看了PingCAP的CTO(黄旭东)的分享如何设计一个分布式数据库,感觉要写点文字记录一下自己的感想。
TiDB在分布式数据库上是一个新贵,虐了不少号称水平扩展能力很好的友商产品,比如:查询10倍以上的性能虐了OceanBase,那么为什么会有这么大的差距?我想看完了黄旭东的分享后,他极客的做法和思考,也就对PingCAP能够打造出碾压平凡人的产品感觉很自然了。
黄旭东的分享没有细节到分布式数据库如何去做,但是谈了作者的取舍。分享没有涉及到分布式数据库运作细节,但是谈了作者的知识结构以及需要掌握哪些分布式知识。
在介绍分享的过程中,会增加笔者自己的所得。
如果是笔者的理解将会以
来开头,以引言的形式来展示。


- 数据量级增长的越来越快
一个很小的业务,如果对于用户的操作能够细致的建模和存储,其实数据量级也不会很小,比如:一个健康记录程序,以往可能记录每天的身体状况,但是如果把用户每个时段的身体状况都通过装置进行存储,那无疑会使数据量增长好几个级别,如果善用存储下来的数据,将会给用户带来更加细致的指导意见。
从
TB级别到今天的PB和EB级别,数据的膨胀只会随着IoT的更加普及而变得愈来愈多。传统的关系数据库面对这种量级的数据,自身由于单体部署约束,导致无法应对海量数据的存储和使用。这个过程中,通过传统关系数据库的上层策略(比如:分库分表)可以一时的解决部分问题,但是数据对于业务的侵入(比如:分库键等)以及对限制(跨库查询等)总会使人用起来有些不快。这时NoSQL的出现缓解了这个问题,通过注重于水平扩展和无限存储(权且这么叫),再加上不错的性能,使得它虽然从开发人员手中拿走了一些东西(比如:额外的学习、新增的概念以及些许简陋的功能),但是它还给开发人员手中的好处确实让人兴奋,因为它解决问题。而结合了
NoSQL以及SQL的NewSQL的出现,是否能够给到开发人员以全新的体验,这不仅是在功能上,而且会在设计范式以及解决问题的模式上再一次带来改变。
- 传统的
RDBMS在水平扩展上存在不足
要水平扩展,就是要CAP中的P,而P一旦满足,C和A总是那么不好拿捏。这些年业务的发展还是在使用传统关系数据库,毕竟使用量大、易维护和功能全,实在不够就在上层搭建一些路由层,以中间件的形式解决一下。但是这种方式面对扩容时都会有些不容易,毕竟相关的操作向前侵入了业务,向后牵扯了运维(需要理解一定业务规则),中间还夹着一个中间件团队,说白了,就是不透明。
OLTP与OLAP相互割裂
OLTP拉出来的数据,通过ETL倒腾到OLAP,绕一圈再送回到OLTP的嘴里,展现给用户。这么做的坏处那是太多了,研发团队负责一块业务,数仓又是横向对多个团队,中间就会出现GAP,这里的GAP不仅是技术上的,也有在业务认知上的,导致产出的数据总是差那么些火候,用在关键场景(比如:根据金额判断某个用户,这一时刻,能不能做某些事情),就是不能用,其实就是有偏差。这里的偏差来自于之前说的理解偏差,也有技术造成的偏差,如果用的是离线计算的那种落后技术,差的就不是一星半点了(毕竟数据一天可能变了N次吧)。
人员、认知和技术的割裂就这么一直搅着这个问题,有数据研发能力的业务技术团队可以解,有超人般的数据团队也可以解,但事实上都不会有。如果能够一份数据存储,又能提供良好的
AP功能,这种HTAP数据库就会好一些了,能够减少一些割裂。为什么说好一些,而不是好多了,原因是在于不可能通过这样一种形式就能解决好实时分析数据获取这件事,能解决2-3成就已经功不可没了。

- F1是SQL层,Spanner是NoSQL
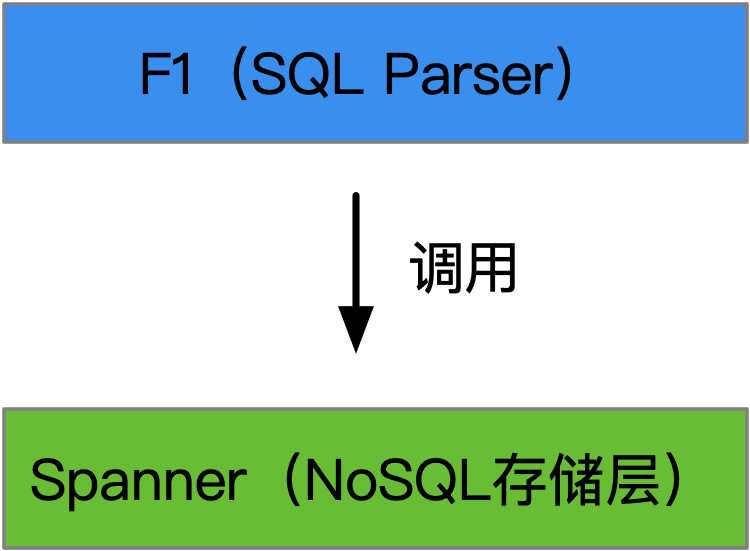
F1是一个逻辑处理层,负责将关系数据库的SQL进行解析,将SQL翻译为Spanner可以理解的一系列指令,然后指令下达给Spanner,由它来完成数据的操作。谷歌的F1和Spanner论文需要了解一下。
- Aurora替换了存储引擎
MySQL为基础,替换了存储引擎,比如:将InnoDB替换为一个具备了分布式水平扩展能力的存储引擎。不愧是具备了电商基因的云厂商,这无疑是一种见效快的方式。如果是一般云厂商,大概率都会使用这种方式,因为用户的编程界面不用改,但是它也会有很多限制,而像谷歌那种颠覆性的做法不常见,因此也能感觉其难能可贵。
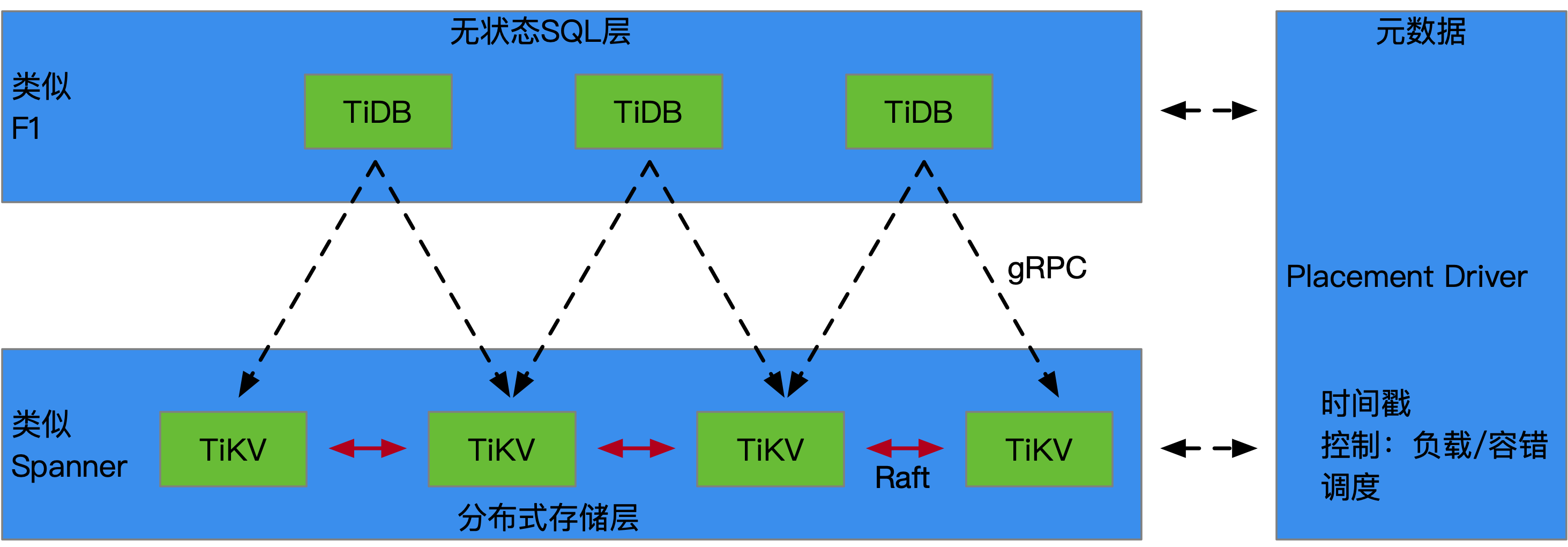
- TiDB的基本架构如上图所示
Redis,但是TiDB要求的是分布式,因此就需要一个能够在分布式环境下工作的KV存储。
TiKV也是单独的项目,TiKV。多个实例间通过Raft一致性算法,将写入数据能够完成多写,做到高可用。这里底层没有使用分布式文件系统,比如:Ceph,HDFS,原因是如果再使用分布式文件系统,那么数据就会写的更多。Raft的3份,文件系统的3份,写9份,因此从效率和经济角度出发,TiKV底层就没有使用分布式文件系统来构造。
TiDB通过gRPC来请求TiKV,目前来看gRPC是要做到终端到服务端,服务端到服务端以及服务端到终端的全通信工具。gRPC的代码(Java版本)在2017年左右看过,写的其实很一般,比较粗糙,没有分层,就更不要提层与层的抽象隔离了,但是架不住谷歌这么一直推动。推动是多方面的,一是谷歌背书和不断的更新,二是基于它来叠罗汉,就是涉及到通信的谷歌产品都会使用它,形成了合力,使得很多开源产品也首要支持它,这点值得很多技术公司学习。整个架构看起来很清晰,职责分离明确,伸缩性应该非常不错。无状态SQL层负责计算,而分布式存储层负责存储,状态数据在
PlacementDriver。黄旭东的另一个作品,codis。一个
golang实现的Redis集群代理,能够组建redis集群。看了一下,使用方不少,关注度不错。
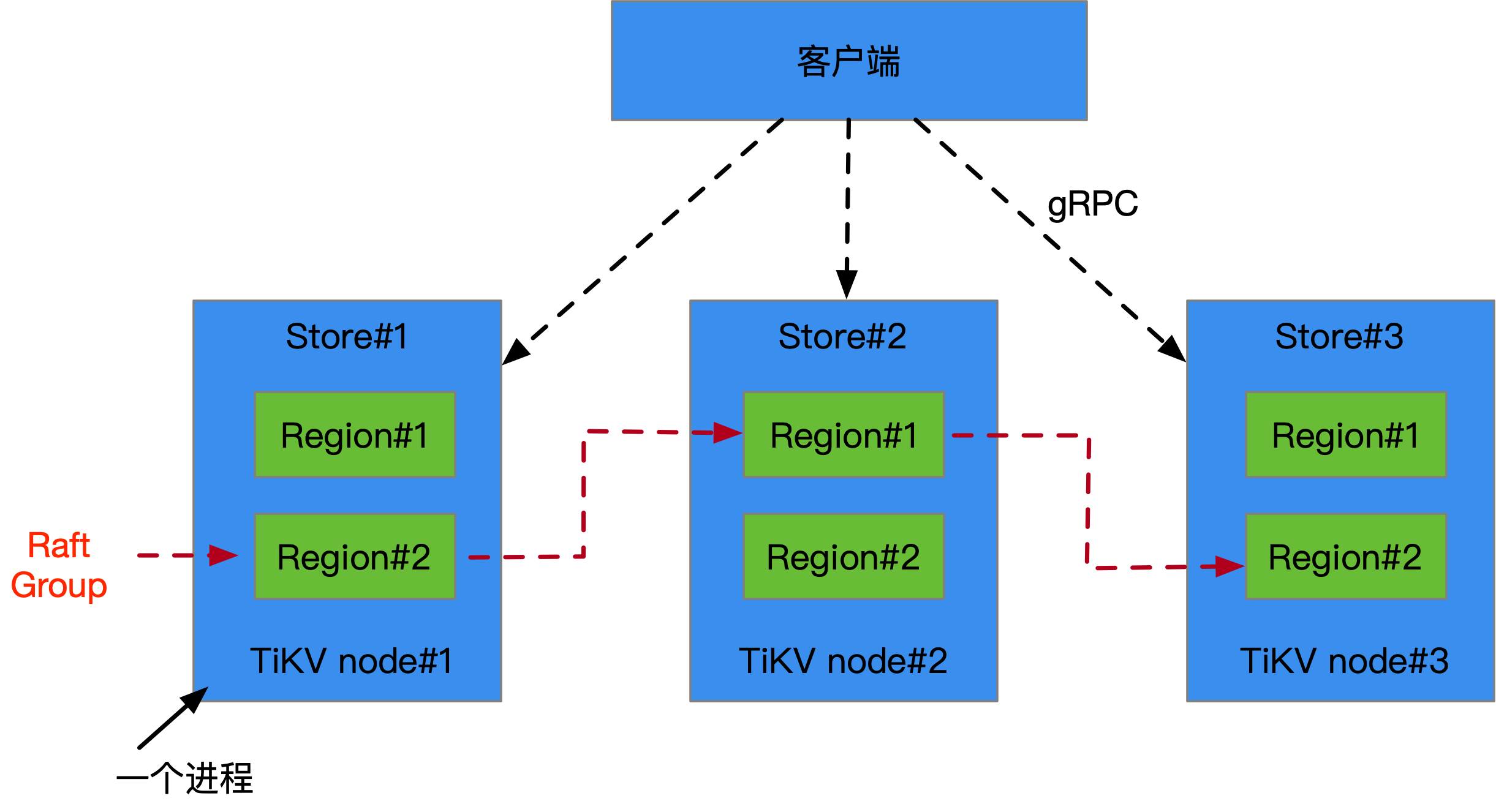
TiKV的基本架构如上图所示。客户端通过gRPC访问TiKV集群,每个TiKV节点都是一个进程,运作在一台计算实例上,在TiKV内部将存储进行了Region分区,切割成为面上使用者的大小以及适合访问的形态,外部通过Raft协议将一次写入能够写到多个TiKV节点上,借由此来提升整体可用性。
LSM Tree,日志结构化合并树,这是一种对随机添加更为友好的数据结构。相比较B+树,它的随机访问能力更好,而B+树是更加适合磁盘的访问形式,在SSD这种场景下,效率并不高。关于LSM Tree可以参考文章。每个
TiKV实际是使用了单机的KV存储引擎—RocksDB,这个是脸书基于谷歌的LevelDB的改进版本,修复了不少问题,同时PingCAP也对RocksDB有捐赠源码(包括问题修复)。任何分布式的装置都是建立在完善的单机装置上的,基于宏观上可靠的策略,将其形成为一个容易伸缩且高可靠的整体解决方案。
TiKV的整体代码是使用Rust编写,这个新一代的系统编程语言是值得关注的。未来在底层高性能软件上可能会越来越多的看到Rust的身影,而系统软件和应用软件之间的中间件将会看到更多的golang。
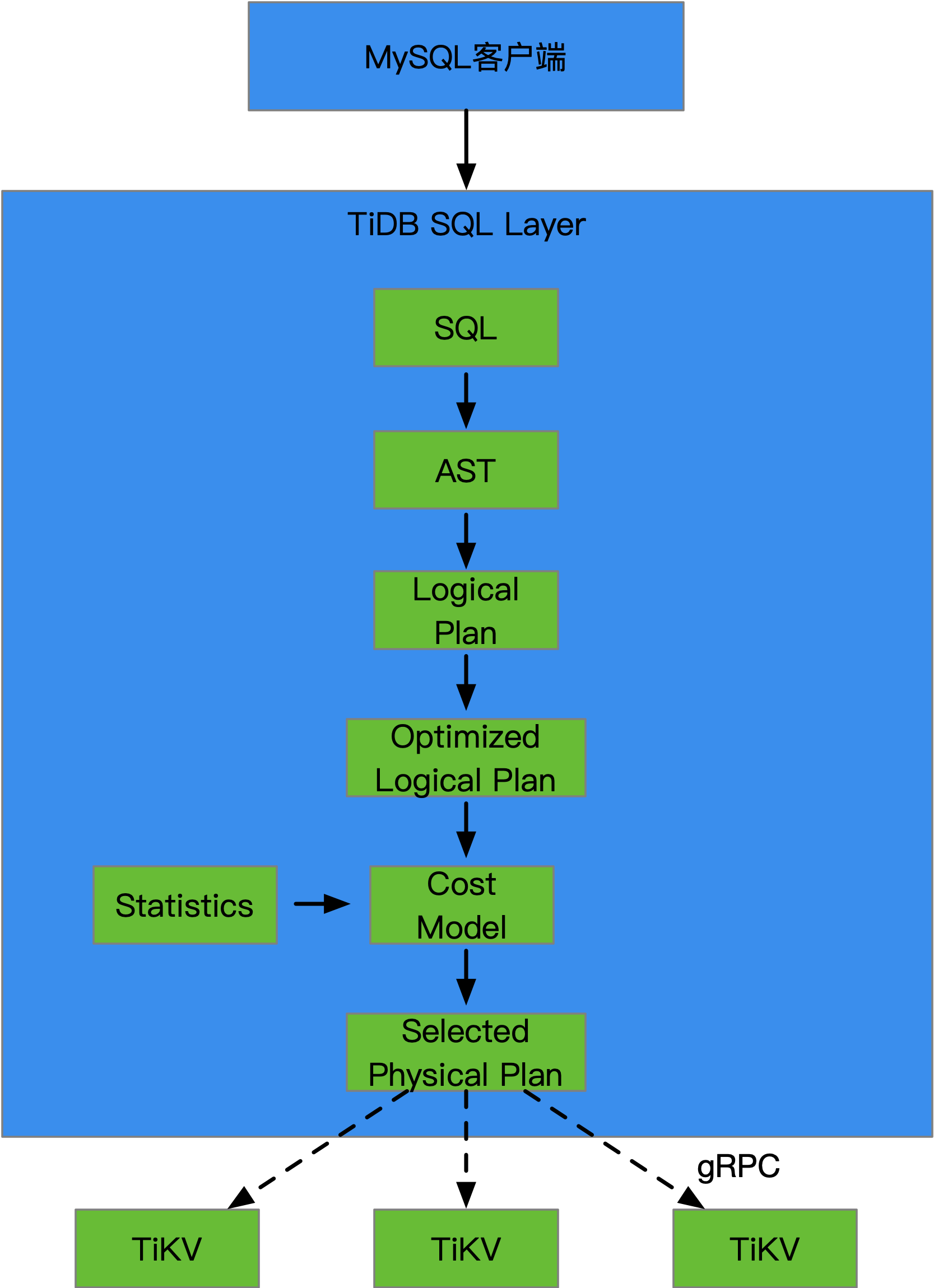
外部请求发起方依旧是MySQL客户端,TiDB会伪装成为一个MySQL Server。当TiDB收到SQL时会进行语法树解析,生成执行计划,这点和MySQL Server工作的步骤有些类似。但是在最终的逻辑执行计划会生成出可选的物理计划,比如一个SUM会发给几个物理节点进行执行,最终会进行所有结果集的SUM。之所以要做这么一个SQL层,就是要将SQL和后端的分布式存储层能够联通。
MySQL的,但是PingCAP并没有这么做,而是抛弃遗留代码,自己做了,目的是在中间能够加入一些自有的优化,同时为解析出来的结果同物理执行计划之间充分分隔开,很有胆略。一个概念意义上的SQL输入,最终被翻译成为一组分布式计算的指令。
- 测试驱动开发
对于任何问题,需要在单测或者测试场景上进行复现,然后通过不断的回归测试来确保正确,同时使用社区的非常多测试样例,保证其测试的覆盖面。
非常多的开发者对于单测总是忽略,这是一种非常不成熟的表现,很难保证你写出考究的代码。
- 故障注入
- 分布式测试
Jepsen和Namazu两款测试软件,搜了一下,基本都和PingCAP有关,看到的是其实习生写的分享,实习生后来还去了阿里云的数据库团队。。。看样子PingCAP对内部分享也非常在意,有点学院的意思。
分布式测试之前没有接触过,更多的单元、功能、集成、性能。。。那些传统的测试。