Remote attendees:
| Name | Abbreviation | Organization |
|---|---|---|
| Waldemar Horwat | WH | |
| Sergey Rubanov | SRV | invited expert |
| Michael Saboff | MLS | Apple |
| Devin Rousso | DRO | Apple |
| Shaheer Shabbir | SSR | Apple |
| Istvan Sebestyen | IS | Ecma International |
| Robin Ricard | RRD | Bloomberg |
| Chip Morningstar | CM | Agoric |
| Michael Ficarra | MF | F5 Networks |
| Richard Gibson | RGN | OpenJS Foundation |
| Yulia Startsev | YSV | Mozilla |
| Danuel Rosenwasser | DRR | Microsoft |
| Chengzhong Wu | CZW | Alibaba |
| Jack Works | JWK | Sujitech |
| Jordan Harband | JHD | Invited Expert |
| Caio Lima | CLA | Igalia |
| Jason Yu | JYU | PayPal |
| Marja Hölttä | MHA | |
| Bradford C. Smith | BSH | |
| Daniel Ehrenberg | DE | Igalia |
| HE Shi-Jun | JHX | 360 |
Presenter: HE Shi-Jun (JHX)
JHX: Okay. Hello, everybody. This is a long slide and I try to go through it as fast as I can. This is the contents of my presentation and I will start from our minimal examples. The extensions proposal introduces some syntax to declare adequate extension method and it could be a code like this to this is just like a real mess of it and it could be explained like this, just like you have [transcription error] And it's the double colon double notation have same precedence [transcription error] could be be changed seamlessly. and the example measures are declaring in a separate namespace, which means it will not conflict with the normal normal bindings. So with this syntax you can borrow the binding methods like that because the children probably do not have the forEach you can use the array prototype for each. And it also adds a syntax that not only the binary form, but also ternary that here just have the same effects of this example. Just you don't do not need to extract the do not need the clear it you can just use it here and exists you can use Constructor has extension object or you could also use namespace extension. It's like this we impose the lodash and use the lodash last method here. We will also use Global namespace with more mass so This is a very simple example. So basically the syntax of the ternary form works exactly like its Constructor. It will use the prototyping method and if it’s not present it will be treated like the namespace object. This is a very simple part 0.
JHX: Actually this proposal is not a new proposal, it actually is based on the old bind operator. If you are familiar with the old bind operator will find the syntax look very similar to this. This is the older proposal and it already has a [transcription error] tc39 report in a day of many discussions on the issue and it also has official bubble support from 2015. And as I know there are some programmers already using it in the production, but the bind operator proposal actually is still in stage 0 and not even stage 1. This is just very surprising. Our chapter the meeting notes of the white operate [?] and Allen said that in 2015 that's yet because of that sort of in that time we decided to get more feet apart from babel. I think the issue Allen raised is no longer an issue, as already five years passed and I think every JavaScript programmer has used ES6 Class.
JHX: this is the old bind operator proposal looks very close to my proposal but they all had the prefix for like the old ::console.log() form.
JHX: The old bind operator actually has three features. We should note that the second one is actually based on the first one. It has 2 motivations: one is close to my proposal and the other one [transcription error]
JHX: The first could be seen as virtual methods. This could be a bad name, as a virtual method usually means that it can be overwritten. In this case, this does not correspond to a real method. I’d like to use the term extension method to describe that. The extension method, defined by wikipedia, is a method which is added to an object after the original object was compiled. I think we understand what that means is the method is on the original object. If you follow the idea we now never rely on the bind concept that was a problem of the bind operator that has a motivation issue. And because of that these 2 features if we think about it indiv they cloud have no relationship. So if we restart from the virtual/ext method themselves [shows slide 22] This is the real method and this is the extension method so what is this?
JHX: The old bind operator to make this means “bind” but it’s not very [?] it’s actually property. It could be an extension property. A new proposal to allow that extension accessors so you can rewrite code like this. [slide 27] If we look back to the old bind operator, it has two ways to invoke a “virtual” method and to extract a real method. If we treat the virtual method the same as a real method it should use the same syntax like this [slide 28] Of course the syntax is now not any good, too many colons. I think this proposal should be split into two proposals, one for virtual methods, and one for method extraction. The third has some use cases, but not strong enough to have its own proposal. In this proposal I focused on the virtual method.
I’d like to discuss something about method extracting. One application for this is “partial application proposal”
The one parameter but there are some discussions about partial application if we have this syntax so if it could just be used to achieve that Or, we can have an individual proposal for that. My intention here is to use the infix operator instead of the prefix form. Prefix form needs the [transcription error]
Even if we do not have those proposal, we can use the extraction method to address the same issue. And, additionally, you don’t need to write the method yourself, they already exist in libraries like lodash.
You can import the lodash module and create a lodash namespace, and use the extension operator on it. So it could just work.
Let’s talk about the virtual part. One discussion is we can replace extensions with the pipeline method. However there are some ergonomics issues. [shows example, slide 34]
The precedence of the pipeline operator is very low, and you would need to add parens, or you can change everything to pipeline, but this would require a dramatic rewrite.
Compared to the original example of the extension method, maybe it is not the best. I think the pipeline operator is very good for functional programming, but in many situations where you want to use the builtin methods in chaining then extensions have a place.
Pipeline can also be a userland implementation, and that can be used with extensions.
[transcription error]
Part two of this, is that extensions are a common feature in many languages -- they are not monkey patched, though monkey patches are often seen as extensions.
Monkey patch has many problems because prototype overrides created a bunch of problems in our history.
Other programming languages adopted extensions.
Here is a complete timeline of other programming languages adopting similar language features. Here is an example of swift (followed by kotlin).
Ruby is interesting: most PLs have extensions in static typing languages but ruby is a dynamic language just like javascript. It introduces a language feature called “refinement” which can be thought of as a “safe” monkey patch.
It uses different dispatch rules.
In a classic extension, they should first look up the real method, and then the extension method. But ruby uses a different rule.
I think it is because the design is better than monkey path because monkey patch has higher precedence.
If you look at all of these examples, they still use the . notation, and the extension can still be dispatched by the type. This question has been asked in typescript in a very old issue (#9). [presents example from the issue, slide 79]
[transcription error]
JHX: Even if it can generate that code, it is hard to infer what it would do and we would overload the dot operation. So that is why we talk about a new syntax here with different semantics. This avoids runtime dispatching cost. For instance Ruby has a runtime cost with extension. If you look at the spec it is very complex. Ruby is a good example of it, here is the look up rule of the refinements (slide [?]).I think we can’t reuse the . and it is very unlikely that we can dispatch by type. I think however extensions are still useful for javascript. For JS, we use 2 different symbols to decouple the behavior. Compared to the classical extension methods, my proposal still keeps the call value of the extension method. And so, we lose something, but we also gain something. Without an IDE also it is hard to know where the method comes from and makes for unpredictable performance. My proposal has a predictable performance.
JHX: Part 3. As I said, this lookup based on the ext, is delegated by the ext. There are three forms: invoke, get, set. It could be customized. This is the previous example [presents slide 95] We could rewrite this like so: The extract can make the syntax much better.
JHX: part 4 is use cases. [Presents examples in slides from slide 97] And in this way it could improve code readability. This is extremely useful if you have a very long expression. And, CSS units should just work. With the exception of a hack that we need to use. [slide 111] There is another proposal, first class protocols, which I really like. One issue of this proposal is that it doesn’t have a good syntax. Maybe we can use extension methods here and use the double colon notation for it. Benefit is it could ensure it really implements the protocol. If you only use the symbol, it can be faked. And maybe it could be shorthand syntax for it. And sensitive code is an example for branding at slide 115. On slide 121: Eventual send, Needs better syntax and needs two types of proxy. Talking about wavy dot proposal: For syntax we have a high bar. [transcription error]. Not as good as wavy dot but saves the syntax space. And the last use case is experimental implementations for new APIs on the prototype. Presents Proposal-array-filtering issue #5.
JHX: If we have the extension method, we can have polyfills and experimental implementations.
JHX: This is the whole thing and the summary is [slide 131] I hope we can revive the old virtual methods from the bind operator.
[continues with points listed in the slide]
MM: I want to express my appreciation for this proposal. I'm very very supportive of this going to stage one. I think this is an excellent investigation. I want to point out a tension here, which is I think what this needs to turn into to go forward from stage one and a viable manner is to identify a very simple core that I think is here where there's a lot. lot of power for very very little mechanism and I think you're focusing on the right starting point there, which was the virtual aspect of the original bind operator. But I also like the fact that you're starting by doing this broader exploration before narrowing down to that simpler core too soon so that we can see what the alternatives are. So I very much like this entire thing. Then I have a question specifically on the ternary form. You're showing me the initial discussion before you showed the symbol dot extension form; you had the thing that switch Behavior based on an is Constructor test where if it's a Constructor you're getting it from the Prototype and otherwise are getting it from the object itself. There's a problem with that is many Constructors or classes have static methods and with regard to the static methods are effectively acting as a namespace object for the static methods. So I'm skeptical that kind of dynamic change in Behavior based on the is Constructor test is a viable thing there ; and the other thing is is I would like you to a show again the definition of your pipe combinator because that went by very very quickly before I was able to absorb the the meaning of it. Where you’re showing how the double colon could be used for pipelining rather than the pipelining operator? You showed that you had a pipe function that was applied to other functions in order to insert that into the in order to use the double colon as if it's a pipeline operator. The at method. (slide 50) Could you explain this?
JWK: yeah, it's receiving the incoming values as it’s “this” value. For example, the first pipe call gets “hello” as it’s “this” value then passes it to the f. Does this clarify?
MM: I think I don't know the double say I'm not. In this one, but I would have expected the pipe to return a function because double colon expects a function.
JWK: Oh. I guess that's a mistake. (Clarify: Actually not, I misunderstood the semantics)
MM: Okay, in any case given what I think you meant pipe to say this makes a lot of sense to me and defend the idea that one operator could subsume the utility of pipelining and subsume the utility of the eventual sand till doc proposal. I find a very nice demonstration that there might be a lot of reach for very little mechanism here. So, thank you.
MF: I saw that a few times you were showing how introducing a new namespace avoids possible collisions with your local scope and I wasn't very convinced by the need for that. I think, considering the pros and cons, it's fine to do the resolution in your local scope instead of introducing a new namespace because I think the the developer burden of having to manage these two separate namespaces is not worth that potential risk of collisions and just having to rename imports on the important side.
JWK: Having a separate namespace and enforcing a stronger rule can help the engine to optimize the extension methods called better?
MF: Oh, I didn't realize that. Can you explain more about that?
JHX: My intention here is mostly for the developer experience. I try to make much of the behaviors close to us the real method because of the real method, they would not conflict with what that for. For example, It’s very common that you will see the code in any place like the last JSON one. So if we use the extent method with the actual method. I try to make the two limits different between the real method and the end of the extension classes, so it should be able to refactor your code for a real method to extension method or vice versa. This is my starting point. But anyway, can we discuss this later? Maybe? This part is not the most important part in my proposal. But I prefer that.
MF: Sure.
JYU: Yeah, actually the proposal is good for me and I'm just curious about the double colon symbol. So are there any other options as substitutions? Because you know, I do a lot of coding with C++. So, it's just a little bit weird to me to use double colon here this way and actually I'm not sure about what the situation is here in other languages in terms of this double colon, so I just want to call this out here and want to hear what others think about it because I just want to know is it natural to use double colons this way from the perspective of a normal JavaScript developer? So this is my little concern from the form of the grammar.
JHX: Yeah, good question. Just decided on this syntax, because syntax is always a problem and I think that we do not have many choices here. It's which is possible, maybe the arrow is possible. I just followed the old operator because it's already there for many years. So, I just follow that and I think the double colon has slightly better ergonomics than all the other options. But it is just syntax problems which we can always discuss.
JHD: Hi, I'm very sorry if you went over this in the slide show; I came in a little late and I tried to skim through the notes and catch up on the slides. The original bind operator kind of had three purposes/functions/uses. When the pipeline proposal was brought up, the discussion we had in plenary was that pipeline satisfies two of the three and maybe I'm not being precise about the number "three", but the thing that pipeline did not offer was a robust form for method extraction. The thing that I brought up in the context of the pipeline operators that I would that it was very important to me that if since the committee had been deciding along with pipeline that the bind operator, was that we were sort of picking one over the other. In other words the sense in the committee at the time was that if the pipeline operator advanced, the bind operator would not, and the constraint that I raised was that I thought it important that before pipeline operators advance to stage 2 that there would be some idea of a solution for method extraction. So I'm very excited that you're bringing this back because it offers that. The concern I have I think is a stage 1 concern and something we don't have to decide today, but it seems like this is doing a lot of things to try to solve a few different problems. The problem that I'm very motivated to see solved is method extraction. The slide that you have where you show the comparison between chaining and using .call - that's the one I'm very interested in seeing go forward. I think that there's a lot of extra complexity that seems to overlap with the pipeline proposal. So I guess that my question is how do you see that overlap and In particular, (I'm trying not to focus too much on this suggested syntax), but in particular the form you're showing with like all the .prototype stuff that I think Mark alluded to as well. Yeah, I guess what are your thoughts on complexity concerns and overlap with the pipeline operator and if you already addressed this, I apologize for that, no need to re-cover it.
JWK: It’s kind of like a language that supports both fp style and oo style. For this maybe we can have both extensions and pipes.
JHX: I think this is really a problem with the pipeline operator, I think actually I like it. Sometimes I use the pure functional programming style and it's over. It’s very helpful, but as my slides showed that if you want to mix styles then the experience is not good. So I think it's hard to say, but my personal opinion about that is if we have the extension methods it may help us to choose which form we adopt as a pipeline operator. For example, I think maybe the abstract style is better if we have the extension method. so we have F# style is very good for mainstream functional programming and the problem is when you use it to waste their [?] methods, but if we have the extension method, we do care about that. You just use the F# style for functional programming. Maybe I'm not sure about it but this is my personal feeling.
SYG: All right. So along the same line as JHD was saying, maybe I have a slightly weaker understanding that the pipeline path and something like this would be mutually exclusive but it seems to certainly lean that way that it would be mutually mutually exclusive and I guess that's okay. So I'll State my high level concern which would be addressed if they were mutually exclusive. My high level concern is that if they were to exist there would be too many. There will be a proliferation of different syntax to do the same things with some of the use cases overlapping but not all and I think that would strictly work for readability. But of course if we only go with one of them then that's fine. So I guess the concrete concern is where the champions for the various pipeline operators are in the room. And when do we expect this question of which path do we take as a committee go forward, I guess from JHD’s point of view. This path has already been decided. It's your take from a previous consensus. Yeah, this was the explicit discussion that we had. I can probably dig up the notes when pipeline went to stage one. I see you thanks.
DE: Can I speak for Pipeline champions. I don't think we have consensus as a committee on whether we want to go forward with pipeline Mozilla raised significant concerns, and I really don't think it's appropriate for us to be saying that these proposals are mutually exclusive at this point. I disagree with that, you know a name that when I presented on Pipeline in the past specifically said that they're not necessarily mutually exclusive though, there would be a cost to having both at this point. We just have not agreed on Pipeline as a community. So I don't think it's appropriate for us to do foreclosed discussions about it. I have other concerns for their down on the cue like I have reasons for why I've been pushing for pipeline rather than rather than than bind. But I don't think we have a process of reason to just propose one one. The current status of pipeline is I would really be happy to have additional co-champions on proposal because I don't have much time to push it forward and I'm not sure how to move forward based on Mozilla’s feedback. So please get in touch with me if you're interested in pipeline.
SYG: Thank you Dan. I think my constraint here. Is stage one. Well right now I guess we're at State 0 for for this proposal, but this does seem too early for us to make a mutual exclusion call, that does seem inappropriate, but I think I would object more strongly come stage 2 proposals become become stage 2 and perhaps by then the shapes of these various proposals have taken in the evolution. Is that they serve completely different purposes of that point and they're no longer so overlapping and that's fine too. But if they remain overlapping by slaves to telegraphing that I will be gravely concerned.
AKI: That's a problem for future tc39 not us.
WH: I did not understand the separate namespace in the presentation. You said that the thing after the :: is in a separate namespace, which I understand, but then you had examples like ::Math.abs. Does that mean that Math is now in a different namespace?
JHX: no the ternary form if it's a ternary form it will use the for for example math. It's just using the normal load that bigger namespace looking rules find [transcription error] and value and because math is a namespace object and we'll use the ABS math do as the extension method. [transcription error] the only in the binary form it will look like math takes time to methods that separate namespace. Yeah, this has been. In some degree you you can't treat that the right side of the double column it have to cost possibility one is the one identified that it's it means local it's an an ad hoc extension Masters all its its name space like Math::abs that just if you look up at the mass the from the Math.
WH: Looking at the longer term consequences if we adopted this: This is mutually exclusive with a pipeline operator. I definitely do not want both in the language. I also see this as not really solving any significant problem. It does not define extension methods because, as you found out, you cannot use the same syntax for regular methods and what you're calling extension methods. So these aren’t really extension methods, but this does create a rift in the ecosystem where some folks will adopt the convention of defining methods in the :: namespace and some folks will adopt the convention of using functions, and there will be lots of unnecessary friction around the boundaries. I see that kind of thing as being harmful to the ecosystem.
JWK: You can import normal functions as namespaced extension functions in the syntax.
DRO: Generally speaking. I feel like the I believe you're calling it The turn a syntax that really feels like it should be a separate proposal because I understand how you might want it to relate to extensions, but the semantics it has itself of sort of this magical behavior of sometimes depending on whether something is a Constructor or not going from from the Prototype or going Static is like that to me seems something that needs its own discussions first. Is this sort of binding calling approach of the double colon? I'm not really comfortable with the two of them being mixed together because they seem to be very different.
JHX: Okay, I understand your point and I think it's possible to divide this proposal into several proposals, but I designed them in a whole way, so what we can discuss is in the repo issues. Personally I like it to be together to keep the consistency but I think it's okay if the committee likes to separate them.
MM: ya I didn't I didn't need to discuss this. I just wanted to weigh in on that. I agree that this is exclusive with Pipeline and I prefer this to Pipeline and do not consider us to have any consensus to do pipeline rather than this.
DE: I wanted to say for this this proposal encourages you to write functions that use this but lots of JavaScript developers find this confusing that was frequent feedback we got for pipeline. Oh finally, I don't have to use this. So I think that's a significant disadvantage of this proposal.
RPR: Okay. So thanks the queue is empty. Would you like to ask for stage 1?
JHX: yes. I like to ask for stage 1 .
RPR:Any objections?
WH: I'm really reluctant about this. It creates a rift in the ecosystem with two different ways of doing the same thing, which means that half of the people will adopt one way and half will adopt the other way. There will be friction at the boundaries. So far, I see this as just a different function calling syntax, but with a separate namespace.
RBN: that they did remind me and I added the topic to the queue if we're looking to advance this to stage one with that supplant the existing stage zero at least as it's listed in the room in the tc39 tc39 GitHub bind proposal?
JWK: Hax said the namespace isn't the necessary part of this. If people feel not happy with a separate Namespace.
RBN: my question is with this should this become just the direction if this moves forward did this just become direction of the existing bind proposal and should probably have their champion of existing champions for that way and if they're carrying if they have interests are all run.
RPR: This is a slightly Divergent topic so I think we need to conclude whether Waldemar is making a true block. Can you confirm that you are blocking stage one?
WH: I haven't heard a response.
JHX: I'm not sure. understand the concern is if the concern is about the separate namespace, I think it could be discussed into stage one.
WH: How are you planning on addressing the rift problem bifurcating APIs?
JHX: I think if most people think separating namespace is bad, we can drop it.
RPR: Okay, so there's a potential to work through that in stage one.
WH: I'm not going to block it from stage 1, but I am really dubious about this proposal advancing past stage 1 due to the rift issue, and I also see this as mutually exclusive with the pipeline proposal.
RPR: Yeah and multiple people have said that last part. Yes. Okay, then say it's a given that you are not locking and I don't think anyone else else has objected. then we conclude this section with a consensus on stage one. Thank you JHX.
RBN: I still don't feel that my concern was addressed. I my concern is there is an existing proposal for bind and using this syntax and although it is sitting at stage zero this would essentially block that proposal and feel like it would be worthwhile to have even though it's been sitting fallow for a while individuals representing the champions for that proposal determine whether or not they're concerned concerned. mean, I know Jordan has a domestic use to say that there's two competing proposals for it. But these are also doing the essentially the same thing. So should it just be that proposal and that proposal to get updated?
JHX: It seems like for the old proposal, the Champions do not want to push forward. So this is just another request that if this proposal, I would also like to ask if I can reuse the bind operator proposal.
RPR: So I think it's state stage 0 / proposals. Don't don't block the stage one, and we've already said that in stage one will figure out whether this conflicts with the pipeline as well. So I don't think this is a stage one concern but this proposal.
RBN: All right. That's all I wanted to make sure. I have no other concern. Thank you, specifically.
JHD: I don't think we should be dictating which; I don't think it makes a difference whether this is a new repo in a new entry on the proposals table, versus whether it reuses the existing one or replaces the existing one. I think that at the time when something advances to Stage 2 is when we should be explicit about which pre-stage-2 things are effectively inactive as a result of that stage to advancement. So, not today.
RBN: I appreciate the clarification. There was one other question earlier about whether this ternary form should be split. But again, it's probably post stage one and down has a good point that we should clarify this nephritis and don't dogs.
DE: So I think yeah the process docs change that we Agreed on that you live proposed as specifically mentions that it's possible to take on proposals that others have dropped. This could be considered part of that if we want that to be a thing that we prefer to not happen until after stage Let's decide on that as a committee and document it.
RBR: Okay. All right, so we conclude this item X you have stage 1. Thank you very much. Thank you.
- proposal advances to stage 1
- stage 1 concerns about pipeline operator and namespace
Presenter: Yulia Startsev (YSV)
YSV: Good, so let's talk about tc39 data. And what do I mean by data? I'm going to clarify that in a second. The problem that I want to raise is that we've got stuff and it gets out of date and I'm talking about looking at the whole range of our proposals plus the website plus other consumers of tc39 data or people who want to programmatically understand what's happening on committee, maybe run their keep their own tabs of what we've been doing. We've had a few people have projects like that from outside of committee and also from inside of committee. How can we make that easier and keep things up to date? Basically, that's the goal.
YSV: What data are we interested in? So generally from my perspective as maintaining the website what I've been been interested in has been the title, stage, Champions and authors, links to past presentations, test 262 status, a link to the spec, a short description and a simplified example. That's what the current tc39 website is interested alternatively as a delegate who keeps a metric of what's going on. In tc39 for my company. I'm also interested in very similar pieces of data. We also have an effort from the JSC IG the JavaScript Chinese interest group who are maintaining a website that also makes use of this data Etc. So the sources of truth that we have for this information - and there might be other information, please let me know if there are other pieces of information we should be tracking - but the sources of Truth are: the meeting itself is the ultimate source of Truth; this is where we make the decisions and that is reflected in the notes. Additionally we have the proposals repository and I mean the proposals as in plural where we aggregate information about all of the proposals. This is usually the most up-to-date location. We've got test 262 and we've got individual proposal repositories. So if you're running an aggregator of some sort, you have to be aware of all four of these resources because if the proposal repository might be out of date for some reason that you might need to go and double check either in test 262 or individual repositories or in the notes. So usually you find yourself bouncing between those different sources of truth, but generally the source of Truth is going to be coming from GitHub. So this slide is just to just to show what we can get directly out of the GitHub API if we're trying to get this information from an API, and what GitHub will give us if we pull for example all of the proposals from tc39, we're going to get the title and the short description description. Additionally we've written that will parse the stage, Champions, authors, and links to past presentations, and the spec can be generated from the title from the proposal URL and we can also And we parse a simple example, that's what get the places where we that's what we've currently got in place. JSCIG also gets this data, this is also from the JSCIG crawler. So they've got their own crawler. They get very similar information from the proposal repo and generate their Json data from that. So and this is what's the website crawler does. We also pull our information from The Proposal repo, so that's our source of truth then we parse individual read me. Is of each proposal to get the spec. Sorry, we generate the spec from the URL and we parse a simple example directly from the repo explainer.
YSV: so problem is stuff getting out of date or not be usable for this kind of machine reading of the repositories. Let's take a look at how this can happen. So the proposals repository is a high-level aggregate of all the proposals. It's manually edited by people such as JHD and others who are often keeping this stuff up to date. Now things sometimes get out of date or or they're not correct. We require a delegate to do this update manually after the meeting and it doesn't always have all of the information necessary for aggregators such as the website. So the modification that I would propose to how we work on the proposals repository - so we're talking about the aggregate proposals repository - is to incorporate the JSCIG link checker, which makes sure that all links are up to date. So one question was have there been examples where something's been not correct and the example, is that the JSCIG link checker did find stuff out of date and posted updates manually. Someone had to go and take information from that link checker and then make manual pull requests to fix issues on the proposals repo. We're talking about a lot of information that could potentially go wrong and we've got people who have been very responsible and keeping the proposals repository up to date. The goal here would be, let's make their job easier by making link checker maybe something part of tc39. Let's join forces with the JSCIG and see how much stuff we can share so that we we can keep each other to date as things go ahead. Septs, who was maintaining the JSCIG link Checker, also recommended that we have automated workflows. I think that is something we can continue the discussion in the issue around merging in the JSCIG link Checker. So please take a look at the reflector for more information there.
YSV: So that brings us to another issue. How do we ensure that data is correct like throughout all of our workflow? So one place is that we've got the notes repository. The notes repository a full proceedings more or less of this meeting. It records in real time what our discussions are about and also the conclusions that we come to in this meeting. So this is fantastic and it's my source of truth when I have some ambiguous understanding of something I go to the notes. The problem with this is that the notes are not machine readable and the conclusions do not have a consistent scheme. So I'll get into the proposed modifications in a second which are to standardize conclusions and make it possible for a GitHub action to verify that meeting notes are up-to-date in the proposals repository and that they have a consistent scheme. That should be pretty easy to do. So, here's an example of one way where we record an advancement. So this is an advancement to stage one: conclusion/resolution is stage one and we have the proposal link here that tells us which proposal we are working with. So we can always match on the basis of the proposal URL because URLs are unique and we can parse the notes for these proposal links and then attach them to a conclusion. Here we have it recorded as stage one. So I want to note that it will be probably impossible to use the titles as machine readable information because there's too much variance in the titles and we can get all of that information from the proposal link and from the conclusion/resolution, assuming that the conclusion resolution is well-formed. We have no rules about how we record conclusions and resolutions at this moment. Here's another example, this is an update that happened in this meeting where Shu asked if it could remain at stage 3 and this is how it was recorded. Now from a machine-readable perspective consensus on stage 3 might sound like an advancement and depending on how we program this it would just be a no op where it advances from stage 3 to stage 3, but we've also got a lot of extra detail here about for arrays and typed arrays and strings Etc. So this information isn't going to be as usable to a program that is scraping the notes, but we could form this in a way that makes sense to a machine and perhaps people who are checking the notes can get more details this way. What about proposals that don't get advancement? We also don't have a clear scheme for this. We can of course do a fuzzy match on no consensus or no matching and then whatever stage is being sought. .And additionally there are pieces of extra information here, details about why this didn't Advance, which in the proposal update presentation I mentioned we should be very clear about why things don't advance so that we can learn from from past presentations. So, what's the proposal for this conclusion segment? I would suggest that we have a scheme that is consistent when we record the conclusion and result so if something gets consensus for advancement to a given stage, we always record it in the same way. So I've proposed this wording: "consensus for advancement to stage one" or "no consensus for advancement to stage one", with additional details being added as extra bullet points and a special segment called "additional comments" for anything that doesn't fit the schema. Same thing goes for - for example if we take SYG’s presentation of item something that remains at stage 3. we could represent this as consensus for the following changes to proposal. So let's say someone's doing an update and they want to get the committee to be aware of certain changes that have happened since the last presentation we should record those as consensus for the following changes and then detail which changes are being are being consented to and if there's no consensus then we say which ones have been rejected and these two fields can exist at the same time in the same conclusion. So we may have consensus for one change and not for another. Again that there will be additional comments in case something doesn't fit into the schema. Finally, there might be something where there are no action items, it's just informative updates on a proposal, and we can say that that's no action items with additional comments. So you'll notice that the schema is very strict. Well, it's not very strict. Basically. The first line is the first set of lines are dedicated to what's the status of the proposal and then we've got an additional comment section for anything that can't be captured by what's the status of the proposal?
YSV: Okay. So, how do we enforce this? We can have a script in the notes repository that verifies conclusions against agenda items just to make sure that we've got the like for example if something incorrectly gets recorded like something was supposed to advance to Stagwe 2. And in the notes, it was supposed to advance to stage three. Maybe there was a mistake there. It wouldn't change the contents of the notes repository. It would instead set a flag that informs us that there is an inconsistency between some of our documents. Additionally, I would recommend that we have a five minute break between agenda items to properly summarize what's going on in the notes. So that would give people who are about to present a little bit of time to make sure their setup is ready and that would give a chance for note takers to make sure that it's properly summarized and for the people who just presented to verify the conclusions. So this would add a little bit of time to our committee meetings to make sure that the data that we're recording in the notes is correct. Finally, we update how0we-work the document we have on note-taking and link that note-taking document from the agenda. We have a recommendation on how new people should start working on the notes but maybe it should be more explicitly linked to on the repository on the Note so the people who are taking notes are aware of this schema.
YSV: Okay, so individual repositories, it's the most complete source of Truth for a single proposal, but at the moment we don't have a consistent schema that is machine readable, and we don't have any metadata now. It's not always up to date. I have found proposals that say that they're in stage 1 when they're in stage 2 or they haven't been updated for a long time or they don't have the most recent link to the notes or something else. So there's often a little bit of distance from an individual proposal repository and the general proposals repository. There's a lag. So w3c has an approach to the problem of metadata. They have a JSON file included in every single repository that gives a little bit of information that's machine readable. So I would propose that we have a similar JSON file that's machine readable and that would be - so we can do this in a couple of different ways. One way is a metadata.json file, another way is strict readme rules about which sections are in the readme, which Fields, so that we can verify those fields directly with the parser. Both are fine. Yeah other stuff here and make sense. And the final thing is we can use GitHub topics. This is also recommended by septs to categorize proposals by their stages. So at the moment we record the stage information in the proposal itself as plain text we can actually just have that as a category. 2 proposals and when a proposal advances we can have it as a stage three category proposal. So those are a couple a couple of adjustments that we can make so if we were to go for the metadata change without changing the readme the reason that I'm proposing using JSON metadata is because the readmes are often needing to address human problems rather than machine problems, and I don't think that we should sacrifice communicating to humans in the explainers in favor of making things machine readable. So the compromise here would be to have a dedicated JSON file with the metadata that is machine readable. So that we have that available for those who need to use it. And then again, we would use GitHub actions to make sure that this is up-to-date and use it sort of as a triaging point. Okay, and this is the thing that I mentioned about using GitHub topics to categorize our proposals accordingly.
YSV: Okay. So this is the enforcement bit. We would have a script in every proposal repository that verifies it against the proposals repo. So if for example the stage is out of date we can say hey, this failing our build step or or our verification step because the proposals repo says that this proposal is now in stage 3 and this proposal is saying that it's in stage 2, that looks like it's wrong, can you check it it? The actual adjustments would have to be verified by humans to make sure that - we don't want the machine accidentally make a mistake for us. So this would all be checked by humans. And in the case that we choose to have JSON metadata to allow crawlers to have an easier time. To get specific machine readable information that they need then we would verify that JSON using this using this GitHub action against the proposal repository itself and the proposals repository.
YSV: Okay, finally test 262 repository. Conformance test Suites are fantastic in the test. 262 team does an amazing job with this. Yes, they have specific issues related to proposals that are called test plans for large-scale features. Again, this is another case where the issues are not machine readable PR and issues don't have a consistent titling scheme. There is some similarity, but it's not consistent. The problem there is that you can't with certainty link a PR to a given proposal, for example, if we're doing something around updating promises you might have you might have an issue saying "update promise tests" and not the specific promise tests related to the new proposal. So here's an example of - these are the best examples that I have for the naming schemes that currently exist in the test 262 repo. And the reason why we want this is just so that when we are tracking which tests are available for a proposal we can just point to one place because there's often multiple PRS related things. Okay. So here's an example. We've got we weakrefs and finalization group test plan atomics waitAsync testing plan Etc. And here is a detailed view of one of those. So this also doesn't link back to the proposal. Also, for example, if we were to pull all of the issues, which we can do from the test 262 repository we wouldn't be able to verify that this weakrefs or finalization group tests plan is issue for weakrefs. So The proposed modification is we standardize issue titles so that their machine readable and test 262 repo is of course the source of Truth for test data and we explore GitHub projects as another potential way to organize proposal data so we can leverage GitHub in certain ways. We'll need to do a little bit of research about how that might work. But this is another way that we can look at keeping the information up to date. So here's an example issue template. The change here is that we use the exact feature name and the second half of the title is stage 3 acceptance test plan then in this issue issue we have proposal info we can link to the proposal repository and verify that indeed this is the test suite related to the proposal in question, and then the the rest is free to use by test 262 authors as they wish. And again, you can tag things with projects of an organization in an issue. So if for example, we have a project weakrefs we could tag this issue with that project. So we don't really have any enforcement that we can do here, but we can format the issues using the issue template.
YSV: This is what the interaction will look like. So proposals repository that is the aggregate of all proposals will remain our source of truth, which is human edited specifically by the people who are keeping that up to date, and what we do is the individual proposal repositories will read the proposals repository and verify that their information is correct. So that'll be done with a GitHub action that can either be schedule or we can have something else. I have a feeling. It'll be scheduled, it will probably be scheduled to run one week after the meeting or something like that. The proposals repository itself will read from two sources. It will read from the test 262 repository to verify that the testing data it has is correct and it will read from the notes repository to verify that the conclusions are correct and that if something advanced a stage, it's been correctly recorded in the proposals repository. This will be communicated to the maintainers of the proposals repository with a GitHub flag that says if something is out of date it will have a red flag saying of date with a link to the failing test run and if it is up to date, it's green and everything is good.
YSV: So here are the concrete suggestions we use. We use proposed templates for the test two six two titles and issues issues. We use the proposed template for the notes conclusions so that it's consistent and machine readable. We create a tc39 actions repo and move all tc39 actions there. So that proposals can globally rely on that and any other GitHub actions work that needs to happen on behalf of all tc39, so we don't have any questions around ownership. That can all live in a dedicated repo. We update the proposals Templates, whatever we decide here in order to make it more machine readable, so that can be a JSON file or it can be a very strict structure to the explainer or the readme. We record this process and how-we-work. Sorry about the slightly messy presentation. I'm looking forward to your comments.
JHD: The first question is just for the sake of the notes. Can you please explain what the JSCIG is?
YSV: JSCIG is the JavaScript China interest group. So we I believe it is composed of a number of tc39 members from China. So I believe that includes JHX and a few other people.
JHD: I think automated updating a links in the proposals repository and elsewhere is a win, we should just do it. And while it's awesome that it's being talked about with the committee, I hope that that's not something we require consensus for.
JWK: In the slides about gathering data of meeting notes I found it seems like you're trying to analyze natural language to like stage advancing information and that might be very error prone. Why not just normalize data in some forms, and it'll be friendly to machine reading.
YSV: that is actually the proposal. The proposal is that we normalize the conclusions in a consistent way so that they are machine readable.
JWK: Oh, thanks.
WH: As part of this presentation you have a proposal to have a 5 minute break between every pair of items. That is incompatible with physical meetings. There is no way you'll be able to get everybody back in the room within 5 minutes. And if you do it with a virtual meeting: we had something like 38 items in this meeting so this would remove two hours from this week’s meeting.
YSV: Yes, we would be sacrificing meeting time for the gain would be that our conclusions are correct from the beginning now the 5 minute breaks wouldn't necessarily mean that people can leave the room in the physical meeting. It would mean that we're just going to take a pause, people set up their laptops or whatever, and during this time. It's just a designated time for it checking the notes. There we can say that we don't want to do this. So that means that our note takers will be rushed. That's currently what happens. If you take notes you will find yourself being rushed to concretely record the conclusion and at times it will be difficult to get everything formatted correctly. So that's why I'm recommending the the break but as I mentioned we can have a GitHub action that before any notes merged into the repository we validate the conclusion by processing the conclusions and checking them against a template if they don't match the pr fails the check and whoever is responsible for merging the pr has to fix it
WH: That's digressing into GitHub actions. My point still stands. In physical meetings there is no way you'll get everybody back from the side conversations after only five minutes.
YSV: I believe I do address it because as I mentioned this is similar to our break time when we transition to the next speaker setting up their laptop. Nobody leaves the room and generally nobody leaves their chair. And additionally if we don't want to have the five minute break, which is an option. We don't have to have the five-minute break. In that case the fallback here is we check using GitHub action which will fail if the conclusions are not in the correct format.
WH: Let's move on.
MS: Isn't one minute enough?
YSV: The time is arbitrary that I suggested. What I meant is a short period of time that's dedicated to making sure that that gets checked. Hopefully that answers your question
JHD: I also think that having structured JSON metadata in the proposals repo that's used to generate the markdown in it is also a great idea, and hope that also wouldn't require consensus.
LEO: (paraphrased) I think it's very cool to have ideas about we do on tests plans. Test262 has received negative feedback when we have tried to add metadata in the past. A template could be proposed on the test262 repo.
YSV: I'm interested in talking about this more offline.
Presenter: Daniel Ehrenberg (DE)
DE: So we were previously talking about the mutable versus immutable question for JSON modules. There were a number of people in the queue. Unfortunately, we lost the queue entries. So if you have comments on the mutable versus immutable-
AKI: I have a screen shot! I can drop it in the chat. https://snaps.akibraun.com/dbzqq.png
{kind=link}
MM: The issue is that rather than the UInt8Array example pushing us towards mutability, it should instead push us towards having some immutable way to represent a string of octets. That's all.
DE: Yeah, so I want to be clear. If we make JSON module immutabile it would not creating a new convention that in general module types are immutable. I think we will have to expect that hosts which we explicitly enfranchised to make other modules - with this proposal are likely to make other mutable module types. So if tc39 makes a sort of data type. It's immutable. that's that's a decision we could make but we're not we're not going to -
MM: Why do you think hosts are biased towards making mutable types rather than making immutable types?
DE: It's not a question of bias. It's a question of looking at which extra module type is concretely on the table right now. So if you look at If you look at HTML or CSS modules, these are both mutable things. So is being discussed in another open standards effort that any of us can comment on but I think we should expect that module types other non JS module types, like JS modules, are likely to be added that are mutable.
MM: Okay strings, binary data - there's a whole bunch of things for which the natural form of the resulting data would be immutable as well.
DE: I think that's a legitimate thing to discuss, but there's no proposal that I'm aware of right now on the website to add string or binary data modules. So if we want to pursue proposals about that then, you know, we don't we don't currently have any competitors that I'm aware of besides the tooling space.
MM: Okay. Okay.
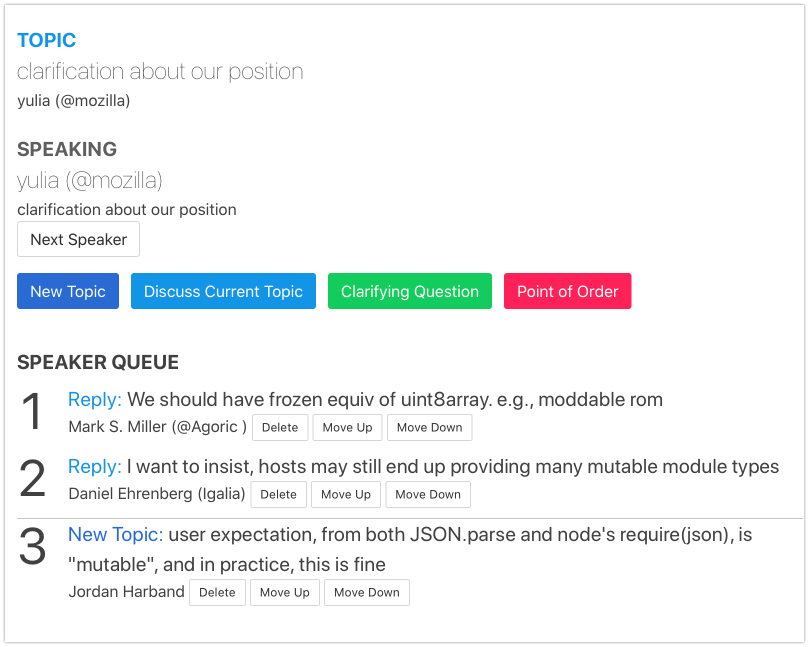
JHD:(topic: "user expectation - JSON.parse is mutable in practice - this is fine") So as was pointed out to me and in chat after I put this on queue it to is probably not the the best analog because you can call it multiple times and every time you get a fresh copy to expect the resulting object immutable. I think the better analog is nodes require of a JSON file. As soon as you require a JSON file, that value is cached for the rest of the program and any mutations to it when - [audio drops] Okay Okay, so node require when require a JSON file that it caches it as a Singleton for the lifetime of the program. Mutations are visible to any user who looks at it after that, just as they would be with the mutable form of this proposal. In practice this is fine. Most people don't mutate anything and if they do it's because they want everyone else to see the mutations and if they want it frozen, they're welcome to do that and that would prevent anyone else from mutating it in the future. So I think that the user expectations here are both that it be mutable. And also I think that about a decade of people doing this in node has shown that there are no problems caused by like in terms of how it works - I'm not talking about like performance or anything, but there seem to be no ergonomics problems caused by having it be mutable. I very strongly prefer that this be mutable to match that.
BSH: I think I wanted to state that a little more strongly. On the whole really think if we were doing this from the start, then it really should be immutable. That's what I would prefer. But since the thing you're replacing is basically the nodejs way, the expectation is that it's mutable and that mutations are seen everywhere. To have a drop-in replacement it's got to act the same way.
DDC: Yes, first also have kind of preference for default mutability here. Like I agree with what JHD said that there's kind of a history here for mutability. It's what users expect from node and from JS modules like I might impression kind of is that the main argument against this is that like if you do need guaranteed unchanged fresh copy, like the workarounds for this were somewhat weak like I need to maybe reorder the Imports to make sure I can be the first and lock it down, or I need to to like proxy through a JS module to lock down the object or get a fresh copy. It seems like maybe there's value in having like a stronger guarantee here. This is sort of the use case I'd vision for evaluator attributes, like I'd be really interested in exploring this space if it turned out to be something that is needed. So that's kind of why I like I'd like to have this default of mutability that like follows the historical case here, but like if it turned out that like this was actually a problem like evaluator attribute seem like an interesting tool to explore to like solve some of the workarounds there if we need something better, but just going with going with the historical Direction so far. That said it's not a super strongly held opinions if the temperature of the room is the other way. My main priority here is just getting consensus on one way way or another.
PST: So on microcontroller XS already has both mutable and immutable modules. The decision is made out of the language, itis made in a manifest or something and so on, but both are useful in fact, especially when the memory is very constrained and so I expect the same will apply to JSON modules when XS will Implement them. I mean we use both. Module that expert I mean binary data and stuff like that and they can be need to be immutable most of the time because of the memory constraints, but I mean both would that's my you just would experience because we already did. Thank you.
CM: Yeah, not to be beating a dead horse here, but it strikes me that when people have made various assertions that people are used to modules being mutable and that's true, but the extent to which they’re mutable is really the extent to which whatever the module exports as affordances for mutability, e.g. functions which can be invoked to change things or a complex data objects that are made available in mutable form, and so code modules are sort of sovereign over their mutability, whereas data modules, since they have no agency, have no way to control this. And it seems like some mechanism for at least indication of intent ought to be made available.
DE: So as a member of the champion group for JSON modules, we'd really like to conclude on this discussion and we've heard arguments for both sides. The champion group hass expressed, know opinions, but but openness to to go either either either way on this question. And so we'd like to return next TC39 meeting to ask for stage 3 based on the committee's decision. The temperature check previously seemed show on balance, but it's very divided, that there was a lot of interest in immutable. So I want to return to CM's previous question about - would people who feel strongly block in either direction?
CM: I wouldn't block, it's just that it's just that I would find the feature much less useful without some means to ensure immutability. It doesn't mean things have to be invariably immutable, I would just like there to be a way, in use cases where that's what you need, for you to have a way to get what you need.
MM: Yeah, so I feel strongly towards immutability but like with CM, it's not a blocking issue for me. I would not block either way.
YSV: I raised that we lean towards immutability, but we wouldn't block it if it was mutable. But if it was immutable we do see that there's a user ergonomics problem that would need to be addressed by maybe a follow-on proposal, and it sounds like - I don't want to put words into anyone's mouth, but it sounds like what Chip just said and maybe what Mark just alluded to - is if it's mutable there may also need to be a follow-on proposal. So yeah.
RPR: I'm chairing but this is just a personal view. I'm strongly leaning to immutable, but would not block.
SYG: I want to ask a question of Chip about your concern about the sovereignty of code modules having agency over whether its exports would be mutable or not. That's a pretty general thing. Right? You've set the categories up to be code modules versus data modules and would like to be some way to signal data modules whether their exports are mutable or immutable. How generalized is that concern for you? like do you want this to be for all data modules going forward in the future that there be some unifying mechanism.
CM: I would lean in that direction. I mean the particular proposal here is just for JSON modules, but the underlying concern that I have I think would be equally applicable to other kinds of modules that just resulted in pure data. It’s just because they don't get any say in how they're used, whereas code modules do
SYG: To make sure I understand, clarifying the agency here. You're specifically talking about, you want the exporter, like the author of the data module, to signal intent of how it should be consumed.
CM: Yes, that would be my desire although in the case of data, since data is sort of self-contained, if it were in that case a matter governed by something indicated at the importation site, I would be okay with that.
SYG: Okay, thanks.
PST: about Chips' concern, even a module cannot completely control if they are mutable. if you module export a date you can still change the date even if you freeze the date object. so there is something else they're there, it's not just freezing. That's all.
DE: Yeah, so I want to come back to CM’s Point briefly. I don't think it's viable for us to say that in general data modules are immutable. I think if we try to overstate that we're going to get push back from for example web module types that don't run code but are mutable. So I want to focus this question on JSON modules. The temperature I'm getting from the room is that there's some - on balance it seems like there's a bit more interest in immutable modules. And I haven't heard anybody say that they would block any either direction. So my plan would be to return next meeting with a proposal for immutable JSON modules and ask for stage 3. I ask that if people are concerned or feel like they would block that they would raise this to the champion group. Is this a reasonable conclusion or do people have concerns with this?
RPR: I think I think that's a reasonable way to wrap this up. Shu is on the queue to say that he leans mutable but won't block. And I think we have to stop now. Thank you very much.
AKI: the conclusion is that the JSON module champion group is going to return for stage 3 next meeting and if you have very strong feelings on either mutability or immutability please bring it to the issues queue. As it stands it would appear that nobody is interested in blocking for either.
DE: and that the current understanding is to go with immutable, though the last couple of comments did make it a bit ambiguous what the temperature was. [Discussion continues in tc39/proposal-json-modules#1]
Presenter: Daniel Ehrenberg (DE)
DE: Okay, so when we were discussing this previously, I think we got a bit off track when we're talking about Ecma’s overall budget situation. That's really out of scope for this committee. It's more a thing for the Ecma execom or general assembly. So I want to focus on the questions that are within our scope asking the committee to questions that the the exact come asked for a signal for from the committee on which is more about what kinds of services we hope to expect from Ecma and less about the exact budget details. So when I asked and thanks to Myles for helping with thinking about how to frame this. One question is does TC39 value MDN. Do we see it as an important thing for us other question is which I don't want to come to a full answer today because it's a broader question, but do we want MDN contributions for TC39 proposals to be part of our process like we have with test262 and and finally do we want help from from Ecma funding this the proposal that I'm making there would not be sufficient by itself. It would be additional things and if anybody else wants to contribute to this, please get in touch me offline, but the question is sort of whether this is a priority for us. I heard that there are many other things that we might benefit for from dedicated funding for example, We previously talked about having a transcriptionist. It seems like even with the automated transcriptions note-taking remains burdensome or also help with some kind of professional typesetting help for the final specification for its PDF form, I think these would also be reasonable things to ask for but the request from the exec committee was to get a clear signal from the from the committee about whether these are requests from the committee then later in the GA and we can discuss the overall budget. So open up to the queue.
MBS: There is nothing in the queue.
DE: Okay, does nobody value mdn? Show me do it.
MM: Yeah, I mean my response is yes. Yes. Yes, but it hardly seems worth putting myself in the queue for that. for that. So temperature check sounds good.
DE: okay, can we do temperature check for sort of like that and of these three first three questions and maybe we can break it down more if needed like of skepticism about any of these then note that a skeptical or we could do one by one. Does anybody have a preference?
AKI: All right. Well, I am on the Queue now. I am a massive supporter of Ecma International finding ways to prop up the MDN documentation. It is vital to JavaScript developers and if we don't have JavaScript developers, no one's going to use our standard. So like there's a clear and black and white line between what we do and what MDN provides. However It's a little unclear to me what the structure here would be like. How would we use the funding? Would we be hiring a person ourselves? Would this involve giving money to an organization like the Mozilla Foundation? I am a big fan of asking for Ecma to utilize our dues in a way that supports the committee big fan of supporting MDN.
DE: Unclear on how we support them Beyond it. It remains unclear how to best support it. There's a lot to work. You're busy. So I'm asking a more narrow question, which it sounds like you're answering. Yes to then once we have this answer then I would like to work with anybody who's interested in working out those this detailed answers. Is that a fair framing?
AKI: Yep.
MF: I can save my topic for the end if we want to keep this on the MDN discussion. Just, there was an empty queue and the last bullet point asks for funding requests. Dan do you want to stay on MDN?
DE: I want to hear your voice.
MF: Okay, so as part of the editor group, I dread having to deal with this PDF creation issue, and I think that it would be a reasonable budget request to have a publisher take the HTML spec and create a PDF. That is mostly consumed by Ecma itself each year. I think we can do that for a reasonable cost and I also think that, unlike other problems that we've solved within the committee by building tooling (such as TCQ for queuing and for this auto transcription service that we're using for the first time this meeting), I think that creating the PDF is far outside of the skill set of the editor group. And I don't think we'll be solving that even though Brian Terlson previously and Jordan and other editors have tried very hard to do the best in the past.
DE: Great, would you be up for working offline to formulate this as a proposal with me to Ecma management?
MF: Yes, if you would be able to join one of our editor group meetings - we have them weekly - I'd love to have the whole editor group participate in the discussion.
DE: Great. I'll do that. Thank you.
LEO: just for the records. This does have strong support from me from the Ecma 402 side and from what we can see also from Ecma. Recording this on the tcq, tcq, but there's no need to talk.
IS: Yeah, so I do not need to talk about it, but that would make a lot of sense because we are fighting with this problem actually at least for four or five years and the last really good version of what we had in PDF format. It was when Allen was editing and it was obviously a lot of work. So I do not really expect that the current editors are doing that and I think it makes a lot of sense and I certainly I would push for that also in the photograph managed in take my management and also for a second because it is one of the standard which is downloaded most from Ecma and it is a shame, you know that it it is not in our best format and this is the one version which goes also into the public libraries, etc. Etc. So, thank you.
LEO: Quickly wanted to add the second and third bullets here. They kind of complete each other if we do require a set and MDN documentation as being part of the TC39 process would also help relieve the work of someone who is maintained. the documentation we have at MDN and at the same time the person maintaining would help doing mentorship and etc. live in the like champions who need to write MDN documentation. So they complete each other. So I am really positive about the idea of having both parts. and also just want to feature here. ECMAScript script does not have a high level or user-friendly documentation of things. We do. We lost a lot of valuable work and from that we have in explainers, but they just get lost when the proposal is done and I think moving things to MDN would transfer very valuable work that have from those who are championing those proposals.
DE: Yeah, I completely agree.
WH: Dan, I find the form of your temperature check to be really inappropriate. You're doing a temperature check on something which starts with a leading question “does TC39 value MDN?”. So it's like starting with "do you want to kill puppies?". I’m really unhappy with trying to use leading language to get what you want here. This is not appropriate.
DE: I'm very confused because it would be totally valid for TC39 to say look MDN is just a random project and it's out of scope for us. I think because it has like Mozilla in the name that does make ambiguous something that has come up in discussion before.
AKI: I love that you think of MDN as a puppy.
WH: That's not a good response to the concern I raised. I would like to separate the issue of whether TC39 “values” MDN from whether ECMA should be funding MDN.
DE: So I can try to clarify. I want this temperature to be on sort of the intersection between them. So if you feel comfortable with any parts of this, I didn't mean like the or I think that would be a little bit unfair because then we wouldn't know what was going on.
WH: I object to doing a temperature check like that. That's inappropriate.
DE: Okay, so let's close the temperature check. I'm wondering if can move forward with this being the message to Ecma that because it's and I haven't heard anybody say no to these questions, the only I mean I heard responses to the broader Ecma funding thing, but that's the GA’s jurisdiction. I wanted to know another Ecma funding item. I'm sorry. I didn't put this on the agenda before but we previously talked about nonviolent communication training or some kind of training to help the committee communicate better. We previously discussed this and approved for our 2019 budget, but that's sort of expired for the 2021 budget. I think would need to reaffirm that we're still interested in this I think he's I personally could use help in how I'm communicating some time. and maybe the committee could is a whole so I wanted to ask if we could reaffirm that as well in addition to these topics. We don't have to do this by temperature.
AKI: Okay. I'm just going to provide a clarifying answer as opposed to a clarifying question. The budget for comms training was for 2020, and then 2020 happened. We had been approved for this budget at the Ecma GA in December of 2019. We talked about this admittedly hadn't gotten it together and then 2020 happened. I'm pretty confident that if we could have some sort of structured plan that we could bring that back to the GA and say this is how we're going to actually execute on what you previously budgeted for us.
DE: So we're discussing this in some more detail in the inclusion calls that we now have every two weeks weeks. They courage we I didn't I didn't realize that you were looking into this also. Well, please come to those calls and so my discussion with the exact was basically they were saying we can't just like carry carry over the 2020 but we have to you know confirm that we're still interested in this so that's why I'm asking the question because you know things don't just get copied from one to the other.
AKI: I was just clarifying that we had gotten approval in the past and I think that if we brought forward a more concrete plan of this is how we are going to spend that money. I'm confident that we could get some manner of continuation of that line item.
DE: Yes. So I think because the budgeting cycle is coming up right now be nice to just Express general interest in this your continued interest which I'm hearing interest from a key and we heard interest from the committee in the past. So does anybody have any concerns with the proposal for raising this? expression of the committee's interest in these areas not what what not.
WH: What exactly are you asking for? Be specific.
DE: So I think there are three questions. Does TC39 I mean TC that I mean the third question to see see the tonight want to seek my help fund yet to designed initiative to work on this and we discussed these other two funding issues one being the the editing of the final the final specification and other being the communication training I mentioned a transcriptionist I don't know if that maybe that's that's more involved request because it's kind of of bigger and harder to scope. But yeah, that's that's what I'm asking then.
WH: That did not answer the question. You said “work on this”, but what is “this” referring to?
DE: The specific question is in this slide. It's the third bullet point. What is this work? And MDN documentation about the output of TC39.
WH: Okay, so you're conflating the MDN work with formatting the PDF with doing transcription with doing team training.
DE: If response or concern about one in particular than I'd like to hear it.
WH: Can you make a clear specific statement about what it is that you're requesting money for?
DE: I’m very confused by the line of questioning. I don't understand how to clarify further. Sorry, maybe the chairs could help me understand.
YSV: Yeah. I would like to help mediate this so I'll just repeat back what I understand to be the misunderstanding here and you two can correct me. About how I understood things. My understanding of what Dan is raising is that among several things that could potentially use Ecma funding one of the larger and more important ones is going to be potentially supporting MDN, because Mozilla has unfortunately cut a number of resources there and one way that we could compensate through that is through Ecma funding. However, there are several other concerns from TC39, which could benefit from this funding and we're talking about this as sort of a package of things that we could bring to a Ecma and if I understood actually Dan, can you correct me on that?
DE: So I when you say package, I think this is these three I mean for items that we've discussed are all separable. It would be totally valid for the committee to say “look. We actually really want to transcriptionist but actually MDN is out of scope for the committee's work”. That would be a totally valid thing for to say and I'm asking for feedback on each of the items that we've discussed.
YSV: Okay, and if I understood Waldemar's concern is that has a concern specifically about funding MDN because this may be out of scope. Is that right Waldemar?
WH: I have concerns because I want to see what it is that we're supposed to be funding and how much we’re asking for. I’d like to see something resembling a budget request.
DE: So I think that's the scope of the GA did present in a previous slide. I'd in this presentation. I presented a concrete amount. I think it's really up to the exact come to propose a budget. I mean the Ecma management to propose a budget for us to discuss those budget details there for the PDF generation and therefore the yeah.
YSV: Can I just interrupt here before? We get too far into details just to make sure that Waldemar's concern is fully addressed. So it looks like Waldemar position. we should have for him to understand this more fully before agreeing to it from the tc39 perspective. He would need to see the budget ahead of time and the disagreement here. is that since we don't have all of the information about Ecma budget that Dan you see that as something that should be raised at the GA. Is that right? Is that a good summary?
DE: I'm really trying to pass along the concrete feedback from the from the exec that they yeah. Along the lines of what you said. I wanted to further say that for, you know, the committee PDF generation. We don't have any estimates for how much that cost for the communication training. We have estimates, but they're old and we'll need to get new estimates, but I feel like these questions about details can be resolved offline.
YSV: So Dan is coming from some feedback that he got from the GA and Waldemar is expressing his concern about his ability to make a decision right now based of the information.
WH: The answers I’ve gotten have been rather evasive. I want to see actual Swiss Franc amounts.
DE: So I had it on a previous slide, which was 20,000 Swiss Francs. Okay. Not sure what's ambiguous about this.
YSV: So For we come back to that topic. Let's hear from Myles and I want to address I want to address the the clarification that Waldemar is asking for after that.
MB: All right, so I think stepping back from the individual items that we're talking about right now, I think as TC39 we should make a decision about how to handle budget requests. For example, we sided against having individual projects having discrete budgets unless they explicitly asked for them. But rather to ask for budget on a per item basis and then in turn, you know, the foundation manages a budget decides what gets approved and what doesn't get approved. There's also a separate cross-project Council that can help manage these things for all of the different projects. I think well tomorrow one of the things that you're asking for here, which seems somewhat reasonable is like a per item budget like we want to do like four or five things how much are all of these four or five things which the total budget that were asking for and of those what are the priorities now the flip side of it, which I think Daniel is saying which also seems very reasonable is like we don't have a budget as the committee and we should be asking for things on a per item basis in the exec who manages these budgets should be the ones who decide you know, like which things we do, but if those committees don't know what the order of priority we have is it's hard for them to make your decisions where it kind of feels like we're stuck at a standstill but I think before we kind of get too much into that, I think it is important that we decide to start with like do we want to just make a request to Ecma for a budget of x francs a year and then we know what our budget is for these kinds of things or do we just want to ask for the things that we want to do TC39 is responsible for quite a lot of money that comes into a Ecma and we historically have not asked for a lot of support and I think it's absolutely reasonable for us to ask for support on things and the flip side they say, I'm sorry, but with the way the world is right now, we just can't afford these things. But I think that we're potentially potentially sabotaging ourselves. By not having consensus on this like fundamental way of thinking about budgeting and I think personally at least that's causing some of the conflict right now.
YSV: Thank you for the summary miles, Waldemar Dan do either of you have anything in response to what miles just said.
DE: I agree completely with what Michael said and I think there's a lot of different ways. We could go about it this way of asking on a per item basis was the recommendation of the Ecma management. So, but I think it would be very reasonable for us to propose other ways of of managing this
YSV: And Waldemar?
WH: Yeah, when asked to decide such things I feel like I have a fiduciary duty to ask how much.
DE: so should we think he belongs to the Ecma management and general assembly.
WH: Look, let's not confuse things by saying you're deferring it to the Ecma General Assembly. The first thing that the General Assembly will ask is how much you want.
YSV: I want to step in here so that we don't start talking about directly about each other because this is fundamentally we're talking about what do we do about asking for this budget and the current presentation suggested that we asked for a fixed amount for it contribution support now we can decide in this current item which were running over and there's other stuff that we want to talk about in this meeting whether or not the fixed amount of 20,000 francs. is the fixed amount that we would go to Ecma to ask for or should this proposal be modified to be something like what myles said we should consider our budget more broadly and Maybe think about how specifically we ask for money and prioritize things which would be a broader proposal possibly out out of the scope of something we can decide with the mission that Dan has currently. Would that's summarized effectively what decision we can make right now.
DE: Yeah, I think those are two good options.
YSV: So I would like to ask for a temperature check on that first question. Do we want to present to Ecma this request for 20,000 francs to support mdn contributions, and that's just a simple temperature check temperature check on that. This is keeping in mind that the next question will be should we work out a more clear budget as what miles brought up in his topic.
DE: Wait, I don't understand the check if you if you support the second one then would you you logically want to oppose first one or would would you support it?
YSV: You support both you can oppose both you're going to pose one or the other.
DE: Okay, thank you.
YSV: So the first temperature check is given the proposal the Dan has made of 20,000 Swiss Francs. Should we go to a Ecma and request this money for in order to support the work of mdn contributions? That's the first question. Michael you have a new topic while people are giving their comments.
MLS: Yeah. I'm not sure I fully understand both the Waldemar comment, but I think the issue is as we don't know what we're trading off if x my has money and enough sure but if ECMA has limited resources, which they do then what is a priorities and I'm not sure that we as a technical committee should be making Are you decisions, you know mdn motherhood apple pie. Yeah, great, But what are we trading off what we spending money on other things?
DE: That's a great answer that question based on my discussions with the Ecma management the just tried to discuss budget trade-offs with them and they said actually what we'd like to hear from the technical committees is what services are you? Are you interested in and then then we can see whether we can fit into the budget and get and get back to you the about this particular request my understanding from them was that it will not be difficult to fit into the budget, but that's something that we'll have to be, you know Revisited in more detail based on our on our feedback. So I think that this is my understanding and we can all you know run run for positions in Ecma management to be involved more, I think I want to respect they said that. we can leave these things to Ecma management and focus on raising our interests.
YSV: Okay. So in the interest of time, I'm going to move on to the second question. So this first question is we would be presenting MDN as a contribution 20,000 francs for GA as a per item basis thing. The second question is do we want to draft a list of items with priorities and the amount that they would cost and present that as a holistic item for Ecma to review. So this is the second temperature check. I have a temperature check screenshot of the first temperature check, please feel free to give your thoughts on a holistic list of items and their priorities that would be presented to Ecma at at some point
AKI: Okay, well people contemplate that question and decide their opinions. I think we are so far over time on this and we need to call it to an end. I would love to see this come back and a little bit more of a concrete form. I made my opinion clear. I am hugely supportive of it conceptually speaking. I would love to see a little bit more structure. We super duper need to move on.
YSV: Alright that concludes this topic item and then I will send you the temperature check screenshots, okay?
DE: Thank you.
Presenter: Ron Buckton (RBN)
RBN: So when we left off the discussion on grouped and auto accessor properties, there was some debate between myself and Daniel Ehrenberg about how this would affect the decorators proposal. I wanted to discuss this with Daniel and offline a bit and I wanted to present some of these to see if we can move past that discussion and continued discussing whether or not we could look for stage 1. So one thing that I wanted to point out is my intention with this proposal is not to block decorators. I do not believe this proposal should be considered blocking. it proposes a new feature that I could not necessarily bring up in the context of decorators on its own as that would be out of scope for the decorators proposal is something that I hope to be able to Leverage. As part of the decorators proposal but not necessarily blocker forces specific decision within that group. This is again something that we have discussed in the decorators call which is why I'm bringing this up to to the contrary. I believe that in general there's value for this proposal even with implicit conversion fields. grouped accessors and auto accessories provide more decoration targets and more flexibility, which I hope I was able to show in some of the earlier flow earlier slides in addition. One of the things that we discussed was migration path and what the migration path is for existing implementations of stage one decorators that go through transpilers such as TypeScript or Babel and that the current proposal does not actually have a clearer migration. Have for decorators on accessors that use get and set based on the current stage one semantics to provide the descriptor the way around this is extremely complex and cumbersome and by being able to provide this you have that flexibility of being able to still have something that decorates the combination of get and set. if we do choose explicit conversion of fields for decorators using a prefix keyword, for example, we have multiple options. users would have the ability to freely choose between using that keyword or the get set syntax the prefix keyword would obviously be shorter for many scenarios for auto accessors. However, allow you to declare the get or set independently and give you a place to actually decorate independently, which you would not be able to do with a field that gets to convert it into an accessor. So it does give you some more expressivity. And auto-accessors still are one of the core features that I want to try to be able to provide with this assuming we can find a syntax that everyone is comfortable with is the ability to succinctly be able to define a public debt and private set type scenario. Another possibility is that since Waldemar mentioned he was concerned about the syntax possibly. Being up too much of possible class in Tech space is that if we did find a perfect keyword that we liked we could theoretically apply it to both scenarios where we could say that keyword whatever keyword we look at says that this actually is an accessor. We could expand that out to be more specific that it has those individual get and set branches so they could theoretically decorate the individual Getters and Setters if we so choose and that essentially is what I show here in this slide is essentially the internal translation of what these things mean. Is that keyword field is essentially the same as property with Get Set initializer, which is essentially the same as declaring some private named filled with a getter and a Setter that wraps it one of the things that I would like to be able to do with this is depending on how quickly this proposal advances it may or may not It does provide an additional option that the decree is proposal can look at and consider. That is more expressive than a simple keyword could provide and again not to block the proposal but to give it more options with that. I'd like to be able to go to the queue and address any discussion that are there.
SYG: All right. Could you clarify what you said as a problem or a problem you'd like to solve or a problem space you'd like to investigate is basically here's the current solution I'm thinking of and here's bunch of different places where my current solution could help out and that was where I got hung up last time which was I saw this is a as kind of disjointed problems that it wants to solve. Maybe it can improve decorators. Maybe it can prove this other stuff, maybe not. What if you could reframe it as just like a problem that would help me a lot.
RBN: Yeah, I think it would help. I'm going to scroll back a little bit to the list here for the grouped accessors. There were a number of motivating reasons. one was to be able to help with logical grouping. This is something that you can do with lenders today to enforce that that grouping exists that the getter and setter next to each other but this logically helps with grouping if you use computed properties such as symbols for Getters and Setters there is even though it's a probably a short startup costs. There is a possible cost for evaluating that expression twice for the each of the names and then the internal class semantics require basically redefining the property but adding in the get in this set as you go for each one of those so this could reduce startup start up cost possibly that would have to be Actually tested to find out if that has any measurable impact. I wanted to be able to provide what so one of my concerns with the current decoratosal proposal that in stage one consensus was that when they operated on a descriptor that we would correlate the getter and the setter before evaluating the decorators so that decorators would have access. the current proposal only decorates the get or set function not the pair and are decorator scenarios that are no longer viable because of this where I might actually need access to both the get and the set of correlating those is difficult. So providing a single declaration allows us to do that is one of the motivating use cases for this so it is essentially an idea of giving us a better story for decorators for accessors moving forward and simplifying and reorganizing some of the syntax we use get and set to be a little bit more convenient on the auto accessors case to me coming from my background with C#. This is an edit for that language was a natural evolution from having accessors in a group was there are a lot of cases and a lot of times when you write code where you have a private field that it stores an object reference and you want a getter for that object reference and there there is a lot of excess necessary to define those semantics and the approach you can see with the class with a property here is a simplification. A way to write this much more succinctly and again the motivations there were to find a way to a simple succinct syntax for these common patterns, which I'll admit don't yet exist as as private fields are a relatively new thing that has not that is has some implementation and some use but isn't everywhere hundred percent just yet. So people aren't necessarily running it into this, but this is coming from my prior experience about this. Another thing is that there we are aware of and we have made decisions about the fact that there is a sub classing hazard with fields that we have to that users generally won't run into but it does exist and there are very it's very difficult to get yourself out of that. And one of the things that this does provide is a way to avoid the hazard by declaring properties, but also I think those are the main motivations.
SYG: I was looking for some kind of sync thing and that was a rehash of the list of things. So for stage one is asking for investigation of a problem space in the problem space as best as I can make out is ergonomics. Okay, so that is something that we should flag.
DE: I'm in favor of continuing to investigate this space. I think it's important also for the relationship with decorators to have a succinct explanation. So I hope we could do that as part of stage 1 and whenever that happens:
LEO: favor of continuing to investigate and I hope if we get to Stage 1. It doesn't seem like it's a full agreement with the current shape. It feels overkill for me on many aspects, but overall I really like this proposal. It's hard because I really like this proposal but it still feels like overkill. I would probably prefer a subset of what is being presented. But it's requires more conversations in a sync.
YSV: Okay, and I want to come back to the point raised by Dan and SYG which is a succinct description of the problem space the proposal is solving. currently unclear to the committee. Ron, Do you think that that's something you can summarize in two minutes or less or should we move to move to say that we don't don't have strong concerns about stage one, but there isn't a clear problem space so we can conditionally advance this as long as there is an issue opened with a summary of the problem space that satisfies the requirements of Dan and SYG. Would that work?
DE: sorry, to clarify, the summary I'm asking for is some succinct summary of the relationship with decorators.
YSV: So those are two different ones.
RBN:So there are two things to address. one is whether we look at this now or we look at this after decorators has already shipped. There are still holes in what we can do with decorators that this is intending to give us ways of working with such as the issue with decorating the get set pair. There's areas that we lose with the current proposal and I'm generally in favor of the current decorators proposal and have been working with the various individuals involved with that for quite some time. The problem space I am trying to investigate is ergonomics, it is expressivity and clarity and it is giving us more decorator targets that allow us to do more interesting things with decorators and on Daniel's side of concerns when it comes to how this works with decorators. Again, my intent is not to use this as a way to block decorators. I believe that this and the decorative proposal can move forward independently on their own. My goal with bringing this forward was to give us something that we can look to as an option in the decorators Champions groups and discussions to determine is this something that we want to be able to use we can't use it if it doesn't exist. So being able to have a space where we can explore that since this type of functionality would be out of scope for the decorators proposal itself. So I want to be able to have a way to investigate these additional decoration targets and ways of solving some problems decorators can't solve that requires syntax that's outside the scope of decorator syntax itself.
YSV: Thank you, RBN. So you address both points raised by Joshua and by down, so are you both satisfied with the explanation given by Ron?
DE: I remain a bit concerned about the relationship with decorators because it sounds like you're saying now we can discuss whether or not it is needed in decorators, which sounds like it may want to block decorators it. I want to continue discussing this offline because I feel like we're a bit over time.
YSV: We are a bit over time. Shu I get your input as well?
SYG: I won't block stage one. I think economics and that's it's fine. I think what Ron said is fine and I agree with his own. recognition that a lot of the ergonomics issues that he is kind of anticipating given his past experience rather than actually seeing and I'm will be interesting to see how that is whether it's actually borne out in JS. But yeah, that's stage one concern. I don't have a stage stage one concern.
YSV: Ron do you want to ask for stage 1?
RBN: yes at this point. I'd like to ask the committee if there is consensus in stage 1 for investigating this proposal. And again I've mentioned on the slide here that I'm interested in the space investigating either the as proposed or an alternative syntax if necessary to achieve the things I'm looking for.
YSV: All right, please speak now if you wish to block this proposal and any concerns. I'm not hearing anything. So congratulations Ron you have stage 1.
- proposal advances to stage 1
Presenter: Shu-yu Guo (SYG)
SYG: so we have two overflow items from the previous charter double ended iterator structuring and ergonomic branch checks for private fields. So those will carry over and in the interest of the people taking PTO and stuff I will propose basically just one more topic. and before I do that, are there any volunteers for proposals early stage proposals who would like to participate in the one additional slot that I am asking for before the next meeting?
CZW: so error causes overflow in this meeting, so I'd like to request for the incubator call for error cost.
SYG: Yeah, that sounds fine to me if there are no others. I am happy to add error cause.
Presenter: Chengzhong Wu (CZW)
CZW: So the ultimate motivation on the proposal is to achieve a better experience of diagnosing errors with contextual information with a certain property written by the language. We can have a more comprehensive message on how to solve the problem and can be suggested a high level error. And there's a key change to the packing an additional step in the cost and if the cost is not undefined they will be done to the newly created property costs and right welcome to the governor, you know rock world have a default value for the course will be an empty string as same as the error error message and Yeah, Yeah Andre iron message. And this one of two of the unit you can also use the first case is constructed from within our object and a as the court and we can access the course guide their own properties. The cost is now the value of girl for me not to and considering the value value of property cost as the message property on our prototype as an empty string rather than undefined and this is just costing the it will not stockings and with some people Jade raise the question the other day we can tell you this but the undefined and with a double question mark to escape the undefined string. And there are alternatives reading by the garbage and then we can make the second term in Taunton option bag so that we can extend the option back with additional properties like name and maybe future JS extension pollute. The error cause is a critical part of common JavaScript application. So we are referring the the current term. positional parameters for the cause and not creating it ephemeral object for the option back and we are taking for stage reviews for stage two advancements and that's all we have for for the presentation.
YSV: Thank you Chengzhong. We have two items on the Queue. And the first one is Kevin Gibbons.
KG: Yeah, just very briefly. I am in support of this proposal. I do want to say before it gets stage 3 I would like to get explicit buy-in from the devtools teams of at least a couple of browsers because this is primarily a dev tools feature. That's all.
YSV: Thank you Kevin and next we have SYG.
SYG: Dan pointed me to the explainer that apparently explains this. Let me confirm my understanding: for AggeregateError nothing special is done. So you dig into each specific errors, is that right? There is no special logic to combine them into some super cause in the aggravator. Does AggeregateError have its own cause?
CZW: [yes]
SGY: So aggregate error is treated just as any other error.
CZW: Yeah.
YSV: Does anyone have any other comments that they would like to get in? I'm not seeing anything show up on the queue. Please speak up if you have something. [silence] Chengzhong, do you want to ask for stage 2?
CZW: Yes, please.
YSV: Are there any objections to stage two for Error cause? [nope] It looks like we have stage 2. Congratulations.
proposal advances to stage 2
Presenter: Daniel Ehrenberg (DE)
DE: My Hope here is that we could find a way to load JavaScript modules native. and efficiently and so, you know, we have a bunch of different ways to load JavaScript now you can make individual modules so that you know, going to talk a lot about the way up here, but these things also apply in node and other environments. So Excuse excuse any sort of web specific references so you can load from individual files or fetches and this means that you're running code directly using the engines's module implementation, but in practice this is often too slow. So people made bundlers going to talk about [interruption] - So API improvements themselves don't seem to be enough to make bundlers not needed and I'll explain why. So we have bundlers that make a bunch of modules into one big script or some number of scripts or modules to reduce the overhead. That means that JavaScript module semantics are emulated. so when after Serma gave his presentation about module blocks, many people said oh, this is great. Module blocks will solve the bundling problem. So I don't know can they? Well, you can have a module block in a local variable. You can import it and then use it locally. Problem is, this falls over if you have multiple module blocks that want to import each other, because they don't close over the same outerscope and they're not present in the module map. So they just have no way to actually reference each other. What we really want instead if we wanted to bundle modules together is to have some kind of shared space where these modules exist. So for example, maybe this could be the module map. Maybe you have a declaration where you declare that things are present in the module map and then they would be able to import from each other. So if we want to proceed with a JS specific bundling solution then we have these JavaScript module bundles as a declarative way of putting multiple modules in one in one file. So in an environment like HTML or or node js. They could be interpreted as inserting entries into the module map. And then once the bundle is loaded then from anywhere in the realm you're using the same module map and you can import those modules, but actually this proposal alone would leave some aspects of loading performance on the table that we get better from individual resources. It would also leave some privacy and security improvements to be desired. So I'm going to talk about these aspects and especially how they relate to existing scripts and modules and bundlers.
DE: So there's a bunch of different things that affect loading performance. One you could you could call the waterfall effect. So you really want to start loading the critical resources that are necessary for the page to run as soon as possible. You could think about this like you want a waterfall rather than rapids or a staircase that are going down gradually because you really want everything to start loading in parallel. If you have a module graph by default you'll have each module references from other modules that it uses and you're loading these things one by one you can opt into prefetching to improve the loading performance, but that can often be difficult. Bundlers handle this by default by just putting everything in the bundle. Load the bundle and you have all the modules. It's also kind of per-resource overhead, each resource that you load has cost. Maybe this is especially bad - I don't want to call out a certain operating system that has kind of slow access to open files on the file system, but this can be slow. And even with HTTP2 and HTTP3 there's overhead. There's less but there's still some so fewer resources mean less overhead, win for bundlers. There can also be caused from emulation now to be fair to Modern bundlers. There are a lot of Advanced Techniques that are used such as bundling CSS rather than putting it in JavaScript that can decrease the cost. But if you try to emulate one file type inside of JavaScript, it can be especially slow to decode because it requires parsing as a string and then interpreting that data again afterwards. It's not even visible to the browser what kind of data that string is until it then gets through JavaScript logic to expose it to the browser. So even for JavaScript modules emulating JavaScript modules with CJS or something like that. It's not quite slower, but it's not spec compliant either. It doesn't tend to have all of the features like temporal dead zones or live bindings completely accurately because these would cause extra performance overhead binary formats are especially bad when emulated because you might need to put them in base64. Emulation cost from bundling makes me sad.
DE: next, inter-process communication. So again, this is this is all kind of with a broad brush, but in many - in both browsers and other JavaScript environments that do sandboxing like Deno there's one place where IO happens in a separate place for JavaScript runs, and this separation separation is very good for security. But it can cause overhead because even if you do all the prefetching like in this second bar, it can still be a lot slower due to processing to try to bring that module into the JavaScript engine. So yeah, I can't strongly claim that this graph shows exactly IPC overhead, but it's a phenomenon that's been noticed across engines. So with bundling it's just in one script and you've handed it off already to JavaScript engine.
DE: compression is also a factor. When things are compressed over the network, it's an individual response that's compressed. So when you have individual resources, it's possible to compress only based on a compression dictionary for one. On the other hand if you have one one bigger resource, one bigger bundle, then the compression can be across the whole bundle. So if you have common strings or common substrings, the result smaller. There was a proposal by YWS in another quarter to share compression dictionaries across responses in HTTP, but this is proven not viable so far.
DE: So, code splitting? so it's important to download only the code that you need on initial load. And not run this extra code too soon because that could help critical path bandwidth and CPU for processing it or memory pressure, everything that could make your responsiveness worse. So individual resources handle this perfectly. You reference the resources you want, you just load those with bundles. It's a bit more complicated because in a lot of set-ups by default (...) tooling one is one big bundle these days to split up into smaller chunks, but this can be somewhat difficult to configure. I'm happy that there's also work on going to bring better defaults. But with all this chunking you start to incrementally lose some of the benefits of bundling and you have to make this trade-off upfront.
DE: Now, parallel processing if you have a script / if you have a multiple graph divided up into many different modules. It's much easier for engines to parallelize it. So this can also be addressed partly with chunking and I'm excited about the ongoing work there. But if it's split up that provides a much easier basis for parallelism. With streaming you want to be able to process code and other resources as soon as they get downloaded. With a bundle it's a bit more towards, you have to download everything before you can get started. So this is also possible to address to some extent with chunking. With binary resources things are particularly bad because you don't just download the binary resource in base64 and double parse it, but you also have to wait for the JavaScript code to process it to expose it to the browser before it can even get started with parsing it again, in that format that it is. It would be great if you could stream loading it immediately as it's coming in over the network, people have invested a lot in streaming processing for things like HTML and CSS. It's a shame to kind of throw those away through these funding strategies.
DE: Caching. This is also a tricky one. So you want to download only what you need, not things that are already in the HTTP cache. So this is one of the older parts of the web that we've had caching of HTTP responses for a long time. Bundling ends up decreasing the hit rate of caches because if anything in the bundle changes you have to download the whole whole bundle again. So if you look at these different performance points, and this is again kind of a little bit unfair a little bit broad brush because there's mitigation strategies for everything, but with each of these strategies you only kind of get part way.
DE: So a cross-cutting concern here is preserving privacy, security, and defenses against tracking in any kind of bundling solution we think of. So here I want to focus less on the current state of the art and more about the kinds of proposals that people have been making about bundling. Google has been working in IETF and WICG on web bundles, which is a proposal to bring a number of different resources into one bundle. This has led to some kind of rebuke from Brave for example, this blog post concerned about the interaction with content blocking and security. So I want to speak to those concerns. It's really important that we maintain the web's origin model. So if a bundle - if we had a concept of a built-in native bundle, if it comes from a particular HTTP origin should really only be able to represent resources from the same origin. Not just that that same HTTPS origin, but also the even the directory is a constraint that matches service workers. Web bundles historically have been developed in connection with signed exchange, but personally, I'm not really a big fan of signed exchange. I'm not working towards that, I'm just working towards bundling. So to me, it's very important that these efforts are separate. Another aspect that Brave mentioned was URL semantics. So content blocking tools work based on their systems like EasyList that provide a number of regular expressions to check URLs based on the assumption that there's some kind of stability based on the observation that there's some kind of stability between these URLs and which things are content that should be blocked. So if bundles can rename places where things are that jeopardizes these systems to some extent. So a kind of operating principle that I've been working under on this is that bundle contents should be named by URLs that you could also individually fetch and get the same result. That's sort of my take away from the blog post. Apple has also a raised a concern in the repository where web bundles are being developed, that a bundle could provide some kind of tracking vector where different bundles are served to different people from the same URL and so it's important that bundles are served the same way to everyone and and not personalized. Finally, when thinking about a system like Brave that does content blocking, it's important to not incur the overhead of loading resources that are blocked where the block is detected based on the page using it. If you have a static bundle that's all or nothing, even if you're blocking content, you're still going to incur the overhead of downloading that resource. So ideally the bundles that are downloaded could be based on just specifically the things that the client requests.
DE: So as I mentioned before a minimal option is these JS module bundles. They could look like this. I don't know if we want them to have a different kind of type or the same kind of type, we could debate details like that here. It's a different type and declares these modules in a module bundle and then you can import them. So say the semantics would be that these modules are written into the module map. When we look at module bundles with privacy goals as a lens to make sure they can support the origin model in terms of URLs semantics. It's unclear how to meet this restriction with module bundles. They're set to operate at the module map level that the individual modules could have been fetched from the same place and getting the same result. Also, if we expect multiple bundles to be written by hand, it's unclear on the server side how to serve them such that they would return the same result. From a tracking perspective if we apply the same mechanism as we have for scripts today where there are credentialed requests, it's unclear to me how to block this, how to assert that. These are not being used as tracking vectors and for content blocking efficiency the scripts are all delivered at the same time. So there's no way to block an individual script and avoid downloading it and I'll come back later to that performance lens to talk about this. It meets performance goals, but not others.
DE: An alternative would be what I'm calling here research batch pre-loading. So you're pre-loading a batch of resources. This is another way of thinking about a limited form of bundling. So it's based heavily on the work of Jeffrey Askin and Yoav Weis in Google. I kind of see this as part of the same effort. Maybe the name makes it confusing if it's a competing effort, but that's not the intention. Also extensive input from Pete Snyder and Brendan Eich of Brave so that we can make sure that the privacy mitigations are integrated. So a resource batch is a map from paths to a pair of metadata plus payload. We would need a binary format for this because it's important to support multiple different data types. If we want to be able to bundle an image in together with a JavaScript file we can't put JavaScript surface syntax. There are existing technologies like CBOR that make it easy to define binary data formats without as much as much bikeshedding and with standard tools. So I think the resource batch file format could make sense on the web and off the web the same. We just need a way to map paths to metadata + payloads and on the web the metadata would be basically the mime type and the payload would be the response body. The path being a URL within that same directory inside of that same origin. Notice that these are these are things that are not just in JavaScript, so I'm not necessarily proposing this as a tc39 proposal, but I want to bring it to the committee because it relates to another potential tc39 proposal of JavaScript module bundles, and I think there's a lot of there's a lot of great expertise here to discuss the ideas.
DE: With these HTML tags to preload a resource batch. We could add a new kind of link tag equals batch preload. This takes a resources list as a parameter that indicates the full set of resources that that the HTML page is interested in so then these will be fetched all together as a batch found at that at that URL and put inside of a memory cache as well as the stable HTTP cache to have further access to them. Then these can be referenced in later script tags or link tags. There would also be a JavaScript API for this, that would be important to use for workers or for dynamic imports that come later. Either way the API takes a URL for both the bundle as a whole and for the resources list. It may be a little difficult to write the resources list by hand and I'll talk later about the tooling story.
DE: So the semantics of pre-loading a resource batch is when you do this preload operation when you do a link rel="batch preload". So we have that resources list you take this subset of the resources list that is not already in the cache - we don't want to ask the server for the cached things - then we send a request to to the server with a representation of that subset of the resources list and we make this credential list request. When the response comes we put each resource that was requested that comes into the cache, both into the network cache persistently, but also into a memory cache they can be accessed just from the render process. So then if a fetch happens against a pre-loaded resource, if we put out the request but we haven't gotten a response yet that we block for then produce a redundant fetch if it's responded already, then we serve them from the cache.
DE: So this proposal meets the Privacy goals that I articulated earlier as far as I know. the origin model is easy too, the bundle can only represent things in the same HTTP origin not a different HTTP origin. The term origin is a little complicated. So I'm glossing over that a little bit in terms of URLs semantics. We could build an enforcement mechanism here that would be optional for browsers. So my understanding is that Brave would be interested in this enforcement mechanism and other browsers might not implement it but some other people have said it would be okay to be as an optional step in the specification: the browsers may decide to do use resources either from the batch or fetching individually. They could do this either by offline analysis, or they could do it by online validating the fetch to the underlying resource. If you have personalized contents, that's just out of scope for this proposal. for [?] verifying things as well as sending uncredentialed requests would help and for Content blocking efficiency. The idea is that browsers that want to do content blocking would use their subsetting step to only request the parts of the bundle that they're interested in so it would look just like if it's in the cache so looking at those performance factors if it works. I mean it's a big proposal, but if it works then resource batch preloading could get kind of the best of all worlds in terms of these different factors. And when it comes to things like chunking, because the set of resources is articulated at the site of importing it, it's a completely kind of dynamic way of splitting up things into chunks. So for something like compression, which is hurt by chunking code if it into small chunks here. We get more dynamic chunking and compression that's more optimal. So, you know this proposal is kind of complicated enough, but as further things in this area, one thing I'm especially interested in is using this kind of resource batch format as a convention in building and serving tools. I think this is this is important for being able to deploy this because we're asking the servers to do a couple different things at once, to do the subsetting of the resource batch and pre compression as well as to serve the individual files the resource batch, but I do think it would have other benefits like making it easier to configure servers in serving different HTTP headers. There's ongoing work from Google from (?) Swierski and Yoav Weis about streaming module graph execution. So part of this is getting the parallel compilation. Another part would be considering actually executing the module graph as a potentially non-atomic operation that we can do as we get the modules. That's something that we can consider once the earlier bottlenecks are solved. There's also a possibility that we could think about schemas for efficient downloading of new versions. So you have this upgrade problem where you have an old version of the site and new version, but you may be incrementally pulling down pieces, so this can be solved some extent through this kind of cache busting like putting a hash in the in the URL but that sometimes complicated and non-optimal, maybe we could use the resource batch itself as this unit of atomicity to build a nicer mechanism on top of. Finally the dep cache proposal by Guy Bedford could give a more kind of centralized automatic way to identify the resources list. I think these are all important and but in this presentation, I've kind of focused on the core web side.
DE: So to go into the resource patches in bundling and serving which I've had just about the idea is that have resource badge represents the whole static part of a site Frameworks and could output resource batches or authors could directly with the resources list being unfilled then it would be up to bundlers or similar build tools to fill in the resources list based on their whole inter-module understand of what's needed. This could also be used as a file format by minifiers or other kinds of optimizers to translate one batch to another batch. And I hope this could have the potential to reduce the need for configuration, not eliminate, but allow some additional commonalities. Then servers could use the resource batches and input to both serve the substance of the batch and serve the individual responses. I think if we get this right it could improve interoperability between tools and reduce the amount of configuration required.
DE: So for discussion, my biggest point is I think resource batch pre-loading would be a more general and more useful construct than JS module bundles, but I do really want to consider JS multiple bundles as well. They've been considered in this committee in the past es6 cycle and I think they're a valid design point. They're a bit overlapping but I also could see us having both in the broader platform. So I want to ask what do you think about that proposition? Does this whole idea seem worthy of further investigation? So one question is, is it important to fund all non JS resources or should the focus really be on just JS bundling? I've. talked about a number of different optimizations or performance factors, and I'm wondering what you think about those. Maybe I'm weighing these in a way that you disagree with. There are also complexity and complexity trade-offs. Maybe this could be solved through other layers and wondering what extensions or applications you're interested in? So this isn't going for a stage. It's a good system safe in and people want to respond because I just said, thank you.
KM: Yes, maybe I don't know the details of how the batch resources would work but one concern that we had internally at Apple over. like web bundles and things like that in the past is that a lot of - if you look at the kind of module graph used by large web applications, they're on the order of like tens of thousands of modules and whence you start having that many resources in the system that just the memory overhead and the overhead of having that many individual resources becomes problematic in and of itself. So that was a reason internally we're thinking of going for inline modules. I don't know whether that's actually the case in the batched resources, but I don't I don't know the details of how to be implemented under the hood. So I don't have an answer right now because I'm like think about that but
DE: I'd be interested in learning more because I feel like this comes down to details. The big observable difference is that one one would be, you know, JS module bundles would be cashed in the module map and a more general mechanism would be cached in kind of a prefetch cash. I don't think that alone would necessarily explain the difference in resource usage. I mean another one is the IPC issue that I mentioned.I think the design here should be compatible with having this prefetch reload cache be in the renderer. I know Apple raised concerns about putting too much logic in the render, but I think we're really just talking about the cache of of URLs to payloads and mime types and interpreting mime types, which I think is -
KM: I think the issue is more that you have one module that isn't inlined into a single resource. The metadata associated with having tens of thousands of like resource maps in - I don't know if like the right way to describe, I don't know the full details because this isn't the area of webkit that I'm an expert in - the actual fact that each individual module is an individual resource becomes problematic
DE: Could we follow up offline so I could learn which thing it is that's having the overhead?
KM: Yeah. I also don't know all those details because again as it's not my area of expertise, so that's good.
SYG: I like the expansiveness of the scope for the resource batch pre-loading and I got the sense that because it's like strictly better - it's more ambitious but it seems strictly better if we can pull it off - I don't see why we really should pursue a JS-only bundling solution in this case. So my opinion is, we should pursue resource batch preloading or something like that. And my question is if that is the direction. What do you think is in scope for this body?
DE: I think this body is good for - we have a lot of domain knowledge here and a lot of connection with the community. I wanted to build off of that. I'm not sure if resource batch pre-loading would be standardized in tc39 because module loading is a host concern, but I do think it's important that we meet needs of different hosts so we could find a standard format that works across hosts. The question of the concrete standards I think is still TBD because - I really wanted to make sure that this is cleanly separated from signed exchange and my understanding is that the other people working on web bundles are kind of in alignment with that. So we'll just have to think this thing over but probably not within TC39 itself.
SYG: Thanks.
Ted Campbell: Hi there. I work on the spider monkey team. I have similar thoughts of SYG here that I think going all in on the bundles kind of the most beneficial my concern with the minimal version that is that it doesn't include wasm and it kind of adds another hurdle to get lightweight integration with wasm in small pieces and I think your example of bundle to bundle. tooling if we can have little fragments of wasm and it really gives a strong compute platform based on ecmascript. But yeah, I think we'd like bundles.
DE: Happy to hear it.
Ted Campbell: Yeah, so this was my initial reaction to your proposal: are we able to leverage some existing format like tar balls or zip files? You know, perhaps like restricted to just top-level files within the directory based on what we talked about today, rather than introducing a new format or do you think there's a kind of more of a fundamental series of restrictions or metadata we need?
DE: For zip that would have the metadata. I think there's no clear place to put it and also the index is at the end which makes streaming difficult. Tar could work because tar does have an index at the beginning so for streaming that's kind of okay, just tar has a lot of different Legacy features that I think we don't want to expose here. Bradley has talked about symbolic links being kind of a minefield and tar has those but also lots of other weirder Legacy Unix features. Additionally for representing the mime type or their metadata, tar does have the capability to leave some space, but it doesn't give us a clear place to put a mime type so we would still need custom tooling around it to use that metadata in the appropriate way. For this reason I feel like overall it would be easier to make a new format because we need new tooling around it anyway, but that makes it a trade-off.
Ted Campbell: my only only reason liking tar and zip is like the ease of developers to be able to just open it up and poke a bit, that kind of easy access to the web type thing, but you're right there are real technical issues. That's all for me next.
YSV: The queue is currently empty. Do we have any other comments that people would like to make about this?
YWS: Yeah, so I don't have any part. I guess my main comment. Is like that you mentioned that you envision the full site like the bundle to contain all static sighs that all the static resources for the side that is one potential deployment mode, but not necessarily the only deployment mode. You could also imagine that sites create multiple bundles, 1 per route, that have overlap between them and that would also work because each one of the internal resources has its own URL. and the browser can know not to fetch the shared pieces. So it does like essentially - you could imagine multiple deployment modes on that front and I expect bundlers to still be opinionated on like - to use web bundles as an output format and still provide Innovation on that front of what is the ideal way to use them.
DE: Yeah, that'll make sense to me. I thought that the route aspects that you mentioned would be subsumed by the resources list, but I might be missing something. There's a lot more to research here and I want to - this slide is to kind of the most poorly researched part of the presentation. I want to iterate on that some more.
Peter Snyder (Brave): I mostly just want to say that this is all a new process on my end. But I think this really addresses a lot of the concerns that we had in me the initial bundles proposal. Mainly breaking the tie between what's in the bundle and - let me say that differently. By preventing the bundle from controlling the page itself removes a bunch of the kind of URL playing games that we were concerned about and I can go into more reasons about why this proposal seems appealing but just in the way that the the larger puzzle seemed concerning, but I think there's just a lot of nice things that makes this really compatible and play well with the kinds of bundling tools that are used commonly in the wild and seems really appealing from that perspective.
DE: That's great. Thanks. Thanks. I want to thank both Yoav and Pete both for being really available to discuss these issues over the past month so we could come to an agreeable proposal.
SYG: Can I ask you a quick question of Yoav here or also Dan. Is there a quick summary of what the delta is from the current web web bundles proposal?
YWS: So I have a document that I need to revise because it has like there has been several iterations on it since but essentially the main delta is just the mechanism with which the client can communicate what it already has in the cache to the server I can paste the document to the chat, and it's not in perfect shape, but it should give you the rough idea of that delta. [link from chat: https://docs.google.com/document/d/11t4Ix2bvF1_ZCV9HKfafGfWu82zbOD7aUhZ_FyDAgmA/edit]
DE: the other thing about this is there's significant there's a strongly delineated scope here. So as Pete mentioned we've eliminated the navigate to web bundle part, and we've also eliminated the package URL scheme. I think the main thing that's useful is not representing cross-origin resources, which is just kind of not permitted in this scheme. This also mentions this optional verification scheme. So this URL semantics enforcement as well as the idea that the bundle requests would be sent uncredentialed. I've also articulated in more detail the caching scheme, which I couldn't find a clear description of. For signed exchange loading the ideas that these things are ephemeral in cache. But with this loading everything is separated persistently into the HTTP cache which I think is the right default if our goal is to encourage efficient loading. I think the ephemerality was really motivated by signed exchange. There may be other differences that I'm leaving out, but there were a lot of different things about the way that web bundles were framed that were a bit incompatible with these privacy goals, but when it came down to the important technical points, we could find a lot of agreement.
SYG: Just to kind of double confirm here, the web bundle stakeholders are on board with this direction as an evolution of web bundles? This is not something that is competing?
YWS: Yeah, so this is yeah this is aligned with what we have in mind for web bundles. I believe that this is a subset of the original proposal and as such it's not competing with web bundles. There may be browsers who will ship a superset of that that will also include other parts that are not included in this.
SYG: I see.
YSV: Great, we currently have an empty queue. I just want to highlight that we've heard a lot from implementers, but not very much from other members of the committee. If anyone would like to speak about this, we've still got five minutes.
DE: so I want to focus on the one narrow question, which is about whether it's important for non-JavaScript resources to be bundled. That was a thing that we heard different views from people in the committee. I wonder if this would be interesting for a temperature check to understand what people are interested in or people adding themselves to the queue would also be good.
YSV: can you rephrase the question again, just a single sentence.
DE: Include non-JS resources in scope.
KKL: Non-javaScript resources, I think are important. That's all I've got to say.
Ted Campbell: I think wasm resources are important. Other resources probably I don't have enough context to know. But wasm what I would like to definitely be included.
KM: I guess I'm not totally sure. So I'm kind of curious if I can get some clarification here. Is this intended to be a replacement for a potential proposal to have inline modules or is this possibly in addition to that?
DE: So personally, I think we could potentially have both where there's a question of how much value in line modules have there's certainly a lot of excitement among web developers about inline modules as we heard from the you know, the people responding to the module blocks proposal with the misunderstanding that I mentioned at the beginning. I think if we have an inline modules proposal we'll have to answer those security questions that I mentioned before. I don't currently have a good answer for those in the case of online modules, but I do have an idea about the answer for batches.
KM: Yes, I think the problem is - the thing that we were talking about before, and I can link you to a slack giant [?] webkit slack discussion from 2 months ago or something about this topic. I think it might be useful to keep inline modules on the table because from my understanding it sounds sounds like this won't solve the problem of very large module graphs using a huge amount of like web in our case like web core data structures because they're each individual resources rather than combining them into one thing where they're just a single resource. And the JS engine only pulls out the data it needs to handle each module.
DE: Yeah, that would be a serious problem if it weren't possible to represent. So I saw that discussion, but I don't understand how it would relate to this exact proposal. It seems to be coming back to that IPC issue.
KM: I don't know all the details, like I said, but yeah, I it's I'm just mentioning that for the record not so much that I have any problem with this proposal.
Peter Snyder: I definitely need to familiarize myself more with the online modules proposal but one thing that's more appealing about this at least from the perspective of working at a browser where we you want to make changes on the initially requested module graph often is that this allows us to place to kind of monkey patch the graph in the way that just a streaming a large number of inline modules wouldn't where we can kind of make those changes as we see for privacy protections and kind of drop in different implementations. That's a very nice thing about this part of this approach from our perspective, or from my perspective.
KM: Are you saying that you're going to monkey patch it? like that you're going to take text that the server would have provided and replace it with text that the browser wasn't seeing.
Peter Snyder: One thing that we think actually we would like to replace a module with the privacy preserving alternate implementation. We can do that through this approach by just not requesting that from the bundle and sticking your own version in there, but it would be difficult to do that. If we just had if we had a streaming in my module that maybe my ignorance of the existing in my module proposal, which I'm only lightly familiar with but that is something that does seem enabled by this approach that's appealing about it.
YSV: And we are at time. Thank you everyone for attending the last meeting of this year and tc39. Also massive thank you to the note editors and takers for their work on keeping the notes for us. Before the closing comments, DE, are you satisfied with this topic?
DE: if you're interested in discussing this more, I guess there's no repo for it right now, but we'll discuss it in the frameworks and tools outreach meetings, and we could do an incubator call if people are interested. Just let me know.