This chapter introduces the topic of Command Query Responsibility Segregation (CQRS): it describes the CQRS pattern that lies at the heart of almost everything discussed in this guidance and shows how applying this pattern facilitates an approach to architecting elements of your enterprise application. It is important to understand that CQRS is not a silver bullet for all the problems that you encounter when you design and build enterprise applications, and that it is not a top-level architectural approach. You will see the full benefits of applying the CQRS pattern when you apply it selectively to key portions of your system. The chapter Decomposing the Domain in "A CQRS Journey" describes how Contoso divided up the Conference Management System into bounded contexts and identified which bounded contexts would benefit from using the CQRS pattern.
Subsequent chapters provide a more in depth guidance on how to apply the CQRS pattern and other related patterns to your implementation.
In his book "Object Oriented Software Construction," Betrand Meyer introduced the term "command query separation" to describe the principle that an object's methods should be either commands, or queries. A query returns data and does not alter the state of the object, a command changes the state of an object but does not return any data. The benefit is improved clarity in relation to understanding what does, and what does not, change the state in your system.
CQRS takes this principal a step further to define a simple pattern:
"CQRS is simply the creation of two objects where there was previously only one. The separation occurs based upon whether the methods are a command or a query (the same definition that is used by Meyer in Command and Query Separation, a command is any method that mutates state and a query is any method that returns a value)."
Greg Young, CQRS, Task Based UIs, Event Sourcing agh!
What is important and interesting about this simple pattern is the "how, where, and why" of using it when you build enterprise systems. Using this simple pattern enables you to meet a wide range of architectural challenges such as achieving scalability, managing complexity, and managing changing business rules in some portions of your system.
CQRS is a simple pattern that strictly segregates the responsibility of handling command input into an autonomous system from the responsibility of handling side-effect-free query/read access on the same system. Consequently, the decoupling allows for any number of homogeneous or heterogeneous query/read modules to be paired with a command processor and this principle presents a very suitable foundation for event sourcing, eventual-consistency state replication/fan-out and, thus, high-scale read access. In simple terms: You don’t service queries via the same module of a service that you process commands through. In REST terminology: GET requests wire up to a different thing from what PUT/POST/DELETE requests wire up to.
- Greg Young (CQRS Advisors Mail List)
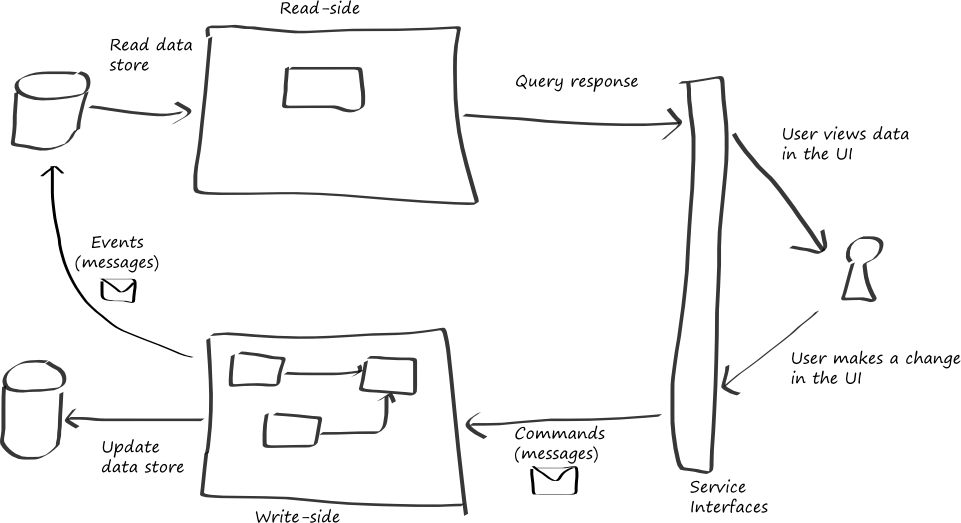
Figure 1 shows a typical application of the CQRS pattern to a portion of an enterprise system. This approach shows how, when you apply the CQRS pattern, you can separate the read and write sides in this portion of the system.

A possible architectural implementation of the CQRS pattern
In figure 1, you can see how this portion of the system is split into a read-side, and a write-side. The object or objects or the read-side contain only query methods, and the objects on the write-side contain only command methods.
There are several motivations for this segregation including:
- In many business systems, there is a large imbalance between the number of reads and the number of writes. A system may process thousands of reads for every write. Segregating the two sides enables you to optimize the two sides independently. For example, you can scale out the read-side to support the larger number of read operations independently of the write-side.
- Typically, commands involve complex business logic to ensure that the system writes correct and consistent data to the data store. Read operations are often much simpler than the write operations. A single conceptual model that tries to encapsulate both read and write operations may do neither well. Segregating the two sides ultimately results in simpler, more maintainable, and more flexible models.
- Segregation can also occur in the data store. The write-side may use a database schema that is close to third normal form (3NF) and optimized for data modification, while the read-side uses a denormalized database that is optimized for fast query operations.
Note: Although figure 1 shows two data stores, applying the CQRS pattern does not mandate you to split the data store, or to use any particular technology such as a relational database, NoSQL store, or event store. You should view CQRS as a pattern that facilitates splitting the data store and enabling you to select from a range of storage mechanisms.
Figure 1 might also suggest a one-to-one relationship between the write-side and the read-side. This is not necessarily the case. It can be useful to consolidate the data from multiple write-models into a single read-model if your UI needs to display consolidated data. The point of the read-side model is to simplify what happens on the read-side, and you may be able to simplify the implementation of your UI if the data that you need to display has already been combined.
There are some questions that might occur to you about the practicalities of adopting architecture such as the one shown in figure 1.
- Although the individual models on the read-side and write-side might be simpler than a single compound model, the overall architecture is more complex than a traditional approach with a single model and a single data store. Haven't we just shifted the complexity?
- How should we manage propagating the changes in the data store on the write-side to the read-side?
- What if there is a delay while the updates on the write-side are propagated to the read-side?
- What exactly do we mean when we talk about models?
The remainder of this chapter will begin to address these questions and to explore the motivations for using the CQRS pattern in more detail. Later chapters will explore these issues in more depth.
The previous chapter "CQRS in Context," introduced some of the concepts and terminology from Domain-Driven Design (DDD) that are relevant to the implementation of the CQRS pattern. Two areas are particularly significant to the CQRS pattern.
Note: "CQRS is an architectural style that is often enabling of DDD."
Eric Evans, tweet February 2012.
The first is the concept of the model:
"The model is a set of concepts built up in the heads of people on the project, with terms and relationships that reflect domain insight. These terms and interrelationships provide the semantics of a language that is tailored to the domain while being precise enough for technical development."
Eric Evans, "Domain-Driven Design," p23.
In his book "Domain-Driven Design," Eric Evans provides the following list of ingredients for effective modeling. This list helps to capture the idea of a model, but is no substitute for reading the book to gain a deeper understanding of the concept:
- Models should be bound to the implementation.
- You should cultivate a language based on the model.
- Models should be knowledge rich.
- You should brainstorm and experiment to develop the model.
In figure 1, the implementation of the model exists on the write-side; it encapsulates the complex business logic in this portion of the system. The read-side is a simpler, read-only view of the system state accessed through queries.
The second important concept is the way that DDD divides large, complex systems into more manageable units known as bounded contexts. A bounded context defines the context for a model:
"Explicitly define the context within which a model applies. Explicitly set boundaries in terms of team organization, usage within specific parts of the application, and physical manifestations such as code bases and database schemas. Keep the model strictly consistent within these bounds, but don't be distracted or confused by issues outside."
Eric Evans, "Domain-Driven Design," p335.
Note: Other design approaches may use different terminology: for example in Event-Driven SOA, the concept of a service is roughly equivalent to a bounded context in DDD.
When we say that you should apply the CQRS pattern to a portion of a system, we mean that you should implement the CQRS pattern within a bounded context.
The reasons for identifying context boundaries for your domain models, are not necessarily the same reasons for choosing the portions of the system that should use the CQRS pattern. In DDD, a bounded context defines the context for a model and the scope of a ubiquitous language. You should implement the CQRS pattern to gain certain benefits for your application such as scalability, simplicity, and maintainability. Because of these differences, it may make sense to think about applying the CQRS pattern to business components rather than bounded contexts.
"A given Bounded Context should be divided into Business Components, where these Business Components have full UI through DB code, and are ultimately put together in composite UI's and other physical pipelines to fulfill the system's functionality.
A Business Component can exist in only one Bounded Context.
CQRS, if it is to be used at all, should be used within a Business Component."
Udi Dahan, Udi & Greg Reach CQRS Agreement.
It is quite possible that your bounded contexts map exactly on to your business components.
Note: For the remainder of this guide, we will choose to use the term bounded context in preference to the term business component to refer to the context within which we are implementing the CQRS pattern.
In summary, you should not apply the CQRS pattern to the top-level of your system. You should clearly identify the different portions of your system that you can design and implement largely independently of each other, and then only apply the CQRS pattern to those portions where there are clear business benefits in doing so.
DDD is an analysis and design approach that encourages you to use models and a ubiquitous language to bridge the gap between the business and the development team by fostering a common understanding of the domain. Of necessity, the DDD approach is oriented towards analyzing behavior rather than just data in the business domain, and this leads to a focus on modeling and implementing behavior in the software. A natural way to implement the domain model in code is to use commands and events. This is particularly true of applications that use a task-oriented UI.
Note: DDD is not the only approach where it is common to see tasks and behavior specified in the domain model implemented using commands and events. However, many advocates of the CQRS pattern are also strongly influenced by the DDD approach so it is common to see DDD terminology in use whenever there is a discussion of CQRS.
Commands are imperatives; they are requests for the system to perform a task or action. For example, "book two places on conference X" or "allocate speaker Y to room Z." Commands are usually processed just once, by a single recipient.
Events are notifications; they report something that has already happened to other interested parties. For example, "the customer's credit card has been billed $200" or "ten seats have been booked on conference X." Events can be processed multiple times, by multiple consumers.
Both commands and events are types of message that are used to exchange data between objects. In DDD terms, these messages represent business behaviors and therefore help the system capture the business intent behind the message.
One possible implementation of the CQRS pattern may use separate data stores for the read-side and the write-side, each data store optimized for the use cases that it supports. Events provide the basis of a mechanism for synchronizing the changes on the write-side (that result from processing commands) with the read-side. If the write-side raises an event whenever the state of the application changes, the read-side should respond to that event and update the data that is used by its queries and views. Figure 2 shows how commands and events could be used if you implement the CQRS pattern.
Commands and Events in the CQRS pattern
We also require some infrastructure to handle commands and events, and we will explore this in more detail in later chapters.
Note: Events are not the only way to manage the push synchronization of updates from the write-side to the read-side.
Stepping back from CQRS for a moment, one of the benefits of dividing the domain into bounded contexts in DDD is to enable you to identify and focus on those portions (bounded contexts) of the system that are more complex, subject to ever-changing business rules, or offer functionality that is key business differentiator.
You should consider applying the CQRS pattern within a specific bounded context only when it provides identifiable business benefits, not because it is the default pattern that you consider.
The most common business benefits that you might gain from applying the CQRS pattern are scalability, simplifying a complex aspect of your domain, and adding flexibility to your solution.
In many enterprise systems, the number of reads vastly exceeds the number of writes, so your scalability requirements will be different for each side. By separating the read-side and the write-side into separate models within the bounded context, you now have the ability to scale each one of them independently. For example, if you are hosting applications in Windows Azure, you can use a different role for each side and then scale them independently by adding a different number of role instances to each.
Note: Scalability should not be the only reason why you choose to implement the CQRS pattern in a specific bounded context:
"In a non-collaborative domain, where you can horizontally add more database servers to support more users/requests/data at the same time you're adding web servers - there is no real scalability problem (caveat, until you're Amazon/Google/Facebook scale).
Database servers can be cheap - if using MySQL/SQL Express/others."
Udi Dahan, When to avoid CQRS.
In complex areas of your domain, designing and implementing objects that are responsible for both reading and writing data can exacerbate the complexity. In many cases, the complex business logic is only applied when the system is handling updates and transactional operations; in comparison, read logic is often much simpler. When the business logic and read logic are mixed together in the same model, it becomes much harder to deal with difficult issues such as multiple-users, shared data, performance, transactions, consistency, and stale data. Separating the read logic and business logic into separate models makes it easier to separate out and address these complex issues. However, in many cases it may require some effort to disentangle and understand the existing model in the domain.
Note: Separation of concerns is the key motivation behind Bertrand Meyer's Command Query Separation Principle:
"The really valuable idea in this principle is that it's extremely handy if you can clearly separate methods that change state from those that don't. This is because you can use queries in many situations with much more confidence, introducing them anywhere, changing their order. You have to be more careful with modifiers."
Martin Fowler, CommandQuerySeparation
Like many patterns, you can view the CQRS pattern as a mechanism for shifting some of the complexity inherent in your domain into something that is well known, well understood, and that offers a standard approach to solving certain categories of problem.
Another potential benefit of simplifying the bounded context by separating out the read logic and the business logic is that it can make testing easier.
The flexibility of a solution that uses the CQRS pattern largely derives from the separation into the read-side and the write-side models. It becomes much easier to make changes on the read-side, for example adding a new query to support a new report screen in the UI, when you can be confident that you won't have any impact on the behavior of the business logic. On the write-side, having a model that concerns itself solely with the core business logic in the domain means that you have a simpler model to deal with than a model that includes read logic as well.
In the longer term, a good, useful model that accurately describes your core domain business logic will become a valuable asset. It will enable you to be more agile in the face of a changing business environment and competitive pressures on your organization.
This is related to the concept of Continuous Integration in DDD:
"Continuous integration means that all work within the context is being merged and made consistent frequently enough that when splinters happen they are caught and corrected quickly."
Eric Evans, "Domain-Driven Design," p342.
In some cases, it may be possible to have different development teams working on the write-side and the read-side, although in practice this will probably depend on how large the particular bounded context is.
If you use an approach like CRUD, then the technology tends to shape the solution. Adopting the CQRS pattern helps you to focus on the business and to build task-oriented UIs. A consequence of separating the different concerns into the read-side and the write-side is a solution that is more adaptable in the face of changing business requirements. This results in lower development and maintenance costs in the longer-term.
Although we have outlined some of the reasons why you might decide to apply the CQRS pattern to some of the bounded contexts in your system, it is helpful to have some rules of thumb to help identify the bounded contexts that might benefit from applying the CQRS pattern.
In general, applying the CQRS pattern may provide most value in those bounded contexts that are complex, include ever changing business rules, and deliver a significant competitive advantage to the business. Analyzing the business requirements, building a useful model, expressing it in code, and implementing it using the CQRS pattern for such a bounded context all take time and cost money. You should expect this investment to pay dividends in the medium to long-term. It is probably not worth making this investment if you don't expect to see returns such as increased adaptability and flexibility in the system, or reduced maintenance costs.
Both Udi Dahan and Greg Young identify collaboration as the characteristic of a bounded context that provides the best indicator that you may see benefits from applying the CQRS pattern.
"In a collaborative domain, an inherent property of the domain is that multiple actors operate in parallel on the same set of data. A reservation system for concerts would be a good example of a collaborative domain – everyone wants the 'good seats'"
Udi Dahan, Why you should be using CQRS almost everywhere…
The CQRS pattern is particularly useful where the collaboration involves complex decisions about what the outcome should be when you have multiple actors operating on the same, shared data. For example, does the rule "last one wins" capture the expected business outcome for your scenario, or do you need something more sophisticated? It's important to note that actors are not necessarily people; they could be other parts of the system that can independently operate on the same data.
Note: Collaborative behavior is a good indicator that there will be benefits from applying the CQRS pattern; this is not a hard and fast rule!
Such collaborative portions of the system are often the most complex, fluid, and significant bounded contexts. However, this characteristic is only a guide: not all collaborative domains benefit from the CQRS pattern, and some non-collaborative domains do benefit from the CQRS pattern.
In a collaborative environment where multiple users can operate on the same data simultaneously, you also encounter the issue of stale data: if one user is viewing a piece of data while another user changes it, then the first user's view of the data is stale.
Whatever architecture you choose, you must address this problem; for example, by using a particular locking scheme in your database, or defining the refresh policy for the cache from which your users read data.
The CQRS pattern helps you address the issue of stale data explicitly at the architectural level. Changes to data happen on the write-side, users view data by querying the read-side. Whatever mechanism you chose to use to push the changes from the write-side to the read-side is also the mechanism that controls when the data on the read-side becomes stale, and for how long. This differs from other architectures, where management of stale data is more of an implementation detail that is not always addressed in a standard or consistent manner.
"Standard layered architectures don't explicitly deal with either of these issues. While putting everything in the same database may be one step in the direction of handling collaboration, staleness is usually exacerbated in those architectures by the use of caches as a performance-improving afterthought."
Udi Dahan talking about collaboration and staleness, Clarified CQRS.
In the chapter "A CQRS/ES Deep Dive," we will look at how the synchronization mechanism between write-side and the read-side determines how you manage the issue of stale data in your application.
Moving an application to the cloud or developing an application for the cloud is not a sufficient reason for choosing to implement to CQRS pattern. However, many of the drivers for using the cloud such as requirements for scalability, elasticity, and agility are also drivers for adopting the CQRS pattern. Furthermore, many of the services typically offered as part of a PaaS cloud-computing platform are well suited for building the infrastructure for a CQRS implementation: for example, highly scalable data stores, messaging services, and caching services.
#When Should I Avoid CQRS? Simple, static, non-core bounded contexts are less likely to warrant the upfront investment in detailed analysis, modeling, and complex implementation. Again, non-collaborative bounded contexts are less likely to see benefits from applying the CQRS pattern.
In most systems, the majority of bounded contexts will probably not benefit from using the CQRS pattern. You should only use the pattern when you can identify clear business benefits from so doing.
Most people using CQRS (and Event Sourcing too) shouldn’t have done so.
Udi Dahan: When to avoid CQRS
The CQRS pattern is an enabler for building individual portions (bounded contexts) in your system. Identifying where to use the CQRS pattern requires you to analyze the trade-offs between the initial cost and overhead of implementing the pattern and the future business benefits. Useful heuristics for identifying where you might apply the CQRS pattern are to look for components that are complex, involve fluid business rules, deliver competitive advantage to the business, and are collaborative.
The next chapters will discuss how to implement the CQRS pattern in more detail, for example explaining specific class-pattern implementations, exploring how to synchronize the data between the write-side and read-side, and describing different options for storing data.