前文提到JUC中的单机锁是一种推模式的锁,对于单机锁而言,每个获取锁的线程都会以节点(Node)的形式进入到队列中,该队列的具体内容可以参考《Java并发编程的艺术》第5章的2.2小节,这里只需要注意对锁的获取行为会进行排队。节点(对应的线程)获取了锁,执行完同步逻辑后释放锁,释放锁的操作会通知处于等待状态的后继节点,后继节点(对应的线程)被通知唤醒后会再次尝试获取锁。

(同步)队列中的节点就是锁的资源状态,它包含了获取锁的执行信息(实例以及线程)。推模式锁的核心在于队列操作和节点事件通知,对于推模式分布式锁也一样,任意实例获取锁的行为都会以节点的形式记录在队列中,同时节点的变化会通知到实例,这就需要存储服务具备(面向队列的)原子新增和删除能力,并且在此基础上提供发布/订阅功能。在推模式分布式锁中,实例和存储服务的结构如下图所示:
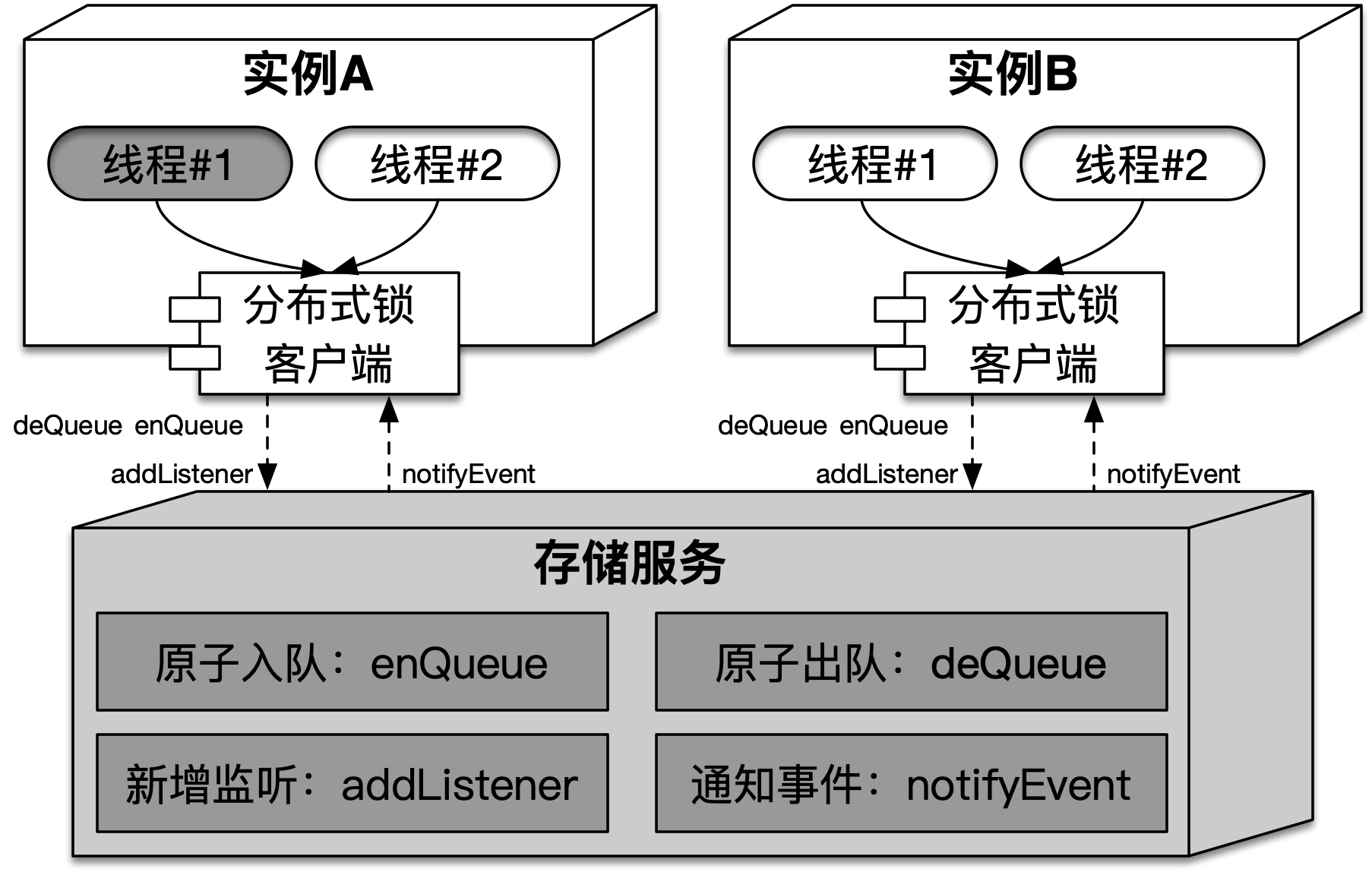
如上图所示,推模式分布式锁在获取锁时会使用enQueue将获取锁的线程以节点的形式加入到同步队列中,通过addListener来监听节点事件。释放锁时,会使用deQueue将节点从队列中删除,通过notifyEvent发布节点事件。存储服务提供的上述功能以及描述,如下表所示:
| 名称 | 参数说明 | 功能 | 描述 |
|---|---|---|---|
enQueue(queue, Node) |
queue,锁对应的队列Node,需要入队的节点 |
原子入队 | 将获取锁的线程(以及实例信息)转换为节点Node,顺序保存到队列queue尾部,该过程需要保证原子性 |
deQueue(queue, Node) |
queue,锁对应的队列Node,需要出队的节点 |
原子出队 | 将队列queue中指定的节点Node出队,该过程需要保证原子性 |
addListener(queue, Node, Listener) |
queue,锁对应的队列Node,需要监听变更的节点Listener,监听器 |
新增监听 | 指定队列queue中的任意节点Node进行监听,当被监听的节点Node发生变化时,存储服务(相当于Broker)会回调监听者Listener,执行其预设的逻辑 |
notifyEvent(queue, Node) |
queue,锁对应的队列Node,发生事件的节点 |
通知事件 | 当节点Node发生变化,比如:修改或者删除,会发送事件。存储服务会将事件通知到节点Node相应的监听者Listener |
每一个分布式锁,在存储服务上都会有一个队列与之对应。任意实例中的线程尝试获取锁,都会转换为节点加入到锁对应的队列中,那怎样才能定义成功获取到锁了呢?因为enQueue能够确保原子化的顺序入队,所以只要(当前线程对应的)节点为队列中的首节点,就表示该节点对应的实例(中的线程)获取到了锁。获取推模式分布式锁的流程如下图所示:
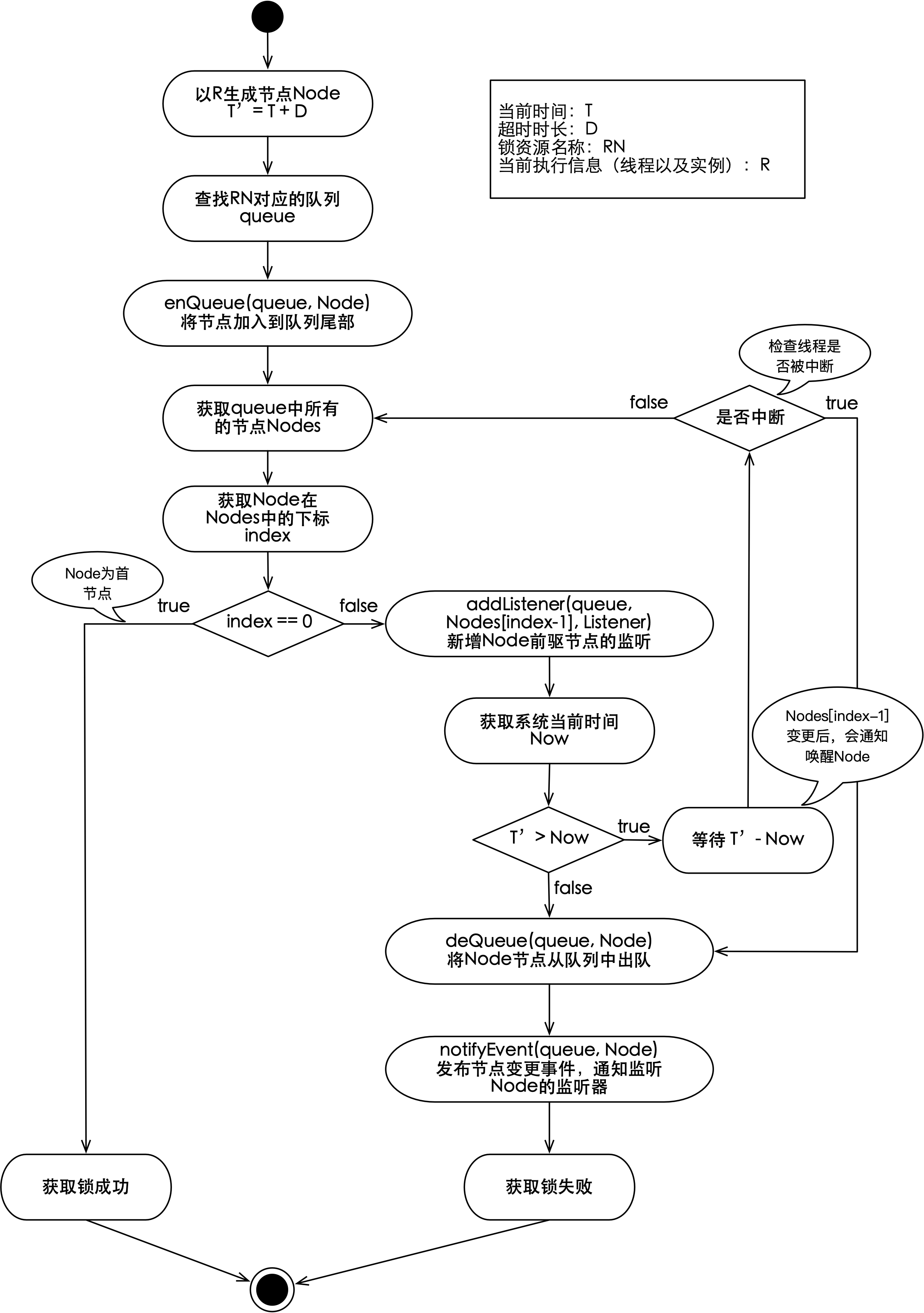
如上图所示,获取锁时的输入描述可以参考《拉模式的分布式锁-什么是拉模式》一节,这里不再赘述。可以看到推模式的分布式锁获取流程与(《Java并发编程的艺术》中的第5章中)独占式超时获取同步状态的流程是相似的,当然也是复杂的。
获取推模式分布式锁时,首先会将执行信息(包括:线程和实例)生成节点,然后通过enQueue将节点加入到锁对应的队列。生成节点的主要目的是能够让获取锁的竞争者进行排队,同时当轮到它们(被通知)出队时,能够按图索骥唤醒它们所对应的实例(或线程)。如果当前节点不是首节点,代表该节点对应的线程没有获取到锁,从而需要通过addListener来监听它的前驱节点,因为前驱节点的变更(包括:获取锁超时、失败或者成功后的删除)都会以事件的形式通知到注册的监听逻辑Listener,通知会唤醒处于等待的节点,而节点对应的线程会执行注册的监听逻辑。
获取锁失败的节点会进入等待状态,而被唤醒后执行的监听逻辑主要是判断节点自身在队列中的位置,如果当前节点是首节点那就表示成功获取到了锁,否则将会做超时判断,如果没有超时,会再次进入等待状态。如果获取锁超时(或被中断),则会将当前节点通过deQueue进行出队,并将节点删除事件使用notifyEvent通知到节点的Listener。
每一个尝试获取锁的线程(以及实例)都会以节点形式穿在锁对应的队列上,除首节点外的任意节点都在监听其前驱节点的变化。释放锁时,会将对应的节点从队列中删除,并通知后继节点,这种击鼓传花的方式我们已经在单机锁释放过程中看到过,释放推模式分布式锁的流程如下图所示:
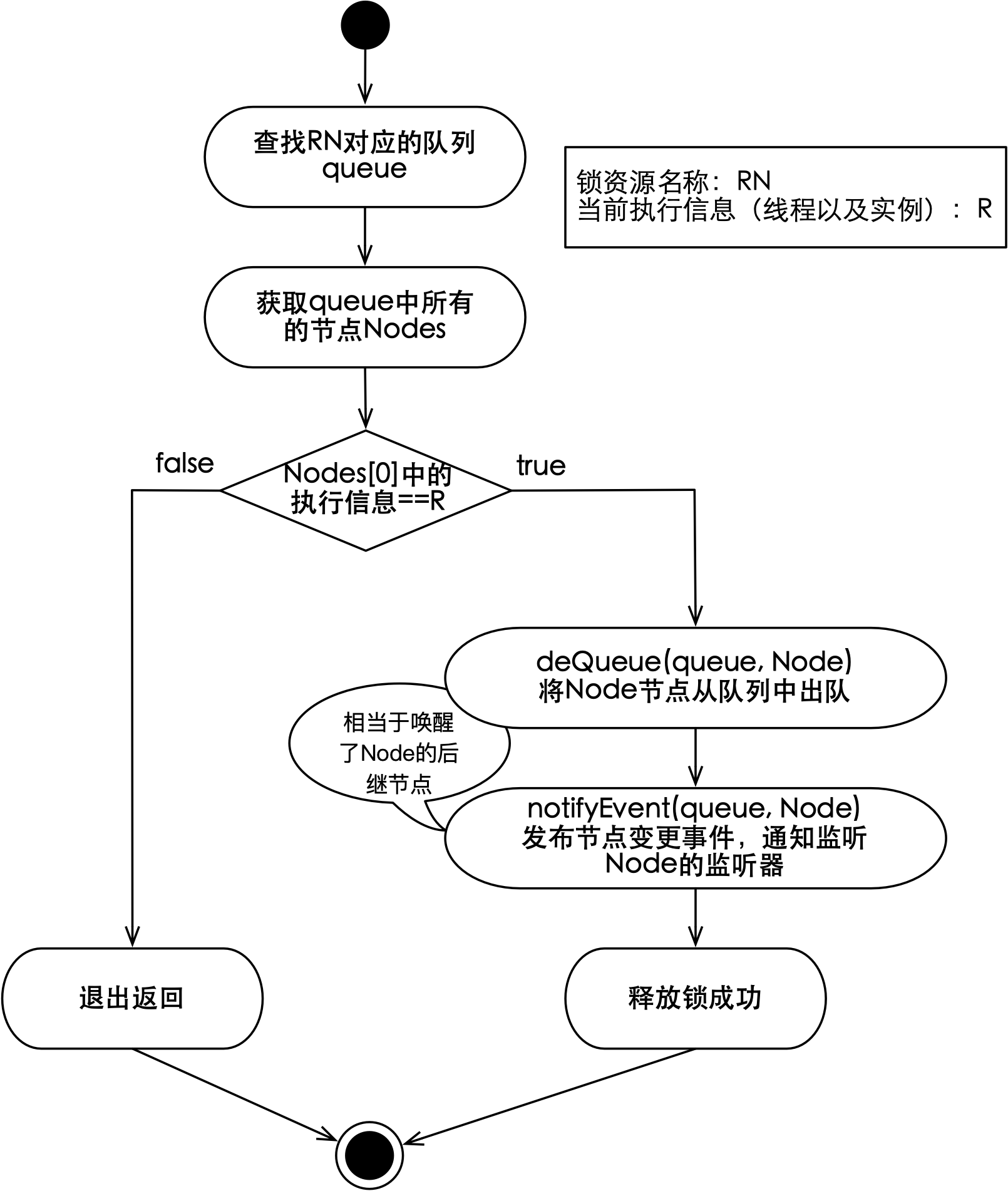
如上图所示,当前线程(以及实例)对应的节点为首节点时,就可以释放锁。释放锁时主要包含两个操作:节点出队和通知节点删除事件,前者会将当前节点从存储服务的队列中删除,后者会将删除事件通知到该节点的监听器。随着节点删除事件的发布,后继节点会被唤醒,而后继节点对应的线程将会尝试再次获取锁。
ZooKeeper(以下简称:ZK)是由雅虎研究院发起的一个项目,后被捐献给Apache,旨在为分布式系统提供可靠的协作处理功能。ZK作为一个树型的数据库,除了支持原子化的节点操作,还具备监听节点变更和变更事件通知的能力,因此它非常适合作为推模式分布式锁的存储服务。
推模式分布式锁对存储服务的诉求主要包括:原子出入队、新增监听和通知事件,共4个操作,ZK并没有直接提供这些API,那么它是如何满足推模式分布式锁对于存储服务的诉求呢?在介绍如何之前,先来快速过一下ZK。
ZK是一个C/S架构的系统,用户可以使用多种客户端来进行操作,客户端不仅限于应用使用的Jar包,也包括ZK提供的脚本等。这些客户端通过与ZK服务端之间的长链接进行通信,服务端一般以集群的形式提供服务,而处于集群中的ZK节点有不同的身份类型,包括:Leader、Follower和Observer,而其中只有Leader能够执行写操作,所以ZK对外的服务是能够保证顺序一致性的。ZK客户端与服务端集群的结构如下图所示:
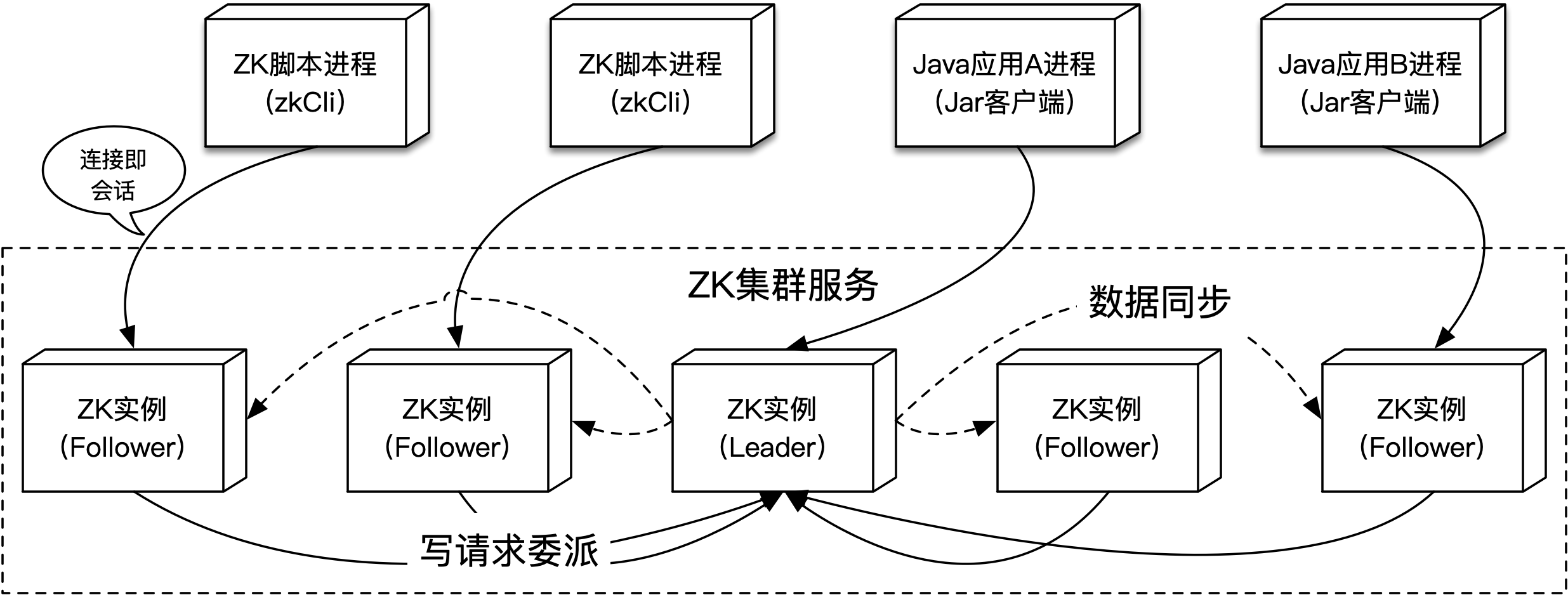
如上图所示,多个不同种类的客户端(包括:ZK自带的zkCli脚本和依赖ZK客户端的应用)会和ZK集群中的实例建立连接,该连接被称为会话(session)。会话通过心跳(也就是客户端和服务端之间连接上定时的Ping-Pong)来保持,当客户端进程停止或心跳中断时,会话就会终止。集群中的ZK实例通过选举产生出一个Leader,数据变更会从Leader向另外两种身份类型的实例同步,客户端会与集群中的任意实例建立链接,如果客户端向一个Follower实例发送写请求,该请求会被委派给Leader。
zkCli脚本通过执行类似shell命令的方式来访问服务端,依赖ZK客户端的应用则需要基于SDK编程,虽然形式不同,但本质是一样的。ZK的选举以及数据更新是通过ZAB协议实现的,这里不做展开。
许多知名项目,比如:Apache HBase、Apache Solr以及Apache Dubbo等都使用ZK来存储元数据(或配置)。由于配置项会在运行时更改,所以ZK支持监听配置项(即节点)的变更,应用可以通过使用ZK客户端来监听某个节点,当节点发生变化时,ZK会以事件的形式通知应用。这些配置项在ZK内部都会以节点(即ZNode)的形式存在,而节点之间会以树的形式来组织,这棵树就如同Linux文件系统中的路径一样,其根节点为/,它的存储结构示意如下图所示:
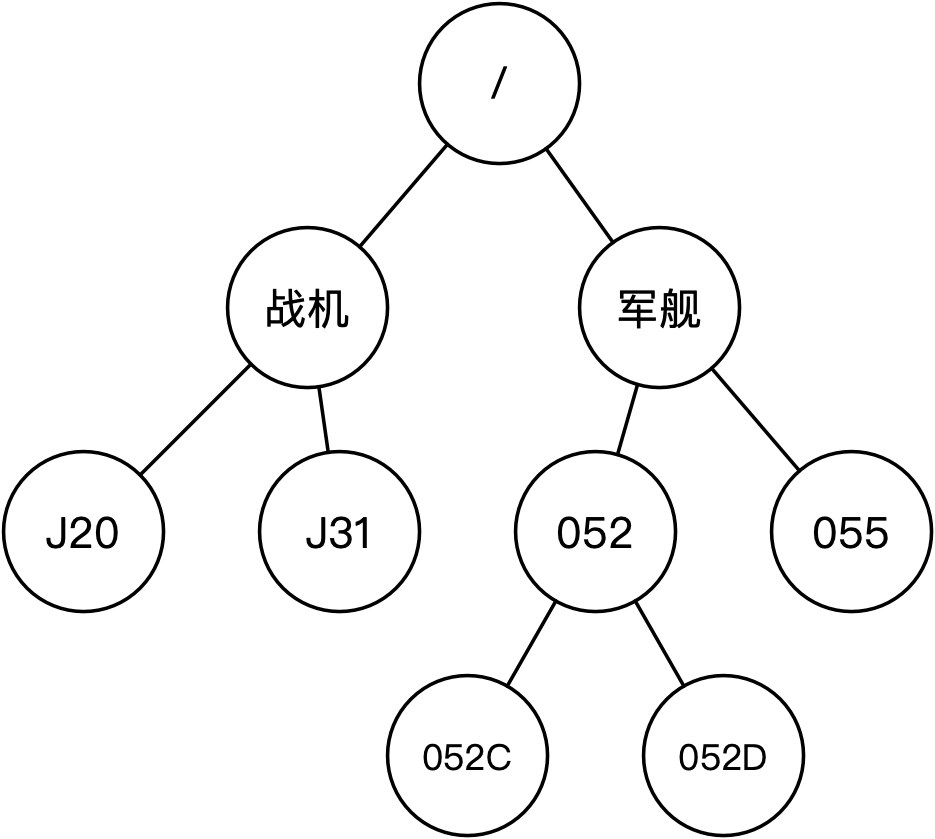
如上图所示,这是一个层高为4的树,而对任意节点的访问需要给出全路径,比如:/军舰/052/052D,新增节点也相同,比如:/军舰/055/055A。节点除了包含路径以外,还可以保存值,同时节点有多种类型,节点(部分)类型、描述以及客户端命令示例如下表所示:
| 类型 | 描述 | 生命周期 | zkCli命令示例 |
|---|---|---|---|
| 持久化(PERSISTENT) | 通过指定全路径可以创建该类型节点 | 持久,节点新增后(非删除)会一直存在,纵使创建节点的会话终止,节点也不会删除 | 新增:create /军舰/055/055A value,表示创建指定的路径节点,且节点的值为value查看: get /军舰/055/055A,表示获取指定路径节点的值 |
| 持久化有序(PERSISTENT_SEQUENTIAL) | 通过指定路径模式来创建该类型节点,节点全路径为路径模式+自增ID | 同持久化类型 | 新增:create -s /军舰/052/052D/052D,按照路径模式创建有序节点,实际创建的节点全路径可能是:/军舰/052/052D/052D0000000000 |
| 临时(EPHEMERAL) | 同持久化类型 | 会话,节点新增后,如果创建节点的会话终止,节点会自动删除 | 新增:create -e /军舰/055/055A,-e选项表示节点类型为临时 |
| 临时有序(EPHEMERAL_SEQUENTIAL) | 同持久化有序类型 | 同临时类型 | 新增:create -se /军舰/052/052D/052D |
如上表所示,从创建节点的角度看,ZK的节点类型主要就2类,一类是指定全路径进行创建,另一类是则是指定全路径的前缀模式。将生命周期这一维度与其相交,就会有4种类型,而实现推模式分布式锁,就需要使用到临时有序类型的节点。
访问ZK的官网可以下载ZK服务器,解压缩后,可以在bin目录下找到zkServer和zkCli脚本。前者是ZK服务器脚本,在类Unix系统下,可以通过zkServer.sh start 在本地启动一个单机版的ZK实例。后者是ZK客户端脚本,如果需要操作本地ZK,可以通过zkCli.sh -server localhost 2181连接到ZK实例上。
需要在conf目录中准备一个zoo.cfg配置,可以简单的拷贝该目录中的示例配置zoo_sample.cfg。
接下来通过启动两个zkCli客户端(分别命名为客户端A和B)来演示一下实现推模式分布式锁会用到的ZK操作,演示过程主要包括客户端各自创建节点,客户端A监听客户端B创建的节点变更。假定已经存在节点*/member-123*,在该节点下,客户端A和B分别创建三个前缀为*/member-123/lock*的临时有序节点,如下图所示(左边为客户端A):

如上图所示,通过执行create -es /member-123/lock,能够在 /member-123节点下创建前缀为lock的临时有序子节点。通过ls /member-123命令,可以列出该节点下所有子节点,能够看到 /member-123拥有6个子节点,节点名称为lock与自增ID的拼接。并发创建节点的请求能够被有序且安全的创建。
接下来客户端A监听客户端B创建的 /member-123/lock0000000003节点,监听的方式可以使用get -w $node_path命令,该命令能够获取节点的内容,并在节点变更时收到通知。然后客户端B通过执行delete命令删除了对应的节点,该过程如下图所示:

如上图所示,当客户端B删除了 /member-123/lock0000000003节点后,客户端A收到了ZK实例的事件通知,该通知表示所监听的节点被删除了。因为创建的子节点均为临时有序类型,所以当客户端退出,会话终止后,由会话创建的(临时类型)节点都会被删除。
最后,客户端A监听客户端B创建的另外两个节点,然后将客户端B退出,再观察通知情况,该过程如下图所示:

如上图所示,随着客户端B的退出,客户端A收到了两个节点的删除事件通知。从上述演示可以看到,ZK支持节点的创建、访问、列表、监听和通知,而这些特性可以被用来实现推模式分布式锁。
ZK兑现原子出入队功能的方式是支持enQueue和deQueue操作,实际就是需要提供线程安全的分布式队列服务。不同客户端并发获取锁的请求都需要在这个分布式队列中排队,使用ZK该如何实现呢?答案是使用临时有序类型节点来构建(同步)队列,以前文中的演示为例,其结构如下图所示:
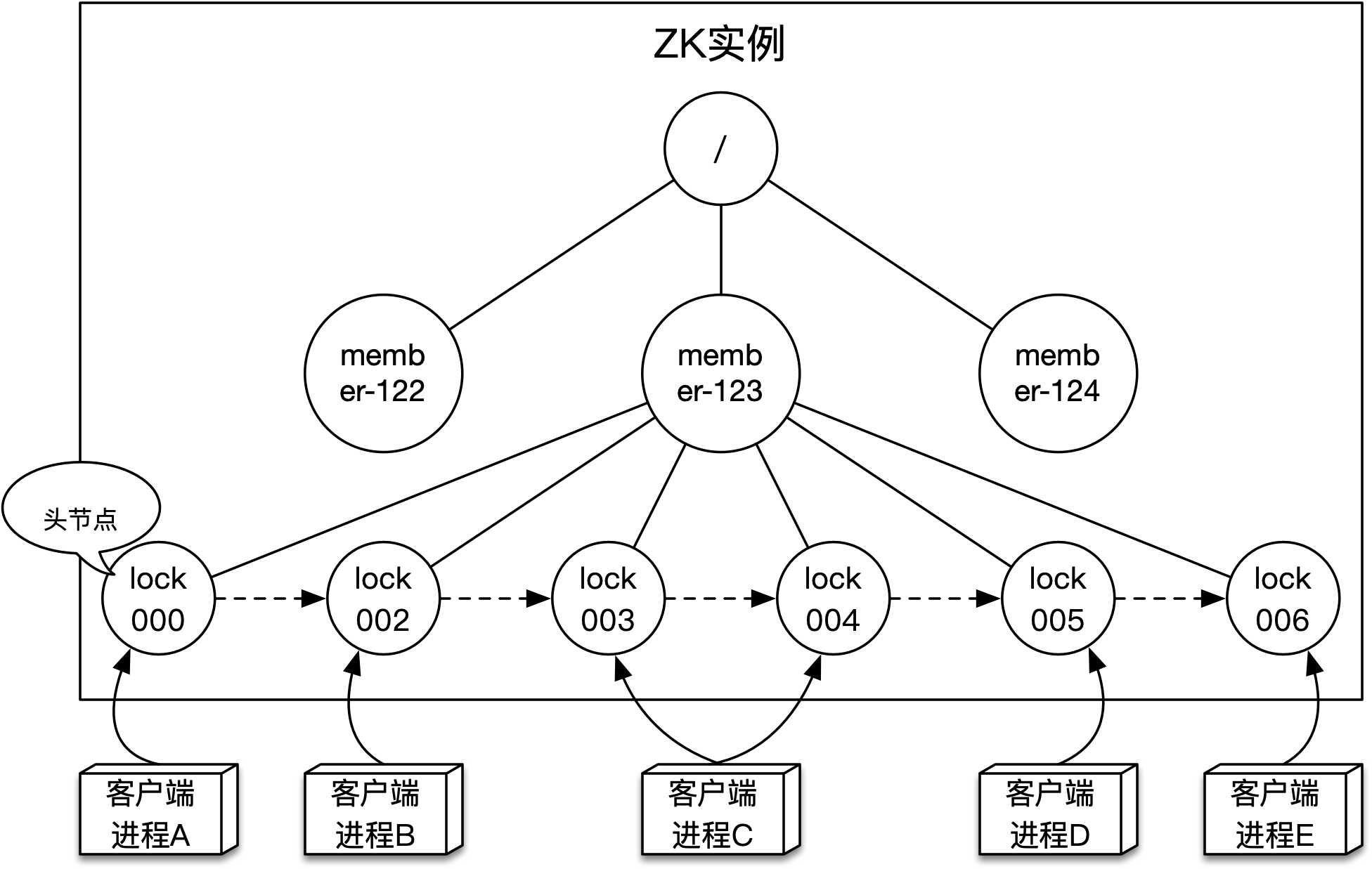
如上图所示,可以看到在根节点下有多个(位于第2层的)子节点,这些节点可以被看作是不同的分布式锁,而它们的名称可以是业务类型+业务主键的形式,比如:对主键为123的会员上锁,这个节点(或者锁)的全路径就是 /member-123。如果客户端要获取相应的锁,就需要在锁节点下创建临时有序类型的子节点,图中的客户端A至E均尝试获取会员123的锁,这些获取锁的请求会在 /member-123节点下创建(第3层的)多个子节点。由于是顺序创建,所以这些节点可以被视作一个线程安全的队列,其中编号最小的子节点为头节点,新获取锁的请求会以大编号节点的形式由尾部添加。
当进行enQueue操作时,以获取会员123的锁为例,使用create -es /member-123/lock命令创建一个临时有序节点即可,由于新增节点ID会全局自增,所以创建的节点自然就会在队尾。创建节点命令会返回节点的全路径,当进行deQueue操作时,可以使用delete命令删除节点。
不同客户端并发获取锁的请求会在这个队列中排队,该队列的底层实现更像一个数组,因为数组的下标会全局自增,而节点之间没有相互指向的引用。那怎么判断排队中的节点获取到锁了呢?可以认为如果一个节点没有前驱节点,即为首节点时,代表它获取到了锁。由于ZK没有提供获取首节点的API,所以只能变相的通过获取全部子节点,然后判断自身在子节点数组中的下标是否最小来完成。
ZK要兑现新增监听和通知事件功能,就需要支持监听节点以及变更通知,在之前的演示中,可以看到ZK是能够支持监听节点变更,并在节点发生变更时通知监听者的。当通过enQueue新入队一个节点时,如果该节点不是首节点,则需要监听它的前驱节点。在任意时刻去看队列里各节点之间的监听关系,会发现它们是链式的,以前文中的演示为例,如下图所示:
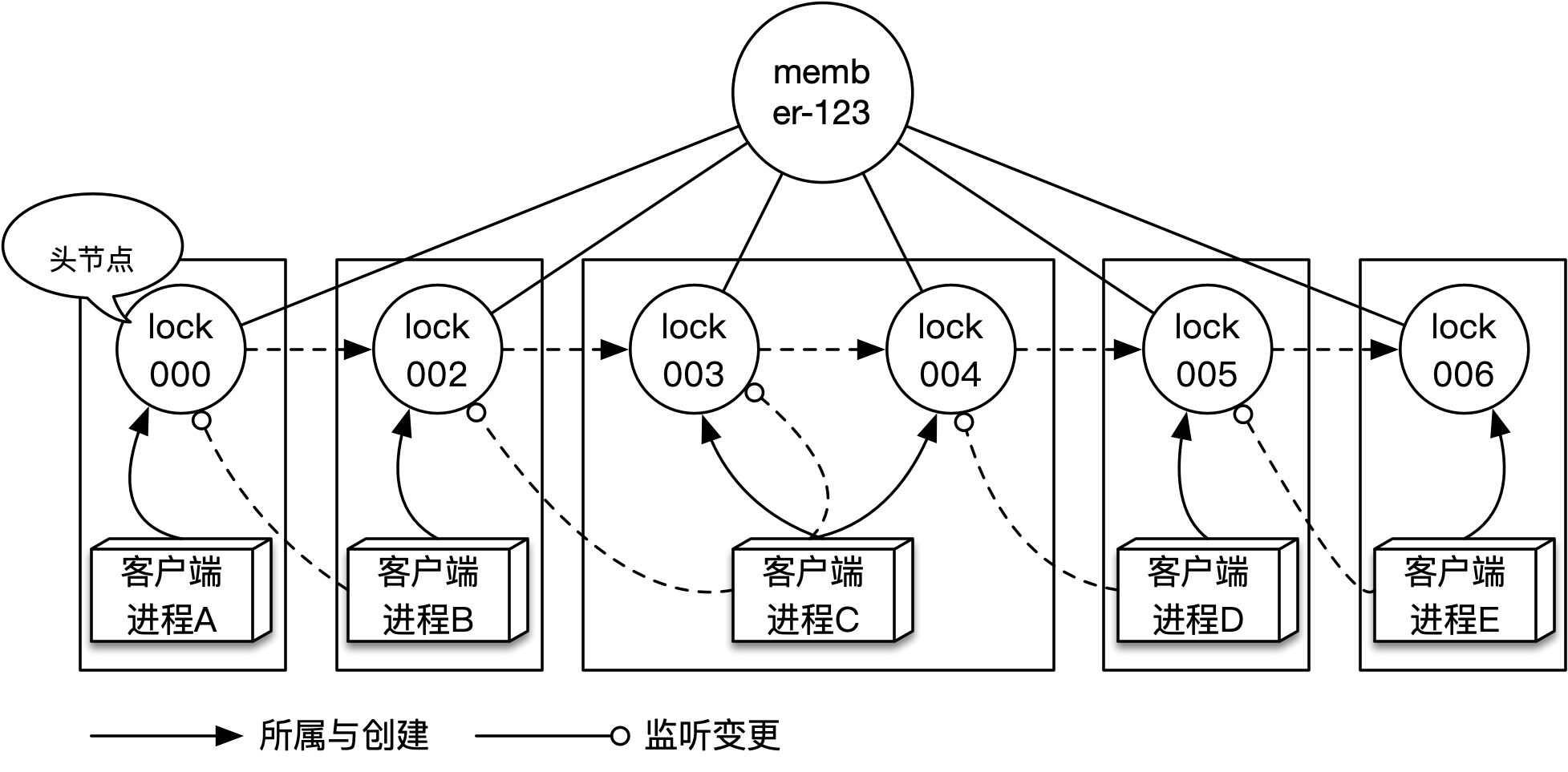
如上图所示,客户端进程A至E共创建了6个节点,每个节点在入队后,该节点在队列中的位置(即下标)也就确定了,这时还需要获取member-123节点下的所有子节点,根据下标找到前驱节点进行监听。
当获取到锁的节点(即首节点)执行完同步操作,就可以释放锁,释放锁会将该节点删除,而删除操作会以事件的形式通知到后继节点注册的监听逻辑。监听逻辑就是获取锁的逻辑,该逻辑会先获取锁节点下的全部子节点,如果当前节点为首节点,则获取锁成功,否则将会对前驱节点进行再次监听。为什么需要再次监听呢?节点入队时不是已经设置了吗?原因在于节点的删除不只是由于锁的释放,也有可能是客户端进程崩溃或重启所致。
在分布式环境中,客户端进程可能随时会重启,也可能会由于各种原因而突然崩溃,当客户端进程终止时,需要其创建的节点能被自动删除,否则同步队列中就会出现僵尸节点,使得通知链路断掉,导致锁的可用性无法保证。ZK的临时有序节点,就能很好的解决这个问题,因为一旦客户端进程退出,它和ZK之间的会话就会终止,而它创建的(临时)节点就会被ZK自动删除。考虑到节点的删除不一定发生在队首,就需要支持再次监听的逻辑,该过程如下图所示:
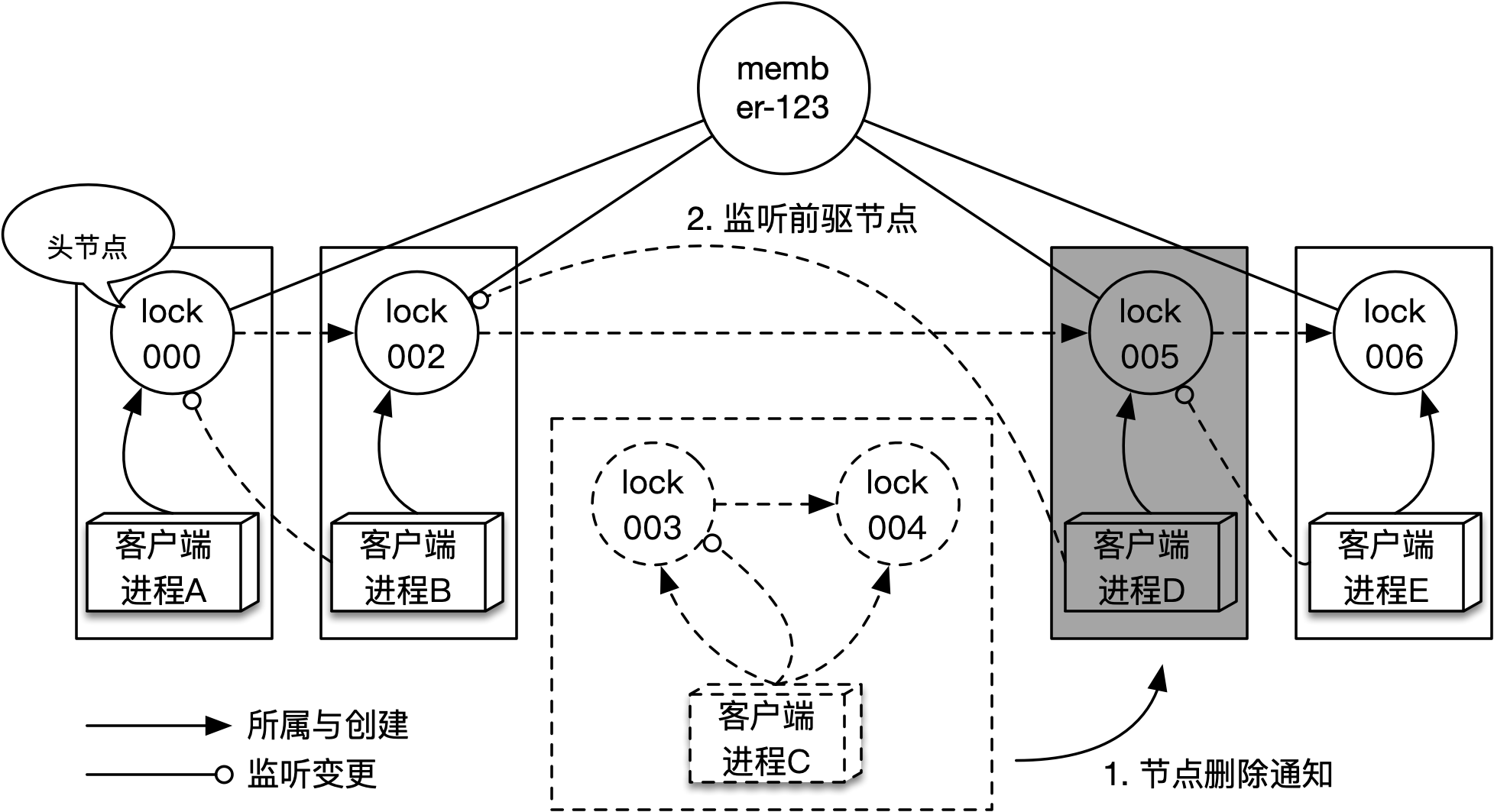
如上图所示,当客户端进程C退出后,它与ZK之间的会话就会随之终止,而它创建的lock003和lock004节点会被自动删除。lock004节点的删除事件会通知到客户端进程D,客户端进程D执行监听逻辑时会将监听对象由lock004改为lock002。
使用ZK来构建分布式锁,肯定不能选择使用zkCli脚本,而是需要依赖ZK客户端进行编程。ZK原生客户端使用起来不是很方便,而网飞开源(并捐赠给Apache)的Curator项目很好的提升了使用体验,该项目不仅支持流式API来简化使用,还提供了诸如:选举、分布式锁和服务注册与发现等多种功能组件(Recipes子项目),对部分分布式问题场景做到了开箱即用。
通过依赖curator-recipes坐标,可以将其分布式锁组件引入到项目中,依赖如下:
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
</dependency>本书使用的Curator版本为:5.2.0。
在使用Curator分布式锁之前,需要先构造CuratorFramework,该接口是Curator框架的入口,创建代码如下所示:
CuratorFramework curatorFramework = CuratorFrameworkFactory.builder()
.connectString(connectString)
.connectionTimeoutMs(connectionTimeoutMs)
.sessionTimeoutMs(sessionTimeoutMs)
.retryPolicy(new ExponentialBackoffRetry(baseSleepTimeMs, maxRetries))
.build();
curatorFramework.start(); CuratorFramework需要调用start方法完成启动后方可使用。通过CuratorFrameworkFactory创建CuratorFramework时,需要设置若干参数,上述代码中的参数以及描述如下表所示:
| 参数名称 | 描述 |
|---|---|
connectString |
ZK服务端地址,包括:IP和端口 |
connectionTimeoutMs |
连接超时时间 |
sessionTimeoutMs |
会话超时时间 |
baseSleepTimeMs |
失败重试策略重试间隔时间 |
maxRetries |
失败重试策略最大重试次数 |
Curator分布式锁提供了多种实现,包括互斥的分布式锁InterProcessMutex,以及分布式读写锁InterProcessReadWriteLock等。以InterProcessMutex为例,示例代码如下所示:
InterProcessMutex lock = new InterProcessMutex(curatorFramework, "/member-123");
lock.acquire(5, TimeUnit.MINUTES);
try {
// 执行同步逻辑
} finally {
lock.release();
}可以看到Curator分布式锁对操作ZK的细节做了很好的封装,它不仅有良好的使用体验,还隐藏了推模式分布式锁复杂的逻辑。
推模式分布式锁的实现要比拉模式复杂,出于可靠性与难易度的考虑,可以将Curator分布式锁适配到LockRemoteResource接口。因为InterProcessMutex已经提供了与锁操作的相关方法,所以适配过程非常简单,适配实现为ZooKeeperLockRemoteResource。以获取锁为例,代码如下所示:
public AcquireResult tryAcquire(String resourceName, String resourceValue, long waitTime,
TimeUnit timeUnit) throws InterruptedException {
InterProcessMutex lock = lockRepo.computeIfAbsent(resourceName,
rn -> new InterProcessMutex(curatorFramework, "/" + rn));
AcquireResultBuilder acquireResultBuilder;
try {
boolean ret = lock.acquire(waitTime, timeUnit);
acquireResultBuilder = new AcquireResultBuilder(ret);
if (!ret) {
acquireResultBuilder.failureType(AcquireResult.FailureType.TIME_OUT);
}
return acquireResultBuilder.build();
} catch (Exception ex) {
throw new RuntimeException("acquire zk lock got exception.", ex);
}
} 可以看到获取锁时,首先从lockRepo中获取锁资源resourceName对应的InterProcessMutex,然后调用它获取锁,并将调用结果适配为AcquireResult返回。需要注意的是,每个创建出来的InterProcessMutex都会被认为是一个独立的锁实例(纵使它的路径是相同的),如果在每次调用tryAcquire方法时都创建InterProcessMutex,结果就是各用各锁,起不到并发控制的作用,锁的正确性也无法保证,因此需要将锁资源与创建出来的InterProcessMutex缓存起来使用。
类型为ConcurrentHashMap的
lockRepo缓存了resourceName与InterProcessMutex。
释放锁的代码也很简单,这里不再赘述,如果感兴趣可以查看分布式锁项目中的distribute-lock-zookeeper-support模块。
ZK是一款典型的CP型存储,能够提供高可用以及顺序一致性的保证,因此基于它实现的分布式锁也会具备良好的可用性和正确性,但并不代表它实现的分布式锁就没有弱点,在性能和正确性上,ZK分布式锁就存在一些问题。
首先是性能问题,主要有两点:一是I/O交互多,二是ZK自身的读写能力一般。以客户端一次获取锁的过程为例:需要新增节点、获取子节点列表以及新增监听等多次对ZK的调用,而这些调用不是并行的,是存在顺序依赖的。与Redis分布式锁的一次SET命令相比,ZK分布式锁交互次数变得更多,开销也比较大。当ZK处理新增节点请求时,需要将数据变更同步到ZK集群中的Follower节点才能返回,虽然同步过程有优化,只需要等待超过半数的Follower同步成功即可,但这种为了确保一致性的同步机制,还是在性能上却有所损失。
其次是正确性问题,也就是还会存在多个实例能够同时获取到锁的情况。ZK能够在分布式环境中保证一致性,而分布式锁正确性的本质其实也就是多个实例对于资源状态需要有一致的视图,从这点来说分布式锁的正确性和存储服务的一致性是正相关的。即然ZK能够保证一致性,为什么ZK分布式锁还会出现正确性问题呢?原因就在于ZK会话存活的实现机制。
ZK分布式锁依靠临时有序节点来避免由于客户端实例宕机导致的可用性问题,因为一旦客户端进程崩溃,它和ZK之间的会话就会终止,进而它创建的节点就会被自动删除。临时节点的存在与否和会话是相关的,而ZK检测会话是否存活的方式是通过(定时)心跳来实现的,如果客户端与ZK实例之间的心跳出现(了一段时间的)中断,ZK会认为客户端可能出现了问题,从而将它们之间的会话终止。
通过心跳来判断存活是分布式环境中常用的策略,但心跳中断的原因不一定是对端崩溃,也有可能是对端负载过高、进程暂停或网络延迟所致,因此心跳没有问题表示对端一定存活,心跳出现问题则表示对端可能终止。
以Java应用为例,如果客户端获取到锁,而在执行同步逻辑时由于负载过高(网络请求堆积)引起心跳中断,则会可能导致ZK分布式锁对于正确性的保证失效,该过程如下图所示:
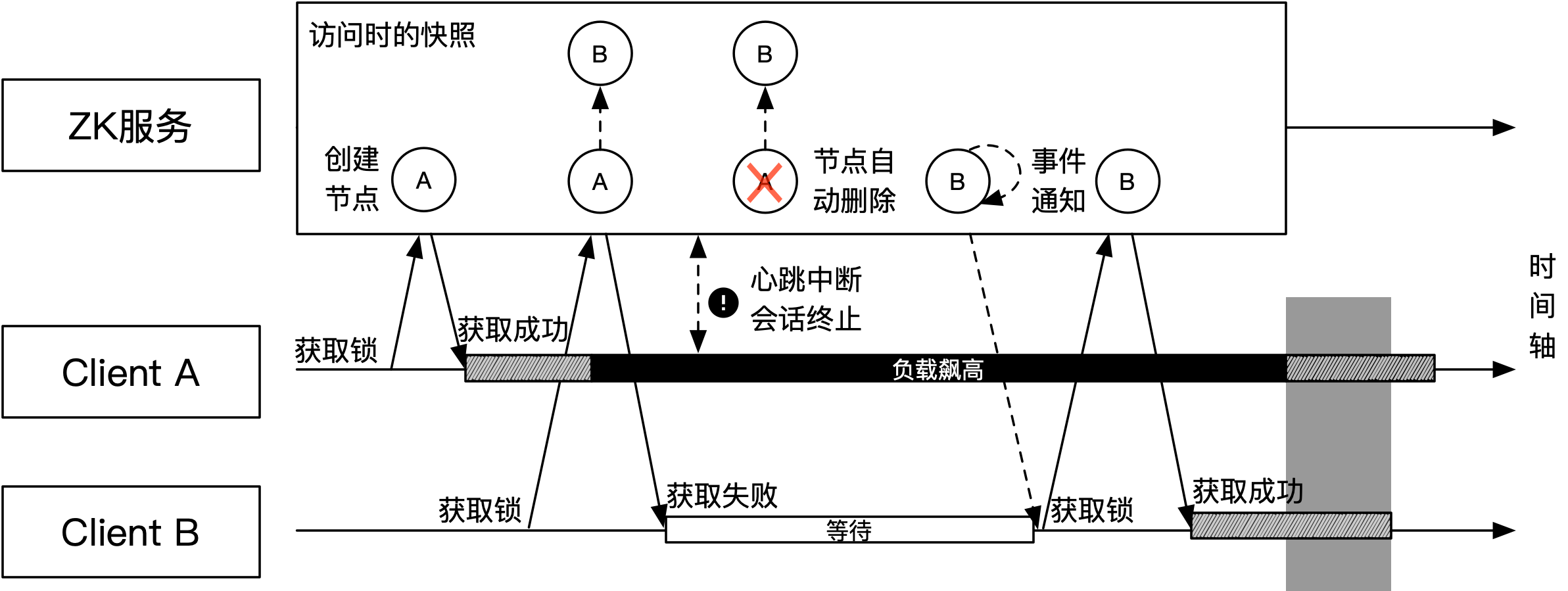
如上图所示,客户端A成功获取到锁,然后开始执行锁保护的同步逻辑。此时客户端B尝试获取锁,该过程会创建节点B,由于不是首节点,所以获取锁失败,进入等待状态。客户端A执行同步逻辑时(由于GC暂停或同步逻辑出现高消耗操作导致)负载飙高,它和ZK之间的心跳处理不及时,导致会话终止。客户端A与ZK之间的会话终止使得节点A被自动删除,由于节点B监听节点A的变化,会收到节点A的删除通知,而该通知会唤醒客户端B,使之重新尝试获取锁。
客户端B尝试获取锁,此时节点B已经是首节点,因此客户端B能够成功获取到锁并开始执行同步逻辑。假如此时客户端A从负载高的桎梏中恢复过来,开始继续执行同步逻辑,那原本被锁保护的同步逻辑就被并发执行了,导致锁的正确性被违反。当然可以通过修改心跳配置来使得客户端A与ZK之间的会话不会很快终止,由此一定程度上避免出现该问题,但该问题的理论模型依旧存在。