分布式锁与(类似JUC的)单机锁区别在于:资源状态由进程内转移到进程外,访问资源状态的方式由本地调用转换成为网络调用,这些变化会带来了问题(与挑战),主要体现在4个方面:性能、正确性、可用性以及成本。

我们先考虑一种最简单的分布式锁实现方案,它依赖一个关系数据库(比如:MySQL,以下简称为:数据库)来维护资源状态,可以称为数据库分布式锁。数据库具备事务特性,因此能够支持原子化的新增和删除,同时依靠唯一约束和Where条件,使之可以成为一个良好的分布式锁存储服务。
在数据库中,创建一张lock表,它的主要字段以及运作过程如下图所示:
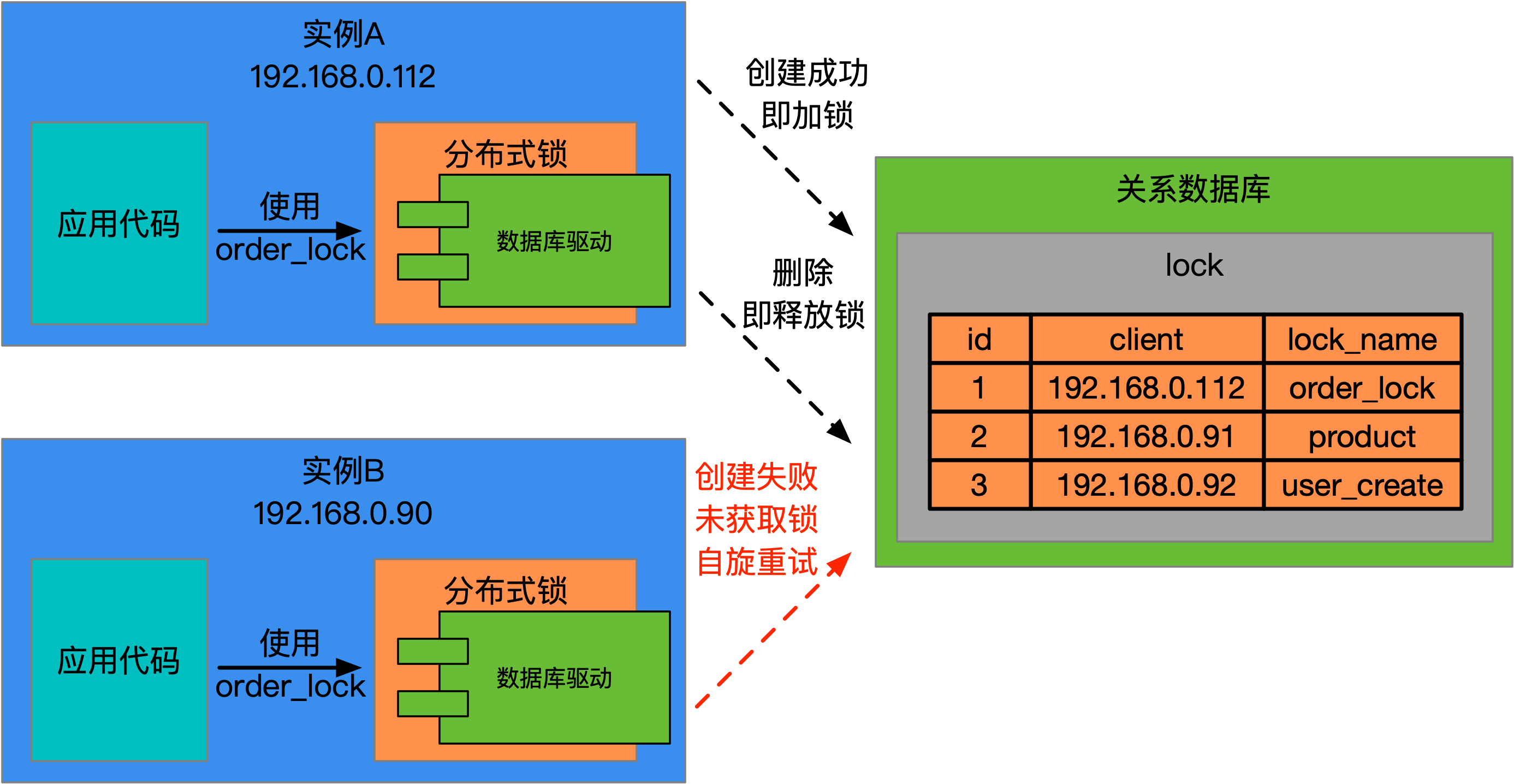
可以看到图中实例A和B在尝试获取一个名为order_lock的锁,获取锁的方式就是在lock表中成功新增一行当前锁与实例对应的记录。lock表包含了两个关键字段,一个是代表锁资源的lock_name,在该字段上建有唯一约束,另一个是代表获取到锁的客户端(或实例)client。不同的分布式锁会有不同的名称,而这个名称就是锁资源,它保存在lock_name中,一旦客户端获取到了某个名称的分布式锁,它的信息会被保存在client中,这表明了这把锁的所属,可以选择保存客户端的IP。
client的值如果要确保严谨,可以选择IP+进程ID+线程ID,这里简单起见,还是选择IP。
如果客户端需要获取锁,就必须在表中成功增加一行记录,如果增加记录成功,则表示该客户端成功的获取到了锁,如果由于主键冲突错误而导致增加失败,则需要不断自旋重试。lock表在lock_name一列上存在唯一约束,所以同一时刻只会有一个实例(图中为:实例A)能够完成新增记录,从而获取到order_lock锁。
当客户端完成操作,需要释放锁时,需要客户端根据锁名称和IP删除之前创建的记录。lock表中client字段,它记录了当前客户端的IP,目的是在删除时,通过SQL语句DELETE FROM LOCK WHERE LOCK_NAME = ? AND CLIENT=?来保证只有拥有锁的实例A才能释放锁,防止其他实例误释放锁。
这个简单的分布式锁看起来(实际上也)是可以完成分布式环境下并发控制工作,接下来介绍实现分布式锁遇到的问题,并基于这些问题,再次审视这个锁。
使用分布式锁时,会给系统带来一定的性能损失。不论是单机锁还是分布式锁,在实现锁时,都需要获取锁的资源状态,然后进行比对。如果是单机锁,只需要读取内存中的值,而分布式锁则需要网络上的一来一回获取远端的值。分布式锁的性能理论上弱于单机锁,而不同分布式锁性能与其存储服务性能以及网络协议有关。
使用网络来获取资源状态对性能有多大影响呢?这里通过访问不同设备的延迟数据来直观的感受一下,如下图所示:
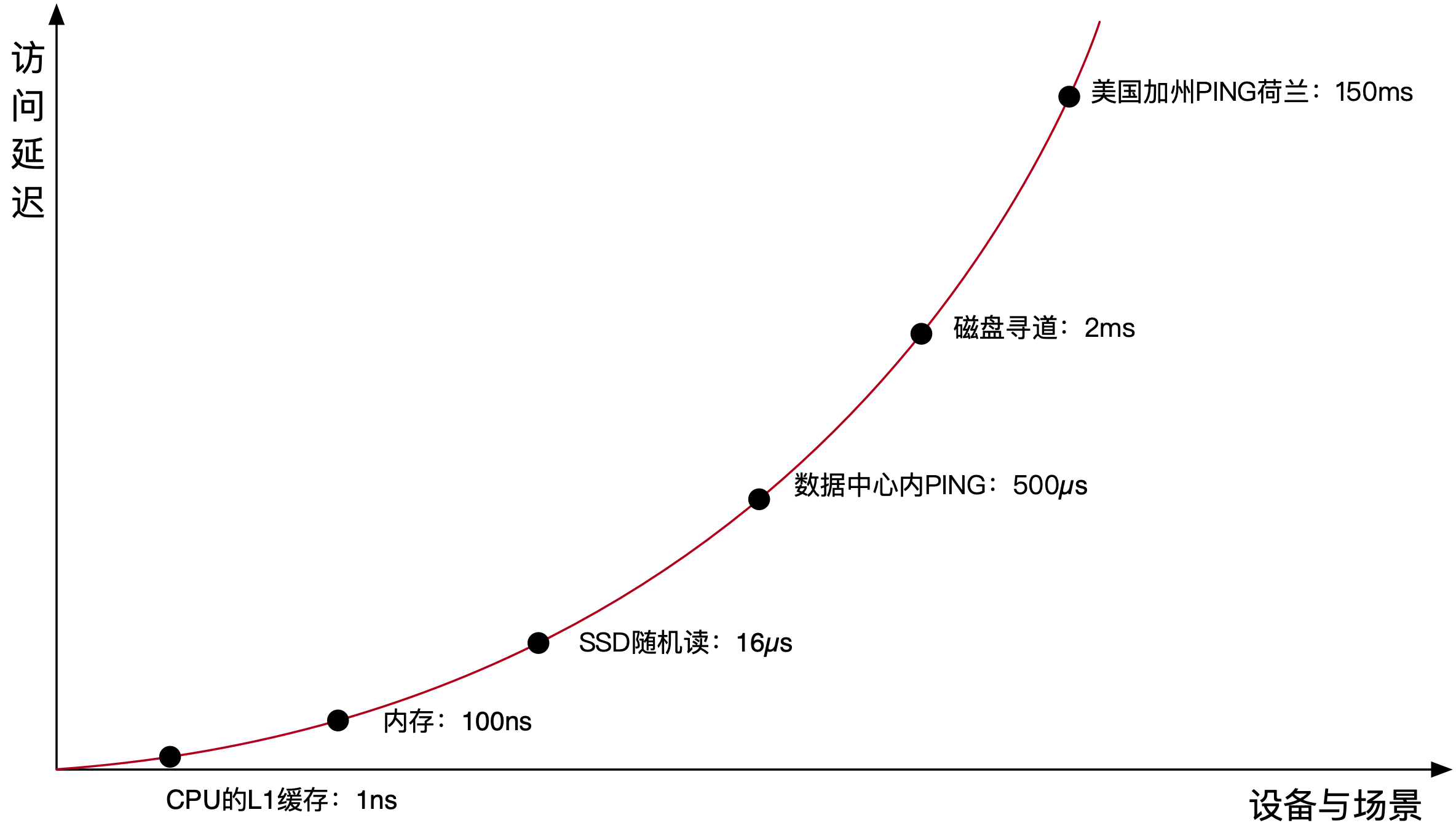
上图参考自Jeff Dean发表的 《Numbers Everyone Should Know》 2020版。通过观察该图可以发现,访问CPU的缓存是纳秒级别,访问内存在百纳秒级别,而在一个数据中心内往返一次在百微秒(或毫秒)级别,一旦跨数据中心将会到达到(甚至超过)百毫秒级别。可以看到单机锁能提供纳秒级别的延迟,而分布式锁的延迟会在毫秒级别,二者存在上千倍差距。
分布式锁的存储服务一般会与应用部署在同一个数据中心。
如果网络变得更快会不会提升分布式锁的性能呢?答案是肯定,但也是存在极限的。从1990年开始到2020年,30年的时间里,计算机访问不同设备的速度有了巨大提升。访问网络的延迟虽然有了很大改善,但是趋势在逐渐变缓,也就是说硬件与工艺提升带来的红利变得很微薄,提升不足以引起质变。
历年访问不同设备的延迟数据,可以参考这里
由于分布式锁在访问存储服务上比单机锁有显著的延迟,所以就锁的性能而言,肯定是低于单机锁的。当然会有同学提出,单机锁不是解决不了分布式环境下的并发控制问题吗?没错,这里就访问延迟来比较二者的性能有所偏颇,但需要读者明白,分布式锁的引入并不是系统高性能的保证,不见得分布式会比单机更加有效率,使用分布式锁就需要接受它带来的延迟,因为它的目的是为分布式环境中水平伸缩的应用服务提供并发控制能力,保障逻辑执行的正确性。
不同的分布式锁实现会依赖不同的存储服务,比如:Redis或ZooKeeper,它们之间的性能也是存在差异的,主要体现在传输协议大小、I/O链路是否非阻塞和功能实现上。传输协议是指客户端与存储服务通信时有格式的二进制数据,一般来说相同类型操作协议体积越小,性能越好。I/O链路是指客户端与存储服务通信的模式,一般非阻塞I/O会优于同步I/O,在支持客户端数量上,前者有显著优势。功能实现主要是存储服务自身实现的复杂度,复杂度越高,性能就会越低,一般来说,越是通用的存储实现,其复杂度会更高。
对于数据库分布式锁而言,客户端与存储服务(也就是关系数据库)通信时传输的是各数据库提供商的专属协议,但由于包含了SQL,所以就协议体积而言,数据库分布式锁传输协议体积是比较大的。在I/O链路上,数据库分布式锁使用同步I/O进行通信,因此支持的客户端额定数量较少。数据库由于其通用性,其实现相对复杂,比如:涉及到SQL解析,索引选择等处理步骤,因此在耗时上较多。
可以看到数据库分布式锁的性能较差,所以它适合客户端少,并发度以及访问量较低的场景,比如:防止后台任务并行运行的工作。
分布式锁的正确性是指,能够保证锁在任意时刻不会被两个(或多于两个以上)客户端同时持有的特性。如果使用过类似JUC的单机锁,一定会觉得保证正确性对于锁而言,不是应该很容易做到的吗?在认为容易之前,先回顾一下在单机锁中是如何保证正确性的。单机锁是依靠CAS操作来进行锁资源状态的设置,如果客户端能够设置成功,才被认为获得了锁。
关于JUC单机锁的实现原理,在《Java并发编程的艺术》中第五章会有详细介绍,想更细致了解的同学可以选择更深入的阅读。
由于单机锁的CAS操作是由系统指令保证,链路极短且可靠,并且资源状态由锁本身维护,从而能够确保其正确性。分布式锁的资源状态在存储服务上,而存储服务会以开放形式部署在数据中心里,如果有其他客户端非法删除了资源状态,而恰好此时有另一个客户端尝试获取锁,这就造成两个客户端都能获取到锁,导致同步逻辑无法被保护。
有同学会问,我的存储服务管理的很好,只有自己的应用使用,这样是不是就没有正确性问题了?客观的讲,专有专用确实提升了正确性,但非法删除资源状态的“凶手”不见得是其他团队的应用,还有可能是存储服务自己。在使用存储服务时,出于保障可用性考虑,一般会使用主从结构的部署方式。考虑一种情况:如果主节点宕机,主从会进行(自动)切换,而主从之间的数据同步由于存在延迟,这会使得另一个客户端在访问新晋升的主节点时,有概率无法看到“已有”的某些资源状态,进而成功获取到锁,导致正确性再次被违反。
存储服务的主从切换对分布式锁正确性的影响,在拉模式的分布式锁中会详细的介绍。
可以看到,纵使有专用的存储服务,也无法完全确保分布式锁的正确性。绝对的正确性是无法做到的,不同的分布式锁实现由于其存储服务的不同,正确性保障也有强弱之分。
数据库分布式锁的正确性保障是比较高的,依托于经典的关系数据库,纵使主从复制带来的问题,也能得到较好的解决,比如:MySQL可以通过开启半同步复制,牺牲一些同步效率来确保主从数据的一致性,进而提升了分布式锁的正确性保障。
分布式锁可用性是指,能够保证客户端在任意时刻都可以对锁进行(获取或者释放)操作的特性。分布式锁的可用性又可以分为:个体和全局可用性,前者关注单个锁的可用性,而后者要求不能出现分布式锁服务整体不可用的情况。不论个体还是全局可用性,它都是由网络和存储服务来保障的,这个过程如下图所示:
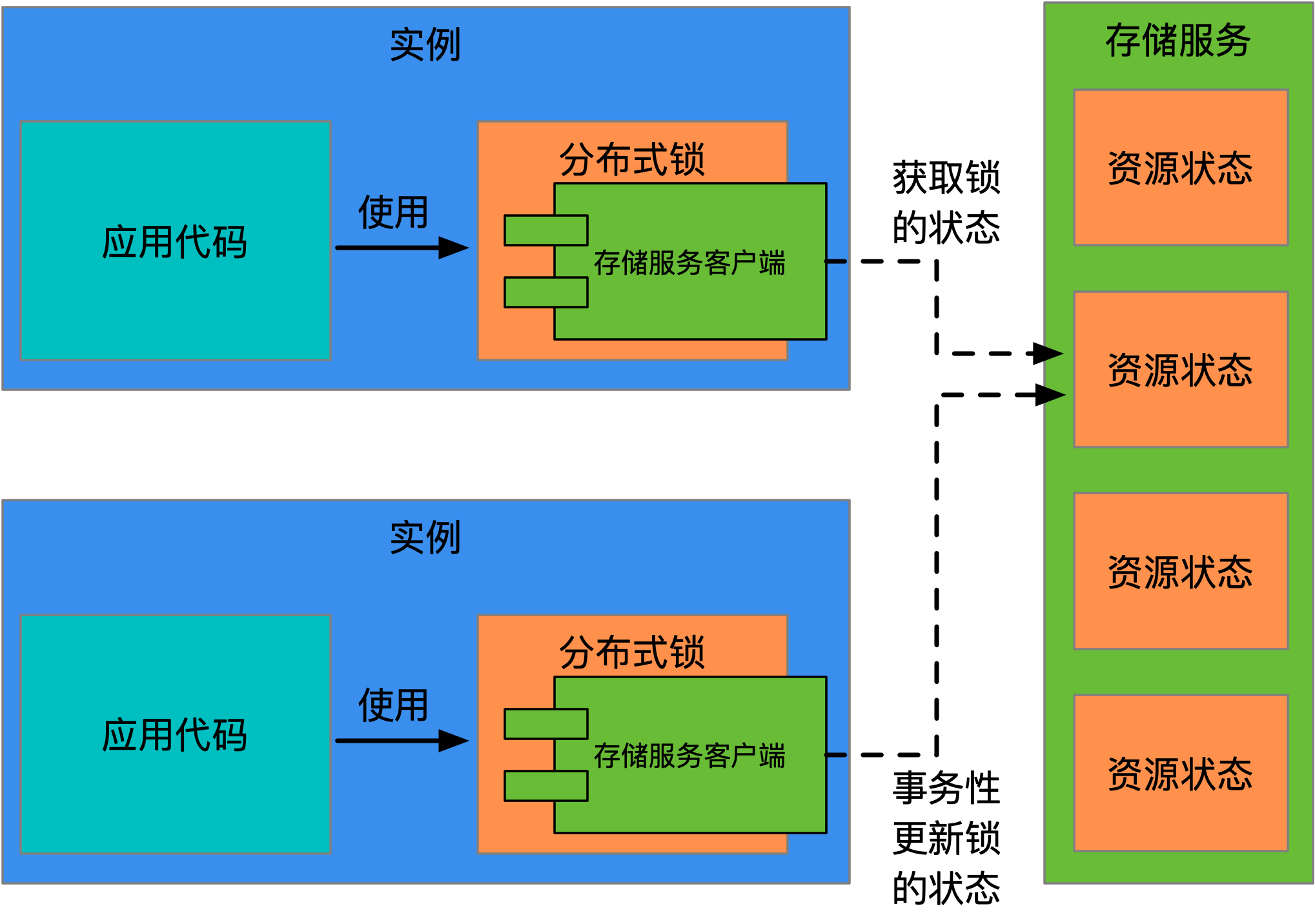
如上图所示,分布式锁的资源状态保存在存储服务上,依靠(使用锁的)实例(或线程)通过网络来进行操作。如果网络设备出现问题,则会导致连接在故障设备上的实例无法使用分布式锁,出现全局可用性问题。针对这个问题,如果实例部署在自建数据中心,则需要专项考虑,如果部署在云上,则由云厂商负责保障。网络是基础设施,本文不做过多探讨,还是将主要视角放在存储服务上,可以狭义的认为:分布式锁的可用性基本等于存储服务的可用性。
先看一下分布式锁的个体可用性问题,在单机锁中,锁的资源状态和应用实例在同一个进程中,是一体的,而分布式锁的资源状态与应用实例相互独立。假设一个场景:实例在获取到锁后,由于发生异常导致没有释放锁(可能是:没有释放锁或实例突然宕机),但锁的资源状态显示锁依旧被持有,这会导致这把锁不会再有实例能够获取,出现了死锁。解决死锁最直接的办法是增加实例占据资源状态的超时时间,通过这一约束,纵使出现了死锁,也会在超时时间到达后完成自愈,避免出现个体不可用的窘境。
以数据库分布式锁为例,如果实例在释放锁之前发生异常,就会出现个体可用性问题。解决方案就是引入超时机制,可以通过在lock表中新增一个expire_time字段,每次实例获取锁时都需要设置超时时间,当超时时间到达时,将会删除该记录。清除超时锁记录的工作可以交给一个专属的实例去完成,该过程如下图所示:
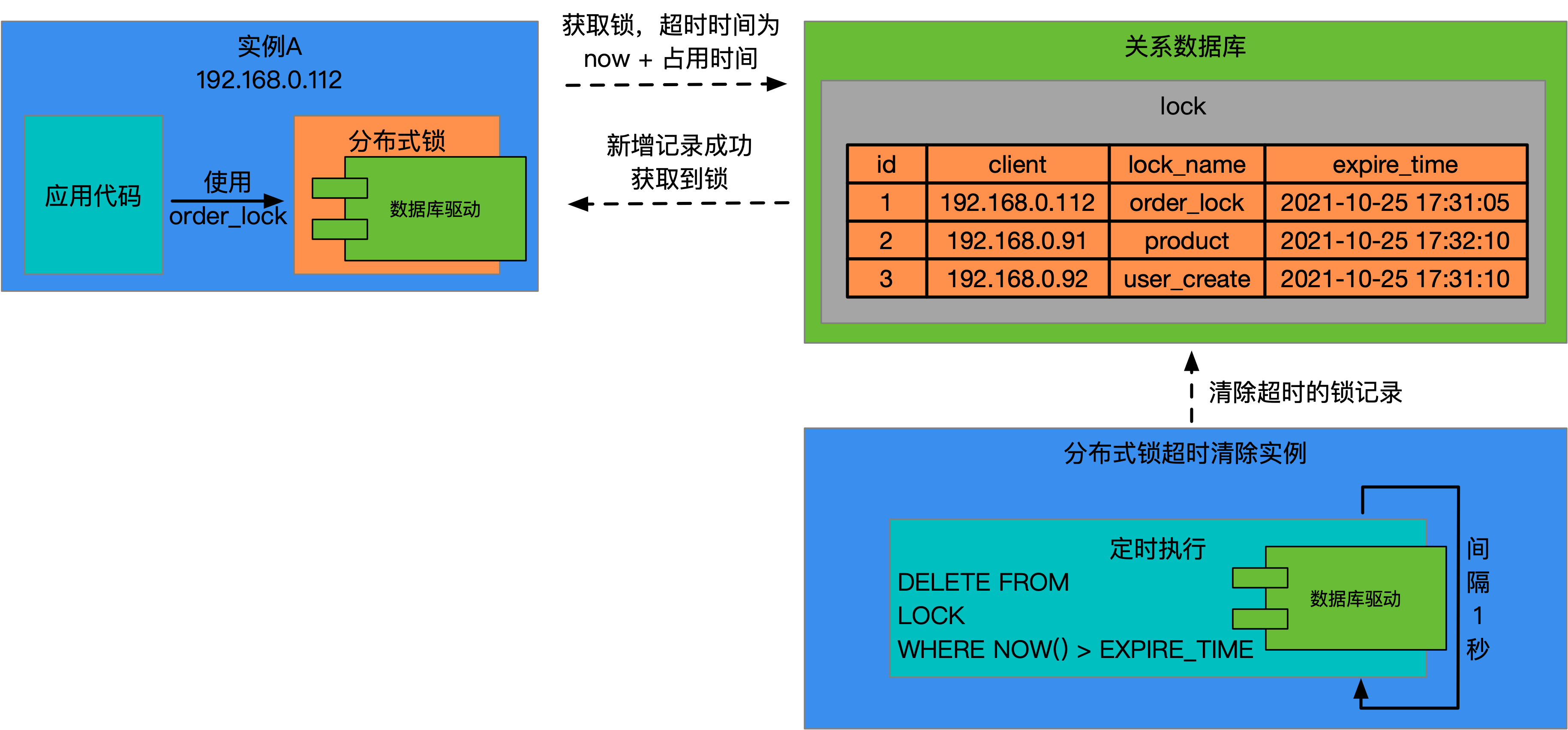
如上图所示,通过增加分布式锁的占用超时时间,可以有效的避免由于实例异常而导致出现资源状态没有释放的问题。应用实例在获取锁时,需要将过期时间计算好,一般是系统当前时间加上一个超时时间差,设置短了,正确性被违反的几率就会增加,设置长了,可用性问题的自愈时间就会增加。至于这个时间差需要设置多少,需要结合应用获取锁后执行同步逻辑的最大耗时来考虑,也就是说时间差设置长短的问题还是抛给了分布式锁的使用者。
使用一个超时清除实例来定期删除过期的资源状态,虽然让整体架构变得清晰,但也显得有些累赘,因此可以使用Redis之类的缓存系统来维护资源状态,通过设置缓存的过期时间,能够做到过期资源状态的自动删除。
接下来再看分布式锁的全局可用性问题,存储服务一般可以通过(主从或其他)集群技术来保障其可用性,当集群中的部分节点发生宕机也不会影响到外界使用存储服务,进而保证了分布式锁的全局可用性。
以Redlock为代表的,基于法定人数(即多数)的机制,就属于非主从模式的集群技术,这种模式将在拉模式的分布式锁中进行介绍。
虽然集群技术保障了全局可用性,但是它也会带来正确性被违反的风险,比如:集群主从切换时,数据同步的延迟会导致正确性存在被违反的可能。不仅是全局可用性,为提升个体可用性而引入的超时机制,也会为给分布式锁带来“个体正确性”被违反的风险,比如:由于进程暂停或者网络延迟,可能会使获取到锁的实例出现停顿,随着超时时间到达,锁被超时释放,其他实例就可以获取到锁,同步逻辑被并行执行,导致正确性被违反。
分布式锁的超时机制与实例暂停导致正确性被违反的问题,在拉模式的分布式锁中会进行详细介绍。
可以看到可用性与正确性如同CAP原理中的可用性(A)和一致性(C)一样,在分布式环境(也就是P)中,是一对矛盾。虽然二者是矛盾,但是需要开发者能够根据实际情况作出权衡和取舍。
与依靠JDK就能满足需求的单机锁不同,分布式锁至少需要一个存储服务,它可以是关系数据库,也可以是分布式协调系统,比如:ZooKeeper。部署存储服务,会涉及到成本问题。如果使用者依赖分布式锁去解决效率问题,比如:避免集群中出现重复计算,而且计算频度很低的话,部署和维护一个存储服务就显得成本很高,不是那么划算了。
有同学会说,存储服务可以共享呀!比如:部署一个Redis主从集群,大家一起使用,这样成本不就降下来了吗?没错,通过共享存储服务,提升其利用率,确实可以拉低成本,但是分布式锁的可用性会受到很大的挑战。可以设想:在电商场景中,交易核心链路依赖分布式锁避免库存扣减的并发问题,由于使用了共享存储服务,如果其他业务导致共享存储服务出现(链接被耗尽,容量达到阈值或负载很高的)问题,导致交易核心链路的订购成功率下跌,影响到了用户体验,这就得不偿失了。
因此,可以通过降低存储服务的规格来节省成本,而尽可能的不做共享使用,除非是很明显的边缘业务。建议以技术的产品线作为划分依据,不同产品线之间不共用存储服务,如下图所示:
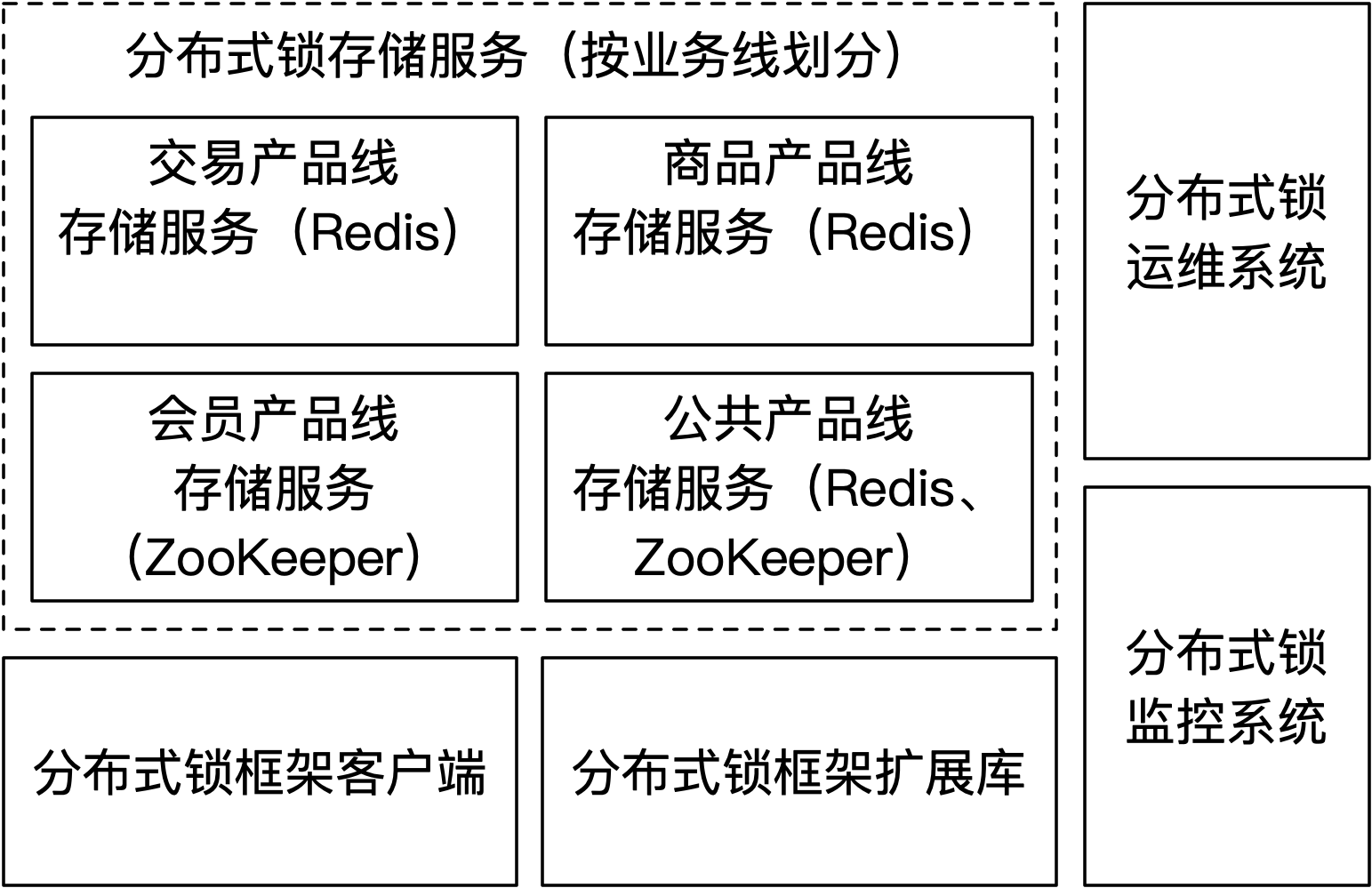
如上图所示,不同的业务线会使用自己的存储服务,这样就可以根据实际需求来裁剪(或定制)它的规格。举个例子,商品产品线维护了库存服务,使用商品ID作为分布式锁名称,单日交易商品的种数并不多(假定是50万),由于单个键值不会超过1/4KB,理论128MB左右的内存空间就足够存储单日使用的分布式锁资源状态。因此,考虑一些Buffer,商品产品线可以将Redis的规格设置在1GB内存,采用主从集群模式部署。
单个键值(也就是一行资源状态,键和值的长度都在
64以内)理论不超过256byte,500000 * (1/4)KB / 1024 = 122MB
虽然不同的业务线使用相互独立的存储服务,但是在代码层面需要使用同一套技术。通过分布式锁框架统一所有的使用方,除了复用率和维护性的提升以外,还可以通过统一的运维系统对数据进行观测,并定义形式统一的监控与报警策略,获得长效收益。
在分布式锁框架中,会对该框架的原因以及设计进行详细介绍。
如果某些业务不需要分布式锁提供很高的可用性保障,甚至可以部署一个单节点的存储服务,虽然存在单点问题,但通过专有专用,一样可以获得很好的效果。不同的存储服务也会有不一样的成本,比如:部署和维护ZooKeeper集群的成本会高于Redis集群。
对于数据库分布式锁而言,如果独立部署和维护一个数据库主从集群来实现分布式锁,是不太现实的。因为锁的资源状态数量有限且对磁盘容量占用很小,所以在业务线中可以选择一个访问量不高的数据库,建立独立的Schema使用会是一个比较经济的方案。