- Authors:- Tero Karras, Samuli Laine, Timo Aila
- Conference name:- The IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
- Year of publication:- 2018
This paper proposes a generative architecture, which is an enhanced version of proGAN, which helps in unsupervised separation of the high-level attributes(like pose and identity in humans) and of stochastic variation in the generated images(like hairs, etc.). The proposed method generates images of very high quality(like 1024x1024) and also improves the disentanglement of the latent vectors of variation.
-
Replace the nearest-neighbour up/downsampling in both networks with bilinear sampling.
-
Instead of giving input as a latent vector, a learned constant input is given and at each convolution layer, a latent vector(w) is given to adjust the styles of the image.
-
The latent vector(w) is obtained by a non-linear mapping from a random generated latent vector(z) using 8 layer MLP. w is then passed to affine transformation which helps to control adaptive instance normalization (AdaIN) operations after each convolution layer. The AdaIn replaces the pixel norm that was used in the original proGAN architecture.
-
Gaussian noise is injected after every convolution layer, which helps in the unsupervised separation of the high-level attributes and the stochastic variation.
-
Use of mixing regularization(using two latent vectoers instead of one) for increasing the localisation of the styles , which increases the FID score.
-
Proposal of two new metrics for the evaluating disentanglement, which do not require an encoder network :-> perceptual path-length and linear separability
-
A new dataset of human faces(Flickr-Faces-HQ, FFHQ) with much higher quality and diversity is presented.
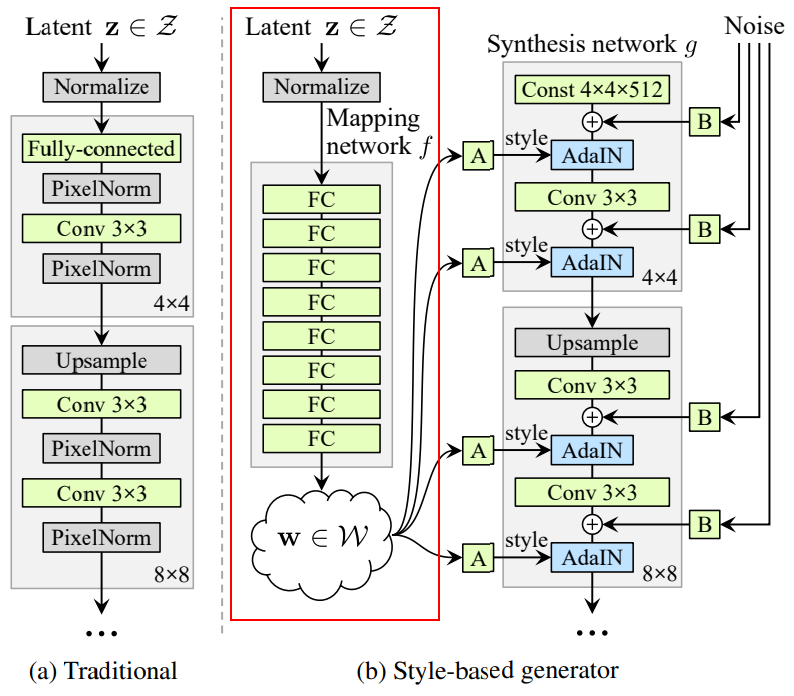
- The generator architecture is modified from the generator architecture of the original proGAN paper.
-
The main idea of the proposed paper is to get a better control over the image synthesis process.
-
The mapping network and the affine tramsformations draw samples for each style from a learned distribution, while the synthesis network generates images based on collection of those styles.
-
There is no modification in the discriminator architecture and the loss functions of proGAN, the major change is in the generator architecture.
-
The collection of styles(in human faces) is like
- Coarse styles(4x4 - 8x8) :-> pose, hair, face shape
- Middle styles(16x16 - 32x32) :-> facial features, eyes
- Fine styles(64x64 - 1024x1024) :-> color scheme
-
Paper :- https://arxiv.org/pdf/1812.04948.pdf
-
Demonstrative Video :- https://youtu.be/kSLJriaOumA
-
Implementation :- https://github.com/NVlabs/stylegan