Adding functionality and refactoring in preparation for the V1 release.
This chapter describes the changes made by the team to prepare for the first production release of the Contoso Conference Management System. This work includes some refactoring and additions to the Orders and Registrations bounded context that was introduced in the previous two chapters as well as a new Conference Management bounded context and Payments bounded context.
One of the key refactorings undertaken by the team during this phase of the journey was to introduce event sourcing into the Orders and Registrations bounded context.
One of the anticipated benefits from implementing the CQRS pattern is that it will help to manage change in a complex system. Having a V1 release during the CQRS journey will help the team to evaluate how the CQRS pattern and event sourcing deliver these benefits when they move forward from the V1 release to the next production release of the system. The following chapters will describe what happens after the V1 release.
This chapter also describes the Metro-style UI that the team added to the public web-site during this phase and includes a discussion of task-based UIs.
Outline any working definitions that were adopted for this chapter.
When a Business Customer creates a new Conference, the system generates a five character Access Code and sends it by email to the Business Customer. The Business Customer can use his email address and the Access Code on the Conference Management Web Site to retrieve the conference details from the system at a later date. The system uses access codes instead of passwords to avoid the overhead for the Business Customer of setting up an account with the system.
Event Sourcing is a way of persisting and reloading the state of aggregates within the system. Whenever the the state of an aggregate changes, the aggregate raises an event detailing the state change. The system then saves this event in an event store. The system can recreate the state of an aggregate by replaying all of the previously saved events associated with that aggregate instance. The event store becomes the book of record for the data stored by the system.
In addition, you can use event sourcing as a source of audit data, as a way to query historic state, and to replay events for debugging and problem analysis.
The team implemented the user stories listed below during this phase of the project.
The Business Customer represents the organization that is using the conference management system to run its conference.
A Seat represents a space at a conference or access to a specific session at the conference such as a cocktail party, a tutorial, or a workshop.
A business customer can create new conferences and manage them. After a business customer creates a new conference, he can access the details of the conference by using his email address and conference locator access code. The system generates the access code when the business customer creates the conference.
The business customer can specify the following information about a conference:
- The name, description, and slug (part of the URL used to access the conference).
- The start and end dates of the conference.
- The different types and quotas of seats available at the conference.
Additionally, the business customer can control the visibility of the conference on the public web-site by either publishing or un-publishing the conference.
The business customer can use the conference management web-site to view a list of attendees.
After a registrant has purchased seats at a conference, she can assign attendees to those seats. The system stores the name and contact details for each attendee.
What are the key architectural features? Server-side, UI, multi-tier, cloud, etc.
Figure 1 illustrates the key architectural elements of the Contoso Conference Management System in the V1 release. The application consists of two web sites and three bounded contexts. The infrastructure includes SQL databases, an event store, and messaging infrastructure.
The first table that follows figure 1 lists all of the messages that the elements shown on the diagram exchange with each other.

Architecture of the V1 release
<tr>
<td align="left">OrderController</td>
<td align="left">MVC Controller</td>
<td align="left">AssignSeat<br/>
UnassignSeat</td>
<td align="left">DraftOrder<br/>
OrderSeats<br/>
PricedOrder</td>
</tr>
<tr>
<td align="left">RegistrationController</td>
<td align="left">MVC Controller</td>
<td align="left">RegisterToConference<br/>
AssignRegistrantDetails<br/>
InitiateThirdPartyProcessorPayment</td>
<td align="left">DraftOrder<br/>
PricedOrder<br/>
SeatType</td>
</tr>
<tr>
<td align="left">PaymentController</td>
<td align="left">MVC Controller</td>
<td align="left">CompleteThirdPartyProcessorPayment<br/>
CancelThirdPartyProcessorPayment</td>
<td align="left">ThirdPartyProcessorPaymentDetails<br/>
InvoiceProcessorPaymentDetails</td>
</tr>
<tr>
<td align="left">Conference Management</td>
<td align="left">CRUD Bounded Context</td>
<td align="left">ConferenceCreated<br/>
ConferenceUpdated<br/>
ConferencePublished<br/>
ConferenceUnpublished<br/>
SeatCreated<br/>
SeatUpdated<br/></td>
<td align="left">OrderPlaced<br/>
OrderRegistrantAssigned<br/>
OrderTotalsCalculated<br/>
OrderPaymentConfirmed<br/>
SeatAssigned<br/>
SeatAssignmentUpdated<br/>
SeatUnassigned</td>
</tr>
<tr>
<td align="left">Order</td>
<td align="left">Aggregate</td>
<td align="left">OrderPlaced<br/>
*OrderExpired<br/>
*OrderUpdated<br/>
*OrderPartiallyReserved<br/>
*OrderReservationCompleted<br/>
*OrderPaymentConfirmed<br/>
*OrderRegistrantAssigned</td>
<td align="left">RegisterToConference<br/>
MarkSeatsAsReserved<br/>
RejectOrder<br/>
AssignRegistrantDetails<br>
ConfirmOrderPayment</td>
</tr>
<tr>
<td align="left">SeatsAvailability</td>
<td align="left">Aggregate</td>
<td align="left">SeatsReserved<br/>
*AvailableSeatsChanged<br/>
*SeatsReservationCommitted<br/>
*SeatsReservationCancelled</td>
<td align="left">MakeSeatReservation<br/>
CancelSeatReservation<br/>
CommitSeatReservation<br/>
AddSeats<br/>
RemoveSeats</td>
</tr>
<tr>
<td align="left">SeatAssignments</td>
<td align="left">Aggregate</td>
<td align="left">*SeatAssignmentsCreated<br/>
*SeatAssigned<br/>
*SeatUnassigned<br/>
*SeatAssignmentUpdated</td>
<td align="left">AssignSeat<br/>
UnassignSeat</td>
</tr>
<tr>
<td align="left">RegistrationProcess</td>
<td align="left">Workflow</td>
<td align="left">MakeSeatReservation<br/>
ExpireRegistrationProcess<br/>
MarkSeatsAsReserved<br/>
CancelSeatReservation<br/>
RejectOrder<br/>
CommitSeatReservation<br/>
ConfirmOrderPayment</td>
<td align="left">OrderPlaced<br/>
PaymentCompleted<br/>
SeatsReserved<br/>
ExpireRegistrationProcess</td>
</tr>
<tr>
<td align="left">OrderViewModelGenerator</td>
<td align="left">Handler</td>
<td align="left">DraftOrder</td>
<td align="left">OrderPlaced<br/>
OrderUpdated<br/>
OrderPartiallyReserved<br/>
OrderReservationCompleted<br/>
OrderRegistrantAssigned</td>
</tr>
<tr>
<td align="left">PricedOrderViewModelGenerator</td>
<td align="left">Handler</td>
<td align="left">N/A</td>
<td align="left">SeatTypeName</td>
</tr>
<tr>
<td align="left">ConferenceViewModelGenerator</td>
<td align="left">Handler</td>
<td align="left">Conference<br/>
AddSeats<br/>
RemoveSeats<br/></td>
<td align="left">ConferenceCreated<br/>
ConferenceUpdated<br/>
ConferencePublished<br/>
ConferenceUnpublished<br/>
**SeatCreated<br/>
**SeatUpdated</td>
</tr>
<tr>
<td align="left">ThirdPartyProcessorPayment</td>
<td align="left">Aggregate</td>
<td align="left">PaymentCompleted<br/>
PaymentRejected<br/>
PaymentInitiated</td>
<td align="left">InitiateThirdPartyProcessorPayment<br/>
CompleteThirdPartyProcessorPayment<br/>
CancelThirdPartyProcessorPayment</td>
</tr>
| Element | Type | Sends | Recieves |
|---|---|---|---|
| ConferenceController | MVC Controller | N/A | ConferenceDetails |
* These events are only used for persisting aggregate state using event sourcing.
** The ConferenceViewModelGenerator creates these commands from the SeatCreated and SeatUpdated events that it handles from the Conference Management bounded context.
Summary of messages in the Contoso Conference Management System
- All events use the past tense the naming convention.
- All commands use the imperative naming convention.
- All DTOs are nouns.
The application is designed to deploy to Windows Azure. At this stage in the journey, the application consists of two web roles that contains the MVC web applications and a worker role that contains the message handlers and domain objects. The application uses SQL Azure databases for data storage, both on the write-side and the read-side. The Orders and Registrations bounded context now uses an event store to persist the state from the write-side. This event store is implemented using Windows Azure table storage to store the events. The application uses the Windows Azure Service Bus to provide its messaging infrastructure.
While you are exploring and testing the solution, you can run it locally, either using the Windows Azure compute emulator or by running the MVC web application directly and running a console application that hosts the handlers and domain objects. When you run the application locally, you can use a local SQL Express database instead of SQL Azure, use a simple messaging infrastructure implemented in a SQL Express database, and a simple event store also implemented using a SQL Express database.
Note: The SQL-based implementations of the event store and the messaging infrastructure are only intended to facilitate running the application locally for understanding and testing. They are not intended to illustrate a production-ready approach.
For more information about the options for running the application, see Appendix 1.
The Conference Management bounded context is a simple two-tier, CRUD-style web application. It is implemented using MVC 4 and Entity Framework.
JanaPersona: The team implemented this bounded context after it implemented the public Conference Management web-site that uses MVC 3.
This bounded context must integrate with other bounded contexts that implement the CQRS pattern.
-
What are the primary patterns or approaches that have been adopted for this bounded context? (CQRS, CQRS/ES, CRUD, ...)
-
What were the motivations for adopting these patterns or approaches for this bounded context?
-
What trade-offs did we evaluate?
-
What alternatives did we consider?
The team at Contoso originally implemented the Orders and Registrations bounded context without using event sourcing. However, during the implementation it became clear that using event sourcing would help to simplify this bounded context.
In the previous chapter Extending and Enhancing the Orders and Registrations Bounded Contexts the team found that they needed to use events to push changes from the write-side to the read-side. On the read-side the OrderViewModelGenerator class subscribed to the events published by the Order aggregate, and used those events to update the views in the database that were queried by the read-model.
This was already half-way to an event sourcing implementation, so it made sense to use a single persistence mechanism based on events for the whole bounded context.
The event sourcing infrastructure is reusable in other bounded contexts, and the implementation of the Orders and Registrations becomes simpler.
PoePersona: As a practical problem, the team had limited time before the V1 release to implement a production quality event store. They created a simple, basic event store based on Windows Azure tables as an interim solution. However, they will potentially face the problem in the future of migrating from one event store to another.
The team implemented the basic event store using Windows Azure table storage. If you are hosting your application in Windows Azure you could also consider using Windows Azure blobs or SQL Azure to store your events.
JanaPersona: One of the issues to consider when choosing between storage mechanisms in Windows Azure is cost. If you use SQL Azure you are billed based on the size of the database, if you use Windows Azure table or blob storage you are billed based on the amount of storage you use and the number of storage transactions. You need to carefully evaluate the usage patterns on the different aggregates in your system to determine which storage mechanism is the most cost effective. It may turn out that different storage mechanisms make sense for different aggregate types. You may be able to intoduce optimizations that lower your costs, for example by using caching to reduce the number of storage transactions.
In the Windows Azure table storage based implementation of the event store that the team created for the V1 release, they used the aggregate id as the partition key. This makes it efficient to locate the partition that holds the events for any particular aggregate.
In some cases the system must locate related aggregates. For example, an order aggregate may have a related registrations aggregate that holds details of the attendees assigned to specific seats. In this scenario, the team decided to reuse the same aggregate id for the related pair of aggregates, the order and registration, in order to facilitate look-ups.
BharathPersona: You want to consider in this case whether you should have two aggregates. You could model the registrations as an entity inside the order aggregate.
A more common scenario is to have a one-to-many relationship between aggregates instead of a one-to-one. In this case it is not possible to share aggregate ids: instead the aggregate on the one-side can store a list of the ids of the aggregates on the many-side, and each aggregate on the many-side can store the id of the aggregate on the one-side.
Sharing aggregate ids is common when the aggregates exist in different bounded contexts. If you have aggregates in different bounded contexts that model different facets of the same real-world entity, it makes sense for them to share the same id. This makes it easier to follow a real-world entity as it is processed by different bounded contexts in your system.
Greg Young - Conversation with the PnP team.
The design of UIs has improved greatly over the last decade: applications are easier to use, more intuitive, and simpler to navigate than they were before. Examples of guidelines for UI designers are the Microsoft Inductive User Interface Guidelines and the UX guidelines for Metro style apps.
Another factor that affects the design and usability of the UI is how the UI communicates with the rest of the application. If the application is based on a CRUD-style architecture, this can leak through to the UI. If the developers focus on CRUD-style operations, this can result in a UI as shown in the first screen design in Figure 2.

Example UIs for conference registration
On the first screen, the labels on the buttons reflect the underlying CRUD operations that the system will perform when the user clicks the Submit button. The first screen also requires the user to apply some deductive knowledge about how the screen and the application function. For example, the function of the Add button is not immediately apparent.
A typical implementation behind the first screen will use a data transfer object (DTO) to exchange data between the back-end and the UI. The UI will request data from the back-end that will arrive encapsulated in a DTO, it will modify the data in the DTO, and then return the DTO to the back-end. The back-end will use the DTO to figure out what CRUD operations it must perform on the underlying datastore.
The second screen is more explicit about what is happening in terms of the business process: the user is selecting quantities of seat types as a part of the conference registration task. Thinking about the UI in terms of the task that the user is performing makes it easier to relate the UI to the write-model in your implementation of the CQRS pattern. The UI can send commands to the write-side, and those commands are a part of the domain model on the write-side. In a bounded context that implements the CQRS pattern, the UI typically queries the read-side and receives a DTO, and sends commands to the write-side.
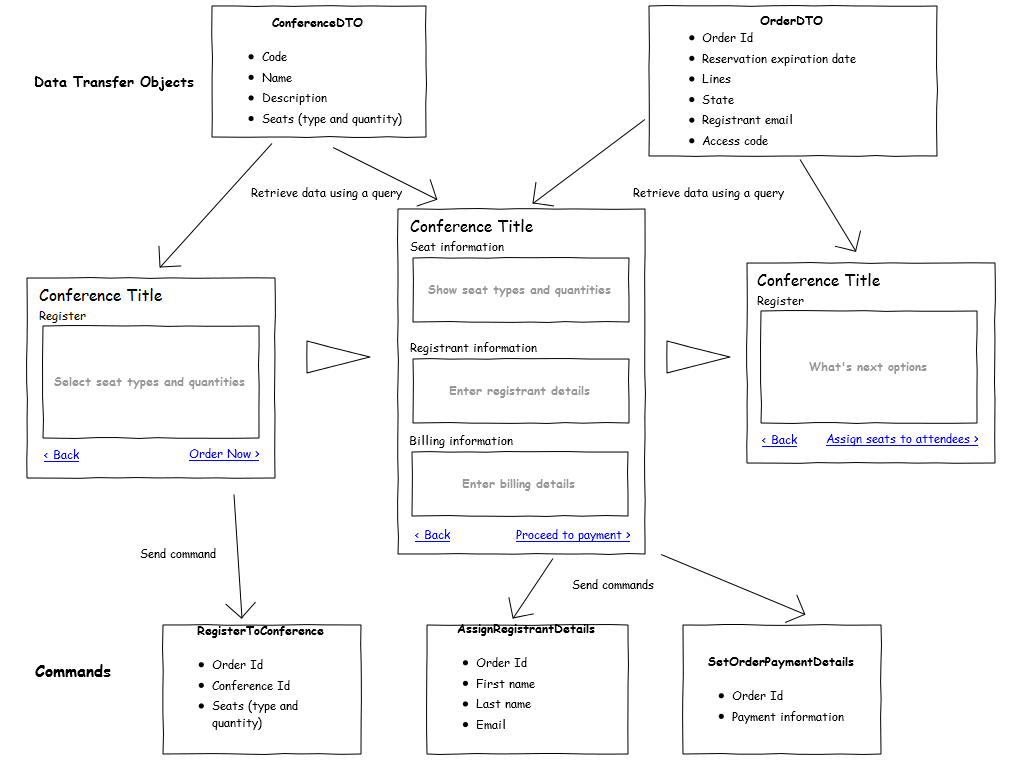
Task-based UI flow
Figure 3 shows a sequence of pages that enable the registrant to complete the "purchase seats at a conference" task. On the first page, the registrant selects the type and quantity of seats. On the second page, the registrant can review the seats she has reserved, enter her contact details, and complete the necessary payment details. The system then redirects the registrant to a payment provider, and if the payment completes successfully, the system displays the third page. The third page shows a summary of the order and provides a link to pages where the registrant can start additional tasks.
The sequence shown in Figure 3 is deliberately simplified in order to highlight the roles of the commands and queries in a task-based UI. For example, the real flow includes pages that the system will display based on the payment type selected by the registrant, and error pages that the system displays if the payment fails.
BharathPersona: You don't always need to use task-based UIs. In some scenarios, simple CRUD-style UIs work well. You must evaluate whether benefits of task-based UIs outweigh the additional implementation effort of a task-based UI. Very often, the bounded contexts where you choose to implement the CQRS pattern, are also the bounded contexts that benefit from task-based UIs because of the more complex business logic and more complex user interactions.
You should not use the CQRS pattern as part of your top-level architecture: you should implement the pattern only in those bounded contexts where it brings clear benefits. In the Contoso Conference Management System, the conference management bounded context is a relatively simple, stable, and low volume element of the overall system. Therefore the team decided that they would implement this bounded context using a traditional two-tier, CRUD-style architecture.
The Conference Management bounded context needs to integrate with the Orders and Registrations bounded context. For example, if the business customer changes the quota for a seat type in the Conference Management bounded context, this change needs to be propagated to the Orders and Registrations bounded context. Also, if a registrant adds a new attendee to a conference, the business customer must be able to view details of the attendee in the list in the Conference Management web-site.
The following conversation between several developers and the domain expert highlights some of the key issues that the team needed to address in planning how this integration should be implemented.
Developer #1: I want to talk about how we should implement two pieces of the integration story associated with our CRUD-style, Conference Management bounded context. First of all, when a Business Customer creates a new conference or defines new seat types for an existing conference in this bounded context, other bounded contexts such as the Orders and Registrations bounded context will need to know about the change. Secondly, when a Business Customer changes the quota for a seat type other bounded contexts will need to know about this change as well.
Developer #2: So in both cases you are pushing changes from the Conference Management bounded context. It's one-way.
Developer #1: Correct.
Developer #2: What are the significant differences between the scenarios that you outlined?
Developer #1: In the first scenario, these changes are relatively infrequent and typically happen when the Business Customer creates the conference. Also, these are append only changes. We don't allow a Business Customer to delete a conference or a seat type after the conference has been published for the first time. In the second scenario, the changes might be more frequent and a Business Customer might increase or decrease a seat quota.
Developer #2: What implementation approaches are you considering for these integration scenarios?
Developer #1: Because we have a two tier CRUD-style bounded context, for the first scenario I was planning on exposing the conference and seat type information directly from the database as a simple read-only service. For the second scenario, I was planning to publish events whenever the Business Customer updates the seat quotas.
Developer #2: Why use two different approaches here, it would be simpler to use a single approach. Using events is more flexible in the long run. If additional bounded contexts need this information, they can easily subscribe to the event. Using events provides for more decoupling between the bounded contexts.
Developer #1: I can see that it would be easier to adapt to changing requirements in the future if we used events. For example, if a new bounded context required information about who changed the quota, we add this information to the event. For existing bounded contexts we could add an adapter that converted the new event format to the old.
Developer #2: You implied that the events that notify subscribers of quota changes would send the change in the quota. For example, the Business Customer increased a seat quota by 50. What happens if a subscriber wasn't there at the beginning and so doesn't receive the full history of updates?
Developer #1: We may have to include some synchronization mechanism that uses snapshots of the current state. However, in this case the event could simply report the new value of the quota. If necessary, the event could report both the delta and the absolute value of the seat quota.
Developer #2: How are you going to ensure consistency? You need to guarantee that your bounded context persists its data to storage and publishes the events on a message queue.
Developer #1: We can wrap the database write and the add to queue operations in a transaction.
Developer #2: That's going to be problematic for two reasons. Firstly, our infrastructure uses the Windows Azure Service Bus for messages. You can't use a transaction to combine sending a message on the Service Bus and write to a database. Secondly, we're trying to avoid two-phase commits because they always cause problems in the long-run.
Domain Expert: We have a similar scenario with another bounded context that we'll be looking at later. In this case we can't make any changes to the bounded context, we no longer have an up to date copy of the source code.
Developer #1: What can we do to avoid using a two-phase commit? And what can we do if we don't have access to the source code and so can't make any changes?
Developer #2: In both cases we use the same technique to solve the problem. Instead of publishing the events from within the application code, we can use another process that monitors the database and sends the events when it detects a change in the database. This solution may introduce a small amount of latency, but it does avoid the need for a two-phase commit and it can be implemented without making any changes to the application code.
A further issue relates to when and where to persist integration events. In the example discussed above, the events are raised in the Conference Management bounded context and handled in the Orders and Registrations bounded context that uses them to populate its read-model. If a failure occurs that causes the system to loose the read-model data, then without saving the events there is no way to re-create this read-model data.
Whether you need to persist these integration events will depend on the specific requirements and implementation of your application. For example:
- Integration events may be handled in the write-model (and not on the read-side as in the current example) and will then result in changes on the write-side that are persisted as other events.
- Integration events may represent transient data that does not need to be persisted.
- Integration events from a CRUD-style bounded context may contain state data so that only the last event is needed. For example if the event from the Conference Management bounded context includes the current seat quota, you may not be interested in previous values.
Another approach to consider is to use an event-store that is shared by multiple bounded contexts. In this way the originating bounded context (for example the CRUD-style Conference Management bounded context) could be responsible for persisting the integration events.
Greg Young - Conversation with the PnP team.
The previous discussion suggested a way to avoid using a distributed two-phase commit in the Conference Management bounded context. However, there are some alternative approaches.
Although the Windows Azure Service Bus does not support distributed transactions with databases, you can use the RequiresDuplicateDetection property when you send messages, and the PeekLock mode when you receive messages to create the desired level of robustness without using a distributed transaction.
As another approach, you can use a distributed transaction to update the database and send a message using a local MSMQ queue. You can then use a bridge to connect the MSMQ queue to a Windows Azure Service Bus queue.
For example of implementing a bridge from MSMQ to Windows Azure Service Bus, see the sample in the Windows Azure AppFabric SDK.
For more information about the Windows Azure Service Bus, see Technologies Used in the Reference Implementation in the Reference Guide.
The previous section that discussed the integration options for the Conference Management bounded context raised the issue of using a distributed, two-phase commit transaction to ensure consistency between the database that stores the conference management data and the messaging infrastructure that publishes changes to other bounded contexts.
The same problem arises when you implement event sourcing: you must ensure consistency between the event store in the bounded context that stores all the events and the messaging infrastructure that publishes those events to other bounded contexts.
A key feature of an event store implementation should be that it offers a way to guarantee consistency between the events that it stores and the events that the bounded context publishes to other bounded contexts.
CarlosPersona: This is a key challenge you should address if you decide to implement an event store yourself. If you are designing a scalable event store that you plan to deploy in a distributed environment such as Windows Azure, you must be very careful to ensure that you meet this requirement.
The Orders and Registrations bounded context is responsible for creating and managing orders on behalf of registrants. The Payments bounded context is responsible for managing the interaction with an external payments system so that registrants can pay for the seats that they have ordered.
When the team were examining the domain models for these two bounded contexts, they discovered that neither of them knew anything about pricing. The Orders and Registrations bounded context created an order that listed the quantities of the different seat types that the registrant requested. The Payments bounded context simply passed a total to the external payments system. At some point the system needed to calculate the total from the order before invoking the payment process.
The team considered two different approaches to solve this problem: favoring autonomy and favoring authority.
In this approach, the responsibility for calculating the order total is assigned to the Orders and Registrations bounded context. The Orders and Registrations bounded context is not dependent on another bounded context at the time that it needs to perform the calculation because it already has the necessary data. At some point in the past it will have collected the pricing information it needs from other bounded contexts (such as the Conference Management bounded context) and cached it.
The advantage of this approach is that the Orders and Registrations bounded context is autonomous. It doesn't rely on the availability of another bounded context or service at the point in time that it needs to perform the calculation.
The disadvantage is that the pricing information could be out of date. The Business Customer might have changed the pricing information in the Conference Management bounded context, but that change might not yet have reached the Orders and Registrations bounded context.
In this approach, the part of the system that calculates the order total obtains the pricing information from the bounded contexts (such as the Conference Management bounded context) at the point in time that it performs the calculation. The calculation could still be performed by the Orders and Registrations bounded context, or be handled by another bounded context or service within the system.
The advantage of this approach is that the system always uses the latest pricing information whenever it is calculating an order total.
The disadvantage is that the Orders and Registrations bounded context is dependent on another bounded context when it needs to determine the total for the order. It either needs to query the Conference Management bounded context for the up to date pricing information, or call another service that performs the calculation.
The choice between the two alternatives is a business decision. The specific business requirements of your scenario should determine which approach to take. Autonomy is often the preference for large, online systems.
The way that the Conference Management System calculates the total for an order provides an example of choosing autonomy over authority.
CarlosPersona: For Contoso, the clear choice is for autonomy. It's a serious problem if Registrants can't purchase seats because some other bounded context is down. However, we don't really care if there's a short lag between the Business Customer modifying the pricing information, and that new pricing information being used to calculate order totals.
The section Calculating Totals below describes how the system performs this calculation.
In the discussions of the read-side in the previous chapters, you saw how the team used a SQL-based store for the denormalized projections of the data from the write-side.
You can use other storage mechanisms for the read-model data, for example the file system or in Windows Azure table or blob storage. In the Orders and Registrations bounded context, the system uses Windows Azure blobs to store information about the seat assignments.
BharathPersona: When you are choosing the underlying storage mechanism for the read-side you should consider the costs associated with the storage (especially in the cloud) in addition to the requirement that the read-side data should be easy and efficient to access using the queries on the read-side.
Note: See the SeatAssignmentsViewModelGenerator class to understand how the data is persisted to blob storage and the SetaAssignmentsDao class to understand how the UI retrieves the data for display.
Describe significant features of the implementation with references to the code. Highlight any specific technologies (including any relevant trade-offs and alternatives).
Provide significantly more detail for those BCs that use CQRS/ES. Significantly less detail for more "traditional" implementations such as CRUD.
The Conference Management Bounded Context that enables a Business Customer to define and manage conferences is implemented using a simple two-tier, CRUD-style application using MVC 4.
In the Visual Studio solution, the Conference project contains the model code, and the Conference.Web project contains the MVC views and controllers.
The Conference Management bounded context pushes notifications of changes to conferences by publishing the following events.
- ConferenceCreated: The bounded context publishes this event whenever a Business Customer creates a new conference.
- ConferenceUpdated: The bounded context publishes this event whenever a Business Customer updates an existing conference.
- ConferencePublished: The bounded context publishes this event whenever a Business Customer publishes a conference.
- ConferenceUnpublished: The bounded context publishes this event whenever a Business Customer un-publishes a new conference.
- SeatCreated: The bounded context publishes this event whenever a Business Customer defines a new seat type.
- SeatsAdded: The bounded context publishes this event whenever a Business Customer increase the quota of a seat type.
The ConferenceService class in the Conference project publishes these events to the event bus.
The Payments bounded context is responsible for handling the interaction with the external systems that validate and process payments. In the V1 release, payments can be processed either by a fake, external, third-party payments processor (that mimics the behavior of systems such as PayPal) or by an invoicing system. The external systems can report either that a payment was successful or that a payment failed.
The sequence diagram in figure 4 illustrates how the key elements that are involved in the payments process interact with each other. The diagram is shows a simplified view, for example by ignoring the handler classes to better describe the process.

Overview of the payment process
The diagram shows how the Orders and Registrations bounded context, the Payments bounded context, and the external payments service all interact with each other. Registrants can also opt to pay by invoice instead of using a third-party payments processing service, however for reason of simplicity, the diagram does not show this option.
The Registrant makes a payment as a part of the overall flow in the UI as shown in figure 3. The PaymentController controller class does not display a view unless it has to wait for the system to create the ThirdPartyProcessorPayment aggregate instance. Its role is to forward to payment information collected from the Registrant to the third-party payments processor.
Typically, when you implement the CQRS pattern, you use events as the mechanism for communicating between bounded contexts. However in this case, the RegistrationController and PaymentController controller classes send commands to the Payments bounded context. The Payments bounded context does use events to communicate back with the RegistrationProcess coordinating workflow in the Orders and Registrations bounded context.
The implementation of the Payments bounded context uses the CQRS pattern without event sourcing.
The write-side model contains an aggregate called ThirdPartyProcessorPayment that consists of two classes: ThirdPartyProcessorPayment and ThirdPartyProcessorPaymentItem. Instances of these classes are persisted to a SQL database by using Entity Framework. The PaymentsDbContext class implements an Entity Framework context.
The ThirdPartyProcessorPaymentCommandHandler implements a command handler for the write-side.
The read-side model is also implemented using Entity Framework. The PaymentDao class exposes the payment data on the read-side. For an example, see the GetThirdPartyProcessorPaymentDetails method.
Figure 5 illustrates the different parts that make up the read-side and the write-side of the Payments bounded context.
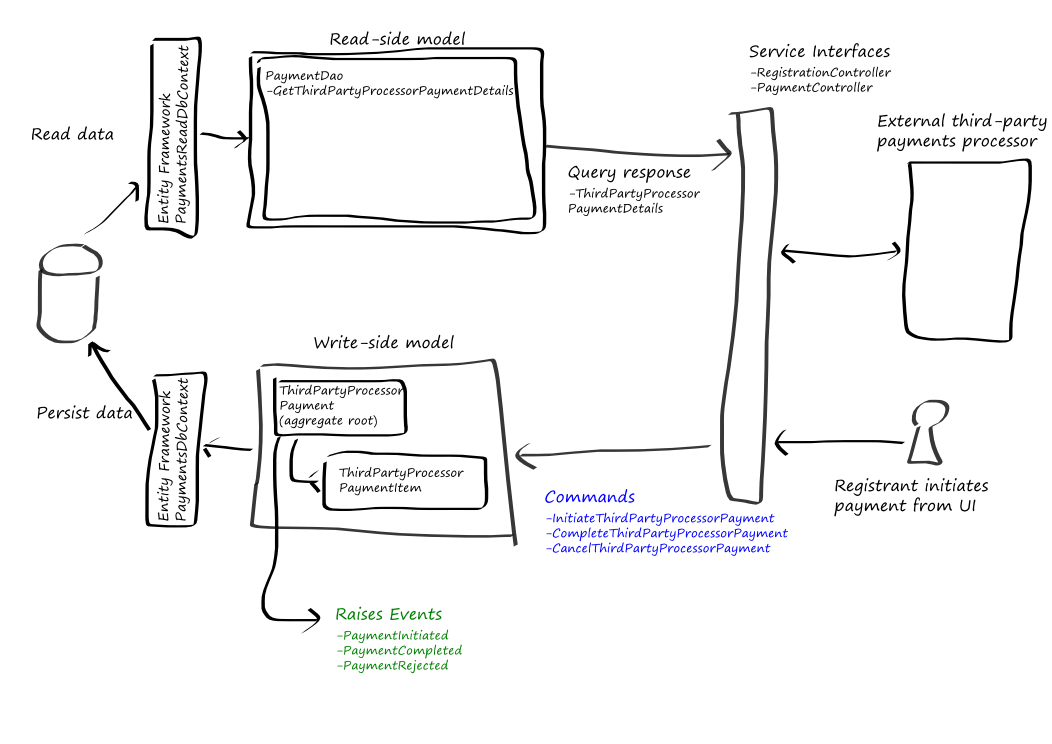
The read-side and the write-side in the Payments bounded context
The initial implementation of the event sourcing infrastructure is extremely basic: the team intends to replace it with a production quality event store in the near future. This section describes the initial, basic, implementation and lists the various ways it must be improved.
The core elements of this basic event sourcing solution are:
- Whenever the state of an aggregate instance changes, the instance raises an event that fully describes the state change.
- The system persists these events in an event store. This solution uses a SQL database to store the events.
- An aggregate can rebuild its state by replaying its past stream of events.
- Other aggregates and workflows (possibly in different bounded contexts) can subscribe to these events.
The following two methods from the Order aggregate are examples of methods that the OrderCommandHandler class invokes when it receives a command for the order. Neither of these methods update the state of the Order aggregate, instead they raise an event that will be handled by the Order aggregate. In the MarkAsReserved method, there is some minimal logic to determine which of two events to raise.
public void MarkAsReserved(DateTime expirationDate, IEnumerable<SeatQuantity> reservedSeats)
{
if (this.isConfirmed)
throw new InvalidOperationException("Cannot modify a confirmed order.");
var reserved = reservedSeats.ToList();
// Is there an order item which didn't get an exact reservation?
if (this.seats.Any(item => !reserved.Any(seat => seat.SeatType == item.SeatType && seat.Quantity == item.Quantity)))
{
this.Update(new OrderPartiallyReserved { ReservationExpiration = expirationDate, Seats = reserved.ToArray() });
}
else
{
this.Update(new OrderReservationCompleted { ReservationExpiration = expirationDate, Seats = reserved.ToArray() });
}
}
public void ConfirmPayment()
{
this.Update(new OrderPaymentConfirmed());
}The Update method is defined in the abstract base class of the Order class. The following code sample shows this method and the Id and Version properties in the EventSourced class.
private readonly Guid id;
private int version = -1;
protected EventSourced(Guid id)
{
this.id = id;
}
public int Version { get { return this.version; } }
protected void Update(VersionedEvent e)
{
e.SourceId = this.Id;
e.Version = this.version + 1;
this.handlers[e.GetType()].Invoke(e);
this.version = e.Version;
this.pendingEvents.Add(e);
}The Update method sets the Id and increments the version of the aggregate, and determines which event handler in the aggregate it should invoke to handle the event type.
MarkusPersona: The version of the aggregate is incremented every time its state is updated.
The following code sample shows the event handler methods in the Order class that are invoked when the command methods shown above are called.
private void OnOrderPartiallyReserved(OrderPartiallyReserved e)
{
this.seats = e.Seats.ToList();
}
private void OnOrderReservationCompleted(OrderReservationCompleted e)
{
this.seats = e.Seats.ToList();
}
private void OnOrderExpired(OrderExpired e)
{
}
private void OnOrderPaymentConfirmed(OrderPaymentConfirmed e)
{
this.isConfirmed = true;
}These methods update the state of the aggregate.
An aggregate must be able to handle both events from other aggregates and events that it raises itself. The protected constructor in the Order class lists all the events that the Order aggregate can handle.
protected Order()
{
base.Handles<OrderPlaced>(this.OnOrderPlaced);
base.Handles<OrderUpdated>(this.OnOrderUpdated);
base.Handles<OrderPartiallyReserved>(this.OnOrderPartiallyReserved);
base.Handles<OrderReservationCompleted>(this.OnOrderReservationCompleted);
base.Handles<OrderExpired>(this.OnOrderExpired);
base.Handles<OrderPaymentConfirmed>(this.OnOrderPaymentConfirmed);
base.Handles<OrderRegistrantAssigned>(this.OnOrderRegistrantAssigned);
}When the aggregate processes an event in the Update method in the EventSourcedAggregateRoot class, it adds the event to a private list of pending events. This list is exposed as a public, IEnumerable property of the abstract EventSourced class called Events.
The following code sample from the OrderCommandHandler class shows how the handler invokes a method in the Order class to handle a command, and then uses a repository to persist the current state of the Order aggregate by appending all of the pending events to the store.
public void Handle(MarkSeatsAsReserved command)
{
var order = repository.Find(command.OrderId);
if (order != null)
{
order.MarkAsReserved(command.Expiration, command.Seats);
repository.Save(order);
}
}The following code sample shows the initial, simple implementation of the Save method in the SqlEventSourcedRepository class.
public void Save(T eventSourced)
{
// TODO: guarantee that only incremental versions of the event are stored
var events = eventSourced.Events.ToArray();
using (var context = this.contextFactory.Invoke())
{
foreach (var e in events)
{
using (var stream = new MemoryStream())
{
this.serializer.Serialize(stream, e);
var serialized = new Event { AggregateId = e.SourceId, Version = e.Version, Payload = stream.ToArray() };
context.Set<Event>().Add(serialized);
}
}
context.SaveChanges();
}
// TODO: guarantee delivery or roll back, or have a way to resume after a system crash
this.eventBus.Publish(events);
}When a handler class loads an aggregate instance from storage, it loads the state of the instance by replaying the stored event stream.
The following code sample from the OrderCommandHandler class shows how this process is initiated by calling the Find method in the repository.
public void Handle(MarkSeatsAsReserved command)
{
var order = repository.Find(command.OrderId);
...
}The following code sample shows how the SqlEventSourcedRepository class loads the event stream associated with the aggregate.
JanaPersona: The team later developed a simple event store using Windows Azure tables instead of the SqlEventSourcedRepository. The next section describes this Windows Azure table storage based implementation.
public T Find(Guid id)
{
using (var context = this.contextFactory.Invoke())
{
var deserialized = context.Set<Event>()
.Where(x => x.AggregateId == id)
.OrderBy(x => x.Version)
.AsEnumerable()
.Select(x => this.serializer.Deserialize(new MemoryStream(x.Payload)))
.Cast<IVersionedEvent>()
.AsCachedAnyEnumerable();
if (deserialized.Any())
{
return entityFactory.Invoke(id, deserialized);
}
return null;
}
}The following code sample shows the constructor in the Order class that rebuilds the state of the order from its event stream when it is invoked by the Invoke method in the previous code sample.
public Order(Guid id, IEnumerable<IVersionedEvent> history) : this(id)
{
this.LoadFrom(history);
}The LoadFrom method is defined in the EventSourced class as shown in the following code sample.
protected void LoadFrom(IEnumerable<IVersionedEvent> pastEvents)
{
foreach (var e in pastEvents)
{
this.handlers[e.GetType()].Invoke(e);
this.version = e.Version;
}
}For each stored event in the history, it determines the appropriate handler method to invoke in the Order class and updates the version number of the aggregate instance.
The simple implementation of event sourcing and an event store outlined in the previous sections has a number of short-comings. The following list identifies some of these short-comings that should be overcome in a production quality implementation.
- There is no guarantee in the Save method in the SqlEventRepository class that the event is persisted to storage and published to the messaging infrastructure. A failure could result in an event being saved to storage but not being published.
- There is no check that when the system persists an event, that it is a later event than the previous one. Potentially, events could be stored out of sequence.
- There are no optimizations in place for aggregate instances that have a large number of events in their event stream. This could result in performance problems when replaying events.
The Windows Azure table storage based event store addresses some of the short-comings of the simple SQL-based event store. Howevere, at this point on time, it is still not a production quality implementation.
The team designed this implementation to guarantee that events are both persisted to storage and published on the message bus. To achieve this, it uses the transactional capabilities of Windows Azure tables.
MarkusPersona: Windows Azure table storage supports transactions across records that share the same partition key.
The EventStore class initially saves two copies of every event to be persisted. One copy is the permanent record of that event, and the other copy becomes part of a virtual queue of events that must be published on the Windows Azure Service Bus. The following code sample shows the Save method in the EventStore class. The prefix "Unpublished" identifies the copy of the event that is part of the virtual queue of unpublished events.
public void Save(string partitionKey, IEnumerable<EventData> events)
{
var context = this.tableClient.GetDataServiceContext();
foreach (var eventData in events)
{
var formattedVersion = eventData.Version.ToString("D10");
context.AddObject(
this.tableName,
new EventTableServiceEntity
{
PartitionKey = partitionKey,
RowKey = formattedVersion,
SourceId = eventData.SourceId,
SourceType = eventData.SourceType,
EventType = eventData.EventType,
Payload = eventData.Payload
});
// Add a duplicate of this event to the Unpublished "queue"
context.AddObject(
this.tableName,
new EventTableServiceEntity
{
PartitionKey = partitionKey,
RowKey = UnpublishedRowKeyPrefix + formattedVersion,
SourceId = eventData.SourceId,
SourceType = eventData.SourceType,
EventType = eventData.EventType,
Payload = eventData.Payload
});
}
try
{
this.eventStoreRetryPolicy.ExecuteAction(() => context.SaveChanges(SaveChangesOptions.Batch));
}
catch (DataServiceRequestException ex)
{
var inner = ex.InnerException as DataServiceClientException;
if (inner != null && inner.StatusCode == (int)HttpStatusCode.Conflict)
{
throw new ConcurrencyException();
}
throw;
}
}Note: This code sample also illustrates how a duplicate key error is used to identify a concurrency error.
The Save method in the repository class is shown below. This method is invoked by the event handler classes, invokes the Save method shown in the previous code sample, and also invokes the SendAsync method of the EventStoreBusPublisher class.
public void Save(T eventSourced)
{
var events = eventSourced.Events.ToArray();
var serialized = events.Select(this.Serialize);
var partitionKey = this.GetPartitionKey(eventSourced.Id);
this.eventStore.Save(partitionKey, serialized);
this.publisher.SendAsync(partitionKey);
}The EventStoreBusPublisher class is responsible for reading the unpublished events for the aggregate from the virtual queue in the Windows Azure table store, publishing the event on the Windows Azure Service Bus, and then deleting the unpublished event from the virtual queue.
If the system fails between publishing the event on the Windows Azure Service Bus and deleting the event from the virtual queue then, when the application restarts, the event is published a second time. To avoid problems caused by duplicate events, the Windows Azure Service Bus is configured to detect duplicate messages and ignore them.
MarkusPersona: In the case of a failure, the system must include a mechanism for scanning all of the partitions in table storage for aggregates with unpublished events and then publishing those events. This process will take some time to run, but will only need to run when the application restarts.
To ensure the autonomy of the Orders and Registrations bounded context it calculates order totals without accessing the Conference Management bounded context. The Conference Management bounded context is responsible for maintaining the prices of seats for conferences.
Whenever a Business Customer adds a new seat type or changes the price of a seat, the Conference Management bounded context raises an event. The Orders and Registrations bounded context handles these events and persists the information in as part of its read-model (see the ConferenceViewModelGenerator class for details).
When the Order aggregate calculates the order total, it uses the data provided by the read-model. See the MarkAsReserved method in the Order aggregate and the PricingService class for details.
JanaPersona: The UI also displays a dynamically calculated total as the registrant adds seats to an order. The application calculates this value using Javascript. When the registrant makes a payment, the system uses the total that was calculated by the Order aggregate.
MarkusPersona: Don't let your passing unit tests lull you into a false sense of security. There are lots of moving parts when you implement the CQRS pattern. You need to test that they all work correctly together.
Describe any special considerations that relate to testing for this bounded context.