-
Notifications
You must be signed in to change notification settings - Fork 1.6k
/
architecture.md
518 lines (356 loc) · 27.3 KB
/
architecture.md
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
368
369
370
371
372
373
374
375
376
377
378
379
380
381
382
383
384
385
386
387
388
389
390
391
392
393
394
395
396
397
398
399
400
401
402
403
404
405
406
407
408
409
410
411
412
413
414
415
416
417
418
419
420
421
422
423
424
425
426
427
428
429
430
431
432
433
434
435
436
437
438
439
440
441
442
443
444
445
446
447
448
449
450
451
452
453
454
455
456
457
458
459
460
461
462
463
464
465
466
467
468
469
470
471
472
473
474
475
476
477
478
479
480
481
482
483
484
485
486
487
488
489
490
491
492
493
494
495
496
497
498
499
500
501
502
503
504
505
506
507
508
509
510
511
512
513
514
515
516
517
518
# Architecture
This document describes the high-level architecture of rust-analyzer.
If you want to familiarize yourself with the code base, you are just in the right place!
You might also enjoy ["Explaining Rust Analyzer"](https://www.youtube.com/playlist?list=PLhb66M_x9UmrqXhQuIpWC5VgTdrGxMx3y) series on YouTube.
It goes deeper than what is covered in this document, but will take some time to watch.
See also these implementation-related blog posts:
* https://rust-analyzer.github.io/blog/2019/11/13/find-usages.html
* https://rust-analyzer.github.io/blog/2020/07/20/three-architectures-for-responsive-ide.html
* https://rust-analyzer.github.io/blog/2020/09/16/challeging-LR-parsing.html
* https://rust-analyzer.github.io/blog/2020/09/28/how-to-make-a-light-bulb.html
* https://rust-analyzer.github.io/blog/2020/10/24/introducing-ungrammar.html
For older, by now mostly outdated stuff, see the [guide](./guide.md) and [another playlist](https://www.youtube.com/playlist?list=PL85XCvVPmGQho7MZkdW-wtPtuJcFpzycE).
## Bird's Eye View
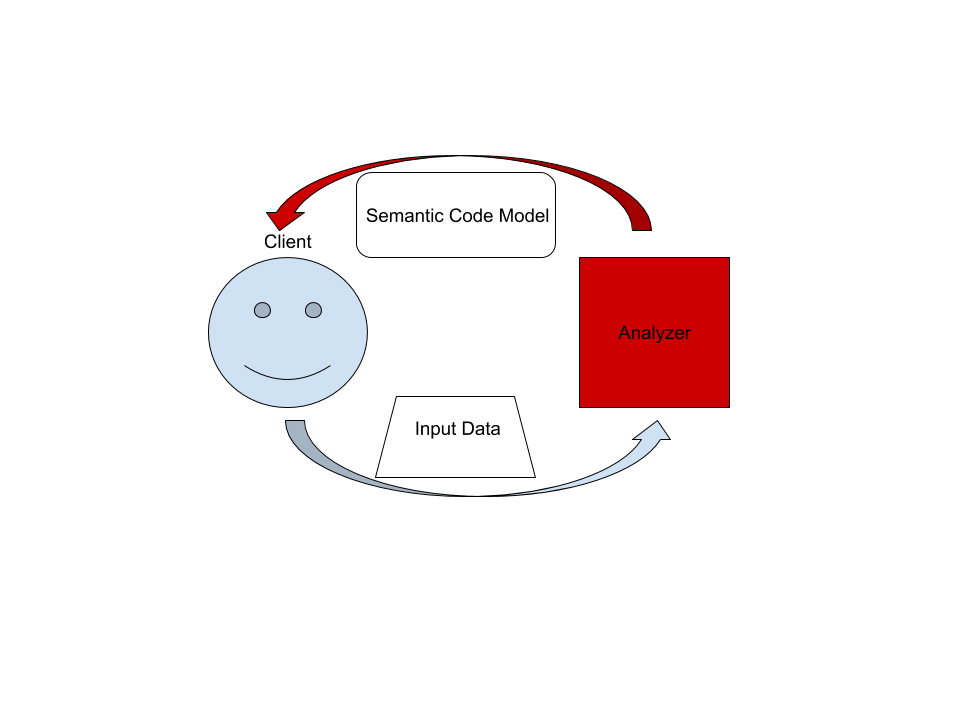
On the highest level, rust-analyzer is a thing which accepts input source code from the client and produces a structured semantic model of the code.
More specifically, input data consists of a set of test files (`(PathBuf, String)` pairs) and information about project structure, captured in the so called `CrateGraph`.
The crate graph specifies which files are crate roots, which cfg flags are specified for each crate and what dependencies exist between the crates.
This is the input (ground) state.
The analyzer keeps all this input data in memory and never does any IO.
Because the input data is source code, which typically measures in tens of megabytes at most, keeping everything in memory is OK.
A "structured semantic model" is basically an object-oriented representation of modules, functions and types which appear in the source code.
This representation is fully "resolved": all expressions have types, all references are bound to declarations, etc.
This is derived state.
The client can submit a small delta of input data (typically, a change to a single file) and get a fresh code model which accounts for changes.
The underlying engine makes sure that model is computed lazily (on-demand) and can be quickly updated for small modifications.
## Entry Points
`crates/rust-analyzer/src/bin/main.rs` contains the main function which spawns LSP.
This is *the* entry point, but it front-loads a lot of complexity, so it's fine to just skim through it.
`crates/rust-analyzer/src/handlers.rs` implements all LSP requests and is a great place to start if you are already familiar with LSP.
`Analysis` and `AnalysisHost` types define the main API for consumers of IDE services.
## Code Map
This section talks briefly about various important directories and data structures.
Pay attention to the **Architecture Invariant** sections.
They often talk about things which are deliberately absent in the source code.
Note also which crates are **API Boundaries**.
Remember, [rules at the boundary are different](https://www.tedinski.com/2018/02/06/system-boundaries.html).
### `xtask`
This is rust-analyzer's "build system".
We use cargo to compile rust code, but there are also various other tasks, like release management or local installation.
They are handled by Rust code in the xtask directory.
### `editors/code`
VS Code plugin.
### `lib/`
rust-analyzer independent libraries which we publish to crates.io.
It's not heavily utilized at the moment.
### `crates/parser`
It is a hand-written recursive descent parser, which produces a sequence of events like "start node X", "finish node Y".
It works similarly to
[kotlin's parser](https://github.com/JetBrains/kotlin/blob/4d951de616b20feca92f3e9cc9679b2de9e65195/compiler/frontend/src/org/jetbrains/kotlin/parsing/KotlinParsing.java),
which is a good source of inspiration for dealing with syntax errors and incomplete input.
Original [libsyntax parser](https://github.com/rust-lang/rust/blob/6b99adeb11313197f409b4f7c4083c2ceca8a4fe/src/libsyntax/parse/parser.rs) is what we use for the definition of the Rust language.
`TreeSink` and `TokenSource` traits bridge the tree-agnostic parser from `grammar` with `rowan` trees.
**Architecture Invariant:** the parser is independent of the particular tree structure and particular representation of the tokens.
It transforms one flat stream of events into another flat stream of events.
Token independence allows us to parse out both text-based source code and `tt`-based macro input.
Tree independence allows us to more easily vary the syntax tree implementation.
It should also unlock efficient light-parsing approaches.
For example, you can extract the set of names defined in a file (for typo correction) without building a syntax tree.
**Architecture Invariant:** parsing never fails, the parser produces `(T, Vec<Error>)` rather than `Result<T, Error>`.
### `crates/syntax`
Rust syntax tree structure and parser.
See [RFC](https://github.com/rust-lang/rfcs/pull/2256) and [./syntax.md](./syntax.md) for some design notes.
- [rowan](https://github.com/rust-analyzer/rowan) library is used for constructing syntax trees.
- `ast` provides a type safe API on top of the raw `rowan` tree.
- `ungrammar` description of the grammar, which is used to generate `syntax_kinds` and `ast` modules, using `cargo test -p xtask` command.
Tests for ra_syntax are mostly data-driven.
`test_data/parser` contains subdirectories with a bunch of `.rs` (test vectors) and `.txt` files with corresponding syntax trees.
During testing, we check `.rs` against `.txt`.
If the `.txt` file is missing, it is created (this is how you update tests).
Additionally, running the xtask test suite with `cargo test -p xtask` will walk the grammar module and collect all `// test test_name` comments into files inside `test_data/parser/inline` directory.
To update test data, run with `UPDATE_EXPECT` variable:
```bash
env UPDATE_EXPECT=1 cargo qt
```
After adding a new inline test you need to run `cargo test -p xtask` and also update the test data as described above.
Note [`api_walkthrough`](https://github.com/rust-lang/rust-analyzer/blob/2fb6af89eb794f775de60b82afe56b6f986c2a40/crates/ra_syntax/src/lib.rs#L190-L348)
in particular: it shows off various methods of working with syntax tree.
See [#93](https://github.com/rust-lang/rust-analyzer/pull/93) for an example PR which fixes a bug in the grammar.
**Architecture Invariant:** `syntax` crate is completely independent from the rest of rust-analyzer. It knows nothing about salsa or LSP.
This is important because it is possible to make useful tooling using only the syntax tree.
Without semantic information, you don't need to be able to _build_ code, which makes the tooling more robust.
See also https://mlfbrown.com/paper.pdf.
You can view the `syntax` crate as an entry point to rust-analyzer.
`syntax` crate is an **API Boundary**.
**Architecture Invariant:** syntax tree is a value type.
The tree is fully determined by the contents of its syntax nodes, it doesn't need global context (like an interner) and doesn't store semantic info.
Using the tree as a store for semantic info is convenient in traditional compilers, but doesn't work nicely in the IDE.
Specifically, assists and refactors require transforming syntax trees, and that becomes awkward if you need to do something with the semantic info.
**Architecture Invariant:** syntax tree is built for a single file.
This is to enable parallel parsing of all files.
**Architecture Invariant:** Syntax trees are by design incomplete and do not enforce well-formedness.
If an AST method returns an `Option`, it *can* be `None` at runtime, even if this is forbidden by the grammar.
### `crates/base-db`
We use the [salsa](https://github.com/salsa-rs/salsa) crate for incremental and on-demand computation.
Roughly, you can think of salsa as a key-value store, but it can also compute derived values using specified functions.
The `base-db` crate provides basic infrastructure for interacting with salsa.
Crucially, it defines most of the "input" queries: facts supplied by the client of the analyzer.
Reading the docs of the `base_db::input` module should be useful: everything else is strictly derived from those inputs.
**Architecture Invariant:** particularities of the build system are *not* the part of the ground state.
In particular, `base-db` knows nothing about cargo.
For example, `cfg` flags are a part of `base_db`, but `feature`s are not.
A `foo` feature is a Cargo-level concept, which is lowered by Cargo to `--cfg feature=foo` argument on the command line.
The `CrateGraph` structure is used to represent the dependencies between the crates abstractly.
**Architecture Invariant:** `base-db` doesn't know about file system and file paths.
Files are represented with opaque `FileId`, there's no operation to get an `std::path::Path` out of the `FileId`.
### `crates/hir-expand`, `crates/hir-def`, `crates/hir_ty`
These crates are the *brain* of rust-analyzer.
This is the compiler part of the IDE.
`hir-xxx` crates have a strong [ECS](https://en.wikipedia.org/wiki/Entity_component_system) flavor, in that they work with raw ids and directly query the database.
There's little abstraction here.
These crates integrate deeply with salsa and chalk.
Name resolution, macro expansion and type inference all happen here.
These crates also define various intermediate representations of the core.
`ItemTree` condenses a single `SyntaxTree` into a "summary" data structure, which is stable over modifications to function bodies.
`DefMap` contains the module tree of a crate and stores module scopes.
`Body` stores information about expressions.
**Architecture Invariant:** these crates are not, and will never be, an api boundary.
**Architecture Invariant:** these crates explicitly care about being incremental.
The core invariant we maintain is "typing inside a function's body never invalidates global derived data".
i.e., if you change the body of `foo`, all facts about `bar` should remain intact.
**Architecture Invariant:** hir exists only in context of particular crate instance with specific CFG flags.
The same syntax may produce several instances of HIR if the crate participates in the crate graph more than once.
### `crates/hir`
The top-level `hir` crate is an **API Boundary**.
If you think about "using rust-analyzer as a library", `hir` crate is most likely the façade you'll be talking to.
It wraps ECS-style internal API into a more OO-flavored API (with an extra `db` argument for each call).
**Architecture Invariant:** `hir` provides a static, fully resolved view of the code.
While internal `hir-*` crates _compute_ things, `hir`, from the outside, looks like an inert data structure.
`hir` also handles the delicate task of going from syntax to the corresponding `hir`.
Remember that the mapping here is one-to-many.
See `Semantics` type and `source_to_def` module.
Note in particular a curious recursive structure in `source_to_def`.
We first resolve the parent _syntax_ node to the parent _hir_ element.
Then we ask the _hir_ parent what _syntax_ children does it have.
Then we look for our node in the set of children.
This is the heart of many IDE features, like goto definition, which start with figuring out the hir node at the cursor.
This is some kind of (yet unnamed) uber-IDE pattern, as it is present in Roslyn and Kotlin as well.
### `crates/ide`, `crates/ide-db`, `crates/ide-assists`, `crates/ide-completion`, `crates/ide-diagnostics`, `crates/ide-ssr`
The `ide` crate builds on top of `hir` semantic model to provide high-level IDE features like completion or goto definition.
It is an **API Boundary**.
If you want to use IDE parts of rust-analyzer via LSP, custom flatbuffers-based protocol or just as a library in your text editor, this is the right API.
**Architecture Invariant:** `ide` crate's API is build out of POD types with public fields.
The API uses editor's terminology, it talks about offsets and string labels rather than in terms of definitions or types.
It is effectively the view in MVC and viewmodel in [MVVM](https://en.wikipedia.org/wiki/Model%E2%80%93view%E2%80%93viewmodel).
All arguments and return types are conceptually serializable.
In particular, syntax trees and hir types are generally absent from the API (but are used heavily in the implementation).
Shout outs to LSP developers for popularizing the idea that "UI" is a good place to draw a boundary at.
`ide` is also the first crate which has the notion of change over time.
`AnalysisHost` is a state to which you can transactionally `apply_change`.
`Analysis` is an immutable snapshot of the state.
Internally, `ide` is split across several crates. `ide-assists`, `ide-completion`, `ide-diagnostics` and `ide-ssr` implement large isolated features.
`ide-db` implements common IDE functionality (notably, reference search is implemented here).
The `ide` contains a public API/façade, as well as implementation for a plethora of smaller features.
**Architecture Invariant:** `ide` crate strives to provide a _perfect_ API.
Although at the moment it has only one consumer, the LSP server, LSP *does not* influence its API design.
Instead, we keep in mind a hypothetical _ideal_ client -- an IDE tailored specifically for rust, every nook and cranny of which is packed with Rust-specific goodies.
### `crates/rust-analyzer`
This crate defines the `rust-analyzer` binary, so it is the **entry point**.
It implements the language server.
**Architecture Invariant:** `rust-analyzer` is the only crate that knows about LSP and JSON serialization.
If you want to expose a data structure `X` from ide to LSP, don't make it serializable.
Instead, create a serializable counterpart in `rust-analyzer` crate and manually convert between the two.
`GlobalState` is the state of the server.
The `main_loop` defines the server event loop which accepts requests and sends responses.
Requests that modify the state or might block user's typing are handled on the main thread.
All other requests are processed in background.
**Architecture Invariant:** the server is stateless, a-la HTTP.
Sometimes state needs to be preserved between requests.
For example, "what is the `edit` for the fifth completion item of the last completion edit?".
For this, the second request should include enough info to re-create the context from scratch.
This generally means including all the parameters of the original request.
`reload` module contains the code that handles configuration and Cargo.toml changes.
This is a tricky business.
**Architecture Invariant:** `rust-analyzer` should be partially available even when the build is broken.
Reloading process should not prevent IDE features from working.
### `crates/toolchain`, `crates/project-model`, `crates/flycheck`
These crates deal with invoking `cargo` to learn about project structure and get compiler errors for the "check on save" feature.
They use `crates/paths` heavily instead of `std::path`.
A single `rust-analyzer` process can serve many projects, so it is important that server's current directory does not leak.
### `crates/mbe`, `crates/tt`, `crates/proc-macro-api`, `crates/proc-macro-srv`, `crates/proc-macro-srv-cli`
These crates implement macros as token tree -> token tree transforms.
They are independent from the rest of the code.
`tt` crate defined `TokenTree`, a single token or a delimited sequence of token trees.
`mbe` crate contains tools for transforming between syntax trees and token tree.
And it also handles the actual parsing and expansion of declarative macro (a-la "Macros By Example" or mbe).
For proc macros, the client-server model are used.
We start a separate process (`proc-macro-srv-cli`) which loads and runs the proc-macros for us.
And the client (`proc-macro-api`) provides an interface to talk to that server separately.
And then token trees are passed from client, and the server will load the corresponding dynamic library (which built by `cargo`).
And due to the fact the api for getting result from proc macro are always unstable in `rustc`,
we maintain our own copy (and paste) of that part of code to allow us to build the whole thing in stable rust.
**Architecture Invariant:**
Bad proc macros may panic or segfault accidentally. So we run it in another process and recover it from fatal error.
And they may be non-deterministic which conflict how `salsa` works, so special attention is required.
### `crates/cfg`
This crate is responsible for parsing, evaluation and general definition of `cfg` attributes.
### `crates/vfs`, `crates/vfs-notify`, `crates/paths`
These crates implement a virtual file system.
They provide consistent snapshots of the underlying file system and insulate messy OS paths.
**Architecture Invariant:** vfs doesn't assume a single unified file system.
i.e., a single rust-analyzer process can act as a remote server for two different machines, where the same `/tmp/foo.rs` path points to different files.
For this reason, all path APIs generally take some existing path as a "file system witness".
### `crates/stdx`
This crate contains various non-rust-analyzer specific utils, which could have been in std, as well
as copies of unstable std items we would like to make use of already, like `std::str::split_once`.
### `crates/profile`
This crate contains utilities for CPU and memory profiling.
### `crates/intern`
This crate contains infrastructure for globally interning things via `Arc`.
### `crates/load-cargo`
This crate exposes several utilities for loading projects, used by the main `rust-analyzer` crate
and other downstream consumers.
### `crates/rustc-dependencies`
This crate wraps the `rustc_*` crates rust-analyzer relies on and conditionally points them to
mirrored crates-io releases such that rust-analyzer keeps building on stable.
### `crates/span`
This crate exposes types and functions related to rust-analyzer's span for macros.
A span is effectively a text range relative to some item in a file with a given `SyntaxContext` (hygiene).
## Cross-Cutting Concerns
This sections talks about the things which are everywhere and nowhere in particular.
### Stability Guarantees
One of the reasons rust-analyzer moves relatively fast is that we don't introduce new stability guarantees.
Instead, as much as possible we leverage existing ones.
Examples:
* The `ide` API of rust-analyzer are explicitly unstable, but the LSP interface is stable, and here we just implement a stable API managed by someone else.
* Rust language and Cargo are stable, and they are the primary inputs to rust-analyzer.
* The `rowan` library is published to crates.io, but it is deliberately kept under `1.0` and always makes semver-incompatible upgrades
Another important example is that rust-analyzer isn't run on CI, so, unlike `rustc` and `clippy`, it is actually ok for us to change runtime behavior.
At some point we might consider opening up APIs or allowing crates.io libraries to include rust-analyzer specific annotations, but that's going to be a big commitment on our side.
Exceptions:
* `rust-project.json` is a de-facto stable format for non-cargo build systems.
It is probably ok enough, but was definitely stabilized implicitly.
Lesson for the future: when designing API which could become a stability boundary, don't wait for the first users until you stabilize it.
By the time you have first users, it is already de-facto stable.
And the users will first use the thing, and *then* inform you that now you have users.
The sad thing is that stuff should be stable before someone uses it for the first time, or it should contain explicit opt-in.
* We ship some LSP extensions, and we try to keep those somewhat stable.
Here, we need to work with a finite set of editor maintainers, so not providing rock-solid guarantees works.
### Code generation
Some components in this repository are generated through automatic processes.
Generated code is updated automatically on `cargo test`.
Generated code is generally committed to the git repository.
In particular, we generate:
* API for working with syntax trees (`syntax::ast`, the [`ungrammar`](https://github.com/rust-analyzer/ungrammar) crate).
* Various sections of the manual:
* features
* assists
* config
* Documentation tests for assists
See the `sourcegen` crate for details.
**Architecture Invariant:** we avoid bootstrapping.
For codegen we need to parse Rust code.
Using rust-analyzer for that would work and would be fun, but it would also complicate the build process a lot.
For that reason, we use syn and manual string parsing.
### Cancellation
Let's say that the IDE is in the process of computing syntax highlighting, when the user types `foo`.
What should happen?
`rust-analyzer`s answer is that the highlighting process should be cancelled -- its results are now stale, and it also blocks modification of the inputs.
The salsa database maintains a global revision counter.
When applying a change, salsa bumps this counter and waits until all other threads using salsa finish.
If a thread does salsa-based computation and notices that the counter is incremented, it panics with a special value (see `Canceled::throw`).
That is, rust-analyzer requires unwinding.
`ide` is the boundary where the panic is caught and transformed into a `Result<T, Cancelled>`.
### Testing
rust-analyzer has three interesting [system boundaries](https://www.tedinski.com/2018/04/10/making-tests-a-positive-influence-on-design.html) to concentrate tests on.
The outermost boundary is the `rust-analyzer` crate, which defines an LSP interface in terms of stdio.
We do integration testing of this component, by feeding it with a stream of LSP requests and checking responses.
These tests are known as "heavy", because they interact with Cargo and read real files from disk.
For this reason, we try to avoid writing too many tests on this boundary: in a statically typed language, it's hard to make an error in the protocol itself if messages are themselves typed.
Heavy tests are only run when `RUN_SLOW_TESTS` env var is set.
The middle, and most important, boundary is `ide`.
Unlike `rust-analyzer`, which exposes API, `ide` uses Rust API and is intended for use by various tools.
A typical test creates an `AnalysisHost`, calls some `Analysis` functions and compares the results against expectation.
The innermost and most elaborate boundary is `hir`.
It has a much richer vocabulary of types than `ide`, but the basic testing setup is the same: we create a database, run some queries, assert result.
For comparisons, we use the `expect` crate for snapshot testing.
To test various analysis corner cases and avoid forgetting about old tests, we use so-called marks.
See the `marks` module in the `test_utils` crate for more.
**Architecture Invariant:** rust-analyzer tests do not use libcore or libstd.
All required library code must be a part of the tests.
This ensures fast test execution.
**Architecture Invariant:** tests are data driven and do not test the API.
Tests which directly call various API functions are a liability, because they make refactoring the API significantly more complicated.
So most of the tests look like this:
```rust
#[track_caller]
fn check(input: &str, expect: expect_test::Expect) {
// The single place that actually exercises a particular API
}
#[test]
fn foo() {
check("foo", expect![["bar"]]);
}
#[test]
fn spam() {
check("spam", expect![["eggs"]]);
}
// ...and a hundred more tests that don't care about the specific API at all.
```
To specify input data, we use a single string literal in a special format, which can describe a set of rust files.
See the `Fixture` its module for fixture examples and documentation.
**Architecture Invariant:** all code invariants are tested by `#[test]` tests.
There's no additional checks in CI, formatting and tidy tests are run with `cargo test`.
**Architecture Invariant:** tests do not depend on any kind of external resources, they are perfectly reproducible.
### Performance Testing
TBA, take a look at the `metrics` xtask and `#[test] fn benchmark_xxx()` functions.
### Error Handling
**Architecture Invariant:** core parts of rust-analyzer (`ide`/`hir`) don't interact with the outside world and thus can't fail.
Only parts touching LSP are allowed to do IO.
Internals of rust-analyzer need to deal with broken code, but this is not an error condition.
rust-analyzer is robust: various analysis compute `(T, Vec<Error>)` rather than `Result<T, Error>`.
rust-analyzer is a complex long-running process.
It will always have bugs and panics.
But a panic in an isolated feature should not bring down the whole process.
Each LSP-request is protected by a `catch_unwind`.
We use `always` and `never` macros instead of `assert` to gracefully recover from impossible conditions.
### Observability
rust-analyzer is a long-running process, so it is important to understand what's going on inside.
We have several instruments for that.
The event loop that runs rust-analyzer is very explicit.
Rather than spawning futures or scheduling callbacks (open), the event loop accepts an `enum` of possible events (closed).
It's easy to see all the things that trigger rust-analyzer processing, together with their performance
rust-analyzer includes a simple hierarchical profiler (`hprof`).
It is enabled with `RA_PROFILE='*>50'` env var (log all (`*`) actions which take more than `50` ms) and produces output like:
```
85ms - handle_completion
68ms - import_on_the_fly
67ms - import_assets::search_for_relative_paths
0ms - crate_def_map:wait (804 calls)
0ms - find_path (16 calls)
2ms - find_similar_imports (1 calls)
0ms - generic_params_query (334 calls)
59ms - trait_solve_query (186 calls)
0ms - Semantics::analyze_impl (1 calls)
1ms - render_resolution (8 calls)
0ms - Semantics::analyze_impl (5 calls)
```
This is cheap enough to enable in production.
Similarly, we save live object counting (`RA_COUNT=1`).
It is not cheap enough to enable in prod, and this is a bug which should be fixed.
### Configurability
rust-analyzer strives to be as configurable as possible while offering reasonable defaults where no configuration exists yet.
The rule of thumb is to enable most features by default unless they are buggy or degrade performance too much.
There will always be features that some people find more annoying than helpful, so giving the users the ability to tweak or disable these is a big part of offering a good user experience.
Enabling them by default is a matter of discoverability, as many users don't know about some features even though they are presented in the manual.
Mind the code--architecture gap: at the moment, we are using fewer feature flags than we really should.
### Serialization
In Rust, it is easy (often too easy) to add serialization to any type by adding `#[derive(Serialize)]`.
This easiness is misleading -- serializable types impose significant backwards compatibility constraints.
If a type is serializable, then it is a part of some IPC boundary.
You often don't control the other side of this boundary, so changing serializable types is hard.
For this reason, the types in `ide`, `base_db` and below are not serializable by design.
If such types need to cross an IPC boundary, then the client of rust-analyzer needs to provide a custom, client-specific serialization format.
This isolates backwards compatibility and migration concerns to a specific client.
For example, `rust-project.json` is its own format -- it doesn't include `CrateGraph` as is.
Instead, it creates a `CrateGraph` by calling appropriate constructing functions.