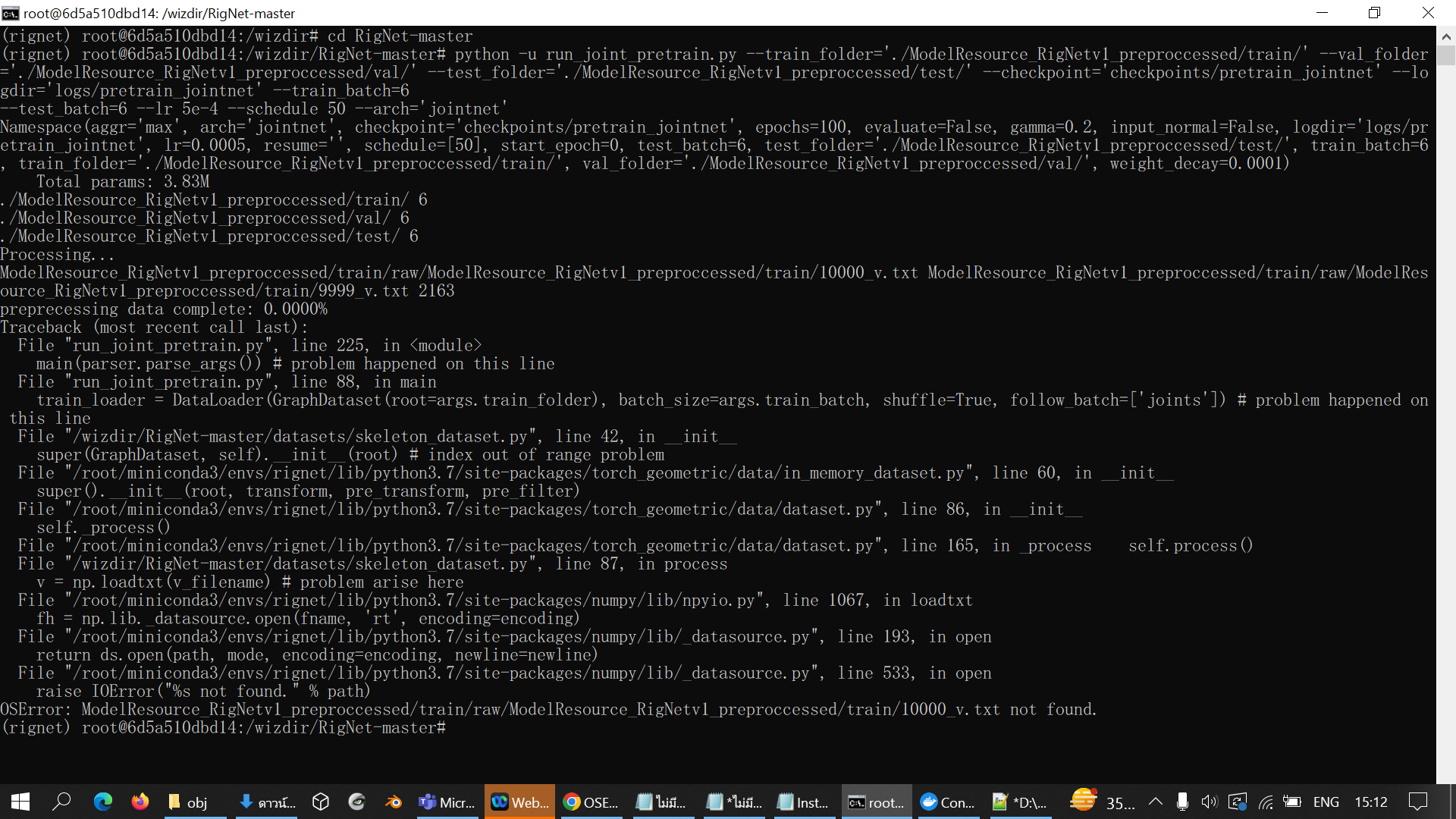
Here the command I have run and detect some issue with the directory name
Here is my debugging code in run_joint_pretrain.py:
def main(args):
...
cudnn.benchmark = True
print(' Total params: %.2fM' % (sum(p.numel() for p in model.parameters()) / 1000000.0))
print(args.train_folder, args.train_batch)
# args.train_folder is ./ModelResource_RigNetv1_preproccessed/train/ and args.train_folder is , args.train_batch is 6
print(args.val_folder, args.test_batch)
# args.train_folder is ./ModelResource_RigNetv1_preproccessed/val/ and args.train_folder is , args.train_batch is 6
print(args.test_folder, args.test_batch)
# args.train_folder is ./ModelResource_RigNetv1_preproccessed/test/ and args.train_folder is , args.train_batch is 6
train_loader = DataLoader(GraphDataset(root=args.train_folder), batch_size=args.train_batch, shuffle=True, follow_batch=['joints']) # problem happened on this line
val_loader = DataLoader(GraphDataset(root=args.val_folder), batch_size=args.test_batch, shuffle=False, follow_batch=['joints'])
test_loader = DataLoader(GraphDataset(root=args.test_folder), batch_size=args.test_batch, shuffle=False, follow_batch=['joints'])
...
if __name__ == '__main__':
...
parser.add_argument('--train_folder', default='wizdir/RigNet-master/ModelResource_RigNetv1_preproccessed/train/',
type=str, help='folder of training data')
parser.add_argument('--val_folder', default='wizdir/RigNet-master/ModelResource_RigNetv1_preproccessed/val/',
type=str, help='folder of validation data')
parser.add_argument('--test_folder', default='wizdir/RigNet-master/ModelResource_RigNetv1_preproccessed/test/',
type=str, help='folder of testing data')
...
Here is my Debug code in dataset/skeleton_dataset.py
class GraphDataset(InMemoryDataset):
def __init__(self, root):
super(GraphDataset, self).__init__(root) # index out of range problem
self.data, self.slices = torch.load(self.processed_paths[0])
.....
def process(self):
data_list = []
i = 0.0
print(self.raw_paths[0], self.raw_paths[len(self.raw_paths)-1], len(self.raw_paths)) # len(self.raw_paths) is 2163 and
for v_filename in self.raw_paths:
print('preprecessing data complete: {:.4f}%'.format(100 * i / len(self.raw_paths)))
i += 1.0
v = np.loadtxt(v_filename) # problem arise here
m = np.loadtxt(v_filename.replace('_v.txt', '_attn.txt'))
tpl_e = np.loadtxt(v_filename.replace('_v.txt', '_tpl_e.txt')).T
geo_e = np.loadtxt(v_filename.replace('_v.txt', '_geo_e.txt')).T
joints = np.loadtxt(v_filename.replace('_v.txt', '_j.txt'))
adj = np.loadtxt(v_filename.replace('_v.txt', '_adj.txt'), dtype=np.uint8)
vox_file = v_filename.replace('_v.txt', '.binvox')
The result has been as shown in this screen capture:
However, the list variable (self.raw_paths) that show the raw path have shown the following value:
print(self.raw_paths[0], self.raw_paths[len(self.raw_paths)-1], len(self.raw_paths))
# self.raw_paths[0] is **ModelResource_RigNetv1_preproccessed/train/raw/ModelResource_RigNetv1_preproccessed/train/10000_v.txt**
# self.raw_paths[ len(self.raw_paths) -1] is **ModelResource_RigNetv1_preproccessed/train/raw/ModelResource_RigNetv1_preproccessed/train/9999_v.txt**
# len(self.raw_paths) is 2163
So, what to be done to make a correct directory link since file 10000_v.txt is in wizdir/RigNet-master/ModelResource_RigNetv1_preproccessed/train directory but self.raw_paths[0] has shown the result as ModelResource_RigNetv1_preproccessed/train/raw/ModelResource_RigNetv1_preproccessed/train/10000_v.txt which is incorrect.
The text was updated successfully, but these errors were encountered:
I thought that DATASET_DIR is referring to the directory that contain 3 text files (test_final.txt, train_final.txt, val_final.txt) along with directory that contain obj files along with the directory that contain vox files. In my case, it is ModelResource_RigNetv1_preproccessed directory inside the working directory (RigNet-master directory).
Here is the way I have set up for the training which I have added the debugging code to countercheck with my working directory as wizdir/RigNet-master:
Here the command I have run and detect some issue with the directory name
Here is my debugging code in run_joint_pretrain.py:
Here is my Debug code in dataset/skeleton_dataset.py
The result has been as shown in this screen capture:
However, the list variable (self.raw_paths) that show the raw path have shown the following value:
So, what to be done to make a correct directory link since file 10000_v.txt is in wizdir/RigNet-master/ModelResource_RigNetv1_preproccessed/train directory but self.raw_paths[0] has shown the result as ModelResource_RigNetv1_preproccessed/train/raw/ModelResource_RigNetv1_preproccessed/train/10000_v.txt which is incorrect.
The text was updated successfully, but these errors were encountered: