| title | category | tag | head | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Redis 3 种特殊数据结构详解 |
数据库 |
|
|
除了 5 种基本的数据结构之外,Redis 还支持 3 种特殊的数据结构 :Bitmap、HyperLogLog、GEO。
Bitmap 存储的是连续的二进制数字(0 和 1),通过 Bitmap, 只需要一个 bit 位来表示某个元素对应的值或者状态,key 就是对应元素本身 。我们知道 8 个 bit 可以组成一个 byte,所以 Bitmap 本身会极大的节省储存空间。
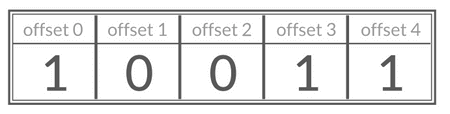
你可以将 Bitmap 看作是一个存储二进制数字(0 和 1)的数组,数组中每个元素的下标叫做 offset(偏移量)。
| 命令 | 介绍 |
|---|---|
| SETBIT key offset value | 设置指定 offset 位置的值 |
| GETBIT key offset | 获取指定 offset 位置的值 |
| BITCOUNT key start end | 获取 start 和 end 之前值为 1 的元素个数 |
| BITOP operation destkey key1 key2 ... | 对一个或多个 Bitmap 进行运算,可用运算符有 AND, OR, XOR 以及 NOT |
Bitmap 基本操作演示 :
# SETBIT 会返回之前位的值(默认是 0)这里会生成 7 个位
> SETBIT mykey 7 1
(integer) 0
> SETBIT mykey 7 0
(integer) 1
> GETBIT mykey 7
(integer) 0
> SETBIT mykey 6 1
(integer) 0
> SETBIT mykey 8 1
(integer) 0
# 通过 bitcount 统计被被设置为 1 的位的数量。
> BITCOUNT mykey
(integer) 2需要保存状态信息(0/1 即可表示)的场景
- 举例 :用户签到情况、活跃用户情况、用户行为统计(比如是否点赞过某个视频)。
- 相关命令 :
SETBIT、GETBIT、BITCOUNT、BITOP。
HyperLogLog 是一种有名的基数计数概率算法 ,基于 LogLog Counting(LLC)优化改进得来,并不是 Redis 特有的,Redis 只是实现了这个算法并提供了一些开箱即用的 API。
Redis 提供的 HyperLogLog 占用空间非常非常小,只需要 12k 的空间就能存储接近2^64个不同元素。这是真的厉害,这就是数学的魅力么!并且,Redis 对 HyperLogLog 的存储结构做了优化,采用两种方式计数:
- 稀疏矩阵 :计数较少的时候,占用空间很小。
- 稠密矩阵 :计数达到某个阈值的时候,占用 12k 的空间。
Redis 官方文档中有对应的详细说明:

基数计数概率算法为了节省内存并不会直接存储元数据,而是通过一定的概率统计方法预估基数值(集合中包含元素的个数)。因此, HyperLogLog 的计数结果并不是一个精确值,存在一定的误差(标准误差为 0.81% 。)。
HyperLogLog 的使用非常简单,但原理非常复杂。HyperLogLog 的原理以及在 Redis 中的实现可以看这篇文章:HyperLogLog 算法的原理讲解以及 Redis 是如何应用它的 。
再推荐一个可以帮助理解 HyperLogLog 原理的工具:Sketch of the Day: HyperLogLog — Cornerstone of a Big Data Infrastructure 。
HyperLogLog 相关的命令非常少,最常用的也就 3 个。
| 命令 | 介绍 |
|---|---|
| PFADD key element1 element2 ... | 添加一个或多个元素到 HyperLogLog 中 |
| PFCOUNT key1 key2 | 获取一个或者多个 HyperLogLog 的唯一计数。 |
| PFMERGE destkey sourcekey1 sourcekey2 ... | 将多个 HyperLogLog 合并到 destkey 中,destkey 会结合多个源,算出对应的唯一计数。 |
HyperLogLog 基本操作演示 :
> PFADD hll foo bar zap
(integer) 1
> PFADD hll zap zap zap
(integer) 0
> PFADD hll foo bar
(integer) 0
> PFCOUNT hll
(integer) 3
> PFADD some-other-hll 1 2 3
(integer) 1
> PFCOUNT hll some-other-hll
(integer) 6
> PFMERGE desthll hll some-other-hll
"OK"
> PFCOUNT desthll
(integer) 6数量量巨大(百万、千万级别以上)的计数场景
- 举例 :热门网站每日/每周/每月访问 ip 数统计、热门帖子 uv 统计、
- 相关命令 :
PFADD、PFCOUNT。
Geospatial index(地理空间索引,简称 GEO) 主要用于存储地理位置信息,基于 Sorted Set 实现。
通过 GEO 我们可以轻松实现两个位置距离的计算、获取指定位置附近的元素等功能。

| 命令 | 介绍 |
|---|---|
| GEOADD key longitude1 latitude1 member1 ... | 添加一个或多个元素对应的经纬度信息到 GEO 中 |
| GEOPOS key member1 member2 ... | 返回给定元素的经纬度信息 |
| GEODIST key member1 member2 M/KM/FT/MI | 返回两个给定元素之间的距离 |
| GEORADIUS key longitude latitude radius distance | 获取指定位置附近 distance 范围内的其他元素,支持 ASC(由近到远)、DESC(由远到近)、Count(数量) 等参数 |
| GEORADIUSBYMEMBER key member radius distance | 类似于 GEORADIUS 命令,只是参照的中心点是 GEO 中的元素 |
基本操作 :
> GEOADD personLocation 116.33 39.89 user1 116.34 39.90 user2 116.35 39.88 user3
3
> GEOPOS personLocation user1
116.3299986720085144
39.89000061669732844
> GEODIST personLocation user1 user2 km
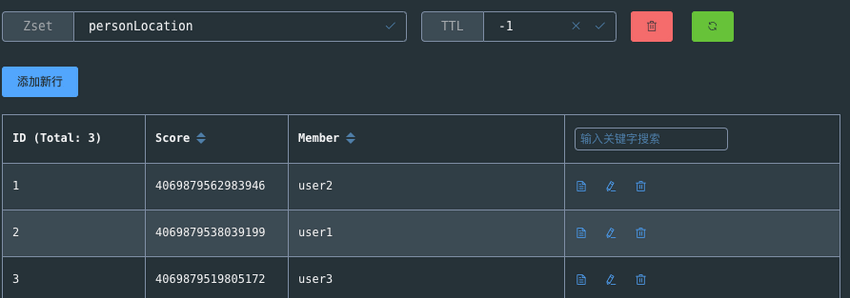
1.4018通过 Redis 可视化工具查看 personLocation ,果不其然,底层就是 Sorted Set。
GEO 中存储的地理位置信息的经纬度数据通过 GeoHash 算法转换成了一个整数,这个整数作为 Sorted Set 的 score(权重参数)使用。
获取指定位置范围内的其他元素 :
> GEORADIUS personLocation 116.33 39.87 3 km
user3
user1
> GEORADIUS personLocation 116.33 39.87 2 km
> GEORADIUS personLocation 116.33 39.87 5 km
user3
user1
user2
> GEORADIUSBYMEMBER personLocation user1 5 km
user3
user1
user2
> GEORADIUSBYMEMBER personLocation user1 2 km
user1
user2GEORADIUS 命令的底层原理解析可以看看阿里的这篇文章:Redis 到底是怎么实现“附近的人”这个功能的呢? 。
移除元素 :
GEO 底层是 Sorted Set ,你可以对 GEO 使用 Sorted Set 相关的命令。
> ZREM personLocation user1
1
> ZRANGE personLocation 0 -1
user3
user2
> ZSCORE personLocation user2
4069879562983946需要管理使用地理空间数据的场景
- 举例:附近的人。
- 相关命令:
GEOADD、GEORADIUS、GEORADIUSBYMEMBER。
- Redis Data Structures :https://redis.com/redis-enterprise/data-structures/ 。
- 《Redis 深度历险:核心原理与应用实践》1.6 四两拨千斤——HyperLogLog
- 布隆过滤器,位图,HyperLogLog:https://hogwartsrico.github.io/2020/06/08/BloomFilter-HyperLogLog-BitMap/index.html