Ashish Vaswani, et al., NeurIPS 2017
The paper introduces the Transformer model, a great neural network architecture designed for sequence-to-sequence tasks. Departing from conventional recurrent and convolutional models, the Transformer relies solely on self-attention mechanisms. This approach enables the model to capture intricate relationships within sequential data, without being hindered by the limitations of sequential processing and uses parallel processing to save computations and cost.
- Develops the Transformer architecture, a game-changer in sequence-to-sequence tasks.
- Advocates for the exclusive use of self-attention mechanisms, challenging the necessity of recurrence and convolution.
- Sequential to parallel processing(eg multi head attention).
-
Introduction & Background:
- Traditional models (e.g., RNNs, LSTMs, CNNs) often struggle with long-range dependencies due to their sequential nature.
- The authors propose the self-attention mechanism, which allows the model to simultaneously weigh the significance of all input elements, producing a weighted sum that captures context more effectively and give importance to positions also.
Mathematical Formulation:
For a sequence of input embeddings (X = [x_1, x_2, ..., x_n]), the self-attention scores for a query at position (i) and key at position (j) are computed as:
{Attention}(Q,K,V) = softmax(frac{QK^T}{sqrt{d_k}})V
where (Q), (K), and (V) are linear projections of (X) made through learned weight matrices), and (d_k) is the dimension of the key vectors and in more simpler way they are query,key and values made from input embedding vector(X).
-
Multi-Head Self-Attention:
- Introduces multi-head self-attention, which employs multiple sets of learned linear projections of the input to compute attention weights in parallel.
- Each head captures different relationships between elements, improving the model's capability to learn a wide range of contextual details.
-
Position-Wise Feed-Forward Networks (FFNs):
- Adds a position-wise feed-forward network after the attention mechanism to further process the information.
- This network consists of two linear transformations separated by a non-linear activation function (e.g., ReLU).
Mathematical Formulation:
Given (X) as the output of the self-attention mechanism, the FFN computes:
{FFN}(X) = max(0, XW_1 + b_1)W_2 + b_2
where (W_1), (b_1), (W_2), and (b_2) are learned weight matrices and biases.
-
Masked Multi-Head Attention:
- In tasks like language modeling , where future information should not be accessible, a masking mechanism is applied to the attention weights.
- The mask prevents the model from attending to future positions in the sequence, ensuring predictions are based only on past information and there is no cheating.
-
Transformer Model:
- Combines the encoder and decoder, each consisting of multiple identical layers, each with sub-layers for multi-head self-attention and position-wise FFNs.
- The encoder processes the input sequence, generating a sequence of hidden states. The decoder generates the output sequence.
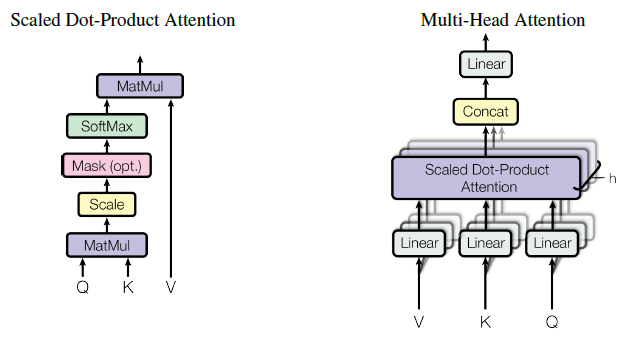
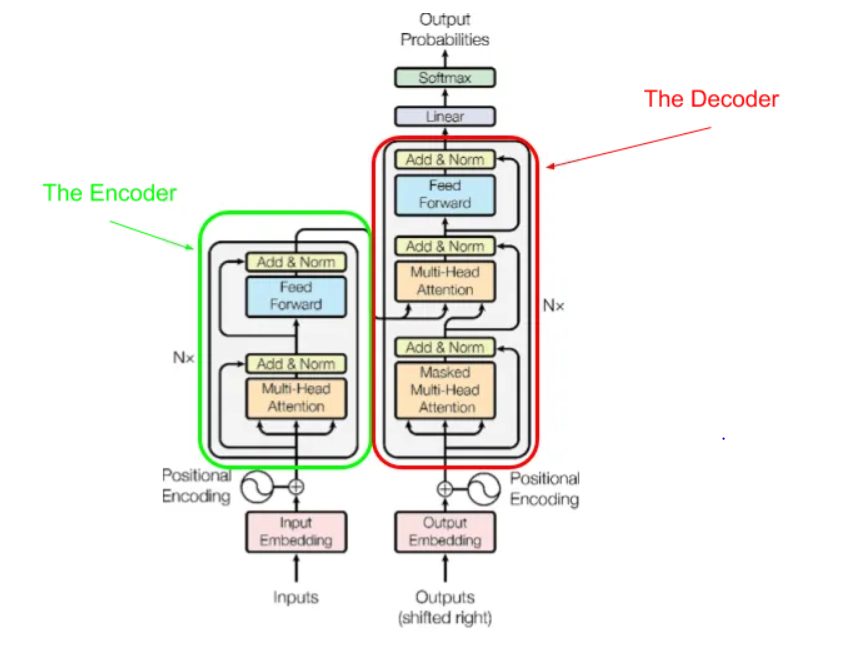
Here is a simplified photo of transformer architecture
The Transformer model showcases superior performance over state-of-the-art RNN and CNN models in various machine translation tasks. Its capacity to capture long-range dependencies and contextual information leads to state-of-the-art results across many benchmark datasets and it performs better even on training with quarter of cost by doing parallel processing and amazing architecture.
Compared to older models, the Transformer is really good at handling big tasks because it can do many things at the same time. Also, it doesn't need to use some older techniques like repeating and combining information as much, which was thought to be really important before. This shows a new way of doing things in machine learning.
Attention Is All You Need" offers a new perspective on how we handle sequences of information. The Transformer's focus on paying attention to important parts, along with its impressive results, shows that this method could really change how we do things. In the future, we should explore using it for many different types of tasks that involve sequences overall I find this paper really interesting .
- Link to Paper - https://arxiv.org/abs/1706.03762
- Project page - http://nlp.seas.harvard.edu/2018/04/03/attention.html
- Youtube video - https://youtu.be/XowwKOAWYoQ?feature=shared
- Code - https://github.com/tensorflow/tensor2tensor/blob/master/tensor2tensor/models/transformer.py