diff --git a/docs-2.0/1.introduction/3.vid.md b/docs-2.0/1.introduction/3.vid.md
index 2c44a7dc076..56ff991f6bd 100644
--- a/docs-2.0/1.introduction/3.vid.md
+++ b/docs-2.0/1.introduction/3.vid.md
@@ -1,6 +1,6 @@
# VID
-In NebulaGraph, a vertex is uniquely identified by its ID, which is called a VID or a Vertex ID.
+In a graph space, a vertex is uniquely identified by its ID, which is called a VID or a Vertex ID.
## Features
diff --git a/docs-2.0/2.quick-start/1.quick-start-workflow.md b/docs-2.0/2.quick-start/1.quick-start-workflow.md
index 5c9b7f0cf49..e8f358fcb3f 100644
--- a/docs-2.0/2.quick-start/1.quick-start-workflow.md
+++ b/docs-2.0/2.quick-start/1.quick-start-workflow.md
@@ -1,10 +1,39 @@
-# Quick start workflow
+# Getting started with NebulaGraph
-The quick start introduces the simplest workflow to use NebulaGraph, including deploying NebulaGraph, connecting to NebulaGraph, and doing basic CRUD.
+This topic describes how to use NebulaGraph with Docker Desktop and on-premises deployment workflow to quickly get started with NebulaGraph.
-## Steps
+## Using NebulaGraph with Docker Desktop
-Users can quickly deploy and use NebulaGraph in the following steps.
+NebulaGraph is available as a [Docker Extension](https://hub.docker.com/extensions/weygu/nebulagraph-dd-ext) that you can easily install and run on your Docker Desktop. You can quickly deploy NebulaGraph using Docker Desktop with just one click.
+
+1. Install Docker Desktop
+
+ - [Install Docker Desktop on Mac](https://docs.docker.com/docker-for-mac/install/)
+ - [Install Docker Desktop on Windows](https://docs.docker.com/docker-for-windows/install/)
+
+ !!! caution
+ To install Docker Desktop, you need to install [WSL 2](https://docs.docker.com/desktop/install/windows-install/#system-requirements) first.
+
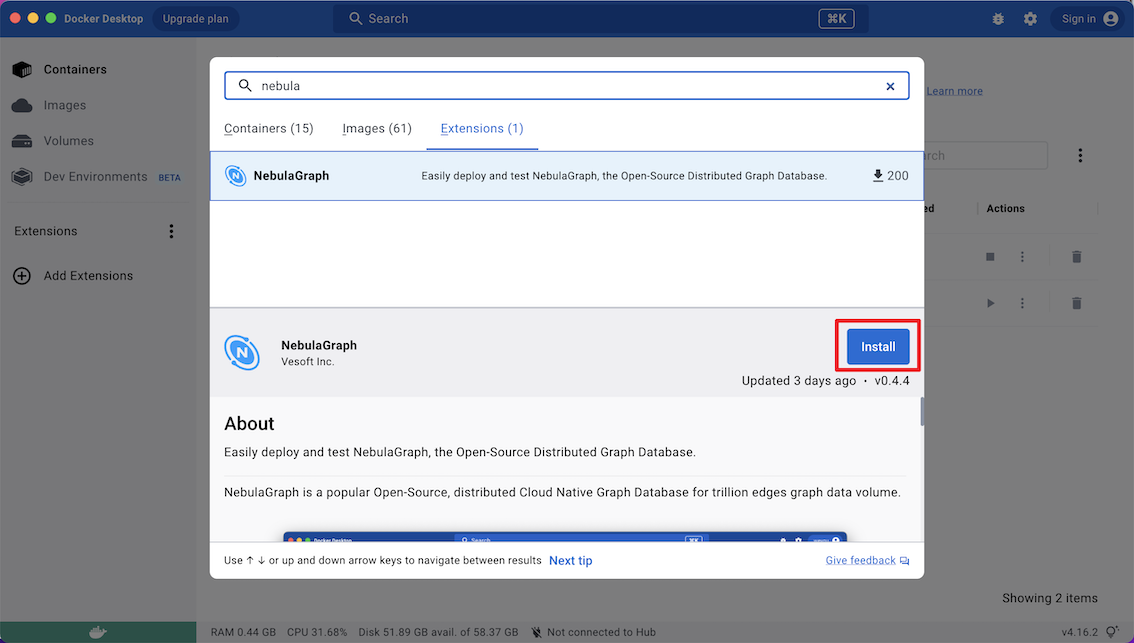
+2. In the left sidebar of Docker Desktop, click **Extensions** or **Add Extensions**.
+3. On the Extensions Marketplace, search for NebulaGraph and click **Install**.
+
+ 
+
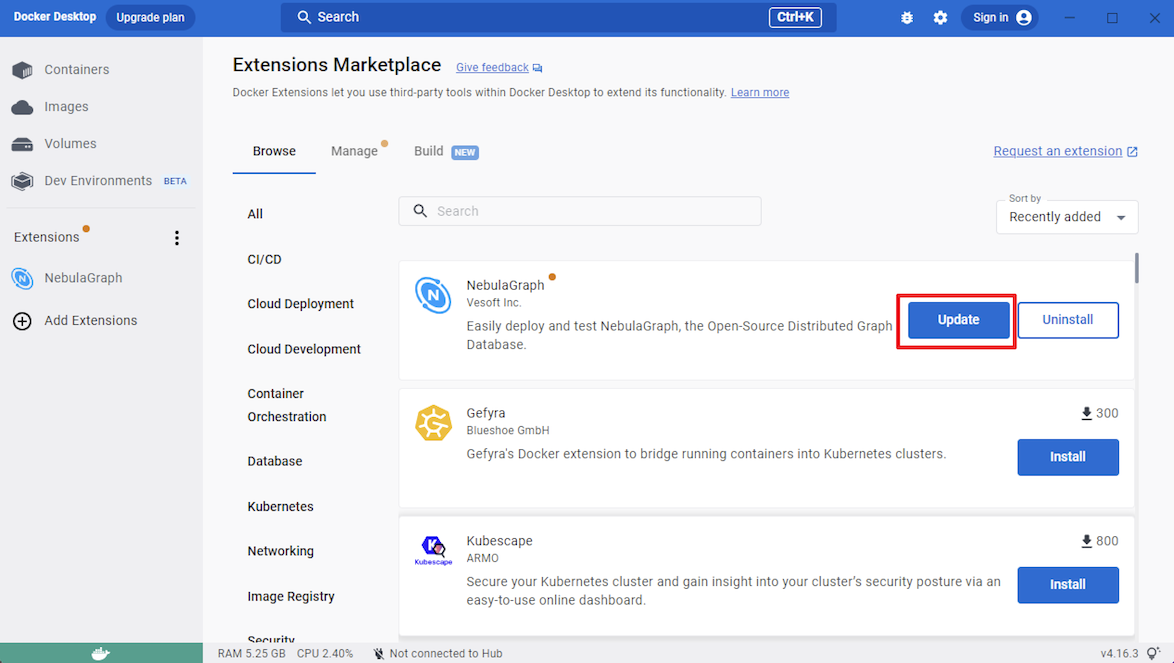
+ Click **Update** to update NebulaGraph to the latest version when a new version is available.
+
+ 
+
+4. Click **Open** to navigate to the NebulaGraph extension page.
+
+5. At the top of the page, click **Studio in Browser** to use NebulaGraph.
+
+For more information about how to use NebulaGraph with Docker Desktop, see the following video:
+
+
+
+## Deploying NebulaGraph on-premises workflow
+
+The following workflow describes how to use NebulaGraph on-premises, including deploying NebulaGraph, connecting to NebulaGraph, and running basic CRUD.
1. [Deploy NebulaGraph](2.install-nebula-graph.md)
diff --git a/docs-2.0/20.appendix/history.md b/docs-2.0/20.appendix/history.md
index 9937ca5115c..dbedd8eb996 100644
--- a/docs-2.0/20.appendix/history.md
+++ b/docs-2.0/20.appendix/history.md
@@ -36,3 +36,9 @@
9. 2022.2: NebulaGraph v3.0.0 was released.
10. 2022.4: NebulaGraph v3.1.0 was released.
+
+11. 2022.7: NebulaGraph v3.2.0 was released.
+
+12. 2022.10: NebulaGraph v3.3.0 was released.
+
+13. 2023.2: NebulaGraph v3.4.0 was released.
\ No newline at end of file
diff --git a/docs-2.0/20.appendix/release-notes/dashboard-comm-release-note.md b/docs-2.0/20.appendix/release-notes/dashboard-comm-release-note.md
index c1af5b77117..a1b2f26f601 100644
--- a/docs-2.0/20.appendix/release-notes/dashboard-comm-release-note.md
+++ b/docs-2.0/20.appendix/release-notes/dashboard-comm-release-note.md
@@ -1,67 +1,12 @@
# NebulaGraph Dashboard Community Edition {{ nebula.release }} release notes
-## Feature
+## Community Edition 3.4.0
-- Support [killing sessions](../../3.ngql-guide/17.query-tuning-statements/2.kill-session.md). [#5146](https://github.com/vesoft-inc/nebula/pull/5146)
-- Support [Memory Tracker](../../5.configurations-and-logs/1.configurations/4.storage-config.md) to optimize memory management. [#5082](https://github.com/vesoft-inc/nebula/pull/5082)
+- Feature
+ - Support the built-in [dashboard.service](../../nebula-dashboard/2.deploy-dashboard.md) script to manage the Dashboard services with one-click and view the Dashboard version.
+ - Support viewing the configuration of Meta services.
-## Enhancement
-
-- Optimize job management. [#5212](https://github.com/vesoft-inc/nebula/pull/5212) [#5093](https://github.com/vesoft-inc/nebula/pull/5093) [#5099](https://github.com/vesoft-inc/nebula/pull/5099) [#4872](https://github.com/vesoft-inc/nebula/pull/4872)
-
-- Modify the default value of the Graph service parameter `session_reclaim_interval_secs` to 60 seconds. [#5246](https://github.com/vesoft-inc/nebula/pull/5246)
-
-- Adjust the default level of `stderrthreshold` in the configuration file. [#5188](https://github.com/vesoft-inc/nebula/pull/5188)
-
-- Optimize the full-text index. [#5077](https://github.com/vesoft-inc/nebula/pull/5077) [#4900](https://github.com/vesoft-inc/nebula/pull/4900) [#4925](https://github.com/vesoft-inc/nebula/pull/4925)
-
-- Limit the maximum depth of the plan tree in the optimizer to avoid stack overflows. [#5050](https://github.com/vesoft-inc/nebula/pull/5050)
-
-- Optimize the treatment scheme when the pattern expressions are used as predicates. [#4916](https://github.com/vesoft-inc/nebula/pull/4916)
-
-## Bugfix
-
-- Fix the bug about query plan generation and optimization. [#4863](https://github.com/vesoft-inc/nebula/pull/4863) [#4813](https://github.com/vesoft-inc/nebula/pull/4813)
-
-- Fix the bugs related to indexes:
-
- - Full-text indexes [#5214](https://github.com/vesoft-inc/nebula/pull/5214) [#5260](https://github.com/vesoft-inc/nebula/pull/5260)
- - String indexes [5126](https://github.com/vesoft-inc/nebula/pull/5126)
-
-- Fix the bugs related to query statements:
-
- - Variables [#5192](https://github.com/vesoft-inc/nebula/pull/5192)
- - Filter conditions and expressions [#4952](https://github.com/vesoft-inc/nebula/pull/4952) [#4893](https://github.com/vesoft-inc/nebula/pull/4893) [#4863](https://github.com/vesoft-inc/nebula/pull/4863)
- - Properties of vertices or edges [#5230](https://github.com/vesoft-inc/nebula/pull/5230) [#4846](https://github.com/vesoft-inc/nebula/pull/4846) [#4841](https://github.com/vesoft-inc/nebula/pull/4841) [#5238](https://github.com/vesoft-inc/nebula/pull/5238)
- - Functions and aggregations [#5135](https://github.com/vesoft-inc/nebula/pull/5135) [#5121](https://github.com/vesoft-inc/nebula/pull/5121) [#4884](https://github.com/vesoft-inc/nebula/pull/4884)
- - Using illegal data types [#5242](https://github.com/vesoft-inc/nebula/pull/5242)
- - Clauses and operators [#5241](https://github.com/vesoft-inc/nebula/pull/5241) [#4965](https://github.com/vesoft-inc/nebula/pull/4965)
-
-- Fix the bugs related to DDL and DML statements:
-
- - ALTER TAG [#5105](https://github.com/vesoft-inc/nebula/pull/5105) [#5136](https://github.com/vesoft-inc/nebula/pull/5136)
- - UPDATE [#4933](https://github.com/vesoft-inc/nebula/pull/4933)
-
-- Fix the bugs related to other functions:
-
- - TTL [#4961](https://github.com/vesoft-inc/nebula/pull/4961)
- - Authentication [#4885](https://github.com/vesoft-inc/nebula/pull/4885)
- - Services [#4896](https://github.com/vesoft-inc/nebula/pull/4896)
-
-## Change
-
-- The added property name can not be the same as an existing or deleted property name, otherwise, the operation of adding a property fails. [#5130](https://github.com/vesoft-inc/nebula/pull/5130)
-- Limit the type conversion when modifying the schema. [#5098](https://github.com/vesoft-inc/nebula/pull/5098)
-- The default value must be specified when creating a property of type `NOT NULL`. [#5105](https://github.com/vesoft-inc/nebula/pull/5105)
-- Add the multithreaded query parameter `query_concurrently` to the configuration file with a default value of `true`. [#5119](https://github.com/vesoft-inc/nebula/pull/5119)
-- Remove the parameter `kv_separation` of the KV separation storage function from the configuration file, which is turned off by default. [#5119](https://github.com/vesoft-inc/nebula/pull/5119)
-- Modify the default value of `local_config` in the configuration file to `true`. [#5119](https://github.com/vesoft-inc/nebula/pull/5119)
-- Consistent use of `v.tag.property` to get property values, because it is necessary to specify the Tag. Using `v.property` to access the property of a Tag on `v` was incorrectly allowed in the previous version. [#5230](https://github.com/vesoft-inc/nebula/pull/5230)
-- Remove the column `HTTP port` from the command `SHOW HOSTS`. [#5056](https://github.com/vesoft-inc/nebula/pull/5056)
-- Disable the queries of the form `OPTIONAL MATCH WHERE `. [#5273](https://github.com/vesoft-inc/nebula/pull/5273)
-- Disable TOSS. [#5119](https://github.com/vesoft-inc/nebula/pull/5119)
-- Rename Listener's pid filename and log directory name. [#5119](https://github.com/vesoft-inc/nebula/pull/5119)
-
-## Legacy versions
-
-[Release notes of legacy versions](https://nebula-graph.io/posts/)
\ No newline at end of file
+- Enhancement
+ - Adjust the directory structure and simplify the [deployment steps](../../nebula-dashboard/2.deploy-dashboard.md).
+ - Display the names of the monitoring metrics on the overview page of `machine`.
+ - Optimize the calculation of monitoring metrics such as `num_queries`, and adjust the display to time series aggregation.
diff --git a/docs-2.0/20.appendix/release-notes/dashboard-ent-release-note.md b/docs-2.0/20.appendix/release-notes/dashboard-ent-release-note.md
index 2f41e8cb386..17775f4fc66 100644
--- a/docs-2.0/20.appendix/release-notes/dashboard-ent-release-note.md
+++ b/docs-2.0/20.appendix/release-notes/dashboard-ent-release-note.md
@@ -1,5 +1,13 @@
# NebulaGraph Dashboard Enterprise Edition release notes
+## Enterprise Edition 3.4.1
+
+- Bugfix
+
+ - Fix the bug that the RPM package cannot execute `nebula-agent` due to permission issues.
+ - Fix the bug that the cluster import information can not be viewed due to the `goconfig` folder permission.
+ - Fix the page error when the license expiration time is less than `30` days and `gracePeriod` is greater than `0`.
+
## Enterprise Edition 3.4.0
- Feature
diff --git a/docs-2.0/20.appendix/release-notes/nebula-comm-release-note.md b/docs-2.0/20.appendix/release-notes/nebula-comm-release-note.md
index 9f941d7c16e..a486162f145 100644
--- a/docs-2.0/20.appendix/release-notes/nebula-comm-release-note.md
+++ b/docs-2.0/20.appendix/release-notes/nebula-comm-release-note.md
@@ -1,75 +1,15 @@
# NebulaGraph {{ nebula.release }} release notes
-## Enhancement
-
-- Optimized the performance of k-hop. [#4560](https://github.com/vesoft-inc/nebula/pull/4560) [#4736](https://github.com/vesoft-inc/nebula/pull/4736) [#4566](https://github.com/vesoft-inc/nebula/pull/4566) [#4582](https://github.com/vesoft-inc/nebula/pull/4582) [#4558](https://github.com/vesoft-inc/nebula/pull/4558) [#4556](https://github.com/vesoft-inc/nebula/pull/4556) [#4555](https://github.com/vesoft-inc/nebula/pull/4555) [#4516](https://github.com/vesoft-inc/nebula/pull/4516) [#4531](https://github.com/vesoft-inc/nebula/pull/4531) [#4522](https://github.com/vesoft-inc/nebula/pull/4522) [#4754](https://github.com/vesoft-inc/nebula/pull/4754) [#4762](https://github.com/vesoft-inc/nebula/pull/4762)
-
-- Optimized `GO` statement join performance. [#4599](https://github.com/vesoft-inc/nebula/pull/4599) [#4750](https://github.com/vesoft-inc/nebula/pull/4750)
-
-- Supported using `GET SUBGRAPH` to filter vertices. [#4357](https://github.com/vesoft-inc/nebula/pull/4357)
-
-- Supported using `GetNeighbors` to filter vertices. [#4671](https://github.com/vesoft-inc/nebula/pull/4671)
-
-- Optimized the loop handling of `FIND SHORTEST PATH`. [#4672](https://github.com/vesoft-inc/nebula/pull/4672)
-
-- Supported the conversion between timestamp and date time. [#4626](https://github.com/vesoft-inc/nebula/pull/4526)
-
-- Supported the reference of local variable in pattern expressions. [#4498](https://github.com/vesoft-inc/nebula/pull/4498)
-
-- Optimized the job manager. [#4446](https://github.com/vesoft-inc/nebula/pull/4446) [#4442](https://github.com/vesoft-inc/nebula/pull/4442) [#4444](https://github.com/vesoft-inc/nebula/pull/4444) [#4460](https://github.com/vesoft-inc/nebula/pull/4460) [#4500](https://github.com/vesoft-inc/nebula/pull/4500) [#4633](https://github.com/vesoft-inc/nebula/pull/4633) [#4654](https://github.com/vesoft-inc/nebula/pull/4654) [#4663](https://github.com/vesoft-inc/nebula/pull/4663) [#4722](https://github.com/vesoft-inc/nebula/pull/4722) [#4742](https://github.com/vesoft-inc/nebula/pull/4742)
-
-- Added flags of experimental features, `enable_data_balance` for `BALANCE DATA`. [#4728](https://github.com/vesoft-inc/nebula/pull/4728)
-
-- Stats log print to console when the process is started. [#4550](https://github.com/vesoft-inc/nebula/pull/4550)
-
-- Supported the `JSON_EXTRACT` function. [#4743](https://github.com/vesoft-inc/nebula/pull/4743)
-
## Bugfix
-- Fixed the crash of variable types collected. [#4724](https://github.com/vesoft-inc/nebula/pull/4724)
-
-- Fixed the crash in the optimization phase of multiple `MATCH`. [#4780](https://github.com/vesoft-inc/nebula/pull/4780)
-
-- Fixed the bug of aggregate expression type deduce. [#4706](https://github.com/vesoft-inc/nebula/pull/4706)
-
-- Fixed the incorrect result of the `OPTIONAL MATCH` statement. [#4670](https://github.com/vesoft-inc/nebula/pull/4670)
-
-- Fixed the bug of parameter expression in the `LOOKUP` statement. [#4664](https://github.com/vesoft-inc/nebula/pull/4664)
+- Fix the crash caused by encoding parameter expressions to the storage layer for execution. [#5336](https://github.com/vesoft-inc/nebula/pull/5336)
-- Fixed the bug that `YIELD DISTINCT` returned a distinct result set in the `LOOKUP` statement. [#4651](https://github.com/vesoft-inc/nebula/pull/4651)
+- Fix some crashes for the list function. [#5383](https://github.com/vesoft-inc/nebula/pull/5383)
-- Fixed the bug that `ColumnExpression` encode and decode are not matched. [#4413](https://github.com/vesoft-inc/nebula/pull/4413)
-
-- Fixed the bug that `id($$)` filter was incorrect in the `GO` statement. [#4768](https://github.com/vesoft-inc/nebula/pull/4768)
-
-- Fixed the bug that full scan of `MATCH` statement when there is a relational `In` predicate. [#4748](https://github.com/vesoft-inc/nebula/pull/4748)
-
-- Fixed the optimizer error of `MATCH` statement.[#4771](https://github.com/vesoft-inc/nebula/pull/4771)
-
-- Fixed wrong output when using `pattern` expression as the filter in `MATCH` statement. [#4778](https://github.com/vesoft-inc/nebula/pull/4778)
-
-- Fixed the bug that tag, edge, tag index and edge index display incorrectly. [#4616](https://github.com/vesoft-inc/nebula/pull/4616)
-
-- Fixed the bug of date time format. [#4524](https://github.com/vesoft-inc/nebula/pull/4524)
-
-- Fixed the bug that the return value of the date time vertex was changed. [#4448](https://github.com/vesoft-inc/nebula/pull/4448)
-
-- Fixed the bug that the startup service failed when the log directory not existed and `enable_breakpad` was enabled. [#4623](https://github.com/vesoft-inc/nebula/pull/4623)
-
-- Fixed the bug that after the metad stopped, the status remained online. [#4610](https://github.com/vesoft-inc/nebula/pull/4610)
-
-- Fixed the corruption of the log file. [#4409](https://github.com/vesoft-inc/nebula/pull/4409)
-
-- Fixed the bug that `ENABLE_CCACHE` option didn't work. [#4648](https://github.com/vesoft-inc/nebula/pull/4648)
-
-- Abandoned uppercase letters in full-text index names. [#4628](https://github.com/vesoft-inc/nebula/pull/4628)
+## Legacy versions
-- Disable `COUNT(DISTINCT *)` . [#4553](https://github.com/vesoft-inc/nebula/pull/4553)
+[Release notes of legacy versions](https://nebula-graph.io/posts/)
-### Change
-- Vertices without tags are not supported by default. If you want to use the vertex without tags, add `--graph_use_vertex_key=true` to the configuration files (`nebula-graphd.conf`) of all Graph services in the cluster, add `--use_vertex_key=true` to the configuration files (`nebula-storaged.conf`) of all Storage services in the cluster. [#4629](https://github.com/vesoft-inc/nebula/pull/4629)
-## Legacy versions
-[Release notes of legacy versions](https://nebula-graph.io/posts/)
diff --git a/docs-2.0/20.appendix/release-notes/nebula-ent-release-note.md b/docs-2.0/20.appendix/release-notes/nebula-ent-release-note.md
index 9fbbd11a97d..6f1ffeb76e2 100644
--- a/docs-2.0/20.appendix/release-notes/nebula-ent-release-note.md
+++ b/docs-2.0/20.appendix/release-notes/nebula-ent-release-note.md
@@ -1,90 +1,11 @@
# NebulaGraph {{ nebula.release }} release notes
-## Feature
-
-- Support [incremental backup](../../backup-and-restore/nebula-br-ent/1.br-ent-overview.md).
-- Support [fine-grained permission management]((../../7.data-security/1.authentication/3.role-list.md)) at the Tag/Edge type level.
-- Support [killing sessions](../../3.ngql-guide/17.query-tuning-statements/2.kill-session.md).
-- Support [Memory Tracker](../../5.configurations-and-logs/1.configurations/4.storage-config.md) to optimize memory management.
-- Support [black-box monitoring](../../6.monitor-and-metrics/3.bbox/3.1.bbox.md).
-- Support function [json_extract](../../3.ngql-guide/6.functions-and-expressions/2.string.md).
-- Support function [extract](../../3.ngql-guide/6.functions-and-expressions/2.string.md).
-
-## Enhancement
-
-- Support using `GET SUBGRAPH` to filter vertices.
-- Support using `GetNeighbors` to filter vertices.
-- Support the conversion between timestamp and date time.
-- Support the reference of local variable in pattern expressions.
-- Optimize job management.
-- Optimize the full-text index.
-- Optimize the treatment scheme when the pattern expressions are used as predicates.
-- Optimize the join performance of the GO statement.
-- Optimize the performance of k-hop.
-- Optimize the performance of the shortest path query.
-- Optimize the push-down of the filtering of the vertex property.
-- Optimize the push-down of the edge filtering.
-- Optimize the loop conditions of the subgraph query.
-- Optimize the rules of the property cropping.
-- Remove the invalid `Project` operators.
-- Remove the invalid `AppendVertices` operators.
-- Reduce the amount of data replication for connection operations.
-- Reduce the amount of data replication for `Traverse` and `AppendVertices` operators.
-- Modify the default value of the Graph service parameter `session_reclaim_interval_secs` to 60 seconds.
-- Adjust the default level of `stderrthreshold` in the configuration file.
-- Get the property values by subscript to reduce the time of property query.
-- Limit the maximum depth of the plan tree in the optimizer to avoid stack overflows.
-
## Bugfix
-- Fix the bug about query plan generation and optimization.
-
-- Fix the bugs related to indexes:
-
- - Full-text indexes
- - String indexes
-
-- Fix the bugs related to query statements:
-
- - Variables
- - Filter conditions and expressions
- - Properties of vertices or edges
- - parameters
- - Functions and aggregations
- - Using illegal data types
- - Time zone, date, time, etc
- - Clauses and operators
-
-- Fix the bugs related to DDL and DML statements:
-
- - ALTER TAG
- - UPDATE
-
-- Fix the bugs related to other functions:
-
- - TTL
- - Synchronization
- - Authentication
- - Services
- - Logs
- - Monitoring and statistics
-
-## Change
+- Fix the crash caused by encoding parameter expressions to the storage layer for execution.
-- If you want to upgrade NebulaGraph from version 3.1 to 3.4, please follow the instructions in the [upgrade document](../../4.deployment-and-installation/3.upgrade-nebula-graph/upgrade-nebula-ent-from-3.x-3.4.md).
-- The added property name can not be the same as an existing or deleted property name, otherwise, the operation of adding a property fails.
-- Limit the type conversion when modifying the schema.
-- The default value must be specified when creating a property of type `NOT NULL`.
-- Add the multithreaded query parameter `query_concurrently` to the configuration file with a default value of `true`.
-- Remove the parameter `kv_separation` of the KV separation storage function from the configuration file, which is turned off by default.
-- Modify the default value of `local_config` in the configuration file to `true`.
-- Consistent use of `v.tag.property` to get property values, because it is necessary to specify the Tag. Using `v.property` to access the property of a Tag on `v` was incorrectly allowed in the previous version.
-- Remove the column `HTTP port` from the command `SHOW HOSTS`.
-- Disable the queries of the form `OPTIONAL MATCH WHERE `.
-- Disable the functions of the form `COUNT(DISTINCT *)`.
-- Disable TOSS.
-- Rename Listener's pid filename and log directory name.
+- Fix some crashes for the list function.
## Legacy versions
-[Release notes of legacy versions](https://nebula-graph.io/posts/)
+[Release notes of legacy versions](https://www.nebula-graph.io/tags/release-notes)
diff --git a/docs-2.0/3.ngql-guide/1.nGQL-overview/keywords-and-reserved-words.md b/docs-2.0/3.ngql-guide/1.nGQL-overview/keywords-and-reserved-words.md
index 7c82add3a0e..578e92e3a15 100644
--- a/docs-2.0/3.ngql-guide/1.nGQL-overview/keywords-and-reserved-words.md
+++ b/docs-2.0/3.ngql-guide/1.nGQL-overview/keywords-and-reserved-words.md
@@ -4,7 +4,7 @@ Keywords have significance in nGQL. It can be classified into reserved keywords
If you must use keywords in schema:
-- Non-reserved keywords are permitted as identifiers without quoting.
+- Non-reserved keywords can be used as identifiers without quotes if they are all in lowercase. However, if a non-reserved keyword contains any uppercase letters when used as an identifier, it must be enclosed in backticks (\`), for example, \`Comment\`.
- To use special characters or reserved keywords as identifiers, quote them with backticks such as `AND`.
diff --git a/docs-2.0/3.ngql-guide/10.tag-statements/1.create-tag.md b/docs-2.0/3.ngql-guide/10.tag-statements/1.create-tag.md
index 3b0cfe7d1cd..7c3f3baf959 100644
--- a/docs-2.0/3.ngql-guide/10.tag-statements/1.create-tag.md
+++ b/docs-2.0/3.ngql-guide/10.tag-statements/1.create-tag.md
@@ -31,7 +31,7 @@ CREATE TAG [IF NOT EXISTS]
|Parameter|Description|
|:---|:---|
|`IF NOT EXISTS`|Detects if the tag that you want to create exists. If it does not exist, a new one will be created. The tag existence detection here only compares the tag names (excluding properties).|
-|``|1. The tag name must be **unique** in a graph space.
2. Once the tag name is set, it can not be altered.
3. The name of the tag starts with a letter, supports 1 to 4 bytes UTF-8 encoded characters, such as English letters (case-sensitive), digits, and Chinese characters, but does not support special characters except underscores. To use special characters (the period character (.) is excluded) or reserved keywords as identifiers, quote them with backticks. For more information, see [Keywords and reserved words](../../3.ngql-guide/1.nGQL-overview/keywords-and-reserved-words.md).|
+|``|1. The tag name must be **unique** in a graph space.
2. Once the tag name is set, it can not be altered.
3. The name of the tag supports 1 to 4 bytes UTF-8 encoded characters, such as English letters (case-sensitive), digits, and Chinese characters, but does not support special characters except underscores. To use special characters (the period character (.) is excluded) or reserved keywords as identifiers, quote them with backticks. For more information, see [Keywords and reserved words](../../3.ngql-guide/1.nGQL-overview/keywords-and-reserved-words.md).|
|``|The name of the property. It must be unique for each tag. The rules for permitted property names are the same as those for tag names.|
|``|Shows the data type of each property. For a full description of the property data types, see [Data types](../3.data-types/1.numeric.md) and [Boolean](../3.data-types/2.boolean.md).|
|`NULL \| NOT NULL`|Specifies if the property supports `NULL | NOT NULL`. The default value is `NULL`. `DEFAULT` must be specified if `NOT NULL` is set.|
diff --git a/docs-2.0/3.ngql-guide/14.native-index-statements/1.create-native-index.md b/docs-2.0/3.ngql-guide/14.native-index-statements/1.create-native-index.md
index 82a5d2f610d..ae4fa2ed47c 100644
--- a/docs-2.0/3.ngql-guide/14.native-index-statements/1.create-native-index.md
+++ b/docs-2.0/3.ngql-guide/14.native-index-statements/1.create-native-index.md
@@ -16,7 +16,7 @@ You can use `CREATE INDEX` to add native indexes for the existing tags, edge typ
- Property indexes apply to property-based queries. For example, you can use the `age` property to retrieve the VID of all vertices that meet `age == 19`.
-If a property index `i_TA` is created for the property `A` of the tag `T`, the indexes can be replaced as follows (the same for edge type indexes):
+If a property index `i_TA` is created for the property `A` of the tag `T` and `i_T` for the tag `T`, the indexes can be replaced as follows (the same for edge type indexes):
- The query engine can use `i_TA` to replace `i_T`.
diff --git a/docs-2.0/3.ngql-guide/16.subgraph-and-path/1.get-subgraph.md b/docs-2.0/3.ngql-guide/16.subgraph-and-path/1.get-subgraph.md
index 82eb136c934..f26f24a0997 100644
--- a/docs-2.0/3.ngql-guide/16.subgraph-and-path/1.get-subgraph.md
+++ b/docs-2.0/3.ngql-guide/16.subgraph-and-path/1.get-subgraph.md
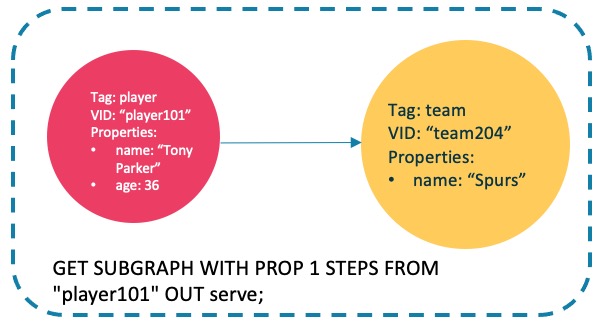
@@ -109,6 +109,20 @@ nebula> INSERT EDGE serve(start_year, end_year) VALUES "player101" -> "team204":
The returned subgraph is as follows.
+
+ * This example goes two steps from the vertex `player101` over `follow` edges, filters by degree > 90 and age > 30, and shows the properties of edges.
+
+ ```ngql
+ nebula> GET SUBGRAPH WITH PROP 2 STEPS FROM "player101" \
+ WHERE follow.degree > 90 AND $$.player.age > 30 \
+ YIELD VERTICES AS nodes, EDGES AS relationships;
+ +-------------------------------------------------------+------------------------------------------------------+
+ | nodes | relationships |
+ +-------------------------------------------------------+------------------------------------------------------+
+ | [("player101" :player{age: 36, name: "Tony Parker"})] | [[:follow "player101"->"player100" @0 {degree: 95}]] |
+ | [("player100" :player{age: 42, name: "Tim Duncan"})] | [] |
+ +-------------------------------------------------------+------------------------------------------------------+
+ ```
## FAQ
diff --git a/docs-2.0/3.ngql-guide/4.variable-and-composite-queries/2.user-defined-variables.md b/docs-2.0/3.ngql-guide/4.variable-and-composite-queries/2.user-defined-variables.md
index b80905d6d48..aeef106bf1f 100644
--- a/docs-2.0/3.ngql-guide/4.variable-and-composite-queries/2.user-defined-variables.md
+++ b/docs-2.0/3.ngql-guide/4.variable-and-composite-queries/2.user-defined-variables.md
@@ -31,7 +31,8 @@ You can use user-defined variables in composite queries. Details about composite
!!! note
- User-defined variables are case-sensitive.
+ - User-defined variables are case-sensitive.
+ - To define a user-defined variable in a compound statement, end the statement with a semicolon (;). For details, please refer to the [nGQL Style Guide](../../3.ngql-guide/1.nGQL-overview/ngql-style-guide.md).
## Example
diff --git a/docs-2.0/3.ngql-guide/5.operators/4.pipe.md b/docs-2.0/3.ngql-guide/5.operators/4.pipe.md
index 7621f6199b6..8bd8c691714 100644
--- a/docs-2.0/3.ngql-guide/5.operators/4.pipe.md
+++ b/docs-2.0/3.ngql-guide/5.operators/4.pipe.md
@@ -31,8 +31,6 @@ nebula> GO FROM "player100" OVER follow \
+-------------+
```
-If there is no `YIELD` clause to define the output, the destination vertex ID is returned by default. If a YIELD clause is applied, the output is defined by the YIELD clause.
-
Users must define aliases in the `YIELD` clause for the reference operator `$-` to use, just like `$-.dstid` in the preceding example.
## Performance tips
diff --git a/docs-2.0/3.ngql-guide/6.functions-and-expressions/4.schema.md b/docs-2.0/3.ngql-guide/6.functions-and-expressions/4.schema.md
index 89a1c26d84f..e6dd6f69523 100644
--- a/docs-2.0/3.ngql-guide/6.functions-and-expressions/4.schema.md
+++ b/docs-2.0/3.ngql-guide/6.functions-and-expressions/4.schema.md
@@ -51,6 +51,19 @@ nebula> LOOKUP ON player WHERE player.age > 45 \
+-------------------------------------+
```
+You can also use the property reference symbols (`$^` and `$$`) instead of the `vertex` field in the `properties()` function to get all properties of a vertex.
+
+- `$^` represents the data of the starting vertex at the beginning of exploration. For example, in `GO FROM "player100" OVER follow reversely YIELD properties($^)`, `$^` refers to the vertex `player100`.
+
+- `$$` represents the data of the end vertex at the end of exploration.
+
+`properties($^)` and `properties($$)` are generally used in `GO` statements. For more information, see [Property reference](../5.operators/5.property-reference.md).
+
+!!! caution
+
+ You can use `properties().` to get a specific property of a vertex. However, it is not recommended to use this method to obtain specific properties because the `properties()` function returns all properties, which can decrease query performance.
+
+
### properties(edge)
properties(edge) returns the properties of an edge.
@@ -72,6 +85,10 @@ nebula> GO FROM "player100" OVER follow \
+------------------+
```
+!!! caution
+
+ You can use `properties(edge).` to get a specific property of an edge. However, it is not recommended to use this method to obtain specific properties because the `properties(edge)` function returns all properties, which can decrease query performance.
+
### type(edge)
type(edge) returns the edge type of an edge.
diff --git a/docs-2.0/4.deployment-and-installation/3.upgrade-nebula-graph/upgrade-nebula-ent-from-3.x-3.4.md b/docs-2.0/4.deployment-and-installation/3.upgrade-nebula-graph/upgrade-nebula-ent-from-3.x-3.4.md
index 6affdf04794..c1571d155d7 100644
--- a/docs-2.0/4.deployment-and-installation/3.upgrade-nebula-graph/upgrade-nebula-ent-from-3.x-3.4.md
+++ b/docs-2.0/4.deployment-and-installation/3.upgrade-nebula-graph/upgrade-nebula-ent-from-3.x-3.4.md
@@ -4,12 +4,17 @@ This topic takes the enterprise edition of NebulaGraph v3.1.0 as an example and
## Notes
-- This upgrade is only applicable for upgrading the enterprise edition of NebulaGraph v3.x to v3.4.0. If your version is below 3.0.0, please upgrade to enterprise edition 3.x before upgrading to v3.4.0. For details, see [Upgrade NebulaGraph Enterprise Edition 2.x to 3.1.0](https://docs.nebula-graph.io/3.1.0/4.deployment-and-installation/3.upgrade-nebula-graph/upgrade-nebula-graph-to-latest/).
+- This upgrade is only applicable for upgrading the enterprise edition of NebulaGraph v3.x to v3.4.0. If your version is below 3.0.0, please upgrade to enterprise edition 3.1.0 before upgrading to v3.4.0. For details, see [Upgrade NebulaGraph Enterprise Edition 2.x to 3.1.0](https://docs.nebula-graph.io/3.1.0/4.deployment-and-installation/3.upgrade-nebula-graph/upgrade-nebula-graph-to-latest/).
- The IP address of the machine performing the upgrade operation must be the same as the original machine.
- The remaining disk space on the machine must be at least 1.5 times the size of the original data directory.
+- Before upgrading a NebulaGraph cluster with full-text indexes deployed, you must manually delete the full-text indexes in Elasticsearch, and then run the `SIGN IN` command to log into ES and recreate the indexes after the upgrade is complete.
+
+ !!! note
+
+ To manually delete the full-text indexes in Elasticsearch, you can use the curl command `curl -XDELETE -u : ':/'`, for example, `curl -XDELETE -u elastic:elastic 'http://192.168.8.223:9200/nebula_index_2534'`. If no username and password are set for Elasticsearch, you can omit the `-u :` part.
## Steps
diff --git a/docs-2.0/4.deployment-and-installation/3.upgrade-nebula-graph/upgrade-nebula-from-300-to-latest.md b/docs-2.0/4.deployment-and-installation/3.upgrade-nebula-graph/upgrade-nebula-from-300-to-latest.md
index 40eeb6cee45..29ed7ff7a2b 100644
--- a/docs-2.0/4.deployment-and-installation/3.upgrade-nebula-graph/upgrade-nebula-from-300-to-latest.md
+++ b/docs-2.0/4.deployment-and-installation/3.upgrade-nebula-graph/upgrade-nebula-from-300-to-latest.md
@@ -2,10 +2,13 @@
To upgrade NebulaGraph v3.x to v{{nebula.release}}, you only need to use the RPM/DEB package of v{{nebula.release}} for the upgrade, or [compile it](../2.compile-and-install-nebula-graph/1.install-nebula-graph-by-compiling-the-source-code.md) and then reinstall.
+!!! caution
+
+ Before upgrading a NebulaGraph cluster with full-text indexes deployed, you must manually delete the full-text indexes in Elasticsearch, and then run the `SIGN IN` command to log into ES and recreate the indexes after the upgrade is complete. To manually delete the full-text indexes in Elasticsearch, you can use the curl command `curl -XDELETE -u : ':/'`, for example, `curl -XDELETE -u elastic:elastic 'http://192.168.8.223:9200/nebula_index_2534'`. If no username and password are set for Elasticsearch, you can omit the `-u :` part.
## Upgrade steps with RPM/DEB packages
-1. Download the [RPM/DEB package](https://github.com/vesoft-inc/nebula-graph/releases/tag/v{{nebula.release}}).
+1. Download the [RPM/DEB package](https://www.nebula-graph.io/download).
2. Stop all NebulaGraph services. For details, see [Manage NebulaGraph Service](../../2.quick-start/5.start-stop-service.md). It is recommended to back up the configuration file before updating.
diff --git a/docs-2.0/4.deployment-and-installation/3.upgrade-nebula-graph/upgrade-nebula-graph-to-latest.md b/docs-2.0/4.deployment-and-installation/3.upgrade-nebula-graph/upgrade-nebula-graph-to-latest.md
index 98045084670..147480e4c0b 100644
--- a/docs-2.0/4.deployment-and-installation/3.upgrade-nebula-graph/upgrade-nebula-graph-to-latest.md
+++ b/docs-2.0/4.deployment-and-installation/3.upgrade-nebula-graph/upgrade-nebula-graph-to-latest.md
@@ -4,11 +4,11 @@ This topic describes how to upgrade NebulaGraph from version 2.x to {{nebula.rel
## Applicable source versions
-This topic applies to upgrading NebulaGraph from 2.0.0 and later 2.x versions to {{nebula.release}}. It does not apply to historical versions earlier than 2.0.0, including the 1.x versions.
+This topic applies to upgrading NebulaGraph from 2.5.0 and later 2.x versions to {{nebula.release}}. It does not apply to historical versions earlier than 2.5.0, including the 1.x versions.
To upgrade NebulaGraph from historical versions to {{nebula.release}}:
-1. Upgrade it to the latest 2.x version according to the docs of that version.
+1. Upgrade it to the latest 2.5 version according to the docs of that version.
2. Follow this topic to upgrade it to {{nebula.release}}.
!!! caution
@@ -63,6 +63,10 @@ To upgrade NebulaGraph from historical versions to {{nebula.release}}:
- It is required to specify a tag to query properties of a vertex in a `MATCH` statement. For example, from `return v.name` to `return v.player.name`.
+- Full-text indexes
+
+ Before upgrading a NebulaGraph cluster with full-text indexes deployed, you must manually delete the full-text indexes in Elasticsearch, and then run the `SIGN IN` command to log into ES and recreate the indexes after the upgrade is complete. To manually delete the full-text indexes in Elasticsearch, you can use the curl command `curl -XDELETE -u : ':/'`, for example, `curl -XDELETE -u elastic:elastic 'http://192.168.8.xxx:9200/nebula_index_2534'`. If no username and password are set for Elasticsearch, you can omit the `-u :` part.
+
!!! caution
There may be other undiscovered influences. Before the upgrade, we recommend that you read the release notes and user manual carefully, and keep an eye on the [posts](https://github.com/vesoft-inc/nebula/discussions) on the forum and [issues](https://github.com/vesoft-inc/nebula/issues) on Github.
diff --git a/docs-2.0/5.configurations-and-logs/1.configurations/.1.get-configurations.md b/docs-2.0/5.configurations-and-logs/1.configurations/.1.get-configurations.md
deleted file mode 100644
index f49843221fd..00000000000
--- a/docs-2.0/5.configurations-and-logs/1.configurations/.1.get-configurations.md
+++ /dev/null
@@ -1,36 +0,0 @@
-# Get configurations
-
-This document gives some methods to get configurations in NebulaGraph.
-
-!!! note
-
- You must use ONLY ONE method in one cluster. To avoid errors, we suggest that you get configurations from local.
-
-## Get configurations from local
-
-Add `--local_config=true` to the top of each configuration file (the default path is `/usr/local/nebula/etc/`). Restart all the NebulaGraph services to make your modifications take effect. We suggest that new users use this method.
-
-## Get configuration from Meta Service
-
-To get configuration from Meta Service, set the `--local_config` parameter to `false` or use the default configuration files.
-
-When the services are started for the first time, NebulaGraph reads the configurations from local and then persists them in the Meta Service. Once the Meta Service is persisted, NebulaGraph reads configurations only from the Meta Service, even you restart NebulaGraph.
-
-## FAQ
-
-## How to modify configurations
-
-You can modify NebulaGraph configurations by using these methods:
-
-- Modify configurations by using `UPDATE CONFIG`. For more information see UPDATE CONFIG (doc TODO).
-- Modify configurations by configuring the configuration files. For more information, see [Get configuration from local](#get_configuration_from_local).
-
-## What is the configuration priority and how to modify it
-
-The **default** configuration reading precedence is Meta Service > `UPDATE CONFIG`> configuration files.
-
-When `--local_config` is set to `true`, the configuration reading precedence is configuration files > Meta Service.
-
-!!! danger
-
- Don't use `UPDATE CONFIG` to update configurations when `--local_config` is set to `true`.
diff --git a/docs-2.0/5.configurations-and-logs/1.configurations/.5.console-config.md b/docs-2.0/5.configurations-and-logs/1.configurations/.5.console-config.md
deleted file mode 100644
index 8889872658f..00000000000
--- a/docs-2.0/5.configurations-and-logs/1.configurations/.5.console-config.md
+++ /dev/null
@@ -1,10 +0,0 @@
-
diff --git a/docs-2.0/5.configurations-and-logs/1.configurations/1.configurations.md b/docs-2.0/5.configurations-and-logs/1.configurations/1.configurations.md
index dbf32455204..f42fe2bfab0 100644
--- a/docs-2.0/5.configurations-and-logs/1.configurations/1.configurations.md
+++ b/docs-2.0/5.configurations-and-logs/1.configurations/1.configurations.md
@@ -104,6 +104,14 @@ For clusters installed with Kubectl through NebulaGraph Operator, the configurat
## Modify configurations
+You can modify the configurations of NebulaGraph in the configuration file or use commands to dynamically modify configurations.
+
+!!! caution
+
+ Using both methods to modify the configuration can cause the configuration information to be managed inconsistently, which may result in confusion. It is recommended to only use the configuration file to manage the configuration, or to make the same modifications to the configuration file after dynamically updating the configuration through commands to ensure consistency.
+
+### Modifying configurations in the configuration file
+
By default, each NebulaGraph service gets configured from its configuration files. You can modify configurations and make them valid according to the following steps:
* For clusters installed from source, with a RPM/DEB, or a TAR package
@@ -120,3 +128,21 @@ By default, each NebulaGraph service gets configured from its configuration file
* For clusters installed with Kubectl
For details, see [Customize configuration parameters for a NebulaGraph cluster](../../nebula-operator/8.custom-cluster-configurations/8.1.custom-conf-parameter.md).
+
+### Dynamically modifying configurations using command
+
+You can dynamically modify the configuration of NebulaGraph by using the curl command. For example, to modify the `wal_ttl` parameter of the Storage service to `600`, use the following command:
+
+```bash
+curl -X PUT -H "Content-Type: application/json" -d'{"wal_ttl":"600"}' -s "http://192.168.15.6:19779/flags"
+```
+
+In this command, ` {"wal_ttl":"600"}` specifies the configuration parameter and its value to be modified, and `192.168.15.6:19779` specifies the IP address and HTTP port number of the Storage service.
+
+!!! caution
+
+ - The functionality of dynamically modifying configurations is only applicable to prototype verification and testing environments. It is not recommended to use this feature in production environments. This is because when the `local_config` value is set to `true`, the dynamically modified configuration is not persisted, and the configuration will be restored to the initial configuration after the service is restarted.
+
+ - Only **part of** the configuration parameters can be dynamically modified. For the specific list of parameters that can be modified, see the description of **Whether supports runtime dynamic modifications** in the respective service configuration.
+
+
diff --git a/docs-2.0/5.configurations-and-logs/1.configurations/2.meta-config.md b/docs-2.0/5.configurations-and-logs/1.configurations/2.meta-config.md
index 2d85008992b..d5344a0ab9d 100644
--- a/docs-2.0/5.configurations-and-logs/1.configurations/2.meta-config.md
+++ b/docs-2.0/5.configurations-and-logs/1.configurations/2.meta-config.md
@@ -15,20 +15,24 @@ To use the initial configuration file, choose one of the above two files and del
If a parameter is not set in the configuration file, NebulaGraph uses the default value. Not all parameters are predefined. And the predefined parameters in the two initial configuration files are different. This topic uses the parameters in `nebula-metad.conf.default`.
+!!! caution
+
+ Some parameter values in the configuration file can be dynamically modified during runtime. We label these parameters as **Yes** that supports runtime dynamic modification in this article. When the `local_config` value is set to `true`, the dynamically modified configuration is not persisted, and the configuration will be restored to the initial configuration after the service is restarted. For more information, see [Modify configurations](1.configurations.md).
+
For all parameters and their current values, see [Configurations](1.configurations.md).
## Basics configurations
-| Name | Predefined value | Description |
-| ----------- | ----------------------- | ---------------------------------------------------- |
-| `daemonize` | `true` | When set to `true`, the process is a daemon process. |
-| `pid_file` | `pids/nebula-metad.pid` | The file that records the process ID. |
-| `timezone_name` | - | Specifies the NebulaGraph time zone. This parameter is not predefined in the initial configuration files. You can manually set it if you need it. The system default value is `UTC+00:00:00`. For the format of the parameter value, see [Specifying the Time Zone with TZ](https://www.gnu.org/software/libc/manual/html_node/TZ-Variable.html "Click to view the timezone-related content in the GNU C Library manual"). For example, `--timezone_name=UTC+08:00` represents the GMT+8 time zone.|
+| Name | Predefined value | Description | Whether supports runtime dynamic modifications|
+| ----------- | ----------------------- | ---------------------------------------------------- |-------------------- |
+| `daemonize` | `true` | When set to `true`, the process is a daemon process. | No|
+| `pid_file` | `pids/nebula-metad.pid` | The file that records the process ID. | No|
+| `timezone_name` | - | Specifies the NebulaGraph time zone. This parameter is not predefined in the initial configuration files. You can manually set it if you need it. The system default value is `UTC+00:00:00`. For the format of the parameter value, see [Specifying the Time Zone with TZ](https://www.gnu.org/software/libc/manual/html_node/TZ-Variable.html "Click to view the timezone-related content in the GNU C Library manual"). For example, `--timezone_name=UTC+08:00` represents the GMT+8 time zone.|No|
{{ ent.ent_begin }}
-| Name | Predefined value | Description |
-| ----------- | ----------------------- | ---------------------------------------------------- |
-|`license_path`|`share/resources/nebula.license`| Path of the license of the NebulaGraph Enterprise Edition. Users need to [deploy a license file](../../4.deployment-and-installation/deploy-license.md) before starting the Enterprise Edition. This parameter is required only for the NebulaGraph Enterprise Edition. For details about how to configure licenses for other ecosystem tools, see the deployment documents of the corresponding ecosystem tools.|
+| Name | Predefined value | Description |Whether supports runtime dynamic modifications|
+| ----------- | ----------------------- | ---------------------------------------------------- |----------------- |
+|`license_path`|`share/resources/nebula.license`| Path of the license of the NebulaGraph Enterprise Edition. Users need to [deploy a license file](../../4.deployment-and-installation/deploy-license.md) before starting the Enterprise Edition. This parameter is required only for the NebulaGraph Enterprise Edition. For details about how to configure licenses for other ecosystem tools, see the deployment documents of the corresponding ecosystem tools.| No|
{{ ent.ent_end }}
@@ -39,29 +43,29 @@ For all parameters and their current values, see [Configurations](1.configuratio
## Logging configurations
-| Name | Predefined value | Description |
-| :------------- | :------------------------ | :------------------------------------------------ |
-| `log_dir` | `logs` | The directory that stores the Meta Service log. It is recommended to put logs on a different hard disk from the data. |
-| `minloglevel` | `0` | Specifies the minimum level of the log. That is, log messages at or above this level. Optional values are `0` (INFO), `1` (WARNING), `2` (ERROR), `3` (FATAL). It is recommended to set it to `0` during debugging and `1` in a production environment. If it is set to `4`, NebulaGraph will not print any logs. |
-| `v` | `0` | Specifies the detailed level of VLOG. That is, log all VLOG messages less or equal to the level. Optional values are `0`, `1`, `2`, `3`, `4`, `5`. The VLOG macro provided by glog allows users to define their own numeric logging levels and control verbose messages that are logged with the parameter `v`. For details, see [Verbose Logging](https://github.com/google/glog#verbose-logging).|
-| `logbufsecs` | `0` | Specifies the maximum time to buffer the logs. If there is a timeout, it will output the buffered log to the log file. `0` means real-time output. This configuration is measured in seconds. |
-|`redirect_stdout` |`true` | When set to `true`, the process redirects the`stdout` and `stderr` to separate output files. |
-|`stdout_log_file` |`metad-stdout.log` | Specifies the filename for the `stdout` log. |
-|`stderr_log_file` |`metad-stderr.log` | Specifies the filename for the `stderr` log. |
-|`stderrthreshold` | `3` | Specifies the `minloglevel` to be copied to the `stderr` log. |
-| `timestamp_in_logfile_name` | `true` | Specifies if the log file name contains a timestamp. `true` indicates yes, `false` indicates no. |
+| Name | Predefined value | Description |Whether supports runtime dynamic modifications|
+| :------------- | :------------------------ | :------------------------------------------------ |:----------------- |
+| `log_dir` | `logs` | The directory that stores the Meta Service log. It is recommended to put logs on a different hard disk from the data. | No|
+| `minloglevel` | `0` | Specifies the minimum level of the log. That is, log messages at or above this level. Optional values are `0` (INFO), `1` (WARNING), `2` (ERROR), `3` (FATAL). It is recommended to set it to `0` during debugging and `1` in a production environment. If it is set to `4`, NebulaGraph will not print any logs. | Yes|
+| `v` | `0` | Specifies the detailed level of VLOG. That is, log all VLOG messages less or equal to the level. Optional values are `0`, `1`, `2`, `3`, `4`, `5`. The VLOG macro provided by glog allows users to define their own numeric logging levels and control verbose messages that are logged with the parameter `v`. For details, see [Verbose Logging](https://github.com/google/glog#verbose-logging).| Yes|
+| `logbufsecs` | `0` | Specifies the maximum time to buffer the logs. If there is a timeout, it will output the buffered log to the log file. `0` means real-time output. This configuration is measured in seconds. | No|
+|`redirect_stdout` |`true` | When set to `true`, the process redirects the`stdout` and `stderr` to separate output files. | No|
+|`stdout_log_file` |`metad-stdout.log` | Specifies the filename for the `stdout` log. | No|
+|`stderr_log_file` |`metad-stderr.log` | Specifies the filename for the `stderr` log. | No|
+|`stderrthreshold` | `3` | Specifies the `minloglevel` to be copied to the `stderr` log. | No|
+| `timestamp_in_logfile_name` | `true` | Specifies if the log file name contains a timestamp. `true` indicates yes, `false` indicates no. | No|
## Networking configurations
-| Name | Predefined value | Description |
-| :----------------------- | :---------------- | :---------------------------------------------------- |
-| `meta_server_addrs` | `127.0.0.1:9559` | Specifies the IP addresses and ports of all Meta Services. Multiple addresses are separated with commas. |
-|`local_ip` | `127.0.0.1` | Specifies the local IP for the Meta Service. The local IP address is used to identify the nebula-metad process. If it is a distributed cluster or requires remote access, modify it to the corresponding address.|
-| `port` | `9559` | Specifies RPC daemon listening port of the Meta service. The external port for the Meta Service is predefined to `9559`. The internal port is predefined to `port + 1`, i.e., `9560`. Nebula Graph uses the internal port for multi-replica interactions. |
-| `ws_ip` | `0.0.0.0` | Specifies the IP address for the HTTP service. |
-| `ws_http_port` | `19559` | Specifies the port for the HTTP service. |
-|`ws_storage_http_port`|`19779`| Specifies the Storage service listening port used by the HTTP protocol. It must be consistent with the `ws_http_port` in the Storage service configuration file. This parameter only applies to standalone NebulaGraph.|
-|`heartbeat_interval_secs` | `10` | Specifies the default heartbeat interval. Make sure the `heartbeat_interval_secs` values for all services are the same, otherwise NebulaGraph **CANNOT** work normally. This configuration is measured in seconds. |
+| Name | Predefined value | Description |Whether supports runtime dynamic modifications|
+| :----------------------- | :---------------- | :---------------------------------------------------- |:----------------- |
+| `meta_server_addrs` | `127.0.0.1:9559` | Specifies the IP addresses and ports of all Meta Services. Multiple addresses are separated with commas. | No|
+|`local_ip` | `127.0.0.1` | Specifies the local IP for the Meta Service. The local IP address is used to identify the nebula-metad process. If it is a distributed cluster or requires remote access, modify it to the corresponding address.| No|
+| `port` | `9559` | Specifies RPC daemon listening port of the Meta service. The external port for the Meta Service is predefined to `9559`. The internal port is predefined to `port + 1`, i.e., `9560`. Nebula Graph uses the internal port for multi-replica interactions. | No|
+| `ws_ip` | `0.0.0.0` | Specifies the IP address for the HTTP service. | No|
+| `ws_http_port` | `19559` | Specifies the port for the HTTP service. | No|
+|`ws_storage_http_port`|`19779`| Specifies the Storage service listening port used by the HTTP protocol. It must be consistent with the `ws_http_port` in the Storage service configuration file. This parameter only applies to standalone NebulaGraph.| No|
+|`heartbeat_interval_secs` | `10` | Specifies the default heartbeat interval. Make sure the `heartbeat_interval_secs` values for all services are the same, otherwise NebulaGraph **CANNOT** work normally. This configuration is measured in seconds. | Yes|
!!! caution
@@ -69,22 +73,22 @@ For all parameters and their current values, see [Configurations](1.configuratio
## Storage configurations
-| Name | Predefined Value | Description |
-| :------------------- | :------------------------ | :------------------------------------------ |
-| `data_path` | `data/meta` | The storage path for Meta data. |
+| Name | Predefined Value | Description |Whether supports runtime dynamic modifications|
+| :------------------- | :------------------------ | :------------------------------------------ |:----------------- |
+| `data_path` | `data/meta` | The storage path for Meta data. | No|
## Misc configurations
-| Name | Predefined Value | Description |
-| :------------------------- | :-------------------- | :---------------------------------------------------------------------------- |
-|`default_parts_num` | `100` | Specifies the default partition number when creating a new graph space. |
-|`default_replica_factor` | `1` | Specifies the default replica number when creating a new graph space. |
+| Name | Predefined Value | Description |Whether supports runtime dynamic modifications|
+| :------------------------- | :-------------------- | :---------------------------------------------------------------------------- |:----------------- |
+|`default_parts_num` | `100` | Specifies the default partition number when creating a new graph space. | No|
+|`default_replica_factor` | `1` | Specifies the default replica number when creating a new graph space. | No|
## RocksDB options configurations
-| Name | Predefined Value | Description |
-| :--------------- | :----------------- | :---------------------------------------- |
-|`rocksdb_wal_sync`| `true` | Enables or disables RocksDB WAL synchronization. Available values are `true` (enable) and `false` (disable).|
+| Name | Predefined Value | Description |Whether supports runtime dynamic modifications|
+| :--------------- | :----------------- | :---------------------------------------- |:----------------- |
+|`rocksdb_wal_sync`| `true` | Enables or disables RocksDB WAL synchronization. Available values are `true` (enable) and `false` (disable).| No|
{{ ent.ent_begin }}
## Black box configurations
@@ -93,11 +97,11 @@ For all parameters and their current values, see [Configurations](1.configuratio
The Nebula-BBox configurations are for the Enterprise Edition only.
-| Name | Predefined Value | Description |
-| :------------------- | :------------------------ | :------------------------------------------ |
-|`ng_black_box_switch` |`true` |Whether to enable the [Nebula-BBox](../../6.monitor-and-metrics/3.bbox/3.1.bbox.md) feature.|
-|`ng_black_box_home` |`black_box` |The name of the directory to store Nebula-BBox file data.|
-|`ng_black_box_dump_period_seconds` |`5` |The time interval for Nebula-BBox to collect metric data. Unit: Second.|
-|`ng_black_box_file_lifetime_seconds` |`1800` |Storage time for Nebula-BBox files generated after collecting metric data. Unit: Second.|
+| Name | Predefined Value | Description |Whether supports runtime dynamic modifications|
+| :------------------- | :------------------------ | :------------------------------------------ |:----------------- |
+|`ng_black_box_switch` |`true` |Whether to enable the [Nebula-BBox](../../6.monitor-and-metrics/3.bbox/3.1.bbox.md) feature.| No|
+|`ng_black_box_home` |`black_box` |The name of the directory to store Nebula-BBox file data.| No|
+|`ng_black_box_dump_period_seconds` |`5` |The time interval for Nebula-BBox to collect metric data. Unit: Second.| No|
+|`ng_black_box_file_lifetime_seconds` |`1800` |Storage time for Nebula-BBox files generated after collecting metric data. Unit: Second.| Yes|
{{ ent.ent_end }}
\ No newline at end of file
diff --git a/docs-2.0/5.configurations-and-logs/1.configurations/3.graph-config.md b/docs-2.0/5.configurations-and-logs/1.configurations/3.graph-config.md
index 85d0e003b42..1e667b8bef0 100644
--- a/docs-2.0/5.configurations-and-logs/1.configurations/3.graph-config.md
+++ b/docs-2.0/5.configurations-and-logs/1.configurations/3.graph-config.md
@@ -15,17 +15,21 @@ To use the initial configuration file, choose one of the above two files and del
If a parameter is not set in the configuration file, NebulaGraph uses the default value. Not all parameters are predefined. And the predefined parameters in the two initial configuration files are different. This topic uses the parameters in `nebula-metad.conf.default`.
+!!! caution
+
+ Some parameter values in the configuration file can be dynamically modified during runtime. We label these parameters as **Yes** that supports runtime dynamic modification in this article. When the `local_config` value is set to `true`, the dynamically modified configuration is not persisted, and the configuration will be restored to the initial configuration after the service is restarted. For more information, see [Modify configurations](1.configurations.md).
+
For all parameters and their current values, see [Configurations](1.configurations.md).
## Basics configurations
-| Name | Predefined value | Description |
-| ----------------- | ----------------------- | ------------------|
-| `daemonize` | `true` | When set to `true`, the process is a daemon process. |
-| `pid_file` | `pids/nebula-graphd.pid`| The file that records the process ID. |
-|`enable_optimizer` |`true` | When set to `true`, the optimizer is enabled. |
-| `timezone_name` | - | Specifies the NebulaGraph time zone. This parameter is not predefined in the initial configuration files. The system default value is `UTC+00:00:00`. For the format of the parameter value, see [Specifying the Time Zone with TZ](https://www.gnu.org/software/libc/manual/html_node/TZ-Variable.html "Click to view the timezone-related content in the GNU C Library manual"). For example, `--timezone_name=UTC+08:00` represents the GMT+8 time zone. |
-| `local_config` | `true` | When set to `true`, the process gets configurations from the configuration files. |
+| Name | Predefined value | Description |Whether supports runtime dynamic modifications|
+| ----------------- | ----------------------- | ------------------|------------------|
+| `daemonize` | `true` | When set to `true`, the process is a daemon process. | No|
+| `pid_file` | `pids/nebula-graphd.pid`| The file that records the process ID. | No|
+|`enable_optimizer` |`true` | When set to `true`, the optimizer is enabled. | No|
+| `timezone_name` | - | Specifies the NebulaGraph time zone. This parameter is not predefined in the initial configuration files. The system default value is `UTC+00:00:00`. For the format of the parameter value, see [Specifying the Time Zone with TZ](https://www.gnu.org/software/libc/manual/html_node/TZ-Variable.html "Click to view the timezone-related content in the GNU C Library manual"). For example, `--timezone_name=UTC+08:00` represents the GMT+8 time zone. | No|
+| `local_config` | `true` | When set to `true`, the process gets configurations from the configuration files. | No|
!!! note
@@ -34,49 +38,49 @@ For all parameters and their current values, see [Configurations](1.configuratio
## Logging configurations
-| Name | Predefined value | Description |
-| ------------- | ------------------------ | ------------------------------------------------ |
-| `log_dir` | `logs` | The directory that stores the Meta Service log. It is recommended to put logs on a different hard disk from the data. |
-| `minloglevel` | `0` | Specifies the minimum level of the log. That is, log messages at or above this level. Optional values are `0` (INFO), `1` (WARNING), `2` (ERROR), `3` (FATAL). It is recommended to set it to `0` during debugging and `1` in a production environment. If it is set to `4`, NebulaGraph will not print any logs. |
-| `v` | `0` | Specifies the detailed level of VLOG. That is, log all VLOG messages less or equal to the level. Optional values are `0`, `1`, `2`, `3`, `4`, `5`. The VLOG macro provided by glog allows users to define their own numeric logging levels and control verbose messages that are logged with the parameter `v`. For details, see [Verbose Logging](https://github.com/google/glog#verbose-logging).|
-| `logbufsecs` | `0` | Specifies the maximum time to buffer the logs. If there is a timeout, it will output the buffered log to the log file. `0` means real-time output. This configuration is measured in seconds. |
-|`redirect_stdout` |`true` | When set to `true`, the process redirects the`stdout` and `stderr` to separate output files. |
-|`stdout_log_file` |`graphd-stdout.log` | Specifies the filename for the `stdout` log. |
-|`stderr_log_file` |`graphd-stderr.log` | Specifies the filename for the `stderr` log. |
-|`stderrthreshold` | `3` | Specifies the `minloglevel` to be copied to the `stderr` log. |
-| `timestamp_in_logfile_name` | `true` | Specifies if the log file name contains a timestamp. `true` indicates yes, `false` indicates no. |
+| Name | Predefined value | Description |Whether supports runtime dynamic modifications|
+| ------------- | ------------------------ | ------------------------------------------------ |------------------|
+| `log_dir` | `logs` | The directory that stores the Meta Service log. It is recommended to put logs on a different hard disk from the data. | No|
+| `minloglevel` | `0` | Specifies the minimum level of the log. That is, log messages at or above this level. Optional values are `0` (INFO), `1` (WARNING), `2` (ERROR), `3` (FATAL). It is recommended to set it to `0` during debugging and `1` in a production environment. If it is set to `4`, NebulaGraph will not print any logs. | Yes|
+| `v` | `0` | Specifies the detailed level of VLOG. That is, log all VLOG messages less or equal to the level. Optional values are `0`, `1`, `2`, `3`, `4`, `5`. The VLOG macro provided by glog allows users to define their own numeric logging levels and control verbose messages that are logged with the parameter `v`. For details, see [Verbose Logging](https://github.com/google/glog#verbose-logging).| Yes|
+| `logbufsecs` | `0` | Specifies the maximum time to buffer the logs. If there is a timeout, it will output the buffered log to the log file. `0` means real-time output. This configuration is measured in seconds. | No|
+|`redirect_stdout` |`true` | When set to `true`, the process redirects the`stdout` and `stderr` to separate output files. | No|
+|`stdout_log_file` |`graphd-stdout.log` | Specifies the filename for the `stdout` log. | No|
+|`stderr_log_file` |`graphd-stderr.log` | Specifies the filename for the `stderr` log. | No|
+|`stderrthreshold` | `3` | Specifies the `minloglevel` to be copied to the `stderr` log. | No|
+| `timestamp_in_logfile_name` | `true` | Specifies if the log file name contains a timestamp. `true` indicates yes, `false` indicates no. | No|
## Query configurations
-| Name | Predefined value | Description |
-| ----------------------------- | ------------------------ | ------------------------------------------ |
-|`accept_partial_success` |`false` | When set to `false`, the process treats partial success as an error. This configuration only applies to read-only requests. Write requests always treat partial success as an error. |
-|`session_reclaim_interval_secs`|`60` | Specifies the interval that the Session information is sent to the Meta service. This configuration is measured in seconds. |
-|`max_allowed_query_size` |`4194304` | Specifies the maximum length of queries. Unit: bytes. The default value is `4194304`, namely 4MB.|
+| Name | Predefined value | Description |Whether supports runtime dynamic modifications|
+| ----------------------------- | ------------------------ | ------------------------------------------ |------------------|
+|`accept_partial_success` |`false` | When set to `false`, the process treats partial success as an error. This configuration only applies to read-only requests. Write requests always treat partial success as an error. | Yes|
+|`session_reclaim_interval_secs`|`60` | Specifies the interval that the Session information is sent to the Meta service. This configuration is measured in seconds. | Yes|
+|`max_allowed_query_size` |`4194304` | Specifies the maximum length of queries. Unit: bytes. The default value is `4194304`, namely 4MB.| Yes|
## Networking configurations
-| Name | Predefined value | Description |
-| ----------------------- | ---------------- | ---------------------------------------------------- |
-| `meta_server_addrs` | `127.0.0.1:9559` | Specifies the IP addresses and ports of all Meta Services. Multiple addresses are separated with commas.|
-|`local_ip` | `127.0.0.1` | Specifies the local IP for the Graph Service. The local IP address is used to identify the nebula-graphd process. If it is a distributed cluster or requires remote access, modify it to the corresponding address.|
-|`listen_netdev` |`any` | Specifies the listening network device. |
-| `port` | `9669` | Specifies RPC daemon listening port of the Graph service. |
-|`reuse_port` |`false` | When set to `false`, the `SO_REUSEPORT` is closed. |
-|`listen_backlog` |`1024` | Specifies the maximum length of the connection queue for socket monitoring. This configuration must be modified together with the `net.core.somaxconn`. |
-|`client_idle_timeout_secs` |`28800` | Specifies the time to expire an idle connection. The value ranges from 1 to 604800. The default is 8 hours. This configuration is measured in seconds. |
-|`session_idle_timeout_secs` |`28800` | Specifies the time to expire an idle session. The value ranges from 1 to 604800. The default is 8 hours. This configuration is measured in seconds. |
-|`num_accept_threads` |`1` | Specifies the number of threads that accept incoming connections. |
-|`num_netio_threads` |`0` | Specifies the number of networking IO threads. `0` is the number of CPU cores. |
-|`num_worker_threads` |`0` | Specifies the number of threads that execute queries. `0` is the number of CPU cores. |
-| `ws_ip` | `0.0.0.0` | Specifies the IP address for the HTTP service. |
-| `ws_http_port` | `19669` | Specifies the port for the HTTP service. |
-|`heartbeat_interval_secs` | `10` | Specifies the default heartbeat interval. Make sure the `heartbeat_interval_secs` values for all services are the same, otherwise NebulaGraph **CANNOT** work normally. This configuration is measured in seconds. |
-|`storage_client_timeout_ms` |-| Specifies the RPC connection timeout threshold between the Graph Service and the Storage Service. This parameter is not predefined in the initial configuration files. You can manually set it if you need it. The system default value is `60000` ms. |
-|`enable_record_slow_query`|`true`|Whether to record slow queries.
Only available in NebulaGraph Enterprise Edition.|
-|`slow_query_limit`|`100`|The maximum number of slow queries that can be recorded.
Only available in NebulaGraph Enterprise Edition.|
-|`slow_query_threshold_us`|`200000`|When the execution time of a query exceeds the value, the query is called a slow query. Unit: Microsecond.|
-|`ws_meta_http_port` |`19559`| Specifies the Meta service listening port used by the HTTP protocol. It must be consistent with the `ws_http_port` in the Meta service configuration file.|
+| Name | Predefined value | Description |Whether supports runtime dynamic modifications|
+| ----------------------- | ---------------- | ---------------------------------------------------- |------------------|
+| `meta_server_addrs` | `127.0.0.1:9559` | Specifies the IP addresses and ports of all Meta Services. Multiple addresses are separated with commas.| No|
+|`local_ip` | `127.0.0.1` | Specifies the local IP for the Graph Service. The local IP address is used to identify the nebula-graphd process. If it is a distributed cluster or requires remote access, modify it to the corresponding address.| No|
+|`listen_netdev` |`any` | Specifies the listening network device. | No|
+| `port` | `9669` | Specifies RPC daemon listening port of the Graph service. | No|
+|`reuse_port` |`false` | When set to `false`, the `SO_REUSEPORT` is closed. | No|
+|`listen_backlog` |`1024` | Specifies the maximum length of the connection queue for socket monitoring. This configuration must be modified together with the `net.core.somaxconn`. | No|
+|`client_idle_timeout_secs` |`28800` | Specifies the time to expire an idle connection. The value ranges from 1 to 604800. The default is 8 hours. This configuration is measured in seconds. | No|
+|`session_idle_timeout_secs` |`28800` | Specifies the time to expire an idle session. The value ranges from 1 to 604800. The default is 8 hours. This configuration is measured in seconds. | No|
+|`num_accept_threads` |`1` | Specifies the number of threads that accept incoming connections. | No|
+|`num_netio_threads` |`0` | Specifies the number of networking IO threads. `0` is the number of CPU cores. | No|
+|`num_worker_threads` |`0` | Specifies the number of threads that execute queries. `0` is the number of CPU cores. | No|
+| `ws_ip` | `0.0.0.0` | Specifies the IP address for the HTTP service. | No|
+| `ws_http_port` | `19669` | Specifies the port for the HTTP service. | No|
+|`heartbeat_interval_secs` | `10` | Specifies the default heartbeat interval. Make sure the `heartbeat_interval_secs` values for all services are the same, otherwise NebulaGraph **CANNOT** work normally. This configuration is measured in seconds. | Yes|
+|`storage_client_timeout_ms` |-| Specifies the RPC connection timeout threshold between the Graph Service and the Storage Service. This parameter is not predefined in the initial configuration files. You can manually set it if you need it. The system default value is `60000` ms. | No|
+|`enable_record_slow_query`|`true`|Whether to record slow queries.
Only available in NebulaGraph Enterprise Edition.| No|
+|`slow_query_limit`|`100`|The maximum number of slow queries that can be recorded.
Only available in NebulaGraph Enterprise Edition.| No|
+|`slow_query_threshold_us`|`200000`|When the execution time of a query exceeds the value, the query is called a slow query. Unit: Microsecond.| No|
+|`ws_meta_http_port` |`19559`| Specifies the Meta service listening port used by the HTTP protocol. It must be consistent with the `ws_http_port` in the Meta service configuration file.| No|
!!! caution
@@ -84,23 +88,23 @@ For all parameters and their current values, see [Configurations](1.configuratio
## Charset and collate configurations
-| Name | Predefined value | Description |
-| ---------------- | ------------------ | -------------------------------------------------------------- |
-|`default_charset` | `utf8` | Specifies the default charset when creating a new graph space. |
-|`default_collate` | `utf8_bin` | Specifies the default collate when creating a new graph space. |
+| Name | Predefined value | Description |Whether supports runtime dynamic modifications|
+| ---------------- | ------------------ | -------------------------------------------------------------- |------------------|
+|`default_charset` | `utf8` | Specifies the default charset when creating a new graph space. | No|
+|`default_collate` | `utf8_bin` | Specifies the default collate when creating a new graph space. | No|
## Authorization configurations
-| Name | Predefined value | Description |
-| ------------------- | ---------------- | ------------------------------------------ |
-|`enable_authorize` |`false` |When set to `false`, the system authentication is not enabled. For more information, see [Authentication](../../7.data-security/1.authentication/1.authentication.md).|
-|`auth_type` |`password` |Specifies the login method. Available values are `password`, `ldap`, and `cloud`.|
+| Name | Predefined value | Description |Whether supports runtime dynamic modifications|
+| ------------------- | ---------------- | ------------------------------------------ |------------------|
+|`enable_authorize` |`false` |When set to `false`, the system authentication is not enabled. For more information, see [Authentication](../../7.data-security/1.authentication/1.authentication.md).| No|
+|`auth_type` |`password` |Specifies the login method. Available values are `password`, `ldap`, and `cloud`.| No|
## Memory configurations
-| Name | Predefined value | Description |
-| ------------------- | ------------------------ | ------------------------------------------ |
-| `system_memory_high_watermark_ratio` | `0.8` | Specifies the trigger threshold of the high-level memory alarm mechanism. If the system memory usage is higher than this value, an alarm mechanism will be triggered, and NebulaGraph will stop querying. This parameter is not predefined in the initial configuration files. |
+| Name | Predefined value | Description |Whether supports runtime dynamic modifications|
+| ------------------- | ------------------------ | ------------------------------------------ |------------------|
+| `system_memory_high_watermark_ratio` | `0.8` | Specifies the trigger threshold of the high-level memory alarm mechanism. If the system memory usage is higher than this value, an alarm mechanism will be triggered, and NebulaGraph will stop querying. This parameter is not predefined in the initial configuration files. | Yes|
{{ ent.ent_begin }}
@@ -116,23 +120,23 @@ For more information about audit log, see [Audit log](../2.log-management/audit-
## Metrics configurations
-| Name | Predefined value | Description |
+| Name | Predefined value | Description |Whether supports runtime dynamic modifications|
| - | - | - |
-| `enable_space_level_metrics` | `false` | Enable or disable space-level metrics. Such metric names contain the name of the graph space that it monitors, for example, `query_latency_us{space=basketballplayer}.avg.3600`. You can view the supported metrics with the `curl` command. For more information, see [Query NebulaGraph metrics](../../6.monitor-and-metrics/1.query-performance-metrics.md). |
+| `enable_space_level_metrics` | `false` | Enable or disable space-level metrics. Such metric names contain the name of the graph space that it monitors, for example, `query_latency_us{space=basketballplayer}.avg.3600`. You can view the supported metrics with the `curl` command. For more information, see [Query NebulaGraph metrics](../../6.monitor-and-metrics/1.query-performance-metrics.md). | No|
-## session configurations
+## Session configurations
-| Name | Predefined value | Description |
-| ------------------- | ------------------------ | ------------------------------------------ |
-|`max_sessions_per_ip_per_user`|`300` | The maximum number of active sessions that can be created from a single IP adddress for a single user.|
+| Name | Predefined value | Description |Whether supports runtime dynamic modifications|
+| ------------------- | ------------------------ | ------------------------------------------ |------------------|
+|`max_sessions_per_ip_per_user`|`300` | The maximum number of active sessions that can be created from a single IP adddress for a single user.| No|
## Experimental configurations
-| Name | Predefined value | Description |
-| ------------------- | ------------------------ | ------------------------------------------ |
-|`enable_experimental_feature`|`false`| Specifies the experimental feature. Optional values are `true` and `false`. For currently supported experimental features, see below.|
-|`enable_data_balance`|`true`|Whether to enable the [BALANCE DATA](../../8.service-tuning/load-balance.md) feature. Only works when `enable_experimental_feature` is `true`. |
+| Name | Predefined value | Description |Whether supports runtime dynamic modifications|
+| ------------------- | ------------------------ | ------------------------------------------ |------------------|
+|`enable_experimental_feature`|`false`| Specifies the experimental feature. Optional values are `true` and `false`. | No|
+|`enable_data_balance`|`true`|Whether to enable the [BALANCE DATA](../../8.service-tuning/load-balance.md) feature. Only works when `enable_experimental_feature` is `true`. | No|
{{ ent.ent_begin }}
@@ -143,23 +147,23 @@ For more information about audit log, see [Audit log](../2.log-management/audit-
The Nebula-BBox configurations are for the Enterprise Edition only.
-| Name | Predefined value | Description |
-| :------------------- | :------------------------ | :------------------------------------------ |
-|`ng_black_box_switch` |`true` |Whether to enable the [Nebula-BBox](../../6.monitor-and-metrics/3.bbox/3.1.bbox.md) feature.|
-|`ng_black_box_home` |`black_box` |The name of the directory to store Nebula-BBox file data.|
-|`ng_black_box_dump_period_seconds` |`5` |The time interval for Nebula-BBox to collect metric data. Unit: Second.|
-|`ng_black_box_file_lifetime_seconds` |`1800` |Storage time for Nebula-BBox files generated after collecting metric data. Unit: Second.|
+| Name | Predefined value | Description |Whether supports runtime dynamic modifications|
+| :------------------- | :------------------------ | :------------------------------------------ |------------------|
+|`ng_black_box_switch` |`true` |Whether to enable the [Nebula-BBox](../../6.monitor-and-metrics/3.bbox/3.1.bbox.md) feature.| No|
+|`ng_black_box_home` |`black_box` |The name of the directory to store Nebula-BBox file data.| No|
+|`ng_black_box_dump_period_seconds` |`5` |The time interval for Nebula-BBox to collect metric data. Unit: Second.| No|
+|`ng_black_box_file_lifetime_seconds` |`1800` |Storage time for Nebula-BBox files generated after collecting metric data. Unit: Second.| Yes|
{{ ent.ent_end }}
-## memory tracker configurations
+## Memory tracker configurations
-| Name | Predefined value | Description |
-| :------------------- | :------------------------ | :------------------------------------------ |
-|`memory_tracker_limit_ratio` |`0.8` | The percentage of free memory. When the free memory is lower than this value, NebulaGraph stops accepting queries.
Calculated as follows:
`Free memory / (Total memory - Reserved memory)`
**Note**: For clusters with a mixed-used environment, the value of `memory_tracker_limit_ratio` should be set to a **lower** value. For example, when Graphd is expected to occupy only 50% of memory, the value can be set to less than `0.5`.|
-|`memory_tracker_untracked_reserved_memory_mb` |`50`| The reserved memory that is not tracked by the memory tracker. Unit: MB.|
-|`memory_tracker_detail_log` |`false` | Whether to enable the memory tracker log. When the value is `true`, the memory tracker log is generated.|
-|`memory_tracker_detail_log_interval_ms` |`60000`| The time interval for generating the memory tracker log. Unit: Millisecond. `memory_tracker_detail_log` is `true` when this parameter takes effect.|
-|`memory_purge_enabled` |`true` |Whether to enable the memory purge feature. When the value is `true`, the memory purge feature is enabled.|
-|`memory_purge_interval_seconds` |`10` |The time interval for the memory purge feature to purge memory. Unit: Second. This parameter only takes effect if `memory_purge_enabled` is set to true.|
+| Name | Predefined value | Description |Whether supports runtime dynamic modifications|
+| :------------------- | :------------------------ | :------------------------------------------ |:------------------|
+|`memory_tracker_limit_ratio` |`0.8` | The percentage of free memory. When the free memory is lower than this value, NebulaGraph stops accepting queries.
Calculated as follows:
`Free memory / (Total memory - Reserved memory)`
**Note**: For clusters with a mixed-used environment, the value of `memory_tracker_limit_ratio` should be set to a **lower** value. For example, when Graphd is expected to occupy only 50% of memory, the value can be set to less than `0.5`.| Yes|
+|`memory_tracker_untracked_reserved_memory_mb` |`50`| The reserved memory that is not tracked by the memory tracker. Unit: MB.| Yes|
+|`memory_tracker_detail_log` |`false` | Whether to enable the memory tracker log. When the value is `true`, the memory tracker log is generated.| Yes|
+|`memory_tracker_detail_log_interval_ms` |`60000`| The time interval for generating the memory tracker log. Unit: Millisecond. `memory_tracker_detail_log` is `true` when this parameter takes effect.| Yes|
+|`memory_purge_enabled` |`true` |Whether to enable the memory purge feature. When the value is `true`, the memory purge feature is enabled.| Yes|
+|`memory_purge_interval_seconds` |`10` |The time interval for the memory purge feature to purge memory. Unit: Second. This parameter only takes effect if `memory_purge_enabled` is set to true.| Yes|
diff --git a/docs-2.0/5.configurations-and-logs/1.configurations/4.storage-config.md b/docs-2.0/5.configurations-and-logs/1.configurations/4.storage-config.md
index f03ce4184be..d775a6464e2 100644
--- a/docs-2.0/5.configurations-and-logs/1.configurations/4.storage-config.md
+++ b/docs-2.0/5.configurations-and-logs/1.configurations/4.storage-config.md
@@ -15,6 +15,10 @@ To use the initial configuration file, choose one of the above two files and del
If a parameter is not set in the configuration file, NebulaGraph uses the default value. Not all parameters are predefined. And the predefined parameters in the two initial configuration files are different. This topic uses the parameters in `nebula-metad.conf.default`. For parameters that are not included in `nebula-metad.conf.default`, see `nebula-storaged.conf.production`.
+!!! caution
+
+ Some parameter values in the configuration file can be dynamically modified during runtime. We label these parameters as **Yes** that supports runtime dynamic modification in this article. When the `local_config` value is set to `true`, the dynamically modified configuration is not persisted, and the configuration will be restored to the initial configuration after the service is restarted. For more information, see [Modify configurations](1.configurations.md).
+
!!! Note
The configurations of the Raft Listener and the Storage service are different. For details, see [Deploy Raft listener](../../4.deployment-and-installation/6.deploy-text-based-index/3.deploy-listener.md).
@@ -23,12 +27,12 @@ For all parameters and their current values, see [Configurations](1.configuratio
## Basics configurations
-| Name | Predefined value | Description |
-| :----------- | :----------------------- | :------------------|
-| `daemonize` | `true` | When set to `true`, the process is a daemon process. |
-| `pid_file` | `pids/nebula-storaged.pid` | The file that records the process ID. |
-| `timezone_name` | `UTC+00:00:00` | Specifies the NebulaGraph time zone. This parameter is not predefined in the initial configuration files, if you need to use this parameter, add it manually. For the format of the parameter value, see [Specifying the Time Zone with TZ](https://www.gnu.org/software/libc/manual/html_node/TZ-Variable.html "Click to view the timezone-related content in the GNU C Library manual"). For example, `--timezone_name=UTC+08:00` represents the GMT+8 time zone. |
-| `local_config` | `true` | When set to `true`, the process gets configurations from the configuration files. |
+| Name | Predefined value | Description |Whether supports runtime dynamic modifications|
+| :----------- | :----------------------- | :------------------|:------------------|
+| `daemonize` | `true` | When set to `true`, the process is a daemon process. | No|
+| `pid_file` | `pids/nebula-storaged.pid` | The file that records the process ID. | No|
+| `timezone_name` | `UTC+00:00:00` | Specifies the NebulaGraph time zone. This parameter is not predefined in the initial configuration files, if you need to use this parameter, add it manually. For the format of the parameter value, see [Specifying the Time Zone with TZ](https://www.gnu.org/software/libc/manual/html_node/TZ-Variable.html "Click to view the timezone-related content in the GNU C Library manual"). For example, `--timezone_name=UTC+08:00` represents the GMT+8 time zone. | No|
+| `local_config` | `true` | When set to `true`, the process gets configurations from the configuration files. | No|
!!! note
@@ -37,28 +41,28 @@ For all parameters and their current values, see [Configurations](1.configuratio
## Logging configurations
-| Name | Predefined value | Description |
-| :------------- | :------------------------ | :------------------------------------------------ |
-| `log_dir` | `logs` | The directory that stores the Meta Service log. It is recommended to put logs on a different hard disk from the data. |
-| `minloglevel` | `0` | Specifies the minimum level of the log. That is, log messages at or above this level. Optional values are `0` (INFO), `1` (WARNING), `2` (ERROR), `3` (FATAL). It is recommended to set it to `0` during debugging and `1` in a production environment. If it is set to `4`, NebulaGraph will not print any logs. |
-| `v` | `0` | Specifies the detailed level of VLOG. That is, log all VLOG messages less or equal to the level. Optional values are `0`, `1`, `2`, `3`, `4`, `5`. The VLOG macro provided by glog allows users to define their own numeric logging levels and control verbose messages that are logged with the parameter `v`. For details, see [Verbose Logging](https://github.com/google/glog#verbose-logging).|
-| `logbufsecs` | `0` | Specifies the maximum time to buffer the logs. If there is a timeout, it will output the buffered log to the log file. `0` means real-time output. This configuration is measured in seconds. |
-|`redirect_stdout` | `true` | When set to `true`, the process redirects the`stdout` and `stderr` to separate output files. |
-|`stdout_log_file` |`graphd-stdout.log` | Specifies the filename for the `stdout` log. |
-|`stderr_log_file` |`graphd-stderr.log` | Specifies the filename for the `stderr` log. |
-|`stderrthreshold` | `3` | Specifies the `minloglevel` to be copied to the `stderr` log. |
-| `timestamp_in_logfile_name` | `true` | Specifies if the log file name contains a timestamp. `true` indicates yes, `false` indicates no. |
+| Name | Predefined value | Description |Whether supports runtime dynamic modifications|
+| :------------- | :------------------------ | :------------------------------------------------ |:------------------|
+| `log_dir` | `logs` | The directory that stores the Meta Service log. It is recommended to put logs on a different hard disk from the data. | No|
+| `minloglevel` | `0` | Specifies the minimum level of the log. That is, log messages at or above this level. Optional values are `0` (INFO), `1` (WARNING), `2` (ERROR), `3` (FATAL). It is recommended to set it to `0` during debugging and `1` in a production environment. If it is set to `4`, NebulaGraph will not print any logs. | Yes|
+| `v` | `0` | Specifies the detailed level of VLOG. That is, log all VLOG messages less or equal to the level. Optional values are `0`, `1`, `2`, `3`, `4`, `5`. The VLOG macro provided by glog allows users to define their own numeric logging levels and control verbose messages that are logged with the parameter `v`. For details, see [Verbose Logging](https://github.com/google/glog#verbose-logging).| Yes|
+| `logbufsecs` | `0` | Specifies the maximum time to buffer the logs. If there is a timeout, it will output the buffered log to the log file. `0` means real-time output. This configuration is measured in seconds. | No|
+|`redirect_stdout` | `true` | When set to `true`, the process redirects the`stdout` and `stderr` to separate output files. | No|
+|`stdout_log_file` |`graphd-stdout.log` | Specifies the filename for the `stdout` log. | No|
+|`stderr_log_file` |`graphd-stderr.log` | Specifies the filename for the `stderr` log. | No|
+|`stderrthreshold` | `3` | Specifies the `minloglevel` to be copied to the `stderr` log. | No|
+| `timestamp_in_logfile_name` | `true` | Specifies if the log file name contains a timestamp. `true` indicates yes, `false` indicates no. | No|
## Networking configurations
-| Name | Predefined value | Description |
-| :----------------------- | :---------------- | :---------------------------------------------------- |
-| `meta_server_addrs` | `127.0.0.1:9559` | Specifies the IP addresses and ports of all Meta Services. Multiple addresses are separated with commas. |
-|`local_ip` | `127.0.0.1` | Specifies the local IP for the Storage Service. The local IP address is used to identify the nebula-storaged process. If it is a distributed cluster or requires remote access, modify it to the corresponding address.|
-| `port` | `9779` | Specifies RPC daemon listening port of the Storage service. The external port for the Meta Service is predefined to `9779`. The internal port is predefined to `9777`, `9778`, and `9780`. Nebula Graph uses the internal port for multi-replica interactions. |
-| `ws_ip` | `0.0.0.0` | Specifies the IP address for the HTTP service. |
-| `ws_http_port` | `19779` | Specifies the port for the HTTP service. |
-|`heartbeat_interval_secs` | `10` | Specifies the default heartbeat interval. Make sure the `heartbeat_interval_secs` values for all services are the same, otherwise NebulaGraph **CANNOT** work normally. This configuration is measured in seconds. |
+| Name | Predefined value | Description |Whether supports runtime dynamic modifications|
+| :----------------------- | :---------------- | :---------------------------------------------------- |:------------------|
+| `meta_server_addrs` | `127.0.0.1:9559` | Specifies the IP addresses and ports of all Meta Services. Multiple addresses are separated with commas. | No|
+|`local_ip` | `127.0.0.1` | Specifies the local IP for the Storage Service. The local IP address is used to identify the nebula-storaged process. If it is a distributed cluster or requires remote access, modify it to the corresponding address.| No|
+| `port` | `9779` | Specifies RPC daemon listening port of the Storage service. The external port for the Meta Service is predefined to `9779`. The internal port is predefined to `9777`, `9778`, and `9780`. Nebula Graph uses the internal port for multi-replica interactions.
`9777`: The port used by the Drainer service, which is only exposed in the Enterprise Edition cluster. `9778`: The port used by the Admin service, which receives Meta commands for Storage. `9780`: The port used for Raft communication.| No|
+| `ws_ip` | `0.0.0.0` | Specifies the IP address for the HTTP service. | No|
+| `ws_http_port` | `19779` | Specifies the port for the HTTP service. | No|
+|`heartbeat_interval_secs` | `10` | Specifies the default heartbeat interval. Make sure the `heartbeat_interval_secs` values for all services are the same, otherwise NebulaGraph **CANNOT** work normally. This configuration is measured in seconds. | Yes|
!!! caution
@@ -66,30 +70,30 @@ For all parameters and their current values, see [Configurations](1.configuratio
## Raft configurations
-| Name | Predefined value | Description |
-| :----------------------------- | :--------------- | :------------------------ |
-| `raft_heartbeat_interval_secs` | `30` | Specifies the time to expire the Raft election. The configuration is measured in seconds. |
-| `raft_rpc_timeout_ms` | `500` | Specifies the time to expire the Raft RPC. The configuration is measured in milliseconds. |
-| `wal_ttl` | `14400` | Specifies the lifetime of the RAFT WAL. The configuration is measured in seconds. |
+| Name | Predefined value | Description |Whether supports runtime dynamic modifications|
+| :----------------------------- | :--------------- | :------------------------ |:------------------|
+| `raft_heartbeat_interval_secs` | `30` | Specifies the time to expire the Raft election. The configuration is measured in seconds. | Yes|
+| `raft_rpc_timeout_ms` | `500` | Specifies the time to expire the Raft RPC. The configuration is measured in milliseconds. | Yes|
+| `wal_ttl` | `14400` | Specifies the lifetime of the RAFT WAL. The configuration is measured in seconds. | Yes|
## Disk configurations
-| Name | Predefined value | Description |
-| :------------------------------- | :--------------- | :------------------------ |
-| `data_path` | `data/storage` | Specifies the data storage path. Multiple paths are separated with commas. One RocksDB example corresponds to one path. |
-| `minimum_reserved_bytes` | `268435456` | Specifies the minimum remaining space of each data storage path. When the value is lower than this standard, the cluster data writing may fail. This configuration is measured in bytes. |
-| `rocksdb_batch_size` | `4096` | Specifies the block cache for a batch operation. The configuration is measured in bytes. |
-| `rocksdb_block_cache` | `4` | Specifies the block cache for BlockBasedTable. The configuration is measured in megabytes.|
-|`disable_page_cache` |`false`|Enables or disables the operating system's page cache for NebulaGraph. By default, the parameter value is `false` and page cache is enabled. If the value is set to `true`, page cache is disabled and sufficient block cache space must be configured for NebulaGraph.|
-| `engine_type` | `rocksdb` | Specifies the engine type. |
-| `rocksdb_compression` | `lz4` | Specifies the compression algorithm for RocksDB. Optional values are `no`, `snappy`, `lz4`, `lz4hc`, `zlib`, `bzip2`, and `zstd`.
This parameter modifies the compression algorithm for each level. If you want to set different compression algorithms for each level, use the parameter `rocksdb_compression_per_level`. |
-| `rocksdb_compression_per_level` | \ | Specifies the compression algorithm for each level. The priority is higher than `rocksdb_compression`. For example, `no:no:lz4:lz4:snappy:zstd:snappy`.
You can also not set certain levels of compression algorithms, for example, `no:no:lz4:lz4::zstd`, level L4 and L6 use the compression algorithm of `rocksdb_compression`. |
-|`enable_rocksdb_statistics` | `false` | When set to `false`, RocksDB statistics is disabled. |
-| `rocksdb_stats_level` | `kExceptHistogramOrTimers` | Specifies the stats level for RocksDB. Optional values are `kExceptHistogramOrTimers`, `kExceptTimers`, `kExceptDetailedTimers`, `kExceptTimeForMutex`, and `kAll`. |
-| `enable_rocksdb_prefix_filtering` | `true` | When set to `true`, the prefix bloom filter for RocksDB is enabled. Enabling prefix bloom filter makes the graph traversal faster but occupies more memory. |
+| Name | Predefined value | Description |Whether supports runtime dynamic modifications|
+| :------------------------------- | :--------------- | :------------------------ |:------------------|
+| `data_path` | `data/storage` | Specifies the data storage path. Multiple paths are separated with commas. One RocksDB example corresponds to one path. | No|
+| `minimum_reserved_bytes` | `268435456` | Specifies the minimum remaining space of each data storage path. When the value is lower than this standard, the cluster data writing may fail. This configuration is measured in bytes. | No|
+| `rocksdb_batch_size` | `4096` | Specifies the block cache for a batch operation. The configuration is measured in bytes. | No|
+| `rocksdb_block_cache` | `4` | Specifies the block cache for BlockBasedTable. The configuration is measured in megabytes.| No|
+|`disable_page_cache` |`false`|Enables or disables the operating system's page cache for NebulaGraph. By default, the parameter value is `false` and page cache is enabled. If the value is set to `true`, page cache is disabled and sufficient block cache space must be configured for NebulaGraph.| No|
+| `engine_type` | `rocksdb` | Specifies the engine type. | No|
+| `rocksdb_compression` | `lz4` | Specifies the compression algorithm for RocksDB. Optional values are `no`, `snappy`, `lz4`, `lz4hc`, `zlib`, `bzip2`, and `zstd`.
This parameter modifies the compression algorithm for each level. If you want to set different compression algorithms for each level, use the parameter `rocksdb_compression_per_level`. | No|
+| `rocksdb_compression_per_level` | \ | Specifies the compression algorithm for each level. The priority is higher than `rocksdb_compression`. For example, `no:no:lz4:lz4:snappy:zstd:snappy`.
You can also not set certain levels of compression algorithms, for example, `no:no:lz4:lz4::zstd`, level L4 and L6 use the compression algorithm of `rocksdb_compression`. | No|
+|`enable_rocksdb_statistics` | `false` | When set to `false`, RocksDB statistics is disabled. | No|
+| `rocksdb_stats_level` | `kExceptHistogramOrTimers` | Specifies the stats level for RocksDB. Optional values are `kExceptHistogramOrTimers`, `kExceptTimers`, `kExceptDetailedTimers`, `kExceptTimeForMutex`, and `kAll`. | No|
+| `enable_rocksdb_prefix_filtering` | `true` | When set to `true`, the prefix bloom filter for RocksDB is enabled. Enabling prefix bloom filter makes the graph traversal faster but occupies more memory. | No|
|`enable_rocksdb_whole_key_filtering` | `false` | When set to `true`, the whole key bloom filter for RocksDB is enabled. |
-| `rocksdb_filtering_prefix_length` | `12` | Specifies the prefix length for each key. Optional values are `12` and `16`. The configuration is measured in bytes. |
-| `enable_partitioned_index_filter` | `false` | When set to `true`, it reduces the amount of memory used by the bloom filter. But in some random-seek situations, it may reduce the read performance. This parameter is not predefined in the initial configuration files, if you need to use this parameter, add it manually.|
+| `rocksdb_filtering_prefix_length` | `12` | Specifies the prefix length for each key. Optional values are `12` and `16`. The configuration is measured in bytes. | No|
+| `enable_partitioned_index_filter` | `false` | When set to `true`, it reduces the amount of memory used by the bloom filter. But in some random-seek situations, it may reduce the read performance. This parameter is not predefined in the initial configuration files, if you need to use this parameter, add it manually.| No|
-## misc configurations
+## Misc configurations
!!! caution
The configuration `snapshot` in the following table is different from the snapshot in NebulaGraph. The `snapshot` here refers to the stock data on the leader when synchronizing Raft.
-| Name | Predefined value | Description |
-| :-- | :----- | :--- |
-| `query_concurrently` |`true`| Whether to turn on multi-threaded queries. Enabling it can improve the latency performance of individual queries, but it will reduce the overall throughput under high pressure. |
-| `auto_remove_invalid_space` | `true` |After executing `DROP SPACE`, the specified graph space will be deleted. This parameter sets whether to delete all the data in the specified graph space at the same time. When the value is `true`, all the data in the specified graph space will be deleted at the same time.|
-| `num_io_threads` | `16` | The number of network I/O threads used to send RPC requests and receive responses. |
-| `num_worker_threads` | `32` | The number of worker threads for one RPC-based Storage service. |
-| `max_concurrent_subtasks` | `10` | The maximum number of concurrent subtasks to be executed by the task manager. |
-| `snapshot_part_rate_limit` | `10485760` | The rate limit when the Raft leader synchronizes the stock data with other members of the Raft group. Unit: bytes/s. |
-| `snapshot_batch_size` | `1048576` | The amount of data sent in each batch when the Raft leader synchronizes the stock data with other members of the Raft group. Unit: bytes. |
-| `rebuild_index_part_rate_limit` | `4194304` | The rate limit when the Raft leader synchronizes the index data rate with other members of the Raft group during the index rebuilding process. Unit: bytes/s. |
-| `rebuild_index_batch_size` | `1048576` | The amount of data sent in each batch when the Raft leader synchronizes the index data with other members of the Raft group during the index rebuilding process. Unit: bytes. |
+| Name | Predefined value | Description |Whether supports runtime dynamic modifications|
+| :-- | :----- | :--- |:------------------|
+| `query_concurrently` |`true`| Whether to turn on multi-threaded queries. Enabling it can improve the latency performance of individual queries, but it will reduce the overall throughput under high pressure. | Yes|
+| `auto_remove_invalid_space` | `true` |After executing `DROP SPACE`, the specified graph space will be deleted. This parameter sets whether to delete all the data in the specified graph space at the same time. When the value is `true`, all the data in the specified graph space will be deleted at the same time.| Yes|
+| `num_io_threads` | `16` | The number of network I/O threads used to send RPC requests and receive responses. | Yes|
+| `num_worker_threads` | `32` | The number of worker threads for one RPC-based Storage service. | Yes|
+| `max_concurrent_subtasks` | `10` | The maximum number of concurrent subtasks to be executed by the task manager. | Yes|
+| `snapshot_part_rate_limit` | `10485760` | The rate limit when the Raft leader synchronizes the stock data with other members of the Raft group. Unit: bytes/s. | Yes|
+| `snapshot_batch_size` | `1048576` | The amount of data sent in each batch when the Raft leader synchronizes the stock data with other members of the Raft group. Unit: bytes. | Yes|
+| `rebuild_index_part_rate_limit` | `4194304` | The rate limit when the Raft leader synchronizes the index data rate with other members of the Raft group during the index rebuilding process. Unit: bytes/s. | Yes|
+| `rebuild_index_batch_size` | `1048576` | The amount of data sent in each batch when the Raft leader synchronizes the index data with other members of the Raft group during the index rebuilding process. Unit: bytes. | Yes|
## RocksDB options
-| Name | Predefined value | Description |
-| :----------- | :------------------------ | :------------------------ |
-| `rocksdb_db_options` | `{}` | Specifies the RocksDB database options. |
-| `rocksdb_column_family_options` | `{"write_buffer_size":"67108864",`
`"max_write_buffer_number":"4",`
`"max_bytes_for_level_base":"268435456"}` | Specifies the RocksDB column family options. |
-| `rocksdb_block_based_table_options` | `{"block_size":"8192"}` | Specifies the RocksDB block based table options. |
+| Name | Predefined value | Description |Whether supports runtime dynamic modifications|
+| :----------- | :------------------------ | :------------------------ |:------------------|
+| `rocksdb_db_options` | `{}` | Specifies the RocksDB database options. | Yes|
+| `rocksdb_column_family_options` | `{"write_buffer_size":"67108864",`
`"max_write_buffer_number":"4",`
`"max_bytes_for_level_base":"268435456"}` | Specifies the RocksDB column family options. | Yes|
+| `rocksdb_block_based_table_options` | `{"block_size":"8192"}` | Specifies the RocksDB block based table options. | Yes|
The format of the RocksDB option is `{"":""}`. Multiple options are separated with commas.
@@ -200,33 +204,33 @@ For more information, see [RocksDB official documentation](https://rocksdb.org/)
The Nebula-BBox configurations are for the Enterprise Edition only.
-| Name | Predefined value | Description |
-| :------------------- | :------------------------ | :------------------------------------------ |
-|`ng_black_box_switch` |`true` |Whether to enable the [Nebula-BBox](../../6.monitor-and-metrics/3.bbox/3.1.bbox.md) feature.|
-|`ng_black_box_home` |`black_box` |The name of the directory to store Nebula-BBox file data.|
-|`ng_black_box_dump_period_seconds` |`5` |The time interval for Nebula-BBox to collect metric data. Unit: Second.|
-|`ng_black_box_file_lifetime_seconds` |`1800` |Storage time for Nebula-BBox files generated after collecting metric data. Unit: Second.|
+| Name | Predefined value | Description |Whether supports runtime dynamic modifications|
+| :------------------- | :------------------------ | :------------------------------------------ |:------------------|
+|`ng_black_box_switch` |`true` |Whether to enable the [Nebula-BBox](../../6.monitor-and-metrics/3.bbox/3.1.bbox.md) feature.| No|
+|`ng_black_box_home` |`black_box` |The name of the directory to store Nebula-BBox file data.| No|
+|`ng_black_box_dump_period_seconds` |`5` |The time interval for Nebula-BBox to collect metric data. Unit: Second.| No|
+|`ng_black_box_file_lifetime_seconds` |`1800` |Storage time for Nebula-BBox files generated after collecting metric data. Unit: Second.| Yes|
{{ ent.ent_end }}
-## memory tracker configurations
+## Memory tracker configurations
-| Name | Predefined value | Description |
-| :------------------- | :------------------------ | :------------------------------------------ |
-|`memory_tracker_limit_ratio` |`0.8` | The value of this parameter can be set to `(0, 1]`, `2`, and `3`.
`(0, 1]`: The percentage of free memory. When the free memory is lower than this value, NebulaGraph stops accepting queries.
Calculated as follows:
`Free memory / (Total memory - Reserved memory)`
**Note**: For clusters with a mixed-used environment, the value of `memory_tracker_limit_ratio` should be set to a **lower** value. For example, when Graphd is expected to occupy only 50% of memory, the value can be set to less than `0.5`.
`2`: Dynamic Self Adaptive mode. MemoryTracker dynamically adjusts the available memory based on the system's current available memory.
**Note**: This feature is experimental. As memory usage cannot be monitored in real time in dynamic adaptive mode, an OOM error may still occur to handle large memory allocations.
`3`: Disable MemoryTracker. MemoryTracker only logs memory usage and does not interfere with executions even if the limit is exceeded.|
-|`memory_tracker_untracked_reserved_memory_mb` |`50`| The reserved memory that is not tracked by the memory tracker. Unit: MB.|
-|`memory_tracker_detail_log` |`false` | Whether to enable the memory tracker log. When the value is `true`, the memory tracker log is generated.|
-|`memory_tracker_detail_log_interval_ms` |`60000`| The time interval for generating the memory tracker log. Unit: Millisecond. `memory_tracker_detail_log` is `true` when this parameter takes effect.|
-|`memory_purge_enabled` |`true` |Whether to enable the memory purge feature. When the value is `true`, the memory purge feature is enabled.|
-|`memory_purge_interval_seconds` |`10` |The time interval for the memory purge feature to purge memory. Unit: Second. This parameter only takes effect if `memory_purge_enabled` is set to true.|
+| Name | Predefined value | Description |Whether supports runtime dynamic modifications|
+| :------------------- | :------------------------ | :------------------------------------------ |:------------------|
+|`memory_tracker_limit_ratio` |`0.8` | The value of this parameter can be set to `(0, 1]`, `2`, and `3`.
`(0, 1]`: The percentage of free memory. When the free memory is lower than this value, NebulaGraph stops accepting queries.
Calculated as follows:
`Free memory / (Total memory - Reserved memory)`
**Note**: For clusters with a mixed-used environment, the value of `memory_tracker_limit_ratio` should be set to a **lower** value. For example, when Graphd is expected to occupy only 50% of memory, the value can be set to less than `0.5`.
`2`: Dynamic Self Adaptive mode. MemoryTracker dynamically adjusts the available memory based on the system's current available memory.
**Note**: This feature is experimental. As memory usage cannot be monitored in real time in dynamic adaptive mode, an OOM error may still occur to handle large memory allocations.
`3`: Disable MemoryTracker. MemoryTracker only logs memory usage and does not interfere with executions even if the limit is exceeded.| Yes|
+|`memory_tracker_untracked_reserved_memory_mb` |`50`| The reserved memory that is not tracked by the memory tracker. Unit: MB.| Yes|
+|`memory_tracker_detail_log` |`false` | Whether to enable the memory tracker log. When the value is `true`, the memory tracker log is generated.| Yes|
+|`memory_tracker_detail_log_interval_ms` |`60000`| The time interval for generating the memory tracker log. Unit: Millisecond. `memory_tracker_detail_log` is `true` when this parameter takes effect.| Yes|
+|`memory_purge_enabled` |`true` |Whether to enable the memory purge feature. When the value is `true`, the memory purge feature is enabled.| Yes|
+|`memory_purge_interval_seconds` |`10` |The time interval for the memory purge feature to purge memory. Unit: Second. This parameter only takes effect if `memory_purge_enabled` is set to true.| Yes|
## For super-Large vertices
When the query starting from each vertex gets an edge, truncate it directly to avoid too many neighboring edges on the super-large vertex, because a single query occupies too much hard disk and memory. Or you can truncate a certain number of edges specified in the `Max_edge_returned_per_vertex` parameter. Excess edges will not be returned. This parameter applies to all spaces.
-| Property name | Default value | Description |
-| :------------------- | :------------------------ | :------------------------------------------ |
-| max_edge_returned_per_vertex | `2147483647` | Specifies the maximum number of edges returned for each dense vertex. Excess edges are truncated and not returned. This parameter is not predefined in the initial configuration files, if you need to use this parameter, add it manually. |
+| Property name | Default value | Description |Whether supports runtime dynamic modifications|
+| :------------------- | :------------------------ | :------------------------------------------ |:------------------|
+| max_edge_returned_per_vertex | `2147483647` | Specifies the maximum number of edges returned for each dense vertex. Excess edges are truncated and not returned. This parameter is not predefined in the initial configuration files, if you need to use this parameter, add it manually. | No|
## Storage configurations for large dataset
diff --git a/docs-2.0/8.service-tuning/enable_autofdo_for_nebulagraph.md b/docs-2.0/8.service-tuning/enable_autofdo_for_nebulagraph.md
index f1be0a7caaf..39cc1fe9422 100644
--- a/docs-2.0/8.service-tuning/enable_autofdo_for_nebulagraph.md
+++ b/docs-2.0/8.service-tuning/enable_autofdo_for_nebulagraph.md
@@ -47,36 +47,36 @@ In our test environment, we use [NebulaGraph Bench](https://github.com/nebula-co
### Collect Perf Data For AutoFdo Tool
-After the test data preparation work done. Collect the perf data for different scenarios.
+1. After the test data preparation work done. Collect the perf data for different scenarios.
Get the pid of `storaged`, `graphd`, `metad`.
-```bash
-$ nebula.service status all
-[INFO] nebula-metad: Running as 305422, Listening on 9559
-[INFO] nebula-graphd: Running as 305516, Listening on 9669
-[INFO] nebula-storaged: Running as 305707, Listening on 9779
-```
+ ```bash
+ $ nebula.service status all
+ [INFO] nebula-metad: Running as 305422, Listening on 9559
+ [INFO] nebula-graphd: Running as 305516, Listening on 9669
+ [INFO] nebula-storaged: Running as 305707, Listening on 9779
+ ```
-Start the ***perf record*** for *nebula-graphd* and *nebula-storaged*.
+2. Start the ***perf record*** for *nebula-graphd* and *nebula-storaged*.
-```bash
-perf record -p 305516,305707 -b -e br_inst_retired.near_taken:pp -o ~/FindShortestPath.data
-```
+ ```bash
+ perf record -p 305516,305707 -b -e br_inst_retired.near_taken:pp -o ~/FindShortestPath.data
+ ```
-!!! note
+ !!! note
- Because the `nebula-metad` service contribution percent is small compared with `nebula-graphd` and `nebula-storaged` services. To reduce effort, we didn't collect the perf data for `nebula-metad` service.
+ Because the `nebula-metad` service contribution percent is small compared with `nebula-graphd` and `nebula-storaged` services. To reduce effort, we didn't collect the perf data for `nebula-metad` service.
-Start the benchmark test for ***FindShortestPath*** scenario.
+3. Start the benchmark test for ***FindShortestPath*** scenario.
-```bash
-cd NebulaGraph-Bench
-python3 run.py stress run -s benchmark -scenario find_path.FindShortestPath -a localhost:9669 --args='-u 100 -i 100000'
-```
+ ```bash
+ cd NebulaGraph-Bench
+ python3 run.py stress run -s benchmark -scenario find_path.FindShortestPath -a localhost:9669 --args='-u 100 -i 100000'
+ ```
-After the benchmark finished, end the ***perf record*** by ***Ctrl + c***.
+4. After the benchmark finished, end the ***perf record*** by ***Ctrl + c***.
-Repeat above steps to collect corresponding profile data for the rest ***Go1Step***, ***Go2Step***, ***Go3Step*** and ***InsertPersonScenario*** scenarios.
+5. Repeat above steps to collect corresponding profile data for the rest ***Go1Step***, ***Go2Step***, ***Go3Step*** and ***InsertPersonScenario*** scenarios.
### Create Gcov File
@@ -124,14 +124,16 @@ diff --git a/cmake/nebula/GeneralCompilerConfig.cmake b/cmake/nebula/GeneralComp
+add_compile_options(-fauto-profile=~/fbdata.afdo)
```
-***Note:*** When you use multiple fbdata.afdo to compile multiple times, please remember to `make clean` before re-compile, baucase only change the fbdata.afdo will not trigger re-compile.
+!!! note
+
+ When you use multiple fbdata.afdo to compile multiple times, please remember to `make clean` before re-compile, baucase only change the fbdata.afdo will not trigger re-compile.
## Performance Test Result
### Hardware & Software Environment
|Key|Value|
-|:---|---:|
+|:---|:---|
|CPU Processor#|2|
|Sockets|2|
|NUMA|2|
diff --git a/docs-2.0/backup-and-restore/nebula-br-ent/2.install-tools.md b/docs-2.0/backup-and-restore/nebula-br-ent/2.install-tools.md
index 55e47ceb247..3fb2d54ed20 100644
--- a/docs-2.0/backup-and-restore/nebula-br-ent/2.install-tools.md
+++ b/docs-2.0/backup-and-restore/nebula-br-ent/2.install-tools.md
@@ -10,7 +10,7 @@ To use the BR (Enterprise Edition) tool, you need to install the NebulaGraph Age
|NebulaGraph Enterprise Edition|BR Enterprise Edition|Agent |
|:---|:---|:---|
-|{{nebula.release}}|{{br_ent.release}}|{{agent.release}}|
+|3.4.1|3.4.0|3.4.0|
## Install BR (Enterprise Edition)
diff --git a/docs-2.0/backup-and-restore/nebula-br/1.what-is-br.md b/docs-2.0/backup-and-restore/nebula-br/1.what-is-br.md
index 762125f8b49..d466344c8df 100644
--- a/docs-2.0/backup-and-restore/nebula-br/1.what-is-br.md
+++ b/docs-2.0/backup-and-restore/nebula-br/1.what-is-br.md
@@ -15,7 +15,7 @@ The BR has the following features. It supports:
## Limitations
-- Supports NebulaGraph v{{ nebula.release }} only.
+- Supports NebulaGraph v3.x only.
- Supports full backup, but not incremental backup.
- Currently, NebulaGraph Listener and full-text indexes do not support backup.
- If you back up data to the local disk, the backup files will be saved in the local path of each server. You can also mount the NFS on your host to restore the backup data to a different host.
diff --git a/docs-2.0/backup-and-restore/nebula-br/2.compile-br.md b/docs-2.0/backup-and-restore/nebula-br/2.compile-br.md
index 2d60c36e3b7..baf9b207632 100644
--- a/docs-2.0/backup-and-restore/nebula-br/2.compile-br.md
+++ b/docs-2.0/backup-and-restore/nebula-br/2.compile-br.md
@@ -12,7 +12,7 @@ To use the BR (Enterprise Edition) tool, you need to install the NebulaGraph Age
|NebulaGraph|BR |Agent |
|:---|:---|:---|
-|3.3.0|3.3.0|0.2.0|
+|3.3.0 ~ 3.4.1|3.3.0|0.2.0 ~ 3.4.0|
|3.0.x ~ 3.2.x|0.6.1|0.1.0 ~ 0.2.0|
## Install BR with a binary file
diff --git a/docs-2.0/graph-computing/algorithm-description.md b/docs-2.0/graph-computing/algorithm-description.md
index a9cac2c2992..ae952b36577 100644
--- a/docs-2.0/graph-computing/algorithm-description.md
+++ b/docs-2.0/graph-computing/algorithm-description.md
@@ -389,6 +389,8 @@ Parameter descriptions are as follows:
|`ITERATIONS`|`10`|The maximum number of iterations.|
|`IS_DIRECTED`|`true`|Whether to consider the direction of the edges. If set to `false`, the system automatically adds the reverse edge.|
|`IS_CALC_MODULARITY`|`false`| Whether to calculate modularity.|
+ |`IS_OUTPUT_MODULARITY`|`false`|Whether to calculate and output module degrees. When set to `true`, the default output is to the third column of the file, but it can also be output to NebulaGraph with options `-nebula_output_props` and `-nebula_output_types`. Output to NebulaGraph is not yet supported when using Explorer.|
+ |`IS_STAT_COMMUNITY`|`false`|Whether to count the number of communities.|
- Output parameters
@@ -423,6 +425,8 @@ Parameter descriptions are as follows:
|`IS_DIRECTED`|`true`|Whether to consider the direction of the edges. If set to `false`, the system automatically adds the reverse edge.|
|`PREFERENCE`|`1.0`| The bias of the neighbor vertex degree. `m>0`indicates biasing the neighbor with high vertex degree, `m<0` indicates biasing the neighbor with low vertex degree, and `m=0` indicates ignoring the neighbor vertex degree.|
|`HOP_ATT`|`0.1`|The attenuation coefficient. The value ranges from `0` to `1`. The larger the value, the faster it decays and the fewer times it can be passed.|
+ |`IS_OUTPUT_MODULARITY`|`false`|Whether to calculate and output module degrees. When set to `true`, the default output is to the third column of the file, but it can also be output to NebulaGraph with options `-nebula_output_props` and `-nebula_output_types`. Output to NebulaGraph is not yet supported when using Explorer.|
+ |`IS_STAT_COMMUNITY`|`false`|Whether to count the number of communities.|
- Output parameters
@@ -457,6 +461,8 @@ Parameter descriptions are as follows:
|:--|:--|:--|
|`IS_DIRECTED`|`true`| Whether to consider the direction of the edges. If set to `false`, the system automatically adds the reverse edge.|
|`IS_CALC_MODULARITY`|`false`| Whether to calculate modularity.|
+ |`IS_OUTPUT_MODULARITY`|`false`|Whether to calculate and output module degrees. When set to `true`, the default output is to the third column of the file, but it can also be output to NebulaGraph with options `-nebula_output_props` and `-nebula_output_types`. Output to NebulaGraph is not yet supported when using Explorer.|
+ |`IS_STAT_COMMUNITY`|`false`|Whether to count the number of communities.|
- Output parameters
@@ -491,6 +497,8 @@ Parameter descriptions are as follows:
|`OUTER_ITERATION`|`20`|The maximum number of iterations in the first phase.|
|`INNER_ITERATION`|`10`|The maximum number of iterations in the second phase.|
|`IS_CALC_MODULARITY`|`false`| Whether to calculate modularity.|
+ |`IS_OUTPUT_MODULARITY`|`false`|Whether to calculate and output module degrees. When set to `true`, the default output is to the third column of the file, but it can also be output to NebulaGraph with options `-nebula_output_props` and `-nebula_output_types`. Output to NebulaGraph is not yet supported when using Explorer.|
+ |`IS_STAT_COMMUNITY`|`false`|Whether to count the number of communities.|
- Output parameters
diff --git a/docs-2.0/graph-computing/nebula-algorithm.md b/docs-2.0/graph-computing/nebula-algorithm.md
index 372955722b8..455e7387106 100644
--- a/docs-2.0/graph-computing/nebula-algorithm.md
+++ b/docs-2.0/graph-computing/nebula-algorithm.md
@@ -9,10 +9,11 @@ The correspondence between the NebulaGraph Algorithm release and the NebulaGraph
|NebulaGraph |NebulaGraph Algorithm |
|:---|:---|
| nightly | 3.0-SNAPSHOT |
-| 3.0.0 ~ 3.3.x | 3.0.0 |
+| 3.0.0 ~ 3.4.x | 3.x.0 |
| 2.6.x | 2.6.x |
| 2.5.0、2.5.1 | 2.5.0 |
| 2.0.0、2.0.1 | 2.1.0 |
+
## Prerequisites
Before using the NebulaGraph Algorithm, users need to confirm the following information:
@@ -27,12 +28,14 @@ Before using the NebulaGraph Algorithm, users need to confirm the following info
## Limitations
-- When submitting the algorithm package directly, the data of the vertex ID must be an integer. That is, the vertex ID can be INT or String, but the data itself is an integer.
-
- For non-integer String data, it is recommended to use the algorithm interface. You can use the `dense_rank` function of SparkSQL to encode the data as the Long type instead of the String type.
- Graph computing outputs vertex datasets, and the algorithm results are stored in DataFrames as the properties of vertices. You can do further operations such as statistics and filtering according to your business requirements.
+!!!
+
+ Before Algorithm v3.1.0, when submitting the algorithm package directly, the data of the vertex ID must be an integer. That is, the vertex ID can be INT or String, but the data itself is an integer.
+
## Supported algorithms
The graph computing algorithms supported by NebulaGraph Algorithm are as follows.
@@ -55,6 +58,7 @@ The graph computing algorithms supported by NebulaGraph Algorithm are as follows
| ClusteringCoefficient |Aggregation coefficient| Recommendation system, telecom fraud analysis| clustercoefficient |double/string|
| Jaccard | Jaccard similarity | Similarity computing, recommendation system| jaccard | string |
| BFS | Breadth-First Search| Sequence traversal, shortest path planning| bfs | string |
+| DFS | Depth-First Search | Sequence traversal, shortest path planning| dfs | string |
| Node2Vec | - | Graph classification | node2vec | string |
!!! note
diff --git a/docs-2.0/graph-computing/nebula-analytics.md b/docs-2.0/graph-computing/nebula-analytics.md
index 257126f1a23..7dd0320019a 100644
--- a/docs-2.0/graph-computing/nebula-analytics.md
+++ b/docs-2.0/graph-computing/nebula-analytics.md
@@ -27,6 +27,7 @@ The version correspondence between NebulaGraph Analytics and NebulaGraph is as f
|NebulaGraph |NebulaGraph Analytics |
|:---|:---|
+|3.4.0 ~ 3.4.1 | 3.4.0 |
|3.3.0 | 3.3.0 |
|3.1.0 ~ 3.2.x| 3.2.0 |
|3.0.x | 1.0.x |
@@ -62,7 +63,7 @@ NebulaGraph Analytics supports the following graph algorithms.
## Install NebulaGraph Analytics
-1. Install the NebulaGraph Analytics.
+1. Install the NebulaGraph Analytics. When installing a cluster of multiple NebulaGraph Analytics on multiple nodes, you need to install NebulaGraph Analytics to the same path and set up SSH-free login between nodes.
```
sudo rpm -ivh --prefix
diff --git a/docs-2.0/nebula-dashboard-ent/1.what-is-dashboard-ent.md b/docs-2.0/nebula-dashboard-ent/1.what-is-dashboard-ent.md
index 76deced05ee..43c8f3347ce 100644
--- a/docs-2.0/nebula-dashboard-ent/1.what-is-dashboard-ent.md
+++ b/docs-2.0/nebula-dashboard-ent/1.what-is-dashboard-ent.md
@@ -60,6 +60,7 @@ The version correspondence between NebulaGraph and Dashboard Enterprise Edition
|NebulaGraph version|Dashboard version|
|:---|:---|
+|3.4.0 ~ 3.4.1 |3.4.1, 3.4.0, 3.2.4, 3.2.3, 3.2.2, 3.2.1, 3.2.0|
|3.3.0 |3.2.4, 3.2.3, 3.2.2, 3.2.1, 3.2.0|
|2.5.0 ~ 3.2.0|3.1.2, 3.1.1, 3.1.0|
|2.5.x ~ 3.1.0|3.0.4|
diff --git a/docs-2.0/nebula-dashboard/1.what-is-dashboard.md b/docs-2.0/nebula-dashboard/1.what-is-dashboard.md
index 209dedbe805..8c00a6b7d93 100644
--- a/docs-2.0/nebula-dashboard/1.what-is-dashboard.md
+++ b/docs-2.0/nebula-dashboard/1.what-is-dashboard.md
@@ -42,6 +42,7 @@ The version correspondence between NebulaGraph and Dashboard Community Edition i
|NebulaGraph version|Dashboard version|
|:---|:---|
+|3.4.0 ~ 3.4.1 |3.4.0、3.2.0|
|3.3.0 |3.2.0|
|2.5.0 ~ 3.2.0|3.1.0|
|2.5.x ~ 3.1.0|1.1.1|
diff --git a/docs-2.0/nebula-exchange/about-exchange/ex-ug-what-is-exchange.md b/docs-2.0/nebula-exchange/about-exchange/ex-ug-what-is-exchange.md
index 3a0c0bca54f..52752caaccd 100644
--- a/docs-2.0/nebula-exchange/about-exchange/ex-ug-what-is-exchange.md
+++ b/docs-2.0/nebula-exchange/about-exchange/ex-ug-what-is-exchange.md
@@ -59,6 +59,9 @@ The correspondence between the NebulaGraph Exchange version (the JAR version), t
|nebula-exchange_spark_3.0-3.0-SNAPSHOT.jar| nightly |3.3.x、3.2.x、3.1.x、3.0.x |
|nebula-exchange_spark_2.4-3.0-SNAPSHOT.jar| nightly |2.4.x |
|nebula-exchange_spark_2.2-3.0-SNAPSHOT.jar| nightly |2.2.x |
+|nebula-exchange_spark_3.0-3.4.0.jar | 3.x.x |3.3.x、3.2.x、3.1.x、3.0.x |
+|nebula-exchange_spark_2.4-3.4.0.jar | 3.x.x |2.4.x |
+|nebula-exchange_spark_2.2-3.4.0.jar | 3.x.x |2.2.x |
|nebula-exchange_spark_3.0-3.3.0.jar | 3.x.x |3.3.x、3.2.x、3.1.x、3.0.x|
|nebula-exchange_spark_2.4-3.3.0.jar | 3.x.x |2.4.x |
|nebula-exchange_spark_2.2-3.3.0.jar | 3.x.x |2.2.x |
@@ -110,7 +113,7 @@ Exchange {{exchange.release}} supports converting data from the following format
In addition to importing data as nGQL statements, Exchange supports generating SST files for data sources and then [importing SST](../use-exchange/ex-ug-import-from-sst.md) files via Console.
-In addition, Exchange Enterprise Edition also supports [exporting data to a CSV file](../use-exchange/ex-ug-export-from-nebula.md) using NebulaGraph as data sources.
+In addition, Exchange Enterprise Edition also supports [exporting data to a CSV file or another graph space](../use-exchange/ex-ug-export-from-nebula.md) using NebulaGraph as data sources.
## Release note
diff --git a/docs-2.0/nebula-exchange/parameter-reference/ex-ug-parameter.md b/docs-2.0/nebula-exchange/parameter-reference/ex-ug-parameter.md
index 4d28728baf0..76245e8fac9 100644
--- a/docs-2.0/nebula-exchange/parameter-reference/ex-ug-parameter.md
+++ b/docs-2.0/nebula-exchange/parameter-reference/ex-ug-parameter.md
@@ -115,7 +115,7 @@ For different data sources, the vertex configurations are different. There are m
|Parameter|Type|Default value|Required|Description|
|:---|:---|:---|:---|:---|
|`tags.path`|string|-|Yes|The path of vertex data files in HDFS. Enclose the path in double quotes and start with `hdfs://`.|
-|`tags.separator`|string|`,`|Yes|The separator. The default value is a comma (,).|
+|`tags.separator`|string|`,`|Yes|The separator. The default value is a comma (,). For special characters, such as the control character `^A`, you can use ASCII octal `\001` or UNICODE encoded hexadecimal `\u0001`, for the control character `^B`, use ASCII octal `\002` or UNICODE encoded hexadecimal `\u0002`, for the control character `^C`, use ASCII octal `\003` or UNICODE encoded hexadecimal `\u0003`.|
|`tags.header`|bool|`true`|Yes|Whether the file has a header.|
### Specific parameters of Hive data sources
diff --git a/docs-2.0/nebula-exchange/use-exchange/ex-ug-export-from-nebula.md b/docs-2.0/nebula-exchange/use-exchange/ex-ug-export-from-nebula.md
index b6bbd818784..bb3adf3a5c6 100644
--- a/docs-2.0/nebula-exchange/use-exchange/ex-ug-export-from-nebula.md
+++ b/docs-2.0/nebula-exchange/use-exchange/ex-ug-export-from-nebula.md
@@ -1,14 +1,10 @@
# Export data from NebulaGraph
-This topic uses an example to illustrate how to use Exchange to export data from NebulaGraph to a CSV file.
+The Exchange allows you to export data from NebulaGraph to a CSV file or another NebulaGraph space (supporting different NebulaGraph clusters). This topic describes the specific procedure.
!!! enterpriseonly
- Only Exchange Enterprise Edition supports exporting data from NebulaGraph to a CSV file.
-
-!!! note
-
- SSL encryption is not supported when exporting data from NebulaGraph.
+ Only Exchange Enterprise Edition supports exporting data from NebulaGraph.
## Preparation
@@ -53,81 +49,239 @@ As the data source, NebulaGraph stores the [basketballplayer dataset](https://do
2. Modify the configuration file.
- Exchange Enterprise Edition provides the configuration template `export_application.conf` for exporting NebulaGraph data. For details, see [Exchange parameters](../parameter-reference/ex-ug-parameter.md). The core content of the configuration file used in this example is as follows:
+ Exchange Enterprise Edition provides the configuration template `export_to_csv.conf` and `export_to_nebula.conf` for exporting NebulaGraph data. For details, see [Exchange parameters](../parameter-reference/ex-ug-parameter.md). The core content of the configuration file used in this example is as follows:
+ - Export to a CSV file:
+
```conf
- ...
+ # Use the command to submit the exchange job:
+
+ # spark-submit \
+ # --master "spark://master_ip:7077" \
+ # --driver-memory=2G --executor-memory=30G \
+ # --total-executor-cores=60 --executor-cores=20 \
+ # --class com.vesoft.nebula.exchange.Exchange \
+ # nebula-exchange-3.0-SNAPSHOT.jar -c export_to_csv.conf
+
+ {
+ # Spark config
+ spark: {
+ app: {
+ name: NebulaGraph Exchange
+ }
+ }
+
+ # Nebula Graph config
+ # if you export nebula data to csv, please ignore these nebula config
+ nebula: {
+ address:{
+ graph:["127.0.0.1:9669"]
+
+ # the address of any of the meta services.
+ # if your NebulaGraph server is in virtual network like k8s, please config the leader address of meta.
+ meta:["127.0.0.1:9559"]
+ }
+ user: root
+ pswd: nebula
+ space: test
+
+ # nebula client connection parameters
+ connection {
+ # socket connect & execute timeout, unit: millisecond
+ timeout: 30000
+ }
+
+ error: {
+ # max number of failures, if the number of failures is bigger than max, then exit the application.
+ max: 32
+ # failed data will be recorded in output path, format with ngql
+ output: /tmp/errors
+ }
+
+ # use google's RateLimiter to limit the requests send to NebulaGraph
+ rate: {
+ # the stable throughput of RateLimiter
+ limit: 1024
+ # Acquires a permit from RateLimiter, unit: MILLISECONDS
+ # if it can't be obtained within the specified timeout, then give up the request.
+ timeout: 1000
+ }
+ }
# Processing tags
- # There are tag config examples for different dataSources.
tags: [
- # export NebulaGraph tag data to csv, only support export to CSV for now.
{
- name: player
+ # you can ignore the tag name when export nebula data to csv
+ name: tag-name-1
type: {
- source: Nebula
- sink: CSV
+ source: nebula
+ sink: csv
}
- # the path to save the NebulaGrpah data, make sure the path doesn't exist.
- path:"hdfs://192.168.8.177:9000/vertex/player"
- # if no need to export any properties when export NebulaGraph tag data
- # if noField is configured true, just export vertexId
- noField:false
- # define properties to export from NebulaGraph tag data
- # if return.fields is configured as empty list, then export all properties
- return.fields:[]
- # nebula space partition number
- partition:10
- }
-
- ...
+ # config the fields you want to export from nebula
+ fields: [nebula-field-0, nebula-field-1, nebula-field-2]
+ noFields:false # default false, if true, just export id
+ partition: 60
+ # config the path to save your csv file. if your file in not in hdfs, config "file:///path/ test.csv"
+ path: "hdfs://ip:port/path/person"
+ separator: ","
+ header: true
+ }
]
- # Processing edges
- # There are edge config examples for different dataSources.
+ # process edges
edges: [
- # export NebulaGraph tag data to csv, only support export to CSV for now.
{
- name: follow
+ # you can ignore the edge name when export nebula data to csv
+ name: edge-name-1
type: {
- source: Nebula
- sink: CSV
+ source: nebula
+ sink: csv
}
- # the path to save the NebulaGrpah data, make sure the path doesn't exist.
- path:"hdfs://192.168.8.177:9000/edge/follow"
- # if no need to export any properties when export NebulaGraph edge data
- # if noField is configured true, just export src,dst,rank
- noField:false
- # define properties to export from NebulaGraph edge data
- # if return.fields is configured as empty list, then export all properties
- return.fields:[]
- # nebula space partition number
- partition:10
+ # config the fields you want to export from nebula
+ fields: [nebula-field-0, nebula-field-1, nebula-field-2]
+ noFields:false # default false, if true, just export id
+ partition: 60
+ # config the path to save your csv file. if your file in not in hdfs, config "file:///path/ test.csv"
+ path: "hdfs://ip:port/path/friend"
+ separator: ","
+ header: true
}
+ ]
+ }
+ ```
+
+ - Export to another graph space:
+
+ ```conf
+ # Use the command to submit the exchange job:
+
+ # spark-submit \
+ # --master "spark://master_ip:7077" \
+ # --driver-memory=2G --executor-memory=30G \
+ # --total-executor-cores=60 --executor-cores=20 \
+ # --class com.vesoft.nebula.exchange.Exchange \
+ # nebula-exchange-3.0-SNAPSHOT.jar -c export_to_nebula.conf
- ...
+ {
+ # Spark config
+ spark: {
+ app: {
+ name: NebulaGraph Exchange
+ }
+ }
+ # Nebula Graph config, just config the sink nebula information
+ nebula: {
+ address:{
+ graph:["127.0.0.1:9669"]
+
+ # the address of any of the meta services
+ meta:["127.0.0.1:9559"]
+ }
+ user: root
+ pswd: nebula
+ space: test
+
+ # nebula client connection parameters
+ connection {
+ # socket connect & execute timeout, unit: millisecond
+ timeout: 30000
+ }
+
+ error: {
+ # max number of failures, if the number of failures is bigger than max, then exit the application.
+ max: 32
+ # failed data will be recorded in output path, format with ngql
+ output: /tmp/errors
+ }
+
+ # use google's RateLimiter to limit the requests send to NebulaGraph
+ rate: {
+ # the stable throughput of RateLimiter
+ limit: 1024
+ # Acquires a permit from RateLimiter, unit: MILLISECONDS
+ # if it can't be obtained within the specified timeout, then give up the request.
+ timeout: 1000
+ }
+ }
+
+ # Processing tags
+ tags: [
+ {
+ name: tag-name-1
+ type: {
+ source: nebula
+ sink: client
+ }
+ # data source nebula config
+ metaAddress:"127.0.0.1:9559"
+ space:"test"
+ label:"person"
+ # mapping the fields of the original NebulaGraph to the fields of the target NebulaGraph.
+ fields: [source_nebula-field-0, source_nebula-field-1, source_nebula-field-2]
+ nebula.fields: [target_nebula-field-0, target_nebula-field-1, target_nebula-field-2]
+ limit:10000
+ vertex: _vertexId # must be `_vertexId`
+ batch: 2000
+ partition: 60
+ }
]
+
+ # process edges
+ edges: [
+ {
+ name: edge-name-1
+ type: {
+ source: csv
+ sink: client
+ }
+ # data source nebula config
+ metaAddress:"127.0.0.1:9559"
+ space:"test"
+ label:"friend"
+ fields: [source_nebula-field-0, source_nebula-field-1, source_nebula-field-2]
+ nebula.fields: [target_nebula-field-0, target_nebula-field-1, target_nebula-field-2]
+ limit:1000
+ source: _srcId # must be `_srcId`
+ target: _dstId # must be `_dstId`
+ ranking: source_nebula-field-2
+ batch: 2000
+ partition: 60
+ }
+ ]
}
```
3. Export data from NebulaGraph with the following command.
+ !!! note
+
+ The parameters of the Driver and Executor process can be modified based on your own machine configuration.
+
```bash
- /bin/spark-submit --master "local" --class com.vesoft.nebula.exchange.Exchange nebula-exchange-x.y.z.jar_path> -c
+ /bin/spark-submit --master "spark://:7077" \
+ --driver-memory=2G --executor-memory=30G \
+ --total-executor-cores=60 --executor-cores=20 \
+ --class com.vesoft.nebula.exchange.Exchange nebula-exchange-x.y.z.jar_path> \
+ -c
```
- The command used in this example is as follows.
+ The following is an example command to export the data to a CSV file.
```bash
- $ ./spark-submit --master "local" --class com.vesoft.nebula.exchange.Exchange \
- ~/exchange-ent/nebula-exchange-ent-{{exchange.release}}.jar -c ~/exchange-ent/export_application.conf
+ $ ./spark-submit --master "spark://192.168.10.100:7077" \
+ --driver-memory=2G --executor-memory=30G \
+ --total-executor-cores=60 --executor-cores=20 \
+ --class com.vesoft.nebula.exchange.Exchange ~/exchange-ent/nebula-exchange-ent-{{exchange.release}}.jar \
+ -c ~/exchange-ent/export_to_csv.conf
```
4. Check the exported data.
- 1. Check whether the CSV file is successfully generated under the target path.
+ - Export to a CSV file:
+
+ Check whether the CSV file is successfully generated under the target path, and check the contents of the CSV file to ensure that the data export is successful.
```bash
$ hadoop fs -ls /vertex/player
@@ -145,4 +299,6 @@ As the data source, NebulaGraph stores the [basketballplayer dataset](https://do
-rw-r--r-- 3 nebula supergroup 119 2021-11-05 07:36 /vertex/player/ part-00009-17293020-ba2e-4243-b834-34495c0536b3-c000.csv
```
- 2. Check the contents of the CSV file to ensure that the data export is successful.
+ - Export to another graph space:
+
+ Log in to the new graph space and check the statistics through `SUBMIT JOB STATS` and `SHOW STATS` commands to ensure the data export is successful.
diff --git a/docs-2.0/nebula-exchange/use-exchange/ex-ug-import-from-clickhouse.md b/docs-2.0/nebula-exchange/use-exchange/ex-ug-import-from-clickhouse.md
index e930f240002..e36e6d9ca4a 100644
--- a/docs-2.0/nebula-exchange/use-exchange/ex-ug-import-from-clickhouse.md
+++ b/docs-2.0/nebula-exchange/use-exchange/ex-ug-import-from-clickhouse.md
@@ -109,6 +109,8 @@ After Exchange is compiled, copy the conf file `target/classes/application.conf`
# If there are multiple addresses, the format is "ip1:port","ip2:port","ip3:port".
# Addresses are separated by commas.
graph:["127.0.0.1:9669"]
+ # the address of any of the meta services.
+ # if your NebulaGraph server is in virtual network like k8s, please config the leader address of meta.
meta:["127.0.0.1:9559"]
}
# The account entered must have write permission for the NebulaGraph space.
@@ -304,7 +306,7 @@ You can search for `batchSuccess.` in the command output to
Users can verify that data has been imported by executing a query in the NebulaGraph client (for example, NebulaGraph Studio). For example:
```ngql
-GO FROM "player100" OVER follow;
+LOOKUP ON player YIELD id(vertex);
```
Users can also run the [SHOW STATS](../../3.ngql-guide/7.general-query-statements/6.show/14.show-stats.md) command to view statistics.
diff --git a/docs-2.0/nebula-exchange/use-exchange/ex-ug-import-from-csv.md b/docs-2.0/nebula-exchange/use-exchange/ex-ug-import-from-csv.md
index d15e9df6b96..7f542151a2f 100644
--- a/docs-2.0/nebula-exchange/use-exchange/ex-ug-import-from-csv.md
+++ b/docs-2.0/nebula-exchange/use-exchange/ex-ug-import-from-csv.md
@@ -127,6 +127,8 @@ After Exchange is compiled, copy the conf file `target/classes/application.conf`
# If there are multiple addresses, the format is "ip1:port","ip2:port","ip3:port".
# Addresses are separated by commas.
graph:["127.0.0.1:9669"]
+ # the address of any of the meta services.
+ # if your NebulaGraph server is in virtual network like k8s, please config the leader address of meta.
meta:["127.0.0.1:9559"]
}
@@ -389,7 +391,7 @@ You can search for `batchSuccess.` in the command output to
Users can verify that data has been imported by executing a query in the NebulaGraph client (for example, NebulaGraph Studio). For example:
```ngql
-GO FROM "player100" OVER follow;
+LOOKUP ON player YIELD id(vertex);
```
Users can also run the [`SHOW STATS`](../../3.ngql-guide/7.general-query-statements/6.show/14.show-stats.md) command to view statistics.
diff --git a/docs-2.0/nebula-exchange/use-exchange/ex-ug-import-from-hbase.md b/docs-2.0/nebula-exchange/use-exchange/ex-ug-import-from-hbase.md
index 244877ac59c..c89bb72bef5 100644
--- a/docs-2.0/nebula-exchange/use-exchange/ex-ug-import-from-hbase.md
+++ b/docs-2.0/nebula-exchange/use-exchange/ex-ug-import-from-hbase.md
@@ -147,6 +147,8 @@ After Exchange is compiled, copy the conf file `target/classes/application.conf`
# If there are multiple addresses, the format is "ip1:port","ip2:port","ip3:port".
# Addresses are separated by commas.
graph:["127.0.0.1:9669"]
+ # the address of any of the meta services.
+ # if your NebulaGraph server is in virtual network like k8s, please config the leader address of meta.
meta:["127.0.0.1:9559"]
}
# The account entered must have write permission for the NebulaGraph space.
@@ -334,7 +336,7 @@ You can search for `batchSuccess.` in the command output to
Users can verify that data has been imported by executing a query in the NebulaGraph client (for example, NebulaGraph Studio). For example:
```ngql
-GO FROM "player100" OVER follow;
+LOOKUP ON player YIELD id(vertex);
```
Users can also run the [SHOW STATS](../../3.ngql-guide/7.general-query-statements/6.show/14.show-stats.md) command to view statistics.
diff --git a/docs-2.0/nebula-exchange/use-exchange/ex-ug-import-from-hive.md b/docs-2.0/nebula-exchange/use-exchange/ex-ug-import-from-hive.md
index 5a75dc6eace..3bcde16d450 100644
--- a/docs-2.0/nebula-exchange/use-exchange/ex-ug-import-from-hive.md
+++ b/docs-2.0/nebula-exchange/use-exchange/ex-ug-import-from-hive.md
@@ -188,6 +188,8 @@ After Exchange is compiled, copy the conf file `target/classes/application.conf`
# If there are multiple addresses, the format is "ip1:port","ip2:port","ip3:port".
# Addresses are separated by commas.
graph:["127.0.0.1:9669"]
+ # the address of any of the meta services.
+ # if your NebulaGraph server is in virtual network like k8s, please config the leader address of meta.
meta:["127.0.0.1:9559"]
}
# The account entered must have write permission for the NebulaGraph space.
@@ -360,7 +362,7 @@ You can search for `batchSuccess.` in the command output to
Users can verify that data has been imported by executing a query in the NebulaGraph client (for example, NebulaGraph Studio). For example:
```ngql
-GO FROM "player100" OVER follow;
+LOOKUP ON player YIELD id(vertex);
```
Users can also run the [SHOW STATS](../../3.ngql-guide/7.general-query-statements/6.show/14.show-stats.md) command to view statistics.
diff --git a/docs-2.0/nebula-exchange/use-exchange/ex-ug-import-from-jdbc.md b/docs-2.0/nebula-exchange/use-exchange/ex-ug-import-from-jdbc.md
index adacace4624..d163d312a1f 100644
--- a/docs-2.0/nebula-exchange/use-exchange/ex-ug-import-from-jdbc.md
+++ b/docs-2.0/nebula-exchange/use-exchange/ex-ug-import-from-jdbc.md
@@ -149,6 +149,8 @@ After Exchange is compiled, copy the conf file `target/classes/application.conf`
# If there are multiple addresses, the format is "ip1:port","ip2:port","ip3:port".
# Addresses are separated by commas.
graph:["127.0.0.1:9669"]
+ # the address of any of the meta services.
+ # if your NebulaGraph server is in virtual network like k8s, please config the leader address of meta.
meta:["127.0.0.1:9559"]
}
# The account entered must have write permission for the NebulaGraph space.
@@ -369,7 +371,7 @@ You can search for `batchSuccess.` in the command output to
Users can verify that data has been imported by executing a query in the NebulaGraph client (for example, NebulaGraph Studio). For example:
```ngql
-GO FROM "player100" OVER follow;
+LOOKUP ON player YIELD id(vertex);
```
Users can also run the [SHOW STATS](../../3.ngql-guide/7.general-query-statements/6.show/14.show-stats.md) command to view statistics.
diff --git a/docs-2.0/nebula-exchange/use-exchange/ex-ug-import-from-json.md b/docs-2.0/nebula-exchange/use-exchange/ex-ug-import-from-json.md
index 5be1ca7d288..3adffebfde8 100644
--- a/docs-2.0/nebula-exchange/use-exchange/ex-ug-import-from-json.md
+++ b/docs-2.0/nebula-exchange/use-exchange/ex-ug-import-from-json.md
@@ -155,6 +155,8 @@ After Exchange is compiled, copy the conf file `target/classes/application.conf`
# If there are multiple addresses, the format is "ip1:port","ip2:port","ip3:port".
# Addresses are separated by commas.
graph:["127.0.0.1:9669"]
+ # the address of any of the meta services.
+ # if your NebulaGraph server is in virtual network like k8s, please config the leader address of meta.
meta:["127.0.0.1:9559"]
}
@@ -388,7 +390,7 @@ You can search for `batchSuccess.` in the command output to
Users can verify that data has been imported by executing a query in the NebulaGraph client (for example, NebulaGraph Studio). For example:
```ngql
-GO FROM "player100" OVER follow;
+LOOKUP ON player YIELD id(vertex);
```
Users can also run the [`SHOW STATS`](../../3.ngql-guide/7.general-query-statements/6.show/14.show-stats.md) command to view statistics.
diff --git a/docs-2.0/nebula-exchange/use-exchange/ex-ug-import-from-kafka.md b/docs-2.0/nebula-exchange/use-exchange/ex-ug-import-from-kafka.md
index 76ff940cc84..48a74f0dc45 100644
--- a/docs-2.0/nebula-exchange/use-exchange/ex-ug-import-from-kafka.md
+++ b/docs-2.0/nebula-exchange/use-exchange/ex-ug-import-from-kafka.md
@@ -106,6 +106,8 @@ After Exchange is compiled, copy the conf file `target/classes/application.conf`
# If there are multiple addresses, the format is "ip1:port","ip2:port","ip3:port".
# Addresses are separated by commas.
graph:["127.0.0.1:9669"]
+ # the address of any of the meta services.
+ # if your NebulaGraph server is in virtual network like k8s, please config the leader address of meta.
meta:["127.0.0.1:9559"]
}
# The account entered must have write permission for the NebulaGraph space.
@@ -296,7 +298,7 @@ You can search for `batchSuccess.` in the command output to
Users can verify that data has been imported by executing a query in the NebulaGraph client (for example, NebulaGraph Studio). For example:
```ngql
-GO FROM "player100" OVER follow;
+LOOKUP ON player YIELD id(vertex);
```
Users can also run the [SHOW STATS](../../3.ngql-guide/7.general-query-statements/6.show/14.show-stats.md) command to view statistics.
diff --git a/docs-2.0/nebula-exchange/use-exchange/ex-ug-import-from-maxcompute.md b/docs-2.0/nebula-exchange/use-exchange/ex-ug-import-from-maxcompute.md
index c6c6b46120c..124716f1a07 100644
--- a/docs-2.0/nebula-exchange/use-exchange/ex-ug-import-from-maxcompute.md
+++ b/docs-2.0/nebula-exchange/use-exchange/ex-ug-import-from-maxcompute.md
@@ -109,6 +109,8 @@ After Exchange is compiled, copy the conf file `target/classes/application.conf`
# If there are multiple addresses, the format is "ip1:port","ip2:port","ip3:port".
# Addresses are separated by commas.
graph:["127.0.0.1:9669"]
+ # the address of any of the meta services.
+ # if your NebulaGraph server is in virtual network like k8s, please config the leader address of meta.
meta:["127.0.0.1:9559"]
}
# The account entered must have write permission for the NebulaGraph space.
@@ -330,7 +332,7 @@ You can search for `batchSuccess.` in the command output to
Users can verify that data has been imported by executing a query in the NebulaGraph client (for example, NebulaGraph Studio). For example:
```ngql
-GO FROM "player100" OVER follow;
+LOOKUP ON player YIELD id(vertex);
```
Users can also run the [`SHOW STATS`](../../3.ngql-guide/7.general-query-statements/6.show/14.show-stats.md) command to view statistics.
diff --git a/docs-2.0/nebula-exchange/use-exchange/ex-ug-import-from-mysql.md b/docs-2.0/nebula-exchange/use-exchange/ex-ug-import-from-mysql.md
index 2036158a2d5..b23bcf80122 100644
--- a/docs-2.0/nebula-exchange/use-exchange/ex-ug-import-from-mysql.md
+++ b/docs-2.0/nebula-exchange/use-exchange/ex-ug-import-from-mysql.md
@@ -149,6 +149,8 @@ After Exchange is compiled, copy the conf file `target/classes/application.conf`
# If there are multiple addresses, the format is "ip1:port","ip2:port","ip3:port".
# Addresses are separated by commas.
graph:["127.0.0.1:9669"]
+ # the address of any of the meta services.
+ # if your NebulaGraph server is in virtual network like k8s, please config the leader address of meta.
meta:["127.0.0.1:9559"]
}
# The account entered must have write permission for the NebulaGraph space.
@@ -342,7 +344,7 @@ You can search for `batchSuccess.` in the command output to
Users can verify that data has been imported by executing a query in the NebulaGraph client (for example, NebulaGraph Studio). For example:
```ngql
-GO FROM "player100" OVER follow;
+LOOKUP ON player YIELD id(vertex);
```
Users can also run the [SHOW STATS](../../3.ngql-guide/7.general-query-statements/6.show/14.show-stats.md) command to view statistics.
diff --git a/docs-2.0/nebula-exchange/use-exchange/ex-ug-import-from-neo4j.md b/docs-2.0/nebula-exchange/use-exchange/ex-ug-import-from-neo4j.md
index 5ca8db7d16f..f840360fc3c 100644
--- a/docs-2.0/nebula-exchange/use-exchange/ex-ug-import-from-neo4j.md
+++ b/docs-2.0/nebula-exchange/use-exchange/ex-ug-import-from-neo4j.md
@@ -136,6 +136,8 @@ After Exchange is compiled, copy the conf file `target/classes/application.conf`
nebula: {
address:{
graph:["127.0.0.1:9669"]
+ # the address of any of the meta services.
+ # if your NebulaGraph server is in virtual network like k8s, please config the leader address of meta.
meta:["127.0.0.1:9559"]
}
user: root
@@ -309,7 +311,7 @@ You can search for `batchSuccess.` in the command output to
Users can verify that data has been imported by executing a query in the NebulaGraph client (for example, NebulaGraph Studio). For example:
```ngql
-GO FROM "player100" OVER follow;
+LOOKUP ON player YIELD id(vertex);
```
Users can also run the [`SHOW STATS`](../../3.ngql-guide/7.general-query-statements/6.show/14.show-stats.md) command to view statistics.
diff --git a/docs-2.0/nebula-exchange/use-exchange/ex-ug-import-from-oracle.md b/docs-2.0/nebula-exchange/use-exchange/ex-ug-import-from-oracle.md
index 7c6e8e4276c..3104e0fd72a 100644
--- a/docs-2.0/nebula-exchange/use-exchange/ex-ug-import-from-oracle.md
+++ b/docs-2.0/nebula-exchange/use-exchange/ex-ug-import-from-oracle.md
@@ -151,6 +151,8 @@ After Exchange is compiled, copy the conf file `target/classes/application.conf`
# If there are multiple addresses, the format is "ip1:port","ip2:port","ip3:port".
# Addresses are separated by commas.
graph:["127.0.0.1:9669"]
+ # the address of any of the meta services.
+ # if your NebulaGraph server is in virtual network like k8s, please config the leader address of meta.
meta:["127.0.0.1:9559"]
}
# The account entered must have write permission for the NebulaGraph space.
@@ -341,7 +343,7 @@ You can search for `batchSuccess.` in the command output to
Users can verify that data has been imported by executing a query in the NebulaGraph client (for example, NebulaGraph Studio). For example:
```ngql
-GO FROM "player100" OVER follow;
+LOOKUP ON player YIELD id(vertex);
```
Users can also run the [SHOW STATS](../../3.ngql-guide/7.general-query-statements/6.show/14.show-stats.md) command to view statistics.
diff --git a/docs-2.0/nebula-exchange/use-exchange/ex-ug-import-from-orc.md b/docs-2.0/nebula-exchange/use-exchange/ex-ug-import-from-orc.md
index e1d0783b547..238f4e03be5 100644
--- a/docs-2.0/nebula-exchange/use-exchange/ex-ug-import-from-orc.md
+++ b/docs-2.0/nebula-exchange/use-exchange/ex-ug-import-from-orc.md
@@ -123,6 +123,8 @@ After Exchange is compiled, copy the conf file `target/classes/application.conf`
# If there are multiple addresses, the format is "ip1:port","ip2:port","ip3:port".
# Addresses are separated by commas.
graph:["127.0.0.1:9669"]
+ # the address of any of the meta services.
+ # if your NebulaGraph server is in virtual network like k8s, please config the leader address of meta.
meta:["127.0.0.1:9559"]
}
@@ -354,7 +356,7 @@ You can search for `batchSuccess.` in the command output to
Users can verify that data has been imported by executing a query in the NebulaGraph client (for example, NebulaGraph Studio). For example:
```ngql
-GO FROM "player100" OVER follow;
+LOOKUP ON player YIELD id(vertex);
```
Users can also run the [`SHOW STATS`](../../3.ngql-guide/7.general-query-statements/6.show/14.show-stats.md) command to view statistics.
diff --git a/docs-2.0/nebula-exchange/use-exchange/ex-ug-import-from-parquet.md b/docs-2.0/nebula-exchange/use-exchange/ex-ug-import-from-parquet.md
index 60796234624..71ea17006b2 100644
--- a/docs-2.0/nebula-exchange/use-exchange/ex-ug-import-from-parquet.md
+++ b/docs-2.0/nebula-exchange/use-exchange/ex-ug-import-from-parquet.md
@@ -123,6 +123,8 @@ After Exchange is compiled, copy the conf file `target/classes/application.conf`
# If there are multiple addresses, the format is "ip1:port","ip2:port","ip3:port".
# Addresses are separated by commas.
graph:["127.0.0.1:9669"]
+ # the address of any of the meta services.
+ # if your NebulaGraph server is in virtual network like k8s, please config the leader address of meta.
meta:["127.0.0.1:9559"]
}
@@ -355,7 +357,7 @@ You can search for `batchSuccess.` in the command output to
Users can verify that data has been imported by executing a query in the NebulaGraph client (for example, NebulaGraph Studio). For example:
```ngql
-GO FROM "player100" OVER follow;
+LOOKUP ON player YIELD id(vertex);
```
Users can also run the [`SHOW STATS`](../../3.ngql-guide/7.general-query-statements/6.show/14.show-stats.md) command to view statistics.
diff --git a/docs-2.0/nebula-exchange/use-exchange/ex-ug-import-from-pulsar.md b/docs-2.0/nebula-exchange/use-exchange/ex-ug-import-from-pulsar.md
index 427fff38484..038e5925603 100644
--- a/docs-2.0/nebula-exchange/use-exchange/ex-ug-import-from-pulsar.md
+++ b/docs-2.0/nebula-exchange/use-exchange/ex-ug-import-from-pulsar.md
@@ -102,6 +102,8 @@ After Exchange is compiled, copy the conf file `target/classes/application.conf`
# If there are multiple addresses, the format is "ip1:port","ip2:port","ip3:port".
# Addresses are separated by commas.
graph:["127.0.0.1:9669"]
+ # the address of any of the meta services.
+ # if your NebulaGraph server is in virtual network like k8s, please config the leader address of meta.
meta:["127.0.0.1:9559"]
}
@@ -305,7 +307,7 @@ You can search for `batchSuccess.` in the command output to
Users can verify that data has been imported by executing a query in the NebulaGraph client (for example, NebulaGraph Studio). For example:
```ngql
-GO FROM "player100" OVER follow;
+LOOKUP ON player YIELD id(vertex);
```
Users can also run the [`SHOW STATS`](../../3.ngql-guide/7.general-query-statements/6.show/14.show-stats.md) command to view statistics.
diff --git a/docs-2.0/nebula-exchange/use-exchange/ex-ug-import-from-sst.md b/docs-2.0/nebula-exchange/use-exchange/ex-ug-import-from-sst.md
index 35d7a8da42a..61f8e979e6e 100644
--- a/docs-2.0/nebula-exchange/use-exchange/ex-ug-import-from-sst.md
+++ b/docs-2.0/nebula-exchange/use-exchange/ex-ug-import-from-sst.md
@@ -191,6 +191,8 @@ After Exchange is compiled, copy the conf file `target/classes/application.conf`
nebula: {
address:{
graph:["127.0.0.1:9669"]
+ # the address of any of the meta services.
+ # if your NebulaGraph server is in virtual network like k8s, please config the leader address of meta.
meta:["127.0.0.1:9559"]
}
user: root
@@ -528,7 +530,7 @@ Connect to the NebulaGraph database using the client tool and import the SST fil
Users can verify that data has been imported by executing a query in the NebulaGraph client (for example, NebulaGraph Studio). For example:
```ngql
-GO FROM "player100" OVER follow;
+LOOKUP ON player YIELD id(vertex);
```
Users can also run the [`SHOW STATS`](../../3.ngql-guide/7.general-query-statements/6.show/14.show-stats.md) command to view statistics.
diff --git a/docs-2.0/nebula-explorer/about-explorer/ex-ug-what-is-explorer.md b/docs-2.0/nebula-explorer/about-explorer/ex-ug-what-is-explorer.md
index b336f58169d..6bee6621771 100644
--- a/docs-2.0/nebula-explorer/about-explorer/ex-ug-what-is-explorer.md
+++ b/docs-2.0/nebula-explorer/about-explorer/ex-ug-what-is-explorer.md
@@ -51,6 +51,7 @@ When NebulaGraph enables authentication, users can only sign into Studio with th
| NebulaGraph version | Explorer version |
| --- | --- |
+| 3.4.0 ~ 3.4.1 | 3.4.0、3.2.1、3.2.0 |
| 3.3.0 | 3.2.1, 3.2.0|
| 3.1.0 ~ 3.2.x| 3.1.0|
| 3.0.0 ~ 3.1.0 | 3.0.0 |
diff --git a/docs-2.0/nebula-explorer/workflow/workflow-api/workflow-api-overview.md b/docs-2.0/nebula-explorer/workflow/workflow-api/workflow-api-overview.md
index 21e49b60571..6095a23b1df 100644
--- a/docs-2.0/nebula-explorer/workflow/workflow-api/workflow-api-overview.md
+++ b/docs-2.0/nebula-explorer/workflow/workflow-api/workflow-api-overview.md
@@ -39,7 +39,7 @@ Token information verification is required when calling an API. Run the followin
curl -i -X POST -H "Content-Type: application/json" -H "Authorization: Bearer " -d '{"address":"","port":}' http://:/api-open/v1/connect
```
-- ``: The Base64 encoded NebulaGraph account and password. Before the encoding, the format is `:`, for example, `root:123`. After the encoding, the result is `cm9vdDoxMjM=`.
+- ``: The character string of the base64 encoded NebulaGraph account and password. Take the username `root` and password `123` as an example, the serialized string is `["root", "123"]`. After the encoding, the result is `WyJyb290IiwiMTIzIl0=`.
- ``: The access address of the NebulaGraph.
- ``: The access port of the NebulaGraph.
- ``: The access address of the NebulaGraph Explorer.
@@ -48,7 +48,7 @@ curl -i -X POST -H "Content-Type: application/json" -H "Authorization: Bearer = 1.4.0.
+- The enterprise edition NebulaGraph cluster deployed on Kubernetes is running.
+- In the YAML file used to create the cluster, `spec.enableBR` is set to true.
+
+ ```
+ // Partial content of a sample cluster YAML file.
+ apiVersion: apps.nebula-graph.io/v1alpha1
+ kind: NebulaCluster
+ metadata:
+ name: nebula
+ spec:
+ enableBR: true // Set to true to enable the backup and restore function.
+ ...
+ ```
+
+- Only storage services that use the S3 protocol (such as AWS S3, Minio, etc.) can be used to back up and restore data.
+- Sufficient computing resources are available in the cluster to restore data.
+
+## Backup
+
+### Notes
+
+- NebulaGraph Operator supports full and incremental backups.
+- During data backup, DDL and DML statements in the specified graph space will be blocked. We recommend performing the operation during off-peak hours, such as from 2:00 am to 5:00 am.
+- The cluster executing incremental backups and the cluster specified for the last backup must be the same, and the (storage bucket) path for the last backup must be the same.
+- Ensure that the time between each incremental backup and the last backup is less than a `wal_ttl`.
+- Specifying the backup data of a specified graph space is not supported.
+
+### Full backup
+
+When backing up data to a storage service compatible with the S3 protocol, you need to create a backup Job, which will back up the full NebulaGraph data to the specified storage location.
+
+Here is an example of the YAML file for a full backup Job:
+
+```yaml
+apiVersion: batch/v1
+kind: Job
+metadata:
+ name: nebula-full-backup
+spec:
+ parallelism: 1
+ ttlSecondsAfterFinished: 60
+ template:
+ spec:
+ restartPolicy: OnFailure
+ containers:
+ - image: vesoft/br-ent:v{{br_ent.release}}
+ imagePullPolicy: Always
+ name: backup
+ command:
+ - /bin/sh
+ - -ecx
+ - exec /usr/local/bin/nebula-br backup full
+ - --meta $META_ADDRESS:9559
+ - --storage s3://$BUCKET
+ - --s3.access_key $ACCESS_KEY
+ - --s3.secret_key $SECRET_KEY
+ - --s3.region $REGION
+ - --s3.endpoint https://s3.$REGION.amazonaws.com
+```
+
+### Incremental backup
+
+Except for the name of the Job and the command specified in `spec.template.spec.containers[0].command`, the YAML file for incremental backup is the same as that for a full backup. Here is an example of the YAML file for incremental backup:
+
+```yaml
+apiVersion: batch/v1
+kind: Job
+metadata:
+ name: nebula-incr-backup
+spec:
+ parallelism: 1
+ ttlSecondsAfterFinished: 60
+ template:
+ spec:
+ restartPolicy: OnFailure
+ containers:
+ - image: vesoft/br-ent:v{{br_ent.release}}
+ imagePullPolicy: Always
+ name: backup
+ command:
+ - /bin/sh
+ - -ecx
+ - exec /usr/local/bin/nebula-br backup incr
+ - --meta $META_ADDRESS:9559
+ - --base $BACKUP_NAME
+ - --storage s3://$BUCKET
+ - --s3.access_key $ACCESS_KEY
+ - --s3.secret_key $SECRET_KEY
+ - --s3.region $REGION
+ - --s3.endpoint https://s3.$REGION.amazonaws.com
+```
+
+### Parameter description
+
+The main parameters are described as follows:
+
+
+| Parameter |Default value | Description |
+| ------------- | ---- | ---- |
+| `spec.parallelism` |1 |The number of tasks executed in parallel. |
+| `spec.ttlSecondsAfterFinished` | 60 | The time to keep task information after the task is completed. |
+| `spec.template.spec.containers[0].image` | `vesoft/br-ent:{{br_ent.release}}`|The image address of the NebulaGraph BR Enterprise Edition tool. |
+| `spec.template.spec.containers[0].command`| - | The command for backing up data to the storage service compatible with the S3 protocol.
For descriptions of the options in the command, see [Parametr description](../backup-and-restore/nebula-br-ent/3.backup-data.md#_12). |
+
+
+For more settings of the Job, see [Kubernetes Jobs](https://kubernetes.io/docs/concepts/workloads/controllers/job/).
+
+After the YAML file for the backup Job is set, run the following command to start the backup Job:
+
+
+
+```bash
+kubectl apply -f .yaml
+```
+
+When the data backup succeeds, a backup file is generated in the specified storage location. For example, the backup file name is `BACKUP_2023_02_12_10_04_16`.
+
+
+## Restore
+
+### Notes
+
+- After the data recovery is successful, a new cluster will be created, and the old cluster will not be deleted. Users can decide whether to delete the old cluster themselves.
+- There will be a period of service unavailability during the data recovery process, so it is recommended to perform the operation during a low period of business activity.
+
+
+
+### Process
+
+When restoring data from a compatible S3 protocol service, you need to create a Secret to store the credentials for accessing the compatible S3 protocol service. Then create a resource object (NebulaRestore) for restoring the data, which will instruct the Operator to create a new NebulaGraph cluster based on the information defined in this resource object and restore the backup data to the newly created cluster.
+
+Here is an example YAML for restoring data based on the backup file `BACKUP_2023_02_12_10_04_16`:
+
+```yaml
+apiVersion: v1
+kind: Secret
+metadata:
+ name: aws-s3-secret
+type: Opaque
+data:
+ access-key: QVNJQVE0WFlxxx
+ secret-key: ZFJ6OEdNcDdxenMwVGxxx
+---
+apiVersion: apps.nebula-graph.io/v1alpha1
+kind: NebulaRestore
+metadata:
+ name: restore1
+spec:
+ br:
+ clusterName: nebula
+ backupName: "BACKUP_2023_02_12_10_04_16"
+ concurrency: 5
+ s3:
+ region: "us-west-2"
+ bucket: "nebula-br-test"
+ endpoint: "https://s3.us-west-2.amazonaws.com"
+ secretName: "aws-s3-secret"
+```
+
+### Parameter Description
+
+- Secret
+
+ |Parameter|Default Value|Description|
+ |:---|:---|:---|
+ |`metadata.name`|-|The name of the Secret.|
+ |`type`|`Opaque`|The type of the Secret. See [Types of Secret](https://kubernetes.io/docs/concepts/configuration/secret/#secret-types) for more information.|
+ |`data.access-key`|-|The AccessKey for accessing the S3 protocol-compatible storage service.|
+ |`data.secret-key`|-|The SecretKey for accessing the S3 protocol-compatible storage service.|
+
+- NebulaRestore
+
+ |Parameter|Default Value|Description|
+ |:---|:---|:---|
+ |`metadata.name`|-|The name of the resource object NebulaRestore.|
+ |`spec.br.clusterName`|-|The name of the backup cluster.|
+ |`spec.br.backupName`|-|The name of the backup file. Restore data based on this backup file.|
+ |`spec.br.concurrency`|`5`|The number of concurrent downloads when restoring data. The default value is `5`.|
+ |`spec.br.s3.region`|-| The geographical region where the S3 storage bucket is located.|
+ |`spec.br.s3.bucket`|-|The path of the S3 storage bucket where backup data is stored.|
+ |`spec.br.s3.endpoint`|-|The access address of the S3 storage bucket.|
+ |`spec.br.s3.secretName`|-|The name of the Secret that is used to access the S3 storage bucket.|
+
+After setting up the YAML file for restoring the data, run the following command to start the restore job:
+
+```bash
+kubectl apply -f .yaml
+```
+
+Run the following command to check the status of the NebulaRestore object.
+
+```bash
+kubectl get rt -w
+
diff --git a/docs-2.0/nebula-operator/8.custom-cluster-configurations/8.2.pv-reclaim.md b/docs-2.0/nebula-operator/8.custom-cluster-configurations/8.2.pv-reclaim.md
index ee93d59aab0..177c9578243 100644
--- a/docs-2.0/nebula-operator/8.custom-cluster-configurations/8.2.pv-reclaim.md
+++ b/docs-2.0/nebula-operator/8.custom-cluster-configurations/8.2.pv-reclaim.md
@@ -1,10 +1,8 @@
# Reclaim PVs
-NebulaGraph Operator uses PVs (Persistent Volumes) and PVCs (Persistent Volume Claims) to store persistent data. If you accidentally deletes a NebulaGraph cluster, PV and PVC objects and the relevant data will be retained to ensure data security.
+NebulaGraph Operator uses PVs (Persistent Volumes) and PVCs (Persistent Volume Claims) to store persistent data. If you accidentally deletes a NebulaGraph cluster, by default, PV and PVC objects and the relevant data will be retained to ensure data security.
-You can define whether to reclaim PVs or not in the configuration file of the cluster's CR instance with the parameter `enablePVReclaim`.
-
-If you need to release a graph space and retain the relevant data, update your nebula cluster by setting the parameter `enablePVReclaim` to `true`.
+You can also define the automatic deletion of PVCs to release data by setting the parameter `spec.enablePVReclaim` to `true` in the configuration file of the cluster instance. As for whether PV will be deleted automatically after PVC is deleted, you need to customize the PV reclaim policy. See [reclaimPolicy in StorageClass](https://kubernetes.io/docs/concepts/storage/storage-classes/#reclaim-policy) and [PV Reclaiming](https://kubernetes.io/docs/concepts/storage/persistent-volumes/#reclaiming) for details.
## Prerequisites
diff --git a/docs-2.0/nebula-spark-connector.md b/docs-2.0/nebula-spark-connector.md
index b6f176c7021..19391260bd5 100644
--- a/docs-2.0/nebula-spark-connector.md
+++ b/docs-2.0/nebula-spark-connector.md
@@ -12,6 +12,28 @@ NebulaGraph Spark Connector is a Spark connector application for reading and wri
For more information, see [NebulaGraph Spark Connector](https://github.com/vesoft-inc/nebula-spark-connector/blob/{{sparkconnector.branch}}/README_CN.md).
+## Version compatibility
+
+The correspondence between the NebulaGraph Spark Connector version, the NebulaGraph core version and the Spark version is as follows.
+
+| Spark Connector version | NebulaGraph version | Spark version |
+|:----------|:-----------|:-------|
+|nebula-spark-connector_3.0-3.0-SNAPSHOT.jar| nightly| 3.x|
+|nebula-spark-connector_2.2-3.0-SNAPSHOT.jar| nightly| 2.2.x|
+|nebula-spark-connector-3.0-SNAPSHOT.jar| nightly| 2.4.x|
+|nebula-spark-connector_2.2-3.4.0.jar| 3.x| 2.2.x|
+|nebula-spark-connector-3.4.0.jar| 3.x| 2.4.x|
+|nebula-spark-connector_2.2-3.3.0.jar| 3.x| 2.2.x|
+|nebula-spark-connector-3.3.0.jar| 3.x| 2.4.x|
+|nebula-spark-connector-3.0.0.jar| 3.x| 2.4.x|
+|nebula-spark-connector-2.6.1.jar| 2.6.0, 2.6.1| 2.4.x|
+|nebula-spark-connector-2.6.0.jar| 2.6.0, 2.6.1| 2.4.x|
+|nebula-spark-connector-2.5.1.jar| 2.5.0, 2.5.1| 2.4.x|
+|nebula-spark-connector-2.5.0.jar| 2.5.0, 2.5.1| 2.4.x|
+|nebula-spark-connector-2.1.0.jar| 2.0.0, 2.0.1| 2.4.x|
+|nebula-spark-connector-2.0.1.jar| 2.0.0, 2.0.1| 2.4.x|
+|nebula-spark-connector-2.0.0.jar| 2.0.0, 2.0.1| 2.4.x|
+
## Use cases
NebulaGraph Spark Connector applies to the following scenarios:
diff --git a/docs-2.0/nebula-studio/about-studio/st-ug-what-is-graph-studio.md b/docs-2.0/nebula-studio/about-studio/st-ug-what-is-graph-studio.md
index a6b786c03a2..d0a308ec1b6 100644
--- a/docs-2.0/nebula-studio/about-studio/st-ug-what-is-graph-studio.md
+++ b/docs-2.0/nebula-studio/about-studio/st-ug-what-is-graph-studio.md
@@ -53,6 +53,8 @@ When NebulaGraph enables authentication, users can only sign into Studio with th
| NebulaGraph version | Studio version |
| --- | --- |
+| 3.4.0 ~ 3.4.1 | 3.6.0、3.5.1、3.5.0 |
+| 3.3.0 | 3.5.1、3.5.0 |
| 3.0.0 ~ 3.2.0| 3.4.1、3.4.0|
| 3.1.0 | 3.3.2 |
| 3.0.0 | 3.2.x |
diff --git a/docs-2.0/nebula-studio/deploy-connect/st-ug-deploy.md b/docs-2.0/nebula-studio/deploy-connect/st-ug-deploy.md
index e7d72a9c440..4acc0d6c1a5 100644
--- a/docs-2.0/nebula-studio/deploy-connect/st-ug-deploy.md
+++ b/docs-2.0/nebula-studio/deploy-connect/st-ug-deploy.md
@@ -304,7 +304,7 @@ Before installing Studio, you need to install the following software and ensure
|-----------|-------------|---------|
| replicaCount | 0 | The number of replicas for Deployment. |
| image.nebulaStudio.name | vesoft/nebula-graph-studio | The image name of nebula-graph-studio. |
- | image.nebulaStudio.version | v3.2.0 | The image version of nebula-graph-studio. |
+ | image.nebulaStudio.version | {{studio.tag}} | The image version of nebula-graph-studio. |
| service.type | ClusterIP | The service type, which should be one of `NodePort`, `ClusterIP`, and `LoadBalancer`. |
| service.port | 7001 | The expose port for nebula-graph-studio's web. |
| service.nodePort | 32701 | The proxy port for accessing nebula-studio outside kubernetes cluster. |
diff --git a/mkdocs.yml b/mkdocs.yml
index 8b6f0ed2fd1..64bb0ab8ad8 100644
--- a/mkdocs.yml
+++ b/mkdocs.yml
@@ -6,7 +6,7 @@ site_url: https://docs.nebula-graph.io/
docs_dir: docs-2.0
repo_name: 'vesoft-inc/nebula'
repo_url: 'https://github.com/vesoft-inc/nebula'
-copyright: Copyright © 2022 NebulaGraph
+copyright: Copyright © 2023 NebulaGraph
# modify
edit_uri: 'https://github.com/vesoft-inc/nebula-docs/edit/master/docs-2.0/'
@@ -81,16 +81,17 @@ plugins:
- nebula-cloud.md
# When publishing a version of a document that includes Enterprise Edition, annotation the following page
# ent.begin
- - 3.ngql-guide/6.functions-and-expressions/17.ES-function.md
- - 4.deployment-and-installation/deploy-license.md
- - 5.configurations-and-logs/2.log-management/audit-log.md
- - 7.data-security/1.authentication/4.ldap.md
- - nebula-operator/8.custom-cluster-configurations/8.3.balance-data-when-scaling-storage.md
- - synchronization-and-migration/replication-between-clusters.md
- - 20.appendix/release-notes/nebula-ent-release-note.md
- - nebula-dashboard-ent/4.cluster-operator/operator/scale.md
- - backup-and-restore/nebula-br-ent/*
- - 6.monitor-and-metrics/3.bbox/*
+ # - 3.ngql-guide/6.functions-and-expressions/17.ES-function.md
+ # - 4.deployment-and-installation/deploy-license.md
+ # - 5.configurations-and-logs/2.log-management/audit-log.md
+ # - 7.data-security/1.authentication/4.ldap.md
+ # - nebula-operator/8.custom-cluster-configurations/8.3.balance-data-when-scaling-storage.md
+ # - nebula-operator/10.backup-restore-using-operator.md
+ # - synchronization-and-migration/replication-between-clusters.md
+ # - 20.appendix/release-notes/nebula-ent-release-note.md
+ # - nebula-dashboard-ent/4.cluster-operator/operator/scale.md
+ # - backup-and-restore/nebula-br-ent/*
+ # - 6.monitor-and-metrics/3.bbox/*
# ent.end
# comm.begin
@@ -102,7 +103,7 @@ plugins:
# - '.*\.(tmp|bin|tar)$'
- with-pdf:
- copyright: 2022 Vesoft Inc.
+ copyright: 2023 Vesoft Inc.
cover_subtitle: master
author: Min Wu, Yao Zhou, Cooper Liang, Foesa Yang, Abby Huang
cover: true
@@ -149,116 +150,116 @@ extra:
- icon: 'fontawesome/brands/github'
link: 'https://github.com/vesoft-inc/nebula-docs'
nebula:
- release: 3.4.0
+ release: 3.4.1
nightly: nightly
master: master
base20: 2.0
base200: 2.0.0
- branch: release-3.3
- tag: v3.3.0
+ branch: release-3.4
+ tag: v3.4.1
studio:
base111b: 1.1.1-beta
base220: 2.2.1
base300: 3.0.0
- release: 3.5.0
- tag: v3.5.0
+ release: 3.6.0
+ tag: v3.6.0
explorer:
- release: 3.2.0
- branch: release-3.2
- tag: v3.2.0
+ release: 3.4.0
+ branch: release-3.4
+ tag: v3.4.0
exchange_ent:
- release: 3.0.0
- branch: v3.0.0
- tag: v3.0.0
+ release: 3.4.0
+ branch: release-3.4
+ tag: v3.4.0
exchange:
- release: 3.3.0
- branch: release-3.3
- tag: v3.3.0
+ release: 3.4.0
+ branch: release-3.4
+ tag: v3.4.0
importer:
- release: 3.1.0
- branch: release-3.1
- tag: v3.1.0
+ release: 3.4.0
+ branch: release-3.4
+ tag: v3.4.0
algorithm:
release: 3.0.0
branch: v3.0.0
tag: v3.0.0
plato:
- release: 3.3.0
- branch: release-3.3
- tag: v3.3.0
+ release: 3.4.0
+ branch: release-3.4
+ tag: v3.4.0
sparkconnector:
- release: 3.3.0
- branch: release-3.3
- tag: v3.3.0
+ release: 3.4.0
+ branch: release-3.4
+ tag: v3.4.0
flinkconnector:
release: 3.3.0
branch: release-3.3
tag: v3.3.0
dockercompose:
- release: 3.2.0
- branch: release-3.2
- tag: v3.2.0
+ release: 3.4.0
+ branch: release-3.4
+ tag: v3.4.0
dashboard:
- release: 3.2.0
- tag: v3.2.0
+ release: 3.4.0
+ tag: v3.4.0
base100: 1.0.0
- branch: release-3.2
+ branch: release-3.4
dashboard_ent:
- release: 3.2.0
- tag: v3.2.0
- branch: release-3.2
+ release: 3.4.1
+ tag: v3.4.1
+ branch: release-3.4
console:
+ release: 3.4.0
+ branch: release-3.4
+ tag: v3.4.0
+ br:
release: 3.3.0
branch: release-3.3
tag: v3.3.0
- br:
- release: 0.6.1
- branch: master
- tag: v0.6.1
br_ent:
- release: 0.7.0
- tag: v0.7.0
+ release: 3.4.0
+ tag: v3.4.0
agent:
- release: 0.2.0
- tag: v0.2.0
+ release: 3.4.0
+ tag: v3.4.0
cpp:
- release: 3.3.0
- branch: release-3.3
- tag: v3.3.0
+ release: 3.4.0
+ branch: release-3.4
+ tag: v3.4.0
java:
- release: 3.3.0
- branch: release-3.3
- tag: v3.3.0
+ release: 3.4.0
+ branch: release-3.4
+ tag: v3.4.0
python:
- release: 3.3.0
- branch: release-3.3
- tag: v3.3.0
+ release: 3.4.0
+ branch: release-3.4
+ tag: v3.4.0
go:
- release: 3.3.0
- branch: release-3.3
- tag: v3.3.0
+ release: 3.4.0
+ branch: release-3.4
+ tag: v3.4.0
bench:
release: 1.2.0
branch: release-1.2
tag: v1.2.0
operator:
- release: 1.3.0
- tag: v1.3.0
- branch: release-1.3
+ release: 1.4.0
+ tag: v1.4.0
+ branch: release-1.4
upgrade_from: 3.0.0
- upgrade_to: 3.3.x
+ upgrade_to: 3.4.0
exporter:
release: 3.3.0
branch: release-3.3
tag: v3.3.0
gateway:
- release: 3.1.2
- branch: release-3.1
- tag: v3.1.2
+ release: 3.4.0
+ branch: release-3.4
+ tag: v3.4.0
bbox:
- release: 3.3.0
- branch: release-3.3
- tag: v3.3.0
+ release: 3.4.0
+ branch: release-3.4
+ tag: v3.4.0
cloud:
azureRelease: 3.1.1 # The latest core version that Azure Cloud is compatible with
aliyunRelease: 3.1.1 # The latest core version that Alibaba Cloud is compatible with
@@ -285,7 +286,7 @@ nav:
- Storage Service: 1.introduction/3.nebula-graph-architecture/4.storage-service.md
- Quick start:
- - Quick start workflow: 2.quick-start/1.quick-start-workflow.md
+ - Getting started with NebulaGraph: 2.quick-start/1.quick-start-workflow.md
- Step 1 Install NebulaGraph: 2.quick-start/2.install-nebula-graph.md
- Step 2 Manage NebulaGraph Service: 2.quick-start/5.start-stop-service.md
- Step 3 Connect to NebulaGraph: 2.quick-start/3.connect-to-nebula-graph.md
@@ -709,6 +710,7 @@ nav:
- Balance storage data after scaling out: nebula-operator/8.custom-cluster-configurations/8.3.balance-data-when-scaling-storage.md
- Upgrade NebulaGraph clusters: nebula-operator/9.upgrade-nebula-cluster.md
- Connect to NebulaGraph databases: nebula-operator/4.connect-to-nebula-graph-service.md
+ - Backup and restore: nebula-operator/10.backup-restore-using-operator.md
- Self-healing: nebula-operator/5.operator-failover.md
- FAQ: nebula-operator/7.operator-faq.md