第二页笔记探讨了主从结构和Paxos算法角色的关系,以及算法中的提案信息结构和批准过程。
关键词:主从结构、提案、决议和批准过程。
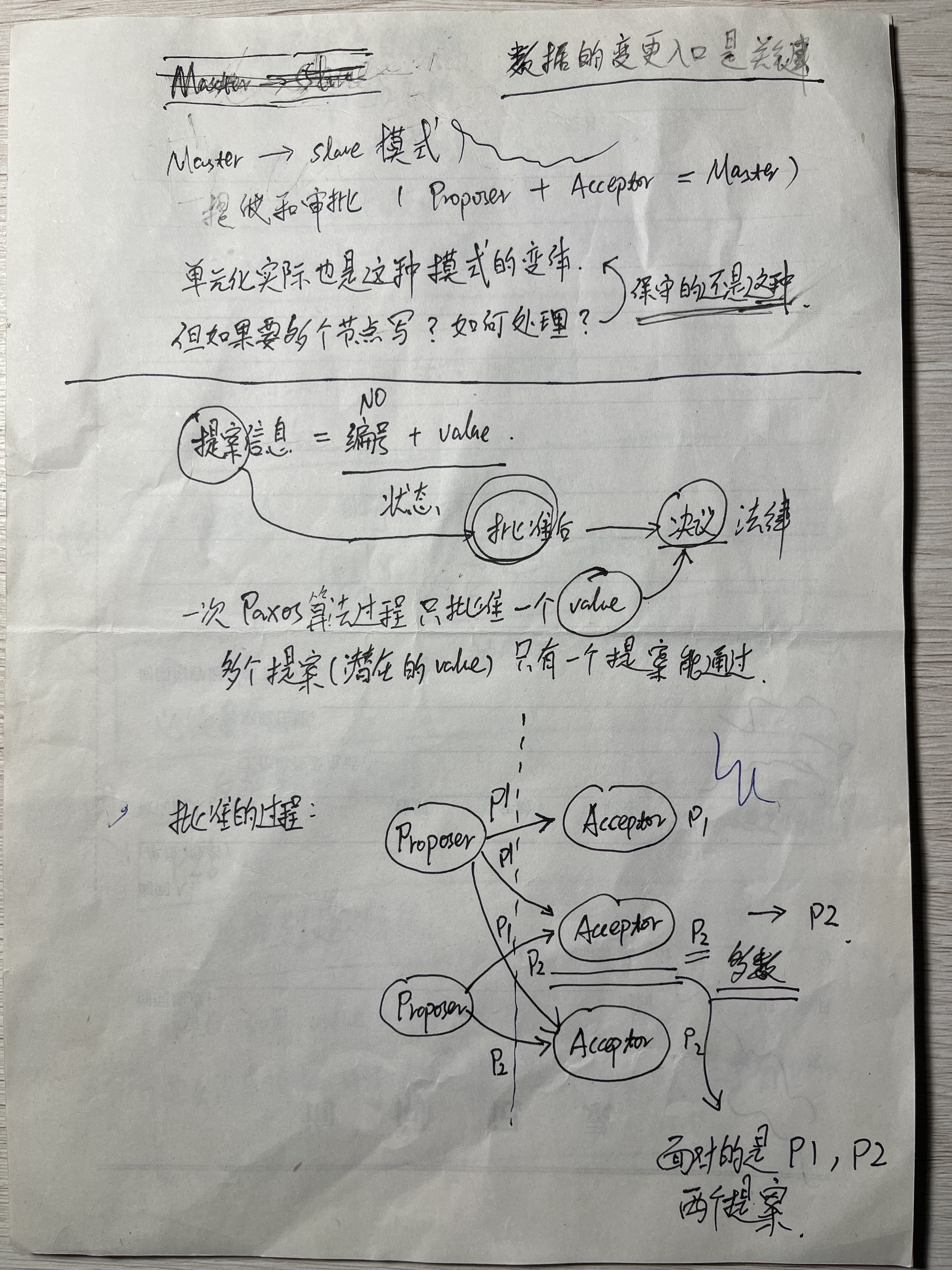
Paxos算法的过程是由Proposer提出提案,Acceptor讨论提案形成决议,可见如果决议是一次被多节点承认的变更,那么该决议对应提案的提出则是数据变更的入口。
如果数据变更的入口是集中的,也就是一个人说了算,那么这个结构就是简单的,比如:主从模式(Master-Slave)。
主从模式是分布式环境中一种常见的节点拓扑关系,它常见于数据存储层,如:Mysql的主从模式,通过将写请求统一派发给唯一的主节点,同时将读请求离散派发到多个读节点,而数据变更首先流入到主节点,然后再异步复制到读节点,通过大量的读节点(在可以容忍极小延迟的情况下)来提升系统吞吐量。
主从模式通过将写收敛到一个节点来达成共识,如果用Paxos算法角色来描述主从模式,那么也就是Master = Proposer + Acceptor,数据变更发起以及生效,在一个节点。如果主从模式的写会发生在多个节点,主从模式将无法工作,因为无法判定各个节点中的变更,哪些是被多节点所认可的,会出现数据混乱。
有同学会问:单元化是不是可以解决主从结构这种只有单点可写的问题呢?
单元化是一种按照业务领域(比如:用户ID)分区的技术,它将部分业务数据的写控制在某一个单元(一批机器,一般在一个机房中),但数据的写也还会同步回其他单元,通过使用多单元的形式,让全量机器都参与工作,提升利用率(不用冷备模式)的同时,也提升了可用性(通过切换单元的方式),其概念如下图:
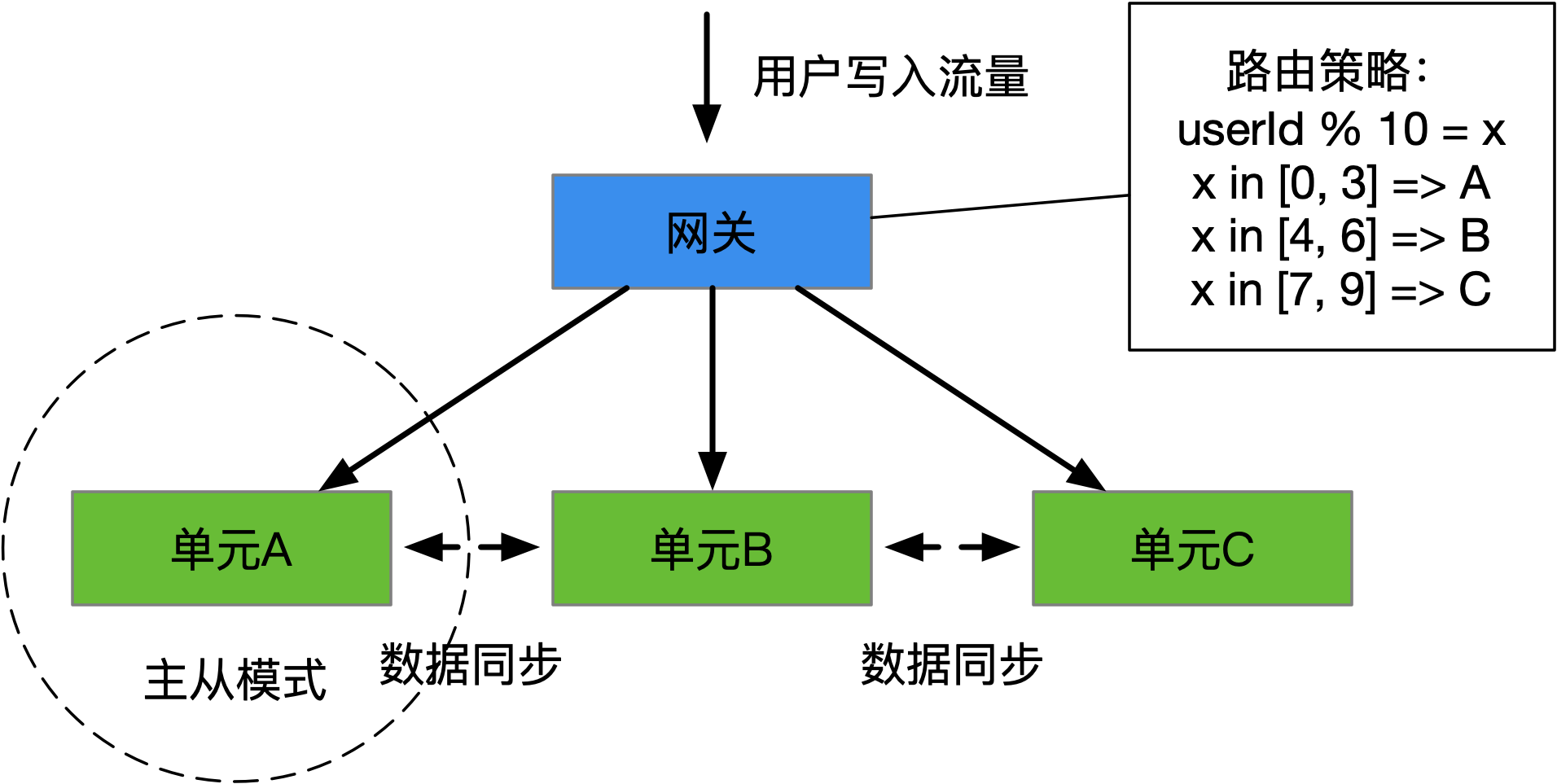
实际仔细看单元化,它也是主从模式的一个变体。因为它将可以预见的一种模式的写,比如:用户ID按10取模为5的写请求,派发到固定的机器上,通过添加了这层路由,使得写吞吐量变大,但每个单元内还是主从结构。这种技术方案只是在原有主从模式基础上,做了一个集群版,并没有真正的解决多节点写的问题。
数据变更请求 = 写请求 = 提案(Proposal)。
Paxos算法将一个写请求抽象为Proposal,如果将Proposal就视为请求的内容,也就是一个值,那多方一起写,就无法区分先后,这属于给自己找麻烦,毕竟写的发起是对方,但写的协议我们是可以控制的。因此,Proposal可以包含两个部分:编号和值,前者可以理解为一个全局唯一且顺序的编号,后者就是变更请求的内容。
当Proposal通过了多数Acceptor的表决同意后,Proposal就通过了,形成了多个节点认可的内容,我们可以称为决议(Resolution)。
决议来自于提案,但高于提案(被多方认可)。
Proposal批准的过程可以看笔记中的示例,多个Proposer可以提出Proposal,然后不同的Acceptor进行表决,如果某个Proposal得到多数Acceptor的支持,那么该Proposal就成为Resolution。
以P1提案为例,一个Proposer提出Proposal,P1到议会讨论,总共有三位Acceptor,它们接受了该Proposal,从而使Proposal成为Resolution。从这里可以看出,Proposer想要提案通过,它必须知晓有多少个Acceptor,也必须将Proposal发给多数的Acceptor寄期望它能够得以通过。
发往多数的Acceptor是论文中始终扭扭捏捏没有正面说明的,可以想象,如果你不知道这个约束,你就会认为Paxos算法是个神仙算法,随便一发,怎么就多数了。
对于提案编号没有重复,这可以理解,但提案产生的一刻会出现重复吗?也就是说不同的Proposer接收到不同客户端的并发请求后,会自然的获取到不同的提案编号,还是会获取到一样的提案编号呢?如果注意力集中在编号唯一的约束上,可能会认为获取到不同的提案编号,一定是Paxos算法要求一个单点的编号生成器,但你通读论文都不会找到它,因为实际是后者,你会看到相同的编号,只是在提案阶段,而最终成文的决议,它一定是唯一的。相同编号的提案一定会在多个Acceptor之间产生角逐和竞争,然后通过一个提案,另外一个,只能再来一遍提案批准流程。
但另外一个提案会看到前一提案形成决议的结果。
至此,我们对于提案批准过程有以下(没有在论文中提到的)隐含约束:
- 隐含约束1. Proposer知晓所有的Acceptor
这样它能够发起有意义的提案,也能判定自己的提案是否得到多数人的支持;
- 隐含约束2. Proposal的编号会产生重复
因为它的生成需要结合相应Proposer的状态信息,而批准过程会使之去重。