ltp4j是语言技术平台(Language Technology Platform, LTP)的Java封装。 关于LTP更多的信息,欢迎访问LTP项目主页。
- 韩冰 << [email protected] >> 2014-05-15 创建文档
ltp4j是语言技术平台(Language Technology Platform, LTP)接口的一个Java封装。 本项目旨在使Java用户可以本地调用LTP。
在使用ltp4j之前,您需要简要了解
- 什么是语言技术平台,它能否帮助您解决问题
- 如何安装语言技术平台
- 语言技术平台提供哪些编程接口
如果您对这些问题不了解,请首先阅读我们提供的有关语言技术平台的文档。 在本文档的后续中,我们假定您已经阅读并成功编译并使用语言技术平台。
ltp4j主要依靠JNI实现。整个项目由两部分组成,他们分别是:
- ltp4j.jar:Java接口程序,利用ant能够直接编译构建为ltp4j.jar,方便用户导入使用。
- C++代理程序,在项目/jni/目录下实现Java接口中的功能,利用CMake编译构建为动态库。
在这一章节中,我们假定您下载并将LTP放置于/path/to/your/ltp-project路径下;
而ltp4j放置于/path/to/your/ltp4j-project路径下。
ltp4j.jar使用ant编译工具编译。 在命令行环境下,可以在项目根目录(/path/to/your/ltp4j-project)下使用
ant
命令编译。编译成功后,将在build_jar/jar下产生ltp4j.jar文件。
如果使用Eclipse,可以按照_"File > New > Project... > Java Project from Existing Ant Buildfile"_的方式从build.xml中创建项目。
选择next后,在Ant buildfile:一栏中填入build.xml的路径,/path/to/your/ltp4j-project/build.xml(window用户请添加盘符并将/改为\),如下图所示。
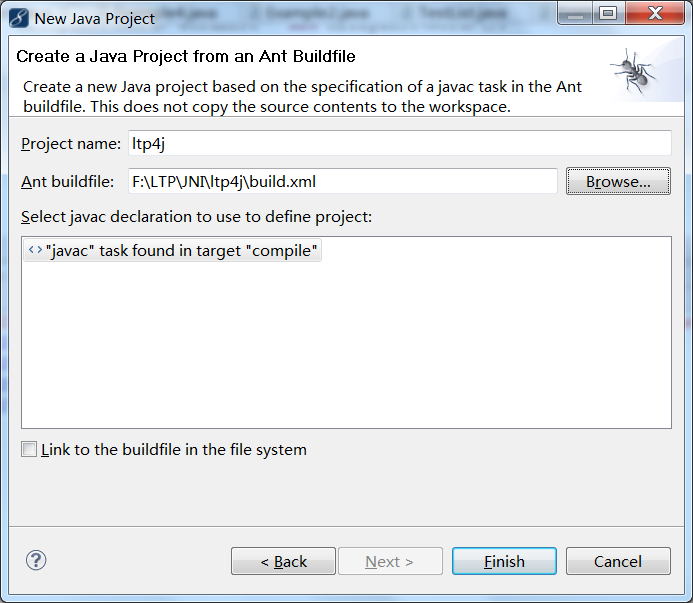
点击Finish就导入了项目。
在导入项目后,右键build.xml选择2 Ant Build。 在弹出的对话框中的选择main选项卡,并在Base Directory:中填入项目路径/path/to/your/ltp4j-project/。
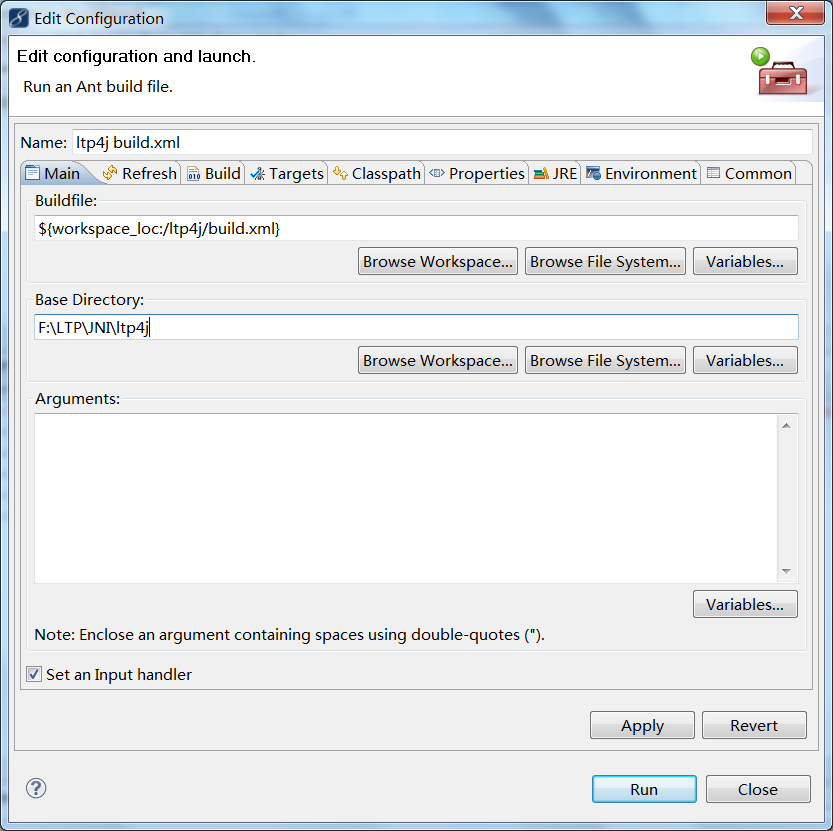
填好后执行run,build/jar下产生名为ltp4j.jar的jar文件。
代理程序jni动态库依赖于ltp的动态库,请先行编译LTP。
ltp4j使用的C++代理程序使用编译工具CMake构建项目。 在编译代理程序之前,你需要首先安装CMake。 CMake的网站在这里。如果你是Windows用户,请下载CMake的二进制安装包; 如果你是Linux,Mac OS或Cygwin的用户,可以通过编译源码的方式安装CMake,当然,你也可以使用Linux的软件源来安装。
第一步:配置ltp的安装路径
因为jni依赖于ltp编译产生的动态库,所以在编译过程中需要给出ltp的路径。
请修改/path/to/your/ltp4j-project/CMakeLists.txt中的LTP_HOME的值为您的LTP项目的路径(/path/to/your/ltp-project),
对应修改的代码为:
set (LTP_HOME "/path/to/your/ltp-project/")
第二步:构建VC Project
在项目文件夹下新建一个名为build的文件夹,使用CMake Gui,在source code中填入项目文件夹,在binaries中填入build文件夹。然后Configure -> Generate。
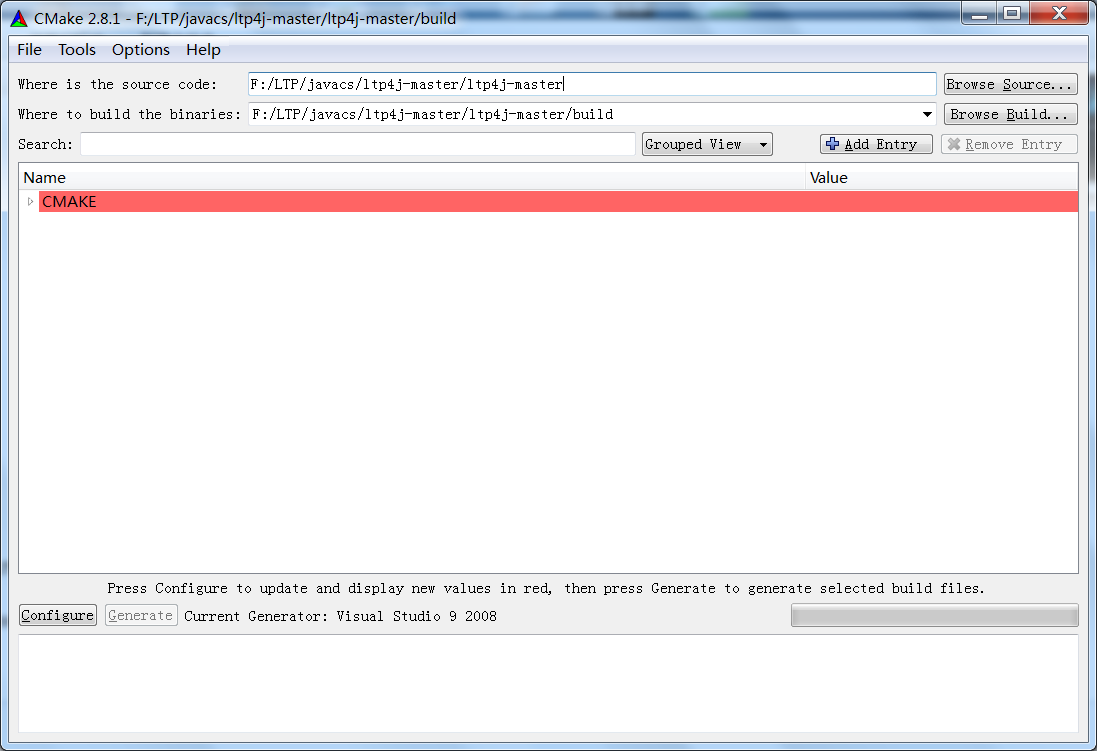
或者在命令行build 路径下运行
cmake ..
第二步:编译
Linux、Mac OSX(*)和Cygwin的用户,可以直接在项目根目录下使用命令
cmake .
make
进行编译。
编译成功后,会在libs文件夹下生成以下一些动态库(**)
| 程序名 | 说明 |
|---|---|
| split_sentence_jni.so | 分句动态库 |
| segmentor_jni.so | 分词动态库 |
| postagger_jni.so | 词性标注动态库 |
| parser_jni.so | 依存句法分析动态库 |
| ner_jni.so | 命名实体识别动态库 |
| srl_jni.so | 语义角色标注动态库 |
###注意事项
- 该处编译需要设置Java环境变量JAVA_HOME。
- 需要保持c++编译器与JDK同是32位或者64位,否则JVM不能加载生成的动态库
#开始使用
构建需要在本地使用ltp的工程
- 导入ltp4j.jar
- windows下将libs文件夹中生成的所有动态库、以及原ltp lib文件夹下的splitsnt、segmentor、postagger、ner、parser、srl 6个动态库拷贝到项目根目录
- linux下export LD_LIBRARY_PATH=#jni动态库路径#
接下来便可仿照下面各个接口的例子使用ltp啦。
#编程接口
edu.ir.hit.ltp4j.Segmentor
分词主要提供四个接口:
int create(带外部词典)
功能:
读取模型文件,初始化分词器。
参数:
| 参数名 | 参数描述 |
|---|---|
| String path | 指定模型文件的路径 |
| String lexicon_path | 指定外部词典路径。如果lexicon_path为NULL,则不加载外部词典 |
返回值:
成功加载模型返回1,否则返回-1。
int create
功能:
读取模型文件,初始化分词器。
参数:
| 参数名 | 参数描述 |
|---|---|
| String path | 指定模型文件的路径 |
返回值:
成功加载模型返回1,否则返回-1。
void release
功能:
释放模型文件,销毁分词器。
参数:无
返回值:无
int Segment
功能:
调用分词接口。
参数:
| 参数名 | 参数描述 |
|---|---|
| String | 待分词句子 |
| java.util.List< String > words | 结果分词序列 |
返回值:
返回结果中词的个数。
一个简单的实例程序可以说明分词接口的用法:
import java.util.ArrayList;
import java.util.List;
import edu.hit.ir.ltp4j.*;
public class TestSegment {
public static void main(String[] args) {
if(Segmentor.create("../../../ltp_data/cws.model")<0){
System.err.println("load failed");
return;
}
String sent = "我是中国人";
List<String> words = new ArrayList<String>();
int size = Segmentor.Segment(sent,words);
for(int i = 0; i<size; i++) {
System.out.print(words.get(i));
if(i==size-1) {
System.out.println();
} else{
System.out.print("\t");
}
}
Segmentor.release();
}
}
edu.ir.hit.ltp4j.Postagger
词性标注主要提供三个接口
int create
功能:
读取模型文件,初始化词性标注器
参数:
| 参数名 | 参数描述 |
|---|---|
| String path | 词性标注模型路径 |
返回值:
成功加载模型返回1,否则返回-1。
void release
功能:
释放模型文件,销毁分词器。
参数:无
返回值:无
int Postag
功能:
调用词性标注接口
参数:
| 参数名 | 参数描述 |
|---|---|
| java.util.List< String > words | 待标注的词序列 |
| java.util.List< String > tags | 词性标注结果,序列中的第i个元素是第i个词的词性 |
返回值:
返回结果中词的个数
一个简单的实例程序可以说明词性标注接口的用法:
import java.util.ArrayList;
import java.util.ArrayList;
import java.util.List;
import edu.hit.ir.ltp4j.*;
public class TestPostag {
public static void main(String[] args) {
if(Postagger.create("../../../ltp_data/pos.model")<0) {
System.err.println("load failed");
return;
}
List<String> words= new ArrayList<String>();
words.add("我"); words.add("是");
words.add("中国"); words.add("人");
List<String> postags= new ArrayList<String>();
int size = Postagger.Postag(words,postags);
for(int i = 0; i < size; i++) {
System.out.print(words.get(i)+"_"+postags.get(i));
if(i==size-1) {
System.out.println();
} else {
System.out.print("|");
}
}
Postagger.release();
}
}
edu.ir.hit.ltp4j.NER
命名实体识别主要提供三个接口:
int create
功能:
参数:
| 参数名 | 参数描述 |
|---|---|
| String path | 命名实体识别模型路径 |
返回值:
成功加载模型返回1,否则返回-1。
void release
功能:
释放模型文件,销毁命名实体识别器。
参数:无
返回值:无
int recognize
功能:
调用命名实体识别接口
参数:
| 参数名 | 参数描述 |
|---|---|
| java.util.List< String > words | 待识别的词序列 |
| java.util.List< String > postags | 待识别的词的词性序列 |
| java.util.List< String > tags | 命名实体识别结果,命名实体识别的结果为O时表示这个词不是命名实体,否则为{POS}-{TYPE}形式的标记,POS代表这个词在命名实体中的位置,TYPE表示命名实体类型 |
返回值:
返回结果中词的个数
import java.util.ArrayList;
import java.util.List;
import edu.hit.ir.ltp4j.*;
public class TestNer {
public static void main(String[] args) {
if(NER.create("../../../ltp_data/ner.model")<0) {
System.err.println("load failed");
return;
}
List<String> words = new ArrayList<String>();
List<String> tags = new ArrayList<String>();
List<String> ners = new ArrayList<String>();
words.add("中国");tags.add("ns");
words.add("国际");tags.add("n");
words.add("广播");tags.add("n");
words.add("电台");tags.add("n");
words.add("创办");tags.add("v");
words.add("于");tags.add("p");
words.add("1941年");tags.add("m");
words.add("12月");tags.add("m");
words.add("3日");tags.add("m");
words.add("。");tags.add("wp");
NER.recognize(words, tags, ners);
for (int i = 0; i < words.size(); i++) {
System.out.println(ners.get(i));
}
NER.release();
}
}
edu.ir.hit.ltp4j.Parser 依存句法分析主要提供三个接口:
int create
功能:
读取模型文件,初始化依存句法分析器
参数:
| 参数名 | 参数描述 |
|---|---|
| String path | 依存句法分析模型路径 |
返回值:
成功加载模型返回1,否则返回-1。
void release
功能:
释放模型文件,销毁依存句法分析器。
参数:无
返回值:无
int parse
功能:
调用依存句法分析接口
参数:
| 参数名 | 参数描述 |
|---|---|
| java.util.List< String > words | 待分析的词序列 |
| java.util.List< String > postags | 待分析的词的词性序列 |
| java.util.List< Integer > heads | 结果依存弧,heads[i]代表第i个词的父亲节点的编号 |
| java.util.List< String > deprels | 结果依存弧关系类型 |
返回值:
返回结果中词的个数
一个简单的实例程序可以说明依存句法分析接口的用法:
import java.util.ArrayList;
import java.util.List;
import edu.hit.ir.ltp4j.*;
public class TestParser {
public static void main(String[] args) {
if(Parser.create("../../../ltp_data/parser.model")<0) {
System.err.println("load failed");
return;
}
List<String> words = new ArrayList<String>();
List<String> tags = new ArrayList<String>();
words.add("一把手");tags.add("n");
words.add("亲自");tags.add("d");
words.add("过问");tags.add("v");
words.add("。");tags.add("wp");
List<Integer> heads = new ArrayList<Integer>();
List<String> deprels = new ArrayList<String>();
int size = Parser.parse(words,tags,heads,deprels);
for(int i = 0;i<size;i++) {
System.out.print(heads.get(i)+":"+deprels.get(i));
if(i==size-1) {
System.out.println();
}
else{
System.out.print(" ");
}
}
Parser.release();
}
}
edu.ir.hit.ltp4j.SRL 依存句法分析主要提供三个接口:
int create
功能:
读取模型文件,初始化语义角色标注分析器
参数:
| 参数名 | 参数描述 |
|---|---|
| String path | 依存句法分析模型路径 |
返回值:
成功加载模型返回1,否则返回-1。
void release
功能:
释放模型文件,销毁语义角色标注分析器。
参数:无
返回值:无
int srl
功能:
调用语义角色标注接口
参数:
| 参数名 | 参数描述 |
|---|---|
| java.util.List< String > words | 待分析的词序列 |
| java.util.List< String > postags | 待分析的词的词性序列 |
| java.util.List< String > ners | 待分析的命名实体序列 |
| java.util.List< Integer > heads | 待分析的依存弧,heads[i]代表第i个词的父亲节点的编号 |
| java.util.List< String > deprels | 待分析的依存弧关系类型 |
| List< Pair< Integer, List< Pair< String, Pair< Integer, Integer > > > > > srls | 结果语义角色标注 |
返回值:
返回角色个数
一个简单的实例程序可以说明依存句法分析接口的用法:
import java.util.ArrayList;
import java.util.List;
import edu.hit.ir.ltp4j.*;
public class TestSrl {
public static void main(String[] args) {
SRL.create("../../../ltp_data/srl");
ArrayList<String> words = new ArrayList<String>();
words.add("一把手");
words.add("亲自");
words.add("过问");
words.add("。");
ArrayList<String> tags = new ArrayList<String>();
tags.add("n");
tags.add("d");
tags.add("v");
tags.add("wp");
ArrayList<String> ners = new ArrayList<String>();
ners.add("O");
ners.add("O");
ners.add("O");
ners.add("O");
ArrayList<Integer> heads = new ArrayList<Integer>();
heads.add(2);
heads.add(2);
heads.add(-1);
heads.add(2);
ArrayList<String> deprels = new ArrayList<String>();
deprels.add("SBV");
deprels.add("ADV");
deprels.add("HED");
deprels.add("WP");
List<Pair<Integer, List<Pair<String, Pair<Integer, Integer>>>>> srls = new ArrayList<Pair<Integer, List<Pair<String, Pair<Integer, Integer>>>>>();
SRL.srl(words, tags, ners, heads, deprels, srls);
for (int i = 0; i < srls.size(); ++i) {
System.out.println(srls.get(i).first + ":");
for (int j = 0; j < srls.get(i).second.size(); ++j) {
System.out.println(" tpye = "+ srls.get(i).second.get(j).first + " beg = "+ srls.get(i).second.get(j).second.first + " end = "+ srls.get(i).second.get(j).second.second);
}
}
SRL.release();
}
}
###注意事项
- 对于一个包含N个词的句子,句法分析返回的父节点范围在0至N之间,而语义角色标注的输入需要在-1至N-1之间。因此,若要在句法分析后进行语义角色标注,需要把heads作减一操作。