diff --git a/.circleci/TROUBLESHOOT.md b/.circleci/TROUBLESHOOT.md
new file mode 100644
index 00000000000000..c662a921ba56f3
--- /dev/null
+++ b/.circleci/TROUBLESHOOT.md
@@ -0,0 +1,7 @@
+# Troubleshooting
+
+This is a document explaining how to deal with various issues on Circle-CI. The entries may include actually solutions or pointers to Issues that cover those.
+
+## Circle CI
+
+* pytest worker runs out of resident RAM and gets killed by `cgroups`: https://github.com/huggingface/transformers/issues/11408
diff --git a/.circleci/config.yml b/.circleci/config.yml
index f8040e7553f7b5..5cf2fab47635b4 100644
--- a/.circleci/config.yml
+++ b/.circleci/config.yml
@@ -3,7 +3,6 @@ orbs:
gcp-gke: circleci/gcp-gke@1.0.4
go: circleci/go@1.3.0
-
# TPU REFERENCES
references:
checkout_ml_testing: &checkout_ml_testing
@@ -66,9 +65,11 @@ jobs:
run_tests_torch_and_tf:
working_directory: ~/transformers
docker:
- - image: circleci/python:3.6
+ - image: circleci/python:3.7
environment:
OMP_NUM_THREADS: 1
+ RUN_PT_TF_CROSS_TESTS: yes
+ TRANSFORMERS_IS_CI: yes
resource_class: xlarge
parallelism: 1
steps:
@@ -77,15 +78,56 @@ jobs:
keys:
- v0.4-torch_and_tf-{{ checksum "setup.py" }}
- v0.4-{{ checksum "setup.py" }}
- - run: sudo apt-get -y update && sudo apt-get install -y libsndfile1-dev
+ - run: sudo apt-get -y update && sudo apt-get install -y libsndfile1-dev espeak-ng
- run: pip install --upgrade pip
- - run: pip install .[sklearn,tf-cpu,torch,testing,sentencepiece,speech]
- - run: pip install tapas torch-scatter -f https://pytorch-geometric.com/whl/torch-1.8.0+cpu.html
+ - run: pip install .[sklearn,tf-cpu,torch,testing,sentencepiece,torch-speech,vision]
+ - run: pip install torch-scatter -f https://pytorch-geometric.com/whl/torch-1.11.0+cpu.html
+ - run: pip install tensorflow_probability
+ - run: pip install https://github.com/kpu/kenlm/archive/master.zip
- save_cache:
key: v0.4-{{ checksum "setup.py" }}
paths:
- '~/.cache/pip'
- - run: RUN_PT_TF_CROSS_TESTS=1 python -m pytest -n 8 --dist=loadfile -rA -s --make-reports=tests_torch_and_tf ./tests/ -m is_pt_tf_cross_test --durations=0 | tee tests_output.txt
+ - run: python utils/tests_fetcher.py | tee test_preparation.txt
+ - store_artifacts:
+ path: ~/transformers/test_preparation.txt
+ - run: |
+ if [ -f test_list.txt ]; then
+ python -m pytest -n 8 --dist=loadfile -rA -s --make-reports=tests_torch_and_tf $(cat test_list.txt) -m is_pt_tf_cross_test --durations=0 | tee tests_output.txt
+ fi
+ - store_artifacts:
+ path: ~/transformers/tests_output.txt
+ - store_artifacts:
+ path: ~/transformers/reports
+
+ run_tests_torch_and_tf_all:
+ working_directory: ~/transformers
+ docker:
+ - image: circleci/python:3.7
+ environment:
+ OMP_NUM_THREADS: 1
+ RUN_PT_TF_CROSS_TESTS: yes
+ TRANSFORMERS_IS_CI: yes
+ resource_class: xlarge
+ parallelism: 1
+ steps:
+ - checkout
+ - restore_cache:
+ keys:
+ - v0.4-torch_and_tf-{{ checksum "setup.py" }}
+ - v0.4-{{ checksum "setup.py" }}
+ - run: sudo apt-get -y update && sudo apt-get install -y libsndfile1-dev espeak-ng
+ - run: pip install --upgrade pip
+ - run: pip install .[sklearn,tf-cpu,torch,testing,sentencepiece,torch-speech,vision]
+ - run: pip install torch-scatter -f https://pytorch-geometric.com/whl/torch-1.11.0+cpu.html
+ - run: pip install tensorflow_probability
+ - run: pip install https://github.com/kpu/kenlm/archive/master.zip
+ - save_cache:
+ key: v0.4-{{ checksum "setup.py" }}
+ paths:
+ - '~/.cache/pip'
+ - run: |
+ python -m pytest -n 8 --dist=loadfile -rA -s --make-reports=tests_torch_and_tf tests -m is_pt_tf_cross_test --durations=0 | tee tests_output.txt
- store_artifacts:
path: ~/transformers/tests_output.txt
- store_artifacts:
@@ -94,9 +136,11 @@ jobs:
run_tests_torch_and_flax:
working_directory: ~/transformers
docker:
- - image: circleci/python:3.6
+ - image: circleci/python:3.7
environment:
OMP_NUM_THREADS: 1
+ RUN_PT_FLAX_CROSS_TESTS: yes
+ TRANSFORMERS_IS_CI: yes
resource_class: xlarge
parallelism: 1
steps:
@@ -105,15 +149,54 @@ jobs:
keys:
- v0.4-torch_and_flax-{{ checksum "setup.py" }}
- v0.4-{{ checksum "setup.py" }}
- - run: sudo apt-get -y update && sudo apt-get install -y libsndfile1-dev
+ - run: sudo apt-get -y update && sudo apt-get install -y libsndfile1-dev espeak-ng
- run: pip install --upgrade pip
- - run: pip install .[sklearn,flax,torch,testing,sentencepiece,speech]
- - run: pip install tapas torch-scatter -f https://pytorch-geometric.com/whl/torch-1.8.0+cpu.html
+ - run: pip install .[sklearn,flax,torch,testing,sentencepiece,torch-speech,vision]
+ - run: pip install torch-scatter -f https://pytorch-geometric.com/whl/torch-1.11.0+cpu.html
+ - run: pip install https://github.com/kpu/kenlm/archive/master.zip
- save_cache:
key: v0.4-{{ checksum "setup.py" }}
paths:
- '~/.cache/pip'
- - run: RUN_PT_FLAX_CROSS_TESTS=1 python -m pytest -n 8 --dist=loadfile -rA -s --make-reports=tests_torch_and_flax ./tests/ -m is_pt_flax_cross_test --durations=0 | tee tests_output.txt
+ - run: python utils/tests_fetcher.py | tee test_preparation.txt
+ - store_artifacts:
+ path: ~/transformers/test_preparation.txt
+ - run: |
+ if [ -f test_list.txt ]; then
+ python -m pytest -n 8 --dist=loadfile -rA -s --make-reports=tests_torch_and_flax $(cat test_list.txt) -m is_pt_flax_cross_test --durations=0 | tee tests_output.txt
+ fi
+ - store_artifacts:
+ path: ~/transformers/tests_output.txt
+ - store_artifacts:
+ path: ~/transformers/reports
+
+ run_tests_torch_and_flax_all:
+ working_directory: ~/transformers
+ docker:
+ - image: circleci/python:3.7
+ environment:
+ OMP_NUM_THREADS: 1
+ RUN_PT_FLAX_CROSS_TESTS: yes
+ TRANSFORMERS_IS_CI: yes
+ resource_class: xlarge
+ parallelism: 1
+ steps:
+ - checkout
+ - restore_cache:
+ keys:
+ - v0.4-torch_and_flax-{{ checksum "setup.py" }}
+ - v0.4-{{ checksum "setup.py" }}
+ - run: sudo apt-get -y update && sudo apt-get install -y libsndfile1-dev espeak-ng
+ - run: pip install --upgrade pip
+ - run: pip install .[sklearn,flax,torch,testing,sentencepiece,torch-speech,vision]
+ - run: pip install torch-scatter -f https://pytorch-geometric.com/whl/torch-1.11.0+cpu.html
+ - run: pip install https://github.com/kpu/kenlm/archive/master.zip
+ - save_cache:
+ key: v0.4-{{ checksum "setup.py" }}
+ paths:
+ - '~/.cache/pip'
+ - run: |
+ python -m pytest -n 8 --dist=loadfile -rA -s --make-reports=tests_torch_and_flax tests -m is_pt_flax_cross_test --durations=0 | tee tests_output.txt
- store_artifacts:
path: ~/transformers/tests_output.txt
- store_artifacts:
@@ -125,6 +208,7 @@ jobs:
- image: circleci/python:3.7
environment:
OMP_NUM_THREADS: 1
+ TRANSFORMERS_IS_CI: yes
resource_class: xlarge
parallelism: 1
steps:
@@ -133,15 +217,53 @@ jobs:
keys:
- v0.4-torch-{{ checksum "setup.py" }}
- v0.4-{{ checksum "setup.py" }}
- - run: sudo apt-get -y update && sudo apt-get install -y libsndfile1-dev
+ - run: sudo apt-get -y update && sudo apt-get install -y libsndfile1-dev espeak-ng time
+ - run: pip install --upgrade pip
+ - run: pip install .[sklearn,torch,testing,sentencepiece,torch-speech,vision,timm]
+ - run: pip install torch-scatter -f https://pytorch-geometric.com/whl/torch-1.11.0+cpu.html
+ - run: pip install https://github.com/kpu/kenlm/archive/master.zip
+ - save_cache:
+ key: v0.4-torch-{{ checksum "setup.py" }}
+ paths:
+ - '~/.cache/pip'
+ - run: python utils/tests_fetcher.py | tee test_preparation.txt
+ - store_artifacts:
+ path: ~/transformers/test_preparation.txt
+ - run: |
+ if [ -f test_list.txt ]; then
+ python -m pytest -n 3 --dist=loadfile -s --make-reports=tests_torch $(cat test_list.txt) | tee tests_output.txt
+ fi
+ - store_artifacts:
+ path: ~/transformers/tests_output.txt
+ - store_artifacts:
+ path: ~/transformers/reports
+
+ run_tests_torch_all:
+ working_directory: ~/transformers
+ docker:
+ - image: circleci/python:3.7
+ environment:
+ OMP_NUM_THREADS: 1
+ TRANSFORMERS_IS_CI: yes
+ resource_class: xlarge
+ parallelism: 1
+ steps:
+ - checkout
+ - restore_cache:
+ keys:
+ - v0.4-torch-{{ checksum "setup.py" }}
+ - v0.4-{{ checksum "setup.py" }}
+ - run: sudo apt-get -y update && sudo apt-get install -y libsndfile1-dev espeak-ng
- run: pip install --upgrade pip
- - run: pip install .[sklearn,torch,testing,sentencepiece,speech]
- - run: pip install tapas torch-scatter -f https://pytorch-geometric.com/whl/torch-1.8.0+cpu.html
+ - run: pip install .[sklearn,torch,testing,sentencepiece,torch-speech,vision,timm]
+ - run: pip install torch-scatter -f https://pytorch-geometric.com/whl/torch-1.11.0+cpu.html
+ - run: pip install https://github.com/kpu/kenlm/archive/master.zip
- save_cache:
key: v0.4-torch-{{ checksum "setup.py" }}
paths:
- '~/.cache/pip'
- - run: python -m pytest -n 8 --dist=loadfile -s --make-reports=tests_torch ./tests/ | tee tests_output.txt
+ - run: |
+ python -m pytest -n 3 --dist=loadfile -s --make-reports=tests_torch tests | tee tests_output.txt
- store_artifacts:
path: ~/transformers/tests_output.txt
- store_artifacts:
@@ -153,6 +275,7 @@ jobs:
- image: circleci/python:3.7
environment:
OMP_NUM_THREADS: 1
+ TRANSFORMERS_IS_CI: yes
resource_class: xlarge
parallelism: 1
steps:
@@ -161,13 +284,53 @@ jobs:
keys:
- v0.4-tf-{{ checksum "setup.py" }}
- v0.4-{{ checksum "setup.py" }}
+ - run: sudo apt-get -y update && sudo apt-get install -y libsndfile1-dev espeak-ng
- run: pip install --upgrade pip
- - run: pip install .[sklearn,tf-cpu,testing,sentencepiece]
+ - run: pip install .[sklearn,tf-cpu,testing,sentencepiece,tf-speech,vision]
+ - run: pip install tensorflow_probability
+ - run: pip install https://github.com/kpu/kenlm/archive/master.zip
+ - save_cache:
+ key: v0.4-tf-{{ checksum "setup.py" }}
+ paths:
+ - '~/.cache/pip'
+ - run: python utils/tests_fetcher.py | tee test_preparation.txt
+ - store_artifacts:
+ path: ~/transformers/test_preparation.txt
+ - run: |
+ if [ -f test_list.txt ]; then
+ python -m pytest -n 8 --dist=loadfile -rA -s --make-reports=tests_tf $(cat test_list.txt) | tee tests_output.txt
+ fi
+ - store_artifacts:
+ path: ~/transformers/tests_output.txt
+ - store_artifacts:
+ path: ~/transformers/reports
+
+ run_tests_tf_all:
+ working_directory: ~/transformers
+ docker:
+ - image: circleci/python:3.7
+ environment:
+ OMP_NUM_THREADS: 1
+ TRANSFORMERS_IS_CI: yes
+ resource_class: xlarge
+ parallelism: 1
+ steps:
+ - checkout
+ - restore_cache:
+ keys:
+ - v0.4-tf-{{ checksum "setup.py" }}
+ - v0.4-{{ checksum "setup.py" }}
+ - run: sudo apt-get -y update && sudo apt-get install -y libsndfile1-dev espeak-ng
+ - run: pip install --upgrade pip
+ - run: pip install .[sklearn,tf-cpu,testing,sentencepiece,tf-speech,vision]
+ - run: pip install tensorflow_probability
+ - run: pip install https://github.com/kpu/kenlm/archive/master.zip
- save_cache:
key: v0.4-tf-{{ checksum "setup.py" }}
paths:
- '~/.cache/pip'
- - run: python -m pytest -n 8 --dist=loadfile -rA -s --make-reports=tests_tf ./tests/ | tee tests_output.txt
+ - run: |
+ python -m pytest -n 8 --dist=loadfile -rA -s --make-reports=tests_tf tests | tee tests_output.txt
- store_artifacts:
path: ~/transformers/tests_output.txt
- store_artifacts:
@@ -179,6 +342,7 @@ jobs:
- image: circleci/python:3.7
environment:
OMP_NUM_THREADS: 1
+ TRANSFORMERS_IS_CI: yes
resource_class: xlarge
parallelism: 1
steps:
@@ -187,13 +351,51 @@ jobs:
keys:
- v0.4-flax-{{ checksum "setup.py" }}
- v0.4-{{ checksum "setup.py" }}
+ - run: sudo apt-get -y update && sudo apt-get install -y libsndfile1-dev espeak-ng
- run: pip install --upgrade pip
- - run: sudo pip install .[flax,testing,sentencepiece]
+ - run: pip install .[flax,testing,sentencepiece,flax-speech,vision]
+ - run: pip install https://github.com/kpu/kenlm/archive/master.zip
- save_cache:
key: v0.4-flax-{{ checksum "setup.py" }}
paths:
- '~/.cache/pip'
- - run: python -m pytest -n 8 --dist=loadfile -rA -s --make-reports=tests_flax ./tests/ | tee tests_output.txt
+ - run: python utils/tests_fetcher.py | tee test_preparation.txt
+ - store_artifacts:
+ path: ~/transformers/test_preparation.txt
+ - run: |
+ if [ -f test_list.txt ]; then
+ python -m pytest -n 8 --dist=loadfile -rA -s --make-reports=tests_flax $(cat test_list.txt) | tee tests_output.txt
+ fi
+ - store_artifacts:
+ path: ~/transformers/tests_output.txt
+ - store_artifacts:
+ path: ~/transformers/reports
+
+ run_tests_flax_all:
+ working_directory: ~/transformers
+ docker:
+ - image: circleci/python:3.7
+ environment:
+ OMP_NUM_THREADS: 1
+ TRANSFORMERS_IS_CI: yes
+ resource_class: xlarge
+ parallelism: 1
+ steps:
+ - checkout
+ - restore_cache:
+ keys:
+ - v0.4-flax-{{ checksum "setup.py" }}
+ - v0.4-{{ checksum "setup.py" }}
+ - run: sudo apt-get -y update && sudo apt-get install -y libsndfile1-dev espeak-ng
+ - run: pip install --upgrade pip
+ - run: pip install .[flax,testing,sentencepiece,vision,flax-speech]
+ - run: pip install https://github.com/kpu/kenlm/archive/master.zip
+ - save_cache:
+ key: v0.4-flax-{{ checksum "setup.py" }}
+ paths:
+ - '~/.cache/pip'
+ - run: |
+ python -m pytest -n 8 --dist=loadfile -rA -s --make-reports=tests_flax tests | tee tests_output.txt
- store_artifacts:
path: ~/transformers/tests_output.txt
- store_artifacts:
@@ -205,6 +407,8 @@ jobs:
- image: circleci/python:3.7
environment:
OMP_NUM_THREADS: 1
+ RUN_PIPELINE_TESTS: yes
+ TRANSFORMERS_IS_CI: yes
resource_class: xlarge
parallelism: 1
steps:
@@ -213,15 +417,54 @@ jobs:
keys:
- v0.4-torch-{{ checksum "setup.py" }}
- v0.4-{{ checksum "setup.py" }}
- - run: sudo apt-get -y update && sudo apt-get install -y libsndfile1-dev
+ - run: sudo apt-get -y update && sudo apt-get install -y libsndfile1-dev espeak-ng
- run: pip install --upgrade pip
- - run: pip install .[sklearn,torch,testing,sentencepiece,speech]
- - run: pip install tapas torch-scatter -f https://pytorch-geometric.com/whl/torch-1.8.0+cpu.html
+ - run: pip install .[sklearn,torch,testing,sentencepiece,torch-speech,vision,timm]
+ - run: pip install torch-scatter -f https://pytorch-geometric.com/whl/torch-1.11.0+cpu.html
+ - run: pip install https://github.com/kpu/kenlm/archive/master.zip
- save_cache:
key: v0.4-torch-{{ checksum "setup.py" }}
paths:
- '~/.cache/pip'
- - run: RUN_PIPELINE_TESTS=1 python -m pytest -n 8 --dist=loadfile -rA -s --make-reports=tests_pipelines_torch -m is_pipeline_test ./tests/ | tee tests_output.txt
+ - run: python utils/tests_fetcher.py | tee test_preparation.txt
+ - store_artifacts:
+ path: ~/transformers/test_preparation.txt
+ - run: |
+ if [ -f test_list.txt ]; then
+ python -m pytest -n 8 --dist=loadfile -rA -s --make-reports=tests_pipelines_torch -m is_pipeline_test $(cat test_list.txt) | tee tests_output.txt
+ fi
+ - store_artifacts:
+ path: ~/transformers/tests_output.txt
+ - store_artifacts:
+ path: ~/transformers/reports
+
+ run_tests_pipelines_torch_all:
+ working_directory: ~/transformers
+ docker:
+ - image: circleci/python:3.7
+ environment:
+ OMP_NUM_THREADS: 1
+ RUN_PIPELINE_TESTS: yes
+ TRANSFORMERS_IS_CI: yes
+ resource_class: xlarge
+ parallelism: 1
+ steps:
+ - checkout
+ - restore_cache:
+ keys:
+ - v0.4-torch-{{ checksum "setup.py" }}
+ - v0.4-{{ checksum "setup.py" }}
+ - run: sudo apt-get -y update && sudo apt-get install -y libsndfile1-dev espeak-ng
+ - run: pip install --upgrade pip
+ - run: pip install .[sklearn,torch,testing,sentencepiece,torch-speech,vision,timm]
+ - run: pip install torch-scatter -f https://pytorch-geometric.com/whl/torch-1.11.0+cpu.html
+ - run: pip install https://github.com/kpu/kenlm/archive/master.zip
+ - save_cache:
+ key: v0.4-torch-{{ checksum "setup.py" }}
+ paths:
+ - '~/.cache/pip'
+ - run: |
+ python -m pytest -n 8 --dist=loadfile -rA -s --make-reports=tests_pipelines_torch -m is_pipeline_test tests | tee tests_output.txt
- store_artifacts:
path: ~/transformers/tests_output.txt
- store_artifacts:
@@ -233,6 +476,43 @@ jobs:
- image: circleci/python:3.7
environment:
OMP_NUM_THREADS: 1
+ RUN_PIPELINE_TESTS: yes
+ TRANSFORMERS_IS_CI: yes
+ resource_class: xlarge
+ parallelism: 1
+ steps:
+ - checkout
+ - restore_cache:
+ keys:
+ - v0.4-tf-{{ checksum "setup.py" }}
+ - v0.4-{{ checksum "setup.py" }}
+ - run: pip install --upgrade pip
+ - run: pip install .[sklearn,tf-cpu,testing,sentencepiece]
+ - run: pip install tensorflow_probability
+ - save_cache:
+ key: v0.4-tf-{{ checksum "setup.py" }}
+ paths:
+ - '~/.cache/pip'
+ - run: python utils/tests_fetcher.py | tee test_preparation.txt
+ - store_artifacts:
+ path: ~/transformers/test_preparation.txt
+ - run: |
+ if [ -f test_list.txt ]; then
+ python -m pytest -n 8 --dist=loadfile -rA -s --make-reports=tests_pipelines_tf $(cat test_list.txt) -m is_pipeline_test | tee tests_output.txt
+ fi
+ - store_artifacts:
+ path: ~/transformers/tests_output.txt
+ - store_artifacts:
+ path: ~/transformers/reports
+
+ run_tests_pipelines_tf_all:
+ working_directory: ~/transformers
+ docker:
+ - image: circleci/python:3.7
+ environment:
+ OMP_NUM_THREADS: 1
+ RUN_PIPELINE_TESTS: yes
+ TRANSFORMERS_IS_CI: yes
resource_class: xlarge
parallelism: 1
steps:
@@ -243,11 +523,13 @@ jobs:
- v0.4-{{ checksum "setup.py" }}
- run: pip install --upgrade pip
- run: pip install .[sklearn,tf-cpu,testing,sentencepiece]
+ - run: pip install tensorflow_probability
- save_cache:
key: v0.4-tf-{{ checksum "setup.py" }}
paths:
- '~/.cache/pip'
- - run: RUN_PIPELINE_TESTS=1 python -m pytest -n 8 --dist=loadfile -rA -s --make-reports=tests_pipelines_tf ./tests/ -m is_pipeline_test | tee tests_output.txt
+ - run: |
+ python -m pytest -n 8 --dist=loadfile -rA -s --make-reports=tests_pipelines_tf tests -m is_pipeline_test | tee tests_output.txt
- store_artifacts:
path: ~/transformers/tests_output.txt
- store_artifacts:
@@ -259,6 +541,7 @@ jobs:
- image: circleci/python:3.7
environment:
RUN_CUSTOM_TOKENIZERS: yes
+ TRANSFORMERS_IS_CI: yes
steps:
- checkout
- restore_cache:
@@ -266,13 +549,20 @@ jobs:
- v0.4-custom_tokenizers-{{ checksum "setup.py" }}
- v0.4-{{ checksum "setup.py" }}
- run: pip install --upgrade pip
- - run: pip install .[ja,testing,sentencepiece]
+ - run: pip install .[ja,testing,sentencepiece,jieba,spacy,ftfy,rjieba]
- run: python -m unidic download
- save_cache:
key: v0.4-custom_tokenizers-{{ checksum "setup.py" }}
paths:
- '~/.cache/pip'
- - run: python -m pytest -s --make-reports=tests_custom_tokenizers ./tests/test_tokenization_bert_japanese.py | tee tests_output.txt
+ - run: |
+ if [ -f test_list.txt ]; then
+ python -m pytest -s --make-reports=tests_custom_tokenizers ./tests/test_tokenization_bert_japanese.py ./tests/test_tokenization_openai.py | tee tests_output.txt
+ fi
+ - run: |
+ if [ -f test_list.txt ]; then
+ python -m pytest -n 1 tests/test_tokenization_clip.py --dist=loadfile -s --make-reports=tests_tokenization_clip --durations=100 | tee tests_output.txt
+ fi
- store_artifacts:
path: ~/transformers/tests_output.txt
- store_artifacts:
@@ -281,9 +571,10 @@ jobs:
run_examples_torch:
working_directory: ~/transformers
docker:
- - image: circleci/python:3.6
+ - image: circleci/python:3.7
environment:
OMP_NUM_THREADS: 1
+ TRANSFORMERS_IS_CI: yes
resource_class: xlarge
parallelism: 1
steps:
@@ -292,81 +583,258 @@ jobs:
keys:
- v0.4-torch_examples-{{ checksum "setup.py" }}
- v0.4-{{ checksum "setup.py" }}
+ - run: sudo apt-get -y update && sudo apt-get install -y libsndfile1-dev espeak-ng
- run: pip install --upgrade pip
- - run: pip install .[sklearn,torch,sentencepiece,testing]
- - run: pip install -r examples/_tests_requirements.txt
+ - run: pip install .[sklearn,torch,sentencepiece,testing,torch-speech]
+ - run: pip install -r examples/pytorch/_tests_requirements.txt
- save_cache:
key: v0.4-torch_examples-{{ checksum "setup.py" }}
paths:
- '~/.cache/pip'
- - run: python -m pytest -n 8 --dist=loadfile -s --make-reports=examples_torch ./examples/ | tee examples_output.txt
+ - run: python utils/tests_fetcher.py --filters examples tests | tee test_preparation.txt
+ - store_artifacts:
+ path: ~/transformers/test_preparation.txt
+ - run: |
+ if [ -f test_list.txt ]; then
+ python -m pytest -n 8 --dist=loadfile -s --make-reports=examples_torch ./examples/pytorch/ | tee tests_output.txt
+ fi
- store_artifacts:
path: ~/transformers/examples_output.txt
- store_artifacts:
path: ~/transformers/reports
- run_tests_git_lfs:
+ run_examples_torch_all:
+ working_directory: ~/transformers
+ docker:
+ - image: circleci/python:3.7
+ environment:
+ OMP_NUM_THREADS: 1
+ TRANSFORMERS_IS_CI: yes
+ resource_class: xlarge
+ parallelism: 1
+ steps:
+ - checkout
+ - restore_cache:
+ keys:
+ - v0.4-torch_examples-{{ checksum "setup.py" }}
+ - v0.4-{{ checksum "setup.py" }}
+ - run: sudo apt-get -y update && sudo apt-get install -y libsndfile1-dev espeak-ng
+ - run: pip install --upgrade pip
+ - run: pip install .[sklearn,torch,sentencepiece,testing,torch-speech]
+ - run: pip install -r examples/pytorch/_tests_requirements.txt
+ - save_cache:
+ key: v0.4-torch_examples-{{ checksum "setup.py" }}
+ paths:
+ - '~/.cache/pip'
+ - run: |
+ TRANSFORMERS_IS_CI=1 python -m pytest -n 8 --dist=loadfile -s --make-reports=examples_torch ./examples/pytorch/ | tee examples_output.txt
+ - store_artifacts:
+ path: ~/transformers/examples_output.txt
+ - store_artifacts:
+ path: ~/transformers/reports
+
+ run_examples_flax:
+ working_directory: ~/transformers
+ docker:
+ - image: circleci/python:3.7
+ environment:
+ OMP_NUM_THREADS: 1
+ TRANSFORMERS_IS_CI: yes
+ resource_class: xlarge
+ parallelism: 1
+ steps:
+ - checkout
+ - restore_cache:
+ keys:
+ - v0.4-flax_examples-{{ checksum "setup.py" }}
+ - v0.4-{{ checksum "setup.py" }}
+ - run: pip install --upgrade pip
+ - run: sudo pip install .[flax,testing,sentencepiece]
+ - run: pip install -r examples/flax/_tests_requirements.txt
+ - save_cache:
+ key: v0.4-flax_examples-{{ checksum "setup.py" }}
+ paths:
+ - '~/.cache/pip'
+ - run: python utils/tests_fetcher.py --filters examples tests | tee test_preparation.txt
+ - store_artifacts:
+ path: ~/transformers/test_preparation.txt
+ - run: |
+ if [ -f test_list.txt ]; then
+ python -m pytest -n 8 --dist=loadfile -s --make-reports=examples_flax ./examples/flax/ | tee tests_output.txt
+ fi
+ - store_artifacts:
+ path: ~/transformers/flax_examples_output.txt
+ - store_artifacts:
+ path: ~/transformers/reports
+
+ run_examples_flax_all:
+ working_directory: ~/transformers
+ docker:
+ - image: circleci/python:3.7
+ environment:
+ OMP_NUM_THREADS: 1
+ TRANSFORMERS_IS_CI: yes
+ resource_class: xlarge
+ parallelism: 1
+ steps:
+ - checkout
+ - restore_cache:
+ keys:
+ - v0.4-flax_examples-{{ checksum "setup.py" }}
+ - v0.4-{{ checksum "setup.py" }}
+ - run: pip install --upgrade pip
+ - run: sudo pip install .[flax,testing,sentencepiece]
+ - run: pip install -r examples/flax/_tests_requirements.txt
+ - save_cache:
+ key: v0.4-flax_examples-{{ checksum "setup.py" }}
+ paths:
+ - '~/.cache/pip'
+ - run: |
+ TRANSFORMERS_IS_CI=1 python -m pytest -n 8 --dist=loadfile -s --make-reports=examples_flax ./examples/flax/ | tee examples_output.txt
+ - store_artifacts:
+ path: ~/transformers/flax_examples_output.txt
+ - store_artifacts:
+ path: ~/transformers/reports
+
+ run_tests_hub:
+ working_directory: ~/transformers
+ docker:
+ - image: circleci/python:3.7
+ environment:
+ HUGGINGFACE_CO_STAGING: yes
+ RUN_GIT_LFS_TESTS: yes
+ TRANSFORMERS_IS_CI: yes
+ resource_class: xlarge
+ parallelism: 1
+ steps:
+ - checkout
+ - restore_cache:
+ keys:
+ - v0.4-hub-{{ checksum "setup.py" }}
+ - v0.4-{{ checksum "setup.py" }}
+ - run: sudo apt-get install git-lfs
+ - run: |
+ git config --global user.email "ci@dummy.com"
+ git config --global user.name "ci"
+ - run: pip install --upgrade pip
+ - run: pip install .[torch,sentencepiece,testing]
+ - save_cache:
+ key: v0.4-hub-{{ checksum "setup.py" }}
+ paths:
+ - '~/.cache/pip'
+ - run: python utils/tests_fetcher.py | tee test_preparation.txt
+ - store_artifacts:
+ path: ~/transformers/test_preparation.txt
+ - run: |
+ if [ -f test_list.txt ]; then
+ python -m pytest -sv --make-reports=tests_hub $(cat test_list.txt) -m is_staging_test | tee tests_output.txt
+ fi
+ - store_artifacts:
+ path: ~/transformers/tests_output.txt
+ - store_artifacts:
+ path: ~/transformers/reports
+
+ run_tests_hub_all:
working_directory: ~/transformers
docker:
- image: circleci/python:3.7
+ environment:
+ HUGGINGFACE_CO_STAGING: yes
+ RUN_GIT_LFS_TESTS: yes
+ TRANSFORMERS_IS_CI: yes
resource_class: xlarge
parallelism: 1
steps:
- checkout
+ - restore_cache:
+ keys:
+ - v0.4-hub-{{ checksum "setup.py" }}
+ - v0.4-{{ checksum "setup.py" }}
- run: sudo apt-get install git-lfs
- run: |
git config --global user.email "ci@dummy.com"
git config --global user.name "ci"
- run: pip install --upgrade pip
- - run: pip install .[testing]
- - run: RUN_GIT_LFS_TESTS=1 python -m pytest -sv ./tests/test_hf_api.py -k "HfLargefilesTest"
+ - run: pip install .[torch,sentencepiece,testing]
+ - save_cache:
+ key: v0.4-hub-{{ checksum "setup.py" }}
+ paths:
+ - '~/.cache/pip'
+ - run: |
+ python -m pytest -sv --make-reports=tests_hub tests -m is_staging_test | tee tests_output.txt
+ - store_artifacts:
+ path: ~/transformers/tests_output.txt
+ - store_artifacts:
+ path: ~/transformers/reports
- build_doc:
+ run_tests_onnxruntime:
working_directory: ~/transformers
docker:
- - image: circleci/python:3.6
+ - image: circleci/python:3.7
+ environment:
+ OMP_NUM_THREADS: 1
+ TRANSFORMERS_IS_CI: yes
+ resource_class: xlarge
+ parallelism: 1
steps:
- checkout
- restore_cache:
keys:
- - v0.4-build_doc-{{ checksum "setup.py" }}
+ - v0.4-torch-{{ checksum "setup.py" }}
- v0.4-{{ checksum "setup.py" }}
- - run: sudo apt-get -y update && sudo apt-get install -y libsndfile1-dev
- run: pip install --upgrade pip
- - run: pip install ."[all, docs]"
+ - run: pip install .[torch,testing,sentencepiece,onnxruntime,vision,rjieba]
- save_cache:
- key: v0.4-build_doc-{{ checksum "setup.py" }}
+ key: v0.4-onnx-{{ checksum "setup.py" }}
paths:
- '~/.cache/pip'
- - run: cd docs && make html SPHINXOPTS="-W -j 4"
+ - run: python utils/tests_fetcher.py | tee test_preparation.txt
+ - store_artifacts:
+ path: ~/transformers/test_preparation.txt
+ - run: |
+ if [ -f test_list.txt ]; then
+ python -m pytest -n 1 --dist=loadfile -s --make-reports=tests_onnx $(cat test_list.txt) -k onnx | tee tests_output.txt
+ fi
+ - store_artifacts:
+ path: ~/transformers/tests_output.txt
- store_artifacts:
- path: ./docs/_build
+ path: ~/transformers/reports
- deploy_doc:
+ run_tests_onnxruntime_all:
working_directory: ~/transformers
docker:
- - image: circleci/python:3.6
+ - image: circleci/python:3.7
+ environment:
+ OMP_NUM_THREADS: 1
+ TRANSFORMERS_IS_CI: yes
+ resource_class: xlarge
+ parallelism: 1
steps:
- - add_ssh_keys:
- fingerprints:
- - "5b:7a:95:18:07:8c:aa:76:4c:60:35:88:ad:60:56:71"
- checkout
- restore_cache:
keys:
- - v0.4-deploy_doc-{{ checksum "setup.py" }}
+ - v0.4-torch-{{ checksum "setup.py" }}
- v0.4-{{ checksum "setup.py" }}
- - run: pip install ."[all,docs]"
+ - run: pip install --upgrade pip
+ - run: pip install .[torch,testing,sentencepiece,onnxruntime,vision]
- save_cache:
- key: v0.4-deploy_doc-{{ checksum "setup.py" }}
+ key: v0.4-onnx-{{ checksum "setup.py" }}
paths:
- '~/.cache/pip'
- - run: ./.circleci/deploy.sh
+ - run: |
+ python -m pytest -n 1 --dist=loadfile -s --make-reports=tests_onnx tests -k onnx | tee tests_output.txt
+ - store_artifacts:
+ path: ~/transformers/tests_output.txt
+ - store_artifacts:
+ path: ~/transformers/reports
check_code_quality:
working_directory: ~/transformers
docker:
- - image: circleci/python:3.6
- resource_class: medium
+ - image: circleci/python:3.7
+ resource_class: large
+ environment:
+ TRANSFORMERS_IS_CI: yes
parallelism: 1
steps:
- checkout
@@ -375,7 +843,6 @@ jobs:
- v0.4-code_quality-{{ checksum "setup.py" }}
- v0.4-{{ checksum "setup.py" }}
- run: pip install --upgrade pip
- - run: pip install isort
- run: pip install .[all,quality]
- save_cache:
key: v0.4-code_quality-{{ checksum "setup.py" }}
@@ -383,30 +850,84 @@ jobs:
- '~/.cache/pip'
- run: black --check examples tests src utils
- run: isort --check-only examples tests src utils
+ - run: python utils/custom_init_isort.py --check_only
- run: flake8 examples tests src utils
- - run: python utils/style_doc.py src/transformers docs/source --max_len 119 --check_only
+ - run: doc-builder style src/transformers docs/source --max_len 119 --check_only --path_to_docs docs/source
+
+ check_repository_consistency:
+ working_directory: ~/transformers
+ docker:
+ - image: circleci/python:3.7
+ resource_class: large
+ environment:
+ TRANSFORMERS_IS_CI: yes
+ parallelism: 1
+ steps:
+ - checkout
+ - restore_cache:
+ keys:
+ - v0.4-repository_consistency-{{ checksum "setup.py" }}
+ - v0.4-{{ checksum "setup.py" }}
+ - run: pip install --upgrade pip
+ - run: pip install .[all,quality]
+ - save_cache:
+ key: v0.4-repository_consistency-{{ checksum "setup.py" }}
+ paths:
+ - '~/.cache/pip'
- run: python utils/check_copies.py
- run: python utils/check_table.py
- run: python utils/check_dummies.py
- run: python utils/check_repo.py
+ - run: python utils/check_inits.py
+ - run: python utils/check_config_docstrings.py
+ - run: make deps_table_check_updated
+ - run: python utils/tests_fetcher.py --sanity_check
- check_repository_consistency:
+ run_tests_layoutlmv2:
working_directory: ~/transformers
docker:
- - image: circleci/python:3.6
- resource_class: small
+ - image: circleci/python:3.7
+ environment:
+ OMP_NUM_THREADS: 1
+ TRANSFORMERS_IS_CI: yes
+ resource_class: xlarge
parallelism: 1
steps:
- checkout
- - run: pip install requests
- - run: python ./utils/link_tester.py
+ - restore_cache:
+ keys:
+ - v0.4-torch-{{ checksum "setup.py" }}
+ - v0.4-{{ checksum "setup.py" }}
+ - run: sudo apt-get -y update && sudo apt-get install -y libsndfile1-dev
+ - run: pip install --upgrade pip
+ - run: pip install .[torch,testing,vision]
+ - run: pip install torchvision
+ - run: python -m pip install 'git+https://github.com/facebookresearch/detectron2.git'
+ - run: sudo apt install tesseract-ocr
+ - run: pip install pytesseract
+ - save_cache:
+ key: v0.4-torch-{{ checksum "setup.py" }}
+ paths:
+ - '~/.cache/pip'
+ - run: python utils/tests_fetcher.py | tee test_preparation.txt
+ - store_artifacts:
+ path: ~/transformers/test_preparation.txt
+ - run: |
+ if [ -f test_list.txt ]; then
+ python -m pytest -n 1 tests/models/*layoutlmv2* --dist=loadfile -s --make-reports=tests_layoutlmv2 --durations=100
+ fi
+ - store_artifacts:
+ path: ~/transformers/tests_output.txt
+ - store_artifacts:
+ path: ~/transformers/reports
# TPU JOBS
run_examples_tpu:
docker:
- - image: circleci/python:3.6
+ - image: circleci/python:3.7
environment:
OMP_NUM_THREADS: 1
+ TRANSFORMERS_IS_CI: yes
resource_class: xlarge
parallelism: 1
steps:
@@ -423,7 +944,7 @@ jobs:
cleanup-gke-jobs:
docker:
- - image: circleci/python:3.6
+ - image: circleci/python:3.7
steps:
- gcp-gke/install
- gcp-gke/update-kubeconfig-with-credentials:
@@ -435,7 +956,7 @@ workflow_filters: &workflow_filters
filters:
branches:
only:
- - master
+ - main
workflows:
version: 2
build_and_test:
@@ -443,6 +964,7 @@ workflows:
- check_code_quality
- check_repository_consistency
- run_examples_torch
+ - run_examples_flax
- run_tests_custom_tokenizers
- run_tests_torch_and_tf
- run_tests_torch_and_flax
@@ -451,9 +973,30 @@ workflows:
- run_tests_flax
- run_tests_pipelines_torch
- run_tests_pipelines_tf
- - run_tests_git_lfs
- - build_doc
- - deploy_doc: *workflow_filters
+ - run_tests_onnxruntime
+ - run_tests_hub
+ - run_tests_layoutlmv2
+ nightly:
+ triggers:
+ - schedule:
+ cron: "0 0 * * *"
+ filters:
+ branches:
+ only:
+ - main
+ jobs:
+ - run_examples_torch_all
+ - run_examples_flax_all
+ - run_tests_torch_and_tf_all
+ - run_tests_torch_and_flax_all
+ - run_tests_torch_all
+ - run_tests_tf_all
+ - run_tests_flax_all
+ - run_tests_pipelines_torch_all
+ - run_tests_pipelines_tf_all
+ - run_tests_onnxruntime_all
+ - run_tests_hub_all
+
# tpu_testing_jobs:
# triggers:
# - schedule:
@@ -462,7 +1005,7 @@ workflows:
# filters:
# branches:
# only:
-# - master
+# - main
# jobs:
# - cleanup-gke-jobs
# - run_examples_tpu
diff --git a/.circleci/deploy.sh b/.circleci/deploy.sh
deleted file mode 100755
index 825832ff2feab7..00000000000000
--- a/.circleci/deploy.sh
+++ /dev/null
@@ -1,62 +0,0 @@
-cd docs
-
-function deploy_doc(){
- echo "Creating doc at commit $1 and pushing to folder $2"
- git checkout $1
- pip install -U ..
- if [ ! -z "$2" ]
- then
- if [ "$2" == "master" ]; then
- echo "Pushing master"
- make clean && make html && scp -r -oStrictHostKeyChecking=no _build/html/* $doc:$dir/$2/
- cp -r _build/html/_static .
- elif ssh -oStrictHostKeyChecking=no $doc "[ -d $dir/$2 ]"; then
- echo "Directory" $2 "already exists"
- scp -r -oStrictHostKeyChecking=no _static/* $doc:$dir/$2/_static/
- else
- echo "Pushing version" $2
- make clean && make html
- rm -rf _build/html/_static
- cp -r _static _build/html
- scp -r -oStrictHostKeyChecking=no _build/html $doc:$dir/$2
- fi
- else
- echo "Pushing stable"
- make clean && make html
- rm -rf _build/html/_static
- cp -r _static _build/html
- scp -r -oStrictHostKeyChecking=no _build/html/* $doc:$dir
- fi
-}
-
-# You can find the commit for each tag on https://github.com/huggingface/transformers/tags
-deploy_doc "master" master
-deploy_doc "b33a385" v1.0.0
-deploy_doc "fe02e45" v1.1.0
-deploy_doc "89fd345" v1.2.0
-deploy_doc "fc9faa8" v2.0.0
-deploy_doc "3ddce1d" v2.1.1
-deploy_doc "3616209" v2.2.0
-deploy_doc "d0f8b9a" v2.3.0
-deploy_doc "6664ea9" v2.4.0
-deploy_doc "fb560dc" v2.5.0
-deploy_doc "b90745c" v2.5.1
-deploy_doc "fbc5bf1" v2.6.0
-deploy_doc "6f5a12a" v2.7.0
-deploy_doc "11c3257" v2.8.0
-deploy_doc "e7cfc1a" v2.9.0
-deploy_doc "7cb203f" v2.9.1
-deploy_doc "10d7239" v2.10.0
-deploy_doc "b42586e" v2.11.0
-deploy_doc "7fb8bdf" v3.0.2
-deploy_doc "4b3ee9c" v3.1.0
-deploy_doc "3ebb1b3" v3.2.0
-deploy_doc "0613f05" v3.3.1
-deploy_doc "eb0e0ce" v3.4.0
-deploy_doc "818878d" v3.5.1
-deploy_doc "c781171" v4.0.1
-deploy_doc "bfa4ccf" v4.1.1
-deploy_doc "7d9a9d0" v4.2.2
-deploy_doc "bae0c79" v4.3.3
-deploy_doc "c988db5" v4.4.0
-deploy_doc "c5d6a28" # v4.4.1 Latest stable release
\ No newline at end of file
diff --git a/.github/ISSUE_TEMPLATE/---new-benchmark.md b/.github/ISSUE_TEMPLATE/---new-benchmark.md
deleted file mode 100644
index 9e1c20689e008c..00000000000000
--- a/.github/ISSUE_TEMPLATE/---new-benchmark.md
+++ /dev/null
@@ -1,22 +0,0 @@
----
-name: "\U0001F5A5 New benchmark"
-about: Benchmark a part of this library and share your results
-title: "[Benchmark]"
-labels: ''
-assignees: ''
-
----
-
-# 🖥 Benchmarking `transformers`
-
-## Benchmark
-
-Which part of `transformers` did you benchmark?
-
-## Set-up
-
-What did you run your benchmarks on? Please include details, such as: CPU, GPU? If using multiple GPUs, which parallelization did you use?
-
-## Results
-
-Put your results here!
diff --git a/.github/ISSUE_TEMPLATE/--new-model-addition.md b/.github/ISSUE_TEMPLATE/--new-model-addition.md
deleted file mode 100644
index 938c0f460527c6..00000000000000
--- a/.github/ISSUE_TEMPLATE/--new-model-addition.md
+++ /dev/null
@@ -1,20 +0,0 @@
----
-name: "\U0001F31F New model addition"
-about: Submit a proposal/request to implement a new Transformer-based model
-title: ''
-labels: New model
-assignees: ''
-
----
-
-# 🌟 New model addition
-
-## Model description
-
-
-
-## Open source status
-
-* [ ] the model implementation is available: (give details)
-* [ ] the model weights are available: (give details)
-* [ ] who are the authors: (mention them, if possible by @gh-username)
diff --git a/.github/ISSUE_TEMPLATE/bug-report.md b/.github/ISSUE_TEMPLATE/bug-report.md
deleted file mode 100644
index 7045ba8b19dfba..00000000000000
--- a/.github/ISSUE_TEMPLATE/bug-report.md
+++ /dev/null
@@ -1,94 +0,0 @@
----
-name: "\U0001F41B Bug Report"
-about: Submit a bug report to help us improve transformers
-title: ''
-labels: ''
-assignees: ''
-
----
-
-
-## Environment info
-
-
-- `transformers` version:
-- Platform:
-- Python version:
-- PyTorch version (GPU?):
-- Tensorflow version (GPU?):
-- Using GPU in script?:
-- Using distributed or parallel set-up in script?:
-
-### Who can help
-
-
-## Information
-
-Model I am using (Bert, XLNet ...):
-
-The problem arises when using:
-* [ ] the official example scripts: (give details below)
-* [ ] my own modified scripts: (give details below)
-
-The tasks I am working on is:
-* [ ] an official GLUE/SQUaD task: (give the name)
-* [ ] my own task or dataset: (give details below)
-
-## To reproduce
-
-Steps to reproduce the behavior:
-
-1.
-2.
-3.
-
-
-
-## Expected behavior
-
-
diff --git a/.github/ISSUE_TEMPLATE/bug-report.yml b/.github/ISSUE_TEMPLATE/bug-report.yml
new file mode 100644
index 00000000000000..90811bea1a2731
--- /dev/null
+++ b/.github/ISSUE_TEMPLATE/bug-report.yml
@@ -0,0 +1,121 @@
+name: "\U0001F41B Bug Report"
+description: Submit a bug report to help us import transformers
+labels: [ "bug" ]
+body:
+ - type: textarea
+ id: system-info
+ attributes:
+ label: System Info
+ description: Please share your system info with us. You can run the command `transformers-cli env` and copy-paste its output below.
+ render: shell
+ placeholder: transformers version, platform, python version, ...
+ validations:
+ required: true
+
+ - type: textarea
+ id: who-can-help
+ attributes:
+ label: Who can help?
+ description: |
+ Your issue will be replied to more quickly if you can figure out the right person to tag with @
+ If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
+ Please tag fewer than 3 people.
+
+ Models:
+
+ - ALBERT, BERT, XLM, DeBERTa, DeBERTa-v2, ELECTRA, MobileBert, SqueezeBert: `@LysandreJik`
+ - T5, Pegasus, EncoderDecoder: `@patrickvonplaten`
+ - Blenderbot, MBART, BART, Marian, Pegasus: `@patil-suraj`
+ - Reformer, TransfoXL, XLNet, FNet: `@patrickvonplaten`
+ - Longformer, BigBird: `@ydshieh`
+ - FSMT: `@stas00`
+ - Funnel: `@sgugger`
+ - GPT-2, GPT: `@patil-suraj`, `@patrickvonplaten`, `@LysandreJik`
+ - RAG, DPR: `@patrickvonplaten`, `@lhoestq`
+ - TensorFlow: `@Rocketknight1`
+ - JAX/Flax: `@patil-suraj`
+ - TAPAS, LayoutLM, LayoutLMv2, LUKE, ViT, BEiT, DEiT, DETR, CANINE: `@NielsRogge`
+ - GPT-Neo, GPT-J, CLIP: `@patil-suraj`
+ - Wav2Vec2, HuBERT, UniSpeech, UniSpeechSAT, SEW, SEW-D: `@patrickvonplaten`, `@anton-l`
+ - SpeechEncoderDecoder, Speech2Text, Speech2Text2: `@sanchit-gandhi`, `@patrickvonplaten`, `@anton-l`
+
+ If the model isn't in the list, ping `@LysandreJik` who will redirect you to the correct contributor.
+
+ Library:
+ - Benchmarks: `@patrickvonplaten`
+ - Deepspeed: `@stas00`
+ - Ray/raytune: `@richardliaw`, `@amogkam`
+ - Text generation: `@patrickvonplaten`, `@Narsil`, `@gante`
+ - Tokenizers: `@SaulLu`
+ - Trainer: `@sgugger`
+ - Pipelines: `@Narsil`
+ - Speech: `@patrickvonplaten`, `@anton-l`, `@sanchit-gandhi`
+ - Vision: `@NielsRogge`, `@sgugger`
+
+ Documentation: `@sgugger`, `@stevhliu`
+
+ Model hub:
+
+ - for issues with a model, report at https://discuss.huggingface.co/ and tag the model's creator.
+
+ HF projects:
+
+ - datasets: [different repo](https://github.com/huggingface/datasets)
+ - rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
+
+ Examples:
+
+ - maintained examples (not research project or legacy): `@sgugger`, `@patil-suraj`
+
+ For research projetcs, please ping the contributor directly. For example, on the following projects:
+
+ - research_projects/bert-loses-patience: `@JetRunner`
+ - research_projects/distillation: `@VictorSanh`
+ placeholder: "@Username ..."
+
+ - type: checkboxes
+ id: information-scripts-examples
+ attributes:
+ label: Information
+ description: 'The problem arises when using:'
+ options:
+ - label: "The official example scripts"
+ - label: "My own modified scripts"
+
+ - type: checkboxes
+ id: information-tasks
+ attributes:
+ label: Tasks
+ description: "The tasks I am working on are:"
+ options:
+ - label: "An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)"
+ - label: "My own task or dataset (give details below)"
+
+ - type: textarea
+ id: reproduction
+ validations:
+ required: true
+ attributes:
+ label: Reproduction
+ description: |
+ Please provide a code sample that reproduces the problem you ran into. It can be a Colab link or just a code snippet.
+ If you have code snippets, error messages, stack traces please provide them here as well.
+ Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
+ Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.
+
+ placeholder: |
+ Steps to reproduce the behavior:
+
+ 1.
+ 2.
+ 3.
+
+
+ - type: textarea
+ id: expected-behavior
+ validations:
+ required: true
+ attributes:
+ label: Expected behavior
+ description: "A clear and concise description of what you would expect to happen."
+ render: shell
\ No newline at end of file
diff --git a/.github/ISSUE_TEMPLATE/config.yml b/.github/ISSUE_TEMPLATE/config.yml
new file mode 100644
index 00000000000000..8694e16f749c1c
--- /dev/null
+++ b/.github/ISSUE_TEMPLATE/config.yml
@@ -0,0 +1,9 @@
+blank_issues_enabled: true
+version: 2.1
+contact_links:
+ - name: Website Related
+ url: https://github.com/huggingface/hub-docs/issues
+ about: Feature requests and bug reports related to the website
+ - name: Forum
+ url: https://discuss.huggingface.co/
+ about: General usage questions and community discussions
\ No newline at end of file
diff --git a/.github/ISSUE_TEMPLATE/feature-request.md b/.github/ISSUE_TEMPLATE/feature-request.md
deleted file mode 100644
index 0d5234af32699e..00000000000000
--- a/.github/ISSUE_TEMPLATE/feature-request.md
+++ /dev/null
@@ -1,25 +0,0 @@
----
-name: "\U0001F680 Feature request"
-about: Submit a proposal/request for a new transformers feature
-title: ''
-labels: ''
-assignees: ''
-
----
-
-# 🚀 Feature request
-
-
-
-## Motivation
-
-
-
-## Your contribution
-
-
diff --git a/.github/ISSUE_TEMPLATE/feature-request.yml b/.github/ISSUE_TEMPLATE/feature-request.yml
new file mode 100644
index 00000000000000..318dc1f9b288c2
--- /dev/null
+++ b/.github/ISSUE_TEMPLATE/feature-request.yml
@@ -0,0 +1,31 @@
+name: "\U0001F680 Feature request"
+description: Submit a proposal/request for a new transformers feature
+labels: [ "feature" ]
+body:
+ - type: textarea
+ id: feature-request
+ validations:
+ required: true
+ attributes:
+ label: Feature request
+ description: |
+ A clear and concise description of the feature proposal. Please provide a link to the paper and code in case they exist.
+
+ - type: textarea
+ id: motivation
+ validations:
+ required: true
+ attributes:
+ label: Motivation
+ description: |
+ Please outline the motivation for the proposal. Is your feature request related to a problem? e.g., I'm always frustrated when [...]. If this is related to another GitHub issue, please link here too.
+
+
+ - type: textarea
+ id: contribution
+ validations:
+ required: true
+ attributes:
+ label: Your contribution
+ description: |
+ Is there any way that you could help, e.g. by submitting a PR? Make sure to read the CONTRIBUTING.MD [readme](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md)
diff --git a/.github/ISSUE_TEMPLATE/migration.md b/.github/ISSUE_TEMPLATE/migration.md
deleted file mode 100644
index 2402568cb182ff..00000000000000
--- a/.github/ISSUE_TEMPLATE/migration.md
+++ /dev/null
@@ -1,58 +0,0 @@
----
-name: "\U0001F4DA Migration from pytorch-pretrained-bert or pytorch-transformers"
-about: Report a problem when migrating from pytorch-pretrained-bert or pytorch-transformers
- to transformers
-title: ''
-labels: Migration
-assignees: ''
-
----
-
-# 📚 Migration
-
-## Information
-
-
-
-Model I am using (Bert, XLNet ...):
-
-Language I am using the model on (English, Chinese ...):
-
-The problem arises when using:
-* [ ] the official example scripts: (give details below)
-* [ ] my own modified scripts: (give details below)
-
-The tasks I am working on is:
-* [ ] an official GLUE/SQUaD task: (give the name)
-* [ ] my own task or dataset: (give details below)
-
-## Details
-
-
-
-## Environment info
-
-
-- `transformers` version:
-- Platform:
-- Python version:
-- PyTorch version (GPU?):
-- Tensorflow version (GPU?):
-- Using GPU in script?:
-- Using distributed or parallel set-up in script?:
-
-
-* `pytorch-transformers` or `pytorch-pretrained-bert` version (or branch):
-
-
-## Checklist
-
-- [ ] I have read the migration guide in the readme.
- ([pytorch-transformers](https://github.com/huggingface/transformers#migrating-from-pytorch-transformers-to-transformers);
- [pytorch-pretrained-bert](https://github.com/huggingface/transformers#migrating-from-pytorch-pretrained-bert-to-transformers))
-- [ ] I checked if a related official extension example runs on my machine.
diff --git a/.github/ISSUE_TEMPLATE/migration.yml b/.github/ISSUE_TEMPLATE/migration.yml
new file mode 100644
index 00000000000000..778413141b1f3b
--- /dev/null
+++ b/.github/ISSUE_TEMPLATE/migration.yml
@@ -0,0 +1,72 @@
+name: "\U0001F4DA Migration from pytorch-pretrained-bert or pytorch-transformers"
+description: Report a problem when migrating from pytorch-pretrained-bert or pytorch-transformers to transformers
+labels: [ "migration" ]
+body:
+ - type: textarea
+ id: system-info
+ attributes:
+ label: System Info
+ description: Please share your system info with us. You can run the command `transformers-cli env` and copy-paste its output below.
+ render: shell
+ placeholder: transformers version, platform, python version, ...
+ validations:
+ required: true
+
+ - type: checkboxes
+ id: information-scripts-examples
+ attributes:
+ label: Information
+ description: 'The problem arises when using:'
+ options:
+ - label: "The official example scripts"
+ - label: "My own modified scripts"
+
+ - type: checkboxes
+ id: information-tasks
+ attributes:
+ label: Tasks
+ description: "The tasks I am working on are:"
+ options:
+ - label: "An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)"
+ - label: "My own task or dataset (give details below)"
+
+ - type: textarea
+ id: reproduction
+ validations:
+ required: true
+ attributes:
+ label: Reproduction
+ description: |
+ Please provide a code sample that reproduces the problem you ran into. It can be a Colab link or just a code snippet.
+ If you have code snippets, error messages, stack traces please provide them here as well.
+ Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
+ Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.
+
+ placeholder: |
+ Steps to reproduce the behavior:
+
+ 1.
+ 2.
+ 3.
+
+
+ - type: textarea
+ id: expected-behavior
+ validations:
+ required: true
+ attributes:
+ label: Expected behavior
+ description: "A clear and concise description of what you would expect to happen."
+ render: shell
+
+ - type: checkboxes
+ id: checklist
+ attributes:
+ label: Checklist
+ options:
+ - label: "I have read the migration guide in the readme.
+ ([pytorch-transformers](https://github.com/huggingface/transformers#migrating-from-pytorch-transformers-to-transformers);
+ [pytorch-pretrained-bert](https://github.com/huggingface/transformers#migrating-from-pytorch-pretrained-bert-to-transformers))"
+ required: true
+ - label: "I checked if a related official extension example runs on my machine."
+ required: true
diff --git a/.github/ISSUE_TEMPLATE/new-model-addition.yml b/.github/ISSUE_TEMPLATE/new-model-addition.yml
new file mode 100644
index 00000000000000..2f3476d3ab095f
--- /dev/null
+++ b/.github/ISSUE_TEMPLATE/new-model-addition.yml
@@ -0,0 +1,31 @@
+name: "\U0001F31F New model addition"
+description: Submit a proposal/request to implement a new model
+labels: [ "New model" ]
+
+body:
+ - type: textarea
+ id: description-request
+ validations:
+ required: true
+ attributes:
+ label: Model description
+ description: |
+ Put any and all important information relative to the model
+
+ - type: checkboxes
+ id: information-tasks
+ attributes:
+ label: Open source status
+ description: |
+ Please note that if the model implementation isn't available or if the weights aren't open-source, we are less likely to implement it in `transformers`.
+ options:
+ - label: "The model implementation is available"
+ - label: "The model weights are available"
+
+ - type: textarea
+ id: additional-info
+ attributes:
+ label: Provide useful links for the implementation
+ description: |
+ Please provide information regarding the implementation, the weights, and the authors.
+ Please mention the authors by @gh-username if you're aware of their usernames.
diff --git a/.github/ISSUE_TEMPLATE/question-help.md b/.github/ISSUE_TEMPLATE/question-help.md
deleted file mode 100644
index 87a1a53c1cee22..00000000000000
--- a/.github/ISSUE_TEMPLATE/question-help.md
+++ /dev/null
@@ -1,26 +0,0 @@
----
-name: "❓ Questions & Help"
-about: Post your general questions on the Hugging Face forum: https://discuss.huggingface.co/
-title: ''
-labels: ''
-assignees: ''
-
----
-
-# ❓ Questions & Help
-
-
-
-## Details
-
-
-
-
-
-**A link to original question on the forum**:
-
-
\ No newline at end of file
diff --git a/.github/PULL_REQUEST_TEMPLATE.md b/.github/PULL_REQUEST_TEMPLATE.md
index 77a0a5cb92c977..222f28d5785c42 100644
--- a/.github/PULL_REQUEST_TEMPLATE.md
+++ b/.github/PULL_REQUEST_TEMPLATE.md
@@ -17,20 +17,20 @@ Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
-- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
+- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
- [documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
- [here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
+ [documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
+ [here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
-members/contributors which may be interested in your PR.
+members/contributors who may be interested in your PR.
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+  +
+
+
+
+
+ English |
+ 简体中文 |
+ 繁體中文 |
+ 한국어
+
+
+
+
+
Jax, Pytorch, TensorFlow를 위한 최첨단 자연어처리
+
+
+
+  +
+
+
+🤗 Transformers는 분류, 정보 추출, 질문 답변, 요약, 번역, 문장 생성 등을 100개 이상의 언어로 수행할 수 있는 수천개의 사전학습된 모델을 제공합니다. 우리의 목표는 모두가 최첨단의 NLP 기술을 쉽게 사용하는 것입니다.
+
+🤗 Transformers는 이러한 사전학습 모델을 빠르게 다운로드해 특정 텍스트에 사용하고, 원하는 데이터로 fine-tuning해 커뮤니티나 우리의 [모델 허브](https://huggingface.co/models)에 공유할 수 있도록 API를 제공합니다. 또한, 모델 구조를 정의하는 각 파이썬 모듈은 완전히 독립적이여서 연구 실험을 위해 손쉽게 수정할 수 있습니다.
+
+🤗 Transformers는 가장 유명한 3개의 딥러닝 라이브러리를 지원합니다. 이들은 서로 완벽히 연동됩니다 — [Jax](https://jax.readthedocs.io/en/latest/), [PyTorch](https://pytorch.org/), [TensorFlow](https://www.tensorflow.org/). 간단하게 이 라이브러리 중 하나로 모델을 학습하고, 또 다른 라이브러리로 추론을 위해 모델을 불러올 수 있습니다.
+
+## 온라인 데모
+
+대부분의 모델을 [모델 허브](https://huggingface.co/models) 페이지에서 바로 테스트해볼 수 있습니다. 공개 및 비공개 모델을 위한 [비공개 모델 호스팅, 버전 관리, 추론 API](https://huggingface.co/pricing)도 제공합니다.
+
+예시:
+- [BERT로 마스킹된 단어 완성하기](https://huggingface.co/bert-base-uncased?text=Paris+is+the+%5BMASK%5D+of+France)
+- [Electra를 이용한 개체명 인식](https://huggingface.co/dbmdz/electra-large-discriminator-finetuned-conll03-english?text=My+name+is+Sarah+and+I+live+in+London+city)
+- [GPT-2로 텍스트 생성하기](https://huggingface.co/gpt2?text=A+long+time+ago%2C+)
+- [RoBERTa로 자연어 추론하기](https://huggingface.co/roberta-large-mnli?text=The+dog+was+lost.+Nobody+lost+any+animal)
+- [BART를 이용한 요약](https://huggingface.co/facebook/bart-large-cnn?text=The+tower+is+324+metres+%281%2C063+ft%29+tall%2C+about+the+same+height+as+an+81-storey+building%2C+and+the+tallest+structure+in+Paris.+Its+base+is+square%2C+measuring+125+metres+%28410+ft%29+on+each+side.+During+its+construction%2C+the+Eiffel+Tower+surpassed+the+Washington+Monument+to+become+the+tallest+man-made+structure+in+the+world%2C+a+title+it+held+for+41+years+until+the+Chrysler+Building+in+New+York+City+was+finished+in+1930.+It+was+the+first+structure+to+reach+a+height+of+300+metres.+Due+to+the+addition+of+a+broadcasting+aerial+at+the+top+of+the+tower+in+1957%2C+it+is+now+taller+than+the+Chrysler+Building+by+5.2+metres+%2817+ft%29.+Excluding+transmitters%2C+the+Eiffel+Tower+is+the+second+tallest+free-standing+structure+in+France+after+the+Millau+Viaduct)
+- [DistilBERT를 이용한 질문 답변](https://huggingface.co/distilbert-base-uncased-distilled-squad?text=Which+name+is+also+used+to+describe+the+Amazon+rainforest+in+English%3F&context=The+Amazon+rainforest+%28Portuguese%3A+Floresta+Amaz%C3%B4nica+or+Amaz%C3%B4nia%3B+Spanish%3A+Selva+Amaz%C3%B3nica%2C+Amazon%C3%ADa+or+usually+Amazonia%3B+French%3A+For%C3%AAt+amazonienne%3B+Dutch%3A+Amazoneregenwoud%29%2C+also+known+in+English+as+Amazonia+or+the+Amazon+Jungle%2C+is+a+moist+broadleaf+forest+that+covers+most+of+the+Amazon+basin+of+South+America.+This+basin+encompasses+7%2C000%2C000+square+kilometres+%282%2C700%2C000+sq+mi%29%2C+of+which+5%2C500%2C000+square+kilometres+%282%2C100%2C000+sq+mi%29+are+covered+by+the+rainforest.+This+region+includes+territory+belonging+to+nine+nations.+The+majority+of+the+forest+is+contained+within+Brazil%2C+with+60%25+of+the+rainforest%2C+followed+by+Peru+with+13%25%2C+Colombia+with+10%25%2C+and+with+minor+amounts+in+Venezuela%2C+Ecuador%2C+Bolivia%2C+Guyana%2C+Suriname+and+French+Guiana.+States+or+departments+in+four+nations+contain+%22Amazonas%22+in+their+names.+The+Amazon+represents+over+half+of+the+planet%27s+remaining+rainforests%2C+and+comprises+the+largest+and+most+biodiverse+tract+of+tropical+rainforest+in+the+world%2C+with+an+estimated+390+billion+individual+trees+divided+into+16%2C000+species)
+- [T5로 번역하기](https://huggingface.co/t5-base?text=My+name+is+Wolfgang+and+I+live+in+Berlin)
+
+**[Transformer와 글쓰기](https://transformer.huggingface.co)** 는 이 저장소의 텍스트 생성 능력에 관한 Hugging Face 팀의 공식 데모입니다.
+
+## Hugging Face 팀의 커스텀 지원을 원한다면
+
+
+  +
+
+
+## 퀵 투어
+
+원하는 텍스트에 바로 모델을 사용할 수 있도록, 우리는 `pipeline` API를 제공합니다. Pipeline은 사전학습 모델과 그 모델을 학습할 때 적용한 전처리 방식을 하나로 합칩니다. 다음은 긍정적인 텍스트와 부정적인 텍스트를 분류하기 위해 pipeline을 사용한 간단한 예시입니다:
+
+```python
+>>> from transformers import pipeline
+
+# Allocate a pipeline for sentiment-analysis
+>>> classifier = pipeline('sentiment-analysis')
+>>> classifier('We are very happy to introduce pipeline to the transformers repository.')
+[{'label': 'POSITIVE', 'score': 0.9996980428695679}]
+```
+
+코드의 두번째 줄은 pipeline이 사용하는 사전학습 모델을 다운로드하고 캐시로 저장합니다. 세번째 줄에선 그 모델이 주어진 텍스트를 평가합니다. 여기서 모델은 99.97%의 확률로 텍스트가 긍정적이라고 평가했습니다.
+
+많은 NLP 과제들을 `pipeline`으로 바로 수행할 수 있습니다. 예를 들어, 질문과 문맥이 주어지면 손쉽게 답변을 추출할 수 있습니다:
+
+``` python
+>>> from transformers import pipeline
+
+# Allocate a pipeline for question-answering
+>>> question_answerer = pipeline('question-answering')
+>>> question_answerer({
+... 'question': 'What is the name of the repository ?',
+... 'context': 'Pipeline has been included in the huggingface/transformers repository'
+... })
+{'score': 0.30970096588134766, 'start': 34, 'end': 58, 'answer': 'huggingface/transformers'}
+
+```
+
+답변뿐만 아니라, 여기에 사용된 사전학습 모델은 확신도와 토크나이즈된 문장 속 답변의 시작점, 끝점까지 반환합니다. [이 튜토리얼](https://huggingface.co/docs/transformers/task_summary)에서 `pipeline` API가 지원하는 다양한 과제를 확인할 수 있습니다.
+
+코드 3줄로 원하는 과제에 맞게 사전학습 모델을 다운로드 받고 사용할 수 있습니다. 다음은 PyTorch 버전입니다:
+```python
+>>> from transformers import AutoTokenizer, AutoModel
+
+>>> tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
+>>> model = AutoModel.from_pretrained("bert-base-uncased")
+
+>>> inputs = tokenizer("Hello world!", return_tensors="pt")
+>>> outputs = model(**inputs)
+```
+다음은 TensorFlow 버전입니다:
+```python
+>>> from transformers import AutoTokenizer, TFAutoModel
+
+>>> tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
+>>> model = TFAutoModel.from_pretrained("bert-base-uncased")
+
+>>> inputs = tokenizer("Hello world!", return_tensors="tf")
+>>> outputs = model(**inputs)
+```
+
+토크나이저는 사전학습 모델의 모든 전처리를 책임집니다. 그리고 (위의 예시처럼) 1개의 스트링이나 리스트도 처리할 수 있습니다. 토크나이저는 딕셔너리를 반환하는데, 이는 다운스트림 코드에 사용하거나 언패킹 연산자 ** 를 이용해 모델에 바로 전달할 수도 있습니다.
+
+모델 자체는 일반적으로 사용되는 [Pytorch `nn.Module`](https://pytorch.org/docs/stable/nn.html#torch.nn.Module)나 [TensorFlow `tf.keras.Model`](https://www.tensorflow.org/api_docs/python/tf/keras/Model)입니다. [이 튜토리얼](https://huggingface.co/transformers/training.html)은 이러한 모델을 표준적인 PyTorch나 TensorFlow 학습 과정에서 사용하는 방법, 또는 새로운 데이터로 fine-tune하기 위해 `Trainer` API를 사용하는 방법을 설명해줍니다.
+
+## 왜 transformers를 사용해야 할까요?
+
+1. 손쉽게 사용할 수 있는 최첨단 모델:
+ - NLU와 NLG 과제에서 뛰어난 성능을 보입니다.
+ - 교육자 실무자에게 진입 장벽이 낮습니다.
+ - 3개의 클래스만 배우면 바로 사용할 수 있습니다.
+ - 하나의 API로 모든 사전학습 모델을 사용할 수 있습니다.
+
+1. 더 적은 계산 비용, 더 적은 탄소 발자국:
+ - 연구자들은 모델을 계속 다시 학습시키는 대신 학습된 모델을 공유할 수 있습니다.
+ - 실무자들은 학습에 필요한 시간과 비용을 절약할 수 있습니다.
+ - 수십개의 모델 구조, 2,000개 이상의 사전학습 모델, 100개 이상의 언어로 학습된 모델 등.
+
+1. 모델의 각 생애주기에 적합한 프레임워크:
+ - 코드 3줄로 최첨단 모델을 학습하세요.
+ - 자유롭게 모델을 TF2.0나 PyTorch 프레임워크로 변환하세요.
+ - 학습, 평가, 공개 등 각 단계에 맞는 프레임워크를 원하는대로 선택하세요.
+
+1. 필요한 대로 모델이나 예시를 커스터마이즈하세요:
+ - 우리는 저자가 공개한 결과를 재현하기 위해 각 모델 구조의 예시를 제공합니다.
+ - 모델 내부 구조는 가능한 일관적으로 공개되어 있습니다.
+ - 빠른 실험을 위해 모델 파일은 라이브러리와 독립적으로 사용될 수 있습니다.
+
+## 왜 transformers를 사용하지 말아야 할까요?
+
+- 이 라이브러리는 신경망 블록을 만들기 위한 모듈이 아닙니다. 연구자들이 여러 파일을 살펴보지 않고 바로 각 모델을 사용할 수 있도록, 모델 파일 코드의 추상화 수준을 적정하게 유지했습니다.
+- 학습 API는 모든 모델에 적용할 수 있도록 만들어지진 않았지만, 라이브러리가 제공하는 모델들에 적용할 수 있도록 최적화되었습니다. 일반적인 머신 러닝을 위해선, 다른 라이브러리를 사용하세요.
+- 가능한 많은 사용 예시를 보여드리고 싶어서, [예시 폴더](https://github.com/huggingface/transformers/tree/main/examples)의 스크립트를 준비했습니다. 이 스크립트들을 수정 없이 특정한 문제에 바로 적용하지 못할 수 있습니다. 필요에 맞게 일부 코드를 수정해야 할 수 있습니다.
+
+## 설치
+
+### pip로 설치하기
+
+이 저장소는 Python 3.6+, Flax 0.3.2+, PyTorch 1.3.1+, TensorFlow 2.3+에서 테스트 되었습니다.
+
+[가상 환경](https://docs.python.org/3/library/venv.html)에 🤗 Transformers를 설치하세요. Python 가상 환경에 익숙하지 않다면, [사용자 가이드](https://packaging.python.org/guides/installing-using-pip-and-virtual-environments/)를 확인하세요.
+
+우선, 사용할 Python 버전으로 가상 환경을 만들고 실행하세요.
+
+그 다음, Flax, PyTorch, TensorFlow 중 적어도 하나는 설치해야 합니다.
+플랫폼에 맞는 설치 명령어를 확인하기 위해 [TensorFlow 설치 페이지](https://www.tensorflow.org/install/), [PyTorch 설치 페이지](https://pytorch.org/get-started/locally/#start-locally), [Flax 설치 페이지](https://github.com/google/flax#quick-install)를 확인하세요.
+
+이들 중 적어도 하나가 설치되었다면, 🤗 Transformers는 다음과 같이 pip을 이용해 설치할 수 있습니다:
+
+```bash
+pip install transformers
+```
+
+예시들을 체험해보고 싶거나, 최최최첨단 코드를 원하거나, 새로운 버전이 나올 때까지 기다릴 수 없다면 [라이브러리를 소스에서 바로 설치](https://huggingface.co/docs/transformers/installation#installing-from-source)하셔야 합니다.
+
+### conda로 설치하기
+
+Transformers 버전 v4.0.0부터, conda 채널이 생겼습니다: `huggingface`.
+
+🤗 Transformers는 다음과 같이 conda로 설치할 수 있습니다:
+
+```shell script
+conda install -c huggingface transformers
+```
+
+Flax, PyTorch, TensorFlow 설치 페이지에서 이들을 conda로 설치하는 방법을 확인하세요.
+
+## 모델 구조
+
+**🤗 Transformers가 제공하는 [모든 모델 체크포인트](https://huggingface.co/models)** 는 huggingface.co [모델 허브](https://huggingface.co)에 완벽히 연동되어 있습니다. [개인](https://huggingface.co/users)과 [기관](https://huggingface.co/organizations)이 모델 허브에 직접 업로드할 수 있습니다.
+
+현재 사용 가능한 모델 체크포인트의 개수: 
+
+🤗 Transformers는 다음 모델들을 제공합니다 (각 모델의 요약은 [여기](https://huggingface.co/docs/transformers/model_summary)서 확인하세요):
+
+1. **[ALBERT](https://huggingface.co/docs/transformers/model_doc/albert)** (from Google Research and the Toyota Technological Institute at Chicago) released with the paper [ALBERT: A Lite BERT for Self-supervised Learning of Language Representations](https://arxiv.org/abs/1909.11942), by Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, Radu Soricut.
+1. **[BART](https://huggingface.co/docs/transformers/model_doc/bart)** (from Facebook) released with the paper [BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension](https://arxiv.org/pdf/1910.13461.pdf) by Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov and Luke Zettlemoyer.
+1. **[BARThez](https://huggingface.co/docs/transformers/model_doc/barthez)** (from École polytechnique) released with the paper [BARThez: a Skilled Pretrained French Sequence-to-Sequence Model](https://arxiv.org/abs/2010.12321) by Moussa Kamal Eddine, Antoine J.-P. Tixier, Michalis Vazirgiannis.
+1. **[BARTpho](https://huggingface.co/docs/transformers/model_doc/bartpho)** (from VinAI Research) released with the paper [BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnamese](https://arxiv.org/abs/2109.09701) by Nguyen Luong Tran, Duong Minh Le and Dat Quoc Nguyen.
+1. **[BEiT](https://huggingface.co/docs/transformers/model_doc/beit)** (from Microsoft) released with the paper [BEiT: BERT Pre-Training of Image Transformers](https://arxiv.org/abs/2106.08254) by Hangbo Bao, Li Dong, Furu Wei.
+1. **[BERT](https://huggingface.co/docs/transformers/model_doc/bert)** (from Google) released with the paper [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://arxiv.org/abs/1810.04805) by Jacob Devlin, Ming-Wei Chang, Kenton Lee and Kristina Toutanova.
+1. **[BERT For Sequence Generation](https://huggingface.co/docs/transformers/model_doc/bert-generation)** (from Google) released with the paper [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
+1. **[BERTweet](https://huggingface.co/docs/transformers/model_doc/bertweet)** (from VinAI Research) released with the paper [BERTweet: A pre-trained language model for English Tweets](https://aclanthology.org/2020.emnlp-demos.2/) by Dat Quoc Nguyen, Thanh Vu and Anh Tuan Nguyen.
+1. **[BigBird-Pegasus](https://huggingface.co/docs/transformers/model_doc/bigbird_pegasus)** (from Google Research) released with the paper [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) by Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed.
+1. **[BigBird-RoBERTa](https://huggingface.co/docs/transformers/model_doc/big_bird)** (from Google Research) released with the paper [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) by Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed.
+1. **[Blenderbot](https://huggingface.co/docs/transformers/model_doc/blenderbot)** (from Facebook) released with the paper [Recipes for building an open-domain chatbot](https://arxiv.org/abs/2004.13637) by Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston.
+1. **[BlenderbotSmall](https://huggingface.co/docs/transformers/model_doc/blenderbot-small)** (from Facebook) released with the paper [Recipes for building an open-domain chatbot](https://arxiv.org/abs/2004.13637) by Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston.
+1. **[BORT](https://huggingface.co/docs/transformers/model_doc/bort)** (from Alexa) released with the paper [Optimal Subarchitecture Extraction For BERT](https://arxiv.org/abs/2010.10499) by Adrian de Wynter and Daniel J. Perry.
+1. **[ByT5](https://huggingface.co/docs/transformers/model_doc/byt5)** (from Google Research) released with the paper [ByT5: Towards a token-free future with pre-trained byte-to-byte models](https://arxiv.org/abs/2105.13626) by Linting Xue, Aditya Barua, Noah Constant, Rami Al-Rfou, Sharan Narang, Mihir Kale, Adam Roberts, Colin Raffel.
+1. **[CamemBERT](https://huggingface.co/docs/transformers/model_doc/camembert)** (from Inria/Facebook/Sorbonne) released with the paper [CamemBERT: a Tasty French Language Model](https://arxiv.org/abs/1911.03894) by Louis Martin*, Benjamin Muller*, Pedro Javier Ortiz Suárez*, Yoann Dupont, Laurent Romary, Éric Villemonte de la Clergerie, Djamé Seddah and Benoît Sagot.
+1. **[CANINE](https://huggingface.co/docs/transformers/model_doc/canine)** (from Google Research) released with the paper [CANINE: Pre-training an Efficient Tokenization-Free Encoder for Language Representation](https://arxiv.org/abs/2103.06874) by Jonathan H. Clark, Dan Garrette, Iulia Turc, John Wieting.
+1. **[CLIP](https://huggingface.co/docs/transformers/model_doc/clip)** (from OpenAI) released with the paper [Learning Transferable Visual Models From Natural Language Supervision](https://arxiv.org/abs/2103.00020) by Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever.
+1. **[ConvBERT](https://huggingface.co/docs/transformers/model_doc/convbert)** (from YituTech) released with the paper [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496) by Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan.
+1. **[ConvNeXT](https://huggingface.co/docs/transformers/main/model_doc/convnext)** (from Facebook AI) released with the paper [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) by Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie.
+1. **[CPM](https://huggingface.co/docs/transformers/model_doc/cpm)** (from Tsinghua University) released with the paper [CPM: A Large-scale Generative Chinese Pre-trained Language Model](https://arxiv.org/abs/2012.00413) by Zhengyan Zhang, Xu Han, Hao Zhou, Pei Ke, Yuxian Gu, Deming Ye, Yujia Qin, Yusheng Su, Haozhe Ji, Jian Guan, Fanchao Qi, Xiaozhi Wang, Yanan Zheng, Guoyang Zeng, Huanqi Cao, Shengqi Chen, Daixuan Li, Zhenbo Sun, Zhiyuan Liu, Minlie Huang, Wentao Han, Jie Tang, Juanzi Li, Xiaoyan Zhu, Maosong Sun.
+1. **[CTRL](https://huggingface.co/docs/transformers/model_doc/ctrl)** (from Salesforce) released with the paper [CTRL: A Conditional Transformer Language Model for Controllable Generation](https://arxiv.org/abs/1909.05858) by Nitish Shirish Keskar*, Bryan McCann*, Lav R. Varshney, Caiming Xiong and Richard Socher.
+1. **[Data2Vec](https://huggingface.co/docs/transformers/main/model_doc/data2vec)** (from Facebook) released with the paper [Data2Vec: A General Framework for Self-supervised Learning in Speech, Vision and Language](https://arxiv.org/abs/2202.03555) by Alexei Baevski, Wei-Ning Hsu, Qiantong Xu, Arun Babu, Jiatao Gu, Michael Auli.
+1. **[DeBERTa](https://huggingface.co/docs/transformers/model_doc/deberta)** (from Microsoft) released with the paper [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654) by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
+1. **[DeBERTa-v2](https://huggingface.co/docs/transformers/model_doc/deberta-v2)** (from Microsoft) released with the paper [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654) by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
+1. **[Decision Transformer](https://huggingface.co/docs/transformers/model_doc/decision_transformer)** (from Berkeley/Facebook/Google) released with the paper [Decision Transformer: Reinforcement Learning via Sequence Modeling](https://arxiv.org/abs/2106.01345) by Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Michael Laskin, Pieter Abbeel, Aravind Srinivas, Igor Mordatch.
+1. **[DeiT](https://huggingface.co/docs/transformers/model_doc/deit)** (from Facebook) released with the paper [Training data-efficient image transformers & distillation through attention](https://arxiv.org/abs/2012.12877) by Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, Hervé Jégou.
+1. **[DETR](https://huggingface.co/docs/transformers/model_doc/detr)** (from Facebook) released with the paper [End-to-End Object Detection with Transformers](https://arxiv.org/abs/2005.12872) by Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, Sergey Zagoruyko.
+1. **[DialoGPT](https://huggingface.co/docs/transformers/model_doc/dialogpt)** (from Microsoft Research) released with the paper [DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation](https://arxiv.org/abs/1911.00536) by Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao, Jianfeng Gao, Jingjing Liu, Bill Dolan.
+1. **[DistilBERT](https://huggingface.co/docs/transformers/model_doc/distilbert)** (from HuggingFace), released together with the paper [DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter](https://arxiv.org/abs/1910.01108) by Victor Sanh, Lysandre Debut and Thomas Wolf. The same method has been applied to compress GPT2 into [DistilGPT2](https://github.com/huggingface/transformers/tree/main/examples/distillation), RoBERTa into [DistilRoBERTa](https://github.com/huggingface/transformers/tree/main/examples/distillation), Multilingual BERT into [DistilmBERT](https://github.com/huggingface/transformers/tree/main/examples/distillation) and a German version of DistilBERT.
+1. **[DiT](https://huggingface.co/docs/transformers/model_doc/dit)** (from Microsoft Research) released with the paper [DiT: Self-supervised Pre-training for Document Image Transformer](https://arxiv.org/abs/2203.02378) by Junlong Li, Yiheng Xu, Tengchao Lv, Lei Cui, Cha Zhang, Furu Wei.
+1. **[DPR](https://huggingface.co/docs/transformers/model_doc/dpr)** (from Facebook) released with the paper [Dense Passage Retrieval for Open-Domain Question Answering](https://arxiv.org/abs/2004.04906) by Vladimir Karpukhin, Barlas Oğuz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih.
+1. **[DPT](https://huggingface.co/docs/transformers/master/model_doc/dpt)** (from Intel Labs) released with the paper [Vision Transformers for Dense Prediction](https://arxiv.org/abs/2103.13413) by René Ranftl, Alexey Bochkovskiy, Vladlen Koltun.
+1. **[ELECTRA](https://huggingface.co/docs/transformers/model_doc/electra)** (from Google Research/Stanford University) released with the paper [ELECTRA: Pre-training text encoders as discriminators rather than generators](https://arxiv.org/abs/2003.10555) by Kevin Clark, Minh-Thang Luong, Quoc V. Le, Christopher D. Manning.
+1. **[EncoderDecoder](https://huggingface.co/docs/transformers/model_doc/encoder-decoder)** (from Google Research) released with the paper [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
+1. **[FlauBERT](https://huggingface.co/docs/transformers/model_doc/flaubert)** (from CNRS) released with the paper [FlauBERT: Unsupervised Language Model Pre-training for French](https://arxiv.org/abs/1912.05372) by Hang Le, Loïc Vial, Jibril Frej, Vincent Segonne, Maximin Coavoux, Benjamin Lecouteux, Alexandre Allauzen, Benoît Crabbé, Laurent Besacier, Didier Schwab.
+1. **[FNet](https://huggingface.co/docs/transformers/model_doc/fnet)** (from Google Research) released with the paper [FNet: Mixing Tokens with Fourier Transforms](https://arxiv.org/abs/2105.03824) by James Lee-Thorp, Joshua Ainslie, Ilya Eckstein, Santiago Ontanon.
+1. **[Funnel Transformer](https://huggingface.co/docs/transformers/model_doc/funnel)** (from CMU/Google Brain) released with the paper [Funnel-Transformer: Filtering out Sequential Redundancy for Efficient Language Processing](https://arxiv.org/abs/2006.03236) by Zihang Dai, Guokun Lai, Yiming Yang, Quoc V. Le.
+1. **[GLPN](https://huggingface.co/docs/transformers/main/model_doc/glpn)** (from KAIST) released with the paper [Global-Local Path Networks for Monocular Depth Estimation with Vertical CutDepth](https://arxiv.org/abs/2201.07436) by Doyeon Kim, Woonghyun Ga, Pyungwhan Ahn, Donggyu Joo, Sehwan Chun, Junmo Kim.
+1. **[GPT](https://huggingface.co/docs/transformers/model_doc/openai-gpt)** (from OpenAI) released with the paper [Improving Language Understanding by Generative Pre-Training](https://blog.openai.com/language-unsupervised/) by Alec Radford, Karthik Narasimhan, Tim Salimans and Ilya Sutskever.
+1. **[GPT Neo](https://huggingface.co/docs/transformers/model_doc/gpt_neo)** (from EleutherAI) released in the repository [EleutherAI/gpt-neo](https://github.com/EleutherAI/gpt-neo) by Sid Black, Stella Biderman, Leo Gao, Phil Wang and Connor Leahy.
+1. **[GPT-2](https://huggingface.co/docs/transformers/model_doc/gpt2)** (from OpenAI) released with the paper [Language Models are Unsupervised Multitask Learners](https://blog.openai.com/better-language-models/) by Alec Radford*, Jeffrey Wu*, Rewon Child, David Luan, Dario Amodei** and Ilya Sutskever**.
+1. **[GPT-J](https://huggingface.co/docs/transformers/model_doc/gptj)** (from EleutherAI) released in the repository [kingoflolz/mesh-transformer-jax](https://github.com/kingoflolz/mesh-transformer-jax/) by Ben Wang and Aran Komatsuzaki.
+1. **[Hubert](https://huggingface.co/docs/transformers/model_doc/hubert)** (from Facebook) released with the paper [HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units](https://arxiv.org/abs/2106.07447) by Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, Abdelrahman Mohamed.
+1. **[I-BERT](https://huggingface.co/docs/transformers/model_doc/ibert)** (from Berkeley) released with the paper [I-BERT: Integer-only BERT Quantization](https://arxiv.org/abs/2101.01321) by Sehoon Kim, Amir Gholami, Zhewei Yao, Michael W. Mahoney, Kurt Keutzer.
+1. **[ImageGPT](https://huggingface.co/docs/transformers/main/model_doc/imagegpt)** (from OpenAI) released with the paper [Generative Pretraining from Pixels](https://openai.com/blog/image-gpt/) by Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, Ilya Sutskever.
+1. **[LayoutLM](https://huggingface.co/docs/transformers/model_doc/layoutlm)** (from Microsoft Research Asia) released with the paper [LayoutLM: Pre-training of Text and Layout for Document Image Understanding](https://arxiv.org/abs/1912.13318) by Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou.
+1. **[LayoutLMv2](https://huggingface.co/docs/transformers/model_doc/layoutlmv2)** (from Microsoft Research Asia) released with the paper [LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding](https://arxiv.org/abs/2012.14740) by Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui, Furu Wei, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Wanxiang Che, Min Zhang, Lidong Zhou.
+1. **[LayoutXLM](https://huggingface.co/docs/transformers/model_doc/layoutlmv2)** (from Microsoft Research Asia) released with the paper [LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding](https://arxiv.org/abs/2104.08836) by Yiheng Xu, Tengchao Lv, Lei Cui, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Furu Wei.
+1. **[LED](https://huggingface.co/docs/transformers/model_doc/led)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
+1. **[Longformer](https://huggingface.co/docs/transformers/model_doc/longformer)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
+1. **[LUKE](https://huggingface.co/docs/transformers/model_doc/luke)** (from Studio Ousia) released with the paper [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://arxiv.org/abs/2010.01057) by Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto.
+1. **[LXMERT](https://huggingface.co/docs/transformers/model_doc/lxmert)** (from UNC Chapel Hill) released with the paper [LXMERT: Learning Cross-Modality Encoder Representations from Transformers for Open-Domain Question Answering](https://arxiv.org/abs/1908.07490) by Hao Tan and Mohit Bansal.
+1. **[M2M100](https://huggingface.co/docs/transformers/model_doc/m2m_100)** (from Facebook) released with the paper [Beyond English-Centric Multilingual Machine Translation](https://arxiv.org/abs/2010.11125) by Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi Ma, Ahmed El-Kishky, Siddharth Goyal, Mandeep Baines, Onur Celebi, Guillaume Wenzek, Vishrav Chaudhary, Naman Goyal, Tom Birch, Vitaliy Liptchinsky, Sergey Edunov, Edouard Grave, Michael Auli, Armand Joulin.
+1. **[MarianMT](https://huggingface.co/docs/transformers/model_doc/marian)** Machine translation models trained using [OPUS](http://opus.nlpl.eu/) data by Jörg Tiedemann. The [Marian Framework](https://marian-nmt.github.io/) is being developed by the Microsoft Translator Team.
+1. **[MaskFormer](https://huggingface.co/docs/transformers/main/model_doc/maskformer)** (from Meta and UIUC) released with the paper [Per-Pixel Classification is Not All You Need for Semantic Segmentation](https://arxiv.org/abs/2107.06278) by Bowen Cheng, Alexander G. Schwing, Alexander Kirillov.
+1. **[MBart](https://huggingface.co/docs/transformers/model_doc/mbart)** (from Facebook) released with the paper [Multilingual Denoising Pre-training for Neural Machine Translation](https://arxiv.org/abs/2001.08210) by Yinhan Liu, Jiatao Gu, Naman Goyal, Xian Li, Sergey Edunov, Marjan Ghazvininejad, Mike Lewis, Luke Zettlemoyer.
+1. **[MBart-50](https://huggingface.co/docs/transformers/model_doc/mbart)** (from Facebook) released with the paper [Multilingual Translation with Extensible Multilingual Pretraining and Finetuning](https://arxiv.org/abs/2008.00401) by Yuqing Tang, Chau Tran, Xian Li, Peng-Jen Chen, Naman Goyal, Vishrav Chaudhary, Jiatao Gu, Angela Fan.
+1. **[Megatron-BERT](https://huggingface.co/docs/transformers/model_doc/megatron-bert)** (from NVIDIA) released with the paper [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://arxiv.org/abs/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper and Bryan Catanzaro.
+1. **[Megatron-GPT2](https://huggingface.co/docs/transformers/model_doc/megatron_gpt2)** (from NVIDIA) released with the paper [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://arxiv.org/abs/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper and Bryan Catanzaro.
+1. **[mLUKE](https://huggingface.co/docs/transformers/model_doc/mluke)** (from Studio Ousia) released with the paper [mLUKE: The Power of Entity Representations in Multilingual Pretrained Language Models](https://arxiv.org/abs/2110.08151) by Ryokan Ri, Ikuya Yamada, and Yoshimasa Tsuruoka.
+1. **[MPNet](https://huggingface.co/docs/transformers/model_doc/mpnet)** (from Microsoft Research) released with the paper [MPNet: Masked and Permuted Pre-training for Language Understanding](https://arxiv.org/abs/2004.09297) by Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, Tie-Yan Liu.
+1. **[MT5](https://huggingface.co/docs/transformers/model_doc/mt5)** (from Google AI) released with the paper [mT5: A massively multilingual pre-trained text-to-text transformer](https://arxiv.org/abs/2010.11934) by Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, Colin Raffel.
+1. **[Nyströmformer](https://huggingface.co/docs/transformers/model_doc/nystromformer)** (from the University of Wisconsin - Madison) released with the paper [Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention](https://arxiv.org/abs/2102.03902) by Yunyang Xiong, Zhanpeng Zeng, Rudrasis Chakraborty, Mingxing Tan, Glenn Fung, Yin Li, Vikas Singh.
+1. **[Pegasus](https://huggingface.co/docs/transformers/model_doc/pegasus)** (from Google) released with the paper [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization](https://arxiv.org/abs/1912.08777) by Jingqing Zhang, Yao Zhao, Mohammad Saleh and Peter J. Liu.
+1. **[Perceiver IO](https://huggingface.co/docs/transformers/model_doc/perceiver)** (from Deepmind) released with the paper [Perceiver IO: A General Architecture for Structured Inputs & Outputs](https://arxiv.org/abs/2107.14795) by Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier Hénaff, Matthew M. Botvinick, Andrew Zisserman, Oriol Vinyals, João Carreira.
+1. **[PhoBERT](https://huggingface.co/docs/transformers/model_doc/phobert)** (from VinAI Research) released with the paper [PhoBERT: Pre-trained language models for Vietnamese](https://www.aclweb.org/anthology/2020.findings-emnlp.92/) by Dat Quoc Nguyen and Anh Tuan Nguyen.
+1. **[PLBart](https://huggingface.co/docs/transformers/model_doc/plbart)** (from UCLA NLP) released with the paper [Unified Pre-training for Program Understanding and Generation](https://arxiv.org/abs/2103.06333) by Wasi Uddin Ahmad, Saikat Chakraborty, Baishakhi Ray, Kai-Wei Chang.
+1. **[PoolFormer](https://huggingface.co/docs/transformers/model_doc/poolformer)** (from Sea AI Labs) released with the paper [MetaFormer is Actually What You Need for Vision](https://arxiv.org/abs/2111.11418) by Yu, Weihao and Luo, Mi and Zhou, Pan and Si, Chenyang and Zhou, Yichen and Wang, Xinchao and Feng, Jiashi and Yan, Shuicheng.
+1. **[ProphetNet](https://huggingface.co/docs/transformers/model_doc/prophetnet)** (from Microsoft Research) released with the paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou.
+1. **[QDQBert](https://huggingface.co/docs/transformers/model_doc/qdqbert)** (from NVIDIA) released with the paper [Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation](https://arxiv.org/abs/2004.09602) by Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius Micikevicius.
+1. **[REALM](https://huggingface.co/docs/transformers/model_doc/realm.html)** (from Google Research) released with the paper [REALM: Retrieval-Augmented Language Model Pre-Training](https://arxiv.org/abs/2002.08909) by Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat and Ming-Wei Chang.
+1. **[Reformer](https://huggingface.co/docs/transformers/model_doc/reformer)** (from Google Research) released with the paper [Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451) by Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya.
+1. **[RegNet](https://huggingface.co/docs/transformers/main/model_doc/regnet)** (from META Research) released with the paper [Designing Network Design Space](https://arxiv.org/abs/2003.13678) by Ilija Radosavovic, Raj Prateek Kosaraju, Ross Girshick, Kaiming He, Piotr Dollár.
+1. **[RemBERT](https://huggingface.co/docs/transformers/model_doc/rembert)** (from Google Research) released with the paper [Rethinking embedding coupling in pre-trained language models](https://arxiv.org/pdf/2010.12821.pdf) by Hyung Won Chung, Thibault Févry, Henry Tsai, M. Johnson, Sebastian Ruder.
+1. **[ResNet](https://huggingface.co/docs/transformers/model_doc/resnet)** (from Microsoft Research) released with the paper [Deep Residual Learning for Image Recognition](https://arxiv.org/abs/1512.03385) by Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun.
+1. **[RoBERTa](https://huggingface.co/docs/transformers/model_doc/roberta)** (from Facebook), released together with the paper a [Robustly Optimized BERT Pretraining Approach](https://arxiv.org/abs/1907.11692) by Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov.
+1. **[RoFormer](https://huggingface.co/docs/transformers/model_doc/roformer)** (from ZhuiyiTechnology), released together with the paper a [RoFormer: Enhanced Transformer with Rotary Position Embedding](https://arxiv.org/pdf/2104.09864v1.pdf) by Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu.
+1. **[SegFormer](https://huggingface.co/docs/transformers/model_doc/segformer)** (from NVIDIA) released with the paper [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://arxiv.org/abs/2105.15203) by Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, Ping Luo.
+1. **[SEW](https://huggingface.co/docs/transformers/model_doc/sew)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
+1. **[SEW-D](https://huggingface.co/docs/transformers/model_doc/sew_d)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
+1. **[SpeechToTextTransformer](https://huggingface.co/docs/transformers/model_doc/speech_to_text)** (from Facebook), released together with the paper [fairseq S2T: Fast Speech-to-Text Modeling with fairseq](https://arxiv.org/abs/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Dmytro Okhonko, Juan Pino.
+1. **[SpeechToTextTransformer2](https://huggingface.co/docs/transformers/model_doc/speech_to_text_2)** (from Facebook), released together with the paper [Large-Scale Self- and Semi-Supervised Learning for Speech Translation](https://arxiv.org/abs/2104.06678) by Changhan Wang, Anne Wu, Juan Pino, Alexei Baevski, Michael Auli, Alexis Conneau.
+1. **[Splinter](https://huggingface.co/docs/transformers/model_doc/splinter)** (from Tel Aviv University), released together with the paper [Few-Shot Question Answering by Pretraining Span Selection](https://arxiv.org/abs/2101.00438) by Ori Ram, Yuval Kirstain, Jonathan Berant, Amir Globerson, Omer Levy.
+1. **[SqueezeBert](https://huggingface.co/docs/transformers/model_doc/squeezebert)** (from Berkeley) released with the paper [SqueezeBERT: What can computer vision teach NLP about efficient neural networks?](https://arxiv.org/abs/2006.11316) by Forrest N. Iandola, Albert E. Shaw, Ravi Krishna, and Kurt W. Keutzer.
+1. **[Swin Transformer](https://huggingface.co/docs/transformers/model_doc/swin)** (from Microsoft) released with the paper [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030) by Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo.
+1. **[T5](https://huggingface.co/docs/transformers/model_doc/t5)** (from Google AI) released with the paper [Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer](https://arxiv.org/abs/1910.10683) by Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu.
+1. **[T5v1.1](https://huggingface.co/docs/transformers/model_doc/t5v1.1)** (from Google AI) released in the repository [google-research/text-to-text-transfer-transformer](https://github.com/google-research/text-to-text-transfer-transformer/blob/main/released_checkpoints.md#t511) by Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu.
+1. **[TAPAS](https://huggingface.co/docs/transformers/model_doc/tapas)** (from Google AI) released with the paper [TAPAS: Weakly Supervised Table Parsing via Pre-training](https://arxiv.org/abs/2004.02349) by Jonathan Herzig, Paweł Krzysztof Nowak, Thomas Müller, Francesco Piccinno and Julian Martin Eisenschlos.
+1. **[TAPEX](https://huggingface.co/docs/transformers/main/model_doc/tapex)** (from Microsoft Research) released with the paper [TAPEX: Table Pre-training via Learning a Neural SQL Executor](https://arxiv.org/abs/2107.07653) by Qian Liu, Bei Chen, Jiaqi Guo, Morteza Ziyadi, Zeqi Lin, Weizhu Chen, Jian-Guang Lou.
+1. **[Transformer-XL](https://huggingface.co/docs/transformers/model_doc/transfo-xl)** (from Google/CMU) released with the paper [Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context](https://arxiv.org/abs/1901.02860) by Zihang Dai*, Zhilin Yang*, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan Salakhutdinov.
+1. **[TrOCR](https://huggingface.co/docs/transformers/model_doc/trocr)** (from Microsoft), released together with the paper [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282) by Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, Furu Wei.
+1. **[UniSpeech](https://huggingface.co/docs/transformers/model_doc/unispeech)** (from Microsoft Research) released with the paper [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597) by Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang.
+1. **[UniSpeechSat](https://huggingface.co/docs/transformers/model_doc/unispeech-sat)** (from Microsoft Research) released with the paper [UNISPEECH-SAT: UNIVERSAL SPEECH REPRESENTATION LEARNING WITH SPEAKER AWARE PRE-TRAINING](https://arxiv.org/abs/2110.05752) by Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen, Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu.
+1. **[VAN](https://huggingface.co/docs/transformers/model_doc/van)** (from Tsinghua University and Nankai University) released with the paper [Visual Attention Network](https://arxiv.org/pdf/2202.09741.pdf) by Meng-Hao Guo, Cheng-Ze Lu, Zheng-Ning Liu, Ming-Ming Cheng, Shi-Min Hu.
+1. **[ViLT](https://huggingface.co/docs/transformers/model_doc/vilt)** (from NAVER AI Lab/Kakao Enterprise/Kakao Brain) released with the paper [ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision](https://arxiv.org/abs/2102.03334) by Wonjae Kim, Bokyung Son, Ildoo Kim.
+1. **[Vision Transformer (ViT)](https://huggingface.co/docs/transformers/model_doc/vit)** (from Google AI) released with the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby.
+1. **[VisualBERT](https://huggingface.co/docs/transformers/model_doc/visual_bert)** (from UCLA NLP) released with the paper [VisualBERT: A Simple and Performant Baseline for Vision and Language](https://arxiv.org/pdf/1908.03557) by Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, Kai-Wei Chang.
+1. **[ViTMAE](https://huggingface.co/docs/transformers/model_doc/vit_mae)** (from Meta AI) released with the paper [Masked Autoencoders Are Scalable Vision Learners](https://arxiv.org/abs/2111.06377) by Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, Ross Girshick.
+1. **[Wav2Vec2](https://huggingface.co/docs/transformers/model_doc/wav2vec2)** (from Facebook AI) released with the paper [wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations](https://arxiv.org/abs/2006.11477) by Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli.
+1. **[Wav2Vec2Phoneme](https://huggingface.co/docs/transformers/model_doc/wav2vec2_phoneme)** (from Facebook AI) released with the paper [Simple and Effective Zero-shot Cross-lingual Phoneme Recognition](https://arxiv.org/abs/2109.11680) by Qiantong Xu, Alexei Baevski, Michael Auli.
+1. **[WavLM](https://huggingface.co/docs/transformers/model_doc/wavlm)** (from Microsoft Research) released with the paper [WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing](https://arxiv.org/abs/2110.13900) by Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, Jian Wu, Long Zhou, Shuo Ren, Yanmin Qian, Yao Qian, Jian Wu, Michael Zeng, Furu Wei.
+1. **[XGLM](https://huggingface.co/docs/transformers/model_doc/xglm)** (From Facebook AI) released with the paper [Few-shot Learning with Multilingual Language Models](https://arxiv.org/abs/2112.10668) by Xi Victoria Lin, Todor Mihaylov, Mikel Artetxe, Tianlu Wang, Shuohui Chen, Daniel Simig, Myle Ott, Naman Goyal, Shruti Bhosale, Jingfei Du, Ramakanth Pasunuru, Sam Shleifer, Punit Singh Koura, Vishrav Chaudhary, Brian O'Horo, Jeff Wang, Luke Zettlemoyer, Zornitsa Kozareva, Mona Diab, Veselin Stoyanov, Xian Li.
+1. **[XLM](https://huggingface.co/docs/transformers/model_doc/xlm)** (from Facebook) released together with the paper [Cross-lingual Language Model Pretraining](https://arxiv.org/abs/1901.07291) by Guillaume Lample and Alexis Conneau.
+1. **[XLM-ProphetNet](https://huggingface.co/docs/transformers/model_doc/xlm-prophetnet)** (from Microsoft Research) released with the paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou.
+1. **[XLM-RoBERTa](https://huggingface.co/docs/transformers/model_doc/xlm-roberta)** (from Facebook AI), released together with the paper [Unsupervised Cross-lingual Representation Learning at Scale](https://arxiv.org/abs/1911.02116) by Alexis Conneau*, Kartikay Khandelwal*, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzmán, Edouard Grave, Myle Ott, Luke Zettlemoyer and Veselin Stoyanov.
+1. **[XLM-RoBERTa-XL](https://huggingface.co/docs/transformers/model_doc/xlm-roberta-xl)** (from Facebook AI) released with the paper [Larger-Scale Transformers for Multilingual Masked Language Modeling](https://arxiv.org/abs/2105.00572) by Naman Goyal, Jingfei Du, Myle Ott, Giri Anantharaman, Alexis Conneau.
+1. **[XLNet](https://huggingface.co/docs/transformers/model_doc/xlnet)** (from Google/CMU) released with the paper [XLNet: Generalized Autoregressive Pretraining for Language Understanding](https://arxiv.org/abs/1906.08237) by Zhilin Yang*, Zihang Dai*, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, Quoc V. Le.
+1. **[XLS-R](https://huggingface.co/docs/transformers/model_doc/xls_r)** (from Facebook AI) released with the paper [XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale](https://arxiv.org/abs/2111.09296) by Arun Babu, Changhan Wang, Andros Tjandra, Kushal Lakhotia, Qiantong Xu, Naman Goyal, Kritika Singh, Patrick von Platen, Yatharth Saraf, Juan Pino, Alexei Baevski, Alexis Conneau, Michael Auli.
+1. **[XLSR-Wav2Vec2](https://huggingface.co/docs/transformers/model_doc/xlsr_wav2vec2)** (from Facebook AI) released with the paper [Unsupervised Cross-Lingual Representation Learning For Speech Recognition](https://arxiv.org/abs/2006.13979) by Alexis Conneau, Alexei Baevski, Ronan Collobert, Abdelrahman Mohamed, Michael Auli.
+1. **[YOLOS](https://huggingface.co/docs/transformers/main/model_doc/yolos)** (from Huazhong University of Science & Technology) released with the paper [You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection](https://arxiv.org/abs/2106.00666) by Yuxin Fang, Bencheng Liao, Xinggang Wang, Jiemin Fang, Jiyang Qi, Rui Wu, Jianwei Niu, Wenyu Liu.
+1. **[YOSO](https://huggingface.co/docs/transformers/model_doc/yoso)** (from the University of Wisconsin - Madison) released with the paper [You Only Sample (Almost) by Zhanpeng Zeng, Yunyang Xiong, Sathya N. Ravi, Shailesh Acharya, Glenn Fung, Vikas Singh.
+1. 새로운 모델을 올리고 싶나요? 우리가 **상세한 가이드와 템플릿** 으로 새로운 모델을 올리도록 도와드릴게요. 가이드와 템플릿은 이 저장소의 [`templates`](./templates) 폴더에서 확인하실 수 있습니다. [컨트리뷰션 가이드라인](./CONTRIBUTING.md)을 꼭 확인해주시고, PR을 올리기 전에 메인테이너에게 연락하거나 이슈를 오픈해 피드백을 받으시길 바랍니다.
+
+각 모델이 Flax, PyTorch, TensorFlow으로 구현되었는지 또는 🤗 Tokenizers 라이브러리가 지원하는 토크나이저를 사용하는지 확인하려면, [이 표](https://huggingface.co/docs/transformers/index#supported-frameworks)를 확인하세요.
+
+이 구현은 여러 데이터로 검증되었고 (예시 스크립트를 참고하세요) 오리지널 구현의 성능과 같아야 합니다. [도큐먼트](https://huggingface.co/docs/transformers/examples)의 Examples 섹션에서 성능에 대한 자세한 설명을 확인할 수 있습니다.
+
+## 더 알아보기
+
+| 섹션 | 설명 |
+|-|-|
+| [도큐먼트](https://huggingface.co/transformers/) | 전체 API 도큐먼트와 튜토리얼 |
+| [과제 요약](https://huggingface.co/docs/transformers/task_summary) | 🤗 Transformers가 지원하는 과제들 |
+| [전처리 튜토리얼](https://huggingface.co/docs/transformers/preprocessing) | `Tokenizer` 클래스를 이용해 모델을 위한 데이터 준비하기 |
+| [학습과 fine-tuning](https://huggingface.co/docs/transformers/training) | 🤗 Transformers가 제공하는 모델 PyTorch/TensorFlow 학습 과정과 `Trainer` API에서 사용하기 |
+| [퀵 투어: Fine-tuning/사용 스크립트](https://github.com/huggingface/transformers/tree/main/examples) | 다양한 과제에서 모델 fine-tuning하는 예시 스크립트 |
+| [모델 공유 및 업로드](https://huggingface.co/docs/transformers/model_sharing) | 커뮤니티에 fine-tune된 모델을 업로드 및 공유하기 |
+| [마이그레이션](https://huggingface.co/docs/transformers/migration) | `pytorch-transformers`나 `pytorch-pretrained-bert`에서 🤗 Transformers로 이동하기|
+
+## 인용
+
+🤗 Transformers 라이브러리를 인용하고 싶다면, 이 [논문](https://www.aclweb.org/anthology/2020.emnlp-demos.6/)을 인용해 주세요:
+```bibtex
+@inproceedings{wolf-etal-2020-transformers,
+ title = "Transformers: State-of-the-Art Natural Language Processing",
+ author = "Thomas Wolf and Lysandre Debut and Victor Sanh and Julien Chaumond and Clement Delangue and Anthony Moi and Pierric Cistac and Tim Rault and Rémi Louf and Morgan Funtowicz and Joe Davison and Sam Shleifer and Patrick von Platen and Clara Ma and Yacine Jernite and Julien Plu and Canwen Xu and Teven Le Scao and Sylvain Gugger and Mariama Drame and Quentin Lhoest and Alexander M. Rush",
+ booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations",
+ month = oct,
+ year = "2020",
+ address = "Online",
+ publisher = "Association for Computational Linguistics",
+ url = "https://www.aclweb.org/anthology/2020.emnlp-demos.6",
+ pages = "38--45"
+}
+```
diff --git a/README_zh-hans.md b/README_zh-hans.md
new file mode 100644
index 00000000000000..ca2c612f8d1199
--- /dev/null
+++ b/README_zh-hans.md
@@ -0,0 +1,381 @@
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ English |
+ 简体中文 |
+ 繁體中文 |
+ 한국어
+
+
+
+
+
为 Jax、PyTorch 和 TensorFlow 打造的先进的自然语言处理
+
+
+
+
+
+
+🤗 Transformers 提供了数以千计的预训练模型,支持 100 多种语言的文本分类、信息抽取、问答、摘要、翻译、文本生成。它的宗旨让最先进的 NLP 技术人人易用。
+
+🤗 Transformers 提供了便于快速下载和使用的API,让你可以把预训练模型用在给定文本、在你的数据集上微调然后通过 [model hub](https://huggingface.co/models) 与社区共享。同时,每个定义的 Python 模块均完全独立,方便修改和快速研究实验。
+
+🤗 Transformers 支持三个最热门的深度学习库: [Jax](https://jax.readthedocs.io/en/latest/), [PyTorch](https://pytorch.org/) and [TensorFlow](https://www.tensorflow.org/) — 并与之无缝整合。你可以直接使用一个框架训练你的模型然后用另一个加载和推理。
+
+## 在线演示
+
+你可以直接在模型页面上测试大多数 [model hub](https://huggingface.co/models) 上的模型。 我们也提供了 [私有模型托管、模型版本管理以及推理API](https://huggingface.co/pricing)。
+
+这里是一些例子:
+- [用 BERT 做掩码填词](https://huggingface.co/bert-base-uncased?text=Paris+is+the+%5BMASK%5D+of+France)
+- [用 Electra 做命名实体识别](https://huggingface.co/dbmdz/electra-large-discriminator-finetuned-conll03-english?text=My+name+is+Sarah+and+I+live+in+London+city)
+- [用 GPT-2 做文本生成](https://huggingface.co/gpt2?text=A+long+time+ago%2C+)
+- [用 RoBERTa 做自然语言推理](https://huggingface.co/roberta-large-mnli?text=The+dog+was+lost.+Nobody+lost+any+animal)
+- [用 BART 做文本摘要](https://huggingface.co/facebook/bart-large-cnn?text=The+tower+is+324+metres+%281%2C063+ft%29+tall%2C+about+the+same+height+as+an+81-storey+building%2C+and+the+tallest+structure+in+Paris.+Its+base+is+square%2C+measuring+125+metres+%28410+ft%29+on+each+side.+During+its+construction%2C+the+Eiffel+Tower+surpassed+the+Washington+Monument+to+become+the+tallest+man-made+structure+in+the+world%2C+a+title+it+held+for+41+years+until+the+Chrysler+Building+in+New+York+City+was+finished+in+1930.+It+was+the+first+structure+to+reach+a+height+of+300+metres.+Due+to+the+addition+of+a+broadcasting+aerial+at+the+top+of+the+tower+in+1957%2C+it+is+now+taller+than+the+Chrysler+Building+by+5.2+metres+%2817+ft%29.+Excluding+transmitters%2C+the+Eiffel+Tower+is+the+second+tallest+free-standing+structure+in+France+after+the+Millau+Viaduct)
+- [用 DistilBERT 做问答](https://huggingface.co/distilbert-base-uncased-distilled-squad?text=Which+name+is+also+used+to+describe+the+Amazon+rainforest+in+English%3F&context=The+Amazon+rainforest+%28Portuguese%3A+Floresta+Amaz%C3%B4nica+or+Amaz%C3%B4nia%3B+Spanish%3A+Selva+Amaz%C3%B3nica%2C+Amazon%C3%ADa+or+usually+Amazonia%3B+French%3A+For%C3%AAt+amazonienne%3B+Dutch%3A+Amazoneregenwoud%29%2C+also+known+in+English+as+Amazonia+or+the+Amazon+Jungle%2C+is+a+moist+broadleaf+forest+that+covers+most+of+the+Amazon+basin+of+South+America.+This+basin+encompasses+7%2C000%2C000+square+kilometres+%282%2C700%2C000+sq+mi%29%2C+of+which+5%2C500%2C000+square+kilometres+%282%2C100%2C000+sq+mi%29+are+covered+by+the+rainforest.+This+region+includes+territory+belonging+to+nine+nations.+The+majority+of+the+forest+is+contained+within+Brazil%2C+with+60%25+of+the+rainforest%2C+followed+by+Peru+with+13%25%2C+Colombia+with+10%25%2C+and+with+minor+amounts+in+Venezuela%2C+Ecuador%2C+Bolivia%2C+Guyana%2C+Suriname+and+French+Guiana.+States+or+departments+in+four+nations+contain+%22Amazonas%22+in+their+names.+The+Amazon+represents+over+half+of+the+planet%27s+remaining+rainforests%2C+and+comprises+the+largest+and+most+biodiverse+tract+of+tropical+rainforest+in+the+world%2C+with+an+estimated+390+billion+individual+trees+divided+into+16%2C000+species)
+- [用 T5 做翻译](https://huggingface.co/t5-base?text=My+name+is+Wolfgang+and+I+live+in+Berlin)
+
+**[Write With Transformer](https://transformer.huggingface.co)**,由抱抱脸团队打造,是一个文本生成的官方 demo。
+
+## 如果你在寻找由抱抱脸团队提供的定制化支持服务
+
+
+
+
+
+## 快速上手
+
+我们为快速使用模型提供了 `pipeline` (流水线)API。流水线聚合了预训练模型和对应的文本预处理。下面是一个快速使用流水线去判断正负面情绪的例子:
+
+```python
+>>> from transformers import pipeline
+
+# 使用情绪分析流水线
+>>> classifier = pipeline('sentiment-analysis')
+>>> classifier('We are very happy to introduce pipeline to the transformers repository.')
+[{'label': 'POSITIVE', 'score': 0.9996980428695679}]
+```
+
+第二行代码下载并缓存了流水线使用的预训练模型,而第三行代码则在给定的文本上进行了评估。这里的答案“正面” (positive) 具有 99 的置信度。
+
+许多的 NLP 任务都有开箱即用的预训练流水线。比如说,我们可以轻松的从给定文本中抽取问题答案:
+
+``` python
+>>> from transformers import pipeline
+
+# 使用问答流水线
+>>> question_answerer = pipeline('question-answering')
+>>> question_answerer({
+... 'question': 'What is the name of the repository ?',
+... 'context': 'Pipeline has been included in the huggingface/transformers repository'
+... })
+{'score': 0.30970096588134766, 'start': 34, 'end': 58, 'answer': 'huggingface/transformers'}
+
+```
+
+除了给出答案,预训练模型还给出了对应的置信度分数、答案在词符化 (tokenized) 后的文本中开始和结束的位置。你可以从[这个教程](https://huggingface.co/docs/transformers/task_summary)了解更多流水线API支持的任务。
+
+要在你的任务上下载和使用任意预训练模型也很简单,只需三行代码。这里是 PyTorch 版的示例:
+```python
+>>> from transformers import AutoTokenizer, AutoModel
+
+>>> tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
+>>> model = AutoModel.from_pretrained("bert-base-uncased")
+
+>>> inputs = tokenizer("Hello world!", return_tensors="pt")
+>>> outputs = model(**inputs)
+```
+这里是等效的 TensorFlow 代码:
+```python
+>>> from transformers import AutoTokenizer, TFAutoModel
+
+>>> tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
+>>> model = TFAutoModel.from_pretrained("bert-base-uncased")
+
+>>> inputs = tokenizer("Hello world!", return_tensors="tf")
+>>> outputs = model(**inputs)
+```
+
+词符化器 (tokenizer) 为所有的预训练模型提供了预处理,并可以直接对单个字符串进行调用(比如上面的例子)或对列表 (list) 调用。它会输出一个你可以在下游代码里使用或直接通过 `**` 解包表达式传给模型的词典 (dict)。
+
+模型本身是一个常规的 [Pytorch `nn.Module`](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) 或 [TensorFlow `tf.keras.Model`](https://www.tensorflow.org/api_docs/python/tf/keras/Model)(取决于你的后端),可以常规方式使用。 [这个教程](https://huggingface.co/transformers/training.html)解释了如何将这样的模型整合到经典的 PyTorch 或 TensorFlow 训练循环中,或是如何使用我们的 `Trainer` 训练器)API 来在一个新的数据集上快速微调。
+
+## 为什么要用 transformers?
+
+1. 便于使用的先进模型:
+ - NLU 和 NLG 上表现优越
+ - 对教学和实践友好且低门槛
+ - 高级抽象,只需了解三个类
+ - 对所有模型统一的API
+
+1. 更低计算开销,更少的碳排放:
+ - 研究人员可以分享亿训练的模型而非次次从头开始训练
+ - 工程师可以减少计算用时和生产环境开销
+ - 数十种模型架构、两千多个预训练模型、100多种语言支持
+
+1. 对于模型生命周期的每一个部分都面面俱到:
+ - 训练先进的模型,只需 3 行代码
+ - 模型在不同深度学习框架间任意转移,随你心意
+ - 为训练、评估和生产选择最适合的框架,衔接无缝
+
+1. 为你的需求轻松定制专属模型和用例:
+ - 我们为每种模型架构提供了多个用例来复现原论文结果
+ - 模型内部结构保持透明一致
+ - 模型文件可单独使用,方便魔改和快速实验
+
+## 什么情况下我不该用 transformers?
+
+- 本库并不是模块化的神经网络工具箱。模型文件中的代码特意呈若璞玉,未经额外抽象封装,以便研究人员快速迭代魔改而不致溺于抽象和文件跳转之中。
+- `Trainer` API 并非兼容任何模型,只为本库之模型优化。若是在寻找适用于通用机器学习的训练循环实现,请另觅他库。
+- 尽管我们已尽力而为,[examples 目录](https://github.com/huggingface/transformers/tree/main/examples)中的脚本也仅为用例而已。对于你的特定问题,它们并不一定开箱即用,可能需要改几行代码以适之。
+
+## 安装
+
+### 使用 pip
+
+这个仓库已在 Python 3.6+、Flax 0.3.2+、PyTorch 1.3.1+ 和 TensorFlow 2.3+ 下经过测试。
+
+你可以在[虚拟环境](https://docs.python.org/3/library/venv.html)中安装 🤗 Transformers。如果你还不熟悉 Python 的虚拟环境,请阅此[用户说明](https://packaging.python.org/guides/installing-using-pip-and-virtual-environments/)。
+
+首先,用你打算使用的版本的 Python 创建一个虚拟环境并激活。
+
+然后,你需要安装 Flax、PyTorch 或 TensorFlow 其中之一。关于在你使用的平台上安装这些框架,请参阅 [TensorFlow 安装页](https://www.tensorflow.org/install/), [PyTorch 安装页](https://pytorch.org/get-started/locally/#start-locally) 或 [Flax 安装页](https://github.com/google/flax#quick-install)。
+
+当这些后端之一安装成功后, 🤗 Transformers 可依此安装:
+
+```bash
+pip install transformers
+```
+
+如果你想要试试用例或者想在正式发布前使用最新的开发中代码,你得[从源代码安装](https://huggingface.co/docs/transformers/installation#installing-from-source)。
+
+### 使用 conda
+
+自 Transformers 4.0.0 版始,我们有了一个 conda 频道: `huggingface`。
+
+🤗 Transformers 可以通过 conda 依此安装:
+
+```shell script
+conda install -c huggingface transformers
+```
+
+要通过 conda 安装 Flax、PyTorch 或 TensorFlow 其中之一,请参阅它们各自安装页的说明。
+
+## 模型架构
+
+🤗 Transformers 支持的[**所有的模型检查点**](https://huggingface.co/models)由[用户](https://huggingface.co/users)和[组织](https://huggingface.co/organizations)上传,均与 huggingface.co [model hub](https://huggingface.co) 无缝整合。
+
+目前的检查点数量: 
+
+🤗 Transformers 目前支持如下的架构(模型概述请阅[这里](https://huggingface.co/docs/transformers/model_summary)):
+
+1. **[ALBERT](https://huggingface.co/docs/transformers/model_doc/albert)** (来自 Google Research and the Toyota Technological Institute at Chicago) 伴随论文 [ALBERT: A Lite BERT for Self-supervised Learning of Language Representations](https://arxiv.org/abs/1909.11942), 由 Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, Radu Soricut 发布。
+1. **[BART](https://huggingface.co/docs/transformers/model_doc/bart)** (来自 Facebook) 伴随论文 [BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension](https://arxiv.org/pdf/1910.13461.pdf) 由 Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov and Luke Zettlemoyer 发布。
+1. **[BARThez](https://huggingface.co/docs/transformers/model_doc/barthez)** (来自 École polytechnique) 伴随论文 [BARThez: a Skilled Pretrained French Sequence-to-Sequence Model](https://arxiv.org/abs/2010.12321) 由 Moussa Kamal Eddine, Antoine J.-P. Tixier, Michalis Vazirgiannis 发布。
+1. **[BARTpho](https://huggingface.co/docs/transformers/model_doc/bartpho)** (来自 VinAI Research) 伴随论文 [BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnamese](https://arxiv.org/abs/2109.09701) 由 Nguyen Luong Tran, Duong Minh Le and Dat Quoc Nguyen 发布。
+1. **[BEiT](https://huggingface.co/docs/transformers/model_doc/beit)** (来自 Microsoft) 伴随论文 [BEiT: BERT Pre-Training of Image Transformers](https://arxiv.org/abs/2106.08254) 由 Hangbo Bao, Li Dong, Furu Wei 发布。
+1. **[BERT](https://huggingface.co/docs/transformers/model_doc/bert)** (来自 Google) 伴随论文 [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://arxiv.org/abs/1810.04805) 由 Jacob Devlin, Ming-Wei Chang, Kenton Lee and Kristina Toutanova 发布。
+1. **[BERT For Sequence Generation](https://huggingface.co/docs/transformers/model_doc/bert-generation)** (来自 Google) 伴随论文 [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461) 由 Sascha Rothe, Shashi Narayan, Aliaksei Severyn 发布。
+1. **[BERTweet](https://huggingface.co/docs/transformers/model_doc/bertweet)** (来自 VinAI Research) 伴随论文 [BERTweet: A pre-trained language model for English Tweets](https://aclanthology.org/2020.emnlp-demos.2/) 由 Dat Quoc Nguyen, Thanh Vu and Anh Tuan Nguyen 发布。
+1. **[BigBird-Pegasus](https://huggingface.co/docs/transformers/model_doc/bigbird_pegasus)** (来自 Google Research) 伴随论文 [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) 由 Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed 发布。
+1. **[BigBird-RoBERTa](https://huggingface.co/docs/transformers/model_doc/big_bird)** (来自 Google Research) 伴随论文 [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) 由 Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed 发布。
+1. **[Blenderbot](https://huggingface.co/docs/transformers/model_doc/blenderbot)** (来自 Facebook) 伴随论文 [Recipes for building an open-domain chatbot](https://arxiv.org/abs/2004.13637) 由 Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston 发布。
+1. **[BlenderbotSmall](https://huggingface.co/docs/transformers/model_doc/blenderbot-small)** (来自 Facebook) 伴随论文 [Recipes for building an open-domain chatbot](https://arxiv.org/abs/2004.13637) 由 Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston 发布。
+1. **[BORT](https://huggingface.co/docs/transformers/model_doc/bort)** (来自 Alexa) 伴随论文 [Optimal Subarchitecture Extraction For BERT](https://arxiv.org/abs/2010.10499) 由 Adrian de Wynter and Daniel J. Perry 发布。
+1. **[ByT5](https://huggingface.co/docs/transformers/model_doc/byt5)** (来自 Google Research) 伴随论文 [ByT5: Towards a token-free future with pre-trained byte-to-byte models](https://arxiv.org/abs/2105.13626) 由 Linting Xue, Aditya Barua, Noah Constant, Rami Al-Rfou, Sharan Narang, Mihir Kale, Adam Roberts, Colin Raffel 发布。
+1. **[CamemBERT](https://huggingface.co/docs/transformers/model_doc/camembert)** (来自 Inria/Facebook/Sorbonne) 伴随论文 [CamemBERT: a Tasty French Language Model](https://arxiv.org/abs/1911.03894) 由 Louis Martin*, Benjamin Muller*, Pedro Javier Ortiz Suárez*, Yoann Dupont, Laurent Romary, Éric Villemonte de la Clergerie, Djamé Seddah and Benoît Sagot 发布。
+1. **[CANINE](https://huggingface.co/docs/transformers/model_doc/canine)** (来自 Google Research) 伴随论文 [CANINE: Pre-training an Efficient Tokenization-Free Encoder for Language Representation](https://arxiv.org/abs/2103.06874) 由 Jonathan H. Clark, Dan Garrette, Iulia Turc, John Wieting 发布。
+1. **[CLIP](https://huggingface.co/docs/transformers/model_doc/clip)** (来自 OpenAI) 伴随论文 [Learning Transferable Visual Models From Natural Language Supervision](https://arxiv.org/abs/2103.00020) 由 Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever 发布。
+1. **[ConvBERT](https://huggingface.co/docs/transformers/model_doc/convbert)** (来自 YituTech) 伴随论文 [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496) 由 Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan 发布。
+1. **[ConvNeXT](https://huggingface.co/docs/transformers/main/model_doc/convnext)** (来自 Facebook AI) 伴随论文 [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) 由 Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie 发布。
+1. **[CPM](https://huggingface.co/docs/transformers/model_doc/cpm)** (来自 Tsinghua University) 伴随论文 [CPM: A Large-scale Generative Chinese Pre-trained Language Model](https://arxiv.org/abs/2012.00413) 由 Zhengyan Zhang, Xu Han, Hao Zhou, Pei Ke, Yuxian Gu, Deming Ye, Yujia Qin, Yusheng Su, Haozhe Ji, Jian Guan, Fanchao Qi, Xiaozhi Wang, Yanan Zheng, Guoyang Zeng, Huanqi Cao, Shengqi Chen, Daixuan Li, Zhenbo Sun, Zhiyuan Liu, Minlie Huang, Wentao Han, Jie Tang, Juanzi Li, Xiaoyan Zhu, Maosong Sun 发布。
+1. **[CTRL](https://huggingface.co/docs/transformers/model_doc/ctrl)** (来自 Salesforce) 伴随论文 [CTRL: A Conditional Transformer Language Model for Controllable Generation](https://arxiv.org/abs/1909.05858) 由 Nitish Shirish Keskar*, Bryan McCann*, Lav R. Varshney, Caiming Xiong and Richard Socher 发布。
+1. **[Data2Vec](https://huggingface.co/docs/transformers/main/model_doc/data2vec)** (来自 Facebook) 伴随论文 [Data2Vec: A General Framework for Self-supervised Learning in Speech, Vision and Language](https://arxiv.org/abs/2202.03555) 由 Alexei Baevski, Wei-Ning Hsu, Qiantong Xu, Arun Babu, Jiatao Gu, Michael Auli 发布。
+1. **[DeBERTa](https://huggingface.co/docs/transformers/model_doc/deberta)** (来自 Microsoft) 伴随论文 [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654) 由 Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen 发布。
+1. **[DeBERTa-v2](https://huggingface.co/docs/transformers/model_doc/deberta-v2)** (来自 Microsoft) 伴随论文 [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654) 由 Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen 发布。
+1. **[Decision Transformer](https://huggingface.co/docs/transformers/model_doc/decision_transformer)** (来自 Berkeley/Facebook/Google) 伴随论文 [Decision Transformer: Reinforcement Learning via Sequence Modeling](https://arxiv.org/abs/2106.01345) 由 Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Michael Laskin, Pieter Abbeel, Aravind Srinivas, Igor Mordatch 发布。
+1. **[DeiT](https://huggingface.co/docs/transformers/model_doc/deit)** (来自 Facebook) 伴随论文 [Training data-efficient image transformers & distillation through attention](https://arxiv.org/abs/2012.12877) 由 Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, Hervé Jégou 发布。
+1. **[DETR](https://huggingface.co/docs/transformers/model_doc/detr)** (来自 Facebook) 伴随论文 [End-to-End Object Detection with Transformers](https://arxiv.org/abs/2005.12872) 由 Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, Sergey Zagoruyko 发布。
+1. **[DialoGPT](https://huggingface.co/docs/transformers/model_doc/dialogpt)** (来自 Microsoft Research) 伴随论文 [DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation](https://arxiv.org/abs/1911.00536) 由 Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao, Jianfeng Gao, Jingjing Liu, Bill Dolan 发布。
+1. **[DistilBERT](https://huggingface.co/docs/transformers/model_doc/distilbert)** (来自 HuggingFace), 伴随论文 [DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter](https://arxiv.org/abs/1910.01108) 由 Victor Sanh, Lysandre Debut and Thomas Wolf 发布。 同样的方法也应用于压缩 GPT-2 到 [DistilGPT2](https://github.com/huggingface/transformers/tree/main/examples/distillation), RoBERTa 到 [DistilRoBERTa](https://github.com/huggingface/transformers/tree/main/examples/distillation), Multilingual BERT 到 [DistilmBERT](https://github.com/huggingface/transformers/tree/main/examples/distillation) 和德语版 DistilBERT。
+1. **[DiT](https://huggingface.co/docs/transformers/model_doc/dit)** (来自 Microsoft Research) 伴随论文 [DiT: Self-supervised Pre-training for Document Image Transformer](https://arxiv.org/abs/2203.02378) 由 Junlong Li, Yiheng Xu, Tengchao Lv, Lei Cui, Cha Zhang, Furu Wei 发布。
+1. **[DPR](https://huggingface.co/docs/transformers/model_doc/dpr)** (来自 Facebook) 伴随论文 [Dense Passage Retrieval for Open-Domain Question Answering](https://arxiv.org/abs/2004.04906) 由 Vladimir Karpukhin, Barlas Oğuz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih 发布。
+1. **[DPT](https://huggingface.co/docs/transformers/master/model_doc/dpt)** (来自 Intel Labs) 伴随论文 [Vision Transformers for Dense Prediction](https://arxiv.org/abs/2103.13413) 由 René Ranftl, Alexey Bochkovskiy, Vladlen Koltun 发布。
+1. **[ELECTRA](https://huggingface.co/docs/transformers/model_doc/electra)** (来自 Google Research/Stanford University) 伴随论文 [ELECTRA: Pre-training text encoders as discriminators rather than generators](https://arxiv.org/abs/2003.10555) 由 Kevin Clark, Minh-Thang Luong, Quoc V. Le, Christopher D. Manning 发布。
+1. **[EncoderDecoder](https://huggingface.co/docs/transformers/model_doc/encoder-decoder)** (来自 Google Research) 伴随论文 [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461) 由 Sascha Rothe, Shashi Narayan, Aliaksei Severyn 发布。
+1. **[FlauBERT](https://huggingface.co/docs/transformers/model_doc/flaubert)** (来自 CNRS) 伴随论文 [FlauBERT: Unsupervised Language Model Pre-training for French](https://arxiv.org/abs/1912.05372) 由 Hang Le, Loïc Vial, Jibril Frej, Vincent Segonne, Maximin Coavoux, Benjamin Lecouteux, Alexandre Allauzen, Benoît Crabbé, Laurent Besacier, Didier Schwab 发布。
+1. **[FNet](https://huggingface.co/docs/transformers/model_doc/fnet)** (来自 Google Research) 伴随论文 [FNet: Mixing Tokens with Fourier Transforms](https://arxiv.org/abs/2105.03824) 由 James Lee-Thorp, Joshua Ainslie, Ilya Eckstein, Santiago Ontanon 发布。
+1. **[Funnel Transformer](https://huggingface.co/docs/transformers/model_doc/funnel)** (来自 CMU/Google Brain) 伴随论文 [Funnel-Transformer: Filtering out Sequential Redundancy for Efficient Language Processing](https://arxiv.org/abs/2006.03236) 由 Zihang Dai, Guokun Lai, Yiming Yang, Quoc V. Le 发布。
+1. **[GLPN](https://huggingface.co/docs/transformers/main/model_doc/glpn)** (来自 KAIST) 伴随论文 [Global-Local Path Networks for Monocular Depth Estimation with Vertical CutDepth](https://arxiv.org/abs/2201.07436) 由 Doyeon Kim, Woonghyun Ga, Pyungwhan Ahn, Donggyu Joo, Sehwan Chun, Junmo Kim 发布。
+1. **[GPT](https://huggingface.co/docs/transformers/model_doc/openai-gpt)** (来自 OpenAI) 伴随论文 [Improving Language Understanding by Generative Pre-Training](https://blog.openai.com/language-unsupervised/) 由 Alec Radford, Karthik Narasimhan, Tim Salimans and Ilya Sutskever 发布。
+1. **[GPT Neo](https://huggingface.co/docs/transformers/model_doc/gpt_neo)** (来自 EleutherAI) 随仓库 [EleutherAI/gpt-neo](https://github.com/EleutherAI/gpt-neo) 发布。作者为 Sid Black, Stella Biderman, Leo Gao, Phil Wang and Connor Leahy 发布。
+1. **[GPT-2](https://huggingface.co/docs/transformers/model_doc/gpt2)** (来自 OpenAI) 伴随论文 [Language Models are Unsupervised Multitask Learners](https://blog.openai.com/better-language-models/) 由 Alec Radford*, Jeffrey Wu*, Rewon Child, David Luan, Dario Amodei** and Ilya Sutskever** 发布。
+1. **[GPT-J](https://huggingface.co/docs/transformers/model_doc/gptj)** (来自 EleutherAI) 伴随论文 [kingoflolz/mesh-transformer-jax](https://github.com/kingoflolz/mesh-transformer-jax/) 由 Ben Wang and Aran Komatsuzaki 发布。
+1. **[Hubert](https://huggingface.co/docs/transformers/model_doc/hubert)** (来自 Facebook) 伴随论文 [HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units](https://arxiv.org/abs/2106.07447) 由 Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, Abdelrahman Mohamed 发布。
+1. **[I-BERT](https://huggingface.co/docs/transformers/model_doc/ibert)** (来自 Berkeley) 伴随论文 [I-BERT: Integer-only BERT Quantization](https://arxiv.org/abs/2101.01321) 由 Sehoon Kim, Amir Gholami, Zhewei Yao, Michael W. Mahoney, Kurt Keutzer 发布。
+1. **[ImageGPT](https://huggingface.co/docs/transformers/main/model_doc/imagegpt)** (来自 OpenAI) 伴随论文 [Generative Pretraining from Pixels](https://openai.com/blog/image-gpt/) 由 Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, Ilya Sutskever 发布。
+1. **[LayoutLM](https://huggingface.co/docs/transformers/model_doc/layoutlm)** (来自 Microsoft Research Asia) 伴随论文 [LayoutLM: Pre-training of Text and Layout for Document Image Understanding](https://arxiv.org/abs/1912.13318) 由 Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou 发布。
+1. **[LayoutLMv2](https://huggingface.co/docs/transformers/model_doc/layoutlmv2)** (来自 Microsoft Research Asia) 伴随论文 [LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding](https://arxiv.org/abs/2012.14740) 由 Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui, Furu Wei, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Wanxiang Che, Min Zhang, Lidong Zhou 发布。
+1. **[LayoutXLM](https://huggingface.co/docs/transformers/model_doc/layoutlmv2)** (来自 Microsoft Research Asia) 伴随论文 [LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding](https://arxiv.org/abs/2104.08836) 由 Yiheng Xu, Tengchao Lv, Lei Cui, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Furu Wei 发布。
+1. **[LED](https://huggingface.co/docs/transformers/model_doc/led)** (来自 AllenAI) 伴随论文 [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) 由 Iz Beltagy, Matthew E. Peters, Arman Cohan 发布。
+1. **[Longformer](https://huggingface.co/docs/transformers/model_doc/longformer)** (来自 AllenAI) 伴随论文 [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) 由 Iz Beltagy, Matthew E. Peters, Arman Cohan 发布。
+1. **[LUKE](https://huggingface.co/docs/transformers/model_doc/luke)** (来自 Studio Ousia) 伴随论文 [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://arxiv.org/abs/2010.01057) 由 Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto 发布。
+1. **[LXMERT](https://huggingface.co/docs/transformers/model_doc/lxmert)** (来自 UNC Chapel Hill) 伴随论文 [LXMERT: Learning Cross-Modality Encoder Representations from Transformers for Open-Domain Question Answering](https://arxiv.org/abs/1908.07490) 由 Hao Tan and Mohit Bansal 发布。
+1. **[M2M100](https://huggingface.co/docs/transformers/model_doc/m2m_100)** (来自 Facebook) 伴随论文 [Beyond English-Centric Multilingual Machine Translation](https://arxiv.org/abs/2010.11125) 由 Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi Ma, Ahmed El-Kishky, Siddharth Goyal, Mandeep Baines, Onur Celebi, Guillaume Wenzek, Vishrav Chaudhary, Naman Goyal, Tom Birch, Vitaliy Liptchinsky, Sergey Edunov, Edouard Grave, Michael Auli, Armand Joulin 发布。
+1. **[MarianMT](https://huggingface.co/docs/transformers/model_doc/marian)** 用 [OPUS](http://opus.nlpl.eu/) 数据训练的机器翻译模型由 Jörg Tiedemann 发布。[Marian Framework](https://marian-nmt.github.io/) 由微软翻译团队开发。
+1. **[MaskFormer](https://huggingface.co/docs/transformers/main/model_doc/maskformer)** (from Meta and UIUC) released with the paper [Per-Pixel Classification is Not All You Need for Semantic Segmentation](https://arxiv.org/abs/2107.06278) by Bowen Cheng, Alexander G. Schwing, Alexander Kirillov
+1. **[MBart](https://huggingface.co/docs/transformers/model_doc/mbart)** (来自 Facebook) 伴随论文 [Multilingual Denoising Pre-training for Neural Machine Translation](https://arxiv.org/abs/2001.08210) 由 Yinhan Liu, Jiatao Gu, Naman Goyal, Xian Li, Sergey Edunov, Marjan Ghazvininejad, Mike Lewis, Luke Zettlemoyer 发布。
+1. **[MBart-50](https://huggingface.co/docs/transformers/model_doc/mbart)** (来自 Facebook) 伴随论文 [Multilingual Translation with Extensible Multilingual Pretraining and Finetuning](https://arxiv.org/abs/2008.00401) 由 Yuqing Tang, Chau Tran, Xian Li, Peng-Jen Chen, Naman Goyal, Vishrav Chaudhary, Jiatao Gu, Angela Fan 发布。
+1. **[Megatron-BERT](https://huggingface.co/docs/transformers/model_doc/megatron-bert)** (来自 NVIDIA) 伴随论文 [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://arxiv.org/abs/1909.08053) 由 Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper and Bryan Catanzaro 发布。
+1. **[Megatron-GPT2](https://huggingface.co/docs/transformers/model_doc/megatron_gpt2)** (来自 NVIDIA) 伴随论文 [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://arxiv.org/abs/1909.08053) 由 Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper and Bryan Catanzaro 发布。
+1. **[mLUKE](https://huggingface.co/docs/transformers/model_doc/mluke)** (来自 Studio Ousia) 伴随论文 [mLUKE: The Power of Entity Representations in Multilingual Pretrained Language Models](https://arxiv.org/abs/2110.08151) 由 Ryokan Ri, Ikuya Yamada, and Yoshimasa Tsuruoka 发布。
+1. **[MPNet](https://huggingface.co/docs/transformers/model_doc/mpnet)** (来自 Microsoft Research) 伴随论文 [MPNet: Masked and Permuted Pre-training for Language Understanding](https://arxiv.org/abs/2004.09297) 由 Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, Tie-Yan Liu 发布。
+1. **[MT5](https://huggingface.co/docs/transformers/model_doc/mt5)** (来自 Google AI) 伴随论文 [mT5: A massively multilingual pre-trained text-to-text transformer](https://arxiv.org/abs/2010.11934) 由 Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, Colin Raffel 发布。
+1. **[Nyströmformer](https://huggingface.co/docs/transformers/model_doc/nystromformer)** (来自 the University of Wisconsin - Madison) 伴随论文 [Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention](https://arxiv.org/abs/2102.03902) 由 Yunyang Xiong, Zhanpeng Zeng, Rudrasis Chakraborty, Mingxing Tan, Glenn Fung, Yin Li, Vikas Singh 发布。
+1. **[Pegasus](https://huggingface.co/docs/transformers/model_doc/pegasus)** (来自 Google) 伴随论文 [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization](https://arxiv.org/abs/1912.08777) 由 Jingqing Zhang, Yao Zhao, Mohammad Saleh and Peter J. Liu 发布。
+1. **[Perceiver IO](https://huggingface.co/docs/transformers/model_doc/perceiver)** (来自 Deepmind) 伴随论文 [Perceiver IO: A General Architecture for Structured Inputs & Outputs](https://arxiv.org/abs/2107.14795) 由 Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier Hénaff, Matthew M. Botvinick, Andrew Zisserman, Oriol Vinyals, João Carreira 发布。
+1. **[PhoBERT](https://huggingface.co/docs/transformers/model_doc/phobert)** (来自 VinAI Research) 伴随论文 [PhoBERT: Pre-trained language models for Vietnamese](https://www.aclweb.org/anthology/2020.findings-emnlp.92/) 由 Dat Quoc Nguyen and Anh Tuan Nguyen 发布。
+1. **[PLBart](https://huggingface.co/docs/transformers/model_doc/plbart)** (来自 UCLA NLP) 伴随论文 [Unified Pre-training for Program Understanding and Generation](https://arxiv.org/abs/2103.06333) 由 Wasi Uddin Ahmad, Saikat Chakraborty, Baishakhi Ray, Kai-Wei Chang 发布。
+1. **[PoolFormer](https://huggingface.co/docs/transformers/model_doc/poolformer)** (来自 Sea AI Labs) 伴随论文 [MetaFormer is Actually What You Need for Vision](https://arxiv.org/abs/2111.11418) 由 Yu, Weihao and Luo, Mi and Zhou, Pan and Si, Chenyang and Zhou, Yichen and Wang, Xinchao and Feng, Jiashi and Yan, Shuicheng 发布。
+1. **[ProphetNet](https://huggingface.co/docs/transformers/model_doc/prophetnet)** (来自 Microsoft Research) 伴随论文 [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) 由 Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou 发布。
+1. **[QDQBert](https://huggingface.co/docs/transformers/model_doc/qdqbert)** (来自 NVIDIA) 伴随论文 [Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation](https://arxiv.org/abs/2004.09602) 由 Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius Micikevicius 发布。
+1. **[REALM](https://huggingface.co/docs/transformers/model_doc/realm.html)** (来自 Google Research) 伴随论文 [REALM: Retrieval-Augmented Language Model Pre-Training](https://arxiv.org/abs/2002.08909) 由 Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat and Ming-Wei Chang 发布。
+1. **[Reformer](https://huggingface.co/docs/transformers/model_doc/reformer)** (来自 Google Research) 伴随论文 [Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451) 由 Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya 发布。
+1. **[RegNet](https://huggingface.co/docs/transformers/main/model_doc/regnet)** (from META Research) released with the paper [Designing Network Design Space](https://arxiv.org/abs/2003.13678) by Ilija Radosavovic, Raj Prateek Kosaraju, Ross Girshick, Kaiming He, Piotr Dollár.
+1. **[RemBERT](https://huggingface.co/docs/transformers/model_doc/rembert)** (来自 Google Research) 伴随论文 [Rethinking embedding coupling in pre-trained language models](https://arxiv.org/pdf/2010.12821.pdf) 由 Hyung Won Chung, Thibault Févry, Henry Tsai, M. Johnson, Sebastian Ruder 发布。
+1. **[ResNet](https://huggingface.co/docs/transformers/model_doc/resnet)** (from Microsoft Research) released with the paper [Deep Residual Learning for Image Recognition](https://arxiv.org/abs/1512.03385) by Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun.
+1. **[RoBERTa](https://huggingface.co/docs/transformers/model_doc/roberta)** (来自 Facebook), 伴随论文 [Robustly Optimized BERT Pretraining Approach](https://arxiv.org/abs/1907.11692) 由 Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov 发布。
+1. **[RoFormer](https://huggingface.co/docs/transformers/model_doc/roformer)** (来自 ZhuiyiTechnology), 伴随论文 [RoFormer: Enhanced Transformer with Rotary Position Embedding](https://arxiv.org/pdf/2104.09864v1.pdf) 由 Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu 发布。
+1. **[SegFormer](https://huggingface.co/docs/transformers/model_doc/segformer)** (来自 NVIDIA) 伴随论文 [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://arxiv.org/abs/2105.15203) 由 Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, Ping Luo 发布。
+1. **[SEW](https://huggingface.co/docs/transformers/model_doc/sew)** (来自 ASAPP) 伴随论文 [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) 由 Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi 发布。
+1. **[SEW-D](https://huggingface.co/docs/transformers/model_doc/sew_d)** (来自 ASAPP) 伴随论文 [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) 由 Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi 发布。
+1. **[SpeechToTextTransformer](https://huggingface.co/docs/transformers/model_doc/speech_to_text)** (来自 Facebook), 伴随论文 [fairseq S2T: Fast Speech-to-Text Modeling with fairseq](https://arxiv.org/abs/2010.05171) 由 Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Dmytro Okhonko, Juan Pino 发布。
+1. **[SpeechToTextTransformer2](https://huggingface.co/docs/transformers/model_doc/speech_to_text_2)** (来自 Facebook) 伴随论文 [Large-Scale Self- and Semi-Supervised Learning for Speech Translation](https://arxiv.org/abs/2104.06678) 由 Changhan Wang, Anne Wu, Juan Pino, Alexei Baevski, Michael Auli, Alexis Conneau 发布。
+1. **[Splinter](https://huggingface.co/docs/transformers/model_doc/splinter)** (来自 Tel Aviv University) 伴随论文 [Few-Shot Question Answering by Pretraining Span Selection](https://arxiv.org/abs/2101.00438) 由 Ori Ram, Yuval Kirstain, Jonathan Berant, Amir Globerson, Omer Levy 发布。
+1. **[SqueezeBert](https://huggingface.co/docs/transformers/model_doc/squeezebert)** (来自 Berkeley) 伴随论文 [SqueezeBERT: What can computer vision teach NLP about efficient neural networks?](https://arxiv.org/abs/2006.11316) 由 Forrest N. Iandola, Albert E. Shaw, Ravi Krishna, and Kurt W. Keutzer 发布。
+1. **[Swin Transformer](https://huggingface.co/docs/transformers/model_doc/swin)** (来自 Microsoft) 伴随论文 [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030) 由 Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo 发布。
+1. **[T5](https://huggingface.co/docs/transformers/model_doc/t5)** (来自 Google AI) 伴随论文 [Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer](https://arxiv.org/abs/1910.10683) 由 Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu 发布。
+1. **[T5v1.1](https://huggingface.co/docs/transformers/model_doc/t5v1.1)** (来自 Google AI) 伴随论文 [google-research/text-to-text-transfer-transformer](https://github.com/google-research/text-to-text-transfer-transformer/blob/main/released_checkpoints.md#t511) 由 Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu 发布。
+1. **[TAPAS](https://huggingface.co/docs/transformers/model_doc/tapas)** (来自 Google AI) 伴随论文 [TAPAS: Weakly Supervised Table Parsing via Pre-training](https://arxiv.org/abs/2004.02349) 由 Jonathan Herzig, Paweł Krzysztof Nowak, Thomas Müller, Francesco Piccinno and Julian Martin Eisenschlos 发布。
+1. **[TAPEX](https://huggingface.co/docs/transformers/main/model_doc/tapex)** (来自 Microsoft Research) 伴随论文 [TAPEX: Table Pre-training via Learning a Neural SQL Executor](https://arxiv.org/abs/2107.07653) 由 Qian Liu, Bei Chen, Jiaqi Guo, Morteza Ziyadi, Zeqi Lin, Weizhu Chen, Jian-Guang Lou 发布。
+1. **[Transformer-XL](https://huggingface.co/docs/transformers/model_doc/transfo-xl)** (来自 Google/CMU) 伴随论文 [Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context](https://arxiv.org/abs/1901.02860) 由 Zihang Dai*, Zhilin Yang*, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan Salakhutdinov 发布。
+1. **[TrOCR](https://huggingface.co/docs/transformers/model_doc/trocr)** (来自 Microsoft) 伴随论文 [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282) 由 Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, Furu Wei 发布。
+1. **[UniSpeech](https://huggingface.co/docs/transformers/model_doc/unispeech)** (来自 Microsoft Research) 伴随论文 [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597) 由 Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang 发布。
+1. **[UniSpeechSat](https://huggingface.co/docs/transformers/model_doc/unispeech-sat)** (来自 Microsoft Research) 伴随论文 [UNISPEECH-SAT: UNIVERSAL SPEECH REPRESENTATION LEARNING WITH SPEAKER AWARE PRE-TRAINING](https://arxiv.org/abs/2110.05752) 由 Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen, Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu 发布。
+1. **[VAN](https://huggingface.co/docs/transformers/model_doc/van)** (来自 Tsinghua University and Nankai University) 伴随论文 [Visual Attention Network](https://arxiv.org/pdf/2202.09741.pdf) 由 Meng-Hao Guo, Cheng-Ze Lu, Zheng-Ning Liu, Ming-Ming Cheng, Shi-Min Hu 发布。
+1. **[ViLT](https://huggingface.co/docs/transformers/model_doc/vilt)** (来自 NAVER AI Lab/Kakao Enterprise/Kakao Brain) 伴随论文 [ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision](https://arxiv.org/abs/2102.03334) 由 Wonjae Kim, Bokyung Son, Ildoo Kim 发布。
+1. **[Vision Transformer (ViT)](https://huggingface.co/docs/transformers/model_doc/vit)** (来自 Google AI) 伴随论文 [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) 由 Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby 发布。
+1. **[VisualBERT](https://huggingface.co/docs/transformers/model_doc/visual_bert)** (来自 UCLA NLP) 伴随论文 [VisualBERT: A Simple and Performant Baseline for Vision and Language](https://arxiv.org/pdf/1908.03557) 由 Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, Kai-Wei Chang 发布。
+1. **[ViTMAE](https://huggingface.co/docs/transformers/model_doc/vit_mae)** (来自 Meta AI) 伴随论文 [Masked Autoencoders Are Scalable Vision Learners](https://arxiv.org/abs/2111.06377) 由 Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, Ross Girshick 发布。
+1. **[Wav2Vec2](https://huggingface.co/docs/transformers/model_doc/wav2vec2)** (来自 Facebook AI) 伴随论文 [wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations](https://arxiv.org/abs/2006.11477) 由 Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli 发布。
+1. **[Wav2Vec2Phoneme](https://huggingface.co/docs/transformers/model_doc/wav2vec2_phoneme)** (来自 Facebook AI) 伴随论文 [Simple and Effective Zero-shot Cross-lingual Phoneme Recognition](https://arxiv.org/abs/2109.11680) 由 Qiantong Xu, Alexei Baevski, Michael Auli 发布。
+1. **[WavLM](https://huggingface.co/docs/transformers/model_doc/wavlm)** (from Microsoft Research) released with the paper [WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing](https://arxiv.org/abs/2110.13900) by Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, Jian Wu, Long Zhou, Shuo Ren, Yanmin Qian, Yao Qian, Jian Wu, Michael Zeng, Furu Wei.
+1. **[XGLM](https://huggingface.co/docs/transformers/model_doc/xglm)** (From Facebook AI) released with the paper [Few-shot Learning with Multilingual Language Models](https://arxiv.org/abs/2112.10668) by Xi Victoria Lin, Todor Mihaylov, Mikel Artetxe, Tianlu Wang, Shuohui Chen, Daniel Simig, Myle Ott, Naman Goyal, Shruti Bhosale, Jingfei Du, Ramakanth Pasunuru, Sam Shleifer, Punit Singh Koura, Vishrav Chaudhary, Brian O'Horo, Jeff Wang, Luke Zettlemoyer, Zornitsa Kozareva, Mona Diab, Veselin Stoyanov, Xian Li.
+1. **[XLM](https://huggingface.co/docs/transformers/model_doc/xlm)** (来自 Facebook) 伴随论文 [Cross-lingual Language Model Pretraining](https://arxiv.org/abs/1901.07291) 由 Guillaume Lample and Alexis Conneau 发布。
+1. **[XLM-ProphetNet](https://huggingface.co/docs/transformers/model_doc/xlm-prophetnet)** (来自 Microsoft Research) 伴随论文 [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) 由 Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou 发布。
+1. **[XLM-RoBERTa](https://huggingface.co/docs/transformers/model_doc/xlm-roberta)** (来自 Facebook AI), 伴随论文 [Unsupervised Cross-lingual Representation Learning at Scale](https://arxiv.org/abs/1911.02116) 由 Alexis Conneau*, Kartikay Khandelwal*, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzmán, Edouard Grave, Myle Ott, Luke Zettlemoyer and Veselin Stoyanov 发布。
+1. **[XLM-RoBERTa-XL](https://huggingface.co/docs/transformers/model_doc/xlm-roberta-xl)** (来自 Facebook AI) 伴随论文 [Larger-Scale Transformers for Multilingual Masked Language Modeling](https://arxiv.org/abs/2105.00572) 由 Naman Goyal, Jingfei Du, Myle Ott, Giri Anantharaman, Alexis Conneau 发布。
+1. **[XLNet](https://huggingface.co/docs/transformers/model_doc/xlnet)** (来自 Google/CMU) 伴随论文 [XLNet: Generalized Autoregressive Pretraining for Language Understanding](https://arxiv.org/abs/1906.08237) 由 Zhilin Yang*, Zihang Dai*, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, Quoc V. Le 发布。
+1. **[XLS-R](https://huggingface.co/docs/transformers/model_doc/xls_r)** (来自 Facebook AI) 伴随论文 [XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale](https://arxiv.org/abs/2111.09296) 由 Arun Babu, Changhan Wang, Andros Tjandra, Kushal Lakhotia, Qiantong Xu, Naman Goyal, Kritika Singh, Patrick von Platen, Yatharth Saraf, Juan Pino, Alexei Baevski, Alexis Conneau, Michael Auli 发布。
+1. **[XLSR-Wav2Vec2](https://huggingface.co/docs/transformers/model_doc/xlsr_wav2vec2)** (来自 Facebook AI) 伴随论文 [Unsupervised Cross-Lingual Representation Learning For Speech Recognition](https://arxiv.org/abs/2006.13979) 由 Alexis Conneau, Alexei Baevski, Ronan Collobert, Abdelrahman Mohamed, Michael Auli 发布。
+1. **[YOLOS](https://huggingface.co/docs/transformers/main/model_doc/yolos)** (来自 Huazhong University of Science & Technology) 伴随论文 [You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection](https://arxiv.org/abs/2106.00666) 由 Yuxin Fang, Bencheng Liao, Xinggang Wang, Jiemin Fang, Jiyang Qi, Rui Wu, Jianwei Niu, Wenyu Liu 发布。
+1. **[YOSO](https://huggingface.co/docs/transformers/model_doc/yoso)** (来自 the University of Wisconsin - Madison) 伴随论文 [You Only Sample (Almost) 由 Zhanpeng Zeng, Yunyang Xiong, Sathya N. Ravi, Shailesh Acharya, Glenn Fung, Vikas Singh 发布。
+1. 想要贡献新的模型?我们这里有一份**详细指引和模板**来引导你添加新的模型。你可以在 [`templates`](./templates) 目录中找到他们。记得查看 [贡献指南](./CONTRIBUTING.md) 并在开始写 PR 前联系维护人员或开一个新的 issue 来获得反馈。
+
+要检查某个模型是否已有 Flax、PyTorch 或 TensorFlow 的实现,或其是否在 🤗 Tokenizers 库中有对应词符化器(tokenizer),敬请参阅[此表](https://huggingface.co/docs/transformers/index#supported-frameworks)。
+
+这些实现均已于多个数据集测试(请参看用例脚本)并应于原版实现表现相当。你可以在用例文档的[此节](https://huggingface.co/docs/transformers/examples)中了解表现的细节。
+
+
+## 了解更多
+
+| 章节 | 描述 |
+|-|-|
+| [文档](https://huggingface.co/transformers/) | 完整的 API 文档和教程 |
+| [任务总结](https://huggingface.co/docs/transformers/task_summary) | 🤗 Transformers 支持的任务 |
+| [预处理教程](https://huggingface.co/docs/transformers/preprocessing) | 使用 `Tokenizer` 来为模型准备数据 |
+| [训练和微调](https://huggingface.co/docstransformers/training) | 在 PyTorch/TensorFlow 的训练循环或 `Trainer` API 中使用 🤗 Transformers 提供的模型 |
+| [快速上手:微调和用例脚本](https://github.com/huggingface/transformers/tree/main/examples) | 为各种任务提供的用例脚本 |
+| [模型分享和上传](https://huggingface.co/docs/transformers/model_sharing) | 和社区上传和分享你微调的模型 |
+| [迁移](https://huggingface.co/docs/transformers/migration) | 从 `pytorch-transformers` 或 `pytorch-pretrained-bert` 迁移到 🤗 Transformers |
+
+## 引用
+
+我们已将此库的[论文](https://www.aclweb.org/anthology/2020.emnlp-demos.6/)正式发表,如果你使用了 🤗 Transformers 库,请引用:
+```bibtex
+@inproceedings{wolf-etal-2020-transformers,
+ title = "Transformers: State-of-the-Art Natural Language Processing",
+ author = "Thomas Wolf and Lysandre Debut and Victor Sanh and Julien Chaumond and Clement Delangue and Anthony Moi and Pierric Cistac and Tim Rault and Rémi Louf and Morgan Funtowicz and Joe Davison and Sam Shleifer and Patrick von Platen and Clara Ma and Yacine Jernite and Julien Plu and Canwen Xu and Teven Le Scao and Sylvain Gugger and Mariama Drame and Quentin Lhoest and Alexander M. Rush",
+ booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations",
+ month = oct,
+ year = "2020",
+ address = "Online",
+ publisher = "Association for Computational Linguistics",
+ url = "https://www.aclweb.org/anthology/2020.emnlp-demos.6",
+ pages = "38--45"
+}
+```
diff --git a/README_zh-hant.md b/README_zh-hant.md
new file mode 100644
index 00000000000000..7e26c22c54c88e
--- /dev/null
+++ b/README_zh-hant.md
@@ -0,0 +1,393 @@
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ English |
+ 简体中文 |
+ 繁體中文 |
+ 한국어
+
+
+
+
+
為 Jax、PyTorch 以及 TensorFlow 打造的先進自然語言處理函式庫
+
+
+
+
+
+
+🤗 Transformers 提供了數以千計的預訓練模型,支援 100 多種語言的文本分類、資訊擷取、問答、摘要、翻譯、文本生成。它的宗旨是讓最先進的 NLP 技術人人易用。
+
+🤗 Transformers 提供了便於快速下載和使用的API,讓你可以將預訓練模型用在給定文本、在你的資料集上微調然後經由 [model hub](https://huggingface.co/models) 與社群共享。同時,每個定義的 Python 模組架構均完全獨立,方便修改和快速研究實驗。
+
+🤗 Transformers 支援三個最熱門的深度學習函式庫: [Jax](https://jax.readthedocs.io/en/latest/), [PyTorch](https://pytorch.org/) 以及 [TensorFlow](https://www.tensorflow.org/) — 並與之完美整合。你可以直接使用其中一個框架訓練你的模型,然後用另一個載入和推論。
+
+## 線上Demo
+
+你可以直接在 [model hub](https://huggingface.co/models) 上測試大多數的模型。我們也提供了 [私有模型託管、模型版本管理以及推論API](https://huggingface.co/pricing)。
+
+這裡是一些範例:
+- [用 BERT 做遮蓋填詞](https://huggingface.co/bert-base-uncased?text=Paris+is+the+%5BMASK%5D+of+France)
+- [用 Electra 做專有名詞辨識](https://huggingface.co/dbmdz/electra-large-discriminator-finetuned-conll03-english?text=My+name+is+Sarah+and+I+live+in+London+city)
+- [用 GPT-2 做文本生成](https://huggingface.co/gpt2?text=A+long+time+ago%2C+)
+- [用 RoBERTa 做自然語言推論](https://huggingface.co/roberta-large-mnli?text=The+dog+was+lost.+Nobody+lost+any+animal)
+- [用 BART 做文本摘要](https://huggingface.co/facebook/bart-large-cnn?text=The+tower+is+324+metres+%281%2C063+ft%29+tall%2C+about+the+same+height+as+an+81-storey+building%2C+and+the+tallest+structure+in+Paris.+Its+base+is+square%2C+measuring+125+metres+%28410+ft%29+on+each+side.+During+its+construction%2C+the+Eiffel+Tower+surpassed+the+Washington+Monument+to+become+the+tallest+man-made+structure+in+the+world%2C+a+title+it+held+for+41+years+until+the+Chrysler+Building+in+New+York+City+was+finished+in+1930.+It+was+the+first+structure+to+reach+a+height+of+300+metres.+Due+to+the+addition+of+a+broadcasting+aerial+at+the+top+of+the+tower+in+1957%2C+it+is+now+taller+than+the+Chrysler+Building+by+5.2+metres+%2817+ft%29.+Excluding+transmitters%2C+the+Eiffel+Tower+is+the+second+tallest+free-standing+structure+in+France+after+the+Millau+Viaduct)
+- [用 DistilBERT 做問答](https://huggingface.co/distilbert-base-uncased-distilled-squad?text=Which+name+is+also+used+to+describe+the+Amazon+rainforest+in+English%3F&context=The+Amazon+rainforest+%28Portuguese%3A+Floresta+Amaz%C3%B4nica+or+Amaz%C3%B4nia%3B+Spanish%3A+Selva+Amaz%C3%B3nica%2C+Amazon%C3%ADa+or+usually+Amazonia%3B+French%3A+For%C3%AAt+amazonienne%3B+Dutch%3A+Amazoneregenwoud%29%2C+also+known+in+English+as+Amazonia+or+the+Amazon+Jungle%2C+is+a+moist+broadleaf+forest+that+covers+most+of+the+Amazon+basin+of+South+America.+This+basin+encompasses+7%2C000%2C000+square+kilometres+%282%2C700%2C000+sq+mi%29%2C+of+which+5%2C500%2C000+square+kilometres+%282%2C100%2C000+sq+mi%29+are+covered+by+the+rainforest.+This+region+includes+territory+belonging+to+nine+nations.+The+majority+of+the+forest+is+contained+within+Brazil%2C+with+60%25+of+the+rainforest%2C+followed+by+Peru+with+13%25%2C+Colombia+with+10%25%2C+and+with+minor+amounts+in+Venezuela%2C+Ecuador%2C+Bolivia%2C+Guyana%2C+Suriname+and+French+Guiana.+States+or+departments+in+four+nations+contain+%22Amazonas%22+in+their+names.+The+Amazon+represents+over+half+of+the+planet%27s+remaining+rainforests%2C+and+comprises+the+largest+and+most+biodiverse+tract+of+tropical+rainforest+in+the+world%2C+with+an+estimated+390+billion+individual+trees+divided+into+16%2C000+species)
+- [用 T5 做翻譯](https://huggingface.co/t5-base?text=My+name+is+Wolfgang+and+I+live+in+Berlin)
+
+**[Write With Transformer](https://transformer.huggingface.co)**,由 Hugging Face 團隊所打造,是一個文本生成的官方 demo。
+
+## 如果你在尋找由 Hugging Face 團隊所提供的客製化支援服務
+
+
+
+
+
+## 快速上手
+
+我們為快速使用模型提供了 `pipeline` API。 Pipeline 包含了預訓練模型和對應的文本預處理。下面是一個快速使用 pipeline 去判斷正負面情緒的例子:
+
+```python
+>>> from transformers import pipeline
+
+# 使用情緒分析 pipeline
+>>> classifier = pipeline('sentiment-analysis')
+>>> classifier('We are very happy to introduce pipeline to the transformers repository.')
+[{'label': 'POSITIVE', 'score': 0.9996980428695679}]
+```
+
+第二行程式碼下載並快取 pipeline 使用的預訓練模型,而第三行程式碼則在給定的文本上進行了評估。這裡的答案“正面” (positive) 具有 99.97% 的信賴度。
+
+許多的 NLP 任務都有隨選即用的預訓練 `pipeline`。例如,我們可以輕鬆地從給定文本中擷取問題答案:
+
+``` python
+>>> from transformers import pipeline
+
+# 使用問答 pipeline
+>>> question_answerer = pipeline('question-answering')
+>>> question_answerer({
+... 'question': 'What is the name of the repository ?',
+... 'context': 'Pipeline has been included in the huggingface/transformers repository'
+... })
+{'score': 0.30970096588134766, 'start': 34, 'end': 58, 'answer': 'huggingface/transformers'}
+
+```
+
+除了提供問題解答,預訓練模型還提供了對應的信賴度分數以及解答在 tokenized 後的文本中開始和結束的位置。你可以從[這個教學](https://huggingface.co/docs/transformers/task_summary)了解更多 `pipeline` API支援的任務。
+
+要在你的任務中下載和使用任何預訓練模型很簡單,只需三行程式碼。這裡是 PyTorch 版的範例:
+```python
+>>> from transformers import AutoTokenizer, AutoModel
+
+>>> tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
+>>> model = AutoModel.from_pretrained("bert-base-uncased")
+
+>>> inputs = tokenizer("Hello world!", return_tensors="pt")
+>>> outputs = model(**inputs)
+```
+這裡是對應的 TensorFlow 程式碼:
+```python
+>>> from transformers import AutoTokenizer, TFAutoModel
+
+>>> tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
+>>> model = TFAutoModel.from_pretrained("bert-base-uncased")
+
+>>> inputs = tokenizer("Hello world!", return_tensors="tf")
+>>> outputs = model(**inputs)
+```
+
+Tokenizer 為所有的預訓練模型提供了預處理,並可以直接轉換單一字串(比如上面的例子)或串列 (list)。它會輸出一個的字典 (dict) 讓你可以在下游程式碼裡使用或直接藉由 `**` 運算式傳給模型。
+
+模型本身是一個常規的 [Pytorch `nn.Module`](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) 或 [TensorFlow `tf.keras.Model`](https://www.tensorflow.org/api_docs/python/tf/keras/Model)(取決於你的後端),可依常規方式使用。 [這個教學](https://huggingface.co/transformers/training.html)解釋了如何將這樣的模型整合到一般的 PyTorch 或 TensorFlow 訓練迴圈中,或是如何使用我們的 `Trainer` API 在一個新的資料集上快速進行微調。
+
+## 為什麼要用 transformers?
+
+1. 便於使用的先進模型:
+ - NLU 和 NLG 上性能卓越
+ - 對教學和實作友好且低門檻
+ - 高度抽象,使用者只須學習 3 個類別
+ - 對所有模型使用的制式化API
+
+1. 更低的運算成本,更少的碳排放:
+ - 研究人員可以分享預訓練的模型而非從頭開始訓練
+ - 工程師可以減少計算時間以及生產成本
+ - 數十種模型架構、兩千多個預訓練模型、100多種語言支援
+
+1. 對於模型生命週期的每一個部分都面面俱到:
+ - 訓練先進的模型,只需 3 行程式碼
+ - 模型可以在不同深度學習框架之間任意轉換
+ - 為訓練、評估和生產選擇最適合的框架,並完美銜接
+
+1. 為你的需求輕鬆客製化專屬模型和範例:
+ - 我們為每種模型架構提供了多個範例來重現原論文結果
+ - 一致的模型內部架構
+ - 模型檔案可單獨使用,便於修改和快速實驗
+
+## 什麼情況下我不該用 transformers?
+
+- 本函式庫並不是模組化的神經網絡工具箱。模型文件中的程式碼並未做額外的抽象封裝,以便研究人員快速地翻閱及修改程式碼,而不會深陷複雜的類別包裝之中。
+- `Trainer` API 並非相容任何模型,它只為本函式庫中的模型最佳化。對於一般的機器學習用途,請使用其他函式庫。
+- 儘管我們已盡力而為,[examples 目錄](https://github.com/huggingface/transformers/tree/main/examples)中的腳本也僅為範例而已。對於特定問題,它們並不一定隨選即用,可能需要修改幾行程式碼以符合需求。
+
+## 安裝
+
+### 使用 pip
+
+這個 Repository 已在 Python 3.6+、Flax 0.3.2+、PyTorch 1.3.1+ 和 TensorFlow 2.3+ 下經過測試。
+
+你可以在[虛擬環境](https://docs.python.org/3/library/venv.html)中安裝 🤗 Transformers。如果你還不熟悉 Python 的虛擬環境,請閱此[使用者指引](https://packaging.python.org/guides/installing-using-pip-and-virtual-environments/)。
+
+首先,用你打算使用的版本的 Python 創建一個虛擬環境並進入。
+
+然後,你需要安裝 Flax、PyTorch 或 TensorFlow 其中之一。對於該如何在你使用的平台上安裝這些框架,請參閱 [TensorFlow 安裝頁面](https://www.tensorflow.org/install/), [PyTorch 安裝頁面](https://pytorch.org/get-started/locally/#start-locally) 或 [Flax 安裝頁面](https://github.com/google/flax#quick-install)。
+
+當其中一個後端安裝成功後,🤗 Transformers 可依此安裝:
+
+```bash
+pip install transformers
+```
+
+如果你想要試試範例或者想在正式發布前使用最新開發中的程式碼,你必須[從原始碼安裝](https://huggingface.co/docs/transformers/installation#installing-from-source)。
+
+### 使用 conda
+
+自 Transformers 4.0.0 版始,我們有了一個 conda channel: `huggingface`。
+
+🤗 Transformers 可以藉由 conda 依此安裝:
+
+```shell script
+conda install -c huggingface transformers
+```
+
+要藉由 conda 安裝 Flax、PyTorch 或 TensorFlow 其中之一,請參閱它們各自安裝頁面的說明。
+
+## 模型架構
+
+**🤗 Transformers 支援的[所有的模型檢查點](https://huggingface.co/models)**,由[使用者](https://huggingface.co/users)和[組織](https://huggingface.co/organizations)上傳,均與 huggingface.co [model hub](https://huggingface.co) 完美結合。
+
+目前的檢查點數量: 
+
+🤗 Transformers 目前支援以下的架構(模型概覽請參閱[這裡](https://huggingface.co/docs/transformers/model_summary)):
+
+1. **[ALBERT](https://huggingface.co/docs/transformers/model_doc/albert)** (from Google Research and the Toyota Technological Institute at Chicago) released with the paper [ALBERT: A Lite BERT for Self-supervised Learning of Language Representations](https://arxiv.org/abs/1909.11942), by Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, Radu Soricut.
+1. **[BART](https://huggingface.co/docs/transformers/model_doc/bart)** (from Facebook) released with the paper [BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension](https://arxiv.org/pdf/1910.13461.pdf) by Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov and Luke Zettlemoyer.
+1. **[BARThez](https://huggingface.co/docs/transformers/model_doc/barthez)** (from École polytechnique) released with the paper [BARThez: a Skilled Pretrained French Sequence-to-Sequence Model](https://arxiv.org/abs/2010.12321) by Moussa Kamal Eddine, Antoine J.-P. Tixier, Michalis Vazirgiannis.
+1. **[BARTpho](https://huggingface.co/docs/transformers/model_doc/bartpho)** (from VinAI Research) released with the paper [BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnamese](https://arxiv.org/abs/2109.09701) by Nguyen Luong Tran, Duong Minh Le and Dat Quoc Nguyen.
+1. **[BEiT](https://huggingface.co/docs/transformers/model_doc/beit)** (from Microsoft) released with the paper [BEiT: BERT Pre-Training of Image Transformers](https://arxiv.org/abs/2106.08254) by Hangbo Bao, Li Dong, Furu Wei.
+1. **[BERT](https://huggingface.co/docs/transformers/model_doc/bert)** (from Google) released with the paper [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://arxiv.org/abs/1810.04805) by Jacob Devlin, Ming-Wei Chang, Kenton Lee and Kristina Toutanova.
+1. **[BERT For Sequence Generation](https://huggingface.co/docs/transformers/model_doc/bert-generation)** (from Google) released with the paper [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
+1. **[BERTweet](https://huggingface.co/docs/transformers/model_doc/bertweet)** (from VinAI Research) released with the paper [BERTweet: A pre-trained language model for English Tweets](https://aclanthology.org/2020.emnlp-demos.2/) by Dat Quoc Nguyen, Thanh Vu and Anh Tuan Nguyen.
+1. **[BigBird-Pegasus](https://huggingface.co/docs/transformers/model_doc/bigbird_pegasus)** (from Google Research) released with the paper [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) by Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed.
+1. **[BigBird-RoBERTa](https://huggingface.co/docs/transformers/model_doc/big_bird)** (from Google Research) released with the paper [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) by Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed.
+1. **[Blenderbot](https://huggingface.co/docs/transformers/model_doc/blenderbot)** (from Facebook) released with the paper [Recipes for building an open-domain chatbot](https://arxiv.org/abs/2004.13637) by Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston.
+1. **[BlenderbotSmall](https://huggingface.co/docs/transformers/model_doc/blenderbot-small)** (from Facebook) released with the paper [Recipes for building an open-domain chatbot](https://arxiv.org/abs/2004.13637) by Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston.
+1. **[BORT](https://huggingface.co/docs/transformers/model_doc/bort)** (from Alexa) released with the paper [Optimal Subarchitecture Extraction For BERT](https://arxiv.org/abs/2010.10499) by Adrian de Wynter and Daniel J. Perry.
+1. **[ByT5](https://huggingface.co/docs/transformers/model_doc/byt5)** (from Google Research) released with the paper [ByT5: Towards a token-free future with pre-trained byte-to-byte models](https://arxiv.org/abs/2105.13626) by Linting Xue, Aditya Barua, Noah Constant, Rami Al-Rfou, Sharan Narang, Mihir Kale, Adam Roberts, Colin Raffel.
+1. **[CamemBERT](https://huggingface.co/docs/transformers/model_doc/camembert)** (from Inria/Facebook/Sorbonne) released with the paper [CamemBERT: a Tasty French Language Model](https://arxiv.org/abs/1911.03894) by Louis Martin*, Benjamin Muller*, Pedro Javier Ortiz Suárez*, Yoann Dupont, Laurent Romary, Éric Villemonte de la Clergerie, Djamé Seddah and Benoît Sagot.
+1. **[CANINE](https://huggingface.co/docs/transformers/model_doc/canine)** (from Google Research) released with the paper [CANINE: Pre-training an Efficient Tokenization-Free Encoder for Language Representation](https://arxiv.org/abs/2103.06874) by Jonathan H. Clark, Dan Garrette, Iulia Turc, John Wieting.
+1. **[CLIP](https://huggingface.co/docs/transformers/model_doc/clip)** (from OpenAI) released with the paper [Learning Transferable Visual Models From Natural Language Supervision](https://arxiv.org/abs/2103.00020) by Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever.
+1. **[ConvBERT](https://huggingface.co/docs/transformers/model_doc/convbert)** (from YituTech) released with the paper [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496) by Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan.
+1. **[ConvNeXT](https://huggingface.co/docs/transformers/main/model_doc/convnext)** (from Facebook AI) released with the paper [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) by Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie.
+1. **[CPM](https://huggingface.co/docs/transformers/model_doc/cpm)** (from Tsinghua University) released with the paper [CPM: A Large-scale Generative Chinese Pre-trained Language Model](https://arxiv.org/abs/2012.00413) by Zhengyan Zhang, Xu Han, Hao Zhou, Pei Ke, Yuxian Gu, Deming Ye, Yujia Qin, Yusheng Su, Haozhe Ji, Jian Guan, Fanchao Qi, Xiaozhi Wang, Yanan Zheng, Guoyang Zeng, Huanqi Cao, Shengqi Chen, Daixuan Li, Zhenbo Sun, Zhiyuan Liu, Minlie Huang, Wentao Han, Jie Tang, Juanzi Li, Xiaoyan Zhu, Maosong Sun.
+1. **[CTRL](https://huggingface.co/docs/transformers/model_doc/ctrl)** (from Salesforce) released with the paper [CTRL: A Conditional Transformer Language Model for Controllable Generation](https://arxiv.org/abs/1909.05858) by Nitish Shirish Keskar*, Bryan McCann*, Lav R. Varshney, Caiming Xiong and Richard Socher.
+1. **[Data2Vec](https://huggingface.co/docs/transformers/main/model_doc/data2vec)** (from Facebook) released with the paper [Data2Vec: A General Framework for Self-supervised Learning in Speech, Vision and Language](https://arxiv.org/abs/2202.03555) by Alexei Baevski, Wei-Ning Hsu, Qiantong Xu, Arun Babu, Jiatao Gu, Michael Auli.
+1. **[DeBERTa](https://huggingface.co/docs/transformers/model_doc/deberta)** (from Microsoft) released with the paper [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654) by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
+1. **[DeBERTa-v2](https://huggingface.co/docs/transformers/model_doc/deberta-v2)** (from Microsoft) released with the paper [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654) by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
+1. **[Decision Transformer](https://huggingface.co/docs/transformers/model_doc/decision_transformer)** (from Berkeley/Facebook/Google) released with the paper [Decision Transformer: Reinforcement Learning via Sequence Modeling](https://arxiv.org/abs/2106.01345) by Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Michael Laskin, Pieter Abbeel, Aravind Srinivas, Igor Mordatch.
+1. **[DeiT](https://huggingface.co/docs/transformers/model_doc/deit)** (from Facebook) released with the paper [Training data-efficient image transformers & distillation through attention](https://arxiv.org/abs/2012.12877) by Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, Hervé Jégou.
+1. **[DETR](https://huggingface.co/docs/transformers/model_doc/detr)** (from Facebook) released with the paper [End-to-End Object Detection with Transformers](https://arxiv.org/abs/2005.12872) by Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, Sergey Zagoruyko.
+1. **[DialoGPT](https://huggingface.co/docs/transformers/model_doc/dialogpt)** (from Microsoft Research) released with the paper [DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation](https://arxiv.org/abs/1911.00536) by Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao, Jianfeng Gao, Jingjing Liu, Bill Dolan.
+1. **[DistilBERT](https://huggingface.co/docs/transformers/model_doc/distilbert)** (from HuggingFace), released together with the paper [DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter](https://arxiv.org/abs/1910.01108) by Victor Sanh, Lysandre Debut and Thomas Wolf. The same method has been applied to compress GPT2 into [DistilGPT2](https://github.com/huggingface/transformers/tree/main/examples/distillation), RoBERTa into [DistilRoBERTa](https://github.com/huggingface/transformers/tree/main/examples/distillation), Multilingual BERT into [DistilmBERT](https://github.com/huggingface/transformers/tree/main/examples/distillation) and a German version of DistilBERT.
+1. **[DiT](https://huggingface.co/docs/transformers/model_doc/dit)** (from Microsoft Research) released with the paper [DiT: Self-supervised Pre-training for Document Image Transformer](https://arxiv.org/abs/2203.02378) by Junlong Li, Yiheng Xu, Tengchao Lv, Lei Cui, Cha Zhang, Furu Wei.
+1. **[DPR](https://huggingface.co/docs/transformers/model_doc/dpr)** (from Facebook) released with the paper [Dense Passage Retrieval for Open-Domain Question Answering](https://arxiv.org/abs/2004.04906) by Vladimir Karpukhin, Barlas Oğuz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih.
+1. **[DPT](https://huggingface.co/docs/transformers/master/model_doc/dpt)** (from Intel Labs) released with the paper [Vision Transformers for Dense Prediction](https://arxiv.org/abs/2103.13413) by René Ranftl, Alexey Bochkovskiy, Vladlen Koltun.
+1. **[ELECTRA](https://huggingface.co/docs/transformers/model_doc/electra)** (from Google Research/Stanford University) released with the paper [ELECTRA: Pre-training text encoders as discriminators rather than generators](https://arxiv.org/abs/2003.10555) by Kevin Clark, Minh-Thang Luong, Quoc V. Le, Christopher D. Manning.
+1. **[EncoderDecoder](https://huggingface.co/docs/transformers/model_doc/encoder-decoder)** (from Google Research) released with the paper [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
+1. **[FlauBERT](https://huggingface.co/docs/transformers/model_doc/flaubert)** (from CNRS) released with the paper [FlauBERT: Unsupervised Language Model Pre-training for French](https://arxiv.org/abs/1912.05372) by Hang Le, Loïc Vial, Jibril Frej, Vincent Segonne, Maximin Coavoux, Benjamin Lecouteux, Alexandre Allauzen, Benoît Crabbé, Laurent Besacier, Didier Schwab.
+1. **[FNet](https://huggingface.co/docs/transformers/model_doc/fnet)** (from Google Research) released with the paper [FNet: Mixing Tokens with Fourier Transforms](https://arxiv.org/abs/2105.03824) by James Lee-Thorp, Joshua Ainslie, Ilya Eckstein, Santiago Ontanon.
+1. **[Funnel Transformer](https://huggingface.co/docs/transformers/model_doc/funnel)** (from CMU/Google Brain) released with the paper [Funnel-Transformer: Filtering out Sequential Redundancy for Efficient Language Processing](https://arxiv.org/abs/2006.03236) by Zihang Dai, Guokun Lai, Yiming Yang, Quoc V. Le.
+1. **[GLPN](https://huggingface.co/docs/transformers/main/model_doc/glpn)** (from KAIST) released with the paper [Global-Local Path Networks for Monocular Depth Estimation with Vertical CutDepth](https://arxiv.org/abs/2201.07436) by Doyeon Kim, Woonghyun Ga, Pyungwhan Ahn, Donggyu Joo, Sehwan Chun, Junmo Kim.
+1. **[GPT](https://huggingface.co/docs/transformers/model_doc/openai-gpt)** (from OpenAI) released with the paper [Improving Language Understanding by Generative Pre-Training](https://blog.openai.com/language-unsupervised/) by Alec Radford, Karthik Narasimhan, Tim Salimans and Ilya Sutskever.
+1. **[GPT Neo](https://huggingface.co/docs/transformers/model_doc/gpt_neo)** (from EleutherAI) released in the repository [EleutherAI/gpt-neo](https://github.com/EleutherAI/gpt-neo) by Sid Black, Stella Biderman, Leo Gao, Phil Wang and Connor Leahy.
+1. **[GPT-2](https://huggingface.co/docs/transformers/model_doc/gpt2)** (from OpenAI) released with the paper [Language Models are Unsupervised Multitask Learners](https://blog.openai.com/better-language-models/) by Alec Radford*, Jeffrey Wu*, Rewon Child, David Luan, Dario Amodei** and Ilya Sutskever**.
+1. **[GPT-J](https://huggingface.co/docs/transformers/model_doc/gptj)** (from EleutherAI) released with the paper [kingoflolz/mesh-transformer-jax](https://github.com/kingoflolz/mesh-transformer-jax/) by Ben Wang and Aran Komatsuzaki.
+1. **[Hubert](https://huggingface.co/docs/transformers/model_doc/hubert)** (from Facebook) released with the paper [HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units](https://arxiv.org/abs/2106.07447) by Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, Abdelrahman Mohamed.
+1. **[I-BERT](https://huggingface.co/docs/transformers/model_doc/ibert)** (from Berkeley) released with the paper [I-BERT: Integer-only BERT Quantization](https://arxiv.org/abs/2101.01321) by Sehoon Kim, Amir Gholami, Zhewei Yao, Michael W. Mahoney, Kurt Keutzer.
+1. **[ImageGPT](https://huggingface.co/docs/transformers/main/model_doc/imagegpt)** (from OpenAI) released with the paper [Generative Pretraining from Pixels](https://openai.com/blog/image-gpt/) by Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, Ilya Sutskever.
+1. **[LayoutLM](https://huggingface.co/docs/transformers/model_doc/layoutlm)** (from Microsoft Research Asia) released with the paper [LayoutLM: Pre-training of Text and Layout for Document Image Understanding](https://arxiv.org/abs/1912.13318) by Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou.
+1. **[LayoutLMv2](https://huggingface.co/docs/transformers/model_doc/layoutlmv2)** (from Microsoft Research Asia) released with the paper [LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding](https://arxiv.org/abs/2012.14740) by Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui, Furu Wei, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Wanxiang Che, Min Zhang, Lidong Zhou.
+1. **[LayoutXLM](https://huggingface.co/docs/transformers/model_doc/layoutlmv2)** (from Microsoft Research Asia) released with the paper [LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding](https://arxiv.org/abs/2104.08836) by Yiheng Xu, Tengchao Lv, Lei Cui, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Furu Wei.
+1. **[LED](https://huggingface.co/docs/transformers/model_doc/led)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
+1. **[Longformer](https://huggingface.co/docs/transformers/model_doc/longformer)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
+1. **[LUKE](https://huggingface.co/docs/transformers/model_doc/luke)** (from Studio Ousia) released with the paper [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://arxiv.org/abs/2010.01057) by Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto.
+1. **[LXMERT](https://huggingface.co/docs/transformers/model_doc/lxmert)** (from UNC Chapel Hill) released with the paper [LXMERT: Learning Cross-Modality Encoder Representations from Transformers for Open-Domain Question Answering](https://arxiv.org/abs/1908.07490) by Hao Tan and Mohit Bansal.
+1. **[M2M100](https://huggingface.co/docs/transformers/model_doc/m2m_100)** (from Facebook) released with the paper [Beyond English-Centric Multilingual Machine Translation](https://arxiv.org/abs/2010.11125) by Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi Ma, Ahmed El-Kishky, Siddharth Goyal, Mandeep Baines, Onur Celebi, Guillaume Wenzek, Vishrav Chaudhary, Naman Goyal, Tom Birch, Vitaliy Liptchinsky, Sergey Edunov, Edouard Grave, Michael Auli, Armand Joulin.
+1. **[MarianMT](https://huggingface.co/docs/transformers/model_doc/marian)** Machine translation models trained using [OPUS](http://opus.nlpl.eu/) data by Jörg Tiedemann. The [Marian Framework](https://marian-nmt.github.io/) is being developed by the Microsoft Translator Team.
+1. **[MaskFormer](https://huggingface.co/docs/transformers/main/model_doc/maskformer)** (from Meta and UIUC) released with the paper [Per-Pixel Classification is Not All You Need for Semantic Segmentation](https://arxiv.org/abs/2107.06278) by Bowen Cheng, Alexander G. Schwing, Alexander Kirillov
+1. **[MBart](https://huggingface.co/docs/transformers/model_doc/mbart)** (from Facebook) released with the paper [Multilingual Denoising Pre-training for Neural Machine Translation](https://arxiv.org/abs/2001.08210) by Yinhan Liu, Jiatao Gu, Naman Goyal, Xian Li, Sergey Edunov, Marjan Ghazvininejad, Mike Lewis, Luke Zettlemoyer.
+1. **[MBart-50](https://huggingface.co/docs/transformers/model_doc/mbart)** (from Facebook) released with the paper [Multilingual Translation with Extensible Multilingual Pretraining and Finetuning](https://arxiv.org/abs/2008.00401) by Yuqing Tang, Chau Tran, Xian Li, Peng-Jen Chen, Naman Goyal, Vishrav Chaudhary, Jiatao Gu, Angela Fan.
+1. **[Megatron-BERT](https://huggingface.co/docs/transformers/model_doc/megatron-bert)** (from NVIDIA) released with the paper [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://arxiv.org/abs/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper and Bryan Catanzaro.
+1. **[Megatron-GPT2](https://huggingface.co/docs/transformers/model_doc/megatron_gpt2)** (from NVIDIA) released with the paper [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://arxiv.org/abs/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper and Bryan Catanzaro.
+1. **[mLUKE](https://huggingface.co/docs/transformers/model_doc/mluke)** (from Studio Ousia) released with the paper [mLUKE: The Power of Entity Representations in Multilingual Pretrained Language Models](https://arxiv.org/abs/2110.08151) by Ryokan Ri, Ikuya Yamada, and Yoshimasa Tsuruoka.
+1. **[MPNet](https://huggingface.co/docs/transformers/model_doc/mpnet)** (from Microsoft Research) released with the paper [MPNet: Masked and Permuted Pre-training for Language Understanding](https://arxiv.org/abs/2004.09297) by Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, Tie-Yan Liu.
+1. **[MT5](https://huggingface.co/docs/transformers/model_doc/mt5)** (from Google AI) released with the paper [mT5: A massively multilingual pre-trained text-to-text transformer](https://arxiv.org/abs/2010.11934) by Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, Colin Raffel.
+1. **[Nyströmformer](https://huggingface.co/docs/transformers/model_doc/nystromformer)** (from the University of Wisconsin - Madison) released with the paper [Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention](https://arxiv.org/abs/2102.03902) by Yunyang Xiong, Zhanpeng Zeng, Rudrasis Chakraborty, Mingxing Tan, Glenn Fung, Yin Li, Vikas Singh.
+1. **[Pegasus](https://huggingface.co/docs/transformers/model_doc/pegasus)** (from Google) released with the paper [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization](https://arxiv.org/abs/1912.08777) by Jingqing Zhang, Yao Zhao, Mohammad Saleh and Peter J. Liu.
+1. **[Perceiver IO](https://huggingface.co/docs/transformers/model_doc/perceiver)** (from Deepmind) released with the paper [Perceiver IO: A General Architecture for Structured Inputs & Outputs](https://arxiv.org/abs/2107.14795) by Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier Hénaff, Matthew M. Botvinick, Andrew Zisserman, Oriol Vinyals, João Carreira.
+1. **[PhoBERT](https://huggingface.co/docs/transformers/model_doc/phobert)** (from VinAI Research) released with the paper [PhoBERT: Pre-trained language models for Vietnamese](https://www.aclweb.org/anthology/2020.findings-emnlp.92/) by Dat Quoc Nguyen and Anh Tuan Nguyen.
+1. **[PLBart](https://huggingface.co/docs/transformers/model_doc/plbart)** (from UCLA NLP) released with the paper [Unified Pre-training for Program Understanding and Generation](https://arxiv.org/abs/2103.06333) by Wasi Uddin Ahmad, Saikat Chakraborty, Baishakhi Ray, Kai-Wei Chang.
+1. **[PoolFormer](https://huggingface.co/docs/transformers/model_doc/poolformer)** (from Sea AI Labs) released with the paper [MetaFormer is Actually What You Need for Vision](https://arxiv.org/abs/2111.11418) by Yu, Weihao and Luo, Mi and Zhou, Pan and Si, Chenyang and Zhou, Yichen and Wang, Xinchao and Feng, Jiashi and Yan, Shuicheng.
+1. **[ProphetNet](https://huggingface.co/docs/transformers/model_doc/prophetnet)** (from Microsoft Research) released with the paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou.
+1. **[QDQBert](https://huggingface.co/docs/transformers/model_doc/qdqbert)** (from NVIDIA) released with the paper [Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation](https://arxiv.org/abs/2004.09602) by Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius Micikevicius.
+1. **[REALM](https://huggingface.co/docs/transformers/model_doc/realm.html)** (from Google Research) released with the paper [REALM: Retrieval-Augmented Language Model Pre-Training](https://arxiv.org/abs/2002.08909) by Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat and Ming-Wei Chang.
+1. **[Reformer](https://huggingface.co/docs/transformers/model_doc/reformer)** (from Google Research) released with the paper [Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451) by Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya.
+1. **[RegNet](https://huggingface.co/docs/transformers/main/model_doc/regnet)** (from META Research) released with the paper [Designing Network Design Space](https://arxiv.org/abs/2003.13678) by Ilija Radosavovic, Raj Prateek Kosaraju, Ross Girshick, Kaiming He, Piotr Dollár.
+1. **[RemBERT](https://huggingface.co/docs/transformers/model_doc/rembert)** (from Google Research) released with the paper [Rethinking embedding coupling in pre-trained language models](https://arxiv.org/pdf/2010.12821.pdf) by Hyung Won Chung, Thibault Févry, Henry Tsai, M. Johnson, Sebastian Ruder.
+1. **[ResNet](https://huggingface.co/docs/transformers/model_doc/resnet)** (from Microsoft Research) released with the paper [Deep Residual Learning for Image Recognition](https://arxiv.org/abs/1512.03385) by Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun.
+1. **[RoBERTa](https://huggingface.co/docs/transformers/model_doc/roberta)** (from Facebook), released together with the paper a [Robustly Optimized BERT Pretraining Approach](https://arxiv.org/abs/1907.11692) by Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov.
+1. **[RoFormer](https://huggingface.co/docs/transformers/model_doc/roformer)** (from ZhuiyiTechnology), released together with the paper a [RoFormer: Enhanced Transformer with Rotary Position Embedding](https://arxiv.org/pdf/2104.09864v1.pdf) by Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu.
+1. **[SegFormer](https://huggingface.co/docs/transformers/model_doc/segformer)** (from NVIDIA) released with the paper [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://arxiv.org/abs/2105.15203) by Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, Ping Luo.
+1. **[SEW](https://huggingface.co/docs/transformers/model_doc/sew)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
+1. **[SEW-D](https://huggingface.co/docs/transformers/model_doc/sew_d)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
+1. **[SpeechToTextTransformer](https://huggingface.co/docs/transformers/model_doc/speech_to_text)** (from Facebook), released together with the paper [fairseq S2T: Fast Speech-to-Text Modeling with fairseq](https://arxiv.org/abs/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Dmytro Okhonko, Juan Pino.
+1. **[SpeechToTextTransformer2](https://huggingface.co/docs/transformers/model_doc/speech_to_text_2)** (from Facebook) released with the paper [Large-Scale Self- and Semi-Supervised Learning for Speech Translation](https://arxiv.org/abs/2104.06678) by Changhan Wang, Anne Wu, Juan Pino, Alexei Baevski, Michael Auli, Alexis Conneau.
+1. **[Splinter](https://huggingface.co/docs/transformers/model_doc/splinter)** (from Tel Aviv University) released with the paper [Few-Shot Question Answering by Pretraining Span Selection](https://arxiv.org/abs/2101.00438) by Ori Ram, Yuval Kirstain, Jonathan Berant, Amir Globerson, Omer Levy.
+1. **[SqueezeBert](https://huggingface.co/docs/transformers/model_doc/squeezebert)** (from Berkeley) released with the paper [SqueezeBERT: What can computer vision teach NLP about efficient neural networks?](https://arxiv.org/abs/2006.11316) by Forrest N. Iandola, Albert E. Shaw, Ravi Krishna, and Kurt W. Keutzer.
+1. **[Swin Transformer](https://huggingface.co/docs/transformers/model_doc/swin)** (from Microsoft) released with the paper [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030) by Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo.
+1. **[T5](https://huggingface.co/docs/transformers/model_doc/t5)** (from Google AI) released with the paper [Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer](https://arxiv.org/abs/1910.10683) by Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu.
+1. **[T5v1.1](https://huggingface.co/docs/transformers/model_doc/t5v1.1)** (from Google AI) released with the paper [google-research/text-to-text-transfer-transformer](https://github.com/google-research/text-to-text-transfer-transformer/blob/main/released_checkpoints.md#t511) by Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu.
+1. **[TAPAS](https://huggingface.co/docs/transformers/model_doc/tapas)** (from Google AI) released with the paper [TAPAS: Weakly Supervised Table Parsing via Pre-training](https://arxiv.org/abs/2004.02349) by Jonathan Herzig, Paweł Krzysztof Nowak, Thomas Müller, Francesco Piccinno and Julian Martin Eisenschlos.
+1. **[TAPEX](https://huggingface.co/docs/transformers/main/model_doc/tapex)** (from Microsoft Research) released with the paper [TAPEX: Table Pre-training via Learning a Neural SQL Executor](https://arxiv.org/abs/2107.07653) by Qian Liu, Bei Chen, Jiaqi Guo, Morteza Ziyadi, Zeqi Lin, Weizhu Chen, Jian-Guang Lou.
+1. **[Transformer-XL](https://huggingface.co/docs/transformers/model_doc/transfo-xl)** (from Google/CMU) released with the paper [Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context](https://arxiv.org/abs/1901.02860) by Zihang Dai*, Zhilin Yang*, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan Salakhutdinov.
+1. **[TrOCR](https://huggingface.co/docs/transformers/model_doc/trocr)** (from Microsoft) released with the paper [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282) by Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, Furu Wei.
+1. **[UniSpeech](https://huggingface.co/docs/transformers/model_doc/unispeech)** (from Microsoft Research) released with the paper [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597) by Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang.
+1. **[UniSpeechSat](https://huggingface.co/docs/transformers/model_doc/unispeech-sat)** (from Microsoft Research) released with the paper [UNISPEECH-SAT: UNIVERSAL SPEECH REPRESENTATION LEARNING WITH SPEAKER AWARE PRE-TRAINING](https://arxiv.org/abs/2110.05752) by Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen, Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu.
+1. **[VAN](https://huggingface.co/docs/transformers/model_doc/van)** (from Tsinghua University and Nankai University) released with the paper [Visual Attention Network](https://arxiv.org/pdf/2202.09741.pdf) by Meng-Hao Guo, Cheng-Ze Lu, Zheng-Ning Liu, Ming-Ming Cheng, Shi-Min Hu.
+1. **[ViLT](https://huggingface.co/docs/transformers/model_doc/vilt)** (from NAVER AI Lab/Kakao Enterprise/Kakao Brain) released with the paper [ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision](https://arxiv.org/abs/2102.03334) by Wonjae Kim, Bokyung Son, Ildoo Kim.
+1. **[Vision Transformer (ViT)](https://huggingface.co/docs/transformers/model_doc/vit)** (from Google AI) released with the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby.
+1. **[VisualBERT](https://huggingface.co/docs/transformers/model_doc/visual_bert)** (from UCLA NLP) released with the paper [VisualBERT: A Simple and Performant Baseline for Vision and Language](https://arxiv.org/pdf/1908.03557) by Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, Kai-Wei Chang.
+1. **[ViTMAE](https://huggingface.co/docs/transformers/model_doc/vit_mae)** (from Meta AI) released with the paper [Masked Autoencoders Are Scalable Vision Learners](https://arxiv.org/abs/2111.06377) by Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, Ross Girshick.
+1. **[Wav2Vec2](https://huggingface.co/docs/transformers/model_doc/wav2vec2)** (from Facebook AI) released with the paper [wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations](https://arxiv.org/abs/2006.11477) by Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli.
+1. **[Wav2Vec2Phoneme](https://huggingface.co/docs/transformers/model_doc/wav2vec2_phoneme)** (from Facebook AI) released with the paper [Simple and Effective Zero-shot Cross-lingual Phoneme Recognition](https://arxiv.org/abs/2109.11680) by Qiantong Xu, Alexei Baevski, Michael Auli.
+1. **[WavLM](https://huggingface.co/docs/transformers/model_doc/wavlm)** (from Microsoft Research) released with the paper [WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing](https://arxiv.org/abs/2110.13900) by Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, Jian Wu, Long Zhou, Shuo Ren, Yanmin Qian, Yao Qian, Jian Wu, Michael Zeng, Furu Wei.
+1. **[XGLM](https://huggingface.co/docs/transformers/model_doc/xglm)** (From Facebook AI) released with the paper [Few-shot Learning with Multilingual Language Models](https://arxiv.org/abs/2112.10668) by Xi Victoria Lin, Todor Mihaylov, Mikel Artetxe, Tianlu Wang, Shuohui Chen, Daniel Simig, Myle Ott, Naman Goyal, Shruti Bhosale, Jingfei Du, Ramakanth Pasunuru, Sam Shleifer, Punit Singh Koura, Vishrav Chaudhary, Brian O'Horo, Jeff Wang, Luke Zettlemoyer, Zornitsa Kozareva, Mona Diab, Veselin Stoyanov, Xian Li.
+1. **[XLM](https://huggingface.co/docs/transformers/model_doc/xlm)** (from Facebook) released together with the paper [Cross-lingual Language Model Pretraining](https://arxiv.org/abs/1901.07291) by Guillaume Lample and Alexis Conneau.
+1. **[XLM-ProphetNet](https://huggingface.co/docs/transformers/model_doc/xlm-prophetnet)** (from Microsoft Research) released with the paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou.
+1. **[XLM-RoBERTa](https://huggingface.co/docs/transformers/model_doc/xlm-roberta)** (from Facebook AI), released together with the paper [Unsupervised Cross-lingual Representation Learning at Scale](https://arxiv.org/abs/1911.02116) by Alexis Conneau*, Kartikay Khandelwal*, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzmán, Edouard Grave, Myle Ott, Luke Zettlemoyer and Veselin Stoyanov.
+1. **[XLM-RoBERTa-XL](https://huggingface.co/docs/transformers/model_doc/xlm-roberta-xl)** (from Facebook AI) released with the paper [Larger-Scale Transformers for Multilingual Masked Language Modeling](https://arxiv.org/abs/2105.00572) by Naman Goyal, Jingfei Du, Myle Ott, Giri Anantharaman, Alexis Conneau.
+1. **[XLNet](https://huggingface.co/docs/transformers/model_doc/xlnet)** (from Google/CMU) released with the paper [XLNet: Generalized Autoregressive Pretraining for Language Understanding](https://arxiv.org/abs/1906.08237) by Zhilin Yang*, Zihang Dai*, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, Quoc V. Le.
+1. **[XLS-R](https://huggingface.co/docs/transformers/model_doc/xls_r)** (from Facebook AI) released with the paper [XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale](https://arxiv.org/abs/2111.09296) by Arun Babu, Changhan Wang, Andros Tjandra, Kushal Lakhotia, Qiantong Xu, Naman Goyal, Kritika Singh, Patrick von Platen, Yatharth Saraf, Juan Pino, Alexei Baevski, Alexis Conneau, Michael Auli.
+1. **[XLSR-Wav2Vec2](https://huggingface.co/docs/transformers/model_doc/xlsr_wav2vec2)** (from Facebook AI) released with the paper [Unsupervised Cross-Lingual Representation Learning For Speech Recognition](https://arxiv.org/abs/2006.13979) by Alexis Conneau, Alexei Baevski, Ronan Collobert, Abdelrahman Mohamed, Michael Auli.
+1. **[YOLOS](https://huggingface.co/docs/transformers/main/model_doc/yolos)** (from Huazhong University of Science & Technology) released with the paper [You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection](https://arxiv.org/abs/2106.00666) by Yuxin Fang, Bencheng Liao, Xinggang Wang, Jiemin Fang, Jiyang Qi, Rui Wu, Jianwei Niu, Wenyu Liu.
+1. **[YOSO](https://huggingface.co/docs/transformers/model_doc/yoso)** (from the University of Wisconsin - Madison) released with the paper [You Only Sample (Almost) by Zhanpeng Zeng, Yunyang Xiong, Sathya N. Ravi, Shailesh Acharya, Glenn Fung, Vikas Singh.
+1. 想要貢獻新的模型?我們這裡有一份**詳細指引和模板**來引導你加入新的模型。你可以在 [`templates`](./templates) 目錄中找到它們。記得查看[貢獻指引](./CONTRIBUTING.md)並在開始寫 PR 前聯繫維護人員或開一個新的 issue 來獲得 feedbacks。
+
+要檢查某個模型是否已有 Flax、PyTorch 或 TensorFlow 的實作,或其是否在🤗 Tokenizers 函式庫中有對應的 tokenizer,敬請參閱[此表](https://huggingface.co/docs/transformers/index#supported-frameworks)。
+
+這些實作均已於多個資料集測試(請參閱範例腳本)並應與原版實作表現相當。你可以在範例文件的[此節](https://huggingface.co/docs/transformers/examples)中了解實作的細節。
+
+
+## 了解更多
+
+| 章節 | 描述 |
+|-|-|
+| [文件](https://huggingface.co/transformers/) | 完整的 API 文件和教學 |
+| [任務概覽](https://huggingface.co/docs/transformers/task_summary) | 🤗 Transformers 支援的任務 |
+| [預處理教學](https://huggingface.co/docs/transformers/preprocessing) | 使用 `Tokenizer` 來為模型準備資料 |
+| [訓練和微調](https://huggingface.co/docs/transformers/training) | 使用 PyTorch/TensorFlow 的內建的訓練方式或於 `Trainer` API 中使用 🤗 Transformers 提供的模型 |
+| [快速上手:微調和範例腳本](https://github.com/huggingface/transformers/tree/main/examples) | 為各種任務提供的範例腳本 |
+| [模型分享和上傳](https://huggingface.co/docs/transformers/model_sharing) | 上傳並與社群分享你微調的模型 |
+| [遷移](https://huggingface.co/docs/transformers/migration) | 從 `pytorch-transformers` 或 `pytorch-pretrained-bert` 遷移到 🤗 Transformers |
+
+## 引用
+
+我們已將此函式庫的[論文](https://www.aclweb.org/anthology/2020.emnlp-demos.6/)正式發表。如果你使用了 🤗 Transformers 函式庫,可以引用:
+```bibtex
+@inproceedings{wolf-etal-2020-transformers,
+ title = "Transformers: State-of-the-Art Natural Language Processing",
+ author = "Thomas Wolf and Lysandre Debut and Victor Sanh and Julien Chaumond and Clement Delangue and Anthony Moi and Pierric Cistac and Tim Rault and Rémi Louf and Morgan Funtowicz and Joe Davison and Sam Shleifer and Patrick von Platen and Clara Ma and Yacine Jernite and Julien Plu and Canwen Xu and Teven Le Scao and Sylvain Gugger and Mariama Drame and Quentin Lhoest and Alexander M. Rush",
+ booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations",
+ month = oct,
+ year = "2020",
+ address = "Online",
+ publisher = "Association for Computational Linguistics",
+ url = "https://www.aclweb.org/anthology/2020.emnlp-demos.6",
+ pages = "38--45"
+}
+```
diff --git a/conftest.py b/conftest.py
new file mode 100644
index 00000000000000..e71ada998a6df9
--- /dev/null
+++ b/conftest.py
@@ -0,0 +1,78 @@
+# Copyright 2020 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+# tests directory-specific settings - this file is run automatically
+# by pytest before any tests are run
+
+import doctest
+import sys
+import warnings
+from os.path import abspath, dirname, join
+
+
+# allow having multiple repository checkouts and not needing to remember to rerun
+# 'pip install -e .[dev]' when switching between checkouts and running tests.
+git_repo_path = abspath(join(dirname(__file__), "src"))
+sys.path.insert(1, git_repo_path)
+
+# silence FutureWarning warnings in tests since often we can't act on them until
+# they become normal warnings - i.e. the tests still need to test the current functionality
+warnings.simplefilter(action="ignore", category=FutureWarning)
+
+
+def pytest_configure(config):
+ config.addinivalue_line("markers", "is_pipeline_test: mark test to run only when pipeline are tested")
+ config.addinivalue_line(
+ "markers", "is_pt_tf_cross_test: mark test to run only when PT and TF interactions are tested"
+ )
+ config.addinivalue_line(
+ "markers", "is_pt_flax_cross_test: mark test to run only when PT and FLAX interactions are tested"
+ )
+ config.addinivalue_line("markers", "is_staging_test: mark test to run only in the staging environment")
+
+
+def pytest_addoption(parser):
+ from transformers.testing_utils import pytest_addoption_shared
+
+ pytest_addoption_shared(parser)
+
+
+def pytest_terminal_summary(terminalreporter):
+ from transformers.testing_utils import pytest_terminal_summary_main
+
+ make_reports = terminalreporter.config.getoption("--make-reports")
+ if make_reports:
+ pytest_terminal_summary_main(terminalreporter, id=make_reports)
+
+
+def pytest_sessionfinish(session, exitstatus):
+ # If no tests are collected, pytest exists with code 5, which makes the CI fail.
+ if exitstatus == 5:
+ session.exitstatus = 0
+
+
+# Doctest custom flag to ignore output.
+IGNORE_RESULT = doctest.register_optionflag('IGNORE_RESULT')
+
+OutputChecker = doctest.OutputChecker
+
+
+class CustomOutputChecker(OutputChecker):
+ def check_output(self, want, got, optionflags):
+ if IGNORE_RESULT & optionflags:
+ return True
+ return OutputChecker.check_output(self, want, got, optionflags)
+
+
+doctest.OutputChecker = CustomOutputChecker
diff --git a/docker/transformers-all-latest-gpu/Dockerfile b/docker/transformers-all-latest-gpu/Dockerfile
new file mode 100644
index 00000000000000..75876dde53e876
--- /dev/null
+++ b/docker/transformers-all-latest-gpu/Dockerfile
@@ -0,0 +1,22 @@
+FROM nvidia/cuda:11.2.2-cudnn8-devel-ubuntu20.04
+LABEL maintainer="Hugging Face"
+
+ARG DEBIAN_FRONTEND=noninteractive
+
+RUN apt update
+RUN apt install -y git libsndfile1-dev tesseract-ocr espeak-ng python3 python3-pip ffmpeg
+RUN python3 -m pip install --no-cache-dir --upgrade pip
+
+ARG REF=main
+RUN git clone https://github.com/huggingface/transformers && cd transformers && git checkout $REF
+RUN python3 -m pip install --no-cache-dir -e ./transformers[dev,onnxruntime]
+
+RUN python3 -m pip install --no-cache-dir -U torch tensorflow
+RUN python3 -m pip uninstall -y flax jax
+RUN python3 -m pip install --no-cache-dir torch-scatter -f https://data.pyg.org/whl/torch-$(python3 -c "from torch import version; print(version.__version__.split('+')[0])")+cu102.html
+RUN python3 -m pip install --no-cache-dir git+https://github.com/facebookresearch/detectron2.git pytesseract https://github.com/kpu/kenlm/archive/master.zip
+RUN python3 -m pip install -U "itsdangerous<2.1.0"
+
+# When installing in editable mode, `transformers` is not recognized as a package.
+# this line must be added in order for python to be aware of transformers.
+RUN cd transformers && python3 setup.py develop
diff --git a/docker/transformers-doc-builder/Dockerfile b/docker/transformers-doc-builder/Dockerfile
new file mode 100644
index 00000000000000..68463a3a696e7a
--- /dev/null
+++ b/docker/transformers-doc-builder/Dockerfile
@@ -0,0 +1,19 @@
+FROM python:3.8
+LABEL maintainer="Hugging Face"
+
+RUN apt update
+RUN git clone https://github.com/huggingface/transformers
+
+RUN python3 -m pip install --no-cache-dir --upgrade pip && python3 -m pip install --no-cache-dir git+https://github.com/huggingface/doc-builder ./transformers[dev]
+RUN apt-get -y update && apt-get install -y libsndfile1-dev && apt install -y tesseract-ocr
+
+# Torch needs to be installed before deepspeed
+RUN python3 -m pip install --no-cache-dir ./transformers[deepspeed]
+
+RUN python3 -m pip install --no-cache-dir torch-scatter -f https://data.pyg.org/whl/torch-$(python -c "from torch import version; print(version.__version__.split('+')[0])")+cpu.html
+RUN python3 -m pip install --no-cache-dir torchvision git+https://github.com/facebookresearch/detectron2.git pytesseract https://github.com/kpu/kenlm/archive/master.zip
+RUN python3 -m pip install --no-cache-dir pytorch-quantization --extra-index-url https://pypi.ngc.nvidia.com
+RUN python3 -m pip install -U "itsdangerous<2.1.0"
+
+RUN doc-builder build transformers transformers/docs/source --build_dir doc-build-dev --notebook_dir notebooks/transformers_doc --clean --version pr_$PR_NUMBER
+RUN rm -rf doc-build-dev
\ No newline at end of file
diff --git a/docker/transformers-pytorch-deepspeed-latest-gpu/Dockerfile b/docker/transformers-pytorch-deepspeed-latest-gpu/Dockerfile
new file mode 100644
index 00000000000000..1dd080c319bb7d
--- /dev/null
+++ b/docker/transformers-pytorch-deepspeed-latest-gpu/Dockerfile
@@ -0,0 +1,21 @@
+FROM nvcr.io/nvidia/pytorch:21.03-py3
+LABEL maintainer="Hugging Face"
+
+ARG DEBIAN_FRONTEND=noninteractive
+
+RUN apt -y update
+RUN apt install -y libaio-dev
+RUN python3 -m pip install --no-cache-dir --upgrade pip
+
+ARG REF=main
+RUN git clone https://github.com/huggingface/transformers && cd transformers && git checkout $REF
+RUN python3 -m pip install --no-cache-dir -e ./transformers[deepspeed-testing]
+
+RUN git clone https://github.com/microsoft/DeepSpeed && cd DeepSpeed && rm -rf build && \
+ DS_BUILD_CPU_ADAM=1 DS_BUILD_AIO=1 DS_BUILD_UTILS=1 python3 -m pip install -e . --global-option="build_ext" --global-option="-j8" --no-cache -v --disable-pip-version-check 2>&1
+
+# When installing in editable mode, `transformers` is not recognized as a package.
+# this line must be added in order for python to be aware of transformers.
+RUN cd transformers && python3 setup.py develop
+
+RUN python3 -c "from deepspeed.launcher.runner import main"
diff --git a/docker/transformers-pytorch-gpu/Dockerfile b/docker/transformers-pytorch-gpu/Dockerfile
index 5ed2bd70fd2faa..d1828190b14ee7 100644
--- a/docker/transformers-pytorch-gpu/Dockerfile
+++ b/docker/transformers-pytorch-gpu/Dockerfile
@@ -1,30 +1,26 @@
-FROM nvidia/cuda:10.2-cudnn7-devel-ubuntu18.04
+FROM nvidia/cuda:11.2.2-cudnn8-devel-ubuntu20.04
LABEL maintainer="Hugging Face"
-LABEL repository="transformers"
-RUN apt update && \
- apt install -y bash \
- build-essential \
- git \
- curl \
- ca-certificates \
- python3 \
- python3-pip && \
- rm -rf /var/lib/apt/lists
+ARG DEBIAN_FRONTEND=noninteractive
-RUN python3 -m pip install --no-cache-dir --upgrade pip && \
- python3 -m pip install --no-cache-dir \
- mkl \
- torch
+RUN apt update
+RUN apt install -y git libsndfile1-dev tesseract-ocr espeak-ng python3 python3-pip ffmpeg
+RUN python3 -m pip install --no-cache-dir --upgrade pip
-RUN git clone https://github.com/NVIDIA/apex
-RUN cd apex && \
- python3 setup.py install && \
- pip install -v --no-cache-dir --global-option="--cpp_ext" --global-option="--cuda_ext" ./
+ARG REF=main
+RUN git clone https://github.com/huggingface/transformers && cd transformers && git checkout $REF
+RUN python3 -m pip install --no-cache-dir -e ./transformers[dev-torch,testing]
-WORKDIR /workspace
-COPY . transformers/
-RUN cd transformers/ && \
- python3 -m pip install --no-cache-dir .
+# If set to nothing, will install the latest version
+ARG PYTORCH=''
-CMD ["/bin/bash"]
+RUN [ ${#PYTORCH} -gt 0 ] && VERSION='torch=='$PYTORCH'.*' || VERSION='torch'; python3 -m pip install --no-cache-dir -U $VERSION
+RUN python3 -m pip uninstall -y tensorflow flax
+
+RUN python3 -m pip install --no-cache-dir torch-scatter -f https://data.pyg.org/whl/torch-$(python3 -c "from torch import version; print(version.__version__.split('+')[0])")+cu102.html
+RUN python3 -m pip install --no-cache-dir git+https://github.com/facebookresearch/detectron2.git pytesseract https://github.com/kpu/kenlm/archive/master.zip
+RUN python3 -m pip install -U "itsdangerous<2.1.0"
+
+# When installing in editable mode, `transformers` is not recognized as a package.
+# this line must be added in order for python to be aware of transformers.
+RUN cd transformers && python3 setup.py develop
diff --git a/docker/transformers-pytorch-tpu/Dockerfile b/docker/transformers-pytorch-tpu/Dockerfile
index 97702affce9836..b61f4add51469b 100644
--- a/docker/transformers-pytorch-tpu/Dockerfile
+++ b/docker/transformers-pytorch-tpu/Dockerfile
@@ -1,7 +1,7 @@
FROM google/cloud-sdk:slim
# Build args.
-ARG GITHUB_REF=refs/heads/master
+ARG GITHUB_REF=refs/heads/main
# TODO: This Dockerfile installs pytorch/xla 3.6 wheels. There are also 3.7
# wheels available; see below.
@@ -53,7 +53,7 @@ RUN git clone https://github.com/huggingface/transformers.git && \
git checkout CI && \
cd .. && \
pip install ./transformers && \
- pip install -r ./transformers/examples/requirements.txt && \
+ pip install -r ./transformers/examples/pytorch/_test_requirements.txt && \
pip install pytest
RUN python -c "import torch_xla; print(torch_xla.__version__)"
diff --git a/docker/transformers-pytorch-tpu/bert-base-cased.jsonnet b/docker/transformers-pytorch-tpu/bert-base-cased.jsonnet
index ca0c86638f357f..84608b5d824994 100644
--- a/docker/transformers-pytorch-tpu/bert-base-cased.jsonnet
+++ b/docker/transformers-pytorch-tpu/bert-base-cased.jsonnet
@@ -27,7 +27,7 @@ local bertBaseCased = base.BaseTest {
},
command: utils.scriptCommand(
|||
- python -m pytest -s transformers/examples/test_xla_examples.py -v
+ python -m pytest -s transformers/examples/pytorch/test_xla_examples.py -v
test_exit_code=$?
echo "\nFinished running commands.\n"
test $test_exit_code -eq 0
diff --git a/docker/transformers-tensorflow-gpu/Dockerfile b/docker/transformers-tensorflow-gpu/Dockerfile
index 3277434c9f0a60..a05ace7d08e268 100644
--- a/docker/transformers-tensorflow-gpu/Dockerfile
+++ b/docker/transformers-tensorflow-gpu/Dockerfile
@@ -1,25 +1,23 @@
-FROM nvidia/cuda:10.1-cudnn7-runtime-ubuntu18.04
+FROM nvidia/cuda:11.2.2-cudnn8-devel-ubuntu20.04
LABEL maintainer="Hugging Face"
-LABEL repository="transformers"
-RUN apt update && \
- apt install -y bash \
- build-essential \
- git \
- curl \
- ca-certificates \
- python3 \
- python3-pip && \
- rm -rf /var/lib/apt/lists
+ARG DEBIAN_FRONTEND=noninteractive
-RUN python3 -m pip install --no-cache-dir --upgrade pip && \
- python3 -m pip install --no-cache-dir \
- mkl \
- tensorflow
+RUN apt update
+RUN apt install -y git libsndfile1-dev tesseract-ocr espeak-ng python3 python3-pip ffmpeg
+RUN python3 -m pip install --no-cache-dir --upgrade pip
-WORKDIR /workspace
-COPY . transformers/
-RUN cd transformers/ && \
- python3 -m pip install --no-cache-dir .
+ARG REF=main
+RUN git clone https://github.com/huggingface/transformers && cd transformers && git checkout $REF
+RUN python3 -m pip install --no-cache-dir -e ./transformers[dev-tensorflow,testing]
-CMD ["/bin/bash"]
\ No newline at end of file
+# If set to nothing, will install the latest version
+ARG TENSORFLOW=''
+
+RUN [ ${#TENSORFLOW} -gt 0 ] && VERSION='tensorflow=='$TENSORFLOW'.*' || VERSION='tensorflow'; python3 -m pip install --no-cache-dir -U $VERSION
+RUN python3 -m pip uninstall -y torch flax
+RUN python3 -m pip install -U "itsdangerous<2.1.0"
+
+# When installing in editable mode, `transformers` is not recognized as a package.
+# this line must be added in order for python to be aware of transformers.
+RUN cd transformers && python3 setup.py develop
diff --git a/docs/Makefile b/docs/Makefile
deleted file mode 100644
index 8879933e6cda15..00000000000000
--- a/docs/Makefile
+++ /dev/null
@@ -1,19 +0,0 @@
-# Minimal makefile for Sphinx documentation
-#
-
-# You can set these variables from the command line.
-SPHINXOPTS =
-SPHINXBUILD = sphinx-build
-SOURCEDIR = source
-BUILDDIR = _build
-
-# Put it first so that "make" without argument is like "make help".
-help:
- @$(SPHINXBUILD) -M help "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
-
-.PHONY: help Makefile
-
-# Catch-all target: route all unknown targets to Sphinx using the new
-# "make mode" option. $(O) is meant as a shortcut for $(SPHINXOPTS).
-%: Makefile
- @$(SPHINXBUILD) -M $@ "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
\ No newline at end of file
diff --git a/docs/README.md b/docs/README.md
index 97100e8ea2d072..69e8cd0c4ff283 100644
--- a/docs/README.md
+++ b/docs/README.md
@@ -23,6 +23,12 @@ you can install them with the following command, at the root of the code reposit
pip install -e ".[docs]"
```
+Then you need to install our special tool that builds the documentation:
+
+```bash
+pip install git+https://github.com/huggingface/doc-builder
+```
+
---
**NOTE**
@@ -31,99 +37,88 @@ check how they look like before committing for instance). You don't have to comm
---
-## Packages installed
-
-Here's an overview of all the packages installed. If you ran the previous command installing all packages from
-`requirements.txt`, you do not need to run the following commands.
+## Building the documentation
-Building it requires the package `sphinx` that you can
-install using:
+Once you have setup the `doc-builder` and additional packages, you can generate the documentation by
+typing the following command:
```bash
-pip install -U sphinx
+doc-builder build transformers docs/source/ --build_dir ~/tmp/test-build
```
-You would also need the custom installed [theme](https://github.com/readthedocs/sphinx_rtd_theme) by
-[Read The Docs](https://readthedocs.org/). You can install it using the following command:
+You can adapt the `--build_dir` to set any temporary folder that you prefer. This command will create it and generate
+the MDX files that will be rendered as the documentation on the main website. You can inspect them in your favorite
+Markdown editor.
-```bash
-pip install sphinx_rtd_theme
-```
+---
+**NOTE**
-The third necessary package is the `recommonmark` package to accept Markdown as well as Restructured text:
+It's not possible to see locally how the final documentation will look like for now. Once you have opened a PR, you
+will see a bot add a comment to a link where the documentation with your changes lives.
-```bash
-pip install recommonmark
-```
+---
-## Building the documentation
+## Adding a new element to the navigation bar
-Once you have setup `sphinx`, you can build the documentation by running the following command in the `/docs` folder:
+Accepted files are Markdown (.md or .mdx).
-```bash
-make html
-```
+Create a file with its extension and put it in the source directory. You can then link it to the toc-tree by putting
+the filename without the extension in the [`_toctree.yml`](https://github.com/huggingface/transformers/blob/main/docs/source/_toctree.yml) file.
-A folder called ``_build/html`` should have been created. You can now open the file ``_build/html/index.html`` in your
-browser.
+## Renaming section headers and moving sections
----
-**NOTE**
+It helps to keep the old links working when renaming section header and/or moving sections from one document to another. This is because the old links are likely to be used in Issues, Forums and Social media and it'd be make for a much more superior user experience if users reading those months later could still easily navigate to the originally intended information.
-If you are adding/removing elements from the toc-tree or from any structural item, it is recommended to clean the build
-directory before rebuilding. Run the following command to clean and build:
+Therefore we simply keep a little map of moved sections at the end of the document where the original section was. The key is to preserve the original anchor.
-```bash
-make clean && make html
-```
+So if you renamed a section from: "Section A" to "Section B", then you can add at the end of the file:
----
+```
+Sections that were moved:
-It should build the static app that will be available under `/docs/_build/html`
+[ Section A ]
+```
+and of course if you moved it to another file, then:
-## Adding a new element to the tree (toc-tree)
+```
+Sections that were moved:
-Accepted files are reStructuredText (.rst) and Markdown (.md). Create a file with its extension and put it
-in the source directory. You can then link it to the toc-tree by putting the filename without the extension.
+[ Section A ]
+```
-## Preview the documentation in a pull request
+Use the relative style to link to the new file so that the versioned docs continue to work.
-Once you have made your pull request, you can check what the documentation will look like after it's merged by
-following these steps:
+For an example of a rich moved sections set please see the very end of [the Trainer doc](https://github.com/huggingface/transformers/blob/main/docs/source/main_classes/trainer.mdx).
-- Look at the checks at the bottom of the conversation page of your PR (you may need to click on "show all checks" to
- expand them).
-- Click on "details" next to the `ci/circleci: build_doc` check.
-- In the new window, click on the "Artifacts" tab.
-- Locate the file "docs/_build/html/index.html" (or any specific page you want to check) and click on it to get a
- preview.
## Writing Documentation - Specification
The `huggingface/transformers` documentation follows the
-[Google documentation](https://sphinxcontrib-napoleon.readthedocs.io/en/latest/example_google.html) style. It is
-mostly written in ReStructuredText
-([Sphinx simple documentation](https://www.sphinx-doc.org/en/master/usage/restructuredtext/index.html),
-[Sourceforge complete documentation](https://docutils.sourceforge.io/docs/ref/rst/restructuredtext.html)).
-
+[Google documentation](https://sphinxcontrib-napoleon.readthedocs.io/en/latest/example_google.html) style for docstrings,
+although we can write them directly in Markdown.
### Adding a new tutorial
Adding a new tutorial or section is done in two steps:
- Add a new file under `./source`. This file can either be ReStructuredText (.rst) or Markdown (.md).
-- Link that file in `./source/index.rst` on the correct toc-tree.
+- Link that file in `./source/_toctree.yml` on the correct toc-tree.
Make sure to put your new file under the proper section. It's unlikely to go in the first section (*Get Started*), so
depending on the intended targets (beginners, more advanced users or researchers) it should go in section two, three or
four.
+### Translating
+
+When translating, refer to the guide at [./TRANSLATING.md](https://github.com/huggingface/transformers/blob/main/docs/TRANSLATING.md).
+
+
### Adding a new model
When adding a new model:
-- Create a file `xxx.rst` under `./source/model_doc` (don't hesitate to copy an existing file as template).
-- Link that file in `./source/index.rst` on the `model_doc` toc-tree.
+- Create a file `xxx.mdx` or under `./source/model_doc` (don't hesitate to copy an existing file as template).
+- Link that file in `./source/_toctree.yml`.
- Write a short overview of the model:
- Overview with paper & authors
- Paper abstract
@@ -137,64 +132,82 @@ When adding a new model:
- PyTorch head models
- TensorFlow base model
- TensorFlow head models
+ - Flax base model
+ - Flax head models
+
+These classes should be added using our Markdown syntax. Usually as follows:
-These classes should be added using the RST syntax. Usually as follows:
```
-XXXConfig
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
+## XXXConfig
-.. autoclass:: transformers.XXXConfig
- :members:
+[[autodoc]] XXXConfig
```
This will include every public method of the configuration that is documented. If for some reason you wish for a method
not to be displayed in the documentation, you can do so by specifying which methods should be in the docs:
```
-XXXTokenizer
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
+## XXXTokenizer
+
+[[autodoc]] XXXTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+```
-.. autoclass:: transformers.XXXTokenizer
- :members: build_inputs_with_special_tokens, get_special_tokens_mask,
- create_token_type_ids_from_sequences, save_vocabulary
+If you just want to add a method that is not documented (for instance magic method like `__call__` are not documented
+byt default) you can put the list of methods to add in a list that contains `all`:
```
+## XXXTokenizer
-### Writing source documentation
+[[autodoc]] XXXTokenizer
+ - all
+ - __call__
+```
-Values that should be put in `code` should either be surrounded by double backticks: \`\`like so\`\` or be written as
-an object using the :obj: syntax: :obj:\`like so\`. Note that argument names and objects like True, None or any strings
-should usually be put in `code`.
+### Writing source documentation
-When mentionning a class, it is recommended to use the :class: syntax as the mentioned class will be automatically
-linked by Sphinx: :class:\`~transformers.XXXClass\`
+Values that should be put in `code` should either be surrounded by backticks: \`like so\`. Note that argument names
+and objects like True, None or any strings should usually be put in `code`.
-When mentioning a function, it is recommended to use the :func: syntax as the mentioned function will be automatically
-linked by Sphinx: :func:\`~transformers.function\`.
+When mentioning a class, function or method, it is recommended to use our syntax for internal links so that our tool
+adds a link to its documentation with this syntax: \[\`XXXClass\`\] or \[\`function\`\]. This requires the class or
+function to be in the main package.
-When mentioning a method, it is recommended to use the :meth: syntax as the mentioned method will be automatically
-linked by Sphinx: :meth:\`~transformers.XXXClass.method\`.
+If you want to create a link to some internal class or function, you need to
+provide its path. For instance: \[\`utils.ModelOutput\`\]. This will be converted into a link with
+`utils.ModelOutput` in the description. To get rid of the path and only keep the name of the object you are
+linking to in the description, add a ~: \[\`~utils.ModelOutput\`\] will generate a link with `ModelOutput` in the description.
-Links should be done as so (note the double underscore at the end): \`text for the link <./local-link-or-global-link#loc>\`__
+The same works for methods so you can either use \[\`XXXClass.method\`\] or \[~\`XXXClass.method\`\].
#### Defining arguments in a method
-Arguments should be defined with the `Args:` prefix, followed by a line return and an indentation.
-The argument should be followed by its type, with its shape if it is a tensor, and a line return.
-Another indentation is necessary before writing the description of the argument.
+Arguments should be defined with the `Args:` (or `Arguments:` or `Parameters:`) prefix, followed by a line return and
+an indentation. The argument should be followed by its type, with its shape if it is a tensor, a colon and its
+description:
+
+```
+ Args:
+ n_layers (`int`): The number of layers of the model.
+```
+
+If the description is too long to fit in one line, another indentation is necessary before writing the description
+after th argument.
Here's an example showcasing everything so far:
```
Args:
- input_ids (:obj:`torch.LongTensor` of shape :obj:`(batch_size, sequence_length)`):
+ input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
Indices of input sequence tokens in the vocabulary.
- Indices can be obtained using :class:`~transformers.AlbertTokenizer`.
- See :meth:`~transformers.PreTrainedTokenizer.encode` and
- :meth:`~transformers.PreTrainedTokenizer.__call__` for details.
+ Indices can be obtained using [`AlbertTokenizer`]. See [`~PreTrainedTokenizer.encode`] and
+ [`~PreTrainedTokenizer.__call__`] for details.
- `What are input IDs? <../glossary.html#input-ids>`__
+ [What are input IDs?](../glossary#input-ids)
```
For optional arguments or arguments with defaults we follow the following syntax: imagine we have a function with the
@@ -208,93 +221,190 @@ then its documentation should look like this:
```
Args:
- x (:obj:`str`, `optional`):
+ x (`str`, *optional*):
This argument controls ...
- a (:obj:`float`, `optional`, defaults to 1):
+ a (`float`, *optional*, defaults to 1):
This argument is used to ...
```
-Note that we always omit the "defaults to :obj:\`None\`" when None is the default for any argument. Also note that even
+Note that we always omit the "defaults to \`None\`" when None is the default for any argument. Also note that even
if the first line describing your argument type and its default gets long, you can't break it on several lines. You can
however write as many lines as you want in the indented description (see the example above with `input_ids`).
#### Writing a multi-line code block
-Multi-line code blocks can be useful for displaying examples. They are done like so:
+Multi-line code blocks can be useful for displaying examples. They are done between two lines of three backticks as usual in Markdown:
-```
-Example::
- # first line of code
- # second line
- # etc
+````
```
-
-The `Example` string at the beginning can be replaced by anything as long as there are two semicolons following it.
+# first line of code
+# second line
+# etc
+```
+````
We follow the [doctest](https://docs.python.org/3/library/doctest.html) syntax for the examples to automatically test
the results stay consistent with the library.
#### Writing a return block
-Arguments should be defined with the `Args:` prefix, followed by a line return and an indentation.
+The return block should be introduced with the `Returns:` prefix, followed by a line return and an indentation.
The first line should be the type of the return, followed by a line return. No need to indent further for the elements
building the return.
-Here's an example for tuple return, comprising several objects:
+Here's an example for a single value return:
```
Returns:
- :obj:`tuple(torch.FloatTensor)` comprising various elements depending on the configuration (:class:`~transformers.BertConfig`) and inputs:
- loss (`optional`, returned when ``masked_lm_labels`` is provided) ``torch.FloatTensor`` of shape ``(1,)``:
- Total loss as the sum of the masked language modeling loss and the next sequence prediction (classification) loss.
- prediction_scores (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length, config.vocab_size)`)
- Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax).
+ `List[int]`: A list of integers in the range [0, 1] --- 1 for a special token, 0 for a sequence token.
```
-Here's an example for a single value return:
+Here's an example for tuple return, comprising several objects:
```
Returns:
- :obj:`List[int]`: A list of integers in the range [0, 1] --- 1 for a special token, 0 for a sequence token.
+ `tuple(torch.FloatTensor)` comprising various elements depending on the configuration ([`BertConfig`]) and inputs:
+ - ** loss** (*optional*, returned when `masked_lm_labels` is provided) `torch.FloatTensor` of shape `(1,)` --
+ Total loss as the sum of the masked language modeling loss and the next sequence prediction (classification) loss.
+ - **prediction_scores** (`torch.FloatTensor` of shape `(batch_size, sequence_length, config.vocab_size)`) --
+ Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax).
```
-#### Adding a new section
+#### Adding an image
+
+Due to the rapidly growing repository, it is important to make sure that no files that would significantly weigh down the repository are added. This includes images, videos and other non-text files. We prefer to leverage a hf.co hosted `dataset` like
+the ones hosted on [`hf-internal-testing`](https://huggingface.co/hf-internal-testing) in which to place these files and reference
+them by URL. We recommend putting them in the following dataset: [huggingface/documentation-images](https://huggingface.co/datasets/huggingface/documentation-images).
+If an external contribution, feel free to add the images to your PR and ask a Hugging Face member to migrate your images
+to this dataset.
+
+## Styling the docstring
+
+We have an automatic script running with the `make style` comment that will make sure that:
+- the docstrings fully take advantage of the line width
+- all code examples are formatted using black, like the code of the Transformers library
+
+This script may have some weird failures if you made a syntax mistake or if you uncover a bug. Therefore, it's
+recommended to commit your changes before running `make style`, so you can revert the changes done by that script
+easily.
+
+# Testing documentation examples
-In ReST section headers are designated as such with the help of a line of underlying characters, e.g.,:
+Good documentation oftens comes with an example of how a specific function or class should be used.
+Each model class should contain at least one example showcasing
+how to use this model class in inference. *E.g.* the class [Wav2Vec2ForCTC](https://huggingface.co/docs/transformers/model_doc/wav2vec2#transformers.Wav2Vec2ForCTC)
+includes an example of how to transcribe speech to text in the
+[docstring of its forward function](https://huggingface.co/docs/transformers/model_doc/wav2vec2#transformers.Wav2Vec2ForCTC.forward).
+## Writing documenation examples
+
+The syntax for Example docstrings can look as follows:
+
+```
+ Example:
+
+ ```python
+ >>> from transformers import Wav2Vec2Processor, Wav2Vec2ForCTC
+ >>> from datasets import load_dataset
+ >>> import torch
+
+ >>> dataset = load_dataset("hf-internal-testing/librispeech_asr_demo", "clean", split="validation")
+ >>> dataset = dataset.sort("id")
+ >>> sampling_rate = dataset.features["audio"].sampling_rate
+
+ >>> processor = Wav2Vec2Processor.from_pretrained("facebook/wav2vec2-base-960h")
+ >>> model = Wav2Vec2ForCTC.from_pretrained("facebook/wav2vec2-base-960h")
+
+ >>> # audio file is decoded on the fly
+ >>> inputs = processor(dataset[0]["audio"]["array"], sampling_rate=sampling_rate, return_tensors="pt")
+ >>> with torch.no_grad():
+ ... logits = model(**inputs).logits
+ >>> predicted_ids = torch.argmax(logits, dim=-1)
+
+ >>> # transcribe speech
+ >>> transcription = processor.batch_decode(predicted_ids)
+ >>> transcription[0]
+ 'MISTER QUILTER IS THE APOSTLE OF THE MIDDLE CLASSES AND WE ARE GLAD TO WELCOME HIS GOSPEL'
+ ```
```
-Section 1
-^^^^^^^^^^^^^^^^^^
-Sub-section 1
-~~~~~~~~~~~~~~~~~~
+The docstring should give a minimal, clear example of how the respective model
+is to be used in inference and also include the expected (ideally sensible)
+output.
+Often, readers will try out the example before even going through the function
+or class definitions. Therefore it is of utmost importance that the example
+works as expected.
+
+## Docstring testing
+
+To do so each example should be included in the doctests.
+We use pytests' [doctest integration](https://docs.pytest.org/doctest.html) to verify that all of our examples run correctly.
+For Transformers, the doctests are run on a daily basis via GitHub Actions as can be
+seen [here](https://github.com/huggingface/transformers/actions/workflows/doctests.yml).
+
+To include your example in the daily doctests, you need add the filename that
+contains the example docstring to the [documentation_tests.txt](../utils/documentation_tests.txt).
+
+### For Python files
+
+You will first need to run the following command (from the root of the repository) to prepare the doc file (doc-testing needs to add additional lines that we don't include in the doc source files):
+
+```bash
+python utils/prepare_for_doc_test.py src docs
```
-ReST allows the use of any characters to designate different section levels, as long as they are used consistently within the same document. For details see [sections doc](https://www.sphinx-doc.org/en/master/usage/restructuredtext/basics.html#sections). Because there is no standard different documents often end up using different characters for the same levels which makes it very difficult to know which character to use when creating a new section.
+If you work on a specific python module, say `modeling_wav2vec2.py`, you can run the command as follows (to avoid the unnecessary temporary changes in irrelevant files):
-Specifically, if when running `make docs` you get an error like:
+```bash
+python utils/prepare_for_doc_test.py src/transformers/utils/doc.py src/transformers/models/wav2vec2/modeling_wav2vec2.py
+```
+(`utils/doc.py` should always be included)
+
+Then you can run all the tests in the docstrings of a given file with the following command, here is how we test the modeling file of Wav2Vec2 for instance:
+
+```bash
+pytest --doctest-modules src/transformers/models/wav2vec2/modeling_wav2vec2.py -sv --doctest-continue-on-failure
```
-docs/source/main_classes/trainer.rst:127:Title level inconsistent:
+
+If you want to isolate a specific docstring, just add `::` after the file name then type the whole path of the function/class/method whose docstring you want to test. For instance, here is how to just test the forward method of `Wav2Vec2ForCTC`:
+
+```bash
+pytest --doctest-modules src/transformers/models/wav2vec2/modeling_wav2vec2.py::transformers.models.wav2vec2.modeling_wav2vec2.Wav2Vec2ForCTC.forward -sv --doctest-continue-on-failure
+```
+
+Once you're done, you can run the following command (still from the root of the repository) to undo the changes made by the first command before committing:
+
+```bash
+python utils/prepare_for_doc_test.py src docs --remove_new_line
```
-you picked an inconsistent character for some of the levels.
-But how do you know which characters you must use for an already existing level or when adding a new level?
+### For Markdown files
+
+You will first need to run the following command (from the root of the repository) to prepare the doc file (doc-testing needs to add additional lines that we don't include in the doc source files):
-You can use this helper script:
+```bash
+python utils/prepare_for_doc_test.py src docs
```
-perl -ne '/^(.)\1{100,}/ && do { $h{$1}=++$c if !$h{$1} }; END { %h = reverse %h ; print "$_ $h{$_}\n" for sort keys %h}' docs/source/main_classes/trainer.rst
-1 -
-2 ~
-3 ^
-4 =
-5 "
+
+Then you can test locally a given file with this command (here testing the quicktour):
+
+```bash
+pytest --doctest-modules docs/source/quicktour.mdx -sv --doctest-continue-on-failure --doctest-glob="*.mdx"
```
-This tells you which characters have already been assigned for each level.
+Once you're done, you can run the following command (still from the root of the repository) to undo the changes made by the first command before committing:
+
+```bash
+python utils/prepare_for_doc_test.py src docs --remove_new_line
+```
-So using this particular example's output -- if your current section's header uses `=` as its underline character, you now know you're at level 4, and if you want to add a sub-section header you know you want `"` as it'd level 5.
+### Writing doctests
-If you needed to add yet another sub-level, then pick a character that is not used already. That is you must pick a character that is not in the output of that script.
+Here are a few tips to help you debug the doctests and make them pass:
-Here is the full list of characters that can be used in this context: `= - ` : ' " ~ ^ _ * + # < >`
+- The outputs of the code need to match the expected output **exactly**, so make sure you have the same outputs. In particular doctest will see a difference between single quotes and double quotes, or a missing parenthesis. The only exceptions to that rule are:
+ * whitespace: one give whitespace (space, tabulation, new line) is equivalent to any number of whitespace, so you can add new lines where there are spaces to make your output more readable.
+ * numerical values: you should never put more than 4 or 5 digits to expected results as different setups or library versions might get you slightly different results. `doctest` is configure to ignore any difference lower than the precision to which you wrote (so 1e-4 if you write 4 digits).
+- Don't leave a block of code that is very long to execute. If you can't make it fast, you can either not use the doctest syntax on it (so that it's ignored), or if you want to use the doctest syntax to show the results, you can add a comment `# doctest: +SKIP` at the end of the lines of code too long to execute
+- Each line of code that produces a result needs to have that result written below. You can ignore an output if you don't want to show it in your code example by adding a comment ` # doctest: +IGNORE_RESULT` at the end of the line of code produing it.
diff --git a/docs/TRANSLATING.md b/docs/TRANSLATING.md
new file mode 100644
index 00000000000000..cc40dd725ec05a
--- /dev/null
+++ b/docs/TRANSLATING.md
@@ -0,0 +1,58 @@
+### Translating the Transformers documentation into your language
+
+As part of our mission to democratize machine learning, we'd love to make the Transformers library available in many more languages! Follow the steps below if you want to help translate the documentation into your language 🙏.
+
+**🗞️ Open an issue**
+
+To get started, navigate to the [Issues](https://github.com/huggingface/transformers/issues) page of this repo and check if anyone else has opened an issue for your language. If not, open a new issue by selecting the "Translation template" from the "New issue" button.
+
+Once an issue exists, post a comment to indicate which chapters you'd like to work on, and we'll add your name to the list.
+
+
+**🍴 Fork the repository**
+
+First, you'll need to [fork the Transformers repo](https://docs.github.com/en/get-started/quickstart/fork-a-repo). You can do this by clicking on the **Fork** button on the top-right corner of this repo's page.
+
+Once you've forked the repo, you'll want to get the files on your local machine for editing. You can do that by cloning the fork with Git as follows:
+
+```bash
+git clone https://github.com/YOUR-USERNAME/transformers.git
+```
+
+**📋 Copy-paste the English version with a new language code**
+
+The documentation files are in one leading directory:
+
+- [`docs/source`](https://github.com/huggingface/transformers/tree/main/docs/source): All the documentation materials are organized here by language.
+
+You'll only need to copy the files in the [`docs/source/en`](https://github.com/huggingface/transformers/tree/main/docs/source/en) directory, so first navigate to your fork of the repo and run the following:
+
+```bash
+cd ~/path/to/transformers/docs
+cp -r source/en source/LANG-ID
+```
+
+Here, `LANG-ID` should be one of the ISO 639-1 or ISO 639-2 language codes -- see [here](https://www.loc.gov/standards/iso639-2/php/code_list.php) for a handy table.
+
+**✍️ Start translating**
+
+The fun part comes - translating the text!
+
+The first thing we recommend is translating the part of the `_toctree.yml` file that corresponds to your doc chapter. This file is used to render the table of contents on the website.
+
+> 🙋 If the `_toctree.yml` file doesn't yet exist for your language, you can create one by copy-pasting from the English version and deleting the sections unrelated to your chapter. Just make sure it exists in the `docs/source/LANG-ID/` directory!
+
+The fields you should add are `local` (with the name of the file containing the translation; e.g. `autoclass_tutorial`), and `title` (with the title of the doc in your language; e.g. `Load pretrained instances with an AutoClass`) -- as a reference, here is the `_toctree.yml` for [English](https://github.com/huggingface/transformers/blob/main/docs/source/en/_toctree.yml):
+
+```yaml
+- sections:
+ - local: pipeline_tutorial # Do not change this! Use the same name for your .md file
+ title: Pipelines for inference # Translate this!
+ ...
+ title: Tutorials # Translate this!
+```
+
+Once you have translated the `_toctree.yml` file, you can start translating the [MDX](https://mdxjs.com/) files associated with your docs chapter.
+
+> 🙋 If you'd like others to help you with the translation, you can either [open an issue](https://github.com/huggingface/transformers/issues) or tag @[espejelomar](https://twitter.com/espejelomar)
+ on Twitter to gain some visibility.
\ No newline at end of file
diff --git a/docs/source/_config.py b/docs/source/_config.py
new file mode 100644
index 00000000000000..cd76263e9a5cb2
--- /dev/null
+++ b/docs/source/_config.py
@@ -0,0 +1,14 @@
+# docstyle-ignore
+INSTALL_CONTENT = """
+# Transformers installation
+! pip install transformers datasets
+# To install from source instead of the last release, comment the command above and uncomment the following one.
+# ! pip install git+https://github.com/huggingface/transformers.git
+"""
+
+notebook_first_cells = [{"type": "code", "content": INSTALL_CONTENT}]
+black_avoid_patterns = {
+ "{processor_class}": "FakeProcessorClass",
+ "{model_class}": "FakeModelClass",
+ "{object_class}": "FakeObjectClass",
+}
diff --git a/docs/source/_static/css/Calibre-Light.ttf b/docs/source/_static/css/Calibre-Light.ttf
deleted file mode 100644
index 2e6631909a671e..00000000000000
Binary files a/docs/source/_static/css/Calibre-Light.ttf and /dev/null differ
diff --git a/docs/source/_static/css/Calibre-Medium.otf b/docs/source/_static/css/Calibre-Medium.otf
deleted file mode 100644
index f9f11ebe430e37..00000000000000
Binary files a/docs/source/_static/css/Calibre-Medium.otf and /dev/null differ
diff --git a/docs/source/_static/css/Calibre-Regular.otf b/docs/source/_static/css/Calibre-Regular.otf
deleted file mode 100644
index 3801b704cc8b83..00000000000000
Binary files a/docs/source/_static/css/Calibre-Regular.otf and /dev/null differ
diff --git a/docs/source/_static/css/Calibre-Thin.otf b/docs/source/_static/css/Calibre-Thin.otf
deleted file mode 100644
index 44f93821ee80e7..00000000000000
Binary files a/docs/source/_static/css/Calibre-Thin.otf and /dev/null differ
diff --git a/docs/source/_static/css/code-snippets.css b/docs/source/_static/css/code-snippets.css
deleted file mode 100644
index ccb07020080d47..00000000000000
--- a/docs/source/_static/css/code-snippets.css
+++ /dev/null
@@ -1,16 +0,0 @@
-
-.highlight .c1, .highlight .sd{
- color: #999
-}
-
-.highlight .nn, .highlight .k, .highlight .s1, .highlight .nb, .highlight .bp, .highlight .kc {
- color: #FB8D68;
-}
-
-.highlight .kn, .highlight .nv, .highlight .s2, .highlight .ow {
- color: #6670FF;
-}
-
-.highlight .gp {
- color: #FB8D68;
-}
\ No newline at end of file
diff --git a/docs/source/_static/css/huggingface.css b/docs/source/_static/css/huggingface.css
deleted file mode 100644
index cee1aac5bc1d77..00000000000000
--- a/docs/source/_static/css/huggingface.css
+++ /dev/null
@@ -1,350 +0,0 @@
-/* Our DOM objects */
-
-/* Colab dropdown */
-
-table.center-aligned-table td {
- text-align: center;
-}
-
-table.center-aligned-table th {
- text-align: center;
- vertical-align: middle;
-}
-
-.colab-dropdown {
- position: relative;
- display: inline-block;
-}
-
-.colab-dropdown-content {
- display: none;
- position: absolute;
- background-color: #f9f9f9;
- min-width: 117px;
- box-shadow: 0px 8px 16px 0px rgba(0,0,0,0.2);
- z-index: 1;
-}
-
-.colab-dropdown-content button {
- color: #6670FF;
- background-color: #f9f9f9;
- font-size: 12px;
- border: none;
- min-width: 117px;
- padding: 5px 5px;
- text-decoration: none;
- display: block;
-}
-
-.colab-dropdown-content button:hover {background-color: #eee;}
-
-.colab-dropdown:hover .colab-dropdown-content {display: block;}
-
-/* Version control */
-
-.version-button {
- background-color: #6670FF;
- color: white;
- border: none;
- padding: 5px;
- font-size: 15px;
- cursor: pointer;
-}
-
-.version-button:hover, .version-button:focus {
- background-color: #A6B0FF;
-}
-
-.version-dropdown {
- display: none;
- background-color: #6670FF;
- min-width: 160px;
- overflow: auto;
- font-size: 15px;
-}
-
-.version-dropdown a {
- color: white;
- padding: 3px 4px;
- text-decoration: none;
- display: block;
-}
-
-.version-dropdown a:hover {
- background-color: #A6B0FF;
-}
-
-.version-show {
- display: block;
-}
-
-/* Framework selector */
-
-.framework-selector {
- display: flex;
- flex-direction: row;
- justify-content: flex-end;
- margin-right: 30px;
-}
-
-.framework-selector > button {
- background-color: white;
- color: #6670FF;
- border: 1px solid #6670FF;
- padding: 5px;
-}
-
-.framework-selector > button.selected{
- background-color: #6670FF;
- color: white;
- border: 1px solid #6670FF;
- padding: 5px;
-}
-
-/* Copy button */
-
-a.copybtn {
- margin: 3px;
-}
-
-/* The literal code blocks */
-.rst-content tt.literal, .rst-content tt.literal, .rst-content code.literal {
- color: #6670FF;
-}
-
-/* To keep the logo centered */
-.wy-side-scroll {
- width: auto;
- font-size: 20px;
-}
-
-/* The div that holds the Hugging Face logo */
-.HuggingFaceDiv {
- width: 100%
-}
-
-/* The research field on top of the toc tree */
-.wy-side-nav-search{
- padding-top: 0;
- background-color: #6670FF;
-}
-
-/* The toc tree */
-.wy-nav-side{
- background-color: #6670FF;
-}
-
-/* The section headers in the toc tree */
-.wy-menu-vertical p.caption{
- background-color: #4d59ff;
- line-height: 40px;
-}
-
-/* The selected items in the toc tree */
-.wy-menu-vertical li.current{
- background-color: #A6B0FF;
-}
-
-/* When a list item that does belong to the selected block from the toc tree is hovered */
-.wy-menu-vertical li.current a:hover{
- background-color: #B6C0FF;
-}
-
-/* When a list item that does NOT belong to the selected block from the toc tree is hovered. */
-.wy-menu-vertical li a:hover{
- background-color: #A7AFFB;
-}
-
-/* The text items on the toc tree */
-.wy-menu-vertical a {
- color: #FFFFDD;
- font-family: Calibre-Light, sans-serif;
-}
-.wy-menu-vertical header, .wy-menu-vertical p.caption{
- color: white;
- font-family: Calibre-Light, sans-serif;
-}
-
-/* The color inside the selected toc tree block */
-.wy-menu-vertical li.toctree-l2 a, .wy-menu-vertical li.toctree-l3 a, .wy-menu-vertical li.toctree-l4 a {
- color: black;
-}
-
-/* Inside the depth-2 selected toc tree block */
-.wy-menu-vertical li.toctree-l2.current>a {
- background-color: #B6C0FF
-}
-.wy-menu-vertical li.toctree-l2.current li.toctree-l3>a {
- background-color: #C6D0FF
-}
-
-/* Inside the depth-3 selected toc tree block */
-.wy-menu-vertical li.toctree-l3.current li.toctree-l4>a{
- background-color: #D6E0FF
-}
-
-/* Inside code snippets */
-.rst-content dl:not(.docutils) dt{
- font-size: 15px;
-}
-
-/* Links */
-a {
- color: #6670FF;
-}
-
-/* Content bars */
-.rst-content dl:not(.docutils) dt {
- background-color: rgba(251, 141, 104, 0.1);
- border-right: solid 2px #FB8D68;
- border-left: solid 2px #FB8D68;
- color: #FB8D68;
- font-family: Calibre-Light, sans-serif;
- border-top: none;
- font-style: normal !important;
-}
-
-/* Expand button */
-.wy-menu-vertical li.toctree-l2 span.toctree-expand,
-.wy-menu-vertical li.on a span.toctree-expand, .wy-menu-vertical li.current>a span.toctree-expand,
-.wy-menu-vertical li.toctree-l3 span.toctree-expand{
- color: black;
-}
-
-/* Max window size */
-.wy-nav-content{
- max-width: 1200px;
-}
-
-/* Mobile header */
-.wy-nav-top{
- background-color: #6670FF;
-}
-
-
-/* Source spans */
-.rst-content .viewcode-link, .rst-content .viewcode-back{
- color: #6670FF;
- font-size: 110%;
- letter-spacing: 2px;
- text-transform: uppercase;
-}
-
-/* It would be better for table to be visible without horizontal scrolling */
-.wy-table-responsive table td, .wy-table-responsive table th{
- white-space: normal;
-}
-
-.footer {
- margin-top: 20px;
-}
-
-.footer__Social {
- display: flex;
- flex-direction: row;
-}
-
-.footer__CustomImage {
- margin: 2px 5px 0 0;
-}
-
-/* class and method names in doc */
-.rst-content dl:not(.docutils) tt.descname, .rst-content dl:not(.docutils) tt.descclassname, .rst-content dl:not(.docutils) tt.descname, .rst-content dl:not(.docutils) code.descname, .rst-content dl:not(.docutils) tt.descclassname, .rst-content dl:not(.docutils) code.descclassname{
- font-family: Calibre, sans-serif;
- font-size: 20px !important;
-}
-
-/* class name in doc*/
-.rst-content dl:not(.docutils) tt.descname, .rst-content dl:not(.docutils) tt.descname, .rst-content dl:not(.docutils) code.descname{
- margin-right: 10px;
- font-family: Calibre-Medium, sans-serif;
-}
-
-/* Method and class parameters */
-.sig-param{
- line-height: 23px;
-}
-
-/* Class introduction "class" string at beginning */
-.rst-content dl:not(.docutils) .property{
- font-size: 18px;
- color: black;
-}
-
-
-/* FONTS */
-body{
- font-family: Calibre, sans-serif;
- font-size: 16px;
-}
-
-h1 {
- font-family: Calibre-Thin, sans-serif;
- font-size: 70px;
-}
-
-h2, .rst-content .toctree-wrapper p.caption, h3, h4, h5, h6, legend{
- font-family: Calibre-Medium, sans-serif;
-}
-
-@font-face {
- font-family: Calibre-Medium;
- src: url(./Calibre-Medium.otf);
- font-weight:400;
-}
-
-@font-face {
- font-family: Calibre;
- src: url(./Calibre-Regular.otf);
- font-weight:400;
-}
-
-@font-face {
- font-family: Calibre-Light;
- src: url(./Calibre-Light.ttf);
- font-weight:400;
-}
-
-@font-face {
- font-family: Calibre-Thin;
- src: url(./Calibre-Thin.otf);
- font-weight:400;
-}
-
-
-/**
- * Nav Links to other parts of huggingface.co
- */
- div.menu {
- position: absolute;
- top: 0;
- right: 0;
- padding-top: 20px;
- padding-right: 20px;
- z-index: 1000;
-}
-div.menu a {
- font-size: 14px;
- letter-spacing: 0.3px;
- text-transform: uppercase;
- color: white;
- -webkit-font-smoothing: antialiased;
- background: linear-gradient(0deg, #6671ffb8, #9a66ffb8 50%);
- padding: 10px 16px 6px 16px;
- border-radius: 3px;
- margin-left: 12px;
- position: relative;
-}
-div.menu a:active {
- top: 1px;
-}
-@media (min-width: 768px) and (max-width: 1750px) {
- .wy-breadcrumbs {
- margin-top: 32px;
- }
-}
-@media (max-width: 768px) {
- div.menu {
- display: none;
- }
-}
diff --git a/docs/source/_static/js/custom.js b/docs/source/_static/js/custom.js
deleted file mode 100644
index d567c9a1d1b158..00000000000000
--- a/docs/source/_static/js/custom.js
+++ /dev/null
@@ -1,320 +0,0 @@
-// These two things need to be updated at each release for the version selector.
-// Last stable version
-const stableVersion = "v4.4.1"
-// Dictionary doc folder to label. The last stable version should have an empty key.
-const versionMapping = {
- "master": "master",
- "": "v4.4.0/v4.4.1 (stable)",
- "v4.3.3": "v4.3.0/v4.3.1/v4.3.2/v4.3.3",
- "v4.2.2": "v4.2.0/v4.2.1/v4.2.2",
- "v4.1.1": "v4.1.0/v4.1.1",
- "v4.0.1": "v4.0.0/v4.0.1",
- "v3.5.1": "v3.5.0/v3.5.1",
- "v3.4.0": "v3.4.0",
- "v3.3.1": "v3.3.0/v3.3.1",
- "v3.2.0": "v3.2.0",
- "v3.1.0": "v3.1.0",
- "v3.0.2": "v3.0.0/v3.0.1/v3.0.2",
- "v2.11.0": "v2.11.0",
- "v2.10.0": "v2.10.0",
- "v2.9.1": "v2.9.0/v2.9.1",
- "v2.8.0": "v2.8.0",
- "v2.7.0": "v2.7.0",
- "v2.6.0": "v2.6.0",
- "v2.5.1": "v2.5.0/v2.5.1",
- "v2.4.0": "v2.4.0/v2.4.1",
- "v2.3.0": "v2.3.0",
- "v2.2.0": "v2.2.0/v2.2.1/v2.2.2",
- "v2.1.1": "v2.1.1",
- "v2.0.0": "v2.0.0",
- "v1.2.0": "v1.2.0",
- "v1.1.0": "v1.1.0",
- "v1.0.0": "v1.0.0"
-}
-// The page that have a notebook and therefore should have the open in colab badge.
-const hasNotebook = [
- "benchmarks",
- "custom_datasets",
- "multilingual",
- "perplexity",
- "preprocessing",
- "quicktour",
- "task_summary",
- "tokenizer_summary",
- "training"
-];
-
-function addIcon() {
- const huggingFaceLogo = "https://huggingface.co/landing/assets/transformers-docs/huggingface_logo.svg";
- const image = document.createElement("img");
- image.setAttribute("src", huggingFaceLogo);
-
- const div = document.createElement("div");
- div.appendChild(image);
- div.style.textAlign = 'center';
- div.style.paddingTop = '30px';
- div.style.backgroundColor = '#6670FF';
-
- const scrollDiv = document.querySelector(".wy-side-scroll");
- scrollDiv.prepend(div);
-}
-
-function addCustomFooter() {
- const customFooter = document.createElement("div");
- const questionOrIssue = document.createElement("div");
- questionOrIssue.innerHTML = "Stuck? Read our Blog posts or Create an issue";
- customFooter.appendChild(questionOrIssue);
- customFooter.classList.add("footer");
-
- const social = document.createElement("div");
- social.classList.add("footer__Social");
-
- const imageDetails = [
- { link: "https://huggingface.co", imageLink: "https://huggingface.co/landing/assets/transformers-docs/website.svg" },
- { link: "https://twitter.com/huggingface", imageLink: "https://huggingface.co/landing/assets/transformers-docs/twitter.svg" },
- { link: "https://github.com/huggingface", imageLink: "https://huggingface.co/landing/assets/transformers-docs/github.svg" },
- { link: "https://www.linkedin.com/company/huggingface/", imageLink: "https://huggingface.co/landing/assets/transformers-docs/linkedin.svg" }
- ];
-
- imageDetails.forEach(imageLinks => {
- const link = document.createElement("a");
- const image = document.createElement("img");
- image.src = imageLinks.imageLink;
- link.href = imageLinks.link;
- image.style.width = "30px";
- image.classList.add("footer__CustomImage");
- link.appendChild(image);
- social.appendChild(link);
- });
-
- customFooter.appendChild(social);
- document.querySelector("footer").appendChild(customFooter);
-}
-
-function addGithubButton() {
- const div = `
-
- `;
- document.querySelector(".wy-side-nav-search .icon-home").insertAdjacentHTML('afterend', div);
-}
-
-function addColabLink() {
- const parts = location.toString().split('/');
- const pageName = parts[parts.length - 1].split(".")[0];
-
- if (hasNotebook.includes(pageName)) {
- const baseURL = "https://colab.research.google.com/github/huggingface/notebooks/blob/master/transformers_doc/"
- const linksColab = `
-
-

-
-
-
-
-
-
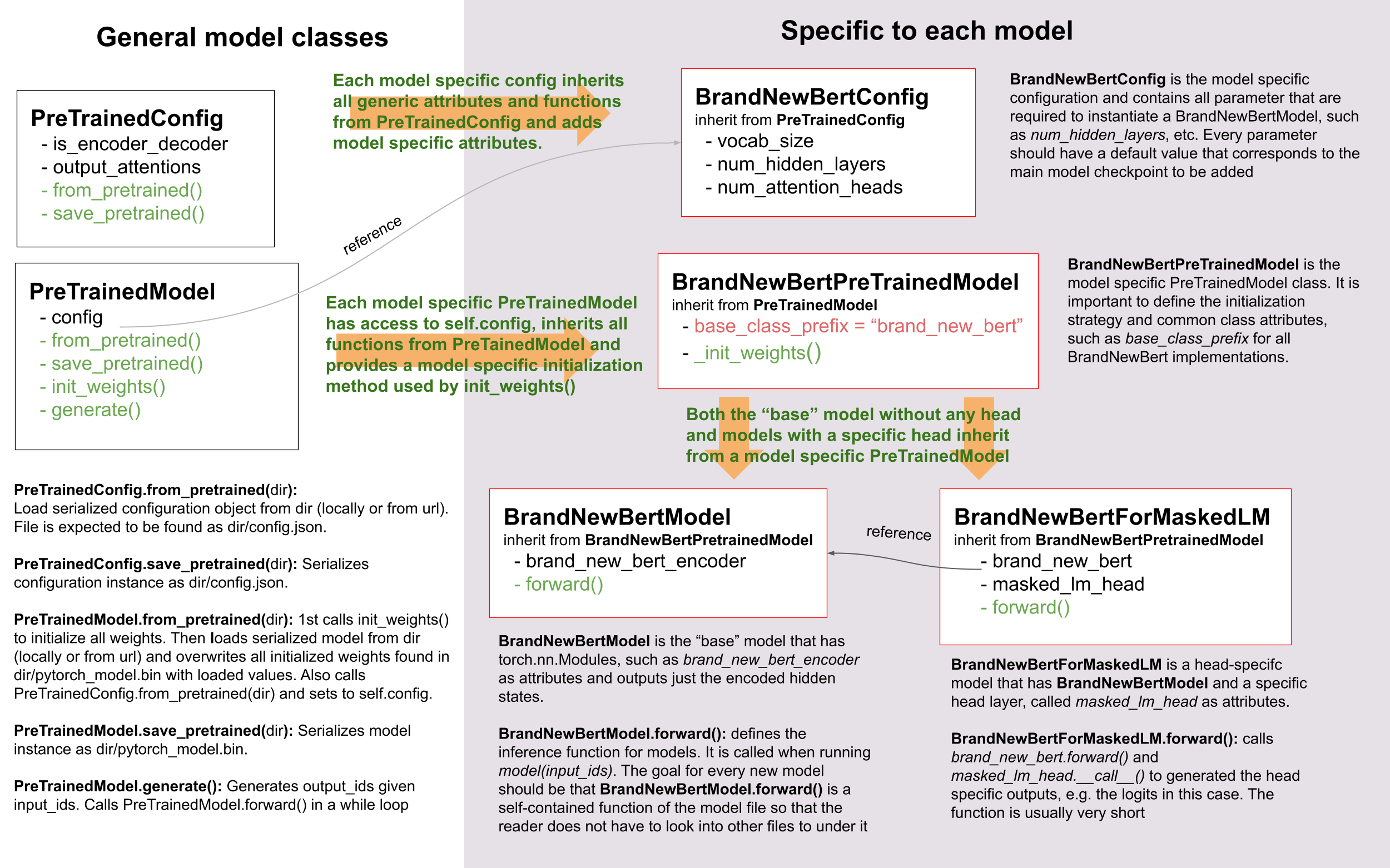 +
+As you can see, we do make use of inheritance in 🤗 Transformers, but we keep the level of abstraction to an absolute
+minimum. There are never more than two levels of abstraction for any model in the library. `BrandNewBertModel`
+inherits from `BrandNewBertPreTrainedModel` which in turn inherits from [`PreTrainedModel`] and
+that's it. As a general rule, we want to make sure that a new model only depends on
+[`PreTrainedModel`]. The important functionalities that are automatically provided to every new
+model are [`~PreTrainedModel.from_pretrained`] and
+[`~PreTrainedModel.save_pretrained`], which are used for serialization and deserialization. All of the
+other important functionalities, such as `BrandNewBertModel.forward` should be completely defined in the new
+`modeling_brand_new_bert.py` script. Next, we want to make sure that a model with a specific head layer, such as
+`BrandNewBertForMaskedLM` does not inherit from `BrandNewBertModel`, but rather uses `BrandNewBertModel`
+as a component that can be called in its forward pass to keep the level of abstraction low. Every new model requires a
+configuration class, called `BrandNewBertConfig`. This configuration is always stored as an attribute in
+[`PreTrainedModel`], and thus can be accessed via the `config` attribute for all classes
+inheriting from `BrandNewBertPreTrainedModel`:
+
+```python
+model = BrandNewBertModel.from_pretrained("brandy/brand_new_bert")
+model.config # model has access to its config
+```
+
+Similar to the model, the configuration inherits basic serialization and deserialization functionalities from
+[`PretrainedConfig`]. Note that the configuration and the model are always serialized into two
+different formats - the model to a *pytorch_model.bin* file and the configuration to a *config.json* file. Calling
+[`~PreTrainedModel.save_pretrained`] will automatically call
+[`~PretrainedConfig.save_pretrained`], so that both model and configuration are saved.
+
+
+### Code style
+
+When coding your new model, keep in mind that Transformers is an opinionated library and we have a few quirks of our
+own regarding how code should be written :-)
+
+1. The forward pass of your model should be fully written in the modeling file while being fully independent of other
+ models in the library. If you want to reuse a block from another model, copy the code and paste it with a
+ `# Copied from` comment on top (see [here](https://github.com/huggingface/transformers/blob/v4.17.0/src/transformers/models/roberta/modeling_roberta.py#L160)
+ for a good example).
+2. The code should be fully understandable, even by a non-native English speaker. This means you should pick
+ descriptive variable names and avoid abbreviations. As an example, `activation` is preferred to `act`.
+ One-letter variable names are strongly discouraged unless it's an index in a for loop.
+3. More generally we prefer longer explicit code to short magical one.
+4. Avoid subclassing `nn.Sequential` in PyTorch but subclass `nn.Module` and write the forward pass, so that anyone
+ using your code can quickly debug it by adding print statements or breaking points.
+5. Your function signature should be type-annotated. For the rest, good variable names are way more readable and
+ understandable than type annotations.
+
+### Overview of tokenizers
+
+Not quite ready yet :-( This section will be added soon!
+
+## Step-by-step recipe to add a model to 🤗 Transformers
+
+Everyone has different preferences of how to port a model so it can be very helpful for you to take a look at summaries
+of how other contributors ported models to Hugging Face. Here is a list of community blog posts on how to port a model:
+
+1. [Porting GPT2 Model](https://medium.com/huggingface/from-tensorflow-to-pytorch-265f40ef2a28) by [Thomas](https://huggingface.co/thomwolf)
+2. [Porting WMT19 MT Model](https://huggingface.co/blog/porting-fsmt) by [Stas](https://huggingface.co/stas)
+
+From experience, we can tell you that the most important things to keep in mind when adding a model are:
+
+- Don't reinvent the wheel! Most parts of the code you will add for the new 🤗 Transformers model already exist
+ somewhere in 🤗 Transformers. Take some time to find similar, already existing models and tokenizers you can copy
+ from. [grep](https://www.gnu.org/software/grep/) and [rg](https://github.com/BurntSushi/ripgrep) are your
+ friends. Note that it might very well happen that your model's tokenizer is based on one model implementation, and
+ your model's modeling code on another one. *E.g.* FSMT's modeling code is based on BART, while FSMT's tokenizer code
+ is based on XLM.
+- It's more of an engineering challenge than a scientific challenge. You should spend more time on creating an
+ efficient debugging environment than trying to understand all theoretical aspects of the model in the paper.
+- Ask for help, when you're stuck! Models are the core component of 🤗 Transformers so that we at Hugging Face are more
+ than happy to help you at every step to add your model. Don't hesitate to ask if you notice you are not making
+ progress.
+
+In the following, we try to give you a general recipe that we found most useful when porting a model to 🤗 Transformers.
+
+The following list is a summary of everything that has to be done to add a model and can be used by you as a To-Do
+List:
+
+- 1. ☐ (Optional) Understood theoretical aspects
+- 2. ☐ Prepared transformers dev environment
+- 3. ☐ Set up debugging environment of the original repository
+- 4. ☐ Created script that successfully runs forward pass using original repository and checkpoint
+- 5. ☐ Successfully added the model skeleton to Transformers
+- 6. ☐ Successfully converted original checkpoint to Transformers checkpoint
+- 7. ☐ Successfully ran forward pass in Transformers that gives identical output to original checkpoint
+- 8. ☐ Finished model tests in Transformers
+- 9. ☐ Successfully added Tokenizer in Transformers
+- 10. ☐ Run end-to-end integration tests
+- 11. ☐ Finished docs
+- 12. ☐ Uploaded model weights to the hub
+- 13. ☐ Submitted the pull request
+- 14. ☐ (Optional) Added a demo notebook
+
+To begin with, we usually recommend to start by getting a good theoretical understanding of `BrandNewBert`. However,
+if you prefer to understand the theoretical aspects of the model *on-the-job*, then it is totally fine to directly dive
+into the `BrandNewBert`'s code-base. This option might suit you better, if your engineering skills are better than
+your theoretical skill, if you have trouble understanding `BrandNewBert`'s paper, or if you just enjoy programming
+much more than reading scientific papers.
+
+### 1. (Optional) Theoretical aspects of BrandNewBert
+
+You should take some time to read *BrandNewBert's* paper, if such descriptive work exists. There might be large
+sections of the paper that are difficult to understand. If this is the case, this is fine - don't worry! The goal is
+not to get a deep theoretical understanding of the paper, but to extract the necessary information required to
+effectively re-implement the model in 🤗 Transformers. That being said, you don't have to spend too much time on the
+theoretical aspects, but rather focus on the practical ones, namely:
+
+- What type of model is *brand_new_bert*? BERT-like encoder-only model? GPT2-like decoder-only model? BART-like
+ encoder-decoder model? Look at the [model_summary](model_summary) if you're not familiar with the differences between those.
+- What are the applications of *brand_new_bert*? Text classification? Text generation? Seq2Seq tasks, *e.g.,*
+ summarization?
+- What is the novel feature of the model making it different from BERT/GPT-2/BART?
+- Which of the already existing [🤗 Transformers models](https://huggingface.co/transformers/#contents) is most
+ similar to *brand_new_bert*?
+- What type of tokenizer is used? A sentencepiece tokenizer? Word piece tokenizer? Is it the same tokenizer as used
+ for BERT or BART?
+
+After you feel like you have gotten a good overview of the architecture of the model, you might want to write to the
+Hugging Face team with any questions you might have. This might include questions regarding the model's architecture,
+its attention layer, etc. We will be more than happy to help you.
+
+### 2. Next prepare your environment
+
+1. Fork the [repository](https://github.com/huggingface/transformers) by clicking on the ‘Fork' button on the
+ repository's page. This creates a copy of the code under your GitHub user account.
+
+2. Clone your `transformers` fork to your local disk, and add the base repository as a remote:
+
+```bash
+git clone https://github.com/[your Github handle]/transformers.git
+cd transformers
+git remote add upstream https://github.com/huggingface/transformers.git
+```
+
+3. Set up a development environment, for instance by running the following command:
+
+```bash
+python -m venv .env
+source .env/bin/activate
+pip install -e ".[dev]"
+```
+
+and return to the parent directory
+
+```bash
+cd ..
+```
+
+4. We recommend adding the PyTorch version of *brand_new_bert* to Transformers. To install PyTorch, please follow the
+ instructions on https://pytorch.org/get-started/locally/.
+
+**Note:** You don't need to have CUDA installed. Making the new model work on CPU is sufficient.
+
+5. To port *brand_new_bert*, you will also need access to its original repository:
+
+```bash
+git clone https://github.com/org_that_created_brand_new_bert_org/brand_new_bert.git
+cd brand_new_bert
+pip install -e .
+```
+
+Now you have set up a development environment to port *brand_new_bert* to 🤗 Transformers.
+
+### 3.-4. Run a pretrained checkpoint using the original repository
+
+At first, you will work on the original *brand_new_bert* repository. Often, the original implementation is very
+“researchy”. Meaning that documentation might be lacking and the code can be difficult to understand. But this should
+be exactly your motivation to reimplement *brand_new_bert*. At Hugging Face, one of our main goals is to *make people
+stand on the shoulders of giants* which translates here very well into taking a working model and rewriting it to make
+it as **accessible, user-friendly, and beautiful** as possible. This is the number-one motivation to re-implement
+models into 🤗 Transformers - trying to make complex new NLP technology accessible to **everybody**.
+
+You should start thereby by diving into the original repository.
+
+Successfully running the official pretrained model in the original repository is often **the most difficult** step.
+From our experience, it is very important to spend some time getting familiar with the original code-base. You need to
+figure out the following:
+
+- Where to find the pretrained weights?
+- How to load the pretrained weights into the corresponding model?
+- How to run the tokenizer independently from the model?
+- Trace one forward pass so that you know which classes and functions are required for a simple forward pass. Usually,
+ you only have to reimplement those functions.
+- Be able to locate the important components of the model: Where is the model's class? Are there model sub-classes,
+ *e.g.* EncoderModel, DecoderModel? Where is the self-attention layer? Are there multiple different attention layers,
+ *e.g.* *self-attention*, *cross-attention*...?
+- How can you debug the model in the original environment of the repo? Do you have to add *print* statements, can you
+ work with an interactive debugger like *ipdb*, or should you use an efficient IDE to debug the model, like PyCharm?
+
+It is very important that before you start the porting process, that you can **efficiently** debug code in the original
+repository! Also, remember that you are working with an open-source library, so do not hesitate to open an issue, or
+even a pull request in the original repository. The maintainers of this repository are most likely very happy about
+someone looking into their code!
+
+At this point, it is really up to you which debugging environment and strategy you prefer to use to debug the original
+model. We strongly advise against setting up a costly GPU environment, but simply work on a CPU both when starting to
+dive into the original repository and also when starting to write the 🤗 Transformers implementation of the model. Only
+at the very end, when the model has already been successfully ported to 🤗 Transformers, one should verify that the
+model also works as expected on GPU.
+
+In general, there are two possible debugging environments for running the original model
+
+- [Jupyter notebooks](https://jupyter.org/) / [google colab](https://colab.research.google.com/notebooks/intro.ipynb)
+- Local python scripts.
+
+Jupyter notebooks have the advantage that they allow for cell-by-cell execution which can be helpful to better split
+logical components from one another and to have faster debugging cycles as intermediate results can be stored. Also,
+notebooks are often easier to share with other contributors, which might be very helpful if you want to ask the Hugging
+Face team for help. If you are familiar with Jupiter notebooks, we strongly recommend you to work with them.
+
+The obvious disadvantage of Jupyter notebooks is that if you are not used to working with them you will have to spend
+some time adjusting to the new programming environment and that you might not be able to use your known debugging tools
+anymore, like `ipdb`.
+
+For each code-base, a good first step is always to load a **small** pretrained checkpoint and to be able to reproduce a
+single forward pass using a dummy integer vector of input IDs as an input. Such a script could look like this (in
+pseudocode):
+
+```python
+model = BrandNewBertModel.load_pretrained_checkpoint("/path/to/checkpoint/")
+input_ids = [0, 4, 5, 2, 3, 7, 9] # vector of input ids
+original_output = model.predict(input_ids)
+```
+
+Next, regarding the debugging strategy, there are generally a few from which to choose from:
+
+- Decompose the original model into many small testable components and run a forward pass on each of those for
+ verification
+- Decompose the original model only into the original *tokenizer* and the original *model*, run a forward pass on
+ those, and use intermediate print statements or breakpoints for verification
+
+Again, it is up to you which strategy to choose. Often, one or the other is advantageous depending on the original code
+base.
+
+If the original code-base allows you to decompose the model into smaller sub-components, *e.g.* if the original
+code-base can easily be run in eager mode, it is usually worth the effort to do so. There are some important advantages
+to taking the more difficult road in the beginning:
+
+- at a later stage when comparing the original model to the Hugging Face implementation, you can verify automatically
+ for each component individually that the corresponding component of the 🤗 Transformers implementation matches instead
+ of relying on visual comparison via print statements
+- it can give you some rope to decompose the big problem of porting a model into smaller problems of just porting
+ individual components and thus structure your work better
+- separating the model into logical meaningful components will help you to get a better overview of the model's design
+ and thus to better understand the model
+- at a later stage those component-by-component tests help you to ensure that no regression occurs as you continue
+ changing your code
+
+[Lysandre's](https://gist.github.com/LysandreJik/db4c948f6b4483960de5cbac598ad4ed) integration checks for ELECTRA
+gives a nice example of how this can be done.
+
+However, if the original code-base is very complex or only allows intermediate components to be run in a compiled mode,
+it might be too time-consuming or even impossible to separate the model into smaller testable sub-components. A good
+example is [T5's MeshTensorFlow](https://github.com/tensorflow/mesh/tree/master/mesh_tensorflow) library which is
+very complex and does not offer a simple way to decompose the model into its sub-components. For such libraries, one
+often relies on verifying print statements.
+
+No matter which strategy you choose, the recommended procedure is often the same in that you should start to debug the
+starting layers first and the ending layers last.
+
+It is recommended that you retrieve the output, either by print statements or sub-component functions, of the following
+layers in the following order:
+
+1. Retrieve the input IDs passed to the model
+2. Retrieve the word embeddings
+3. Retrieve the input of the first Transformer layer
+4. Retrieve the output of the first Transformer layer
+5. Retrieve the output of the following n - 1 Transformer layers
+6. Retrieve the output of the whole BrandNewBert Model
+
+Input IDs should thereby consists of an array of integers, *e.g.* `input_ids = [0, 4, 4, 3, 2, 4, 1, 7, 19]`
+
+The outputs of the following layers often consist of multi-dimensional float arrays and can look like this:
+
+```
+[[
+ [-0.1465, -0.6501, 0.1993, ..., 0.1451, 0.3430, 0.6024],
+ [-0.4417, -0.5920, 0.3450, ..., -0.3062, 0.6182, 0.7132],
+ [-0.5009, -0.7122, 0.4548, ..., -0.3662, 0.6091, 0.7648],
+ ...,
+ [-0.5613, -0.6332, 0.4324, ..., -0.3792, 0.7372, 0.9288],
+ [-0.5416, -0.6345, 0.4180, ..., -0.3564, 0.6992, 0.9191],
+ [-0.5334, -0.6403, 0.4271, ..., -0.3339, 0.6533, 0.8694]]],
+```
+
+We expect that every model added to 🤗 Transformers passes a couple of integration tests, meaning that the original
+model and the reimplemented version in 🤗 Transformers have to give the exact same output up to a precision of 0.001!
+Since it is normal that the exact same model written in different libraries can give a slightly different output
+depending on the library framework, we accept an error tolerance of 1e-3 (0.001). It is not enough if the model gives
+nearly the same output, they have to be the almost identical. Therefore, you will certainly compare the intermediate
+outputs of the 🤗 Transformers version multiple times against the intermediate outputs of the original implementation of
+*brand_new_bert* in which case an **efficient** debugging environment of the original repository is absolutely
+important. Here is some advice is to make your debugging environment as efficient as possible.
+
+- Find the best way of debugging intermediate results. Is the original repository written in PyTorch? Then you should
+ probably take the time to write a longer script that decomposes the original model into smaller sub-components to
+ retrieve intermediate values. Is the original repository written in Tensorflow 1? Then you might have to rely on
+ TensorFlow print operations like [tf.print](https://www.tensorflow.org/api_docs/python/tf/print) to output
+ intermediate values. Is the original repository written in Jax? Then make sure that the model is **not jitted** when
+ running the forward pass, *e.g.* check-out [this link](https://github.com/google/jax/issues/196).
+- Use the smallest pretrained checkpoint you can find. The smaller the checkpoint, the faster your debug cycle
+ becomes. It is not efficient if your pretrained model is so big that your forward pass takes more than 10 seconds.
+ In case only very large checkpoints are available, it might make more sense to create a dummy model in the new
+ environment with randomly initialized weights and save those weights for comparison with the 🤗 Transformers version
+ of your model
+- Make sure you are using the easiest way of calling a forward pass in the original repository. Ideally, you want to
+ find the function in the original repository that **only** calls a single forward pass, *i.e.* that is often called
+ `predict`, `evaluate`, `forward` or `__call__`. You don't want to debug a function that calls `forward`
+ multiple times, *e.g.* to generate text, like `autoregressive_sample`, `generate`.
+- Try to separate the tokenization from the model's *forward* pass. If the original repository shows examples where
+ you have to input a string, then try to find out where in the forward call the string input is changed to input ids
+ and start from this point. This might mean that you have to possibly write a small script yourself or change the
+ original code so that you can directly input the ids instead of an input string.
+- Make sure that the model in your debugging setup is **not** in training mode, which often causes the model to yield
+ random outputs due to multiple dropout layers in the model. Make sure that the forward pass in your debugging
+ environment is **deterministic** so that the dropout layers are not used. Or use *transformers.utils.set_seed*
+ if the old and new implementations are in the same framework.
+
+The following section gives you more specific details/tips on how you can do this for *brand_new_bert*.
+
+### 5.-14. Port BrandNewBert to 🤗 Transformers
+
+Next, you can finally start adding new code to 🤗 Transformers. Go into the clone of your 🤗 Transformers' fork:
+
+```bash
+cd transformers
+```
+
+In the special case that you are adding a model whose architecture exactly matches the model architecture of an
+existing model you only have to add a conversion script as described in [this section](#write-a-conversion-script).
+In this case, you can just re-use the whole model architecture of the already existing model.
+
+Otherwise, let's start generating a new model. You have two choices here:
+
+- `transformers-cli add-new-model-like` to add a new model like an existing one
+- `transformers-cli add-new-model` to add a new model from our template (will look like BERT or Bart depending on the type of model you select)
+
+In both cases, you will be prompted with a questionnaire to fill the basic information of your model. The second command requires to install `cookiecutter`, you can find more information on it [here](https://github.com/huggingface/transformers/tree/main/templates/adding_a_new_model).
+
+**Open a Pull Request on the main huggingface/transformers repo**
+
+Before starting to adapt the automatically generated code, now is the time to open a “Work in progress (WIP)” pull
+request, *e.g.* “[WIP] Add *brand_new_bert*”, in 🤗 Transformers so that you and the Hugging Face team can work
+side-by-side on integrating the model into 🤗 Transformers.
+
+You should do the following:
+
+1. Create a branch with a descriptive name from your main branch
+
+```bash
+git checkout -b add_brand_new_bert
+```
+
+2. Commit the automatically generated code:
+
+```bash
+git add .
+git commit
+```
+
+3. Fetch and rebase to current main
+
+```bash
+git fetch upstream
+git rebase upstream/main
+```
+
+4. Push the changes to your account using:
+
+```bash
+git push -u origin a-descriptive-name-for-my-changes
+```
+
+5. Once you are satisfied, go to the webpage of your fork on GitHub. Click on “Pull request”. Make sure to add the
+ GitHub handle of some members of the Hugging Face team as reviewers, so that the Hugging Face team gets notified for
+ future changes.
+
+6. Change the PR into a draft by clicking on “Convert to draft” on the right of the GitHub pull request web page.
+
+In the following, whenever you have done some progress, don't forget to commit your work and push it to your account so
+that it shows in the pull request. Additionally, you should make sure to update your work with the current main from
+time to time by doing:
+
+```bash
+git fetch upstream
+git merge upstream/main
+```
+
+In general, all questions you might have regarding the model or your implementation should be asked in your PR and
+discussed/solved in the PR. This way, the Hugging Face team will always be notified when you are committing new code or
+if you have a question. It is often very helpful to point the Hugging Face team to your added code so that the Hugging
+Face team can efficiently understand your problem or question.
+
+To do so, you can go to the “Files changed” tab where you see all of your changes, go to a line regarding which you
+want to ask a question, and click on the “+” symbol to add a comment. Whenever a question or problem has been solved,
+you can click on the “Resolve” button of the created comment.
+
+In the same way, the Hugging Face team will open comments when reviewing your code. We recommend asking most questions
+on GitHub on your PR. For some very general questions that are not very useful for the public, feel free to ping the
+Hugging Face team by Slack or email.
+
+**5. Adapt the generated models code for brand_new_bert**
+
+At first, we will focus only on the model itself and not care about the tokenizer. All the relevant code should be
+found in the generated files `src/transformers/models/brand_new_bert/modeling_brand_new_bert.py` and
+`src/transformers/models/brand_new_bert/configuration_brand_new_bert.py`.
+
+Now you can finally start coding :). The generated code in
+`src/transformers/models/brand_new_bert/modeling_brand_new_bert.py` will either have the same architecture as BERT if
+it's an encoder-only model or BART if it's an encoder-decoder model. At this point, you should remind yourself what
+you've learned in the beginning about the theoretical aspects of the model: *How is the model different from BERT or
+BART?*". Implement those changes which often means to change the *self-attention* layer, the order of the normalization
+layer, etc… Again, it is often useful to look at the similar architecture of already existing models in Transformers to
+get a better feeling of how your model should be implemented.
+
+**Note** that at this point, you don't have to be very sure that your code is fully correct or clean. Rather, it is
+advised to add a first *unclean*, copy-pasted version of the original code to
+`src/transformers/models/brand_new_bert/modeling_brand_new_bert.py` until you feel like all the necessary code is
+added. From our experience, it is much more efficient to quickly add a first version of the required code and
+improve/correct the code iteratively with the conversion script as described in the next section. The only thing that
+has to work at this point is that you can instantiate the 🤗 Transformers implementation of *brand_new_bert*, *i.e.* the
+following command should work:
+
+```python
+from transformers import BrandNewBertModel, BrandNewBertConfig
+
+model = BrandNewBertModel(BrandNewBertConfig())
+```
+
+The above command will create a model according to the default parameters as defined in `BrandNewBertConfig()` with
+random weights, thus making sure that the `init()` methods of all components works.
+
+**6. Write a conversion script**
+
+Next, you should write a conversion script that lets you convert the checkpoint you used to debug *brand_new_bert* in
+the original repository to a checkpoint compatible with your just created 🤗 Transformers implementation of
+*brand_new_bert*. It is not advised to write the conversion script from scratch, but rather to look through already
+existing conversion scripts in 🤗 Transformers for one that has been used to convert a similar model that was written in
+the same framework as *brand_new_bert*. Usually, it is enough to copy an already existing conversion script and
+slightly adapt it for your use case. Don't hesitate to ask the Hugging Face team to point you to a similar already
+existing conversion script for your model.
+
+- If you are porting a model from TensorFlow to PyTorch, a good starting point might be BERT's conversion script [here](https://github.com/huggingface/transformers/blob/7acfa95afb8194f8f9c1f4d2c6028224dbed35a2/src/transformers/models/bert/modeling_bert.py#L91)
+- If you are porting a model from PyTorch to PyTorch, a good starting point might be BART's conversion script [here](https://github.com/huggingface/transformers/blob/main/src/transformers/models/bart/convert_bart_original_pytorch_checkpoint_to_pytorch.py)
+
+In the following, we'll quickly explain how PyTorch models store layer weights and define layer names. In PyTorch, the
+name of a layer is defined by the name of the class attribute you give the layer. Let's define a dummy model in
+PyTorch, called `SimpleModel` as follows:
+
+```python
+from torch import nn
+
+
+class SimpleModel(nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.dense = nn.Linear(10, 10)
+ self.intermediate = nn.Linear(10, 10)
+ self.layer_norm = nn.LayerNorm(10)
+```
+
+Now we can create an instance of this model definition which will fill all weights: `dense`, `intermediate`,
+`layer_norm` with random weights. We can print the model to see its architecture
+
+```python
+model = SimpleModel()
+
+print(model)
+```
+
+This will print out the following:
+
+```
+SimpleModel(
+ (dense): Linear(in_features=10, out_features=10, bias=True)
+ (intermediate): Linear(in_features=10, out_features=10, bias=True)
+ (layer_norm): LayerNorm((10,), eps=1e-05, elementwise_affine=True)
+)
+```
+
+We can see that the layer names are defined by the name of the class attribute in PyTorch. You can print out the weight
+values of a specific layer:
+
+```python
+print(model.dense.weight.data)
+```
+
+to see that the weights were randomly initialized
+
+```
+tensor([[-0.0818, 0.2207, -0.0749, -0.0030, 0.0045, -0.1569, -0.1598, 0.0212,
+ -0.2077, 0.2157],
+ [ 0.1044, 0.0201, 0.0990, 0.2482, 0.3116, 0.2509, 0.2866, -0.2190,
+ 0.2166, -0.0212],
+ [-0.2000, 0.1107, -0.1999, -0.3119, 0.1559, 0.0993, 0.1776, -0.1950,
+ -0.1023, -0.0447],
+ [-0.0888, -0.1092, 0.2281, 0.0336, 0.1817, -0.0115, 0.2096, 0.1415,
+ -0.1876, -0.2467],
+ [ 0.2208, -0.2352, -0.1426, -0.2636, -0.2889, -0.2061, -0.2849, -0.0465,
+ 0.2577, 0.0402],
+ [ 0.1502, 0.2465, 0.2566, 0.0693, 0.2352, -0.0530, 0.1859, -0.0604,
+ 0.2132, 0.1680],
+ [ 0.1733, -0.2407, -0.1721, 0.1484, 0.0358, -0.0633, -0.0721, -0.0090,
+ 0.2707, -0.2509],
+ [-0.1173, 0.1561, 0.2945, 0.0595, -0.1996, 0.2988, -0.0802, 0.0407,
+ 0.1829, -0.1568],
+ [-0.1164, -0.2228, -0.0403, 0.0428, 0.1339, 0.0047, 0.1967, 0.2923,
+ 0.0333, -0.0536],
+ [-0.1492, -0.1616, 0.1057, 0.1950, -0.2807, -0.2710, -0.1586, 0.0739,
+ 0.2220, 0.2358]]).
+```
+
+In the conversion script, you should fill those randomly initialized weights with the exact weights of the
+corresponding layer in the checkpoint. *E.g.*
+
+```python
+# retrieve matching layer weights, e.g. by
+# recursive algorithm
+layer_name = "dense"
+pretrained_weight = array_of_dense_layer
+
+model_pointer = getattr(model, "dense")
+
+model_pointer.weight.data = torch.from_numpy(pretrained_weight)
+```
+
+While doing so, you must verify that each randomly initialized weight of your PyTorch model and its corresponding
+pretrained checkpoint weight exactly match in both **shape and name**. To do so, it is **necessary** to add assert
+statements for the shape and print out the names of the checkpoints weights. E.g. you should add statements like:
+
+```python
+assert (
+ model_pointer.weight.shape == pretrained_weight.shape
+), f"Pointer shape of random weight {model_pointer.shape} and array shape of checkpoint weight {pretrained_weight.shape} mismatched"
+```
+
+Besides, you should also print out the names of both weights to make sure they match, *e.g.*
+
+```python
+logger.info(f"Initialize PyTorch weight {layer_name} from {pretrained_weight.name}")
+```
+
+If either the shape or the name doesn't match, you probably assigned the wrong checkpoint weight to a randomly
+initialized layer of the 🤗 Transformers implementation.
+
+An incorrect shape is most likely due to an incorrect setting of the config parameters in `BrandNewBertConfig()` that
+do not exactly match those that were used for the checkpoint you want to convert. However, it could also be that
+PyTorch's implementation of a layer requires the weight to be transposed beforehand.
+
+Finally, you should also check that **all** required weights are initialized and print out all checkpoint weights that
+were not used for initialization to make sure the model is correctly converted. It is completely normal, that the
+conversion trials fail with either a wrong shape statement or wrong name assignment. This is most likely because either
+you used incorrect parameters in `BrandNewBertConfig()`, have a wrong architecture in the 🤗 Transformers
+implementation, you have a bug in the `init()` functions of one of the components of the 🤗 Transformers
+implementation or you need to transpose one of the checkpoint weights.
+
+This step should be iterated with the previous step until all weights of the checkpoint are correctly loaded in the
+Transformers model. Having correctly loaded the checkpoint into the 🤗 Transformers implementation, you can then save
+the model under a folder of your choice `/path/to/converted/checkpoint/folder` that should then contain both a
+`pytorch_model.bin` file and a `config.json` file:
+
+```python
+model.save_pretrained("/path/to/converted/checkpoint/folder")
+```
+
+**7. Implement the forward pass**
+
+Having managed to correctly load the pretrained weights into the 🤗 Transformers implementation, you should now make
+sure that the forward pass is correctly implemented. In [Get familiar with the original repository](#run-a-pretrained-checkpoint-using-the-original-repository), you have already created a script that runs a forward
+pass of the model using the original repository. Now you should write an analogous script using the 🤗 Transformers
+implementation instead of the original one. It should look as follows:
+
+```python
+model = BrandNewBertModel.from_pretrained("/path/to/converted/checkpoint/folder")
+input_ids = [0, 4, 4, 3, 2, 4, 1, 7, 19]
+output = model(input_ids).last_hidden_states
+```
+
+It is very likely that the 🤗 Transformers implementation and the original model implementation don't give the exact
+same output the very first time or that the forward pass throws an error. Don't be disappointed - it's expected! First,
+you should make sure that the forward pass doesn't throw any errors. It often happens that the wrong dimensions are
+used leading to a *Dimensionality mismatch* error or that the wrong data type object is used, *e.g.* `torch.long`
+instead of `torch.float32`. Don't hesitate to ask the Hugging Face team for help, if you don't manage to solve
+certain errors.
+
+The final part to make sure the 🤗 Transformers implementation works correctly is to ensure that the outputs are
+equivalent to a precision of `1e-3`. First, you should ensure that the output shapes are identical, *i.e.*
+`outputs.shape` should yield the same value for the script of the 🤗 Transformers implementation and the original
+implementation. Next, you should make sure that the output values are identical as well. This one of the most difficult
+parts of adding a new model. Common mistakes why the outputs are not identical are:
+
+- Some layers were not added, *i.e.* an *activation* layer was not added, or the residual connection was forgotten
+- The word embedding matrix was not tied
+- The wrong positional embeddings are used because the original implementation uses on offset
+- Dropout is applied during the forward pass. To fix this make sure *model.training is False* and that no dropout
+ layer is falsely activated during the forward pass, *i.e.* pass *self.training* to [PyTorch's functional dropout](https://pytorch.org/docs/stable/nn.functional.html?highlight=dropout#torch.nn.functional.dropout)
+
+The best way to fix the problem is usually to look at the forward pass of the original implementation and the 🤗
+Transformers implementation side-by-side and check if there are any differences. Ideally, you should debug/print out
+intermediate outputs of both implementations of the forward pass to find the exact position in the network where the 🤗
+Transformers implementation shows a different output than the original implementation. First, make sure that the
+hard-coded `input_ids` in both scripts are identical. Next, verify that the outputs of the first transformation of
+the `input_ids` (usually the word embeddings) are identical. And then work your way up to the very last layer of the
+network. At some point, you will notice a difference between the two implementations, which should point you to the bug
+in the 🤗 Transformers implementation. From our experience, a simple and efficient way is to add many print statements
+in both the original implementation and 🤗 Transformers implementation, at the same positions in the network
+respectively, and to successively remove print statements showing the same values for intermediate presentations.
+
+When you're confident that both implementations yield the same output, verifying the outputs with
+`torch.allclose(original_output, output, atol=1e-3)`, you're done with the most difficult part! Congratulations - the
+work left to be done should be a cakewalk 😊.
+
+**8. Adding all necessary model tests**
+
+At this point, you have successfully added a new model. However, it is very much possible that the model does not yet
+fully comply with the required design. To make sure, the implementation is fully compatible with 🤗 Transformers, all
+common tests should pass. The Cookiecutter should have automatically added a test file for your model, probably under
+the same `tests/test_modeling_brand_new_bert.py`. Run this test file to verify that all common tests pass:
+
+```bash
+pytest tests/test_modeling_brand_new_bert.py
+```
+
+Having fixed all common tests, it is now crucial to ensure that all the nice work you have done is well tested, so that
+
+- a) The community can easily understand your work by looking at specific tests of *brand_new_bert*
+- b) Future changes to your model will not break any important feature of the model.
+
+At first, integration tests should be added. Those integration tests essentially do the same as the debugging scripts
+you used earlier to implement the model to 🤗 Transformers. A template of those model tests is already added by the
+Cookiecutter, called `BrandNewBertModelIntegrationTests` and only has to be filled out by you. To ensure that those
+tests are passing, run
+
+```bash
+RUN_SLOW=1 pytest -sv tests/test_modeling_brand_new_bert.py::BrandNewBertModelIntegrationTests
+```
+
+
+
+In case you are using Windows, you should replace `RUN_SLOW=1` with `SET RUN_SLOW=1`
+
+
+
+Second, all features that are special to *brand_new_bert* should be tested additionally in a separate test under
+`BrandNewBertModelTester`/``BrandNewBertModelTest`. This part is often forgotten but is extremely useful in two
+ways:
+
+- It helps to transfer the knowledge you have acquired during the model addition to the community by showing how the
+ special features of *brand_new_bert* should work.
+- Future contributors can quickly test changes to the model by running those special tests.
+
+
+**9. Implement the tokenizer**
+
+Next, we should add the tokenizer of *brand_new_bert*. Usually, the tokenizer is equivalent or very similar to an
+already existing tokenizer of 🤗 Transformers.
+
+It is very important to find/extract the original tokenizer file and to manage to load this file into the 🤗
+Transformers' implementation of the tokenizer.
+
+To ensure that the tokenizer works correctly, it is recommended to first create a script in the original repository
+that inputs a string and returns the `input_ids``. It could look similar to this (in pseudo-code):
+
+```python
+input_str = "This is a long example input string containing special characters .$?-, numbers 2872 234 12 and words."
+model = BrandNewBertModel.load_pretrained_checkpoint("/path/to/checkpoint/")
+input_ids = model.tokenize(input_str)
+```
+
+You might have to take a deeper look again into the original repository to find the correct tokenizer function or you
+might even have to do changes to your clone of the original repository to only output the `input_ids`. Having written
+a functional tokenization script that uses the original repository, an analogous script for 🤗 Transformers should be
+created. It should look similar to this:
+
+```python
+from transformers import BrandNewBertTokenizer
+
+input_str = "This is a long example input string containing special characters .$?-, numbers 2872 234 12 and words."
+
+tokenizer = BrandNewBertTokenizer.from_pretrained("/path/to/tokenizer/folder/")
+
+input_ids = tokenizer(input_str).input_ids
+```
+
+When both `input_ids` yield the same values, as a final step a tokenizer test file should also be added.
+
+Analogous to the modeling test files of *brand_new_bert*, the tokenization test files of *brand_new_bert* should
+contain a couple of hard-coded integration tests.
+
+**10. Run End-to-end integration tests**
+
+Having added the tokenizer, you should also add a couple of end-to-end integration tests using both the model and the
+tokenizer to `tests/test_modeling_brand_new_bert.py` in 🤗 Transformers. Such a test should show on a meaningful
+text-to-text sample that the 🤗 Transformers implementation works as expected. A meaningful text-to-text sample can
+include *e.g.* a source-to-target-translation pair, an article-to-summary pair, a question-to-answer pair, etc… If none
+of the ported checkpoints has been fine-tuned on a downstream task it is enough to simply rely on the model tests. In a
+final step to ensure that the model is fully functional, it is advised that you also run all tests on GPU. It can
+happen that you forgot to add some `.to(self.device)` statements to internal tensors of the model, which in such a
+test would show in an error. In case you have no access to a GPU, the Hugging Face team can take care of running those
+tests for you.
+
+**11. Add Docstring**
+
+Now, all the necessary functionality for *brand_new_bert* is added - you're almost done! The only thing left to add is
+a nice docstring and a doc page. The Cookiecutter should have added a template file called
+`docs/source/model_doc/brand_new_bert.rst` that you should fill out. Users of your model will usually first look at
+this page before using your model. Hence, the documentation must be understandable and concise. It is very useful for
+the community to add some *Tips* to show how the model should be used. Don't hesitate to ping the Hugging Face team
+regarding the docstrings.
+
+Next, make sure that the docstring added to `src/transformers/models/brand_new_bert/modeling_brand_new_bert.py` is
+correct and included all necessary inputs and outputs. We have a detailed guide about writing documentation and our docstring format [here](writing-documentation). It is always to good to remind oneself that documentation should
+be treated at least as carefully as the code in 🤗 Transformers since the documentation is usually the first contact
+point of the community with the model.
+
+**Code refactor**
+
+Great, now you have added all the necessary code for *brand_new_bert*. At this point, you should correct some potential
+incorrect code style by running:
+
+```bash
+make style
+```
+
+and verify that your coding style passes the quality check:
+
+```bash
+make quality
+```
+
+There are a couple of other very strict design tests in 🤗 Transformers that might still be failing, which shows up in
+the tests of your pull request. This is often because of some missing information in the docstring or some incorrect
+naming. The Hugging Face team will surely help you if you're stuck here.
+
+Lastly, it is always a good idea to refactor one's code after having ensured that the code works correctly. With all
+tests passing, now it's a good time to go over the added code again and do some refactoring.
+
+You have now finished the coding part, congratulation! 🎉 You are Awesome! 😎
+
+**12. Upload the models to the model hub**
+
+In this final part, you should convert and upload all checkpoints to the model hub and add a model card for each
+uploaded model checkpoint. You can get familiar with the hub functionalities by reading our [Model sharing and uploading Page](model_sharing). You should work alongside the Hugging Face team here to decide on a fitting name for each
+checkpoint and to get the required access rights to be able to upload the model under the author's organization of
+*brand_new_bert*. The `push_to_hub` method, present in all models in `transformers`, is a quick and efficient way to push your checkpoint to the hub. A little snippet is pasted below:
+
+```python
+brand_new_bert.push_to_hub(
+ repo_path_or_name="brand_new_bert",
+ # Uncomment the following line to push to an organization
+ # organization="",
+ commit_message="Add model",
+ use_temp_dir=True,
+)
+```
+
+It is worth spending some time to create fitting model cards for each checkpoint. The model cards should highlight the
+specific characteristics of this particular checkpoint, *e.g.* On which dataset was the checkpoint
+pretrained/fine-tuned on? On what down-stream task should the model be used? And also include some code on how to
+correctly use the model.
+
+**13. (Optional) Add notebook**
+
+It is very helpful to add a notebook that showcases in-detail how *brand_new_bert* can be used for inference and/or
+fine-tuned on a downstream task. This is not mandatory to merge your PR, but very useful for the community.
+
+**14. Submit your finished PR**
+
+You're done programming now and can move to the last step, which is getting your PR merged into main. Usually, the
+Hugging Face team should have helped you already at this point, but it is worth taking some time to give your finished
+PR a nice description and eventually add comments to your code, if you want to point out certain design choices to your
+reviewer.
+
+### Share your work!!
+
+Now, it's time to get some credit from the community for your work! Having completed a model addition is a major
+contribution to Transformers and the whole NLP community. Your code and the ported pre-trained models will certainly be
+used by hundreds and possibly even thousands of developers and researchers. You should be proud of your work and share
+your achievement with the community.
+
+**You have made another model that is super easy to access for everyone in the community! 🤯**
diff --git a/docs/source/en/add_new_pipeline.mdx b/docs/source/en/add_new_pipeline.mdx
new file mode 100644
index 00000000000000..096ea423ec6bdf
--- /dev/null
+++ b/docs/source/en/add_new_pipeline.mdx
@@ -0,0 +1,140 @@
+
+
+# How to add a pipeline to 🤗 Transformers?
+
+First and foremost, you need to decide the raw entries the pipeline will be able to take. It can be strings, raw bytes,
+dictionaries or whatever seems to be the most likely desired input. Try to keep these inputs as pure Python as possible
+as it makes compatibility easier (even through other languages via JSON). Those will be the `inputs` of the
+pipeline (`preprocess`).
+
+Then define the `outputs`. Same policy as the `inputs`. The simpler, the better. Those will be the outputs of
+`postprocess` method.
+
+Start by inheriting the base class `Pipeline`. with the 4 methods needed to implement `preprocess`,
+`_forward`, `postprocess` and `_sanitize_parameters`.
+
+
+```python
+from transformers import Pipeline
+
+
+class MyPipeline(Pipeline):
+ def _sanitize_parameters(self, **kwargs):
+ preprocess_kwargs = {}
+ if "maybe_arg" in kwargs:
+ preprocess_kwargs["maybe_arg"] = kwargs["maybe_arg"]
+ return preprocess_kwargs, {}, {}
+
+ def preprocess(self, inputs, maybe_arg=2):
+ model_input = Tensor(inputs["input_ids"])
+ return {"model_input": model_input}
+
+ def _forward(self, model_inputs):
+ # model_inputs == {"model_input": model_input}
+ outputs = self.model(**model_inputs)
+ # Maybe {"logits": Tensor(...)}
+ return outputs
+
+ def postprocess(self, model_outputs):
+ best_class = model_outputs["logits"].softmax(-1)
+ return best_class
+```
+
+The structure of this breakdown is to support relatively seamless support for CPU/GPU, while supporting doing
+pre/postprocessing on the CPU on different threads
+
+`preprocess` will take the originally defined inputs, and turn them into something feedable to the model. It might
+contain more information and is usually a `Dict`.
+
+`_forward` is the implementation detail and is not meant to be called directly. `forward` is the preferred
+called method as it contains safeguards to make sure everything is working on the expected device. If anything is
+linked to a real model it belongs in the `_forward` method, anything else is in the preprocess/postprocess.
+
+`postprocess` methods will take the output of `_forward` and turn it into the final output that were decided
+earlier.
+
+`_sanitize_parameters` exists to allow users to pass any parameters whenever they wish, be it at initialization
+time `pipeline(...., maybe_arg=4)` or at call time `pipe = pipeline(...); output = pipe(...., maybe_arg=4)`.
+
+The returns of `_sanitize_parameters` are the 3 dicts of kwargs that will be passed directly to `preprocess`,
+`_forward` and `postprocess`. Don't fill anything if the caller didn't call with any extra parameter. That
+allows to keep the default arguments in the function definition which is always more "natural".
+
+A classic example would be a `top_k` argument in the post processing in classification tasks.
+
+```python
+>>> pipe = pipeline("my-new-task")
+>>> pipe("This is a test")
+[{"label": "1-star", "score": 0.8}, {"label": "2-star", "score": 0.1}, {"label": "3-star", "score": 0.05}
+{"label": "4-star", "score": 0.025}, {"label": "5-star", "score": 0.025}]
+
+>>> pipe("This is a test", top_k=2)
+[{"label": "1-star", "score": 0.8}, {"label": "2-star", "score": 0.1}]
+```
+
+In order to achieve that, we'll update our `postprocess` method with a default parameter to `5`. and edit
+`_sanitize_parameters` to allow this new parameter.
+
+
+```python
+def postprocess(self, model_outputs, top_k=5):
+ best_class = model_outputs["logits"].softmax(-1)
+ # Add logic to handle top_k
+ return best_class
+
+
+def _sanitize_parameters(self, **kwargs):
+ preprocess_kwargs = {}
+ if "maybe_arg" in kwargs:
+ preprocess_kwargs["maybe_arg"] = kwargs["maybe_arg"]
+
+ postprocess_kwargs = {}
+ if "top_k" in kwargs:
+ preprocess_kwargs["top_k"] = kwargs["top_k"]
+ return preprocess_kwargs, {}, postprocess_kwargs
+```
+
+Try to keep the inputs/outputs very simple and ideally JSON-serializable as it makes the pipeline usage very easy
+without requiring users to understand new kind of objects. It's also relatively common to support many different types
+of arguments for ease of use (audio files, can be filenames, URLs or pure bytes)
+
+
+
+## Adding it to the list of supported tasks
+
+Go to `src/transformers/pipelines/__init__.py` and fill in `SUPPORTED_TASKS` with your newly created pipeline.
+If possible it should provide a default model.
+
+## Adding tests
+
+Create a new file `tests/test_pipelines_MY_PIPELINE.py` with example with the other tests.
+
+The `run_pipeline_test` function will be very generic and run on small random models on every possible
+architecture as defined by `model_mapping` and `tf_model_mapping`.
+
+This is very important to test future compatibility, meaning if someone adds a new model for
+`XXXForQuestionAnswering` then the pipeline test will attempt to run on it. Because the models are random it's
+impossible to check for actual values, that's why There is a helper `ANY` that will simply attempt to match the
+output of the pipeline TYPE.
+
+You also *need* to implement 2 (ideally 4) tests.
+
+- `test_small_model_pt` : Define 1 small model for this pipeline (doesn't matter if the results don't make sense)
+ and test the pipeline outputs. The results should be the same as `test_small_model_tf`.
+- `test_small_model_tf` : Define 1 small model for this pipeline (doesn't matter if the results don't make sense)
+ and test the pipeline outputs. The results should be the same as `test_small_model_pt`.
+- `test_large_model_pt` (`optional`): Tests the pipeline on a real pipeline where the results are supposed to
+ make sense. These tests are slow and should be marked as such. Here the goal is to showcase the pipeline and to make
+ sure there is no drift in future releases
+- `test_large_model_tf` (`optional`): Tests the pipeline on a real pipeline where the results are supposed to
+ make sense. These tests are slow and should be marked as such. Here the goal is to showcase the pipeline and to make
+ sure there is no drift in future releases
diff --git a/docs/source/en/autoclass_tutorial.mdx b/docs/source/en/autoclass_tutorial.mdx
new file mode 100644
index 00000000000000..51270302f23329
--- /dev/null
+++ b/docs/source/en/autoclass_tutorial.mdx
@@ -0,0 +1,119 @@
+
+
+# Load pretrained instances with an AutoClass
+
+With so many different Transformer architectures, it can be challenging to create one for your checkpoint. As a part of 🤗 Transformers core philosophy to make the library easy, simple and flexible to use, an `AutoClass` automatically infer and load the correct architecture from a given checkpoint. The `from_pretrained` method lets you quickly load a pretrained model for any architecture so you don't have to devote time and resources to train a model from scratch. Producing this type of checkpoint-agnostic code means if your code works for one checkpoint, it will work with another checkpoint - as long as it was trained for a similar task - even if the architecture is different.
+
+
+
+Remember, architecture refers to the skeleton of the model and checkpoints are the weights for a given architecture. For example, [BERT](https://huggingface.co/bert-base-uncased) is an architecture, while `bert-base-uncased` is a checkpoint. Model is a general term that can mean either architecture or checkpoint.
+
+
+
+In this tutorial, learn to:
+
+* Load a pretrained tokenizer.
+* Load a pretrained feature extractor.
+* Load a pretrained processor.
+* Load a pretrained model.
+
+## AutoTokenizer
+
+Nearly every NLP task begins with a tokenizer. A tokenizer converts your input into a format that can be processed by the model.
+
+Load a tokenizer with [`AutoTokenizer.from_pretrained`]:
+
+```py
+>>> from transformers import AutoTokenizer
+
+>>> tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
+```
+
+Then tokenize your input as shown below:
+
+```py
+>>> sequence = "In a hole in the ground there lived a hobbit."
+>>> print(tokenizer(sequence))
+{'input_ids': [101, 1999, 1037, 4920, 1999, 1996, 2598, 2045, 2973, 1037, 7570, 10322, 4183, 1012, 102],
+ 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
+ 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
+```
+
+## AutoFeatureExtractor
+
+For audio and vision tasks, a feature extractor processes the audio signal or image into the correct input format.
+
+Load a feature extractor with [`AutoFeatureExtractor.from_pretrained`]:
+
+```py
+>>> from transformers import AutoFeatureExtractor
+
+>>> feature_extractor = AutoFeatureExtractor.from_pretrained(
+... "ehcalabres/wav2vec2-lg-xlsr-en-speech-emotion-recognition"
+... )
+```
+
+## AutoProcessor
+
+Multimodal tasks require a processor that combines two types of preprocessing tools. For example, the [LayoutLMV2](model_doc/layoutlmv2) model requires a feature extractor to handle images and a tokenizer to handle text; a processor combines both of them.
+
+Load a processor with [`AutoProcessor.from_pretrained`]:
+
+```py
+>>> from transformers import AutoProcessor
+
+>>> processor = AutoProcessor.from_pretrained("microsoft/layoutlmv2-base-uncased")
+```
+
+## AutoModel
+
+
+
+Finally, the `AutoModelFor` classes let you load a pretrained model for a given task (see [here](model_doc/auto) for a complete list of available tasks). For example, load a model for sequence classification with [`AutoModelForSequenceClassification.from_pretrained`]:
+
+```py
+>>> from transformers import AutoModelForSequenceClassification
+
+>>> model = AutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased")
+```
+
+Easily reuse the same checkpoint to load an architecture for a different task:
+
+```py
+>>> from transformers import AutoModelForTokenClassification
+
+>>> model = AutoModelForTokenClassification.from_pretrained("distilbert-base-uncased")
+```
+
+Generally, we recommend using the `AutoTokenizer` class and the `AutoModelFor` class to load pretrained instances of models. This will ensure you load the correct architecture every time. In the next [tutorial](preprocessing), learn how to use your newly loaded tokenizer, feature extractor and processor to preprocess a dataset for fine-tuning.
+
+
+Finally, the `TFAutoModelFor` classes let you load a pretrained model for a given task (see [here](model_doc/auto) for a complete list of available tasks). For example, load a model for sequence classification with [`TFAutoModelForSequenceClassification.from_pretrained`]:
+
+```py
+>>> from transformers import TFAutoModelForSequenceClassification
+
+>>> model = TFAutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased")
+```
+
+Easily reuse the same checkpoint to load an architecture for a different task:
+
+```py
+>>> from transformers import TFAutoModelForTokenClassification
+
+>>> model = TFAutoModelForTokenClassification.from_pretrained("distilbert-base-uncased")
+```
+
+Generally, we recommend using the `AutoTokenizer` class and the `TFAutoModelFor` class to load pretrained instances of models. This will ensure you load the correct architecture every time. In the next [tutorial](preprocessing), learn how to use your newly loaded tokenizer, feature extractor and processor to preprocess a dataset for fine-tuning.
+
+
diff --git a/docs/source/en/benchmarks.mdx b/docs/source/en/benchmarks.mdx
new file mode 100644
index 00000000000000..244112001f5ccf
--- /dev/null
+++ b/docs/source/en/benchmarks.mdx
@@ -0,0 +1,383 @@
+
+
+# Benchmarks
+
+
+
+Hugging Face's Benchmarking tools are deprecated and it is advised to use external Benchmarking libraries to measure the speed
+and memory complexity of Transformer models.
+
+
+
+[[open-in-colab]]
+
+Let's take a look at how 🤗 Transformers models can be benchmarked, best practices, and already available benchmarks.
+
+A notebook explaining in more detail how to benchmark 🤗 Transformers models can be found [here](https://github.com/huggingface/notebooks/tree/main/examples/benchmark.ipynb).
+
+## How to benchmark 🤗 Transformers models
+
+The classes [`PyTorchBenchmark`] and [`TensorFlowBenchmark`] allow to flexibly benchmark 🤗 Transformers models. The benchmark classes allow us to measure the _peak memory usage_ and _required time_ for both _inference_ and _training_.
+
+
+
+Hereby, _inference_ is defined by a single forward pass, and _training_ is defined by a single forward pass and
+backward pass.
+
+
+
+The benchmark classes [`PyTorchBenchmark`] and [`TensorFlowBenchmark`] expect an object of type [`PyTorchBenchmarkArguments`] and
+[`TensorFlowBenchmarkArguments`], respectively, for instantiation. [`PyTorchBenchmarkArguments`] and [`TensorFlowBenchmarkArguments`] are data classes and contain all relevant configurations for their corresponding benchmark class. In the following example, it is shown how a BERT model of type _bert-base-cased_ can be benchmarked.
+
+
+
+```py
+>>> from transformers import PyTorchBenchmark, PyTorchBenchmarkArguments
+
+>>> args = PyTorchBenchmarkArguments(models=["bert-base-uncased"], batch_sizes=[8], sequence_lengths=[8, 32, 128, 512])
+>>> benchmark = PyTorchBenchmark(args)
+```
+
+
+```py
+>>> from transformers import TensorFlowBenchmark, TensorFlowBenchmarkArguments
+
+>>> args = TensorFlowBenchmarkArguments(
+... models=["bert-base-uncased"], batch_sizes=[8], sequence_lengths=[8, 32, 128, 512]
+... )
+>>> benchmark = TensorFlowBenchmark(args)
+```
+
+
+
+Here, three arguments are given to the benchmark argument data classes, namely `models`, `batch_sizes`, and
+`sequence_lengths`. The argument `models` is required and expects a `list` of model identifiers from the
+[model hub](https://huggingface.co/models) The `list` arguments `batch_sizes` and `sequence_lengths` define
+the size of the `input_ids` on which the model is benchmarked. There are many more parameters that can be configured
+via the benchmark argument data classes. For more detail on these one can either directly consult the files
+`src/transformers/benchmark/benchmark_args_utils.py`, `src/transformers/benchmark/benchmark_args.py` (for PyTorch)
+and `src/transformers/benchmark/benchmark_args_tf.py` (for Tensorflow). Alternatively, running the following shell
+commands from root will print out a descriptive list of all configurable parameters for PyTorch and Tensorflow
+respectively.
+
+
+
+```bash
+python examples/pytorch/benchmarking/run_benchmark.py --help
+```
+
+An instantiated benchmark object can then simply be run by calling `benchmark.run()`.
+
+```py
+>>> results = benchmark.run()
+>>> print(results)
+==================== INFERENCE - SPEED - RESULT ====================
+--------------------------------------------------------------------------------
+Model Name Batch Size Seq Length Time in s
+--------------------------------------------------------------------------------
+bert-base-uncased 8 8 0.006
+bert-base-uncased 8 32 0.006
+bert-base-uncased 8 128 0.018
+bert-base-uncased 8 512 0.088
+--------------------------------------------------------------------------------
+
+==================== INFERENCE - MEMORY - RESULT ====================
+--------------------------------------------------------------------------------
+Model Name Batch Size Seq Length Memory in MB
+--------------------------------------------------------------------------------
+bert-base-uncased 8 8 1227
+bert-base-uncased 8 32 1281
+bert-base-uncased 8 128 1307
+bert-base-uncased 8 512 1539
+--------------------------------------------------------------------------------
+
+==================== ENVIRONMENT INFORMATION ====================
+
+- transformers_version: 2.11.0
+- framework: PyTorch
+- use_torchscript: False
+- framework_version: 1.4.0
+- python_version: 3.6.10
+- system: Linux
+- cpu: x86_64
+- architecture: 64bit
+- date: 2020-06-29
+- time: 08:58:43.371351
+- fp16: False
+- use_multiprocessing: True
+- only_pretrain_model: False
+- cpu_ram_mb: 32088
+- use_gpu: True
+- num_gpus: 1
+- gpu: TITAN RTX
+- gpu_ram_mb: 24217
+- gpu_power_watts: 280.0
+- gpu_performance_state: 2
+- use_tpu: False
+```
+
+
+```bash
+python examples/tensorflow/benchmarking/run_benchmark_tf.py --help
+```
+
+An instantiated benchmark object can then simply be run by calling `benchmark.run()`.
+
+```py
+>>> results = benchmark.run()
+>>> print(results)
+>>> results = benchmark.run()
+>>> print(results)
+==================== INFERENCE - SPEED - RESULT ====================
+--------------------------------------------------------------------------------
+Model Name Batch Size Seq Length Time in s
+--------------------------------------------------------------------------------
+bert-base-uncased 8 8 0.005
+bert-base-uncased 8 32 0.008
+bert-base-uncased 8 128 0.022
+bert-base-uncased 8 512 0.105
+--------------------------------------------------------------------------------
+
+==================== INFERENCE - MEMORY - RESULT ====================
+--------------------------------------------------------------------------------
+Model Name Batch Size Seq Length Memory in MB
+--------------------------------------------------------------------------------
+bert-base-uncased 8 8 1330
+bert-base-uncased 8 32 1330
+bert-base-uncased 8 128 1330
+bert-base-uncased 8 512 1770
+--------------------------------------------------------------------------------
+
+==================== ENVIRONMENT INFORMATION ====================
+
+- transformers_version: 2.11.0
+- framework: Tensorflow
+- use_xla: False
+- framework_version: 2.2.0
+- python_version: 3.6.10
+- system: Linux
+- cpu: x86_64
+- architecture: 64bit
+- date: 2020-06-29
+- time: 09:26:35.617317
+- fp16: False
+- use_multiprocessing: True
+- only_pretrain_model: False
+- cpu_ram_mb: 32088
+- use_gpu: True
+- num_gpus: 1
+- gpu: TITAN RTX
+- gpu_ram_mb: 24217
+- gpu_power_watts: 280.0
+- gpu_performance_state: 2
+- use_tpu: False
+```
+
+
+
+By default, the _time_ and the _required memory_ for _inference_ are benchmarked. In the example output above the first
+two sections show the result corresponding to _inference time_ and _inference memory_. In addition, all relevant
+information about the computing environment, _e.g._ the GPU type, the system, the library versions, etc... are printed
+out in the third section under _ENVIRONMENT INFORMATION_. This information can optionally be saved in a _.csv_ file
+when adding the argument `save_to_csv=True` to [`PyTorchBenchmarkArguments`] and
+[`TensorFlowBenchmarkArguments`] respectively. In this case, every section is saved in a separate
+_.csv_ file. The path to each _.csv_ file can optionally be defined via the argument data classes.
+
+Instead of benchmarking pre-trained models via their model identifier, _e.g._ `bert-base-uncased`, the user can
+alternatively benchmark an arbitrary configuration of any available model class. In this case, a `list` of
+configurations must be inserted with the benchmark args as follows.
+
+
+
+```py
+>>> from transformers import PyTorchBenchmark, PyTorchBenchmarkArguments, BertConfig
+
+>>> args = PyTorchBenchmarkArguments(
+... models=["bert-base", "bert-384-hid", "bert-6-lay"], batch_sizes=[8], sequence_lengths=[8, 32, 128, 512]
+... )
+>>> config_base = BertConfig()
+>>> config_384_hid = BertConfig(hidden_size=384)
+>>> config_6_lay = BertConfig(num_hidden_layers=6)
+
+>>> benchmark = PyTorchBenchmark(args, configs=[config_base, config_384_hid, config_6_lay])
+>>> benchmark.run()
+==================== INFERENCE - SPEED - RESULT ====================
+--------------------------------------------------------------------------------
+Model Name Batch Size Seq Length Time in s
+--------------------------------------------------------------------------------
+bert-base 8 128 0.006
+bert-base 8 512 0.006
+bert-base 8 128 0.018
+bert-base 8 512 0.088
+bert-384-hid 8 8 0.006
+bert-384-hid 8 32 0.006
+bert-384-hid 8 128 0.011
+bert-384-hid 8 512 0.054
+bert-6-lay 8 8 0.003
+bert-6-lay 8 32 0.004
+bert-6-lay 8 128 0.009
+bert-6-lay 8 512 0.044
+--------------------------------------------------------------------------------
+
+==================== INFERENCE - MEMORY - RESULT ====================
+--------------------------------------------------------------------------------
+Model Name Batch Size Seq Length Memory in MB
+--------------------------------------------------------------------------------
+bert-base 8 8 1277
+bert-base 8 32 1281
+bert-base 8 128 1307
+bert-base 8 512 1539
+bert-384-hid 8 8 1005
+bert-384-hid 8 32 1027
+bert-384-hid 8 128 1035
+bert-384-hid 8 512 1255
+bert-6-lay 8 8 1097
+bert-6-lay 8 32 1101
+bert-6-lay 8 128 1127
+bert-6-lay 8 512 1359
+--------------------------------------------------------------------------------
+
+==================== ENVIRONMENT INFORMATION ====================
+
+- transformers_version: 2.11.0
+- framework: PyTorch
+- use_torchscript: False
+- framework_version: 1.4.0
+- python_version: 3.6.10
+- system: Linux
+- cpu: x86_64
+- architecture: 64bit
+- date: 2020-06-29
+- time: 09:35:25.143267
+- fp16: False
+- use_multiprocessing: True
+- only_pretrain_model: False
+- cpu_ram_mb: 32088
+- use_gpu: True
+- num_gpus: 1
+- gpu: TITAN RTX
+- gpu_ram_mb: 24217
+- gpu_power_watts: 280.0
+- gpu_performance_state: 2
+- use_tpu: False
+```
+
+
+```py
+>>> from transformers import TensorFlowBenchmark, TensorFlowBenchmarkArguments, BertConfig
+
+>>> args = TensorFlowBenchmarkArguments(
+... models=["bert-base", "bert-384-hid", "bert-6-lay"], batch_sizes=[8], sequence_lengths=[8, 32, 128, 512]
+... )
+>>> config_base = BertConfig()
+>>> config_384_hid = BertConfig(hidden_size=384)
+>>> config_6_lay = BertConfig(num_hidden_layers=6)
+
+>>> benchmark = TensorFlowBenchmark(args, configs=[config_base, config_384_hid, config_6_lay])
+>>> benchmark.run()
+==================== INFERENCE - SPEED - RESULT ====================
+--------------------------------------------------------------------------------
+Model Name Batch Size Seq Length Time in s
+--------------------------------------------------------------------------------
+bert-base 8 8 0.005
+bert-base 8 32 0.008
+bert-base 8 128 0.022
+bert-base 8 512 0.106
+bert-384-hid 8 8 0.005
+bert-384-hid 8 32 0.007
+bert-384-hid 8 128 0.018
+bert-384-hid 8 512 0.064
+bert-6-lay 8 8 0.002
+bert-6-lay 8 32 0.003
+bert-6-lay 8 128 0.0011
+bert-6-lay 8 512 0.074
+--------------------------------------------------------------------------------
+
+==================== INFERENCE - MEMORY - RESULT ====================
+--------------------------------------------------------------------------------
+Model Name Batch Size Seq Length Memory in MB
+--------------------------------------------------------------------------------
+bert-base 8 8 1330
+bert-base 8 32 1330
+bert-base 8 128 1330
+bert-base 8 512 1770
+bert-384-hid 8 8 1330
+bert-384-hid 8 32 1330
+bert-384-hid 8 128 1330
+bert-384-hid 8 512 1540
+bert-6-lay 8 8 1330
+bert-6-lay 8 32 1330
+bert-6-lay 8 128 1330
+bert-6-lay 8 512 1540
+--------------------------------------------------------------------------------
+
+==================== ENVIRONMENT INFORMATION ====================
+
+- transformers_version: 2.11.0
+- framework: Tensorflow
+- use_xla: False
+- framework_version: 2.2.0
+- python_version: 3.6.10
+- system: Linux
+- cpu: x86_64
+- architecture: 64bit
+- date: 2020-06-29
+- time: 09:38:15.487125
+- fp16: False
+- use_multiprocessing: True
+- only_pretrain_model: False
+- cpu_ram_mb: 32088
+- use_gpu: True
+- num_gpus: 1
+- gpu: TITAN RTX
+- gpu_ram_mb: 24217
+- gpu_power_watts: 280.0
+- gpu_performance_state: 2
+- use_tpu: False
+```
+
+
+
+Again, _inference time_ and _required memory_ for _inference_ are measured, but this time for customized configurations
+of the `BertModel` class. This feature can especially be helpful when deciding for which configuration the model
+should be trained.
+
+
+## Benchmark best practices
+
+This section lists a couple of best practices one should be aware of when benchmarking a model.
+
+- Currently, only single device benchmarking is supported. When benchmarking on GPU, it is recommended that the user
+ specifies on which device the code should be run by setting the `CUDA_VISIBLE_DEVICES` environment variable in the
+ shell, _e.g._ `export CUDA_VISIBLE_DEVICES=0` before running the code.
+- The option `no_multi_processing` should only be set to `True` for testing and debugging. To ensure accurate
+ memory measurement it is recommended to run each memory benchmark in a separate process by making sure
+ `no_multi_processing` is set to `True`.
+- One should always state the environment information when sharing the results of a model benchmark. Results can vary
+ heavily between different GPU devices, library versions, etc., so that benchmark results on their own are not very
+ useful for the community.
+
+
+## Sharing your benchmark
+
+Previously all available core models (10 at the time) have been benchmarked for _inference time_, across many different
+settings: using PyTorch, with and without TorchScript, using TensorFlow, with and without XLA. All of those tests were
+done across CPUs (except for TensorFlow XLA) and GPUs.
+
+The approach is detailed in the [following blogpost](https://medium.com/huggingface/benchmarking-transformers-pytorch-and-tensorflow-e2917fb891c2) and the results are
+available [here](https://docs.google.com/spreadsheets/d/1sryqufw2D0XlUH4sq3e9Wnxu5EAQkaohzrJbd5HdQ_w/edit?usp=sharing).
+
+With the new _benchmark_ tools, it is easier than ever to share your benchmark results with the community
+
+- [PyTorch Benchmarking Results](https://github.com/huggingface/transformers/tree/main/examples/pytorch/benchmarking/README.md).
+- [TensorFlow Benchmarking Results](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/benchmarking/README.md).
diff --git a/docs/source/en/bertology.mdx b/docs/source/en/bertology.mdx
new file mode 100644
index 00000000000000..e64379d6580da5
--- /dev/null
+++ b/docs/source/en/bertology.mdx
@@ -0,0 +1,36 @@
+
+
+# BERTology
+
+There is a growing field of study concerned with investigating the inner working of large-scale transformers like BERT
+(that some call "BERTology"). Some good examples of this field are:
+
+
+- BERT Rediscovers the Classical NLP Pipeline by Ian Tenney, Dipanjan Das, Ellie Pavlick:
+ https://arxiv.org/abs/1905.05950
+- Are Sixteen Heads Really Better than One? by Paul Michel, Omer Levy, Graham Neubig: https://arxiv.org/abs/1905.10650
+- What Does BERT Look At? An Analysis of BERT's Attention by Kevin Clark, Urvashi Khandelwal, Omer Levy, Christopher D.
+ Manning: https://arxiv.org/abs/1906.04341
+
+In order to help this new field develop, we have included a few additional features in the BERT/GPT/GPT-2 models to
+help people access the inner representations, mainly adapted from the great work of Paul Michel
+(https://arxiv.org/abs/1905.10650):
+
+
+- accessing all the hidden-states of BERT/GPT/GPT-2,
+- accessing all the attention weights for each head of BERT/GPT/GPT-2,
+- retrieving heads output values and gradients to be able to compute head importance score and prune head as explained
+ in https://arxiv.org/abs/1905.10650.
+
+To help you understand and use these features, we have added a specific example script: [bertology.py](https://github.com/huggingface/transformers/tree/main/examples/research_projects/bertology/run_bertology.py) while extract information and prune a model pre-trained on
+GLUE.
diff --git a/docs/source/en/big_models.mdx b/docs/source/en/big_models.mdx
new file mode 100644
index 00000000000000..a313e4e1fb2f4e
--- /dev/null
+++ b/docs/source/en/big_models.mdx
@@ -0,0 +1,128 @@
+
+
+# Instantiating a big model
+
+When you want to use a very big pretrained model, one challenge is to minimize the use of the RAM. The usual workflow
+from PyTorch is:
+
+1. Create your model with random weights.
+2. Load your pretrained weights.
+3. Put those pretrained weights in your random model.
+
+Step 1 and 2 both require a full version of the model in memory, which is not a problem in most cases, but if your model starts weighing several GigaBytes, those two copies can make you got our of RAM. Even worse, if you are using `torch.distributed` to launch a distributed training, each process will load the pretrained model and store these two copies in RAM.
+
+
+
+Note that the randomly created model is initialized with "empty" tensors, which take the space in memory without filling it (thus the random values are whatever was in this chunk of memory at a given time). The random initialization following the appropriate distribution for the kind of model/parameters instatiated (like a normal distribution for instance) is only performed after step 3 on the non-initialized weights, to be as fast as possible!
+
+
+
+In this guide, we explore the solutions Transformers offer to deal with this issue. Note that this is an area of active development, so the APIs explained here may change slightly in the future.
+
+## Sharded checkpoints
+
+Since version 4.18.0, model checkpoints that end up taking more than 10GB of space are automatically sharded in smaller pieces. In terms of having one single checkpoint when you do `model.save_pretrained(save_dir)`, you will end up with several partial checkpoints (each of which being of size < 10GB) and an index that maps parameter names to the files they are stored in.
+
+You can control the maximum size before sharding with the `max_shard_size` parameter, so for the sake of an example, we'll use a normal-size models with a small shard size: let's take a traditional BERT model.
+
+```py
+from transformers import AutoModel
+
+model = AutoModel.from_pretrained("bert-base-cased")
+```
+
+If you save it using [`~PreTrainedModel.save_pretrained`], you will get a new folder with two files: the config of the model and its weights:
+
+```py
+>>> import os
+>>> import tempfile
+
+>>> with tempfile.TemporaryDirectory() as tmp_dir:
+... model.save_pretrained(tmp_dir)
+... print(sorted(os.listdir(tmp_dir)))
+['config.json', 'pytorch_model.bin']
+```
+
+Now let's use a maximum shard size of 200MB:
+
+```py
+>>> with tempfile.TemporaryDirectory() as tmp_dir:
+... model.save_pretrained(tmp_dir, max_shard_size="200MB")
+... print(sorted(os.listdir(tmp_dir)))
+['config.json', 'pytorch_model-00001-of-00003.bin', 'pytorch_model-00002-of-00003.bin', 'pytorch_model-00003-of-00003.bin', 'pytorch_model.bin.index.json']
+```
+
+On top of the configuration of the model, we see three different weights files, and an `index.json` file which is our index. A checkpoint like this can be fully reloaded using the [`~PreTrainedModel.from_pretrained`] method:
+
+```py
+>>> with tempfile.TemporaryDirectory() as tmp_dir:
+... model.save_pretrained(tmp_dir, max_shard_size="200MB")
+... new_model = AutoModel.from_pretrained(tmp_dir)
+```
+
+The main advantage of doing this for big models is that during step 2 of the workflow shown above, each shard of the checkpoint is loaded after the previous one, capping the memory usage in RAM to the model size plus the size of the biggest shard.
+
+Beind the scenes, the index file is used to determine which keys are in the checkpoint, and where the corresponding weights are stored. We can load that index like any json and get a dictionary:
+
+```py
+>>> import json
+
+>>> with tempfile.TemporaryDirectory() as tmp_dir:
+... model.save_pretrained(tmp_dir, max_shard_size="200MB")
+... with open(os.path.join(tmp_dir, "pytorch_model.bin.index.json"), "r") as f:
+... index = json.load(f)
+
+>>> print(index.keys())
+dict_keys(['metadata', 'weight_map'])
+```
+
+The metadata just consists of the total size of the model for now. We plan to add several other informations in the future:
+
+```py
+>>> index["metadata"]
+{'total_size': 433245184}
+```
+
+The weights map is the main part of this index, which maps each parameter name (as usually found in a PyTorch model `state_dict`) to the file it's stored in:
+
+```py
+>>> index["weight_map"]
+{'embeddings.LayerNorm.bias': 'pytorch_model-00001-of-00003.bin',
+ 'embeddings.LayerNorm.weight': 'pytorch_model-00001-of-00003.bin',
+ ...
+```
+
+If you want to directly load such a sharded checkpoint inside a model without using [`~PreTrainedModel.from_pretrained`] (like you would do `model.load_state_dict()` for a full checkpoint) you should use [`~modeling_utils.load_sharded_checkpoint`]:
+
+```py
+>>> from transformers.modeling_utils import load_sharded_checkpoint
+
+>>> with tempfile.TemporaryDirectory() as tmp_dir:
+... model.save_pretrained(tmp_dir, max_shard_size="200MB")
+... load_sharded_checkpoint(model, tmp_dir)
+```
+
+## Low memory loading
+
+Sharded checkpoints reduce the memory usage during step 2 of the worflow mentioned above, but when loadin a pretrained model, why keep the random weights in memory? The option `low_cpu_mem_usage` will destroy the weights of the randomly initialized model, then progressively load the weights inside, then perform a random initialization for potential missing weights (if you are loadding a model with a newly initialized head for a fine-tuning task for instance).
+
+It's very easy to use, just add `low_cpu_mem_usage=True` to your call to [`~PreTrainedModel.from_pretrained`]:
+
+```py
+from transformers import AutoModelForSequenceClas
+
+model = AutoModel.from_pretrained("bert-base-cased", low_cpu_mem_usage=True)
+```
+
+This can be used in conjunction with a sharded checkpoint.
+
diff --git a/docs/source/en/community.mdx b/docs/source/en/community.mdx
new file mode 100644
index 00000000000000..808b16779dd94a
--- /dev/null
+++ b/docs/source/en/community.mdx
@@ -0,0 +1,65 @@
+# Community
+
+This page regroups resources around 🤗 Transformers developed by the community.
+
+## Community resources:
+
+| Resource | Description | Author |
+|:----------|:-------------|------:|
+| [Hugging Face Transformers Glossary Flashcards](https://www.darigovresearch.com/huggingface-transformers-glossary-flashcards) | A set of flashcards based on the [Transformers Docs Glossary](glossary) that has been put into a form which can be easily learnt/revised using [Anki ](https://apps.ankiweb.net/) an open source, cross platform app specifically designed for long term knowledge retention. See this [Introductory video on how to use the flashcards](https://www.youtube.com/watch?v=Dji_h7PILrw). | [Darigov Research](https://www.darigovresearch.com/) |
+
+## Community notebooks:
+
+| Notebook | Description | Author | |
+|:----------|:-------------|:-------------|------:|
+| [Fine-tune a pre-trained Transformer to generate lyrics](https://github.com/AlekseyKorshuk/huggingartists) | How to generate lyrics in the style of your favorite artist by fine-tuning a GPT-2 model | [Aleksey Korshuk](https://github.com/AlekseyKorshuk) | [](https://colab.research.google.com/github/AlekseyKorshuk/huggingartists/blob/master/huggingartists-demo.ipynb) |
+| [Train T5 in Tensorflow 2 ](https://github.com/snapthat/TF-T5-text-to-text) | How to train T5 for any task using Tensorflow 2. This notebook demonstrates a Question & Answer task implemented in Tensorflow 2 using SQUAD | [Muhammad Harris](https://github.com/HarrisDePerceptron) |[](https://colab.research.google.com/github/snapthat/TF-T5-text-to-text/blob/master/snapthatT5/notebooks/TF-T5-Datasets%20Training.ipynb) |
+| [Train T5 on TPU](https://github.com/patil-suraj/exploring-T5/blob/master/T5_on_TPU.ipynb) | How to train T5 on SQUAD with Transformers and Nlp | [Suraj Patil](https://github.com/patil-suraj) |[](https://colab.research.google.com/github/patil-suraj/exploring-T5/blob/master/T5_on_TPU.ipynb#scrollTo=QLGiFCDqvuil) |
+| [Fine-tune T5 for Classification and Multiple Choice](https://github.com/patil-suraj/exploring-T5/blob/master/t5_fine_tuning.ipynb) | How to fine-tune T5 for classification and multiple choice tasks using a text-to-text format with PyTorch Lightning | [Suraj Patil](https://github.com/patil-suraj) | [](https://colab.research.google.com/github/patil-suraj/exploring-T5/blob/master/t5_fine_tuning.ipynb) |
+| [Fine-tune DialoGPT on New Datasets and Languages](https://github.com/ncoop57/i-am-a-nerd/blob/master/_notebooks/2020-05-12-chatbot-part-1.ipynb) | How to fine-tune the DialoGPT model on a new dataset for open-dialog conversational chatbots | [Nathan Cooper](https://github.com/ncoop57) | [](https://colab.research.google.com/github/ncoop57/i-am-a-nerd/blob/master/_notebooks/2020-05-12-chatbot-part-1.ipynb) |
+| [Long Sequence Modeling with Reformer](https://github.com/patrickvonplaten/notebooks/blob/master/PyTorch_Reformer.ipynb) | How to train on sequences as long as 500,000 tokens with Reformer | [Patrick von Platen](https://github.com/patrickvonplaten) | [](https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/PyTorch_Reformer.ipynb) |
+| [Fine-tune BART for Summarization](https://github.com/ohmeow/ohmeow_website/blob/master/_notebooks/2020-05-23-text-generation-with-blurr.ipynb) | How to fine-tune BART for summarization with fastai using blurr | [Wayde Gilliam](https://ohmeow.com/) | [](https://colab.research.google.com/github/ohmeow/ohmeow_website/blob/master/_notebooks/2020-05-23-text-generation-with-blurr.ipynb) |
+| [Fine-tune a pre-trained Transformer on anyone's tweets](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb) | How to generate tweets in the style of your favorite Twitter account by fine-tuning a GPT-2 model | [Boris Dayma](https://github.com/borisdayma) | [](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb) |
+| [Optimize 🤗 Hugging Face models with Weights & Biases](https://colab.research.google.com/github/wandb/examples/blob/master/colabs/huggingface/Optimize_Hugging_Face_models_with_Weights_%26_Biases.ipynb) | A complete tutorial showcasing W&B integration with Hugging Face | [Boris Dayma](https://github.com/borisdayma) | [](https://colab.research.google.com/github/wandb/examples/blob/master/colabs/huggingface/Optimize_Hugging_Face_models_with_Weights_%26_Biases.ipynb) |
+| [Pretrain Longformer](https://github.com/allenai/longformer/blob/master/scripts/convert_model_to_long.ipynb) | How to build a "long" version of existing pretrained models | [Iz Beltagy](https://beltagy.net) | [](https://colab.research.google.com/github/allenai/longformer/blob/master/scripts/convert_model_to_long.ipynb) |
+| [Fine-tune Longformer for QA](https://github.com/patil-suraj/Notebooks/blob/master/longformer_qa_training.ipynb) | How to fine-tune longformer model for QA task | [Suraj Patil](https://github.com/patil-suraj) | [](https://colab.research.google.com/github/patil-suraj/Notebooks/blob/master/longformer_qa_training.ipynb) |
+| [Evaluate Model with 🤗nlp](https://github.com/patrickvonplaten/notebooks/blob/master/How_to_evaluate_Longformer_on_TriviaQA_using_NLP.ipynb) | How to evaluate longformer on TriviaQA with `nlp` | [Patrick von Platen](https://github.com/patrickvonplaten) | [](https://colab.research.google.com/drive/1m7eTGlPmLRgoPkkA7rkhQdZ9ydpmsdLE?usp=sharing) |
+| [Fine-tune T5 for Sentiment Span Extraction](https://github.com/enzoampil/t5-intro/blob/master/t5_qa_training_pytorch_span_extraction.ipynb) | How to fine-tune T5 for sentiment span extraction using a text-to-text format with PyTorch Lightning | [Lorenzo Ampil](https://github.com/enzoampil) | [](https://colab.research.google.com/github/enzoampil/t5-intro/blob/master/t5_qa_training_pytorch_span_extraction.ipynb) |
+| [Fine-tune DistilBert for Multiclass Classification](https://github.com/abhimishra91/transformers-tutorials/blob/master/transformers_multiclass_classification.ipynb) | How to fine-tune DistilBert for multiclass classification with PyTorch | [Abhishek Kumar Mishra](https://github.com/abhimishra91) | [](https://colab.research.google.com/github/abhimishra91/transformers-tutorials/blob/master/transformers_multiclass_classification.ipynb)|
+|[Fine-tune BERT for Multi-label Classification](https://github.com/abhimishra91/transformers-tutorials/blob/master/transformers_multi_label_classification.ipynb)|How to fine-tune BERT for multi-label classification using PyTorch|[Abhishek Kumar Mishra](https://github.com/abhimishra91) |[](https://colab.research.google.com/github/abhimishra91/transformers-tutorials/blob/master/transformers_multi_label_classification.ipynb)|
+|[Fine-tune T5 for Summarization](https://github.com/abhimishra91/transformers-tutorials/blob/master/transformers_summarization_wandb.ipynb)|How to fine-tune T5 for summarization in PyTorch and track experiments with WandB|[Abhishek Kumar Mishra](https://github.com/abhimishra91) |[](https://colab.research.google.com/github/abhimishra91/transformers-tutorials/blob/master/transformers_summarization_wandb.ipynb)|
+|[Speed up Fine-Tuning in Transformers with Dynamic Padding / Bucketing](https://github.com/ELS-RD/transformers-notebook/blob/master/Divide_Hugging_Face_Transformers_training_time_by_2_or_more.ipynb)|How to speed up fine-tuning by a factor of 2 using dynamic padding / bucketing|[Michael Benesty](https://github.com/pommedeterresautee) |[](https://colab.research.google.com/drive/1CBfRU1zbfu7-ijiOqAAQUA-RJaxfcJoO?usp=sharing)|
+|[Pretrain Reformer for Masked Language Modeling](https://github.com/patrickvonplaten/notebooks/blob/master/Reformer_For_Masked_LM.ipynb)| How to train a Reformer model with bi-directional self-attention layers | [Patrick von Platen](https://github.com/patrickvonplaten) | [](https://colab.research.google.com/drive/1tzzh0i8PgDQGV3SMFUGxM7_gGae3K-uW?usp=sharing)|
+|[Expand and Fine Tune Sci-BERT](https://github.com/lordtt13/word-embeddings/blob/master/COVID-19%20Research%20Data/COVID-SciBERT.ipynb)| How to increase vocabulary of a pretrained SciBERT model from AllenAI on the CORD dataset and pipeline it. | [Tanmay Thakur](https://github.com/lordtt13) | [](https://colab.research.google.com/drive/1rqAR40goxbAfez1xvF3hBJphSCsvXmh8)|
+|[Fine Tune BlenderBotSmall for Summarization using the Trainer API](https://github.com/lordtt13/transformers-experiments/blob/master/Custom%20Tasks/fine-tune-blenderbot_small-for-summarization.ipynb)| How to fine tune BlenderBotSmall for summarization on a custom dataset, using the Trainer API. | [Tanmay Thakur](https://github.com/lordtt13) | [](https://colab.research.google.com/drive/19Wmupuls7mykSGyRN_Qo6lPQhgp56ymq?usp=sharing)|
+|[Fine-tune Electra and interpret with Integrated Gradients](https://github.com/elsanns/xai-nlp-notebooks/blob/master/electra_fine_tune_interpret_captum_ig.ipynb) | How to fine-tune Electra for sentiment analysis and interpret predictions with Captum Integrated Gradients | [Eliza Szczechla](https://elsanns.github.io) | [](https://colab.research.google.com/github/elsanns/xai-nlp-notebooks/blob/master/electra_fine_tune_interpret_captum_ig.ipynb)|
+|[fine-tune a non-English GPT-2 Model with Trainer class](https://github.com/philschmid/fine-tune-GPT-2/blob/master/Fine_tune_a_non_English_GPT_2_Model_with_Huggingface.ipynb) | How to fine-tune a non-English GPT-2 Model with Trainer class | [Philipp Schmid](https://www.philschmid.de) | [](https://colab.research.google.com/github/philschmid/fine-tune-GPT-2/blob/master/Fine_tune_a_non_English_GPT_2_Model_with_Huggingface.ipynb)|
+|[Fine-tune a DistilBERT Model for Multi Label Classification task](https://github.com/DhavalTaunk08/Transformers_scripts/blob/master/Transformers_multilabel_distilbert.ipynb) | How to fine-tune a DistilBERT Model for Multi Label Classification task | [Dhaval Taunk](https://github.com/DhavalTaunk08) | [](https://colab.research.google.com/github/DhavalTaunk08/Transformers_scripts/blob/master/Transformers_multilabel_distilbert.ipynb)|
+|[Fine-tune ALBERT for sentence-pair classification](https://github.com/NadirEM/nlp-notebooks/blob/master/Fine_tune_ALBERT_sentence_pair_classification.ipynb) | How to fine-tune an ALBERT model or another BERT-based model for the sentence-pair classification task | [Nadir El Manouzi](https://github.com/NadirEM) | [](https://colab.research.google.com/github/NadirEM/nlp-notebooks/blob/master/Fine_tune_ALBERT_sentence_pair_classification.ipynb)|
+|[Fine-tune Roberta for sentiment analysis](https://github.com/DhavalTaunk08/NLP_scripts/blob/master/sentiment_analysis_using_roberta.ipynb) | How to fine-tune a Roberta model for sentiment analysis | [Dhaval Taunk](https://github.com/DhavalTaunk08) | [](https://colab.research.google.com/github/DhavalTaunk08/NLP_scripts/blob/master/sentiment_analysis_using_roberta.ipynb)|
+|[Evaluating Question Generation Models](https://github.com/flexudy-pipe/qugeev) | How accurate are the answers to questions generated by your seq2seq transformer model? | [Pascal Zoleko](https://github.com/zolekode) | [](https://colab.research.google.com/drive/1bpsSqCQU-iw_5nNoRm_crPq6FRuJthq_?usp=sharing)|
+|[Classify text with DistilBERT and Tensorflow](https://github.com/peterbayerle/huggingface_notebook/blob/main/distilbert_tf.ipynb) | How to fine-tune DistilBERT for text classification in TensorFlow | [Peter Bayerle](https://github.com/peterbayerle) | [](https://colab.research.google.com/github/peterbayerle/huggingface_notebook/blob/main/distilbert_tf.ipynb)|
+|[Leverage BERT for Encoder-Decoder Summarization on CNN/Dailymail](https://github.com/patrickvonplaten/notebooks/blob/master/BERT2BERT_for_CNN_Dailymail.ipynb) | How to warm-start a *EncoderDecoderModel* with a *bert-base-uncased* checkpoint for summarization on CNN/Dailymail | [Patrick von Platen](https://github.com/patrickvonplaten) | [](https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/BERT2BERT_for_CNN_Dailymail.ipynb)|
+|[Leverage RoBERTa for Encoder-Decoder Summarization on BBC XSum](https://github.com/patrickvonplaten/notebooks/blob/master/RoBERTaShared_for_BBC_XSum.ipynb) | How to warm-start a shared *EncoderDecoderModel* with a *roberta-base* checkpoint for summarization on BBC/XSum | [Patrick von Platen](https://github.com/patrickvonplaten) | [](https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/RoBERTaShared_for_BBC_XSum.ipynb)|
+|[Fine-tune TAPAS on Sequential Question Answering (SQA)](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/TAPAS/Fine_tuning_TapasForQuestionAnswering_on_SQA.ipynb) | How to fine-tune *TapasForQuestionAnswering* with a *tapas-base* checkpoint on the Sequential Question Answering (SQA) dataset | [Niels Rogge](https://github.com/nielsrogge) | [](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/TAPAS/Fine_tuning_TapasForQuestionAnswering_on_SQA.ipynb)|
+|[Evaluate TAPAS on Table Fact Checking (TabFact)](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/TAPAS/Evaluating_TAPAS_on_the_Tabfact_test_set.ipynb) | How to evaluate a fine-tuned *TapasForSequenceClassification* with a *tapas-base-finetuned-tabfact* checkpoint using a combination of the 🤗 datasets and 🤗 transformers libraries | [Niels Rogge](https://github.com/nielsrogge) | [](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/TAPAS/Evaluating_TAPAS_on_the_Tabfact_test_set.ipynb)|
+|[Fine-tuning mBART for translation](https://colab.research.google.com/github/vasudevgupta7/huggingface-tutorials/blob/main/translation_training.ipynb) | How to fine-tune mBART using Seq2SeqTrainer for Hindi to English translation | [Vasudev Gupta](https://github.com/vasudevgupta7) | [](https://colab.research.google.com/github/vasudevgupta7/huggingface-tutorials/blob/main/translation_training.ipynb)|
+|[Fine-tune LayoutLM on FUNSD (a form understanding dataset)](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/LayoutLM/Fine_tuning_LayoutLMForTokenClassification_on_FUNSD.ipynb) | How to fine-tune *LayoutLMForTokenClassification* on the FUNSD dataset for information extraction from scanned documents | [Niels Rogge](https://github.com/nielsrogge) | [](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/LayoutLM/Fine_tuning_LayoutLMForTokenClassification_on_FUNSD.ipynb)|
+|[Fine-Tune DistilGPT2 and Generate Text](https://colab.research.google.com/github/tripathiaakash/DistilGPT2-Tutorial/blob/main/distilgpt2_fine_tuning.ipynb) | How to fine-tune DistilGPT2 and generate text | [Aakash Tripathi](https://github.com/tripathiaakash) | [](https://colab.research.google.com/github/tripathiaakash/DistilGPT2-Tutorial/blob/main/distilgpt2_fine_tuning.ipynb)|
+|[Fine-Tune LED on up to 8K tokens](https://github.com/patrickvonplaten/notebooks/blob/master/Fine_tune_Longformer_Encoder_Decoder_(LED)_for_Summarization_on_pubmed.ipynb) | How to fine-tune LED on pubmed for long-range summarization | [Patrick von Platen](https://github.com/patrickvonplaten) | [](https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/Fine_tune_Longformer_Encoder_Decoder_(LED)_for_Summarization_on_pubmed.ipynb)|
+|[Evaluate LED on Arxiv](https://github.com/patrickvonplaten/notebooks/blob/master/LED_on_Arxiv.ipynb) | How to effectively evaluate LED on long-range summarization | [Patrick von Platen](https://github.com/patrickvonplaten) | [](https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/LED_on_Arxiv.ipynb)|
+|[Fine-tune LayoutLM on RVL-CDIP (a document image classification dataset)](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/LayoutLM/Fine_tuning_LayoutLMForSequenceClassification_on_RVL_CDIP.ipynb) | How to fine-tune *LayoutLMForSequenceClassification* on the RVL-CDIP dataset for scanned document classification | [Niels Rogge](https://github.com/nielsrogge) | [](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/LayoutLM/Fine_tuning_LayoutLMForSequenceClassification_on_RVL_CDIP.ipynb)|
+|[Wav2Vec2 CTC decoding with GPT2 adjustment](https://github.com/voidful/huggingface_notebook/blob/main/xlsr_gpt.ipynb) | How to decode CTC sequence with language model adjustment | [Eric Lam](https://github.com/voidful) | [](https://colab.research.google.com/drive/1e_z5jQHYbO2YKEaUgzb1ww1WwiAyydAj?usp=sharing)|
+|[Fine-tune BART for summarization in two languages with Trainer class](https://github.com/elsanns/xai-nlp-notebooks/blob/master/fine_tune_bart_summarization_two_langs.ipynb) | How to fine-tune BART for summarization in two languages with Trainer class | [Eliza Szczechla](https://github.com/elsanns) | [](https://colab.research.google.com/github/elsanns/xai-nlp-notebooks/blob/master/fine_tune_bart_summarization_two_langs.ipynb)|
+|[Evaluate Big Bird on Trivia QA](https://github.com/patrickvonplaten/notebooks/blob/master/Evaluating_Big_Bird_on_TriviaQA.ipynb) | How to evaluate BigBird on long document question answering on Trivia QA | [Patrick von Platen](https://github.com/patrickvonplaten) | [](https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/Evaluating_Big_Bird_on_TriviaQA.ipynb)|
+| [Create video captions using Wav2Vec2](https://github.com/Muennighoff/ytclipcc/blob/main/wav2vec_youtube_captions.ipynb) | How to create YouTube captions from any video by transcribing the audio with Wav2Vec | [Niklas Muennighoff](https://github.com/Muennighoff) |[](https://colab.research.google.com/github/Muennighoff/ytclipcc/blob/main/wav2vec_youtube_captions.ipynb) |
+| [Fine-tune the Vision Transformer on CIFAR-10 using PyTorch Lightning](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/VisionTransformer/Fine_tuning_the_Vision_Transformer_on_CIFAR_10_with_PyTorch_Lightning.ipynb) | How to fine-tune the Vision Transformer (ViT) on CIFAR-10 using HuggingFace Transformers, Datasets and PyTorch Lightning | [Niels Rogge](https://github.com/nielsrogge) |[](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/VisionTransformer/Fine_tuning_the_Vision_Transformer_on_CIFAR_10_with_PyTorch_Lightning.ipynb) |
+| [Fine-tune the Vision Transformer on CIFAR-10 using the 🤗 Trainer](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/VisionTransformer/Fine_tuning_the_Vision_Transformer_on_CIFAR_10_with_the_%F0%9F%A4%97_Trainer.ipynb) | How to fine-tune the Vision Transformer (ViT) on CIFAR-10 using HuggingFace Transformers, Datasets and the 🤗 Trainer | [Niels Rogge](https://github.com/nielsrogge) |[](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/VisionTransformer/Fine_tuning_the_Vision_Transformer_on_CIFAR_10_with_the_%F0%9F%A4%97_Trainer.ipynb) |
+| [Evaluate LUKE on Open Entity, an entity typing dataset](https://github.com/studio-ousia/luke/blob/master/notebooks/huggingface_open_entity.ipynb) | How to evaluate *LukeForEntityClassification* on the Open Entity dataset | [Ikuya Yamada](https://github.com/ikuyamada) |[](https://colab.research.google.com/github/studio-ousia/luke/blob/master/notebooks/huggingface_open_entity.ipynb) |
+| [Evaluate LUKE on TACRED, a relation extraction dataset](https://github.com/studio-ousia/luke/blob/master/notebooks/huggingface_tacred.ipynb) | How to evaluate *LukeForEntityPairClassification* on the TACRED dataset | [Ikuya Yamada](https://github.com/ikuyamada) |[](https://colab.research.google.com/github/studio-ousia/luke/blob/master/notebooks/huggingface_tacred.ipynb) |
+| [Evaluate LUKE on CoNLL-2003, an important NER benchmark](https://github.com/studio-ousia/luke/blob/master/notebooks/huggingface_conll_2003.ipynb) | How to evaluate *LukeForEntitySpanClassification* on the CoNLL-2003 dataset | [Ikuya Yamada](https://github.com/ikuyamada) |[](https://colab.research.google.com/github/studio-ousia/luke/blob/master/notebooks/huggingface_conll_2003.ipynb) |
+| [Evaluate BigBird-Pegasus on PubMed dataset](https://github.com/vasudevgupta7/bigbird/blob/main/notebooks/bigbird_pegasus_evaluation.ipynb) | How to evaluate *BigBirdPegasusForConditionalGeneration* on PubMed dataset | [Vasudev Gupta](https://github.com/vasudevgupta7) | [](https://colab.research.google.com/github/vasudevgupta7/bigbird/blob/main/notebooks/bigbird_pegasus_evaluation.ipynb) |
+| [Speech Emotion Classification with Wav2Vec2](https://github/m3hrdadfi/soxan/blob/main/notebooks/Emotion_recognition_in_Greek_speech_using_Wav2Vec2.ipynb) | How to leverage a pretrained Wav2Vec2 model for Emotion Classification on the MEGA dataset | [Mehrdad Farahani](https://github.com/m3hrdadfi) | [](https://colab.research.google.com/github/m3hrdadfi/soxan/blob/main/notebooks/Emotion_recognition_in_Greek_speech_using_Wav2Vec2.ipynb) |
+| [Detect objects in an image with DETR](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/DETR/DETR_minimal_example_(with_DetrFeatureExtractor).ipynb) | How to use a trained *DetrForObjectDetection* model to detect objects in an image and visualize attention | [Niels Rogge](https://github.com/NielsRogge) | [](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/DETR/DETR_minimal_example_(with_DetrFeatureExtractor).ipynb) |
+| [Fine-tune DETR on a custom object detection dataset](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/DETR/Fine_tuning_DetrForObjectDetection_on_custom_dataset_(balloon).ipynb) | How to fine-tune *DetrForObjectDetection* on a custom object detection dataset | [Niels Rogge](https://github.com/NielsRogge) | [](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/DETR/Fine_tuning_DetrForObjectDetection_on_custom_dataset_(balloon).ipynb) |
+| [Finetune T5 for Named Entity Recognition](https://github.com/ToluClassics/Notebooks/blob/main/T5_Ner_Finetuning.ipynb) | How to fine-tune *T5* on a Named Entity Recognition Task | [Ogundepo Odunayo](https://github.com/ToluClassics) | [](https://colab.research.google.com/drive/1obr78FY_cBmWY5ODViCmzdY6O1KB65Vc?usp=sharing) |
diff --git a/docs/source/en/contributing.md b/docs/source/en/contributing.md
new file mode 120000
index 00000000000000..c97564d93a7f0a
--- /dev/null
+++ b/docs/source/en/contributing.md
@@ -0,0 +1 @@
+../../../CONTRIBUTING.md
\ No newline at end of file
diff --git a/docs/source/en/converting_tensorflow_models.mdx b/docs/source/en/converting_tensorflow_models.mdx
new file mode 100644
index 00000000000000..c11e4e62b8086e
--- /dev/null
+++ b/docs/source/en/converting_tensorflow_models.mdx
@@ -0,0 +1,162 @@
+
+
+# Converting Tensorflow Checkpoints
+
+A command-line interface is provided to convert original Bert/GPT/GPT-2/Transformer-XL/XLNet/XLM checkpoints to models
+that can be loaded using the `from_pretrained` methods of the library.
+
+
+
+Since 2.3.0 the conversion script is now part of the transformers CLI (**transformers-cli**) available in any
+transformers >= 2.3.0 installation.
+
+The documentation below reflects the **transformers-cli convert** command format.
+
+
+
+## BERT
+
+You can convert any TensorFlow checkpoint for BERT (in particular [the pre-trained models released by Google](https://github.com/google-research/bert#pre-trained-models)) in a PyTorch save file by using the
+[convert_bert_original_tf_checkpoint_to_pytorch.py](https://github.com/huggingface/transformers/tree/main/src/transformers/models/bert/convert_bert_original_tf_checkpoint_to_pytorch.py) script.
+
+This CLI takes as input a TensorFlow checkpoint (three files starting with `bert_model.ckpt`) and the associated
+configuration file (`bert_config.json`), and creates a PyTorch model for this configuration, loads the weights from
+the TensorFlow checkpoint in the PyTorch model and saves the resulting model in a standard PyTorch save file that can
+be imported using `from_pretrained()` (see example in [quicktour](quicktour) , [run_glue.py](https://github.com/huggingface/transformers/tree/main/examples/pytorch/text-classification/run_glue.py) ).
+
+You only need to run this conversion script **once** to get a PyTorch model. You can then disregard the TensorFlow
+checkpoint (the three files starting with `bert_model.ckpt`) but be sure to keep the configuration file (\
+`bert_config.json`) and the vocabulary file (`vocab.txt`) as these are needed for the PyTorch model too.
+
+To run this specific conversion script you will need to have TensorFlow and PyTorch installed (`pip install tensorflow`). The rest of the repository only requires PyTorch.
+
+Here is an example of the conversion process for a pre-trained `BERT-Base Uncased` model:
+
+```bash
+export BERT_BASE_DIR=/path/to/bert/uncased_L-12_H-768_A-12
+
+transformers-cli convert --model_type bert \
+ --tf_checkpoint $BERT_BASE_DIR/bert_model.ckpt \
+ --config $BERT_BASE_DIR/bert_config.json \
+ --pytorch_dump_output $BERT_BASE_DIR/pytorch_model.bin
+```
+
+You can download Google's pre-trained models for the conversion [here](https://github.com/google-research/bert#pre-trained-models).
+
+## ALBERT
+
+Convert TensorFlow model checkpoints of ALBERT to PyTorch using the
+[convert_albert_original_tf_checkpoint_to_pytorch.py](https://github.com/huggingface/transformers/tree/main/src/transformers/models/albert/convert_albert_original_tf_checkpoint_to_pytorch.py) script.
+
+The CLI takes as input a TensorFlow checkpoint (three files starting with `model.ckpt-best`) and the accompanying
+configuration file (`albert_config.json`), then creates and saves a PyTorch model. To run this conversion you will
+need to have TensorFlow and PyTorch installed.
+
+Here is an example of the conversion process for the pre-trained `ALBERT Base` model:
+
+```bash
+export ALBERT_BASE_DIR=/path/to/albert/albert_base
+
+transformers-cli convert --model_type albert \
+ --tf_checkpoint $ALBERT_BASE_DIR/model.ckpt-best \
+ --config $ALBERT_BASE_DIR/albert_config.json \
+ --pytorch_dump_output $ALBERT_BASE_DIR/pytorch_model.bin
+```
+
+You can download Google's pre-trained models for the conversion [here](https://github.com/google-research/albert#pre-trained-models).
+
+## OpenAI GPT
+
+Here is an example of the conversion process for a pre-trained OpenAI GPT model, assuming that your NumPy checkpoint
+save as the same format than OpenAI pretrained model (see [here](https://github.com/openai/finetune-transformer-lm)\
+)
+
+```bash
+export OPENAI_GPT_CHECKPOINT_FOLDER_PATH=/path/to/openai/pretrained/numpy/weights
+
+transformers-cli convert --model_type gpt \
+ --tf_checkpoint $OPENAI_GPT_CHECKPOINT_FOLDER_PATH \
+ --pytorch_dump_output $PYTORCH_DUMP_OUTPUT \
+ [--config OPENAI_GPT_CONFIG] \
+ [--finetuning_task_name OPENAI_GPT_FINETUNED_TASK] \
+```
+
+## OpenAI GPT-2
+
+Here is an example of the conversion process for a pre-trained OpenAI GPT-2 model (see [here](https://github.com/openai/gpt-2))
+
+```bash
+export OPENAI_GPT2_CHECKPOINT_PATH=/path/to/gpt2/pretrained/weights
+
+transformers-cli convert --model_type gpt2 \
+ --tf_checkpoint $OPENAI_GPT2_CHECKPOINT_PATH \
+ --pytorch_dump_output $PYTORCH_DUMP_OUTPUT \
+ [--config OPENAI_GPT2_CONFIG] \
+ [--finetuning_task_name OPENAI_GPT2_FINETUNED_TASK]
+```
+
+## Transformer-XL
+
+Here is an example of the conversion process for a pre-trained Transformer-XL model (see [here](https://github.com/kimiyoung/transformer-xl/tree/master/tf#obtain-and-evaluate-pretrained-sota-models))
+
+```bash
+export TRANSFO_XL_CHECKPOINT_FOLDER_PATH=/path/to/transfo/xl/checkpoint
+
+transformers-cli convert --model_type transfo_xl \
+ --tf_checkpoint $TRANSFO_XL_CHECKPOINT_FOLDER_PATH \
+ --pytorch_dump_output $PYTORCH_DUMP_OUTPUT \
+ [--config TRANSFO_XL_CONFIG] \
+ [--finetuning_task_name TRANSFO_XL_FINETUNED_TASK]
+```
+
+## XLNet
+
+Here is an example of the conversion process for a pre-trained XLNet model:
+
+```bash
+export TRANSFO_XL_CHECKPOINT_PATH=/path/to/xlnet/checkpoint
+export TRANSFO_XL_CONFIG_PATH=/path/to/xlnet/config
+
+transformers-cli convert --model_type xlnet \
+ --tf_checkpoint $TRANSFO_XL_CHECKPOINT_PATH \
+ --config $TRANSFO_XL_CONFIG_PATH \
+ --pytorch_dump_output $PYTORCH_DUMP_OUTPUT \
+ [--finetuning_task_name XLNET_FINETUNED_TASK] \
+```
+
+## XLM
+
+Here is an example of the conversion process for a pre-trained XLM model:
+
+```bash
+export XLM_CHECKPOINT_PATH=/path/to/xlm/checkpoint
+
+transformers-cli convert --model_type xlm \
+ --tf_checkpoint $XLM_CHECKPOINT_PATH \
+ --pytorch_dump_output $PYTORCH_DUMP_OUTPUT
+ [--config XML_CONFIG] \
+ [--finetuning_task_name XML_FINETUNED_TASK]
+```
+
+## T5
+
+Here is an example of the conversion process for a pre-trained T5 model:
+
+```bash
+export T5=/path/to/t5/uncased_L-12_H-768_A-12
+
+transformers-cli convert --model_type t5 \
+ --tf_checkpoint $T5/t5_model.ckpt \
+ --config $T5/t5_config.json \
+ --pytorch_dump_output $T5/pytorch_model.bin
+```
diff --git a/docs/source/en/create_a_model.mdx b/docs/source/en/create_a_model.mdx
new file mode 100644
index 00000000000000..51d2b2cb90cb4b
--- /dev/null
+++ b/docs/source/en/create_a_model.mdx
@@ -0,0 +1,355 @@
+
+
+# Create a custom architecture
+
+An [`AutoClass`](model_doc/auto) automatically infers the model architecture and downloads pretrained configuration and weights. Generally, we recommend using an `AutoClass` to produce checkpoint-agnostic code. But users who want more control over specific model parameters can create a custom 🤗 Transformers model from just a few base classes. This could be particularly useful for anyone who is interested in studying, training or experimenting with a 🤗 Transformers model. In this guide, dive deeper into creating a custom model without an `AutoClass`. Learn how to:
+
+- Load and customize a model configuration.
+- Create a model architecture.
+- Create a slow and fast tokenizer for text.
+- Create a feature extractor for audio or image tasks.
+- Create a processor for multimodal tasks.
+
+## Configuration
+
+A [configuration](main_classes/configuration) refers to a model's specific attributes. Each model configuration has different attributes; for instance, all NLP models have the `hidden_size`, `num_attention_heads`, `num_hidden_layers` and `vocab_size` attributes in common. These attributes specify the number of attention heads or hidden layers to construct a model with.
+
+Get a closer look at [DistilBERT](model_doc/distilbert) by accessing [`DistilBertConfig`] to inspect it's attributes:
+
+```py
+>>> from transformers import DistilBertConfig
+
+>>> config = DistilBertConfig()
+>>> print(config)
+DistilBertConfig {
+ "activation": "gelu",
+ "attention_dropout": 0.1,
+ "dim": 768,
+ "dropout": 0.1,
+ "hidden_dim": 3072,
+ "initializer_range": 0.02,
+ "max_position_embeddings": 512,
+ "model_type": "distilbert",
+ "n_heads": 12,
+ "n_layers": 6,
+ "pad_token_id": 0,
+ "qa_dropout": 0.1,
+ "seq_classif_dropout": 0.2,
+ "sinusoidal_pos_embds": false,
+ "transformers_version": "4.16.2",
+ "vocab_size": 30522
+}
+```
+
+[`DistilBertConfig`] displays all the default attributes used to build a base [`DistilBertModel`]. All attributes are customizable, creating space for experimentation. For example, you can customize a default model to:
+
+- Try a different activation function with the `activation` parameter.
+- Use a higher dropout ratio for the attention probabilities with the `attention_dropout` parameter.
+
+```py
+>>> my_config = DistilBertConfig(activation="relu", attention_dropout=0.4)
+>>> print(my_config)
+DistilBertConfig {
+ "activation": "relu",
+ "attention_dropout": 0.4,
+ "dim": 768,
+ "dropout": 0.1,
+ "hidden_dim": 3072,
+ "initializer_range": 0.02,
+ "max_position_embeddings": 512,
+ "model_type": "distilbert",
+ "n_heads": 12,
+ "n_layers": 6,
+ "pad_token_id": 0,
+ "qa_dropout": 0.1,
+ "seq_classif_dropout": 0.2,
+ "sinusoidal_pos_embds": false,
+ "transformers_version": "4.16.2",
+ "vocab_size": 30522
+}
+```
+
+Pretrained model attributes can be modified in the [`~PretrainedConfig.from_pretrained`] function:
+
+```py
+>>> my_config = DistilBertConfig.from_pretrained("distilbert-base-uncased", activation="relu", attention_dropout=0.4)
+```
+
+Once you are satisfied with your model configuration, you can save it with [`~PretrainedConfig.save_pretrained`]. Your configuration file is stored as a JSON file in the specified save directory:
+
+```py
+>>> my_config.save_pretrained(save_directory="./your_model_save_path")
+```
+
+To reuse the configuration file, load it with [`~PretrainedConfig.from_pretrained`]:
+
+```py
+>>> my_config = DistilBertConfig.from_pretrained("./your_model_save_path/my_config.json")
+```
+
+
+
+You can also save your configuration file as a dictionary or even just the difference between your custom configuration attributes and the default configuration attributes! See the [configuration](main_classes/configuration) documentation for more details.
+
+
+
+## Model
+
+The next step is to create a [model](main_classes/models). The model - also loosely referred to as the architecture - defines what each layer is doing and what operations are happening. Attributes like `num_hidden_layers` from the configuration are used to define the architecture. Every model shares the base class [`PreTrainedModel`] and a few common methods like resizing input embeddings and pruning self-attention heads. In addition, all models are also either a [`torch.nn.Module`](https://pytorch.org/docs/stable/generated/torch.nn.Module.html), [`tf.keras.Model`](https://www.tensorflow.org/api_docs/python/tf/keras/Model) or [`flax.linen.Module`](https://flax.readthedocs.io/en/latest/flax.linen.html#module) subclass. This means models are compatible with each of their respective framework's usage.
+
+
+
+Load your custom configuration attributes into the model:
+
+```py
+>>> from transformers import DistilBertModel
+
+>>> my_config = DistilBertConfig.from_pretrained("./your_model_save_path/my_config.json")
+>>> model = DistilBertModel(my_config)
+```
+
+This creates a model with random values instead of pretrained weights. You won't be able to use this model for anything useful yet until you train it. Training is a costly and time-consuming process. It is generally better to use a pretrained model to obtain better results faster, while using only a fraction of the resources required for training.
+
+Create a pretrained model with [`~PreTrainedModel.from_pretrained`]:
+
+```py
+>>> model = DistilBertModel.from_pretrained("distilbert-base-uncased")
+```
+
+When you load pretrained weights, the default model configuration is automatically loaded if the model is provided by 🤗 Transformers. However, you can still replace - some or all of - the default model configuration attributes with your own if you'd like:
+
+```py
+>>> model = DistilBertModel.from_pretrained("distilbert-base-uncased", config=my_config)
+```
+
+
+Load your custom configuration attributes into the model:
+
+```py
+>>> from transformers import TFDistilBertModel
+
+>>> my_config = DistilBertConfig.from_pretrained("./your_model_save_path/my_config.json")
+>>> tf_model = TFDistilBertModel(my_config)
+```
+
+This creates a model with random values instead of pretrained weights. You won't be able to use this model for anything useful yet until you train it. Training is a costly and time-consuming process. It is generally better to use a pretrained model to obtain better results faster, while using only a fraction of the resources required for training.
+
+Create a pretrained model with [`~TFPreTrainedModel.from_pretrained`]:
+
+```py
+>>> tf_model = TFDistilBertModel.from_pretrained("distilbert-base-uncased")
+```
+
+When you load pretrained weights, the default model configuration is automatically loaded if the model is provided by 🤗 Transformers. However, you can still replace - some or all of - the default model configuration attributes with your own if you'd like:
+
+```py
+>>> tf_model = TFDistilBertModel.from_pretrained("distilbert-base-uncased", config=my_config)
+```
+
+
+
+### Model heads
+
+At this point, you have a base DistilBERT model which outputs the *hidden states*. The hidden states are passed as inputs to a model head to produce the final output. 🤗 Transformers provides a different model head for each task as long as a model supports the task (i.e., you can't use DistilBERT for a sequence-to-sequence task like translation).
+
+
+
+For example, [`DistilBertForSequenceClassification`] is a base DistilBERT model with a sequence classification head. The sequence classification head is a linear layer on top of the pooled outputs.
+
+```py
+>>> from transformers import DistilBertForSequenceClassification
+
+>>> model = DistilBertForSequenceClassification.from_pretrained("distilbert-base-uncased")
+```
+
+Easily reuse this checkpoint for another task by switching to a different model head. For a question answering task, you would use the [`DistilBertForQuestionAnswering`] model head. The question answering head is similar to the sequence classification head except it is a linear layer on top of the hidden states output.
+
+```py
+>>> from transformers import DistilBertForQuestionAnswering
+
+>>> model = DistilBertForQuestionAnswering.from_pretrained("distilbert-base-uncased")
+```
+
+
+For example, [`TFDistilBertForSequenceClassification`] is a base DistilBERT model with a sequence classification head. The sequence classification head is a linear layer on top of the pooled outputs.
+
+```py
+>>> from transformers import TFDistilBertForSequenceClassification
+
+>>> tf_model = TFDistilBertForSequenceClassification.from_pretrained("distilbert-base-uncased")
+```
+
+Easily reuse this checkpoint for another task by switching to a different model head. For a question answering task, you would use the [`TFDistilBertForQuestionAnswering`] model head. The question answering head is similar to the sequence classification head except it is a linear layer on top of the hidden states output.
+
+```py
+>>> from transformers import TFDistilBertForQuestionAnswering
+
+>>> tf_model = TFDistilBertForQuestionAnswering.from_pretrained("distilbert-base-uncased")
+```
+
+
+
+## Tokenizer
+
+The last base class you need before using a model for textual data is a [tokenizer](main_classes/tokenizer) to convert raw text to tensors. There are two types of tokenizers you can use with 🤗 Transformers:
+
+- [`PreTrainedTokenizer`]: a Python implementation of a tokenizer.
+- [`PreTrainedTokenizerFast`]: a tokenizer from our Rust-based [🤗 Tokenizer](https://huggingface.co/docs/tokenizers/python/latest/) library. This tokenizer type is significantly faster - especially during batch tokenization - due to it's Rust implementation. The fast tokenizer also offers additional methods like *offset mapping* which maps tokens to their original words or characters.
+
+Both tokenizers support common methods such as encoding and decoding, adding new tokens, and managing special tokens.
+
+
+
+Not every model supports a fast tokenizer. Take a look at this [table](index#supported-frameworks) to check if a model has fast tokenizer support.
+
+
+
+If you trained your own tokenizer, you can create one from your *vocabulary* file:
+
+```py
+>>> from transformers import DistilBertTokenizer
+
+>>> my_tokenizer = DistilBertTokenizer(vocab_file="my_vocab_file.txt", do_lower_case=False, padding_side="left")
+```
+
+It is important to remember the vocabulary from a custom tokenizer will be different from the vocabulary generated by a pretrained model's tokenizer. You need to use a pretrained model's vocabulary if you are using a pretrained model, otherwise the inputs won't make sense. Create a tokenizer with a pretrained model's vocabulary with the [`DistilBertTokenizer`] class:
+
+```py
+>>> from transformers import DistilBertTokenizer
+
+>>> slow_tokenizer = DistilBertTokenizer.from_pretrained("distilbert-base-uncased")
+```
+
+Create a fast tokenizer with the [`DistilBertTokenizerFast`] class:
+
+```py
+>>> from transformers import DistilBertTokenizerFast
+
+>>> fast_tokenizer = DistilBertTokenizerFast.from_pretrained("distilbert-base-uncased")
+```
+
+
+
+By default, [`AutoTokenizer`] will try to load a fast tokenizer. You can disable this behavior by setting `use_fast=False` in `from_pretrained`.
+
+
+
+## Feature Extractor
+
+A feature extractor processes audio or image inputs. It inherits from the base [`~feature_extraction_utils.FeatureExtractionMixin`] class, and may also inherit from the [`ImageFeatureExtractionMixin`] class for processing image features or the [`SequenceFeatureExtractor`] class for processing audio inputs.
+
+Depending on whether you are working on an audio or vision task, create a feature extractor associated with the model you're using. For example, create a default [`ViTFeatureExtractor`] if you are using [ViT](model_doc/vit) for image classification:
+
+```py
+>>> from transformers import ViTFeatureExtractor
+
+>>> vit_extractor = ViTFeatureExtractor()
+>>> print(vit_extractor)
+ViTFeatureExtractor {
+ "do_normalize": true,
+ "do_resize": true,
+ "feature_extractor_type": "ViTFeatureExtractor",
+ "image_mean": [
+ 0.5,
+ 0.5,
+ 0.5
+ ],
+ "image_std": [
+ 0.5,
+ 0.5,
+ 0.5
+ ],
+ "resample": 2,
+ "size": 224
+}
+```
+
+
+
+If you aren't looking for any customization, just use the `from_pretrained` method to load a model's default feature extractor parameters.
+
+
+
+Modify any of the [`ViTFeatureExtractor`] parameters to create your custom feature extractor:
+
+```py
+>>> from transformers import ViTFeatureExtractor
+
+>>> my_vit_extractor = ViTFeatureExtractor(resample="PIL.Image.BOX", do_normalize=False, image_mean=[0.3, 0.3, 0.3])
+>>> print(my_vit_extractor)
+ViTFeatureExtractor {
+ "do_normalize": false,
+ "do_resize": true,
+ "feature_extractor_type": "ViTFeatureExtractor",
+ "image_mean": [
+ 0.3,
+ 0.3,
+ 0.3
+ ],
+ "image_std": [
+ 0.5,
+ 0.5,
+ 0.5
+ ],
+ "resample": "PIL.Image.BOX",
+ "size": 224
+}
+```
+
+For audio inputs, you can create a [`Wav2Vec2FeatureExtractor`] and customize the parameters in a similar way:
+
+```py
+>>> from transformers import Wav2Vec2FeatureExtractor
+
+>>> w2v2_extractor = Wav2Vec2FeatureExtractor()
+>>> print(w2v2_extractor)
+Wav2Vec2FeatureExtractor {
+ "do_normalize": true,
+ "feature_extractor_type": "Wav2Vec2FeatureExtractor",
+ "feature_size": 1,
+ "padding_side": "right",
+ "padding_value": 0.0,
+ "return_attention_mask": false,
+ "sampling_rate": 16000
+}
+```
+
+## Processor
+
+For models that support multimodal tasks, 🤗 Transformers offers a processor class that conveniently wraps a feature extractor and tokenizer into a single object. For example, let's use the [`Wav2Vec2Processor`] for an automatic speech recognition task (ASR). ASR transcribes audio to text, so you will need a feature extractor and a tokenizer.
+
+Create a feature extractor to handle the audio inputs:
+
+```py
+>>> from transformers import Wav2Vec2FeatureExtractor
+
+>>> feature_extractor = Wav2Vec2FeatureExtractor(padding_value=1.0, do_normalize=True)
+```
+
+Create a tokenizer to handle the text inputs:
+
+```py
+>>> from transformers import Wav2Vec2CTCTokenizer
+
+>>> tokenizer = Wav2Vec2CTCTokenizer(vocab_file="my_vocab_file.txt")
+```
+
+Combine the feature extractor and tokenizer in [`Wav2Vec2Processor`]:
+
+```py
+>>> from transformers import Wav2Vec2Processor
+
+>>> processor = Wav2Vec2Processor(feature_extractor=feature_extractor, tokenizer=tokenizer)
+```
+
+With two basic classes - configuration and model - and an additional preprocessing class (tokenizer, feature extractor, or processor), you can create any of the models supported by 🤗 Transformers. Each of these base classes are configurable, allowing you to use the specific attributes you want. You can easily setup a model for training or modify an existing pretrained model to fine-tune.
\ No newline at end of file
diff --git a/docs/source/en/custom_models.mdx b/docs/source/en/custom_models.mdx
new file mode 100644
index 00000000000000..05d0a6c2acf62d
--- /dev/null
+++ b/docs/source/en/custom_models.mdx
@@ -0,0 +1,349 @@
+
+
+# Sharing custom models
+
+The 🤗 Transformers library is designed to be easily extensible. Every model is fully coded in a given subfolder
+of the repository with no abstraction, so you can easily copy a modeling file and tweak it to your needs.
+
+If you are writing a brand new model, it might be easier to start from scratch. In this tutorial, we will show you
+how to write a custom model and its configuration so it can be used inside Transformers, and how you can share it
+with the community (with the code it relies on) so that anyone can use it, even if it's not present in the 🤗
+Transformers library.
+
+We will illustrate all of this on a ResNet model, by wrapping the ResNet class of the
+[timm library](https://github.com/rwightman/pytorch-image-models/tree/master/timm) into a [`PreTrainedModel`].
+
+## Writing a custom configuration
+
+Before we dive into the model, let's first write its configuration. The configuration of a model is an object that
+will contain all the necessary information to build the model. As we will see in the next section, the model can only
+take a `config` to be initialized, so we really need that object to be as complete as possible.
+
+In our example, we will take a couple of arguments of the ResNet class that we might want to tweak. Different
+configurations will then give us the different types of ResNets that are possible. We then just store those arguments,
+after checking the validity of a few of them.
+
+```python
+from transformers import PretrainedConfig
+from typing import List
+
+
+class ResnetConfig(PretrainedConfig):
+ model_type = "resnet"
+
+ def __init__(
+ self,
+ block_type="bottleneck",
+ layers: List[int] = [3, 4, 6, 3],
+ num_classes: int = 1000,
+ input_channels: int = 3,
+ cardinality: int = 1,
+ base_width: int = 64,
+ stem_width: int = 64,
+ stem_type: str = "",
+ avg_down: bool = False,
+ **kwargs,
+ ):
+ if block_type not in ["basic", "bottleneck"]:
+ raise ValueError(f"`block` must be 'basic' or bottleneck', got {block}.")
+ if stem_type not in ["", "deep", "deep-tiered"]:
+ raise ValueError(f"`stem_type` must be '', 'deep' or 'deep-tiered', got {block}.")
+
+ self.block_type = block_type
+ self.layers = layers
+ self.num_classes = num_classes
+ self.input_channels = input_channels
+ self.cardinality = cardinality
+ self.base_width = base_width
+ self.stem_width = stem_width
+ self.stem_type = stem_type
+ self.avg_down = avg_down
+ super().__init__(**kwargs)
+```
+
+The three important things to remember when writing you own configuration are the following:
+- you have to inherit from `PretrainedConfig`,
+- the `__init__` of your `PretrainedConfig` must accept any kwargs,
+- those `kwargs` need to be passed to the superclass `__init__`.
+
+The inheritance is to make sure you get all the functionality from the 🤗 Transformers library, while the two other
+constraints come from the fact a `PretrainedConfig` has more fields than the ones you are setting. When reloading a
+config with the `from_pretrained` method, those fields need to be accepted by your config and then sent to the
+superclass.
+
+Defining a `model_type` for your configuration (here `model_type="resnet"`) is not mandatory, unless you want to
+register your model with the auto classes (see last section).
+
+With this done, you can easily create and save your configuration like you would do with any other model config of the
+library. Here is how we can create a resnet50d config and save it:
+
+```py
+resnet50d_config = ResnetConfig(block_type="bottleneck", stem_width=32, stem_type="deep", avg_down=True)
+resnet50d_config.save_pretrained("custom-resnet")
+```
+
+This will save a file named `config.json` inside the folder `custom-resnet`. You can then reload your config with the
+`from_pretrained` method:
+
+```py
+resnet50d_config = ResnetConfig.from_pretrained("custom-resnet")
+```
+
+You can also use any other method of the [`PretrainedConfig`] class, like [`~PretrainedConfig.push_to_hub`] to
+directly upload your config to the Hub.
+
+## Writing a custom model
+
+Now that we have our ResNet configuration, we can go on writing the model. We will actually write two: one that
+extracts the hidden features from a batch of images (like [`BertModel`]) and one that is suitable for image
+classification (like [`BertForSequenceClassification`]).
+
+As we mentioned before, we'll only write a loose wrapper of the model to keep it simple for this example. The only
+thing we need to do before writing this class is a map between the block types and actual block classes. Then the
+model is defined from the configuration by passing everything to the `ResNet` class:
+
+```py
+from transformers import PreTrainedModel
+from timm.models.resnet import BasicBlock, Bottleneck, ResNet
+from .configuration_resnet import ResnetConfig
+
+
+BLOCK_MAPPING = {"basic": BasicBlock, "bottleneck": Bottleneck}
+
+
+class ResnetModel(PreTrainedModel):
+ config_class = ResnetConfig
+
+ def __init__(self, config):
+ super().__init__(config)
+ block_layer = BLOCK_MAPPING[config.block_type]
+ self.model = ResNet(
+ block_layer,
+ config.layers,
+ num_classes=config.num_classes,
+ in_chans=config.input_channels,
+ cardinality=config.cardinality,
+ base_width=config.base_width,
+ stem_width=config.stem_width,
+ stem_type=config.stem_type,
+ avg_down=config.avg_down,
+ )
+
+ def forward(self, tensor):
+ return self.model.forward_features(tensor)
+```
+
+For the model that will classify images, we just change the forward method:
+
+```py
+class ResnetModelForImageClassification(PreTrainedModel):
+ config_class = ResnetConfig
+
+ def __init__(self, config):
+ super().__init__(config)
+ block_layer = BLOCK_MAPPING[config.block_type]
+ self.model = ResNet(
+ block_layer,
+ config.layers,
+ num_classes=config.num_classes,
+ in_chans=config.input_channels,
+ cardinality=config.cardinality,
+ base_width=config.base_width,
+ stem_width=config.stem_width,
+ stem_type=config.stem_type,
+ avg_down=config.avg_down,
+ )
+
+ def forward(self, tensor, labels=None):
+ logits = self.model(tensor)
+ if labels is not None:
+ loss = torch.nn.cross_entropy(logits, labels)
+ return {"loss": loss, "logits": logits}
+ return {"logits": logits}
+```
+
+In both cases, notice how we inherit from `PreTrainedModel` and call the superclass initialization with the `config`
+(a bit like when you write a regular `torch.nn.Module`). The line that sets the `config_class` is not mandatory, unless
+you want to register your model with the auto classes (see last section).
+
+
+
+If your model is very similar to a model inside the library, you can re-use the same configuration as this model.
+
+
+
+You can have your model return anything you want, but returning a dictionary like we did for
+`ResnetModelForImageClassification`, with the loss included when labels are passed, will make your model directly
+usable inside the [`Trainer`] class. Using another output format is fine as long as you are planning on using your own
+training loop or another library for training.
+
+Now that we have our model class, let's create one:
+
+```py
+resnet50d = ResnetModelForImageClassification(resnet50d_config)
+```
+
+Again, you can use any of the methods of [`PreTrainedModel`], like [`~PreTrainedModel.save_pretrained`] or
+[`~PreTrainedModel.push_to_hub`]. We will use the second in the next section, and see how to push the model weights
+with the code of our model. But first, let's load some pretrained weights inside our model.
+
+In your own use case, you will probably be training your custom model on your own data. To go fast for this tutorial,
+we will use the pretrained version of the resnet50d. Since our model is just a wrapper around it, it's going to be
+easy to transfer those weights:
+
+```py
+import timm
+
+pretrained_model = timm.create_model("resnet50d", pretrained=True)
+resnet50d.model.load_state_dict(pretrained_model.state_dict())
+```
+
+Now let's see how to make sure that when we do [`~PreTrainedModel.save_pretrained`] or [`~PreTrainedModel.push_to_hub`], the
+code of the model is saved.
+
+## Sending the code to the Hub
+
+
+
+This API is experimental and may have some slight breaking changes in the next releases.
+
+
+
+First, make sure your model is fully defined in a `.py` file. It can rely on relative imports to some other files as
+long as all the files are in the same directory (we don't support submodules for this feature yet). For our example,
+we'll define a `modeling_resnet.py` file and a `configuration_resnet.py` file in a folder of the current working
+directory named `resnet_model`. The configuration file contains the code for `ResnetConfig` and the modeling file
+contains the code of `ResnetModel` and `ResnetModelForImageClassification`.
+
+```
+.
+└── resnet_model
+ ├── __init__.py
+ ├── configuration_resnet.py
+ └── modeling_resnet.py
+```
+
+The `__init__.py` can be empty, it's just there so that Python detects `resnet_model` can be use as a module.
+
+
+
+If copying a modeling files from the library, you will need to replace all the relative imports at the top of the file
+to import from the `transformers` package.
+
+
+
+Note that you can re-use (or subclass) an existing configuration/model.
+
+To share your model with the community, follow those steps: first import the ResNet model and config from the newly
+created files:
+
+```py
+from resnet_model.configuration_resnet import ResnetConfig
+from resnet_model.modeling_resnet import ResnetModel, ResnetModelForImageClassification
+```
+
+Then you have to tell the library you want to copy the code files of those objects when using the `save_pretrained`
+method and properly register them with a given Auto class (especially for models), just run:
+
+```py
+ResnetConfig.register_for_auto_class()
+ResnetModel.register_for_auto_class("AutoModel")
+ResnetModelForImageClassification.register_for_auto_class("AutoModelForImageClassification")
+```
+
+Note that there is no need to specify an auto class for the configuration (there is only one auto class for them,
+[`AutoConfig`]) but it's different for models. Your custom model could be suitable for many different tasks, so you
+have to specify which one of the auto classes is the correct one for your model.
+
+Next, let's create the config and models as we did before:
+
+```py
+resnet50d_config = ResnetConfig(block_type="bottleneck", stem_width=32, stem_type="deep", avg_down=True)
+resnet50d = ResnetModelForImageClassification(resnet50d_config)
+
+pretrained_model = timm.create_model("resnet50d", pretrained=True)
+resnet50d.model.load_state_dict(pretrained_model.state_dict())
+```
+
+Now to send the model to the Hub, make sure you are logged in. Either run in your terminal:
+
+```bash
+huggingface-cli login
+```
+
+or from a notebook:
+
+```py
+from huggingface_hub import notebook_login
+
+notebook_login()
+```
+
+You can then push to to your own namespace (or an organization you are a member of) like this:
+
+```py
+resnet50d.push_to_hub("custom-resnet50d")
+```
+
+On top of the modeling weights and the configuration in json format, this also copied the modeling and
+configuration `.py` files in the folder `custom-resnet50d` and uploaded the result to the Hub. You can check the result
+in this [model repo](https://huggingface.co/sgugger/custom-resnet50d).
+
+See the [sharing tutorial](model_sharing) for more information on the push to Hub method.
+
+## Using a model with custom code
+
+You can use any configuration, model or tokenizer with custom code files in its repository with the auto-classes and
+the `from_pretrained` method. All files and code uploaded to the Hub are scanned for malware (refer to the [Hub security](https://huggingface.co/docs/hub/security#malware-scanning) documentation for more information), but you should still
+review the model code and author to avoid executing malicious code on your machine. Set `trust_remote_code=True` to use
+a model with custom code:
+
+```py
+from transformers import AutoModelForImageClassification
+
+model = AutoModelForImageClassification.from_pretrained("sgugger/custom-resnet50d", trust_remote_code=True)
+```
+
+It is also strongly encouraged to pass a commit hash as a `revision` to make sure the author of the models did not
+update the code with some malicious new lines (unless you fully trust the authors of the models).
+
+```py
+commit_hash = "ed94a7c6247d8aedce4647f00f20de6875b5b292"
+model = AutoModelForImageClassification.from_pretrained(
+ "sgugger/custom-resnet50d", trust_remote_code=True, revision=commit_hash
+)
+```
+
+Note that when browsing the commit history of the model repo on the Hub, there is a button to easily copy the commit
+hash of any commit.
+
+## Registering a model with custom code to the auto classes
+
+If you are writing a library that extends 🤗 Transformers, you may want to extend the auto classes to include your own
+model. This is different from pushing the code to the Hub in the sense that users will need to import your library to
+get the custom models (contrarily to automatically downloading the model code from the Hub).
+
+As long as your config has a `model_type` attribute that is different from existing model types, and that your model
+classes have the right `config_class` attributes, you can just add them to the auto classes likes this:
+
+```py
+from transformers import AutoConfig, AutoModel, AutoModelForImageClassification
+
+AutoConfig.register("resnet", ResnetConfig)
+AutoModel.register(ResnetConfig, ResnetModel)
+AutoModelForImageClassification.register(ResnetConfig, ResnetModelForImageClassification)
+```
+
+Note that the first argument used when registering your custom config to [`AutoConfig`] needs to match the `model_type`
+of your custom config, and the first argument used when registering your custom models to any auto model class needs
+to match the `config_class` of those models.
diff --git a/docs/source/en/debugging.mdx b/docs/source/en/debugging.mdx
new file mode 100644
index 00000000000000..7339d61a057527
--- /dev/null
+++ b/docs/source/en/debugging.mdx
@@ -0,0 +1,335 @@
+
+
+# Debugging
+
+## Multi-GPU Network Issues Debug
+
+When training or inferencing with `DistributedDataParallel` and multiple GPU, if you run into issue of inter-communication between processes and/or nodes, you can use the following script to diagnose network issues.
+
+```bash
+wget https://raw.githubusercontent.com/huggingface/transformers/main/scripts/distributed/torch-distributed-gpu-test.py
+```
+
+For example to test how 2 GPUs interact do:
+
+```bash
+python -m torch.distributed.run --nproc_per_node 2 --nnodes 1 torch-distributed-gpu-test.py
+```
+If both processes can talk to each and allocate GPU memory each will print an OK status.
+
+For more GPUs or nodes adjust the arguments in the script.
+
+You will find a lot more details inside the diagnostics script and even a recipe to how you could run it in a SLURM environment.
+
+An additional level of debug is to add `NCCL_DEBUG=INFO` environment variable as follows:
+
+```bash
+NCCL_DEBUG=INFO python -m torch.distributed.run --nproc_per_node 2 --nnodes 1 torch-distributed-gpu-test.py
+```
+
+This will dump a lot of NCCL-related debug information, which you can then search online if you find that some problems are reported. Or if you're not sure how to interpret the output you can share the log file in an Issue.
+
+
+
+## Underflow and Overflow Detection
+
+
+
+This feature is currently available for PyTorch-only.
+
+
+
+
+
+For multi-GPU training it requires DDP (`torch.distributed.launch`).
+
+
+
+
+
+This feature can be used with any `nn.Module`-based model.
+
+
+
+If you start getting `loss=NaN` or the model inhibits some other abnormal behavior due to `inf` or `nan` in
+activations or weights one needs to discover where the first underflow or overflow happens and what led to it. Luckily
+you can accomplish that easily by activating a special module that will do the detection automatically.
+
+If you're using [`Trainer`], you just need to add:
+
+```bash
+--debug underflow_overflow
+```
+
+to the normal command line arguments, or pass `debug="underflow_overflow"` when creating the
+[`TrainingArguments`] object.
+
+If you're using your own training loop or another Trainer you can accomplish the same with:
+
+```python
+from .debug_utils import DebugUnderflowOverflow
+
+debug_overflow = DebugUnderflowOverflow(model)
+```
+
+[`~debug_utils.DebugUnderflowOverflow`] inserts hooks into the model that immediately after each
+forward call will test input and output variables and also the corresponding module's weights. As soon as `inf` or
+`nan` is detected in at least one element of the activations or weights, the program will assert and print a report
+like this (this was caught with `google/mt5-small` under fp16 mixed precision):
+
+```
+Detected inf/nan during batch_number=0
+Last 21 forward frames:
+abs min abs max metadata
+ encoder.block.1.layer.1.DenseReluDense.dropout Dropout
+0.00e+00 2.57e+02 input[0]
+0.00e+00 2.85e+02 output
+[...]
+ encoder.block.2.layer.0 T5LayerSelfAttention
+6.78e-04 3.15e+03 input[0]
+2.65e-04 3.42e+03 output[0]
+ None output[1]
+2.25e-01 1.00e+04 output[2]
+ encoder.block.2.layer.1.layer_norm T5LayerNorm
+8.69e-02 4.18e-01 weight
+2.65e-04 3.42e+03 input[0]
+1.79e-06 4.65e+00 output
+ encoder.block.2.layer.1.DenseReluDense.wi_0 Linear
+2.17e-07 4.50e+00 weight
+1.79e-06 4.65e+00 input[0]
+2.68e-06 3.70e+01 output
+ encoder.block.2.layer.1.DenseReluDense.wi_1 Linear
+8.08e-07 2.66e+01 weight
+1.79e-06 4.65e+00 input[0]
+1.27e-04 2.37e+02 output
+ encoder.block.2.layer.1.DenseReluDense.dropout Dropout
+0.00e+00 8.76e+03 input[0]
+0.00e+00 9.74e+03 output
+ encoder.block.2.layer.1.DenseReluDense.wo Linear
+1.01e-06 6.44e+00 weight
+0.00e+00 9.74e+03 input[0]
+3.18e-04 6.27e+04 output
+ encoder.block.2.layer.1.DenseReluDense T5DenseGatedGeluDense
+1.79e-06 4.65e+00 input[0]
+3.18e-04 6.27e+04 output
+ encoder.block.2.layer.1.dropout Dropout
+3.18e-04 6.27e+04 input[0]
+0.00e+00 inf output
+```
+
+The example output has been trimmed in the middle for brevity.
+
+The second column shows the value of the absolute largest element, so if you have a closer look at the last few frames,
+the inputs and outputs were in the range of `1e4`. So when this training was done under fp16 mixed precision the very
+last step overflowed (since under `fp16` the largest number before `inf` is `64e3`). To avoid overflows under
+`fp16` the activations must remain way below `1e4`, because `1e4 * 1e4 = 1e8` so any matrix multiplication with
+large activations is going to lead to a numerical overflow condition.
+
+At the very start of the trace you can discover at which batch number the problem occurred (here `Detected inf/nan during batch_number=0` means the problem occurred on the first batch).
+
+Each reported frame starts by declaring the fully qualified entry for the corresponding module this frame is reporting
+for. If we look just at this frame:
+
+```
+ encoder.block.2.layer.1.layer_norm T5LayerNorm
+8.69e-02 4.18e-01 weight
+2.65e-04 3.42e+03 input[0]
+1.79e-06 4.65e+00 output
+```
+
+Here, `encoder.block.2.layer.1.layer_norm` indicates that it was a layer norm for the first layer, of the second
+block of the encoder. And the specific calls of the `forward` is `T5LayerNorm`.
+
+Let's look at the last few frames of that report:
+
+```
+Detected inf/nan during batch_number=0
+Last 21 forward frames:
+abs min abs max metadata
+[...]
+ encoder.block.2.layer.1.DenseReluDense.wi_0 Linear
+2.17e-07 4.50e+00 weight
+1.79e-06 4.65e+00 input[0]
+2.68e-06 3.70e+01 output
+ encoder.block.2.layer.1.DenseReluDense.wi_1 Linear
+8.08e-07 2.66e+01 weight
+1.79e-06 4.65e+00 input[0]
+1.27e-04 2.37e+02 output
+ encoder.block.2.layer.1.DenseReluDense.wo Linear
+1.01e-06 6.44e+00 weight
+0.00e+00 9.74e+03 input[0]
+3.18e-04 6.27e+04 output
+ encoder.block.2.layer.1.DenseReluDense T5DenseGatedGeluDense
+1.79e-06 4.65e+00 input[0]
+3.18e-04 6.27e+04 output
+ encoder.block.2.layer.1.dropout Dropout
+3.18e-04 6.27e+04 input[0]
+0.00e+00 inf output
+```
+
+The last frame reports for `Dropout.forward` function with the first entry for the only input and the second for the
+only output. You can see that it was called from an attribute `dropout` inside `DenseReluDense` class. We can see
+that it happened during the first layer, of the 2nd block, during the very first batch. Finally, the absolute largest
+input elements was `6.27e+04` and same for the output was `inf`.
+
+You can see here, that `T5DenseGatedGeluDense.forward` resulted in output activations, whose absolute max value was
+around 62.7K, which is very close to fp16's top limit of 64K. In the next frame we have `Dropout` which renormalizes
+the weights, after it zeroed some of the elements, which pushes the absolute max value to more than 64K, and we get an
+overflow (`inf`).
+
+As you can see it's the previous frames that we need to look into when the numbers start going into very large for fp16
+numbers.
+
+Let's match the report to the code from `models/t5/modeling_t5.py`:
+
+```python
+class T5DenseGatedGeluDense(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.wi_0 = nn.Linear(config.d_model, config.d_ff, bias=False)
+ self.wi_1 = nn.Linear(config.d_model, config.d_ff, bias=False)
+ self.wo = nn.Linear(config.d_ff, config.d_model, bias=False)
+ self.dropout = nn.Dropout(config.dropout_rate)
+ self.gelu_act = ACT2FN["gelu_new"]
+
+ def forward(self, hidden_states):
+ hidden_gelu = self.gelu_act(self.wi_0(hidden_states))
+ hidden_linear = self.wi_1(hidden_states)
+ hidden_states = hidden_gelu * hidden_linear
+ hidden_states = self.dropout(hidden_states)
+ hidden_states = self.wo(hidden_states)
+ return hidden_states
+```
+
+Now it's easy to see the `dropout` call, and all the previous calls as well.
+
+Since the detection is happening in a forward hook, these reports are printed immediately after each `forward`
+returns.
+
+Going back to the full report, to act on it and to fix the problem, we need to go a few frames up where the numbers
+started to go up and most likely switch to the `fp32` mode here, so that the numbers don't overflow when multiplied
+or summed up. Of course, there might be other solutions. For example, we could turn off `amp` temporarily if it's
+enabled, after moving the original `forward` into a helper wrapper, like so:
+
+```python
+def _forward(self, hidden_states):
+ hidden_gelu = self.gelu_act(self.wi_0(hidden_states))
+ hidden_linear = self.wi_1(hidden_states)
+ hidden_states = hidden_gelu * hidden_linear
+ hidden_states = self.dropout(hidden_states)
+ hidden_states = self.wo(hidden_states)
+ return hidden_states
+
+
+import torch
+
+
+def forward(self, hidden_states):
+ if torch.is_autocast_enabled():
+ with torch.cuda.amp.autocast(enabled=False):
+ return self._forward(hidden_states)
+ else:
+ return self._forward(hidden_states)
+```
+
+Since the automatic detector only reports on inputs and outputs of full frames, once you know where to look, you may
+want to analyse the intermediary stages of any specific `forward` function as well. In such a case you can use the
+`detect_overflow` helper function to inject the detector where you want it, for example:
+
+```python
+from debug_utils import detect_overflow
+
+
+class T5LayerFF(nn.Module):
+ [...]
+
+ def forward(self, hidden_states):
+ forwarded_states = self.layer_norm(hidden_states)
+ detect_overflow(forwarded_states, "after layer_norm")
+ forwarded_states = self.DenseReluDense(forwarded_states)
+ detect_overflow(forwarded_states, "after DenseReluDense")
+ return hidden_states + self.dropout(forwarded_states)
+```
+
+You can see that we added 2 of these and now we track if `inf` or `nan` for `forwarded_states` was detected
+somewhere in between.
+
+Actually, the detector already reports these because each of the calls in the example above is a `nn.Module`, but
+let's say if you had some local direct calculations this is how you'd do that.
+
+Additionally, if you're instantiating the debugger in your own code, you can adjust the number of frames printed from
+its default, e.g.:
+
+```python
+from .debug_utils import DebugUnderflowOverflow
+
+debug_overflow = DebugUnderflowOverflow(model, max_frames_to_save=100)
+```
+
+### Specific batch absolute mix and max value tracing
+
+The same debugging class can be used for per-batch tracing with the underflow/overflow detection feature turned off.
+
+Let's say you want to watch the absolute min and max values for all the ingredients of each `forward` call of a given
+batch, and only do that for batches 1 and 3. Then you instantiate this class as:
+
+```python
+debug_overflow = DebugUnderflowOverflow(model, trace_batch_nums=[1, 3])
+```
+
+And now full batches 1 and 3 will be traced using the same format as the underflow/overflow detector does.
+
+Batches are 0-indexed.
+
+This is helpful if you know that the program starts misbehaving after a certain batch number, so you can fast-forward
+right to that area. Here is a sample truncated output for such configuration:
+
+```
+ *** Starting batch number=1 ***
+abs min abs max metadata
+ shared Embedding
+1.01e-06 7.92e+02 weight
+0.00e+00 2.47e+04 input[0]
+5.36e-05 7.92e+02 output
+[...]
+ decoder.dropout Dropout
+1.60e-07 2.27e+01 input[0]
+0.00e+00 2.52e+01 output
+ decoder T5Stack
+ not a tensor output
+ lm_head Linear
+1.01e-06 7.92e+02 weight
+0.00e+00 1.11e+00 input[0]
+6.06e-02 8.39e+01 output
+ T5ForConditionalGeneration
+ not a tensor output
+
+ *** Starting batch number=3 ***
+abs min abs max metadata
+ shared Embedding
+1.01e-06 7.92e+02 weight
+0.00e+00 2.78e+04 input[0]
+5.36e-05 7.92e+02 output
+[...]
+```
+
+Here you will get a huge number of frames dumped - as many as there were forward calls in your model, so it may or may
+not what you want, but sometimes it can be easier to use for debugging purposes than a normal debugger. For example, if
+a problem starts happening at batch number 150. So you can dump traces for batches 149 and 150 and compare where
+numbers started to diverge.
+
+You can also specify the batch number after which to stop the training, with:
+
+```python
+debug_overflow = DebugUnderflowOverflow(model, trace_batch_nums=[1, 3], abort_after_batch_num=3)
+```
diff --git a/docs/source/en/fast_tokenizers.mdx b/docs/source/en/fast_tokenizers.mdx
new file mode 100644
index 00000000000000..234f9bb42d1933
--- /dev/null
+++ b/docs/source/en/fast_tokenizers.mdx
@@ -0,0 +1,70 @@
+
+
+# Use tokenizers from 🤗 Tokenizers
+
+The [`PreTrainedTokenizerFast`] depends on the [🤗 Tokenizers](https://huggingface.co/docs/tokenizers) library. The tokenizers obtained from the 🤗 Tokenizers library can be
+loaded very simply into 🤗 Transformers.
+
+Before getting in the specifics, let's first start by creating a dummy tokenizer in a few lines:
+
+```python
+>>> from tokenizers import Tokenizer
+>>> from tokenizers.models import BPE
+>>> from tokenizers.trainers import BpeTrainer
+>>> from tokenizers.pre_tokenizers import Whitespace
+
+>>> tokenizer = Tokenizer(BPE(unk_token="[UNK]"))
+>>> trainer = BpeTrainer(special_tokens=["[UNK]", "[CLS]", "[SEP]", "[PAD]", "[MASK]"])
+
+>>> tokenizer.pre_tokenizer = Whitespace()
+>>> files = [...]
+>>> tokenizer.train(files, trainer)
+```
+
+We now have a tokenizer trained on the files we defined. We can either continue using it in that runtime, or save it to
+a JSON file for future re-use.
+
+## Loading directly from the tokenizer object
+
+Let's see how to leverage this tokenizer object in the 🤗 Transformers library. The
+[`PreTrainedTokenizerFast`] class allows for easy instantiation, by accepting the instantiated
+*tokenizer* object as an argument:
+
+```python
+>>> from transformers import PreTrainedTokenizerFast
+
+>>> fast_tokenizer = PreTrainedTokenizerFast(tokenizer_object=tokenizer)
+```
+
+This object can now be used with all the methods shared by the 🤗 Transformers tokenizers! Head to [the tokenizer
+page](main_classes/tokenizer) for more information.
+
+## Loading from a JSON file
+
+In order to load a tokenizer from a JSON file, let's first start by saving our tokenizer:
+
+```python
+>>> tokenizer.save("tokenizer.json")
+```
+
+The path to which we saved this file can be passed to the [`PreTrainedTokenizerFast`] initialization
+method using the `tokenizer_file` parameter:
+
+```python
+>>> from transformers import PreTrainedTokenizerFast
+
+>>> fast_tokenizer = PreTrainedTokenizerFast(tokenizer_file="tokenizer.json")
+```
+
+This object can now be used with all the methods shared by the 🤗 Transformers tokenizers! Head to [the tokenizer
+page](main_classes/tokenizer) for more information.
diff --git a/docs/source/en/glossary.mdx b/docs/source/en/glossary.mdx
new file mode 100644
index 00000000000000..b6cb2259d67da7
--- /dev/null
+++ b/docs/source/en/glossary.mdx
@@ -0,0 +1,300 @@
+
+
+# Glossary
+
+## General terms
+
+- autoencoding models: see MLM
+- autoregressive models: see CLM
+- CLM: causal language modeling, a pretraining task where the model reads the texts in order and has to predict the
+ next word. It's usually done by reading the whole sentence but using a mask inside the model to hide the future
+ tokens at a certain timestep.
+- deep learning: machine learning algorithms which uses neural networks with several layers.
+- MLM: masked language modeling, a pretraining task where the model sees a corrupted version of the texts, usually done
+ by masking some tokens randomly, and has to predict the original text.
+- multimodal: a task that combines texts with another kind of inputs (for instance images).
+- NLG: natural language generation, all tasks related to generating text (for instance talk with transformers,
+ translation).
+- NLP: natural language processing, a generic way to say "deal with texts".
+- NLU: natural language understanding, all tasks related to understanding what is in a text (for instance classifying
+ the whole text, individual words).
+- pretrained model: a model that has been pretrained on some data (for instance all of Wikipedia). Pretraining methods
+ involve a self-supervised objective, which can be reading the text and trying to predict the next word (see CLM) or
+ masking some words and trying to predict them (see MLM).
+- RNN: recurrent neural network, a type of model that uses a loop over a layer to process texts.
+- self-attention: each element of the input finds out which other elements of the input they should attend to.
+- seq2seq or sequence-to-sequence: models that generate a new sequence from an input, like translation models, or
+ summarization models (such as [Bart](model_doc/bart) or [T5](model_doc/t5)).
+- token: a part of a sentence, usually a word, but can also be a subword (non-common words are often split in subwords)
+ or a punctuation symbol.
+- transformer: self-attention based deep learning model architecture.
+
+## Model inputs
+
+Every model is different yet bears similarities with the others. Therefore most models use the same inputs, which are
+detailed here alongside usage examples.
+
+
+
+### Input IDs
+
+The input ids are often the only required parameters to be passed to the model as input. *They are token indices,
+numerical representations of tokens building the sequences that will be used as input by the model*.
+
+
+
+Each tokenizer works differently but the underlying mechanism remains the same. Here's an example using the BERT
+tokenizer, which is a [WordPiece](https://arxiv.org/pdf/1609.08144.pdf) tokenizer:
+
+```python
+>>> from transformers import BertTokenizer
+
+>>> tokenizer = BertTokenizer.from_pretrained("bert-base-cased")
+
+>>> sequence = "A Titan RTX has 24GB of VRAM"
+```
+
+The tokenizer takes care of splitting the sequence into tokens available in the tokenizer vocabulary.
+
+```python
+>>> tokenized_sequence = tokenizer.tokenize(sequence)
+```
+
+The tokens are either words or subwords. Here for instance, "VRAM" wasn't in the model vocabulary, so it's been split
+in "V", "RA" and "M". To indicate those tokens are not separate words but parts of the same word, a double-hash prefix
+is added for "RA" and "M":
+
+```python
+>>> print(tokenized_sequence)
+['A', 'Titan', 'R', '##T', '##X', 'has', '24', '##GB', 'of', 'V', '##RA', '##M']
+```
+
+These tokens can then be converted into IDs which are understandable by the model. This can be done by directly feeding
+the sentence to the tokenizer, which leverages the Rust implementation of [🤗 Tokenizers](https://github.com/huggingface/tokenizers) for peak performance.
+
+```python
+>>> inputs = tokenizer(sequence)
+```
+
+The tokenizer returns a dictionary with all the arguments necessary for its corresponding model to work properly. The
+token indices are under the key "input_ids":
+
+```python
+>>> encoded_sequence = inputs["input_ids"]
+>>> print(encoded_sequence)
+[101, 138, 18696, 155, 1942, 3190, 1144, 1572, 13745, 1104, 159, 9664, 2107, 102]
+```
+
+Note that the tokenizer automatically adds "special tokens" (if the associated model relies on them) which are special
+IDs the model sometimes uses.
+
+If we decode the previous sequence of ids,
+
+```python
+>>> decoded_sequence = tokenizer.decode(encoded_sequence)
+```
+
+we will see
+
+```python
+>>> print(decoded_sequence)
+[CLS] A Titan RTX has 24GB of VRAM [SEP]
+```
+
+because this is the way a [`BertModel`] is going to expect its inputs.
+
+
+
+### Attention mask
+
+The attention mask is an optional argument used when batching sequences together.
+
+
+
+This argument indicates to the model which tokens should be attended to, and which should not.
+
+For example, consider these two sequences:
+
+```python
+>>> from transformers import BertTokenizer
+
+>>> tokenizer = BertTokenizer.from_pretrained("bert-base-cased")
+
+>>> sequence_a = "This is a short sequence."
+>>> sequence_b = "This is a rather long sequence. It is at least longer than the sequence A."
+
+>>> encoded_sequence_a = tokenizer(sequence_a)["input_ids"]
+>>> encoded_sequence_b = tokenizer(sequence_b)["input_ids"]
+```
+
+The encoded versions have different lengths:
+
+```python
+>>> len(encoded_sequence_a), len(encoded_sequence_b)
+(8, 19)
+```
+
+Therefore, we can't put them together in the same tensor as-is. The first sequence needs to be padded up to the length
+of the second one, or the second one needs to be truncated down to the length of the first one.
+
+In the first case, the list of IDs will be extended by the padding indices. We can pass a list to the tokenizer and ask
+it to pad like this:
+
+```python
+>>> padded_sequences = tokenizer([sequence_a, sequence_b], padding=True)
+```
+
+We can see that 0s have been added on the right of the first sentence to make it the same length as the second one:
+
+```python
+>>> padded_sequences["input_ids"]
+[[101, 1188, 1110, 170, 1603, 4954, 119, 102, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [101, 1188, 1110, 170, 1897, 1263, 4954, 119, 1135, 1110, 1120, 1655, 2039, 1190, 1103, 4954, 138, 119, 102]]
+```
+
+This can then be converted into a tensor in PyTorch or TensorFlow. The attention mask is a binary tensor indicating the
+position of the padded indices so that the model does not attend to them. For the [`BertTokenizer`],
+`1` indicates a value that should be attended to, while `0` indicates a padded value. This attention mask is
+in the dictionary returned by the tokenizer under the key "attention_mask":
+
+```python
+>>> padded_sequences["attention_mask"]
+[[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]
+```
+
+
+
+### Token Type IDs
+
+Some models' purpose is to do classification on pairs of sentences or question answering.
+
+
+
+These require two different sequences to be joined in a single "input_ids" entry, which usually is performed with the
+help of special tokens, such as the classifier (`[CLS]`) and separator (`[SEP]`) tokens. For example, the BERT
+model builds its two sequence input as such:
+
+```python
+>>> # [CLS] SEQUENCE_A [SEP] SEQUENCE_B [SEP]
+```
+
+We can use our tokenizer to automatically generate such a sentence by passing the two sequences to `tokenizer` as two
+arguments (and not a list, like before) like this:
+
+```python
+>>> from transformers import BertTokenizer
+
+>>> tokenizer = BertTokenizer.from_pretrained("bert-base-cased")
+>>> sequence_a = "HuggingFace is based in NYC"
+>>> sequence_b = "Where is HuggingFace based?"
+
+>>> encoded_dict = tokenizer(sequence_a, sequence_b)
+>>> decoded = tokenizer.decode(encoded_dict["input_ids"])
+```
+
+which will return:
+
+```python
+>>> print(decoded)
+[CLS] HuggingFace is based in NYC [SEP] Where is HuggingFace based? [SEP]
+```
+
+This is enough for some models to understand where one sequence ends and where another begins. However, other models,
+such as BERT, also deploy token type IDs (also called segment IDs). They are represented as a binary mask identifying
+the two types of sequence in the model.
+
+The tokenizer returns this mask as the "token_type_ids" entry:
+
+```python
+>>> encoded_dict["token_type_ids"]
+[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1]
+```
+
+The first sequence, the "context" used for the question, has all its tokens represented by a `0`, whereas the
+second sequence, corresponding to the "question", has all its tokens represented by a `1`.
+
+Some models, like [`XLNetModel`] use an additional token represented by a `2`.
+
+
+
+### Position IDs
+
+Contrary to RNNs that have the position of each token embedded within them, transformers are unaware of the position of
+each token. Therefore, the position IDs (`position_ids`) are used by the model to identify each token's position in
+the list of tokens.
+
+They are an optional parameter. If no `position_ids` are passed to the model, the IDs are automatically created as
+absolute positional embeddings.
+
+Absolute positional embeddings are selected in the range `[0, config.max_position_embeddings - 1]`. Some models use
+other types of positional embeddings, such as sinusoidal position embeddings or relative position embeddings.
+
+
+
+### Labels
+
+The labels are an optional argument which can be passed in order for the model to compute the loss itself. These labels
+should be the expected prediction of the model: it will use the standard loss in order to compute the loss between its
+predictions and the expected value (the label).
+
+These labels are different according to the model head, for example:
+
+- For sequence classification models (e.g., [`BertForSequenceClassification`]), the model expects a
+ tensor of dimension `(batch_size)` with each value of the batch corresponding to the expected label of the
+ entire sequence.
+- For token classification models (e.g., [`BertForTokenClassification`]), the model expects a tensor
+ of dimension `(batch_size, seq_length)` with each value corresponding to the expected label of each individual
+ token.
+- For masked language modeling (e.g., [`BertForMaskedLM`]), the model expects a tensor of dimension
+ `(batch_size, seq_length)` with each value corresponding to the expected label of each individual token: the
+ labels being the token ID for the masked token, and values to be ignored for the rest (usually -100).
+- For sequence to sequence tasks,(e.g., [`BartForConditionalGeneration`],
+ [`MBartForConditionalGeneration`]), the model expects a tensor of dimension `(batch_size, tgt_seq_length)` with each value corresponding to the target sequences associated with each input sequence. During
+ training, both *BART* and *T5* will make the appropriate *decoder_input_ids* and decoder attention masks internally.
+ They usually do not need to be supplied. This does not apply to models leveraging the Encoder-Decoder framework. See
+ the documentation of each model for more information on each specific model's labels.
+
+The base models (e.g., [`BertModel`]) do not accept labels, as these are the base transformer
+models, simply outputting features.
+
+
+
+### Decoder input IDs
+
+This input is specific to encoder-decoder models, and contains the input IDs that will be fed to the decoder. These
+inputs should be used for sequence to sequence tasks, such as translation or summarization, and are usually built in a
+way specific to each model.
+
+Most encoder-decoder models (BART, T5) create their `decoder_input_ids` on their own from the `labels`. In
+such models, passing the `labels` is the preferred way to handle training.
+
+Please check each model's docs to see how they handle these input IDs for sequence to sequence training.
+
+
+
+### Feed Forward Chunking
+
+In each residual attention block in transformers the self-attention layer is usually followed by 2 feed forward layers.
+The intermediate embedding size of the feed forward layers is often bigger than the hidden size of the model (e.g., for
+`bert-base-uncased`).
+
+For an input of size `[batch_size, sequence_length]`, the memory required to store the intermediate feed forward
+embeddings `[batch_size, sequence_length, config.intermediate_size]` can account for a large fraction of the memory
+use. The authors of [Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451) noticed that since the
+computation is independent of the `sequence_length` dimension, it is mathematically equivalent to compute the output
+embeddings of both feed forward layers `[batch_size, config.hidden_size]_0, ..., [batch_size, config.hidden_size]_n`
+individually and concat them afterward to `[batch_size, sequence_length, config.hidden_size]` with `n = sequence_length`, which trades increased computation time against reduced memory use, but yields a mathematically
+**equivalent** result.
+
+For models employing the function [`apply_chunking_to_forward`], the `chunk_size` defines the
+number of output embeddings that are computed in parallel and thus defines the trade-off between memory and time
+complexity. If `chunk_size` is set to 0, no feed forward chunking is done.
diff --git a/docs/source/en/index.mdx b/docs/source/en/index.mdx
new file mode 100644
index 00000000000000..2ceb1b8dfa0ec9
--- /dev/null
+++ b/docs/source/en/index.mdx
@@ -0,0 +1,281 @@
+
+
+# 🤗 Transformers
+
+State-of-the-art Machine Learning for PyTorch, TensorFlow and JAX.
+
+🤗 Transformers provides APIs to easily download and train state-of-the-art pretrained models. Using pretrained models can reduce your compute costs, carbon footprint, and save you time from training a model from scratch. The models can be used across different modalities such as:
+
+* 📝 Text: text classification, information extraction, question answering, summarization, translation, and text generation in over 100 languages.
+* 🖼️ Images: image classification, object detection, and segmentation.
+* 🗣️ Audio: speech recognition and audio classification.
+* 🐙 Multimodal: table question answering, optical character recognition, information extraction from scanned documents, video classification, and visual question answering.
+
+Our library supports seamless integration between three of the most popular deep learning libraries: [PyTorch](https://pytorch.org/), [TensorFlow](https://www.tensorflow.org/) and [JAX](https://jax.readthedocs.io/en/latest/). Train your model in three lines of code in one framework, and load it for inference with another.
+
+Each 🤗 Transformers architecture is defined in a standalone Python module so they can be easily customized for research and experiments.
+
+## If you are looking for custom support from the Hugging Face team
+
+
+
+
+
+As you can see, we do make use of inheritance in 🤗 Transformers, but we keep the level of abstraction to an absolute
+minimum. There are never more than two levels of abstraction for any model in the library. `BrandNewBertModel`
+inherits from `BrandNewBertPreTrainedModel` which in turn inherits from [`PreTrainedModel`] and
+that's it. As a general rule, we want to make sure that a new model only depends on
+[`PreTrainedModel`]. The important functionalities that are automatically provided to every new
+model are [`~PreTrainedModel.from_pretrained`] and
+[`~PreTrainedModel.save_pretrained`], which are used for serialization and deserialization. All of the
+other important functionalities, such as `BrandNewBertModel.forward` should be completely defined in the new
+`modeling_brand_new_bert.py` script. Next, we want to make sure that a model with a specific head layer, such as
+`BrandNewBertForMaskedLM` does not inherit from `BrandNewBertModel`, but rather uses `BrandNewBertModel`
+as a component that can be called in its forward pass to keep the level of abstraction low. Every new model requires a
+configuration class, called `BrandNewBertConfig`. This configuration is always stored as an attribute in
+[`PreTrainedModel`], and thus can be accessed via the `config` attribute for all classes
+inheriting from `BrandNewBertPreTrainedModel`:
+
+```python
+model = BrandNewBertModel.from_pretrained("brandy/brand_new_bert")
+model.config # model has access to its config
+```
+
+Similar to the model, the configuration inherits basic serialization and deserialization functionalities from
+[`PretrainedConfig`]. Note that the configuration and the model are always serialized into two
+different formats - the model to a *pytorch_model.bin* file and the configuration to a *config.json* file. Calling
+[`~PreTrainedModel.save_pretrained`] will automatically call
+[`~PretrainedConfig.save_pretrained`], so that both model and configuration are saved.
+
+
+### Code style
+
+When coding your new model, keep in mind that Transformers is an opinionated library and we have a few quirks of our
+own regarding how code should be written :-)
+
+1. The forward pass of your model should be fully written in the modeling file while being fully independent of other
+ models in the library. If you want to reuse a block from another model, copy the code and paste it with a
+ `# Copied from` comment on top (see [here](https://github.com/huggingface/transformers/blob/v4.17.0/src/transformers/models/roberta/modeling_roberta.py#L160)
+ for a good example).
+2. The code should be fully understandable, even by a non-native English speaker. This means you should pick
+ descriptive variable names and avoid abbreviations. As an example, `activation` is preferred to `act`.
+ One-letter variable names are strongly discouraged unless it's an index in a for loop.
+3. More generally we prefer longer explicit code to short magical one.
+4. Avoid subclassing `nn.Sequential` in PyTorch but subclass `nn.Module` and write the forward pass, so that anyone
+ using your code can quickly debug it by adding print statements or breaking points.
+5. Your function signature should be type-annotated. For the rest, good variable names are way more readable and
+ understandable than type annotations.
+
+### Overview of tokenizers
+
+Not quite ready yet :-( This section will be added soon!
+
+## Step-by-step recipe to add a model to 🤗 Transformers
+
+Everyone has different preferences of how to port a model so it can be very helpful for you to take a look at summaries
+of how other contributors ported models to Hugging Face. Here is a list of community blog posts on how to port a model:
+
+1. [Porting GPT2 Model](https://medium.com/huggingface/from-tensorflow-to-pytorch-265f40ef2a28) by [Thomas](https://huggingface.co/thomwolf)
+2. [Porting WMT19 MT Model](https://huggingface.co/blog/porting-fsmt) by [Stas](https://huggingface.co/stas)
+
+From experience, we can tell you that the most important things to keep in mind when adding a model are:
+
+- Don't reinvent the wheel! Most parts of the code you will add for the new 🤗 Transformers model already exist
+ somewhere in 🤗 Transformers. Take some time to find similar, already existing models and tokenizers you can copy
+ from. [grep](https://www.gnu.org/software/grep/) and [rg](https://github.com/BurntSushi/ripgrep) are your
+ friends. Note that it might very well happen that your model's tokenizer is based on one model implementation, and
+ your model's modeling code on another one. *E.g.* FSMT's modeling code is based on BART, while FSMT's tokenizer code
+ is based on XLM.
+- It's more of an engineering challenge than a scientific challenge. You should spend more time on creating an
+ efficient debugging environment than trying to understand all theoretical aspects of the model in the paper.
+- Ask for help, when you're stuck! Models are the core component of 🤗 Transformers so that we at Hugging Face are more
+ than happy to help you at every step to add your model. Don't hesitate to ask if you notice you are not making
+ progress.
+
+In the following, we try to give you a general recipe that we found most useful when porting a model to 🤗 Transformers.
+
+The following list is a summary of everything that has to be done to add a model and can be used by you as a To-Do
+List:
+
+- 1. ☐ (Optional) Understood theoretical aspects
+- 2. ☐ Prepared transformers dev environment
+- 3. ☐ Set up debugging environment of the original repository
+- 4. ☐ Created script that successfully runs forward pass using original repository and checkpoint
+- 5. ☐ Successfully added the model skeleton to Transformers
+- 6. ☐ Successfully converted original checkpoint to Transformers checkpoint
+- 7. ☐ Successfully ran forward pass in Transformers that gives identical output to original checkpoint
+- 8. ☐ Finished model tests in Transformers
+- 9. ☐ Successfully added Tokenizer in Transformers
+- 10. ☐ Run end-to-end integration tests
+- 11. ☐ Finished docs
+- 12. ☐ Uploaded model weights to the hub
+- 13. ☐ Submitted the pull request
+- 14. ☐ (Optional) Added a demo notebook
+
+To begin with, we usually recommend to start by getting a good theoretical understanding of `BrandNewBert`. However,
+if you prefer to understand the theoretical aspects of the model *on-the-job*, then it is totally fine to directly dive
+into the `BrandNewBert`'s code-base. This option might suit you better, if your engineering skills are better than
+your theoretical skill, if you have trouble understanding `BrandNewBert`'s paper, or if you just enjoy programming
+much more than reading scientific papers.
+
+### 1. (Optional) Theoretical aspects of BrandNewBert
+
+You should take some time to read *BrandNewBert's* paper, if such descriptive work exists. There might be large
+sections of the paper that are difficult to understand. If this is the case, this is fine - don't worry! The goal is
+not to get a deep theoretical understanding of the paper, but to extract the necessary information required to
+effectively re-implement the model in 🤗 Transformers. That being said, you don't have to spend too much time on the
+theoretical aspects, but rather focus on the practical ones, namely:
+
+- What type of model is *brand_new_bert*? BERT-like encoder-only model? GPT2-like decoder-only model? BART-like
+ encoder-decoder model? Look at the [model_summary](model_summary) if you're not familiar with the differences between those.
+- What are the applications of *brand_new_bert*? Text classification? Text generation? Seq2Seq tasks, *e.g.,*
+ summarization?
+- What is the novel feature of the model making it different from BERT/GPT-2/BART?
+- Which of the already existing [🤗 Transformers models](https://huggingface.co/transformers/#contents) is most
+ similar to *brand_new_bert*?
+- What type of tokenizer is used? A sentencepiece tokenizer? Word piece tokenizer? Is it the same tokenizer as used
+ for BERT or BART?
+
+After you feel like you have gotten a good overview of the architecture of the model, you might want to write to the
+Hugging Face team with any questions you might have. This might include questions regarding the model's architecture,
+its attention layer, etc. We will be more than happy to help you.
+
+### 2. Next prepare your environment
+
+1. Fork the [repository](https://github.com/huggingface/transformers) by clicking on the ‘Fork' button on the
+ repository's page. This creates a copy of the code under your GitHub user account.
+
+2. Clone your `transformers` fork to your local disk, and add the base repository as a remote:
+
+```bash
+git clone https://github.com/[your Github handle]/transformers.git
+cd transformers
+git remote add upstream https://github.com/huggingface/transformers.git
+```
+
+3. Set up a development environment, for instance by running the following command:
+
+```bash
+python -m venv .env
+source .env/bin/activate
+pip install -e ".[dev]"
+```
+
+and return to the parent directory
+
+```bash
+cd ..
+```
+
+4. We recommend adding the PyTorch version of *brand_new_bert* to Transformers. To install PyTorch, please follow the
+ instructions on https://pytorch.org/get-started/locally/.
+
+**Note:** You don't need to have CUDA installed. Making the new model work on CPU is sufficient.
+
+5. To port *brand_new_bert*, you will also need access to its original repository:
+
+```bash
+git clone https://github.com/org_that_created_brand_new_bert_org/brand_new_bert.git
+cd brand_new_bert
+pip install -e .
+```
+
+Now you have set up a development environment to port *brand_new_bert* to 🤗 Transformers.
+
+### 3.-4. Run a pretrained checkpoint using the original repository
+
+At first, you will work on the original *brand_new_bert* repository. Often, the original implementation is very
+“researchy”. Meaning that documentation might be lacking and the code can be difficult to understand. But this should
+be exactly your motivation to reimplement *brand_new_bert*. At Hugging Face, one of our main goals is to *make people
+stand on the shoulders of giants* which translates here very well into taking a working model and rewriting it to make
+it as **accessible, user-friendly, and beautiful** as possible. This is the number-one motivation to re-implement
+models into 🤗 Transformers - trying to make complex new NLP technology accessible to **everybody**.
+
+You should start thereby by diving into the original repository.
+
+Successfully running the official pretrained model in the original repository is often **the most difficult** step.
+From our experience, it is very important to spend some time getting familiar with the original code-base. You need to
+figure out the following:
+
+- Where to find the pretrained weights?
+- How to load the pretrained weights into the corresponding model?
+- How to run the tokenizer independently from the model?
+- Trace one forward pass so that you know which classes and functions are required for a simple forward pass. Usually,
+ you only have to reimplement those functions.
+- Be able to locate the important components of the model: Where is the model's class? Are there model sub-classes,
+ *e.g.* EncoderModel, DecoderModel? Where is the self-attention layer? Are there multiple different attention layers,
+ *e.g.* *self-attention*, *cross-attention*...?
+- How can you debug the model in the original environment of the repo? Do you have to add *print* statements, can you
+ work with an interactive debugger like *ipdb*, or should you use an efficient IDE to debug the model, like PyCharm?
+
+It is very important that before you start the porting process, that you can **efficiently** debug code in the original
+repository! Also, remember that you are working with an open-source library, so do not hesitate to open an issue, or
+even a pull request in the original repository. The maintainers of this repository are most likely very happy about
+someone looking into their code!
+
+At this point, it is really up to you which debugging environment and strategy you prefer to use to debug the original
+model. We strongly advise against setting up a costly GPU environment, but simply work on a CPU both when starting to
+dive into the original repository and also when starting to write the 🤗 Transformers implementation of the model. Only
+at the very end, when the model has already been successfully ported to 🤗 Transformers, one should verify that the
+model also works as expected on GPU.
+
+In general, there are two possible debugging environments for running the original model
+
+- [Jupyter notebooks](https://jupyter.org/) / [google colab](https://colab.research.google.com/notebooks/intro.ipynb)
+- Local python scripts.
+
+Jupyter notebooks have the advantage that they allow for cell-by-cell execution which can be helpful to better split
+logical components from one another and to have faster debugging cycles as intermediate results can be stored. Also,
+notebooks are often easier to share with other contributors, which might be very helpful if you want to ask the Hugging
+Face team for help. If you are familiar with Jupiter notebooks, we strongly recommend you to work with them.
+
+The obvious disadvantage of Jupyter notebooks is that if you are not used to working with them you will have to spend
+some time adjusting to the new programming environment and that you might not be able to use your known debugging tools
+anymore, like `ipdb`.
+
+For each code-base, a good first step is always to load a **small** pretrained checkpoint and to be able to reproduce a
+single forward pass using a dummy integer vector of input IDs as an input. Such a script could look like this (in
+pseudocode):
+
+```python
+model = BrandNewBertModel.load_pretrained_checkpoint("/path/to/checkpoint/")
+input_ids = [0, 4, 5, 2, 3, 7, 9] # vector of input ids
+original_output = model.predict(input_ids)
+```
+
+Next, regarding the debugging strategy, there are generally a few from which to choose from:
+
+- Decompose the original model into many small testable components and run a forward pass on each of those for
+ verification
+- Decompose the original model only into the original *tokenizer* and the original *model*, run a forward pass on
+ those, and use intermediate print statements or breakpoints for verification
+
+Again, it is up to you which strategy to choose. Often, one or the other is advantageous depending on the original code
+base.
+
+If the original code-base allows you to decompose the model into smaller sub-components, *e.g.* if the original
+code-base can easily be run in eager mode, it is usually worth the effort to do so. There are some important advantages
+to taking the more difficult road in the beginning:
+
+- at a later stage when comparing the original model to the Hugging Face implementation, you can verify automatically
+ for each component individually that the corresponding component of the 🤗 Transformers implementation matches instead
+ of relying on visual comparison via print statements
+- it can give you some rope to decompose the big problem of porting a model into smaller problems of just porting
+ individual components and thus structure your work better
+- separating the model into logical meaningful components will help you to get a better overview of the model's design
+ and thus to better understand the model
+- at a later stage those component-by-component tests help you to ensure that no regression occurs as you continue
+ changing your code
+
+[Lysandre's](https://gist.github.com/LysandreJik/db4c948f6b4483960de5cbac598ad4ed) integration checks for ELECTRA
+gives a nice example of how this can be done.
+
+However, if the original code-base is very complex or only allows intermediate components to be run in a compiled mode,
+it might be too time-consuming or even impossible to separate the model into smaller testable sub-components. A good
+example is [T5's MeshTensorFlow](https://github.com/tensorflow/mesh/tree/master/mesh_tensorflow) library which is
+very complex and does not offer a simple way to decompose the model into its sub-components. For such libraries, one
+often relies on verifying print statements.
+
+No matter which strategy you choose, the recommended procedure is often the same in that you should start to debug the
+starting layers first and the ending layers last.
+
+It is recommended that you retrieve the output, either by print statements or sub-component functions, of the following
+layers in the following order:
+
+1. Retrieve the input IDs passed to the model
+2. Retrieve the word embeddings
+3. Retrieve the input of the first Transformer layer
+4. Retrieve the output of the first Transformer layer
+5. Retrieve the output of the following n - 1 Transformer layers
+6. Retrieve the output of the whole BrandNewBert Model
+
+Input IDs should thereby consists of an array of integers, *e.g.* `input_ids = [0, 4, 4, 3, 2, 4, 1, 7, 19]`
+
+The outputs of the following layers often consist of multi-dimensional float arrays and can look like this:
+
+```
+[[
+ [-0.1465, -0.6501, 0.1993, ..., 0.1451, 0.3430, 0.6024],
+ [-0.4417, -0.5920, 0.3450, ..., -0.3062, 0.6182, 0.7132],
+ [-0.5009, -0.7122, 0.4548, ..., -0.3662, 0.6091, 0.7648],
+ ...,
+ [-0.5613, -0.6332, 0.4324, ..., -0.3792, 0.7372, 0.9288],
+ [-0.5416, -0.6345, 0.4180, ..., -0.3564, 0.6992, 0.9191],
+ [-0.5334, -0.6403, 0.4271, ..., -0.3339, 0.6533, 0.8694]]],
+```
+
+We expect that every model added to 🤗 Transformers passes a couple of integration tests, meaning that the original
+model and the reimplemented version in 🤗 Transformers have to give the exact same output up to a precision of 0.001!
+Since it is normal that the exact same model written in different libraries can give a slightly different output
+depending on the library framework, we accept an error tolerance of 1e-3 (0.001). It is not enough if the model gives
+nearly the same output, they have to be the almost identical. Therefore, you will certainly compare the intermediate
+outputs of the 🤗 Transformers version multiple times against the intermediate outputs of the original implementation of
+*brand_new_bert* in which case an **efficient** debugging environment of the original repository is absolutely
+important. Here is some advice is to make your debugging environment as efficient as possible.
+
+- Find the best way of debugging intermediate results. Is the original repository written in PyTorch? Then you should
+ probably take the time to write a longer script that decomposes the original model into smaller sub-components to
+ retrieve intermediate values. Is the original repository written in Tensorflow 1? Then you might have to rely on
+ TensorFlow print operations like [tf.print](https://www.tensorflow.org/api_docs/python/tf/print) to output
+ intermediate values. Is the original repository written in Jax? Then make sure that the model is **not jitted** when
+ running the forward pass, *e.g.* check-out [this link](https://github.com/google/jax/issues/196).
+- Use the smallest pretrained checkpoint you can find. The smaller the checkpoint, the faster your debug cycle
+ becomes. It is not efficient if your pretrained model is so big that your forward pass takes more than 10 seconds.
+ In case only very large checkpoints are available, it might make more sense to create a dummy model in the new
+ environment with randomly initialized weights and save those weights for comparison with the 🤗 Transformers version
+ of your model
+- Make sure you are using the easiest way of calling a forward pass in the original repository. Ideally, you want to
+ find the function in the original repository that **only** calls a single forward pass, *i.e.* that is often called
+ `predict`, `evaluate`, `forward` or `__call__`. You don't want to debug a function that calls `forward`
+ multiple times, *e.g.* to generate text, like `autoregressive_sample`, `generate`.
+- Try to separate the tokenization from the model's *forward* pass. If the original repository shows examples where
+ you have to input a string, then try to find out where in the forward call the string input is changed to input ids
+ and start from this point. This might mean that you have to possibly write a small script yourself or change the
+ original code so that you can directly input the ids instead of an input string.
+- Make sure that the model in your debugging setup is **not** in training mode, which often causes the model to yield
+ random outputs due to multiple dropout layers in the model. Make sure that the forward pass in your debugging
+ environment is **deterministic** so that the dropout layers are not used. Or use *transformers.utils.set_seed*
+ if the old and new implementations are in the same framework.
+
+The following section gives you more specific details/tips on how you can do this for *brand_new_bert*.
+
+### 5.-14. Port BrandNewBert to 🤗 Transformers
+
+Next, you can finally start adding new code to 🤗 Transformers. Go into the clone of your 🤗 Transformers' fork:
+
+```bash
+cd transformers
+```
+
+In the special case that you are adding a model whose architecture exactly matches the model architecture of an
+existing model you only have to add a conversion script as described in [this section](#write-a-conversion-script).
+In this case, you can just re-use the whole model architecture of the already existing model.
+
+Otherwise, let's start generating a new model. You have two choices here:
+
+- `transformers-cli add-new-model-like` to add a new model like an existing one
+- `transformers-cli add-new-model` to add a new model from our template (will look like BERT or Bart depending on the type of model you select)
+
+In both cases, you will be prompted with a questionnaire to fill the basic information of your model. The second command requires to install `cookiecutter`, you can find more information on it [here](https://github.com/huggingface/transformers/tree/main/templates/adding_a_new_model).
+
+**Open a Pull Request on the main huggingface/transformers repo**
+
+Before starting to adapt the automatically generated code, now is the time to open a “Work in progress (WIP)” pull
+request, *e.g.* “[WIP] Add *brand_new_bert*”, in 🤗 Transformers so that you and the Hugging Face team can work
+side-by-side on integrating the model into 🤗 Transformers.
+
+You should do the following:
+
+1. Create a branch with a descriptive name from your main branch
+
+```bash
+git checkout -b add_brand_new_bert
+```
+
+2. Commit the automatically generated code:
+
+```bash
+git add .
+git commit
+```
+
+3. Fetch and rebase to current main
+
+```bash
+git fetch upstream
+git rebase upstream/main
+```
+
+4. Push the changes to your account using:
+
+```bash
+git push -u origin a-descriptive-name-for-my-changes
+```
+
+5. Once you are satisfied, go to the webpage of your fork on GitHub. Click on “Pull request”. Make sure to add the
+ GitHub handle of some members of the Hugging Face team as reviewers, so that the Hugging Face team gets notified for
+ future changes.
+
+6. Change the PR into a draft by clicking on “Convert to draft” on the right of the GitHub pull request web page.
+
+In the following, whenever you have done some progress, don't forget to commit your work and push it to your account so
+that it shows in the pull request. Additionally, you should make sure to update your work with the current main from
+time to time by doing:
+
+```bash
+git fetch upstream
+git merge upstream/main
+```
+
+In general, all questions you might have regarding the model or your implementation should be asked in your PR and
+discussed/solved in the PR. This way, the Hugging Face team will always be notified when you are committing new code or
+if you have a question. It is often very helpful to point the Hugging Face team to your added code so that the Hugging
+Face team can efficiently understand your problem or question.
+
+To do so, you can go to the “Files changed” tab where you see all of your changes, go to a line regarding which you
+want to ask a question, and click on the “+” symbol to add a comment. Whenever a question or problem has been solved,
+you can click on the “Resolve” button of the created comment.
+
+In the same way, the Hugging Face team will open comments when reviewing your code. We recommend asking most questions
+on GitHub on your PR. For some very general questions that are not very useful for the public, feel free to ping the
+Hugging Face team by Slack or email.
+
+**5. Adapt the generated models code for brand_new_bert**
+
+At first, we will focus only on the model itself and not care about the tokenizer. All the relevant code should be
+found in the generated files `src/transformers/models/brand_new_bert/modeling_brand_new_bert.py` and
+`src/transformers/models/brand_new_bert/configuration_brand_new_bert.py`.
+
+Now you can finally start coding :). The generated code in
+`src/transformers/models/brand_new_bert/modeling_brand_new_bert.py` will either have the same architecture as BERT if
+it's an encoder-only model or BART if it's an encoder-decoder model. At this point, you should remind yourself what
+you've learned in the beginning about the theoretical aspects of the model: *How is the model different from BERT or
+BART?*". Implement those changes which often means to change the *self-attention* layer, the order of the normalization
+layer, etc… Again, it is often useful to look at the similar architecture of already existing models in Transformers to
+get a better feeling of how your model should be implemented.
+
+**Note** that at this point, you don't have to be very sure that your code is fully correct or clean. Rather, it is
+advised to add a first *unclean*, copy-pasted version of the original code to
+`src/transformers/models/brand_new_bert/modeling_brand_new_bert.py` until you feel like all the necessary code is
+added. From our experience, it is much more efficient to quickly add a first version of the required code and
+improve/correct the code iteratively with the conversion script as described in the next section. The only thing that
+has to work at this point is that you can instantiate the 🤗 Transformers implementation of *brand_new_bert*, *i.e.* the
+following command should work:
+
+```python
+from transformers import BrandNewBertModel, BrandNewBertConfig
+
+model = BrandNewBertModel(BrandNewBertConfig())
+```
+
+The above command will create a model according to the default parameters as defined in `BrandNewBertConfig()` with
+random weights, thus making sure that the `init()` methods of all components works.
+
+**6. Write a conversion script**
+
+Next, you should write a conversion script that lets you convert the checkpoint you used to debug *brand_new_bert* in
+the original repository to a checkpoint compatible with your just created 🤗 Transformers implementation of
+*brand_new_bert*. It is not advised to write the conversion script from scratch, but rather to look through already
+existing conversion scripts in 🤗 Transformers for one that has been used to convert a similar model that was written in
+the same framework as *brand_new_bert*. Usually, it is enough to copy an already existing conversion script and
+slightly adapt it for your use case. Don't hesitate to ask the Hugging Face team to point you to a similar already
+existing conversion script for your model.
+
+- If you are porting a model from TensorFlow to PyTorch, a good starting point might be BERT's conversion script [here](https://github.com/huggingface/transformers/blob/7acfa95afb8194f8f9c1f4d2c6028224dbed35a2/src/transformers/models/bert/modeling_bert.py#L91)
+- If you are porting a model from PyTorch to PyTorch, a good starting point might be BART's conversion script [here](https://github.com/huggingface/transformers/blob/main/src/transformers/models/bart/convert_bart_original_pytorch_checkpoint_to_pytorch.py)
+
+In the following, we'll quickly explain how PyTorch models store layer weights and define layer names. In PyTorch, the
+name of a layer is defined by the name of the class attribute you give the layer. Let's define a dummy model in
+PyTorch, called `SimpleModel` as follows:
+
+```python
+from torch import nn
+
+
+class SimpleModel(nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.dense = nn.Linear(10, 10)
+ self.intermediate = nn.Linear(10, 10)
+ self.layer_norm = nn.LayerNorm(10)
+```
+
+Now we can create an instance of this model definition which will fill all weights: `dense`, `intermediate`,
+`layer_norm` with random weights. We can print the model to see its architecture
+
+```python
+model = SimpleModel()
+
+print(model)
+```
+
+This will print out the following:
+
+```
+SimpleModel(
+ (dense): Linear(in_features=10, out_features=10, bias=True)
+ (intermediate): Linear(in_features=10, out_features=10, bias=True)
+ (layer_norm): LayerNorm((10,), eps=1e-05, elementwise_affine=True)
+)
+```
+
+We can see that the layer names are defined by the name of the class attribute in PyTorch. You can print out the weight
+values of a specific layer:
+
+```python
+print(model.dense.weight.data)
+```
+
+to see that the weights were randomly initialized
+
+```
+tensor([[-0.0818, 0.2207, -0.0749, -0.0030, 0.0045, -0.1569, -0.1598, 0.0212,
+ -0.2077, 0.2157],
+ [ 0.1044, 0.0201, 0.0990, 0.2482, 0.3116, 0.2509, 0.2866, -0.2190,
+ 0.2166, -0.0212],
+ [-0.2000, 0.1107, -0.1999, -0.3119, 0.1559, 0.0993, 0.1776, -0.1950,
+ -0.1023, -0.0447],
+ [-0.0888, -0.1092, 0.2281, 0.0336, 0.1817, -0.0115, 0.2096, 0.1415,
+ -0.1876, -0.2467],
+ [ 0.2208, -0.2352, -0.1426, -0.2636, -0.2889, -0.2061, -0.2849, -0.0465,
+ 0.2577, 0.0402],
+ [ 0.1502, 0.2465, 0.2566, 0.0693, 0.2352, -0.0530, 0.1859, -0.0604,
+ 0.2132, 0.1680],
+ [ 0.1733, -0.2407, -0.1721, 0.1484, 0.0358, -0.0633, -0.0721, -0.0090,
+ 0.2707, -0.2509],
+ [-0.1173, 0.1561, 0.2945, 0.0595, -0.1996, 0.2988, -0.0802, 0.0407,
+ 0.1829, -0.1568],
+ [-0.1164, -0.2228, -0.0403, 0.0428, 0.1339, 0.0047, 0.1967, 0.2923,
+ 0.0333, -0.0536],
+ [-0.1492, -0.1616, 0.1057, 0.1950, -0.2807, -0.2710, -0.1586, 0.0739,
+ 0.2220, 0.2358]]).
+```
+
+In the conversion script, you should fill those randomly initialized weights with the exact weights of the
+corresponding layer in the checkpoint. *E.g.*
+
+```python
+# retrieve matching layer weights, e.g. by
+# recursive algorithm
+layer_name = "dense"
+pretrained_weight = array_of_dense_layer
+
+model_pointer = getattr(model, "dense")
+
+model_pointer.weight.data = torch.from_numpy(pretrained_weight)
+```
+
+While doing so, you must verify that each randomly initialized weight of your PyTorch model and its corresponding
+pretrained checkpoint weight exactly match in both **shape and name**. To do so, it is **necessary** to add assert
+statements for the shape and print out the names of the checkpoints weights. E.g. you should add statements like:
+
+```python
+assert (
+ model_pointer.weight.shape == pretrained_weight.shape
+), f"Pointer shape of random weight {model_pointer.shape} and array shape of checkpoint weight {pretrained_weight.shape} mismatched"
+```
+
+Besides, you should also print out the names of both weights to make sure they match, *e.g.*
+
+```python
+logger.info(f"Initialize PyTorch weight {layer_name} from {pretrained_weight.name}")
+```
+
+If either the shape or the name doesn't match, you probably assigned the wrong checkpoint weight to a randomly
+initialized layer of the 🤗 Transformers implementation.
+
+An incorrect shape is most likely due to an incorrect setting of the config parameters in `BrandNewBertConfig()` that
+do not exactly match those that were used for the checkpoint you want to convert. However, it could also be that
+PyTorch's implementation of a layer requires the weight to be transposed beforehand.
+
+Finally, you should also check that **all** required weights are initialized and print out all checkpoint weights that
+were not used for initialization to make sure the model is correctly converted. It is completely normal, that the
+conversion trials fail with either a wrong shape statement or wrong name assignment. This is most likely because either
+you used incorrect parameters in `BrandNewBertConfig()`, have a wrong architecture in the 🤗 Transformers
+implementation, you have a bug in the `init()` functions of one of the components of the 🤗 Transformers
+implementation or you need to transpose one of the checkpoint weights.
+
+This step should be iterated with the previous step until all weights of the checkpoint are correctly loaded in the
+Transformers model. Having correctly loaded the checkpoint into the 🤗 Transformers implementation, you can then save
+the model under a folder of your choice `/path/to/converted/checkpoint/folder` that should then contain both a
+`pytorch_model.bin` file and a `config.json` file:
+
+```python
+model.save_pretrained("/path/to/converted/checkpoint/folder")
+```
+
+**7. Implement the forward pass**
+
+Having managed to correctly load the pretrained weights into the 🤗 Transformers implementation, you should now make
+sure that the forward pass is correctly implemented. In [Get familiar with the original repository](#run-a-pretrained-checkpoint-using-the-original-repository), you have already created a script that runs a forward
+pass of the model using the original repository. Now you should write an analogous script using the 🤗 Transformers
+implementation instead of the original one. It should look as follows:
+
+```python
+model = BrandNewBertModel.from_pretrained("/path/to/converted/checkpoint/folder")
+input_ids = [0, 4, 4, 3, 2, 4, 1, 7, 19]
+output = model(input_ids).last_hidden_states
+```
+
+It is very likely that the 🤗 Transformers implementation and the original model implementation don't give the exact
+same output the very first time or that the forward pass throws an error. Don't be disappointed - it's expected! First,
+you should make sure that the forward pass doesn't throw any errors. It often happens that the wrong dimensions are
+used leading to a *Dimensionality mismatch* error or that the wrong data type object is used, *e.g.* `torch.long`
+instead of `torch.float32`. Don't hesitate to ask the Hugging Face team for help, if you don't manage to solve
+certain errors.
+
+The final part to make sure the 🤗 Transformers implementation works correctly is to ensure that the outputs are
+equivalent to a precision of `1e-3`. First, you should ensure that the output shapes are identical, *i.e.*
+`outputs.shape` should yield the same value for the script of the 🤗 Transformers implementation and the original
+implementation. Next, you should make sure that the output values are identical as well. This one of the most difficult
+parts of adding a new model. Common mistakes why the outputs are not identical are:
+
+- Some layers were not added, *i.e.* an *activation* layer was not added, or the residual connection was forgotten
+- The word embedding matrix was not tied
+- The wrong positional embeddings are used because the original implementation uses on offset
+- Dropout is applied during the forward pass. To fix this make sure *model.training is False* and that no dropout
+ layer is falsely activated during the forward pass, *i.e.* pass *self.training* to [PyTorch's functional dropout](https://pytorch.org/docs/stable/nn.functional.html?highlight=dropout#torch.nn.functional.dropout)
+
+The best way to fix the problem is usually to look at the forward pass of the original implementation and the 🤗
+Transformers implementation side-by-side and check if there are any differences. Ideally, you should debug/print out
+intermediate outputs of both implementations of the forward pass to find the exact position in the network where the 🤗
+Transformers implementation shows a different output than the original implementation. First, make sure that the
+hard-coded `input_ids` in both scripts are identical. Next, verify that the outputs of the first transformation of
+the `input_ids` (usually the word embeddings) are identical. And then work your way up to the very last layer of the
+network. At some point, you will notice a difference between the two implementations, which should point you to the bug
+in the 🤗 Transformers implementation. From our experience, a simple and efficient way is to add many print statements
+in both the original implementation and 🤗 Transformers implementation, at the same positions in the network
+respectively, and to successively remove print statements showing the same values for intermediate presentations.
+
+When you're confident that both implementations yield the same output, verifying the outputs with
+`torch.allclose(original_output, output, atol=1e-3)`, you're done with the most difficult part! Congratulations - the
+work left to be done should be a cakewalk 😊.
+
+**8. Adding all necessary model tests**
+
+At this point, you have successfully added a new model. However, it is very much possible that the model does not yet
+fully comply with the required design. To make sure, the implementation is fully compatible with 🤗 Transformers, all
+common tests should pass. The Cookiecutter should have automatically added a test file for your model, probably under
+the same `tests/test_modeling_brand_new_bert.py`. Run this test file to verify that all common tests pass:
+
+```bash
+pytest tests/test_modeling_brand_new_bert.py
+```
+
+Having fixed all common tests, it is now crucial to ensure that all the nice work you have done is well tested, so that
+
+- a) The community can easily understand your work by looking at specific tests of *brand_new_bert*
+- b) Future changes to your model will not break any important feature of the model.
+
+At first, integration tests should be added. Those integration tests essentially do the same as the debugging scripts
+you used earlier to implement the model to 🤗 Transformers. A template of those model tests is already added by the
+Cookiecutter, called `BrandNewBertModelIntegrationTests` and only has to be filled out by you. To ensure that those
+tests are passing, run
+
+```bash
+RUN_SLOW=1 pytest -sv tests/test_modeling_brand_new_bert.py::BrandNewBertModelIntegrationTests
+```
+
+
+
+In case you are using Windows, you should replace `RUN_SLOW=1` with `SET RUN_SLOW=1`
+
+
+
+Second, all features that are special to *brand_new_bert* should be tested additionally in a separate test under
+`BrandNewBertModelTester`/``BrandNewBertModelTest`. This part is often forgotten but is extremely useful in two
+ways:
+
+- It helps to transfer the knowledge you have acquired during the model addition to the community by showing how the
+ special features of *brand_new_bert* should work.
+- Future contributors can quickly test changes to the model by running those special tests.
+
+
+**9. Implement the tokenizer**
+
+Next, we should add the tokenizer of *brand_new_bert*. Usually, the tokenizer is equivalent or very similar to an
+already existing tokenizer of 🤗 Transformers.
+
+It is very important to find/extract the original tokenizer file and to manage to load this file into the 🤗
+Transformers' implementation of the tokenizer.
+
+To ensure that the tokenizer works correctly, it is recommended to first create a script in the original repository
+that inputs a string and returns the `input_ids``. It could look similar to this (in pseudo-code):
+
+```python
+input_str = "This is a long example input string containing special characters .$?-, numbers 2872 234 12 and words."
+model = BrandNewBertModel.load_pretrained_checkpoint("/path/to/checkpoint/")
+input_ids = model.tokenize(input_str)
+```
+
+You might have to take a deeper look again into the original repository to find the correct tokenizer function or you
+might even have to do changes to your clone of the original repository to only output the `input_ids`. Having written
+a functional tokenization script that uses the original repository, an analogous script for 🤗 Transformers should be
+created. It should look similar to this:
+
+```python
+from transformers import BrandNewBertTokenizer
+
+input_str = "This is a long example input string containing special characters .$?-, numbers 2872 234 12 and words."
+
+tokenizer = BrandNewBertTokenizer.from_pretrained("/path/to/tokenizer/folder/")
+
+input_ids = tokenizer(input_str).input_ids
+```
+
+When both `input_ids` yield the same values, as a final step a tokenizer test file should also be added.
+
+Analogous to the modeling test files of *brand_new_bert*, the tokenization test files of *brand_new_bert* should
+contain a couple of hard-coded integration tests.
+
+**10. Run End-to-end integration tests**
+
+Having added the tokenizer, you should also add a couple of end-to-end integration tests using both the model and the
+tokenizer to `tests/test_modeling_brand_new_bert.py` in 🤗 Transformers. Such a test should show on a meaningful
+text-to-text sample that the 🤗 Transformers implementation works as expected. A meaningful text-to-text sample can
+include *e.g.* a source-to-target-translation pair, an article-to-summary pair, a question-to-answer pair, etc… If none
+of the ported checkpoints has been fine-tuned on a downstream task it is enough to simply rely on the model tests. In a
+final step to ensure that the model is fully functional, it is advised that you also run all tests on GPU. It can
+happen that you forgot to add some `.to(self.device)` statements to internal tensors of the model, which in such a
+test would show in an error. In case you have no access to a GPU, the Hugging Face team can take care of running those
+tests for you.
+
+**11. Add Docstring**
+
+Now, all the necessary functionality for *brand_new_bert* is added - you're almost done! The only thing left to add is
+a nice docstring and a doc page. The Cookiecutter should have added a template file called
+`docs/source/model_doc/brand_new_bert.rst` that you should fill out. Users of your model will usually first look at
+this page before using your model. Hence, the documentation must be understandable and concise. It is very useful for
+the community to add some *Tips* to show how the model should be used. Don't hesitate to ping the Hugging Face team
+regarding the docstrings.
+
+Next, make sure that the docstring added to `src/transformers/models/brand_new_bert/modeling_brand_new_bert.py` is
+correct and included all necessary inputs and outputs. We have a detailed guide about writing documentation and our docstring format [here](writing-documentation). It is always to good to remind oneself that documentation should
+be treated at least as carefully as the code in 🤗 Transformers since the documentation is usually the first contact
+point of the community with the model.
+
+**Code refactor**
+
+Great, now you have added all the necessary code for *brand_new_bert*. At this point, you should correct some potential
+incorrect code style by running:
+
+```bash
+make style
+```
+
+and verify that your coding style passes the quality check:
+
+```bash
+make quality
+```
+
+There are a couple of other very strict design tests in 🤗 Transformers that might still be failing, which shows up in
+the tests of your pull request. This is often because of some missing information in the docstring or some incorrect
+naming. The Hugging Face team will surely help you if you're stuck here.
+
+Lastly, it is always a good idea to refactor one's code after having ensured that the code works correctly. With all
+tests passing, now it's a good time to go over the added code again and do some refactoring.
+
+You have now finished the coding part, congratulation! 🎉 You are Awesome! 😎
+
+**12. Upload the models to the model hub**
+
+In this final part, you should convert and upload all checkpoints to the model hub and add a model card for each
+uploaded model checkpoint. You can get familiar with the hub functionalities by reading our [Model sharing and uploading Page](model_sharing). You should work alongside the Hugging Face team here to decide on a fitting name for each
+checkpoint and to get the required access rights to be able to upload the model under the author's organization of
+*brand_new_bert*. The `push_to_hub` method, present in all models in `transformers`, is a quick and efficient way to push your checkpoint to the hub. A little snippet is pasted below:
+
+```python
+brand_new_bert.push_to_hub(
+ repo_path_or_name="brand_new_bert",
+ # Uncomment the following line to push to an organization
+ # organization="",
+ commit_message="Add model",
+ use_temp_dir=True,
+)
+```
+
+It is worth spending some time to create fitting model cards for each checkpoint. The model cards should highlight the
+specific characteristics of this particular checkpoint, *e.g.* On which dataset was the checkpoint
+pretrained/fine-tuned on? On what down-stream task should the model be used? And also include some code on how to
+correctly use the model.
+
+**13. (Optional) Add notebook**
+
+It is very helpful to add a notebook that showcases in-detail how *brand_new_bert* can be used for inference and/or
+fine-tuned on a downstream task. This is not mandatory to merge your PR, but very useful for the community.
+
+**14. Submit your finished PR**
+
+You're done programming now and can move to the last step, which is getting your PR merged into main. Usually, the
+Hugging Face team should have helped you already at this point, but it is worth taking some time to give your finished
+PR a nice description and eventually add comments to your code, if you want to point out certain design choices to your
+reviewer.
+
+### Share your work!!
+
+Now, it's time to get some credit from the community for your work! Having completed a model addition is a major
+contribution to Transformers and the whole NLP community. Your code and the ported pre-trained models will certainly be
+used by hundreds and possibly even thousands of developers and researchers. You should be proud of your work and share
+your achievement with the community.
+
+**You have made another model that is super easy to access for everyone in the community! 🤯**
diff --git a/docs/source/en/add_new_pipeline.mdx b/docs/source/en/add_new_pipeline.mdx
new file mode 100644
index 00000000000000..096ea423ec6bdf
--- /dev/null
+++ b/docs/source/en/add_new_pipeline.mdx
@@ -0,0 +1,140 @@
+
+
+# How to add a pipeline to 🤗 Transformers?
+
+First and foremost, you need to decide the raw entries the pipeline will be able to take. It can be strings, raw bytes,
+dictionaries or whatever seems to be the most likely desired input. Try to keep these inputs as pure Python as possible
+as it makes compatibility easier (even through other languages via JSON). Those will be the `inputs` of the
+pipeline (`preprocess`).
+
+Then define the `outputs`. Same policy as the `inputs`. The simpler, the better. Those will be the outputs of
+`postprocess` method.
+
+Start by inheriting the base class `Pipeline`. with the 4 methods needed to implement `preprocess`,
+`_forward`, `postprocess` and `_sanitize_parameters`.
+
+
+```python
+from transformers import Pipeline
+
+
+class MyPipeline(Pipeline):
+ def _sanitize_parameters(self, **kwargs):
+ preprocess_kwargs = {}
+ if "maybe_arg" in kwargs:
+ preprocess_kwargs["maybe_arg"] = kwargs["maybe_arg"]
+ return preprocess_kwargs, {}, {}
+
+ def preprocess(self, inputs, maybe_arg=2):
+ model_input = Tensor(inputs["input_ids"])
+ return {"model_input": model_input}
+
+ def _forward(self, model_inputs):
+ # model_inputs == {"model_input": model_input}
+ outputs = self.model(**model_inputs)
+ # Maybe {"logits": Tensor(...)}
+ return outputs
+
+ def postprocess(self, model_outputs):
+ best_class = model_outputs["logits"].softmax(-1)
+ return best_class
+```
+
+The structure of this breakdown is to support relatively seamless support for CPU/GPU, while supporting doing
+pre/postprocessing on the CPU on different threads
+
+`preprocess` will take the originally defined inputs, and turn them into something feedable to the model. It might
+contain more information and is usually a `Dict`.
+
+`_forward` is the implementation detail and is not meant to be called directly. `forward` is the preferred
+called method as it contains safeguards to make sure everything is working on the expected device. If anything is
+linked to a real model it belongs in the `_forward` method, anything else is in the preprocess/postprocess.
+
+`postprocess` methods will take the output of `_forward` and turn it into the final output that were decided
+earlier.
+
+`_sanitize_parameters` exists to allow users to pass any parameters whenever they wish, be it at initialization
+time `pipeline(...., maybe_arg=4)` or at call time `pipe = pipeline(...); output = pipe(...., maybe_arg=4)`.
+
+The returns of `_sanitize_parameters` are the 3 dicts of kwargs that will be passed directly to `preprocess`,
+`_forward` and `postprocess`. Don't fill anything if the caller didn't call with any extra parameter. That
+allows to keep the default arguments in the function definition which is always more "natural".
+
+A classic example would be a `top_k` argument in the post processing in classification tasks.
+
+```python
+>>> pipe = pipeline("my-new-task")
+>>> pipe("This is a test")
+[{"label": "1-star", "score": 0.8}, {"label": "2-star", "score": 0.1}, {"label": "3-star", "score": 0.05}
+{"label": "4-star", "score": 0.025}, {"label": "5-star", "score": 0.025}]
+
+>>> pipe("This is a test", top_k=2)
+[{"label": "1-star", "score": 0.8}, {"label": "2-star", "score": 0.1}]
+```
+
+In order to achieve that, we'll update our `postprocess` method with a default parameter to `5`. and edit
+`_sanitize_parameters` to allow this new parameter.
+
+
+```python
+def postprocess(self, model_outputs, top_k=5):
+ best_class = model_outputs["logits"].softmax(-1)
+ # Add logic to handle top_k
+ return best_class
+
+
+def _sanitize_parameters(self, **kwargs):
+ preprocess_kwargs = {}
+ if "maybe_arg" in kwargs:
+ preprocess_kwargs["maybe_arg"] = kwargs["maybe_arg"]
+
+ postprocess_kwargs = {}
+ if "top_k" in kwargs:
+ preprocess_kwargs["top_k"] = kwargs["top_k"]
+ return preprocess_kwargs, {}, postprocess_kwargs
+```
+
+Try to keep the inputs/outputs very simple and ideally JSON-serializable as it makes the pipeline usage very easy
+without requiring users to understand new kind of objects. It's also relatively common to support many different types
+of arguments for ease of use (audio files, can be filenames, URLs or pure bytes)
+
+
+
+## Adding it to the list of supported tasks
+
+Go to `src/transformers/pipelines/__init__.py` and fill in `SUPPORTED_TASKS` with your newly created pipeline.
+If possible it should provide a default model.
+
+## Adding tests
+
+Create a new file `tests/test_pipelines_MY_PIPELINE.py` with example with the other tests.
+
+The `run_pipeline_test` function will be very generic and run on small random models on every possible
+architecture as defined by `model_mapping` and `tf_model_mapping`.
+
+This is very important to test future compatibility, meaning if someone adds a new model for
+`XXXForQuestionAnswering` then the pipeline test will attempt to run on it. Because the models are random it's
+impossible to check for actual values, that's why There is a helper `ANY` that will simply attempt to match the
+output of the pipeline TYPE.
+
+You also *need* to implement 2 (ideally 4) tests.
+
+- `test_small_model_pt` : Define 1 small model for this pipeline (doesn't matter if the results don't make sense)
+ and test the pipeline outputs. The results should be the same as `test_small_model_tf`.
+- `test_small_model_tf` : Define 1 small model for this pipeline (doesn't matter if the results don't make sense)
+ and test the pipeline outputs. The results should be the same as `test_small_model_pt`.
+- `test_large_model_pt` (`optional`): Tests the pipeline on a real pipeline where the results are supposed to
+ make sense. These tests are slow and should be marked as such. Here the goal is to showcase the pipeline and to make
+ sure there is no drift in future releases
+- `test_large_model_tf` (`optional`): Tests the pipeline on a real pipeline where the results are supposed to
+ make sense. These tests are slow and should be marked as such. Here the goal is to showcase the pipeline and to make
+ sure there is no drift in future releases
diff --git a/docs/source/en/autoclass_tutorial.mdx b/docs/source/en/autoclass_tutorial.mdx
new file mode 100644
index 00000000000000..51270302f23329
--- /dev/null
+++ b/docs/source/en/autoclass_tutorial.mdx
@@ -0,0 +1,119 @@
+
+
+# Load pretrained instances with an AutoClass
+
+With so many different Transformer architectures, it can be challenging to create one for your checkpoint. As a part of 🤗 Transformers core philosophy to make the library easy, simple and flexible to use, an `AutoClass` automatically infer and load the correct architecture from a given checkpoint. The `from_pretrained` method lets you quickly load a pretrained model for any architecture so you don't have to devote time and resources to train a model from scratch. Producing this type of checkpoint-agnostic code means if your code works for one checkpoint, it will work with another checkpoint - as long as it was trained for a similar task - even if the architecture is different.
+
+
+
+Remember, architecture refers to the skeleton of the model and checkpoints are the weights for a given architecture. For example, [BERT](https://huggingface.co/bert-base-uncased) is an architecture, while `bert-base-uncased` is a checkpoint. Model is a general term that can mean either architecture or checkpoint.
+
+
+
+In this tutorial, learn to:
+
+* Load a pretrained tokenizer.
+* Load a pretrained feature extractor.
+* Load a pretrained processor.
+* Load a pretrained model.
+
+## AutoTokenizer
+
+Nearly every NLP task begins with a tokenizer. A tokenizer converts your input into a format that can be processed by the model.
+
+Load a tokenizer with [`AutoTokenizer.from_pretrained`]:
+
+```py
+>>> from transformers import AutoTokenizer
+
+>>> tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
+```
+
+Then tokenize your input as shown below:
+
+```py
+>>> sequence = "In a hole in the ground there lived a hobbit."
+>>> print(tokenizer(sequence))
+{'input_ids': [101, 1999, 1037, 4920, 1999, 1996, 2598, 2045, 2973, 1037, 7570, 10322, 4183, 1012, 102],
+ 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
+ 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
+```
+
+## AutoFeatureExtractor
+
+For audio and vision tasks, a feature extractor processes the audio signal or image into the correct input format.
+
+Load a feature extractor with [`AutoFeatureExtractor.from_pretrained`]:
+
+```py
+>>> from transformers import AutoFeatureExtractor
+
+>>> feature_extractor = AutoFeatureExtractor.from_pretrained(
+... "ehcalabres/wav2vec2-lg-xlsr-en-speech-emotion-recognition"
+... )
+```
+
+## AutoProcessor
+
+Multimodal tasks require a processor that combines two types of preprocessing tools. For example, the [LayoutLMV2](model_doc/layoutlmv2) model requires a feature extractor to handle images and a tokenizer to handle text; a processor combines both of them.
+
+Load a processor with [`AutoProcessor.from_pretrained`]:
+
+```py
+>>> from transformers import AutoProcessor
+
+>>> processor = AutoProcessor.from_pretrained("microsoft/layoutlmv2-base-uncased")
+```
+
+## AutoModel
+
+
+
+Finally, the `AutoModelFor` classes let you load a pretrained model for a given task (see [here](model_doc/auto) for a complete list of available tasks). For example, load a model for sequence classification with [`AutoModelForSequenceClassification.from_pretrained`]:
+
+```py
+>>> from transformers import AutoModelForSequenceClassification
+
+>>> model = AutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased")
+```
+
+Easily reuse the same checkpoint to load an architecture for a different task:
+
+```py
+>>> from transformers import AutoModelForTokenClassification
+
+>>> model = AutoModelForTokenClassification.from_pretrained("distilbert-base-uncased")
+```
+
+Generally, we recommend using the `AutoTokenizer` class and the `AutoModelFor` class to load pretrained instances of models. This will ensure you load the correct architecture every time. In the next [tutorial](preprocessing), learn how to use your newly loaded tokenizer, feature extractor and processor to preprocess a dataset for fine-tuning.
+
+
+Finally, the `TFAutoModelFor` classes let you load a pretrained model for a given task (see [here](model_doc/auto) for a complete list of available tasks). For example, load a model for sequence classification with [`TFAutoModelForSequenceClassification.from_pretrained`]:
+
+```py
+>>> from transformers import TFAutoModelForSequenceClassification
+
+>>> model = TFAutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased")
+```
+
+Easily reuse the same checkpoint to load an architecture for a different task:
+
+```py
+>>> from transformers import TFAutoModelForTokenClassification
+
+>>> model = TFAutoModelForTokenClassification.from_pretrained("distilbert-base-uncased")
+```
+
+Generally, we recommend using the `AutoTokenizer` class and the `TFAutoModelFor` class to load pretrained instances of models. This will ensure you load the correct architecture every time. In the next [tutorial](preprocessing), learn how to use your newly loaded tokenizer, feature extractor and processor to preprocess a dataset for fine-tuning.
+
+
diff --git a/docs/source/en/benchmarks.mdx b/docs/source/en/benchmarks.mdx
new file mode 100644
index 00000000000000..244112001f5ccf
--- /dev/null
+++ b/docs/source/en/benchmarks.mdx
@@ -0,0 +1,383 @@
+
+
+# Benchmarks
+
+
+
+Hugging Face's Benchmarking tools are deprecated and it is advised to use external Benchmarking libraries to measure the speed
+and memory complexity of Transformer models.
+
+
+
+[[open-in-colab]]
+
+Let's take a look at how 🤗 Transformers models can be benchmarked, best practices, and already available benchmarks.
+
+A notebook explaining in more detail how to benchmark 🤗 Transformers models can be found [here](https://github.com/huggingface/notebooks/tree/main/examples/benchmark.ipynb).
+
+## How to benchmark 🤗 Transformers models
+
+The classes [`PyTorchBenchmark`] and [`TensorFlowBenchmark`] allow to flexibly benchmark 🤗 Transformers models. The benchmark classes allow us to measure the _peak memory usage_ and _required time_ for both _inference_ and _training_.
+
+
+
+Hereby, _inference_ is defined by a single forward pass, and _training_ is defined by a single forward pass and
+backward pass.
+
+
+
+The benchmark classes [`PyTorchBenchmark`] and [`TensorFlowBenchmark`] expect an object of type [`PyTorchBenchmarkArguments`] and
+[`TensorFlowBenchmarkArguments`], respectively, for instantiation. [`PyTorchBenchmarkArguments`] and [`TensorFlowBenchmarkArguments`] are data classes and contain all relevant configurations for their corresponding benchmark class. In the following example, it is shown how a BERT model of type _bert-base-cased_ can be benchmarked.
+
+
+
+```py
+>>> from transformers import PyTorchBenchmark, PyTorchBenchmarkArguments
+
+>>> args = PyTorchBenchmarkArguments(models=["bert-base-uncased"], batch_sizes=[8], sequence_lengths=[8, 32, 128, 512])
+>>> benchmark = PyTorchBenchmark(args)
+```
+
+
+```py
+>>> from transformers import TensorFlowBenchmark, TensorFlowBenchmarkArguments
+
+>>> args = TensorFlowBenchmarkArguments(
+... models=["bert-base-uncased"], batch_sizes=[8], sequence_lengths=[8, 32, 128, 512]
+... )
+>>> benchmark = TensorFlowBenchmark(args)
+```
+
+
+
+Here, three arguments are given to the benchmark argument data classes, namely `models`, `batch_sizes`, and
+`sequence_lengths`. The argument `models` is required and expects a `list` of model identifiers from the
+[model hub](https://huggingface.co/models) The `list` arguments `batch_sizes` and `sequence_lengths` define
+the size of the `input_ids` on which the model is benchmarked. There are many more parameters that can be configured
+via the benchmark argument data classes. For more detail on these one can either directly consult the files
+`src/transformers/benchmark/benchmark_args_utils.py`, `src/transformers/benchmark/benchmark_args.py` (for PyTorch)
+and `src/transformers/benchmark/benchmark_args_tf.py` (for Tensorflow). Alternatively, running the following shell
+commands from root will print out a descriptive list of all configurable parameters for PyTorch and Tensorflow
+respectively.
+
+
+
+```bash
+python examples/pytorch/benchmarking/run_benchmark.py --help
+```
+
+An instantiated benchmark object can then simply be run by calling `benchmark.run()`.
+
+```py
+>>> results = benchmark.run()
+>>> print(results)
+==================== INFERENCE - SPEED - RESULT ====================
+--------------------------------------------------------------------------------
+Model Name Batch Size Seq Length Time in s
+--------------------------------------------------------------------------------
+bert-base-uncased 8 8 0.006
+bert-base-uncased 8 32 0.006
+bert-base-uncased 8 128 0.018
+bert-base-uncased 8 512 0.088
+--------------------------------------------------------------------------------
+
+==================== INFERENCE - MEMORY - RESULT ====================
+--------------------------------------------------------------------------------
+Model Name Batch Size Seq Length Memory in MB
+--------------------------------------------------------------------------------
+bert-base-uncased 8 8 1227
+bert-base-uncased 8 32 1281
+bert-base-uncased 8 128 1307
+bert-base-uncased 8 512 1539
+--------------------------------------------------------------------------------
+
+==================== ENVIRONMENT INFORMATION ====================
+
+- transformers_version: 2.11.0
+- framework: PyTorch
+- use_torchscript: False
+- framework_version: 1.4.0
+- python_version: 3.6.10
+- system: Linux
+- cpu: x86_64
+- architecture: 64bit
+- date: 2020-06-29
+- time: 08:58:43.371351
+- fp16: False
+- use_multiprocessing: True
+- only_pretrain_model: False
+- cpu_ram_mb: 32088
+- use_gpu: True
+- num_gpus: 1
+- gpu: TITAN RTX
+- gpu_ram_mb: 24217
+- gpu_power_watts: 280.0
+- gpu_performance_state: 2
+- use_tpu: False
+```
+
+
+```bash
+python examples/tensorflow/benchmarking/run_benchmark_tf.py --help
+```
+
+An instantiated benchmark object can then simply be run by calling `benchmark.run()`.
+
+```py
+>>> results = benchmark.run()
+>>> print(results)
+>>> results = benchmark.run()
+>>> print(results)
+==================== INFERENCE - SPEED - RESULT ====================
+--------------------------------------------------------------------------------
+Model Name Batch Size Seq Length Time in s
+--------------------------------------------------------------------------------
+bert-base-uncased 8 8 0.005
+bert-base-uncased 8 32 0.008
+bert-base-uncased 8 128 0.022
+bert-base-uncased 8 512 0.105
+--------------------------------------------------------------------------------
+
+==================== INFERENCE - MEMORY - RESULT ====================
+--------------------------------------------------------------------------------
+Model Name Batch Size Seq Length Memory in MB
+--------------------------------------------------------------------------------
+bert-base-uncased 8 8 1330
+bert-base-uncased 8 32 1330
+bert-base-uncased 8 128 1330
+bert-base-uncased 8 512 1770
+--------------------------------------------------------------------------------
+
+==================== ENVIRONMENT INFORMATION ====================
+
+- transformers_version: 2.11.0
+- framework: Tensorflow
+- use_xla: False
+- framework_version: 2.2.0
+- python_version: 3.6.10
+- system: Linux
+- cpu: x86_64
+- architecture: 64bit
+- date: 2020-06-29
+- time: 09:26:35.617317
+- fp16: False
+- use_multiprocessing: True
+- only_pretrain_model: False
+- cpu_ram_mb: 32088
+- use_gpu: True
+- num_gpus: 1
+- gpu: TITAN RTX
+- gpu_ram_mb: 24217
+- gpu_power_watts: 280.0
+- gpu_performance_state: 2
+- use_tpu: False
+```
+
+
+
+By default, the _time_ and the _required memory_ for _inference_ are benchmarked. In the example output above the first
+two sections show the result corresponding to _inference time_ and _inference memory_. In addition, all relevant
+information about the computing environment, _e.g._ the GPU type, the system, the library versions, etc... are printed
+out in the third section under _ENVIRONMENT INFORMATION_. This information can optionally be saved in a _.csv_ file
+when adding the argument `save_to_csv=True` to [`PyTorchBenchmarkArguments`] and
+[`TensorFlowBenchmarkArguments`] respectively. In this case, every section is saved in a separate
+_.csv_ file. The path to each _.csv_ file can optionally be defined via the argument data classes.
+
+Instead of benchmarking pre-trained models via their model identifier, _e.g._ `bert-base-uncased`, the user can
+alternatively benchmark an arbitrary configuration of any available model class. In this case, a `list` of
+configurations must be inserted with the benchmark args as follows.
+
+
+
+```py
+>>> from transformers import PyTorchBenchmark, PyTorchBenchmarkArguments, BertConfig
+
+>>> args = PyTorchBenchmarkArguments(
+... models=["bert-base", "bert-384-hid", "bert-6-lay"], batch_sizes=[8], sequence_lengths=[8, 32, 128, 512]
+... )
+>>> config_base = BertConfig()
+>>> config_384_hid = BertConfig(hidden_size=384)
+>>> config_6_lay = BertConfig(num_hidden_layers=6)
+
+>>> benchmark = PyTorchBenchmark(args, configs=[config_base, config_384_hid, config_6_lay])
+>>> benchmark.run()
+==================== INFERENCE - SPEED - RESULT ====================
+--------------------------------------------------------------------------------
+Model Name Batch Size Seq Length Time in s
+--------------------------------------------------------------------------------
+bert-base 8 128 0.006
+bert-base 8 512 0.006
+bert-base 8 128 0.018
+bert-base 8 512 0.088
+bert-384-hid 8 8 0.006
+bert-384-hid 8 32 0.006
+bert-384-hid 8 128 0.011
+bert-384-hid 8 512 0.054
+bert-6-lay 8 8 0.003
+bert-6-lay 8 32 0.004
+bert-6-lay 8 128 0.009
+bert-6-lay 8 512 0.044
+--------------------------------------------------------------------------------
+
+==================== INFERENCE - MEMORY - RESULT ====================
+--------------------------------------------------------------------------------
+Model Name Batch Size Seq Length Memory in MB
+--------------------------------------------------------------------------------
+bert-base 8 8 1277
+bert-base 8 32 1281
+bert-base 8 128 1307
+bert-base 8 512 1539
+bert-384-hid 8 8 1005
+bert-384-hid 8 32 1027
+bert-384-hid 8 128 1035
+bert-384-hid 8 512 1255
+bert-6-lay 8 8 1097
+bert-6-lay 8 32 1101
+bert-6-lay 8 128 1127
+bert-6-lay 8 512 1359
+--------------------------------------------------------------------------------
+
+==================== ENVIRONMENT INFORMATION ====================
+
+- transformers_version: 2.11.0
+- framework: PyTorch
+- use_torchscript: False
+- framework_version: 1.4.0
+- python_version: 3.6.10
+- system: Linux
+- cpu: x86_64
+- architecture: 64bit
+- date: 2020-06-29
+- time: 09:35:25.143267
+- fp16: False
+- use_multiprocessing: True
+- only_pretrain_model: False
+- cpu_ram_mb: 32088
+- use_gpu: True
+- num_gpus: 1
+- gpu: TITAN RTX
+- gpu_ram_mb: 24217
+- gpu_power_watts: 280.0
+- gpu_performance_state: 2
+- use_tpu: False
+```
+
+
+```py
+>>> from transformers import TensorFlowBenchmark, TensorFlowBenchmarkArguments, BertConfig
+
+>>> args = TensorFlowBenchmarkArguments(
+... models=["bert-base", "bert-384-hid", "bert-6-lay"], batch_sizes=[8], sequence_lengths=[8, 32, 128, 512]
+... )
+>>> config_base = BertConfig()
+>>> config_384_hid = BertConfig(hidden_size=384)
+>>> config_6_lay = BertConfig(num_hidden_layers=6)
+
+>>> benchmark = TensorFlowBenchmark(args, configs=[config_base, config_384_hid, config_6_lay])
+>>> benchmark.run()
+==================== INFERENCE - SPEED - RESULT ====================
+--------------------------------------------------------------------------------
+Model Name Batch Size Seq Length Time in s
+--------------------------------------------------------------------------------
+bert-base 8 8 0.005
+bert-base 8 32 0.008
+bert-base 8 128 0.022
+bert-base 8 512 0.106
+bert-384-hid 8 8 0.005
+bert-384-hid 8 32 0.007
+bert-384-hid 8 128 0.018
+bert-384-hid 8 512 0.064
+bert-6-lay 8 8 0.002
+bert-6-lay 8 32 0.003
+bert-6-lay 8 128 0.0011
+bert-6-lay 8 512 0.074
+--------------------------------------------------------------------------------
+
+==================== INFERENCE - MEMORY - RESULT ====================
+--------------------------------------------------------------------------------
+Model Name Batch Size Seq Length Memory in MB
+--------------------------------------------------------------------------------
+bert-base 8 8 1330
+bert-base 8 32 1330
+bert-base 8 128 1330
+bert-base 8 512 1770
+bert-384-hid 8 8 1330
+bert-384-hid 8 32 1330
+bert-384-hid 8 128 1330
+bert-384-hid 8 512 1540
+bert-6-lay 8 8 1330
+bert-6-lay 8 32 1330
+bert-6-lay 8 128 1330
+bert-6-lay 8 512 1540
+--------------------------------------------------------------------------------
+
+==================== ENVIRONMENT INFORMATION ====================
+
+- transformers_version: 2.11.0
+- framework: Tensorflow
+- use_xla: False
+- framework_version: 2.2.0
+- python_version: 3.6.10
+- system: Linux
+- cpu: x86_64
+- architecture: 64bit
+- date: 2020-06-29
+- time: 09:38:15.487125
+- fp16: False
+- use_multiprocessing: True
+- only_pretrain_model: False
+- cpu_ram_mb: 32088
+- use_gpu: True
+- num_gpus: 1
+- gpu: TITAN RTX
+- gpu_ram_mb: 24217
+- gpu_power_watts: 280.0
+- gpu_performance_state: 2
+- use_tpu: False
+```
+
+
+
+Again, _inference time_ and _required memory_ for _inference_ are measured, but this time for customized configurations
+of the `BertModel` class. This feature can especially be helpful when deciding for which configuration the model
+should be trained.
+
+
+## Benchmark best practices
+
+This section lists a couple of best practices one should be aware of when benchmarking a model.
+
+- Currently, only single device benchmarking is supported. When benchmarking on GPU, it is recommended that the user
+ specifies on which device the code should be run by setting the `CUDA_VISIBLE_DEVICES` environment variable in the
+ shell, _e.g._ `export CUDA_VISIBLE_DEVICES=0` before running the code.
+- The option `no_multi_processing` should only be set to `True` for testing and debugging. To ensure accurate
+ memory measurement it is recommended to run each memory benchmark in a separate process by making sure
+ `no_multi_processing` is set to `True`.
+- One should always state the environment information when sharing the results of a model benchmark. Results can vary
+ heavily between different GPU devices, library versions, etc., so that benchmark results on their own are not very
+ useful for the community.
+
+
+## Sharing your benchmark
+
+Previously all available core models (10 at the time) have been benchmarked for _inference time_, across many different
+settings: using PyTorch, with and without TorchScript, using TensorFlow, with and without XLA. All of those tests were
+done across CPUs (except for TensorFlow XLA) and GPUs.
+
+The approach is detailed in the [following blogpost](https://medium.com/huggingface/benchmarking-transformers-pytorch-and-tensorflow-e2917fb891c2) and the results are
+available [here](https://docs.google.com/spreadsheets/d/1sryqufw2D0XlUH4sq3e9Wnxu5EAQkaohzrJbd5HdQ_w/edit?usp=sharing).
+
+With the new _benchmark_ tools, it is easier than ever to share your benchmark results with the community
+
+- [PyTorch Benchmarking Results](https://github.com/huggingface/transformers/tree/main/examples/pytorch/benchmarking/README.md).
+- [TensorFlow Benchmarking Results](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/benchmarking/README.md).
diff --git a/docs/source/en/bertology.mdx b/docs/source/en/bertology.mdx
new file mode 100644
index 00000000000000..e64379d6580da5
--- /dev/null
+++ b/docs/source/en/bertology.mdx
@@ -0,0 +1,36 @@
+
+
+# BERTology
+
+There is a growing field of study concerned with investigating the inner working of large-scale transformers like BERT
+(that some call "BERTology"). Some good examples of this field are:
+
+
+- BERT Rediscovers the Classical NLP Pipeline by Ian Tenney, Dipanjan Das, Ellie Pavlick:
+ https://arxiv.org/abs/1905.05950
+- Are Sixteen Heads Really Better than One? by Paul Michel, Omer Levy, Graham Neubig: https://arxiv.org/abs/1905.10650
+- What Does BERT Look At? An Analysis of BERT's Attention by Kevin Clark, Urvashi Khandelwal, Omer Levy, Christopher D.
+ Manning: https://arxiv.org/abs/1906.04341
+
+In order to help this new field develop, we have included a few additional features in the BERT/GPT/GPT-2 models to
+help people access the inner representations, mainly adapted from the great work of Paul Michel
+(https://arxiv.org/abs/1905.10650):
+
+
+- accessing all the hidden-states of BERT/GPT/GPT-2,
+- accessing all the attention weights for each head of BERT/GPT/GPT-2,
+- retrieving heads output values and gradients to be able to compute head importance score and prune head as explained
+ in https://arxiv.org/abs/1905.10650.
+
+To help you understand and use these features, we have added a specific example script: [bertology.py](https://github.com/huggingface/transformers/tree/main/examples/research_projects/bertology/run_bertology.py) while extract information and prune a model pre-trained on
+GLUE.
diff --git a/docs/source/en/big_models.mdx b/docs/source/en/big_models.mdx
new file mode 100644
index 00000000000000..a313e4e1fb2f4e
--- /dev/null
+++ b/docs/source/en/big_models.mdx
@@ -0,0 +1,128 @@
+
+
+# Instantiating a big model
+
+When you want to use a very big pretrained model, one challenge is to minimize the use of the RAM. The usual workflow
+from PyTorch is:
+
+1. Create your model with random weights.
+2. Load your pretrained weights.
+3. Put those pretrained weights in your random model.
+
+Step 1 and 2 both require a full version of the model in memory, which is not a problem in most cases, but if your model starts weighing several GigaBytes, those two copies can make you got our of RAM. Even worse, if you are using `torch.distributed` to launch a distributed training, each process will load the pretrained model and store these two copies in RAM.
+
+
+
+Note that the randomly created model is initialized with "empty" tensors, which take the space in memory without filling it (thus the random values are whatever was in this chunk of memory at a given time). The random initialization following the appropriate distribution for the kind of model/parameters instatiated (like a normal distribution for instance) is only performed after step 3 on the non-initialized weights, to be as fast as possible!
+
+
+
+In this guide, we explore the solutions Transformers offer to deal with this issue. Note that this is an area of active development, so the APIs explained here may change slightly in the future.
+
+## Sharded checkpoints
+
+Since version 4.18.0, model checkpoints that end up taking more than 10GB of space are automatically sharded in smaller pieces. In terms of having one single checkpoint when you do `model.save_pretrained(save_dir)`, you will end up with several partial checkpoints (each of which being of size < 10GB) and an index that maps parameter names to the files they are stored in.
+
+You can control the maximum size before sharding with the `max_shard_size` parameter, so for the sake of an example, we'll use a normal-size models with a small shard size: let's take a traditional BERT model.
+
+```py
+from transformers import AutoModel
+
+model = AutoModel.from_pretrained("bert-base-cased")
+```
+
+If you save it using [`~PreTrainedModel.save_pretrained`], you will get a new folder with two files: the config of the model and its weights:
+
+```py
+>>> import os
+>>> import tempfile
+
+>>> with tempfile.TemporaryDirectory() as tmp_dir:
+... model.save_pretrained(tmp_dir)
+... print(sorted(os.listdir(tmp_dir)))
+['config.json', 'pytorch_model.bin']
+```
+
+Now let's use a maximum shard size of 200MB:
+
+```py
+>>> with tempfile.TemporaryDirectory() as tmp_dir:
+... model.save_pretrained(tmp_dir, max_shard_size="200MB")
+... print(sorted(os.listdir(tmp_dir)))
+['config.json', 'pytorch_model-00001-of-00003.bin', 'pytorch_model-00002-of-00003.bin', 'pytorch_model-00003-of-00003.bin', 'pytorch_model.bin.index.json']
+```
+
+On top of the configuration of the model, we see three different weights files, and an `index.json` file which is our index. A checkpoint like this can be fully reloaded using the [`~PreTrainedModel.from_pretrained`] method:
+
+```py
+>>> with tempfile.TemporaryDirectory() as tmp_dir:
+... model.save_pretrained(tmp_dir, max_shard_size="200MB")
+... new_model = AutoModel.from_pretrained(tmp_dir)
+```
+
+The main advantage of doing this for big models is that during step 2 of the workflow shown above, each shard of the checkpoint is loaded after the previous one, capping the memory usage in RAM to the model size plus the size of the biggest shard.
+
+Beind the scenes, the index file is used to determine which keys are in the checkpoint, and where the corresponding weights are stored. We can load that index like any json and get a dictionary:
+
+```py
+>>> import json
+
+>>> with tempfile.TemporaryDirectory() as tmp_dir:
+... model.save_pretrained(tmp_dir, max_shard_size="200MB")
+... with open(os.path.join(tmp_dir, "pytorch_model.bin.index.json"), "r") as f:
+... index = json.load(f)
+
+>>> print(index.keys())
+dict_keys(['metadata', 'weight_map'])
+```
+
+The metadata just consists of the total size of the model for now. We plan to add several other informations in the future:
+
+```py
+>>> index["metadata"]
+{'total_size': 433245184}
+```
+
+The weights map is the main part of this index, which maps each parameter name (as usually found in a PyTorch model `state_dict`) to the file it's stored in:
+
+```py
+>>> index["weight_map"]
+{'embeddings.LayerNorm.bias': 'pytorch_model-00001-of-00003.bin',
+ 'embeddings.LayerNorm.weight': 'pytorch_model-00001-of-00003.bin',
+ ...
+```
+
+If you want to directly load such a sharded checkpoint inside a model without using [`~PreTrainedModel.from_pretrained`] (like you would do `model.load_state_dict()` for a full checkpoint) you should use [`~modeling_utils.load_sharded_checkpoint`]:
+
+```py
+>>> from transformers.modeling_utils import load_sharded_checkpoint
+
+>>> with tempfile.TemporaryDirectory() as tmp_dir:
+... model.save_pretrained(tmp_dir, max_shard_size="200MB")
+... load_sharded_checkpoint(model, tmp_dir)
+```
+
+## Low memory loading
+
+Sharded checkpoints reduce the memory usage during step 2 of the worflow mentioned above, but when loadin a pretrained model, why keep the random weights in memory? The option `low_cpu_mem_usage` will destroy the weights of the randomly initialized model, then progressively load the weights inside, then perform a random initialization for potential missing weights (if you are loadding a model with a newly initialized head for a fine-tuning task for instance).
+
+It's very easy to use, just add `low_cpu_mem_usage=True` to your call to [`~PreTrainedModel.from_pretrained`]:
+
+```py
+from transformers import AutoModelForSequenceClas
+
+model = AutoModel.from_pretrained("bert-base-cased", low_cpu_mem_usage=True)
+```
+
+This can be used in conjunction with a sharded checkpoint.
+
diff --git a/docs/source/en/community.mdx b/docs/source/en/community.mdx
new file mode 100644
index 00000000000000..808b16779dd94a
--- /dev/null
+++ b/docs/source/en/community.mdx
@@ -0,0 +1,65 @@
+# Community
+
+This page regroups resources around 🤗 Transformers developed by the community.
+
+## Community resources:
+
+| Resource | Description | Author |
+|:----------|:-------------|------:|
+| [Hugging Face Transformers Glossary Flashcards](https://www.darigovresearch.com/huggingface-transformers-glossary-flashcards) | A set of flashcards based on the [Transformers Docs Glossary](glossary) that has been put into a form which can be easily learnt/revised using [Anki ](https://apps.ankiweb.net/) an open source, cross platform app specifically designed for long term knowledge retention. See this [Introductory video on how to use the flashcards](https://www.youtube.com/watch?v=Dji_h7PILrw). | [Darigov Research](https://www.darigovresearch.com/) |
+
+## Community notebooks:
+
+| Notebook | Description | Author | |
+|:----------|:-------------|:-------------|------:|
+| [Fine-tune a pre-trained Transformer to generate lyrics](https://github.com/AlekseyKorshuk/huggingartists) | How to generate lyrics in the style of your favorite artist by fine-tuning a GPT-2 model | [Aleksey Korshuk](https://github.com/AlekseyKorshuk) | [](https://colab.research.google.com/github/AlekseyKorshuk/huggingartists/blob/master/huggingartists-demo.ipynb) |
+| [Train T5 in Tensorflow 2 ](https://github.com/snapthat/TF-T5-text-to-text) | How to train T5 for any task using Tensorflow 2. This notebook demonstrates a Question & Answer task implemented in Tensorflow 2 using SQUAD | [Muhammad Harris](https://github.com/HarrisDePerceptron) |[](https://colab.research.google.com/github/snapthat/TF-T5-text-to-text/blob/master/snapthatT5/notebooks/TF-T5-Datasets%20Training.ipynb) |
+| [Train T5 on TPU](https://github.com/patil-suraj/exploring-T5/blob/master/T5_on_TPU.ipynb) | How to train T5 on SQUAD with Transformers and Nlp | [Suraj Patil](https://github.com/patil-suraj) |[](https://colab.research.google.com/github/patil-suraj/exploring-T5/blob/master/T5_on_TPU.ipynb#scrollTo=QLGiFCDqvuil) |
+| [Fine-tune T5 for Classification and Multiple Choice](https://github.com/patil-suraj/exploring-T5/blob/master/t5_fine_tuning.ipynb) | How to fine-tune T5 for classification and multiple choice tasks using a text-to-text format with PyTorch Lightning | [Suraj Patil](https://github.com/patil-suraj) | [](https://colab.research.google.com/github/patil-suraj/exploring-T5/blob/master/t5_fine_tuning.ipynb) |
+| [Fine-tune DialoGPT on New Datasets and Languages](https://github.com/ncoop57/i-am-a-nerd/blob/master/_notebooks/2020-05-12-chatbot-part-1.ipynb) | How to fine-tune the DialoGPT model on a new dataset for open-dialog conversational chatbots | [Nathan Cooper](https://github.com/ncoop57) | [](https://colab.research.google.com/github/ncoop57/i-am-a-nerd/blob/master/_notebooks/2020-05-12-chatbot-part-1.ipynb) |
+| [Long Sequence Modeling with Reformer](https://github.com/patrickvonplaten/notebooks/blob/master/PyTorch_Reformer.ipynb) | How to train on sequences as long as 500,000 tokens with Reformer | [Patrick von Platen](https://github.com/patrickvonplaten) | [](https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/PyTorch_Reformer.ipynb) |
+| [Fine-tune BART for Summarization](https://github.com/ohmeow/ohmeow_website/blob/master/_notebooks/2020-05-23-text-generation-with-blurr.ipynb) | How to fine-tune BART for summarization with fastai using blurr | [Wayde Gilliam](https://ohmeow.com/) | [](https://colab.research.google.com/github/ohmeow/ohmeow_website/blob/master/_notebooks/2020-05-23-text-generation-with-blurr.ipynb) |
+| [Fine-tune a pre-trained Transformer on anyone's tweets](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb) | How to generate tweets in the style of your favorite Twitter account by fine-tuning a GPT-2 model | [Boris Dayma](https://github.com/borisdayma) | [](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb) |
+| [Optimize 🤗 Hugging Face models with Weights & Biases](https://colab.research.google.com/github/wandb/examples/blob/master/colabs/huggingface/Optimize_Hugging_Face_models_with_Weights_%26_Biases.ipynb) | A complete tutorial showcasing W&B integration with Hugging Face | [Boris Dayma](https://github.com/borisdayma) | [](https://colab.research.google.com/github/wandb/examples/blob/master/colabs/huggingface/Optimize_Hugging_Face_models_with_Weights_%26_Biases.ipynb) |
+| [Pretrain Longformer](https://github.com/allenai/longformer/blob/master/scripts/convert_model_to_long.ipynb) | How to build a "long" version of existing pretrained models | [Iz Beltagy](https://beltagy.net) | [](https://colab.research.google.com/github/allenai/longformer/blob/master/scripts/convert_model_to_long.ipynb) |
+| [Fine-tune Longformer for QA](https://github.com/patil-suraj/Notebooks/blob/master/longformer_qa_training.ipynb) | How to fine-tune longformer model for QA task | [Suraj Patil](https://github.com/patil-suraj) | [](https://colab.research.google.com/github/patil-suraj/Notebooks/blob/master/longformer_qa_training.ipynb) |
+| [Evaluate Model with 🤗nlp](https://github.com/patrickvonplaten/notebooks/blob/master/How_to_evaluate_Longformer_on_TriviaQA_using_NLP.ipynb) | How to evaluate longformer on TriviaQA with `nlp` | [Patrick von Platen](https://github.com/patrickvonplaten) | [](https://colab.research.google.com/drive/1m7eTGlPmLRgoPkkA7rkhQdZ9ydpmsdLE?usp=sharing) |
+| [Fine-tune T5 for Sentiment Span Extraction](https://github.com/enzoampil/t5-intro/blob/master/t5_qa_training_pytorch_span_extraction.ipynb) | How to fine-tune T5 for sentiment span extraction using a text-to-text format with PyTorch Lightning | [Lorenzo Ampil](https://github.com/enzoampil) | [](https://colab.research.google.com/github/enzoampil/t5-intro/blob/master/t5_qa_training_pytorch_span_extraction.ipynb) |
+| [Fine-tune DistilBert for Multiclass Classification](https://github.com/abhimishra91/transformers-tutorials/blob/master/transformers_multiclass_classification.ipynb) | How to fine-tune DistilBert for multiclass classification with PyTorch | [Abhishek Kumar Mishra](https://github.com/abhimishra91) | [](https://colab.research.google.com/github/abhimishra91/transformers-tutorials/blob/master/transformers_multiclass_classification.ipynb)|
+|[Fine-tune BERT for Multi-label Classification](https://github.com/abhimishra91/transformers-tutorials/blob/master/transformers_multi_label_classification.ipynb)|How to fine-tune BERT for multi-label classification using PyTorch|[Abhishek Kumar Mishra](https://github.com/abhimishra91) |[](https://colab.research.google.com/github/abhimishra91/transformers-tutorials/blob/master/transformers_multi_label_classification.ipynb)|
+|[Fine-tune T5 for Summarization](https://github.com/abhimishra91/transformers-tutorials/blob/master/transformers_summarization_wandb.ipynb)|How to fine-tune T5 for summarization in PyTorch and track experiments with WandB|[Abhishek Kumar Mishra](https://github.com/abhimishra91) |[](https://colab.research.google.com/github/abhimishra91/transformers-tutorials/blob/master/transformers_summarization_wandb.ipynb)|
+|[Speed up Fine-Tuning in Transformers with Dynamic Padding / Bucketing](https://github.com/ELS-RD/transformers-notebook/blob/master/Divide_Hugging_Face_Transformers_training_time_by_2_or_more.ipynb)|How to speed up fine-tuning by a factor of 2 using dynamic padding / bucketing|[Michael Benesty](https://github.com/pommedeterresautee) |[](https://colab.research.google.com/drive/1CBfRU1zbfu7-ijiOqAAQUA-RJaxfcJoO?usp=sharing)|
+|[Pretrain Reformer for Masked Language Modeling](https://github.com/patrickvonplaten/notebooks/blob/master/Reformer_For_Masked_LM.ipynb)| How to train a Reformer model with bi-directional self-attention layers | [Patrick von Platen](https://github.com/patrickvonplaten) | [](https://colab.research.google.com/drive/1tzzh0i8PgDQGV3SMFUGxM7_gGae3K-uW?usp=sharing)|
+|[Expand and Fine Tune Sci-BERT](https://github.com/lordtt13/word-embeddings/blob/master/COVID-19%20Research%20Data/COVID-SciBERT.ipynb)| How to increase vocabulary of a pretrained SciBERT model from AllenAI on the CORD dataset and pipeline it. | [Tanmay Thakur](https://github.com/lordtt13) | [](https://colab.research.google.com/drive/1rqAR40goxbAfez1xvF3hBJphSCsvXmh8)|
+|[Fine Tune BlenderBotSmall for Summarization using the Trainer API](https://github.com/lordtt13/transformers-experiments/blob/master/Custom%20Tasks/fine-tune-blenderbot_small-for-summarization.ipynb)| How to fine tune BlenderBotSmall for summarization on a custom dataset, using the Trainer API. | [Tanmay Thakur](https://github.com/lordtt13) | [](https://colab.research.google.com/drive/19Wmupuls7mykSGyRN_Qo6lPQhgp56ymq?usp=sharing)|
+|[Fine-tune Electra and interpret with Integrated Gradients](https://github.com/elsanns/xai-nlp-notebooks/blob/master/electra_fine_tune_interpret_captum_ig.ipynb) | How to fine-tune Electra for sentiment analysis and interpret predictions with Captum Integrated Gradients | [Eliza Szczechla](https://elsanns.github.io) | [](https://colab.research.google.com/github/elsanns/xai-nlp-notebooks/blob/master/electra_fine_tune_interpret_captum_ig.ipynb)|
+|[fine-tune a non-English GPT-2 Model with Trainer class](https://github.com/philschmid/fine-tune-GPT-2/blob/master/Fine_tune_a_non_English_GPT_2_Model_with_Huggingface.ipynb) | How to fine-tune a non-English GPT-2 Model with Trainer class | [Philipp Schmid](https://www.philschmid.de) | [](https://colab.research.google.com/github/philschmid/fine-tune-GPT-2/blob/master/Fine_tune_a_non_English_GPT_2_Model_with_Huggingface.ipynb)|
+|[Fine-tune a DistilBERT Model for Multi Label Classification task](https://github.com/DhavalTaunk08/Transformers_scripts/blob/master/Transformers_multilabel_distilbert.ipynb) | How to fine-tune a DistilBERT Model for Multi Label Classification task | [Dhaval Taunk](https://github.com/DhavalTaunk08) | [](https://colab.research.google.com/github/DhavalTaunk08/Transformers_scripts/blob/master/Transformers_multilabel_distilbert.ipynb)|
+|[Fine-tune ALBERT for sentence-pair classification](https://github.com/NadirEM/nlp-notebooks/blob/master/Fine_tune_ALBERT_sentence_pair_classification.ipynb) | How to fine-tune an ALBERT model or another BERT-based model for the sentence-pair classification task | [Nadir El Manouzi](https://github.com/NadirEM) | [](https://colab.research.google.com/github/NadirEM/nlp-notebooks/blob/master/Fine_tune_ALBERT_sentence_pair_classification.ipynb)|
+|[Fine-tune Roberta for sentiment analysis](https://github.com/DhavalTaunk08/NLP_scripts/blob/master/sentiment_analysis_using_roberta.ipynb) | How to fine-tune a Roberta model for sentiment analysis | [Dhaval Taunk](https://github.com/DhavalTaunk08) | [](https://colab.research.google.com/github/DhavalTaunk08/NLP_scripts/blob/master/sentiment_analysis_using_roberta.ipynb)|
+|[Evaluating Question Generation Models](https://github.com/flexudy-pipe/qugeev) | How accurate are the answers to questions generated by your seq2seq transformer model? | [Pascal Zoleko](https://github.com/zolekode) | [](https://colab.research.google.com/drive/1bpsSqCQU-iw_5nNoRm_crPq6FRuJthq_?usp=sharing)|
+|[Classify text with DistilBERT and Tensorflow](https://github.com/peterbayerle/huggingface_notebook/blob/main/distilbert_tf.ipynb) | How to fine-tune DistilBERT for text classification in TensorFlow | [Peter Bayerle](https://github.com/peterbayerle) | [](https://colab.research.google.com/github/peterbayerle/huggingface_notebook/blob/main/distilbert_tf.ipynb)|
+|[Leverage BERT for Encoder-Decoder Summarization on CNN/Dailymail](https://github.com/patrickvonplaten/notebooks/blob/master/BERT2BERT_for_CNN_Dailymail.ipynb) | How to warm-start a *EncoderDecoderModel* with a *bert-base-uncased* checkpoint for summarization on CNN/Dailymail | [Patrick von Platen](https://github.com/patrickvonplaten) | [](https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/BERT2BERT_for_CNN_Dailymail.ipynb)|
+|[Leverage RoBERTa for Encoder-Decoder Summarization on BBC XSum](https://github.com/patrickvonplaten/notebooks/blob/master/RoBERTaShared_for_BBC_XSum.ipynb) | How to warm-start a shared *EncoderDecoderModel* with a *roberta-base* checkpoint for summarization on BBC/XSum | [Patrick von Platen](https://github.com/patrickvonplaten) | [](https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/RoBERTaShared_for_BBC_XSum.ipynb)|
+|[Fine-tune TAPAS on Sequential Question Answering (SQA)](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/TAPAS/Fine_tuning_TapasForQuestionAnswering_on_SQA.ipynb) | How to fine-tune *TapasForQuestionAnswering* with a *tapas-base* checkpoint on the Sequential Question Answering (SQA) dataset | [Niels Rogge](https://github.com/nielsrogge) | [](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/TAPAS/Fine_tuning_TapasForQuestionAnswering_on_SQA.ipynb)|
+|[Evaluate TAPAS on Table Fact Checking (TabFact)](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/TAPAS/Evaluating_TAPAS_on_the_Tabfact_test_set.ipynb) | How to evaluate a fine-tuned *TapasForSequenceClassification* with a *tapas-base-finetuned-tabfact* checkpoint using a combination of the 🤗 datasets and 🤗 transformers libraries | [Niels Rogge](https://github.com/nielsrogge) | [](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/TAPAS/Evaluating_TAPAS_on_the_Tabfact_test_set.ipynb)|
+|[Fine-tuning mBART for translation](https://colab.research.google.com/github/vasudevgupta7/huggingface-tutorials/blob/main/translation_training.ipynb) | How to fine-tune mBART using Seq2SeqTrainer for Hindi to English translation | [Vasudev Gupta](https://github.com/vasudevgupta7) | [](https://colab.research.google.com/github/vasudevgupta7/huggingface-tutorials/blob/main/translation_training.ipynb)|
+|[Fine-tune LayoutLM on FUNSD (a form understanding dataset)](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/LayoutLM/Fine_tuning_LayoutLMForTokenClassification_on_FUNSD.ipynb) | How to fine-tune *LayoutLMForTokenClassification* on the FUNSD dataset for information extraction from scanned documents | [Niels Rogge](https://github.com/nielsrogge) | [](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/LayoutLM/Fine_tuning_LayoutLMForTokenClassification_on_FUNSD.ipynb)|
+|[Fine-Tune DistilGPT2 and Generate Text](https://colab.research.google.com/github/tripathiaakash/DistilGPT2-Tutorial/blob/main/distilgpt2_fine_tuning.ipynb) | How to fine-tune DistilGPT2 and generate text | [Aakash Tripathi](https://github.com/tripathiaakash) | [](https://colab.research.google.com/github/tripathiaakash/DistilGPT2-Tutorial/blob/main/distilgpt2_fine_tuning.ipynb)|
+|[Fine-Tune LED on up to 8K tokens](https://github.com/patrickvonplaten/notebooks/blob/master/Fine_tune_Longformer_Encoder_Decoder_(LED)_for_Summarization_on_pubmed.ipynb) | How to fine-tune LED on pubmed for long-range summarization | [Patrick von Platen](https://github.com/patrickvonplaten) | [](https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/Fine_tune_Longformer_Encoder_Decoder_(LED)_for_Summarization_on_pubmed.ipynb)|
+|[Evaluate LED on Arxiv](https://github.com/patrickvonplaten/notebooks/blob/master/LED_on_Arxiv.ipynb) | How to effectively evaluate LED on long-range summarization | [Patrick von Platen](https://github.com/patrickvonplaten) | [](https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/LED_on_Arxiv.ipynb)|
+|[Fine-tune LayoutLM on RVL-CDIP (a document image classification dataset)](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/LayoutLM/Fine_tuning_LayoutLMForSequenceClassification_on_RVL_CDIP.ipynb) | How to fine-tune *LayoutLMForSequenceClassification* on the RVL-CDIP dataset for scanned document classification | [Niels Rogge](https://github.com/nielsrogge) | [](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/LayoutLM/Fine_tuning_LayoutLMForSequenceClassification_on_RVL_CDIP.ipynb)|
+|[Wav2Vec2 CTC decoding with GPT2 adjustment](https://github.com/voidful/huggingface_notebook/blob/main/xlsr_gpt.ipynb) | How to decode CTC sequence with language model adjustment | [Eric Lam](https://github.com/voidful) | [](https://colab.research.google.com/drive/1e_z5jQHYbO2YKEaUgzb1ww1WwiAyydAj?usp=sharing)|
+|[Fine-tune BART for summarization in two languages with Trainer class](https://github.com/elsanns/xai-nlp-notebooks/blob/master/fine_tune_bart_summarization_two_langs.ipynb) | How to fine-tune BART for summarization in two languages with Trainer class | [Eliza Szczechla](https://github.com/elsanns) | [](https://colab.research.google.com/github/elsanns/xai-nlp-notebooks/blob/master/fine_tune_bart_summarization_two_langs.ipynb)|
+|[Evaluate Big Bird on Trivia QA](https://github.com/patrickvonplaten/notebooks/blob/master/Evaluating_Big_Bird_on_TriviaQA.ipynb) | How to evaluate BigBird on long document question answering on Trivia QA | [Patrick von Platen](https://github.com/patrickvonplaten) | [](https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/Evaluating_Big_Bird_on_TriviaQA.ipynb)|
+| [Create video captions using Wav2Vec2](https://github.com/Muennighoff/ytclipcc/blob/main/wav2vec_youtube_captions.ipynb) | How to create YouTube captions from any video by transcribing the audio with Wav2Vec | [Niklas Muennighoff](https://github.com/Muennighoff) |[](https://colab.research.google.com/github/Muennighoff/ytclipcc/blob/main/wav2vec_youtube_captions.ipynb) |
+| [Fine-tune the Vision Transformer on CIFAR-10 using PyTorch Lightning](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/VisionTransformer/Fine_tuning_the_Vision_Transformer_on_CIFAR_10_with_PyTorch_Lightning.ipynb) | How to fine-tune the Vision Transformer (ViT) on CIFAR-10 using HuggingFace Transformers, Datasets and PyTorch Lightning | [Niels Rogge](https://github.com/nielsrogge) |[](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/VisionTransformer/Fine_tuning_the_Vision_Transformer_on_CIFAR_10_with_PyTorch_Lightning.ipynb) |
+| [Fine-tune the Vision Transformer on CIFAR-10 using the 🤗 Trainer](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/VisionTransformer/Fine_tuning_the_Vision_Transformer_on_CIFAR_10_with_the_%F0%9F%A4%97_Trainer.ipynb) | How to fine-tune the Vision Transformer (ViT) on CIFAR-10 using HuggingFace Transformers, Datasets and the 🤗 Trainer | [Niels Rogge](https://github.com/nielsrogge) |[](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/VisionTransformer/Fine_tuning_the_Vision_Transformer_on_CIFAR_10_with_the_%F0%9F%A4%97_Trainer.ipynb) |
+| [Evaluate LUKE on Open Entity, an entity typing dataset](https://github.com/studio-ousia/luke/blob/master/notebooks/huggingface_open_entity.ipynb) | How to evaluate *LukeForEntityClassification* on the Open Entity dataset | [Ikuya Yamada](https://github.com/ikuyamada) |[](https://colab.research.google.com/github/studio-ousia/luke/blob/master/notebooks/huggingface_open_entity.ipynb) |
+| [Evaluate LUKE on TACRED, a relation extraction dataset](https://github.com/studio-ousia/luke/blob/master/notebooks/huggingface_tacred.ipynb) | How to evaluate *LukeForEntityPairClassification* on the TACRED dataset | [Ikuya Yamada](https://github.com/ikuyamada) |[](https://colab.research.google.com/github/studio-ousia/luke/blob/master/notebooks/huggingface_tacred.ipynb) |
+| [Evaluate LUKE on CoNLL-2003, an important NER benchmark](https://github.com/studio-ousia/luke/blob/master/notebooks/huggingface_conll_2003.ipynb) | How to evaluate *LukeForEntitySpanClassification* on the CoNLL-2003 dataset | [Ikuya Yamada](https://github.com/ikuyamada) |[](https://colab.research.google.com/github/studio-ousia/luke/blob/master/notebooks/huggingface_conll_2003.ipynb) |
+| [Evaluate BigBird-Pegasus on PubMed dataset](https://github.com/vasudevgupta7/bigbird/blob/main/notebooks/bigbird_pegasus_evaluation.ipynb) | How to evaluate *BigBirdPegasusForConditionalGeneration* on PubMed dataset | [Vasudev Gupta](https://github.com/vasudevgupta7) | [](https://colab.research.google.com/github/vasudevgupta7/bigbird/blob/main/notebooks/bigbird_pegasus_evaluation.ipynb) |
+| [Speech Emotion Classification with Wav2Vec2](https://github/m3hrdadfi/soxan/blob/main/notebooks/Emotion_recognition_in_Greek_speech_using_Wav2Vec2.ipynb) | How to leverage a pretrained Wav2Vec2 model for Emotion Classification on the MEGA dataset | [Mehrdad Farahani](https://github.com/m3hrdadfi) | [](https://colab.research.google.com/github/m3hrdadfi/soxan/blob/main/notebooks/Emotion_recognition_in_Greek_speech_using_Wav2Vec2.ipynb) |
+| [Detect objects in an image with DETR](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/DETR/DETR_minimal_example_(with_DetrFeatureExtractor).ipynb) | How to use a trained *DetrForObjectDetection* model to detect objects in an image and visualize attention | [Niels Rogge](https://github.com/NielsRogge) | [](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/DETR/DETR_minimal_example_(with_DetrFeatureExtractor).ipynb) |
+| [Fine-tune DETR on a custom object detection dataset](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/DETR/Fine_tuning_DetrForObjectDetection_on_custom_dataset_(balloon).ipynb) | How to fine-tune *DetrForObjectDetection* on a custom object detection dataset | [Niels Rogge](https://github.com/NielsRogge) | [](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/DETR/Fine_tuning_DetrForObjectDetection_on_custom_dataset_(balloon).ipynb) |
+| [Finetune T5 for Named Entity Recognition](https://github.com/ToluClassics/Notebooks/blob/main/T5_Ner_Finetuning.ipynb) | How to fine-tune *T5* on a Named Entity Recognition Task | [Ogundepo Odunayo](https://github.com/ToluClassics) | [](https://colab.research.google.com/drive/1obr78FY_cBmWY5ODViCmzdY6O1KB65Vc?usp=sharing) |
diff --git a/docs/source/en/contributing.md b/docs/source/en/contributing.md
new file mode 120000
index 00000000000000..c97564d93a7f0a
--- /dev/null
+++ b/docs/source/en/contributing.md
@@ -0,0 +1 @@
+../../../CONTRIBUTING.md
\ No newline at end of file
diff --git a/docs/source/en/converting_tensorflow_models.mdx b/docs/source/en/converting_tensorflow_models.mdx
new file mode 100644
index 00000000000000..c11e4e62b8086e
--- /dev/null
+++ b/docs/source/en/converting_tensorflow_models.mdx
@@ -0,0 +1,162 @@
+
+
+# Converting Tensorflow Checkpoints
+
+A command-line interface is provided to convert original Bert/GPT/GPT-2/Transformer-XL/XLNet/XLM checkpoints to models
+that can be loaded using the `from_pretrained` methods of the library.
+
+
+
+Since 2.3.0 the conversion script is now part of the transformers CLI (**transformers-cli**) available in any
+transformers >= 2.3.0 installation.
+
+The documentation below reflects the **transformers-cli convert** command format.
+
+
+
+## BERT
+
+You can convert any TensorFlow checkpoint for BERT (in particular [the pre-trained models released by Google](https://github.com/google-research/bert#pre-trained-models)) in a PyTorch save file by using the
+[convert_bert_original_tf_checkpoint_to_pytorch.py](https://github.com/huggingface/transformers/tree/main/src/transformers/models/bert/convert_bert_original_tf_checkpoint_to_pytorch.py) script.
+
+This CLI takes as input a TensorFlow checkpoint (three files starting with `bert_model.ckpt`) and the associated
+configuration file (`bert_config.json`), and creates a PyTorch model for this configuration, loads the weights from
+the TensorFlow checkpoint in the PyTorch model and saves the resulting model in a standard PyTorch save file that can
+be imported using `from_pretrained()` (see example in [quicktour](quicktour) , [run_glue.py](https://github.com/huggingface/transformers/tree/main/examples/pytorch/text-classification/run_glue.py) ).
+
+You only need to run this conversion script **once** to get a PyTorch model. You can then disregard the TensorFlow
+checkpoint (the three files starting with `bert_model.ckpt`) but be sure to keep the configuration file (\
+`bert_config.json`) and the vocabulary file (`vocab.txt`) as these are needed for the PyTorch model too.
+
+To run this specific conversion script you will need to have TensorFlow and PyTorch installed (`pip install tensorflow`). The rest of the repository only requires PyTorch.
+
+Here is an example of the conversion process for a pre-trained `BERT-Base Uncased` model:
+
+```bash
+export BERT_BASE_DIR=/path/to/bert/uncased_L-12_H-768_A-12
+
+transformers-cli convert --model_type bert \
+ --tf_checkpoint $BERT_BASE_DIR/bert_model.ckpt \
+ --config $BERT_BASE_DIR/bert_config.json \
+ --pytorch_dump_output $BERT_BASE_DIR/pytorch_model.bin
+```
+
+You can download Google's pre-trained models for the conversion [here](https://github.com/google-research/bert#pre-trained-models).
+
+## ALBERT
+
+Convert TensorFlow model checkpoints of ALBERT to PyTorch using the
+[convert_albert_original_tf_checkpoint_to_pytorch.py](https://github.com/huggingface/transformers/tree/main/src/transformers/models/albert/convert_albert_original_tf_checkpoint_to_pytorch.py) script.
+
+The CLI takes as input a TensorFlow checkpoint (three files starting with `model.ckpt-best`) and the accompanying
+configuration file (`albert_config.json`), then creates and saves a PyTorch model. To run this conversion you will
+need to have TensorFlow and PyTorch installed.
+
+Here is an example of the conversion process for the pre-trained `ALBERT Base` model:
+
+```bash
+export ALBERT_BASE_DIR=/path/to/albert/albert_base
+
+transformers-cli convert --model_type albert \
+ --tf_checkpoint $ALBERT_BASE_DIR/model.ckpt-best \
+ --config $ALBERT_BASE_DIR/albert_config.json \
+ --pytorch_dump_output $ALBERT_BASE_DIR/pytorch_model.bin
+```
+
+You can download Google's pre-trained models for the conversion [here](https://github.com/google-research/albert#pre-trained-models).
+
+## OpenAI GPT
+
+Here is an example of the conversion process for a pre-trained OpenAI GPT model, assuming that your NumPy checkpoint
+save as the same format than OpenAI pretrained model (see [here](https://github.com/openai/finetune-transformer-lm)\
+)
+
+```bash
+export OPENAI_GPT_CHECKPOINT_FOLDER_PATH=/path/to/openai/pretrained/numpy/weights
+
+transformers-cli convert --model_type gpt \
+ --tf_checkpoint $OPENAI_GPT_CHECKPOINT_FOLDER_PATH \
+ --pytorch_dump_output $PYTORCH_DUMP_OUTPUT \
+ [--config OPENAI_GPT_CONFIG] \
+ [--finetuning_task_name OPENAI_GPT_FINETUNED_TASK] \
+```
+
+## OpenAI GPT-2
+
+Here is an example of the conversion process for a pre-trained OpenAI GPT-2 model (see [here](https://github.com/openai/gpt-2))
+
+```bash
+export OPENAI_GPT2_CHECKPOINT_PATH=/path/to/gpt2/pretrained/weights
+
+transformers-cli convert --model_type gpt2 \
+ --tf_checkpoint $OPENAI_GPT2_CHECKPOINT_PATH \
+ --pytorch_dump_output $PYTORCH_DUMP_OUTPUT \
+ [--config OPENAI_GPT2_CONFIG] \
+ [--finetuning_task_name OPENAI_GPT2_FINETUNED_TASK]
+```
+
+## Transformer-XL
+
+Here is an example of the conversion process for a pre-trained Transformer-XL model (see [here](https://github.com/kimiyoung/transformer-xl/tree/master/tf#obtain-and-evaluate-pretrained-sota-models))
+
+```bash
+export TRANSFO_XL_CHECKPOINT_FOLDER_PATH=/path/to/transfo/xl/checkpoint
+
+transformers-cli convert --model_type transfo_xl \
+ --tf_checkpoint $TRANSFO_XL_CHECKPOINT_FOLDER_PATH \
+ --pytorch_dump_output $PYTORCH_DUMP_OUTPUT \
+ [--config TRANSFO_XL_CONFIG] \
+ [--finetuning_task_name TRANSFO_XL_FINETUNED_TASK]
+```
+
+## XLNet
+
+Here is an example of the conversion process for a pre-trained XLNet model:
+
+```bash
+export TRANSFO_XL_CHECKPOINT_PATH=/path/to/xlnet/checkpoint
+export TRANSFO_XL_CONFIG_PATH=/path/to/xlnet/config
+
+transformers-cli convert --model_type xlnet \
+ --tf_checkpoint $TRANSFO_XL_CHECKPOINT_PATH \
+ --config $TRANSFO_XL_CONFIG_PATH \
+ --pytorch_dump_output $PYTORCH_DUMP_OUTPUT \
+ [--finetuning_task_name XLNET_FINETUNED_TASK] \
+```
+
+## XLM
+
+Here is an example of the conversion process for a pre-trained XLM model:
+
+```bash
+export XLM_CHECKPOINT_PATH=/path/to/xlm/checkpoint
+
+transformers-cli convert --model_type xlm \
+ --tf_checkpoint $XLM_CHECKPOINT_PATH \
+ --pytorch_dump_output $PYTORCH_DUMP_OUTPUT
+ [--config XML_CONFIG] \
+ [--finetuning_task_name XML_FINETUNED_TASK]
+```
+
+## T5
+
+Here is an example of the conversion process for a pre-trained T5 model:
+
+```bash
+export T5=/path/to/t5/uncased_L-12_H-768_A-12
+
+transformers-cli convert --model_type t5 \
+ --tf_checkpoint $T5/t5_model.ckpt \
+ --config $T5/t5_config.json \
+ --pytorch_dump_output $T5/pytorch_model.bin
+```
diff --git a/docs/source/en/create_a_model.mdx b/docs/source/en/create_a_model.mdx
new file mode 100644
index 00000000000000..51d2b2cb90cb4b
--- /dev/null
+++ b/docs/source/en/create_a_model.mdx
@@ -0,0 +1,355 @@
+
+
+# Create a custom architecture
+
+An [`AutoClass`](model_doc/auto) automatically infers the model architecture and downloads pretrained configuration and weights. Generally, we recommend using an `AutoClass` to produce checkpoint-agnostic code. But users who want more control over specific model parameters can create a custom 🤗 Transformers model from just a few base classes. This could be particularly useful for anyone who is interested in studying, training or experimenting with a 🤗 Transformers model. In this guide, dive deeper into creating a custom model without an `AutoClass`. Learn how to:
+
+- Load and customize a model configuration.
+- Create a model architecture.
+- Create a slow and fast tokenizer for text.
+- Create a feature extractor for audio or image tasks.
+- Create a processor for multimodal tasks.
+
+## Configuration
+
+A [configuration](main_classes/configuration) refers to a model's specific attributes. Each model configuration has different attributes; for instance, all NLP models have the `hidden_size`, `num_attention_heads`, `num_hidden_layers` and `vocab_size` attributes in common. These attributes specify the number of attention heads or hidden layers to construct a model with.
+
+Get a closer look at [DistilBERT](model_doc/distilbert) by accessing [`DistilBertConfig`] to inspect it's attributes:
+
+```py
+>>> from transformers import DistilBertConfig
+
+>>> config = DistilBertConfig()
+>>> print(config)
+DistilBertConfig {
+ "activation": "gelu",
+ "attention_dropout": 0.1,
+ "dim": 768,
+ "dropout": 0.1,
+ "hidden_dim": 3072,
+ "initializer_range": 0.02,
+ "max_position_embeddings": 512,
+ "model_type": "distilbert",
+ "n_heads": 12,
+ "n_layers": 6,
+ "pad_token_id": 0,
+ "qa_dropout": 0.1,
+ "seq_classif_dropout": 0.2,
+ "sinusoidal_pos_embds": false,
+ "transformers_version": "4.16.2",
+ "vocab_size": 30522
+}
+```
+
+[`DistilBertConfig`] displays all the default attributes used to build a base [`DistilBertModel`]. All attributes are customizable, creating space for experimentation. For example, you can customize a default model to:
+
+- Try a different activation function with the `activation` parameter.
+- Use a higher dropout ratio for the attention probabilities with the `attention_dropout` parameter.
+
+```py
+>>> my_config = DistilBertConfig(activation="relu", attention_dropout=0.4)
+>>> print(my_config)
+DistilBertConfig {
+ "activation": "relu",
+ "attention_dropout": 0.4,
+ "dim": 768,
+ "dropout": 0.1,
+ "hidden_dim": 3072,
+ "initializer_range": 0.02,
+ "max_position_embeddings": 512,
+ "model_type": "distilbert",
+ "n_heads": 12,
+ "n_layers": 6,
+ "pad_token_id": 0,
+ "qa_dropout": 0.1,
+ "seq_classif_dropout": 0.2,
+ "sinusoidal_pos_embds": false,
+ "transformers_version": "4.16.2",
+ "vocab_size": 30522
+}
+```
+
+Pretrained model attributes can be modified in the [`~PretrainedConfig.from_pretrained`] function:
+
+```py
+>>> my_config = DistilBertConfig.from_pretrained("distilbert-base-uncased", activation="relu", attention_dropout=0.4)
+```
+
+Once you are satisfied with your model configuration, you can save it with [`~PretrainedConfig.save_pretrained`]. Your configuration file is stored as a JSON file in the specified save directory:
+
+```py
+>>> my_config.save_pretrained(save_directory="./your_model_save_path")
+```
+
+To reuse the configuration file, load it with [`~PretrainedConfig.from_pretrained`]:
+
+```py
+>>> my_config = DistilBertConfig.from_pretrained("./your_model_save_path/my_config.json")
+```
+
+
+
+You can also save your configuration file as a dictionary or even just the difference between your custom configuration attributes and the default configuration attributes! See the [configuration](main_classes/configuration) documentation for more details.
+
+
+
+## Model
+
+The next step is to create a [model](main_classes/models). The model - also loosely referred to as the architecture - defines what each layer is doing and what operations are happening. Attributes like `num_hidden_layers` from the configuration are used to define the architecture. Every model shares the base class [`PreTrainedModel`] and a few common methods like resizing input embeddings and pruning self-attention heads. In addition, all models are also either a [`torch.nn.Module`](https://pytorch.org/docs/stable/generated/torch.nn.Module.html), [`tf.keras.Model`](https://www.tensorflow.org/api_docs/python/tf/keras/Model) or [`flax.linen.Module`](https://flax.readthedocs.io/en/latest/flax.linen.html#module) subclass. This means models are compatible with each of their respective framework's usage.
+
+
+
+Load your custom configuration attributes into the model:
+
+```py
+>>> from transformers import DistilBertModel
+
+>>> my_config = DistilBertConfig.from_pretrained("./your_model_save_path/my_config.json")
+>>> model = DistilBertModel(my_config)
+```
+
+This creates a model with random values instead of pretrained weights. You won't be able to use this model for anything useful yet until you train it. Training is a costly and time-consuming process. It is generally better to use a pretrained model to obtain better results faster, while using only a fraction of the resources required for training.
+
+Create a pretrained model with [`~PreTrainedModel.from_pretrained`]:
+
+```py
+>>> model = DistilBertModel.from_pretrained("distilbert-base-uncased")
+```
+
+When you load pretrained weights, the default model configuration is automatically loaded if the model is provided by 🤗 Transformers. However, you can still replace - some or all of - the default model configuration attributes with your own if you'd like:
+
+```py
+>>> model = DistilBertModel.from_pretrained("distilbert-base-uncased", config=my_config)
+```
+
+
+Load your custom configuration attributes into the model:
+
+```py
+>>> from transformers import TFDistilBertModel
+
+>>> my_config = DistilBertConfig.from_pretrained("./your_model_save_path/my_config.json")
+>>> tf_model = TFDistilBertModel(my_config)
+```
+
+This creates a model with random values instead of pretrained weights. You won't be able to use this model for anything useful yet until you train it. Training is a costly and time-consuming process. It is generally better to use a pretrained model to obtain better results faster, while using only a fraction of the resources required for training.
+
+Create a pretrained model with [`~TFPreTrainedModel.from_pretrained`]:
+
+```py
+>>> tf_model = TFDistilBertModel.from_pretrained("distilbert-base-uncased")
+```
+
+When you load pretrained weights, the default model configuration is automatically loaded if the model is provided by 🤗 Transformers. However, you can still replace - some or all of - the default model configuration attributes with your own if you'd like:
+
+```py
+>>> tf_model = TFDistilBertModel.from_pretrained("distilbert-base-uncased", config=my_config)
+```
+
+
+
+### Model heads
+
+At this point, you have a base DistilBERT model which outputs the *hidden states*. The hidden states are passed as inputs to a model head to produce the final output. 🤗 Transformers provides a different model head for each task as long as a model supports the task (i.e., you can't use DistilBERT for a sequence-to-sequence task like translation).
+
+
+
+For example, [`DistilBertForSequenceClassification`] is a base DistilBERT model with a sequence classification head. The sequence classification head is a linear layer on top of the pooled outputs.
+
+```py
+>>> from transformers import DistilBertForSequenceClassification
+
+>>> model = DistilBertForSequenceClassification.from_pretrained("distilbert-base-uncased")
+```
+
+Easily reuse this checkpoint for another task by switching to a different model head. For a question answering task, you would use the [`DistilBertForQuestionAnswering`] model head. The question answering head is similar to the sequence classification head except it is a linear layer on top of the hidden states output.
+
+```py
+>>> from transformers import DistilBertForQuestionAnswering
+
+>>> model = DistilBertForQuestionAnswering.from_pretrained("distilbert-base-uncased")
+```
+
+
+For example, [`TFDistilBertForSequenceClassification`] is a base DistilBERT model with a sequence classification head. The sequence classification head is a linear layer on top of the pooled outputs.
+
+```py
+>>> from transformers import TFDistilBertForSequenceClassification
+
+>>> tf_model = TFDistilBertForSequenceClassification.from_pretrained("distilbert-base-uncased")
+```
+
+Easily reuse this checkpoint for another task by switching to a different model head. For a question answering task, you would use the [`TFDistilBertForQuestionAnswering`] model head. The question answering head is similar to the sequence classification head except it is a linear layer on top of the hidden states output.
+
+```py
+>>> from transformers import TFDistilBertForQuestionAnswering
+
+>>> tf_model = TFDistilBertForQuestionAnswering.from_pretrained("distilbert-base-uncased")
+```
+
+
+
+## Tokenizer
+
+The last base class you need before using a model for textual data is a [tokenizer](main_classes/tokenizer) to convert raw text to tensors. There are two types of tokenizers you can use with 🤗 Transformers:
+
+- [`PreTrainedTokenizer`]: a Python implementation of a tokenizer.
+- [`PreTrainedTokenizerFast`]: a tokenizer from our Rust-based [🤗 Tokenizer](https://huggingface.co/docs/tokenizers/python/latest/) library. This tokenizer type is significantly faster - especially during batch tokenization - due to it's Rust implementation. The fast tokenizer also offers additional methods like *offset mapping* which maps tokens to their original words or characters.
+
+Both tokenizers support common methods such as encoding and decoding, adding new tokens, and managing special tokens.
+
+
+
+Not every model supports a fast tokenizer. Take a look at this [table](index#supported-frameworks) to check if a model has fast tokenizer support.
+
+
+
+If you trained your own tokenizer, you can create one from your *vocabulary* file:
+
+```py
+>>> from transformers import DistilBertTokenizer
+
+>>> my_tokenizer = DistilBertTokenizer(vocab_file="my_vocab_file.txt", do_lower_case=False, padding_side="left")
+```
+
+It is important to remember the vocabulary from a custom tokenizer will be different from the vocabulary generated by a pretrained model's tokenizer. You need to use a pretrained model's vocabulary if you are using a pretrained model, otherwise the inputs won't make sense. Create a tokenizer with a pretrained model's vocabulary with the [`DistilBertTokenizer`] class:
+
+```py
+>>> from transformers import DistilBertTokenizer
+
+>>> slow_tokenizer = DistilBertTokenizer.from_pretrained("distilbert-base-uncased")
+```
+
+Create a fast tokenizer with the [`DistilBertTokenizerFast`] class:
+
+```py
+>>> from transformers import DistilBertTokenizerFast
+
+>>> fast_tokenizer = DistilBertTokenizerFast.from_pretrained("distilbert-base-uncased")
+```
+
+
+
+By default, [`AutoTokenizer`] will try to load a fast tokenizer. You can disable this behavior by setting `use_fast=False` in `from_pretrained`.
+
+
+
+## Feature Extractor
+
+A feature extractor processes audio or image inputs. It inherits from the base [`~feature_extraction_utils.FeatureExtractionMixin`] class, and may also inherit from the [`ImageFeatureExtractionMixin`] class for processing image features or the [`SequenceFeatureExtractor`] class for processing audio inputs.
+
+Depending on whether you are working on an audio or vision task, create a feature extractor associated with the model you're using. For example, create a default [`ViTFeatureExtractor`] if you are using [ViT](model_doc/vit) for image classification:
+
+```py
+>>> from transformers import ViTFeatureExtractor
+
+>>> vit_extractor = ViTFeatureExtractor()
+>>> print(vit_extractor)
+ViTFeatureExtractor {
+ "do_normalize": true,
+ "do_resize": true,
+ "feature_extractor_type": "ViTFeatureExtractor",
+ "image_mean": [
+ 0.5,
+ 0.5,
+ 0.5
+ ],
+ "image_std": [
+ 0.5,
+ 0.5,
+ 0.5
+ ],
+ "resample": 2,
+ "size": 224
+}
+```
+
+
+
+If you aren't looking for any customization, just use the `from_pretrained` method to load a model's default feature extractor parameters.
+
+
+
+Modify any of the [`ViTFeatureExtractor`] parameters to create your custom feature extractor:
+
+```py
+>>> from transformers import ViTFeatureExtractor
+
+>>> my_vit_extractor = ViTFeatureExtractor(resample="PIL.Image.BOX", do_normalize=False, image_mean=[0.3, 0.3, 0.3])
+>>> print(my_vit_extractor)
+ViTFeatureExtractor {
+ "do_normalize": false,
+ "do_resize": true,
+ "feature_extractor_type": "ViTFeatureExtractor",
+ "image_mean": [
+ 0.3,
+ 0.3,
+ 0.3
+ ],
+ "image_std": [
+ 0.5,
+ 0.5,
+ 0.5
+ ],
+ "resample": "PIL.Image.BOX",
+ "size": 224
+}
+```
+
+For audio inputs, you can create a [`Wav2Vec2FeatureExtractor`] and customize the parameters in a similar way:
+
+```py
+>>> from transformers import Wav2Vec2FeatureExtractor
+
+>>> w2v2_extractor = Wav2Vec2FeatureExtractor()
+>>> print(w2v2_extractor)
+Wav2Vec2FeatureExtractor {
+ "do_normalize": true,
+ "feature_extractor_type": "Wav2Vec2FeatureExtractor",
+ "feature_size": 1,
+ "padding_side": "right",
+ "padding_value": 0.0,
+ "return_attention_mask": false,
+ "sampling_rate": 16000
+}
+```
+
+## Processor
+
+For models that support multimodal tasks, 🤗 Transformers offers a processor class that conveniently wraps a feature extractor and tokenizer into a single object. For example, let's use the [`Wav2Vec2Processor`] for an automatic speech recognition task (ASR). ASR transcribes audio to text, so you will need a feature extractor and a tokenizer.
+
+Create a feature extractor to handle the audio inputs:
+
+```py
+>>> from transformers import Wav2Vec2FeatureExtractor
+
+>>> feature_extractor = Wav2Vec2FeatureExtractor(padding_value=1.0, do_normalize=True)
+```
+
+Create a tokenizer to handle the text inputs:
+
+```py
+>>> from transformers import Wav2Vec2CTCTokenizer
+
+>>> tokenizer = Wav2Vec2CTCTokenizer(vocab_file="my_vocab_file.txt")
+```
+
+Combine the feature extractor and tokenizer in [`Wav2Vec2Processor`]:
+
+```py
+>>> from transformers import Wav2Vec2Processor
+
+>>> processor = Wav2Vec2Processor(feature_extractor=feature_extractor, tokenizer=tokenizer)
+```
+
+With two basic classes - configuration and model - and an additional preprocessing class (tokenizer, feature extractor, or processor), you can create any of the models supported by 🤗 Transformers. Each of these base classes are configurable, allowing you to use the specific attributes you want. You can easily setup a model for training or modify an existing pretrained model to fine-tune.
\ No newline at end of file
diff --git a/docs/source/en/custom_models.mdx b/docs/source/en/custom_models.mdx
new file mode 100644
index 00000000000000..05d0a6c2acf62d
--- /dev/null
+++ b/docs/source/en/custom_models.mdx
@@ -0,0 +1,349 @@
+
+
+# Sharing custom models
+
+The 🤗 Transformers library is designed to be easily extensible. Every model is fully coded in a given subfolder
+of the repository with no abstraction, so you can easily copy a modeling file and tweak it to your needs.
+
+If you are writing a brand new model, it might be easier to start from scratch. In this tutorial, we will show you
+how to write a custom model and its configuration so it can be used inside Transformers, and how you can share it
+with the community (with the code it relies on) so that anyone can use it, even if it's not present in the 🤗
+Transformers library.
+
+We will illustrate all of this on a ResNet model, by wrapping the ResNet class of the
+[timm library](https://github.com/rwightman/pytorch-image-models/tree/master/timm) into a [`PreTrainedModel`].
+
+## Writing a custom configuration
+
+Before we dive into the model, let's first write its configuration. The configuration of a model is an object that
+will contain all the necessary information to build the model. As we will see in the next section, the model can only
+take a `config` to be initialized, so we really need that object to be as complete as possible.
+
+In our example, we will take a couple of arguments of the ResNet class that we might want to tweak. Different
+configurations will then give us the different types of ResNets that are possible. We then just store those arguments,
+after checking the validity of a few of them.
+
+```python
+from transformers import PretrainedConfig
+from typing import List
+
+
+class ResnetConfig(PretrainedConfig):
+ model_type = "resnet"
+
+ def __init__(
+ self,
+ block_type="bottleneck",
+ layers: List[int] = [3, 4, 6, 3],
+ num_classes: int = 1000,
+ input_channels: int = 3,
+ cardinality: int = 1,
+ base_width: int = 64,
+ stem_width: int = 64,
+ stem_type: str = "",
+ avg_down: bool = False,
+ **kwargs,
+ ):
+ if block_type not in ["basic", "bottleneck"]:
+ raise ValueError(f"`block` must be 'basic' or bottleneck', got {block}.")
+ if stem_type not in ["", "deep", "deep-tiered"]:
+ raise ValueError(f"`stem_type` must be '', 'deep' or 'deep-tiered', got {block}.")
+
+ self.block_type = block_type
+ self.layers = layers
+ self.num_classes = num_classes
+ self.input_channels = input_channels
+ self.cardinality = cardinality
+ self.base_width = base_width
+ self.stem_width = stem_width
+ self.stem_type = stem_type
+ self.avg_down = avg_down
+ super().__init__(**kwargs)
+```
+
+The three important things to remember when writing you own configuration are the following:
+- you have to inherit from `PretrainedConfig`,
+- the `__init__` of your `PretrainedConfig` must accept any kwargs,
+- those `kwargs` need to be passed to the superclass `__init__`.
+
+The inheritance is to make sure you get all the functionality from the 🤗 Transformers library, while the two other
+constraints come from the fact a `PretrainedConfig` has more fields than the ones you are setting. When reloading a
+config with the `from_pretrained` method, those fields need to be accepted by your config and then sent to the
+superclass.
+
+Defining a `model_type` for your configuration (here `model_type="resnet"`) is not mandatory, unless you want to
+register your model with the auto classes (see last section).
+
+With this done, you can easily create and save your configuration like you would do with any other model config of the
+library. Here is how we can create a resnet50d config and save it:
+
+```py
+resnet50d_config = ResnetConfig(block_type="bottleneck", stem_width=32, stem_type="deep", avg_down=True)
+resnet50d_config.save_pretrained("custom-resnet")
+```
+
+This will save a file named `config.json` inside the folder `custom-resnet`. You can then reload your config with the
+`from_pretrained` method:
+
+```py
+resnet50d_config = ResnetConfig.from_pretrained("custom-resnet")
+```
+
+You can also use any other method of the [`PretrainedConfig`] class, like [`~PretrainedConfig.push_to_hub`] to
+directly upload your config to the Hub.
+
+## Writing a custom model
+
+Now that we have our ResNet configuration, we can go on writing the model. We will actually write two: one that
+extracts the hidden features from a batch of images (like [`BertModel`]) and one that is suitable for image
+classification (like [`BertForSequenceClassification`]).
+
+As we mentioned before, we'll only write a loose wrapper of the model to keep it simple for this example. The only
+thing we need to do before writing this class is a map between the block types and actual block classes. Then the
+model is defined from the configuration by passing everything to the `ResNet` class:
+
+```py
+from transformers import PreTrainedModel
+from timm.models.resnet import BasicBlock, Bottleneck, ResNet
+from .configuration_resnet import ResnetConfig
+
+
+BLOCK_MAPPING = {"basic": BasicBlock, "bottleneck": Bottleneck}
+
+
+class ResnetModel(PreTrainedModel):
+ config_class = ResnetConfig
+
+ def __init__(self, config):
+ super().__init__(config)
+ block_layer = BLOCK_MAPPING[config.block_type]
+ self.model = ResNet(
+ block_layer,
+ config.layers,
+ num_classes=config.num_classes,
+ in_chans=config.input_channels,
+ cardinality=config.cardinality,
+ base_width=config.base_width,
+ stem_width=config.stem_width,
+ stem_type=config.stem_type,
+ avg_down=config.avg_down,
+ )
+
+ def forward(self, tensor):
+ return self.model.forward_features(tensor)
+```
+
+For the model that will classify images, we just change the forward method:
+
+```py
+class ResnetModelForImageClassification(PreTrainedModel):
+ config_class = ResnetConfig
+
+ def __init__(self, config):
+ super().__init__(config)
+ block_layer = BLOCK_MAPPING[config.block_type]
+ self.model = ResNet(
+ block_layer,
+ config.layers,
+ num_classes=config.num_classes,
+ in_chans=config.input_channels,
+ cardinality=config.cardinality,
+ base_width=config.base_width,
+ stem_width=config.stem_width,
+ stem_type=config.stem_type,
+ avg_down=config.avg_down,
+ )
+
+ def forward(self, tensor, labels=None):
+ logits = self.model(tensor)
+ if labels is not None:
+ loss = torch.nn.cross_entropy(logits, labels)
+ return {"loss": loss, "logits": logits}
+ return {"logits": logits}
+```
+
+In both cases, notice how we inherit from `PreTrainedModel` and call the superclass initialization with the `config`
+(a bit like when you write a regular `torch.nn.Module`). The line that sets the `config_class` is not mandatory, unless
+you want to register your model with the auto classes (see last section).
+
+
+
+If your model is very similar to a model inside the library, you can re-use the same configuration as this model.
+
+
+
+You can have your model return anything you want, but returning a dictionary like we did for
+`ResnetModelForImageClassification`, with the loss included when labels are passed, will make your model directly
+usable inside the [`Trainer`] class. Using another output format is fine as long as you are planning on using your own
+training loop or another library for training.
+
+Now that we have our model class, let's create one:
+
+```py
+resnet50d = ResnetModelForImageClassification(resnet50d_config)
+```
+
+Again, you can use any of the methods of [`PreTrainedModel`], like [`~PreTrainedModel.save_pretrained`] or
+[`~PreTrainedModel.push_to_hub`]. We will use the second in the next section, and see how to push the model weights
+with the code of our model. But first, let's load some pretrained weights inside our model.
+
+In your own use case, you will probably be training your custom model on your own data. To go fast for this tutorial,
+we will use the pretrained version of the resnet50d. Since our model is just a wrapper around it, it's going to be
+easy to transfer those weights:
+
+```py
+import timm
+
+pretrained_model = timm.create_model("resnet50d", pretrained=True)
+resnet50d.model.load_state_dict(pretrained_model.state_dict())
+```
+
+Now let's see how to make sure that when we do [`~PreTrainedModel.save_pretrained`] or [`~PreTrainedModel.push_to_hub`], the
+code of the model is saved.
+
+## Sending the code to the Hub
+
+
+
+This API is experimental and may have some slight breaking changes in the next releases.
+
+
+
+First, make sure your model is fully defined in a `.py` file. It can rely on relative imports to some other files as
+long as all the files are in the same directory (we don't support submodules for this feature yet). For our example,
+we'll define a `modeling_resnet.py` file and a `configuration_resnet.py` file in a folder of the current working
+directory named `resnet_model`. The configuration file contains the code for `ResnetConfig` and the modeling file
+contains the code of `ResnetModel` and `ResnetModelForImageClassification`.
+
+```
+.
+└── resnet_model
+ ├── __init__.py
+ ├── configuration_resnet.py
+ └── modeling_resnet.py
+```
+
+The `__init__.py` can be empty, it's just there so that Python detects `resnet_model` can be use as a module.
+
+
+
+If copying a modeling files from the library, you will need to replace all the relative imports at the top of the file
+to import from the `transformers` package.
+
+
+
+Note that you can re-use (or subclass) an existing configuration/model.
+
+To share your model with the community, follow those steps: first import the ResNet model and config from the newly
+created files:
+
+```py
+from resnet_model.configuration_resnet import ResnetConfig
+from resnet_model.modeling_resnet import ResnetModel, ResnetModelForImageClassification
+```
+
+Then you have to tell the library you want to copy the code files of those objects when using the `save_pretrained`
+method and properly register them with a given Auto class (especially for models), just run:
+
+```py
+ResnetConfig.register_for_auto_class()
+ResnetModel.register_for_auto_class("AutoModel")
+ResnetModelForImageClassification.register_for_auto_class("AutoModelForImageClassification")
+```
+
+Note that there is no need to specify an auto class for the configuration (there is only one auto class for them,
+[`AutoConfig`]) but it's different for models. Your custom model could be suitable for many different tasks, so you
+have to specify which one of the auto classes is the correct one for your model.
+
+Next, let's create the config and models as we did before:
+
+```py
+resnet50d_config = ResnetConfig(block_type="bottleneck", stem_width=32, stem_type="deep", avg_down=True)
+resnet50d = ResnetModelForImageClassification(resnet50d_config)
+
+pretrained_model = timm.create_model("resnet50d", pretrained=True)
+resnet50d.model.load_state_dict(pretrained_model.state_dict())
+```
+
+Now to send the model to the Hub, make sure you are logged in. Either run in your terminal:
+
+```bash
+huggingface-cli login
+```
+
+or from a notebook:
+
+```py
+from huggingface_hub import notebook_login
+
+notebook_login()
+```
+
+You can then push to to your own namespace (or an organization you are a member of) like this:
+
+```py
+resnet50d.push_to_hub("custom-resnet50d")
+```
+
+On top of the modeling weights and the configuration in json format, this also copied the modeling and
+configuration `.py` files in the folder `custom-resnet50d` and uploaded the result to the Hub. You can check the result
+in this [model repo](https://huggingface.co/sgugger/custom-resnet50d).
+
+See the [sharing tutorial](model_sharing) for more information on the push to Hub method.
+
+## Using a model with custom code
+
+You can use any configuration, model or tokenizer with custom code files in its repository with the auto-classes and
+the `from_pretrained` method. All files and code uploaded to the Hub are scanned for malware (refer to the [Hub security](https://huggingface.co/docs/hub/security#malware-scanning) documentation for more information), but you should still
+review the model code and author to avoid executing malicious code on your machine. Set `trust_remote_code=True` to use
+a model with custom code:
+
+```py
+from transformers import AutoModelForImageClassification
+
+model = AutoModelForImageClassification.from_pretrained("sgugger/custom-resnet50d", trust_remote_code=True)
+```
+
+It is also strongly encouraged to pass a commit hash as a `revision` to make sure the author of the models did not
+update the code with some malicious new lines (unless you fully trust the authors of the models).
+
+```py
+commit_hash = "ed94a7c6247d8aedce4647f00f20de6875b5b292"
+model = AutoModelForImageClassification.from_pretrained(
+ "sgugger/custom-resnet50d", trust_remote_code=True, revision=commit_hash
+)
+```
+
+Note that when browsing the commit history of the model repo on the Hub, there is a button to easily copy the commit
+hash of any commit.
+
+## Registering a model with custom code to the auto classes
+
+If you are writing a library that extends 🤗 Transformers, you may want to extend the auto classes to include your own
+model. This is different from pushing the code to the Hub in the sense that users will need to import your library to
+get the custom models (contrarily to automatically downloading the model code from the Hub).
+
+As long as your config has a `model_type` attribute that is different from existing model types, and that your model
+classes have the right `config_class` attributes, you can just add them to the auto classes likes this:
+
+```py
+from transformers import AutoConfig, AutoModel, AutoModelForImageClassification
+
+AutoConfig.register("resnet", ResnetConfig)
+AutoModel.register(ResnetConfig, ResnetModel)
+AutoModelForImageClassification.register(ResnetConfig, ResnetModelForImageClassification)
+```
+
+Note that the first argument used when registering your custom config to [`AutoConfig`] needs to match the `model_type`
+of your custom config, and the first argument used when registering your custom models to any auto model class needs
+to match the `config_class` of those models.
diff --git a/docs/source/en/debugging.mdx b/docs/source/en/debugging.mdx
new file mode 100644
index 00000000000000..7339d61a057527
--- /dev/null
+++ b/docs/source/en/debugging.mdx
@@ -0,0 +1,335 @@
+
+
+# Debugging
+
+## Multi-GPU Network Issues Debug
+
+When training or inferencing with `DistributedDataParallel` and multiple GPU, if you run into issue of inter-communication between processes and/or nodes, you can use the following script to diagnose network issues.
+
+```bash
+wget https://raw.githubusercontent.com/huggingface/transformers/main/scripts/distributed/torch-distributed-gpu-test.py
+```
+
+For example to test how 2 GPUs interact do:
+
+```bash
+python -m torch.distributed.run --nproc_per_node 2 --nnodes 1 torch-distributed-gpu-test.py
+```
+If both processes can talk to each and allocate GPU memory each will print an OK status.
+
+For more GPUs or nodes adjust the arguments in the script.
+
+You will find a lot more details inside the diagnostics script and even a recipe to how you could run it in a SLURM environment.
+
+An additional level of debug is to add `NCCL_DEBUG=INFO` environment variable as follows:
+
+```bash
+NCCL_DEBUG=INFO python -m torch.distributed.run --nproc_per_node 2 --nnodes 1 torch-distributed-gpu-test.py
+```
+
+This will dump a lot of NCCL-related debug information, which you can then search online if you find that some problems are reported. Or if you're not sure how to interpret the output you can share the log file in an Issue.
+
+
+
+## Underflow and Overflow Detection
+
+
+
+This feature is currently available for PyTorch-only.
+
+
+
+
+
+For multi-GPU training it requires DDP (`torch.distributed.launch`).
+
+
+
+
+
+This feature can be used with any `nn.Module`-based model.
+
+
+
+If you start getting `loss=NaN` or the model inhibits some other abnormal behavior due to `inf` or `nan` in
+activations or weights one needs to discover where the first underflow or overflow happens and what led to it. Luckily
+you can accomplish that easily by activating a special module that will do the detection automatically.
+
+If you're using [`Trainer`], you just need to add:
+
+```bash
+--debug underflow_overflow
+```
+
+to the normal command line arguments, or pass `debug="underflow_overflow"` when creating the
+[`TrainingArguments`] object.
+
+If you're using your own training loop or another Trainer you can accomplish the same with:
+
+```python
+from .debug_utils import DebugUnderflowOverflow
+
+debug_overflow = DebugUnderflowOverflow(model)
+```
+
+[`~debug_utils.DebugUnderflowOverflow`] inserts hooks into the model that immediately after each
+forward call will test input and output variables and also the corresponding module's weights. As soon as `inf` or
+`nan` is detected in at least one element of the activations or weights, the program will assert and print a report
+like this (this was caught with `google/mt5-small` under fp16 mixed precision):
+
+```
+Detected inf/nan during batch_number=0
+Last 21 forward frames:
+abs min abs max metadata
+ encoder.block.1.layer.1.DenseReluDense.dropout Dropout
+0.00e+00 2.57e+02 input[0]
+0.00e+00 2.85e+02 output
+[...]
+ encoder.block.2.layer.0 T5LayerSelfAttention
+6.78e-04 3.15e+03 input[0]
+2.65e-04 3.42e+03 output[0]
+ None output[1]
+2.25e-01 1.00e+04 output[2]
+ encoder.block.2.layer.1.layer_norm T5LayerNorm
+8.69e-02 4.18e-01 weight
+2.65e-04 3.42e+03 input[0]
+1.79e-06 4.65e+00 output
+ encoder.block.2.layer.1.DenseReluDense.wi_0 Linear
+2.17e-07 4.50e+00 weight
+1.79e-06 4.65e+00 input[0]
+2.68e-06 3.70e+01 output
+ encoder.block.2.layer.1.DenseReluDense.wi_1 Linear
+8.08e-07 2.66e+01 weight
+1.79e-06 4.65e+00 input[0]
+1.27e-04 2.37e+02 output
+ encoder.block.2.layer.1.DenseReluDense.dropout Dropout
+0.00e+00 8.76e+03 input[0]
+0.00e+00 9.74e+03 output
+ encoder.block.2.layer.1.DenseReluDense.wo Linear
+1.01e-06 6.44e+00 weight
+0.00e+00 9.74e+03 input[0]
+3.18e-04 6.27e+04 output
+ encoder.block.2.layer.1.DenseReluDense T5DenseGatedGeluDense
+1.79e-06 4.65e+00 input[0]
+3.18e-04 6.27e+04 output
+ encoder.block.2.layer.1.dropout Dropout
+3.18e-04 6.27e+04 input[0]
+0.00e+00 inf output
+```
+
+The example output has been trimmed in the middle for brevity.
+
+The second column shows the value of the absolute largest element, so if you have a closer look at the last few frames,
+the inputs and outputs were in the range of `1e4`. So when this training was done under fp16 mixed precision the very
+last step overflowed (since under `fp16` the largest number before `inf` is `64e3`). To avoid overflows under
+`fp16` the activations must remain way below `1e4`, because `1e4 * 1e4 = 1e8` so any matrix multiplication with
+large activations is going to lead to a numerical overflow condition.
+
+At the very start of the trace you can discover at which batch number the problem occurred (here `Detected inf/nan during batch_number=0` means the problem occurred on the first batch).
+
+Each reported frame starts by declaring the fully qualified entry for the corresponding module this frame is reporting
+for. If we look just at this frame:
+
+```
+ encoder.block.2.layer.1.layer_norm T5LayerNorm
+8.69e-02 4.18e-01 weight
+2.65e-04 3.42e+03 input[0]
+1.79e-06 4.65e+00 output
+```
+
+Here, `encoder.block.2.layer.1.layer_norm` indicates that it was a layer norm for the first layer, of the second
+block of the encoder. And the specific calls of the `forward` is `T5LayerNorm`.
+
+Let's look at the last few frames of that report:
+
+```
+Detected inf/nan during batch_number=0
+Last 21 forward frames:
+abs min abs max metadata
+[...]
+ encoder.block.2.layer.1.DenseReluDense.wi_0 Linear
+2.17e-07 4.50e+00 weight
+1.79e-06 4.65e+00 input[0]
+2.68e-06 3.70e+01 output
+ encoder.block.2.layer.1.DenseReluDense.wi_1 Linear
+8.08e-07 2.66e+01 weight
+1.79e-06 4.65e+00 input[0]
+1.27e-04 2.37e+02 output
+ encoder.block.2.layer.1.DenseReluDense.wo Linear
+1.01e-06 6.44e+00 weight
+0.00e+00 9.74e+03 input[0]
+3.18e-04 6.27e+04 output
+ encoder.block.2.layer.1.DenseReluDense T5DenseGatedGeluDense
+1.79e-06 4.65e+00 input[0]
+3.18e-04 6.27e+04 output
+ encoder.block.2.layer.1.dropout Dropout
+3.18e-04 6.27e+04 input[0]
+0.00e+00 inf output
+```
+
+The last frame reports for `Dropout.forward` function with the first entry for the only input and the second for the
+only output. You can see that it was called from an attribute `dropout` inside `DenseReluDense` class. We can see
+that it happened during the first layer, of the 2nd block, during the very first batch. Finally, the absolute largest
+input elements was `6.27e+04` and same for the output was `inf`.
+
+You can see here, that `T5DenseGatedGeluDense.forward` resulted in output activations, whose absolute max value was
+around 62.7K, which is very close to fp16's top limit of 64K. In the next frame we have `Dropout` which renormalizes
+the weights, after it zeroed some of the elements, which pushes the absolute max value to more than 64K, and we get an
+overflow (`inf`).
+
+As you can see it's the previous frames that we need to look into when the numbers start going into very large for fp16
+numbers.
+
+Let's match the report to the code from `models/t5/modeling_t5.py`:
+
+```python
+class T5DenseGatedGeluDense(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.wi_0 = nn.Linear(config.d_model, config.d_ff, bias=False)
+ self.wi_1 = nn.Linear(config.d_model, config.d_ff, bias=False)
+ self.wo = nn.Linear(config.d_ff, config.d_model, bias=False)
+ self.dropout = nn.Dropout(config.dropout_rate)
+ self.gelu_act = ACT2FN["gelu_new"]
+
+ def forward(self, hidden_states):
+ hidden_gelu = self.gelu_act(self.wi_0(hidden_states))
+ hidden_linear = self.wi_1(hidden_states)
+ hidden_states = hidden_gelu * hidden_linear
+ hidden_states = self.dropout(hidden_states)
+ hidden_states = self.wo(hidden_states)
+ return hidden_states
+```
+
+Now it's easy to see the `dropout` call, and all the previous calls as well.
+
+Since the detection is happening in a forward hook, these reports are printed immediately after each `forward`
+returns.
+
+Going back to the full report, to act on it and to fix the problem, we need to go a few frames up where the numbers
+started to go up and most likely switch to the `fp32` mode here, so that the numbers don't overflow when multiplied
+or summed up. Of course, there might be other solutions. For example, we could turn off `amp` temporarily if it's
+enabled, after moving the original `forward` into a helper wrapper, like so:
+
+```python
+def _forward(self, hidden_states):
+ hidden_gelu = self.gelu_act(self.wi_0(hidden_states))
+ hidden_linear = self.wi_1(hidden_states)
+ hidden_states = hidden_gelu * hidden_linear
+ hidden_states = self.dropout(hidden_states)
+ hidden_states = self.wo(hidden_states)
+ return hidden_states
+
+
+import torch
+
+
+def forward(self, hidden_states):
+ if torch.is_autocast_enabled():
+ with torch.cuda.amp.autocast(enabled=False):
+ return self._forward(hidden_states)
+ else:
+ return self._forward(hidden_states)
+```
+
+Since the automatic detector only reports on inputs and outputs of full frames, once you know where to look, you may
+want to analyse the intermediary stages of any specific `forward` function as well. In such a case you can use the
+`detect_overflow` helper function to inject the detector where you want it, for example:
+
+```python
+from debug_utils import detect_overflow
+
+
+class T5LayerFF(nn.Module):
+ [...]
+
+ def forward(self, hidden_states):
+ forwarded_states = self.layer_norm(hidden_states)
+ detect_overflow(forwarded_states, "after layer_norm")
+ forwarded_states = self.DenseReluDense(forwarded_states)
+ detect_overflow(forwarded_states, "after DenseReluDense")
+ return hidden_states + self.dropout(forwarded_states)
+```
+
+You can see that we added 2 of these and now we track if `inf` or `nan` for `forwarded_states` was detected
+somewhere in between.
+
+Actually, the detector already reports these because each of the calls in the example above is a `nn.Module`, but
+let's say if you had some local direct calculations this is how you'd do that.
+
+Additionally, if you're instantiating the debugger in your own code, you can adjust the number of frames printed from
+its default, e.g.:
+
+```python
+from .debug_utils import DebugUnderflowOverflow
+
+debug_overflow = DebugUnderflowOverflow(model, max_frames_to_save=100)
+```
+
+### Specific batch absolute mix and max value tracing
+
+The same debugging class can be used for per-batch tracing with the underflow/overflow detection feature turned off.
+
+Let's say you want to watch the absolute min and max values for all the ingredients of each `forward` call of a given
+batch, and only do that for batches 1 and 3. Then you instantiate this class as:
+
+```python
+debug_overflow = DebugUnderflowOverflow(model, trace_batch_nums=[1, 3])
+```
+
+And now full batches 1 and 3 will be traced using the same format as the underflow/overflow detector does.
+
+Batches are 0-indexed.
+
+This is helpful if you know that the program starts misbehaving after a certain batch number, so you can fast-forward
+right to that area. Here is a sample truncated output for such configuration:
+
+```
+ *** Starting batch number=1 ***
+abs min abs max metadata
+ shared Embedding
+1.01e-06 7.92e+02 weight
+0.00e+00 2.47e+04 input[0]
+5.36e-05 7.92e+02 output
+[...]
+ decoder.dropout Dropout
+1.60e-07 2.27e+01 input[0]
+0.00e+00 2.52e+01 output
+ decoder T5Stack
+ not a tensor output
+ lm_head Linear
+1.01e-06 7.92e+02 weight
+0.00e+00 1.11e+00 input[0]
+6.06e-02 8.39e+01 output
+ T5ForConditionalGeneration
+ not a tensor output
+
+ *** Starting batch number=3 ***
+abs min abs max metadata
+ shared Embedding
+1.01e-06 7.92e+02 weight
+0.00e+00 2.78e+04 input[0]
+5.36e-05 7.92e+02 output
+[...]
+```
+
+Here you will get a huge number of frames dumped - as many as there were forward calls in your model, so it may or may
+not what you want, but sometimes it can be easier to use for debugging purposes than a normal debugger. For example, if
+a problem starts happening at batch number 150. So you can dump traces for batches 149 and 150 and compare where
+numbers started to diverge.
+
+You can also specify the batch number after which to stop the training, with:
+
+```python
+debug_overflow = DebugUnderflowOverflow(model, trace_batch_nums=[1, 3], abort_after_batch_num=3)
+```
diff --git a/docs/source/en/fast_tokenizers.mdx b/docs/source/en/fast_tokenizers.mdx
new file mode 100644
index 00000000000000..234f9bb42d1933
--- /dev/null
+++ b/docs/source/en/fast_tokenizers.mdx
@@ -0,0 +1,70 @@
+
+
+# Use tokenizers from 🤗 Tokenizers
+
+The [`PreTrainedTokenizerFast`] depends on the [🤗 Tokenizers](https://huggingface.co/docs/tokenizers) library. The tokenizers obtained from the 🤗 Tokenizers library can be
+loaded very simply into 🤗 Transformers.
+
+Before getting in the specifics, let's first start by creating a dummy tokenizer in a few lines:
+
+```python
+>>> from tokenizers import Tokenizer
+>>> from tokenizers.models import BPE
+>>> from tokenizers.trainers import BpeTrainer
+>>> from tokenizers.pre_tokenizers import Whitespace
+
+>>> tokenizer = Tokenizer(BPE(unk_token="[UNK]"))
+>>> trainer = BpeTrainer(special_tokens=["[UNK]", "[CLS]", "[SEP]", "[PAD]", "[MASK]"])
+
+>>> tokenizer.pre_tokenizer = Whitespace()
+>>> files = [...]
+>>> tokenizer.train(files, trainer)
+```
+
+We now have a tokenizer trained on the files we defined. We can either continue using it in that runtime, or save it to
+a JSON file for future re-use.
+
+## Loading directly from the tokenizer object
+
+Let's see how to leverage this tokenizer object in the 🤗 Transformers library. The
+[`PreTrainedTokenizerFast`] class allows for easy instantiation, by accepting the instantiated
+*tokenizer* object as an argument:
+
+```python
+>>> from transformers import PreTrainedTokenizerFast
+
+>>> fast_tokenizer = PreTrainedTokenizerFast(tokenizer_object=tokenizer)
+```
+
+This object can now be used with all the methods shared by the 🤗 Transformers tokenizers! Head to [the tokenizer
+page](main_classes/tokenizer) for more information.
+
+## Loading from a JSON file
+
+In order to load a tokenizer from a JSON file, let's first start by saving our tokenizer:
+
+```python
+>>> tokenizer.save("tokenizer.json")
+```
+
+The path to which we saved this file can be passed to the [`PreTrainedTokenizerFast`] initialization
+method using the `tokenizer_file` parameter:
+
+```python
+>>> from transformers import PreTrainedTokenizerFast
+
+>>> fast_tokenizer = PreTrainedTokenizerFast(tokenizer_file="tokenizer.json")
+```
+
+This object can now be used with all the methods shared by the 🤗 Transformers tokenizers! Head to [the tokenizer
+page](main_classes/tokenizer) for more information.
diff --git a/docs/source/en/glossary.mdx b/docs/source/en/glossary.mdx
new file mode 100644
index 00000000000000..b6cb2259d67da7
--- /dev/null
+++ b/docs/source/en/glossary.mdx
@@ -0,0 +1,300 @@
+
+
+# Glossary
+
+## General terms
+
+- autoencoding models: see MLM
+- autoregressive models: see CLM
+- CLM: causal language modeling, a pretraining task where the model reads the texts in order and has to predict the
+ next word. It's usually done by reading the whole sentence but using a mask inside the model to hide the future
+ tokens at a certain timestep.
+- deep learning: machine learning algorithms which uses neural networks with several layers.
+- MLM: masked language modeling, a pretraining task where the model sees a corrupted version of the texts, usually done
+ by masking some tokens randomly, and has to predict the original text.
+- multimodal: a task that combines texts with another kind of inputs (for instance images).
+- NLG: natural language generation, all tasks related to generating text (for instance talk with transformers,
+ translation).
+- NLP: natural language processing, a generic way to say "deal with texts".
+- NLU: natural language understanding, all tasks related to understanding what is in a text (for instance classifying
+ the whole text, individual words).
+- pretrained model: a model that has been pretrained on some data (for instance all of Wikipedia). Pretraining methods
+ involve a self-supervised objective, which can be reading the text and trying to predict the next word (see CLM) or
+ masking some words and trying to predict them (see MLM).
+- RNN: recurrent neural network, a type of model that uses a loop over a layer to process texts.
+- self-attention: each element of the input finds out which other elements of the input they should attend to.
+- seq2seq or sequence-to-sequence: models that generate a new sequence from an input, like translation models, or
+ summarization models (such as [Bart](model_doc/bart) or [T5](model_doc/t5)).
+- token: a part of a sentence, usually a word, but can also be a subword (non-common words are often split in subwords)
+ or a punctuation symbol.
+- transformer: self-attention based deep learning model architecture.
+
+## Model inputs
+
+Every model is different yet bears similarities with the others. Therefore most models use the same inputs, which are
+detailed here alongside usage examples.
+
+
+
+### Input IDs
+
+The input ids are often the only required parameters to be passed to the model as input. *They are token indices,
+numerical representations of tokens building the sequences that will be used as input by the model*.
+
+
+
+Each tokenizer works differently but the underlying mechanism remains the same. Here's an example using the BERT
+tokenizer, which is a [WordPiece](https://arxiv.org/pdf/1609.08144.pdf) tokenizer:
+
+```python
+>>> from transformers import BertTokenizer
+
+>>> tokenizer = BertTokenizer.from_pretrained("bert-base-cased")
+
+>>> sequence = "A Titan RTX has 24GB of VRAM"
+```
+
+The tokenizer takes care of splitting the sequence into tokens available in the tokenizer vocabulary.
+
+```python
+>>> tokenized_sequence = tokenizer.tokenize(sequence)
+```
+
+The tokens are either words or subwords. Here for instance, "VRAM" wasn't in the model vocabulary, so it's been split
+in "V", "RA" and "M". To indicate those tokens are not separate words but parts of the same word, a double-hash prefix
+is added for "RA" and "M":
+
+```python
+>>> print(tokenized_sequence)
+['A', 'Titan', 'R', '##T', '##X', 'has', '24', '##GB', 'of', 'V', '##RA', '##M']
+```
+
+These tokens can then be converted into IDs which are understandable by the model. This can be done by directly feeding
+the sentence to the tokenizer, which leverages the Rust implementation of [🤗 Tokenizers](https://github.com/huggingface/tokenizers) for peak performance.
+
+```python
+>>> inputs = tokenizer(sequence)
+```
+
+The tokenizer returns a dictionary with all the arguments necessary for its corresponding model to work properly. The
+token indices are under the key "input_ids":
+
+```python
+>>> encoded_sequence = inputs["input_ids"]
+>>> print(encoded_sequence)
+[101, 138, 18696, 155, 1942, 3190, 1144, 1572, 13745, 1104, 159, 9664, 2107, 102]
+```
+
+Note that the tokenizer automatically adds "special tokens" (if the associated model relies on them) which are special
+IDs the model sometimes uses.
+
+If we decode the previous sequence of ids,
+
+```python
+>>> decoded_sequence = tokenizer.decode(encoded_sequence)
+```
+
+we will see
+
+```python
+>>> print(decoded_sequence)
+[CLS] A Titan RTX has 24GB of VRAM [SEP]
+```
+
+because this is the way a [`BertModel`] is going to expect its inputs.
+
+
+
+### Attention mask
+
+The attention mask is an optional argument used when batching sequences together.
+
+
+
+This argument indicates to the model which tokens should be attended to, and which should not.
+
+For example, consider these two sequences:
+
+```python
+>>> from transformers import BertTokenizer
+
+>>> tokenizer = BertTokenizer.from_pretrained("bert-base-cased")
+
+>>> sequence_a = "This is a short sequence."
+>>> sequence_b = "This is a rather long sequence. It is at least longer than the sequence A."
+
+>>> encoded_sequence_a = tokenizer(sequence_a)["input_ids"]
+>>> encoded_sequence_b = tokenizer(sequence_b)["input_ids"]
+```
+
+The encoded versions have different lengths:
+
+```python
+>>> len(encoded_sequence_a), len(encoded_sequence_b)
+(8, 19)
+```
+
+Therefore, we can't put them together in the same tensor as-is. The first sequence needs to be padded up to the length
+of the second one, or the second one needs to be truncated down to the length of the first one.
+
+In the first case, the list of IDs will be extended by the padding indices. We can pass a list to the tokenizer and ask
+it to pad like this:
+
+```python
+>>> padded_sequences = tokenizer([sequence_a, sequence_b], padding=True)
+```
+
+We can see that 0s have been added on the right of the first sentence to make it the same length as the second one:
+
+```python
+>>> padded_sequences["input_ids"]
+[[101, 1188, 1110, 170, 1603, 4954, 119, 102, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [101, 1188, 1110, 170, 1897, 1263, 4954, 119, 1135, 1110, 1120, 1655, 2039, 1190, 1103, 4954, 138, 119, 102]]
+```
+
+This can then be converted into a tensor in PyTorch or TensorFlow. The attention mask is a binary tensor indicating the
+position of the padded indices so that the model does not attend to them. For the [`BertTokenizer`],
+`1` indicates a value that should be attended to, while `0` indicates a padded value. This attention mask is
+in the dictionary returned by the tokenizer under the key "attention_mask":
+
+```python
+>>> padded_sequences["attention_mask"]
+[[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]
+```
+
+
+
+### Token Type IDs
+
+Some models' purpose is to do classification on pairs of sentences or question answering.
+
+
+
+These require two different sequences to be joined in a single "input_ids" entry, which usually is performed with the
+help of special tokens, such as the classifier (`[CLS]`) and separator (`[SEP]`) tokens. For example, the BERT
+model builds its two sequence input as such:
+
+```python
+>>> # [CLS] SEQUENCE_A [SEP] SEQUENCE_B [SEP]
+```
+
+We can use our tokenizer to automatically generate such a sentence by passing the two sequences to `tokenizer` as two
+arguments (and not a list, like before) like this:
+
+```python
+>>> from transformers import BertTokenizer
+
+>>> tokenizer = BertTokenizer.from_pretrained("bert-base-cased")
+>>> sequence_a = "HuggingFace is based in NYC"
+>>> sequence_b = "Where is HuggingFace based?"
+
+>>> encoded_dict = tokenizer(sequence_a, sequence_b)
+>>> decoded = tokenizer.decode(encoded_dict["input_ids"])
+```
+
+which will return:
+
+```python
+>>> print(decoded)
+[CLS] HuggingFace is based in NYC [SEP] Where is HuggingFace based? [SEP]
+```
+
+This is enough for some models to understand where one sequence ends and where another begins. However, other models,
+such as BERT, also deploy token type IDs (also called segment IDs). They are represented as a binary mask identifying
+the two types of sequence in the model.
+
+The tokenizer returns this mask as the "token_type_ids" entry:
+
+```python
+>>> encoded_dict["token_type_ids"]
+[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1]
+```
+
+The first sequence, the "context" used for the question, has all its tokens represented by a `0`, whereas the
+second sequence, corresponding to the "question", has all its tokens represented by a `1`.
+
+Some models, like [`XLNetModel`] use an additional token represented by a `2`.
+
+
+
+### Position IDs
+
+Contrary to RNNs that have the position of each token embedded within them, transformers are unaware of the position of
+each token. Therefore, the position IDs (`position_ids`) are used by the model to identify each token's position in
+the list of tokens.
+
+They are an optional parameter. If no `position_ids` are passed to the model, the IDs are automatically created as
+absolute positional embeddings.
+
+Absolute positional embeddings are selected in the range `[0, config.max_position_embeddings - 1]`. Some models use
+other types of positional embeddings, such as sinusoidal position embeddings or relative position embeddings.
+
+
+
+### Labels
+
+The labels are an optional argument which can be passed in order for the model to compute the loss itself. These labels
+should be the expected prediction of the model: it will use the standard loss in order to compute the loss between its
+predictions and the expected value (the label).
+
+These labels are different according to the model head, for example:
+
+- For sequence classification models (e.g., [`BertForSequenceClassification`]), the model expects a
+ tensor of dimension `(batch_size)` with each value of the batch corresponding to the expected label of the
+ entire sequence.
+- For token classification models (e.g., [`BertForTokenClassification`]), the model expects a tensor
+ of dimension `(batch_size, seq_length)` with each value corresponding to the expected label of each individual
+ token.
+- For masked language modeling (e.g., [`BertForMaskedLM`]), the model expects a tensor of dimension
+ `(batch_size, seq_length)` with each value corresponding to the expected label of each individual token: the
+ labels being the token ID for the masked token, and values to be ignored for the rest (usually -100).
+- For sequence to sequence tasks,(e.g., [`BartForConditionalGeneration`],
+ [`MBartForConditionalGeneration`]), the model expects a tensor of dimension `(batch_size, tgt_seq_length)` with each value corresponding to the target sequences associated with each input sequence. During
+ training, both *BART* and *T5* will make the appropriate *decoder_input_ids* and decoder attention masks internally.
+ They usually do not need to be supplied. This does not apply to models leveraging the Encoder-Decoder framework. See
+ the documentation of each model for more information on each specific model's labels.
+
+The base models (e.g., [`BertModel`]) do not accept labels, as these are the base transformer
+models, simply outputting features.
+
+
+
+### Decoder input IDs
+
+This input is specific to encoder-decoder models, and contains the input IDs that will be fed to the decoder. These
+inputs should be used for sequence to sequence tasks, such as translation or summarization, and are usually built in a
+way specific to each model.
+
+Most encoder-decoder models (BART, T5) create their `decoder_input_ids` on their own from the `labels`. In
+such models, passing the `labels` is the preferred way to handle training.
+
+Please check each model's docs to see how they handle these input IDs for sequence to sequence training.
+
+
+
+### Feed Forward Chunking
+
+In each residual attention block in transformers the self-attention layer is usually followed by 2 feed forward layers.
+The intermediate embedding size of the feed forward layers is often bigger than the hidden size of the model (e.g., for
+`bert-base-uncased`).
+
+For an input of size `[batch_size, sequence_length]`, the memory required to store the intermediate feed forward
+embeddings `[batch_size, sequence_length, config.intermediate_size]` can account for a large fraction of the memory
+use. The authors of [Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451) noticed that since the
+computation is independent of the `sequence_length` dimension, it is mathematically equivalent to compute the output
+embeddings of both feed forward layers `[batch_size, config.hidden_size]_0, ..., [batch_size, config.hidden_size]_n`
+individually and concat them afterward to `[batch_size, sequence_length, config.hidden_size]` with `n = sequence_length`, which trades increased computation time against reduced memory use, but yields a mathematically
+**equivalent** result.
+
+For models employing the function [`apply_chunking_to_forward`], the `chunk_size` defines the
+number of output embeddings that are computed in parallel and thus defines the trade-off between memory and time
+complexity. If `chunk_size` is set to 0, no feed forward chunking is done.
diff --git a/docs/source/en/index.mdx b/docs/source/en/index.mdx
new file mode 100644
index 00000000000000..2ceb1b8dfa0ec9
--- /dev/null
+++ b/docs/source/en/index.mdx
@@ -0,0 +1,281 @@
+
+
+# 🤗 Transformers
+
+State-of-the-art Machine Learning for PyTorch, TensorFlow and JAX.
+
+🤗 Transformers provides APIs to easily download and train state-of-the-art pretrained models. Using pretrained models can reduce your compute costs, carbon footprint, and save you time from training a model from scratch. The models can be used across different modalities such as:
+
+* 📝 Text: text classification, information extraction, question answering, summarization, translation, and text generation in over 100 languages.
+* 🖼️ Images: image classification, object detection, and segmentation.
+* 🗣️ Audio: speech recognition and audio classification.
+* 🐙 Multimodal: table question answering, optical character recognition, information extraction from scanned documents, video classification, and visual question answering.
+
+Our library supports seamless integration between three of the most popular deep learning libraries: [PyTorch](https://pytorch.org/), [TensorFlow](https://www.tensorflow.org/) and [JAX](https://jax.readthedocs.io/en/latest/). Train your model in three lines of code in one framework, and load it for inference with another.
+
+Each 🤗 Transformers architecture is defined in a standalone Python module so they can be easily customized for research and experiments.
+
+## If you are looking for custom support from the Hugging Face team
+
+
+
+
+
+## Contents
+
+The documentation is organized in five parts:
+
+- **GET STARTED** contains a quick tour and installation instructions to get up and running with 🤗 Transformers.
+- **TUTORIALS** are a great place to begin if you are new to our library. This section will help you gain the basic skills you need to start using 🤗 Transformers.
+- **HOW-TO GUIDES** will show you how to achieve a specific goal like fine-tuning a pretrained model for language modeling or how to create a custom model head.
+- **CONCEPTUAL GUIDES** provides more discussion and explanation of the underlying concepts and ideas behind models, tasks, and the design philosophy of 🤗 Transformers.
+- **API** describes each class and function, grouped in:
+
+ - **MAIN CLASSES** for the main classes exposing the important APIs of the library.
+ - **MODELS** for the classes and functions related to each model implemented in the library.
+ - **INTERNAL HELPERS** for the classes and functions we use internally.
+
+The library currently contains JAX, PyTorch and TensorFlow implementations, pretrained model weights, usage scripts and conversion utilities for the following models.
+
+### Supported models
+
+
+
+1. **[ALBERT](model_doc/albert)** (from Google Research and the Toyota Technological Institute at Chicago) released with the paper [ALBERT: A Lite BERT for Self-supervised Learning of Language Representations](https://arxiv.org/abs/1909.11942), by Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, Radu Soricut.
+1. **[BART](model_doc/bart)** (from Facebook) released with the paper [BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension](https://arxiv.org/abs/1910.13461) by Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov and Luke Zettlemoyer.
+1. **[BARThez](model_doc/barthez)** (from École polytechnique) released with the paper [BARThez: a Skilled Pretrained French Sequence-to-Sequence Model](https://arxiv.org/abs/2010.12321) by Moussa Kamal Eddine, Antoine J.-P. Tixier, Michalis Vazirgiannis.
+1. **[BARTpho](model_doc/bartpho)** (from VinAI Research) released with the paper [BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnamese](https://arxiv.org/abs/2109.09701) by Nguyen Luong Tran, Duong Minh Le and Dat Quoc Nguyen.
+1. **[BEiT](model_doc/beit)** (from Microsoft) released with the paper [BEiT: BERT Pre-Training of Image Transformers](https://arxiv.org/abs/2106.08254) by Hangbo Bao, Li Dong, Furu Wei.
+1. **[BERT](model_doc/bert)** (from Google) released with the paper [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://arxiv.org/abs/1810.04805) by Jacob Devlin, Ming-Wei Chang, Kenton Lee and Kristina Toutanova.
+1. **[BERTweet](model_doc/bertweet)** (from VinAI Research) released with the paper [BERTweet: A pre-trained language model for English Tweets](https://aclanthology.org/2020.emnlp-demos.2/) by Dat Quoc Nguyen, Thanh Vu and Anh Tuan Nguyen.
+1. **[BERT For Sequence Generation](model_doc/bert-generation)** (from Google) released with the paper [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
+1. **[BigBird-RoBERTa](model_doc/big_bird)** (from Google Research) released with the paper [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) by Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed.
+1. **[BigBird-Pegasus](model_doc/bigbird_pegasus)** (from Google Research) released with the paper [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) by Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed.
+1. **[Blenderbot](model_doc/blenderbot)** (from Facebook) released with the paper [Recipes for building an open-domain chatbot](https://arxiv.org/abs/2004.13637) by Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston.
+1. **[BlenderbotSmall](model_doc/blenderbot-small)** (from Facebook) released with the paper [Recipes for building an open-domain chatbot](https://arxiv.org/abs/2004.13637) by Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston.
+1. **[BORT](model_doc/bort)** (from Alexa) released with the paper [Optimal Subarchitecture Extraction For BERT](https://arxiv.org/abs/2010.10499) by Adrian de Wynter and Daniel J. Perry.
+1. **[ByT5](model_doc/byt5)** (from Google Research) released with the paper [ByT5: Towards a token-free future with pre-trained byte-to-byte models](https://arxiv.org/abs/2105.13626) by Linting Xue, Aditya Barua, Noah Constant, Rami Al-Rfou, Sharan Narang, Mihir Kale, Adam Roberts, Colin Raffel.
+1. **[CamemBERT](model_doc/camembert)** (from Inria/Facebook/Sorbonne) released with the paper [CamemBERT: a Tasty French Language Model](https://arxiv.org/abs/1911.03894) by Louis Martin*, Benjamin Muller*, Pedro Javier Ortiz Suárez*, Yoann Dupont, Laurent Romary, Éric Villemonte de la Clergerie, Djamé Seddah and Benoît Sagot.
+1. **[CANINE](model_doc/canine)** (from Google Research) released with the paper [CANINE: Pre-training an Efficient Tokenization-Free Encoder for Language Representation](https://arxiv.org/abs/2103.06874) by Jonathan H. Clark, Dan Garrette, Iulia Turc, John Wieting.
+1. **[ConvNeXT](model_doc/convnext)** (from Facebook AI) released with the paper [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) by Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie.
+1. **[CLIP](model_doc/clip)** (from OpenAI) released with the paper [Learning Transferable Visual Models From Natural Language Supervision](https://arxiv.org/abs/2103.00020) by Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever.
+1. **[ConvBERT](model_doc/convbert)** (from YituTech) released with the paper [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496) by Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan.
+1. **[CPM](model_doc/cpm)** (from Tsinghua University) released with the paper [CPM: A Large-scale Generative Chinese Pre-trained Language Model](https://arxiv.org/abs/2012.00413) by Zhengyan Zhang, Xu Han, Hao Zhou, Pei Ke, Yuxian Gu, Deming Ye, Yujia Qin, Yusheng Su, Haozhe Ji, Jian Guan, Fanchao Qi, Xiaozhi Wang, Yanan Zheng, Guoyang Zeng, Huanqi Cao, Shengqi Chen, Daixuan Li, Zhenbo Sun, Zhiyuan Liu, Minlie Huang, Wentao Han, Jie Tang, Juanzi Li, Xiaoyan Zhu, Maosong Sun.
+1. **[CTRL](model_doc/ctrl)** (from Salesforce) released with the paper [CTRL: A Conditional Transformer Language Model for Controllable Generation](https://arxiv.org/abs/1909.05858) by Nitish Shirish Keskar*, Bryan McCann*, Lav R. Varshney, Caiming Xiong and Richard Socher.
+1. **[Data2Vec](model_doc/data2vec)** (from Facebook) released with the paper [Data2Vec: A General Framework for Self-supervised Learning in Speech, Vision and Language](https://arxiv.org/abs/2202.03555) by Alexei Baevski, Wei-Ning Hsu, Qiantong Xu, Arun Babu, Jiatao Gu, Michael Auli.
+1. **[DeBERTa](model_doc/deberta)** (from Microsoft) released with the paper [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654) by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
+1. **[DeBERTa-v2](model_doc/deberta-v2)** (from Microsoft) released with the paper [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654) by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
+1. **[Decision Transformer](model_doc/decision_transformer)** (from Berkeley/Facebook/Google) released with the paper [Decision Transformer: Reinforcement Learning via Sequence Modeling](https://arxiv.org/abs/2106.01345) by Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Michael Laskin, Pieter Abbeel, Aravind Srinivas, Igor Mordatch.
+1. **[DiT](model_doc/dit)** (from Microsoft Research) released with the paper [DiT: Self-supervised Pre-training for Document Image Transformer](https://arxiv.org/abs/2203.02378) by Junlong Li, Yiheng Xu, Tengchao Lv, Lei Cui, Cha Zhang, Furu Wei.
+1. **[DeiT](model_doc/deit)** (from Facebook) released with the paper [Training data-efficient image transformers & distillation through attention](https://arxiv.org/abs/2012.12877) by Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, Hervé Jégou.
+1. **[DETR](model_doc/detr)** (from Facebook) released with the paper [End-to-End Object Detection with Transformers](https://arxiv.org/abs/2005.12872) by Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, Sergey Zagoruyko.
+1. **[DialoGPT](model_doc/dialogpt)** (from Microsoft Research) released with the paper [DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation](https://arxiv.org/abs/1911.00536) by Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao, Jianfeng Gao, Jingjing Liu, Bill Dolan.
+1. **[DistilBERT](model_doc/distilbert)** (from HuggingFace), released together with the paper [DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter](https://arxiv.org/abs/1910.01108) by Victor Sanh, Lysandre Debut and Thomas Wolf. The same method has been applied to compress GPT2 into [DistilGPT2](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation), RoBERTa into [DistilRoBERTa](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation), Multilingual BERT into [DistilmBERT](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation) and a German version of DistilBERT.
+1. **[DPR](model_doc/dpr)** (from Facebook) released with the paper [Dense Passage Retrieval for Open-Domain Question Answering](https://arxiv.org/abs/2004.04906) by Vladimir Karpukhin, Barlas Oğuz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih.
+1. **[DPT](master/model_doc/dpt)** (from Intel Labs) released with the paper [Vision Transformers for Dense Prediction](https://arxiv.org/abs/2103.13413) by René Ranftl, Alexey Bochkovskiy, Vladlen Koltun.
+1. **[EncoderDecoder](model_doc/encoder-decoder)** (from Google Research) released with the paper [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
+1. **[ELECTRA](model_doc/electra)** (from Google Research/Stanford University) released with the paper [ELECTRA: Pre-training text encoders as discriminators rather than generators](https://arxiv.org/abs/2003.10555) by Kevin Clark, Minh-Thang Luong, Quoc V. Le, Christopher D. Manning.
+1. **[FlauBERT](model_doc/flaubert)** (from CNRS) released with the paper [FlauBERT: Unsupervised Language Model Pre-training for French](https://arxiv.org/abs/1912.05372) by Hang Le, Loïc Vial, Jibril Frej, Vincent Segonne, Maximin Coavoux, Benjamin Lecouteux, Alexandre Allauzen, Benoît Crabbé, Laurent Besacier, Didier Schwab.
+1. **[FNet](model_doc/fnet)** (from Google Research) released with the paper [FNet: Mixing Tokens with Fourier Transforms](https://arxiv.org/abs/2105.03824) by James Lee-Thorp, Joshua Ainslie, Ilya Eckstein, Santiago Ontanon.
+1. **[Funnel Transformer](model_doc/funnel)** (from CMU/Google Brain) released with the paper [Funnel-Transformer: Filtering out Sequential Redundancy for Efficient Language Processing](https://arxiv.org/abs/2006.03236) by Zihang Dai, Guokun Lai, Yiming Yang, Quoc V. Le.
+1. **[GLPN](model_doc/glpn)** (from KAIST) released with the paper [Global-Local Path Networks for Monocular Depth Estimation with Vertical CutDepth](https://arxiv.org/abs/2201.07436) by Doyeon Kim, Woonghyun Ga, Pyungwhan Ahn, Donggyu Joo, Sehwan Chun, Junmo Kim.
+1. **[GPT](model_doc/openai-gpt)** (from OpenAI) released with the paper [Improving Language Understanding by Generative Pre-Training](https://blog.openai.com/language-unsupervised/) by Alec Radford, Karthik Narasimhan, Tim Salimans and Ilya Sutskever.
+1. **[GPT-2](model_doc/gpt2)** (from OpenAI) released with the paper [Language Models are Unsupervised Multitask Learners](https://blog.openai.com/better-language-models/) by Alec Radford*, Jeffrey Wu*, Rewon Child, David Luan, Dario Amodei** and Ilya Sutskever**.
+1. **[GPT-J](model_doc/gptj)** (from EleutherAI) released in the repository [kingoflolz/mesh-transformer-jax](https://github.com/kingoflolz/mesh-transformer-jax/) by Ben Wang and Aran Komatsuzaki.
+1. **[GPT Neo](model_doc/gpt_neo)** (from EleutherAI) released in the repository [EleutherAI/gpt-neo](https://github.com/EleutherAI/gpt-neo) by Sid Black, Stella Biderman, Leo Gao, Phil Wang and Connor Leahy.
+1. **[Hubert](model_doc/hubert)** (from Facebook) released with the paper [HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units](https://arxiv.org/abs/2106.07447) by Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, Abdelrahman Mohamed.
+1. **[I-BERT](model_doc/ibert)** (from Berkeley) released with the paper [I-BERT: Integer-only BERT Quantization](https://arxiv.org/abs/2101.01321) by Sehoon Kim, Amir Gholami, Zhewei Yao, Michael W. Mahoney, Kurt Keutzer.
+1. **[ImageGPT](model_doc/imagegpt)** (from OpenAI) released with the paper [Generative Pretraining from Pixels](https://openai.com/blog/image-gpt/) by Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, Ilya Sutskever.
+1. **[LayoutLM](model_doc/layoutlm)** (from Microsoft Research Asia) released with the paper [LayoutLM: Pre-training of Text and Layout for Document Image Understanding](https://arxiv.org/abs/1912.13318) by Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou.
+1. **[LayoutLMv2](model_doc/layoutlmv2)** (from Microsoft Research Asia) released with the paper [LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding](https://arxiv.org/abs/2012.14740) by Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui, Furu Wei, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Wanxiang Che, Min Zhang, Lidong Zhou.
+1. **[LayoutXLM](model_doc/layoutlmv2)** (from Microsoft Research Asia) released with the paper [LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding](https://arxiv.org/abs/2104.08836) by Yiheng Xu, Tengchao Lv, Lei Cui, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Furu Wei.
+1. **[LED](model_doc/led)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
+1. **[Longformer](model_doc/longformer)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
+1. **[LUKE](model_doc/luke)** (from Studio Ousia) released with the paper [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://arxiv.org/abs/2010.01057) by Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto.
+1. **[mLUKE](model_doc/mluke)** (from Studio Ousia) released with the paper [mLUKE: The Power of Entity Representations in Multilingual Pretrained Language Models](https://arxiv.org/abs/2110.08151) by Ryokan Ri, Ikuya Yamada, and Yoshimasa Tsuruoka.
+1. **[LXMERT](model_doc/lxmert)** (from UNC Chapel Hill) released with the paper [LXMERT: Learning Cross-Modality Encoder Representations from Transformers for Open-Domain Question Answering](https://arxiv.org/abs/1908.07490) by Hao Tan and Mohit Bansal.
+1. **[M2M100](model_doc/m2m_100)** (from Facebook) released with the paper [Beyond English-Centric Multilingual Machine Translation](https://arxiv.org/abs/2010.11125) by Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi Ma, Ahmed El-Kishky, Siddharth Goyal, Mandeep Baines, Onur Celebi, Guillaume Wenzek, Vishrav Chaudhary, Naman Goyal, Tom Birch, Vitaliy Liptchinsky, Sergey Edunov, Edouard Grave, Michael Auli, Armand Joulin.
+1. **[MarianMT](model_doc/marian)** Machine translation models trained using [OPUS](http://opus.nlpl.eu/) data by Jörg Tiedemann. The [Marian Framework](https://marian-nmt.github.io/) is being developed by the Microsoft Translator Team.
+1. **[MaskFormer](model_doc/maskformer)** (from Meta and UIUC) released with the paper [Per-Pixel Classification is Not All You Need for Semantic Segmentation](https://arxiv.org/abs/2107.06278) by Bowen Cheng, Alexander G. Schwing, Alexander Kirillov.
+1. **[MBart](model_doc/mbart)** (from Facebook) released with the paper [Multilingual Denoising Pre-training for Neural Machine Translation](https://arxiv.org/abs/2001.08210) by Yinhan Liu, Jiatao Gu, Naman Goyal, Xian Li, Sergey Edunov, Marjan Ghazvininejad, Mike Lewis, Luke Zettlemoyer.
+1. **[MBart-50](model_doc/mbart)** (from Facebook) released with the paper [Multilingual Translation with Extensible Multilingual Pretraining and Finetuning](https://arxiv.org/abs/2008.00401) by Yuqing Tang, Chau Tran, Xian Li, Peng-Jen Chen, Naman Goyal, Vishrav Chaudhary, Jiatao Gu, Angela Fan.
+1. **[Megatron-BERT](model_doc/megatron-bert)** (from NVIDIA) released with the paper [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://arxiv.org/abs/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper and Bryan Catanzaro.
+1. **[Megatron-GPT2](model_doc/megatron_gpt2)** (from NVIDIA) released with the paper [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://arxiv.org/abs/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper and Bryan Catanzaro.
+1. **[MPNet](model_doc/mpnet)** (from Microsoft Research) released with the paper [MPNet: Masked and Permuted Pre-training for Language Understanding](https://arxiv.org/abs/2004.09297) by Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, Tie-Yan Liu.
+1. **[MT5](model_doc/mt5)** (from Google AI) released with the paper [mT5: A massively multilingual pre-trained text-to-text transformer](https://arxiv.org/abs/2010.11934) by Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, Colin Raffel.
+1. **[Nyströmformer](model_doc/nystromformer)** (from the University of Wisconsin - Madison) released with the paper [Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention](https://arxiv.org/abs/2102.03902) by Yunyang Xiong, Zhanpeng Zeng, Rudrasis Chakraborty, Mingxing Tan, Glenn Fung, Yin Li, Vikas Singh.
+1. **[Pegasus](model_doc/pegasus)** (from Google) released with the paper [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization](https://arxiv.org/abs/1912.08777) by Jingqing Zhang, Yao Zhao, Mohammad Saleh and Peter J. Liu.
+1. **[Perceiver IO](model_doc/perceiver)** (from Deepmind) released with the paper [Perceiver IO: A General Architecture for Structured Inputs & Outputs](https://arxiv.org/abs/2107.14795) by Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier Hénaff, Matthew M. Botvinick, Andrew Zisserman, Oriol Vinyals, João Carreira.
+1. **[PhoBERT](model_doc/phobert)** (from VinAI Research) released with the paper [PhoBERT: Pre-trained language models for Vietnamese](https://www.aclweb.org/anthology/2020.findings-emnlp.92/) by Dat Quoc Nguyen and Anh Tuan Nguyen.
+1. **[PLBart](model_doc/plbart)** (from UCLA NLP) released with the paper [Unified Pre-training for Program Understanding and Generation](https://arxiv.org/abs/2103.06333) by Wasi Uddin Ahmad, Saikat Chakraborty, Baishakhi Ray, Kai-Wei Chang.
+1. **[PoolFormer](model_doc/poolformer)** (from Sea AI Labs) released with the paper [MetaFormer is Actually What You Need for Vision](https://arxiv.org/abs/2111.11418) by Yu, Weihao and Luo, Mi and Zhou, Pan and Si, Chenyang and Zhou, Yichen and Wang, Xinchao and Feng, Jiashi and Yan, Shuicheng.
+1. **[ProphetNet](model_doc/prophetnet)** (from Microsoft Research) released with the paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou.
+1. **[QDQBert](model_doc/qdqbert)** (from NVIDIA) released with the paper [Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation](https://arxiv.org/abs/2004.09602) by Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius Micikevicius.
+1. **[REALM](model_doc/realm.html)** (from Google Research) released with the paper [REALM: Retrieval-Augmented Language Model Pre-Training](https://arxiv.org/abs/2002.08909) by Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat and Ming-Wei Chang.
+1. **[Reformer](model_doc/reformer)** (from Google Research) released with the paper [Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451) by Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya.
+1. **[RemBERT](model_doc/rembert)** (from Google Research) released with the paper [Rethinking embedding coupling in pre-trained language models](https://arxiv.org/abs/2010.12821) by Hyung Won Chung, Thibault Févry, Henry Tsai, M. Johnson, Sebastian Ruder.
+1. **[RegNet](model_doc/regnet)** (from META Platforms) released with the paper [Designing Network Design Space](https://arxiv.org/abs/2003.13678) by Ilija Radosavovic, Raj Prateek Kosaraju, Ross Girshick, Kaiming He, Piotr Dollár.
+1. **[ResNet](model_doc/resnet)** (from Microsoft Research) released with the paper [Deep Residual Learning for Image Recognition](https://arxiv.org/abs/1512.03385) by Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun.
+1. **[RoBERTa](model_doc/roberta)** (from Facebook), released together with the paper [RoBERTa: A Robustly Optimized BERT Pretraining Approach](https://arxiv.org/abs/1907.11692) by Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov.
+1. **[RoFormer](model_doc/roformer)** (from ZhuiyiTechnology), released together with the paper [RoFormer: Enhanced Transformer with Rotary Position Embedding](https://arxiv.org/abs/2104.09864) by Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu.
+1. **[SegFormer](model_doc/segformer)** (from NVIDIA) released with the paper [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://arxiv.org/abs/2105.15203) by Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, Ping Luo.
+1. **[SEW](model_doc/sew)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
+1. **[SEW-D](model_doc/sew_d)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
+1. **[SpeechToTextTransformer](model_doc/speech_to_text)** (from Facebook), released together with the paper [fairseq S2T: Fast Speech-to-Text Modeling with fairseq](https://arxiv.org/abs/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Dmytro Okhonko, Juan Pino.
+1. **[SpeechToTextTransformer2](model_doc/speech_to_text_2)** (from Facebook), released together with the paper [Large-Scale Self- and Semi-Supervised Learning for Speech Translation](https://arxiv.org/abs/2104.06678) by Changhan Wang, Anne Wu, Juan Pino, Alexei Baevski, Michael Auli, Alexis Conneau.
+1. **[Splinter](model_doc/splinter)** (from Tel Aviv University), released together with the paper [Few-Shot Question Answering by Pretraining Span Selection](https://arxiv.org/abs/2101.00438) by Ori Ram, Yuval Kirstain, Jonathan Berant, Amir Globerson, Omer Levy.
+1. **[SqueezeBert](model_doc/squeezebert)** (from Berkeley) released with the paper [SqueezeBERT: What can computer vision teach NLP about efficient neural networks?](https://arxiv.org/abs/2006.11316) by Forrest N. Iandola, Albert E. Shaw, Ravi Krishna, and Kurt W. Keutzer.
+1. **[Swin Transformer](model_doc/swin)** (from Microsoft) released with the paper [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030) by Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo.
+1. **[T5](model_doc/t5)** (from Google AI) released with the paper [Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer](https://arxiv.org/abs/1910.10683) by Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu.
+1. **[T5v1.1](model_doc/t5v1.1)** (from Google AI) released in the repository [google-research/text-to-text-transfer-transformer](https://github.com/google-research/text-to-text-transfer-transformer/blob/main/released_checkpoints.md#t511) by Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu.
+1. **[TAPAS](model_doc/tapas)** (from Google AI) released with the paper [TAPAS: Weakly Supervised Table Parsing via Pre-training](https://arxiv.org/abs/2004.02349) by Jonathan Herzig, Paweł Krzysztof Nowak, Thomas Müller, Francesco Piccinno and Julian Martin Eisenschlos.
+1. **[TAPEX](model_doc/tapex)** (from Microsoft Research) released with the paper [TAPEX: Table Pre-training via Learning a Neural SQL Executor](https://arxiv.org/abs/2107.07653) by Qian Liu, Bei Chen, Jiaqi Guo, Morteza Ziyadi, Zeqi Lin, Weizhu Chen, Jian-Guang Lou.
+1. **[Transformer-XL](model_doc/transfo-xl)** (from Google/CMU) released with the paper [Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context](https://arxiv.org/abs/1901.02860) by Zihang Dai*, Zhilin Yang*, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan Salakhutdinov.
+1. **[TrOCR](model_doc/trocr)** (from Microsoft), released together with the paper [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282) by Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, Furu Wei.
+1. **[UniSpeech](model_doc/unispeech)** (from Microsoft Research) released with the paper [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597) by Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang.
+1. **[UniSpeechSat](model_doc/unispeech-sat)** (from Microsoft Research) released with the paper [UNISPEECH-SAT: UNIVERSAL SPEECH REPRESENTATION LEARNING WITH SPEAKER AWARE PRE-TRAINING](https://arxiv.org/abs/2110.05752) by Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen, Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu.
+1. **[VAN](model_doc/van)** (from Tsinghua University and Nankai University) released with the paper [Visual Attention Network](https://arxiv.org/abs/2202.09741) by Meng-Hao Guo, Cheng-Ze Lu, Zheng-Ning Liu, Ming-Ming Cheng, Shi-Min Hu.
+1. **[ViLT](model_doc/vilt)** (from NAVER AI Lab/Kakao Enterprise/Kakao Brain) released with the paper [ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision](https://arxiv.org/abs/2102.03334) by Wonjae Kim, Bokyung Son, Ildoo Kim.
+1. **[Vision Transformer (ViT)](model_doc/vit)** (from Google AI) released with the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby.
+1. **[ViTMAE](model_doc/vit_mae)** (from Meta AI) released with the paper [Masked Autoencoders Are Scalable Vision Learners](https://arxiv.org/abs/2111.06377) by Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, Ross Girshick.
+1. **[VisualBERT](model_doc/visual_bert)** (from UCLA NLP) released with the paper [VisualBERT: A Simple and Performant Baseline for Vision and Language](https://arxiv.org/pdf/1908.03557) by Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, Kai-Wei Chang.
+1. **[WavLM](model_doc/wavlm)** (from Microsoft Research) released with the paper [WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing](https://arxiv.org/abs/2110.13900) by Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, Jian Wu, Long Zhou, Shuo Ren, Yanmin Qian, Yao Qian, Jian Wu, Michael Zeng, Furu Wei.
+1. **[Wav2Vec2](model_doc/wav2vec2)** (from Facebook AI) released with the paper [wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations](https://arxiv.org/abs/2006.11477) by Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli.
+1. **[Wav2Vec2Phoneme](model_doc/wav2vec2_phoneme)** (from Facebook AI) released with the paper [Simple and Effective Zero-shot Cross-lingual Phoneme Recognition](https://arxiv.org/abs/2109.11680) by Qiantong Xu, Alexei Baevski, Michael Auli.
+1. **[XGLM](model_doc/xglm)** (From Facebook AI) released with the paper [Few-shot Learning with Multilingual Language Models](https://arxiv.org/abs/2112.10668) by Xi Victoria Lin, Todor Mihaylov, Mikel Artetxe, Tianlu Wang, Shuohui Chen, Daniel Simig, Myle Ott, Naman Goyal, Shruti Bhosale, Jingfei Du, Ramakanth Pasunuru, Sam Shleifer, Punit Singh Koura, Vishrav Chaudhary, Brian O'Horo, Jeff Wang, Luke Zettlemoyer, Zornitsa Kozareva, Mona Diab, Veselin Stoyanov, Xian Li.
+1. **[XLM](model_doc/xlm)** (from Facebook) released together with the paper [Cross-lingual Language Model Pretraining](https://arxiv.org/abs/1901.07291) by Guillaume Lample and Alexis Conneau.
+1. **[XLM-ProphetNet](model_doc/xlm-prophetnet)** (from Microsoft Research) released with the paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou.
+1. **[XLM-RoBERTa](model_doc/xlm-roberta)** (from Facebook AI), released together with the paper [Unsupervised Cross-lingual Representation Learning at Scale](https://arxiv.org/abs/1911.02116) by Alexis Conneau*, Kartikay Khandelwal*, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzmán, Edouard Grave, Myle Ott, Luke Zettlemoyer and Veselin Stoyanov.
+1. **[XLM-RoBERTa-XL](model_doc/xlm-roberta-xl)** (from Facebook AI), released together with the paper [Larger-Scale Transformers for Multilingual Masked Language Modeling](https://arxiv.org/abs/2105.00572) by Naman Goyal, Jingfei Du, Myle Ott, Giri Anantharaman, Alexis Conneau.
+1. **[XLNet](model_doc/xlnet)** (from Google/CMU) released with the paper [XLNet: Generalized Autoregressive Pretraining for Language Understanding](https://arxiv.org/abs/1906.08237) by Zhilin Yang*, Zihang Dai*, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, Quoc V. Le.
+1. **[XLSR-Wav2Vec2](model_doc/xlsr_wav2vec2)** (from Facebook AI) released with the paper [Unsupervised Cross-Lingual Representation Learning For Speech Recognition](https://arxiv.org/abs/2006.13979) by Alexis Conneau, Alexei Baevski, Ronan Collobert, Abdelrahman Mohamed, Michael Auli.
+1. **[XLS-R](model_doc/xls_r)** (from Facebook AI) released with the paper [XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale](https://arxiv.org/abs/2111.09296) by Arun Babu, Changhan Wang, Andros Tjandra, Kushal Lakhotia, Qiantong Xu, Naman Goyal, Kritika Singh, Patrick von Platen, Yatharth Saraf, Juan Pino, Alexei Baevski, Alexis Conneau, Michael Auli.
+1. **[YOLOS](model_doc/yolos)** (from Huazhong University of Science & Technology) released with the paper [You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection](https://arxiv.org/abs/2106.00666) by Yuxin Fang, Bencheng Liao, Xinggang Wang, Jiemin Fang, Jiyang Qi, Rui Wu, Jianwei Niu, Wenyu Liu.
+1. **[YOSO](model_doc/yoso)** (from the University of Wisconsin - Madison) released with the paper [You Only Sample (Almost) Once: Linear Cost Self-Attention Via Bernoulli Sampling](https://arxiv.org/abs/2111.09714) by Zhanpeng Zeng, Yunyang Xiong, Sathya N. Ravi, Shailesh Acharya, Glenn Fung, Vikas Singh.
+
+
+### Supported frameworks
+
+The table below represents the current support in the library for each of those models, whether they have a Python
+tokenizer (called "slow"). A "fast" tokenizer backed by the 🤗 Tokenizers library, whether they have support in Jax (via
+Flax), PyTorch, and/or TensorFlow.
+
+
+
+| Model | Tokenizer slow | Tokenizer fast | PyTorch support | TensorFlow support | Flax Support |
+|:---------------------------:|:--------------:|:--------------:|:---------------:|:------------------:|:------------:|
+| ALBERT | ✅ | ✅ | ✅ | ✅ | ✅ |
+| BART | ✅ | ✅ | ✅ | ✅ | ✅ |
+| BEiT | ❌ | ❌ | ✅ | ❌ | ✅ |
+| BERT | ✅ | ✅ | ✅ | ✅ | ✅ |
+| Bert Generation | ✅ | ❌ | ✅ | ❌ | ❌ |
+| BigBird | ✅ | ✅ | ✅ | ❌ | ✅ |
+| BigBirdPegasus | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Blenderbot | ✅ | ✅ | ✅ | ✅ | ✅ |
+| BlenderbotSmall | ✅ | ✅ | ✅ | ✅ | ✅ |
+| CamemBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
+| Canine | ✅ | ❌ | ✅ | ❌ | ❌ |
+| CLIP | ✅ | ✅ | ✅ | ✅ | ✅ |
+| ConvBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
+| ConvNext | ❌ | ❌ | ✅ | ✅ | ❌ |
+| CTRL | ✅ | ❌ | ✅ | ✅ | ❌ |
+| Data2VecAudio | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Data2VecText | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Data2VecVision | ❌ | ❌ | ✅ | ✅ | ❌ |
+| DeBERTa | ✅ | ✅ | ✅ | ✅ | ❌ |
+| DeBERTa-v2 | ✅ | ✅ | ✅ | ✅ | ❌ |
+| Decision Transformer | ❌ | ❌ | ✅ | ❌ | ❌ |
+| DeiT | ❌ | ❌ | ✅ | ❌ | ❌ |
+| DETR | ❌ | ❌ | ✅ | ❌ | ❌ |
+| DistilBERT | ✅ | ✅ | ✅ | ✅ | ✅ |
+| DPR | ✅ | ✅ | ✅ | ✅ | ❌ |
+| DPT | ❌ | ❌ | ✅ | ❌ | ❌ |
+| ELECTRA | ✅ | ✅ | ✅ | ✅ | ✅ |
+| Encoder decoder | ❌ | ❌ | ✅ | ✅ | ✅ |
+| FairSeq Machine-Translation | ✅ | ❌ | ✅ | ❌ | ❌ |
+| FlauBERT | ✅ | ❌ | ✅ | ✅ | ❌ |
+| FNet | ✅ | ✅ | ✅ | ❌ | ❌ |
+| Funnel Transformer | ✅ | ✅ | ✅ | ✅ | ❌ |
+| GLPN | ❌ | ❌ | ✅ | ❌ | ❌ |
+| GPT Neo | ❌ | ❌ | ✅ | ❌ | ✅ |
+| GPT-J | ❌ | ❌ | ✅ | ✅ | ✅ |
+| Hubert | ❌ | ❌ | ✅ | ✅ | ❌ |
+| I-BERT | ❌ | ❌ | ✅ | ❌ | ❌ |
+| ImageGPT | ❌ | ❌ | ✅ | ❌ | ❌ |
+| LayoutLM | ✅ | ✅ | ✅ | ✅ | ❌ |
+| LayoutLMv2 | ✅ | ✅ | ✅ | ❌ | ❌ |
+| LED | ✅ | ✅ | ✅ | ✅ | ❌ |
+| Longformer | ✅ | ✅ | ✅ | ✅ | ❌ |
+| LUKE | ✅ | ❌ | ✅ | ❌ | ❌ |
+| LXMERT | ✅ | ✅ | ✅ | ✅ | ❌ |
+| M2M100 | ✅ | ❌ | ✅ | ❌ | ❌ |
+| Marian | ✅ | ❌ | ✅ | ✅ | ✅ |
+| MaskFormer | ❌ | ❌ | ✅ | ❌ | ❌ |
+| mBART | ✅ | ✅ | ✅ | ✅ | ✅ |
+| MegatronBert | ❌ | ❌ | ✅ | ❌ | ❌ |
+| MobileBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
+| MPNet | ✅ | ✅ | ✅ | ✅ | ❌ |
+| mT5 | ✅ | ✅ | ✅ | ✅ | ✅ |
+| Nystromformer | ❌ | ❌ | ✅ | ❌ | ❌ |
+| OpenAI GPT | ✅ | ✅ | ✅ | ✅ | ❌ |
+| OpenAI GPT-2 | ✅ | ✅ | ✅ | ✅ | ✅ |
+| Pegasus | ✅ | ✅ | ✅ | ✅ | ✅ |
+| Perceiver | ✅ | ❌ | ✅ | ❌ | ❌ |
+| PLBart | ✅ | ❌ | ✅ | ❌ | ❌ |
+| PoolFormer | ❌ | ❌ | ✅ | ❌ | ❌ |
+| ProphetNet | ✅ | ❌ | ✅ | ❌ | ❌ |
+| QDQBert | ❌ | ❌ | ✅ | ❌ | ❌ |
+| RAG | ✅ | ❌ | ✅ | ✅ | ❌ |
+| Realm | ✅ | ✅ | ✅ | ❌ | ❌ |
+| Reformer | ✅ | ✅ | ✅ | ❌ | ❌ |
+| RegNet | ❌ | ❌ | ✅ | ❌ | ❌ |
+| RemBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
+| ResNet | ❌ | ❌ | ✅ | ❌ | ❌ |
+| RetriBERT | ✅ | ✅ | ✅ | ❌ | ❌ |
+| RoBERTa | ✅ | ✅ | ✅ | ✅ | ✅ |
+| RoFormer | ✅ | ✅ | ✅ | ✅ | ✅ |
+| SegFormer | ❌ | ❌ | ✅ | ❌ | ❌ |
+| SEW | ❌ | ❌ | ✅ | ❌ | ❌ |
+| SEW-D | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Speech Encoder decoder | ❌ | ❌ | ✅ | ❌ | ✅ |
+| Speech2Text | ✅ | ❌ | ✅ | ✅ | ❌ |
+| Speech2Text2 | ✅ | ❌ | ❌ | ❌ | ❌ |
+| Splinter | ✅ | ✅ | ✅ | ❌ | ❌ |
+| SqueezeBERT | ✅ | ✅ | ✅ | ❌ | ❌ |
+| Swin | ❌ | ❌ | ✅ | ❌ | ❌ |
+| T5 | ✅ | ✅ | ✅ | ✅ | ✅ |
+| TAPAS | ✅ | ❌ | ✅ | ✅ | ❌ |
+| TAPEX | ✅ | ✅ | ✅ | ✅ | ✅ |
+| Transformer-XL | ✅ | ❌ | ✅ | ✅ | ❌ |
+| TrOCR | ❌ | ❌ | ✅ | ❌ | ❌ |
+| UniSpeech | ❌ | ❌ | ✅ | ❌ | ❌ |
+| UniSpeechSat | ❌ | ❌ | ✅ | ❌ | ❌ |
+| VAN | ❌ | ❌ | ✅ | ❌ | ❌ |
+| ViLT | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Vision Encoder decoder | ❌ | ❌ | ✅ | ✅ | ✅ |
+| VisionTextDualEncoder | ❌ | ❌ | ✅ | ❌ | ✅ |
+| VisualBert | ❌ | ❌ | ✅ | ❌ | ❌ |
+| ViT | ❌ | ❌ | ✅ | ✅ | ✅ |
+| ViTMAE | ❌ | ❌ | ✅ | ✅ | ❌ |
+| Wav2Vec2 | ✅ | ❌ | ✅ | ✅ | ✅ |
+| WavLM | ❌ | ❌ | ✅ | ❌ | ❌ |
+| XGLM | ✅ | ✅ | ✅ | ❌ | ✅ |
+| XLM | ✅ | ❌ | ✅ | ✅ | ❌ |
+| XLM-RoBERTa | ✅ | ✅ | ✅ | ✅ | ✅ |
+| XLM-RoBERTa-XL | ❌ | ❌ | ✅ | ❌ | ❌ |
+| XLMProphetNet | ✅ | ❌ | ✅ | ❌ | ❌ |
+| XLNet | ✅ | ✅ | ✅ | ✅ | ❌ |
+| YOLOS | ❌ | ❌ | ✅ | ❌ | ❌ |
+| YOSO | ❌ | ❌ | ✅ | ❌ | ❌ |
+
+
diff --git a/docs/source/en/installation.mdx b/docs/source/en/installation.mdx
new file mode 100644
index 00000000000000..5e25b60b48f957
--- /dev/null
+++ b/docs/source/en/installation.mdx
@@ -0,0 +1,235 @@
+
+
+# Installation
+
+Install 🤗 Transformers for whichever deep learning library you're working with, setup your cache, and optionally configure 🤗 Transformers to run offline.
+
+🤗 Transformers is tested on Python 3.6+, PyTorch 1.1.0+, TensorFlow 2.0+, and Flax. Follow the installation instructions below for the deep learning library you are using:
+
+* [PyTorch](https://pytorch.org/get-started/locally/) installation instructions.
+* [TensorFlow 2.0](https://www.tensorflow.org/install/pip) installation instructions.
+* [Flax](https://flax.readthedocs.io/en/latest/) installation instructions.
+
+## Install with pip
+
+You should install 🤗 Transformers in a [virtual environment](https://docs.python.org/3/library/venv.html). If you're unfamiliar with Python virtual environments, take a look at this [guide](https://packaging.python.org/guides/installing-using-pip-and-virtual-environments/). A virtual environment makes it easier to manage different projects, and avoid compatibility issues between dependencies.
+
+Start by creating a virtual environment in your project directory:
+
+```bash
+python -m venv .env
+```
+
+Activate the virtual environment:
+
+```bash
+source .env/bin/activate
+```
+
+Now you're ready to install 🤗 Transformers with the following command:
+
+```bash
+pip install transformers
+```
+
+For CPU-support only, you can conveniently install 🤗 Transformers and a deep learning library in one line. For example, install 🤗 Transformers and PyTorch with:
+
+```bash
+pip install transformers[torch]
+```
+
+🤗 Transformers and TensorFlow 2.0:
+
+```bash
+pip install transformers[tf-cpu]
+```
+
+🤗 Transformers and Flax:
+
+```bash
+pip install transformers[flax]
+```
+
+Finally, check if 🤗 Transformers has been properly installed by running the following command. It will download a pretrained model:
+
+```bash
+python -c "from transformers import pipeline; print(pipeline('sentiment-analysis')('we love you'))"
+```
+
+Then print out the label and score:
+
+```bash
+[{'label': 'POSITIVE', 'score': 0.9998704791069031}]
+```
+
+## Install from source
+
+Install 🤗 Transformers from source with the following command:
+
+```bash
+pip install git+https://github.com/huggingface/transformers
+```
+
+This command installs the bleeding edge `main` version rather than the latest `stable` version. The `main` version is useful for staying up-to-date with the latest developments. For instance, if a bug has been fixed since the last official release but a new release hasn't been rolled out yet. However, this means the `main` version may not always be stable. We strive to keep the `main` version operational, and most issues are usually resolved within a few hours or a day. If you run into a problem, please open an [Issue](https://github.com/huggingface/transformers/issues) so we can fix it even sooner!
+
+Check if 🤗 Transformers has been properly installed by running the following command:
+
+```bash
+python -c "from transformers import pipeline; print(pipeline('sentiment-analysis')('I love you'))"
+```
+
+## Editable install
+
+You will need an editable install if you'd like to:
+
+* Use the `main` version of the source code.
+* Contribute to 🤗 Transformers and need to test changes in the code.
+
+Clone the repository and install 🤗 Transformers with the following commands:
+
+```bash
+git clone https://github.com/huggingface/transformers.git
+cd transformers
+pip install -e .
+```
+
+These commands will link the folder you cloned the repository to and your Python library paths. Python will now look inside the folder you cloned to in addition to the normal library paths. For example, if your Python packages are typically installed in `~/anaconda3/envs/main/lib/python3.7/site-packages/`, Python will also search the folder you cloned to: `~/transformers/`.
+
+
+
+You must keep the `transformers` folder if you want to keep using the library.
+
+
+
+Now you can easily update your clone to the latest version of 🤗 Transformers with the following command:
+
+```bash
+cd ~/transformers/
+git pull
+```
+
+Your Python environment will find the `main` version of 🤗 Transformers on the next run.
+
+## Install with conda
+
+Install from the conda channel `huggingface`:
+
+```bash
+conda install -c huggingface transformers
+```
+
+## Cache setup
+
+Pretrained models are downloaded and locally cached at: `~/.cache/huggingface/transformers/`. This is the default directory given by the shell environment variable `TRANSFORMERS_CACHE`. On Windows, the default directory is given by `C:\Users\username\.cache\huggingface\transformers`. You can change the shell environment variables shown below - in order of priority - to specify a different cache directory:
+
+1. Shell environment variable (default): `TRANSFORMERS_CACHE`.
+2. Shell environment variable: `HF_HOME` + `transformers/`.
+3. Shell environment variable: `XDG_CACHE_HOME` + `/huggingface/transformers`.
+
+
+
+🤗 Transformers will use the shell environment variables `PYTORCH_TRANSFORMERS_CACHE` or `PYTORCH_PRETRAINED_BERT_CACHE` if you are coming from an earlier iteration of this library and have set those environment variables, unless you specify the shell environment variable `TRANSFORMERS_CACHE`.
+
+
+
+## Offline mode
+
+🤗 Transformers is able to run in a firewalled or offline environment by only using local files. Set the environment variable `TRANSFORMERS_OFFLINE=1` to enable this behavior.
+
+
+
+Add [🤗 Datasets](https://huggingface.co/docs/datasets/) to your offline training workflow by setting the environment variable `HF_DATASETS_OFFLINE=1`.
+
+
+
+For example, you would typically run a program on a normal network firewalled to external instances with the following command:
+
+```bash
+python examples/pytorch/translation/run_translation.py --model_name_or_path t5-small --dataset_name wmt16 --dataset_config ro-en ...
+```
+
+Run this same program in an offline instance with:
+
+```bash
+HF_DATASETS_OFFLINE=1 TRANSFORMERS_OFFLINE=1 \
+python examples/pytorch/translation/run_translation.py --model_name_or_path t5-small --dataset_name wmt16 --dataset_config ro-en ...
+```
+
+The script should now run without hanging or waiting to timeout because it knows it should only look for local files.
+
+### Fetch models and tokenizers to use offline
+
+Another option for using 🤗 Transformers offline is to download the files ahead of time, and then point to their local path when you need to use them offline. There are three ways to do this:
+
+* Download a file through the user interface on the [Model Hub](https://huggingface.co/models) by clicking on the ↓ icon.
+
+ 
+
+* Use the [`PreTrainedModel.from_pretrained`] and [`PreTrainedModel.save_pretrained`] workflow:
+
+ 1. Download your files ahead of time with [`PreTrainedModel.from_pretrained`]:
+
+ ```py
+ >>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
+
+ >>> tokenizer = AutoTokenizer.from_pretrained("bigscience/T0_3B")
+ >>> model = AutoModelForSeq2SeqLM.from_pretrained("bigscience/T0_3B")
+ ```
+
+ 2. Save your files to a specified directory with [`PreTrainedModel.save_pretrained`]:
+
+ ```py
+ >>> tokenizer.save_pretrained("./your/path/bigscience_t0")
+ >>> model.save_pretrained("./your/path/bigscience_t0")
+ ```
+
+ 3. Now when you're offline, reload your files with [`PreTrainedModel.from_pretrained`] from the specified directory:
+
+ ```py
+ >>> tokenizer = AutoTokenizer.from_pretrained("./your/path/bigscience_t0")
+ >>> model = AutoModel.from_pretrained("./your/path/bigscience_t0")
+ ```
+
+* Programmatically download files with the [huggingface_hub](https://github.com/huggingface/huggingface_hub/tree/main/src/huggingface_hub) library:
+
+ 1. Install the `huggingface_hub` library in your virtual environment:
+
+ ```bash
+ python -m pip install huggingface_hub
+ ```
+
+ 2. Use the [`hf_hub_download`](https://huggingface.co/docs/hub/adding-a-library#download-files-from-the-hub) function to download a file to a specific path. For example, the following command downloads the `config.json` file from the [T0](https://huggingface.co/bigscience/T0_3B) model to your desired path:
+
+ ```py
+ >>> from huggingface_hub import hf_hub_download
+
+ >>> hf_hub_download(repo_id="bigscience/T0_3B", filename="config.json", cache_dir="./your/path/bigscience_t0")
+ ```
+
+Once your file is downloaded and locally cached, specify it's local path to load and use it:
+
+```py
+>>> from transformers import AutoConfig
+
+>>> config = AutoConfig.from_pretrained("./your/path/bigscience_t0/config.json")
+```
+
+
+
+See the [How to download files from the Hub](https://huggingface.co/docs/hub/how-to-downstream) section for more details on downloading files stored on the Hub.
+
+
\ No newline at end of file
diff --git a/docs/source/en/internal/file_utils.mdx b/docs/source/en/internal/file_utils.mdx
new file mode 100644
index 00000000000000..9366293143585f
--- /dev/null
+++ b/docs/source/en/internal/file_utils.mdx
@@ -0,0 +1,46 @@
+
+
+# General Utilities
+
+This page lists all of Transformers general utility functions that are found in the file `utils.py`.
+
+Most of those are only useful if you are studying the general code in the library.
+
+
+## Enums and namedtuples
+
+[[autodoc]] utils.ExplicitEnum
+
+[[autodoc]] utils.PaddingStrategy
+
+[[autodoc]] utils.TensorType
+
+## Special Decorators
+
+[[autodoc]] utils.add_start_docstrings
+
+[[autodoc]] utils.add_start_docstrings_to_model_forward
+
+[[autodoc]] utils.add_end_docstrings
+
+[[autodoc]] utils.add_code_sample_docstrings
+
+[[autodoc]] utils.replace_return_docstrings
+
+## Special Properties
+
+[[autodoc]] utils.cached_property
+
+## Other Utilities
+
+[[autodoc]] utils._LazyModule
diff --git a/docs/source/en/internal/generation_utils.mdx b/docs/source/en/internal/generation_utils.mdx
new file mode 100644
index 00000000000000..5a717edb98fbb0
--- /dev/null
+++ b/docs/source/en/internal/generation_utils.mdx
@@ -0,0 +1,260 @@
+
+
+# Utilities for Generation
+
+This page lists all the utility functions used by [`~generation_utils.GenerationMixin.generate`],
+[`~generation_utils.GenerationMixin.greedy_search`],
+[`~generation_utils.GenerationMixin.sample`],
+[`~generation_utils.GenerationMixin.beam_search`],
+[`~generation_utils.GenerationMixin.beam_sample`],
+[`~generation_utils.GenerationMixin.group_beam_search`], and
+[`~generation_utils.GenerationMixin.constrained_beam_search`].
+
+Most of those are only useful if you are studying the code of the generate methods in the library.
+
+## Generate Outputs
+
+The output of [`~generation_utils.GenerationMixin.generate`] is an instance of a subclass of
+[`~utils.ModelOutput`]. This output is a data structure containing all the information returned
+by [`~generation_utils.GenerationMixin.generate`], but that can also be used as tuple or dictionary.
+
+Here's an example:
+
+```python
+from transformers import GPT2Tokenizer, GPT2LMHeadModel
+
+tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
+model = GPT2LMHeadModel.from_pretrained("gpt2")
+
+inputs = tokenizer("Hello, my dog is cute and ", return_tensors="pt")
+generation_output = model.generate(**inputs, return_dict_in_generate=True, output_scores=True)
+```
+
+The `generation_output` object is a [`~generation_utils.GreedySearchDecoderOnlyOutput`], as we can
+see in the documentation of that class below, it means it has the following attributes:
+
+- `sequences`: the generated sequences of tokens
+- `scores` (optional): the prediction scores of the language modelling head, for each generation step
+- `hidden_states` (optional): the hidden states of the model, for each generation step
+- `attentions` (optional): the attention weights of the model, for each generation step
+
+Here we have the `scores` since we passed along `output_scores=True`, but we don't have `hidden_states` and
+`attentions` because we didn't pass `output_hidden_states=True` or `output_attentions=True`.
+
+You can access each attribute as you would usually do, and if that attribute has not been returned by the model, you
+will get `None`. Here for instance `generation_output.scores` are all the generated prediction scores of the
+language modeling head, and `generation_output.attentions` is `None`.
+
+When using our `generation_output` object as a tuple, it only keeps the attributes that don't have `None` values.
+Here, for instance, it has two elements, `loss` then `logits`, so
+
+```python
+generation_output[:2]
+```
+
+will return the tuple `(generation_output.sequences, generation_output.scores)` for instance.
+
+When using our `generation_output` object as a dictionary, it only keeps the attributes that don't have `None`
+values. Here, for instance, it has two keys that are `sequences` and `scores`.
+
+We document here all output types.
+
+
+### GreedySearchOutput
+
+[[autodoc]] generation_utils.GreedySearchDecoderOnlyOutput
+
+[[autodoc]] generation_utils.GreedySearchEncoderDecoderOutput
+
+[[autodoc]] generation_flax_utils.FlaxGreedySearchOutput
+
+### SampleOutput
+
+[[autodoc]] generation_utils.SampleDecoderOnlyOutput
+
+[[autodoc]] generation_utils.SampleEncoderDecoderOutput
+
+[[autodoc]] generation_flax_utils.FlaxSampleOutput
+
+### BeamSearchOutput
+
+[[autodoc]] generation_utils.BeamSearchDecoderOnlyOutput
+
+[[autodoc]] generation_utils.BeamSearchEncoderDecoderOutput
+
+### BeamSampleOutput
+
+[[autodoc]] generation_utils.BeamSampleDecoderOnlyOutput
+
+[[autodoc]] generation_utils.BeamSampleEncoderDecoderOutput
+
+## LogitsProcessor
+
+A [`LogitsProcessor`] can be used to modify the prediction scores of a language model head for
+generation.
+
+[[autodoc]] LogitsProcessor
+ - __call__
+
+[[autodoc]] LogitsProcessorList
+ - __call__
+
+[[autodoc]] LogitsWarper
+ - __call__
+
+[[autodoc]] MinLengthLogitsProcessor
+ - __call__
+
+[[autodoc]] TemperatureLogitsWarper
+ - __call__
+
+[[autodoc]] RepetitionPenaltyLogitsProcessor
+ - __call__
+
+[[autodoc]] TopPLogitsWarper
+ - __call__
+
+[[autodoc]] TopKLogitsWarper
+ - __call__
+
+[[autodoc]] NoRepeatNGramLogitsProcessor
+ - __call__
+
+[[autodoc]] NoBadWordsLogitsProcessor
+ - __call__
+
+[[autodoc]] PrefixConstrainedLogitsProcessor
+ - __call__
+
+[[autodoc]] HammingDiversityLogitsProcessor
+ - __call__
+
+[[autodoc]] ForcedBOSTokenLogitsProcessor
+ - __call__
+
+[[autodoc]] ForcedEOSTokenLogitsProcessor
+ - __call__
+
+[[autodoc]] InfNanRemoveLogitsProcessor
+ - __call__
+
+[[autodoc]] TFLogitsProcessor
+ - __call__
+
+[[autodoc]] TFLogitsProcessorList
+ - __call__
+
+[[autodoc]] TFLogitsWarper
+ - __call__
+
+[[autodoc]] TFTemperatureLogitsWarper
+ - __call__
+
+[[autodoc]] TFTopPLogitsWarper
+ - __call__
+
+[[autodoc]] TFTopKLogitsWarper
+ - __call__
+
+[[autodoc]] TFMinLengthLogitsProcessor
+ - __call__
+
+[[autodoc]] TFNoBadWordsLogitsProcessor
+ - __call__
+
+[[autodoc]] TFNoRepeatNGramLogitsProcessor
+ - __call__
+
+[[autodoc]] TFRepetitionPenaltyLogitsProcessor
+ - __call__
+
+[[autodoc]] TFForcedBOSTokenLogitsProcessor
+ - __call__
+
+[[autodoc]] TFForcedEOSTokenLogitsProcessor
+ - __call__
+
+[[autodoc]] FlaxLogitsProcessor
+ - __call__
+
+[[autodoc]] FlaxLogitsProcessorList
+ - __call__
+
+[[autodoc]] FlaxLogitsWarper
+ - __call__
+
+[[autodoc]] FlaxTemperatureLogitsWarper
+ - __call__
+
+[[autodoc]] FlaxTopPLogitsWarper
+ - __call__
+
+[[autodoc]] FlaxTopKLogitsWarper
+ - __call__
+
+[[autodoc]] FlaxForcedBOSTokenLogitsProcessor
+ - __call__
+
+[[autodoc]] FlaxForcedEOSTokenLogitsProcessor
+ - __call__
+
+[[autodoc]] FlaxMinLengthLogitsProcessor
+ - __call__
+
+## StoppingCriteria
+
+A [`StoppingCriteria`] can be used to change when to stop generation (other than EOS token).
+
+[[autodoc]] StoppingCriteria
+ - __call__
+
+[[autodoc]] StoppingCriteriaList
+ - __call__
+
+[[autodoc]] MaxLengthCriteria
+ - __call__
+
+[[autodoc]] MaxTimeCriteria
+ - __call__
+
+## Constraints
+
+A [`Constraint`] can be used to force the generation to include specific tokens or sequences in the output.
+
+[[autodoc]] Constraint
+
+[[autodoc]] PhrasalConstraint
+
+[[autodoc]] DisjunctiveConstraint
+
+[[autodoc]] ConstraintListState
+
+## BeamSearch
+
+[[autodoc]] BeamScorer
+ - process
+ - finalize
+
+[[autodoc]] BeamSearchScorer
+ - process
+ - finalize
+
+[[autodoc]] ConstrainedBeamSearchScorer
+ - process
+ - finalize
+
+## Utilities
+
+[[autodoc]] top_k_top_p_filtering
+
+[[autodoc]] tf_top_k_top_p_filtering
diff --git a/docs/source/en/internal/modeling_utils.mdx b/docs/source/en/internal/modeling_utils.mdx
new file mode 100644
index 00000000000000..914b8ca36798fa
--- /dev/null
+++ b/docs/source/en/internal/modeling_utils.mdx
@@ -0,0 +1,82 @@
+
+
+# Custom Layers and Utilities
+
+This page lists all the custom layers used by the library, as well as the utility functions it provides for modeling.
+
+Most of those are only useful if you are studying the code of the models in the library.
+
+
+## Pytorch custom modules
+
+[[autodoc]] pytorch_utils.Conv1D
+
+[[autodoc]] modeling_utils.PoolerStartLogits
+ - forward
+
+[[autodoc]] modeling_utils.PoolerEndLogits
+ - forward
+
+[[autodoc]] modeling_utils.PoolerAnswerClass
+ - forward
+
+[[autodoc]] modeling_utils.SquadHeadOutput
+
+[[autodoc]] modeling_utils.SQuADHead
+ - forward
+
+[[autodoc]] modeling_utils.SequenceSummary
+ - forward
+
+## PyTorch Helper Functions
+
+[[autodoc]] pytorch_utils.apply_chunking_to_forward
+
+[[autodoc]] pytorch_utils.find_pruneable_heads_and_indices
+
+[[autodoc]] pytorch_utils.prune_layer
+
+[[autodoc]] pytorch_utils.prune_conv1d_layer
+
+[[autodoc]] pytorch_utils.prune_linear_layer
+
+## TensorFlow custom layers
+
+[[autodoc]] modeling_tf_utils.TFConv1D
+
+[[autodoc]] modeling_tf_utils.TFSharedEmbeddings
+ - call
+
+[[autodoc]] modeling_tf_utils.TFSequenceSummary
+
+## TensorFlow loss functions
+
+[[autodoc]] modeling_tf_utils.TFCausalLanguageModelingLoss
+
+[[autodoc]] modeling_tf_utils.TFMaskedLanguageModelingLoss
+
+[[autodoc]] modeling_tf_utils.TFMultipleChoiceLoss
+
+[[autodoc]] modeling_tf_utils.TFQuestionAnsweringLoss
+
+[[autodoc]] modeling_tf_utils.TFSequenceClassificationLoss
+
+[[autodoc]] modeling_tf_utils.TFTokenClassificationLoss
+
+## TensorFlow Helper Functions
+
+[[autodoc]] modeling_tf_utils.get_initializer
+
+[[autodoc]] modeling_tf_utils.keras_serializable
+
+[[autodoc]] modeling_tf_utils.shape_list
diff --git a/docs/source/en/internal/pipelines_utils.mdx b/docs/source/en/internal/pipelines_utils.mdx
new file mode 100644
index 00000000000000..ed8e75b414bb7f
--- /dev/null
+++ b/docs/source/en/internal/pipelines_utils.mdx
@@ -0,0 +1,40 @@
+
+
+# Utilities for pipelines
+
+This page lists all the utility functions the library provides for pipelines.
+
+Most of those are only useful if you are studying the code of the models in the library.
+
+
+## Argument handling
+
+[[autodoc]] pipelines.ArgumentHandler
+
+[[autodoc]] pipelines.ZeroShotClassificationArgumentHandler
+
+[[autodoc]] pipelines.QuestionAnsweringArgumentHandler
+
+## Data format
+
+[[autodoc]] pipelines.PipelineDataFormat
+
+[[autodoc]] pipelines.CsvPipelineDataFormat
+
+[[autodoc]] pipelines.JsonPipelineDataFormat
+
+[[autodoc]] pipelines.PipedPipelineDataFormat
+
+## Utilities
+
+[[autodoc]] pipelines.PipelineException
diff --git a/docs/source/en/internal/tokenization_utils.mdx b/docs/source/en/internal/tokenization_utils.mdx
new file mode 100644
index 00000000000000..24e81f7020643a
--- /dev/null
+++ b/docs/source/en/internal/tokenization_utils.mdx
@@ -0,0 +1,38 @@
+
+
+# Utilities for Tokenizers
+
+This page lists all the utility functions used by the tokenizers, mainly the class
+[`~tokenization_utils_base.PreTrainedTokenizerBase`] that implements the common methods between
+[`PreTrainedTokenizer`] and [`PreTrainedTokenizerFast`] and the mixin
+[`~tokenization_utils_base.SpecialTokensMixin`].
+
+Most of those are only useful if you are studying the code of the tokenizers in the library.
+
+## PreTrainedTokenizerBase
+
+[[autodoc]] tokenization_utils_base.PreTrainedTokenizerBase
+ - __call__
+ - all
+
+## SpecialTokensMixin
+
+[[autodoc]] tokenization_utils_base.SpecialTokensMixin
+
+## Enums and namedtuples
+
+[[autodoc]] tokenization_utils_base.TruncationStrategy
+
+[[autodoc]] tokenization_utils_base.CharSpan
+
+[[autodoc]] tokenization_utils_base.TokenSpan
diff --git a/docs/source/en/internal/trainer_utils.mdx b/docs/source/en/internal/trainer_utils.mdx
new file mode 100644
index 00000000000000..054bd69b440c4c
--- /dev/null
+++ b/docs/source/en/internal/trainer_utils.mdx
@@ -0,0 +1,43 @@
+
+
+# Utilities for Trainer
+
+This page lists all the utility functions used by [`Trainer`].
+
+Most of those are only useful if you are studying the code of the Trainer in the library.
+
+## Utilities
+
+[[autodoc]] EvalPrediction
+
+[[autodoc]] IntervalStrategy
+
+[[autodoc]] set_seed
+
+[[autodoc]] torch_distributed_zero_first
+
+## Callbacks internals
+
+[[autodoc]] trainer_callback.CallbackHandler
+
+## Distributed Evaluation
+
+[[autodoc]] trainer_pt_utils.DistributedTensorGatherer
+
+## Distributed Evaluation
+
+[[autodoc]] HfArgumentParser
+
+## Debug Utilities
+
+[[autodoc]] debug_utils.DebugUnderflowOverflow
diff --git a/docs/source/en/main_classes/callback.mdx b/docs/source/en/main_classes/callback.mdx
new file mode 100644
index 00000000000000..1d7d0b03d23253
--- /dev/null
+++ b/docs/source/en/main_classes/callback.mdx
@@ -0,0 +1,111 @@
+
+
+# Callbacks
+
+Callbacks are objects that can customize the behavior of the training loop in the PyTorch
+[`Trainer`] (this feature is not yet implemented in TensorFlow) that can inspect the training loop
+state (for progress reporting, logging on TensorBoard or other ML platforms...) and take decisions (like early
+stopping).
+
+Callbacks are "read only" pieces of code, apart from the [`TrainerControl`] object they return, they
+cannot change anything in the training loop. For customizations that require changes in the training loop, you should
+subclass [`Trainer`] and override the methods you need (see [trainer](trainer) for examples).
+
+By default a [`Trainer`] will use the following callbacks:
+
+- [`DefaultFlowCallback`] which handles the default behavior for logging, saving and evaluation.
+- [`PrinterCallback`] or [`ProgressCallback`] to display progress and print the
+ logs (the first one is used if you deactivate tqdm through the [`TrainingArguments`], otherwise
+ it's the second one).
+- [`~integrations.TensorBoardCallback`] if tensorboard is accessible (either through PyTorch >= 1.4
+ or tensorboardX).
+- [`~integrations.WandbCallback`] if [wandb](https://www.wandb.com/) is installed.
+- [`~integrations.CometCallback`] if [comet_ml](https://www.comet.ml/site/) is installed.
+- [`~integrations.MLflowCallback`] if [mlflow](https://www.mlflow.org/) is installed.
+- [`~integrations.AzureMLCallback`] if [azureml-sdk](https://pypi.org/project/azureml-sdk/) is
+ installed.
+- [`~integrations.CodeCarbonCallback`] if [codecarbon](https://pypi.org/project/codecarbon/) is
+ installed.
+
+The main class that implements callbacks is [`TrainerCallback`]. It gets the
+[`TrainingArguments`] used to instantiate the [`Trainer`], can access that
+Trainer's internal state via [`TrainerState`], and can take some actions on the training loop via
+[`TrainerControl`].
+
+
+## Available Callbacks
+
+Here is the list of the available [`TrainerCallback`] in the library:
+
+[[autodoc]] integrations.CometCallback
+ - setup
+
+[[autodoc]] DefaultFlowCallback
+
+[[autodoc]] PrinterCallback
+
+[[autodoc]] ProgressCallback
+
+[[autodoc]] EarlyStoppingCallback
+
+[[autodoc]] integrations.TensorBoardCallback
+
+[[autodoc]] integrations.WandbCallback
+ - setup
+
+[[autodoc]] integrations.MLflowCallback
+ - setup
+
+[[autodoc]] integrations.AzureMLCallback
+
+[[autodoc]] integrations.CodeCarbonCallback
+
+## TrainerCallback
+
+[[autodoc]] TrainerCallback
+
+Here is an example of how to register a custom callback with the PyTorch [`Trainer`]:
+
+```python
+class MyCallback(TrainerCallback):
+ "A callback that prints a message at the beginning of training"
+
+ def on_train_begin(self, args, state, control, **kwargs):
+ print("Starting training")
+
+
+trainer = Trainer(
+ model,
+ args,
+ train_dataset=train_dataset,
+ eval_dataset=eval_dataset,
+ callbacks=[MyCallback], # We can either pass the callback class this way or an instance of it (MyCallback())
+)
+```
+
+Another way to register a callback is to call `trainer.add_callback()` as follows:
+
+```python
+trainer = Trainer(...)
+trainer.add_callback(MyCallback)
+# Alternatively, we can pass an instance of the callback class
+trainer.add_callback(MyCallback())
+```
+
+## TrainerState
+
+[[autodoc]] TrainerState
+
+## TrainerControl
+
+[[autodoc]] TrainerControl
diff --git a/docs/source/en/main_classes/configuration.mdx b/docs/source/en/main_classes/configuration.mdx
new file mode 100644
index 00000000000000..541781eff76a03
--- /dev/null
+++ b/docs/source/en/main_classes/configuration.mdx
@@ -0,0 +1,28 @@
+
+
+# Configuration
+
+The base class [`PretrainedConfig`] implements the common methods for loading/saving a configuration
+either from a local file or directory, or from a pretrained model configuration provided by the library (downloaded
+from HuggingFace's AWS S3 repository).
+
+Each derived config class implements model specific attributes. Common attributes present in all config classes are:
+`hidden_size`, `num_attention_heads`, and `num_hidden_layers`. Text models further implement:
+`vocab_size`.
+
+
+## PretrainedConfig
+
+[[autodoc]] PretrainedConfig
+ - push_to_hub
+ - all
diff --git a/docs/source/en/main_classes/data_collator.mdx b/docs/source/en/main_classes/data_collator.mdx
new file mode 100644
index 00000000000000..ee1c1418e493a2
--- /dev/null
+++ b/docs/source/en/main_classes/data_collator.mdx
@@ -0,0 +1,64 @@
+
+
+# Data Collator
+
+Data collators are objects that will form a batch by using a list of dataset elements as input. These elements are of
+the same type as the elements of `train_dataset` or `eval_dataset`.
+
+To be able to build batches, data collators may apply some processing (like padding). Some of them (like
+[`DataCollatorForLanguageModeling`]) also apply some random data augmentation (like random masking)
+on the formed batch.
+
+Examples of use can be found in the [example scripts](../examples) or [example notebooks](../notebooks).
+
+
+## Default data collator
+
+[[autodoc]] data.data_collator.default_data_collator
+
+## DefaultDataCollator
+
+[[autodoc]] data.data_collator.DefaultDataCollator
+
+## DataCollatorWithPadding
+
+[[autodoc]] data.data_collator.DataCollatorWithPadding
+
+## DataCollatorForTokenClassification
+
+[[autodoc]] data.data_collator.DataCollatorForTokenClassification
+
+## DataCollatorForSeq2Seq
+
+[[autodoc]] data.data_collator.DataCollatorForSeq2Seq
+
+## DataCollatorForLanguageModeling
+
+[[autodoc]] data.data_collator.DataCollatorForLanguageModeling
+ - numpy_mask_tokens
+ - tf_mask_tokens
+ - torch_mask_tokens
+
+## DataCollatorForWholeWordMask
+
+[[autodoc]] data.data_collator.DataCollatorForWholeWordMask
+ - numpy_mask_tokens
+ - tf_mask_tokens
+ - torch_mask_tokens
+
+## DataCollatorForPermutationLanguageModeling
+
+[[autodoc]] data.data_collator.DataCollatorForPermutationLanguageModeling
+ - numpy_mask_tokens
+ - tf_mask_tokens
+ - torch_mask_tokens
diff --git a/docs/source/en/main_classes/deepspeed.mdx b/docs/source/en/main_classes/deepspeed.mdx
new file mode 100644
index 00000000000000..11831dbdc401da
--- /dev/null
+++ b/docs/source/en/main_classes/deepspeed.mdx
@@ -0,0 +1,2080 @@
+
+
+# DeepSpeed Integration
+
+[DeepSpeed](https://github.com/microsoft/DeepSpeed) implements everything described in the [ZeRO paper](https://arxiv.org/abs/1910.02054). Currently it provides full support for:
+
+1. Optimizer state partitioning (ZeRO stage 1)
+2. Gradient partitioning (ZeRO stage 2)
+3. Parameter partitioning (ZeRO stage 3)
+4. Custom mixed precision training handling
+5. A range of fast CUDA-extension-based optimizers
+6. ZeRO-Offload to CPU and NVMe
+
+ZeRO-Offload has its own dedicated paper: [ZeRO-Offload: Democratizing Billion-Scale Model Training](https://arxiv.org/abs/2101.06840). And NVMe-support is described in the paper [ZeRO-Infinity: Breaking the GPU
+Memory Wall for Extreme Scale Deep Learning](https://arxiv.org/abs/2104.07857).
+
+DeepSpeed ZeRO-2 is primarily used only for training, as its features are of no use to inference.
+
+DeepSpeed ZeRO-3 can be used for inference as well, since it allows huge models to be loaded on multiple GPUs, which
+won't be possible on a single GPU.
+
+🤗 Transformers integrates [DeepSpeed](https://github.com/microsoft/DeepSpeed) via 2 options:
+
+1. Integration of the core DeepSpeed features via [`Trainer`]. This is an everything-done-for-you type
+ of integration - just supply your custom config file or use our template and you have nothing else to do. Most of
+ this document is focused on this feature.
+2. If you don't use [`Trainer`] and want to use your own Trainer where you integrated DeepSpeed
+ yourself, core functionality functions like `from_pretrained` and `from_config` include integration of essential
+ parts of DeepSpeed like `zero.Init` for ZeRO stage 3 and higher. To tap into this feature read the docs on
+ [deepspeed-non-trainer-integration](#deepspeed-non-trainer-integration).
+
+What is integrated:
+
+Training:
+
+1. DeepSpeed ZeRO training supports the full ZeRO stages 1, 2 and 3 with ZeRO-Infinity (CPU and NVME offload).
+
+Inference:
+
+1. DeepSpeed ZeRO Inference supports ZeRO stage 3 with ZeRO-Infinity. It uses the same ZeRO protocol as training, but
+ it doesn't use an optimizer and a lr scheduler and only stage 3 is relevant. For more details see:
+ [deepspeed-zero-inference](#deepspeed-zero-inference).
+
+There is also DeepSpeed Inference - this is a totally different technology which uses Tensor Parallelism instead of
+ZeRO (coming soon).
+
+
+
+
+
+
+## Trainer Deepspeed Integration
+
+
+
+
+### Installation
+
+Install the library via pypi:
+
+```bash
+pip install deepspeed
+```
+
+or via `transformers`' `extras`:
+
+```bash
+pip install transformers[deepspeed]
+```
+
+or find more details on [the DeepSpeed's GitHub page](https://github.com/microsoft/deepspeed#installation) and
+[advanced install](https://www.deepspeed.ai/tutorials/advanced-install/).
+
+If you're still struggling with the build, first make sure to read [zero-install-notes](#zero-install-notes).
+
+If you don't prebuild the extensions and rely on them to be built at run time and you tried all of the above solutions
+to no avail, the next thing to try is to pre-build the modules before installing them.
+
+To make a local build for DeepSpeed:
+
+```bash
+git clone https://github.com/microsoft/DeepSpeed/
+cd DeepSpeed
+rm -rf build
+TORCH_CUDA_ARCH_LIST="8.6" DS_BUILD_CPU_ADAM=1 DS_BUILD_UTILS=1 pip install . \
+--global-option="build_ext" --global-option="-j8" --no-cache -v \
+--disable-pip-version-check 2>&1 | tee build.log
+```
+
+If you intend to use NVMe offload you will also need to include `DS_BUILD_AIO=1` in the instructions above (and also
+install *libaio-dev* system-wide).
+
+Edit `TORCH_CUDA_ARCH_LIST` to insert the code for the architectures of the GPU cards you intend to use. Assuming all
+your cards are the same you can get the arch via:
+
+```bash
+CUDA_VISIBLE_DEVICES=0 python -c "import torch; print(torch.cuda.get_device_capability())"
+```
+
+So if you get `8, 6`, then use `TORCH_CUDA_ARCH_LIST="8.6"`. If you have multiple different cards, you can list all
+of them like so `TORCH_CUDA_ARCH_LIST="6.1;8.6"`
+
+If you need to use the same setup on multiple machines, make a binary wheel:
+
+```bash
+git clone https://github.com/microsoft/DeepSpeed/
+cd DeepSpeed
+rm -rf build
+TORCH_CUDA_ARCH_LIST="8.6" DS_BUILD_CPU_ADAM=1 DS_BUILD_UTILS=1 \
+python setup.py build_ext -j8 bdist_wheel
+```
+
+it will generate something like `dist/deepspeed-0.3.13+8cd046f-cp38-cp38-linux_x86_64.whl` which now you can install
+as `pip install deepspeed-0.3.13+8cd046f-cp38-cp38-linux_x86_64.whl` locally or on any other machine.
+
+Again, remember to ensure to adjust `TORCH_CUDA_ARCH_LIST` to the target architectures.
+
+You can find the complete list of NVIDIA GPUs and their corresponding **Compute Capabilities** (same as arch in this
+context) [here](https://developer.nvidia.com/cuda-gpus).
+
+You can check the archs pytorch was built with using:
+
+```bash
+python -c "import torch; print(torch.cuda.get_arch_list())"
+```
+
+Here is how to find out the arch for one of the installed GPUs. For example, for GPU 0:
+
+```bash
+CUDA_VISIBLE_DEVICES=0 python -c "import torch; \
+print(torch.cuda.get_device_properties(torch.device('cuda')))"
+```
+
+If the output is:
+
+```bash
+_CudaDeviceProperties(name='GeForce RTX 3090', major=8, minor=6, total_memory=24268MB, multi_processor_count=82)
+```
+
+then you know that this card's arch is `8.6`.
+
+You can also leave `TORCH_CUDA_ARCH_LIST` out completely and then the build program will automatically query the
+architecture of the GPUs the build is made on. This may or may not match the GPUs on the target machines, that's why
+it's best to specify the desired archs explicitly.
+
+If after trying everything suggested you still encounter build issues, please, proceed with the GitHub Issue of
+[Deepspeed](https://github.com/microsoft/DeepSpeed/issues),
+
+
+
+
+
+### Deployment with multiple GPUs
+
+To deploy this feature with multiple GPUs adjust the [`Trainer`] command line arguments as
+following:
+
+1. replace `python -m torch.distributed.launch` with `deepspeed`.
+2. add a new argument `--deepspeed ds_config.json`, where `ds_config.json` is the DeepSpeed configuration file as
+ documented [here](https://www.deepspeed.ai/docs/config-json/). The file naming is up to you.
+
+Therefore, if your original command line looked as follows:
+
+```bash
+python -m torch.distributed.launch --nproc_per_node=2 your_program.py
+```
+
+Now it should be:
+
+```bash
+deepspeed --num_gpus=2 your_program.py --deepspeed ds_config.json
+```
+
+Unlike, `torch.distributed.launch` where you have to specify how many GPUs to use with `--nproc_per_node`, with the
+`deepspeed` launcher you don't have to use the corresponding `--num_gpus` if you want all of your GPUs used. The
+full details on how to configure various nodes and GPUs can be found [here](https://www.deepspeed.ai/getting-started/#resource-configuration-multi-node).
+
+In fact, you can continue using `-m torch.distributed.launch` with DeepSpeed as long as you don't need to use
+`deepspeed` launcher-specific arguments. Typically if you don't need a multi-node setup you're not required to use
+the `deepspeed` launcher. But since in the DeepSpeed documentation it'll be used everywhere, for consistency we will
+use it here as well.
+
+Here is an example of running `run_translation.py` under DeepSpeed deploying all available GPUs:
+
+```bash
+deepspeed examples/pytorch/translation/run_translation.py \
+--deepspeed tests/deepspeed/ds_config_zero3.json \
+--model_name_or_path t5-small --per_device_train_batch_size 1 \
+--output_dir output_dir --overwrite_output_dir --fp16 \
+--do_train --max_train_samples 500 --num_train_epochs 1 \
+--dataset_name wmt16 --dataset_config "ro-en" \
+--source_lang en --target_lang ro
+```
+
+Note that in the DeepSpeed documentation you are likely to see `--deepspeed --deepspeed_config ds_config.json` - i.e.
+two DeepSpeed-related arguments, but for the sake of simplicity, and since there are already so many arguments to deal
+with, we combined the two into a single argument.
+
+For some practical usage examples, please, see this [post](https://github.com/huggingface/transformers/issues/8771#issuecomment-759248400).
+
+
+
+
+
+### Deployment with one GPU
+
+To deploy DeepSpeed with one GPU adjust the [`Trainer`] command line arguments as follows:
+
+```bash
+deepspeed --num_gpus=1 examples/pytorch/translation/run_translation.py \
+--deepspeed tests/deepspeed/ds_config_zero2.json \
+--model_name_or_path t5-small --per_device_train_batch_size 1 \
+--output_dir output_dir --overwrite_output_dir --fp16 \
+--do_train --max_train_samples 500 --num_train_epochs 1 \
+--dataset_name wmt16 --dataset_config "ro-en" \
+--source_lang en --target_lang ro
+```
+
+This is almost the same as with multiple-GPUs, but here we tell DeepSpeed explicitly to use just one GPU via
+`--num_gpus=1`. By default, DeepSpeed deploys all GPUs it can see on the given node. If you have only 1 GPU to start
+with, then you don't need this argument. The following [documentation](https://www.deepspeed.ai/getting-started/#resource-configuration-multi-node) discusses the launcher options.
+
+Why would you want to use DeepSpeed with just one GPU?
+
+1. It has a ZeRO-offload feature which can delegate some computations and memory to the host's CPU and RAM, and thus
+ leave more GPU resources for model's needs - e.g. larger batch size, or enabling a fitting of a very big model which
+ normally won't fit.
+2. It provides a smart GPU memory management system, that minimizes memory fragmentation, which again allows you to fit
+ bigger models and data batches.
+
+While we are going to discuss the configuration in details next, the key to getting a huge improvement on a single GPU
+with DeepSpeed is to have at least the following configuration in the configuration file:
+
+```json
+{
+ "zero_optimization": {
+ "stage": 2,
+ "offload_optimizer": {
+ "device": "cpu",
+ "pin_memory": true
+ },
+ "allgather_partitions": true,
+ "allgather_bucket_size": 2e8,
+ "reduce_scatter": true,
+ "reduce_bucket_size": 2e8,
+ "overlap_comm": true,
+ "contiguous_gradients": true
+ }
+}
+```
+
+which enables optimizer offload and some other important features. You may experiment with the buffer sizes, you will
+find more details in the discussion below.
+
+For a practical usage example of this type of deployment, please, see this [post](https://github.com/huggingface/transformers/issues/8771#issuecomment-759176685).
+
+You may also try the ZeRO-3 with CPU and NVMe offload as explained further in this document.
+
+
+
+Notes:
+
+- if you need to run on a specific GPU, which is different from GPU 0, you can't use `CUDA_VISIBLE_DEVICES` to limit
+ the visible scope of available GPUs. Instead, you have to use the following syntax:
+
+ ```bash
+ deepspeed --include localhost:1 examples/pytorch/translation/run_translation.py ...
+ ```
+
+ In this example, we tell DeepSpeed to use GPU 1 (second gpu).
+
+
+
+
+
+### Deployment in Notebooks
+
+The problem with running notebook cells as a script is that there is no normal `deepspeed` launcher to rely on, so
+under certain setups we have to emulate it.
+
+If you're using only 1 GPU, here is how you'd have to adjust your training code in the notebook to use DeepSpeed.
+
+```python
+# DeepSpeed requires a distributed environment even when only one process is used.
+# This emulates a launcher in the notebook
+import os
+
+os.environ["MASTER_ADDR"] = "localhost"
+os.environ["MASTER_PORT"] = "9994" # modify if RuntimeError: Address already in use
+os.environ["RANK"] = "0"
+os.environ["LOCAL_RANK"] = "0"
+os.environ["WORLD_SIZE"] = "1"
+
+# Now proceed as normal, plus pass the deepspeed config file
+training_args = TrainingArguments(..., deepspeed="ds_config_zero3.json")
+trainer = Trainer(...)
+trainer.train()
+```
+
+Note: `...` stands for the normal arguments that you'd pass to the functions.
+
+If you want to use more than 1 GPU, you must use a multi-process environment for DeepSpeed to work. That is, you have
+to use the launcher for that purpose and this cannot be accomplished by emulating the distributed environment presented
+at the beginning of this section.
+
+If you want to create the config file on the fly in the notebook in the current directory, you could have a dedicated
+cell with:
+
+```python no-style
+%%bash
+cat <<'EOT' > ds_config_zero3.json
+{
+ "fp16": {
+ "enabled": "auto",
+ "loss_scale": 0,
+ "loss_scale_window": 1000,
+ "initial_scale_power": 16,
+ "hysteresis": 2,
+ "min_loss_scale": 1
+ },
+
+ "optimizer": {
+ "type": "AdamW",
+ "params": {
+ "lr": "auto",
+ "betas": "auto",
+ "eps": "auto",
+ "weight_decay": "auto"
+ }
+ },
+
+ "scheduler": {
+ "type": "WarmupLR",
+ "params": {
+ "warmup_min_lr": "auto",
+ "warmup_max_lr": "auto",
+ "warmup_num_steps": "auto"
+ }
+ },
+
+ "zero_optimization": {
+ "stage": 3,
+ "offload_optimizer": {
+ "device": "cpu",
+ "pin_memory": true
+ },
+ "offload_param": {
+ "device": "cpu",
+ "pin_memory": true
+ },
+ "overlap_comm": true,
+ "contiguous_gradients": true,
+ "sub_group_size": 1e9,
+ "reduce_bucket_size": "auto",
+ "stage3_prefetch_bucket_size": "auto",
+ "stage3_param_persistence_threshold": "auto",
+ "stage3_max_live_parameters": 1e9,
+ "stage3_max_reuse_distance": 1e9,
+ "stage3_gather_16bit_weights_on_model_save": true
+ },
+
+ "gradient_accumulation_steps": "auto",
+ "gradient_clipping": "auto",
+ "steps_per_print": 2000,
+ "train_batch_size": "auto",
+ "train_micro_batch_size_per_gpu": "auto",
+ "wall_clock_breakdown": false
+}
+EOT
+```
+
+If the training script is in a normal file and not in the notebook cells, you can launch `deepspeed` normally via
+shell from a cell. For example, to use `run_translation.py` you would launch it with:
+
+```python no-style
+!git clone https://github.com/huggingface/transformers
+!cd transformers; deepspeed examples/pytorch/translation/run_translation.py ...
+```
+
+or with `%%bash` magic, where you can write a multi-line code for the shell program to run:
+
+```python no-style
+%%bash
+
+git clone https://github.com/huggingface/transformers
+cd transformers
+deepspeed examples/pytorch/translation/run_translation.py ...
+```
+
+In such case you don't need any of the code presented at the beginning of this section.
+
+Note: While `%%bash` magic is neat, but currently it buffers the output so you won't see the logs until the process
+completes.
+
+
+
+
+
+
+### Configuration
+
+For the complete guide to the DeepSpeed configuration options that can be used in its configuration file please refer
+to the [following documentation](https://www.deepspeed.ai/docs/config-json/).
+
+You can find dozens of DeepSpeed configuration examples that address various practical needs in [the DeepSpeedExamples
+repo](https://github.com/microsoft/DeepSpeedExamples):
+
+```bash
+git clone https://github.com/microsoft/DeepSpeedExamples
+cd DeepSpeedExamples
+find . -name '*json'
+```
+
+Continuing the code from above, let's say you're looking to configure the Lamb optimizer. So you can search through the
+example `.json` files with:
+
+```bash
+grep -i Lamb $(find . -name '*json')
+```
+
+Some more examples are to be found in the [main repo](https://github.com/microsoft/DeepSpeed) as well.
+
+When using DeepSpeed you always need to supply a DeepSpeed configuration file, yet some configuration parameters have
+to be configured via the command line. You will find the nuances in the rest of this guide.
+
+To get an idea of what DeepSpeed configuration file looks like, here is one that activates ZeRO stage 2 features,
+including optimizer states cpu offload, uses `AdamW` optimizer and `WarmupLR` scheduler and will enable mixed
+precision training if `--fp16` is passed:
+
+```json
+{
+ "fp16": {
+ "enabled": "auto",
+ "loss_scale": 0,
+ "loss_scale_window": 1000,
+ "initial_scale_power": 16,
+ "hysteresis": 2,
+ "min_loss_scale": 1
+ },
+
+ "optimizer": {
+ "type": "AdamW",
+ "params": {
+ "lr": "auto",
+ "betas": "auto",
+ "eps": "auto",
+ "weight_decay": "auto"
+ }
+ },
+
+ "scheduler": {
+ "type": "WarmupLR",
+ "params": {
+ "warmup_min_lr": "auto",
+ "warmup_max_lr": "auto",
+ "warmup_num_steps": "auto"
+ }
+ },
+
+ "zero_optimization": {
+ "stage": 2,
+ "offload_optimizer": {
+ "device": "cpu",
+ "pin_memory": true
+ },
+ "allgather_partitions": true,
+ "allgather_bucket_size": 2e8,
+ "overlap_comm": true,
+ "reduce_scatter": true,
+ "reduce_bucket_size": 2e8,
+ "contiguous_gradients": true
+ },
+
+ "gradient_accumulation_steps": "auto",
+ "gradient_clipping": "auto",
+ "train_batch_size": "auto",
+ "train_micro_batch_size_per_gpu": "auto",
+}
+```
+
+When you execute the program, DeepSpeed will log the configuration it received from the [`Trainer`]
+to the console, so you can see exactly what was the final configuration passed to it.
+
+
+
+
+
+### Passing Configuration
+
+As discussed in this document normally the DeepSpeed configuration is passed as a path to a json file, but if you're
+not using the command line interface to configure the training, and instead instantiate the
+[`Trainer`] via [`TrainingArguments`] then for the `deepspeed` argument you can
+pass a nested `dict`. This allows you to create the configuration on the fly and doesn't require you to write it to
+the file system before passing it to [`TrainingArguments`].
+
+To summarize you can do:
+
+```python
+TrainingArguments(..., deepspeed="/path/to/ds_config.json")
+```
+
+or:
+
+```python
+ds_config_dict = dict(scheduler=scheduler_params, optimizer=optimizer_params)
+TrainingArguments(..., deepspeed=ds_config_dict)
+```
+
+
+
+### Shared Configuration
+
+
+
+
+This section is a must-read
+
+
+
+Some configuration values are required by both the [`Trainer`] and DeepSpeed to function correctly,
+therefore, to prevent conflicting definitions, which could lead to hard to detect errors, we chose to configure those
+via the [`Trainer`] command line arguments.
+
+Additionally, some configuration values are derived automatically based on the model's configuration, so instead of
+remembering to manually adjust multiple values, it's the best to let the [`Trainer`] do the majority
+of configuration for you.
+
+Therefore, in the rest of this guide you will find a special configuration value: `auto`, which when set will be
+automatically replaced with the correct or most efficient value. Please feel free to choose to ignore this
+recommendation and set the values explicitly, in which case be very careful that your the
+[`Trainer`] arguments and DeepSpeed configurations agree. For example, are you using the same
+learning rate, or batch size, or gradient accumulation settings? if these mismatch the training may fail in very
+difficult to detect ways. You have been warned.
+
+There are multiple other values that are specific to DeepSpeed-only and those you will have to set manually to suit
+your needs.
+
+In your own programs, you can also use the following approach if you'd like to modify the DeepSpeed config as a master
+and configure [`TrainingArguments`] based on that. The steps are:
+
+1. Create or load the DeepSpeed configuration to be used as a master configuration
+2. Create the [`TrainingArguments`] object based on these values
+
+Do note that some values, such as `scheduler.params.total_num_steps` are calculated by
+[`Trainer`] during `train`, but you can of course do the math yourself.
+
+
+
+### ZeRO
+
+[Zero Redundancy Optimizer (ZeRO)](https://www.deepspeed.ai/tutorials/zero/) is the workhorse of DeepSpeed. It
+supports 3 different levels (stages) of optimization. The first one is not quite interesting for scalability purposes,
+therefore this document focuses on stages 2 and 3. Stage 3 is further improved by the latest addition of ZeRO-Infinity.
+You will find more indepth information in the DeepSpeed documentation.
+
+The `zero_optimization` section of the configuration file is the most important part ([docs](https://www.deepspeed.ai/docs/config-json/#zero-optimizations-for-fp16-training)), since that is where you define
+which ZeRO stages you want to enable and how to configure them. You will find the explanation for each parameter in the
+DeepSpeed docs.
+
+This section has to be configured exclusively via DeepSpeed configuration - the [`Trainer`] provides
+no equivalent command line arguments.
+
+Note: currently DeepSpeed doesn't validate parameter names, so if you misspell any, it'll use the default setting for
+the parameter that got misspelled. You can watch the DeepSpeed engine start up log messages to see what values it is
+going to use.
+
+
+
+
+
+#### ZeRO-2 Config
+
+The following is an example of configuration for ZeRO stage 2:
+
+```json
+{
+ "zero_optimization": {
+ "stage": 2,
+ "offload_optimizer": {
+ "device": "cpu",
+ "pin_memory": true
+ },
+ "allgather_partitions": true,
+ "allgather_bucket_size": 5e8,
+ "overlap_comm": true,
+ "reduce_scatter": true,
+ "reduce_bucket_size": 5e8,
+ "contiguous_gradients": true
+ }
+}
+```
+
+**Performance tuning:**
+
+- enabling `offload_optimizer` should reduce GPU RAM usage (it requires `"stage": 2`)
+- `"overlap_comm": true` trades off increased GPU RAM usage to lower all-reduce latency. `overlap_comm` uses 4.5x
+ the `allgather_bucket_size` and `reduce_bucket_size` values. So if they are set to 5e8, this requires a 9GB
+ footprint (`5e8 x 2Bytes x 2 x 4.5`). Therefore, if you have a GPU with 8GB or less RAM, to avoid getting
+ OOM-errors you will need to reduce those parameters to about `2e8`, which would require 3.6GB. You will want to do
+ the same on larger capacity GPU as well, if you're starting to hit OOM.
+- when reducing these buffers you're trading communication speed to avail more GPU RAM. The smaller the buffer size is,
+ the slower the communication gets, and the more GPU RAM will be available to other tasks. So if a bigger batch size is
+ important, getting a slightly slower training time could be a good trade.
+
+Additionally, `deepspeed==0.4.4` added a new option `round_robin_gradients` which you can enable with:
+
+```json
+{
+ "zero_optimization": {
+ "round_robin_gradients": true
+ }
+}
+```
+
+This is a stage 2 optimization for CPU offloading that parallelizes gradient copying to CPU memory among ranks by fine-grained gradient partitioning. Performance benefit grows with gradient accumulation steps (more copying between optimizer steps) or GPU count (increased parallelism).
+
+
+
+
+#### ZeRO-3 Config
+
+The following is an example of configuration for ZeRO stage 3:
+
+```json
+{
+ "zero_optimization": {
+ "stage": 3,
+ "offload_optimizer": {
+ "device": "cpu",
+ "pin_memory": true
+ },
+ "offload_param": {
+ "device": "cpu",
+ "pin_memory": true
+ },
+ "overlap_comm": true,
+ "contiguous_gradients": true,
+ "sub_group_size": 1e9,
+ "reduce_bucket_size": "auto",
+ "stage3_prefetch_bucket_size": "auto",
+ "stage3_param_persistence_threshold": "auto",
+ "stage3_max_live_parameters": 1e9,
+ "stage3_max_reuse_distance": 1e9,
+ "stage3_gather_16bit_weights_on_model_save": true
+ }
+}
+```
+
+If you are getting OOMs, because your model or activations don't fit into the GPU memory and you have unutilized CPU
+memory offloading the optimizer states and parameters to CPU memory with `"device": "cpu"` may solve this limitation.
+If you don't want to offload to CPU memory, use `none` instead of `cpu` for the `device` entry. Offloading to
+NVMe is discussed further down.
+
+Pinned memory is enabled with `pin_memory` set to `true`. This feature can improve the throughput at the cost of
+making less memory available to other processes. Pinned memory is set aside to the specific process that requested it
+and its typically accessed much faster than normal CPU memory.
+
+**Performance tuning:**
+
+- `stage3_max_live_parameters`: `1e9`
+- `stage3_max_reuse_distance`: `1e9`
+
+If hitting OOM reduce `stage3_max_live_parameters` and `stage3_max_reuse_distance`. They should have minimal impact
+on performance unless you are doing activation checkpointing. `1e9` would consume ~2GB. The memory is shared by
+`stage3_max_live_parameters` and `stage3_max_reuse_distance`, so it's not additive, it's just 2GB total.
+
+`stage3_max_live_parameters` is the upper limit on how many full parameters you want to keep on the GPU at any given
+time. "reuse distance" is a metric we are using to figure out when will a parameter be used again in the future, and we
+use the `stage3_max_reuse_distance` to decide whether to throw away the parameter or to keep it. If a parameter is
+going to be used again in near future (less than `stage3_max_reuse_distance`) then we keep it to reduce communication
+overhead. This is super helpful when you have activation checkpointing enabled, where we do a forward recompute and
+backward passes a a single layer granularity and want to keep the parameter in the forward recompute till the backward
+
+The following configuration values depend on the model's hidden size:
+
+- `reduce_bucket_size`: `hidden_size*hidden_size`
+- `stage3_prefetch_bucket_size`: `0.9 * hidden_size * hidden_size`
+- `stage3_param_persistence_threshold`: `10 * hidden_size`
+
+therefore set these values to `auto` and the [`Trainer`] will automatically assign the recommended
+values. But, of course, feel free to set these explicitly as well.
+
+`stage3_gather_16bit_weights_on_model_save` enables model fp16 weights consolidation when model gets saved. With large
+models and multiple GPUs this is an expensive operation both in terms of memory and speed. It's currently required if
+you plan to resume the training. Watch out for future updates that will remove this limitation and make things more
+flexible.
+
+If you're migrating from ZeRO-2 configuration note that `allgather_partitions`, `allgather_bucket_size` and
+`reduce_scatter` configuration parameters are not used in ZeRO-3. If you keep these in the config file they will just
+be ignored.
+
+- `sub_group_size`: `1e9`
+
+`sub_group_size` controls the granularity in which parameters are updated during optimizer steps. Parameters are
+grouped into buckets of `sub_group_size` and each buckets is updated one at a time. When used with NVMe offload in
+ZeRO-Infinity, `sub_group_size` therefore controls the granularity in which model states are moved in and out of CPU
+memory from NVMe during the optimizer step. This prevents running out of CPU memory for extremely large models.
+
+You can leave `sub_group_size` to its default value of *1e9* when not using NVMe offload. You may want to change its
+default value in the following cases:
+
+1. Running into OOM during optimizer step: Reduce `sub_group_size` to reduce memory utilization of temporary buffers
+2. Optimizer Step is taking a long time: Increase `sub_group_size` to improve bandwidth utilization as a result of
+ the increased data buffers.
+
+
+
+
+### NVMe Support
+
+ZeRO-Infinity allows for training incredibly large models by extending GPU and CPU memory with NVMe memory. Thanks to
+smart partitioning and tiling algorithms each GPU needs to send and receive very small amounts of data during
+offloading so modern NVMe proved to be fit to allow for an even larger total memory pool available to your training
+process. ZeRO-Infinity requires ZeRO-3 enabled.
+
+The following configuration example enables NVMe to offload both optimizer states and the params:
+
+```json
+{
+ "zero_optimization": {
+ "stage": 3,
+ "offload_optimizer": {
+ "device": "nvme",
+ "nvme_path": "/local_nvme",
+ "pin_memory": true,
+ "buffer_count": 4,
+ "fast_init": false
+ },
+ "offload_param": {
+ "device": "nvme",
+ "nvme_path": "/local_nvme",
+ "pin_memory": true,
+ "buffer_count": 5,
+ "buffer_size": 1e8,
+ "max_in_cpu": 1e9
+ },
+ "aio": {
+ "block_size": 262144,
+ "queue_depth": 32,
+ "thread_count": 1,
+ "single_submit": false,
+ "overlap_events": true
+ },
+ "overlap_comm": true,
+ "contiguous_gradients": true,
+ "sub_group_size": 1e9,
+ "reduce_bucket_size": "auto",
+ "stage3_prefetch_bucket_size": "auto",
+ "stage3_param_persistence_threshold": "auto",
+ "stage3_max_live_parameters": 1e9,
+ "stage3_max_reuse_distance": 1e9,
+ "stage3_gather_16bit_weights_on_model_save": true
+ },
+}
+```
+
+You can choose to offload both optimizer states and params to NVMe, or just one of them or none. For example, if you
+have copious amounts of CPU memory available, by all means offload to CPU memory only as it'd be faster (hint:
+*"device": "cpu"*).
+
+Here is the full documentation for offloading [optimizer states](https://www.deepspeed.ai/docs/config-json/#optimizer-offloading) and [parameters](https://www.deepspeed.ai/docs/config-json/#parameter-offloading).
+
+Make sure that your `nvme_path` is actually an NVMe, since it will work with the normal hard drive or SSD, but it'll
+be much much slower. The fast scalable training was designed with modern NVMe transfer speeds in mind (as of this
+writing one can have ~3.5GB/s read, ~3GB/s write peak speeds).
+
+In order to figure out the optimal `aio` configuration block you must run a benchmark on your target setup, as
+[explained here](https://github.com/microsoft/DeepSpeed/issues/998).
+
+
+
+
+
+#### ZeRO-2 vs ZeRO-3 Performance
+
+ZeRO-3 is likely to be slower than ZeRO-2 if everything else is configured the same because the former has to gather
+model weights in addition to what ZeRO-2 does. If ZeRO-2 meets your needs and you don't need to scale beyond a few GPUs
+then you may choose to stick to it. It's important to understand that ZeRO-3 enables a much higher scalability capacity
+at a cost of speed.
+
+It's possible to adjust ZeRO-3 configuration to make it perform closer to ZeRO-2:
+
+- set `stage3_param_persistence_threshold` to a very large number - larger than the largest parameter, e.g., `6 * hidden_size * hidden_size`. This will keep the parameters on the GPUs.
+- turn off `offload_params` since ZeRO-2 doesn't have that option.
+
+The performance will likely improve significantly with just `offload_params` turned off, even if you don't change
+`stage3_param_persistence_threshold`. Of course, these changes will impact the size of the model you can train. So
+these help you to trade scalability for speed depending on your needs.
+
+
+
+
+
+#### ZeRO-2 Example
+
+Here is a full ZeRO-2 auto-configuration file `ds_config_zero2.json`:
+
+```json
+{
+ "fp16": {
+ "enabled": "auto",
+ "loss_scale": 0,
+ "loss_scale_window": 1000,
+ "initial_scale_power": 16,
+ "hysteresis": 2,
+ "min_loss_scale": 1
+ },
+
+ "optimizer": {
+ "type": "AdamW",
+ "params": {
+ "lr": "auto",
+ "betas": "auto",
+ "eps": "auto",
+ "weight_decay": "auto"
+ }
+ },
+
+ "scheduler": {
+ "type": "WarmupLR",
+ "params": {
+ "warmup_min_lr": "auto",
+ "warmup_max_lr": "auto",
+ "warmup_num_steps": "auto"
+ }
+ },
+
+ "zero_optimization": {
+ "stage": 2,
+ "offload_optimizer": {
+ "device": "cpu",
+ "pin_memory": true
+ },
+ "allgather_partitions": true,
+ "allgather_bucket_size": 2e8,
+ "overlap_comm": true,
+ "reduce_scatter": true,
+ "reduce_bucket_size": 2e8,
+ "contiguous_gradients": true
+ },
+
+ "gradient_accumulation_steps": "auto",
+ "gradient_clipping": "auto",
+ "steps_per_print": 2000,
+ "train_batch_size": "auto",
+ "train_micro_batch_size_per_gpu": "auto",
+ "wall_clock_breakdown": false
+}
+```
+
+Here is a full ZeRO-2 all-enabled manually set configuration file. It is here mainly for you to see what the typical
+values look like, but we highly recommend using the one with multiple `auto` settings in it.
+
+```json
+{
+ "fp16": {
+ "enabled": true,
+ "loss_scale": 0,
+ "loss_scale_window": 1000,
+ "initial_scale_power": 16,
+ "hysteresis": 2,
+ "min_loss_scale": 1
+ },
+
+ "optimizer": {
+ "type": "AdamW",
+ "params": {
+ "lr": 3e-5,
+ "betas": [0.8, 0.999],
+ "eps": 1e-8,
+ "weight_decay": 3e-7
+ }
+ },
+
+ "scheduler": {
+ "type": "WarmupLR",
+ "params": {
+ "warmup_min_lr": 0,
+ "warmup_max_lr": 3e-5,
+ "warmup_num_steps": 500
+ }
+ },
+
+ "zero_optimization": {
+ "stage": 2,
+ "offload_optimizer": {
+ "device": "cpu",
+ "pin_memory": true
+ },
+ "allgather_partitions": true,
+ "allgather_bucket_size": 2e8,
+ "overlap_comm": true,
+ "reduce_scatter": true,
+ "reduce_bucket_size": 2e8,
+ "contiguous_gradients": true
+ },
+
+ "steps_per_print": 2000,
+ "wall_clock_breakdown": false
+}
+```
+
+
+
+#### ZeRO-3 Example
+
+Here is a full ZeRO-3 auto-configuration file `ds_config_zero3.json`:
+
+
+```json
+{
+ "fp16": {
+ "enabled": "auto",
+ "loss_scale": 0,
+ "loss_scale_window": 1000,
+ "initial_scale_power": 16,
+ "hysteresis": 2,
+ "min_loss_scale": 1
+ },
+
+ "optimizer": {
+ "type": "AdamW",
+ "params": {
+ "lr": "auto",
+ "betas": "auto",
+ "eps": "auto",
+ "weight_decay": "auto"
+ }
+ },
+
+ "scheduler": {
+ "type": "WarmupLR",
+ "params": {
+ "warmup_min_lr": "auto",
+ "warmup_max_lr": "auto",
+ "warmup_num_steps": "auto"
+ }
+ },
+
+ "zero_optimization": {
+ "stage": 3,
+ "offload_optimizer": {
+ "device": "cpu",
+ "pin_memory": true
+ },
+ "offload_param": {
+ "device": "cpu",
+ "pin_memory": true
+ },
+ "overlap_comm": true,
+ "contiguous_gradients": true,
+ "sub_group_size": 1e9,
+ "reduce_bucket_size": "auto",
+ "stage3_prefetch_bucket_size": "auto",
+ "stage3_param_persistence_threshold": "auto",
+ "stage3_max_live_parameters": 1e9,
+ "stage3_max_reuse_distance": 1e9,
+ "stage3_gather_16bit_weights_on_model_save": true
+ },
+
+ "gradient_accumulation_steps": "auto",
+ "gradient_clipping": "auto",
+ "steps_per_print": 2000,
+ "train_batch_size": "auto",
+ "train_micro_batch_size_per_gpu": "auto",
+ "wall_clock_breakdown": false
+}
+```
+
+Here is a full ZeRO-3 all-enabled manually set configuration file. It is here mainly for you to see what the typical
+values look like, but we highly recommend using the one with multiple `auto` settings in it.
+
+```json
+{
+ "fp16": {
+ "enabled": true,
+ "loss_scale": 0,
+ "loss_scale_window": 1000,
+ "initial_scale_power": 16,
+ "hysteresis": 2,
+ "min_loss_scale": 1
+ },
+
+ "optimizer": {
+ "type": "AdamW",
+ "params": {
+ "lr": 3e-5,
+ "betas": [0.8, 0.999],
+ "eps": 1e-8,
+ "weight_decay": 3e-7
+ }
+ },
+
+ "scheduler": {
+ "type": "WarmupLR",
+ "params": {
+ "warmup_min_lr": 0,
+ "warmup_max_lr": 3e-5,
+ "warmup_num_steps": 500
+ }
+ },
+
+ "zero_optimization": {
+ "stage": 3,
+ "offload_optimizer": {
+ "device": "cpu",
+ "pin_memory": true
+ },
+ "offload_param": {
+ "device": "cpu",
+ "pin_memory": true
+ },
+ "overlap_comm": true,
+ "contiguous_gradients": true,
+ "sub_group_size": 1e9,
+ "reduce_bucket_size": 1e6,
+ "stage3_prefetch_bucket_size": 0.94e6,
+ "stage3_param_persistence_threshold": 1e4,
+ "stage3_max_live_parameters": 1e9,
+ "stage3_max_reuse_distance": 1e9,
+ "stage3_gather_16bit_weights_on_model_save": true
+ },
+
+ "steps_per_print": 2000,
+ "wall_clock_breakdown": false
+}
+```
+
+### Optimizer and Scheduler
+
+As long as you don't enable `offload_optimizer` you can mix and match DeepSpeed and HuggingFace schedulers and
+optimizers, with the exception of using the combination of HuggingFace scheduler and DeepSpeed optimizer:
+
+| Combos | HF Scheduler | DS Scheduler |
+| HF Optimizer | Yes | Yes |
+| DS Optimizer | No | Yes |
+
+It is possible to use a non-DeepSpeed optimizer when `offload_optimizer` is enabled, as long as it has both CPU and
+GPU implementation (except LAMB).
+
+
+
+
+
+
+#### Optimizer
+
+
+DeepSpeed's main optimizers are Adam, AdamW, OneBitAdam, and Lamb. These have been thoroughly tested with ZeRO and are
+thus recommended to be used. It, however, can import other optimizers from `torch`. The full documentation is [here](https://www.deepspeed.ai/docs/config-json/#optimizer-parameters).
+
+If you don't configure the `optimizer` entry in the configuration file, the [`Trainer`] will
+automatically set it to `AdamW` and will use the supplied values or the defaults for the following command line
+arguments: `--learning_rate`, `--adam_beta1`, `--adam_beta2`, `--adam_epsilon` and `--weight_decay`.
+
+Here is an example of the auto-configured `optimizer` entry for `AdamW`:
+
+```json
+{
+ "optimizer": {
+ "type": "AdamW",
+ "params": {
+ "lr": "auto",
+ "betas": "auto",
+ "eps": "auto",
+ "weight_decay": "auto"
+ }
+ }
+}
+```
+
+Note that the command line arguments will set the values in the configuration file. This is so that there is one
+definitive source of the values and to avoid hard to find errors when for example, the learning rate is set to
+different values in different places. Command line rules. The values that get overridden are:
+
+- `lr` with the value of `--learning_rate`
+- `betas` with the value of `--adam_beta1 --adam_beta2`
+- `eps` with the value of `--adam_epsilon`
+- `weight_decay` with the value of `--weight_decay`
+
+Therefore please remember to tune the shared hyperparameters on the command line.
+
+You can also set the values explicitly:
+
+```json
+{
+ "optimizer": {
+ "type": "AdamW",
+ "params": {
+ "lr": 0.001,
+ "betas": [0.8, 0.999],
+ "eps": 1e-8,
+ "weight_decay": 3e-7
+ }
+ }
+}
+```
+
+But then you're on your own synchronizing the [`Trainer`] command line arguments and the DeepSpeed
+configuration.
+
+If you want to use another optimizer which is not listed above, you will have to add to the top level configuration.
+
+```json
+{
+ "zero_allow_untested_optimizer": true
+}
+```
+
+Similarly to `AdamW`, you can configure other officially supported optimizers. Just remember that may have different
+config values. e.g. for Adam you will want `weight_decay` around `0.01`.
+
+
+
+
+
+#### Scheduler
+
+DeepSpeed supports `LRRangeTest`, `OneCycle`, `WarmupLR` and `WarmupDecayLR` learning rate schedulers. The full
+documentation is [here](https://www.deepspeed.ai/docs/config-json/#scheduler-parameters).
+
+Here is where the schedulers overlap between 🤗 Transformers and DeepSpeed:
+
+- `WarmupLR` via `--lr_scheduler_type constant_with_warmup`
+- `WarmupDecayLR` via `--lr_scheduler_type linear`. This is also the default value for `--lr_scheduler_type`,
+ therefore, if you don't configure the scheduler this is scheduler that will get configured by default.
+
+If you don't configure the `scheduler` entry in the configuration file, the [`Trainer`] will use
+the values of `--lr_scheduler_type`, `--learning_rate` and `--warmup_steps` or `--warmup_ratio` to configure a
+🤗 Transformers version of it.
+
+Here is an example of the auto-configured `scheduler` entry for `WarmupLR`:
+
+```json
+{
+ "scheduler": {
+ "type": "WarmupLR",
+ "params": {
+ "warmup_min_lr": "auto",
+ "warmup_max_lr": "auto",
+ "warmup_num_steps": "auto"
+ }
+ }
+}
+```
+
+Since *"auto"* is used the [`Trainer`] arguments will set the correct values in the configuration
+file. This is so that there is one definitive source of the values and to avoid hard to find errors when, for example,
+the learning rate is set to different values in different places. Command line rules. The values that get set are:
+
+- `warmup_min_lr` with the value of `0`.
+- `warmup_max_lr` with the value of `--learning_rate`.
+- `warmup_num_steps` with the value of `--warmup_steps` if provided. Otherwise will use `--warmup_ratio`
+ multiplied by the number of training steps and rounded up.
+- `total_num_steps` with either the value of `--max_steps` or if it is not provided, derived automatically at run
+ time based on the environment and the size of the dataset and other command line arguments (needed for
+ `WarmupDecayLR`).
+
+You can, of course, take over any or all of the configuration values and set those yourself:
+
+```json
+{
+ "scheduler": {
+ "type": "WarmupLR",
+ "params": {
+ "warmup_min_lr": 0,
+ "warmup_max_lr": 0.001,
+ "warmup_num_steps": 1000
+ }
+ }
+}
+```
+
+But then you're on your own synchronizing the [`Trainer`] command line arguments and the DeepSpeed
+configuration.
+
+For example, for `WarmupDecayLR`, you can use the following entry:
+
+```json
+{
+ "scheduler": {
+ "type": "WarmupDecayLR",
+ "params": {
+ "last_batch_iteration": -1,
+ "total_num_steps": "auto",
+ "warmup_min_lr": "auto",
+ "warmup_max_lr": "auto",
+ "warmup_num_steps": "auto"
+ }
+ }
+}
+```
+
+and `total_num_steps`, `warmup_max_lr`, `warmup_num_steps` and `total_num_steps` will be set at loading time.
+
+
+
+
+
+
+### fp32 Precision
+
+Deepspeed supports the full fp32 and the fp16 mixed precision.
+
+Because of the much reduced memory needs and faster speed one gets with the fp16 mixed precision, the only time you
+will want to not use it is when the model you're using doesn't behave well under this training mode. Typically this
+happens when the model wasn't pretrained in the fp16 mixed precision (e.g. often this happens with bf16-pretrained
+models). Such models may overflow or underflow leading to `NaN` loss. If this is your case then you will want to use
+the full fp32 mode, by explicitly disabling the otherwise default fp16 mixed precision mode with:
+
+```json
+{
+ "fp16": {
+ "enabled": "false",
+ }
+}
+```
+
+If you're using the Ampere-architecture based GPU, pytorch version 1.7 and higher will automatically switch to using
+the much more efficient tf32 format for some operations, but the results will still be in fp32. For details and
+benchmarks, please, see [TensorFloat-32(TF32) on Ampere devices](https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices). The document includes
+instructions on how to disable this automatic conversion if for some reason you prefer not to use it.
+
+With the 🤗 Trainer you can use `--tf32` to enable it, or disable it with `--tf32 0` or `--no_tf32`. By default the PyTorch default is used.
+
+
+
+
+
+### Automatic Mixed Precision
+
+You can use automatic mixed precision with either a pytorch-like AMP way or the apex-like way:
+
+### fp16
+
+To configure pytorch AMP-like mode with fp16 (float16) set:
+
+```json
+{
+ "fp16": {
+ "enabled": "auto",
+ "loss_scale": 0,
+ "loss_scale_window": 1000,
+ "initial_scale_power": 16,
+ "hysteresis": 2,
+ "min_loss_scale": 1
+ }
+}
+```
+
+and the [`Trainer`] will automatically enable or disable it based on the value of
+`args.fp16_backend`. The rest of config values are up to you.
+
+This mode gets enabled when `--fp16 --fp16_backend amp` or `--fp16_full_eval` command line args are passed.
+
+You can also enable/disable this mode explicitly:
+
+```json
+{
+ "fp16": {
+ "enabled": true,
+ "loss_scale": 0,
+ "loss_scale_window": 1000,
+ "initial_scale_power": 16,
+ "hysteresis": 2,
+ "min_loss_scale": 1
+ }
+}
+```
+
+But then you're on your own synchronizing the [`Trainer`] command line arguments and the DeepSpeed
+configuration.
+
+Here is the [documentation](https://www.deepspeed.ai/docs/config-json/#fp16-training-options).
+
+### bf16
+
+If bf16 (bfloat16) is desired instead of fp16 then the following configuration section is to be used:
+
+```json
+{
+ "bf16": {
+ "enabled": "auto"
+ }
+}
+```
+
+bf16 has the same dynamic range as fp32 and thus doesn't require loss scaling.
+
+This mode gets enabled when `--bf16` or `--bf16_full_eval` command line args are passed.
+
+You can also enable/disable this mode explicitly:
+
+```json
+{
+ "bf16": {
+ "enabled": true
+ }
+}
+```
+
+
+
+As of `deepspeed==0.6.0` the bf16 support is new and experimental.
+
+If you use [gradient accumulation](#gradient-accumulation) with bf16-enabled, you need to be aware that it'll accumulate gradients in bf16, which may not be what you want due to this format's low precision, as it may lead to a lossy accumulation.
+
+
+
+
+### apex
+
+To configure apex AMP-like mode set:
+
+```json
+"amp": {
+ "enabled": "auto",
+ "opt_level": "auto"
+}
+```
+
+and the [`Trainer`] will automatically configure it based on the values of `args.fp16_backend` and
+`args.fp16_opt_level`.
+
+This mode gets enabled when `--fp16 --fp16_backend apex --fp16_opt_level 01` command line args are passed.
+
+You can also configure this mode explicitly:
+
+```json
+{
+ "amp": {
+ "enabled": true,
+ "opt_level": "O1"
+ }
+}
+```
+
+But then you're on your own synchronizing the [`Trainer`] command line arguments and the DeepSpeed
+configuration.
+
+Here is the [documentation](https://www.deepspeed.ai/docs/config-json/#automatic-mixed-precision-amp-training-options).
+
+
+
+
+
+### Batch Size
+
+To configure batch size, use:
+
+```json
+{
+ "train_batch_size": "auto",
+ "train_micro_batch_size_per_gpu": "auto"
+}
+```
+
+and the [`Trainer`] will automatically set `train_micro_batch_size_per_gpu` to the value of
+`args.per_device_train_batch_size` and `train_batch_size` to `args.world_size * args.per_device_train_batch_size * args.gradient_accumulation_steps`.
+
+You can also set the values explicitly:
+
+```json
+{
+ "train_batch_size": 12,
+ "train_micro_batch_size_per_gpu": 4
+}
+```
+
+But then you're on your own synchronizing the [`Trainer`] command line arguments and the DeepSpeed
+configuration.
+
+
+
+
+
+### Gradient Accumulation
+
+To configure gradient accumulation set:
+
+```json
+{
+ "gradient_accumulation_steps": "auto"
+}
+```
+
+and the [`Trainer`] will automatically set it to the value of `args.gradient_accumulation_steps`.
+
+You can also set the value explicitly:
+
+```json
+{
+ "gradient_accumulation_steps": 3
+}
+```
+
+But then you're on your own synchronizing the [`Trainer`] command line arguments and the DeepSpeed
+configuration.
+
+
+
+
+
+### Gradient Clipping
+
+To configure gradient gradient clipping set:
+
+```json
+{
+ "gradient_clipping": "auto"
+}
+```
+
+and the [`Trainer`] will automatically set it to the value of `args.max_grad_norm`.
+
+You can also set the value explicitly:
+
+```json
+{
+ "gradient_clipping": 1.0
+}
+```
+
+But then you're on your own synchronizing the [`Trainer`] command line arguments and the DeepSpeed
+configuration.
+
+
+
+
+
+### Getting The Model Weights Out
+
+As long as you continue training and resuming using DeepSpeed you don't need to worry about anything. DeepSpeed stores
+fp32 master weights in its custom checkpoint optimizer files, which are `global_step*/*optim_states.pt` (this is glob
+pattern), and are saved under the normal checkpoint.
+
+**FP16 Weights:**
+
+When a model is saved under ZeRO-2, you end up having the normal `pytorch_model.bin` file with the model weights, but
+they are only the fp16 version of the weights.
+
+Under ZeRO-3, things are much more complicated, since the model weights are partitioned out over multiple GPUs,
+therefore `"stage3_gather_16bit_weights_on_model_save": true` is required to get the `Trainer` to save the fp16
+version of the weights. If this setting is `False` `pytorch_model.bin` won't be created. This is because by default DeepSpeed's `state_dict` contains a placeholder and not the real weights. If we were to save this `state_dict` it won't be possible to load it back.
+
+
+```json
+{
+ "zero_optimization": {
+ "stage3_gather_16bit_weights_on_model_save": true
+ }
+}
+```
+
+**FP32 Weights:**
+
+While the fp16 weights are fine for resuming training, if you finished finetuning your model and want to upload it to
+the [models hub](https://huggingface.co/models) or pass it to someone else you most likely will want to get the fp32
+weights. This ideally shouldn't be done during training since this is a process that requires a lot of memory, and
+therefore best to be performed offline after the training is complete. But if desired and you have plenty of free CPU
+memory it can be done in the same training script. The following sections will discuss both approaches.
+
+
+**Live FP32 Weights Recovery:**
+
+This approach may not work if you model is large and you have little free CPU memory left, at the end of the training.
+
+If you have saved at least one checkpoint, and you want to use the latest one, you can do the following:
+
+```python
+from transformers.trainer_utils import get_last_checkpoint
+from deepspeed.utils.zero_to_fp32 import load_state_dict_from_zero_checkpoint
+
+checkpoint_dir = get_last_checkpoint(trainer.args.output_dir)
+fp32_model = load_state_dict_from_zero_checkpoint(trainer.model, checkpoint_dir)
+```
+
+If you're using the `--load_best_model_at_end` class:*~transformers.TrainingArguments* argument (to track the best
+checkpoint), then you can finish the training by first saving the final model explicitly and then do the same as above:
+
+```python
+from deepspeed.utils.zero_to_fp32 import load_state_dict_from_zero_checkpoint
+
+checkpoint_dir = os.path.join(trainer.args.output_dir, "checkpoint-final")
+trainer.deepspeed.save_checkpoint(checkpoint_dir)
+fp32_model = load_state_dict_from_zero_checkpoint(trainer.model, checkpoint_dir)
+```
+
+
+
+Note, that once `load_state_dict_from_zero_checkpoint` was run, the `model` will no longer be useable in the
+DeepSpeed context of the same application. i.e. you will need to re-initialize the deepspeed engine, since
+`model.load_state_dict(state_dict)` will remove all the DeepSpeed magic from it. So do this only at the very end
+of the training.
+
+
+
+Of course, you don't have to use class:*~transformers.Trainer* and you can adjust the examples above to your own
+trainer.
+
+If for some reason you want more refinement, you can also extract the fp32 `state_dict` of the weights and apply
+these yourself as is shown in the following example:
+
+```python
+from deepspeed.utils.zero_to_fp32 import get_fp32_state_dict_from_zero_checkpoint
+
+state_dict = get_fp32_state_dict_from_zero_checkpoint(checkpoint_dir) # already on cpu
+model = model.cpu()
+model.load_state_dict(state_dict)
+```
+
+**Offline FP32 Weights Recovery:**
+
+DeepSpeed creates a special conversion script `zero_to_fp32.py` which it places in the top-level of the checkpoint
+folder. Using this script you can extract the weights at any point. The script is standalone and you no longer need to
+have the configuration file or a `Trainer` to do the extraction.
+
+Let's say your checkpoint folder looks like this:
+
+```bash
+$ ls -l output_dir/checkpoint-1/
+-rw-rw-r-- 1 stas stas 1.4K Mar 27 20:42 config.json
+drwxrwxr-x 2 stas stas 4.0K Mar 25 19:52 global_step1/
+-rw-rw-r-- 1 stas stas 12 Mar 27 13:16 latest
+-rw-rw-r-- 1 stas stas 827K Mar 27 20:42 optimizer.pt
+-rw-rw-r-- 1 stas stas 231M Mar 27 20:42 pytorch_model.bin
+-rw-rw-r-- 1 stas stas 623 Mar 27 20:42 scheduler.pt
+-rw-rw-r-- 1 stas stas 1.8K Mar 27 20:42 special_tokens_map.json
+-rw-rw-r-- 1 stas stas 774K Mar 27 20:42 spiece.model
+-rw-rw-r-- 1 stas stas 1.9K Mar 27 20:42 tokenizer_config.json
+-rw-rw-r-- 1 stas stas 339 Mar 27 20:42 trainer_state.json
+-rw-rw-r-- 1 stas stas 2.3K Mar 27 20:42 training_args.bin
+-rwxrw-r-- 1 stas stas 5.5K Mar 27 13:16 zero_to_fp32.py*
+```
+
+In this example there is just one DeepSpeed checkpoint sub-folder *global_step1*. Therefore to reconstruct the fp32
+weights just run:
+
+```bash
+python zero_to_fp32.py . pytorch_model.bin
+```
+
+This is it. `pytorch_model.bin` will now contain the full fp32 model weights consolidated from multiple GPUs.
+
+The script will automatically be able to handle either a ZeRO-2 or ZeRO-3 checkpoint.
+
+`python zero_to_fp32.py -h` will give you usage details.
+
+The script will auto-discover the deepspeed sub-folder using the contents of the file `latest`, which in the current
+example will contain `global_step1`.
+
+Note: currently the script requires 2x general RAM of the final fp32 model weights.
+
+
+### ZeRO-3 and Infinity Nuances
+
+ZeRO-3 is quite different from ZeRO-2 because of its param sharding feature.
+
+ZeRO-Infinity further extends ZeRO-3 to support NVMe memory and multiple other speed and scalability improvements.
+
+While all the efforts were made for things to just work without needing any special changes to your models, in certain
+circumstances you may find the following information to be needed.
+
+
+
+#### Constructing Massive Models
+
+DeepSpeed/ZeRO-3 can handle models with Trillions of parameters which may not fit onto the existing RAM. In such cases,
+but also if you want the initialization to happen much faster, initialize the model using *deepspeed.zero.Init()*
+context manager (which is also a function decorator), like so:
+
+```python
+from transformers import T5ForConditionalGeneration, T5Config
+import deepspeed
+
+with deepspeed.zero.Init():
+ config = T5Config.from_pretrained("t5-small")
+ model = T5ForConditionalGeneration(config)
+```
+
+As you can see this gives you a randomly initialized model.
+
+If you want to use a pretrained model, `model_class.from_pretrained` will activate this feature as long as
+`is_deepspeed_zero3_enabled()` returns `True`, which currently is setup by the
+[`TrainingArguments`] object if the passed DeepSpeed configuration file contains ZeRO-3 config
+section. Thus you must create the [`TrainingArguments`] object **before** calling
+`from_pretrained`. Here is an example of a possible sequence:
+
+```python
+from transformers import AutoModel, Trainer, TrainingArguments
+
+training_args = TrainingArguments(..., deepspeed=ds_config)
+model = AutoModel.from_pretrained("t5-small")
+trainer = Trainer(model=model, args=training_args, ...)
+```
+
+If you're using the official example scripts and your command line arguments include `--deepspeed ds_config.json`
+with ZeRO-3 config enabled, then everything is already done for you, since this is how example scripts are written.
+
+Note: If the fp16 weights of the model can't fit onto the memory of a single GPU this feature must be used.
+
+For full details on this method and other related features please refer to [Constructing Massive Models](https://deepspeed.readthedocs.io/en/latest/zero3.html#constructing-massive-models).
+
+Also when loading fp16-pretrained models, you will want to tell `from_pretrained` to use
+`torch_dtype=torch.float16`. For details, please, see [from_pretrained-torch-dtype](#from_pretrained-torch-dtype).
+
+
+#### Gathering Parameters
+
+Under ZeRO-3 on multiple GPUs no single GPU has all the parameters unless it's the parameters for the currently
+executing layer. So if you need to access all parameters from all layers at once there is a specific method to do it.
+Most likely you won't need it, but if you do please refer to [Gathering Parameters](https://deepspeed.readthedocs.io/en/latest/zero3.html#manual-parameter-coordination)
+
+We do however use it internally in several places, one such example is when loading pretrained model weights in
+`from_pretrained`. We load one layer at a time and immediately partition it to all participating GPUs, as for very
+large models it won't be possible to load it on one GPU and then spread it out to multiple GPUs, due to memory
+limitations.
+
+Also under ZeRO-3, if you write your own code and run into a model parameter weight that looks like:
+
+```python
+tensor([1.0], device="cuda:0", dtype=torch.float16, requires_grad=True)
+```
+
+stress on `tensor([1.])`, or if you get an error where it says the parameter is of size `1`, instead of some much
+larger multi-dimensional shape, this means that the parameter is partitioned and what you see is a ZeRO-3 placeholder.
+
+
+
+
+
+
+### ZeRO Inference
+
+ZeRO Inference uses the same config as ZeRO-3 Training. You just don't need the optimizer and scheduler sections. In
+fact you can leave these in the config file if you want to share the same one with the training. They will just be
+ignored.
+
+Otherwise you just need to pass the usual [`TrainingArguments`] arguments. For example:
+
+```bash
+deepspeed --num_gpus=2 your_program.py --do_eval --deepspeed ds_config.json
+```
+
+The only important thing is that you need to use a ZeRO-3 configuration, since ZeRO-2 provides no benefit whatsoever
+for the inference as only ZeRO-3 performs sharding of parameters, whereas ZeRO-1 shards gradients and optimizer states.
+
+Here is an example of running `run_translation.py` under DeepSpeed deploying all available GPUs:
+
+```bash
+deepspeed examples/pytorch/translation/run_translation.py \
+--deepspeed tests/deepspeed/ds_config_zero3.json \
+--model_name_or_path t5-small --output_dir output_dir \
+--do_eval --max_eval_samples 50 --warmup_steps 50 \
+--max_source_length 128 --val_max_target_length 128 \
+--overwrite_output_dir --per_device_eval_batch_size 4 \
+--predict_with_generate --dataset_config "ro-en" --fp16 \
+--source_lang en --target_lang ro --dataset_name wmt16 \
+--source_prefix "translate English to Romanian: "
+```
+
+Since for inference there is no need for additional large memory used by the optimizer states and the gradients you
+should be able to fit much larger batches and/or sequence length onto the same hardware.
+
+Additionally DeepSpeed is currently developing a related product called Deepspeed-Inference which has no relationship
+to the ZeRO technology, but instead uses tensor parallelism to scale models that can't fit onto a single GPU. This is a
+work in progress and we will provide the integration once that product is complete.
+
+
+### Memory Requirements
+
+Since Deepspeed ZeRO can offload memory to CPU (and NVMe) the framework provides utils that allow one to tell how much CPU and GPU memory will be needed depending on the number of GPUs being used.
+
+Let's estimate how much memory is needed to finetune "bigscience/T0_3B" on a single GPU:
+
+```bash
+$ python -c 'from transformers import AutoModel; \
+from deepspeed.runtime.zero.stage3 import estimate_zero3_model_states_mem_needs_all_live; \
+model = AutoModel.from_pretrained("bigscience/T0_3B"); \
+estimate_zero3_model_states_mem_needs_all_live(model, num_gpus_per_node=1, num_nodes=1)'
+[...]
+Estimated memory needed for params, optim states and gradients for a:
+HW: Setup with 1 node, 1 GPU per node.
+SW: Model with 2783M total params, 65M largest layer params.
+ per CPU | per GPU | Options
+ 70.00GB | 0.25GB | offload_param=cpu , offload_optimizer=cpu , zero_init=1
+ 70.00GB | 0.25GB | offload_param=cpu , offload_optimizer=cpu , zero_init=0
+ 62.23GB | 5.43GB | offload_param=none, offload_optimizer=cpu , zero_init=1
+ 62.23GB | 5.43GB | offload_param=none, offload_optimizer=cpu , zero_init=0
+ 0.37GB | 46.91GB | offload_param=none, offload_optimizer=none, zero_init=1
+ 15.56GB | 46.91GB | offload_param=none, offload_optimizer=none, zero_init=0
+```
+
+So you can fit it on a single 80GB GPU and no CPU offload, or a tiny 8GB GPU but then need ~60GB of CPU memory. (Remember this is just the memory for params, optimizer states and gradients - you will need a bit more memory for cuda kernels, activations and temps.)
+
+Then it's a tradeoff of cost vs speed. It'll be cheaper to buy/rent a smaller GPU (or less GPUs since you can use multiple GPUs with Deepspeed ZeRO. But then it'll be slower, so even if you don't care about how fast something will be done, the slowdown has a direct impact on the duration of using the GPU and thus bigger cost. So experiment and compare which works the best.
+
+If you have enough GPU memory make sure to disable the CPU/NVMe offload as it'll make everything faster.
+
+For example, let's repeat the same for 2 GPUs:
+
+```bash
+$ python -c 'from transformers import AutoModel; \
+from deepspeed.runtime.zero.stage3 import estimate_zero3_model_states_mem_needs_all_live; \
+model = AutoModel.from_pretrained("bigscience/T0_3B"); \
+estimate_zero3_model_states_mem_needs_all_live(model, num_gpus_per_node=2, num_nodes=1)'
+[...]
+Estimated memory needed for params, optim states and gradients for a:
+HW: Setup with 1 node, 2 GPUs per node.
+SW: Model with 2783M total params, 65M largest layer params.
+ per CPU | per GPU | Options
+ 70.00GB | 0.25GB | offload_param=cpu , offload_optimizer=cpu , zero_init=1
+ 70.00GB | 0.25GB | offload_param=cpu , offload_optimizer=cpu , zero_init=0
+ 62.23GB | 2.84GB | offload_param=none, offload_optimizer=cpu , zero_init=1
+ 62.23GB | 2.84GB | offload_param=none, offload_optimizer=cpu , zero_init=0
+ 0.74GB | 23.58GB | offload_param=none, offload_optimizer=none, zero_init=1
+ 31.11GB | 23.58GB | offload_param=none, offload_optimizer=none, zero_init=0
+
+```
+
+So here you'd want 2x 32GB GPUs or higher without offloading to CPU.
+
+For full information please see [memory estimators](https://deepspeed.readthedocs.io/en/latest/memory.html).
+
+
+
+### Filing Issues
+
+Here is how to file an issue so that we could quickly get to the bottom of the issue and help you to unblock your work.
+
+In your report please always include:
+
+1. the full Deepspeed config file in the report
+
+2. either the command line arguments if you were using the [`Trainer`] or
+ [`TrainingArguments`] arguments if you were scripting the Trainer setup yourself. Please do not
+ dump the [`TrainingArguments`] as it has dozens of entries that are irrelevant.
+
+3. Output of:
+
+ ```bash
+ python -c 'import torch; print(f"torch: {torch.__version__}")'
+ python -c 'import transformers; print(f"transformers: {transformers.__version__}")'
+ python -c 'import deepspeed; print(f"deepspeed: {deepspeed.__version__}")'
+ ```
+
+4. If possible include a link to a Google Colab notebook that we can reproduce the problem with. You can use this
+ [notebook](https://github.com/stas00/porting/blob/master/transformers/deepspeed/DeepSpeed_on_colab_CLI.ipynb) as
+ a starting point.
+
+5. Unless it's impossible please always use a standard dataset that we can use and not something custom.
+
+6. If possible try to use one of the existing [examples](https://github.com/huggingface/transformers/tree/main/examples/pytorch) to reproduce the problem with.
+
+Things to consider:
+
+- Deepspeed is often not the cause of the problem.
+
+ Some of the filed issues proved to be Deepspeed-unrelated. That is once Deepspeed was removed from the setup, the
+ problem was still there.
+
+ Therefore, if it's not absolutely obvious it's a DeepSpeed-related problem, as in you can see that there is an
+ exception and you can see that DeepSpeed modules are involved, first re-test your setup without DeepSpeed in it.
+ And only if the problem persists then do mentioned Deepspeed and supply all the required details.
+
+- If it's clear to you that the issue is in the DeepSpeed core and not the integration part, please file the Issue
+ directly with [Deepspeed](https://github.com/microsoft/DeepSpeed/). If you aren't sure, please do not worry,
+ either Issue tracker will do, we will figure it out once you posted it and redirect you to another Issue tracker if
+ need be.
+
+
+
+### Troubleshooting
+
+#### the `deepspeed` process gets killed at startup without a traceback
+
+If the `deepspeed` process gets killed at launch time without a traceback, that usually means that the program tried
+to allocate more CPU memory than your system has or your process is allowed to allocate and the OS kernel killed that
+process. This is because your configuration file most likely has either `offload_optimizer` or `offload_param` or
+both configured to offload to `cpu`. If you have NVMe, experiment with offloading to NVMe if you're running under
+ZeRO-3. Here is how you can [estimate how much memory is needed for a specific model](https://deepspeed.readthedocs.io/en/latest/memory.html).
+
+
+#### training and/or eval/predict loss is `NaN`
+
+This often happens when one takes a model pre-trained in bf16 mixed precision mode and tries to use it under fp16 (with or without mixed precision). Most models trained on TPU and often the ones released by Google are in this category (e.g. almost all t5-based models). Here the solution is to either use fp32 or bf16 if your hardware supports it (TPU, Ampere GPUs or newer).
+
+The other problem may have to do with using fp16. When you configure this section:
+
+```json
+{
+ "fp16": {
+ "enabled": "auto",
+ "loss_scale": 0,
+ "loss_scale_window": 1000,
+ "initial_scale_power": 16,
+ "hysteresis": 2,
+ "min_loss_scale": 1
+ }
+}
+```
+
+and you see in your log that Deepspeed reports `OVERFLOW!` as follows:
+
+```
+0%| | 0/189 [00:00
+
+## Non-Trainer Deepspeed Integration
+
+The [`~deepspeed.HfDeepSpeedConfig`] is used to integrate Deepspeed into the 🤗 Transformers core
+functionality, when [`Trainer`] is not used. The only thing that it does is handling Deepspeed ZeRO-3 param gathering and automatically splitting the model onto multiple gpus during `from_pretrained` call. Everything else you have to do by yourself.
+
+When using [`Trainer`] everything is automatically taken care of.
+
+When not using [`Trainer`], to efficiently deploy DeepSpeed ZeRO-3, you must instantiate the
+[`~deepspeed.HfDeepSpeedConfig`] object before instantiating the model and keep that object alive.
+
+If you're using Deepspeed ZeRO-1 or ZeRO-2 you don't need to use `HfDeepSpeedConfig` at all.
+
+For example for a pretrained model:
+
+```python
+from transformers.deepspeed import HfDeepSpeedConfig
+from transformers import AutoModel
+import deepspeed
+
+ds_config = {...} # deepspeed config object or path to the file
+# must run before instantiating the model to detect zero 3
+dschf = HfDeepSpeedConfig(ds_config) # keep this object alive
+model = AutoModel.from_pretrained("gpt2")
+engine = deepspeed.initialize(model=model, config_params=ds_config, ...)
+```
+
+or for non-pretrained model:
+
+```python
+from transformers.deepspeed import HfDeepSpeedConfig
+from transformers import AutoModel, AutoConfig
+import deepspeed
+
+ds_config = {...} # deepspeed config object or path to the file
+# must run before instantiating the model to detect zero 3
+dschf = HfDeepSpeedConfig(ds_config) # keep this object alive
+config = AutoConfig.from_pretrained("gpt2")
+model = AutoModel.from_config(config)
+engine = deepspeed.initialize(model=model, config_params=ds_config, ...)
+```
+
+Please note that if you're not using the [`Trainer`] integration, you're completely on your own. Basically follow the documentation on the [Deepspeed](https://www.deepspeed.ai/) website. Also you have to configure explicitly the config file - you can't use `"auto"` values and you will have to put real values instead.
+
+## HfDeepSpeedConfig
+
+[[autodoc]] deepspeed.HfDeepSpeedConfig
+ - all
+
+### Custom DeepSpeed ZeRO Inference
+
+Here is an example of how one could do DeepSpeed ZeRO Inference without using [`Trainer`] when one can't fit a model onto a single GPU. The solution includes using additional GPUs or/and offloading GPU memory to CPU memory.
+
+The important nuance to understand here is that the way ZeRO is designed you can process different inputs on different GPUs in parallel.
+
+The example has copious notes and is self-documenting.
+
+Make sure to:
+
+1. disable CPU offload if you have enough GPU memory (since it slows things down)
+2. enable bf16 if you own an Ampere or a newer GPU to make things faster. If you don't have that hardware you may enable fp16 as long as you don't use any model that was pre-trained in bf16 mixed precision (such as most t5 models). These usually overflow in fp16 and you will see garbage as output.
+
+```python
+#!/usr/bin/env python
+
+# This script demonstrates how to use Deepspeed ZeRO in an inference mode when one can't fit a model
+# into a single GPU
+#
+# 1. Use 1 GPU with CPU offload
+# 2. Or use multiple GPUs instead
+#
+# First you need to install deepspeed: pip install deepspeed
+#
+# Here we use a 3B "bigscience/T0_3B" model which needs about 15GB GPU RAM - so 1 largish or 2
+# small GPUs can handle it. or 1 small GPU and a lot of CPU memory.
+#
+# To use a larger model like "bigscience/T0" which needs about 50GB, unless you have an 80GB GPU -
+# you will need 2-4 gpus. And then you can adapt the script to handle more gpus if you want to
+# process multiple inputs at once.
+#
+# The provided deepspeed config also activates CPU memory offloading, so chances are that if you
+# have a lot of available CPU memory and you don't mind a slowdown you should be able to load a
+# model that doesn't normally fit into a single GPU. If you have enough GPU memory the program will
+# run faster if you don't want offload to CPU - so disable that section then.
+#
+# To deploy on 1 gpu:
+#
+# deepspeed --num_gpus 1 t0.py
+# or:
+# python -m torch.distributed.run --nproc_per_node=1 t0.py
+#
+# To deploy on 2 gpus:
+#
+# deepspeed --num_gpus 2 t0.py
+# or:
+# python -m torch.distributed.run --nproc_per_node=2 t0.py
+
+
+from transformers import AutoTokenizer, AutoConfig, AutoModelForSeq2SeqLM
+from transformers.deepspeed import HfDeepSpeedConfig
+import deepspeed
+import os
+import torch
+
+os.environ["TOKENIZERS_PARALLELISM"] = "false" # To avoid warnings about parallelism in tokenizers
+
+# distributed setup
+local_rank = int(os.getenv("LOCAL_RANK", "0"))
+world_size = int(os.getenv("WORLD_SIZE", "1"))
+torch.cuda.set_device(local_rank)
+deepspeed.init_distributed()
+
+model_name = "bigscience/T0_3B"
+
+config = AutoConfig.from_pretrained(model_name)
+model_hidden_size = config.d_model
+
+# batch size has to be divisible by world_size, but can be bigger than world_size
+train_batch_size = 1 * world_size
+
+# ds_config notes
+#
+# - enable bf16 if you use Ampere or higher GPU - this will run in mixed precision and will be
+# faster.
+#
+# - for older GPUs you can enable fp16, but it'll only work for non-bf16 pretrained models - e.g.
+# all official t5 models are bf16-pretrained
+#
+# - set offload_param.device to "none" or completely remove the `offload_param` section if you don't
+# - want CPU offload
+#
+# - if using `offload_param` you can manually finetune stage3_param_persistence_threshold to control
+# - which params should remain on gpus - the larger the value the smaller the offload size
+#
+# For indepth info on Deepspeed config see
+# https://huggingface.co/docs/transformers/main/main_classes/deepspeed
+
+# keeping the same format as json for consistency, except it uses lower case for true/false
+# fmt: off
+ds_config = {
+ "fp16": {
+ "enabled": False
+ },
+ "bf16": {
+ "enabled": False
+ },
+ "zero_optimization": {
+ "stage": 3,
+ "offload_param": {
+ "device": "cpu",
+ "pin_memory": True
+ },
+ "overlap_comm": True,
+ "contiguous_gradients": True,
+ "reduce_bucket_size": model_hidden_size * model_hidden_size,
+ "stage3_prefetch_bucket_size": 0.9 * model_hidden_size * model_hidden_size,
+ "stage3_param_persistence_threshold": 10 * model_hidden_size
+ },
+ "steps_per_print": 2000,
+ "train_batch_size": train_batch_size,
+ "train_micro_batch_size_per_gpu": 1,
+ "wall_clock_breakdown": False
+}
+# fmt: on
+
+# next line instructs transformers to partition the model directly over multiple gpus using
+# deepspeed.zero.Init when model's `from_pretrained` method is called.
+#
+# **it has to be run before loading the model AutoModelForSeq2SeqLM.from_pretrained(model_name)**
+#
+# otherwise the model will first be loaded normally and only partitioned at forward time which is
+# less efficient and when there is little CPU RAM may fail
+dschf = HfDeepSpeedConfig(ds_config) # keep this object alive
+
+# now a model can be loaded.
+model = AutoModelForSeq2SeqLM.from_pretrained(model_name)
+
+# initialise Deepspeed ZeRO and store only the engine object
+ds_engine = deepspeed.initialize(model=model, config_params=ds_config)[0]
+ds_engine.module.eval() # inference
+
+# Deepspeed ZeRO can process unrelated inputs on each GPU. So for 2 gpus you process 2 inputs at once.
+# If you use more GPUs adjust for more.
+# And of course if you have just one input to process you then need to pass the same string to both gpus
+# If you use only one GPU, then you will have only rank 0.
+rank = torch.distributed.get_rank()
+if rank == 0:
+ text_in = "Is this review positive or negative? Review: this is the best cast iron skillet you will ever buy"
+elif rank == 1:
+ text_in = "Is this review positive or negative? Review: this is the worst restaurant ever"
+
+tokenizer = AutoTokenizer.from_pretrained(model_name)
+inputs = tokenizer.encode(text_in, return_tensors="pt").to(device=local_rank)
+with torch.no_grad():
+ outputs = ds_engine.module.generate(inputs, synced_gpus=True)
+text_out = tokenizer.decode(outputs[0], skip_special_tokens=True)
+print(f"rank{rank}:\n in={text_in}\n out={text_out}")
+```
+
+Let's save it as `t0.py` and run it:
+```
+$ deepspeed --num_gpus 2 t0.py
+rank0:
+ in=Is this review positive or negative? Review: this is the best cast iron skillet you will ever buy
+ out=Positive
+rank1:
+ in=Is this review positive or negative? Review: this is the worst restaurant ever
+ out=negative
+```
+
+This was a very basic example and you will want to adapt it to your needs.
+
+
+## Main DeepSpeed Resources
+
+- [Project's github](https://github.com/microsoft/deepspeed)
+- [Usage docs](https://www.deepspeed.ai/getting-started/)
+- [API docs](https://deepspeed.readthedocs.io/en/latest/index.html)
+- [Blog posts](https://www.microsoft.com/en-us/research/search/?q=deepspeed)
+
+Papers:
+
+- [ZeRO: Memory Optimizations Toward Training Trillion Parameter Models](https://arxiv.org/abs/1910.02054)
+- [ZeRO-Offload: Democratizing Billion-Scale Model Training](https://arxiv.org/abs/2101.06840)
+- [ZeRO-Infinity: Breaking the GPU Memory Wall for Extreme Scale Deep Learning](https://arxiv.org/abs/2104.07857)
+
+Finally, please, remember that, HuggingFace [`Trainer`] only integrates DeepSpeed, therefore if you
+have any problems or questions with regards to DeepSpeed usage, please, file an issue with [DeepSpeed GitHub](https://github.com/microsoft/DeepSpeed/issues).
diff --git a/docs/source/en/main_classes/feature_extractor.mdx b/docs/source/en/main_classes/feature_extractor.mdx
new file mode 100644
index 00000000000000..959c4a001fb974
--- /dev/null
+++ b/docs/source/en/main_classes/feature_extractor.mdx
@@ -0,0 +1,38 @@
+
+
+# Feature Extractor
+
+A feature extractor is in charge of preparing input features for a multi-modal model. This includes feature extraction
+from sequences, *e.g.*, pre-processing audio files to Log-Mel Spectrogram features, feature extraction from images
+*e.g.* cropping image image files, but also padding, normalization, and conversion to Numpy, PyTorch, and TensorFlow
+tensors.
+
+
+## FeatureExtractionMixin
+
+[[autodoc]] feature_extraction_utils.FeatureExtractionMixin
+ - from_pretrained
+ - save_pretrained
+
+## SequenceFeatureExtractor
+
+[[autodoc]] SequenceFeatureExtractor
+ - pad
+
+## BatchFeature
+
+[[autodoc]] BatchFeature
+
+## ImageFeatureExtractionMixin
+
+[[autodoc]] image_utils.ImageFeatureExtractionMixin
diff --git a/docs/source/en/main_classes/keras_callbacks.mdx b/docs/source/en/main_classes/keras_callbacks.mdx
new file mode 100644
index 00000000000000..bc44a0967cc9cb
--- /dev/null
+++ b/docs/source/en/main_classes/keras_callbacks.mdx
@@ -0,0 +1,24 @@
+
+
+# Keras callbacks
+
+When training a Transformers model with Keras, there are some library-specific callbacks available to automate common
+tasks:
+
+## KerasMetricCallback
+
+[[autodoc]] KerasMetricCallback
+
+## PushToHubCallback
+
+[[autodoc]] PushToHubCallback
diff --git a/docs/source/en/main_classes/logging.mdx b/docs/source/en/main_classes/logging.mdx
new file mode 100644
index 00000000000000..3137be805cadc4
--- /dev/null
+++ b/docs/source/en/main_classes/logging.mdx
@@ -0,0 +1,110 @@
+
+
+# Logging
+
+🤗 Transformers has a centralized logging system, so that you can setup the verbosity of the library easily.
+
+Currently the default verbosity of the library is `WARNING`.
+
+To change the level of verbosity, just use one of the direct setters. For instance, here is how to change the verbosity
+to the INFO level.
+
+```python
+import transformers
+
+transformers.logging.set_verbosity_info()
+```
+
+You can also use the environment variable `TRANSFORMERS_VERBOSITY` to override the default verbosity. You can set it
+to one of the following: `debug`, `info`, `warning`, `error`, `critical`. For example:
+
+```bash
+TRANSFORMERS_VERBOSITY=error ./myprogram.py
+```
+
+Additionally, some `warnings` can be disabled by setting the environment variable
+`TRANSFORMERS_NO_ADVISORY_WARNINGS` to a true value, like *1*. This will disable any warning that is logged using
+[`logger.warning_advice`]. For example:
+
+```bash
+TRANSFORMERS_NO_ADVISORY_WARNINGS=1 ./myprogram.py
+```
+
+Here is an example of how to use `logging` in a module:
+
+```python
+from transformers.utils import logging
+
+logging.set_verbosity_info()
+logger = logging.get_logger(__name__)
+logger.info("INFO")
+logger.warning("WARN")
+```
+
+Above, a `logger` instance is created from `logging.get_logger(__name__)`. If you want to use `logging` in a script, you shouldn't pass `__name__` to `logging.get_logger`. For example:
+
+```python
+from transformers.utils import logging
+
+if __name__ == "__main__":
+ logging.set_verbosity_info()
+ # leave it empy or use a string
+ logger = logging.get_logger()
+ logger.info("INFO")
+ logger.warning("WARN")
+```
+
+All the methods of this logging module are documented below, the main ones are
+[`logging.get_verbosity`] to get the current level of verbosity in the logger and
+[`logging.set_verbosity`] to set the verbosity to the level of your choice. In order (from the least
+verbose to the most verbose), those levels (with their corresponding int values in parenthesis) are:
+
+- `transformers.logging.CRITICAL` or `transformers.logging.FATAL` (int value, 50): only report the most
+ critical errors.
+- `transformers.logging.ERROR` (int value, 40): only report errors.
+- `transformers.logging.WARNING` or `transformers.logging.WARN` (int value, 30): only reports error and
+ warnings. This the default level used by the library.
+- `transformers.logging.INFO` (int value, 20): reports error, warnings and basic information.
+- `transformers.logging.DEBUG` (int value, 10): report all information.
+
+By default, `tqdm` progress bars will be displayed during model download. [`logging.disable_progress_bar`] and [`logging.enable_progress_bar`] can be used to suppress or unsuppress this behavior.
+
+## Base setters
+
+[[autodoc]] logging.set_verbosity_error
+
+[[autodoc]] logging.set_verbosity_warning
+
+[[autodoc]] logging.set_verbosity_info
+
+[[autodoc]] logging.set_verbosity_debug
+
+## Other functions
+
+[[autodoc]] logging.get_verbosity
+
+[[autodoc]] logging.set_verbosity
+
+[[autodoc]] logging.get_logger
+
+[[autodoc]] logging.enable_default_handler
+
+[[autodoc]] logging.disable_default_handler
+
+[[autodoc]] logging.enable_explicit_format
+
+[[autodoc]] logging.reset_format
+
+[[autodoc]] logging.enable_progress_bar
+
+[[autodoc]] logging.disable_progress_bar
diff --git a/docs/source/en/main_classes/model.mdx b/docs/source/en/main_classes/model.mdx
new file mode 100644
index 00000000000000..7a61e739582410
--- /dev/null
+++ b/docs/source/en/main_classes/model.mdx
@@ -0,0 +1,95 @@
+
+
+# Models
+
+The base classes [`PreTrainedModel`], [`TFPreTrainedModel`], and
+[`FlaxPreTrainedModel`] implement the common methods for loading/saving a model either from a local
+file or directory, or from a pretrained model configuration provided by the library (downloaded from HuggingFace's AWS
+S3 repository).
+
+[`PreTrainedModel`] and [`TFPreTrainedModel`] also implement a few methods which
+are common among all the models to:
+
+- resize the input token embeddings when new tokens are added to the vocabulary
+- prune the attention heads of the model.
+
+The other methods that are common to each model are defined in [`~modeling_utils.ModuleUtilsMixin`]
+(for the PyTorch models) and [`~modeling_tf_utils.TFModuleUtilsMixin`] (for the TensorFlow models) or
+for text generation, [`~generation_utils.GenerationMixin`] (for the PyTorch models),
+[`~generation_tf_utils.TFGenerationMixin`] (for the TensorFlow models) and
+[`~generation_flax_utils.FlaxGenerationMixin`] (for the Flax/JAX models).
+
+
+## PreTrainedModel
+
+[[autodoc]] PreTrainedModel
+ - push_to_hub
+ - all
+
+
+
+### Model Instantiation dtype
+
+Under Pytorch a model normally gets instantiated with `torch.float32` format. This can be an issue if one tries to
+load a model whose weights are in fp16, since it'd require twice as much memory. To overcome this limitation, you can
+either explicitly pass the desired `dtype` using `torch_dtype` argument:
+
+```python
+model = T5ForConditionalGeneration.from_pretrained("t5", torch_dtype=torch.float16)
+```
+
+or, if you want the model to always load in the most optimal memory pattern, you can use the special value `"auto"`,
+and then `dtype` will be automatically derived from the model's weights:
+
+```python
+model = T5ForConditionalGeneration.from_pretrained("t5", torch_dtype="auto")
+```
+
+Models instantiated from scratch can also be told which `dtype` to use with:
+
+```python
+config = T5Config.from_pretrained("t5")
+model = AutoModel.from_config(config)
+```
+
+Due to Pytorch design, this functionality is only available for floating dtypes.
+
+
+
+## ModuleUtilsMixin
+
+[[autodoc]] modeling_utils.ModuleUtilsMixin
+
+## TFPreTrainedModel
+
+[[autodoc]] TFPreTrainedModel
+ - push_to_hub
+ - all
+
+## TFModelUtilsMixin
+
+[[autodoc]] modeling_tf_utils.TFModelUtilsMixin
+
+## FlaxPreTrainedModel
+
+[[autodoc]] FlaxPreTrainedModel
+ - push_to_hub
+ - all
+
+## Pushing to the Hub
+
+[[autodoc]] utils.PushToHubMixin
+
+## Sharded checkpoints
+
+[[autodoc]] modeling_utils.load_sharded_checkpoint
diff --git a/docs/source/en/main_classes/onnx.mdx b/docs/source/en/main_classes/onnx.mdx
new file mode 100644
index 00000000000000..ff20f315a1a9a0
--- /dev/null
+++ b/docs/source/en/main_classes/onnx.mdx
@@ -0,0 +1,50 @@
+
+
+# Exporting 🤗 Transformers models to ONNX
+
+🤗 Transformers provides a `transformers.onnx` package that enables you to
+convert model checkpoints to an ONNX graph by leveraging configuration objects.
+
+See the [guide](../serialization) on exporting 🤗 Transformers models for more
+details.
+
+## ONNX Configurations
+
+We provide three abstract classes that you should inherit from, depending on the
+type of model architecture you wish to export:
+
+* Encoder-based models inherit from [`~onnx.config.OnnxConfig`]
+* Decoder-based models inherit from [`~onnx.config.OnnxConfigWithPast`]
+* Encoder-decoder models inherit from [`~onnx.config.OnnxSeq2SeqConfigWithPast`]
+
+### OnnxConfig
+
+[[autodoc]] onnx.config.OnnxConfig
+
+### OnnxConfigWithPast
+
+[[autodoc]] onnx.config.OnnxConfigWithPast
+
+### OnnxSeq2SeqConfigWithPast
+
+[[autodoc]] onnx.config.OnnxSeq2SeqConfigWithPast
+
+## ONNX Features
+
+Each ONNX configuration is associated with a set of _features_ that enable you
+to export models for different types of topologies or tasks.
+
+### FeaturesManager
+
+[[autodoc]] onnx.features.FeaturesManager
+
diff --git a/docs/source/en/main_classes/optimizer_schedules.mdx b/docs/source/en/main_classes/optimizer_schedules.mdx
new file mode 100644
index 00000000000000..c842c8d1aa6a8d
--- /dev/null
+++ b/docs/source/en/main_classes/optimizer_schedules.mdx
@@ -0,0 +1,71 @@
+
+
+# Optimization
+
+The `.optimization` module provides:
+
+- an optimizer with weight decay fixed that can be used to fine-tuned models, and
+- several schedules in the form of schedule objects that inherit from `_LRSchedule`:
+- a gradient accumulation class to accumulate the gradients of multiple batches
+
+## AdamW (PyTorch)
+
+[[autodoc]] AdamW
+
+## AdaFactor (PyTorch)
+
+[[autodoc]] Adafactor
+
+## AdamWeightDecay (TensorFlow)
+
+[[autodoc]] AdamWeightDecay
+
+[[autodoc]] create_optimizer
+
+## Schedules
+
+### Learning Rate Schedules (Pytorch)
+
+[[autodoc]] SchedulerType
+
+[[autodoc]] get_scheduler
+
+[[autodoc]] get_constant_schedule
+
+[[autodoc]] get_constant_schedule_with_warmup
+
+ +
+[[autodoc]] get_cosine_schedule_with_warmup
+
+
+
+[[autodoc]] get_cosine_schedule_with_warmup
+
+ +
+[[autodoc]] get_cosine_with_hard_restarts_schedule_with_warmup
+
+
+
+[[autodoc]] get_cosine_with_hard_restarts_schedule_with_warmup
+
+ +
+[[autodoc]] get_linear_schedule_with_warmup
+
+
+
+[[autodoc]] get_linear_schedule_with_warmup
+
+ +
+[[autodoc]] get_polynomial_decay_schedule_with_warmup
+
+### Warmup (TensorFlow)
+
+[[autodoc]] WarmUp
+
+## Gradient Strategies
+
+### GradientAccumulator (TensorFlow)
+
+[[autodoc]] GradientAccumulator
diff --git a/docs/source/en/main_classes/output.mdx b/docs/source/en/main_classes/output.mdx
new file mode 100644
index 00000000000000..efca867a0435aa
--- /dev/null
+++ b/docs/source/en/main_classes/output.mdx
@@ -0,0 +1,269 @@
+
+
+# Model outputs
+
+All models have outputs that are instances of subclasses of [`~utils.ModelOutput`]. Those are
+data structures containing all the information returned by the model, but that can also be used as tuples or
+dictionaries.
+
+Let's see of this looks on an example:
+
+```python
+from transformers import BertTokenizer, BertForSequenceClassification
+import torch
+
+tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
+model = BertForSequenceClassification.from_pretrained("bert-base-uncased")
+
+inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
+labels = torch.tensor([1]).unsqueeze(0) # Batch size 1
+outputs = model(**inputs, labels=labels)
+```
+
+The `outputs` object is a [`~modeling_outputs.SequenceClassifierOutput`], as we can see in the
+documentation of that class below, it means it has an optional `loss`, a `logits` an optional `hidden_states` and
+an optional `attentions` attribute. Here we have the `loss` since we passed along `labels`, but we don't have
+`hidden_states` and `attentions` because we didn't pass `output_hidden_states=True` or
+`output_attentions=True`.
+
+You can access each attribute as you would usually do, and if that attribute has not been returned by the model, you
+will get `None`. Here for instance `outputs.loss` is the loss computed by the model, and `outputs.attentions` is
+`None`.
+
+When considering our `outputs` object as tuple, it only considers the attributes that don't have `None` values.
+Here for instance, it has two elements, `loss` then `logits`, so
+
+```python
+outputs[:2]
+```
+
+will return the tuple `(outputs.loss, outputs.logits)` for instance.
+
+When considering our `outputs` object as dictionary, it only considers the attributes that don't have `None`
+values. Here for instance, it has two keys that are `loss` and `logits`.
+
+We document here the generic model outputs that are used by more than one model type. Specific output types are
+documented on their corresponding model page.
+
+## ModelOutput
+
+[[autodoc]] utils.ModelOutput
+ - to_tuple
+
+## BaseModelOutput
+
+[[autodoc]] modeling_outputs.BaseModelOutput
+
+## BaseModelOutputWithPooling
+
+[[autodoc]] modeling_outputs.BaseModelOutputWithPooling
+
+## BaseModelOutputWithCrossAttentions
+
+[[autodoc]] modeling_outputs.BaseModelOutputWithCrossAttentions
+
+## BaseModelOutputWithPoolingAndCrossAttentions
+
+[[autodoc]] modeling_outputs.BaseModelOutputWithPoolingAndCrossAttentions
+
+## BaseModelOutputWithPast
+
+[[autodoc]] modeling_outputs.BaseModelOutputWithPast
+
+## BaseModelOutputWithPastAndCrossAttentions
+
+[[autodoc]] modeling_outputs.BaseModelOutputWithPastAndCrossAttentions
+
+## Seq2SeqModelOutput
+
+[[autodoc]] modeling_outputs.Seq2SeqModelOutput
+
+## CausalLMOutput
+
+[[autodoc]] modeling_outputs.CausalLMOutput
+
+## CausalLMOutputWithCrossAttentions
+
+[[autodoc]] modeling_outputs.CausalLMOutputWithCrossAttentions
+
+## CausalLMOutputWithPast
+
+[[autodoc]] modeling_outputs.CausalLMOutputWithPast
+
+## MaskedLMOutput
+
+[[autodoc]] modeling_outputs.MaskedLMOutput
+
+## Seq2SeqLMOutput
+
+[[autodoc]] modeling_outputs.Seq2SeqLMOutput
+
+## NextSentencePredictorOutput
+
+[[autodoc]] modeling_outputs.NextSentencePredictorOutput
+
+## SequenceClassifierOutput
+
+[[autodoc]] modeling_outputs.SequenceClassifierOutput
+
+## Seq2SeqSequenceClassifierOutput
+
+[[autodoc]] modeling_outputs.Seq2SeqSequenceClassifierOutput
+
+## MultipleChoiceModelOutput
+
+[[autodoc]] modeling_outputs.MultipleChoiceModelOutput
+
+## TokenClassifierOutput
+
+[[autodoc]] modeling_outputs.TokenClassifierOutput
+
+## QuestionAnsweringModelOutput
+
+[[autodoc]] modeling_outputs.QuestionAnsweringModelOutput
+
+## Seq2SeqQuestionAnsweringModelOutput
+
+[[autodoc]] modeling_outputs.Seq2SeqQuestionAnsweringModelOutput
+
+## TFBaseModelOutput
+
+[[autodoc]] modeling_tf_outputs.TFBaseModelOutput
+
+## TFBaseModelOutputWithPooling
+
+[[autodoc]] modeling_tf_outputs.TFBaseModelOutputWithPooling
+
+## TFBaseModelOutputWithPoolingAndCrossAttentions
+
+[[autodoc]] modeling_tf_outputs.TFBaseModelOutputWithPoolingAndCrossAttentions
+
+## TFBaseModelOutputWithPast
+
+[[autodoc]] modeling_tf_outputs.TFBaseModelOutputWithPast
+
+## TFBaseModelOutputWithPastAndCrossAttentions
+
+[[autodoc]] modeling_tf_outputs.TFBaseModelOutputWithPastAndCrossAttentions
+
+## TFSeq2SeqModelOutput
+
+[[autodoc]] modeling_tf_outputs.TFSeq2SeqModelOutput
+
+## TFCausalLMOutput
+
+[[autodoc]] modeling_tf_outputs.TFCausalLMOutput
+
+## TFCausalLMOutputWithCrossAttentions
+
+[[autodoc]] modeling_tf_outputs.TFCausalLMOutputWithCrossAttentions
+
+## TFCausalLMOutputWithPast
+
+[[autodoc]] modeling_tf_outputs.TFCausalLMOutputWithPast
+
+## TFMaskedLMOutput
+
+[[autodoc]] modeling_tf_outputs.TFMaskedLMOutput
+
+## TFSeq2SeqLMOutput
+
+[[autodoc]] modeling_tf_outputs.TFSeq2SeqLMOutput
+
+## TFNextSentencePredictorOutput
+
+[[autodoc]] modeling_tf_outputs.TFNextSentencePredictorOutput
+
+## TFSequenceClassifierOutput
+
+[[autodoc]] modeling_tf_outputs.TFSequenceClassifierOutput
+
+## TFSeq2SeqSequenceClassifierOutput
+
+[[autodoc]] modeling_tf_outputs.TFSeq2SeqSequenceClassifierOutput
+
+## TFMultipleChoiceModelOutput
+
+[[autodoc]] modeling_tf_outputs.TFMultipleChoiceModelOutput
+
+## TFTokenClassifierOutput
+
+[[autodoc]] modeling_tf_outputs.TFTokenClassifierOutput
+
+## TFQuestionAnsweringModelOutput
+
+[[autodoc]] modeling_tf_outputs.TFQuestionAnsweringModelOutput
+
+## TFSeq2SeqQuestionAnsweringModelOutput
+
+[[autodoc]] modeling_tf_outputs.TFSeq2SeqQuestionAnsweringModelOutput
+
+## FlaxBaseModelOutput
+
+[[autodoc]] modeling_flax_outputs.FlaxBaseModelOutput
+
+## FlaxBaseModelOutputWithPast
+
+[[autodoc]] modeling_flax_outputs.FlaxBaseModelOutputWithPast
+
+## FlaxBaseModelOutputWithPooling
+
+[[autodoc]] modeling_flax_outputs.FlaxBaseModelOutputWithPooling
+
+## FlaxBaseModelOutputWithPastAndCrossAttentions
+
+[[autodoc]] modeling_flax_outputs.FlaxBaseModelOutputWithPastAndCrossAttentions
+
+## FlaxSeq2SeqModelOutput
+
+[[autodoc]] modeling_flax_outputs.FlaxSeq2SeqModelOutput
+
+## FlaxCausalLMOutputWithCrossAttentions
+
+[[autodoc]] modeling_flax_outputs.FlaxCausalLMOutputWithCrossAttentions
+
+## FlaxMaskedLMOutput
+
+[[autodoc]] modeling_flax_outputs.FlaxMaskedLMOutput
+
+## FlaxSeq2SeqLMOutput
+
+[[autodoc]] modeling_flax_outputs.FlaxSeq2SeqLMOutput
+
+## FlaxNextSentencePredictorOutput
+
+[[autodoc]] modeling_flax_outputs.FlaxNextSentencePredictorOutput
+
+## FlaxSequenceClassifierOutput
+
+[[autodoc]] modeling_flax_outputs.FlaxSequenceClassifierOutput
+
+## FlaxSeq2SeqSequenceClassifierOutput
+
+[[autodoc]] modeling_flax_outputs.FlaxSeq2SeqSequenceClassifierOutput
+
+## FlaxMultipleChoiceModelOutput
+
+[[autodoc]] modeling_flax_outputs.FlaxMultipleChoiceModelOutput
+
+## FlaxTokenClassifierOutput
+
+[[autodoc]] modeling_flax_outputs.FlaxTokenClassifierOutput
+
+## FlaxQuestionAnsweringModelOutput
+
+[[autodoc]] modeling_flax_outputs.FlaxQuestionAnsweringModelOutput
+
+## FlaxSeq2SeqQuestionAnsweringModelOutput
+
+[[autodoc]] modeling_flax_outputs.FlaxSeq2SeqQuestionAnsweringModelOutput
diff --git a/docs/source/en/main_classes/pipelines.mdx b/docs/source/en/main_classes/pipelines.mdx
new file mode 100644
index 00000000000000..af82d16750120e
--- /dev/null
+++ b/docs/source/en/main_classes/pipelines.mdx
@@ -0,0 +1,440 @@
+
+
+# Pipelines
+
+The pipelines are a great and easy way to use models for inference. These pipelines are objects that abstract most of
+the complex code from the library, offering a simple API dedicated to several tasks, including Named Entity
+Recognition, Masked Language Modeling, Sentiment Analysis, Feature Extraction and Question Answering. See the
+[task summary](../task_summary) for examples of use.
+
+There are two categories of pipeline abstractions to be aware about:
+
+- The [`pipeline`] which is the most powerful object encapsulating all other pipelines.
+- The other task-specific pipelines:
+
+ - [`AudioClassificationPipeline`]
+ - [`AutomaticSpeechRecognitionPipeline`]
+ - [`ConversationalPipeline`]
+ - [`FeatureExtractionPipeline`]
+ - [`FillMaskPipeline`]
+ - [`ImageClassificationPipeline`]
+ - [`ImageSegmentationPipeline`]
+ - [`ObjectDetectionPipeline`]
+ - [`QuestionAnsweringPipeline`]
+ - [`SummarizationPipeline`]
+ - [`TableQuestionAnsweringPipeline`]
+ - [`TextClassificationPipeline`]
+ - [`TextGenerationPipeline`]
+ - [`Text2TextGenerationPipeline`]
+ - [`TokenClassificationPipeline`]
+ - [`TranslationPipeline`]
+ - [`ZeroShotClassificationPipeline`]
+ - [`ZeroShotImageClassificationPipeline`]
+
+## The pipeline abstraction
+
+The *pipeline* abstraction is a wrapper around all the other available pipelines. It is instantiated as any other
+pipeline but can provide additional quality of life.
+
+Simple call on one item:
+
+```python
+>>> pipe = pipeline("text-classification")
+>>> pipe("This restaurant is awesome")
+[{'label': 'POSITIVE', 'score': 0.9998743534088135}]
+```
+
+If you want to use a specific model from the [hub](https://huggingface.co) you can ignore the task if the model on
+the hub already defines it:
+
+```python
+>>> pipe = pipeline(model="roberta-large-mnli")
+>>> pipe("This restaurant is awesome")
+[{'label': 'POSITIVE', 'score': 0.9998743534088135}]
+```
+
+To call a pipeline on many items, you can either call with a *list*.
+
+```python
+>>> pipe = pipeline("text-classification")
+>>> pipe(["This restaurant is awesome", "This restaurant is aweful"])
+[{'label': 'POSITIVE', 'score': 0.9998743534088135},
+ {'label': 'NEGATIVE', 'score': 0.9996669292449951}]
+```
+
+To iterate of full datasets it is recommended to use a `dataset` directly. This means you don't need to allocate
+the whole dataset at once, nor do you need to do batching yourself. This should work just as fast as custom loops on
+GPU. If it doesn't don't hesitate to create an issue.
+
+```python
+import datasets
+from transformers import pipeline
+from transformers.pipelines.pt_utils import KeyDataset
+from tqdm.auto import tqdm
+
+pipe = pipeline("automatic-speech-recognition", model="facebook/wav2vec2-base-960h", device=0)
+dataset = datasets.load_dataset("superb", name="asr", split="test")
+
+# KeyDataset (only *pt*) will simply return the item in the dict returned by the dataset item
+# as we're not interested in the *target* part of the dataset.
+for out in tqdm(pipe(KeyDataset(dataset, "file"))):
+ print(out)
+ # {"text": "NUMBER TEN FRESH NELLY IS WAITING ON YOU GOOD NIGHT HUSBAND"}
+ # {"text": ....}
+ # ....
+```
+
+For ease of use, a generator is also possible:
+
+
+```python
+from transformers import pipeline
+
+pipe = pipeline("text-classification")
+
+
+def data():
+ while True:
+ # This could come from a dataset, a database, a queue or HTTP request
+ # in a server
+ # Caveat: because this is iterative, you cannot use `num_workers > 1` variable
+ # to use multiple threads to preprocess data. You can still have 1 thread that
+ # does the preprocessing while the main runs the big inference
+ yield "This is a test"
+
+
+for out in pipe(data()):
+ print(out)
+ # {"text": "NUMBER TEN FRESH NELLY IS WAITING ON YOU GOOD NIGHT HUSBAND"}
+ # {"text": ....}
+ # ....
+```
+
+[[autodoc]] pipeline
+
+## Pipeline batching
+
+All pipelines can use batching. This will work
+whenever the pipeline uses its streaming ability (so when passing lists or `Dataset` or `generator`).
+
+```python
+from transformers import pipeline
+from transformers.pipelines.pt_utils import KeyDataset
+import datasets
+
+dataset = datasets.load_dataset("imdb", name="plain_text", split="unsupervised")
+pipe = pipeline("text-classification", device=0)
+for out in pipe(KeyDataset(dataset, "text"), batch_size=8, truncation="only_first"):
+ print(out)
+ # [{'label': 'POSITIVE', 'score': 0.9998743534088135}]
+ # Exactly the same output as before, but the content are passed
+ # as batches to the model
+```
+
+
+
+However, this is not automatically a win for performance. It can be either a 10x speedup or 5x slowdown depending
+on hardware, data and the actual model being used.
+
+Example where it's mostly a speedup:
+
+
+
+```python
+from transformers import pipeline
+from torch.utils.data import Dataset
+from tqdm.auto import tqdm
+
+pipe = pipeline("text-classification", device=0)
+
+
+class MyDataset(Dataset):
+ def __len__(self):
+ return 5000
+
+ def __getitem__(self, i):
+ return "This is a test"
+
+
+dataset = MyDataset()
+
+for batch_size in [1, 8, 64, 256]:
+ print("-" * 30)
+ print(f"Streaming batch_size={batch_size}")
+ for out in tqdm(pipe(dataset, batch_size=batch_size), total=len(dataset)):
+ pass
+```
+
+```
+# On GTX 970
+------------------------------
+Streaming no batching
+100%|██████████████████████████████████████████████████████████████████████| 5000/5000 [00:26<00:00, 187.52it/s]
+------------------------------
+Streaming batch_size=8
+100%|█████████████████████████████████████████████████████████████████████| 5000/5000 [00:04<00:00, 1205.95it/s]
+------------------------------
+Streaming batch_size=64
+100%|█████████████████████████████████████████████████████████████████████| 5000/5000 [00:02<00:00, 2478.24it/s]
+------------------------------
+Streaming batch_size=256
+100%|█████████████████████████████████████████████████████████████████████| 5000/5000 [00:01<00:00, 2554.43it/s]
+(diminishing returns, saturated the GPU)
+```
+
+Example where it's most a slowdown:
+
+```python
+class MyDataset(Dataset):
+ def __len__(self):
+ return 5000
+
+ def __getitem__(self, i):
+ if i % 64 == 0:
+ n = 100
+ else:
+ n = 1
+ return "This is a test" * n
+```
+
+This is a occasional very long sentence compared to the other. In that case, the **whole** batch will need to be 400
+tokens long, so the whole batch will be [64, 400] instead of [64, 4], leading to the high slowdown. Even worse, on
+bigger batches, the program simply crashes.
+
+
+```
+------------------------------
+Streaming no batching
+100%|█████████████████████████████████████████████████████████████████████| 1000/1000 [00:05<00:00, 183.69it/s]
+------------------------------
+Streaming batch_size=8
+100%|█████████████████████████████████████████████████████████████████████| 1000/1000 [00:03<00:00, 265.74it/s]
+------------------------------
+Streaming batch_size=64
+100%|██████████████████████████████████████████████████████████████████████| 1000/1000 [00:26<00:00, 37.80it/s]
+------------------------------
+Streaming batch_size=256
+ 0%| | 0/1000 [00:00
+ for out in tqdm(pipe(dataset, batch_size=256), total=len(dataset)):
+....
+ q = q / math.sqrt(dim_per_head) # (bs, n_heads, q_length, dim_per_head)
+RuntimeError: CUDA out of memory. Tried to allocate 376.00 MiB (GPU 0; 3.95 GiB total capacity; 1.72 GiB already allocated; 354.88 MiB free; 2.46 GiB reserved in total by PyTorch)
+```
+
+There are no good (general) solutions for this problem, and your mileage may vary depending on your use cases. Rule of
+thumb:
+
+For users, a rule of thumb is:
+
+- **Measure performance on your load, with your hardware. Measure, measure, and keep measuring. Real numbers are the
+ only way to go.**
+- If you are latency constrained (live product doing inference), don't batch
+- If you are using CPU, don't batch.
+- If you are using throughput (you want to run your model on a bunch of static data), on GPU, then:
+
+ - If you have no clue about the size of the sequence_length ("natural" data), by default don't batch, measure and
+ try tentatively to add it, add OOM checks to recover when it will fail (and it will at some point if you don't
+ control the sequence_length.)
+ - If your sequence_length is super regular, then batching is more likely to be VERY interesting, measure and push
+ it until you get OOMs.
+ - The larger the GPU the more likely batching is going to be more interesting
+- As soon as you enable batching, make sure you can handle OOMs nicely.
+
+## Pipeline chunk batching
+
+`zero-shot-classification` and `question-answering` are slightly specific in the sense, that a single input might yield
+multiple forward pass of a model. Under normal circumstances, this would yield issues with `batch_size` argument.
+
+In order to circumvent this issue, both of these pipelines are a bit specific, they are `ChunkPipeline` instead of
+regular `Pipeline`. In short:
+
+
+```python
+preprocessed = pipe.preprocess(inputs)
+model_outputs = pipe.forward(preprocessed)
+outputs = pipe.postprocess(model_outputs)
+```
+
+Now becomes:
+
+
+```python
+all_model_outputs = []
+for preprocessed in pipe.preprocess(inputs):
+ model_outputs = pipe.forward(preprocessed)
+ all_model_outputs.append(model_outputs)
+outputs = pipe.postprocess(all_model_outputs)
+```
+
+This should be very transparent to your code because the pipelines are used in
+the same way.
+
+This is a simplified view, since the pipeline can handle automatically the batch to ! Meaning you don't have to care
+about how many forward passes you inputs are actually going to trigger, you can optimize the `batch_size`
+independently of the inputs. The caveats from the previous section still apply.
+
+## Pipeline custom code
+
+If you want to override a specific pipeline.
+
+Don't hesitate to create an issue for your task at hand, the goal of the pipeline is to be easy to use and support most
+cases, so `transformers` could maybe support your use case.
+
+
+If you want to try simply you can:
+
+- Subclass your pipeline of choice
+
+```python
+class MyPipeline(TextClassificationPipeline):
+ def postprocess():
+ # Your code goes here
+ scores = scores * 100
+ # And here
+
+
+my_pipeline = MyPipeline(model=model, tokenizer=tokenizer, ...)
+# or if you use *pipeline* function, then:
+my_pipeline = pipeline(model="xxxx", pipeline_class=MyPipeline)
+```
+
+That should enable you to do all the custom code you want.
+
+
+## Implementing a pipeline
+
+[Implementing a new pipeline](../add_new_pipeline)
+
+## The task specific pipelines
+
+
+### AudioClassificationPipeline
+
+[[autodoc]] AudioClassificationPipeline
+ - __call__
+ - all
+
+### AutomaticSpeechRecognitionPipeline
+
+[[autodoc]] AutomaticSpeechRecognitionPipeline
+ - __call__
+ - all
+
+### ConversationalPipeline
+
+[[autodoc]] Conversation
+
+[[autodoc]] ConversationalPipeline
+ - __call__
+ - all
+
+### FeatureExtractionPipeline
+
+[[autodoc]] FeatureExtractionPipeline
+ - __call__
+ - all
+
+### FillMaskPipeline
+
+[[autodoc]] FillMaskPipeline
+ - __call__
+ - all
+
+### ImageClassificationPipeline
+
+[[autodoc]] ImageClassificationPipeline
+ - __call__
+ - all
+
+### ImageSegmentationPipeline
+
+[[autodoc]] ImageSegmentationPipeline
+ - __call__
+ - all
+
+### NerPipeline
+
+[[autodoc]] NerPipeline
+
+See [`TokenClassificationPipeline`] for all details.
+
+### ObjectDetectionPipeline
+
+[[autodoc]] ObjectDetectionPipeline
+ - __call__
+ - all
+
+### QuestionAnsweringPipeline
+
+[[autodoc]] QuestionAnsweringPipeline
+ - __call__
+ - all
+
+### SummarizationPipeline
+
+[[autodoc]] SummarizationPipeline
+ - __call__
+ - all
+
+### TableQuestionAnsweringPipeline
+
+[[autodoc]] TableQuestionAnsweringPipeline
+ - __call__
+
+### TextClassificationPipeline
+
+[[autodoc]] TextClassificationPipeline
+ - __call__
+ - all
+
+### TextGenerationPipeline
+
+[[autodoc]] TextGenerationPipeline
+ - __call__
+ - all
+
+### Text2TextGenerationPipeline
+
+[[autodoc]] Text2TextGenerationPipeline
+ - __call__
+ - all
+
+### TokenClassificationPipeline
+
+[[autodoc]] TokenClassificationPipeline
+ - __call__
+ - all
+
+### TranslationPipeline
+
+[[autodoc]] TranslationPipeline
+ - __call__
+ - all
+
+### ZeroShotClassificationPipeline
+
+[[autodoc]] ZeroShotClassificationPipeline
+ - __call__
+ - all
+
+### ZeroShotImageClassificationPipeline
+
+[[autodoc]] ZeroShotImageClassificationPipeline
+ - __call__
+ - all
+
+## Parent class: `Pipeline`
+
+[[autodoc]] Pipeline
diff --git a/docs/source/en/main_classes/processors.mdx b/docs/source/en/main_classes/processors.mdx
new file mode 100644
index 00000000000000..5d0d3f8307b8f0
--- /dev/null
+++ b/docs/source/en/main_classes/processors.mdx
@@ -0,0 +1,159 @@
+
+
+# Processors
+
+Processors can mean two different things in the Transformers library:
+- the objects that pre-process inputs for multi-modal models such as [Wav2Vec2](../model_doc/wav2vec2) (speech and text)
+ or [CLIP](../model_doc/clip) (text and vision)
+- deprecated objects that were used in older versions of the library to preprocess data for GLUE or SQUAD.
+
+## Multi-modal processors
+
+Any multi-modal model will require an object to encode or decode the data that groups several modalities (among text,
+vision and audio). This is handled by objects called processors, which group tokenizers (for the text modality) and
+feature extractors (for vision and audio).
+
+Those processors inherit from the following base class that implements the saving and loading functionality:
+
+[[autodoc]] ProcessorMixin
+
+## Deprecated processors
+
+All processors follow the same architecture which is that of the
+[`~data.processors.utils.DataProcessor`]. The processor returns a list of
+[`~data.processors.utils.InputExample`]. These
+[`~data.processors.utils.InputExample`] can be converted to
+[`~data.processors.utils.InputFeatures`] in order to be fed to the model.
+
+[[autodoc]] data.processors.utils.DataProcessor
+
+[[autodoc]] data.processors.utils.InputExample
+
+[[autodoc]] data.processors.utils.InputFeatures
+
+## GLUE
+
+[General Language Understanding Evaluation (GLUE)](https://gluebenchmark.com/) is a benchmark that evaluates the
+performance of models across a diverse set of existing NLU tasks. It was released together with the paper [GLUE: A
+multi-task benchmark and analysis platform for natural language understanding](https://openreview.net/pdf?id=rJ4km2R5t7)
+
+This library hosts a total of 10 processors for the following tasks: MRPC, MNLI, MNLI (mismatched), CoLA, SST2, STSB,
+QQP, QNLI, RTE and WNLI.
+
+Those processors are:
+
+- [`~data.processors.utils.MrpcProcessor`]
+- [`~data.processors.utils.MnliProcessor`]
+- [`~data.processors.utils.MnliMismatchedProcessor`]
+- [`~data.processors.utils.Sst2Processor`]
+- [`~data.processors.utils.StsbProcessor`]
+- [`~data.processors.utils.QqpProcessor`]
+- [`~data.processors.utils.QnliProcessor`]
+- [`~data.processors.utils.RteProcessor`]
+- [`~data.processors.utils.WnliProcessor`]
+
+Additionally, the following method can be used to load values from a data file and convert them to a list of
+[`~data.processors.utils.InputExample`].
+
+[[autodoc]] data.processors.glue.glue_convert_examples_to_features
+
+
+## XNLI
+
+[The Cross-Lingual NLI Corpus (XNLI)](https://www.nyu.edu/projects/bowman/xnli/) is a benchmark that evaluates the
+quality of cross-lingual text representations. XNLI is crowd-sourced dataset based on [*MultiNLI*](http://www.nyu.edu/projects/bowman/multinli/): pairs of text are labeled with textual entailment annotations for 15
+different languages (including both high-resource language such as English and low-resource languages such as Swahili).
+
+It was released together with the paper [XNLI: Evaluating Cross-lingual Sentence Representations](https://arxiv.org/abs/1809.05053)
+
+This library hosts the processor to load the XNLI data:
+
+- [`~data.processors.utils.XnliProcessor`]
+
+Please note that since the gold labels are available on the test set, evaluation is performed on the test set.
+
+An example using these processors is given in the [run_xnli.py](https://github.com/huggingface/transformers/tree/main/examples/legacy/text-classification/run_xnli.py) script.
+
+
+## SQuAD
+
+[The Stanford Question Answering Dataset (SQuAD)](https://rajpurkar.github.io/SQuAD-explorer//) is a benchmark that
+evaluates the performance of models on question answering. Two versions are available, v1.1 and v2.0. The first version
+(v1.1) was released together with the paper [SQuAD: 100,000+ Questions for Machine Comprehension of Text](https://arxiv.org/abs/1606.05250). The second version (v2.0) was released alongside the paper [Know What You Don't
+Know: Unanswerable Questions for SQuAD](https://arxiv.org/abs/1806.03822).
+
+This library hosts a processor for each of the two versions:
+
+### Processors
+
+Those processors are:
+
+- [`~data.processors.utils.SquadV1Processor`]
+- [`~data.processors.utils.SquadV2Processor`]
+
+They both inherit from the abstract class [`~data.processors.utils.SquadProcessor`]
+
+[[autodoc]] data.processors.squad.SquadProcessor
+ - all
+
+Additionally, the following method can be used to convert SQuAD examples into
+[`~data.processors.utils.SquadFeatures`] that can be used as model inputs.
+
+[[autodoc]] data.processors.squad.squad_convert_examples_to_features
+
+
+These processors as well as the aforementionned method can be used with files containing the data as well as with the
+*tensorflow_datasets* package. Examples are given below.
+
+
+### Example usage
+
+Here is an example using the processors as well as the conversion method using data files:
+
+```python
+# Loading a V2 processor
+processor = SquadV2Processor()
+examples = processor.get_dev_examples(squad_v2_data_dir)
+
+# Loading a V1 processor
+processor = SquadV1Processor()
+examples = processor.get_dev_examples(squad_v1_data_dir)
+
+features = squad_convert_examples_to_features(
+ examples=examples,
+ tokenizer=tokenizer,
+ max_seq_length=max_seq_length,
+ doc_stride=args.doc_stride,
+ max_query_length=max_query_length,
+ is_training=not evaluate,
+)
+```
+
+Using *tensorflow_datasets* is as easy as using a data file:
+
+```python
+# tensorflow_datasets only handle Squad V1.
+tfds_examples = tfds.load("squad")
+examples = SquadV1Processor().get_examples_from_dataset(tfds_examples, evaluate=evaluate)
+
+features = squad_convert_examples_to_features(
+ examples=examples,
+ tokenizer=tokenizer,
+ max_seq_length=max_seq_length,
+ doc_stride=args.doc_stride,
+ max_query_length=max_query_length,
+ is_training=not evaluate,
+)
+```
+
+Another example using these processors is given in the [run_squad.py](https://github.com/huggingface/transformers/tree/main/examples/legacy/question-answering/run_squad.py) script.
diff --git a/docs/source/en/main_classes/text_generation.mdx b/docs/source/en/main_classes/text_generation.mdx
new file mode 100644
index 00000000000000..94deeeae89411b
--- /dev/null
+++ b/docs/source/en/main_classes/text_generation.mdx
@@ -0,0 +1,40 @@
+
+
+# Generation
+
+Each framework has a generate method for auto-regressive text generation implemented in their respective `GenerationMixin` class:
+
+- PyTorch [`~generation_utils.GenerationMixin.generate`] is implemented in [`~generation_utils.GenerationMixin`].
+- TensorFlow [`~generation_tf_utils.TFGenerationMixin.generate`] is implemented in [`~generation_tf_utils.TFGenerationMixin`].
+- Flax/JAX [`~generation_flax_utils.FlaxGenerationMixin.generate`] is implemented in [`~generation_flax_utils.FlaxGenerationMixin`].
+
+## GenerationMixin
+
+[[autodoc]] generation_utils.GenerationMixin
+ - generate
+ - greedy_search
+ - sample
+ - beam_search
+ - beam_sample
+ - group_beam_search
+ - constrained_beam_search
+
+## TFGenerationMixin
+
+[[autodoc]] generation_tf_utils.TFGenerationMixin
+ - generate
+
+## FlaxGenerationMixin
+
+[[autodoc]] generation_flax_utils.FlaxGenerationMixin
+ - generate
diff --git a/docs/source/en/main_classes/tokenizer.mdx b/docs/source/en/main_classes/tokenizer.mdx
new file mode 100644
index 00000000000000..032373435cd5f4
--- /dev/null
+++ b/docs/source/en/main_classes/tokenizer.mdx
@@ -0,0 +1,75 @@
+
+
+# Tokenizer
+
+A tokenizer is in charge of preparing the inputs for a model. The library contains tokenizers for all the models. Most
+of the tokenizers are available in two flavors: a full python implementation and a "Fast" implementation based on the
+Rust library [🤗 Tokenizers](https://github.com/huggingface/tokenizers). The "Fast" implementations allows:
+
+1. a significant speed-up in particular when doing batched tokenization and
+2. additional methods to map between the original string (character and words) and the token space (e.g. getting the
+ index of the token comprising a given character or the span of characters corresponding to a given token).
+
+The base classes [`PreTrainedTokenizer`] and [`PreTrainedTokenizerFast`]
+implement the common methods for encoding string inputs in model inputs (see below) and instantiating/saving python and
+"Fast" tokenizers either from a local file or directory or from a pretrained tokenizer provided by the library
+(downloaded from HuggingFace's AWS S3 repository). They both rely on
+[`~tokenization_utils_base.PreTrainedTokenizerBase`] that contains the common methods, and
+[`~tokenization_utils_base.SpecialTokensMixin`].
+
+[`PreTrainedTokenizer`] and [`PreTrainedTokenizerFast`] thus implement the main
+methods for using all the tokenizers:
+
+- Tokenizing (splitting strings in sub-word token strings), converting tokens strings to ids and back, and
+ encoding/decoding (i.e., tokenizing and converting to integers).
+- Adding new tokens to the vocabulary in a way that is independent of the underlying structure (BPE, SentencePiece...).
+- Managing special tokens (like mask, beginning-of-sentence, etc.): adding them, assigning them to attributes in the
+ tokenizer for easy access and making sure they are not split during tokenization.
+
+[`BatchEncoding`] holds the output of the
+[`~tokenization_utils_base.PreTrainedTokenizerBase`]'s encoding methods (`__call__`,
+`encode_plus` and `batch_encode_plus`) and is derived from a Python dictionary. When the tokenizer is a pure python
+tokenizer, this class behaves just like a standard python dictionary and holds the various model inputs computed by
+these methods (`input_ids`, `attention_mask`...). When the tokenizer is a "Fast" tokenizer (i.e., backed by
+HuggingFace [tokenizers library](https://github.com/huggingface/tokenizers)), this class provides in addition
+several advanced alignment methods which can be used to map between the original string (character and words) and the
+token space (e.g., getting the index of the token comprising a given character or the span of characters corresponding
+to a given token).
+
+
+## PreTrainedTokenizer
+
+[[autodoc]] PreTrainedTokenizer
+ - __call__
+ - batch_decode
+ - decode
+ - encode
+ - push_to_hub
+ - all
+
+## PreTrainedTokenizerFast
+
+The [`PreTrainedTokenizerFast`] depend on the [tokenizers](https://huggingface.co/docs/tokenizers) library. The tokenizers obtained from the 🤗 tokenizers library can be
+loaded very simply into 🤗 transformers. Take a look at the [Using tokenizers from 🤗 tokenizers](../fast_tokenizers) page to understand how this is done.
+
+[[autodoc]] PreTrainedTokenizerFast
+ - __call__
+ - batch_decode
+ - decode
+ - encode
+ - push_to_hub
+ - all
+
+## BatchEncoding
+
+[[autodoc]] BatchEncoding
diff --git a/docs/source/en/main_classes/trainer.mdx b/docs/source/en/main_classes/trainer.mdx
new file mode 100644
index 00000000000000..a3c57b51f570b3
--- /dev/null
+++ b/docs/source/en/main_classes/trainer.mdx
@@ -0,0 +1,569 @@
+
+
+# Trainer
+
+The [`Trainer`] class provides an API for feature-complete training in PyTorch for most standard use cases. It's used in most of the [example scripts](../examples).
+
+Before instantiating your [`Trainer`], create a [`TrainingArguments`] to access all the points of customization during training.
+
+The API supports distributed training on multiple GPUs/TPUs, mixed precision through [NVIDIA Apex](https://github.com/NVIDIA/apex) and Native AMP for PyTorch.
+
+The [`Trainer`] contains the basic training loop which supports the above features. To inject custom behavior you can subclass them and override the following methods:
+
+- **get_train_dataloader** -- Creates the training DataLoader.
+- **get_eval_dataloader** -- Creates the evaluation DataLoader.
+- **get_test_dataloader** -- Creates the test DataLoader.
+- **log** -- Logs information on the various objects watching training.
+- **create_optimizer_and_scheduler** -- Sets up the optimizer and learning rate scheduler if they were not passed at
+ init. Note, that you can also subclass or override the `create_optimizer` and `create_scheduler` methods
+ separately.
+- **create_optimizer** -- Sets up the optimizer if it wasn't passed at init.
+- **create_scheduler** -- Sets up the learning rate scheduler if it wasn't passed at init.
+- **compute_loss** - Computes the loss on a batch of training inputs.
+- **training_step** -- Performs a training step.
+- **prediction_step** -- Performs an evaluation/test step.
+- **evaluate** -- Runs an evaluation loop and returns metrics.
+- **predict** -- Returns predictions (with metrics if labels are available) on a test set.
+
+
+
+The [`Trainer`] class is optimized for 🤗 Transformers models and can have surprising behaviors
+when you use it on other models. When using it on your own model, make sure:
+
+- your model always return tuples or subclasses of [`~utils.ModelOutput`].
+- your model can compute the loss if a `labels` argument is provided and that loss is returned as the first
+ element of the tuple (if your model returns tuples)
+- your model can accept multiple label arguments (use the `label_names` in your [`TrainingArguments`] to indicate their name to the [`Trainer`]) but none of them should be named `"label"`.
+
+
+
+Here is an example of how to customize [`Trainer`] to use a weighted loss (useful when you have an unbalanced training set):
+
+```python
+from torch import nn
+from transformers import Trainer
+
+
+class CustomTrainer(Trainer):
+ def compute_loss(self, model, inputs, return_outputs=False):
+ labels = inputs.get("labels")
+ # forward pass
+ outputs = model(**inputs)
+ logits = outputs.get("logits")
+ # compute custom loss (suppose one has 3 labels with different weights)
+ loss_fct = nn.CrossEntropyLoss(weight=torch.tensor([1.0, 2.0, 3.0]))
+ loss = loss_fct(logits.view(-1, self.model.config.num_labels), labels.view(-1))
+ return (loss, outputs) if return_outputs else loss
+```
+
+Another way to customize the training loop behavior for the PyTorch [`Trainer`] is to use [callbacks](callback) that can inspect the training loop state (for progress reporting, logging on TensorBoard or other ML platforms...) and take decisions (like early stopping).
+
+
+## Trainer
+
+[[autodoc]] Trainer
+ - all
+
+## Seq2SeqTrainer
+
+[[autodoc]] Seq2SeqTrainer
+ - evaluate
+ - predict
+
+## TrainingArguments
+
+[[autodoc]] TrainingArguments
+ - all
+
+## Seq2SeqTrainingArguments
+
+[[autodoc]] Seq2SeqTrainingArguments
+ - all
+
+## Checkpoints
+
+By default, [`Trainer`] will save all checkpoints in the `output_dir` you set in the
+[`TrainingArguments`] you are using. Those will go in subfolder named `checkpoint-xxx` with xxx
+being the step at which the training was at.
+
+Resuming training from a checkpoint can be done when calling [`Trainer.train`] with either:
+
+- `resume_from_checkpoint=True` which will resume training from the latest checkpoint
+- `resume_from_checkpoint=checkpoint_dir` which will resume training from the specific checkpoint in the directory
+ passed.
+
+In addition, you can easily save your checkpoints on the Model Hub when using `push_to_hub=True`. By default, all
+the models saved in intermediate checkpoints are saved in different commits, but not the optimizer state. You can adapt
+the `hub-strategy` value of your [`TrainingArguments`] to either:
+
+- `"checkpoint"`: the latest checkpoint is also pushed in a subfolder named last-checkpoint, allowing you to
+ resume training easily with `trainer.train(resume_from_checkpoint="output_dir/last-checkpoint")`.
+- `"all_checkpoints"`: all checkpoints are pushed like they appear in the output folder (so you will get one
+ checkpoint folder per folder in your final repository)
+
+
+## Logging
+
+By default [`Trainer`] will use `logging.INFO` for the main process and `logging.WARNING` for the replicas if any.
+
+These defaults can be overridden to use any of the 5 `logging` levels with [`TrainingArguments`]'s
+arguments:
+
+- `log_level` - for the main process
+- `log_level_replica` - for the replicas
+
+Further, if [`TrainingArguments`]'s `log_on_each_node` is set to `False` only the main node will
+use the log level settings for its main process, all other nodes will use the log level settings for replicas.
+
+Note that [`Trainer`] is going to set `transformers`'s log level separately for each node in its
+[`Trainer.__init__`]. So you may want to set this sooner (see the next example) if you tap into other
+`transformers` functionality before creating the [`Trainer`] object.
+
+Here is an example of how this can be used in an application:
+
+```python
+[...]
+logger = logging.getLogger(__name__)
+
+# Setup logging
+logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ handlers=[logging.StreamHandler(sys.stdout)],
+)
+
+# set the main code and the modules it uses to the same log-level according to the node
+log_level = training_args.get_process_log_level()
+logger.setLevel(log_level)
+datasets.utils.logging.set_verbosity(log_level)
+transformers.utils.logging.set_verbosity(log_level)
+
+trainer = Trainer(...)
+```
+
+And then if you only want to see warnings on the main node and all other nodes to not print any most likely duplicated
+warnings you could run it as:
+
+```bash
+my_app.py ... --log_level warning --log_level_replica error
+```
+
+In the multi-node environment if you also don't want the logs to repeat for each node's main process, you will want to
+change the above to:
+
+```bash
+my_app.py ... --log_level warning --log_level_replica error --log_on_each_node 0
+```
+
+and then only the main process of the first node will log at the "warning" level, and all other processes on the main
+node and all processes on other nodes will log at the "error" level.
+
+If you need your application to be as quiet as possible you could do:
+
+```bash
+my_app.py ... --log_level error --log_level_replica error --log_on_each_node 0
+```
+
+(add `--log_on_each_node 0` if on multi-node environment)
+
+
+## Randomness
+
+When resuming from a checkpoint generated by [`Trainer`] all efforts are made to restore the
+_python_, _numpy_ and _pytorch_ RNG states to the same states as they were at the moment of saving that checkpoint,
+which should make the "stop and resume" style of training as close as possible to non-stop training.
+
+However, due to various default non-deterministic pytorch settings this might not fully work. If you want full
+determinism please refer to [Controlling sources of randomness](https://pytorch.org/docs/stable/notes/randomness). As explained in the document, that some of those settings
+that make things deterministic (.e.g., `torch.backends.cudnn.deterministic`) may slow things down, therefore this
+can't be done by default, but you can enable those yourself if needed.
+
+
+## Specific GPUs Selection
+
+Let's discuss how you can tell your program which GPUs are to be used and in what order.
+
+When using [`DistributedDataParallel`](https://pytorch.org/docs/stable/generated/torch.nn.parallel.DistributedDataParallel.html) to use only a subset of your GPUs, you simply specify the number of GPUs to use. For example, if you have 4 GPUs, but you wish to use the first 2 you can do:
+
+```bash
+python -m torch.distributed.launch --nproc_per_node=2 trainer-program.py ...
+```
+
+if you have either [`accelerate`](https://github.com/huggingface/accelerate) or [`deepspeed`](https://github.com/microsoft/DeepSpeed) installed you can also accomplish the same by using one of:
+```bash
+accelerate launch --num_processes 2 trainer-program.py ...
+```
+
+```bash
+deepspeed --num_gpus 2 trainer-program.py ...
+```
+
+You don't need to use the Accelerate or [the Deepspeed integration](Deepspeed) features to use these launchers.
+
+
+Until now you were able to tell the program how many GPUs to use. Now let's discuss how to select specific GPUs and control their order.
+
+The following environment variables help you control which GPUs to use and their order.
+
+**`CUDA_VISIBLE_DEVICES`**
+
+If you have multiple GPUs and you'd like to use only 1 or a few of those GPUs, set the environment variable `CUDA_VISIBLE_DEVICES` to a list of the GPUs to be used.
+
+For example, let's say you have 4 GPUs: 0, 1, 2 and 3. To run only on the physical GPUs 0 and 2, you can do:
+
+```bash
+CUDA_VISIBLE_DEVICES=0,2 python -m torch.distributed.launch trainer-program.py ...
+```
+
+So now pytorch will see only 2 GPUs, where your physical GPUs 0 and 2 are mapped to `cuda:0` and `cuda:1` correspondingly.
+
+You can even change their order:
+
+```bash
+CUDA_VISIBLE_DEVICES=2,0 python -m torch.distributed.launch trainer-program.py ...
+```
+
+Here your physical GPUs 0 and 2 are mapped to `cuda:1` and `cuda:0` correspondingly.
+
+The above examples were all for `DistributedDataParallel` use pattern, but the same method works for [`DataParallel`](https://pytorch.org/docs/stable/generated/torch.nn.DataParallel.html) as well:
+```bash
+CUDA_VISIBLE_DEVICES=2,0 python trainer-program.py ...
+```
+
+To emulate an environment without GPUs simply set this environment variable to an empty value like so:
+
+```bash
+CUDA_VISIBLE_DEVICES= python trainer-program.py ...
+```
+
+As with any environment variable you can, of course, export those instead of adding these to the command line, as in:
+
+
+```bash
+export CUDA_VISIBLE_DEVICES=0,2
+python -m torch.distributed.launch trainer-program.py ...
+```
+
+but this approach can be confusing since you may forget you set up the environment variable earlier and not understand why the wrong GPUs are used. Therefore, it's a common practice to set the environment variable just for a specific run on the same command line as it's shown in most examples of this section.
+
+**`CUDA_DEVICE_ORDER`**
+
+There is an additional environment variable `CUDA_DEVICE_ORDER` that controls how the physical devices are ordered. The two choices are:
+
+1. ordered by PCIe bus IDs (matches `nvidia-smi`'s order) - this is the default.
+
+```bash
+export CUDA_DEVICE_ORDER=PCI_BUS_ID
+```
+
+2. ordered by GPU compute capabilities
+
+```bash
+export CUDA_DEVICE_ORDER=FASTEST_FIRST
+```
+
+Most of the time you don't need to care about this environment variable, but it's very helpful if you have a lopsided setup where you have an old and a new GPUs physically inserted in such a way so that the slow older card appears to be first. One way to fix that is to swap the cards. But if you can't swap the cards (e.g., if the cooling of the devices gets impacted) then setting `CUDA_DEVICE_ORDER=FASTEST_FIRST` will always put the newer faster card first. It'll be somewhat confusing though since `nvidia-smi` will still report them in the PCIe order.
+
+The other solution to swapping the order is to use:
+
+```bash
+export CUDA_VISIBLE_DEVICES=1,0
+```
+In this example we are working with just 2 GPUs, but of course the same would apply to as many GPUs as your computer has.
+
+Also if you do set this environment variable it's the best to set it in your `~/.bashrc` file or some other startup config file and forget about it.
+
+
+
+
+## Trainer Integrations
+
+The [`Trainer`] has been extended to support libraries that may dramatically improve your training
+time and fit much bigger models.
+
+Currently it supports third party solutions, [DeepSpeed](https://github.com/microsoft/DeepSpeed) and [FairScale](https://github.com/facebookresearch/fairscale/), which implement parts of the paper [ZeRO: Memory Optimizations
+Toward Training Trillion Parameter Models, by Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, Yuxiong He](https://arxiv.org/abs/1910.02054).
+
+This provided support is new and experimental as of this writing.
+
+
+
+### CUDA Extension Installation Notes
+
+As of this writing, both FairScale and Deepspeed require compilation of CUDA C++ code, before they can be used.
+
+While all installation issues should be dealt with through the corresponding GitHub Issues of [FairScale](https://github.com/facebookresearch/fairscale/issues) and [Deepspeed](https://github.com/microsoft/DeepSpeed/issues), there are a few common issues that one may encounter while building
+any PyTorch extension that needs to build CUDA extensions.
+
+Therefore, if you encounter a CUDA-related build issue while doing one of the following or both:
+
+```bash
+pip install fairscale
+pip install deepspeed
+```
+
+please, read the following notes first.
+
+In these notes we give examples for what to do when `pytorch` has been built with CUDA `10.2`. If your situation is
+different remember to adjust the version number to the one you are after.
+
+#### Possible problem #1
+
+While, Pytorch comes with its own CUDA toolkit, to build these two projects you must have an identical version of CUDA
+installed system-wide.
+
+For example, if you installed `pytorch` with `cudatoolkit==10.2` in the Python environment, you also need to have
+CUDA `10.2` installed system-wide.
+
+The exact location may vary from system to system, but `/usr/local/cuda-10.2` is the most common location on many
+Unix systems. When CUDA is correctly set up and added to the `PATH` environment variable, one can find the
+installation location by doing:
+
+```bash
+which nvcc
+```
+
+If you don't have CUDA installed system-wide, install it first. You will find the instructions by using your favorite
+search engine. For example, if you're on Ubuntu you may want to search for: [ubuntu cuda 10.2 install](https://www.google.com/search?q=ubuntu+cuda+10.2+install).
+
+#### Possible problem #2
+
+Another possible common problem is that you may have more than one CUDA toolkit installed system-wide. For example you
+may have:
+
+```bash
+/usr/local/cuda-10.2
+/usr/local/cuda-11.0
+```
+
+Now, in this situation you need to make sure that your `PATH` and `LD_LIBRARY_PATH` environment variables contain
+the correct paths to the desired CUDA version. Typically, package installers will set these to contain whatever the
+last version was installed. If you encounter the problem, where the package build fails because it can't find the right
+CUDA version despite you having it installed system-wide, it means that you need to adjust the 2 aforementioned
+environment variables.
+
+First, you may look at their contents:
+
+```bash
+echo $PATH
+echo $LD_LIBRARY_PATH
+```
+
+so you get an idea of what is inside.
+
+It's possible that `LD_LIBRARY_PATH` is empty.
+
+`PATH` lists the locations of where executables can be found and `LD_LIBRARY_PATH` is for where shared libraries
+are to looked for. In both cases, earlier entries have priority over the later ones. `:` is used to separate multiple
+entries.
+
+Now, to tell the build program where to find the specific CUDA toolkit, insert the desired paths to be listed first by
+doing:
+
+```bash
+export PATH=/usr/local/cuda-10.2/bin:$PATH
+export LD_LIBRARY_PATH=/usr/local/cuda-10.2/lib64:$LD_LIBRARY_PATH
+```
+
+Note that we aren't overwriting the existing values, but prepending instead.
+
+Of course, adjust the version number, the full path if need be. Check that the directories you assign actually do
+exist. `lib64` sub-directory is where the various CUDA `.so` objects, like `libcudart.so` reside, it's unlikely
+that your system will have it named differently, but if it is adjust it to reflect your reality.
+
+
+#### Possible problem #3
+
+Some older CUDA versions may refuse to build with newer compilers. For example, you my have `gcc-9` but it wants
+`gcc-7`.
+
+There are various ways to go about it.
+
+If you can install the latest CUDA toolkit it typically should support the newer compiler.
+
+Alternatively, you could install the lower version of the compiler in addition to the one you already have, or you may
+already have it but it's not the default one, so the build system can't see it. If you have `gcc-7` installed but the
+build system complains it can't find it, the following might do the trick:
+
+```bash
+sudo ln -s /usr/bin/gcc-7 /usr/local/cuda-10.2/bin/gcc
+sudo ln -s /usr/bin/g++-7 /usr/local/cuda-10.2/bin/g++
+```
+
+Here, we are making a symlink to `gcc-7` from `/usr/local/cuda-10.2/bin/gcc` and since
+`/usr/local/cuda-10.2/bin/` should be in the `PATH` environment variable (see the previous problem's solution), it
+should find `gcc-7` (and `g++7`) and then the build will succeed.
+
+As always make sure to edit the paths in the example to match your situation.
+
+### FairScale
+
+By integrating [FairScale](https://github.com/facebookresearch/fairscale/) the [`Trainer`]
+provides support for the following features from [the ZeRO paper](https://arxiv.org/abs/1910.02054):
+
+1. Optimizer State Sharding
+2. Gradient Sharding
+3. Model Parameters Sharding (new and very experimental)
+4. CPU offload (new and very experimental)
+
+You will need at least two GPUs to use this feature.
+
+
+**Installation**:
+
+Install the library via pypi:
+
+```bash
+pip install fairscale
+```
+
+or via `transformers`' `extras`:
+
+```bash
+pip install transformers[fairscale]
+```
+
+(available starting from `transformers==4.6.0`) or find more details on [the FairScale's GitHub page](https://github.com/facebookresearch/fairscale/#installation).
+
+If you're still struggling with the build, first make sure to read [CUDA Extension Installation Notes](#zero-install-notes).
+
+If it's still not resolved the build issue, here are a few more ideas.
+
+`fairscale` seems to have an issue with the recently introduced by pip build isolation feature. If you have a problem
+with it, you may want to try one of:
+
+```bash
+pip install fairscale --no-build-isolation .
+```
+
+or:
+
+```bash
+git clone https://github.com/facebookresearch/fairscale/
+cd fairscale
+rm -r dist build
+python setup.py bdist_wheel
+pip uninstall -y fairscale
+pip install dist/fairscale-*.whl
+```
+
+`fairscale` also has issues with building against pytorch-nightly, so if you use it you may have to try one of:
+
+```bash
+pip uninstall -y fairscale; pip install fairscale --pre \
+-f https://download.pytorch.org/whl/nightly/cu110/torch_nightly \
+--no-cache --no-build-isolation
+```
+
+or:
+
+```bash
+pip install -v --disable-pip-version-check . \
+-f https://download.pytorch.org/whl/nightly/cu110/torch_nightly --pre
+```
+
+Of course, adjust the urls to match the cuda version you use.
+
+If after trying everything suggested you still encounter build issues, please, proceed with the GitHub Issue of
+[FairScale](https://github.com/facebookresearch/fairscale/issues).
+
+
+
+**Usage**:
+
+To use the first version of Sharded data-parallelism, add `--sharded_ddp simple` to the command line arguments, and
+make sure you have added the distributed launcher `-m torch.distributed.launch --nproc_per_node=NUMBER_OF_GPUS_YOU_HAVE` if you haven't been using it already.
+
+For example here is how you could use it for `run_translation.py` with 2 GPUs:
+
+```bash
+python -m torch.distributed.launch --nproc_per_node=2 examples/pytorch/translation/run_translation.py \
+--model_name_or_path t5-small --per_device_train_batch_size 1 \
+--output_dir output_dir --overwrite_output_dir \
+--do_train --max_train_samples 500 --num_train_epochs 1 \
+--dataset_name wmt16 --dataset_config "ro-en" \
+--source_lang en --target_lang ro \
+--fp16 --sharded_ddp simple
+```
+
+Notes:
+
+- This feature requires distributed training (so multiple GPUs).
+- It is not implemented for TPUs.
+- It works with `--fp16` too, to make things even faster.
+- One of the main benefits of enabling `--sharded_ddp simple` is that it uses a lot less GPU memory, so you should be
+ able to use significantly larger batch sizes using the same hardware (e.g. 3x and even bigger) which should lead to
+ significantly shorter training time.
+
+3. To use the second version of Sharded data-parallelism, add `--sharded_ddp zero_dp_2` or `--sharded_ddp zero_dp_3` to the command line arguments, and make sure you have added the distributed launcher `-m torch.distributed.launch --nproc_per_node=NUMBER_OF_GPUS_YOU_HAVE` if you haven't been using it already.
+
+For example here is how you could use it for `run_translation.py` with 2 GPUs:
+
+```bash
+python -m torch.distributed.launch --nproc_per_node=2 examples/pytorch/translation/run_translation.py \
+--model_name_or_path t5-small --per_device_train_batch_size 1 \
+--output_dir output_dir --overwrite_output_dir \
+--do_train --max_train_samples 500 --num_train_epochs 1 \
+--dataset_name wmt16 --dataset_config "ro-en" \
+--source_lang en --target_lang ro \
+--fp16 --sharded_ddp zero_dp_2
+```
+
+`zero_dp_2` is an optimized version of the simple wrapper, while `zero_dp_3` fully shards model weights,
+gradients and optimizer states.
+
+Both are compatible with adding `cpu_offload` to enable ZeRO-offload (activate it like this: `--sharded_ddp "zero_dp_2 cpu_offload"`).
+
+Notes:
+
+- This feature requires distributed training (so multiple GPUs).
+- It is not implemented for TPUs.
+- It works with `--fp16` too, to make things even faster.
+- The `cpu_offload` additional option requires `--fp16`.
+- This is an area of active development, so make sure you have a source install of fairscale to use this feature as
+ some bugs you encounter may have been fixed there already.
+
+Known caveats:
+
+- This feature is incompatible with `--predict_with_generate` in the _run_translation.py_ script.
+- Using `--sharded_ddp zero_dp_3` requires wrapping each layer of the model in the special container
+ `FullyShardedDataParallelism` of fairscale. It should be used with the option `auto_wrap` if you are not
+ doing this yourself: `--sharded_ddp "zero_dp_3 auto_wrap"`.
+
+
+Sections that were moved:
+
+[ DeepSpeed
+| Installation
+| Deployment with multiple GPUs
+| Deployment with one GPU
+| Deployment in Notebooks
+| Configuration
+| Passing Configuration
+| Shared Configuration
+| ZeRO
+| ZeRO-2 Config
+| ZeRO-3 Config
+| NVMe Support
+| ZeRO-2 vs ZeRO-3 Performance
+| ZeRO-2 Example
+| ZeRO-3 Example
+| Optimizer
+| Scheduler
+| fp32 Precision
+| Automatic Mixed Precision
+| Batch Size
+| Gradient Accumulation
+| Gradient Clipping
+| Getting The Model Weights Out
+]
diff --git a/docs/source/en/migration.mdx b/docs/source/en/migration.mdx
new file mode 100644
index 00000000000000..7abf95875154ca
--- /dev/null
+++ b/docs/source/en/migration.mdx
@@ -0,0 +1,315 @@
+
+
+# Migrating from previous packages
+
+## Migrating from transformers `v3.x` to `v4.x`
+
+A couple of changes were introduced when the switch from version 3 to version 4 was done. Below is a summary of the
+expected changes:
+
+#### 1. AutoTokenizers and pipelines now use fast (rust) tokenizers by default.
+
+The python and rust tokenizers have roughly the same API, but the rust tokenizers have a more complete feature set.
+
+This introduces two breaking changes:
+- The handling of overflowing tokens between the python and rust tokenizers is different.
+- The rust tokenizers do not accept integers in the encoding methods.
+
+##### How to obtain the same behavior as v3.x in v4.x
+
+- The pipelines now contain additional features out of the box. See the [token-classification pipeline with the `grouped_entities` flag](main_classes/pipelines#transformers.TokenClassificationPipeline).
+- The auto-tokenizers now return rust tokenizers. In order to obtain the python tokenizers instead, the user may use the `use_fast` flag by setting it to `False`:
+
+In version `v3.x`:
+```py
+from transformers import AutoTokenizer
+
+tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
+```
+to obtain the same in version `v4.x`:
+```py
+from transformers import AutoTokenizer
+
+tokenizer = AutoTokenizer.from_pretrained("bert-base-cased", use_fast=False)
+```
+
+#### 2. SentencePiece is removed from the required dependencies
+
+The requirement on the SentencePiece dependency has been lifted from the `setup.py`. This is done so that we may have a channel on anaconda cloud without relying on `conda-forge`. This means that the tokenizers that depend on the SentencePiece library will not be available with a standard `transformers` installation.
+
+This includes the **slow** versions of:
+- `XLNetTokenizer`
+- `AlbertTokenizer`
+- `CamembertTokenizer`
+- `MBartTokenizer`
+- `PegasusTokenizer`
+- `T5Tokenizer`
+- `ReformerTokenizer`
+- `XLMRobertaTokenizer`
+
+##### How to obtain the same behavior as v3.x in v4.x
+
+In order to obtain the same behavior as version `v3.x`, you should install `sentencepiece` additionally:
+
+In version `v3.x`:
+```bash
+pip install transformers
+```
+to obtain the same in version `v4.x`:
+```bash
+pip install transformers[sentencepiece]
+```
+or
+```bash
+pip install transformers sentencepiece
+```
+#### 3. The architecture of the repo has been updated so that each model resides in its folder
+
+The past and foreseeable addition of new models means that the number of files in the directory `src/transformers` keeps growing and becomes harder to navigate and understand. We made the choice to put each model and the files accompanying it in their own sub-directories.
+
+This is a breaking change as importing intermediary layers using a model's module directly needs to be done via a different path.
+
+##### How to obtain the same behavior as v3.x in v4.x
+
+In order to obtain the same behavior as version `v3.x`, you should update the path used to access the layers.
+
+In version `v3.x`:
+```bash
+from transformers.modeling_bert import BertLayer
+```
+to obtain the same in version `v4.x`:
+```bash
+from transformers.models.bert.modeling_bert import BertLayer
+```
+
+#### 4. Switching the `return_dict` argument to `True` by default
+
+The [`return_dict` argument](main_classes/output) enables the return of dict-like python objects containing the model outputs, instead of the standard tuples. This object is self-documented as keys can be used to retrieve values, while also behaving as a tuple as users may retrieve objects by index or by slice.
+
+This is a breaking change as the limitation of that tuple is that it cannot be unpacked: `value0, value1 = outputs` will not work.
+
+##### How to obtain the same behavior as v3.x in v4.x
+
+In order to obtain the same behavior as version `v3.x`, you should specify the `return_dict` argument to `False`, either in the model configuration or during the forward pass.
+
+In version `v3.x`:
+```bash
+model = BertModel.from_pretrained("bert-base-cased")
+outputs = model(**inputs)
+```
+to obtain the same in version `v4.x`:
+```bash
+model = BertModel.from_pretrained("bert-base-cased")
+outputs = model(**inputs, return_dict=False)
+```
+or
+```bash
+model = BertModel.from_pretrained("bert-base-cased", return_dict=False)
+outputs = model(**inputs)
+```
+
+#### 5. Removed some deprecated attributes
+
+Attributes that were deprecated have been removed if they had been deprecated for at least a month. The full list of deprecated attributes can be found in [#8604](https://github.com/huggingface/transformers/pull/8604).
+
+Here is a list of these attributes/methods/arguments and what their replacements should be:
+
+In several models, the labels become consistent with the other models:
+- `masked_lm_labels` becomes `labels` in `AlbertForMaskedLM` and `AlbertForPreTraining`.
+- `masked_lm_labels` becomes `labels` in `BertForMaskedLM` and `BertForPreTraining`.
+- `masked_lm_labels` becomes `labels` in `DistilBertForMaskedLM`.
+- `masked_lm_labels` becomes `labels` in `ElectraForMaskedLM`.
+- `masked_lm_labels` becomes `labels` in `LongformerForMaskedLM`.
+- `masked_lm_labels` becomes `labels` in `MobileBertForMaskedLM`.
+- `masked_lm_labels` becomes `labels` in `RobertaForMaskedLM`.
+- `lm_labels` becomes `labels` in `BartForConditionalGeneration`.
+- `lm_labels` becomes `labels` in `GPT2DoubleHeadsModel`.
+- `lm_labels` becomes `labels` in `OpenAIGPTDoubleHeadsModel`.
+- `lm_labels` becomes `labels` in `T5ForConditionalGeneration`.
+
+In several models, the caching mechanism becomes consistent with the other models:
+- `decoder_cached_states` becomes `past_key_values` in all BART-like, FSMT and T5 models.
+- `decoder_past_key_values` becomes `past_key_values` in all BART-like, FSMT and T5 models.
+- `past` becomes `past_key_values` in all CTRL models.
+- `past` becomes `past_key_values` in all GPT-2 models.
+
+Regarding the tokenizer classes:
+- The tokenizer attribute `max_len` becomes `model_max_length`.
+- The tokenizer attribute `return_lengths` becomes `return_length`.
+- The tokenizer encoding argument `is_pretokenized` becomes `is_split_into_words`.
+
+Regarding the `Trainer` class:
+- The `Trainer` argument `tb_writer` is removed in favor of the callback `TensorBoardCallback(tb_writer=...)`.
+- The `Trainer` argument `prediction_loss_only` is removed in favor of the class argument `args.prediction_loss_only`.
+- The `Trainer` attribute `data_collator` should be a callable.
+- The `Trainer` method `_log` is deprecated in favor of `log`.
+- The `Trainer` method `_training_step` is deprecated in favor of `training_step`.
+- The `Trainer` method `_prediction_loop` is deprecated in favor of `prediction_loop`.
+- The `Trainer` method `is_local_master` is deprecated in favor of `is_local_process_zero`.
+- The `Trainer` method `is_world_master` is deprecated in favor of `is_world_process_zero`.
+
+Regarding the `TFTrainer` class:
+- The `TFTrainer` argument `prediction_loss_only` is removed in favor of the class argument `args.prediction_loss_only`.
+- The `Trainer` method `_log` is deprecated in favor of `log`.
+- The `TFTrainer` method `_prediction_loop` is deprecated in favor of `prediction_loop`.
+- The `TFTrainer` method `_setup_wandb` is deprecated in favor of `setup_wandb`.
+- The `TFTrainer` method `_run_model` is deprecated in favor of `run_model`.
+
+Regarding the `TrainingArguments` class:
+- The `TrainingArguments` argument `evaluate_during_training` is deprecated in favor of `evaluation_strategy`.
+
+Regarding the Transfo-XL model:
+- The Transfo-XL configuration attribute `tie_weight` becomes `tie_words_embeddings`.
+- The Transfo-XL modeling method `reset_length` becomes `reset_memory_length`.
+
+Regarding pipelines:
+- The `FillMaskPipeline` argument `topk` becomes `top_k`.
+
+
+
+## Migrating from pytorch-transformers to 🤗 Transformers
+
+Here is a quick summary of what you should take care of when migrating from `pytorch-transformers` to 🤗 Transformers.
+
+### Positional order of some models' keywords inputs (`attention_mask`, `token_type_ids`...) changed
+
+To be able to use Torchscript (see #1010, #1204 and #1195) the specific order of some models **keywords inputs** (`attention_mask`, `token_type_ids`...) has been changed.
+
+If you used to call the models with keyword names for keyword arguments, e.g. `model(inputs_ids, attention_mask=attention_mask, token_type_ids=token_type_ids)`, this should not cause any change.
+
+If you used to call the models with positional inputs for keyword arguments, e.g. `model(inputs_ids, attention_mask, token_type_ids)`, you may have to double check the exact order of input arguments.
+
+## Migrating from pytorch-pretrained-bert
+
+Here is a quick summary of what you should take care of when migrating from `pytorch-pretrained-bert` to 🤗 Transformers
+
+### Models always output `tuples`
+
+The main breaking change when migrating from `pytorch-pretrained-bert` to 🤗 Transformers is that the models forward method always outputs a `tuple` with various elements depending on the model and the configuration parameters.
+
+The exact content of the tuples for each model are detailed in the models' docstrings and the [documentation](https://huggingface.co/transformers/).
+
+In pretty much every case, you will be fine by taking the first element of the output as the output you previously used in `pytorch-pretrained-bert`.
+
+Here is a `pytorch-pretrained-bert` to 🤗 Transformers conversion example for a `BertForSequenceClassification` classification model:
+
+```python
+# Let's load our model
+model = BertForSequenceClassification.from_pretrained("bert-base-uncased")
+
+# If you used to have this line in pytorch-pretrained-bert:
+loss = model(input_ids, labels=labels)
+
+# Now just use this line in 🤗 Transformers to extract the loss from the output tuple:
+outputs = model(input_ids, labels=labels)
+loss = outputs[0]
+
+# In 🤗 Transformers you can also have access to the logits:
+loss, logits = outputs[:2]
+
+# And even the attention weights if you configure the model to output them (and other outputs too, see the docstrings and documentation)
+model = BertForSequenceClassification.from_pretrained("bert-base-uncased", output_attentions=True)
+outputs = model(input_ids, labels=labels)
+loss, logits, attentions = outputs
+```
+
+### Serialization
+
+Breaking change in the `from_pretrained()`method:
+
+1. Models are now set in evaluation mode by default when instantiated with the `from_pretrained()` method. To train them don't forget to set them back in training mode (`model.train()`) to activate the dropout modules.
+
+2. The additional `*inputs` and `**kwargs` arguments supplied to the `from_pretrained()` method used to be directly passed to the underlying model's class `__init__()` method. They are now used to update the model configuration attribute first which can break derived model classes build based on the previous `BertForSequenceClassification` examples. More precisely, the positional arguments `*inputs` provided to `from_pretrained()` are directly forwarded the model `__init__()` method while the keyword arguments `**kwargs` (i) which match configuration class attributes are used to update said attributes (ii) which don't match any configuration class attributes are forwarded to the model `__init__()` method.
+
+Also, while not a breaking change, the serialization methods have been standardized and you probably should switch to the new method `save_pretrained(save_directory)` if you were using any other serialization method before.
+
+Here is an example:
+
+```python
+### Let's load a model and tokenizer
+model = BertForSequenceClassification.from_pretrained("bert-base-uncased")
+tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
+
+### Do some stuff to our model and tokenizer
+# Ex: add new tokens to the vocabulary and embeddings of our model
+tokenizer.add_tokens(["[SPECIAL_TOKEN_1]", "[SPECIAL_TOKEN_2]"])
+model.resize_token_embeddings(len(tokenizer))
+# Train our model
+train(model)
+
+### Now let's save our model and tokenizer to a directory
+model.save_pretrained("./my_saved_model_directory/")
+tokenizer.save_pretrained("./my_saved_model_directory/")
+
+### Reload the model and the tokenizer
+model = BertForSequenceClassification.from_pretrained("./my_saved_model_directory/")
+tokenizer = BertTokenizer.from_pretrained("./my_saved_model_directory/")
+```
+
+### Optimizers: BertAdam & OpenAIAdam are now AdamW, schedules are standard PyTorch schedules
+
+The two optimizers previously included, `BertAdam` and `OpenAIAdam`, have been replaced by a single `AdamW` optimizer which has a few differences:
+
+- it only implements weights decay correction,
+- schedules are now externals (see below),
+- gradient clipping is now also external (see below).
+
+The new optimizer `AdamW` matches PyTorch `Adam` optimizer API and let you use standard PyTorch or apex methods for the schedule and clipping.
+
+The schedules are now standard [PyTorch learning rate schedulers](https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate) and not part of the optimizer anymore.
+
+Here is a conversion examples from `BertAdam` with a linear warmup and decay schedule to `AdamW` and the same schedule:
+
+```python
+# Parameters:
+lr = 1e-3
+max_grad_norm = 1.0
+num_training_steps = 1000
+num_warmup_steps = 100
+warmup_proportion = float(num_warmup_steps) / float(num_training_steps) # 0.1
+
+### Previously BertAdam optimizer was instantiated like this:
+optimizer = BertAdam(
+ model.parameters(),
+ lr=lr,
+ schedule="warmup_linear",
+ warmup=warmup_proportion,
+ num_training_steps=num_training_steps,
+)
+### and used like this:
+for batch in train_data:
+ loss = model(batch)
+ loss.backward()
+ optimizer.step()
+
+### In 🤗 Transformers, optimizer and schedules are split and instantiated like this:
+optimizer = AdamW(
+ model.parameters(), lr=lr, correct_bias=False
+) # To reproduce BertAdam specific behavior set correct_bias=False
+scheduler = get_linear_schedule_with_warmup(
+ optimizer, num_warmup_steps=num_warmup_steps, num_training_steps=num_training_steps
+) # PyTorch scheduler
+### and used like this:
+for batch in train_data:
+ loss = model(batch)
+ loss.backward()
+ torch.nn.utils.clip_grad_norm_(
+ model.parameters(), max_grad_norm
+ ) # Gradient clipping is not in AdamW anymore (so you can use amp without issue)
+ optimizer.step()
+ scheduler.step()
+```
diff --git a/docs/source/en/model_doc/albert.mdx b/docs/source/en/model_doc/albert.mdx
new file mode 100644
index 00000000000000..54873c0fa9c609
--- /dev/null
+++ b/docs/source/en/model_doc/albert.mdx
@@ -0,0 +1,170 @@
+
+
+# ALBERT
+
+## Overview
+
+The ALBERT model was proposed in [ALBERT: A Lite BERT for Self-supervised Learning of Language Representations](https://arxiv.org/abs/1909.11942) by Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma,
+Radu Soricut. It presents two parameter-reduction techniques to lower memory consumption and increase the training
+speed of BERT:
+
+- Splitting the embedding matrix into two smaller matrices.
+- Using repeating layers split among groups.
+
+The abstract from the paper is the following:
+
+*Increasing model size when pretraining natural language representations often results in improved performance on
+downstream tasks. However, at some point further model increases become harder due to GPU/TPU memory limitations,
+longer training times, and unexpected model degradation. To address these problems, we present two parameter-reduction
+techniques to lower memory consumption and increase the training speed of BERT. Comprehensive empirical evidence shows
+that our proposed methods lead to models that scale much better compared to the original BERT. We also use a
+self-supervised loss that focuses on modeling inter-sentence coherence, and show it consistently helps downstream tasks
+with multi-sentence inputs. As a result, our best model establishes new state-of-the-art results on the GLUE, RACE, and
+SQuAD benchmarks while having fewer parameters compared to BERT-large.*
+
+Tips:
+
+- ALBERT is a model with absolute position embeddings so it's usually advised to pad the inputs on the right rather
+ than the left.
+- ALBERT uses repeating layers which results in a small memory footprint, however the computational cost remains
+ similar to a BERT-like architecture with the same number of hidden layers as it has to iterate through the same
+ number of (repeating) layers.
+
+This model was contributed by [lysandre](https://huggingface.co/lysandre). This model jax version was contributed by
+[kamalkraj](https://huggingface.co/kamalkraj). The original code can be found [here](https://github.com/google-research/ALBERT).
+
+## AlbertConfig
+
+[[autodoc]] AlbertConfig
+
+## AlbertTokenizer
+
+[[autodoc]] AlbertTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## AlbertTokenizerFast
+
+[[autodoc]] AlbertTokenizerFast
+
+## Albert specific outputs
+
+[[autodoc]] models.albert.modeling_albert.AlbertForPreTrainingOutput
+
+[[autodoc]] models.albert.modeling_tf_albert.TFAlbertForPreTrainingOutput
+
+## AlbertModel
+
+[[autodoc]] AlbertModel
+ - forward
+
+## AlbertForPreTraining
+
+[[autodoc]] AlbertForPreTraining
+ - forward
+
+## AlbertForMaskedLM
+
+[[autodoc]] AlbertForMaskedLM
+ - forward
+
+## AlbertForSequenceClassification
+
+[[autodoc]] AlbertForSequenceClassification
+ - forward
+
+## AlbertForMultipleChoice
+
+[[autodoc]] AlbertForMultipleChoice
+
+## AlbertForTokenClassification
+
+[[autodoc]] AlbertForTokenClassification
+ - forward
+
+## AlbertForQuestionAnswering
+
+[[autodoc]] AlbertForQuestionAnswering
+ - forward
+
+## TFAlbertModel
+
+[[autodoc]] TFAlbertModel
+ - call
+
+## TFAlbertForPreTraining
+
+[[autodoc]] TFAlbertForPreTraining
+ - call
+
+## TFAlbertForMaskedLM
+
+[[autodoc]] TFAlbertForMaskedLM
+ - call
+
+## TFAlbertForSequenceClassification
+
+[[autodoc]] TFAlbertForSequenceClassification
+ - call
+
+## TFAlbertForMultipleChoice
+
+[[autodoc]] TFAlbertForMultipleChoice
+ - call
+
+## TFAlbertForTokenClassification
+
+[[autodoc]] TFAlbertForTokenClassification
+ - call
+
+## TFAlbertForQuestionAnswering
+
+[[autodoc]] TFAlbertForQuestionAnswering
+ - call
+
+## FlaxAlbertModel
+
+[[autodoc]] FlaxAlbertModel
+ - __call__
+
+## FlaxAlbertForPreTraining
+
+[[autodoc]] FlaxAlbertForPreTraining
+ - __call__
+
+## FlaxAlbertForMaskedLM
+
+[[autodoc]] FlaxAlbertForMaskedLM
+ - __call__
+
+## FlaxAlbertForSequenceClassification
+
+[[autodoc]] FlaxAlbertForSequenceClassification
+ - __call__
+
+## FlaxAlbertForMultipleChoice
+
+[[autodoc]] FlaxAlbertForMultipleChoice
+ - __call__
+
+## FlaxAlbertForTokenClassification
+
+[[autodoc]] FlaxAlbertForTokenClassification
+ - __call__
+
+## FlaxAlbertForQuestionAnswering
+
+[[autodoc]] FlaxAlbertForQuestionAnswering
+ - __call__
diff --git a/docs/source/en/model_doc/auto.mdx b/docs/source/en/model_doc/auto.mdx
new file mode 100644
index 00000000000000..d941b00318b086
--- /dev/null
+++ b/docs/source/en/model_doc/auto.mdx
@@ -0,0 +1,263 @@
+
+
+# Auto Classes
+
+In many cases, the architecture you want to use can be guessed from the name or the path of the pretrained model you
+are supplying to the `from_pretrained()` method. AutoClasses are here to do this job for you so that you
+automatically retrieve the relevant model given the name/path to the pretrained weights/config/vocabulary.
+
+Instantiating one of [`AutoConfig`], [`AutoModel`], and
+[`AutoTokenizer`] will directly create a class of the relevant architecture. For instance
+
+
+```python
+model = AutoModel.from_pretrained("bert-base-cased")
+```
+
+will create a model that is an instance of [`BertModel`].
+
+There is one class of `AutoModel` for each task, and for each backend (PyTorch, TensorFlow, or Flax).
+
+## Extending the Auto Classes
+
+Each of the auto classes has a method to be extended with your custom classes. For instance, if you have defined a
+custom class of model `NewModel`, make sure you have a `NewModelConfig` then you can add those to the auto
+classes like this:
+
+```python
+from transformers import AutoConfig, AutoModel
+
+AutoConfig.register("new-model", NewModelConfig)
+AutoModel.register(NewModelConfig, NewModel)
+```
+
+You will then be able to use the auto classes like you would usually do!
+
+
+
+If your `NewModelConfig` is a subclass of [`~transformer.PretrainedConfig`], make sure its
+`model_type` attribute is set to the same key you use when registering the config (here `"new-model"`).
+
+Likewise, if your `NewModel` is a subclass of [`PreTrainedModel`], make sure its
+`config_class` attribute is set to the same class you use when registering the model (here
+`NewModelConfig`).
+
+
+
+## AutoConfig
+
+[[autodoc]] AutoConfig
+
+## AutoTokenizer
+
+[[autodoc]] AutoTokenizer
+
+## AutoFeatureExtractor
+
+[[autodoc]] AutoFeatureExtractor
+
+## AutoProcessor
+
+[[autodoc]] AutoProcessor
+
+## AutoModel
+
+[[autodoc]] AutoModel
+
+## AutoModelForPreTraining
+
+[[autodoc]] AutoModelForPreTraining
+
+## AutoModelForCausalLM
+
+[[autodoc]] AutoModelForCausalLM
+
+## AutoModelForMaskedLM
+
+[[autodoc]] AutoModelForMaskedLM
+
+## AutoModelForSeq2SeqLM
+
+[[autodoc]] AutoModelForSeq2SeqLM
+
+## AutoModelForSequenceClassification
+
+[[autodoc]] AutoModelForSequenceClassification
+
+## AutoModelForMultipleChoice
+
+[[autodoc]] AutoModelForMultipleChoice
+
+## AutoModelForNextSentencePrediction
+
+[[autodoc]] AutoModelForNextSentencePrediction
+
+## AutoModelForTokenClassification
+
+[[autodoc]] AutoModelForTokenClassification
+
+## AutoModelForQuestionAnswering
+
+[[autodoc]] AutoModelForQuestionAnswering
+
+## AutoModelForTableQuestionAnswering
+
+[[autodoc]] AutoModelForTableQuestionAnswering
+
+## AutoModelForImageClassification
+
+[[autodoc]] AutoModelForImageClassification
+
+## AutoModelForVision2Seq
+
+[[autodoc]] AutoModelForVision2Seq
+
+## AutoModelForAudioClassification
+
+[[autodoc]] AutoModelForAudioClassification
+
+## AutoModelForAudioFrameClassification
+
+[[autodoc]] AutoModelForAudioFrameClassification
+
+## AutoModelForCTC
+
+[[autodoc]] AutoModelForCTC
+
+## AutoModelForSpeechSeq2Seq
+
+[[autodoc]] AutoModelForSpeechSeq2Seq
+
+## AutoModelForAudioXVector
+
+[[autodoc]] AutoModelForAudioXVector
+
+## AutoModelForMaskedImageModeling
+
+[[autodoc]] AutoModelForMaskedImageModeling
+
+## AutoModelForObjectDetection
+
+[[autodoc]] AutoModelForObjectDetection
+
+## AutoModelForImageSegmentation
+
+[[autodoc]] AutoModelForImageSegmentation
+
+## AutoModelForSemanticSegmentation
+
+[[autodoc]] AutoModelForSemanticSegmentation
+
+## AutoModelForInstanceSegmentation
+
+[[autodoc]] AutoModelForInstanceSegmentation
+
+## TFAutoModel
+
+[[autodoc]] TFAutoModel
+
+## TFAutoModelForPreTraining
+
+[[autodoc]] TFAutoModelForPreTraining
+
+## TFAutoModelForCausalLM
+
+[[autodoc]] TFAutoModelForCausalLM
+
+## TFAutoModelForImageClassification
+
+[[autodoc]] TFAutoModelForImageClassification
+
+## TFAutoModelForMaskedLM
+
+[[autodoc]] TFAutoModelForMaskedLM
+
+## TFAutoModelForSeq2SeqLM
+
+[[autodoc]] TFAutoModelForSeq2SeqLM
+
+## TFAutoModelForSequenceClassification
+
+[[autodoc]] TFAutoModelForSequenceClassification
+
+## TFAutoModelForMultipleChoice
+
+[[autodoc]] TFAutoModelForMultipleChoice
+
+## TFAutoModelForTableQuestionAnswering
+
+[[autodoc]] TFAutoModelForTableQuestionAnswering
+
+## TFAutoModelForTokenClassification
+
+[[autodoc]] TFAutoModelForTokenClassification
+
+## TFAutoModelForQuestionAnswering
+
+[[autodoc]] TFAutoModelForQuestionAnswering
+
+## TFAutoModelForVision2Seq
+
+[[autodoc]] TFAutoModelForVision2Seq
+
+## TFAutoModelForSpeechSeq2Seq
+
+[[autodoc]] TFAutoModelForSpeechSeq2Seq
+
+## FlaxAutoModel
+
+[[autodoc]] FlaxAutoModel
+
+## FlaxAutoModelForCausalLM
+
+[[autodoc]] FlaxAutoModelForCausalLM
+
+## FlaxAutoModelForPreTraining
+
+[[autodoc]] FlaxAutoModelForPreTraining
+
+## FlaxAutoModelForMaskedLM
+
+[[autodoc]] FlaxAutoModelForMaskedLM
+
+## FlaxAutoModelForSeq2SeqLM
+
+[[autodoc]] FlaxAutoModelForSeq2SeqLM
+
+## FlaxAutoModelForSequenceClassification
+
+[[autodoc]] FlaxAutoModelForSequenceClassification
+
+## FlaxAutoModelForQuestionAnswering
+
+[[autodoc]] FlaxAutoModelForQuestionAnswering
+
+## FlaxAutoModelForTokenClassification
+
+[[autodoc]] FlaxAutoModelForTokenClassification
+
+## FlaxAutoModelForMultipleChoice
+
+[[autodoc]] FlaxAutoModelForMultipleChoice
+
+## FlaxAutoModelForNextSentencePrediction
+
+[[autodoc]] FlaxAutoModelForNextSentencePrediction
+
+## FlaxAutoModelForImageClassification
+
+[[autodoc]] FlaxAutoModelForImageClassification
+
+## FlaxAutoModelForVision2Seq
+
+[[autodoc]] FlaxAutoModelForVision2Seq
diff --git a/docs/source/en/model_doc/bart.mdx b/docs/source/en/model_doc/bart.mdx
new file mode 100644
index 00000000000000..da13011bc43601
--- /dev/null
+++ b/docs/source/en/model_doc/bart.mdx
@@ -0,0 +1,159 @@
+
+
+# BART
+
+**DISCLAIMER:** If you see something strange, file a [Github Issue](https://github.com/huggingface/transformers/issues/new?assignees=&labels=&template=bug-report.md&title) and assign
+@patrickvonplaten
+
+## Overview
+
+The Bart model was proposed in [BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation,
+Translation, and Comprehension](https://arxiv.org/abs/1910.13461) by Mike Lewis, Yinhan Liu, Naman Goyal, Marjan
+Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov and Luke Zettlemoyer on 29 Oct, 2019.
+
+According to the abstract,
+
+- Bart uses a standard seq2seq/machine translation architecture with a bidirectional encoder (like BERT) and a
+ left-to-right decoder (like GPT).
+- The pretraining task involves randomly shuffling the order of the original sentences and a novel in-filling scheme,
+ where spans of text are replaced with a single mask token.
+- BART is particularly effective when fine tuned for text generation but also works well for comprehension tasks. It
+ matches the performance of RoBERTa with comparable training resources on GLUE and SQuAD, achieves new
+ state-of-the-art results on a range of abstractive dialogue, question answering, and summarization tasks, with gains
+ of up to 6 ROUGE.
+
+This model was contributed by [sshleifer](https://huggingface.co/sshleifer). The Authors' code can be found [here](https://github.com/pytorch/fairseq/tree/master/examples/bart).
+
+
+### Examples
+
+- Examples and scripts for fine-tuning BART and other models for sequence to sequence tasks can be found in
+ [examples/pytorch/summarization/](https://github.com/huggingface/transformers/tree/main/examples/pytorch/summarization/README.md).
+- An example of how to train [`BartForConditionalGeneration`] with a Hugging Face `datasets`
+ object can be found in this [forum discussion](https://discuss.huggingface.co/t/train-bart-for-conditional-generation-e-g-summarization/1904).
+- [Distilled checkpoints](https://huggingface.co/models?search=distilbart) are described in this [paper](https://arxiv.org/abs/2010.13002).
+
+
+## Implementation Notes
+
+- Bart doesn't use `token_type_ids` for sequence classification. Use [`BartTokenizer`] or
+ [`~BartTokenizer.encode`] to get the proper splitting.
+- The forward pass of [`BartModel`] will create the `decoder_input_ids` if they are not passed.
+ This is different than some other modeling APIs. A typical use case of this feature is mask filling.
+- Model predictions are intended to be identical to the original implementation when
+ `forced_bos_token_id=0`. This only works, however, if the string you pass to
+ [`fairseq.encode`] starts with a space.
+- [`~generation_utils.GenerationMixin.generate`] should be used for conditional generation tasks like
+ summarization, see the example in that docstrings.
+- Models that load the *facebook/bart-large-cnn* weights will not have a `mask_token_id`, or be able to perform
+ mask-filling tasks.
+
+## Mask Filling
+
+The `facebook/bart-base` and `facebook/bart-large` checkpoints can be used to fill multi-token masks.
+
+```python
+from transformers import BartForConditionalGeneration, BartTokenizer
+
+model = BartForConditionalGeneration.from_pretrained("facebook/bart-large", forced_bos_token_id=0)
+tok = BartTokenizer.from_pretrained("facebook/bart-large")
+example_english_phrase = "UN Chief Says There Is No in Syria"
+batch = tok(example_english_phrase, return_tensors="pt")
+generated_ids = model.generate(batch["input_ids"])
+assert tok.batch_decode(generated_ids, skip_special_tokens=True) == [
+ "UN Chief Says There Is No Plan to Stop Chemical Weapons in Syria"
+]
+```
+
+## BartConfig
+
+[[autodoc]] BartConfig
+ - all
+
+## BartTokenizer
+
+[[autodoc]] BartTokenizer
+ - all
+
+## BartTokenizerFast
+
+[[autodoc]] BartTokenizerFast
+ - all
+
+## BartModel
+
+[[autodoc]] BartModel
+ - forward
+
+## BartForConditionalGeneration
+
+[[autodoc]] BartForConditionalGeneration
+ - forward
+
+## BartForSequenceClassification
+
+[[autodoc]] BartForSequenceClassification
+ - forward
+
+## BartForQuestionAnswering
+
+[[autodoc]] BartForQuestionAnswering
+ - forward
+
+## BartForCausalLM
+
+[[autodoc]] BartForCausalLM
+ - forward
+
+## TFBartModel
+
+[[autodoc]] TFBartModel
+ - call
+
+## TFBartForConditionalGeneration
+
+[[autodoc]] TFBartForConditionalGeneration
+ - call
+
+## FlaxBartModel
+
+[[autodoc]] FlaxBartModel
+ - __call__
+ - encode
+ - decode
+
+## FlaxBartForConditionalGeneration
+
+[[autodoc]] FlaxBartForConditionalGeneration
+ - __call__
+ - encode
+ - decode
+
+## FlaxBartForSequenceClassification
+
+[[autodoc]] FlaxBartForSequenceClassification
+ - __call__
+ - encode
+ - decode
+
+## FlaxBartForQuestionAnswering
+
+[[autodoc]] FlaxBartForQuestionAnswering
+ - __call__
+ - encode
+ - decode
+
+## FlaxBartForCausalLM
+
+[[autodoc]] FlaxBartForCausalLM
+ - __call__
\ No newline at end of file
diff --git a/docs/source/en/model_doc/barthez.mdx b/docs/source/en/model_doc/barthez.mdx
new file mode 100644
index 00000000000000..f1969e8e942422
--- /dev/null
+++ b/docs/source/en/model_doc/barthez.mdx
@@ -0,0 +1,50 @@
+
+
+# BARThez
+
+## Overview
+
+The BARThez model was proposed in [BARThez: a Skilled Pretrained French Sequence-to-Sequence Model](https://arxiv.org/abs/2010.12321) by Moussa Kamal Eddine, Antoine J.-P. Tixier, Michalis Vazirgiannis on 23 Oct,
+2020.
+
+The abstract of the paper:
+
+
+*Inductive transfer learning, enabled by self-supervised learning, have taken the entire Natural Language Processing
+(NLP) field by storm, with models such as BERT and BART setting new state of the art on countless natural language
+understanding tasks. While there are some notable exceptions, most of the available models and research have been
+conducted for the English language. In this work, we introduce BARThez, the first BART model for the French language
+(to the best of our knowledge). BARThez was pretrained on a very large monolingual French corpus from past research
+that we adapted to suit BART's perturbation schemes. Unlike already existing BERT-based French language models such as
+CamemBERT and FlauBERT, BARThez is particularly well-suited for generative tasks, since not only its encoder but also
+its decoder is pretrained. In addition to discriminative tasks from the FLUE benchmark, we evaluate BARThez on a novel
+summarization dataset, OrangeSum, that we release with this paper. We also continue the pretraining of an already
+pretrained multilingual BART on BARThez's corpus, and we show that the resulting model, which we call mBARTHez,
+provides a significant boost over vanilla BARThez, and is on par with or outperforms CamemBERT and FlauBERT.*
+
+This model was contributed by [moussakam](https://huggingface.co/moussakam). The Authors' code can be found [here](https://github.com/moussaKam/BARThez).
+
+
+### Examples
+
+- BARThez can be fine-tuned on sequence-to-sequence tasks in a similar way as BART, check:
+ [examples/pytorch/summarization/](https://github.com/huggingface/transformers/tree/main/examples/pytorch/summarization/README.md).
+
+
+## BarthezTokenizer
+
+[[autodoc]] BarthezTokenizer
+
+## BarthezTokenizerFast
+
+[[autodoc]] BarthezTokenizerFast
diff --git a/docs/source/en/model_doc/bartpho.mdx b/docs/source/en/model_doc/bartpho.mdx
new file mode 100644
index 00000000000000..d940173b42f861
--- /dev/null
+++ b/docs/source/en/model_doc/bartpho.mdx
@@ -0,0 +1,82 @@
+
+
+# BARTpho
+
+## Overview
+
+The BARTpho model was proposed in [BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnamese](https://arxiv.org/abs/2109.09701) by Nguyen Luong Tran, Duong Minh Le and Dat Quoc Nguyen.
+
+The abstract from the paper is the following:
+
+*We present BARTpho with two versions -- BARTpho_word and BARTpho_syllable -- the first public large-scale monolingual
+sequence-to-sequence models pre-trained for Vietnamese. Our BARTpho uses the "large" architecture and pre-training
+scheme of the sequence-to-sequence denoising model BART, thus especially suitable for generative NLP tasks. Experiments
+on a downstream task of Vietnamese text summarization show that in both automatic and human evaluations, our BARTpho
+outperforms the strong baseline mBART and improves the state-of-the-art. We release BARTpho to facilitate future
+research and applications of generative Vietnamese NLP tasks.*
+
+Example of use:
+
+```python
+>>> import torch
+>>> from transformers import AutoModel, AutoTokenizer
+
+>>> bartpho = AutoModel.from_pretrained("vinai/bartpho-syllable")
+
+>>> tokenizer = AutoTokenizer.from_pretrained("vinai/bartpho-syllable")
+
+>>> line = "Chúng tôi là những nghiên cứu viên."
+
+>>> input_ids = tokenizer(line, return_tensors="pt")
+
+>>> with torch.no_grad():
+... features = bartpho(**input_ids) # Models outputs are now tuples
+
+>>> # With TensorFlow 2.0+:
+>>> from transformers import TFAutoModel
+
+>>> bartpho = TFAutoModel.from_pretrained("vinai/bartpho-syllable")
+>>> input_ids = tokenizer(line, return_tensors="tf")
+>>> features = bartpho(**input_ids)
+```
+
+Tips:
+
+- Following mBART, BARTpho uses the "large" architecture of BART with an additional layer-normalization layer on top of
+ both the encoder and decoder. Thus, usage examples in the [documentation of BART](bart), when adapting to use
+ with BARTpho, should be adjusted by replacing the BART-specialized classes with the mBART-specialized counterparts.
+ For example:
+
+```python
+>>> from transformers import MBartForConditionalGeneration
+
+>>> bartpho = MBartForConditionalGeneration.from_pretrained("vinai/bartpho-syllable")
+>>> TXT = "Chúng tôi là nghiên cứu viên."
+>>> input_ids = tokenizer([TXT], return_tensors="pt")["input_ids"]
+>>> logits = bartpho(input_ids).logits
+>>> masked_index = (input_ids[0] == tokenizer.mask_token_id).nonzero().item()
+>>> probs = logits[0, masked_index].softmax(dim=0)
+>>> values, predictions = probs.topk(5)
+>>> print(tokenizer.decode(predictions).split())
+```
+
+- This implementation is only for tokenization: "monolingual_vocab_file" consists of Vietnamese-specialized types
+ extracted from the pre-trained SentencePiece model "vocab_file" that is available from the multilingual XLM-RoBERTa.
+ Other languages, if employing this pre-trained multilingual SentencePiece model "vocab_file" for subword
+ segmentation, can reuse BartphoTokenizer with their own language-specialized "monolingual_vocab_file".
+
+This model was contributed by [dqnguyen](https://huggingface.co/dqnguyen). The original code can be found [here](https://github.com/VinAIResearch/BARTpho).
+
+## BartphoTokenizer
+
+[[autodoc]] BartphoTokenizer
diff --git a/docs/source/en/model_doc/beit.mdx b/docs/source/en/model_doc/beit.mdx
new file mode 100644
index 00000000000000..625357810ded9f
--- /dev/null
+++ b/docs/source/en/model_doc/beit.mdx
@@ -0,0 +1,114 @@
+
+
+# BEiT
+
+## Overview
+
+The BEiT model was proposed in [BEiT: BERT Pre-Training of Image Transformers](https://arxiv.org/abs/2106.08254) by
+Hangbo Bao, Li Dong and Furu Wei. Inspired by BERT, BEiT is the first paper that makes self-supervised pre-training of
+Vision Transformers (ViTs) outperform supervised pre-training. Rather than pre-training the model to predict the class
+of an image (as done in the [original ViT paper](https://arxiv.org/abs/2010.11929)), BEiT models are pre-trained to
+predict visual tokens from the codebook of OpenAI's [DALL-E model](https://arxiv.org/abs/2102.12092) given masked
+patches.
+
+The abstract from the paper is the following:
+
+*We introduce a self-supervised vision representation model BEiT, which stands for Bidirectional Encoder representation
+from Image Transformers. Following BERT developed in the natural language processing area, we propose a masked image
+modeling task to pretrain vision Transformers. Specifically, each image has two views in our pre-training, i.e, image
+patches (such as 16x16 pixels), and visual tokens (i.e., discrete tokens). We first "tokenize" the original image into
+visual tokens. Then we randomly mask some image patches and fed them into the backbone Transformer. The pre-training
+objective is to recover the original visual tokens based on the corrupted image patches. After pre-training BEiT, we
+directly fine-tune the model parameters on downstream tasks by appending task layers upon the pretrained encoder.
+Experimental results on image classification and semantic segmentation show that our model achieves competitive results
+with previous pre-training methods. For example, base-size BEiT achieves 83.2% top-1 accuracy on ImageNet-1K,
+significantly outperforming from-scratch DeiT training (81.8%) with the same setup. Moreover, large-size BEiT obtains
+86.3% only using ImageNet-1K, even outperforming ViT-L with supervised pre-training on ImageNet-22K (85.2%).*
+
+Tips:
+
+- BEiT models are regular Vision Transformers, but pre-trained in a self-supervised way rather than supervised. They
+ outperform both the [original model (ViT)](vit) as well as [Data-efficient Image Transformers (DeiT)](deit) when fine-tuned on ImageNet-1K and CIFAR-100. You can check out demo notebooks regarding inference as well as
+ fine-tuning on custom data [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/VisionTransformer) (you can just replace
+ [`ViTFeatureExtractor`] by [`BeitFeatureExtractor`] and
+ [`ViTForImageClassification`] by [`BeitForImageClassification`]).
+- There's also a demo notebook available which showcases how to combine DALL-E's image tokenizer with BEiT for
+ performing masked image modeling. You can find it [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/BEiT).
+- As the BEiT models expect each image to be of the same size (resolution), one can use
+ [`BeitFeatureExtractor`] to resize (or rescale) and normalize images for the model.
+- Both the patch resolution and image resolution used during pre-training or fine-tuning are reflected in the name of
+ each checkpoint. For example, `microsoft/beit-base-patch16-224` refers to a base-sized architecture with patch
+ resolution of 16x16 and fine-tuning resolution of 224x224. All checkpoints can be found on the [hub](https://huggingface.co/models?search=microsoft/beit).
+- The available checkpoints are either (1) pre-trained on [ImageNet-22k](http://www.image-net.org/) (a collection of
+ 14 million images and 22k classes) only, (2) also fine-tuned on ImageNet-22k or (3) also fine-tuned on [ImageNet-1k](http://www.image-net.org/challenges/LSVRC/2012/) (also referred to as ILSVRC 2012, a collection of 1.3 million
+ images and 1,000 classes).
+- BEiT uses relative position embeddings, inspired by the T5 model. During pre-training, the authors shared the
+ relative position bias among the several self-attention layers. During fine-tuning, each layer's relative position
+ bias is initialized with the shared relative position bias obtained after pre-training. Note that, if one wants to
+ pre-train a model from scratch, one needs to either set the `use_relative_position_bias` or the
+ `use_relative_position_bias` attribute of [`BeitConfig`] to `True` in order to add
+ position embeddings.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The JAX/FLAX version of this model was
+contributed by [kamalkraj](https://huggingface.co/kamalkraj). The original code can be found [here](https://github.com/microsoft/unilm/tree/master/beit).
+
+
+## BEiT specific outputs
+
+[[autodoc]] models.beit.modeling_beit.BeitModelOutputWithPooling
+
+[[autodoc]] models.beit.modeling_flax_beit.FlaxBeitModelOutputWithPooling
+
+## BeitConfig
+
+[[autodoc]] BeitConfig
+
+## BeitFeatureExtractor
+
+[[autodoc]] BeitFeatureExtractor
+ - __call__
+
+## BeitModel
+
+[[autodoc]] BeitModel
+ - forward
+
+## BeitForMaskedImageModeling
+
+[[autodoc]] BeitForMaskedImageModeling
+ - forward
+
+## BeitForImageClassification
+
+[[autodoc]] BeitForImageClassification
+ - forward
+
+## BeitForSemanticSegmentation
+
+[[autodoc]] BeitForSemanticSegmentation
+ - forward
+
+## FlaxBeitModel
+
+[[autodoc]] FlaxBeitModel
+ - __call__
+
+## FlaxBeitForMaskedImageModeling
+
+[[autodoc]] FlaxBeitForMaskedImageModeling
+ - __call__
+
+## FlaxBeitForImageClassification
+
+[[autodoc]] FlaxBeitForImageClassification
+ - __call__
diff --git a/docs/source/en/model_doc/bert-generation.mdx b/docs/source/en/model_doc/bert-generation.mdx
new file mode 100644
index 00000000000000..e300917ea5e6f7
--- /dev/null
+++ b/docs/source/en/model_doc/bert-generation.mdx
@@ -0,0 +1,104 @@
+
+
+# BertGeneration
+
+## Overview
+
+The BertGeneration model is a BERT model that can be leveraged for sequence-to-sequence tasks using
+[`EncoderDecoderModel`] as proposed in [Leveraging Pre-trained Checkpoints for Sequence Generation
+Tasks](https://arxiv.org/abs/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
+
+The abstract from the paper is the following:
+
+*Unsupervised pretraining of large neural models has recently revolutionized Natural Language Processing. By
+warm-starting from the publicly released checkpoints, NLP practitioners have pushed the state-of-the-art on multiple
+benchmarks while saving significant amounts of compute time. So far the focus has been mainly on the Natural Language
+Understanding tasks. In this paper, we demonstrate the efficacy of pre-trained checkpoints for Sequence Generation. We
+developed a Transformer-based sequence-to-sequence model that is compatible with publicly available pre-trained BERT,
+GPT-2 and RoBERTa checkpoints and conducted an extensive empirical study on the utility of initializing our model, both
+encoder and decoder, with these checkpoints. Our models result in new state-of-the-art results on Machine Translation,
+Text Summarization, Sentence Splitting, and Sentence Fusion.*
+
+Usage:
+
+- The model can be used in combination with the [`EncoderDecoderModel`] to leverage two pretrained
+ BERT checkpoints for subsequent fine-tuning.
+
+```python
+>>> # leverage checkpoints for Bert2Bert model...
+>>> # use BERT's cls token as BOS token and sep token as EOS token
+>>> encoder = BertGenerationEncoder.from_pretrained("bert-large-uncased", bos_token_id=101, eos_token_id=102)
+>>> # add cross attention layers and use BERT's cls token as BOS token and sep token as EOS token
+>>> decoder = BertGenerationDecoder.from_pretrained(
+... "bert-large-uncased", add_cross_attention=True, is_decoder=True, bos_token_id=101, eos_token_id=102
+... )
+>>> bert2bert = EncoderDecoderModel(encoder=encoder, decoder=decoder)
+
+>>> # create tokenizer...
+>>> tokenizer = BertTokenizer.from_pretrained("bert-large-uncased")
+
+>>> input_ids = tokenizer(
+... "This is a long article to summarize", add_special_tokens=False, return_tensors="pt"
+... ).input_ids
+>>> labels = tokenizer("This is a short summary", return_tensors="pt").input_ids
+
+>>> # train...
+>>> loss = bert2bert(input_ids=input_ids, decoder_input_ids=labels, labels=labels).loss
+>>> loss.backward()
+```
+
+- Pretrained [`EncoderDecoderModel`] are also directly available in the model hub, e.g.,
+
+
+```python
+>>> # instantiate sentence fusion model
+>>> sentence_fuser = EncoderDecoderModel.from_pretrained("google/roberta2roberta_L-24_discofuse")
+>>> tokenizer = AutoTokenizer.from_pretrained("google/roberta2roberta_L-24_discofuse")
+
+>>> input_ids = tokenizer(
+... "This is the first sentence. This is the second sentence.", add_special_tokens=False, return_tensors="pt"
+... ).input_ids
+
+>>> outputs = sentence_fuser.generate(input_ids)
+
+>>> print(tokenizer.decode(outputs[0]))
+```
+
+Tips:
+
+- [`BertGenerationEncoder`] and [`BertGenerationDecoder`] should be used in
+ combination with [`EncoderDecoder`].
+- For summarization, sentence splitting, sentence fusion and translation, no special tokens are required for the input.
+ Therefore, no EOS token should be added to the end of the input.
+
+This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten). The original code can be
+found [here](https://tfhub.dev/s?module-type=text-generation&subtype=module,placeholder).
+
+## BertGenerationConfig
+
+[[autodoc]] BertGenerationConfig
+
+## BertGenerationTokenizer
+
+[[autodoc]] BertGenerationTokenizer
+ - save_vocabulary
+
+## BertGenerationEncoder
+
+[[autodoc]] BertGenerationEncoder
+ - forward
+
+## BertGenerationDecoder
+
+[[autodoc]] BertGenerationDecoder
+ - forward
diff --git a/docs/source/en/model_doc/bert-japanese.mdx b/docs/source/en/model_doc/bert-japanese.mdx
new file mode 100644
index 00000000000000..312714b379e8f2
--- /dev/null
+++ b/docs/source/en/model_doc/bert-japanese.mdx
@@ -0,0 +1,74 @@
+
+
+# BertJapanese
+
+## Overview
+
+The BERT models trained on Japanese text.
+
+There are models with two different tokenization methods:
+
+- Tokenize with MeCab and WordPiece. This requires some extra dependencies, [fugashi](https://github.com/polm/fugashi) which is a wrapper around [MeCab](https://taku910.github.io/mecab/).
+- Tokenize into characters.
+
+To use *MecabTokenizer*, you should `pip install transformers["ja"]` (or `pip install -e .["ja"]` if you install
+from source) to install dependencies.
+
+See [details on cl-tohoku repository](https://github.com/cl-tohoku/bert-japanese).
+
+Example of using a model with MeCab and WordPiece tokenization:
+
+```python
+>>> import torch
+>>> from transformers import AutoModel, AutoTokenizer
+
+>>> bertjapanese = AutoModel.from_pretrained("cl-tohoku/bert-base-japanese")
+>>> tokenizer = AutoTokenizer.from_pretrained("cl-tohoku/bert-base-japanese")
+
+>>> ## Input Japanese Text
+>>> line = "吾輩は猫である。"
+
+>>> inputs = tokenizer(line, return_tensors="pt")
+
+>>> print(tokenizer.decode(inputs["input_ids"][0]))
+[CLS] 吾輩 は 猫 で ある 。 [SEP]
+
+>>> outputs = bertjapanese(**inputs)
+```
+
+Example of using a model with Character tokenization:
+
+```python
+>>> bertjapanese = AutoModel.from_pretrained("cl-tohoku/bert-base-japanese-char")
+>>> tokenizer = AutoTokenizer.from_pretrained("cl-tohoku/bert-base-japanese-char")
+
+>>> ## Input Japanese Text
+>>> line = "吾輩は猫である。"
+
+>>> inputs = tokenizer(line, return_tensors="pt")
+
+>>> print(tokenizer.decode(inputs["input_ids"][0]))
+[CLS] 吾 輩 は 猫 で あ る 。 [SEP]
+
+>>> outputs = bertjapanese(**inputs)
+```
+
+Tips:
+
+- This implementation is the same as BERT, except for tokenization method. Refer to the [documentation of BERT](bert) for more usage examples.
+
+This model was contributed by [cl-tohoku](https://huggingface.co/cl-tohoku).
+
+## BertJapaneseTokenizer
+
+[[autodoc]] BertJapaneseTokenizer
diff --git a/docs/source/en/model_doc/bert.mdx b/docs/source/en/model_doc/bert.mdx
new file mode 100644
index 00000000000000..4975346a7a52a5
--- /dev/null
+++ b/docs/source/en/model_doc/bert.mdx
@@ -0,0 +1,202 @@
+
+
+# BERT
+
+## Overview
+
+The BERT model was proposed in [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://arxiv.org/abs/1810.04805) by Jacob Devlin, Ming-Wei Chang, Kenton Lee and Kristina Toutanova. It's a
+bidirectional transformer pretrained using a combination of masked language modeling objective and next sentence
+prediction on a large corpus comprising the Toronto Book Corpus and Wikipedia.
+
+The abstract from the paper is the following:
+
+*We introduce a new language representation model called BERT, which stands for Bidirectional Encoder Representations
+from Transformers. Unlike recent language representation models, BERT is designed to pre-train deep bidirectional
+representations from unlabeled text by jointly conditioning on both left and right context in all layers. As a result,
+the pre-trained BERT model can be fine-tuned with just one additional output layer to create state-of-the-art models
+for a wide range of tasks, such as question answering and language inference, without substantial task-specific
+architecture modifications.*
+
+*BERT is conceptually simple and empirically powerful. It obtains new state-of-the-art results on eleven natural
+language processing tasks, including pushing the GLUE score to 80.5% (7.7% point absolute improvement), MultiNLI
+accuracy to 86.7% (4.6% absolute improvement), SQuAD v1.1 question answering Test F1 to 93.2 (1.5 point absolute
+improvement) and SQuAD v2.0 Test F1 to 83.1 (5.1 point absolute improvement).*
+
+Tips:
+
+- BERT is a model with absolute position embeddings so it's usually advised to pad the inputs on the right rather than
+ the left.
+- BERT was trained with the masked language modeling (MLM) and next sentence prediction (NSP) objectives. It is
+ efficient at predicting masked tokens and at NLU in general, but is not optimal for text generation.
+
+This model was contributed by [thomwolf](https://huggingface.co/thomwolf). The original code can be found [here](https://github.com/google-research/bert).
+
+## BertConfig
+
+[[autodoc]] BertConfig
+ - all
+
+## BertTokenizer
+
+[[autodoc]] BertTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## BertTokenizerFast
+
+[[autodoc]] BertTokenizerFast
+
+## Bert specific outputs
+
+[[autodoc]] models.bert.modeling_bert.BertForPreTrainingOutput
+
+[[autodoc]] models.bert.modeling_tf_bert.TFBertForPreTrainingOutput
+
+[[autodoc]] models.bert.modeling_flax_bert.FlaxBertForPreTrainingOutput
+
+## BertModel
+
+[[autodoc]] BertModel
+ - forward
+
+## BertForPreTraining
+
+[[autodoc]] BertForPreTraining
+ - forward
+
+## BertLMHeadModel
+
+[[autodoc]] BertLMHeadModel
+ - forward
+
+## BertForMaskedLM
+
+[[autodoc]] BertForMaskedLM
+ - forward
+
+## BertForNextSentencePrediction
+
+[[autodoc]] BertForNextSentencePrediction
+ - forward
+
+## BertForSequenceClassification
+
+[[autodoc]] BertForSequenceClassification
+ - forward
+
+## BertForMultipleChoice
+
+[[autodoc]] BertForMultipleChoice
+ - forward
+
+## BertForTokenClassification
+
+[[autodoc]] BertForTokenClassification
+ - forward
+
+## BertForQuestionAnswering
+
+[[autodoc]] BertForQuestionAnswering
+ - forward
+
+## TFBertModel
+
+[[autodoc]] TFBertModel
+ - call
+
+## TFBertForPreTraining
+
+[[autodoc]] TFBertForPreTraining
+ - call
+
+## TFBertModelLMHeadModel
+
+[[autodoc]] TFBertLMHeadModel
+ - call
+
+## TFBertForMaskedLM
+
+[[autodoc]] TFBertForMaskedLM
+ - call
+
+## TFBertForNextSentencePrediction
+
+[[autodoc]] TFBertForNextSentencePrediction
+ - call
+
+## TFBertForSequenceClassification
+
+[[autodoc]] TFBertForSequenceClassification
+ - call
+
+## TFBertForMultipleChoice
+
+[[autodoc]] TFBertForMultipleChoice
+ - call
+
+## TFBertForTokenClassification
+
+[[autodoc]] TFBertForTokenClassification
+ - call
+
+## TFBertForQuestionAnswering
+
+[[autodoc]] TFBertForQuestionAnswering
+ - call
+
+## FlaxBertModel
+
+[[autodoc]] FlaxBertModel
+ - __call__
+
+## FlaxBertForPreTraining
+
+[[autodoc]] FlaxBertForPreTraining
+ - __call__
+
+## FlaxBertForCausalLM
+
+[[autodoc]] FlaxBertForCausalLM
+ - __call__
+
+## FlaxBertForMaskedLM
+
+[[autodoc]] FlaxBertForMaskedLM
+ - __call__
+
+## FlaxBertForNextSentencePrediction
+
+[[autodoc]] FlaxBertForNextSentencePrediction
+ - __call__
+
+## FlaxBertForSequenceClassification
+
+[[autodoc]] FlaxBertForSequenceClassification
+ - __call__
+
+## FlaxBertForMultipleChoice
+
+[[autodoc]] FlaxBertForMultipleChoice
+ - __call__
+
+## FlaxBertForTokenClassification
+
+[[autodoc]] FlaxBertForTokenClassification
+ - __call__
+
+## FlaxBertForQuestionAnswering
+
+[[autodoc]] FlaxBertForQuestionAnswering
+ - __call__
diff --git a/docs/source/en/model_doc/bertweet.mdx b/docs/source/en/model_doc/bertweet.mdx
new file mode 100644
index 00000000000000..df55360646f931
--- /dev/null
+++ b/docs/source/en/model_doc/bertweet.mdx
@@ -0,0 +1,58 @@
+
+
+# BERTweet
+
+## Overview
+
+The BERTweet model was proposed in [BERTweet: A pre-trained language model for English Tweets](https://www.aclweb.org/anthology/2020.emnlp-demos.2.pdf) by Dat Quoc Nguyen, Thanh Vu, Anh Tuan Nguyen.
+
+The abstract from the paper is the following:
+
+*We present BERTweet, the first public large-scale pre-trained language model for English Tweets. Our BERTweet, having
+the same architecture as BERT-base (Devlin et al., 2019), is trained using the RoBERTa pre-training procedure (Liu et
+al., 2019). Experiments show that BERTweet outperforms strong baselines RoBERTa-base and XLM-R-base (Conneau et al.,
+2020), producing better performance results than the previous state-of-the-art models on three Tweet NLP tasks:
+Part-of-speech tagging, Named-entity recognition and text classification.*
+
+Example of use:
+
+```python
+>>> import torch
+>>> from transformers import AutoModel, AutoTokenizer
+
+>>> bertweet = AutoModel.from_pretrained("vinai/bertweet-base")
+
+>>> # For transformers v4.x+:
+>>> tokenizer = AutoTokenizer.from_pretrained("vinai/bertweet-base", use_fast=False)
+
+>>> # For transformers v3.x:
+>>> # tokenizer = AutoTokenizer.from_pretrained("vinai/bertweet-base")
+
+>>> # INPUT TWEET IS ALREADY NORMALIZED!
+>>> line = "SC has first two presumptive cases of coronavirus , DHEC confirms HTTPURL via @USER :cry:"
+
+>>> input_ids = torch.tensor([tokenizer.encode(line)])
+
+>>> with torch.no_grad():
+... features = bertweet(input_ids) # Models outputs are now tuples
+
+>>> # With TensorFlow 2.0+:
+>>> # from transformers import TFAutoModel
+>>> # bertweet = TFAutoModel.from_pretrained("vinai/bertweet-base")
+```
+
+This model was contributed by [dqnguyen](https://huggingface.co/dqnguyen). The original code can be found [here](https://github.com/VinAIResearch/BERTweet).
+
+## BertweetTokenizer
+
+[[autodoc]] BertweetTokenizer
diff --git a/docs/source/en/model_doc/big_bird.mdx b/docs/source/en/model_doc/big_bird.mdx
new file mode 100644
index 00000000000000..0e1e6ac53ec300
--- /dev/null
+++ b/docs/source/en/model_doc/big_bird.mdx
@@ -0,0 +1,151 @@
+
+
+# BigBird
+
+## Overview
+
+The BigBird model was proposed in [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) by
+Zaheer, Manzil and Guruganesh, Guru and Dubey, Kumar Avinava and Ainslie, Joshua and Alberti, Chris and Ontanon,
+Santiago and Pham, Philip and Ravula, Anirudh and Wang, Qifan and Yang, Li and others. BigBird, is a sparse-attention
+based transformer which extends Transformer based models, such as BERT to much longer sequences. In addition to sparse
+attention, BigBird also applies global attention as well as random attention to the input sequence. Theoretically, it
+has been shown that applying sparse, global, and random attention approximates full attention, while being
+computationally much more efficient for longer sequences. As a consequence of the capability to handle longer context,
+BigBird has shown improved performance on various long document NLP tasks, such as question answering and
+summarization, compared to BERT or RoBERTa.
+
+The abstract from the paper is the following:
+
+*Transformers-based models, such as BERT, have been one of the most successful deep learning models for NLP.
+Unfortunately, one of their core limitations is the quadratic dependency (mainly in terms of memory) on the sequence
+length due to their full attention mechanism. To remedy this, we propose, BigBird, a sparse attention mechanism that
+reduces this quadratic dependency to linear. We show that BigBird is a universal approximator of sequence functions and
+is Turing complete, thereby preserving these properties of the quadratic, full attention model. Along the way, our
+theoretical analysis reveals some of the benefits of having O(1) global tokens (such as CLS), that attend to the entire
+sequence as part of the sparse attention mechanism. The proposed sparse attention can handle sequences of length up to
+8x of what was previously possible using similar hardware. As a consequence of the capability to handle longer context,
+BigBird drastically improves performance on various NLP tasks such as question answering and summarization. We also
+propose novel applications to genomics data.*
+
+Tips:
+
+- For an in-detail explanation on how BigBird's attention works, see [this blog post](https://huggingface.co/blog/big-bird).
+- BigBird comes with 2 implementations: **original_full** & **block_sparse**. For the sequence length < 1024, using
+ **original_full** is advised as there is no benefit in using **block_sparse** attention.
+- The code currently uses window size of 3 blocks and 2 global blocks.
+- Sequence length must be divisible by block size.
+- Current implementation supports only **ITC**.
+- Current implementation doesn't support **num_random_blocks = 0**
+
+This model was contributed by [vasudevgupta](https://huggingface.co/vasudevgupta). The original code can be found
+[here](https://github.com/google-research/bigbird).
+
+## BigBirdConfig
+
+[[autodoc]] BigBirdConfig
+
+## BigBirdTokenizer
+
+[[autodoc]] BigBirdTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## BigBirdTokenizerFast
+
+[[autodoc]] BigBirdTokenizerFast
+
+## BigBird specific outputs
+
+[[autodoc]] models.big_bird.modeling_big_bird.BigBirdForPreTrainingOutput
+
+## BigBirdModel
+
+[[autodoc]] BigBirdModel
+ - forward
+
+## BigBirdForPreTraining
+
+[[autodoc]] BigBirdForPreTraining
+ - forward
+
+## BigBirdForCausalLM
+
+[[autodoc]] BigBirdForCausalLM
+ - forward
+
+## BigBirdForMaskedLM
+
+[[autodoc]] BigBirdForMaskedLM
+ - forward
+
+## BigBirdForSequenceClassification
+
+[[autodoc]] BigBirdForSequenceClassification
+ - forward
+
+## BigBirdForMultipleChoice
+
+[[autodoc]] BigBirdForMultipleChoice
+ - forward
+
+## BigBirdForTokenClassification
+
+[[autodoc]] BigBirdForTokenClassification
+ - forward
+
+## BigBirdForQuestionAnswering
+
+[[autodoc]] BigBirdForQuestionAnswering
+ - forward
+
+## FlaxBigBirdModel
+
+[[autodoc]] FlaxBigBirdModel
+ - __call__
+
+## FlaxBigBirdForPreTraining
+
+[[autodoc]] FlaxBigBirdForPreTraining
+ - __call__
+
+## FlaxBigBirdForCausalLM
+
+[[autodoc]] FlaxBigBirdForCausalLM
+ - __call__
+
+## FlaxBigBirdForMaskedLM
+
+[[autodoc]] FlaxBigBirdForMaskedLM
+ - __call__
+
+## FlaxBigBirdForSequenceClassification
+
+[[autodoc]] FlaxBigBirdForSequenceClassification
+ - __call__
+
+## FlaxBigBirdForMultipleChoice
+
+[[autodoc]] FlaxBigBirdForMultipleChoice
+ - __call__
+
+## FlaxBigBirdForTokenClassification
+
+[[autodoc]] FlaxBigBirdForTokenClassification
+ - __call__
+
+## FlaxBigBirdForQuestionAnswering
+
+[[autodoc]] FlaxBigBirdForQuestionAnswering
+ - __call__
diff --git a/docs/source/en/model_doc/bigbird_pegasus.mdx b/docs/source/en/model_doc/bigbird_pegasus.mdx
new file mode 100644
index 00000000000000..50ef4720e3ec10
--- /dev/null
+++ b/docs/source/en/model_doc/bigbird_pegasus.mdx
@@ -0,0 +1,81 @@
+
+
+# BigBirdPegasus
+
+## Overview
+
+The BigBird model was proposed in [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) by
+Zaheer, Manzil and Guruganesh, Guru and Dubey, Kumar Avinava and Ainslie, Joshua and Alberti, Chris and Ontanon,
+Santiago and Pham, Philip and Ravula, Anirudh and Wang, Qifan and Yang, Li and others. BigBird, is a sparse-attention
+based transformer which extends Transformer based models, such as BERT to much longer sequences. In addition to sparse
+attention, BigBird also applies global attention as well as random attention to the input sequence. Theoretically, it
+has been shown that applying sparse, global, and random attention approximates full attention, while being
+computationally much more efficient for longer sequences. As a consequence of the capability to handle longer context,
+BigBird has shown improved performance on various long document NLP tasks, such as question answering and
+summarization, compared to BERT or RoBERTa.
+
+The abstract from the paper is the following:
+
+*Transformers-based models, such as BERT, have been one of the most successful deep learning models for NLP.
+Unfortunately, one of their core limitations is the quadratic dependency (mainly in terms of memory) on the sequence
+length due to their full attention mechanism. To remedy this, we propose, BigBird, a sparse attention mechanism that
+reduces this quadratic dependency to linear. We show that BigBird is a universal approximator of sequence functions and
+is Turing complete, thereby preserving these properties of the quadratic, full attention model. Along the way, our
+theoretical analysis reveals some of the benefits of having O(1) global tokens (such as CLS), that attend to the entire
+sequence as part of the sparse attention mechanism. The proposed sparse attention can handle sequences of length up to
+8x of what was previously possible using similar hardware. As a consequence of the capability to handle longer context,
+BigBird drastically improves performance on various NLP tasks such as question answering and summarization. We also
+propose novel applications to genomics data.*
+
+Tips:
+
+- For an in-detail explanation on how BigBird's attention works, see [this blog post](https://huggingface.co/blog/big-bird).
+- BigBird comes with 2 implementations: **original_full** & **block_sparse**. For the sequence length < 1024, using
+ **original_full** is advised as there is no benefit in using **block_sparse** attention.
+- The code currently uses window size of 3 blocks and 2 global blocks.
+- Sequence length must be divisible by block size.
+- Current implementation supports only **ITC**.
+- Current implementation doesn't support **num_random_blocks = 0**.
+- BigBirdPegasus uses the [PegasusTokenizer](https://github.com/huggingface/transformers/blob/main/src/transformers/models/pegasus/tokenization_pegasus.py).
+
+The original code can be found [here](https://github.com/google-research/bigbird).
+
+## BigBirdPegasusConfig
+
+[[autodoc]] BigBirdPegasusConfig
+ - all
+
+## BigBirdPegasusModel
+
+[[autodoc]] BigBirdPegasusModel
+ - forward
+
+## BigBirdPegasusForConditionalGeneration
+
+[[autodoc]] BigBirdPegasusForConditionalGeneration
+ - forward
+
+## BigBirdPegasusForSequenceClassification
+
+[[autodoc]] BigBirdPegasusForSequenceClassification
+ - forward
+
+## BigBirdPegasusForQuestionAnswering
+
+[[autodoc]] BigBirdPegasusForQuestionAnswering
+ - forward
+
+## BigBirdPegasusForCausalLM
+
+[[autodoc]] BigBirdPegasusForCausalLM
+ - forward
diff --git a/docs/source/en/model_doc/blenderbot-small.mdx b/docs/source/en/model_doc/blenderbot-small.mdx
new file mode 100644
index 00000000000000..2b762838c4c7d5
--- /dev/null
+++ b/docs/source/en/model_doc/blenderbot-small.mdx
@@ -0,0 +1,95 @@
+
+
+# Blenderbot Small
+
+Note that [`BlenderbotSmallModel`] and
+[`BlenderbotSmallForConditionalGeneration`] are only used in combination with the checkpoint
+[facebook/blenderbot-90M](https://huggingface.co/facebook/blenderbot-90M). Larger Blenderbot checkpoints should
+instead be used with [`BlenderbotModel`] and
+[`BlenderbotForConditionalGeneration`]
+
+## Overview
+
+The Blender chatbot model was proposed in [Recipes for building an open-domain chatbot](https://arxiv.org/pdf/2004.13637.pdf) Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu,
+Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston on 30 Apr 2020.
+
+The abstract of the paper is the following:
+
+*Building open-domain chatbots is a challenging area for machine learning research. While prior work has shown that
+scaling neural models in the number of parameters and the size of the data they are trained on gives improved results,
+we show that other ingredients are important for a high-performing chatbot. Good conversation requires a number of
+skills that an expert conversationalist blends in a seamless way: providing engaging talking points and listening to
+their partners, and displaying knowledge, empathy and personality appropriately, while maintaining a consistent
+persona. We show that large scale models can learn these skills when given appropriate training data and choice of
+generation strategy. We build variants of these recipes with 90M, 2.7B and 9.4B parameter models, and make our models
+and code publicly available. Human evaluations show our best models are superior to existing approaches in multi-turn
+dialogue in terms of engagingness and humanness measurements. We then discuss the limitations of this work by analyzing
+failure cases of our models.*
+
+This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten). The authors' code can be
+found [here](https://github.com/facebookresearch/ParlAI) .
+
+## BlenderbotSmallConfig
+
+[[autodoc]] BlenderbotSmallConfig
+
+## BlenderbotSmallTokenizer
+
+[[autodoc]] BlenderbotSmallTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## BlenderbotSmallTokenizerFast
+
+[[autodoc]] BlenderbotSmallTokenizerFast
+
+## BlenderbotSmallModel
+
+[[autodoc]] BlenderbotSmallModel
+ - forward
+
+## BlenderbotSmallForConditionalGeneration
+
+[[autodoc]] BlenderbotSmallForConditionalGeneration
+ - forward
+
+## BlenderbotSmallForCausalLM
+
+[[autodoc]] BlenderbotSmallForCausalLM
+ - forward
+
+## TFBlenderbotSmallModel
+
+[[autodoc]] TFBlenderbotSmallModel
+ - call
+
+## TFBlenderbotSmallForConditionalGeneration
+
+[[autodoc]] TFBlenderbotSmallForConditionalGeneration
+ - call
+
+## FlaxBlenderbotSmallModel
+
+[[autodoc]] FlaxBlenderbotSmallModel
+ - __call__
+ - encode
+ - decode
+
+## FlaxBlenderbotForConditionalGeneration
+
+[[autodoc]] FlaxBlenderbotSmallForConditionalGeneration
+ - __call__
+ - encode
+ - decode
diff --git a/docs/source/en/model_doc/blenderbot.mdx b/docs/source/en/model_doc/blenderbot.mdx
new file mode 100644
index 00000000000000..97cbd62e57d151
--- /dev/null
+++ b/docs/source/en/model_doc/blenderbot.mdx
@@ -0,0 +1,119 @@
+
+
+# Blenderbot
+
+**DISCLAIMER:** If you see something strange, file a [Github Issue](https://github.com/huggingface/transformers/issues/new?assignees=&labels=&template=bug-report.md&title) .
+
+## Overview
+
+The Blender chatbot model was proposed in [Recipes for building an open-domain chatbot](https://arxiv.org/pdf/2004.13637.pdf) Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu,
+Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston on 30 Apr 2020.
+
+The abstract of the paper is the following:
+
+*Building open-domain chatbots is a challenging area for machine learning research. While prior work has shown that
+scaling neural models in the number of parameters and the size of the data they are trained on gives improved results,
+we show that other ingredients are important for a high-performing chatbot. Good conversation requires a number of
+skills that an expert conversationalist blends in a seamless way: providing engaging talking points and listening to
+their partners, and displaying knowledge, empathy and personality appropriately, while maintaining a consistent
+persona. We show that large scale models can learn these skills when given appropriate training data and choice of
+generation strategy. We build variants of these recipes with 90M, 2.7B and 9.4B parameter models, and make our models
+and code publicly available. Human evaluations show our best models are superior to existing approaches in multi-turn
+dialogue in terms of engagingness and humanness measurements. We then discuss the limitations of this work by analyzing
+failure cases of our models.*
+
+This model was contributed by [sshleifer](https://huggingface.co/sshleifer). The authors' code can be found [here](https://github.com/facebookresearch/ParlAI) .
+
+
+## Implementation Notes
+
+- Blenderbot uses a standard [seq2seq model transformer](https://arxiv.org/pdf/1706.03762.pdf) based architecture.
+- Available checkpoints can be found in the [model hub](https://huggingface.co/models?search=blenderbot).
+- This is the *default* Blenderbot model class. However, some smaller checkpoints, such as
+ `facebook/blenderbot_small_90M`, have a different architecture and consequently should be used with
+ [BlenderbotSmall](blenderbot-small).
+
+
+## Usage
+
+Here is an example of model usage:
+
+```python
+>>> from transformers import BlenderbotTokenizer, BlenderbotForConditionalGeneration
+
+>>> mname = "facebook/blenderbot-400M-distill"
+>>> model = BlenderbotForConditionalGeneration.from_pretrained(mname)
+>>> tokenizer = BlenderbotTokenizer.from_pretrained(mname)
+>>> UTTERANCE = "My friends are cool but they eat too many carbs."
+>>> inputs = tokenizer([UTTERANCE], return_tensors="pt")
+>>> reply_ids = model.generate(**inputs)
+>>> print(tokenizer.batch_decode(reply_ids))
+["
+
+[[autodoc]] get_polynomial_decay_schedule_with_warmup
+
+### Warmup (TensorFlow)
+
+[[autodoc]] WarmUp
+
+## Gradient Strategies
+
+### GradientAccumulator (TensorFlow)
+
+[[autodoc]] GradientAccumulator
diff --git a/docs/source/en/main_classes/output.mdx b/docs/source/en/main_classes/output.mdx
new file mode 100644
index 00000000000000..efca867a0435aa
--- /dev/null
+++ b/docs/source/en/main_classes/output.mdx
@@ -0,0 +1,269 @@
+
+
+# Model outputs
+
+All models have outputs that are instances of subclasses of [`~utils.ModelOutput`]. Those are
+data structures containing all the information returned by the model, but that can also be used as tuples or
+dictionaries.
+
+Let's see of this looks on an example:
+
+```python
+from transformers import BertTokenizer, BertForSequenceClassification
+import torch
+
+tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
+model = BertForSequenceClassification.from_pretrained("bert-base-uncased")
+
+inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
+labels = torch.tensor([1]).unsqueeze(0) # Batch size 1
+outputs = model(**inputs, labels=labels)
+```
+
+The `outputs` object is a [`~modeling_outputs.SequenceClassifierOutput`], as we can see in the
+documentation of that class below, it means it has an optional `loss`, a `logits` an optional `hidden_states` and
+an optional `attentions` attribute. Here we have the `loss` since we passed along `labels`, but we don't have
+`hidden_states` and `attentions` because we didn't pass `output_hidden_states=True` or
+`output_attentions=True`.
+
+You can access each attribute as you would usually do, and if that attribute has not been returned by the model, you
+will get `None`. Here for instance `outputs.loss` is the loss computed by the model, and `outputs.attentions` is
+`None`.
+
+When considering our `outputs` object as tuple, it only considers the attributes that don't have `None` values.
+Here for instance, it has two elements, `loss` then `logits`, so
+
+```python
+outputs[:2]
+```
+
+will return the tuple `(outputs.loss, outputs.logits)` for instance.
+
+When considering our `outputs` object as dictionary, it only considers the attributes that don't have `None`
+values. Here for instance, it has two keys that are `loss` and `logits`.
+
+We document here the generic model outputs that are used by more than one model type. Specific output types are
+documented on their corresponding model page.
+
+## ModelOutput
+
+[[autodoc]] utils.ModelOutput
+ - to_tuple
+
+## BaseModelOutput
+
+[[autodoc]] modeling_outputs.BaseModelOutput
+
+## BaseModelOutputWithPooling
+
+[[autodoc]] modeling_outputs.BaseModelOutputWithPooling
+
+## BaseModelOutputWithCrossAttentions
+
+[[autodoc]] modeling_outputs.BaseModelOutputWithCrossAttentions
+
+## BaseModelOutputWithPoolingAndCrossAttentions
+
+[[autodoc]] modeling_outputs.BaseModelOutputWithPoolingAndCrossAttentions
+
+## BaseModelOutputWithPast
+
+[[autodoc]] modeling_outputs.BaseModelOutputWithPast
+
+## BaseModelOutputWithPastAndCrossAttentions
+
+[[autodoc]] modeling_outputs.BaseModelOutputWithPastAndCrossAttentions
+
+## Seq2SeqModelOutput
+
+[[autodoc]] modeling_outputs.Seq2SeqModelOutput
+
+## CausalLMOutput
+
+[[autodoc]] modeling_outputs.CausalLMOutput
+
+## CausalLMOutputWithCrossAttentions
+
+[[autodoc]] modeling_outputs.CausalLMOutputWithCrossAttentions
+
+## CausalLMOutputWithPast
+
+[[autodoc]] modeling_outputs.CausalLMOutputWithPast
+
+## MaskedLMOutput
+
+[[autodoc]] modeling_outputs.MaskedLMOutput
+
+## Seq2SeqLMOutput
+
+[[autodoc]] modeling_outputs.Seq2SeqLMOutput
+
+## NextSentencePredictorOutput
+
+[[autodoc]] modeling_outputs.NextSentencePredictorOutput
+
+## SequenceClassifierOutput
+
+[[autodoc]] modeling_outputs.SequenceClassifierOutput
+
+## Seq2SeqSequenceClassifierOutput
+
+[[autodoc]] modeling_outputs.Seq2SeqSequenceClassifierOutput
+
+## MultipleChoiceModelOutput
+
+[[autodoc]] modeling_outputs.MultipleChoiceModelOutput
+
+## TokenClassifierOutput
+
+[[autodoc]] modeling_outputs.TokenClassifierOutput
+
+## QuestionAnsweringModelOutput
+
+[[autodoc]] modeling_outputs.QuestionAnsweringModelOutput
+
+## Seq2SeqQuestionAnsweringModelOutput
+
+[[autodoc]] modeling_outputs.Seq2SeqQuestionAnsweringModelOutput
+
+## TFBaseModelOutput
+
+[[autodoc]] modeling_tf_outputs.TFBaseModelOutput
+
+## TFBaseModelOutputWithPooling
+
+[[autodoc]] modeling_tf_outputs.TFBaseModelOutputWithPooling
+
+## TFBaseModelOutputWithPoolingAndCrossAttentions
+
+[[autodoc]] modeling_tf_outputs.TFBaseModelOutputWithPoolingAndCrossAttentions
+
+## TFBaseModelOutputWithPast
+
+[[autodoc]] modeling_tf_outputs.TFBaseModelOutputWithPast
+
+## TFBaseModelOutputWithPastAndCrossAttentions
+
+[[autodoc]] modeling_tf_outputs.TFBaseModelOutputWithPastAndCrossAttentions
+
+## TFSeq2SeqModelOutput
+
+[[autodoc]] modeling_tf_outputs.TFSeq2SeqModelOutput
+
+## TFCausalLMOutput
+
+[[autodoc]] modeling_tf_outputs.TFCausalLMOutput
+
+## TFCausalLMOutputWithCrossAttentions
+
+[[autodoc]] modeling_tf_outputs.TFCausalLMOutputWithCrossAttentions
+
+## TFCausalLMOutputWithPast
+
+[[autodoc]] modeling_tf_outputs.TFCausalLMOutputWithPast
+
+## TFMaskedLMOutput
+
+[[autodoc]] modeling_tf_outputs.TFMaskedLMOutput
+
+## TFSeq2SeqLMOutput
+
+[[autodoc]] modeling_tf_outputs.TFSeq2SeqLMOutput
+
+## TFNextSentencePredictorOutput
+
+[[autodoc]] modeling_tf_outputs.TFNextSentencePredictorOutput
+
+## TFSequenceClassifierOutput
+
+[[autodoc]] modeling_tf_outputs.TFSequenceClassifierOutput
+
+## TFSeq2SeqSequenceClassifierOutput
+
+[[autodoc]] modeling_tf_outputs.TFSeq2SeqSequenceClassifierOutput
+
+## TFMultipleChoiceModelOutput
+
+[[autodoc]] modeling_tf_outputs.TFMultipleChoiceModelOutput
+
+## TFTokenClassifierOutput
+
+[[autodoc]] modeling_tf_outputs.TFTokenClassifierOutput
+
+## TFQuestionAnsweringModelOutput
+
+[[autodoc]] modeling_tf_outputs.TFQuestionAnsweringModelOutput
+
+## TFSeq2SeqQuestionAnsweringModelOutput
+
+[[autodoc]] modeling_tf_outputs.TFSeq2SeqQuestionAnsweringModelOutput
+
+## FlaxBaseModelOutput
+
+[[autodoc]] modeling_flax_outputs.FlaxBaseModelOutput
+
+## FlaxBaseModelOutputWithPast
+
+[[autodoc]] modeling_flax_outputs.FlaxBaseModelOutputWithPast
+
+## FlaxBaseModelOutputWithPooling
+
+[[autodoc]] modeling_flax_outputs.FlaxBaseModelOutputWithPooling
+
+## FlaxBaseModelOutputWithPastAndCrossAttentions
+
+[[autodoc]] modeling_flax_outputs.FlaxBaseModelOutputWithPastAndCrossAttentions
+
+## FlaxSeq2SeqModelOutput
+
+[[autodoc]] modeling_flax_outputs.FlaxSeq2SeqModelOutput
+
+## FlaxCausalLMOutputWithCrossAttentions
+
+[[autodoc]] modeling_flax_outputs.FlaxCausalLMOutputWithCrossAttentions
+
+## FlaxMaskedLMOutput
+
+[[autodoc]] modeling_flax_outputs.FlaxMaskedLMOutput
+
+## FlaxSeq2SeqLMOutput
+
+[[autodoc]] modeling_flax_outputs.FlaxSeq2SeqLMOutput
+
+## FlaxNextSentencePredictorOutput
+
+[[autodoc]] modeling_flax_outputs.FlaxNextSentencePredictorOutput
+
+## FlaxSequenceClassifierOutput
+
+[[autodoc]] modeling_flax_outputs.FlaxSequenceClassifierOutput
+
+## FlaxSeq2SeqSequenceClassifierOutput
+
+[[autodoc]] modeling_flax_outputs.FlaxSeq2SeqSequenceClassifierOutput
+
+## FlaxMultipleChoiceModelOutput
+
+[[autodoc]] modeling_flax_outputs.FlaxMultipleChoiceModelOutput
+
+## FlaxTokenClassifierOutput
+
+[[autodoc]] modeling_flax_outputs.FlaxTokenClassifierOutput
+
+## FlaxQuestionAnsweringModelOutput
+
+[[autodoc]] modeling_flax_outputs.FlaxQuestionAnsweringModelOutput
+
+## FlaxSeq2SeqQuestionAnsweringModelOutput
+
+[[autodoc]] modeling_flax_outputs.FlaxSeq2SeqQuestionAnsweringModelOutput
diff --git a/docs/source/en/main_classes/pipelines.mdx b/docs/source/en/main_classes/pipelines.mdx
new file mode 100644
index 00000000000000..af82d16750120e
--- /dev/null
+++ b/docs/source/en/main_classes/pipelines.mdx
@@ -0,0 +1,440 @@
+
+
+# Pipelines
+
+The pipelines are a great and easy way to use models for inference. These pipelines are objects that abstract most of
+the complex code from the library, offering a simple API dedicated to several tasks, including Named Entity
+Recognition, Masked Language Modeling, Sentiment Analysis, Feature Extraction and Question Answering. See the
+[task summary](../task_summary) for examples of use.
+
+There are two categories of pipeline abstractions to be aware about:
+
+- The [`pipeline`] which is the most powerful object encapsulating all other pipelines.
+- The other task-specific pipelines:
+
+ - [`AudioClassificationPipeline`]
+ - [`AutomaticSpeechRecognitionPipeline`]
+ - [`ConversationalPipeline`]
+ - [`FeatureExtractionPipeline`]
+ - [`FillMaskPipeline`]
+ - [`ImageClassificationPipeline`]
+ - [`ImageSegmentationPipeline`]
+ - [`ObjectDetectionPipeline`]
+ - [`QuestionAnsweringPipeline`]
+ - [`SummarizationPipeline`]
+ - [`TableQuestionAnsweringPipeline`]
+ - [`TextClassificationPipeline`]
+ - [`TextGenerationPipeline`]
+ - [`Text2TextGenerationPipeline`]
+ - [`TokenClassificationPipeline`]
+ - [`TranslationPipeline`]
+ - [`ZeroShotClassificationPipeline`]
+ - [`ZeroShotImageClassificationPipeline`]
+
+## The pipeline abstraction
+
+The *pipeline* abstraction is a wrapper around all the other available pipelines. It is instantiated as any other
+pipeline but can provide additional quality of life.
+
+Simple call on one item:
+
+```python
+>>> pipe = pipeline("text-classification")
+>>> pipe("This restaurant is awesome")
+[{'label': 'POSITIVE', 'score': 0.9998743534088135}]
+```
+
+If you want to use a specific model from the [hub](https://huggingface.co) you can ignore the task if the model on
+the hub already defines it:
+
+```python
+>>> pipe = pipeline(model="roberta-large-mnli")
+>>> pipe("This restaurant is awesome")
+[{'label': 'POSITIVE', 'score': 0.9998743534088135}]
+```
+
+To call a pipeline on many items, you can either call with a *list*.
+
+```python
+>>> pipe = pipeline("text-classification")
+>>> pipe(["This restaurant is awesome", "This restaurant is aweful"])
+[{'label': 'POSITIVE', 'score': 0.9998743534088135},
+ {'label': 'NEGATIVE', 'score': 0.9996669292449951}]
+```
+
+To iterate of full datasets it is recommended to use a `dataset` directly. This means you don't need to allocate
+the whole dataset at once, nor do you need to do batching yourself. This should work just as fast as custom loops on
+GPU. If it doesn't don't hesitate to create an issue.
+
+```python
+import datasets
+from transformers import pipeline
+from transformers.pipelines.pt_utils import KeyDataset
+from tqdm.auto import tqdm
+
+pipe = pipeline("automatic-speech-recognition", model="facebook/wav2vec2-base-960h", device=0)
+dataset = datasets.load_dataset("superb", name="asr", split="test")
+
+# KeyDataset (only *pt*) will simply return the item in the dict returned by the dataset item
+# as we're not interested in the *target* part of the dataset.
+for out in tqdm(pipe(KeyDataset(dataset, "file"))):
+ print(out)
+ # {"text": "NUMBER TEN FRESH NELLY IS WAITING ON YOU GOOD NIGHT HUSBAND"}
+ # {"text": ....}
+ # ....
+```
+
+For ease of use, a generator is also possible:
+
+
+```python
+from transformers import pipeline
+
+pipe = pipeline("text-classification")
+
+
+def data():
+ while True:
+ # This could come from a dataset, a database, a queue or HTTP request
+ # in a server
+ # Caveat: because this is iterative, you cannot use `num_workers > 1` variable
+ # to use multiple threads to preprocess data. You can still have 1 thread that
+ # does the preprocessing while the main runs the big inference
+ yield "This is a test"
+
+
+for out in pipe(data()):
+ print(out)
+ # {"text": "NUMBER TEN FRESH NELLY IS WAITING ON YOU GOOD NIGHT HUSBAND"}
+ # {"text": ....}
+ # ....
+```
+
+[[autodoc]] pipeline
+
+## Pipeline batching
+
+All pipelines can use batching. This will work
+whenever the pipeline uses its streaming ability (so when passing lists or `Dataset` or `generator`).
+
+```python
+from transformers import pipeline
+from transformers.pipelines.pt_utils import KeyDataset
+import datasets
+
+dataset = datasets.load_dataset("imdb", name="plain_text", split="unsupervised")
+pipe = pipeline("text-classification", device=0)
+for out in pipe(KeyDataset(dataset, "text"), batch_size=8, truncation="only_first"):
+ print(out)
+ # [{'label': 'POSITIVE', 'score': 0.9998743534088135}]
+ # Exactly the same output as before, but the content are passed
+ # as batches to the model
+```
+
+
+
+However, this is not automatically a win for performance. It can be either a 10x speedup or 5x slowdown depending
+on hardware, data and the actual model being used.
+
+Example where it's mostly a speedup:
+
+
+
+```python
+from transformers import pipeline
+from torch.utils.data import Dataset
+from tqdm.auto import tqdm
+
+pipe = pipeline("text-classification", device=0)
+
+
+class MyDataset(Dataset):
+ def __len__(self):
+ return 5000
+
+ def __getitem__(self, i):
+ return "This is a test"
+
+
+dataset = MyDataset()
+
+for batch_size in [1, 8, 64, 256]:
+ print("-" * 30)
+ print(f"Streaming batch_size={batch_size}")
+ for out in tqdm(pipe(dataset, batch_size=batch_size), total=len(dataset)):
+ pass
+```
+
+```
+# On GTX 970
+------------------------------
+Streaming no batching
+100%|██████████████████████████████████████████████████████████████████████| 5000/5000 [00:26<00:00, 187.52it/s]
+------------------------------
+Streaming batch_size=8
+100%|█████████████████████████████████████████████████████████████████████| 5000/5000 [00:04<00:00, 1205.95it/s]
+------------------------------
+Streaming batch_size=64
+100%|█████████████████████████████████████████████████████████████████████| 5000/5000 [00:02<00:00, 2478.24it/s]
+------------------------------
+Streaming batch_size=256
+100%|█████████████████████████████████████████████████████████████████████| 5000/5000 [00:01<00:00, 2554.43it/s]
+(diminishing returns, saturated the GPU)
+```
+
+Example where it's most a slowdown:
+
+```python
+class MyDataset(Dataset):
+ def __len__(self):
+ return 5000
+
+ def __getitem__(self, i):
+ if i % 64 == 0:
+ n = 100
+ else:
+ n = 1
+ return "This is a test" * n
+```
+
+This is a occasional very long sentence compared to the other. In that case, the **whole** batch will need to be 400
+tokens long, so the whole batch will be [64, 400] instead of [64, 4], leading to the high slowdown. Even worse, on
+bigger batches, the program simply crashes.
+
+
+```
+------------------------------
+Streaming no batching
+100%|█████████████████████████████████████████████████████████████████████| 1000/1000 [00:05<00:00, 183.69it/s]
+------------------------------
+Streaming batch_size=8
+100%|█████████████████████████████████████████████████████████████████████| 1000/1000 [00:03<00:00, 265.74it/s]
+------------------------------
+Streaming batch_size=64
+100%|██████████████████████████████████████████████████████████████████████| 1000/1000 [00:26<00:00, 37.80it/s]
+------------------------------
+Streaming batch_size=256
+ 0%| | 0/1000 [00:00
+ for out in tqdm(pipe(dataset, batch_size=256), total=len(dataset)):
+....
+ q = q / math.sqrt(dim_per_head) # (bs, n_heads, q_length, dim_per_head)
+RuntimeError: CUDA out of memory. Tried to allocate 376.00 MiB (GPU 0; 3.95 GiB total capacity; 1.72 GiB already allocated; 354.88 MiB free; 2.46 GiB reserved in total by PyTorch)
+```
+
+There are no good (general) solutions for this problem, and your mileage may vary depending on your use cases. Rule of
+thumb:
+
+For users, a rule of thumb is:
+
+- **Measure performance on your load, with your hardware. Measure, measure, and keep measuring. Real numbers are the
+ only way to go.**
+- If you are latency constrained (live product doing inference), don't batch
+- If you are using CPU, don't batch.
+- If you are using throughput (you want to run your model on a bunch of static data), on GPU, then:
+
+ - If you have no clue about the size of the sequence_length ("natural" data), by default don't batch, measure and
+ try tentatively to add it, add OOM checks to recover when it will fail (and it will at some point if you don't
+ control the sequence_length.)
+ - If your sequence_length is super regular, then batching is more likely to be VERY interesting, measure and push
+ it until you get OOMs.
+ - The larger the GPU the more likely batching is going to be more interesting
+- As soon as you enable batching, make sure you can handle OOMs nicely.
+
+## Pipeline chunk batching
+
+`zero-shot-classification` and `question-answering` are slightly specific in the sense, that a single input might yield
+multiple forward pass of a model. Under normal circumstances, this would yield issues with `batch_size` argument.
+
+In order to circumvent this issue, both of these pipelines are a bit specific, they are `ChunkPipeline` instead of
+regular `Pipeline`. In short:
+
+
+```python
+preprocessed = pipe.preprocess(inputs)
+model_outputs = pipe.forward(preprocessed)
+outputs = pipe.postprocess(model_outputs)
+```
+
+Now becomes:
+
+
+```python
+all_model_outputs = []
+for preprocessed in pipe.preprocess(inputs):
+ model_outputs = pipe.forward(preprocessed)
+ all_model_outputs.append(model_outputs)
+outputs = pipe.postprocess(all_model_outputs)
+```
+
+This should be very transparent to your code because the pipelines are used in
+the same way.
+
+This is a simplified view, since the pipeline can handle automatically the batch to ! Meaning you don't have to care
+about how many forward passes you inputs are actually going to trigger, you can optimize the `batch_size`
+independently of the inputs. The caveats from the previous section still apply.
+
+## Pipeline custom code
+
+If you want to override a specific pipeline.
+
+Don't hesitate to create an issue for your task at hand, the goal of the pipeline is to be easy to use and support most
+cases, so `transformers` could maybe support your use case.
+
+
+If you want to try simply you can:
+
+- Subclass your pipeline of choice
+
+```python
+class MyPipeline(TextClassificationPipeline):
+ def postprocess():
+ # Your code goes here
+ scores = scores * 100
+ # And here
+
+
+my_pipeline = MyPipeline(model=model, tokenizer=tokenizer, ...)
+# or if you use *pipeline* function, then:
+my_pipeline = pipeline(model="xxxx", pipeline_class=MyPipeline)
+```
+
+That should enable you to do all the custom code you want.
+
+
+## Implementing a pipeline
+
+[Implementing a new pipeline](../add_new_pipeline)
+
+## The task specific pipelines
+
+
+### AudioClassificationPipeline
+
+[[autodoc]] AudioClassificationPipeline
+ - __call__
+ - all
+
+### AutomaticSpeechRecognitionPipeline
+
+[[autodoc]] AutomaticSpeechRecognitionPipeline
+ - __call__
+ - all
+
+### ConversationalPipeline
+
+[[autodoc]] Conversation
+
+[[autodoc]] ConversationalPipeline
+ - __call__
+ - all
+
+### FeatureExtractionPipeline
+
+[[autodoc]] FeatureExtractionPipeline
+ - __call__
+ - all
+
+### FillMaskPipeline
+
+[[autodoc]] FillMaskPipeline
+ - __call__
+ - all
+
+### ImageClassificationPipeline
+
+[[autodoc]] ImageClassificationPipeline
+ - __call__
+ - all
+
+### ImageSegmentationPipeline
+
+[[autodoc]] ImageSegmentationPipeline
+ - __call__
+ - all
+
+### NerPipeline
+
+[[autodoc]] NerPipeline
+
+See [`TokenClassificationPipeline`] for all details.
+
+### ObjectDetectionPipeline
+
+[[autodoc]] ObjectDetectionPipeline
+ - __call__
+ - all
+
+### QuestionAnsweringPipeline
+
+[[autodoc]] QuestionAnsweringPipeline
+ - __call__
+ - all
+
+### SummarizationPipeline
+
+[[autodoc]] SummarizationPipeline
+ - __call__
+ - all
+
+### TableQuestionAnsweringPipeline
+
+[[autodoc]] TableQuestionAnsweringPipeline
+ - __call__
+
+### TextClassificationPipeline
+
+[[autodoc]] TextClassificationPipeline
+ - __call__
+ - all
+
+### TextGenerationPipeline
+
+[[autodoc]] TextGenerationPipeline
+ - __call__
+ - all
+
+### Text2TextGenerationPipeline
+
+[[autodoc]] Text2TextGenerationPipeline
+ - __call__
+ - all
+
+### TokenClassificationPipeline
+
+[[autodoc]] TokenClassificationPipeline
+ - __call__
+ - all
+
+### TranslationPipeline
+
+[[autodoc]] TranslationPipeline
+ - __call__
+ - all
+
+### ZeroShotClassificationPipeline
+
+[[autodoc]] ZeroShotClassificationPipeline
+ - __call__
+ - all
+
+### ZeroShotImageClassificationPipeline
+
+[[autodoc]] ZeroShotImageClassificationPipeline
+ - __call__
+ - all
+
+## Parent class: `Pipeline`
+
+[[autodoc]] Pipeline
diff --git a/docs/source/en/main_classes/processors.mdx b/docs/source/en/main_classes/processors.mdx
new file mode 100644
index 00000000000000..5d0d3f8307b8f0
--- /dev/null
+++ b/docs/source/en/main_classes/processors.mdx
@@ -0,0 +1,159 @@
+
+
+# Processors
+
+Processors can mean two different things in the Transformers library:
+- the objects that pre-process inputs for multi-modal models such as [Wav2Vec2](../model_doc/wav2vec2) (speech and text)
+ or [CLIP](../model_doc/clip) (text and vision)
+- deprecated objects that were used in older versions of the library to preprocess data for GLUE or SQUAD.
+
+## Multi-modal processors
+
+Any multi-modal model will require an object to encode or decode the data that groups several modalities (among text,
+vision and audio). This is handled by objects called processors, which group tokenizers (for the text modality) and
+feature extractors (for vision and audio).
+
+Those processors inherit from the following base class that implements the saving and loading functionality:
+
+[[autodoc]] ProcessorMixin
+
+## Deprecated processors
+
+All processors follow the same architecture which is that of the
+[`~data.processors.utils.DataProcessor`]. The processor returns a list of
+[`~data.processors.utils.InputExample`]. These
+[`~data.processors.utils.InputExample`] can be converted to
+[`~data.processors.utils.InputFeatures`] in order to be fed to the model.
+
+[[autodoc]] data.processors.utils.DataProcessor
+
+[[autodoc]] data.processors.utils.InputExample
+
+[[autodoc]] data.processors.utils.InputFeatures
+
+## GLUE
+
+[General Language Understanding Evaluation (GLUE)](https://gluebenchmark.com/) is a benchmark that evaluates the
+performance of models across a diverse set of existing NLU tasks. It was released together with the paper [GLUE: A
+multi-task benchmark and analysis platform for natural language understanding](https://openreview.net/pdf?id=rJ4km2R5t7)
+
+This library hosts a total of 10 processors for the following tasks: MRPC, MNLI, MNLI (mismatched), CoLA, SST2, STSB,
+QQP, QNLI, RTE and WNLI.
+
+Those processors are:
+
+- [`~data.processors.utils.MrpcProcessor`]
+- [`~data.processors.utils.MnliProcessor`]
+- [`~data.processors.utils.MnliMismatchedProcessor`]
+- [`~data.processors.utils.Sst2Processor`]
+- [`~data.processors.utils.StsbProcessor`]
+- [`~data.processors.utils.QqpProcessor`]
+- [`~data.processors.utils.QnliProcessor`]
+- [`~data.processors.utils.RteProcessor`]
+- [`~data.processors.utils.WnliProcessor`]
+
+Additionally, the following method can be used to load values from a data file and convert them to a list of
+[`~data.processors.utils.InputExample`].
+
+[[autodoc]] data.processors.glue.glue_convert_examples_to_features
+
+
+## XNLI
+
+[The Cross-Lingual NLI Corpus (XNLI)](https://www.nyu.edu/projects/bowman/xnli/) is a benchmark that evaluates the
+quality of cross-lingual text representations. XNLI is crowd-sourced dataset based on [*MultiNLI*](http://www.nyu.edu/projects/bowman/multinli/): pairs of text are labeled with textual entailment annotations for 15
+different languages (including both high-resource language such as English and low-resource languages such as Swahili).
+
+It was released together with the paper [XNLI: Evaluating Cross-lingual Sentence Representations](https://arxiv.org/abs/1809.05053)
+
+This library hosts the processor to load the XNLI data:
+
+- [`~data.processors.utils.XnliProcessor`]
+
+Please note that since the gold labels are available on the test set, evaluation is performed on the test set.
+
+An example using these processors is given in the [run_xnli.py](https://github.com/huggingface/transformers/tree/main/examples/legacy/text-classification/run_xnli.py) script.
+
+
+## SQuAD
+
+[The Stanford Question Answering Dataset (SQuAD)](https://rajpurkar.github.io/SQuAD-explorer//) is a benchmark that
+evaluates the performance of models on question answering. Two versions are available, v1.1 and v2.0. The first version
+(v1.1) was released together with the paper [SQuAD: 100,000+ Questions for Machine Comprehension of Text](https://arxiv.org/abs/1606.05250). The second version (v2.0) was released alongside the paper [Know What You Don't
+Know: Unanswerable Questions for SQuAD](https://arxiv.org/abs/1806.03822).
+
+This library hosts a processor for each of the two versions:
+
+### Processors
+
+Those processors are:
+
+- [`~data.processors.utils.SquadV1Processor`]
+- [`~data.processors.utils.SquadV2Processor`]
+
+They both inherit from the abstract class [`~data.processors.utils.SquadProcessor`]
+
+[[autodoc]] data.processors.squad.SquadProcessor
+ - all
+
+Additionally, the following method can be used to convert SQuAD examples into
+[`~data.processors.utils.SquadFeatures`] that can be used as model inputs.
+
+[[autodoc]] data.processors.squad.squad_convert_examples_to_features
+
+
+These processors as well as the aforementionned method can be used with files containing the data as well as with the
+*tensorflow_datasets* package. Examples are given below.
+
+
+### Example usage
+
+Here is an example using the processors as well as the conversion method using data files:
+
+```python
+# Loading a V2 processor
+processor = SquadV2Processor()
+examples = processor.get_dev_examples(squad_v2_data_dir)
+
+# Loading a V1 processor
+processor = SquadV1Processor()
+examples = processor.get_dev_examples(squad_v1_data_dir)
+
+features = squad_convert_examples_to_features(
+ examples=examples,
+ tokenizer=tokenizer,
+ max_seq_length=max_seq_length,
+ doc_stride=args.doc_stride,
+ max_query_length=max_query_length,
+ is_training=not evaluate,
+)
+```
+
+Using *tensorflow_datasets* is as easy as using a data file:
+
+```python
+# tensorflow_datasets only handle Squad V1.
+tfds_examples = tfds.load("squad")
+examples = SquadV1Processor().get_examples_from_dataset(tfds_examples, evaluate=evaluate)
+
+features = squad_convert_examples_to_features(
+ examples=examples,
+ tokenizer=tokenizer,
+ max_seq_length=max_seq_length,
+ doc_stride=args.doc_stride,
+ max_query_length=max_query_length,
+ is_training=not evaluate,
+)
+```
+
+Another example using these processors is given in the [run_squad.py](https://github.com/huggingface/transformers/tree/main/examples/legacy/question-answering/run_squad.py) script.
diff --git a/docs/source/en/main_classes/text_generation.mdx b/docs/source/en/main_classes/text_generation.mdx
new file mode 100644
index 00000000000000..94deeeae89411b
--- /dev/null
+++ b/docs/source/en/main_classes/text_generation.mdx
@@ -0,0 +1,40 @@
+
+
+# Generation
+
+Each framework has a generate method for auto-regressive text generation implemented in their respective `GenerationMixin` class:
+
+- PyTorch [`~generation_utils.GenerationMixin.generate`] is implemented in [`~generation_utils.GenerationMixin`].
+- TensorFlow [`~generation_tf_utils.TFGenerationMixin.generate`] is implemented in [`~generation_tf_utils.TFGenerationMixin`].
+- Flax/JAX [`~generation_flax_utils.FlaxGenerationMixin.generate`] is implemented in [`~generation_flax_utils.FlaxGenerationMixin`].
+
+## GenerationMixin
+
+[[autodoc]] generation_utils.GenerationMixin
+ - generate
+ - greedy_search
+ - sample
+ - beam_search
+ - beam_sample
+ - group_beam_search
+ - constrained_beam_search
+
+## TFGenerationMixin
+
+[[autodoc]] generation_tf_utils.TFGenerationMixin
+ - generate
+
+## FlaxGenerationMixin
+
+[[autodoc]] generation_flax_utils.FlaxGenerationMixin
+ - generate
diff --git a/docs/source/en/main_classes/tokenizer.mdx b/docs/source/en/main_classes/tokenizer.mdx
new file mode 100644
index 00000000000000..032373435cd5f4
--- /dev/null
+++ b/docs/source/en/main_classes/tokenizer.mdx
@@ -0,0 +1,75 @@
+
+
+# Tokenizer
+
+A tokenizer is in charge of preparing the inputs for a model. The library contains tokenizers for all the models. Most
+of the tokenizers are available in two flavors: a full python implementation and a "Fast" implementation based on the
+Rust library [🤗 Tokenizers](https://github.com/huggingface/tokenizers). The "Fast" implementations allows:
+
+1. a significant speed-up in particular when doing batched tokenization and
+2. additional methods to map between the original string (character and words) and the token space (e.g. getting the
+ index of the token comprising a given character or the span of characters corresponding to a given token).
+
+The base classes [`PreTrainedTokenizer`] and [`PreTrainedTokenizerFast`]
+implement the common methods for encoding string inputs in model inputs (see below) and instantiating/saving python and
+"Fast" tokenizers either from a local file or directory or from a pretrained tokenizer provided by the library
+(downloaded from HuggingFace's AWS S3 repository). They both rely on
+[`~tokenization_utils_base.PreTrainedTokenizerBase`] that contains the common methods, and
+[`~tokenization_utils_base.SpecialTokensMixin`].
+
+[`PreTrainedTokenizer`] and [`PreTrainedTokenizerFast`] thus implement the main
+methods for using all the tokenizers:
+
+- Tokenizing (splitting strings in sub-word token strings), converting tokens strings to ids and back, and
+ encoding/decoding (i.e., tokenizing and converting to integers).
+- Adding new tokens to the vocabulary in a way that is independent of the underlying structure (BPE, SentencePiece...).
+- Managing special tokens (like mask, beginning-of-sentence, etc.): adding them, assigning them to attributes in the
+ tokenizer for easy access and making sure they are not split during tokenization.
+
+[`BatchEncoding`] holds the output of the
+[`~tokenization_utils_base.PreTrainedTokenizerBase`]'s encoding methods (`__call__`,
+`encode_plus` and `batch_encode_plus`) and is derived from a Python dictionary. When the tokenizer is a pure python
+tokenizer, this class behaves just like a standard python dictionary and holds the various model inputs computed by
+these methods (`input_ids`, `attention_mask`...). When the tokenizer is a "Fast" tokenizer (i.e., backed by
+HuggingFace [tokenizers library](https://github.com/huggingface/tokenizers)), this class provides in addition
+several advanced alignment methods which can be used to map between the original string (character and words) and the
+token space (e.g., getting the index of the token comprising a given character or the span of characters corresponding
+to a given token).
+
+
+## PreTrainedTokenizer
+
+[[autodoc]] PreTrainedTokenizer
+ - __call__
+ - batch_decode
+ - decode
+ - encode
+ - push_to_hub
+ - all
+
+## PreTrainedTokenizerFast
+
+The [`PreTrainedTokenizerFast`] depend on the [tokenizers](https://huggingface.co/docs/tokenizers) library. The tokenizers obtained from the 🤗 tokenizers library can be
+loaded very simply into 🤗 transformers. Take a look at the [Using tokenizers from 🤗 tokenizers](../fast_tokenizers) page to understand how this is done.
+
+[[autodoc]] PreTrainedTokenizerFast
+ - __call__
+ - batch_decode
+ - decode
+ - encode
+ - push_to_hub
+ - all
+
+## BatchEncoding
+
+[[autodoc]] BatchEncoding
diff --git a/docs/source/en/main_classes/trainer.mdx b/docs/source/en/main_classes/trainer.mdx
new file mode 100644
index 00000000000000..a3c57b51f570b3
--- /dev/null
+++ b/docs/source/en/main_classes/trainer.mdx
@@ -0,0 +1,569 @@
+
+
+# Trainer
+
+The [`Trainer`] class provides an API for feature-complete training in PyTorch for most standard use cases. It's used in most of the [example scripts](../examples).
+
+Before instantiating your [`Trainer`], create a [`TrainingArguments`] to access all the points of customization during training.
+
+The API supports distributed training on multiple GPUs/TPUs, mixed precision through [NVIDIA Apex](https://github.com/NVIDIA/apex) and Native AMP for PyTorch.
+
+The [`Trainer`] contains the basic training loop which supports the above features. To inject custom behavior you can subclass them and override the following methods:
+
+- **get_train_dataloader** -- Creates the training DataLoader.
+- **get_eval_dataloader** -- Creates the evaluation DataLoader.
+- **get_test_dataloader** -- Creates the test DataLoader.
+- **log** -- Logs information on the various objects watching training.
+- **create_optimizer_and_scheduler** -- Sets up the optimizer and learning rate scheduler if they were not passed at
+ init. Note, that you can also subclass or override the `create_optimizer` and `create_scheduler` methods
+ separately.
+- **create_optimizer** -- Sets up the optimizer if it wasn't passed at init.
+- **create_scheduler** -- Sets up the learning rate scheduler if it wasn't passed at init.
+- **compute_loss** - Computes the loss on a batch of training inputs.
+- **training_step** -- Performs a training step.
+- **prediction_step** -- Performs an evaluation/test step.
+- **evaluate** -- Runs an evaluation loop and returns metrics.
+- **predict** -- Returns predictions (with metrics if labels are available) on a test set.
+
+
+
+The [`Trainer`] class is optimized for 🤗 Transformers models and can have surprising behaviors
+when you use it on other models. When using it on your own model, make sure:
+
+- your model always return tuples or subclasses of [`~utils.ModelOutput`].
+- your model can compute the loss if a `labels` argument is provided and that loss is returned as the first
+ element of the tuple (if your model returns tuples)
+- your model can accept multiple label arguments (use the `label_names` in your [`TrainingArguments`] to indicate their name to the [`Trainer`]) but none of them should be named `"label"`.
+
+
+
+Here is an example of how to customize [`Trainer`] to use a weighted loss (useful when you have an unbalanced training set):
+
+```python
+from torch import nn
+from transformers import Trainer
+
+
+class CustomTrainer(Trainer):
+ def compute_loss(self, model, inputs, return_outputs=False):
+ labels = inputs.get("labels")
+ # forward pass
+ outputs = model(**inputs)
+ logits = outputs.get("logits")
+ # compute custom loss (suppose one has 3 labels with different weights)
+ loss_fct = nn.CrossEntropyLoss(weight=torch.tensor([1.0, 2.0, 3.0]))
+ loss = loss_fct(logits.view(-1, self.model.config.num_labels), labels.view(-1))
+ return (loss, outputs) if return_outputs else loss
+```
+
+Another way to customize the training loop behavior for the PyTorch [`Trainer`] is to use [callbacks](callback) that can inspect the training loop state (for progress reporting, logging on TensorBoard or other ML platforms...) and take decisions (like early stopping).
+
+
+## Trainer
+
+[[autodoc]] Trainer
+ - all
+
+## Seq2SeqTrainer
+
+[[autodoc]] Seq2SeqTrainer
+ - evaluate
+ - predict
+
+## TrainingArguments
+
+[[autodoc]] TrainingArguments
+ - all
+
+## Seq2SeqTrainingArguments
+
+[[autodoc]] Seq2SeqTrainingArguments
+ - all
+
+## Checkpoints
+
+By default, [`Trainer`] will save all checkpoints in the `output_dir` you set in the
+[`TrainingArguments`] you are using. Those will go in subfolder named `checkpoint-xxx` with xxx
+being the step at which the training was at.
+
+Resuming training from a checkpoint can be done when calling [`Trainer.train`] with either:
+
+- `resume_from_checkpoint=True` which will resume training from the latest checkpoint
+- `resume_from_checkpoint=checkpoint_dir` which will resume training from the specific checkpoint in the directory
+ passed.
+
+In addition, you can easily save your checkpoints on the Model Hub when using `push_to_hub=True`. By default, all
+the models saved in intermediate checkpoints are saved in different commits, but not the optimizer state. You can adapt
+the `hub-strategy` value of your [`TrainingArguments`] to either:
+
+- `"checkpoint"`: the latest checkpoint is also pushed in a subfolder named last-checkpoint, allowing you to
+ resume training easily with `trainer.train(resume_from_checkpoint="output_dir/last-checkpoint")`.
+- `"all_checkpoints"`: all checkpoints are pushed like they appear in the output folder (so you will get one
+ checkpoint folder per folder in your final repository)
+
+
+## Logging
+
+By default [`Trainer`] will use `logging.INFO` for the main process and `logging.WARNING` for the replicas if any.
+
+These defaults can be overridden to use any of the 5 `logging` levels with [`TrainingArguments`]'s
+arguments:
+
+- `log_level` - for the main process
+- `log_level_replica` - for the replicas
+
+Further, if [`TrainingArguments`]'s `log_on_each_node` is set to `False` only the main node will
+use the log level settings for its main process, all other nodes will use the log level settings for replicas.
+
+Note that [`Trainer`] is going to set `transformers`'s log level separately for each node in its
+[`Trainer.__init__`]. So you may want to set this sooner (see the next example) if you tap into other
+`transformers` functionality before creating the [`Trainer`] object.
+
+Here is an example of how this can be used in an application:
+
+```python
+[...]
+logger = logging.getLogger(__name__)
+
+# Setup logging
+logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ handlers=[logging.StreamHandler(sys.stdout)],
+)
+
+# set the main code and the modules it uses to the same log-level according to the node
+log_level = training_args.get_process_log_level()
+logger.setLevel(log_level)
+datasets.utils.logging.set_verbosity(log_level)
+transformers.utils.logging.set_verbosity(log_level)
+
+trainer = Trainer(...)
+```
+
+And then if you only want to see warnings on the main node and all other nodes to not print any most likely duplicated
+warnings you could run it as:
+
+```bash
+my_app.py ... --log_level warning --log_level_replica error
+```
+
+In the multi-node environment if you also don't want the logs to repeat for each node's main process, you will want to
+change the above to:
+
+```bash
+my_app.py ... --log_level warning --log_level_replica error --log_on_each_node 0
+```
+
+and then only the main process of the first node will log at the "warning" level, and all other processes on the main
+node and all processes on other nodes will log at the "error" level.
+
+If you need your application to be as quiet as possible you could do:
+
+```bash
+my_app.py ... --log_level error --log_level_replica error --log_on_each_node 0
+```
+
+(add `--log_on_each_node 0` if on multi-node environment)
+
+
+## Randomness
+
+When resuming from a checkpoint generated by [`Trainer`] all efforts are made to restore the
+_python_, _numpy_ and _pytorch_ RNG states to the same states as they were at the moment of saving that checkpoint,
+which should make the "stop and resume" style of training as close as possible to non-stop training.
+
+However, due to various default non-deterministic pytorch settings this might not fully work. If you want full
+determinism please refer to [Controlling sources of randomness](https://pytorch.org/docs/stable/notes/randomness). As explained in the document, that some of those settings
+that make things deterministic (.e.g., `torch.backends.cudnn.deterministic`) may slow things down, therefore this
+can't be done by default, but you can enable those yourself if needed.
+
+
+## Specific GPUs Selection
+
+Let's discuss how you can tell your program which GPUs are to be used and in what order.
+
+When using [`DistributedDataParallel`](https://pytorch.org/docs/stable/generated/torch.nn.parallel.DistributedDataParallel.html) to use only a subset of your GPUs, you simply specify the number of GPUs to use. For example, if you have 4 GPUs, but you wish to use the first 2 you can do:
+
+```bash
+python -m torch.distributed.launch --nproc_per_node=2 trainer-program.py ...
+```
+
+if you have either [`accelerate`](https://github.com/huggingface/accelerate) or [`deepspeed`](https://github.com/microsoft/DeepSpeed) installed you can also accomplish the same by using one of:
+```bash
+accelerate launch --num_processes 2 trainer-program.py ...
+```
+
+```bash
+deepspeed --num_gpus 2 trainer-program.py ...
+```
+
+You don't need to use the Accelerate or [the Deepspeed integration](Deepspeed) features to use these launchers.
+
+
+Until now you were able to tell the program how many GPUs to use. Now let's discuss how to select specific GPUs and control their order.
+
+The following environment variables help you control which GPUs to use and their order.
+
+**`CUDA_VISIBLE_DEVICES`**
+
+If you have multiple GPUs and you'd like to use only 1 or a few of those GPUs, set the environment variable `CUDA_VISIBLE_DEVICES` to a list of the GPUs to be used.
+
+For example, let's say you have 4 GPUs: 0, 1, 2 and 3. To run only on the physical GPUs 0 and 2, you can do:
+
+```bash
+CUDA_VISIBLE_DEVICES=0,2 python -m torch.distributed.launch trainer-program.py ...
+```
+
+So now pytorch will see only 2 GPUs, where your physical GPUs 0 and 2 are mapped to `cuda:0` and `cuda:1` correspondingly.
+
+You can even change their order:
+
+```bash
+CUDA_VISIBLE_DEVICES=2,0 python -m torch.distributed.launch trainer-program.py ...
+```
+
+Here your physical GPUs 0 and 2 are mapped to `cuda:1` and `cuda:0` correspondingly.
+
+The above examples were all for `DistributedDataParallel` use pattern, but the same method works for [`DataParallel`](https://pytorch.org/docs/stable/generated/torch.nn.DataParallel.html) as well:
+```bash
+CUDA_VISIBLE_DEVICES=2,0 python trainer-program.py ...
+```
+
+To emulate an environment without GPUs simply set this environment variable to an empty value like so:
+
+```bash
+CUDA_VISIBLE_DEVICES= python trainer-program.py ...
+```
+
+As with any environment variable you can, of course, export those instead of adding these to the command line, as in:
+
+
+```bash
+export CUDA_VISIBLE_DEVICES=0,2
+python -m torch.distributed.launch trainer-program.py ...
+```
+
+but this approach can be confusing since you may forget you set up the environment variable earlier and not understand why the wrong GPUs are used. Therefore, it's a common practice to set the environment variable just for a specific run on the same command line as it's shown in most examples of this section.
+
+**`CUDA_DEVICE_ORDER`**
+
+There is an additional environment variable `CUDA_DEVICE_ORDER` that controls how the physical devices are ordered. The two choices are:
+
+1. ordered by PCIe bus IDs (matches `nvidia-smi`'s order) - this is the default.
+
+```bash
+export CUDA_DEVICE_ORDER=PCI_BUS_ID
+```
+
+2. ordered by GPU compute capabilities
+
+```bash
+export CUDA_DEVICE_ORDER=FASTEST_FIRST
+```
+
+Most of the time you don't need to care about this environment variable, but it's very helpful if you have a lopsided setup where you have an old and a new GPUs physically inserted in such a way so that the slow older card appears to be first. One way to fix that is to swap the cards. But if you can't swap the cards (e.g., if the cooling of the devices gets impacted) then setting `CUDA_DEVICE_ORDER=FASTEST_FIRST` will always put the newer faster card first. It'll be somewhat confusing though since `nvidia-smi` will still report them in the PCIe order.
+
+The other solution to swapping the order is to use:
+
+```bash
+export CUDA_VISIBLE_DEVICES=1,0
+```
+In this example we are working with just 2 GPUs, but of course the same would apply to as many GPUs as your computer has.
+
+Also if you do set this environment variable it's the best to set it in your `~/.bashrc` file or some other startup config file and forget about it.
+
+
+
+
+## Trainer Integrations
+
+The [`Trainer`] has been extended to support libraries that may dramatically improve your training
+time and fit much bigger models.
+
+Currently it supports third party solutions, [DeepSpeed](https://github.com/microsoft/DeepSpeed) and [FairScale](https://github.com/facebookresearch/fairscale/), which implement parts of the paper [ZeRO: Memory Optimizations
+Toward Training Trillion Parameter Models, by Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, Yuxiong He](https://arxiv.org/abs/1910.02054).
+
+This provided support is new and experimental as of this writing.
+
+
+
+### CUDA Extension Installation Notes
+
+As of this writing, both FairScale and Deepspeed require compilation of CUDA C++ code, before they can be used.
+
+While all installation issues should be dealt with through the corresponding GitHub Issues of [FairScale](https://github.com/facebookresearch/fairscale/issues) and [Deepspeed](https://github.com/microsoft/DeepSpeed/issues), there are a few common issues that one may encounter while building
+any PyTorch extension that needs to build CUDA extensions.
+
+Therefore, if you encounter a CUDA-related build issue while doing one of the following or both:
+
+```bash
+pip install fairscale
+pip install deepspeed
+```
+
+please, read the following notes first.
+
+In these notes we give examples for what to do when `pytorch` has been built with CUDA `10.2`. If your situation is
+different remember to adjust the version number to the one you are after.
+
+#### Possible problem #1
+
+While, Pytorch comes with its own CUDA toolkit, to build these two projects you must have an identical version of CUDA
+installed system-wide.
+
+For example, if you installed `pytorch` with `cudatoolkit==10.2` in the Python environment, you also need to have
+CUDA `10.2` installed system-wide.
+
+The exact location may vary from system to system, but `/usr/local/cuda-10.2` is the most common location on many
+Unix systems. When CUDA is correctly set up and added to the `PATH` environment variable, one can find the
+installation location by doing:
+
+```bash
+which nvcc
+```
+
+If you don't have CUDA installed system-wide, install it first. You will find the instructions by using your favorite
+search engine. For example, if you're on Ubuntu you may want to search for: [ubuntu cuda 10.2 install](https://www.google.com/search?q=ubuntu+cuda+10.2+install).
+
+#### Possible problem #2
+
+Another possible common problem is that you may have more than one CUDA toolkit installed system-wide. For example you
+may have:
+
+```bash
+/usr/local/cuda-10.2
+/usr/local/cuda-11.0
+```
+
+Now, in this situation you need to make sure that your `PATH` and `LD_LIBRARY_PATH` environment variables contain
+the correct paths to the desired CUDA version. Typically, package installers will set these to contain whatever the
+last version was installed. If you encounter the problem, where the package build fails because it can't find the right
+CUDA version despite you having it installed system-wide, it means that you need to adjust the 2 aforementioned
+environment variables.
+
+First, you may look at their contents:
+
+```bash
+echo $PATH
+echo $LD_LIBRARY_PATH
+```
+
+so you get an idea of what is inside.
+
+It's possible that `LD_LIBRARY_PATH` is empty.
+
+`PATH` lists the locations of where executables can be found and `LD_LIBRARY_PATH` is for where shared libraries
+are to looked for. In both cases, earlier entries have priority over the later ones. `:` is used to separate multiple
+entries.
+
+Now, to tell the build program where to find the specific CUDA toolkit, insert the desired paths to be listed first by
+doing:
+
+```bash
+export PATH=/usr/local/cuda-10.2/bin:$PATH
+export LD_LIBRARY_PATH=/usr/local/cuda-10.2/lib64:$LD_LIBRARY_PATH
+```
+
+Note that we aren't overwriting the existing values, but prepending instead.
+
+Of course, adjust the version number, the full path if need be. Check that the directories you assign actually do
+exist. `lib64` sub-directory is where the various CUDA `.so` objects, like `libcudart.so` reside, it's unlikely
+that your system will have it named differently, but if it is adjust it to reflect your reality.
+
+
+#### Possible problem #3
+
+Some older CUDA versions may refuse to build with newer compilers. For example, you my have `gcc-9` but it wants
+`gcc-7`.
+
+There are various ways to go about it.
+
+If you can install the latest CUDA toolkit it typically should support the newer compiler.
+
+Alternatively, you could install the lower version of the compiler in addition to the one you already have, or you may
+already have it but it's not the default one, so the build system can't see it. If you have `gcc-7` installed but the
+build system complains it can't find it, the following might do the trick:
+
+```bash
+sudo ln -s /usr/bin/gcc-7 /usr/local/cuda-10.2/bin/gcc
+sudo ln -s /usr/bin/g++-7 /usr/local/cuda-10.2/bin/g++
+```
+
+Here, we are making a symlink to `gcc-7` from `/usr/local/cuda-10.2/bin/gcc` and since
+`/usr/local/cuda-10.2/bin/` should be in the `PATH` environment variable (see the previous problem's solution), it
+should find `gcc-7` (and `g++7`) and then the build will succeed.
+
+As always make sure to edit the paths in the example to match your situation.
+
+### FairScale
+
+By integrating [FairScale](https://github.com/facebookresearch/fairscale/) the [`Trainer`]
+provides support for the following features from [the ZeRO paper](https://arxiv.org/abs/1910.02054):
+
+1. Optimizer State Sharding
+2. Gradient Sharding
+3. Model Parameters Sharding (new and very experimental)
+4. CPU offload (new and very experimental)
+
+You will need at least two GPUs to use this feature.
+
+
+**Installation**:
+
+Install the library via pypi:
+
+```bash
+pip install fairscale
+```
+
+or via `transformers`' `extras`:
+
+```bash
+pip install transformers[fairscale]
+```
+
+(available starting from `transformers==4.6.0`) or find more details on [the FairScale's GitHub page](https://github.com/facebookresearch/fairscale/#installation).
+
+If you're still struggling with the build, first make sure to read [CUDA Extension Installation Notes](#zero-install-notes).
+
+If it's still not resolved the build issue, here are a few more ideas.
+
+`fairscale` seems to have an issue with the recently introduced by pip build isolation feature. If you have a problem
+with it, you may want to try one of:
+
+```bash
+pip install fairscale --no-build-isolation .
+```
+
+or:
+
+```bash
+git clone https://github.com/facebookresearch/fairscale/
+cd fairscale
+rm -r dist build
+python setup.py bdist_wheel
+pip uninstall -y fairscale
+pip install dist/fairscale-*.whl
+```
+
+`fairscale` also has issues with building against pytorch-nightly, so if you use it you may have to try one of:
+
+```bash
+pip uninstall -y fairscale; pip install fairscale --pre \
+-f https://download.pytorch.org/whl/nightly/cu110/torch_nightly \
+--no-cache --no-build-isolation
+```
+
+or:
+
+```bash
+pip install -v --disable-pip-version-check . \
+-f https://download.pytorch.org/whl/nightly/cu110/torch_nightly --pre
+```
+
+Of course, adjust the urls to match the cuda version you use.
+
+If after trying everything suggested you still encounter build issues, please, proceed with the GitHub Issue of
+[FairScale](https://github.com/facebookresearch/fairscale/issues).
+
+
+
+**Usage**:
+
+To use the first version of Sharded data-parallelism, add `--sharded_ddp simple` to the command line arguments, and
+make sure you have added the distributed launcher `-m torch.distributed.launch --nproc_per_node=NUMBER_OF_GPUS_YOU_HAVE` if you haven't been using it already.
+
+For example here is how you could use it for `run_translation.py` with 2 GPUs:
+
+```bash
+python -m torch.distributed.launch --nproc_per_node=2 examples/pytorch/translation/run_translation.py \
+--model_name_or_path t5-small --per_device_train_batch_size 1 \
+--output_dir output_dir --overwrite_output_dir \
+--do_train --max_train_samples 500 --num_train_epochs 1 \
+--dataset_name wmt16 --dataset_config "ro-en" \
+--source_lang en --target_lang ro \
+--fp16 --sharded_ddp simple
+```
+
+Notes:
+
+- This feature requires distributed training (so multiple GPUs).
+- It is not implemented for TPUs.
+- It works with `--fp16` too, to make things even faster.
+- One of the main benefits of enabling `--sharded_ddp simple` is that it uses a lot less GPU memory, so you should be
+ able to use significantly larger batch sizes using the same hardware (e.g. 3x and even bigger) which should lead to
+ significantly shorter training time.
+
+3. To use the second version of Sharded data-parallelism, add `--sharded_ddp zero_dp_2` or `--sharded_ddp zero_dp_3` to the command line arguments, and make sure you have added the distributed launcher `-m torch.distributed.launch --nproc_per_node=NUMBER_OF_GPUS_YOU_HAVE` if you haven't been using it already.
+
+For example here is how you could use it for `run_translation.py` with 2 GPUs:
+
+```bash
+python -m torch.distributed.launch --nproc_per_node=2 examples/pytorch/translation/run_translation.py \
+--model_name_or_path t5-small --per_device_train_batch_size 1 \
+--output_dir output_dir --overwrite_output_dir \
+--do_train --max_train_samples 500 --num_train_epochs 1 \
+--dataset_name wmt16 --dataset_config "ro-en" \
+--source_lang en --target_lang ro \
+--fp16 --sharded_ddp zero_dp_2
+```
+
+`zero_dp_2` is an optimized version of the simple wrapper, while `zero_dp_3` fully shards model weights,
+gradients and optimizer states.
+
+Both are compatible with adding `cpu_offload` to enable ZeRO-offload (activate it like this: `--sharded_ddp "zero_dp_2 cpu_offload"`).
+
+Notes:
+
+- This feature requires distributed training (so multiple GPUs).
+- It is not implemented for TPUs.
+- It works with `--fp16` too, to make things even faster.
+- The `cpu_offload` additional option requires `--fp16`.
+- This is an area of active development, so make sure you have a source install of fairscale to use this feature as
+ some bugs you encounter may have been fixed there already.
+
+Known caveats:
+
+- This feature is incompatible with `--predict_with_generate` in the _run_translation.py_ script.
+- Using `--sharded_ddp zero_dp_3` requires wrapping each layer of the model in the special container
+ `FullyShardedDataParallelism` of fairscale. It should be used with the option `auto_wrap` if you are not
+ doing this yourself: `--sharded_ddp "zero_dp_3 auto_wrap"`.
+
+
+Sections that were moved:
+
+[ DeepSpeed
+| Installation
+| Deployment with multiple GPUs
+| Deployment with one GPU
+| Deployment in Notebooks
+| Configuration
+| Passing Configuration
+| Shared Configuration
+| ZeRO
+| ZeRO-2 Config
+| ZeRO-3 Config
+| NVMe Support
+| ZeRO-2 vs ZeRO-3 Performance
+| ZeRO-2 Example
+| ZeRO-3 Example
+| Optimizer
+| Scheduler
+| fp32 Precision
+| Automatic Mixed Precision
+| Batch Size
+| Gradient Accumulation
+| Gradient Clipping
+| Getting The Model Weights Out
+]
diff --git a/docs/source/en/migration.mdx b/docs/source/en/migration.mdx
new file mode 100644
index 00000000000000..7abf95875154ca
--- /dev/null
+++ b/docs/source/en/migration.mdx
@@ -0,0 +1,315 @@
+
+
+# Migrating from previous packages
+
+## Migrating from transformers `v3.x` to `v4.x`
+
+A couple of changes were introduced when the switch from version 3 to version 4 was done. Below is a summary of the
+expected changes:
+
+#### 1. AutoTokenizers and pipelines now use fast (rust) tokenizers by default.
+
+The python and rust tokenizers have roughly the same API, but the rust tokenizers have a more complete feature set.
+
+This introduces two breaking changes:
+- The handling of overflowing tokens between the python and rust tokenizers is different.
+- The rust tokenizers do not accept integers in the encoding methods.
+
+##### How to obtain the same behavior as v3.x in v4.x
+
+- The pipelines now contain additional features out of the box. See the [token-classification pipeline with the `grouped_entities` flag](main_classes/pipelines#transformers.TokenClassificationPipeline).
+- The auto-tokenizers now return rust tokenizers. In order to obtain the python tokenizers instead, the user may use the `use_fast` flag by setting it to `False`:
+
+In version `v3.x`:
+```py
+from transformers import AutoTokenizer
+
+tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
+```
+to obtain the same in version `v4.x`:
+```py
+from transformers import AutoTokenizer
+
+tokenizer = AutoTokenizer.from_pretrained("bert-base-cased", use_fast=False)
+```
+
+#### 2. SentencePiece is removed from the required dependencies
+
+The requirement on the SentencePiece dependency has been lifted from the `setup.py`. This is done so that we may have a channel on anaconda cloud without relying on `conda-forge`. This means that the tokenizers that depend on the SentencePiece library will not be available with a standard `transformers` installation.
+
+This includes the **slow** versions of:
+- `XLNetTokenizer`
+- `AlbertTokenizer`
+- `CamembertTokenizer`
+- `MBartTokenizer`
+- `PegasusTokenizer`
+- `T5Tokenizer`
+- `ReformerTokenizer`
+- `XLMRobertaTokenizer`
+
+##### How to obtain the same behavior as v3.x in v4.x
+
+In order to obtain the same behavior as version `v3.x`, you should install `sentencepiece` additionally:
+
+In version `v3.x`:
+```bash
+pip install transformers
+```
+to obtain the same in version `v4.x`:
+```bash
+pip install transformers[sentencepiece]
+```
+or
+```bash
+pip install transformers sentencepiece
+```
+#### 3. The architecture of the repo has been updated so that each model resides in its folder
+
+The past and foreseeable addition of new models means that the number of files in the directory `src/transformers` keeps growing and becomes harder to navigate and understand. We made the choice to put each model and the files accompanying it in their own sub-directories.
+
+This is a breaking change as importing intermediary layers using a model's module directly needs to be done via a different path.
+
+##### How to obtain the same behavior as v3.x in v4.x
+
+In order to obtain the same behavior as version `v3.x`, you should update the path used to access the layers.
+
+In version `v3.x`:
+```bash
+from transformers.modeling_bert import BertLayer
+```
+to obtain the same in version `v4.x`:
+```bash
+from transformers.models.bert.modeling_bert import BertLayer
+```
+
+#### 4. Switching the `return_dict` argument to `True` by default
+
+The [`return_dict` argument](main_classes/output) enables the return of dict-like python objects containing the model outputs, instead of the standard tuples. This object is self-documented as keys can be used to retrieve values, while also behaving as a tuple as users may retrieve objects by index or by slice.
+
+This is a breaking change as the limitation of that tuple is that it cannot be unpacked: `value0, value1 = outputs` will not work.
+
+##### How to obtain the same behavior as v3.x in v4.x
+
+In order to obtain the same behavior as version `v3.x`, you should specify the `return_dict` argument to `False`, either in the model configuration or during the forward pass.
+
+In version `v3.x`:
+```bash
+model = BertModel.from_pretrained("bert-base-cased")
+outputs = model(**inputs)
+```
+to obtain the same in version `v4.x`:
+```bash
+model = BertModel.from_pretrained("bert-base-cased")
+outputs = model(**inputs, return_dict=False)
+```
+or
+```bash
+model = BertModel.from_pretrained("bert-base-cased", return_dict=False)
+outputs = model(**inputs)
+```
+
+#### 5. Removed some deprecated attributes
+
+Attributes that were deprecated have been removed if they had been deprecated for at least a month. The full list of deprecated attributes can be found in [#8604](https://github.com/huggingface/transformers/pull/8604).
+
+Here is a list of these attributes/methods/arguments and what their replacements should be:
+
+In several models, the labels become consistent with the other models:
+- `masked_lm_labels` becomes `labels` in `AlbertForMaskedLM` and `AlbertForPreTraining`.
+- `masked_lm_labels` becomes `labels` in `BertForMaskedLM` and `BertForPreTraining`.
+- `masked_lm_labels` becomes `labels` in `DistilBertForMaskedLM`.
+- `masked_lm_labels` becomes `labels` in `ElectraForMaskedLM`.
+- `masked_lm_labels` becomes `labels` in `LongformerForMaskedLM`.
+- `masked_lm_labels` becomes `labels` in `MobileBertForMaskedLM`.
+- `masked_lm_labels` becomes `labels` in `RobertaForMaskedLM`.
+- `lm_labels` becomes `labels` in `BartForConditionalGeneration`.
+- `lm_labels` becomes `labels` in `GPT2DoubleHeadsModel`.
+- `lm_labels` becomes `labels` in `OpenAIGPTDoubleHeadsModel`.
+- `lm_labels` becomes `labels` in `T5ForConditionalGeneration`.
+
+In several models, the caching mechanism becomes consistent with the other models:
+- `decoder_cached_states` becomes `past_key_values` in all BART-like, FSMT and T5 models.
+- `decoder_past_key_values` becomes `past_key_values` in all BART-like, FSMT and T5 models.
+- `past` becomes `past_key_values` in all CTRL models.
+- `past` becomes `past_key_values` in all GPT-2 models.
+
+Regarding the tokenizer classes:
+- The tokenizer attribute `max_len` becomes `model_max_length`.
+- The tokenizer attribute `return_lengths` becomes `return_length`.
+- The tokenizer encoding argument `is_pretokenized` becomes `is_split_into_words`.
+
+Regarding the `Trainer` class:
+- The `Trainer` argument `tb_writer` is removed in favor of the callback `TensorBoardCallback(tb_writer=...)`.
+- The `Trainer` argument `prediction_loss_only` is removed in favor of the class argument `args.prediction_loss_only`.
+- The `Trainer` attribute `data_collator` should be a callable.
+- The `Trainer` method `_log` is deprecated in favor of `log`.
+- The `Trainer` method `_training_step` is deprecated in favor of `training_step`.
+- The `Trainer` method `_prediction_loop` is deprecated in favor of `prediction_loop`.
+- The `Trainer` method `is_local_master` is deprecated in favor of `is_local_process_zero`.
+- The `Trainer` method `is_world_master` is deprecated in favor of `is_world_process_zero`.
+
+Regarding the `TFTrainer` class:
+- The `TFTrainer` argument `prediction_loss_only` is removed in favor of the class argument `args.prediction_loss_only`.
+- The `Trainer` method `_log` is deprecated in favor of `log`.
+- The `TFTrainer` method `_prediction_loop` is deprecated in favor of `prediction_loop`.
+- The `TFTrainer` method `_setup_wandb` is deprecated in favor of `setup_wandb`.
+- The `TFTrainer` method `_run_model` is deprecated in favor of `run_model`.
+
+Regarding the `TrainingArguments` class:
+- The `TrainingArguments` argument `evaluate_during_training` is deprecated in favor of `evaluation_strategy`.
+
+Regarding the Transfo-XL model:
+- The Transfo-XL configuration attribute `tie_weight` becomes `tie_words_embeddings`.
+- The Transfo-XL modeling method `reset_length` becomes `reset_memory_length`.
+
+Regarding pipelines:
+- The `FillMaskPipeline` argument `topk` becomes `top_k`.
+
+
+
+## Migrating from pytorch-transformers to 🤗 Transformers
+
+Here is a quick summary of what you should take care of when migrating from `pytorch-transformers` to 🤗 Transformers.
+
+### Positional order of some models' keywords inputs (`attention_mask`, `token_type_ids`...) changed
+
+To be able to use Torchscript (see #1010, #1204 and #1195) the specific order of some models **keywords inputs** (`attention_mask`, `token_type_ids`...) has been changed.
+
+If you used to call the models with keyword names for keyword arguments, e.g. `model(inputs_ids, attention_mask=attention_mask, token_type_ids=token_type_ids)`, this should not cause any change.
+
+If you used to call the models with positional inputs for keyword arguments, e.g. `model(inputs_ids, attention_mask, token_type_ids)`, you may have to double check the exact order of input arguments.
+
+## Migrating from pytorch-pretrained-bert
+
+Here is a quick summary of what you should take care of when migrating from `pytorch-pretrained-bert` to 🤗 Transformers
+
+### Models always output `tuples`
+
+The main breaking change when migrating from `pytorch-pretrained-bert` to 🤗 Transformers is that the models forward method always outputs a `tuple` with various elements depending on the model and the configuration parameters.
+
+The exact content of the tuples for each model are detailed in the models' docstrings and the [documentation](https://huggingface.co/transformers/).
+
+In pretty much every case, you will be fine by taking the first element of the output as the output you previously used in `pytorch-pretrained-bert`.
+
+Here is a `pytorch-pretrained-bert` to 🤗 Transformers conversion example for a `BertForSequenceClassification` classification model:
+
+```python
+# Let's load our model
+model = BertForSequenceClassification.from_pretrained("bert-base-uncased")
+
+# If you used to have this line in pytorch-pretrained-bert:
+loss = model(input_ids, labels=labels)
+
+# Now just use this line in 🤗 Transformers to extract the loss from the output tuple:
+outputs = model(input_ids, labels=labels)
+loss = outputs[0]
+
+# In 🤗 Transformers you can also have access to the logits:
+loss, logits = outputs[:2]
+
+# And even the attention weights if you configure the model to output them (and other outputs too, see the docstrings and documentation)
+model = BertForSequenceClassification.from_pretrained("bert-base-uncased", output_attentions=True)
+outputs = model(input_ids, labels=labels)
+loss, logits, attentions = outputs
+```
+
+### Serialization
+
+Breaking change in the `from_pretrained()`method:
+
+1. Models are now set in evaluation mode by default when instantiated with the `from_pretrained()` method. To train them don't forget to set them back in training mode (`model.train()`) to activate the dropout modules.
+
+2. The additional `*inputs` and `**kwargs` arguments supplied to the `from_pretrained()` method used to be directly passed to the underlying model's class `__init__()` method. They are now used to update the model configuration attribute first which can break derived model classes build based on the previous `BertForSequenceClassification` examples. More precisely, the positional arguments `*inputs` provided to `from_pretrained()` are directly forwarded the model `__init__()` method while the keyword arguments `**kwargs` (i) which match configuration class attributes are used to update said attributes (ii) which don't match any configuration class attributes are forwarded to the model `__init__()` method.
+
+Also, while not a breaking change, the serialization methods have been standardized and you probably should switch to the new method `save_pretrained(save_directory)` if you were using any other serialization method before.
+
+Here is an example:
+
+```python
+### Let's load a model and tokenizer
+model = BertForSequenceClassification.from_pretrained("bert-base-uncased")
+tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
+
+### Do some stuff to our model and tokenizer
+# Ex: add new tokens to the vocabulary and embeddings of our model
+tokenizer.add_tokens(["[SPECIAL_TOKEN_1]", "[SPECIAL_TOKEN_2]"])
+model.resize_token_embeddings(len(tokenizer))
+# Train our model
+train(model)
+
+### Now let's save our model and tokenizer to a directory
+model.save_pretrained("./my_saved_model_directory/")
+tokenizer.save_pretrained("./my_saved_model_directory/")
+
+### Reload the model and the tokenizer
+model = BertForSequenceClassification.from_pretrained("./my_saved_model_directory/")
+tokenizer = BertTokenizer.from_pretrained("./my_saved_model_directory/")
+```
+
+### Optimizers: BertAdam & OpenAIAdam are now AdamW, schedules are standard PyTorch schedules
+
+The two optimizers previously included, `BertAdam` and `OpenAIAdam`, have been replaced by a single `AdamW` optimizer which has a few differences:
+
+- it only implements weights decay correction,
+- schedules are now externals (see below),
+- gradient clipping is now also external (see below).
+
+The new optimizer `AdamW` matches PyTorch `Adam` optimizer API and let you use standard PyTorch or apex methods for the schedule and clipping.
+
+The schedules are now standard [PyTorch learning rate schedulers](https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate) and not part of the optimizer anymore.
+
+Here is a conversion examples from `BertAdam` with a linear warmup and decay schedule to `AdamW` and the same schedule:
+
+```python
+# Parameters:
+lr = 1e-3
+max_grad_norm = 1.0
+num_training_steps = 1000
+num_warmup_steps = 100
+warmup_proportion = float(num_warmup_steps) / float(num_training_steps) # 0.1
+
+### Previously BertAdam optimizer was instantiated like this:
+optimizer = BertAdam(
+ model.parameters(),
+ lr=lr,
+ schedule="warmup_linear",
+ warmup=warmup_proportion,
+ num_training_steps=num_training_steps,
+)
+### and used like this:
+for batch in train_data:
+ loss = model(batch)
+ loss.backward()
+ optimizer.step()
+
+### In 🤗 Transformers, optimizer and schedules are split and instantiated like this:
+optimizer = AdamW(
+ model.parameters(), lr=lr, correct_bias=False
+) # To reproduce BertAdam specific behavior set correct_bias=False
+scheduler = get_linear_schedule_with_warmup(
+ optimizer, num_warmup_steps=num_warmup_steps, num_training_steps=num_training_steps
+) # PyTorch scheduler
+### and used like this:
+for batch in train_data:
+ loss = model(batch)
+ loss.backward()
+ torch.nn.utils.clip_grad_norm_(
+ model.parameters(), max_grad_norm
+ ) # Gradient clipping is not in AdamW anymore (so you can use amp without issue)
+ optimizer.step()
+ scheduler.step()
+```
diff --git a/docs/source/en/model_doc/albert.mdx b/docs/source/en/model_doc/albert.mdx
new file mode 100644
index 00000000000000..54873c0fa9c609
--- /dev/null
+++ b/docs/source/en/model_doc/albert.mdx
@@ -0,0 +1,170 @@
+
+
+# ALBERT
+
+## Overview
+
+The ALBERT model was proposed in [ALBERT: A Lite BERT for Self-supervised Learning of Language Representations](https://arxiv.org/abs/1909.11942) by Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma,
+Radu Soricut. It presents two parameter-reduction techniques to lower memory consumption and increase the training
+speed of BERT:
+
+- Splitting the embedding matrix into two smaller matrices.
+- Using repeating layers split among groups.
+
+The abstract from the paper is the following:
+
+*Increasing model size when pretraining natural language representations often results in improved performance on
+downstream tasks. However, at some point further model increases become harder due to GPU/TPU memory limitations,
+longer training times, and unexpected model degradation. To address these problems, we present two parameter-reduction
+techniques to lower memory consumption and increase the training speed of BERT. Comprehensive empirical evidence shows
+that our proposed methods lead to models that scale much better compared to the original BERT. We also use a
+self-supervised loss that focuses on modeling inter-sentence coherence, and show it consistently helps downstream tasks
+with multi-sentence inputs. As a result, our best model establishes new state-of-the-art results on the GLUE, RACE, and
+SQuAD benchmarks while having fewer parameters compared to BERT-large.*
+
+Tips:
+
+- ALBERT is a model with absolute position embeddings so it's usually advised to pad the inputs on the right rather
+ than the left.
+- ALBERT uses repeating layers which results in a small memory footprint, however the computational cost remains
+ similar to a BERT-like architecture with the same number of hidden layers as it has to iterate through the same
+ number of (repeating) layers.
+
+This model was contributed by [lysandre](https://huggingface.co/lysandre). This model jax version was contributed by
+[kamalkraj](https://huggingface.co/kamalkraj). The original code can be found [here](https://github.com/google-research/ALBERT).
+
+## AlbertConfig
+
+[[autodoc]] AlbertConfig
+
+## AlbertTokenizer
+
+[[autodoc]] AlbertTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## AlbertTokenizerFast
+
+[[autodoc]] AlbertTokenizerFast
+
+## Albert specific outputs
+
+[[autodoc]] models.albert.modeling_albert.AlbertForPreTrainingOutput
+
+[[autodoc]] models.albert.modeling_tf_albert.TFAlbertForPreTrainingOutput
+
+## AlbertModel
+
+[[autodoc]] AlbertModel
+ - forward
+
+## AlbertForPreTraining
+
+[[autodoc]] AlbertForPreTraining
+ - forward
+
+## AlbertForMaskedLM
+
+[[autodoc]] AlbertForMaskedLM
+ - forward
+
+## AlbertForSequenceClassification
+
+[[autodoc]] AlbertForSequenceClassification
+ - forward
+
+## AlbertForMultipleChoice
+
+[[autodoc]] AlbertForMultipleChoice
+
+## AlbertForTokenClassification
+
+[[autodoc]] AlbertForTokenClassification
+ - forward
+
+## AlbertForQuestionAnswering
+
+[[autodoc]] AlbertForQuestionAnswering
+ - forward
+
+## TFAlbertModel
+
+[[autodoc]] TFAlbertModel
+ - call
+
+## TFAlbertForPreTraining
+
+[[autodoc]] TFAlbertForPreTraining
+ - call
+
+## TFAlbertForMaskedLM
+
+[[autodoc]] TFAlbertForMaskedLM
+ - call
+
+## TFAlbertForSequenceClassification
+
+[[autodoc]] TFAlbertForSequenceClassification
+ - call
+
+## TFAlbertForMultipleChoice
+
+[[autodoc]] TFAlbertForMultipleChoice
+ - call
+
+## TFAlbertForTokenClassification
+
+[[autodoc]] TFAlbertForTokenClassification
+ - call
+
+## TFAlbertForQuestionAnswering
+
+[[autodoc]] TFAlbertForQuestionAnswering
+ - call
+
+## FlaxAlbertModel
+
+[[autodoc]] FlaxAlbertModel
+ - __call__
+
+## FlaxAlbertForPreTraining
+
+[[autodoc]] FlaxAlbertForPreTraining
+ - __call__
+
+## FlaxAlbertForMaskedLM
+
+[[autodoc]] FlaxAlbertForMaskedLM
+ - __call__
+
+## FlaxAlbertForSequenceClassification
+
+[[autodoc]] FlaxAlbertForSequenceClassification
+ - __call__
+
+## FlaxAlbertForMultipleChoice
+
+[[autodoc]] FlaxAlbertForMultipleChoice
+ - __call__
+
+## FlaxAlbertForTokenClassification
+
+[[autodoc]] FlaxAlbertForTokenClassification
+ - __call__
+
+## FlaxAlbertForQuestionAnswering
+
+[[autodoc]] FlaxAlbertForQuestionAnswering
+ - __call__
diff --git a/docs/source/en/model_doc/auto.mdx b/docs/source/en/model_doc/auto.mdx
new file mode 100644
index 00000000000000..d941b00318b086
--- /dev/null
+++ b/docs/source/en/model_doc/auto.mdx
@@ -0,0 +1,263 @@
+
+
+# Auto Classes
+
+In many cases, the architecture you want to use can be guessed from the name or the path of the pretrained model you
+are supplying to the `from_pretrained()` method. AutoClasses are here to do this job for you so that you
+automatically retrieve the relevant model given the name/path to the pretrained weights/config/vocabulary.
+
+Instantiating one of [`AutoConfig`], [`AutoModel`], and
+[`AutoTokenizer`] will directly create a class of the relevant architecture. For instance
+
+
+```python
+model = AutoModel.from_pretrained("bert-base-cased")
+```
+
+will create a model that is an instance of [`BertModel`].
+
+There is one class of `AutoModel` for each task, and for each backend (PyTorch, TensorFlow, or Flax).
+
+## Extending the Auto Classes
+
+Each of the auto classes has a method to be extended with your custom classes. For instance, if you have defined a
+custom class of model `NewModel`, make sure you have a `NewModelConfig` then you can add those to the auto
+classes like this:
+
+```python
+from transformers import AutoConfig, AutoModel
+
+AutoConfig.register("new-model", NewModelConfig)
+AutoModel.register(NewModelConfig, NewModel)
+```
+
+You will then be able to use the auto classes like you would usually do!
+
+
+
+If your `NewModelConfig` is a subclass of [`~transformer.PretrainedConfig`], make sure its
+`model_type` attribute is set to the same key you use when registering the config (here `"new-model"`).
+
+Likewise, if your `NewModel` is a subclass of [`PreTrainedModel`], make sure its
+`config_class` attribute is set to the same class you use when registering the model (here
+`NewModelConfig`).
+
+
+
+## AutoConfig
+
+[[autodoc]] AutoConfig
+
+## AutoTokenizer
+
+[[autodoc]] AutoTokenizer
+
+## AutoFeatureExtractor
+
+[[autodoc]] AutoFeatureExtractor
+
+## AutoProcessor
+
+[[autodoc]] AutoProcessor
+
+## AutoModel
+
+[[autodoc]] AutoModel
+
+## AutoModelForPreTraining
+
+[[autodoc]] AutoModelForPreTraining
+
+## AutoModelForCausalLM
+
+[[autodoc]] AutoModelForCausalLM
+
+## AutoModelForMaskedLM
+
+[[autodoc]] AutoModelForMaskedLM
+
+## AutoModelForSeq2SeqLM
+
+[[autodoc]] AutoModelForSeq2SeqLM
+
+## AutoModelForSequenceClassification
+
+[[autodoc]] AutoModelForSequenceClassification
+
+## AutoModelForMultipleChoice
+
+[[autodoc]] AutoModelForMultipleChoice
+
+## AutoModelForNextSentencePrediction
+
+[[autodoc]] AutoModelForNextSentencePrediction
+
+## AutoModelForTokenClassification
+
+[[autodoc]] AutoModelForTokenClassification
+
+## AutoModelForQuestionAnswering
+
+[[autodoc]] AutoModelForQuestionAnswering
+
+## AutoModelForTableQuestionAnswering
+
+[[autodoc]] AutoModelForTableQuestionAnswering
+
+## AutoModelForImageClassification
+
+[[autodoc]] AutoModelForImageClassification
+
+## AutoModelForVision2Seq
+
+[[autodoc]] AutoModelForVision2Seq
+
+## AutoModelForAudioClassification
+
+[[autodoc]] AutoModelForAudioClassification
+
+## AutoModelForAudioFrameClassification
+
+[[autodoc]] AutoModelForAudioFrameClassification
+
+## AutoModelForCTC
+
+[[autodoc]] AutoModelForCTC
+
+## AutoModelForSpeechSeq2Seq
+
+[[autodoc]] AutoModelForSpeechSeq2Seq
+
+## AutoModelForAudioXVector
+
+[[autodoc]] AutoModelForAudioXVector
+
+## AutoModelForMaskedImageModeling
+
+[[autodoc]] AutoModelForMaskedImageModeling
+
+## AutoModelForObjectDetection
+
+[[autodoc]] AutoModelForObjectDetection
+
+## AutoModelForImageSegmentation
+
+[[autodoc]] AutoModelForImageSegmentation
+
+## AutoModelForSemanticSegmentation
+
+[[autodoc]] AutoModelForSemanticSegmentation
+
+## AutoModelForInstanceSegmentation
+
+[[autodoc]] AutoModelForInstanceSegmentation
+
+## TFAutoModel
+
+[[autodoc]] TFAutoModel
+
+## TFAutoModelForPreTraining
+
+[[autodoc]] TFAutoModelForPreTraining
+
+## TFAutoModelForCausalLM
+
+[[autodoc]] TFAutoModelForCausalLM
+
+## TFAutoModelForImageClassification
+
+[[autodoc]] TFAutoModelForImageClassification
+
+## TFAutoModelForMaskedLM
+
+[[autodoc]] TFAutoModelForMaskedLM
+
+## TFAutoModelForSeq2SeqLM
+
+[[autodoc]] TFAutoModelForSeq2SeqLM
+
+## TFAutoModelForSequenceClassification
+
+[[autodoc]] TFAutoModelForSequenceClassification
+
+## TFAutoModelForMultipleChoice
+
+[[autodoc]] TFAutoModelForMultipleChoice
+
+## TFAutoModelForTableQuestionAnswering
+
+[[autodoc]] TFAutoModelForTableQuestionAnswering
+
+## TFAutoModelForTokenClassification
+
+[[autodoc]] TFAutoModelForTokenClassification
+
+## TFAutoModelForQuestionAnswering
+
+[[autodoc]] TFAutoModelForQuestionAnswering
+
+## TFAutoModelForVision2Seq
+
+[[autodoc]] TFAutoModelForVision2Seq
+
+## TFAutoModelForSpeechSeq2Seq
+
+[[autodoc]] TFAutoModelForSpeechSeq2Seq
+
+## FlaxAutoModel
+
+[[autodoc]] FlaxAutoModel
+
+## FlaxAutoModelForCausalLM
+
+[[autodoc]] FlaxAutoModelForCausalLM
+
+## FlaxAutoModelForPreTraining
+
+[[autodoc]] FlaxAutoModelForPreTraining
+
+## FlaxAutoModelForMaskedLM
+
+[[autodoc]] FlaxAutoModelForMaskedLM
+
+## FlaxAutoModelForSeq2SeqLM
+
+[[autodoc]] FlaxAutoModelForSeq2SeqLM
+
+## FlaxAutoModelForSequenceClassification
+
+[[autodoc]] FlaxAutoModelForSequenceClassification
+
+## FlaxAutoModelForQuestionAnswering
+
+[[autodoc]] FlaxAutoModelForQuestionAnswering
+
+## FlaxAutoModelForTokenClassification
+
+[[autodoc]] FlaxAutoModelForTokenClassification
+
+## FlaxAutoModelForMultipleChoice
+
+[[autodoc]] FlaxAutoModelForMultipleChoice
+
+## FlaxAutoModelForNextSentencePrediction
+
+[[autodoc]] FlaxAutoModelForNextSentencePrediction
+
+## FlaxAutoModelForImageClassification
+
+[[autodoc]] FlaxAutoModelForImageClassification
+
+## FlaxAutoModelForVision2Seq
+
+[[autodoc]] FlaxAutoModelForVision2Seq
diff --git a/docs/source/en/model_doc/bart.mdx b/docs/source/en/model_doc/bart.mdx
new file mode 100644
index 00000000000000..da13011bc43601
--- /dev/null
+++ b/docs/source/en/model_doc/bart.mdx
@@ -0,0 +1,159 @@
+
+
+# BART
+
+**DISCLAIMER:** If you see something strange, file a [Github Issue](https://github.com/huggingface/transformers/issues/new?assignees=&labels=&template=bug-report.md&title) and assign
+@patrickvonplaten
+
+## Overview
+
+The Bart model was proposed in [BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation,
+Translation, and Comprehension](https://arxiv.org/abs/1910.13461) by Mike Lewis, Yinhan Liu, Naman Goyal, Marjan
+Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov and Luke Zettlemoyer on 29 Oct, 2019.
+
+According to the abstract,
+
+- Bart uses a standard seq2seq/machine translation architecture with a bidirectional encoder (like BERT) and a
+ left-to-right decoder (like GPT).
+- The pretraining task involves randomly shuffling the order of the original sentences and a novel in-filling scheme,
+ where spans of text are replaced with a single mask token.
+- BART is particularly effective when fine tuned for text generation but also works well for comprehension tasks. It
+ matches the performance of RoBERTa with comparable training resources on GLUE and SQuAD, achieves new
+ state-of-the-art results on a range of abstractive dialogue, question answering, and summarization tasks, with gains
+ of up to 6 ROUGE.
+
+This model was contributed by [sshleifer](https://huggingface.co/sshleifer). The Authors' code can be found [here](https://github.com/pytorch/fairseq/tree/master/examples/bart).
+
+
+### Examples
+
+- Examples and scripts for fine-tuning BART and other models for sequence to sequence tasks can be found in
+ [examples/pytorch/summarization/](https://github.com/huggingface/transformers/tree/main/examples/pytorch/summarization/README.md).
+- An example of how to train [`BartForConditionalGeneration`] with a Hugging Face `datasets`
+ object can be found in this [forum discussion](https://discuss.huggingface.co/t/train-bart-for-conditional-generation-e-g-summarization/1904).
+- [Distilled checkpoints](https://huggingface.co/models?search=distilbart) are described in this [paper](https://arxiv.org/abs/2010.13002).
+
+
+## Implementation Notes
+
+- Bart doesn't use `token_type_ids` for sequence classification. Use [`BartTokenizer`] or
+ [`~BartTokenizer.encode`] to get the proper splitting.
+- The forward pass of [`BartModel`] will create the `decoder_input_ids` if they are not passed.
+ This is different than some other modeling APIs. A typical use case of this feature is mask filling.
+- Model predictions are intended to be identical to the original implementation when
+ `forced_bos_token_id=0`. This only works, however, if the string you pass to
+ [`fairseq.encode`] starts with a space.
+- [`~generation_utils.GenerationMixin.generate`] should be used for conditional generation tasks like
+ summarization, see the example in that docstrings.
+- Models that load the *facebook/bart-large-cnn* weights will not have a `mask_token_id`, or be able to perform
+ mask-filling tasks.
+
+## Mask Filling
+
+The `facebook/bart-base` and `facebook/bart-large` checkpoints can be used to fill multi-token masks.
+
+```python
+from transformers import BartForConditionalGeneration, BartTokenizer
+
+model = BartForConditionalGeneration.from_pretrained("facebook/bart-large", forced_bos_token_id=0)
+tok = BartTokenizer.from_pretrained("facebook/bart-large")
+example_english_phrase = "UN Chief Says There Is No in Syria"
+batch = tok(example_english_phrase, return_tensors="pt")
+generated_ids = model.generate(batch["input_ids"])
+assert tok.batch_decode(generated_ids, skip_special_tokens=True) == [
+ "UN Chief Says There Is No Plan to Stop Chemical Weapons in Syria"
+]
+```
+
+## BartConfig
+
+[[autodoc]] BartConfig
+ - all
+
+## BartTokenizer
+
+[[autodoc]] BartTokenizer
+ - all
+
+## BartTokenizerFast
+
+[[autodoc]] BartTokenizerFast
+ - all
+
+## BartModel
+
+[[autodoc]] BartModel
+ - forward
+
+## BartForConditionalGeneration
+
+[[autodoc]] BartForConditionalGeneration
+ - forward
+
+## BartForSequenceClassification
+
+[[autodoc]] BartForSequenceClassification
+ - forward
+
+## BartForQuestionAnswering
+
+[[autodoc]] BartForQuestionAnswering
+ - forward
+
+## BartForCausalLM
+
+[[autodoc]] BartForCausalLM
+ - forward
+
+## TFBartModel
+
+[[autodoc]] TFBartModel
+ - call
+
+## TFBartForConditionalGeneration
+
+[[autodoc]] TFBartForConditionalGeneration
+ - call
+
+## FlaxBartModel
+
+[[autodoc]] FlaxBartModel
+ - __call__
+ - encode
+ - decode
+
+## FlaxBartForConditionalGeneration
+
+[[autodoc]] FlaxBartForConditionalGeneration
+ - __call__
+ - encode
+ - decode
+
+## FlaxBartForSequenceClassification
+
+[[autodoc]] FlaxBartForSequenceClassification
+ - __call__
+ - encode
+ - decode
+
+## FlaxBartForQuestionAnswering
+
+[[autodoc]] FlaxBartForQuestionAnswering
+ - __call__
+ - encode
+ - decode
+
+## FlaxBartForCausalLM
+
+[[autodoc]] FlaxBartForCausalLM
+ - __call__
\ No newline at end of file
diff --git a/docs/source/en/model_doc/barthez.mdx b/docs/source/en/model_doc/barthez.mdx
new file mode 100644
index 00000000000000..f1969e8e942422
--- /dev/null
+++ b/docs/source/en/model_doc/barthez.mdx
@@ -0,0 +1,50 @@
+
+
+# BARThez
+
+## Overview
+
+The BARThez model was proposed in [BARThez: a Skilled Pretrained French Sequence-to-Sequence Model](https://arxiv.org/abs/2010.12321) by Moussa Kamal Eddine, Antoine J.-P. Tixier, Michalis Vazirgiannis on 23 Oct,
+2020.
+
+The abstract of the paper:
+
+
+*Inductive transfer learning, enabled by self-supervised learning, have taken the entire Natural Language Processing
+(NLP) field by storm, with models such as BERT and BART setting new state of the art on countless natural language
+understanding tasks. While there are some notable exceptions, most of the available models and research have been
+conducted for the English language. In this work, we introduce BARThez, the first BART model for the French language
+(to the best of our knowledge). BARThez was pretrained on a very large monolingual French corpus from past research
+that we adapted to suit BART's perturbation schemes. Unlike already existing BERT-based French language models such as
+CamemBERT and FlauBERT, BARThez is particularly well-suited for generative tasks, since not only its encoder but also
+its decoder is pretrained. In addition to discriminative tasks from the FLUE benchmark, we evaluate BARThez on a novel
+summarization dataset, OrangeSum, that we release with this paper. We also continue the pretraining of an already
+pretrained multilingual BART on BARThez's corpus, and we show that the resulting model, which we call mBARTHez,
+provides a significant boost over vanilla BARThez, and is on par with or outperforms CamemBERT and FlauBERT.*
+
+This model was contributed by [moussakam](https://huggingface.co/moussakam). The Authors' code can be found [here](https://github.com/moussaKam/BARThez).
+
+
+### Examples
+
+- BARThez can be fine-tuned on sequence-to-sequence tasks in a similar way as BART, check:
+ [examples/pytorch/summarization/](https://github.com/huggingface/transformers/tree/main/examples/pytorch/summarization/README.md).
+
+
+## BarthezTokenizer
+
+[[autodoc]] BarthezTokenizer
+
+## BarthezTokenizerFast
+
+[[autodoc]] BarthezTokenizerFast
diff --git a/docs/source/en/model_doc/bartpho.mdx b/docs/source/en/model_doc/bartpho.mdx
new file mode 100644
index 00000000000000..d940173b42f861
--- /dev/null
+++ b/docs/source/en/model_doc/bartpho.mdx
@@ -0,0 +1,82 @@
+
+
+# BARTpho
+
+## Overview
+
+The BARTpho model was proposed in [BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnamese](https://arxiv.org/abs/2109.09701) by Nguyen Luong Tran, Duong Minh Le and Dat Quoc Nguyen.
+
+The abstract from the paper is the following:
+
+*We present BARTpho with two versions -- BARTpho_word and BARTpho_syllable -- the first public large-scale monolingual
+sequence-to-sequence models pre-trained for Vietnamese. Our BARTpho uses the "large" architecture and pre-training
+scheme of the sequence-to-sequence denoising model BART, thus especially suitable for generative NLP tasks. Experiments
+on a downstream task of Vietnamese text summarization show that in both automatic and human evaluations, our BARTpho
+outperforms the strong baseline mBART and improves the state-of-the-art. We release BARTpho to facilitate future
+research and applications of generative Vietnamese NLP tasks.*
+
+Example of use:
+
+```python
+>>> import torch
+>>> from transformers import AutoModel, AutoTokenizer
+
+>>> bartpho = AutoModel.from_pretrained("vinai/bartpho-syllable")
+
+>>> tokenizer = AutoTokenizer.from_pretrained("vinai/bartpho-syllable")
+
+>>> line = "Chúng tôi là những nghiên cứu viên."
+
+>>> input_ids = tokenizer(line, return_tensors="pt")
+
+>>> with torch.no_grad():
+... features = bartpho(**input_ids) # Models outputs are now tuples
+
+>>> # With TensorFlow 2.0+:
+>>> from transformers import TFAutoModel
+
+>>> bartpho = TFAutoModel.from_pretrained("vinai/bartpho-syllable")
+>>> input_ids = tokenizer(line, return_tensors="tf")
+>>> features = bartpho(**input_ids)
+```
+
+Tips:
+
+- Following mBART, BARTpho uses the "large" architecture of BART with an additional layer-normalization layer on top of
+ both the encoder and decoder. Thus, usage examples in the [documentation of BART](bart), when adapting to use
+ with BARTpho, should be adjusted by replacing the BART-specialized classes with the mBART-specialized counterparts.
+ For example:
+
+```python
+>>> from transformers import MBartForConditionalGeneration
+
+>>> bartpho = MBartForConditionalGeneration.from_pretrained("vinai/bartpho-syllable")
+>>> TXT = "Chúng tôi là nghiên cứu viên."
+>>> input_ids = tokenizer([TXT], return_tensors="pt")["input_ids"]
+>>> logits = bartpho(input_ids).logits
+>>> masked_index = (input_ids[0] == tokenizer.mask_token_id).nonzero().item()
+>>> probs = logits[0, masked_index].softmax(dim=0)
+>>> values, predictions = probs.topk(5)
+>>> print(tokenizer.decode(predictions).split())
+```
+
+- This implementation is only for tokenization: "monolingual_vocab_file" consists of Vietnamese-specialized types
+ extracted from the pre-trained SentencePiece model "vocab_file" that is available from the multilingual XLM-RoBERTa.
+ Other languages, if employing this pre-trained multilingual SentencePiece model "vocab_file" for subword
+ segmentation, can reuse BartphoTokenizer with their own language-specialized "monolingual_vocab_file".
+
+This model was contributed by [dqnguyen](https://huggingface.co/dqnguyen). The original code can be found [here](https://github.com/VinAIResearch/BARTpho).
+
+## BartphoTokenizer
+
+[[autodoc]] BartphoTokenizer
diff --git a/docs/source/en/model_doc/beit.mdx b/docs/source/en/model_doc/beit.mdx
new file mode 100644
index 00000000000000..625357810ded9f
--- /dev/null
+++ b/docs/source/en/model_doc/beit.mdx
@@ -0,0 +1,114 @@
+
+
+# BEiT
+
+## Overview
+
+The BEiT model was proposed in [BEiT: BERT Pre-Training of Image Transformers](https://arxiv.org/abs/2106.08254) by
+Hangbo Bao, Li Dong and Furu Wei. Inspired by BERT, BEiT is the first paper that makes self-supervised pre-training of
+Vision Transformers (ViTs) outperform supervised pre-training. Rather than pre-training the model to predict the class
+of an image (as done in the [original ViT paper](https://arxiv.org/abs/2010.11929)), BEiT models are pre-trained to
+predict visual tokens from the codebook of OpenAI's [DALL-E model](https://arxiv.org/abs/2102.12092) given masked
+patches.
+
+The abstract from the paper is the following:
+
+*We introduce a self-supervised vision representation model BEiT, which stands for Bidirectional Encoder representation
+from Image Transformers. Following BERT developed in the natural language processing area, we propose a masked image
+modeling task to pretrain vision Transformers. Specifically, each image has two views in our pre-training, i.e, image
+patches (such as 16x16 pixels), and visual tokens (i.e., discrete tokens). We first "tokenize" the original image into
+visual tokens. Then we randomly mask some image patches and fed them into the backbone Transformer. The pre-training
+objective is to recover the original visual tokens based on the corrupted image patches. After pre-training BEiT, we
+directly fine-tune the model parameters on downstream tasks by appending task layers upon the pretrained encoder.
+Experimental results on image classification and semantic segmentation show that our model achieves competitive results
+with previous pre-training methods. For example, base-size BEiT achieves 83.2% top-1 accuracy on ImageNet-1K,
+significantly outperforming from-scratch DeiT training (81.8%) with the same setup. Moreover, large-size BEiT obtains
+86.3% only using ImageNet-1K, even outperforming ViT-L with supervised pre-training on ImageNet-22K (85.2%).*
+
+Tips:
+
+- BEiT models are regular Vision Transformers, but pre-trained in a self-supervised way rather than supervised. They
+ outperform both the [original model (ViT)](vit) as well as [Data-efficient Image Transformers (DeiT)](deit) when fine-tuned on ImageNet-1K and CIFAR-100. You can check out demo notebooks regarding inference as well as
+ fine-tuning on custom data [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/VisionTransformer) (you can just replace
+ [`ViTFeatureExtractor`] by [`BeitFeatureExtractor`] and
+ [`ViTForImageClassification`] by [`BeitForImageClassification`]).
+- There's also a demo notebook available which showcases how to combine DALL-E's image tokenizer with BEiT for
+ performing masked image modeling. You can find it [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/BEiT).
+- As the BEiT models expect each image to be of the same size (resolution), one can use
+ [`BeitFeatureExtractor`] to resize (or rescale) and normalize images for the model.
+- Both the patch resolution and image resolution used during pre-training or fine-tuning are reflected in the name of
+ each checkpoint. For example, `microsoft/beit-base-patch16-224` refers to a base-sized architecture with patch
+ resolution of 16x16 and fine-tuning resolution of 224x224. All checkpoints can be found on the [hub](https://huggingface.co/models?search=microsoft/beit).
+- The available checkpoints are either (1) pre-trained on [ImageNet-22k](http://www.image-net.org/) (a collection of
+ 14 million images and 22k classes) only, (2) also fine-tuned on ImageNet-22k or (3) also fine-tuned on [ImageNet-1k](http://www.image-net.org/challenges/LSVRC/2012/) (also referred to as ILSVRC 2012, a collection of 1.3 million
+ images and 1,000 classes).
+- BEiT uses relative position embeddings, inspired by the T5 model. During pre-training, the authors shared the
+ relative position bias among the several self-attention layers. During fine-tuning, each layer's relative position
+ bias is initialized with the shared relative position bias obtained after pre-training. Note that, if one wants to
+ pre-train a model from scratch, one needs to either set the `use_relative_position_bias` or the
+ `use_relative_position_bias` attribute of [`BeitConfig`] to `True` in order to add
+ position embeddings.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The JAX/FLAX version of this model was
+contributed by [kamalkraj](https://huggingface.co/kamalkraj). The original code can be found [here](https://github.com/microsoft/unilm/tree/master/beit).
+
+
+## BEiT specific outputs
+
+[[autodoc]] models.beit.modeling_beit.BeitModelOutputWithPooling
+
+[[autodoc]] models.beit.modeling_flax_beit.FlaxBeitModelOutputWithPooling
+
+## BeitConfig
+
+[[autodoc]] BeitConfig
+
+## BeitFeatureExtractor
+
+[[autodoc]] BeitFeatureExtractor
+ - __call__
+
+## BeitModel
+
+[[autodoc]] BeitModel
+ - forward
+
+## BeitForMaskedImageModeling
+
+[[autodoc]] BeitForMaskedImageModeling
+ - forward
+
+## BeitForImageClassification
+
+[[autodoc]] BeitForImageClassification
+ - forward
+
+## BeitForSemanticSegmentation
+
+[[autodoc]] BeitForSemanticSegmentation
+ - forward
+
+## FlaxBeitModel
+
+[[autodoc]] FlaxBeitModel
+ - __call__
+
+## FlaxBeitForMaskedImageModeling
+
+[[autodoc]] FlaxBeitForMaskedImageModeling
+ - __call__
+
+## FlaxBeitForImageClassification
+
+[[autodoc]] FlaxBeitForImageClassification
+ - __call__
diff --git a/docs/source/en/model_doc/bert-generation.mdx b/docs/source/en/model_doc/bert-generation.mdx
new file mode 100644
index 00000000000000..e300917ea5e6f7
--- /dev/null
+++ b/docs/source/en/model_doc/bert-generation.mdx
@@ -0,0 +1,104 @@
+
+
+# BertGeneration
+
+## Overview
+
+The BertGeneration model is a BERT model that can be leveraged for sequence-to-sequence tasks using
+[`EncoderDecoderModel`] as proposed in [Leveraging Pre-trained Checkpoints for Sequence Generation
+Tasks](https://arxiv.org/abs/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
+
+The abstract from the paper is the following:
+
+*Unsupervised pretraining of large neural models has recently revolutionized Natural Language Processing. By
+warm-starting from the publicly released checkpoints, NLP practitioners have pushed the state-of-the-art on multiple
+benchmarks while saving significant amounts of compute time. So far the focus has been mainly on the Natural Language
+Understanding tasks. In this paper, we demonstrate the efficacy of pre-trained checkpoints for Sequence Generation. We
+developed a Transformer-based sequence-to-sequence model that is compatible with publicly available pre-trained BERT,
+GPT-2 and RoBERTa checkpoints and conducted an extensive empirical study on the utility of initializing our model, both
+encoder and decoder, with these checkpoints. Our models result in new state-of-the-art results on Machine Translation,
+Text Summarization, Sentence Splitting, and Sentence Fusion.*
+
+Usage:
+
+- The model can be used in combination with the [`EncoderDecoderModel`] to leverage two pretrained
+ BERT checkpoints for subsequent fine-tuning.
+
+```python
+>>> # leverage checkpoints for Bert2Bert model...
+>>> # use BERT's cls token as BOS token and sep token as EOS token
+>>> encoder = BertGenerationEncoder.from_pretrained("bert-large-uncased", bos_token_id=101, eos_token_id=102)
+>>> # add cross attention layers and use BERT's cls token as BOS token and sep token as EOS token
+>>> decoder = BertGenerationDecoder.from_pretrained(
+... "bert-large-uncased", add_cross_attention=True, is_decoder=True, bos_token_id=101, eos_token_id=102
+... )
+>>> bert2bert = EncoderDecoderModel(encoder=encoder, decoder=decoder)
+
+>>> # create tokenizer...
+>>> tokenizer = BertTokenizer.from_pretrained("bert-large-uncased")
+
+>>> input_ids = tokenizer(
+... "This is a long article to summarize", add_special_tokens=False, return_tensors="pt"
+... ).input_ids
+>>> labels = tokenizer("This is a short summary", return_tensors="pt").input_ids
+
+>>> # train...
+>>> loss = bert2bert(input_ids=input_ids, decoder_input_ids=labels, labels=labels).loss
+>>> loss.backward()
+```
+
+- Pretrained [`EncoderDecoderModel`] are also directly available in the model hub, e.g.,
+
+
+```python
+>>> # instantiate sentence fusion model
+>>> sentence_fuser = EncoderDecoderModel.from_pretrained("google/roberta2roberta_L-24_discofuse")
+>>> tokenizer = AutoTokenizer.from_pretrained("google/roberta2roberta_L-24_discofuse")
+
+>>> input_ids = tokenizer(
+... "This is the first sentence. This is the second sentence.", add_special_tokens=False, return_tensors="pt"
+... ).input_ids
+
+>>> outputs = sentence_fuser.generate(input_ids)
+
+>>> print(tokenizer.decode(outputs[0]))
+```
+
+Tips:
+
+- [`BertGenerationEncoder`] and [`BertGenerationDecoder`] should be used in
+ combination with [`EncoderDecoder`].
+- For summarization, sentence splitting, sentence fusion and translation, no special tokens are required for the input.
+ Therefore, no EOS token should be added to the end of the input.
+
+This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten). The original code can be
+found [here](https://tfhub.dev/s?module-type=text-generation&subtype=module,placeholder).
+
+## BertGenerationConfig
+
+[[autodoc]] BertGenerationConfig
+
+## BertGenerationTokenizer
+
+[[autodoc]] BertGenerationTokenizer
+ - save_vocabulary
+
+## BertGenerationEncoder
+
+[[autodoc]] BertGenerationEncoder
+ - forward
+
+## BertGenerationDecoder
+
+[[autodoc]] BertGenerationDecoder
+ - forward
diff --git a/docs/source/en/model_doc/bert-japanese.mdx b/docs/source/en/model_doc/bert-japanese.mdx
new file mode 100644
index 00000000000000..312714b379e8f2
--- /dev/null
+++ b/docs/source/en/model_doc/bert-japanese.mdx
@@ -0,0 +1,74 @@
+
+
+# BertJapanese
+
+## Overview
+
+The BERT models trained on Japanese text.
+
+There are models with two different tokenization methods:
+
+- Tokenize with MeCab and WordPiece. This requires some extra dependencies, [fugashi](https://github.com/polm/fugashi) which is a wrapper around [MeCab](https://taku910.github.io/mecab/).
+- Tokenize into characters.
+
+To use *MecabTokenizer*, you should `pip install transformers["ja"]` (or `pip install -e .["ja"]` if you install
+from source) to install dependencies.
+
+See [details on cl-tohoku repository](https://github.com/cl-tohoku/bert-japanese).
+
+Example of using a model with MeCab and WordPiece tokenization:
+
+```python
+>>> import torch
+>>> from transformers import AutoModel, AutoTokenizer
+
+>>> bertjapanese = AutoModel.from_pretrained("cl-tohoku/bert-base-japanese")
+>>> tokenizer = AutoTokenizer.from_pretrained("cl-tohoku/bert-base-japanese")
+
+>>> ## Input Japanese Text
+>>> line = "吾輩は猫である。"
+
+>>> inputs = tokenizer(line, return_tensors="pt")
+
+>>> print(tokenizer.decode(inputs["input_ids"][0]))
+[CLS] 吾輩 は 猫 で ある 。 [SEP]
+
+>>> outputs = bertjapanese(**inputs)
+```
+
+Example of using a model with Character tokenization:
+
+```python
+>>> bertjapanese = AutoModel.from_pretrained("cl-tohoku/bert-base-japanese-char")
+>>> tokenizer = AutoTokenizer.from_pretrained("cl-tohoku/bert-base-japanese-char")
+
+>>> ## Input Japanese Text
+>>> line = "吾輩は猫である。"
+
+>>> inputs = tokenizer(line, return_tensors="pt")
+
+>>> print(tokenizer.decode(inputs["input_ids"][0]))
+[CLS] 吾 輩 は 猫 で あ る 。 [SEP]
+
+>>> outputs = bertjapanese(**inputs)
+```
+
+Tips:
+
+- This implementation is the same as BERT, except for tokenization method. Refer to the [documentation of BERT](bert) for more usage examples.
+
+This model was contributed by [cl-tohoku](https://huggingface.co/cl-tohoku).
+
+## BertJapaneseTokenizer
+
+[[autodoc]] BertJapaneseTokenizer
diff --git a/docs/source/en/model_doc/bert.mdx b/docs/source/en/model_doc/bert.mdx
new file mode 100644
index 00000000000000..4975346a7a52a5
--- /dev/null
+++ b/docs/source/en/model_doc/bert.mdx
@@ -0,0 +1,202 @@
+
+
+# BERT
+
+## Overview
+
+The BERT model was proposed in [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://arxiv.org/abs/1810.04805) by Jacob Devlin, Ming-Wei Chang, Kenton Lee and Kristina Toutanova. It's a
+bidirectional transformer pretrained using a combination of masked language modeling objective and next sentence
+prediction on a large corpus comprising the Toronto Book Corpus and Wikipedia.
+
+The abstract from the paper is the following:
+
+*We introduce a new language representation model called BERT, which stands for Bidirectional Encoder Representations
+from Transformers. Unlike recent language representation models, BERT is designed to pre-train deep bidirectional
+representations from unlabeled text by jointly conditioning on both left and right context in all layers. As a result,
+the pre-trained BERT model can be fine-tuned with just one additional output layer to create state-of-the-art models
+for a wide range of tasks, such as question answering and language inference, without substantial task-specific
+architecture modifications.*
+
+*BERT is conceptually simple and empirically powerful. It obtains new state-of-the-art results on eleven natural
+language processing tasks, including pushing the GLUE score to 80.5% (7.7% point absolute improvement), MultiNLI
+accuracy to 86.7% (4.6% absolute improvement), SQuAD v1.1 question answering Test F1 to 93.2 (1.5 point absolute
+improvement) and SQuAD v2.0 Test F1 to 83.1 (5.1 point absolute improvement).*
+
+Tips:
+
+- BERT is a model with absolute position embeddings so it's usually advised to pad the inputs on the right rather than
+ the left.
+- BERT was trained with the masked language modeling (MLM) and next sentence prediction (NSP) objectives. It is
+ efficient at predicting masked tokens and at NLU in general, but is not optimal for text generation.
+
+This model was contributed by [thomwolf](https://huggingface.co/thomwolf). The original code can be found [here](https://github.com/google-research/bert).
+
+## BertConfig
+
+[[autodoc]] BertConfig
+ - all
+
+## BertTokenizer
+
+[[autodoc]] BertTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## BertTokenizerFast
+
+[[autodoc]] BertTokenizerFast
+
+## Bert specific outputs
+
+[[autodoc]] models.bert.modeling_bert.BertForPreTrainingOutput
+
+[[autodoc]] models.bert.modeling_tf_bert.TFBertForPreTrainingOutput
+
+[[autodoc]] models.bert.modeling_flax_bert.FlaxBertForPreTrainingOutput
+
+## BertModel
+
+[[autodoc]] BertModel
+ - forward
+
+## BertForPreTraining
+
+[[autodoc]] BertForPreTraining
+ - forward
+
+## BertLMHeadModel
+
+[[autodoc]] BertLMHeadModel
+ - forward
+
+## BertForMaskedLM
+
+[[autodoc]] BertForMaskedLM
+ - forward
+
+## BertForNextSentencePrediction
+
+[[autodoc]] BertForNextSentencePrediction
+ - forward
+
+## BertForSequenceClassification
+
+[[autodoc]] BertForSequenceClassification
+ - forward
+
+## BertForMultipleChoice
+
+[[autodoc]] BertForMultipleChoice
+ - forward
+
+## BertForTokenClassification
+
+[[autodoc]] BertForTokenClassification
+ - forward
+
+## BertForQuestionAnswering
+
+[[autodoc]] BertForQuestionAnswering
+ - forward
+
+## TFBertModel
+
+[[autodoc]] TFBertModel
+ - call
+
+## TFBertForPreTraining
+
+[[autodoc]] TFBertForPreTraining
+ - call
+
+## TFBertModelLMHeadModel
+
+[[autodoc]] TFBertLMHeadModel
+ - call
+
+## TFBertForMaskedLM
+
+[[autodoc]] TFBertForMaskedLM
+ - call
+
+## TFBertForNextSentencePrediction
+
+[[autodoc]] TFBertForNextSentencePrediction
+ - call
+
+## TFBertForSequenceClassification
+
+[[autodoc]] TFBertForSequenceClassification
+ - call
+
+## TFBertForMultipleChoice
+
+[[autodoc]] TFBertForMultipleChoice
+ - call
+
+## TFBertForTokenClassification
+
+[[autodoc]] TFBertForTokenClassification
+ - call
+
+## TFBertForQuestionAnswering
+
+[[autodoc]] TFBertForQuestionAnswering
+ - call
+
+## FlaxBertModel
+
+[[autodoc]] FlaxBertModel
+ - __call__
+
+## FlaxBertForPreTraining
+
+[[autodoc]] FlaxBertForPreTraining
+ - __call__
+
+## FlaxBertForCausalLM
+
+[[autodoc]] FlaxBertForCausalLM
+ - __call__
+
+## FlaxBertForMaskedLM
+
+[[autodoc]] FlaxBertForMaskedLM
+ - __call__
+
+## FlaxBertForNextSentencePrediction
+
+[[autodoc]] FlaxBertForNextSentencePrediction
+ - __call__
+
+## FlaxBertForSequenceClassification
+
+[[autodoc]] FlaxBertForSequenceClassification
+ - __call__
+
+## FlaxBertForMultipleChoice
+
+[[autodoc]] FlaxBertForMultipleChoice
+ - __call__
+
+## FlaxBertForTokenClassification
+
+[[autodoc]] FlaxBertForTokenClassification
+ - __call__
+
+## FlaxBertForQuestionAnswering
+
+[[autodoc]] FlaxBertForQuestionAnswering
+ - __call__
diff --git a/docs/source/en/model_doc/bertweet.mdx b/docs/source/en/model_doc/bertweet.mdx
new file mode 100644
index 00000000000000..df55360646f931
--- /dev/null
+++ b/docs/source/en/model_doc/bertweet.mdx
@@ -0,0 +1,58 @@
+
+
+# BERTweet
+
+## Overview
+
+The BERTweet model was proposed in [BERTweet: A pre-trained language model for English Tweets](https://www.aclweb.org/anthology/2020.emnlp-demos.2.pdf) by Dat Quoc Nguyen, Thanh Vu, Anh Tuan Nguyen.
+
+The abstract from the paper is the following:
+
+*We present BERTweet, the first public large-scale pre-trained language model for English Tweets. Our BERTweet, having
+the same architecture as BERT-base (Devlin et al., 2019), is trained using the RoBERTa pre-training procedure (Liu et
+al., 2019). Experiments show that BERTweet outperforms strong baselines RoBERTa-base and XLM-R-base (Conneau et al.,
+2020), producing better performance results than the previous state-of-the-art models on three Tweet NLP tasks:
+Part-of-speech tagging, Named-entity recognition and text classification.*
+
+Example of use:
+
+```python
+>>> import torch
+>>> from transformers import AutoModel, AutoTokenizer
+
+>>> bertweet = AutoModel.from_pretrained("vinai/bertweet-base")
+
+>>> # For transformers v4.x+:
+>>> tokenizer = AutoTokenizer.from_pretrained("vinai/bertweet-base", use_fast=False)
+
+>>> # For transformers v3.x:
+>>> # tokenizer = AutoTokenizer.from_pretrained("vinai/bertweet-base")
+
+>>> # INPUT TWEET IS ALREADY NORMALIZED!
+>>> line = "SC has first two presumptive cases of coronavirus , DHEC confirms HTTPURL via @USER :cry:"
+
+>>> input_ids = torch.tensor([tokenizer.encode(line)])
+
+>>> with torch.no_grad():
+... features = bertweet(input_ids) # Models outputs are now tuples
+
+>>> # With TensorFlow 2.0+:
+>>> # from transformers import TFAutoModel
+>>> # bertweet = TFAutoModel.from_pretrained("vinai/bertweet-base")
+```
+
+This model was contributed by [dqnguyen](https://huggingface.co/dqnguyen). The original code can be found [here](https://github.com/VinAIResearch/BERTweet).
+
+## BertweetTokenizer
+
+[[autodoc]] BertweetTokenizer
diff --git a/docs/source/en/model_doc/big_bird.mdx b/docs/source/en/model_doc/big_bird.mdx
new file mode 100644
index 00000000000000..0e1e6ac53ec300
--- /dev/null
+++ b/docs/source/en/model_doc/big_bird.mdx
@@ -0,0 +1,151 @@
+
+
+# BigBird
+
+## Overview
+
+The BigBird model was proposed in [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) by
+Zaheer, Manzil and Guruganesh, Guru and Dubey, Kumar Avinava and Ainslie, Joshua and Alberti, Chris and Ontanon,
+Santiago and Pham, Philip and Ravula, Anirudh and Wang, Qifan and Yang, Li and others. BigBird, is a sparse-attention
+based transformer which extends Transformer based models, such as BERT to much longer sequences. In addition to sparse
+attention, BigBird also applies global attention as well as random attention to the input sequence. Theoretically, it
+has been shown that applying sparse, global, and random attention approximates full attention, while being
+computationally much more efficient for longer sequences. As a consequence of the capability to handle longer context,
+BigBird has shown improved performance on various long document NLP tasks, such as question answering and
+summarization, compared to BERT or RoBERTa.
+
+The abstract from the paper is the following:
+
+*Transformers-based models, such as BERT, have been one of the most successful deep learning models for NLP.
+Unfortunately, one of their core limitations is the quadratic dependency (mainly in terms of memory) on the sequence
+length due to their full attention mechanism. To remedy this, we propose, BigBird, a sparse attention mechanism that
+reduces this quadratic dependency to linear. We show that BigBird is a universal approximator of sequence functions and
+is Turing complete, thereby preserving these properties of the quadratic, full attention model. Along the way, our
+theoretical analysis reveals some of the benefits of having O(1) global tokens (such as CLS), that attend to the entire
+sequence as part of the sparse attention mechanism. The proposed sparse attention can handle sequences of length up to
+8x of what was previously possible using similar hardware. As a consequence of the capability to handle longer context,
+BigBird drastically improves performance on various NLP tasks such as question answering and summarization. We also
+propose novel applications to genomics data.*
+
+Tips:
+
+- For an in-detail explanation on how BigBird's attention works, see [this blog post](https://huggingface.co/blog/big-bird).
+- BigBird comes with 2 implementations: **original_full** & **block_sparse**. For the sequence length < 1024, using
+ **original_full** is advised as there is no benefit in using **block_sparse** attention.
+- The code currently uses window size of 3 blocks and 2 global blocks.
+- Sequence length must be divisible by block size.
+- Current implementation supports only **ITC**.
+- Current implementation doesn't support **num_random_blocks = 0**
+
+This model was contributed by [vasudevgupta](https://huggingface.co/vasudevgupta). The original code can be found
+[here](https://github.com/google-research/bigbird).
+
+## BigBirdConfig
+
+[[autodoc]] BigBirdConfig
+
+## BigBirdTokenizer
+
+[[autodoc]] BigBirdTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## BigBirdTokenizerFast
+
+[[autodoc]] BigBirdTokenizerFast
+
+## BigBird specific outputs
+
+[[autodoc]] models.big_bird.modeling_big_bird.BigBirdForPreTrainingOutput
+
+## BigBirdModel
+
+[[autodoc]] BigBirdModel
+ - forward
+
+## BigBirdForPreTraining
+
+[[autodoc]] BigBirdForPreTraining
+ - forward
+
+## BigBirdForCausalLM
+
+[[autodoc]] BigBirdForCausalLM
+ - forward
+
+## BigBirdForMaskedLM
+
+[[autodoc]] BigBirdForMaskedLM
+ - forward
+
+## BigBirdForSequenceClassification
+
+[[autodoc]] BigBirdForSequenceClassification
+ - forward
+
+## BigBirdForMultipleChoice
+
+[[autodoc]] BigBirdForMultipleChoice
+ - forward
+
+## BigBirdForTokenClassification
+
+[[autodoc]] BigBirdForTokenClassification
+ - forward
+
+## BigBirdForQuestionAnswering
+
+[[autodoc]] BigBirdForQuestionAnswering
+ - forward
+
+## FlaxBigBirdModel
+
+[[autodoc]] FlaxBigBirdModel
+ - __call__
+
+## FlaxBigBirdForPreTraining
+
+[[autodoc]] FlaxBigBirdForPreTraining
+ - __call__
+
+## FlaxBigBirdForCausalLM
+
+[[autodoc]] FlaxBigBirdForCausalLM
+ - __call__
+
+## FlaxBigBirdForMaskedLM
+
+[[autodoc]] FlaxBigBirdForMaskedLM
+ - __call__
+
+## FlaxBigBirdForSequenceClassification
+
+[[autodoc]] FlaxBigBirdForSequenceClassification
+ - __call__
+
+## FlaxBigBirdForMultipleChoice
+
+[[autodoc]] FlaxBigBirdForMultipleChoice
+ - __call__
+
+## FlaxBigBirdForTokenClassification
+
+[[autodoc]] FlaxBigBirdForTokenClassification
+ - __call__
+
+## FlaxBigBirdForQuestionAnswering
+
+[[autodoc]] FlaxBigBirdForQuestionAnswering
+ - __call__
diff --git a/docs/source/en/model_doc/bigbird_pegasus.mdx b/docs/source/en/model_doc/bigbird_pegasus.mdx
new file mode 100644
index 00000000000000..50ef4720e3ec10
--- /dev/null
+++ b/docs/source/en/model_doc/bigbird_pegasus.mdx
@@ -0,0 +1,81 @@
+
+
+# BigBirdPegasus
+
+## Overview
+
+The BigBird model was proposed in [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) by
+Zaheer, Manzil and Guruganesh, Guru and Dubey, Kumar Avinava and Ainslie, Joshua and Alberti, Chris and Ontanon,
+Santiago and Pham, Philip and Ravula, Anirudh and Wang, Qifan and Yang, Li and others. BigBird, is a sparse-attention
+based transformer which extends Transformer based models, such as BERT to much longer sequences. In addition to sparse
+attention, BigBird also applies global attention as well as random attention to the input sequence. Theoretically, it
+has been shown that applying sparse, global, and random attention approximates full attention, while being
+computationally much more efficient for longer sequences. As a consequence of the capability to handle longer context,
+BigBird has shown improved performance on various long document NLP tasks, such as question answering and
+summarization, compared to BERT or RoBERTa.
+
+The abstract from the paper is the following:
+
+*Transformers-based models, such as BERT, have been one of the most successful deep learning models for NLP.
+Unfortunately, one of their core limitations is the quadratic dependency (mainly in terms of memory) on the sequence
+length due to their full attention mechanism. To remedy this, we propose, BigBird, a sparse attention mechanism that
+reduces this quadratic dependency to linear. We show that BigBird is a universal approximator of sequence functions and
+is Turing complete, thereby preserving these properties of the quadratic, full attention model. Along the way, our
+theoretical analysis reveals some of the benefits of having O(1) global tokens (such as CLS), that attend to the entire
+sequence as part of the sparse attention mechanism. The proposed sparse attention can handle sequences of length up to
+8x of what was previously possible using similar hardware. As a consequence of the capability to handle longer context,
+BigBird drastically improves performance on various NLP tasks such as question answering and summarization. We also
+propose novel applications to genomics data.*
+
+Tips:
+
+- For an in-detail explanation on how BigBird's attention works, see [this blog post](https://huggingface.co/blog/big-bird).
+- BigBird comes with 2 implementations: **original_full** & **block_sparse**. For the sequence length < 1024, using
+ **original_full** is advised as there is no benefit in using **block_sparse** attention.
+- The code currently uses window size of 3 blocks and 2 global blocks.
+- Sequence length must be divisible by block size.
+- Current implementation supports only **ITC**.
+- Current implementation doesn't support **num_random_blocks = 0**.
+- BigBirdPegasus uses the [PegasusTokenizer](https://github.com/huggingface/transformers/blob/main/src/transformers/models/pegasus/tokenization_pegasus.py).
+
+The original code can be found [here](https://github.com/google-research/bigbird).
+
+## BigBirdPegasusConfig
+
+[[autodoc]] BigBirdPegasusConfig
+ - all
+
+## BigBirdPegasusModel
+
+[[autodoc]] BigBirdPegasusModel
+ - forward
+
+## BigBirdPegasusForConditionalGeneration
+
+[[autodoc]] BigBirdPegasusForConditionalGeneration
+ - forward
+
+## BigBirdPegasusForSequenceClassification
+
+[[autodoc]] BigBirdPegasusForSequenceClassification
+ - forward
+
+## BigBirdPegasusForQuestionAnswering
+
+[[autodoc]] BigBirdPegasusForQuestionAnswering
+ - forward
+
+## BigBirdPegasusForCausalLM
+
+[[autodoc]] BigBirdPegasusForCausalLM
+ - forward
diff --git a/docs/source/en/model_doc/blenderbot-small.mdx b/docs/source/en/model_doc/blenderbot-small.mdx
new file mode 100644
index 00000000000000..2b762838c4c7d5
--- /dev/null
+++ b/docs/source/en/model_doc/blenderbot-small.mdx
@@ -0,0 +1,95 @@
+
+
+# Blenderbot Small
+
+Note that [`BlenderbotSmallModel`] and
+[`BlenderbotSmallForConditionalGeneration`] are only used in combination with the checkpoint
+[facebook/blenderbot-90M](https://huggingface.co/facebook/blenderbot-90M). Larger Blenderbot checkpoints should
+instead be used with [`BlenderbotModel`] and
+[`BlenderbotForConditionalGeneration`]
+
+## Overview
+
+The Blender chatbot model was proposed in [Recipes for building an open-domain chatbot](https://arxiv.org/pdf/2004.13637.pdf) Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu,
+Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston on 30 Apr 2020.
+
+The abstract of the paper is the following:
+
+*Building open-domain chatbots is a challenging area for machine learning research. While prior work has shown that
+scaling neural models in the number of parameters and the size of the data they are trained on gives improved results,
+we show that other ingredients are important for a high-performing chatbot. Good conversation requires a number of
+skills that an expert conversationalist blends in a seamless way: providing engaging talking points and listening to
+their partners, and displaying knowledge, empathy and personality appropriately, while maintaining a consistent
+persona. We show that large scale models can learn these skills when given appropriate training data and choice of
+generation strategy. We build variants of these recipes with 90M, 2.7B and 9.4B parameter models, and make our models
+and code publicly available. Human evaluations show our best models are superior to existing approaches in multi-turn
+dialogue in terms of engagingness and humanness measurements. We then discuss the limitations of this work by analyzing
+failure cases of our models.*
+
+This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten). The authors' code can be
+found [here](https://github.com/facebookresearch/ParlAI) .
+
+## BlenderbotSmallConfig
+
+[[autodoc]] BlenderbotSmallConfig
+
+## BlenderbotSmallTokenizer
+
+[[autodoc]] BlenderbotSmallTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## BlenderbotSmallTokenizerFast
+
+[[autodoc]] BlenderbotSmallTokenizerFast
+
+## BlenderbotSmallModel
+
+[[autodoc]] BlenderbotSmallModel
+ - forward
+
+## BlenderbotSmallForConditionalGeneration
+
+[[autodoc]] BlenderbotSmallForConditionalGeneration
+ - forward
+
+## BlenderbotSmallForCausalLM
+
+[[autodoc]] BlenderbotSmallForCausalLM
+ - forward
+
+## TFBlenderbotSmallModel
+
+[[autodoc]] TFBlenderbotSmallModel
+ - call
+
+## TFBlenderbotSmallForConditionalGeneration
+
+[[autodoc]] TFBlenderbotSmallForConditionalGeneration
+ - call
+
+## FlaxBlenderbotSmallModel
+
+[[autodoc]] FlaxBlenderbotSmallModel
+ - __call__
+ - encode
+ - decode
+
+## FlaxBlenderbotForConditionalGeneration
+
+[[autodoc]] FlaxBlenderbotSmallForConditionalGeneration
+ - __call__
+ - encode
+ - decode
diff --git a/docs/source/en/model_doc/blenderbot.mdx b/docs/source/en/model_doc/blenderbot.mdx
new file mode 100644
index 00000000000000..97cbd62e57d151
--- /dev/null
+++ b/docs/source/en/model_doc/blenderbot.mdx
@@ -0,0 +1,119 @@
+
+
+# Blenderbot
+
+**DISCLAIMER:** If you see something strange, file a [Github Issue](https://github.com/huggingface/transformers/issues/new?assignees=&labels=&template=bug-report.md&title) .
+
+## Overview
+
+The Blender chatbot model was proposed in [Recipes for building an open-domain chatbot](https://arxiv.org/pdf/2004.13637.pdf) Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu,
+Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston on 30 Apr 2020.
+
+The abstract of the paper is the following:
+
+*Building open-domain chatbots is a challenging area for machine learning research. While prior work has shown that
+scaling neural models in the number of parameters and the size of the data they are trained on gives improved results,
+we show that other ingredients are important for a high-performing chatbot. Good conversation requires a number of
+skills that an expert conversationalist blends in a seamless way: providing engaging talking points and listening to
+their partners, and displaying knowledge, empathy and personality appropriately, while maintaining a consistent
+persona. We show that large scale models can learn these skills when given appropriate training data and choice of
+generation strategy. We build variants of these recipes with 90M, 2.7B and 9.4B parameter models, and make our models
+and code publicly available. Human evaluations show our best models are superior to existing approaches in multi-turn
+dialogue in terms of engagingness and humanness measurements. We then discuss the limitations of this work by analyzing
+failure cases of our models.*
+
+This model was contributed by [sshleifer](https://huggingface.co/sshleifer). The authors' code can be found [here](https://github.com/facebookresearch/ParlAI) .
+
+
+## Implementation Notes
+
+- Blenderbot uses a standard [seq2seq model transformer](https://arxiv.org/pdf/1706.03762.pdf) based architecture.
+- Available checkpoints can be found in the [model hub](https://huggingface.co/models?search=blenderbot).
+- This is the *default* Blenderbot model class. However, some smaller checkpoints, such as
+ `facebook/blenderbot_small_90M`, have a different architecture and consequently should be used with
+ [BlenderbotSmall](blenderbot-small).
+
+
+## Usage
+
+Here is an example of model usage:
+
+```python
+>>> from transformers import BlenderbotTokenizer, BlenderbotForConditionalGeneration
+
+>>> mname = "facebook/blenderbot-400M-distill"
+>>> model = BlenderbotForConditionalGeneration.from_pretrained(mname)
+>>> tokenizer = BlenderbotTokenizer.from_pretrained(mname)
+>>> UTTERANCE = "My friends are cool but they eat too many carbs."
+>>> inputs = tokenizer([UTTERANCE], return_tensors="pt")
+>>> reply_ids = model.generate(**inputs)
+>>> print(tokenizer.batch_decode(reply_ids))
+[" That's unfortunate. Are they trying to lose weight or are they just trying to be healthier?"]
+```
+
+## BlenderbotConfig
+
+[[autodoc]] BlenderbotConfig
+
+## BlenderbotTokenizer
+
+[[autodoc]] BlenderbotTokenizer
+ - build_inputs_with_special_tokens
+
+## BlenderbotTokenizerFast
+
+[[autodoc]] BlenderbotTokenizerFast
+ - build_inputs_with_special_tokens
+
+## BlenderbotModel
+
+See `transformers.BartModel` for arguments to *forward* and *generate*
+
+[[autodoc]] BlenderbotModel
+ - forward
+
+## BlenderbotForConditionalGeneration
+
+See [`~transformers.BartForConditionalGeneration`] for arguments to *forward* and *generate*
+
+[[autodoc]] BlenderbotForConditionalGeneration
+ - forward
+
+## BlenderbotForCausalLM
+
+[[autodoc]] BlenderbotForCausalLM
+ - forward
+
+## TFBlenderbotModel
+
+[[autodoc]] TFBlenderbotModel
+ - call
+
+## TFBlenderbotForConditionalGeneration
+
+[[autodoc]] TFBlenderbotForConditionalGeneration
+ - call
+
+## FlaxBlenderbotModel
+
+[[autodoc]] FlaxBlenderbotModel
+ - __call__
+ - encode
+ - decode
+
+## FlaxBlenderbotForConditionalGeneration
+
+[[autodoc]] FlaxBlenderbotForConditionalGeneration
+ - __call__
+ - encode
+ - decode
diff --git a/docs/source/en/model_doc/bort.mdx b/docs/source/en/model_doc/bort.mdx
new file mode 100644
index 00000000000000..e90f042b6566b7
--- /dev/null
+++ b/docs/source/en/model_doc/bort.mdx
@@ -0,0 +1,42 @@
+
+
+# BORT
+
+## Overview
+
+The BORT model was proposed in [Optimal Subarchitecture Extraction for BERT](https://arxiv.org/abs/2010.10499) by
+Adrian de Wynter and Daniel J. Perry. It is an optimal subset of architectural parameters for the BERT, which the
+authors refer to as "Bort".
+
+The abstract from the paper is the following:
+
+*We extract an optimal subset of architectural parameters for the BERT architecture from Devlin et al. (2018) by
+applying recent breakthroughs in algorithms for neural architecture search. This optimal subset, which we refer to as
+"Bort", is demonstrably smaller, having an effective (that is, not counting the embedding layer) size of 5.5% the
+original BERT-large architecture, and 16% of the net size. Bort is also able to be pretrained in 288 GPU hours, which
+is 1.2% of the time required to pretrain the highest-performing BERT parametric architectural variant, RoBERTa-large
+(Liu et al., 2019), and about 33% of that of the world-record, in GPU hours, required to train BERT-large on the same
+hardware. It is also 7.9x faster on a CPU, as well as being better performing than other compressed variants of the
+architecture, and some of the non-compressed variants: it obtains performance improvements of between 0.3% and 31%,
+absolute, with respect to BERT-large, on multiple public natural language understanding (NLU) benchmarks.*
+
+Tips:
+
+- BORT's model architecture is based on BERT, so one can refer to [BERT's documentation page](bert) for the
+ model's API as well as usage examples.
+- BORT uses the RoBERTa tokenizer instead of the BERT tokenizer, so one can refer to [RoBERTa's documentation page](roberta) for the tokenizer's API as well as usage examples.
+- BORT requires a specific fine-tuning algorithm, called [Agora](https://adewynter.github.io/notes/bort_algorithms_and_applications.html#fine-tuning-with-algebraic-topology) ,
+ that is sadly not open-sourced yet. It would be very useful for the community, if someone tries to implement the
+ algorithm to make BORT fine-tuning work.
+
+This model was contributed by [stefan-it](https://huggingface.co/stefan-it). The original code can be found [here](https://github.com/alexa/bort/).
diff --git a/docs/source/en/model_doc/byt5.mdx b/docs/source/en/model_doc/byt5.mdx
new file mode 100644
index 00000000000000..dc4c5a6caf8f6f
--- /dev/null
+++ b/docs/source/en/model_doc/byt5.mdx
@@ -0,0 +1,147 @@
+
+
+# ByT5
+
+## Overview
+
+The ByT5 model was presented in [ByT5: Towards a token-free future with pre-trained byte-to-byte models](https://arxiv.org/abs/2105.13626) by Linting Xue, Aditya Barua, Noah Constant, Rami Al-Rfou, Sharan Narang, Mihir
+Kale, Adam Roberts, Colin Raffel.
+
+The abstract from the paper is the following:
+
+*Most widely-used pre-trained language models operate on sequences of tokens corresponding to word or subword units.
+Encoding text as a sequence of tokens requires a tokenizer, which is typically created as an independent artifact from
+the model. Token-free models that instead operate directly on raw text (bytes or characters) have many benefits: they
+can process text in any language out of the box, they are more robust to noise, and they minimize technical debt by
+removing complex and error-prone text preprocessing pipelines. Since byte or character sequences are longer than token
+sequences, past work on token-free models has often introduced new model architectures designed to amortize the cost of
+operating directly on raw text. In this paper, we show that a standard Transformer architecture can be used with
+minimal modifications to process byte sequences. We carefully characterize the trade-offs in terms of parameter count,
+training FLOPs, and inference speed, and show that byte-level models are competitive with their token-level
+counterparts. We also demonstrate that byte-level models are significantly more robust to noise and perform better on
+tasks that are sensitive to spelling and pronunciation. As part of our contribution, we release a new set of
+pre-trained byte-level Transformer models based on the T5 architecture, as well as all code and data used in our
+experiments.*
+
+This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten). The original code can be
+found [here](https://github.com/google-research/byt5).
+
+ByT5's architecture is based on the T5v1.1 model, so one can refer to [T5v1.1's documentation page](t5v1.1). They
+only differ in how inputs should be prepared for the model, see the code examples below.
+
+Since ByT5 was pre-trained unsupervisedly, there's no real advantage to using a task prefix during single-task
+fine-tuning. If you are doing multi-task fine-tuning, you should use a prefix.
+
+
+### Example
+
+ByT5 works on raw UTF-8 bytes, so it can be used without a tokenizer:
+
+```python
+>>> from transformers import T5ForConditionalGeneration
+>>> import torch
+
+>>> model = T5ForConditionalGeneration.from_pretrained("google/byt5-small")
+
+>>> num_special_tokens = 3
+>>> # Model has 3 special tokens which take up the input ids 0,1,2 of ByT5.
+>>> # => Need to shift utf-8 character encodings by 3 before passing ids to model.
+
+>>> input_ids = torch.tensor([list("Life is like a box of chocolates.".encode("utf-8"))]) + num_special_tokens
+
+>>> labels = torch.tensor([list("La vie est comme une boîte de chocolat.".encode("utf-8"))]) + num_special_tokens
+
+>>> loss = model(input_ids, labels=labels).loss
+>>> loss.item()
+2.66
+```
+
+For batched inference and training it is however recommended to make use of the tokenizer:
+
+```python
+>>> from transformers import T5ForConditionalGeneration, AutoTokenizer
+
+>>> model = T5ForConditionalGeneration.from_pretrained("google/byt5-small")
+>>> tokenizer = AutoTokenizer.from_pretrained("google/byt5-small")
+
+>>> model_inputs = tokenizer(
+... ["Life is like a box of chocolates.", "Today is Monday."], padding="longest", return_tensors="pt"
+... )
+>>> labels_dict = tokenizer(
+... ["La vie est comme une boîte de chocolat.", "Aujourd'hui c'est lundi."], padding="longest", return_tensors="pt"
+... )
+>>> labels = labels_dict.input_ids
+
+>>> loss = model(**model_inputs, labels=labels).loss
+>>> loss.item()
+17.9
+```
+
+Similar to [T5](t5), ByT5 was trained on the span-mask denoising task. However,
+since the model works directly on characters, the pretraining task is a bit
+different. Let's corrupt some characters of the
+input sentence `"The dog chases a ball in the park."` and ask ByT5 to predict them
+for us.
+
+```python
+>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
+>>> import torch
+
+>>> tokenizer = AutoTokenizer.from_pretrained("google/byt5-base")
+>>> model = AutoModelForSeq2SeqLM.from_pretrained("google/byt5-base")
+
+>>> input_ids_prompt = "The dog chases a ball in the park."
+>>> input_ids = tokenizer(input_ids_prompt).input_ids
+
+>>> # Note that we cannot add "{extra_id_...}" to the string directly
+>>> # as the Byte tokenizer would incorrectly merge the tokens
+>>> # For ByT5, we need to work directly on the character level
+>>> # Contrary to T5, ByT5 does not use sentinel tokens for masking, but instead
+>>> # uses final utf character ids.
+>>> # UTF-8 is represented by 8 bits and ByT5 has 3 special tokens.
+>>> # => There are 2**8+2 = 259 input ids and mask tokens count down from index 258.
+>>> # => mask to "The dog [258]a ball [257]park."
+
+>>> input_ids = torch.tensor([input_ids[:8] + [258] + input_ids[14:21] + [257] + input_ids[28:]])
+>>> input_ids
+tensor([[ 87, 107, 104, 35, 103, 114, 106, 35, 258, 35, 100, 35, 101, 100, 111, 111, 257, 35, 115, 100, 117, 110, 49, 1]])
+
+>>> # ByT5 produces only one char at a time so we need to produce many more output characters here -> set `max_length=100`.
+>>> output_ids = model.generate(input_ids, max_length=100)[0].tolist()
+>>> output_ids
+[0, 258, 108, 118, 35, 119, 107, 104, 35, 114, 113, 104, 35, 122, 107, 114, 35, 103, 114, 104, 118, 257, 35, 108, 113, 35, 119, 107, 104, 35, 103, 108, 118, 102, 114, 256, 108, 113, 35, 119, 107, 104, 35, 115, 100, 117, 110, 49, 35, 87, 107, 104, 35, 103, 114, 106, 35, 108, 118, 35, 119, 107, 104, 35, 114, 113, 104, 35, 122, 107, 114, 35, 103, 114, 104, 118, 35, 100, 35, 101, 100, 111, 111, 35, 108, 113, 255, 35, 108, 113, 35, 119, 107, 104, 35, 115, 100, 117, 110, 49]
+
+>>> # ^- Note how 258 descends to 257, 256, 255
+
+>>> # Now we need to split on the sentinel tokens, let's write a short loop for this
+>>> output_ids_list = []
+>>> start_token = 0
+>>> sentinel_token = 258
+>>> while sentinel_token in output_ids:
+... split_idx = output_ids.index(sentinel_token)
+... output_ids_list.append(output_ids[start_token:split_idx])
+... start_token = split_idx
+... sentinel_token -= 1
+
+>>> output_ids_list.append(output_ids[start_token:])
+>>> output_string = tokenizer.batch_decode(output_ids_list)
+>>> output_string
+['', 'is the one who does', ' in the disco', 'in the park. The dog is the one who does a ball in', ' in the park.']
+```
+
+
+## ByT5Tokenizer
+
+[[autodoc]] ByT5Tokenizer
+
+See [`ByT5Tokenizer`] for all details.
diff --git a/docs/source/en/model_doc/camembert.mdx b/docs/source/en/model_doc/camembert.mdx
new file mode 100644
index 00000000000000..a35d5aefca67a4
--- /dev/null
+++ b/docs/source/en/model_doc/camembert.mdx
@@ -0,0 +1,110 @@
+
+
+# CamemBERT
+
+## Overview
+
+The CamemBERT model was proposed in [CamemBERT: a Tasty French Language Model](https://arxiv.org/abs/1911.03894) by
+Louis Martin, Benjamin Muller, Pedro Javier Ortiz Suárez, Yoann Dupont, Laurent Romary, Éric Villemonte de la
+Clergerie, Djamé Seddah, and Benoît Sagot. It is based on Facebook's RoBERTa model released in 2019. It is a model
+trained on 138GB of French text.
+
+The abstract from the paper is the following:
+
+*Pretrained language models are now ubiquitous in Natural Language Processing. Despite their success, most available
+models have either been trained on English data or on the concatenation of data in multiple languages. This makes
+practical use of such models --in all languages except English-- very limited. Aiming to address this issue for French,
+we release CamemBERT, a French version of the Bi-directional Encoders for Transformers (BERT). We measure the
+performance of CamemBERT compared to multilingual models in multiple downstream tasks, namely part-of-speech tagging,
+dependency parsing, named-entity recognition, and natural language inference. CamemBERT improves the state of the art
+for most of the tasks considered. We release the pretrained model for CamemBERT hoping to foster research and
+downstream applications for French NLP.*
+
+Tips:
+
+- This implementation is the same as RoBERTa. Refer to the [documentation of RoBERTa](roberta) for usage examples
+ as well as the information relative to the inputs and outputs.
+
+This model was contributed by [camembert](https://huggingface.co/camembert). The original code can be found [here](https://camembert-model.fr/).
+
+## CamembertConfig
+
+[[autodoc]] CamembertConfig
+
+## CamembertTokenizer
+
+[[autodoc]] CamembertTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## CamembertTokenizerFast
+
+[[autodoc]] CamembertTokenizerFast
+
+## CamembertModel
+
+[[autodoc]] CamembertModel
+
+## CamembertForCausalLM
+
+[[autodoc]] CamembertForCausalLM
+
+## CamembertForMaskedLM
+
+[[autodoc]] CamembertForMaskedLM
+
+## CamembertForSequenceClassification
+
+[[autodoc]] CamembertForSequenceClassification
+
+## CamembertForMultipleChoice
+
+[[autodoc]] CamembertForMultipleChoice
+
+## CamembertForTokenClassification
+
+[[autodoc]] CamembertForTokenClassification
+
+## CamembertForQuestionAnswering
+
+[[autodoc]] CamembertForQuestionAnswering
+
+## TFCamembertModel
+
+[[autodoc]] TFCamembertModel
+
+## TFCamembertForCasualLM
+
+[[autodoc]] TFCamembertForCausalLM
+
+## TFCamembertForMaskedLM
+
+[[autodoc]] TFCamembertForMaskedLM
+
+## TFCamembertForSequenceClassification
+
+[[autodoc]] TFCamembertForSequenceClassification
+
+## TFCamembertForMultipleChoice
+
+[[autodoc]] TFCamembertForMultipleChoice
+
+## TFCamembertForTokenClassification
+
+[[autodoc]] TFCamembertForTokenClassification
+
+## TFCamembertForQuestionAnswering
+
+[[autodoc]] TFCamembertForQuestionAnswering
diff --git a/docs/source/en/model_doc/canine.mdx b/docs/source/en/model_doc/canine.mdx
new file mode 100644
index 00000000000000..e73777d000827f
--- /dev/null
+++ b/docs/source/en/model_doc/canine.mdx
@@ -0,0 +1,133 @@
+
+
+# CANINE
+
+## Overview
+
+The CANINE model was proposed in [CANINE: Pre-training an Efficient Tokenization-Free Encoder for Language
+Representation](https://arxiv.org/abs/2103.06874) by Jonathan H. Clark, Dan Garrette, Iulia Turc, John Wieting. It's
+among the first papers that trains a Transformer without using an explicit tokenization step (such as Byte Pair
+Encoding (BPE), WordPiece or SentencePiece). Instead, the model is trained directly at a Unicode character-level.
+Training at a character-level inevitably comes with a longer sequence length, which CANINE solves with an efficient
+downsampling strategy, before applying a deep Transformer encoder.
+
+The abstract from the paper is the following:
+
+*Pipelined NLP systems have largely been superseded by end-to-end neural modeling, yet nearly all commonly-used models
+still require an explicit tokenization step. While recent tokenization approaches based on data-derived subword
+lexicons are less brittle than manually engineered tokenizers, these techniques are not equally suited to all
+languages, and the use of any fixed vocabulary may limit a model's ability to adapt. In this paper, we present CANINE,
+a neural encoder that operates directly on character sequences, without explicit tokenization or vocabulary, and a
+pre-training strategy that operates either directly on characters or optionally uses subwords as a soft inductive bias.
+To use its finer-grained input effectively and efficiently, CANINE combines downsampling, which reduces the input
+sequence length, with a deep transformer stack, which encodes context. CANINE outperforms a comparable mBERT model by
+2.8 F1 on TyDi QA, a challenging multilingual benchmark, despite having 28% fewer model parameters.*
+
+Tips:
+
+- CANINE uses no less than 3 Transformer encoders internally: 2 "shallow" encoders (which only consist of a single
+ layer) and 1 "deep" encoder (which is a regular BERT encoder). First, a "shallow" encoder is used to contextualize
+ the character embeddings, using local attention. Next, after downsampling, a "deep" encoder is applied. Finally,
+ after upsampling, a "shallow" encoder is used to create the final character embeddings. Details regarding up- and
+ downsampling can be found in the paper.
+- CANINE uses a max sequence length of 2048 characters by default. One can use [`CanineTokenizer`]
+ to prepare text for the model.
+- Classification can be done by placing a linear layer on top of the final hidden state of the special [CLS] token
+ (which has a predefined Unicode code point). For token classification tasks however, the downsampled sequence of
+ tokens needs to be upsampled again to match the length of the original character sequence (which is 2048). The
+ details for this can be found in the paper.
+- Models:
+
+ - [google/canine-c](https://huggingface.co/google/canine-c): Pre-trained with autoregressive character loss,
+ 12-layer, 768-hidden, 12-heads, 121M parameters (size ~500 MB).
+ - [google/canine-s](https://huggingface.co/google/canine-s): Pre-trained with subword loss, 12-layer,
+ 768-hidden, 12-heads, 121M parameters (size ~500 MB).
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/google-research/language/tree/master/language/canine).
+
+
+### Example
+
+CANINE works on raw characters, so it can be used without a tokenizer:
+
+```python
+>>> from transformers import CanineModel
+>>> import torch
+
+>>> model = CanineModel.from_pretrained("google/canine-c") # model pre-trained with autoregressive character loss
+
+>>> text = "hello world"
+>>> # use Python's built-in ord() function to turn each character into its unicode code point id
+>>> input_ids = torch.tensor([[ord(char) for char in text]])
+
+>>> outputs = model(input_ids) # forward pass
+>>> pooled_output = outputs.pooler_output
+>>> sequence_output = outputs.last_hidden_state
+```
+
+For batched inference and training, it is however recommended to make use of the tokenizer (to pad/truncate all
+sequences to the same length):
+
+```python
+>>> from transformers import CanineTokenizer, CanineModel
+
+>>> model = CanineModel.from_pretrained("google/canine-c")
+>>> tokenizer = CanineTokenizer.from_pretrained("google/canine-c")
+
+>>> inputs = ["Life is like a box of chocolates.", "You never know what you gonna get."]
+>>> encoding = tokenizer(inputs, padding="longest", truncation=True, return_tensors="pt")
+
+>>> outputs = model(**encoding) # forward pass
+>>> pooled_output = outputs.pooler_output
+>>> sequence_output = outputs.last_hidden_state
+```
+
+## CANINE specific outputs
+
+[[autodoc]] models.canine.modeling_canine.CanineModelOutputWithPooling
+
+## CanineConfig
+
+[[autodoc]] CanineConfig
+
+## CanineTokenizer
+
+[[autodoc]] CanineTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+
+## CanineModel
+
+[[autodoc]] CanineModel
+ - forward
+
+## CanineForSequenceClassification
+
+[[autodoc]] CanineForSequenceClassification
+ - forward
+
+## CanineForMultipleChoice
+
+[[autodoc]] CanineForMultipleChoice
+ - forward
+
+## CanineForTokenClassification
+
+[[autodoc]] CanineForTokenClassification
+ - forward
+
+## CanineForQuestionAnswering
+
+[[autodoc]] CanineForQuestionAnswering
+ - forward
diff --git a/docs/source/en/model_doc/clip.mdx b/docs/source/en/model_doc/clip.mdx
new file mode 100644
index 00000000000000..0ab0ec7689d510
--- /dev/null
+++ b/docs/source/en/model_doc/clip.mdx
@@ -0,0 +1,160 @@
+
+
+# CLIP
+
+## Overview
+
+The CLIP model was proposed in [Learning Transferable Visual Models From Natural Language Supervision](https://arxiv.org/abs/2103.00020) by Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh,
+Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever. CLIP
+(Contrastive Language-Image Pre-Training) is a neural network trained on a variety of (image, text) pairs. It can be
+instructed in natural language to predict the most relevant text snippet, given an image, without directly optimizing
+for the task, similarly to the zero-shot capabilities of GPT-2 and 3.
+
+The abstract from the paper is the following:
+
+*State-of-the-art computer vision systems are trained to predict a fixed set of predetermined object categories. This
+restricted form of supervision limits their generality and usability since additional labeled data is needed to specify
+any other visual concept. Learning directly from raw text about images is a promising alternative which leverages a
+much broader source of supervision. We demonstrate that the simple pre-training task of predicting which caption goes
+with which image is an efficient and scalable way to learn SOTA image representations from scratch on a dataset of 400
+million (image, text) pairs collected from the internet. After pre-training, natural language is used to reference
+learned visual concepts (or describe new ones) enabling zero-shot transfer of the model to downstream tasks. We study
+the performance of this approach by benchmarking on over 30 different existing computer vision datasets, spanning tasks
+such as OCR, action recognition in videos, geo-localization, and many types of fine-grained object classification. The
+model transfers non-trivially to most tasks and is often competitive with a fully supervised baseline without the need
+for any dataset specific training. For instance, we match the accuracy of the original ResNet-50 on ImageNet zero-shot
+without needing to use any of the 1.28 million training examples it was trained on. We release our code and pre-trained
+model weights at this https URL.*
+
+## Usage
+
+CLIP is a multi-modal vision and language model. It can be used for image-text similarity and for zero-shot image
+classification. CLIP uses a ViT like transformer to get visual features and a causal language model to get the text
+features. Both the text and visual features are then projected to a latent space with identical dimension. The dot
+product between the projected image and text features is then used as a similar score.
+
+To feed images to the Transformer encoder, each image is split into a sequence of fixed-size non-overlapping patches,
+which are then linearly embedded. A [CLS] token is added to serve as representation of an entire image. The authors
+also add absolute position embeddings, and feed the resulting sequence of vectors to a standard Transformer encoder.
+The [`CLIPFeatureExtractor`] can be used to resize (or rescale) and normalize images for the model.
+
+The [`CLIPTokenizer`] is used to encode the text. The [`CLIPProcessor`] wraps
+[`CLIPFeatureExtractor`] and [`CLIPTokenizer`] into a single instance to both
+encode the text and prepare the images. The following example shows how to get the image-text similarity scores using
+[`CLIPProcessor`] and [`CLIPModel`].
+
+
+```python
+>>> from PIL import Image
+>>> import requests
+
+>>> from transformers import CLIPProcessor, CLIPModel
+
+>>> model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
+>>> processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
+
+>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+
+>>> inputs = processor(text=["a photo of a cat", "a photo of a dog"], images=image, return_tensors="pt", padding=True)
+
+>>> outputs = model(**inputs)
+>>> logits_per_image = outputs.logits_per_image # this is the image-text similarity score
+>>> probs = logits_per_image.softmax(dim=1) # we can take the softmax to get the label probabilities
+```
+
+This model was contributed by [valhalla](https://huggingface.co/valhalla). The original code can be found [here](https://github.com/openai/CLIP).
+
+## CLIPConfig
+
+[[autodoc]] CLIPConfig
+ - from_text_vision_configs
+
+## CLIPTextConfig
+
+[[autodoc]] CLIPTextConfig
+
+## CLIPVisionConfig
+
+[[autodoc]] CLIPVisionConfig
+
+## CLIPTokenizer
+
+[[autodoc]] CLIPTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## CLIPTokenizerFast
+
+[[autodoc]] CLIPTokenizerFast
+
+## CLIPFeatureExtractor
+
+[[autodoc]] CLIPFeatureExtractor
+
+## CLIPProcessor
+
+[[autodoc]] CLIPProcessor
+
+## CLIPModel
+
+[[autodoc]] CLIPModel
+ - forward
+ - get_text_features
+ - get_image_features
+
+## CLIPTextModel
+
+[[autodoc]] CLIPTextModel
+ - forward
+
+## CLIPVisionModel
+
+[[autodoc]] CLIPVisionModel
+ - forward
+
+## TFCLIPModel
+
+[[autodoc]] TFCLIPModel
+ - call
+ - get_text_features
+ - get_image_features
+
+## TFCLIPTextModel
+
+[[autodoc]] TFCLIPTextModel
+ - call
+
+## TFCLIPVisionModel
+
+[[autodoc]] TFCLIPVisionModel
+ - call
+
+## FlaxCLIPModel
+
+[[autodoc]] FlaxCLIPModel
+ - __call__
+ - get_text_features
+ - get_image_features
+
+## FlaxCLIPTextModel
+
+[[autodoc]] FlaxCLIPTextModel
+ - __call__
+
+## FlaxCLIPVisionModel
+
+[[autodoc]] FlaxCLIPVisionModel
+ - __call__
diff --git a/docs/source/en/model_doc/convbert.mdx b/docs/source/en/model_doc/convbert.mdx
new file mode 100644
index 00000000000000..723640f5aa634f
--- /dev/null
+++ b/docs/source/en/model_doc/convbert.mdx
@@ -0,0 +1,113 @@
+
+
+# ConvBERT
+
+## Overview
+
+The ConvBERT model was proposed in [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496) by Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng
+Yan.
+
+The abstract from the paper is the following:
+
+*Pre-trained language models like BERT and its variants have recently achieved impressive performance in various
+natural language understanding tasks. However, BERT heavily relies on the global self-attention block and thus suffers
+large memory footprint and computation cost. Although all its attention heads query on the whole input sequence for
+generating the attention map from a global perspective, we observe some heads only need to learn local dependencies,
+which means the existence of computation redundancy. We therefore propose a novel span-based dynamic convolution to
+replace these self-attention heads to directly model local dependencies. The novel convolution heads, together with the
+rest self-attention heads, form a new mixed attention block that is more efficient at both global and local context
+learning. We equip BERT with this mixed attention design and build a ConvBERT model. Experiments have shown that
+ConvBERT significantly outperforms BERT and its variants in various downstream tasks, with lower training cost and
+fewer model parameters. Remarkably, ConvBERTbase model achieves 86.4 GLUE score, 0.7 higher than ELECTRAbase, while
+using less than 1/4 training cost. Code and pre-trained models will be released.*
+
+ConvBERT training tips are similar to those of BERT.
+
+This model was contributed by [abhishek](https://huggingface.co/abhishek). The original implementation can be found
+here: https://github.com/yitu-opensource/ConvBert
+
+## ConvBertConfig
+
+[[autodoc]] ConvBertConfig
+
+## ConvBertTokenizer
+
+[[autodoc]] ConvBertTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## ConvBertTokenizerFast
+
+[[autodoc]] ConvBertTokenizerFast
+
+## ConvBertModel
+
+[[autodoc]] ConvBertModel
+ - forward
+
+## ConvBertForMaskedLM
+
+[[autodoc]] ConvBertForMaskedLM
+ - forward
+
+## ConvBertForSequenceClassification
+
+[[autodoc]] ConvBertForSequenceClassification
+ - forward
+
+## ConvBertForMultipleChoice
+
+[[autodoc]] ConvBertForMultipleChoice
+ - forward
+
+## ConvBertForTokenClassification
+
+[[autodoc]] ConvBertForTokenClassification
+ - forward
+
+## ConvBertForQuestionAnswering
+
+[[autodoc]] ConvBertForQuestionAnswering
+ - forward
+
+## TFConvBertModel
+
+[[autodoc]] TFConvBertModel
+ - call
+
+## TFConvBertForMaskedLM
+
+[[autodoc]] TFConvBertForMaskedLM
+ - call
+
+## TFConvBertForSequenceClassification
+
+[[autodoc]] TFConvBertForSequenceClassification
+ - call
+
+## TFConvBertForMultipleChoice
+
+[[autodoc]] TFConvBertForMultipleChoice
+ - call
+
+## TFConvBertForTokenClassification
+
+[[autodoc]] TFConvBertForTokenClassification
+ - call
+
+## TFConvBertForQuestionAnswering
+
+[[autodoc]] TFConvBertForQuestionAnswering
+ - call
diff --git a/docs/source/en/model_doc/convnext.mdx b/docs/source/en/model_doc/convnext.mdx
new file mode 100644
index 00000000000000..732e0eb7a59fcd
--- /dev/null
+++ b/docs/source/en/model_doc/convnext.mdx
@@ -0,0 +1,74 @@
+
+
+# ConvNeXT
+
+## Overview
+
+The ConvNeXT model was proposed in [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) by Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie.
+ConvNeXT is a pure convolutional model (ConvNet), inspired by the design of Vision Transformers, that claims to outperform them.
+
+The abstract from the paper is the following:
+
+*The "Roaring 20s" of visual recognition began with the introduction of Vision Transformers (ViTs), which quickly superseded ConvNets as the state-of-the-art image classification model.
+A vanilla ViT, on the other hand, faces difficulties when applied to general computer vision tasks such as object detection and semantic segmentation. It is the hierarchical Transformers
+(e.g., Swin Transformers) that reintroduced several ConvNet priors, making Transformers practically viable as a generic vision backbone and demonstrating remarkable performance on a wide
+variety of vision tasks. However, the effectiveness of such hybrid approaches is still largely credited to the intrinsic superiority of Transformers, rather than the inherent inductive
+biases of convolutions. In this work, we reexamine the design spaces and test the limits of what a pure ConvNet can achieve. We gradually "modernize" a standard ResNet toward the design
+of a vision Transformer, and discover several key components that contribute to the performance difference along the way. The outcome of this exploration is a family of pure ConvNet models
+dubbed ConvNeXt. Constructed entirely from standard ConvNet modules, ConvNeXts compete favorably with Transformers in terms of accuracy and scalability, achieving 87.8% ImageNet top-1 accuracy
+and outperforming Swin Transformers on COCO detection and ADE20K segmentation, while maintaining the simplicity and efficiency of standard ConvNets.*
+
+Tips:
+
+- See the code examples below each model regarding usage.
+
+ +
+ ConvNeXT architecture. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). TensorFlow version of the model was contributed by [ariG23498](https://github.com/ariG23498),
+[gante](https://github.com/gante), and [sayakpaul](https://github.com/sayakpaul) (equal contribution). The original code can be found [here](https://github.com/facebookresearch/ConvNeXt).
+
+## ConvNextConfig
+
+[[autodoc]] ConvNextConfig
+
+
+## ConvNextFeatureExtractor
+
+[[autodoc]] ConvNextFeatureExtractor
+
+
+## ConvNextModel
+
+[[autodoc]] ConvNextModel
+ - forward
+
+
+## ConvNextForImageClassification
+
+[[autodoc]] ConvNextForImageClassification
+ - forward
+
+
+## TFConvNextModel
+
+[[autodoc]] TFConvNextModel
+ - call
+
+
+## TFConvNextForImageClassification
+
+[[autodoc]] TFConvNextForImageClassification
+ - call
\ No newline at end of file
diff --git a/docs/source/en/model_doc/cpm.mdx b/docs/source/en/model_doc/cpm.mdx
new file mode 100644
index 00000000000000..ac8ed8fdbafbd8
--- /dev/null
+++ b/docs/source/en/model_doc/cpm.mdx
@@ -0,0 +1,44 @@
+
+
+# CPM
+
+## Overview
+
+The CPM model was proposed in [CPM: A Large-scale Generative Chinese Pre-trained Language Model](https://arxiv.org/abs/2012.00413) by Zhengyan Zhang, Xu Han, Hao Zhou, Pei Ke, Yuxian Gu, Deming Ye, Yujia Qin,
+Yusheng Su, Haozhe Ji, Jian Guan, Fanchao Qi, Xiaozhi Wang, Yanan Zheng, Guoyang Zeng, Huanqi Cao, Shengqi Chen,
+Daixuan Li, Zhenbo Sun, Zhiyuan Liu, Minlie Huang, Wentao Han, Jie Tang, Juanzi Li, Xiaoyan Zhu, Maosong Sun.
+
+The abstract from the paper is the following:
+
+*Pre-trained Language Models (PLMs) have proven to be beneficial for various downstream NLP tasks. Recently, GPT-3,
+with 175 billion parameters and 570GB training data, drew a lot of attention due to the capacity of few-shot (even
+zero-shot) learning. However, applying GPT-3 to address Chinese NLP tasks is still challenging, as the training corpus
+of GPT-3 is primarily English, and the parameters are not publicly available. In this technical report, we release the
+Chinese Pre-trained Language Model (CPM) with generative pre-training on large-scale Chinese training data. To the best
+of our knowledge, CPM, with 2.6 billion parameters and 100GB Chinese training data, is the largest Chinese pre-trained
+language model, which could facilitate several downstream Chinese NLP tasks, such as conversation, essay generation,
+cloze test, and language understanding. Extensive experiments demonstrate that CPM achieves strong performance on many
+NLP tasks in the settings of few-shot (even zero-shot) learning.*
+
+This model was contributed by [canwenxu](https://huggingface.co/canwenxu). The original implementation can be found
+here: https://github.com/TsinghuaAI/CPM-Generate
+
+Note: We only have a tokenizer here, since the model architecture is the same as GPT-2.
+
+## CpmTokenizer
+
+[[autodoc]] CpmTokenizer
+
+## CpmTokenizerFast
+
+[[autodoc]] CpmTokenizerFast
diff --git a/docs/source/en/model_doc/ctrl.mdx b/docs/source/en/model_doc/ctrl.mdx
new file mode 100644
index 00000000000000..6f35e487e148a1
--- /dev/null
+++ b/docs/source/en/model_doc/ctrl.mdx
@@ -0,0 +1,87 @@
+
+
+# CTRL
+
+## Overview
+
+CTRL model was proposed in [CTRL: A Conditional Transformer Language Model for Controllable Generation](https://arxiv.org/abs/1909.05858) by Nitish Shirish Keskar*, Bryan McCann*, Lav R. Varshney, Caiming Xiong and
+Richard Socher. It's a causal (unidirectional) transformer pre-trained using language modeling on a very large corpus
+of ~140 GB of text data with the first token reserved as a control code (such as Links, Books, Wikipedia etc.).
+
+The abstract from the paper is the following:
+
+*Large-scale language models show promising text generation capabilities, but users cannot easily control particular
+aspects of the generated text. We release CTRL, a 1.63 billion-parameter conditional transformer language model,
+trained to condition on control codes that govern style, content, and task-specific behavior. Control codes were
+derived from structure that naturally co-occurs with raw text, preserving the advantages of unsupervised learning while
+providing more explicit control over text generation. These codes also allow CTRL to predict which parts of the
+training data are most likely given a sequence. This provides a potential method for analyzing large amounts of data
+via model-based source attribution.*
+
+Tips:
+
+- CTRL makes use of control codes to generate text: it requires generations to be started by certain words, sentences
+ or links to generate coherent text. Refer to the [original implementation](https://github.com/salesforce/ctrl) for
+ more information.
+- CTRL is a model with absolute position embeddings so it's usually advised to pad the inputs on the right rather than
+ the left.
+- CTRL was trained with a causal language modeling (CLM) objective and is therefore powerful at predicting the next
+ token in a sequence. Leveraging this feature allows CTRL to generate syntactically coherent text as it can be
+ observed in the *run_generation.py* example script.
+- The PyTorch models can take the `past_key_values` as input, which is the previously computed key/value attention pairs.
+ TensorFlow models accepts `past` as input. Using the `past_key_values` value prevents the model from re-computing
+ pre-computed values in the context of text generation. See the [`forward`](model_doc/ctrl#transformers.CTRLModel.forward)
+ method for more information on the usage of this argument.
+
+This model was contributed by [keskarnitishr](https://huggingface.co/keskarnitishr). The original code can be found
+[here](https://github.com/salesforce/ctrl).
+
+
+## CTRLConfig
+
+[[autodoc]] CTRLConfig
+
+## CTRLTokenizer
+
+[[autodoc]] CTRLTokenizer
+ - save_vocabulary
+
+## CTRLModel
+
+[[autodoc]] CTRLModel
+ - forward
+
+## CTRLLMHeadModel
+
+[[autodoc]] CTRLLMHeadModel
+ - forward
+
+## CTRLForSequenceClassification
+
+[[autodoc]] CTRLForSequenceClassification
+ - forward
+
+## TFCTRLModel
+
+[[autodoc]] TFCTRLModel
+ - call
+
+## TFCTRLLMHeadModel
+
+[[autodoc]] TFCTRLLMHeadModel
+ - call
+
+## TFCTRLForSequenceClassification
+
+[[autodoc]] TFCTRLForSequenceClassification
+ - call
diff --git a/docs/source/en/model_doc/data2vec.mdx b/docs/source/en/model_doc/data2vec.mdx
new file mode 100644
index 00000000000000..748e43cab5176e
--- /dev/null
+++ b/docs/source/en/model_doc/data2vec.mdx
@@ -0,0 +1,144 @@
+
+
+# Data2Vec
+
+## Overview
+
+The Data2Vec model was proposed in [data2vec: A General Framework for Self-supervised Learning in Speech, Vision and Language](https://arxiv.org/pdf/2202.03555) by Alexei Baevski, Wei-Ning Hsu, Qiantong Xu, Arun Babu, Jiatao Gu and Michael Auli.
+Data2Vec proposes a unified framework for self-supervised learning across different data modalities - text, audio and images.
+Importantly, predicted targets for pre-training are contextualized latent representations of the inputs, rather than modality-specific, context-independent targets.
+
+The abstract from the paper is the following:
+
+*While the general idea of self-supervised learning is identical across modalities, the actual algorithms and
+objectives differ widely because they were developed with a single modality in mind. To get us closer to general
+self-supervised learning, we present data2vec, a framework that uses the same learning method for either speech,
+NLP or computer vision. The core idea is to predict latent representations of the full input data based on a
+masked view of the input in a selfdistillation setup using a standard Transformer architecture.
+Instead of predicting modality-specific targets such as words, visual tokens or units of human speech which
+are local in nature, data2vec predicts contextualized latent representations that contain information from
+the entire input. Experiments on the major benchmarks of speech recognition, image classification, and
+natural language understanding demonstrate a new state of the art or competitive performance to predominant approaches.
+Models and code are available at www.github.com/pytorch/fairseq/tree/master/examples/data2vec.*
+
+Tips:
+
+- Data2VecAudio, Data2VecText, and Data2VecVision have all been trained using the same self-supervised learning method.
+- For Data2VecAudio, preprocessing is identical to [`Wav2Vec2Model`], including feature extraction
+- For Data2VecText, preprocessing is identical to [`RobertaModel`], including tokenization.
+- For Data2VecVision, preprocessing is identical to [`BeitModel`], including feature extraction.
+
+This model was contributed by [edugp](https://huggingface.co/edugp) and [patrickvonplaten](https://huggingface.co/patrickvonplaten).
+[sayakpaul](https://github.com/sayakpaul) contributed Data2Vec for vision in TensorFlow.
+
+The original code (for NLP and Speech) can be found [here](https://github.com/pytorch/fairseq/tree/main/examples/data2vec).
+The original code for vision can be found [here](https://github.com/facebookresearch/data2vec_vision/tree/main/beit).
+
+
+## Data2VecTextConfig
+
+[[autodoc]] Data2VecTextConfig
+
+## Data2VecAudioConfig
+
+[[autodoc]] Data2VecAudioConfig
+
+## Data2VecVisionConfig
+
+[[autodoc]] Data2VecVisionConfig
+
+
+## Data2VecAudioModel
+
+[[autodoc]] Data2VecAudioModel
+ - forward
+
+## Data2VecAudioForAudioFrameClassification
+
+[[autodoc]] Data2VecAudioForAudioFrameClassification
+ - forward
+
+## Data2VecAudioForCTC
+
+[[autodoc]] Data2VecAudioForCTC
+ - forward
+
+## Data2VecAudioForSequenceClassification
+
+[[autodoc]] Data2VecAudioForSequenceClassification
+ - forward
+
+## Data2VecAudioForXVector
+
+[[autodoc]] Data2VecAudioForXVector
+ - forward
+
+## Data2VecTextModel
+
+[[autodoc]] Data2VecTextModel
+ - forward
+
+## Data2VecTextForCausalLM
+
+[[autodoc]] Data2VecTextForCausalLM
+ - forward
+
+## Data2VecTextForMaskedLM
+
+[[autodoc]] Data2VecTextForMaskedLM
+ - forward
+
+## Data2VecTextForSequenceClassification
+
+[[autodoc]] Data2VecTextForSequenceClassification
+ - forward
+
+## Data2VecTextForMultipleChoice
+
+[[autodoc]] Data2VecTextForMultipleChoice
+ - forward
+
+## Data2VecTextForTokenClassification
+
+[[autodoc]] Data2VecTextForTokenClassification
+ - forward
+
+## Data2VecTextForQuestionAnswering
+
+[[autodoc]] Data2VecTextForQuestionAnswering
+ - forward
+
+## Data2VecVisionModel
+
+[[autodoc]] Data2VecVisionModel
+ - forward
+
+## Data2VecVisionForImageClassification
+
+[[autodoc]] Data2VecVisionForImageClassification
+ - forward
+
+## Data2VecVisionForSemanticSegmentation
+
+[[autodoc]] Data2VecVisionForSemanticSegmentation
+ - forward
+
+## TFData2VecVisionModel
+
+[[autodoc]] TFData2VecVisionModel
+ - call
+
+## TFData2VecVisionForImageClassification
+
+[[autodoc]] TFData2VecVisionForImageClassification
+ - call
\ No newline at end of file
diff --git a/docs/source/en/model_doc/deberta-v2.mdx b/docs/source/en/model_doc/deberta-v2.mdx
new file mode 100644
index 00000000000000..7dd34790def1ab
--- /dev/null
+++ b/docs/source/en/model_doc/deberta-v2.mdx
@@ -0,0 +1,138 @@
+
+
+# DeBERTa-v2
+
+## Overview
+
+The DeBERTa model was proposed in [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654) by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen It is based on Google's
+BERT model released in 2018 and Facebook's RoBERTa model released in 2019.
+
+It builds on RoBERTa with disentangled attention and enhanced mask decoder training with half of the data used in
+RoBERTa.
+
+The abstract from the paper is the following:
+
+*Recent progress in pre-trained neural language models has significantly improved the performance of many natural
+language processing (NLP) tasks. In this paper we propose a new model architecture DeBERTa (Decoding-enhanced BERT with
+disentangled attention) that improves the BERT and RoBERTa models using two novel techniques. The first is the
+disentangled attention mechanism, where each word is represented using two vectors that encode its content and
+position, respectively, and the attention weights among words are computed using disentangled matrices on their
+contents and relative positions. Second, an enhanced mask decoder is used to replace the output softmax layer to
+predict the masked tokens for model pretraining. We show that these two techniques significantly improve the efficiency
+of model pretraining and performance of downstream tasks. Compared to RoBERTa-Large, a DeBERTa model trained on half of
+the training data performs consistently better on a wide range of NLP tasks, achieving improvements on MNLI by +0.9%
+(90.2% vs. 91.1%), on SQuAD v2.0 by +2.3% (88.4% vs. 90.7%) and RACE by +3.6% (83.2% vs. 86.8%). The DeBERTa code and
+pre-trained models will be made publicly available at https://github.com/microsoft/DeBERTa.*
+
+
+The following information is visible directly on the [original implementation
+repository](https://github.com/microsoft/DeBERTa). DeBERTa v2 is the second version of the DeBERTa model. It includes
+the 1.5B model used for the SuperGLUE single-model submission and achieving 89.9, versus human baseline 89.8. You can
+find more details about this submission in the authors'
+[blog](https://www.microsoft.com/en-us/research/blog/microsoft-deberta-surpasses-human-performance-on-the-superglue-benchmark/)
+
+New in v2:
+
+- **Vocabulary** In v2 the tokenizer is changed to use a new vocabulary of size 128K built from the training data.
+ Instead of a GPT2-based tokenizer, the tokenizer is now
+ [sentencepiece-based](https://github.com/google/sentencepiece) tokenizer.
+- **nGiE(nGram Induced Input Encoding)** The DeBERTa-v2 model uses an additional convolution layer aside with the first
+ transformer layer to better learn the local dependency of input tokens.
+- **Sharing position projection matrix with content projection matrix in attention layer** Based on previous
+ experiments, this can save parameters without affecting the performance.
+- **Apply bucket to encode relative positions** The DeBERTa-v2 model uses log bucket to encode relative positions
+ similar to T5.
+- **900M model & 1.5B model** Two additional model sizes are available: 900M and 1.5B, which significantly improves the
+ performance of downstream tasks.
+
+This model was contributed by [DeBERTa](https://huggingface.co/DeBERTa). This model TF 2.0 implementation was
+contributed by [kamalkraj](https://huggingface.co/kamalkraj). The original code can be found [here](https://github.com/microsoft/DeBERTa).
+
+
+## DebertaV2Config
+
+[[autodoc]] DebertaV2Config
+
+## DebertaV2Tokenizer
+
+[[autodoc]] DebertaV2Tokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## DebertaV2TokenizerFast
+
+[[autodoc]] DebertaV2TokenizerFast
+ - build_inputs_with_special_tokens
+ - create_token_type_ids_from_sequences
+
+## DebertaV2Model
+
+[[autodoc]] DebertaV2Model
+ - forward
+
+## DebertaV2PreTrainedModel
+
+[[autodoc]] DebertaV2PreTrainedModel
+ - forward
+
+## DebertaV2ForMaskedLM
+
+[[autodoc]] DebertaV2ForMaskedLM
+ - forward
+
+## DebertaV2ForSequenceClassification
+
+[[autodoc]] DebertaV2ForSequenceClassification
+ - forward
+
+## DebertaV2ForTokenClassification
+
+[[autodoc]] DebertaV2ForTokenClassification
+ - forward
+
+## DebertaV2ForQuestionAnswering
+
+[[autodoc]] DebertaV2ForQuestionAnswering
+ - forward
+
+## TFDebertaV2Model
+
+[[autodoc]] TFDebertaV2Model
+ - call
+
+## TFDebertaV2PreTrainedModel
+
+[[autodoc]] TFDebertaV2PreTrainedModel
+ - call
+
+## TFDebertaV2ForMaskedLM
+
+[[autodoc]] TFDebertaV2ForMaskedLM
+ - call
+
+## TFDebertaV2ForSequenceClassification
+
+[[autodoc]] TFDebertaV2ForSequenceClassification
+ - call
+
+## TFDebertaV2ForTokenClassification
+
+[[autodoc]] TFDebertaV2ForTokenClassification
+ - call
+
+## TFDebertaV2ForQuestionAnswering
+
+[[autodoc]] TFDebertaV2ForQuestionAnswering
+ - call
diff --git a/docs/source/en/model_doc/deberta.mdx b/docs/source/en/model_doc/deberta.mdx
new file mode 100644
index 00000000000000..fed18b9fd50fe7
--- /dev/null
+++ b/docs/source/en/model_doc/deberta.mdx
@@ -0,0 +1,117 @@
+
+
+# DeBERTa
+
+## Overview
+
+The DeBERTa model was proposed in [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654) by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen It is based on Google's
+BERT model released in 2018 and Facebook's RoBERTa model released in 2019.
+
+It builds on RoBERTa with disentangled attention and enhanced mask decoder training with half of the data used in
+RoBERTa.
+
+The abstract from the paper is the following:
+
+*Recent progress in pre-trained neural language models has significantly improved the performance of many natural
+language processing (NLP) tasks. In this paper we propose a new model architecture DeBERTa (Decoding-enhanced BERT with
+disentangled attention) that improves the BERT and RoBERTa models using two novel techniques. The first is the
+disentangled attention mechanism, where each word is represented using two vectors that encode its content and
+position, respectively, and the attention weights among words are computed using disentangled matrices on their
+contents and relative positions. Second, an enhanced mask decoder is used to replace the output softmax layer to
+predict the masked tokens for model pretraining. We show that these two techniques significantly improve the efficiency
+of model pretraining and performance of downstream tasks. Compared to RoBERTa-Large, a DeBERTa model trained on half of
+the training data performs consistently better on a wide range of NLP tasks, achieving improvements on MNLI by +0.9%
+(90.2% vs. 91.1%), on SQuAD v2.0 by +2.3% (88.4% vs. 90.7%) and RACE by +3.6% (83.2% vs. 86.8%). The DeBERTa code and
+pre-trained models will be made publicly available at https://github.com/microsoft/DeBERTa.*
+
+
+This model was contributed by [DeBERTa](https://huggingface.co/DeBERTa). This model TF 2.0 implementation was
+contributed by [kamalkraj](https://huggingface.co/kamalkraj) . The original code can be found [here](https://github.com/microsoft/DeBERTa).
+
+
+## DebertaConfig
+
+[[autodoc]] DebertaConfig
+
+## DebertaTokenizer
+
+[[autodoc]] DebertaTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## DebertaTokenizerFast
+
+[[autodoc]] DebertaTokenizerFast
+ - build_inputs_with_special_tokens
+ - create_token_type_ids_from_sequences
+
+## DebertaModel
+
+[[autodoc]] DebertaModel
+ - forward
+
+## DebertaPreTrainedModel
+
+[[autodoc]] DebertaPreTrainedModel
+
+## DebertaForMaskedLM
+
+[[autodoc]] DebertaForMaskedLM
+ - forward
+
+## DebertaForSequenceClassification
+
+[[autodoc]] DebertaForSequenceClassification
+ - forward
+
+## DebertaForTokenClassification
+
+[[autodoc]] DebertaForTokenClassification
+ - forward
+
+## DebertaForQuestionAnswering
+
+[[autodoc]] DebertaForQuestionAnswering
+ - forward
+
+## TFDebertaModel
+
+[[autodoc]] TFDebertaModel
+ - call
+
+## TFDebertaPreTrainedModel
+
+[[autodoc]] TFDebertaPreTrainedModel
+ - call
+
+## TFDebertaForMaskedLM
+
+[[autodoc]] TFDebertaForMaskedLM
+ - call
+
+## TFDebertaForSequenceClassification
+
+[[autodoc]] TFDebertaForSequenceClassification
+ - call
+
+## TFDebertaForTokenClassification
+
+[[autodoc]] TFDebertaForTokenClassification
+ - call
+
+## TFDebertaForQuestionAnswering
+
+[[autodoc]] TFDebertaForQuestionAnswering
+ - call
diff --git a/docs/source/en/model_doc/decision_transformer.mdx b/docs/source/en/model_doc/decision_transformer.mdx
new file mode 100644
index 00000000000000..2f0c70b6791bdc
--- /dev/null
+++ b/docs/source/en/model_doc/decision_transformer.mdx
@@ -0,0 +1,51 @@
+
+
+# Decision Transformer
+
+## Overview
+
+The Decision Transformer model was proposed in [Decision Transformer: Reinforcement Learning via Sequence Modeling](https://arxiv.org/abs/2106.01345)
+by Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Michael Laskin, Pieter Abbeel, Aravind Srinivas, Igor Mordatch.
+
+The abstract from the paper is the following:
+
+*We introduce a framework that abstracts Reinforcement Learning (RL) as a sequence modeling problem.
+This allows us to draw upon the simplicity and scalability of the Transformer architecture, and associated advances
+ in language modeling such as GPT-x and BERT. In particular, we present Decision Transformer, an architecture that
+ casts the problem of RL as conditional sequence modeling. Unlike prior approaches to RL that fit value functions or
+ compute policy gradients, Decision Transformer simply outputs the optimal actions by leveraging a causally masked
+ Transformer. By conditioning an autoregressive model on the desired return (reward), past states, and actions, our
+ Decision Transformer model can generate future actions that achieve the desired return. Despite its simplicity,
+ Decision Transformer matches or exceeds the performance of state-of-the-art model-free offline RL baselines on
+ Atari, OpenAI Gym, and Key-to-Door tasks.*
+
+Tips:
+
+This version of the model is for tasks where the state is a vector, image-based states will come soon.
+
+This model was contributed by [edbeeching](https://huggingface.co/edbeeching). The original code can be found [here](https://github.com/kzl/decision-transformer).
+
+## DecisionTransformerConfig
+
+[[autodoc]] DecisionTransformerConfig
+
+
+## DecisionTransformerGPT2Model
+
+[[autodoc]] DecisionTransformerGPT2Model
+ - forward
+
+## DecisionTransformerModel
+
+[[autodoc]] DecisionTransformerModel
+ - forward
diff --git a/docs/source/en/model_doc/deit.mdx b/docs/source/en/model_doc/deit.mdx
new file mode 100644
index 00000000000000..e03920e93ef4fa
--- /dev/null
+++ b/docs/source/en/model_doc/deit.mdx
@@ -0,0 +1,102 @@
+
+
+# DeiT
+
+
+
+This is a recently introduced model so the API hasn't been tested extensively. There may be some bugs or slight
+breaking changes to fix it in the future. If you see something strange, file a [Github Issue](https://github.com/huggingface/transformers/issues/new?assignees=&labels=&template=bug-report.md&title).
+
+
+
+## Overview
+
+The DeiT model was proposed in [Training data-efficient image transformers & distillation through attention](https://arxiv.org/abs/2012.12877) by Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre
+Sablayrolles, Hervé Jégou. The [Vision Transformer (ViT)](vit) introduced in [Dosovitskiy et al., 2020](https://arxiv.org/abs/2010.11929) has shown that one can match or even outperform existing convolutional neural
+networks using a Transformer encoder (BERT-like). However, the ViT models introduced in that paper required training on
+expensive infrastructure for multiple weeks, using external data. DeiT (data-efficient image transformers) are more
+efficiently trained transformers for image classification, requiring far less data and far less computing resources
+compared to the original ViT models.
+
+The abstract from the paper is the following:
+
+*Recently, neural networks purely based on attention were shown to address image understanding tasks such as image
+classification. However, these visual transformers are pre-trained with hundreds of millions of images using an
+expensive infrastructure, thereby limiting their adoption. In this work, we produce a competitive convolution-free
+transformer by training on Imagenet only. We train them on a single computer in less than 3 days. Our reference vision
+transformer (86M parameters) achieves top-1 accuracy of 83.1% (single-crop evaluation) on ImageNet with no external
+data. More importantly, we introduce a teacher-student strategy specific to transformers. It relies on a distillation
+token ensuring that the student learns from the teacher through attention. We show the interest of this token-based
+distillation, especially when using a convnet as a teacher. This leads us to report results competitive with convnets
+for both Imagenet (where we obtain up to 85.2% accuracy) and when transferring to other tasks. We share our code and
+models.*
+
+Tips:
+
+- Compared to ViT, DeiT models use a so-called distillation token to effectively learn from a teacher (which, in the
+ DeiT paper, is a ResNet like-model). The distillation token is learned through backpropagation, by interacting with
+ the class ([CLS]) and patch tokens through the self-attention layers.
+- There are 2 ways to fine-tune distilled models, either (1) in a classic way, by only placing a prediction head on top
+ of the final hidden state of the class token and not using the distillation signal, or (2) by placing both a
+ prediction head on top of the class token and on top of the distillation token. In that case, the [CLS] prediction
+ head is trained using regular cross-entropy between the prediction of the head and the ground-truth label, while the
+ distillation prediction head is trained using hard distillation (cross-entropy between the prediction of the
+ distillation head and the label predicted by the teacher). At inference time, one takes the average prediction
+ between both heads as final prediction. (2) is also called "fine-tuning with distillation", because one relies on a
+ teacher that has already been fine-tuned on the downstream dataset. In terms of models, (1) corresponds to
+ [`DeiTForImageClassification`] and (2) corresponds to
+ [`DeiTForImageClassificationWithTeacher`].
+- Note that the authors also did try soft distillation for (2) (in which case the distillation prediction head is
+ trained using KL divergence to match the softmax output of the teacher), but hard distillation gave the best results.
+- All released checkpoints were pre-trained and fine-tuned on ImageNet-1k only. No external data was used. This is in
+ contrast with the original ViT model, which used external data like the JFT-300M dataset/Imagenet-21k for
+ pre-training.
+- The authors of DeiT also released more efficiently trained ViT models, which you can directly plug into
+ [`ViTModel`] or [`ViTForImageClassification`]. Techniques like data
+ augmentation, optimization, and regularization were used in order to simulate training on a much larger dataset
+ (while only using ImageNet-1k for pre-training). There are 4 variants available (in 3 different sizes):
+ *facebook/deit-tiny-patch16-224*, *facebook/deit-small-patch16-224*, *facebook/deit-base-patch16-224* and
+ *facebook/deit-base-patch16-384*. Note that one should use [`DeiTFeatureExtractor`] in order to
+ prepare images for the model.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr).
+
+
+## DeiTConfig
+
+[[autodoc]] DeiTConfig
+
+## DeiTFeatureExtractor
+
+[[autodoc]] DeiTFeatureExtractor
+ - __call__
+
+## DeiTModel
+
+[[autodoc]] DeiTModel
+ - forward
+
+## DeiTForMaskedImageModeling
+
+[[autodoc]] DeiTForMaskedImageModeling
+ - forward
+
+## DeiTForImageClassification
+
+[[autodoc]] DeiTForImageClassification
+ - forward
+
+## DeiTForImageClassificationWithTeacher
+
+[[autodoc]] DeiTForImageClassificationWithTeacher
+ - forward
diff --git a/docs/source/en/model_doc/detr.mdx b/docs/source/en/model_doc/detr.mdx
new file mode 100644
index 00000000000000..4c29efc52e30d8
--- /dev/null
+++ b/docs/source/en/model_doc/detr.mdx
@@ -0,0 +1,169 @@
+
+
+# DETR
+
+## Overview
+
+The DETR model was proposed in [End-to-End Object Detection with Transformers](https://arxiv.org/abs/2005.12872) by
+Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov and Sergey Zagoruyko. DETR
+consists of a convolutional backbone followed by an encoder-decoder Transformer which can be trained end-to-end for
+object detection. It greatly simplifies a lot of the complexity of models like Faster-R-CNN and Mask-R-CNN, which use
+things like region proposals, non-maximum suppression procedure and anchor generation. Moreover, DETR can also be
+naturally extended to perform panoptic segmentation, by simply adding a mask head on top of the decoder outputs.
+
+The abstract from the paper is the following:
+
+*We present a new method that views object detection as a direct set prediction problem. Our approach streamlines the
+detection pipeline, effectively removing the need for many hand-designed components like a non-maximum suppression
+procedure or anchor generation that explicitly encode our prior knowledge about the task. The main ingredients of the
+new framework, called DEtection TRansformer or DETR, are a set-based global loss that forces unique predictions via
+bipartite matching, and a transformer encoder-decoder architecture. Given a fixed small set of learned object queries,
+DETR reasons about the relations of the objects and the global image context to directly output the final set of
+predictions in parallel. The new model is conceptually simple and does not require a specialized library, unlike many
+other modern detectors. DETR demonstrates accuracy and run-time performance on par with the well-established and
+highly-optimized Faster RCNN baseline on the challenging COCO object detection dataset. Moreover, DETR can be easily
+generalized to produce panoptic segmentation in a unified manner. We show that it significantly outperforms competitive
+baselines.*
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/facebookresearch/detr).
+
+The quickest way to get started with DETR is by checking the [example notebooks](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/DETR) (which showcase both inference and
+fine-tuning on custom data).
+
+Here's a TLDR explaining how [`~transformers.DetrForObjectDetection`] works:
+
+First, an image is sent through a pre-trained convolutional backbone (in the paper, the authors use
+ResNet-50/ResNet-101). Let's assume we also add a batch dimension. This means that the input to the backbone is a
+tensor of shape `(batch_size, 3, height, width)`, assuming the image has 3 color channels (RGB). The CNN backbone
+outputs a new lower-resolution feature map, typically of shape `(batch_size, 2048, height/32, width/32)`. This is
+then projected to match the hidden dimension of the Transformer of DETR, which is `256` by default, using a
+`nn.Conv2D` layer. So now, we have a tensor of shape `(batch_size, 256, height/32, width/32).` Next, the
+feature map is flattened and transposed to obtain a tensor of shape `(batch_size, seq_len, d_model)` =
+`(batch_size, width/32*height/32, 256)`. So a difference with NLP models is that the sequence length is actually
+longer than usual, but with a smaller `d_model` (which in NLP is typically 768 or higher).
+
+Next, this is sent through the encoder, outputting `encoder_hidden_states` of the same shape (you can consider
+these as image features). Next, so-called **object queries** are sent through the decoder. This is a tensor of shape
+`(batch_size, num_queries, d_model)`, with `num_queries` typically set to 100 and initialized with zeros.
+These input embeddings are learnt positional encodings that the authors refer to as object queries, and similarly to
+the encoder, they are added to the input of each attention layer. Each object query will look for a particular object
+in the image. The decoder updates these embeddings through multiple self-attention and encoder-decoder attention layers
+to output `decoder_hidden_states` of the same shape: `(batch_size, num_queries, d_model)`. Next, two heads
+are added on top for object detection: a linear layer for classifying each object query into one of the objects or "no
+object", and a MLP to predict bounding boxes for each query.
+
+The model is trained using a **bipartite matching loss**: so what we actually do is compare the predicted classes +
+bounding boxes of each of the N = 100 object queries to the ground truth annotations, padded up to the same length N
+(so if an image only contains 4 objects, 96 annotations will just have a "no object" as class and "no bounding box" as
+bounding box). The [Hungarian matching algorithm](https://en.wikipedia.org/wiki/Hungarian_algorithm) is used to find
+an optimal one-to-one mapping of each of the N queries to each of the N annotations. Next, standard cross-entropy (for
+the classes) and a linear combination of the L1 and [generalized IoU loss](https://giou.stanford.edu/) (for the
+bounding boxes) are used to optimize the parameters of the model.
+
+DETR can be naturally extended to perform panoptic segmentation (which unifies semantic segmentation and instance
+segmentation). [`~transformers.DetrForSegmentation`] adds a segmentation mask head on top of
+[`~transformers.DetrForObjectDetection`]. The mask head can be trained either jointly, or in a two steps process,
+where one first trains a [`~transformers.DetrForObjectDetection`] model to detect bounding boxes around both
+"things" (instances) and "stuff" (background things like trees, roads, sky), then freeze all the weights and train only
+the mask head for 25 epochs. Experimentally, these two approaches give similar results. Note that predicting boxes is
+required for the training to be possible, since the Hungarian matching is computed using distances between boxes.
+
+Tips:
+
+- DETR uses so-called **object queries** to detect objects in an image. The number of queries determines the maximum
+ number of objects that can be detected in a single image, and is set to 100 by default (see parameter
+ `num_queries` of [`~transformers.DetrConfig`]). Note that it's good to have some slack (in COCO, the
+ authors used 100, while the maximum number of objects in a COCO image is ~70).
+- The decoder of DETR updates the query embeddings in parallel. This is different from language models like GPT-2,
+ which use autoregressive decoding instead of parallel. Hence, no causal attention mask is used.
+- DETR adds position embeddings to the hidden states at each self-attention and cross-attention layer before projecting
+ to queries and keys. For the position embeddings of the image, one can choose between fixed sinusoidal or learned
+ absolute position embeddings. By default, the parameter `position_embedding_type` of
+ [`~transformers.DetrConfig`] is set to `"sine"`.
+- During training, the authors of DETR did find it helpful to use auxiliary losses in the decoder, especially to help
+ the model output the correct number of objects of each class. If you set the parameter `auxiliary_loss` of
+ [`~transformers.DetrConfig`] to `True`, then prediction feedforward neural networks and Hungarian losses
+ are added after each decoder layer (with the FFNs sharing parameters).
+- If you want to train the model in a distributed environment across multiple nodes, then one should update the
+ _num_boxes_ variable in the _DetrLoss_ class of _modeling_detr.py_. When training on multiple nodes, this should be
+ set to the average number of target boxes across all nodes, as can be seen in the original implementation [here](https://github.com/facebookresearch/detr/blob/a54b77800eb8e64e3ad0d8237789fcbf2f8350c5/models/detr.py#L227-L232).
+- [`~transformers.DetrForObjectDetection`] and [`~transformers.DetrForSegmentation`] can be initialized with
+ any convolutional backbone available in the [timm library](https://github.com/rwightman/pytorch-image-models).
+ Initializing with a MobileNet backbone for example can be done by setting the `backbone` attribute of
+ [`~transformers.DetrConfig`] to `"tf_mobilenetv3_small_075"`, and then initializing the model with that
+ config.
+- DETR resizes the input images such that the shortest side is at least a certain amount of pixels while the longest is
+ at most 1333 pixels. At training time, scale augmentation is used such that the shortest side is randomly set to at
+ least 480 and at most 800 pixels. At inference time, the shortest side is set to 800. One can use
+ [`~transformers.DetrFeatureExtractor`] to prepare images (and optional annotations in COCO format) for the
+ model. Due to this resizing, images in a batch can have different sizes. DETR solves this by padding images up to the
+ largest size in a batch, and by creating a pixel mask that indicates which pixels are real/which are padding.
+ Alternatively, one can also define a custom `collate_fn` in order to batch images together, using
+ [`~transformers.DetrFeatureExtractor.pad_and_create_pixel_mask`].
+- The size of the images will determine the amount of memory being used, and will thus determine the `batch_size`.
+ It is advised to use a batch size of 2 per GPU. See [this Github thread](https://github.com/facebookresearch/detr/issues/150) for more info.
+
+As a summary, consider the following table:
+
+| Task | Object detection | Instance segmentation | Panoptic segmentation |
+|------|------------------|-----------------------|-----------------------|
+| **Description** | Predicting bounding boxes and class labels around objects in an image | Predicting masks around objects (i.e. instances) in an image | Predicting masks around both objects (i.e. instances) as well as "stuff" (i.e. background things like trees and roads) in an image |
+| **Model** | [`~transformers.DetrForObjectDetection`] | [`~transformers.DetrForSegmentation`] | [`~transformers.DetrForSegmentation`] |
+| **Example dataset** | COCO detection | COCO detection, COCO panoptic | COCO panoptic | |
+| **Format of annotations to provide to** [`~transformers.DetrFeatureExtractor`] | {'image_id': `int`, 'annotations': `List[Dict]`} each Dict being a COCO object annotation | {'image_id': `int`, 'annotations': `List[Dict]`} (in case of COCO detection) or {'file_name': `str`, 'image_id': `int`, 'segments_info': `List[Dict]`} (in case of COCO panoptic) | {'file_name': `str`, 'image_id': `int`, 'segments_info': `List[Dict]`} and masks_path (path to directory containing PNG files of the masks) |
+| **Postprocessing** (i.e. converting the output of the model to COCO API) | [`~transformers.DetrFeatureExtractor.post_process`] | [`~transformers.DetrFeatureExtractor.post_process_segmentation`] | [`~transformers.DetrFeatureExtractor.post_process_segmentation`], [`~transformers.DetrFeatureExtractor.post_process_panoptic`] |
+| **evaluators** | `CocoEvaluator` with `iou_types="bbox"` | `CocoEvaluator` with `iou_types="bbox"` or `"segm"` | `CocoEvaluator` with `iou_tupes="bbox"` or `"segm"`, `PanopticEvaluator` |
+
+In short, one should prepare the data either in COCO detection or COCO panoptic format, then use
+[`~transformers.DetrFeatureExtractor`] to create `pixel_values`, `pixel_mask` and optional
+`labels`, which can then be used to train (or fine-tune) a model. For evaluation, one should first convert the
+outputs of the model using one of the postprocessing methods of [`~transformers.DetrFeatureExtractor`]. These can
+be be provided to either `CocoEvaluator` or `PanopticEvaluator`, which allow you to calculate metrics like
+mean Average Precision (mAP) and Panoptic Quality (PQ). The latter objects are implemented in the [original repository](https://github.com/facebookresearch/detr). See the [example notebooks](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/DETR) for more info regarding evaluation.
+
+
+## DETR specific outputs
+
+[[autodoc]] models.detr.modeling_detr.DetrModelOutput
+
+[[autodoc]] models.detr.modeling_detr.DetrObjectDetectionOutput
+
+[[autodoc]] models.detr.modeling_detr.DetrSegmentationOutput
+
+## DetrConfig
+
+[[autodoc]] DetrConfig
+
+## DetrFeatureExtractor
+
+[[autodoc]] DetrFeatureExtractor
+ - __call__
+ - pad_and_create_pixel_mask
+ - post_process
+ - post_process_segmentation
+ - post_process_panoptic
+
+## DetrModel
+
+[[autodoc]] DetrModel
+ - forward
+
+## DetrForObjectDetection
+
+[[autodoc]] DetrForObjectDetection
+ - forward
+
+## DetrForSegmentation
+
+[[autodoc]] DetrForSegmentation
+ - forward
\ No newline at end of file
diff --git a/docs/source/en/model_doc/dialogpt.mdx b/docs/source/en/model_doc/dialogpt.mdx
new file mode 100644
index 00000000000000..62c6b45130e346
--- /dev/null
+++ b/docs/source/en/model_doc/dialogpt.mdx
@@ -0,0 +1,49 @@
+
+
+# DialoGPT
+
+## Overview
+
+DialoGPT was proposed in [DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation](https://arxiv.org/abs/1911.00536) by Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao,
+Jianfeng Gao, Jingjing Liu, Bill Dolan. It's a GPT2 Model trained on 147M conversation-like exchanges extracted from
+Reddit.
+
+The abstract from the paper is the following:
+
+*We present a large, tunable neural conversational response generation model, DialoGPT (dialogue generative pre-trained
+transformer). Trained on 147M conversation-like exchanges extracted from Reddit comment chains over a period spanning
+from 2005 through 2017, DialoGPT extends the Hugging Face PyTorch transformer to attain a performance close to human
+both in terms of automatic and human evaluation in single-turn dialogue settings. We show that conversational systems
+that leverage DialoGPT generate more relevant, contentful and context-consistent responses than strong baseline
+systems. The pre-trained model and training pipeline are publicly released to facilitate research into neural response
+generation and the development of more intelligent open-domain dialogue systems.*
+
+Tips:
+
+- DialoGPT is a model with absolute position embeddings so it's usually advised to pad the inputs on the right rather
+ than the left.
+- DialoGPT was trained with a causal language modeling (CLM) objective on conversational data and is therefore powerful
+ at response generation in open-domain dialogue systems.
+- DialoGPT enables the user to create a chat bot in just 10 lines of code as shown on [DialoGPT's model card](https://huggingface.co/microsoft/DialoGPT-medium).
+
+Training:
+
+In order to train or fine-tune DialoGPT, one can use causal language modeling training. To cite the official paper: *We
+follow the OpenAI GPT-2 to model a multiturn dialogue session as a long text and frame the generation task as language
+modeling. We first concatenate all dialog turns within a dialogue session into a long text x_1,..., x_N (N is the
+sequence length), ended by the end-of-text token.* For more information please confer to the original paper.
+
+
+DialoGPT's architecture is based on the GPT2 model, so one can refer to [GPT2's documentation page](gpt2).
+
+The original code can be found [here](https://github.com/microsoft/DialoGPT).
diff --git a/docs/source/en/model_doc/distilbert.mdx b/docs/source/en/model_doc/distilbert.mdx
new file mode 100644
index 00000000000000..b8886c5d6f8f6d
--- /dev/null
+++ b/docs/source/en/model_doc/distilbert.mdx
@@ -0,0 +1,149 @@
+
+
+# DistilBERT
+
+## Overview
+
+The DistilBERT model was proposed in the blog post [Smaller, faster, cheaper, lighter: Introducing DistilBERT, a
+distilled version of BERT](https://medium.com/huggingface/distilbert-8cf3380435b5), and the paper [DistilBERT, a
+distilled version of BERT: smaller, faster, cheaper and lighter](https://arxiv.org/abs/1910.01108). DistilBERT is a
+small, fast, cheap and light Transformer model trained by distilling BERT base. It has 40% less parameters than
+*bert-base-uncased*, runs 60% faster while preserving over 95% of BERT's performances as measured on the GLUE language
+understanding benchmark.
+
+The abstract from the paper is the following:
+
+*As Transfer Learning from large-scale pre-trained models becomes more prevalent in Natural Language Processing (NLP),
+operating these large models in on-the-edge and/or under constrained computational training or inference budgets
+remains challenging. In this work, we propose a method to pre-train a smaller general-purpose language representation
+model, called DistilBERT, which can then be fine-tuned with good performances on a wide range of tasks like its larger
+counterparts. While most prior work investigated the use of distillation for building task-specific models, we leverage
+knowledge distillation during the pretraining phase and show that it is possible to reduce the size of a BERT model by
+40%, while retaining 97% of its language understanding capabilities and being 60% faster. To leverage the inductive
+biases learned by larger models during pretraining, we introduce a triple loss combining language modeling,
+distillation and cosine-distance losses. Our smaller, faster and lighter model is cheaper to pre-train and we
+demonstrate its capabilities for on-device computations in a proof-of-concept experiment and a comparative on-device
+study.*
+
+Tips:
+
+- DistilBERT doesn't have `token_type_ids`, you don't need to indicate which token belongs to which segment. Just
+ separate your segments with the separation token `tokenizer.sep_token` (or `[SEP]`).
+- DistilBERT doesn't have options to select the input positions (`position_ids` input). This could be added if
+ necessary though, just let us know if you need this option.
+
+This model was contributed by [victorsanh](https://huggingface.co/victorsanh). This model jax version was
+contributed by [kamalkraj](https://huggingface.co/kamalkraj). The original code can be found [here](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation).
+
+
+## DistilBertConfig
+
+[[autodoc]] DistilBertConfig
+
+## DistilBertTokenizer
+
+[[autodoc]] DistilBertTokenizer
+
+## DistilBertTokenizerFast
+
+[[autodoc]] DistilBertTokenizerFast
+
+## DistilBertModel
+
+[[autodoc]] DistilBertModel
+ - forward
+
+## DistilBertForMaskedLM
+
+[[autodoc]] DistilBertForMaskedLM
+ - forward
+
+## DistilBertForSequenceClassification
+
+[[autodoc]] DistilBertForSequenceClassification
+ - forward
+
+## DistilBertForMultipleChoice
+
+[[autodoc]] DistilBertForMultipleChoice
+ - forward
+
+## DistilBertForTokenClassification
+
+[[autodoc]] DistilBertForTokenClassification
+ - forward
+
+## DistilBertForQuestionAnswering
+
+[[autodoc]] DistilBertForQuestionAnswering
+ - forward
+
+## TFDistilBertModel
+
+[[autodoc]] TFDistilBertModel
+ - call
+
+## TFDistilBertForMaskedLM
+
+[[autodoc]] TFDistilBertForMaskedLM
+ - call
+
+## TFDistilBertForSequenceClassification
+
+[[autodoc]] TFDistilBertForSequenceClassification
+ - call
+
+## TFDistilBertForMultipleChoice
+
+[[autodoc]] TFDistilBertForMultipleChoice
+ - call
+
+## TFDistilBertForTokenClassification
+
+[[autodoc]] TFDistilBertForTokenClassification
+ - call
+
+## TFDistilBertForQuestionAnswering
+
+[[autodoc]] TFDistilBertForQuestionAnswering
+ - call
+
+## FlaxDistilBertModel
+
+[[autodoc]] FlaxDistilBertModel
+ - __call__
+
+## FlaxDistilBertForMaskedLM
+
+[[autodoc]] FlaxDistilBertForMaskedLM
+ - __call__
+
+## FlaxDistilBertForSequenceClassification
+
+[[autodoc]] FlaxDistilBertForSequenceClassification
+ - __call__
+
+## FlaxDistilBertForMultipleChoice
+
+[[autodoc]] FlaxDistilBertForMultipleChoice
+ - __call__
+
+## FlaxDistilBertForTokenClassification
+
+[[autodoc]] FlaxDistilBertForTokenClassification
+ - __call__
+
+## FlaxDistilBertForQuestionAnswering
+
+[[autodoc]] FlaxDistilBertForQuestionAnswering
+ - __call__
diff --git a/docs/source/en/model_doc/dit.mdx b/docs/source/en/model_doc/dit.mdx
new file mode 100644
index 00000000000000..e3830ce7c3e167
--- /dev/null
+++ b/docs/source/en/model_doc/dit.mdx
@@ -0,0 +1,67 @@
+
+
+# DiT
+
+## Overview
+
+DiT was proposed in [DiT: Self-supervised Pre-training for Document Image Transformer](https://arxiv.org/abs/2203.02378) by Junlong Li, Yiheng Xu, Tengchao Lv, Lei Cui, Cha Zhang, Furu Wei.
+DiT applies the self-supervised objective of [BEiT](beit) (BERT pre-training of Image Transformers) to 42 million document images, allowing for state-of-the-art results on tasks including:
+
+- document image classification: the [RVL-CDIP](https://www.cs.cmu.edu/~aharley/rvl-cdip/) dataset (a collection of
+ 400,000 images belonging to one of 16 classes).
+- document layout analysis: the [PubLayNet](https://github.com/ibm-aur-nlp/PubLayNet) dataset (a collection of more
+ than 360,000 document images constructed by automatically parsing PubMed XML files).
+- table detection: the [ICDAR 2019 cTDaR](https://github.com/cndplab-founder/ICDAR2019_cTDaR) dataset (a collection of
+ 600 training images and 240 testing images).
+
+The abstract from the paper is the following:
+
+*Image Transformer has recently achieved significant progress for natural image understanding, either using supervised (ViT, DeiT, etc.) or self-supervised (BEiT, MAE, etc.) pre-training techniques. In this paper, we propose DiT, a self-supervised pre-trained Document Image Transformer model using large-scale unlabeled text images for Document AI tasks, which is essential since no supervised counterparts ever exist due to the lack of human labeled document images. We leverage DiT as the backbone network in a variety of vision-based Document AI tasks, including document image classification, document layout analysis, as well as table detection. Experiment results have illustrated that the self-supervised pre-trained DiT model achieves new state-of-the-art results on these downstream tasks, e.g. document image classification (91.11 → 92.69), document layout analysis (91.0 → 94.9) and table detection (94.23 → 96.55). *
+
+
+
+ ConvNeXT architecture. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). TensorFlow version of the model was contributed by [ariG23498](https://github.com/ariG23498),
+[gante](https://github.com/gante), and [sayakpaul](https://github.com/sayakpaul) (equal contribution). The original code can be found [here](https://github.com/facebookresearch/ConvNeXt).
+
+## ConvNextConfig
+
+[[autodoc]] ConvNextConfig
+
+
+## ConvNextFeatureExtractor
+
+[[autodoc]] ConvNextFeatureExtractor
+
+
+## ConvNextModel
+
+[[autodoc]] ConvNextModel
+ - forward
+
+
+## ConvNextForImageClassification
+
+[[autodoc]] ConvNextForImageClassification
+ - forward
+
+
+## TFConvNextModel
+
+[[autodoc]] TFConvNextModel
+ - call
+
+
+## TFConvNextForImageClassification
+
+[[autodoc]] TFConvNextForImageClassification
+ - call
\ No newline at end of file
diff --git a/docs/source/en/model_doc/cpm.mdx b/docs/source/en/model_doc/cpm.mdx
new file mode 100644
index 00000000000000..ac8ed8fdbafbd8
--- /dev/null
+++ b/docs/source/en/model_doc/cpm.mdx
@@ -0,0 +1,44 @@
+
+
+# CPM
+
+## Overview
+
+The CPM model was proposed in [CPM: A Large-scale Generative Chinese Pre-trained Language Model](https://arxiv.org/abs/2012.00413) by Zhengyan Zhang, Xu Han, Hao Zhou, Pei Ke, Yuxian Gu, Deming Ye, Yujia Qin,
+Yusheng Su, Haozhe Ji, Jian Guan, Fanchao Qi, Xiaozhi Wang, Yanan Zheng, Guoyang Zeng, Huanqi Cao, Shengqi Chen,
+Daixuan Li, Zhenbo Sun, Zhiyuan Liu, Minlie Huang, Wentao Han, Jie Tang, Juanzi Li, Xiaoyan Zhu, Maosong Sun.
+
+The abstract from the paper is the following:
+
+*Pre-trained Language Models (PLMs) have proven to be beneficial for various downstream NLP tasks. Recently, GPT-3,
+with 175 billion parameters and 570GB training data, drew a lot of attention due to the capacity of few-shot (even
+zero-shot) learning. However, applying GPT-3 to address Chinese NLP tasks is still challenging, as the training corpus
+of GPT-3 is primarily English, and the parameters are not publicly available. In this technical report, we release the
+Chinese Pre-trained Language Model (CPM) with generative pre-training on large-scale Chinese training data. To the best
+of our knowledge, CPM, with 2.6 billion parameters and 100GB Chinese training data, is the largest Chinese pre-trained
+language model, which could facilitate several downstream Chinese NLP tasks, such as conversation, essay generation,
+cloze test, and language understanding. Extensive experiments demonstrate that CPM achieves strong performance on many
+NLP tasks in the settings of few-shot (even zero-shot) learning.*
+
+This model was contributed by [canwenxu](https://huggingface.co/canwenxu). The original implementation can be found
+here: https://github.com/TsinghuaAI/CPM-Generate
+
+Note: We only have a tokenizer here, since the model architecture is the same as GPT-2.
+
+## CpmTokenizer
+
+[[autodoc]] CpmTokenizer
+
+## CpmTokenizerFast
+
+[[autodoc]] CpmTokenizerFast
diff --git a/docs/source/en/model_doc/ctrl.mdx b/docs/source/en/model_doc/ctrl.mdx
new file mode 100644
index 00000000000000..6f35e487e148a1
--- /dev/null
+++ b/docs/source/en/model_doc/ctrl.mdx
@@ -0,0 +1,87 @@
+
+
+# CTRL
+
+## Overview
+
+CTRL model was proposed in [CTRL: A Conditional Transformer Language Model for Controllable Generation](https://arxiv.org/abs/1909.05858) by Nitish Shirish Keskar*, Bryan McCann*, Lav R. Varshney, Caiming Xiong and
+Richard Socher. It's a causal (unidirectional) transformer pre-trained using language modeling on a very large corpus
+of ~140 GB of text data with the first token reserved as a control code (such as Links, Books, Wikipedia etc.).
+
+The abstract from the paper is the following:
+
+*Large-scale language models show promising text generation capabilities, but users cannot easily control particular
+aspects of the generated text. We release CTRL, a 1.63 billion-parameter conditional transformer language model,
+trained to condition on control codes that govern style, content, and task-specific behavior. Control codes were
+derived from structure that naturally co-occurs with raw text, preserving the advantages of unsupervised learning while
+providing more explicit control over text generation. These codes also allow CTRL to predict which parts of the
+training data are most likely given a sequence. This provides a potential method for analyzing large amounts of data
+via model-based source attribution.*
+
+Tips:
+
+- CTRL makes use of control codes to generate text: it requires generations to be started by certain words, sentences
+ or links to generate coherent text. Refer to the [original implementation](https://github.com/salesforce/ctrl) for
+ more information.
+- CTRL is a model with absolute position embeddings so it's usually advised to pad the inputs on the right rather than
+ the left.
+- CTRL was trained with a causal language modeling (CLM) objective and is therefore powerful at predicting the next
+ token in a sequence. Leveraging this feature allows CTRL to generate syntactically coherent text as it can be
+ observed in the *run_generation.py* example script.
+- The PyTorch models can take the `past_key_values` as input, which is the previously computed key/value attention pairs.
+ TensorFlow models accepts `past` as input. Using the `past_key_values` value prevents the model from re-computing
+ pre-computed values in the context of text generation. See the [`forward`](model_doc/ctrl#transformers.CTRLModel.forward)
+ method for more information on the usage of this argument.
+
+This model was contributed by [keskarnitishr](https://huggingface.co/keskarnitishr). The original code can be found
+[here](https://github.com/salesforce/ctrl).
+
+
+## CTRLConfig
+
+[[autodoc]] CTRLConfig
+
+## CTRLTokenizer
+
+[[autodoc]] CTRLTokenizer
+ - save_vocabulary
+
+## CTRLModel
+
+[[autodoc]] CTRLModel
+ - forward
+
+## CTRLLMHeadModel
+
+[[autodoc]] CTRLLMHeadModel
+ - forward
+
+## CTRLForSequenceClassification
+
+[[autodoc]] CTRLForSequenceClassification
+ - forward
+
+## TFCTRLModel
+
+[[autodoc]] TFCTRLModel
+ - call
+
+## TFCTRLLMHeadModel
+
+[[autodoc]] TFCTRLLMHeadModel
+ - call
+
+## TFCTRLForSequenceClassification
+
+[[autodoc]] TFCTRLForSequenceClassification
+ - call
diff --git a/docs/source/en/model_doc/data2vec.mdx b/docs/source/en/model_doc/data2vec.mdx
new file mode 100644
index 00000000000000..748e43cab5176e
--- /dev/null
+++ b/docs/source/en/model_doc/data2vec.mdx
@@ -0,0 +1,144 @@
+
+
+# Data2Vec
+
+## Overview
+
+The Data2Vec model was proposed in [data2vec: A General Framework for Self-supervised Learning in Speech, Vision and Language](https://arxiv.org/pdf/2202.03555) by Alexei Baevski, Wei-Ning Hsu, Qiantong Xu, Arun Babu, Jiatao Gu and Michael Auli.
+Data2Vec proposes a unified framework for self-supervised learning across different data modalities - text, audio and images.
+Importantly, predicted targets for pre-training are contextualized latent representations of the inputs, rather than modality-specific, context-independent targets.
+
+The abstract from the paper is the following:
+
+*While the general idea of self-supervised learning is identical across modalities, the actual algorithms and
+objectives differ widely because they were developed with a single modality in mind. To get us closer to general
+self-supervised learning, we present data2vec, a framework that uses the same learning method for either speech,
+NLP or computer vision. The core idea is to predict latent representations of the full input data based on a
+masked view of the input in a selfdistillation setup using a standard Transformer architecture.
+Instead of predicting modality-specific targets such as words, visual tokens or units of human speech which
+are local in nature, data2vec predicts contextualized latent representations that contain information from
+the entire input. Experiments on the major benchmarks of speech recognition, image classification, and
+natural language understanding demonstrate a new state of the art or competitive performance to predominant approaches.
+Models and code are available at www.github.com/pytorch/fairseq/tree/master/examples/data2vec.*
+
+Tips:
+
+- Data2VecAudio, Data2VecText, and Data2VecVision have all been trained using the same self-supervised learning method.
+- For Data2VecAudio, preprocessing is identical to [`Wav2Vec2Model`], including feature extraction
+- For Data2VecText, preprocessing is identical to [`RobertaModel`], including tokenization.
+- For Data2VecVision, preprocessing is identical to [`BeitModel`], including feature extraction.
+
+This model was contributed by [edugp](https://huggingface.co/edugp) and [patrickvonplaten](https://huggingface.co/patrickvonplaten).
+[sayakpaul](https://github.com/sayakpaul) contributed Data2Vec for vision in TensorFlow.
+
+The original code (for NLP and Speech) can be found [here](https://github.com/pytorch/fairseq/tree/main/examples/data2vec).
+The original code for vision can be found [here](https://github.com/facebookresearch/data2vec_vision/tree/main/beit).
+
+
+## Data2VecTextConfig
+
+[[autodoc]] Data2VecTextConfig
+
+## Data2VecAudioConfig
+
+[[autodoc]] Data2VecAudioConfig
+
+## Data2VecVisionConfig
+
+[[autodoc]] Data2VecVisionConfig
+
+
+## Data2VecAudioModel
+
+[[autodoc]] Data2VecAudioModel
+ - forward
+
+## Data2VecAudioForAudioFrameClassification
+
+[[autodoc]] Data2VecAudioForAudioFrameClassification
+ - forward
+
+## Data2VecAudioForCTC
+
+[[autodoc]] Data2VecAudioForCTC
+ - forward
+
+## Data2VecAudioForSequenceClassification
+
+[[autodoc]] Data2VecAudioForSequenceClassification
+ - forward
+
+## Data2VecAudioForXVector
+
+[[autodoc]] Data2VecAudioForXVector
+ - forward
+
+## Data2VecTextModel
+
+[[autodoc]] Data2VecTextModel
+ - forward
+
+## Data2VecTextForCausalLM
+
+[[autodoc]] Data2VecTextForCausalLM
+ - forward
+
+## Data2VecTextForMaskedLM
+
+[[autodoc]] Data2VecTextForMaskedLM
+ - forward
+
+## Data2VecTextForSequenceClassification
+
+[[autodoc]] Data2VecTextForSequenceClassification
+ - forward
+
+## Data2VecTextForMultipleChoice
+
+[[autodoc]] Data2VecTextForMultipleChoice
+ - forward
+
+## Data2VecTextForTokenClassification
+
+[[autodoc]] Data2VecTextForTokenClassification
+ - forward
+
+## Data2VecTextForQuestionAnswering
+
+[[autodoc]] Data2VecTextForQuestionAnswering
+ - forward
+
+## Data2VecVisionModel
+
+[[autodoc]] Data2VecVisionModel
+ - forward
+
+## Data2VecVisionForImageClassification
+
+[[autodoc]] Data2VecVisionForImageClassification
+ - forward
+
+## Data2VecVisionForSemanticSegmentation
+
+[[autodoc]] Data2VecVisionForSemanticSegmentation
+ - forward
+
+## TFData2VecVisionModel
+
+[[autodoc]] TFData2VecVisionModel
+ - call
+
+## TFData2VecVisionForImageClassification
+
+[[autodoc]] TFData2VecVisionForImageClassification
+ - call
\ No newline at end of file
diff --git a/docs/source/en/model_doc/deberta-v2.mdx b/docs/source/en/model_doc/deberta-v2.mdx
new file mode 100644
index 00000000000000..7dd34790def1ab
--- /dev/null
+++ b/docs/source/en/model_doc/deberta-v2.mdx
@@ -0,0 +1,138 @@
+
+
+# DeBERTa-v2
+
+## Overview
+
+The DeBERTa model was proposed in [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654) by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen It is based on Google's
+BERT model released in 2018 and Facebook's RoBERTa model released in 2019.
+
+It builds on RoBERTa with disentangled attention and enhanced mask decoder training with half of the data used in
+RoBERTa.
+
+The abstract from the paper is the following:
+
+*Recent progress in pre-trained neural language models has significantly improved the performance of many natural
+language processing (NLP) tasks. In this paper we propose a new model architecture DeBERTa (Decoding-enhanced BERT with
+disentangled attention) that improves the BERT and RoBERTa models using two novel techniques. The first is the
+disentangled attention mechanism, where each word is represented using two vectors that encode its content and
+position, respectively, and the attention weights among words are computed using disentangled matrices on their
+contents and relative positions. Second, an enhanced mask decoder is used to replace the output softmax layer to
+predict the masked tokens for model pretraining. We show that these two techniques significantly improve the efficiency
+of model pretraining and performance of downstream tasks. Compared to RoBERTa-Large, a DeBERTa model trained on half of
+the training data performs consistently better on a wide range of NLP tasks, achieving improvements on MNLI by +0.9%
+(90.2% vs. 91.1%), on SQuAD v2.0 by +2.3% (88.4% vs. 90.7%) and RACE by +3.6% (83.2% vs. 86.8%). The DeBERTa code and
+pre-trained models will be made publicly available at https://github.com/microsoft/DeBERTa.*
+
+
+The following information is visible directly on the [original implementation
+repository](https://github.com/microsoft/DeBERTa). DeBERTa v2 is the second version of the DeBERTa model. It includes
+the 1.5B model used for the SuperGLUE single-model submission and achieving 89.9, versus human baseline 89.8. You can
+find more details about this submission in the authors'
+[blog](https://www.microsoft.com/en-us/research/blog/microsoft-deberta-surpasses-human-performance-on-the-superglue-benchmark/)
+
+New in v2:
+
+- **Vocabulary** In v2 the tokenizer is changed to use a new vocabulary of size 128K built from the training data.
+ Instead of a GPT2-based tokenizer, the tokenizer is now
+ [sentencepiece-based](https://github.com/google/sentencepiece) tokenizer.
+- **nGiE(nGram Induced Input Encoding)** The DeBERTa-v2 model uses an additional convolution layer aside with the first
+ transformer layer to better learn the local dependency of input tokens.
+- **Sharing position projection matrix with content projection matrix in attention layer** Based on previous
+ experiments, this can save parameters without affecting the performance.
+- **Apply bucket to encode relative positions** The DeBERTa-v2 model uses log bucket to encode relative positions
+ similar to T5.
+- **900M model & 1.5B model** Two additional model sizes are available: 900M and 1.5B, which significantly improves the
+ performance of downstream tasks.
+
+This model was contributed by [DeBERTa](https://huggingface.co/DeBERTa). This model TF 2.0 implementation was
+contributed by [kamalkraj](https://huggingface.co/kamalkraj). The original code can be found [here](https://github.com/microsoft/DeBERTa).
+
+
+## DebertaV2Config
+
+[[autodoc]] DebertaV2Config
+
+## DebertaV2Tokenizer
+
+[[autodoc]] DebertaV2Tokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## DebertaV2TokenizerFast
+
+[[autodoc]] DebertaV2TokenizerFast
+ - build_inputs_with_special_tokens
+ - create_token_type_ids_from_sequences
+
+## DebertaV2Model
+
+[[autodoc]] DebertaV2Model
+ - forward
+
+## DebertaV2PreTrainedModel
+
+[[autodoc]] DebertaV2PreTrainedModel
+ - forward
+
+## DebertaV2ForMaskedLM
+
+[[autodoc]] DebertaV2ForMaskedLM
+ - forward
+
+## DebertaV2ForSequenceClassification
+
+[[autodoc]] DebertaV2ForSequenceClassification
+ - forward
+
+## DebertaV2ForTokenClassification
+
+[[autodoc]] DebertaV2ForTokenClassification
+ - forward
+
+## DebertaV2ForQuestionAnswering
+
+[[autodoc]] DebertaV2ForQuestionAnswering
+ - forward
+
+## TFDebertaV2Model
+
+[[autodoc]] TFDebertaV2Model
+ - call
+
+## TFDebertaV2PreTrainedModel
+
+[[autodoc]] TFDebertaV2PreTrainedModel
+ - call
+
+## TFDebertaV2ForMaskedLM
+
+[[autodoc]] TFDebertaV2ForMaskedLM
+ - call
+
+## TFDebertaV2ForSequenceClassification
+
+[[autodoc]] TFDebertaV2ForSequenceClassification
+ - call
+
+## TFDebertaV2ForTokenClassification
+
+[[autodoc]] TFDebertaV2ForTokenClassification
+ - call
+
+## TFDebertaV2ForQuestionAnswering
+
+[[autodoc]] TFDebertaV2ForQuestionAnswering
+ - call
diff --git a/docs/source/en/model_doc/deberta.mdx b/docs/source/en/model_doc/deberta.mdx
new file mode 100644
index 00000000000000..fed18b9fd50fe7
--- /dev/null
+++ b/docs/source/en/model_doc/deberta.mdx
@@ -0,0 +1,117 @@
+
+
+# DeBERTa
+
+## Overview
+
+The DeBERTa model was proposed in [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654) by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen It is based on Google's
+BERT model released in 2018 and Facebook's RoBERTa model released in 2019.
+
+It builds on RoBERTa with disentangled attention and enhanced mask decoder training with half of the data used in
+RoBERTa.
+
+The abstract from the paper is the following:
+
+*Recent progress in pre-trained neural language models has significantly improved the performance of many natural
+language processing (NLP) tasks. In this paper we propose a new model architecture DeBERTa (Decoding-enhanced BERT with
+disentangled attention) that improves the BERT and RoBERTa models using two novel techniques. The first is the
+disentangled attention mechanism, where each word is represented using two vectors that encode its content and
+position, respectively, and the attention weights among words are computed using disentangled matrices on their
+contents and relative positions. Second, an enhanced mask decoder is used to replace the output softmax layer to
+predict the masked tokens for model pretraining. We show that these two techniques significantly improve the efficiency
+of model pretraining and performance of downstream tasks. Compared to RoBERTa-Large, a DeBERTa model trained on half of
+the training data performs consistently better on a wide range of NLP tasks, achieving improvements on MNLI by +0.9%
+(90.2% vs. 91.1%), on SQuAD v2.0 by +2.3% (88.4% vs. 90.7%) and RACE by +3.6% (83.2% vs. 86.8%). The DeBERTa code and
+pre-trained models will be made publicly available at https://github.com/microsoft/DeBERTa.*
+
+
+This model was contributed by [DeBERTa](https://huggingface.co/DeBERTa). This model TF 2.0 implementation was
+contributed by [kamalkraj](https://huggingface.co/kamalkraj) . The original code can be found [here](https://github.com/microsoft/DeBERTa).
+
+
+## DebertaConfig
+
+[[autodoc]] DebertaConfig
+
+## DebertaTokenizer
+
+[[autodoc]] DebertaTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## DebertaTokenizerFast
+
+[[autodoc]] DebertaTokenizerFast
+ - build_inputs_with_special_tokens
+ - create_token_type_ids_from_sequences
+
+## DebertaModel
+
+[[autodoc]] DebertaModel
+ - forward
+
+## DebertaPreTrainedModel
+
+[[autodoc]] DebertaPreTrainedModel
+
+## DebertaForMaskedLM
+
+[[autodoc]] DebertaForMaskedLM
+ - forward
+
+## DebertaForSequenceClassification
+
+[[autodoc]] DebertaForSequenceClassification
+ - forward
+
+## DebertaForTokenClassification
+
+[[autodoc]] DebertaForTokenClassification
+ - forward
+
+## DebertaForQuestionAnswering
+
+[[autodoc]] DebertaForQuestionAnswering
+ - forward
+
+## TFDebertaModel
+
+[[autodoc]] TFDebertaModel
+ - call
+
+## TFDebertaPreTrainedModel
+
+[[autodoc]] TFDebertaPreTrainedModel
+ - call
+
+## TFDebertaForMaskedLM
+
+[[autodoc]] TFDebertaForMaskedLM
+ - call
+
+## TFDebertaForSequenceClassification
+
+[[autodoc]] TFDebertaForSequenceClassification
+ - call
+
+## TFDebertaForTokenClassification
+
+[[autodoc]] TFDebertaForTokenClassification
+ - call
+
+## TFDebertaForQuestionAnswering
+
+[[autodoc]] TFDebertaForQuestionAnswering
+ - call
diff --git a/docs/source/en/model_doc/decision_transformer.mdx b/docs/source/en/model_doc/decision_transformer.mdx
new file mode 100644
index 00000000000000..2f0c70b6791bdc
--- /dev/null
+++ b/docs/source/en/model_doc/decision_transformer.mdx
@@ -0,0 +1,51 @@
+
+
+# Decision Transformer
+
+## Overview
+
+The Decision Transformer model was proposed in [Decision Transformer: Reinforcement Learning via Sequence Modeling](https://arxiv.org/abs/2106.01345)
+by Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Michael Laskin, Pieter Abbeel, Aravind Srinivas, Igor Mordatch.
+
+The abstract from the paper is the following:
+
+*We introduce a framework that abstracts Reinforcement Learning (RL) as a sequence modeling problem.
+This allows us to draw upon the simplicity and scalability of the Transformer architecture, and associated advances
+ in language modeling such as GPT-x and BERT. In particular, we present Decision Transformer, an architecture that
+ casts the problem of RL as conditional sequence modeling. Unlike prior approaches to RL that fit value functions or
+ compute policy gradients, Decision Transformer simply outputs the optimal actions by leveraging a causally masked
+ Transformer. By conditioning an autoregressive model on the desired return (reward), past states, and actions, our
+ Decision Transformer model can generate future actions that achieve the desired return. Despite its simplicity,
+ Decision Transformer matches or exceeds the performance of state-of-the-art model-free offline RL baselines on
+ Atari, OpenAI Gym, and Key-to-Door tasks.*
+
+Tips:
+
+This version of the model is for tasks where the state is a vector, image-based states will come soon.
+
+This model was contributed by [edbeeching](https://huggingface.co/edbeeching). The original code can be found [here](https://github.com/kzl/decision-transformer).
+
+## DecisionTransformerConfig
+
+[[autodoc]] DecisionTransformerConfig
+
+
+## DecisionTransformerGPT2Model
+
+[[autodoc]] DecisionTransformerGPT2Model
+ - forward
+
+## DecisionTransformerModel
+
+[[autodoc]] DecisionTransformerModel
+ - forward
diff --git a/docs/source/en/model_doc/deit.mdx b/docs/source/en/model_doc/deit.mdx
new file mode 100644
index 00000000000000..e03920e93ef4fa
--- /dev/null
+++ b/docs/source/en/model_doc/deit.mdx
@@ -0,0 +1,102 @@
+
+
+# DeiT
+
+
+
+This is a recently introduced model so the API hasn't been tested extensively. There may be some bugs or slight
+breaking changes to fix it in the future. If you see something strange, file a [Github Issue](https://github.com/huggingface/transformers/issues/new?assignees=&labels=&template=bug-report.md&title).
+
+
+
+## Overview
+
+The DeiT model was proposed in [Training data-efficient image transformers & distillation through attention](https://arxiv.org/abs/2012.12877) by Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre
+Sablayrolles, Hervé Jégou. The [Vision Transformer (ViT)](vit) introduced in [Dosovitskiy et al., 2020](https://arxiv.org/abs/2010.11929) has shown that one can match or even outperform existing convolutional neural
+networks using a Transformer encoder (BERT-like). However, the ViT models introduced in that paper required training on
+expensive infrastructure for multiple weeks, using external data. DeiT (data-efficient image transformers) are more
+efficiently trained transformers for image classification, requiring far less data and far less computing resources
+compared to the original ViT models.
+
+The abstract from the paper is the following:
+
+*Recently, neural networks purely based on attention were shown to address image understanding tasks such as image
+classification. However, these visual transformers are pre-trained with hundreds of millions of images using an
+expensive infrastructure, thereby limiting their adoption. In this work, we produce a competitive convolution-free
+transformer by training on Imagenet only. We train them on a single computer in less than 3 days. Our reference vision
+transformer (86M parameters) achieves top-1 accuracy of 83.1% (single-crop evaluation) on ImageNet with no external
+data. More importantly, we introduce a teacher-student strategy specific to transformers. It relies on a distillation
+token ensuring that the student learns from the teacher through attention. We show the interest of this token-based
+distillation, especially when using a convnet as a teacher. This leads us to report results competitive with convnets
+for both Imagenet (where we obtain up to 85.2% accuracy) and when transferring to other tasks. We share our code and
+models.*
+
+Tips:
+
+- Compared to ViT, DeiT models use a so-called distillation token to effectively learn from a teacher (which, in the
+ DeiT paper, is a ResNet like-model). The distillation token is learned through backpropagation, by interacting with
+ the class ([CLS]) and patch tokens through the self-attention layers.
+- There are 2 ways to fine-tune distilled models, either (1) in a classic way, by only placing a prediction head on top
+ of the final hidden state of the class token and not using the distillation signal, or (2) by placing both a
+ prediction head on top of the class token and on top of the distillation token. In that case, the [CLS] prediction
+ head is trained using regular cross-entropy between the prediction of the head and the ground-truth label, while the
+ distillation prediction head is trained using hard distillation (cross-entropy between the prediction of the
+ distillation head and the label predicted by the teacher). At inference time, one takes the average prediction
+ between both heads as final prediction. (2) is also called "fine-tuning with distillation", because one relies on a
+ teacher that has already been fine-tuned on the downstream dataset. In terms of models, (1) corresponds to
+ [`DeiTForImageClassification`] and (2) corresponds to
+ [`DeiTForImageClassificationWithTeacher`].
+- Note that the authors also did try soft distillation for (2) (in which case the distillation prediction head is
+ trained using KL divergence to match the softmax output of the teacher), but hard distillation gave the best results.
+- All released checkpoints were pre-trained and fine-tuned on ImageNet-1k only. No external data was used. This is in
+ contrast with the original ViT model, which used external data like the JFT-300M dataset/Imagenet-21k for
+ pre-training.
+- The authors of DeiT also released more efficiently trained ViT models, which you can directly plug into
+ [`ViTModel`] or [`ViTForImageClassification`]. Techniques like data
+ augmentation, optimization, and regularization were used in order to simulate training on a much larger dataset
+ (while only using ImageNet-1k for pre-training). There are 4 variants available (in 3 different sizes):
+ *facebook/deit-tiny-patch16-224*, *facebook/deit-small-patch16-224*, *facebook/deit-base-patch16-224* and
+ *facebook/deit-base-patch16-384*. Note that one should use [`DeiTFeatureExtractor`] in order to
+ prepare images for the model.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr).
+
+
+## DeiTConfig
+
+[[autodoc]] DeiTConfig
+
+## DeiTFeatureExtractor
+
+[[autodoc]] DeiTFeatureExtractor
+ - __call__
+
+## DeiTModel
+
+[[autodoc]] DeiTModel
+ - forward
+
+## DeiTForMaskedImageModeling
+
+[[autodoc]] DeiTForMaskedImageModeling
+ - forward
+
+## DeiTForImageClassification
+
+[[autodoc]] DeiTForImageClassification
+ - forward
+
+## DeiTForImageClassificationWithTeacher
+
+[[autodoc]] DeiTForImageClassificationWithTeacher
+ - forward
diff --git a/docs/source/en/model_doc/detr.mdx b/docs/source/en/model_doc/detr.mdx
new file mode 100644
index 00000000000000..4c29efc52e30d8
--- /dev/null
+++ b/docs/source/en/model_doc/detr.mdx
@@ -0,0 +1,169 @@
+
+
+# DETR
+
+## Overview
+
+The DETR model was proposed in [End-to-End Object Detection with Transformers](https://arxiv.org/abs/2005.12872) by
+Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov and Sergey Zagoruyko. DETR
+consists of a convolutional backbone followed by an encoder-decoder Transformer which can be trained end-to-end for
+object detection. It greatly simplifies a lot of the complexity of models like Faster-R-CNN and Mask-R-CNN, which use
+things like region proposals, non-maximum suppression procedure and anchor generation. Moreover, DETR can also be
+naturally extended to perform panoptic segmentation, by simply adding a mask head on top of the decoder outputs.
+
+The abstract from the paper is the following:
+
+*We present a new method that views object detection as a direct set prediction problem. Our approach streamlines the
+detection pipeline, effectively removing the need for many hand-designed components like a non-maximum suppression
+procedure or anchor generation that explicitly encode our prior knowledge about the task. The main ingredients of the
+new framework, called DEtection TRansformer or DETR, are a set-based global loss that forces unique predictions via
+bipartite matching, and a transformer encoder-decoder architecture. Given a fixed small set of learned object queries,
+DETR reasons about the relations of the objects and the global image context to directly output the final set of
+predictions in parallel. The new model is conceptually simple and does not require a specialized library, unlike many
+other modern detectors. DETR demonstrates accuracy and run-time performance on par with the well-established and
+highly-optimized Faster RCNN baseline on the challenging COCO object detection dataset. Moreover, DETR can be easily
+generalized to produce panoptic segmentation in a unified manner. We show that it significantly outperforms competitive
+baselines.*
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/facebookresearch/detr).
+
+The quickest way to get started with DETR is by checking the [example notebooks](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/DETR) (which showcase both inference and
+fine-tuning on custom data).
+
+Here's a TLDR explaining how [`~transformers.DetrForObjectDetection`] works:
+
+First, an image is sent through a pre-trained convolutional backbone (in the paper, the authors use
+ResNet-50/ResNet-101). Let's assume we also add a batch dimension. This means that the input to the backbone is a
+tensor of shape `(batch_size, 3, height, width)`, assuming the image has 3 color channels (RGB). The CNN backbone
+outputs a new lower-resolution feature map, typically of shape `(batch_size, 2048, height/32, width/32)`. This is
+then projected to match the hidden dimension of the Transformer of DETR, which is `256` by default, using a
+`nn.Conv2D` layer. So now, we have a tensor of shape `(batch_size, 256, height/32, width/32).` Next, the
+feature map is flattened and transposed to obtain a tensor of shape `(batch_size, seq_len, d_model)` =
+`(batch_size, width/32*height/32, 256)`. So a difference with NLP models is that the sequence length is actually
+longer than usual, but with a smaller `d_model` (which in NLP is typically 768 or higher).
+
+Next, this is sent through the encoder, outputting `encoder_hidden_states` of the same shape (you can consider
+these as image features). Next, so-called **object queries** are sent through the decoder. This is a tensor of shape
+`(batch_size, num_queries, d_model)`, with `num_queries` typically set to 100 and initialized with zeros.
+These input embeddings are learnt positional encodings that the authors refer to as object queries, and similarly to
+the encoder, they are added to the input of each attention layer. Each object query will look for a particular object
+in the image. The decoder updates these embeddings through multiple self-attention and encoder-decoder attention layers
+to output `decoder_hidden_states` of the same shape: `(batch_size, num_queries, d_model)`. Next, two heads
+are added on top for object detection: a linear layer for classifying each object query into one of the objects or "no
+object", and a MLP to predict bounding boxes for each query.
+
+The model is trained using a **bipartite matching loss**: so what we actually do is compare the predicted classes +
+bounding boxes of each of the N = 100 object queries to the ground truth annotations, padded up to the same length N
+(so if an image only contains 4 objects, 96 annotations will just have a "no object" as class and "no bounding box" as
+bounding box). The [Hungarian matching algorithm](https://en.wikipedia.org/wiki/Hungarian_algorithm) is used to find
+an optimal one-to-one mapping of each of the N queries to each of the N annotations. Next, standard cross-entropy (for
+the classes) and a linear combination of the L1 and [generalized IoU loss](https://giou.stanford.edu/) (for the
+bounding boxes) are used to optimize the parameters of the model.
+
+DETR can be naturally extended to perform panoptic segmentation (which unifies semantic segmentation and instance
+segmentation). [`~transformers.DetrForSegmentation`] adds a segmentation mask head on top of
+[`~transformers.DetrForObjectDetection`]. The mask head can be trained either jointly, or in a two steps process,
+where one first trains a [`~transformers.DetrForObjectDetection`] model to detect bounding boxes around both
+"things" (instances) and "stuff" (background things like trees, roads, sky), then freeze all the weights and train only
+the mask head for 25 epochs. Experimentally, these two approaches give similar results. Note that predicting boxes is
+required for the training to be possible, since the Hungarian matching is computed using distances between boxes.
+
+Tips:
+
+- DETR uses so-called **object queries** to detect objects in an image. The number of queries determines the maximum
+ number of objects that can be detected in a single image, and is set to 100 by default (see parameter
+ `num_queries` of [`~transformers.DetrConfig`]). Note that it's good to have some slack (in COCO, the
+ authors used 100, while the maximum number of objects in a COCO image is ~70).
+- The decoder of DETR updates the query embeddings in parallel. This is different from language models like GPT-2,
+ which use autoregressive decoding instead of parallel. Hence, no causal attention mask is used.
+- DETR adds position embeddings to the hidden states at each self-attention and cross-attention layer before projecting
+ to queries and keys. For the position embeddings of the image, one can choose between fixed sinusoidal or learned
+ absolute position embeddings. By default, the parameter `position_embedding_type` of
+ [`~transformers.DetrConfig`] is set to `"sine"`.
+- During training, the authors of DETR did find it helpful to use auxiliary losses in the decoder, especially to help
+ the model output the correct number of objects of each class. If you set the parameter `auxiliary_loss` of
+ [`~transformers.DetrConfig`] to `True`, then prediction feedforward neural networks and Hungarian losses
+ are added after each decoder layer (with the FFNs sharing parameters).
+- If you want to train the model in a distributed environment across multiple nodes, then one should update the
+ _num_boxes_ variable in the _DetrLoss_ class of _modeling_detr.py_. When training on multiple nodes, this should be
+ set to the average number of target boxes across all nodes, as can be seen in the original implementation [here](https://github.com/facebookresearch/detr/blob/a54b77800eb8e64e3ad0d8237789fcbf2f8350c5/models/detr.py#L227-L232).
+- [`~transformers.DetrForObjectDetection`] and [`~transformers.DetrForSegmentation`] can be initialized with
+ any convolutional backbone available in the [timm library](https://github.com/rwightman/pytorch-image-models).
+ Initializing with a MobileNet backbone for example can be done by setting the `backbone` attribute of
+ [`~transformers.DetrConfig`] to `"tf_mobilenetv3_small_075"`, and then initializing the model with that
+ config.
+- DETR resizes the input images such that the shortest side is at least a certain amount of pixels while the longest is
+ at most 1333 pixels. At training time, scale augmentation is used such that the shortest side is randomly set to at
+ least 480 and at most 800 pixels. At inference time, the shortest side is set to 800. One can use
+ [`~transformers.DetrFeatureExtractor`] to prepare images (and optional annotations in COCO format) for the
+ model. Due to this resizing, images in a batch can have different sizes. DETR solves this by padding images up to the
+ largest size in a batch, and by creating a pixel mask that indicates which pixels are real/which are padding.
+ Alternatively, one can also define a custom `collate_fn` in order to batch images together, using
+ [`~transformers.DetrFeatureExtractor.pad_and_create_pixel_mask`].
+- The size of the images will determine the amount of memory being used, and will thus determine the `batch_size`.
+ It is advised to use a batch size of 2 per GPU. See [this Github thread](https://github.com/facebookresearch/detr/issues/150) for more info.
+
+As a summary, consider the following table:
+
+| Task | Object detection | Instance segmentation | Panoptic segmentation |
+|------|------------------|-----------------------|-----------------------|
+| **Description** | Predicting bounding boxes and class labels around objects in an image | Predicting masks around objects (i.e. instances) in an image | Predicting masks around both objects (i.e. instances) as well as "stuff" (i.e. background things like trees and roads) in an image |
+| **Model** | [`~transformers.DetrForObjectDetection`] | [`~transformers.DetrForSegmentation`] | [`~transformers.DetrForSegmentation`] |
+| **Example dataset** | COCO detection | COCO detection, COCO panoptic | COCO panoptic | |
+| **Format of annotations to provide to** [`~transformers.DetrFeatureExtractor`] | {'image_id': `int`, 'annotations': `List[Dict]`} each Dict being a COCO object annotation | {'image_id': `int`, 'annotations': `List[Dict]`} (in case of COCO detection) or {'file_name': `str`, 'image_id': `int`, 'segments_info': `List[Dict]`} (in case of COCO panoptic) | {'file_name': `str`, 'image_id': `int`, 'segments_info': `List[Dict]`} and masks_path (path to directory containing PNG files of the masks) |
+| **Postprocessing** (i.e. converting the output of the model to COCO API) | [`~transformers.DetrFeatureExtractor.post_process`] | [`~transformers.DetrFeatureExtractor.post_process_segmentation`] | [`~transformers.DetrFeatureExtractor.post_process_segmentation`], [`~transformers.DetrFeatureExtractor.post_process_panoptic`] |
+| **evaluators** | `CocoEvaluator` with `iou_types="bbox"` | `CocoEvaluator` with `iou_types="bbox"` or `"segm"` | `CocoEvaluator` with `iou_tupes="bbox"` or `"segm"`, `PanopticEvaluator` |
+
+In short, one should prepare the data either in COCO detection or COCO panoptic format, then use
+[`~transformers.DetrFeatureExtractor`] to create `pixel_values`, `pixel_mask` and optional
+`labels`, which can then be used to train (or fine-tune) a model. For evaluation, one should first convert the
+outputs of the model using one of the postprocessing methods of [`~transformers.DetrFeatureExtractor`]. These can
+be be provided to either `CocoEvaluator` or `PanopticEvaluator`, which allow you to calculate metrics like
+mean Average Precision (mAP) and Panoptic Quality (PQ). The latter objects are implemented in the [original repository](https://github.com/facebookresearch/detr). See the [example notebooks](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/DETR) for more info regarding evaluation.
+
+
+## DETR specific outputs
+
+[[autodoc]] models.detr.modeling_detr.DetrModelOutput
+
+[[autodoc]] models.detr.modeling_detr.DetrObjectDetectionOutput
+
+[[autodoc]] models.detr.modeling_detr.DetrSegmentationOutput
+
+## DetrConfig
+
+[[autodoc]] DetrConfig
+
+## DetrFeatureExtractor
+
+[[autodoc]] DetrFeatureExtractor
+ - __call__
+ - pad_and_create_pixel_mask
+ - post_process
+ - post_process_segmentation
+ - post_process_panoptic
+
+## DetrModel
+
+[[autodoc]] DetrModel
+ - forward
+
+## DetrForObjectDetection
+
+[[autodoc]] DetrForObjectDetection
+ - forward
+
+## DetrForSegmentation
+
+[[autodoc]] DetrForSegmentation
+ - forward
\ No newline at end of file
diff --git a/docs/source/en/model_doc/dialogpt.mdx b/docs/source/en/model_doc/dialogpt.mdx
new file mode 100644
index 00000000000000..62c6b45130e346
--- /dev/null
+++ b/docs/source/en/model_doc/dialogpt.mdx
@@ -0,0 +1,49 @@
+
+
+# DialoGPT
+
+## Overview
+
+DialoGPT was proposed in [DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation](https://arxiv.org/abs/1911.00536) by Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao,
+Jianfeng Gao, Jingjing Liu, Bill Dolan. It's a GPT2 Model trained on 147M conversation-like exchanges extracted from
+Reddit.
+
+The abstract from the paper is the following:
+
+*We present a large, tunable neural conversational response generation model, DialoGPT (dialogue generative pre-trained
+transformer). Trained on 147M conversation-like exchanges extracted from Reddit comment chains over a period spanning
+from 2005 through 2017, DialoGPT extends the Hugging Face PyTorch transformer to attain a performance close to human
+both in terms of automatic and human evaluation in single-turn dialogue settings. We show that conversational systems
+that leverage DialoGPT generate more relevant, contentful and context-consistent responses than strong baseline
+systems. The pre-trained model and training pipeline are publicly released to facilitate research into neural response
+generation and the development of more intelligent open-domain dialogue systems.*
+
+Tips:
+
+- DialoGPT is a model with absolute position embeddings so it's usually advised to pad the inputs on the right rather
+ than the left.
+- DialoGPT was trained with a causal language modeling (CLM) objective on conversational data and is therefore powerful
+ at response generation in open-domain dialogue systems.
+- DialoGPT enables the user to create a chat bot in just 10 lines of code as shown on [DialoGPT's model card](https://huggingface.co/microsoft/DialoGPT-medium).
+
+Training:
+
+In order to train or fine-tune DialoGPT, one can use causal language modeling training. To cite the official paper: *We
+follow the OpenAI GPT-2 to model a multiturn dialogue session as a long text and frame the generation task as language
+modeling. We first concatenate all dialog turns within a dialogue session into a long text x_1,..., x_N (N is the
+sequence length), ended by the end-of-text token.* For more information please confer to the original paper.
+
+
+DialoGPT's architecture is based on the GPT2 model, so one can refer to [GPT2's documentation page](gpt2).
+
+The original code can be found [here](https://github.com/microsoft/DialoGPT).
diff --git a/docs/source/en/model_doc/distilbert.mdx b/docs/source/en/model_doc/distilbert.mdx
new file mode 100644
index 00000000000000..b8886c5d6f8f6d
--- /dev/null
+++ b/docs/source/en/model_doc/distilbert.mdx
@@ -0,0 +1,149 @@
+
+
+# DistilBERT
+
+## Overview
+
+The DistilBERT model was proposed in the blog post [Smaller, faster, cheaper, lighter: Introducing DistilBERT, a
+distilled version of BERT](https://medium.com/huggingface/distilbert-8cf3380435b5), and the paper [DistilBERT, a
+distilled version of BERT: smaller, faster, cheaper and lighter](https://arxiv.org/abs/1910.01108). DistilBERT is a
+small, fast, cheap and light Transformer model trained by distilling BERT base. It has 40% less parameters than
+*bert-base-uncased*, runs 60% faster while preserving over 95% of BERT's performances as measured on the GLUE language
+understanding benchmark.
+
+The abstract from the paper is the following:
+
+*As Transfer Learning from large-scale pre-trained models becomes more prevalent in Natural Language Processing (NLP),
+operating these large models in on-the-edge and/or under constrained computational training or inference budgets
+remains challenging. In this work, we propose a method to pre-train a smaller general-purpose language representation
+model, called DistilBERT, which can then be fine-tuned with good performances on a wide range of tasks like its larger
+counterparts. While most prior work investigated the use of distillation for building task-specific models, we leverage
+knowledge distillation during the pretraining phase and show that it is possible to reduce the size of a BERT model by
+40%, while retaining 97% of its language understanding capabilities and being 60% faster. To leverage the inductive
+biases learned by larger models during pretraining, we introduce a triple loss combining language modeling,
+distillation and cosine-distance losses. Our smaller, faster and lighter model is cheaper to pre-train and we
+demonstrate its capabilities for on-device computations in a proof-of-concept experiment and a comparative on-device
+study.*
+
+Tips:
+
+- DistilBERT doesn't have `token_type_ids`, you don't need to indicate which token belongs to which segment. Just
+ separate your segments with the separation token `tokenizer.sep_token` (or `[SEP]`).
+- DistilBERT doesn't have options to select the input positions (`position_ids` input). This could be added if
+ necessary though, just let us know if you need this option.
+
+This model was contributed by [victorsanh](https://huggingface.co/victorsanh). This model jax version was
+contributed by [kamalkraj](https://huggingface.co/kamalkraj). The original code can be found [here](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation).
+
+
+## DistilBertConfig
+
+[[autodoc]] DistilBertConfig
+
+## DistilBertTokenizer
+
+[[autodoc]] DistilBertTokenizer
+
+## DistilBertTokenizerFast
+
+[[autodoc]] DistilBertTokenizerFast
+
+## DistilBertModel
+
+[[autodoc]] DistilBertModel
+ - forward
+
+## DistilBertForMaskedLM
+
+[[autodoc]] DistilBertForMaskedLM
+ - forward
+
+## DistilBertForSequenceClassification
+
+[[autodoc]] DistilBertForSequenceClassification
+ - forward
+
+## DistilBertForMultipleChoice
+
+[[autodoc]] DistilBertForMultipleChoice
+ - forward
+
+## DistilBertForTokenClassification
+
+[[autodoc]] DistilBertForTokenClassification
+ - forward
+
+## DistilBertForQuestionAnswering
+
+[[autodoc]] DistilBertForQuestionAnswering
+ - forward
+
+## TFDistilBertModel
+
+[[autodoc]] TFDistilBertModel
+ - call
+
+## TFDistilBertForMaskedLM
+
+[[autodoc]] TFDistilBertForMaskedLM
+ - call
+
+## TFDistilBertForSequenceClassification
+
+[[autodoc]] TFDistilBertForSequenceClassification
+ - call
+
+## TFDistilBertForMultipleChoice
+
+[[autodoc]] TFDistilBertForMultipleChoice
+ - call
+
+## TFDistilBertForTokenClassification
+
+[[autodoc]] TFDistilBertForTokenClassification
+ - call
+
+## TFDistilBertForQuestionAnswering
+
+[[autodoc]] TFDistilBertForQuestionAnswering
+ - call
+
+## FlaxDistilBertModel
+
+[[autodoc]] FlaxDistilBertModel
+ - __call__
+
+## FlaxDistilBertForMaskedLM
+
+[[autodoc]] FlaxDistilBertForMaskedLM
+ - __call__
+
+## FlaxDistilBertForSequenceClassification
+
+[[autodoc]] FlaxDistilBertForSequenceClassification
+ - __call__
+
+## FlaxDistilBertForMultipleChoice
+
+[[autodoc]] FlaxDistilBertForMultipleChoice
+ - __call__
+
+## FlaxDistilBertForTokenClassification
+
+[[autodoc]] FlaxDistilBertForTokenClassification
+ - __call__
+
+## FlaxDistilBertForQuestionAnswering
+
+[[autodoc]] FlaxDistilBertForQuestionAnswering
+ - __call__
diff --git a/docs/source/en/model_doc/dit.mdx b/docs/source/en/model_doc/dit.mdx
new file mode 100644
index 00000000000000..e3830ce7c3e167
--- /dev/null
+++ b/docs/source/en/model_doc/dit.mdx
@@ -0,0 +1,67 @@
+
+
+# DiT
+
+## Overview
+
+DiT was proposed in [DiT: Self-supervised Pre-training for Document Image Transformer](https://arxiv.org/abs/2203.02378) by Junlong Li, Yiheng Xu, Tengchao Lv, Lei Cui, Cha Zhang, Furu Wei.
+DiT applies the self-supervised objective of [BEiT](beit) (BERT pre-training of Image Transformers) to 42 million document images, allowing for state-of-the-art results on tasks including:
+
+- document image classification: the [RVL-CDIP](https://www.cs.cmu.edu/~aharley/rvl-cdip/) dataset (a collection of
+ 400,000 images belonging to one of 16 classes).
+- document layout analysis: the [PubLayNet](https://github.com/ibm-aur-nlp/PubLayNet) dataset (a collection of more
+ than 360,000 document images constructed by automatically parsing PubMed XML files).
+- table detection: the [ICDAR 2019 cTDaR](https://github.com/cndplab-founder/ICDAR2019_cTDaR) dataset (a collection of
+ 600 training images and 240 testing images).
+
+The abstract from the paper is the following:
+
+*Image Transformer has recently achieved significant progress for natural image understanding, either using supervised (ViT, DeiT, etc.) or self-supervised (BEiT, MAE, etc.) pre-training techniques. In this paper, we propose DiT, a self-supervised pre-trained Document Image Transformer model using large-scale unlabeled text images for Document AI tasks, which is essential since no supervised counterparts ever exist due to the lack of human labeled document images. We leverage DiT as the backbone network in a variety of vision-based Document AI tasks, including document image classification, document layout analysis, as well as table detection. Experiment results have illustrated that the self-supervised pre-trained DiT model achieves new state-of-the-art results on these downstream tasks, e.g. document image classification (91.11 → 92.69), document layout analysis (91.0 → 94.9) and table detection (94.23 → 96.55). *
+
+ +
+ Summary of the approach. Taken from the [original paper](https://arxiv.org/abs/2203.02378).
+
+One can directly use the weights of DiT with the AutoModel API:
+
+```python
+from transformers import AutoModel
+
+model = AutoModel.from_pretrained("microsoft/dit-base")
+```
+
+This will load the model pre-trained on masked image modeling. Note that this won't include the language modeling head on top, used to predict visual tokens.
+
+To include the head, you can load the weights into a `BeitForMaskedImageModeling` model, like so:
+
+```python
+from transformers import BeitForMaskedImageModeling
+
+model = BeitForMaskedImageModeling.from_pretrained("microsoft/dit-base")
+```
+
+You can also load a fine-tuned model from the [hub](https://huggingface.co/models?other=dit), like so:
+
+```python
+from transformers import AutoModelForImageClassification
+
+model = AutoModelForImageClassification.from_pretrained("microsoft/dit-base-finetuned-rvlcdip")
+```
+
+This particular checkpoint was fine-tuned on [RVL-CDIP](https://www.cs.cmu.edu/~aharley/rvl-cdip/), an important benchmark for document image classification.
+A notebook that illustrates inference for document image classification can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/DiT/Inference_with_DiT_(Document_Image_Transformer)_for_document_image_classification.ipynb).
+
+As DiT's architecture is equivalent to that of BEiT, one can refer to [BEiT's documentation page](beit) for all tips, code examples and notebooks.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/microsoft/unilm/tree/master/dit).
\ No newline at end of file
diff --git a/docs/source/en/model_doc/dpr.mdx b/docs/source/en/model_doc/dpr.mdx
new file mode 100644
index 00000000000000..2010a17fcc6df2
--- /dev/null
+++ b/docs/source/en/model_doc/dpr.mdx
@@ -0,0 +1,98 @@
+
+
+# DPR
+
+## Overview
+
+Dense Passage Retrieval (DPR) is a set of tools and models for state-of-the-art open-domain Q&A research. It was
+introduced in [Dense Passage Retrieval for Open-Domain Question Answering](https://arxiv.org/abs/2004.04906) by
+Vladimir Karpukhin, Barlas Oğuz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, Wen-tau Yih.
+
+The abstract from the paper is the following:
+
+*Open-domain question answering relies on efficient passage retrieval to select candidate contexts, where traditional
+sparse vector space models, such as TF-IDF or BM25, are the de facto method. In this work, we show that retrieval can
+be practically implemented using dense representations alone, where embeddings are learned from a small number of
+questions and passages by a simple dual-encoder framework. When evaluated on a wide range of open-domain QA datasets,
+our dense retriever outperforms a strong Lucene-BM25 system largely by 9%-19% absolute in terms of top-20 passage
+retrieval accuracy, and helps our end-to-end QA system establish new state-of-the-art on multiple open-domain QA
+benchmarks.*
+
+This model was contributed by [lhoestq](https://huggingface.co/lhoestq). The original code can be found [here](https://github.com/facebookresearch/DPR).
+
+
+## DPRConfig
+
+[[autodoc]] DPRConfig
+
+## DPRContextEncoderTokenizer
+
+[[autodoc]] DPRContextEncoderTokenizer
+
+## DPRContextEncoderTokenizerFast
+
+[[autodoc]] DPRContextEncoderTokenizerFast
+
+## DPRQuestionEncoderTokenizer
+
+[[autodoc]] DPRQuestionEncoderTokenizer
+
+## DPRQuestionEncoderTokenizerFast
+
+[[autodoc]] DPRQuestionEncoderTokenizerFast
+
+## DPRReaderTokenizer
+
+[[autodoc]] DPRReaderTokenizer
+
+## DPRReaderTokenizerFast
+
+[[autodoc]] DPRReaderTokenizerFast
+
+## DPR specific outputs
+
+[[autodoc]] models.dpr.modeling_dpr.DPRContextEncoderOutput
+
+[[autodoc]] models.dpr.modeling_dpr.DPRQuestionEncoderOutput
+
+[[autodoc]] models.dpr.modeling_dpr.DPRReaderOutput
+
+## DPRContextEncoder
+
+[[autodoc]] DPRContextEncoder
+ - forward
+
+## DPRQuestionEncoder
+
+[[autodoc]] DPRQuestionEncoder
+ - forward
+
+## DPRReader
+
+[[autodoc]] DPRReader
+ - forward
+
+## TFDPRContextEncoder
+
+[[autodoc]] TFDPRContextEncoder
+ - call
+
+## TFDPRQuestionEncoder
+
+[[autodoc]] TFDPRQuestionEncoder
+ - call
+
+## TFDPRReader
+
+[[autodoc]] TFDPRReader
+ - call
diff --git a/docs/source/en/model_doc/dpt.mdx b/docs/source/en/model_doc/dpt.mdx
new file mode 100644
index 00000000000000..cdf009c6c8a071
--- /dev/null
+++ b/docs/source/en/model_doc/dpt.mdx
@@ -0,0 +1,57 @@
+
+
+# DPT
+
+## Overview
+
+The DPT model was proposed in [Vision Transformers for Dense Prediction](https://arxiv.org/abs/2103.13413) by René Ranftl, Alexey Bochkovskiy, Vladlen Koltun.
+DPT is a model that leverages the [Vision Transformer (ViT)](vit) as backbone for dense prediction tasks like semantic segmentation and depth estimation.
+
+The abstract from the paper is the following:
+
+*We introduce dense vision transformers, an architecture that leverages vision transformers in place of convolutional networks as a backbone for dense prediction tasks. We assemble tokens from various stages of the vision transformer into image-like representations at various resolutions and progressively combine them into full-resolution predictions using a convolutional decoder. The transformer backbone processes representations at a constant and relatively high resolution and has a global receptive field at every stage. These properties allow the dense vision transformer to provide finer-grained and more globally coherent predictions when compared to fully-convolutional networks. Our experiments show that this architecture yields substantial improvements on dense prediction tasks, especially when a large amount of training data is available. For monocular depth estimation, we observe an improvement of up to 28% in relative performance when compared to a state-of-the-art fully-convolutional network. When applied to semantic segmentation, dense vision transformers set a new state of the art on ADE20K with 49.02% mIoU. We further show that the architecture can be fine-tuned on smaller datasets such as NYUv2, KITTI, and Pascal Context where it also sets the new state of the art.*
+
+
+
+ Summary of the approach. Taken from the [original paper](https://arxiv.org/abs/2203.02378).
+
+One can directly use the weights of DiT with the AutoModel API:
+
+```python
+from transformers import AutoModel
+
+model = AutoModel.from_pretrained("microsoft/dit-base")
+```
+
+This will load the model pre-trained on masked image modeling. Note that this won't include the language modeling head on top, used to predict visual tokens.
+
+To include the head, you can load the weights into a `BeitForMaskedImageModeling` model, like so:
+
+```python
+from transformers import BeitForMaskedImageModeling
+
+model = BeitForMaskedImageModeling.from_pretrained("microsoft/dit-base")
+```
+
+You can also load a fine-tuned model from the [hub](https://huggingface.co/models?other=dit), like so:
+
+```python
+from transformers import AutoModelForImageClassification
+
+model = AutoModelForImageClassification.from_pretrained("microsoft/dit-base-finetuned-rvlcdip")
+```
+
+This particular checkpoint was fine-tuned on [RVL-CDIP](https://www.cs.cmu.edu/~aharley/rvl-cdip/), an important benchmark for document image classification.
+A notebook that illustrates inference for document image classification can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/DiT/Inference_with_DiT_(Document_Image_Transformer)_for_document_image_classification.ipynb).
+
+As DiT's architecture is equivalent to that of BEiT, one can refer to [BEiT's documentation page](beit) for all tips, code examples and notebooks.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/microsoft/unilm/tree/master/dit).
\ No newline at end of file
diff --git a/docs/source/en/model_doc/dpr.mdx b/docs/source/en/model_doc/dpr.mdx
new file mode 100644
index 00000000000000..2010a17fcc6df2
--- /dev/null
+++ b/docs/source/en/model_doc/dpr.mdx
@@ -0,0 +1,98 @@
+
+
+# DPR
+
+## Overview
+
+Dense Passage Retrieval (DPR) is a set of tools and models for state-of-the-art open-domain Q&A research. It was
+introduced in [Dense Passage Retrieval for Open-Domain Question Answering](https://arxiv.org/abs/2004.04906) by
+Vladimir Karpukhin, Barlas Oğuz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, Wen-tau Yih.
+
+The abstract from the paper is the following:
+
+*Open-domain question answering relies on efficient passage retrieval to select candidate contexts, where traditional
+sparse vector space models, such as TF-IDF or BM25, are the de facto method. In this work, we show that retrieval can
+be practically implemented using dense representations alone, where embeddings are learned from a small number of
+questions and passages by a simple dual-encoder framework. When evaluated on a wide range of open-domain QA datasets,
+our dense retriever outperforms a strong Lucene-BM25 system largely by 9%-19% absolute in terms of top-20 passage
+retrieval accuracy, and helps our end-to-end QA system establish new state-of-the-art on multiple open-domain QA
+benchmarks.*
+
+This model was contributed by [lhoestq](https://huggingface.co/lhoestq). The original code can be found [here](https://github.com/facebookresearch/DPR).
+
+
+## DPRConfig
+
+[[autodoc]] DPRConfig
+
+## DPRContextEncoderTokenizer
+
+[[autodoc]] DPRContextEncoderTokenizer
+
+## DPRContextEncoderTokenizerFast
+
+[[autodoc]] DPRContextEncoderTokenizerFast
+
+## DPRQuestionEncoderTokenizer
+
+[[autodoc]] DPRQuestionEncoderTokenizer
+
+## DPRQuestionEncoderTokenizerFast
+
+[[autodoc]] DPRQuestionEncoderTokenizerFast
+
+## DPRReaderTokenizer
+
+[[autodoc]] DPRReaderTokenizer
+
+## DPRReaderTokenizerFast
+
+[[autodoc]] DPRReaderTokenizerFast
+
+## DPR specific outputs
+
+[[autodoc]] models.dpr.modeling_dpr.DPRContextEncoderOutput
+
+[[autodoc]] models.dpr.modeling_dpr.DPRQuestionEncoderOutput
+
+[[autodoc]] models.dpr.modeling_dpr.DPRReaderOutput
+
+## DPRContextEncoder
+
+[[autodoc]] DPRContextEncoder
+ - forward
+
+## DPRQuestionEncoder
+
+[[autodoc]] DPRQuestionEncoder
+ - forward
+
+## DPRReader
+
+[[autodoc]] DPRReader
+ - forward
+
+## TFDPRContextEncoder
+
+[[autodoc]] TFDPRContextEncoder
+ - call
+
+## TFDPRQuestionEncoder
+
+[[autodoc]] TFDPRQuestionEncoder
+ - call
+
+## TFDPRReader
+
+[[autodoc]] TFDPRReader
+ - call
diff --git a/docs/source/en/model_doc/dpt.mdx b/docs/source/en/model_doc/dpt.mdx
new file mode 100644
index 00000000000000..cdf009c6c8a071
--- /dev/null
+++ b/docs/source/en/model_doc/dpt.mdx
@@ -0,0 +1,57 @@
+
+
+# DPT
+
+## Overview
+
+The DPT model was proposed in [Vision Transformers for Dense Prediction](https://arxiv.org/abs/2103.13413) by René Ranftl, Alexey Bochkovskiy, Vladlen Koltun.
+DPT is a model that leverages the [Vision Transformer (ViT)](vit) as backbone for dense prediction tasks like semantic segmentation and depth estimation.
+
+The abstract from the paper is the following:
+
+*We introduce dense vision transformers, an architecture that leverages vision transformers in place of convolutional networks as a backbone for dense prediction tasks. We assemble tokens from various stages of the vision transformer into image-like representations at various resolutions and progressively combine them into full-resolution predictions using a convolutional decoder. The transformer backbone processes representations at a constant and relatively high resolution and has a global receptive field at every stage. These properties allow the dense vision transformer to provide finer-grained and more globally coherent predictions when compared to fully-convolutional networks. Our experiments show that this architecture yields substantial improvements on dense prediction tasks, especially when a large amount of training data is available. For monocular depth estimation, we observe an improvement of up to 28% in relative performance when compared to a state-of-the-art fully-convolutional network. When applied to semantic segmentation, dense vision transformers set a new state of the art on ADE20K with 49.02% mIoU. We further show that the architecture can be fine-tuned on smaller datasets such as NYUv2, KITTI, and Pascal Context where it also sets the new state of the art.*
+
+ +
+ DPT architecture. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/isl-org/DPT).
+
+## DPTConfig
+
+[[autodoc]] DPTConfig
+
+
+## DPTFeatureExtractor
+
+[[autodoc]] DPTFeatureExtractor
+ - __call__
+
+
+## DPTModel
+
+[[autodoc]] DPTModel
+ - forward
+
+
+## DPTForDepthEstimation
+
+[[autodoc]] DPTForDepthEstimation
+ - forward
+
+
+## DPTForSemanticSegmentation
+
+[[autodoc]] DPTForSemanticSegmentation
+ - forward
\ No newline at end of file
diff --git a/docs/source/en/model_doc/electra.mdx b/docs/source/en/model_doc/electra.mdx
new file mode 100644
index 00000000000000..c5a38f2431174f
--- /dev/null
+++ b/docs/source/en/model_doc/electra.mdx
@@ -0,0 +1,189 @@
+
+
+# ELECTRA
+
+## Overview
+
+The ELECTRA model was proposed in the paper [ELECTRA: Pre-training Text Encoders as Discriminators Rather Than
+Generators](https://openreview.net/pdf?id=r1xMH1BtvB). ELECTRA is a new pretraining approach which trains two
+transformer models: the generator and the discriminator. The generator's role is to replace tokens in a sequence, and
+is therefore trained as a masked language model. The discriminator, which is the model we're interested in, tries to
+identify which tokens were replaced by the generator in the sequence.
+
+The abstract from the paper is the following:
+
+*Masked language modeling (MLM) pretraining methods such as BERT corrupt the input by replacing some tokens with [MASK]
+and then train a model to reconstruct the original tokens. While they produce good results when transferred to
+downstream NLP tasks, they generally require large amounts of compute to be effective. As an alternative, we propose a
+more sample-efficient pretraining task called replaced token detection. Instead of masking the input, our approach
+corrupts it by replacing some tokens with plausible alternatives sampled from a small generator network. Then, instead
+of training a model that predicts the original identities of the corrupted tokens, we train a discriminative model that
+predicts whether each token in the corrupted input was replaced by a generator sample or not. Thorough experiments
+demonstrate this new pretraining task is more efficient than MLM because the task is defined over all input tokens
+rather than just the small subset that was masked out. As a result, the contextual representations learned by our
+approach substantially outperform the ones learned by BERT given the same model size, data, and compute. The gains are
+particularly strong for small models; for example, we train a model on one GPU for 4 days that outperforms GPT (trained
+using 30x more compute) on the GLUE natural language understanding benchmark. Our approach also works well at scale,
+where it performs comparably to RoBERTa and XLNet while using less than 1/4 of their compute and outperforms them when
+using the same amount of compute.*
+
+Tips:
+
+- ELECTRA is the pretraining approach, therefore there is nearly no changes done to the underlying model: BERT. The
+ only change is the separation of the embedding size and the hidden size: the embedding size is generally smaller,
+ while the hidden size is larger. An additional projection layer (linear) is used to project the embeddings from their
+ embedding size to the hidden size. In the case where the embedding size is the same as the hidden size, no projection
+ layer is used.
+- The ELECTRA checkpoints saved using [Google Research's implementation](https://github.com/google-research/electra)
+ contain both the generator and discriminator. The conversion script requires the user to name which model to export
+ into the correct architecture. Once converted to the HuggingFace format, these checkpoints may be loaded into all
+ available ELECTRA models, however. This means that the discriminator may be loaded in the
+ [`ElectraForMaskedLM`] model, and the generator may be loaded in the
+ [`ElectraForPreTraining`] model (the classification head will be randomly initialized as it
+ doesn't exist in the generator).
+
+This model was contributed by [lysandre](https://huggingface.co/lysandre). The original code can be found [here](https://github.com/google-research/electra).
+
+
+## ElectraConfig
+
+[[autodoc]] ElectraConfig
+
+## ElectraTokenizer
+
+[[autodoc]] ElectraTokenizer
+
+## ElectraTokenizerFast
+
+[[autodoc]] ElectraTokenizerFast
+
+## Electra specific outputs
+
+[[autodoc]] models.electra.modeling_electra.ElectraForPreTrainingOutput
+
+[[autodoc]] models.electra.modeling_tf_electra.TFElectraForPreTrainingOutput
+
+## ElectraModel
+
+[[autodoc]] ElectraModel
+ - forward
+
+## ElectraForPreTraining
+
+[[autodoc]] ElectraForPreTraining
+ - forward
+
+## ElectraForCausalLM
+
+[[autodoc]] ElectraForCausalLM
+ - forward
+
+## ElectraForMaskedLM
+
+[[autodoc]] ElectraForMaskedLM
+ - forward
+
+## ElectraForSequenceClassification
+
+[[autodoc]] ElectraForSequenceClassification
+ - forward
+
+## ElectraForMultipleChoice
+
+[[autodoc]] ElectraForMultipleChoice
+ - forward
+
+## ElectraForTokenClassification
+
+[[autodoc]] ElectraForTokenClassification
+ - forward
+
+## ElectraForQuestionAnswering
+
+[[autodoc]] ElectraForQuestionAnswering
+ - forward
+
+## TFElectraModel
+
+[[autodoc]] TFElectraModel
+ - call
+
+## TFElectraForPreTraining
+
+[[autodoc]] TFElectraForPreTraining
+ - call
+
+## TFElectraForMaskedLM
+
+[[autodoc]] TFElectraForMaskedLM
+ - call
+
+## TFElectraForSequenceClassification
+
+[[autodoc]] TFElectraForSequenceClassification
+ - call
+
+## TFElectraForMultipleChoice
+
+[[autodoc]] TFElectraForMultipleChoice
+ - call
+
+## TFElectraForTokenClassification
+
+[[autodoc]] TFElectraForTokenClassification
+ - call
+
+## TFElectraForQuestionAnswering
+
+[[autodoc]] TFElectraForQuestionAnswering
+ - call
+
+## FlaxElectraModel
+
+[[autodoc]] FlaxElectraModel
+ - __call__
+
+## FlaxElectraForPreTraining
+
+[[autodoc]] FlaxElectraForPreTraining
+ - __call__
+
+## FlaxElectraForCausalLM
+
+[[autodoc]] FlaxElectraForCausalLM
+ - __call__
+
+## FlaxElectraForMaskedLM
+
+[[autodoc]] FlaxElectraForMaskedLM
+ - __call__
+
+## FlaxElectraForSequenceClassification
+
+[[autodoc]] FlaxElectraForSequenceClassification
+ - __call__
+
+## FlaxElectraForMultipleChoice
+
+[[autodoc]] FlaxElectraForMultipleChoice
+ - __call__
+
+## FlaxElectraForTokenClassification
+
+[[autodoc]] FlaxElectraForTokenClassification
+ - __call__
+
+## FlaxElectraForQuestionAnswering
+
+[[autodoc]] FlaxElectraForQuestionAnswering
+ - __call__
diff --git a/docs/source/en/model_doc/encoder-decoder.mdx b/docs/source/en/model_doc/encoder-decoder.mdx
new file mode 100644
index 00000000000000..b6bda8fcfbae52
--- /dev/null
+++ b/docs/source/en/model_doc/encoder-decoder.mdx
@@ -0,0 +1,68 @@
+
+
+# Encoder Decoder Models
+
+The [`EncoderDecoderModel`] can be used to initialize a sequence-to-sequence model with any
+pretrained autoencoding model as the encoder and any pretrained autoregressive model as the decoder.
+
+The effectiveness of initializing sequence-to-sequence models with pretrained checkpoints for sequence generation tasks
+was shown in [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461) by
+Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
+
+After such an [`EncoderDecoderModel`] has been trained/fine-tuned, it can be saved/loaded just like
+any other models (see the examples for more information).
+
+An application of this architecture could be to leverage two pretrained [`BertModel`] as the encoder
+and decoder for a summarization model as was shown in: [Text Summarization with Pretrained Encoders](https://arxiv.org/abs/1908.08345) by Yang Liu and Mirella Lapata.
+
+The [`~TFEncoderDecoderModel.from_pretrained`] currently doesn't support initializing the model from a
+pytorch checkpoint. Passing `from_pt=True` to this method will throw an exception. If there are only pytorch
+checkpoints for a particular encoder-decoder model, a workaround is:
+
+```python
+>>> # a workaround to load from pytorch checkpoint
+>>> _model = EncoderDecoderModel.from_pretrained("patrickvonplaten/bert2bert-cnn_dailymail-fp16")
+>>> _model.encoder.save_pretrained("./encoder")
+>>> _model.decoder.save_pretrained("./decoder")
+>>> model = TFEncoderDecoderModel.from_encoder_decoder_pretrained(
+... "./encoder", "./decoder", encoder_from_pt=True, decoder_from_pt=True
+... )
+>>> # This is only for copying some specific attributes of this particular model.
+>>> model.config = _model.config
+```
+
+This model was contributed by [thomwolf](https://github.com/thomwolf). This model's TensorFlow and Flax versions
+were contributed by [ydshieh](https://github.com/ydshieh).
+
+
+## EncoderDecoderConfig
+
+[[autodoc]] EncoderDecoderConfig
+
+## EncoderDecoderModel
+
+[[autodoc]] EncoderDecoderModel
+ - forward
+ - from_encoder_decoder_pretrained
+
+## TFEncoderDecoderModel
+
+[[autodoc]] TFEncoderDecoderModel
+ - call
+ - from_encoder_decoder_pretrained
+
+## FlaxEncoderDecoderModel
+
+[[autodoc]] FlaxEncoderDecoderModel
+ - __call__
+ - from_encoder_decoder_pretrained
diff --git a/docs/source/en/model_doc/flaubert.mdx b/docs/source/en/model_doc/flaubert.mdx
new file mode 100644
index 00000000000000..c36e0eec8f4c48
--- /dev/null
+++ b/docs/source/en/model_doc/flaubert.mdx
@@ -0,0 +1,109 @@
+
+
+# FlauBERT
+
+## Overview
+
+The FlauBERT model was proposed in the paper [FlauBERT: Unsupervised Language Model Pre-training for French](https://arxiv.org/abs/1912.05372) by Hang Le et al. It's a transformer model pretrained using a masked language
+modeling (MLM) objective (like BERT).
+
+The abstract from the paper is the following:
+
+*Language models have become a key step to achieve state-of-the art results in many different Natural Language
+Processing (NLP) tasks. Leveraging the huge amount of unlabeled texts nowadays available, they provide an efficient way
+to pre-train continuous word representations that can be fine-tuned for a downstream task, along with their
+contextualization at the sentence level. This has been widely demonstrated for English using contextualized
+representations (Dai and Le, 2015; Peters et al., 2018; Howard and Ruder, 2018; Radford et al., 2018; Devlin et al.,
+2019; Yang et al., 2019b). In this paper, we introduce and share FlauBERT, a model learned on a very large and
+heterogeneous French corpus. Models of different sizes are trained using the new CNRS (French National Centre for
+Scientific Research) Jean Zay supercomputer. We apply our French language models to diverse NLP tasks (text
+classification, paraphrasing, natural language inference, parsing, word sense disambiguation) and show that most of the
+time they outperform other pretraining approaches. Different versions of FlauBERT as well as a unified evaluation
+protocol for the downstream tasks, called FLUE (French Language Understanding Evaluation), are shared to the research
+community for further reproducible experiments in French NLP.*
+
+This model was contributed by [formiel](https://huggingface.co/formiel). The original code can be found [here](https://github.com/getalp/Flaubert).
+
+
+## FlaubertConfig
+
+[[autodoc]] FlaubertConfig
+
+## FlaubertTokenizer
+
+[[autodoc]] FlaubertTokenizer
+
+## FlaubertModel
+
+[[autodoc]] FlaubertModel
+ - forward
+
+## FlaubertWithLMHeadModel
+
+[[autodoc]] FlaubertWithLMHeadModel
+ - forward
+
+## FlaubertForSequenceClassification
+
+[[autodoc]] FlaubertForSequenceClassification
+ - forward
+
+## FlaubertForMultipleChoice
+
+[[autodoc]] FlaubertForMultipleChoice
+ - forward
+
+## FlaubertForTokenClassification
+
+[[autodoc]] FlaubertForTokenClassification
+ - forward
+
+## FlaubertForQuestionAnsweringSimple
+
+[[autodoc]] FlaubertForQuestionAnsweringSimple
+ - forward
+
+## FlaubertForQuestionAnswering
+
+[[autodoc]] FlaubertForQuestionAnswering
+ - forward
+
+## TFFlaubertModel
+
+[[autodoc]] TFFlaubertModel
+ - call
+
+## TFFlaubertWithLMHeadModel
+
+[[autodoc]] TFFlaubertWithLMHeadModel
+ - call
+
+## TFFlaubertForSequenceClassification
+
+[[autodoc]] TFFlaubertForSequenceClassification
+ - call
+
+## TFFlaubertForMultipleChoice
+
+[[autodoc]] TFFlaubertForMultipleChoice
+ - call
+
+## TFFlaubertForTokenClassification
+
+[[autodoc]] TFFlaubertForTokenClassification
+ - call
+
+## TFFlaubertForQuestionAnsweringSimple
+
+[[autodoc]] TFFlaubertForQuestionAnsweringSimple
+ - call
diff --git a/docs/source/en/model_doc/fnet.mdx b/docs/source/en/model_doc/fnet.mdx
new file mode 100644
index 00000000000000..19afcc8051102f
--- /dev/null
+++ b/docs/source/en/model_doc/fnet.mdx
@@ -0,0 +1,98 @@
+
+
+# FNet
+
+## Overview
+
+The FNet model was proposed in [FNet: Mixing Tokens with Fourier Transforms](https://arxiv.org/abs/2105.03824) by
+James Lee-Thorp, Joshua Ainslie, Ilya Eckstein, Santiago Ontanon. The model replaces the self-attention layer in a BERT
+model with a fourier transform which returns only the real parts of the transform. The model is significantly faster
+than the BERT model because it has fewer parameters and is more memory efficient. The model achieves about 92-97%
+accuracy of BERT counterparts on GLUE benchmark, and trains much faster than the BERT model. The abstract from the
+paper is the following:
+
+*We show that Transformer encoder architectures can be sped up, with limited accuracy costs, by replacing the
+self-attention sublayers with simple linear transformations that "mix" input tokens. These linear mixers, along with
+standard nonlinearities in feed-forward layers, prove competent at modeling semantic relationships in several text
+classification tasks. Most surprisingly, we find that replacing the self-attention sublayer in a Transformer encoder
+with a standard, unparameterized Fourier Transform achieves 92-97% of the accuracy of BERT counterparts on the GLUE
+benchmark, but trains 80% faster on GPUs and 70% faster on TPUs at standard 512 input lengths. At longer input lengths,
+our FNet model is significantly faster: when compared to the "efficient" Transformers on the Long Range Arena
+benchmark, FNet matches the accuracy of the most accurate models, while outpacing the fastest models across all
+sequence lengths on GPUs (and across relatively shorter lengths on TPUs). Finally, FNet has a light memory footprint
+and is particularly efficient at smaller model sizes; for a fixed speed and accuracy budget, small FNet models
+outperform Transformer counterparts.*
+
+Tips on usage:
+
+- The model was trained without an attention mask as it is based on Fourier Transform. The model was trained with
+ maximum sequence length 512 which includes pad tokens. Hence, it is highly recommended to use the same maximum
+ sequence length for fine-tuning and inference.
+
+This model was contributed by [gchhablani](https://huggingface.co/gchhablani). The original code can be found [here](https://github.com/google-research/google-research/tree/master/f_net).
+
+## FNetConfig
+
+[[autodoc]] FNetConfig
+
+## FNetTokenizer
+
+[[autodoc]] FNetTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## FNetTokenizerFast
+
+[[autodoc]] FNetTokenizerFast
+
+## FNetModel
+
+[[autodoc]] FNetModel
+ - forward
+
+## FNetForPreTraining
+
+[[autodoc]] FNetForPreTraining
+ - forward
+
+## FNetForMaskedLM
+
+[[autodoc]] FNetForMaskedLM
+ - forward
+
+## FNetForNextSentencePrediction
+
+[[autodoc]] FNetForNextSentencePrediction
+ - forward
+
+## FNetForSequenceClassification
+
+[[autodoc]] FNetForSequenceClassification
+ - forward
+
+## FNetForMultipleChoice
+
+[[autodoc]] FNetForMultipleChoice
+ - forward
+
+## FNetForTokenClassification
+
+[[autodoc]] FNetForTokenClassification
+ - forward
+
+## FNetForQuestionAnswering
+
+[[autodoc]] FNetForQuestionAnswering
+ - forward
diff --git a/docs/source/en/model_doc/fsmt.mdx b/docs/source/en/model_doc/fsmt.mdx
new file mode 100644
index 00000000000000..25c8d85cf48606
--- /dev/null
+++ b/docs/source/en/model_doc/fsmt.mdx
@@ -0,0 +1,63 @@
+
+
+# FSMT
+
+**DISCLAIMER:** If you see something strange, file a [Github Issue](https://github.com/huggingface/transformers/issues/new?assignees=&labels=&template=bug-report.md&title) and assign
+@stas00.
+
+## Overview
+
+FSMT (FairSeq MachineTranslation) models were introduced in [Facebook FAIR's WMT19 News Translation Task Submission](https://arxiv.org/abs/1907.06616) by Nathan Ng, Kyra Yee, Alexei Baevski, Myle Ott, Michael Auli, Sergey Edunov.
+
+The abstract of the paper is the following:
+
+*This paper describes Facebook FAIR's submission to the WMT19 shared news translation task. We participate in two
+language pairs and four language directions, English <-> German and English <-> Russian. Following our submission from
+last year, our baseline systems are large BPE-based transformer models trained with the Fairseq sequence modeling
+toolkit which rely on sampled back-translations. This year we experiment with different bitext data filtering schemes,
+as well as with adding filtered back-translated data. We also ensemble and fine-tune our models on domain-specific
+data, then decode using noisy channel model reranking. Our submissions are ranked first in all four directions of the
+human evaluation campaign. On En->De, our system significantly outperforms other systems as well as human translations.
+This system improves upon our WMT'18 submission by 4.5 BLEU points.*
+
+This model was contributed by [stas](https://huggingface.co/stas). The original code can be found
+[here](https://github.com/pytorch/fairseq/tree/master/examples/wmt19).
+
+## Implementation Notes
+
+- FSMT uses source and target vocabulary pairs that aren't combined into one. It doesn't share embeddings tokens
+ either. Its tokenizer is very similar to [`XLMTokenizer`] and the main model is derived from
+ [`BartModel`].
+
+
+## FSMTConfig
+
+[[autodoc]] FSMTConfig
+
+## FSMTTokenizer
+
+[[autodoc]] FSMTTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## FSMTModel
+
+[[autodoc]] FSMTModel
+ - forward
+
+## FSMTForConditionalGeneration
+
+[[autodoc]] FSMTForConditionalGeneration
+ - forward
diff --git a/docs/source/en/model_doc/funnel.mdx b/docs/source/en/model_doc/funnel.mdx
new file mode 100644
index 00000000000000..b7743d84a6a8c3
--- /dev/null
+++ b/docs/source/en/model_doc/funnel.mdx
@@ -0,0 +1,153 @@
+
+
+# Funnel Transformer
+
+## Overview
+
+The Funnel Transformer model was proposed in the paper [Funnel-Transformer: Filtering out Sequential Redundancy for
+Efficient Language Processing](https://arxiv.org/abs/2006.03236). It is a bidirectional transformer model, like
+BERT, but with a pooling operation after each block of layers, a bit like in traditional convolutional neural networks
+(CNN) in computer vision.
+
+The abstract from the paper is the following:
+
+*With the success of language pretraining, it is highly desirable to develop more efficient architectures of good
+scalability that can exploit the abundant unlabeled data at a lower cost. To improve the efficiency, we examine the
+much-overlooked redundancy in maintaining a full-length token-level presentation, especially for tasks that only
+require a single-vector presentation of the sequence. With this intuition, we propose Funnel-Transformer which
+gradually compresses the sequence of hidden states to a shorter one and hence reduces the computation cost. More
+importantly, by re-investing the saved FLOPs from length reduction in constructing a deeper or wider model, we further
+improve the model capacity. In addition, to perform token-level predictions as required by common pretraining
+objectives, Funnel-Transformer is able to recover a deep representation for each token from the reduced hidden sequence
+via a decoder. Empirically, with comparable or fewer FLOPs, Funnel-Transformer outperforms the standard Transformer on
+a wide variety of sequence-level prediction tasks, including text classification, language understanding, and reading
+comprehension.*
+
+Tips:
+
+- Since Funnel Transformer uses pooling, the sequence length of the hidden states changes after each block of layers.
+ The base model therefore has a final sequence length that is a quarter of the original one. This model can be used
+ directly for tasks that just require a sentence summary (like sequence classification or multiple choice). For other
+ tasks, the full model is used; this full model has a decoder that upsamples the final hidden states to the same
+ sequence length as the input.
+- The Funnel Transformer checkpoints are all available with a full version and a base version. The first ones should be
+ used for [`FunnelModel`], [`FunnelForPreTraining`],
+ [`FunnelForMaskedLM`], [`FunnelForTokenClassification`] and
+ class:*~transformers.FunnelForQuestionAnswering*. The second ones should be used for
+ [`FunnelBaseModel`], [`FunnelForSequenceClassification`] and
+ [`FunnelForMultipleChoice`].
+
+This model was contributed by [sgugger](https://huggingface.co/sgugger). The original code can be found [here](https://github.com/laiguokun/Funnel-Transformer).
+
+
+## FunnelConfig
+
+[[autodoc]] FunnelConfig
+
+## FunnelTokenizer
+
+[[autodoc]] FunnelTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## FunnelTokenizerFast
+
+[[autodoc]] FunnelTokenizerFast
+
+## Funnel specific outputs
+
+[[autodoc]] models.funnel.modeling_funnel.FunnelForPreTrainingOutput
+
+[[autodoc]] models.funnel.modeling_tf_funnel.TFFunnelForPreTrainingOutput
+
+## FunnelBaseModel
+
+[[autodoc]] FunnelBaseModel
+ - forward
+
+## FunnelModel
+
+[[autodoc]] FunnelModel
+ - forward
+
+## FunnelModelForPreTraining
+
+[[autodoc]] FunnelForPreTraining
+ - forward
+
+## FunnelForMaskedLM
+
+[[autodoc]] FunnelForMaskedLM
+ - forward
+
+## FunnelForSequenceClassification
+
+[[autodoc]] FunnelForSequenceClassification
+ - forward
+
+## FunnelForMultipleChoice
+
+[[autodoc]] FunnelForMultipleChoice
+ - forward
+
+## FunnelForTokenClassification
+
+[[autodoc]] FunnelForTokenClassification
+ - forward
+
+## FunnelForQuestionAnswering
+
+[[autodoc]] FunnelForQuestionAnswering
+ - forward
+
+## TFFunnelBaseModel
+
+[[autodoc]] TFFunnelBaseModel
+ - call
+
+## TFFunnelModel
+
+[[autodoc]] TFFunnelModel
+ - call
+
+## TFFunnelModelForPreTraining
+
+[[autodoc]] TFFunnelForPreTraining
+ - call
+
+## TFFunnelForMaskedLM
+
+[[autodoc]] TFFunnelForMaskedLM
+ - call
+
+## TFFunnelForSequenceClassification
+
+[[autodoc]] TFFunnelForSequenceClassification
+ - call
+
+## TFFunnelForMultipleChoice
+
+[[autodoc]] TFFunnelForMultipleChoice
+ - call
+
+## TFFunnelForTokenClassification
+
+[[autodoc]] TFFunnelForTokenClassification
+ - call
+
+## TFFunnelForQuestionAnswering
+
+[[autodoc]] TFFunnelForQuestionAnswering
+ - call
diff --git a/docs/source/en/model_doc/glpn.mdx b/docs/source/en/model_doc/glpn.mdx
new file mode 100644
index 00000000000000..428aede4deba66
--- /dev/null
+++ b/docs/source/en/model_doc/glpn.mdx
@@ -0,0 +1,61 @@
+
+
+# GLPN
+
+
+
+This is a recently introduced model so the API hasn't been tested extensively. There may be some bugs or slight
+breaking changes to fix it in the future. If you see something strange, file a [Github Issue](https://github.com/huggingface/transformers/issues/new?assignees=&labels=&template=bug-report.md&title).
+
+
+
+## Overview
+
+The GLPN model was proposed in [Global-Local Path Networks for Monocular Depth Estimation with Vertical CutDepth](https://arxiv.org/abs/2201.07436) by Doyeon Kim, Woonghyun Ga, Pyungwhan Ahn, Donggyu Joo, Sehwan Chun, Junmo Kim.
+GLPN combines [SegFormer](segformer)'s hierarchical mix-Transformer with a lightweight decoder for monocular depth estimation. The proposed decoder shows better performance than the previously proposed decoders, with considerably
+less computational complexity.
+
+The abstract from the paper is the following:
+
+*Depth estimation from a single image is an important task that can be applied to various fields in computer vision, and has grown rapidly with the development of convolutional neural networks. In this paper, we propose a novel structure and training strategy for monocular depth estimation to further improve the prediction accuracy of the network. We deploy a hierarchical transformer encoder to capture and convey the global context, and design a lightweight yet powerful decoder to generate an estimated depth map while considering local connectivity. By constructing connected paths between multi-scale local features and the global decoding stream with our proposed selective feature fusion module, the network can integrate both representations and recover fine details. In addition, the proposed decoder shows better performance than the previously proposed decoders, with considerably less computational complexity. Furthermore, we improve the depth-specific augmentation method by utilizing an important observation in depth estimation to enhance the model. Our network achieves state-of-the-art performance over the challenging depth dataset NYU Depth V2. Extensive experiments have been conducted to validate and show the effectiveness of the proposed approach. Finally, our model shows better generalisation ability and robustness than other comparative models.*
+
+Tips:
+
+- A notebook illustrating inference with [`GLPNForDepthEstimation`] can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/GLPN/GLPN_inference_(depth_estimation).ipynb).
+- One can use [`GLPNFeatureExtractor`] to prepare images for the model.
+
+
+
+ DPT architecture. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/isl-org/DPT).
+
+## DPTConfig
+
+[[autodoc]] DPTConfig
+
+
+## DPTFeatureExtractor
+
+[[autodoc]] DPTFeatureExtractor
+ - __call__
+
+
+## DPTModel
+
+[[autodoc]] DPTModel
+ - forward
+
+
+## DPTForDepthEstimation
+
+[[autodoc]] DPTForDepthEstimation
+ - forward
+
+
+## DPTForSemanticSegmentation
+
+[[autodoc]] DPTForSemanticSegmentation
+ - forward
\ No newline at end of file
diff --git a/docs/source/en/model_doc/electra.mdx b/docs/source/en/model_doc/electra.mdx
new file mode 100644
index 00000000000000..c5a38f2431174f
--- /dev/null
+++ b/docs/source/en/model_doc/electra.mdx
@@ -0,0 +1,189 @@
+
+
+# ELECTRA
+
+## Overview
+
+The ELECTRA model was proposed in the paper [ELECTRA: Pre-training Text Encoders as Discriminators Rather Than
+Generators](https://openreview.net/pdf?id=r1xMH1BtvB). ELECTRA is a new pretraining approach which trains two
+transformer models: the generator and the discriminator. The generator's role is to replace tokens in a sequence, and
+is therefore trained as a masked language model. The discriminator, which is the model we're interested in, tries to
+identify which tokens were replaced by the generator in the sequence.
+
+The abstract from the paper is the following:
+
+*Masked language modeling (MLM) pretraining methods such as BERT corrupt the input by replacing some tokens with [MASK]
+and then train a model to reconstruct the original tokens. While they produce good results when transferred to
+downstream NLP tasks, they generally require large amounts of compute to be effective. As an alternative, we propose a
+more sample-efficient pretraining task called replaced token detection. Instead of masking the input, our approach
+corrupts it by replacing some tokens with plausible alternatives sampled from a small generator network. Then, instead
+of training a model that predicts the original identities of the corrupted tokens, we train a discriminative model that
+predicts whether each token in the corrupted input was replaced by a generator sample or not. Thorough experiments
+demonstrate this new pretraining task is more efficient than MLM because the task is defined over all input tokens
+rather than just the small subset that was masked out. As a result, the contextual representations learned by our
+approach substantially outperform the ones learned by BERT given the same model size, data, and compute. The gains are
+particularly strong for small models; for example, we train a model on one GPU for 4 days that outperforms GPT (trained
+using 30x more compute) on the GLUE natural language understanding benchmark. Our approach also works well at scale,
+where it performs comparably to RoBERTa and XLNet while using less than 1/4 of their compute and outperforms them when
+using the same amount of compute.*
+
+Tips:
+
+- ELECTRA is the pretraining approach, therefore there is nearly no changes done to the underlying model: BERT. The
+ only change is the separation of the embedding size and the hidden size: the embedding size is generally smaller,
+ while the hidden size is larger. An additional projection layer (linear) is used to project the embeddings from their
+ embedding size to the hidden size. In the case where the embedding size is the same as the hidden size, no projection
+ layer is used.
+- The ELECTRA checkpoints saved using [Google Research's implementation](https://github.com/google-research/electra)
+ contain both the generator and discriminator. The conversion script requires the user to name which model to export
+ into the correct architecture. Once converted to the HuggingFace format, these checkpoints may be loaded into all
+ available ELECTRA models, however. This means that the discriminator may be loaded in the
+ [`ElectraForMaskedLM`] model, and the generator may be loaded in the
+ [`ElectraForPreTraining`] model (the classification head will be randomly initialized as it
+ doesn't exist in the generator).
+
+This model was contributed by [lysandre](https://huggingface.co/lysandre). The original code can be found [here](https://github.com/google-research/electra).
+
+
+## ElectraConfig
+
+[[autodoc]] ElectraConfig
+
+## ElectraTokenizer
+
+[[autodoc]] ElectraTokenizer
+
+## ElectraTokenizerFast
+
+[[autodoc]] ElectraTokenizerFast
+
+## Electra specific outputs
+
+[[autodoc]] models.electra.modeling_electra.ElectraForPreTrainingOutput
+
+[[autodoc]] models.electra.modeling_tf_electra.TFElectraForPreTrainingOutput
+
+## ElectraModel
+
+[[autodoc]] ElectraModel
+ - forward
+
+## ElectraForPreTraining
+
+[[autodoc]] ElectraForPreTraining
+ - forward
+
+## ElectraForCausalLM
+
+[[autodoc]] ElectraForCausalLM
+ - forward
+
+## ElectraForMaskedLM
+
+[[autodoc]] ElectraForMaskedLM
+ - forward
+
+## ElectraForSequenceClassification
+
+[[autodoc]] ElectraForSequenceClassification
+ - forward
+
+## ElectraForMultipleChoice
+
+[[autodoc]] ElectraForMultipleChoice
+ - forward
+
+## ElectraForTokenClassification
+
+[[autodoc]] ElectraForTokenClassification
+ - forward
+
+## ElectraForQuestionAnswering
+
+[[autodoc]] ElectraForQuestionAnswering
+ - forward
+
+## TFElectraModel
+
+[[autodoc]] TFElectraModel
+ - call
+
+## TFElectraForPreTraining
+
+[[autodoc]] TFElectraForPreTraining
+ - call
+
+## TFElectraForMaskedLM
+
+[[autodoc]] TFElectraForMaskedLM
+ - call
+
+## TFElectraForSequenceClassification
+
+[[autodoc]] TFElectraForSequenceClassification
+ - call
+
+## TFElectraForMultipleChoice
+
+[[autodoc]] TFElectraForMultipleChoice
+ - call
+
+## TFElectraForTokenClassification
+
+[[autodoc]] TFElectraForTokenClassification
+ - call
+
+## TFElectraForQuestionAnswering
+
+[[autodoc]] TFElectraForQuestionAnswering
+ - call
+
+## FlaxElectraModel
+
+[[autodoc]] FlaxElectraModel
+ - __call__
+
+## FlaxElectraForPreTraining
+
+[[autodoc]] FlaxElectraForPreTraining
+ - __call__
+
+## FlaxElectraForCausalLM
+
+[[autodoc]] FlaxElectraForCausalLM
+ - __call__
+
+## FlaxElectraForMaskedLM
+
+[[autodoc]] FlaxElectraForMaskedLM
+ - __call__
+
+## FlaxElectraForSequenceClassification
+
+[[autodoc]] FlaxElectraForSequenceClassification
+ - __call__
+
+## FlaxElectraForMultipleChoice
+
+[[autodoc]] FlaxElectraForMultipleChoice
+ - __call__
+
+## FlaxElectraForTokenClassification
+
+[[autodoc]] FlaxElectraForTokenClassification
+ - __call__
+
+## FlaxElectraForQuestionAnswering
+
+[[autodoc]] FlaxElectraForQuestionAnswering
+ - __call__
diff --git a/docs/source/en/model_doc/encoder-decoder.mdx b/docs/source/en/model_doc/encoder-decoder.mdx
new file mode 100644
index 00000000000000..b6bda8fcfbae52
--- /dev/null
+++ b/docs/source/en/model_doc/encoder-decoder.mdx
@@ -0,0 +1,68 @@
+
+
+# Encoder Decoder Models
+
+The [`EncoderDecoderModel`] can be used to initialize a sequence-to-sequence model with any
+pretrained autoencoding model as the encoder and any pretrained autoregressive model as the decoder.
+
+The effectiveness of initializing sequence-to-sequence models with pretrained checkpoints for sequence generation tasks
+was shown in [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461) by
+Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
+
+After such an [`EncoderDecoderModel`] has been trained/fine-tuned, it can be saved/loaded just like
+any other models (see the examples for more information).
+
+An application of this architecture could be to leverage two pretrained [`BertModel`] as the encoder
+and decoder for a summarization model as was shown in: [Text Summarization with Pretrained Encoders](https://arxiv.org/abs/1908.08345) by Yang Liu and Mirella Lapata.
+
+The [`~TFEncoderDecoderModel.from_pretrained`] currently doesn't support initializing the model from a
+pytorch checkpoint. Passing `from_pt=True` to this method will throw an exception. If there are only pytorch
+checkpoints for a particular encoder-decoder model, a workaround is:
+
+```python
+>>> # a workaround to load from pytorch checkpoint
+>>> _model = EncoderDecoderModel.from_pretrained("patrickvonplaten/bert2bert-cnn_dailymail-fp16")
+>>> _model.encoder.save_pretrained("./encoder")
+>>> _model.decoder.save_pretrained("./decoder")
+>>> model = TFEncoderDecoderModel.from_encoder_decoder_pretrained(
+... "./encoder", "./decoder", encoder_from_pt=True, decoder_from_pt=True
+... )
+>>> # This is only for copying some specific attributes of this particular model.
+>>> model.config = _model.config
+```
+
+This model was contributed by [thomwolf](https://github.com/thomwolf). This model's TensorFlow and Flax versions
+were contributed by [ydshieh](https://github.com/ydshieh).
+
+
+## EncoderDecoderConfig
+
+[[autodoc]] EncoderDecoderConfig
+
+## EncoderDecoderModel
+
+[[autodoc]] EncoderDecoderModel
+ - forward
+ - from_encoder_decoder_pretrained
+
+## TFEncoderDecoderModel
+
+[[autodoc]] TFEncoderDecoderModel
+ - call
+ - from_encoder_decoder_pretrained
+
+## FlaxEncoderDecoderModel
+
+[[autodoc]] FlaxEncoderDecoderModel
+ - __call__
+ - from_encoder_decoder_pretrained
diff --git a/docs/source/en/model_doc/flaubert.mdx b/docs/source/en/model_doc/flaubert.mdx
new file mode 100644
index 00000000000000..c36e0eec8f4c48
--- /dev/null
+++ b/docs/source/en/model_doc/flaubert.mdx
@@ -0,0 +1,109 @@
+
+
+# FlauBERT
+
+## Overview
+
+The FlauBERT model was proposed in the paper [FlauBERT: Unsupervised Language Model Pre-training for French](https://arxiv.org/abs/1912.05372) by Hang Le et al. It's a transformer model pretrained using a masked language
+modeling (MLM) objective (like BERT).
+
+The abstract from the paper is the following:
+
+*Language models have become a key step to achieve state-of-the art results in many different Natural Language
+Processing (NLP) tasks. Leveraging the huge amount of unlabeled texts nowadays available, they provide an efficient way
+to pre-train continuous word representations that can be fine-tuned for a downstream task, along with their
+contextualization at the sentence level. This has been widely demonstrated for English using contextualized
+representations (Dai and Le, 2015; Peters et al., 2018; Howard and Ruder, 2018; Radford et al., 2018; Devlin et al.,
+2019; Yang et al., 2019b). In this paper, we introduce and share FlauBERT, a model learned on a very large and
+heterogeneous French corpus. Models of different sizes are trained using the new CNRS (French National Centre for
+Scientific Research) Jean Zay supercomputer. We apply our French language models to diverse NLP tasks (text
+classification, paraphrasing, natural language inference, parsing, word sense disambiguation) and show that most of the
+time they outperform other pretraining approaches. Different versions of FlauBERT as well as a unified evaluation
+protocol for the downstream tasks, called FLUE (French Language Understanding Evaluation), are shared to the research
+community for further reproducible experiments in French NLP.*
+
+This model was contributed by [formiel](https://huggingface.co/formiel). The original code can be found [here](https://github.com/getalp/Flaubert).
+
+
+## FlaubertConfig
+
+[[autodoc]] FlaubertConfig
+
+## FlaubertTokenizer
+
+[[autodoc]] FlaubertTokenizer
+
+## FlaubertModel
+
+[[autodoc]] FlaubertModel
+ - forward
+
+## FlaubertWithLMHeadModel
+
+[[autodoc]] FlaubertWithLMHeadModel
+ - forward
+
+## FlaubertForSequenceClassification
+
+[[autodoc]] FlaubertForSequenceClassification
+ - forward
+
+## FlaubertForMultipleChoice
+
+[[autodoc]] FlaubertForMultipleChoice
+ - forward
+
+## FlaubertForTokenClassification
+
+[[autodoc]] FlaubertForTokenClassification
+ - forward
+
+## FlaubertForQuestionAnsweringSimple
+
+[[autodoc]] FlaubertForQuestionAnsweringSimple
+ - forward
+
+## FlaubertForQuestionAnswering
+
+[[autodoc]] FlaubertForQuestionAnswering
+ - forward
+
+## TFFlaubertModel
+
+[[autodoc]] TFFlaubertModel
+ - call
+
+## TFFlaubertWithLMHeadModel
+
+[[autodoc]] TFFlaubertWithLMHeadModel
+ - call
+
+## TFFlaubertForSequenceClassification
+
+[[autodoc]] TFFlaubertForSequenceClassification
+ - call
+
+## TFFlaubertForMultipleChoice
+
+[[autodoc]] TFFlaubertForMultipleChoice
+ - call
+
+## TFFlaubertForTokenClassification
+
+[[autodoc]] TFFlaubertForTokenClassification
+ - call
+
+## TFFlaubertForQuestionAnsweringSimple
+
+[[autodoc]] TFFlaubertForQuestionAnsweringSimple
+ - call
diff --git a/docs/source/en/model_doc/fnet.mdx b/docs/source/en/model_doc/fnet.mdx
new file mode 100644
index 00000000000000..19afcc8051102f
--- /dev/null
+++ b/docs/source/en/model_doc/fnet.mdx
@@ -0,0 +1,98 @@
+
+
+# FNet
+
+## Overview
+
+The FNet model was proposed in [FNet: Mixing Tokens with Fourier Transforms](https://arxiv.org/abs/2105.03824) by
+James Lee-Thorp, Joshua Ainslie, Ilya Eckstein, Santiago Ontanon. The model replaces the self-attention layer in a BERT
+model with a fourier transform which returns only the real parts of the transform. The model is significantly faster
+than the BERT model because it has fewer parameters and is more memory efficient. The model achieves about 92-97%
+accuracy of BERT counterparts on GLUE benchmark, and trains much faster than the BERT model. The abstract from the
+paper is the following:
+
+*We show that Transformer encoder architectures can be sped up, with limited accuracy costs, by replacing the
+self-attention sublayers with simple linear transformations that "mix" input tokens. These linear mixers, along with
+standard nonlinearities in feed-forward layers, prove competent at modeling semantic relationships in several text
+classification tasks. Most surprisingly, we find that replacing the self-attention sublayer in a Transformer encoder
+with a standard, unparameterized Fourier Transform achieves 92-97% of the accuracy of BERT counterparts on the GLUE
+benchmark, but trains 80% faster on GPUs and 70% faster on TPUs at standard 512 input lengths. At longer input lengths,
+our FNet model is significantly faster: when compared to the "efficient" Transformers on the Long Range Arena
+benchmark, FNet matches the accuracy of the most accurate models, while outpacing the fastest models across all
+sequence lengths on GPUs (and across relatively shorter lengths on TPUs). Finally, FNet has a light memory footprint
+and is particularly efficient at smaller model sizes; for a fixed speed and accuracy budget, small FNet models
+outperform Transformer counterparts.*
+
+Tips on usage:
+
+- The model was trained without an attention mask as it is based on Fourier Transform. The model was trained with
+ maximum sequence length 512 which includes pad tokens. Hence, it is highly recommended to use the same maximum
+ sequence length for fine-tuning and inference.
+
+This model was contributed by [gchhablani](https://huggingface.co/gchhablani). The original code can be found [here](https://github.com/google-research/google-research/tree/master/f_net).
+
+## FNetConfig
+
+[[autodoc]] FNetConfig
+
+## FNetTokenizer
+
+[[autodoc]] FNetTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## FNetTokenizerFast
+
+[[autodoc]] FNetTokenizerFast
+
+## FNetModel
+
+[[autodoc]] FNetModel
+ - forward
+
+## FNetForPreTraining
+
+[[autodoc]] FNetForPreTraining
+ - forward
+
+## FNetForMaskedLM
+
+[[autodoc]] FNetForMaskedLM
+ - forward
+
+## FNetForNextSentencePrediction
+
+[[autodoc]] FNetForNextSentencePrediction
+ - forward
+
+## FNetForSequenceClassification
+
+[[autodoc]] FNetForSequenceClassification
+ - forward
+
+## FNetForMultipleChoice
+
+[[autodoc]] FNetForMultipleChoice
+ - forward
+
+## FNetForTokenClassification
+
+[[autodoc]] FNetForTokenClassification
+ - forward
+
+## FNetForQuestionAnswering
+
+[[autodoc]] FNetForQuestionAnswering
+ - forward
diff --git a/docs/source/en/model_doc/fsmt.mdx b/docs/source/en/model_doc/fsmt.mdx
new file mode 100644
index 00000000000000..25c8d85cf48606
--- /dev/null
+++ b/docs/source/en/model_doc/fsmt.mdx
@@ -0,0 +1,63 @@
+
+
+# FSMT
+
+**DISCLAIMER:** If you see something strange, file a [Github Issue](https://github.com/huggingface/transformers/issues/new?assignees=&labels=&template=bug-report.md&title) and assign
+@stas00.
+
+## Overview
+
+FSMT (FairSeq MachineTranslation) models were introduced in [Facebook FAIR's WMT19 News Translation Task Submission](https://arxiv.org/abs/1907.06616) by Nathan Ng, Kyra Yee, Alexei Baevski, Myle Ott, Michael Auli, Sergey Edunov.
+
+The abstract of the paper is the following:
+
+*This paper describes Facebook FAIR's submission to the WMT19 shared news translation task. We participate in two
+language pairs and four language directions, English <-> German and English <-> Russian. Following our submission from
+last year, our baseline systems are large BPE-based transformer models trained with the Fairseq sequence modeling
+toolkit which rely on sampled back-translations. This year we experiment with different bitext data filtering schemes,
+as well as with adding filtered back-translated data. We also ensemble and fine-tune our models on domain-specific
+data, then decode using noisy channel model reranking. Our submissions are ranked first in all four directions of the
+human evaluation campaign. On En->De, our system significantly outperforms other systems as well as human translations.
+This system improves upon our WMT'18 submission by 4.5 BLEU points.*
+
+This model was contributed by [stas](https://huggingface.co/stas). The original code can be found
+[here](https://github.com/pytorch/fairseq/tree/master/examples/wmt19).
+
+## Implementation Notes
+
+- FSMT uses source and target vocabulary pairs that aren't combined into one. It doesn't share embeddings tokens
+ either. Its tokenizer is very similar to [`XLMTokenizer`] and the main model is derived from
+ [`BartModel`].
+
+
+## FSMTConfig
+
+[[autodoc]] FSMTConfig
+
+## FSMTTokenizer
+
+[[autodoc]] FSMTTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## FSMTModel
+
+[[autodoc]] FSMTModel
+ - forward
+
+## FSMTForConditionalGeneration
+
+[[autodoc]] FSMTForConditionalGeneration
+ - forward
diff --git a/docs/source/en/model_doc/funnel.mdx b/docs/source/en/model_doc/funnel.mdx
new file mode 100644
index 00000000000000..b7743d84a6a8c3
--- /dev/null
+++ b/docs/source/en/model_doc/funnel.mdx
@@ -0,0 +1,153 @@
+
+
+# Funnel Transformer
+
+## Overview
+
+The Funnel Transformer model was proposed in the paper [Funnel-Transformer: Filtering out Sequential Redundancy for
+Efficient Language Processing](https://arxiv.org/abs/2006.03236). It is a bidirectional transformer model, like
+BERT, but with a pooling operation after each block of layers, a bit like in traditional convolutional neural networks
+(CNN) in computer vision.
+
+The abstract from the paper is the following:
+
+*With the success of language pretraining, it is highly desirable to develop more efficient architectures of good
+scalability that can exploit the abundant unlabeled data at a lower cost. To improve the efficiency, we examine the
+much-overlooked redundancy in maintaining a full-length token-level presentation, especially for tasks that only
+require a single-vector presentation of the sequence. With this intuition, we propose Funnel-Transformer which
+gradually compresses the sequence of hidden states to a shorter one and hence reduces the computation cost. More
+importantly, by re-investing the saved FLOPs from length reduction in constructing a deeper or wider model, we further
+improve the model capacity. In addition, to perform token-level predictions as required by common pretraining
+objectives, Funnel-Transformer is able to recover a deep representation for each token from the reduced hidden sequence
+via a decoder. Empirically, with comparable or fewer FLOPs, Funnel-Transformer outperforms the standard Transformer on
+a wide variety of sequence-level prediction tasks, including text classification, language understanding, and reading
+comprehension.*
+
+Tips:
+
+- Since Funnel Transformer uses pooling, the sequence length of the hidden states changes after each block of layers.
+ The base model therefore has a final sequence length that is a quarter of the original one. This model can be used
+ directly for tasks that just require a sentence summary (like sequence classification or multiple choice). For other
+ tasks, the full model is used; this full model has a decoder that upsamples the final hidden states to the same
+ sequence length as the input.
+- The Funnel Transformer checkpoints are all available with a full version and a base version. The first ones should be
+ used for [`FunnelModel`], [`FunnelForPreTraining`],
+ [`FunnelForMaskedLM`], [`FunnelForTokenClassification`] and
+ class:*~transformers.FunnelForQuestionAnswering*. The second ones should be used for
+ [`FunnelBaseModel`], [`FunnelForSequenceClassification`] and
+ [`FunnelForMultipleChoice`].
+
+This model was contributed by [sgugger](https://huggingface.co/sgugger). The original code can be found [here](https://github.com/laiguokun/Funnel-Transformer).
+
+
+## FunnelConfig
+
+[[autodoc]] FunnelConfig
+
+## FunnelTokenizer
+
+[[autodoc]] FunnelTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## FunnelTokenizerFast
+
+[[autodoc]] FunnelTokenizerFast
+
+## Funnel specific outputs
+
+[[autodoc]] models.funnel.modeling_funnel.FunnelForPreTrainingOutput
+
+[[autodoc]] models.funnel.modeling_tf_funnel.TFFunnelForPreTrainingOutput
+
+## FunnelBaseModel
+
+[[autodoc]] FunnelBaseModel
+ - forward
+
+## FunnelModel
+
+[[autodoc]] FunnelModel
+ - forward
+
+## FunnelModelForPreTraining
+
+[[autodoc]] FunnelForPreTraining
+ - forward
+
+## FunnelForMaskedLM
+
+[[autodoc]] FunnelForMaskedLM
+ - forward
+
+## FunnelForSequenceClassification
+
+[[autodoc]] FunnelForSequenceClassification
+ - forward
+
+## FunnelForMultipleChoice
+
+[[autodoc]] FunnelForMultipleChoice
+ - forward
+
+## FunnelForTokenClassification
+
+[[autodoc]] FunnelForTokenClassification
+ - forward
+
+## FunnelForQuestionAnswering
+
+[[autodoc]] FunnelForQuestionAnswering
+ - forward
+
+## TFFunnelBaseModel
+
+[[autodoc]] TFFunnelBaseModel
+ - call
+
+## TFFunnelModel
+
+[[autodoc]] TFFunnelModel
+ - call
+
+## TFFunnelModelForPreTraining
+
+[[autodoc]] TFFunnelForPreTraining
+ - call
+
+## TFFunnelForMaskedLM
+
+[[autodoc]] TFFunnelForMaskedLM
+ - call
+
+## TFFunnelForSequenceClassification
+
+[[autodoc]] TFFunnelForSequenceClassification
+ - call
+
+## TFFunnelForMultipleChoice
+
+[[autodoc]] TFFunnelForMultipleChoice
+ - call
+
+## TFFunnelForTokenClassification
+
+[[autodoc]] TFFunnelForTokenClassification
+ - call
+
+## TFFunnelForQuestionAnswering
+
+[[autodoc]] TFFunnelForQuestionAnswering
+ - call
diff --git a/docs/source/en/model_doc/glpn.mdx b/docs/source/en/model_doc/glpn.mdx
new file mode 100644
index 00000000000000..428aede4deba66
--- /dev/null
+++ b/docs/source/en/model_doc/glpn.mdx
@@ -0,0 +1,61 @@
+
+
+# GLPN
+
+
+
+This is a recently introduced model so the API hasn't been tested extensively. There may be some bugs or slight
+breaking changes to fix it in the future. If you see something strange, file a [Github Issue](https://github.com/huggingface/transformers/issues/new?assignees=&labels=&template=bug-report.md&title).
+
+
+
+## Overview
+
+The GLPN model was proposed in [Global-Local Path Networks for Monocular Depth Estimation with Vertical CutDepth](https://arxiv.org/abs/2201.07436) by Doyeon Kim, Woonghyun Ga, Pyungwhan Ahn, Donggyu Joo, Sehwan Chun, Junmo Kim.
+GLPN combines [SegFormer](segformer)'s hierarchical mix-Transformer with a lightweight decoder for monocular depth estimation. The proposed decoder shows better performance than the previously proposed decoders, with considerably
+less computational complexity.
+
+The abstract from the paper is the following:
+
+*Depth estimation from a single image is an important task that can be applied to various fields in computer vision, and has grown rapidly with the development of convolutional neural networks. In this paper, we propose a novel structure and training strategy for monocular depth estimation to further improve the prediction accuracy of the network. We deploy a hierarchical transformer encoder to capture and convey the global context, and design a lightweight yet powerful decoder to generate an estimated depth map while considering local connectivity. By constructing connected paths between multi-scale local features and the global decoding stream with our proposed selective feature fusion module, the network can integrate both representations and recover fine details. In addition, the proposed decoder shows better performance than the previously proposed decoders, with considerably less computational complexity. Furthermore, we improve the depth-specific augmentation method by utilizing an important observation in depth estimation to enhance the model. Our network achieves state-of-the-art performance over the challenging depth dataset NYU Depth V2. Extensive experiments have been conducted to validate and show the effectiveness of the proposed approach. Finally, our model shows better generalisation ability and robustness than other comparative models.*
+
+Tips:
+
+- A notebook illustrating inference with [`GLPNForDepthEstimation`] can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/GLPN/GLPN_inference_(depth_estimation).ipynb).
+- One can use [`GLPNFeatureExtractor`] to prepare images for the model.
+
+ +
+ Summary of the approach. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/vinvino02/GLPDepth).
+
+## GLPNConfig
+
+[[autodoc]] GLPNConfig
+
+## GLPNFeatureExtractor
+
+[[autodoc]] GLPNFeatureExtractor
+ - __call__
+
+## GLPNModel
+
+[[autodoc]] GLPNModel
+ - forward
+
+## GLPNForDepthEstimation
+
+[[autodoc]] GLPNForDepthEstimation
+ - forward
\ No newline at end of file
diff --git a/docs/source/en/model_doc/gpt2.mdx b/docs/source/en/model_doc/gpt2.mdx
new file mode 100644
index 00000000000000..8cefe7eaa2673e
--- /dev/null
+++ b/docs/source/en/model_doc/gpt2.mdx
@@ -0,0 +1,131 @@
+
+
+# OpenAI GPT2
+
+## Overview
+
+OpenAI GPT-2 model was proposed in [Language Models are Unsupervised Multitask Learners](https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf) by Alec
+Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei and Ilya Sutskever. It's a causal (unidirectional)
+transformer pretrained using language modeling on a very large corpus of ~40 GB of text data.
+
+The abstract from the paper is the following:
+
+*GPT-2 is a large transformer-based language model with 1.5 billion parameters, trained on a dataset[1] of 8 million
+web pages. GPT-2 is trained with a simple objective: predict the next word, given all of the previous words within some
+text. The diversity of the dataset causes this simple goal to contain naturally occurring demonstrations of many tasks
+across diverse domains. GPT-2 is a direct scale-up of GPT, with more than 10X the parameters and trained on more than
+10X the amount of data.*
+
+Tips:
+
+- GPT-2 is a model with absolute position embeddings so it's usually advised to pad the inputs on the right rather than
+ the left.
+- GPT-2 was trained with a causal language modeling (CLM) objective and is therefore powerful at predicting the next
+ token in a sequence. Leveraging this feature allows GPT-2 to generate syntactically coherent text as it can be
+ observed in the *run_generation.py* example script.
+- The model can take the *past_key_values* (for PyTorch) or *past* (for TF) as input, which is the previously computed
+ key/value attention pairs. Using this (*past_key_values* or *past*) value prevents the model from re-computing
+ pre-computed values in the context of text generation. For PyTorch, see *past_key_values* argument of the
+ [`GPT2Model.forward`] method, or for TF the *past* argument of the
+ [`TFGPT2Model.call`] method for more information on its usage.
+- Enabling the *scale_attn_by_inverse_layer_idx* and *reorder_and_upcast_attn* flags will apply the training stability
+ improvements from [Mistral](https://github.com/stanford-crfm/mistral/) (for PyTorch only).
+
+[Write With Transformer](https://transformer.huggingface.co/doc/gpt2-large) is a webapp created and hosted by
+Hugging Face showcasing the generative capabilities of several models. GPT-2 is one of them and is available in five
+different sizes: small, medium, large, xl and a distilled version of the small checkpoint: *distilgpt-2*.
+
+This model was contributed by [thomwolf](https://huggingface.co/thomwolf). The original code can be found [here](https://openai.com/blog/better-language-models/).
+
+
+## GPT2Config
+
+[[autodoc]] GPT2Config
+
+## GPT2Tokenizer
+
+[[autodoc]] GPT2Tokenizer
+ - save_vocabulary
+
+## GPT2TokenizerFast
+
+[[autodoc]] GPT2TokenizerFast
+
+## GPT2 specific outputs
+
+[[autodoc]] models.gpt2.modeling_gpt2.GPT2DoubleHeadsModelOutput
+
+[[autodoc]] models.gpt2.modeling_tf_gpt2.TFGPT2DoubleHeadsModelOutput
+
+## GPT2Model
+
+[[autodoc]] GPT2Model
+ - forward
+ - parallelize
+ - deparallelize
+
+## GPT2LMHeadModel
+
+[[autodoc]] GPT2LMHeadModel
+ - forward
+ - parallelize
+ - deparallelize
+
+## GPT2DoubleHeadsModel
+
+[[autodoc]] GPT2DoubleHeadsModel
+ - forward
+
+## GPT2ForSequenceClassification
+
+[[autodoc]] GPT2ForSequenceClassification
+ - forward
+
+## GPT2ForTokenClassification
+
+[[autodoc]] GPT2ForTokenClassification
+ - forward
+
+## TFGPT2Model
+
+[[autodoc]] TFGPT2Model
+ - call
+
+## TFGPT2LMHeadModel
+
+[[autodoc]] TFGPT2LMHeadModel
+ - call
+
+## TFGPT2DoubleHeadsModel
+
+[[autodoc]] TFGPT2DoubleHeadsModel
+ - call
+
+## TFGPT2ForSequenceClassification
+
+[[autodoc]] TFGPT2ForSequenceClassification
+ - call
+
+## TFSequenceClassifierOutputWithPast
+
+[[autodoc]] modeling_tf_outputs.TFSequenceClassifierOutputWithPast
+
+## FlaxGPT2Model
+
+[[autodoc]] FlaxGPT2Model
+ - __call__
+
+## FlaxGPT2LMHeadModel
+
+[[autodoc]] FlaxGPT2LMHeadModel
+ - __call__
diff --git a/docs/source/en/model_doc/gpt_neo.mdx b/docs/source/en/model_doc/gpt_neo.mdx
new file mode 100644
index 00000000000000..f68b92b213270b
--- /dev/null
+++ b/docs/source/en/model_doc/gpt_neo.mdx
@@ -0,0 +1,80 @@
+
+
+# GPT Neo
+
+## Overview
+
+The GPTNeo model was released in the [EleutherAI/gpt-neo](https://github.com/EleutherAI/gpt-neo) repository by Sid
+Black, Stella Biderman, Leo Gao, Phil Wang and Connor Leahy. It is a GPT2 like causal language model trained on the
+[Pile](https://pile.eleuther.ai/) dataset.
+
+The architecture is similar to GPT2 except that GPT Neo uses local attention in every other layer with a window size of
+256 tokens.
+
+This model was contributed by [valhalla](https://huggingface.co/valhalla).
+
+### Generation
+
+The `generate()` method can be used to generate text using GPT Neo model.
+
+```python
+>>> from transformers import GPTNeoForCausalLM, GPT2Tokenizer
+
+>>> model = GPTNeoForCausalLM.from_pretrained("EleutherAI/gpt-neo-1.3B")
+>>> tokenizer = GPT2Tokenizer.from_pretrained("EleutherAI/gpt-neo-1.3B")
+
+>>> prompt = (
+... "In a shocking finding, scientists discovered a herd of unicorns living in a remote, "
+... "previously unexplored valley, in the Andes Mountains. Even more surprising to the "
+... "researchers was the fact that the unicorns spoke perfect English."
+... )
+
+>>> input_ids = tokenizer(prompt, return_tensors="pt").input_ids
+
+>>> gen_tokens = model.generate(
+... input_ids,
+... do_sample=True,
+... temperature=0.9,
+... max_length=100,
+... )
+>>> gen_text = tokenizer.batch_decode(gen_tokens)[0]
+```
+
+## GPTNeoConfig
+
+[[autodoc]] GPTNeoConfig
+
+## GPTNeoModel
+
+[[autodoc]] GPTNeoModel
+ - forward
+
+## GPTNeoForCausalLM
+
+[[autodoc]] GPTNeoForCausalLM
+ - forward
+
+## GPTNeoForSequenceClassification
+
+[[autodoc]] GPTNeoForSequenceClassification
+ - forward
+
+## FlaxGPTNeoModel
+
+[[autodoc]] FlaxGPTNeoModel
+ - __call__
+
+## FlaxGPTNeoForCausalLM
+
+[[autodoc]] FlaxGPTNeoForCausalLM
+ - __call__
diff --git a/docs/source/en/model_doc/gptj.mdx b/docs/source/en/model_doc/gptj.mdx
new file mode 100644
index 00000000000000..62bd224746a4c0
--- /dev/null
+++ b/docs/source/en/model_doc/gptj.mdx
@@ -0,0 +1,161 @@
+
+
+# GPT-J
+
+## Overview
+
+The GPT-J model was released in the [kingoflolz/mesh-transformer-jax](https://github.com/kingoflolz/mesh-transformer-jax) repository by Ben Wang and Aran Komatsuzaki. It is a GPT-2-like
+causal language model trained on [the Pile](https://pile.eleuther.ai/) dataset.
+
+This model was contributed by [Stella Biderman](https://huggingface.co/stellaathena).
+
+Tips:
+
+- To load [GPT-J](https://huggingface.co/EleutherAI/gpt-j-6B) in float32 one would need at least 2x model size CPU
+ RAM: 1x for initial weights and another 1x to load the checkpoint. So for GPT-J it would take at least 48GB of CPU
+ RAM to just load the model. To reduce the CPU RAM usage there are a few options. The `torch_dtype` argument can be
+ used to initialize the model in half-precision. And the `low_cpu_mem_usage` argument can be used to keep the RAM
+ usage to 1x. There is also a [fp16 branch](https://huggingface.co/EleutherAI/gpt-j-6B/tree/float16) which stores
+ the fp16 weights, which could be used to further minimize the RAM usage. Combining all this it should take roughly
+ 12.1GB of CPU RAM to load the model.
+
+```python
+>>> from transformers import GPTJForCausalLM
+>>> import torch
+
+>>> model = GPTJForCausalLM.from_pretrained(
+... "EleutherAI/gpt-j-6B", revision="float16", torch_dtype=torch.float16, low_cpu_mem_usage=True
+... )
+```
+
+- The model should fit on 16GB GPU for inference. For training/fine-tuning it would take much more GPU RAM. Adam
+ optimizer for example makes four copies of the model: model, gradients, average and squared average of the gradients.
+ So it would need at least 4x model size GPU memory, even with mixed precision as gradient updates are in fp32. This
+ is not including the activations and data batches, which would again require some more GPU RAM. So one should explore
+ solutions such as DeepSpeed, to train/fine-tune the model. Another option is to use the original codebase to
+ train/fine-tune the model on TPU and then convert the model to Transformers format for inference. Instructions for
+ that could be found [here](https://github.com/kingoflolz/mesh-transformer-jax/blob/master/howto_finetune.md)
+
+- Although the embedding matrix has a size of 50400, only 50257 entries are used by the GPT-2 tokenizer. These extra
+ tokens are added for the sake of efficiency on TPUs. To avoid the mis-match between embedding matrix size and vocab
+ size, the tokenizer for [GPT-J](https://huggingface.co/EleutherAI/gpt-j-6B) contains 143 extra tokens
+ `<|extratoken_1|>... <|extratoken_143|>`, so the `vocab_size` of tokenizer also becomes 50400.
+
+### Generation
+
+The [`~generation_utils.GenerationMixin.generate`] method can be used to generate text using GPT-J
+model.
+
+```python
+>>> from transformers import AutoModelForCausalLM, AutoTokenizer
+
+>>> model = AutoModelForCausalLM.from_pretrained("EleutherAI/gpt-j-6B")
+>>> tokenizer = AutoTokenizer.from_pretrained("EleutherAI/gpt-j-6B")
+
+>>> prompt = (
+... "In a shocking finding, scientists discovered a herd of unicorns living in a remote, "
+... "previously unexplored valley, in the Andes Mountains. Even more surprising to the "
+... "researchers was the fact that the unicorns spoke perfect English."
+... )
+
+>>> input_ids = tokenizer(prompt, return_tensors="pt").input_ids
+
+>>> gen_tokens = model.generate(
+... input_ids,
+... do_sample=True,
+... temperature=0.9,
+... max_length=100,
+... )
+>>> gen_text = tokenizer.batch_decode(gen_tokens)[0]
+```
+
+...or in float16 precision:
+
+```python
+>>> from transformers import GPTJForCausalLM, AutoTokenizer
+>>> import torch
+
+>>> model = GPTJForCausalLM.from_pretrained("EleutherAI/gpt-j-6B", torch_dtype=torch.float16)
+>>> tokenizer = AutoTokenizer.from_pretrained("EleutherAI/gpt-j-6B")
+
+>>> prompt = (
+... "In a shocking finding, scientists discovered a herd of unicorns living in a remote, "
+... "previously unexplored valley, in the Andes Mountains. Even more surprising to the "
+... "researchers was the fact that the unicorns spoke perfect English."
+... )
+
+>>> input_ids = tokenizer(prompt, return_tensors="pt").input_ids
+
+>>> gen_tokens = model.generate(
+... input_ids,
+... do_sample=True,
+... temperature=0.9,
+... max_length=100,
+... )
+>>> gen_text = tokenizer.batch_decode(gen_tokens)[0]
+```
+
+## GPTJConfig
+
+[[autodoc]] GPTJConfig
+ - all
+
+## GPTJModel
+
+[[autodoc]] GPTJModel
+ - forward
+
+## GPTJForCausalLM
+
+[[autodoc]] GPTJForCausalLM
+ - forward
+
+## GPTJForSequenceClassification
+
+[[autodoc]] GPTJForSequenceClassification
+ - forward
+
+## GPTJForQuestionAnswering
+
+[[autodoc]] GPTJForQuestionAnswering
+ - forward
+
+## TFGPTJModel
+
+[[autodoc]] TFGPTJModel
+ - call
+
+## TFGPTJForCausalLM
+
+[[autodoc]] TFGPTJForCausalLM
+ - call
+
+## TFGPTJForSequenceClassification
+
+[[autodoc]] TFGPTJForSequenceClassification
+ - call
+
+## TFGPTJForQuestionAnswering
+
+[[autodoc]] TFGPTJForQuestionAnswering
+ - call
+
+## FlaxGPTJModel
+
+[[autodoc]] FlaxGPTJModel
+ - __call__
+
+## FlaxGPTJForCausalLM
+
+[[autodoc]] FlaxGPTJForCausalLM
+ - __call__
diff --git a/docs/source/en/model_doc/herbert.mdx b/docs/source/en/model_doc/herbert.mdx
new file mode 100644
index 00000000000000..90e08ebe9ac744
--- /dev/null
+++ b/docs/source/en/model_doc/herbert.mdx
@@ -0,0 +1,65 @@
+
+
+# HerBERT
+
+## Overview
+
+The HerBERT model was proposed in [KLEJ: Comprehensive Benchmark for Polish Language Understanding](https://www.aclweb.org/anthology/2020.acl-main.111.pdf) by Piotr Rybak, Robert Mroczkowski, Janusz Tracz, and
+Ireneusz Gawlik. It is a BERT-based Language Model trained on Polish Corpora using only MLM objective with dynamic
+masking of whole words.
+
+The abstract from the paper is the following:
+
+*In recent years, a series of Transformer-based models unlocked major improvements in general natural language
+understanding (NLU) tasks. Such a fast pace of research would not be possible without general NLU benchmarks, which
+allow for a fair comparison of the proposed methods. However, such benchmarks are available only for a handful of
+languages. To alleviate this issue, we introduce a comprehensive multi-task benchmark for the Polish language
+understanding, accompanied by an online leaderboard. It consists of a diverse set of tasks, adopted from existing
+datasets for named entity recognition, question-answering, textual entailment, and others. We also introduce a new
+sentiment analysis task for the e-commerce domain, named Allegro Reviews (AR). To ensure a common evaluation scheme and
+promote models that generalize to different NLU tasks, the benchmark includes datasets from varying domains and
+applications. Additionally, we release HerBERT, a Transformer-based model trained specifically for the Polish language,
+which has the best average performance and obtains the best results for three out of nine tasks. Finally, we provide an
+extensive evaluation, including several standard baselines and recently proposed, multilingual Transformer-based
+models.*
+
+Examples of use:
+
+```python
+>>> from transformers import HerbertTokenizer, RobertaModel
+
+>>> tokenizer = HerbertTokenizer.from_pretrained("allegro/herbert-klej-cased-tokenizer-v1")
+>>> model = RobertaModel.from_pretrained("allegro/herbert-klej-cased-v1")
+
+>>> encoded_input = tokenizer.encode("Kto ma lepszą sztukę, ma lepszy rząd – to jasne.", return_tensors="pt")
+>>> outputs = model(encoded_input)
+
+>>> # HerBERT can also be loaded using AutoTokenizer and AutoModel:
+>>> import torch
+>>> from transformers import AutoModel, AutoTokenizer
+
+>>> tokenizer = AutoTokenizer.from_pretrained("allegro/herbert-klej-cased-tokenizer-v1")
+>>> model = AutoModel.from_pretrained("allegro/herbert-klej-cased-v1")
+```
+
+This model was contributed by [rmroczkowski](https://huggingface.co/rmroczkowski). The original code can be found
+[here](https://github.com/allegro/HerBERT).
+
+
+## HerbertTokenizer
+
+[[autodoc]] HerbertTokenizer
+
+## HerbertTokenizerFast
+
+[[autodoc]] HerbertTokenizerFast
diff --git a/docs/source/en/model_doc/hubert.mdx b/docs/source/en/model_doc/hubert.mdx
new file mode 100644
index 00000000000000..faab44b89d587c
--- /dev/null
+++ b/docs/source/en/model_doc/hubert.mdx
@@ -0,0 +1,71 @@
+
+
+# Hubert
+
+## Overview
+
+Hubert was proposed in [HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units](https://arxiv.org/abs/2106.07447) by Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan
+Salakhutdinov, Abdelrahman Mohamed.
+
+The abstract from the paper is the following:
+
+*Self-supervised approaches for speech representation learning are challenged by three unique problems: (1) there are
+multiple sound units in each input utterance, (2) there is no lexicon of input sound units during the pre-training
+phase, and (3) sound units have variable lengths with no explicit segmentation. To deal with these three problems, we
+propose the Hidden-Unit BERT (HuBERT) approach for self-supervised speech representation learning, which utilizes an
+offline clustering step to provide aligned target labels for a BERT-like prediction loss. A key ingredient of our
+approach is applying the prediction loss over the masked regions only, which forces the model to learn a combined
+acoustic and language model over the continuous inputs. HuBERT relies primarily on the consistency of the unsupervised
+clustering step rather than the intrinsic quality of the assigned cluster labels. Starting with a simple k-means
+teacher of 100 clusters, and using two iterations of clustering, the HuBERT model either matches or improves upon the
+state-of-the-art wav2vec 2.0 performance on the Librispeech (960h) and Libri-light (60,000h) benchmarks with 10min, 1h,
+10h, 100h, and 960h fine-tuning subsets. Using a 1B parameter model, HuBERT shows up to 19% and 13% relative WER
+reduction on the more challenging dev-other and test-other evaluation subsets.*
+
+Tips:
+
+- Hubert is a speech model that accepts a float array corresponding to the raw waveform of the speech signal.
+- Hubert model was fine-tuned using connectionist temporal classification (CTC) so the model output has to be decoded
+ using [`Wav2Vec2CTCTokenizer`].
+
+This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten).
+
+
+## HubertConfig
+
+[[autodoc]] HubertConfig
+
+## HubertModel
+
+[[autodoc]] HubertModel
+ - forward
+
+## HubertForCTC
+
+[[autodoc]] HubertForCTC
+ - forward
+
+## HubertForSequenceClassification
+
+[[autodoc]] HubertForSequenceClassification
+ - forward
+
+## TFHubertModel
+
+[[autodoc]] TFHubertModel
+ - call
+
+## TFHubertForCTC
+
+[[autodoc]] TFHubertForCTC
+ - call
diff --git a/docs/source/en/model_doc/ibert.mdx b/docs/source/en/model_doc/ibert.mdx
new file mode 100644
index 00000000000000..086e615fe5b424
--- /dev/null
+++ b/docs/source/en/model_doc/ibert.mdx
@@ -0,0 +1,72 @@
+
+
+# I-BERT
+
+## Overview
+
+The I-BERT model was proposed in [I-BERT: Integer-only BERT Quantization](https://arxiv.org/abs/2101.01321) by
+Sehoon Kim, Amir Gholami, Zhewei Yao, Michael W. Mahoney and Kurt Keutzer. It's a quantized version of RoBERTa running
+inference up to four times faster.
+
+The abstract from the paper is the following:
+
+*Transformer based models, like BERT and RoBERTa, have achieved state-of-the-art results in many Natural Language
+Processing tasks. However, their memory footprint, inference latency, and power consumption are prohibitive for
+efficient inference at the edge, and even at the data center. While quantization can be a viable solution for this,
+previous work on quantizing Transformer based models use floating-point arithmetic during inference, which cannot
+efficiently utilize integer-only logical units such as the recent Turing Tensor Cores, or traditional integer-only ARM
+processors. In this work, we propose I-BERT, a novel quantization scheme for Transformer based models that quantizes
+the entire inference with integer-only arithmetic. Based on lightweight integer-only approximation methods for
+nonlinear operations, e.g., GELU, Softmax, and Layer Normalization, I-BERT performs an end-to-end integer-only BERT
+inference without any floating point calculation. We evaluate our approach on GLUE downstream tasks using
+RoBERTa-Base/Large. We show that for both cases, I-BERT achieves similar (and slightly higher) accuracy as compared to
+the full-precision baseline. Furthermore, our preliminary implementation of I-BERT shows a speedup of 2.4 - 4.0x for
+INT8 inference on a T4 GPU system as compared to FP32 inference. The framework has been developed in PyTorch and has
+been open-sourced.*
+
+This model was contributed by [kssteven](https://huggingface.co/kssteven). The original code can be found [here](https://github.com/kssteven418/I-BERT).
+
+
+## IBertConfig
+
+[[autodoc]] IBertConfig
+
+## IBertModel
+
+[[autodoc]] IBertModel
+ - forward
+
+## IBertForMaskedLM
+
+[[autodoc]] IBertForMaskedLM
+ - forward
+
+## IBertForSequenceClassification
+
+[[autodoc]] IBertForSequenceClassification
+ - forward
+
+## IBertForMultipleChoice
+
+[[autodoc]] IBertForMultipleChoice
+ - forward
+
+## IBertForTokenClassification
+
+[[autodoc]] IBertForTokenClassification
+ - forward
+
+## IBertForQuestionAnswering
+
+[[autodoc]] IBertForQuestionAnswering
+ - forward
diff --git a/docs/source/en/model_doc/imagegpt.mdx b/docs/source/en/model_doc/imagegpt.mdx
new file mode 100644
index 00000000000000..679cdfd30aacb6
--- /dev/null
+++ b/docs/source/en/model_doc/imagegpt.mdx
@@ -0,0 +1,100 @@
+
+
+# ImageGPT
+
+## Overview
+
+The ImageGPT model was proposed in [Generative Pretraining from Pixels](https://openai.com/blog/image-gpt) by Mark
+Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, Ilya Sutskever. ImageGPT (iGPT) is a GPT-2-like
+model trained to predict the next pixel value, allowing for both unconditional and conditional image generation.
+
+The abstract from the paper is the following:
+
+*Inspired by progress in unsupervised representation learning for natural language, we examine whether similar models
+can learn useful representations for images. We train a sequence Transformer to auto-regressively predict pixels,
+without incorporating knowledge of the 2D input structure. Despite training on low-resolution ImageNet without labels,
+we find that a GPT-2 scale model learns strong image representations as measured by linear probing, fine-tuning, and
+low-data classification. On CIFAR-10, we achieve 96.3% accuracy with a linear probe, outperforming a supervised Wide
+ResNet, and 99.0% accuracy with full fine-tuning, matching the top supervised pre-trained models. We are also
+competitive with self-supervised benchmarks on ImageNet when substituting pixels for a VQVAE encoding, achieving 69.0%
+top-1 accuracy on a linear probe of our features.*
+
+
+
+ Summary of the approach. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/vinvino02/GLPDepth).
+
+## GLPNConfig
+
+[[autodoc]] GLPNConfig
+
+## GLPNFeatureExtractor
+
+[[autodoc]] GLPNFeatureExtractor
+ - __call__
+
+## GLPNModel
+
+[[autodoc]] GLPNModel
+ - forward
+
+## GLPNForDepthEstimation
+
+[[autodoc]] GLPNForDepthEstimation
+ - forward
\ No newline at end of file
diff --git a/docs/source/en/model_doc/gpt2.mdx b/docs/source/en/model_doc/gpt2.mdx
new file mode 100644
index 00000000000000..8cefe7eaa2673e
--- /dev/null
+++ b/docs/source/en/model_doc/gpt2.mdx
@@ -0,0 +1,131 @@
+
+
+# OpenAI GPT2
+
+## Overview
+
+OpenAI GPT-2 model was proposed in [Language Models are Unsupervised Multitask Learners](https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf) by Alec
+Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei and Ilya Sutskever. It's a causal (unidirectional)
+transformer pretrained using language modeling on a very large corpus of ~40 GB of text data.
+
+The abstract from the paper is the following:
+
+*GPT-2 is a large transformer-based language model with 1.5 billion parameters, trained on a dataset[1] of 8 million
+web pages. GPT-2 is trained with a simple objective: predict the next word, given all of the previous words within some
+text. The diversity of the dataset causes this simple goal to contain naturally occurring demonstrations of many tasks
+across diverse domains. GPT-2 is a direct scale-up of GPT, with more than 10X the parameters and trained on more than
+10X the amount of data.*
+
+Tips:
+
+- GPT-2 is a model with absolute position embeddings so it's usually advised to pad the inputs on the right rather than
+ the left.
+- GPT-2 was trained with a causal language modeling (CLM) objective and is therefore powerful at predicting the next
+ token in a sequence. Leveraging this feature allows GPT-2 to generate syntactically coherent text as it can be
+ observed in the *run_generation.py* example script.
+- The model can take the *past_key_values* (for PyTorch) or *past* (for TF) as input, which is the previously computed
+ key/value attention pairs. Using this (*past_key_values* or *past*) value prevents the model from re-computing
+ pre-computed values in the context of text generation. For PyTorch, see *past_key_values* argument of the
+ [`GPT2Model.forward`] method, or for TF the *past* argument of the
+ [`TFGPT2Model.call`] method for more information on its usage.
+- Enabling the *scale_attn_by_inverse_layer_idx* and *reorder_and_upcast_attn* flags will apply the training stability
+ improvements from [Mistral](https://github.com/stanford-crfm/mistral/) (for PyTorch only).
+
+[Write With Transformer](https://transformer.huggingface.co/doc/gpt2-large) is a webapp created and hosted by
+Hugging Face showcasing the generative capabilities of several models. GPT-2 is one of them and is available in five
+different sizes: small, medium, large, xl and a distilled version of the small checkpoint: *distilgpt-2*.
+
+This model was contributed by [thomwolf](https://huggingface.co/thomwolf). The original code can be found [here](https://openai.com/blog/better-language-models/).
+
+
+## GPT2Config
+
+[[autodoc]] GPT2Config
+
+## GPT2Tokenizer
+
+[[autodoc]] GPT2Tokenizer
+ - save_vocabulary
+
+## GPT2TokenizerFast
+
+[[autodoc]] GPT2TokenizerFast
+
+## GPT2 specific outputs
+
+[[autodoc]] models.gpt2.modeling_gpt2.GPT2DoubleHeadsModelOutput
+
+[[autodoc]] models.gpt2.modeling_tf_gpt2.TFGPT2DoubleHeadsModelOutput
+
+## GPT2Model
+
+[[autodoc]] GPT2Model
+ - forward
+ - parallelize
+ - deparallelize
+
+## GPT2LMHeadModel
+
+[[autodoc]] GPT2LMHeadModel
+ - forward
+ - parallelize
+ - deparallelize
+
+## GPT2DoubleHeadsModel
+
+[[autodoc]] GPT2DoubleHeadsModel
+ - forward
+
+## GPT2ForSequenceClassification
+
+[[autodoc]] GPT2ForSequenceClassification
+ - forward
+
+## GPT2ForTokenClassification
+
+[[autodoc]] GPT2ForTokenClassification
+ - forward
+
+## TFGPT2Model
+
+[[autodoc]] TFGPT2Model
+ - call
+
+## TFGPT2LMHeadModel
+
+[[autodoc]] TFGPT2LMHeadModel
+ - call
+
+## TFGPT2DoubleHeadsModel
+
+[[autodoc]] TFGPT2DoubleHeadsModel
+ - call
+
+## TFGPT2ForSequenceClassification
+
+[[autodoc]] TFGPT2ForSequenceClassification
+ - call
+
+## TFSequenceClassifierOutputWithPast
+
+[[autodoc]] modeling_tf_outputs.TFSequenceClassifierOutputWithPast
+
+## FlaxGPT2Model
+
+[[autodoc]] FlaxGPT2Model
+ - __call__
+
+## FlaxGPT2LMHeadModel
+
+[[autodoc]] FlaxGPT2LMHeadModel
+ - __call__
diff --git a/docs/source/en/model_doc/gpt_neo.mdx b/docs/source/en/model_doc/gpt_neo.mdx
new file mode 100644
index 00000000000000..f68b92b213270b
--- /dev/null
+++ b/docs/source/en/model_doc/gpt_neo.mdx
@@ -0,0 +1,80 @@
+
+
+# GPT Neo
+
+## Overview
+
+The GPTNeo model was released in the [EleutherAI/gpt-neo](https://github.com/EleutherAI/gpt-neo) repository by Sid
+Black, Stella Biderman, Leo Gao, Phil Wang and Connor Leahy. It is a GPT2 like causal language model trained on the
+[Pile](https://pile.eleuther.ai/) dataset.
+
+The architecture is similar to GPT2 except that GPT Neo uses local attention in every other layer with a window size of
+256 tokens.
+
+This model was contributed by [valhalla](https://huggingface.co/valhalla).
+
+### Generation
+
+The `generate()` method can be used to generate text using GPT Neo model.
+
+```python
+>>> from transformers import GPTNeoForCausalLM, GPT2Tokenizer
+
+>>> model = GPTNeoForCausalLM.from_pretrained("EleutherAI/gpt-neo-1.3B")
+>>> tokenizer = GPT2Tokenizer.from_pretrained("EleutherAI/gpt-neo-1.3B")
+
+>>> prompt = (
+... "In a shocking finding, scientists discovered a herd of unicorns living in a remote, "
+... "previously unexplored valley, in the Andes Mountains. Even more surprising to the "
+... "researchers was the fact that the unicorns spoke perfect English."
+... )
+
+>>> input_ids = tokenizer(prompt, return_tensors="pt").input_ids
+
+>>> gen_tokens = model.generate(
+... input_ids,
+... do_sample=True,
+... temperature=0.9,
+... max_length=100,
+... )
+>>> gen_text = tokenizer.batch_decode(gen_tokens)[0]
+```
+
+## GPTNeoConfig
+
+[[autodoc]] GPTNeoConfig
+
+## GPTNeoModel
+
+[[autodoc]] GPTNeoModel
+ - forward
+
+## GPTNeoForCausalLM
+
+[[autodoc]] GPTNeoForCausalLM
+ - forward
+
+## GPTNeoForSequenceClassification
+
+[[autodoc]] GPTNeoForSequenceClassification
+ - forward
+
+## FlaxGPTNeoModel
+
+[[autodoc]] FlaxGPTNeoModel
+ - __call__
+
+## FlaxGPTNeoForCausalLM
+
+[[autodoc]] FlaxGPTNeoForCausalLM
+ - __call__
diff --git a/docs/source/en/model_doc/gptj.mdx b/docs/source/en/model_doc/gptj.mdx
new file mode 100644
index 00000000000000..62bd224746a4c0
--- /dev/null
+++ b/docs/source/en/model_doc/gptj.mdx
@@ -0,0 +1,161 @@
+
+
+# GPT-J
+
+## Overview
+
+The GPT-J model was released in the [kingoflolz/mesh-transformer-jax](https://github.com/kingoflolz/mesh-transformer-jax) repository by Ben Wang and Aran Komatsuzaki. It is a GPT-2-like
+causal language model trained on [the Pile](https://pile.eleuther.ai/) dataset.
+
+This model was contributed by [Stella Biderman](https://huggingface.co/stellaathena).
+
+Tips:
+
+- To load [GPT-J](https://huggingface.co/EleutherAI/gpt-j-6B) in float32 one would need at least 2x model size CPU
+ RAM: 1x for initial weights and another 1x to load the checkpoint. So for GPT-J it would take at least 48GB of CPU
+ RAM to just load the model. To reduce the CPU RAM usage there are a few options. The `torch_dtype` argument can be
+ used to initialize the model in half-precision. And the `low_cpu_mem_usage` argument can be used to keep the RAM
+ usage to 1x. There is also a [fp16 branch](https://huggingface.co/EleutherAI/gpt-j-6B/tree/float16) which stores
+ the fp16 weights, which could be used to further minimize the RAM usage. Combining all this it should take roughly
+ 12.1GB of CPU RAM to load the model.
+
+```python
+>>> from transformers import GPTJForCausalLM
+>>> import torch
+
+>>> model = GPTJForCausalLM.from_pretrained(
+... "EleutherAI/gpt-j-6B", revision="float16", torch_dtype=torch.float16, low_cpu_mem_usage=True
+... )
+```
+
+- The model should fit on 16GB GPU for inference. For training/fine-tuning it would take much more GPU RAM. Adam
+ optimizer for example makes four copies of the model: model, gradients, average and squared average of the gradients.
+ So it would need at least 4x model size GPU memory, even with mixed precision as gradient updates are in fp32. This
+ is not including the activations and data batches, which would again require some more GPU RAM. So one should explore
+ solutions such as DeepSpeed, to train/fine-tune the model. Another option is to use the original codebase to
+ train/fine-tune the model on TPU and then convert the model to Transformers format for inference. Instructions for
+ that could be found [here](https://github.com/kingoflolz/mesh-transformer-jax/blob/master/howto_finetune.md)
+
+- Although the embedding matrix has a size of 50400, only 50257 entries are used by the GPT-2 tokenizer. These extra
+ tokens are added for the sake of efficiency on TPUs. To avoid the mis-match between embedding matrix size and vocab
+ size, the tokenizer for [GPT-J](https://huggingface.co/EleutherAI/gpt-j-6B) contains 143 extra tokens
+ `<|extratoken_1|>... <|extratoken_143|>`, so the `vocab_size` of tokenizer also becomes 50400.
+
+### Generation
+
+The [`~generation_utils.GenerationMixin.generate`] method can be used to generate text using GPT-J
+model.
+
+```python
+>>> from transformers import AutoModelForCausalLM, AutoTokenizer
+
+>>> model = AutoModelForCausalLM.from_pretrained("EleutherAI/gpt-j-6B")
+>>> tokenizer = AutoTokenizer.from_pretrained("EleutherAI/gpt-j-6B")
+
+>>> prompt = (
+... "In a shocking finding, scientists discovered a herd of unicorns living in a remote, "
+... "previously unexplored valley, in the Andes Mountains. Even more surprising to the "
+... "researchers was the fact that the unicorns spoke perfect English."
+... )
+
+>>> input_ids = tokenizer(prompt, return_tensors="pt").input_ids
+
+>>> gen_tokens = model.generate(
+... input_ids,
+... do_sample=True,
+... temperature=0.9,
+... max_length=100,
+... )
+>>> gen_text = tokenizer.batch_decode(gen_tokens)[0]
+```
+
+...or in float16 precision:
+
+```python
+>>> from transformers import GPTJForCausalLM, AutoTokenizer
+>>> import torch
+
+>>> model = GPTJForCausalLM.from_pretrained("EleutherAI/gpt-j-6B", torch_dtype=torch.float16)
+>>> tokenizer = AutoTokenizer.from_pretrained("EleutherAI/gpt-j-6B")
+
+>>> prompt = (
+... "In a shocking finding, scientists discovered a herd of unicorns living in a remote, "
+... "previously unexplored valley, in the Andes Mountains. Even more surprising to the "
+... "researchers was the fact that the unicorns spoke perfect English."
+... )
+
+>>> input_ids = tokenizer(prompt, return_tensors="pt").input_ids
+
+>>> gen_tokens = model.generate(
+... input_ids,
+... do_sample=True,
+... temperature=0.9,
+... max_length=100,
+... )
+>>> gen_text = tokenizer.batch_decode(gen_tokens)[0]
+```
+
+## GPTJConfig
+
+[[autodoc]] GPTJConfig
+ - all
+
+## GPTJModel
+
+[[autodoc]] GPTJModel
+ - forward
+
+## GPTJForCausalLM
+
+[[autodoc]] GPTJForCausalLM
+ - forward
+
+## GPTJForSequenceClassification
+
+[[autodoc]] GPTJForSequenceClassification
+ - forward
+
+## GPTJForQuestionAnswering
+
+[[autodoc]] GPTJForQuestionAnswering
+ - forward
+
+## TFGPTJModel
+
+[[autodoc]] TFGPTJModel
+ - call
+
+## TFGPTJForCausalLM
+
+[[autodoc]] TFGPTJForCausalLM
+ - call
+
+## TFGPTJForSequenceClassification
+
+[[autodoc]] TFGPTJForSequenceClassification
+ - call
+
+## TFGPTJForQuestionAnswering
+
+[[autodoc]] TFGPTJForQuestionAnswering
+ - call
+
+## FlaxGPTJModel
+
+[[autodoc]] FlaxGPTJModel
+ - __call__
+
+## FlaxGPTJForCausalLM
+
+[[autodoc]] FlaxGPTJForCausalLM
+ - __call__
diff --git a/docs/source/en/model_doc/herbert.mdx b/docs/source/en/model_doc/herbert.mdx
new file mode 100644
index 00000000000000..90e08ebe9ac744
--- /dev/null
+++ b/docs/source/en/model_doc/herbert.mdx
@@ -0,0 +1,65 @@
+
+
+# HerBERT
+
+## Overview
+
+The HerBERT model was proposed in [KLEJ: Comprehensive Benchmark for Polish Language Understanding](https://www.aclweb.org/anthology/2020.acl-main.111.pdf) by Piotr Rybak, Robert Mroczkowski, Janusz Tracz, and
+Ireneusz Gawlik. It is a BERT-based Language Model trained on Polish Corpora using only MLM objective with dynamic
+masking of whole words.
+
+The abstract from the paper is the following:
+
+*In recent years, a series of Transformer-based models unlocked major improvements in general natural language
+understanding (NLU) tasks. Such a fast pace of research would not be possible without general NLU benchmarks, which
+allow for a fair comparison of the proposed methods. However, such benchmarks are available only for a handful of
+languages. To alleviate this issue, we introduce a comprehensive multi-task benchmark for the Polish language
+understanding, accompanied by an online leaderboard. It consists of a diverse set of tasks, adopted from existing
+datasets for named entity recognition, question-answering, textual entailment, and others. We also introduce a new
+sentiment analysis task for the e-commerce domain, named Allegro Reviews (AR). To ensure a common evaluation scheme and
+promote models that generalize to different NLU tasks, the benchmark includes datasets from varying domains and
+applications. Additionally, we release HerBERT, a Transformer-based model trained specifically for the Polish language,
+which has the best average performance and obtains the best results for three out of nine tasks. Finally, we provide an
+extensive evaluation, including several standard baselines and recently proposed, multilingual Transformer-based
+models.*
+
+Examples of use:
+
+```python
+>>> from transformers import HerbertTokenizer, RobertaModel
+
+>>> tokenizer = HerbertTokenizer.from_pretrained("allegro/herbert-klej-cased-tokenizer-v1")
+>>> model = RobertaModel.from_pretrained("allegro/herbert-klej-cased-v1")
+
+>>> encoded_input = tokenizer.encode("Kto ma lepszą sztukę, ma lepszy rząd – to jasne.", return_tensors="pt")
+>>> outputs = model(encoded_input)
+
+>>> # HerBERT can also be loaded using AutoTokenizer and AutoModel:
+>>> import torch
+>>> from transformers import AutoModel, AutoTokenizer
+
+>>> tokenizer = AutoTokenizer.from_pretrained("allegro/herbert-klej-cased-tokenizer-v1")
+>>> model = AutoModel.from_pretrained("allegro/herbert-klej-cased-v1")
+```
+
+This model was contributed by [rmroczkowski](https://huggingface.co/rmroczkowski). The original code can be found
+[here](https://github.com/allegro/HerBERT).
+
+
+## HerbertTokenizer
+
+[[autodoc]] HerbertTokenizer
+
+## HerbertTokenizerFast
+
+[[autodoc]] HerbertTokenizerFast
diff --git a/docs/source/en/model_doc/hubert.mdx b/docs/source/en/model_doc/hubert.mdx
new file mode 100644
index 00000000000000..faab44b89d587c
--- /dev/null
+++ b/docs/source/en/model_doc/hubert.mdx
@@ -0,0 +1,71 @@
+
+
+# Hubert
+
+## Overview
+
+Hubert was proposed in [HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units](https://arxiv.org/abs/2106.07447) by Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan
+Salakhutdinov, Abdelrahman Mohamed.
+
+The abstract from the paper is the following:
+
+*Self-supervised approaches for speech representation learning are challenged by three unique problems: (1) there are
+multiple sound units in each input utterance, (2) there is no lexicon of input sound units during the pre-training
+phase, and (3) sound units have variable lengths with no explicit segmentation. To deal with these three problems, we
+propose the Hidden-Unit BERT (HuBERT) approach for self-supervised speech representation learning, which utilizes an
+offline clustering step to provide aligned target labels for a BERT-like prediction loss. A key ingredient of our
+approach is applying the prediction loss over the masked regions only, which forces the model to learn a combined
+acoustic and language model over the continuous inputs. HuBERT relies primarily on the consistency of the unsupervised
+clustering step rather than the intrinsic quality of the assigned cluster labels. Starting with a simple k-means
+teacher of 100 clusters, and using two iterations of clustering, the HuBERT model either matches or improves upon the
+state-of-the-art wav2vec 2.0 performance on the Librispeech (960h) and Libri-light (60,000h) benchmarks with 10min, 1h,
+10h, 100h, and 960h fine-tuning subsets. Using a 1B parameter model, HuBERT shows up to 19% and 13% relative WER
+reduction on the more challenging dev-other and test-other evaluation subsets.*
+
+Tips:
+
+- Hubert is a speech model that accepts a float array corresponding to the raw waveform of the speech signal.
+- Hubert model was fine-tuned using connectionist temporal classification (CTC) so the model output has to be decoded
+ using [`Wav2Vec2CTCTokenizer`].
+
+This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten).
+
+
+## HubertConfig
+
+[[autodoc]] HubertConfig
+
+## HubertModel
+
+[[autodoc]] HubertModel
+ - forward
+
+## HubertForCTC
+
+[[autodoc]] HubertForCTC
+ - forward
+
+## HubertForSequenceClassification
+
+[[autodoc]] HubertForSequenceClassification
+ - forward
+
+## TFHubertModel
+
+[[autodoc]] TFHubertModel
+ - call
+
+## TFHubertForCTC
+
+[[autodoc]] TFHubertForCTC
+ - call
diff --git a/docs/source/en/model_doc/ibert.mdx b/docs/source/en/model_doc/ibert.mdx
new file mode 100644
index 00000000000000..086e615fe5b424
--- /dev/null
+++ b/docs/source/en/model_doc/ibert.mdx
@@ -0,0 +1,72 @@
+
+
+# I-BERT
+
+## Overview
+
+The I-BERT model was proposed in [I-BERT: Integer-only BERT Quantization](https://arxiv.org/abs/2101.01321) by
+Sehoon Kim, Amir Gholami, Zhewei Yao, Michael W. Mahoney and Kurt Keutzer. It's a quantized version of RoBERTa running
+inference up to four times faster.
+
+The abstract from the paper is the following:
+
+*Transformer based models, like BERT and RoBERTa, have achieved state-of-the-art results in many Natural Language
+Processing tasks. However, their memory footprint, inference latency, and power consumption are prohibitive for
+efficient inference at the edge, and even at the data center. While quantization can be a viable solution for this,
+previous work on quantizing Transformer based models use floating-point arithmetic during inference, which cannot
+efficiently utilize integer-only logical units such as the recent Turing Tensor Cores, or traditional integer-only ARM
+processors. In this work, we propose I-BERT, a novel quantization scheme for Transformer based models that quantizes
+the entire inference with integer-only arithmetic. Based on lightweight integer-only approximation methods for
+nonlinear operations, e.g., GELU, Softmax, and Layer Normalization, I-BERT performs an end-to-end integer-only BERT
+inference without any floating point calculation. We evaluate our approach on GLUE downstream tasks using
+RoBERTa-Base/Large. We show that for both cases, I-BERT achieves similar (and slightly higher) accuracy as compared to
+the full-precision baseline. Furthermore, our preliminary implementation of I-BERT shows a speedup of 2.4 - 4.0x for
+INT8 inference on a T4 GPU system as compared to FP32 inference. The framework has been developed in PyTorch and has
+been open-sourced.*
+
+This model was contributed by [kssteven](https://huggingface.co/kssteven). The original code can be found [here](https://github.com/kssteven418/I-BERT).
+
+
+## IBertConfig
+
+[[autodoc]] IBertConfig
+
+## IBertModel
+
+[[autodoc]] IBertModel
+ - forward
+
+## IBertForMaskedLM
+
+[[autodoc]] IBertForMaskedLM
+ - forward
+
+## IBertForSequenceClassification
+
+[[autodoc]] IBertForSequenceClassification
+ - forward
+
+## IBertForMultipleChoice
+
+[[autodoc]] IBertForMultipleChoice
+ - forward
+
+## IBertForTokenClassification
+
+[[autodoc]] IBertForTokenClassification
+ - forward
+
+## IBertForQuestionAnswering
+
+[[autodoc]] IBertForQuestionAnswering
+ - forward
diff --git a/docs/source/en/model_doc/imagegpt.mdx b/docs/source/en/model_doc/imagegpt.mdx
new file mode 100644
index 00000000000000..679cdfd30aacb6
--- /dev/null
+++ b/docs/source/en/model_doc/imagegpt.mdx
@@ -0,0 +1,100 @@
+
+
+# ImageGPT
+
+## Overview
+
+The ImageGPT model was proposed in [Generative Pretraining from Pixels](https://openai.com/blog/image-gpt) by Mark
+Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, Ilya Sutskever. ImageGPT (iGPT) is a GPT-2-like
+model trained to predict the next pixel value, allowing for both unconditional and conditional image generation.
+
+The abstract from the paper is the following:
+
+*Inspired by progress in unsupervised representation learning for natural language, we examine whether similar models
+can learn useful representations for images. We train a sequence Transformer to auto-regressively predict pixels,
+without incorporating knowledge of the 2D input structure. Despite training on low-resolution ImageNet without labels,
+we find that a GPT-2 scale model learns strong image representations as measured by linear probing, fine-tuning, and
+low-data classification. On CIFAR-10, we achieve 96.3% accuracy with a linear probe, outperforming a supervised Wide
+ResNet, and 99.0% accuracy with full fine-tuning, matching the top supervised pre-trained models. We are also
+competitive with self-supervised benchmarks on ImageNet when substituting pixels for a VQVAE encoding, achieving 69.0%
+top-1 accuracy on a linear probe of our features.*
+
+ +
+ Summary of the approach. Taken from the [original paper](https://cdn.openai.com/papers/Generative_Pretraining_from_Pixels_V2.pdf).
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr), based on [this issue](https://github.com/openai/image-gpt/issues/7). The original code can be found
+[here](https://github.com/openai/image-gpt).
+
+Tips:
+
+- Demo notebooks for ImageGPT can be found
+ [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/ImageGPT).
+- ImageGPT is almost exactly the same as [GPT-2](gpt2), with the exception that a different activation
+ function is used (namely "quick gelu"), and the layer normalization layers don't mean center the inputs. ImageGPT
+ also doesn't have tied input- and output embeddings.
+- As the time- and memory requirements of the attention mechanism of Transformers scales quadratically in the sequence
+ length, the authors pre-trained ImageGPT on smaller input resolutions, such as 32x32 and 64x64. However, feeding a
+ sequence of 32x32x3=3072 tokens from 0..255 into a Transformer is still prohibitively large. Therefore, the authors
+ applied k-means clustering to the (R,G,B) pixel values with k=512. This way, we only have a 32*32 = 1024-long
+ sequence, but now of integers in the range 0..511. So we are shrinking the sequence length at the cost of a bigger
+ embedding matrix. In other words, the vocabulary size of ImageGPT is 512, + 1 for a special "start of sentence" (SOS)
+ token, used at the beginning of every sequence. One can use [`ImageGPTFeatureExtractor`] to prepare
+ images for the model.
+- Despite being pre-trained entirely unsupervised (i.e. without the use of any labels), ImageGPT produces fairly
+ performant image features useful for downstream tasks, such as image classification. The authors showed that the
+ features in the middle of the network are the most performant, and can be used as-is to train a linear model (such as
+ a sklearn logistic regression model for example). This is also referred to as "linear probing". Features can be
+ easily obtained by first forwarding the image through the model, then specifying `output_hidden_states=True`, and
+ then average-pool the hidden states at whatever layer you like.
+- Alternatively, one can further fine-tune the entire model on a downstream dataset, similar to BERT. For this, you can
+ use [`ImageGPTForImageClassification`].
+- ImageGPT comes in different sizes: there's ImageGPT-small, ImageGPT-medium and ImageGPT-large. The authors did also
+ train an XL variant, which they didn't release. The differences in size are summarized in the following table:
+
+| **Model variant** | **Depths** | **Hidden sizes** | **Decoder hidden size** | **Params (M)** | **ImageNet-1k Top 1** |
+|---|---|---|---|---|---|
+| MiT-b0 | [2, 2, 2, 2] | [32, 64, 160, 256] | 256 | 3.7 | 70.5 |
+| MiT-b1 | [2, 2, 2, 2] | [64, 128, 320, 512] | 256 | 14.0 | 78.7 |
+| MiT-b2 | [3, 4, 6, 3] | [64, 128, 320, 512] | 768 | 25.4 | 81.6 |
+| MiT-b3 | [3, 4, 18, 3] | [64, 128, 320, 512] | 768 | 45.2 | 83.1 |
+| MiT-b4 | [3, 8, 27, 3] | [64, 128, 320, 512] | 768 | 62.6 | 83.6 |
+| MiT-b5 | [3, 6, 40, 3] | [64, 128, 320, 512] | 768 | 82.0 | 83.8 |
+
+## ImageGPTConfig
+
+[[autodoc]] ImageGPTConfig
+
+## ImageGPTFeatureExtractor
+
+[[autodoc]] ImageGPTFeatureExtractor
+
+ - __call__
+
+## ImageGPTModel
+
+[[autodoc]] ImageGPTModel
+
+ - forward
+
+## ImageGPTForCausalImageModeling
+
+[[autodoc]] ImageGPTForCausalImageModeling
+
+ - forward
+
+## ImageGPTForImageClassification
+
+[[autodoc]] ImageGPTForImageClassification
+
+ - forward
\ No newline at end of file
diff --git a/docs/source/en/model_doc/layoutlm.mdx b/docs/source/en/model_doc/layoutlm.mdx
new file mode 100644
index 00000000000000..b1ee2a8cdbbc52
--- /dev/null
+++ b/docs/source/en/model_doc/layoutlm.mdx
@@ -0,0 +1,124 @@
+
+
+# LayoutLM
+
+
+
+## Overview
+
+The LayoutLM model was proposed in the paper [LayoutLM: Pre-training of Text and Layout for Document Image
+Understanding](https://arxiv.org/abs/1912.13318) by Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, and
+Ming Zhou. It's a simple but effective pretraining method of text and layout for document image understanding and
+information extraction tasks, such as form understanding and receipt understanding. It obtains state-of-the-art results
+on several downstream tasks:
+
+- form understanding: the [FUNSD](https://guillaumejaume.github.io/FUNSD/) dataset (a collection of 199 annotated
+ forms comprising more than 30,000 words).
+- receipt understanding: the [SROIE](https://rrc.cvc.uab.es/?ch=13) dataset (a collection of 626 receipts for
+ training and 347 receipts for testing).
+- document image classification: the [RVL-CDIP](https://www.cs.cmu.edu/~aharley/rvl-cdip/) dataset (a collection of
+ 400,000 images belonging to one of 16 classes).
+
+The abstract from the paper is the following:
+
+*Pre-training techniques have been verified successfully in a variety of NLP tasks in recent years. Despite the
+widespread use of pretraining models for NLP applications, they almost exclusively focus on text-level manipulation,
+while neglecting layout and style information that is vital for document image understanding. In this paper, we propose
+the LayoutLM to jointly model interactions between text and layout information across scanned document images, which is
+beneficial for a great number of real-world document image understanding tasks such as information extraction from
+scanned documents. Furthermore, we also leverage image features to incorporate words' visual information into LayoutLM.
+To the best of our knowledge, this is the first time that text and layout are jointly learned in a single framework for
+document-level pretraining. It achieves new state-of-the-art results in several downstream tasks, including form
+understanding (from 70.72 to 79.27), receipt understanding (from 94.02 to 95.24) and document image classification
+(from 93.07 to 94.42).*
+
+Tips:
+
+- In addition to *input_ids*, [`~transformers.LayoutLMModel.forward`] also expects the input `bbox`, which are
+ the bounding boxes (i.e. 2D-positions) of the input tokens. These can be obtained using an external OCR engine such
+ as Google's [Tesseract](https://github.com/tesseract-ocr/tesseract) (there's a [Python wrapper](https://pypi.org/project/pytesseract/) available). Each bounding box should be in (x0, y0, x1, y1) format, where
+ (x0, y0) corresponds to the position of the upper left corner in the bounding box, and (x1, y1) represents the
+ position of the lower right corner. Note that one first needs to normalize the bounding boxes to be on a 0-1000
+ scale. To normalize, you can use the following function:
+
+```python
+def normalize_bbox(bbox, width, height):
+ return [
+ int(1000 * (bbox[0] / width)),
+ int(1000 * (bbox[1] / height)),
+ int(1000 * (bbox[2] / width)),
+ int(1000 * (bbox[3] / height)),
+ ]
+```
+
+Here, `width` and `height` correspond to the width and height of the original document in which the token
+occurs. Those can be obtained using the Python Image Library (PIL) library for example, as follows:
+
+```python
+from PIL import Image
+
+image = Image.open("name_of_your_document - can be a png file, pdf, etc.")
+
+width, height = image.size
+```
+
+- For a demo which shows how to fine-tune [`LayoutLMForTokenClassification`] on the [FUNSD dataset](https://guillaumejaume.github.io/FUNSD/) (a collection of annotated forms), see [this notebook](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/LayoutLM/Fine_tuning_LayoutLMForTokenClassification_on_FUNSD.ipynb).
+ It includes an inference part, which shows how to use Google's Tesseract on a new document.
+
+This model was contributed by [liminghao1630](https://huggingface.co/liminghao1630). The original code can be found
+[here](https://github.com/microsoft/unilm/tree/master/layoutlm).
+
+
+## LayoutLMConfig
+
+[[autodoc]] LayoutLMConfig
+
+## LayoutLMTokenizer
+
+[[autodoc]] LayoutLMTokenizer
+
+## LayoutLMTokenizerFast
+
+[[autodoc]] LayoutLMTokenizerFast
+
+## LayoutLMModel
+
+[[autodoc]] LayoutLMModel
+
+## LayoutLMForMaskedLM
+
+[[autodoc]] LayoutLMForMaskedLM
+
+## LayoutLMForSequenceClassification
+
+[[autodoc]] LayoutLMForSequenceClassification
+
+## LayoutLMForTokenClassification
+
+[[autodoc]] LayoutLMForTokenClassification
+
+## TFLayoutLMModel
+
+[[autodoc]] TFLayoutLMModel
+
+## TFLayoutLMForMaskedLM
+
+[[autodoc]] TFLayoutLMForMaskedLM
+
+## TFLayoutLMForSequenceClassification
+
+[[autodoc]] TFLayoutLMForSequenceClassification
+
+## TFLayoutLMForTokenClassification
+
+[[autodoc]] TFLayoutLMForTokenClassification
diff --git a/docs/source/en/model_doc/layoutlmv2.mdx b/docs/source/en/model_doc/layoutlmv2.mdx
new file mode 100644
index 00000000000000..374cbcb775452d
--- /dev/null
+++ b/docs/source/en/model_doc/layoutlmv2.mdx
@@ -0,0 +1,301 @@
+
+
+# LayoutLMV2
+
+## Overview
+
+The LayoutLMV2 model was proposed in [LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding](https://arxiv.org/abs/2012.14740) by Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui, Furu Wei, Guoxin Wang, Yijuan Lu,
+Dinei Florencio, Cha Zhang, Wanxiang Che, Min Zhang, Lidong Zhou. LayoutLMV2 improves [LayoutLM](layoutlm) to obtain
+state-of-the-art results across several document image understanding benchmarks:
+
+- information extraction from scanned documents: the [FUNSD](https://guillaumejaume.github.io/FUNSD/) dataset (a
+ collection of 199 annotated forms comprising more than 30,000 words), the [CORD](https://github.com/clovaai/cord)
+ dataset (a collection of 800 receipts for training, 100 for validation and 100 for testing), the [SROIE](https://rrc.cvc.uab.es/?ch=13) dataset (a collection of 626 receipts for training and 347 receipts for testing)
+ and the [Kleister-NDA](https://github.com/applicaai/kleister-nda) dataset (a collection of non-disclosure
+ agreements from the EDGAR database, including 254 documents for training, 83 documents for validation, and 203
+ documents for testing).
+- document image classification: the [RVL-CDIP](https://www.cs.cmu.edu/~aharley/rvl-cdip/) dataset (a collection of
+ 400,000 images belonging to one of 16 classes).
+- document visual question answering: the [DocVQA](https://arxiv.org/abs/2007.00398) dataset (a collection of 50,000
+ questions defined on 12,000+ document images).
+
+The abstract from the paper is the following:
+
+*Pre-training of text and layout has proved effective in a variety of visually-rich document understanding tasks due to
+its effective model architecture and the advantage of large-scale unlabeled scanned/digital-born documents. In this
+paper, we present LayoutLMv2 by pre-training text, layout and image in a multi-modal framework, where new model
+architectures and pre-training tasks are leveraged. Specifically, LayoutLMv2 not only uses the existing masked
+visual-language modeling task but also the new text-image alignment and text-image matching tasks in the pre-training
+stage, where cross-modality interaction is better learned. Meanwhile, it also integrates a spatial-aware self-attention
+mechanism into the Transformer architecture, so that the model can fully understand the relative positional
+relationship among different text blocks. Experiment results show that LayoutLMv2 outperforms strong baselines and
+achieves new state-of-the-art results on a wide variety of downstream visually-rich document understanding tasks,
+including FUNSD (0.7895 -> 0.8420), CORD (0.9493 -> 0.9601), SROIE (0.9524 -> 0.9781), Kleister-NDA (0.834 -> 0.852),
+RVL-CDIP (0.9443 -> 0.9564), and DocVQA (0.7295 -> 0.8672). The pre-trained LayoutLMv2 model is publicly available at
+this https URL.*
+
+Tips:
+
+- The main difference between LayoutLMv1 and LayoutLMv2 is that the latter incorporates visual embeddings during
+ pre-training (while LayoutLMv1 only adds visual embeddings during fine-tuning).
+- LayoutLMv2 adds both a relative 1D attention bias as well as a spatial 2D attention bias to the attention scores in
+ the self-attention layers. Details can be found on page 5 of the [paper](https://arxiv.org/abs/2012.14740).
+- Demo notebooks on how to use the LayoutLMv2 model on RVL-CDIP, FUNSD, DocVQA, CORD can be found [here](https://github.com/NielsRogge/Transformers-Tutorials).
+- LayoutLMv2 uses Facebook AI's [Detectron2](https://github.com/facebookresearch/detectron2/) package for its visual
+ backbone. See [this link](https://detectron2.readthedocs.io/en/latest/tutorials/install.html) for installation
+ instructions.
+- In addition to `input_ids`, [`~LayoutLMv2Model.forward`] expects 2 additional inputs, namely
+ `image` and `bbox`. The `image` input corresponds to the original document image in which the text
+ tokens occur. The model expects each document image to be of size 224x224. This means that if you have a batch of
+ document images, `image` should be a tensor of shape (batch_size, 3, 224, 224). This can be either a
+ `torch.Tensor` or a `Detectron2.structures.ImageList`. You don't need to normalize the channels, as this is
+ done by the model. Important to note is that the visual backbone expects BGR channels instead of RGB, as all models
+ in Detectron2 are pre-trained using the BGR format. The `bbox` input are the bounding boxes (i.e. 2D-positions)
+ of the input text tokens. This is identical to [`LayoutLMModel`]. These can be obtained using an
+ external OCR engine such as Google's [Tesseract](https://github.com/tesseract-ocr/tesseract) (there's a [Python
+ wrapper](https://pypi.org/project/pytesseract/) available). Each bounding box should be in (x0, y0, x1, y1)
+ format, where (x0, y0) corresponds to the position of the upper left corner in the bounding box, and (x1, y1)
+ represents the position of the lower right corner. Note that one first needs to normalize the bounding boxes to be on
+ a 0-1000 scale. To normalize, you can use the following function:
+
+```python
+def normalize_bbox(bbox, width, height):
+ return [
+ int(1000 * (bbox[0] / width)),
+ int(1000 * (bbox[1] / height)),
+ int(1000 * (bbox[2] / width)),
+ int(1000 * (bbox[3] / height)),
+ ]
+```
+
+Here, `width` and `height` correspond to the width and height of the original document in which the token
+occurs (before resizing the image). Those can be obtained using the Python Image Library (PIL) library for example, as
+follows:
+
+```python
+from PIL import Image
+
+image = Image.open(
+ "name_of_your_document - can be a png, jpg, etc. of your documents (PDFs must be converted to images)."
+)
+
+width, height = image.size
+```
+
+However, this model includes a brand new [`~transformers.LayoutLMv2Processor`] which can be used to directly
+prepare data for the model (including applying OCR under the hood). More information can be found in the "Usage"
+section below.
+
+- Internally, [`~transformers.LayoutLMv2Model`] will send the `image` input through its visual backbone to
+ obtain a lower-resolution feature map, whose shape is equal to the `image_feature_pool_shape` attribute of
+ [`~transformers.LayoutLMv2Config`]. This feature map is then flattened to obtain a sequence of image tokens. As
+ the size of the feature map is 7x7 by default, one obtains 49 image tokens. These are then concatenated with the text
+ tokens, and send through the Transformer encoder. This means that the last hidden states of the model will have a
+ length of 512 + 49 = 561, if you pad the text tokens up to the max length. More generally, the last hidden states
+ will have a shape of `seq_length` + `image_feature_pool_shape[0]` *
+ `config.image_feature_pool_shape[1]`.
+- When calling [`~transformers.LayoutLMv2Model.from_pretrained`], a warning will be printed with a long list of
+ parameter names that are not initialized. This is not a problem, as these parameters are batch normalization
+ statistics, which are going to have values when fine-tuning on a custom dataset.
+- If you want to train the model in a distributed environment, make sure to call [`synchronize_batch_norm`] on the
+ model in order to properly synchronize the batch normalization layers of the visual backbone.
+
+In addition, there's LayoutXLM, which is a multilingual version of LayoutLMv2. More information can be found on
+[LayoutXLM's documentation page](layoutxlm).
+
+## Usage: LayoutLMv2Processor
+
+The easiest way to prepare data for the model is to use [`LayoutLMv2Processor`], which internally
+combines a feature extractor ([`LayoutLMv2FeatureExtractor`]) and a tokenizer
+([`LayoutLMv2Tokenizer`] or [`LayoutLMv2TokenizerFast`]). The feature extractor
+handles the image modality, while the tokenizer handles the text modality. A processor combines both, which is ideal
+for a multi-modal model like LayoutLMv2. Note that you can still use both separately, if you only want to handle one
+modality.
+
+```python
+from transformers import LayoutLMv2FeatureExtractor, LayoutLMv2TokenizerFast, LayoutLMv2Processor
+
+feature_extractor = LayoutLMv2FeatureExtractor() # apply_ocr is set to True by default
+tokenizer = LayoutLMv2TokenizerFast.from_pretrained("microsoft/layoutlmv2-base-uncased")
+processor = LayoutLMv2Processor(feature_extractor, tokenizer)
+```
+
+In short, one can provide a document image (and possibly additional data) to [`LayoutLMv2Processor`],
+and it will create the inputs expected by the model. Internally, the processor first uses
+[`LayoutLMv2FeatureExtractor`] to apply OCR on the image to get a list of words and normalized
+bounding boxes, as well to resize the image to a given size in order to get the `image` input. The words and
+normalized bounding boxes are then provided to [`LayoutLMv2Tokenizer`] or
+[`LayoutLMv2TokenizerFast`], which converts them to token-level `input_ids`,
+`attention_mask`, `token_type_ids`, `bbox`. Optionally, one can provide word labels to the processor,
+which are turned into token-level `labels`.
+
+[`LayoutLMv2Processor`] uses [PyTesseract](https://pypi.org/project/pytesseract/), a Python
+wrapper around Google's Tesseract OCR engine, under the hood. Note that you can still use your own OCR engine of
+choice, and provide the words and normalized boxes yourself. This requires initializing
+[`LayoutLMv2FeatureExtractor`] with `apply_ocr` set to `False`.
+
+In total, there are 5 use cases that are supported by the processor. Below, we list them all. Note that each of these
+use cases work for both batched and non-batched inputs (we illustrate them for non-batched inputs).
+
+**Use case 1: document image classification (training, inference) + token classification (inference), apply_ocr =
+True**
+
+This is the simplest case, in which the processor (actually the feature extractor) will perform OCR on the image to get
+the words and normalized bounding boxes.
+
+```python
+from transformers import LayoutLMv2Processor
+from PIL import Image
+
+processor = LayoutLMv2Processor.from_pretrained("microsoft/layoutlmv2-base-uncased")
+
+image = Image.open(
+ "name_of_your_document - can be a png, jpg, etc. of your documents (PDFs must be converted to images)."
+).convert("RGB")
+encoding = processor(
+ image, return_tensors="pt"
+) # you can also add all tokenizer parameters here such as padding, truncation
+print(encoding.keys())
+# dict_keys(['input_ids', 'token_type_ids', 'attention_mask', 'bbox', 'image'])
+```
+
+**Use case 2: document image classification (training, inference) + token classification (inference), apply_ocr=False**
+
+In case one wants to do OCR themselves, one can initialize the feature extractor with `apply_ocr` set to
+`False`. In that case, one should provide the words and corresponding (normalized) bounding boxes themselves to
+the processor.
+
+```python
+from transformers import LayoutLMv2Processor
+from PIL import Image
+
+processor = LayoutLMv2Processor.from_pretrained("microsoft/layoutlmv2-base-uncased", revision="no_ocr")
+
+image = Image.open(
+ "name_of_your_document - can be a png, jpg, etc. of your documents (PDFs must be converted to images)."
+).convert("RGB")
+words = ["hello", "world"]
+boxes = [[1, 2, 3, 4], [5, 6, 7, 8]] # make sure to normalize your bounding boxes
+encoding = processor(image, words, boxes=boxes, return_tensors="pt")
+print(encoding.keys())
+# dict_keys(['input_ids', 'token_type_ids', 'attention_mask', 'bbox', 'image'])
+```
+
+**Use case 3: token classification (training), apply_ocr=False**
+
+For token classification tasks (such as FUNSD, CORD, SROIE, Kleister-NDA), one can also provide the corresponding word
+labels in order to train a model. The processor will then convert these into token-level `labels`. By default, it
+will only label the first wordpiece of a word, and label the remaining wordpieces with -100, which is the
+`ignore_index` of PyTorch's CrossEntropyLoss. In case you want all wordpieces of a word to be labeled, you can
+initialize the tokenizer with `only_label_first_subword` set to `False`.
+
+```python
+from transformers import LayoutLMv2Processor
+from PIL import Image
+
+processor = LayoutLMv2Processor.from_pretrained("microsoft/layoutlmv2-base-uncased", revision="no_ocr")
+
+image = Image.open(
+ "name_of_your_document - can be a png, jpg, etc. of your documents (PDFs must be converted to images)."
+).convert("RGB")
+words = ["hello", "world"]
+boxes = [[1, 2, 3, 4], [5, 6, 7, 8]] # make sure to normalize your bounding boxes
+word_labels = [1, 2]
+encoding = processor(image, words, boxes=boxes, word_labels=word_labels, return_tensors="pt")
+print(encoding.keys())
+# dict_keys(['input_ids', 'token_type_ids', 'attention_mask', 'bbox', 'labels', 'image'])
+```
+
+**Use case 4: visual question answering (inference), apply_ocr=True**
+
+For visual question answering tasks (such as DocVQA), you can provide a question to the processor. By default, the
+processor will apply OCR on the image, and create [CLS] question tokens [SEP] word tokens [SEP].
+
+```python
+from transformers import LayoutLMv2Processor
+from PIL import Image
+
+processor = LayoutLMv2Processor.from_pretrained("microsoft/layoutlmv2-base-uncased")
+
+image = Image.open(
+ "name_of_your_document - can be a png, jpg, etc. of your documents (PDFs must be converted to images)."
+).convert("RGB")
+question = "What's his name?"
+encoding = processor(image, question, return_tensors="pt")
+print(encoding.keys())
+# dict_keys(['input_ids', 'token_type_ids', 'attention_mask', 'bbox', 'image'])
+```
+
+**Use case 5: visual question answering (inference), apply_ocr=False**
+
+For visual question answering tasks (such as DocVQA), you can provide a question to the processor. If you want to
+perform OCR yourself, you can provide your own words and (normalized) bounding boxes to the processor.
+
+```python
+from transformers import LayoutLMv2Processor
+from PIL import Image
+
+processor = LayoutLMv2Processor.from_pretrained("microsoft/layoutlmv2-base-uncased", revision="no_ocr")
+
+image = Image.open(
+ "name_of_your_document - can be a png, jpg, etc. of your documents (PDFs must be converted to images)."
+).convert("RGB")
+question = "What's his name?"
+words = ["hello", "world"]
+boxes = [[1, 2, 3, 4], [5, 6, 7, 8]] # make sure to normalize your bounding boxes
+encoding = processor(image, question, words, boxes=boxes, return_tensors="pt")
+print(encoding.keys())
+# dict_keys(['input_ids', 'token_type_ids', 'attention_mask', 'bbox', 'image'])
+```
+
+## LayoutLMv2Config
+
+[[autodoc]] LayoutLMv2Config
+
+## LayoutLMv2FeatureExtractor
+
+[[autodoc]] LayoutLMv2FeatureExtractor
+ - __call__
+
+## LayoutLMv2Tokenizer
+
+[[autodoc]] LayoutLMv2Tokenizer
+ - __call__
+ - save_vocabulary
+
+## LayoutLMv2TokenizerFast
+
+[[autodoc]] LayoutLMv2TokenizerFast
+ - __call__
+
+## LayoutLMv2Processor
+
+[[autodoc]] LayoutLMv2Processor
+ - __call__
+
+## LayoutLMv2Model
+
+[[autodoc]] LayoutLMv2Model
+ - forward
+
+## LayoutLMv2ForSequenceClassification
+
+[[autodoc]] LayoutLMv2ForSequenceClassification
+
+## LayoutLMv2ForTokenClassification
+
+[[autodoc]] LayoutLMv2ForTokenClassification
+
+## LayoutLMv2ForQuestionAnswering
+
+[[autodoc]] LayoutLMv2ForQuestionAnswering
diff --git a/docs/source/en/model_doc/layoutxlm.mdx b/docs/source/en/model_doc/layoutxlm.mdx
new file mode 100644
index 00000000000000..ed112453beae4f
--- /dev/null
+++ b/docs/source/en/model_doc/layoutxlm.mdx
@@ -0,0 +1,77 @@
+
+
+# LayoutXLM
+
+## Overview
+
+LayoutXLM was proposed in [LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding](https://arxiv.org/abs/2104.08836) by Yiheng Xu, Tengchao Lv, Lei Cui, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha
+Zhang, Furu Wei. It's a multilingual extension of the [LayoutLMv2 model](https://arxiv.org/abs/2012.14740) trained
+on 53 languages.
+
+The abstract from the paper is the following:
+
+*Multimodal pre-training with text, layout, and image has achieved SOTA performance for visually-rich document
+understanding tasks recently, which demonstrates the great potential for joint learning across different modalities. In
+this paper, we present LayoutXLM, a multimodal pre-trained model for multilingual document understanding, which aims to
+bridge the language barriers for visually-rich document understanding. To accurately evaluate LayoutXLM, we also
+introduce a multilingual form understanding benchmark dataset named XFUN, which includes form understanding samples in
+7 languages (Chinese, Japanese, Spanish, French, Italian, German, Portuguese), and key-value pairs are manually labeled
+for each language. Experiment results show that the LayoutXLM model has significantly outperformed the existing SOTA
+cross-lingual pre-trained models on the XFUN dataset.*
+
+One can directly plug in the weights of LayoutXLM into a LayoutLMv2 model, like so:
+
+```python
+from transformers import LayoutLMv2Model
+
+model = LayoutLMv2Model.from_pretrained("microsoft/layoutxlm-base")
+```
+
+Note that LayoutXLM has its own tokenizer, based on
+[`LayoutXLMTokenizer`]/[`LayoutXLMTokenizerFast`]. You can initialize it as
+follows:
+
+```python
+from transformers import LayoutXLMTokenizer
+
+tokenizer = LayoutXLMTokenizer.from_pretrained("microsoft/layoutxlm-base")
+```
+
+Similar to LayoutLMv2, you can use [`LayoutXLMProcessor`] (which internally applies
+[`LayoutLMv2FeatureExtractor`] and
+[`LayoutXLMTokenizer`]/[`LayoutXLMTokenizerFast`] in sequence) to prepare all
+data for the model.
+
+As LayoutXLM's architecture is equivalent to that of LayoutLMv2, one can refer to [LayoutLMv2's documentation page](layoutlmv2) for all tips, code examples and notebooks.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/microsoft/unilm).
+
+
+## LayoutXLMTokenizer
+
+[[autodoc]] LayoutXLMTokenizer
+ - __call__
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## LayoutXLMTokenizerFast
+
+[[autodoc]] LayoutXLMTokenizerFast
+ - __call__
+
+## LayoutXLMProcessor
+
+[[autodoc]] LayoutXLMProcessor
+ - __call__
diff --git a/docs/source/en/model_doc/led.mdx b/docs/source/en/model_doc/led.mdx
new file mode 100644
index 00000000000000..db6b559bc2d603
--- /dev/null
+++ b/docs/source/en/model_doc/led.mdx
@@ -0,0 +1,117 @@
+
+
+# LED
+
+## Overview
+
+The LED model was proposed in [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz
+Beltagy, Matthew E. Peters, Arman Cohan.
+
+The abstract from the paper is the following:
+
+*Transformer-based models are unable to process long sequences due to their self-attention operation, which scales
+quadratically with the sequence length. To address this limitation, we introduce the Longformer with an attention
+mechanism that scales linearly with sequence length, making it easy to process documents of thousands of tokens or
+longer. Longformer's attention mechanism is a drop-in replacement for the standard self-attention and combines a local
+windowed attention with a task motivated global attention. Following prior work on long-sequence transformers, we
+evaluate Longformer on character-level language modeling and achieve state-of-the-art results on text8 and enwik8. In
+contrast to most prior work, we also pretrain Longformer and finetune it on a variety of downstream tasks. Our
+pretrained Longformer consistently outperforms RoBERTa on long document tasks and sets new state-of-the-art results on
+WikiHop and TriviaQA. We finally introduce the Longformer-Encoder-Decoder (LED), a Longformer variant for supporting
+long document generative sequence-to-sequence tasks, and demonstrate its effectiveness on the arXiv summarization
+dataset.*
+
+Tips:
+
+- [`LEDForConditionalGeneration`] is an extension of
+ [`BartForConditionalGeneration`] exchanging the traditional *self-attention* layer with
+ *Longformer*'s *chunked self-attention* layer. [`LEDTokenizer`] is an alias of
+ [`BartTokenizer`].
+- LED works very well on long-range *sequence-to-sequence* tasks where the `input_ids` largely exceed a length of
+ 1024 tokens.
+- LED pads the `input_ids` to be a multiple of `config.attention_window` if required. Therefore a small speed-up is
+ gained, when [`LEDTokenizer`] is used with the `pad_to_multiple_of` argument.
+- LED makes use of *global attention* by means of the `global_attention_mask` (see
+ [`LongformerModel`]). For summarization, it is advised to put *global attention* only on the first
+ `
+
+ Summary of the approach. Taken from the [original paper](https://cdn.openai.com/papers/Generative_Pretraining_from_Pixels_V2.pdf).
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr), based on [this issue](https://github.com/openai/image-gpt/issues/7). The original code can be found
+[here](https://github.com/openai/image-gpt).
+
+Tips:
+
+- Demo notebooks for ImageGPT can be found
+ [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/ImageGPT).
+- ImageGPT is almost exactly the same as [GPT-2](gpt2), with the exception that a different activation
+ function is used (namely "quick gelu"), and the layer normalization layers don't mean center the inputs. ImageGPT
+ also doesn't have tied input- and output embeddings.
+- As the time- and memory requirements of the attention mechanism of Transformers scales quadratically in the sequence
+ length, the authors pre-trained ImageGPT on smaller input resolutions, such as 32x32 and 64x64. However, feeding a
+ sequence of 32x32x3=3072 tokens from 0..255 into a Transformer is still prohibitively large. Therefore, the authors
+ applied k-means clustering to the (R,G,B) pixel values with k=512. This way, we only have a 32*32 = 1024-long
+ sequence, but now of integers in the range 0..511. So we are shrinking the sequence length at the cost of a bigger
+ embedding matrix. In other words, the vocabulary size of ImageGPT is 512, + 1 for a special "start of sentence" (SOS)
+ token, used at the beginning of every sequence. One can use [`ImageGPTFeatureExtractor`] to prepare
+ images for the model.
+- Despite being pre-trained entirely unsupervised (i.e. without the use of any labels), ImageGPT produces fairly
+ performant image features useful for downstream tasks, such as image classification. The authors showed that the
+ features in the middle of the network are the most performant, and can be used as-is to train a linear model (such as
+ a sklearn logistic regression model for example). This is also referred to as "linear probing". Features can be
+ easily obtained by first forwarding the image through the model, then specifying `output_hidden_states=True`, and
+ then average-pool the hidden states at whatever layer you like.
+- Alternatively, one can further fine-tune the entire model on a downstream dataset, similar to BERT. For this, you can
+ use [`ImageGPTForImageClassification`].
+- ImageGPT comes in different sizes: there's ImageGPT-small, ImageGPT-medium and ImageGPT-large. The authors did also
+ train an XL variant, which they didn't release. The differences in size are summarized in the following table:
+
+| **Model variant** | **Depths** | **Hidden sizes** | **Decoder hidden size** | **Params (M)** | **ImageNet-1k Top 1** |
+|---|---|---|---|---|---|
+| MiT-b0 | [2, 2, 2, 2] | [32, 64, 160, 256] | 256 | 3.7 | 70.5 |
+| MiT-b1 | [2, 2, 2, 2] | [64, 128, 320, 512] | 256 | 14.0 | 78.7 |
+| MiT-b2 | [3, 4, 6, 3] | [64, 128, 320, 512] | 768 | 25.4 | 81.6 |
+| MiT-b3 | [3, 4, 18, 3] | [64, 128, 320, 512] | 768 | 45.2 | 83.1 |
+| MiT-b4 | [3, 8, 27, 3] | [64, 128, 320, 512] | 768 | 62.6 | 83.6 |
+| MiT-b5 | [3, 6, 40, 3] | [64, 128, 320, 512] | 768 | 82.0 | 83.8 |
+
+## ImageGPTConfig
+
+[[autodoc]] ImageGPTConfig
+
+## ImageGPTFeatureExtractor
+
+[[autodoc]] ImageGPTFeatureExtractor
+
+ - __call__
+
+## ImageGPTModel
+
+[[autodoc]] ImageGPTModel
+
+ - forward
+
+## ImageGPTForCausalImageModeling
+
+[[autodoc]] ImageGPTForCausalImageModeling
+
+ - forward
+
+## ImageGPTForImageClassification
+
+[[autodoc]] ImageGPTForImageClassification
+
+ - forward
\ No newline at end of file
diff --git a/docs/source/en/model_doc/layoutlm.mdx b/docs/source/en/model_doc/layoutlm.mdx
new file mode 100644
index 00000000000000..b1ee2a8cdbbc52
--- /dev/null
+++ b/docs/source/en/model_doc/layoutlm.mdx
@@ -0,0 +1,124 @@
+
+
+# LayoutLM
+
+
+
+## Overview
+
+The LayoutLM model was proposed in the paper [LayoutLM: Pre-training of Text and Layout for Document Image
+Understanding](https://arxiv.org/abs/1912.13318) by Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, and
+Ming Zhou. It's a simple but effective pretraining method of text and layout for document image understanding and
+information extraction tasks, such as form understanding and receipt understanding. It obtains state-of-the-art results
+on several downstream tasks:
+
+- form understanding: the [FUNSD](https://guillaumejaume.github.io/FUNSD/) dataset (a collection of 199 annotated
+ forms comprising more than 30,000 words).
+- receipt understanding: the [SROIE](https://rrc.cvc.uab.es/?ch=13) dataset (a collection of 626 receipts for
+ training and 347 receipts for testing).
+- document image classification: the [RVL-CDIP](https://www.cs.cmu.edu/~aharley/rvl-cdip/) dataset (a collection of
+ 400,000 images belonging to one of 16 classes).
+
+The abstract from the paper is the following:
+
+*Pre-training techniques have been verified successfully in a variety of NLP tasks in recent years. Despite the
+widespread use of pretraining models for NLP applications, they almost exclusively focus on text-level manipulation,
+while neglecting layout and style information that is vital for document image understanding. In this paper, we propose
+the LayoutLM to jointly model interactions between text and layout information across scanned document images, which is
+beneficial for a great number of real-world document image understanding tasks such as information extraction from
+scanned documents. Furthermore, we also leverage image features to incorporate words' visual information into LayoutLM.
+To the best of our knowledge, this is the first time that text and layout are jointly learned in a single framework for
+document-level pretraining. It achieves new state-of-the-art results in several downstream tasks, including form
+understanding (from 70.72 to 79.27), receipt understanding (from 94.02 to 95.24) and document image classification
+(from 93.07 to 94.42).*
+
+Tips:
+
+- In addition to *input_ids*, [`~transformers.LayoutLMModel.forward`] also expects the input `bbox`, which are
+ the bounding boxes (i.e. 2D-positions) of the input tokens. These can be obtained using an external OCR engine such
+ as Google's [Tesseract](https://github.com/tesseract-ocr/tesseract) (there's a [Python wrapper](https://pypi.org/project/pytesseract/) available). Each bounding box should be in (x0, y0, x1, y1) format, where
+ (x0, y0) corresponds to the position of the upper left corner in the bounding box, and (x1, y1) represents the
+ position of the lower right corner. Note that one first needs to normalize the bounding boxes to be on a 0-1000
+ scale. To normalize, you can use the following function:
+
+```python
+def normalize_bbox(bbox, width, height):
+ return [
+ int(1000 * (bbox[0] / width)),
+ int(1000 * (bbox[1] / height)),
+ int(1000 * (bbox[2] / width)),
+ int(1000 * (bbox[3] / height)),
+ ]
+```
+
+Here, `width` and `height` correspond to the width and height of the original document in which the token
+occurs. Those can be obtained using the Python Image Library (PIL) library for example, as follows:
+
+```python
+from PIL import Image
+
+image = Image.open("name_of_your_document - can be a png file, pdf, etc.")
+
+width, height = image.size
+```
+
+- For a demo which shows how to fine-tune [`LayoutLMForTokenClassification`] on the [FUNSD dataset](https://guillaumejaume.github.io/FUNSD/) (a collection of annotated forms), see [this notebook](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/LayoutLM/Fine_tuning_LayoutLMForTokenClassification_on_FUNSD.ipynb).
+ It includes an inference part, which shows how to use Google's Tesseract on a new document.
+
+This model was contributed by [liminghao1630](https://huggingface.co/liminghao1630). The original code can be found
+[here](https://github.com/microsoft/unilm/tree/master/layoutlm).
+
+
+## LayoutLMConfig
+
+[[autodoc]] LayoutLMConfig
+
+## LayoutLMTokenizer
+
+[[autodoc]] LayoutLMTokenizer
+
+## LayoutLMTokenizerFast
+
+[[autodoc]] LayoutLMTokenizerFast
+
+## LayoutLMModel
+
+[[autodoc]] LayoutLMModel
+
+## LayoutLMForMaskedLM
+
+[[autodoc]] LayoutLMForMaskedLM
+
+## LayoutLMForSequenceClassification
+
+[[autodoc]] LayoutLMForSequenceClassification
+
+## LayoutLMForTokenClassification
+
+[[autodoc]] LayoutLMForTokenClassification
+
+## TFLayoutLMModel
+
+[[autodoc]] TFLayoutLMModel
+
+## TFLayoutLMForMaskedLM
+
+[[autodoc]] TFLayoutLMForMaskedLM
+
+## TFLayoutLMForSequenceClassification
+
+[[autodoc]] TFLayoutLMForSequenceClassification
+
+## TFLayoutLMForTokenClassification
+
+[[autodoc]] TFLayoutLMForTokenClassification
diff --git a/docs/source/en/model_doc/layoutlmv2.mdx b/docs/source/en/model_doc/layoutlmv2.mdx
new file mode 100644
index 00000000000000..374cbcb775452d
--- /dev/null
+++ b/docs/source/en/model_doc/layoutlmv2.mdx
@@ -0,0 +1,301 @@
+
+
+# LayoutLMV2
+
+## Overview
+
+The LayoutLMV2 model was proposed in [LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding](https://arxiv.org/abs/2012.14740) by Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui, Furu Wei, Guoxin Wang, Yijuan Lu,
+Dinei Florencio, Cha Zhang, Wanxiang Che, Min Zhang, Lidong Zhou. LayoutLMV2 improves [LayoutLM](layoutlm) to obtain
+state-of-the-art results across several document image understanding benchmarks:
+
+- information extraction from scanned documents: the [FUNSD](https://guillaumejaume.github.io/FUNSD/) dataset (a
+ collection of 199 annotated forms comprising more than 30,000 words), the [CORD](https://github.com/clovaai/cord)
+ dataset (a collection of 800 receipts for training, 100 for validation and 100 for testing), the [SROIE](https://rrc.cvc.uab.es/?ch=13) dataset (a collection of 626 receipts for training and 347 receipts for testing)
+ and the [Kleister-NDA](https://github.com/applicaai/kleister-nda) dataset (a collection of non-disclosure
+ agreements from the EDGAR database, including 254 documents for training, 83 documents for validation, and 203
+ documents for testing).
+- document image classification: the [RVL-CDIP](https://www.cs.cmu.edu/~aharley/rvl-cdip/) dataset (a collection of
+ 400,000 images belonging to one of 16 classes).
+- document visual question answering: the [DocVQA](https://arxiv.org/abs/2007.00398) dataset (a collection of 50,000
+ questions defined on 12,000+ document images).
+
+The abstract from the paper is the following:
+
+*Pre-training of text and layout has proved effective in a variety of visually-rich document understanding tasks due to
+its effective model architecture and the advantage of large-scale unlabeled scanned/digital-born documents. In this
+paper, we present LayoutLMv2 by pre-training text, layout and image in a multi-modal framework, where new model
+architectures and pre-training tasks are leveraged. Specifically, LayoutLMv2 not only uses the existing masked
+visual-language modeling task but also the new text-image alignment and text-image matching tasks in the pre-training
+stage, where cross-modality interaction is better learned. Meanwhile, it also integrates a spatial-aware self-attention
+mechanism into the Transformer architecture, so that the model can fully understand the relative positional
+relationship among different text blocks. Experiment results show that LayoutLMv2 outperforms strong baselines and
+achieves new state-of-the-art results on a wide variety of downstream visually-rich document understanding tasks,
+including FUNSD (0.7895 -> 0.8420), CORD (0.9493 -> 0.9601), SROIE (0.9524 -> 0.9781), Kleister-NDA (0.834 -> 0.852),
+RVL-CDIP (0.9443 -> 0.9564), and DocVQA (0.7295 -> 0.8672). The pre-trained LayoutLMv2 model is publicly available at
+this https URL.*
+
+Tips:
+
+- The main difference between LayoutLMv1 and LayoutLMv2 is that the latter incorporates visual embeddings during
+ pre-training (while LayoutLMv1 only adds visual embeddings during fine-tuning).
+- LayoutLMv2 adds both a relative 1D attention bias as well as a spatial 2D attention bias to the attention scores in
+ the self-attention layers. Details can be found on page 5 of the [paper](https://arxiv.org/abs/2012.14740).
+- Demo notebooks on how to use the LayoutLMv2 model on RVL-CDIP, FUNSD, DocVQA, CORD can be found [here](https://github.com/NielsRogge/Transformers-Tutorials).
+- LayoutLMv2 uses Facebook AI's [Detectron2](https://github.com/facebookresearch/detectron2/) package for its visual
+ backbone. See [this link](https://detectron2.readthedocs.io/en/latest/tutorials/install.html) for installation
+ instructions.
+- In addition to `input_ids`, [`~LayoutLMv2Model.forward`] expects 2 additional inputs, namely
+ `image` and `bbox`. The `image` input corresponds to the original document image in which the text
+ tokens occur. The model expects each document image to be of size 224x224. This means that if you have a batch of
+ document images, `image` should be a tensor of shape (batch_size, 3, 224, 224). This can be either a
+ `torch.Tensor` or a `Detectron2.structures.ImageList`. You don't need to normalize the channels, as this is
+ done by the model. Important to note is that the visual backbone expects BGR channels instead of RGB, as all models
+ in Detectron2 are pre-trained using the BGR format. The `bbox` input are the bounding boxes (i.e. 2D-positions)
+ of the input text tokens. This is identical to [`LayoutLMModel`]. These can be obtained using an
+ external OCR engine such as Google's [Tesseract](https://github.com/tesseract-ocr/tesseract) (there's a [Python
+ wrapper](https://pypi.org/project/pytesseract/) available). Each bounding box should be in (x0, y0, x1, y1)
+ format, where (x0, y0) corresponds to the position of the upper left corner in the bounding box, and (x1, y1)
+ represents the position of the lower right corner. Note that one first needs to normalize the bounding boxes to be on
+ a 0-1000 scale. To normalize, you can use the following function:
+
+```python
+def normalize_bbox(bbox, width, height):
+ return [
+ int(1000 * (bbox[0] / width)),
+ int(1000 * (bbox[1] / height)),
+ int(1000 * (bbox[2] / width)),
+ int(1000 * (bbox[3] / height)),
+ ]
+```
+
+Here, `width` and `height` correspond to the width and height of the original document in which the token
+occurs (before resizing the image). Those can be obtained using the Python Image Library (PIL) library for example, as
+follows:
+
+```python
+from PIL import Image
+
+image = Image.open(
+ "name_of_your_document - can be a png, jpg, etc. of your documents (PDFs must be converted to images)."
+)
+
+width, height = image.size
+```
+
+However, this model includes a brand new [`~transformers.LayoutLMv2Processor`] which can be used to directly
+prepare data for the model (including applying OCR under the hood). More information can be found in the "Usage"
+section below.
+
+- Internally, [`~transformers.LayoutLMv2Model`] will send the `image` input through its visual backbone to
+ obtain a lower-resolution feature map, whose shape is equal to the `image_feature_pool_shape` attribute of
+ [`~transformers.LayoutLMv2Config`]. This feature map is then flattened to obtain a sequence of image tokens. As
+ the size of the feature map is 7x7 by default, one obtains 49 image tokens. These are then concatenated with the text
+ tokens, and send through the Transformer encoder. This means that the last hidden states of the model will have a
+ length of 512 + 49 = 561, if you pad the text tokens up to the max length. More generally, the last hidden states
+ will have a shape of `seq_length` + `image_feature_pool_shape[0]` *
+ `config.image_feature_pool_shape[1]`.
+- When calling [`~transformers.LayoutLMv2Model.from_pretrained`], a warning will be printed with a long list of
+ parameter names that are not initialized. This is not a problem, as these parameters are batch normalization
+ statistics, which are going to have values when fine-tuning on a custom dataset.
+- If you want to train the model in a distributed environment, make sure to call [`synchronize_batch_norm`] on the
+ model in order to properly synchronize the batch normalization layers of the visual backbone.
+
+In addition, there's LayoutXLM, which is a multilingual version of LayoutLMv2. More information can be found on
+[LayoutXLM's documentation page](layoutxlm).
+
+## Usage: LayoutLMv2Processor
+
+The easiest way to prepare data for the model is to use [`LayoutLMv2Processor`], which internally
+combines a feature extractor ([`LayoutLMv2FeatureExtractor`]) and a tokenizer
+([`LayoutLMv2Tokenizer`] or [`LayoutLMv2TokenizerFast`]). The feature extractor
+handles the image modality, while the tokenizer handles the text modality. A processor combines both, which is ideal
+for a multi-modal model like LayoutLMv2. Note that you can still use both separately, if you only want to handle one
+modality.
+
+```python
+from transformers import LayoutLMv2FeatureExtractor, LayoutLMv2TokenizerFast, LayoutLMv2Processor
+
+feature_extractor = LayoutLMv2FeatureExtractor() # apply_ocr is set to True by default
+tokenizer = LayoutLMv2TokenizerFast.from_pretrained("microsoft/layoutlmv2-base-uncased")
+processor = LayoutLMv2Processor(feature_extractor, tokenizer)
+```
+
+In short, one can provide a document image (and possibly additional data) to [`LayoutLMv2Processor`],
+and it will create the inputs expected by the model. Internally, the processor first uses
+[`LayoutLMv2FeatureExtractor`] to apply OCR on the image to get a list of words and normalized
+bounding boxes, as well to resize the image to a given size in order to get the `image` input. The words and
+normalized bounding boxes are then provided to [`LayoutLMv2Tokenizer`] or
+[`LayoutLMv2TokenizerFast`], which converts them to token-level `input_ids`,
+`attention_mask`, `token_type_ids`, `bbox`. Optionally, one can provide word labels to the processor,
+which are turned into token-level `labels`.
+
+[`LayoutLMv2Processor`] uses [PyTesseract](https://pypi.org/project/pytesseract/), a Python
+wrapper around Google's Tesseract OCR engine, under the hood. Note that you can still use your own OCR engine of
+choice, and provide the words and normalized boxes yourself. This requires initializing
+[`LayoutLMv2FeatureExtractor`] with `apply_ocr` set to `False`.
+
+In total, there are 5 use cases that are supported by the processor. Below, we list them all. Note that each of these
+use cases work for both batched and non-batched inputs (we illustrate them for non-batched inputs).
+
+**Use case 1: document image classification (training, inference) + token classification (inference), apply_ocr =
+True**
+
+This is the simplest case, in which the processor (actually the feature extractor) will perform OCR on the image to get
+the words and normalized bounding boxes.
+
+```python
+from transformers import LayoutLMv2Processor
+from PIL import Image
+
+processor = LayoutLMv2Processor.from_pretrained("microsoft/layoutlmv2-base-uncased")
+
+image = Image.open(
+ "name_of_your_document - can be a png, jpg, etc. of your documents (PDFs must be converted to images)."
+).convert("RGB")
+encoding = processor(
+ image, return_tensors="pt"
+) # you can also add all tokenizer parameters here such as padding, truncation
+print(encoding.keys())
+# dict_keys(['input_ids', 'token_type_ids', 'attention_mask', 'bbox', 'image'])
+```
+
+**Use case 2: document image classification (training, inference) + token classification (inference), apply_ocr=False**
+
+In case one wants to do OCR themselves, one can initialize the feature extractor with `apply_ocr` set to
+`False`. In that case, one should provide the words and corresponding (normalized) bounding boxes themselves to
+the processor.
+
+```python
+from transformers import LayoutLMv2Processor
+from PIL import Image
+
+processor = LayoutLMv2Processor.from_pretrained("microsoft/layoutlmv2-base-uncased", revision="no_ocr")
+
+image = Image.open(
+ "name_of_your_document - can be a png, jpg, etc. of your documents (PDFs must be converted to images)."
+).convert("RGB")
+words = ["hello", "world"]
+boxes = [[1, 2, 3, 4], [5, 6, 7, 8]] # make sure to normalize your bounding boxes
+encoding = processor(image, words, boxes=boxes, return_tensors="pt")
+print(encoding.keys())
+# dict_keys(['input_ids', 'token_type_ids', 'attention_mask', 'bbox', 'image'])
+```
+
+**Use case 3: token classification (training), apply_ocr=False**
+
+For token classification tasks (such as FUNSD, CORD, SROIE, Kleister-NDA), one can also provide the corresponding word
+labels in order to train a model. The processor will then convert these into token-level `labels`. By default, it
+will only label the first wordpiece of a word, and label the remaining wordpieces with -100, which is the
+`ignore_index` of PyTorch's CrossEntropyLoss. In case you want all wordpieces of a word to be labeled, you can
+initialize the tokenizer with `only_label_first_subword` set to `False`.
+
+```python
+from transformers import LayoutLMv2Processor
+from PIL import Image
+
+processor = LayoutLMv2Processor.from_pretrained("microsoft/layoutlmv2-base-uncased", revision="no_ocr")
+
+image = Image.open(
+ "name_of_your_document - can be a png, jpg, etc. of your documents (PDFs must be converted to images)."
+).convert("RGB")
+words = ["hello", "world"]
+boxes = [[1, 2, 3, 4], [5, 6, 7, 8]] # make sure to normalize your bounding boxes
+word_labels = [1, 2]
+encoding = processor(image, words, boxes=boxes, word_labels=word_labels, return_tensors="pt")
+print(encoding.keys())
+# dict_keys(['input_ids', 'token_type_ids', 'attention_mask', 'bbox', 'labels', 'image'])
+```
+
+**Use case 4: visual question answering (inference), apply_ocr=True**
+
+For visual question answering tasks (such as DocVQA), you can provide a question to the processor. By default, the
+processor will apply OCR on the image, and create [CLS] question tokens [SEP] word tokens [SEP].
+
+```python
+from transformers import LayoutLMv2Processor
+from PIL import Image
+
+processor = LayoutLMv2Processor.from_pretrained("microsoft/layoutlmv2-base-uncased")
+
+image = Image.open(
+ "name_of_your_document - can be a png, jpg, etc. of your documents (PDFs must be converted to images)."
+).convert("RGB")
+question = "What's his name?"
+encoding = processor(image, question, return_tensors="pt")
+print(encoding.keys())
+# dict_keys(['input_ids', 'token_type_ids', 'attention_mask', 'bbox', 'image'])
+```
+
+**Use case 5: visual question answering (inference), apply_ocr=False**
+
+For visual question answering tasks (such as DocVQA), you can provide a question to the processor. If you want to
+perform OCR yourself, you can provide your own words and (normalized) bounding boxes to the processor.
+
+```python
+from transformers import LayoutLMv2Processor
+from PIL import Image
+
+processor = LayoutLMv2Processor.from_pretrained("microsoft/layoutlmv2-base-uncased", revision="no_ocr")
+
+image = Image.open(
+ "name_of_your_document - can be a png, jpg, etc. of your documents (PDFs must be converted to images)."
+).convert("RGB")
+question = "What's his name?"
+words = ["hello", "world"]
+boxes = [[1, 2, 3, 4], [5, 6, 7, 8]] # make sure to normalize your bounding boxes
+encoding = processor(image, question, words, boxes=boxes, return_tensors="pt")
+print(encoding.keys())
+# dict_keys(['input_ids', 'token_type_ids', 'attention_mask', 'bbox', 'image'])
+```
+
+## LayoutLMv2Config
+
+[[autodoc]] LayoutLMv2Config
+
+## LayoutLMv2FeatureExtractor
+
+[[autodoc]] LayoutLMv2FeatureExtractor
+ - __call__
+
+## LayoutLMv2Tokenizer
+
+[[autodoc]] LayoutLMv2Tokenizer
+ - __call__
+ - save_vocabulary
+
+## LayoutLMv2TokenizerFast
+
+[[autodoc]] LayoutLMv2TokenizerFast
+ - __call__
+
+## LayoutLMv2Processor
+
+[[autodoc]] LayoutLMv2Processor
+ - __call__
+
+## LayoutLMv2Model
+
+[[autodoc]] LayoutLMv2Model
+ - forward
+
+## LayoutLMv2ForSequenceClassification
+
+[[autodoc]] LayoutLMv2ForSequenceClassification
+
+## LayoutLMv2ForTokenClassification
+
+[[autodoc]] LayoutLMv2ForTokenClassification
+
+## LayoutLMv2ForQuestionAnswering
+
+[[autodoc]] LayoutLMv2ForQuestionAnswering
diff --git a/docs/source/en/model_doc/layoutxlm.mdx b/docs/source/en/model_doc/layoutxlm.mdx
new file mode 100644
index 00000000000000..ed112453beae4f
--- /dev/null
+++ b/docs/source/en/model_doc/layoutxlm.mdx
@@ -0,0 +1,77 @@
+
+
+# LayoutXLM
+
+## Overview
+
+LayoutXLM was proposed in [LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding](https://arxiv.org/abs/2104.08836) by Yiheng Xu, Tengchao Lv, Lei Cui, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha
+Zhang, Furu Wei. It's a multilingual extension of the [LayoutLMv2 model](https://arxiv.org/abs/2012.14740) trained
+on 53 languages.
+
+The abstract from the paper is the following:
+
+*Multimodal pre-training with text, layout, and image has achieved SOTA performance for visually-rich document
+understanding tasks recently, which demonstrates the great potential for joint learning across different modalities. In
+this paper, we present LayoutXLM, a multimodal pre-trained model for multilingual document understanding, which aims to
+bridge the language barriers for visually-rich document understanding. To accurately evaluate LayoutXLM, we also
+introduce a multilingual form understanding benchmark dataset named XFUN, which includes form understanding samples in
+7 languages (Chinese, Japanese, Spanish, French, Italian, German, Portuguese), and key-value pairs are manually labeled
+for each language. Experiment results show that the LayoutXLM model has significantly outperformed the existing SOTA
+cross-lingual pre-trained models on the XFUN dataset.*
+
+One can directly plug in the weights of LayoutXLM into a LayoutLMv2 model, like so:
+
+```python
+from transformers import LayoutLMv2Model
+
+model = LayoutLMv2Model.from_pretrained("microsoft/layoutxlm-base")
+```
+
+Note that LayoutXLM has its own tokenizer, based on
+[`LayoutXLMTokenizer`]/[`LayoutXLMTokenizerFast`]. You can initialize it as
+follows:
+
+```python
+from transformers import LayoutXLMTokenizer
+
+tokenizer = LayoutXLMTokenizer.from_pretrained("microsoft/layoutxlm-base")
+```
+
+Similar to LayoutLMv2, you can use [`LayoutXLMProcessor`] (which internally applies
+[`LayoutLMv2FeatureExtractor`] and
+[`LayoutXLMTokenizer`]/[`LayoutXLMTokenizerFast`] in sequence) to prepare all
+data for the model.
+
+As LayoutXLM's architecture is equivalent to that of LayoutLMv2, one can refer to [LayoutLMv2's documentation page](layoutlmv2) for all tips, code examples and notebooks.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/microsoft/unilm).
+
+
+## LayoutXLMTokenizer
+
+[[autodoc]] LayoutXLMTokenizer
+ - __call__
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## LayoutXLMTokenizerFast
+
+[[autodoc]] LayoutXLMTokenizerFast
+ - __call__
+
+## LayoutXLMProcessor
+
+[[autodoc]] LayoutXLMProcessor
+ - __call__
diff --git a/docs/source/en/model_doc/led.mdx b/docs/source/en/model_doc/led.mdx
new file mode 100644
index 00000000000000..db6b559bc2d603
--- /dev/null
+++ b/docs/source/en/model_doc/led.mdx
@@ -0,0 +1,117 @@
+
+
+# LED
+
+## Overview
+
+The LED model was proposed in [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz
+Beltagy, Matthew E. Peters, Arman Cohan.
+
+The abstract from the paper is the following:
+
+*Transformer-based models are unable to process long sequences due to their self-attention operation, which scales
+quadratically with the sequence length. To address this limitation, we introduce the Longformer with an attention
+mechanism that scales linearly with sequence length, making it easy to process documents of thousands of tokens or
+longer. Longformer's attention mechanism is a drop-in replacement for the standard self-attention and combines a local
+windowed attention with a task motivated global attention. Following prior work on long-sequence transformers, we
+evaluate Longformer on character-level language modeling and achieve state-of-the-art results on text8 and enwik8. In
+contrast to most prior work, we also pretrain Longformer and finetune it on a variety of downstream tasks. Our
+pretrained Longformer consistently outperforms RoBERTa on long document tasks and sets new state-of-the-art results on
+WikiHop and TriviaQA. We finally introduce the Longformer-Encoder-Decoder (LED), a Longformer variant for supporting
+long document generative sequence-to-sequence tasks, and demonstrate its effectiveness on the arXiv summarization
+dataset.*
+
+Tips:
+
+- [`LEDForConditionalGeneration`] is an extension of
+ [`BartForConditionalGeneration`] exchanging the traditional *self-attention* layer with
+ *Longformer*'s *chunked self-attention* layer. [`LEDTokenizer`] is an alias of
+ [`BartTokenizer`].
+- LED works very well on long-range *sequence-to-sequence* tasks where the `input_ids` largely exceed a length of
+ 1024 tokens.
+- LED pads the `input_ids` to be a multiple of `config.attention_window` if required. Therefore a small speed-up is
+ gained, when [`LEDTokenizer`] is used with the `pad_to_multiple_of` argument.
+- LED makes use of *global attention* by means of the `global_attention_mask` (see
+ [`LongformerModel`]). For summarization, it is advised to put *global attention* only on the first
+ `` token. For question answering, it is advised to put *global attention* on all tokens of the question.
+- To fine-tune LED on all 16384, it is necessary to enable *gradient checkpointing* by executing
+ `model.gradient_checkpointing_enable()`.
+- A notebook showing how to evaluate LED, can be accessed [here](https://colab.research.google.com/drive/12INTTR6n64TzS4RrXZxMSXfrOd9Xzamo?usp=sharing).
+- A notebook showing how to fine-tune LED, can be accessed [here](https://colab.research.google.com/drive/12LjJazBl7Gam0XBPy_y0CTOJZeZ34c2v?usp=sharing).
+
+This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten).
+
+
+## LEDConfig
+
+[[autodoc]] LEDConfig
+
+## LEDTokenizer
+
+[[autodoc]] LEDTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## LEDTokenizerFast
+
+[[autodoc]] LEDTokenizerFast
+
+## LED specific outputs
+
+[[autodoc]] models.led.modeling_led.LEDEncoderBaseModelOutput
+
+[[autodoc]] models.led.modeling_led.LEDSeq2SeqModelOutput
+
+[[autodoc]] models.led.modeling_led.LEDSeq2SeqLMOutput
+
+[[autodoc]] models.led.modeling_led.LEDSeq2SeqSequenceClassifierOutput
+
+[[autodoc]] models.led.modeling_led.LEDSeq2SeqQuestionAnsweringModelOutput
+
+[[autodoc]] models.led.modeling_tf_led.TFLEDEncoderBaseModelOutput
+
+[[autodoc]] models.led.modeling_tf_led.TFLEDSeq2SeqModelOutput
+
+[[autodoc]] models.led.modeling_tf_led.TFLEDSeq2SeqLMOutput
+
+## LEDModel
+
+[[autodoc]] LEDModel
+ - forward
+
+## LEDForConditionalGeneration
+
+[[autodoc]] LEDForConditionalGeneration
+ - forward
+
+## LEDForSequenceClassification
+
+[[autodoc]] LEDForSequenceClassification
+ - forward
+
+## LEDForQuestionAnswering
+
+[[autodoc]] LEDForQuestionAnswering
+ - forward
+
+## TFLEDModel
+
+[[autodoc]] TFLEDModel
+ - call
+
+## TFLEDForConditionalGeneration
+
+[[autodoc]] TFLEDForConditionalGeneration
+ - call
diff --git a/docs/source/en/model_doc/longformer.mdx b/docs/source/en/model_doc/longformer.mdx
new file mode 100644
index 00000000000000..2ebc63b2bec09a
--- /dev/null
+++ b/docs/source/en/model_doc/longformer.mdx
@@ -0,0 +1,182 @@
+
+
+# Longformer
+
+## Overview
+
+The Longformer model was presented in [Longformer: The Long-Document Transformer](https://arxiv.org/pdf/2004.05150.pdf) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
+
+The abstract from the paper is the following:
+
+*Transformer-based models are unable to process long sequences due to their self-attention operation, which scales
+quadratically with the sequence length. To address this limitation, we introduce the Longformer with an attention
+mechanism that scales linearly with sequence length, making it easy to process documents of thousands of tokens or
+longer. Longformer's attention mechanism is a drop-in replacement for the standard self-attention and combines a local
+windowed attention with a task motivated global attention. Following prior work on long-sequence transformers, we
+evaluate Longformer on character-level language modeling and achieve state-of-the-art results on text8 and enwik8. In
+contrast to most prior work, we also pretrain Longformer and finetune it on a variety of downstream tasks. Our
+pretrained Longformer consistently outperforms RoBERTa on long document tasks and sets new state-of-the-art results on
+WikiHop and TriviaQA.*
+
+Tips:
+
+- Since the Longformer is based on RoBERTa, it doesn't have `token_type_ids`. You don't need to indicate which
+ token belongs to which segment. Just separate your segments with the separation token `tokenizer.sep_token` (or
+ ``).
+
+This model was contributed by [beltagy](https://huggingface.co/beltagy). The Authors' code can be found [here](https://github.com/allenai/longformer).
+
+## Longformer Self Attention
+
+Longformer self attention employs self attention on both a "local" context and a "global" context. Most tokens only
+attend "locally" to each other meaning that each token attends to its \\(\frac{1}{2} w\\) previous tokens and
+\\(\frac{1}{2} w\\) succeding tokens with \\(w\\) being the window length as defined in
+`config.attention_window`. Note that `config.attention_window` can be of type `List` to define a
+different \\(w\\) for each layer. A selected few tokens attend "globally" to all other tokens, as it is
+conventionally done for all tokens in `BertSelfAttention`.
+
+Note that "locally" and "globally" attending tokens are projected by different query, key and value matrices. Also note
+that every "locally" attending token not only attends to tokens within its window \\(w\\), but also to all "globally"
+attending tokens so that global attention is *symmetric*.
+
+The user can define which tokens attend "locally" and which tokens attend "globally" by setting the tensor
+`global_attention_mask` at run-time appropriately. All Longformer models employ the following logic for
+`global_attention_mask`:
+
+- 0: the token attends "locally",
+- 1: the token attends "globally".
+
+For more information please also refer to [`~LongformerModel.forward`] method.
+
+Using Longformer self attention, the memory and time complexity of the query-key matmul operation, which usually
+represents the memory and time bottleneck, can be reduced from \\(\mathcal{O}(n_s \times n_s)\\) to
+\\(\mathcal{O}(n_s \times w)\\), with \\(n_s\\) being the sequence length and \\(w\\) being the average window
+size. It is assumed that the number of "globally" attending tokens is insignificant as compared to the number of
+"locally" attending tokens.
+
+For more information, please refer to the official [paper](https://arxiv.org/pdf/2004.05150.pdf).
+
+
+## Training
+
+[`LongformerForMaskedLM`] is trained the exact same way [`RobertaForMaskedLM`] is
+trained and should be used as follows:
+
+```python
+input_ids = tokenizer.encode("This is a sentence from [MASK] training data", return_tensors="pt")
+mlm_labels = tokenizer.encode("This is a sentence from the training data", return_tensors="pt")
+
+loss = model(input_ids, labels=input_ids, masked_lm_labels=mlm_labels)[0]
+```
+
+## LongformerConfig
+
+[[autodoc]] LongformerConfig
+
+## LongformerTokenizer
+
+[[autodoc]] LongformerTokenizer
+
+## LongformerTokenizerFast
+
+[[autodoc]] LongformerTokenizerFast
+
+## Longformer specific outputs
+
+[[autodoc]] models.longformer.modeling_longformer.LongformerBaseModelOutput
+
+[[autodoc]] models.longformer.modeling_longformer.LongformerBaseModelOutputWithPooling
+
+[[autodoc]] models.longformer.modeling_longformer.LongformerMaskedLMOutput
+
+[[autodoc]] models.longformer.modeling_longformer.LongformerQuestionAnsweringModelOutput
+
+[[autodoc]] models.longformer.modeling_longformer.LongformerSequenceClassifierOutput
+
+[[autodoc]] models.longformer.modeling_longformer.LongformerMultipleChoiceModelOutput
+
+[[autodoc]] models.longformer.modeling_longformer.LongformerTokenClassifierOutput
+
+[[autodoc]] models.longformer.modeling_tf_longformer.TFLongformerBaseModelOutput
+
+[[autodoc]] models.longformer.modeling_tf_longformer.TFLongformerBaseModelOutputWithPooling
+
+[[autodoc]] models.longformer.modeling_tf_longformer.TFLongformerMaskedLMOutput
+
+[[autodoc]] models.longformer.modeling_tf_longformer.TFLongformerQuestionAnsweringModelOutput
+
+[[autodoc]] models.longformer.modeling_tf_longformer.TFLongformerSequenceClassifierOutput
+
+[[autodoc]] models.longformer.modeling_tf_longformer.TFLongformerMultipleChoiceModelOutput
+
+[[autodoc]] models.longformer.modeling_tf_longformer.TFLongformerTokenClassifierOutput
+
+## LongformerModel
+
+[[autodoc]] LongformerModel
+ - forward
+
+## LongformerForMaskedLM
+
+[[autodoc]] LongformerForMaskedLM
+ - forward
+
+## LongformerForSequenceClassification
+
+[[autodoc]] LongformerForSequenceClassification
+ - forward
+
+## LongformerForMultipleChoice
+
+[[autodoc]] LongformerForMultipleChoice
+ - forward
+
+## LongformerForTokenClassification
+
+[[autodoc]] LongformerForTokenClassification
+ - forward
+
+## LongformerForQuestionAnswering
+
+[[autodoc]] LongformerForQuestionAnswering
+ - forward
+
+## TFLongformerModel
+
+[[autodoc]] TFLongformerModel
+ - call
+
+## TFLongformerForMaskedLM
+
+[[autodoc]] TFLongformerForMaskedLM
+ - call
+
+## TFLongformerForQuestionAnswering
+
+[[autodoc]] TFLongformerForQuestionAnswering
+ - call
+
+## TFLongformerForSequenceClassification
+
+[[autodoc]] TFLongformerForSequenceClassification
+ - call
+
+## TFLongformerForTokenClassification
+
+[[autodoc]] TFLongformerForTokenClassification
+ - call
+
+## TFLongformerForMultipleChoice
+
+[[autodoc]] TFLongformerForMultipleChoice
+ - call
diff --git a/docs/source/en/model_doc/luke.mdx b/docs/source/en/model_doc/luke.mdx
new file mode 100644
index 00000000000000..6900367bb8369e
--- /dev/null
+++ b/docs/source/en/model_doc/luke.mdx
@@ -0,0 +1,154 @@
+
+
+# LUKE
+
+## Overview
+
+The LUKE model was proposed in [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://arxiv.org/abs/2010.01057) by Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda and Yuji Matsumoto.
+It is based on RoBERTa and adds entity embeddings as well as an entity-aware self-attention mechanism, which helps
+improve performance on various downstream tasks involving reasoning about entities such as named entity recognition,
+extractive and cloze-style question answering, entity typing, and relation classification.
+
+The abstract from the paper is the following:
+
+*Entity representations are useful in natural language tasks involving entities. In this paper, we propose new
+pretrained contextualized representations of words and entities based on the bidirectional transformer. The proposed
+model treats words and entities in a given text as independent tokens, and outputs contextualized representations of
+them. Our model is trained using a new pretraining task based on the masked language model of BERT. The task involves
+predicting randomly masked words and entities in a large entity-annotated corpus retrieved from Wikipedia. We also
+propose an entity-aware self-attention mechanism that is an extension of the self-attention mechanism of the
+transformer, and considers the types of tokens (words or entities) when computing attention scores. The proposed model
+achieves impressive empirical performance on a wide range of entity-related tasks. In particular, it obtains
+state-of-the-art results on five well-known datasets: Open Entity (entity typing), TACRED (relation classification),
+CoNLL-2003 (named entity recognition), ReCoRD (cloze-style question answering), and SQuAD 1.1 (extractive question
+answering).*
+
+Tips:
+
+- This implementation is the same as [`RobertaModel`] with the addition of entity embeddings as well
+ as an entity-aware self-attention mechanism, which improves performance on tasks involving reasoning about entities.
+- LUKE treats entities as input tokens; therefore, it takes `entity_ids`, `entity_attention_mask`,
+ `entity_token_type_ids` and `entity_position_ids` as extra input. You can obtain those using
+ [`LukeTokenizer`].
+- [`LukeTokenizer`] takes `entities` and `entity_spans` (character-based start and end
+ positions of the entities in the input text) as extra input. `entities` typically consist of [MASK] entities or
+ Wikipedia entities. The brief description when inputting these entities are as follows:
+
+ - *Inputting [MASK] entities to compute entity representations*: The [MASK] entity is used to mask entities to be
+ predicted during pretraining. When LUKE receives the [MASK] entity, it tries to predict the original entity by
+ gathering the information about the entity from the input text. Therefore, the [MASK] entity can be used to address
+ downstream tasks requiring the information of entities in text such as entity typing, relation classification, and
+ named entity recognition.
+ - *Inputting Wikipedia entities to compute knowledge-enhanced token representations*: LUKE learns rich information
+ (or knowledge) about Wikipedia entities during pretraining and stores the information in its entity embedding. By
+ using Wikipedia entities as input tokens, LUKE outputs token representations enriched by the information stored in
+ the embeddings of these entities. This is particularly effective for tasks requiring real-world knowledge, such as
+ question answering.
+
+- There are three head models for the former use case:
+
+ - [`LukeForEntityClassification`], for tasks to classify a single entity in an input text such as
+ entity typing, e.g. the [Open Entity dataset](https://www.cs.utexas.edu/~eunsol/html_pages/open_entity.html).
+ This model places a linear head on top of the output entity representation.
+ - [`LukeForEntityPairClassification`], for tasks to classify the relationship between two entities
+ such as relation classification, e.g. the [TACRED dataset](https://nlp.stanford.edu/projects/tacred/). This
+ model places a linear head on top of the concatenated output representation of the pair of given entities.
+ - [`LukeForEntitySpanClassification`], for tasks to classify the sequence of entity spans, such as
+ named entity recognition (NER). This model places a linear head on top of the output entity representations. You
+ can address NER using this model by inputting all possible entity spans in the text to the model.
+
+ [`LukeTokenizer`] has a `task` argument, which enables you to easily create an input to these
+ head models by specifying `task="entity_classification"`, `task="entity_pair_classification"`, or
+ `task="entity_span_classification"`. Please refer to the example code of each head models.
+
+ A demo notebook on how to fine-tune [`LukeForEntityPairClassification`] for relation
+ classification can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/LUKE).
+
+ There are also 3 notebooks available, which showcase how you can reproduce the results as reported in the paper with
+ the HuggingFace implementation of LUKE. They can be found [here](https://github.com/studio-ousia/luke/tree/master/notebooks).
+
+Example:
+
+```python
+>>> from transformers import LukeTokenizer, LukeModel, LukeForEntityPairClassification
+
+>>> model = LukeModel.from_pretrained("studio-ousia/luke-base")
+>>> tokenizer = LukeTokenizer.from_pretrained("studio-ousia/luke-base")
+# Example 1: Computing the contextualized entity representation corresponding to the entity mention "Beyoncé"
+
+>>> text = "Beyoncé lives in Los Angeles."
+>>> entity_spans = [(0, 7)] # character-based entity span corresponding to "Beyoncé"
+>>> inputs = tokenizer(text, entity_spans=entity_spans, add_prefix_space=True, return_tensors="pt")
+>>> outputs = model(**inputs)
+>>> word_last_hidden_state = outputs.last_hidden_state
+>>> entity_last_hidden_state = outputs.entity_last_hidden_state
+# Example 2: Inputting Wikipedia entities to obtain enriched contextualized representations
+
+>>> entities = [
+... "Beyoncé",
+... "Los Angeles",
+... ] # Wikipedia entity titles corresponding to the entity mentions "Beyoncé" and "Los Angeles"
+>>> entity_spans = [(0, 7), (17, 28)] # character-based entity spans corresponding to "Beyoncé" and "Los Angeles"
+>>> inputs = tokenizer(text, entities=entities, entity_spans=entity_spans, add_prefix_space=True, return_tensors="pt")
+>>> outputs = model(**inputs)
+>>> word_last_hidden_state = outputs.last_hidden_state
+>>> entity_last_hidden_state = outputs.entity_last_hidden_state
+# Example 3: Classifying the relationship between two entities using LukeForEntityPairClassification head model
+
+>>> model = LukeForEntityPairClassification.from_pretrained("studio-ousia/luke-large-finetuned-tacred")
+>>> tokenizer = LukeTokenizer.from_pretrained("studio-ousia/luke-large-finetuned-tacred")
+>>> entity_spans = [(0, 7), (17, 28)] # character-based entity spans corresponding to "Beyoncé" and "Los Angeles"
+>>> inputs = tokenizer(text, entity_spans=entity_spans, return_tensors="pt")
+>>> outputs = model(**inputs)
+>>> logits = outputs.logits
+>>> predicted_class_idx = int(logits[0].argmax())
+>>> print("Predicted class:", model.config.id2label[predicted_class_idx])
+```
+
+This model was contributed by [ikuyamada](https://huggingface.co/ikuyamada) and [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/studio-ousia/luke).
+
+
+## LukeConfig
+
+[[autodoc]] LukeConfig
+
+## LukeTokenizer
+
+[[autodoc]] LukeTokenizer
+ - __call__
+ - save_vocabulary
+
+## LukeModel
+
+[[autodoc]] LukeModel
+ - forward
+
+## LukeForMaskedLM
+
+[[autodoc]] LukeForMaskedLM
+ - forward
+
+## LukeForEntityClassification
+
+[[autodoc]] LukeForEntityClassification
+ - forward
+
+## LukeForEntityPairClassification
+
+[[autodoc]] LukeForEntityPairClassification
+ - forward
+
+## LukeForEntitySpanClassification
+
+[[autodoc]] LukeForEntitySpanClassification
+ - forward
diff --git a/docs/source/en/model_doc/lxmert.mdx b/docs/source/en/model_doc/lxmert.mdx
new file mode 100644
index 00000000000000..51a5be07d7ed90
--- /dev/null
+++ b/docs/source/en/model_doc/lxmert.mdx
@@ -0,0 +1,102 @@
+
+
+# LXMERT
+
+## Overview
+
+The LXMERT model was proposed in [LXMERT: Learning Cross-Modality Encoder Representations from Transformers](https://arxiv.org/abs/1908.07490) by Hao Tan & Mohit Bansal. It is a series of bidirectional transformer encoders
+(one for the vision modality, one for the language modality, and then one to fuse both modalities) pretrained using a
+combination of masked language modeling, visual-language text alignment, ROI-feature regression, masked
+visual-attribute modeling, masked visual-object modeling, and visual-question answering objectives. The pretraining
+consists of multiple multi-modal datasets: MSCOCO, Visual-Genome + Visual-Genome Question Answering, VQA 2.0, and GQA.
+
+The abstract from the paper is the following:
+
+*Vision-and-language reasoning requires an understanding of visual concepts, language semantics, and, most importantly,
+the alignment and relationships between these two modalities. We thus propose the LXMERT (Learning Cross-Modality
+Encoder Representations from Transformers) framework to learn these vision-and-language connections. In LXMERT, we
+build a large-scale Transformer model that consists of three encoders: an object relationship encoder, a language
+encoder, and a cross-modality encoder. Next, to endow our model with the capability of connecting vision and language
+semantics, we pre-train the model with large amounts of image-and-sentence pairs, via five diverse representative
+pretraining tasks: masked language modeling, masked object prediction (feature regression and label classification),
+cross-modality matching, and image question answering. These tasks help in learning both intra-modality and
+cross-modality relationships. After fine-tuning from our pretrained parameters, our model achieves the state-of-the-art
+results on two visual question answering datasets (i.e., VQA and GQA). We also show the generalizability of our
+pretrained cross-modality model by adapting it to a challenging visual-reasoning task, NLVR, and improve the previous
+best result by 22% absolute (54% to 76%). Lastly, we demonstrate detailed ablation studies to prove that both our novel
+model components and pretraining strategies significantly contribute to our strong results; and also present several
+attention visualizations for the different encoders*
+
+Tips:
+
+- Bounding boxes are not necessary to be used in the visual feature embeddings, any kind of visual-spacial features
+ will work.
+- Both the language hidden states and the visual hidden states that LXMERT outputs are passed through the
+ cross-modality layer, so they contain information from both modalities. To access a modality that only attends to
+ itself, select the vision/language hidden states from the first input in the tuple.
+- The bidirectional cross-modality encoder attention only returns attention values when the language modality is used
+ as the input and the vision modality is used as the context vector. Further, while the cross-modality encoder
+ contains self-attention for each respective modality and cross-attention, only the cross attention is returned and
+ both self attention outputs are disregarded.
+
+This model was contributed by [eltoto1219](https://huggingface.co/eltoto1219). The original code can be found [here](https://github.com/airsplay/lxmert).
+
+
+## LxmertConfig
+
+[[autodoc]] LxmertConfig
+
+## LxmertTokenizer
+
+[[autodoc]] LxmertTokenizer
+
+## LxmertTokenizerFast
+
+[[autodoc]] LxmertTokenizerFast
+
+## Lxmert specific outputs
+
+[[autodoc]] models.lxmert.modeling_lxmert.LxmertModelOutput
+
+[[autodoc]] models.lxmert.modeling_lxmert.LxmertForPreTrainingOutput
+
+[[autodoc]] models.lxmert.modeling_lxmert.LxmertForQuestionAnsweringOutput
+
+[[autodoc]] models.lxmert.modeling_tf_lxmert.TFLxmertModelOutput
+
+[[autodoc]] models.lxmert.modeling_tf_lxmert.TFLxmertForPreTrainingOutput
+
+## LxmertModel
+
+[[autodoc]] LxmertModel
+ - forward
+
+## LxmertForPreTraining
+
+[[autodoc]] LxmertForPreTraining
+ - forward
+
+## LxmertForQuestionAnswering
+
+[[autodoc]] LxmertForQuestionAnswering
+ - forward
+
+## TFLxmertModel
+
+[[autodoc]] TFLxmertModel
+ - call
+
+## TFLxmertForPreTraining
+
+[[autodoc]] TFLxmertForPreTraining
+ - call
diff --git a/docs/source/en/model_doc/m2m_100.mdx b/docs/source/en/model_doc/m2m_100.mdx
new file mode 100644
index 00000000000000..65e119aa4eea5d
--- /dev/null
+++ b/docs/source/en/model_doc/m2m_100.mdx
@@ -0,0 +1,116 @@
+
+
+# M2M100
+
+## Overview
+
+The M2M100 model was proposed in [Beyond English-Centric Multilingual Machine Translation](https://arxiv.org/abs/2010.11125) by Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi Ma, Ahmed El-Kishky,
+Siddharth Goyal, Mandeep Baines, Onur Celebi, Guillaume Wenzek, Vishrav Chaudhary, Naman Goyal, Tom Birch, Vitaliy
+Liptchinsky, Sergey Edunov, Edouard Grave, Michael Auli, Armand Joulin.
+
+The abstract from the paper is the following:
+
+*Existing work in translation demonstrated the potential of massively multilingual machine translation by training a
+single model able to translate between any pair of languages. However, much of this work is English-Centric by training
+only on data which was translated from or to English. While this is supported by large sources of training data, it
+does not reflect translation needs worldwide. In this work, we create a true Many-to-Many multilingual translation
+model that can translate directly between any pair of 100 languages. We build and open source a training dataset that
+covers thousands of language directions with supervised data, created through large-scale mining. Then, we explore how
+to effectively increase model capacity through a combination of dense scaling and language-specific sparse parameters
+to create high quality models. Our focus on non-English-Centric models brings gains of more than 10 BLEU when directly
+translating between non-English directions while performing competitively to the best single systems of WMT. We
+open-source our scripts so that others may reproduce the data, evaluation, and final M2M-100 model.*
+
+This model was contributed by [valhalla](https://huggingface.co/valhalla).
+
+
+### Training and Generation
+
+M2M100 is a multilingual encoder-decoder (seq-to-seq) model primarily intended for translation tasks. As the model is
+multilingual it expects the sequences in a certain format: A special language id token is used as prefix in both the
+source and target text. The source text format is `[lang_code] X [eos]`, where `lang_code` is source language
+id for source text and target language id for target text, with `X` being the source or target text.
+
+The [`M2M100Tokenizer`] depends on `sentencepiece` so be sure to install it before running the
+examples. To install `sentencepiece` run `pip install sentencepiece`.
+
+- Supervised Training
+
+```python
+from transformers import M2M100Config, M2M100ForConditionalGeneration, M2M100Tokenizer
+
+model = M2M100ForConditionalGeneration.from_pretrained("facebook/m2m100_418M")
+tokenizer = M2M100Tokenizer.from_pretrained("facebook/m2m100_418M", src_lang="en", tgt_lang="fr")
+
+src_text = "Life is like a box of chocolates."
+tgt_text = "La vie est comme une boîte de chocolat."
+
+model_inputs = tokenizer(src_text, return_tensors="pt")
+with tokenizer.as_target_tokenizer():
+ labels = tokenizer(tgt_text, return_tensors="pt").input_ids
+
+loss = model(**model_inputs, labels=labels) # forward pass
+```
+
+- Generation
+
+ M2M100 uses the `eos_token_id` as the `decoder_start_token_id` for generation with the target language id
+ being forced as the first generated token. To force the target language id as the first generated token, pass the
+ *forced_bos_token_id* parameter to the *generate* method. The following example shows how to translate between
+ Hindi to French and Chinese to English using the *facebook/m2m100_418M* checkpoint.
+
+```python
+>>> from transformers import M2M100ForConditionalGeneration, M2M100Tokenizer
+
+>>> hi_text = "जीवन एक चॉकलेट बॉक्स की तरह है।"
+>>> chinese_text = "生活就像一盒巧克力。"
+
+>>> model = M2M100ForConditionalGeneration.from_pretrained("facebook/m2m100_418M")
+>>> tokenizer = M2M100Tokenizer.from_pretrained("facebook/m2m100_418M")
+
+>>> # translate Hindi to French
+>>> tokenizer.src_lang = "hi"
+>>> encoded_hi = tokenizer(hi_text, return_tensors="pt")
+>>> generated_tokens = model.generate(**encoded_hi, forced_bos_token_id=tokenizer.get_lang_id("fr"))
+>>> tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
+"La vie est comme une boîte de chocolat."
+
+>>> # translate Chinese to English
+>>> tokenizer.src_lang = "zh"
+>>> encoded_zh = tokenizer(chinese_text, return_tensors="pt")
+>>> generated_tokens = model.generate(**encoded_zh, forced_bos_token_id=tokenizer.get_lang_id("en"))
+>>> tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
+"Life is like a box of chocolate."
+```
+
+## M2M100Config
+
+[[autodoc]] M2M100Config
+
+## M2M100Tokenizer
+
+[[autodoc]] M2M100Tokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## M2M100Model
+
+[[autodoc]] M2M100Model
+ - forward
+
+## M2M100ForConditionalGeneration
+
+[[autodoc]] M2M100ForConditionalGeneration
+ - forward
diff --git a/docs/source/en/model_doc/marian.mdx b/docs/source/en/model_doc/marian.mdx
new file mode 100644
index 00000000000000..7b10c9309a0bb0
--- /dev/null
+++ b/docs/source/en/model_doc/marian.mdx
@@ -0,0 +1,193 @@
+
+
+# MarianMT
+
+**Bugs:** If you see something strange, file a [Github Issue](https://github.com/huggingface/transformers/issues/new?assignees=sshleifer&labels=&template=bug-report.md&title)
+and assign @patrickvonplaten.
+
+Translations should be similar, but not identical to output in the test set linked to in each model card.
+
+## Implementation Notes
+
+- Each model is about 298 MB on disk, there are more than 1,000 models.
+- The list of supported language pairs can be found [here](https://huggingface.co/Helsinki-NLP).
+- Models were originally trained by [Jörg Tiedemann](https://researchportal.helsinki.fi/en/persons/j%C3%B6rg-tiedemann) using the [Marian](https://marian-nmt.github.io/) C++ library, which supports fast training and translation.
+- All models are transformer encoder-decoders with 6 layers in each component. Each model's performance is documented
+ in a model card.
+- The 80 opus models that require BPE preprocessing are not supported.
+- The modeling code is the same as [`BartForConditionalGeneration`] with a few minor modifications:
+
+ - static (sinusoid) positional embeddings (`MarianConfig.static_position_embeddings=True`)
+ - no layernorm_embedding (`MarianConfig.normalize_embedding=False`)
+ - the model starts generating with `pad_token_id` (which has 0 as a token_embedding) as the prefix (Bart uses
+ ` +
+This model was contributed by [francesco](https://huggingface.co/francesco). The original code can be found [here](https://github.com/facebookresearch/MaskFormer).
+
+## MaskFormer specific outputs
+
+[[autodoc]] models.maskformer.modeling_maskformer.MaskFormerModelOutput
+
+[[autodoc]] models.maskformer.modeling_maskformer.MaskFormerForInstanceSegmentationOutput
+
+## MaskFormerConfig
+
+[[autodoc]] MaskFormerConfig
+
+## MaskFormerFeatureExtractor
+
+[[autodoc]] MaskFormerFeatureExtractor
+ - __call__
+ - encode_inputs
+ - post_process_segmentation
+ - post_process_semantic_segmentation
+ - post_process_panoptic_segmentation
+
+## MaskFormerModel
+
+[[autodoc]] MaskFormerModel
+ - forward
+
+## MaskFormerForInstanceSegmentation
+
+[[autodoc]] MaskFormerForInstanceSegmentation
+ - forward
diff --git a/docs/source/en/model_doc/mbart.mdx b/docs/source/en/model_doc/mbart.mdx
new file mode 100644
index 00000000000000..0f3d82ce5dac7a
--- /dev/null
+++ b/docs/source/en/model_doc/mbart.mdx
@@ -0,0 +1,229 @@
+
+
+# MBart and MBart-50
+
+**DISCLAIMER:** If you see something strange, file a [Github Issue](https://github.com/huggingface/transformers/issues/new?assignees=&labels=&template=bug-report.md&title) and assign
+@patrickvonplaten
+
+## Overview of MBart
+
+The MBart model was presented in [Multilingual Denoising Pre-training for Neural Machine Translation](https://arxiv.org/abs/2001.08210) by Yinhan Liu, Jiatao Gu, Naman Goyal, Xian Li, Sergey Edunov Marjan
+Ghazvininejad, Mike Lewis, Luke Zettlemoyer.
+
+According to the abstract, MBART is a sequence-to-sequence denoising auto-encoder pretrained on large-scale monolingual
+corpora in many languages using the BART objective. mBART is one of the first methods for pretraining a complete
+sequence-to-sequence model by denoising full texts in multiple languages, while previous approaches have focused only
+on the encoder, decoder, or reconstructing parts of the text.
+
+This model was contributed by [valhalla](https://huggingface.co/valhalla). The Authors' code can be found [here](https://github.com/pytorch/fairseq/tree/master/examples/mbart)
+
+### Training of MBart
+
+MBart is a multilingual encoder-decoder (sequence-to-sequence) model primarily intended for translation task. As the
+model is multilingual it expects the sequences in a different format. A special language id token is added in both the
+source and target text. The source text format is `X [eos, src_lang_code]` where `X` is the source text. The
+target text format is `[tgt_lang_code] X [eos]`. `bos` is never used.
+
+The regular [`~MBartTokenizer.__call__`] will encode source text format, and it should be wrapped
+inside the context manager [`~MBartTokenizer.as_target_tokenizer`] to encode target text format.
+
+- Supervised training
+
+```python
+>>> from transformers import MBartForConditionalGeneration, MBartTokenizer
+
+>>> tokenizer = MBartTokenizer.from_pretrained("facebook/mbart-large-en-ro", src_lang="en_XX", tgt_lang="ro_RO")
+>>> example_english_phrase = "UN Chief Says There Is No Military Solution in Syria"
+>>> expected_translation_romanian = "Şeful ONU declară că nu există o soluţie militară în Siria"
+
+>>> inputs = tokenizer(example_english_phrase, return_tensors="pt")
+>>> with tokenizer.as_target_tokenizer():
+... labels = tokenizer(expected_translation_romanian, return_tensors="pt")
+
+>>> model = MBartForConditionalGeneration.from_pretrained("facebook/mbart-large-en-ro")
+>>> # forward pass
+>>> model(**inputs, labels=batch["labels"])
+```
+
+- Generation
+
+ While generating the target text set the `decoder_start_token_id` to the target language id. The following
+ example shows how to translate English to Romanian using the *facebook/mbart-large-en-ro* model.
+
+```python
+>>> from transformers import MBartForConditionalGeneration, MBartTokenizer
+
+>>> tokenizer = MBartTokenizer.from_pretrained("facebook/mbart-large-en-ro", src_lang="en_XX")
+>>> article = "UN Chief Says There Is No Military Solution in Syria"
+>>> inputs = tokenizer(article, return_tensors="pt")
+>>> translated_tokens = model.generate(**inputs, decoder_start_token_id=tokenizer.lang_code_to_id["ro_RO"])
+>>> tokenizer.batch_decode(translated_tokens, skip_special_tokens=True)[0]
+"Şeful ONU declară că nu există o soluţie militară în Siria"
+```
+
+## Overview of MBart-50
+
+MBart-50 was introduced in the [Multilingual Translation with Extensible Multilingual Pretraining and Finetuning](https://arxiv.org/abs/2008.00401) paper by Yuqing Tang, Chau Tran, Xian Li, Peng-Jen Chen, Naman Goyal, Vishrav
+Chaudhary, Jiatao Gu, Angela Fan. MBart-50 is created using the original *mbart-large-cc25* checkpoint by extendeding
+its embedding layers with randomly initialized vectors for an extra set of 25 language tokens and then pretrained on 50
+languages.
+
+According to the abstract
+
+*Multilingual translation models can be created through multilingual finetuning. Instead of finetuning on one
+direction, a pretrained model is finetuned on many directions at the same time. It demonstrates that pretrained models
+can be extended to incorporate additional languages without loss of performance. Multilingual finetuning improves on
+average 1 BLEU over the strongest baselines (being either multilingual from scratch or bilingual finetuning) while
+improving 9.3 BLEU on average over bilingual baselines from scratch.*
+
+
+### Training of MBart-50
+
+The text format for MBart-50 is slightly different from mBART. For MBart-50 the language id token is used as a prefix
+for both source and target text i.e the text format is `[lang_code] X [eos]`, where `lang_code` is source
+language id for source text and target language id for target text, with `X` being the source or target text
+respectively.
+
+
+MBart-50 has its own tokenizer [`MBart50Tokenizer`].
+
+- Supervised training
+
+```python
+from transformers import MBartForConditionalGeneration, MBart50TokenizerFast
+
+model = MBartForConditionalGeneration.from_pretrained("facebook/mbart-large-50")
+tokenizer = MBart50TokenizerFast.from_pretrained("facebook/mbart-large-50", src_lang="en_XX", tgt_lang="ro_RO")
+
+src_text = " UN Chief Says There Is No Military Solution in Syria"
+tgt_text = "Şeful ONU declară că nu există o soluţie militară în Siria"
+
+model_inputs = tokenizer(src_text, return_tensors="pt")
+with tokenizer.as_target_tokenizer():
+ labels = tokenizer(tgt_text, return_tensors="pt").input_ids
+
+model(**model_inputs, labels=labels) # forward pass
+```
+
+- Generation
+
+ To generate using the mBART-50 multilingual translation models, `eos_token_id` is used as the
+ `decoder_start_token_id` and the target language id is forced as the first generated token. To force the
+ target language id as the first generated token, pass the *forced_bos_token_id* parameter to the *generate* method.
+ The following example shows how to translate between Hindi to French and Arabic to English using the
+ *facebook/mbart-50-large-many-to-many* checkpoint.
+
+```python
+from transformers import MBartForConditionalGeneration, MBart50TokenizerFast
+
+article_hi = "संयुक्त राष्ट्र के प्रमुख का कहना है कि सीरिया में कोई सैन्य समाधान नहीं है"
+article_ar = "الأمين العام للأمم المتحدة يقول إنه لا يوجد حل عسكري في سوريا."
+
+model = MBartForConditionalGeneration.from_pretrained("facebook/mbart-large-50-many-to-many-mmt")
+tokenizer = MBart50TokenizerFast.from_pretrained("facebook/mbart-large-50-many-to-many-mmt")
+
+# translate Hindi to French
+tokenizer.src_lang = "hi_IN"
+encoded_hi = tokenizer(article_hi, return_tensors="pt")
+generated_tokens = model.generate(**encoded_hi, forced_bos_token_id=tokenizer.lang_code_to_id["fr_XX"])
+tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
+# => "Le chef de l 'ONU affirme qu 'il n 'y a pas de solution militaire en Syria."
+
+# translate Arabic to English
+tokenizer.src_lang = "ar_AR"
+encoded_ar = tokenizer(article_ar, return_tensors="pt")
+generated_tokens = model.generate(**encoded_ar, forced_bos_token_id=tokenizer.lang_code_to_id["en_XX"])
+tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
+# => "The Secretary-General of the United Nations says there is no military solution in Syria."
+```
+
+## MBartConfig
+
+[[autodoc]] MBartConfig
+
+## MBartTokenizer
+
+[[autodoc]] MBartTokenizer
+ - as_target_tokenizer
+ - build_inputs_with_special_tokens
+
+## MBartTokenizerFast
+
+[[autodoc]] MBartTokenizerFast
+
+## MBart50Tokenizer
+
+[[autodoc]] MBart50Tokenizer
+
+## MBart50TokenizerFast
+
+[[autodoc]] MBart50TokenizerFast
+
+## MBartModel
+
+[[autodoc]] MBartModel
+
+## MBartForConditionalGeneration
+
+[[autodoc]] MBartForConditionalGeneration
+
+## MBartForQuestionAnswering
+
+[[autodoc]] MBartForQuestionAnswering
+
+## MBartForSequenceClassification
+
+[[autodoc]] MBartForSequenceClassification
+
+## MBartForCausalLM
+
+[[autodoc]] MBartForCausalLM
+ - forward
+
+## TFMBartModel
+
+[[autodoc]] TFMBartModel
+ - call
+
+## TFMBartForConditionalGeneration
+
+[[autodoc]] TFMBartForConditionalGeneration
+ - call
+
+## FlaxMBartModel
+
+[[autodoc]] FlaxMBartModel
+ - __call__
+ - encode
+ - decode
+
+## FlaxMBartForConditionalGeneration
+
+[[autodoc]] FlaxMBartForConditionalGeneration
+ - __call__
+ - encode
+ - decode
+
+## FlaxMBartForSequenceClassification
+
+[[autodoc]] FlaxMBartForSequenceClassification
+ - __call__
+ - encode
+ - decode
+
+## FlaxMBartForQuestionAnswering
+
+[[autodoc]] FlaxMBartForQuestionAnswering
+ - __call__
+ - encode
+ - decode
diff --git a/docs/source/en/model_doc/megatron-bert.mdx b/docs/source/en/model_doc/megatron-bert.mdx
new file mode 100644
index 00000000000000..911bf76aec2789
--- /dev/null
+++ b/docs/source/en/model_doc/megatron-bert.mdx
@@ -0,0 +1,128 @@
+
+
+# MegatronBERT
+
+## Overview
+
+The MegatronBERT model was proposed in [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model
+Parallelism](https://arxiv.org/abs/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley,
+Jared Casper and Bryan Catanzaro.
+
+The abstract from the paper is the following:
+
+*Recent work in language modeling demonstrates that training large transformer models advances the state of the art in
+Natural Language Processing applications. However, very large models can be quite difficult to train due to memory
+constraints. In this work, we present our techniques for training very large transformer models and implement a simple,
+efficient intra-layer model parallel approach that enables training transformer models with billions of parameters. Our
+approach does not require a new compiler or library changes, is orthogonal and complimentary to pipeline model
+parallelism, and can be fully implemented with the insertion of a few communication operations in native PyTorch. We
+illustrate this approach by converging transformer based models up to 8.3 billion parameters using 512 GPUs. We sustain
+15.1 PetaFLOPs across the entire application with 76% scaling efficiency when compared to a strong single GPU baseline
+that sustains 39 TeraFLOPs, which is 30% of peak FLOPs. To demonstrate that large language models can further advance
+the state of the art (SOTA), we train an 8.3 billion parameter transformer language model similar to GPT-2 and a 3.9
+billion parameter model similar to BERT. We show that careful attention to the placement of layer normalization in
+BERT-like models is critical to achieving increased performance as the model size grows. Using the GPT-2 model we
+achieve SOTA results on the WikiText103 (10.8 compared to SOTA perplexity of 15.8) and LAMBADA (66.5% compared to SOTA
+accuracy of 63.2%) datasets. Our BERT model achieves SOTA results on the RACE dataset (90.9% compared to SOTA accuracy
+of 89.4%).*
+
+Tips:
+
+We have provided pretrained [BERT-345M](https://ngc.nvidia.com/catalog/models/nvidia:megatron_bert_345m) checkpoints
+for use to evaluate or finetuning downstream tasks.
+
+To access these checkpoints, first [sign up](https://ngc.nvidia.com/signup) for and setup the NVIDIA GPU Cloud (NGC)
+Registry CLI. Further documentation for downloading models can be found in the [NGC documentation](https://docs.nvidia.com/dgx/ngc-registry-cli-user-guide/index.html#topic_6_4_1).
+
+Alternatively, you can directly download the checkpoints using:
+
+BERT-345M-uncased:
+
+```bash
+wget --content-disposition https://api.ngc.nvidia.com/v2/models/nvidia/megatron_bert_345m/versions/v0.1_uncased/zip
+-O megatron_bert_345m_v0_1_uncased.zip
+```
+
+BERT-345M-cased:
+
+```bash
+wget --content-disposition https://api.ngc.nvidia.com/v2/models/nvidia/megatron_bert_345m/versions/v0.1_cased/zip -O
+megatron_bert_345m_v0_1_cased.zip
+```
+
+Once you have obtained the checkpoints from NVIDIA GPU Cloud (NGC), you have to convert them to a format that will
+easily be loaded by Hugging Face Transformers and our port of the BERT code.
+
+The following commands allow you to do the conversion. We assume that the folder `models/megatron_bert` contains
+`megatron_bert_345m_v0_1_{cased, uncased}.zip` and that the commands are run from inside that folder:
+
+```bash
+python3 $PATH_TO_TRANSFORMERS/models/megatron_bert/convert_megatron_bert_checkpoint.py megatron_bert_345m_v0_1_uncased.zip
+```
+
+```bash
+python3 $PATH_TO_TRANSFORMERS/models/megatron_bert/convert_megatron_bert_checkpoint.py megatron_bert_345m_v0_1_cased.zip
+```
+
+This model was contributed by [jdemouth](https://huggingface.co/jdemouth). The original code can be found [here](https://github.com/NVIDIA/Megatron-LM). That repository contains a multi-GPU and multi-node implementation of the
+Megatron Language models. In particular, it contains a hybrid model parallel approach using "tensor parallel" and
+"pipeline parallel" techniques.
+
+## MegatronBertConfig
+
+[[autodoc]] MegatronBertConfig
+
+## MegatronBertModel
+
+[[autodoc]] MegatronBertModel
+ - forward
+
+## MegatronBertForMaskedLM
+
+[[autodoc]] MegatronBertForMaskedLM
+ - forward
+
+## MegatronBertForCausalLM
+
+[[autodoc]] MegatronBertForCausalLM
+ - forward
+
+## MegatronBertForNextSentencePrediction
+
+[[autodoc]] MegatronBertForNextSentencePrediction
+ - forward
+
+## MegatronBertForPreTraining
+
+[[autodoc]] MegatronBertForPreTraining
+ - forward
+
+## MegatronBertForSequenceClassification
+
+[[autodoc]] MegatronBertForSequenceClassification
+ - forward
+
+## MegatronBertForMultipleChoice
+
+[[autodoc]] MegatronBertForMultipleChoice
+ - forward
+
+## MegatronBertForTokenClassification
+
+[[autodoc]] MegatronBertForTokenClassification
+ - forward
+
+## MegatronBertForQuestionAnswering
+
+[[autodoc]] MegatronBertForQuestionAnswering
+ - forward
diff --git a/docs/source/en/model_doc/megatron_gpt2.mdx b/docs/source/en/model_doc/megatron_gpt2.mdx
new file mode 100644
index 00000000000000..a0d91e5a163055
--- /dev/null
+++ b/docs/source/en/model_doc/megatron_gpt2.mdx
@@ -0,0 +1,67 @@
+
+
+# MegatronGPT2
+
+## Overview
+
+The MegatronGPT2 model was proposed in [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model
+Parallelism](https://arxiv.org/abs/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley,
+Jared Casper and Bryan Catanzaro.
+
+The abstract from the paper is the following:
+
+*Recent work in language modeling demonstrates that training large transformer models advances the state of the art in
+Natural Language Processing applications. However, very large models can be quite difficult to train due to memory
+constraints. In this work, we present our techniques for training very large transformer models and implement a simple,
+efficient intra-layer model parallel approach that enables training transformer models with billions of parameters. Our
+approach does not require a new compiler or library changes, is orthogonal and complimentary to pipeline model
+parallelism, and can be fully implemented with the insertion of a few communication operations in native PyTorch. We
+illustrate this approach by converging transformer based models up to 8.3 billion parameters using 512 GPUs. We sustain
+15.1 PetaFLOPs across the entire application with 76% scaling efficiency when compared to a strong single GPU baseline
+that sustains 39 TeraFLOPs, which is 30% of peak FLOPs. To demonstrate that large language models can further advance
+the state of the art (SOTA), we train an 8.3 billion parameter transformer language model similar to GPT-2 and a 3.9
+billion parameter model similar to BERT. We show that careful attention to the placement of layer normalization in
+BERT-like models is critical to achieving increased performance as the model size grows. Using the GPT-2 model we
+achieve SOTA results on the WikiText103 (10.8 compared to SOTA perplexity of 15.8) and LAMBADA (66.5% compared to SOTA
+accuracy of 63.2%) datasets. Our BERT model achieves SOTA results on the RACE dataset (90.9% compared to SOTA accuracy
+of 89.4%).*
+
+Tips:
+
+We have provided pretrained [GPT2-345M](https://ngc.nvidia.com/catalog/models/nvidia:megatron_lm_345m) checkpoints
+for use to evaluate or finetuning downstream tasks.
+
+To access these checkpoints, first [sign up](https://ngc.nvidia.com/signup) for and setup the NVIDIA GPU Cloud (NGC)
+Registry CLI. Further documentation for downloading models can be found in the [NGC documentation](https://docs.nvidia.com/dgx/ngc-registry-cli-user-guide/index.html#topic_6_4_1).
+
+Alternatively, you can directly download the checkpoints using:
+
+```bash
+wget --content-disposition https://api.ngc.nvidia.com/v2/models/nvidia/megatron_lm_345m/versions/v0.0/zip -O
+megatron_gpt2_345m_v0_0.zip
+```
+
+Once you have obtained the checkpoint from NVIDIA GPU Cloud (NGC), you have to convert it to a format that will easily
+be loaded by Hugging Face Transformers GPT2 implementation.
+
+The following command allows you to do the conversion. We assume that the folder `models/megatron_gpt2` contains
+`megatron_gpt2_345m_v0_0.zip` and that the command is run from that folder:
+
+```bash
+python3 $PATH_TO_TRANSFORMERS/models/megatron_gpt2/convert_megatron_gpt2_checkpoint.py megatron_gpt2_345m_v0_0.zip
+```
+
+This model was contributed by [jdemouth](https://huggingface.co/jdemouth). The original code can be found [here](https://github.com/NVIDIA/Megatron-LM). That repository contains a multi-GPU and multi-node implementation of the
+Megatron Language models. In particular, it contains a hybrid model parallel approach using "tensor parallel" and
+"pipeline parallel" techniques.
+
diff --git a/docs/source/en/model_doc/mluke.mdx b/docs/source/en/model_doc/mluke.mdx
new file mode 100644
index 00000000000000..b910f17ae2f6b1
--- /dev/null
+++ b/docs/source/en/model_doc/mluke.mdx
@@ -0,0 +1,61 @@
+
+
+# mLUKE
+
+## Overview
+
+The mLUKE model was proposed in [mLUKE: The Power of Entity Representations in Multilingual Pretrained Language Models](https://arxiv.org/abs/2110.08151) by Ryokan Ri, Ikuya Yamada, and Yoshimasa Tsuruoka. It's a multilingual extension
+of the [LUKE model](https://arxiv.org/abs/2010.01057) trained on the basis of XLM-RoBERTa.
+
+It is based on XLM-RoBERTa and adds entity embeddings, which helps improve performance on various downstream tasks
+involving reasoning about entities such as named entity recognition, extractive question answering, relation
+classification, cloze-style knowledge completion.
+
+The abstract from the paper is the following:
+
+*Recent studies have shown that multilingual pretrained language models can be effectively improved with cross-lingual
+alignment information from Wikipedia entities. However, existing methods only exploit entity information in pretraining
+and do not explicitly use entities in downstream tasks. In this study, we explore the effectiveness of leveraging
+entity representations for downstream cross-lingual tasks. We train a multilingual language model with 24 languages
+with entity representations and show the model consistently outperforms word-based pretrained models in various
+cross-lingual transfer tasks. We also analyze the model and the key insight is that incorporating entity
+representations into the input allows us to extract more language-agnostic features. We also evaluate the model with a
+multilingual cloze prompt task with the mLAMA dataset. We show that entity-based prompt elicits correct factual
+knowledge more likely than using only word representations.*
+
+One can directly plug in the weights of mLUKE into a LUKE model, like so:
+
+```python
+from transformers import LukeModel
+
+model = LukeModel.from_pretrained("studio-ousia/mluke-base")
+```
+
+Note that mLUKE has its own tokenizer, [`MLukeTokenizer`]. You can initialize it as follows:
+
+```python
+from transformers import MLukeTokenizer
+
+tokenizer = MLukeTokenizer.from_pretrained("studio-ousia/mluke-base")
+```
+
+As mLUKE's architecture is equivalent to that of LUKE, one can refer to [LUKE's documentation page](luke) for all
+tips, code examples and notebooks.
+
+This model was contributed by [ryo0634](https://huggingface.co/ryo0634). The original code can be found [here](https://github.com/studio-ousia/luke).
+
+## MLukeTokenizer
+
+[[autodoc]] MLukeTokenizer
+ - __call__
+ - save_vocabulary
diff --git a/docs/source/en/model_doc/mobilebert.mdx b/docs/source/en/model_doc/mobilebert.mdx
new file mode 100644
index 00000000000000..8305903d23c70e
--- /dev/null
+++ b/docs/source/en/model_doc/mobilebert.mdx
@@ -0,0 +1,142 @@
+
+
+# MobileBERT
+
+## Overview
+
+The MobileBERT model was proposed in [MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices](https://arxiv.org/abs/2004.02984) by Zhiqing Sun, Hongkun Yu, Xiaodan Song, Renjie Liu, Yiming Yang, and Denny
+Zhou. It's a bidirectional transformer based on the BERT model, which is compressed and accelerated using several
+approaches.
+
+The abstract from the paper is the following:
+
+*Natural Language Processing (NLP) has recently achieved great success by using huge pre-trained models with hundreds
+of millions of parameters. However, these models suffer from heavy model sizes and high latency such that they cannot
+be deployed to resource-limited mobile devices. In this paper, we propose MobileBERT for compressing and accelerating
+the popular BERT model. Like the original BERT, MobileBERT is task-agnostic, that is, it can be generically applied to
+various downstream NLP tasks via simple fine-tuning. Basically, MobileBERT is a thin version of BERT_LARGE, while
+equipped with bottleneck structures and a carefully designed balance between self-attentions and feed-forward networks.
+To train MobileBERT, we first train a specially designed teacher model, an inverted-bottleneck incorporated BERT_LARGE
+model. Then, we conduct knowledge transfer from this teacher to MobileBERT. Empirical studies show that MobileBERT is
+4.3x smaller and 5.5x faster than BERT_BASE while achieving competitive results on well-known benchmarks. On the
+natural language inference tasks of GLUE, MobileBERT achieves a GLUEscore o 77.7 (0.6 lower than BERT_BASE), and 62 ms
+latency on a Pixel 4 phone. On the SQuAD v1.1/v2.0 question answering task, MobileBERT achieves a dev F1 score of
+90.0/79.2 (1.5/2.1 higher than BERT_BASE).*
+
+Tips:
+
+- MobileBERT is a model with absolute position embeddings so it's usually advised to pad the inputs on the right rather
+ than the left.
+- MobileBERT is similar to BERT and therefore relies on the masked language modeling (MLM) objective. It is therefore
+ efficient at predicting masked tokens and at NLU in general, but is not optimal for text generation. Models trained
+ with a causal language modeling (CLM) objective are better in that regard.
+
+This model was contributed by [vshampor](https://huggingface.co/vshampor). The original code can be found [here](https://github.com/google-research/mobilebert).
+
+## MobileBertConfig
+
+[[autodoc]] MobileBertConfig
+
+## MobileBertTokenizer
+
+[[autodoc]] MobileBertTokenizer
+
+## MobileBertTokenizerFast
+
+[[autodoc]] MobileBertTokenizerFast
+
+## MobileBert specific outputs
+
+[[autodoc]] models.mobilebert.modeling_mobilebert.MobileBertForPreTrainingOutput
+
+[[autodoc]] models.mobilebert.modeling_tf_mobilebert.TFMobileBertForPreTrainingOutput
+
+## MobileBertModel
+
+[[autodoc]] MobileBertModel
+ - forward
+
+## MobileBertForPreTraining
+
+[[autodoc]] MobileBertForPreTraining
+ - forward
+
+## MobileBertForMaskedLM
+
+[[autodoc]] MobileBertForMaskedLM
+ - forward
+
+## MobileBertForNextSentencePrediction
+
+[[autodoc]] MobileBertForNextSentencePrediction
+ - forward
+
+## MobileBertForSequenceClassification
+
+[[autodoc]] MobileBertForSequenceClassification
+ - forward
+
+## MobileBertForMultipleChoice
+
+[[autodoc]] MobileBertForMultipleChoice
+ - forward
+
+## MobileBertForTokenClassification
+
+[[autodoc]] MobileBertForTokenClassification
+ - forward
+
+## MobileBertForQuestionAnswering
+
+[[autodoc]] MobileBertForQuestionAnswering
+ - forward
+
+## TFMobileBertModel
+
+[[autodoc]] TFMobileBertModel
+ - call
+
+## TFMobileBertForPreTraining
+
+[[autodoc]] TFMobileBertForPreTraining
+ - call
+
+## TFMobileBertForMaskedLM
+
+[[autodoc]] TFMobileBertForMaskedLM
+ - call
+
+## TFMobileBertForNextSentencePrediction
+
+[[autodoc]] TFMobileBertForNextSentencePrediction
+ - call
+
+## TFMobileBertForSequenceClassification
+
+[[autodoc]] TFMobileBertForSequenceClassification
+ - call
+
+## TFMobileBertForMultipleChoice
+
+[[autodoc]] TFMobileBertForMultipleChoice
+ - call
+
+## TFMobileBertForTokenClassification
+
+[[autodoc]] TFMobileBertForTokenClassification
+ - call
+
+## TFMobileBertForQuestionAnswering
+
+[[autodoc]] TFMobileBertForQuestionAnswering
+ - call
diff --git a/docs/source/en/model_doc/mpnet.mdx b/docs/source/en/model_doc/mpnet.mdx
new file mode 100644
index 00000000000000..0fa88ee87b7259
--- /dev/null
+++ b/docs/source/en/model_doc/mpnet.mdx
@@ -0,0 +1,117 @@
+
+
+# MPNet
+
+## Overview
+
+The MPNet model was proposed in [MPNet: Masked and Permuted Pre-training for Language Understanding](https://arxiv.org/abs/2004.09297) by Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, Tie-Yan Liu.
+
+MPNet adopts a novel pre-training method, named masked and permuted language modeling, to inherit the advantages of
+masked language modeling and permuted language modeling for natural language understanding.
+
+The abstract from the paper is the following:
+
+*BERT adopts masked language modeling (MLM) for pre-training and is one of the most successful pre-training models.
+Since BERT neglects dependency among predicted tokens, XLNet introduces permuted language modeling (PLM) for
+pre-training to address this problem. However, XLNet does not leverage the full position information of a sentence and
+thus suffers from position discrepancy between pre-training and fine-tuning. In this paper, we propose MPNet, a novel
+pre-training method that inherits the advantages of BERT and XLNet and avoids their limitations. MPNet leverages the
+dependency among predicted tokens through permuted language modeling (vs. MLM in BERT), and takes auxiliary position
+information as input to make the model see a full sentence and thus reducing the position discrepancy (vs. PLM in
+XLNet). We pre-train MPNet on a large-scale dataset (over 160GB text corpora) and fine-tune on a variety of
+down-streaming tasks (GLUE, SQuAD, etc). Experimental results show that MPNet outperforms MLM and PLM by a large
+margin, and achieves better results on these tasks compared with previous state-of-the-art pre-trained methods (e.g.,
+BERT, XLNet, RoBERTa) under the same model setting.*
+
+Tips:
+
+- MPNet doesn't have `token_type_ids`, you don't need to indicate which token belongs to which segment. just
+ separate your segments with the separation token `tokenizer.sep_token` (or `[sep]`).
+
+The original code can be found [here](https://github.com/microsoft/MPNet).
+
+## MPNetConfig
+
+[[autodoc]] MPNetConfig
+
+## MPNetTokenizer
+
+[[autodoc]] MPNetTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## MPNetTokenizerFast
+
+[[autodoc]] MPNetTokenizerFast
+
+## MPNetModel
+
+[[autodoc]] MPNetModel
+ - forward
+
+## MPNetForMaskedLM
+
+[[autodoc]] MPNetForMaskedLM
+ - forward
+
+## MPNetForSequenceClassification
+
+[[autodoc]] MPNetForSequenceClassification
+ - forward
+
+## MPNetForMultipleChoice
+
+[[autodoc]] MPNetForMultipleChoice
+ - forward
+
+## MPNetForTokenClassification
+
+[[autodoc]] MPNetForTokenClassification
+ - forward
+
+## MPNetForQuestionAnswering
+
+[[autodoc]] MPNetForQuestionAnswering
+ - forward
+
+## TFMPNetModel
+
+[[autodoc]] TFMPNetModel
+ - call
+
+## TFMPNetForMaskedLM
+
+[[autodoc]] TFMPNetForMaskedLM
+ - call
+
+## TFMPNetForSequenceClassification
+
+[[autodoc]] TFMPNetForSequenceClassification
+ - call
+
+## TFMPNetForMultipleChoice
+
+[[autodoc]] TFMPNetForMultipleChoice
+ - call
+
+## TFMPNetForTokenClassification
+
+[[autodoc]] TFMPNetForTokenClassification
+ - call
+
+## TFMPNetForQuestionAnswering
+
+[[autodoc]] TFMPNetForQuestionAnswering
+ - call
diff --git a/docs/source/en/model_doc/mt5.mdx b/docs/source/en/model_doc/mt5.mdx
new file mode 100644
index 00000000000000..fa39e4ab2cd0a0
--- /dev/null
+++ b/docs/source/en/model_doc/mt5.mdx
@@ -0,0 +1,98 @@
+
+
+# mT5
+
+## Overview
+
+The mT5 model was presented in [mT5: A massively multilingual pre-trained text-to-text transformer](https://arxiv.org/abs/2010.11934) by Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya
+Siddhant, Aditya Barua, Colin Raffel.
+
+The abstract from the paper is the following:
+
+*The recent "Text-to-Text Transfer Transformer" (T5) leveraged a unified text-to-text format and scale to attain
+state-of-the-art results on a wide variety of English-language NLP tasks. In this paper, we introduce mT5, a
+multilingual variant of T5 that was pre-trained on a new Common Crawl-based dataset covering 101 languages. We detail
+the design and modified training of mT5 and demonstrate its state-of-the-art performance on many multilingual
+benchmarks. We also describe a simple technique to prevent "accidental translation" in the zero-shot setting, where a
+generative model chooses to (partially) translate its prediction into the wrong language. All of the code and model
+checkpoints used in this work are publicly available.*
+
+Note: mT5 was only pre-trained on [mC4](https://huggingface.co/datasets/mc4) excluding any supervised training.
+Therefore, this model has to be fine-tuned before it is useable on a downstream task, unlike the original T5 model.
+Since mT5 was pre-trained unsupervisedly, there's no real advantage to using a task prefix during single-task
+fine-tuning. If you are doing multi-task fine-tuning, you should use a prefix.
+
+Google has released the following variants:
+
+- [google/mt5-small](https://huggingface.co/google/mt5-small)
+
+- [google/mt5-base](https://huggingface.co/google/mt5-base)
+
+- [google/mt5-large](https://huggingface.co/google/mt5-large)
+
+- [google/mt5-xl](https://huggingface.co/google/mt5-xl)
+
+- [google/mt5-xxl](https://huggingface.co/google/mt5-xxl).
+
+This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten). The original code can be
+found [here](https://github.com/google-research/multilingual-t5).
+
+## MT5Config
+
+[[autodoc]] MT5Config
+
+## MT5Tokenizer
+
+[[autodoc]] MT5Tokenizer
+
+See [`T5Tokenizer`] for all details.
+
+
+## MT5TokenizerFast
+
+[[autodoc]] MT5TokenizerFast
+
+See [`T5TokenizerFast`] for all details.
+
+
+## MT5Model
+
+[[autodoc]] MT5Model
+
+## MT5ForConditionalGeneration
+
+[[autodoc]] MT5ForConditionalGeneration
+
+## MT5EncoderModel
+
+[[autodoc]] MT5EncoderModel
+
+## TFMT5Model
+
+[[autodoc]] TFMT5Model
+
+## TFMT5ForConditionalGeneration
+
+[[autodoc]] TFMT5ForConditionalGeneration
+
+## TFMT5EncoderModel
+
+[[autodoc]] TFMT5EncoderModel
+
+## FlaxMT5Model
+
+[[autodoc]] FlaxMT5Model
+
+## FlaxMT5ForConditionalGeneration
+
+[[autodoc]] FlaxMT5ForConditionalGeneration
diff --git a/docs/source/en/model_doc/nystromformer.mdx b/docs/source/en/model_doc/nystromformer.mdx
new file mode 100644
index 00000000000000..5c1619b57f1ea9
--- /dev/null
+++ b/docs/source/en/model_doc/nystromformer.mdx
@@ -0,0 +1,68 @@
+
+
+# Nyströmformer
+
+## Overview
+
+The Nyströmformer model was proposed in [*Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention*](https://arxiv.org/abs/2102.03902) by Yunyang Xiong, Zhanpeng Zeng, Rudrasis Chakraborty, Mingxing Tan, Glenn
+Fung, Yin Li, and Vikas Singh.
+
+The abstract from the paper is the following:
+
+*Transformers have emerged as a powerful tool for a broad range of natural language processing tasks. A key component
+that drives the impressive performance of Transformers is the self-attention mechanism that encodes the influence or
+dependence of other tokens on each specific token. While beneficial, the quadratic complexity of self-attention on the
+input sequence length has limited its application to longer sequences -- a topic being actively studied in the
+community. To address this limitation, we propose Nyströmformer -- a model that exhibits favorable scalability as a
+function of sequence length. Our idea is based on adapting the Nyström method to approximate standard self-attention
+with O(n) complexity. The scalability of Nyströmformer enables application to longer sequences with thousands of
+tokens. We perform evaluations on multiple downstream tasks on the GLUE benchmark and IMDB reviews with standard
+sequence length, and find that our Nyströmformer performs comparably, or in a few cases, even slightly better, than
+standard self-attention. On longer sequence tasks in the Long Range Arena (LRA) benchmark, Nyströmformer performs
+favorably relative to other efficient self-attention methods. Our code is available at this https URL.*
+
+This model was contributed by [novice03](https://huggingface.co/novice03). The original code can be found [here](https://github.com/mlpen/Nystromformer).
+
+## NystromformerConfig
+
+[[autodoc]] NystromformerConfig
+
+## NystromformerModel
+
+[[autodoc]] NystromformerModel
+ - forward
+
+## NystromformerForMaskedLM
+
+[[autodoc]] NystromformerForMaskedLM
+ - forward
+
+## NystromformerForSequenceClassification
+
+[[autodoc]] NystromformerForSequenceClassification
+ - forward
+
+## NystromformerForMultipleChoice
+
+[[autodoc]] NystromformerForMultipleChoice
+ - forward
+
+## NystromformerForTokenClassification
+
+[[autodoc]] NystromformerForTokenClassification
+ - forward
+
+## NystromformerForQuestionAnswering
+
+[[autodoc]] NystromformerForQuestionAnswering
+ - forward
diff --git a/docs/source/en/model_doc/openai-gpt.mdx b/docs/source/en/model_doc/openai-gpt.mdx
new file mode 100644
index 00000000000000..70213e795e9fa8
--- /dev/null
+++ b/docs/source/en/model_doc/openai-gpt.mdx
@@ -0,0 +1,117 @@
+
+
+# OpenAI GPT
+
+## Overview
+
+OpenAI GPT model was proposed in [Improving Language Understanding by Generative Pre-Training](https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf)
+by Alec Radford, Karthik Narasimhan, Tim Salimans and Ilya Sutskever. It's a causal (unidirectional) transformer
+pre-trained using language modeling on a large corpus will long range dependencies, the Toronto Book Corpus.
+
+The abstract from the paper is the following:
+
+*Natural language understanding comprises a wide range of diverse tasks such as textual entailment, question answering,
+semantic similarity assessment, and document classification. Although large unlabeled text corpora are abundant,
+labeled data for learning these specific tasks is scarce, making it challenging for discriminatively trained models to
+perform adequately. We demonstrate that large gains on these tasks can be realized by generative pretraining of a
+language model on a diverse corpus of unlabeled text, followed by discriminative fine-tuning on each specific task. In
+contrast to previous approaches, we make use of task-aware input transformations during fine-tuning to achieve
+effective transfer while requiring minimal changes to the model architecture. We demonstrate the effectiveness of our
+approach on a wide range of benchmarks for natural language understanding. Our general task-agnostic model outperforms
+discriminatively trained models that use architectures specifically crafted for each task, significantly improving upon
+the state of the art in 9 out of the 12 tasks studied.*
+
+Tips:
+
+- GPT is a model with absolute position embeddings so it's usually advised to pad the inputs on the right rather than
+ the left.
+- GPT was trained with a causal language modeling (CLM) objective and is therefore powerful at predicting the next
+ token in a sequence. Leveraging this feature allows GPT-2 to generate syntactically coherent text as it can be
+ observed in the *run_generation.py* example script.
+
+[Write With Transformer](https://transformer.huggingface.co/doc/gpt) is a webapp created and hosted by Hugging Face
+showcasing the generative capabilities of several models. GPT is one of them.
+
+This model was contributed by [thomwolf](https://huggingface.co/thomwolf). The original code can be found [here](https://github.com/openai/finetune-transformer-lm).
+
+Note:
+
+If you want to reproduce the original tokenization process of the *OpenAI GPT* paper, you will need to install `ftfy`
+and `SpaCy`:
+
+```bash
+pip install spacy ftfy==4.4.3
+python -m spacy download en
+```
+
+If you don't install `ftfy` and `SpaCy`, the [`OpenAIGPTTokenizer`] will default to tokenize
+using BERT's `BasicTokenizer` followed by Byte-Pair Encoding (which should be fine for most usage, don't worry).
+
+## OpenAIGPTConfig
+
+[[autodoc]] OpenAIGPTConfig
+
+## OpenAIGPTTokenizer
+
+[[autodoc]] OpenAIGPTTokenizer
+ - save_vocabulary
+
+## OpenAIGPTTokenizerFast
+
+[[autodoc]] OpenAIGPTTokenizerFast
+
+## OpenAI specific outputs
+
+[[autodoc]] models.openai.modeling_openai.OpenAIGPTDoubleHeadsModelOutput
+
+[[autodoc]] models.openai.modeling_tf_openai.TFOpenAIGPTDoubleHeadsModelOutput
+
+## OpenAIGPTModel
+
+[[autodoc]] OpenAIGPTModel
+ - forward
+
+## OpenAIGPTLMHeadModel
+
+[[autodoc]] OpenAIGPTLMHeadModel
+ - forward
+
+## OpenAIGPTDoubleHeadsModel
+
+[[autodoc]] OpenAIGPTDoubleHeadsModel
+ - forward
+
+## OpenAIGPTForSequenceClassification
+
+[[autodoc]] OpenAIGPTForSequenceClassification
+ - forward
+
+## TFOpenAIGPTModel
+
+[[autodoc]] TFOpenAIGPTModel
+ - call
+
+## TFOpenAIGPTLMHeadModel
+
+[[autodoc]] TFOpenAIGPTLMHeadModel
+ - call
+
+## TFOpenAIGPTDoubleHeadsModel
+
+[[autodoc]] TFOpenAIGPTDoubleHeadsModel
+ - call
+
+## TFOpenAIGPTForSequenceClassification
+
+[[autodoc]] TFOpenAIGPTForSequenceClassification
+ - call
diff --git a/docs/source/en/model_doc/pegasus.mdx b/docs/source/en/model_doc/pegasus.mdx
new file mode 100644
index 00000000000000..52dd10b9bfa790
--- /dev/null
+++ b/docs/source/en/model_doc/pegasus.mdx
@@ -0,0 +1,141 @@
+
+
+# Pegasus
+
+**DISCLAIMER:** If you see something strange, file a [Github Issue](https://github.com/huggingface/transformers/issues/new?assignees=sshleifer&labels=&template=bug-report.md&title)
+and assign @patrickvonplaten.
+
+
+## Overview
+
+The Pegasus model was proposed in [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization](https://arxiv.org/pdf/1912.08777.pdf) by Jingqing Zhang, Yao Zhao, Mohammad Saleh and Peter J. Liu on Dec 18, 2019.
+
+According to the abstract,
+
+- Pegasus' pretraining task is intentionally similar to summarization: important sentences are removed/masked from an
+ input document and are generated together as one output sequence from the remaining sentences, similar to an
+ extractive summary.
+- Pegasus achieves SOTA summarization performance on all 12 downstream tasks, as measured by ROUGE and human eval.
+
+This model was contributed by [sshleifer](https://huggingface.co/sshleifer). The Authors' code can be found [here](https://github.com/google-research/pegasus).
+
+
+## Checkpoints
+
+All the [checkpoints](https://huggingface.co/models?search=pegasus) are fine-tuned for summarization, besides
+*pegasus-large*, whence the other checkpoints are fine-tuned:
+
+- Each checkpoint is 2.2 GB on disk and 568M parameters.
+- FP16 is not supported (help/ideas on this appreciated!).
+- Summarizing xsum in fp32 takes about 400ms/sample, with default parameters on a v100 GPU.
+- Full replication results and correctly pre-processed data can be found in this [Issue](https://github.com/huggingface/transformers/issues/6844#issue-689259666).
+- [Distilled checkpoints](https://huggingface.co/models?search=distill-pegasus) are described in this [paper](https://arxiv.org/abs/2010.13002).
+
+### Examples
+
+- [Script](https://github.com/huggingface/transformers/tree/main/examples/research_projects/seq2seq-distillation/finetune_pegasus_xsum.sh) to fine-tune pegasus
+ on the XSUM dataset. Data download instructions at [examples/pytorch/summarization/](https://github.com/huggingface/transformers/tree/main/examples/pytorch/summarization/README.md).
+- FP16 is not supported (help/ideas on this appreciated!).
+- The adafactor optimizer is recommended for pegasus fine-tuning.
+
+
+## Implementation Notes
+
+- All models are transformer encoder-decoders with 16 layers in each component.
+- The implementation is completely inherited from [`BartForConditionalGeneration`]
+- Some key configuration differences:
+
+ - static, sinusoidal position embeddings
+ - the model starts generating with pad_token_id (which has 0 token_embedding) as the prefix.
+ - more beams are used (`num_beams=8`)
+- All pretrained pegasus checkpoints are the same besides three attributes: `tokenizer.model_max_length` (maximum
+ input size), `max_length` (the maximum number of tokens to generate) and `length_penalty`.
+- The code to convert checkpoints trained in the author's [repo](https://github.com/google-research/pegasus) can be
+ found in `convert_pegasus_tf_to_pytorch.py`.
+
+
+## Usage Example
+
+```python
+>>> from transformers import PegasusForConditionalGeneration, PegasusTokenizer
+>>> import torch
+
+>>> src_text = [
+... """ PG&E stated it scheduled the blackouts in response to forecasts for high winds amid dry conditions. The aim is to reduce the risk of wildfires. Nearly 800 thousand customers were scheduled to be affected by the shutoffs which were expected to last through at least midday tomorrow."""
+... ]
+
+... model_name = "google/pegasus-xsum"
+... device = "cuda" if torch.cuda.is_available() else "cpu"
+... tokenizer = PegasusTokenizer.from_pretrained(model_name)
+... model = PegasusForConditionalGeneration.from_pretrained(model_name).to(device)
+... batch = tokenizer(src_text, truncation=True, padding="longest", return_tensors="pt").to(device)
+... translated = model.generate(**batch)
+... tgt_text = tokenizer.batch_decode(translated, skip_special_tokens=True)
+... assert (
+... tgt_text[0]
+... == "California's largest electricity provider has turned off power to hundreds of thousands of customers."
+... )
+```
+
+## PegasusConfig
+
+[[autodoc]] PegasusConfig
+
+## PegasusTokenizer
+
+warning: `add_tokens` does not work at the moment.
+
+[[autodoc]] PegasusTokenizer
+
+## PegasusTokenizerFast
+
+[[autodoc]] PegasusTokenizerFast
+
+## PegasusModel
+
+[[autodoc]] PegasusModel
+ - forward
+
+## PegasusForConditionalGeneration
+
+[[autodoc]] PegasusForConditionalGeneration
+ - forward
+
+## PegasusForCausalLM
+
+[[autodoc]] PegasusForCausalLM
+ - forward
+
+## TFPegasusModel
+
+[[autodoc]] TFPegasusModel
+ - call
+
+## TFPegasusForConditionalGeneration
+
+[[autodoc]] TFPegasusForConditionalGeneration
+ - call
+
+## FlaxPegasusModel
+
+[[autodoc]] FlaxPegasusModel
+ - __call__
+ - encode
+ - decode
+
+## FlaxPegasusForConditionalGeneration
+
+[[autodoc]] FlaxPegasusForConditionalGeneration
+ - __call__
+ - encode
+ - decode
diff --git a/docs/source/en/model_doc/perceiver.mdx b/docs/source/en/model_doc/perceiver.mdx
new file mode 100644
index 00000000000000..0dbfd3e00494bd
--- /dev/null
+++ b/docs/source/en/model_doc/perceiver.mdx
@@ -0,0 +1,215 @@
+
+
+# Perceiver
+
+## Overview
+
+The Perceiver IO model was proposed in [Perceiver IO: A General Architecture for Structured Inputs &
+Outputs](https://arxiv.org/abs/2107.14795) by Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch,
+Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier Hénaff, Matthew M.
+Botvinick, Andrew Zisserman, Oriol Vinyals, João Carreira.
+
+Perceiver IO is a generalization of [Perceiver](https://arxiv.org/abs/2103.03206) to handle arbitrary outputs in
+addition to arbitrary inputs. The original Perceiver only produced a single classification label. In addition to
+classification labels, Perceiver IO can produce (for example) language, optical flow, and multimodal videos with audio.
+This is done using the same building blocks as the original Perceiver. The computational complexity of Perceiver IO is
+linear in the input and output size and the bulk of the processing occurs in the latent space, allowing us to process
+inputs and outputs that are much larger than can be handled by standard Transformers. This means, for example,
+Perceiver IO can do BERT-style masked language modeling directly using bytes instead of tokenized inputs.
+
+The abstract from the paper is the following:
+
+*The recently-proposed Perceiver model obtains good results on several domains (images, audio, multimodal, point
+clouds) while scaling linearly in compute and memory with the input size. While the Perceiver supports many kinds of
+inputs, it can only produce very simple outputs such as class scores. Perceiver IO overcomes this limitation without
+sacrificing the original's appealing properties by learning to flexibly query the model's latent space to produce
+outputs of arbitrary size and semantics. Perceiver IO still decouples model depth from data size and still scales
+linearly with data size, but now with respect to both input and output sizes. The full Perceiver IO model achieves
+strong results on tasks with highly structured output spaces, such as natural language and visual understanding,
+StarCraft II, and multi-task and multi-modal domains. As highlights, Perceiver IO matches a Transformer-based BERT
+baseline on the GLUE language benchmark without the need for input tokenization and achieves state-of-the-art
+performance on Sintel optical flow estimation.*
+
+Here's a TLDR explaining how Perceiver works:
+
+The main problem with the self-attention mechanism of the Transformer is that the time and memory requirements scale
+quadratically with the sequence length. Hence, models like BERT and RoBERTa are limited to a max sequence length of 512
+tokens. Perceiver aims to solve this issue by, instead of performing self-attention on the inputs, perform it on a set
+of latent variables, and only use the inputs for cross-attention. In this way, the time and memory requirements don't
+depend on the length of the inputs anymore, as one uses a fixed amount of latent variables, like 256 or 512. These are
+randomly initialized, after which they are trained end-to-end using backpropagation.
+
+Internally, [`PerceiverModel`] will create the latents, which is a tensor of shape `(batch_size, num_latents,
+d_latents)`. One must provide `inputs` (which could be text, images, audio, you name it!) to the model, which it will
+use to perform cross-attention with the latents. The output of the Perceiver encoder is a tensor of the same shape. One
+can then, similar to BERT, convert the last hidden states of the latents to classification logits by averaging along
+the sequence dimension, and placing a linear layer on top of that to project the `d_latents` to `num_labels`.
+
+This was the idea of the original Perceiver paper. However, it could only output classification logits. In a follow-up
+work, PerceiverIO, they generalized it to let the model also produce outputs of arbitrary size. How, you might ask? The
+idea is actually relatively simple: one defines outputs of an arbitrary size, and then applies cross-attention with the
+last hidden states of the latents, using the outputs as queries, and the latents as keys and values.
+
+So let's say one wants to perform masked language modeling (BERT-style) with the Perceiver. As the Perceiver's input
+length will not have an impact on the computation time of the self-attention layers, one can provide raw bytes,
+providing `inputs` of length 2048 to the model. If one now masks out certain of these 2048 tokens, one can define the
+`outputs` as being of shape: `(batch_size, 2048, 768)`. Next, one performs cross-attention with the final hidden states
+of the latents to update the `outputs` tensor. After cross-attention, one still has a tensor of shape `(batch_size,
+2048, 768)`. One can then place a regular language modeling head on top, to project the last dimension to the
+vocabulary size of the model, i.e. creating logits of shape `(batch_size, 2048, 262)` (as Perceiver uses a vocabulary
+size of 262 byte IDs).
+
+
+
+This model was contributed by [francesco](https://huggingface.co/francesco). The original code can be found [here](https://github.com/facebookresearch/MaskFormer).
+
+## MaskFormer specific outputs
+
+[[autodoc]] models.maskformer.modeling_maskformer.MaskFormerModelOutput
+
+[[autodoc]] models.maskformer.modeling_maskformer.MaskFormerForInstanceSegmentationOutput
+
+## MaskFormerConfig
+
+[[autodoc]] MaskFormerConfig
+
+## MaskFormerFeatureExtractor
+
+[[autodoc]] MaskFormerFeatureExtractor
+ - __call__
+ - encode_inputs
+ - post_process_segmentation
+ - post_process_semantic_segmentation
+ - post_process_panoptic_segmentation
+
+## MaskFormerModel
+
+[[autodoc]] MaskFormerModel
+ - forward
+
+## MaskFormerForInstanceSegmentation
+
+[[autodoc]] MaskFormerForInstanceSegmentation
+ - forward
diff --git a/docs/source/en/model_doc/mbart.mdx b/docs/source/en/model_doc/mbart.mdx
new file mode 100644
index 00000000000000..0f3d82ce5dac7a
--- /dev/null
+++ b/docs/source/en/model_doc/mbart.mdx
@@ -0,0 +1,229 @@
+
+
+# MBart and MBart-50
+
+**DISCLAIMER:** If you see something strange, file a [Github Issue](https://github.com/huggingface/transformers/issues/new?assignees=&labels=&template=bug-report.md&title) and assign
+@patrickvonplaten
+
+## Overview of MBart
+
+The MBart model was presented in [Multilingual Denoising Pre-training for Neural Machine Translation](https://arxiv.org/abs/2001.08210) by Yinhan Liu, Jiatao Gu, Naman Goyal, Xian Li, Sergey Edunov Marjan
+Ghazvininejad, Mike Lewis, Luke Zettlemoyer.
+
+According to the abstract, MBART is a sequence-to-sequence denoising auto-encoder pretrained on large-scale monolingual
+corpora in many languages using the BART objective. mBART is one of the first methods for pretraining a complete
+sequence-to-sequence model by denoising full texts in multiple languages, while previous approaches have focused only
+on the encoder, decoder, or reconstructing parts of the text.
+
+This model was contributed by [valhalla](https://huggingface.co/valhalla). The Authors' code can be found [here](https://github.com/pytorch/fairseq/tree/master/examples/mbart)
+
+### Training of MBart
+
+MBart is a multilingual encoder-decoder (sequence-to-sequence) model primarily intended for translation task. As the
+model is multilingual it expects the sequences in a different format. A special language id token is added in both the
+source and target text. The source text format is `X [eos, src_lang_code]` where `X` is the source text. The
+target text format is `[tgt_lang_code] X [eos]`. `bos` is never used.
+
+The regular [`~MBartTokenizer.__call__`] will encode source text format, and it should be wrapped
+inside the context manager [`~MBartTokenizer.as_target_tokenizer`] to encode target text format.
+
+- Supervised training
+
+```python
+>>> from transformers import MBartForConditionalGeneration, MBartTokenizer
+
+>>> tokenizer = MBartTokenizer.from_pretrained("facebook/mbart-large-en-ro", src_lang="en_XX", tgt_lang="ro_RO")
+>>> example_english_phrase = "UN Chief Says There Is No Military Solution in Syria"
+>>> expected_translation_romanian = "Şeful ONU declară că nu există o soluţie militară în Siria"
+
+>>> inputs = tokenizer(example_english_phrase, return_tensors="pt")
+>>> with tokenizer.as_target_tokenizer():
+... labels = tokenizer(expected_translation_romanian, return_tensors="pt")
+
+>>> model = MBartForConditionalGeneration.from_pretrained("facebook/mbart-large-en-ro")
+>>> # forward pass
+>>> model(**inputs, labels=batch["labels"])
+```
+
+- Generation
+
+ While generating the target text set the `decoder_start_token_id` to the target language id. The following
+ example shows how to translate English to Romanian using the *facebook/mbart-large-en-ro* model.
+
+```python
+>>> from transformers import MBartForConditionalGeneration, MBartTokenizer
+
+>>> tokenizer = MBartTokenizer.from_pretrained("facebook/mbart-large-en-ro", src_lang="en_XX")
+>>> article = "UN Chief Says There Is No Military Solution in Syria"
+>>> inputs = tokenizer(article, return_tensors="pt")
+>>> translated_tokens = model.generate(**inputs, decoder_start_token_id=tokenizer.lang_code_to_id["ro_RO"])
+>>> tokenizer.batch_decode(translated_tokens, skip_special_tokens=True)[0]
+"Şeful ONU declară că nu există o soluţie militară în Siria"
+```
+
+## Overview of MBart-50
+
+MBart-50 was introduced in the [Multilingual Translation with Extensible Multilingual Pretraining and Finetuning](https://arxiv.org/abs/2008.00401) paper by Yuqing Tang, Chau Tran, Xian Li, Peng-Jen Chen, Naman Goyal, Vishrav
+Chaudhary, Jiatao Gu, Angela Fan. MBart-50 is created using the original *mbart-large-cc25* checkpoint by extendeding
+its embedding layers with randomly initialized vectors for an extra set of 25 language tokens and then pretrained on 50
+languages.
+
+According to the abstract
+
+*Multilingual translation models can be created through multilingual finetuning. Instead of finetuning on one
+direction, a pretrained model is finetuned on many directions at the same time. It demonstrates that pretrained models
+can be extended to incorporate additional languages without loss of performance. Multilingual finetuning improves on
+average 1 BLEU over the strongest baselines (being either multilingual from scratch or bilingual finetuning) while
+improving 9.3 BLEU on average over bilingual baselines from scratch.*
+
+
+### Training of MBart-50
+
+The text format for MBart-50 is slightly different from mBART. For MBart-50 the language id token is used as a prefix
+for both source and target text i.e the text format is `[lang_code] X [eos]`, where `lang_code` is source
+language id for source text and target language id for target text, with `X` being the source or target text
+respectively.
+
+
+MBart-50 has its own tokenizer [`MBart50Tokenizer`].
+
+- Supervised training
+
+```python
+from transformers import MBartForConditionalGeneration, MBart50TokenizerFast
+
+model = MBartForConditionalGeneration.from_pretrained("facebook/mbart-large-50")
+tokenizer = MBart50TokenizerFast.from_pretrained("facebook/mbart-large-50", src_lang="en_XX", tgt_lang="ro_RO")
+
+src_text = " UN Chief Says There Is No Military Solution in Syria"
+tgt_text = "Şeful ONU declară că nu există o soluţie militară în Siria"
+
+model_inputs = tokenizer(src_text, return_tensors="pt")
+with tokenizer.as_target_tokenizer():
+ labels = tokenizer(tgt_text, return_tensors="pt").input_ids
+
+model(**model_inputs, labels=labels) # forward pass
+```
+
+- Generation
+
+ To generate using the mBART-50 multilingual translation models, `eos_token_id` is used as the
+ `decoder_start_token_id` and the target language id is forced as the first generated token. To force the
+ target language id as the first generated token, pass the *forced_bos_token_id* parameter to the *generate* method.
+ The following example shows how to translate between Hindi to French and Arabic to English using the
+ *facebook/mbart-50-large-many-to-many* checkpoint.
+
+```python
+from transformers import MBartForConditionalGeneration, MBart50TokenizerFast
+
+article_hi = "संयुक्त राष्ट्र के प्रमुख का कहना है कि सीरिया में कोई सैन्य समाधान नहीं है"
+article_ar = "الأمين العام للأمم المتحدة يقول إنه لا يوجد حل عسكري في سوريا."
+
+model = MBartForConditionalGeneration.from_pretrained("facebook/mbart-large-50-many-to-many-mmt")
+tokenizer = MBart50TokenizerFast.from_pretrained("facebook/mbart-large-50-many-to-many-mmt")
+
+# translate Hindi to French
+tokenizer.src_lang = "hi_IN"
+encoded_hi = tokenizer(article_hi, return_tensors="pt")
+generated_tokens = model.generate(**encoded_hi, forced_bos_token_id=tokenizer.lang_code_to_id["fr_XX"])
+tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
+# => "Le chef de l 'ONU affirme qu 'il n 'y a pas de solution militaire en Syria."
+
+# translate Arabic to English
+tokenizer.src_lang = "ar_AR"
+encoded_ar = tokenizer(article_ar, return_tensors="pt")
+generated_tokens = model.generate(**encoded_ar, forced_bos_token_id=tokenizer.lang_code_to_id["en_XX"])
+tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
+# => "The Secretary-General of the United Nations says there is no military solution in Syria."
+```
+
+## MBartConfig
+
+[[autodoc]] MBartConfig
+
+## MBartTokenizer
+
+[[autodoc]] MBartTokenizer
+ - as_target_tokenizer
+ - build_inputs_with_special_tokens
+
+## MBartTokenizerFast
+
+[[autodoc]] MBartTokenizerFast
+
+## MBart50Tokenizer
+
+[[autodoc]] MBart50Tokenizer
+
+## MBart50TokenizerFast
+
+[[autodoc]] MBart50TokenizerFast
+
+## MBartModel
+
+[[autodoc]] MBartModel
+
+## MBartForConditionalGeneration
+
+[[autodoc]] MBartForConditionalGeneration
+
+## MBartForQuestionAnswering
+
+[[autodoc]] MBartForQuestionAnswering
+
+## MBartForSequenceClassification
+
+[[autodoc]] MBartForSequenceClassification
+
+## MBartForCausalLM
+
+[[autodoc]] MBartForCausalLM
+ - forward
+
+## TFMBartModel
+
+[[autodoc]] TFMBartModel
+ - call
+
+## TFMBartForConditionalGeneration
+
+[[autodoc]] TFMBartForConditionalGeneration
+ - call
+
+## FlaxMBartModel
+
+[[autodoc]] FlaxMBartModel
+ - __call__
+ - encode
+ - decode
+
+## FlaxMBartForConditionalGeneration
+
+[[autodoc]] FlaxMBartForConditionalGeneration
+ - __call__
+ - encode
+ - decode
+
+## FlaxMBartForSequenceClassification
+
+[[autodoc]] FlaxMBartForSequenceClassification
+ - __call__
+ - encode
+ - decode
+
+## FlaxMBartForQuestionAnswering
+
+[[autodoc]] FlaxMBartForQuestionAnswering
+ - __call__
+ - encode
+ - decode
diff --git a/docs/source/en/model_doc/megatron-bert.mdx b/docs/source/en/model_doc/megatron-bert.mdx
new file mode 100644
index 00000000000000..911bf76aec2789
--- /dev/null
+++ b/docs/source/en/model_doc/megatron-bert.mdx
@@ -0,0 +1,128 @@
+
+
+# MegatronBERT
+
+## Overview
+
+The MegatronBERT model was proposed in [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model
+Parallelism](https://arxiv.org/abs/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley,
+Jared Casper and Bryan Catanzaro.
+
+The abstract from the paper is the following:
+
+*Recent work in language modeling demonstrates that training large transformer models advances the state of the art in
+Natural Language Processing applications. However, very large models can be quite difficult to train due to memory
+constraints. In this work, we present our techniques for training very large transformer models and implement a simple,
+efficient intra-layer model parallel approach that enables training transformer models with billions of parameters. Our
+approach does not require a new compiler or library changes, is orthogonal and complimentary to pipeline model
+parallelism, and can be fully implemented with the insertion of a few communication operations in native PyTorch. We
+illustrate this approach by converging transformer based models up to 8.3 billion parameters using 512 GPUs. We sustain
+15.1 PetaFLOPs across the entire application with 76% scaling efficiency when compared to a strong single GPU baseline
+that sustains 39 TeraFLOPs, which is 30% of peak FLOPs. To demonstrate that large language models can further advance
+the state of the art (SOTA), we train an 8.3 billion parameter transformer language model similar to GPT-2 and a 3.9
+billion parameter model similar to BERT. We show that careful attention to the placement of layer normalization in
+BERT-like models is critical to achieving increased performance as the model size grows. Using the GPT-2 model we
+achieve SOTA results on the WikiText103 (10.8 compared to SOTA perplexity of 15.8) and LAMBADA (66.5% compared to SOTA
+accuracy of 63.2%) datasets. Our BERT model achieves SOTA results on the RACE dataset (90.9% compared to SOTA accuracy
+of 89.4%).*
+
+Tips:
+
+We have provided pretrained [BERT-345M](https://ngc.nvidia.com/catalog/models/nvidia:megatron_bert_345m) checkpoints
+for use to evaluate or finetuning downstream tasks.
+
+To access these checkpoints, first [sign up](https://ngc.nvidia.com/signup) for and setup the NVIDIA GPU Cloud (NGC)
+Registry CLI. Further documentation for downloading models can be found in the [NGC documentation](https://docs.nvidia.com/dgx/ngc-registry-cli-user-guide/index.html#topic_6_4_1).
+
+Alternatively, you can directly download the checkpoints using:
+
+BERT-345M-uncased:
+
+```bash
+wget --content-disposition https://api.ngc.nvidia.com/v2/models/nvidia/megatron_bert_345m/versions/v0.1_uncased/zip
+-O megatron_bert_345m_v0_1_uncased.zip
+```
+
+BERT-345M-cased:
+
+```bash
+wget --content-disposition https://api.ngc.nvidia.com/v2/models/nvidia/megatron_bert_345m/versions/v0.1_cased/zip -O
+megatron_bert_345m_v0_1_cased.zip
+```
+
+Once you have obtained the checkpoints from NVIDIA GPU Cloud (NGC), you have to convert them to a format that will
+easily be loaded by Hugging Face Transformers and our port of the BERT code.
+
+The following commands allow you to do the conversion. We assume that the folder `models/megatron_bert` contains
+`megatron_bert_345m_v0_1_{cased, uncased}.zip` and that the commands are run from inside that folder:
+
+```bash
+python3 $PATH_TO_TRANSFORMERS/models/megatron_bert/convert_megatron_bert_checkpoint.py megatron_bert_345m_v0_1_uncased.zip
+```
+
+```bash
+python3 $PATH_TO_TRANSFORMERS/models/megatron_bert/convert_megatron_bert_checkpoint.py megatron_bert_345m_v0_1_cased.zip
+```
+
+This model was contributed by [jdemouth](https://huggingface.co/jdemouth). The original code can be found [here](https://github.com/NVIDIA/Megatron-LM). That repository contains a multi-GPU and multi-node implementation of the
+Megatron Language models. In particular, it contains a hybrid model parallel approach using "tensor parallel" and
+"pipeline parallel" techniques.
+
+## MegatronBertConfig
+
+[[autodoc]] MegatronBertConfig
+
+## MegatronBertModel
+
+[[autodoc]] MegatronBertModel
+ - forward
+
+## MegatronBertForMaskedLM
+
+[[autodoc]] MegatronBertForMaskedLM
+ - forward
+
+## MegatronBertForCausalLM
+
+[[autodoc]] MegatronBertForCausalLM
+ - forward
+
+## MegatronBertForNextSentencePrediction
+
+[[autodoc]] MegatronBertForNextSentencePrediction
+ - forward
+
+## MegatronBertForPreTraining
+
+[[autodoc]] MegatronBertForPreTraining
+ - forward
+
+## MegatronBertForSequenceClassification
+
+[[autodoc]] MegatronBertForSequenceClassification
+ - forward
+
+## MegatronBertForMultipleChoice
+
+[[autodoc]] MegatronBertForMultipleChoice
+ - forward
+
+## MegatronBertForTokenClassification
+
+[[autodoc]] MegatronBertForTokenClassification
+ - forward
+
+## MegatronBertForQuestionAnswering
+
+[[autodoc]] MegatronBertForQuestionAnswering
+ - forward
diff --git a/docs/source/en/model_doc/megatron_gpt2.mdx b/docs/source/en/model_doc/megatron_gpt2.mdx
new file mode 100644
index 00000000000000..a0d91e5a163055
--- /dev/null
+++ b/docs/source/en/model_doc/megatron_gpt2.mdx
@@ -0,0 +1,67 @@
+
+
+# MegatronGPT2
+
+## Overview
+
+The MegatronGPT2 model was proposed in [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model
+Parallelism](https://arxiv.org/abs/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley,
+Jared Casper and Bryan Catanzaro.
+
+The abstract from the paper is the following:
+
+*Recent work in language modeling demonstrates that training large transformer models advances the state of the art in
+Natural Language Processing applications. However, very large models can be quite difficult to train due to memory
+constraints. In this work, we present our techniques for training very large transformer models and implement a simple,
+efficient intra-layer model parallel approach that enables training transformer models with billions of parameters. Our
+approach does not require a new compiler or library changes, is orthogonal and complimentary to pipeline model
+parallelism, and can be fully implemented with the insertion of a few communication operations in native PyTorch. We
+illustrate this approach by converging transformer based models up to 8.3 billion parameters using 512 GPUs. We sustain
+15.1 PetaFLOPs across the entire application with 76% scaling efficiency when compared to a strong single GPU baseline
+that sustains 39 TeraFLOPs, which is 30% of peak FLOPs. To demonstrate that large language models can further advance
+the state of the art (SOTA), we train an 8.3 billion parameter transformer language model similar to GPT-2 and a 3.9
+billion parameter model similar to BERT. We show that careful attention to the placement of layer normalization in
+BERT-like models is critical to achieving increased performance as the model size grows. Using the GPT-2 model we
+achieve SOTA results on the WikiText103 (10.8 compared to SOTA perplexity of 15.8) and LAMBADA (66.5% compared to SOTA
+accuracy of 63.2%) datasets. Our BERT model achieves SOTA results on the RACE dataset (90.9% compared to SOTA accuracy
+of 89.4%).*
+
+Tips:
+
+We have provided pretrained [GPT2-345M](https://ngc.nvidia.com/catalog/models/nvidia:megatron_lm_345m) checkpoints
+for use to evaluate or finetuning downstream tasks.
+
+To access these checkpoints, first [sign up](https://ngc.nvidia.com/signup) for and setup the NVIDIA GPU Cloud (NGC)
+Registry CLI. Further documentation for downloading models can be found in the [NGC documentation](https://docs.nvidia.com/dgx/ngc-registry-cli-user-guide/index.html#topic_6_4_1).
+
+Alternatively, you can directly download the checkpoints using:
+
+```bash
+wget --content-disposition https://api.ngc.nvidia.com/v2/models/nvidia/megatron_lm_345m/versions/v0.0/zip -O
+megatron_gpt2_345m_v0_0.zip
+```
+
+Once you have obtained the checkpoint from NVIDIA GPU Cloud (NGC), you have to convert it to a format that will easily
+be loaded by Hugging Face Transformers GPT2 implementation.
+
+The following command allows you to do the conversion. We assume that the folder `models/megatron_gpt2` contains
+`megatron_gpt2_345m_v0_0.zip` and that the command is run from that folder:
+
+```bash
+python3 $PATH_TO_TRANSFORMERS/models/megatron_gpt2/convert_megatron_gpt2_checkpoint.py megatron_gpt2_345m_v0_0.zip
+```
+
+This model was contributed by [jdemouth](https://huggingface.co/jdemouth). The original code can be found [here](https://github.com/NVIDIA/Megatron-LM). That repository contains a multi-GPU and multi-node implementation of the
+Megatron Language models. In particular, it contains a hybrid model parallel approach using "tensor parallel" and
+"pipeline parallel" techniques.
+
diff --git a/docs/source/en/model_doc/mluke.mdx b/docs/source/en/model_doc/mluke.mdx
new file mode 100644
index 00000000000000..b910f17ae2f6b1
--- /dev/null
+++ b/docs/source/en/model_doc/mluke.mdx
@@ -0,0 +1,61 @@
+
+
+# mLUKE
+
+## Overview
+
+The mLUKE model was proposed in [mLUKE: The Power of Entity Representations in Multilingual Pretrained Language Models](https://arxiv.org/abs/2110.08151) by Ryokan Ri, Ikuya Yamada, and Yoshimasa Tsuruoka. It's a multilingual extension
+of the [LUKE model](https://arxiv.org/abs/2010.01057) trained on the basis of XLM-RoBERTa.
+
+It is based on XLM-RoBERTa and adds entity embeddings, which helps improve performance on various downstream tasks
+involving reasoning about entities such as named entity recognition, extractive question answering, relation
+classification, cloze-style knowledge completion.
+
+The abstract from the paper is the following:
+
+*Recent studies have shown that multilingual pretrained language models can be effectively improved with cross-lingual
+alignment information from Wikipedia entities. However, existing methods only exploit entity information in pretraining
+and do not explicitly use entities in downstream tasks. In this study, we explore the effectiveness of leveraging
+entity representations for downstream cross-lingual tasks. We train a multilingual language model with 24 languages
+with entity representations and show the model consistently outperforms word-based pretrained models in various
+cross-lingual transfer tasks. We also analyze the model and the key insight is that incorporating entity
+representations into the input allows us to extract more language-agnostic features. We also evaluate the model with a
+multilingual cloze prompt task with the mLAMA dataset. We show that entity-based prompt elicits correct factual
+knowledge more likely than using only word representations.*
+
+One can directly plug in the weights of mLUKE into a LUKE model, like so:
+
+```python
+from transformers import LukeModel
+
+model = LukeModel.from_pretrained("studio-ousia/mluke-base")
+```
+
+Note that mLUKE has its own tokenizer, [`MLukeTokenizer`]. You can initialize it as follows:
+
+```python
+from transformers import MLukeTokenizer
+
+tokenizer = MLukeTokenizer.from_pretrained("studio-ousia/mluke-base")
+```
+
+As mLUKE's architecture is equivalent to that of LUKE, one can refer to [LUKE's documentation page](luke) for all
+tips, code examples and notebooks.
+
+This model was contributed by [ryo0634](https://huggingface.co/ryo0634). The original code can be found [here](https://github.com/studio-ousia/luke).
+
+## MLukeTokenizer
+
+[[autodoc]] MLukeTokenizer
+ - __call__
+ - save_vocabulary
diff --git a/docs/source/en/model_doc/mobilebert.mdx b/docs/source/en/model_doc/mobilebert.mdx
new file mode 100644
index 00000000000000..8305903d23c70e
--- /dev/null
+++ b/docs/source/en/model_doc/mobilebert.mdx
@@ -0,0 +1,142 @@
+
+
+# MobileBERT
+
+## Overview
+
+The MobileBERT model was proposed in [MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices](https://arxiv.org/abs/2004.02984) by Zhiqing Sun, Hongkun Yu, Xiaodan Song, Renjie Liu, Yiming Yang, and Denny
+Zhou. It's a bidirectional transformer based on the BERT model, which is compressed and accelerated using several
+approaches.
+
+The abstract from the paper is the following:
+
+*Natural Language Processing (NLP) has recently achieved great success by using huge pre-trained models with hundreds
+of millions of parameters. However, these models suffer from heavy model sizes and high latency such that they cannot
+be deployed to resource-limited mobile devices. In this paper, we propose MobileBERT for compressing and accelerating
+the popular BERT model. Like the original BERT, MobileBERT is task-agnostic, that is, it can be generically applied to
+various downstream NLP tasks via simple fine-tuning. Basically, MobileBERT is a thin version of BERT_LARGE, while
+equipped with bottleneck structures and a carefully designed balance between self-attentions and feed-forward networks.
+To train MobileBERT, we first train a specially designed teacher model, an inverted-bottleneck incorporated BERT_LARGE
+model. Then, we conduct knowledge transfer from this teacher to MobileBERT. Empirical studies show that MobileBERT is
+4.3x smaller and 5.5x faster than BERT_BASE while achieving competitive results on well-known benchmarks. On the
+natural language inference tasks of GLUE, MobileBERT achieves a GLUEscore o 77.7 (0.6 lower than BERT_BASE), and 62 ms
+latency on a Pixel 4 phone. On the SQuAD v1.1/v2.0 question answering task, MobileBERT achieves a dev F1 score of
+90.0/79.2 (1.5/2.1 higher than BERT_BASE).*
+
+Tips:
+
+- MobileBERT is a model with absolute position embeddings so it's usually advised to pad the inputs on the right rather
+ than the left.
+- MobileBERT is similar to BERT and therefore relies on the masked language modeling (MLM) objective. It is therefore
+ efficient at predicting masked tokens and at NLU in general, but is not optimal for text generation. Models trained
+ with a causal language modeling (CLM) objective are better in that regard.
+
+This model was contributed by [vshampor](https://huggingface.co/vshampor). The original code can be found [here](https://github.com/google-research/mobilebert).
+
+## MobileBertConfig
+
+[[autodoc]] MobileBertConfig
+
+## MobileBertTokenizer
+
+[[autodoc]] MobileBertTokenizer
+
+## MobileBertTokenizerFast
+
+[[autodoc]] MobileBertTokenizerFast
+
+## MobileBert specific outputs
+
+[[autodoc]] models.mobilebert.modeling_mobilebert.MobileBertForPreTrainingOutput
+
+[[autodoc]] models.mobilebert.modeling_tf_mobilebert.TFMobileBertForPreTrainingOutput
+
+## MobileBertModel
+
+[[autodoc]] MobileBertModel
+ - forward
+
+## MobileBertForPreTraining
+
+[[autodoc]] MobileBertForPreTraining
+ - forward
+
+## MobileBertForMaskedLM
+
+[[autodoc]] MobileBertForMaskedLM
+ - forward
+
+## MobileBertForNextSentencePrediction
+
+[[autodoc]] MobileBertForNextSentencePrediction
+ - forward
+
+## MobileBertForSequenceClassification
+
+[[autodoc]] MobileBertForSequenceClassification
+ - forward
+
+## MobileBertForMultipleChoice
+
+[[autodoc]] MobileBertForMultipleChoice
+ - forward
+
+## MobileBertForTokenClassification
+
+[[autodoc]] MobileBertForTokenClassification
+ - forward
+
+## MobileBertForQuestionAnswering
+
+[[autodoc]] MobileBertForQuestionAnswering
+ - forward
+
+## TFMobileBertModel
+
+[[autodoc]] TFMobileBertModel
+ - call
+
+## TFMobileBertForPreTraining
+
+[[autodoc]] TFMobileBertForPreTraining
+ - call
+
+## TFMobileBertForMaskedLM
+
+[[autodoc]] TFMobileBertForMaskedLM
+ - call
+
+## TFMobileBertForNextSentencePrediction
+
+[[autodoc]] TFMobileBertForNextSentencePrediction
+ - call
+
+## TFMobileBertForSequenceClassification
+
+[[autodoc]] TFMobileBertForSequenceClassification
+ - call
+
+## TFMobileBertForMultipleChoice
+
+[[autodoc]] TFMobileBertForMultipleChoice
+ - call
+
+## TFMobileBertForTokenClassification
+
+[[autodoc]] TFMobileBertForTokenClassification
+ - call
+
+## TFMobileBertForQuestionAnswering
+
+[[autodoc]] TFMobileBertForQuestionAnswering
+ - call
diff --git a/docs/source/en/model_doc/mpnet.mdx b/docs/source/en/model_doc/mpnet.mdx
new file mode 100644
index 00000000000000..0fa88ee87b7259
--- /dev/null
+++ b/docs/source/en/model_doc/mpnet.mdx
@@ -0,0 +1,117 @@
+
+
+# MPNet
+
+## Overview
+
+The MPNet model was proposed in [MPNet: Masked and Permuted Pre-training for Language Understanding](https://arxiv.org/abs/2004.09297) by Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, Tie-Yan Liu.
+
+MPNet adopts a novel pre-training method, named masked and permuted language modeling, to inherit the advantages of
+masked language modeling and permuted language modeling for natural language understanding.
+
+The abstract from the paper is the following:
+
+*BERT adopts masked language modeling (MLM) for pre-training and is one of the most successful pre-training models.
+Since BERT neglects dependency among predicted tokens, XLNet introduces permuted language modeling (PLM) for
+pre-training to address this problem. However, XLNet does not leverage the full position information of a sentence and
+thus suffers from position discrepancy between pre-training and fine-tuning. In this paper, we propose MPNet, a novel
+pre-training method that inherits the advantages of BERT and XLNet and avoids their limitations. MPNet leverages the
+dependency among predicted tokens through permuted language modeling (vs. MLM in BERT), and takes auxiliary position
+information as input to make the model see a full sentence and thus reducing the position discrepancy (vs. PLM in
+XLNet). We pre-train MPNet on a large-scale dataset (over 160GB text corpora) and fine-tune on a variety of
+down-streaming tasks (GLUE, SQuAD, etc). Experimental results show that MPNet outperforms MLM and PLM by a large
+margin, and achieves better results on these tasks compared with previous state-of-the-art pre-trained methods (e.g.,
+BERT, XLNet, RoBERTa) under the same model setting.*
+
+Tips:
+
+- MPNet doesn't have `token_type_ids`, you don't need to indicate which token belongs to which segment. just
+ separate your segments with the separation token `tokenizer.sep_token` (or `[sep]`).
+
+The original code can be found [here](https://github.com/microsoft/MPNet).
+
+## MPNetConfig
+
+[[autodoc]] MPNetConfig
+
+## MPNetTokenizer
+
+[[autodoc]] MPNetTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## MPNetTokenizerFast
+
+[[autodoc]] MPNetTokenizerFast
+
+## MPNetModel
+
+[[autodoc]] MPNetModel
+ - forward
+
+## MPNetForMaskedLM
+
+[[autodoc]] MPNetForMaskedLM
+ - forward
+
+## MPNetForSequenceClassification
+
+[[autodoc]] MPNetForSequenceClassification
+ - forward
+
+## MPNetForMultipleChoice
+
+[[autodoc]] MPNetForMultipleChoice
+ - forward
+
+## MPNetForTokenClassification
+
+[[autodoc]] MPNetForTokenClassification
+ - forward
+
+## MPNetForQuestionAnswering
+
+[[autodoc]] MPNetForQuestionAnswering
+ - forward
+
+## TFMPNetModel
+
+[[autodoc]] TFMPNetModel
+ - call
+
+## TFMPNetForMaskedLM
+
+[[autodoc]] TFMPNetForMaskedLM
+ - call
+
+## TFMPNetForSequenceClassification
+
+[[autodoc]] TFMPNetForSequenceClassification
+ - call
+
+## TFMPNetForMultipleChoice
+
+[[autodoc]] TFMPNetForMultipleChoice
+ - call
+
+## TFMPNetForTokenClassification
+
+[[autodoc]] TFMPNetForTokenClassification
+ - call
+
+## TFMPNetForQuestionAnswering
+
+[[autodoc]] TFMPNetForQuestionAnswering
+ - call
diff --git a/docs/source/en/model_doc/mt5.mdx b/docs/source/en/model_doc/mt5.mdx
new file mode 100644
index 00000000000000..fa39e4ab2cd0a0
--- /dev/null
+++ b/docs/source/en/model_doc/mt5.mdx
@@ -0,0 +1,98 @@
+
+
+# mT5
+
+## Overview
+
+The mT5 model was presented in [mT5: A massively multilingual pre-trained text-to-text transformer](https://arxiv.org/abs/2010.11934) by Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya
+Siddhant, Aditya Barua, Colin Raffel.
+
+The abstract from the paper is the following:
+
+*The recent "Text-to-Text Transfer Transformer" (T5) leveraged a unified text-to-text format and scale to attain
+state-of-the-art results on a wide variety of English-language NLP tasks. In this paper, we introduce mT5, a
+multilingual variant of T5 that was pre-trained on a new Common Crawl-based dataset covering 101 languages. We detail
+the design and modified training of mT5 and demonstrate its state-of-the-art performance on many multilingual
+benchmarks. We also describe a simple technique to prevent "accidental translation" in the zero-shot setting, where a
+generative model chooses to (partially) translate its prediction into the wrong language. All of the code and model
+checkpoints used in this work are publicly available.*
+
+Note: mT5 was only pre-trained on [mC4](https://huggingface.co/datasets/mc4) excluding any supervised training.
+Therefore, this model has to be fine-tuned before it is useable on a downstream task, unlike the original T5 model.
+Since mT5 was pre-trained unsupervisedly, there's no real advantage to using a task prefix during single-task
+fine-tuning. If you are doing multi-task fine-tuning, you should use a prefix.
+
+Google has released the following variants:
+
+- [google/mt5-small](https://huggingface.co/google/mt5-small)
+
+- [google/mt5-base](https://huggingface.co/google/mt5-base)
+
+- [google/mt5-large](https://huggingface.co/google/mt5-large)
+
+- [google/mt5-xl](https://huggingface.co/google/mt5-xl)
+
+- [google/mt5-xxl](https://huggingface.co/google/mt5-xxl).
+
+This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten). The original code can be
+found [here](https://github.com/google-research/multilingual-t5).
+
+## MT5Config
+
+[[autodoc]] MT5Config
+
+## MT5Tokenizer
+
+[[autodoc]] MT5Tokenizer
+
+See [`T5Tokenizer`] for all details.
+
+
+## MT5TokenizerFast
+
+[[autodoc]] MT5TokenizerFast
+
+See [`T5TokenizerFast`] for all details.
+
+
+## MT5Model
+
+[[autodoc]] MT5Model
+
+## MT5ForConditionalGeneration
+
+[[autodoc]] MT5ForConditionalGeneration
+
+## MT5EncoderModel
+
+[[autodoc]] MT5EncoderModel
+
+## TFMT5Model
+
+[[autodoc]] TFMT5Model
+
+## TFMT5ForConditionalGeneration
+
+[[autodoc]] TFMT5ForConditionalGeneration
+
+## TFMT5EncoderModel
+
+[[autodoc]] TFMT5EncoderModel
+
+## FlaxMT5Model
+
+[[autodoc]] FlaxMT5Model
+
+## FlaxMT5ForConditionalGeneration
+
+[[autodoc]] FlaxMT5ForConditionalGeneration
diff --git a/docs/source/en/model_doc/nystromformer.mdx b/docs/source/en/model_doc/nystromformer.mdx
new file mode 100644
index 00000000000000..5c1619b57f1ea9
--- /dev/null
+++ b/docs/source/en/model_doc/nystromformer.mdx
@@ -0,0 +1,68 @@
+
+
+# Nyströmformer
+
+## Overview
+
+The Nyströmformer model was proposed in [*Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention*](https://arxiv.org/abs/2102.03902) by Yunyang Xiong, Zhanpeng Zeng, Rudrasis Chakraborty, Mingxing Tan, Glenn
+Fung, Yin Li, and Vikas Singh.
+
+The abstract from the paper is the following:
+
+*Transformers have emerged as a powerful tool for a broad range of natural language processing tasks. A key component
+that drives the impressive performance of Transformers is the self-attention mechanism that encodes the influence or
+dependence of other tokens on each specific token. While beneficial, the quadratic complexity of self-attention on the
+input sequence length has limited its application to longer sequences -- a topic being actively studied in the
+community. To address this limitation, we propose Nyströmformer -- a model that exhibits favorable scalability as a
+function of sequence length. Our idea is based on adapting the Nyström method to approximate standard self-attention
+with O(n) complexity. The scalability of Nyströmformer enables application to longer sequences with thousands of
+tokens. We perform evaluations on multiple downstream tasks on the GLUE benchmark and IMDB reviews with standard
+sequence length, and find that our Nyströmformer performs comparably, or in a few cases, even slightly better, than
+standard self-attention. On longer sequence tasks in the Long Range Arena (LRA) benchmark, Nyströmformer performs
+favorably relative to other efficient self-attention methods. Our code is available at this https URL.*
+
+This model was contributed by [novice03](https://huggingface.co/novice03). The original code can be found [here](https://github.com/mlpen/Nystromformer).
+
+## NystromformerConfig
+
+[[autodoc]] NystromformerConfig
+
+## NystromformerModel
+
+[[autodoc]] NystromformerModel
+ - forward
+
+## NystromformerForMaskedLM
+
+[[autodoc]] NystromformerForMaskedLM
+ - forward
+
+## NystromformerForSequenceClassification
+
+[[autodoc]] NystromformerForSequenceClassification
+ - forward
+
+## NystromformerForMultipleChoice
+
+[[autodoc]] NystromformerForMultipleChoice
+ - forward
+
+## NystromformerForTokenClassification
+
+[[autodoc]] NystromformerForTokenClassification
+ - forward
+
+## NystromformerForQuestionAnswering
+
+[[autodoc]] NystromformerForQuestionAnswering
+ - forward
diff --git a/docs/source/en/model_doc/openai-gpt.mdx b/docs/source/en/model_doc/openai-gpt.mdx
new file mode 100644
index 00000000000000..70213e795e9fa8
--- /dev/null
+++ b/docs/source/en/model_doc/openai-gpt.mdx
@@ -0,0 +1,117 @@
+
+
+# OpenAI GPT
+
+## Overview
+
+OpenAI GPT model was proposed in [Improving Language Understanding by Generative Pre-Training](https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf)
+by Alec Radford, Karthik Narasimhan, Tim Salimans and Ilya Sutskever. It's a causal (unidirectional) transformer
+pre-trained using language modeling on a large corpus will long range dependencies, the Toronto Book Corpus.
+
+The abstract from the paper is the following:
+
+*Natural language understanding comprises a wide range of diverse tasks such as textual entailment, question answering,
+semantic similarity assessment, and document classification. Although large unlabeled text corpora are abundant,
+labeled data for learning these specific tasks is scarce, making it challenging for discriminatively trained models to
+perform adequately. We demonstrate that large gains on these tasks can be realized by generative pretraining of a
+language model on a diverse corpus of unlabeled text, followed by discriminative fine-tuning on each specific task. In
+contrast to previous approaches, we make use of task-aware input transformations during fine-tuning to achieve
+effective transfer while requiring minimal changes to the model architecture. We demonstrate the effectiveness of our
+approach on a wide range of benchmarks for natural language understanding. Our general task-agnostic model outperforms
+discriminatively trained models that use architectures specifically crafted for each task, significantly improving upon
+the state of the art in 9 out of the 12 tasks studied.*
+
+Tips:
+
+- GPT is a model with absolute position embeddings so it's usually advised to pad the inputs on the right rather than
+ the left.
+- GPT was trained with a causal language modeling (CLM) objective and is therefore powerful at predicting the next
+ token in a sequence. Leveraging this feature allows GPT-2 to generate syntactically coherent text as it can be
+ observed in the *run_generation.py* example script.
+
+[Write With Transformer](https://transformer.huggingface.co/doc/gpt) is a webapp created and hosted by Hugging Face
+showcasing the generative capabilities of several models. GPT is one of them.
+
+This model was contributed by [thomwolf](https://huggingface.co/thomwolf). The original code can be found [here](https://github.com/openai/finetune-transformer-lm).
+
+Note:
+
+If you want to reproduce the original tokenization process of the *OpenAI GPT* paper, you will need to install `ftfy`
+and `SpaCy`:
+
+```bash
+pip install spacy ftfy==4.4.3
+python -m spacy download en
+```
+
+If you don't install `ftfy` and `SpaCy`, the [`OpenAIGPTTokenizer`] will default to tokenize
+using BERT's `BasicTokenizer` followed by Byte-Pair Encoding (which should be fine for most usage, don't worry).
+
+## OpenAIGPTConfig
+
+[[autodoc]] OpenAIGPTConfig
+
+## OpenAIGPTTokenizer
+
+[[autodoc]] OpenAIGPTTokenizer
+ - save_vocabulary
+
+## OpenAIGPTTokenizerFast
+
+[[autodoc]] OpenAIGPTTokenizerFast
+
+## OpenAI specific outputs
+
+[[autodoc]] models.openai.modeling_openai.OpenAIGPTDoubleHeadsModelOutput
+
+[[autodoc]] models.openai.modeling_tf_openai.TFOpenAIGPTDoubleHeadsModelOutput
+
+## OpenAIGPTModel
+
+[[autodoc]] OpenAIGPTModel
+ - forward
+
+## OpenAIGPTLMHeadModel
+
+[[autodoc]] OpenAIGPTLMHeadModel
+ - forward
+
+## OpenAIGPTDoubleHeadsModel
+
+[[autodoc]] OpenAIGPTDoubleHeadsModel
+ - forward
+
+## OpenAIGPTForSequenceClassification
+
+[[autodoc]] OpenAIGPTForSequenceClassification
+ - forward
+
+## TFOpenAIGPTModel
+
+[[autodoc]] TFOpenAIGPTModel
+ - call
+
+## TFOpenAIGPTLMHeadModel
+
+[[autodoc]] TFOpenAIGPTLMHeadModel
+ - call
+
+## TFOpenAIGPTDoubleHeadsModel
+
+[[autodoc]] TFOpenAIGPTDoubleHeadsModel
+ - call
+
+## TFOpenAIGPTForSequenceClassification
+
+[[autodoc]] TFOpenAIGPTForSequenceClassification
+ - call
diff --git a/docs/source/en/model_doc/pegasus.mdx b/docs/source/en/model_doc/pegasus.mdx
new file mode 100644
index 00000000000000..52dd10b9bfa790
--- /dev/null
+++ b/docs/source/en/model_doc/pegasus.mdx
@@ -0,0 +1,141 @@
+
+
+# Pegasus
+
+**DISCLAIMER:** If you see something strange, file a [Github Issue](https://github.com/huggingface/transformers/issues/new?assignees=sshleifer&labels=&template=bug-report.md&title)
+and assign @patrickvonplaten.
+
+
+## Overview
+
+The Pegasus model was proposed in [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization](https://arxiv.org/pdf/1912.08777.pdf) by Jingqing Zhang, Yao Zhao, Mohammad Saleh and Peter J. Liu on Dec 18, 2019.
+
+According to the abstract,
+
+- Pegasus' pretraining task is intentionally similar to summarization: important sentences are removed/masked from an
+ input document and are generated together as one output sequence from the remaining sentences, similar to an
+ extractive summary.
+- Pegasus achieves SOTA summarization performance on all 12 downstream tasks, as measured by ROUGE and human eval.
+
+This model was contributed by [sshleifer](https://huggingface.co/sshleifer). The Authors' code can be found [here](https://github.com/google-research/pegasus).
+
+
+## Checkpoints
+
+All the [checkpoints](https://huggingface.co/models?search=pegasus) are fine-tuned for summarization, besides
+*pegasus-large*, whence the other checkpoints are fine-tuned:
+
+- Each checkpoint is 2.2 GB on disk and 568M parameters.
+- FP16 is not supported (help/ideas on this appreciated!).
+- Summarizing xsum in fp32 takes about 400ms/sample, with default parameters on a v100 GPU.
+- Full replication results and correctly pre-processed data can be found in this [Issue](https://github.com/huggingface/transformers/issues/6844#issue-689259666).
+- [Distilled checkpoints](https://huggingface.co/models?search=distill-pegasus) are described in this [paper](https://arxiv.org/abs/2010.13002).
+
+### Examples
+
+- [Script](https://github.com/huggingface/transformers/tree/main/examples/research_projects/seq2seq-distillation/finetune_pegasus_xsum.sh) to fine-tune pegasus
+ on the XSUM dataset. Data download instructions at [examples/pytorch/summarization/](https://github.com/huggingface/transformers/tree/main/examples/pytorch/summarization/README.md).
+- FP16 is not supported (help/ideas on this appreciated!).
+- The adafactor optimizer is recommended for pegasus fine-tuning.
+
+
+## Implementation Notes
+
+- All models are transformer encoder-decoders with 16 layers in each component.
+- The implementation is completely inherited from [`BartForConditionalGeneration`]
+- Some key configuration differences:
+
+ - static, sinusoidal position embeddings
+ - the model starts generating with pad_token_id (which has 0 token_embedding) as the prefix.
+ - more beams are used (`num_beams=8`)
+- All pretrained pegasus checkpoints are the same besides three attributes: `tokenizer.model_max_length` (maximum
+ input size), `max_length` (the maximum number of tokens to generate) and `length_penalty`.
+- The code to convert checkpoints trained in the author's [repo](https://github.com/google-research/pegasus) can be
+ found in `convert_pegasus_tf_to_pytorch.py`.
+
+
+## Usage Example
+
+```python
+>>> from transformers import PegasusForConditionalGeneration, PegasusTokenizer
+>>> import torch
+
+>>> src_text = [
+... """ PG&E stated it scheduled the blackouts in response to forecasts for high winds amid dry conditions. The aim is to reduce the risk of wildfires. Nearly 800 thousand customers were scheduled to be affected by the shutoffs which were expected to last through at least midday tomorrow."""
+... ]
+
+... model_name = "google/pegasus-xsum"
+... device = "cuda" if torch.cuda.is_available() else "cpu"
+... tokenizer = PegasusTokenizer.from_pretrained(model_name)
+... model = PegasusForConditionalGeneration.from_pretrained(model_name).to(device)
+... batch = tokenizer(src_text, truncation=True, padding="longest", return_tensors="pt").to(device)
+... translated = model.generate(**batch)
+... tgt_text = tokenizer.batch_decode(translated, skip_special_tokens=True)
+... assert (
+... tgt_text[0]
+... == "California's largest electricity provider has turned off power to hundreds of thousands of customers."
+... )
+```
+
+## PegasusConfig
+
+[[autodoc]] PegasusConfig
+
+## PegasusTokenizer
+
+warning: `add_tokens` does not work at the moment.
+
+[[autodoc]] PegasusTokenizer
+
+## PegasusTokenizerFast
+
+[[autodoc]] PegasusTokenizerFast
+
+## PegasusModel
+
+[[autodoc]] PegasusModel
+ - forward
+
+## PegasusForConditionalGeneration
+
+[[autodoc]] PegasusForConditionalGeneration
+ - forward
+
+## PegasusForCausalLM
+
+[[autodoc]] PegasusForCausalLM
+ - forward
+
+## TFPegasusModel
+
+[[autodoc]] TFPegasusModel
+ - call
+
+## TFPegasusForConditionalGeneration
+
+[[autodoc]] TFPegasusForConditionalGeneration
+ - call
+
+## FlaxPegasusModel
+
+[[autodoc]] FlaxPegasusModel
+ - __call__
+ - encode
+ - decode
+
+## FlaxPegasusForConditionalGeneration
+
+[[autodoc]] FlaxPegasusForConditionalGeneration
+ - __call__
+ - encode
+ - decode
diff --git a/docs/source/en/model_doc/perceiver.mdx b/docs/source/en/model_doc/perceiver.mdx
new file mode 100644
index 00000000000000..0dbfd3e00494bd
--- /dev/null
+++ b/docs/source/en/model_doc/perceiver.mdx
@@ -0,0 +1,215 @@
+
+
+# Perceiver
+
+## Overview
+
+The Perceiver IO model was proposed in [Perceiver IO: A General Architecture for Structured Inputs &
+Outputs](https://arxiv.org/abs/2107.14795) by Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch,
+Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier Hénaff, Matthew M.
+Botvinick, Andrew Zisserman, Oriol Vinyals, João Carreira.
+
+Perceiver IO is a generalization of [Perceiver](https://arxiv.org/abs/2103.03206) to handle arbitrary outputs in
+addition to arbitrary inputs. The original Perceiver only produced a single classification label. In addition to
+classification labels, Perceiver IO can produce (for example) language, optical flow, and multimodal videos with audio.
+This is done using the same building blocks as the original Perceiver. The computational complexity of Perceiver IO is
+linear in the input and output size and the bulk of the processing occurs in the latent space, allowing us to process
+inputs and outputs that are much larger than can be handled by standard Transformers. This means, for example,
+Perceiver IO can do BERT-style masked language modeling directly using bytes instead of tokenized inputs.
+
+The abstract from the paper is the following:
+
+*The recently-proposed Perceiver model obtains good results on several domains (images, audio, multimodal, point
+clouds) while scaling linearly in compute and memory with the input size. While the Perceiver supports many kinds of
+inputs, it can only produce very simple outputs such as class scores. Perceiver IO overcomes this limitation without
+sacrificing the original's appealing properties by learning to flexibly query the model's latent space to produce
+outputs of arbitrary size and semantics. Perceiver IO still decouples model depth from data size and still scales
+linearly with data size, but now with respect to both input and output sizes. The full Perceiver IO model achieves
+strong results on tasks with highly structured output spaces, such as natural language and visual understanding,
+StarCraft II, and multi-task and multi-modal domains. As highlights, Perceiver IO matches a Transformer-based BERT
+baseline on the GLUE language benchmark without the need for input tokenization and achieves state-of-the-art
+performance on Sintel optical flow estimation.*
+
+Here's a TLDR explaining how Perceiver works:
+
+The main problem with the self-attention mechanism of the Transformer is that the time and memory requirements scale
+quadratically with the sequence length. Hence, models like BERT and RoBERTa are limited to a max sequence length of 512
+tokens. Perceiver aims to solve this issue by, instead of performing self-attention on the inputs, perform it on a set
+of latent variables, and only use the inputs for cross-attention. In this way, the time and memory requirements don't
+depend on the length of the inputs anymore, as one uses a fixed amount of latent variables, like 256 or 512. These are
+randomly initialized, after which they are trained end-to-end using backpropagation.
+
+Internally, [`PerceiverModel`] will create the latents, which is a tensor of shape `(batch_size, num_latents,
+d_latents)`. One must provide `inputs` (which could be text, images, audio, you name it!) to the model, which it will
+use to perform cross-attention with the latents. The output of the Perceiver encoder is a tensor of the same shape. One
+can then, similar to BERT, convert the last hidden states of the latents to classification logits by averaging along
+the sequence dimension, and placing a linear layer on top of that to project the `d_latents` to `num_labels`.
+
+This was the idea of the original Perceiver paper. However, it could only output classification logits. In a follow-up
+work, PerceiverIO, they generalized it to let the model also produce outputs of arbitrary size. How, you might ask? The
+idea is actually relatively simple: one defines outputs of an arbitrary size, and then applies cross-attention with the
+last hidden states of the latents, using the outputs as queries, and the latents as keys and values.
+
+So let's say one wants to perform masked language modeling (BERT-style) with the Perceiver. As the Perceiver's input
+length will not have an impact on the computation time of the self-attention layers, one can provide raw bytes,
+providing `inputs` of length 2048 to the model. If one now masks out certain of these 2048 tokens, one can define the
+`outputs` as being of shape: `(batch_size, 2048, 768)`. Next, one performs cross-attention with the final hidden states
+of the latents to update the `outputs` tensor. After cross-attention, one still has a tensor of shape `(batch_size,
+2048, 768)`. One can then place a regular language modeling head on top, to project the last dimension to the
+vocabulary size of the model, i.e. creating logits of shape `(batch_size, 2048, 262)` (as Perceiver uses a vocabulary
+size of 262 byte IDs).
+
+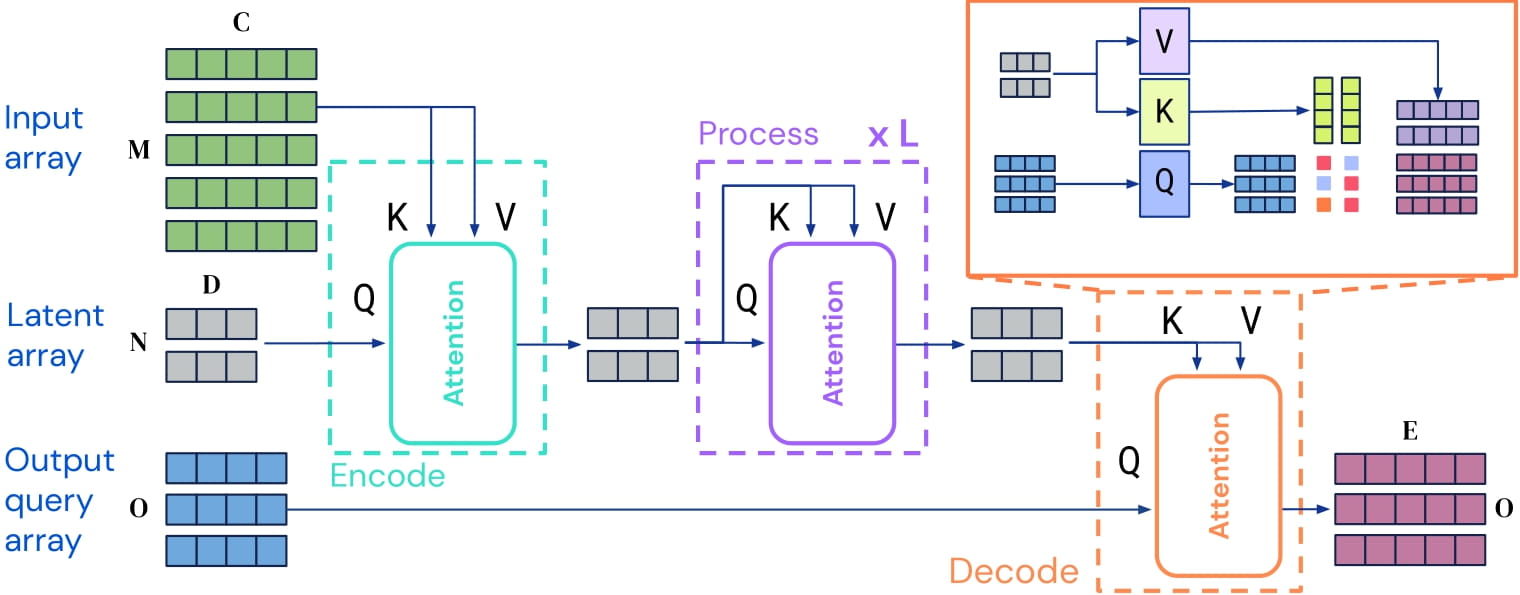 +
+ Perceiver IO architecture. Taken from the original paper
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found
+[here](https://github.com/deepmind/deepmind-research/tree/master/perceiver).
+
+Tips:
+
+- The quickest way to get started with the Perceiver is by checking the [tutorial
+ notebooks](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/Perceiver).
+- Refer to the [blog post](https://huggingface.co/blog/perceiver) if you want to fully understand how the model works and
+is implemented in the library. Note that the models available in the library only showcase some examples of what you can do
+with the Perceiver. There are many more use cases, including question answering, named-entity recognition, object detection,
+audio classification, video classification, etc.
+
+**Note**:
+
+- Perceiver does **not** work with `torch.nn.DataParallel` due to a bug in PyTorch, see [issue #36035](https://github.com/pytorch/pytorch/issues/36035)
+
+## Perceiver specific outputs
+
+[[autodoc]] models.perceiver.modeling_perceiver.PerceiverModelOutput
+
+[[autodoc]] models.perceiver.modeling_perceiver.PerceiverDecoderOutput
+
+[[autodoc]] models.perceiver.modeling_perceiver.PerceiverMaskedLMOutput
+
+[[autodoc]] models.perceiver.modeling_perceiver.PerceiverClassifierOutput
+
+## PerceiverConfig
+
+[[autodoc]] PerceiverConfig
+
+## PerceiverTokenizer
+
+[[autodoc]] PerceiverTokenizer
+ - __call__
+
+## PerceiverFeatureExtractor
+
+[[autodoc]] PerceiverFeatureExtractor
+ - __call__
+
+## PerceiverTextPreprocessor
+
+[[autodoc]] models.perceiver.modeling_perceiver.PerceiverTextPreprocessor
+
+## PerceiverImagePreprocessor
+
+[[autodoc]] models.perceiver.modeling_perceiver.PerceiverImagePreprocessor
+
+## PerceiverOneHotPreprocessor
+
+[[autodoc]] models.perceiver.modeling_perceiver.PerceiverOneHotPreprocessor
+
+## PerceiverAudioPreprocessor
+
+[[autodoc]] models.perceiver.modeling_perceiver.PerceiverAudioPreprocessor
+
+## PerceiverMultimodalPreprocessor
+
+[[autodoc]] models.perceiver.modeling_perceiver.PerceiverMultimodalPreprocessor
+
+## PerceiverProjectionDecoder
+
+[[autodoc]] models.perceiver.modeling_perceiver.PerceiverProjectionDecoder
+
+## PerceiverBasicDecoder
+
+[[autodoc]] models.perceiver.modeling_perceiver.PerceiverBasicDecoder
+
+## PerceiverClassificationDecoder
+
+[[autodoc]] models.perceiver.modeling_perceiver.PerceiverClassificationDecoder
+
+## PerceiverOpticalFlowDecoder
+
+[[autodoc]] models.perceiver.modeling_perceiver.PerceiverOpticalFlowDecoder
+
+## PerceiverBasicVideoAutoencodingDecoder
+
+[[autodoc]] models.perceiver.modeling_perceiver.PerceiverBasicVideoAutoencodingDecoder
+
+## PerceiverMultimodalDecoder
+
+[[autodoc]] models.perceiver.modeling_perceiver.PerceiverMultimodalDecoder
+
+## PerceiverProjectionPostprocessor
+
+[[autodoc]] models.perceiver.modeling_perceiver.PerceiverProjectionPostprocessor
+
+## PerceiverAudioPostprocessor
+
+[[autodoc]] models.perceiver.modeling_perceiver.PerceiverAudioPostprocessor
+
+## PerceiverClassificationPostprocessor
+
+[[autodoc]] models.perceiver.modeling_perceiver.PerceiverClassificationPostprocessor
+
+## PerceiverMultimodalPostprocessor
+
+[[autodoc]] models.perceiver.modeling_perceiver.PerceiverMultimodalPostprocessor
+
+## PerceiverModel
+
+[[autodoc]] PerceiverModel
+ - forward
+
+## PerceiverForMaskedLM
+
+[[autodoc]] PerceiverForMaskedLM
+ - forward
+
+## PerceiverForSequenceClassification
+
+[[autodoc]] PerceiverForSequenceClassification
+ - forward
+
+## PerceiverForImageClassificationLearned
+
+[[autodoc]] PerceiverForImageClassificationLearned
+ - forward
+
+## PerceiverForImageClassificationFourier
+
+[[autodoc]] PerceiverForImageClassificationFourier
+ - forward
+
+## PerceiverForImageClassificationConvProcessing
+
+[[autodoc]] PerceiverForImageClassificationConvProcessing
+ - forward
+
+## PerceiverForOpticalFlow
+
+[[autodoc]] PerceiverForOpticalFlow
+ - forward
+
+## PerceiverForMultimodalAutoencoding
+
+[[autodoc]] PerceiverForMultimodalAutoencoding
+ - forward
diff --git a/docs/source/en/model_doc/phobert.mdx b/docs/source/en/model_doc/phobert.mdx
new file mode 100644
index 00000000000000..4ae9b0aa625153
--- /dev/null
+++ b/docs/source/en/model_doc/phobert.mdx
@@ -0,0 +1,53 @@
+
+
+# PhoBERT
+
+## Overview
+
+The PhoBERT model was proposed in [PhoBERT: Pre-trained language models for Vietnamese](https://www.aclweb.org/anthology/2020.findings-emnlp.92.pdf) by Dat Quoc Nguyen, Anh Tuan Nguyen.
+
+The abstract from the paper is the following:
+
+*We present PhoBERT with two versions, PhoBERT-base and PhoBERT-large, the first public large-scale monolingual
+language models pre-trained for Vietnamese. Experimental results show that PhoBERT consistently outperforms the recent
+best pre-trained multilingual model XLM-R (Conneau et al., 2020) and improves the state-of-the-art in multiple
+Vietnamese-specific NLP tasks including Part-of-speech tagging, Dependency parsing, Named-entity recognition and
+Natural language inference.*
+
+Example of use:
+
+```python
+>>> import torch
+>>> from transformers import AutoModel, AutoTokenizer
+
+>>> phobert = AutoModel.from_pretrained("vinai/phobert-base")
+>>> tokenizer = AutoTokenizer.from_pretrained("vinai/phobert-base")
+
+>>> # INPUT TEXT MUST BE ALREADY WORD-SEGMENTED!
+>>> line = "Tôi là sinh_viên trường đại_học Công_nghệ ."
+
+>>> input_ids = torch.tensor([tokenizer.encode(line)])
+
+>>> with torch.no_grad():
+... features = phobert(input_ids) # Models outputs are now tuples
+
+>>> # With TensorFlow 2.0+:
+>>> # from transformers import TFAutoModel
+>>> # phobert = TFAutoModel.from_pretrained("vinai/phobert-base")
+```
+
+This model was contributed by [dqnguyen](https://huggingface.co/dqnguyen). The original code can be found [here](https://github.com/VinAIResearch/PhoBERT).
+
+## PhobertTokenizer
+
+[[autodoc]] PhobertTokenizer
diff --git a/docs/source/en/model_doc/plbart.mdx b/docs/source/en/model_doc/plbart.mdx
new file mode 100644
index 00000000000000..6e3e4a5b7773b8
--- /dev/null
+++ b/docs/source/en/model_doc/plbart.mdx
@@ -0,0 +1,112 @@
+
+
+# PLBart
+
+**DISCLAIMER:** If you see something strange, file a [Github Issue](https://github.com/huggingface/transformers/issues/new?assignees=&labels=&template=bug-report.md&title) and assign
+[@gchhablani](https://www.github.com/gchhablani).
+
+## Overview of PLBart
+
+The PLBART model was proposed in [Unified Pre-training for Program Understanding and Generation](https://arxiv.org/abs/2103.06333) by Wasi Uddin Ahmad, Saikat Chakraborty, Baishakhi Ray, Kai-Wei Chang.
+This is a BART-like model which can be used to perform code-summarization, code-generation, and code-translation tasks. The pre-trained model `plbart-base` has been trained using multilingual denoising task
+on Java, Python and English.
+
+According to the abstract
+
+*Code summarization and generation empower conversion between programming language (PL) and natural language (NL),
+while code translation avails the migration of legacy code from one PL to another. This paper introduces PLBART,
+a sequence-to-sequence model capable of performing a broad spectrum of program and language understanding and generation tasks.
+PLBART is pre-trained on an extensive collection of Java and Python functions and associated NL text via denoising autoencoding.
+Experiments on code summarization in the English language, code generation, and code translation in seven programming languages
+show that PLBART outperforms or rivals state-of-the-art models. Moreover, experiments on discriminative tasks, e.g., program
+repair, clone detection, and vulnerable code detection, demonstrate PLBART's effectiveness in program understanding.
+Furthermore, analysis reveals that PLBART learns program syntax, style (e.g., identifier naming convention), logical flow
+(e.g., if block inside an else block is equivalent to else if block) that are crucial to program semantics and thus excels
+even with limited annotations.*
+
+This model was contributed by [gchhablani](https://huggingface.co/gchhablani). The Authors' code can be found [here](https://github.com/wasiahmad/PLBART).
+
+### Training of PLBart
+
+PLBart is a multilingual encoder-decoder (sequence-to-sequence) model primarily intended for code-to-text, text-to-code, code-to-code tasks. As the
+model is multilingual it expects the sequences in a different format. A special language id token is added in both the
+source and target text. The source text format is `X [eos, src_lang_code]` where `X` is the source text. The
+target text format is `[tgt_lang_code] X [eos]`. `bos` is never used.
+
+However, for fine-tuning, in some cases no language token is provided in cases where a single language is used. Please refer to [the paper](https://arxiv.org/abs/2103.06333) to learn more about this.
+
+In cases where the language code is needed, The regular [`~PLBartTokenizer.__call__`] will encode source text format, and it should be wrapped
+inside the context manager [`~PLBartTokenizer.as_target_tokenizer`] to encode target text format.
+
+- Supervised training
+
+```python
+>>> from transformers import PLBartForConditionalGeneration, PLBartTokenizer
+
+>>> tokenizer = PLBartTokenizer.from_pretrained("uclanlp/plbart-base", src_lang="en_XX", tgt_lang="python")
+>>> example_python_phrase = "def maximum(a,b,c):NEW_LINE_INDENTreturn max([a,b,c])"
+>>> expected_translation_english = "Returns the maximum value of a b c."
+>>> inputs = tokenizer(example_python_phrase, return_tensors="pt")
+>>> with tokenizer.as_target_tokenizer():
+... labels = tokenizer(expected_translation_english, return_tensors="pt")
+>>> inputs["labels"] = labels["input_ids"]
+>>> # forward pass
+>>> model(**inputs)
+```
+
+- Generation
+
+ While generating the target text set the `decoder_start_token_id` to the target language id. The following
+ example shows how to translate Python to English using the `uclanlp/plbart-python-en_XX` model.
+
+```python
+>>> from transformers import PLBartForConditionalGeneration, PLBartTokenizer
+
+>>> tokenizer = PLBartTokenizer.from_pretrained("uclanlp/plbart-python-en_XX", src_lang="python", tgt_lang="en_XX")
+>>> example_python_phrase = "def maximum(a,b,c):NEW_LINE_INDENTreturn max([a,b,c])"
+>>> inputs = tokenizer(example_python_phrase, return_tensors="pt")
+>>> model = PLBartForConditionalGeneration.from_pretrained("uclanlp/plbart-python-en_XX")
+>>> translated_tokens = model.generate(**inputs, decoder_start_token_id=tokenizer.lang_code_to_id["en_XX"])
+>>> tokenizer.batch_decode(translated_tokens, skip_special_tokens=True)[0]
+"Returns the maximum value of a b c."
+```
+
+## PLBartConfig
+
+[[autodoc]] PLBartConfig
+
+## PLBartTokenizer
+
+[[autodoc]] PLBartTokenizer
+ - as_target_tokenizer
+ - build_inputs_with_special_tokens
+
+## PLBartModel
+
+[[autodoc]] PLBartModel
+ - forward
+
+## PLBartForConditionalGeneration
+
+[[autodoc]] PLBartForConditionalGeneration
+ - forward
+
+## PLBartForSequenceClassification
+
+[[autodoc]] PLBartForSequenceClassification
+ - forward
+
+## PLBartForCausalLM
+
+[[autodoc]] PLBartForCausalLM
+ - forward
\ No newline at end of file
diff --git a/docs/source/en/model_doc/poolformer.mdx b/docs/source/en/model_doc/poolformer.mdx
new file mode 100644
index 00000000000000..ac06bb63dbce5f
--- /dev/null
+++ b/docs/source/en/model_doc/poolformer.mdx
@@ -0,0 +1,61 @@
+
+
+# PoolFormer
+
+## Overview
+
+The PoolFormer model was proposed in [MetaFormer is Actually What You Need for Vision](https://arxiv.org/abs/2111.11418) by Sea AI Labs. Instead of designing complicated token mixer to achieve SOTA performance, the target of this work is to demonstrate the competence of transformer models largely stem from the general architecture MetaFormer.
+
+The abstract from the paper is the following:
+
+*Transformers have shown great potential in computer vision tasks. A common belief is their attention-based token mixer module contributes most to their competence. However, recent works show the attention-based module in transformers can be replaced by spatial MLPs and the resulted models still perform quite well. Based on this observation, we hypothesize that the general architecture of the transformers, instead of the specific token mixer module, is more essential to the model's performance. To verify this, we deliberately replace the attention module in transformers with an embarrassingly simple spatial pooling operator to conduct only the most basic token mixing. Surprisingly, we observe that the derived model, termed as PoolFormer, achieves competitive performance on multiple computer vision tasks. For example, on ImageNet-1K, PoolFormer achieves 82.1% top-1 accuracy, surpassing well-tuned vision transformer/MLP-like baselines DeiT-B/ResMLP-B24 by 0.3%/1.1% accuracy with 35%/52% fewer parameters and 48%/60% fewer MACs. The effectiveness of PoolFormer verifies our hypothesis and urges us to initiate the concept of "MetaFormer", a general architecture abstracted from transformers without specifying the token mixer. Based on the extensive experiments, we argue that MetaFormer is the key player in achieving superior results for recent transformer and MLP-like models on vision tasks. This work calls for more future research dedicated to improving MetaFormer instead of focusing on the token mixer modules. Additionally, our proposed PoolFormer could serve as a starting baseline for future MetaFormer architecture design.*
+
+The figure below illustrates the architecture of PoolFormer. Taken from the [original paper](https://arxiv.org/abs/2111.11418).
+
+
+
+ Perceiver IO architecture. Taken from the original paper
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found
+[here](https://github.com/deepmind/deepmind-research/tree/master/perceiver).
+
+Tips:
+
+- The quickest way to get started with the Perceiver is by checking the [tutorial
+ notebooks](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/Perceiver).
+- Refer to the [blog post](https://huggingface.co/blog/perceiver) if you want to fully understand how the model works and
+is implemented in the library. Note that the models available in the library only showcase some examples of what you can do
+with the Perceiver. There are many more use cases, including question answering, named-entity recognition, object detection,
+audio classification, video classification, etc.
+
+**Note**:
+
+- Perceiver does **not** work with `torch.nn.DataParallel` due to a bug in PyTorch, see [issue #36035](https://github.com/pytorch/pytorch/issues/36035)
+
+## Perceiver specific outputs
+
+[[autodoc]] models.perceiver.modeling_perceiver.PerceiverModelOutput
+
+[[autodoc]] models.perceiver.modeling_perceiver.PerceiverDecoderOutput
+
+[[autodoc]] models.perceiver.modeling_perceiver.PerceiverMaskedLMOutput
+
+[[autodoc]] models.perceiver.modeling_perceiver.PerceiverClassifierOutput
+
+## PerceiverConfig
+
+[[autodoc]] PerceiverConfig
+
+## PerceiverTokenizer
+
+[[autodoc]] PerceiverTokenizer
+ - __call__
+
+## PerceiverFeatureExtractor
+
+[[autodoc]] PerceiverFeatureExtractor
+ - __call__
+
+## PerceiverTextPreprocessor
+
+[[autodoc]] models.perceiver.modeling_perceiver.PerceiverTextPreprocessor
+
+## PerceiverImagePreprocessor
+
+[[autodoc]] models.perceiver.modeling_perceiver.PerceiverImagePreprocessor
+
+## PerceiverOneHotPreprocessor
+
+[[autodoc]] models.perceiver.modeling_perceiver.PerceiverOneHotPreprocessor
+
+## PerceiverAudioPreprocessor
+
+[[autodoc]] models.perceiver.modeling_perceiver.PerceiverAudioPreprocessor
+
+## PerceiverMultimodalPreprocessor
+
+[[autodoc]] models.perceiver.modeling_perceiver.PerceiverMultimodalPreprocessor
+
+## PerceiverProjectionDecoder
+
+[[autodoc]] models.perceiver.modeling_perceiver.PerceiverProjectionDecoder
+
+## PerceiverBasicDecoder
+
+[[autodoc]] models.perceiver.modeling_perceiver.PerceiverBasicDecoder
+
+## PerceiverClassificationDecoder
+
+[[autodoc]] models.perceiver.modeling_perceiver.PerceiverClassificationDecoder
+
+## PerceiverOpticalFlowDecoder
+
+[[autodoc]] models.perceiver.modeling_perceiver.PerceiverOpticalFlowDecoder
+
+## PerceiverBasicVideoAutoencodingDecoder
+
+[[autodoc]] models.perceiver.modeling_perceiver.PerceiverBasicVideoAutoencodingDecoder
+
+## PerceiverMultimodalDecoder
+
+[[autodoc]] models.perceiver.modeling_perceiver.PerceiverMultimodalDecoder
+
+## PerceiverProjectionPostprocessor
+
+[[autodoc]] models.perceiver.modeling_perceiver.PerceiverProjectionPostprocessor
+
+## PerceiverAudioPostprocessor
+
+[[autodoc]] models.perceiver.modeling_perceiver.PerceiverAudioPostprocessor
+
+## PerceiverClassificationPostprocessor
+
+[[autodoc]] models.perceiver.modeling_perceiver.PerceiverClassificationPostprocessor
+
+## PerceiverMultimodalPostprocessor
+
+[[autodoc]] models.perceiver.modeling_perceiver.PerceiverMultimodalPostprocessor
+
+## PerceiverModel
+
+[[autodoc]] PerceiverModel
+ - forward
+
+## PerceiverForMaskedLM
+
+[[autodoc]] PerceiverForMaskedLM
+ - forward
+
+## PerceiverForSequenceClassification
+
+[[autodoc]] PerceiverForSequenceClassification
+ - forward
+
+## PerceiverForImageClassificationLearned
+
+[[autodoc]] PerceiverForImageClassificationLearned
+ - forward
+
+## PerceiverForImageClassificationFourier
+
+[[autodoc]] PerceiverForImageClassificationFourier
+ - forward
+
+## PerceiverForImageClassificationConvProcessing
+
+[[autodoc]] PerceiverForImageClassificationConvProcessing
+ - forward
+
+## PerceiverForOpticalFlow
+
+[[autodoc]] PerceiverForOpticalFlow
+ - forward
+
+## PerceiverForMultimodalAutoencoding
+
+[[autodoc]] PerceiverForMultimodalAutoencoding
+ - forward
diff --git a/docs/source/en/model_doc/phobert.mdx b/docs/source/en/model_doc/phobert.mdx
new file mode 100644
index 00000000000000..4ae9b0aa625153
--- /dev/null
+++ b/docs/source/en/model_doc/phobert.mdx
@@ -0,0 +1,53 @@
+
+
+# PhoBERT
+
+## Overview
+
+The PhoBERT model was proposed in [PhoBERT: Pre-trained language models for Vietnamese](https://www.aclweb.org/anthology/2020.findings-emnlp.92.pdf) by Dat Quoc Nguyen, Anh Tuan Nguyen.
+
+The abstract from the paper is the following:
+
+*We present PhoBERT with two versions, PhoBERT-base and PhoBERT-large, the first public large-scale monolingual
+language models pre-trained for Vietnamese. Experimental results show that PhoBERT consistently outperforms the recent
+best pre-trained multilingual model XLM-R (Conneau et al., 2020) and improves the state-of-the-art in multiple
+Vietnamese-specific NLP tasks including Part-of-speech tagging, Dependency parsing, Named-entity recognition and
+Natural language inference.*
+
+Example of use:
+
+```python
+>>> import torch
+>>> from transformers import AutoModel, AutoTokenizer
+
+>>> phobert = AutoModel.from_pretrained("vinai/phobert-base")
+>>> tokenizer = AutoTokenizer.from_pretrained("vinai/phobert-base")
+
+>>> # INPUT TEXT MUST BE ALREADY WORD-SEGMENTED!
+>>> line = "Tôi là sinh_viên trường đại_học Công_nghệ ."
+
+>>> input_ids = torch.tensor([tokenizer.encode(line)])
+
+>>> with torch.no_grad():
+... features = phobert(input_ids) # Models outputs are now tuples
+
+>>> # With TensorFlow 2.0+:
+>>> # from transformers import TFAutoModel
+>>> # phobert = TFAutoModel.from_pretrained("vinai/phobert-base")
+```
+
+This model was contributed by [dqnguyen](https://huggingface.co/dqnguyen). The original code can be found [here](https://github.com/VinAIResearch/PhoBERT).
+
+## PhobertTokenizer
+
+[[autodoc]] PhobertTokenizer
diff --git a/docs/source/en/model_doc/plbart.mdx b/docs/source/en/model_doc/plbart.mdx
new file mode 100644
index 00000000000000..6e3e4a5b7773b8
--- /dev/null
+++ b/docs/source/en/model_doc/plbart.mdx
@@ -0,0 +1,112 @@
+
+
+# PLBart
+
+**DISCLAIMER:** If you see something strange, file a [Github Issue](https://github.com/huggingface/transformers/issues/new?assignees=&labels=&template=bug-report.md&title) and assign
+[@gchhablani](https://www.github.com/gchhablani).
+
+## Overview of PLBart
+
+The PLBART model was proposed in [Unified Pre-training for Program Understanding and Generation](https://arxiv.org/abs/2103.06333) by Wasi Uddin Ahmad, Saikat Chakraborty, Baishakhi Ray, Kai-Wei Chang.
+This is a BART-like model which can be used to perform code-summarization, code-generation, and code-translation tasks. The pre-trained model `plbart-base` has been trained using multilingual denoising task
+on Java, Python and English.
+
+According to the abstract
+
+*Code summarization and generation empower conversion between programming language (PL) and natural language (NL),
+while code translation avails the migration of legacy code from one PL to another. This paper introduces PLBART,
+a sequence-to-sequence model capable of performing a broad spectrum of program and language understanding and generation tasks.
+PLBART is pre-trained on an extensive collection of Java and Python functions and associated NL text via denoising autoencoding.
+Experiments on code summarization in the English language, code generation, and code translation in seven programming languages
+show that PLBART outperforms or rivals state-of-the-art models. Moreover, experiments on discriminative tasks, e.g., program
+repair, clone detection, and vulnerable code detection, demonstrate PLBART's effectiveness in program understanding.
+Furthermore, analysis reveals that PLBART learns program syntax, style (e.g., identifier naming convention), logical flow
+(e.g., if block inside an else block is equivalent to else if block) that are crucial to program semantics and thus excels
+even with limited annotations.*
+
+This model was contributed by [gchhablani](https://huggingface.co/gchhablani). The Authors' code can be found [here](https://github.com/wasiahmad/PLBART).
+
+### Training of PLBart
+
+PLBart is a multilingual encoder-decoder (sequence-to-sequence) model primarily intended for code-to-text, text-to-code, code-to-code tasks. As the
+model is multilingual it expects the sequences in a different format. A special language id token is added in both the
+source and target text. The source text format is `X [eos, src_lang_code]` where `X` is the source text. The
+target text format is `[tgt_lang_code] X [eos]`. `bos` is never used.
+
+However, for fine-tuning, in some cases no language token is provided in cases where a single language is used. Please refer to [the paper](https://arxiv.org/abs/2103.06333) to learn more about this.
+
+In cases where the language code is needed, The regular [`~PLBartTokenizer.__call__`] will encode source text format, and it should be wrapped
+inside the context manager [`~PLBartTokenizer.as_target_tokenizer`] to encode target text format.
+
+- Supervised training
+
+```python
+>>> from transformers import PLBartForConditionalGeneration, PLBartTokenizer
+
+>>> tokenizer = PLBartTokenizer.from_pretrained("uclanlp/plbart-base", src_lang="en_XX", tgt_lang="python")
+>>> example_python_phrase = "def maximum(a,b,c):NEW_LINE_INDENTreturn max([a,b,c])"
+>>> expected_translation_english = "Returns the maximum value of a b c."
+>>> inputs = tokenizer(example_python_phrase, return_tensors="pt")
+>>> with tokenizer.as_target_tokenizer():
+... labels = tokenizer(expected_translation_english, return_tensors="pt")
+>>> inputs["labels"] = labels["input_ids"]
+>>> # forward pass
+>>> model(**inputs)
+```
+
+- Generation
+
+ While generating the target text set the `decoder_start_token_id` to the target language id. The following
+ example shows how to translate Python to English using the `uclanlp/plbart-python-en_XX` model.
+
+```python
+>>> from transformers import PLBartForConditionalGeneration, PLBartTokenizer
+
+>>> tokenizer = PLBartTokenizer.from_pretrained("uclanlp/plbart-python-en_XX", src_lang="python", tgt_lang="en_XX")
+>>> example_python_phrase = "def maximum(a,b,c):NEW_LINE_INDENTreturn max([a,b,c])"
+>>> inputs = tokenizer(example_python_phrase, return_tensors="pt")
+>>> model = PLBartForConditionalGeneration.from_pretrained("uclanlp/plbart-python-en_XX")
+>>> translated_tokens = model.generate(**inputs, decoder_start_token_id=tokenizer.lang_code_to_id["en_XX"])
+>>> tokenizer.batch_decode(translated_tokens, skip_special_tokens=True)[0]
+"Returns the maximum value of a b c."
+```
+
+## PLBartConfig
+
+[[autodoc]] PLBartConfig
+
+## PLBartTokenizer
+
+[[autodoc]] PLBartTokenizer
+ - as_target_tokenizer
+ - build_inputs_with_special_tokens
+
+## PLBartModel
+
+[[autodoc]] PLBartModel
+ - forward
+
+## PLBartForConditionalGeneration
+
+[[autodoc]] PLBartForConditionalGeneration
+ - forward
+
+## PLBartForSequenceClassification
+
+[[autodoc]] PLBartForSequenceClassification
+ - forward
+
+## PLBartForCausalLM
+
+[[autodoc]] PLBartForCausalLM
+ - forward
\ No newline at end of file
diff --git a/docs/source/en/model_doc/poolformer.mdx b/docs/source/en/model_doc/poolformer.mdx
new file mode 100644
index 00000000000000..ac06bb63dbce5f
--- /dev/null
+++ b/docs/source/en/model_doc/poolformer.mdx
@@ -0,0 +1,61 @@
+
+
+# PoolFormer
+
+## Overview
+
+The PoolFormer model was proposed in [MetaFormer is Actually What You Need for Vision](https://arxiv.org/abs/2111.11418) by Sea AI Labs. Instead of designing complicated token mixer to achieve SOTA performance, the target of this work is to demonstrate the competence of transformer models largely stem from the general architecture MetaFormer.
+
+The abstract from the paper is the following:
+
+*Transformers have shown great potential in computer vision tasks. A common belief is their attention-based token mixer module contributes most to their competence. However, recent works show the attention-based module in transformers can be replaced by spatial MLPs and the resulted models still perform quite well. Based on this observation, we hypothesize that the general architecture of the transformers, instead of the specific token mixer module, is more essential to the model's performance. To verify this, we deliberately replace the attention module in transformers with an embarrassingly simple spatial pooling operator to conduct only the most basic token mixing. Surprisingly, we observe that the derived model, termed as PoolFormer, achieves competitive performance on multiple computer vision tasks. For example, on ImageNet-1K, PoolFormer achieves 82.1% top-1 accuracy, surpassing well-tuned vision transformer/MLP-like baselines DeiT-B/ResMLP-B24 by 0.3%/1.1% accuracy with 35%/52% fewer parameters and 48%/60% fewer MACs. The effectiveness of PoolFormer verifies our hypothesis and urges us to initiate the concept of "MetaFormer", a general architecture abstracted from transformers without specifying the token mixer. Based on the extensive experiments, we argue that MetaFormer is the key player in achieving superior results for recent transformer and MLP-like models on vision tasks. This work calls for more future research dedicated to improving MetaFormer instead of focusing on the token mixer modules. Additionally, our proposed PoolFormer could serve as a starting baseline for future MetaFormer architecture design.*
+
+The figure below illustrates the architecture of PoolFormer. Taken from the [original paper](https://arxiv.org/abs/2111.11418).
+
+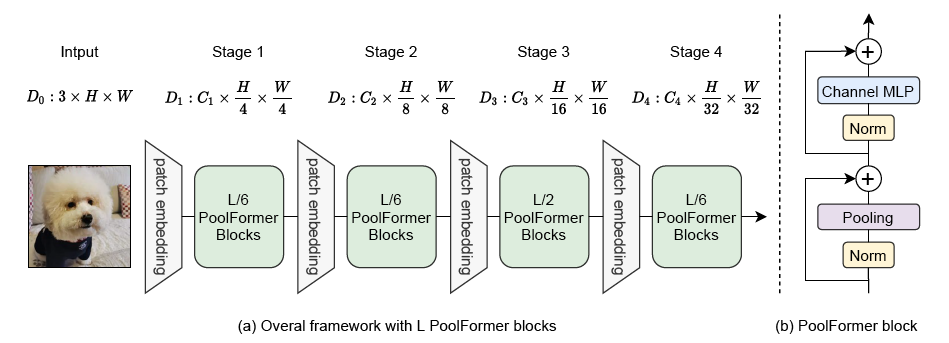 +
+
+Tips:
+
+- PoolFormer has a hierarchical architecture, where instead of Attention, a simple Average Pooling layer is present. All checkpoints of the model can be found on the [hub](https://huggingface.co/models?other=poolformer).
+- One can use [`PoolFormerFeatureExtractor`] to prepare images for the model.
+- As most models, PoolFormer comes in different sizes, the details of which can be found in the table below.
+
+| **Model variant** | **Depths** | **Hidden sizes** | **Params (M)** | **ImageNet-1k Top 1** |
+| :---------------: | ------------- | ------------------- | :------------: | :-------------------: |
+| s12 | [2, 2, 6, 2] | [64, 128, 320, 512] | 12 | 77.2 |
+| s24 | [4, 4, 12, 4] | [64, 128, 320, 512] | 21 | 80.3 |
+| s36 | [6, 6, 18, 6] | [64, 128, 320, 512] | 31 | 81.4 |
+| m36 | [6, 6, 18, 6] | [96, 192, 384, 768] | 56 | 82.1 |
+| m48 | [8, 8, 24, 8] | [96, 192, 384, 768] | 73 | 82.5 |
+
+This model was contributed by [heytanay](https://huggingface.co/heytanay). The original code can be found [here](https://github.com/sail-sg/poolformer).
+
+## PoolFormerConfig
+
+[[autodoc]] PoolFormerConfig
+
+## PoolFormerFeatureExtractor
+
+[[autodoc]] PoolFormerFeatureExtractor
+ - __call__
+
+## PoolFormerModel
+
+[[autodoc]] PoolFormerModel
+ - forward
+
+## PoolFormerForImageClassification
+
+[[autodoc]] PoolFormerForImageClassification
+ - forward
\ No newline at end of file
diff --git a/docs/source/en/model_doc/prophetnet.mdx b/docs/source/en/model_doc/prophetnet.mdx
new file mode 100644
index 00000000000000..951bbc5b96514c
--- /dev/null
+++ b/docs/source/en/model_doc/prophetnet.mdx
@@ -0,0 +1,82 @@
+
+
+# ProphetNet
+
+**DISCLAIMER:** If you see something strange, file a [Github Issue](https://github.com/huggingface/transformers/issues/new?assignees=&labels=&template=bug-report.md&title) and assign
+@patrickvonplaten
+
+## Overview
+
+The ProphetNet model was proposed in [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training,](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei
+Zhang, Ming Zhou on 13 Jan, 2020.
+
+ProphetNet is an encoder-decoder model and can predict n-future tokens for "ngram" language modeling instead of just
+the next token.
+
+The abstract from the paper is the following:
+
+*In this paper, we present a new sequence-to-sequence pretraining model called ProphetNet, which introduces a novel
+self-supervised objective named future n-gram prediction and the proposed n-stream self-attention mechanism. Instead of
+the optimization of one-step ahead prediction in traditional sequence-to-sequence model, the ProphetNet is optimized by
+n-step ahead prediction which predicts the next n tokens simultaneously based on previous context tokens at each time
+step. The future n-gram prediction explicitly encourages the model to plan for the future tokens and prevent
+overfitting on strong local correlations. We pre-train ProphetNet using a base scale dataset (16GB) and a large scale
+dataset (160GB) respectively. Then we conduct experiments on CNN/DailyMail, Gigaword, and SQuAD 1.1 benchmarks for
+abstractive summarization and question generation tasks. Experimental results show that ProphetNet achieves new
+state-of-the-art results on all these datasets compared to the models using the same scale pretraining corpus.*
+
+The Authors' code can be found [here](https://github.com/microsoft/ProphetNet).
+
+
+## ProphetNetConfig
+
+[[autodoc]] ProphetNetConfig
+
+## ProphetNetTokenizer
+
+[[autodoc]] ProphetNetTokenizer
+
+## ProphetNet specific outputs
+
+[[autodoc]] models.prophetnet.modeling_prophetnet.ProphetNetSeq2SeqLMOutput
+
+[[autodoc]] models.prophetnet.modeling_prophetnet.ProphetNetSeq2SeqModelOutput
+
+[[autodoc]] models.prophetnet.modeling_prophetnet.ProphetNetDecoderModelOutput
+
+[[autodoc]] models.prophetnet.modeling_prophetnet.ProphetNetDecoderLMOutput
+
+## ProphetNetModel
+
+[[autodoc]] ProphetNetModel
+ - forward
+
+## ProphetNetEncoder
+
+[[autodoc]] ProphetNetEncoder
+ - forward
+
+## ProphetNetDecoder
+
+[[autodoc]] ProphetNetDecoder
+ - forward
+
+## ProphetNetForConditionalGeneration
+
+[[autodoc]] ProphetNetForConditionalGeneration
+ - forward
+
+## ProphetNetForCausalLM
+
+[[autodoc]] ProphetNetForCausalLM
+ - forward
diff --git a/docs/source/en/model_doc/qdqbert.mdx b/docs/source/en/model_doc/qdqbert.mdx
new file mode 100644
index 00000000000000..df7b7bcee62516
--- /dev/null
+++ b/docs/source/en/model_doc/qdqbert.mdx
@@ -0,0 +1,159 @@
+
+
+# QDQBERT
+
+## Overview
+
+The QDQBERT model can be referenced in [Integer Quantization for Deep Learning Inference: Principles and Empirical
+Evaluation](https://arxiv.org/abs/2004.09602) by Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius
+Micikevicius.
+
+The abstract from the paper is the following:
+
+*Quantization techniques can reduce the size of Deep Neural Networks and improve inference latency and throughput by
+taking advantage of high throughput integer instructions. In this paper we review the mathematical aspects of
+quantization parameters and evaluate their choices on a wide range of neural network models for different application
+domains, including vision, speech, and language. We focus on quantization techniques that are amenable to acceleration
+by processors with high-throughput integer math pipelines. We also present a workflow for 8-bit quantization that is
+able to maintain accuracy within 1% of the floating-point baseline on all networks studied, including models that are
+more difficult to quantize, such as MobileNets and BERT-large.*
+
+Tips:
+
+- QDQBERT model adds fake quantization operations (pair of QuantizeLinear/DequantizeLinear ops) to (i) linear layer
+ inputs and weights, (ii) matmul inputs, (iii) residual add inputs, in BERT model.
+
+- QDQBERT requires the dependency of [Pytorch Quantization Toolkit](https://github.com/NVIDIA/TensorRT/tree/master/tools/pytorch-quantization). To install `pip install pytorch-quantization --extra-index-url https://pypi.ngc.nvidia.com`
+
+- QDQBERT model can be loaded from any checkpoint of HuggingFace BERT model (for example *bert-base-uncased*), and
+ perform Quantization Aware Training/Post Training Quantization.
+
+- A complete example of using QDQBERT model to perform Quatization Aware Training and Post Training Quantization for
+ SQUAD task can be found at [transformers/examples/research_projects/quantization-qdqbert/](examples/research_projects/quantization-qdqbert/).
+
+This model was contributed by [shangz](https://huggingface.co/shangz).
+
+
+### Set default quantizers
+
+QDQBERT model adds fake quantization operations (pair of QuantizeLinear/DequantizeLinear ops) to BERT by
+`TensorQuantizer` in [Pytorch Quantization Toolkit](https://github.com/NVIDIA/TensorRT/tree/master/tools/pytorch-quantization). `TensorQuantizer` is the module
+for quantizing tensors, with `QuantDescriptor` defining how the tensor should be quantized. Refer to [Pytorch
+Quantization Toolkit userguide](https://docs.nvidia.com/deeplearning/tensorrt/pytorch-quantization-toolkit/docs/userguide.html) for more details.
+
+Before creating QDQBERT model, one has to set the default `QuantDescriptor` defining default tensor quantizers.
+
+Example:
+
+```python
+>>> import pytorch_quantization.nn as quant_nn
+>>> from pytorch_quantization.tensor_quant import QuantDescriptor
+
+>>> # The default tensor quantizer is set to use Max calibration method
+>>> input_desc = QuantDescriptor(num_bits=8, calib_method="max")
+>>> # The default tensor quantizer is set to be per-channel quantization for weights
+>>> weight_desc = QuantDescriptor(num_bits=8, axis=((0,)))
+>>> quant_nn.QuantLinear.set_default_quant_desc_input(input_desc)
+>>> quant_nn.QuantLinear.set_default_quant_desc_weight(weight_desc)
+```
+
+### Calibration
+
+Calibration is the terminology of passing data samples to the quantizer and deciding the best scaling factors for
+tensors. After setting up the tensor quantizers, one can use the following example to calibrate the model:
+
+```python
+>>> # Find the TensorQuantizer and enable calibration
+>>> for name, module in model.named_modules():
+... if name.endswith("_input_quantizer"):
+... module.enable_calib()
+... module.disable_quant() # Use full precision data to calibrate
+
+>>> # Feeding data samples
+>>> model(x)
+>>> # ...
+
+>>> # Finalize calibration
+>>> for name, module in model.named_modules():
+... if name.endswith("_input_quantizer"):
+... module.load_calib_amax()
+... module.enable_quant()
+
+>>> # If running on GPU, it needs to call .cuda() again because new tensors will be created by calibration process
+>>> model.cuda()
+
+>>> # Keep running the quantized model
+>>> # ...
+```
+
+### Export to ONNX
+
+The goal of exporting to ONNX is to deploy inference by [TensorRT](https://developer.nvidia.com/tensorrt). Fake
+quantization will be broken into a pair of QuantizeLinear/DequantizeLinear ONNX ops. After setting static member of
+TensorQuantizer to use Pytorch’s own fake quantization functions, fake quantized model can be exported to ONNX, follow
+the instructions in [torch.onnx](https://pytorch.org/docs/stable/onnx.html). Example:
+
+```python
+>>> from pytorch_quantization.nn import TensorQuantizer
+
+>>> TensorQuantizer.use_fb_fake_quant = True
+
+>>> # Load the calibrated model
+>>> ...
+>>> # ONNX export
+>>> torch.onnx.export(...)
+```
+
+## QDQBertConfig
+
+[[autodoc]] QDQBertConfig
+
+## QDQBertModel
+
+[[autodoc]] QDQBertModel
+ - forward
+
+## QDQBertLMHeadModel
+
+[[autodoc]] QDQBertLMHeadModel
+ - forward
+
+## QDQBertForMaskedLM
+
+[[autodoc]] QDQBertForMaskedLM
+ - forward
+
+## QDQBertForSequenceClassification
+
+[[autodoc]] QDQBertForSequenceClassification
+ - forward
+
+## QDQBertForNextSentencePrediction
+
+[[autodoc]] QDQBertForNextSentencePrediction
+ - forward
+
+## QDQBertForMultipleChoice
+
+[[autodoc]] QDQBertForMultipleChoice
+ - forward
+
+## QDQBertForTokenClassification
+
+[[autodoc]] QDQBertForTokenClassification
+ - forward
+
+## QDQBertForQuestionAnswering
+
+[[autodoc]] QDQBertForQuestionAnswering
+ - forward
diff --git a/docs/source/en/model_doc/rag.mdx b/docs/source/en/model_doc/rag.mdx
new file mode 100644
index 00000000000000..2f5d3498d8cf58
--- /dev/null
+++ b/docs/source/en/model_doc/rag.mdx
@@ -0,0 +1,96 @@
+
+
+# RAG
+
+## Overview
+
+Retrieval-augmented generation ("RAG") models combine the powers of pretrained dense retrieval (DPR) and
+sequence-to-sequence models. RAG models retrieve documents, pass them to a seq2seq model, then marginalize to generate
+outputs. The retriever and seq2seq modules are initialized from pretrained models, and fine-tuned jointly, allowing
+both retrieval and generation to adapt to downstream tasks.
+
+It is based on the paper [Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks](https://arxiv.org/abs/2005.11401) by Patrick Lewis, Ethan Perez, Aleksandara Piktus, Fabio Petroni, Vladimir
+Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela.
+
+The abstract from the paper is the following:
+
+*Large pre-trained language models have been shown to store factual knowledge in their parameters, and achieve
+state-of-the-art results when fine-tuned on downstream NLP tasks. However, their ability to access and precisely
+manipulate knowledge is still limited, and hence on knowledge-intensive tasks, their performance lags behind
+task-specific architectures. Additionally, providing provenance for their decisions and updating their world knowledge
+remain open research problems. Pre-trained models with a differentiable access mechanism to explicit nonparametric
+memory can overcome this issue, but have so far been only investigated for extractive downstream tasks. We explore a
+general-purpose fine-tuning recipe for retrieval-augmented generation (RAG) — models which combine pre-trained
+parametric and non-parametric memory for language generation. We introduce RAG models where the parametric memory is a
+pre-trained seq2seq model and the non-parametric memory is a dense vector index of Wikipedia, accessed with a
+pre-trained neural retriever. We compare two RAG formulations, one which conditions on the same retrieved passages
+across the whole generated sequence, the other can use different passages per token. We fine-tune and evaluate our
+models on a wide range of knowledge-intensive NLP tasks and set the state-of-the-art on three open domain QA tasks,
+outperforming parametric seq2seq models and task-specific retrieve-and-extract architectures. For language generation
+tasks, we find that RAG models generate more specific, diverse and factual language than a state-of-the-art
+parametric-only seq2seq baseline.*
+
+This model was contributed by [ola13](https://huggingface.co/ola13).
+
+
+## RagConfig
+
+[[autodoc]] RagConfig
+
+## RagTokenizer
+
+[[autodoc]] RagTokenizer
+
+## Rag specific outputs
+
+[[autodoc]] models.rag.modeling_rag.RetrievAugLMMarginOutput
+
+[[autodoc]] models.rag.modeling_rag.RetrievAugLMOutput
+
+## RagRetriever
+
+[[autodoc]] RagRetriever
+
+## RagModel
+
+[[autodoc]] RagModel
+ - forward
+
+## RagSequenceForGeneration
+
+[[autodoc]] RagSequenceForGeneration
+ - forward
+ - generate
+
+## RagTokenForGeneration
+
+[[autodoc]] RagTokenForGeneration
+ - forward
+ - generate
+
+## TFRagModel
+
+[[autodoc]] TFRagModel
+ - call
+
+## TFRagSequenceForGeneration
+
+[[autodoc]] TFRagSequenceForGeneration
+ - call
+ - generate
+
+## TFRagTokenForGeneration
+
+[[autodoc]] TFRagTokenForGeneration
+ - call
+ - generate
diff --git a/docs/source/en/model_doc/realm.mdx b/docs/source/en/model_doc/realm.mdx
new file mode 100644
index 00000000000000..545b1e0a3bf8f9
--- /dev/null
+++ b/docs/source/en/model_doc/realm.mdx
@@ -0,0 +1,85 @@
+
+
+# REALM
+
+## Overview
+
+The REALM model was proposed in [REALM: Retrieval-Augmented Language Model Pre-Training](https://arxiv.org/abs/2002.08909) by Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat and Ming-Wei Chang. It's a
+retrieval-augmented language model that firstly retrieves documents from a textual knowledge corpus and then
+utilizes retrieved documents to process question answering tasks.
+
+The abstract from the paper is the following:
+
+*Language model pre-training has been shown to capture a surprising amount of world knowledge, crucial for NLP tasks
+such as question answering. However, this knowledge is stored implicitly in the parameters of a neural network,
+requiring ever-larger networks to cover more facts. To capture knowledge in a more modular and interpretable way, we
+augment language model pre-training with a latent knowledge retriever, which allows the model to retrieve and attend
+over documents from a large corpus such as Wikipedia, used during pre-training, fine-tuning and inference. For the
+first time, we show how to pre-train such a knowledge retriever in an unsupervised manner, using masked language
+modeling as the learning signal and backpropagating through a retrieval step that considers millions of documents. We
+demonstrate the effectiveness of Retrieval-Augmented Language Model pre-training (REALM) by fine-tuning on the
+challenging task of Open-domain Question Answering (Open-QA). We compare against state-of-the-art models for both
+explicit and implicit knowledge storage on three popular Open-QA benchmarks, and find that we outperform all previous
+methods by a significant margin (4-16% absolute accuracy), while also providing qualitative benefits such as
+interpretability and modularity.*
+
+This model was contributed by [qqaatw](https://huggingface.co/qqaatw). The original code can be found
+[here](https://github.com/google-research/language/tree/master/language/realm).
+
+## RealmConfig
+
+[[autodoc]] RealmConfig
+
+## RealmTokenizer
+
+[[autodoc]] RealmTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+ - batch_encode_candidates
+
+## RealmTokenizerFast
+
+[[autodoc]] RealmTokenizerFast
+ - batch_encode_candidates
+
+## RealmRetriever
+
+[[autodoc]] RealmRetriever
+
+## RealmEmbedder
+
+[[autodoc]] RealmEmbedder
+ - forward
+
+## RealmScorer
+
+[[autodoc]] RealmScorer
+ - forward
+
+## RealmKnowledgeAugEncoder
+
+[[autodoc]] RealmKnowledgeAugEncoder
+ - forward
+
+## RealmReader
+
+[[autodoc]] RealmReader
+ - forward
+
+## RealmForOpenQA
+
+[[autodoc]] RealmForOpenQA
+ - block_embedding_to
+ - forward
\ No newline at end of file
diff --git a/docs/source/en/model_doc/reformer.mdx b/docs/source/en/model_doc/reformer.mdx
new file mode 100644
index 00000000000000..777a333e7b1f5d
--- /dev/null
+++ b/docs/source/en/model_doc/reformer.mdx
@@ -0,0 +1,177 @@
+
+
+# Reformer
+
+**DISCLAIMER:** This model is still a work in progress, if you see something strange, file a [Github Issue](https://github.com/huggingface/transformers/issues/new?assignees=&labels=&template=bug-report.md&title).
+
+## Overview
+
+The Reformer model was proposed in the paper [Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451.pdf) by Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya.
+
+The abstract from the paper is the following:
+
+*Large Transformer models routinely achieve state-of-the-art results on a number of tasks but training these models can
+be prohibitively costly, especially on long sequences. We introduce two techniques to improve the efficiency of
+Transformers. For one, we replace dot-product attention by one that uses locality-sensitive hashing, changing its
+complexity from O(L^2) to O(Llog(L)), where L is the length of the sequence. Furthermore, we use reversible residual
+layers instead of the standard residuals, which allows storing activations only once in the training process instead of
+N times, where N is the number of layers. The resulting model, the Reformer, performs on par with Transformer models
+while being much more memory-efficient and much faster on long sequences.*
+
+This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten). The Authors' code can be
+found [here](https://github.com/google/trax/tree/master/trax/models/reformer).
+
+**Note**:
+
+- Reformer does **not** work with *torch.nn.DataParallel* due to a bug in PyTorch, see [issue #36035](https://github.com/pytorch/pytorch/issues/36035)
+
+## Axial Positional Encodings
+
+Axial Positional Encodings were first implemented in Google's [trax library](https://github.com/google/trax/blob/4d99ad4965bab1deba227539758d59f0df0fef48/trax/layers/research/position_encodings.py#L29)
+and developed by the authors of this model's paper. In models that are treating very long input sequences, the
+conventional position id encodings store an embedings vector of size \\(d\\) being the `config.hidden_size` for
+every position \\(i, \ldots, n_s\\), with \\(n_s\\) being `config.max_embedding_size`. This means that having
+a sequence length of \\(n_s = 2^{19} \approx 0.5M\\) and a `config.hidden_size` of \\(d = 2^{10} \approx 1000\\)
+would result in a position encoding matrix:
+
+$$X_{i,j}, \text{ with } i \in \left[1,\ldots, d\right] \text{ and } j \in \left[1,\ldots, n_s\right]$$
+
+which alone has over 500M parameters to store. Axial positional encodings factorize \\(X_{i,j}\\) into two matrices:
+
+$$X^{1}_{i,j}, \text{ with } i \in \left[1,\ldots, d^1\right] \text{ and } j \in \left[1,\ldots, n_s^1\right]$$
+
+and
+
+$$X^{2}_{i,j}, \text{ with } i \in \left[1,\ldots, d^2\right] \text{ and } j \in \left[1,\ldots, n_s^2\right]$$
+
+with:
+
+$$d = d^1 + d^2 \text{ and } n_s = n_s^1 \times n_s^2 .$$
+
+Therefore the following holds:
+
+$$X_{i,j} = \begin{cases}
+X^{1}_{i, k}, & \text{if }\ i < d^1 \text{ with } k = j \mod n_s^1 \\
+X^{2}_{i - d^1, l}, & \text{if } i \ge d^1 \text{ with } l = \lfloor\frac{j}{n_s^1}\rfloor
+\end{cases}$$
+
+Intuitively, this means that a position embedding vector \\(x_j \in \mathbb{R}^{d}\\) is now the composition of two
+factorized embedding vectors: \\(x^1_{k, l} + x^2_{l, k}\\), where as the `config.max_embedding_size` dimension
+\\(j\\) is factorized into \\(k \text{ and } l\\). This design ensures that each position embedding vector
+\\(x_j\\) is unique.
+
+Using the above example again, axial position encoding with \\(d^1 = 2^5, d^2 = 2^5, n_s^1 = 2^9, n_s^2 = 2^{10}\\)
+can drastically reduced the number of parameters to \\(2^{14} + 2^{15} \approx 49000\\) parameters.
+
+In practice, the parameter `config.axial_pos_embds_dim` is set to a tuple \\((d^1, d^2)\\) which sum has to be
+equal to `config.hidden_size` and `config.axial_pos_shape` is set to a tuple \\((n_s^1, n_s^2)\\) which
+product has to be equal to `config.max_embedding_size`, which during training has to be equal to the *sequence
+length* of the `input_ids`.
+
+
+## LSH Self Attention
+
+In Locality sensitive hashing (LSH) self attention the key and query projection weights are tied. Therefore, the key
+query embedding vectors are also tied. LSH self attention uses the locality sensitive hashing mechanism proposed in
+[Practical and Optimal LSH for Angular Distance](https://arxiv.org/abs/1509.02897) to assign each of the tied key
+query embedding vectors to one of `config.num_buckets` possible buckets. The premise is that the more "similar"
+key query embedding vectors (in terms of *cosine similarity*) are to each other, the more likely they are assigned to
+the same bucket.
+
+The accuracy of the LSH mechanism can be improved by increasing `config.num_hashes` or directly the argument
+`num_hashes` of the forward function so that the output of the LSH self attention better approximates the output
+of the "normal" full self attention. The buckets are then sorted and chunked into query key embedding vector chunks
+each of length `config.lsh_chunk_length`. For each chunk, the query embedding vectors attend to its key vectors
+(which are tied to themselves) and to the key embedding vectors of `config.lsh_num_chunks_before` previous
+neighboring chunks and `config.lsh_num_chunks_after` following neighboring chunks.
+
+For more information, see the [original Paper](https://arxiv.org/abs/2001.04451) or this great [blog post](https://www.pragmatic.ml/reformer-deep-dive/).
+
+Note that `config.num_buckets` can also be factorized into a list \\((n_{\text{buckets}}^1,
+n_{\text{buckets}}^2)\\). This way instead of assigning the query key embedding vectors to one of \\((1,\ldots,
+n_{\text{buckets}})\\) they are assigned to one of \\((1-1,\ldots, n_{\text{buckets}}^1-1, \ldots,
+1-n_{\text{buckets}}^2, \ldots, n_{\text{buckets}}^1-n_{\text{buckets}}^2)\\). This is crucial for very long sequences to
+save memory.
+
+When training a model from scratch, it is recommended to leave `config.num_buckets=None`, so that depending on the
+sequence length a good value for `num_buckets` is calculated on the fly. This value will then automatically be
+saved in the config and should be reused for inference.
+
+Using LSH self attention, the memory and time complexity of the query-key matmul operation can be reduced from
+\\(\mathcal{O}(n_s \times n_s)\\) to \\(\mathcal{O}(n_s \times \log(n_s))\\), which usually represents the memory
+and time bottleneck in a transformer model, with \\(n_s\\) being the sequence length.
+
+
+## Local Self Attention
+
+Local self attention is essentially a "normal" self attention layer with key, query and value projections, but is
+chunked so that in each chunk of length `config.local_chunk_length` the query embedding vectors only attends to
+the key embedding vectors in its chunk and to the key embedding vectors of `config.local_num_chunks_before`
+previous neighboring chunks and `config.local_num_chunks_after` following neighboring chunks.
+
+Using Local self attention, the memory and time complexity of the query-key matmul operation can be reduced from
+\\(\mathcal{O}(n_s \times n_s)\\) to \\(\mathcal{O}(n_s \times \log(n_s))\\), which usually represents the memory
+and time bottleneck in a transformer model, with \\(n_s\\) being the sequence length.
+
+
+## Training
+
+During training, we must ensure that the sequence length is set to a value that can be divided by the least common
+multiple of `config.lsh_chunk_length` and `config.local_chunk_length` and that the parameters of the Axial
+Positional Encodings are correctly set as described above. Reformer is very memory efficient so that the model can
+easily be trained on sequences as long as 64000 tokens.
+
+For training, the [`ReformerModelWithLMHead`] should be used as follows:
+
+```python
+input_ids = tokenizer.encode("This is a sentence from the training data", return_tensors="pt")
+loss = model(input_ids, labels=input_ids)[0]
+```
+
+## ReformerConfig
+
+[[autodoc]] ReformerConfig
+
+## ReformerTokenizer
+
+[[autodoc]] ReformerTokenizer
+ - save_vocabulary
+
+## ReformerTokenizerFast
+
+[[autodoc]] ReformerTokenizerFast
+
+## ReformerModel
+
+[[autodoc]] ReformerModel
+ - forward
+
+## ReformerModelWithLMHead
+
+[[autodoc]] ReformerModelWithLMHead
+ - forward
+
+## ReformerForMaskedLM
+
+[[autodoc]] ReformerForMaskedLM
+ - forward
+
+## ReformerForSequenceClassification
+
+[[autodoc]] ReformerForSequenceClassification
+ - forward
+
+## ReformerForQuestionAnswering
+
+[[autodoc]] ReformerForQuestionAnswering
+ - forward
diff --git a/docs/source/en/model_doc/regnet.mdx b/docs/source/en/model_doc/regnet.mdx
new file mode 100644
index 00000000000000..666a9ee39675d0
--- /dev/null
+++ b/docs/source/en/model_doc/regnet.mdx
@@ -0,0 +1,48 @@
+
+
+# RegNet
+
+## Overview
+
+The RegNet model was proposed in [Designing Network Design Spaces](https://arxiv.org/abs/2003.13678) by Ilija Radosavovic, Raj Prateek Kosaraju, Ross Girshick, Kaiming He, Piotr Dollár.
+
+The authors design search spaces to perform Neural Architecture Search (NAS). They first start from a high dimensional search space and iteratively reduce the search space by empirically applying constraints based on the best-performing models sampled by the current search space.
+
+The abstract from the paper is the following:
+
+*In this work, we present a new network design paradigm. Our goal is to help advance the understanding of network design and discover design principles that generalize across settings. Instead of focusing on designing individual network instances, we design network design spaces that parametrize populations of networks. The overall process is analogous to classic manual design of networks, but elevated to the design space level. Using our methodology we explore the structure aspect of network design and arrive at a low-dimensional design space consisting of simple, regular networks that we call RegNet. The core insight of the RegNet parametrization is surprisingly simple: widths and depths of good networks can be explained by a quantized linear function. We analyze the RegNet design space and arrive at interesting findings that do not match the current practice of network design. The RegNet design space provides simple and fast networks that work well across a wide range of flop regimes. Under comparable training settings and flops, the RegNet models outperform the popular EfficientNet models while being up to 5x faster on GPUs.*
+
+Tips:
+
+- One can use [`AutoFeatureExtractor`] to prepare images for the model.
+- The huge 10B model from [Self-supervised Pretraining of Visual Features in the Wild](https://arxiv.org/abs/2103.01988), trained on one billion Instagram images, is available on the [hub](https://huggingface.co/facebook/regnet-y-10b-seer)
+
+This model was contributed by [Francesco](https://huggingface.co/Francesco).
+The original code can be found [here](https://github.com/facebookresearch/pycls).
+
+
+## RegNetConfig
+
+[[autodoc]] RegNetConfig
+
+
+## RegNetModel
+
+[[autodoc]] RegNetModel
+ - forward
+
+
+## RegNetForImageClassification
+
+[[autodoc]] RegNetForImageClassification
+ - forward
\ No newline at end of file
diff --git a/docs/source/en/model_doc/rembert.mdx b/docs/source/en/model_doc/rembert.mdx
new file mode 100644
index 00000000000000..0edb8e5202d956
--- /dev/null
+++ b/docs/source/en/model_doc/rembert.mdx
@@ -0,0 +1,128 @@
+
+
+# RemBERT
+
+## Overview
+
+The RemBERT model was proposed in [Rethinking Embedding Coupling in Pre-trained Language Models](https://arxiv.org/abs/2010.12821) by Hyung Won Chung, Thibault Févry, Henry Tsai, Melvin Johnson, Sebastian Ruder.
+
+The abstract from the paper is the following:
+
+*We re-evaluate the standard practice of sharing weights between input and output embeddings in state-of-the-art
+pre-trained language models. We show that decoupled embeddings provide increased modeling flexibility, allowing us to
+significantly improve the efficiency of parameter allocation in the input embedding of multilingual models. By
+reallocating the input embedding parameters in the Transformer layers, we achieve dramatically better performance on
+standard natural language understanding tasks with the same number of parameters during fine-tuning. We also show that
+allocating additional capacity to the output embedding provides benefits to the model that persist through the
+fine-tuning stage even though the output embedding is discarded after pre-training. Our analysis shows that larger
+output embeddings prevent the model's last layers from overspecializing to the pre-training task and encourage
+Transformer representations to be more general and more transferable to other tasks and languages. Harnessing these
+findings, we are able to train models that achieve strong performance on the XTREME benchmark without increasing the
+number of parameters at the fine-tuning stage.*
+
+Tips:
+
+For fine-tuning, RemBERT can be thought of as a bigger version of mBERT with an ALBERT-like factorization of the
+embedding layer. The embeddings are not tied in pre-training, in contrast with BERT, which enables smaller input
+embeddings (preserved during fine-tuning) and bigger output embeddings (discarded at fine-tuning). The tokenizer is
+also similar to the Albert one rather than the BERT one.
+
+## RemBertConfig
+
+[[autodoc]] RemBertConfig
+
+## RemBertTokenizer
+
+[[autodoc]] RemBertTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## RemBertTokenizerFast
+
+[[autodoc]] RemBertTokenizerFast
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## RemBertModel
+
+[[autodoc]] RemBertModel
+ - forward
+
+## RemBertForCausalLM
+
+[[autodoc]] RemBertForCausalLM
+ - forward
+
+## RemBertForMaskedLM
+
+[[autodoc]] RemBertForMaskedLM
+ - forward
+
+## RemBertForSequenceClassification
+
+[[autodoc]] RemBertForSequenceClassification
+ - forward
+
+## RemBertForMultipleChoice
+
+[[autodoc]] RemBertForMultipleChoice
+ - forward
+
+## RemBertForTokenClassification
+
+[[autodoc]] RemBertForTokenClassification
+ - forward
+
+## RemBertForQuestionAnswering
+
+[[autodoc]] RemBertForQuestionAnswering
+ - forward
+
+## TFRemBertModel
+
+[[autodoc]] TFRemBertModel
+ - call
+
+## TFRemBertForMaskedLM
+
+[[autodoc]] TFRemBertForMaskedLM
+ - call
+
+## TFRemBertForCausalLM
+
+[[autodoc]] TFRemBertForCausalLM
+ - call
+
+## TFRemBertForSequenceClassification
+
+[[autodoc]] TFRemBertForSequenceClassification
+ - call
+
+## TFRemBertForMultipleChoice
+
+[[autodoc]] TFRemBertForMultipleChoice
+ - call
+
+## TFRemBertForTokenClassification
+
+[[autodoc]] TFRemBertForTokenClassification
+ - call
+
+## TFRemBertForQuestionAnswering
+
+[[autodoc]] TFRemBertForQuestionAnswering
+ - call
diff --git a/docs/source/en/model_doc/resnet.mdx b/docs/source/en/model_doc/resnet.mdx
new file mode 100644
index 00000000000000..88131c24ba1ec3
--- /dev/null
+++ b/docs/source/en/model_doc/resnet.mdx
@@ -0,0 +1,50 @@
+
+
+# ResNet
+
+## Overview
+
+The ResNet model was proposed in [Deep Residual Learning for Image Recognition](https://arxiv.org/abs/1512.03385) by Kaiming He, Xiangyu Zhang, Shaoqing Ren and Jian Sun. Our implementation follows the small changes made by [Nvidia](https://catalog.ngc.nvidia.com/orgs/nvidia/resources/resnet_50_v1_5_for_pytorch), we apply the `stride=2` for downsampling in bottleneck's `3x3` conv and not in the first `1x1`. This is generally known as "ResNet v1.5".
+
+ResNet introduced residual connections, they allow to train networks with an unseen number of layers (up to 1000). ResNet won the 2015 ILSVRC & COCO competition, one important milestone in deep computer vision.
+
+The abstract from the paper is the following:
+
+*Deeper neural networks are more difficult to train. We present a residual learning framework to ease the training of networks that are substantially deeper than those used previously. We explicitly reformulate the layers as learning residual functions with reference to the layer inputs, instead of learning unreferenced functions. We provide comprehensive empirical evidence showing that these residual networks are easier to optimize, and can gain accuracy from considerably increased depth. On the ImageNet dataset we evaluate residual nets with a depth of up to 152 layers---8x deeper than VGG nets but still having lower complexity. An ensemble of these residual nets achieves 3.57% error on the ImageNet test set. This result won the 1st place on the ILSVRC 2015 classification task. We also present analysis on CIFAR-10 with 100 and 1000 layers.
+The depth of representations is of central importance for many visual recognition tasks. Solely due to our extremely deep representations, we obtain a 28% relative improvement on the COCO object detection dataset. Deep residual nets are foundations of our submissions to ILSVRC & COCO 2015 competitions, where we also won the 1st places on the tasks of ImageNet detection, ImageNet localization, COCO detection, and COCO segmentation.*
+
+Tips:
+
+- One can use [`AutoFeatureExtractor`] to prepare images for the model.
+
+The figure below illustrates the architecture of ResNet. Taken from the [original paper](https://arxiv.org/abs/1512.03385).
+
+
+
+
+Tips:
+
+- PoolFormer has a hierarchical architecture, where instead of Attention, a simple Average Pooling layer is present. All checkpoints of the model can be found on the [hub](https://huggingface.co/models?other=poolformer).
+- One can use [`PoolFormerFeatureExtractor`] to prepare images for the model.
+- As most models, PoolFormer comes in different sizes, the details of which can be found in the table below.
+
+| **Model variant** | **Depths** | **Hidden sizes** | **Params (M)** | **ImageNet-1k Top 1** |
+| :---------------: | ------------- | ------------------- | :------------: | :-------------------: |
+| s12 | [2, 2, 6, 2] | [64, 128, 320, 512] | 12 | 77.2 |
+| s24 | [4, 4, 12, 4] | [64, 128, 320, 512] | 21 | 80.3 |
+| s36 | [6, 6, 18, 6] | [64, 128, 320, 512] | 31 | 81.4 |
+| m36 | [6, 6, 18, 6] | [96, 192, 384, 768] | 56 | 82.1 |
+| m48 | [8, 8, 24, 8] | [96, 192, 384, 768] | 73 | 82.5 |
+
+This model was contributed by [heytanay](https://huggingface.co/heytanay). The original code can be found [here](https://github.com/sail-sg/poolformer).
+
+## PoolFormerConfig
+
+[[autodoc]] PoolFormerConfig
+
+## PoolFormerFeatureExtractor
+
+[[autodoc]] PoolFormerFeatureExtractor
+ - __call__
+
+## PoolFormerModel
+
+[[autodoc]] PoolFormerModel
+ - forward
+
+## PoolFormerForImageClassification
+
+[[autodoc]] PoolFormerForImageClassification
+ - forward
\ No newline at end of file
diff --git a/docs/source/en/model_doc/prophetnet.mdx b/docs/source/en/model_doc/prophetnet.mdx
new file mode 100644
index 00000000000000..951bbc5b96514c
--- /dev/null
+++ b/docs/source/en/model_doc/prophetnet.mdx
@@ -0,0 +1,82 @@
+
+
+# ProphetNet
+
+**DISCLAIMER:** If you see something strange, file a [Github Issue](https://github.com/huggingface/transformers/issues/new?assignees=&labels=&template=bug-report.md&title) and assign
+@patrickvonplaten
+
+## Overview
+
+The ProphetNet model was proposed in [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training,](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei
+Zhang, Ming Zhou on 13 Jan, 2020.
+
+ProphetNet is an encoder-decoder model and can predict n-future tokens for "ngram" language modeling instead of just
+the next token.
+
+The abstract from the paper is the following:
+
+*In this paper, we present a new sequence-to-sequence pretraining model called ProphetNet, which introduces a novel
+self-supervised objective named future n-gram prediction and the proposed n-stream self-attention mechanism. Instead of
+the optimization of one-step ahead prediction in traditional sequence-to-sequence model, the ProphetNet is optimized by
+n-step ahead prediction which predicts the next n tokens simultaneously based on previous context tokens at each time
+step. The future n-gram prediction explicitly encourages the model to plan for the future tokens and prevent
+overfitting on strong local correlations. We pre-train ProphetNet using a base scale dataset (16GB) and a large scale
+dataset (160GB) respectively. Then we conduct experiments on CNN/DailyMail, Gigaword, and SQuAD 1.1 benchmarks for
+abstractive summarization and question generation tasks. Experimental results show that ProphetNet achieves new
+state-of-the-art results on all these datasets compared to the models using the same scale pretraining corpus.*
+
+The Authors' code can be found [here](https://github.com/microsoft/ProphetNet).
+
+
+## ProphetNetConfig
+
+[[autodoc]] ProphetNetConfig
+
+## ProphetNetTokenizer
+
+[[autodoc]] ProphetNetTokenizer
+
+## ProphetNet specific outputs
+
+[[autodoc]] models.prophetnet.modeling_prophetnet.ProphetNetSeq2SeqLMOutput
+
+[[autodoc]] models.prophetnet.modeling_prophetnet.ProphetNetSeq2SeqModelOutput
+
+[[autodoc]] models.prophetnet.modeling_prophetnet.ProphetNetDecoderModelOutput
+
+[[autodoc]] models.prophetnet.modeling_prophetnet.ProphetNetDecoderLMOutput
+
+## ProphetNetModel
+
+[[autodoc]] ProphetNetModel
+ - forward
+
+## ProphetNetEncoder
+
+[[autodoc]] ProphetNetEncoder
+ - forward
+
+## ProphetNetDecoder
+
+[[autodoc]] ProphetNetDecoder
+ - forward
+
+## ProphetNetForConditionalGeneration
+
+[[autodoc]] ProphetNetForConditionalGeneration
+ - forward
+
+## ProphetNetForCausalLM
+
+[[autodoc]] ProphetNetForCausalLM
+ - forward
diff --git a/docs/source/en/model_doc/qdqbert.mdx b/docs/source/en/model_doc/qdqbert.mdx
new file mode 100644
index 00000000000000..df7b7bcee62516
--- /dev/null
+++ b/docs/source/en/model_doc/qdqbert.mdx
@@ -0,0 +1,159 @@
+
+
+# QDQBERT
+
+## Overview
+
+The QDQBERT model can be referenced in [Integer Quantization for Deep Learning Inference: Principles and Empirical
+Evaluation](https://arxiv.org/abs/2004.09602) by Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius
+Micikevicius.
+
+The abstract from the paper is the following:
+
+*Quantization techniques can reduce the size of Deep Neural Networks and improve inference latency and throughput by
+taking advantage of high throughput integer instructions. In this paper we review the mathematical aspects of
+quantization parameters and evaluate their choices on a wide range of neural network models for different application
+domains, including vision, speech, and language. We focus on quantization techniques that are amenable to acceleration
+by processors with high-throughput integer math pipelines. We also present a workflow for 8-bit quantization that is
+able to maintain accuracy within 1% of the floating-point baseline on all networks studied, including models that are
+more difficult to quantize, such as MobileNets and BERT-large.*
+
+Tips:
+
+- QDQBERT model adds fake quantization operations (pair of QuantizeLinear/DequantizeLinear ops) to (i) linear layer
+ inputs and weights, (ii) matmul inputs, (iii) residual add inputs, in BERT model.
+
+- QDQBERT requires the dependency of [Pytorch Quantization Toolkit](https://github.com/NVIDIA/TensorRT/tree/master/tools/pytorch-quantization). To install `pip install pytorch-quantization --extra-index-url https://pypi.ngc.nvidia.com`
+
+- QDQBERT model can be loaded from any checkpoint of HuggingFace BERT model (for example *bert-base-uncased*), and
+ perform Quantization Aware Training/Post Training Quantization.
+
+- A complete example of using QDQBERT model to perform Quatization Aware Training and Post Training Quantization for
+ SQUAD task can be found at [transformers/examples/research_projects/quantization-qdqbert/](examples/research_projects/quantization-qdqbert/).
+
+This model was contributed by [shangz](https://huggingface.co/shangz).
+
+
+### Set default quantizers
+
+QDQBERT model adds fake quantization operations (pair of QuantizeLinear/DequantizeLinear ops) to BERT by
+`TensorQuantizer` in [Pytorch Quantization Toolkit](https://github.com/NVIDIA/TensorRT/tree/master/tools/pytorch-quantization). `TensorQuantizer` is the module
+for quantizing tensors, with `QuantDescriptor` defining how the tensor should be quantized. Refer to [Pytorch
+Quantization Toolkit userguide](https://docs.nvidia.com/deeplearning/tensorrt/pytorch-quantization-toolkit/docs/userguide.html) for more details.
+
+Before creating QDQBERT model, one has to set the default `QuantDescriptor` defining default tensor quantizers.
+
+Example:
+
+```python
+>>> import pytorch_quantization.nn as quant_nn
+>>> from pytorch_quantization.tensor_quant import QuantDescriptor
+
+>>> # The default tensor quantizer is set to use Max calibration method
+>>> input_desc = QuantDescriptor(num_bits=8, calib_method="max")
+>>> # The default tensor quantizer is set to be per-channel quantization for weights
+>>> weight_desc = QuantDescriptor(num_bits=8, axis=((0,)))
+>>> quant_nn.QuantLinear.set_default_quant_desc_input(input_desc)
+>>> quant_nn.QuantLinear.set_default_quant_desc_weight(weight_desc)
+```
+
+### Calibration
+
+Calibration is the terminology of passing data samples to the quantizer and deciding the best scaling factors for
+tensors. After setting up the tensor quantizers, one can use the following example to calibrate the model:
+
+```python
+>>> # Find the TensorQuantizer and enable calibration
+>>> for name, module in model.named_modules():
+... if name.endswith("_input_quantizer"):
+... module.enable_calib()
+... module.disable_quant() # Use full precision data to calibrate
+
+>>> # Feeding data samples
+>>> model(x)
+>>> # ...
+
+>>> # Finalize calibration
+>>> for name, module in model.named_modules():
+... if name.endswith("_input_quantizer"):
+... module.load_calib_amax()
+... module.enable_quant()
+
+>>> # If running on GPU, it needs to call .cuda() again because new tensors will be created by calibration process
+>>> model.cuda()
+
+>>> # Keep running the quantized model
+>>> # ...
+```
+
+### Export to ONNX
+
+The goal of exporting to ONNX is to deploy inference by [TensorRT](https://developer.nvidia.com/tensorrt). Fake
+quantization will be broken into a pair of QuantizeLinear/DequantizeLinear ONNX ops. After setting static member of
+TensorQuantizer to use Pytorch’s own fake quantization functions, fake quantized model can be exported to ONNX, follow
+the instructions in [torch.onnx](https://pytorch.org/docs/stable/onnx.html). Example:
+
+```python
+>>> from pytorch_quantization.nn import TensorQuantizer
+
+>>> TensorQuantizer.use_fb_fake_quant = True
+
+>>> # Load the calibrated model
+>>> ...
+>>> # ONNX export
+>>> torch.onnx.export(...)
+```
+
+## QDQBertConfig
+
+[[autodoc]] QDQBertConfig
+
+## QDQBertModel
+
+[[autodoc]] QDQBertModel
+ - forward
+
+## QDQBertLMHeadModel
+
+[[autodoc]] QDQBertLMHeadModel
+ - forward
+
+## QDQBertForMaskedLM
+
+[[autodoc]] QDQBertForMaskedLM
+ - forward
+
+## QDQBertForSequenceClassification
+
+[[autodoc]] QDQBertForSequenceClassification
+ - forward
+
+## QDQBertForNextSentencePrediction
+
+[[autodoc]] QDQBertForNextSentencePrediction
+ - forward
+
+## QDQBertForMultipleChoice
+
+[[autodoc]] QDQBertForMultipleChoice
+ - forward
+
+## QDQBertForTokenClassification
+
+[[autodoc]] QDQBertForTokenClassification
+ - forward
+
+## QDQBertForQuestionAnswering
+
+[[autodoc]] QDQBertForQuestionAnswering
+ - forward
diff --git a/docs/source/en/model_doc/rag.mdx b/docs/source/en/model_doc/rag.mdx
new file mode 100644
index 00000000000000..2f5d3498d8cf58
--- /dev/null
+++ b/docs/source/en/model_doc/rag.mdx
@@ -0,0 +1,96 @@
+
+
+# RAG
+
+## Overview
+
+Retrieval-augmented generation ("RAG") models combine the powers of pretrained dense retrieval (DPR) and
+sequence-to-sequence models. RAG models retrieve documents, pass them to a seq2seq model, then marginalize to generate
+outputs. The retriever and seq2seq modules are initialized from pretrained models, and fine-tuned jointly, allowing
+both retrieval and generation to adapt to downstream tasks.
+
+It is based on the paper [Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks](https://arxiv.org/abs/2005.11401) by Patrick Lewis, Ethan Perez, Aleksandara Piktus, Fabio Petroni, Vladimir
+Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela.
+
+The abstract from the paper is the following:
+
+*Large pre-trained language models have been shown to store factual knowledge in their parameters, and achieve
+state-of-the-art results when fine-tuned on downstream NLP tasks. However, their ability to access and precisely
+manipulate knowledge is still limited, and hence on knowledge-intensive tasks, their performance lags behind
+task-specific architectures. Additionally, providing provenance for their decisions and updating their world knowledge
+remain open research problems. Pre-trained models with a differentiable access mechanism to explicit nonparametric
+memory can overcome this issue, but have so far been only investigated for extractive downstream tasks. We explore a
+general-purpose fine-tuning recipe for retrieval-augmented generation (RAG) — models which combine pre-trained
+parametric and non-parametric memory for language generation. We introduce RAG models where the parametric memory is a
+pre-trained seq2seq model and the non-parametric memory is a dense vector index of Wikipedia, accessed with a
+pre-trained neural retriever. We compare two RAG formulations, one which conditions on the same retrieved passages
+across the whole generated sequence, the other can use different passages per token. We fine-tune and evaluate our
+models on a wide range of knowledge-intensive NLP tasks and set the state-of-the-art on three open domain QA tasks,
+outperforming parametric seq2seq models and task-specific retrieve-and-extract architectures. For language generation
+tasks, we find that RAG models generate more specific, diverse and factual language than a state-of-the-art
+parametric-only seq2seq baseline.*
+
+This model was contributed by [ola13](https://huggingface.co/ola13).
+
+
+## RagConfig
+
+[[autodoc]] RagConfig
+
+## RagTokenizer
+
+[[autodoc]] RagTokenizer
+
+## Rag specific outputs
+
+[[autodoc]] models.rag.modeling_rag.RetrievAugLMMarginOutput
+
+[[autodoc]] models.rag.modeling_rag.RetrievAugLMOutput
+
+## RagRetriever
+
+[[autodoc]] RagRetriever
+
+## RagModel
+
+[[autodoc]] RagModel
+ - forward
+
+## RagSequenceForGeneration
+
+[[autodoc]] RagSequenceForGeneration
+ - forward
+ - generate
+
+## RagTokenForGeneration
+
+[[autodoc]] RagTokenForGeneration
+ - forward
+ - generate
+
+## TFRagModel
+
+[[autodoc]] TFRagModel
+ - call
+
+## TFRagSequenceForGeneration
+
+[[autodoc]] TFRagSequenceForGeneration
+ - call
+ - generate
+
+## TFRagTokenForGeneration
+
+[[autodoc]] TFRagTokenForGeneration
+ - call
+ - generate
diff --git a/docs/source/en/model_doc/realm.mdx b/docs/source/en/model_doc/realm.mdx
new file mode 100644
index 00000000000000..545b1e0a3bf8f9
--- /dev/null
+++ b/docs/source/en/model_doc/realm.mdx
@@ -0,0 +1,85 @@
+
+
+# REALM
+
+## Overview
+
+The REALM model was proposed in [REALM: Retrieval-Augmented Language Model Pre-Training](https://arxiv.org/abs/2002.08909) by Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat and Ming-Wei Chang. It's a
+retrieval-augmented language model that firstly retrieves documents from a textual knowledge corpus and then
+utilizes retrieved documents to process question answering tasks.
+
+The abstract from the paper is the following:
+
+*Language model pre-training has been shown to capture a surprising amount of world knowledge, crucial for NLP tasks
+such as question answering. However, this knowledge is stored implicitly in the parameters of a neural network,
+requiring ever-larger networks to cover more facts. To capture knowledge in a more modular and interpretable way, we
+augment language model pre-training with a latent knowledge retriever, which allows the model to retrieve and attend
+over documents from a large corpus such as Wikipedia, used during pre-training, fine-tuning and inference. For the
+first time, we show how to pre-train such a knowledge retriever in an unsupervised manner, using masked language
+modeling as the learning signal and backpropagating through a retrieval step that considers millions of documents. We
+demonstrate the effectiveness of Retrieval-Augmented Language Model pre-training (REALM) by fine-tuning on the
+challenging task of Open-domain Question Answering (Open-QA). We compare against state-of-the-art models for both
+explicit and implicit knowledge storage on three popular Open-QA benchmarks, and find that we outperform all previous
+methods by a significant margin (4-16% absolute accuracy), while also providing qualitative benefits such as
+interpretability and modularity.*
+
+This model was contributed by [qqaatw](https://huggingface.co/qqaatw). The original code can be found
+[here](https://github.com/google-research/language/tree/master/language/realm).
+
+## RealmConfig
+
+[[autodoc]] RealmConfig
+
+## RealmTokenizer
+
+[[autodoc]] RealmTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+ - batch_encode_candidates
+
+## RealmTokenizerFast
+
+[[autodoc]] RealmTokenizerFast
+ - batch_encode_candidates
+
+## RealmRetriever
+
+[[autodoc]] RealmRetriever
+
+## RealmEmbedder
+
+[[autodoc]] RealmEmbedder
+ - forward
+
+## RealmScorer
+
+[[autodoc]] RealmScorer
+ - forward
+
+## RealmKnowledgeAugEncoder
+
+[[autodoc]] RealmKnowledgeAugEncoder
+ - forward
+
+## RealmReader
+
+[[autodoc]] RealmReader
+ - forward
+
+## RealmForOpenQA
+
+[[autodoc]] RealmForOpenQA
+ - block_embedding_to
+ - forward
\ No newline at end of file
diff --git a/docs/source/en/model_doc/reformer.mdx b/docs/source/en/model_doc/reformer.mdx
new file mode 100644
index 00000000000000..777a333e7b1f5d
--- /dev/null
+++ b/docs/source/en/model_doc/reformer.mdx
@@ -0,0 +1,177 @@
+
+
+# Reformer
+
+**DISCLAIMER:** This model is still a work in progress, if you see something strange, file a [Github Issue](https://github.com/huggingface/transformers/issues/new?assignees=&labels=&template=bug-report.md&title).
+
+## Overview
+
+The Reformer model was proposed in the paper [Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451.pdf) by Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya.
+
+The abstract from the paper is the following:
+
+*Large Transformer models routinely achieve state-of-the-art results on a number of tasks but training these models can
+be prohibitively costly, especially on long sequences. We introduce two techniques to improve the efficiency of
+Transformers. For one, we replace dot-product attention by one that uses locality-sensitive hashing, changing its
+complexity from O(L^2) to O(Llog(L)), where L is the length of the sequence. Furthermore, we use reversible residual
+layers instead of the standard residuals, which allows storing activations only once in the training process instead of
+N times, where N is the number of layers. The resulting model, the Reformer, performs on par with Transformer models
+while being much more memory-efficient and much faster on long sequences.*
+
+This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten). The Authors' code can be
+found [here](https://github.com/google/trax/tree/master/trax/models/reformer).
+
+**Note**:
+
+- Reformer does **not** work with *torch.nn.DataParallel* due to a bug in PyTorch, see [issue #36035](https://github.com/pytorch/pytorch/issues/36035)
+
+## Axial Positional Encodings
+
+Axial Positional Encodings were first implemented in Google's [trax library](https://github.com/google/trax/blob/4d99ad4965bab1deba227539758d59f0df0fef48/trax/layers/research/position_encodings.py#L29)
+and developed by the authors of this model's paper. In models that are treating very long input sequences, the
+conventional position id encodings store an embedings vector of size \\(d\\) being the `config.hidden_size` for
+every position \\(i, \ldots, n_s\\), with \\(n_s\\) being `config.max_embedding_size`. This means that having
+a sequence length of \\(n_s = 2^{19} \approx 0.5M\\) and a `config.hidden_size` of \\(d = 2^{10} \approx 1000\\)
+would result in a position encoding matrix:
+
+$$X_{i,j}, \text{ with } i \in \left[1,\ldots, d\right] \text{ and } j \in \left[1,\ldots, n_s\right]$$
+
+which alone has over 500M parameters to store. Axial positional encodings factorize \\(X_{i,j}\\) into two matrices:
+
+$$X^{1}_{i,j}, \text{ with } i \in \left[1,\ldots, d^1\right] \text{ and } j \in \left[1,\ldots, n_s^1\right]$$
+
+and
+
+$$X^{2}_{i,j}, \text{ with } i \in \left[1,\ldots, d^2\right] \text{ and } j \in \left[1,\ldots, n_s^2\right]$$
+
+with:
+
+$$d = d^1 + d^2 \text{ and } n_s = n_s^1 \times n_s^2 .$$
+
+Therefore the following holds:
+
+$$X_{i,j} = \begin{cases}
+X^{1}_{i, k}, & \text{if }\ i < d^1 \text{ with } k = j \mod n_s^1 \\
+X^{2}_{i - d^1, l}, & \text{if } i \ge d^1 \text{ with } l = \lfloor\frac{j}{n_s^1}\rfloor
+\end{cases}$$
+
+Intuitively, this means that a position embedding vector \\(x_j \in \mathbb{R}^{d}\\) is now the composition of two
+factorized embedding vectors: \\(x^1_{k, l} + x^2_{l, k}\\), where as the `config.max_embedding_size` dimension
+\\(j\\) is factorized into \\(k \text{ and } l\\). This design ensures that each position embedding vector
+\\(x_j\\) is unique.
+
+Using the above example again, axial position encoding with \\(d^1 = 2^5, d^2 = 2^5, n_s^1 = 2^9, n_s^2 = 2^{10}\\)
+can drastically reduced the number of parameters to \\(2^{14} + 2^{15} \approx 49000\\) parameters.
+
+In practice, the parameter `config.axial_pos_embds_dim` is set to a tuple \\((d^1, d^2)\\) which sum has to be
+equal to `config.hidden_size` and `config.axial_pos_shape` is set to a tuple \\((n_s^1, n_s^2)\\) which
+product has to be equal to `config.max_embedding_size`, which during training has to be equal to the *sequence
+length* of the `input_ids`.
+
+
+## LSH Self Attention
+
+In Locality sensitive hashing (LSH) self attention the key and query projection weights are tied. Therefore, the key
+query embedding vectors are also tied. LSH self attention uses the locality sensitive hashing mechanism proposed in
+[Practical and Optimal LSH for Angular Distance](https://arxiv.org/abs/1509.02897) to assign each of the tied key
+query embedding vectors to one of `config.num_buckets` possible buckets. The premise is that the more "similar"
+key query embedding vectors (in terms of *cosine similarity*) are to each other, the more likely they are assigned to
+the same bucket.
+
+The accuracy of the LSH mechanism can be improved by increasing `config.num_hashes` or directly the argument
+`num_hashes` of the forward function so that the output of the LSH self attention better approximates the output
+of the "normal" full self attention. The buckets are then sorted and chunked into query key embedding vector chunks
+each of length `config.lsh_chunk_length`. For each chunk, the query embedding vectors attend to its key vectors
+(which are tied to themselves) and to the key embedding vectors of `config.lsh_num_chunks_before` previous
+neighboring chunks and `config.lsh_num_chunks_after` following neighboring chunks.
+
+For more information, see the [original Paper](https://arxiv.org/abs/2001.04451) or this great [blog post](https://www.pragmatic.ml/reformer-deep-dive/).
+
+Note that `config.num_buckets` can also be factorized into a list \\((n_{\text{buckets}}^1,
+n_{\text{buckets}}^2)\\). This way instead of assigning the query key embedding vectors to one of \\((1,\ldots,
+n_{\text{buckets}})\\) they are assigned to one of \\((1-1,\ldots, n_{\text{buckets}}^1-1, \ldots,
+1-n_{\text{buckets}}^2, \ldots, n_{\text{buckets}}^1-n_{\text{buckets}}^2)\\). This is crucial for very long sequences to
+save memory.
+
+When training a model from scratch, it is recommended to leave `config.num_buckets=None`, so that depending on the
+sequence length a good value for `num_buckets` is calculated on the fly. This value will then automatically be
+saved in the config and should be reused for inference.
+
+Using LSH self attention, the memory and time complexity of the query-key matmul operation can be reduced from
+\\(\mathcal{O}(n_s \times n_s)\\) to \\(\mathcal{O}(n_s \times \log(n_s))\\), which usually represents the memory
+and time bottleneck in a transformer model, with \\(n_s\\) being the sequence length.
+
+
+## Local Self Attention
+
+Local self attention is essentially a "normal" self attention layer with key, query and value projections, but is
+chunked so that in each chunk of length `config.local_chunk_length` the query embedding vectors only attends to
+the key embedding vectors in its chunk and to the key embedding vectors of `config.local_num_chunks_before`
+previous neighboring chunks and `config.local_num_chunks_after` following neighboring chunks.
+
+Using Local self attention, the memory and time complexity of the query-key matmul operation can be reduced from
+\\(\mathcal{O}(n_s \times n_s)\\) to \\(\mathcal{O}(n_s \times \log(n_s))\\), which usually represents the memory
+and time bottleneck in a transformer model, with \\(n_s\\) being the sequence length.
+
+
+## Training
+
+During training, we must ensure that the sequence length is set to a value that can be divided by the least common
+multiple of `config.lsh_chunk_length` and `config.local_chunk_length` and that the parameters of the Axial
+Positional Encodings are correctly set as described above. Reformer is very memory efficient so that the model can
+easily be trained on sequences as long as 64000 tokens.
+
+For training, the [`ReformerModelWithLMHead`] should be used as follows:
+
+```python
+input_ids = tokenizer.encode("This is a sentence from the training data", return_tensors="pt")
+loss = model(input_ids, labels=input_ids)[0]
+```
+
+## ReformerConfig
+
+[[autodoc]] ReformerConfig
+
+## ReformerTokenizer
+
+[[autodoc]] ReformerTokenizer
+ - save_vocabulary
+
+## ReformerTokenizerFast
+
+[[autodoc]] ReformerTokenizerFast
+
+## ReformerModel
+
+[[autodoc]] ReformerModel
+ - forward
+
+## ReformerModelWithLMHead
+
+[[autodoc]] ReformerModelWithLMHead
+ - forward
+
+## ReformerForMaskedLM
+
+[[autodoc]] ReformerForMaskedLM
+ - forward
+
+## ReformerForSequenceClassification
+
+[[autodoc]] ReformerForSequenceClassification
+ - forward
+
+## ReformerForQuestionAnswering
+
+[[autodoc]] ReformerForQuestionAnswering
+ - forward
diff --git a/docs/source/en/model_doc/regnet.mdx b/docs/source/en/model_doc/regnet.mdx
new file mode 100644
index 00000000000000..666a9ee39675d0
--- /dev/null
+++ b/docs/source/en/model_doc/regnet.mdx
@@ -0,0 +1,48 @@
+
+
+# RegNet
+
+## Overview
+
+The RegNet model was proposed in [Designing Network Design Spaces](https://arxiv.org/abs/2003.13678) by Ilija Radosavovic, Raj Prateek Kosaraju, Ross Girshick, Kaiming He, Piotr Dollár.
+
+The authors design search spaces to perform Neural Architecture Search (NAS). They first start from a high dimensional search space and iteratively reduce the search space by empirically applying constraints based on the best-performing models sampled by the current search space.
+
+The abstract from the paper is the following:
+
+*In this work, we present a new network design paradigm. Our goal is to help advance the understanding of network design and discover design principles that generalize across settings. Instead of focusing on designing individual network instances, we design network design spaces that parametrize populations of networks. The overall process is analogous to classic manual design of networks, but elevated to the design space level. Using our methodology we explore the structure aspect of network design and arrive at a low-dimensional design space consisting of simple, regular networks that we call RegNet. The core insight of the RegNet parametrization is surprisingly simple: widths and depths of good networks can be explained by a quantized linear function. We analyze the RegNet design space and arrive at interesting findings that do not match the current practice of network design. The RegNet design space provides simple and fast networks that work well across a wide range of flop regimes. Under comparable training settings and flops, the RegNet models outperform the popular EfficientNet models while being up to 5x faster on GPUs.*
+
+Tips:
+
+- One can use [`AutoFeatureExtractor`] to prepare images for the model.
+- The huge 10B model from [Self-supervised Pretraining of Visual Features in the Wild](https://arxiv.org/abs/2103.01988), trained on one billion Instagram images, is available on the [hub](https://huggingface.co/facebook/regnet-y-10b-seer)
+
+This model was contributed by [Francesco](https://huggingface.co/Francesco).
+The original code can be found [here](https://github.com/facebookresearch/pycls).
+
+
+## RegNetConfig
+
+[[autodoc]] RegNetConfig
+
+
+## RegNetModel
+
+[[autodoc]] RegNetModel
+ - forward
+
+
+## RegNetForImageClassification
+
+[[autodoc]] RegNetForImageClassification
+ - forward
\ No newline at end of file
diff --git a/docs/source/en/model_doc/rembert.mdx b/docs/source/en/model_doc/rembert.mdx
new file mode 100644
index 00000000000000..0edb8e5202d956
--- /dev/null
+++ b/docs/source/en/model_doc/rembert.mdx
@@ -0,0 +1,128 @@
+
+
+# RemBERT
+
+## Overview
+
+The RemBERT model was proposed in [Rethinking Embedding Coupling in Pre-trained Language Models](https://arxiv.org/abs/2010.12821) by Hyung Won Chung, Thibault Févry, Henry Tsai, Melvin Johnson, Sebastian Ruder.
+
+The abstract from the paper is the following:
+
+*We re-evaluate the standard practice of sharing weights between input and output embeddings in state-of-the-art
+pre-trained language models. We show that decoupled embeddings provide increased modeling flexibility, allowing us to
+significantly improve the efficiency of parameter allocation in the input embedding of multilingual models. By
+reallocating the input embedding parameters in the Transformer layers, we achieve dramatically better performance on
+standard natural language understanding tasks with the same number of parameters during fine-tuning. We also show that
+allocating additional capacity to the output embedding provides benefits to the model that persist through the
+fine-tuning stage even though the output embedding is discarded after pre-training. Our analysis shows that larger
+output embeddings prevent the model's last layers from overspecializing to the pre-training task and encourage
+Transformer representations to be more general and more transferable to other tasks and languages. Harnessing these
+findings, we are able to train models that achieve strong performance on the XTREME benchmark without increasing the
+number of parameters at the fine-tuning stage.*
+
+Tips:
+
+For fine-tuning, RemBERT can be thought of as a bigger version of mBERT with an ALBERT-like factorization of the
+embedding layer. The embeddings are not tied in pre-training, in contrast with BERT, which enables smaller input
+embeddings (preserved during fine-tuning) and bigger output embeddings (discarded at fine-tuning). The tokenizer is
+also similar to the Albert one rather than the BERT one.
+
+## RemBertConfig
+
+[[autodoc]] RemBertConfig
+
+## RemBertTokenizer
+
+[[autodoc]] RemBertTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## RemBertTokenizerFast
+
+[[autodoc]] RemBertTokenizerFast
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## RemBertModel
+
+[[autodoc]] RemBertModel
+ - forward
+
+## RemBertForCausalLM
+
+[[autodoc]] RemBertForCausalLM
+ - forward
+
+## RemBertForMaskedLM
+
+[[autodoc]] RemBertForMaskedLM
+ - forward
+
+## RemBertForSequenceClassification
+
+[[autodoc]] RemBertForSequenceClassification
+ - forward
+
+## RemBertForMultipleChoice
+
+[[autodoc]] RemBertForMultipleChoice
+ - forward
+
+## RemBertForTokenClassification
+
+[[autodoc]] RemBertForTokenClassification
+ - forward
+
+## RemBertForQuestionAnswering
+
+[[autodoc]] RemBertForQuestionAnswering
+ - forward
+
+## TFRemBertModel
+
+[[autodoc]] TFRemBertModel
+ - call
+
+## TFRemBertForMaskedLM
+
+[[autodoc]] TFRemBertForMaskedLM
+ - call
+
+## TFRemBertForCausalLM
+
+[[autodoc]] TFRemBertForCausalLM
+ - call
+
+## TFRemBertForSequenceClassification
+
+[[autodoc]] TFRemBertForSequenceClassification
+ - call
+
+## TFRemBertForMultipleChoice
+
+[[autodoc]] TFRemBertForMultipleChoice
+ - call
+
+## TFRemBertForTokenClassification
+
+[[autodoc]] TFRemBertForTokenClassification
+ - call
+
+## TFRemBertForQuestionAnswering
+
+[[autodoc]] TFRemBertForQuestionAnswering
+ - call
diff --git a/docs/source/en/model_doc/resnet.mdx b/docs/source/en/model_doc/resnet.mdx
new file mode 100644
index 00000000000000..88131c24ba1ec3
--- /dev/null
+++ b/docs/source/en/model_doc/resnet.mdx
@@ -0,0 +1,50 @@
+
+
+# ResNet
+
+## Overview
+
+The ResNet model was proposed in [Deep Residual Learning for Image Recognition](https://arxiv.org/abs/1512.03385) by Kaiming He, Xiangyu Zhang, Shaoqing Ren and Jian Sun. Our implementation follows the small changes made by [Nvidia](https://catalog.ngc.nvidia.com/orgs/nvidia/resources/resnet_50_v1_5_for_pytorch), we apply the `stride=2` for downsampling in bottleneck's `3x3` conv and not in the first `1x1`. This is generally known as "ResNet v1.5".
+
+ResNet introduced residual connections, they allow to train networks with an unseen number of layers (up to 1000). ResNet won the 2015 ILSVRC & COCO competition, one important milestone in deep computer vision.
+
+The abstract from the paper is the following:
+
+*Deeper neural networks are more difficult to train. We present a residual learning framework to ease the training of networks that are substantially deeper than those used previously. We explicitly reformulate the layers as learning residual functions with reference to the layer inputs, instead of learning unreferenced functions. We provide comprehensive empirical evidence showing that these residual networks are easier to optimize, and can gain accuracy from considerably increased depth. On the ImageNet dataset we evaluate residual nets with a depth of up to 152 layers---8x deeper than VGG nets but still having lower complexity. An ensemble of these residual nets achieves 3.57% error on the ImageNet test set. This result won the 1st place on the ILSVRC 2015 classification task. We also present analysis on CIFAR-10 with 100 and 1000 layers.
+The depth of representations is of central importance for many visual recognition tasks. Solely due to our extremely deep representations, we obtain a 28% relative improvement on the COCO object detection dataset. Deep residual nets are foundations of our submissions to ILSVRC & COCO 2015 competitions, where we also won the 1st places on the tasks of ImageNet detection, ImageNet localization, COCO detection, and COCO segmentation.*
+
+Tips:
+
+- One can use [`AutoFeatureExtractor`] to prepare images for the model.
+
+The figure below illustrates the architecture of ResNet. Taken from the [original paper](https://arxiv.org/abs/1512.03385).
+
+ +
+This model was contributed by [Francesco](https://huggingface.co/Francesco). The original code can be found [here](https://github.com/KaimingHe/deep-residual-networks).
+
+## ResNetConfig
+
+[[autodoc]] ResNetConfig
+
+
+## ResNetModel
+
+[[autodoc]] ResNetModel
+ - forward
+
+
+## ResNetForImageClassification
+
+[[autodoc]] ResNetForImageClassification
+ - forward
\ No newline at end of file
diff --git a/docs/source/en/model_doc/retribert.mdx b/docs/source/en/model_doc/retribert.mdx
new file mode 100644
index 00000000000000..e83fae32300da9
--- /dev/null
+++ b/docs/source/en/model_doc/retribert.mdx
@@ -0,0 +1,40 @@
+
+
+# RetriBERT
+
+## Overview
+
+The RetriBERT model was proposed in the blog post [Explain Anything Like I'm Five: A Model for Open Domain Long Form
+Question Answering](https://yjernite.github.io/lfqa.html). RetriBERT is a small model that uses either a single or
+pair of BERT encoders with lower-dimension projection for dense semantic indexing of text.
+
+This model was contributed by [yjernite](https://huggingface.co/yjernite). Code to train and use the model can be
+found [here](https://github.com/huggingface/transformers/tree/main/examples/research-projects/distillation).
+
+
+## RetriBertConfig
+
+[[autodoc]] RetriBertConfig
+
+## RetriBertTokenizer
+
+[[autodoc]] RetriBertTokenizer
+
+## RetriBertTokenizerFast
+
+[[autodoc]] RetriBertTokenizerFast
+
+## RetriBertModel
+
+[[autodoc]] RetriBertModel
+ - forward
diff --git a/docs/source/en/model_doc/roberta.mdx b/docs/source/en/model_doc/roberta.mdx
new file mode 100644
index 00000000000000..b3b3e62064a22b
--- /dev/null
+++ b/docs/source/en/model_doc/roberta.mdx
@@ -0,0 +1,167 @@
+
+
+# RoBERTa
+
+## Overview
+
+The RoBERTa model was proposed in [RoBERTa: A Robustly Optimized BERT Pretraining Approach](https://arxiv.org/abs/1907.11692) by Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer
+Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov. It is based on Google's BERT model released in 2018.
+
+It builds on BERT and modifies key hyperparameters, removing the next-sentence pretraining objective and training with
+much larger mini-batches and learning rates.
+
+The abstract from the paper is the following:
+
+*Language model pretraining has led to significant performance gains but careful comparison between different
+approaches is challenging. Training is computationally expensive, often done on private datasets of different sizes,
+and, as we will show, hyperparameter choices have significant impact on the final results. We present a replication
+study of BERT pretraining (Devlin et al., 2019) that carefully measures the impact of many key hyperparameters and
+training data size. We find that BERT was significantly undertrained, and can match or exceed the performance of every
+model published after it. Our best model achieves state-of-the-art results on GLUE, RACE and SQuAD. These results
+highlight the importance of previously overlooked design choices, and raise questions about the source of recently
+reported improvements. We release our models and code.*
+
+Tips:
+
+- This implementation is the same as [`BertModel`] with a tiny embeddings tweak as well as a setup
+ for Roberta pretrained models.
+- RoBERTa has the same architecture as BERT, but uses a byte-level BPE as a tokenizer (same as GPT-2) and uses a
+ different pretraining scheme.
+- RoBERTa doesn't have `token_type_ids`, you don't need to indicate which token belongs to which segment. Just
+ separate your segments with the separation token `tokenizer.sep_token` (or ``)
+- [CamemBERT](camembert) is a wrapper around RoBERTa. Refer to this page for usage examples.
+
+This model was contributed by [julien-c](https://huggingface.co/julien-c). The original code can be found [here](https://github.com/pytorch/fairseq/tree/master/examples/roberta).
+
+
+## RobertaConfig
+
+[[autodoc]] RobertaConfig
+
+## RobertaTokenizer
+
+[[autodoc]] RobertaTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## RobertaTokenizerFast
+
+[[autodoc]] RobertaTokenizerFast
+ - build_inputs_with_special_tokens
+
+## RobertaModel
+
+[[autodoc]] RobertaModel
+ - forward
+
+## RobertaForCausalLM
+
+[[autodoc]] RobertaForCausalLM
+ - forward
+
+## RobertaForMaskedLM
+
+[[autodoc]] RobertaForMaskedLM
+ - forward
+
+## RobertaForSequenceClassification
+
+[[autodoc]] RobertaForSequenceClassification
+ - forward
+
+## RobertaForMultipleChoice
+
+[[autodoc]] RobertaForMultipleChoice
+ - forward
+
+## RobertaForTokenClassification
+
+[[autodoc]] RobertaForTokenClassification
+ - forward
+
+## RobertaForQuestionAnswering
+
+[[autodoc]] RobertaForQuestionAnswering
+ - forward
+
+## TFRobertaModel
+
+[[autodoc]] TFRobertaModel
+ - call
+
+## TFRobertaForCausalLM
+
+[[autodoc]] TFRobertaForCausalLM
+ - call
+
+## TFRobertaForMaskedLM
+
+[[autodoc]] TFRobertaForMaskedLM
+ - call
+
+## TFRobertaForSequenceClassification
+
+[[autodoc]] TFRobertaForSequenceClassification
+ - call
+
+## TFRobertaForMultipleChoice
+
+[[autodoc]] TFRobertaForMultipleChoice
+ - call
+
+## TFRobertaForTokenClassification
+
+[[autodoc]] TFRobertaForTokenClassification
+ - call
+
+## TFRobertaForQuestionAnswering
+
+[[autodoc]] TFRobertaForQuestionAnswering
+ - call
+
+## FlaxRobertaModel
+
+[[autodoc]] FlaxRobertaModel
+ - __call__
+
+## FlaxRobertaForCausalLM
+
+[[autodoc]] FlaxRobertaForCausalLM
+ - __call__
+
+## FlaxRobertaForMaskedLM
+
+[[autodoc]] FlaxRobertaForMaskedLM
+ - __call__
+
+## FlaxRobertaForSequenceClassification
+
+[[autodoc]] FlaxRobertaForSequenceClassification
+ - __call__
+
+## FlaxRobertaForMultipleChoice
+
+[[autodoc]] FlaxRobertaForMultipleChoice
+ - __call__
+
+## FlaxRobertaForTokenClassification
+
+[[autodoc]] FlaxRobertaForTokenClassification
+ - __call__
+
+## FlaxRobertaForQuestionAnswering
+
+[[autodoc]] FlaxRobertaForQuestionAnswering
+ - __call__
diff --git a/docs/source/en/model_doc/roformer.mdx b/docs/source/en/model_doc/roformer.mdx
new file mode 100644
index 00000000000000..435941d9f29ac1
--- /dev/null
+++ b/docs/source/en/model_doc/roformer.mdx
@@ -0,0 +1,155 @@
+
+
+# RoFormer
+
+## Overview
+
+The RoFormer model was proposed in [RoFormer: Enhanced Transformer with Rotary Position Embedding](https://arxiv.org/pdf/2104.09864v1.pdf) by Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu.
+
+The abstract from the paper is the following:
+
+*Position encoding in transformer architecture provides supervision for dependency modeling between elements at
+different positions in the sequence. We investigate various methods to encode positional information in
+transformer-based language models and propose a novel implementation named Rotary Position Embedding(RoPE). The
+proposed RoPE encodes absolute positional information with rotation matrix and naturally incorporates explicit relative
+position dependency in self-attention formulation. Notably, RoPE comes with valuable properties such as flexibility of
+being expand to any sequence lengths, decaying inter-token dependency with increasing relative distances, and
+capability of equipping the linear self-attention with relative position encoding. As a result, the enhanced
+transformer with rotary position embedding, or RoFormer, achieves superior performance in tasks with long texts. We
+release the theoretical analysis along with some preliminary experiment results on Chinese data. The undergoing
+experiment for English benchmark will soon be updated.*
+
+Tips:
+
+- RoFormer is a BERT-like autoencoding model with rotary position embeddings. Rotary position embeddings have shown
+ improved performance on classification tasks with long texts.
+
+
+This model was contributed by [junnyu](https://huggingface.co/junnyu). The original code can be found [here](https://github.com/ZhuiyiTechnology/roformer).
+
+## RoFormerConfig
+
+[[autodoc]] RoFormerConfig
+
+## RoFormerTokenizer
+
+[[autodoc]] RoFormerTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## RoFormerTokenizerFast
+
+[[autodoc]] RoFormerTokenizerFast
+ - build_inputs_with_special_tokens
+
+## RoFormerModel
+
+[[autodoc]] RoFormerModel
+ - forward
+
+## RoFormerForCausalLM
+
+[[autodoc]] RoFormerForCausalLM
+ - forward
+
+## RoFormerForMaskedLM
+
+[[autodoc]] RoFormerForMaskedLM
+ - forward
+
+## RoFormerForSequenceClassification
+
+[[autodoc]] RoFormerForSequenceClassification
+ - forward
+
+## RoFormerForMultipleChoice
+
+[[autodoc]] RoFormerForMultipleChoice
+ - forward
+
+## RoFormerForTokenClassification
+
+[[autodoc]] RoFormerForTokenClassification
+ - forward
+
+## RoFormerForQuestionAnswering
+
+[[autodoc]] RoFormerForQuestionAnswering
+ - forward
+
+## TFRoFormerModel
+
+[[autodoc]] TFRoFormerModel
+ - call
+
+## TFRoFormerForMaskedLM
+
+[[autodoc]] TFRoFormerForMaskedLM
+ - call
+
+## TFRoFormerForCausalLM
+
+[[autodoc]] TFRoFormerForCausalLM
+ - call
+
+## TFRoFormerForSequenceClassification
+
+[[autodoc]] TFRoFormerForSequenceClassification
+ - call
+
+## TFRoFormerForMultipleChoice
+
+[[autodoc]] TFRoFormerForMultipleChoice
+ - call
+
+## TFRoFormerForTokenClassification
+
+[[autodoc]] TFRoFormerForTokenClassification
+ - call
+
+## TFRoFormerForQuestionAnswering
+
+[[autodoc]] TFRoFormerForQuestionAnswering
+ - call
+
+## FlaxRoFormerModel
+
+[[autodoc]] FlaxRoFormerModel
+ - __call__
+
+## FlaxRoFormerForMaskedLM
+
+[[autodoc]] FlaxRoFormerForMaskedLM
+ - __call__
+
+## FlaxRoFormerForSequenceClassification
+
+[[autodoc]] FlaxRoFormerForSequenceClassification
+ - __call__
+
+## FlaxRoFormerForMultipleChoice
+
+[[autodoc]] FlaxRoFormerForMultipleChoice
+ - __call__
+
+## FlaxRoFormerForTokenClassification
+
+[[autodoc]] FlaxRoFormerForTokenClassification
+ - __call__
+
+## FlaxRoFormerForQuestionAnswering
+
+[[autodoc]] FlaxRoFormerForQuestionAnswering
+ - __call__
diff --git a/docs/source/en/model_doc/segformer.mdx b/docs/source/en/model_doc/segformer.mdx
new file mode 100644
index 00000000000000..9563e0843073ee
--- /dev/null
+++ b/docs/source/en/model_doc/segformer.mdx
@@ -0,0 +1,106 @@
+
+
+# SegFormer
+
+## Overview
+
+The SegFormer model was proposed in [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://arxiv.org/abs/2105.15203) by Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, Ping
+Luo. The model consists of a hierarchical Transformer encoder and a lightweight all-MLP decode head to achieve great
+results on image segmentation benchmarks such as ADE20K and Cityscapes.
+
+The abstract from the paper is the following:
+
+*We present SegFormer, a simple, efficient yet powerful semantic segmentation framework which unifies Transformers with
+lightweight multilayer perception (MLP) decoders. SegFormer has two appealing features: 1) SegFormer comprises a novel
+hierarchically structured Transformer encoder which outputs multiscale features. It does not need positional encoding,
+thereby avoiding the interpolation of positional codes which leads to decreased performance when the testing resolution
+differs from training. 2) SegFormer avoids complex decoders. The proposed MLP decoder aggregates information from
+different layers, and thus combining both local attention and global attention to render powerful representations. We
+show that this simple and lightweight design is the key to efficient segmentation on Transformers. We scale our
+approach up to obtain a series of models from SegFormer-B0 to SegFormer-B5, reaching significantly better performance
+and efficiency than previous counterparts. For example, SegFormer-B4 achieves 50.3% mIoU on ADE20K with 64M parameters,
+being 5x smaller and 2.2% better than the previous best method. Our best model, SegFormer-B5, achieves 84.0% mIoU on
+Cityscapes validation set and shows excellent zero-shot robustness on Cityscapes-C.*
+
+The figure below illustrates the architecture of SegFormer. Taken from the [original paper](https://arxiv.org/abs/2105.15203).
+
+
+
+This model was contributed by [Francesco](https://huggingface.co/Francesco). The original code can be found [here](https://github.com/KaimingHe/deep-residual-networks).
+
+## ResNetConfig
+
+[[autodoc]] ResNetConfig
+
+
+## ResNetModel
+
+[[autodoc]] ResNetModel
+ - forward
+
+
+## ResNetForImageClassification
+
+[[autodoc]] ResNetForImageClassification
+ - forward
\ No newline at end of file
diff --git a/docs/source/en/model_doc/retribert.mdx b/docs/source/en/model_doc/retribert.mdx
new file mode 100644
index 00000000000000..e83fae32300da9
--- /dev/null
+++ b/docs/source/en/model_doc/retribert.mdx
@@ -0,0 +1,40 @@
+
+
+# RetriBERT
+
+## Overview
+
+The RetriBERT model was proposed in the blog post [Explain Anything Like I'm Five: A Model for Open Domain Long Form
+Question Answering](https://yjernite.github.io/lfqa.html). RetriBERT is a small model that uses either a single or
+pair of BERT encoders with lower-dimension projection for dense semantic indexing of text.
+
+This model was contributed by [yjernite](https://huggingface.co/yjernite). Code to train and use the model can be
+found [here](https://github.com/huggingface/transformers/tree/main/examples/research-projects/distillation).
+
+
+## RetriBertConfig
+
+[[autodoc]] RetriBertConfig
+
+## RetriBertTokenizer
+
+[[autodoc]] RetriBertTokenizer
+
+## RetriBertTokenizerFast
+
+[[autodoc]] RetriBertTokenizerFast
+
+## RetriBertModel
+
+[[autodoc]] RetriBertModel
+ - forward
diff --git a/docs/source/en/model_doc/roberta.mdx b/docs/source/en/model_doc/roberta.mdx
new file mode 100644
index 00000000000000..b3b3e62064a22b
--- /dev/null
+++ b/docs/source/en/model_doc/roberta.mdx
@@ -0,0 +1,167 @@
+
+
+# RoBERTa
+
+## Overview
+
+The RoBERTa model was proposed in [RoBERTa: A Robustly Optimized BERT Pretraining Approach](https://arxiv.org/abs/1907.11692) by Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer
+Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov. It is based on Google's BERT model released in 2018.
+
+It builds on BERT and modifies key hyperparameters, removing the next-sentence pretraining objective and training with
+much larger mini-batches and learning rates.
+
+The abstract from the paper is the following:
+
+*Language model pretraining has led to significant performance gains but careful comparison between different
+approaches is challenging. Training is computationally expensive, often done on private datasets of different sizes,
+and, as we will show, hyperparameter choices have significant impact on the final results. We present a replication
+study of BERT pretraining (Devlin et al., 2019) that carefully measures the impact of many key hyperparameters and
+training data size. We find that BERT was significantly undertrained, and can match or exceed the performance of every
+model published after it. Our best model achieves state-of-the-art results on GLUE, RACE and SQuAD. These results
+highlight the importance of previously overlooked design choices, and raise questions about the source of recently
+reported improvements. We release our models and code.*
+
+Tips:
+
+- This implementation is the same as [`BertModel`] with a tiny embeddings tweak as well as a setup
+ for Roberta pretrained models.
+- RoBERTa has the same architecture as BERT, but uses a byte-level BPE as a tokenizer (same as GPT-2) and uses a
+ different pretraining scheme.
+- RoBERTa doesn't have `token_type_ids`, you don't need to indicate which token belongs to which segment. Just
+ separate your segments with the separation token `tokenizer.sep_token` (or ``)
+- [CamemBERT](camembert) is a wrapper around RoBERTa. Refer to this page for usage examples.
+
+This model was contributed by [julien-c](https://huggingface.co/julien-c). The original code can be found [here](https://github.com/pytorch/fairseq/tree/master/examples/roberta).
+
+
+## RobertaConfig
+
+[[autodoc]] RobertaConfig
+
+## RobertaTokenizer
+
+[[autodoc]] RobertaTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## RobertaTokenizerFast
+
+[[autodoc]] RobertaTokenizerFast
+ - build_inputs_with_special_tokens
+
+## RobertaModel
+
+[[autodoc]] RobertaModel
+ - forward
+
+## RobertaForCausalLM
+
+[[autodoc]] RobertaForCausalLM
+ - forward
+
+## RobertaForMaskedLM
+
+[[autodoc]] RobertaForMaskedLM
+ - forward
+
+## RobertaForSequenceClassification
+
+[[autodoc]] RobertaForSequenceClassification
+ - forward
+
+## RobertaForMultipleChoice
+
+[[autodoc]] RobertaForMultipleChoice
+ - forward
+
+## RobertaForTokenClassification
+
+[[autodoc]] RobertaForTokenClassification
+ - forward
+
+## RobertaForQuestionAnswering
+
+[[autodoc]] RobertaForQuestionAnswering
+ - forward
+
+## TFRobertaModel
+
+[[autodoc]] TFRobertaModel
+ - call
+
+## TFRobertaForCausalLM
+
+[[autodoc]] TFRobertaForCausalLM
+ - call
+
+## TFRobertaForMaskedLM
+
+[[autodoc]] TFRobertaForMaskedLM
+ - call
+
+## TFRobertaForSequenceClassification
+
+[[autodoc]] TFRobertaForSequenceClassification
+ - call
+
+## TFRobertaForMultipleChoice
+
+[[autodoc]] TFRobertaForMultipleChoice
+ - call
+
+## TFRobertaForTokenClassification
+
+[[autodoc]] TFRobertaForTokenClassification
+ - call
+
+## TFRobertaForQuestionAnswering
+
+[[autodoc]] TFRobertaForQuestionAnswering
+ - call
+
+## FlaxRobertaModel
+
+[[autodoc]] FlaxRobertaModel
+ - __call__
+
+## FlaxRobertaForCausalLM
+
+[[autodoc]] FlaxRobertaForCausalLM
+ - __call__
+
+## FlaxRobertaForMaskedLM
+
+[[autodoc]] FlaxRobertaForMaskedLM
+ - __call__
+
+## FlaxRobertaForSequenceClassification
+
+[[autodoc]] FlaxRobertaForSequenceClassification
+ - __call__
+
+## FlaxRobertaForMultipleChoice
+
+[[autodoc]] FlaxRobertaForMultipleChoice
+ - __call__
+
+## FlaxRobertaForTokenClassification
+
+[[autodoc]] FlaxRobertaForTokenClassification
+ - __call__
+
+## FlaxRobertaForQuestionAnswering
+
+[[autodoc]] FlaxRobertaForQuestionAnswering
+ - __call__
diff --git a/docs/source/en/model_doc/roformer.mdx b/docs/source/en/model_doc/roformer.mdx
new file mode 100644
index 00000000000000..435941d9f29ac1
--- /dev/null
+++ b/docs/source/en/model_doc/roformer.mdx
@@ -0,0 +1,155 @@
+
+
+# RoFormer
+
+## Overview
+
+The RoFormer model was proposed in [RoFormer: Enhanced Transformer with Rotary Position Embedding](https://arxiv.org/pdf/2104.09864v1.pdf) by Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu.
+
+The abstract from the paper is the following:
+
+*Position encoding in transformer architecture provides supervision for dependency modeling between elements at
+different positions in the sequence. We investigate various methods to encode positional information in
+transformer-based language models and propose a novel implementation named Rotary Position Embedding(RoPE). The
+proposed RoPE encodes absolute positional information with rotation matrix and naturally incorporates explicit relative
+position dependency in self-attention formulation. Notably, RoPE comes with valuable properties such as flexibility of
+being expand to any sequence lengths, decaying inter-token dependency with increasing relative distances, and
+capability of equipping the linear self-attention with relative position encoding. As a result, the enhanced
+transformer with rotary position embedding, or RoFormer, achieves superior performance in tasks with long texts. We
+release the theoretical analysis along with some preliminary experiment results on Chinese data. The undergoing
+experiment for English benchmark will soon be updated.*
+
+Tips:
+
+- RoFormer is a BERT-like autoencoding model with rotary position embeddings. Rotary position embeddings have shown
+ improved performance on classification tasks with long texts.
+
+
+This model was contributed by [junnyu](https://huggingface.co/junnyu). The original code can be found [here](https://github.com/ZhuiyiTechnology/roformer).
+
+## RoFormerConfig
+
+[[autodoc]] RoFormerConfig
+
+## RoFormerTokenizer
+
+[[autodoc]] RoFormerTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## RoFormerTokenizerFast
+
+[[autodoc]] RoFormerTokenizerFast
+ - build_inputs_with_special_tokens
+
+## RoFormerModel
+
+[[autodoc]] RoFormerModel
+ - forward
+
+## RoFormerForCausalLM
+
+[[autodoc]] RoFormerForCausalLM
+ - forward
+
+## RoFormerForMaskedLM
+
+[[autodoc]] RoFormerForMaskedLM
+ - forward
+
+## RoFormerForSequenceClassification
+
+[[autodoc]] RoFormerForSequenceClassification
+ - forward
+
+## RoFormerForMultipleChoice
+
+[[autodoc]] RoFormerForMultipleChoice
+ - forward
+
+## RoFormerForTokenClassification
+
+[[autodoc]] RoFormerForTokenClassification
+ - forward
+
+## RoFormerForQuestionAnswering
+
+[[autodoc]] RoFormerForQuestionAnswering
+ - forward
+
+## TFRoFormerModel
+
+[[autodoc]] TFRoFormerModel
+ - call
+
+## TFRoFormerForMaskedLM
+
+[[autodoc]] TFRoFormerForMaskedLM
+ - call
+
+## TFRoFormerForCausalLM
+
+[[autodoc]] TFRoFormerForCausalLM
+ - call
+
+## TFRoFormerForSequenceClassification
+
+[[autodoc]] TFRoFormerForSequenceClassification
+ - call
+
+## TFRoFormerForMultipleChoice
+
+[[autodoc]] TFRoFormerForMultipleChoice
+ - call
+
+## TFRoFormerForTokenClassification
+
+[[autodoc]] TFRoFormerForTokenClassification
+ - call
+
+## TFRoFormerForQuestionAnswering
+
+[[autodoc]] TFRoFormerForQuestionAnswering
+ - call
+
+## FlaxRoFormerModel
+
+[[autodoc]] FlaxRoFormerModel
+ - __call__
+
+## FlaxRoFormerForMaskedLM
+
+[[autodoc]] FlaxRoFormerForMaskedLM
+ - __call__
+
+## FlaxRoFormerForSequenceClassification
+
+[[autodoc]] FlaxRoFormerForSequenceClassification
+ - __call__
+
+## FlaxRoFormerForMultipleChoice
+
+[[autodoc]] FlaxRoFormerForMultipleChoice
+ - __call__
+
+## FlaxRoFormerForTokenClassification
+
+[[autodoc]] FlaxRoFormerForTokenClassification
+ - __call__
+
+## FlaxRoFormerForQuestionAnswering
+
+[[autodoc]] FlaxRoFormerForQuestionAnswering
+ - __call__
diff --git a/docs/source/en/model_doc/segformer.mdx b/docs/source/en/model_doc/segformer.mdx
new file mode 100644
index 00000000000000..9563e0843073ee
--- /dev/null
+++ b/docs/source/en/model_doc/segformer.mdx
@@ -0,0 +1,106 @@
+
+
+# SegFormer
+
+## Overview
+
+The SegFormer model was proposed in [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://arxiv.org/abs/2105.15203) by Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, Ping
+Luo. The model consists of a hierarchical Transformer encoder and a lightweight all-MLP decode head to achieve great
+results on image segmentation benchmarks such as ADE20K and Cityscapes.
+
+The abstract from the paper is the following:
+
+*We present SegFormer, a simple, efficient yet powerful semantic segmentation framework which unifies Transformers with
+lightweight multilayer perception (MLP) decoders. SegFormer has two appealing features: 1) SegFormer comprises a novel
+hierarchically structured Transformer encoder which outputs multiscale features. It does not need positional encoding,
+thereby avoiding the interpolation of positional codes which leads to decreased performance when the testing resolution
+differs from training. 2) SegFormer avoids complex decoders. The proposed MLP decoder aggregates information from
+different layers, and thus combining both local attention and global attention to render powerful representations. We
+show that this simple and lightweight design is the key to efficient segmentation on Transformers. We scale our
+approach up to obtain a series of models from SegFormer-B0 to SegFormer-B5, reaching significantly better performance
+and efficiency than previous counterparts. For example, SegFormer-B4 achieves 50.3% mIoU on ADE20K with 64M parameters,
+being 5x smaller and 2.2% better than the previous best method. Our best model, SegFormer-B5, achieves 84.0% mIoU on
+Cityscapes validation set and shows excellent zero-shot robustness on Cityscapes-C.*
+
+The figure below illustrates the architecture of SegFormer. Taken from the [original paper](https://arxiv.org/abs/2105.15203).
+
+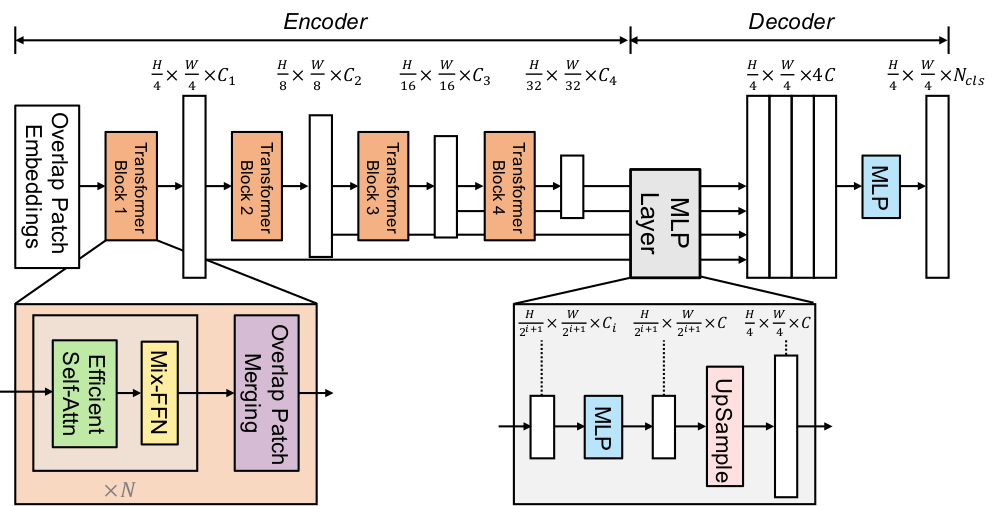 +
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/NVlabs/SegFormer).
+
+Tips:
+
+- SegFormer consists of a hierarchical Transformer encoder, and a lightweight all-MLP decode head.
+ [`SegformerModel`] is the hierarchical Transformer encoder (which in the paper is also referred to
+ as Mix Transformer or MiT). [`SegformerForSemanticSegmentation`] adds the all-MLP decode head on
+ top to perform semantic segmentation of images. In addition, there's
+ [`SegformerForImageClassification`] which can be used to - you guessed it - classify images. The
+ authors of SegFormer first pre-trained the Transformer encoder on ImageNet-1k to classify images. Next, they throw
+ away the classification head, and replace it by the all-MLP decode head. Next, they fine-tune the model altogether on
+ ADE20K, Cityscapes and COCO-stuff, which are important benchmarks for semantic segmentation. All checkpoints can be
+ found on the [hub](https://huggingface.co/models?other=segformer).
+- The quickest way to get started with SegFormer is by checking the [example notebooks](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/SegFormer) (which showcase both inference and
+ fine-tuning on custom data). One can also check out the [blog post](https://huggingface.co/blog/fine-tune-segformer) introducing SegFormer and illustrating how it can be fine-tuned on custom data.
+- SegFormer works on any input size, as it pads the input to be divisible by `config.patch_sizes`.
+- One can use [`SegformerFeatureExtractor`] to prepare images and corresponding segmentation maps
+ for the model. Note that this feature extractor is fairly basic and does not include all data augmentations used in
+ the original paper. The original preprocessing pipelines (for the ADE20k dataset for instance) can be found [here](https://github.com/NVlabs/SegFormer/blob/master/local_configs/_base_/datasets/ade20k_repeat.py). The most
+ important preprocessing step is that images and segmentation maps are randomly cropped and padded to the same size,
+ such as 512x512 or 640x640, after which they are normalized.
+- One additional thing to keep in mind is that one can initialize [`SegformerFeatureExtractor`] with
+ `reduce_labels` set to `True` or `False`. In some datasets (like ADE20k), the 0 index is used in the annotated
+ segmentation maps for background. However, ADE20k doesn't include the "background" class in its 150 labels.
+ Therefore, `reduce_labels` is used to reduce all labels by 1, and to make sure no loss is computed for the
+ background class (i.e. it replaces 0 in the annotated maps by 255, which is the *ignore_index* of the loss function
+ used by [`SegformerForSemanticSegmentation`]). However, other datasets use the 0 index as
+ background class and include this class as part of all labels. In that case, `reduce_labels` should be set to
+ `False`, as loss should also be computed for the background class.
+- As most models, SegFormer comes in different sizes, the details of which can be found in the table below.
+
+| **Model variant** | **Depths** | **Hidden sizes** | **Decoder hidden size** | **Params (M)** | **ImageNet-1k Top 1** |
+| :---------------: | ------------- | ------------------- | :---------------------: | :------------: | :-------------------: |
+| MiT-b0 | [2, 2, 2, 2] | [32, 64, 160, 256] | 256 | 3.7 | 70.5 |
+| MiT-b1 | [2, 2, 2, 2] | [64, 128, 320, 512] | 256 | 14.0 | 78.7 |
+| MiT-b2 | [3, 4, 6, 3] | [64, 128, 320, 512] | 768 | 25.4 | 81.6 |
+| MiT-b3 | [3, 4, 18, 3] | [64, 128, 320, 512] | 768 | 45.2 | 83.1 |
+| MiT-b4 | [3, 8, 27, 3] | [64, 128, 320, 512] | 768 | 62.6 | 83.6 |
+| MiT-b5 | [3, 6, 40, 3] | [64, 128, 320, 512] | 768 | 82.0 | 83.8 |
+
+## SegformerConfig
+
+[[autodoc]] SegformerConfig
+
+## SegformerFeatureExtractor
+
+[[autodoc]] SegformerFeatureExtractor
+ - __call__
+
+## SegformerModel
+
+[[autodoc]] SegformerModel
+ - forward
+
+## SegformerDecodeHead
+
+[[autodoc]] SegformerDecodeHead
+ - forward
+
+## SegformerForImageClassification
+
+[[autodoc]] SegformerForImageClassification
+ - forward
+
+## SegformerForSemanticSegmentation
+
+[[autodoc]] SegformerForSemanticSegmentation
+ - forward
diff --git a/docs/source/en/model_doc/sew-d.mdx b/docs/source/en/model_doc/sew-d.mdx
new file mode 100644
index 00000000000000..ceeb4f1ec35fcc
--- /dev/null
+++ b/docs/source/en/model_doc/sew-d.mdx
@@ -0,0 +1,57 @@
+
+
+# SEW-D
+
+## Overview
+
+SEW-D (Squeezed and Efficient Wav2Vec with Disentangled attention) was proposed in [Performance-Efficiency Trade-offs
+in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim,
+Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
+
+The abstract from the paper is the following:
+
+*This paper is a study of performance-efficiency trade-offs in pre-trained models for automatic speech recognition
+(ASR). We focus on wav2vec 2.0, and formalize several architecture designs that influence both the model performance
+and its efficiency. Putting together all our observations, we introduce SEW (Squeezed and Efficient Wav2vec), a
+pre-trained model architecture with significant improvements along both performance and efficiency dimensions across a
+variety of training setups. For example, under the 100h-960h semi-supervised setup on LibriSpeech, SEW achieves a 1.9x
+inference speedup compared to wav2vec 2.0, with a 13.5% relative reduction in word error rate. With a similar inference
+time, SEW reduces word error rate by 25-50% across different model sizes.*
+
+Tips:
+
+- SEW-D is a speech model that accepts a float array corresponding to the raw waveform of the speech signal.
+- SEWDForCTC is fine-tuned using connectionist temporal classification (CTC) so the model output has to be decoded
+ using [`Wav2Vec2CTCTokenizer`].
+
+This model was contributed by [anton-l](https://huggingface.co/anton-l).
+
+
+## SEWDConfig
+
+[[autodoc]] SEWDConfig
+
+## SEWDModel
+
+[[autodoc]] SEWDModel
+ - forward
+
+## SEWDForCTC
+
+[[autodoc]] SEWDForCTC
+ - forward
+
+## SEWDForSequenceClassification
+
+[[autodoc]] SEWDForSequenceClassification
+ - forward
diff --git a/docs/source/en/model_doc/sew.mdx b/docs/source/en/model_doc/sew.mdx
new file mode 100644
index 00000000000000..dce949a856b345
--- /dev/null
+++ b/docs/source/en/model_doc/sew.mdx
@@ -0,0 +1,57 @@
+
+
+# SEW
+
+## Overview
+
+SEW (Squeezed and Efficient Wav2Vec) was proposed in [Performance-Efficiency Trade-offs in Unsupervised Pre-training
+for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q.
+Weinberger, Yoav Artzi.
+
+The abstract from the paper is the following:
+
+*This paper is a study of performance-efficiency trade-offs in pre-trained models for automatic speech recognition
+(ASR). We focus on wav2vec 2.0, and formalize several architecture designs that influence both the model performance
+and its efficiency. Putting together all our observations, we introduce SEW (Squeezed and Efficient Wav2vec), a
+pre-trained model architecture with significant improvements along both performance and efficiency dimensions across a
+variety of training setups. For example, under the 100h-960h semi-supervised setup on LibriSpeech, SEW achieves a 1.9x
+inference speedup compared to wav2vec 2.0, with a 13.5% relative reduction in word error rate. With a similar inference
+time, SEW reduces word error rate by 25-50% across different model sizes.*
+
+Tips:
+
+- SEW is a speech model that accepts a float array corresponding to the raw waveform of the speech signal.
+- SEWForCTC is fine-tuned using connectionist temporal classification (CTC) so the model output has to be decoded using
+ [`Wav2Vec2CTCTokenizer`].
+
+This model was contributed by [anton-l](https://huggingface.co/anton-l).
+
+
+## SEWConfig
+
+[[autodoc]] SEWConfig
+
+## SEWModel
+
+[[autodoc]] SEWModel
+ - forward
+
+## SEWForCTC
+
+[[autodoc]] SEWForCTC
+ - forward
+
+## SEWForSequenceClassification
+
+[[autodoc]] SEWForSequenceClassification
+ - forward
diff --git a/docs/source/en/model_doc/speech-encoder-decoder.mdx b/docs/source/en/model_doc/speech-encoder-decoder.mdx
new file mode 100644
index 00000000000000..a0dd20bb4dee31
--- /dev/null
+++ b/docs/source/en/model_doc/speech-encoder-decoder.mdx
@@ -0,0 +1,41 @@
+
+
+# Speech Encoder Decoder Models
+
+The [`SpeechEncoderDecoderModel`] can be used to initialize a speech-sequence-to-text-sequence model
+with any pretrained speech autoencoding model as the encoder (*e.g.* [Wav2Vec2](wav2vec2), [Hubert](hubert)) and any pretrained autoregressive model as the decoder.
+
+The effectiveness of initializing speech-sequence-to-text-sequence models with pretrained checkpoints for speech
+recognition and speech translation has *e.g.* been shown in [Large-Scale Self- and Semi-Supervised Learning for Speech
+Translation](https://arxiv.org/abs/2104.06678) by Changhan Wang, Anne Wu, Juan Pino, Alexei Baevski, Michael Auli,
+Alexis Conneau.
+
+An example of how to use a [`SpeechEncoderDecoderModel`] for inference can be seen in
+[Speech2Text2](speech_to_text_2).
+
+
+## SpeechEncoderDecoderConfig
+
+[[autodoc]] SpeechEncoderDecoderConfig
+
+## SpeechEncoderDecoderModel
+
+[[autodoc]] SpeechEncoderDecoderModel
+ - forward
+ - from_encoder_decoder_pretrained
+
+## FlaxSpeechEncoderDecoderModel
+
+[[autodoc]] FlaxSpeechEncoderDecoderModel
+ - __call__
+ - from_encoder_decoder_pretrained
\ No newline at end of file
diff --git a/docs/source/en/model_doc/speech_to_text.mdx b/docs/source/en/model_doc/speech_to_text.mdx
new file mode 100644
index 00000000000000..0a3b00b1d5dd30
--- /dev/null
+++ b/docs/source/en/model_doc/speech_to_text.mdx
@@ -0,0 +1,143 @@
+
+
+# Speech2Text
+
+## Overview
+
+The Speech2Text model was proposed in [fairseq S2T: Fast Speech-to-Text Modeling with fairseq](https://arxiv.org/abs/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Dmytro Okhonko, Juan Pino. It's a
+transformer-based seq2seq (encoder-decoder) model designed for end-to-end Automatic Speech Recognition (ASR) and Speech
+Translation (ST). It uses a convolutional downsampler to reduce the length of speech inputs by 3/4th before they are
+fed into the encoder. The model is trained with standard autoregressive cross-entropy loss and generates the
+transcripts/translations autoregressively. Speech2Text has been fine-tuned on several datasets for ASR and ST:
+[LibriSpeech](http://www.openslr.org/12), [CoVoST 2](https://github.com/facebookresearch/covost), [MuST-C](https://ict.fbk.eu/must-c/).
+
+This model was contributed by [valhalla](https://huggingface.co/valhalla). The original code can be found [here](https://github.com/pytorch/fairseq/tree/master/examples/speech_to_text).
+
+
+## Inference
+
+Speech2Text is a speech model that accepts a float tensor of log-mel filter-bank features extracted from the speech
+signal. It's a transformer-based seq2seq model, so the transcripts/translations are generated autoregressively. The
+`generate()` method can be used for inference.
+
+The [`Speech2TextFeatureExtractor`] class is responsible for extracting the log-mel filter-bank
+features. The [`Speech2TextProcessor`] wraps [`Speech2TextFeatureExtractor`] and
+[`Speech2TextTokenizer`] into a single instance to both extract the input features and decode the
+predicted token ids.
+
+The feature extractor depends on `torchaudio` and the tokenizer depends on `sentencepiece` so be sure to
+install those packages before running the examples. You could either install those as extra speech dependencies with
+`pip install transformers"[speech, sentencepiece]"` or install the packages seperately with `pip install torchaudio sentencepiece`. Also `torchaudio` requires the development version of the [libsndfile](http://www.mega-nerd.com/libsndfile/) package which can be installed via a system package manager. On Ubuntu it can
+be installed as follows: `apt install libsndfile1-dev`
+
+
+- ASR and Speech Translation
+
+```python
+>>> import torch
+>>> from transformers import Speech2TextProcessor, Speech2TextForConditionalGeneration
+>>> from datasets import load_dataset
+
+>>> model = Speech2TextForConditionalGeneration.from_pretrained("facebook/s2t-small-librispeech-asr")
+>>> processor = Speech2TextProcessor.from_pretrained("facebook/s2t-small-librispeech-asr")
+
+
+>>> ds = load_dataset("hf-internal-testing/librispeech_asr_demo", "clean", split="validation")
+
+>>> inputs = processor(ds[0]["audio"]["array"], sampling_rate=ds[0]["audio"]["sampling_rate"], return_tensors="pt")
+>>> generated_ids = model.generate(inputs["input_features"], attention_mask=inputs["attention_mask"])
+
+>>> transcription = processor.batch_decode(generated_ids)
+>>> transcription
+['mister quilter is the apostle of the middle classes and we are glad to welcome his gospel']
+```
+
+- Multilingual speech translation
+
+ For multilingual speech translation models, `eos_token_id` is used as the `decoder_start_token_id` and
+ the target language id is forced as the first generated token. To force the target language id as the first
+ generated token, pass the `forced_bos_token_id` parameter to the `generate()` method. The following
+ example shows how to transate English speech to French text using the *facebook/s2t-medium-mustc-multilingual-st*
+ checkpoint.
+
+```python
+>>> import torch
+>>> from transformers import Speech2TextProcessor, Speech2TextForConditionalGeneration
+>>> from datasets import load_dataset
+
+>>> model = Speech2TextForConditionalGeneration.from_pretrained("facebook/s2t-medium-mustc-multilingual-st")
+>>> processor = Speech2TextProcessor.from_pretrained("facebook/s2t-medium-mustc-multilingual-st")
+
+>>> ds = load_dataset("hf-internal-testing/librispeech_asr_demo", "clean", split="validation")
+
+>>> inputs = processor(ds[0]["audio"]["array"], sampling_rate=ds[0]["audio"]["sampling_rate"], return_tensors="pt")
+>>> generated_ids = model.generate(
+... inputs["input_features"],
+... attention_mask=inputs["attention_mask"],
+... forced_bos_token_id=processor.tokenizer.lang_code_to_id["fr"],
+... )
+
+>>> translation = processor.batch_decode(generated_ids)
+>>> translation
+[" (Vidéo) Si M. Kilder est l'apossible des classes moyennes, et nous sommes heureux d'être accueillis dans son évangile."]
+```
+
+See the [model hub](https://huggingface.co/models?filter=speech_to_text) to look for Speech2Text checkpoints.
+
+
+## Speech2TextConfig
+
+[[autodoc]] Speech2TextConfig
+
+## Speech2TextTokenizer
+
+[[autodoc]] Speech2TextTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## Speech2TextFeatureExtractor
+
+[[autodoc]] Speech2TextFeatureExtractor
+ - __call__
+
+## Speech2TextProcessor
+
+[[autodoc]] Speech2TextProcessor
+ - __call__
+ - from_pretrained
+ - save_pretrained
+ - batch_decode
+ - decode
+ - as_target_processor
+
+## Speech2TextModel
+
+[[autodoc]] Speech2TextModel
+ - forward
+
+## Speech2TextForConditionalGeneration
+
+[[autodoc]] Speech2TextForConditionalGeneration
+ - forward
+
+## TFSpeech2TextModel
+
+[[autodoc]] TFSpeech2TextModel
+ - call
+
+## TFSpeech2TextForConditionalGeneration
+
+[[autodoc]] TFSpeech2TextForConditionalGeneration
+ - call
diff --git a/docs/source/en/model_doc/speech_to_text_2.mdx b/docs/source/en/model_doc/speech_to_text_2.mdx
new file mode 100644
index 00000000000000..72754b67aab9a2
--- /dev/null
+++ b/docs/source/en/model_doc/speech_to_text_2.mdx
@@ -0,0 +1,122 @@
+
+
+# Speech2Text2
+
+## Overview
+
+The Speech2Text2 model is used together with [Wav2Vec2](wav2vec2) for Speech Translation models proposed in
+[Large-Scale Self- and Semi-Supervised Learning for Speech Translation](https://arxiv.org/abs/2104.06678) by
+Changhan Wang, Anne Wu, Juan Pino, Alexei Baevski, Michael Auli, Alexis Conneau.
+
+Speech2Text2 is a *decoder-only* transformer model that can be used with any speech *encoder-only*, such as
+[Wav2Vec2](wav2vec2) or [HuBERT](hubert) for Speech-to-Text tasks. Please refer to the
+[SpeechEncoderDecoder](speech-encoder-decoder) class on how to combine Speech2Text2 with any speech *encoder-only*
+model.
+
+This model was contributed by [Patrick von Platen](https://huggingface.co/patrickvonplaten).
+
+The original code can be found [here](https://github.com/pytorch/fairseq/blob/1f7ef9ed1e1061f8c7f88f8b94c7186834398690/fairseq/models/wav2vec/wav2vec2_asr.py#L266).
+
+
+Tips:
+
+- Speech2Text2 achieves state-of-the-art results on the CoVoST Speech Translation dataset. For more information, see
+ the [official models](https://huggingface.co/models?other=speech2text2) .
+- Speech2Text2 is always used within the [SpeechEncoderDecoder](speech-encoder-decoder) framework.
+- Speech2Text2's tokenizer is based on [fastBPE](https://github.com/glample/fastBPE).
+
+## Inference
+
+Speech2Text2's [`SpeechEncoderDecoderModel`] model accepts raw waveform input values from speech and
+makes use of [`~generation_utils.GenerationMixin.generate`] to translate the input speech
+autoregressively to the target language.
+
+The [`Wav2Vec2FeatureExtractor`] class is responsible for preprocessing the input speech and
+[`Speech2Text2Tokenizer`] decodes the generated target tokens to the target string. The
+[`Speech2Text2Processor`] wraps [`Wav2Vec2FeatureExtractor`] and
+[`Speech2Text2Tokenizer`] into a single instance to both extract the input features and decode the
+predicted token ids.
+
+- Step-by-step Speech Translation
+
+```python
+>>> import torch
+>>> from transformers import Speech2Text2Processor, SpeechEncoderDecoderModel
+>>> from datasets import load_dataset
+>>> import soundfile as sf
+
+>>> model = SpeechEncoderDecoderModel.from_pretrained("facebook/s2t-wav2vec2-large-en-de")
+>>> processor = Speech2Text2Processor.from_pretrained("facebook/s2t-wav2vec2-large-en-de")
+
+
+>>> def map_to_array(batch):
+... speech, _ = sf.read(batch["file"])
+... batch["speech"] = speech
+... return batch
+
+
+>>> ds = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
+>>> ds = ds.map(map_to_array)
+
+>>> inputs = processor(ds["speech"][0], sampling_rate=16_000, return_tensors="pt")
+>>> generated_ids = model.generate(inputs=inputs["input_values"], attention_mask=inputs["attention_mask"])
+
+>>> transcription = processor.batch_decode(generated_ids)
+```
+
+- Speech Translation via Pipelines
+
+ The automatic speech recognition pipeline can also be used to translate speech in just a couple lines of code
+
+```python
+>>> from datasets import load_dataset
+>>> from transformers import pipeline
+
+>>> librispeech_en = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
+>>> asr = pipeline(
+... "automatic-speech-recognition",
+... model="facebook/s2t-wav2vec2-large-en-de",
+... feature_extractor="facebook/s2t-wav2vec2-large-en-de",
+... )
+
+>>> translation_de = asr(librispeech_en[0]["file"])
+```
+
+See [model hub](https://huggingface.co/models?filter=speech2text2) to look for Speech2Text2 checkpoints.
+
+
+## Speech2Text2Config
+
+[[autodoc]] Speech2Text2Config
+
+## Speech2TextTokenizer
+
+[[autodoc]] Speech2Text2Tokenizer
+ - batch_decode
+ - decode
+ - save_vocabulary
+
+## Speech2Text2Processor
+
+[[autodoc]] Speech2Text2Processor
+ - __call__
+ - from_pretrained
+ - save_pretrained
+ - batch_decode
+ - decode
+ - as_target_processor
+
+## Speech2Text2ForCausalLM
+
+[[autodoc]] Speech2Text2ForCausalLM
+ - forward
diff --git a/docs/source/en/model_doc/splinter.mdx b/docs/source/en/model_doc/splinter.mdx
new file mode 100644
index 00000000000000..50d4e8db74816d
--- /dev/null
+++ b/docs/source/en/model_doc/splinter.mdx
@@ -0,0 +1,74 @@
+
+
+# Splinter
+
+## Overview
+
+The Splinter model was proposed in [Few-Shot Question Answering by Pretraining Span Selection](https://arxiv.org/abs/2101.00438) by Ori Ram, Yuval Kirstain, Jonathan Berant, Amir Globerson, Omer Levy. Splinter
+is an encoder-only transformer (similar to BERT) pretrained using the recurring span selection task on a large corpus
+comprising Wikipedia and the Toronto Book Corpus.
+
+The abstract from the paper is the following:
+
+In several question answering benchmarks, pretrained models have reached human parity through fine-tuning on an order
+of 100,000 annotated questions and answers. We explore the more realistic few-shot setting, where only a few hundred
+training examples are available, and observe that standard models perform poorly, highlighting the discrepancy between
+current pretraining objectives and question answering. We propose a new pretraining scheme tailored for question
+answering: recurring span selection. Given a passage with multiple sets of recurring spans, we mask in each set all
+recurring spans but one, and ask the model to select the correct span in the passage for each masked span. Masked spans
+are replaced with a special token, viewed as a question representation, that is later used during fine-tuning to select
+the answer span. The resulting model obtains surprisingly good results on multiple benchmarks (e.g., 72.7 F1 on SQuAD
+with only 128 training examples), while maintaining competitive performance in the high-resource setting.
+
+Tips:
+
+- Splinter was trained to predict answers spans conditioned on a special [QUESTION] token. These tokens contextualize
+ to question representations which are used to predict the answers. This layer is called QASS, and is the default
+ behaviour in the [`SplinterForQuestionAnswering`] class. Therefore:
+- Use [`SplinterTokenizer`] (rather than [`BertTokenizer`]), as it already
+ contains this special token. Also, its default behavior is to use this token when two sequences are given (for
+ example, in the *run_qa.py* script).
+- If you plan on using Splinter outside *run_qa.py*, please keep in mind the question token - it might be important for
+ the success of your model, especially in a few-shot setting.
+- Please note there are two different checkpoints for each size of Splinter. Both are basically the same, except that
+ one also has the pretrained wights of the QASS layer (*tau/splinter-base-qass* and *tau/splinter-large-qass*) and one
+ doesn't (*tau/splinter-base* and *tau/splinter-large*). This is done to support randomly initializing this layer at
+ fine-tuning, as it is shown to yield better results for some cases in the paper.
+
+This model was contributed by [yuvalkirstain](https://huggingface.co/yuvalkirstain) and [oriram](https://huggingface.co/oriram). The original code can be found [here](https://github.com/oriram/splinter).
+
+## SplinterConfig
+
+[[autodoc]] SplinterConfig
+
+## SplinterTokenizer
+
+[[autodoc]] SplinterTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## SplinterTokenizerFast
+
+[[autodoc]] SplinterTokenizerFast
+
+## SplinterModel
+
+[[autodoc]] SplinterModel
+ - forward
+
+## SplinterForQuestionAnswering
+
+[[autodoc]] SplinterForQuestionAnswering
+ - forward
diff --git a/docs/source/en/model_doc/squeezebert.mdx b/docs/source/en/model_doc/squeezebert.mdx
new file mode 100644
index 00000000000000..c6219582c838e3
--- /dev/null
+++ b/docs/source/en/model_doc/squeezebert.mdx
@@ -0,0 +1,88 @@
+
+
+# SqueezeBERT
+
+## Overview
+
+The SqueezeBERT model was proposed in [SqueezeBERT: What can computer vision teach NLP about efficient neural networks?](https://arxiv.org/abs/2006.11316) by Forrest N. Iandola, Albert E. Shaw, Ravi Krishna, Kurt W. Keutzer. It's a
+bidirectional transformer similar to the BERT model. The key difference between the BERT architecture and the
+SqueezeBERT architecture is that SqueezeBERT uses [grouped convolutions](https://blog.yani.io/filter-group-tutorial)
+instead of fully-connected layers for the Q, K, V and FFN layers.
+
+The abstract from the paper is the following:
+
+*Humans read and write hundreds of billions of messages every day. Further, due to the availability of large datasets,
+large computing systems, and better neural network models, natural language processing (NLP) technology has made
+significant strides in understanding, proofreading, and organizing these messages. Thus, there is a significant
+opportunity to deploy NLP in myriad applications to help web users, social networks, and businesses. In particular, we
+consider smartphones and other mobile devices as crucial platforms for deploying NLP models at scale. However, today's
+highly-accurate NLP neural network models such as BERT and RoBERTa are extremely computationally expensive, with
+BERT-base taking 1.7 seconds to classify a text snippet on a Pixel 3 smartphone. In this work, we observe that methods
+such as grouped convolutions have yielded significant speedups for computer vision networks, but many of these
+techniques have not been adopted by NLP neural network designers. We demonstrate how to replace several operations in
+self-attention layers with grouped convolutions, and we use this technique in a novel network architecture called
+SqueezeBERT, which runs 4.3x faster than BERT-base on the Pixel 3 while achieving competitive accuracy on the GLUE test
+set. The SqueezeBERT code will be released.*
+
+Tips:
+
+- SqueezeBERT is a model with absolute position embeddings so it's usually advised to pad the inputs on the right
+ rather than the left.
+- SqueezeBERT is similar to BERT and therefore relies on the masked language modeling (MLM) objective. It is therefore
+ efficient at predicting masked tokens and at NLU in general, but is not optimal for text generation. Models trained
+ with a causal language modeling (CLM) objective are better in that regard.
+- For best results when finetuning on sequence classification tasks, it is recommended to start with the
+ *squeezebert/squeezebert-mnli-headless* checkpoint.
+
+This model was contributed by [forresti](https://huggingface.co/forresti).
+
+
+## SqueezeBertConfig
+
+[[autodoc]] SqueezeBertConfig
+
+## SqueezeBertTokenizer
+
+[[autodoc]] SqueezeBertTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## SqueezeBertTokenizerFast
+
+[[autodoc]] SqueezeBertTokenizerFast
+
+## SqueezeBertModel
+
+[[autodoc]] SqueezeBertModel
+
+## SqueezeBertForMaskedLM
+
+[[autodoc]] SqueezeBertForMaskedLM
+
+## SqueezeBertForSequenceClassification
+
+[[autodoc]] SqueezeBertForSequenceClassification
+
+## SqueezeBertForMultipleChoice
+
+[[autodoc]] SqueezeBertForMultipleChoice
+
+## SqueezeBertForTokenClassification
+
+[[autodoc]] SqueezeBertForTokenClassification
+
+## SqueezeBertForQuestionAnswering
+
+[[autodoc]] SqueezeBertForQuestionAnswering
diff --git a/docs/source/en/model_doc/swin.mdx b/docs/source/en/model_doc/swin.mdx
new file mode 100644
index 00000000000000..1f247284afbc39
--- /dev/null
+++ b/docs/source/en/model_doc/swin.mdx
@@ -0,0 +1,66 @@
+
+
+# Swin Transformer
+
+## Overview
+
+The Swin Transformer was proposed in [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030)
+by Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo.
+
+The abstract from the paper is the following:
+
+*This paper presents a new vision Transformer, called Swin Transformer, that capably serves as a general-purpose backbone
+for computer vision. Challenges in adapting Transformer from language to vision arise from differences between the two domains,
+such as large variations in the scale of visual entities and the high resolution of pixels in images compared to words in text.
+To address these differences, we propose a hierarchical Transformer whose representation is computed with \bold{S}hifted
+\bold{win}dows. The shifted windowing scheme brings greater efficiency by limiting self-attention computation to non-overlapping
+local windows while also allowing for cross-window connection. This hierarchical architecture has the flexibility to model at
+various scales and has linear computational complexity with respect to image size. These qualities of Swin Transformer make it
+compatible with a broad range of vision tasks, including image classification (87.3 top-1 accuracy on ImageNet-1K) and dense
+prediction tasks such as object detection (58.7 box AP and 51.1 mask AP on COCO test-dev) and semantic segmentation
+(53.5 mIoU on ADE20K val). Its performance surpasses the previous state-of-the-art by a large margin of +2.7 box AP and
++2.6 mask AP on COCO, and +3.2 mIoU on ADE20K, demonstrating the potential of Transformer-based models as vision backbones.
+The hierarchical design and the shifted window approach also prove beneficial for all-MLP architectures.*
+
+Tips:
+- One can use the [`AutoFeatureExtractor`] API to prepare images for the model.
+- Swin pads the inputs supporting any input height and width (if divisible by `32`).
+- Swin can be used as a *backbone*. When `output_hidden_states = True`, it will output both `hidden_states` and `reshaped_hidden_states`. The `reshaped_hidden_states` have a shape of `(batch, num_channels, height, width)` rather than `(batch_size, sequence_length, num_channels)`.
+
+
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/NVlabs/SegFormer).
+
+Tips:
+
+- SegFormer consists of a hierarchical Transformer encoder, and a lightweight all-MLP decode head.
+ [`SegformerModel`] is the hierarchical Transformer encoder (which in the paper is also referred to
+ as Mix Transformer or MiT). [`SegformerForSemanticSegmentation`] adds the all-MLP decode head on
+ top to perform semantic segmentation of images. In addition, there's
+ [`SegformerForImageClassification`] which can be used to - you guessed it - classify images. The
+ authors of SegFormer first pre-trained the Transformer encoder on ImageNet-1k to classify images. Next, they throw
+ away the classification head, and replace it by the all-MLP decode head. Next, they fine-tune the model altogether on
+ ADE20K, Cityscapes and COCO-stuff, which are important benchmarks for semantic segmentation. All checkpoints can be
+ found on the [hub](https://huggingface.co/models?other=segformer).
+- The quickest way to get started with SegFormer is by checking the [example notebooks](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/SegFormer) (which showcase both inference and
+ fine-tuning on custom data). One can also check out the [blog post](https://huggingface.co/blog/fine-tune-segformer) introducing SegFormer and illustrating how it can be fine-tuned on custom data.
+- SegFormer works on any input size, as it pads the input to be divisible by `config.patch_sizes`.
+- One can use [`SegformerFeatureExtractor`] to prepare images and corresponding segmentation maps
+ for the model. Note that this feature extractor is fairly basic and does not include all data augmentations used in
+ the original paper. The original preprocessing pipelines (for the ADE20k dataset for instance) can be found [here](https://github.com/NVlabs/SegFormer/blob/master/local_configs/_base_/datasets/ade20k_repeat.py). The most
+ important preprocessing step is that images and segmentation maps are randomly cropped and padded to the same size,
+ such as 512x512 or 640x640, after which they are normalized.
+- One additional thing to keep in mind is that one can initialize [`SegformerFeatureExtractor`] with
+ `reduce_labels` set to `True` or `False`. In some datasets (like ADE20k), the 0 index is used in the annotated
+ segmentation maps for background. However, ADE20k doesn't include the "background" class in its 150 labels.
+ Therefore, `reduce_labels` is used to reduce all labels by 1, and to make sure no loss is computed for the
+ background class (i.e. it replaces 0 in the annotated maps by 255, which is the *ignore_index* of the loss function
+ used by [`SegformerForSemanticSegmentation`]). However, other datasets use the 0 index as
+ background class and include this class as part of all labels. In that case, `reduce_labels` should be set to
+ `False`, as loss should also be computed for the background class.
+- As most models, SegFormer comes in different sizes, the details of which can be found in the table below.
+
+| **Model variant** | **Depths** | **Hidden sizes** | **Decoder hidden size** | **Params (M)** | **ImageNet-1k Top 1** |
+| :---------------: | ------------- | ------------------- | :---------------------: | :------------: | :-------------------: |
+| MiT-b0 | [2, 2, 2, 2] | [32, 64, 160, 256] | 256 | 3.7 | 70.5 |
+| MiT-b1 | [2, 2, 2, 2] | [64, 128, 320, 512] | 256 | 14.0 | 78.7 |
+| MiT-b2 | [3, 4, 6, 3] | [64, 128, 320, 512] | 768 | 25.4 | 81.6 |
+| MiT-b3 | [3, 4, 18, 3] | [64, 128, 320, 512] | 768 | 45.2 | 83.1 |
+| MiT-b4 | [3, 8, 27, 3] | [64, 128, 320, 512] | 768 | 62.6 | 83.6 |
+| MiT-b5 | [3, 6, 40, 3] | [64, 128, 320, 512] | 768 | 82.0 | 83.8 |
+
+## SegformerConfig
+
+[[autodoc]] SegformerConfig
+
+## SegformerFeatureExtractor
+
+[[autodoc]] SegformerFeatureExtractor
+ - __call__
+
+## SegformerModel
+
+[[autodoc]] SegformerModel
+ - forward
+
+## SegformerDecodeHead
+
+[[autodoc]] SegformerDecodeHead
+ - forward
+
+## SegformerForImageClassification
+
+[[autodoc]] SegformerForImageClassification
+ - forward
+
+## SegformerForSemanticSegmentation
+
+[[autodoc]] SegformerForSemanticSegmentation
+ - forward
diff --git a/docs/source/en/model_doc/sew-d.mdx b/docs/source/en/model_doc/sew-d.mdx
new file mode 100644
index 00000000000000..ceeb4f1ec35fcc
--- /dev/null
+++ b/docs/source/en/model_doc/sew-d.mdx
@@ -0,0 +1,57 @@
+
+
+# SEW-D
+
+## Overview
+
+SEW-D (Squeezed and Efficient Wav2Vec with Disentangled attention) was proposed in [Performance-Efficiency Trade-offs
+in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim,
+Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
+
+The abstract from the paper is the following:
+
+*This paper is a study of performance-efficiency trade-offs in pre-trained models for automatic speech recognition
+(ASR). We focus on wav2vec 2.0, and formalize several architecture designs that influence both the model performance
+and its efficiency. Putting together all our observations, we introduce SEW (Squeezed and Efficient Wav2vec), a
+pre-trained model architecture with significant improvements along both performance and efficiency dimensions across a
+variety of training setups. For example, under the 100h-960h semi-supervised setup on LibriSpeech, SEW achieves a 1.9x
+inference speedup compared to wav2vec 2.0, with a 13.5% relative reduction in word error rate. With a similar inference
+time, SEW reduces word error rate by 25-50% across different model sizes.*
+
+Tips:
+
+- SEW-D is a speech model that accepts a float array corresponding to the raw waveform of the speech signal.
+- SEWDForCTC is fine-tuned using connectionist temporal classification (CTC) so the model output has to be decoded
+ using [`Wav2Vec2CTCTokenizer`].
+
+This model was contributed by [anton-l](https://huggingface.co/anton-l).
+
+
+## SEWDConfig
+
+[[autodoc]] SEWDConfig
+
+## SEWDModel
+
+[[autodoc]] SEWDModel
+ - forward
+
+## SEWDForCTC
+
+[[autodoc]] SEWDForCTC
+ - forward
+
+## SEWDForSequenceClassification
+
+[[autodoc]] SEWDForSequenceClassification
+ - forward
diff --git a/docs/source/en/model_doc/sew.mdx b/docs/source/en/model_doc/sew.mdx
new file mode 100644
index 00000000000000..dce949a856b345
--- /dev/null
+++ b/docs/source/en/model_doc/sew.mdx
@@ -0,0 +1,57 @@
+
+
+# SEW
+
+## Overview
+
+SEW (Squeezed and Efficient Wav2Vec) was proposed in [Performance-Efficiency Trade-offs in Unsupervised Pre-training
+for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q.
+Weinberger, Yoav Artzi.
+
+The abstract from the paper is the following:
+
+*This paper is a study of performance-efficiency trade-offs in pre-trained models for automatic speech recognition
+(ASR). We focus on wav2vec 2.0, and formalize several architecture designs that influence both the model performance
+and its efficiency. Putting together all our observations, we introduce SEW (Squeezed and Efficient Wav2vec), a
+pre-trained model architecture with significant improvements along both performance and efficiency dimensions across a
+variety of training setups. For example, under the 100h-960h semi-supervised setup on LibriSpeech, SEW achieves a 1.9x
+inference speedup compared to wav2vec 2.0, with a 13.5% relative reduction in word error rate. With a similar inference
+time, SEW reduces word error rate by 25-50% across different model sizes.*
+
+Tips:
+
+- SEW is a speech model that accepts a float array corresponding to the raw waveform of the speech signal.
+- SEWForCTC is fine-tuned using connectionist temporal classification (CTC) so the model output has to be decoded using
+ [`Wav2Vec2CTCTokenizer`].
+
+This model was contributed by [anton-l](https://huggingface.co/anton-l).
+
+
+## SEWConfig
+
+[[autodoc]] SEWConfig
+
+## SEWModel
+
+[[autodoc]] SEWModel
+ - forward
+
+## SEWForCTC
+
+[[autodoc]] SEWForCTC
+ - forward
+
+## SEWForSequenceClassification
+
+[[autodoc]] SEWForSequenceClassification
+ - forward
diff --git a/docs/source/en/model_doc/speech-encoder-decoder.mdx b/docs/source/en/model_doc/speech-encoder-decoder.mdx
new file mode 100644
index 00000000000000..a0dd20bb4dee31
--- /dev/null
+++ b/docs/source/en/model_doc/speech-encoder-decoder.mdx
@@ -0,0 +1,41 @@
+
+
+# Speech Encoder Decoder Models
+
+The [`SpeechEncoderDecoderModel`] can be used to initialize a speech-sequence-to-text-sequence model
+with any pretrained speech autoencoding model as the encoder (*e.g.* [Wav2Vec2](wav2vec2), [Hubert](hubert)) and any pretrained autoregressive model as the decoder.
+
+The effectiveness of initializing speech-sequence-to-text-sequence models with pretrained checkpoints for speech
+recognition and speech translation has *e.g.* been shown in [Large-Scale Self- and Semi-Supervised Learning for Speech
+Translation](https://arxiv.org/abs/2104.06678) by Changhan Wang, Anne Wu, Juan Pino, Alexei Baevski, Michael Auli,
+Alexis Conneau.
+
+An example of how to use a [`SpeechEncoderDecoderModel`] for inference can be seen in
+[Speech2Text2](speech_to_text_2).
+
+
+## SpeechEncoderDecoderConfig
+
+[[autodoc]] SpeechEncoderDecoderConfig
+
+## SpeechEncoderDecoderModel
+
+[[autodoc]] SpeechEncoderDecoderModel
+ - forward
+ - from_encoder_decoder_pretrained
+
+## FlaxSpeechEncoderDecoderModel
+
+[[autodoc]] FlaxSpeechEncoderDecoderModel
+ - __call__
+ - from_encoder_decoder_pretrained
\ No newline at end of file
diff --git a/docs/source/en/model_doc/speech_to_text.mdx b/docs/source/en/model_doc/speech_to_text.mdx
new file mode 100644
index 00000000000000..0a3b00b1d5dd30
--- /dev/null
+++ b/docs/source/en/model_doc/speech_to_text.mdx
@@ -0,0 +1,143 @@
+
+
+# Speech2Text
+
+## Overview
+
+The Speech2Text model was proposed in [fairseq S2T: Fast Speech-to-Text Modeling with fairseq](https://arxiv.org/abs/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Dmytro Okhonko, Juan Pino. It's a
+transformer-based seq2seq (encoder-decoder) model designed for end-to-end Automatic Speech Recognition (ASR) and Speech
+Translation (ST). It uses a convolutional downsampler to reduce the length of speech inputs by 3/4th before they are
+fed into the encoder. The model is trained with standard autoregressive cross-entropy loss and generates the
+transcripts/translations autoregressively. Speech2Text has been fine-tuned on several datasets for ASR and ST:
+[LibriSpeech](http://www.openslr.org/12), [CoVoST 2](https://github.com/facebookresearch/covost), [MuST-C](https://ict.fbk.eu/must-c/).
+
+This model was contributed by [valhalla](https://huggingface.co/valhalla). The original code can be found [here](https://github.com/pytorch/fairseq/tree/master/examples/speech_to_text).
+
+
+## Inference
+
+Speech2Text is a speech model that accepts a float tensor of log-mel filter-bank features extracted from the speech
+signal. It's a transformer-based seq2seq model, so the transcripts/translations are generated autoregressively. The
+`generate()` method can be used for inference.
+
+The [`Speech2TextFeatureExtractor`] class is responsible for extracting the log-mel filter-bank
+features. The [`Speech2TextProcessor`] wraps [`Speech2TextFeatureExtractor`] and
+[`Speech2TextTokenizer`] into a single instance to both extract the input features and decode the
+predicted token ids.
+
+The feature extractor depends on `torchaudio` and the tokenizer depends on `sentencepiece` so be sure to
+install those packages before running the examples. You could either install those as extra speech dependencies with
+`pip install transformers"[speech, sentencepiece]"` or install the packages seperately with `pip install torchaudio sentencepiece`. Also `torchaudio` requires the development version of the [libsndfile](http://www.mega-nerd.com/libsndfile/) package which can be installed via a system package manager. On Ubuntu it can
+be installed as follows: `apt install libsndfile1-dev`
+
+
+- ASR and Speech Translation
+
+```python
+>>> import torch
+>>> from transformers import Speech2TextProcessor, Speech2TextForConditionalGeneration
+>>> from datasets import load_dataset
+
+>>> model = Speech2TextForConditionalGeneration.from_pretrained("facebook/s2t-small-librispeech-asr")
+>>> processor = Speech2TextProcessor.from_pretrained("facebook/s2t-small-librispeech-asr")
+
+
+>>> ds = load_dataset("hf-internal-testing/librispeech_asr_demo", "clean", split="validation")
+
+>>> inputs = processor(ds[0]["audio"]["array"], sampling_rate=ds[0]["audio"]["sampling_rate"], return_tensors="pt")
+>>> generated_ids = model.generate(inputs["input_features"], attention_mask=inputs["attention_mask"])
+
+>>> transcription = processor.batch_decode(generated_ids)
+>>> transcription
+['mister quilter is the apostle of the middle classes and we are glad to welcome his gospel']
+```
+
+- Multilingual speech translation
+
+ For multilingual speech translation models, `eos_token_id` is used as the `decoder_start_token_id` and
+ the target language id is forced as the first generated token. To force the target language id as the first
+ generated token, pass the `forced_bos_token_id` parameter to the `generate()` method. The following
+ example shows how to transate English speech to French text using the *facebook/s2t-medium-mustc-multilingual-st*
+ checkpoint.
+
+```python
+>>> import torch
+>>> from transformers import Speech2TextProcessor, Speech2TextForConditionalGeneration
+>>> from datasets import load_dataset
+
+>>> model = Speech2TextForConditionalGeneration.from_pretrained("facebook/s2t-medium-mustc-multilingual-st")
+>>> processor = Speech2TextProcessor.from_pretrained("facebook/s2t-medium-mustc-multilingual-st")
+
+>>> ds = load_dataset("hf-internal-testing/librispeech_asr_demo", "clean", split="validation")
+
+>>> inputs = processor(ds[0]["audio"]["array"], sampling_rate=ds[0]["audio"]["sampling_rate"], return_tensors="pt")
+>>> generated_ids = model.generate(
+... inputs["input_features"],
+... attention_mask=inputs["attention_mask"],
+... forced_bos_token_id=processor.tokenizer.lang_code_to_id["fr"],
+... )
+
+>>> translation = processor.batch_decode(generated_ids)
+>>> translation
+[" (Vidéo) Si M. Kilder est l'apossible des classes moyennes, et nous sommes heureux d'être accueillis dans son évangile."]
+```
+
+See the [model hub](https://huggingface.co/models?filter=speech_to_text) to look for Speech2Text checkpoints.
+
+
+## Speech2TextConfig
+
+[[autodoc]] Speech2TextConfig
+
+## Speech2TextTokenizer
+
+[[autodoc]] Speech2TextTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## Speech2TextFeatureExtractor
+
+[[autodoc]] Speech2TextFeatureExtractor
+ - __call__
+
+## Speech2TextProcessor
+
+[[autodoc]] Speech2TextProcessor
+ - __call__
+ - from_pretrained
+ - save_pretrained
+ - batch_decode
+ - decode
+ - as_target_processor
+
+## Speech2TextModel
+
+[[autodoc]] Speech2TextModel
+ - forward
+
+## Speech2TextForConditionalGeneration
+
+[[autodoc]] Speech2TextForConditionalGeneration
+ - forward
+
+## TFSpeech2TextModel
+
+[[autodoc]] TFSpeech2TextModel
+ - call
+
+## TFSpeech2TextForConditionalGeneration
+
+[[autodoc]] TFSpeech2TextForConditionalGeneration
+ - call
diff --git a/docs/source/en/model_doc/speech_to_text_2.mdx b/docs/source/en/model_doc/speech_to_text_2.mdx
new file mode 100644
index 00000000000000..72754b67aab9a2
--- /dev/null
+++ b/docs/source/en/model_doc/speech_to_text_2.mdx
@@ -0,0 +1,122 @@
+
+
+# Speech2Text2
+
+## Overview
+
+The Speech2Text2 model is used together with [Wav2Vec2](wav2vec2) for Speech Translation models proposed in
+[Large-Scale Self- and Semi-Supervised Learning for Speech Translation](https://arxiv.org/abs/2104.06678) by
+Changhan Wang, Anne Wu, Juan Pino, Alexei Baevski, Michael Auli, Alexis Conneau.
+
+Speech2Text2 is a *decoder-only* transformer model that can be used with any speech *encoder-only*, such as
+[Wav2Vec2](wav2vec2) or [HuBERT](hubert) for Speech-to-Text tasks. Please refer to the
+[SpeechEncoderDecoder](speech-encoder-decoder) class on how to combine Speech2Text2 with any speech *encoder-only*
+model.
+
+This model was contributed by [Patrick von Platen](https://huggingface.co/patrickvonplaten).
+
+The original code can be found [here](https://github.com/pytorch/fairseq/blob/1f7ef9ed1e1061f8c7f88f8b94c7186834398690/fairseq/models/wav2vec/wav2vec2_asr.py#L266).
+
+
+Tips:
+
+- Speech2Text2 achieves state-of-the-art results on the CoVoST Speech Translation dataset. For more information, see
+ the [official models](https://huggingface.co/models?other=speech2text2) .
+- Speech2Text2 is always used within the [SpeechEncoderDecoder](speech-encoder-decoder) framework.
+- Speech2Text2's tokenizer is based on [fastBPE](https://github.com/glample/fastBPE).
+
+## Inference
+
+Speech2Text2's [`SpeechEncoderDecoderModel`] model accepts raw waveform input values from speech and
+makes use of [`~generation_utils.GenerationMixin.generate`] to translate the input speech
+autoregressively to the target language.
+
+The [`Wav2Vec2FeatureExtractor`] class is responsible for preprocessing the input speech and
+[`Speech2Text2Tokenizer`] decodes the generated target tokens to the target string. The
+[`Speech2Text2Processor`] wraps [`Wav2Vec2FeatureExtractor`] and
+[`Speech2Text2Tokenizer`] into a single instance to both extract the input features and decode the
+predicted token ids.
+
+- Step-by-step Speech Translation
+
+```python
+>>> import torch
+>>> from transformers import Speech2Text2Processor, SpeechEncoderDecoderModel
+>>> from datasets import load_dataset
+>>> import soundfile as sf
+
+>>> model = SpeechEncoderDecoderModel.from_pretrained("facebook/s2t-wav2vec2-large-en-de")
+>>> processor = Speech2Text2Processor.from_pretrained("facebook/s2t-wav2vec2-large-en-de")
+
+
+>>> def map_to_array(batch):
+... speech, _ = sf.read(batch["file"])
+... batch["speech"] = speech
+... return batch
+
+
+>>> ds = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
+>>> ds = ds.map(map_to_array)
+
+>>> inputs = processor(ds["speech"][0], sampling_rate=16_000, return_tensors="pt")
+>>> generated_ids = model.generate(inputs=inputs["input_values"], attention_mask=inputs["attention_mask"])
+
+>>> transcription = processor.batch_decode(generated_ids)
+```
+
+- Speech Translation via Pipelines
+
+ The automatic speech recognition pipeline can also be used to translate speech in just a couple lines of code
+
+```python
+>>> from datasets import load_dataset
+>>> from transformers import pipeline
+
+>>> librispeech_en = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
+>>> asr = pipeline(
+... "automatic-speech-recognition",
+... model="facebook/s2t-wav2vec2-large-en-de",
+... feature_extractor="facebook/s2t-wav2vec2-large-en-de",
+... )
+
+>>> translation_de = asr(librispeech_en[0]["file"])
+```
+
+See [model hub](https://huggingface.co/models?filter=speech2text2) to look for Speech2Text2 checkpoints.
+
+
+## Speech2Text2Config
+
+[[autodoc]] Speech2Text2Config
+
+## Speech2TextTokenizer
+
+[[autodoc]] Speech2Text2Tokenizer
+ - batch_decode
+ - decode
+ - save_vocabulary
+
+## Speech2Text2Processor
+
+[[autodoc]] Speech2Text2Processor
+ - __call__
+ - from_pretrained
+ - save_pretrained
+ - batch_decode
+ - decode
+ - as_target_processor
+
+## Speech2Text2ForCausalLM
+
+[[autodoc]] Speech2Text2ForCausalLM
+ - forward
diff --git a/docs/source/en/model_doc/splinter.mdx b/docs/source/en/model_doc/splinter.mdx
new file mode 100644
index 00000000000000..50d4e8db74816d
--- /dev/null
+++ b/docs/source/en/model_doc/splinter.mdx
@@ -0,0 +1,74 @@
+
+
+# Splinter
+
+## Overview
+
+The Splinter model was proposed in [Few-Shot Question Answering by Pretraining Span Selection](https://arxiv.org/abs/2101.00438) by Ori Ram, Yuval Kirstain, Jonathan Berant, Amir Globerson, Omer Levy. Splinter
+is an encoder-only transformer (similar to BERT) pretrained using the recurring span selection task on a large corpus
+comprising Wikipedia and the Toronto Book Corpus.
+
+The abstract from the paper is the following:
+
+In several question answering benchmarks, pretrained models have reached human parity through fine-tuning on an order
+of 100,000 annotated questions and answers. We explore the more realistic few-shot setting, where only a few hundred
+training examples are available, and observe that standard models perform poorly, highlighting the discrepancy between
+current pretraining objectives and question answering. We propose a new pretraining scheme tailored for question
+answering: recurring span selection. Given a passage with multiple sets of recurring spans, we mask in each set all
+recurring spans but one, and ask the model to select the correct span in the passage for each masked span. Masked spans
+are replaced with a special token, viewed as a question representation, that is later used during fine-tuning to select
+the answer span. The resulting model obtains surprisingly good results on multiple benchmarks (e.g., 72.7 F1 on SQuAD
+with only 128 training examples), while maintaining competitive performance in the high-resource setting.
+
+Tips:
+
+- Splinter was trained to predict answers spans conditioned on a special [QUESTION] token. These tokens contextualize
+ to question representations which are used to predict the answers. This layer is called QASS, and is the default
+ behaviour in the [`SplinterForQuestionAnswering`] class. Therefore:
+- Use [`SplinterTokenizer`] (rather than [`BertTokenizer`]), as it already
+ contains this special token. Also, its default behavior is to use this token when two sequences are given (for
+ example, in the *run_qa.py* script).
+- If you plan on using Splinter outside *run_qa.py*, please keep in mind the question token - it might be important for
+ the success of your model, especially in a few-shot setting.
+- Please note there are two different checkpoints for each size of Splinter. Both are basically the same, except that
+ one also has the pretrained wights of the QASS layer (*tau/splinter-base-qass* and *tau/splinter-large-qass*) and one
+ doesn't (*tau/splinter-base* and *tau/splinter-large*). This is done to support randomly initializing this layer at
+ fine-tuning, as it is shown to yield better results for some cases in the paper.
+
+This model was contributed by [yuvalkirstain](https://huggingface.co/yuvalkirstain) and [oriram](https://huggingface.co/oriram). The original code can be found [here](https://github.com/oriram/splinter).
+
+## SplinterConfig
+
+[[autodoc]] SplinterConfig
+
+## SplinterTokenizer
+
+[[autodoc]] SplinterTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## SplinterTokenizerFast
+
+[[autodoc]] SplinterTokenizerFast
+
+## SplinterModel
+
+[[autodoc]] SplinterModel
+ - forward
+
+## SplinterForQuestionAnswering
+
+[[autodoc]] SplinterForQuestionAnswering
+ - forward
diff --git a/docs/source/en/model_doc/squeezebert.mdx b/docs/source/en/model_doc/squeezebert.mdx
new file mode 100644
index 00000000000000..c6219582c838e3
--- /dev/null
+++ b/docs/source/en/model_doc/squeezebert.mdx
@@ -0,0 +1,88 @@
+
+
+# SqueezeBERT
+
+## Overview
+
+The SqueezeBERT model was proposed in [SqueezeBERT: What can computer vision teach NLP about efficient neural networks?](https://arxiv.org/abs/2006.11316) by Forrest N. Iandola, Albert E. Shaw, Ravi Krishna, Kurt W. Keutzer. It's a
+bidirectional transformer similar to the BERT model. The key difference between the BERT architecture and the
+SqueezeBERT architecture is that SqueezeBERT uses [grouped convolutions](https://blog.yani.io/filter-group-tutorial)
+instead of fully-connected layers for the Q, K, V and FFN layers.
+
+The abstract from the paper is the following:
+
+*Humans read and write hundreds of billions of messages every day. Further, due to the availability of large datasets,
+large computing systems, and better neural network models, natural language processing (NLP) technology has made
+significant strides in understanding, proofreading, and organizing these messages. Thus, there is a significant
+opportunity to deploy NLP in myriad applications to help web users, social networks, and businesses. In particular, we
+consider smartphones and other mobile devices as crucial platforms for deploying NLP models at scale. However, today's
+highly-accurate NLP neural network models such as BERT and RoBERTa are extremely computationally expensive, with
+BERT-base taking 1.7 seconds to classify a text snippet on a Pixel 3 smartphone. In this work, we observe that methods
+such as grouped convolutions have yielded significant speedups for computer vision networks, but many of these
+techniques have not been adopted by NLP neural network designers. We demonstrate how to replace several operations in
+self-attention layers with grouped convolutions, and we use this technique in a novel network architecture called
+SqueezeBERT, which runs 4.3x faster than BERT-base on the Pixel 3 while achieving competitive accuracy on the GLUE test
+set. The SqueezeBERT code will be released.*
+
+Tips:
+
+- SqueezeBERT is a model with absolute position embeddings so it's usually advised to pad the inputs on the right
+ rather than the left.
+- SqueezeBERT is similar to BERT and therefore relies on the masked language modeling (MLM) objective. It is therefore
+ efficient at predicting masked tokens and at NLU in general, but is not optimal for text generation. Models trained
+ with a causal language modeling (CLM) objective are better in that regard.
+- For best results when finetuning on sequence classification tasks, it is recommended to start with the
+ *squeezebert/squeezebert-mnli-headless* checkpoint.
+
+This model was contributed by [forresti](https://huggingface.co/forresti).
+
+
+## SqueezeBertConfig
+
+[[autodoc]] SqueezeBertConfig
+
+## SqueezeBertTokenizer
+
+[[autodoc]] SqueezeBertTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## SqueezeBertTokenizerFast
+
+[[autodoc]] SqueezeBertTokenizerFast
+
+## SqueezeBertModel
+
+[[autodoc]] SqueezeBertModel
+
+## SqueezeBertForMaskedLM
+
+[[autodoc]] SqueezeBertForMaskedLM
+
+## SqueezeBertForSequenceClassification
+
+[[autodoc]] SqueezeBertForSequenceClassification
+
+## SqueezeBertForMultipleChoice
+
+[[autodoc]] SqueezeBertForMultipleChoice
+
+## SqueezeBertForTokenClassification
+
+[[autodoc]] SqueezeBertForTokenClassification
+
+## SqueezeBertForQuestionAnswering
+
+[[autodoc]] SqueezeBertForQuestionAnswering
diff --git a/docs/source/en/model_doc/swin.mdx b/docs/source/en/model_doc/swin.mdx
new file mode 100644
index 00000000000000..1f247284afbc39
--- /dev/null
+++ b/docs/source/en/model_doc/swin.mdx
@@ -0,0 +1,66 @@
+
+
+# Swin Transformer
+
+## Overview
+
+The Swin Transformer was proposed in [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030)
+by Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo.
+
+The abstract from the paper is the following:
+
+*This paper presents a new vision Transformer, called Swin Transformer, that capably serves as a general-purpose backbone
+for computer vision. Challenges in adapting Transformer from language to vision arise from differences between the two domains,
+such as large variations in the scale of visual entities and the high resolution of pixels in images compared to words in text.
+To address these differences, we propose a hierarchical Transformer whose representation is computed with \bold{S}hifted
+\bold{win}dows. The shifted windowing scheme brings greater efficiency by limiting self-attention computation to non-overlapping
+local windows while also allowing for cross-window connection. This hierarchical architecture has the flexibility to model at
+various scales and has linear computational complexity with respect to image size. These qualities of Swin Transformer make it
+compatible with a broad range of vision tasks, including image classification (87.3 top-1 accuracy on ImageNet-1K) and dense
+prediction tasks such as object detection (58.7 box AP and 51.1 mask AP on COCO test-dev) and semantic segmentation
+(53.5 mIoU on ADE20K val). Its performance surpasses the previous state-of-the-art by a large margin of +2.7 box AP and
++2.6 mask AP on COCO, and +3.2 mIoU on ADE20K, demonstrating the potential of Transformer-based models as vision backbones.
+The hierarchical design and the shifted window approach also prove beneficial for all-MLP architectures.*
+
+Tips:
+- One can use the [`AutoFeatureExtractor`] API to prepare images for the model.
+- Swin pads the inputs supporting any input height and width (if divisible by `32`).
+- Swin can be used as a *backbone*. When `output_hidden_states = True`, it will output both `hidden_states` and `reshaped_hidden_states`. The `reshaped_hidden_states` have a shape of `(batch, num_channels, height, width)` rather than `(batch_size, sequence_length, num_channels)`.
+
+ +
+ Swin Transformer architecture. Taken from the original paper.
+
+This model was contributed by [novice03](https://huggingface.co/novice03>). The original code can be found [here](https://github.com/microsoft/Swin-Transformer).
+
+
+## SwinConfig
+
+[[autodoc]] SwinConfig
+
+
+## SwinModel
+
+[[autodoc]] SwinModel
+ - forward
+
+## SwinForMaskedImageModeling
+
+[[autodoc]] SwinForMaskedImageModeling
+ - forward
+
+## SwinForImageClassification
+
+[[autodoc]] transformers.SwinForImageClassification
+ - forward
\ No newline at end of file
diff --git a/docs/source/en/model_doc/t5.mdx b/docs/source/en/model_doc/t5.mdx
new file mode 100644
index 00000000000000..8034fc010a1cc1
--- /dev/null
+++ b/docs/source/en/model_doc/t5.mdx
@@ -0,0 +1,373 @@
+
+
+# T5
+
+## Overview
+
+The T5 model was presented in [Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer](https://arxiv.org/pdf/1910.10683.pdf) by Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang,
+Michael Matena, Yanqi Zhou, Wei Li, Peter J. Liu.
+
+The abstract from the paper is the following:
+
+*Transfer learning, where a model is first pre-trained on a data-rich task before being fine-tuned on a downstream
+task, has emerged as a powerful technique in natural language processing (NLP). The effectiveness of transfer learning
+has given rise to a diversity of approaches, methodology, and practice. In this paper, we explore the landscape of
+transfer learning techniques for NLP by introducing a unified framework that converts every language problem into a
+text-to-text format. Our systematic study compares pretraining objectives, architectures, unlabeled datasets, transfer
+approaches, and other factors on dozens of language understanding tasks. By combining the insights from our exploration
+with scale and our new "Colossal Clean Crawled Corpus", we achieve state-of-the-art results on many benchmarks covering
+summarization, question answering, text classification, and more. To facilitate future work on transfer learning for
+NLP, we release our dataset, pre-trained models, and code.*
+
+Tips:
+
+- T5 is an encoder-decoder model pre-trained on a multi-task mixture of unsupervised and supervised tasks and for which
+each task is converted into a text-to-text format. T5 works well on a variety of tasks out-of-the-box by prepending a
+different prefix to the input corresponding to each task, e.g., for translation: *translate English to German: ...*,
+for summarization: *summarize: ...*.
+
+- T5 uses relative scalar embeddings. Encoder input padding can be done on the left and on the right.
+
+- See the [training](#training), [inference](#inference) and [scripts](#scripts) sections below for all details regarding usage.
+
+T5 comes in different sizes:
+
+- [t5-small](https://huggingface.co/t5-small)
+
+- [t5-base](https://huggingface.co/t5-base)
+
+- [t5-large](https://huggingface.co/t5-large)
+
+- [t5-3b](https://huggingface.co/t5-3b)
+
+- [t5-11b](https://huggingface.co/t5-11b).
+
+Based on the original T5 model, Google has released some follow-up works:
+
+- **T5v1.1**: T5v1.1 is an improved version of T5 with some architectural tweaks, and is pre-trained on C4 only without
+ mixing in the supervised tasks. Refer to the documentation of T5v1.1 which can be found [here](t5v1.1).
+
+- **mT5**: mT5 is a multilingual T5 model. It is pre-trained on the mC4 corpus, which includes 101 languages. Refer to
+ the documentation of mT5 which can be found [here](mt5).
+
+- **byT5**: byT5 is a T5 model pre-trained on byte sequences rather than SentencePiece subword token sequences. Refer
+ to the documentation of byT5 which can be found [here](byt5).
+
+All checkpoints can be found on the [hub](https://huggingface.co/models?search=t5).
+
+This model was contributed by [thomwolf](https://huggingface.co/thomwolf). The original code can be found [here](https://github.com/google-research/text-to-text-transfer-transformer).
+
+
+
+## Training
+
+T5 is an encoder-decoder model and converts all NLP problems into a text-to-text format. It is trained using teacher
+forcing. This means that for training, we always need an input sequence and a corresponding target sequence. The input
+sequence is fed to the model using `input_ids`. The target sequence is shifted to the right, i.e., prepended by a
+start-sequence token and fed to the decoder using the `decoder_input_ids`. In teacher-forcing style, the target
+sequence is then appended by the EOS token and corresponds to the `labels`. The PAD token is hereby used as the
+start-sequence token. T5 can be trained / fine-tuned both in a supervised and unsupervised fashion.
+
+One can use [`T5ForConditionalGeneration`] (or the Tensorflow/Flax variant), which includes the
+language modeling head on top of the decoder.
+
+- Unsupervised denoising training
+
+In this setup, spans of the input sequence are masked by so-called sentinel tokens (*a.k.a* unique mask tokens) and
+the output sequence is formed as a concatenation of the same sentinel tokens and the *real* masked tokens. Each
+sentinel token represents a unique mask token for this sentence and should start with ``,
+``, ... up to ``. As a default, 100 sentinel tokens are available in
+[`T5Tokenizer`].
+
+For instance, the sentence "The cute dog walks in the park" with the masks put on "cute dog" and "the" should be
+processed as follows:
+
+```python
+>>> from transformers import T5Tokenizer, T5ForConditionalGeneration
+
+>>> tokenizer = T5Tokenizer.from_pretrained("t5-small")
+>>> model = T5ForConditionalGeneration.from_pretrained("t5-small")
+
+>>> input_ids = tokenizer("The walks in park", return_tensors="pt").input_ids
+>>> labels = tokenizer(" cute dog the ", return_tensors="pt").input_ids
+
+>>> # the forward function automatically creates the correct decoder_input_ids
+>>> loss = model(input_ids=input_ids, labels=labels).loss
+>>> loss.item()
+3.7837
+```
+
+If you're interested in pre-training T5 on a new corpus, check out the [run_t5_mlm_flax.py](https://github.com/huggingface/transformers/tree/main/examples/flax/language-modeling) script in the Examples
+directory.
+
+- Supervised training
+
+In this setup, the input sequence and output sequence are a standard sequence-to-sequence input-output mapping.
+Suppose that we want to fine-tune the model for translation for example, and we have a training example: the input
+sequence "The house is wonderful." and output sequence "Das Haus ist wunderbar.", then they should be prepared for
+the model as follows:
+
+```python
+>>> from transformers import T5Tokenizer, T5ForConditionalGeneration
+
+>>> tokenizer = T5Tokenizer.from_pretrained("t5-small")
+>>> model = T5ForConditionalGeneration.from_pretrained("t5-small")
+
+>>> input_ids = tokenizer("translate English to German: The house is wonderful.", return_tensors="pt").input_ids
+>>> labels = tokenizer("Das Haus ist wunderbar.", return_tensors="pt").input_ids
+
+>>> # the forward function automatically creates the correct decoder_input_ids
+>>> loss = model(input_ids=input_ids, labels=labels).loss
+>>> loss.item()
+0.2542
+```
+
+As you can see, only 2 inputs are required for the model in order to compute a loss: `input_ids` (which are the
+`input_ids` of the encoded input sequence) and `labels` (which are the `input_ids` of the encoded
+target sequence). The model will automatically create the `decoder_input_ids` based on the `labels`, by
+shifting them one position to the right and prepending the `config.decoder_start_token_id`, which for T5 is
+equal to 0 (i.e. the id of the pad token). Also note the task prefix: we prepend the input sequence with 'translate
+English to German: ' before encoding it. This will help in improving the performance, as this task prefix was used
+during T5's pre-training.
+
+However, the example above only shows a single training example. In practice, one trains deep learning models in
+batches. This entails that we must pad/truncate examples to the same length. For encoder-decoder models, one
+typically defines a `max_source_length` and `max_target_length`, which determine the maximum length of the
+input and output sequences respectively (otherwise they are truncated). These should be carefully set depending on
+the task.
+
+In addition, we must make sure that padding token id's of the `labels` are not taken into account by the loss
+function. In PyTorch and Tensorflow, this can be done by replacing them with -100, which is the `ignore_index`
+of the `CrossEntropyLoss`. In Flax, one can use the `decoder_attention_mask` to ignore padded tokens from
+the loss (see the [Flax summarization script](https://github.com/huggingface/transformers/tree/main/examples/flax/summarization) for details). We also pass
+`attention_mask` as additional input to the model, which makes sure that padding tokens of the inputs are
+ignored. The code example below illustrates all of this.
+
+```python
+>>> from transformers import T5Tokenizer, T5ForConditionalGeneration
+>>> import torch
+
+>>> tokenizer = T5Tokenizer.from_pretrained("t5-small")
+>>> model = T5ForConditionalGeneration.from_pretrained("t5-small")
+
+>>> # the following 2 hyperparameters are task-specific
+>>> max_source_length = 512
+>>> max_target_length = 128
+
+>>> # Suppose we have the following 2 training examples:
+>>> input_sequence_1 = "Welcome to NYC"
+>>> output_sequence_1 = "Bienvenue à NYC"
+
+>>> input_sequence_2 = "HuggingFace is a company"
+>>> output_sequence_2 = "HuggingFace est une entreprise"
+
+>>> # encode the inputs
+>>> task_prefix = "translate English to French: "
+>>> input_sequences = [input_sequence_1, input_sequence_2]
+
+>>> encoding = tokenizer(
+... [task_prefix + sequence for sequence in input_sequences],
+... padding="longest",
+... max_length=max_source_length,
+... truncation=True,
+... return_tensors="pt",
+... )
+
+>>> input_ids, attention_mask = encoding.input_ids, encoding.attention_mask
+
+>>> # encode the targets
+>>> target_encoding = tokenizer(
+... [output_sequence_1, output_sequence_2], padding="longest", max_length=max_target_length, truncation=True
+... )
+>>> labels = target_encoding.input_ids
+
+>>> # replace padding token id's of the labels by -100 so it's ignored by the loss
+>>> labels = torch.tensor(labels)
+>>> labels[labels == tokenizer.pad_token_id] = -100
+
+>>> # forward pass
+>>> loss = model(input_ids=input_ids, attention_mask=attention_mask, labels=labels).loss
+>>> loss.item()
+0.188
+```
+
+Additional training tips:
+
+- T5 models need a slightly higher learning rate than the default one set in the `Trainer` when using the AdamW
+optimizer. Typically, 1e-4 and 3e-4 work well for most problems (classification, summarization, translation, question
+answering, question generation). Note that T5 was pre-trained using the AdaFactor optimizer.
+
+According to [this forum post](https://discuss.huggingface.co/t/t5-finetuning-tips/684), task prefixes matter when
+(1) doing multi-task training (2) your task is similar or related to one of the supervised tasks used in T5's
+pre-training mixture (see Appendix D of the [paper](https://arxiv.org/pdf/1910.10683.pdf) for the task prefixes
+used).
+
+If training on TPU, it is recommended to pad all examples of the dataset to the same length or make use of
+*pad_to_multiple_of* to have a small number of predefined bucket sizes to fit all examples in. Dynamically padding
+batches to the longest example is not recommended on TPU as it triggers a recompilation for every batch shape that is
+encountered during training thus significantly slowing down the training. only padding up to the longest example in a
+batch) leads to very slow training on TPU.
+
+
+
+## Inference
+
+At inference time, it is recommended to use [`~generation_utils.GenerationMixin.generate`]. This
+method takes care of encoding the input and feeding the encoded hidden states via cross-attention layers to the decoder
+and auto-regressively generates the decoder output. Check out [this blog post](https://huggingface.co/blog/how-to-generate) to know all the details about generating text with Transformers.
+There's also [this blog post](https://huggingface.co/blog/encoder-decoder#encoder-decoder) which explains how
+generation works in general in encoder-decoder models.
+
+```python
+>>> from transformers import T5Tokenizer, T5ForConditionalGeneration
+
+>>> tokenizer = T5Tokenizer.from_pretrained("t5-small")
+>>> model = T5ForConditionalGeneration.from_pretrained("t5-small")
+
+>>> input_ids = tokenizer("translate English to German: The house is wonderful.", return_tensors="pt").input_ids
+>>> outputs = model.generate(input_ids)
+>>> print(tokenizer.decode(outputs[0], skip_special_tokens=True))
+Das Haus ist wunderbar.
+```
+
+Note that T5 uses the `pad_token_id` as the `decoder_start_token_id`, so when doing generation without using
+[`~generation_utils.GenerationMixin.generate`], make sure you start it with the `pad_token_id`.
+
+The example above only shows a single example. You can also do batched inference, like so:
+
+```python
+>>> from transformers import T5Tokenizer, T5ForConditionalGeneration
+
+>>> tokenizer = T5Tokenizer.from_pretrained("t5-small")
+>>> model = T5ForConditionalGeneration.from_pretrained("t5-small")
+
+>>> task_prefix = "translate English to German: "
+>>> # use different length sentences to test batching
+>>> sentences = ["The house is wonderful.", "I like to work in NYC."]
+
+>>> inputs = tokenizer([task_prefix + sentence for sentence in sentences], return_tensors="pt", padding=True)
+
+>>> output_sequences = model.generate(
+... input_ids=inputs["input_ids"],
+... attention_mask=inputs["attention_mask"],
+... do_sample=False, # disable sampling to test if batching affects output
+... )
+
+>>> print(tokenizer.batch_decode(output_sequences, skip_special_tokens=True))
+['Das Haus ist wunderbar.', 'Ich arbeite gerne in NYC.']
+```
+
+Because T5 has been trained with the span-mask denoising objective,
+it can be used to predict the sentinel (masked-out) tokens during inference.
+The predicted tokens will then be placed between the sentinel tokens.
+
+```python
+>>> from transformers import T5Tokenizer, T5ForConditionalGeneration
+
+>>> tokenizer = T5Tokenizer.from_pretrained("t5-small")
+>>> model = T5ForConditionalGeneration.from_pretrained("t5-small")
+
+>>> input_ids = tokenizer("The walks in park", return_tensors="pt").input_ids
+
+>>> sequence_ids = model.generate(input_ids)
+>>> sequences = tokenizer.batch_decode(sequence_ids)
+>>> sequences
+[' park offers the park.']
+```
+
+
+
+
+## Performance
+
+If you'd like a faster training and inference performance, install [apex](https://github.com/NVIDIA/apex#quick-start) and then the model will automatically use `apex.normalization.FusedRMSNorm` instead of `T5LayerNorm`. The former uses an optimized fused kernel which is several times faster than the latter.
+
+
+## Example scripts
+
+T5 is supported by several example scripts, both for pre-training and fine-tuning.
+
+- pre-training: the [run_t5_mlm_flax.py](https://github.com/huggingface/transformers/blob/main/examples/flax/language-modeling/run_t5_mlm_flax.py)
+ script allows you to further pre-train T5 or pre-train T5 from scratch on your own data. The [t5_tokenizer_model.py](https://github.com/huggingface/transformers/blob/main/examples/flax/language-modeling/t5_tokenizer_model.py)
+ script allows you to further train a T5 tokenizer or train a T5 Tokenizer from scratch on your own data. Note that
+ Flax (a neural network library on top of JAX) is particularly useful to train on TPU hardware.
+
+- fine-tuning: T5 is supported by the official summarization scripts ([PyTorch](https://github.com/huggingface/transformers/tree/main/examples/pytorch/summarization), [Tensorflow](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/summarization), and [Flax](https://github.com/huggingface/transformers/tree/main/examples/flax/summarization)) and translation scripts
+ ([PyTorch](https://github.com/huggingface/transformers/tree/main/examples/pytorch/translation) and [Tensorflow](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/translation)). These scripts allow
+ you to easily fine-tune T5 on custom data for summarization/translation.
+
+## T5Config
+
+[[autodoc]] T5Config
+
+## T5Tokenizer
+
+[[autodoc]] T5Tokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## T5TokenizerFast
+
+[[autodoc]] T5TokenizerFast
+
+## T5Model
+
+[[autodoc]] T5Model
+ - forward
+ - parallelize
+ - deparallelize
+
+## T5ForConditionalGeneration
+
+[[autodoc]] T5ForConditionalGeneration
+ - forward
+ - parallelize
+ - deparallelize
+
+## T5EncoderModel
+
+[[autodoc]] T5EncoderModel
+ - forward
+ - parallelize
+ - deparallelize
+
+## TFT5Model
+
+[[autodoc]] TFT5Model
+ - call
+
+## TFT5ForConditionalGeneration
+
+[[autodoc]] TFT5ForConditionalGeneration
+ - call
+
+## TFT5EncoderModel
+
+[[autodoc]] TFT5EncoderModel
+ - call
+
+## FlaxT5Model
+
+[[autodoc]] FlaxT5Model
+ - __call__
+ - encode
+ - decode
+
+## FlaxT5ForConditionalGeneration
+
+[[autodoc]] FlaxT5ForConditionalGeneration
+ - __call__
+ - encode
+ - decode
diff --git a/docs/source/en/model_doc/t5v1.1.mdx b/docs/source/en/model_doc/t5v1.1.mdx
new file mode 100644
index 00000000000000..b15188961d3330
--- /dev/null
+++ b/docs/source/en/model_doc/t5v1.1.mdx
@@ -0,0 +1,61 @@
+
+
+# T5v1.1
+
+## Overview
+
+T5v1.1 was released in the [google-research/text-to-text-transfer-transformer](https://github.com/google-research/text-to-text-transfer-transformer/blob/main/released_checkpoints.md#t511)
+repository by Colin Raffel et al. It's an improved version of the original T5 model.
+
+One can directly plug in the weights of T5v1.1 into a T5 model, like so:
+
+```python
+>>> from transformers import T5ForConditionalGeneration
+
+>>> model = T5ForConditionalGeneration.from_pretrained("google/t5-v1_1-base")
+```
+
+T5 Version 1.1 includes the following improvements compared to the original T5 model:
+
+- GEGLU activation in the feed-forward hidden layer, rather than ReLU. See [this paper](https://arxiv.org/abs/2002.05202).
+
+- Dropout was turned off in pre-training (quality win). Dropout should be re-enabled during fine-tuning.
+
+- Pre-trained on C4 only without mixing in the downstream tasks.
+
+- No parameter sharing between the embedding and classifier layer.
+
+- "xl" and "xxl" replace "3B" and "11B". The model shapes are a bit different - larger `d_model` and smaller
+ `num_heads` and `d_ff`.
+
+Note: T5 Version 1.1 was only pre-trained on [C4](https://huggingface.co/datasets/c4) excluding any supervised
+training. Therefore, this model has to be fine-tuned before it is useable on a downstream task, unlike the original T5
+model. Since t5v1.1 was pre-trained unsupervisedly, there's no real advantage to using a task prefix during single-task
+fine-tuning. If you are doing multi-task fine-tuning, you should use a prefix.
+
+Google has released the following variants:
+
+- [google/t5-v1_1-small](https://huggingface.co/google/t5-v1_1-small)
+
+- [google/t5-v1_1-base](https://huggingface.co/google/t5-v1_1-base)
+
+- [google/t5-v1_1-large](https://huggingface.co/google/t5-v1_1-large)
+
+- [google/t5-v1_1-xl](https://huggingface.co/google/t5-v1_1-xl)
+
+- [google/t5-v1_1-xxl](https://huggingface.co/google/t5-v1_1-xxl).
+
+One can refer to [T5's documentation page](t5) for all tips, code examples and notebooks.
+
+This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten). The original code can be
+found [here](https://github.com/google-research/text-to-text-transfer-transformer/blob/main/released_checkpoints.md#t511).
diff --git a/docs/source/en/model_doc/tapas.mdx b/docs/source/en/model_doc/tapas.mdx
new file mode 100644
index 00000000000000..172800004fbb4b
--- /dev/null
+++ b/docs/source/en/model_doc/tapas.mdx
@@ -0,0 +1,615 @@
+
+
+# TAPAS
+
+## Overview
+
+The TAPAS model was proposed in [TAPAS: Weakly Supervised Table Parsing via Pre-training](https://www.aclweb.org/anthology/2020.acl-main.398)
+by Jonathan Herzig, Paweł Krzysztof Nowak, Thomas Müller, Francesco Piccinno and Julian Martin Eisenschlos. It's a BERT-based model specifically
+designed (and pre-trained) for answering questions about tabular data. Compared to BERT, TAPAS uses relative position embeddings and has 7
+token types that encode tabular structure. TAPAS is pre-trained on the masked language modeling (MLM) objective on a large dataset comprising
+millions of tables from English Wikipedia and corresponding texts.
+
+For question answering, TAPAS has 2 heads on top: a cell selection head and an aggregation head, for (optionally) performing aggregations (such as counting or summing) among selected cells. TAPAS has been fine-tuned on several datasets:
+- [SQA](https://www.microsoft.com/en-us/download/details.aspx?id=54253) (Sequential Question Answering by Microsoft)
+- [WTQ](https://github.com/ppasupat/WikiTableQuestions) (Wiki Table Questions by Stanford University)
+- [WikiSQL](https://github.com/salesforce/WikiSQL) (by Salesforce).
+
+It achieves state-of-the-art on both SQA and WTQ, while having comparable performance to SOTA on WikiSQL, with a much simpler architecture.
+
+The abstract from the paper is the following:
+
+*Answering natural language questions over tables is usually seen as a semantic parsing task. To alleviate the collection cost of full logical forms, one popular approach focuses on weak supervision consisting of denotations instead of logical forms. However, training semantic parsers from weak supervision poses difficulties, and in addition, the generated logical forms are only used as an intermediate step prior to retrieving the denotation. In this paper, we present TAPAS, an approach to question answering over tables without generating logical forms. TAPAS trains from weak supervision, and predicts the denotation by selecting table cells and optionally applying a corresponding aggregation operator to such selection. TAPAS extends BERT's architecture to encode tables as input, initializes from an effective joint pre-training of text segments and tables crawled from Wikipedia, and is trained end-to-end. We experiment with three different semantic parsing datasets, and find that TAPAS outperforms or rivals semantic parsing models by improving state-of-the-art accuracy on SQA from 55.1 to 67.2 and performing on par with the state-of-the-art on WIKISQL and WIKITQ, but with a simpler model architecture. We additionally find that transfer learning, which is trivial in our setting, from WIKISQL to WIKITQ, yields 48.7 accuracy, 4.2 points above the state-of-the-art.*
+
+In addition, the authors have further pre-trained TAPAS to recognize **table entailment**, by creating a balanced dataset of millions of automatically created training examples which are learned in an intermediate step prior to fine-tuning. The authors of TAPAS call this further pre-training intermediate pre-training (since TAPAS is first pre-trained on MLM, and then on another dataset). They found that intermediate pre-training further improves performance on SQA, achieving a new state-of-the-art as well as state-of-the-art on [TabFact](https://github.com/wenhuchen/Table-Fact-Checking), a large-scale dataset with 16k Wikipedia tables for table entailment (a binary classification task). For more details, see their follow-up paper: [Understanding tables with intermediate pre-training](https://www.aclweb.org/anthology/2020.findings-emnlp.27/) by Julian Martin Eisenschlos, Syrine Krichene and Thomas Müller.
+
+
+
+ Swin Transformer architecture. Taken from the original paper.
+
+This model was contributed by [novice03](https://huggingface.co/novice03>). The original code can be found [here](https://github.com/microsoft/Swin-Transformer).
+
+
+## SwinConfig
+
+[[autodoc]] SwinConfig
+
+
+## SwinModel
+
+[[autodoc]] SwinModel
+ - forward
+
+## SwinForMaskedImageModeling
+
+[[autodoc]] SwinForMaskedImageModeling
+ - forward
+
+## SwinForImageClassification
+
+[[autodoc]] transformers.SwinForImageClassification
+ - forward
\ No newline at end of file
diff --git a/docs/source/en/model_doc/t5.mdx b/docs/source/en/model_doc/t5.mdx
new file mode 100644
index 00000000000000..8034fc010a1cc1
--- /dev/null
+++ b/docs/source/en/model_doc/t5.mdx
@@ -0,0 +1,373 @@
+
+
+# T5
+
+## Overview
+
+The T5 model was presented in [Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer](https://arxiv.org/pdf/1910.10683.pdf) by Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang,
+Michael Matena, Yanqi Zhou, Wei Li, Peter J. Liu.
+
+The abstract from the paper is the following:
+
+*Transfer learning, where a model is first pre-trained on a data-rich task before being fine-tuned on a downstream
+task, has emerged as a powerful technique in natural language processing (NLP). The effectiveness of transfer learning
+has given rise to a diversity of approaches, methodology, and practice. In this paper, we explore the landscape of
+transfer learning techniques for NLP by introducing a unified framework that converts every language problem into a
+text-to-text format. Our systematic study compares pretraining objectives, architectures, unlabeled datasets, transfer
+approaches, and other factors on dozens of language understanding tasks. By combining the insights from our exploration
+with scale and our new "Colossal Clean Crawled Corpus", we achieve state-of-the-art results on many benchmarks covering
+summarization, question answering, text classification, and more. To facilitate future work on transfer learning for
+NLP, we release our dataset, pre-trained models, and code.*
+
+Tips:
+
+- T5 is an encoder-decoder model pre-trained on a multi-task mixture of unsupervised and supervised tasks and for which
+each task is converted into a text-to-text format. T5 works well on a variety of tasks out-of-the-box by prepending a
+different prefix to the input corresponding to each task, e.g., for translation: *translate English to German: ...*,
+for summarization: *summarize: ...*.
+
+- T5 uses relative scalar embeddings. Encoder input padding can be done on the left and on the right.
+
+- See the [training](#training), [inference](#inference) and [scripts](#scripts) sections below for all details regarding usage.
+
+T5 comes in different sizes:
+
+- [t5-small](https://huggingface.co/t5-small)
+
+- [t5-base](https://huggingface.co/t5-base)
+
+- [t5-large](https://huggingface.co/t5-large)
+
+- [t5-3b](https://huggingface.co/t5-3b)
+
+- [t5-11b](https://huggingface.co/t5-11b).
+
+Based on the original T5 model, Google has released some follow-up works:
+
+- **T5v1.1**: T5v1.1 is an improved version of T5 with some architectural tweaks, and is pre-trained on C4 only without
+ mixing in the supervised tasks. Refer to the documentation of T5v1.1 which can be found [here](t5v1.1).
+
+- **mT5**: mT5 is a multilingual T5 model. It is pre-trained on the mC4 corpus, which includes 101 languages. Refer to
+ the documentation of mT5 which can be found [here](mt5).
+
+- **byT5**: byT5 is a T5 model pre-trained on byte sequences rather than SentencePiece subword token sequences. Refer
+ to the documentation of byT5 which can be found [here](byt5).
+
+All checkpoints can be found on the [hub](https://huggingface.co/models?search=t5).
+
+This model was contributed by [thomwolf](https://huggingface.co/thomwolf). The original code can be found [here](https://github.com/google-research/text-to-text-transfer-transformer).
+
+
+
+## Training
+
+T5 is an encoder-decoder model and converts all NLP problems into a text-to-text format. It is trained using teacher
+forcing. This means that for training, we always need an input sequence and a corresponding target sequence. The input
+sequence is fed to the model using `input_ids`. The target sequence is shifted to the right, i.e., prepended by a
+start-sequence token and fed to the decoder using the `decoder_input_ids`. In teacher-forcing style, the target
+sequence is then appended by the EOS token and corresponds to the `labels`. The PAD token is hereby used as the
+start-sequence token. T5 can be trained / fine-tuned both in a supervised and unsupervised fashion.
+
+One can use [`T5ForConditionalGeneration`] (or the Tensorflow/Flax variant), which includes the
+language modeling head on top of the decoder.
+
+- Unsupervised denoising training
+
+In this setup, spans of the input sequence are masked by so-called sentinel tokens (*a.k.a* unique mask tokens) and
+the output sequence is formed as a concatenation of the same sentinel tokens and the *real* masked tokens. Each
+sentinel token represents a unique mask token for this sentence and should start with ``,
+``, ... up to ``. As a default, 100 sentinel tokens are available in
+[`T5Tokenizer`].
+
+For instance, the sentence "The cute dog walks in the park" with the masks put on "cute dog" and "the" should be
+processed as follows:
+
+```python
+>>> from transformers import T5Tokenizer, T5ForConditionalGeneration
+
+>>> tokenizer = T5Tokenizer.from_pretrained("t5-small")
+>>> model = T5ForConditionalGeneration.from_pretrained("t5-small")
+
+>>> input_ids = tokenizer("The walks in park", return_tensors="pt").input_ids
+>>> labels = tokenizer(" cute dog the ", return_tensors="pt").input_ids
+
+>>> # the forward function automatically creates the correct decoder_input_ids
+>>> loss = model(input_ids=input_ids, labels=labels).loss
+>>> loss.item()
+3.7837
+```
+
+If you're interested in pre-training T5 on a new corpus, check out the [run_t5_mlm_flax.py](https://github.com/huggingface/transformers/tree/main/examples/flax/language-modeling) script in the Examples
+directory.
+
+- Supervised training
+
+In this setup, the input sequence and output sequence are a standard sequence-to-sequence input-output mapping.
+Suppose that we want to fine-tune the model for translation for example, and we have a training example: the input
+sequence "The house is wonderful." and output sequence "Das Haus ist wunderbar.", then they should be prepared for
+the model as follows:
+
+```python
+>>> from transformers import T5Tokenizer, T5ForConditionalGeneration
+
+>>> tokenizer = T5Tokenizer.from_pretrained("t5-small")
+>>> model = T5ForConditionalGeneration.from_pretrained("t5-small")
+
+>>> input_ids = tokenizer("translate English to German: The house is wonderful.", return_tensors="pt").input_ids
+>>> labels = tokenizer("Das Haus ist wunderbar.", return_tensors="pt").input_ids
+
+>>> # the forward function automatically creates the correct decoder_input_ids
+>>> loss = model(input_ids=input_ids, labels=labels).loss
+>>> loss.item()
+0.2542
+```
+
+As you can see, only 2 inputs are required for the model in order to compute a loss: `input_ids` (which are the
+`input_ids` of the encoded input sequence) and `labels` (which are the `input_ids` of the encoded
+target sequence). The model will automatically create the `decoder_input_ids` based on the `labels`, by
+shifting them one position to the right and prepending the `config.decoder_start_token_id`, which for T5 is
+equal to 0 (i.e. the id of the pad token). Also note the task prefix: we prepend the input sequence with 'translate
+English to German: ' before encoding it. This will help in improving the performance, as this task prefix was used
+during T5's pre-training.
+
+However, the example above only shows a single training example. In practice, one trains deep learning models in
+batches. This entails that we must pad/truncate examples to the same length. For encoder-decoder models, one
+typically defines a `max_source_length` and `max_target_length`, which determine the maximum length of the
+input and output sequences respectively (otherwise they are truncated). These should be carefully set depending on
+the task.
+
+In addition, we must make sure that padding token id's of the `labels` are not taken into account by the loss
+function. In PyTorch and Tensorflow, this can be done by replacing them with -100, which is the `ignore_index`
+of the `CrossEntropyLoss`. In Flax, one can use the `decoder_attention_mask` to ignore padded tokens from
+the loss (see the [Flax summarization script](https://github.com/huggingface/transformers/tree/main/examples/flax/summarization) for details). We also pass
+`attention_mask` as additional input to the model, which makes sure that padding tokens of the inputs are
+ignored. The code example below illustrates all of this.
+
+```python
+>>> from transformers import T5Tokenizer, T5ForConditionalGeneration
+>>> import torch
+
+>>> tokenizer = T5Tokenizer.from_pretrained("t5-small")
+>>> model = T5ForConditionalGeneration.from_pretrained("t5-small")
+
+>>> # the following 2 hyperparameters are task-specific
+>>> max_source_length = 512
+>>> max_target_length = 128
+
+>>> # Suppose we have the following 2 training examples:
+>>> input_sequence_1 = "Welcome to NYC"
+>>> output_sequence_1 = "Bienvenue à NYC"
+
+>>> input_sequence_2 = "HuggingFace is a company"
+>>> output_sequence_2 = "HuggingFace est une entreprise"
+
+>>> # encode the inputs
+>>> task_prefix = "translate English to French: "
+>>> input_sequences = [input_sequence_1, input_sequence_2]
+
+>>> encoding = tokenizer(
+... [task_prefix + sequence for sequence in input_sequences],
+... padding="longest",
+... max_length=max_source_length,
+... truncation=True,
+... return_tensors="pt",
+... )
+
+>>> input_ids, attention_mask = encoding.input_ids, encoding.attention_mask
+
+>>> # encode the targets
+>>> target_encoding = tokenizer(
+... [output_sequence_1, output_sequence_2], padding="longest", max_length=max_target_length, truncation=True
+... )
+>>> labels = target_encoding.input_ids
+
+>>> # replace padding token id's of the labels by -100 so it's ignored by the loss
+>>> labels = torch.tensor(labels)
+>>> labels[labels == tokenizer.pad_token_id] = -100
+
+>>> # forward pass
+>>> loss = model(input_ids=input_ids, attention_mask=attention_mask, labels=labels).loss
+>>> loss.item()
+0.188
+```
+
+Additional training tips:
+
+- T5 models need a slightly higher learning rate than the default one set in the `Trainer` when using the AdamW
+optimizer. Typically, 1e-4 and 3e-4 work well for most problems (classification, summarization, translation, question
+answering, question generation). Note that T5 was pre-trained using the AdaFactor optimizer.
+
+According to [this forum post](https://discuss.huggingface.co/t/t5-finetuning-tips/684), task prefixes matter when
+(1) doing multi-task training (2) your task is similar or related to one of the supervised tasks used in T5's
+pre-training mixture (see Appendix D of the [paper](https://arxiv.org/pdf/1910.10683.pdf) for the task prefixes
+used).
+
+If training on TPU, it is recommended to pad all examples of the dataset to the same length or make use of
+*pad_to_multiple_of* to have a small number of predefined bucket sizes to fit all examples in. Dynamically padding
+batches to the longest example is not recommended on TPU as it triggers a recompilation for every batch shape that is
+encountered during training thus significantly slowing down the training. only padding up to the longest example in a
+batch) leads to very slow training on TPU.
+
+
+
+## Inference
+
+At inference time, it is recommended to use [`~generation_utils.GenerationMixin.generate`]. This
+method takes care of encoding the input and feeding the encoded hidden states via cross-attention layers to the decoder
+and auto-regressively generates the decoder output. Check out [this blog post](https://huggingface.co/blog/how-to-generate) to know all the details about generating text with Transformers.
+There's also [this blog post](https://huggingface.co/blog/encoder-decoder#encoder-decoder) which explains how
+generation works in general in encoder-decoder models.
+
+```python
+>>> from transformers import T5Tokenizer, T5ForConditionalGeneration
+
+>>> tokenizer = T5Tokenizer.from_pretrained("t5-small")
+>>> model = T5ForConditionalGeneration.from_pretrained("t5-small")
+
+>>> input_ids = tokenizer("translate English to German: The house is wonderful.", return_tensors="pt").input_ids
+>>> outputs = model.generate(input_ids)
+>>> print(tokenizer.decode(outputs[0], skip_special_tokens=True))
+Das Haus ist wunderbar.
+```
+
+Note that T5 uses the `pad_token_id` as the `decoder_start_token_id`, so when doing generation without using
+[`~generation_utils.GenerationMixin.generate`], make sure you start it with the `pad_token_id`.
+
+The example above only shows a single example. You can also do batched inference, like so:
+
+```python
+>>> from transformers import T5Tokenizer, T5ForConditionalGeneration
+
+>>> tokenizer = T5Tokenizer.from_pretrained("t5-small")
+>>> model = T5ForConditionalGeneration.from_pretrained("t5-small")
+
+>>> task_prefix = "translate English to German: "
+>>> # use different length sentences to test batching
+>>> sentences = ["The house is wonderful.", "I like to work in NYC."]
+
+>>> inputs = tokenizer([task_prefix + sentence for sentence in sentences], return_tensors="pt", padding=True)
+
+>>> output_sequences = model.generate(
+... input_ids=inputs["input_ids"],
+... attention_mask=inputs["attention_mask"],
+... do_sample=False, # disable sampling to test if batching affects output
+... )
+
+>>> print(tokenizer.batch_decode(output_sequences, skip_special_tokens=True))
+['Das Haus ist wunderbar.', 'Ich arbeite gerne in NYC.']
+```
+
+Because T5 has been trained with the span-mask denoising objective,
+it can be used to predict the sentinel (masked-out) tokens during inference.
+The predicted tokens will then be placed between the sentinel tokens.
+
+```python
+>>> from transformers import T5Tokenizer, T5ForConditionalGeneration
+
+>>> tokenizer = T5Tokenizer.from_pretrained("t5-small")
+>>> model = T5ForConditionalGeneration.from_pretrained("t5-small")
+
+>>> input_ids = tokenizer("The walks in park", return_tensors="pt").input_ids
+
+>>> sequence_ids = model.generate(input_ids)
+>>> sequences = tokenizer.batch_decode(sequence_ids)
+>>> sequences
+[' park offers the park.']
+```
+
+
+
+
+## Performance
+
+If you'd like a faster training and inference performance, install [apex](https://github.com/NVIDIA/apex#quick-start) and then the model will automatically use `apex.normalization.FusedRMSNorm` instead of `T5LayerNorm`. The former uses an optimized fused kernel which is several times faster than the latter.
+
+
+## Example scripts
+
+T5 is supported by several example scripts, both for pre-training and fine-tuning.
+
+- pre-training: the [run_t5_mlm_flax.py](https://github.com/huggingface/transformers/blob/main/examples/flax/language-modeling/run_t5_mlm_flax.py)
+ script allows you to further pre-train T5 or pre-train T5 from scratch on your own data. The [t5_tokenizer_model.py](https://github.com/huggingface/transformers/blob/main/examples/flax/language-modeling/t5_tokenizer_model.py)
+ script allows you to further train a T5 tokenizer or train a T5 Tokenizer from scratch on your own data. Note that
+ Flax (a neural network library on top of JAX) is particularly useful to train on TPU hardware.
+
+- fine-tuning: T5 is supported by the official summarization scripts ([PyTorch](https://github.com/huggingface/transformers/tree/main/examples/pytorch/summarization), [Tensorflow](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/summarization), and [Flax](https://github.com/huggingface/transformers/tree/main/examples/flax/summarization)) and translation scripts
+ ([PyTorch](https://github.com/huggingface/transformers/tree/main/examples/pytorch/translation) and [Tensorflow](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/translation)). These scripts allow
+ you to easily fine-tune T5 on custom data for summarization/translation.
+
+## T5Config
+
+[[autodoc]] T5Config
+
+## T5Tokenizer
+
+[[autodoc]] T5Tokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## T5TokenizerFast
+
+[[autodoc]] T5TokenizerFast
+
+## T5Model
+
+[[autodoc]] T5Model
+ - forward
+ - parallelize
+ - deparallelize
+
+## T5ForConditionalGeneration
+
+[[autodoc]] T5ForConditionalGeneration
+ - forward
+ - parallelize
+ - deparallelize
+
+## T5EncoderModel
+
+[[autodoc]] T5EncoderModel
+ - forward
+ - parallelize
+ - deparallelize
+
+## TFT5Model
+
+[[autodoc]] TFT5Model
+ - call
+
+## TFT5ForConditionalGeneration
+
+[[autodoc]] TFT5ForConditionalGeneration
+ - call
+
+## TFT5EncoderModel
+
+[[autodoc]] TFT5EncoderModel
+ - call
+
+## FlaxT5Model
+
+[[autodoc]] FlaxT5Model
+ - __call__
+ - encode
+ - decode
+
+## FlaxT5ForConditionalGeneration
+
+[[autodoc]] FlaxT5ForConditionalGeneration
+ - __call__
+ - encode
+ - decode
diff --git a/docs/source/en/model_doc/t5v1.1.mdx b/docs/source/en/model_doc/t5v1.1.mdx
new file mode 100644
index 00000000000000..b15188961d3330
--- /dev/null
+++ b/docs/source/en/model_doc/t5v1.1.mdx
@@ -0,0 +1,61 @@
+
+
+# T5v1.1
+
+## Overview
+
+T5v1.1 was released in the [google-research/text-to-text-transfer-transformer](https://github.com/google-research/text-to-text-transfer-transformer/blob/main/released_checkpoints.md#t511)
+repository by Colin Raffel et al. It's an improved version of the original T5 model.
+
+One can directly plug in the weights of T5v1.1 into a T5 model, like so:
+
+```python
+>>> from transformers import T5ForConditionalGeneration
+
+>>> model = T5ForConditionalGeneration.from_pretrained("google/t5-v1_1-base")
+```
+
+T5 Version 1.1 includes the following improvements compared to the original T5 model:
+
+- GEGLU activation in the feed-forward hidden layer, rather than ReLU. See [this paper](https://arxiv.org/abs/2002.05202).
+
+- Dropout was turned off in pre-training (quality win). Dropout should be re-enabled during fine-tuning.
+
+- Pre-trained on C4 only without mixing in the downstream tasks.
+
+- No parameter sharing between the embedding and classifier layer.
+
+- "xl" and "xxl" replace "3B" and "11B". The model shapes are a bit different - larger `d_model` and smaller
+ `num_heads` and `d_ff`.
+
+Note: T5 Version 1.1 was only pre-trained on [C4](https://huggingface.co/datasets/c4) excluding any supervised
+training. Therefore, this model has to be fine-tuned before it is useable on a downstream task, unlike the original T5
+model. Since t5v1.1 was pre-trained unsupervisedly, there's no real advantage to using a task prefix during single-task
+fine-tuning. If you are doing multi-task fine-tuning, you should use a prefix.
+
+Google has released the following variants:
+
+- [google/t5-v1_1-small](https://huggingface.co/google/t5-v1_1-small)
+
+- [google/t5-v1_1-base](https://huggingface.co/google/t5-v1_1-base)
+
+- [google/t5-v1_1-large](https://huggingface.co/google/t5-v1_1-large)
+
+- [google/t5-v1_1-xl](https://huggingface.co/google/t5-v1_1-xl)
+
+- [google/t5-v1_1-xxl](https://huggingface.co/google/t5-v1_1-xxl).
+
+One can refer to [T5's documentation page](t5) for all tips, code examples and notebooks.
+
+This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten). The original code can be
+found [here](https://github.com/google-research/text-to-text-transfer-transformer/blob/main/released_checkpoints.md#t511).
diff --git a/docs/source/en/model_doc/tapas.mdx b/docs/source/en/model_doc/tapas.mdx
new file mode 100644
index 00000000000000..172800004fbb4b
--- /dev/null
+++ b/docs/source/en/model_doc/tapas.mdx
@@ -0,0 +1,615 @@
+
+
+# TAPAS
+
+## Overview
+
+The TAPAS model was proposed in [TAPAS: Weakly Supervised Table Parsing via Pre-training](https://www.aclweb.org/anthology/2020.acl-main.398)
+by Jonathan Herzig, Paweł Krzysztof Nowak, Thomas Müller, Francesco Piccinno and Julian Martin Eisenschlos. It's a BERT-based model specifically
+designed (and pre-trained) for answering questions about tabular data. Compared to BERT, TAPAS uses relative position embeddings and has 7
+token types that encode tabular structure. TAPAS is pre-trained on the masked language modeling (MLM) objective on a large dataset comprising
+millions of tables from English Wikipedia and corresponding texts.
+
+For question answering, TAPAS has 2 heads on top: a cell selection head and an aggregation head, for (optionally) performing aggregations (such as counting or summing) among selected cells. TAPAS has been fine-tuned on several datasets:
+- [SQA](https://www.microsoft.com/en-us/download/details.aspx?id=54253) (Sequential Question Answering by Microsoft)
+- [WTQ](https://github.com/ppasupat/WikiTableQuestions) (Wiki Table Questions by Stanford University)
+- [WikiSQL](https://github.com/salesforce/WikiSQL) (by Salesforce).
+
+It achieves state-of-the-art on both SQA and WTQ, while having comparable performance to SOTA on WikiSQL, with a much simpler architecture.
+
+The abstract from the paper is the following:
+
+*Answering natural language questions over tables is usually seen as a semantic parsing task. To alleviate the collection cost of full logical forms, one popular approach focuses on weak supervision consisting of denotations instead of logical forms. However, training semantic parsers from weak supervision poses difficulties, and in addition, the generated logical forms are only used as an intermediate step prior to retrieving the denotation. In this paper, we present TAPAS, an approach to question answering over tables without generating logical forms. TAPAS trains from weak supervision, and predicts the denotation by selecting table cells and optionally applying a corresponding aggregation operator to such selection. TAPAS extends BERT's architecture to encode tables as input, initializes from an effective joint pre-training of text segments and tables crawled from Wikipedia, and is trained end-to-end. We experiment with three different semantic parsing datasets, and find that TAPAS outperforms or rivals semantic parsing models by improving state-of-the-art accuracy on SQA from 55.1 to 67.2 and performing on par with the state-of-the-art on WIKISQL and WIKITQ, but with a simpler model architecture. We additionally find that transfer learning, which is trivial in our setting, from WIKISQL to WIKITQ, yields 48.7 accuracy, 4.2 points above the state-of-the-art.*
+
+In addition, the authors have further pre-trained TAPAS to recognize **table entailment**, by creating a balanced dataset of millions of automatically created training examples which are learned in an intermediate step prior to fine-tuning. The authors of TAPAS call this further pre-training intermediate pre-training (since TAPAS is first pre-trained on MLM, and then on another dataset). They found that intermediate pre-training further improves performance on SQA, achieving a new state-of-the-art as well as state-of-the-art on [TabFact](https://github.com/wenhuchen/Table-Fact-Checking), a large-scale dataset with 16k Wikipedia tables for table entailment (a binary classification task). For more details, see their follow-up paper: [Understanding tables with intermediate pre-training](https://www.aclweb.org/anthology/2020.findings-emnlp.27/) by Julian Martin Eisenschlos, Syrine Krichene and Thomas Müller.
+
+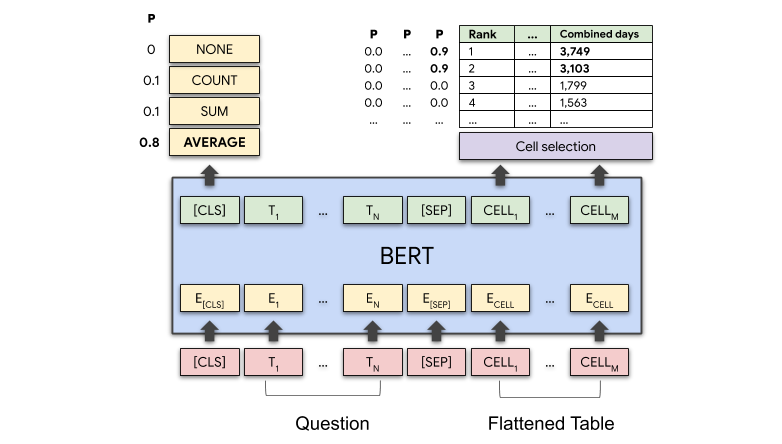 +
+ TAPAS architecture. Taken from the original blog post.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The Tensorflow version of this model was contributed by [kamalkraj](https://huggingface.co/kamalkraj). The original code can be found [here](https://github.com/google-research/tapas).
+
+Tips:
+
+- TAPAS is a model that uses relative position embeddings by default (restarting the position embeddings at every cell of the table). Note that this is something that was added after the publication of the original TAPAS paper. According to the authors, this usually results in a slightly better performance, and allows you to encode longer sequences without running out of embeddings. This is reflected in the `reset_position_index_per_cell` parameter of [`TapasConfig`], which is set to `True` by default. The default versions of the models available on the [hub](https://huggingface.co/models?search=tapas) all use relative position embeddings. You can still use the ones with absolute position embeddings by passing in an additional argument `revision="no_reset"` when calling the `from_pretrained()` method. Note that it's usually advised to pad the inputs on the right rather than the left.
+- TAPAS is based on BERT, so `TAPAS-base` for example corresponds to a `BERT-base` architecture. Of course, `TAPAS-large` will result in the best performance (the results reported in the paper are from `TAPAS-large`). Results of the various sized models are shown on the [original Github repository](https://github.com/google-research/tapas>).
+- TAPAS has checkpoints fine-tuned on SQA, which are capable of answering questions related to a table in a conversational set-up. This means that you can ask follow-up questions such as "what is his age?" related to the previous question. Note that the forward pass of TAPAS is a bit different in case of a conversational set-up: in that case, you have to feed every table-question pair one by one to the model, such that the `prev_labels` token type ids can be overwritten by the predicted `labels` of the model to the previous question. See "Usage" section for more info.
+- TAPAS is similar to BERT and therefore relies on the masked language modeling (MLM) objective. It is therefore efficient at predicting masked tokens and at NLU in general, but is not optimal for text generation. Models trained with a causal language modeling (CLM) objective are better in that regard. Note that TAPAS can be used as an encoder in the EncoderDecoderModel framework, to combine it with an autoregressive text decoder such as GPT-2.
+
+## Usage: fine-tuning
+
+Here we explain how you can fine-tune [`TapasForQuestionAnswering`] on your own dataset.
+
+**STEP 1: Choose one of the 3 ways in which you can use TAPAS - or experiment**
+
+Basically, there are 3 different ways in which one can fine-tune [`TapasForQuestionAnswering`], corresponding to the different datasets on which Tapas was fine-tuned:
+
+1. SQA: if you're interested in asking follow-up questions related to a table, in a conversational set-up. For example if you first ask "what's the name of the first actor?" then you can ask a follow-up question such as "how old is he?". Here, questions do not involve any aggregation (all questions are cell selection questions).
+2. WTQ: if you're not interested in asking questions in a conversational set-up, but rather just asking questions related to a table, which might involve aggregation, such as counting a number of rows, summing up cell values or averaging cell values. You can then for example ask "what's the total number of goals Cristiano Ronaldo made in his career?". This case is also called **weak supervision**, since the model itself must learn the appropriate aggregation operator (SUM/COUNT/AVERAGE/NONE) given only the answer to the question as supervision.
+3. WikiSQL-supervised: this dataset is based on WikiSQL with the model being given the ground truth aggregation operator during training. This is also called **strong supervision**. Here, learning the appropriate aggregation operator is much easier.
+
+To summarize:
+
+| **Task** | **Example dataset** | **Description** |
+|-------------------------------------|---------------------|---------------------------------------------------------------------------------------------------------|
+| Conversational | SQA | Conversational, only cell selection questions |
+| Weak supervision for aggregation | WTQ | Questions might involve aggregation, and the model must learn this given only the answer as supervision |
+| Strong supervision for aggregation | WikiSQL-supervised | Questions might involve aggregation, and the model must learn this given the gold aggregation operator |
+
+
+
+Initializing a model with a pre-trained base and randomly initialized classification heads from the hub can be done as shown below. Be sure to have installed the
+[torch-scatter](https://github.com/rusty1s/pytorch_scatter) dependency:
+
+```py
+>>> from transformers import TapasConfig, TapasForQuestionAnswering
+
+>>> # for example, the base sized model with default SQA configuration
+>>> model = TapasForQuestionAnswering.from_pretrained("google/tapas-base")
+
+>>> # or, the base sized model with WTQ configuration
+>>> config = TapasConfig.from_pretrained("google/tapas-base-finetuned-wtq")
+>>> model = TapasForQuestionAnswering.from_pretrained("google/tapas-base", config=config)
+
+>>> # or, the base sized model with WikiSQL configuration
+>>> config = TapasConfig("google-base-finetuned-wikisql-supervised")
+>>> model = TapasForQuestionAnswering.from_pretrained("google/tapas-base", config=config)
+```
+
+Of course, you don't necessarily have to follow one of these three ways in which TAPAS was fine-tuned. You can also experiment by defining any hyperparameters you want when initializing [`TapasConfig`], and then create a [`TapasForQuestionAnswering`] based on that configuration. For example, if you have a dataset that has both conversational questions and questions that might involve aggregation, then you can do it this way. Here's an example:
+
+```py
+>>> from transformers import TapasConfig, TapasForQuestionAnswering
+
+>>> # you can initialize the classification heads any way you want (see docs of TapasConfig)
+>>> config = TapasConfig(num_aggregation_labels=3, average_logits_per_cell=True)
+>>> # initializing the pre-trained base sized model with our custom classification heads
+>>> model = TapasForQuestionAnswering.from_pretrained("google/tapas-base", config=config)
+```
+
+
+Initializing a model with a pre-trained base and randomly initialized classification heads from the hub can be done as shown below. Be sure to have installed the [tensorflow_probability](https://github.com/tensorflow/probability) dependency:
+
+```py
+>>> from transformers import TapasConfig, TFTapasForQuestionAnswering
+
+>>> # for example, the base sized model with default SQA configuration
+>>> model = TFTapasForQuestionAnswering.from_pretrained("google/tapas-base")
+
+>>> # or, the base sized model with WTQ configuration
+>>> config = TapasConfig.from_pretrained("google/tapas-base-finetuned-wtq")
+>>> model = TFTapasForQuestionAnswering.from_pretrained("google/tapas-base", config=config)
+
+>>> # or, the base sized model with WikiSQL configuration
+>>> config = TapasConfig("google-base-finetuned-wikisql-supervised")
+>>> model = TFTapasForQuestionAnswering.from_pretrained("google/tapas-base", config=config)
+```
+
+Of course, you don't necessarily have to follow one of these three ways in which TAPAS was fine-tuned. You can also experiment by defining any hyperparameters you want when initializing [`TapasConfig`], and then create a [`TFTapasForQuestionAnswering`] based on that configuration. For example, if you have a dataset that has both conversational questions and questions that might involve aggregation, then you can do it this way. Here's an example:
+
+```py
+>>> from transformers import TapasConfig, TFTapasForQuestionAnswering
+
+>>> # you can initialize the classification heads any way you want (see docs of TapasConfig)
+>>> config = TapasConfig(num_aggregation_labels=3, average_logits_per_cell=True)
+>>> # initializing the pre-trained base sized model with our custom classification heads
+>>> model = TFTapasForQuestionAnswering.from_pretrained("google/tapas-base", config=config)
+```
+
+
+
+What you can also do is start from an already fine-tuned checkpoint. A note here is that the already fine-tuned checkpoint on WTQ has some issues due to the L2-loss which is somewhat brittle. See [here](https://github.com/google-research/tapas/issues/91#issuecomment-735719340) for more info.
+
+For a list of all pre-trained and fine-tuned TAPAS checkpoints available on HuggingFace's hub, see [here](https://huggingface.co/models?search=tapas).
+
+**STEP 2: Prepare your data in the SQA format**
+
+Second, no matter what you picked above, you should prepare your dataset in the [SQA](https://www.microsoft.com/en-us/download/details.aspx?id=54253) format. This format is a TSV/CSV file with the following columns:
+
+- `id`: optional, id of the table-question pair, for bookkeeping purposes.
+- `annotator`: optional, id of the person who annotated the table-question pair, for bookkeeping purposes.
+- `position`: integer indicating if the question is the first, second, third,... related to the table. Only required in case of conversational setup (SQA). You don't need this column in case you're going for WTQ/WikiSQL-supervised.
+- `question`: string
+- `table_file`: string, name of a csv file containing the tabular data
+- `answer_coordinates`: list of one or more tuples (each tuple being a cell coordinate, i.e. row, column pair that is part of the answer)
+- `answer_text`: list of one or more strings (each string being a cell value that is part of the answer)
+- `aggregation_label`: index of the aggregation operator. Only required in case of strong supervision for aggregation (the WikiSQL-supervised case)
+- `float_answer`: the float answer to the question, if there is one (np.nan if there isn't). Only required in case of weak supervision for aggregation (such as WTQ and WikiSQL)
+
+The tables themselves should be present in a folder, each table being a separate csv file. Note that the authors of the TAPAS algorithm used conversion scripts with some automated logic to convert the other datasets (WTQ, WikiSQL) into the SQA format. The author explains this [here](https://github.com/google-research/tapas/issues/50#issuecomment-705465960). A conversion of this script that works with HuggingFace's implementation can be found [here](https://github.com/NielsRogge/tapas_utils). Interestingly, these conversion scripts are not perfect (the `answer_coordinates` and `float_answer` fields are populated based on the `answer_text`), meaning that WTQ and WikiSQL results could actually be improved.
+
+**STEP 3: Convert your data into tensors using TapasTokenizer**
+
+
+
+Third, given that you've prepared your data in this TSV/CSV format (and corresponding CSV files containing the tabular data), you can then use [`TapasTokenizer`] to convert table-question pairs into `input_ids`, `attention_mask`, `token_type_ids` and so on. Again, based on which of the three cases you picked above, [`TapasForQuestionAnswering`] requires different
+inputs to be fine-tuned:
+
+| **Task** | **Required inputs** |
+|------------------------------------|---------------------------------------------------------------------------------------------------------------------|
+| Conversational | `input_ids`, `attention_mask`, `token_type_ids`, `labels` |
+| Weak supervision for aggregation | `input_ids`, `attention_mask`, `token_type_ids`, `labels`, `numeric_values`, `numeric_values_scale`, `float_answer` |
+| Strong supervision for aggregation | `input ids`, `attention mask`, `token type ids`, `labels`, `aggregation_labels` |
+
+[`TapasTokenizer`] creates the `labels`, `numeric_values` and `numeric_values_scale` based on the `answer_coordinates` and `answer_text` columns of the TSV file. The `float_answer` and `aggregation_labels` are already in the TSV file of step 2. Here's an example:
+
+```py
+>>> from transformers import TapasTokenizer
+>>> import pandas as pd
+
+>>> model_name = "google/tapas-base"
+>>> tokenizer = TapasTokenizer.from_pretrained(model_name)
+
+>>> data = {"Actors": ["Brad Pitt", "Leonardo Di Caprio", "George Clooney"], "Number of movies": ["87", "53", "69"]}
+>>> queries = [
+... "What is the name of the first actor?",
+... "How many movies has George Clooney played in?",
+... "What is the total number of movies?",
+... ]
+>>> answer_coordinates = [[(0, 0)], [(2, 1)], [(0, 1), (1, 1), (2, 1)]]
+>>> answer_text = [["Brad Pitt"], ["69"], ["209"]]
+>>> table = pd.DataFrame.from_dict(data)
+>>> inputs = tokenizer(
+... table=table,
+... queries=queries,
+... answer_coordinates=answer_coordinates,
+... answer_text=answer_text,
+... padding="max_length",
+... return_tensors="pt",
+... )
+>>> inputs
+{'input_ids': tensor([[ ... ]]), 'attention_mask': tensor([[...]]), 'token_type_ids': tensor([[[...]]]),
+'numeric_values': tensor([[ ... ]]), 'numeric_values_scale: tensor([[ ... ]]), labels: tensor([[ ... ]])}
+```
+
+Note that [`TapasTokenizer`] expects the data of the table to be **text-only**. You can use `.astype(str)` on a dataframe to turn it into text-only data.
+Of course, this only shows how to encode a single training example. It is advised to create a dataloader to iterate over batches:
+
+```py
+>>> import torch
+>>> import pandas as pd
+
+>>> tsv_path = "your_path_to_the_tsv_file"
+>>> table_csv_path = "your_path_to_a_directory_containing_all_csv_files"
+
+
+>>> class TableDataset(torch.utils.data.Dataset):
+... def __init__(self, data, tokenizer):
+... self.data = data
+... self.tokenizer = tokenizer
+
+... def __getitem__(self, idx):
+... item = data.iloc[idx]
+... table = pd.read_csv(table_csv_path + item.table_file).astype(
+... str
+... ) # be sure to make your table data text only
+... encoding = self.tokenizer(
+... table=table,
+... queries=item.question,
+... answer_coordinates=item.answer_coordinates,
+... answer_text=item.answer_text,
+... truncation=True,
+... padding="max_length",
+... return_tensors="pt",
+... )
+... # remove the batch dimension which the tokenizer adds by default
+... encoding = {key: val.squeeze(0) for key, val in encoding.items()}
+... # add the float_answer which is also required (weak supervision for aggregation case)
+... encoding["float_answer"] = torch.tensor(item.float_answer)
+... return encoding
+
+... def __len__(self):
+... return len(self.data)
+
+
+>>> data = pd.read_csv(tsv_path, sep="\t")
+>>> train_dataset = TableDataset(data, tokenizer)
+>>> train_dataloader = torch.utils.data.DataLoader(train_dataset, batch_size=32)
+```
+
+
+Third, given that you've prepared your data in this TSV/CSV format (and corresponding CSV files containing the tabular data), you can then use [`TapasTokenizer`] to convert table-question pairs into `input_ids`, `attention_mask`, `token_type_ids` and so on. Again, based on which of the three cases you picked above, [`TFTapasForQuestionAnswering`] requires different
+inputs to be fine-tuned:
+
+| **Task** | **Required inputs** |
+|------------------------------------|---------------------------------------------------------------------------------------------------------------------|
+| Conversational | `input_ids`, `attention_mask`, `token_type_ids`, `labels` |
+| Weak supervision for aggregation | `input_ids`, `attention_mask`, `token_type_ids`, `labels`, `numeric_values`, `numeric_values_scale`, `float_answer` |
+| Strong supervision for aggregation | `input ids`, `attention mask`, `token type ids`, `labels`, `aggregation_labels` |
+
+[`TapasTokenizer`] creates the `labels`, `numeric_values` and `numeric_values_scale` based on the `answer_coordinates` and `answer_text` columns of the TSV file. The `float_answer` and `aggregation_labels` are already in the TSV file of step 2. Here's an example:
+
+```py
+>>> from transformers import TapasTokenizer
+>>> import pandas as pd
+
+>>> model_name = "google/tapas-base"
+>>> tokenizer = TapasTokenizer.from_pretrained(model_name)
+
+>>> data = {"Actors": ["Brad Pitt", "Leonardo Di Caprio", "George Clooney"], "Number of movies": ["87", "53", "69"]}
+>>> queries = [
+... "What is the name of the first actor?",
+... "How many movies has George Clooney played in?",
+... "What is the total number of movies?",
+... ]
+>>> answer_coordinates = [[(0, 0)], [(2, 1)], [(0, 1), (1, 1), (2, 1)]]
+>>> answer_text = [["Brad Pitt"], ["69"], ["209"]]
+>>> table = pd.DataFrame.from_dict(data)
+>>> inputs = tokenizer(
+... table=table,
+... queries=queries,
+... answer_coordinates=answer_coordinates,
+... answer_text=answer_text,
+... padding="max_length",
+... return_tensors="tf",
+... )
+>>> inputs
+{'input_ids': tensor([[ ... ]]), 'attention_mask': tensor([[...]]), 'token_type_ids': tensor([[[...]]]),
+'numeric_values': tensor([[ ... ]]), 'numeric_values_scale: tensor([[ ... ]]), labels: tensor([[ ... ]])}
+```
+
+Note that [`TapasTokenizer`] expects the data of the table to be **text-only**. You can use `.astype(str)` on a dataframe to turn it into text-only data.
+Of course, this only shows how to encode a single training example. It is advised to create a dataloader to iterate over batches:
+
+```py
+>>> import tensorflow as tf
+>>> import pandas as pd
+
+>>> tsv_path = "your_path_to_the_tsv_file"
+>>> table_csv_path = "your_path_to_a_directory_containing_all_csv_files"
+
+
+>>> class TableDataset:
+... def __init__(self, data, tokenizer):
+... self.data = data
+... self.tokenizer = tokenizer
+
+... def __iter__(self):
+... for idx in range(self.__len__()):
+... item = self.data.iloc[idx]
+... table = pd.read_csv(table_csv_path + item.table_file).astype(
+... str
+... ) # be sure to make your table data text only
+... encoding = self.tokenizer(
+... table=table,
+... queries=item.question,
+... answer_coordinates=item.answer_coordinates,
+... answer_text=item.answer_text,
+... truncation=True,
+... padding="max_length",
+... return_tensors="tf",
+... )
+... # remove the batch dimension which the tokenizer adds by default
+... encoding = {key: tf.squeeze(val, 0) for key, val in encoding.items()}
+... # add the float_answer which is also required (weak supervision for aggregation case)
+... encoding["float_answer"] = tf.convert_to_tensor(item.float_answer, dtype=tf.float32)
+... yield encoding["input_ids"], encoding["attention_mask"], encoding["numeric_values"], encoding[
+... "numeric_values_scale"
+... ], encoding["token_type_ids"], encoding["labels"], encoding["float_answer"]
+
+... def __len__(self):
+... return len(self.data)
+
+
+>>> data = pd.read_csv(tsv_path, sep="\t")
+>>> train_dataset = TableDataset(data, tokenizer)
+>>> output_signature = (
+... tf.TensorSpec(shape=(512,), dtype=tf.int32),
+... tf.TensorSpec(shape=(512,), dtype=tf.int32),
+... tf.TensorSpec(shape=(512,), dtype=tf.float32),
+... tf.TensorSpec(shape=(512,), dtype=tf.float32),
+... tf.TensorSpec(shape=(512, 7), dtype=tf.int32),
+... tf.TensorSpec(shape=(512,), dtype=tf.int32),
+... tf.TensorSpec(shape=(512,), dtype=tf.float32),
+... )
+>>> train_dataloader = tf.data.Dataset.from_generator(train_dataset, output_signature=output_signature).batch(32)
+```
+
+
+
+Note that here, we encode each table-question pair independently. This is fine as long as your dataset is **not conversational**. In case your dataset involves conversational questions (such as in SQA), then you should first group together the `queries`, `answer_coordinates` and `answer_text` per table (in the order of their `position`
+index) and batch encode each table with its questions. This will make sure that the `prev_labels` token types (see docs of [`TapasTokenizer`]) are set correctly. See [this notebook](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/TAPAS/Fine_tuning_TapasForQuestionAnswering_on_SQA.ipynb) for more info. See [this notebook](https://github.com/kamalkraj/Tapas-Tutorial/blob/master/TAPAS/Fine_tuning_TapasForQuestionAnswering_on_SQA.ipynb) for more info regarding using the TensorFlow model.
+
+**STEP 4: Train (fine-tune) the model
+
+
+
+You can then fine-tune [`TapasForQuestionAnswering`] as follows (shown here for the weak supervision for aggregation case):
+
+```py
+>>> from transformers import TapasConfig, TapasForQuestionAnswering, AdamW
+
+>>> # this is the default WTQ configuration
+>>> config = TapasConfig(
+... num_aggregation_labels=4,
+... use_answer_as_supervision=True,
+... answer_loss_cutoff=0.664694,
+... cell_selection_preference=0.207951,
+... huber_loss_delta=0.121194,
+... init_cell_selection_weights_to_zero=True,
+... select_one_column=True,
+... allow_empty_column_selection=False,
+... temperature=0.0352513,
+... )
+>>> model = TapasForQuestionAnswering.from_pretrained("google/tapas-base", config=config)
+
+>>> optimizer = AdamW(model.parameters(), lr=5e-5)
+
+>>> model.train()
+>>> for epoch in range(2): # loop over the dataset multiple times
+... for batch in train_dataloader:
+... # get the inputs;
+... input_ids = batch["input_ids"]
+... attention_mask = batch["attention_mask"]
+... token_type_ids = batch["token_type_ids"]
+... labels = batch["labels"]
+... numeric_values = batch["numeric_values"]
+... numeric_values_scale = batch["numeric_values_scale"]
+... float_answer = batch["float_answer"]
+
+... # zero the parameter gradients
+... optimizer.zero_grad()
+
+... # forward + backward + optimize
+... outputs = model(
+... input_ids=input_ids,
+... attention_mask=attention_mask,
+... token_type_ids=token_type_ids,
+... labels=labels,
+... numeric_values=numeric_values,
+... numeric_values_scale=numeric_values_scale,
+... float_answer=float_answer,
+... )
+... loss = outputs.loss
+... loss.backward()
+... optimizer.step()
+```
+
+
+You can then fine-tune [`TFTapasForQuestionAnswering`] as follows (shown here for the weak supervision for aggregation case):
+
+```py
+>>> import tensorflow as tf
+>>> from transformers import TapasConfig, TFTapasForQuestionAnswering
+
+>>> # this is the default WTQ configuration
+>>> config = TapasConfig(
+... num_aggregation_labels=4,
+... use_answer_as_supervision=True,
+... answer_loss_cutoff=0.664694,
+... cell_selection_preference=0.207951,
+... huber_loss_delta=0.121194,
+... init_cell_selection_weights_to_zero=True,
+... select_one_column=True,
+... allow_empty_column_selection=False,
+... temperature=0.0352513,
+... )
+>>> model = TFTapasForQuestionAnswering.from_pretrained("google/tapas-base", config=config)
+
+>>> optimizer = tf.keras.optimizers.Adam(learning_rate=5e-5)
+
+>>> for epoch in range(2): # loop over the dataset multiple times
+... for batch in train_dataloader:
+... # get the inputs;
+... input_ids = batch[0]
+... attention_mask = batch[1]
+... token_type_ids = batch[4]
+... labels = batch[-1]
+... numeric_values = batch[2]
+... numeric_values_scale = batch[3]
+... float_answer = batch[6]
+
+... # forward + backward + optimize
+... with tf.GradientTape() as tape:
+... outputs = model(
+... input_ids=input_ids,
+... attention_mask=attention_mask,
+... token_type_ids=token_type_ids,
+... labels=labels,
+... numeric_values=numeric_values,
+... numeric_values_scale=numeric_values_scale,
+... float_answer=float_answer,
+... )
+... grads = tape.gradient(outputs.loss, model.trainable_weights)
+... optimizer.apply_gradients(zip(grads, model.trainable_weights))
+```
+
+
+
+## Usage: inference
+
+
+
+Here we explain how you can use [`TapasForQuestionAnswering`] or [`TFTapasForQuestionAnswering`] for inference (i.e. making predictions on new data). For inference, only `input_ids`, `attention_mask` and `token_type_ids` (which you can obtain using [`TapasTokenizer`]) have to be provided to the model to obtain the logits. Next, you can use the handy [`~models.tapas.tokenization_tapas.convert_logits_to_predictions`] method to convert these into predicted coordinates and optional aggregation indices.
+
+However, note that inference is **different** depending on whether or not the setup is conversational. In a non-conversational set-up, inference can be done in parallel on all table-question pairs of a batch. Here's an example of that:
+
+```py
+>>> from transformers import TapasTokenizer, TapasForQuestionAnswering
+>>> import pandas as pd
+
+>>> model_name = "google/tapas-base-finetuned-wtq"
+>>> model = TapasForQuestionAnswering.from_pretrained(model_name)
+>>> tokenizer = TapasTokenizer.from_pretrained(model_name)
+
+>>> data = {"Actors": ["Brad Pitt", "Leonardo Di Caprio", "George Clooney"], "Number of movies": ["87", "53", "69"]}
+>>> queries = [
+... "What is the name of the first actor?",
+... "How many movies has George Clooney played in?",
+... "What is the total number of movies?",
+... ]
+>>> table = pd.DataFrame.from_dict(data)
+>>> inputs = tokenizer(table=table, queries=queries, padding="max_length", return_tensors="pt")
+>>> outputs = model(**inputs)
+>>> predicted_answer_coordinates, predicted_aggregation_indices = tokenizer.convert_logits_to_predictions(
+... inputs, outputs.logits.detach(), outputs.logits_aggregation.detach()
+... )
+
+>>> # let's print out the results:
+>>> id2aggregation = {0: "NONE", 1: "SUM", 2: "AVERAGE", 3: "COUNT"}
+>>> aggregation_predictions_string = [id2aggregation[x] for x in predicted_aggregation_indices]
+
+>>> answers = []
+>>> for coordinates in predicted_answer_coordinates:
+... if len(coordinates) == 1:
+... # only a single cell:
+... answers.append(table.iat[coordinates[0]])
+... else:
+... # multiple cells
+... cell_values = []
+... for coordinate in coordinates:
+... cell_values.append(table.iat[coordinate])
+... answers.append(", ".join(cell_values))
+
+>>> display(table)
+>>> print("")
+>>> for query, answer, predicted_agg in zip(queries, answers, aggregation_predictions_string):
+... print(query)
+... if predicted_agg == "NONE":
+... print("Predicted answer: " + answer)
+... else:
+... print("Predicted answer: " + predicted_agg + " > " + answer)
+What is the name of the first actor?
+Predicted answer: Brad Pitt
+How many movies has George Clooney played in?
+Predicted answer: COUNT > 69
+What is the total number of movies?
+Predicted answer: SUM > 87, 53, 69
+```
+
+
+Here we explain how you can use [`TFTapasForQuestionAnswering`] for inference (i.e. making predictions on new data). For inference, only `input_ids`, `attention_mask` and `token_type_ids` (which you can obtain using [`TapasTokenizer`]) have to be provided to the model to obtain the logits. Next, you can use the handy [`~models.tapas.tokenization_tapas.convert_logits_to_predictions`] method to convert these into predicted coordinates and optional aggregation indices.
+
+However, note that inference is **different** depending on whether or not the setup is conversational. In a non-conversational set-up, inference can be done in parallel on all table-question pairs of a batch. Here's an example of that:
+
+```py
+>>> from transformers import TapasTokenizer, TFTapasForQuestionAnswering
+>>> import pandas as pd
+
+>>> model_name = "google/tapas-base-finetuned-wtq"
+>>> model = TFTapasForQuestionAnswering.from_pretrained(model_name)
+>>> tokenizer = TapasTokenizer.from_pretrained(model_name)
+
+>>> data = {"Actors": ["Brad Pitt", "Leonardo Di Caprio", "George Clooney"], "Number of movies": ["87", "53", "69"]}
+>>> queries = [
+... "What is the name of the first actor?",
+... "How many movies has George Clooney played in?",
+... "What is the total number of movies?",
+... ]
+>>> table = pd.DataFrame.from_dict(data)
+>>> inputs = tokenizer(table=table, queries=queries, padding="max_length", return_tensors="tf")
+>>> outputs = model(**inputs)
+>>> predicted_answer_coordinates, predicted_aggregation_indices = tokenizer.convert_logits_to_predictions(
+... inputs, outputs.logits, outputs.logits_aggregation
+... )
+
+>>> # let's print out the results:
+>>> id2aggregation = {0: "NONE", 1: "SUM", 2: "AVERAGE", 3: "COUNT"}
+>>> aggregation_predictions_string = [id2aggregation[x] for x in predicted_aggregation_indices]
+
+>>> answers = []
+>>> for coordinates in predicted_answer_coordinates:
+... if len(coordinates) == 1:
+... # only a single cell:
+... answers.append(table.iat[coordinates[0]])
+... else:
+... # multiple cells
+... cell_values = []
+... for coordinate in coordinates:
+... cell_values.append(table.iat[coordinate])
+... answers.append(", ".join(cell_values))
+
+>>> display(table)
+>>> print("")
+>>> for query, answer, predicted_agg in zip(queries, answers, aggregation_predictions_string):
+... print(query)
+... if predicted_agg == "NONE":
+... print("Predicted answer: " + answer)
+... else:
+... print("Predicted answer: " + predicted_agg + " > " + answer)
+What is the name of the first actor?
+Predicted answer: Brad Pitt
+How many movies has George Clooney played in?
+Predicted answer: COUNT > 69
+What is the total number of movies?
+Predicted answer: SUM > 87, 53, 69
+```
+
+
+
+In case of a conversational set-up, then each table-question pair must be provided **sequentially** to the model, such that the `prev_labels` token types can be overwritten by the predicted `labels` of the previous table-question pair. Again, more info can be found in [this notebook](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/TAPAS/Fine_tuning_TapasForQuestionAnswering_on_SQA.ipynb) (for PyTorch) and [this notebook](https://github.com/kamalkraj/Tapas-Tutorial/blob/master/TAPAS/Fine_tuning_TapasForQuestionAnswering_on_SQA.ipynb) (for TensorFlow).
+
+## TAPAS specific outputs
+[[autodoc]] models.tapas.modeling_tapas.TableQuestionAnsweringOutput
+
+## TapasConfig
+[[autodoc]] TapasConfig
+
+## TapasTokenizer
+[[autodoc]] TapasTokenizer
+ - __call__
+ - convert_logits_to_predictions
+ - save_vocabulary
+
+## TapasModel
+[[autodoc]] TapasModel
+ - forward
+
+## TapasForMaskedLM
+[[autodoc]] TapasForMaskedLM
+ - forward
+
+## TapasForSequenceClassification
+[[autodoc]] TapasForSequenceClassification
+ - forward
+
+## TapasForQuestionAnswering
+[[autodoc]] TapasForQuestionAnswering
+ - forward
+
+## TFTapasModel
+[[autodoc]] TFTapasModel
+ - call
+
+## TFTapasForMaskedLM
+[[autodoc]] TFTapasForMaskedLM
+ - call
+
+## TFTapasForSequenceClassification
+[[autodoc]] TFTapasForSequenceClassification
+ - call
+
+## TFTapasForQuestionAnswering
+[[autodoc]] TFTapasForQuestionAnswering
+ - call
\ No newline at end of file
diff --git a/docs/source/en/model_doc/tapex.mdx b/docs/source/en/model_doc/tapex.mdx
new file mode 100644
index 00000000000000..f6e65764e50d46
--- /dev/null
+++ b/docs/source/en/model_doc/tapex.mdx
@@ -0,0 +1,130 @@
+
+
+# TAPEX
+
+## Overview
+
+The TAPEX model was proposed in [TAPEX: Table Pre-training via Learning a Neural SQL Executor](https://arxiv.org/abs/2107.07653) by Qian Liu,
+Bei Chen, Jiaqi Guo, Morteza Ziyadi, Zeqi Lin, Weizhu Chen, Jian-Guang Lou. TAPEX pre-trains a BART model to solve synthetic SQL queries, after
+which it can be fine-tuned to answer natural language questions related to tabular data, as well as performing table fact checking.
+
+TAPEX has been fine-tuned on several datasets:
+- [SQA](https://www.microsoft.com/en-us/download/details.aspx?id=54253) (Sequential Question Answering by Microsoft)
+- [WTQ](https://github.com/ppasupat/WikiTableQuestions) (Wiki Table Questions by Stanford University)
+- [WikiSQL](https://github.com/salesforce/WikiSQL) (by Salesforce)
+- [TabFact](https://tabfact.github.io/) (by USCB NLP Lab).
+
+The abstract from the paper is the following:
+
+*Recent progress in language model pre-training has achieved a great success via leveraging large-scale unstructured textual data. However, it is
+still a challenge to apply pre-training on structured tabular data due to the absence of large-scale high-quality tabular data. In this paper, we
+propose TAPEX to show that table pre-training can be achieved by learning a neural SQL executor over a synthetic corpus, which is obtained by automatically
+synthesizing executable SQL queries and their execution outputs. TAPEX addresses the data scarcity challenge via guiding the language model to mimic a SQL
+executor on the diverse, large-scale and high-quality synthetic corpus. We evaluate TAPEX on four benchmark datasets. Experimental results demonstrate that
+TAPEX outperforms previous table pre-training approaches by a large margin and achieves new state-of-the-art results on all of them. This includes improvements
+on the weakly-supervised WikiSQL denotation accuracy to 89.5% (+2.3%), the WikiTableQuestions denotation accuracy to 57.5% (+4.8%), the SQA denotation accuracy
+to 74.5% (+3.5%), and the TabFact accuracy to 84.2% (+3.2%). To our knowledge, this is the first work to exploit table pre-training via synthetic executable programs
+and to achieve new state-of-the-art results on various downstream tasks.*
+
+Tips:
+
+- TAPEX is a generative (seq2seq) model. One can directly plug in the weights of TAPEX into a BART model.
+- TAPEX has checkpoints on the hub that are either pre-trained only, or fine-tuned on WTQ, SQA, WikiSQL and TabFact.
+- Sentences + tables are presented to the model as `sentence + " " + linearized table`. The linearized table has the following format:
+ `col: col1 | col2 | col 3 row 1 : val1 | val2 | val3 row 2 : ...`.
+- TAPEX has its own tokenizer, that allows to prepare all data for the model easily. One can pass Pandas DataFrames and strings to the tokenizer,
+ and it will automatically create the `input_ids` and `attention_mask` (as shown in the usage examples below).
+
+## Usage: inference
+
+Below, we illustrate how to use TAPEX for table question answering. As one can see, one can directly plug in the weights of TAPEX into a BART model.
+We use the [Auto API](auto), which will automatically instantiate the appropriate tokenizer ([`TapexTokenizer`]) and model ([`BartForConditionalGeneration`]) for us,
+based on the configuration file of the checkpoint on the hub.
+
+```python
+>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
+>>> import pandas as pd
+
+>>> tokenizer = AutoTokenizer.from_pretrained("microsoft/tapex-large-finetuned-wtq")
+>>> model = AutoModelForSeq2SeqLM.from_pretrained("microsoft/tapex-large-finetuned-wtq")
+
+>>> # prepare table + question
+>>> data = {"Actors": ["Brad Pitt", "Leonardo Di Caprio", "George Clooney"], "Number of movies": ["87", "53", "69"]}
+>>> table = pd.DataFrame.from_dict(data)
+>>> question = "how many movies does Leonardo Di Caprio have?"
+
+>>> encoding = tokenizer(table, question, return_tensors="pt")
+
+>>> # let the model generate an answer autoregressively
+>>> outputs = model.generate(**encoding)
+
+>>> # decode back to text
+>>> predicted_answer = tokenizer.batch_decode(outputs, skip_special_tokens=True)[0]
+>>> print(predicted_answer)
+53
+```
+
+Note that [`TapexTokenizer`] also supports batched inference. Hence, one can provide a batch of different tables/questions, or a batch of a single table
+and multiple questions, or a batch of a single query and multiple tables. Let's illustrate this:
+
+```python
+>>> # prepare table + question
+>>> data = {"Actors": ["Brad Pitt", "Leonardo Di Caprio", "George Clooney"], "Number of movies": ["87", "53", "69"]}
+>>> table = pd.DataFrame.from_dict(data)
+>>> questions = [
+... "how many movies does Leonardo Di Caprio have?",
+... "which actor has 69 movies?",
+... "what's the first name of the actor who has 87 movies?",
+... ]
+>>> encoding = tokenizer(table, questions, padding=True, return_tensors="pt")
+
+>>> # let the model generate an answer autoregressively
+>>> outputs = model.generate(**encoding)
+
+>>> # decode back to text
+>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
+[' 53', ' george clooney', ' brad pitt']
+```
+
+In case one wants to do table verification (i.e. the task of determining whether a given sentence is supported or refuted by the contents
+of a table), one can instantiate a [`BartForSequenceClassification`] model. TAPEX has checkpoints on the hub fine-tuned on TabFact, an important
+benchmark for table fact checking (it achieves 84% accuracy). The code example below again leverages the [Auto API](auto).
+
+```python
+>>> from transformers import AutoTokenizer, AutoModelForSequenceClassification
+
+>>> tokenizer = AutoTokenizer.from_pretrained("microsoft/tapex-large-finetuned-tabfact")
+>>> model = AutoModelForSequenceClassification.from_pretrained("microsoft/tapex-large-finetuned-tabfact")
+
+>>> # prepare table + sentence
+>>> data = {"Actors": ["Brad Pitt", "Leonardo Di Caprio", "George Clooney"], "Number of movies": ["87", "53", "69"]}
+>>> table = pd.DataFrame.from_dict(data)
+>>> sentence = "George Clooney has 30 movies"
+
+>>> encoding = tokenizer(table, sentence, return_tensors="pt")
+
+>>> # forward pass
+>>> outputs = model(**encoding)
+
+>>> # print prediction
+>>> predicted_class_idx = outputs.logits[0].argmax(dim=0).item()
+>>> print(model.config.id2label[predicted_class_idx])
+Refused
+```
+
+
+## TapexTokenizer
+
+[[autodoc]] TapexTokenizer
+ - __call__
+ - save_vocabulary
\ No newline at end of file
diff --git a/docs/source/en/model_doc/transfo-xl.mdx b/docs/source/en/model_doc/transfo-xl.mdx
new file mode 100644
index 00000000000000..7e2a7701426c8c
--- /dev/null
+++ b/docs/source/en/model_doc/transfo-xl.mdx
@@ -0,0 +1,103 @@
+
+
+# Transformer XL
+
+## Overview
+
+The Transformer-XL model was proposed in [Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context](https://arxiv.org/abs/1901.02860) by Zihang Dai, Zhilin Yang, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan
+Salakhutdinov. It's a causal (uni-directional) transformer with relative positioning (sinusoïdal) embeddings which can
+reuse previously computed hidden-states to attend to longer context (memory). This model also uses adaptive softmax
+inputs and outputs (tied).
+
+The abstract from the paper is the following:
+
+*Transformers have a potential of learning longer-term dependency, but are limited by a fixed-length context in the
+setting of language modeling. We propose a novel neural architecture Transformer-XL that enables learning dependency
+beyond a fixed length without disrupting temporal coherence. It consists of a segment-level recurrence mechanism and a
+novel positional encoding scheme. Our method not only enables capturing longer-term dependency, but also resolves the
+context fragmentation problem. As a result, Transformer-XL learns dependency that is 80% longer than RNNs and 450%
+longer than vanilla Transformers, achieves better performance on both short and long sequences, and is up to 1,800+
+times faster than vanilla Transformers during evaluation. Notably, we improve the state-of-the-art results of
+bpc/perplexity to 0.99 on enwiki8, 1.08 on text8, 18.3 on WikiText-103, 21.8 on One Billion Word, and 54.5 on Penn
+Treebank (without finetuning). When trained only on WikiText-103, Transformer-XL manages to generate reasonably
+coherent, novel text articles with thousands of tokens.*
+
+Tips:
+
+- Transformer-XL uses relative sinusoidal positional embeddings. Padding can be done on the left or on the right. The
+ original implementation trains on SQuAD with padding on the left, therefore the padding defaults are set to left.
+- Transformer-XL is one of the few models that has no sequence length limit.
+
+This model was contributed by [thomwolf](https://huggingface.co/thomwolf). The original code can be found [here](https://github.com/kimiyoung/transformer-xl).
+
+
+
+TransformerXL does **not** work with *torch.nn.DataParallel* due to a bug in PyTorch, see [issue #36035](https://github.com/pytorch/pytorch/issues/36035)
+
+
+
+
+## TransfoXLConfig
+
+[[autodoc]] TransfoXLConfig
+
+## TransfoXLTokenizer
+
+[[autodoc]] TransfoXLTokenizer
+ - save_vocabulary
+
+## TransfoXL specific outputs
+
+[[autodoc]] models.transfo_xl.modeling_transfo_xl.TransfoXLModelOutput
+
+[[autodoc]] models.transfo_xl.modeling_transfo_xl.TransfoXLLMHeadModelOutput
+
+[[autodoc]] models.transfo_xl.modeling_tf_transfo_xl.TFTransfoXLModelOutput
+
+[[autodoc]] models.transfo_xl.modeling_tf_transfo_xl.TFTransfoXLLMHeadModelOutput
+
+## TransfoXLModel
+
+[[autodoc]] TransfoXLModel
+ - forward
+
+## TransfoXLLMHeadModel
+
+[[autodoc]] TransfoXLLMHeadModel
+ - forward
+
+## TransfoXLForSequenceClassification
+
+[[autodoc]] TransfoXLForSequenceClassification
+ - forward
+
+## TFTransfoXLModel
+
+[[autodoc]] TFTransfoXLModel
+ - call
+
+## TFTransfoXLLMHeadModel
+
+[[autodoc]] TFTransfoXLLMHeadModel
+ - call
+
+## TFTransfoXLForSequenceClassification
+
+[[autodoc]] TFTransfoXLForSequenceClassification
+ - call
+
+## Internal Layers
+
+[[autodoc]] AdaptiveEmbedding
+
+[[autodoc]] TFAdaptiveEmbedding
diff --git a/docs/source/en/model_doc/trocr.mdx b/docs/source/en/model_doc/trocr.mdx
new file mode 100644
index 00000000000000..08de107e434c34
--- /dev/null
+++ b/docs/source/en/model_doc/trocr.mdx
@@ -0,0 +1,102 @@
+
+
+# TrOCR
+
+## Overview
+
+The TrOCR model was proposed in [TrOCR: Transformer-based Optical Character Recognition with Pre-trained
+Models](https://arxiv.org/abs/2109.10282) by Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang,
+Zhoujun Li, Furu Wei. TrOCR consists of an image Transformer encoder and an autoregressive text Transformer decoder to
+perform [optical character recognition (OCR)](https://en.wikipedia.org/wiki/Optical_character_recognition).
+
+The abstract from the paper is the following:
+
+*Text recognition is a long-standing research problem for document digitalization. Existing approaches for text recognition
+are usually built based on CNN for image understanding and RNN for char-level text generation. In addition, another language
+model is usually needed to improve the overall accuracy as a post-processing step. In this paper, we propose an end-to-end
+text recognition approach with pre-trained image Transformer and text Transformer models, namely TrOCR, which leverages the
+Transformer architecture for both image understanding and wordpiece-level text generation. The TrOCR model is simple but
+effective, and can be pre-trained with large-scale synthetic data and fine-tuned with human-labeled datasets. Experiments
+show that the TrOCR model outperforms the current state-of-the-art models on both printed and handwritten text recognition
+tasks.*
+
+
+
+ TAPAS architecture. Taken from the original blog post.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The Tensorflow version of this model was contributed by [kamalkraj](https://huggingface.co/kamalkraj). The original code can be found [here](https://github.com/google-research/tapas).
+
+Tips:
+
+- TAPAS is a model that uses relative position embeddings by default (restarting the position embeddings at every cell of the table). Note that this is something that was added after the publication of the original TAPAS paper. According to the authors, this usually results in a slightly better performance, and allows you to encode longer sequences without running out of embeddings. This is reflected in the `reset_position_index_per_cell` parameter of [`TapasConfig`], which is set to `True` by default. The default versions of the models available on the [hub](https://huggingface.co/models?search=tapas) all use relative position embeddings. You can still use the ones with absolute position embeddings by passing in an additional argument `revision="no_reset"` when calling the `from_pretrained()` method. Note that it's usually advised to pad the inputs on the right rather than the left.
+- TAPAS is based on BERT, so `TAPAS-base` for example corresponds to a `BERT-base` architecture. Of course, `TAPAS-large` will result in the best performance (the results reported in the paper are from `TAPAS-large`). Results of the various sized models are shown on the [original Github repository](https://github.com/google-research/tapas>).
+- TAPAS has checkpoints fine-tuned on SQA, which are capable of answering questions related to a table in a conversational set-up. This means that you can ask follow-up questions such as "what is his age?" related to the previous question. Note that the forward pass of TAPAS is a bit different in case of a conversational set-up: in that case, you have to feed every table-question pair one by one to the model, such that the `prev_labels` token type ids can be overwritten by the predicted `labels` of the model to the previous question. See "Usage" section for more info.
+- TAPAS is similar to BERT and therefore relies on the masked language modeling (MLM) objective. It is therefore efficient at predicting masked tokens and at NLU in general, but is not optimal for text generation. Models trained with a causal language modeling (CLM) objective are better in that regard. Note that TAPAS can be used as an encoder in the EncoderDecoderModel framework, to combine it with an autoregressive text decoder such as GPT-2.
+
+## Usage: fine-tuning
+
+Here we explain how you can fine-tune [`TapasForQuestionAnswering`] on your own dataset.
+
+**STEP 1: Choose one of the 3 ways in which you can use TAPAS - or experiment**
+
+Basically, there are 3 different ways in which one can fine-tune [`TapasForQuestionAnswering`], corresponding to the different datasets on which Tapas was fine-tuned:
+
+1. SQA: if you're interested in asking follow-up questions related to a table, in a conversational set-up. For example if you first ask "what's the name of the first actor?" then you can ask a follow-up question such as "how old is he?". Here, questions do not involve any aggregation (all questions are cell selection questions).
+2. WTQ: if you're not interested in asking questions in a conversational set-up, but rather just asking questions related to a table, which might involve aggregation, such as counting a number of rows, summing up cell values or averaging cell values. You can then for example ask "what's the total number of goals Cristiano Ronaldo made in his career?". This case is also called **weak supervision**, since the model itself must learn the appropriate aggregation operator (SUM/COUNT/AVERAGE/NONE) given only the answer to the question as supervision.
+3. WikiSQL-supervised: this dataset is based on WikiSQL with the model being given the ground truth aggregation operator during training. This is also called **strong supervision**. Here, learning the appropriate aggregation operator is much easier.
+
+To summarize:
+
+| **Task** | **Example dataset** | **Description** |
+|-------------------------------------|---------------------|---------------------------------------------------------------------------------------------------------|
+| Conversational | SQA | Conversational, only cell selection questions |
+| Weak supervision for aggregation | WTQ | Questions might involve aggregation, and the model must learn this given only the answer as supervision |
+| Strong supervision for aggregation | WikiSQL-supervised | Questions might involve aggregation, and the model must learn this given the gold aggregation operator |
+
+
+
+Initializing a model with a pre-trained base and randomly initialized classification heads from the hub can be done as shown below. Be sure to have installed the
+[torch-scatter](https://github.com/rusty1s/pytorch_scatter) dependency:
+
+```py
+>>> from transformers import TapasConfig, TapasForQuestionAnswering
+
+>>> # for example, the base sized model with default SQA configuration
+>>> model = TapasForQuestionAnswering.from_pretrained("google/tapas-base")
+
+>>> # or, the base sized model with WTQ configuration
+>>> config = TapasConfig.from_pretrained("google/tapas-base-finetuned-wtq")
+>>> model = TapasForQuestionAnswering.from_pretrained("google/tapas-base", config=config)
+
+>>> # or, the base sized model with WikiSQL configuration
+>>> config = TapasConfig("google-base-finetuned-wikisql-supervised")
+>>> model = TapasForQuestionAnswering.from_pretrained("google/tapas-base", config=config)
+```
+
+Of course, you don't necessarily have to follow one of these three ways in which TAPAS was fine-tuned. You can also experiment by defining any hyperparameters you want when initializing [`TapasConfig`], and then create a [`TapasForQuestionAnswering`] based on that configuration. For example, if you have a dataset that has both conversational questions and questions that might involve aggregation, then you can do it this way. Here's an example:
+
+```py
+>>> from transformers import TapasConfig, TapasForQuestionAnswering
+
+>>> # you can initialize the classification heads any way you want (see docs of TapasConfig)
+>>> config = TapasConfig(num_aggregation_labels=3, average_logits_per_cell=True)
+>>> # initializing the pre-trained base sized model with our custom classification heads
+>>> model = TapasForQuestionAnswering.from_pretrained("google/tapas-base", config=config)
+```
+
+
+Initializing a model with a pre-trained base and randomly initialized classification heads from the hub can be done as shown below. Be sure to have installed the [tensorflow_probability](https://github.com/tensorflow/probability) dependency:
+
+```py
+>>> from transformers import TapasConfig, TFTapasForQuestionAnswering
+
+>>> # for example, the base sized model with default SQA configuration
+>>> model = TFTapasForQuestionAnswering.from_pretrained("google/tapas-base")
+
+>>> # or, the base sized model with WTQ configuration
+>>> config = TapasConfig.from_pretrained("google/tapas-base-finetuned-wtq")
+>>> model = TFTapasForQuestionAnswering.from_pretrained("google/tapas-base", config=config)
+
+>>> # or, the base sized model with WikiSQL configuration
+>>> config = TapasConfig("google-base-finetuned-wikisql-supervised")
+>>> model = TFTapasForQuestionAnswering.from_pretrained("google/tapas-base", config=config)
+```
+
+Of course, you don't necessarily have to follow one of these three ways in which TAPAS was fine-tuned. You can also experiment by defining any hyperparameters you want when initializing [`TapasConfig`], and then create a [`TFTapasForQuestionAnswering`] based on that configuration. For example, if you have a dataset that has both conversational questions and questions that might involve aggregation, then you can do it this way. Here's an example:
+
+```py
+>>> from transformers import TapasConfig, TFTapasForQuestionAnswering
+
+>>> # you can initialize the classification heads any way you want (see docs of TapasConfig)
+>>> config = TapasConfig(num_aggregation_labels=3, average_logits_per_cell=True)
+>>> # initializing the pre-trained base sized model with our custom classification heads
+>>> model = TFTapasForQuestionAnswering.from_pretrained("google/tapas-base", config=config)
+```
+
+
+
+What you can also do is start from an already fine-tuned checkpoint. A note here is that the already fine-tuned checkpoint on WTQ has some issues due to the L2-loss which is somewhat brittle. See [here](https://github.com/google-research/tapas/issues/91#issuecomment-735719340) for more info.
+
+For a list of all pre-trained and fine-tuned TAPAS checkpoints available on HuggingFace's hub, see [here](https://huggingface.co/models?search=tapas).
+
+**STEP 2: Prepare your data in the SQA format**
+
+Second, no matter what you picked above, you should prepare your dataset in the [SQA](https://www.microsoft.com/en-us/download/details.aspx?id=54253) format. This format is a TSV/CSV file with the following columns:
+
+- `id`: optional, id of the table-question pair, for bookkeeping purposes.
+- `annotator`: optional, id of the person who annotated the table-question pair, for bookkeeping purposes.
+- `position`: integer indicating if the question is the first, second, third,... related to the table. Only required in case of conversational setup (SQA). You don't need this column in case you're going for WTQ/WikiSQL-supervised.
+- `question`: string
+- `table_file`: string, name of a csv file containing the tabular data
+- `answer_coordinates`: list of one or more tuples (each tuple being a cell coordinate, i.e. row, column pair that is part of the answer)
+- `answer_text`: list of one or more strings (each string being a cell value that is part of the answer)
+- `aggregation_label`: index of the aggregation operator. Only required in case of strong supervision for aggregation (the WikiSQL-supervised case)
+- `float_answer`: the float answer to the question, if there is one (np.nan if there isn't). Only required in case of weak supervision for aggregation (such as WTQ and WikiSQL)
+
+The tables themselves should be present in a folder, each table being a separate csv file. Note that the authors of the TAPAS algorithm used conversion scripts with some automated logic to convert the other datasets (WTQ, WikiSQL) into the SQA format. The author explains this [here](https://github.com/google-research/tapas/issues/50#issuecomment-705465960). A conversion of this script that works with HuggingFace's implementation can be found [here](https://github.com/NielsRogge/tapas_utils). Interestingly, these conversion scripts are not perfect (the `answer_coordinates` and `float_answer` fields are populated based on the `answer_text`), meaning that WTQ and WikiSQL results could actually be improved.
+
+**STEP 3: Convert your data into tensors using TapasTokenizer**
+
+
+
+Third, given that you've prepared your data in this TSV/CSV format (and corresponding CSV files containing the tabular data), you can then use [`TapasTokenizer`] to convert table-question pairs into `input_ids`, `attention_mask`, `token_type_ids` and so on. Again, based on which of the three cases you picked above, [`TapasForQuestionAnswering`] requires different
+inputs to be fine-tuned:
+
+| **Task** | **Required inputs** |
+|------------------------------------|---------------------------------------------------------------------------------------------------------------------|
+| Conversational | `input_ids`, `attention_mask`, `token_type_ids`, `labels` |
+| Weak supervision for aggregation | `input_ids`, `attention_mask`, `token_type_ids`, `labels`, `numeric_values`, `numeric_values_scale`, `float_answer` |
+| Strong supervision for aggregation | `input ids`, `attention mask`, `token type ids`, `labels`, `aggregation_labels` |
+
+[`TapasTokenizer`] creates the `labels`, `numeric_values` and `numeric_values_scale` based on the `answer_coordinates` and `answer_text` columns of the TSV file. The `float_answer` and `aggregation_labels` are already in the TSV file of step 2. Here's an example:
+
+```py
+>>> from transformers import TapasTokenizer
+>>> import pandas as pd
+
+>>> model_name = "google/tapas-base"
+>>> tokenizer = TapasTokenizer.from_pretrained(model_name)
+
+>>> data = {"Actors": ["Brad Pitt", "Leonardo Di Caprio", "George Clooney"], "Number of movies": ["87", "53", "69"]}
+>>> queries = [
+... "What is the name of the first actor?",
+... "How many movies has George Clooney played in?",
+... "What is the total number of movies?",
+... ]
+>>> answer_coordinates = [[(0, 0)], [(2, 1)], [(0, 1), (1, 1), (2, 1)]]
+>>> answer_text = [["Brad Pitt"], ["69"], ["209"]]
+>>> table = pd.DataFrame.from_dict(data)
+>>> inputs = tokenizer(
+... table=table,
+... queries=queries,
+... answer_coordinates=answer_coordinates,
+... answer_text=answer_text,
+... padding="max_length",
+... return_tensors="pt",
+... )
+>>> inputs
+{'input_ids': tensor([[ ... ]]), 'attention_mask': tensor([[...]]), 'token_type_ids': tensor([[[...]]]),
+'numeric_values': tensor([[ ... ]]), 'numeric_values_scale: tensor([[ ... ]]), labels: tensor([[ ... ]])}
+```
+
+Note that [`TapasTokenizer`] expects the data of the table to be **text-only**. You can use `.astype(str)` on a dataframe to turn it into text-only data.
+Of course, this only shows how to encode a single training example. It is advised to create a dataloader to iterate over batches:
+
+```py
+>>> import torch
+>>> import pandas as pd
+
+>>> tsv_path = "your_path_to_the_tsv_file"
+>>> table_csv_path = "your_path_to_a_directory_containing_all_csv_files"
+
+
+>>> class TableDataset(torch.utils.data.Dataset):
+... def __init__(self, data, tokenizer):
+... self.data = data
+... self.tokenizer = tokenizer
+
+... def __getitem__(self, idx):
+... item = data.iloc[idx]
+... table = pd.read_csv(table_csv_path + item.table_file).astype(
+... str
+... ) # be sure to make your table data text only
+... encoding = self.tokenizer(
+... table=table,
+... queries=item.question,
+... answer_coordinates=item.answer_coordinates,
+... answer_text=item.answer_text,
+... truncation=True,
+... padding="max_length",
+... return_tensors="pt",
+... )
+... # remove the batch dimension which the tokenizer adds by default
+... encoding = {key: val.squeeze(0) for key, val in encoding.items()}
+... # add the float_answer which is also required (weak supervision for aggregation case)
+... encoding["float_answer"] = torch.tensor(item.float_answer)
+... return encoding
+
+... def __len__(self):
+... return len(self.data)
+
+
+>>> data = pd.read_csv(tsv_path, sep="\t")
+>>> train_dataset = TableDataset(data, tokenizer)
+>>> train_dataloader = torch.utils.data.DataLoader(train_dataset, batch_size=32)
+```
+
+
+Third, given that you've prepared your data in this TSV/CSV format (and corresponding CSV files containing the tabular data), you can then use [`TapasTokenizer`] to convert table-question pairs into `input_ids`, `attention_mask`, `token_type_ids` and so on. Again, based on which of the three cases you picked above, [`TFTapasForQuestionAnswering`] requires different
+inputs to be fine-tuned:
+
+| **Task** | **Required inputs** |
+|------------------------------------|---------------------------------------------------------------------------------------------------------------------|
+| Conversational | `input_ids`, `attention_mask`, `token_type_ids`, `labels` |
+| Weak supervision for aggregation | `input_ids`, `attention_mask`, `token_type_ids`, `labels`, `numeric_values`, `numeric_values_scale`, `float_answer` |
+| Strong supervision for aggregation | `input ids`, `attention mask`, `token type ids`, `labels`, `aggregation_labels` |
+
+[`TapasTokenizer`] creates the `labels`, `numeric_values` and `numeric_values_scale` based on the `answer_coordinates` and `answer_text` columns of the TSV file. The `float_answer` and `aggregation_labels` are already in the TSV file of step 2. Here's an example:
+
+```py
+>>> from transformers import TapasTokenizer
+>>> import pandas as pd
+
+>>> model_name = "google/tapas-base"
+>>> tokenizer = TapasTokenizer.from_pretrained(model_name)
+
+>>> data = {"Actors": ["Brad Pitt", "Leonardo Di Caprio", "George Clooney"], "Number of movies": ["87", "53", "69"]}
+>>> queries = [
+... "What is the name of the first actor?",
+... "How many movies has George Clooney played in?",
+... "What is the total number of movies?",
+... ]
+>>> answer_coordinates = [[(0, 0)], [(2, 1)], [(0, 1), (1, 1), (2, 1)]]
+>>> answer_text = [["Brad Pitt"], ["69"], ["209"]]
+>>> table = pd.DataFrame.from_dict(data)
+>>> inputs = tokenizer(
+... table=table,
+... queries=queries,
+... answer_coordinates=answer_coordinates,
+... answer_text=answer_text,
+... padding="max_length",
+... return_tensors="tf",
+... )
+>>> inputs
+{'input_ids': tensor([[ ... ]]), 'attention_mask': tensor([[...]]), 'token_type_ids': tensor([[[...]]]),
+'numeric_values': tensor([[ ... ]]), 'numeric_values_scale: tensor([[ ... ]]), labels: tensor([[ ... ]])}
+```
+
+Note that [`TapasTokenizer`] expects the data of the table to be **text-only**. You can use `.astype(str)` on a dataframe to turn it into text-only data.
+Of course, this only shows how to encode a single training example. It is advised to create a dataloader to iterate over batches:
+
+```py
+>>> import tensorflow as tf
+>>> import pandas as pd
+
+>>> tsv_path = "your_path_to_the_tsv_file"
+>>> table_csv_path = "your_path_to_a_directory_containing_all_csv_files"
+
+
+>>> class TableDataset:
+... def __init__(self, data, tokenizer):
+... self.data = data
+... self.tokenizer = tokenizer
+
+... def __iter__(self):
+... for idx in range(self.__len__()):
+... item = self.data.iloc[idx]
+... table = pd.read_csv(table_csv_path + item.table_file).astype(
+... str
+... ) # be sure to make your table data text only
+... encoding = self.tokenizer(
+... table=table,
+... queries=item.question,
+... answer_coordinates=item.answer_coordinates,
+... answer_text=item.answer_text,
+... truncation=True,
+... padding="max_length",
+... return_tensors="tf",
+... )
+... # remove the batch dimension which the tokenizer adds by default
+... encoding = {key: tf.squeeze(val, 0) for key, val in encoding.items()}
+... # add the float_answer which is also required (weak supervision for aggregation case)
+... encoding["float_answer"] = tf.convert_to_tensor(item.float_answer, dtype=tf.float32)
+... yield encoding["input_ids"], encoding["attention_mask"], encoding["numeric_values"], encoding[
+... "numeric_values_scale"
+... ], encoding["token_type_ids"], encoding["labels"], encoding["float_answer"]
+
+... def __len__(self):
+... return len(self.data)
+
+
+>>> data = pd.read_csv(tsv_path, sep="\t")
+>>> train_dataset = TableDataset(data, tokenizer)
+>>> output_signature = (
+... tf.TensorSpec(shape=(512,), dtype=tf.int32),
+... tf.TensorSpec(shape=(512,), dtype=tf.int32),
+... tf.TensorSpec(shape=(512,), dtype=tf.float32),
+... tf.TensorSpec(shape=(512,), dtype=tf.float32),
+... tf.TensorSpec(shape=(512, 7), dtype=tf.int32),
+... tf.TensorSpec(shape=(512,), dtype=tf.int32),
+... tf.TensorSpec(shape=(512,), dtype=tf.float32),
+... )
+>>> train_dataloader = tf.data.Dataset.from_generator(train_dataset, output_signature=output_signature).batch(32)
+```
+
+
+
+Note that here, we encode each table-question pair independently. This is fine as long as your dataset is **not conversational**. In case your dataset involves conversational questions (such as in SQA), then you should first group together the `queries`, `answer_coordinates` and `answer_text` per table (in the order of their `position`
+index) and batch encode each table with its questions. This will make sure that the `prev_labels` token types (see docs of [`TapasTokenizer`]) are set correctly. See [this notebook](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/TAPAS/Fine_tuning_TapasForQuestionAnswering_on_SQA.ipynb) for more info. See [this notebook](https://github.com/kamalkraj/Tapas-Tutorial/blob/master/TAPAS/Fine_tuning_TapasForQuestionAnswering_on_SQA.ipynb) for more info regarding using the TensorFlow model.
+
+**STEP 4: Train (fine-tune) the model
+
+
+
+You can then fine-tune [`TapasForQuestionAnswering`] as follows (shown here for the weak supervision for aggregation case):
+
+```py
+>>> from transformers import TapasConfig, TapasForQuestionAnswering, AdamW
+
+>>> # this is the default WTQ configuration
+>>> config = TapasConfig(
+... num_aggregation_labels=4,
+... use_answer_as_supervision=True,
+... answer_loss_cutoff=0.664694,
+... cell_selection_preference=0.207951,
+... huber_loss_delta=0.121194,
+... init_cell_selection_weights_to_zero=True,
+... select_one_column=True,
+... allow_empty_column_selection=False,
+... temperature=0.0352513,
+... )
+>>> model = TapasForQuestionAnswering.from_pretrained("google/tapas-base", config=config)
+
+>>> optimizer = AdamW(model.parameters(), lr=5e-5)
+
+>>> model.train()
+>>> for epoch in range(2): # loop over the dataset multiple times
+... for batch in train_dataloader:
+... # get the inputs;
+... input_ids = batch["input_ids"]
+... attention_mask = batch["attention_mask"]
+... token_type_ids = batch["token_type_ids"]
+... labels = batch["labels"]
+... numeric_values = batch["numeric_values"]
+... numeric_values_scale = batch["numeric_values_scale"]
+... float_answer = batch["float_answer"]
+
+... # zero the parameter gradients
+... optimizer.zero_grad()
+
+... # forward + backward + optimize
+... outputs = model(
+... input_ids=input_ids,
+... attention_mask=attention_mask,
+... token_type_ids=token_type_ids,
+... labels=labels,
+... numeric_values=numeric_values,
+... numeric_values_scale=numeric_values_scale,
+... float_answer=float_answer,
+... )
+... loss = outputs.loss
+... loss.backward()
+... optimizer.step()
+```
+
+
+You can then fine-tune [`TFTapasForQuestionAnswering`] as follows (shown here for the weak supervision for aggregation case):
+
+```py
+>>> import tensorflow as tf
+>>> from transformers import TapasConfig, TFTapasForQuestionAnswering
+
+>>> # this is the default WTQ configuration
+>>> config = TapasConfig(
+... num_aggregation_labels=4,
+... use_answer_as_supervision=True,
+... answer_loss_cutoff=0.664694,
+... cell_selection_preference=0.207951,
+... huber_loss_delta=0.121194,
+... init_cell_selection_weights_to_zero=True,
+... select_one_column=True,
+... allow_empty_column_selection=False,
+... temperature=0.0352513,
+... )
+>>> model = TFTapasForQuestionAnswering.from_pretrained("google/tapas-base", config=config)
+
+>>> optimizer = tf.keras.optimizers.Adam(learning_rate=5e-5)
+
+>>> for epoch in range(2): # loop over the dataset multiple times
+... for batch in train_dataloader:
+... # get the inputs;
+... input_ids = batch[0]
+... attention_mask = batch[1]
+... token_type_ids = batch[4]
+... labels = batch[-1]
+... numeric_values = batch[2]
+... numeric_values_scale = batch[3]
+... float_answer = batch[6]
+
+... # forward + backward + optimize
+... with tf.GradientTape() as tape:
+... outputs = model(
+... input_ids=input_ids,
+... attention_mask=attention_mask,
+... token_type_ids=token_type_ids,
+... labels=labels,
+... numeric_values=numeric_values,
+... numeric_values_scale=numeric_values_scale,
+... float_answer=float_answer,
+... )
+... grads = tape.gradient(outputs.loss, model.trainable_weights)
+... optimizer.apply_gradients(zip(grads, model.trainable_weights))
+```
+
+
+
+## Usage: inference
+
+
+
+Here we explain how you can use [`TapasForQuestionAnswering`] or [`TFTapasForQuestionAnswering`] for inference (i.e. making predictions on new data). For inference, only `input_ids`, `attention_mask` and `token_type_ids` (which you can obtain using [`TapasTokenizer`]) have to be provided to the model to obtain the logits. Next, you can use the handy [`~models.tapas.tokenization_tapas.convert_logits_to_predictions`] method to convert these into predicted coordinates and optional aggregation indices.
+
+However, note that inference is **different** depending on whether or not the setup is conversational. In a non-conversational set-up, inference can be done in parallel on all table-question pairs of a batch. Here's an example of that:
+
+```py
+>>> from transformers import TapasTokenizer, TapasForQuestionAnswering
+>>> import pandas as pd
+
+>>> model_name = "google/tapas-base-finetuned-wtq"
+>>> model = TapasForQuestionAnswering.from_pretrained(model_name)
+>>> tokenizer = TapasTokenizer.from_pretrained(model_name)
+
+>>> data = {"Actors": ["Brad Pitt", "Leonardo Di Caprio", "George Clooney"], "Number of movies": ["87", "53", "69"]}
+>>> queries = [
+... "What is the name of the first actor?",
+... "How many movies has George Clooney played in?",
+... "What is the total number of movies?",
+... ]
+>>> table = pd.DataFrame.from_dict(data)
+>>> inputs = tokenizer(table=table, queries=queries, padding="max_length", return_tensors="pt")
+>>> outputs = model(**inputs)
+>>> predicted_answer_coordinates, predicted_aggregation_indices = tokenizer.convert_logits_to_predictions(
+... inputs, outputs.logits.detach(), outputs.logits_aggregation.detach()
+... )
+
+>>> # let's print out the results:
+>>> id2aggregation = {0: "NONE", 1: "SUM", 2: "AVERAGE", 3: "COUNT"}
+>>> aggregation_predictions_string = [id2aggregation[x] for x in predicted_aggregation_indices]
+
+>>> answers = []
+>>> for coordinates in predicted_answer_coordinates:
+... if len(coordinates) == 1:
+... # only a single cell:
+... answers.append(table.iat[coordinates[0]])
+... else:
+... # multiple cells
+... cell_values = []
+... for coordinate in coordinates:
+... cell_values.append(table.iat[coordinate])
+... answers.append(", ".join(cell_values))
+
+>>> display(table)
+>>> print("")
+>>> for query, answer, predicted_agg in zip(queries, answers, aggregation_predictions_string):
+... print(query)
+... if predicted_agg == "NONE":
+... print("Predicted answer: " + answer)
+... else:
+... print("Predicted answer: " + predicted_agg + " > " + answer)
+What is the name of the first actor?
+Predicted answer: Brad Pitt
+How many movies has George Clooney played in?
+Predicted answer: COUNT > 69
+What is the total number of movies?
+Predicted answer: SUM > 87, 53, 69
+```
+
+
+Here we explain how you can use [`TFTapasForQuestionAnswering`] for inference (i.e. making predictions on new data). For inference, only `input_ids`, `attention_mask` and `token_type_ids` (which you can obtain using [`TapasTokenizer`]) have to be provided to the model to obtain the logits. Next, you can use the handy [`~models.tapas.tokenization_tapas.convert_logits_to_predictions`] method to convert these into predicted coordinates and optional aggregation indices.
+
+However, note that inference is **different** depending on whether or not the setup is conversational. In a non-conversational set-up, inference can be done in parallel on all table-question pairs of a batch. Here's an example of that:
+
+```py
+>>> from transformers import TapasTokenizer, TFTapasForQuestionAnswering
+>>> import pandas as pd
+
+>>> model_name = "google/tapas-base-finetuned-wtq"
+>>> model = TFTapasForQuestionAnswering.from_pretrained(model_name)
+>>> tokenizer = TapasTokenizer.from_pretrained(model_name)
+
+>>> data = {"Actors": ["Brad Pitt", "Leonardo Di Caprio", "George Clooney"], "Number of movies": ["87", "53", "69"]}
+>>> queries = [
+... "What is the name of the first actor?",
+... "How many movies has George Clooney played in?",
+... "What is the total number of movies?",
+... ]
+>>> table = pd.DataFrame.from_dict(data)
+>>> inputs = tokenizer(table=table, queries=queries, padding="max_length", return_tensors="tf")
+>>> outputs = model(**inputs)
+>>> predicted_answer_coordinates, predicted_aggregation_indices = tokenizer.convert_logits_to_predictions(
+... inputs, outputs.logits, outputs.logits_aggregation
+... )
+
+>>> # let's print out the results:
+>>> id2aggregation = {0: "NONE", 1: "SUM", 2: "AVERAGE", 3: "COUNT"}
+>>> aggregation_predictions_string = [id2aggregation[x] for x in predicted_aggregation_indices]
+
+>>> answers = []
+>>> for coordinates in predicted_answer_coordinates:
+... if len(coordinates) == 1:
+... # only a single cell:
+... answers.append(table.iat[coordinates[0]])
+... else:
+... # multiple cells
+... cell_values = []
+... for coordinate in coordinates:
+... cell_values.append(table.iat[coordinate])
+... answers.append(", ".join(cell_values))
+
+>>> display(table)
+>>> print("")
+>>> for query, answer, predicted_agg in zip(queries, answers, aggregation_predictions_string):
+... print(query)
+... if predicted_agg == "NONE":
+... print("Predicted answer: " + answer)
+... else:
+... print("Predicted answer: " + predicted_agg + " > " + answer)
+What is the name of the first actor?
+Predicted answer: Brad Pitt
+How many movies has George Clooney played in?
+Predicted answer: COUNT > 69
+What is the total number of movies?
+Predicted answer: SUM > 87, 53, 69
+```
+
+
+
+In case of a conversational set-up, then each table-question pair must be provided **sequentially** to the model, such that the `prev_labels` token types can be overwritten by the predicted `labels` of the previous table-question pair. Again, more info can be found in [this notebook](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/TAPAS/Fine_tuning_TapasForQuestionAnswering_on_SQA.ipynb) (for PyTorch) and [this notebook](https://github.com/kamalkraj/Tapas-Tutorial/blob/master/TAPAS/Fine_tuning_TapasForQuestionAnswering_on_SQA.ipynb) (for TensorFlow).
+
+## TAPAS specific outputs
+[[autodoc]] models.tapas.modeling_tapas.TableQuestionAnsweringOutput
+
+## TapasConfig
+[[autodoc]] TapasConfig
+
+## TapasTokenizer
+[[autodoc]] TapasTokenizer
+ - __call__
+ - convert_logits_to_predictions
+ - save_vocabulary
+
+## TapasModel
+[[autodoc]] TapasModel
+ - forward
+
+## TapasForMaskedLM
+[[autodoc]] TapasForMaskedLM
+ - forward
+
+## TapasForSequenceClassification
+[[autodoc]] TapasForSequenceClassification
+ - forward
+
+## TapasForQuestionAnswering
+[[autodoc]] TapasForQuestionAnswering
+ - forward
+
+## TFTapasModel
+[[autodoc]] TFTapasModel
+ - call
+
+## TFTapasForMaskedLM
+[[autodoc]] TFTapasForMaskedLM
+ - call
+
+## TFTapasForSequenceClassification
+[[autodoc]] TFTapasForSequenceClassification
+ - call
+
+## TFTapasForQuestionAnswering
+[[autodoc]] TFTapasForQuestionAnswering
+ - call
\ No newline at end of file
diff --git a/docs/source/en/model_doc/tapex.mdx b/docs/source/en/model_doc/tapex.mdx
new file mode 100644
index 00000000000000..f6e65764e50d46
--- /dev/null
+++ b/docs/source/en/model_doc/tapex.mdx
@@ -0,0 +1,130 @@
+
+
+# TAPEX
+
+## Overview
+
+The TAPEX model was proposed in [TAPEX: Table Pre-training via Learning a Neural SQL Executor](https://arxiv.org/abs/2107.07653) by Qian Liu,
+Bei Chen, Jiaqi Guo, Morteza Ziyadi, Zeqi Lin, Weizhu Chen, Jian-Guang Lou. TAPEX pre-trains a BART model to solve synthetic SQL queries, after
+which it can be fine-tuned to answer natural language questions related to tabular data, as well as performing table fact checking.
+
+TAPEX has been fine-tuned on several datasets:
+- [SQA](https://www.microsoft.com/en-us/download/details.aspx?id=54253) (Sequential Question Answering by Microsoft)
+- [WTQ](https://github.com/ppasupat/WikiTableQuestions) (Wiki Table Questions by Stanford University)
+- [WikiSQL](https://github.com/salesforce/WikiSQL) (by Salesforce)
+- [TabFact](https://tabfact.github.io/) (by USCB NLP Lab).
+
+The abstract from the paper is the following:
+
+*Recent progress in language model pre-training has achieved a great success via leveraging large-scale unstructured textual data. However, it is
+still a challenge to apply pre-training on structured tabular data due to the absence of large-scale high-quality tabular data. In this paper, we
+propose TAPEX to show that table pre-training can be achieved by learning a neural SQL executor over a synthetic corpus, which is obtained by automatically
+synthesizing executable SQL queries and their execution outputs. TAPEX addresses the data scarcity challenge via guiding the language model to mimic a SQL
+executor on the diverse, large-scale and high-quality synthetic corpus. We evaluate TAPEX on four benchmark datasets. Experimental results demonstrate that
+TAPEX outperforms previous table pre-training approaches by a large margin and achieves new state-of-the-art results on all of them. This includes improvements
+on the weakly-supervised WikiSQL denotation accuracy to 89.5% (+2.3%), the WikiTableQuestions denotation accuracy to 57.5% (+4.8%), the SQA denotation accuracy
+to 74.5% (+3.5%), and the TabFact accuracy to 84.2% (+3.2%). To our knowledge, this is the first work to exploit table pre-training via synthetic executable programs
+and to achieve new state-of-the-art results on various downstream tasks.*
+
+Tips:
+
+- TAPEX is a generative (seq2seq) model. One can directly plug in the weights of TAPEX into a BART model.
+- TAPEX has checkpoints on the hub that are either pre-trained only, or fine-tuned on WTQ, SQA, WikiSQL and TabFact.
+- Sentences + tables are presented to the model as `sentence + " " + linearized table`. The linearized table has the following format:
+ `col: col1 | col2 | col 3 row 1 : val1 | val2 | val3 row 2 : ...`.
+- TAPEX has its own tokenizer, that allows to prepare all data for the model easily. One can pass Pandas DataFrames and strings to the tokenizer,
+ and it will automatically create the `input_ids` and `attention_mask` (as shown in the usage examples below).
+
+## Usage: inference
+
+Below, we illustrate how to use TAPEX for table question answering. As one can see, one can directly plug in the weights of TAPEX into a BART model.
+We use the [Auto API](auto), which will automatically instantiate the appropriate tokenizer ([`TapexTokenizer`]) and model ([`BartForConditionalGeneration`]) for us,
+based on the configuration file of the checkpoint on the hub.
+
+```python
+>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
+>>> import pandas as pd
+
+>>> tokenizer = AutoTokenizer.from_pretrained("microsoft/tapex-large-finetuned-wtq")
+>>> model = AutoModelForSeq2SeqLM.from_pretrained("microsoft/tapex-large-finetuned-wtq")
+
+>>> # prepare table + question
+>>> data = {"Actors": ["Brad Pitt", "Leonardo Di Caprio", "George Clooney"], "Number of movies": ["87", "53", "69"]}
+>>> table = pd.DataFrame.from_dict(data)
+>>> question = "how many movies does Leonardo Di Caprio have?"
+
+>>> encoding = tokenizer(table, question, return_tensors="pt")
+
+>>> # let the model generate an answer autoregressively
+>>> outputs = model.generate(**encoding)
+
+>>> # decode back to text
+>>> predicted_answer = tokenizer.batch_decode(outputs, skip_special_tokens=True)[0]
+>>> print(predicted_answer)
+53
+```
+
+Note that [`TapexTokenizer`] also supports batched inference. Hence, one can provide a batch of different tables/questions, or a batch of a single table
+and multiple questions, or a batch of a single query and multiple tables. Let's illustrate this:
+
+```python
+>>> # prepare table + question
+>>> data = {"Actors": ["Brad Pitt", "Leonardo Di Caprio", "George Clooney"], "Number of movies": ["87", "53", "69"]}
+>>> table = pd.DataFrame.from_dict(data)
+>>> questions = [
+... "how many movies does Leonardo Di Caprio have?",
+... "which actor has 69 movies?",
+... "what's the first name of the actor who has 87 movies?",
+... ]
+>>> encoding = tokenizer(table, questions, padding=True, return_tensors="pt")
+
+>>> # let the model generate an answer autoregressively
+>>> outputs = model.generate(**encoding)
+
+>>> # decode back to text
+>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
+[' 53', ' george clooney', ' brad pitt']
+```
+
+In case one wants to do table verification (i.e. the task of determining whether a given sentence is supported or refuted by the contents
+of a table), one can instantiate a [`BartForSequenceClassification`] model. TAPEX has checkpoints on the hub fine-tuned on TabFact, an important
+benchmark for table fact checking (it achieves 84% accuracy). The code example below again leverages the [Auto API](auto).
+
+```python
+>>> from transformers import AutoTokenizer, AutoModelForSequenceClassification
+
+>>> tokenizer = AutoTokenizer.from_pretrained("microsoft/tapex-large-finetuned-tabfact")
+>>> model = AutoModelForSequenceClassification.from_pretrained("microsoft/tapex-large-finetuned-tabfact")
+
+>>> # prepare table + sentence
+>>> data = {"Actors": ["Brad Pitt", "Leonardo Di Caprio", "George Clooney"], "Number of movies": ["87", "53", "69"]}
+>>> table = pd.DataFrame.from_dict(data)
+>>> sentence = "George Clooney has 30 movies"
+
+>>> encoding = tokenizer(table, sentence, return_tensors="pt")
+
+>>> # forward pass
+>>> outputs = model(**encoding)
+
+>>> # print prediction
+>>> predicted_class_idx = outputs.logits[0].argmax(dim=0).item()
+>>> print(model.config.id2label[predicted_class_idx])
+Refused
+```
+
+
+## TapexTokenizer
+
+[[autodoc]] TapexTokenizer
+ - __call__
+ - save_vocabulary
\ No newline at end of file
diff --git a/docs/source/en/model_doc/transfo-xl.mdx b/docs/source/en/model_doc/transfo-xl.mdx
new file mode 100644
index 00000000000000..7e2a7701426c8c
--- /dev/null
+++ b/docs/source/en/model_doc/transfo-xl.mdx
@@ -0,0 +1,103 @@
+
+
+# Transformer XL
+
+## Overview
+
+The Transformer-XL model was proposed in [Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context](https://arxiv.org/abs/1901.02860) by Zihang Dai, Zhilin Yang, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan
+Salakhutdinov. It's a causal (uni-directional) transformer with relative positioning (sinusoïdal) embeddings which can
+reuse previously computed hidden-states to attend to longer context (memory). This model also uses adaptive softmax
+inputs and outputs (tied).
+
+The abstract from the paper is the following:
+
+*Transformers have a potential of learning longer-term dependency, but are limited by a fixed-length context in the
+setting of language modeling. We propose a novel neural architecture Transformer-XL that enables learning dependency
+beyond a fixed length without disrupting temporal coherence. It consists of a segment-level recurrence mechanism and a
+novel positional encoding scheme. Our method not only enables capturing longer-term dependency, but also resolves the
+context fragmentation problem. As a result, Transformer-XL learns dependency that is 80% longer than RNNs and 450%
+longer than vanilla Transformers, achieves better performance on both short and long sequences, and is up to 1,800+
+times faster than vanilla Transformers during evaluation. Notably, we improve the state-of-the-art results of
+bpc/perplexity to 0.99 on enwiki8, 1.08 on text8, 18.3 on WikiText-103, 21.8 on One Billion Word, and 54.5 on Penn
+Treebank (without finetuning). When trained only on WikiText-103, Transformer-XL manages to generate reasonably
+coherent, novel text articles with thousands of tokens.*
+
+Tips:
+
+- Transformer-XL uses relative sinusoidal positional embeddings. Padding can be done on the left or on the right. The
+ original implementation trains on SQuAD with padding on the left, therefore the padding defaults are set to left.
+- Transformer-XL is one of the few models that has no sequence length limit.
+
+This model was contributed by [thomwolf](https://huggingface.co/thomwolf). The original code can be found [here](https://github.com/kimiyoung/transformer-xl).
+
+
+
+TransformerXL does **not** work with *torch.nn.DataParallel* due to a bug in PyTorch, see [issue #36035](https://github.com/pytorch/pytorch/issues/36035)
+
+
+
+
+## TransfoXLConfig
+
+[[autodoc]] TransfoXLConfig
+
+## TransfoXLTokenizer
+
+[[autodoc]] TransfoXLTokenizer
+ - save_vocabulary
+
+## TransfoXL specific outputs
+
+[[autodoc]] models.transfo_xl.modeling_transfo_xl.TransfoXLModelOutput
+
+[[autodoc]] models.transfo_xl.modeling_transfo_xl.TransfoXLLMHeadModelOutput
+
+[[autodoc]] models.transfo_xl.modeling_tf_transfo_xl.TFTransfoXLModelOutput
+
+[[autodoc]] models.transfo_xl.modeling_tf_transfo_xl.TFTransfoXLLMHeadModelOutput
+
+## TransfoXLModel
+
+[[autodoc]] TransfoXLModel
+ - forward
+
+## TransfoXLLMHeadModel
+
+[[autodoc]] TransfoXLLMHeadModel
+ - forward
+
+## TransfoXLForSequenceClassification
+
+[[autodoc]] TransfoXLForSequenceClassification
+ - forward
+
+## TFTransfoXLModel
+
+[[autodoc]] TFTransfoXLModel
+ - call
+
+## TFTransfoXLLMHeadModel
+
+[[autodoc]] TFTransfoXLLMHeadModel
+ - call
+
+## TFTransfoXLForSequenceClassification
+
+[[autodoc]] TFTransfoXLForSequenceClassification
+ - call
+
+## Internal Layers
+
+[[autodoc]] AdaptiveEmbedding
+
+[[autodoc]] TFAdaptiveEmbedding
diff --git a/docs/source/en/model_doc/trocr.mdx b/docs/source/en/model_doc/trocr.mdx
new file mode 100644
index 00000000000000..08de107e434c34
--- /dev/null
+++ b/docs/source/en/model_doc/trocr.mdx
@@ -0,0 +1,102 @@
+
+
+# TrOCR
+
+## Overview
+
+The TrOCR model was proposed in [TrOCR: Transformer-based Optical Character Recognition with Pre-trained
+Models](https://arxiv.org/abs/2109.10282) by Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang,
+Zhoujun Li, Furu Wei. TrOCR consists of an image Transformer encoder and an autoregressive text Transformer decoder to
+perform [optical character recognition (OCR)](https://en.wikipedia.org/wiki/Optical_character_recognition).
+
+The abstract from the paper is the following:
+
+*Text recognition is a long-standing research problem for document digitalization. Existing approaches for text recognition
+are usually built based on CNN for image understanding and RNN for char-level text generation. In addition, another language
+model is usually needed to improve the overall accuracy as a post-processing step. In this paper, we propose an end-to-end
+text recognition approach with pre-trained image Transformer and text Transformer models, namely TrOCR, which leverages the
+Transformer architecture for both image understanding and wordpiece-level text generation. The TrOCR model is simple but
+effective, and can be pre-trained with large-scale synthetic data and fine-tuned with human-labeled datasets. Experiments
+show that the TrOCR model outperforms the current state-of-the-art models on both printed and handwritten text recognition
+tasks.*
+
+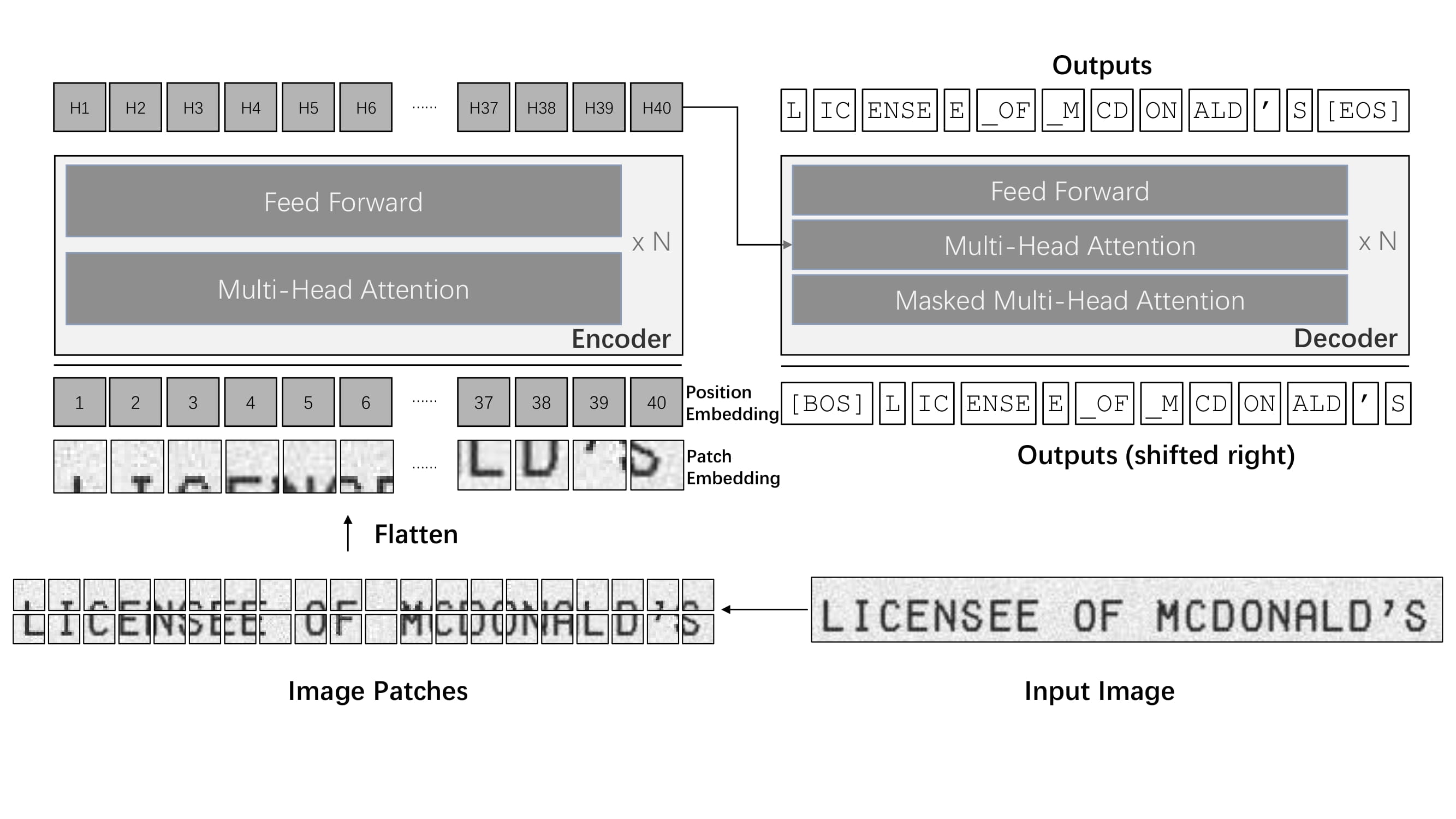 +
+ TrOCR architecture. Taken from the original paper.
+
+Please refer to the [`VisionEncoderDecoder`] class on how to use this model.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found
+[here](https://github.com/microsoft/unilm/tree/6f60612e7cc86a2a1ae85c47231507a587ab4e01/trocr).
+
+Tips:
+
+- The quickest way to get started with TrOCR is by checking the [tutorial
+ notebooks](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/TrOCR), which show how to use the model
+ at inference time as well as fine-tuning on custom data.
+- TrOCR is pre-trained in 2 stages before being fine-tuned on downstream datasets. It achieves state-of-the-art results
+ on both printed (e.g. the [SROIE dataset](https://paperswithcode.com/dataset/sroie) and handwritten (e.g. the [IAM
+ Handwriting dataset](https://fki.tic.heia-fr.ch/databases/iam-handwriting-database>) text recognition tasks. For more
+ information, see the [official models](https://huggingface.co/models?other=trocr>).
+- TrOCR is always used within the [VisionEncoderDecoder](vision-encoder-decoder) framework.
+
+## Inference
+
+TrOCR's [`VisionEncoderDecoder`] model accepts images as input and makes use of
+[`~generation_utils.GenerationMixin.generate`] to autoregressively generate text given the input image.
+
+The [`ViTFeatureExtractor`/`DeiTFeatureExtractor`] class is responsible for preprocessing the input image and
+[`RobertaTokenizer`/`XLMRobertaTokenizer`] decodes the generated target tokens to the target string. The
+[`TrOCRProcessor`] wraps [`ViTFeatureExtractor`/`DeiTFeatureExtractor`] and [`RobertaTokenizer`/`XLMRobertaTokenizer`]
+into a single instance to both extract the input features and decode the predicted token ids.
+
+- Step-by-step Optical Character Recognition (OCR)
+
+``` py
+>>> from transformers import TrOCRProcessor, VisionEncoderDecoderModel
+>>> import requests
+>>> from PIL import Image
+
+>>> processor = TrOCRProcessor.from_pretrained("microsoft/trocr-base-handwritten")
+>>> model = VisionEncoderDecoderModel.from_pretrained("microsoft/trocr-base-handwritten")
+
+>>> # load image from the IAM dataset
+>>> url = "https://fki.tic.heia-fr.ch/static/img/a01-122-02.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw).convert("RGB")
+
+>>> pixel_values = processor(image, return_tensors="pt").pixel_values
+>>> generated_ids = model.generate(pixel_values)
+
+>>> generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
+```
+
+See the [model hub](https://huggingface.co/models?filter=trocr) to look for TrOCR checkpoints.
+
+## TrOCRConfig
+
+[[autodoc]] TrOCRConfig
+
+## TrOCRProcessor
+
+[[autodoc]] TrOCRProcessor
+ - __call__
+ - from_pretrained
+ - save_pretrained
+ - batch_decode
+ - decode
+ - as_target_processor
+
+## TrOCRForCausalLM
+
+[[autodoc]] TrOCRForCausalLM
+ - forward
diff --git a/docs/source/en/model_doc/unispeech-sat.mdx b/docs/source/en/model_doc/unispeech-sat.mdx
new file mode 100644
index 00000000000000..724f5f908a4eb1
--- /dev/null
+++ b/docs/source/en/model_doc/unispeech-sat.mdx
@@ -0,0 +1,86 @@
+
+
+# UniSpeech-SAT
+
+## Overview
+
+The UniSpeech-SAT model was proposed in [UniSpeech-SAT: Universal Speech Representation Learning with Speaker Aware
+Pre-Training](https://arxiv.org/abs/2110.05752) by Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen,
+Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu .
+
+The abstract from the paper is the following:
+
+*Self-supervised learning (SSL) is a long-standing goal for speech processing, since it utilizes large-scale unlabeled
+data and avoids extensive human labeling. Recent years witness great successes in applying self-supervised learning in
+speech recognition, while limited exploration was attempted in applying SSL for modeling speaker characteristics. In
+this paper, we aim to improve the existing SSL framework for speaker representation learning. Two methods are
+introduced for enhancing the unsupervised speaker information extraction. First, we apply the multi-task learning to
+the current SSL framework, where we integrate the utterance-wise contrastive loss with the SSL objective function.
+Second, for better speaker discrimination, we propose an utterance mixing strategy for data augmentation, where
+additional overlapped utterances are created unsupervisely and incorporate during training. We integrate the proposed
+methods into the HuBERT framework. Experiment results on SUPERB benchmark show that the proposed system achieves
+state-of-the-art performance in universal representation learning, especially for speaker identification oriented
+tasks. An ablation study is performed verifying the efficacy of each proposed method. Finally, we scale up training
+dataset to 94 thousand hours public audio data and achieve further performance improvement in all SUPERB tasks.*
+
+Tips:
+
+- UniSpeechSat is a speech model that accepts a float array corresponding to the raw waveform of the speech signal.
+ Please use [`Wav2Vec2Processor`] for the feature extraction.
+- UniSpeechSat model can be fine-tuned using connectionist temporal classification (CTC) so the model output has to be
+ decoded using [`Wav2Vec2CTCTokenizer`].
+- UniSpeechSat performs especially well on speaker verification, speaker identification, and speaker diarization tasks.
+
+This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten). The Authors' code can be
+found [here](https://github.com/microsoft/UniSpeech/tree/main/UniSpeech-SAT).
+
+
+## UniSpeechSatConfig
+
+[[autodoc]] UniSpeechSatConfig
+
+## UniSpeechSat specific outputs
+
+[[autodoc]] models.unispeech_sat.modeling_unispeech_sat.UniSpeechSatBaseModelOutput
+
+[[autodoc]] models.unispeech_sat.modeling_unispeech_sat.UniSpeechSatForPreTrainingOutput
+
+## UniSpeechSatModel
+
+[[autodoc]] UniSpeechSatModel
+ - forward
+
+## UniSpeechSatForCTC
+
+[[autodoc]] UniSpeechSatForCTC
+ - forward
+
+## UniSpeechSatForSequenceClassification
+
+[[autodoc]] UniSpeechSatForSequenceClassification
+ - forward
+
+## UniSpeechSatForAudioFrameClassification
+
+[[autodoc]] UniSpeechSatForAudioFrameClassification
+ - forward
+
+## UniSpeechSatForXVector
+
+[[autodoc]] UniSpeechSatForXVector
+ - forward
+
+## UniSpeechSatForPreTraining
+
+[[autodoc]] UniSpeechSatForPreTraining
+ - forward
diff --git a/docs/source/en/model_doc/unispeech.mdx b/docs/source/en/model_doc/unispeech.mdx
new file mode 100644
index 00000000000000..a55d759396f0ce
--- /dev/null
+++ b/docs/source/en/model_doc/unispeech.mdx
@@ -0,0 +1,71 @@
+
+
+# UniSpeech
+
+## Overview
+
+The UniSpeech model was proposed in [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597) by Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael
+Zeng, Xuedong Huang .
+
+The abstract from the paper is the following:
+
+*In this paper, we propose a unified pre-training approach called UniSpeech to learn speech representations with both
+unlabeled and labeled data, in which supervised phonetic CTC learning and phonetically-aware contrastive
+self-supervised learning are conducted in a multi-task learning manner. The resultant representations can capture
+information more correlated with phonetic structures and improve the generalization across languages and domains. We
+evaluate the effectiveness of UniSpeech for cross-lingual representation learning on public CommonVoice corpus. The
+results show that UniSpeech outperforms self-supervised pretraining and supervised transfer learning for speech
+recognition by a maximum of 13.4% and 17.8% relative phone error rate reductions respectively (averaged over all
+testing languages). The transferability of UniSpeech is also demonstrated on a domain-shift speech recognition task,
+i.e., a relative word error rate reduction of 6% against the previous approach.*
+
+Tips:
+
+- UniSpeech is a speech model that accepts a float array corresponding to the raw waveform of the speech signal. Please
+ use [`Wav2Vec2Processor`] for the feature extraction.
+- UniSpeech model can be fine-tuned using connectionist temporal classification (CTC) so the model output has to be
+ decoded using [`Wav2Vec2CTCTokenizer`].
+
+This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten). The Authors' code can be
+found [here](https://github.com/microsoft/UniSpeech/tree/main/UniSpeech).
+
+
+## UniSpeechConfig
+
+[[autodoc]] UniSpeechConfig
+
+## UniSpeech specific outputs
+
+[[autodoc]] models.unispeech.modeling_unispeech.UniSpeechBaseModelOutput
+
+[[autodoc]] models.unispeech.modeling_unispeech.UniSpeechForPreTrainingOutput
+
+## UniSpeechModel
+
+[[autodoc]] UniSpeechModel
+ - forward
+
+## UniSpeechForCTC
+
+[[autodoc]] UniSpeechForCTC
+ - forward
+
+## UniSpeechForSequenceClassification
+
+[[autodoc]] UniSpeechForSequenceClassification
+ - forward
+
+## UniSpeechForPreTraining
+
+[[autodoc]] UniSpeechForPreTraining
+ - forward
diff --git a/docs/source/en/model_doc/van.mdx b/docs/source/en/model_doc/van.mdx
new file mode 100644
index 00000000000000..9fc05ab3e752f3
--- /dev/null
+++ b/docs/source/en/model_doc/van.mdx
@@ -0,0 +1,51 @@
+
+
+# VAN
+
+## Overview
+
+The VAN model was proposed in [Visual Attention Network](https://arxiv.org/abs/2202.09741) by Meng-Hao Guo, Cheng-Ze Lu, Zheng-Ning Liu, Ming-Ming Cheng, Shi-Min Hu.
+
+This paper introduces a new attention layer based on convolution operations able to capture both local and distant relationships. This is done by combining normal and large kernel convolution layers. The latter uses a dilated convolution to capture distant correlations.
+
+The abstract from the paper is the following:
+
+*While originally designed for natural language processing tasks, the self-attention mechanism has recently taken various computer vision areas by storm. However, the 2D nature of images brings three challenges for applying self-attention in computer vision. (1) Treating images as 1D sequences neglects their 2D structures. (2) The quadratic complexity is too expensive for high-resolution images. (3) It only captures spatial adaptability but ignores channel adaptability. In this paper, we propose a novel large kernel attention (LKA) module to enable self-adaptive and long-range correlations in self-attention while avoiding the above issues. We further introduce a novel neural network based on LKA, namely Visual Attention Network (VAN). While extremely simple, VAN outperforms the state-of-the-art vision transformers and convolutional neural networks with a large margin in extensive experiments, including image classification, object detection, semantic segmentation, instance segmentation, etc. Code is available at [this https URL](https://github.com/Visual-Attention-Network/VAN-Classification).*
+
+Tips:
+
+- VAN does not have an embedding layer, thus the `hidden_states` will have a length equal to the number of stages.
+
+The figure below illustrates the architecture of a Visual Aattention Layer. Taken from the [original paper](https://arxiv.org/abs/2202.09741).
+
+
+
+ TrOCR architecture. Taken from the original paper.
+
+Please refer to the [`VisionEncoderDecoder`] class on how to use this model.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found
+[here](https://github.com/microsoft/unilm/tree/6f60612e7cc86a2a1ae85c47231507a587ab4e01/trocr).
+
+Tips:
+
+- The quickest way to get started with TrOCR is by checking the [tutorial
+ notebooks](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/TrOCR), which show how to use the model
+ at inference time as well as fine-tuning on custom data.
+- TrOCR is pre-trained in 2 stages before being fine-tuned on downstream datasets. It achieves state-of-the-art results
+ on both printed (e.g. the [SROIE dataset](https://paperswithcode.com/dataset/sroie) and handwritten (e.g. the [IAM
+ Handwriting dataset](https://fki.tic.heia-fr.ch/databases/iam-handwriting-database>) text recognition tasks. For more
+ information, see the [official models](https://huggingface.co/models?other=trocr>).
+- TrOCR is always used within the [VisionEncoderDecoder](vision-encoder-decoder) framework.
+
+## Inference
+
+TrOCR's [`VisionEncoderDecoder`] model accepts images as input and makes use of
+[`~generation_utils.GenerationMixin.generate`] to autoregressively generate text given the input image.
+
+The [`ViTFeatureExtractor`/`DeiTFeatureExtractor`] class is responsible for preprocessing the input image and
+[`RobertaTokenizer`/`XLMRobertaTokenizer`] decodes the generated target tokens to the target string. The
+[`TrOCRProcessor`] wraps [`ViTFeatureExtractor`/`DeiTFeatureExtractor`] and [`RobertaTokenizer`/`XLMRobertaTokenizer`]
+into a single instance to both extract the input features and decode the predicted token ids.
+
+- Step-by-step Optical Character Recognition (OCR)
+
+``` py
+>>> from transformers import TrOCRProcessor, VisionEncoderDecoderModel
+>>> import requests
+>>> from PIL import Image
+
+>>> processor = TrOCRProcessor.from_pretrained("microsoft/trocr-base-handwritten")
+>>> model = VisionEncoderDecoderModel.from_pretrained("microsoft/trocr-base-handwritten")
+
+>>> # load image from the IAM dataset
+>>> url = "https://fki.tic.heia-fr.ch/static/img/a01-122-02.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw).convert("RGB")
+
+>>> pixel_values = processor(image, return_tensors="pt").pixel_values
+>>> generated_ids = model.generate(pixel_values)
+
+>>> generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
+```
+
+See the [model hub](https://huggingface.co/models?filter=trocr) to look for TrOCR checkpoints.
+
+## TrOCRConfig
+
+[[autodoc]] TrOCRConfig
+
+## TrOCRProcessor
+
+[[autodoc]] TrOCRProcessor
+ - __call__
+ - from_pretrained
+ - save_pretrained
+ - batch_decode
+ - decode
+ - as_target_processor
+
+## TrOCRForCausalLM
+
+[[autodoc]] TrOCRForCausalLM
+ - forward
diff --git a/docs/source/en/model_doc/unispeech-sat.mdx b/docs/source/en/model_doc/unispeech-sat.mdx
new file mode 100644
index 00000000000000..724f5f908a4eb1
--- /dev/null
+++ b/docs/source/en/model_doc/unispeech-sat.mdx
@@ -0,0 +1,86 @@
+
+
+# UniSpeech-SAT
+
+## Overview
+
+The UniSpeech-SAT model was proposed in [UniSpeech-SAT: Universal Speech Representation Learning with Speaker Aware
+Pre-Training](https://arxiv.org/abs/2110.05752) by Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen,
+Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu .
+
+The abstract from the paper is the following:
+
+*Self-supervised learning (SSL) is a long-standing goal for speech processing, since it utilizes large-scale unlabeled
+data and avoids extensive human labeling. Recent years witness great successes in applying self-supervised learning in
+speech recognition, while limited exploration was attempted in applying SSL for modeling speaker characteristics. In
+this paper, we aim to improve the existing SSL framework for speaker representation learning. Two methods are
+introduced for enhancing the unsupervised speaker information extraction. First, we apply the multi-task learning to
+the current SSL framework, where we integrate the utterance-wise contrastive loss with the SSL objective function.
+Second, for better speaker discrimination, we propose an utterance mixing strategy for data augmentation, where
+additional overlapped utterances are created unsupervisely and incorporate during training. We integrate the proposed
+methods into the HuBERT framework. Experiment results on SUPERB benchmark show that the proposed system achieves
+state-of-the-art performance in universal representation learning, especially for speaker identification oriented
+tasks. An ablation study is performed verifying the efficacy of each proposed method. Finally, we scale up training
+dataset to 94 thousand hours public audio data and achieve further performance improvement in all SUPERB tasks.*
+
+Tips:
+
+- UniSpeechSat is a speech model that accepts a float array corresponding to the raw waveform of the speech signal.
+ Please use [`Wav2Vec2Processor`] for the feature extraction.
+- UniSpeechSat model can be fine-tuned using connectionist temporal classification (CTC) so the model output has to be
+ decoded using [`Wav2Vec2CTCTokenizer`].
+- UniSpeechSat performs especially well on speaker verification, speaker identification, and speaker diarization tasks.
+
+This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten). The Authors' code can be
+found [here](https://github.com/microsoft/UniSpeech/tree/main/UniSpeech-SAT).
+
+
+## UniSpeechSatConfig
+
+[[autodoc]] UniSpeechSatConfig
+
+## UniSpeechSat specific outputs
+
+[[autodoc]] models.unispeech_sat.modeling_unispeech_sat.UniSpeechSatBaseModelOutput
+
+[[autodoc]] models.unispeech_sat.modeling_unispeech_sat.UniSpeechSatForPreTrainingOutput
+
+## UniSpeechSatModel
+
+[[autodoc]] UniSpeechSatModel
+ - forward
+
+## UniSpeechSatForCTC
+
+[[autodoc]] UniSpeechSatForCTC
+ - forward
+
+## UniSpeechSatForSequenceClassification
+
+[[autodoc]] UniSpeechSatForSequenceClassification
+ - forward
+
+## UniSpeechSatForAudioFrameClassification
+
+[[autodoc]] UniSpeechSatForAudioFrameClassification
+ - forward
+
+## UniSpeechSatForXVector
+
+[[autodoc]] UniSpeechSatForXVector
+ - forward
+
+## UniSpeechSatForPreTraining
+
+[[autodoc]] UniSpeechSatForPreTraining
+ - forward
diff --git a/docs/source/en/model_doc/unispeech.mdx b/docs/source/en/model_doc/unispeech.mdx
new file mode 100644
index 00000000000000..a55d759396f0ce
--- /dev/null
+++ b/docs/source/en/model_doc/unispeech.mdx
@@ -0,0 +1,71 @@
+
+
+# UniSpeech
+
+## Overview
+
+The UniSpeech model was proposed in [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597) by Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael
+Zeng, Xuedong Huang .
+
+The abstract from the paper is the following:
+
+*In this paper, we propose a unified pre-training approach called UniSpeech to learn speech representations with both
+unlabeled and labeled data, in which supervised phonetic CTC learning and phonetically-aware contrastive
+self-supervised learning are conducted in a multi-task learning manner. The resultant representations can capture
+information more correlated with phonetic structures and improve the generalization across languages and domains. We
+evaluate the effectiveness of UniSpeech for cross-lingual representation learning on public CommonVoice corpus. The
+results show that UniSpeech outperforms self-supervised pretraining and supervised transfer learning for speech
+recognition by a maximum of 13.4% and 17.8% relative phone error rate reductions respectively (averaged over all
+testing languages). The transferability of UniSpeech is also demonstrated on a domain-shift speech recognition task,
+i.e., a relative word error rate reduction of 6% against the previous approach.*
+
+Tips:
+
+- UniSpeech is a speech model that accepts a float array corresponding to the raw waveform of the speech signal. Please
+ use [`Wav2Vec2Processor`] for the feature extraction.
+- UniSpeech model can be fine-tuned using connectionist temporal classification (CTC) so the model output has to be
+ decoded using [`Wav2Vec2CTCTokenizer`].
+
+This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten). The Authors' code can be
+found [here](https://github.com/microsoft/UniSpeech/tree/main/UniSpeech).
+
+
+## UniSpeechConfig
+
+[[autodoc]] UniSpeechConfig
+
+## UniSpeech specific outputs
+
+[[autodoc]] models.unispeech.modeling_unispeech.UniSpeechBaseModelOutput
+
+[[autodoc]] models.unispeech.modeling_unispeech.UniSpeechForPreTrainingOutput
+
+## UniSpeechModel
+
+[[autodoc]] UniSpeechModel
+ - forward
+
+## UniSpeechForCTC
+
+[[autodoc]] UniSpeechForCTC
+ - forward
+
+## UniSpeechForSequenceClassification
+
+[[autodoc]] UniSpeechForSequenceClassification
+ - forward
+
+## UniSpeechForPreTraining
+
+[[autodoc]] UniSpeechForPreTraining
+ - forward
diff --git a/docs/source/en/model_doc/van.mdx b/docs/source/en/model_doc/van.mdx
new file mode 100644
index 00000000000000..9fc05ab3e752f3
--- /dev/null
+++ b/docs/source/en/model_doc/van.mdx
@@ -0,0 +1,51 @@
+
+
+# VAN
+
+## Overview
+
+The VAN model was proposed in [Visual Attention Network](https://arxiv.org/abs/2202.09741) by Meng-Hao Guo, Cheng-Ze Lu, Zheng-Ning Liu, Ming-Ming Cheng, Shi-Min Hu.
+
+This paper introduces a new attention layer based on convolution operations able to capture both local and distant relationships. This is done by combining normal and large kernel convolution layers. The latter uses a dilated convolution to capture distant correlations.
+
+The abstract from the paper is the following:
+
+*While originally designed for natural language processing tasks, the self-attention mechanism has recently taken various computer vision areas by storm. However, the 2D nature of images brings three challenges for applying self-attention in computer vision. (1) Treating images as 1D sequences neglects their 2D structures. (2) The quadratic complexity is too expensive for high-resolution images. (3) It only captures spatial adaptability but ignores channel adaptability. In this paper, we propose a novel large kernel attention (LKA) module to enable self-adaptive and long-range correlations in self-attention while avoiding the above issues. We further introduce a novel neural network based on LKA, namely Visual Attention Network (VAN). While extremely simple, VAN outperforms the state-of-the-art vision transformers and convolutional neural networks with a large margin in extensive experiments, including image classification, object detection, semantic segmentation, instance segmentation, etc. Code is available at [this https URL](https://github.com/Visual-Attention-Network/VAN-Classification).*
+
+Tips:
+
+- VAN does not have an embedding layer, thus the `hidden_states` will have a length equal to the number of stages.
+
+The figure below illustrates the architecture of a Visual Aattention Layer. Taken from the [original paper](https://arxiv.org/abs/2202.09741).
+
+ +
+This model was contributed by [Francesco](https://huggingface.co/Francesco). The original code can be found [here](https://github.com/Visual-Attention-Network/VAN-Classification).
+
+
+## VanConfig
+
+[[autodoc]] VanConfig
+
+
+## VanModel
+
+[[autodoc]] VanModel
+ - forward
+
+
+## VanForImageClassification
+
+[[autodoc]] VanForImageClassification
+ - forward
+
diff --git a/docs/source/en/model_doc/vilt.mdx b/docs/source/en/model_doc/vilt.mdx
new file mode 100644
index 00000000000000..34397e7b3c574f
--- /dev/null
+++ b/docs/source/en/model_doc/vilt.mdx
@@ -0,0 +1,89 @@
+
+
+# ViLT
+
+## Overview
+
+The ViLT model was proposed in [ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision](https://arxiv.org/abs/2102.03334)
+by Wonjae Kim, Bokyung Son, Ildoo Kim. ViLT incorporates text embeddings into a Vision Transformer (ViT), allowing it to have a minimal design
+for Vision-and-Language Pre-training (VLP).
+
+The abstract from the paper is the following:
+
+*Vision-and-Language Pre-training (VLP) has improved performance on various joint vision-and-language downstream tasks.
+Current approaches to VLP heavily rely on image feature extraction processes, most of which involve region supervision
+(e.g., object detection) and the convolutional architecture (e.g., ResNet). Although disregarded in the literature, we
+find it problematic in terms of both (1) efficiency/speed, that simply extracting input features requires much more
+computation than the multimodal interaction steps; and (2) expressive power, as it is upper bounded to the expressive
+power of the visual embedder and its predefined visual vocabulary. In this paper, we present a minimal VLP model,
+Vision-and-Language Transformer (ViLT), monolithic in the sense that the processing of visual inputs is drastically
+simplified to just the same convolution-free manner that we process textual inputs. We show that ViLT is up to tens of
+times faster than previous VLP models, yet with competitive or better downstream task performance.*
+
+Tips:
+
+- The quickest way to get started with ViLT is by checking the [example notebooks](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/ViLT)
+ (which showcase both inference and fine-tuning on custom data).
+- ViLT is a model that takes both `pixel_values` and `input_ids` as input. One can use [`ViltProcessor`] to prepare data for the model.
+ This processor wraps a feature extractor (for the image modality) and a tokenizer (for the language modality) into one.
+- ViLT is trained with images of various sizes: the authors resize the shorter edge of input images to 384 and limit the longer edge to
+ under 640 while preserving the aspect ratio. To make batching of images possible, the authors use a `pixel_mask` that indicates
+ which pixel values are real and which are padding. [`ViltProcessor`] automatically creates this for you.
+- The design of ViLT is very similar to that of a standard Vision Transformer (ViT). The only difference is that the model includes
+ additional embedding layers for the language modality.
+
+
+
+This model was contributed by [Francesco](https://huggingface.co/Francesco). The original code can be found [here](https://github.com/Visual-Attention-Network/VAN-Classification).
+
+
+## VanConfig
+
+[[autodoc]] VanConfig
+
+
+## VanModel
+
+[[autodoc]] VanModel
+ - forward
+
+
+## VanForImageClassification
+
+[[autodoc]] VanForImageClassification
+ - forward
+
diff --git a/docs/source/en/model_doc/vilt.mdx b/docs/source/en/model_doc/vilt.mdx
new file mode 100644
index 00000000000000..34397e7b3c574f
--- /dev/null
+++ b/docs/source/en/model_doc/vilt.mdx
@@ -0,0 +1,89 @@
+
+
+# ViLT
+
+## Overview
+
+The ViLT model was proposed in [ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision](https://arxiv.org/abs/2102.03334)
+by Wonjae Kim, Bokyung Son, Ildoo Kim. ViLT incorporates text embeddings into a Vision Transformer (ViT), allowing it to have a minimal design
+for Vision-and-Language Pre-training (VLP).
+
+The abstract from the paper is the following:
+
+*Vision-and-Language Pre-training (VLP) has improved performance on various joint vision-and-language downstream tasks.
+Current approaches to VLP heavily rely on image feature extraction processes, most of which involve region supervision
+(e.g., object detection) and the convolutional architecture (e.g., ResNet). Although disregarded in the literature, we
+find it problematic in terms of both (1) efficiency/speed, that simply extracting input features requires much more
+computation than the multimodal interaction steps; and (2) expressive power, as it is upper bounded to the expressive
+power of the visual embedder and its predefined visual vocabulary. In this paper, we present a minimal VLP model,
+Vision-and-Language Transformer (ViLT), monolithic in the sense that the processing of visual inputs is drastically
+simplified to just the same convolution-free manner that we process textual inputs. We show that ViLT is up to tens of
+times faster than previous VLP models, yet with competitive or better downstream task performance.*
+
+Tips:
+
+- The quickest way to get started with ViLT is by checking the [example notebooks](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/ViLT)
+ (which showcase both inference and fine-tuning on custom data).
+- ViLT is a model that takes both `pixel_values` and `input_ids` as input. One can use [`ViltProcessor`] to prepare data for the model.
+ This processor wraps a feature extractor (for the image modality) and a tokenizer (for the language modality) into one.
+- ViLT is trained with images of various sizes: the authors resize the shorter edge of input images to 384 and limit the longer edge to
+ under 640 while preserving the aspect ratio. To make batching of images possible, the authors use a `pixel_mask` that indicates
+ which pixel values are real and which are padding. [`ViltProcessor`] automatically creates this for you.
+- The design of ViLT is very similar to that of a standard Vision Transformer (ViT). The only difference is that the model includes
+ additional embedding layers for the language modality.
+
+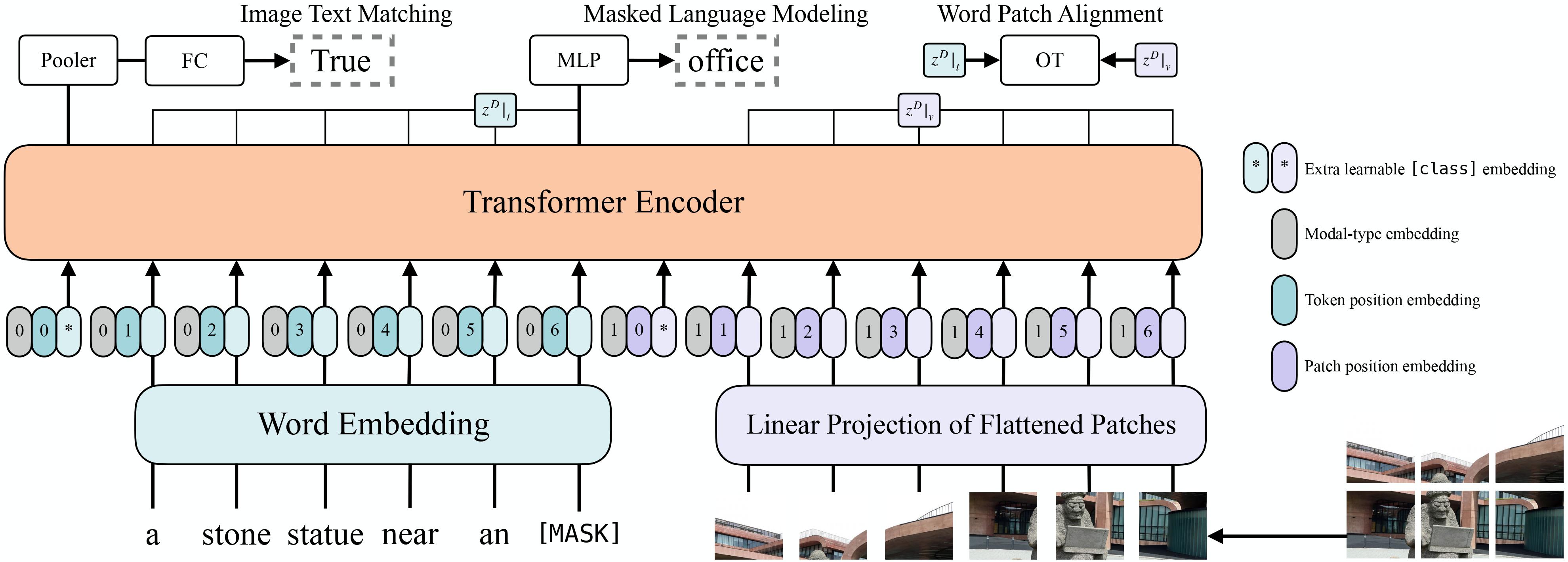 +
+ ViLT architecture. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/dandelin/ViLT).
+
+## ViltConfig
+
+[[autodoc]] ViltConfig
+
+## ViltFeatureExtractor
+
+[[autodoc]] ViltFeatureExtractor
+ - __call__
+
+## ViltProcessor
+
+[[autodoc]] ViltProcessor
+ - __call__
+
+## ViltModel
+
+[[autodoc]] ViltModel
+ - forward
+
+## ViltForMaskedLM
+
+[[autodoc]] ViltForMaskedLM
+ - forward
+
+## ViltForQuestionAnswering
+
+[[autodoc]] ViltForQuestionAnswering
+ - forward
+
+## ViltForImagesAndTextClassification
+
+[[autodoc]] ViltForImagesAndTextClassification
+ - forward
+
+## ViltForImageAndTextRetrieval
+
+[[autodoc]] ViltForImageAndTextRetrieval
+ - forward
diff --git a/docs/source/en/model_doc/vision-encoder-decoder.mdx b/docs/source/en/model_doc/vision-encoder-decoder.mdx
new file mode 100644
index 00000000000000..987924d4ad7c03
--- /dev/null
+++ b/docs/source/en/model_doc/vision-encoder-decoder.mdx
@@ -0,0 +1,46 @@
+
+
+# Vision Encoder Decoder Models
+
+The [`VisionEncoderDecoderModel`] can be used to initialize an image-to-text-sequence model with any
+pretrained Transformer-based vision autoencoding model as the encoder (*e.g.* [ViT](vit), [BEiT](beit), [DeiT](deit), [Swin](swin))
+and any pretrained language model as the decoder (*e.g.* [RoBERTa](roberta), [GPT2](gpt2), [BERT](bert), [DistilBERT](distilbert)).
+
+The effectiveness of initializing image-to-text-sequence models with pretrained checkpoints has been shown in (for
+example) [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282) by Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang,
+Zhoujun Li, Furu Wei.
+
+An example of how to use a [`VisionEncoderDecoderModel`] for inference can be seen in [TrOCR](trocr).
+
+
+## VisionEncoderDecoderConfig
+
+[[autodoc]] VisionEncoderDecoderConfig
+
+## VisionEncoderDecoderModel
+
+[[autodoc]] VisionEncoderDecoderModel
+ - forward
+ - from_encoder_decoder_pretrained
+
+## TFVisionEncoderDecoderModel
+
+[[autodoc]] TFVisionEncoderDecoderModel
+ - call
+ - from_encoder_decoder_pretrained
+
+## FlaxVisionEncoderDecoderModel
+
+[[autodoc]] FlaxVisionEncoderDecoderModel
+ - __call__
+ - from_encoder_decoder_pretrained
diff --git a/docs/source/en/model_doc/vision-text-dual-encoder.mdx b/docs/source/en/model_doc/vision-text-dual-encoder.mdx
new file mode 100644
index 00000000000000..fcc4f38288d011
--- /dev/null
+++ b/docs/source/en/model_doc/vision-text-dual-encoder.mdx
@@ -0,0 +1,43 @@
+
+
+# VisionTextDualEncoder
+
+## Overview
+
+The [`VisionTextDualEncoderModel`] can be used to initialize a vision-text dual encoder model with
+any pretrained vision autoencoding model as the vision encoder (*e.g.* [ViT](vit), [BEiT](beit), [DeiT](deit)) and any pretrained text autoencoding model as the text encoder (*e.g.* [RoBERTa](roberta), [BERT](bert)). Two projection layers are added on top of both the vision and text encoder to project the output embeddings
+to a shared latent space. The projection layers are randomly initialized so the model should be fine-tuned on a
+downstream task. This model can be used to align the vision-text embeddings using CLIP like contrastive image-text
+training and then can be used for zero-shot vision tasks such image-classification or retrieval.
+
+In [LiT: Zero-Shot Transfer with Locked-image Text Tuning](https://arxiv.org/abs/2111.07991) it is shown how
+leveraging pre-trained (locked/frozen) image and text model for contrastive learning yields significant improvment on
+new zero-shot vision tasks such as image classification or retrieval.
+
+## VisionTextDualEncoderConfig
+
+[[autodoc]] VisionTextDualEncoderConfig
+
+## VisionTextDualEncoderProcessor
+
+[[autodoc]] VisionTextDualEncoderProcessor
+
+## VisionTextDualEncoderModel
+
+[[autodoc]] VisionTextDualEncoderModel
+ - forward
+
+## FlaxVisionTextDualEncoderModel
+
+[[autodoc]] FlaxVisionTextDualEncoderModel
+ - __call__
diff --git a/docs/source/en/model_doc/visual_bert.mdx b/docs/source/en/model_doc/visual_bert.mdx
new file mode 100644
index 00000000000000..dd722b919eb708
--- /dev/null
+++ b/docs/source/en/model_doc/visual_bert.mdx
@@ -0,0 +1,125 @@
+
+
+# VisualBERT
+
+## Overview
+
+The VisualBERT model was proposed in [VisualBERT: A Simple and Performant Baseline for Vision and Language](https://arxiv.org/pdf/1908.03557) by Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, Kai-Wei Chang.
+VisualBERT is a neural network trained on a variety of (image, text) pairs.
+
+The abstract from the paper is the following:
+
+*We propose VisualBERT, a simple and flexible framework for modeling a broad range of vision-and-language tasks.
+VisualBERT consists of a stack of Transformer layers that implicitly align elements of an input text and regions in an
+associated input image with self-attention. We further propose two visually-grounded language model objectives for
+pre-training VisualBERT on image caption data. Experiments on four vision-and-language tasks including VQA, VCR, NLVR2,
+and Flickr30K show that VisualBERT outperforms or rivals with state-of-the-art models while being significantly
+simpler. Further analysis demonstrates that VisualBERT can ground elements of language to image regions without any
+explicit supervision and is even sensitive to syntactic relationships, tracking, for example, associations between
+verbs and image regions corresponding to their arguments.*
+
+Tips:
+
+1. Most of the checkpoints provided work with the [`VisualBertForPreTraining`] configuration. Other
+ checkpoints provided are the fine-tuned checkpoints for down-stream tasks - VQA ('visualbert-vqa'), VCR
+ ('visualbert-vcr'), NLVR2 ('visualbert-nlvr2'). Hence, if you are not working on these downstream tasks, it is
+ recommended that you use the pretrained checkpoints.
+
+2. For the VCR task, the authors use a fine-tuned detector for generating visual embeddings, for all the checkpoints.
+ We do not provide the detector and its weights as a part of the package, but it will be available in the research
+ projects, and the states can be loaded directly into the detector provided.
+
+## Usage
+
+VisualBERT is a multi-modal vision and language model. It can be used for visual question answering, multiple choice,
+visual reasoning and region-to-phrase correspondence tasks. VisualBERT uses a BERT-like transformer to prepare
+embeddings for image-text pairs. Both the text and visual features are then projected to a latent space with identical
+dimension.
+
+To feed images to the model, each image is passed through a pre-trained object detector and the regions and the
+bounding boxes are extracted. The authors use the features generated after passing these regions through a pre-trained
+CNN like ResNet as visual embeddings. They also add absolute position embeddings, and feed the resulting sequence of
+vectors to a standard BERT model. The text input is concatenated in the front of the visual embeddings in the embedding
+layer, and is expected to be bound by [CLS] and a [SEP] tokens, as in BERT. The segment IDs must also be set
+appropriately for the textual and visual parts.
+
+The [`BertTokenizer`] is used to encode the text. A custom detector/feature extractor must be used
+to get the visual embeddings. The following example notebooks show how to use VisualBERT with Detectron-like models:
+
+- [VisualBERT VQA demo notebook](https://github.com/huggingface/transformers/tree/main/examples/research_projects/visual_bert) : This notebook
+ contains an example on VisualBERT VQA.
+
+- [Generate Embeddings for VisualBERT (Colab Notebook)](https://colab.research.google.com/drive/1bLGxKdldwqnMVA5x4neY7-l_8fKGWQYI?usp=sharing) : This notebook contains
+ an example on how to generate visual embeddings.
+
+The following example shows how to get the last hidden state using [`VisualBertModel`]:
+
+```python
+>>> import torch
+>>> from transformers import BertTokenizer, VisualBertModel
+
+>>> model = VisualBertModel.from_pretrained("uclanlp/visualbert-vqa-coco-pre")
+>>> tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
+
+>>> inputs = tokenizer("What is the man eating?", return_tensors="pt")
+>>> # this is a custom function that returns the visual embeddings given the image path
+>>> visual_embeds = get_visual_embeddings(image_path)
+
+>>> visual_token_type_ids = torch.ones(visual_embeds.shape[:-1], dtype=torch.long)
+>>> visual_attention_mask = torch.ones(visual_embeds.shape[:-1], dtype=torch.float)
+>>> inputs.update(
+... {
+... "visual_embeds": visual_embeds,
+... "visual_token_type_ids": visual_token_type_ids,
+... "visual_attention_mask": visual_attention_mask,
+... }
+... )
+>>> outputs = model(**inputs)
+>>> last_hidden_state = outputs.last_hidden_state
+```
+
+This model was contributed by [gchhablani](https://huggingface.co/gchhablani). The original code can be found [here](https://github.com/uclanlp/visualbert).
+
+## VisualBertConfig
+
+[[autodoc]] VisualBertConfig
+
+## VisualBertModel
+
+[[autodoc]] VisualBertModel
+ - forward
+
+## VisualBertForPreTraining
+
+[[autodoc]] VisualBertForPreTraining
+ - forward
+
+## VisualBertForQuestionAnswering
+
+[[autodoc]] VisualBertForQuestionAnswering
+ - forward
+
+## VisualBertForMultipleChoice
+
+[[autodoc]] VisualBertForMultipleChoice
+ - forward
+
+## VisualBertForVisualReasoning
+
+[[autodoc]] VisualBertForVisualReasoning
+ - forward
+
+## VisualBertForRegionToPhraseAlignment
+
+[[autodoc]] VisualBertForRegionToPhraseAlignment
+ - forward
diff --git a/docs/source/en/model_doc/vit.mdx b/docs/source/en/model_doc/vit.mdx
new file mode 100644
index 00000000000000..37c469f6aaaefc
--- /dev/null
+++ b/docs/source/en/model_doc/vit.mdx
@@ -0,0 +1,134 @@
+
+
+# Vision Transformer (ViT)
+
+
+
+This is a recently introduced model so the API hasn't been tested extensively. There may be some bugs or slight
+breaking changes to fix it in the future. If you see something strange, file a [Github Issue](https://github.com/huggingface/transformers/issues/new?assignees=&labels=&template=bug-report.md&title).
+
+
+
+## Overview
+
+The Vision Transformer (ViT) model was proposed in [An Image is Worth 16x16 Words: Transformers for Image Recognition
+at Scale](https://arxiv.org/abs/2010.11929) by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk
+Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob
+Uszkoreit, Neil Houlsby. It's the first paper that successfully trains a Transformer encoder on ImageNet, attaining
+very good results compared to familiar convolutional architectures.
+
+
+The abstract from the paper is the following:
+
+*While the Transformer architecture has become the de-facto standard for natural language processing tasks, its
+applications to computer vision remain limited. In vision, attention is either applied in conjunction with
+convolutional networks, or used to replace certain components of convolutional networks while keeping their overall
+structure in place. We show that this reliance on CNNs is not necessary and a pure transformer applied directly to
+sequences of image patches can perform very well on image classification tasks. When pre-trained on large amounts of
+data and transferred to multiple mid-sized or small image recognition benchmarks (ImageNet, CIFAR-100, VTAB, etc.),
+Vision Transformer (ViT) attains excellent results compared to state-of-the-art convolutional networks while requiring
+substantially fewer computational resources to train.*
+
+Tips:
+
+- Demo notebooks regarding inference as well as fine-tuning ViT on custom data can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/VisionTransformer).
+- To feed images to the Transformer encoder, each image is split into a sequence of fixed-size non-overlapping patches,
+ which are then linearly embedded. A [CLS] token is added to serve as representation of an entire image, which can be
+ used for classification. The authors also add absolute position embeddings, and feed the resulting sequence of
+ vectors to a standard Transformer encoder.
+- As the Vision Transformer expects each image to be of the same size (resolution), one can use
+ [`ViTFeatureExtractor`] to resize (or rescale) and normalize images for the model.
+- Both the patch resolution and image resolution used during pre-training or fine-tuning are reflected in the name of
+ each checkpoint. For example, `google/vit-base-patch16-224` refers to a base-sized architecture with patch
+ resolution of 16x16 and fine-tuning resolution of 224x224. All checkpoints can be found on the [hub](https://huggingface.co/models?search=vit).
+- The available checkpoints are either (1) pre-trained on [ImageNet-21k](http://www.image-net.org/) (a collection of
+ 14 million images and 21k classes) only, or (2) also fine-tuned on [ImageNet](http://www.image-net.org/challenges/LSVRC/2012/) (also referred to as ILSVRC 2012, a collection of 1.3 million
+ images and 1,000 classes).
+- The Vision Transformer was pre-trained using a resolution of 224x224. During fine-tuning, it is often beneficial to
+ use a higher resolution than pre-training [(Touvron et al., 2019)](https://arxiv.org/abs/1906.06423), [(Kolesnikov
+ et al., 2020)](https://arxiv.org/abs/1912.11370). In order to fine-tune at higher resolution, the authors perform
+ 2D interpolation of the pre-trained position embeddings, according to their location in the original image.
+- The best results are obtained with supervised pre-training, which is not the case in NLP. The authors also performed
+ an experiment with a self-supervised pre-training objective, namely masked patched prediction (inspired by masked
+ language modeling). With this approach, the smaller ViT-B/16 model achieves 79.9% accuracy on ImageNet, a significant
+ improvement of 2% to training from scratch, but still 4% behind supervised pre-training.
+
+Following the original Vision Transformer, some follow-up works have been made:
+
+- [DeiT](deit) (Data-efficient Image Transformers) by Facebook AI. DeiT models are distilled vision transformers.
+ The authors of DeiT also released more efficiently trained ViT models, which you can directly plug into [`ViTModel`] or
+ [`ViTForImageClassification`]. There are 4 variants available (in 3 different sizes): *facebook/deit-tiny-patch16-224*,
+ *facebook/deit-small-patch16-224*, *facebook/deit-base-patch16-224* and *facebook/deit-base-patch16-384*. Note that one should
+ use [`DeiTFeatureExtractor`] in order to prepare images for the model.
+
+- [BEiT](beit) (BERT pre-training of Image Transformers) by Microsoft Research. BEiT models outperform supervised pre-trained
+ vision transformers using a self-supervised method inspired by BERT (masked image modeling) and based on a VQ-VAE.
+
+- DINO (a method for self-supervised training of Vision Transformers) by Facebook AI. Vision Transformers trained using
+ the DINO method show very interesting properties not seen with convolutional models. They are capable of segmenting
+ objects, without having ever been trained to do so. DINO checkpoints can be found on the [hub](https://huggingface.co/models?other=dino).
+
+- [MAE](vit_mae) (Masked Autoencoders) by Facebook AI. By pre-training Vision Transformers to reconstruct pixel values for a high portion
+ (75%) of masked patches (using an asymmetric encoder-decoder architecture), the authors show that this simple method outperforms
+ supervised pre-training after fine-tuning.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code (written in JAX) can be
+found [here](https://github.com/google-research/vision_transformer).
+
+Note that we converted the weights from Ross Wightman's [timm library](https://github.com/rwightman/pytorch-image-models), who already converted the weights from JAX to PyTorch. Credits
+go to him!
+
+
+## ViTConfig
+
+[[autodoc]] ViTConfig
+
+## ViTFeatureExtractor
+
+[[autodoc]] ViTFeatureExtractor
+ - __call__
+
+## ViTModel
+
+[[autodoc]] ViTModel
+ - forward
+
+## ViTForMaskedImageModeling
+
+[[autodoc]] ViTForMaskedImageModeling
+ - forward
+
+## ViTForImageClassification
+
+[[autodoc]] ViTForImageClassification
+ - forward
+
+## TFViTModel
+
+[[autodoc]] TFViTModel
+ - call
+
+## TFViTForImageClassification
+
+[[autodoc]] TFViTForImageClassification
+ - call
+
+## FlaxVitModel
+
+[[autodoc]] FlaxViTModel
+ - __call__
+
+## FlaxViTForImageClassification
+
+[[autodoc]] FlaxViTForImageClassification
+ - __call__
diff --git a/docs/source/en/model_doc/vit_mae.mdx b/docs/source/en/model_doc/vit_mae.mdx
new file mode 100644
index 00000000000000..aeb19b96a15493
--- /dev/null
+++ b/docs/source/en/model_doc/vit_mae.mdx
@@ -0,0 +1,81 @@
+
+
+# ViTMAE
+
+## Overview
+
+The ViTMAE model was proposed in [Masked Autoencoders Are Scalable Vision Learners](https://arxiv.org/abs/2111.06377v2) by Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li,
+Piotr Dollár, Ross Girshick. The paper shows that, by pre-training a Vision Transformer (ViT) to reconstruct pixel values for masked patches, one can get results after
+fine-tuning that outperform supervised pre-training.
+
+The abstract from the paper is the following:
+
+*This paper shows that masked autoencoders (MAE) are scalable self-supervised learners for computer vision. Our MAE approach is simple: we mask random patches of the
+input image and reconstruct the missing pixels. It is based on two core designs. First, we develop an asymmetric encoder-decoder architecture, with an encoder that operates
+only on the visible subset of patches (without mask tokens), along with a lightweight decoder that reconstructs the original image from the latent representation and mask
+tokens. Second, we find that masking a high proportion of the input image, e.g., 75%, yields a nontrivial and meaningful self-supervisory task. Coupling these two designs
+enables us to train large models efficiently and effectively: we accelerate training (by 3x or more) and improve accuracy. Our scalable approach allows for learning high-capacity
+models that generalize well: e.g., a vanilla ViT-Huge model achieves the best accuracy (87.8%) among methods that use only ImageNet-1K data. Transfer performance in downstream
+tasks outperforms supervised pre-training and shows promising scaling behavior.*
+
+Tips:
+
+- MAE (masked auto encoding) is a method for self-supervised pre-training of Vision Transformers (ViTs). The pre-training objective is relatively simple:
+by masking a large portion (75%) of the image patches, the model must reconstruct raw pixel values. One can use [`ViTMAEForPreTraining`] for this purpose.
+- An example Python script that illustrates how to pre-train [`ViTMAEForPreTraining`] from scratch can be found [here](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-pretraining).
+One can easily tweak it for their own use case.
+- A notebook that illustrates how to visualize reconstructed pixel values with [`ViTMAEForPreTraining`] can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/ViTMAE/ViT_MAE_visualization_demo.ipynb).
+- After pre-training, one "throws away" the decoder used to reconstruct pixels, and one uses the encoder for fine-tuning/linear probing. This means that after
+fine-tuning, one can directly plug in the weights into a [`ViTForImageClassification`].
+- One can use [`ViTFeatureExtractor`] to prepare images for the model. See the code examples for more info.
+- Note that the encoder of MAE is only used to encode the visual patches. The encoded patches are then concatenated with mask tokens, which the decoder (which also
+consists of Transformer blocks) takes as input. Each mask token is a shared, learned vector that indicates the presence of a missing patch to be predicted. Fixed
+sin/cos position embeddings are added both to the input of the encoder and the decoder.
+- For a visual understanding of how MAEs work you can check out this [post](https://keras.io/examples/vision/masked_image_modeling/).
+
+
+
+ ViLT architecture. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/dandelin/ViLT).
+
+## ViltConfig
+
+[[autodoc]] ViltConfig
+
+## ViltFeatureExtractor
+
+[[autodoc]] ViltFeatureExtractor
+ - __call__
+
+## ViltProcessor
+
+[[autodoc]] ViltProcessor
+ - __call__
+
+## ViltModel
+
+[[autodoc]] ViltModel
+ - forward
+
+## ViltForMaskedLM
+
+[[autodoc]] ViltForMaskedLM
+ - forward
+
+## ViltForQuestionAnswering
+
+[[autodoc]] ViltForQuestionAnswering
+ - forward
+
+## ViltForImagesAndTextClassification
+
+[[autodoc]] ViltForImagesAndTextClassification
+ - forward
+
+## ViltForImageAndTextRetrieval
+
+[[autodoc]] ViltForImageAndTextRetrieval
+ - forward
diff --git a/docs/source/en/model_doc/vision-encoder-decoder.mdx b/docs/source/en/model_doc/vision-encoder-decoder.mdx
new file mode 100644
index 00000000000000..987924d4ad7c03
--- /dev/null
+++ b/docs/source/en/model_doc/vision-encoder-decoder.mdx
@@ -0,0 +1,46 @@
+
+
+# Vision Encoder Decoder Models
+
+The [`VisionEncoderDecoderModel`] can be used to initialize an image-to-text-sequence model with any
+pretrained Transformer-based vision autoencoding model as the encoder (*e.g.* [ViT](vit), [BEiT](beit), [DeiT](deit), [Swin](swin))
+and any pretrained language model as the decoder (*e.g.* [RoBERTa](roberta), [GPT2](gpt2), [BERT](bert), [DistilBERT](distilbert)).
+
+The effectiveness of initializing image-to-text-sequence models with pretrained checkpoints has been shown in (for
+example) [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282) by Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang,
+Zhoujun Li, Furu Wei.
+
+An example of how to use a [`VisionEncoderDecoderModel`] for inference can be seen in [TrOCR](trocr).
+
+
+## VisionEncoderDecoderConfig
+
+[[autodoc]] VisionEncoderDecoderConfig
+
+## VisionEncoderDecoderModel
+
+[[autodoc]] VisionEncoderDecoderModel
+ - forward
+ - from_encoder_decoder_pretrained
+
+## TFVisionEncoderDecoderModel
+
+[[autodoc]] TFVisionEncoderDecoderModel
+ - call
+ - from_encoder_decoder_pretrained
+
+## FlaxVisionEncoderDecoderModel
+
+[[autodoc]] FlaxVisionEncoderDecoderModel
+ - __call__
+ - from_encoder_decoder_pretrained
diff --git a/docs/source/en/model_doc/vision-text-dual-encoder.mdx b/docs/source/en/model_doc/vision-text-dual-encoder.mdx
new file mode 100644
index 00000000000000..fcc4f38288d011
--- /dev/null
+++ b/docs/source/en/model_doc/vision-text-dual-encoder.mdx
@@ -0,0 +1,43 @@
+
+
+# VisionTextDualEncoder
+
+## Overview
+
+The [`VisionTextDualEncoderModel`] can be used to initialize a vision-text dual encoder model with
+any pretrained vision autoencoding model as the vision encoder (*e.g.* [ViT](vit), [BEiT](beit), [DeiT](deit)) and any pretrained text autoencoding model as the text encoder (*e.g.* [RoBERTa](roberta), [BERT](bert)). Two projection layers are added on top of both the vision and text encoder to project the output embeddings
+to a shared latent space. The projection layers are randomly initialized so the model should be fine-tuned on a
+downstream task. This model can be used to align the vision-text embeddings using CLIP like contrastive image-text
+training and then can be used for zero-shot vision tasks such image-classification or retrieval.
+
+In [LiT: Zero-Shot Transfer with Locked-image Text Tuning](https://arxiv.org/abs/2111.07991) it is shown how
+leveraging pre-trained (locked/frozen) image and text model for contrastive learning yields significant improvment on
+new zero-shot vision tasks such as image classification or retrieval.
+
+## VisionTextDualEncoderConfig
+
+[[autodoc]] VisionTextDualEncoderConfig
+
+## VisionTextDualEncoderProcessor
+
+[[autodoc]] VisionTextDualEncoderProcessor
+
+## VisionTextDualEncoderModel
+
+[[autodoc]] VisionTextDualEncoderModel
+ - forward
+
+## FlaxVisionTextDualEncoderModel
+
+[[autodoc]] FlaxVisionTextDualEncoderModel
+ - __call__
diff --git a/docs/source/en/model_doc/visual_bert.mdx b/docs/source/en/model_doc/visual_bert.mdx
new file mode 100644
index 00000000000000..dd722b919eb708
--- /dev/null
+++ b/docs/source/en/model_doc/visual_bert.mdx
@@ -0,0 +1,125 @@
+
+
+# VisualBERT
+
+## Overview
+
+The VisualBERT model was proposed in [VisualBERT: A Simple and Performant Baseline for Vision and Language](https://arxiv.org/pdf/1908.03557) by Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, Kai-Wei Chang.
+VisualBERT is a neural network trained on a variety of (image, text) pairs.
+
+The abstract from the paper is the following:
+
+*We propose VisualBERT, a simple and flexible framework for modeling a broad range of vision-and-language tasks.
+VisualBERT consists of a stack of Transformer layers that implicitly align elements of an input text and regions in an
+associated input image with self-attention. We further propose two visually-grounded language model objectives for
+pre-training VisualBERT on image caption data. Experiments on four vision-and-language tasks including VQA, VCR, NLVR2,
+and Flickr30K show that VisualBERT outperforms or rivals with state-of-the-art models while being significantly
+simpler. Further analysis demonstrates that VisualBERT can ground elements of language to image regions without any
+explicit supervision and is even sensitive to syntactic relationships, tracking, for example, associations between
+verbs and image regions corresponding to their arguments.*
+
+Tips:
+
+1. Most of the checkpoints provided work with the [`VisualBertForPreTraining`] configuration. Other
+ checkpoints provided are the fine-tuned checkpoints for down-stream tasks - VQA ('visualbert-vqa'), VCR
+ ('visualbert-vcr'), NLVR2 ('visualbert-nlvr2'). Hence, if you are not working on these downstream tasks, it is
+ recommended that you use the pretrained checkpoints.
+
+2. For the VCR task, the authors use a fine-tuned detector for generating visual embeddings, for all the checkpoints.
+ We do not provide the detector and its weights as a part of the package, but it will be available in the research
+ projects, and the states can be loaded directly into the detector provided.
+
+## Usage
+
+VisualBERT is a multi-modal vision and language model. It can be used for visual question answering, multiple choice,
+visual reasoning and region-to-phrase correspondence tasks. VisualBERT uses a BERT-like transformer to prepare
+embeddings for image-text pairs. Both the text and visual features are then projected to a latent space with identical
+dimension.
+
+To feed images to the model, each image is passed through a pre-trained object detector and the regions and the
+bounding boxes are extracted. The authors use the features generated after passing these regions through a pre-trained
+CNN like ResNet as visual embeddings. They also add absolute position embeddings, and feed the resulting sequence of
+vectors to a standard BERT model. The text input is concatenated in the front of the visual embeddings in the embedding
+layer, and is expected to be bound by [CLS] and a [SEP] tokens, as in BERT. The segment IDs must also be set
+appropriately for the textual and visual parts.
+
+The [`BertTokenizer`] is used to encode the text. A custom detector/feature extractor must be used
+to get the visual embeddings. The following example notebooks show how to use VisualBERT with Detectron-like models:
+
+- [VisualBERT VQA demo notebook](https://github.com/huggingface/transformers/tree/main/examples/research_projects/visual_bert) : This notebook
+ contains an example on VisualBERT VQA.
+
+- [Generate Embeddings for VisualBERT (Colab Notebook)](https://colab.research.google.com/drive/1bLGxKdldwqnMVA5x4neY7-l_8fKGWQYI?usp=sharing) : This notebook contains
+ an example on how to generate visual embeddings.
+
+The following example shows how to get the last hidden state using [`VisualBertModel`]:
+
+```python
+>>> import torch
+>>> from transformers import BertTokenizer, VisualBertModel
+
+>>> model = VisualBertModel.from_pretrained("uclanlp/visualbert-vqa-coco-pre")
+>>> tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
+
+>>> inputs = tokenizer("What is the man eating?", return_tensors="pt")
+>>> # this is a custom function that returns the visual embeddings given the image path
+>>> visual_embeds = get_visual_embeddings(image_path)
+
+>>> visual_token_type_ids = torch.ones(visual_embeds.shape[:-1], dtype=torch.long)
+>>> visual_attention_mask = torch.ones(visual_embeds.shape[:-1], dtype=torch.float)
+>>> inputs.update(
+... {
+... "visual_embeds": visual_embeds,
+... "visual_token_type_ids": visual_token_type_ids,
+... "visual_attention_mask": visual_attention_mask,
+... }
+... )
+>>> outputs = model(**inputs)
+>>> last_hidden_state = outputs.last_hidden_state
+```
+
+This model was contributed by [gchhablani](https://huggingface.co/gchhablani). The original code can be found [here](https://github.com/uclanlp/visualbert).
+
+## VisualBertConfig
+
+[[autodoc]] VisualBertConfig
+
+## VisualBertModel
+
+[[autodoc]] VisualBertModel
+ - forward
+
+## VisualBertForPreTraining
+
+[[autodoc]] VisualBertForPreTraining
+ - forward
+
+## VisualBertForQuestionAnswering
+
+[[autodoc]] VisualBertForQuestionAnswering
+ - forward
+
+## VisualBertForMultipleChoice
+
+[[autodoc]] VisualBertForMultipleChoice
+ - forward
+
+## VisualBertForVisualReasoning
+
+[[autodoc]] VisualBertForVisualReasoning
+ - forward
+
+## VisualBertForRegionToPhraseAlignment
+
+[[autodoc]] VisualBertForRegionToPhraseAlignment
+ - forward
diff --git a/docs/source/en/model_doc/vit.mdx b/docs/source/en/model_doc/vit.mdx
new file mode 100644
index 00000000000000..37c469f6aaaefc
--- /dev/null
+++ b/docs/source/en/model_doc/vit.mdx
@@ -0,0 +1,134 @@
+
+
+# Vision Transformer (ViT)
+
+
+
+This is a recently introduced model so the API hasn't been tested extensively. There may be some bugs or slight
+breaking changes to fix it in the future. If you see something strange, file a [Github Issue](https://github.com/huggingface/transformers/issues/new?assignees=&labels=&template=bug-report.md&title).
+
+
+
+## Overview
+
+The Vision Transformer (ViT) model was proposed in [An Image is Worth 16x16 Words: Transformers for Image Recognition
+at Scale](https://arxiv.org/abs/2010.11929) by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk
+Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob
+Uszkoreit, Neil Houlsby. It's the first paper that successfully trains a Transformer encoder on ImageNet, attaining
+very good results compared to familiar convolutional architectures.
+
+
+The abstract from the paper is the following:
+
+*While the Transformer architecture has become the de-facto standard for natural language processing tasks, its
+applications to computer vision remain limited. In vision, attention is either applied in conjunction with
+convolutional networks, or used to replace certain components of convolutional networks while keeping their overall
+structure in place. We show that this reliance on CNNs is not necessary and a pure transformer applied directly to
+sequences of image patches can perform very well on image classification tasks. When pre-trained on large amounts of
+data and transferred to multiple mid-sized or small image recognition benchmarks (ImageNet, CIFAR-100, VTAB, etc.),
+Vision Transformer (ViT) attains excellent results compared to state-of-the-art convolutional networks while requiring
+substantially fewer computational resources to train.*
+
+Tips:
+
+- Demo notebooks regarding inference as well as fine-tuning ViT on custom data can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/VisionTransformer).
+- To feed images to the Transformer encoder, each image is split into a sequence of fixed-size non-overlapping patches,
+ which are then linearly embedded. A [CLS] token is added to serve as representation of an entire image, which can be
+ used for classification. The authors also add absolute position embeddings, and feed the resulting sequence of
+ vectors to a standard Transformer encoder.
+- As the Vision Transformer expects each image to be of the same size (resolution), one can use
+ [`ViTFeatureExtractor`] to resize (or rescale) and normalize images for the model.
+- Both the patch resolution and image resolution used during pre-training or fine-tuning are reflected in the name of
+ each checkpoint. For example, `google/vit-base-patch16-224` refers to a base-sized architecture with patch
+ resolution of 16x16 and fine-tuning resolution of 224x224. All checkpoints can be found on the [hub](https://huggingface.co/models?search=vit).
+- The available checkpoints are either (1) pre-trained on [ImageNet-21k](http://www.image-net.org/) (a collection of
+ 14 million images and 21k classes) only, or (2) also fine-tuned on [ImageNet](http://www.image-net.org/challenges/LSVRC/2012/) (also referred to as ILSVRC 2012, a collection of 1.3 million
+ images and 1,000 classes).
+- The Vision Transformer was pre-trained using a resolution of 224x224. During fine-tuning, it is often beneficial to
+ use a higher resolution than pre-training [(Touvron et al., 2019)](https://arxiv.org/abs/1906.06423), [(Kolesnikov
+ et al., 2020)](https://arxiv.org/abs/1912.11370). In order to fine-tune at higher resolution, the authors perform
+ 2D interpolation of the pre-trained position embeddings, according to their location in the original image.
+- The best results are obtained with supervised pre-training, which is not the case in NLP. The authors also performed
+ an experiment with a self-supervised pre-training objective, namely masked patched prediction (inspired by masked
+ language modeling). With this approach, the smaller ViT-B/16 model achieves 79.9% accuracy on ImageNet, a significant
+ improvement of 2% to training from scratch, but still 4% behind supervised pre-training.
+
+Following the original Vision Transformer, some follow-up works have been made:
+
+- [DeiT](deit) (Data-efficient Image Transformers) by Facebook AI. DeiT models are distilled vision transformers.
+ The authors of DeiT also released more efficiently trained ViT models, which you can directly plug into [`ViTModel`] or
+ [`ViTForImageClassification`]. There are 4 variants available (in 3 different sizes): *facebook/deit-tiny-patch16-224*,
+ *facebook/deit-small-patch16-224*, *facebook/deit-base-patch16-224* and *facebook/deit-base-patch16-384*. Note that one should
+ use [`DeiTFeatureExtractor`] in order to prepare images for the model.
+
+- [BEiT](beit) (BERT pre-training of Image Transformers) by Microsoft Research. BEiT models outperform supervised pre-trained
+ vision transformers using a self-supervised method inspired by BERT (masked image modeling) and based on a VQ-VAE.
+
+- DINO (a method for self-supervised training of Vision Transformers) by Facebook AI. Vision Transformers trained using
+ the DINO method show very interesting properties not seen with convolutional models. They are capable of segmenting
+ objects, without having ever been trained to do so. DINO checkpoints can be found on the [hub](https://huggingface.co/models?other=dino).
+
+- [MAE](vit_mae) (Masked Autoencoders) by Facebook AI. By pre-training Vision Transformers to reconstruct pixel values for a high portion
+ (75%) of masked patches (using an asymmetric encoder-decoder architecture), the authors show that this simple method outperforms
+ supervised pre-training after fine-tuning.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code (written in JAX) can be
+found [here](https://github.com/google-research/vision_transformer).
+
+Note that we converted the weights from Ross Wightman's [timm library](https://github.com/rwightman/pytorch-image-models), who already converted the weights from JAX to PyTorch. Credits
+go to him!
+
+
+## ViTConfig
+
+[[autodoc]] ViTConfig
+
+## ViTFeatureExtractor
+
+[[autodoc]] ViTFeatureExtractor
+ - __call__
+
+## ViTModel
+
+[[autodoc]] ViTModel
+ - forward
+
+## ViTForMaskedImageModeling
+
+[[autodoc]] ViTForMaskedImageModeling
+ - forward
+
+## ViTForImageClassification
+
+[[autodoc]] ViTForImageClassification
+ - forward
+
+## TFViTModel
+
+[[autodoc]] TFViTModel
+ - call
+
+## TFViTForImageClassification
+
+[[autodoc]] TFViTForImageClassification
+ - call
+
+## FlaxVitModel
+
+[[autodoc]] FlaxViTModel
+ - __call__
+
+## FlaxViTForImageClassification
+
+[[autodoc]] FlaxViTForImageClassification
+ - __call__
diff --git a/docs/source/en/model_doc/vit_mae.mdx b/docs/source/en/model_doc/vit_mae.mdx
new file mode 100644
index 00000000000000..aeb19b96a15493
--- /dev/null
+++ b/docs/source/en/model_doc/vit_mae.mdx
@@ -0,0 +1,81 @@
+
+
+# ViTMAE
+
+## Overview
+
+The ViTMAE model was proposed in [Masked Autoencoders Are Scalable Vision Learners](https://arxiv.org/abs/2111.06377v2) by Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li,
+Piotr Dollár, Ross Girshick. The paper shows that, by pre-training a Vision Transformer (ViT) to reconstruct pixel values for masked patches, one can get results after
+fine-tuning that outperform supervised pre-training.
+
+The abstract from the paper is the following:
+
+*This paper shows that masked autoencoders (MAE) are scalable self-supervised learners for computer vision. Our MAE approach is simple: we mask random patches of the
+input image and reconstruct the missing pixels. It is based on two core designs. First, we develop an asymmetric encoder-decoder architecture, with an encoder that operates
+only on the visible subset of patches (without mask tokens), along with a lightweight decoder that reconstructs the original image from the latent representation and mask
+tokens. Second, we find that masking a high proportion of the input image, e.g., 75%, yields a nontrivial and meaningful self-supervisory task. Coupling these two designs
+enables us to train large models efficiently and effectively: we accelerate training (by 3x or more) and improve accuracy. Our scalable approach allows for learning high-capacity
+models that generalize well: e.g., a vanilla ViT-Huge model achieves the best accuracy (87.8%) among methods that use only ImageNet-1K data. Transfer performance in downstream
+tasks outperforms supervised pre-training and shows promising scaling behavior.*
+
+Tips:
+
+- MAE (masked auto encoding) is a method for self-supervised pre-training of Vision Transformers (ViTs). The pre-training objective is relatively simple:
+by masking a large portion (75%) of the image patches, the model must reconstruct raw pixel values. One can use [`ViTMAEForPreTraining`] for this purpose.
+- An example Python script that illustrates how to pre-train [`ViTMAEForPreTraining`] from scratch can be found [here](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-pretraining).
+One can easily tweak it for their own use case.
+- A notebook that illustrates how to visualize reconstructed pixel values with [`ViTMAEForPreTraining`] can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/ViTMAE/ViT_MAE_visualization_demo.ipynb).
+- After pre-training, one "throws away" the decoder used to reconstruct pixels, and one uses the encoder for fine-tuning/linear probing. This means that after
+fine-tuning, one can directly plug in the weights into a [`ViTForImageClassification`].
+- One can use [`ViTFeatureExtractor`] to prepare images for the model. See the code examples for more info.
+- Note that the encoder of MAE is only used to encode the visual patches. The encoded patches are then concatenated with mask tokens, which the decoder (which also
+consists of Transformer blocks) takes as input. Each mask token is a shared, learned vector that indicates the presence of a missing patch to be predicted. Fixed
+sin/cos position embeddings are added both to the input of the encoder and the decoder.
+- For a visual understanding of how MAEs work you can check out this [post](https://keras.io/examples/vision/masked_image_modeling/).
+
+ +
+ MAE architecture. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). TensorFlow version of the model was contributed by [sayakpaul](https://github.com/sayakpaul) and
+[ariG23498](https://github.com/ariG23498) (equal contribution). The original code can be found [here](https://github.com/facebookresearch/mae).
+
+
+## ViTMAEConfig
+
+[[autodoc]] ViTMAEConfig
+
+
+## ViTMAEModel
+
+[[autodoc]] ViTMAEModel
+ - forward
+
+
+## ViTMAEForPreTraining
+
+[[autodoc]] transformers.ViTMAEForPreTraining
+ - forward
+
+
+## TFViTMAEModel
+
+[[autodoc]] TFViTMAEModel
+ - call
+
+
+## TFViTMAEForPreTraining
+
+[[autodoc]] transformers.TFViTMAEForPreTraining
+ - call
diff --git a/docs/source/en/model_doc/wav2vec2.mdx b/docs/source/en/model_doc/wav2vec2.mdx
new file mode 100644
index 00000000000000..9b2f13ea4541ee
--- /dev/null
+++ b/docs/source/en/model_doc/wav2vec2.mdx
@@ -0,0 +1,143 @@
+
+
+# Wav2Vec2
+
+## Overview
+
+The Wav2Vec2 model was proposed in [wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations](https://arxiv.org/abs/2006.11477) by Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli.
+
+The abstract from the paper is the following:
+
+*We show for the first time that learning powerful representations from speech audio alone followed by fine-tuning on
+transcribed speech can outperform the best semi-supervised methods while being conceptually simpler. wav2vec 2.0 masks
+the speech input in the latent space and solves a contrastive task defined over a quantization of the latent
+representations which are jointly learned. Experiments using all labeled data of Librispeech achieve 1.8/3.3 WER on the
+clean/other test sets. When lowering the amount of labeled data to one hour, wav2vec 2.0 outperforms the previous state
+of the art on the 100 hour subset while using 100 times less labeled data. Using just ten minutes of labeled data and
+pre-training on 53k hours of unlabeled data still achieves 4.8/8.2 WER. This demonstrates the feasibility of speech
+recognition with limited amounts of labeled data.*
+
+Tips:
+
+- Wav2Vec2 is a speech model that accepts a float array corresponding to the raw waveform of the speech signal.
+- Wav2Vec2 model was trained using connectionist temporal classification (CTC) so the model output has to be decoded
+ using [`Wav2Vec2CTCTokenizer`].
+
+This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten).
+
+
+## Wav2Vec2Config
+
+[[autodoc]] Wav2Vec2Config
+
+## Wav2Vec2CTCTokenizer
+
+[[autodoc]] Wav2Vec2CTCTokenizer
+ - __call__
+ - save_vocabulary
+ - decode
+ - batch_decode
+
+## Wav2Vec2FeatureExtractor
+
+[[autodoc]] Wav2Vec2FeatureExtractor
+ - __call__
+
+## Wav2Vec2Processor
+
+[[autodoc]] Wav2Vec2Processor
+ - __call__
+ - pad
+ - from_pretrained
+ - save_pretrained
+ - batch_decode
+ - decode
+ - as_target_processor
+
+## Wav2Vec2ProcessorWithLM
+
+[[autodoc]] Wav2Vec2ProcessorWithLM
+ - __call__
+ - pad
+ - from_pretrained
+ - save_pretrained
+ - batch_decode
+ - decode
+ - as_target_processor
+
+## Wav2Vec2 specific outputs
+
+[[autodoc]] models.wav2vec2_with_lm.processing_wav2vec2_with_lm.Wav2Vec2DecoderWithLMOutput
+
+[[autodoc]] models.wav2vec2.modeling_wav2vec2.Wav2Vec2BaseModelOutput
+
+[[autodoc]] models.wav2vec2.modeling_wav2vec2.Wav2Vec2ForPreTrainingOutput
+
+[[autodoc]] models.wav2vec2.modeling_flax_wav2vec2.FlaxWav2Vec2BaseModelOutput
+
+[[autodoc]] models.wav2vec2.modeling_flax_wav2vec2.FlaxWav2Vec2ForPreTrainingOutput
+
+## Wav2Vec2Model
+
+[[autodoc]] Wav2Vec2Model
+ - forward
+
+## Wav2Vec2ForCTC
+
+[[autodoc]] Wav2Vec2ForCTC
+ - forward
+
+## Wav2Vec2ForSequenceClassification
+
+[[autodoc]] Wav2Vec2ForSequenceClassification
+ - forward
+
+## Wav2Vec2ForAudioFrameClassification
+
+[[autodoc]] Wav2Vec2ForAudioFrameClassification
+ - forward
+
+## Wav2Vec2ForXVector
+
+[[autodoc]] Wav2Vec2ForXVector
+ - forward
+
+## Wav2Vec2ForPreTraining
+
+[[autodoc]] Wav2Vec2ForPreTraining
+ - forward
+
+## TFWav2Vec2Model
+
+[[autodoc]] TFWav2Vec2Model
+ - call
+
+## TFWav2Vec2ForCTC
+
+[[autodoc]] TFWav2Vec2ForCTC
+ - call
+
+## FlaxWav2Vec2Model
+
+[[autodoc]] FlaxWav2Vec2Model
+ - __call__
+
+## FlaxWav2Vec2ForCTC
+
+[[autodoc]] FlaxWav2Vec2ForCTC
+ - __call__
+
+## FlaxWav2Vec2ForPreTraining
+
+[[autodoc]] FlaxWav2Vec2ForPreTraining
+ - __call__
diff --git a/docs/source/en/model_doc/wav2vec2_phoneme.mdx b/docs/source/en/model_doc/wav2vec2_phoneme.mdx
new file mode 100644
index 00000000000000..b39cf66ce1368c
--- /dev/null
+++ b/docs/source/en/model_doc/wav2vec2_phoneme.mdx
@@ -0,0 +1,56 @@
+
+
+# Wav2Vec2Phoneme
+
+## Overview
+
+The Wav2Vec2Phoneme model was proposed in [Simple and Effective Zero-shot Cross-lingual Phoneme Recognition (Xu et al.,
+2021](https://arxiv.org/abs/2109.11680) by Qiantong Xu, Alexei Baevski, Michael Auli.
+
+The abstract from the paper is the following:
+
+*Recent progress in self-training, self-supervised pretraining and unsupervised learning enabled well performing speech
+recognition systems without any labeled data. However, in many cases there is labeled data available for related
+languages which is not utilized by these methods. This paper extends previous work on zero-shot cross-lingual transfer
+learning by fine-tuning a multilingually pretrained wav2vec 2.0 model to transcribe unseen languages. This is done by
+mapping phonemes of the training languages to the target language using articulatory features. Experiments show that
+this simple method significantly outperforms prior work which introduced task-specific architectures and used only part
+of a monolingually pretrained model.*
+
+Tips:
+
+- Wav2Vec2Phoneme uses the exact same architecture as Wav2Vec2
+- Wav2Vec2Phoneme is a speech model that accepts a float array corresponding to the raw waveform of the speech signal.
+- Wav2Vec2Phoneme model was trained using connectionist temporal classification (CTC) so the model output has to be
+ decoded using [`Wav2Vec2PhonemeCTCTokenizer`].
+- Wav2Vec2Phoneme can be fine-tuned on multiple language at once and decode unseen languages in a single forward pass
+ to a sequence of phonemes
+- By default the model outputs a sequence of phonemes. In order to transform the phonemes to a sequence of words one
+ should make use of a dictionary and language model.
+
+Relevant checkpoints can be found under https://huggingface.co/models?other=phoneme-recognition.
+
+This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten)
+
+The original code can be found [here](https://github.com/pytorch/fairseq/tree/master/fairseq/models/wav2vec).
+
+Wav2Vec2Phoneme's architecture is based on the Wav2Vec2 model, so one can refer to [`Wav2Vec2`]'s documentation page except for the tokenizer.
+
+
+## Wav2Vec2PhonemeCTCTokenizer
+
+[[autodoc]] Wav2Vec2PhonemeCTCTokenizer
+ - __call__
+ - batch_decode
+ - decode
+ - phonemize
diff --git a/docs/source/en/model_doc/wavlm.mdx b/docs/source/en/model_doc/wavlm.mdx
new file mode 100644
index 00000000000000..254321cd7fcc90
--- /dev/null
+++ b/docs/source/en/model_doc/wavlm.mdx
@@ -0,0 +1,79 @@
+
+
+# WavLM
+
+## Overview
+
+The WavLM model was proposed in [WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing](https://arxiv.org/abs/2110.13900) by Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen,
+Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, Jian Wu, Long Zhou, Shuo Ren, Yanmin Qian, Yao Qian, Jian Wu,
+Michael Zeng, Furu Wei.
+
+The abstract from the paper is the following:
+
+*Self-supervised learning (SSL) achieves great success in speech recognition, while limited exploration has been
+attempted for other speech processing tasks. As speech signal contains multi-faceted information including speaker
+identity, paralinguistics, spoken content, etc., learning universal representations for all speech tasks is
+challenging. In this paper, we propose a new pre-trained model, WavLM, to solve full-stack downstream speech tasks.
+WavLM is built based on the HuBERT framework, with an emphasis on both spoken content modeling and speaker identity
+preservation. We first equip the Transformer structure with gated relative position bias to improve its capability on
+recognition tasks. For better speaker discrimination, we propose an utterance mixing training strategy, where
+additional overlapped utterances are created unsupervisely and incorporated during model training. Lastly, we scale up
+the training dataset from 60k hours to 94k hours. WavLM Large achieves state-of-the-art performance on the SUPERB
+benchmark, and brings significant improvements for various speech processing tasks on their representative benchmarks.*
+
+Tips:
+
+- WavLM is a speech model that accepts a float array corresponding to the raw waveform of the speech signal. Please use
+ [`Wav2Vec2Processor`] for the feature extraction.
+- WavLM model can be fine-tuned using connectionist temporal classification (CTC) so the model output has to be decoded
+ using [`Wav2Vec2CTCTokenizer`].
+- WavLM performs especially well on speaker verification, speaker identification, and speaker diarization tasks.
+
+Relevant checkpoints can be found under https://huggingface.co/models?other=wavlm.
+
+This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten). The Authors' code can be
+found [here](https://github.com/microsoft/unilm/tree/master/wavlm).
+
+
+## WavLMConfig
+
+[[autodoc]] WavLMConfig
+
+## WavLM specific outputs
+
+[[autodoc]] models.wavlm.modeling_wavlm.WavLMBaseModelOutput
+
+## WavLMModel
+
+[[autodoc]] WavLMModel
+ - forward
+
+## WavLMForCTC
+
+[[autodoc]] WavLMForCTC
+ - forward
+
+## WavLMForSequenceClassification
+
+[[autodoc]] WavLMForSequenceClassification
+ - forward
+
+## WavLMForAudioFrameClassification
+
+[[autodoc]] WavLMForAudioFrameClassification
+ - forward
+
+## WavLMForXVector
+
+[[autodoc]] WavLMForXVector
+ - forward
diff --git a/docs/source/en/model_doc/xglm.mdx b/docs/source/en/model_doc/xglm.mdx
new file mode 100644
index 00000000000000..b8c395ce021133
--- /dev/null
+++ b/docs/source/en/model_doc/xglm.mdx
@@ -0,0 +1,75 @@
+
+
+# XGLM
+
+## Overview
+
+The XGLM model was proposed in [Few-shot Learning with Multilingual Language Models](https://arxiv.org/abs/2112.10668)
+by Xi Victoria Lin, Todor Mihaylov, Mikel Artetxe, Tianlu Wang, Shuohui Chen, Daniel Simig, Myle Ott, Naman Goyal,
+Shruti Bhosale, Jingfei Du, Ramakanth Pasunuru, Sam Shleifer, Punit Singh Koura, Vishrav Chaudhary, Brian O'Horo,
+Jeff Wang, Luke Zettlemoyer, Zornitsa Kozareva, Mona Diab, Veselin Stoyanov, Xian Li.
+
+The abstract from the paper is the following:
+
+*Large-scale autoregressive language models such as GPT-3 are few-shot learners that can perform a wide range of language
+tasks without fine-tuning. While these models are known to be able to jointly represent many different languages,
+their training data is dominated by English, potentially limiting their cross-lingual generalization.
+In this work, we train multilingual autoregressive language models on a balanced corpus covering a diverse set of languages,
+and study their few- and zero-shot learning capabilities in a wide range of tasks. Our largest model with 7.5 billion parameters
+sets new state of the art in few-shot learning in more than 20 representative languages, outperforming GPT-3 of comparable size
+in multilingual commonsense reasoning (with +7.4% absolute accuracy improvement in 0-shot settings and +9.4% in 4-shot settings)
+and natural language inference (+5.4% in each of 0-shot and 4-shot settings). On the FLORES-101 machine translation benchmark,
+our model outperforms GPT-3 on 171 out of 182 translation directions with 32 training examples, while surpassing the
+official supervised baseline in 45 directions. We present a detailed analysis of where the model succeeds and fails,
+showing in particular that it enables cross-lingual in-context learning on some tasks, while there is still room for improvement
+on surface form robustness and adaptation to tasks that do not have a natural cloze form. Finally, we evaluate our models
+in social value tasks such as hate speech detection in five languages and find it has limitations similar to comparable sized GPT-3 models.*
+
+
+This model was contributed by [Suraj](https://huggingface.co/valhalla). The original code can be found [here](https://github.com/pytorch/fairseq/tree/main/examples/xglm).
+
+## XGLMConfig
+
+[[autodoc]] XGLMConfig
+
+## XGLMTokenizer
+
+[[autodoc]] XGLMTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## XGLMTokenizerFast
+
+[[autodoc]] XGLMTokenizerFast
+
+## XGLMModel
+
+[[autodoc]] XGLMModel
+ - forward
+
+## XGLMForCausalLM
+
+[[autodoc]] XGLMForCausalLM
+ - forward
+
+## FlaxXGLMModel
+
+[[autodoc]] FlaxXGLMModel
+ - __call__
+
+## FlaxXGLMForCausalLM
+
+[[autodoc]] FlaxXGLMForCausalLM
+ - __call__
\ No newline at end of file
diff --git a/docs/source/en/model_doc/xlm-prophetnet.mdx b/docs/source/en/model_doc/xlm-prophetnet.mdx
new file mode 100644
index 00000000000000..af4a3bb6e87ec9
--- /dev/null
+++ b/docs/source/en/model_doc/xlm-prophetnet.mdx
@@ -0,0 +1,68 @@
+
+
+# XLM-ProphetNet
+
+**DISCLAIMER:** If you see something strange, file a [Github Issue](https://github.com/huggingface/transformers/issues/new?assignees=&labels=&template=bug-report.md&title) and assign
+@patrickvonplaten
+
+
+## Overview
+
+The XLM-ProphetNet model was proposed in [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training,](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei
+Zhang, Ming Zhou on 13 Jan, 2020.
+
+XLM-ProphetNet is an encoder-decoder model and can predict n-future tokens for "ngram" language modeling instead of
+just the next token. Its architecture is identical to ProhpetNet, but the model was trained on the multi-lingual
+"wiki100" Wikipedia dump.
+
+The abstract from the paper is the following:
+
+*In this paper, we present a new sequence-to-sequence pretraining model called ProphetNet, which introduces a novel
+self-supervised objective named future n-gram prediction and the proposed n-stream self-attention mechanism. Instead of
+the optimization of one-step ahead prediction in traditional sequence-to-sequence model, the ProphetNet is optimized by
+n-step ahead prediction which predicts the next n tokens simultaneously based on previous context tokens at each time
+step. The future n-gram prediction explicitly encourages the model to plan for the future tokens and prevent
+overfitting on strong local correlations. We pre-train ProphetNet using a base scale dataset (16GB) and a large scale
+dataset (160GB) respectively. Then we conduct experiments on CNN/DailyMail, Gigaword, and SQuAD 1.1 benchmarks for
+abstractive summarization and question generation tasks. Experimental results show that ProphetNet achieves new
+state-of-the-art results on all these datasets compared to the models using the same scale pretraining corpus.*
+
+The Authors' code can be found [here](https://github.com/microsoft/ProphetNet).
+
+## XLMProphetNetConfig
+
+[[autodoc]] XLMProphetNetConfig
+
+## XLMProphetNetTokenizer
+
+[[autodoc]] XLMProphetNetTokenizer
+
+## XLMProphetNetModel
+
+[[autodoc]] XLMProphetNetModel
+
+## XLMProphetNetEncoder
+
+[[autodoc]] XLMProphetNetEncoder
+
+## XLMProphetNetDecoder
+
+[[autodoc]] XLMProphetNetDecoder
+
+## XLMProphetNetForConditionalGeneration
+
+[[autodoc]] XLMProphetNetForConditionalGeneration
+
+## XLMProphetNetForCausalLM
+
+[[autodoc]] XLMProphetNetForCausalLM
diff --git a/docs/source/en/model_doc/xlm-roberta-xl.mdx b/docs/source/en/model_doc/xlm-roberta-xl.mdx
new file mode 100644
index 00000000000000..01829a128c00f3
--- /dev/null
+++ b/docs/source/en/model_doc/xlm-roberta-xl.mdx
@@ -0,0 +1,69 @@
+
+
+# XLM-RoBERTa-XL
+
+## Overview
+
+The XLM-RoBERTa-XL model was proposed in [Larger-Scale Transformers for Multilingual Masked Language Modeling](https://arxiv.org/abs/2105.00572) by Naman Goyal, Jingfei Du, Myle Ott, Giri Anantharaman, Alexis Conneau.
+
+The abstract from the paper is the following:
+
+*Recent work has demonstrated the effectiveness of cross-lingual language model pretraining for cross-lingual understanding. In this study, we present the results of two larger multilingual masked language models, with 3.5B and 10.7B parameters. Our two new models dubbed XLM-R XL and XLM-R XXL outperform XLM-R by 1.8% and 2.4% average accuracy on XNLI. Our model also outperforms the RoBERTa-Large model on several English tasks of the GLUE benchmark by 0.3% on average while handling 99 more languages. This suggests pretrained models with larger capacity may obtain both strong performance on high-resource languages while greatly improving low-resource languages. We make our code and models publicly available.*
+
+Tips:
+
+- XLM-RoBERTa-XL is a multilingual model trained on 100 different languages. Unlike some XLM multilingual models, it does
+ not require `lang` tensors to understand which language is used, and should be able to determine the correct
+ language from the input ids.
+
+This model was contributed by [Soonhwan-Kwon](https://github.com/Soonhwan-Kwon) and [stefan-it](https://huggingface.co/stefan-it). The original code can be found [here](https://github.com/pytorch/fairseq/tree/master/examples/xlmr).
+
+
+## XLMRobertaXLConfig
+
+[[autodoc]] XLMRobertaXLConfig
+
+## XLMRobertaXLModel
+
+[[autodoc]] XLMRobertaXLModel
+ - forward
+
+## XLMRobertaXLForCausalLM
+
+[[autodoc]] XLMRobertaXLForCausalLM
+ - forward
+
+## XLMRobertaXLForMaskedLM
+
+[[autodoc]] XLMRobertaXLForMaskedLM
+ - forward
+
+## XLMRobertaXLForSequenceClassification
+
+[[autodoc]] XLMRobertaXLForSequenceClassification
+ - forward
+
+## XLMRobertaXLForMultipleChoice
+
+[[autodoc]] XLMRobertaXLForMultipleChoice
+ - forward
+
+## XLMRobertaXLForTokenClassification
+
+[[autodoc]] XLMRobertaXLForTokenClassification
+ - forward
+
+## XLMRobertaXLForQuestionAnswering
+
+[[autodoc]] XLMRobertaXLForQuestionAnswering
+ - forward
diff --git a/docs/source/en/model_doc/xlm-roberta.mdx b/docs/source/en/model_doc/xlm-roberta.mdx
new file mode 100644
index 00000000000000..5ca4ae2ad3292f
--- /dev/null
+++ b/docs/source/en/model_doc/xlm-roberta.mdx
@@ -0,0 +1,156 @@
+
+
+# XLM-RoBERTa
+
+## Overview
+
+The XLM-RoBERTa model was proposed in [Unsupervised Cross-lingual Representation Learning at Scale](https://arxiv.org/abs/1911.02116) by Alexis Conneau, Kartikay Khandelwal, Naman Goyal, Vishrav Chaudhary, Guillaume
+Wenzek, Francisco Guzmán, Edouard Grave, Myle Ott, Luke Zettlemoyer and Veselin Stoyanov. It is based on Facebook's
+RoBERTa model released in 2019. It is a large multi-lingual language model, trained on 2.5TB of filtered CommonCrawl
+data.
+
+The abstract from the paper is the following:
+
+*This paper shows that pretraining multilingual language models at scale leads to significant performance gains for a
+wide range of cross-lingual transfer tasks. We train a Transformer-based masked language model on one hundred
+languages, using more than two terabytes of filtered CommonCrawl data. Our model, dubbed XLM-R, significantly
+outperforms multilingual BERT (mBERT) on a variety of cross-lingual benchmarks, including +13.8% average accuracy on
+XNLI, +12.3% average F1 score on MLQA, and +2.1% average F1 score on NER. XLM-R performs particularly well on
+low-resource languages, improving 11.8% in XNLI accuracy for Swahili and 9.2% for Urdu over the previous XLM model. We
+also present a detailed empirical evaluation of the key factors that are required to achieve these gains, including the
+trade-offs between (1) positive transfer and capacity dilution and (2) the performance of high and low resource
+languages at scale. Finally, we show, for the first time, the possibility of multilingual modeling without sacrificing
+per-language performance; XLM-Ris very competitive with strong monolingual models on the GLUE and XNLI benchmarks. We
+will make XLM-R code, data, and models publicly available.*
+
+Tips:
+
+- XLM-RoBERTa is a multilingual model trained on 100 different languages. Unlike some XLM multilingual models, it does
+ not require `lang` tensors to understand which language is used, and should be able to determine the correct
+ language from the input ids.
+- This implementation is the same as RoBERTa. Refer to the [documentation of RoBERTa](roberta) for usage examples
+ as well as the information relative to the inputs and outputs.
+
+This model was contributed by [stefan-it](https://huggingface.co/stefan-it). The original code can be found [here](https://github.com/pytorch/fairseq/tree/master/examples/xlmr).
+
+
+## XLMRobertaConfig
+
+[[autodoc]] XLMRobertaConfig
+
+## XLMRobertaTokenizer
+
+[[autodoc]] XLMRobertaTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## XLMRobertaTokenizerFast
+
+[[autodoc]] XLMRobertaTokenizerFast
+
+## XLMRobertaModel
+
+[[autodoc]] XLMRobertaModel
+ - forward
+
+## XLMRobertaForCausalLM
+
+[[autodoc]] XLMRobertaForCausalLM
+ - forward
+
+## XLMRobertaForMaskedLM
+
+[[autodoc]] XLMRobertaForMaskedLM
+ - forward
+
+## XLMRobertaForSequenceClassification
+
+[[autodoc]] XLMRobertaForSequenceClassification
+ - forward
+
+## XLMRobertaForMultipleChoice
+
+[[autodoc]] XLMRobertaForMultipleChoice
+ - forward
+
+## XLMRobertaForTokenClassification
+
+[[autodoc]] XLMRobertaForTokenClassification
+ - forward
+
+## XLMRobertaForQuestionAnswering
+
+[[autodoc]] XLMRobertaForQuestionAnswering
+ - forward
+
+## TFXLMRobertaModel
+
+[[autodoc]] TFXLMRobertaModel
+ - call
+
+## TFXLMRobertaForMaskedLM
+
+[[autodoc]] TFXLMRobertaForMaskedLM
+ - call
+
+## TFXLMRobertaForSequenceClassification
+
+[[autodoc]] TFXLMRobertaForSequenceClassification
+ - call
+
+## TFXLMRobertaForMultipleChoice
+
+[[autodoc]] TFXLMRobertaForMultipleChoice
+ - call
+
+## TFXLMRobertaForTokenClassification
+
+[[autodoc]] TFXLMRobertaForTokenClassification
+ - call
+
+## TFXLMRobertaForQuestionAnswering
+
+[[autodoc]] TFXLMRobertaForQuestionAnswering
+ - call
+
+## FlaxXLMRobertaModel
+
+[[autodoc]] FlaxXLMRobertaModel
+ - __call__
+
+## FlaxXLMRobertaForMaskedLM
+
+[[autodoc]] FlaxXLMRobertaForMaskedLM
+ - __call__
+
+## FlaxXLMRobertaForSequenceClassification
+
+[[autodoc]] FlaxXLMRobertaForSequenceClassification
+ - __call__
+
+## FlaxXLMRobertaForMultipleChoice
+
+[[autodoc]] FlaxXLMRobertaForMultipleChoice
+ - __call__
+
+## FlaxXLMRobertaForTokenClassification
+
+[[autodoc]] FlaxXLMRobertaForTokenClassification
+ - __call__
+
+## FlaxXLMRobertaForQuestionAnswering
+
+[[autodoc]] FlaxXLMRobertaForQuestionAnswering
+ - __call__
diff --git a/docs/source/en/model_doc/xlm.mdx b/docs/source/en/model_doc/xlm.mdx
new file mode 100644
index 00000000000000..a441c64c86c932
--- /dev/null
+++ b/docs/source/en/model_doc/xlm.mdx
@@ -0,0 +1,124 @@
+
+
+# XLM
+
+## Overview
+
+The XLM model was proposed in [Cross-lingual Language Model Pretraining](https://arxiv.org/abs/1901.07291) by
+Guillaume Lample, Alexis Conneau. It's a transformer pretrained using one of the following objectives:
+
+- a causal language modeling (CLM) objective (next token prediction),
+- a masked language modeling (MLM) objective (BERT-like), or
+- a Translation Language Modeling (TLM) object (extension of BERT's MLM to multiple language inputs)
+
+The abstract from the paper is the following:
+
+*Recent studies have demonstrated the efficiency of generative pretraining for English natural language understanding.
+In this work, we extend this approach to multiple languages and show the effectiveness of cross-lingual pretraining. We
+propose two methods to learn cross-lingual language models (XLMs): one unsupervised that only relies on monolingual
+data, and one supervised that leverages parallel data with a new cross-lingual language model objective. We obtain
+state-of-the-art results on cross-lingual classification, unsupervised and supervised machine translation. On XNLI, our
+approach pushes the state of the art by an absolute gain of 4.9% accuracy. On unsupervised machine translation, we
+obtain 34.3 BLEU on WMT'16 German-English, improving the previous state of the art by more than 9 BLEU. On supervised
+machine translation, we obtain a new state of the art of 38.5 BLEU on WMT'16 Romanian-English, outperforming the
+previous best approach by more than 4 BLEU. Our code and pretrained models will be made publicly available.*
+
+Tips:
+
+- XLM has many different checkpoints, which were trained using different objectives: CLM, MLM or TLM. Make sure to
+ select the correct objective for your task (e.g. MLM checkpoints are not suitable for generation).
+- XLM has multilingual checkpoints which leverage a specific `lang` parameter. Check out the [multi-lingual](../multilingual) page for more information.
+
+This model was contributed by [thomwolf](https://huggingface.co/thomwolf). The original code can be found [here](https://github.com/facebookresearch/XLM/).
+
+
+## XLMConfig
+
+[[autodoc]] XLMConfig
+
+## XLMTokenizer
+
+[[autodoc]] XLMTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## XLM specific outputs
+
+[[autodoc]] models.xlm.modeling_xlm.XLMForQuestionAnsweringOutput
+
+## XLMModel
+
+[[autodoc]] XLMModel
+ - forward
+
+## XLMWithLMHeadModel
+
+[[autodoc]] XLMWithLMHeadModel
+ - forward
+
+## XLMForSequenceClassification
+
+[[autodoc]] XLMForSequenceClassification
+ - forward
+
+## XLMForMultipleChoice
+
+[[autodoc]] XLMForMultipleChoice
+ - forward
+
+## XLMForTokenClassification
+
+[[autodoc]] XLMForTokenClassification
+ - forward
+
+## XLMForQuestionAnsweringSimple
+
+[[autodoc]] XLMForQuestionAnsweringSimple
+ - forward
+
+## XLMForQuestionAnswering
+
+[[autodoc]] XLMForQuestionAnswering
+ - forward
+
+## TFXLMModel
+
+[[autodoc]] TFXLMModel
+ - call
+
+## TFXLMWithLMHeadModel
+
+[[autodoc]] TFXLMWithLMHeadModel
+ - call
+
+## TFXLMForSequenceClassification
+
+[[autodoc]] TFXLMForSequenceClassification
+ - call
+
+## TFXLMForMultipleChoice
+
+[[autodoc]] TFXLMForMultipleChoice
+ - call
+
+## TFXLMForTokenClassification
+
+[[autodoc]] TFXLMForTokenClassification
+ - call
+
+## TFXLMForQuestionAnsweringSimple
+
+[[autodoc]] TFXLMForQuestionAnsweringSimple
+ - call
diff --git a/docs/source/en/model_doc/xlnet.mdx b/docs/source/en/model_doc/xlnet.mdx
new file mode 100644
index 00000000000000..ca30574690c5c9
--- /dev/null
+++ b/docs/source/en/model_doc/xlnet.mdx
@@ -0,0 +1,154 @@
+
+
+# XLNet
+
+## Overview
+
+The XLNet model was proposed in [XLNet: Generalized Autoregressive Pretraining for Language Understanding](https://arxiv.org/abs/1906.08237) by Zhilin Yang, Zihang Dai, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov,
+Quoc V. Le. XLnet is an extension of the Transformer-XL model pre-trained using an autoregressive method to learn
+bidirectional contexts by maximizing the expected likelihood over all permutations of the input sequence factorization
+order.
+
+The abstract from the paper is the following:
+
+*With the capability of modeling bidirectional contexts, denoising autoencoding based pretraining like BERT achieves
+better performance than pretraining approaches based on autoregressive language modeling. However, relying on
+corrupting the input with masks, BERT neglects dependency between the masked positions and suffers from a
+pretrain-finetune discrepancy. In light of these pros and cons, we propose XLNet, a generalized autoregressive
+pretraining method that (1) enables learning bidirectional contexts by maximizing the expected likelihood over all
+permutations of the factorization order and (2) overcomes the limitations of BERT thanks to its autoregressive
+formulation. Furthermore, XLNet integrates ideas from Transformer-XL, the state-of-the-art autoregressive model, into
+pretraining. Empirically, under comparable experiment settings, XLNet outperforms BERT on 20 tasks, often by a large
+margin, including question answering, natural language inference, sentiment analysis, and document ranking.*
+
+Tips:
+
+- The specific attention pattern can be controlled at training and test time using the `perm_mask` input.
+- Due to the difficulty of training a fully auto-regressive model over various factorization order, XLNet is pretrained
+ using only a sub-set of the output tokens as target which are selected with the `target_mapping` input.
+- To use XLNet for sequential decoding (i.e. not in fully bi-directional setting), use the `perm_mask` and
+ `target_mapping` inputs to control the attention span and outputs (see examples in
+ *examples/pytorch/text-generation/run_generation.py*)
+- XLNet is one of the few models that has no sequence length limit.
+
+This model was contributed by [thomwolf](https://huggingface.co/thomwolf). The original code can be found [here](https://github.com/zihangdai/xlnet/).
+
+
+## XLNetConfig
+
+[[autodoc]] XLNetConfig
+
+## XLNetTokenizer
+
+[[autodoc]] XLNetTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## XLNetTokenizerFast
+
+[[autodoc]] XLNetTokenizerFast
+
+## XLNet specific outputs
+
+[[autodoc]] models.xlnet.modeling_xlnet.XLNetModelOutput
+
+[[autodoc]] models.xlnet.modeling_xlnet.XLNetLMHeadModelOutput
+
+[[autodoc]] models.xlnet.modeling_xlnet.XLNetForSequenceClassificationOutput
+
+[[autodoc]] models.xlnet.modeling_xlnet.XLNetForMultipleChoiceOutput
+
+[[autodoc]] models.xlnet.modeling_xlnet.XLNetForTokenClassificationOutput
+
+[[autodoc]] models.xlnet.modeling_xlnet.XLNetForQuestionAnsweringSimpleOutput
+
+[[autodoc]] models.xlnet.modeling_xlnet.XLNetForQuestionAnsweringOutput
+
+[[autodoc]] models.xlnet.modeling_tf_xlnet.TFXLNetModelOutput
+
+[[autodoc]] models.xlnet.modeling_tf_xlnet.TFXLNetLMHeadModelOutput
+
+[[autodoc]] models.xlnet.modeling_tf_xlnet.TFXLNetForSequenceClassificationOutput
+
+[[autodoc]] models.xlnet.modeling_tf_xlnet.TFXLNetForMultipleChoiceOutput
+
+[[autodoc]] models.xlnet.modeling_tf_xlnet.TFXLNetForTokenClassificationOutput
+
+[[autodoc]] models.xlnet.modeling_tf_xlnet.TFXLNetForQuestionAnsweringSimpleOutput
+
+## XLNetModel
+
+[[autodoc]] XLNetModel
+ - forward
+
+## XLNetLMHeadModel
+
+[[autodoc]] XLNetLMHeadModel
+ - forward
+
+## XLNetForSequenceClassification
+
+[[autodoc]] XLNetForSequenceClassification
+ - forward
+
+## XLNetForMultipleChoice
+
+[[autodoc]] XLNetForMultipleChoice
+ - forward
+
+## XLNetForTokenClassification
+
+[[autodoc]] XLNetForTokenClassification
+ - forward
+
+## XLNetForQuestionAnsweringSimple
+
+[[autodoc]] XLNetForQuestionAnsweringSimple
+ - forward
+
+## XLNetForQuestionAnswering
+
+[[autodoc]] XLNetForQuestionAnswering
+ - forward
+
+## TFXLNetModel
+
+[[autodoc]] TFXLNetModel
+ - call
+
+## TFXLNetLMHeadModel
+
+[[autodoc]] TFXLNetLMHeadModel
+ - call
+
+## TFXLNetForSequenceClassification
+
+[[autodoc]] TFXLNetForSequenceClassification
+ - call
+
+## TFLNetForMultipleChoice
+
+[[autodoc]] TFXLNetForMultipleChoice
+ - call
+
+## TFXLNetForTokenClassification
+
+[[autodoc]] TFXLNetForTokenClassification
+ - call
+
+## TFXLNetForQuestionAnsweringSimple
+
+[[autodoc]] TFXLNetForQuestionAnsweringSimple
+ - call
diff --git a/docs/source/en/model_doc/xls_r.mdx b/docs/source/en/model_doc/xls_r.mdx
new file mode 100644
index 00000000000000..82a7e3b8afbd31
--- /dev/null
+++ b/docs/source/en/model_doc/xls_r.mdx
@@ -0,0 +1,43 @@
+
+
+# XLS-R
+
+## Overview
+
+The XLS-R model was proposed in [XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale](https://arxiv.org/abs/2111.09296) by Arun Babu, Changhan Wang, Andros Tjandra, Kushal Lakhotia, Qiantong Xu, Naman
+Goyal, Kritika Singh, Patrick von Platen, Yatharth Saraf, Juan Pino, Alexei Baevski, Alexis Conneau, Michael Auli.
+
+The abstract from the paper is the following:
+
+*This paper presents XLS-R, a large-scale model for cross-lingual speech representation learning based on wav2vec 2.0.
+We train models with up to 2B parameters on nearly half a million hours of publicly available speech audio in 128
+languages, an order of magnitude more public data than the largest known prior work. Our evaluation covers a wide range
+of tasks, domains, data regimes and languages, both high and low-resource. On the CoVoST-2 speech translation
+benchmark, we improve the previous state of the art by an average of 7.4 BLEU over 21 translation directions into
+English. For speech recognition, XLS-R improves over the best known prior work on BABEL, MLS, CommonVoice as well as
+VoxPopuli, lowering error rates by 14-34% relative on average. XLS-R also sets a new state of the art on VoxLingua107
+language identification. Moreover, we show that with sufficient model size, cross-lingual pretraining can outperform
+English-only pretraining when translating English speech into other languages, a setting which favors monolingual
+pretraining. We hope XLS-R can help to improve speech processing tasks for many more languages of the world.*
+
+Tips:
+
+- XLS-R is a speech model that accepts a float array corresponding to the raw waveform of the speech signal.
+- XLS-R model was trained using connectionist temporal classification (CTC) so the model output has to be decoded using
+ [`Wav2Vec2CTCTokenizer`].
+
+Relevant checkpoints can be found under https://huggingface.co/models?other=xls_r.
+
+XLS-R's architecture is based on the Wav2Vec2 model, so one can refer to [Wav2Vec2's documentation page](wav2vec2).
+
+The original code can be found [here](https://github.com/pytorch/fairseq/tree/master/fairseq/models/wav2vec).
diff --git a/docs/source/en/model_doc/xlsr_wav2vec2.mdx b/docs/source/en/model_doc/xlsr_wav2vec2.mdx
new file mode 100644
index 00000000000000..32229f28b14763
--- /dev/null
+++ b/docs/source/en/model_doc/xlsr_wav2vec2.mdx
@@ -0,0 +1,41 @@
+
+
+# XLSR-Wav2Vec2
+
+## Overview
+
+The XLSR-Wav2Vec2 model was proposed in [Unsupervised Cross-Lingual Representation Learning For Speech Recognition](https://arxiv.org/abs/2006.13979) by Alexis Conneau, Alexei Baevski, Ronan Collobert, Abdelrahman Mohamed, Michael
+Auli.
+
+The abstract from the paper is the following:
+
+*This paper presents XLSR which learns cross-lingual speech representations by pretraining a single model from the raw
+waveform of speech in multiple languages. We build on wav2vec 2.0 which is trained by solving a contrastive task over
+masked latent speech representations and jointly learns a quantization of the latents shared across languages. The
+resulting model is fine-tuned on labeled data and experiments show that cross-lingual pretraining significantly
+outperforms monolingual pretraining. On the CommonVoice benchmark, XLSR shows a relative phoneme error rate reduction
+of 72% compared to the best known results. On BABEL, our approach improves word error rate by 16% relative compared to
+a comparable system. Our approach enables a single multilingual speech recognition model which is competitive to strong
+individual models. Analysis shows that the latent discrete speech representations are shared across languages with
+increased sharing for related languages. We hope to catalyze research in low-resource speech understanding by releasing
+XLSR-53, a large model pretrained in 53 languages.*
+
+Tips:
+
+- XLSR-Wav2Vec2 is a speech model that accepts a float array corresponding to the raw waveform of the speech signal.
+- XLSR-Wav2Vec2 model was trained using connectionist temporal classification (CTC) so the model output has to be
+ decoded using [`Wav2Vec2CTCTokenizer`].
+
+XLSR-Wav2Vec2's architecture is based on the Wav2Vec2 model, so one can refer to [Wav2Vec2's documentation page](wav2vec2).
+
+The original code can be found [here](https://github.com/pytorch/fairseq/tree/master/fairseq/models/wav2vec).
diff --git a/docs/source/en/model_doc/yolos.mdx b/docs/source/en/model_doc/yolos.mdx
new file mode 100644
index 00000000000000..bda65bec913786
--- /dev/null
+++ b/docs/source/en/model_doc/yolos.mdx
@@ -0,0 +1,60 @@
+
+
+# YOLOS
+
+## Overview
+
+The YOLOS model was proposed in [You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection](https://arxiv.org/abs/2106.00666) by Yuxin Fang, Bencheng Liao, Xinggang Wang, Jiemin Fang, Jiyang Qi, Rui Wu, Jianwei Niu, Wenyu Liu.
+YOLOS proposes to just leverage the plain [Vision Transformer (ViT)](vit) for object detection, inspired by DETR. It turns out that a base-sized encoder-only Transformer can also achieve 42 AP on COCO, similar to DETR and much more complex frameworks such as Faster R-CNN.
+
+The abstract from the paper is the following:
+
+*Can Transformer perform 2D object- and region-level recognition from a pure sequence-to-sequence perspective with minimal knowledge about the 2D spatial structure? To answer this question, we present You Only Look at One Sequence (YOLOS), a series of object detection models based on the vanilla Vision Transformer with the fewest possible modifications, region priors, as well as inductive biases of the target task. We find that YOLOS pre-trained on the mid-sized ImageNet-1k dataset only can already achieve quite competitive performance on the challenging COCO object detection benchmark, e.g., YOLOS-Base directly adopted from BERT-Base architecture can obtain 42.0 box AP on COCO val. We also discuss the impacts as well as limitations of current pre-train schemes and model scaling strategies for Transformer in vision through YOLOS.*
+
+Tips:
+
+- One can use [`YolosFeatureExtractor`] for preparing images (and optional targets) for the model. Contrary to [DETR](detr), YOLOS doesn't require a `pixel_mask` to be created.
+- Demo notebooks (regarding inference and fine-tuning on custom data) can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/YOLOS).
+
+
+
+ MAE architecture. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). TensorFlow version of the model was contributed by [sayakpaul](https://github.com/sayakpaul) and
+[ariG23498](https://github.com/ariG23498) (equal contribution). The original code can be found [here](https://github.com/facebookresearch/mae).
+
+
+## ViTMAEConfig
+
+[[autodoc]] ViTMAEConfig
+
+
+## ViTMAEModel
+
+[[autodoc]] ViTMAEModel
+ - forward
+
+
+## ViTMAEForPreTraining
+
+[[autodoc]] transformers.ViTMAEForPreTraining
+ - forward
+
+
+## TFViTMAEModel
+
+[[autodoc]] TFViTMAEModel
+ - call
+
+
+## TFViTMAEForPreTraining
+
+[[autodoc]] transformers.TFViTMAEForPreTraining
+ - call
diff --git a/docs/source/en/model_doc/wav2vec2.mdx b/docs/source/en/model_doc/wav2vec2.mdx
new file mode 100644
index 00000000000000..9b2f13ea4541ee
--- /dev/null
+++ b/docs/source/en/model_doc/wav2vec2.mdx
@@ -0,0 +1,143 @@
+
+
+# Wav2Vec2
+
+## Overview
+
+The Wav2Vec2 model was proposed in [wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations](https://arxiv.org/abs/2006.11477) by Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli.
+
+The abstract from the paper is the following:
+
+*We show for the first time that learning powerful representations from speech audio alone followed by fine-tuning on
+transcribed speech can outperform the best semi-supervised methods while being conceptually simpler. wav2vec 2.0 masks
+the speech input in the latent space and solves a contrastive task defined over a quantization of the latent
+representations which are jointly learned. Experiments using all labeled data of Librispeech achieve 1.8/3.3 WER on the
+clean/other test sets. When lowering the amount of labeled data to one hour, wav2vec 2.0 outperforms the previous state
+of the art on the 100 hour subset while using 100 times less labeled data. Using just ten minutes of labeled data and
+pre-training on 53k hours of unlabeled data still achieves 4.8/8.2 WER. This demonstrates the feasibility of speech
+recognition with limited amounts of labeled data.*
+
+Tips:
+
+- Wav2Vec2 is a speech model that accepts a float array corresponding to the raw waveform of the speech signal.
+- Wav2Vec2 model was trained using connectionist temporal classification (CTC) so the model output has to be decoded
+ using [`Wav2Vec2CTCTokenizer`].
+
+This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten).
+
+
+## Wav2Vec2Config
+
+[[autodoc]] Wav2Vec2Config
+
+## Wav2Vec2CTCTokenizer
+
+[[autodoc]] Wav2Vec2CTCTokenizer
+ - __call__
+ - save_vocabulary
+ - decode
+ - batch_decode
+
+## Wav2Vec2FeatureExtractor
+
+[[autodoc]] Wav2Vec2FeatureExtractor
+ - __call__
+
+## Wav2Vec2Processor
+
+[[autodoc]] Wav2Vec2Processor
+ - __call__
+ - pad
+ - from_pretrained
+ - save_pretrained
+ - batch_decode
+ - decode
+ - as_target_processor
+
+## Wav2Vec2ProcessorWithLM
+
+[[autodoc]] Wav2Vec2ProcessorWithLM
+ - __call__
+ - pad
+ - from_pretrained
+ - save_pretrained
+ - batch_decode
+ - decode
+ - as_target_processor
+
+## Wav2Vec2 specific outputs
+
+[[autodoc]] models.wav2vec2_with_lm.processing_wav2vec2_with_lm.Wav2Vec2DecoderWithLMOutput
+
+[[autodoc]] models.wav2vec2.modeling_wav2vec2.Wav2Vec2BaseModelOutput
+
+[[autodoc]] models.wav2vec2.modeling_wav2vec2.Wav2Vec2ForPreTrainingOutput
+
+[[autodoc]] models.wav2vec2.modeling_flax_wav2vec2.FlaxWav2Vec2BaseModelOutput
+
+[[autodoc]] models.wav2vec2.modeling_flax_wav2vec2.FlaxWav2Vec2ForPreTrainingOutput
+
+## Wav2Vec2Model
+
+[[autodoc]] Wav2Vec2Model
+ - forward
+
+## Wav2Vec2ForCTC
+
+[[autodoc]] Wav2Vec2ForCTC
+ - forward
+
+## Wav2Vec2ForSequenceClassification
+
+[[autodoc]] Wav2Vec2ForSequenceClassification
+ - forward
+
+## Wav2Vec2ForAudioFrameClassification
+
+[[autodoc]] Wav2Vec2ForAudioFrameClassification
+ - forward
+
+## Wav2Vec2ForXVector
+
+[[autodoc]] Wav2Vec2ForXVector
+ - forward
+
+## Wav2Vec2ForPreTraining
+
+[[autodoc]] Wav2Vec2ForPreTraining
+ - forward
+
+## TFWav2Vec2Model
+
+[[autodoc]] TFWav2Vec2Model
+ - call
+
+## TFWav2Vec2ForCTC
+
+[[autodoc]] TFWav2Vec2ForCTC
+ - call
+
+## FlaxWav2Vec2Model
+
+[[autodoc]] FlaxWav2Vec2Model
+ - __call__
+
+## FlaxWav2Vec2ForCTC
+
+[[autodoc]] FlaxWav2Vec2ForCTC
+ - __call__
+
+## FlaxWav2Vec2ForPreTraining
+
+[[autodoc]] FlaxWav2Vec2ForPreTraining
+ - __call__
diff --git a/docs/source/en/model_doc/wav2vec2_phoneme.mdx b/docs/source/en/model_doc/wav2vec2_phoneme.mdx
new file mode 100644
index 00000000000000..b39cf66ce1368c
--- /dev/null
+++ b/docs/source/en/model_doc/wav2vec2_phoneme.mdx
@@ -0,0 +1,56 @@
+
+
+# Wav2Vec2Phoneme
+
+## Overview
+
+The Wav2Vec2Phoneme model was proposed in [Simple and Effective Zero-shot Cross-lingual Phoneme Recognition (Xu et al.,
+2021](https://arxiv.org/abs/2109.11680) by Qiantong Xu, Alexei Baevski, Michael Auli.
+
+The abstract from the paper is the following:
+
+*Recent progress in self-training, self-supervised pretraining and unsupervised learning enabled well performing speech
+recognition systems without any labeled data. However, in many cases there is labeled data available for related
+languages which is not utilized by these methods. This paper extends previous work on zero-shot cross-lingual transfer
+learning by fine-tuning a multilingually pretrained wav2vec 2.0 model to transcribe unseen languages. This is done by
+mapping phonemes of the training languages to the target language using articulatory features. Experiments show that
+this simple method significantly outperforms prior work which introduced task-specific architectures and used only part
+of a monolingually pretrained model.*
+
+Tips:
+
+- Wav2Vec2Phoneme uses the exact same architecture as Wav2Vec2
+- Wav2Vec2Phoneme is a speech model that accepts a float array corresponding to the raw waveform of the speech signal.
+- Wav2Vec2Phoneme model was trained using connectionist temporal classification (CTC) so the model output has to be
+ decoded using [`Wav2Vec2PhonemeCTCTokenizer`].
+- Wav2Vec2Phoneme can be fine-tuned on multiple language at once and decode unseen languages in a single forward pass
+ to a sequence of phonemes
+- By default the model outputs a sequence of phonemes. In order to transform the phonemes to a sequence of words one
+ should make use of a dictionary and language model.
+
+Relevant checkpoints can be found under https://huggingface.co/models?other=phoneme-recognition.
+
+This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten)
+
+The original code can be found [here](https://github.com/pytorch/fairseq/tree/master/fairseq/models/wav2vec).
+
+Wav2Vec2Phoneme's architecture is based on the Wav2Vec2 model, so one can refer to [`Wav2Vec2`]'s documentation page except for the tokenizer.
+
+
+## Wav2Vec2PhonemeCTCTokenizer
+
+[[autodoc]] Wav2Vec2PhonemeCTCTokenizer
+ - __call__
+ - batch_decode
+ - decode
+ - phonemize
diff --git a/docs/source/en/model_doc/wavlm.mdx b/docs/source/en/model_doc/wavlm.mdx
new file mode 100644
index 00000000000000..254321cd7fcc90
--- /dev/null
+++ b/docs/source/en/model_doc/wavlm.mdx
@@ -0,0 +1,79 @@
+
+
+# WavLM
+
+## Overview
+
+The WavLM model was proposed in [WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing](https://arxiv.org/abs/2110.13900) by Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen,
+Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, Jian Wu, Long Zhou, Shuo Ren, Yanmin Qian, Yao Qian, Jian Wu,
+Michael Zeng, Furu Wei.
+
+The abstract from the paper is the following:
+
+*Self-supervised learning (SSL) achieves great success in speech recognition, while limited exploration has been
+attempted for other speech processing tasks. As speech signal contains multi-faceted information including speaker
+identity, paralinguistics, spoken content, etc., learning universal representations for all speech tasks is
+challenging. In this paper, we propose a new pre-trained model, WavLM, to solve full-stack downstream speech tasks.
+WavLM is built based on the HuBERT framework, with an emphasis on both spoken content modeling and speaker identity
+preservation. We first equip the Transformer structure with gated relative position bias to improve its capability on
+recognition tasks. For better speaker discrimination, we propose an utterance mixing training strategy, where
+additional overlapped utterances are created unsupervisely and incorporated during model training. Lastly, we scale up
+the training dataset from 60k hours to 94k hours. WavLM Large achieves state-of-the-art performance on the SUPERB
+benchmark, and brings significant improvements for various speech processing tasks on their representative benchmarks.*
+
+Tips:
+
+- WavLM is a speech model that accepts a float array corresponding to the raw waveform of the speech signal. Please use
+ [`Wav2Vec2Processor`] for the feature extraction.
+- WavLM model can be fine-tuned using connectionist temporal classification (CTC) so the model output has to be decoded
+ using [`Wav2Vec2CTCTokenizer`].
+- WavLM performs especially well on speaker verification, speaker identification, and speaker diarization tasks.
+
+Relevant checkpoints can be found under https://huggingface.co/models?other=wavlm.
+
+This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten). The Authors' code can be
+found [here](https://github.com/microsoft/unilm/tree/master/wavlm).
+
+
+## WavLMConfig
+
+[[autodoc]] WavLMConfig
+
+## WavLM specific outputs
+
+[[autodoc]] models.wavlm.modeling_wavlm.WavLMBaseModelOutput
+
+## WavLMModel
+
+[[autodoc]] WavLMModel
+ - forward
+
+## WavLMForCTC
+
+[[autodoc]] WavLMForCTC
+ - forward
+
+## WavLMForSequenceClassification
+
+[[autodoc]] WavLMForSequenceClassification
+ - forward
+
+## WavLMForAudioFrameClassification
+
+[[autodoc]] WavLMForAudioFrameClassification
+ - forward
+
+## WavLMForXVector
+
+[[autodoc]] WavLMForXVector
+ - forward
diff --git a/docs/source/en/model_doc/xglm.mdx b/docs/source/en/model_doc/xglm.mdx
new file mode 100644
index 00000000000000..b8c395ce021133
--- /dev/null
+++ b/docs/source/en/model_doc/xglm.mdx
@@ -0,0 +1,75 @@
+
+
+# XGLM
+
+## Overview
+
+The XGLM model was proposed in [Few-shot Learning with Multilingual Language Models](https://arxiv.org/abs/2112.10668)
+by Xi Victoria Lin, Todor Mihaylov, Mikel Artetxe, Tianlu Wang, Shuohui Chen, Daniel Simig, Myle Ott, Naman Goyal,
+Shruti Bhosale, Jingfei Du, Ramakanth Pasunuru, Sam Shleifer, Punit Singh Koura, Vishrav Chaudhary, Brian O'Horo,
+Jeff Wang, Luke Zettlemoyer, Zornitsa Kozareva, Mona Diab, Veselin Stoyanov, Xian Li.
+
+The abstract from the paper is the following:
+
+*Large-scale autoregressive language models such as GPT-3 are few-shot learners that can perform a wide range of language
+tasks without fine-tuning. While these models are known to be able to jointly represent many different languages,
+their training data is dominated by English, potentially limiting their cross-lingual generalization.
+In this work, we train multilingual autoregressive language models on a balanced corpus covering a diverse set of languages,
+and study their few- and zero-shot learning capabilities in a wide range of tasks. Our largest model with 7.5 billion parameters
+sets new state of the art in few-shot learning in more than 20 representative languages, outperforming GPT-3 of comparable size
+in multilingual commonsense reasoning (with +7.4% absolute accuracy improvement in 0-shot settings and +9.4% in 4-shot settings)
+and natural language inference (+5.4% in each of 0-shot and 4-shot settings). On the FLORES-101 machine translation benchmark,
+our model outperforms GPT-3 on 171 out of 182 translation directions with 32 training examples, while surpassing the
+official supervised baseline in 45 directions. We present a detailed analysis of where the model succeeds and fails,
+showing in particular that it enables cross-lingual in-context learning on some tasks, while there is still room for improvement
+on surface form robustness and adaptation to tasks that do not have a natural cloze form. Finally, we evaluate our models
+in social value tasks such as hate speech detection in five languages and find it has limitations similar to comparable sized GPT-3 models.*
+
+
+This model was contributed by [Suraj](https://huggingface.co/valhalla). The original code can be found [here](https://github.com/pytorch/fairseq/tree/main/examples/xglm).
+
+## XGLMConfig
+
+[[autodoc]] XGLMConfig
+
+## XGLMTokenizer
+
+[[autodoc]] XGLMTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## XGLMTokenizerFast
+
+[[autodoc]] XGLMTokenizerFast
+
+## XGLMModel
+
+[[autodoc]] XGLMModel
+ - forward
+
+## XGLMForCausalLM
+
+[[autodoc]] XGLMForCausalLM
+ - forward
+
+## FlaxXGLMModel
+
+[[autodoc]] FlaxXGLMModel
+ - __call__
+
+## FlaxXGLMForCausalLM
+
+[[autodoc]] FlaxXGLMForCausalLM
+ - __call__
\ No newline at end of file
diff --git a/docs/source/en/model_doc/xlm-prophetnet.mdx b/docs/source/en/model_doc/xlm-prophetnet.mdx
new file mode 100644
index 00000000000000..af4a3bb6e87ec9
--- /dev/null
+++ b/docs/source/en/model_doc/xlm-prophetnet.mdx
@@ -0,0 +1,68 @@
+
+
+# XLM-ProphetNet
+
+**DISCLAIMER:** If you see something strange, file a [Github Issue](https://github.com/huggingface/transformers/issues/new?assignees=&labels=&template=bug-report.md&title) and assign
+@patrickvonplaten
+
+
+## Overview
+
+The XLM-ProphetNet model was proposed in [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training,](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei
+Zhang, Ming Zhou on 13 Jan, 2020.
+
+XLM-ProphetNet is an encoder-decoder model and can predict n-future tokens for "ngram" language modeling instead of
+just the next token. Its architecture is identical to ProhpetNet, but the model was trained on the multi-lingual
+"wiki100" Wikipedia dump.
+
+The abstract from the paper is the following:
+
+*In this paper, we present a new sequence-to-sequence pretraining model called ProphetNet, which introduces a novel
+self-supervised objective named future n-gram prediction and the proposed n-stream self-attention mechanism. Instead of
+the optimization of one-step ahead prediction in traditional sequence-to-sequence model, the ProphetNet is optimized by
+n-step ahead prediction which predicts the next n tokens simultaneously based on previous context tokens at each time
+step. The future n-gram prediction explicitly encourages the model to plan for the future tokens and prevent
+overfitting on strong local correlations. We pre-train ProphetNet using a base scale dataset (16GB) and a large scale
+dataset (160GB) respectively. Then we conduct experiments on CNN/DailyMail, Gigaword, and SQuAD 1.1 benchmarks for
+abstractive summarization and question generation tasks. Experimental results show that ProphetNet achieves new
+state-of-the-art results on all these datasets compared to the models using the same scale pretraining corpus.*
+
+The Authors' code can be found [here](https://github.com/microsoft/ProphetNet).
+
+## XLMProphetNetConfig
+
+[[autodoc]] XLMProphetNetConfig
+
+## XLMProphetNetTokenizer
+
+[[autodoc]] XLMProphetNetTokenizer
+
+## XLMProphetNetModel
+
+[[autodoc]] XLMProphetNetModel
+
+## XLMProphetNetEncoder
+
+[[autodoc]] XLMProphetNetEncoder
+
+## XLMProphetNetDecoder
+
+[[autodoc]] XLMProphetNetDecoder
+
+## XLMProphetNetForConditionalGeneration
+
+[[autodoc]] XLMProphetNetForConditionalGeneration
+
+## XLMProphetNetForCausalLM
+
+[[autodoc]] XLMProphetNetForCausalLM
diff --git a/docs/source/en/model_doc/xlm-roberta-xl.mdx b/docs/source/en/model_doc/xlm-roberta-xl.mdx
new file mode 100644
index 00000000000000..01829a128c00f3
--- /dev/null
+++ b/docs/source/en/model_doc/xlm-roberta-xl.mdx
@@ -0,0 +1,69 @@
+
+
+# XLM-RoBERTa-XL
+
+## Overview
+
+The XLM-RoBERTa-XL model was proposed in [Larger-Scale Transformers for Multilingual Masked Language Modeling](https://arxiv.org/abs/2105.00572) by Naman Goyal, Jingfei Du, Myle Ott, Giri Anantharaman, Alexis Conneau.
+
+The abstract from the paper is the following:
+
+*Recent work has demonstrated the effectiveness of cross-lingual language model pretraining for cross-lingual understanding. In this study, we present the results of two larger multilingual masked language models, with 3.5B and 10.7B parameters. Our two new models dubbed XLM-R XL and XLM-R XXL outperform XLM-R by 1.8% and 2.4% average accuracy on XNLI. Our model also outperforms the RoBERTa-Large model on several English tasks of the GLUE benchmark by 0.3% on average while handling 99 more languages. This suggests pretrained models with larger capacity may obtain both strong performance on high-resource languages while greatly improving low-resource languages. We make our code and models publicly available.*
+
+Tips:
+
+- XLM-RoBERTa-XL is a multilingual model trained on 100 different languages. Unlike some XLM multilingual models, it does
+ not require `lang` tensors to understand which language is used, and should be able to determine the correct
+ language from the input ids.
+
+This model was contributed by [Soonhwan-Kwon](https://github.com/Soonhwan-Kwon) and [stefan-it](https://huggingface.co/stefan-it). The original code can be found [here](https://github.com/pytorch/fairseq/tree/master/examples/xlmr).
+
+
+## XLMRobertaXLConfig
+
+[[autodoc]] XLMRobertaXLConfig
+
+## XLMRobertaXLModel
+
+[[autodoc]] XLMRobertaXLModel
+ - forward
+
+## XLMRobertaXLForCausalLM
+
+[[autodoc]] XLMRobertaXLForCausalLM
+ - forward
+
+## XLMRobertaXLForMaskedLM
+
+[[autodoc]] XLMRobertaXLForMaskedLM
+ - forward
+
+## XLMRobertaXLForSequenceClassification
+
+[[autodoc]] XLMRobertaXLForSequenceClassification
+ - forward
+
+## XLMRobertaXLForMultipleChoice
+
+[[autodoc]] XLMRobertaXLForMultipleChoice
+ - forward
+
+## XLMRobertaXLForTokenClassification
+
+[[autodoc]] XLMRobertaXLForTokenClassification
+ - forward
+
+## XLMRobertaXLForQuestionAnswering
+
+[[autodoc]] XLMRobertaXLForQuestionAnswering
+ - forward
diff --git a/docs/source/en/model_doc/xlm-roberta.mdx b/docs/source/en/model_doc/xlm-roberta.mdx
new file mode 100644
index 00000000000000..5ca4ae2ad3292f
--- /dev/null
+++ b/docs/source/en/model_doc/xlm-roberta.mdx
@@ -0,0 +1,156 @@
+
+
+# XLM-RoBERTa
+
+## Overview
+
+The XLM-RoBERTa model was proposed in [Unsupervised Cross-lingual Representation Learning at Scale](https://arxiv.org/abs/1911.02116) by Alexis Conneau, Kartikay Khandelwal, Naman Goyal, Vishrav Chaudhary, Guillaume
+Wenzek, Francisco Guzmán, Edouard Grave, Myle Ott, Luke Zettlemoyer and Veselin Stoyanov. It is based on Facebook's
+RoBERTa model released in 2019. It is a large multi-lingual language model, trained on 2.5TB of filtered CommonCrawl
+data.
+
+The abstract from the paper is the following:
+
+*This paper shows that pretraining multilingual language models at scale leads to significant performance gains for a
+wide range of cross-lingual transfer tasks. We train a Transformer-based masked language model on one hundred
+languages, using more than two terabytes of filtered CommonCrawl data. Our model, dubbed XLM-R, significantly
+outperforms multilingual BERT (mBERT) on a variety of cross-lingual benchmarks, including +13.8% average accuracy on
+XNLI, +12.3% average F1 score on MLQA, and +2.1% average F1 score on NER. XLM-R performs particularly well on
+low-resource languages, improving 11.8% in XNLI accuracy for Swahili and 9.2% for Urdu over the previous XLM model. We
+also present a detailed empirical evaluation of the key factors that are required to achieve these gains, including the
+trade-offs between (1) positive transfer and capacity dilution and (2) the performance of high and low resource
+languages at scale. Finally, we show, for the first time, the possibility of multilingual modeling without sacrificing
+per-language performance; XLM-Ris very competitive with strong monolingual models on the GLUE and XNLI benchmarks. We
+will make XLM-R code, data, and models publicly available.*
+
+Tips:
+
+- XLM-RoBERTa is a multilingual model trained on 100 different languages. Unlike some XLM multilingual models, it does
+ not require `lang` tensors to understand which language is used, and should be able to determine the correct
+ language from the input ids.
+- This implementation is the same as RoBERTa. Refer to the [documentation of RoBERTa](roberta) for usage examples
+ as well as the information relative to the inputs and outputs.
+
+This model was contributed by [stefan-it](https://huggingface.co/stefan-it). The original code can be found [here](https://github.com/pytorch/fairseq/tree/master/examples/xlmr).
+
+
+## XLMRobertaConfig
+
+[[autodoc]] XLMRobertaConfig
+
+## XLMRobertaTokenizer
+
+[[autodoc]] XLMRobertaTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## XLMRobertaTokenizerFast
+
+[[autodoc]] XLMRobertaTokenizerFast
+
+## XLMRobertaModel
+
+[[autodoc]] XLMRobertaModel
+ - forward
+
+## XLMRobertaForCausalLM
+
+[[autodoc]] XLMRobertaForCausalLM
+ - forward
+
+## XLMRobertaForMaskedLM
+
+[[autodoc]] XLMRobertaForMaskedLM
+ - forward
+
+## XLMRobertaForSequenceClassification
+
+[[autodoc]] XLMRobertaForSequenceClassification
+ - forward
+
+## XLMRobertaForMultipleChoice
+
+[[autodoc]] XLMRobertaForMultipleChoice
+ - forward
+
+## XLMRobertaForTokenClassification
+
+[[autodoc]] XLMRobertaForTokenClassification
+ - forward
+
+## XLMRobertaForQuestionAnswering
+
+[[autodoc]] XLMRobertaForQuestionAnswering
+ - forward
+
+## TFXLMRobertaModel
+
+[[autodoc]] TFXLMRobertaModel
+ - call
+
+## TFXLMRobertaForMaskedLM
+
+[[autodoc]] TFXLMRobertaForMaskedLM
+ - call
+
+## TFXLMRobertaForSequenceClassification
+
+[[autodoc]] TFXLMRobertaForSequenceClassification
+ - call
+
+## TFXLMRobertaForMultipleChoice
+
+[[autodoc]] TFXLMRobertaForMultipleChoice
+ - call
+
+## TFXLMRobertaForTokenClassification
+
+[[autodoc]] TFXLMRobertaForTokenClassification
+ - call
+
+## TFXLMRobertaForQuestionAnswering
+
+[[autodoc]] TFXLMRobertaForQuestionAnswering
+ - call
+
+## FlaxXLMRobertaModel
+
+[[autodoc]] FlaxXLMRobertaModel
+ - __call__
+
+## FlaxXLMRobertaForMaskedLM
+
+[[autodoc]] FlaxXLMRobertaForMaskedLM
+ - __call__
+
+## FlaxXLMRobertaForSequenceClassification
+
+[[autodoc]] FlaxXLMRobertaForSequenceClassification
+ - __call__
+
+## FlaxXLMRobertaForMultipleChoice
+
+[[autodoc]] FlaxXLMRobertaForMultipleChoice
+ - __call__
+
+## FlaxXLMRobertaForTokenClassification
+
+[[autodoc]] FlaxXLMRobertaForTokenClassification
+ - __call__
+
+## FlaxXLMRobertaForQuestionAnswering
+
+[[autodoc]] FlaxXLMRobertaForQuestionAnswering
+ - __call__
diff --git a/docs/source/en/model_doc/xlm.mdx b/docs/source/en/model_doc/xlm.mdx
new file mode 100644
index 00000000000000..a441c64c86c932
--- /dev/null
+++ b/docs/source/en/model_doc/xlm.mdx
@@ -0,0 +1,124 @@
+
+
+# XLM
+
+## Overview
+
+The XLM model was proposed in [Cross-lingual Language Model Pretraining](https://arxiv.org/abs/1901.07291) by
+Guillaume Lample, Alexis Conneau. It's a transformer pretrained using one of the following objectives:
+
+- a causal language modeling (CLM) objective (next token prediction),
+- a masked language modeling (MLM) objective (BERT-like), or
+- a Translation Language Modeling (TLM) object (extension of BERT's MLM to multiple language inputs)
+
+The abstract from the paper is the following:
+
+*Recent studies have demonstrated the efficiency of generative pretraining for English natural language understanding.
+In this work, we extend this approach to multiple languages and show the effectiveness of cross-lingual pretraining. We
+propose two methods to learn cross-lingual language models (XLMs): one unsupervised that only relies on monolingual
+data, and one supervised that leverages parallel data with a new cross-lingual language model objective. We obtain
+state-of-the-art results on cross-lingual classification, unsupervised and supervised machine translation. On XNLI, our
+approach pushes the state of the art by an absolute gain of 4.9% accuracy. On unsupervised machine translation, we
+obtain 34.3 BLEU on WMT'16 German-English, improving the previous state of the art by more than 9 BLEU. On supervised
+machine translation, we obtain a new state of the art of 38.5 BLEU on WMT'16 Romanian-English, outperforming the
+previous best approach by more than 4 BLEU. Our code and pretrained models will be made publicly available.*
+
+Tips:
+
+- XLM has many different checkpoints, which were trained using different objectives: CLM, MLM or TLM. Make sure to
+ select the correct objective for your task (e.g. MLM checkpoints are not suitable for generation).
+- XLM has multilingual checkpoints which leverage a specific `lang` parameter. Check out the [multi-lingual](../multilingual) page for more information.
+
+This model was contributed by [thomwolf](https://huggingface.co/thomwolf). The original code can be found [here](https://github.com/facebookresearch/XLM/).
+
+
+## XLMConfig
+
+[[autodoc]] XLMConfig
+
+## XLMTokenizer
+
+[[autodoc]] XLMTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## XLM specific outputs
+
+[[autodoc]] models.xlm.modeling_xlm.XLMForQuestionAnsweringOutput
+
+## XLMModel
+
+[[autodoc]] XLMModel
+ - forward
+
+## XLMWithLMHeadModel
+
+[[autodoc]] XLMWithLMHeadModel
+ - forward
+
+## XLMForSequenceClassification
+
+[[autodoc]] XLMForSequenceClassification
+ - forward
+
+## XLMForMultipleChoice
+
+[[autodoc]] XLMForMultipleChoice
+ - forward
+
+## XLMForTokenClassification
+
+[[autodoc]] XLMForTokenClassification
+ - forward
+
+## XLMForQuestionAnsweringSimple
+
+[[autodoc]] XLMForQuestionAnsweringSimple
+ - forward
+
+## XLMForQuestionAnswering
+
+[[autodoc]] XLMForQuestionAnswering
+ - forward
+
+## TFXLMModel
+
+[[autodoc]] TFXLMModel
+ - call
+
+## TFXLMWithLMHeadModel
+
+[[autodoc]] TFXLMWithLMHeadModel
+ - call
+
+## TFXLMForSequenceClassification
+
+[[autodoc]] TFXLMForSequenceClassification
+ - call
+
+## TFXLMForMultipleChoice
+
+[[autodoc]] TFXLMForMultipleChoice
+ - call
+
+## TFXLMForTokenClassification
+
+[[autodoc]] TFXLMForTokenClassification
+ - call
+
+## TFXLMForQuestionAnsweringSimple
+
+[[autodoc]] TFXLMForQuestionAnsweringSimple
+ - call
diff --git a/docs/source/en/model_doc/xlnet.mdx b/docs/source/en/model_doc/xlnet.mdx
new file mode 100644
index 00000000000000..ca30574690c5c9
--- /dev/null
+++ b/docs/source/en/model_doc/xlnet.mdx
@@ -0,0 +1,154 @@
+
+
+# XLNet
+
+## Overview
+
+The XLNet model was proposed in [XLNet: Generalized Autoregressive Pretraining for Language Understanding](https://arxiv.org/abs/1906.08237) by Zhilin Yang, Zihang Dai, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov,
+Quoc V. Le. XLnet is an extension of the Transformer-XL model pre-trained using an autoregressive method to learn
+bidirectional contexts by maximizing the expected likelihood over all permutations of the input sequence factorization
+order.
+
+The abstract from the paper is the following:
+
+*With the capability of modeling bidirectional contexts, denoising autoencoding based pretraining like BERT achieves
+better performance than pretraining approaches based on autoregressive language modeling. However, relying on
+corrupting the input with masks, BERT neglects dependency between the masked positions and suffers from a
+pretrain-finetune discrepancy. In light of these pros and cons, we propose XLNet, a generalized autoregressive
+pretraining method that (1) enables learning bidirectional contexts by maximizing the expected likelihood over all
+permutations of the factorization order and (2) overcomes the limitations of BERT thanks to its autoregressive
+formulation. Furthermore, XLNet integrates ideas from Transformer-XL, the state-of-the-art autoregressive model, into
+pretraining. Empirically, under comparable experiment settings, XLNet outperforms BERT on 20 tasks, often by a large
+margin, including question answering, natural language inference, sentiment analysis, and document ranking.*
+
+Tips:
+
+- The specific attention pattern can be controlled at training and test time using the `perm_mask` input.
+- Due to the difficulty of training a fully auto-regressive model over various factorization order, XLNet is pretrained
+ using only a sub-set of the output tokens as target which are selected with the `target_mapping` input.
+- To use XLNet for sequential decoding (i.e. not in fully bi-directional setting), use the `perm_mask` and
+ `target_mapping` inputs to control the attention span and outputs (see examples in
+ *examples/pytorch/text-generation/run_generation.py*)
+- XLNet is one of the few models that has no sequence length limit.
+
+This model was contributed by [thomwolf](https://huggingface.co/thomwolf). The original code can be found [here](https://github.com/zihangdai/xlnet/).
+
+
+## XLNetConfig
+
+[[autodoc]] XLNetConfig
+
+## XLNetTokenizer
+
+[[autodoc]] XLNetTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## XLNetTokenizerFast
+
+[[autodoc]] XLNetTokenizerFast
+
+## XLNet specific outputs
+
+[[autodoc]] models.xlnet.modeling_xlnet.XLNetModelOutput
+
+[[autodoc]] models.xlnet.modeling_xlnet.XLNetLMHeadModelOutput
+
+[[autodoc]] models.xlnet.modeling_xlnet.XLNetForSequenceClassificationOutput
+
+[[autodoc]] models.xlnet.modeling_xlnet.XLNetForMultipleChoiceOutput
+
+[[autodoc]] models.xlnet.modeling_xlnet.XLNetForTokenClassificationOutput
+
+[[autodoc]] models.xlnet.modeling_xlnet.XLNetForQuestionAnsweringSimpleOutput
+
+[[autodoc]] models.xlnet.modeling_xlnet.XLNetForQuestionAnsweringOutput
+
+[[autodoc]] models.xlnet.modeling_tf_xlnet.TFXLNetModelOutput
+
+[[autodoc]] models.xlnet.modeling_tf_xlnet.TFXLNetLMHeadModelOutput
+
+[[autodoc]] models.xlnet.modeling_tf_xlnet.TFXLNetForSequenceClassificationOutput
+
+[[autodoc]] models.xlnet.modeling_tf_xlnet.TFXLNetForMultipleChoiceOutput
+
+[[autodoc]] models.xlnet.modeling_tf_xlnet.TFXLNetForTokenClassificationOutput
+
+[[autodoc]] models.xlnet.modeling_tf_xlnet.TFXLNetForQuestionAnsweringSimpleOutput
+
+## XLNetModel
+
+[[autodoc]] XLNetModel
+ - forward
+
+## XLNetLMHeadModel
+
+[[autodoc]] XLNetLMHeadModel
+ - forward
+
+## XLNetForSequenceClassification
+
+[[autodoc]] XLNetForSequenceClassification
+ - forward
+
+## XLNetForMultipleChoice
+
+[[autodoc]] XLNetForMultipleChoice
+ - forward
+
+## XLNetForTokenClassification
+
+[[autodoc]] XLNetForTokenClassification
+ - forward
+
+## XLNetForQuestionAnsweringSimple
+
+[[autodoc]] XLNetForQuestionAnsweringSimple
+ - forward
+
+## XLNetForQuestionAnswering
+
+[[autodoc]] XLNetForQuestionAnswering
+ - forward
+
+## TFXLNetModel
+
+[[autodoc]] TFXLNetModel
+ - call
+
+## TFXLNetLMHeadModel
+
+[[autodoc]] TFXLNetLMHeadModel
+ - call
+
+## TFXLNetForSequenceClassification
+
+[[autodoc]] TFXLNetForSequenceClassification
+ - call
+
+## TFLNetForMultipleChoice
+
+[[autodoc]] TFXLNetForMultipleChoice
+ - call
+
+## TFXLNetForTokenClassification
+
+[[autodoc]] TFXLNetForTokenClassification
+ - call
+
+## TFXLNetForQuestionAnsweringSimple
+
+[[autodoc]] TFXLNetForQuestionAnsweringSimple
+ - call
diff --git a/docs/source/en/model_doc/xls_r.mdx b/docs/source/en/model_doc/xls_r.mdx
new file mode 100644
index 00000000000000..82a7e3b8afbd31
--- /dev/null
+++ b/docs/source/en/model_doc/xls_r.mdx
@@ -0,0 +1,43 @@
+
+
+# XLS-R
+
+## Overview
+
+The XLS-R model was proposed in [XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale](https://arxiv.org/abs/2111.09296) by Arun Babu, Changhan Wang, Andros Tjandra, Kushal Lakhotia, Qiantong Xu, Naman
+Goyal, Kritika Singh, Patrick von Platen, Yatharth Saraf, Juan Pino, Alexei Baevski, Alexis Conneau, Michael Auli.
+
+The abstract from the paper is the following:
+
+*This paper presents XLS-R, a large-scale model for cross-lingual speech representation learning based on wav2vec 2.0.
+We train models with up to 2B parameters on nearly half a million hours of publicly available speech audio in 128
+languages, an order of magnitude more public data than the largest known prior work. Our evaluation covers a wide range
+of tasks, domains, data regimes and languages, both high and low-resource. On the CoVoST-2 speech translation
+benchmark, we improve the previous state of the art by an average of 7.4 BLEU over 21 translation directions into
+English. For speech recognition, XLS-R improves over the best known prior work on BABEL, MLS, CommonVoice as well as
+VoxPopuli, lowering error rates by 14-34% relative on average. XLS-R also sets a new state of the art on VoxLingua107
+language identification. Moreover, we show that with sufficient model size, cross-lingual pretraining can outperform
+English-only pretraining when translating English speech into other languages, a setting which favors monolingual
+pretraining. We hope XLS-R can help to improve speech processing tasks for many more languages of the world.*
+
+Tips:
+
+- XLS-R is a speech model that accepts a float array corresponding to the raw waveform of the speech signal.
+- XLS-R model was trained using connectionist temporal classification (CTC) so the model output has to be decoded using
+ [`Wav2Vec2CTCTokenizer`].
+
+Relevant checkpoints can be found under https://huggingface.co/models?other=xls_r.
+
+XLS-R's architecture is based on the Wav2Vec2 model, so one can refer to [Wav2Vec2's documentation page](wav2vec2).
+
+The original code can be found [here](https://github.com/pytorch/fairseq/tree/master/fairseq/models/wav2vec).
diff --git a/docs/source/en/model_doc/xlsr_wav2vec2.mdx b/docs/source/en/model_doc/xlsr_wav2vec2.mdx
new file mode 100644
index 00000000000000..32229f28b14763
--- /dev/null
+++ b/docs/source/en/model_doc/xlsr_wav2vec2.mdx
@@ -0,0 +1,41 @@
+
+
+# XLSR-Wav2Vec2
+
+## Overview
+
+The XLSR-Wav2Vec2 model was proposed in [Unsupervised Cross-Lingual Representation Learning For Speech Recognition](https://arxiv.org/abs/2006.13979) by Alexis Conneau, Alexei Baevski, Ronan Collobert, Abdelrahman Mohamed, Michael
+Auli.
+
+The abstract from the paper is the following:
+
+*This paper presents XLSR which learns cross-lingual speech representations by pretraining a single model from the raw
+waveform of speech in multiple languages. We build on wav2vec 2.0 which is trained by solving a contrastive task over
+masked latent speech representations and jointly learns a quantization of the latents shared across languages. The
+resulting model is fine-tuned on labeled data and experiments show that cross-lingual pretraining significantly
+outperforms monolingual pretraining. On the CommonVoice benchmark, XLSR shows a relative phoneme error rate reduction
+of 72% compared to the best known results. On BABEL, our approach improves word error rate by 16% relative compared to
+a comparable system. Our approach enables a single multilingual speech recognition model which is competitive to strong
+individual models. Analysis shows that the latent discrete speech representations are shared across languages with
+increased sharing for related languages. We hope to catalyze research in low-resource speech understanding by releasing
+XLSR-53, a large model pretrained in 53 languages.*
+
+Tips:
+
+- XLSR-Wav2Vec2 is a speech model that accepts a float array corresponding to the raw waveform of the speech signal.
+- XLSR-Wav2Vec2 model was trained using connectionist temporal classification (CTC) so the model output has to be
+ decoded using [`Wav2Vec2CTCTokenizer`].
+
+XLSR-Wav2Vec2's architecture is based on the Wav2Vec2 model, so one can refer to [Wav2Vec2's documentation page](wav2vec2).
+
+The original code can be found [here](https://github.com/pytorch/fairseq/tree/master/fairseq/models/wav2vec).
diff --git a/docs/source/en/model_doc/yolos.mdx b/docs/source/en/model_doc/yolos.mdx
new file mode 100644
index 00000000000000..bda65bec913786
--- /dev/null
+++ b/docs/source/en/model_doc/yolos.mdx
@@ -0,0 +1,60 @@
+
+
+# YOLOS
+
+## Overview
+
+The YOLOS model was proposed in [You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection](https://arxiv.org/abs/2106.00666) by Yuxin Fang, Bencheng Liao, Xinggang Wang, Jiemin Fang, Jiyang Qi, Rui Wu, Jianwei Niu, Wenyu Liu.
+YOLOS proposes to just leverage the plain [Vision Transformer (ViT)](vit) for object detection, inspired by DETR. It turns out that a base-sized encoder-only Transformer can also achieve 42 AP on COCO, similar to DETR and much more complex frameworks such as Faster R-CNN.
+
+The abstract from the paper is the following:
+
+*Can Transformer perform 2D object- and region-level recognition from a pure sequence-to-sequence perspective with minimal knowledge about the 2D spatial structure? To answer this question, we present You Only Look at One Sequence (YOLOS), a series of object detection models based on the vanilla Vision Transformer with the fewest possible modifications, region priors, as well as inductive biases of the target task. We find that YOLOS pre-trained on the mid-sized ImageNet-1k dataset only can already achieve quite competitive performance on the challenging COCO object detection benchmark, e.g., YOLOS-Base directly adopted from BERT-Base architecture can obtain 42.0 box AP on COCO val. We also discuss the impacts as well as limitations of current pre-train schemes and model scaling strategies for Transformer in vision through YOLOS.*
+
+Tips:
+
+- One can use [`YolosFeatureExtractor`] for preparing images (and optional targets) for the model. Contrary to [DETR](detr), YOLOS doesn't require a `pixel_mask` to be created.
+- Demo notebooks (regarding inference and fine-tuning on custom data) can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/YOLOS).
+
+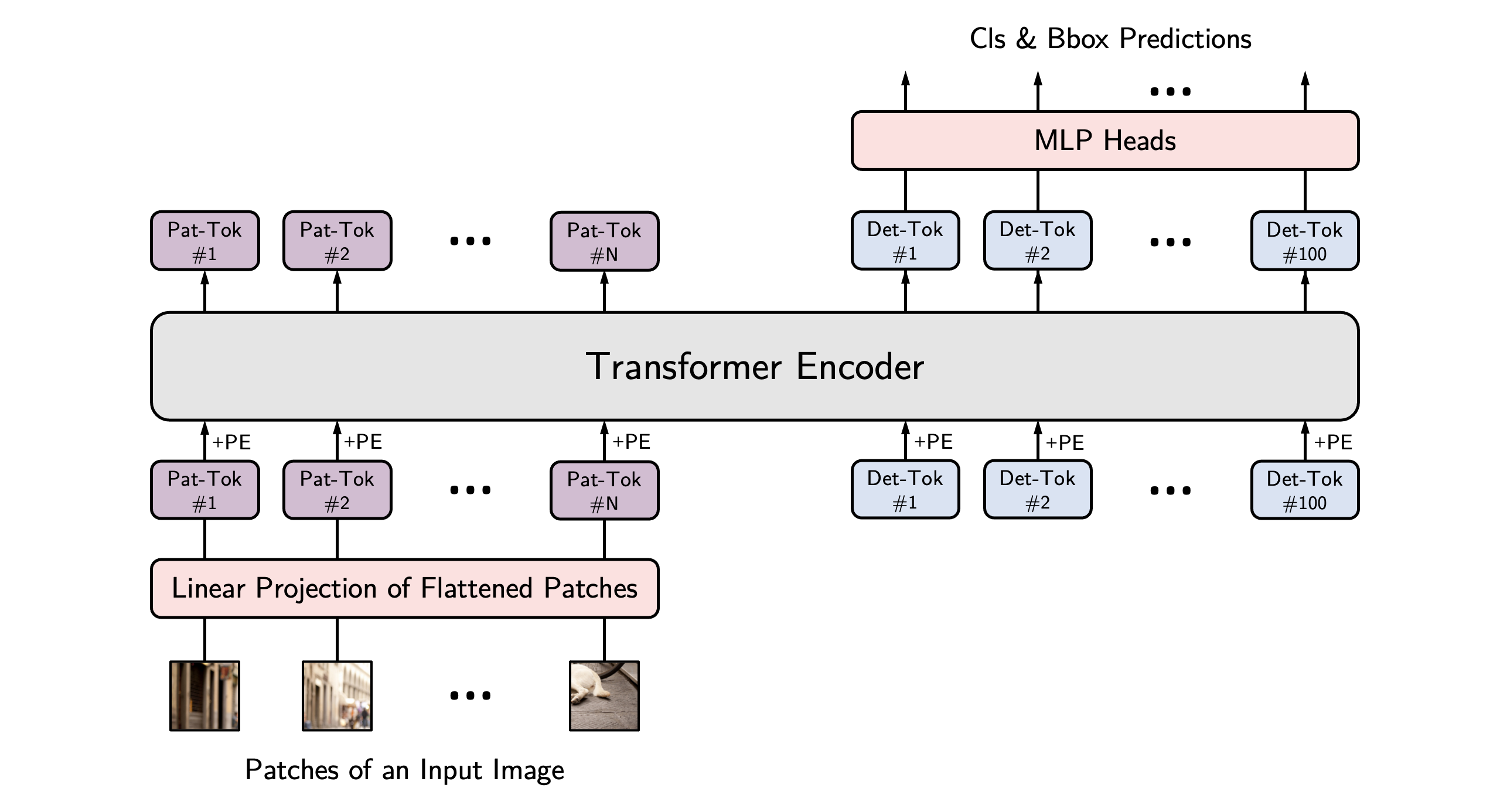 +
+ YOLOS architecture. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/hustvl/YOLOS).
+
+## YolosConfig
+
+[[autodoc]] YolosConfig
+
+
+## YolosFeatureExtractor
+
+[[autodoc]] YolosFeatureExtractor
+ - __call__
+ - pad
+ - post_process
+ - post_process_segmentation
+ - post_process_panoptic
+
+
+## YolosModel
+
+[[autodoc]] YolosModel
+ - forward
+
+
+## YolosForObjectDetection
+
+[[autodoc]] YolosForObjectDetection
+ - forward
\ No newline at end of file
diff --git a/docs/source/en/model_doc/yoso.mdx b/docs/source/en/model_doc/yoso.mdx
new file mode 100644
index 00000000000000..997ab4d0941639
--- /dev/null
+++ b/docs/source/en/model_doc/yoso.mdx
@@ -0,0 +1,91 @@
+
+
+# YOSO
+
+## Overview
+
+The YOSO model was proposed in [You Only Sample (Almost) Once: Linear Cost Self-Attention Via Bernoulli Sampling](https://arxiv.org/abs/2111.09714)
+by Zhanpeng Zeng, Yunyang Xiong, Sathya N. Ravi, Shailesh Acharya, Glenn Fung, Vikas Singh. YOSO approximates standard softmax self-attention
+via a Bernoulli sampling scheme based on Locality Sensitive Hashing (LSH). In principle, all the Bernoulli random variables can be sampled with
+a single hash.
+
+The abstract from the paper is the following:
+
+*Transformer-based models are widely used in natural language processing (NLP). Central to the transformer model is
+the self-attention mechanism, which captures the interactions of token pairs in the input sequences and depends quadratically
+on the sequence length. Training such models on longer sequences is expensive. In this paper, we show that a Bernoulli sampling
+attention mechanism based on Locality Sensitive Hashing (LSH), decreases the quadratic complexity of such models to linear.
+We bypass the quadratic cost by considering self-attention as a sum of individual tokens associated with Bernoulli random
+variables that can, in principle, be sampled at once by a single hash (although in practice, this number may be a small constant).
+This leads to an efficient sampling scheme to estimate self-attention which relies on specific modifications of
+LSH (to enable deployment on GPU architectures). We evaluate our algorithm on the GLUE benchmark with standard 512 sequence
+length where we see favorable performance relative to a standard pretrained Transformer. On the Long Range Arena (LRA) benchmark,
+for evaluating performance on long sequences, our method achieves results consistent with softmax self-attention but with sizable
+speed-ups and memory savings and often outperforms other efficient self-attention methods. Our code is available at this https URL*
+
+Tips:
+
+- The YOSO attention algorithm is implemented through custom CUDA kernels, functions written in CUDA C++ that can be executed multiple times
+in parallel on a GPU.
+- The kernels provide a `fast_hash` function, which approximates the random projections of the queries and keys using the Fast Hadamard Transform. Using these
+hash codes, the `lsh_cumulation` function approximates self-attention via LSH-based Bernoulli sampling.
+- To use the custom kernels, the user should set `config.use_expectation = False`. To ensure that the kernels are compiled successfully,
+the user must install the correct version of PyTorch and cudatoolkit. By default, `config.use_expectation = True`, which uses YOSO-E and
+does not require compiling CUDA kernels.
+
+
+
+ YOLOS architecture. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/hustvl/YOLOS).
+
+## YolosConfig
+
+[[autodoc]] YolosConfig
+
+
+## YolosFeatureExtractor
+
+[[autodoc]] YolosFeatureExtractor
+ - __call__
+ - pad
+ - post_process
+ - post_process_segmentation
+ - post_process_panoptic
+
+
+## YolosModel
+
+[[autodoc]] YolosModel
+ - forward
+
+
+## YolosForObjectDetection
+
+[[autodoc]] YolosForObjectDetection
+ - forward
\ No newline at end of file
diff --git a/docs/source/en/model_doc/yoso.mdx b/docs/source/en/model_doc/yoso.mdx
new file mode 100644
index 00000000000000..997ab4d0941639
--- /dev/null
+++ b/docs/source/en/model_doc/yoso.mdx
@@ -0,0 +1,91 @@
+
+
+# YOSO
+
+## Overview
+
+The YOSO model was proposed in [You Only Sample (Almost) Once: Linear Cost Self-Attention Via Bernoulli Sampling](https://arxiv.org/abs/2111.09714)
+by Zhanpeng Zeng, Yunyang Xiong, Sathya N. Ravi, Shailesh Acharya, Glenn Fung, Vikas Singh. YOSO approximates standard softmax self-attention
+via a Bernoulli sampling scheme based on Locality Sensitive Hashing (LSH). In principle, all the Bernoulli random variables can be sampled with
+a single hash.
+
+The abstract from the paper is the following:
+
+*Transformer-based models are widely used in natural language processing (NLP). Central to the transformer model is
+the self-attention mechanism, which captures the interactions of token pairs in the input sequences and depends quadratically
+on the sequence length. Training such models on longer sequences is expensive. In this paper, we show that a Bernoulli sampling
+attention mechanism based on Locality Sensitive Hashing (LSH), decreases the quadratic complexity of such models to linear.
+We bypass the quadratic cost by considering self-attention as a sum of individual tokens associated with Bernoulli random
+variables that can, in principle, be sampled at once by a single hash (although in practice, this number may be a small constant).
+This leads to an efficient sampling scheme to estimate self-attention which relies on specific modifications of
+LSH (to enable deployment on GPU architectures). We evaluate our algorithm on the GLUE benchmark with standard 512 sequence
+length where we see favorable performance relative to a standard pretrained Transformer. On the Long Range Arena (LRA) benchmark,
+for evaluating performance on long sequences, our method achieves results consistent with softmax self-attention but with sizable
+speed-ups and memory savings and often outperforms other efficient self-attention methods. Our code is available at this https URL*
+
+Tips:
+
+- The YOSO attention algorithm is implemented through custom CUDA kernels, functions written in CUDA C++ that can be executed multiple times
+in parallel on a GPU.
+- The kernels provide a `fast_hash` function, which approximates the random projections of the queries and keys using the Fast Hadamard Transform. Using these
+hash codes, the `lsh_cumulation` function approximates self-attention via LSH-based Bernoulli sampling.
+- To use the custom kernels, the user should set `config.use_expectation = False`. To ensure that the kernels are compiled successfully,
+the user must install the correct version of PyTorch and cudatoolkit. By default, `config.use_expectation = True`, which uses YOSO-E and
+does not require compiling CUDA kernels.
+
+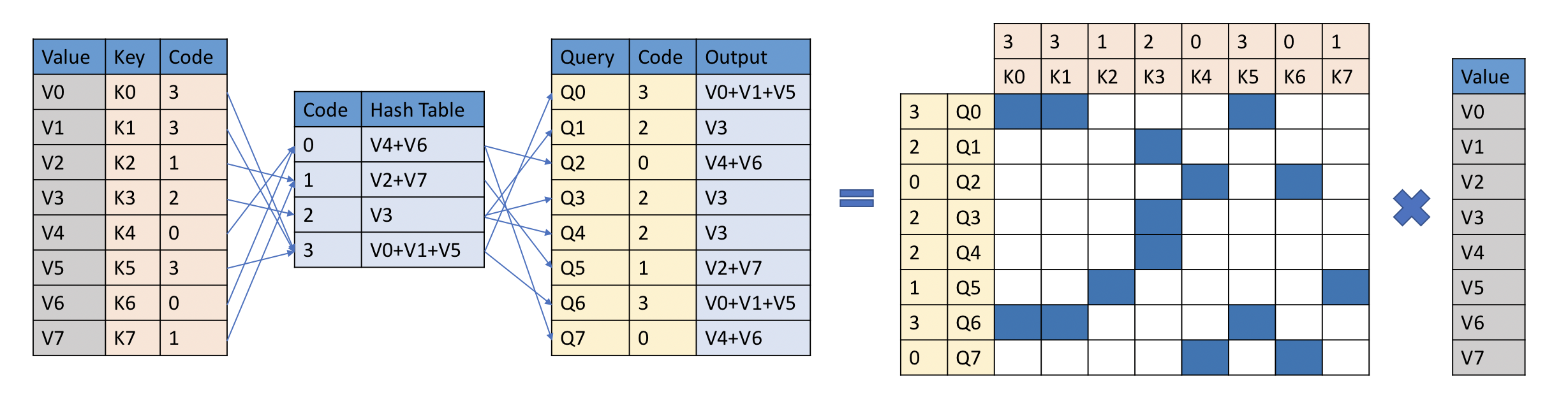 +
+ YOSO Attention Algorithm. Taken from the original paper.
+
+This model was contributed by [novice03](https://huggingface.co/novice03). The original code can be found [here](https://github.com/mlpen/YOSO).
+
+
+## YosoConfig
+
+[[autodoc]] YosoConfig
+
+
+## YosoModel
+
+[[autodoc]] YosoModel
+ - forward
+
+
+## YosoForMaskedLM
+
+[[autodoc]] YosoForMaskedLM
+ - forward
+
+
+## YosoForSequenceClassification
+
+[[autodoc]] YosoForSequenceClassification
+ - forward
+
+## YosoForMultipleChoice
+
+[[autodoc]] YosoForMultipleChoice
+ - forward
+
+
+## YosoForTokenClassification
+
+[[autodoc]] YosoForTokenClassification
+ - forward
+
+
+## YosoForQuestionAnswering
+
+[[autodoc]] YosoForQuestionAnswering
+ - forward
\ No newline at end of file
diff --git a/docs/source/en/model_sharing.mdx b/docs/source/en/model_sharing.mdx
new file mode 100644
index 00000000000000..fb8a30a9cc13d1
--- /dev/null
+++ b/docs/source/en/model_sharing.mdx
@@ -0,0 +1,228 @@
+
+
+# Share a model
+
+The last two tutorials showed how you can fine-tune a model with PyTorch, Keras, and 🤗 Accelerate for distributed setups. The next step is to share your model with the community! At Hugging Face, we believe in openly sharing knowledge and resources to democratize artificial intelligence for everyone. We encourage you to consider sharing your model with the community to help others save time and resources.
+
+In this tutorial, you will learn two methods for sharing a trained or fine-tuned model on the [Model Hub](https://huggingface.co/models):
+
+- Programmatically push your files to the Hub.
+- Drag-and-drop your files to the Hub with the web interface.
+
+
+
+
+
+To share a model with the community, you need an account on [huggingface.co](https://huggingface.co/join). You can also join an existing organization or create a new one.
+
+
+
+## Repository features
+
+Each repository on the Model Hub behaves like a typical GitHub repository. Our repositories offer versioning, commit history, and the ability to visualize differences.
+
+The Model Hub's built-in versioning is based on git and [git-lfs](https://git-lfs.github.com/). In other words, you can treat one model as one repository, enabling greater access control and scalability. Version control allows *revisions*, a method for pinning a specific version of a model with a commit hash, tag or branch.
+
+As a result, you can load a specific model version with the `revision` parameter:
+
+```py
+>>> model = AutoModel.from_pretrained(
+... "julien-c/EsperBERTo-small", revision="v2.0.1" # tag name, or branch name, or commit hash
+... )
+```
+
+Files are also easily edited in a repository, and you can view the commit history as well as the difference:
+
+
+
+## Setup
+
+Before sharing a model to the Hub, you will need your Hugging Face credentials. If you have access to a terminal, run the following command in the virtual environment where 🤗 Transformers is installed. This will store your access token in your Hugging Face cache folder (`~/.cache/` by default):
+
+```bash
+huggingface-cli login
+```
+
+If you are using a notebook like Jupyter or Colaboratory, make sure you have the [`huggingface_hub`](https://huggingface.co/docs/hub/adding-a-library) library installed. This library allows you to programmatically interact with the Hub.
+
+```bash
+pip install huggingface_hub
+```
+
+Then use `notebook_login` to sign-in to the Hub, and follow the link [here](https://huggingface.co/settings/token) to generate a token to login with:
+
+```py
+>>> from huggingface_hub import notebook_login
+
+>>> notebook_login()
+```
+
+## Convert a model for all frameworks
+
+To ensure your model can be used by someone working with a different framework, we recommend you convert and upload your model with both PyTorch and TensorFlow checkpoints. While users are still able to load your model from a different framework if you skip this step, it will be slower because 🤗 Transformers will need to convert the checkpoint on-the-fly.
+
+Converting a checkpoint for another framework is easy. Make sure you have PyTorch and TensorFlow installed (see [here](installation) for installation instructions), and then find the specific model for your task in the other framework.
+
+
+
+Specify `from_tf=True` to convert a checkpoint from TensorFlow to PyTorch:
+
+```py
+>>> pt_model = DistilBertForSequenceClassification.from_pretrained("path/to/awesome-name-you-picked", from_tf=True)
+>>> pt_model.save_pretrained("path/to/awesome-name-you-picked")
+```
+
+
+Specify `from_pt=True` to convert a checkpoint from PyTorch to TensorFlow:
+
+```py
+>>> tf_model = TFDistilBertForSequenceClassification.from_pretrained("path/to/awesome-name-you-picked", from_pt=True)
+```
+
+Then you can save your new TensorFlow model with it's new checkpoint:
+
+```py
+>>> tf_model.save_pretrained("path/to/awesome-name-you-picked")
+```
+
+
+If a model is available in Flax, you can also convert a checkpoint from PyTorch to Flax:
+
+```py
+>>> flax_model = FlaxDistilBertForSequenceClassification.from_pretrained(
+... "path/to/awesome-name-you-picked", from_pt=True
+... )
+```
+
+
+
+## Push a model during training
+
+
+
+
+
+Sharing a model to the Hub is as simple as adding an extra parameter or callback. Remember from the [fine-tuning tutorial](training), the [`TrainingArguments`] class is where you specify hyperparameters and additional training options. One of these training options includes the ability to push a model directly to the Hub. Set `push_to_hub=True` in your [`TrainingArguments`]:
+
+```py
+>>> training_args = TrainingArguments(output_dir="my-awesome-model", push_to_hub=True)
+```
+
+Pass your training arguments as usual to [`Trainer`]:
+
+```py
+>>> trainer = Trainer(
+... model=model,
+... args=training_args,
+... train_dataset=small_train_dataset,
+... eval_dataset=small_eval_dataset,
+... compute_metrics=compute_metrics,
+... )
+```
+
+After you fine-tune your model, call [`~transformers.Trainer.push_to_hub`] on [`Trainer`] to push the trained model to the Hub. 🤗 Transformers will even automatically add training hyperparameters, training results and framework versions to your model card!
+
+```py
+>>> trainer.push_to_hub()
+```
+
+
+Share a model to the Hub with [`PushToHubCallback`]. In the [`PushToHubCallback`] function, add:
+
+- An output directory for your model.
+- A tokenizer.
+- The `hub_model_id`, which is your Hub username and model name.
+
+```py
+>>> from transformers.keras.callbacks import PushToHubCallback
+
+>>> push_to_hub_callback = PushToHubCallback(
+... output_dir="./your_model_save_path", tokenizer=tokenizer, hub_model_id="your-username/my-awesome-model"
+... )
+```
+
+Add the callback to [`fit`](https://keras.io/api/models/model_training_apis/), and 🤗 Transformers will push the trained model to the Hub:
+
+```py
+>>> model.fit(tf_train_dataset, validation_data=tf_validation_dataset, epochs=3, callbacks=push_to_hub_callback)
+```
+
+
+
+## Use the `push_to_hub` function
+
+You can also call `push_to_hub` directly on your model to upload it to the Hub.
+
+Specify your model name in `push_to_hub`:
+
+```py
+>>> pt_model.push_to_hub("my-awesome-model")
+```
+
+This creates a repository under your username with the model name `my-awesome-model`. Users can now load your model with the `from_pretrained` function:
+
+```py
+>>> from transformers import AutoModel
+
+>>> model = AutoModel.from_pretrained("your_username/my-awesome-model")
+```
+
+If you belong to an organization and want to push your model under the organization name instead, add the `organization` parameter:
+
+```py
+>>> pt_model.push_to_hub("my-awesome-model", organization="my-awesome-org")
+```
+
+The `push_to_hub` function can also be used to add other files to a model repository. For example, add a tokenizer to a model repository:
+
+```py
+>>> tokenizer.push_to_hub("my-awesome-model")
+```
+
+Or perhaps you'd like to add the TensorFlow version of your fine-tuned PyTorch model:
+
+```py
+>>> tf_model.push_to_hub("my-awesome-model")
+```
+
+Now when you navigate to the your Hugging Face profile, you should see your newly created model repository. Clicking on the **Files** tab will display all the files you've uploaded to the repository.
+
+For more details on how to create and upload files to a repository, refer to the Hub documentation [here](https://huggingface.co/docs/hub/how-to-upstream).
+
+## Upload with the web interface
+
+Users who prefer a no-code approach are able to upload a model through the Hub's web interface. Visit [huggingface.co/new](https://huggingface.co/new) to create a new repository:
+
+
+
+From here, add some information about your model:
+
+- Select the **owner** of the repository. This can be yourself or any of the organizations you belong to.
+- Pick a name for your model, which will also be the repository name.
+- Choose whether your model is public or private.
+- Specify the license usage for your model.
+
+Now click on the **Files** tab and click on the **Add file** button to upload a new file to your repository. Then drag-and-drop a file to upload and add a commit message.
+
+
+
+## Add a model card
+
+To make sure users understand your model's capabilities, limitations, potential biases and ethical considerations, please add a model card to your repository. The model card is defined in the `README.md` file. You can add a model card by:
+
+* Manually creating and uploading a `README.md` file.
+* Clicking on the **Edit model card** button in your model repository.
+
+Take a look at the DistilBert [model card](https://huggingface.co/distilbert-base-uncased) for a good example of the type of information a model card should include. For more details about other options you can control in the `README.md` file such as a model's carbon footprint or widget examples, refer to the documentation [here](https://huggingface.co/docs/hub/model-repos).
diff --git a/docs/source/en/model_summary.mdx b/docs/source/en/model_summary.mdx
new file mode 100644
index 00000000000000..6b267fb201f0c4
--- /dev/null
+++ b/docs/source/en/model_summary.mdx
@@ -0,0 +1,950 @@
+
+
+# Summary of the models
+
+This is a summary of the models available in 🤗 Transformers. It assumes you’re familiar with the original [transformer
+model](https://arxiv.org/abs/1706.03762). For a gentle introduction check the [annotated transformer](http://nlp.seas.harvard.edu/2018/04/03/attention.html). Here we focus on the high-level differences between the
+models. You can check them more in detail in their respective documentation. Also check out [the Model Hub](https://huggingface.co/models) where you can filter the checkpoints by model architecture.
+
+Each one of the models in the library falls into one of the following categories:
+
+- [autoregressive-models](#autoregressive-models)
+- [autoencoding-models](#autoencoding-models)
+- [seq-to-seq-models](#seq-to-seq-models)
+- [multimodal-models](#multimodal-models)
+- [retrieval-based-models](#retrieval-based-models)
+
+
+
+Autoregressive models are pretrained on the classic language modeling task: guess the next token having read all the
+previous ones. They correspond to the decoder of the original transformer model, and a mask is used on top of the full
+sentence so that the attention heads can only see what was before in the text, and not what’s after. Although those
+models can be fine-tuned and achieve great results on many tasks, the most natural application is text generation. A
+typical example of such models is GPT.
+
+Autoencoding models are pretrained by corrupting the input tokens in some way and trying to reconstruct the original
+sentence. They correspond to the encoder of the original transformer model in the sense that they get access to the
+full inputs without any mask. Those models usually build a bidirectional representation of the whole sentence. They can
+be fine-tuned and achieve great results on many tasks such as text generation, but their most natural application is
+sentence classification or token classification. A typical example of such models is BERT.
+
+Note that the only difference between autoregressive models and autoencoding models is in the way the model is
+pretrained. Therefore, the same architecture can be used for both autoregressive and autoencoding models. When a given
+model has been used for both types of pretraining, we have put it in the category corresponding to the article where it
+was first introduced.
+
+Sequence-to-sequence models use both the encoder and the decoder of the original transformer, either for translation
+tasks or by transforming other tasks to sequence-to-sequence problems. They can be fine-tuned to many tasks but their
+most natural applications are translation, summarization and question answering. The original transformer model is an
+example of such a model (only for translation), T5 is an example that can be fine-tuned on other tasks.
+
+Multimodal models mix text inputs with other kinds (e.g. images) and are more specific to a given task.
+
+
+
+## Decoders or autoregressive models
+
+As mentioned before, these models rely on the decoder part of the original transformer and use an attention mask so
+that at each position, the model can only look at the tokens before the attention heads.
+
+
+
+### Original GPT
+
+
+
+
+[Improving Language Understanding by Generative Pre-Training](https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf), Alec Radford et al.
+
+The first autoregressive model based on the transformer architecture, pretrained on the Book Corpus dataset.
+
+The library provides versions of the model for language modeling and multitask language modeling/multiple choice
+classification.
+
+### GPT-2
+
+
+
+
+[Language Models are Unsupervised Multitask Learners](https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf),
+Alec Radford et al.
+
+A bigger and better version of GPT, pretrained on WebText (web pages from outgoing links in Reddit with 3 karmas or
+more).
+
+The library provides versions of the model for language modeling and multitask language modeling/multiple choice
+classification.
+
+### CTRL
+
+
+
+
+[CTRL: A Conditional Transformer Language Model for Controllable Generation](https://arxiv.org/abs/1909.05858),
+Nitish Shirish Keskar et al.
+
+Same as the GPT model but adds the idea of control codes. Text is generated from a prompt (can be empty) and one (or
+several) of those control codes which are then used to influence the text generation: generate with the style of
+wikipedia article, a book or a movie review.
+
+The library provides a version of the model for language modeling only.
+
+### Transformer-XL
+
+
+
+
+[Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context](https://arxiv.org/abs/1901.02860), Zihang
+Dai et al.
+
+Same as a regular GPT model, but introduces a recurrence mechanism for two consecutive segments (similar to a regular
+RNNs with two consecutive inputs). In this context, a segment is a number of consecutive tokens (for instance 512) that
+may span across multiple documents, and segments are fed in order to the model.
+
+Basically, the hidden states of the previous segment are concatenated to the current input to compute the attention
+scores. This allows the model to pay attention to information that was in the previous segment as well as the current
+one. By stacking multiple attention layers, the receptive field can be increased to multiple previous segments.
+
+This changes the positional embeddings to positional relative embeddings (as the regular positional embeddings would
+give the same results in the current input and the current hidden state at a given position) and needs to make some
+adjustments in the way attention scores are computed.
+
+The library provides a version of the model for language modeling only.
+
+
+
+### Reformer
+
+
+
+
+[Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451), Nikita Kitaev et al .
+
+An autoregressive transformer model with lots of tricks to reduce memory footprint and compute time. Those tricks
+include:
+
+- Use [Axial position encoding](#axial-pos-encoding) (see below for more details). It’s a mechanism to avoid
+ having a huge positional encoding matrix (when the sequence length is very big) by factorizing it into smaller
+ matrices.
+- Replace traditional attention by [LSH (local-sensitive hashing) attention](#lsh-attention) (see below for more
+ details). It's a technique to avoid computing the full product query-key in the attention layers.
+- Avoid storing the intermediate results of each layer by using reversible transformer layers to obtain them during
+ the backward pass (subtracting the residuals from the input of the next layer gives them back) or recomputing them
+ for results inside a given layer (less efficient than storing them but saves memory).
+- Compute the feedforward operations by chunks and not on the whole batch.
+
+With those tricks, the model can be fed much larger sentences than traditional transformer autoregressive models.
+
+
+
+This model could be very well be used in an autoencoding setting, there is no checkpoint for such a
+pretraining yet, though.
+
+
+
+The library provides a version of the model for language modeling only.
+
+### XLNet
+
+
+
+
+[XLNet: Generalized Autoregressive Pretraining for Language Understanding](https://arxiv.org/abs/1906.08237), Zhilin
+Yang et al.
+
+XLNet is not a traditional autoregressive model but uses a training strategy that builds on that. It permutes the
+tokens in the sentence, then allows the model to use the last n tokens to predict the token n+1. Since this is all done
+with a mask, the sentence is actually fed in the model in the right order, but instead of masking the first n tokens
+for n+1, XLNet uses a mask that hides the previous tokens in some given permutation of 1,...,sequence length.
+
+XLNet also uses the same recurrence mechanism as Transformer-XL to build long-term dependencies.
+
+The library provides a version of the model for language modeling, token classification, sentence classification,
+multiple choice classification and question answering.
+
+
+
+## Encoders or autoencoding models
+
+As mentioned before, these models rely on the encoder part of the original transformer and use no mask so the model can
+look at all the tokens in the attention heads. For pretraining, targets are the original sentences and inputs are their
+corrupted versions.
+
+
+
+### BERT
+
+
+
+[BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://arxiv.org/abs/1810.04805),
+Jacob Devlin et al.
+
+Corrupts the inputs by using random masking, more precisely, during pretraining, a given percentage of tokens (usually
+15%) is masked by:
+
+- a special mask token with probability 0.8
+- a random token different from the one masked with probability 0.1
+- the same token with probability 0.1
+
+The model must predict the original sentence, but has a second objective: inputs are two sentences A and B (with a
+separation token in between). With probability 50%, the sentences are consecutive in the corpus, in the remaining 50%
+they are not related. The model has to predict if the sentences are consecutive or not.
+
+The library provides a version of the model for language modeling (traditional or masked), next sentence prediction,
+token classification, sentence classification, multiple choice classification and question answering.
+
+### ALBERT
+
+
+
+
+[ALBERT: A Lite BERT for Self-supervised Learning of Language Representations](https://arxiv.org/abs/1909.11942),
+Zhenzhong Lan et al.
+
+Same as BERT but with a few tweaks:
+
+- Embedding size E is different from hidden size H justified because the embeddings are context independent (one
+ embedding vector represents one token), whereas hidden states are context dependent (one hidden state represents a
+ sequence of tokens) so it's more logical to have H >> E. Also, the embedding matrix is large since it's V x E (V
+ being the vocab size). If E < H, it has less parameters.
+- Layers are split in groups that share parameters (to save memory).
+- Next sentence prediction is replaced by a sentence ordering prediction: in the inputs, we have two sentences A and
+ B (that are consecutive) and we either feed A followed by B or B followed by A. The model must predict if they have
+ been swapped or not.
+
+The library provides a version of the model for masked language modeling, token classification, sentence
+classification, multiple choice classification and question answering.
+
+### RoBERTa
+
+
+
+
+[RoBERTa: A Robustly Optimized BERT Pretraining Approach](https://arxiv.org/abs/1907.11692), Yinhan Liu et al.
+
+Same as BERT with better pretraining tricks:
+
+- dynamic masking: tokens are masked differently at each epoch, whereas BERT does it once and for all
+- no NSP (next sentence prediction) loss and instead of putting just two sentences together, put a chunk of
+ contiguous texts together to reach 512 tokens (so the sentences are in an order than may span several documents)
+- train with larger batches
+- use BPE with bytes as a subunit and not characters (because of unicode characters)
+
+The library provides a version of the model for masked language modeling, token classification, sentence
+classification, multiple choice classification and question answering.
+
+### DistilBERT
+
+
+
+
+[DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter](https://arxiv.org/abs/1910.01108),
+Victor Sanh et al.
+
+Same as BERT but smaller. Trained by distillation of the pretrained BERT model, meaning it's been trained to predict
+the same probabilities as the larger model. The actual objective is a combination of:
+
+- finding the same probabilities as the teacher model
+- predicting the masked tokens correctly (but no next-sentence objective)
+- a cosine similarity between the hidden states of the student and the teacher model
+
+The library provides a version of the model for masked language modeling, token classification, sentence classification
+and question answering.
+
+### ConvBERT
+
+
+
+
+[ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496), Zihang Jiang,
+Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan.
+
+Pre-trained language models like BERT and its variants have recently achieved impressive performance in various natural
+language understanding tasks. However, BERT heavily relies on the global self-attention block and thus suffers large
+memory footprint and computation cost. Although all its attention heads query on the whole input sequence for
+generating the attention map from a global perspective, we observe some heads only need to learn local dependencies,
+which means the existence of computation redundancy. We therefore propose a novel span-based dynamic convolution to
+replace these self-attention heads to directly model local dependencies. The novel convolution heads, together with the
+rest self-attention heads, form a new mixed attention block that is more efficient at both global and local context
+learning. We equip BERT with this mixed attention design and build a ConvBERT model. Experiments have shown that
+ConvBERT significantly outperforms BERT and its variants in various downstream tasks, with lower training cost and
+fewer model parameters. Remarkably, ConvBERTbase model achieves 86.4 GLUE score, 0.7 higher than ELECTRAbase, while
+using less than 1/4 training cost.
+
+The library provides a version of the model for masked language modeling, token classification, sentence classification
+and question answering.
+
+### XLM
+
+
+
+
+[Cross-lingual Language Model Pretraining](https://arxiv.org/abs/1901.07291), Guillaume Lample and Alexis Conneau
+
+A transformer model trained on several languages. There are three different type of training for this model and the
+library provides checkpoints for all of them:
+
+- Causal language modeling (CLM) which is the traditional autoregressive training (so this model could be in the
+ previous section as well). One of the languages is selected for each training sample, and the model input is a
+ sentence of 256 tokens, that may span over several documents in one of those languages.
+- Masked language modeling (MLM) which is like RoBERTa. One of the languages is selected for each training sample,
+ and the model input is a sentence of 256 tokens, that may span over several documents in one of those languages,
+ with dynamic masking of the tokens.
+- A combination of MLM and translation language modeling (TLM). This consists of concatenating a sentence in two
+ different languages, with random masking. To predict one of the masked tokens, the model can use both, the
+ surrounding context in language 1 and the context given by language 2.
+
+Checkpoints refer to which method was used for pretraining by having *clm*, *mlm* or *mlm-tlm* in their names. On top
+of positional embeddings, the model has language embeddings. When training using MLM/CLM, this gives the model an
+indication of the language used, and when training using MLM+TLM, an indication of the language used for each part.
+
+The library provides a version of the model for language modeling, token classification, sentence classification and
+question answering.
+
+### XLM-RoBERTa
+
+
+
+
+[Unsupervised Cross-lingual Representation Learning at Scale](https://arxiv.org/abs/1911.02116), Alexis Conneau et
+al.
+
+Uses RoBERTa tricks on the XLM approach, but does not use the translation language modeling objective. It only uses
+masked language modeling on sentences coming from one language. However, the model is trained on many more languages
+(100) and doesn't use the language embeddings, so it's capable of detecting the input language by itself.
+
+The library provides a version of the model for masked language modeling, token classification, sentence
+classification, multiple choice classification and question answering.
+
+### FlauBERT
+
+
+
+
+[FlauBERT: Unsupervised Language Model Pre-training for French](https://arxiv.org/abs/1912.05372), Hang Le et al.
+
+Like RoBERTa, without the sentence ordering prediction (so just trained on the MLM objective).
+
+The library provides a version of the model for language modeling and sentence classification.
+
+### ELECTRA
+
+
+
+
+[ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators](https://arxiv.org/abs/2003.10555),
+Kevin Clark et al.
+
+ELECTRA is a transformer model pretrained with the use of another (small) masked language model. The inputs are
+corrupted by that language model, which takes an input text that is randomly masked and outputs a text in which ELECTRA
+has to predict which token is an original and which one has been replaced. Like for GAN training, the small language
+model is trained for a few steps (but with the original texts as objective, not to fool the ELECTRA model like in a
+traditional GAN setting) then the ELECTRA model is trained for a few steps.
+
+The library provides a version of the model for masked language modeling, token classification and sentence
+classification.
+
+### Funnel Transformer
+
+
+
+
+[Funnel-Transformer: Filtering out Sequential Redundancy for Efficient Language Processing](https://arxiv.org/abs/2006.03236), Zihang Dai et al.
+
+Funnel Transformer is a transformer model using pooling, a bit like a ResNet model: layers are grouped in blocks, and
+at the beginning of each block (except the first one), the hidden states are pooled among the sequence dimension. This
+way, their length is divided by 2, which speeds up the computation of the next hidden states. All pretrained models
+have three blocks, which means the final hidden state has a sequence length that is one fourth of the original sequence
+length.
+
+For tasks such as classification, this is not a problem, but for tasks like masked language modeling or token
+classification, we need a hidden state with the same sequence length as the original input. In those cases, the final
+hidden states are upsampled to the input sequence length and go through two additional layers. That's why there are two
+versions of each checkpoint. The version suffixed with "-base" contains only the three blocks, while the version
+without that suffix contains the three blocks and the upsampling head with its additional layers.
+
+The pretrained models available use the same pretraining objective as ELECTRA.
+
+The library provides a version of the model for masked language modeling, token classification, sentence
+classification, multiple choice classification and question answering.
+
+
+
+### Longformer
+
+
+
+
+[Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150), Iz Beltagy et al.
+
+A transformer model replacing the attention matrices by sparse matrices to go faster. Often, the local context (e.g.,
+what are the two tokens left and right?) is enough to take action for a given token. Some preselected input tokens are
+still given global attention, but the attention matrix has way less parameters, resulting in a speed-up. See the
+[local attention section](#local-attention) for more information.
+
+It is pretrained the same way a RoBERTa otherwise.
+
+
+
+This model could be very well be used in an autoregressive setting, there is no checkpoint for such a
+pretraining yet, though.
+
+
+
+The library provides a version of the model for masked language modeling, token classification, sentence
+classification, multiple choice classification and question answering.
+
+
+
+## Sequence-to-sequence models
+
+As mentioned before, these models keep both the encoder and the decoder of the original transformer.
+
+
+
+### BART
+
+
+
+
+[BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension](https://arxiv.org/abs/1910.13461), Mike Lewis et al.
+
+Sequence-to-sequence model with an encoder and a decoder. Encoder is fed a corrupted version of the tokens, decoder is
+fed the original tokens (but has a mask to hide the future words like a regular transformers decoder). A composition of
+the following transformations are applied on the pretraining tasks for the encoder:
+
+- mask random tokens (like in BERT)
+- delete random tokens
+- mask a span of k tokens with a single mask token (a span of 0 tokens is an insertion of a mask token)
+- permute sentences
+- rotate the document to make it start at a specific token
+
+The library provides a version of this model for conditional generation and sequence classification.
+
+### Pegasus
+
+
+
+
+[PEGASUS: Pre-training with Extracted Gap-sentences forAbstractive Summarization](https://arxiv.org/pdf/1912.08777.pdf), Jingqing Zhang, Yao Zhao, Mohammad Saleh and Peter J. Liu on Dec 18, 2019.
+
+Sequence-to-sequence model with the same encoder-decoder model architecture as BART. Pegasus is pre-trained jointly on
+two self-supervised objective functions: Masked Language Modeling (MLM) and a novel summarization specific pretraining
+objective, called Gap Sentence Generation (GSG).
+
+- MLM: encoder input tokens are randomly replaced by a mask tokens and have to be predicted by the encoder (like in
+ BERT)
+- GSG: whole encoder input sentences are replaced by a second mask token and fed to the decoder, but which has a
+ causal mask to hide the future words like a regular auto-regressive transformer decoder.
+
+In contrast to BART, Pegasus' pretraining task is intentionally similar to summarization: important sentences are
+masked and are generated together as one output sequence from the remaining sentences, similar to an extractive
+summary.
+
+The library provides a version of this model for conditional generation, which should be used for summarization.
+
+
+### MarianMT
+
+
+
+
+[Marian: Fast Neural Machine Translation in C++](https://arxiv.org/abs/1804.00344), Marcin Junczys-Dowmunt et al.
+
+A framework for translation models, using the same models as BART
+
+The library provides a version of this model for conditional generation.
+
+
+### T5
+
+
+
+
+[Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer](https://arxiv.org/abs/1910.10683), Colin Raffel et al.
+
+Uses the traditional transformer model (with a slight change in the positional embeddings, which are learned at each
+layer). To be able to operate on all NLP tasks, it transforms them into text-to-text problems by using specific
+prefixes: “summarize: ”, “question: ”, “translate English to German: ” and so forth.
+
+The pretraining includes both supervised and self-supervised training. Supervised training is conducted on downstream
+tasks provided by the GLUE and SuperGLUE benchmarks (converting them into text-to-text tasks as explained above).
+
+Self-supervised training uses corrupted tokens, by randomly removing 15% of the tokens and replacing them with
+individual sentinel tokens (if several consecutive tokens are marked for removal, the whole group is replaced with a
+single sentinel token). The input of the encoder is the corrupted sentence, the input of the decoder is the original
+sentence and the target is then the dropped out tokens delimited by their sentinel tokens.
+
+For instance, if we have the sentence “My dog is very cute .”, and we decide to remove the tokens: "dog", "is" and
+"cute", the encoder input becomes “My very .” and the target input becomes “ dog is cute .”
+
+The library provides a version of this model for conditional generation.
+
+
+### MT5
+
+
+
+
+[mT5: A massively multilingual pre-trained text-to-text transformer](https://arxiv.org/abs/2010.11934), Linting Xue
+et al.
+
+The model architecture is same as T5. mT5's pretraining objective includes T5's self-supervised training, but not T5's
+supervised training. mT5 is trained on 101 languages.
+
+The library provides a version of this model for conditional generation.
+
+
+### MBart
+
+
+
+
+[Multilingual Denoising Pre-training for Neural Machine Translation](https://arxiv.org/abs/2001.08210) by Yinhan Liu,
+Jiatao Gu, Naman Goyal, Xian Li, Sergey Edunov Marjan Ghazvininejad, Mike Lewis, Luke Zettlemoyer.
+
+The model architecture and pretraining objective is same as BART, but MBart is trained on 25 languages and is intended
+for supervised and unsupervised machine translation. MBart is one of the first methods for pretraining a complete
+sequence-to-sequence model by denoising full texts in multiple languages,
+
+The library provides a version of this model for conditional generation.
+
+The [mbart-large-en-ro checkpoint](https://huggingface.co/facebook/mbart-large-en-ro) can be used for english ->
+romanian translation.
+
+The [mbart-large-cc25](https://huggingface.co/facebook/mbart-large-cc25) checkpoint can be finetuned for other
+translation and summarization tasks, using code in ```examples/pytorch/translation/``` , but is not very useful without
+finetuning.
+
+
+### ProphetNet
+
+
+
+
+[ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training,](https://arxiv.org/abs/2001.04063) by
+Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang, Ming Zhou.
+
+ProphetNet introduces a novel *sequence-to-sequence* pretraining objective, called *future n-gram prediction*. In
+future n-gram prediction, the model predicts the next n tokens simultaneously based on previous context tokens at each
+time step instead instead of just the single next token. The future n-gram prediction explicitly encourages the model
+to plan for the future tokens and prevent overfitting on strong local correlations. The model architecture is based on
+the original Transformer, but replaces the "standard" self-attention mechanism in the decoder by a a main
+self-attention mechanism and a self and n-stream (predict) self-attention mechanism.
+
+The library provides a pre-trained version of this model for conditional generation and a fine-tuned version for
+summarization.
+
+### XLM-ProphetNet
+
+
+
+
+[ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training,](https://arxiv.org/abs/2001.04063) by
+Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang, Ming Zhou.
+
+XLM-ProphetNet's model architecture and pretraining objective is same as ProphetNet, but XLM-ProphetNet was pre-trained
+on the cross-lingual dataset [XGLUE](https://arxiv.org/abs/2004.01401).
+
+The library provides a pre-trained version of this model for multi-lingual conditional generation and fine-tuned
+versions for headline generation and question generation, respectively.
+
+
+
+## Multimodal models
+
+There is one multimodal model in the library which has not been pretrained in the self-supervised fashion like the
+others.
+
+### MMBT
+
+[Supervised Multimodal Bitransformers for Classifying Images and Text](https://arxiv.org/abs/1909.02950), Douwe Kiela
+et al.
+
+A transformers model used in multimodal settings, combining a text and an image to make predictions. The transformer
+model takes as inputs the embeddings of the tokenized text and the final activations of a pretrained on images resnet
+(after the pooling layer) that goes through a linear layer (to go from number of features at the end of the resnet to
+the hidden state dimension of the transformer).
+
+The different inputs are concatenated, and on top of the positional embeddings, a segment embedding is added to let the
+model know which part of the input vector corresponds to the text and which to the image.
+
+The pretrained model only works for classification.
+
+
+
+
+
+## Retrieval-based models
+
+Some models use documents retrieval during (pre)training and inference for open-domain question answering, for example.
+
+
+### DPR
+
+
+
+
+[Dense Passage Retrieval for Open-Domain Question Answering](https://arxiv.org/abs/2004.04906), Vladimir Karpukhin et
+al.
+
+Dense Passage Retrieval (DPR) - is a set of tools and models for state-of-the-art open-domain question-answering
+research.
+
+
+DPR consists in three models:
+
+- Question encoder: encode questions as vectors
+- Context encoder: encode contexts as vectors
+- Reader: extract the answer of the questions inside retrieved contexts, along with a relevance score (high if the
+ inferred span actually answers the question).
+
+DPR's pipeline (not implemented yet) uses a retrieval step to find the top k contexts given a certain question, and
+then it calls the reader with the question and the retrieved documents to get the answer.
+
+### RAG
+
+
+
+[Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks](https://arxiv.org/abs/2005.11401), Patrick Lewis,
+Ethan Perez, Aleksandara Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau
+Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela
+
+Retrieval-augmented generation ("RAG") models combine the powers of pretrained dense retrieval (DPR) and Seq2Seq
+models. RAG models retrieve docs, pass them to a seq2seq model, then marginalize to generate outputs. The retriever and
+seq2seq modules are initialized from pretrained models, and fine-tuned jointly, allowing both retrieval and generation
+to adapt to downstream tasks.
+
+The two models RAG-Token and RAG-Sequence are available for generation.
+
+## More technical aspects
+
+### Full vs sparse attention
+
+Most transformer models use full attention in the sense that the attention matrix is square. It can be a big
+computational bottleneck when you have long texts. Longformer and reformer are models that try to be more efficient and
+use a sparse version of the attention matrix to speed up training.
+
+
+
+**LSH attention**
+
+[Reformer](#reformer) uses LSH attention. In the softmax(QK^t), only the biggest elements (in the softmax
+dimension) of the matrix QK^t are going to give useful contributions. So for each query q in Q, we can consider only
+the keys k in K that are close to q. A hash function is used to determine if q and k are close. The attention mask is
+modified to mask the current token (except at the first position), because it will give a query and a key equal (so
+very similar to each other). Since the hash can be a bit random, several hash functions are used in practice
+(determined by a n_rounds parameter) and then are averaged together.
+
+
+
+**Local attention**
+
+[Longformer](#longformer) uses local attention: often, the local context (e.g., what are the two tokens to the
+left and right?) is enough to take action for a given token. Also, by stacking attention layers that have a small
+window, the last layer will have a receptive field of more than just the tokens in the window, allowing them to build a
+representation of the whole sentence.
+
+Some preselected input tokens are also given global attention: for those few tokens, the attention matrix can access
+all tokens and this process is symmetric: all other tokens have access to those specific tokens (on top of the ones in
+their local window). This is shown in Figure 2d of the paper, see below for a sample attention mask:
+
+
+
+ YOSO Attention Algorithm. Taken from the original paper.
+
+This model was contributed by [novice03](https://huggingface.co/novice03). The original code can be found [here](https://github.com/mlpen/YOSO).
+
+
+## YosoConfig
+
+[[autodoc]] YosoConfig
+
+
+## YosoModel
+
+[[autodoc]] YosoModel
+ - forward
+
+
+## YosoForMaskedLM
+
+[[autodoc]] YosoForMaskedLM
+ - forward
+
+
+## YosoForSequenceClassification
+
+[[autodoc]] YosoForSequenceClassification
+ - forward
+
+## YosoForMultipleChoice
+
+[[autodoc]] YosoForMultipleChoice
+ - forward
+
+
+## YosoForTokenClassification
+
+[[autodoc]] YosoForTokenClassification
+ - forward
+
+
+## YosoForQuestionAnswering
+
+[[autodoc]] YosoForQuestionAnswering
+ - forward
\ No newline at end of file
diff --git a/docs/source/en/model_sharing.mdx b/docs/source/en/model_sharing.mdx
new file mode 100644
index 00000000000000..fb8a30a9cc13d1
--- /dev/null
+++ b/docs/source/en/model_sharing.mdx
@@ -0,0 +1,228 @@
+
+
+# Share a model
+
+The last two tutorials showed how you can fine-tune a model with PyTorch, Keras, and 🤗 Accelerate for distributed setups. The next step is to share your model with the community! At Hugging Face, we believe in openly sharing knowledge and resources to democratize artificial intelligence for everyone. We encourage you to consider sharing your model with the community to help others save time and resources.
+
+In this tutorial, you will learn two methods for sharing a trained or fine-tuned model on the [Model Hub](https://huggingface.co/models):
+
+- Programmatically push your files to the Hub.
+- Drag-and-drop your files to the Hub with the web interface.
+
+
+
+
+
+To share a model with the community, you need an account on [huggingface.co](https://huggingface.co/join). You can also join an existing organization or create a new one.
+
+
+
+## Repository features
+
+Each repository on the Model Hub behaves like a typical GitHub repository. Our repositories offer versioning, commit history, and the ability to visualize differences.
+
+The Model Hub's built-in versioning is based on git and [git-lfs](https://git-lfs.github.com/). In other words, you can treat one model as one repository, enabling greater access control and scalability. Version control allows *revisions*, a method for pinning a specific version of a model with a commit hash, tag or branch.
+
+As a result, you can load a specific model version with the `revision` parameter:
+
+```py
+>>> model = AutoModel.from_pretrained(
+... "julien-c/EsperBERTo-small", revision="v2.0.1" # tag name, or branch name, or commit hash
+... )
+```
+
+Files are also easily edited in a repository, and you can view the commit history as well as the difference:
+
+
+
+## Setup
+
+Before sharing a model to the Hub, you will need your Hugging Face credentials. If you have access to a terminal, run the following command in the virtual environment where 🤗 Transformers is installed. This will store your access token in your Hugging Face cache folder (`~/.cache/` by default):
+
+```bash
+huggingface-cli login
+```
+
+If you are using a notebook like Jupyter or Colaboratory, make sure you have the [`huggingface_hub`](https://huggingface.co/docs/hub/adding-a-library) library installed. This library allows you to programmatically interact with the Hub.
+
+```bash
+pip install huggingface_hub
+```
+
+Then use `notebook_login` to sign-in to the Hub, and follow the link [here](https://huggingface.co/settings/token) to generate a token to login with:
+
+```py
+>>> from huggingface_hub import notebook_login
+
+>>> notebook_login()
+```
+
+## Convert a model for all frameworks
+
+To ensure your model can be used by someone working with a different framework, we recommend you convert and upload your model with both PyTorch and TensorFlow checkpoints. While users are still able to load your model from a different framework if you skip this step, it will be slower because 🤗 Transformers will need to convert the checkpoint on-the-fly.
+
+Converting a checkpoint for another framework is easy. Make sure you have PyTorch and TensorFlow installed (see [here](installation) for installation instructions), and then find the specific model for your task in the other framework.
+
+
+
+Specify `from_tf=True` to convert a checkpoint from TensorFlow to PyTorch:
+
+```py
+>>> pt_model = DistilBertForSequenceClassification.from_pretrained("path/to/awesome-name-you-picked", from_tf=True)
+>>> pt_model.save_pretrained("path/to/awesome-name-you-picked")
+```
+
+
+Specify `from_pt=True` to convert a checkpoint from PyTorch to TensorFlow:
+
+```py
+>>> tf_model = TFDistilBertForSequenceClassification.from_pretrained("path/to/awesome-name-you-picked", from_pt=True)
+```
+
+Then you can save your new TensorFlow model with it's new checkpoint:
+
+```py
+>>> tf_model.save_pretrained("path/to/awesome-name-you-picked")
+```
+
+
+If a model is available in Flax, you can also convert a checkpoint from PyTorch to Flax:
+
+```py
+>>> flax_model = FlaxDistilBertForSequenceClassification.from_pretrained(
+... "path/to/awesome-name-you-picked", from_pt=True
+... )
+```
+
+
+
+## Push a model during training
+
+
+
+
+
+Sharing a model to the Hub is as simple as adding an extra parameter or callback. Remember from the [fine-tuning tutorial](training), the [`TrainingArguments`] class is where you specify hyperparameters and additional training options. One of these training options includes the ability to push a model directly to the Hub. Set `push_to_hub=True` in your [`TrainingArguments`]:
+
+```py
+>>> training_args = TrainingArguments(output_dir="my-awesome-model", push_to_hub=True)
+```
+
+Pass your training arguments as usual to [`Trainer`]:
+
+```py
+>>> trainer = Trainer(
+... model=model,
+... args=training_args,
+... train_dataset=small_train_dataset,
+... eval_dataset=small_eval_dataset,
+... compute_metrics=compute_metrics,
+... )
+```
+
+After you fine-tune your model, call [`~transformers.Trainer.push_to_hub`] on [`Trainer`] to push the trained model to the Hub. 🤗 Transformers will even automatically add training hyperparameters, training results and framework versions to your model card!
+
+```py
+>>> trainer.push_to_hub()
+```
+
+
+Share a model to the Hub with [`PushToHubCallback`]. In the [`PushToHubCallback`] function, add:
+
+- An output directory for your model.
+- A tokenizer.
+- The `hub_model_id`, which is your Hub username and model name.
+
+```py
+>>> from transformers.keras.callbacks import PushToHubCallback
+
+>>> push_to_hub_callback = PushToHubCallback(
+... output_dir="./your_model_save_path", tokenizer=tokenizer, hub_model_id="your-username/my-awesome-model"
+... )
+```
+
+Add the callback to [`fit`](https://keras.io/api/models/model_training_apis/), and 🤗 Transformers will push the trained model to the Hub:
+
+```py
+>>> model.fit(tf_train_dataset, validation_data=tf_validation_dataset, epochs=3, callbacks=push_to_hub_callback)
+```
+
+
+
+## Use the `push_to_hub` function
+
+You can also call `push_to_hub` directly on your model to upload it to the Hub.
+
+Specify your model name in `push_to_hub`:
+
+```py
+>>> pt_model.push_to_hub("my-awesome-model")
+```
+
+This creates a repository under your username with the model name `my-awesome-model`. Users can now load your model with the `from_pretrained` function:
+
+```py
+>>> from transformers import AutoModel
+
+>>> model = AutoModel.from_pretrained("your_username/my-awesome-model")
+```
+
+If you belong to an organization and want to push your model under the organization name instead, add the `organization` parameter:
+
+```py
+>>> pt_model.push_to_hub("my-awesome-model", organization="my-awesome-org")
+```
+
+The `push_to_hub` function can also be used to add other files to a model repository. For example, add a tokenizer to a model repository:
+
+```py
+>>> tokenizer.push_to_hub("my-awesome-model")
+```
+
+Or perhaps you'd like to add the TensorFlow version of your fine-tuned PyTorch model:
+
+```py
+>>> tf_model.push_to_hub("my-awesome-model")
+```
+
+Now when you navigate to the your Hugging Face profile, you should see your newly created model repository. Clicking on the **Files** tab will display all the files you've uploaded to the repository.
+
+For more details on how to create and upload files to a repository, refer to the Hub documentation [here](https://huggingface.co/docs/hub/how-to-upstream).
+
+## Upload with the web interface
+
+Users who prefer a no-code approach are able to upload a model through the Hub's web interface. Visit [huggingface.co/new](https://huggingface.co/new) to create a new repository:
+
+
+
+From here, add some information about your model:
+
+- Select the **owner** of the repository. This can be yourself or any of the organizations you belong to.
+- Pick a name for your model, which will also be the repository name.
+- Choose whether your model is public or private.
+- Specify the license usage for your model.
+
+Now click on the **Files** tab and click on the **Add file** button to upload a new file to your repository. Then drag-and-drop a file to upload and add a commit message.
+
+
+
+## Add a model card
+
+To make sure users understand your model's capabilities, limitations, potential biases and ethical considerations, please add a model card to your repository. The model card is defined in the `README.md` file. You can add a model card by:
+
+* Manually creating and uploading a `README.md` file.
+* Clicking on the **Edit model card** button in your model repository.
+
+Take a look at the DistilBert [model card](https://huggingface.co/distilbert-base-uncased) for a good example of the type of information a model card should include. For more details about other options you can control in the `README.md` file such as a model's carbon footprint or widget examples, refer to the documentation [here](https://huggingface.co/docs/hub/model-repos).
diff --git a/docs/source/en/model_summary.mdx b/docs/source/en/model_summary.mdx
new file mode 100644
index 00000000000000..6b267fb201f0c4
--- /dev/null
+++ b/docs/source/en/model_summary.mdx
@@ -0,0 +1,950 @@
+
+
+# Summary of the models
+
+This is a summary of the models available in 🤗 Transformers. It assumes you’re familiar with the original [transformer
+model](https://arxiv.org/abs/1706.03762). For a gentle introduction check the [annotated transformer](http://nlp.seas.harvard.edu/2018/04/03/attention.html). Here we focus on the high-level differences between the
+models. You can check them more in detail in their respective documentation. Also check out [the Model Hub](https://huggingface.co/models) where you can filter the checkpoints by model architecture.
+
+Each one of the models in the library falls into one of the following categories:
+
+- [autoregressive-models](#autoregressive-models)
+- [autoencoding-models](#autoencoding-models)
+- [seq-to-seq-models](#seq-to-seq-models)
+- [multimodal-models](#multimodal-models)
+- [retrieval-based-models](#retrieval-based-models)
+
+
+
+Autoregressive models are pretrained on the classic language modeling task: guess the next token having read all the
+previous ones. They correspond to the decoder of the original transformer model, and a mask is used on top of the full
+sentence so that the attention heads can only see what was before in the text, and not what’s after. Although those
+models can be fine-tuned and achieve great results on many tasks, the most natural application is text generation. A
+typical example of such models is GPT.
+
+Autoencoding models are pretrained by corrupting the input tokens in some way and trying to reconstruct the original
+sentence. They correspond to the encoder of the original transformer model in the sense that they get access to the
+full inputs without any mask. Those models usually build a bidirectional representation of the whole sentence. They can
+be fine-tuned and achieve great results on many tasks such as text generation, but their most natural application is
+sentence classification or token classification. A typical example of such models is BERT.
+
+Note that the only difference between autoregressive models and autoencoding models is in the way the model is
+pretrained. Therefore, the same architecture can be used for both autoregressive and autoencoding models. When a given
+model has been used for both types of pretraining, we have put it in the category corresponding to the article where it
+was first introduced.
+
+Sequence-to-sequence models use both the encoder and the decoder of the original transformer, either for translation
+tasks or by transforming other tasks to sequence-to-sequence problems. They can be fine-tuned to many tasks but their
+most natural applications are translation, summarization and question answering. The original transformer model is an
+example of such a model (only for translation), T5 is an example that can be fine-tuned on other tasks.
+
+Multimodal models mix text inputs with other kinds (e.g. images) and are more specific to a given task.
+
+
+
+## Decoders or autoregressive models
+
+As mentioned before, these models rely on the decoder part of the original transformer and use an attention mask so
+that at each position, the model can only look at the tokens before the attention heads.
+
+
+
+### Original GPT
+
+
+
+
+[Improving Language Understanding by Generative Pre-Training](https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf), Alec Radford et al.
+
+The first autoregressive model based on the transformer architecture, pretrained on the Book Corpus dataset.
+
+The library provides versions of the model for language modeling and multitask language modeling/multiple choice
+classification.
+
+### GPT-2
+
+
+
+
+[Language Models are Unsupervised Multitask Learners](https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf),
+Alec Radford et al.
+
+A bigger and better version of GPT, pretrained on WebText (web pages from outgoing links in Reddit with 3 karmas or
+more).
+
+The library provides versions of the model for language modeling and multitask language modeling/multiple choice
+classification.
+
+### CTRL
+
+
+
+
+[CTRL: A Conditional Transformer Language Model for Controllable Generation](https://arxiv.org/abs/1909.05858),
+Nitish Shirish Keskar et al.
+
+Same as the GPT model but adds the idea of control codes. Text is generated from a prompt (can be empty) and one (or
+several) of those control codes which are then used to influence the text generation: generate with the style of
+wikipedia article, a book or a movie review.
+
+The library provides a version of the model for language modeling only.
+
+### Transformer-XL
+
+
+
+
+[Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context](https://arxiv.org/abs/1901.02860), Zihang
+Dai et al.
+
+Same as a regular GPT model, but introduces a recurrence mechanism for two consecutive segments (similar to a regular
+RNNs with two consecutive inputs). In this context, a segment is a number of consecutive tokens (for instance 512) that
+may span across multiple documents, and segments are fed in order to the model.
+
+Basically, the hidden states of the previous segment are concatenated to the current input to compute the attention
+scores. This allows the model to pay attention to information that was in the previous segment as well as the current
+one. By stacking multiple attention layers, the receptive field can be increased to multiple previous segments.
+
+This changes the positional embeddings to positional relative embeddings (as the regular positional embeddings would
+give the same results in the current input and the current hidden state at a given position) and needs to make some
+adjustments in the way attention scores are computed.
+
+The library provides a version of the model for language modeling only.
+
+
+
+### Reformer
+
+
+
+
+[Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451), Nikita Kitaev et al .
+
+An autoregressive transformer model with lots of tricks to reduce memory footprint and compute time. Those tricks
+include:
+
+- Use [Axial position encoding](#axial-pos-encoding) (see below for more details). It’s a mechanism to avoid
+ having a huge positional encoding matrix (when the sequence length is very big) by factorizing it into smaller
+ matrices.
+- Replace traditional attention by [LSH (local-sensitive hashing) attention](#lsh-attention) (see below for more
+ details). It's a technique to avoid computing the full product query-key in the attention layers.
+- Avoid storing the intermediate results of each layer by using reversible transformer layers to obtain them during
+ the backward pass (subtracting the residuals from the input of the next layer gives them back) or recomputing them
+ for results inside a given layer (less efficient than storing them but saves memory).
+- Compute the feedforward operations by chunks and not on the whole batch.
+
+With those tricks, the model can be fed much larger sentences than traditional transformer autoregressive models.
+
+
+
+This model could be very well be used in an autoencoding setting, there is no checkpoint for such a
+pretraining yet, though.
+
+
+
+The library provides a version of the model for language modeling only.
+
+### XLNet
+
+
+
+
+[XLNet: Generalized Autoregressive Pretraining for Language Understanding](https://arxiv.org/abs/1906.08237), Zhilin
+Yang et al.
+
+XLNet is not a traditional autoregressive model but uses a training strategy that builds on that. It permutes the
+tokens in the sentence, then allows the model to use the last n tokens to predict the token n+1. Since this is all done
+with a mask, the sentence is actually fed in the model in the right order, but instead of masking the first n tokens
+for n+1, XLNet uses a mask that hides the previous tokens in some given permutation of 1,...,sequence length.
+
+XLNet also uses the same recurrence mechanism as Transformer-XL to build long-term dependencies.
+
+The library provides a version of the model for language modeling, token classification, sentence classification,
+multiple choice classification and question answering.
+
+
+
+## Encoders or autoencoding models
+
+As mentioned before, these models rely on the encoder part of the original transformer and use no mask so the model can
+look at all the tokens in the attention heads. For pretraining, targets are the original sentences and inputs are their
+corrupted versions.
+
+
+
+### BERT
+
+
+
+[BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://arxiv.org/abs/1810.04805),
+Jacob Devlin et al.
+
+Corrupts the inputs by using random masking, more precisely, during pretraining, a given percentage of tokens (usually
+15%) is masked by:
+
+- a special mask token with probability 0.8
+- a random token different from the one masked with probability 0.1
+- the same token with probability 0.1
+
+The model must predict the original sentence, but has a second objective: inputs are two sentences A and B (with a
+separation token in between). With probability 50%, the sentences are consecutive in the corpus, in the remaining 50%
+they are not related. The model has to predict if the sentences are consecutive or not.
+
+The library provides a version of the model for language modeling (traditional or masked), next sentence prediction,
+token classification, sentence classification, multiple choice classification and question answering.
+
+### ALBERT
+
+
+
+
+[ALBERT: A Lite BERT for Self-supervised Learning of Language Representations](https://arxiv.org/abs/1909.11942),
+Zhenzhong Lan et al.
+
+Same as BERT but with a few tweaks:
+
+- Embedding size E is different from hidden size H justified because the embeddings are context independent (one
+ embedding vector represents one token), whereas hidden states are context dependent (one hidden state represents a
+ sequence of tokens) so it's more logical to have H >> E. Also, the embedding matrix is large since it's V x E (V
+ being the vocab size). If E < H, it has less parameters.
+- Layers are split in groups that share parameters (to save memory).
+- Next sentence prediction is replaced by a sentence ordering prediction: in the inputs, we have two sentences A and
+ B (that are consecutive) and we either feed A followed by B or B followed by A. The model must predict if they have
+ been swapped or not.
+
+The library provides a version of the model for masked language modeling, token classification, sentence
+classification, multiple choice classification and question answering.
+
+### RoBERTa
+
+
+
+
+[RoBERTa: A Robustly Optimized BERT Pretraining Approach](https://arxiv.org/abs/1907.11692), Yinhan Liu et al.
+
+Same as BERT with better pretraining tricks:
+
+- dynamic masking: tokens are masked differently at each epoch, whereas BERT does it once and for all
+- no NSP (next sentence prediction) loss and instead of putting just two sentences together, put a chunk of
+ contiguous texts together to reach 512 tokens (so the sentences are in an order than may span several documents)
+- train with larger batches
+- use BPE with bytes as a subunit and not characters (because of unicode characters)
+
+The library provides a version of the model for masked language modeling, token classification, sentence
+classification, multiple choice classification and question answering.
+
+### DistilBERT
+
+
+
+
+[DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter](https://arxiv.org/abs/1910.01108),
+Victor Sanh et al.
+
+Same as BERT but smaller. Trained by distillation of the pretrained BERT model, meaning it's been trained to predict
+the same probabilities as the larger model. The actual objective is a combination of:
+
+- finding the same probabilities as the teacher model
+- predicting the masked tokens correctly (but no next-sentence objective)
+- a cosine similarity between the hidden states of the student and the teacher model
+
+The library provides a version of the model for masked language modeling, token classification, sentence classification
+and question answering.
+
+### ConvBERT
+
+
+
+
+[ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496), Zihang Jiang,
+Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan.
+
+Pre-trained language models like BERT and its variants have recently achieved impressive performance in various natural
+language understanding tasks. However, BERT heavily relies on the global self-attention block and thus suffers large
+memory footprint and computation cost. Although all its attention heads query on the whole input sequence for
+generating the attention map from a global perspective, we observe some heads only need to learn local dependencies,
+which means the existence of computation redundancy. We therefore propose a novel span-based dynamic convolution to
+replace these self-attention heads to directly model local dependencies. The novel convolution heads, together with the
+rest self-attention heads, form a new mixed attention block that is more efficient at both global and local context
+learning. We equip BERT with this mixed attention design and build a ConvBERT model. Experiments have shown that
+ConvBERT significantly outperforms BERT and its variants in various downstream tasks, with lower training cost and
+fewer model parameters. Remarkably, ConvBERTbase model achieves 86.4 GLUE score, 0.7 higher than ELECTRAbase, while
+using less than 1/4 training cost.
+
+The library provides a version of the model for masked language modeling, token classification, sentence classification
+and question answering.
+
+### XLM
+
+
+
+
+[Cross-lingual Language Model Pretraining](https://arxiv.org/abs/1901.07291), Guillaume Lample and Alexis Conneau
+
+A transformer model trained on several languages. There are three different type of training for this model and the
+library provides checkpoints for all of them:
+
+- Causal language modeling (CLM) which is the traditional autoregressive training (so this model could be in the
+ previous section as well). One of the languages is selected for each training sample, and the model input is a
+ sentence of 256 tokens, that may span over several documents in one of those languages.
+- Masked language modeling (MLM) which is like RoBERTa. One of the languages is selected for each training sample,
+ and the model input is a sentence of 256 tokens, that may span over several documents in one of those languages,
+ with dynamic masking of the tokens.
+- A combination of MLM and translation language modeling (TLM). This consists of concatenating a sentence in two
+ different languages, with random masking. To predict one of the masked tokens, the model can use both, the
+ surrounding context in language 1 and the context given by language 2.
+
+Checkpoints refer to which method was used for pretraining by having *clm*, *mlm* or *mlm-tlm* in their names. On top
+of positional embeddings, the model has language embeddings. When training using MLM/CLM, this gives the model an
+indication of the language used, and when training using MLM+TLM, an indication of the language used for each part.
+
+The library provides a version of the model for language modeling, token classification, sentence classification and
+question answering.
+
+### XLM-RoBERTa
+
+
+
+
+[Unsupervised Cross-lingual Representation Learning at Scale](https://arxiv.org/abs/1911.02116), Alexis Conneau et
+al.
+
+Uses RoBERTa tricks on the XLM approach, but does not use the translation language modeling objective. It only uses
+masked language modeling on sentences coming from one language. However, the model is trained on many more languages
+(100) and doesn't use the language embeddings, so it's capable of detecting the input language by itself.
+
+The library provides a version of the model for masked language modeling, token classification, sentence
+classification, multiple choice classification and question answering.
+
+### FlauBERT
+
+
+
+
+[FlauBERT: Unsupervised Language Model Pre-training for French](https://arxiv.org/abs/1912.05372), Hang Le et al.
+
+Like RoBERTa, without the sentence ordering prediction (so just trained on the MLM objective).
+
+The library provides a version of the model for language modeling and sentence classification.
+
+### ELECTRA
+
+
+
+
+[ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators](https://arxiv.org/abs/2003.10555),
+Kevin Clark et al.
+
+ELECTRA is a transformer model pretrained with the use of another (small) masked language model. The inputs are
+corrupted by that language model, which takes an input text that is randomly masked and outputs a text in which ELECTRA
+has to predict which token is an original and which one has been replaced. Like for GAN training, the small language
+model is trained for a few steps (but with the original texts as objective, not to fool the ELECTRA model like in a
+traditional GAN setting) then the ELECTRA model is trained for a few steps.
+
+The library provides a version of the model for masked language modeling, token classification and sentence
+classification.
+
+### Funnel Transformer
+
+
+
+
+[Funnel-Transformer: Filtering out Sequential Redundancy for Efficient Language Processing](https://arxiv.org/abs/2006.03236), Zihang Dai et al.
+
+Funnel Transformer is a transformer model using pooling, a bit like a ResNet model: layers are grouped in blocks, and
+at the beginning of each block (except the first one), the hidden states are pooled among the sequence dimension. This
+way, their length is divided by 2, which speeds up the computation of the next hidden states. All pretrained models
+have three blocks, which means the final hidden state has a sequence length that is one fourth of the original sequence
+length.
+
+For tasks such as classification, this is not a problem, but for tasks like masked language modeling or token
+classification, we need a hidden state with the same sequence length as the original input. In those cases, the final
+hidden states are upsampled to the input sequence length and go through two additional layers. That's why there are two
+versions of each checkpoint. The version suffixed with "-base" contains only the three blocks, while the version
+without that suffix contains the three blocks and the upsampling head with its additional layers.
+
+The pretrained models available use the same pretraining objective as ELECTRA.
+
+The library provides a version of the model for masked language modeling, token classification, sentence
+classification, multiple choice classification and question answering.
+
+
+
+### Longformer
+
+
+
+
+[Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150), Iz Beltagy et al.
+
+A transformer model replacing the attention matrices by sparse matrices to go faster. Often, the local context (e.g.,
+what are the two tokens left and right?) is enough to take action for a given token. Some preselected input tokens are
+still given global attention, but the attention matrix has way less parameters, resulting in a speed-up. See the
+[local attention section](#local-attention) for more information.
+
+It is pretrained the same way a RoBERTa otherwise.
+
+
+
+This model could be very well be used in an autoregressive setting, there is no checkpoint for such a
+pretraining yet, though.
+
+
+
+The library provides a version of the model for masked language modeling, token classification, sentence
+classification, multiple choice classification and question answering.
+
+
+
+## Sequence-to-sequence models
+
+As mentioned before, these models keep both the encoder and the decoder of the original transformer.
+
+
+
+### BART
+
+
+
+
+[BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension](https://arxiv.org/abs/1910.13461), Mike Lewis et al.
+
+Sequence-to-sequence model with an encoder and a decoder. Encoder is fed a corrupted version of the tokens, decoder is
+fed the original tokens (but has a mask to hide the future words like a regular transformers decoder). A composition of
+the following transformations are applied on the pretraining tasks for the encoder:
+
+- mask random tokens (like in BERT)
+- delete random tokens
+- mask a span of k tokens with a single mask token (a span of 0 tokens is an insertion of a mask token)
+- permute sentences
+- rotate the document to make it start at a specific token
+
+The library provides a version of this model for conditional generation and sequence classification.
+
+### Pegasus
+
+
+
+
+[PEGASUS: Pre-training with Extracted Gap-sentences forAbstractive Summarization](https://arxiv.org/pdf/1912.08777.pdf), Jingqing Zhang, Yao Zhao, Mohammad Saleh and Peter J. Liu on Dec 18, 2019.
+
+Sequence-to-sequence model with the same encoder-decoder model architecture as BART. Pegasus is pre-trained jointly on
+two self-supervised objective functions: Masked Language Modeling (MLM) and a novel summarization specific pretraining
+objective, called Gap Sentence Generation (GSG).
+
+- MLM: encoder input tokens are randomly replaced by a mask tokens and have to be predicted by the encoder (like in
+ BERT)
+- GSG: whole encoder input sentences are replaced by a second mask token and fed to the decoder, but which has a
+ causal mask to hide the future words like a regular auto-regressive transformer decoder.
+
+In contrast to BART, Pegasus' pretraining task is intentionally similar to summarization: important sentences are
+masked and are generated together as one output sequence from the remaining sentences, similar to an extractive
+summary.
+
+The library provides a version of this model for conditional generation, which should be used for summarization.
+
+
+### MarianMT
+
+
+
+
+[Marian: Fast Neural Machine Translation in C++](https://arxiv.org/abs/1804.00344), Marcin Junczys-Dowmunt et al.
+
+A framework for translation models, using the same models as BART
+
+The library provides a version of this model for conditional generation.
+
+
+### T5
+
+
+
+
+[Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer](https://arxiv.org/abs/1910.10683), Colin Raffel et al.
+
+Uses the traditional transformer model (with a slight change in the positional embeddings, which are learned at each
+layer). To be able to operate on all NLP tasks, it transforms them into text-to-text problems by using specific
+prefixes: “summarize: ”, “question: ”, “translate English to German: ” and so forth.
+
+The pretraining includes both supervised and self-supervised training. Supervised training is conducted on downstream
+tasks provided by the GLUE and SuperGLUE benchmarks (converting them into text-to-text tasks as explained above).
+
+Self-supervised training uses corrupted tokens, by randomly removing 15% of the tokens and replacing them with
+individual sentinel tokens (if several consecutive tokens are marked for removal, the whole group is replaced with a
+single sentinel token). The input of the encoder is the corrupted sentence, the input of the decoder is the original
+sentence and the target is then the dropped out tokens delimited by their sentinel tokens.
+
+For instance, if we have the sentence “My dog is very cute .”, and we decide to remove the tokens: "dog", "is" and
+"cute", the encoder input becomes “My very .” and the target input becomes “ dog is cute .”
+
+The library provides a version of this model for conditional generation.
+
+
+### MT5
+
+
+
+
+[mT5: A massively multilingual pre-trained text-to-text transformer](https://arxiv.org/abs/2010.11934), Linting Xue
+et al.
+
+The model architecture is same as T5. mT5's pretraining objective includes T5's self-supervised training, but not T5's
+supervised training. mT5 is trained on 101 languages.
+
+The library provides a version of this model for conditional generation.
+
+
+### MBart
+
+
+
+
+[Multilingual Denoising Pre-training for Neural Machine Translation](https://arxiv.org/abs/2001.08210) by Yinhan Liu,
+Jiatao Gu, Naman Goyal, Xian Li, Sergey Edunov Marjan Ghazvininejad, Mike Lewis, Luke Zettlemoyer.
+
+The model architecture and pretraining objective is same as BART, but MBart is trained on 25 languages and is intended
+for supervised and unsupervised machine translation. MBart is one of the first methods for pretraining a complete
+sequence-to-sequence model by denoising full texts in multiple languages,
+
+The library provides a version of this model for conditional generation.
+
+The [mbart-large-en-ro checkpoint](https://huggingface.co/facebook/mbart-large-en-ro) can be used for english ->
+romanian translation.
+
+The [mbart-large-cc25](https://huggingface.co/facebook/mbart-large-cc25) checkpoint can be finetuned for other
+translation and summarization tasks, using code in ```examples/pytorch/translation/``` , but is not very useful without
+finetuning.
+
+
+### ProphetNet
+
+
+
+
+[ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training,](https://arxiv.org/abs/2001.04063) by
+Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang, Ming Zhou.
+
+ProphetNet introduces a novel *sequence-to-sequence* pretraining objective, called *future n-gram prediction*. In
+future n-gram prediction, the model predicts the next n tokens simultaneously based on previous context tokens at each
+time step instead instead of just the single next token. The future n-gram prediction explicitly encourages the model
+to plan for the future tokens and prevent overfitting on strong local correlations. The model architecture is based on
+the original Transformer, but replaces the "standard" self-attention mechanism in the decoder by a a main
+self-attention mechanism and a self and n-stream (predict) self-attention mechanism.
+
+The library provides a pre-trained version of this model for conditional generation and a fine-tuned version for
+summarization.
+
+### XLM-ProphetNet
+
+
+
+
+[ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training,](https://arxiv.org/abs/2001.04063) by
+Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang, Ming Zhou.
+
+XLM-ProphetNet's model architecture and pretraining objective is same as ProphetNet, but XLM-ProphetNet was pre-trained
+on the cross-lingual dataset [XGLUE](https://arxiv.org/abs/2004.01401).
+
+The library provides a pre-trained version of this model for multi-lingual conditional generation and fine-tuned
+versions for headline generation and question generation, respectively.
+
+
+
+## Multimodal models
+
+There is one multimodal model in the library which has not been pretrained in the self-supervised fashion like the
+others.
+
+### MMBT
+
+[Supervised Multimodal Bitransformers for Classifying Images and Text](https://arxiv.org/abs/1909.02950), Douwe Kiela
+et al.
+
+A transformers model used in multimodal settings, combining a text and an image to make predictions. The transformer
+model takes as inputs the embeddings of the tokenized text and the final activations of a pretrained on images resnet
+(after the pooling layer) that goes through a linear layer (to go from number of features at the end of the resnet to
+the hidden state dimension of the transformer).
+
+The different inputs are concatenated, and on top of the positional embeddings, a segment embedding is added to let the
+model know which part of the input vector corresponds to the text and which to the image.
+
+The pretrained model only works for classification.
+
+
+
+
+
+## Retrieval-based models
+
+Some models use documents retrieval during (pre)training and inference for open-domain question answering, for example.
+
+
+### DPR
+
+
+
+
+[Dense Passage Retrieval for Open-Domain Question Answering](https://arxiv.org/abs/2004.04906), Vladimir Karpukhin et
+al.
+
+Dense Passage Retrieval (DPR) - is a set of tools and models for state-of-the-art open-domain question-answering
+research.
+
+
+DPR consists in three models:
+
+- Question encoder: encode questions as vectors
+- Context encoder: encode contexts as vectors
+- Reader: extract the answer of the questions inside retrieved contexts, along with a relevance score (high if the
+ inferred span actually answers the question).
+
+DPR's pipeline (not implemented yet) uses a retrieval step to find the top k contexts given a certain question, and
+then it calls the reader with the question and the retrieved documents to get the answer.
+
+### RAG
+
+
+
+[Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks](https://arxiv.org/abs/2005.11401), Patrick Lewis,
+Ethan Perez, Aleksandara Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau
+Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela
+
+Retrieval-augmented generation ("RAG") models combine the powers of pretrained dense retrieval (DPR) and Seq2Seq
+models. RAG models retrieve docs, pass them to a seq2seq model, then marginalize to generate outputs. The retriever and
+seq2seq modules are initialized from pretrained models, and fine-tuned jointly, allowing both retrieval and generation
+to adapt to downstream tasks.
+
+The two models RAG-Token and RAG-Sequence are available for generation.
+
+## More technical aspects
+
+### Full vs sparse attention
+
+Most transformer models use full attention in the sense that the attention matrix is square. It can be a big
+computational bottleneck when you have long texts. Longformer and reformer are models that try to be more efficient and
+use a sparse version of the attention matrix to speed up training.
+
+
+
+**LSH attention**
+
+[Reformer](#reformer) uses LSH attention. In the softmax(QK^t), only the biggest elements (in the softmax
+dimension) of the matrix QK^t are going to give useful contributions. So for each query q in Q, we can consider only
+the keys k in K that are close to q. A hash function is used to determine if q and k are close. The attention mask is
+modified to mask the current token (except at the first position), because it will give a query and a key equal (so
+very similar to each other). Since the hash can be a bit random, several hash functions are used in practice
+(determined by a n_rounds parameter) and then are averaged together.
+
+
+
+**Local attention**
+
+[Longformer](#longformer) uses local attention: often, the local context (e.g., what are the two tokens to the
+left and right?) is enough to take action for a given token. Also, by stacking attention layers that have a small
+window, the last layer will have a receptive field of more than just the tokens in the window, allowing them to build a
+representation of the whole sentence.
+
+Some preselected input tokens are also given global attention: for those few tokens, the attention matrix can access
+all tokens and this process is symmetric: all other tokens have access to those specific tokens (on top of the ones in
+their local window). This is shown in Figure 2d of the paper, see below for a sample attention mask:
+
+ +
+Using those attention matrices with less parameters then allows the model to have inputs having a bigger sequence
+length.
+
+### Other tricks
+
+
+
+**Axial positional encodings**
+
+[Reformer](#reformer) uses axial positional encodings: in traditional transformer models, the positional encoding
+E is a matrix of size \\(l\\) by \\(d\\), \\(l\\) being the sequence length and \\(d\\) the dimension of the
+hidden state. If you have very long texts, this matrix can be huge and take way too much space on the GPU. To alleviate
+that, axial positional encodings consist of factorizing that big matrix E in two smaller matrices E1 and E2, with
+dimensions \\(l_{1} \times d_{1}\\) and \\(l_{2} \times d_{2}\\), such that \\(l_{1} \times l_{2} = l\\) and
+\\(d_{1} + d_{2} = d\\) (with the product for the lengths, this ends up being way smaller). The embedding for time
+step \\(j\\) in E is obtained by concatenating the embeddings for timestep \\(j \% l1\\) in E1 and \\(j // l1\\)
+in E2.
diff --git a/docs/source/en/multilingual.mdx b/docs/source/en/multilingual.mdx
new file mode 100644
index 00000000000000..7c95de6ffc0909
--- /dev/null
+++ b/docs/source/en/multilingual.mdx
@@ -0,0 +1,175 @@
+
+
+# Multilingual models for inference
+
+[[open-in-colab]]
+
+There are several multilingual models in 🤗 Transformers, and their inference usage differs from monolingual models. Not *all* multilingual model usage is different though. Some models, like [bert-base-multilingual-uncased](https://huggingface.co/bert-base-multilingual-uncased), can be used just like a monolingual model. This guide will show you how to use multilingual models whose usage differs for inference.
+
+## XLM
+
+XLM has ten different checkpoints, only one of which is monolingual. The nine remaining model checkpoints can be split into two categories: the checkpoints that use language embeddings and those that don't.
+
+### XLM with language embeddings
+
+The following XLM models use language embeddings to specify the language used at inference:
+
+- `xlm-mlm-ende-1024` (Masked language modeling, English-German)
+- `xlm-mlm-enfr-1024` (Masked language modeling, English-French)
+- `xlm-mlm-enro-1024` (Masked language modeling, English-Romanian)
+- `xlm-mlm-xnli15-1024` (Masked language modeling, XNLI languages)
+- `xlm-mlm-tlm-xnli15-1024` (Masked language modeling + translation, XNLI languages)
+- `xlm-clm-enfr-1024` (Causal language modeling, English-French)
+- `xlm-clm-ende-1024` (Causal language modeling, English-German)
+
+Language embeddings are represented as a tensor of the same shape as the `input_ids` passed to the model. The values in these tensors depend on the language used and are identified by the tokenizer's `lang2id` and `id2lang` attributes.
+
+In this example, load the `xlm-clm-enfr-1024` checkpoint (Causal language modeling, English-French):
+
+```py
+>>> import torch
+>>> from transformers import XLMTokenizer, XLMWithLMHeadModel
+
+>>> tokenizer = XLMTokenizer.from_pretrained("xlm-clm-enfr-1024")
+>>> model = XLMWithLMHeadModel.from_pretrained("xlm-clm-enfr-1024")
+```
+
+The `lang2id` attribute of the tokenizer displays this model's languages and their ids:
+
+```py
+>>> print(tokenizer.lang2id)
+{'en': 0, 'fr': 1}
+```
+
+Next, create an example input:
+
+```py
+>>> input_ids = torch.tensor([tokenizer.encode("Wikipedia was used to")]) # batch size of 1
+```
+
+Set the language id as `"en"` and use it to define the language embedding. The language embedding is a tensor filled with `0` since that is the language id for English. This tensor should be the same size as `input_ids`.
+
+```py
+>>> language_id = tokenizer.lang2id["en"] # 0
+>>> langs = torch.tensor([language_id] * input_ids.shape[1]) # torch.tensor([0, 0, 0, ..., 0])
+
+>>> # We reshape it to be of size (batch_size, sequence_length)
+>>> langs = langs.view(1, -1) # is now of shape [1, sequence_length] (we have a batch size of 1)
+```
+
+Now you can pass the `input_ids` and language embedding to the model:
+
+```py
+>>> outputs = model(input_ids, langs=langs)
+```
+
+The [run_generation.py](https://github.com/huggingface/transformers/tree/main/examples/pytorch/text-generation/run_generation.py) script can generate text with language embeddings using the `xlm-clm` checkpoints.
+
+### XLM without language embeddings
+
+The following XLM models do not require language embeddings during inference:
+
+- `xlm-mlm-17-1280` (Masked language modeling, 17 languages)
+- `xlm-mlm-100-1280` (Masked language modeling, 100 languages)
+
+These models are used for generic sentence representations, unlike the previous XLM checkpoints.
+
+## BERT
+
+The following BERT models can be used for multilingual tasks:
+
+- `bert-base-multilingual-uncased` (Masked language modeling + Next sentence prediction, 102 languages)
+- `bert-base-multilingual-cased` (Masked language modeling + Next sentence prediction, 104 languages)
+
+These models do not require language embeddings during inference. They should identify the language from the
+context and infer accordingly.
+
+## XLM-RoBERTa
+
+The following XLM-RoBERTa models can be used for multilingual tasks:
+
+- `xlm-roberta-base` (Masked language modeling, 100 languages)
+- `xlm-roberta-large` (Masked language modeling, 100 languages)
+
+XLM-RoBERTa was trained on 2.5TB of newly created and cleaned CommonCrawl data in 100 languages. It provides strong gains over previously released multilingual models like mBERT or XLM on downstream tasks like classification, sequence labeling, and question answering.
+
+## M2M100
+
+The following M2M100 models can be used for multilingual translation:
+
+- `facebook/m2m100_418M` (Translation)
+- `facebook/m2m100_1.2B` (Translation)
+
+In this example, load the `facebook/m2m100_418M` checkpoint to translate from Chinese to English. You can set the source language in the tokenizer:
+
+```py
+>>> from transformers import M2M100ForConditionalGeneration, M2M100Tokenizer
+
+>>> en_text = "Do not meddle in the affairs of wizards, for they are subtle and quick to anger."
+>>> chinese_text = "不要插手巫師的事務, 因為他們是微妙的, 很快就會發怒."
+
+>>> tokenizer = M2M100Tokenizer.from_pretrained("facebook/m2m100_418M", src_lang="zh")
+>>> model = M2M100ForConditionalGeneration.from_pretrained("facebook/m2m100_418M")
+```
+
+Tokenize the text:
+
+```py
+>>> encoded_zh = tokenizer(chinese_text, return_tensors="pt")
+```
+
+M2M100 forces the target language id as the first generated token to translate to the target language. Set the `forced_bos_token_id` to `en` in the `generate` method to translate to English:
+
+```py
+>>> generated_tokens = model.generate(**encoded_zh, forced_bos_token_id=tokenizer.get_lang_id("en"))
+>>> tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
+'Do not interfere with the matters of the witches, because they are delicate and will soon be angry.'
+```
+
+## MBart
+
+The following MBart models can be used for multilingual translation:
+
+- `facebook/mbart-large-50-one-to-many-mmt` (One-to-many multilingual machine translation, 50 languages)
+- `facebook/mbart-large-50-many-to-many-mmt` (Many-to-many multilingual machine translation, 50 languages)
+- `facebook/mbart-large-50-many-to-one-mmt` (Many-to-one multilingual machine translation, 50 languages)
+- `facebook/mbart-large-50` (Multilingual translation, 50 languages)
+- `facebook/mbart-large-cc25`
+
+In this example, load the `facebook/mbart-large-50-many-to-many-mmt` checkpoint to translate Finnish to English. You can set the source language in the tokenizer:
+
+```py
+>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
+
+>>> en_text = "Do not meddle in the affairs of wizards, for they are subtle and quick to anger."
+>>> fi_text = "Älä sekaannu velhojen asioihin, sillä ne ovat hienovaraisia ja nopeasti vihaisia."
+
+>>> tokenizer = AutoTokenizer.from_pretrained("facebook/mbart-large-50-many-to-many-mmt", src_lang="fi_FI")
+>>> model = AutoModelForSeq2SeqLM.from_pretrained("facebook/mbart-large-50-many-to-many-mmt")
+```
+
+Tokenize the text:
+
+```py
+>>> encoded_en = tokenizer(en_text, return_tensors="pt")
+```
+
+MBart forces the target language id as the first generated token to translate to the target language. Set the `forced_bos_token_id` to `en` in the `generate` method to translate to English:
+
+```py
+>>> generated_tokens = model.generate(**encoded_en, forced_bos_token_id=tokenizer.lang_code_to_id("en_XX"))
+>>> tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
+"Don't interfere with the wizard's affairs, because they are subtle, will soon get angry."
+```
+
+If you are using the `facebook/mbart-large-50-many-to-one-mmt` checkpoint, you don't need to force the target language id as the first generated token otherwise the usage is the same.
\ No newline at end of file
diff --git a/docs/source/en/notebooks.md b/docs/source/en/notebooks.md
new file mode 120000
index 00000000000000..10fb7a7b979ad8
--- /dev/null
+++ b/docs/source/en/notebooks.md
@@ -0,0 +1 @@
+../../../notebooks/README.md
\ No newline at end of file
diff --git a/docs/source/en/pad_truncation.mdx b/docs/source/en/pad_truncation.mdx
new file mode 100644
index 00000000000000..f848e23bed502e
--- /dev/null
+++ b/docs/source/en/pad_truncation.mdx
@@ -0,0 +1,66 @@
+
+
+# Padding and truncation
+
+Batched inputs are often different lengths, so they can't be converted to fixed-size tensors. Padding and truncation are strategies for dealing with this problem, to create rectangular tensors from batches of varying lengths. Padding adds a special **padding token** to ensure shorter sequences will have the same length as either the longest sequence in a batch or the maximum length accepted by the model. Truncation works in the other direction by truncating long sequences.
+
+In most cases, padding your batch to the length of the longest sequence and truncating to the maximum length a model can accept works pretty well. However, the API supports more strategies if you need them. The three arguments you need to are: `padding`, `truncation` and `max_length`.
+
+The `padding` argument controls padding. It can be a boolean or a string:
+
+ - `True` or `'longest'`: pad to the longest sequence in the batch (no padding is applied if you only provide
+ a single sequence).
+ - `'max_length'`: pad to a length specified by the `max_length` argument or the maximum length accepted
+ by the model if no `max_length` is provided (`max_length=None`). Padding will still be applied if you only provide a single sequence.
+ - `False` or `'do_not_pad'`: no padding is applied. This is the default behavior.
+
+The `truncation` argument controls truncation. It can be a boolean or a string:
+
+ - `True` or `'longest_first'`: truncate to a maximum length specified by the `max_length` argument or
+ the maximum length accepted by the model if no `max_length` is provided (`max_length=None`). This will
+ truncate token by token, removing a token from the longest sequence in the pair until the proper length is
+ reached.
+ - `'only_second'`: truncate to a maximum length specified by the `max_length` argument or the maximum
+ length accepted by the model if no `max_length` is provided (`max_length=None`). This will only truncate
+ the second sentence of a pair if a pair of sequences (or a batch of pairs of sequences) is provided.
+ - `'only_first'`: truncate to a maximum length specified by the `max_length` argument or the maximum
+ length accepted by the model if no `max_length` is provided (`max_length=None`). This will only truncate
+ the first sentence of a pair if a pair of sequences (or a batch of pairs of sequences) is provided.
+ - `False` or `'do_not_truncate'`: no truncation is applied. This is the default behavior.
+
+The `max_length` argument controls the length of the padding and truncation. It can be an integer or `None`, in which case it will default to the maximum length the model can accept. If the model has no specific maximum input length, truncation or padding to `max_length` is deactivated.
+
+The following table summarizes the recommended way to setup padding and truncation. If you use pairs of input sequences in any of the following examples, you can replace `truncation=True` by a `STRATEGY` selected in
+`['only_first', 'only_second', 'longest_first']`, i.e. `truncation='only_second'` or `truncation='longest_first'` to control how both sequences in the pair are truncated as detailed before.
+
+| Truncation | Padding | Instruction |
+|--------------------------------------|-----------------------------------|---------------------------------------------------------------------------------------------|
+| no truncation | no padding | `tokenizer(batch_sentences)` |
+| | padding to max sequence in batch | `tokenizer(batch_sentences, padding=True)` or |
+| | | `tokenizer(batch_sentences, padding='longest')` |
+| | padding to max model input length | `tokenizer(batch_sentences, padding='max_length')` |
+| | padding to specific length | `tokenizer(batch_sentences, padding='max_length', max_length=42)` |
+| truncation to max model input length | no padding | `tokenizer(batch_sentences, truncation=True)` or |
+| | | `tokenizer(batch_sentences, truncation=STRATEGY)` |
+| | padding to max sequence in batch | `tokenizer(batch_sentences, padding=True, truncation=True)` or |
+| | | `tokenizer(batch_sentences, padding=True, truncation=STRATEGY)` |
+| | padding to max model input length | `tokenizer(batch_sentences, padding='max_length', truncation=True)` or |
+| | | `tokenizer(batch_sentences, padding='max_length', truncation=STRATEGY)` |
+| | padding to specific length | Not possible |
+| truncation to specific length | no padding | `tokenizer(batch_sentences, truncation=True, max_length=42)` or |
+| | | `tokenizer(batch_sentences, truncation=STRATEGY, max_length=42)` |
+| | padding to max sequence in batch | `tokenizer(batch_sentences, padding=True, truncation=True, max_length=42)` or |
+| | | `tokenizer(batch_sentences, padding=True, truncation=STRATEGY, max_length=42)` |
+| | padding to max model input length | Not possible |
+| | padding to specific length | `tokenizer(batch_sentences, padding='max_length', truncation=True, max_length=42)` or |
+| | | `tokenizer(batch_sentences, padding='max_length', truncation=STRATEGY, max_length=42)` |
diff --git a/docs/source/en/parallelism.mdx b/docs/source/en/parallelism.mdx
new file mode 100644
index 00000000000000..f13d85ac7372c1
--- /dev/null
+++ b/docs/source/en/parallelism.mdx
@@ -0,0 +1,413 @@
+
+
+# Model Parallelism
+
+
+## Parallelism overview
+
+In the modern machine learning the various approaches to parallelism are used to:
+1. fit very large models onto limited hardware - e.g. t5-11b is 45GB in just model params
+2. significantly speed up training - finish training that would take a year in hours
+
+We will first discuss in depth various 1D parallelism techniques and their pros and cons and then look at how they can be combined into 2D and 3D parallelism to enable an even faster training and to support even bigger models. Various other powerful alternative approaches will be presented.
+
+While the main concepts most likely will apply to any other framework, this article is focused on PyTorch-based implementations.
+
+
+## Concepts
+
+The following is the brief description of the main concepts that will be described later in depth in this document.
+
+1. DataParallel (DP) - the same setup is replicated multiple times, and each being fed a slice of the data. The processing is done in parallel and all setups are synchronized at the end of each training step.
+2. TensorParallel (TP) - each tensor is split up into multiple chunks, so instead of having the whole tensor reside on a single gpu, each shard of the tensor resides on its designated gpu. During processing each shard gets processed separately and in parallel on different GPUs and the results are synced at the end of the step. This is what one may call horizontal parallelism, as the splitting happens on horizontal level.
+3. PipelineParallel (PP) - the model is split up vertically (layer-level) across multiple GPUs, so that only one or several layers of the model are places on a single gpu. Each gpu processes in parallel different stages of the pipeline and working on a small chunk of the batch.
+4. Zero Redundancy Optimizer (ZeRO) - Also performs sharding of the tensors somewhat similar to TP, except the whole tensor gets reconstructed in time for a forward or backward computation, therefore the model doesn't need to be modified. It also supports various offloading techniques to compensate for limited GPU memory.
+5. Sharded DDP - is another name for the foundational ZeRO concept as used by various other implementations of ZeRO.
+
+
+## Data Parallelism
+
+Most users with just 2 GPUs already enjoy the increased training speed up thanks to `DataParallel` (DP) and `DistributedDataParallel` (DDP) that are almost trivial to use. This is a built-in feature of Pytorch.
+
+## ZeRO Data Parallelism
+
+ZeRO-powered data parallelism (ZeRO-DP) is described on the following diagram from this [blog post](https://www.microsoft.com/en-us/research/blog/zero-deepspeed-new-system-optimizations-enable-training-models-with-over-100-billion-parameters/)
+
+
+It can be difficult to wrap one's head around it, but in reality the concept is quite simple. This is just the usual `DataParallel` (DP), except, instead of replicating the full model params, gradients and optimizer states, each GPU stores only a slice of it. And then at run-time when the full layer params are needed just for the given layer, all GPUs synchronize to give each other parts that they miss - this is it.
+
+Consider this simple model with 3 layers, where each layer has 3 params:
+```
+La | Lb | Lc
+---|----|---
+a0 | b0 | c0
+a1 | b1 | c1
+a2 | b2 | c2
+```
+Layer La has weights a0, a1 and a2.
+
+If we have 3 GPUs, the Sharded DDP (= Zero-DP) splits the model onto 3 GPUs like so:
+
+```
+GPU0:
+La | Lb | Lc
+---|----|---
+a0 | b0 | c0
+
+GPU1:
+La | Lb | Lc
+---|----|---
+a1 | b1 | c1
+
+GPU2:
+La | Lb | Lc
+---|----|---
+a2 | b2 | c2
+```
+
+In a way this is the same horizontal slicing, as tensor parallelism, if you imagine the typical DNN diagram. Vertical slicing is where one puts whole layer-groups on different GPUs. But it's just the starting point.
+
+Now each of these GPUs will get the usual mini-batch as it works in DP:
+```
+x0 => GPU0
+x1 => GPU1
+x2 => GPU2
+```
+
+The inputs are unmodified - they think they are going to be processed by the normal model.
+
+First, the inputs hit the layer La.
+
+Let's focus just on GPU0: x0 needs a0, a1, a2 params to do its forward path, but GPU0 has only a0 - it gets sent a1 from GPU1 and a2 from GPU2, bringing all pieces of the model together.
+
+In parallel, GPU1 gets mini-batch x1 and it only has a1, but needs a0 and a2 params, so it gets those from GPU0 and GPU2.
+
+Same happens to GPU2 that gets input x2. It gets a0 and a1 from GPU0 and GPU1, and with its a2 it reconstructs the full tensor.
+
+All 3 GPUs get the full tensors reconstructed and a forward happens.
+
+As soon as the calculation is done, the data that is no longer needed gets dropped - it's only used during the calculation. The reconstruction is done efficiently via a pre-fetch.
+
+And the whole process is repeated for layer Lb, then Lc forward-wise, and then backward Lc -> Lb -> La.
+
+To me this sounds like an efficient group backpacking weight distribution strategy:
+
+1. person A carries the tent
+2. person B carries the stove
+3. person C carries the axe
+
+Now each night they all share what they have with others and get from others what they don't have, and in the morning they pack up their allocated type of gear and continue on their way. This is Sharded DDP / Zero DP.
+
+Compare this strategy to the simple one where each person has to carry their own tent, stove and axe, which would be far more inefficient. This is DataParallel (DP and DDP) in Pytorch.
+
+While reading the literature on this topic you may encounter the following synonyms: Sharded, Partitioned.
+
+If you pay close attention the way ZeRO partitions the model's weights - it looks very similar to tensor parallelism which will be discussed later. This is because it partitions/shards each layer's weights, unlike vertical model parallelism which is discussed next.
+
+Implementations:
+
+- [DeepSpeed](https://www.deepspeed.ai/features/#the-zero-redundancy-optimizer) ZeRO-DP stages 1+2+3
+- [Fairscale](https://github.com/facebookresearch/fairscale/#optimizer-state-sharding-zero) ZeRO-DP stages 1+2+3
+- [`transformers` integration](main_classes/trainer#trainer-integrations)
+
+## Naive Model Parallelism (Vertical) and Pipeline Parallelism
+
+Naive Model Parallelism (MP) is where one spreads groups of model layers across multiple GPUs. The mechanism is relatively simple - switch the desired layers `.to()` the desired devices and now whenever the data goes in and out those layers switch the data to the same device as the layer and leave the rest unmodified.
+
+We refer to it as Vertical MP, because if you remember how most models are drawn, we slice the layers vertically. For example, if the following diagram shows an 8-layer model:
+
+```
+=================== ===================
+| 0 | 1 | 2 | 3 | | 4 | 5 | 6 | 7 |
+=================== ===================
+ gpu0 gpu1
+```
+we just sliced it in 2 vertically, placing layers 0-3 onto GPU0 and 4-7 to GPU1.
+
+Now while data travels from layer 0 to 1, 1 to 2 and 2 to 3 this is just the normal model. But when data needs to pass from layer 3 to layer 4 it needs to travel from GPU0 to GPU1 which introduces a communication overhead. If the participating GPUs are on the same compute node (e.g. same physical machine) this copying is pretty fast, but if the GPUs are located on different compute nodes (e.g. multiple machines) the communication overhead could be significantly larger.
+
+Then layers 4 to 5 to 6 to 7 are as a normal model would have and when the 7th layer completes we often need to send the data back to layer 0 where the labels are (or alternatively send the labels to the last layer). Now the loss can be computed and the optimizer can do its work.
+
+Problems:
+- the main deficiency and why this one is called "naive" MP, is that all but one GPU is idle at any given moment. So if 4 GPUs are used, it's almost identical to quadrupling the amount of memory of a single GPU, and ignoring the rest of the hardware. Plus there is the overhead of copying the data between devices. So 4x 6GB cards will be able to accommodate the same size as 1x 24GB card using naive MP, except the latter will complete the training faster, since it doesn't have the data copying overhead. But, say, if you have 40GB cards and need to fit a 45GB model you can with 4x 40GB cards (but barely because of the gradient and optimizer states)
+- shared embeddings may need to get copied back and forth between GPUs.
+
+Pipeline Parallelism (PP) is almost identical to a naive MP, but it solves the GPU idling problem, by chunking the incoming batch into micro-batches and artificially creating a pipeline, which allows different GPUs to concurrently participate in the computation process.
+
+The following illustration from the [GPipe paper](https://ai.googleblog.com/2019/03/introducing-gpipe-open-source-library.html) shows the naive MP on the top, and PP on the bottom:
+
+
+
+It's easy to see from the bottom diagram how PP has less dead zones, where GPUs are idle. The idle parts are referred to as the "bubble".
+
+Both parts of the diagram show a parallelism that is of degree 4. That is 4 GPUs are participating in the pipeline. So there is the forward path of 4 pipe stages F0, F1, F2 and F3 and then the return reverse order backward path of B3, B2, B1 and B0.
+
+PP introduces a new hyper-parameter to tune and it's `chunks` which defines how many chunks of data are sent in a sequence through the same pipe stage. For example, in the bottomw diagram you can see that `chunks=4`. GPU0 performs the same forward path on chunk 0, 1, 2 and 3 (F0,0, F0,1, F0,2, F0,3) and then it waits for other GPUs to do their work and only when their work is starting to be complete, GPU0 starts to work again doing the backward path for chunks 3, 2, 1 and 0 (B0,3, B0,2, B0,1, B0,0).
+
+Note that conceptually this is the same concept as gradient accumulation steps (GAS). Pytorch uses `chunks`, whereas DeepSpeed refers to the same hyper-parameter as GAS.
+
+Because of the chunks, PP introduces the concept of micro-batches (MBS). DP splits the global data batch size into mini-batches, so if you have a DP degree of 4, a global batch size of 1024 gets split up into 4 mini-batches of 256 each (1024/4). And if the number of `chunks` (or GAS) is 32 we end up with a micro-batch size of 8 (256/32). Each Pipeline stage works with a single micro-batch at a time.
+
+To calculate the global batch size of the DP + PP setup we then do: `mbs*chunks*dp_degree` (`8*32*4=1024`).
+
+Let's go back to the diagram.
+
+With `chunks=1` you end up with the naive MP, which is very inefficient. With a very large `chunks` value you end up with tiny micro-batch sizes which could be not every efficient either. So one has to experiment to find the value that leads to the highest efficient utilization of the gpus.
+
+While the diagram shows that there is a bubble of "dead" time that can't be parallelized because the last `forward` stage has to wait for `backward` to complete the pipeline, the purpose of finding the best value for `chunks` is to enable a high concurrent GPU utilization across all participating GPUs which translates to minimizing the size of the bubble.
+
+There are 2 groups of solutions - the traditional Pipeline API and the more modern solutions that make things much easier for the end user.
+
+Traditional Pipeline API solutions:
+- PyTorch
+- FairScale
+- DeepSpeed
+- Megatron-LM
+
+Modern solutions:
+- Varuna
+- Sagemaker
+
+Problems with traditional Pipeline API solutions:
+- have to modify the model quite heavily, because Pipeline requires one to rewrite the normal flow of modules into a `nn.Sequential` sequence of the same, which may require changes to the design of the model.
+- currently the Pipeline API is very restricted. If you had a bunch of python variables being passed in the very first stage of the Pipeline, you will have to find a way around it. Currently, the pipeline interface requires either a single Tensor or a tuple of Tensors as the only input and output. These tensors must have a batch size as the very first dimension, since pipeline is going to chunk the mini batch into micro-batches. Possible improvements are being discussed here https://github.com/pytorch/pytorch/pull/50693
+- conditional control flow at the level of pipe stages is not possible - e.g., Encoder-Decoder models like T5 require special workarounds to handle a conditional encoder stage.
+- have to arrange each layer so that the output of one model becomes an input to the other model.
+
+We are yet to experiment with Varuna and SageMaker but their papers report that they have overcome the list of problems mentioned above and that they require much smaller changes to the user's model.
+
+Implementations:
+- [Pytorch](https://pytorch.org/docs/stable/pipeline.html) (initial support in pytorch-1.8, and progressively getting improved in 1.9 and more so in 1.10). Some [examples](https://github.com/pytorch/pytorch/blob/master/benchmarks/distributed/pipeline/pipe.py)
+- [FairScale](https://fairscale.readthedocs.io/en/latest/tutorials/pipe.html)
+- [DeepSpeed](https://www.deepspeed.ai/tutorials/pipeline/)
+- [Megatron-LM](https://github.com/NVIDIA/Megatron-LM) has an internal implementation - no API.
+- [Varuna](https://github.com/microsoft/varuna)
+- [SageMaker](https://arxiv.org/abs/2111.05972) - this is a proprietary solution that can only be used on AWS.
+- [OSLO](https://github.com/tunib-ai/oslo) - this is implemented based on the Hugging Face Transformers.
+
+🤗 Transformers status: as of this writing none of the models supports full-PP. GPT2 and T5 models have naive MP support. The main obstacle is being unable to convert the models to `nn.Sequential` and have all the inputs to be Tensors. This is because currently the models include many features that make the conversion very complicated, and will need to be removed to accomplish that.
+
+Other approaches:
+
+DeepSpeed, Varuna and SageMaker use the concept of an [Interleaved Pipeline](https://docs.aws.amazon.com/sagemaker/latest/dg/model-parallel-core-features.html)
+
+
+Here the bubble (idle time) is further minimized by prioritizing backward passes.
+
+Varuna further tries to improve the schedule by using simulations to discover the most efficient scheduling.
+
+OSLO has pipeline parallelism implementation based on the Transformers without `nn.Sequential` converting.
+
+## Tensor Parallelism
+
+In Tensor Parallelism each GPU processes only a slice of a tensor and only aggregates the full tensor for operations that require the whole thing.
+
+In this section we use concepts and diagrams from the [Megatron-LM](https://github.com/NVIDIA/Megatron-LM) paper: [Efficient Large-Scale Language Model Training on GPU Clusters](https://arxiv.org/abs/2104.04473).
+
+The main building block of any transformer is a fully connected `nn.Linear` followed by a nonlinear activation `GeLU`.
+
+Following the Megatron's paper notation, we can write the dot-product part of it as `Y = GeLU(XA)`, where `X` and `Y` are the input and output vectors, and `A` is the weight matrix.
+
+If we look at the computation in matrix form, it's easy to see how the matrix multiplication can be split between multiple GPUs:
+
+
+If we split the weight matrix `A` column-wise across `N` GPUs and perform matrix multiplications `XA_1` through `XA_n` in parallel, then we will end up with `N` output vectors `Y_1, Y_2, ..., Y_n` which can be fed into `GeLU` independently:
+
+
+Using this principle, we can update an MLP of arbitrary depth, without the need for any synchronization between GPUs until the very end, where we need to reconstruct the output vector from shards. The Megatron-LM paper authors provide a helpful illustration for that:
+
+
+Parallelizing the multi-headed attention layers is even simpler, since they are already inherently parallel, due to having multiple independent heads!
+
+
+Special considerations: TP requires very fast network, and therefore it's not advisable to do TP across more than one node. Practically, if a node has 4 GPUs, the highest TP degree is therefore 4. If you need a TP degree of 8, you need to use nodes that have at least 8 GPUs.
+
+This section is based on the original much more [detailed TP overview](https://github.com/huggingface/transformers/issues/10321#issuecomment-783543530).
+by [@anton-l](https://github.com/anton-l).
+
+SageMaker combines TP with DP for a more efficient processing.
+
+Alternative names:
+- DeepSpeed calls it [tensor slicing](https://www.deepspeed.ai/features/#model-parallelism)
+
+Implementations:
+- [Megatron-LM](https://github.com/NVIDIA/Megatron-LM) has an internal implementation, as it's very model-specific
+- [parallelformers](https://github.com/tunib-ai/parallelformers) (only inference at the moment)
+- [SageMaker](https://arxiv.org/abs/2111.05972) - this is a proprietary solution that can only be used on AWS.
+- [OSLO](https://github.com/tunib-ai/oslo) has the tensor parallelism implementation based on the Transformers.
+
+🤗 Transformers status:
+- core: not yet implemented in the core
+- but if you want inference [parallelformers](https://github.com/tunib-ai/parallelformers) provides this support for most of our models. So until this is implemented in the core you can use theirs. And hopefully training mode will be supported too.
+- Deepspeed-Inference also supports our BERT, GPT-2, and GPT-Neo models in their super-fast CUDA-kernel-based inference mode, see more [here](https://www.deepspeed.ai/tutorials/inference-tutorial/)
+
+## DP+PP
+
+The following diagram from the DeepSpeed [pipeline tutorial](https://www.deepspeed.ai/tutorials/pipeline/) demonstrates how one combines DP with PP.
+
+
+
+Here it's important to see how DP rank 0 doesn't see GPU2 and DP rank 1 doesn't see GPU3. To DP there is just GPUs 0 and 1 where it feeds data as if there were just 2 GPUs. GPU0 "secretly" offloads some of its load to GPU2 using PP. And GPU1 does the same by enlisting GPU3 to its aid.
+
+Since each dimension requires at least 2 GPUs, here you'd need at least 4 GPUs.
+
+Implementations:
+- [DeepSpeed](https://github.com/microsoft/DeepSpeed)
+- [Megatron-LM](https://github.com/NVIDIA/Megatron-LM)
+- [Varuna](https://github.com/microsoft/varuna)
+- [SageMaker](https://arxiv.org/abs/2111.05972)
+- [OSLO](https://github.com/tunib-ai/oslo)
+
+🤗 Transformers status: not yet implemented
+
+## DP+PP+TP
+
+To get an even more efficient training a 3D parallelism is used where PP is combined with TP and DP. This can be seen in the following diagram.
+
+
+
+This diagram is from a blog post [3D parallelism: Scaling to trillion-parameter models](https://www.microsoft.com/en-us/research/blog/deepspeed-extreme-scale-model-training-for-everyone/), which is a good read as well.
+
+Since each dimension requires at least 2 GPUs, here you'd need at least 8 GPUs.
+
+Implementations:
+- [DeepSpeed](https://github.com/microsoft/DeepSpeed) - DeepSpeed also includes an even more efficient DP, which they call ZeRO-DP.
+- [Megatron-LM](https://github.com/NVIDIA/Megatron-LM)
+- [Varuna](https://github.com/microsoft/varuna)
+- [SageMaker](https://arxiv.org/abs/2111.05972)
+- [OSLO](https://github.com/tunib-ai/oslo)
+
+🤗 Transformers status: not yet implemented, since we have no PP and TP.
+
+## ZeRO DP+PP+TP
+
+One of the main features of DeepSpeed is ZeRO, which is a super-scalable extension of DP. It has already been discussed in [ZeRO Data Parallelism](#zero-data-parallelism). Normally it's a standalone feature that doesn't require PP or TP. But it can be combined with PP and TP.
+
+When ZeRO-DP is combined with PP (and optionally TP) it typically enables only ZeRO stage 1 (optimizer sharding).
+
+While it's theoretically possible to use ZeRO stage 2 (gradient sharding) with Pipeline Parallelism, it will have bad performance impacts. There would need to be an additional reduce-scatter collective for every micro-batch to aggregate the gradients before sharding, which adds a potentially significant communication overhead. By nature of Pipeline Parallelism, small micro-batches are used and instead the focus is on trying to balance arithmetic intensity (micro-batch size) with minimizing the Pipeline bubble (number of micro-batches). Therefore those communication costs are going to hurt.
+
+In addition, There are already fewer layers than normal due to PP and so the memory savings won't be huge. PP already reduces gradient size by ``1/PP``, and so gradient sharding savings on top of that are less significant than pure DP.
+
+ZeRO stage 3 is not a good choice either for the same reason - more inter-node communications required.
+
+And since we have ZeRO, the other benefit is ZeRO-Offload. Since this is stage 1 optimizer states can be offloaded to CPU.
+
+Implementations:
+- [Megatron-DeepSpeed](https://github.com/microsoft/Megatron-DeepSpeed) and [Megatron-Deepspeed from BigScience](https://github.com/bigscience-workshop/Megatron-DeepSpeed), which is the fork of the former repo.
+- [OSLO](https://github.com/tunib-ai/oslo)
+
+Important papers:
+
+- [Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, A Large-Scale Generative Language Model](
+https://arxiv.org/abs/2201.11990)
+
+🤗 Transformers status: not yet implemented, since we have no PP and TP.
+
+## FlexFlow
+
+[FlexFlow](https://github.com/flexflow/FlexFlow) also solves the parallelization problem in a slightly different approach.
+
+Paper: ["Beyond Data and Model Parallelism for Deep Neural Networks" by Zhihao Jia, Matei Zaharia, Alex Aiken](https://arxiv.org/abs/1807.05358)
+
+It performs a sort of 4D Parallelism over Sample-Operator-Attribute-Parameter.
+
+1. Sample = Data Parallelism (sample-wise parallel)
+2. Operator = Parallelize a single operation into several sub-operations
+3. Attribute = Data Parallelism (length-wise parallel)
+4. Parameter = Model Parallelism (regardless of dimension - horizontal or vertical)
+
+Examples:
+* Sample
+
+Let's take 10 batches of sequence length 512. If we parallelize them by sample dimension into 2 devices, we get 10 x 512 which becomes be 5 x 2 x 512.
+
+* Operator
+
+If we perform layer normalization, we compute std first and mean second, and then we can normalize data. Operator parallelism allows computing std and mean in parallel. So if we parallelize them by operator dimension into 2 devices (cuda:0, cuda:1), first we copy input data into both devices, and cuda:0 computes std, cuda:1 computes mean at the same time.
+
+* Attribute
+
+We have 10 batches of 512 length. If we parallelize them by attribute dimension into 2 devices, 10 x 512 will be 10 x 2 x 256.
+
+* Parameter
+
+It is similar with tensor model parallelism or naive layer-wise model parallelism.
+
+
+
+The significance of this framework is that it takes resources like (1) GPU/TPU/CPU vs. (2) RAM/DRAM vs. (3) fast-intra-connect/slow-inter-connect and it automatically optimizes all these algorithmically deciding which parallelisation to use where.
+
+One very important aspect is that FlexFlow is designed for optimizing DNN parallelizations for models with static and fixed workloads, since models with dynamic behavior may prefer different parallelization strategies across iterations.
+
+So the promise is very attractive - it runs a 30min simulation on the cluster of choice and it comes up with the best strategy to utilise this specific environment. If you add/remove/replace any parts it'll run and re-optimize the plan for that. And then you can train. A different setup will have its own custom optimization.
+
+🤗 Transformers status: not yet integrated. We already have our models FX-trace-able via [transformers.utils.fx](https://github.com/huggingface/transformers/blob/main/src/transformers/utils/fx.py), which is a prerequisite for FlexFlow, so someone needs to figure out what needs to be done to make FlexFlow work with our models.
+
+
+## Which Strategy To Use When
+
+Here is a very rough outline at which parallelism strategy to use when. The first on each list is typically faster.
+
+**⇨ Single GPU**
+
+* Model fits onto a single GPU:
+
+ 1. Normal use
+
+* Model doesn't fit onto a single GPU:
+
+ 1. ZeRO + Offload CPU and optionally NVMe
+ 2. as above plus Memory Centric Tiling (see below for details) if the largest layer can't fit into a single GPU
+
+* Largest Layer not fitting into a single GPU:
+
+1. ZeRO - Enable [Memory Centric Tiling](https://deepspeed.readthedocs.io/en/latest/zero3.html#memory-centric-tiling) (MCT). It allows you to run arbitrarily large layers by automatically splitting them and executing them sequentially. MCT reduces the number of parameters that are live on a GPU, but it does not affect the activation memory. As this need is very rare as of this writing a manual override of `torch.nn.Linear` needs to be done by the user.
+
+**⇨ Single Node / Multi-GPU**
+
+* Model fits onto a single GPU:
+
+ 1. DDP - Distributed DP
+ 2. ZeRO - may or may not be faster depending on the situation and configuration used
+
+* Model doesn't fit onto a single GPU:
+
+ 1. PP
+ 2. ZeRO
+ 3. TP
+
+ With very fast intra-node connectivity of NVLINK or NVSwitch all three should be mostly on par, without these PP will be faster than TP or ZeRO. The degree of TP may also make a difference. Best to experiment to find the winner on your particular setup.
+
+ TP is almost always used within a single node. That is TP size <= gpus per node.
+
+* Largest Layer not fitting into a single GPU:
+
+ 1. If not using ZeRO - must use TP, as PP alone won't be able to fit.
+ 2. With ZeRO see the same entry for "Single GPU" above
+
+
+**⇨ Multi-Node / Multi-GPU**
+
+* When you have fast inter-node connectivity:
+
+ 1. ZeRO - as it requires close to no modifications to the model
+ 2. PP+TP+DP - less communications, but requires massive changes to the model
+
+* when you have slow inter-node connectivity and still low on GPU memory:
+
+ 1. DP+PP+TP+ZeRO-1
diff --git a/docs/source/en/performance.mdx b/docs/source/en/performance.mdx
new file mode 100644
index 00000000000000..0656a644517bc0
--- /dev/null
+++ b/docs/source/en/performance.mdx
@@ -0,0 +1,1092 @@
+
+
+# Performance and Scalability: How To Fit a Bigger Model and Train It Faster
+
+> _Or how to escape the dreaded "RuntimeError: CUDA error: out of memory" error._
+
+[[open-in-colab]]
+
+Training ever larger models can become challenging even on modern GPUs. Due to their immense size we often run out of GPU memory and training can take very long. In this section we have a look at a few tricks to reduce the memory footprint and speed up training for large models and how they are integrated in the [`Trainer`] and [🤗 Accelerate](https://huggingface.co/docs/accelerate/). Before we start make sure you have installed the following libraries:
+
+```bash
+pip install transformers datasets accelerate nvidia-ml-py3
+```
+
+The `nvidia-ml-py3` library allows us to monitor the memory usage of the models from within Python. You might be familiar with the `nvidia-smi` command in the terminal - this library allows to access the same information in Python directly.
+
+Then we create some dummy data. We create random token IDs between 100 and 30000 and binary labels for a classifier. In total we get 512 sequences each with length 512 and store them in a [`Dataset`](https://huggingface.co/docs/datasets/package_reference/main_classes.html?highlight=dataset#datasets.Dataset) with PyTorch format.
+
+
+```py
+import numpy as np
+from datasets import Dataset
+
+
+seq_len, dataset_size = 512, 512
+dummy_data = {
+ "input_ids": np.random.randint(100, 30000, (dataset_size, seq_len)),
+ "labels": np.random.randint(0, 1, (dataset_size)),
+}
+ds = Dataset.from_dict(dummy_data)
+ds.set_format("pt")
+```
+
+We want to print some summary statistics for the GPU utilization and the training run with the [`Trainer`]. We setup a two helper functions to do just that:
+
+```py
+from pynvml import *
+
+
+def print_gpu_utilization():
+ nvmlInit()
+ handle = nvmlDeviceGetHandleByIndex(0)
+ info = nvmlDeviceGetMemoryInfo(handle)
+ print(f"GPU memory occupied: {info.used//1024**2} MB.")
+
+
+def print_summary(result):
+ print(f"Time: {result.metrics['train_runtime']:.2f}")
+ print(f"Samples/second: {result.metrics['train_samples_per_second']:.2f}")
+ print_gpu_utilization()
+```
+
+Let's verify that we start with a free GPU memory:
+
+```py
+>>> print_gpu_utilization()
+GPU memory occupied: 0 MB.
+```
+
+That looks good: the GPU memory is not occupied as we would expect before we load any models. If that's not the case on your machine make sure to stop all processes that are using GPU memory. However, not all free GPU memory can be used by the user. When a model is loaded to the GPU also the kernels are loaded which can take up 1-2GB of memory. To see how much it is we load a tiny tensor into the GPU which triggers the kernels to be loaded as well.
+
+```py
+>>> import torch
+
+
+>>> torch.ones((1, 1)).to("cuda")
+>>> print_gpu_utilization()
+GPU memory occupied: 1343 MB.
+```
+
+We see that the kernels alone take up 1.3GB of GPU memory. Now let's see how much space the model uses.
+
+## Load Model
+
+First, we load the `bert-large-uncased` model. We load the model weights directly to the GPU so that we can check how much space just weights use.
+
+
+```py
+>>> from transformers import AutoModelForSequenceClassification
+
+
+>>> model = AutoModelForSequenceClassification.from_pretrained("bert-large-uncased").to("cuda")
+>>> print_gpu_utilization()
+GPU memory occupied: 2631 MB.
+```
+
+We can see that the model weights alone take up 1.3 GB of the GPU memory. The exact number depends on the specific GPU you are using. Note that on newer GPUs a model can sometimes take up more space since the weights are loaded in an optimized fashion that speeds up the usage of the model. Now we can also quickly check if we get the same result as with `nvidia-smi` CLI:
+
+
+```bash
+nvidia-smi
+```
+
+```bash
+Tue Jan 11 08:58:05 2022
++-----------------------------------------------------------------------------+
+| NVIDIA-SMI 460.91.03 Driver Version: 460.91.03 CUDA Version: 11.2 |
+|-------------------------------+----------------------+----------------------+
+| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
+| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
+| | | MIG M. |
+|===============================+======================+======================|
+| 0 Tesla V100-SXM2... On | 00000000:00:04.0 Off | 0 |
+| N/A 37C P0 39W / 300W | 2631MiB / 16160MiB | 0% Default |
+| | | N/A |
++-------------------------------+----------------------+----------------------+
+
++-----------------------------------------------------------------------------+
+| Processes: |
+| GPU GI CI PID Type Process name GPU Memory |
+| ID ID Usage |
+|=============================================================================|
+| 0 N/A N/A 3721 C ...nvs/codeparrot/bin/python 2629MiB |
++-----------------------------------------------------------------------------+
+```
+
+We get the same number as before and you can also see that we are using a V100 GPU with 16GB of memory. So now we can start training the model and see how the GPU memory consumption changes. First, we set up a few standard training arguments that we will use across all our experiments:
+
+```py
+default_args = {
+ "output_dir": "tmp",
+ "evaluation_strategy": "steps",
+ "num_train_epochs": 1,
+ "log_level": "error",
+ "report_to": "none",
+}
+```
+
+
+
+ Note: In order to properly clear the memory after experiments we need restart the Python kernel between experiments. Run all steps above and then just one of the experiments below.
+
+
+
+## Vanilla Training
+
+As a first experiment we will use the [`Trainer`] and train the model without any further modifications and a batch size of 4:
+
+```py
+from transformers import TrainingArguments, Trainer, logging
+
+logging.set_verbosity_error()
+
+
+training_args = TrainingArguments(per_device_train_batch_size=4, **default_args)
+trainer = Trainer(model=model, args=training_args, train_dataset=ds)
+result = trainer.train()
+print_summary(result)
+```
+
+```
+Time: 57.82
+Samples/second: 8.86
+GPU memory occupied: 14949 MB.
+```
+
+We see that already a relatively small batch size almost fills up our GPU's entire memory. However, a larger batch size can often result in faster model convergence or better end performance. So ideally we want to tune the batch size to our model's needs and not to the GPU limitations. A simple trick to effectively train larger batch size is gradient accumulation.
+
+## Gradient Accumulation
+
+The idea behind gradient accumulation is to instead of calculating the gradients for the whole batch at once to do it in smaller steps. The way we do that is to calculate the gradients iteratively in smaller batches by doing a forward and backward pass through the model and accumulating the gradients in the process. When enough gradients are accumulated we run the model's optimization step. This way we can easily increase the overall batch size to numbers that would never fit into the GPU's memory. In turn, however, the added forward and backward passes can slow down the training a bit.
+
+We can use gradient accumulation in the [`Trainer`] by simply adding the `gradient_accumulation_steps` argument to [`TrainingArguments`]. Let's see how it impacts the models memory footprint:
+
+```py
+training_args = TrainingArguments(per_device_train_batch_size=1, gradient_accumulation_steps=4, **default_args)
+
+trainer = Trainer(model=model, args=training_args, train_dataset=ds)
+result = trainer.train()
+print_summary(result)
+```
+
+```
+Time: 66.03
+Samples/second: 7.75
+GPU memory occupied: 8681 MB.
+```
+
+We can see that the memory footprint was dramatically reduced at the cost of being only slightly slower than the vanilla run. Of course, this would change as you increase the number of accumulation steps. In general you would want to max out the GPU usage as much as possible. So in our case, the batch_size of 4 was already pretty close to the GPU's limit. If we wanted to train with a batch size of 64 we should not use `per_device_train_batch_size=1` and `gradient_accumulation_steps=64` but instead `per_device_train_batch_size=4` and `gradient_accumulation_steps=16` which has the same effective batch size while making better use of the available GPU resources.
+
+Next we have a look at another trick to save a little bit more GPU memory called gradient checkpointing.
+
+## Gradient Checkpointing
+
+Even when we set the batch size to 1 and use gradient accumulation we can still run out of memory when working with large models. In order to compute the gradients during the backward pass all activations from the forward pass are normally saved. This can create a big memory overhead. Alternatively, one could forget all activations during the forward pass and recompute them on demand during the backward pass. This would however add a significant computational overhead and slow down training.
+
+Gradient checkpointing strikes a compromise between the two approaches and saves strategically selected activations throughout the computational graph so only a fraction of the activations need to be re-computed for the gradients. See [this great article](https://medium.com/tensorflow/fitting-larger-networks-into-memory-583e3c758ff9) explaining the ideas behind gradient checkpointing.
+
+To enable gradient checkpointing in the [`Trainer`] we only need ot pass it as a flag to the [`TrainingArguments`]. Everything else is handled under the hood:
+
+```py
+training_args = TrainingArguments(
+ per_device_train_batch_size=1, gradient_accumulation_steps=4, gradient_checkpointing=True, **default_args
+)
+
+trainer = Trainer(model=model, args=training_args, train_dataset=ds)
+result = trainer.train()
+print_summary(result)
+```
+
+```
+Time: 85.47
+Samples/second: 5.99
+GPU memory occupied: 6775 MB.
+```
+
+We can see that this saved some more memory but at the same time training became a bit slower. A general rule of thumb is that gradient checkpointing slows down training by about 20%. Let's have a look at another method with which we can regain some speed: mixed precision training.
+
+## FP16 Training
+
+The idea of mixed precision training is that no all variables need to be stored in full (32-bit) floating point precision. If we can reduce the precision the variales and their computations are faster. The main advantage comes from saving the activations in half (16-bit) precision. Although the gradients are also computed in half precision they are converted back to full precision for the optimization step so no memory is saved here. Since the model is present on the GPU in both 16-bit and 32-bit precision this can use more GPU memory (1.5x the original model is on the GPU), especially for small batch sizes. Since some computations are performed in full and some in half precision this approach is also called mixed precision training. Enabling mixed precision training is also just a matter of setting the `fp16` flag to `True`:
+
+```py
+training_args = TrainingArguments(per_device_train_batch_size=4, fp16=True, **default_args)
+
+trainer = Trainer(model=model, args=training_args, train_dataset=ds)
+result = trainer.train()
+print_summary(result)
+```
+
+```
+Time: 27.46
+Samples/second: 18.64
+GPU memory occupied: 13939 MB.
+```
+
+We can see that this is almost twice as fast as the vanilla training. Let's add it to the mix of the previous methods:
+
+
+```py
+training_args = TrainingArguments(
+ per_device_train_batch_size=1,
+ gradient_accumulation_steps=4,
+ gradient_checkpointing=True,
+ fp16=True,
+ **default_args,
+)
+
+trainer = Trainer(model=model, args=training_args, train_dataset=ds)
+result = trainer.train()
+print_summary(result)
+```
+
+```
+Time: 50.76
+Samples/second: 10.09
+GPU memory occupied: 7275 MB.
+```
+
+We can see that with these tweaks we use about half the GPU memory as at the beginning while also being slightly faster. But we are not done, yet! There is another area where we can save GPU memory: the optimizer.
+
+## Optimizer
+
+The most common optimizer used to train transformer model is Adam or AdamW (Adam with weight decay). Adam achieves good convergence by storing the rolling average of the previous gradients which, however, adds an additional memory footprint of the order of the number of model parameters. One remedy to this is to use an alternative optimizer such as Adafactor.
+
+### Adafactor
+
+Instead of keeping the rolling average for each element in the weight matrices Adafactor only stores aggregated information (row- and column-wise sums of the rolling averages) which reduces the footprint considerably. One downside of Adafactor is that in some instances convergence can be slower than Adam's so some experimentation is advised here. We can use Adafactor simply by setting `optim="adafactor"`:
+
+
+```py
+training_args = TrainingArguments(per_device_train_batch_size=4, optim="adafactor", **default_args)
+
+trainer = Trainer(model=model, args=training_args, train_dataset=ds)
+result = trainer.train()
+print_summary(result)
+```
+
+```
+Time: 64.31
+Samples/second: 7.96
+GPU memory occupied: 12295 MB.
+```
+
+We can see that this saves a few more GB on the GPU. Let's see how it looks when we add it to the other methods we introduced earlier:
+
+
+```py
+training_args = TrainingArguments(
+ per_device_train_batch_size=1,
+ gradient_accumulation_steps=4,
+ gradient_checkpointing=True,
+ fp16=True,
+ optim="adafactor",
+ **default_args,
+)
+
+trainer = Trainer(model=model, args=training_args, train_dataset=ds)
+result = trainer.train()
+print_summary(result)
+```
+
+```
+Time: 56.54
+Samples/second: 9.06
+GPU memory occupied: 4847 MB.
+```
+
+We went from 15 GB memory usage to 5 GB - a 3x improvement while maintaining the throughput! However, as mentioned before, the convergence of Adafactor can be worse than Adam. There is an alternative to Adafactor called 8-bit Adam that takes a slightly different approach.
+
+### 8-bit Adam
+
+Instead of aggregating optimizer states like Adafactor, 8-bit Adam keeps the full state and quantizes it. Quantization means that it stores the state with lower precision and dequantizes it only for the optimization. This is similar to the idea behind FP16 training where using variables with lower precision saves memory.
+
+In contrast to the previous approaches is this one not integrated into the [`Trainer`] as a simple flag. We need to install the 8-bit optimizer and then pass it as a custom optimizer to the [`Trainer`]. Follow the installation guide in the Github [repo](https://github.com/facebookresearch/bitsandbytes) to install the `bitsandbytes` library that implements the 8-bit Adam optimizer.
+
+Once installed, we just need to initialize the the optimizer. Although this looks like a considerable amount of work it actually just involves two steps: first we need to group the model's parameters into two groups where to one group we apply weight decay and to the other we don't. Usually, biases and layer norm parameters are not weight decayed. Then in a second step we just do some argument housekeeping to use the same parameters as the previously used AdamW optimizer.
+
+
+Note that in order to use the 8-bit optimizer with an existing pretrained model a change to the embedding layer is needed.
+Read [this issue](https://github.com/huggingface/transformers/issues/14819) for more information.
+
+
+```py
+import bitsandbytes as bnb
+from torch import nn
+from transformers.trainer_pt_utils import get_parameter_names
+
+training_args = TrainingArguments(per_device_train_batch_size=4, **default_args)
+
+decay_parameters = get_parameter_names(model, [nn.LayerNorm])
+decay_parameters = [name for name in decay_parameters if "bias" not in name]
+optimizer_grouped_parameters = [
+ {
+ "params": [p for n, p in model.named_parameters() if n in decay_parameters],
+ "weight_decay": training_args.weight_decay,
+ },
+ {
+ "params": [p for n, p in model.named_parameters() if n not in decay_parameters],
+ "weight_decay": 0.0,
+ },
+]
+
+optimizer_kwargs = {
+ "betas": (training_args.adam_beta1, training_args.adam_beta2),
+ "eps": training_args.adam_epsilon,
+}
+optimizer_kwargs["lr"] = training_args.learning_rate
+adam_bnb_optim = bnb.optim.Adam8bit(
+ optimizer_grouped_parameters,
+ betas=(training_args.adam_beta1, training_args.adam_beta2),
+ eps=training_args.adam_epsilon,
+ lr=training_args.learning_rate,
+)
+```
+
+We can now pass the custom optimizer as an argument to the `Trainer`:
+```py
+trainer = Trainer(model=model, args=training_args, train_dataset=ds, optimizers=(adam_bnb_optim, None))
+result = trainer.train()
+print_summary(result)
+```
+
+```
+Time: 55.95
+Samples/second: 9.15
+GPU memory occupied: 13085 MB.
+```
+
+We can see that we get a similar memory improvement as with Adafactor while keeping the full rolling average of the gradients. Let's repeat the experiment with the full settings:
+
+```py
+training_args = TrainingArguments(
+ per_device_train_batch_size=1,
+ gradient_accumulation_steps=4,
+ gradient_checkpointing=True,
+ fp16=True,
+ **default_args,
+)
+
+trainer = Trainer(model=model, args=training_args, train_dataset=ds, optimizers=(adam_bnb_optim, None))
+result = trainer.train()
+print_summary(result)
+```
+
+```
+Time: 49.46
+Samples/second: 10.35
+GPU memory occupied: 5363 MB.
+```
+
+Again, we get about a 3x memory improvement and even slightly higher throughput as using Adafactor. So we have seen how we can optimize the memory footprint of large models. The following plot summarizes all our experiments:
+
+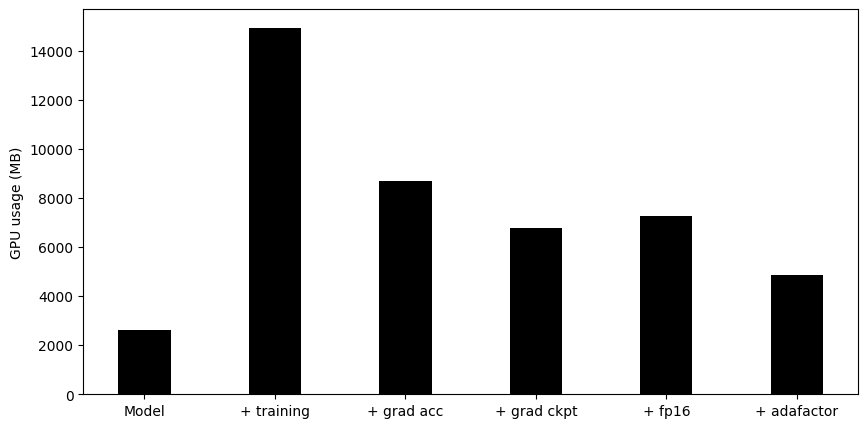
+
+## Using 🤗 Accelerate
+
+So far we have used the [`Trainer`] to run the experiments but a more flexible alternative to that approach is to use 🤗 Accelerate. With 🤗 Accelerate you have full control over the training loop and can essentially write the loop in pure PyTorch with some minor modifications. In turn it allows you to easily scale across different infrastructures such as CPUs, GPUs, TPUs, or distributed multi-GPU setups without changing any code. Let's see what it takes to implement all of the above tweaks in 🤗 Accelerate. We can still use the [`TrainingArguments`] to wrap the training settings:
+
+
+```py
+training_args = TrainingArguments(
+ per_device_train_batch_size=1,
+ gradient_accumulation_steps=4,
+ gradient_checkpointing=True,
+ fp16=True,
+ **default_args,
+)
+```
+
+The full example training loop with 🤗 Accelerate is only a handful of lines of code long:
+
+
+```py
+from accelerate import Accelerator
+from torch.utils.data.dataloader import DataLoader
+
+dataloader = DataLoader(ds, batch_size=training_args.per_device_train_batch_size)
+
+if training_args.gradient_checkpointing:
+ model.gradient_checkpointing_enable()
+
+accelerator = Accelerator(fp16=training_args.fp16)
+model, optimizer, dataloader = accelerator.prepare(model, adam_bnb_optim, dataloader)
+
+model.train()
+for step, batch in enumerate(dataloader, start=1):
+ loss = model(**batch).loss
+ loss = loss / training_args.gradient_accumulation_steps
+ accelerator.backward(loss)
+ if step % training_args.gradient_accumulation_steps == 0:
+ optimizer.step()
+ optimizer.zero_grad()
+```
+
+First we wrap the dataset in a [`DataLoader`](https://pytorch.org/docs/stable/data.html#torch.utils.data.DataLoader). Then we can enable gradient checkpointing by calling the model's [`~PreTrainedModel.gradient_checkpointing_enable`] method. When we initialize the [`Accelerator`](https://huggingface.co/docs/accelerate/accelerator.html#accelerate.Accelerator) we can specifiy if we want to use mixed precision training and it will take care of it for us in the [`prepare`] call. During the [`prepare`](https://huggingface.co/docs/accelerate/accelerator.html#accelerate.Accelerator.prepare) call the dataloader will also be distributed across workers should we use multiple GPUs. We use the same 8-bit optimizer from the earlier experiments.
+
+Finally, we can write the main training loop. Note that the `backward` call is handled by 🤗 Accelerate. We can also see how gradient accumulation works: we normalize the loss so we get the average at the end of accumulation and once we have enough steps we run the optimization. Now the question is: does this use the same amount of memory as the previous steps? Let's check:
+
+
+```py
+>>> print_gpu_utilization()
+GPU memory occupied: 5363 MB.
+```
+
+
+Indeed it does. Implementing these optimization techniques with 🤗 Accelerate only takes a handful of lines of code and comes with the benefit of more flexiblity in the training loop.
+
+Now, let's take a step back and discuss what we should optimize for when scaling the training of large models.
+
+## How to scale
+
+When we train models there are a two aspects we want to optimize at the same time:
+
+- Data throughput/training time
+- Model performance
+
+We have seen that each method changes the memory usage and throughput. In general we want to maximize the throughput (samples/second) to minimize the training cost. This is generally achieved by utilizing the GPU as much as possible and thus filling GPU memory to its limit. For example, as mentioned earlier, we only employ gradient accumulation when we want to use a batch size beyond the size of the GPU memory. If the desired batch size fits into memory then there is no reason to apply gradient accumulation which will only slow down training.
+
+The second objective is model performance. Just because we can does not mean we should use a large batch size. As part of hyperparameter tuning you should determine which batch size yields the best result and then optimize the throughput accordingly.
+
+Sometimes, even when applying all the above tweaks the throughput on a given GPU might still not be good enough. One easy solution is to change the type of GPU. For example switching from let's say a K80 (which you typically get on Google Colab) to a fancier GPU such as the V100 or A100. Although they are more expensive they are usually more cost effective than cheaper GPUs due to their larger memory and faster architecture. For some applications, such as pretraining, this might still not be fast enough. In this case you want to scale your experiment to several GPUs.
+
+## Multi-GPU Training
+
+If your model fits on a single GPU scaling to many GPUs can be achieved fairly easily with data parallelism. The idea is very similar to gradient accumulation with the distinction that instead of running the forward and backward passes during the accumulation in sequence on a single machine they are performed in parallel on multiple machines. So each GPU gets a small batch, runs the forward and backward passes and then the gradients from all machines are aggregated and the model is optimized. You can combine this with all the methods we described before. For example, if you have 4 GPUs and use `per_device_train_batch_size=12` and `gradient_accumulation_steps=3` you will have an effective batch size of `4*12*3=144`.
+
+The [`Trainer`] allows for distributed training and if you execute your [`Trainer`] training script on a machine with multiple GPUs it will automatically utilize all of them, hence the name `per_device_train_batch_size`. In 🤗 Accelerate you can configure the infrastructure setup with the following command:
+
+```bash
+accelerate config
+```
+
+Until now we have opperated under the assumption that we can fit the model onto a single GPU without or with the introduced tricks . But what if this is not possible? We still have a few tricks up our sleeves!
+
+## What if my model still does not fit?
+
+If the model does not fit on a single GPU with all the mentioned tricks there are still more methods we can apply although life starts to get a bit more complicated. This usually involves some form of pipeline or tensor parallelism where the model itself is distributed across several GPUs. One can also make use of DeepSpeed which implements some of these parallelism strategies along with some more optimization to reduce the memory footprint such as partitioning the optimizer states. You can read more about this in the ["Model Parallelism" section](parallelism).
+
+This concludes the practical part of this guide for scaling the training of large models. The following section goes into more details on some of the aspects discussed above.
+
+
+## Further discussions
+
+This section gives brief ideas on how to make training faster and support bigger models. Later sections will expand, demonstrate and elucidate each of these.
+
+## Faster Training
+
+Hardware:
+
+- fast connectivity between GPUs
+ * intra-node: NVLink
+ * inter-node: Infiniband / Intel OPA
+
+Software:
+
+- Data Parallel / Distributed Data Parallel
+- fp16 (autocast caching)
+
+
+## Bigger Models
+
+Hardware:
+
+- bigger GPUs
+- more GPUs
+- more CPU and NVMe (offloaded to by [DeepSpeed-Infinity](main_classes/deepspeed#nvme-support))
+
+Software:
+
+- Model Scalability (ZeRO and 3D Parallelism)
+- Low-memory Optimizers
+- fp16/bf16 (smaller data/faster throughput)
+- tf32 (faster throughput)
+- Gradient accumulation
+- Gradient checkpointing
+- Sparsity
+
+
+## Hardware
+
+
+### Power and Cooling
+
+If you bought an expensive high end GPU make sure you give it the correct power and sufficient cooling.
+
+**Power**:
+
+Some high end consumer GPU cards have 2 and sometimes 3 PCI-E 8-Pin power sockets. Make sure you have as many independent 12V PCI-E 8-Pin cables plugged into the card as there are sockets. Do not use the 2 splits at one end of the same cable (also known as pigtail cable). That is if you have 2 sockets on the GPU, you want 2 PCI-E 8-Pin cables going from your PSU to the card and not one that has 2 PCI-E 8-Pin connectors at the end! You won't get the full performance out of your card otherwise.
+
+Each PCI-E 8-Pin power cable needs to be plugged into a 12V rail on the PSU side and can supply up to 150W of power.
+
+Some other cards may use a PCI-E 12-Pin connectors, and these can deliver up to 500-600W of power.
+
+Low end cards may use 6-Pin connectors, which supply up to 75W of power.
+
+Additionally you want the high-end PSU that has stable voltage. Some lower quality ones may not give the card the stable voltage it needs to function at its peak.
+
+And of course the PSU needs to have enough unused Watts to power the card.
+
+**Cooling**:
+
+When a GPU gets overheated it would start throttling down and will not deliver full performance. And it will shutdown if it gets too hot.
+
+It's hard to tell the exact best temperature to strive for when a GPU is heavily loaded, but probably anything under +80C is good, but lower is better - perhaps 70-75C is an excellent range to be in. The throttling down is likely to start at around 84-90C. But other than throttling performance a prolonged very higher temperature is likely to reduce the lifespan of a GPU.
+
+
+
+### Multi-GPU Connectivity
+
+If you use multiple GPUs the way cards are inter-connected can have a huge impact on the total training time.
+
+If the GPUs are on the same physical node, you can run:
+
+```
+nvidia-smi topo -m
+```
+
+and it will tell you how the GPUs are inter-connected.
+
+On a machine with dual-GPU and which are connected with NVLink, you will most likely see something like:
+
+```
+ GPU0 GPU1 CPU Affinity NUMA Affinity
+GPU0 X NV2 0-23 N/A
+GPU1 NV2 X 0-23 N/A
+```
+
+on a different machine w/o NVLink we may see:
+```
+ GPU0 GPU1 CPU Affinity NUMA Affinity
+GPU0 X PHB 0-11 N/A
+GPU1 PHB X 0-11 N/A
+```
+
+The report includes this legend:
+
+```
+ X = Self
+ SYS = Connection traversing PCIe as well as the SMP interconnect between NUMA nodes (e.g., QPI/UPI)
+ NODE = Connection traversing PCIe as well as the interconnect between PCIe Host Bridges within a NUMA node
+ PHB = Connection traversing PCIe as well as a PCIe Host Bridge (typically the CPU)
+ PXB = Connection traversing multiple PCIe bridges (without traversing the PCIe Host Bridge)
+ PIX = Connection traversing at most a single PCIe bridge
+ NV# = Connection traversing a bonded set of # NVLinks
+```
+
+So the first report `NV2` tells us the GPUs are interconnected with 2 NVLinks, and the second report `PHB` we have a typical consumer-level PCIe+Bridge setup.
+
+Check what type of connectivity you have on your setup. Some of these will make the communication between cards faster (e.g. NVLink), others slower (e.g. PHB).
+
+Depending on the type of scalability solution used, the connectivity speed could have a major or a minor impact. If the GPUs need to sync rarely, as in DDP, the impact of a slower connection will be less significant. If the GPUs need to send messages to each other often, as in ZeRO-DP, then faster connectivity becomes super important to achieve faster training.
+
+### NVlink
+
+[NVLink](https://en.wikipedia.org/wiki/NVLink) is a wire-based serial multi-lane near-range communications link developed by Nvidia.
+
+Each new generation provides a faster bandwidth, e.g. here is a quote from [Nvidia Ampere GA102 GPU Architecture](https://www.nvidia.com/content/dam/en-zz/Solutions/geforce/ampere/pdf/NVIDIA-ampere-GA102-GPU-Architecture-Whitepaper-V1.pdf):
+
+> Third-Generation NVLink®
+> GA102 GPUs utilize NVIDIA’s third-generation NVLink interface, which includes four x4 links,
+> with each link providing 14.0625 GB/sec bandwidth in each direction between two GPUs. Four
+> links provide 56.25 GB/sec bandwidth in each direction, and 112.5 GB/sec total bandwidth
+> between two GPUs. Two RTX 3090 GPUs can be connected together for SLI using NVLink.
+> (Note that 3-Way and 4-Way SLI configurations are not supported.)
+
+So the higher `X` you get in the report of `NVX` in the output of `nvidia-smi topo -m` the better. The generation will depend on your GPU architecture.
+
+Let's compare the execution of a gpt2 language model training over a small sample of wikitext.
+
+The results are:
+
+
+| NVlink | Time |
+| ----- | ---: |
+| Y | 101s |
+| N | 131s |
+
+
+You can see that NVLink completes the training ~23% faster.
+
+In the second benchmark we use `NCCL_P2P_DISABLE=1` to tell the GPUs not to use NVLink.
+
+Here is the full benchmark code and outputs:
+
+```
+# DDP w/ NVLink
+
+rm -r /tmp/test-clm; CUDA_VISIBLE_DEVICES=0,1 python -m torch.distributed.launch \
+--nproc_per_node 2 examples/pytorch/language-modeling/run_clm.py --model_name_or_path gpt2 \
+--dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 --do_train \
+--output_dir /tmp/test-clm --per_device_train_batch_size 4 --max_steps 200
+
+{'train_runtime': 101.9003, 'train_samples_per_second': 1.963, 'epoch': 0.69}
+
+# DDP w/o NVLink
+
+rm -r /tmp/test-clm; CUDA_VISIBLE_DEVICES=0,1 NCCL_P2P_DISABLE=1 python -m torch.distributed.launch \
+--nproc_per_node 2 examples/pytorch/language-modeling/run_clm.py --model_name_or_path gpt2 \
+--dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 --do_train
+--output_dir /tmp/test-clm --per_device_train_batch_size 4 --max_steps 200
+
+{'train_runtime': 131.4367, 'train_samples_per_second': 1.522, 'epoch': 0.69}
+```
+
+Hardware: 2x TITAN RTX 24GB each + NVlink with 2 NVLinks (`NV2` in `nvidia-smi topo -m`)
+Software: `pytorch-1.8-to-be` + `cuda-11.0` / `transformers==4.3.0.dev0`
+
+## Software
+
+
+### Model Scalability
+
+When you can't fit a model into the available GPU memory, you need to start using a solution that allows you to scale a large model to use multiple GPUs in parallel.
+
+For indepth details on ZeRO and various other model parallelism protocols please see: [Model Parallelism](parallelism)
+
+
+
+### Anatomy of Model's Operations
+
+Transformers architecture includes 3 main groups of operations grouped below by compute-intensity.
+
+1. **Tensor Contractions**
+
+ Linear layers and components of Multi-Head Attention all do batched **matrix-matrix multiplications**. These operations are the most compute-intensive part of training a transformer.
+
+2. **Statistical Normalizations**
+
+ Softmax and layer normalization are less compute-intensive than tensor contractions, and involve one or more **reduction operations**, the result of which is then applied via a map.
+
+3. **Element-wise Operators**
+
+ These are the remaining operators: **biases, dropout, activations, and residual connections**. These are the least compute-intensive operations.
+
+This knowledge can be helpful to know when analyzing performance bottlenecks.
+
+This summary is derived from [Data Movement Is All You Need: A Case Study on Optimizing Transformers 2020](https://arxiv.org/abs/2007.00072)
+
+
+
+### Anatomy of Model's Memory
+
+The components on GPU memory are the following:
+1. model weights
+2. optimizer states
+3. gradients
+4. forward activations saved for gradient computation
+5. temporary buffers
+6. functionality-specific memory
+
+A typical model trained in mixed precision with AdamW requires 18 bytes per model parameter plus activation memory.
+
+For inference there are no optimizer states and gradients, so we can subtract those. And thus we end up with 6 bytes per model parameter for mixed precision inference, plus activation memory.
+
+Let's look at the details.
+
+#### Model Weights
+
+- 4 bytes * number of parameters for fp32 training
+- 6 bytes * number of parameters for mixed precision training
+
+#### Optimizer States
+
+- 8 bytes * number of parameters for normal AdamW (maintains 2 states)
+- 2 bytes * number of parameters for 8-bit AdamW optimizers like [bitsandbytes](https://github.com/facebookresearch/bitsandbytes)
+- 4 bytes * number of parameters for optimizers like SGD (maintains only 1 state)
+
+#### Gradients
+
+- 4 bytes * number of parameters for either fp32 or mixed precision training
+
+#### Forward Activations
+
+- size depends on many factors, the key ones being sequence length, hidden size and batch size.
+
+There are the input and output that are being passed and returned by the forward and the backward functions and the forward activations saved for gradient computation.
+
+#### Temporary Memory
+
+Additionally there are all kinds of temporary variables which get released once the calculation is done, but in the moment these could require additional memory and could push to OOM. Therefore when coding it's crucial to think strategically about such temporary variables and sometimes to explicitly free those as soon as they are no longer needed.
+
+#### Functionality-specific memory
+
+Then your software could have special memory needs. For example, when generating text using beam search, the software needs to maintain multiple copies of inputs and outputs.
+
+
+
+### `forward` vs `backward` Execution Speed
+
+For convolutions and linear layers there are 2x flops in the backward compared to the forward, which generally translates into ~2x slower (sometimes more, because sizes in the backward tend to be more awkward). Activations are usually bandwidth-limited, and it’s typical for an activation to have to read more data in the backward than in the forward (e.g. activation forward reads once, writes once, activation backward reads twice, gradOutput and output of the forward, and writes once, gradInput).
+
+
+### Floating Data Types
+
+Here are the commonly used floating point data types choice of which impacts both memory usage and throughput:
+
+- fp32 (`float32`)
+- fp16 (`float16`)
+- bf16 (`bfloat16`)
+- tf32 (CUDA internal data type)
+
+Here is a diagram that shows how these data types correlate to each other.
+
+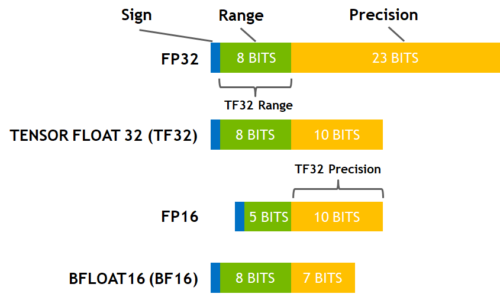
+
+(source: [NVIDIA Blog](https://developer.nvidia.com/blog/accelerating-ai-training-with-tf32-tensor-cores/))
+
+While fp16 and fp32 have been around for quite some time, bf16 and tf32 are only available on the Ampere architecture GPUS. TPUs support bf16 as well.
+
+
+#### fp16
+
+AMP = Automatic Mixed Precision
+
+If we look at what's happening with FP16 training (mixed precision) we have:
+- the model has two copies in memory: one in half-precision for the forward/backward computations and one in full precision - no memory saved here
+- the forward activations saved for gradient computation are in half-precision - memory is saved here
+- the gradients are computed in half-precision *but* converted to full-precision for the update, no saving there
+- the optimizer states are in full precision as all the updates are done in full-precision
+
+So the savings only happen for the forward activations saved for the backward computation, and there is a slight overhead because the model weights are stored both in half- and full-precision.
+
+In 🤗 Transformers fp16 mixed precision is enabled by passing `--fp16` to the 🤗 Trainer.
+
+Now let's look at a simple text-classification fine-tuning on 2 GPUs (I'm giving the command for reference):
+```
+export BS=16
+python -m torch.distributed.launch \
+ --nproc_per_node 2 examples/pytorch/text-classification/run_glue.py \
+ --model_name_or_path bert-base-cased \
+ --task_name mrpc \
+ --do_train \
+ --do_eval \
+ --max_seq_length 128 \
+ --per_device_train_batch_size $BS \
+ --learning_rate 2e-5 \
+ --num_train_epochs 3.0 \
+ --output_dir /tmp/mrpc \
+ --overwrite_output_dir \
+ --fp16
+```
+Since the only savings we get are in the model activations saved for the backward passed, it's logical that the bigger those activations are, the bigger the saving will be. If we try different batch sizes, I indeed get (this is with `nvidia-smi` so not completely reliable as said above but it will be a fair comparison):
+
+| batch size | w/o --fp16 | w/ --fp16 | savings |
+| ---------: | ---------: | --------: | ------: |
+| 8 | 4247 | 4163 | 84 |
+| 16 | 4971 | 4793 | 178 |
+| 32 | 6827 | 6207 | 620 |
+| 64 | 10037 | 8061 | 1976 |
+
+So there is only a real memory saving if we train at a high batch size (and it's not half) and at batch sizes lower than 8, you actually get a bigger memory footprint (because of the overhead mentioned above). The gain for FP16 training is that in each of those cases, the training with the flag `--fp16` is twice as fast, which does require every tensor to have every dimension be a multiple of 8 (examples pad the tensors to a sequence length that is a multiple of 8).
+
+Summary: FP16 with apex or AMP will only give you some memory savings with a reasonably high batch size.
+
+Additionally, under mixed precision when possible, it's important that the batch size is a multiple of 8 to efficiently use tensor cores.
+
+Note that in some situations the speed up can be as big as 5x when using mixed precision. e.g. we have observed that while using [Megatron-Deepspeed](https://github.com/bigscience-workshop/Megatron-DeepSpeed).
+
+Some amazing tutorials to read on mixed precision:
+- @sgugger wrote a great explanation of mixed precision [here](https://docs.fast.ai/callback.fp16.html#A-little-bit-of-theory)
+- Aleksey Bilogur's [A developer-friendly guide to mixed precision training with PyTorch](https://spell.ml/blog/mixed-precision-training-with-pytorch-Xuk7YBEAACAASJam)
+
+You can also see a variety of benchmarks on fp16 vs other precisions:
+[RTX-3090](https://github.com/huggingface/transformers/issues/14608#issuecomment-1004390803) and
+[A100](https://github.com/huggingface/transformers/issues/15026#issuecomment-1004543189).
+
+
+
+##### fp16 caching
+
+pytorch `autocast` which performs AMP include a caching feature, which speed things up by caching fp16-converted values. Here is the full description from this [comment](https://discuss.pytorch.org/t/autocast-and-torch-no-grad-unexpected-behaviour/93475/3):
+
+Autocast maintains a cache of the FP16 casts of model parameters (leaves). This helps streamline parameter reuse: if the same FP32 param is used in several different FP16list ops, like several matmuls, instead of re-casting the param to FP16 on entering each matmul, the cast will occur on the first matmul, the casted FP16 copy will be cached, and for all later matmuls the FP16 copy will be reused. The cache is maintained only within a particular outermost autocast context. When you exit the autocast context the cache is dropped. For recommended usage, in which autocast wraps the forward pass, and then you exit the context before calling backward(), this means the cache only lasts the duration of the forward pass each iteration, and will be rebuilt next iteration. (The cache of FP16-casted copies MUST be rebuilt each iteration. The FP32 parameters get updated by the optimizer, so the FP16 copies must be recreated, otherwise the FP16 values will be stale.)
+
+##### fp16 Inference
+
+While normally inference is done with fp16/amp as with training, it's also possible to use the full fp16 mode without using mixed precision. This is especially a good fit if the pretrained model weights are already in fp16. So a lot less memory is used: 2 bytes per parameter vs 6 bytes with mixed precision!
+
+How good the results this will deliver will depend on the model. If it can handle fp16 without overflows and accuracy issues, then it'll definitely better to use the full fp16 mode.
+
+For example, LayerNorm has to be done in fp32 and recent pytorch (1.10+) has been fixed to do that regardless of the input types, but earlier pytorch versions accumulate in the input type which can be an issue.
+
+In 🤗 Transformers the full fp16 inference is enabled by passing `--fp16_full_eval` to the 🤗 Trainer.
+
+
+#### bf16
+
+If you own Ampere or newer hardware you can start using bf16 for your training and evaluation. While bf16 has a worse precision than fp16, it has a much much bigger dynamic range. Therefore, if in the past you were experiencing overflow issues while training the model, bf16 will prevent this from happening most of the time. Remember that in fp16 the biggest number you can have is `65535` and any number above that will overflow. A bf16 number can be as large as `3.39e+38` (!) which is about the same as fp32 - because both have 8-bits used for the numerical range.
+
+Automatic Mixed Precision (AMP) is the same as with fp16, except it'll use bf16.
+
+Thanks to the fp32-like dynamic range with bf16 mixed precision loss scaling is no longer needed.
+
+If you have tried to finetune models pre-trained under bf16 mixed precision (e.g. T5) it's very likely that you have encountered overflow issues. Now you should be able to finetune those models without any issues.
+
+That said, also be aware that if you pre-trained a model in bf16, it's likely to have overflow issues if someone tries to finetune it in fp16 down the road. So once started on the bf16-mode path it's best to remain on it and not switch to fp16.
+
+In 🤗 Transformers bf16 mixed precision is enabled by passing `--bf16` to the 🤗 Trainer.
+
+If you use your own trainer, this is just:
+
+```
+from torch.cuda.amp import autocast
+with autocast(dtype=torch.bfloat16):
+ loss, outputs = ...
+```
+
+If you need to switch a tensor to bf16, it's just: `t.to(dtype=torch.bfloat16)`
+
+Here is how you can check if your setup supports bf16:
+
+```
+python -c 'import transformers; print(f"BF16 support is {transformers.utils.is_torch_bf16_available()}")'
+```
+
+On the other hand bf16 has a much worse precision than fp16, so there are certain situations where you'd still want to use fp16 and not bf16.
+
+You can also see a variety of benchmarks on bf16 vs other precisions:
+[RTX-3090](https://github.com/huggingface/transformers/issues/14608#issuecomment-1004390803) and
+[A100](https://github.com/huggingface/transformers/issues/15026#issuecomment-1004543189).
+
+
+##### bf16 Inference
+
+Same as with fp16, you can do inference in either the mixed precision bf16 or using the full bf16 mode. The same caveats apply. For details see [fp16 Inference](#fp16-inference).
+
+In 🤗 Transformers the full bf16 inference is enabled by passing `--bf16_full_eval` to the 🤗 Trainer.
+
+
+#### tf32
+
+The Ampere hardware uses a magical data type called tf32. It has the same numerical range as fp32 (8-bits), but instead of 23 bits precision it has only 10 bits (same as fp16). In total it uses only 19 bits.
+
+It's magical in the sense that you can use the normal fp32 training and/or inference code and by enabling tf32 support you can get up to 3x throughput improvement. All you need to do is to add this to your code:
+
+```
+import torch
+torch.backends.cuda.matmul.allow_tf32 = True
+```
+
+When this is done CUDA will automatically switch to using tf32 instead of fp32 where it's possible. This, of course, assumes that the used GPU is from the Ampere series.
+
+Like all cases with reduced precision this may or may not be satisfactory for your needs, so you have to experiment and see. According to [NVIDIA research](https://developer.nvidia.com/blog/accelerating-ai-training-with-tf32-tensor-cores/) the majority of machine learning training shouldn't be impacted and showed the same perplexity and convergence as the fp32 training.
+
+If you're already using fp16 or bf16 mixed precision it may help with the throughput as well.
+
+You can enable this mode in the 🤗 Trainer with `--tf32`, or disable it with `--tf32 0` or `--no_tf32`.
+By default the PyTorch default is used.
+
+Note: tf32 mode is internal to CUDA and can't be accessed directly via `tensor.to(dtype=torch.tf32)` as `torch.tf32` doesn't exit.
+
+Note: you need `torch>=1.7` to enjoy this feature.
+
+You can also see a variety of benchmarks on tf32 vs other precisions:
+[RTX-3090](https://github.com/huggingface/transformers/issues/14608#issuecomment-1004390803) and
+[A100](https://github.com/huggingface/transformers/issues/15026#issuecomment-1004543189).
+
+
+
+### Gradient Accumulation
+
+Since gradient accumulation essentially is identical to having a larger batch size, just as with the larger batch size here you are likely to see a 20-30% speedup due to the optimizer running less often. For example, see benchmarks for [RTX-3090](https://github.com/huggingface/transformers/issues/14608#issuecomment-1004392537)
+and [A100](https://github.com/huggingface/transformers/issues/15026#issuecomment-1004592231).
+
+To activate this feature in 🤗 Trainer add `--gradient_accumulation_steps 4` to its arguments (experiment with the value to get the best performance).
+
+It's important to remember that using gradient accumulation you may end up with a much larger effective batch size, so you may need to adjust the learning rate, its warm up and for very short datasets it'll impact the loss as the training will end up doing less steps than normal.
+
+
+
+### Gradient Checkpointing
+
+One way to use significantly less GPU memory is to enabled "Gradient Checkpointing" (also known as "activation checkpointing"). When enabled, a lot of memory can be freed at the cost of small decrease in the training speed due to recomputing parts of the graph during back-propagation. The slowdown will depend on the model but quite often it is around 20-30%.
+
+This technique was first shared in the paper: [Training Deep Nets with Sublinear Memory Cost](https://arxiv.org/abs/1604.06174). The paper will also give you the exact details on the savings, but it's in the ballpark of `O(sqrt(n))`, where `n` is the number of feed-forward layers.
+
+To activate this feature in 🤗 Transformers for models that support it, use:
+
+```python
+model.gradient_checkpointing_enable()
+```
+or add `--gradient_checkpointing` to the Trainer arguments.
+
+
+### Batch sizes
+
+One gets the most efficient performance when batch sizes and input/output neuron counts are divisible by a certain number, which typically starts at 8, but can be much higher as well. That number varies a lot depending on the specific hardware being used and the dtype of the model.
+
+For example for fully connected layers (which correspond to GEMMs), NVIDIA provides recommendations for [input/output neuron counts](
+https://docs.nvidia.com/deeplearning/performance/dl-performance-fully-connected/index.html#input-features) and [batch size](https://docs.nvidia.com/deeplearning/performance/dl-performance-fully-connected/index.html#batch-size).
+
+[Tensor Core Requirements](https://docs.nvidia.com/deeplearning/performance/dl-performance-matrix-multiplication/index.html#requirements-tc) define the multiplier based on the dtype and the hardware. For example, for fp16 a multiple of 8 is recommended, but on A100 it's 64!
+
+For parameters that are small, there is also [Dimension Quantization Effects](https://docs.nvidia.com/deeplearning/performance/dl-performance-matrix-multiplication/index.html#dim-quantization) to consider, this is where tiling happens and the right multiplier can have a significant speedup.
+
+Additionally, as explained in the [Gradient Accumulation](#gradient-accumulation) section, the bigger the batch size the less often the optimizer is run, the faster the training is (considering the same dataset length). See benchmarks
+for [RTX-3090](https://github.com/huggingface/transformers/issues/14608#issuecomment-1004392537)
+and [A100](https://github.com/huggingface/transformers/issues/15026#issuecomment-1005033957).
+
+
+### DP vs DDP
+
+`DistributedDataParallel` (DDP) is typically faster than `DataParallel` (DP), but it is not always the case:
+* while DP is python threads-based, DDP is multiprocess-based - and as such it has no python threads limitations, such as GIL
+* on the other hand a slow inter-connectivity between the GPU cards could lead to an actual slower outcome with DDP
+
+Here are the main differences in the inter-GPU communication overhead between the two modes:
+
+[DDP](https://pytorch.org/docs/master/notes/ddp.html):
+
+- At the start time the main process replicates the model once from gpu 0 to the rest of gpus
+- Then for each batch:
+ 1. each gpu consumes each own mini-batch of data directly
+ 2. during `backward`, once the local gradients are ready, they are then averaged across all processes
+
+[DP](https://pytorch.org/docs/master/generated/torch.nn.DataParallel.html):
+
+For each batch:
+ 1. gpu 0 reads the batch of data and then sends a mini-batch to each gpu
+ 2. replicates the up-to-date model from gpu 0 to each gpu
+ 3. runs `forward` and sends output from each gpu to gpu 0, computes loss
+ 4. scatters loss from gpu 0 to all gpus, runs `backward`
+ 5. sends gradients from each gpu to gpu 0 and averages those
+
+The only communication DDP performs per batch is sending gradients, whereas DP does 5 different data exchanges per batch.
+
+DP copies data within the process via python threads, whereas DDP copies data via [torch.distributed](https://pytorch.org/docs/master/distributed.html).
+
+Under DP gpu 0 performs a lot more work than the rest of the gpus, thus resulting in under-utilization of gpus.
+
+You can use DDP across multiple machines, but this is not the case with DP.
+
+There are other differences between DP and DDP but they aren't relevant to this discussion.
+
+If you want to go really deep into understanding these 2 modes, this [article](https://www.telesens.co/2019/04/04/distributed-data-parallel-training-using-pytorch-on-aws/) is highly recommended, as it has great diagrams, includes multiple benchmarks and profiler outputs on various hardware, explains all the nuances that you may need to know.
+
+Let's look at an actual benchmark:
+
+| Type | NVlink | Time |
+| :----- | ----- | ---: |
+| 2:DP | Y | 110s |
+| 2:DDP | Y | 101s |
+| 2:DDP | N | 131s |
+
+
+Analysis:
+
+Here DP is ~10% slower than DDP w/ NVlink, but ~15% faster than DDP w/o NVlink
+
+The real difference will depend on how much data each GPU needs to sync with the others - the more there is to sync, the more a slow link will slow down the total runtime.
+
+Here is the full benchmark code and outputs:
+
+`NCCL_P2P_DISABLE=1` was used to disable the NVLink feature on the corresponding benchmark.
+
+```
+
+# DP
+rm -r /tmp/test-clm; CUDA_VISIBLE_DEVICES=0,1 \
+python examples/pytorch/language-modeling/run_clm.py \
+--model_name_or_path gpt2 --dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 \
+--do_train --output_dir /tmp/test-clm --per_device_train_batch_size 4 --max_steps 200
+
+{'train_runtime': 110.5948, 'train_samples_per_second': 1.808, 'epoch': 0.69}
+
+# DDP w/ NVlink
+rm -r /tmp/test-clm; CUDA_VISIBLE_DEVICES=0,1 \
+python -m torch.distributed.launch --nproc_per_node 2 examples/pytorch/language-modeling/run_clm.py \
+--model_name_or_path gpt2 --dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 \
+--do_train --output_dir /tmp/test-clm --per_device_train_batch_size 4 --max_steps 200
+
+{'train_runtime': 101.9003, 'train_samples_per_second': 1.963, 'epoch': 0.69}
+
+# DDP w/o NVlink
+rm -r /tmp/test-clm; NCCL_P2P_DISABLE=1 CUDA_VISIBLE_DEVICES=0,1 \
+python -m torch.distributed.launch --nproc_per_node 2 examples/pytorch/language-modeling/run_clm.py \
+--model_name_or_path gpt2 --dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 \
+--do_train --output_dir /tmp/test-clm --per_device_train_batch_size 4 --max_steps 200
+
+{'train_runtime': 131.4367, 'train_samples_per_second': 1.522, 'epoch': 0.69}
+```
+
+Hardware: 2x TITAN RTX 24GB each + NVlink with 2 NVLinks (`NV2` in `nvidia-smi topo -m`)
+Software: `pytorch-1.8-to-be` + `cuda-11.0` / `transformers==4.3.0.dev0`
+
+
+### DataLoader
+
+One of the important requirements to reach great training speed is the ability to feed the GPU at the maximum speed it can handle. By default everything happens in the main process and it might not be able to read the data from disk fast enough, and thus create a bottleneck, leading to GPU under-utilization.
+
+- `DataLoader(pin_memory=True, ...)` which ensures that the data gets preloaded into the pinned memory on CPU and typically leads to much faster transfers from CPU to GPU memory.
+- `DataLoader(num_workers=4, ...)` - spawn several workers to pre-load data faster - during training watch the GPU utilization stats and if it's far from 100% experiment with raising the number of workers. Of course, the problem could be elsewhere so a very big number of workers won't necessarily lead to a better performance.
+
+## Faster optimizer
+
+pytorch-nightly introduced `torch.optim._multi_tensor` which should significantly speed up the optimizers for situations with lots of small feature tensors. It should eventually become the default, but if you want to experiment with it sooner and don't mind using the bleed-edge, see: https://github.com/huggingface/transformers/issues/9965
+
+
+### Sparsity
+
+#### Mixture of Experts
+
+Quite a few of the recent papers reported a 4-5x training speedup and a faster inference by integrating
+Mixture of Experts (MoE) into the Transformer models.
+
+Since it has been discovered that more parameters lead to better performance, this technique allows to increase the number of parameters by an order of magnitude without increasing training costs.
+
+In this approach every other FFN layer is replaced with a MoE Layer which consists of many experts, with a gated function that trains each expert in a balanced way depending on the input token's position in a sequence.
+
+
+
+(source: [GLAM](https://ai.googleblog.com/2021/12/more-efficient-in-context-learning-with.html))
+
+You can find exhaustive details and comparison tables in the papers listed at the end of this section.
+
+The main drawback of this approach is that it requires staggering amounts of GPU memory - almost an order of magnitude larger than its dense equivalent. Various distillation and approaches are proposed to how to overcome the much higher memory requirements.
+
+There is direct trade-off though, you can use just a few experts with a 2-3x smaller base model instead of dozens or hundreds experts leading to a 5x smaller model and thus increase the training speed moderately while increasing the memory requirements moderately as well.
+
+Most related papers and implementations are built around Tensorflow/TPUs:
+
+- [GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding](https://arxiv.org/abs/2006.16668)
+- [Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity](https://arxiv.org/abs/2101.03961)
+- [GLaM: Generalist Language Model (GLaM)](https://ai.googleblog.com/2021/12/more-efficient-in-context-learning-with.html)
+
+And for Pytorch DeepSpeed has built one as well: [DeepSpeed-MoE: Advancing Mixture-of-Experts Inference and Training to Power Next-Generation AI Scale](https://arxiv.org/abs/2201.05596), [Mixture of Experts](https://www.deepspeed.ai/tutorials/mixture-of-experts/) - blog posts: [1](https://www.microsoft.com/en-us/research/blog/deepspeed-powers-8x-larger-moe-model-training-with-high-performance/), [2](https://www.microsoft.com/en-us/research/publication/scalable-and-efficient-moe-training-for-multitask-multilingual-models/) and specific deployment with large transformer-based natural language generation models: [blog post](https://www.deepspeed.ai/news/2021/12/09/deepspeed-moe-nlg.html), [Megatron-Deepspeed branch](Thttps://github.com/microsoft/Megatron-DeepSpeed/tree/moe-training).
+
+
+
+### Efficient Software Prebuilds
+
+PyTorch's [pip and conda builds](https://pytorch.org/get-started/locally/#start-locally) come prebuit with the cuda toolkit which is enough to run PyTorch, but it is insufficient if you need to build cuda extensions.
+
+At times it may take an additional effort to pre-build some components, e.g., if you're using libraries like `apex` that don't come pre-compiled. In other situations figuring out how to install the right cuda toolkit system-wide can be complicated. To address these users' needs PyTorch and NVIDIA release a new version of NGC docker container which already comes with everything prebuilt and you just need to install your programs on it and it will run out of the box.
+
+This approach is also useful if you want to tweak the pytorch source and/or make a new customized build.
+
+To find the docker image version you want start [here](https://docs.nvidia.com/deeplearning/frameworks/pytorch-release-notes/), choose one of the latest monthly releases. Go into the release's notes for the desired release, check that the environment's components are matching your needs (including NVIDIA Driver requirements!) and then at the very top of that document go to the corresponding NGC page. If for some reason you get lost, here is [the index of all PyTorch NGC images](https://ngc.nvidia.com/catalog/containers/nvidia:pytorch).
+
+Next follow the instructions to download and deploy the docker image.
+
+
+## Contribute
+
+This document is far from being complete and a lot more needs to be added, so if you have additions or corrections to make please don't hesitate to open a PR or if you aren't sure start an Issue and we can discuss the details there.
+
+When making contributions that A is better than B, please try to include a reproducible benchmark and/or a link to the source of that information (unless it comes directly from you).
diff --git a/docs/source/en/perplexity.mdx b/docs/source/en/perplexity.mdx
new file mode 100644
index 00000000000000..3706a40091c2ca
--- /dev/null
+++ b/docs/source/en/perplexity.mdx
@@ -0,0 +1,130 @@
+
+
+# Perplexity of fixed-length models
+
+[[open-in-colab]]
+
+Perplexity (PPL) is one of the most common metrics for evaluating language models. Before diving in, we should note
+that the metric applies specifically to classical language models (sometimes called autoregressive or causal language
+models) and is not well defined for masked language models like BERT (see [summary of the models](model_summary)).
+
+Perplexity is defined as the exponentiated average negative log-likelihood of a sequence. If we have a tokenized
+sequence \\(X = (x_0, x_1, \dots, x_t)\\), then the perplexity of \\(X\\) is,
+
+$$\text{PPL}(X) = \exp \left\{ {-\frac{1}{t}\sum_i^t \log p_\theta (x_i|x_{
+
+When working with approximate models, however, we typically have a constraint on the number of tokens the model can
+process. The largest version of [GPT-2](model_doc/gpt2), for example, has a fixed length of 1024 tokens, so we
+cannot calculate \\(p_\theta(x_t|x_{
+
+This is quick to compute since the perplexity of each segment can be computed in one forward pass, but serves as a poor
+approximation of the fully-factorized perplexity and will typically yield a higher (worse) PPL because the model will
+have less context at most of the prediction steps.
+
+Instead, the PPL of fixed-length models should be evaluated with a sliding-window strategy. This involves repeatedly
+sliding the context window so that the model has more context when making each prediction.
+
+
+
+Using those attention matrices with less parameters then allows the model to have inputs having a bigger sequence
+length.
+
+### Other tricks
+
+
+
+**Axial positional encodings**
+
+[Reformer](#reformer) uses axial positional encodings: in traditional transformer models, the positional encoding
+E is a matrix of size \\(l\\) by \\(d\\), \\(l\\) being the sequence length and \\(d\\) the dimension of the
+hidden state. If you have very long texts, this matrix can be huge and take way too much space on the GPU. To alleviate
+that, axial positional encodings consist of factorizing that big matrix E in two smaller matrices E1 and E2, with
+dimensions \\(l_{1} \times d_{1}\\) and \\(l_{2} \times d_{2}\\), such that \\(l_{1} \times l_{2} = l\\) and
+\\(d_{1} + d_{2} = d\\) (with the product for the lengths, this ends up being way smaller). The embedding for time
+step \\(j\\) in E is obtained by concatenating the embeddings for timestep \\(j \% l1\\) in E1 and \\(j // l1\\)
+in E2.
diff --git a/docs/source/en/multilingual.mdx b/docs/source/en/multilingual.mdx
new file mode 100644
index 00000000000000..7c95de6ffc0909
--- /dev/null
+++ b/docs/source/en/multilingual.mdx
@@ -0,0 +1,175 @@
+
+
+# Multilingual models for inference
+
+[[open-in-colab]]
+
+There are several multilingual models in 🤗 Transformers, and their inference usage differs from monolingual models. Not *all* multilingual model usage is different though. Some models, like [bert-base-multilingual-uncased](https://huggingface.co/bert-base-multilingual-uncased), can be used just like a monolingual model. This guide will show you how to use multilingual models whose usage differs for inference.
+
+## XLM
+
+XLM has ten different checkpoints, only one of which is monolingual. The nine remaining model checkpoints can be split into two categories: the checkpoints that use language embeddings and those that don't.
+
+### XLM with language embeddings
+
+The following XLM models use language embeddings to specify the language used at inference:
+
+- `xlm-mlm-ende-1024` (Masked language modeling, English-German)
+- `xlm-mlm-enfr-1024` (Masked language modeling, English-French)
+- `xlm-mlm-enro-1024` (Masked language modeling, English-Romanian)
+- `xlm-mlm-xnli15-1024` (Masked language modeling, XNLI languages)
+- `xlm-mlm-tlm-xnli15-1024` (Masked language modeling + translation, XNLI languages)
+- `xlm-clm-enfr-1024` (Causal language modeling, English-French)
+- `xlm-clm-ende-1024` (Causal language modeling, English-German)
+
+Language embeddings are represented as a tensor of the same shape as the `input_ids` passed to the model. The values in these tensors depend on the language used and are identified by the tokenizer's `lang2id` and `id2lang` attributes.
+
+In this example, load the `xlm-clm-enfr-1024` checkpoint (Causal language modeling, English-French):
+
+```py
+>>> import torch
+>>> from transformers import XLMTokenizer, XLMWithLMHeadModel
+
+>>> tokenizer = XLMTokenizer.from_pretrained("xlm-clm-enfr-1024")
+>>> model = XLMWithLMHeadModel.from_pretrained("xlm-clm-enfr-1024")
+```
+
+The `lang2id` attribute of the tokenizer displays this model's languages and their ids:
+
+```py
+>>> print(tokenizer.lang2id)
+{'en': 0, 'fr': 1}
+```
+
+Next, create an example input:
+
+```py
+>>> input_ids = torch.tensor([tokenizer.encode("Wikipedia was used to")]) # batch size of 1
+```
+
+Set the language id as `"en"` and use it to define the language embedding. The language embedding is a tensor filled with `0` since that is the language id for English. This tensor should be the same size as `input_ids`.
+
+```py
+>>> language_id = tokenizer.lang2id["en"] # 0
+>>> langs = torch.tensor([language_id] * input_ids.shape[1]) # torch.tensor([0, 0, 0, ..., 0])
+
+>>> # We reshape it to be of size (batch_size, sequence_length)
+>>> langs = langs.view(1, -1) # is now of shape [1, sequence_length] (we have a batch size of 1)
+```
+
+Now you can pass the `input_ids` and language embedding to the model:
+
+```py
+>>> outputs = model(input_ids, langs=langs)
+```
+
+The [run_generation.py](https://github.com/huggingface/transformers/tree/main/examples/pytorch/text-generation/run_generation.py) script can generate text with language embeddings using the `xlm-clm` checkpoints.
+
+### XLM without language embeddings
+
+The following XLM models do not require language embeddings during inference:
+
+- `xlm-mlm-17-1280` (Masked language modeling, 17 languages)
+- `xlm-mlm-100-1280` (Masked language modeling, 100 languages)
+
+These models are used for generic sentence representations, unlike the previous XLM checkpoints.
+
+## BERT
+
+The following BERT models can be used for multilingual tasks:
+
+- `bert-base-multilingual-uncased` (Masked language modeling + Next sentence prediction, 102 languages)
+- `bert-base-multilingual-cased` (Masked language modeling + Next sentence prediction, 104 languages)
+
+These models do not require language embeddings during inference. They should identify the language from the
+context and infer accordingly.
+
+## XLM-RoBERTa
+
+The following XLM-RoBERTa models can be used for multilingual tasks:
+
+- `xlm-roberta-base` (Masked language modeling, 100 languages)
+- `xlm-roberta-large` (Masked language modeling, 100 languages)
+
+XLM-RoBERTa was trained on 2.5TB of newly created and cleaned CommonCrawl data in 100 languages. It provides strong gains over previously released multilingual models like mBERT or XLM on downstream tasks like classification, sequence labeling, and question answering.
+
+## M2M100
+
+The following M2M100 models can be used for multilingual translation:
+
+- `facebook/m2m100_418M` (Translation)
+- `facebook/m2m100_1.2B` (Translation)
+
+In this example, load the `facebook/m2m100_418M` checkpoint to translate from Chinese to English. You can set the source language in the tokenizer:
+
+```py
+>>> from transformers import M2M100ForConditionalGeneration, M2M100Tokenizer
+
+>>> en_text = "Do not meddle in the affairs of wizards, for they are subtle and quick to anger."
+>>> chinese_text = "不要插手巫師的事務, 因為他們是微妙的, 很快就會發怒."
+
+>>> tokenizer = M2M100Tokenizer.from_pretrained("facebook/m2m100_418M", src_lang="zh")
+>>> model = M2M100ForConditionalGeneration.from_pretrained("facebook/m2m100_418M")
+```
+
+Tokenize the text:
+
+```py
+>>> encoded_zh = tokenizer(chinese_text, return_tensors="pt")
+```
+
+M2M100 forces the target language id as the first generated token to translate to the target language. Set the `forced_bos_token_id` to `en` in the `generate` method to translate to English:
+
+```py
+>>> generated_tokens = model.generate(**encoded_zh, forced_bos_token_id=tokenizer.get_lang_id("en"))
+>>> tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
+'Do not interfere with the matters of the witches, because they are delicate and will soon be angry.'
+```
+
+## MBart
+
+The following MBart models can be used for multilingual translation:
+
+- `facebook/mbart-large-50-one-to-many-mmt` (One-to-many multilingual machine translation, 50 languages)
+- `facebook/mbart-large-50-many-to-many-mmt` (Many-to-many multilingual machine translation, 50 languages)
+- `facebook/mbart-large-50-many-to-one-mmt` (Many-to-one multilingual machine translation, 50 languages)
+- `facebook/mbart-large-50` (Multilingual translation, 50 languages)
+- `facebook/mbart-large-cc25`
+
+In this example, load the `facebook/mbart-large-50-many-to-many-mmt` checkpoint to translate Finnish to English. You can set the source language in the tokenizer:
+
+```py
+>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
+
+>>> en_text = "Do not meddle in the affairs of wizards, for they are subtle and quick to anger."
+>>> fi_text = "Älä sekaannu velhojen asioihin, sillä ne ovat hienovaraisia ja nopeasti vihaisia."
+
+>>> tokenizer = AutoTokenizer.from_pretrained("facebook/mbart-large-50-many-to-many-mmt", src_lang="fi_FI")
+>>> model = AutoModelForSeq2SeqLM.from_pretrained("facebook/mbart-large-50-many-to-many-mmt")
+```
+
+Tokenize the text:
+
+```py
+>>> encoded_en = tokenizer(en_text, return_tensors="pt")
+```
+
+MBart forces the target language id as the first generated token to translate to the target language. Set the `forced_bos_token_id` to `en` in the `generate` method to translate to English:
+
+```py
+>>> generated_tokens = model.generate(**encoded_en, forced_bos_token_id=tokenizer.lang_code_to_id("en_XX"))
+>>> tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
+"Don't interfere with the wizard's affairs, because they are subtle, will soon get angry."
+```
+
+If you are using the `facebook/mbart-large-50-many-to-one-mmt` checkpoint, you don't need to force the target language id as the first generated token otherwise the usage is the same.
\ No newline at end of file
diff --git a/docs/source/en/notebooks.md b/docs/source/en/notebooks.md
new file mode 120000
index 00000000000000..10fb7a7b979ad8
--- /dev/null
+++ b/docs/source/en/notebooks.md
@@ -0,0 +1 @@
+../../../notebooks/README.md
\ No newline at end of file
diff --git a/docs/source/en/pad_truncation.mdx b/docs/source/en/pad_truncation.mdx
new file mode 100644
index 00000000000000..f848e23bed502e
--- /dev/null
+++ b/docs/source/en/pad_truncation.mdx
@@ -0,0 +1,66 @@
+
+
+# Padding and truncation
+
+Batched inputs are often different lengths, so they can't be converted to fixed-size tensors. Padding and truncation are strategies for dealing with this problem, to create rectangular tensors from batches of varying lengths. Padding adds a special **padding token** to ensure shorter sequences will have the same length as either the longest sequence in a batch or the maximum length accepted by the model. Truncation works in the other direction by truncating long sequences.
+
+In most cases, padding your batch to the length of the longest sequence and truncating to the maximum length a model can accept works pretty well. However, the API supports more strategies if you need them. The three arguments you need to are: `padding`, `truncation` and `max_length`.
+
+The `padding` argument controls padding. It can be a boolean or a string:
+
+ - `True` or `'longest'`: pad to the longest sequence in the batch (no padding is applied if you only provide
+ a single sequence).
+ - `'max_length'`: pad to a length specified by the `max_length` argument or the maximum length accepted
+ by the model if no `max_length` is provided (`max_length=None`). Padding will still be applied if you only provide a single sequence.
+ - `False` or `'do_not_pad'`: no padding is applied. This is the default behavior.
+
+The `truncation` argument controls truncation. It can be a boolean or a string:
+
+ - `True` or `'longest_first'`: truncate to a maximum length specified by the `max_length` argument or
+ the maximum length accepted by the model if no `max_length` is provided (`max_length=None`). This will
+ truncate token by token, removing a token from the longest sequence in the pair until the proper length is
+ reached.
+ - `'only_second'`: truncate to a maximum length specified by the `max_length` argument or the maximum
+ length accepted by the model if no `max_length` is provided (`max_length=None`). This will only truncate
+ the second sentence of a pair if a pair of sequences (or a batch of pairs of sequences) is provided.
+ - `'only_first'`: truncate to a maximum length specified by the `max_length` argument or the maximum
+ length accepted by the model if no `max_length` is provided (`max_length=None`). This will only truncate
+ the first sentence of a pair if a pair of sequences (or a batch of pairs of sequences) is provided.
+ - `False` or `'do_not_truncate'`: no truncation is applied. This is the default behavior.
+
+The `max_length` argument controls the length of the padding and truncation. It can be an integer or `None`, in which case it will default to the maximum length the model can accept. If the model has no specific maximum input length, truncation or padding to `max_length` is deactivated.
+
+The following table summarizes the recommended way to setup padding and truncation. If you use pairs of input sequences in any of the following examples, you can replace `truncation=True` by a `STRATEGY` selected in
+`['only_first', 'only_second', 'longest_first']`, i.e. `truncation='only_second'` or `truncation='longest_first'` to control how both sequences in the pair are truncated as detailed before.
+
+| Truncation | Padding | Instruction |
+|--------------------------------------|-----------------------------------|---------------------------------------------------------------------------------------------|
+| no truncation | no padding | `tokenizer(batch_sentences)` |
+| | padding to max sequence in batch | `tokenizer(batch_sentences, padding=True)` or |
+| | | `tokenizer(batch_sentences, padding='longest')` |
+| | padding to max model input length | `tokenizer(batch_sentences, padding='max_length')` |
+| | padding to specific length | `tokenizer(batch_sentences, padding='max_length', max_length=42)` |
+| truncation to max model input length | no padding | `tokenizer(batch_sentences, truncation=True)` or |
+| | | `tokenizer(batch_sentences, truncation=STRATEGY)` |
+| | padding to max sequence in batch | `tokenizer(batch_sentences, padding=True, truncation=True)` or |
+| | | `tokenizer(batch_sentences, padding=True, truncation=STRATEGY)` |
+| | padding to max model input length | `tokenizer(batch_sentences, padding='max_length', truncation=True)` or |
+| | | `tokenizer(batch_sentences, padding='max_length', truncation=STRATEGY)` |
+| | padding to specific length | Not possible |
+| truncation to specific length | no padding | `tokenizer(batch_sentences, truncation=True, max_length=42)` or |
+| | | `tokenizer(batch_sentences, truncation=STRATEGY, max_length=42)` |
+| | padding to max sequence in batch | `tokenizer(batch_sentences, padding=True, truncation=True, max_length=42)` or |
+| | | `tokenizer(batch_sentences, padding=True, truncation=STRATEGY, max_length=42)` |
+| | padding to max model input length | Not possible |
+| | padding to specific length | `tokenizer(batch_sentences, padding='max_length', truncation=True, max_length=42)` or |
+| | | `tokenizer(batch_sentences, padding='max_length', truncation=STRATEGY, max_length=42)` |
diff --git a/docs/source/en/parallelism.mdx b/docs/source/en/parallelism.mdx
new file mode 100644
index 00000000000000..f13d85ac7372c1
--- /dev/null
+++ b/docs/source/en/parallelism.mdx
@@ -0,0 +1,413 @@
+
+
+# Model Parallelism
+
+
+## Parallelism overview
+
+In the modern machine learning the various approaches to parallelism are used to:
+1. fit very large models onto limited hardware - e.g. t5-11b is 45GB in just model params
+2. significantly speed up training - finish training that would take a year in hours
+
+We will first discuss in depth various 1D parallelism techniques and their pros and cons and then look at how they can be combined into 2D and 3D parallelism to enable an even faster training and to support even bigger models. Various other powerful alternative approaches will be presented.
+
+While the main concepts most likely will apply to any other framework, this article is focused on PyTorch-based implementations.
+
+
+## Concepts
+
+The following is the brief description of the main concepts that will be described later in depth in this document.
+
+1. DataParallel (DP) - the same setup is replicated multiple times, and each being fed a slice of the data. The processing is done in parallel and all setups are synchronized at the end of each training step.
+2. TensorParallel (TP) - each tensor is split up into multiple chunks, so instead of having the whole tensor reside on a single gpu, each shard of the tensor resides on its designated gpu. During processing each shard gets processed separately and in parallel on different GPUs and the results are synced at the end of the step. This is what one may call horizontal parallelism, as the splitting happens on horizontal level.
+3. PipelineParallel (PP) - the model is split up vertically (layer-level) across multiple GPUs, so that only one or several layers of the model are places on a single gpu. Each gpu processes in parallel different stages of the pipeline and working on a small chunk of the batch.
+4. Zero Redundancy Optimizer (ZeRO) - Also performs sharding of the tensors somewhat similar to TP, except the whole tensor gets reconstructed in time for a forward or backward computation, therefore the model doesn't need to be modified. It also supports various offloading techniques to compensate for limited GPU memory.
+5. Sharded DDP - is another name for the foundational ZeRO concept as used by various other implementations of ZeRO.
+
+
+## Data Parallelism
+
+Most users with just 2 GPUs already enjoy the increased training speed up thanks to `DataParallel` (DP) and `DistributedDataParallel` (DDP) that are almost trivial to use. This is a built-in feature of Pytorch.
+
+## ZeRO Data Parallelism
+
+ZeRO-powered data parallelism (ZeRO-DP) is described on the following diagram from this [blog post](https://www.microsoft.com/en-us/research/blog/zero-deepspeed-new-system-optimizations-enable-training-models-with-over-100-billion-parameters/)
+
+
+It can be difficult to wrap one's head around it, but in reality the concept is quite simple. This is just the usual `DataParallel` (DP), except, instead of replicating the full model params, gradients and optimizer states, each GPU stores only a slice of it. And then at run-time when the full layer params are needed just for the given layer, all GPUs synchronize to give each other parts that they miss - this is it.
+
+Consider this simple model with 3 layers, where each layer has 3 params:
+```
+La | Lb | Lc
+---|----|---
+a0 | b0 | c0
+a1 | b1 | c1
+a2 | b2 | c2
+```
+Layer La has weights a0, a1 and a2.
+
+If we have 3 GPUs, the Sharded DDP (= Zero-DP) splits the model onto 3 GPUs like so:
+
+```
+GPU0:
+La | Lb | Lc
+---|----|---
+a0 | b0 | c0
+
+GPU1:
+La | Lb | Lc
+---|----|---
+a1 | b1 | c1
+
+GPU2:
+La | Lb | Lc
+---|----|---
+a2 | b2 | c2
+```
+
+In a way this is the same horizontal slicing, as tensor parallelism, if you imagine the typical DNN diagram. Vertical slicing is where one puts whole layer-groups on different GPUs. But it's just the starting point.
+
+Now each of these GPUs will get the usual mini-batch as it works in DP:
+```
+x0 => GPU0
+x1 => GPU1
+x2 => GPU2
+```
+
+The inputs are unmodified - they think they are going to be processed by the normal model.
+
+First, the inputs hit the layer La.
+
+Let's focus just on GPU0: x0 needs a0, a1, a2 params to do its forward path, but GPU0 has only a0 - it gets sent a1 from GPU1 and a2 from GPU2, bringing all pieces of the model together.
+
+In parallel, GPU1 gets mini-batch x1 and it only has a1, but needs a0 and a2 params, so it gets those from GPU0 and GPU2.
+
+Same happens to GPU2 that gets input x2. It gets a0 and a1 from GPU0 and GPU1, and with its a2 it reconstructs the full tensor.
+
+All 3 GPUs get the full tensors reconstructed and a forward happens.
+
+As soon as the calculation is done, the data that is no longer needed gets dropped - it's only used during the calculation. The reconstruction is done efficiently via a pre-fetch.
+
+And the whole process is repeated for layer Lb, then Lc forward-wise, and then backward Lc -> Lb -> La.
+
+To me this sounds like an efficient group backpacking weight distribution strategy:
+
+1. person A carries the tent
+2. person B carries the stove
+3. person C carries the axe
+
+Now each night they all share what they have with others and get from others what they don't have, and in the morning they pack up their allocated type of gear and continue on their way. This is Sharded DDP / Zero DP.
+
+Compare this strategy to the simple one where each person has to carry their own tent, stove and axe, which would be far more inefficient. This is DataParallel (DP and DDP) in Pytorch.
+
+While reading the literature on this topic you may encounter the following synonyms: Sharded, Partitioned.
+
+If you pay close attention the way ZeRO partitions the model's weights - it looks very similar to tensor parallelism which will be discussed later. This is because it partitions/shards each layer's weights, unlike vertical model parallelism which is discussed next.
+
+Implementations:
+
+- [DeepSpeed](https://www.deepspeed.ai/features/#the-zero-redundancy-optimizer) ZeRO-DP stages 1+2+3
+- [Fairscale](https://github.com/facebookresearch/fairscale/#optimizer-state-sharding-zero) ZeRO-DP stages 1+2+3
+- [`transformers` integration](main_classes/trainer#trainer-integrations)
+
+## Naive Model Parallelism (Vertical) and Pipeline Parallelism
+
+Naive Model Parallelism (MP) is where one spreads groups of model layers across multiple GPUs. The mechanism is relatively simple - switch the desired layers `.to()` the desired devices and now whenever the data goes in and out those layers switch the data to the same device as the layer and leave the rest unmodified.
+
+We refer to it as Vertical MP, because if you remember how most models are drawn, we slice the layers vertically. For example, if the following diagram shows an 8-layer model:
+
+```
+=================== ===================
+| 0 | 1 | 2 | 3 | | 4 | 5 | 6 | 7 |
+=================== ===================
+ gpu0 gpu1
+```
+we just sliced it in 2 vertically, placing layers 0-3 onto GPU0 and 4-7 to GPU1.
+
+Now while data travels from layer 0 to 1, 1 to 2 and 2 to 3 this is just the normal model. But when data needs to pass from layer 3 to layer 4 it needs to travel from GPU0 to GPU1 which introduces a communication overhead. If the participating GPUs are on the same compute node (e.g. same physical machine) this copying is pretty fast, but if the GPUs are located on different compute nodes (e.g. multiple machines) the communication overhead could be significantly larger.
+
+Then layers 4 to 5 to 6 to 7 are as a normal model would have and when the 7th layer completes we often need to send the data back to layer 0 where the labels are (or alternatively send the labels to the last layer). Now the loss can be computed and the optimizer can do its work.
+
+Problems:
+- the main deficiency and why this one is called "naive" MP, is that all but one GPU is idle at any given moment. So if 4 GPUs are used, it's almost identical to quadrupling the amount of memory of a single GPU, and ignoring the rest of the hardware. Plus there is the overhead of copying the data between devices. So 4x 6GB cards will be able to accommodate the same size as 1x 24GB card using naive MP, except the latter will complete the training faster, since it doesn't have the data copying overhead. But, say, if you have 40GB cards and need to fit a 45GB model you can with 4x 40GB cards (but barely because of the gradient and optimizer states)
+- shared embeddings may need to get copied back and forth between GPUs.
+
+Pipeline Parallelism (PP) is almost identical to a naive MP, but it solves the GPU idling problem, by chunking the incoming batch into micro-batches and artificially creating a pipeline, which allows different GPUs to concurrently participate in the computation process.
+
+The following illustration from the [GPipe paper](https://ai.googleblog.com/2019/03/introducing-gpipe-open-source-library.html) shows the naive MP on the top, and PP on the bottom:
+
+
+
+It's easy to see from the bottom diagram how PP has less dead zones, where GPUs are idle. The idle parts are referred to as the "bubble".
+
+Both parts of the diagram show a parallelism that is of degree 4. That is 4 GPUs are participating in the pipeline. So there is the forward path of 4 pipe stages F0, F1, F2 and F3 and then the return reverse order backward path of B3, B2, B1 and B0.
+
+PP introduces a new hyper-parameter to tune and it's `chunks` which defines how many chunks of data are sent in a sequence through the same pipe stage. For example, in the bottomw diagram you can see that `chunks=4`. GPU0 performs the same forward path on chunk 0, 1, 2 and 3 (F0,0, F0,1, F0,2, F0,3) and then it waits for other GPUs to do their work and only when their work is starting to be complete, GPU0 starts to work again doing the backward path for chunks 3, 2, 1 and 0 (B0,3, B0,2, B0,1, B0,0).
+
+Note that conceptually this is the same concept as gradient accumulation steps (GAS). Pytorch uses `chunks`, whereas DeepSpeed refers to the same hyper-parameter as GAS.
+
+Because of the chunks, PP introduces the concept of micro-batches (MBS). DP splits the global data batch size into mini-batches, so if you have a DP degree of 4, a global batch size of 1024 gets split up into 4 mini-batches of 256 each (1024/4). And if the number of `chunks` (or GAS) is 32 we end up with a micro-batch size of 8 (256/32). Each Pipeline stage works with a single micro-batch at a time.
+
+To calculate the global batch size of the DP + PP setup we then do: `mbs*chunks*dp_degree` (`8*32*4=1024`).
+
+Let's go back to the diagram.
+
+With `chunks=1` you end up with the naive MP, which is very inefficient. With a very large `chunks` value you end up with tiny micro-batch sizes which could be not every efficient either. So one has to experiment to find the value that leads to the highest efficient utilization of the gpus.
+
+While the diagram shows that there is a bubble of "dead" time that can't be parallelized because the last `forward` stage has to wait for `backward` to complete the pipeline, the purpose of finding the best value for `chunks` is to enable a high concurrent GPU utilization across all participating GPUs which translates to minimizing the size of the bubble.
+
+There are 2 groups of solutions - the traditional Pipeline API and the more modern solutions that make things much easier for the end user.
+
+Traditional Pipeline API solutions:
+- PyTorch
+- FairScale
+- DeepSpeed
+- Megatron-LM
+
+Modern solutions:
+- Varuna
+- Sagemaker
+
+Problems with traditional Pipeline API solutions:
+- have to modify the model quite heavily, because Pipeline requires one to rewrite the normal flow of modules into a `nn.Sequential` sequence of the same, which may require changes to the design of the model.
+- currently the Pipeline API is very restricted. If you had a bunch of python variables being passed in the very first stage of the Pipeline, you will have to find a way around it. Currently, the pipeline interface requires either a single Tensor or a tuple of Tensors as the only input and output. These tensors must have a batch size as the very first dimension, since pipeline is going to chunk the mini batch into micro-batches. Possible improvements are being discussed here https://github.com/pytorch/pytorch/pull/50693
+- conditional control flow at the level of pipe stages is not possible - e.g., Encoder-Decoder models like T5 require special workarounds to handle a conditional encoder stage.
+- have to arrange each layer so that the output of one model becomes an input to the other model.
+
+We are yet to experiment with Varuna and SageMaker but their papers report that they have overcome the list of problems mentioned above and that they require much smaller changes to the user's model.
+
+Implementations:
+- [Pytorch](https://pytorch.org/docs/stable/pipeline.html) (initial support in pytorch-1.8, and progressively getting improved in 1.9 and more so in 1.10). Some [examples](https://github.com/pytorch/pytorch/blob/master/benchmarks/distributed/pipeline/pipe.py)
+- [FairScale](https://fairscale.readthedocs.io/en/latest/tutorials/pipe.html)
+- [DeepSpeed](https://www.deepspeed.ai/tutorials/pipeline/)
+- [Megatron-LM](https://github.com/NVIDIA/Megatron-LM) has an internal implementation - no API.
+- [Varuna](https://github.com/microsoft/varuna)
+- [SageMaker](https://arxiv.org/abs/2111.05972) - this is a proprietary solution that can only be used on AWS.
+- [OSLO](https://github.com/tunib-ai/oslo) - this is implemented based on the Hugging Face Transformers.
+
+🤗 Transformers status: as of this writing none of the models supports full-PP. GPT2 and T5 models have naive MP support. The main obstacle is being unable to convert the models to `nn.Sequential` and have all the inputs to be Tensors. This is because currently the models include many features that make the conversion very complicated, and will need to be removed to accomplish that.
+
+Other approaches:
+
+DeepSpeed, Varuna and SageMaker use the concept of an [Interleaved Pipeline](https://docs.aws.amazon.com/sagemaker/latest/dg/model-parallel-core-features.html)
+
+
+Here the bubble (idle time) is further minimized by prioritizing backward passes.
+
+Varuna further tries to improve the schedule by using simulations to discover the most efficient scheduling.
+
+OSLO has pipeline parallelism implementation based on the Transformers without `nn.Sequential` converting.
+
+## Tensor Parallelism
+
+In Tensor Parallelism each GPU processes only a slice of a tensor and only aggregates the full tensor for operations that require the whole thing.
+
+In this section we use concepts and diagrams from the [Megatron-LM](https://github.com/NVIDIA/Megatron-LM) paper: [Efficient Large-Scale Language Model Training on GPU Clusters](https://arxiv.org/abs/2104.04473).
+
+The main building block of any transformer is a fully connected `nn.Linear` followed by a nonlinear activation `GeLU`.
+
+Following the Megatron's paper notation, we can write the dot-product part of it as `Y = GeLU(XA)`, where `X` and `Y` are the input and output vectors, and `A` is the weight matrix.
+
+If we look at the computation in matrix form, it's easy to see how the matrix multiplication can be split between multiple GPUs:
+
+
+If we split the weight matrix `A` column-wise across `N` GPUs and perform matrix multiplications `XA_1` through `XA_n` in parallel, then we will end up with `N` output vectors `Y_1, Y_2, ..., Y_n` which can be fed into `GeLU` independently:
+
+
+Using this principle, we can update an MLP of arbitrary depth, without the need for any synchronization between GPUs until the very end, where we need to reconstruct the output vector from shards. The Megatron-LM paper authors provide a helpful illustration for that:
+
+
+Parallelizing the multi-headed attention layers is even simpler, since they are already inherently parallel, due to having multiple independent heads!
+
+
+Special considerations: TP requires very fast network, and therefore it's not advisable to do TP across more than one node. Practically, if a node has 4 GPUs, the highest TP degree is therefore 4. If you need a TP degree of 8, you need to use nodes that have at least 8 GPUs.
+
+This section is based on the original much more [detailed TP overview](https://github.com/huggingface/transformers/issues/10321#issuecomment-783543530).
+by [@anton-l](https://github.com/anton-l).
+
+SageMaker combines TP with DP for a more efficient processing.
+
+Alternative names:
+- DeepSpeed calls it [tensor slicing](https://www.deepspeed.ai/features/#model-parallelism)
+
+Implementations:
+- [Megatron-LM](https://github.com/NVIDIA/Megatron-LM) has an internal implementation, as it's very model-specific
+- [parallelformers](https://github.com/tunib-ai/parallelformers) (only inference at the moment)
+- [SageMaker](https://arxiv.org/abs/2111.05972) - this is a proprietary solution that can only be used on AWS.
+- [OSLO](https://github.com/tunib-ai/oslo) has the tensor parallelism implementation based on the Transformers.
+
+🤗 Transformers status:
+- core: not yet implemented in the core
+- but if you want inference [parallelformers](https://github.com/tunib-ai/parallelformers) provides this support for most of our models. So until this is implemented in the core you can use theirs. And hopefully training mode will be supported too.
+- Deepspeed-Inference also supports our BERT, GPT-2, and GPT-Neo models in their super-fast CUDA-kernel-based inference mode, see more [here](https://www.deepspeed.ai/tutorials/inference-tutorial/)
+
+## DP+PP
+
+The following diagram from the DeepSpeed [pipeline tutorial](https://www.deepspeed.ai/tutorials/pipeline/) demonstrates how one combines DP with PP.
+
+
+
+Here it's important to see how DP rank 0 doesn't see GPU2 and DP rank 1 doesn't see GPU3. To DP there is just GPUs 0 and 1 where it feeds data as if there were just 2 GPUs. GPU0 "secretly" offloads some of its load to GPU2 using PP. And GPU1 does the same by enlisting GPU3 to its aid.
+
+Since each dimension requires at least 2 GPUs, here you'd need at least 4 GPUs.
+
+Implementations:
+- [DeepSpeed](https://github.com/microsoft/DeepSpeed)
+- [Megatron-LM](https://github.com/NVIDIA/Megatron-LM)
+- [Varuna](https://github.com/microsoft/varuna)
+- [SageMaker](https://arxiv.org/abs/2111.05972)
+- [OSLO](https://github.com/tunib-ai/oslo)
+
+🤗 Transformers status: not yet implemented
+
+## DP+PP+TP
+
+To get an even more efficient training a 3D parallelism is used where PP is combined with TP and DP. This can be seen in the following diagram.
+
+
+
+This diagram is from a blog post [3D parallelism: Scaling to trillion-parameter models](https://www.microsoft.com/en-us/research/blog/deepspeed-extreme-scale-model-training-for-everyone/), which is a good read as well.
+
+Since each dimension requires at least 2 GPUs, here you'd need at least 8 GPUs.
+
+Implementations:
+- [DeepSpeed](https://github.com/microsoft/DeepSpeed) - DeepSpeed also includes an even more efficient DP, which they call ZeRO-DP.
+- [Megatron-LM](https://github.com/NVIDIA/Megatron-LM)
+- [Varuna](https://github.com/microsoft/varuna)
+- [SageMaker](https://arxiv.org/abs/2111.05972)
+- [OSLO](https://github.com/tunib-ai/oslo)
+
+🤗 Transformers status: not yet implemented, since we have no PP and TP.
+
+## ZeRO DP+PP+TP
+
+One of the main features of DeepSpeed is ZeRO, which is a super-scalable extension of DP. It has already been discussed in [ZeRO Data Parallelism](#zero-data-parallelism). Normally it's a standalone feature that doesn't require PP or TP. But it can be combined with PP and TP.
+
+When ZeRO-DP is combined with PP (and optionally TP) it typically enables only ZeRO stage 1 (optimizer sharding).
+
+While it's theoretically possible to use ZeRO stage 2 (gradient sharding) with Pipeline Parallelism, it will have bad performance impacts. There would need to be an additional reduce-scatter collective for every micro-batch to aggregate the gradients before sharding, which adds a potentially significant communication overhead. By nature of Pipeline Parallelism, small micro-batches are used and instead the focus is on trying to balance arithmetic intensity (micro-batch size) with minimizing the Pipeline bubble (number of micro-batches). Therefore those communication costs are going to hurt.
+
+In addition, There are already fewer layers than normal due to PP and so the memory savings won't be huge. PP already reduces gradient size by ``1/PP``, and so gradient sharding savings on top of that are less significant than pure DP.
+
+ZeRO stage 3 is not a good choice either for the same reason - more inter-node communications required.
+
+And since we have ZeRO, the other benefit is ZeRO-Offload. Since this is stage 1 optimizer states can be offloaded to CPU.
+
+Implementations:
+- [Megatron-DeepSpeed](https://github.com/microsoft/Megatron-DeepSpeed) and [Megatron-Deepspeed from BigScience](https://github.com/bigscience-workshop/Megatron-DeepSpeed), which is the fork of the former repo.
+- [OSLO](https://github.com/tunib-ai/oslo)
+
+Important papers:
+
+- [Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, A Large-Scale Generative Language Model](
+https://arxiv.org/abs/2201.11990)
+
+🤗 Transformers status: not yet implemented, since we have no PP and TP.
+
+## FlexFlow
+
+[FlexFlow](https://github.com/flexflow/FlexFlow) also solves the parallelization problem in a slightly different approach.
+
+Paper: ["Beyond Data and Model Parallelism for Deep Neural Networks" by Zhihao Jia, Matei Zaharia, Alex Aiken](https://arxiv.org/abs/1807.05358)
+
+It performs a sort of 4D Parallelism over Sample-Operator-Attribute-Parameter.
+
+1. Sample = Data Parallelism (sample-wise parallel)
+2. Operator = Parallelize a single operation into several sub-operations
+3. Attribute = Data Parallelism (length-wise parallel)
+4. Parameter = Model Parallelism (regardless of dimension - horizontal or vertical)
+
+Examples:
+* Sample
+
+Let's take 10 batches of sequence length 512. If we parallelize them by sample dimension into 2 devices, we get 10 x 512 which becomes be 5 x 2 x 512.
+
+* Operator
+
+If we perform layer normalization, we compute std first and mean second, and then we can normalize data. Operator parallelism allows computing std and mean in parallel. So if we parallelize them by operator dimension into 2 devices (cuda:0, cuda:1), first we copy input data into both devices, and cuda:0 computes std, cuda:1 computes mean at the same time.
+
+* Attribute
+
+We have 10 batches of 512 length. If we parallelize them by attribute dimension into 2 devices, 10 x 512 will be 10 x 2 x 256.
+
+* Parameter
+
+It is similar with tensor model parallelism or naive layer-wise model parallelism.
+
+
+
+The significance of this framework is that it takes resources like (1) GPU/TPU/CPU vs. (2) RAM/DRAM vs. (3) fast-intra-connect/slow-inter-connect and it automatically optimizes all these algorithmically deciding which parallelisation to use where.
+
+One very important aspect is that FlexFlow is designed for optimizing DNN parallelizations for models with static and fixed workloads, since models with dynamic behavior may prefer different parallelization strategies across iterations.
+
+So the promise is very attractive - it runs a 30min simulation on the cluster of choice and it comes up with the best strategy to utilise this specific environment. If you add/remove/replace any parts it'll run and re-optimize the plan for that. And then you can train. A different setup will have its own custom optimization.
+
+🤗 Transformers status: not yet integrated. We already have our models FX-trace-able via [transformers.utils.fx](https://github.com/huggingface/transformers/blob/main/src/transformers/utils/fx.py), which is a prerequisite for FlexFlow, so someone needs to figure out what needs to be done to make FlexFlow work with our models.
+
+
+## Which Strategy To Use When
+
+Here is a very rough outline at which parallelism strategy to use when. The first on each list is typically faster.
+
+**⇨ Single GPU**
+
+* Model fits onto a single GPU:
+
+ 1. Normal use
+
+* Model doesn't fit onto a single GPU:
+
+ 1. ZeRO + Offload CPU and optionally NVMe
+ 2. as above plus Memory Centric Tiling (see below for details) if the largest layer can't fit into a single GPU
+
+* Largest Layer not fitting into a single GPU:
+
+1. ZeRO - Enable [Memory Centric Tiling](https://deepspeed.readthedocs.io/en/latest/zero3.html#memory-centric-tiling) (MCT). It allows you to run arbitrarily large layers by automatically splitting them and executing them sequentially. MCT reduces the number of parameters that are live on a GPU, but it does not affect the activation memory. As this need is very rare as of this writing a manual override of `torch.nn.Linear` needs to be done by the user.
+
+**⇨ Single Node / Multi-GPU**
+
+* Model fits onto a single GPU:
+
+ 1. DDP - Distributed DP
+ 2. ZeRO - may or may not be faster depending on the situation and configuration used
+
+* Model doesn't fit onto a single GPU:
+
+ 1. PP
+ 2. ZeRO
+ 3. TP
+
+ With very fast intra-node connectivity of NVLINK or NVSwitch all three should be mostly on par, without these PP will be faster than TP or ZeRO. The degree of TP may also make a difference. Best to experiment to find the winner on your particular setup.
+
+ TP is almost always used within a single node. That is TP size <= gpus per node.
+
+* Largest Layer not fitting into a single GPU:
+
+ 1. If not using ZeRO - must use TP, as PP alone won't be able to fit.
+ 2. With ZeRO see the same entry for "Single GPU" above
+
+
+**⇨ Multi-Node / Multi-GPU**
+
+* When you have fast inter-node connectivity:
+
+ 1. ZeRO - as it requires close to no modifications to the model
+ 2. PP+TP+DP - less communications, but requires massive changes to the model
+
+* when you have slow inter-node connectivity and still low on GPU memory:
+
+ 1. DP+PP+TP+ZeRO-1
diff --git a/docs/source/en/performance.mdx b/docs/source/en/performance.mdx
new file mode 100644
index 00000000000000..0656a644517bc0
--- /dev/null
+++ b/docs/source/en/performance.mdx
@@ -0,0 +1,1092 @@
+
+
+# Performance and Scalability: How To Fit a Bigger Model and Train It Faster
+
+> _Or how to escape the dreaded "RuntimeError: CUDA error: out of memory" error._
+
+[[open-in-colab]]
+
+Training ever larger models can become challenging even on modern GPUs. Due to their immense size we often run out of GPU memory and training can take very long. In this section we have a look at a few tricks to reduce the memory footprint and speed up training for large models and how they are integrated in the [`Trainer`] and [🤗 Accelerate](https://huggingface.co/docs/accelerate/). Before we start make sure you have installed the following libraries:
+
+```bash
+pip install transformers datasets accelerate nvidia-ml-py3
+```
+
+The `nvidia-ml-py3` library allows us to monitor the memory usage of the models from within Python. You might be familiar with the `nvidia-smi` command in the terminal - this library allows to access the same information in Python directly.
+
+Then we create some dummy data. We create random token IDs between 100 and 30000 and binary labels for a classifier. In total we get 512 sequences each with length 512 and store them in a [`Dataset`](https://huggingface.co/docs/datasets/package_reference/main_classes.html?highlight=dataset#datasets.Dataset) with PyTorch format.
+
+
+```py
+import numpy as np
+from datasets import Dataset
+
+
+seq_len, dataset_size = 512, 512
+dummy_data = {
+ "input_ids": np.random.randint(100, 30000, (dataset_size, seq_len)),
+ "labels": np.random.randint(0, 1, (dataset_size)),
+}
+ds = Dataset.from_dict(dummy_data)
+ds.set_format("pt")
+```
+
+We want to print some summary statistics for the GPU utilization and the training run with the [`Trainer`]. We setup a two helper functions to do just that:
+
+```py
+from pynvml import *
+
+
+def print_gpu_utilization():
+ nvmlInit()
+ handle = nvmlDeviceGetHandleByIndex(0)
+ info = nvmlDeviceGetMemoryInfo(handle)
+ print(f"GPU memory occupied: {info.used//1024**2} MB.")
+
+
+def print_summary(result):
+ print(f"Time: {result.metrics['train_runtime']:.2f}")
+ print(f"Samples/second: {result.metrics['train_samples_per_second']:.2f}")
+ print_gpu_utilization()
+```
+
+Let's verify that we start with a free GPU memory:
+
+```py
+>>> print_gpu_utilization()
+GPU memory occupied: 0 MB.
+```
+
+That looks good: the GPU memory is not occupied as we would expect before we load any models. If that's not the case on your machine make sure to stop all processes that are using GPU memory. However, not all free GPU memory can be used by the user. When a model is loaded to the GPU also the kernels are loaded which can take up 1-2GB of memory. To see how much it is we load a tiny tensor into the GPU which triggers the kernels to be loaded as well.
+
+```py
+>>> import torch
+
+
+>>> torch.ones((1, 1)).to("cuda")
+>>> print_gpu_utilization()
+GPU memory occupied: 1343 MB.
+```
+
+We see that the kernels alone take up 1.3GB of GPU memory. Now let's see how much space the model uses.
+
+## Load Model
+
+First, we load the `bert-large-uncased` model. We load the model weights directly to the GPU so that we can check how much space just weights use.
+
+
+```py
+>>> from transformers import AutoModelForSequenceClassification
+
+
+>>> model = AutoModelForSequenceClassification.from_pretrained("bert-large-uncased").to("cuda")
+>>> print_gpu_utilization()
+GPU memory occupied: 2631 MB.
+```
+
+We can see that the model weights alone take up 1.3 GB of the GPU memory. The exact number depends on the specific GPU you are using. Note that on newer GPUs a model can sometimes take up more space since the weights are loaded in an optimized fashion that speeds up the usage of the model. Now we can also quickly check if we get the same result as with `nvidia-smi` CLI:
+
+
+```bash
+nvidia-smi
+```
+
+```bash
+Tue Jan 11 08:58:05 2022
++-----------------------------------------------------------------------------+
+| NVIDIA-SMI 460.91.03 Driver Version: 460.91.03 CUDA Version: 11.2 |
+|-------------------------------+----------------------+----------------------+
+| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
+| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
+| | | MIG M. |
+|===============================+======================+======================|
+| 0 Tesla V100-SXM2... On | 00000000:00:04.0 Off | 0 |
+| N/A 37C P0 39W / 300W | 2631MiB / 16160MiB | 0% Default |
+| | | N/A |
++-------------------------------+----------------------+----------------------+
+
++-----------------------------------------------------------------------------+
+| Processes: |
+| GPU GI CI PID Type Process name GPU Memory |
+| ID ID Usage |
+|=============================================================================|
+| 0 N/A N/A 3721 C ...nvs/codeparrot/bin/python 2629MiB |
++-----------------------------------------------------------------------------+
+```
+
+We get the same number as before and you can also see that we are using a V100 GPU with 16GB of memory. So now we can start training the model and see how the GPU memory consumption changes. First, we set up a few standard training arguments that we will use across all our experiments:
+
+```py
+default_args = {
+ "output_dir": "tmp",
+ "evaluation_strategy": "steps",
+ "num_train_epochs": 1,
+ "log_level": "error",
+ "report_to": "none",
+}
+```
+
+
+
+ Note: In order to properly clear the memory after experiments we need restart the Python kernel between experiments. Run all steps above and then just one of the experiments below.
+
+
+
+## Vanilla Training
+
+As a first experiment we will use the [`Trainer`] and train the model without any further modifications and a batch size of 4:
+
+```py
+from transformers import TrainingArguments, Trainer, logging
+
+logging.set_verbosity_error()
+
+
+training_args = TrainingArguments(per_device_train_batch_size=4, **default_args)
+trainer = Trainer(model=model, args=training_args, train_dataset=ds)
+result = trainer.train()
+print_summary(result)
+```
+
+```
+Time: 57.82
+Samples/second: 8.86
+GPU memory occupied: 14949 MB.
+```
+
+We see that already a relatively small batch size almost fills up our GPU's entire memory. However, a larger batch size can often result in faster model convergence or better end performance. So ideally we want to tune the batch size to our model's needs and not to the GPU limitations. A simple trick to effectively train larger batch size is gradient accumulation.
+
+## Gradient Accumulation
+
+The idea behind gradient accumulation is to instead of calculating the gradients for the whole batch at once to do it in smaller steps. The way we do that is to calculate the gradients iteratively in smaller batches by doing a forward and backward pass through the model and accumulating the gradients in the process. When enough gradients are accumulated we run the model's optimization step. This way we can easily increase the overall batch size to numbers that would never fit into the GPU's memory. In turn, however, the added forward and backward passes can slow down the training a bit.
+
+We can use gradient accumulation in the [`Trainer`] by simply adding the `gradient_accumulation_steps` argument to [`TrainingArguments`]. Let's see how it impacts the models memory footprint:
+
+```py
+training_args = TrainingArguments(per_device_train_batch_size=1, gradient_accumulation_steps=4, **default_args)
+
+trainer = Trainer(model=model, args=training_args, train_dataset=ds)
+result = trainer.train()
+print_summary(result)
+```
+
+```
+Time: 66.03
+Samples/second: 7.75
+GPU memory occupied: 8681 MB.
+```
+
+We can see that the memory footprint was dramatically reduced at the cost of being only slightly slower than the vanilla run. Of course, this would change as you increase the number of accumulation steps. In general you would want to max out the GPU usage as much as possible. So in our case, the batch_size of 4 was already pretty close to the GPU's limit. If we wanted to train with a batch size of 64 we should not use `per_device_train_batch_size=1` and `gradient_accumulation_steps=64` but instead `per_device_train_batch_size=4` and `gradient_accumulation_steps=16` which has the same effective batch size while making better use of the available GPU resources.
+
+Next we have a look at another trick to save a little bit more GPU memory called gradient checkpointing.
+
+## Gradient Checkpointing
+
+Even when we set the batch size to 1 and use gradient accumulation we can still run out of memory when working with large models. In order to compute the gradients during the backward pass all activations from the forward pass are normally saved. This can create a big memory overhead. Alternatively, one could forget all activations during the forward pass and recompute them on demand during the backward pass. This would however add a significant computational overhead and slow down training.
+
+Gradient checkpointing strikes a compromise between the two approaches and saves strategically selected activations throughout the computational graph so only a fraction of the activations need to be re-computed for the gradients. See [this great article](https://medium.com/tensorflow/fitting-larger-networks-into-memory-583e3c758ff9) explaining the ideas behind gradient checkpointing.
+
+To enable gradient checkpointing in the [`Trainer`] we only need ot pass it as a flag to the [`TrainingArguments`]. Everything else is handled under the hood:
+
+```py
+training_args = TrainingArguments(
+ per_device_train_batch_size=1, gradient_accumulation_steps=4, gradient_checkpointing=True, **default_args
+)
+
+trainer = Trainer(model=model, args=training_args, train_dataset=ds)
+result = trainer.train()
+print_summary(result)
+```
+
+```
+Time: 85.47
+Samples/second: 5.99
+GPU memory occupied: 6775 MB.
+```
+
+We can see that this saved some more memory but at the same time training became a bit slower. A general rule of thumb is that gradient checkpointing slows down training by about 20%. Let's have a look at another method with which we can regain some speed: mixed precision training.
+
+## FP16 Training
+
+The idea of mixed precision training is that no all variables need to be stored in full (32-bit) floating point precision. If we can reduce the precision the variales and their computations are faster. The main advantage comes from saving the activations in half (16-bit) precision. Although the gradients are also computed in half precision they are converted back to full precision for the optimization step so no memory is saved here. Since the model is present on the GPU in both 16-bit and 32-bit precision this can use more GPU memory (1.5x the original model is on the GPU), especially for small batch sizes. Since some computations are performed in full and some in half precision this approach is also called mixed precision training. Enabling mixed precision training is also just a matter of setting the `fp16` flag to `True`:
+
+```py
+training_args = TrainingArguments(per_device_train_batch_size=4, fp16=True, **default_args)
+
+trainer = Trainer(model=model, args=training_args, train_dataset=ds)
+result = trainer.train()
+print_summary(result)
+```
+
+```
+Time: 27.46
+Samples/second: 18.64
+GPU memory occupied: 13939 MB.
+```
+
+We can see that this is almost twice as fast as the vanilla training. Let's add it to the mix of the previous methods:
+
+
+```py
+training_args = TrainingArguments(
+ per_device_train_batch_size=1,
+ gradient_accumulation_steps=4,
+ gradient_checkpointing=True,
+ fp16=True,
+ **default_args,
+)
+
+trainer = Trainer(model=model, args=training_args, train_dataset=ds)
+result = trainer.train()
+print_summary(result)
+```
+
+```
+Time: 50.76
+Samples/second: 10.09
+GPU memory occupied: 7275 MB.
+```
+
+We can see that with these tweaks we use about half the GPU memory as at the beginning while also being slightly faster. But we are not done, yet! There is another area where we can save GPU memory: the optimizer.
+
+## Optimizer
+
+The most common optimizer used to train transformer model is Adam or AdamW (Adam with weight decay). Adam achieves good convergence by storing the rolling average of the previous gradients which, however, adds an additional memory footprint of the order of the number of model parameters. One remedy to this is to use an alternative optimizer such as Adafactor.
+
+### Adafactor
+
+Instead of keeping the rolling average for each element in the weight matrices Adafactor only stores aggregated information (row- and column-wise sums of the rolling averages) which reduces the footprint considerably. One downside of Adafactor is that in some instances convergence can be slower than Adam's so some experimentation is advised here. We can use Adafactor simply by setting `optim="adafactor"`:
+
+
+```py
+training_args = TrainingArguments(per_device_train_batch_size=4, optim="adafactor", **default_args)
+
+trainer = Trainer(model=model, args=training_args, train_dataset=ds)
+result = trainer.train()
+print_summary(result)
+```
+
+```
+Time: 64.31
+Samples/second: 7.96
+GPU memory occupied: 12295 MB.
+```
+
+We can see that this saves a few more GB on the GPU. Let's see how it looks when we add it to the other methods we introduced earlier:
+
+
+```py
+training_args = TrainingArguments(
+ per_device_train_batch_size=1,
+ gradient_accumulation_steps=4,
+ gradient_checkpointing=True,
+ fp16=True,
+ optim="adafactor",
+ **default_args,
+)
+
+trainer = Trainer(model=model, args=training_args, train_dataset=ds)
+result = trainer.train()
+print_summary(result)
+```
+
+```
+Time: 56.54
+Samples/second: 9.06
+GPU memory occupied: 4847 MB.
+```
+
+We went from 15 GB memory usage to 5 GB - a 3x improvement while maintaining the throughput! However, as mentioned before, the convergence of Adafactor can be worse than Adam. There is an alternative to Adafactor called 8-bit Adam that takes a slightly different approach.
+
+### 8-bit Adam
+
+Instead of aggregating optimizer states like Adafactor, 8-bit Adam keeps the full state and quantizes it. Quantization means that it stores the state with lower precision and dequantizes it only for the optimization. This is similar to the idea behind FP16 training where using variables with lower precision saves memory.
+
+In contrast to the previous approaches is this one not integrated into the [`Trainer`] as a simple flag. We need to install the 8-bit optimizer and then pass it as a custom optimizer to the [`Trainer`]. Follow the installation guide in the Github [repo](https://github.com/facebookresearch/bitsandbytes) to install the `bitsandbytes` library that implements the 8-bit Adam optimizer.
+
+Once installed, we just need to initialize the the optimizer. Although this looks like a considerable amount of work it actually just involves two steps: first we need to group the model's parameters into two groups where to one group we apply weight decay and to the other we don't. Usually, biases and layer norm parameters are not weight decayed. Then in a second step we just do some argument housekeeping to use the same parameters as the previously used AdamW optimizer.
+
+
+Note that in order to use the 8-bit optimizer with an existing pretrained model a change to the embedding layer is needed.
+Read [this issue](https://github.com/huggingface/transformers/issues/14819) for more information.
+
+
+```py
+import bitsandbytes as bnb
+from torch import nn
+from transformers.trainer_pt_utils import get_parameter_names
+
+training_args = TrainingArguments(per_device_train_batch_size=4, **default_args)
+
+decay_parameters = get_parameter_names(model, [nn.LayerNorm])
+decay_parameters = [name for name in decay_parameters if "bias" not in name]
+optimizer_grouped_parameters = [
+ {
+ "params": [p for n, p in model.named_parameters() if n in decay_parameters],
+ "weight_decay": training_args.weight_decay,
+ },
+ {
+ "params": [p for n, p in model.named_parameters() if n not in decay_parameters],
+ "weight_decay": 0.0,
+ },
+]
+
+optimizer_kwargs = {
+ "betas": (training_args.adam_beta1, training_args.adam_beta2),
+ "eps": training_args.adam_epsilon,
+}
+optimizer_kwargs["lr"] = training_args.learning_rate
+adam_bnb_optim = bnb.optim.Adam8bit(
+ optimizer_grouped_parameters,
+ betas=(training_args.adam_beta1, training_args.adam_beta2),
+ eps=training_args.adam_epsilon,
+ lr=training_args.learning_rate,
+)
+```
+
+We can now pass the custom optimizer as an argument to the `Trainer`:
+```py
+trainer = Trainer(model=model, args=training_args, train_dataset=ds, optimizers=(adam_bnb_optim, None))
+result = trainer.train()
+print_summary(result)
+```
+
+```
+Time: 55.95
+Samples/second: 9.15
+GPU memory occupied: 13085 MB.
+```
+
+We can see that we get a similar memory improvement as with Adafactor while keeping the full rolling average of the gradients. Let's repeat the experiment with the full settings:
+
+```py
+training_args = TrainingArguments(
+ per_device_train_batch_size=1,
+ gradient_accumulation_steps=4,
+ gradient_checkpointing=True,
+ fp16=True,
+ **default_args,
+)
+
+trainer = Trainer(model=model, args=training_args, train_dataset=ds, optimizers=(adam_bnb_optim, None))
+result = trainer.train()
+print_summary(result)
+```
+
+```
+Time: 49.46
+Samples/second: 10.35
+GPU memory occupied: 5363 MB.
+```
+
+Again, we get about a 3x memory improvement and even slightly higher throughput as using Adafactor. So we have seen how we can optimize the memory footprint of large models. The following plot summarizes all our experiments:
+
+
+
+## Using 🤗 Accelerate
+
+So far we have used the [`Trainer`] to run the experiments but a more flexible alternative to that approach is to use 🤗 Accelerate. With 🤗 Accelerate you have full control over the training loop and can essentially write the loop in pure PyTorch with some minor modifications. In turn it allows you to easily scale across different infrastructures such as CPUs, GPUs, TPUs, or distributed multi-GPU setups without changing any code. Let's see what it takes to implement all of the above tweaks in 🤗 Accelerate. We can still use the [`TrainingArguments`] to wrap the training settings:
+
+
+```py
+training_args = TrainingArguments(
+ per_device_train_batch_size=1,
+ gradient_accumulation_steps=4,
+ gradient_checkpointing=True,
+ fp16=True,
+ **default_args,
+)
+```
+
+The full example training loop with 🤗 Accelerate is only a handful of lines of code long:
+
+
+```py
+from accelerate import Accelerator
+from torch.utils.data.dataloader import DataLoader
+
+dataloader = DataLoader(ds, batch_size=training_args.per_device_train_batch_size)
+
+if training_args.gradient_checkpointing:
+ model.gradient_checkpointing_enable()
+
+accelerator = Accelerator(fp16=training_args.fp16)
+model, optimizer, dataloader = accelerator.prepare(model, adam_bnb_optim, dataloader)
+
+model.train()
+for step, batch in enumerate(dataloader, start=1):
+ loss = model(**batch).loss
+ loss = loss / training_args.gradient_accumulation_steps
+ accelerator.backward(loss)
+ if step % training_args.gradient_accumulation_steps == 0:
+ optimizer.step()
+ optimizer.zero_grad()
+```
+
+First we wrap the dataset in a [`DataLoader`](https://pytorch.org/docs/stable/data.html#torch.utils.data.DataLoader). Then we can enable gradient checkpointing by calling the model's [`~PreTrainedModel.gradient_checkpointing_enable`] method. When we initialize the [`Accelerator`](https://huggingface.co/docs/accelerate/accelerator.html#accelerate.Accelerator) we can specifiy if we want to use mixed precision training and it will take care of it for us in the [`prepare`] call. During the [`prepare`](https://huggingface.co/docs/accelerate/accelerator.html#accelerate.Accelerator.prepare) call the dataloader will also be distributed across workers should we use multiple GPUs. We use the same 8-bit optimizer from the earlier experiments.
+
+Finally, we can write the main training loop. Note that the `backward` call is handled by 🤗 Accelerate. We can also see how gradient accumulation works: we normalize the loss so we get the average at the end of accumulation and once we have enough steps we run the optimization. Now the question is: does this use the same amount of memory as the previous steps? Let's check:
+
+
+```py
+>>> print_gpu_utilization()
+GPU memory occupied: 5363 MB.
+```
+
+
+Indeed it does. Implementing these optimization techniques with 🤗 Accelerate only takes a handful of lines of code and comes with the benefit of more flexiblity in the training loop.
+
+Now, let's take a step back and discuss what we should optimize for when scaling the training of large models.
+
+## How to scale
+
+When we train models there are a two aspects we want to optimize at the same time:
+
+- Data throughput/training time
+- Model performance
+
+We have seen that each method changes the memory usage and throughput. In general we want to maximize the throughput (samples/second) to minimize the training cost. This is generally achieved by utilizing the GPU as much as possible and thus filling GPU memory to its limit. For example, as mentioned earlier, we only employ gradient accumulation when we want to use a batch size beyond the size of the GPU memory. If the desired batch size fits into memory then there is no reason to apply gradient accumulation which will only slow down training.
+
+The second objective is model performance. Just because we can does not mean we should use a large batch size. As part of hyperparameter tuning you should determine which batch size yields the best result and then optimize the throughput accordingly.
+
+Sometimes, even when applying all the above tweaks the throughput on a given GPU might still not be good enough. One easy solution is to change the type of GPU. For example switching from let's say a K80 (which you typically get on Google Colab) to a fancier GPU such as the V100 or A100. Although they are more expensive they are usually more cost effective than cheaper GPUs due to their larger memory and faster architecture. For some applications, such as pretraining, this might still not be fast enough. In this case you want to scale your experiment to several GPUs.
+
+## Multi-GPU Training
+
+If your model fits on a single GPU scaling to many GPUs can be achieved fairly easily with data parallelism. The idea is very similar to gradient accumulation with the distinction that instead of running the forward and backward passes during the accumulation in sequence on a single machine they are performed in parallel on multiple machines. So each GPU gets a small batch, runs the forward and backward passes and then the gradients from all machines are aggregated and the model is optimized. You can combine this with all the methods we described before. For example, if you have 4 GPUs and use `per_device_train_batch_size=12` and `gradient_accumulation_steps=3` you will have an effective batch size of `4*12*3=144`.
+
+The [`Trainer`] allows for distributed training and if you execute your [`Trainer`] training script on a machine with multiple GPUs it will automatically utilize all of them, hence the name `per_device_train_batch_size`. In 🤗 Accelerate you can configure the infrastructure setup with the following command:
+
+```bash
+accelerate config
+```
+
+Until now we have opperated under the assumption that we can fit the model onto a single GPU without or with the introduced tricks . But what if this is not possible? We still have a few tricks up our sleeves!
+
+## What if my model still does not fit?
+
+If the model does not fit on a single GPU with all the mentioned tricks there are still more methods we can apply although life starts to get a bit more complicated. This usually involves some form of pipeline or tensor parallelism where the model itself is distributed across several GPUs. One can also make use of DeepSpeed which implements some of these parallelism strategies along with some more optimization to reduce the memory footprint such as partitioning the optimizer states. You can read more about this in the ["Model Parallelism" section](parallelism).
+
+This concludes the practical part of this guide for scaling the training of large models. The following section goes into more details on some of the aspects discussed above.
+
+
+## Further discussions
+
+This section gives brief ideas on how to make training faster and support bigger models. Later sections will expand, demonstrate and elucidate each of these.
+
+## Faster Training
+
+Hardware:
+
+- fast connectivity between GPUs
+ * intra-node: NVLink
+ * inter-node: Infiniband / Intel OPA
+
+Software:
+
+- Data Parallel / Distributed Data Parallel
+- fp16 (autocast caching)
+
+
+## Bigger Models
+
+Hardware:
+
+- bigger GPUs
+- more GPUs
+- more CPU and NVMe (offloaded to by [DeepSpeed-Infinity](main_classes/deepspeed#nvme-support))
+
+Software:
+
+- Model Scalability (ZeRO and 3D Parallelism)
+- Low-memory Optimizers
+- fp16/bf16 (smaller data/faster throughput)
+- tf32 (faster throughput)
+- Gradient accumulation
+- Gradient checkpointing
+- Sparsity
+
+
+## Hardware
+
+
+### Power and Cooling
+
+If you bought an expensive high end GPU make sure you give it the correct power and sufficient cooling.
+
+**Power**:
+
+Some high end consumer GPU cards have 2 and sometimes 3 PCI-E 8-Pin power sockets. Make sure you have as many independent 12V PCI-E 8-Pin cables plugged into the card as there are sockets. Do not use the 2 splits at one end of the same cable (also known as pigtail cable). That is if you have 2 sockets on the GPU, you want 2 PCI-E 8-Pin cables going from your PSU to the card and not one that has 2 PCI-E 8-Pin connectors at the end! You won't get the full performance out of your card otherwise.
+
+Each PCI-E 8-Pin power cable needs to be plugged into a 12V rail on the PSU side and can supply up to 150W of power.
+
+Some other cards may use a PCI-E 12-Pin connectors, and these can deliver up to 500-600W of power.
+
+Low end cards may use 6-Pin connectors, which supply up to 75W of power.
+
+Additionally you want the high-end PSU that has stable voltage. Some lower quality ones may not give the card the stable voltage it needs to function at its peak.
+
+And of course the PSU needs to have enough unused Watts to power the card.
+
+**Cooling**:
+
+When a GPU gets overheated it would start throttling down and will not deliver full performance. And it will shutdown if it gets too hot.
+
+It's hard to tell the exact best temperature to strive for when a GPU is heavily loaded, but probably anything under +80C is good, but lower is better - perhaps 70-75C is an excellent range to be in. The throttling down is likely to start at around 84-90C. But other than throttling performance a prolonged very higher temperature is likely to reduce the lifespan of a GPU.
+
+
+
+### Multi-GPU Connectivity
+
+If you use multiple GPUs the way cards are inter-connected can have a huge impact on the total training time.
+
+If the GPUs are on the same physical node, you can run:
+
+```
+nvidia-smi topo -m
+```
+
+and it will tell you how the GPUs are inter-connected.
+
+On a machine with dual-GPU and which are connected with NVLink, you will most likely see something like:
+
+```
+ GPU0 GPU1 CPU Affinity NUMA Affinity
+GPU0 X NV2 0-23 N/A
+GPU1 NV2 X 0-23 N/A
+```
+
+on a different machine w/o NVLink we may see:
+```
+ GPU0 GPU1 CPU Affinity NUMA Affinity
+GPU0 X PHB 0-11 N/A
+GPU1 PHB X 0-11 N/A
+```
+
+The report includes this legend:
+
+```
+ X = Self
+ SYS = Connection traversing PCIe as well as the SMP interconnect between NUMA nodes (e.g., QPI/UPI)
+ NODE = Connection traversing PCIe as well as the interconnect between PCIe Host Bridges within a NUMA node
+ PHB = Connection traversing PCIe as well as a PCIe Host Bridge (typically the CPU)
+ PXB = Connection traversing multiple PCIe bridges (without traversing the PCIe Host Bridge)
+ PIX = Connection traversing at most a single PCIe bridge
+ NV# = Connection traversing a bonded set of # NVLinks
+```
+
+So the first report `NV2` tells us the GPUs are interconnected with 2 NVLinks, and the second report `PHB` we have a typical consumer-level PCIe+Bridge setup.
+
+Check what type of connectivity you have on your setup. Some of these will make the communication between cards faster (e.g. NVLink), others slower (e.g. PHB).
+
+Depending on the type of scalability solution used, the connectivity speed could have a major or a minor impact. If the GPUs need to sync rarely, as in DDP, the impact of a slower connection will be less significant. If the GPUs need to send messages to each other often, as in ZeRO-DP, then faster connectivity becomes super important to achieve faster training.
+
+### NVlink
+
+[NVLink](https://en.wikipedia.org/wiki/NVLink) is a wire-based serial multi-lane near-range communications link developed by Nvidia.
+
+Each new generation provides a faster bandwidth, e.g. here is a quote from [Nvidia Ampere GA102 GPU Architecture](https://www.nvidia.com/content/dam/en-zz/Solutions/geforce/ampere/pdf/NVIDIA-ampere-GA102-GPU-Architecture-Whitepaper-V1.pdf):
+
+> Third-Generation NVLink®
+> GA102 GPUs utilize NVIDIA’s third-generation NVLink interface, which includes four x4 links,
+> with each link providing 14.0625 GB/sec bandwidth in each direction between two GPUs. Four
+> links provide 56.25 GB/sec bandwidth in each direction, and 112.5 GB/sec total bandwidth
+> between two GPUs. Two RTX 3090 GPUs can be connected together for SLI using NVLink.
+> (Note that 3-Way and 4-Way SLI configurations are not supported.)
+
+So the higher `X` you get in the report of `NVX` in the output of `nvidia-smi topo -m` the better. The generation will depend on your GPU architecture.
+
+Let's compare the execution of a gpt2 language model training over a small sample of wikitext.
+
+The results are:
+
+
+| NVlink | Time |
+| ----- | ---: |
+| Y | 101s |
+| N | 131s |
+
+
+You can see that NVLink completes the training ~23% faster.
+
+In the second benchmark we use `NCCL_P2P_DISABLE=1` to tell the GPUs not to use NVLink.
+
+Here is the full benchmark code and outputs:
+
+```
+# DDP w/ NVLink
+
+rm -r /tmp/test-clm; CUDA_VISIBLE_DEVICES=0,1 python -m torch.distributed.launch \
+--nproc_per_node 2 examples/pytorch/language-modeling/run_clm.py --model_name_or_path gpt2 \
+--dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 --do_train \
+--output_dir /tmp/test-clm --per_device_train_batch_size 4 --max_steps 200
+
+{'train_runtime': 101.9003, 'train_samples_per_second': 1.963, 'epoch': 0.69}
+
+# DDP w/o NVLink
+
+rm -r /tmp/test-clm; CUDA_VISIBLE_DEVICES=0,1 NCCL_P2P_DISABLE=1 python -m torch.distributed.launch \
+--nproc_per_node 2 examples/pytorch/language-modeling/run_clm.py --model_name_or_path gpt2 \
+--dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 --do_train
+--output_dir /tmp/test-clm --per_device_train_batch_size 4 --max_steps 200
+
+{'train_runtime': 131.4367, 'train_samples_per_second': 1.522, 'epoch': 0.69}
+```
+
+Hardware: 2x TITAN RTX 24GB each + NVlink with 2 NVLinks (`NV2` in `nvidia-smi topo -m`)
+Software: `pytorch-1.8-to-be` + `cuda-11.0` / `transformers==4.3.0.dev0`
+
+## Software
+
+
+### Model Scalability
+
+When you can't fit a model into the available GPU memory, you need to start using a solution that allows you to scale a large model to use multiple GPUs in parallel.
+
+For indepth details on ZeRO and various other model parallelism protocols please see: [Model Parallelism](parallelism)
+
+
+
+### Anatomy of Model's Operations
+
+Transformers architecture includes 3 main groups of operations grouped below by compute-intensity.
+
+1. **Tensor Contractions**
+
+ Linear layers and components of Multi-Head Attention all do batched **matrix-matrix multiplications**. These operations are the most compute-intensive part of training a transformer.
+
+2. **Statistical Normalizations**
+
+ Softmax and layer normalization are less compute-intensive than tensor contractions, and involve one or more **reduction operations**, the result of which is then applied via a map.
+
+3. **Element-wise Operators**
+
+ These are the remaining operators: **biases, dropout, activations, and residual connections**. These are the least compute-intensive operations.
+
+This knowledge can be helpful to know when analyzing performance bottlenecks.
+
+This summary is derived from [Data Movement Is All You Need: A Case Study on Optimizing Transformers 2020](https://arxiv.org/abs/2007.00072)
+
+
+
+### Anatomy of Model's Memory
+
+The components on GPU memory are the following:
+1. model weights
+2. optimizer states
+3. gradients
+4. forward activations saved for gradient computation
+5. temporary buffers
+6. functionality-specific memory
+
+A typical model trained in mixed precision with AdamW requires 18 bytes per model parameter plus activation memory.
+
+For inference there are no optimizer states and gradients, so we can subtract those. And thus we end up with 6 bytes per model parameter for mixed precision inference, plus activation memory.
+
+Let's look at the details.
+
+#### Model Weights
+
+- 4 bytes * number of parameters for fp32 training
+- 6 bytes * number of parameters for mixed precision training
+
+#### Optimizer States
+
+- 8 bytes * number of parameters for normal AdamW (maintains 2 states)
+- 2 bytes * number of parameters for 8-bit AdamW optimizers like [bitsandbytes](https://github.com/facebookresearch/bitsandbytes)
+- 4 bytes * number of parameters for optimizers like SGD (maintains only 1 state)
+
+#### Gradients
+
+- 4 bytes * number of parameters for either fp32 or mixed precision training
+
+#### Forward Activations
+
+- size depends on many factors, the key ones being sequence length, hidden size and batch size.
+
+There are the input and output that are being passed and returned by the forward and the backward functions and the forward activations saved for gradient computation.
+
+#### Temporary Memory
+
+Additionally there are all kinds of temporary variables which get released once the calculation is done, but in the moment these could require additional memory and could push to OOM. Therefore when coding it's crucial to think strategically about such temporary variables and sometimes to explicitly free those as soon as they are no longer needed.
+
+#### Functionality-specific memory
+
+Then your software could have special memory needs. For example, when generating text using beam search, the software needs to maintain multiple copies of inputs and outputs.
+
+
+
+### `forward` vs `backward` Execution Speed
+
+For convolutions and linear layers there are 2x flops in the backward compared to the forward, which generally translates into ~2x slower (sometimes more, because sizes in the backward tend to be more awkward). Activations are usually bandwidth-limited, and it’s typical for an activation to have to read more data in the backward than in the forward (e.g. activation forward reads once, writes once, activation backward reads twice, gradOutput and output of the forward, and writes once, gradInput).
+
+
+### Floating Data Types
+
+Here are the commonly used floating point data types choice of which impacts both memory usage and throughput:
+
+- fp32 (`float32`)
+- fp16 (`float16`)
+- bf16 (`bfloat16`)
+- tf32 (CUDA internal data type)
+
+Here is a diagram that shows how these data types correlate to each other.
+
+
+
+(source: [NVIDIA Blog](https://developer.nvidia.com/blog/accelerating-ai-training-with-tf32-tensor-cores/))
+
+While fp16 and fp32 have been around for quite some time, bf16 and tf32 are only available on the Ampere architecture GPUS. TPUs support bf16 as well.
+
+
+#### fp16
+
+AMP = Automatic Mixed Precision
+
+If we look at what's happening with FP16 training (mixed precision) we have:
+- the model has two copies in memory: one in half-precision for the forward/backward computations and one in full precision - no memory saved here
+- the forward activations saved for gradient computation are in half-precision - memory is saved here
+- the gradients are computed in half-precision *but* converted to full-precision for the update, no saving there
+- the optimizer states are in full precision as all the updates are done in full-precision
+
+So the savings only happen for the forward activations saved for the backward computation, and there is a slight overhead because the model weights are stored both in half- and full-precision.
+
+In 🤗 Transformers fp16 mixed precision is enabled by passing `--fp16` to the 🤗 Trainer.
+
+Now let's look at a simple text-classification fine-tuning on 2 GPUs (I'm giving the command for reference):
+```
+export BS=16
+python -m torch.distributed.launch \
+ --nproc_per_node 2 examples/pytorch/text-classification/run_glue.py \
+ --model_name_or_path bert-base-cased \
+ --task_name mrpc \
+ --do_train \
+ --do_eval \
+ --max_seq_length 128 \
+ --per_device_train_batch_size $BS \
+ --learning_rate 2e-5 \
+ --num_train_epochs 3.0 \
+ --output_dir /tmp/mrpc \
+ --overwrite_output_dir \
+ --fp16
+```
+Since the only savings we get are in the model activations saved for the backward passed, it's logical that the bigger those activations are, the bigger the saving will be. If we try different batch sizes, I indeed get (this is with `nvidia-smi` so not completely reliable as said above but it will be a fair comparison):
+
+| batch size | w/o --fp16 | w/ --fp16 | savings |
+| ---------: | ---------: | --------: | ------: |
+| 8 | 4247 | 4163 | 84 |
+| 16 | 4971 | 4793 | 178 |
+| 32 | 6827 | 6207 | 620 |
+| 64 | 10037 | 8061 | 1976 |
+
+So there is only a real memory saving if we train at a high batch size (and it's not half) and at batch sizes lower than 8, you actually get a bigger memory footprint (because of the overhead mentioned above). The gain for FP16 training is that in each of those cases, the training with the flag `--fp16` is twice as fast, which does require every tensor to have every dimension be a multiple of 8 (examples pad the tensors to a sequence length that is a multiple of 8).
+
+Summary: FP16 with apex or AMP will only give you some memory savings with a reasonably high batch size.
+
+Additionally, under mixed precision when possible, it's important that the batch size is a multiple of 8 to efficiently use tensor cores.
+
+Note that in some situations the speed up can be as big as 5x when using mixed precision. e.g. we have observed that while using [Megatron-Deepspeed](https://github.com/bigscience-workshop/Megatron-DeepSpeed).
+
+Some amazing tutorials to read on mixed precision:
+- @sgugger wrote a great explanation of mixed precision [here](https://docs.fast.ai/callback.fp16.html#A-little-bit-of-theory)
+- Aleksey Bilogur's [A developer-friendly guide to mixed precision training with PyTorch](https://spell.ml/blog/mixed-precision-training-with-pytorch-Xuk7YBEAACAASJam)
+
+You can also see a variety of benchmarks on fp16 vs other precisions:
+[RTX-3090](https://github.com/huggingface/transformers/issues/14608#issuecomment-1004390803) and
+[A100](https://github.com/huggingface/transformers/issues/15026#issuecomment-1004543189).
+
+
+
+##### fp16 caching
+
+pytorch `autocast` which performs AMP include a caching feature, which speed things up by caching fp16-converted values. Here is the full description from this [comment](https://discuss.pytorch.org/t/autocast-and-torch-no-grad-unexpected-behaviour/93475/3):
+
+Autocast maintains a cache of the FP16 casts of model parameters (leaves). This helps streamline parameter reuse: if the same FP32 param is used in several different FP16list ops, like several matmuls, instead of re-casting the param to FP16 on entering each matmul, the cast will occur on the first matmul, the casted FP16 copy will be cached, and for all later matmuls the FP16 copy will be reused. The cache is maintained only within a particular outermost autocast context. When you exit the autocast context the cache is dropped. For recommended usage, in which autocast wraps the forward pass, and then you exit the context before calling backward(), this means the cache only lasts the duration of the forward pass each iteration, and will be rebuilt next iteration. (The cache of FP16-casted copies MUST be rebuilt each iteration. The FP32 parameters get updated by the optimizer, so the FP16 copies must be recreated, otherwise the FP16 values will be stale.)
+
+##### fp16 Inference
+
+While normally inference is done with fp16/amp as with training, it's also possible to use the full fp16 mode without using mixed precision. This is especially a good fit if the pretrained model weights are already in fp16. So a lot less memory is used: 2 bytes per parameter vs 6 bytes with mixed precision!
+
+How good the results this will deliver will depend on the model. If it can handle fp16 without overflows and accuracy issues, then it'll definitely better to use the full fp16 mode.
+
+For example, LayerNorm has to be done in fp32 and recent pytorch (1.10+) has been fixed to do that regardless of the input types, but earlier pytorch versions accumulate in the input type which can be an issue.
+
+In 🤗 Transformers the full fp16 inference is enabled by passing `--fp16_full_eval` to the 🤗 Trainer.
+
+
+#### bf16
+
+If you own Ampere or newer hardware you can start using bf16 for your training and evaluation. While bf16 has a worse precision than fp16, it has a much much bigger dynamic range. Therefore, if in the past you were experiencing overflow issues while training the model, bf16 will prevent this from happening most of the time. Remember that in fp16 the biggest number you can have is `65535` and any number above that will overflow. A bf16 number can be as large as `3.39e+38` (!) which is about the same as fp32 - because both have 8-bits used for the numerical range.
+
+Automatic Mixed Precision (AMP) is the same as with fp16, except it'll use bf16.
+
+Thanks to the fp32-like dynamic range with bf16 mixed precision loss scaling is no longer needed.
+
+If you have tried to finetune models pre-trained under bf16 mixed precision (e.g. T5) it's very likely that you have encountered overflow issues. Now you should be able to finetune those models without any issues.
+
+That said, also be aware that if you pre-trained a model in bf16, it's likely to have overflow issues if someone tries to finetune it in fp16 down the road. So once started on the bf16-mode path it's best to remain on it and not switch to fp16.
+
+In 🤗 Transformers bf16 mixed precision is enabled by passing `--bf16` to the 🤗 Trainer.
+
+If you use your own trainer, this is just:
+
+```
+from torch.cuda.amp import autocast
+with autocast(dtype=torch.bfloat16):
+ loss, outputs = ...
+```
+
+If you need to switch a tensor to bf16, it's just: `t.to(dtype=torch.bfloat16)`
+
+Here is how you can check if your setup supports bf16:
+
+```
+python -c 'import transformers; print(f"BF16 support is {transformers.utils.is_torch_bf16_available()}")'
+```
+
+On the other hand bf16 has a much worse precision than fp16, so there are certain situations where you'd still want to use fp16 and not bf16.
+
+You can also see a variety of benchmarks on bf16 vs other precisions:
+[RTX-3090](https://github.com/huggingface/transformers/issues/14608#issuecomment-1004390803) and
+[A100](https://github.com/huggingface/transformers/issues/15026#issuecomment-1004543189).
+
+
+##### bf16 Inference
+
+Same as with fp16, you can do inference in either the mixed precision bf16 or using the full bf16 mode. The same caveats apply. For details see [fp16 Inference](#fp16-inference).
+
+In 🤗 Transformers the full bf16 inference is enabled by passing `--bf16_full_eval` to the 🤗 Trainer.
+
+
+#### tf32
+
+The Ampere hardware uses a magical data type called tf32. It has the same numerical range as fp32 (8-bits), but instead of 23 bits precision it has only 10 bits (same as fp16). In total it uses only 19 bits.
+
+It's magical in the sense that you can use the normal fp32 training and/or inference code and by enabling tf32 support you can get up to 3x throughput improvement. All you need to do is to add this to your code:
+
+```
+import torch
+torch.backends.cuda.matmul.allow_tf32 = True
+```
+
+When this is done CUDA will automatically switch to using tf32 instead of fp32 where it's possible. This, of course, assumes that the used GPU is from the Ampere series.
+
+Like all cases with reduced precision this may or may not be satisfactory for your needs, so you have to experiment and see. According to [NVIDIA research](https://developer.nvidia.com/blog/accelerating-ai-training-with-tf32-tensor-cores/) the majority of machine learning training shouldn't be impacted and showed the same perplexity and convergence as the fp32 training.
+
+If you're already using fp16 or bf16 mixed precision it may help with the throughput as well.
+
+You can enable this mode in the 🤗 Trainer with `--tf32`, or disable it with `--tf32 0` or `--no_tf32`.
+By default the PyTorch default is used.
+
+Note: tf32 mode is internal to CUDA and can't be accessed directly via `tensor.to(dtype=torch.tf32)` as `torch.tf32` doesn't exit.
+
+Note: you need `torch>=1.7` to enjoy this feature.
+
+You can also see a variety of benchmarks on tf32 vs other precisions:
+[RTX-3090](https://github.com/huggingface/transformers/issues/14608#issuecomment-1004390803) and
+[A100](https://github.com/huggingface/transformers/issues/15026#issuecomment-1004543189).
+
+
+
+### Gradient Accumulation
+
+Since gradient accumulation essentially is identical to having a larger batch size, just as with the larger batch size here you are likely to see a 20-30% speedup due to the optimizer running less often. For example, see benchmarks for [RTX-3090](https://github.com/huggingface/transformers/issues/14608#issuecomment-1004392537)
+and [A100](https://github.com/huggingface/transformers/issues/15026#issuecomment-1004592231).
+
+To activate this feature in 🤗 Trainer add `--gradient_accumulation_steps 4` to its arguments (experiment with the value to get the best performance).
+
+It's important to remember that using gradient accumulation you may end up with a much larger effective batch size, so you may need to adjust the learning rate, its warm up and for very short datasets it'll impact the loss as the training will end up doing less steps than normal.
+
+
+
+### Gradient Checkpointing
+
+One way to use significantly less GPU memory is to enabled "Gradient Checkpointing" (also known as "activation checkpointing"). When enabled, a lot of memory can be freed at the cost of small decrease in the training speed due to recomputing parts of the graph during back-propagation. The slowdown will depend on the model but quite often it is around 20-30%.
+
+This technique was first shared in the paper: [Training Deep Nets with Sublinear Memory Cost](https://arxiv.org/abs/1604.06174). The paper will also give you the exact details on the savings, but it's in the ballpark of `O(sqrt(n))`, where `n` is the number of feed-forward layers.
+
+To activate this feature in 🤗 Transformers for models that support it, use:
+
+```python
+model.gradient_checkpointing_enable()
+```
+or add `--gradient_checkpointing` to the Trainer arguments.
+
+
+### Batch sizes
+
+One gets the most efficient performance when batch sizes and input/output neuron counts are divisible by a certain number, which typically starts at 8, but can be much higher as well. That number varies a lot depending on the specific hardware being used and the dtype of the model.
+
+For example for fully connected layers (which correspond to GEMMs), NVIDIA provides recommendations for [input/output neuron counts](
+https://docs.nvidia.com/deeplearning/performance/dl-performance-fully-connected/index.html#input-features) and [batch size](https://docs.nvidia.com/deeplearning/performance/dl-performance-fully-connected/index.html#batch-size).
+
+[Tensor Core Requirements](https://docs.nvidia.com/deeplearning/performance/dl-performance-matrix-multiplication/index.html#requirements-tc) define the multiplier based on the dtype and the hardware. For example, for fp16 a multiple of 8 is recommended, but on A100 it's 64!
+
+For parameters that are small, there is also [Dimension Quantization Effects](https://docs.nvidia.com/deeplearning/performance/dl-performance-matrix-multiplication/index.html#dim-quantization) to consider, this is where tiling happens and the right multiplier can have a significant speedup.
+
+Additionally, as explained in the [Gradient Accumulation](#gradient-accumulation) section, the bigger the batch size the less often the optimizer is run, the faster the training is (considering the same dataset length). See benchmarks
+for [RTX-3090](https://github.com/huggingface/transformers/issues/14608#issuecomment-1004392537)
+and [A100](https://github.com/huggingface/transformers/issues/15026#issuecomment-1005033957).
+
+
+### DP vs DDP
+
+`DistributedDataParallel` (DDP) is typically faster than `DataParallel` (DP), but it is not always the case:
+* while DP is python threads-based, DDP is multiprocess-based - and as such it has no python threads limitations, such as GIL
+* on the other hand a slow inter-connectivity between the GPU cards could lead to an actual slower outcome with DDP
+
+Here are the main differences in the inter-GPU communication overhead between the two modes:
+
+[DDP](https://pytorch.org/docs/master/notes/ddp.html):
+
+- At the start time the main process replicates the model once from gpu 0 to the rest of gpus
+- Then for each batch:
+ 1. each gpu consumes each own mini-batch of data directly
+ 2. during `backward`, once the local gradients are ready, they are then averaged across all processes
+
+[DP](https://pytorch.org/docs/master/generated/torch.nn.DataParallel.html):
+
+For each batch:
+ 1. gpu 0 reads the batch of data and then sends a mini-batch to each gpu
+ 2. replicates the up-to-date model from gpu 0 to each gpu
+ 3. runs `forward` and sends output from each gpu to gpu 0, computes loss
+ 4. scatters loss from gpu 0 to all gpus, runs `backward`
+ 5. sends gradients from each gpu to gpu 0 and averages those
+
+The only communication DDP performs per batch is sending gradients, whereas DP does 5 different data exchanges per batch.
+
+DP copies data within the process via python threads, whereas DDP copies data via [torch.distributed](https://pytorch.org/docs/master/distributed.html).
+
+Under DP gpu 0 performs a lot more work than the rest of the gpus, thus resulting in under-utilization of gpus.
+
+You can use DDP across multiple machines, but this is not the case with DP.
+
+There are other differences between DP and DDP but they aren't relevant to this discussion.
+
+If you want to go really deep into understanding these 2 modes, this [article](https://www.telesens.co/2019/04/04/distributed-data-parallel-training-using-pytorch-on-aws/) is highly recommended, as it has great diagrams, includes multiple benchmarks and profiler outputs on various hardware, explains all the nuances that you may need to know.
+
+Let's look at an actual benchmark:
+
+| Type | NVlink | Time |
+| :----- | ----- | ---: |
+| 2:DP | Y | 110s |
+| 2:DDP | Y | 101s |
+| 2:DDP | N | 131s |
+
+
+Analysis:
+
+Here DP is ~10% slower than DDP w/ NVlink, but ~15% faster than DDP w/o NVlink
+
+The real difference will depend on how much data each GPU needs to sync with the others - the more there is to sync, the more a slow link will slow down the total runtime.
+
+Here is the full benchmark code and outputs:
+
+`NCCL_P2P_DISABLE=1` was used to disable the NVLink feature on the corresponding benchmark.
+
+```
+
+# DP
+rm -r /tmp/test-clm; CUDA_VISIBLE_DEVICES=0,1 \
+python examples/pytorch/language-modeling/run_clm.py \
+--model_name_or_path gpt2 --dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 \
+--do_train --output_dir /tmp/test-clm --per_device_train_batch_size 4 --max_steps 200
+
+{'train_runtime': 110.5948, 'train_samples_per_second': 1.808, 'epoch': 0.69}
+
+# DDP w/ NVlink
+rm -r /tmp/test-clm; CUDA_VISIBLE_DEVICES=0,1 \
+python -m torch.distributed.launch --nproc_per_node 2 examples/pytorch/language-modeling/run_clm.py \
+--model_name_or_path gpt2 --dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 \
+--do_train --output_dir /tmp/test-clm --per_device_train_batch_size 4 --max_steps 200
+
+{'train_runtime': 101.9003, 'train_samples_per_second': 1.963, 'epoch': 0.69}
+
+# DDP w/o NVlink
+rm -r /tmp/test-clm; NCCL_P2P_DISABLE=1 CUDA_VISIBLE_DEVICES=0,1 \
+python -m torch.distributed.launch --nproc_per_node 2 examples/pytorch/language-modeling/run_clm.py \
+--model_name_or_path gpt2 --dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 \
+--do_train --output_dir /tmp/test-clm --per_device_train_batch_size 4 --max_steps 200
+
+{'train_runtime': 131.4367, 'train_samples_per_second': 1.522, 'epoch': 0.69}
+```
+
+Hardware: 2x TITAN RTX 24GB each + NVlink with 2 NVLinks (`NV2` in `nvidia-smi topo -m`)
+Software: `pytorch-1.8-to-be` + `cuda-11.0` / `transformers==4.3.0.dev0`
+
+
+### DataLoader
+
+One of the important requirements to reach great training speed is the ability to feed the GPU at the maximum speed it can handle. By default everything happens in the main process and it might not be able to read the data from disk fast enough, and thus create a bottleneck, leading to GPU under-utilization.
+
+- `DataLoader(pin_memory=True, ...)` which ensures that the data gets preloaded into the pinned memory on CPU and typically leads to much faster transfers from CPU to GPU memory.
+- `DataLoader(num_workers=4, ...)` - spawn several workers to pre-load data faster - during training watch the GPU utilization stats and if it's far from 100% experiment with raising the number of workers. Of course, the problem could be elsewhere so a very big number of workers won't necessarily lead to a better performance.
+
+## Faster optimizer
+
+pytorch-nightly introduced `torch.optim._multi_tensor` which should significantly speed up the optimizers for situations with lots of small feature tensors. It should eventually become the default, but if you want to experiment with it sooner and don't mind using the bleed-edge, see: https://github.com/huggingface/transformers/issues/9965
+
+
+### Sparsity
+
+#### Mixture of Experts
+
+Quite a few of the recent papers reported a 4-5x training speedup and a faster inference by integrating
+Mixture of Experts (MoE) into the Transformer models.
+
+Since it has been discovered that more parameters lead to better performance, this technique allows to increase the number of parameters by an order of magnitude without increasing training costs.
+
+In this approach every other FFN layer is replaced with a MoE Layer which consists of many experts, with a gated function that trains each expert in a balanced way depending on the input token's position in a sequence.
+
+
+
+(source: [GLAM](https://ai.googleblog.com/2021/12/more-efficient-in-context-learning-with.html))
+
+You can find exhaustive details and comparison tables in the papers listed at the end of this section.
+
+The main drawback of this approach is that it requires staggering amounts of GPU memory - almost an order of magnitude larger than its dense equivalent. Various distillation and approaches are proposed to how to overcome the much higher memory requirements.
+
+There is direct trade-off though, you can use just a few experts with a 2-3x smaller base model instead of dozens or hundreds experts leading to a 5x smaller model and thus increase the training speed moderately while increasing the memory requirements moderately as well.
+
+Most related papers and implementations are built around Tensorflow/TPUs:
+
+- [GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding](https://arxiv.org/abs/2006.16668)
+- [Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity](https://arxiv.org/abs/2101.03961)
+- [GLaM: Generalist Language Model (GLaM)](https://ai.googleblog.com/2021/12/more-efficient-in-context-learning-with.html)
+
+And for Pytorch DeepSpeed has built one as well: [DeepSpeed-MoE: Advancing Mixture-of-Experts Inference and Training to Power Next-Generation AI Scale](https://arxiv.org/abs/2201.05596), [Mixture of Experts](https://www.deepspeed.ai/tutorials/mixture-of-experts/) - blog posts: [1](https://www.microsoft.com/en-us/research/blog/deepspeed-powers-8x-larger-moe-model-training-with-high-performance/), [2](https://www.microsoft.com/en-us/research/publication/scalable-and-efficient-moe-training-for-multitask-multilingual-models/) and specific deployment with large transformer-based natural language generation models: [blog post](https://www.deepspeed.ai/news/2021/12/09/deepspeed-moe-nlg.html), [Megatron-Deepspeed branch](Thttps://github.com/microsoft/Megatron-DeepSpeed/tree/moe-training).
+
+
+
+### Efficient Software Prebuilds
+
+PyTorch's [pip and conda builds](https://pytorch.org/get-started/locally/#start-locally) come prebuit with the cuda toolkit which is enough to run PyTorch, but it is insufficient if you need to build cuda extensions.
+
+At times it may take an additional effort to pre-build some components, e.g., if you're using libraries like `apex` that don't come pre-compiled. In other situations figuring out how to install the right cuda toolkit system-wide can be complicated. To address these users' needs PyTorch and NVIDIA release a new version of NGC docker container which already comes with everything prebuilt and you just need to install your programs on it and it will run out of the box.
+
+This approach is also useful if you want to tweak the pytorch source and/or make a new customized build.
+
+To find the docker image version you want start [here](https://docs.nvidia.com/deeplearning/frameworks/pytorch-release-notes/), choose one of the latest monthly releases. Go into the release's notes for the desired release, check that the environment's components are matching your needs (including NVIDIA Driver requirements!) and then at the very top of that document go to the corresponding NGC page. If for some reason you get lost, here is [the index of all PyTorch NGC images](https://ngc.nvidia.com/catalog/containers/nvidia:pytorch).
+
+Next follow the instructions to download and deploy the docker image.
+
+
+## Contribute
+
+This document is far from being complete and a lot more needs to be added, so if you have additions or corrections to make please don't hesitate to open a PR or if you aren't sure start an Issue and we can discuss the details there.
+
+When making contributions that A is better than B, please try to include a reproducible benchmark and/or a link to the source of that information (unless it comes directly from you).
diff --git a/docs/source/en/perplexity.mdx b/docs/source/en/perplexity.mdx
new file mode 100644
index 00000000000000..3706a40091c2ca
--- /dev/null
+++ b/docs/source/en/perplexity.mdx
@@ -0,0 +1,130 @@
+
+
+# Perplexity of fixed-length models
+
+[[open-in-colab]]
+
+Perplexity (PPL) is one of the most common metrics for evaluating language models. Before diving in, we should note
+that the metric applies specifically to classical language models (sometimes called autoregressive or causal language
+models) and is not well defined for masked language models like BERT (see [summary of the models](model_summary)).
+
+Perplexity is defined as the exponentiated average negative log-likelihood of a sequence. If we have a tokenized
+sequence \\(X = (x_0, x_1, \dots, x_t)\\), then the perplexity of \\(X\\) is,
+
+$$\text{PPL}(X) = \exp \left\{ {-\frac{1}{t}\sum_i^t \log p_\theta (x_i|x_{
+
+When working with approximate models, however, we typically have a constraint on the number of tokens the model can
+process. The largest version of [GPT-2](model_doc/gpt2), for example, has a fixed length of 1024 tokens, so we
+cannot calculate \\(p_\theta(x_t|x_{
+
+This is quick to compute since the perplexity of each segment can be computed in one forward pass, but serves as a poor
+approximation of the fully-factorized perplexity and will typically yield a higher (worse) PPL because the model will
+have less context at most of the prediction steps.
+
+Instead, the PPL of fixed-length models should be evaluated with a sliding-window strategy. This involves repeatedly
+sliding the context window so that the model has more context when making each prediction.
+
+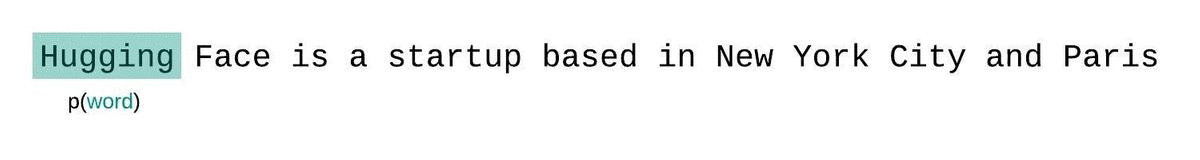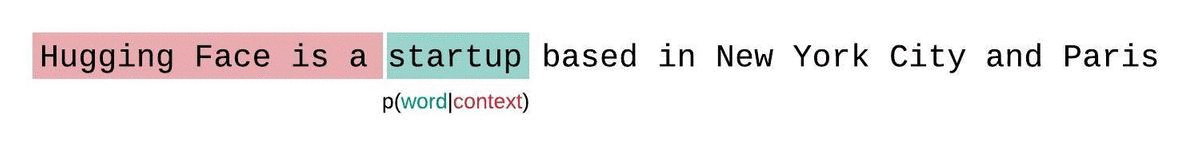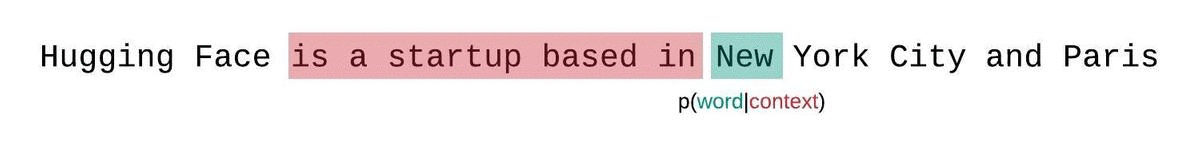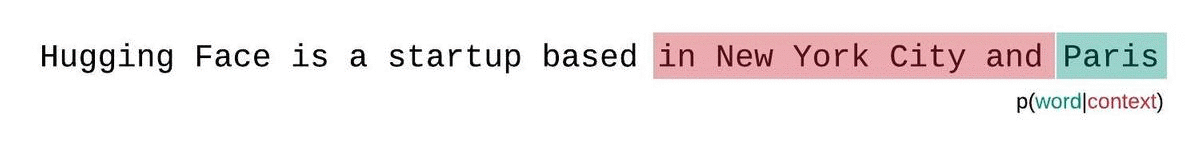 +
+This is a closer approximation to the true decomposition of the sequence probability and will typically yield a more
+favorable score. The downside is that it requires a separate forward pass for each token in the corpus. A good
+practical compromise is to employ a strided sliding window, moving the context by larger strides rather than sliding by
+1 token a time. This allows computation to proceed much faster while still giving the model a large context to make
+predictions at each step.
+
+## Example: Calculating perplexity with GPT-2 in 🤗 Transformers
+
+Let's demonstrate this process with GPT-2.
+
+```python
+from transformers import GPT2LMHeadModel, GPT2TokenizerFast
+
+device = "cuda"
+model_id = "gpt2-large"
+model = GPT2LMHeadModel.from_pretrained(model_id).to(device)
+tokenizer = GPT2TokenizerFast.from_pretrained(model_id)
+```
+
+We'll load in the WikiText-2 dataset and evaluate the perplexity using a few different sliding-window strategies. Since
+this dataset is small and we're just doing one forward pass over the set, we can just load and encode the entire
+dataset in memory.
+
+```python
+from datasets import load_dataset
+
+test = load_dataset("wikitext", "wikitext-2-raw-v1", split="test")
+encodings = tokenizer("\n\n".join(test["text"]), return_tensors="pt")
+```
+
+With 🤗 Transformers, we can simply pass the `input_ids` as the `labels` to our model, and the average negative
+log-likelihood for each token is returned as the loss. With our sliding window approach, however, there is overlap in
+the tokens we pass to the model at each iteration. We don't want the log-likelihood for the tokens we're just treating
+as context to be included in our loss, so we can set these targets to `-100` so that they are ignored. The following
+is an example of how we could do this with a stride of `512`. This means that the model will have at least 512 tokens
+for context when calculating the conditional likelihood of any one token (provided there are 512 preceding tokens
+available to condition on).
+
+```python
+import torch
+from tqdm import tqdm
+
+max_length = model.config.n_positions
+stride = 512
+
+nlls = []
+for i in tqdm(range(0, encodings.input_ids.size(1), stride)):
+ begin_loc = max(i + stride - max_length, 0)
+ end_loc = min(i + stride, encodings.input_ids.size(1))
+ trg_len = end_loc - i # may be different from stride on last loop
+ input_ids = encodings.input_ids[:, begin_loc:end_loc].to(device)
+ target_ids = input_ids.clone()
+ target_ids[:, :-trg_len] = -100
+
+ with torch.no_grad():
+ outputs = model(input_ids, labels=target_ids)
+ neg_log_likelihood = outputs[0] * trg_len
+
+ nlls.append(neg_log_likelihood)
+
+ppl = torch.exp(torch.stack(nlls).sum() / end_loc)
+```
+
+Running this with the stride length equal to the max input length is equivalent to the suboptimal, non-sliding-window
+strategy we discussed above. The smaller the stride, the more context the model will have in making each prediction,
+and the better the reported perplexity will typically be.
+
+When we run the above with `stride = 1024`, i.e. no overlap, the resulting PPL is `19.64`, which is about the same
+as the `19.93` reported in the GPT-2 paper. By using `stride = 512` and thereby employing our striding window
+strategy, this jumps down to `16.53`. This is not only a more favorable score, but is calculated in a way that is
+closer to the true autoregressive decomposition of a sequence likelihood.
diff --git a/docs/source/en/philosophy.mdx b/docs/source/en/philosophy.mdx
new file mode 100644
index 00000000000000..13134c31d4a6b9
--- /dev/null
+++ b/docs/source/en/philosophy.mdx
@@ -0,0 +1,80 @@
+
+
+# Philosophy
+
+🤗 Transformers is an opinionated library built for:
+
+- NLP researchers and educators seeking to use/study/extend large-scale transformers models
+- hands-on practitioners who want to fine-tune those models and/or serve them in production
+- engineers who just want to download a pretrained model and use it to solve a given NLP task.
+
+The library was designed with two strong goals in mind:
+
+- Be as easy and fast to use as possible:
+
+ - We strongly limited the number of user-facing abstractions to learn, in fact, there are almost no abstractions,
+ just three standard classes required to use each model: [configuration](main_classes/configuration),
+ [models](main_classes/model) and [tokenizer](main_classes/tokenizer).
+ - All of these classes can be initialized in a simple and unified way from pretrained instances by using a common
+ `from_pretrained()` instantiation method which will take care of downloading (if needed), caching and
+ loading the related class instance and associated data (configurations' hyper-parameters, tokenizers' vocabulary,
+ and models' weights) from a pretrained checkpoint provided on [Hugging Face Hub](https://huggingface.co/models) or your own saved checkpoint.
+ - On top of those three base classes, the library provides two APIs: [`pipeline`] for quickly
+ using a model (plus its associated tokenizer and configuration) on a given task and
+ [`Trainer`]/`Keras.fit` to quickly train or fine-tune a given model.
+ - As a consequence, this library is NOT a modular toolbox of building blocks for neural nets. If you want to
+ extend/build-upon the library, just use regular Python/PyTorch/TensorFlow/Keras modules and inherit from the base
+ classes of the library to reuse functionalities like model loading/saving.
+
+- Provide state-of-the-art models with performances as close as possible to the original models:
+
+ - We provide at least one example for each architecture which reproduces a result provided by the official authors
+ of said architecture.
+ - The code is usually as close to the original code base as possible which means some PyTorch code may be not as
+ *pytorchic* as it could be as a result of being converted TensorFlow code and vice versa.
+
+A few other goals:
+
+- Expose the models' internals as consistently as possible:
+
+ - We give access, using a single API, to the full hidden-states and attention weights.
+ - Tokenizer and base model's API are standardized to easily switch between models.
+
+- Incorporate a subjective selection of promising tools for fine-tuning/investigating these models:
+
+ - A simple/consistent way to add new tokens to the vocabulary and embeddings for fine-tuning.
+ - Simple ways to mask and prune transformer heads.
+
+- Switch easily between PyTorch and TensorFlow 2.0, allowing training using one framework and inference using another.
+
+## Main concepts
+
+The library is built around three types of classes for each model:
+
+- **Model classes** such as [`BertModel`], which are 30+ PyTorch models ([torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module)) or Keras models ([tf.keras.Model](https://www.tensorflow.org/api_docs/python/tf/keras/Model)) that work with the pretrained weights provided in the
+ library.
+- **Configuration classes** such as [`BertConfig`], which store all the parameters required to build
+ a model. You don't always need to instantiate these yourself. In particular, if you are using a pretrained model
+ without any modification, creating the model will automatically take care of instantiating the configuration (which
+ is part of the model).
+- **Tokenizer classes** such as [`BertTokenizer`], which store the vocabulary for each model and
+ provide methods for encoding/decoding strings in a list of token embeddings indices to be fed to a model.
+
+All these classes can be instantiated from pretrained instances and saved locally using two methods:
+
+- `from_pretrained()` lets you instantiate a model/configuration/tokenizer from a pretrained version either
+ provided by the library itself (the supported models can be found on the [Model Hub](https://huggingface.co/models)) or
+ stored locally (or on a server) by the user,
+- `save_pretrained()` lets you save a model/configuration/tokenizer locally so that it can be reloaded using
+ `from_pretrained()`.
+
diff --git a/docs/source/en/pipeline_tutorial.mdx b/docs/source/en/pipeline_tutorial.mdx
new file mode 100644
index 00000000000000..b59ff82a9b02e0
--- /dev/null
+++ b/docs/source/en/pipeline_tutorial.mdx
@@ -0,0 +1,148 @@
+
+
+# Pipelines for inference
+
+The [`pipeline`] makes it simple to use any model from the [Model Hub](https://huggingface.co/models) for inference on a variety of tasks such as text generation, image segmentation and audio classification. Even if you don't have experience with a specific modality or understand the code powering the models, you can still use them with the [`pipeline`]! This tutorial will teach you to:
+
+* Use a [`pipeline`] for inference.
+* Use a specific tokenizer or model.
+* Use a [`pipeline`] for audio and vision tasks.
+
+
+
+Take a look at the [`pipeline`] documentation for a complete list of supported taska.
+
+
+
+## Pipeline usage
+
+While each task has an associated [`pipeline`], it is simpler to use the general [`pipeline`] abstraction which contains all the specific task pipelines. The [`pipeline`] automatically loads a default model and tokenizer capable of inference for your task.
+
+1. Start by creating a [`pipeline`] and specify an inference task:
+
+```py
+>>> from transformers import pipeline
+
+>>> generator = pipeline(task="text-generation")
+```
+
+2. Pass your input text to the [`pipeline`]:
+
+```py
+>>> generator(
+... "Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone"
+... ) # doctest: +SKIP
+[{'generated_text': 'Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone, Seven for the Iron-priests at the door to the east, and thirteen for the Lord Kings at the end of the mountain'}]
+```
+
+If you have more than one input, pass your input as a list:
+
+```py
+>>> generator(
+... [
+... "Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone",
+... "Nine for Mortal Men, doomed to die, One for the Dark Lord on his dark throne",
+... ]
+... ) # doctest: +SKIP
+```
+
+Any additional parameters for your task can also be included in the [`pipeline`]. The `text-generation` task has a [`~generation_utils.GenerationMixin.generate`] method with several parameters for controlling the output. For example, if you want to generate more than one output, set the `num_return_sequences` parameter:
+
+```py
+>>> generator(
+... "Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone",
+... num_return_sequences=2,
+... ) # doctest: +SKIP
+```
+
+### Choose a model and tokenizer
+
+The [`pipeline`] accepts any model from the [Model Hub](https://huggingface.co/models). There are tags on the Model Hub that allow you to filter for a model you'd like to use for your task. Once you've picked an appropriate model, load it with the corresponding `AutoModelFor` and [`AutoTokenizer'] class. For example, load the [`AutoModelForCausalLM`] class for a causal language modeling task:
+
+```py
+>>> from transformers import AutoTokenizer, AutoModelForCausalLM
+
+>>> tokenizer = AutoTokenizer.from_pretrained("distilgpt2")
+>>> model = AutoModelForCausalLM.from_pretrained("distilgpt2")
+```
+
+Create a [`pipeline`] for your task, and specify the model and tokenizer you've loaded:
+
+```py
+>>> from transformers import pipeline
+
+>>> generator = pipeline(task="text-generation", model=model, tokenizer=tokenizer)
+```
+
+Pass your input text to the [`pipeline`] to generate some text:
+
+```py
+>>> generator(
+... "Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone"
+... ) # doctest: +SKIP
+[{'generated_text': 'Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone, Seven for the Dragon-lords (for them to rule in a world ruled by their rulers, and all who live within the realm'}]
+```
+
+## Audio pipeline
+
+The flexibility of the [`pipeline`] means it can also be extended to audio tasks.
+
+For example, let's classify the emotion in this audio clip:
+
+```py
+>>> from datasets import load_dataset
+>>> import torch
+
+>>> torch.manual_seed(42) # doctest: +IGNORE_RESULT
+>>> ds = load_dataset("hf-internal-testing/librispeech_asr_demo", "clean", split="validation")
+>>> audio_file = ds[0]["audio"]["path"]
+```
+
+Find an [audio classification](https://huggingface.co/models?pipeline_tag=audio-classification) model on the Model Hub for emotion recognition and load it in the [`pipeline`]:
+
+```py
+>>> from transformers import pipeline
+
+>>> audio_classifier = pipeline(
+... task="audio-classification", model="ehcalabres/wav2vec2-lg-xlsr-en-speech-emotion-recognition"
+... )
+```
+
+Pass the audio file to the [`pipeline`]:
+
+```py
+>>> preds = audio_classifier(audio_file)
+>>> preds = [{"score": round(pred["score"], 4), "label": pred["label"]} for pred in preds]
+>>> preds
+[{'score': 0.1315, 'label': 'calm'}, {'score': 0.1307, 'label': 'neutral'}, {'score': 0.1274, 'label': 'sad'}, {'score': 0.1261, 'label': 'fearful'}, {'score': 0.1242, 'label': 'happy'}]
+```
+
+## Vision pipeline
+
+Finally, using a [`pipeline`] for vision tasks is practically identical.
+
+Specify your vision task and pass your image to the classifier. The imaage can be a link or a local path to the image. For example, what species of cat is shown below?
+
+
+
+```py
+>>> from transformers import pipeline
+
+>>> vision_classifier = pipeline(task="image-classification")
+>>> preds = vision_classifier(
+... images="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
+... )
+>>> preds = [{"score": round(pred["score"], 4), "label": pred["label"]} for pred in preds]
+>>> preds
+[{'score': 0.4335, 'label': 'lynx, catamount'}, {'score': 0.0348, 'label': 'cougar, puma, catamount, mountain lion, painter, panther, Felis concolor'}, {'score': 0.0324, 'label': 'snow leopard, ounce, Panthera uncia'}, {'score': 0.0239, 'label': 'Egyptian cat'}, {'score': 0.0229, 'label': 'tiger cat'}]
+```
diff --git a/docs/source/en/pr_checks.mdx b/docs/source/en/pr_checks.mdx
new file mode 100644
index 00000000000000..57e0766c7f6776
--- /dev/null
+++ b/docs/source/en/pr_checks.mdx
@@ -0,0 +1,132 @@
+
+
+# Checks on a Pull Request
+
+When you open a pull request on 🤗 Transformers, a fair number of checks will be run to make sure the patch you are adding is not breaking anything existing. Those checks are of four types:
+- regular tests
+- documentation build
+- code and documentation style
+- general repository consistency
+
+In this document, we will take a stab at explaining what those various checks are and the reason behind them, as well as how to debug them locally if one of them fails on your PR.
+
+Note that they all require you to have a dev install:
+
+```bash
+pip install transformers[dev]
+```
+
+or for an editable install:
+
+```bash
+pip install -e .[dev]
+```
+
+inside the Transformers repo.
+
+## Tests
+
+All the jobs that begin with `ci/circleci: run_tests_` run parts of the Transformers testing suite. Each of those jobs focuses on a part of the library in a certain environment: for instance `ci/circleci: run_tests_pipelines_tf` runs the pipelines test in an environment where TensorFlow only is installed.
+
+Note that to avoid running tests when there is no real change in the modules they are testing, only part of the test suite is run each time: a utility is run to determine the differences in the library between before and after the PR (what GitHub shows you in the "Files changes" tab) and picks the tests impacted by that diff. That utility can be run locally with:
+
+```bash
+python utils/tests_fetcher.py
+```
+
+from the root of the Transformers repo. It will:
+
+1. Check for each file in the diff if the changes are in the code or only in comments or docstrings. Only the files with real code changes are kept.
+2. Build an internal map that gives for each file of the source code of the library all the files it recursively impacts. Module A is said to impact module B if module B imports module A. For the recursive impact, we need a chain of modules going from module A to module B in which each module imports the previous one.
+3. Apply this map on the files gathered in step 1, which gives us the list of model files impacted by the PR.
+4. Map each of those files to their corresponding test file(s) and get the list of tests to run.
+
+When executing the script locally, you should get the results of step 1, 3 and 4 printed and thus know which tests are run. The script will also create a file named `test_list.txt` which contains the list of tests to run, and you can run them locally with the following command:
+
+```bash
+python -m pytest -n 8 --dist=loadfile -rA -s $(cat test_list.txt)
+```
+
+Just in case anything slipped through the cracks, the full test suite is also run daily.
+
+## Documentation build
+
+The job `ci/circleci: build_doc` runs a build of the documentation just to make sure everything will be okay once your PR is merged. If that steps fails, you can inspect it locally by going into the `docs` folder of the Transformers repo and then typing
+
+```bash
+make html
+```
+
+Sphinx is not known for its helpful error messages, so you might have to try a few things to really find the source of the error.
+
+## Code and documentation style
+
+Code formatting is applied to all the source files, the examples and the tests using `black` and `isort`. We also have a custom tool taking care of the formatting of docstrings and `rst` files (`utils/style_doc.py`), as well as the order of the lazy imports performed in the Transformers `__init__.py` files (`utils/custom_init_isort.py`). All of this can be launched by executing
+
+```bash
+make style
+```
+
+The CI checks those have been applied inside the `ci/circleci: check_code_quality` check. It also runs `flake8`, that will have a basic look at your code and will complain if it finds an undefined variable, or one that is not used. To run that check locally, use
+
+```bash
+make quality
+```
+
+This can take a lot of time, so to run the same thing on only the files you modified in the current branch, run
+
+```bash
+make fixup
+```
+
+This last command will also run all the additional checks for the repository consistency. Let's have a look at them.
+
+## Repository consistency
+
+This regroups all the tests to make sure your PR leaves the repository in a good state, and is performed by the `ci/circleci: check_repository_consistency` check. You can locally run that check by executing the following:
+
+```bash
+make repo-consistency
+```
+
+This checks that:
+
+- All objects added to the init are documented (performed by `utils/check_repo.py`)
+- All `__init__.py` files have the same content in their two sections (performed by `utils/check_inits.py`)
+- All code identified as a copy from another module is consistent with the original (performed by `utils/check_copies.py`)
+- All configuration classes have at least one valid checkpoint mentioned in their docstrings (performed by `utils/check_config_docstrings.py`)
+- The translations of the READMEs and the index of the doc have the same model list as the main README (performed by `utils/check_copies.py`)
+- The auto-generated tables in the documentation are up to date (performed by `utils/check_table.py`)
+- The library has all objects available even if not all optional dependencies are installed (performed by `utils/check_dummies.py`)
+
+Should this check fail, the first two items require manual fixing, the last four can be fixed automatically for you by running the command
+
+```bash
+make fix-copies
+```
+
+Additional checks concern PRs that add new models, mainly that:
+
+- All models added are in an Auto-mapping (performed by `utils/check_repo.py`)
+
+- All models are properly tested (performed by `utils/check_repo.py`)
+
+
diff --git a/docs/source/en/preprocessing.mdx b/docs/source/en/preprocessing.mdx
new file mode 100644
index 00000000000000..947129b34aafa4
--- /dev/null
+++ b/docs/source/en/preprocessing.mdx
@@ -0,0 +1,498 @@
+
+
+# Preprocess
+
+[[open-in-colab]]
+
+Before you can use your data in a model, the data needs to be processed into an acceptable format for the model. A model does not understand raw text, images or audio. These inputs need to be converted into numbers and assembled into tensors. In this tutorial, you will:
+
+* Preprocess textual data with a tokenizer.
+* Preprocess image or audio data with a feature extractor.
+* Preprocess data for a multimodal task with a processor.
+
+## NLP
+
+
+
+The main tool for processing textual data is a [tokenizer](main_classes/tokenizer). A tokenizer starts by splitting text into *tokens* according to a set of rules. The tokens are converted into numbers, which are used to build tensors as input to a model. Any additional inputs required by a model are also added by the tokenizer.
+
+
+
+If you plan on using a pretrained model, it's important to use the associated pretrained tokenizer. This ensures the text is split the same way as the pretraining corpus, and uses the same corresponding tokens-to-index (usually referrred to as the *vocab*) during pretraining.
+
+
+
+Get started quickly by loading a pretrained tokenizer with the [`AutoTokenizer`] class. This downloads the *vocab* used when a model is pretrained.
+
+### Tokenize
+
+Load a pretrained tokenizer with [`AutoTokenizer.from_pretrained`]:
+
+```py
+>>> from transformers import AutoTokenizer
+
+>>> tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
+```
+
+Then pass your sentence to the tokenizer:
+
+```py
+>>> encoded_input = tokenizer("Do not meddle in the affairs of wizards, for they are subtle and quick to anger.")
+>>> print(encoded_input)
+{'input_ids': [101, 2079, 2025, 19960, 10362, 1999, 1996, 3821, 1997, 16657, 1010, 2005, 2027, 2024, 11259, 1998, 4248, 2000, 4963, 1012, 102],
+ 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
+ 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
+```
+
+The tokenizer returns a dictionary with three important itmes:
+
+* [input_ids](glossary#input-ids) are the indices corresponding to each token in the sentence.
+* [attention_mask](glossary#attention-mask) indicates whether a token should be attended to or not.
+* [token_type_ids](glossary#token-type-ids) identifies which sequence a token belongs to when there is more than one sequence.
+
+You can decode the `input_ids` to return the original input:
+
+```py
+>>> tokenizer.decode(encoded_input["input_ids"])
+'[CLS] Do not meddle in the affairs of wizards, for they are subtle and quick to anger. [SEP]'
+```
+
+As you can see, the tokenizer added two special tokens - `CLS` and `SEP` (classifier and separator) - to the sentence. Not all models need
+special tokens, but if they do, the tokenizer will automatically add them for you.
+
+If there are several sentences you want to process, pass the sentences as a list to the tokenizer:
+
+```py
+>>> batch_sentences = [
+... "But what about second breakfast?",
+... "Don't think he knows about second breakfast, Pip.",
+... "What about elevensies?",
+... ]
+>>> encoded_inputs = tokenizer(batch_sentences)
+>>> print(encoded_inputs)
+{'input_ids': [[101, 1252, 1184, 1164, 1248, 6462, 136, 102],
+ [101, 1790, 112, 189, 1341, 1119, 3520, 1164, 1248, 6462, 117, 21902, 1643, 119, 102],
+ [101, 1327, 1164, 5450, 23434, 136, 102]],
+ 'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0],
+ [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
+ [0, 0, 0, 0, 0, 0, 0]],
+ 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1],
+ [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
+ [1, 1, 1, 1, 1, 1, 1]]}
+```
+
+### Pad
+
+This brings us to an important topic. When you process a batch of sentences, they aren't always the same length. This is a problem because tensors, the input to the model, need to have a uniform shape. Padding is a strategy for ensuring tensors are rectangular by adding a special *padding token* to sentences with fewer tokens.
+
+Set the `padding` parameter to `True` to pad the shorter sequences in the batch to match the longest sequence:
+
+```py
+>>> batch_sentences = [
+... "But what about second breakfast?",
+... "Don't think he knows about second breakfast, Pip.",
+... "What about elevensies?",
+... ]
+>>> encoded_input = tokenizer(batch_sentences, padding=True)
+>>> print(encoded_input)
+{'input_ids': [[101, 1252, 1184, 1164, 1248, 6462, 136, 102, 0, 0, 0, 0, 0, 0, 0],
+ [101, 1790, 112, 189, 1341, 1119, 3520, 1164, 1248, 6462, 117, 21902, 1643, 119, 102],
+ [101, 1327, 1164, 5450, 23434, 136, 102, 0, 0, 0, 0, 0, 0, 0, 0]],
+ 'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
+ [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
+ [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]],
+ 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0],
+ [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
+ [1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0]]}
+```
+
+Notice the tokenizer padded the first and third sentences with a `0` because they are shorter!
+
+### Truncation
+
+On the other end of the spectrum, sometimes a sequence may be too long for a model to handle. In this case, you will need to truncate the sequence to a shorter length.
+
+Set the `truncation` parameter to `True` to truncate a sequence to the maximum length accepted by the model:
+
+```py
+>>> batch_sentences = [
+... "But what about second breakfast?",
+... "Don't think he knows about second breakfast, Pip.",
+... "What about elevensies?",
+... ]
+>>> encoded_input = tokenizer(batch_sentences, padding=True, truncation=True)
+>>> print(encoded_input)
+{'input_ids': [[101, 1252, 1184, 1164, 1248, 6462, 136, 102, 0, 0, 0, 0, 0, 0, 0],
+ [101, 1790, 112, 189, 1341, 1119, 3520, 1164, 1248, 6462, 117, 21902, 1643, 119, 102],
+ [101, 1327, 1164, 5450, 23434, 136, 102, 0, 0, 0, 0, 0, 0, 0, 0]],
+ 'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
+ [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
+ [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]],
+ 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0],
+ [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
+ [1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0]]}
+```
+
+### Build tensors
+
+Finally, you want the tokenizer to return the actual tensors that are fed to the model.
+
+Set the `return_tensors` parameter to either `pt` for PyTorch, or `tf` for TensorFlow:
+
+
+
+
+```py
+>>> batch_sentences = [
+... "But what about second breakfast?",
+... "Don't think he knows about second breakfast, Pip.",
+... "What about elevensies?",
+... ]
+>>> encoded_input = tokenizer(batch, padding=True, truncation=True, return_tensors="pt")
+>>> print(encoded_input)
+{'input_ids': tensor([[ 101, 153, 7719, 21490, 1122, 1114, 9582, 1623, 102],
+ [ 101, 5226, 1122, 9649, 1199, 2610, 1236, 102, 0]]),
+ 'token_type_ids': tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0],
+ [0, 0, 0, 0, 0, 0, 0, 0, 0]]),
+ 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1],
+ [1, 1, 1, 1, 1, 1, 1, 1, 0]])}
+```
+
+
+```py
+>>> batch_sentences = [
+... "But what about second breakfast?",
+... "Don't think he knows about second breakfast, Pip.",
+... "What about elevensies?",
+... ]
+>>> encoded_input = tokenizer(batch_sentences, padding=True, truncation=True, return_tensors="tf")
+>>> print(encoded_input)
+{'input_ids': ,
+ 'token_type_ids': ,
+ 'attention_mask': }
+```
+
+
+
+## Audio
+
+Audio inputs are preprocessed differently than textual inputs, but the end goal remains the same: create numerical sequences the model can understand. A [feature extractor](main_classes/feature_extractor) is designed for the express purpose of extracting features from raw image or audio data and converting them into tensors. Before you begin, install 🤗 Datasets to load an audio dataset to experiment with:
+
+```bash
+pip install datasets
+```
+
+Load the [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) dataset (see the 🤗 [Datasets tutorial](https://huggingface.co/docs/datasets/load_hub.html) for more details on how to load a dataset):
+
+```py
+>>> from datasets import load_dataset, Audio
+
+>>> dataset = load_dataset("PolyAI/minds14", name="en-US", split="train")
+```
+
+Access the first element of the `audio` column to take a look at the input. Calling the `audio` column will automatically load and resample the audio file:
+
+```py
+>>> dataset[0]["audio"]
+{'array': array([ 0. , 0.00024414, -0.00024414, ..., -0.00024414,
+ 0. , 0. ], dtype=float32),
+ 'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~JOINT_ACCOUNT/602ba55abb1e6d0fbce92065.wav',
+ 'sampling_rate': 8000}
+```
+
+This returns three items:
+
+* `array` is the speech signal loaded - and potentially resampled - as a 1D array.
+* `path` points to the location of the audio file.
+* `sampling_rate` refers to how many data points in the speech signal are measured per second.
+
+### Resample
+
+For this tutorial, you will use the [Wav2Vec2](https://huggingface.co/facebook/wav2vec2-base) model. As you can see from the model card, the Wav2Vec2 model is pretrained on 16kHz sampled speech audio. It is important your audio data's sampling rate matches the sampling rate of the dataset used to pretrain the model. If your data's sampling rate isn't the same, then you need to resample your audio data.
+
+For example, the [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) dataset has a sampling rate of 8000kHz. In order to use the Wav2Vec2 model with this dataset, upsample the sampling rate to 16kHz:
+
+```py
+>>> dataset = load_dataset("PolyAI/minds14", name="en-US", split="train")
+>>> dataset[0]["audio"]
+{'array': array([ 0. , 0.00024414, -0.00024414, ..., -0.00024414,
+ 0. , 0. ], dtype=float32),
+ 'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~JOINT_ACCOUNT/602ba55abb1e6d0fbce92065.wav',
+ 'sampling_rate': 8000}
+```
+
+1. Use 🤗 Datasets' [`cast_column`](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.cast_column) method to upsample the sampling rate to 16kHz:
+
+```py
+>>> dataset = dataset.cast_column("audio", Audio(sampling_rate=16_000))
+```
+
+2. Load the audio file:
+
+```py
+>>> dataset[0]["audio"]
+{'array': array([ 2.3443763e-05, 2.1729663e-04, 2.2145823e-04, ...,
+ 3.8356509e-05, -7.3497440e-06, -2.1754686e-05], dtype=float32),
+ 'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~JOINT_ACCOUNT/602ba55abb1e6d0fbce92065.wav',
+ 'sampling_rate': 16000}
+```
+
+As you can see, the `sampling_rate` is now 16kHz!
+
+### Feature extractor
+
+The next step is to load a feature extractor to normalize and pad the input. When padding textual data, a `0` is added for shorter sequences. The same idea applies to audio data, and the audio feature extractor will add a `0` - interpreted as silence - to `array`.
+
+Load the feature extractor with [`AutoFeatureExtractor.from_pretrained`]:
+
+```py
+>>> from transformers import AutoFeatureExtractor
+
+>>> feature_extractor = AutoFeatureExtractor.from_pretrained("facebook/wav2vec2-base")
+```
+
+Pass the audio `array` to the feature extractor. We also recommend adding the `sampling_rate` argument in the feature extractor in order to better debug any silent errors that may occur.
+
+```py
+>>> audio_input = [dataset[0]["audio"]["array"]]
+>>> feature_extractor(audio_input, sampling_rate=16000)
+{'input_values': [array([ 3.8106556e-04, 2.7506407e-03, 2.8015103e-03, ...,
+ 5.6335266e-04, 4.6588284e-06, -1.7142107e-04], dtype=float32)]}
+```
+
+### Pad and truncate
+
+Just like the tokenizer, you can apply padding or truncation to handle variable sequences in a batch. Take a look at the sequence length of these two audio samples:
+
+```py
+>>> dataset[0]["audio"]["array"].shape
+(173398,)
+
+>>> dataset[1]["audio"]["array"].shape
+(106496,)
+```
+
+As you can see, the first sample has a longer sequence than the second sample. Let's create a function that will preprocess the dataset. Specify a maximum sample length, and the feature extractor will either pad or truncate the sequences to match it:
+
+```py
+>>> def preprocess_function(examples):
+... audio_arrays = [x["array"] for x in examples["audio"]]
+... inputs = feature_extractor(
+... audio_arrays,
+... sampling_rate=16000,
+... padding=True,
+... max_length=100000,
+... truncation=True,
+... )
+... return inputs
+```
+
+Apply the function to the the first few examples in the dataset:
+
+```py
+>>> processed_dataset = preprocess_function(dataset[:5])
+```
+
+Now take another look at the processed sample lengths:
+
+```py
+>>> processed_dataset["input_values"][0].shape
+(100000,)
+
+>>> processed_dataset["input_values"][1].shape
+(100000,)
+```
+
+The lengths of the first two samples now match the maximum length you specified.
+
+## Vision
+
+A feature extractor is also used to process images for vision tasks. Once again, the goal is to convert the raw image into a batch of tensors as input.
+
+Let's load the [food101](https://huggingface.co/datasets/food101) dataset for this tutorial. Use 🤗 Datasets `split` parameter to only load a small sample from the training split since the dataset is quite large:
+
+```py
+>>> from datasets import load_dataset
+
+>>> dataset = load_dataset("food101", split="train[:100]")
+```
+
+Next, take a look at the image with 🤗 Datasets [`Image`](https://huggingface.co/docs/datasets/package_reference/main_classes.html?highlight=image#datasets.Image) feature:
+
+```py
+>>> dataset[0]["image"]
+```
+
+
+
+### Feature extractor
+
+Load the feature extractor with [`AutoFeatureExtractor.from_pretrained`]:
+
+```py
+>>> from transformers import AutoFeatureExtractor
+
+>>> feature_extractor = AutoFeatureExtractor.from_pretrained("google/vit-base-patch16-224")
+```
+
+### Data augmentation
+
+For vision tasks, it is common to add some type of data augmentation to the images as a part of preprocessing. You can add augmentations with any library you'd like, but in this tutorial, you will use torchvision's [`transforms`](https://pytorch.org/vision/stable/transforms.html) module.
+
+1. Normalize the image and use [`Compose`](https://pytorch.org/vision/master/generated/torchvision.transforms.Compose.html) to chain some transforms - [`RandomResizedCrop`](https://pytorch.org/vision/main/generated/torchvision.transforms.RandomResizedCrop.html) and [`ColorJitter`](https://pytorch.org/vision/main/generated/torchvision.transforms.ColorJitter.html) - together:
+
+```py
+>>> from torchvision.transforms import Compose, Normalize, RandomResizedCrop, ColorJitter, ToTensor
+
+>>> normalize = Normalize(mean=feature_extractor.image_mean, std=feature_extractor.image_std)
+>>> _transforms = Compose(
+... [RandomResizedCrop(feature_extractor.size), ColorJitter(brightness=0.5, hue=0.5), ToTensor(), normalize]
+... )
+```
+
+2. The model accepts [`pixel_values`](model_doc/visionencoderdecoder#transformers.VisionEncoderDecoderModel.forward.pixel_values) as it's input. This value is generated by the feature extractor. Create a function that generates `pixel_values` from the transforms:
+
+```py
+>>> def transforms(examples):
+... examples["pixel_values"] = [_transforms(image.convert("RGB")) for image in examples["image"]]
+... return examples
+```
+
+3. Then use 🤗 Datasets [`set_transform`](https://huggingface.co/docs/datasets/process.html#format-transform) to apply the transforms on-the-fly:
+
+```py
+>>> dataset.set_transform(transforms)
+```
+
+4. Now when you access the image, you will notice the feature extractor has added the model input `pixel_values`:
+
+```py
+>>> dataset[0]["image"]
+{'image': ,
+ 'label': 6,
+ 'pixel_values': tensor([[[ 0.0353, 0.0745, 0.1216, ..., -0.9922, -0.9922, -0.9922],
+ [-0.0196, 0.0667, 0.1294, ..., -0.9765, -0.9843, -0.9922],
+ [ 0.0196, 0.0824, 0.1137, ..., -0.9765, -0.9686, -0.8667],
+ ...,
+ [ 0.0275, 0.0745, 0.0510, ..., -0.1137, -0.1216, -0.0824],
+ [ 0.0667, 0.0824, 0.0667, ..., -0.0588, -0.0745, -0.0980],
+ [ 0.0353, 0.0353, 0.0431, ..., -0.0039, -0.0039, -0.0588]],
+
+ [[ 0.2078, 0.2471, 0.2863, ..., -0.9451, -0.9373, -0.9451],
+ [ 0.1608, 0.2471, 0.3098, ..., -0.9373, -0.9451, -0.9373],
+ [ 0.2078, 0.2706, 0.3020, ..., -0.9608, -0.9373, -0.8275],
+ ...,
+ [-0.0353, 0.0118, -0.0039, ..., -0.2392, -0.2471, -0.2078],
+ [ 0.0196, 0.0353, 0.0196, ..., -0.1843, -0.2000, -0.2235],
+ [-0.0118, -0.0039, -0.0039, ..., -0.0980, -0.0980, -0.1529]],
+
+ [[ 0.3961, 0.4431, 0.4980, ..., -0.9216, -0.9137, -0.9216],
+ [ 0.3569, 0.4510, 0.5216, ..., -0.9059, -0.9137, -0.9137],
+ [ 0.4118, 0.4745, 0.5216, ..., -0.9137, -0.8902, -0.7804],
+ ...,
+ [-0.2314, -0.1922, -0.2078, ..., -0.4196, -0.4275, -0.3882],
+ [-0.1843, -0.1686, -0.2000, ..., -0.3647, -0.3804, -0.4039],
+ [-0.1922, -0.1922, -0.1922, ..., -0.2941, -0.2863, -0.3412]]])}
+```
+
+Here is what the image looks like after you preprocess it. Just as you'd expect from the applied transforms, the image has been randomly cropped and it's color properties are different.
+
+```py
+>>> import numpy as np
+>>> import matplotlib.pyplot as plt
+
+>>> img = dataset[0]["pixel_values"]
+>>> plt.imshow(img.permute(1, 2, 0))
+```
+
+
+
+## Multimodal
+
+For multimodal tasks. you will use a combination of everything you've learned so far and apply your skills to a automatic speech recognition (ASR) task. This means you will need a:
+
+* Feature extractor to preprocess the audio data.
+* Tokenizer to process the text.
+
+Let's return to the [LJ Speech](https://huggingface.co/datasets/lj_speech) dataset:
+
+```py
+>>> from datasets import load_dataset
+
+>>> lj_speech = load_dataset("lj_speech", split="train")
+```
+
+Since you are mainly interested in the `audio` and `text` column, remove the other columns:
+
+```py
+>>> lj_speech = lj_speech.map(remove_columns=["file", "id", "normalized_text"])
+```
+
+Now take a look at the `audio` and `text` columns:
+
+```py
+>>> lj_speech[0]["audio"]
+{'array': array([-7.3242188e-04, -7.6293945e-04, -6.4086914e-04, ...,
+ 7.3242188e-04, 2.1362305e-04, 6.1035156e-05], dtype=float32),
+ 'path': '/root/.cache/huggingface/datasets/downloads/extracted/917ece08c95cf0c4115e45294e3cd0dee724a1165b7fc11798369308a465bd26/LJSpeech-1.1/wavs/LJ001-0001.wav',
+ 'sampling_rate': 22050}
+
+>>> lj_speech[0]["text"]
+'Printing, in the only sense with which we are at present concerned, differs from most if not from all the arts and crafts represented in the Exhibition'
+```
+
+Remember from the earlier section on processing audio data, you should always [resample](preprocessing#audio) your audio data's sampling rate to match the sampling rate of the dataset used to pretrain a model:
+
+```py
+>>> lj_speech = lj_speech.cast_column("audio", Audio(sampling_rate=16_000))
+```
+
+### Processor
+
+A processor combines a feature extractor and tokenizer. Load a processor with [`AutoProcessor.from_pretrained]:
+
+```py
+>>> from transformers import AutoProcessor
+
+>>> processor = AutoProcessor.from_pretrained("facebook/wav2vec2-base-960h")
+```
+
+1. Create a function to process the audio data to `input_values`, and tokenizes the text to `labels`. These are your inputs to the model:
+
+```py
+>>> def prepare_dataset(example):
+... audio = example["audio"]
+
+... example["input_values"] = processor(audio["array"], sampling_rate=16000)
+
+... with processor.as_target_processor():
+... example["labels"] = processor(example["text"]).input_ids
+... return example
+```
+
+2. Apply the `prepare_dataset` function to a sample:
+
+```py
+>>> prepare_dataset(lj_speech[0])
+```
+
+Notice the processor has added `input_values` and `labels`. The sampling rate has also been correctly downsampled to 16kHz.
+
+Awesome, you should now be able to preprocess data for any modality and even combine different modalities! In the next tutorial, learn how to fine-tune a model on your newly preprocessed data.
diff --git a/docs/source/en/quicktour.mdx b/docs/source/en/quicktour.mdx
new file mode 100644
index 00000000000000..180ea36fc895cd
--- /dev/null
+++ b/docs/source/en/quicktour.mdx
@@ -0,0 +1,391 @@
+
+
+# Quick tour
+
+[[open-in-colab]]
+
+Get up and running with 🤗 Transformers! Start using the [`pipeline`] for rapid inference, and quickly load a pretrained model and tokenizer with an [AutoClass](./model_doc/auto) to solve your text, vision or audio task.
+
+
+
+All code examples presented in the documentation have a toggle on the top left for PyTorch and TensorFlow. If
+not, the code is expected to work for both backends without any change.
+
+
+
+## Pipeline
+
+[`pipeline`] is the easiest way to use a pretrained model for a given task.
+
+
+
+The [`pipeline`] supports many common tasks out-of-the-box:
+
+**Text**:
+* Sentiment analysis: classify the polarity of a given text.
+* Text generation (in English): generate text from a given input.
+* Name entity recognition (NER): label each word with the entity it represents (person, date, location, etc.).
+* Question answering: extract the answer from the context, given some context and a question.
+* Fill-mask: fill in the blank given a text with masked words.
+* Summarization: generate a summary of a long sequence of text or document.
+* Translation: translate text into another language.
+* Feature extraction: create a tensor representation of the text.
+
+**Image**:
+* Image classification: classify an image.
+* Image segmentation: classify every pixel in an image.
+* Object detection: detect objects within an image.
+
+**Audio**:
+* Audio classification: assign a label to a given segment of audio.
+* Automatic speech recognition (ASR): transcribe audio data into text.
+
+
+
+For more details about the [`pipeline`] and associated tasks, refer to the documentation [here](./main_classes/pipelines).
+
+
+
+### Pipeline usage
+
+In the following example, you will use the [`pipeline`] for sentiment analysis.
+
+Install the following dependencies if you haven't already:
+
+
+
+```bash
+pip install torch
+```
+
+
+```bash
+pip install tensorflow
+```
+
+
+
+Import [`pipeline`] and specify the task you want to complete:
+
+```py
+>>> from transformers import pipeline
+
+>>> classifier = pipeline("sentiment-analysis")
+```
+
+The pipeline downloads and caches a default [pretrained model](https://huggingface.co/distilbert-base-uncased-finetuned-sst-2-english) and tokenizer for sentiment analysis. Now you can use the `classifier` on your target text:
+
+```py
+>>> classifier("We are very happy to show you the 🤗 Transformers library.")
+[{'label': 'POSITIVE', 'score': 0.9998}]
+```
+
+For more than one sentence, pass a list of sentences to the [`pipeline`] which returns a list of dictionaries:
+
+```py
+>>> results = classifier(["We are very happy to show you the 🤗 Transformers library.", "We hope you don't hate it."])
+>>> for result in results:
+... print(f"label: {result['label']}, with score: {round(result['score'], 4)}")
+label: POSITIVE, with score: 0.9998
+label: NEGATIVE, with score: 0.5309
+```
+
+The [`pipeline`] can also iterate over an entire dataset. Start by installing the [🤗 Datasets](https://huggingface.co/docs/datasets/) library:
+
+```bash
+pip install datasets
+```
+
+Create a [`pipeline`] with the task you want to solve for and the model you want to use.
+
+```py
+>>> import torch
+>>> from transformers import pipeline
+
+>>> speech_recognizer = pipeline("automatic-speech-recognition", model="facebook/wav2vec2-base-960h")
+```
+
+Next, load a dataset (see the 🤗 Datasets [Quick Start](https://huggingface.co/docs/datasets/quickstart.html) for more details) you'd like to iterate over. For example, let's load the [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) dataset:
+
+```py
+>>> from datasets import load_dataset, Audio
+
+>>> dataset = load_dataset("PolyAI/minds14", name="en-US", split="train") # doctest: +IGNORE_RESULT
+```
+
+We need to make sure that the sampling rate of the dataset matches the sampling
+rate `facebook/wav2vec2-base-960h` was trained on.
+
+```py
+>>> dataset = dataset.cast_column("audio", Audio(sampling_rate=speech_recognizer.feature_extractor.sampling_rate))
+```
+
+Audio files are automatically loaded and resampled when calling the `"audio"` column.
+Let's extract the raw waveform arrays of the first 4 samples and pass it as a list to the pipeline:
+
+```py
+>>> result = speech_recognizer(dataset[:4]["audio"])
+>>> print([d["text"] for d in result])
+['I WOULD LIKE TO SET UP A JOINT ACCOUNT WITH MY PARTNER HOW DO I PROCEED WITH DOING THAT', "FONDERING HOW I'D SET UP A JOIN TO HET WITH MY WIFE AND WHERE THE AP MIGHT BE", "I I'D LIKE TOY SET UP A JOINT ACCOUNT WITH MY PARTNER I'M NOT SEEING THE OPTION TO DO IT ON THE APSO I CALLED IN TO GET SOME HELP CAN I JUST DO IT OVER THE PHONE WITH YOU AND GIVE YOU THE INFORMATION OR SHOULD I DO IT IN THE AP AND I'M MISSING SOMETHING UQUETTE HAD PREFERRED TO JUST DO IT OVER THE PHONE OF POSSIBLE THINGS", 'HOW DO I TURN A JOIN A COUNT']
+```
+
+For a larger dataset where the inputs are big (like in speech or vision), you will want to pass along a generator instead of a list that loads all the inputs in memory. See the [pipeline documentation](./main_classes/pipelines) for more information.
+
+### Use another model and tokenizer in the pipeline
+
+The [`pipeline`] can accommodate any model from the [Model Hub](https://huggingface.co/models), making it easy to adapt the [`pipeline`] for other use-cases. For example, if you'd like a model capable of handling French text, use the tags on the Model Hub to filter for an appropriate model. The top filtered result returns a multilingual [BERT model](https://huggingface.co/nlptown/bert-base-multilingual-uncased-sentiment) fine-tuned for sentiment analysis. Great, let's use this model!
+
+```py
+>>> model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
+```
+
+
+
+Use the [`AutoModelForSequenceClassification`] and [`AutoTokenizer`] to load the pretrained model and it's associated tokenizer (more on an `AutoClass` below):
+
+```py
+>>> from transformers import AutoTokenizer, AutoModelForSequenceClassification
+
+>>> model = AutoModelForSequenceClassification.from_pretrained(model_name)
+>>> tokenizer = AutoTokenizer.from_pretrained(model_name)
+```
+
+
+Use the [`TFAutoModelForSequenceClassification`] and [`AutoTokenizer`] to load the pretrained model and it's associated tokenizer (more on an `TFAutoClass` below):
+
+```py
+>>> from transformers import AutoTokenizer, TFAutoModelForSequenceClassification
+
+>>> model = TFAutoModelForSequenceClassification.from_pretrained(model_name)
+>>> tokenizer = AutoTokenizer.from_pretrained(model_name)
+```
+
+
+
+Then you can specify the model and tokenizer in the [`pipeline`], and apply the `classifier` on your target text:
+
+```py
+>>> classifier = pipeline("sentiment-analysis", model=model, tokenizer=tokenizer)
+>>> classifier("Nous sommes très heureux de vous présenter la bibliothèque 🤗 Transformers.")
+[{'label': '5 stars', 'score': 0.7273}]
+```
+
+If you can't find a model for your use-case, you will need to fine-tune a pretrained model on your data. Take a look at our [fine-tuning tutorial](./training) to learn how. Finally, after you've fine-tuned your pretrained model, please consider sharing it (see tutorial [here](./model_sharing)) with the community on the Model Hub to democratize NLP for everyone! 🤗
+
+## AutoClass
+
+
+
+Under the hood, the [`AutoModelForSequenceClassification`] and [`AutoTokenizer`] classes work together to power the [`pipeline`]. An [AutoClass](./model_doc/auto) is a shortcut that automatically retrieves the architecture of a pretrained model from it's name or path. You only need to select the appropriate `AutoClass` for your task and it's associated tokenizer with [`AutoTokenizer`].
+
+Let's return to our example and see how you can use the `AutoClass` to replicate the results of the [`pipeline`].
+
+### AutoTokenizer
+
+A tokenizer is responsible for preprocessing text into a format that is understandable to the model. First, the tokenizer will split the text into words called *tokens*. There are multiple rules that govern the tokenization process, including how to split a word and at what level (learn more about tokenization [here](./tokenizer_summary)). The most important thing to remember though is you need to instantiate the tokenizer with the same model name to ensure you're using the same tokenization rules a model was pretrained with.
+
+Load a tokenizer with [`AutoTokenizer`]:
+
+```py
+>>> from transformers import AutoTokenizer
+
+>>> model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
+>>> tokenizer = AutoTokenizer.from_pretrained(model_name)
+```
+
+Next, the tokenizer converts the tokens into numbers in order to construct a tensor as input to the model. This is known as the model's *vocabulary*.
+
+Pass your text to the tokenizer:
+
+```py
+>>> encoding = tokenizer("We are very happy to show you the 🤗 Transformers library.")
+>>> print(encoding)
+{'input_ids': [101, 11312, 10320, 12495, 19308, 10114, 11391, 10855, 10103, 100, 58263, 13299, 119, 102],
+ 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
+ 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
+```
+
+The tokenizer will return a dictionary containing:
+
+* [input_ids](./glossary#input-ids): numerical representions of your tokens.
+* [atttention_mask](.glossary#attention-mask): indicates which tokens should be attended to.
+
+Just like the [`pipeline`], the tokenizer will accept a list of inputs. In addition, the tokenizer can also pad and truncate the text to return a batch with uniform length:
+
+
+
+```py
+>>> pt_batch = tokenizer(
+... ["We are very happy to show you the 🤗 Transformers library.", "We hope you don't hate it."],
+... padding=True,
+... truncation=True,
+... max_length=512,
+... return_tensors="pt",
+... )
+```
+
+
+```py
+>>> tf_batch = tokenizer(
+... ["We are very happy to show you the 🤗 Transformers library.", "We hope you don't hate it."],
+... padding=True,
+... truncation=True,
+... max_length=512,
+... return_tensors="tf",
+... )
+```
+
+
+
+Read the [preprocessing](./preprocessing) tutorial for more details about tokenization.
+
+### AutoModel
+
+
+
+🤗 Transformers provides a simple and unified way to load pretrained instances. This means you can load an [`AutoModel`] like you would load an [`AutoTokenizer`]. The only difference is selecting the correct [`AutoModel`] for the task. Since you are doing text - or sequence - classification, load [`AutoModelForSequenceClassification`]:
+
+```py
+>>> from transformers import AutoModelForSequenceClassification
+
+>>> model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
+>>> pt_model = AutoModelForSequenceClassification.from_pretrained(model_name)
+```
+
+
+
+See the [task summary](./task_summary) for which [`AutoModel`] class to use for which task.
+
+
+
+Now you can pass your preprocessed batch of inputs directly to the model. You just have to unpack the dictionary by adding `**`:
+
+```py
+>>> pt_outputs = pt_model(**pt_batch)
+```
+
+The model outputs the final activations in the `logits` attribute. Apply the softmax function to the `logits` to retrieve the probabilities:
+
+```py
+>>> from torch import nn
+
+>>> pt_predictions = nn.functional.softmax(pt_outputs.logits, dim=-1)
+>>> print(pt_predictions)
+tensor([[0.0021, 0.0018, 0.0115, 0.2121, 0.7725],
+ [0.2084, 0.1826, 0.1969, 0.1755, 0.2365]], grad_fn=)
+```
+
+
+🤗 Transformers provides a simple and unified way to load pretrained instances. This means you can load an [`TFAutoModel`] like you would load an [`AutoTokenizer`]. The only difference is selecting the correct [`TFAutoModel`] for the task. Since you are doing text - or sequence - classification, load [`TFAutoModelForSequenceClassification`]:
+
+```py
+>>> from transformers import TFAutoModelForSequenceClassification
+
+>>> model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
+>>> tf_model = TFAutoModelForSequenceClassification.from_pretrained(model_name)
+```
+
+
+
+See the [task summary](./task_summary) for which [`AutoModel`] class to use for which task.
+
+
+
+Now you can pass your preprocessed batch of inputs directly to the model by passing the dictionary keys directly to the tensors:
+
+```py
+>>> tf_outputs = tf_model(tf_batch)
+```
+
+The model outputs the final activations in the `logits` attribute. Apply the softmax function to the `logits` to retrieve the probabilities:
+
+```py
+>>> import tensorflow as tf
+
+>>> tf_predictions = tf.nn.softmax(tf_outputs.logits, axis=-1)
+>>> tf_predictions # doctest: +IGNORE_RESULT
+```
+
+
+
+
+
+All 🤗 Transformers models (PyTorch or TensorFlow) outputs the tensors *before* the final activation
+function (like softmax) because the final activation function is often fused with the loss.
+
+
+
+Models are a standard [`torch.nn.Module`](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) or a [`tf.keras.Model`](https://www.tensorflow.org/api_docs/python/tf/keras/Model) so you can use them in your usual training loop. However, to make things easier, 🤗 Transformers provides a [`Trainer`] class for PyTorch that adds functionality for distributed training, mixed precision, and more. For TensorFlow, you can use the `fit` method from [Keras](https://keras.io/). Refer to the [training tutorial](./training) for more details.
+
+
+
+🤗 Transformers model outputs are special dataclasses so their attributes are autocompleted in an IDE.
+The model outputs also behave like a tuple or a dictionary (e.g., you can index with an integer, a slice or a string) in which case the attributes that are `None` are ignored.
+
+
+
+### Save a model
+
+
+
+Once your model is fine-tuned, you can save it with its tokenizer using [`PreTrainedModel.save_pretrained`]:
+
+```py
+>>> pt_save_directory = "./pt_save_pretrained"
+>>> tokenizer.save_pretrained(pt_save_directory) # doctest: +IGNORE_RESULT
+>>> pt_model.save_pretrained(pt_save_directory)
+```
+
+When you are ready to use the model again, reload it with [`PreTrainedModel.from_pretrained`]:
+
+```py
+>>> pt_model = AutoModelForSequenceClassification.from_pretrained("./pt_save_pretrained")
+```
+
+
+Once your model is fine-tuned, you can save it with its tokenizer using [`TFPreTrainedModel.save_pretrained`]:
+
+```py
+>>> tf_save_directory = "./tf_save_pretrained"
+>>> tokenizer.save_pretrained(tf_save_directory) # doctest: +IGNORE_RESULT
+>>> tf_model.save_pretrained(tf_save_directory)
+```
+
+When you are ready to use the model again, reload it with [`TFPreTrainedModel.from_pretrained`]:
+
+```py
+>>> tf_model = TFAutoModelForSequenceClassification.from_pretrained("./tf_save_pretrained")
+```
+
+
+
+One particularly cool 🤗 Transformers feature is the ability to save a model and reload it as either a PyTorch or TensorFlow model. The `from_pt` or `from_tf` parameter can convert the model from one framework to the other:
+
+
+
+```py
+>>> from transformers import AutoModel
+
+>>> tokenizer = AutoTokenizer.from_pretrained(tf_save_directory)
+>>> pt_model = AutoModelForSequenceClassification.from_pretrained(tf_save_directory, from_tf=True)
+```
+
+
+```py
+>>> from transformers import TFAutoModel
+
+>>> tokenizer = AutoTokenizer.from_pretrained(pt_save_directory)
+>>> tf_model = TFAutoModelForSequenceClassification.from_pretrained(pt_save_directory, from_pt=True)
+```
+
+
diff --git a/docs/source/en/run_scripts.mdx b/docs/source/en/run_scripts.mdx
new file mode 100644
index 00000000000000..ca8f8df5e86ccb
--- /dev/null
+++ b/docs/source/en/run_scripts.mdx
@@ -0,0 +1,346 @@
+
+
+# Train with a script
+
+Along with the 🤗 Transformers [notebooks](./noteboks/README), there are also example scripts demonstrating how to train a model for a task with [PyTorch](https://github.com/huggingface/transformers/tree/main/examples/pytorch), [TensorFlow](https://github.com/huggingface/transformers/tree/main/examples/tensorflow), or [JAX/Flax](https://github.com/huggingface/transformers/tree/main/examples/flax).
+
+You will also find scripts we've used in our [research projects](https://github.com/huggingface/transformers/tree/main/examples/research_projects) and [legacy examples](https://github.com/huggingface/transformers/tree/main/examples/legacy) which are mostly community contributed. These scripts are not actively maintained and require a specific version of 🤗 Transformers that will most likely be incompatible with the latest version of the library.
+
+The example scripts are not expected to work out-of-the-box on every problem, and you may need to adapt the script to the problem you're trying to solve. To help you with this, most of the scripts fully expose how data is preprocessed, allowing you to edit it as necessary for your use case.
+
+For any feature you'd like to implement in an example script, please discuss it on the [forum](https://discuss.huggingface.co/) or in an [issue](https://github.com/huggingface/transformers/issues) before submitting a Pull Request. While we welcome bug fixes, it is unlikely we will merge a Pull Request that adds more functionality at the cost of readability.
+
+This guide will show you how to run an example summarization training script in [PyTorch](https://github.com/huggingface/transformers/tree/main/examples/pytorch/summarization) and [TensorFlow](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/summarization). All examples are expected to work with both frameworks unless otherwise specified.
+
+## Setup
+
+To successfully run the latest version of the example scripts, you have to **install 🤗 Transformers from source** in a new virtual environment:
+
+```bash
+git clone https://github.com/huggingface/transformers
+cd transformers
+pip install .
+```
+
+For older versions of the example scripts, click on the toggle below:
+
+
+
+This is a closer approximation to the true decomposition of the sequence probability and will typically yield a more
+favorable score. The downside is that it requires a separate forward pass for each token in the corpus. A good
+practical compromise is to employ a strided sliding window, moving the context by larger strides rather than sliding by
+1 token a time. This allows computation to proceed much faster while still giving the model a large context to make
+predictions at each step.
+
+## Example: Calculating perplexity with GPT-2 in 🤗 Transformers
+
+Let's demonstrate this process with GPT-2.
+
+```python
+from transformers import GPT2LMHeadModel, GPT2TokenizerFast
+
+device = "cuda"
+model_id = "gpt2-large"
+model = GPT2LMHeadModel.from_pretrained(model_id).to(device)
+tokenizer = GPT2TokenizerFast.from_pretrained(model_id)
+```
+
+We'll load in the WikiText-2 dataset and evaluate the perplexity using a few different sliding-window strategies. Since
+this dataset is small and we're just doing one forward pass over the set, we can just load and encode the entire
+dataset in memory.
+
+```python
+from datasets import load_dataset
+
+test = load_dataset("wikitext", "wikitext-2-raw-v1", split="test")
+encodings = tokenizer("\n\n".join(test["text"]), return_tensors="pt")
+```
+
+With 🤗 Transformers, we can simply pass the `input_ids` as the `labels` to our model, and the average negative
+log-likelihood for each token is returned as the loss. With our sliding window approach, however, there is overlap in
+the tokens we pass to the model at each iteration. We don't want the log-likelihood for the tokens we're just treating
+as context to be included in our loss, so we can set these targets to `-100` so that they are ignored. The following
+is an example of how we could do this with a stride of `512`. This means that the model will have at least 512 tokens
+for context when calculating the conditional likelihood of any one token (provided there are 512 preceding tokens
+available to condition on).
+
+```python
+import torch
+from tqdm import tqdm
+
+max_length = model.config.n_positions
+stride = 512
+
+nlls = []
+for i in tqdm(range(0, encodings.input_ids.size(1), stride)):
+ begin_loc = max(i + stride - max_length, 0)
+ end_loc = min(i + stride, encodings.input_ids.size(1))
+ trg_len = end_loc - i # may be different from stride on last loop
+ input_ids = encodings.input_ids[:, begin_loc:end_loc].to(device)
+ target_ids = input_ids.clone()
+ target_ids[:, :-trg_len] = -100
+
+ with torch.no_grad():
+ outputs = model(input_ids, labels=target_ids)
+ neg_log_likelihood = outputs[0] * trg_len
+
+ nlls.append(neg_log_likelihood)
+
+ppl = torch.exp(torch.stack(nlls).sum() / end_loc)
+```
+
+Running this with the stride length equal to the max input length is equivalent to the suboptimal, non-sliding-window
+strategy we discussed above. The smaller the stride, the more context the model will have in making each prediction,
+and the better the reported perplexity will typically be.
+
+When we run the above with `stride = 1024`, i.e. no overlap, the resulting PPL is `19.64`, which is about the same
+as the `19.93` reported in the GPT-2 paper. By using `stride = 512` and thereby employing our striding window
+strategy, this jumps down to `16.53`. This is not only a more favorable score, but is calculated in a way that is
+closer to the true autoregressive decomposition of a sequence likelihood.
diff --git a/docs/source/en/philosophy.mdx b/docs/source/en/philosophy.mdx
new file mode 100644
index 00000000000000..13134c31d4a6b9
--- /dev/null
+++ b/docs/source/en/philosophy.mdx
@@ -0,0 +1,80 @@
+
+
+# Philosophy
+
+🤗 Transformers is an opinionated library built for:
+
+- NLP researchers and educators seeking to use/study/extend large-scale transformers models
+- hands-on practitioners who want to fine-tune those models and/or serve them in production
+- engineers who just want to download a pretrained model and use it to solve a given NLP task.
+
+The library was designed with two strong goals in mind:
+
+- Be as easy and fast to use as possible:
+
+ - We strongly limited the number of user-facing abstractions to learn, in fact, there are almost no abstractions,
+ just three standard classes required to use each model: [configuration](main_classes/configuration),
+ [models](main_classes/model) and [tokenizer](main_classes/tokenizer).
+ - All of these classes can be initialized in a simple and unified way from pretrained instances by using a common
+ `from_pretrained()` instantiation method which will take care of downloading (if needed), caching and
+ loading the related class instance and associated data (configurations' hyper-parameters, tokenizers' vocabulary,
+ and models' weights) from a pretrained checkpoint provided on [Hugging Face Hub](https://huggingface.co/models) or your own saved checkpoint.
+ - On top of those three base classes, the library provides two APIs: [`pipeline`] for quickly
+ using a model (plus its associated tokenizer and configuration) on a given task and
+ [`Trainer`]/`Keras.fit` to quickly train or fine-tune a given model.
+ - As a consequence, this library is NOT a modular toolbox of building blocks for neural nets. If you want to
+ extend/build-upon the library, just use regular Python/PyTorch/TensorFlow/Keras modules and inherit from the base
+ classes of the library to reuse functionalities like model loading/saving.
+
+- Provide state-of-the-art models with performances as close as possible to the original models:
+
+ - We provide at least one example for each architecture which reproduces a result provided by the official authors
+ of said architecture.
+ - The code is usually as close to the original code base as possible which means some PyTorch code may be not as
+ *pytorchic* as it could be as a result of being converted TensorFlow code and vice versa.
+
+A few other goals:
+
+- Expose the models' internals as consistently as possible:
+
+ - We give access, using a single API, to the full hidden-states and attention weights.
+ - Tokenizer and base model's API are standardized to easily switch between models.
+
+- Incorporate a subjective selection of promising tools for fine-tuning/investigating these models:
+
+ - A simple/consistent way to add new tokens to the vocabulary and embeddings for fine-tuning.
+ - Simple ways to mask and prune transformer heads.
+
+- Switch easily between PyTorch and TensorFlow 2.0, allowing training using one framework and inference using another.
+
+## Main concepts
+
+The library is built around three types of classes for each model:
+
+- **Model classes** such as [`BertModel`], which are 30+ PyTorch models ([torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module)) or Keras models ([tf.keras.Model](https://www.tensorflow.org/api_docs/python/tf/keras/Model)) that work with the pretrained weights provided in the
+ library.
+- **Configuration classes** such as [`BertConfig`], which store all the parameters required to build
+ a model. You don't always need to instantiate these yourself. In particular, if you are using a pretrained model
+ without any modification, creating the model will automatically take care of instantiating the configuration (which
+ is part of the model).
+- **Tokenizer classes** such as [`BertTokenizer`], which store the vocabulary for each model and
+ provide methods for encoding/decoding strings in a list of token embeddings indices to be fed to a model.
+
+All these classes can be instantiated from pretrained instances and saved locally using two methods:
+
+- `from_pretrained()` lets you instantiate a model/configuration/tokenizer from a pretrained version either
+ provided by the library itself (the supported models can be found on the [Model Hub](https://huggingface.co/models)) or
+ stored locally (or on a server) by the user,
+- `save_pretrained()` lets you save a model/configuration/tokenizer locally so that it can be reloaded using
+ `from_pretrained()`.
+
diff --git a/docs/source/en/pipeline_tutorial.mdx b/docs/source/en/pipeline_tutorial.mdx
new file mode 100644
index 00000000000000..b59ff82a9b02e0
--- /dev/null
+++ b/docs/source/en/pipeline_tutorial.mdx
@@ -0,0 +1,148 @@
+
+
+# Pipelines for inference
+
+The [`pipeline`] makes it simple to use any model from the [Model Hub](https://huggingface.co/models) for inference on a variety of tasks such as text generation, image segmentation and audio classification. Even if you don't have experience with a specific modality or understand the code powering the models, you can still use them with the [`pipeline`]! This tutorial will teach you to:
+
+* Use a [`pipeline`] for inference.
+* Use a specific tokenizer or model.
+* Use a [`pipeline`] for audio and vision tasks.
+
+
+
+Take a look at the [`pipeline`] documentation for a complete list of supported taska.
+
+
+
+## Pipeline usage
+
+While each task has an associated [`pipeline`], it is simpler to use the general [`pipeline`] abstraction which contains all the specific task pipelines. The [`pipeline`] automatically loads a default model and tokenizer capable of inference for your task.
+
+1. Start by creating a [`pipeline`] and specify an inference task:
+
+```py
+>>> from transformers import pipeline
+
+>>> generator = pipeline(task="text-generation")
+```
+
+2. Pass your input text to the [`pipeline`]:
+
+```py
+>>> generator(
+... "Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone"
+... ) # doctest: +SKIP
+[{'generated_text': 'Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone, Seven for the Iron-priests at the door to the east, and thirteen for the Lord Kings at the end of the mountain'}]
+```
+
+If you have more than one input, pass your input as a list:
+
+```py
+>>> generator(
+... [
+... "Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone",
+... "Nine for Mortal Men, doomed to die, One for the Dark Lord on his dark throne",
+... ]
+... ) # doctest: +SKIP
+```
+
+Any additional parameters for your task can also be included in the [`pipeline`]. The `text-generation` task has a [`~generation_utils.GenerationMixin.generate`] method with several parameters for controlling the output. For example, if you want to generate more than one output, set the `num_return_sequences` parameter:
+
+```py
+>>> generator(
+... "Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone",
+... num_return_sequences=2,
+... ) # doctest: +SKIP
+```
+
+### Choose a model and tokenizer
+
+The [`pipeline`] accepts any model from the [Model Hub](https://huggingface.co/models). There are tags on the Model Hub that allow you to filter for a model you'd like to use for your task. Once you've picked an appropriate model, load it with the corresponding `AutoModelFor` and [`AutoTokenizer'] class. For example, load the [`AutoModelForCausalLM`] class for a causal language modeling task:
+
+```py
+>>> from transformers import AutoTokenizer, AutoModelForCausalLM
+
+>>> tokenizer = AutoTokenizer.from_pretrained("distilgpt2")
+>>> model = AutoModelForCausalLM.from_pretrained("distilgpt2")
+```
+
+Create a [`pipeline`] for your task, and specify the model and tokenizer you've loaded:
+
+```py
+>>> from transformers import pipeline
+
+>>> generator = pipeline(task="text-generation", model=model, tokenizer=tokenizer)
+```
+
+Pass your input text to the [`pipeline`] to generate some text:
+
+```py
+>>> generator(
+... "Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone"
+... ) # doctest: +SKIP
+[{'generated_text': 'Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone, Seven for the Dragon-lords (for them to rule in a world ruled by their rulers, and all who live within the realm'}]
+```
+
+## Audio pipeline
+
+The flexibility of the [`pipeline`] means it can also be extended to audio tasks.
+
+For example, let's classify the emotion in this audio clip:
+
+```py
+>>> from datasets import load_dataset
+>>> import torch
+
+>>> torch.manual_seed(42) # doctest: +IGNORE_RESULT
+>>> ds = load_dataset("hf-internal-testing/librispeech_asr_demo", "clean", split="validation")
+>>> audio_file = ds[0]["audio"]["path"]
+```
+
+Find an [audio classification](https://huggingface.co/models?pipeline_tag=audio-classification) model on the Model Hub for emotion recognition and load it in the [`pipeline`]:
+
+```py
+>>> from transformers import pipeline
+
+>>> audio_classifier = pipeline(
+... task="audio-classification", model="ehcalabres/wav2vec2-lg-xlsr-en-speech-emotion-recognition"
+... )
+```
+
+Pass the audio file to the [`pipeline`]:
+
+```py
+>>> preds = audio_classifier(audio_file)
+>>> preds = [{"score": round(pred["score"], 4), "label": pred["label"]} for pred in preds]
+>>> preds
+[{'score': 0.1315, 'label': 'calm'}, {'score': 0.1307, 'label': 'neutral'}, {'score': 0.1274, 'label': 'sad'}, {'score': 0.1261, 'label': 'fearful'}, {'score': 0.1242, 'label': 'happy'}]
+```
+
+## Vision pipeline
+
+Finally, using a [`pipeline`] for vision tasks is practically identical.
+
+Specify your vision task and pass your image to the classifier. The imaage can be a link or a local path to the image. For example, what species of cat is shown below?
+
+
+
+```py
+>>> from transformers import pipeline
+
+>>> vision_classifier = pipeline(task="image-classification")
+>>> preds = vision_classifier(
+... images="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
+... )
+>>> preds = [{"score": round(pred["score"], 4), "label": pred["label"]} for pred in preds]
+>>> preds
+[{'score': 0.4335, 'label': 'lynx, catamount'}, {'score': 0.0348, 'label': 'cougar, puma, catamount, mountain lion, painter, panther, Felis concolor'}, {'score': 0.0324, 'label': 'snow leopard, ounce, Panthera uncia'}, {'score': 0.0239, 'label': 'Egyptian cat'}, {'score': 0.0229, 'label': 'tiger cat'}]
+```
diff --git a/docs/source/en/pr_checks.mdx b/docs/source/en/pr_checks.mdx
new file mode 100644
index 00000000000000..57e0766c7f6776
--- /dev/null
+++ b/docs/source/en/pr_checks.mdx
@@ -0,0 +1,132 @@
+
+
+# Checks on a Pull Request
+
+When you open a pull request on 🤗 Transformers, a fair number of checks will be run to make sure the patch you are adding is not breaking anything existing. Those checks are of four types:
+- regular tests
+- documentation build
+- code and documentation style
+- general repository consistency
+
+In this document, we will take a stab at explaining what those various checks are and the reason behind them, as well as how to debug them locally if one of them fails on your PR.
+
+Note that they all require you to have a dev install:
+
+```bash
+pip install transformers[dev]
+```
+
+or for an editable install:
+
+```bash
+pip install -e .[dev]
+```
+
+inside the Transformers repo.
+
+## Tests
+
+All the jobs that begin with `ci/circleci: run_tests_` run parts of the Transformers testing suite. Each of those jobs focuses on a part of the library in a certain environment: for instance `ci/circleci: run_tests_pipelines_tf` runs the pipelines test in an environment where TensorFlow only is installed.
+
+Note that to avoid running tests when there is no real change in the modules they are testing, only part of the test suite is run each time: a utility is run to determine the differences in the library between before and after the PR (what GitHub shows you in the "Files changes" tab) and picks the tests impacted by that diff. That utility can be run locally with:
+
+```bash
+python utils/tests_fetcher.py
+```
+
+from the root of the Transformers repo. It will:
+
+1. Check for each file in the diff if the changes are in the code or only in comments or docstrings. Only the files with real code changes are kept.
+2. Build an internal map that gives for each file of the source code of the library all the files it recursively impacts. Module A is said to impact module B if module B imports module A. For the recursive impact, we need a chain of modules going from module A to module B in which each module imports the previous one.
+3. Apply this map on the files gathered in step 1, which gives us the list of model files impacted by the PR.
+4. Map each of those files to their corresponding test file(s) and get the list of tests to run.
+
+When executing the script locally, you should get the results of step 1, 3 and 4 printed and thus know which tests are run. The script will also create a file named `test_list.txt` which contains the list of tests to run, and you can run them locally with the following command:
+
+```bash
+python -m pytest -n 8 --dist=loadfile -rA -s $(cat test_list.txt)
+```
+
+Just in case anything slipped through the cracks, the full test suite is also run daily.
+
+## Documentation build
+
+The job `ci/circleci: build_doc` runs a build of the documentation just to make sure everything will be okay once your PR is merged. If that steps fails, you can inspect it locally by going into the `docs` folder of the Transformers repo and then typing
+
+```bash
+make html
+```
+
+Sphinx is not known for its helpful error messages, so you might have to try a few things to really find the source of the error.
+
+## Code and documentation style
+
+Code formatting is applied to all the source files, the examples and the tests using `black` and `isort`. We also have a custom tool taking care of the formatting of docstrings and `rst` files (`utils/style_doc.py`), as well as the order of the lazy imports performed in the Transformers `__init__.py` files (`utils/custom_init_isort.py`). All of this can be launched by executing
+
+```bash
+make style
+```
+
+The CI checks those have been applied inside the `ci/circleci: check_code_quality` check. It also runs `flake8`, that will have a basic look at your code and will complain if it finds an undefined variable, or one that is not used. To run that check locally, use
+
+```bash
+make quality
+```
+
+This can take a lot of time, so to run the same thing on only the files you modified in the current branch, run
+
+```bash
+make fixup
+```
+
+This last command will also run all the additional checks for the repository consistency. Let's have a look at them.
+
+## Repository consistency
+
+This regroups all the tests to make sure your PR leaves the repository in a good state, and is performed by the `ci/circleci: check_repository_consistency` check. You can locally run that check by executing the following:
+
+```bash
+make repo-consistency
+```
+
+This checks that:
+
+- All objects added to the init are documented (performed by `utils/check_repo.py`)
+- All `__init__.py` files have the same content in their two sections (performed by `utils/check_inits.py`)
+- All code identified as a copy from another module is consistent with the original (performed by `utils/check_copies.py`)
+- All configuration classes have at least one valid checkpoint mentioned in their docstrings (performed by `utils/check_config_docstrings.py`)
+- The translations of the READMEs and the index of the doc have the same model list as the main README (performed by `utils/check_copies.py`)
+- The auto-generated tables in the documentation are up to date (performed by `utils/check_table.py`)
+- The library has all objects available even if not all optional dependencies are installed (performed by `utils/check_dummies.py`)
+
+Should this check fail, the first two items require manual fixing, the last four can be fixed automatically for you by running the command
+
+```bash
+make fix-copies
+```
+
+Additional checks concern PRs that add new models, mainly that:
+
+- All models added are in an Auto-mapping (performed by `utils/check_repo.py`)
+
+- All models are properly tested (performed by `utils/check_repo.py`)
+
+
diff --git a/docs/source/en/preprocessing.mdx b/docs/source/en/preprocessing.mdx
new file mode 100644
index 00000000000000..947129b34aafa4
--- /dev/null
+++ b/docs/source/en/preprocessing.mdx
@@ -0,0 +1,498 @@
+
+
+# Preprocess
+
+[[open-in-colab]]
+
+Before you can use your data in a model, the data needs to be processed into an acceptable format for the model. A model does not understand raw text, images or audio. These inputs need to be converted into numbers and assembled into tensors. In this tutorial, you will:
+
+* Preprocess textual data with a tokenizer.
+* Preprocess image or audio data with a feature extractor.
+* Preprocess data for a multimodal task with a processor.
+
+## NLP
+
+
+
+The main tool for processing textual data is a [tokenizer](main_classes/tokenizer). A tokenizer starts by splitting text into *tokens* according to a set of rules. The tokens are converted into numbers, which are used to build tensors as input to a model. Any additional inputs required by a model are also added by the tokenizer.
+
+
+
+If you plan on using a pretrained model, it's important to use the associated pretrained tokenizer. This ensures the text is split the same way as the pretraining corpus, and uses the same corresponding tokens-to-index (usually referrred to as the *vocab*) during pretraining.
+
+
+
+Get started quickly by loading a pretrained tokenizer with the [`AutoTokenizer`] class. This downloads the *vocab* used when a model is pretrained.
+
+### Tokenize
+
+Load a pretrained tokenizer with [`AutoTokenizer.from_pretrained`]:
+
+```py
+>>> from transformers import AutoTokenizer
+
+>>> tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
+```
+
+Then pass your sentence to the tokenizer:
+
+```py
+>>> encoded_input = tokenizer("Do not meddle in the affairs of wizards, for they are subtle and quick to anger.")
+>>> print(encoded_input)
+{'input_ids': [101, 2079, 2025, 19960, 10362, 1999, 1996, 3821, 1997, 16657, 1010, 2005, 2027, 2024, 11259, 1998, 4248, 2000, 4963, 1012, 102],
+ 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
+ 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
+```
+
+The tokenizer returns a dictionary with three important itmes:
+
+* [input_ids](glossary#input-ids) are the indices corresponding to each token in the sentence.
+* [attention_mask](glossary#attention-mask) indicates whether a token should be attended to or not.
+* [token_type_ids](glossary#token-type-ids) identifies which sequence a token belongs to when there is more than one sequence.
+
+You can decode the `input_ids` to return the original input:
+
+```py
+>>> tokenizer.decode(encoded_input["input_ids"])
+'[CLS] Do not meddle in the affairs of wizards, for they are subtle and quick to anger. [SEP]'
+```
+
+As you can see, the tokenizer added two special tokens - `CLS` and `SEP` (classifier and separator) - to the sentence. Not all models need
+special tokens, but if they do, the tokenizer will automatically add them for you.
+
+If there are several sentences you want to process, pass the sentences as a list to the tokenizer:
+
+```py
+>>> batch_sentences = [
+... "But what about second breakfast?",
+... "Don't think he knows about second breakfast, Pip.",
+... "What about elevensies?",
+... ]
+>>> encoded_inputs = tokenizer(batch_sentences)
+>>> print(encoded_inputs)
+{'input_ids': [[101, 1252, 1184, 1164, 1248, 6462, 136, 102],
+ [101, 1790, 112, 189, 1341, 1119, 3520, 1164, 1248, 6462, 117, 21902, 1643, 119, 102],
+ [101, 1327, 1164, 5450, 23434, 136, 102]],
+ 'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0],
+ [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
+ [0, 0, 0, 0, 0, 0, 0]],
+ 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1],
+ [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
+ [1, 1, 1, 1, 1, 1, 1]]}
+```
+
+### Pad
+
+This brings us to an important topic. When you process a batch of sentences, they aren't always the same length. This is a problem because tensors, the input to the model, need to have a uniform shape. Padding is a strategy for ensuring tensors are rectangular by adding a special *padding token* to sentences with fewer tokens.
+
+Set the `padding` parameter to `True` to pad the shorter sequences in the batch to match the longest sequence:
+
+```py
+>>> batch_sentences = [
+... "But what about second breakfast?",
+... "Don't think he knows about second breakfast, Pip.",
+... "What about elevensies?",
+... ]
+>>> encoded_input = tokenizer(batch_sentences, padding=True)
+>>> print(encoded_input)
+{'input_ids': [[101, 1252, 1184, 1164, 1248, 6462, 136, 102, 0, 0, 0, 0, 0, 0, 0],
+ [101, 1790, 112, 189, 1341, 1119, 3520, 1164, 1248, 6462, 117, 21902, 1643, 119, 102],
+ [101, 1327, 1164, 5450, 23434, 136, 102, 0, 0, 0, 0, 0, 0, 0, 0]],
+ 'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
+ [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
+ [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]],
+ 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0],
+ [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
+ [1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0]]}
+```
+
+Notice the tokenizer padded the first and third sentences with a `0` because they are shorter!
+
+### Truncation
+
+On the other end of the spectrum, sometimes a sequence may be too long for a model to handle. In this case, you will need to truncate the sequence to a shorter length.
+
+Set the `truncation` parameter to `True` to truncate a sequence to the maximum length accepted by the model:
+
+```py
+>>> batch_sentences = [
+... "But what about second breakfast?",
+... "Don't think he knows about second breakfast, Pip.",
+... "What about elevensies?",
+... ]
+>>> encoded_input = tokenizer(batch_sentences, padding=True, truncation=True)
+>>> print(encoded_input)
+{'input_ids': [[101, 1252, 1184, 1164, 1248, 6462, 136, 102, 0, 0, 0, 0, 0, 0, 0],
+ [101, 1790, 112, 189, 1341, 1119, 3520, 1164, 1248, 6462, 117, 21902, 1643, 119, 102],
+ [101, 1327, 1164, 5450, 23434, 136, 102, 0, 0, 0, 0, 0, 0, 0, 0]],
+ 'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
+ [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
+ [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]],
+ 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0],
+ [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
+ [1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0]]}
+```
+
+### Build tensors
+
+Finally, you want the tokenizer to return the actual tensors that are fed to the model.
+
+Set the `return_tensors` parameter to either `pt` for PyTorch, or `tf` for TensorFlow:
+
+
+
+
+```py
+>>> batch_sentences = [
+... "But what about second breakfast?",
+... "Don't think he knows about second breakfast, Pip.",
+... "What about elevensies?",
+... ]
+>>> encoded_input = tokenizer(batch, padding=True, truncation=True, return_tensors="pt")
+>>> print(encoded_input)
+{'input_ids': tensor([[ 101, 153, 7719, 21490, 1122, 1114, 9582, 1623, 102],
+ [ 101, 5226, 1122, 9649, 1199, 2610, 1236, 102, 0]]),
+ 'token_type_ids': tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0],
+ [0, 0, 0, 0, 0, 0, 0, 0, 0]]),
+ 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1],
+ [1, 1, 1, 1, 1, 1, 1, 1, 0]])}
+```
+
+
+```py
+>>> batch_sentences = [
+... "But what about second breakfast?",
+... "Don't think he knows about second breakfast, Pip.",
+... "What about elevensies?",
+... ]
+>>> encoded_input = tokenizer(batch_sentences, padding=True, truncation=True, return_tensors="tf")
+>>> print(encoded_input)
+{'input_ids': ,
+ 'token_type_ids': ,
+ 'attention_mask': }
+```
+
+
+
+## Audio
+
+Audio inputs are preprocessed differently than textual inputs, but the end goal remains the same: create numerical sequences the model can understand. A [feature extractor](main_classes/feature_extractor) is designed for the express purpose of extracting features from raw image or audio data and converting them into tensors. Before you begin, install 🤗 Datasets to load an audio dataset to experiment with:
+
+```bash
+pip install datasets
+```
+
+Load the [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) dataset (see the 🤗 [Datasets tutorial](https://huggingface.co/docs/datasets/load_hub.html) for more details on how to load a dataset):
+
+```py
+>>> from datasets import load_dataset, Audio
+
+>>> dataset = load_dataset("PolyAI/minds14", name="en-US", split="train")
+```
+
+Access the first element of the `audio` column to take a look at the input. Calling the `audio` column will automatically load and resample the audio file:
+
+```py
+>>> dataset[0]["audio"]
+{'array': array([ 0. , 0.00024414, -0.00024414, ..., -0.00024414,
+ 0. , 0. ], dtype=float32),
+ 'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~JOINT_ACCOUNT/602ba55abb1e6d0fbce92065.wav',
+ 'sampling_rate': 8000}
+```
+
+This returns three items:
+
+* `array` is the speech signal loaded - and potentially resampled - as a 1D array.
+* `path` points to the location of the audio file.
+* `sampling_rate` refers to how many data points in the speech signal are measured per second.
+
+### Resample
+
+For this tutorial, you will use the [Wav2Vec2](https://huggingface.co/facebook/wav2vec2-base) model. As you can see from the model card, the Wav2Vec2 model is pretrained on 16kHz sampled speech audio. It is important your audio data's sampling rate matches the sampling rate of the dataset used to pretrain the model. If your data's sampling rate isn't the same, then you need to resample your audio data.
+
+For example, the [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) dataset has a sampling rate of 8000kHz. In order to use the Wav2Vec2 model with this dataset, upsample the sampling rate to 16kHz:
+
+```py
+>>> dataset = load_dataset("PolyAI/minds14", name="en-US", split="train")
+>>> dataset[0]["audio"]
+{'array': array([ 0. , 0.00024414, -0.00024414, ..., -0.00024414,
+ 0. , 0. ], dtype=float32),
+ 'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~JOINT_ACCOUNT/602ba55abb1e6d0fbce92065.wav',
+ 'sampling_rate': 8000}
+```
+
+1. Use 🤗 Datasets' [`cast_column`](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.cast_column) method to upsample the sampling rate to 16kHz:
+
+```py
+>>> dataset = dataset.cast_column("audio", Audio(sampling_rate=16_000))
+```
+
+2. Load the audio file:
+
+```py
+>>> dataset[0]["audio"]
+{'array': array([ 2.3443763e-05, 2.1729663e-04, 2.2145823e-04, ...,
+ 3.8356509e-05, -7.3497440e-06, -2.1754686e-05], dtype=float32),
+ 'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~JOINT_ACCOUNT/602ba55abb1e6d0fbce92065.wav',
+ 'sampling_rate': 16000}
+```
+
+As you can see, the `sampling_rate` is now 16kHz!
+
+### Feature extractor
+
+The next step is to load a feature extractor to normalize and pad the input. When padding textual data, a `0` is added for shorter sequences. The same idea applies to audio data, and the audio feature extractor will add a `0` - interpreted as silence - to `array`.
+
+Load the feature extractor with [`AutoFeatureExtractor.from_pretrained`]:
+
+```py
+>>> from transformers import AutoFeatureExtractor
+
+>>> feature_extractor = AutoFeatureExtractor.from_pretrained("facebook/wav2vec2-base")
+```
+
+Pass the audio `array` to the feature extractor. We also recommend adding the `sampling_rate` argument in the feature extractor in order to better debug any silent errors that may occur.
+
+```py
+>>> audio_input = [dataset[0]["audio"]["array"]]
+>>> feature_extractor(audio_input, sampling_rate=16000)
+{'input_values': [array([ 3.8106556e-04, 2.7506407e-03, 2.8015103e-03, ...,
+ 5.6335266e-04, 4.6588284e-06, -1.7142107e-04], dtype=float32)]}
+```
+
+### Pad and truncate
+
+Just like the tokenizer, you can apply padding or truncation to handle variable sequences in a batch. Take a look at the sequence length of these two audio samples:
+
+```py
+>>> dataset[0]["audio"]["array"].shape
+(173398,)
+
+>>> dataset[1]["audio"]["array"].shape
+(106496,)
+```
+
+As you can see, the first sample has a longer sequence than the second sample. Let's create a function that will preprocess the dataset. Specify a maximum sample length, and the feature extractor will either pad or truncate the sequences to match it:
+
+```py
+>>> def preprocess_function(examples):
+... audio_arrays = [x["array"] for x in examples["audio"]]
+... inputs = feature_extractor(
+... audio_arrays,
+... sampling_rate=16000,
+... padding=True,
+... max_length=100000,
+... truncation=True,
+... )
+... return inputs
+```
+
+Apply the function to the the first few examples in the dataset:
+
+```py
+>>> processed_dataset = preprocess_function(dataset[:5])
+```
+
+Now take another look at the processed sample lengths:
+
+```py
+>>> processed_dataset["input_values"][0].shape
+(100000,)
+
+>>> processed_dataset["input_values"][1].shape
+(100000,)
+```
+
+The lengths of the first two samples now match the maximum length you specified.
+
+## Vision
+
+A feature extractor is also used to process images for vision tasks. Once again, the goal is to convert the raw image into a batch of tensors as input.
+
+Let's load the [food101](https://huggingface.co/datasets/food101) dataset for this tutorial. Use 🤗 Datasets `split` parameter to only load a small sample from the training split since the dataset is quite large:
+
+```py
+>>> from datasets import load_dataset
+
+>>> dataset = load_dataset("food101", split="train[:100]")
+```
+
+Next, take a look at the image with 🤗 Datasets [`Image`](https://huggingface.co/docs/datasets/package_reference/main_classes.html?highlight=image#datasets.Image) feature:
+
+```py
+>>> dataset[0]["image"]
+```
+
+
+
+### Feature extractor
+
+Load the feature extractor with [`AutoFeatureExtractor.from_pretrained`]:
+
+```py
+>>> from transformers import AutoFeatureExtractor
+
+>>> feature_extractor = AutoFeatureExtractor.from_pretrained("google/vit-base-patch16-224")
+```
+
+### Data augmentation
+
+For vision tasks, it is common to add some type of data augmentation to the images as a part of preprocessing. You can add augmentations with any library you'd like, but in this tutorial, you will use torchvision's [`transforms`](https://pytorch.org/vision/stable/transforms.html) module.
+
+1. Normalize the image and use [`Compose`](https://pytorch.org/vision/master/generated/torchvision.transforms.Compose.html) to chain some transforms - [`RandomResizedCrop`](https://pytorch.org/vision/main/generated/torchvision.transforms.RandomResizedCrop.html) and [`ColorJitter`](https://pytorch.org/vision/main/generated/torchvision.transforms.ColorJitter.html) - together:
+
+```py
+>>> from torchvision.transforms import Compose, Normalize, RandomResizedCrop, ColorJitter, ToTensor
+
+>>> normalize = Normalize(mean=feature_extractor.image_mean, std=feature_extractor.image_std)
+>>> _transforms = Compose(
+... [RandomResizedCrop(feature_extractor.size), ColorJitter(brightness=0.5, hue=0.5), ToTensor(), normalize]
+... )
+```
+
+2. The model accepts [`pixel_values`](model_doc/visionencoderdecoder#transformers.VisionEncoderDecoderModel.forward.pixel_values) as it's input. This value is generated by the feature extractor. Create a function that generates `pixel_values` from the transforms:
+
+```py
+>>> def transforms(examples):
+... examples["pixel_values"] = [_transforms(image.convert("RGB")) for image in examples["image"]]
+... return examples
+```
+
+3. Then use 🤗 Datasets [`set_transform`](https://huggingface.co/docs/datasets/process.html#format-transform) to apply the transforms on-the-fly:
+
+```py
+>>> dataset.set_transform(transforms)
+```
+
+4. Now when you access the image, you will notice the feature extractor has added the model input `pixel_values`:
+
+```py
+>>> dataset[0]["image"]
+{'image': ,
+ 'label': 6,
+ 'pixel_values': tensor([[[ 0.0353, 0.0745, 0.1216, ..., -0.9922, -0.9922, -0.9922],
+ [-0.0196, 0.0667, 0.1294, ..., -0.9765, -0.9843, -0.9922],
+ [ 0.0196, 0.0824, 0.1137, ..., -0.9765, -0.9686, -0.8667],
+ ...,
+ [ 0.0275, 0.0745, 0.0510, ..., -0.1137, -0.1216, -0.0824],
+ [ 0.0667, 0.0824, 0.0667, ..., -0.0588, -0.0745, -0.0980],
+ [ 0.0353, 0.0353, 0.0431, ..., -0.0039, -0.0039, -0.0588]],
+
+ [[ 0.2078, 0.2471, 0.2863, ..., -0.9451, -0.9373, -0.9451],
+ [ 0.1608, 0.2471, 0.3098, ..., -0.9373, -0.9451, -0.9373],
+ [ 0.2078, 0.2706, 0.3020, ..., -0.9608, -0.9373, -0.8275],
+ ...,
+ [-0.0353, 0.0118, -0.0039, ..., -0.2392, -0.2471, -0.2078],
+ [ 0.0196, 0.0353, 0.0196, ..., -0.1843, -0.2000, -0.2235],
+ [-0.0118, -0.0039, -0.0039, ..., -0.0980, -0.0980, -0.1529]],
+
+ [[ 0.3961, 0.4431, 0.4980, ..., -0.9216, -0.9137, -0.9216],
+ [ 0.3569, 0.4510, 0.5216, ..., -0.9059, -0.9137, -0.9137],
+ [ 0.4118, 0.4745, 0.5216, ..., -0.9137, -0.8902, -0.7804],
+ ...,
+ [-0.2314, -0.1922, -0.2078, ..., -0.4196, -0.4275, -0.3882],
+ [-0.1843, -0.1686, -0.2000, ..., -0.3647, -0.3804, -0.4039],
+ [-0.1922, -0.1922, -0.1922, ..., -0.2941, -0.2863, -0.3412]]])}
+```
+
+Here is what the image looks like after you preprocess it. Just as you'd expect from the applied transforms, the image has been randomly cropped and it's color properties are different.
+
+```py
+>>> import numpy as np
+>>> import matplotlib.pyplot as plt
+
+>>> img = dataset[0]["pixel_values"]
+>>> plt.imshow(img.permute(1, 2, 0))
+```
+
+
+
+## Multimodal
+
+For multimodal tasks. you will use a combination of everything you've learned so far and apply your skills to a automatic speech recognition (ASR) task. This means you will need a:
+
+* Feature extractor to preprocess the audio data.
+* Tokenizer to process the text.
+
+Let's return to the [LJ Speech](https://huggingface.co/datasets/lj_speech) dataset:
+
+```py
+>>> from datasets import load_dataset
+
+>>> lj_speech = load_dataset("lj_speech", split="train")
+```
+
+Since you are mainly interested in the `audio` and `text` column, remove the other columns:
+
+```py
+>>> lj_speech = lj_speech.map(remove_columns=["file", "id", "normalized_text"])
+```
+
+Now take a look at the `audio` and `text` columns:
+
+```py
+>>> lj_speech[0]["audio"]
+{'array': array([-7.3242188e-04, -7.6293945e-04, -6.4086914e-04, ...,
+ 7.3242188e-04, 2.1362305e-04, 6.1035156e-05], dtype=float32),
+ 'path': '/root/.cache/huggingface/datasets/downloads/extracted/917ece08c95cf0c4115e45294e3cd0dee724a1165b7fc11798369308a465bd26/LJSpeech-1.1/wavs/LJ001-0001.wav',
+ 'sampling_rate': 22050}
+
+>>> lj_speech[0]["text"]
+'Printing, in the only sense with which we are at present concerned, differs from most if not from all the arts and crafts represented in the Exhibition'
+```
+
+Remember from the earlier section on processing audio data, you should always [resample](preprocessing#audio) your audio data's sampling rate to match the sampling rate of the dataset used to pretrain a model:
+
+```py
+>>> lj_speech = lj_speech.cast_column("audio", Audio(sampling_rate=16_000))
+```
+
+### Processor
+
+A processor combines a feature extractor and tokenizer. Load a processor with [`AutoProcessor.from_pretrained]:
+
+```py
+>>> from transformers import AutoProcessor
+
+>>> processor = AutoProcessor.from_pretrained("facebook/wav2vec2-base-960h")
+```
+
+1. Create a function to process the audio data to `input_values`, and tokenizes the text to `labels`. These are your inputs to the model:
+
+```py
+>>> def prepare_dataset(example):
+... audio = example["audio"]
+
+... example["input_values"] = processor(audio["array"], sampling_rate=16000)
+
+... with processor.as_target_processor():
+... example["labels"] = processor(example["text"]).input_ids
+... return example
+```
+
+2. Apply the `prepare_dataset` function to a sample:
+
+```py
+>>> prepare_dataset(lj_speech[0])
+```
+
+Notice the processor has added `input_values` and `labels`. The sampling rate has also been correctly downsampled to 16kHz.
+
+Awesome, you should now be able to preprocess data for any modality and even combine different modalities! In the next tutorial, learn how to fine-tune a model on your newly preprocessed data.
diff --git a/docs/source/en/quicktour.mdx b/docs/source/en/quicktour.mdx
new file mode 100644
index 00000000000000..180ea36fc895cd
--- /dev/null
+++ b/docs/source/en/quicktour.mdx
@@ -0,0 +1,391 @@
+
+
+# Quick tour
+
+[[open-in-colab]]
+
+Get up and running with 🤗 Transformers! Start using the [`pipeline`] for rapid inference, and quickly load a pretrained model and tokenizer with an [AutoClass](./model_doc/auto) to solve your text, vision or audio task.
+
+
+
+All code examples presented in the documentation have a toggle on the top left for PyTorch and TensorFlow. If
+not, the code is expected to work for both backends without any change.
+
+
+
+## Pipeline
+
+[`pipeline`] is the easiest way to use a pretrained model for a given task.
+
+
+
+The [`pipeline`] supports many common tasks out-of-the-box:
+
+**Text**:
+* Sentiment analysis: classify the polarity of a given text.
+* Text generation (in English): generate text from a given input.
+* Name entity recognition (NER): label each word with the entity it represents (person, date, location, etc.).
+* Question answering: extract the answer from the context, given some context and a question.
+* Fill-mask: fill in the blank given a text with masked words.
+* Summarization: generate a summary of a long sequence of text or document.
+* Translation: translate text into another language.
+* Feature extraction: create a tensor representation of the text.
+
+**Image**:
+* Image classification: classify an image.
+* Image segmentation: classify every pixel in an image.
+* Object detection: detect objects within an image.
+
+**Audio**:
+* Audio classification: assign a label to a given segment of audio.
+* Automatic speech recognition (ASR): transcribe audio data into text.
+
+
+
+For more details about the [`pipeline`] and associated tasks, refer to the documentation [here](./main_classes/pipelines).
+
+
+
+### Pipeline usage
+
+In the following example, you will use the [`pipeline`] for sentiment analysis.
+
+Install the following dependencies if you haven't already:
+
+
+
+```bash
+pip install torch
+```
+
+
+```bash
+pip install tensorflow
+```
+
+
+
+Import [`pipeline`] and specify the task you want to complete:
+
+```py
+>>> from transformers import pipeline
+
+>>> classifier = pipeline("sentiment-analysis")
+```
+
+The pipeline downloads and caches a default [pretrained model](https://huggingface.co/distilbert-base-uncased-finetuned-sst-2-english) and tokenizer for sentiment analysis. Now you can use the `classifier` on your target text:
+
+```py
+>>> classifier("We are very happy to show you the 🤗 Transformers library.")
+[{'label': 'POSITIVE', 'score': 0.9998}]
+```
+
+For more than one sentence, pass a list of sentences to the [`pipeline`] which returns a list of dictionaries:
+
+```py
+>>> results = classifier(["We are very happy to show you the 🤗 Transformers library.", "We hope you don't hate it."])
+>>> for result in results:
+... print(f"label: {result['label']}, with score: {round(result['score'], 4)}")
+label: POSITIVE, with score: 0.9998
+label: NEGATIVE, with score: 0.5309
+```
+
+The [`pipeline`] can also iterate over an entire dataset. Start by installing the [🤗 Datasets](https://huggingface.co/docs/datasets/) library:
+
+```bash
+pip install datasets
+```
+
+Create a [`pipeline`] with the task you want to solve for and the model you want to use.
+
+```py
+>>> import torch
+>>> from transformers import pipeline
+
+>>> speech_recognizer = pipeline("automatic-speech-recognition", model="facebook/wav2vec2-base-960h")
+```
+
+Next, load a dataset (see the 🤗 Datasets [Quick Start](https://huggingface.co/docs/datasets/quickstart.html) for more details) you'd like to iterate over. For example, let's load the [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) dataset:
+
+```py
+>>> from datasets import load_dataset, Audio
+
+>>> dataset = load_dataset("PolyAI/minds14", name="en-US", split="train") # doctest: +IGNORE_RESULT
+```
+
+We need to make sure that the sampling rate of the dataset matches the sampling
+rate `facebook/wav2vec2-base-960h` was trained on.
+
+```py
+>>> dataset = dataset.cast_column("audio", Audio(sampling_rate=speech_recognizer.feature_extractor.sampling_rate))
+```
+
+Audio files are automatically loaded and resampled when calling the `"audio"` column.
+Let's extract the raw waveform arrays of the first 4 samples and pass it as a list to the pipeline:
+
+```py
+>>> result = speech_recognizer(dataset[:4]["audio"])
+>>> print([d["text"] for d in result])
+['I WOULD LIKE TO SET UP A JOINT ACCOUNT WITH MY PARTNER HOW DO I PROCEED WITH DOING THAT', "FONDERING HOW I'D SET UP A JOIN TO HET WITH MY WIFE AND WHERE THE AP MIGHT BE", "I I'D LIKE TOY SET UP A JOINT ACCOUNT WITH MY PARTNER I'M NOT SEEING THE OPTION TO DO IT ON THE APSO I CALLED IN TO GET SOME HELP CAN I JUST DO IT OVER THE PHONE WITH YOU AND GIVE YOU THE INFORMATION OR SHOULD I DO IT IN THE AP AND I'M MISSING SOMETHING UQUETTE HAD PREFERRED TO JUST DO IT OVER THE PHONE OF POSSIBLE THINGS", 'HOW DO I TURN A JOIN A COUNT']
+```
+
+For a larger dataset where the inputs are big (like in speech or vision), you will want to pass along a generator instead of a list that loads all the inputs in memory. See the [pipeline documentation](./main_classes/pipelines) for more information.
+
+### Use another model and tokenizer in the pipeline
+
+The [`pipeline`] can accommodate any model from the [Model Hub](https://huggingface.co/models), making it easy to adapt the [`pipeline`] for other use-cases. For example, if you'd like a model capable of handling French text, use the tags on the Model Hub to filter for an appropriate model. The top filtered result returns a multilingual [BERT model](https://huggingface.co/nlptown/bert-base-multilingual-uncased-sentiment) fine-tuned for sentiment analysis. Great, let's use this model!
+
+```py
+>>> model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
+```
+
+
+
+Use the [`AutoModelForSequenceClassification`] and [`AutoTokenizer`] to load the pretrained model and it's associated tokenizer (more on an `AutoClass` below):
+
+```py
+>>> from transformers import AutoTokenizer, AutoModelForSequenceClassification
+
+>>> model = AutoModelForSequenceClassification.from_pretrained(model_name)
+>>> tokenizer = AutoTokenizer.from_pretrained(model_name)
+```
+
+
+Use the [`TFAutoModelForSequenceClassification`] and [`AutoTokenizer`] to load the pretrained model and it's associated tokenizer (more on an `TFAutoClass` below):
+
+```py
+>>> from transformers import AutoTokenizer, TFAutoModelForSequenceClassification
+
+>>> model = TFAutoModelForSequenceClassification.from_pretrained(model_name)
+>>> tokenizer = AutoTokenizer.from_pretrained(model_name)
+```
+
+
+
+Then you can specify the model and tokenizer in the [`pipeline`], and apply the `classifier` on your target text:
+
+```py
+>>> classifier = pipeline("sentiment-analysis", model=model, tokenizer=tokenizer)
+>>> classifier("Nous sommes très heureux de vous présenter la bibliothèque 🤗 Transformers.")
+[{'label': '5 stars', 'score': 0.7273}]
+```
+
+If you can't find a model for your use-case, you will need to fine-tune a pretrained model on your data. Take a look at our [fine-tuning tutorial](./training) to learn how. Finally, after you've fine-tuned your pretrained model, please consider sharing it (see tutorial [here](./model_sharing)) with the community on the Model Hub to democratize NLP for everyone! 🤗
+
+## AutoClass
+
+
+
+Under the hood, the [`AutoModelForSequenceClassification`] and [`AutoTokenizer`] classes work together to power the [`pipeline`]. An [AutoClass](./model_doc/auto) is a shortcut that automatically retrieves the architecture of a pretrained model from it's name or path. You only need to select the appropriate `AutoClass` for your task and it's associated tokenizer with [`AutoTokenizer`].
+
+Let's return to our example and see how you can use the `AutoClass` to replicate the results of the [`pipeline`].
+
+### AutoTokenizer
+
+A tokenizer is responsible for preprocessing text into a format that is understandable to the model. First, the tokenizer will split the text into words called *tokens*. There are multiple rules that govern the tokenization process, including how to split a word and at what level (learn more about tokenization [here](./tokenizer_summary)). The most important thing to remember though is you need to instantiate the tokenizer with the same model name to ensure you're using the same tokenization rules a model was pretrained with.
+
+Load a tokenizer with [`AutoTokenizer`]:
+
+```py
+>>> from transformers import AutoTokenizer
+
+>>> model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
+>>> tokenizer = AutoTokenizer.from_pretrained(model_name)
+```
+
+Next, the tokenizer converts the tokens into numbers in order to construct a tensor as input to the model. This is known as the model's *vocabulary*.
+
+Pass your text to the tokenizer:
+
+```py
+>>> encoding = tokenizer("We are very happy to show you the 🤗 Transformers library.")
+>>> print(encoding)
+{'input_ids': [101, 11312, 10320, 12495, 19308, 10114, 11391, 10855, 10103, 100, 58263, 13299, 119, 102],
+ 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
+ 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
+```
+
+The tokenizer will return a dictionary containing:
+
+* [input_ids](./glossary#input-ids): numerical representions of your tokens.
+* [atttention_mask](.glossary#attention-mask): indicates which tokens should be attended to.
+
+Just like the [`pipeline`], the tokenizer will accept a list of inputs. In addition, the tokenizer can also pad and truncate the text to return a batch with uniform length:
+
+
+
+```py
+>>> pt_batch = tokenizer(
+... ["We are very happy to show you the 🤗 Transformers library.", "We hope you don't hate it."],
+... padding=True,
+... truncation=True,
+... max_length=512,
+... return_tensors="pt",
+... )
+```
+
+
+```py
+>>> tf_batch = tokenizer(
+... ["We are very happy to show you the 🤗 Transformers library.", "We hope you don't hate it."],
+... padding=True,
+... truncation=True,
+... max_length=512,
+... return_tensors="tf",
+... )
+```
+
+
+
+Read the [preprocessing](./preprocessing) tutorial for more details about tokenization.
+
+### AutoModel
+
+
+
+🤗 Transformers provides a simple and unified way to load pretrained instances. This means you can load an [`AutoModel`] like you would load an [`AutoTokenizer`]. The only difference is selecting the correct [`AutoModel`] for the task. Since you are doing text - or sequence - classification, load [`AutoModelForSequenceClassification`]:
+
+```py
+>>> from transformers import AutoModelForSequenceClassification
+
+>>> model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
+>>> pt_model = AutoModelForSequenceClassification.from_pretrained(model_name)
+```
+
+
+
+See the [task summary](./task_summary) for which [`AutoModel`] class to use for which task.
+
+
+
+Now you can pass your preprocessed batch of inputs directly to the model. You just have to unpack the dictionary by adding `**`:
+
+```py
+>>> pt_outputs = pt_model(**pt_batch)
+```
+
+The model outputs the final activations in the `logits` attribute. Apply the softmax function to the `logits` to retrieve the probabilities:
+
+```py
+>>> from torch import nn
+
+>>> pt_predictions = nn.functional.softmax(pt_outputs.logits, dim=-1)
+>>> print(pt_predictions)
+tensor([[0.0021, 0.0018, 0.0115, 0.2121, 0.7725],
+ [0.2084, 0.1826, 0.1969, 0.1755, 0.2365]], grad_fn=)
+```
+
+
+🤗 Transformers provides a simple and unified way to load pretrained instances. This means you can load an [`TFAutoModel`] like you would load an [`AutoTokenizer`]. The only difference is selecting the correct [`TFAutoModel`] for the task. Since you are doing text - or sequence - classification, load [`TFAutoModelForSequenceClassification`]:
+
+```py
+>>> from transformers import TFAutoModelForSequenceClassification
+
+>>> model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
+>>> tf_model = TFAutoModelForSequenceClassification.from_pretrained(model_name)
+```
+
+
+
+See the [task summary](./task_summary) for which [`AutoModel`] class to use for which task.
+
+
+
+Now you can pass your preprocessed batch of inputs directly to the model by passing the dictionary keys directly to the tensors:
+
+```py
+>>> tf_outputs = tf_model(tf_batch)
+```
+
+The model outputs the final activations in the `logits` attribute. Apply the softmax function to the `logits` to retrieve the probabilities:
+
+```py
+>>> import tensorflow as tf
+
+>>> tf_predictions = tf.nn.softmax(tf_outputs.logits, axis=-1)
+>>> tf_predictions # doctest: +IGNORE_RESULT
+```
+
+
+
+
+
+All 🤗 Transformers models (PyTorch or TensorFlow) outputs the tensors *before* the final activation
+function (like softmax) because the final activation function is often fused with the loss.
+
+
+
+Models are a standard [`torch.nn.Module`](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) or a [`tf.keras.Model`](https://www.tensorflow.org/api_docs/python/tf/keras/Model) so you can use them in your usual training loop. However, to make things easier, 🤗 Transformers provides a [`Trainer`] class for PyTorch that adds functionality for distributed training, mixed precision, and more. For TensorFlow, you can use the `fit` method from [Keras](https://keras.io/). Refer to the [training tutorial](./training) for more details.
+
+
+
+🤗 Transformers model outputs are special dataclasses so their attributes are autocompleted in an IDE.
+The model outputs also behave like a tuple or a dictionary (e.g., you can index with an integer, a slice or a string) in which case the attributes that are `None` are ignored.
+
+
+
+### Save a model
+
+
+
+Once your model is fine-tuned, you can save it with its tokenizer using [`PreTrainedModel.save_pretrained`]:
+
+```py
+>>> pt_save_directory = "./pt_save_pretrained"
+>>> tokenizer.save_pretrained(pt_save_directory) # doctest: +IGNORE_RESULT
+>>> pt_model.save_pretrained(pt_save_directory)
+```
+
+When you are ready to use the model again, reload it with [`PreTrainedModel.from_pretrained`]:
+
+```py
+>>> pt_model = AutoModelForSequenceClassification.from_pretrained("./pt_save_pretrained")
+```
+
+
+Once your model is fine-tuned, you can save it with its tokenizer using [`TFPreTrainedModel.save_pretrained`]:
+
+```py
+>>> tf_save_directory = "./tf_save_pretrained"
+>>> tokenizer.save_pretrained(tf_save_directory) # doctest: +IGNORE_RESULT
+>>> tf_model.save_pretrained(tf_save_directory)
+```
+
+When you are ready to use the model again, reload it with [`TFPreTrainedModel.from_pretrained`]:
+
+```py
+>>> tf_model = TFAutoModelForSequenceClassification.from_pretrained("./tf_save_pretrained")
+```
+
+
+
+One particularly cool 🤗 Transformers feature is the ability to save a model and reload it as either a PyTorch or TensorFlow model. The `from_pt` or `from_tf` parameter can convert the model from one framework to the other:
+
+
+
+```py
+>>> from transformers import AutoModel
+
+>>> tokenizer = AutoTokenizer.from_pretrained(tf_save_directory)
+>>> pt_model = AutoModelForSequenceClassification.from_pretrained(tf_save_directory, from_tf=True)
+```
+
+
+```py
+>>> from transformers import TFAutoModel
+
+>>> tokenizer = AutoTokenizer.from_pretrained(pt_save_directory)
+>>> tf_model = TFAutoModelForSequenceClassification.from_pretrained(pt_save_directory, from_pt=True)
+```
+
+
diff --git a/docs/source/en/run_scripts.mdx b/docs/source/en/run_scripts.mdx
new file mode 100644
index 00000000000000..ca8f8df5e86ccb
--- /dev/null
+++ b/docs/source/en/run_scripts.mdx
@@ -0,0 +1,346 @@
+
+
+# Train with a script
+
+Along with the 🤗 Transformers [notebooks](./noteboks/README), there are also example scripts demonstrating how to train a model for a task with [PyTorch](https://github.com/huggingface/transformers/tree/main/examples/pytorch), [TensorFlow](https://github.com/huggingface/transformers/tree/main/examples/tensorflow), or [JAX/Flax](https://github.com/huggingface/transformers/tree/main/examples/flax).
+
+You will also find scripts we've used in our [research projects](https://github.com/huggingface/transformers/tree/main/examples/research_projects) and [legacy examples](https://github.com/huggingface/transformers/tree/main/examples/legacy) which are mostly community contributed. These scripts are not actively maintained and require a specific version of 🤗 Transformers that will most likely be incompatible with the latest version of the library.
+
+The example scripts are not expected to work out-of-the-box on every problem, and you may need to adapt the script to the problem you're trying to solve. To help you with this, most of the scripts fully expose how data is preprocessed, allowing you to edit it as necessary for your use case.
+
+For any feature you'd like to implement in an example script, please discuss it on the [forum](https://discuss.huggingface.co/) or in an [issue](https://github.com/huggingface/transformers/issues) before submitting a Pull Request. While we welcome bug fixes, it is unlikely we will merge a Pull Request that adds more functionality at the cost of readability.
+
+This guide will show you how to run an example summarization training script in [PyTorch](https://github.com/huggingface/transformers/tree/main/examples/pytorch/summarization) and [TensorFlow](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/summarization). All examples are expected to work with both frameworks unless otherwise specified.
+
+## Setup
+
+To successfully run the latest version of the example scripts, you have to **install 🤗 Transformers from source** in a new virtual environment:
+
+```bash
+git clone https://github.com/huggingface/transformers
+cd transformers
+pip install .
+```
+
+For older versions of the example scripts, click on the toggle below:
+
+
+ Examples for older versions of 🤗 Transformers
+
+
+
+Then switch your current clone of 🤗 Transformers to a specific version, like v3.5.1 for example:
+
+```bash
+git checkout tags/v3.5.1
+```
+
+After you've setup the correct library version, navigate to the example folder of your choice and install the example specific requirements:
+
+```bash
+pip install -r requirements.txt
+```
+
+## Run a script
+
+
+
+The example script downloads and preprocesses a dataset from the 🤗 [Datasets](https://huggingface.co/docs/datasets/) library. Then the script fine-tunes a dataset with the [Trainer](https://huggingface.co/docs/transformers/main_classes/trainer) on an architecture that supports summarization. The following example shows how to fine-tune [T5-small](https://huggingface.co/t5-small) on the [CNN/DailyMail](https://huggingface.co/datasets/cnn_dailymail) dataset. The T5 model requires an additional `source_prefix` argument due to how it was trained. This prompt lets T5 know this is a summarization task.
+
+```bash
+python examples/pytorch/summarization/run_summarization.py \
+ --model_name_or_path t5-small \
+ --do_train \
+ --do_eval \
+ --dataset_name cnn_dailymail \
+ --dataset_config "3.0.0" \
+ --source_prefix "summarize: " \
+ --output_dir /tmp/tst-summarization \
+ --per_device_train_batch_size=4 \
+ --per_device_eval_batch_size=4 \
+ --overwrite_output_dir \
+ --predict_with_generate
+```
+
+
+The example script downloads and preprocesses a dataset from the 🤗 [Datasets](https://huggingface.co/docs/datasets/) library. Then the script fine-tunes a dataset using Keras on an architecture that supports summarization. The following example shows how to fine-tune [T5-small](https://huggingface.co/t5-small) on the [CNN/DailyMail](https://huggingface.co/datasets/cnn_dailymail) dataset. The T5 model requires an additional `source_prefix` argument due to how it was trained. This prompt lets T5 know this is a summarization task.
+
+```bash
+python examples/tensorflow/summarization/run_summarization.py \
+ --model_name_or_path t5-small \
+ --dataset_name cnn_dailymail \
+ --dataset_config "3.0.0" \
+ --output_dir /tmp/tst-summarization \
+ --per_device_train_batch_size 8 \
+ --per_device_eval_batch_size 16 \
+ --num_train_epochs 3 \
+ --do_train \
+ --do_eval
+```
+
+
+
+## Distributed training and mixed precision
+
+The [Trainer](https://huggingface.co/docs/transformers/main_classes/trainer) supports distributed training and mixed precision, which means you can also use it in a script. To enable both of these features:
+
+- Add the `fp16` argument to enable mixed precision.
+- Set the number of GPUs to use with the `nproc_per_node` argument.
+
+```bash
+python -m torch.distributed.launch \
+ --nproc_per_node 8 pytorch/summarization/run_summarization.py \
+ --fp16 \
+ --model_name_or_path t5-small \
+ --do_train \
+ --do_eval \
+ --dataset_name cnn_dailymail \
+ --dataset_config "3.0.0" \
+ --source_prefix "summarize: " \
+ --output_dir /tmp/tst-summarization \
+ --per_device_train_batch_size=4 \
+ --per_device_eval_batch_size=4 \
+ --overwrite_output_dir \
+ --predict_with_generate
+```
+
+TensorFlow scripts utilize a [`MirroredStrategy`](https://www.tensorflow.org/guide/distributed_training#mirroredstrategy) for distributed training, and you don't need to add any additional arguments to the training script. The TensorFlow script will use multiple GPUs by default if they are available.
+
+## Run a script on a TPU
+
+
+
+Tensor Processing Units (TPUs) are specifically designed to accelerate performance. PyTorch supports TPUs with the [XLA](https://www.tensorflow.org/xla) deep learning compiler (see [here](https://github.com/pytorch/xla/blob/master/README.md) for more details). To use a TPU, launch the `xla_spawn.py` script and use the `num_cores` argument to set the number of TPU cores you want to use.
+
+```bash
+python xla_spawn.py --num_cores 8 \
+ summarization/run_summarization.py \
+ --model_name_or_path t5-small \
+ --do_train \
+ --do_eval \
+ --dataset_name cnn_dailymail \
+ --dataset_config "3.0.0" \
+ --source_prefix "summarize: " \
+ --output_dir /tmp/tst-summarization \
+ --per_device_train_batch_size=4 \
+ --per_device_eval_batch_size=4 \
+ --overwrite_output_dir \
+ --predict_with_generate
+```
+
+
+Tensor Processing Units (TPUs) are specifically designed to accelerate performance. TensorFlow scripts utilize a [`TPUStrategy`](https://www.tensorflow.org/guide/distributed_training#tpustrategy) for training on TPUs. To use a TPU, pass the name of the TPU resource to the `tpu` argument.
+
+```bash
+python run_summarization.py \
+ --tpu name_of_tpu_resource \
+ --model_name_or_path t5-small \
+ --dataset_name cnn_dailymail \
+ --dataset_config "3.0.0" \
+ --output_dir /tmp/tst-summarization \
+ --per_device_train_batch_size 8 \
+ --per_device_eval_batch_size 16 \
+ --num_train_epochs 3 \
+ --do_train \
+ --do_eval
+```
+
+
+
+## Run a script with 🤗 Accelerate
+
+🤗 [Accelerate](https://huggingface.co/docs/accelerate/index.html) is a PyTorch-only library that offers a unified method for training a model on several types of setups (CPU-only, multiple GPUs, TPUs) while maintaining complete visibility into the PyTorch training loop. Make sure you have 🤗 Accelerate installed if you don't already have it:
+
+```bash
+pip install accelerate
+```
+
+Instead of the `run_summarization.py` script, you need to use the `run_summarization_no_trainer.py` script. 🤗 Accelerate supported scripts will have a `task_no_trainer.py` file in the folder. Begin by running the following command to create and save a configuration file:
+
+```bash
+accelerate config
+```
+
+Test your setup to make sure it is configured correctly:
+
+```bash
+accelerate test
+```
+
+Now you are ready to launch the training:
+
+```bash
+accelerate launch run_summarization_no_trainer.py \
+ --model_name_or_path t5-small \
+ --dataset_name cnn_dailymail \
+ --dataset_config "3.0.0" \
+ --source_prefix "summarize: " \
+ --output_dir ~/tmp/tst-summarization
+```
+
+## Use a custom dataset
+
+The summarization script supports custom datasets as long as they are a CSV or JSON Line file. When you use your own dataset, you need to specify several additional arguments:
+
+- `train_file` and `validation_file` specify the path to your training and validation files.
+- `text_column` is the input text to summarize.
+- `summary_column` is the target text to output.
+
+A summarization script using a custom dataset would look like this:
+
+```bash
+python examples/pytorch/summarization/run_summarization.py \
+ --model_name_or_path t5-small \
+ --do_train \
+ --do_eval \
+ --train_file path_to_csv_or_jsonlines_file \
+ --validation_file path_to_csv_or_jsonlines_file \
+ --text_column text_column_name \
+ --summary_column summary_column_name \
+ --source_prefix "summarize: " \
+ --output_dir /tmp/tst-summarization \
+ --overwrite_output_dir \
+ --per_device_train_batch_size=4 \
+ --per_device_eval_batch_size=4 \
+ --predict_with_generate
+```
+
+## Test a script
+
+It is often a good idea to run your script on a smaller number of dataset examples to ensure everything works as expected before committing to an entire dataset which may take hours to complete. Use the following arguments to truncate the dataset to a maximum number of samples:
+
+- `max_train_samples`
+- `max_eval_samples`
+- `max_predict_samples`
+
+```bash
+python examples/pytorch/summarization/run_summarization.py \
+ --model_name_or_path t5-small \
+ --max_train_samples 50 \
+ --max_eval_samples 50 \
+ --max_predict_samples 50 \
+ --do_train \
+ --do_eval \
+ --dataset_name cnn_dailymail \
+ --dataset_config "3.0.0" \
+ --source_prefix "summarize: " \
+ --output_dir /tmp/tst-summarization \
+ --per_device_train_batch_size=4 \
+ --per_device_eval_batch_size=4 \
+ --overwrite_output_dir \
+ --predict_with_generate
+```
+
+Not all example scripts support the `max_predict_samples` argument. If you aren't sure whether your script supports this argument, add the `-h` argument to check:
+
+```bash
+examples/pytorch/summarization/run_summarization.py -h
+```
+
+## Resume training from checkpoint
+
+Another helpful option to enable is resuming training from a previous checkpoint. This will ensure you can pick up where you left off without starting over if your training gets interrupted. There are two methods to resume training from a checkpoint.
+
+The first method uses the `output_dir previous_output_dir` argument to resume training from the latest checkpoint stored in `output_dir`. In this case, you should remove `overwrite_output_dir`:
+
+```bash
+python examples/pytorch/summarization/run_summarization.py
+ --model_name_or_path t5-small \
+ --do_train \
+ --do_eval \
+ --dataset_name cnn_dailymail \
+ --dataset_config "3.0.0" \
+ --source_prefix "summarize: " \
+ --output_dir /tmp/tst-summarization \
+ --per_device_train_batch_size=4 \
+ --per_device_eval_batch_size=4 \
+ --output_dir previous_output_dir \
+ --predict_with_generate
+```
+
+The second method uses the `resume_from_checkpoint path_to_specific_checkpoint` argument to resume training from a specific checkpoint folder.
+
+```bash
+python examples/pytorch/summarization/run_summarization.py
+ --model_name_or_path t5-small \
+ --do_train \
+ --do_eval \
+ --dataset_name cnn_dailymail \
+ --dataset_config "3.0.0" \
+ --source_prefix "summarize: " \
+ --output_dir /tmp/tst-summarization \
+ --per_device_train_batch_size=4 \
+ --per_device_eval_batch_size=4 \
+ --overwrite_output_dir \
+ --resume_from_checkpoint path_to_specific_checkpoint \
+ --predict_with_generate
+```
+
+## Share your model
+
+All scripts can upload your final model to the [Model Hub](https://huggingface.co/models). Make sure you are logged into Hugging Face before you begin:
+
+```bash
+huggingface-cli login
+```
+
+Then add the `push_to_hub` argument to the script. This argument will create a repository with your Hugging Face username and the folder name specified in `output_dir`.
+
+To give your repository a specific name, use the `push_to_hub_model_id` argument to add it. The repository will be automatically listed under your namespace.
+
+The following example shows how to upload a model with a specific repository name:
+
+```bash
+python examples/pytorch/summarization/run_summarization.py
+ --model_name_or_path t5-small \
+ --do_train \
+ --do_eval \
+ --dataset_name cnn_dailymail \
+ --dataset_config "3.0.0" \
+ --source_prefix "summarize: " \
+ --push_to_hub \
+ --push_to_hub_model_id finetuned-t5-cnn_dailymail \
+ --output_dir /tmp/tst-summarization \
+ --per_device_train_batch_size=4 \
+ --per_device_eval_batch_size=4 \
+ --overwrite_output_dir \
+ --predict_with_generate
+```
\ No newline at end of file
diff --git a/docs/source/en/sagemaker.mdx b/docs/source/en/sagemaker.mdx
new file mode 100644
index 00000000000000..1ffdd4326e4d65
--- /dev/null
+++ b/docs/source/en/sagemaker.mdx
@@ -0,0 +1,25 @@
+
+
+# Run training on Amazon SageMaker
+
+The documentation has been moved to [hf.co/docs/sagemaker](https://huggingface.co/docs/sagemaker). This page will be removed in `transformers` 5.0.
+
+### Table of Content
+
+- [Train Hugging Face models on Amazon SageMaker with the SageMaker Python SDK](https://huggingface.co/docs/sagemaker/train)
+- [Deploy Hugging Face models to Amazon SageMaker with the SageMaker Python SDK](https://huggingface.co/docs/sagemaker/inference)
+- [Frequently Asked Questions](https://huggingface.co/docs/sagemaker/faq)
diff --git a/docs/source/en/serialization.mdx b/docs/source/en/serialization.mdx
new file mode 100644
index 00000000000000..4ae5c9a57ecbdd
--- /dev/null
+++ b/docs/source/en/serialization.mdx
@@ -0,0 +1,669 @@
+
+
+# Export 🤗 Transformers Models
+
+If you need to deploy 🤗 Transformers models in production environments, we
+recommend exporting them to a serialized format that can be loaded and executed
+on specialized runtimes and hardware. In this guide, we'll show you how to
+export 🤗 Transformers models in two widely used formats: ONNX and TorchScript.
+
+Once exported, a model can optimized for inference via techniques such as
+quantization and pruning. If you are interested in optimizing your models to run
+with maximum efficiency, check out the [🤗 Optimum
+library](https://github.com/huggingface/optimum).
+
+## ONNX
+
+The [ONNX (Open Neural Network eXchange)](http://onnx.ai) project is an open
+standard that defines a common set of operators and a common file format to
+represent deep learning models in a wide variety of frameworks, including
+PyTorch and TensorFlow. When a model is exported to the ONNX format, these
+operators are used to construct a computational graph (often called an
+_intermediate representation_) which represents the flow of data through the
+neural network.
+
+By exposing a graph with standardized operators and data types, ONNX makes it
+easy to switch between frameworks. For example, a model trained in PyTorch can
+be exported to ONNX format and then imported in TensorFlow (and vice versa).
+
+🤗 Transformers provides a `transformers.onnx` package that enables you to
+convert model checkpoints to an ONNX graph by leveraging configuration objects.
+These configuration objects come ready made for a number of model architectures,
+and are designed to be easily extendable to other architectures.
+
+Ready-made configurations include the following architectures:
+
+
+
+- ALBERT
+- BART
+- BEiT
+- BERT
+- BigBird
+- Blenderbot
+- BlenderbotSmall
+- CamemBERT
+- ConvBERT
+- Data2VecText
+- Data2VecVision
+- DeiT
+- DistilBERT
+- ELECTRA
+- FlauBERT
+- GPT Neo
+- GPT-J
+- I-BERT
+- LayoutLM
+- M2M100
+- Marian
+- mBART
+- OpenAI GPT-2
+- PLBart
+- RoBERTa
+- RoFormer
+- T5
+- TAPEX
+- ViT
+- XLM-RoBERTa
+- XLM-RoBERTa-XL
+
+In the next two sections, we'll show you how to:
+
+* Export a supported model using the `transformers.onnx` package.
+* Export a custom model for an unsupported architecture.
+
+### Exporting a model to ONNX
+
+To export a 🤗 Transformers model to ONNX, you'll first need to install some
+extra dependencies:
+
+```bash
+pip install transformers[onnx]
+```
+
+The `transformers.onnx` package can then be used as a Python module:
+
+```bash
+python -m transformers.onnx --help
+
+usage: Hugging Face Transformers ONNX exporter [-h] -m MODEL [--feature {causal-lm, ...}] [--opset OPSET] [--atol ATOL] output
+
+positional arguments:
+ output Path indicating where to store generated ONNX model.
+
+optional arguments:
+ -h, --help show this help message and exit
+ -m MODEL, --model MODEL
+ Model ID on huggingface.co or path on disk to load model from.
+ --feature {causal-lm, ...}
+ The type of features to export the model with.
+ --opset OPSET ONNX opset version to export the model with.
+ --atol ATOL Absolute difference tolerence when validating the model.
+```
+
+Exporting a checkpoint using a ready-made configuration can be done as follows:
+
+```bash
+python -m transformers.onnx --model=distilbert-base-uncased onnx/
+```
+
+which should show the following logs:
+
+```bash
+Validating ONNX model...
+ -[✓] ONNX model output names match reference model ({'last_hidden_state'})
+ - Validating ONNX Model output "last_hidden_state":
+ -[✓] (2, 8, 768) matches (2, 8, 768)
+ -[✓] all values close (atol: 1e-05)
+All good, model saved at: onnx/model.onnx
+```
+
+This exports an ONNX graph of the checkpoint defined by the `--model` argument.
+In this example it is `distilbert-base-uncased`, but it can be any checkpoint on
+the Hugging Face Hub or one that's stored locally.
+
+The resulting `model.onnx` file can then be run on one of the [many
+accelerators](https://onnx.ai/supported-tools.html#deployModel) that support the
+ONNX standard. For example, we can load and run the model with [ONNX
+Runtime](https://onnxruntime.ai/) as follows:
+
+```python
+>>> from transformers import AutoTokenizer
+>>> from onnxruntime import InferenceSession
+
+>>> tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
+>>> session = InferenceSession("onnx/model.onnx")
+>>> # ONNX Runtime expects NumPy arrays as input
+>>> inputs = tokenizer("Using DistilBERT with ONNX Runtime!", return_tensors="np")
+>>> outputs = session.run(output_names=["last_hidden_state"], input_feed=dict(inputs))
+```
+
+The required output names (i.e. `["last_hidden_state"]`) can be obtained by
+taking a look at the ONNX configuration of each model. For example, for
+DistilBERT we have:
+
+```python
+>>> from transformers.models.distilbert import DistilBertConfig, DistilBertOnnxConfig
+
+>>> config = DistilBertConfig()
+>>> onnx_config = DistilBertOnnxConfig(config)
+>>> print(list(onnx_config.outputs.keys()))
+["last_hidden_state"]
+```
+
+The process is identical for TensorFlow checkpoints on the Hub. For example, we
+can export a pure TensorFlow checkpoint from the [Keras
+organization](https://huggingface.co/keras-io) as follows:
+
+```bash
+python -m transformers.onnx --model=keras-io/transformers-qa onnx/
+```
+
+To export a model that's stored locally, you'll need to have the model's weights
+and tokenizer files stored in a directory. For example, we can load and save a
+checkpoint as follows:
+
+
+
+```python
+>>> from transformers import AutoTokenizer, AutoModelForSequenceClassification
+
+>>> # Load tokenizer and PyTorch weights form the Hub
+>>> tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
+>>> pt_model = AutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased")
+>>> # Save to disk
+>>> tokenizer.save_pretrained("local-pt-checkpoint")
+>>> pt_model.save_pretrained("local-pt-checkpoint")
+```
+
+Once the checkpoint is saved, we can export it to ONNX by pointing the `--model`
+argument of the `transformers.onnx` package to the desired directory:
+
+```bash
+python -m transformers.onnx --model=local-pt-checkpoint onnx/
+```
+
+
+```python
+>>> from transformers import AutoTokenizer, TFAutoModelForSequenceClassification
+
+>>> # Load tokenizer and TensorFlow weights from the Hub
+>>> tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
+>>> tf_model = TFAutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased")
+>>> # Save to disk
+>>> tokenizer.save_pretrained("local-tf-checkpoint")
+>>> tf_model.save_pretrained("local-tf-checkpoint")
+```
+
+Once the checkpoint is saved, we can export it to ONNX by pointing the `--model`
+argument of the `transformers.onnx` package to the desired directory:
+
+```bash
+python -m transformers.onnx --model=local-tf-checkpoint onnx/
+```
+
+
+
+### Selecting features for different model topologies
+
+Each ready-made configuration comes with a set of _features_ that enable you to
+export models for different types of topologies or tasks. As shown in the table
+below, each feature is associated with a different auto class:
+
+| Feature | Auto Class |
+| ------------------------------------ | ------------------------------------ |
+| `causal-lm`, `causal-lm-with-past` | `AutoModelForCausalLM` |
+| `default`, `default-with-past` | `AutoModel` |
+| `masked-lm` | `AutoModelForMaskedLM` |
+| `question-answering` | `AutoModelForQuestionAnswering` |
+| `seq2seq-lm`, `seq2seq-lm-with-past` | `AutoModelForSeq2SeqLM` |
+| `sequence-classification` | `AutoModelForSequenceClassification` |
+| `token-classification` | `AutoModelForTokenClassification` |
+
+For each configuration, you can find the list of supported features via the
+`FeaturesManager`. For example, for DistilBERT we have:
+
+```python
+>>> from transformers.onnx.features import FeaturesManager
+
+>>> distilbert_features = list(FeaturesManager.get_supported_features_for_model_type("distilbert").keys())
+>>> print(distilbert_features)
+["default", "masked-lm", "causal-lm", "sequence-classification", "token-classification", "question-answering"]
+```
+
+You can then pass one of these features to the `--feature` argument in the
+`transformers.onnx` package. For example, to export a text-classification model
+we can pick a fine-tuned model from the Hub and run:
+
+```bash
+python -m transformers.onnx --model=distilbert-base-uncased-finetuned-sst-2-english \
+ --feature=sequence-classification onnx/
+```
+
+which will display the following logs:
+
+```bash
+Validating ONNX model...
+ -[✓] ONNX model output names match reference model ({'logits'})
+ - Validating ONNX Model output "logits":
+ -[✓] (2, 2) matches (2, 2)
+ -[✓] all values close (atol: 1e-05)
+All good, model saved at: onnx/model.onnx
+```
+
+Notice that in this case, the output names from the fine-tuned model are
+`logits` instead of the `last_hidden_state` we saw with the
+`distilbert-base-uncased` checkpoint earlier. This is expected since the
+fine-tuned model has a sequence classification head.
+
+
+
+The features that have a `with-past` suffix (e.g. `causal-lm-with-past`)
+correspond to model topologies with precomputed hidden states (key and values
+in the attention blocks) that can be used for fast autoregressive decoding.
+
+
+
+
+### Exporting a model for an unsupported architecture
+
+If you wish to export a model whose architecture is not natively supported by
+the library, there are three main steps to follow:
+
+1. Implement a custom ONNX configuration.
+2. Export the model to ONNX.
+3. Validate the outputs of the PyTorch and exported models.
+
+In this section, we'll look at how DistilBERT was implemented to show what's
+involved with each step.
+
+#### Implementing a custom ONNX configuration
+
+Let's start with the ONNX configuration object. We provide three abstract
+classes that you should inherit from, depending on the type of model
+architecture you wish to export:
+
+* Encoder-based models inherit from [`~onnx.config.OnnxConfig`]
+* Decoder-based models inherit from [`~onnx.config.OnnxConfigWithPast`]
+* Encoder-decoder models inherit from [`~onnx.config.OnnxSeq2SeqConfigWithPast`]
+
+
+
+A good way to implement a custom ONNX configuration is to look at the existing
+implementation in the `configuration_.py` file of a similar architecture.
+
+
+
+Since DistilBERT is an encoder-based model, its configuration inherits from
+`OnnxConfig`:
+
+```python
+>>> from typing import Mapping, OrderedDict
+>>> from transformers.onnx import OnnxConfig
+
+
+>>> class DistilBertOnnxConfig(OnnxConfig):
+... @property
+... def inputs(self) -> Mapping[str, Mapping[int, str]]:
+... return OrderedDict(
+... [
+... ("input_ids", {0: "batch", 1: "sequence"}),
+... ("attention_mask", {0: "batch", 1: "sequence"}),
+... ]
+... )
+```
+
+Every configuration object must implement the `inputs` property and return a
+mapping, where each key corresponds to an expected input, and each value
+indicates the axis of that input. For DistilBERT, we can see that two inputs are
+required: `input_ids` and `attention_mask`. These inputs have the same shape of
+`(batch_size, sequence_length)` which is why we see the same axes used in the
+configuration.
+
+
+
+Notice that `inputs` property for `DistilBertOnnxConfig` returns an
+`OrderedDict`. This ensures that the inputs are matched with their relative
+position within the `PreTrainedModel.forward()` method when tracing the graph.
+We recommend using an `OrderedDict` for the `inputs` and `outputs` properties
+when implementing custom ONNX configurations.
+
+
+
+Once you have implemented an ONNX configuration, you can instantiate it by
+providing the base model's configuration as follows:
+
+```python
+>>> from transformers import AutoConfig
+
+>>> config = AutoConfig.from_pretrained("distilbert-base-uncased")
+>>> onnx_config = DistilBertOnnxConfig(config)
+```
+
+The resulting object has several useful properties. For example you can view the
+ONNX operator set that will be used during the export:
+
+```python
+>>> print(onnx_config.default_onnx_opset)
+11
+```
+
+You can also view the outputs associated with the model as follows:
+
+```python
+>>> print(onnx_config.outputs)
+OrderedDict([("last_hidden_state", {0: "batch", 1: "sequence"})])
+```
+
+Notice that the outputs property follows the same structure as the inputs; it
+returns an `OrderedDict` of named outputs and their shapes. The output structure
+is linked to the choice of feature that the configuration is initialised with.
+By default, the ONNX configuration is initialized with the `default` feature
+that corresponds to exporting a model loaded with the `AutoModel` class. If you
+want to export a different model topology, just provide a different feature to
+the `task` argument when you initialize the ONNX configuration. For example, if
+we wished to export DistilBERT with a sequence classification head, we could
+use:
+
+```python
+>>> from transformers import AutoConfig
+
+>>> config = AutoConfig.from_pretrained("distilbert-base-uncased")
+>>> onnx_config_for_seq_clf = DistilBertOnnxConfig(config, task="sequence-classification")
+>>> print(onnx_config_for_seq_clf.outputs)
+OrderedDict([('logits', {0: 'batch'})])
+```
+
+
+
+All of the base properties and methods associated with [`~onnx.config.OnnxConfig`] and the
+other configuration classes can be overriden if needed. Check out
+[`BartOnnxConfig`] for an advanced example.
+
+
+
+#### Exporting the model
+
+Once you have implemented the ONNX configuration, the next step is to export the
+model. Here we can use the `export()` function provided by the
+`transformers.onnx` package. This function expects the ONNX configuration, along
+with the base model and tokenizer, and the path to save the exported file:
+
+```python
+>>> from pathlib import Path
+>>> from transformers.onnx import export
+>>> from transformers import AutoTokenizer, AutoModel
+
+>>> onnx_path = Path("model.onnx")
+>>> model_ckpt = "distilbert-base-uncased"
+>>> base_model = AutoModel.from_pretrained(model_ckpt)
+>>> tokenizer = AutoTokenizer.from_pretrained(model_ckpt)
+
+>>> onnx_inputs, onnx_outputs = export(tokenizer, base_model, onnx_config, onnx_config.default_onnx_opset, onnx_path)
+```
+
+The `onnx_inputs` and `onnx_outputs` returned by the `export()` function are
+lists of the keys defined in the `inputs` and `outputs` properties of the
+configuration. Once the model is exported, you can test that the model is well
+formed as follows:
+
+```python
+>>> import onnx
+
+>>> onnx_model = onnx.load("model.onnx")
+>>> onnx.checker.check_model(onnx_model)
+```
+
+
+
+If your model is larger than 2GB, you will see that many additional files are
+created during the export. This is _expected_ because ONNX uses [Protocol
+Buffers](https://developers.google.com/protocol-buffers/) to store the model and
+these have a size limit of 2GB. See the [ONNX
+documentation](https://github.com/onnx/onnx/blob/master/docs/ExternalData.md)
+for instructions on how to load models with external data.
+
+
+
+#### Validating the model outputs
+
+The final step is to validate that the outputs from the base and exported model
+agree within some absolute tolerance. Here we can use the
+`validate_model_outputs()` function provided by the `transformers.onnx` package
+as follows:
+
+```python
+>>> from transformers.onnx import validate_model_outputs
+
+>>> validate_model_outputs(
+... onnx_config, tokenizer, base_model, onnx_path, onnx_outputs, onnx_config.atol_for_validation
+... )
+```
+
+This function uses the `OnnxConfig.generate_dummy_inputs()` method to generate
+inputs for the base and exported model, and the absolute tolerance can be
+defined in the configuration. We generally find numerical agreement in the 1e-6
+to 1e-4 range, although anything smaller than 1e-3 is likely to be OK.
+
+### Contributing a new configuration to 🤗 Transformers
+
+We are looking to expand the set of ready-made configurations and welcome
+contributions from the community! If you would like to contribute your addition
+to the library, you will need to:
+
+* Implement the ONNX configuration in the corresponding `configuration_.py`
+file
+* Include the model architecture and corresponding features in [`~onnx.features.FeatureManager`]
+* Add your model architecture to the tests in `test_onnx_v2.py`
+
+Check out how the configuration for [IBERT was
+contributed](https://github.com/huggingface/transformers/pull/14868/files) to
+get an idea of what's involved.
+
+## TorchScript
+
+
+
+This is the very beginning of our experiments with TorchScript and we are still exploring its capabilities with
+variable-input-size models. It is a focus of interest to us and we will deepen our analysis in upcoming releases,
+with more code examples, a more flexible implementation, and benchmarks comparing python-based codes with compiled
+TorchScript.
+
+
+
+According to Pytorch's documentation: "TorchScript is a way to create serializable and optimizable models from PyTorch
+code". Pytorch's two modules [JIT and TRACE](https://pytorch.org/docs/stable/jit.html) allow the developer to export
+their model to be re-used in other programs, such as efficiency-oriented C++ programs.
+
+We have provided an interface that allows the export of 🤗 Transformers models to TorchScript so that they can be reused
+in a different environment than a Pytorch-based python program. Here we explain how to export and use our models using
+TorchScript.
+
+Exporting a model requires two things:
+
+- a forward pass with dummy inputs.
+- model instantiation with the `torchscript` flag.
+
+These necessities imply several things developers should be careful about. These are detailed below.
+
+### TorchScript flag and tied weights
+
+This flag is necessary because most of the language models in this repository have tied weights between their
+`Embedding` layer and their `Decoding` layer. TorchScript does not allow the export of models that have tied
+weights, therefore it is necessary to untie and clone the weights beforehand.
+
+This implies that models instantiated with the `torchscript` flag have their `Embedding` layer and `Decoding`
+layer separate, which means that they should not be trained down the line. Training would de-synchronize the two
+layers, leading to unexpected results.
+
+This is not the case for models that do not have a Language Model head, as those do not have tied weights. These models
+can be safely exported without the `torchscript` flag.
+
+### Dummy inputs and standard lengths
+
+The dummy inputs are used to do a model forward pass. While the inputs' values are propagating through the layers,
+Pytorch keeps track of the different operations executed on each tensor. These recorded operations are then used to
+create the "trace" of the model.
+
+The trace is created relatively to the inputs' dimensions. It is therefore constrained by the dimensions of the dummy
+input, and will not work for any other sequence length or batch size. When trying with a different size, an error such
+as:
+
+`The expanded size of the tensor (3) must match the existing size (7) at non-singleton dimension 2`
+
+will be raised. It is therefore recommended to trace the model with a dummy input size at least as large as the largest
+input that will be fed to the model during inference. Padding can be performed to fill the missing values. As the model
+will have been traced with a large input size however, the dimensions of the different matrix will be large as well,
+resulting in more calculations.
+
+It is recommended to be careful of the total number of operations done on each input and to follow performance closely
+when exporting varying sequence-length models.
+
+### Using TorchScript in Python
+
+Below is an example, showing how to save, load models as well as how to use the trace for inference.
+
+#### Saving a model
+
+This snippet shows how to use TorchScript to export a `BertModel`. Here the `BertModel` is instantiated according
+to a `BertConfig` class and then saved to disk under the filename `traced_bert.pt`
+
+```python
+from transformers import BertModel, BertTokenizer, BertConfig
+import torch
+
+enc = BertTokenizer.from_pretrained("bert-base-uncased")
+
+# Tokenizing input text
+text = "[CLS] Who was Jim Henson ? [SEP] Jim Henson was a puppeteer [SEP]"
+tokenized_text = enc.tokenize(text)
+
+# Masking one of the input tokens
+masked_index = 8
+tokenized_text[masked_index] = "[MASK]"
+indexed_tokens = enc.convert_tokens_to_ids(tokenized_text)
+segments_ids = [0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1]
+
+# Creating a dummy input
+tokens_tensor = torch.tensor([indexed_tokens])
+segments_tensors = torch.tensor([segments_ids])
+dummy_input = [tokens_tensor, segments_tensors]
+
+# Initializing the model with the torchscript flag
+# Flag set to True even though it is not necessary as this model does not have an LM Head.
+config = BertConfig(
+ vocab_size_or_config_json_file=32000,
+ hidden_size=768,
+ num_hidden_layers=12,
+ num_attention_heads=12,
+ intermediate_size=3072,
+ torchscript=True,
+)
+
+# Instantiating the model
+model = BertModel(config)
+
+# The model needs to be in evaluation mode
+model.eval()
+
+# If you are instantiating the model with *from_pretrained* you can also easily set the TorchScript flag
+model = BertModel.from_pretrained("bert-base-uncased", torchscript=True)
+
+# Creating the trace
+traced_model = torch.jit.trace(model, [tokens_tensor, segments_tensors])
+torch.jit.save(traced_model, "traced_bert.pt")
+```
+
+#### Loading a model
+
+This snippet shows how to load the `BertModel` that was previously saved to disk under the name `traced_bert.pt`.
+We are re-using the previously initialised `dummy_input`.
+
+```python
+loaded_model = torch.jit.load("traced_bert.pt")
+loaded_model.eval()
+
+all_encoder_layers, pooled_output = loaded_model(*dummy_input)
+```
+
+#### Using a traced model for inference
+
+Using the traced model for inference is as simple as using its `__call__` dunder method:
+
+```python
+traced_model(tokens_tensor, segments_tensors)
+```
+
+### Deploying HuggingFace TorchScript models on AWS using the Neuron SDK
+
+AWS introduced the [Amazon EC2 Inf1](https://aws.amazon.com/ec2/instance-types/inf1/)
+instance family for low cost, high performance machine learning inference in the cloud.
+The Inf1 instances are powered by the AWS Inferentia chip, a custom-built hardware accelerator,
+specializing in deep learning inferencing workloads.
+[AWS Neuron](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/#)
+is the SDK for Inferentia that supports tracing and optimizing transformers models for
+deployment on Inf1. The Neuron SDK provides:
+
+
+1. Easy-to-use API with one line of code change to trace and optimize a TorchScript model for inference in the cloud.
+2. Out of the box performance optimizations for [improved cost-performance](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/neuron-guide/benchmark/>)
+3. Support for HuggingFace transformers models built with either [PyTorch](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/src/examples/pytorch/bert_tutorial/tutorial_pretrained_bert.html)
+ or [TensorFlow](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/src/examples/tensorflow/huggingface_bert/huggingface_bert.html).
+
+#### Implications
+
+Transformers Models based on the [BERT (Bidirectional Encoder Representations from Transformers)](https://huggingface.co/docs/transformers/main/model_doc/bert)
+architecture, or its variants such as [distilBERT](https://huggingface.co/docs/transformers/main/model_doc/distilbert)
+ and [roBERTa](https://huggingface.co/docs/transformers/main/model_doc/roberta)
+ will run best on Inf1 for non-generative tasks such as Extractive Question Answering,
+ Sequence Classification, Token Classification. Alternatively, text generation
+tasks can be adapted to run on Inf1, according to this [AWS Neuron MarianMT tutorial](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/src/examples/pytorch/transformers-marianmt.html).
+More information about models that can be converted out of the box on Inferentia can be
+found in the [Model Architecture Fit section of the Neuron documentation](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/neuron-guide/models/models-inferentia.html#models-inferentia).
+
+#### Dependencies
+
+Using AWS Neuron to convert models requires the following dependencies and environment:
+
+* A [Neuron SDK environment](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/neuron-guide/neuron-frameworks/pytorch-neuron/index.html#installation-guide),
+ which comes pre-configured on [AWS Deep Learning AMI](https://docs.aws.amazon.com/dlami/latest/devguide/tutorial-inferentia-launching.html).
+
+#### Converting a Model for AWS Neuron
+
+Using the same script as in [Using TorchScript in Python](https://huggingface.co/docs/transformers/main/en/serialization#using-torchscript-in-python)
+to trace a "BertModel", you import `torch.neuron` framework extension to access
+the components of the Neuron SDK through a Python API.
+
+```python
+from transformers import BertModel, BertTokenizer, BertConfig
+import torch
+import torch.neuron
+```
+And only modify the tracing line of code
+
+from:
+
+```python
+torch.jit.trace(model, [tokens_tensor, segments_tensors])
+```
+
+to:
+
+```python
+torch.neuron.trace(model, [token_tensor, segments_tensors])
+```
+
+This change enables Neuron SDK to trace the model and optimize it to run in Inf1 instances.
+
+To learn more about AWS Neuron SDK features, tools, example tutorials and latest updates,
+please see the [AWS NeuronSDK documentation](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/index.html).
diff --git a/docs/source/en/task_summary.mdx b/docs/source/en/task_summary.mdx
new file mode 100644
index 00000000000000..27781ccc0503f0
--- /dev/null
+++ b/docs/source/en/task_summary.mdx
@@ -0,0 +1,1134 @@
+
+
+# Summary of the tasks
+
+[[open-in-colab]]
+
+This page shows the most frequent use-cases when using the library. The models available allow for many different
+configurations and a great versatility in use-cases. The most simple ones are presented here, showcasing usage for
+tasks such as question answering, sequence classification, named entity recognition and others.
+
+These examples leverage auto-models, which are classes that will instantiate a model according to a given checkpoint,
+automatically selecting the correct model architecture. Please check the [`AutoModel`] documentation
+for more information. Feel free to modify the code to be more specific and adapt it to your specific use-case.
+
+In order for a model to perform well on a task, it must be loaded from a checkpoint corresponding to that task. These
+checkpoints are usually pre-trained on a large corpus of data and fine-tuned on a specific task. This means the
+following:
+
+- Not all models were fine-tuned on all tasks. If you want to fine-tune a model on a specific task, you can leverage
+ one of the *run_$TASK.py* scripts in the [examples](https://github.com/huggingface/transformers/tree/main/examples) directory.
+- Fine-tuned models were fine-tuned on a specific dataset. This dataset may or may not overlap with your use-case and
+ domain. As mentioned previously, you may leverage the [examples](https://github.com/huggingface/transformers/tree/main/examples) scripts to fine-tune your model, or you may
+ create your own training script.
+
+In order to do an inference on a task, several mechanisms are made available by the library:
+
+- Pipelines: very easy-to-use abstractions, which require as little as two lines of code.
+- Direct model use: Less abstractions, but more flexibility and power via a direct access to a tokenizer
+ (PyTorch/TensorFlow) and full inference capacity.
+
+Both approaches are showcased here.
+
+
+
+All tasks presented here leverage pre-trained checkpoints that were fine-tuned on specific tasks. Loading a
+checkpoint that was not fine-tuned on a specific task would load only the base transformer layers and not the
+additional head that is used for the task, initializing the weights of that head randomly.
+
+This would produce random output.
+
+
+
+## Sequence Classification
+
+Sequence classification is the task of classifying sequences according to a given number of classes. An example of
+sequence classification is the GLUE dataset, which is entirely based on that task. If you would like to fine-tune a
+model on a GLUE sequence classification task, you may leverage the [run_glue.py](https://github.com/huggingface/transformers/tree/main/examples/pytorch/text-classification/run_glue.py), [run_tf_glue.py](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/text-classification/run_tf_glue.py), [run_tf_text_classification.py](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/text-classification/run_tf_text_classification.py) or [run_xnli.py](https://github.com/huggingface/transformers/tree/main/examples/pytorch/text-classification/run_xnli.py) scripts.
+
+Here is an example of using pipelines to do sentiment analysis: identifying if a sequence is positive or negative. It
+leverages a fine-tuned model on sst2, which is a GLUE task.
+
+This returns a label ("POSITIVE" or "NEGATIVE") alongside a score, as follows:
+
+```py
+>>> from transformers import pipeline
+
+>>> classifier = pipeline("sentiment-analysis")
+
+>>> result = classifier("I hate you")[0]
+>>> print(f"label: {result['label']}, with score: {round(result['score'], 4)}")
+label: NEGATIVE, with score: 0.9991
+
+>>> result = classifier("I love you")[0]
+>>> print(f"label: {result['label']}, with score: {round(result['score'], 4)}")
+label: POSITIVE, with score: 0.9999
+```
+
+Here is an example of doing a sequence classification using a model to determine if two sequences are paraphrases of
+each other. The process is the following:
+
+1. Instantiate a tokenizer and a model from the checkpoint name. The model is identified as a BERT model and loads it
+ with the weights stored in the checkpoint.
+2. Build a sequence from the two sentences, with the correct model-specific separators, token type ids and attention
+ masks (which will be created automatically by the tokenizer).
+3. Pass this sequence through the model so that it is classified in one of the two available classes: 0 (not a
+ paraphrase) and 1 (is a paraphrase).
+4. Compute the softmax of the result to get probabilities over the classes.
+5. Print the results.
+
+
+
+```py
+>>> from transformers import AutoTokenizer, AutoModelForSequenceClassification
+>>> import torch
+
+>>> tokenizer = AutoTokenizer.from_pretrained("bert-base-cased-finetuned-mrpc")
+>>> model = AutoModelForSequenceClassification.from_pretrained("bert-base-cased-finetuned-mrpc")
+
+>>> classes = ["not paraphrase", "is paraphrase"]
+
+>>> sequence_0 = "The company HuggingFace is based in New York City"
+>>> sequence_1 = "Apples are especially bad for your health"
+>>> sequence_2 = "HuggingFace's headquarters are situated in Manhattan"
+
+>>> # The tokenizer will automatically add any model specific separators (i.e. and ) and tokens to
+>>> # the sequence, as well as compute the attention masks.
+>>> paraphrase = tokenizer(sequence_0, sequence_2, return_tensors="pt")
+>>> not_paraphrase = tokenizer(sequence_0, sequence_1, return_tensors="pt")
+
+>>> paraphrase_classification_logits = model(**paraphrase).logits
+>>> not_paraphrase_classification_logits = model(**not_paraphrase).logits
+
+>>> paraphrase_results = torch.softmax(paraphrase_classification_logits, dim=1).tolist()[0]
+>>> not_paraphrase_results = torch.softmax(not_paraphrase_classification_logits, dim=1).tolist()[0]
+
+>>> # Should be paraphrase
+>>> for i in range(len(classes)):
+... print(f"{classes[i]}: {int(round(paraphrase_results[i] * 100))}%")
+not paraphrase: 10%
+is paraphrase: 90%
+
+>>> # Should not be paraphrase
+>>> for i in range(len(classes)):
+... print(f"{classes[i]}: {int(round(not_paraphrase_results[i] * 100))}%")
+not paraphrase: 94%
+is paraphrase: 6%
+```
+
+
+```py
+>>> from transformers import AutoTokenizer, TFAutoModelForSequenceClassification
+>>> import tensorflow as tf
+
+>>> tokenizer = AutoTokenizer.from_pretrained("bert-base-cased-finetuned-mrpc")
+>>> model = TFAutoModelForSequenceClassification.from_pretrained("bert-base-cased-finetuned-mrpc")
+
+>>> classes = ["not paraphrase", "is paraphrase"]
+
+>>> sequence_0 = "The company HuggingFace is based in New York City"
+>>> sequence_1 = "Apples are especially bad for your health"
+>>> sequence_2 = "HuggingFace's headquarters are situated in Manhattan"
+
+>>> # The tokenizer will automatically add any model specific separators (i.e. and ) and tokens to
+>>> # the sequence, as well as compute the attention masks.
+>>> paraphrase = tokenizer(sequence_0, sequence_2, return_tensors="tf")
+>>> not_paraphrase = tokenizer(sequence_0, sequence_1, return_tensors="tf")
+
+>>> paraphrase_classification_logits = model(paraphrase).logits
+>>> not_paraphrase_classification_logits = model(not_paraphrase).logits
+
+>>> paraphrase_results = tf.nn.softmax(paraphrase_classification_logits, axis=1).numpy()[0]
+>>> not_paraphrase_results = tf.nn.softmax(not_paraphrase_classification_logits, axis=1).numpy()[0]
+
+>>> # Should be paraphrase
+>>> for i in range(len(classes)):
+... print(f"{classes[i]}: {int(round(paraphrase_results[i] * 100))}%")
+not paraphrase: 10%
+is paraphrase: 90%
+
+>>> # Should not be paraphrase
+>>> for i in range(len(classes)):
+... print(f"{classes[i]}: {int(round(not_paraphrase_results[i] * 100))}%")
+not paraphrase: 94%
+is paraphrase: 6%
+```
+
+
+
+## Extractive Question Answering
+
+Extractive Question Answering is the task of extracting an answer from a text given a question. An example of a
+question answering dataset is the SQuAD dataset, which is entirely based on that task. If you would like to fine-tune a
+model on a SQuAD task, you may leverage the [run_qa.py](https://github.com/huggingface/transformers/tree/main/examples/pytorch/question-answering/run_qa.py) and
+[run_tf_squad.py](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/question-answering/run_tf_squad.py)
+scripts.
+
+
+Here is an example of using pipelines to do question answering: extracting an answer from a text given a question. It
+leverages a fine-tuned model on SQuAD.
+
+```py
+>>> from transformers import pipeline
+
+>>> question_answerer = pipeline("question-answering")
+
+>>> context = r"""
+... Extractive Question Answering is the task of extracting an answer from a text given a question. An example of a
+... question answering dataset is the SQuAD dataset, which is entirely based on that task. If you would like to fine-tune
+... a model on a SQuAD task, you may leverage the examples/pytorch/question-answering/run_squad.py script.
+... """
+```
+
+This returns an answer extracted from the text, a confidence score, alongside "start" and "end" values, which are the
+positions of the extracted answer in the text.
+
+```py
+>>> result = question_answerer(question="What is extractive question answering?", context=context)
+>>> print(
+... f"Answer: '{result['answer']}', score: {round(result['score'], 4)}, start: {result['start']}, end: {result['end']}"
+... )
+Answer: 'the task of extracting an answer from a text given a question', score: 0.6177, start: 34, end: 95
+
+>>> result = question_answerer(question="What is a good example of a question answering dataset?", context=context)
+>>> print(
+... f"Answer: '{result['answer']}', score: {round(result['score'], 4)}, start: {result['start']}, end: {result['end']}"
+... )
+Answer: 'SQuAD dataset', score: 0.5152, start: 147, end: 160
+```
+
+Here is an example of question answering using a model and a tokenizer. The process is the following:
+
+1. Instantiate a tokenizer and a model from the checkpoint name. The model is identified as a BERT model and loads it
+ with the weights stored in the checkpoint.
+2. Define a text and a few questions.
+3. Iterate over the questions and build a sequence from the text and the current question, with the correct
+ model-specific separators, token type ids and attention masks.
+4. Pass this sequence through the model. This outputs a range of scores across the entire sequence tokens (question and
+ text), for both the start and end positions.
+5. Compute the softmax of the result to get probabilities over the tokens.
+6. Fetch the tokens from the identified start and stop values, convert those tokens to a string.
+7. Print the results.
+
+
+
+```py
+>>> from transformers import AutoTokenizer, AutoModelForQuestionAnswering
+>>> import torch
+
+>>> tokenizer = AutoTokenizer.from_pretrained("bert-large-uncased-whole-word-masking-finetuned-squad")
+>>> model = AutoModelForQuestionAnswering.from_pretrained("bert-large-uncased-whole-word-masking-finetuned-squad")
+
+>>> text = r"""
+... 🤗 Transformers (formerly known as pytorch-transformers and pytorch-pretrained-bert) provides general-purpose
+... architectures (BERT, GPT-2, RoBERTa, XLM, DistilBert, XLNet…) for Natural Language Understanding (NLU) and Natural
+... Language Generation (NLG) with over 32+ pretrained models in 100+ languages and deep interoperability between
+... TensorFlow 2.0 and PyTorch.
+... """
+
+>>> questions = [
+... "How many pretrained models are available in 🤗 Transformers?",
+... "What does 🤗 Transformers provide?",
+... "🤗 Transformers provides interoperability between which frameworks?",
+... ]
+
+>>> for question in questions:
+... inputs = tokenizer(question, text, add_special_tokens=True, return_tensors="pt")
+... input_ids = inputs["input_ids"].tolist()[0]
+
+... outputs = model(**inputs)
+... answer_start_scores = outputs.start_logits
+... answer_end_scores = outputs.end_logits
+
+... # Get the most likely beginning of answer with the argmax of the score
+... answer_start = torch.argmax(answer_start_scores)
+... # Get the most likely end of answer with the argmax of the score
+... answer_end = torch.argmax(answer_end_scores) + 1
+
+... answer = tokenizer.convert_tokens_to_string(
+... tokenizer.convert_ids_to_tokens(input_ids[answer_start:answer_end])
+... )
+
+... print(f"Question: {question}")
+... print(f"Answer: {answer}")
+Question: How many pretrained models are available in 🤗 Transformers?
+Answer: over 32 +
+Question: What does 🤗 Transformers provide?
+Answer: general - purpose architectures
+Question: 🤗 Transformers provides interoperability between which frameworks?
+Answer: tensorflow 2. 0 and pytorch
+```
+
+
+```py
+>>> from transformers import AutoTokenizer, TFAutoModelForQuestionAnswering
+>>> import tensorflow as tf
+
+>>> tokenizer = AutoTokenizer.from_pretrained("bert-large-uncased-whole-word-masking-finetuned-squad")
+>>> model = TFAutoModelForQuestionAnswering.from_pretrained("bert-large-uncased-whole-word-masking-finetuned-squad")
+
+>>> text = r"""
+... 🤗 Transformers (formerly known as pytorch-transformers and pytorch-pretrained-bert) provides general-purpose
+... architectures (BERT, GPT-2, RoBERTa, XLM, DistilBert, XLNet…) for Natural Language Understanding (NLU) and Natural
+... Language Generation (NLG) with over 32+ pretrained models in 100+ languages and deep interoperability between
+... TensorFlow 2.0 and PyTorch.
+... """
+
+>>> questions = [
+... "How many pretrained models are available in 🤗 Transformers?",
+... "What does 🤗 Transformers provide?",
+... "🤗 Transformers provides interoperability between which frameworks?",
+... ]
+
+>>> for question in questions:
+... inputs = tokenizer(question, text, add_special_tokens=True, return_tensors="tf")
+... input_ids = inputs["input_ids"].numpy()[0]
+
+... outputs = model(inputs)
+... answer_start_scores = outputs.start_logits
+... answer_end_scores = outputs.end_logits
+
+... # Get the most likely beginning of answer with the argmax of the score
+... answer_start = tf.argmax(answer_start_scores, axis=1).numpy()[0]
+... # Get the most likely end of answer with the argmax of the score
+... answer_end = tf.argmax(answer_end_scores, axis=1).numpy()[0] + 1
+
+... answer = tokenizer.convert_tokens_to_string(
+... tokenizer.convert_ids_to_tokens(input_ids[answer_start:answer_end])
+... )
+
+... print(f"Question: {question}")
+... print(f"Answer: {answer}")
+Question: How many pretrained models are available in 🤗 Transformers?
+Answer: over 32 +
+Question: What does 🤗 Transformers provide?
+Answer: general - purpose architectures
+Question: 🤗 Transformers provides interoperability between which frameworks?
+Answer: tensorflow 2. 0 and pytorch
+```
+
+
+
+## Language Modeling
+
+Language modeling is the task of fitting a model to a corpus, which can be domain specific. All popular
+transformer-based models are trained using a variant of language modeling, e.g. BERT with masked language modeling,
+GPT-2 with causal language modeling.
+
+Language modeling can be useful outside of pretraining as well, for example to shift the model distribution to be
+domain-specific: using a language model trained over a very large corpus, and then fine-tuning it to a news dataset or
+on scientific papers e.g. [LysandreJik/arxiv-nlp](https://huggingface.co/lysandre/arxiv-nlp).
+
+### Masked Language Modeling
+
+Masked language modeling is the task of masking tokens in a sequence with a masking token, and prompting the model to
+fill that mask with an appropriate token. This allows the model to attend to both the right context (tokens on the
+right of the mask) and the left context (tokens on the left of the mask). Such a training creates a strong basis for
+downstream tasks requiring bi-directional context, such as SQuAD (question answering, see [Lewis, Lui, Goyal et al.](https://arxiv.org/abs/1910.13461), part 4.2). If you would like to fine-tune a model on a masked language modeling
+task, you may leverage the [run_mlm.py](https://github.com/huggingface/transformers/tree/main/examples/pytorch/language-modeling/run_mlm.py) script.
+
+Here is an example of using pipelines to replace a mask from a sequence:
+
+```py
+>>> from transformers import pipeline
+
+>>> unmasker = pipeline("fill-mask")
+```
+
+This outputs the sequences with the mask filled, the confidence score, and the token id in the tokenizer vocabulary:
+
+```py
+>>> from pprint import pprint
+
+>>> pprint(
+... unmasker(
+... f"HuggingFace is creating a {unmasker.tokenizer.mask_token} that the community uses to solve NLP tasks."
+... )
+... )
+[{'score': 0.1793,
+ 'sequence': 'HuggingFace is creating a tool that the community uses to solve '
+ 'NLP tasks.',
+ 'token': 3944,
+ 'token_str': ' tool'},
+ {'score': 0.1135,
+ 'sequence': 'HuggingFace is creating a framework that the community uses to '
+ 'solve NLP tasks.',
+ 'token': 7208,
+ 'token_str': ' framework'},
+ {'score': 0.0524,
+ 'sequence': 'HuggingFace is creating a library that the community uses to '
+ 'solve NLP tasks.',
+ 'token': 5560,
+ 'token_str': ' library'},
+ {'score': 0.0349,
+ 'sequence': 'HuggingFace is creating a database that the community uses to '
+ 'solve NLP tasks.',
+ 'token': 8503,
+ 'token_str': ' database'},
+ {'score': 0.0286,
+ 'sequence': 'HuggingFace is creating a prototype that the community uses to '
+ 'solve NLP tasks.',
+ 'token': 17715,
+ 'token_str': ' prototype'}]
+```
+
+Here is an example of doing masked language modeling using a model and a tokenizer. The process is the following:
+
+1. Instantiate a tokenizer and a model from the checkpoint name. The model is identified as a DistilBERT model and
+ loads it with the weights stored in the checkpoint.
+2. Define a sequence with a masked token, placing the `tokenizer.mask_token` instead of a word.
+3. Encode that sequence into a list of IDs and find the position of the masked token in that list.
+4. Retrieve the predictions at the index of the mask token: this tensor has the same size as the vocabulary, and the
+ values are the scores attributed to each token. The model gives higher score to tokens it deems probable in that
+ context.
+5. Retrieve the top 5 tokens using the PyTorch `topk` or TensorFlow `top_k` methods.
+6. Replace the mask token by the tokens and print the results
+
+
+
+```py
+>>> from transformers import AutoModelForMaskedLM, AutoTokenizer
+>>> import torch
+
+>>> tokenizer = AutoTokenizer.from_pretrained("distilbert-base-cased")
+>>> model = AutoModelForMaskedLM.from_pretrained("distilbert-base-cased")
+
+>>> sequence = (
+... "Distilled models are smaller than the models they mimic. Using them instead of the large "
+... f"versions would help {tokenizer.mask_token} our carbon footprint."
+... )
+
+>>> inputs = tokenizer(sequence, return_tensors="pt")
+>>> mask_token_index = torch.where(inputs["input_ids"] == tokenizer.mask_token_id)[1]
+
+>>> token_logits = model(**inputs).logits
+>>> mask_token_logits = token_logits[0, mask_token_index, :]
+
+>>> top_5_tokens = torch.topk(mask_token_logits, 5, dim=1).indices[0].tolist()
+
+>>> for token in top_5_tokens:
+... print(sequence.replace(tokenizer.mask_token, tokenizer.decode([token])))
+Distilled models are smaller than the models they mimic. Using them instead of the large versions would help reduce our carbon footprint.
+Distilled models are smaller than the models they mimic. Using them instead of the large versions would help increase our carbon footprint.
+Distilled models are smaller than the models they mimic. Using them instead of the large versions would help decrease our carbon footprint.
+Distilled models are smaller than the models they mimic. Using them instead of the large versions would help offset our carbon footprint.
+Distilled models are smaller than the models they mimic. Using them instead of the large versions would help improve our carbon footprint.
+```
+
+
+```py
+>>> from transformers import TFAutoModelForMaskedLM, AutoTokenizer
+>>> import tensorflow as tf
+
+>>> tokenizer = AutoTokenizer.from_pretrained("distilbert-base-cased")
+>>> model = TFAutoModelForMaskedLM.from_pretrained("distilbert-base-cased")
+
+>>> sequence = (
+... "Distilled models are smaller than the models they mimic. Using them instead of the large "
+... f"versions would help {tokenizer.mask_token} our carbon footprint."
+... )
+
+>>> inputs = tokenizer(sequence, return_tensors="tf")
+>>> mask_token_index = tf.where(inputs["input_ids"] == tokenizer.mask_token_id)[0, 1]
+
+>>> token_logits = model(**inputs).logits
+>>> mask_token_logits = token_logits[0, mask_token_index, :]
+
+>>> top_5_tokens = tf.math.top_k(mask_token_logits, 5).indices.numpy()
+
+>>> for token in top_5_tokens:
+... print(sequence.replace(tokenizer.mask_token, tokenizer.decode([token])))
+Distilled models are smaller than the models they mimic. Using them instead of the large versions would help reduce our carbon footprint.
+Distilled models are smaller than the models they mimic. Using them instead of the large versions would help increase our carbon footprint.
+Distilled models are smaller than the models they mimic. Using them instead of the large versions would help decrease our carbon footprint.
+Distilled models are smaller than the models they mimic. Using them instead of the large versions would help offset our carbon footprint.
+Distilled models are smaller than the models they mimic. Using them instead of the large versions would help improve our carbon footprint.
+```
+
+
+
+This prints five sequences, with the top 5 tokens predicted by the model.
+
+
+### Causal Language Modeling
+
+Causal language modeling is the task of predicting the token following a sequence of tokens. In this situation, the
+model only attends to the left context (tokens on the left of the mask). Such a training is particularly interesting
+for generation tasks. If you would like to fine-tune a model on a causal language modeling task, you may leverage the
+[run_clm.py](https://github.com/huggingface/transformers/tree/main/examples/pytorch/language-modeling/run_clm.py) script.
+
+Usually, the next token is predicted by sampling from the logits of the last hidden state the model produces from the
+input sequence.
+
+
+
+Here is an example of using the tokenizer and model and leveraging the
+[`top_k_top_p_filtering`] method to sample the next token following an input sequence
+of tokens.
+
+```py
+>>> from transformers import AutoModelForCausalLM, AutoTokenizer, top_k_top_p_filtering
+>>> import torch
+>>> from torch import nn
+
+>>> tokenizer = AutoTokenizer.from_pretrained("gpt2")
+>>> model = AutoModelForCausalLM.from_pretrained("gpt2")
+
+>>> sequence = f"Hugging Face is based in DUMBO, New York City, and"
+
+>>> inputs = tokenizer(sequence, return_tensors="pt")
+>>> input_ids = inputs["input_ids"]
+
+>>> # get logits of last hidden state
+>>> next_token_logits = model(**inputs).logits[:, -1, :]
+
+>>> # filter
+>>> filtered_next_token_logits = top_k_top_p_filtering(next_token_logits, top_k=50, top_p=1.0)
+
+>>> # sample
+>>> probs = nn.functional.softmax(filtered_next_token_logits, dim=-1)
+>>> next_token = torch.multinomial(probs, num_samples=1)
+
+>>> generated = torch.cat([input_ids, next_token], dim=-1)
+
+>>> resulting_string = tokenizer.decode(generated.tolist()[0])
+>>> print(resulting_string)
+Hugging Face is based in DUMBO, New York City, and ...
+```
+
+
+Here is an example of using the tokenizer and model and leveraging the
+[`tf_top_k_top_p_filtering`] method to sample the next token following an input sequence
+of tokens.
+
+```py
+>>> from transformers import TFAutoModelForCausalLM, AutoTokenizer, tf_top_k_top_p_filtering
+>>> import tensorflow as tf
+
+>>> tokenizer = AutoTokenizer.from_pretrained("gpt2")
+>>> model = TFAutoModelForCausalLM.from_pretrained("gpt2")
+
+>>> sequence = f"Hugging Face is based in DUMBO, New York City, and"
+
+>>> inputs = tokenizer(sequence, return_tensors="tf")
+>>> input_ids = inputs["input_ids"]
+
+>>> # get logits of last hidden state
+>>> next_token_logits = model(**inputs).logits[:, -1, :]
+
+>>> # filter
+>>> filtered_next_token_logits = tf_top_k_top_p_filtering(next_token_logits, top_k=50, top_p=1.0)
+
+>>> # sample
+>>> next_token = tf.random.categorical(filtered_next_token_logits, dtype=tf.int32, num_samples=1)
+
+>>> generated = tf.concat([input_ids, next_token], axis=1)
+
+>>> resulting_string = tokenizer.decode(generated.numpy().tolist()[0])
+>>> print(resulting_string)
+Hugging Face is based in DUMBO, New York City, and ...
+```
+
+
+
+This outputs a (hopefully) coherent next token following the original sequence, which in our case is the word *is* or
+*features*.
+
+In the next section, we show how [`generation_utils.GenerationMixin.generate`] can be used to
+generate multiple tokens up to a specified length instead of one token at a time.
+
+### Text Generation
+
+In text generation (*a.k.a* *open-ended text generation*) the goal is to create a coherent portion of text that is a
+continuation from the given context. The following example shows how *GPT-2* can be used in pipelines to generate text.
+As a default all models apply *Top-K* sampling when used in pipelines, as configured in their respective configurations
+(see [gpt-2 config](https://huggingface.co/gpt2/blob/main/config.json) for example).
+
+
+
+```py
+>>> from transformers import pipeline
+
+>>> text_generator = pipeline("text-generation")
+>>> print(text_generator("As far as I am concerned, I will", max_length=50, do_sample=False))
+[{'generated_text': 'As far as I am concerned, I will be the first to admit that I am not a fan of the idea of a
+"free market." I think that the idea of a free market is a bit of a stretch. I think that the idea'}]
+```
+
+Here, the model generates a random text with a total maximal length of *50* tokens from context *"As far as I am
+concerned, I will"*. Behind the scenes, the pipeline object calls the method
+[`PreTrainedModel.generate`] to generate text. The default arguments for this method can be
+overridden in the pipeline, as is shown above for the arguments `max_length` and `do_sample`.
+
+Below is an example of text generation using `XLNet` and its tokenizer, which includes calling `generate()` directly:
+
+```py
+>>> from transformers import AutoModelForCausalLM, AutoTokenizer
+
+>>> model = AutoModelForCausalLM.from_pretrained("xlnet-base-cased")
+>>> tokenizer = AutoTokenizer.from_pretrained("xlnet-base-cased")
+
+>>> # Padding text helps XLNet with short prompts - proposed by Aman Rusia in https://github.com/rusiaaman/XLNet-gen#methodology
+>>> PADDING_TEXT = """In 1991, the remains of Russian Tsar Nicholas II and his family
+... (except for Alexei and Maria) are discovered.
+... The voice of Nicholas's young son, Tsarevich Alexei Nikolaevich, narrates the
+... remainder of the story. 1883 Western Siberia,
+... a young Grigori Rasputin is asked by his father and a group of men to perform magic.
+... Rasputin has a vision and denounces one of the men as a horse thief. Although his
+... father initially slaps him for making such an accusation, Rasputin watches as the
+... man is chased outside and beaten. Twenty years later, Rasputin sees a vision of
+... the Virgin Mary, prompting him to become a priest. Rasputin quickly becomes famous,
+... with people, even a bishop, begging for his blessing. """
+
+>>> prompt = "Today the weather is really nice and I am planning on "
+>>> inputs = tokenizer(PADDING_TEXT + prompt, add_special_tokens=False, return_tensors="pt")["input_ids"]
+
+>>> prompt_length = len(tokenizer.decode(inputs[0]))
+>>> outputs = model.generate(inputs, max_length=250, do_sample=True, top_p=0.95, top_k=60)
+>>> generated = prompt + tokenizer.decode(outputs[0])[prompt_length + 1 :]
+
+>>> print(generated)
+Today the weather is really nice and I am planning ...
+```
+
+
+```py
+>>> from transformers import TFAutoModelForCausalLM, AutoTokenizer
+
+>>> model = TFAutoModelForCausalLM.from_pretrained("xlnet-base-cased")
+>>> tokenizer = AutoTokenizer.from_pretrained("xlnet-base-cased")
+
+>>> # Padding text helps XLNet with short prompts - proposed by Aman Rusia in https://github.com/rusiaaman/XLNet-gen#methodology
+>>> PADDING_TEXT = """In 1991, the remains of Russian Tsar Nicholas II and his family
+... (except for Alexei and Maria) are discovered.
+... The voice of Nicholas's young son, Tsarevich Alexei Nikolaevich, narrates the
+... remainder of the story. 1883 Western Siberia,
+... a young Grigori Rasputin is asked by his father and a group of men to perform magic.
+... Rasputin has a vision and denounces one of the men as a horse thief. Although his
+... father initially slaps him for making such an accusation, Rasputin watches as the
+... man is chased outside and beaten. Twenty years later, Rasputin sees a vision of
+... the Virgin Mary, prompting him to become a priest. Rasputin quickly becomes famous,
+... with people, even a bishop, begging for his blessing. """
+
+>>> prompt = "Today the weather is really nice and I am planning on "
+>>> inputs = tokenizer(PADDING_TEXT + prompt, add_special_tokens=False, return_tensors="tf")["input_ids"]
+
+>>> prompt_length = len(tokenizer.decode(inputs[0]))
+>>> outputs = model.generate(inputs, max_length=250, do_sample=True, top_p=0.95, top_k=60)
+>>> generated = prompt + tokenizer.decode(outputs[0])[prompt_length + 1 :]
+
+>>> print(generated)
+Today the weather is really nice and I am planning ...
+```
+
+
+
+Text generation is currently possible with *GPT-2*, *OpenAi-GPT*, *CTRL*, *XLNet*, *Transfo-XL* and *Reformer* in
+PyTorch and for most models in Tensorflow as well. As can be seen in the example above *XLNet* and *Transfo-XL* often
+need to be padded to work well. GPT-2 is usually a good choice for *open-ended text generation* because it was trained
+on millions of webpages with a causal language modeling objective.
+
+For more information on how to apply different decoding strategies for text generation, please also refer to our text
+generation blog post [here](https://huggingface.co/blog/how-to-generate).
+
+
+## Named Entity Recognition
+
+Named Entity Recognition (NER) is the task of classifying tokens according to a class, for example, identifying a token
+as a person, an organisation or a location. An example of a named entity recognition dataset is the CoNLL-2003 dataset,
+which is entirely based on that task. If you would like to fine-tune a model on an NER task, you may leverage the
+[run_ner.py](https://github.com/huggingface/transformers/tree/main/examples/pytorch/token-classification/run_ner.py) script.
+
+Here is an example of using pipelines to do named entity recognition, specifically, trying to identify tokens as
+belonging to one of 9 classes:
+
+- O, Outside of a named entity
+- B-MIS, Beginning of a miscellaneous entity right after another miscellaneous entity
+- I-MIS, Miscellaneous entity
+- B-PER, Beginning of a person's name right after another person's name
+- I-PER, Person's name
+- B-ORG, Beginning of an organisation right after another organisation
+- I-ORG, Organisation
+- B-LOC, Beginning of a location right after another location
+- I-LOC, Location
+
+It leverages a fine-tuned model on CoNLL-2003, fine-tuned by [@stefan-it](https://github.com/stefan-it) from [dbmdz](https://github.com/dbmdz).
+
+```py
+>>> from transformers import pipeline
+
+>>> ner_pipe = pipeline("ner")
+
+>>> sequence = """Hugging Face Inc. is a company based in New York City. Its headquarters are in DUMBO,
+... therefore very close to the Manhattan Bridge which is visible from the window."""
+```
+
+This outputs a list of all words that have been identified as one of the entities from the 9 classes defined above.
+Here are the expected results:
+
+```py
+>>> for entity in ner_pipe(sequence):
+... print(entity)
+{'entity': 'I-ORG', 'score': 0.9996, 'index': 1, 'word': 'Hu', 'start': 0, 'end': 2}
+{'entity': 'I-ORG', 'score': 0.9910, 'index': 2, 'word': '##gging', 'start': 2, 'end': 7}
+{'entity': 'I-ORG', 'score': 0.9982, 'index': 3, 'word': 'Face', 'start': 8, 'end': 12}
+{'entity': 'I-ORG', 'score': 0.9995, 'index': 4, 'word': 'Inc', 'start': 13, 'end': 16}
+{'entity': 'I-LOC', 'score': 0.9994, 'index': 11, 'word': 'New', 'start': 40, 'end': 43}
+{'entity': 'I-LOC', 'score': 0.9993, 'index': 12, 'word': 'York', 'start': 44, 'end': 48}
+{'entity': 'I-LOC', 'score': 0.9994, 'index': 13, 'word': 'City', 'start': 49, 'end': 53}
+{'entity': 'I-LOC', 'score': 0.9863, 'index': 19, 'word': 'D', 'start': 79, 'end': 80}
+{'entity': 'I-LOC', 'score': 0.9514, 'index': 20, 'word': '##UM', 'start': 80, 'end': 82}
+{'entity': 'I-LOC', 'score': 0.9337, 'index': 21, 'word': '##BO', 'start': 82, 'end': 84}
+{'entity': 'I-LOC', 'score': 0.9762, 'index': 28, 'word': 'Manhattan', 'start': 114, 'end': 123}
+{'entity': 'I-LOC', 'score': 0.9915, 'index': 29, 'word': 'Bridge', 'start': 124, 'end': 130}
+```
+
+Note how the tokens of the sequence "Hugging Face" have been identified as an organisation, and "New York City",
+"DUMBO" and "Manhattan Bridge" have been identified as locations.
+
+Here is an example of doing named entity recognition, using a model and a tokenizer. The process is the following:
+
+1. Instantiate a tokenizer and a model from the checkpoint name. The model is identified as a BERT model and loads it
+ with the weights stored in the checkpoint.
+2. Define a sequence with known entities, such as "Hugging Face" as an organisation and "New York City" as a location.
+3. Split words into tokens so that they can be mapped to predictions. We use a small hack by, first, completely
+ encoding and decoding the sequence, so that we're left with a string that contains the special tokens.
+4. Encode that sequence into IDs (special tokens are added automatically).
+5. Retrieve the predictions by passing the input to the model and getting the first output. This results in a
+ distribution over the 9 possible classes for each token. We take the argmax to retrieve the most likely class for
+ each token.
+6. Zip together each token with its prediction and print it.
+
+
+
+```py
+>>> from transformers import AutoModelForTokenClassification, AutoTokenizer
+>>> import torch
+
+>>> model = AutoModelForTokenClassification.from_pretrained("dbmdz/bert-large-cased-finetuned-conll03-english")
+>>> tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
+
+>>> sequence = (
+... "Hugging Face Inc. is a company based in New York City. Its headquarters are in DUMBO, "
+... "therefore very close to the Manhattan Bridge."
+... )
+
+>>> inputs = tokenizer(sequence, return_tensors="pt")
+>>> tokens = inputs.tokens()
+
+>>> outputs = model(**inputs).logits
+>>> predictions = torch.argmax(outputs, dim=2)
+```
+
+
+```py
+>>> from transformers import TFAutoModelForTokenClassification, AutoTokenizer
+>>> import tensorflow as tf
+
+>>> model = TFAutoModelForTokenClassification.from_pretrained("dbmdz/bert-large-cased-finetuned-conll03-english")
+>>> tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
+
+>>> sequence = (
+... "Hugging Face Inc. is a company based in New York City. Its headquarters are in DUMBO, "
+... "therefore very close to the Manhattan Bridge."
+... )
+
+>>> inputs = tokenizer(sequence, return_tensors="tf")
+>>> tokens = inputs.tokens()
+
+>>> outputs = model(**inputs)[0]
+>>> predictions = tf.argmax(outputs, axis=2)
+```
+
+
+
+This outputs a list of each token mapped to its corresponding prediction. Differently from the pipeline, here every
+token has a prediction as we didn't remove the "0"th class, which means that no particular entity was found on that
+token.
+
+In the above example, `predictions` is an integer that corresponds to the predicted class. We can use the
+`model.config.id2label` property in order to recover the class name corresponding to the class number, which is
+illustrated below:
+
+```py
+>>> for token, prediction in zip(tokens, predictions[0].numpy()):
+... print((token, model.config.id2label[prediction]))
+('[CLS]', 'O')
+('Hu', 'I-ORG')
+('##gging', 'I-ORG')
+('Face', 'I-ORG')
+('Inc', 'I-ORG')
+('.', 'O')
+('is', 'O')
+('a', 'O')
+('company', 'O')
+('based', 'O')
+('in', 'O')
+('New', 'I-LOC')
+('York', 'I-LOC')
+('City', 'I-LOC')
+('.', 'O')
+('Its', 'O')
+('headquarters', 'O')
+('are', 'O')
+('in', 'O')
+('D', 'I-LOC')
+('##UM', 'I-LOC')
+('##BO', 'I-LOC')
+(',', 'O')
+('therefore', 'O')
+('very', 'O')
+('close', 'O')
+('to', 'O')
+('the', 'O')
+('Manhattan', 'I-LOC')
+('Bridge', 'I-LOC')
+('.', 'O')
+('[SEP]', 'O')
+```
+
+## Summarization
+
+Summarization is the task of summarizing a document or an article into a shorter text. If you would like to fine-tune a
+model on a summarization task, you may leverage the [run_summarization.py](https://github.com/huggingface/transformers/tree/main/examples/pytorch/summarization/run_summarization.py)
+script.
+
+An example of a summarization dataset is the CNN / Daily Mail dataset, which consists of long news articles and was
+created for the task of summarization. If you would like to fine-tune a model on a summarization task, various
+approaches are described in this [document](https://github.com/huggingface/transformers/tree/main/examples/pytorch/summarization/README.md).
+
+Here is an example of using the pipelines to do summarization. It leverages a Bart model that was fine-tuned on the CNN
+/ Daily Mail data set.
+
+```py
+>>> from transformers import pipeline
+
+>>> summarizer = pipeline("summarization")
+
+>>> ARTICLE = """ New York (CNN)When Liana Barrientos was 23 years old, she got married in Westchester County, New York.
+... A year later, she got married again in Westchester County, but to a different man and without divorcing her first husband.
+... Only 18 days after that marriage, she got hitched yet again. Then, Barrientos declared "I do" five more times, sometimes only within two weeks of each other.
+... In 2010, she married once more, this time in the Bronx. In an application for a marriage license, she stated it was her "first and only" marriage.
+... Barrientos, now 39, is facing two criminal counts of "offering a false instrument for filing in the first degree," referring to her false statements on the
+... 2010 marriage license application, according to court documents.
+... Prosecutors said the marriages were part of an immigration scam.
+... On Friday, she pleaded not guilty at State Supreme Court in the Bronx, according to her attorney, Christopher Wright, who declined to comment further.
+... After leaving court, Barrientos was arrested and charged with theft of service and criminal trespass for allegedly sneaking into the New York subway through an emergency exit, said Detective
+... Annette Markowski, a police spokeswoman. In total, Barrientos has been married 10 times, with nine of her marriages occurring between 1999 and 2002.
+... All occurred either in Westchester County, Long Island, New Jersey or the Bronx. She is believed to still be married to four men, and at one time, she was married to eight men at once, prosecutors say.
+... Prosecutors said the immigration scam involved some of her husbands, who filed for permanent residence status shortly after the marriages.
+... Any divorces happened only after such filings were approved. It was unclear whether any of the men will be prosecuted.
+... The case was referred to the Bronx District Attorney\'s Office by Immigration and Customs Enforcement and the Department of Homeland Security\'s
+... Investigation Division. Seven of the men are from so-called "red-flagged" countries, including Egypt, Turkey, Georgia, Pakistan and Mali.
+... Her eighth husband, Rashid Rajput, was deported in 2006 to his native Pakistan after an investigation by the Joint Terrorism Task Force.
+... If convicted, Barrientos faces up to four years in prison. Her next court appearance is scheduled for May 18.
+... """
+```
+
+Because the summarization pipeline depends on the `PreTrainedModel.generate()` method, we can override the default
+arguments of `PreTrainedModel.generate()` directly in the pipeline for `max_length` and `min_length` as shown
+below. This outputs the following summary:
+
+```py
+>>> print(summarizer(ARTICLE, max_length=130, min_length=30, do_sample=False))
+[{'summary_text': ' Liana Barrientos, 39, is charged with two counts of "offering a false instrument for filing in
+the first degree" In total, she has been married 10 times, with nine of her marriages occurring between 1999 and
+2002 . At one time, she was married to eight men at once, prosecutors say .'}]
+```
+
+Here is an example of doing summarization using a model and a tokenizer. The process is the following:
+
+1. Instantiate a tokenizer and a model from the checkpoint name. Summarization is usually done using an encoder-decoder
+ model, such as `Bart` or `T5`.
+2. Define the article that should be summarized.
+3. Add the T5 specific prefix "summarize: ".
+4. Use the `PreTrainedModel.generate()` method to generate the summary.
+
+In this example we use Google's T5 model. Even though it was pre-trained only on a multi-task mixed dataset (including
+CNN / Daily Mail), it yields very good results.
+
+
+
+```py
+>>> from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
+
+>>> model = AutoModelForSeq2SeqLM.from_pretrained("t5-base")
+>>> tokenizer = AutoTokenizer.from_pretrained("t5-base")
+
+>>> # T5 uses a max_length of 512 so we cut the article to 512 tokens.
+>>> inputs = tokenizer("summarize: " + ARTICLE, return_tensors="pt", max_length=512, truncation=True)
+>>> outputs = model.generate(
+... inputs["input_ids"], max_length=150, min_length=40, length_penalty=2.0, num_beams=4, early_stopping=True
+... )
+
+>>> print(tokenizer.decode(outputs[0], skip_special_tokens=True))
+prosecutors say the marriages were part of an immigration scam. if convicted, barrientos faces two criminal
+counts of "offering a false instrument for filing in the first degree" she has been married 10 times, nine of them
+between 1999 and 2002.
+```
+
+
+```py
+>>> from transformers import TFAutoModelForSeq2SeqLM, AutoTokenizer
+
+>>> model = TFAutoModelForSeq2SeqLM.from_pretrained("t5-base")
+>>> tokenizer = AutoTokenizer.from_pretrained("t5-base")
+
+>>> # T5 uses a max_length of 512 so we cut the article to 512 tokens.
+>>> inputs = tokenizer("summarize: " + ARTICLE, return_tensors="tf", max_length=512)
+>>> outputs = model.generate(
+... inputs["input_ids"], max_length=150, min_length=40, length_penalty=2.0, num_beams=4, early_stopping=True
+... )
+
+>>> print(tokenizer.decode(outputs[0], skip_special_tokens=True))
+prosecutors say the marriages were part of an immigration scam. if convicted, barrientos faces two criminal
+counts of "offering a false instrument for filing in the first degree" she has been married 10 times, nine of them
+between 1999 and 2002.
+```
+
+
+
+## Translation
+
+Translation is the task of translating a text from one language to another. If you would like to fine-tune a model on a
+translation task, you may leverage the [run_translation.py](https://github.com/huggingface/transformers/tree/main/examples/pytorch/translation/run_translation.py) script.
+
+An example of a translation dataset is the WMT English to German dataset, which has sentences in English as the input
+data and the corresponding sentences in German as the target data. If you would like to fine-tune a model on a
+translation task, various approaches are described in this [document](https://github.com/huggingface/transformers/tree/main/examples/pytorch/translation/README.md).
+
+Here is an example of using the pipelines to do translation. It leverages a T5 model that was only pre-trained on a
+multi-task mixture dataset (including WMT), yet, yielding impressive translation results.
+
+```py
+>>> from transformers import pipeline
+
+>>> translator = pipeline("translation_en_to_de")
+>>> print(translator("Hugging Face is a technology company based in New York and Paris", max_length=40))
+[{'translation_text': 'Hugging Face ist ein Technologieunternehmen mit Sitz in New York und Paris.'}]
+```
+
+Because the translation pipeline depends on the `PreTrainedModel.generate()` method, we can override the default
+arguments of `PreTrainedModel.generate()` directly in the pipeline as is shown for `max_length` above.
+
+Here is an example of doing translation using a model and a tokenizer. The process is the following:
+
+1. Instantiate a tokenizer and a model from the checkpoint name. Summarization is usually done using an encoder-decoder
+ model, such as `Bart` or `T5`.
+2. Define the article that should be summarized.
+3. Add the T5 specific prefix "translate English to German: "
+4. Use the `PreTrainedModel.generate()` method to perform the translation.
+
+
+
+```py
+>>> from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
+
+>>> model = AutoModelForSeq2SeqLM.from_pretrained("t5-base")
+>>> tokenizer = AutoTokenizer.from_pretrained("t5-base")
+
+>>> inputs = tokenizer(
+... "translate English to German: Hugging Face is a technology company based in New York and Paris",
+... return_tensors="pt",
+... )
+>>> outputs = model.generate(inputs["input_ids"], max_length=40, num_beams=4, early_stopping=True)
+
+>>> print(tokenizer.decode(outputs[0], skip_special_tokens=True))
+Hugging Face ist ein Technologieunternehmen mit Sitz in New York und Paris.
+```
+
+
+```py
+>>> from transformers import TFAutoModelForSeq2SeqLM, AutoTokenizer
+
+>>> model = TFAutoModelForSeq2SeqLM.from_pretrained("t5-base")
+>>> tokenizer = AutoTokenizer.from_pretrained("t5-base")
+
+>>> inputs = tokenizer(
+... "translate English to German: Hugging Face is a technology company based in New York and Paris",
+... return_tensors="tf",
+... )
+>>> outputs = model.generate(inputs["input_ids"], max_length=40, num_beams=4, early_stopping=True)
+
+>>> print(tokenizer.decode(outputs[0], skip_special_tokens=True))
+Hugging Face ist ein Technologieunternehmen mit Sitz in New York und Paris.
+```
+
+
+
+We get the same translation as with the pipeline example.
+
+## Audio classification
+
+Audio classification assigns a class to an audio signal. The Keyword Spotting dataset from the [SUPERB](https://huggingface.co/datasets/superb) benchmark is an example dataset that can be used for audio classification fine-tuning. This dataset contains ten classes of keywords for classification. If you'd like to fine-tune a model for audio classification, take a look at the [run_audio_classification.py](https://github.com/huggingface/transformers/blob/main/examples/pytorch/audio-classification/run_audio_classification.py) script or this [how-to guide](./tasks/audio_classification).
+
+The following examples demonstrate how to use a [`pipeline`] and a model and tokenizer for audio classification inference:
+
+```py
+>>> from transformers import pipeline
+>>> from datasets import load_dataset
+>>> import torch
+
+>>> torch.manual_seed(42) # doctest: +IGNORE_RESULT
+
+>>> dataset = load_dataset("hf-internal-testing/librispeech_asr_demo", "clean", split="validation")
+>>> dataset = dataset.sort("id")
+>>> audio_file = dataset[0]["audio"]["path"]
+
+>>> audio_classifier = pipeline(
+... task="audio-classification", model="ehcalabres/wav2vec2-lg-xlsr-en-speech-emotion-recognition"
+... )
+>>> predictions = audio_classifier(audio_file)
+>>> predictions = [{"score": round(pred["score"], 4), "label": pred["label"]} for pred in predictions]
+>>> predictions
+[{'score': 0.1315, 'label': 'calm'}, {'score': 0.1307, 'label': 'neutral'}, {'score': 0.1274, 'label': 'sad'}, {'score': 0.1261, 'label': 'fearful'}, {'score': 0.1242, 'label': 'happy'}]
+```
+
+The general process for using a model and feature extractor for audio classification is:
+
+1. Instantiate a feature extractor and a model from the checkpoint name.
+2. Process the audio signal to be classified with a feature extractor.
+3. Pass the input through the model and take the `argmax` to retrieve the most likely class.
+4. Convert the class id to a class name with `id2label` to return an interpretable result.
+
+
+
+```py
+>>> from transformers import AutoFeatureExtractor, AutoModelForAudioClassification
+>>> from datasets import load_dataset
+>>> import torch
+
+>>> dataset = load_dataset("hf-internal-testing/librispeech_asr_demo", "clean", split="validation")
+>>> dataset = dataset.sort("id")
+>>> sampling_rate = dataset.features["audio"].sampling_rate
+
+>>> feature_extractor = AutoFeatureExtractor.from_pretrained("superb/wav2vec2-base-superb-ks")
+>>> model = AutoModelForAudioClassification.from_pretrained("superb/wav2vec2-base-superb-ks")
+
+>>> inputs = feature_extractor(dataset[0]["audio"]["array"], sampling_rate=sampling_rate, return_tensors="pt")
+
+>>> with torch.no_grad():
+... logits = model(**inputs).logits
+
+>>> predicted_class_ids = torch.argmax(logits, dim=-1).item()
+>>> predicted_label = model.config.id2label[predicted_class_ids]
+>>> predicted_label
+'_unknown_'
+```
+
+
+
+## Automatic speech recognition
+
+Automatic speech recognition transcribes an audio signal to text. The [Common Voice](https://huggingface.co/datasets/common_voice) dataset is an example dataset that can be used for automatic speech recognition fine-tuning. It contains an audio file of a speaker and the corresponding sentence. If you'd like to fine-tune a model for automatic speech recognition, take a look at the [run_speech_recognition_ctc.py](https://github.com/huggingface/transformers/blob/main/examples/pytorch/speech-recognition/run_speech_recognition_ctc.py) or [run_speech_recognition_seq2seq.py](https://github.com/huggingface/transformers/blob/main/examples/pytorch/speech-recognition/run_speech_recognition_seq2seq.py) scripts or this [how-to guide](./tasks/asr).
+
+The following examples demonstrate how to use a [`pipeline`] and a model and tokenizer for automatic speech recognition inference:
+
+```py
+>>> from transformers import pipeline
+>>> from datasets import load_dataset
+
+>>> dataset = load_dataset("hf-internal-testing/librispeech_asr_demo", "clean", split="validation")
+>>> dataset = dataset.sort("id")
+>>> audio_file = dataset[0]["audio"]["path"]
+
+>>> speech_recognizer = pipeline(task="automatic-speech-recognition", model="facebook/wav2vec2-base-960h")
+>>> speech_recognizer(audio_file)
+{'text': 'MISTER QUILTER IS THE APOSTLE OF THE MIDDLE CLASSES AND WE ARE GLAD TO WELCOME HIS GOSPEL'}
+```
+
+The general process for using a model and processor for automatic speech recognition is:
+
+1. Instantiate a processor (which regroups a feature extractor for input processing and a tokenizer for decoding) and a model from the checkpoint name.
+2. Process the audio signal and text with a processor.
+3. Pass the input through the model and take the `argmax` to retrieve the predicted text.
+4. Decode the text with a tokenizer to obtain the transcription.
+
+
+
+```py
+>>> from transformers import AutoProcessor, AutoModelForCTC
+>>> from datasets import load_dataset
+>>> import torch
+
+>>> dataset = load_dataset("hf-internal-testing/librispeech_asr_demo", "clean", split="validation")
+>>> dataset = dataset.sort("id")
+>>> sampling_rate = dataset.features["audio"].sampling_rate
+
+>>> processor = AutoProcessor.from_pretrained("facebook/wav2vec2-base-960h")
+>>> model = AutoModelForCTC.from_pretrained("facebook/wav2vec2-base-960h")
+
+>>> inputs = processor(dataset[0]["audio"]["array"], sampling_rate=sampling_rate, return_tensors="pt")
+>>> with torch.no_grad():
+... logits = model(**inputs).logits
+>>> predicted_ids = torch.argmax(logits, dim=-1)
+
+>>> transcription = processor.batch_decode(predicted_ids)
+>>> transcription[0]
+'MISTER QUILTER IS THE APOSTLE OF THE MIDDLE CLASSES AND WE ARE GLAD TO WELCOME HIS GOSPEL'
+```
+
+
+
+## Image classification
+
+Like text and audio classification, image classification assigns a class to an image. The [CIFAR-100](https://huggingface.co/datasets/cifar100) dataset is an example dataset that can be used for image classification fine-tuning. It contains an image and the corresponding class. If you'd like to fine-tune a model for image classification, take a look at the [run_image_classification.py](https://github.com/huggingface/transformers/blob/main/examples/pytorch/image-classification/run_image_classification.py) script or this [how-to guide](./tasks/image_classification).
+
+The following examples demonstrate how to use a [`pipeline`] and a model and tokenizer for image classification inference:
+
+```py
+>>> from transformers import pipeline
+
+>>> vision_classifier = pipeline(task="image-classification")
+>>> result = vision_classifier(
+... images="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
+... )
+>>> print("\n".join([f"Class {d['label']} with score {round(d['score'], 4)}" for d in result]))
+Class lynx, catamount with score 0.4335
+Class cougar, puma, catamount, mountain lion, painter, panther, Felis concolor with score 0.0348
+Class snow leopard, ounce, Panthera uncia with score 0.0324
+Class Egyptian cat with score 0.0239
+Class tiger cat with score 0.0229
+```
+
+The general process for using a model and feature extractor for image classification is:
+
+1. Instantiate a feature extractor and a model from the checkpoint name.
+2. Process the image to be classified with a feature extractor.
+3. Pass the input through the model and take the `argmax` to retrieve the predicted class.
+4. Convert the class id to a class name with `id2label` to return an interpretable result.
+
+
+
+```py
+>>> from transformers import AutoFeatureExtractor, AutoModelForImageClassification
+>>> import torch
+>>> from datasets import load_dataset
+
+>>> dataset = load_dataset("huggingface/cats-image")
+>>> image = dataset["test"]["image"][0]
+
+>>> feature_extractor = AutoFeatureExtractor.from_pretrained("google/vit-base-patch16-224")
+>>> model = AutoModelForImageClassification.from_pretrained("google/vit-base-patch16-224")
+
+>>> inputs = feature_extractor(image, return_tensors="pt")
+
+>>> with torch.no_grad():
+... logits = model(**inputs).logits
+
+>>> predicted_label = logits.argmax(-1).item()
+>>> print(model.config.id2label[predicted_label])
+Egyptian cat
+```
+
+
diff --git a/docs/source/en/tasks/asr.mdx b/docs/source/en/tasks/asr.mdx
new file mode 100644
index 00000000000000..dac5015bf8158b
--- /dev/null
+++ b/docs/source/en/tasks/asr.mdx
@@ -0,0 +1,235 @@
+
+
+# Automatic speech recognition
+
+
+
+Automatic speech recognition (ASR) converts a speech signal to text. It is an example of a sequence-to-sequence task, going from a sequence of audio inputs to textual outputs. Voice assistants like Siri and Alexa utilize ASR models to assist users.
+
+This guide will show you how to fine-tune [Wav2Vec2](https://huggingface.co/facebook/wav2vec2-base) on the [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) dataset to transcribe audio to text.
+
+
+
+See the automatic speech recognition [task page](https://huggingface.co/tasks/automatic-speech-recognition) for more information about its associated models, datasets, and metrics.
+
+
+
+## Load MInDS-14 dataset
+
+Load the [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) from the 🤗 Datasets library:
+
+```py
+>>> from datasets import load_dataset, Audio
+
+>>> minds = load_dataset("PolyAI/minds14", name="en-US", split="train")
+```
+
+Split this dataset into a train and test set:
+
+```py
+>>> minds = minds.train_test_split(test_size=0.2)
+```
+
+Then take a look at the dataset:
+
+```py
+>>> minds
+DatasetDict({
+ train: Dataset({
+ features: ['path', 'audio', 'transcription', 'english_transcription', 'intent_class', 'lang_id'],
+ num_rows: 450
+ })
+ test: Dataset({
+ features: ['path', 'audio', 'transcription', 'english_transcription', 'intent_class', 'lang_id'],
+ num_rows: 113
+ })
+})
+```
+
+While the dataset contains a lot of helpful information, like `lang_id` and `intent_class`, you will focus on the `audio` and `transcription` columns in this guide. Remove the other columns:
+
+```py
+>>> minds = minds.remove_columns(["english_transcription", "intent_class", "lang_id"])
+```
+
+Take a look at the example again:
+
+```py
+>>> minds["train"][0]
+{'audio': {'array': array([-0.00024414, 0. , 0. , ..., 0.00024414,
+ 0.00024414, 0.00024414], dtype=float32),
+ 'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~APP_ERROR/602ba9e2963e11ccd901cd4f.wav',
+ 'sampling_rate': 8000},
+ 'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~APP_ERROR/602ba9e2963e11ccd901cd4f.wav',
+ 'transcription': "hi I'm trying to use the banking app on my phone and currently my checking and savings account balance is not refreshing"}
+```
+
+The `audio` column contains a 1-dimensional `array` of the speech signal that must be called to load and resample the audio file.
+
+## Preprocess
+
+Load the Wav2Vec2 processor to process the audio signal and transcribed text:
+
+```py
+>>> from transformers import AutoProcessor
+
+>>> processor = AutoProcessor.from_pretrained("facebook/wav2vec2-base")
+```
+
+The [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) dataset has a sampling rate of 8000khz. You will need to resample the dataset to use the pretrained Wav2Vec2 model:
+
+```py
+>>> minds = minds.cast_column("audio", Audio(sampling_rate=16_000))
+>>> minds["train"][0]
+{'audio': {'array': array([-2.38064706e-04, -1.58618059e-04, -5.43987835e-06, ...,
+ 2.78103951e-04, 2.38446111e-04, 1.18740834e-04], dtype=float32),
+ 'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~APP_ERROR/602ba9e2963e11ccd901cd4f.wav',
+ 'sampling_rate': 16000},
+ 'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~APP_ERROR/602ba9e2963e11ccd901cd4f.wav',
+ 'transcription': "hi I'm trying to use the banking app on my phone and currently my checking and savings account balance is not refreshing"}
+```
+
+The preprocessing function needs to:
+
+1. Call the `audio` column to load and resample the audio file.
+2. Extract the `input_values` from the audio file.
+3. Typically, when you call the processor, you call the feature extractor. Since you also want to tokenize text, instruct the processor to call the tokenizer instead with a context manager.
+
+```py
+>>> def prepare_dataset(batch):
+... audio = batch["audio"]
+
+... batch["input_values"] = processor(audio["array"], sampling_rate=audio["sampling_rate"]).input_values[0]
+... batch["input_length"] = len(batch["input_values"])
+
+... with processor.as_target_processor():
+... batch["labels"] = processor(batch["transcription"]).input_ids
+... return batch
+```
+
+Use 🤗 Datasets [`map`](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.map) function to apply the preprocessing function over the entire dataset. You can speed up the map function by increasing the number of processes with `num_proc`. Remove the columns you don't need:
+
+```py
+>>> encoded_minds = minds.map(prepare_dataset, remove_columns=minds.column_names["train"], num_proc=4)
+```
+
+🤗 Transformers doesn't have a data collator for automatic speech recognition, so you will need to create one. You can adapt the [`DataCollatorWithPadding`] to create a batch of examples for automatic speech recognition. It will also dynamically pad your text and labels to the length of the longest element in its batch, so they are a uniform length. While it is possible to pad your text in the `tokenizer` function by setting `padding=True`, dynamic padding is more efficient.
+
+Unlike other data collators, this specific data collator needs to apply a different padding method to `input_values` and `labels`. You can apply a different padding method with a context manager:
+
+```py
+>>> import torch
+
+>>> from dataclasses import dataclass, field
+>>> from typing import Any, Dict, List, Optional, Union
+
+
+>>> @dataclass
+... class DataCollatorCTCWithPadding:
+
+... processor: AutoProcessor
+... padding: Union[bool, str] = True
+
+... def __call__(self, features: List[Dict[str, Union[List[int], torch.Tensor]]]) -> Dict[str, torch.Tensor]:
+... # split inputs and labels since they have to be of different lengths and need
+... # different padding methods
+... input_features = [{"input_values": feature["input_values"]} for feature in features]
+... label_features = [{"input_ids": feature["labels"]} for feature in features]
+
+... batch = self.processor.pad(
+... input_features,
+... padding=self.padding,
+... return_tensors="pt",
+... )
+... with self.processor.as_target_processor():
+... labels_batch = self.processor.pad(
+... label_features,
+... padding=self.padding,
+... return_tensors="pt",
+... )
+
+... # replace padding with -100 to ignore loss correctly
+... labels = labels_batch["input_ids"].masked_fill(labels_batch.attention_mask.ne(1), -100)
+
+... batch["labels"] = labels
+
+... return batch
+```
+
+Create a batch of examples and dynamically pad them with `DataCollatorForCTCWithPadding`:
+
+```py
+>>> data_collator = DataCollatorCTCWithPadding(processor=processor, padding=True)
+```
+
+## Train
+
+
+
+Load Wav2Vec2 with [`AutoModelForCTC`]. For `ctc_loss_reduction`, it is often better to use the average instead of the default summation:
+
+```py
+>>> from transformers import AutoModelForCTC, TrainingArguments, Trainer
+
+>>> model = AutoModelForCTC.from_pretrained(
+... "facebook/wav2vec2-base",
+... ctc_loss_reduction="mean",
+... pad_token_id=processor.tokenizer.pad_token_id,
+... )
+```
+
+
+
+If you aren't familiar with fine-tuning a model with the [`Trainer`], take a look at the basic tutorial [here](../training#finetune-with-trainer)!
+
+
+
+At this point, only three steps remain:
+
+1. Define your training hyperparameters in [`TrainingArguments`].
+2. Pass the training arguments to [`Trainer`] along with the model, datasets, tokenizer, and data collator.
+3. Call [`~Trainer.train`] to fine-tune your model.
+
+```py
+>>> training_args = TrainingArguments(
+... output_dir="./results",
+... group_by_length=True,
+... per_device_train_batch_size=16,
+... evaluation_strategy="steps",
+... num_train_epochs=3,
+... fp16=True,
+... gradient_checkpointing=True,
+... learning_rate=1e-4,
+... weight_decay=0.005,
+... save_total_limit=2,
+... )
+
+>>> trainer = Trainer(
+... model=model,
+... args=training_args,
+... train_dataset=encoded_minds["train"],
+... eval_dataset=encoded_minds["test"],
+... tokenizer=processor.feature_extractor,
+... data_collator=data_collator,
+... )
+
+>>> trainer.train()
+```
+
+
+
+
+
+For a more in-depth example of how to fine-tune a model for automatic speech recognition, take a look at this blog [post](https://huggingface.co/blog/fine-tune-wav2vec2-english) for English ASR and this [post](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2) for multilingual ASR.
+
+
\ No newline at end of file
diff --git a/docs/source/en/tasks/audio_classification.mdx b/docs/source/en/tasks/audio_classification.mdx
new file mode 100644
index 00000000000000..6dee7a19dd5dc1
--- /dev/null
+++ b/docs/source/en/tasks/audio_classification.mdx
@@ -0,0 +1,192 @@
+
+
+# Audio classification
+
+
+
+Audio classification assigns a label or class to audio data. It is similar to text classification, except an audio input is continuous and must be discretized, whereas text can be split into tokens. Some practical applications of audio classification include identifying intent, speakers, and even animal species by their sounds.
+
+This guide will show you how to fine-tune [Wav2Vec2](https://huggingface.co/facebook/wav2vec2-base) on the [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) to classify intent.
+
+
+
+See the audio classification [task page](https://huggingface.co/tasks/audio-classification) for more information about its associated models, datasets, and metrics.
+
+
+
+## Load MInDS-14 dataset
+
+Load the [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) from the 🤗 Datasets library:
+
+```py
+>>> from datasets import load_dataset, Audio
+
+>>> minds = load_dataset("PolyAI/minds14", name="en-US", split="train")
+```
+
+Split this dataset into a train and test set:
+
+```py
+>>> minds = minds.train_test_split(test_size=0.2)
+```
+
+Then take a look at the dataset:
+
+```py
+>>> minds
+DatasetDict({
+ train: Dataset({
+ features: ['path', 'audio', 'transcription', 'english_transcription', 'intent_class', 'lang_id'],
+ num_rows: 450
+ })
+ test: Dataset({
+ features: ['path', 'audio', 'transcription', 'english_transcription', 'intent_class', 'lang_id'],
+ num_rows: 113
+ })
+})
+```
+
+While the dataset contains a lot of other useful information, like `lang_id` and `english_transcription`, you will focus on the `audio` and `intent_class` in this guide. Remove the other columns:
+
+```py
+>>> minds = minds.remove_columns(["path", "transcription", "english_transcription", "lang_id"])
+```
+
+Take a look at an example now:
+
+```py
+>>> minds["train"][0]
+{'audio': {'array': array([ 0. , 0. , 0. , ..., -0.00048828,
+ -0.00024414, -0.00024414], dtype=float32),
+ 'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~APP_ERROR/602b9a5fbb1e6d0fbce91f52.wav',
+ 'sampling_rate': 8000},
+ 'intent_class': 2}
+```
+
+The `audio` column contains a 1-dimensional `array` of the speech signal that must be called to load and resample the audio file. The `intent_class` column is an integer that represents the class id of intent. Create a dictionary that maps a label name to an integer and vice versa. The mapping will help the model recover the label name from the label number:
+
+```py
+>>> labels = minds["train"].features["intent_class"].names
+>>> label2id, id2label = dict(), dict()
+>>> for i, label in enumerate(labels):
+... label2id[label] = str(i)
+... id2label[str(i)] = label
+```
+
+Now you can convert the label number to a label name for more information:
+
+```py
+>>> id2label[str(2)]
+'app_error'
+```
+
+Each keyword - or label - corresponds to a number; `2` indicates `app_error` in the example above.
+
+## Preprocess
+
+Load the Wav2Vec2 feature extractor to process the audio signal:
+
+```py
+>>> from transformers import AutoFeatureExtractor
+
+>>> feature_extractor = AutoFeatureExtractor.from_pretrained("facebook/wav2vec2-base")
+```
+
+The [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) dataset has a sampling rate of 8000khz. You will need to resample the dataset to use the pretrained Wav2Vec2 model:
+
+```py
+>>> minds = minds.cast_column("audio", Audio(sampling_rate=16_000))
+>>> minds["train"][0]
+{'audio': {'array': array([ 2.2098757e-05, 4.6582241e-05, -2.2803260e-05, ...,
+ -2.8419291e-04, -2.3305941e-04, -1.1425107e-04], dtype=float32),
+ 'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~APP_ERROR/602b9a5fbb1e6d0fbce91f52.wav',
+ 'sampling_rate': 16000},
+ 'intent_class': 2}
+```
+
+The preprocessing function needs to:
+
+1. Call the `audio` column to load and if necessary resample the audio file.
+2. Check the sampling rate of the audio file matches the sampling rate of the audio data a model was pretrained with. You can find this information on the Wav2Vec2 [model card]((https://huggingface.co/facebook/wav2vec2-base)).
+3. Set a maximum input length so longer inputs are batched without being truncated.
+
+```py
+>>> def preprocess_function(examples):
+... audio_arrays = [x["array"] for x in examples["audio"]]
+... inputs = feature_extractor(
+... audio_arrays, sampling_rate=feature_extractor.sampling_rate, max_length=16000, truncation=True
+... )
+... return inputs
+```
+
+Use 🤗 Datasets [`map`](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.map) function to apply the preprocessing function over the entire dataset. You can speed up the `map` function by setting `batched=True` to process multiple elements of the dataset at once. Remove the columns you don't need, and rename `intent_class` to `label` because that is what the model expects:
+
+```py
+>>> encoded_minds = minds.map(preprocess_function, remove_columns="audio", batched=True)
+>>> encoded_minds = encoded_minds.rename_column("intent_class", "label")
+```
+
+## Train
+
+
+
+Load Wav2Vec2 with [`AutoModelForAudioClassification`]. Specify the number of labels, and pass the model the mapping between label number and label class:
+
+```py
+>>> from transformers import AutoModelForAudioClassification, TrainingArguments, Trainer
+
+>>> num_labels = len(id2label)
+>>> model = AutoModelForAudioClassification.from_pretrained(
+... "facebook/wav2vec2-base", num_labels=num_labels, label2id=label2id, id2label=id2label
+... )
+```
+
+
+
+If you aren't familiar with fine-tuning a model with the [`Trainer`], take a look at the basic tutorial [here](../training#finetune-with-trainer)!
+
+
+
+At this point, only three steps remain:
+
+1. Define your training hyperparameters in [`TrainingArguments`].
+2. Pass the training arguments to [`Trainer`] along with the model, datasets, and feature extractor.
+3. Call [`~Trainer.train`] to fine-tune your model.
+
+```py
+>>> training_args = TrainingArguments(
+... output_dir="./results",
+... evaluation_strategy="epoch",
+... save_strategy="epoch",
+... learning_rate=3e-5,
+... num_train_epochs=5,
+... )
+
+>>> trainer = Trainer(
+... model=model,
+... args=training_args,
+... train_dataset=encoded_minds["train"],
+... eval_dataset=encoded_minds["test"],
+... tokenizer=feature_extractor,
+... )
+
+>>> trainer.train()
+```
+
+
+
+
+
+For a more in-depth example of how to fine-tune a model for audio classification, take a look at the corresponding [PyTorch notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/audio_classification.ipynb).
+
+
\ No newline at end of file
diff --git a/docs/source/en/tasks/image_classification.mdx b/docs/source/en/tasks/image_classification.mdx
new file mode 100644
index 00000000000000..0ca317e79d6e97
--- /dev/null
+++ b/docs/source/en/tasks/image_classification.mdx
@@ -0,0 +1,174 @@
+
+
+# Image classification
+
+
+
+Image classification assigns a label or class to an image. Unlike text or audio classification, the inputs are the pixel values that represent an image. There are many uses for image classification, like detecting damage after a disaster, monitoring crop health, or helping screen medical images for signs of disease.
+
+This guide will show you how to fine-tune [ViT](https://huggingface.co/docs/transformers/v4.16.2/en/model_doc/vit) on the [Food-101](https://huggingface.co/datasets/food101) dataset to classify a food item in an image.
+
+
+
+See the image classification [task page](https://huggingface.co/tasks/audio-classification) for more information about its associated models, datasets, and metrics.
+
+
+
+## Load Food-101 dataset
+
+Load only the first 5000 images of the Food-101 dataset from the 🤗 Datasets library since it is pretty large:
+
+```py
+>>> from datasets import load_dataset
+
+>>> food = load_dataset("food101", split="train[:5000]")
+```
+
+Split this dataset into a train and test set:
+
+```py
+>>> food = food.train_test_split(test_size=0.2)
+```
+
+Then take a look at an example:
+
+```py
+>>> food["train"][0]
+{'image': ,
+ 'label': 79}
+```
+
+The `image` field contains a PIL image, and each `label` is an integer that represents a class. Create a dictionary that maps a label name to an integer and vice versa. The mapping will help the model recover the label name from the label number:
+
+```py
+>>> labels = food["train"].features["label"].names
+>>> label2id, id2label = dict(), dict()
+>>> for i, label in enumerate(labels):
+... label2id[label] = str(i)
+... id2label[str(i)] = label
+```
+
+Now you can convert the label number to a label name for more information:
+
+```py
+>>> id2label[str(79)]
+'prime_rib'
+```
+
+Each food class - or label - corresponds to a number; `79` indicates a prime rib in the example above.
+
+## Preprocess
+
+Load the ViT feature extractor to process the image into a tensor:
+
+```py
+>>> from transformers import AutoFeatureExtractor
+
+>>> feature_extractor = AutoFeatureExtractor.from_pretrained("google/vit-base-patch16-224-in21k")
+```
+
+Apply several image transformations to the dataset to make the model more robust against overfitting. Here you'll use torchvision's [`transforms`](https://pytorch.org/vision/stable/transforms.html) module. Crop a random part of the image, resize it, and normalize it with the image mean and standard deviation:
+
+```py
+>>> from torchvision.transforms import RandomResizedCrop, Compose, Normalize, ToTensor
+
+>>> normalize = Normalize(mean=feature_extractor.image_mean, std=feature_extractor.image_std)
+>>> _transforms = Compose([RandomResizedCrop(feature_extractor.size), ToTensor(), normalize])
+```
+
+Create a preprocessing function that will apply the transforms and return the `pixel_values` - the inputs to the model - of the image:
+
+```py
+>>> def transforms(examples):
+... examples["pixel_values"] = [_transforms(img.convert("RGB")) for img in examples["image"]]
+... del examples["image"]
+... return examples
+```
+
+Use 🤗 Dataset's [`with_transform`](https://huggingface.co/docs/datasets/package_reference/main_classes.html?#datasets.Dataset.with_transform) method to apply the transforms over the entire dataset. The transforms are applied on-the-fly when you load an element of the dataset:
+
+```py
+>>> food = food.with_transform(transforms)
+```
+
+Use [`DefaultDataCollator`] to create a batch of examples. Unlike other data collators in 🤗 Transformers, the DefaultDataCollator does not apply additional preprocessing such as padding.
+
+```py
+>>> from transformers import DefaultDataCollator
+
+>>> data_collator = DefaultDataCollator()
+```
+
+## Train
+
+
+
+Load ViT with [`AutoModelForImageClassification`]. Specify the number of labels, and pass the model the mapping between label number and label class:
+
+```py
+>>> from transformers import AutoModelForImageClassification, TrainingArguments, Trainer
+
+>>> model = AutoModelForImageClassification.from_pretrained(
+... "google/vit-base-patch16-224-in21k",
+... num_labels=len(labels),
+... id2label=id2label,
+... label2id=label2id,
+... )
+```
+
+
+
+If you aren't familiar with fine-tuning a model with the [`Trainer`], take a look at the basic tutorial [here](../training#finetune-with-trainer)!
+
+
+
+At this point, only three steps remain:
+
+1. Define your training hyperparameters in [`TrainingArguments`]. It is important you don't remove unused columns because this will drop the `image` column. Without the `image` column, you can't create `pixel_values`. Set `remove_unused_columns=False` to prevent this behavior!
+2. Pass the training arguments to [`Trainer`] along with the model, datasets, tokenizer, and data collator.
+3. Call [`~Trainer.train`] to fine-tune your model.
+
+```py
+>>> training_args = TrainingArguments(
+... output_dir="./results",
+... per_device_train_batch_size=16,
+... evaluation_strategy="steps",
+... num_train_epochs=4,
+... fp16=True,
+... save_steps=100,
+... eval_steps=100,
+... logging_steps=10,
+... learning_rate=2e-4,
+... save_total_limit=2,
+... remove_unused_columns=False,
+... )
+
+>>> trainer = Trainer(
+... model=model,
+... args=training_args,
+... data_collator=data_collator,
+... train_dataset=food["train"],
+... eval_dataset=food["test"],
+... tokenizer=feature_extractor,
+... )
+
+>>> trainer.train()
+```
+
+
+
+
+
+For a more in-depth example of how to fine-tune a model for image classification, take a look at the corresponding [PyTorch notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
+
+
\ No newline at end of file
diff --git a/docs/source/en/tasks/language_modeling.mdx b/docs/source/en/tasks/language_modeling.mdx
new file mode 100644
index 00000000000000..b3b6dd7530104c
--- /dev/null
+++ b/docs/source/en/tasks/language_modeling.mdx
@@ -0,0 +1,418 @@
+
+
+# Language modeling
+
+Language modeling predicts words in a sentence. There are two forms of language modeling.
+
+
+
+Causal language modeling predicts the next token in a sequence of tokens, and the model can only attend to tokens on the left.
+
+
+
+Masked language modeling predicts a masked token in a sequence, and the model can attend to tokens bidirectionally.
+
+This guide will show you how to fine-tune [DistilGPT2](https://huggingface.co/distilgpt2) for causal language modeling and [DistilRoBERTa](https://huggingface.co/distilroberta-base) for masked language modeling on the [r/askscience](https://www.reddit.com/r/askscience/) subset of the [ELI5](https://huggingface.co/datasets/eli5) dataset.
+
+
+
+You can fine-tune other architectures for language modeling such as [GPT-Neo](https://huggingface.co/EleutherAI/gpt-neo-125M), [GPT-J](https://huggingface.co/EleutherAI/gpt-j-6B), and [BERT](https://huggingface.co/bert-base-uncased), following the same steps presented in this guide!
+
+See the text generation [task page](https://huggingface.co/tasks/text-generation) and fill mask [task page](https://huggingface.co/tasks/fill-mask) for more information about their associated models, datasets, and metrics.
+
+
+
+## Load ELI5 dataset
+
+Load only the first 5000 rows of the ELI5 dataset from the 🤗 Datasets library since it is pretty large:
+
+```py
+>>> from datasets import load_dataset
+
+>>> eli5 = load_dataset("eli5", split="train_asks[:5000]")
+```
+
+Split this dataset into a train and test set:
+
+```py
+eli5 = eli5.train_test_split(test_size=0.2)
+```
+
+Then take a look at an example:
+
+```py
+>>> eli5["train"][0]
+{'answers': {'a_id': ['c3d1aib', 'c3d4lya'],
+ 'score': [6, 3],
+ 'text': ["The velocity needed to remain in orbit is equal to the square root of Newton's constant times the mass of earth divided by the distance from the center of the earth. I don't know the altitude of that specific mission, but they're usually around 300 km. That means he's going 7-8 km/s.\n\nIn space there are no other forces acting on either the shuttle or the guy, so they stay in the same position relative to each other. If he were to become unable to return to the ship, he would presumably run out of oxygen, or slowly fall into the atmosphere and burn up.",
+ "Hope you don't mind me asking another question, but why aren't there any stars visible in this photo?"]},
+ 'answers_urls': {'url': []},
+ 'document': '',
+ 'q_id': 'nyxfp',
+ 'selftext': '_URL_0_\n\nThis was on the front page earlier and I have a few questions about it. Is it possible to calculate how fast the astronaut would be orbiting the earth? Also how does he stay close to the shuttle so that he can return safely, i.e is he orbiting at the same speed and can therefore stay next to it? And finally if his propulsion system failed, would he eventually re-enter the atmosphere and presumably die?',
+ 'selftext_urls': {'url': ['http://apod.nasa.gov/apod/image/1201/freeflyer_nasa_3000.jpg']},
+ 'subreddit': 'askscience',
+ 'title': 'Few questions about this space walk photograph.',
+ 'title_urls': {'url': []}}
+```
+
+Notice `text` is a subfield nested inside the `answers` dictionary. When you preprocess the dataset, you will need to extract the `text` subfield into a separate column.
+
+## Preprocess
+
+
+
+For causal language modeling, load the DistilGPT2 tokenizer to process the `text` subfield:
+
+```py
+>>> from transformers import AutoTokenizer
+
+>>> tokenizer = AutoTokenizer.from_pretrained("distilgpt2")
+```
+
+
+
+For masked language modeling, load the DistilRoBERTa tokenizer instead:
+
+```py
+>>> from transformers import AutoTokenizer
+
+>>> tokenizer = AutoTokenizer.from_pretrained("distilroberta-base")
+```
+
+Extract the `text` subfield from its nested structure with the [`flatten`](https://huggingface.co/docs/datasets/process.html#flatten) method:
+
+```py
+>>> eli5 = eli5.flatten()
+>>> eli5["train"][0]
+{'answers.a_id': ['c3d1aib', 'c3d4lya'],
+ 'answers.score': [6, 3],
+ 'answers.text': ["The velocity needed to remain in orbit is equal to the square root of Newton's constant times the mass of earth divided by the distance from the center of the earth. I don't know the altitude of that specific mission, but they're usually around 300 km. That means he's going 7-8 km/s.\n\nIn space there are no other forces acting on either the shuttle or the guy, so they stay in the same position relative to each other. If he were to become unable to return to the ship, he would presumably run out of oxygen, or slowly fall into the atmosphere and burn up.",
+ "Hope you don't mind me asking another question, but why aren't there any stars visible in this photo?"],
+ 'answers_urls.url': [],
+ 'document': '',
+ 'q_id': 'nyxfp',
+ 'selftext': '_URL_0_\n\nThis was on the front page earlier and I have a few questions about it. Is it possible to calculate how fast the astronaut would be orbiting the earth? Also how does he stay close to the shuttle so that he can return safely, i.e is he orbiting at the same speed and can therefore stay next to it? And finally if his propulsion system failed, would he eventually re-enter the atmosphere and presumably die?',
+ 'selftext_urls.url': ['http://apod.nasa.gov/apod/image/1201/freeflyer_nasa_3000.jpg'],
+ 'subreddit': 'askscience',
+ 'title': 'Few questions about this space walk photograph.',
+ 'title_urls.url': []}
+```
+
+Each subfield is now a separate column as indicated by the `answers` prefix. Notice that `answers.text` is a list. Instead of tokenizing each sentence separately, convert the list to a string to jointly tokenize them.
+
+Here is how you can create a preprocessing function to convert the list to a string and truncate sequences to be no longer than DistilGPT2's maximum input length:
+
+```py
+>>> def preprocess_function(examples):
+... return tokenizer([" ".join(x) for x in examples["answers.text"]], truncation=True)
+```
+
+Use 🤗 Datasets [`map`](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.map) function to apply the preprocessing function over the entire dataset. You can speed up the `map` function by setting `batched=True` to process multiple elements of the dataset at once and increasing the number of processes with `num_proc`. Remove the columns you don't need:
+
+```py
+>>> tokenized_eli5 = eli5.map(
+... preprocess_function,
+... batched=True,
+... num_proc=4,
+... remove_columns=eli5["train"].column_names,
+... )
+```
+
+Now you need a second preprocessing function to capture text truncated from any lengthy examples to prevent loss of information. This preprocessing function should:
+
+- Concatenate all the text.
+- Split the concatenated text into smaller chunks defined by `block_size`.
+
+```py
+>>> block_size = 128
+
+
+>>> def group_texts(examples):
+... concatenated_examples = {k: sum(examples[k], []) for k in examples.keys()}
+... total_length = len(concatenated_examples[list(examples.keys())[0]])
+... result = {
+... k: [t[i : i + block_size] for i in range(0, total_length, block_size)]
+... for k, t in concatenated_examples.items()
+... }
+... result["labels"] = result["input_ids"].copy()
+... return result
+```
+
+Apply the `group_texts` function over the entire dataset:
+
+```py
+>>> lm_dataset = tokenized_eli5.map(group_texts, batched=True, num_proc=4)
+```
+
+For causal language modeling, use [`DataCollatorForLanguageModeling`] to create a batch of examples. It will also *dynamically pad* your text to the length of the longest element in its batch, so they are a uniform length. While it is possible to pad your text in the `tokenizer` function by setting `padding=True`, dynamic padding is more efficient.
+
+
+
+You can use the end of sequence token as the padding token, and set `mlm=False`. This will use the inputs as labels shifted to the right by one element:
+
+```py
+>>> from transformers import DataCollatorForLanguageModeling
+
+>>> tokenizer.pad_token = tokenizer.eos_token
+>>> data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=False)
+```
+
+For masked language modeling, use the same [`DataCollatorForLanguageModeling`] except you should specify `mlm_probability` to randomly mask tokens each time you iterate over the data.
+
+```py
+>>> from transformers import DataCollatorForLanguageModeling
+
+>>> tokenizer.pad_token = tokenizer.eos_token
+>>> data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm_probability=0.15)
+```
+
+
+You can use the end of sequence token as the padding token, and set `mlm=False`. This will use the inputs as labels shifted to the right by one element:
+
+```py
+>>> from transformers import DataCollatorForLanguageModeling
+
+>>> data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=False, return_tensors="tf")
+```
+
+For masked language modeling, use the same [`DataCollatorForLanguageModeling`] except you should specify `mlm_probability` to randomly mask tokens each time you iterate over the data.
+
+```py
+>>> from transformers import DataCollatorForLanguageModeling
+
+>>> data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=False, return_tensors="tf")
+```
+
+
+
+## Causal language modeling
+
+Causal language modeling is frequently used for text generation. This section shows you how to fine-tune [DistilGPT2](https://huggingface.co/distilgpt2) to generate new text.
+
+### Train
+
+
+
+Load DistilGPT2 with [`AutoModelForCausalLM`]:
+
+```py
+>>> from transformers import AutoModelForCausalLM, TrainingArguments, Trainer
+
+>>> model = AutoModelForCausalLM.from_pretrained("distilgpt2")
+```
+
+
+
+If you aren't familiar with fine-tuning a model with the [`Trainer`], take a look at the basic tutorial [here](../training#finetune-with-trainer)!
+
+
+
+At this point, only three steps remain:
+
+1. Define your training hyperparameters in [`TrainingArguments`].
+2. Pass the training arguments to [`Trainer`] along with the model, datasets, and data collator.
+3. Call [`~Trainer.train`] to fine-tune your model.
+
+```py
+>>> training_args = TrainingArguments(
+... output_dir="./results",
+... evaluation_strategy="epoch",
+... learning_rate=2e-5,
+... weight_decay=0.01,
+... )
+
+>>> trainer = Trainer(
+... model=model,
+... args=training_args,
+... train_dataset=lm_dataset["train"],
+... eval_dataset=lm_dataset["test"],
+... data_collator=data_collator,
+... )
+
+>>> trainer.train()
+```
+
+
+To fine-tune a model in TensorFlow, start by converting your datasets to the `tf.data.Dataset` format with [`to_tf_dataset`](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.to_tf_dataset). Specify inputs and labels in `columns`, whether to shuffle the dataset order, batch size, and the data collator:
+
+```py
+>>> tf_train_set = lm_dataset["train"].to_tf_dataset(
+... columns=["attention_mask", "input_ids", "labels"],
+... dummy_labels=True,
+... shuffle=True,
+... batch_size=16,
+... collate_fn=data_collator,
+... )
+
+>>> tf_test_set = lm_dataset["test"].to_tf_dataset(
+... columns=["attention_mask", "input_ids", "labels"],
+... dummy_labels=True,
+... shuffle=False,
+... batch_size=16,
+... collate_fn=data_collator,
+... )
+```
+
+
+
+If you aren't familiar with fine-tuning a model with Keras, take a look at the basic tutorial [here](training#finetune-with-keras)!
+
+
+
+Set up an optimizer function, learning rate, and some training hyperparameters:
+
+```py
+>>> from transformers import create_optimizer, AdamWeightDecay
+
+>>> optimizer = AdamWeightDecay(learning_rate=2e-5, weight_decay_rate=0.01)
+```
+
+Load DistilGPT2 with [`TFAutoModelForCausalLM`]:
+
+```py
+>>> from transformers import TFAutoModelForCausalLM
+
+>>> model = TFAutoModelForCausalLM.from_pretrained("distilgpt2")
+```
+
+Configure the model for training with [`compile`](https://keras.io/api/models/model_training_apis/#compile-method):
+
+```py
+>>> import tensorflow as tf
+
+>>> model.compile(optimizer=optimizer)
+```
+
+Call [`fit`](https://keras.io/api/models/model_training_apis/#fit-method) to fine-tune the model:
+
+```py
+>>> model.fit(x=tf_train_set, validation_data=tf_test_set, epochs=3)
+```
+
+
+
+## Masked language modeling
+
+Masked language modeling is also known as a fill-mask task because it predicts a masked token in a sequence. Models for masked language modeling require a good contextual understanding of an entire sequence instead of only the left context. This section shows you how to fine-tune [DistilRoBERTa](https://huggingface.co/distilroberta-base) to predict a masked word.
+
+### Train
+
+
+
+Load DistilRoBERTa with [`AutoModelForMaskedlM`]:
+
+```py
+>>> from transformers import AutoModelForMaskedLM
+
+>>> model = AutoModelForMaskedLM.from_pretrained("distilroberta-base")
+```
+
+
+
+If you aren't familiar with fine-tuning a model with the [`Trainer`], take a look at the basic tutorial [here](../training#finetune-with-trainer)!
+
+
+
+At this point, only three steps remain:
+
+1. Define your training hyperparameters in [`TrainingArguments`].
+2. Pass the training arguments to [`Trainer`] along with the model, datasets, and data collator.
+3. Call [`~Trainer.train`] to fine-tune your model.
+
+```py
+>>> training_args = TrainingArguments(
+... output_dir="./results",
+... evaluation_strategy="epoch",
+... learning_rate=2e-5,
+... num_train_epochs=3,
+... weight_decay=0.01,
+... )
+
+>>> trainer = Trainer(
+... model=model,
+... args=training_args,
+... train_dataset=lm_dataset["train"],
+... eval_dataset=lm_dataset["test"],
+... data_collator=data_collator,
+... )
+
+>>> trainer.train()
+```
+
+
+To fine-tune a model in TensorFlow, start by converting your datasets to the `tf.data.Dataset` format with [`to_tf_dataset`](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.to_tf_dataset). Specify inputs and labels in `columns`, whether to shuffle the dataset order, batch size, and the data collator:
+
+```py
+>>> tf_train_set = lm_dataset["train"].to_tf_dataset(
+... columns=["attention_mask", "input_ids", "labels"],
+... dummy_labels=True,
+... shuffle=True,
+... batch_size=16,
+... collate_fn=data_collator,
+... )
+
+>>> tf_test_set = lm_dataset["test"].to_tf_dataset(
+... columns=["attention_mask", "input_ids", "labels"],
+... dummy_labels=True,
+... shuffle=False,
+... batch_size=16,
+... collate_fn=data_collator,
+... )
+```
+
+
+
+If you aren't familiar with fine-tuning a model with Keras, take a look at the basic tutorial [here](training#finetune-with-keras)!
+
+
+
+Set up an optimizer function, learning rate, and some training hyperparameters:
+
+```py
+>>> from transformers import create_optimizer, AdamWeightDecay
+
+>>> optimizer = AdamWeightDecay(learning_rate=2e-5, weight_decay_rate=0.01)
+```
+
+Load DistilRoBERTa with [`TFAutoModelForMaskedLM`]:
+
+```py
+>>> from transformers import TFAutoModelForMaskedLM
+
+>>> model = TFAutoModelForCausalLM.from_pretrained("distilroberta-base")
+```
+
+Configure the model for training with [`compile`](https://keras.io/api/models/model_training_apis/#compile-method):
+
+```py
+>>> import tensorflow as tf
+
+>>> model.compile(optimizer=optimizer)
+```
+
+Call [`fit`](https://keras.io/api/models/model_training_apis/#fit-method) to fine-tune the model:
+
+```py
+>>> model.fit(x=tf_train_set, validation_data=tf_test_set, epochs=3)
+```
+
+
+
+
+
+For a more in-depth example of how to fine-tune a model for causal language modeling, take a look at the corresponding
+[PyTorch notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling.ipynb)
+or [TensorFlow notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling-tf.ipynb).
+
+
\ No newline at end of file
diff --git a/docs/source/en/tasks/multiple_choice.mdx b/docs/source/en/tasks/multiple_choice.mdx
new file mode 100644
index 00000000000000..2ec7019a153252
--- /dev/null
+++ b/docs/source/en/tasks/multiple_choice.mdx
@@ -0,0 +1,288 @@
+
+
+# Multiple choice
+
+A multiple choice task is similar to question answering, except several candidate answers are provided along with a context. The model is trained to select the correct answer from multiple inputs given a context.
+
+This guide will show you how to fine-tune [BERT](https://huggingface.co/bert-base-uncased) on the `regular` configuration of the [SWAG](https://huggingface.co/datasets/swag) dataset to select the best answer given multiple options and some context.
+
+## Load SWAG dataset
+
+Load the SWAG dataset from the 🤗 Datasets library:
+
+```py
+>>> from datasets import load_dataset
+
+>>> swag = load_dataset("swag", "regular")
+```
+
+Then take a look at an example:
+
+```py
+>>> swag["train"][0]
+{'ending0': 'passes by walking down the street playing their instruments.',
+ 'ending1': 'has heard approaching them.',
+ 'ending2': "arrives and they're outside dancing and asleep.",
+ 'ending3': 'turns the lead singer watches the performance.',
+ 'fold-ind': '3416',
+ 'gold-source': 'gold',
+ 'label': 0,
+ 'sent1': 'Members of the procession walk down the street holding small horn brass instruments.',
+ 'sent2': 'A drum line',
+ 'startphrase': 'Members of the procession walk down the street holding small horn brass instruments. A drum line',
+ 'video-id': 'anetv_jkn6uvmqwh4'}
+```
+
+The `sent1` and `sent2` fields show how a sentence begins, and each `ending` field shows how a sentence could end. Given the sentence beginning, the model must pick the correct sentence ending as indicated by the `label` field.
+
+## Preprocess
+
+Load the BERT tokenizer to process the start of each sentence and the four possible endings:
+
+```py
+>>> from transformers import AutoTokenizer
+
+>>> tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
+```
+
+The preprocessing function needs to do:
+
+1. Make four copies of the `sent1` field so you can combine each of them with `sent2` to recreate how a sentence starts.
+2. Combine `sent2` with each of the four possible sentence endings.
+3. Flatten these two lists so you can tokenize them, and then unflatten them afterward so each example has a corresponding `input_ids`, `attention_mask`, and `labels` field.
+
+```py
+>>> ending_names = ["ending0", "ending1", "ending2", "ending3"]
+
+
+>>> def preprocess_function(examples):
+... first_sentences = [[context] * 4 for context in examples["sent1"]]
+... question_headers = examples["sent2"]
+... second_sentences = [
+... [f"{header} {examples[end][i]}" for end in ending_names] for i, header in enumerate(question_headers)
+... ]
+
+... first_sentences = sum(first_sentences, [])
+... second_sentences = sum(second_sentences, [])
+
+... tokenized_examples = tokenizer(first_sentences, second_sentences, truncation=True)
+... return {k: [v[i : i + 4] for i in range(0, len(v), 4)] for k, v in tokenized_examples.items()}
+```
+
+Use 🤗 Datasets [`map`](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.map) function to apply the preprocessing function over the entire dataset. You can speed up the `map` function by setting `batched=True` to process multiple elements of the dataset at once:
+
+```py
+tokenized_swag = swag.map(preprocess_function, batched=True)
+```
+
+🤗 Transformers doesn't have a data collator for multiple choice, so you will need to create one. You can adapt the [`DataCollatorWithPadding`] to create a batch of examples for multiple choice. It will also *dynamically pad* your text and labels to the length of the longest element in its batch, so they are a uniform length. While it is possible to pad your text in the `tokenizer` function by setting `padding=True`, dynamic padding is more efficient.
+
+`DataCollatorForMultipleChoice` will flatten all the model inputs, apply padding, and then unflatten the results:
+
+
+
+```py
+>>> from dataclasses import dataclass
+>>> from transformers.tokenization_utils_base import PreTrainedTokenizerBase, PaddingStrategy
+>>> from typing import Optional, Union
+>>> import torch
+
+
+>>> @dataclass
+... class DataCollatorForMultipleChoice:
+... """
+... Data collator that will dynamically pad the inputs for multiple choice received.
+... """
+
+... tokenizer: PreTrainedTokenizerBase
+... padding: Union[bool, str, PaddingStrategy] = True
+... max_length: Optional[int] = None
+... pad_to_multiple_of: Optional[int] = None
+
+... def __call__(self, features):
+... label_name = "label" if "label" in features[0].keys() else "labels"
+... labels = [feature.pop(label_name) for feature in features]
+... batch_size = len(features)
+... num_choices = len(features[0]["input_ids"])
+... flattened_features = [
+... [{k: v[i] for k, v in feature.items()} for i in range(num_choices)] for feature in features
+... ]
+... flattened_features = sum(flattened_features, [])
+
+... batch = self.tokenizer.pad(
+... flattened_features,
+... padding=self.padding,
+... max_length=self.max_length,
+... pad_to_multiple_of=self.pad_to_multiple_of,
+... return_tensors="pt",
+... )
+
+... batch = {k: v.view(batch_size, num_choices, -1) for k, v in batch.items()}
+... batch["labels"] = torch.tensor(labels, dtype=torch.int64)
+... return batch
+```
+
+
+```py
+>>> from dataclasses import dataclass
+>>> from transformers.tokenization_utils_base import PreTrainedTokenizerBase, PaddingStrategy
+>>> from typing import Optional, Union
+>>> import tensorflow as tf
+
+
+>>> @dataclass
+... class DataCollatorForMultipleChoice:
+... """
+... Data collator that will dynamically pad the inputs for multiple choice received.
+... """
+
+... tokenizer: PreTrainedTokenizerBase
+... padding: Union[bool, str, PaddingStrategy] = True
+... max_length: Optional[int] = None
+... pad_to_multiple_of: Optional[int] = None
+
+... def __call__(self, features):
+... label_name = "label" if "label" in features[0].keys() else "labels"
+... labels = [feature.pop(label_name) for feature in features]
+... batch_size = len(features)
+... num_choices = len(features[0]["input_ids"])
+... flattened_features = [
+... [{k: v[i] for k, v in feature.items()} for i in range(num_choices)] for feature in features
+... ]
+... flattened_features = sum(flattened_features, [])
+
+... batch = self.tokenizer.pad(
+... flattened_features,
+... padding=self.padding,
+... max_length=self.max_length,
+... pad_to_multiple_of=self.pad_to_multiple_of,
+... return_tensors="tf",
+... )
+
+... batch = {k: tf.reshape(v, (batch_size, num_choices, -1)) for k, v in batch.items()}
+... batch["labels"] = tf.convert_to_tensor(labels, dtype=tf.int64)
+... return batch
+```
+
+
+
+## Train
+
+
+
+Load BERT with [`AutoModelForMultipleChoice`]:
+
+```py
+>>> from transformers import AutoModelForMultipleChoice, TrainingArguments, Trainer
+
+>>> model = AutoModelForMultipleChoice.from_pretrained("bert-base-uncased")
+```
+
+
+
+If you aren't familiar with fine-tuning a model with Trainer, take a look at the basic tutorial [here](../training#finetune-with-trainer)!
+
+
+
+At this point, only three steps remain:
+
+1. Define your training hyperparameters in [`TrainingArguments`].
+2. Pass the training arguments to [`Trainer`] along with the model, dataset, tokenizer, and data collator.
+3. Call [`~Trainer.train`] to fine-tune your model.
+
+```py
+>>> training_args = TrainingArguments(
+... output_dir="./results",
+... evaluation_strategy="epoch",
+... learning_rate=5e-5,
+... per_device_train_batch_size=16,
+... per_device_eval_batch_size=16,
+... num_train_epochs=3,
+... weight_decay=0.01,
+... )
+
+>>> trainer = Trainer(
+... model=model,
+... args=training_args,
+... train_dataset=tokenized_swag["train"],
+... eval_dataset=tokenized_swag["validation"],
+... tokenizer=tokenizer,
+... data_collator=DataCollatorForMultipleChoice(tokenizer=tokenizer),
+... )
+
+>>> trainer.train()
+```
+
+
+To fine-tune a model in TensorFlow, start by converting your datasets to the `tf.data.Dataset` format with [`to_tf_dataset`](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.to_tf_dataset). Specify inputs in `columns`, targets in `label_cols`, whether to shuffle the dataset order, batch size, and the data collator:
+
+```py
+>>> data_collator = DataCollatorForMultipleChoice(tokenizer=tokenizer)
+>>> tf_train_set = tokenized_swag["train"].to_tf_dataset(
+... columns=["attention_mask", "input_ids"],
+... label_cols=["labels"],
+... shuffle=True,
+... batch_size=batch_size,
+... collate_fn=data_collator,
+... )
+
+>>> tf_validation_set = tokenized_swag["validation"].to_tf_dataset(
+... columns=["attention_mask", "input_ids"],
+... label_cols=["labels"],
+... shuffle=False,
+... batch_size=batch_size,
+... collate_fn=data_collator,
+... )
+```
+
+
+
+If you aren't familiar with fine-tuning a model with Keras, take a look at the basic tutorial [here](training#finetune-with-keras)!
+
+
+
+Set up an optimizer function, learning rate schedule, and some training hyperparameters:
+
+```py
+>>> from transformers import create_optimizer
+
+>>> batch_size = 16
+>>> num_train_epochs = 2
+>>> total_train_steps = (len(tokenized_swag["train"]) // batch_size) * num_train_epochs
+>>> optimizer, schedule = create_optimizer(init_lr=5e-5, num_warmup_steps=0, num_train_steps=total_train_steps)
+```
+
+Load BERT with [`TFAutoModelForMultipleChoice`]:
+
+```py
+>>> from transformers import TFAutoModelForMultipleChoice
+
+>>> model = TFAutoModelForMultipleChoice.from_pretrained("bert-base-uncased")
+```
+
+Configure the model for training with [`compile`](https://keras.io/api/models/model_training_apis/#compile-method):
+
+```py
+>>> model.compile(
+... optimizer=optimizer,
+... loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
+... )
+```
+
+Call [`fit`](https://keras.io/api/models/model_training_apis/#fit-method) to fine-tune the model:
+
+```py
+>>> model.fit(x=tf_train_set, validation_data=tf_validation_set, epochs=2)
+```
+
+
\ No newline at end of file
diff --git a/docs/source/en/tasks/question_answering.mdx b/docs/source/en/tasks/question_answering.mdx
new file mode 100644
index 00000000000000..d5df758db3acb8
--- /dev/null
+++ b/docs/source/en/tasks/question_answering.mdx
@@ -0,0 +1,273 @@
+
+
+# Question answering
+
+
+
+Question answering tasks return an answer given a question. There are two common forms of question answering:
+
+- Extractive: extract the answer from the given context.
+- Abstractive: generate an answer from the context that correctly answers the question.
+
+This guide will show you how to fine-tune [DistilBERT](https://huggingface.co/distilbert-base-uncased) on the [SQuAD](https://huggingface.co/datasets/squad) dataset for extractive question answering.
+
+
+
+See the question answering [task page](https://huggingface.co/tasks/question-answering) for more information about other forms of question answering and their associated models, datasets, and metrics.
+
+
+
+## Load SQuAD dataset
+
+Load the SQuAD dataset from the 🤗 Datasets library:
+
+```py
+>>> from datasets import load_dataset
+
+>>> squad = load_dataset("squad")
+```
+
+Then take a look at an example:
+
+```py
+>>> squad["train"][0]
+{'answers': {'answer_start': [515], 'text': ['Saint Bernadette Soubirous']},
+ 'context': 'Architecturally, the school has a Catholic character. Atop the Main Building\'s gold dome is a golden statue of the Virgin Mary. Immediately in front of the Main Building and facing it, is a copper statue of Christ with arms upraised with the legend "Venite Ad Me Omnes". Next to the Main Building is the Basilica of the Sacred Heart. Immediately behind the basilica is the Grotto, a Marian place of prayer and reflection. It is a replica of the grotto at Lourdes, France where the Virgin Mary reputedly appeared to Saint Bernadette Soubirous in 1858. At the end of the main drive (and in a direct line that connects through 3 statues and the Gold Dome), is a simple, modern stone statue of Mary.',
+ 'id': '5733be284776f41900661182',
+ 'question': 'To whom did the Virgin Mary allegedly appear in 1858 in Lourdes France?',
+ 'title': 'University_of_Notre_Dame'
+}
+```
+
+The `answers` field is a dictionary containing the starting position of the answer and the `text` of the answer.
+
+## Preprocess
+
+
+
+Load the DistilBERT tokenizer to process the `question` and `context` fields:
+
+```py
+>>> from transformers import AutoTokenizer
+
+>>> tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
+```
+
+There are a few preprocessing steps particular to question answering that you should be aware of:
+
+1. Some examples in a dataset may have a very long `context` that exceeds the maximum input length of the model. Truncate only the `context` by setting `truncation="only_second"`.
+2. Next, map the start and end positions of the answer to the original `context` by setting
+ `return_offset_mapping=True`.
+3. With the mapping in hand, you can find the start and end tokens of the answer. Use the [`sequence_ids`](https://huggingface.co/docs/tokenizers/python/latest/api/reference.html#tokenizers.Encoding.sequence_ids) method to
+ find which part of the offset corresponds to the `question` and which corresponds to the `context`.
+
+Here is how you can create a function to truncate and map the start and end tokens of the answer to the `context`:
+
+```py
+>>> def preprocess_function(examples):
+... questions = [q.strip() for q in examples["question"]]
+... inputs = tokenizer(
+... questions,
+... examples["context"],
+... max_length=384,
+... truncation="only_second",
+... return_offsets_mapping=True,
+... padding="max_length",
+... )
+
+... offset_mapping = inputs.pop("offset_mapping")
+... answers = examples["answers"]
+... start_positions = []
+... end_positions = []
+
+... for i, offset in enumerate(offset_mapping):
+... answer = answers[i]
+... start_char = answer["answer_start"][0]
+... end_char = answer["answer_start"][0] + len(answer["text"][0])
+... sequence_ids = inputs.sequence_ids(i)
+
+... # Find the start and end of the context
+... idx = 0
+... while sequence_ids[idx] != 1:
+... idx += 1
+... context_start = idx
+... while sequence_ids[idx] == 1:
+... idx += 1
+... context_end = idx - 1
+
+... # If the answer is not fully inside the context, label it (0, 0)
+... if offset[context_start][0] > end_char or offset[context_end][1] < start_char:
+... start_positions.append(0)
+... end_positions.append(0)
+... else:
+... # Otherwise it's the start and end token positions
+... idx = context_start
+... while idx <= context_end and offset[idx][0] <= start_char:
+... idx += 1
+... start_positions.append(idx - 1)
+
+... idx = context_end
+... while idx >= context_start and offset[idx][1] >= end_char:
+... idx -= 1
+... end_positions.append(idx + 1)
+
+... inputs["start_positions"] = start_positions
+... inputs["end_positions"] = end_positions
+... return inputs
+```
+
+Use 🤗 Datasets [`map`](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.map) function to apply the preprocessing function over the entire dataset. You can speed up the `map` function by setting `batched=True` to process multiple elements of the dataset at once. Remove the columns you don't need:
+
+```py
+>>> tokenized_squad = squad.map(preprocess_function, batched=True, remove_columns=squad["train"].column_names)
+```
+
+Use [`DefaultDataCollator`] to create a batch of examples. Unlike other data collators in 🤗 Transformers, the `DefaultDataCollator` does not apply additional preprocessing such as padding.
+
+
+
+```py
+>>> from transformers import DefaultDataCollator
+
+>>> data_collator = DefaultDataCollator()
+```
+
+
+```py
+>>> from transformers import DefaultDataCollator
+
+>>> data_collator = DefaultDataCollator(return_tensors="tf")
+```
+
+
+
+## Train
+
+
+
+Load DistilBERT with [`AutoModelForQuestionAnswering`]:
+
+```py
+>>> from transformers import AutoModelForQuestionAnswering, TrainingArguments, Trainer
+
+>>> model = AutoModelForQuestionAnswering.from_pretrained("distilbert-base-uncased")
+```
+
+
+
+If you aren't familiar with fine-tuning a model with the [`Trainer`], take a look at the basic tutorial [here](../training#finetune-with-trainer)!
+
+
+
+At this point, only three steps remain:
+
+1. Define your training hyperparameters in [`TrainingArguments`].
+2. Pass the training arguments to [`Trainer`] along with the model, dataset, tokenizer, and data collator.
+3. Call [`~Trainer.train`] to fine-tune your model.
+
+```py
+>>> training_args = TrainingArguments(
+... output_dir="./results",
+... evaluation_strategy="epoch",
+... learning_rate=2e-5,
+... per_device_train_batch_size=16,
+... per_device_eval_batch_size=16,
+... num_train_epochs=3,
+... weight_decay=0.01,
+... )
+
+>>> trainer = Trainer(
+... model=model,
+... args=training_args,
+... train_dataset=tokenized_squad["train"],
+... eval_dataset=tokenized_squad["validation"],
+... tokenizer=tokenizer,
+... data_collator=data_collator,
+... )
+
+>>> trainer.train()
+```
+
+
+To fine-tune a model in TensorFlow, start by converting your datasets to the `tf.data.Dataset` format with [`to_tf_dataset`](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.to_tf_dataset). Specify inputs and the start and end positions of an answer in `columns`, whether to shuffle the dataset order, batch size, and the data collator:
+
+```py
+>>> tf_train_set = tokenized_squad["train"].to_tf_dataset(
+... columns=["attention_mask", "input_ids", "start_positions", "end_positions"],
+... dummy_labels=True,
+... shuffle=True,
+... batch_size=16,
+... collate_fn=data_collator,
+... )
+
+>>> tf_validation_set = tokenized_squad["validation"].to_tf_dataset(
+... columns=["attention_mask", "input_ids", "start_positions", "end_positions"],
+... dummy_labels=True,
+... shuffle=False,
+... batch_size=16,
+... collate_fn=data_collator,
+... )
+```
+
+
+
+If you aren't familiar with fine-tuning a model with Keras, take a look at the basic tutorial [here](training#finetune-with-keras)!
+
+
+
+Set up an optimizer function, learning rate schedule, and some training hyperparameters:
+
+```py
+>>> from transformers import create_optimizer
+
+>>> batch_size = 16
+>>> num_epochs = 2
+>>> total_train_steps = (len(tokenized_squad["train"]) // batch_size) * num_epochs
+>>> optimizer, schedule = create_optimizer(
+... init_lr=2e-5,
+... num_warmup_steps=0,
+... num_train_steps=total_train_steps,
+... )
+```
+
+Load DistilBERT with [`TFAutoModelForQuestionAnswering`]:
+
+```py
+>>> from transformers import TFAutoModelForQuestionAnswering
+
+>>> model = TFAutoModelForQuestionAnswering("distilbert-base-uncased")
+```
+
+Configure the model for training with [`compile`](https://keras.io/api/models/model_training_apis/#compile-method):
+
+```py
+>>> import tensorflow as tf
+
+>>> model.compile(optimizer=optimizer)
+```
+
+Call [`fit`](https://keras.io/api/models/model_training_apis/#fit-method) to fine-tune the model:
+
+```py
+>>> model.fit(x=tf_train_set, validation_data=tf_validation_set, epochs=3)
+```
+
+
+
+
+
+For a more in-depth example of how to fine-tune a model for question answering, take a look at the corresponding
+[PyTorch notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/question_answering.ipynb)
+or [TensorFlow notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/question_answering-tf.ipynb).
+
+
\ No newline at end of file
diff --git a/docs/source/en/tasks/sequence_classification.mdx b/docs/source/en/tasks/sequence_classification.mdx
new file mode 100644
index 00000000000000..97c98bb88821ff
--- /dev/null
+++ b/docs/source/en/tasks/sequence_classification.mdx
@@ -0,0 +1,214 @@
+
+
+# Text classification
+
+
+
+Text classification is a common NLP task that assigns a label or class to text. There are many practical applications of text classification widely used in production by some of today's largest companies. One of the most popular forms of text classification is sentiment analysis, which assigns a label like positive, negative, or neutral to a sequence of text.
+
+This guide will show you how to fine-tune [DistilBERT](https://huggingface.co/distilbert-base-uncased) on the [IMDb](https://huggingface.co/datasets/imdb) dataset to determine whether a movie review is positive or negative.
+
+
+
+See the text classification [task page](https://huggingface.co/tasks/text-classification) for more information about other forms of text classification and their associated models, datasets, and metrics.
+
+
+
+## Load IMDb dataset
+
+Load the IMDb dataset from the 🤗 Datasets library:
+
+```py
+>>> from datasets import load_dataset
+
+>>> imdb = load_dataset("imdb")
+```
+
+Then take a look at an example:
+
+```py
+>>> imdb["test"][0]
+{
+ "label": 0,
+ "text": "I love sci-fi and am willing to put up with a lot. Sci-fi movies/TV are usually underfunded, under-appreciated and misunderstood. I tried to like this, I really did, but it is to good TV sci-fi as Babylon 5 is to Star Trek (the original). Silly prosthetics, cheap cardboard sets, stilted dialogues, CG that doesn't match the background, and painfully one-dimensional characters cannot be overcome with a 'sci-fi' setting. (I'm sure there are those of you out there who think Babylon 5 is good sci-fi TV. It's not. It's clichéd and uninspiring.) While US viewers might like emotion and character development, sci-fi is a genre that does not take itself seriously (cf. Star Trek). It may treat important issues, yet not as a serious philosophy. It's really difficult to care about the characters here as they are not simply foolish, just missing a spark of life. Their actions and reactions are wooden and predictable, often painful to watch. The makers of Earth KNOW it's rubbish as they have to always say \"Gene Roddenberry's Earth...\" otherwise people would not continue watching. Roddenberry's ashes must be turning in their orbit as this dull, cheap, poorly edited (watching it without advert breaks really brings this home) trudging Trabant of a show lumbers into space. Spoiler. So, kill off a main character. And then bring him back as another actor. Jeeez! Dallas all over again.",
+}
+```
+
+There are two fields in this dataset:
+
+- `text`: a string containing the text of the movie review.
+- `label`: a value that can either be `0` for a negative review or `1` for a positive review.
+
+## Preprocess
+
+Load the DistilBERT tokenizer to process the `text` field:
+
+```py
+>>> from transformers import AutoTokenizer
+
+>>> tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
+```
+
+Create a preprocessing function to tokenize `text` and truncate sequences to be no longer than DistilBERT's maximum input length:
+
+```py
+>>> def preprocess_function(examples):
+... return tokenizer(examples["text"], truncation=True)
+```
+
+Use 🤗 Datasets [`map`](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.map) function to apply the preprocessing function over the entire dataset. You can speed up the `map` function by setting `batched=True` to process multiple elements of the dataset at once:
+
+```py
+tokenized_imdb = imdb.map(preprocess_function, batched=True)
+```
+
+Use [`DataCollatorWithPadding`] to create a batch of examples. It will also *dynamically pad* your text to the length of the longest element in its batch, so they are a uniform length. While it is possible to pad your text in the `tokenizer` function by setting `padding=True`, dynamic padding is more efficient.
+
+
+
+```py
+>>> from transformers import DataCollatorWithPadding
+
+>>> data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
+```
+
+
+```py
+>>> from transformers import DataCollatorWithPadding
+
+>>> data_collator = DataCollatorWithPadding(tokenizer=tokenizer, return_tensors="tf")
+```
+
+
+
+## Train
+
+
+
+Load DistilBERT with [`AutoModelForSequenceClassification`] along with the number of expected labels:
+
+```py
+>>> from transformers import AutoModelForSequenceClassification, TrainingArguments, Trainer
+
+>>> model = AutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased", num_labels=2)
+```
+
+
+
+If you aren't familiar with fine-tuning a model with the [`Trainer`], take a look at the basic tutorial [here](../training#finetune-with-trainer)!
+
+
+
+At this point, only three steps remain:
+
+1. Define your training hyperparameters in [`TrainingArguments`].
+2. Pass the training arguments to [`Trainer`] along with the model, dataset, tokenizer, and data collator.
+3. Call [`~Trainer.train`] to fine-tune your model.
+
+```py
+>>> training_args = TrainingArguments(
+... output_dir="./results",
+... learning_rate=2e-5,
+... per_device_train_batch_size=16,
+... per_device_eval_batch_size=16,
+... num_train_epochs=5,
+... weight_decay=0.01,
+... )
+
+>>> trainer = Trainer(
+... model=model,
+... args=training_args,
+... train_dataset=tokenized_imdb["train"],
+... eval_dataset=tokenized_imdb["test"],
+... tokenizer=tokenizer,
+... data_collator=data_collator,
+... )
+
+>>> trainer.train()
+```
+
+
+
+[`Trainer`] will apply dynamic padding by default when you pass `tokenizer` to it. In this case, you don't need to specify a data collator explicitly.
+
+
+
+
+To fine-tune a model in TensorFlow, start by converting your datasets to the `tf.data.Dataset` format with [`to_tf_dataset`](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.to_tf_dataset). Specify inputs and labels in `columns`, whether to shuffle the dataset order, batch size, and the data collator:
+
+```py
+>>> tf_train_set = tokenized_imdb["train"].to_tf_dataset(
+... columns=["attention_mask", "input_ids", "label"],
+... shuffle=True,
+... batch_size=16,
+... collate_fn=data_collator,
+... )
+
+>>> tf_validation_set = tokenized_imdb["test"].to_tf_dataset(
+... columns=["attention_mask", "input_ids", "label"],
+... shuffle=False,
+... batch_size=16,
+... collate_fn=data_collator,
+... )
+```
+
+
+
+If you aren't familiar with fine-tuning a model with Keras, take a look at the basic tutorial [here](training#finetune-with-keras)!
+
+
+
+Set up an optimizer function, learning rate schedule, and some training hyperparameters:
+
+```py
+>>> from transformers import create_optimizer
+>>> import tensorflow as tf
+
+>>> batch_size = 16
+>>> num_epochs = 5
+>>> batches_per_epoch = len(tokenized_imdb["train"]) // batch_size
+>>> total_train_steps = int(batches_per_epoch * num_epochs)
+>>> optimizer, schedule = create_optimizer(init_lr=2e-5, num_warmup_steps=0, num_train_steps=total_train_steps)
+```
+
+Load DistilBERT with [`TFAutoModelForSequenceClassification`] along with the number of expected labels:
+
+```py
+>>> from transformers import TFAutoModelForSequenceClassification
+
+>>> model = TFAutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased", num_labels=2)
+```
+
+Configure the model for training with [`compile`](https://keras.io/api/models/model_training_apis/#compile-method):
+
+```py
+>>> import tensorflow as tf
+
+>>> model.compile(optimizer=optimizer)
+```
+
+Call [`fit`](https://keras.io/api/models/model_training_apis/#fit-method) to fine-tune the model:
+
+```py
+>>> model.fit(x=tf_train_set, validation_data=tf_validation_set, epochs=3)
+```
+
+
+
+
+
+For a more in-depth example of how to fine-tune a model for text classification, take a look at the corresponding
+[PyTorch notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification.ipynb)
+or [TensorFlow notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification-tf.ipynb).
+
+
\ No newline at end of file
diff --git a/docs/source/en/tasks/summarization.mdx b/docs/source/en/tasks/summarization.mdx
new file mode 100644
index 00000000000000..c750e4732829ae
--- /dev/null
+++ b/docs/source/en/tasks/summarization.mdx
@@ -0,0 +1,223 @@
+
+
+# Summarization
+
+
+
+Summarization creates a shorter version of a document or an article that captures all the important information. Along with translation, it is another example of a task that can be formulated as a sequence-to-sequence task. Summarization can be:
+
+- Extractive: extract the most relevant information from a document.
+- Abstractive: generate new text that captures the most relevant information.
+
+This guide will show you how to fine-tune [T5](https://huggingface.co/t5-small) on the California state bill subset of the [BillSum](https://huggingface.co/datasets/billsum) dataset for abstractive summarization.
+
+
+
+See the summarization [task page](https://huggingface.co/tasks/summarization) for more information about its associated models, datasets, and metrics.
+
+
+
+## Load BillSum dataset
+
+Load the BillSum dataset from the 🤗 Datasets library:
+
+```py
+>>> from datasets import load_dataset
+
+>>> billsum = load_dataset("billsum", split="ca_test")
+```
+
+Split this dataset into a train and test set:
+
+```py
+>>> billsum = billsum.train_test_split(test_size=0.2)
+```
+
+Then take a look at an example:
+
+```py
+>>> billsum["train"][0]
+{'summary': 'Existing law authorizes state agencies to enter into contracts for the acquisition of goods or services upon approval by the Department of General Services. Existing law sets forth various requirements and prohibitions for those contracts, including, but not limited to, a prohibition on entering into contracts for the acquisition of goods or services of $100,000 or more with a contractor that discriminates between spouses and domestic partners or same-sex and different-sex couples in the provision of benefits. Existing law provides that a contract entered into in violation of those requirements and prohibitions is void and authorizes the state or any person acting on behalf of the state to bring a civil action seeking a determination that a contract is in violation and therefore void. Under existing law, a willful violation of those requirements and prohibitions is a misdemeanor.\nThis bill would also prohibit a state agency from entering into contracts for the acquisition of goods or services of $100,000 or more with a contractor that discriminates between employees on the basis of gender identity in the provision of benefits, as specified. By expanding the scope of a crime, this bill would impose a state-mandated local program.\nThe California Constitution requires the state to reimburse local agencies and school districts for certain costs mandated by the state. Statutory provisions establish procedures for making that reimbursement.\nThis bill would provide that no reimbursement is required by this act for a specified reason.',
+ 'text': 'The people of the State of California do enact as follows:\n\n\nSECTION 1.\nSection 10295.35 is added to the Public Contract Code, to read:\n10295.35.\n(a) (1) Notwithstanding any other law, a state agency shall not enter into any contract for the acquisition of goods or services in the amount of one hundred thousand dollars ($100,000) or more with a contractor that, in the provision of benefits, discriminates between employees on the basis of an employee’s or dependent’s actual or perceived gender identity, including, but not limited to, the employee’s or dependent’s identification as transgender.\n(2) For purposes of this section, “contract” includes contracts with a cumulative amount of one hundred thousand dollars ($100,000) or more per contractor in each fiscal year.\n(3) For purposes of this section, an employee health plan is discriminatory if the plan is not consistent with Section 1365.5 of the Health and Safety Code and Section 10140 of the Insurance Code.\n(4) The requirements of this section shall apply only to those portions of a contractor’s operations that occur under any of the following conditions:\n(A) Within the state.\n(B) On real property outside the state if the property is owned by the state or if the state has a right to occupy the property, and if the contractor’s presence at that location is connected to a contract with the state.\n(C) Elsewhere in the United States where work related to a state contract is being performed.\n(b) Contractors shall treat as confidential, to the maximum extent allowed by law or by the requirement of the contractor’s insurance provider, any request by an employee or applicant for employment benefits or any documentation of eligibility for benefits submitted by an employee or applicant for employment.\n(c) After taking all reasonable measures to find a contractor that complies with this section, as determined by the state agency, the requirements of this section may be waived under any of the following circumstances:\n(1) There is only one prospective contractor willing to enter into a specific contract with the state agency.\n(2) The contract is necessary to respond to an emergency, as determined by the state agency, that endangers the public health, welfare, or safety, or the contract is necessary for the provision of essential services, and no entity that complies with the requirements of this section capable of responding to the emergency is immediately available.\n(3) The requirements of this section violate, or are inconsistent with, the terms or conditions of a grant, subvention, or agreement, if the agency has made a good faith attempt to change the terms or conditions of any grant, subvention, or agreement to authorize application of this section.\n(4) The contractor is providing wholesale or bulk water, power, or natural gas, the conveyance or transmission of the same, or ancillary services, as required for ensuring reliable services in accordance with good utility practice, if the purchase of the same cannot practically be accomplished through the standard competitive bidding procedures and the contractor is not providing direct retail services to end users.\n(d) (1) A contractor shall not be deemed to discriminate in the provision of benefits if the contractor, in providing the benefits, pays the actual costs incurred in obtaining the benefit.\n(2) If a contractor is unable to provide a certain benefit, despite taking reasonable measures to do so, the contractor shall not be deemed to discriminate in the provision of benefits.\n(e) (1) Every contract subject to this chapter shall contain a statement by which the contractor certifies that the contractor is in compliance with this section.\n(2) The department or other contracting agency shall enforce this section pursuant to its existing enforcement powers.\n(3) (A) If a contractor falsely certifies that it is in compliance with this section, the contract with that contractor shall be subject to Article 9 (commencing with Section 10420), unless, within a time period specified by the department or other contracting agency, the contractor provides to the department or agency proof that it has complied, or is in the process of complying, with this section.\n(B) The application of the remedies or penalties contained in Article 9 (commencing with Section 10420) to a contract subject to this chapter shall not preclude the application of any existing remedies otherwise available to the department or other contracting agency under its existing enforcement powers.\n(f) Nothing in this section is intended to regulate the contracting practices of any local jurisdiction.\n(g) This section shall be construed so as not to conflict with applicable federal laws, rules, or regulations. In the event that a court or agency of competent jurisdiction holds that federal law, rule, or regulation invalidates any clause, sentence, paragraph, or section of this code or the application thereof to any person or circumstances, it is the intent of the state that the court or agency sever that clause, sentence, paragraph, or section so that the remainder of this section shall remain in effect.\nSEC. 2.\nSection 10295.35 of the Public Contract Code shall not be construed to create any new enforcement authority or responsibility in the Department of General Services or any other contracting agency.\nSEC. 3.\nNo reimbursement is required by this act pursuant to Section 6 of Article XIII\u2009B of the California Constitution because the only costs that may be incurred by a local agency or school district will be incurred because this act creates a new crime or infraction, eliminates a crime or infraction, or changes the penalty for a crime or infraction, within the meaning of Section 17556 of the Government Code, or changes the definition of a crime within the meaning of Section 6 of Article XIII\u2009B of the California Constitution.',
+ 'title': 'An act to add Section 10295.35 to the Public Contract Code, relating to public contracts.'}
+```
+
+The `text` field is the input and the `summary` field is the target.
+
+## Preprocess
+
+Load the T5 tokenizer to process `text` and `summary`:
+
+```py
+>>> from transformers import AutoTokenizer
+
+>>> tokenizer = AutoTokenizer.from_pretrained("t5-small")
+```
+
+The preprocessing function needs to:
+
+1. Prefix the input with a prompt so T5 knows this is a summarization task. Some models capable of multiple NLP tasks require prompting for specific tasks.
+2. Use a context manager with the `as_target_tokenizer()` function to parallelize tokenization of inputs and labels.
+3. Truncate sequences to be no longer than the maximum length set by the `max_length` parameter.
+
+```py
+>>> prefix = "summarize: "
+
+
+>>> def preprocess_function(examples):
+... inputs = [prefix + doc for doc in examples["text"]]
+... model_inputs = tokenizer(inputs, max_length=1024, truncation=True)
+
+... with tokenizer.as_target_tokenizer():
+... labels = tokenizer(examples["summary"], max_length=128, truncation=True)
+
+... model_inputs["labels"] = labels["input_ids"]
+... return model_inputs
+```
+
+Use 🤗 Datasets [`map`](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.map) function to apply the preprocessing function over the entire dataset. You can speed up the `map` function by setting `batched=True` to process multiple elements of the dataset at once:
+
+```py
+>>> tokenized_billsum = billsum.map(preprocess_function, batched=True)
+```
+
+Use [`DataCollatorForSeq2Seq`] to create a batch of examples. It will also *dynamically pad* your text and labels to the length of the longest element in its batch, so they are a uniform length. While it is possible to pad your text in the `tokenizer` function by setting `padding=True`, dynamic padding is more efficient.
+
+
+
+```py
+>>> from transformers import DataCollatorForSeq2Seq
+
+>>> data_collator = DataCollatorForSeq2Seq(tokenizer=tokenizer, model=model)
+```
+
+
+```py
+>>> from transformers import DataCollatorForSeq2Seq
+
+>>> data_collator = DataCollatorForSeq2Seq(tokenizer=tokenizer, model=model, return_tensors="tf")
+```
+
+
+
+## Train
+
+
+
+Load T5 with [`AutoModelForSeq2SeqLM`]:
+
+```py
+>>> from transformers import AutoModelForSeq2SeqLM, Seq2SeqTrainingArguments, Seq2SeqTrainer
+
+>>> model = AutoModelForSeq2SeqLM.from_pretrained("t5-small")
+```
+
+
+
+If you aren't familiar with fine-tuning a model with the [`Trainer`], take a look at the basic tutorial [here](../training#finetune-with-trainer)!
+
+
+
+At this point, only three steps remain:
+
+1. Define your training hyperparameters in [`Seq2SeqTrainingArguments`].
+2. Pass the training arguments to [`Seq2SeqTrainer`] along with the model, dataset, tokenizer, and data collator.
+3. Call [`~Trainer.train`] to fine-tune your model.
+
+```py
+>>> training_args = Seq2SeqTrainingArguments(
+... output_dir="./results",
+... evaluation_strategy="epoch",
+... learning_rate=2e-5,
+... per_device_train_batch_size=16,
+... per_device_eval_batch_size=16,
+... weight_decay=0.01,
+... save_total_limit=3,
+... num_train_epochs=1,
+... fp16=True,
+... )
+
+>>> trainer = Seq2SeqTrainer(
+... model=model,
+... args=training_args,
+... train_dataset=tokenized_billsum["train"],
+... eval_dataset=tokenized_billsum["test"],
+... tokenizer=tokenizer,
+... data_collator=data_collator,
+... )
+
+>>> trainer.train()
+```
+
+
+To fine-tune a model in TensorFlow, start by converting your datasets to the `tf.data.Dataset` format with [`to_tf_dataset`](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.to_tf_dataset). Specify inputs and labels in `columns`, whether to shuffle the dataset order, batch size, and the data collator:
+
+```py
+>>> tf_train_set = tokenized_billsum["train"].to_tf_dataset(
+... columns=["attention_mask", "input_ids", "labels"],
+... shuffle=True,
+... batch_size=16,
+... collate_fn=data_collator,
+... )
+
+>>> tf_test_set = tokenized_billsum["test"].to_tf_dataset(
+... columns=["attention_mask", "input_ids", "labels"],
+... shuffle=False,
+... batch_size=16,
+... collate_fn=data_collator,
+... )
+```
+
+
+
+If you aren't familiar with fine-tuning a model with Keras, take a look at the basic tutorial [here](training#finetune-with-keras)!
+
+
+
+Set up an optimizer function, learning rate schedule, and some training hyperparameters:
+
+```py
+>>> from transformers import create_optimizer, AdamWeightDecay
+
+>>> optimizer = AdamWeightDecay(learning_rate=2e-5, weight_decay_rate=0.01)
+```
+
+Load T5 with [`TFAutoModelForSeq2SeqLM`]:
+
+```py
+>>> from transformers import TFAutoModelForSeq2SeqLM
+
+>>> model = TFAutoModelForSeq2SeqLM.from_pretrained("t5-small")
+```
+
+Configure the model for training with [`compile`](https://keras.io/api/models/model_training_apis/#compile-method):
+
+```py
+>>> model.compile(optimizer=optimizer)
+```
+
+Call [`fit`](https://keras.io/api/models/model_training_apis/#fit-method) to fine-tune the model:
+
+```py
+>>> model.fit(x=tf_train_set, validation_data=tf_test_set, epochs=3)
+```
+
+
+
+
+
+For a more in-depth example of how to fine-tune a model for summarization, take a look at the corresponding
+[PyTorch notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/summarization.ipynb)
+or [TensorFlow notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/summarization-tf.ipynb).
+
+
\ No newline at end of file
diff --git a/docs/source/en/tasks/token_classification.mdx b/docs/source/en/tasks/token_classification.mdx
new file mode 100644
index 00000000000000..03cd304898b543
--- /dev/null
+++ b/docs/source/en/tasks/token_classification.mdx
@@ -0,0 +1,272 @@
+
+
+# Token classification
+
+
+
+Token classification assigns a label to individual tokens in a sentence. One of the most common token classification tasks is Named Entity Recognition (NER). NER attempts to find a label for each entity in a sentence, such as a person, location, or organization.
+
+This guide will show you how to fine-tune [DistilBERT](https://huggingface.co/distilbert-base-uncased) on the [WNUT 17](https://huggingface.co/datasets/wnut_17) dataset to detect new entities.
+
+
+
+See the token classification [task page](https://huggingface.co/tasks/token-classification) for more information about other forms of token classification and their associated models, datasets, and metrics.
+
+
+
+## Load WNUT 17 dataset
+
+Load the WNUT 17 dataset from the 🤗 Datasets library:
+
+```py
+>>> from datasets import load_dataset
+
+>>> wnut = load_dataset("wnut_17")
+```
+
+Then take a look at an example:
+
+```py
+>>> wnut["train"][0]
+{'id': '0',
+ 'ner_tags': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 7, 8, 8, 0, 7, 0, 0, 0, 0, 0, 0, 0, 0],
+ 'tokens': ['@paulwalk', 'It', "'s", 'the', 'view', 'from', 'where', 'I', "'m", 'living', 'for', 'two', 'weeks', '.', 'Empire', 'State', 'Building', '=', 'ESB', '.', 'Pretty', 'bad', 'storm', 'here', 'last', 'evening', '.']
+}
+```
+
+Each number in `ner_tags` represents an entity. Convert the number to a label name for more information:
+
+```py
+>>> label_list = wnut["train"].features[f"ner_tags"].feature.names
+>>> label_list
+[
+ "O",
+ "B-corporation",
+ "I-corporation",
+ "B-creative-work",
+ "I-creative-work",
+ "B-group",
+ "I-group",
+ "B-location",
+ "I-location",
+ "B-person",
+ "I-person",
+ "B-product",
+ "I-product",
+]
+```
+
+The `ner_tag` describes an entity, such as a corporation, location, or person. The letter that prefixes each `ner_tag` indicates the token position of the entity:
+
+- `B-` indicates the beginning of an entity.
+- `I-` indicates a token is contained inside the same entity (e.g., the `State` token is a part of an entity like
+ `Empire State Building`).
+- `0` indicates the token doesn't correspond to any entity.
+
+## Preprocess
+
+
+
+Load the DistilBERT tokenizer to process the `tokens`:
+
+```py
+>>> from transformers import AutoTokenizer
+
+>>> tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
+```
+
+Since the input has already been split into words, set `is_split_into_words=True` to tokenize the words into subwords:
+
+```py
+>>> tokenized_input = tokenizer(example["tokens"], is_split_into_words=True)
+>>> tokens = tokenizer.convert_ids_to_tokens(tokenized_input["input_ids"])
+>>> tokens
+['[CLS]', '@', 'paul', '##walk', 'it', "'", 's', 'the', 'view', 'from', 'where', 'i', "'", 'm', 'living', 'for', 'two', 'weeks', '.', 'empire', 'state', 'building', '=', 'es', '##b', '.', 'pretty', 'bad', 'storm', 'here', 'last', 'evening', '.', '[SEP]']
+```
+
+Adding the special tokens `[CLS]` and `[SEP]` and subword tokenization creates a mismatch between the input and labels. A single word corresponding to a single label may be split into two subwords. You will need to realign the tokens and labels by:
+
+1. Mapping all tokens to their corresponding word with the [`word_ids`](https://huggingface.co/docs/tokenizers/python/latest/api/reference.html#tokenizers.Encoding.word_ids) method.
+2. Assigning the label `-100` to the special tokens `[CLS]` and `[SEP]` so the PyTorch loss function ignores
+ them.
+3. Only labeling the first token of a given word. Assign `-100` to other subtokens from the same word.
+
+Here is how you can create a function to realign the tokens and labels, and truncate sequences to be no longer than DistilBERT's maximum input length::
+
+```py
+>>> def tokenize_and_align_labels(examples):
+... tokenized_inputs = tokenizer(examples["tokens"], truncation=True, is_split_into_words=True)
+
+... labels = []
+... for i, label in enumerate(examples[f"ner_tags"]):
+... word_ids = tokenized_inputs.word_ids(batch_index=i) # Map tokens to their respective word.
+... previous_word_idx = None
+... label_ids = []
+... for word_idx in word_ids: # Set the special tokens to -100.
+... if word_idx is None:
+... label_ids.append(-100)
+... elif word_idx != previous_word_idx: # Only label the first token of a given word.
+... label_ids.append(label[word_idx])
+... else:
+... label_ids.append(-100)
+... previous_word_idx = word_idx
+... labels.append(label_ids)
+
+... tokenized_inputs["labels"] = labels
+... return tokenized_inputs
+```
+
+Use 🤗 Datasets [`map`](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.map) function to tokenize and align the labels over the entire dataset. You can speed up the `map` function by setting `batched=True` to process multiple elements of the dataset at once:
+
+```py
+>>> tokenized_wnut = wnut.map(tokenize_and_align_labels, batched=True)
+```
+
+Use [`DataCollatorForTokenClassification`] to create a batch of examples. It will also *dynamically pad* your text and labels to the length of the longest element in its batch, so they are a uniform length. While it is possible to pad your text in the `tokenizer` function by setting `padding=True`, dynamic padding is more efficient.
+
+
+
+```py
+>>> from transformers import DataCollatorForTokenClassification
+
+>>> data_collator = DataCollatorForTokenClassification(tokenizer=tokenizer)
+```
+
+
+```py
+>>> from transformers import DataCollatorForTokenClassification
+
+>>> data_collator = DataCollatorForTokenClassification(tokenizer=tokenizer, return_tensors="tf")
+```
+
+
+
+## Train
+
+
+
+Load DistilBERT with [`AutoModelForTokenClassification`] along with the number of expected labels:
+
+```py
+>>> from transformers import AutoModelForTokenClassification, TrainingArguments, Trainer
+
+>>> model = AutoModelForTokenClassification.from_pretrained("distilbert-base-uncased", num_labels=14)
+```
+
+
+
+If you aren't familiar with fine-tuning a model with the [`Trainer`], take a look at the basic tutorial [here](../training#finetune-with-trainer)!
+
+
+
+At this point, only three steps remain:
+
+1. Define your training hyperparameters in [`TrainingArguments`].
+2. Pass the training arguments to [`Trainer`] along with the model, dataset, tokenizer, and data collator.
+3. Call [`~Trainer.train`] to fine-tune your model.
+
+```py
+>>> training_args = TrainingArguments(
+... output_dir="./results",
+... evaluation_strategy="epoch",
+... learning_rate=2e-5,
+... per_device_train_batch_size=16,
+... per_device_eval_batch_size=16,
+... num_train_epochs=3,
+... weight_decay=0.01,
+... )
+
+>>> trainer = Trainer(
+... model=model,
+... args=training_args,
+... train_dataset=tokenized_wnut["train"],
+... eval_dataset=tokenized_wnut["test"],
+... tokenizer=tokenizer,
+... data_collator=data_collator,
+... )
+
+>>> trainer.train()
+```
+
+
+To fine-tune a model in TensorFlow, start by converting your datasets to the `tf.data.Dataset` format with [`to_tf_dataset`](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.to_tf_dataset). Specify inputs and labels in `columns`, whether to shuffle the dataset order, batch size, and the data collator:
+
+```py
+>>> tf_train_set = tokenized_wnut["train"].to_tf_dataset(
+... columns=["attention_mask", "input_ids", "labels"],
+... shuffle=True,
+... batch_size=16,
+... collate_fn=data_collator,
+... )
+
+>>> tf_validation_set = tokenized_wnut["validation"].to_tf_dataset(
+... columns=["attention_mask", "input_ids", "labels"],
+... shuffle=False,
+... batch_size=16,
+... collate_fn=data_collator,
+... )
+```
+
+
+
+If you aren't familiar with fine-tuning a model with Keras, take a look at the basic tutorial [here](training#finetune-with-keras)!
+
+
+
+Set up an optimizer function, learning rate schedule, and some training hyperparameters:
+
+```py
+>>> from transformers import create_optimizer
+
+>>> batch_size = 16
+>>> num_train_epochs = 3
+>>> num_train_steps = (len(tokenized_wnut["train"]) // batch_size) * num_train_epochs
+>>> optimizer, lr_schedule = create_optimizer(
+... init_lr=2e-5,
+... num_train_steps=num_train_steps,
+... weight_decay_rate=0.01,
+... num_warmup_steps=0,
+... )
+```
+
+Load DistilBERT with [`TFAutoModelForTokenClassification`] along with the number of expected labels:
+
+```py
+>>> from transformers import TFAutoModelForTokenClassification
+
+>>> model = TFAutoModelForTokenClassification.from_pretrained("distilbert-base-uncased", num_labels=2)
+```
+
+Configure the model for training with [`compile`](https://keras.io/api/models/model_training_apis/#compile-method):
+
+```py
+>>> import tensorflow as tf
+
+>>> model.compile(optimizer=optimizer)
+```
+
+Call [`fit`](https://keras.io/api/models/model_training_apis/#fit-method) to fine-tune the model:
+
+```py
+>>> model.fit(x=tf_train_set, validation_data=tf_validation_set, epochs=3)
+```
+
+
+
+
+
+For a more in-depth example of how to fine-tune a model for token classification, take a look at the corresponding
+[PyTorch notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/token_classification.ipynb)
+or [TensorFlow notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/token_classification-tf.ipynb).
+
+
\ No newline at end of file
diff --git a/docs/source/en/tasks/translation.mdx b/docs/source/en/tasks/translation.mdx
new file mode 100644
index 00000000000000..b3ecec6e1ce7e3
--- /dev/null
+++ b/docs/source/en/tasks/translation.mdx
@@ -0,0 +1,225 @@
+
+
+# Translation
+
+
+
+Translation converts a sequence of text from one language to another. It is one of several tasks you can formulate as a sequence-to-sequence problem, a powerful framework that extends to vision and audio tasks.
+
+This guide will show you how to fine-tune [T5](https://huggingface.co/t5-small) on the English-French subset of the [OPUS Books](https://huggingface.co/datasets/opus_books) dataset to translate English text to French.
+
+
+
+See the translation [task page](https://huggingface.co/tasks/translation) for more information about its associated models, datasets, and metrics.
+
+
+
+## Load OPUS Books dataset
+
+Load the OPUS Books dataset from the 🤗 Datasets library:
+
+```py
+>>> from datasets import load_dataset
+
+>>> books = load_dataset("opus_books", "en-fr")
+```
+
+Split this dataset into a train and test set:
+
+```py
+books = books["train"].train_test_split(test_size=0.2)
+```
+
+Then take a look at an example:
+
+```py
+>>> books["train"][0]
+{'id': '90560',
+ 'translation': {'en': 'But this lofty plateau measured only a few fathoms, and soon we reentered Our Element.',
+ 'fr': 'Mais ce plateau élevé ne mesurait que quelques toises, et bientôt nous fûmes rentrés dans notre élément.'}}
+```
+
+The `translation` field is a dictionary containing the English and French translations of the text.
+
+## Preprocess
+
+
+
+Load the T5 tokenizer to process the language pairs:
+
+```py
+>>> from transformers import AutoTokenizer
+
+>>> tokenizer = AutoTokenizer.from_pretrained("t5-small")
+```
+
+The preprocessing function needs to:
+
+1. Prefix the input with a prompt so T5 knows this is a translation task. Some models capable of multiple NLP tasks require prompting for specific tasks.
+2. Tokenize the input (English) and target (French) separately. You can't tokenize French text with a tokenizer pretrained on an English vocabulary. A context manager will help set the tokenizer to French first before tokenizing it.
+3. Truncate sequences to be no longer than the maximum length set by the `max_length` parameter.
+
+```py
+>>> source_lang = "en"
+>>> target_lang = "fr"
+>>> prefix = "translate English to French: "
+
+
+>>> def preprocess_function(examples):
+... inputs = [prefix + example[source_lang] for example in examples["translation"]]
+... targets = [example[target_lang] for example in examples["translation"]]
+... model_inputs = tokenizer(inputs, max_length=128, truncation=True)
+
+... with tokenizer.as_target_tokenizer():
+... labels = tokenizer(targets, max_length=128, truncation=True)
+
+... model_inputs["labels"] = labels["input_ids"]
+... return model_inputs
+```
+
+Use 🤗 Datasets [`map`](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.map) function to apply the preprocessing function over the entire dataset. You can speed up the `map` function by setting `batched=True` to process multiple elements of the dataset at once:
+
+```py
+>>> tokenized_books = books.map(preprocess_function, batched=True)
+```
+
+Use [`DataCollatorForSeq2Seq`] to create a batch of examples. It will also *dynamically pad* your text and labels to the length of the longest element in its batch, so they are a uniform length. While it is possible to pad your text in the `tokenizer` function by setting `padding=True`, dynamic padding is more efficient.
+
+
+
+```py
+>>> from transformers import DataCollatorForSeq2Seq
+
+>>> data_collator = DataCollatorForSeq2Seq(tokenizer=tokenizer, model=model)
+```
+
+
+```py
+>>> from transformers import DataCollatorForSeq2Seq
+
+>>> data_collator = DataCollatorForSeq2Seq(tokenizer=tokenizer, model=model, return_tensors="tf")
+```
+
+
+
+## Train
+
+
+
+Load T5 with [`AutoModelForSeq2SeqLM`]:
+
+```py
+>>> from transformers import AutoModelForSeq2SeqLM, Seq2SeqTrainingArguments, Seq2SeqTrainer
+
+>>> model = AutoModelForSeq2SeqLM.from_pretrained("t5-small")
+```
+
+
+
+If you aren't familiar with fine-tuning a model with the [`Trainer`], take a look at the basic tutorial [here](../training#finetune-with-trainer)!
+
+
+
+At this point, only three steps remain:
+
+1. Define your training hyperparameters in [`Seq2SeqTrainingArguments`].
+2. Pass the training arguments to [`Seq2SeqTrainer`] along with the model, dataset, tokenizer, and data collator.
+3. Call [`~Trainer.train`] to fine-tune your model.
+
+```py
+>>> training_args = Seq2SeqTrainingArguments(
+... output_dir="./results",
+... evaluation_strategy="epoch",
+... learning_rate=2e-5,
+... per_device_train_batch_size=16,
+... per_device_eval_batch_size=16,
+... weight_decay=0.01,
+... save_total_limit=3,
+... num_train_epochs=1,
+... fp16=True,
+... )
+
+>>> trainer = Seq2SeqTrainer(
+... model=model,
+... args=training_args,
+... train_dataset=tokenized_books["train"],
+... eval_dataset=tokenized_books["test"],
+... tokenizer=tokenizer,
+... data_collator=data_collator,
+... )
+
+>>> trainer.train()
+```
+
+
+To fine-tune a model in TensorFlow, start by converting your datasets to the `tf.data.Dataset` format with [`to_tf_dataset`](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.to_tf_dataset). Specify inputs and labels in `columns`, whether to shuffle the dataset order, batch size, and the data collator:
+
+```py
+>>> tf_train_set = tokenized_books["train"].to_tf_dataset(
+... columns=["attention_mask", "input_ids", "labels"],
+... shuffle=True,
+... batch_size=16,
+... collate_fn=data_collator,
+... )
+
+>>> tf_test_set = tokenized_books["test"].to_tf_dataset(
+... columns=["attention_mask", "input_ids", "labels"],
+... shuffle=False,
+... batch_size=16,
+... collate_fn=data_collator,
+... )
+```
+
+
+
+If you aren't familiar with fine-tuning a model with Keras, take a look at the basic tutorial [here](training#finetune-with-keras)!
+
+
+
+Set up an optimizer function, learning rate schedule, and some training hyperparameters:
+
+```py
+>>> from transformers import create_optimizer, AdamWeightDecay
+
+>>> optimizer = AdamWeightDecay(learning_rate=2e-5, weight_decay_rate=0.01)
+```
+
+Load T5 with [`TFAutoModelForSeq2SeqLM`]:
+
+```py
+>>> from transformers import TFAutoModelForSeq2SeqLM
+
+>>> model = TFAutoModelForSeq2SeqLM.from_pretrained("t5-small")
+```
+
+Configure the model for training with [`compile`](https://keras.io/api/models/model_training_apis/#compile-method):
+
+```py
+>>> model.compile(optimizer=optimizer)
+```
+
+Call [`fit`](https://keras.io/api/models/model_training_apis/#fit-method) to fine-tune the model:
+
+```py
+>>> model.fit(x=tf_train_set, validation_data=tf_test_set, epochs=3)
+```
+
+
+
+
+
+For a more in-depth example of how to fine-tune a model for translation, take a look at the corresponding
+[PyTorch notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/translation.ipynb)
+or [TensorFlow notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/translation-tf.ipynb).
+
+
\ No newline at end of file
diff --git a/docs/source/en/testing.mdx b/docs/source/en/testing.mdx
new file mode 100644
index 00000000000000..a5e2268092ec39
--- /dev/null
+++ b/docs/source/en/testing.mdx
@@ -0,0 +1,1232 @@
+
+
+# Testing
+
+
+Let's take a look at how 🤗 Transformers models are tested and how you can write new tests and improve the existing ones.
+
+There are 2 test suites in the repository:
+
+1. `tests` -- tests for the general API
+2. `examples` -- tests primarily for various applications that aren't part of the API
+
+## How transformers are tested
+
+1. Once a PR is submitted it gets tested with 9 CircleCi jobs. Every new commit to that PR gets retested. These jobs
+ are defined in this [config file](https://github.com/huggingface/transformers/tree/main/.circleci/config.yml), so that if needed you can reproduce the same
+ environment on your machine.
+
+ These CI jobs don't run `@slow` tests.
+
+2. There are 3 jobs run by [github actions](https://github.com/huggingface/transformers/actions):
+
+ - [torch hub integration](https://github.com/huggingface/transformers/tree/main/.github/workflows/github-torch-hub.yml): checks whether torch hub
+ integration works.
+
+ - [self-hosted (push)](https://github.com/huggingface/transformers/tree/main/.github/workflows/self-push.yml): runs fast tests on GPU only on commits on
+ `main`. It only runs if a commit on `main` has updated the code in one of the following folders: `src`,
+ `tests`, `.github` (to prevent running on added model cards, notebooks, etc.)
+
+ - [self-hosted runner](https://github.com/huggingface/transformers/tree/main/.github/workflows/self-scheduled.yml): runs normal and slow tests on GPU in
+ `tests` and `examples`:
+
+```bash
+RUN_SLOW=1 pytest tests/
+RUN_SLOW=1 pytest examples/
+```
+
+ The results can be observed [here](https://github.com/huggingface/transformers/actions).
+
+
+
+## Running tests
+
+
+
+
+
+### Choosing which tests to run
+
+This document goes into many details of how tests can be run. If after reading everything, you need even more details
+you will find them [here](https://docs.pytest.org/en/latest/usage.html).
+
+Here are some most useful ways of running tests.
+
+Run all:
+
+```console
+pytest
+```
+
+or:
+
+```bash
+make test
+```
+
+Note that the latter is defined as:
+
+```bash
+python -m pytest -n auto --dist=loadfile -s -v ./tests/
+```
+
+which tells pytest to:
+
+- run as many test processes as they are CPU cores (which could be too many if you don't have a ton of RAM!)
+- ensure that all tests from the same file will be run by the same test process
+- do not capture output
+- run in verbose mode
+
+
+
+### Getting the list of all tests
+
+All tests of the test suite:
+
+```bash
+pytest --collect-only -q
+```
+
+All tests of a given test file:
+
+```bash
+pytest tests/test_optimization.py --collect-only -q
+```
+
+### Run a specific test module
+
+To run an individual test module:
+
+```bash
+pytest tests/test_logging.py
+```
+
+### Run specific tests
+
+Since unittest is used inside most of the tests, to run specific subtests you need to know the name of the unittest
+class containing those tests. For example, it could be:
+
+```bash
+pytest tests/test_optimization.py::OptimizationTest::test_adam_w
+```
+
+Here:
+
+- `tests/test_optimization.py` - the file with tests
+- `OptimizationTest` - the name of the class
+- `test_adam_w` - the name of the specific test function
+
+If the file contains multiple classes, you can choose to run only tests of a given class. For example:
+
+```bash
+pytest tests/test_optimization.py::OptimizationTest
+```
+
+will run all the tests inside that class.
+
+As mentioned earlier you can see what tests are contained inside the `OptimizationTest` class by running:
+
+```bash
+pytest tests/test_optimization.py::OptimizationTest --collect-only -q
+```
+
+You can run tests by keyword expressions.
+
+To run only tests whose name contains `adam`:
+
+```bash
+pytest -k adam tests/test_optimization.py
+```
+
+Logical `and` and `or` can be used to indicate whether all keywords should match or either. `not` can be used to
+negate.
+
+To run all tests except those whose name contains `adam`:
+
+```bash
+pytest -k "not adam" tests/test_optimization.py
+```
+
+And you can combine the two patterns in one:
+
+```bash
+pytest -k "ada and not adam" tests/test_optimization.py
+```
+
+For example to run both `test_adafactor` and `test_adam_w` you can use:
+
+```bash
+pytest -k "test_adam_w or test_adam_w" tests/test_optimization.py
+```
+
+Note that we use `or` here, since we want either of the keywords to match to include both.
+
+If you want to include only tests that include both patterns, `and` is to be used:
+
+```bash
+pytest -k "test and ada" tests/test_optimization.py
+```
+
+### Run only modified tests
+
+You can run the tests related to the unstaged files or the current branch (according to Git) by using [pytest-picked](https://github.com/anapaulagomes/pytest-picked). This is a great way of quickly testing your changes didn't break
+anything, since it won't run the tests related to files you didn't touch.
+
+```bash
+pip install pytest-picked
+```
+
+```bash
+pytest --picked
+```
+
+All tests will be run from files and folders which are modified, but not yet committed.
+
+### Automatically rerun failed tests on source modification
+
+[pytest-xdist](https://github.com/pytest-dev/pytest-xdist) provides a very useful feature of detecting all failed
+tests, and then waiting for you to modify files and continuously re-rerun those failing tests until they pass while you
+fix them. So that you don't need to re start pytest after you made the fix. This is repeated until all tests pass after
+which again a full run is performed.
+
+```bash
+pip install pytest-xdist
+```
+
+To enter the mode: `pytest -f` or `pytest --looponfail`
+
+File changes are detected by looking at `looponfailroots` root directories and all of their contents (recursively).
+If the default for this value does not work for you, you can change it in your project by setting a configuration
+option in `setup.cfg`:
+
+```ini
+[tool:pytest]
+looponfailroots = transformers tests
+```
+
+or `pytest.ini`/``tox.ini`` files:
+
+```ini
+[pytest]
+looponfailroots = transformers tests
+```
+
+This would lead to only looking for file changes in the respective directories, specified relatively to the ini-file’s
+directory.
+
+[pytest-watch](https://github.com/joeyespo/pytest-watch) is an alternative implementation of this functionality.
+
+
+### Skip a test module
+
+If you want to run all test modules, except a few you can exclude them by giving an explicit list of tests to run. For
+example, to run all except `test_modeling_*.py` tests:
+
+```bash
+pytest *ls -1 tests/*py | grep -v test_modeling*
+```
+
+### Clearing state
+
+CI builds and when isolation is important (against speed), cache should be cleared:
+
+```bash
+pytest --cache-clear tests
+```
+
+### Running tests in parallel
+
+As mentioned earlier `make test` runs tests in parallel via `pytest-xdist` plugin (`-n X` argument, e.g. `-n 2`
+to run 2 parallel jobs).
+
+`pytest-xdist`'s `--dist=` option allows one to control how the tests are grouped. `--dist=loadfile` puts the
+tests located in one file onto the same process.
+
+Since the order of executed tests is different and unpredictable, if running the test suite with `pytest-xdist`
+produces failures (meaning we have some undetected coupled tests), use [pytest-replay](https://github.com/ESSS/pytest-replay) to replay the tests in the same order, which should help with then somehow
+reducing that failing sequence to a minimum.
+
+### Test order and repetition
+
+It's good to repeat the tests several times, in sequence, randomly, or in sets, to detect any potential
+inter-dependency and state-related bugs (tear down). And the straightforward multiple repetition is just good to detect
+some problems that get uncovered by randomness of DL.
+
+
+#### Repeat tests
+
+- [pytest-flakefinder](https://github.com/dropbox/pytest-flakefinder):
+
+```bash
+pip install pytest-flakefinder
+```
+
+And then run every test multiple times (50 by default):
+
+```bash
+pytest --flake-finder --flake-runs=5 tests/test_failing_test.py
+```
+
+
+
+This plugin doesn't work with `-n` flag from `pytest-xdist`.
+
+
+
+
+
+There is another plugin `pytest-repeat`, but it doesn't work with `unittest`.
+
+
+
+#### Run tests in a random order
+
+```bash
+pip install pytest-random-order
+```
+
+Important: the presence of `pytest-random-order` will automatically randomize tests, no configuration change or
+command line options is required.
+
+As explained earlier this allows detection of coupled tests - where one test's state affects the state of another. When
+`pytest-random-order` is installed it will print the random seed it used for that session, e.g:
+
+```bash
+pytest tests
+[...]
+Using --random-order-bucket=module
+Using --random-order-seed=573663
+```
+
+So that if the given particular sequence fails, you can reproduce it by adding that exact seed, e.g.:
+
+```bash
+pytest --random-order-seed=573663
+[...]
+Using --random-order-bucket=module
+Using --random-order-seed=573663
+```
+
+It will only reproduce the exact order if you use the exact same list of tests (or no list at all). Once you start to
+manually narrowing down the list you can no longer rely on the seed, but have to list them manually in the exact order
+they failed and tell pytest to not randomize them instead using `--random-order-bucket=none`, e.g.:
+
+```bash
+pytest --random-order-bucket=none tests/test_a.py tests/test_c.py tests/test_b.py
+```
+
+To disable the shuffling for all tests:
+
+```bash
+pytest --random-order-bucket=none
+```
+
+By default `--random-order-bucket=module` is implied, which will shuffle the files on the module levels. It can also
+shuffle on `class`, `package`, `global` and `none` levels. For the complete details please see its
+[documentation](https://github.com/jbasko/pytest-random-order).
+
+Another randomization alternative is: [`pytest-randomly`](https://github.com/pytest-dev/pytest-randomly). This
+module has a very similar functionality/interface, but it doesn't have the bucket modes available in
+`pytest-random-order`. It has the same problem of imposing itself once installed.
+
+### Look and feel variations
+
+#### pytest-sugar
+
+[pytest-sugar](https://github.com/Frozenball/pytest-sugar) is a plugin that improves the look-n-feel, adds a
+progressbar, and show tests that fail and the assert instantly. It gets activated automatically upon installation.
+
+```bash
+pip install pytest-sugar
+```
+
+To run tests without it, run:
+
+```bash
+pytest -p no:sugar
+```
+
+or uninstall it.
+
+
+
+#### Report each sub-test name and its progress
+
+For a single or a group of tests via `pytest` (after `pip install pytest-pspec`):
+
+```bash
+pytest --pspec tests/test_optimization.py
+```
+
+#### Instantly shows failed tests
+
+[pytest-instafail](https://github.com/pytest-dev/pytest-instafail) shows failures and errors instantly instead of
+waiting until the end of test session.
+
+```bash
+pip install pytest-instafail
+```
+
+```bash
+pytest --instafail
+```
+
+### To GPU or not to GPU
+
+On a GPU-enabled setup, to test in CPU-only mode add `CUDA_VISIBLE_DEVICES=""`:
+
+```bash
+CUDA_VISIBLE_DEVICES="" pytest tests/test_logging.py
+```
+
+or if you have multiple gpus, you can specify which one is to be used by `pytest`. For example, to use only the
+second gpu if you have gpus `0` and `1`, you can run:
+
+```bash
+CUDA_VISIBLE_DEVICES="1" pytest tests/test_logging.py
+```
+
+This is handy when you want to run different tasks on different GPUs.
+
+Some tests must be run on CPU-only, others on either CPU or GPU or TPU, yet others on multiple-GPUs. The following skip
+decorators are used to set the requirements of tests CPU/GPU/TPU-wise:
+
+- `require_torch` - this test will run only under torch
+- `require_torch_gpu` - as `require_torch` plus requires at least 1 GPU
+- `require_torch_multi_gpu` - as `require_torch` plus requires at least 2 GPUs
+- `require_torch_non_multi_gpu` - as `require_torch` plus requires 0 or 1 GPUs
+- `require_torch_up_to_2_gpus` - as `require_torch` plus requires 0 or 1 or 2 GPUs
+- `require_torch_tpu` - as `require_torch` plus requires at least 1 TPU
+
+Let's depict the GPU requirements in the following table:
+
+
+| n gpus | decorator |
+|--------+--------------------------------|
+| `>= 0` | `@require_torch` |
+| `>= 1` | `@require_torch_gpu` |
+| `>= 2` | `@require_torch_multi_gpu` |
+| `< 2` | `@require_torch_non_multi_gpu` |
+| `< 3` | `@require_torch_up_to_2_gpus` |
+
+
+For example, here is a test that must be run only when there are 2 or more GPUs available and pytorch is installed:
+
+```python no-style
+@require_torch_multi_gpu
+def test_example_with_multi_gpu():
+```
+
+If a test requires `tensorflow` use the `require_tf` decorator. For example:
+
+```python no-style
+@require_tf
+def test_tf_thing_with_tensorflow():
+```
+
+These decorators can be stacked. For example, if a test is slow and requires at least one GPU under pytorch, here is
+how to set it up:
+
+```python no-style
+@require_torch_gpu
+@slow
+def test_example_slow_on_gpu():
+```
+
+Some decorators like `@parametrized` rewrite test names, therefore `@require_*` skip decorators have to be listed
+last for them to work correctly. Here is an example of the correct usage:
+
+```python no-style
+@parameterized.expand(...)
+@require_torch_multi_gpu
+def test_integration_foo():
+```
+
+This order problem doesn't exist with `@pytest.mark.parametrize`, you can put it first or last and it will still
+work. But it only works with non-unittests.
+
+Inside tests:
+
+- How many GPUs are available:
+
+```python
+from transformers.testing_utils import get_gpu_count
+
+n_gpu = get_gpu_count() # works with torch and tf
+```
+
+### Distributed training
+
+`pytest` can't deal with distributed training directly. If this is attempted - the sub-processes don't do the right
+thing and end up thinking they are `pytest` and start running the test suite in loops. It works, however, if one
+spawns a normal process that then spawns off multiple workers and manages the IO pipes.
+
+Here are some tests that use it:
+
+- [test_trainer_distributed.py](https://github.com/huggingface/transformers/tree/main/tests/test_trainer_distributed.py)
+- [test_deepspeed.py](https://github.com/huggingface/transformers/tree/main/tests/deepspeed/test_deepspeed.py)
+
+To jump right into the execution point, search for the `execute_subprocess_async` call in those tests.
+
+You will need at least 2 GPUs to see these tests in action:
+
+```bash
+CUDA_VISIBLE_DEVICES=0,1 RUN_SLOW=1 pytest -sv tests/test_trainer_distributed.py
+```
+
+### Output capture
+
+During test execution any output sent to `stdout` and `stderr` is captured. If a test or a setup method fails, its
+according captured output will usually be shown along with the failure traceback.
+
+To disable output capturing and to get the `stdout` and `stderr` normally, use `-s` or `--capture=no`:
+
+```bash
+pytest -s tests/test_logging.py
+```
+
+To send test results to JUnit format output:
+
+```bash
+py.test tests --junitxml=result.xml
+```
+
+### Color control
+
+To have no color (e.g., yellow on white background is not readable):
+
+```bash
+pytest --color=no tests/test_logging.py
+```
+
+### Sending test report to online pastebin service
+
+Creating a URL for each test failure:
+
+```bash
+pytest --pastebin=failed tests/test_logging.py
+```
+
+This will submit test run information to a remote Paste service and provide a URL for each failure. You may select
+tests as usual or add for example -x if you only want to send one particular failure.
+
+Creating a URL for a whole test session log:
+
+```bash
+pytest --pastebin=all tests/test_logging.py
+```
+
+## Writing tests
+
+🤗 transformers tests are based on `unittest`, but run by `pytest`, so most of the time features from both systems
+can be used.
+
+You can read [here](https://docs.pytest.org/en/stable/unittest.html) which features are supported, but the important
+thing to remember is that most `pytest` fixtures don't work. Neither parametrization, but we use the module
+`parameterized` that works in a similar way.
+
+
+### Parametrization
+
+Often, there is a need to run the same test multiple times, but with different arguments. It could be done from within
+the test, but then there is no way of running that test for just one set of arguments.
+
+```python
+# test_this1.py
+import unittest
+from parameterized import parameterized
+
+
+class TestMathUnitTest(unittest.TestCase):
+ @parameterized.expand(
+ [
+ ("negative", -1.5, -2.0),
+ ("integer", 1, 1.0),
+ ("large fraction", 1.6, 1),
+ ]
+ )
+ def test_floor(self, name, input, expected):
+ assert_equal(math.floor(input), expected)
+```
+
+Now, by default this test will be run 3 times, each time with the last 3 arguments of `test_floor` being assigned the
+corresponding arguments in the parameter list.
+
+and you could run just the `negative` and `integer` sets of params with:
+
+```bash
+pytest -k "negative and integer" tests/test_mytest.py
+```
+
+or all but `negative` sub-tests, with:
+
+```bash
+pytest -k "not negative" tests/test_mytest.py
+```
+
+Besides using the `-k` filter that was just mentioned, you can find out the exact name of each sub-test and run any
+or all of them using their exact names.
+
+```bash
+pytest test_this1.py --collect-only -q
+```
+
+and it will list:
+
+```bash
+test_this1.py::TestMathUnitTest::test_floor_0_negative
+test_this1.py::TestMathUnitTest::test_floor_1_integer
+test_this1.py::TestMathUnitTest::test_floor_2_large_fraction
+```
+
+So now you can run just 2 specific sub-tests:
+
+```bash
+pytest test_this1.py::TestMathUnitTest::test_floor_0_negative test_this1.py::TestMathUnitTest::test_floor_1_integer
+```
+
+The module [parameterized](https://pypi.org/project/parameterized/) which is already in the developer dependencies
+of `transformers` works for both: `unittests` and `pytest` tests.
+
+If, however, the test is not a `unittest`, you may use `pytest.mark.parametrize` (or you may see it being used in
+some existing tests, mostly under `examples`).
+
+Here is the same example, this time using `pytest`'s `parametrize` marker:
+
+```python
+# test_this2.py
+import pytest
+
+
+@pytest.mark.parametrize(
+ "name, input, expected",
+ [
+ ("negative", -1.5, -2.0),
+ ("integer", 1, 1.0),
+ ("large fraction", 1.6, 1),
+ ],
+)
+def test_floor(name, input, expected):
+ assert_equal(math.floor(input), expected)
+```
+
+Same as with `parameterized`, with `pytest.mark.parametrize` you can have a fine control over which sub-tests are
+run, if the `-k` filter doesn't do the job. Except, this parametrization function creates a slightly different set of
+names for the sub-tests. Here is what they look like:
+
+```bash
+pytest test_this2.py --collect-only -q
+```
+
+and it will list:
+
+```bash
+test_this2.py::test_floor[integer-1-1.0]
+test_this2.py::test_floor[negative--1.5--2.0]
+test_this2.py::test_floor[large fraction-1.6-1]
+```
+
+So now you can run just the specific test:
+
+```bash
+pytest test_this2.py::test_floor[negative--1.5--2.0] test_this2.py::test_floor[integer-1-1.0]
+```
+
+as in the previous example.
+
+
+
+### Files and directories
+
+In tests often we need to know where things are relative to the current test file, and it's not trivial since the test
+could be invoked from more than one directory or could reside in sub-directories with different depths. A helper class
+`transformers.test_utils.TestCasePlus` solves this problem by sorting out all the basic paths and provides easy
+accessors to them:
+
+- `pathlib` objects (all fully resolved):
+
+ - `test_file_path` - the current test file path, i.e. `__file__`
+ - `test_file_dir` - the directory containing the current test file
+ - `tests_dir` - the directory of the `tests` test suite
+ - `examples_dir` - the directory of the `examples` test suite
+ - `repo_root_dir` - the directory of the repository
+ - `src_dir` - the directory of `src` (i.e. where the `transformers` sub-dir resides)
+
+- stringified paths---same as above but these return paths as strings, rather than `pathlib` objects:
+
+ - `test_file_path_str`
+ - `test_file_dir_str`
+ - `tests_dir_str`
+ - `examples_dir_str`
+ - `repo_root_dir_str`
+ - `src_dir_str`
+
+To start using those all you need is to make sure that the test resides in a subclass of
+`transformers.test_utils.TestCasePlus`. For example:
+
+```python
+from transformers.testing_utils import TestCasePlus
+
+
+class PathExampleTest(TestCasePlus):
+ def test_something_involving_local_locations(self):
+ data_dir = self.tests_dir / "fixtures/tests_samples/wmt_en_ro"
+```
+
+If you don't need to manipulate paths via `pathlib` or you just need a path as a string, you can always invoked
+`str()` on the `pathlib` object or use the accessors ending with `_str`. For example:
+
+```python
+from transformers.testing_utils import TestCasePlus
+
+
+class PathExampleTest(TestCasePlus):
+ def test_something_involving_stringified_locations(self):
+ examples_dir = self.examples_dir_str
+```
+
+### Temporary files and directories
+
+Using unique temporary files and directories are essential for parallel test running, so that the tests won't overwrite
+each other's data. Also we want to get the temporary files and directories removed at the end of each test that created
+them. Therefore, using packages like `tempfile`, which address these needs is essential.
+
+However, when debugging tests, you need to be able to see what goes into the temporary file or directory and you want
+to know it's exact path and not having it randomized on every test re-run.
+
+A helper class `transformers.test_utils.TestCasePlus` is best used for such purposes. It's a sub-class of
+`unittest.TestCase`, so we can easily inherit from it in the test modules.
+
+Here is an example of its usage:
+
+```python
+from transformers.testing_utils import TestCasePlus
+
+
+class ExamplesTests(TestCasePlus):
+ def test_whatever(self):
+ tmp_dir = self.get_auto_remove_tmp_dir()
+```
+
+This code creates a unique temporary directory, and sets `tmp_dir` to its location.
+
+- Create a unique temporary dir:
+
+```python
+def test_whatever(self):
+ tmp_dir = self.get_auto_remove_tmp_dir()
+```
+
+`tmp_dir` will contain the path to the created temporary dir. It will be automatically removed at the end of the
+test.
+
+- Create a temporary dir of my choice, ensure it's empty before the test starts and don't empty it after the test.
+
+```python
+def test_whatever(self):
+ tmp_dir = self.get_auto_remove_tmp_dir("./xxx")
+```
+
+This is useful for debug when you want to monitor a specific directory and want to make sure the previous tests didn't
+leave any data in there.
+
+- You can override the default behavior by directly overriding the `before` and `after` args, leading to one of the
+ following behaviors:
+
+ - `before=True`: the temporary dir will always be cleared at the beginning of the test.
+ - `before=False`: if the temporary dir already existed, any existing files will remain there.
+ - `after=True`: the temporary dir will always be deleted at the end of the test.
+ - `after=False`: the temporary dir will always be left intact at the end of the test.
+
+
+
+In order to run the equivalent of `rm -r` safely, only subdirs of the project repository checkout are allowed if
+an explicit `tmp_dir` is used, so that by mistake no `/tmp` or similar important part of the filesystem will
+get nuked. i.e. please always pass paths that start with `./`.
+
+
+
+
+
+Each test can register multiple temporary directories and they all will get auto-removed, unless requested
+otherwise.
+
+
+
+### Temporary sys.path override
+
+If you need to temporary override `sys.path` to import from another test for example, you can use the
+`ExtendSysPath` context manager. Example:
+
+
+```python
+import os
+from transformers.testing_utils import ExtendSysPath
+
+bindir = os.path.abspath(os.path.dirname(__file__))
+with ExtendSysPath(f"{bindir}/.."):
+ from test_trainer import TrainerIntegrationCommon # noqa
+```
+
+### Skipping tests
+
+This is useful when a bug is found and a new test is written, yet the bug is not fixed yet. In order to be able to
+commit it to the main repository we need make sure it's skipped during `make test`.
+
+Methods:
+
+- A **skip** means that you expect your test to pass only if some conditions are met, otherwise pytest should skip
+ running the test altogether. Common examples are skipping windows-only tests on non-windows platforms, or skipping
+ tests that depend on an external resource which is not available at the moment (for example a database).
+
+- A **xfail** means that you expect a test to fail for some reason. A common example is a test for a feature not yet
+ implemented, or a bug not yet fixed. When a test passes despite being expected to fail (marked with
+ pytest.mark.xfail), it’s an xpass and will be reported in the test summary.
+
+One of the important differences between the two is that `skip` doesn't run the test, and `xfail` does. So if the
+code that's buggy causes some bad state that will affect other tests, do not use `xfail`.
+
+#### Implementation
+
+- Here is how to skip whole test unconditionally:
+
+```python no-style
+@unittest.skip("this bug needs to be fixed")
+def test_feature_x():
+```
+
+or via pytest:
+
+```python no-style
+@pytest.mark.skip(reason="this bug needs to be fixed")
+```
+
+or the `xfail` way:
+
+```python no-style
+@pytest.mark.xfail
+def test_feature_x():
+```
+
+- Here is how to skip a test based on some internal check inside the test:
+
+```python
+def test_feature_x():
+ if not has_something():
+ pytest.skip("unsupported configuration")
+```
+
+or the whole module:
+
+```python
+import pytest
+
+if not pytest.config.getoption("--custom-flag"):
+ pytest.skip("--custom-flag is missing, skipping tests", allow_module_level=True)
+```
+
+or the `xfail` way:
+
+```python
+def test_feature_x():
+ pytest.xfail("expected to fail until bug XYZ is fixed")
+```
+
+- Here is how to skip all tests in a module if some import is missing:
+
+```python
+docutils = pytest.importorskip("docutils", minversion="0.3")
+```
+
+- Skip a test based on a condition:
+
+```python no-style
+@pytest.mark.skipif(sys.version_info < (3,6), reason="requires python3.6 or higher")
+def test_feature_x():
+```
+
+or:
+
+```python no-style
+@unittest.skipIf(torch_device == "cpu", "Can't do half precision")
+def test_feature_x():
+```
+
+or skip the whole module:
+
+```python no-style
+@pytest.mark.skipif(sys.platform == 'win32', reason="does not run on windows")
+class TestClass():
+ def test_feature_x(self):
+```
+
+More details, example and ways are [here](https://docs.pytest.org/en/latest/skipping.html).
+
+### Slow tests
+
+The library of tests is ever-growing, and some of the tests take minutes to run, therefore we can't afford waiting for
+an hour for the test suite to complete on CI. Therefore, with some exceptions for essential tests, slow tests should be
+marked as in the example below:
+
+```python no-style
+from transformers.testing_utils import slow
+@slow
+def test_integration_foo():
+```
+
+Once a test is marked as `@slow`, to run such tests set `RUN_SLOW=1` env var, e.g.:
+
+```bash
+RUN_SLOW=1 pytest tests
+```
+
+Some decorators like `@parameterized` rewrite test names, therefore `@slow` and the rest of the skip decorators
+`@require_*` have to be listed last for them to work correctly. Here is an example of the correct usage:
+
+```python no-style
+@parameteriz ed.expand(...)
+@slow
+def test_integration_foo():
+```
+
+As explained at the beginning of this document, slow tests get to run on a scheduled basis, rather than in PRs CI
+checks. So it's possible that some problems will be missed during a PR submission and get merged. Such problems will
+get caught during the next scheduled CI job. But it also means that it's important to run the slow tests on your
+machine before submitting the PR.
+
+Here is a rough decision making mechanism for choosing which tests should be marked as slow:
+
+If the test is focused on one of the library's internal components (e.g., modeling files, tokenization files,
+pipelines), then we should run that test in the non-slow test suite. If it's focused on an other aspect of the library,
+such as the documentation or the examples, then we should run these tests in the slow test suite. And then, to refine
+this approach we should have exceptions:
+
+- All tests that need to download a heavy set of weights or a dataset that is larger than ~50MB (e.g., model or
+ tokenizer integration tests, pipeline integration tests) should be set to slow. If you're adding a new model, you
+ should create and upload to the hub a tiny version of it (with random weights) for integration tests. This is
+ discussed in the following paragraphs.
+- All tests that need to do a training not specifically optimized to be fast should be set to slow.
+- We can introduce exceptions if some of these should-be-non-slow tests are excruciatingly slow, and set them to
+ `@slow`. Auto-modeling tests, which save and load large files to disk, are a good example of tests that are marked
+ as `@slow`.
+- If a test completes under 1 second on CI (including downloads if any) then it should be a normal test regardless.
+
+Collectively, all the non-slow tests need to cover entirely the different internals, while remaining fast. For example,
+a significant coverage can be achieved by testing with specially created tiny models with random weights. Such models
+have the very minimal number of layers (e.g., 2), vocab size (e.g., 1000), etc. Then the `@slow` tests can use large
+slow models to do qualitative testing. To see the use of these simply look for *tiny* models with:
+
+```bash
+grep tiny tests examples
+```
+
+Here is a an example of a [script](https://github.com/huggingface/transformers/tree/main/scripts/fsmt/fsmt-make-tiny-model.py) that created the tiny model
+[stas/tiny-wmt19-en-de](https://huggingface.co/stas/tiny-wmt19-en-de). You can easily adjust it to your specific
+model's architecture.
+
+It's easy to measure the run-time incorrectly if for example there is an overheard of downloading a huge model, but if
+you test it locally the downloaded files would be cached and thus the download time not measured. Hence check the
+execution speed report in CI logs instead (the output of `pytest --durations=0 tests`).
+
+That report is also useful to find slow outliers that aren't marked as such, or which need to be re-written to be fast.
+If you notice that the test suite starts getting slow on CI, the top listing of this report will show the slowest
+tests.
+
+
+### Testing the stdout/stderr output
+
+In order to test functions that write to `stdout` and/or `stderr`, the test can access those streams using the
+`pytest`'s [capsys system](https://docs.pytest.org/en/latest/capture.html). Here is how this is accomplished:
+
+```python
+import sys
+
+
+def print_to_stdout(s):
+ print(s)
+
+
+def print_to_stderr(s):
+ sys.stderr.write(s)
+
+
+def test_result_and_stdout(capsys):
+ msg = "Hello"
+ print_to_stdout(msg)
+ print_to_stderr(msg)
+ out, err = capsys.readouterr() # consume the captured output streams
+ # optional: if you want to replay the consumed streams:
+ sys.stdout.write(out)
+ sys.stderr.write(err)
+ # test:
+ assert msg in out
+ assert msg in err
+```
+
+And, of course, most of the time, `stderr` will come as a part of an exception, so try/except has to be used in such
+a case:
+
+```python
+def raise_exception(msg):
+ raise ValueError(msg)
+
+
+def test_something_exception():
+ msg = "Not a good value"
+ error = ""
+ try:
+ raise_exception(msg)
+ except Exception as e:
+ error = str(e)
+ assert msg in error, f"{msg} is in the exception:\n{error}"
+```
+
+Another approach to capturing stdout is via `contextlib.redirect_stdout`:
+
+```python
+from io import StringIO
+from contextlib import redirect_stdout
+
+
+def print_to_stdout(s):
+ print(s)
+
+
+def test_result_and_stdout():
+ msg = "Hello"
+ buffer = StringIO()
+ with redirect_stdout(buffer):
+ print_to_stdout(msg)
+ out = buffer.getvalue()
+ # optional: if you want to replay the consumed streams:
+ sys.stdout.write(out)
+ # test:
+ assert msg in out
+```
+
+An important potential issue with capturing stdout is that it may contain `\r` characters that in normal `print`
+reset everything that has been printed so far. There is no problem with `pytest`, but with `pytest -s` these
+characters get included in the buffer, so to be able to have the test run with and without `-s`, you have to make an
+extra cleanup to the captured output, using `re.sub(r'~.*\r', '', buf, 0, re.M)`.
+
+But, then we have a helper context manager wrapper to automatically take care of it all, regardless of whether it has
+some `\r`'s in it or not, so it's a simple:
+
+```python
+from transformers.testing_utils import CaptureStdout
+
+with CaptureStdout() as cs:
+ function_that_writes_to_stdout()
+print(cs.out)
+```
+
+Here is a full test example:
+
+```python
+from transformers.testing_utils import CaptureStdout
+
+msg = "Secret message\r"
+final = "Hello World"
+with CaptureStdout() as cs:
+ print(msg + final)
+assert cs.out == final + "\n", f"captured: {cs.out}, expecting {final}"
+```
+
+If you'd like to capture `stderr` use the `CaptureStderr` class instead:
+
+```python
+from transformers.testing_utils import CaptureStderr
+
+with CaptureStderr() as cs:
+ function_that_writes_to_stderr()
+print(cs.err)
+```
+
+If you need to capture both streams at once, use the parent `CaptureStd` class:
+
+```python
+from transformers.testing_utils import CaptureStd
+
+with CaptureStd() as cs:
+ function_that_writes_to_stdout_and_stderr()
+print(cs.err, cs.out)
+```
+
+Also, to aid debugging test issues, by default these context managers automatically replay the captured streams on exit
+from the context.
+
+
+### Capturing logger stream
+
+If you need to validate the output of a logger, you can use `CaptureLogger`:
+
+```python
+from transformers import logging
+from transformers.testing_utils import CaptureLogger
+
+msg = "Testing 1, 2, 3"
+logging.set_verbosity_info()
+logger = logging.get_logger("transformers.models.bart.tokenization_bart")
+with CaptureLogger(logger) as cl:
+ logger.info(msg)
+assert cl.out, msg + "\n"
+```
+
+### Testing with environment variables
+
+If you want to test the impact of environment variables for a specific test you can use a helper decorator
+`transformers.testing_utils.mockenv`
+
+```python
+from transformers.testing_utils import mockenv
+
+
+class HfArgumentParserTest(unittest.TestCase):
+ @mockenv(TRANSFORMERS_VERBOSITY="error")
+ def test_env_override(self):
+ env_level_str = os.getenv("TRANSFORMERS_VERBOSITY", None)
+```
+
+At times an external program needs to be called, which requires setting `PYTHONPATH` in `os.environ` to include
+multiple local paths. A helper class `transformers.test_utils.TestCasePlus` comes to help:
+
+```python
+from transformers.testing_utils import TestCasePlus
+
+
+class EnvExampleTest(TestCasePlus):
+ def test_external_prog(self):
+ env = self.get_env()
+ # now call the external program, passing `env` to it
+```
+
+Depending on whether the test file was under the `tests` test suite or `examples` it'll correctly set up
+`env[PYTHONPATH]` to include one of these two directories, and also the `src` directory to ensure the testing is
+done against the current repo, and finally with whatever `env[PYTHONPATH]` was already set to before the test was
+called if anything.
+
+This helper method creates a copy of the `os.environ` object, so the original remains intact.
+
+
+### Getting reproducible results
+
+In some situations you may want to remove randomness for your tests. To get identical reproducable results set, you
+will need to fix the seed:
+
+```python
+seed = 42
+
+# python RNG
+import random
+
+random.seed(seed)
+
+# pytorch RNGs
+import torch
+
+torch.manual_seed(seed)
+torch.backends.cudnn.deterministic = True
+if torch.cuda.is_available():
+ torch.cuda.manual_seed_all(seed)
+
+# numpy RNG
+import numpy as np
+
+np.random.seed(seed)
+
+# tf RNG
+tf.random.set_seed(seed)
+```
+
+### Debugging tests
+
+To start a debugger at the point of the warning, do this:
+
+```bash
+pytest tests/test_logging.py -W error::UserWarning --pdb
+```
+
+## Working with github actions workflows
+
+To trigger a self-push workflow CI job, you must:
+
+1. Create a new branch on `transformers` origin (not a fork!).
+2. The branch name has to start with either `ci_` or `ci-` (`main` triggers it too, but we can't do PRs on
+ `main`). It also gets triggered only for specific paths - you can find the up-to-date definition in case it
+ changed since this document has been written [here](https://github.com/huggingface/transformers/blob/main/.github/workflows/self-push.yml) under *push:*
+3. Create a PR from this branch.
+4. Then you can see the job appear [here](https://github.com/huggingface/transformers/actions/workflows/self-push.yml). It may not run right away if there
+ is a backlog.
+
+
+
+
+## Testing Experimental CI Features
+
+Testing CI features can be potentially problematic as it can interfere with the normal CI functioning. Therefore if a
+new CI feature is to be added, it should be done as following.
+
+1. Create a new dedicated job that tests what needs to be tested
+2. The new job must always succeed so that it gives us a green ✓ (details below).
+3. Let it run for some days to see that a variety of different PR types get to run on it (user fork branches,
+ non-forked branches, branches originating from github.com UI direct file edit, various forced pushes, etc. - there
+ are so many) while monitoring the experimental job's logs (not the overall job green as it's purposefully always
+ green)
+4. When it's clear that everything is solid, then merge the new changes into existing jobs.
+
+That way experiments on CI functionality itself won't interfere with the normal workflow.
+
+Now how can we make the job always succeed while the new CI feature is being developed?
+
+Some CIs, like TravisCI support ignore-step-failure and will report the overall job as successful, but CircleCI and
+Github Actions as of this writing don't support that.
+
+So the following workaround can be used:
+
+1. `set +euo pipefail` at the beginning of the run command to suppress most potential failures in the bash script.
+2. the last command must be a success: `echo "done"` or just `true` will do
+
+Here is an example:
+
+```yaml
+- run:
+ name: run CI experiment
+ command: |
+ set +euo pipefail
+ echo "setting run-all-despite-any-errors-mode"
+ this_command_will_fail
+ echo "but bash continues to run"
+ # emulate another failure
+ false
+ # but the last command must be a success
+ echo "during experiment do not remove: reporting success to CI, even if there were failures"
+```
+
+For simple commands you could also do:
+
+```bash
+cmd_that_may_fail || true
+```
+
+Of course, once satisfied with the results, integrate the experimental step or job with the rest of the normal jobs,
+while removing `set +euo pipefail` or any other things you may have added to ensure that the experimental job doesn't
+interfere with the normal CI functioning.
+
+This whole process would have been much easier if we only could set something like `allow-failure` for the
+experimental step, and let it fail without impacting the overall status of PRs. But as mentioned earlier CircleCI and
+Github Actions don't support it at the moment.
+
+You can vote for this feature and see where it is at at these CI-specific threads:
+
+- [Github Actions:](https://github.com/actions/toolkit/issues/399)
+- [CircleCI:](https://ideas.circleci.com/ideas/CCI-I-344)
diff --git a/docs/source/en/tokenizer_summary.mdx b/docs/source/en/tokenizer_summary.mdx
new file mode 100644
index 00000000000000..78278390302b0a
--- /dev/null
+++ b/docs/source/en/tokenizer_summary.mdx
@@ -0,0 +1,278 @@
+
+
+# Summary of the tokenizers
+
+[[open-in-colab]]
+
+On this page, we will have a closer look at tokenization.
+
+
+
+As we saw in [the preprocessing tutorial](preprocessing), tokenizing a text is splitting it into words or
+subwords, which then are converted to ids through a look-up table. Converting words or subwords to ids is
+straightforward, so in this summary, we will focus on splitting a text into words or subwords (i.e. tokenizing a text).
+More specifically, we will look at the three main types of tokenizers used in 🤗 Transformers: [Byte-Pair Encoding
+(BPE)](#byte-pair-encoding), [WordPiece](#wordpiece), and [SentencePiece](#sentencepiece), and show examples
+of which tokenizer type is used by which model.
+
+Note that on each model page, you can look at the documentation of the associated tokenizer to know which tokenizer
+type was used by the pretrained model. For instance, if we look at [`BertTokenizer`], we can see
+that the model uses [WordPiece](#wordpiece).
+
+## Introduction
+
+Splitting a text into smaller chunks is a task that is harder than it looks, and there are multiple ways of doing so.
+For instance, let's look at the sentence `"Don't you love 🤗 Transformers? We sure do."`
+
+
+
+A simple way of tokenizing this text is to split it by spaces, which would give:
+
+```
+["Don't", "you", "love", "🤗", "Transformers?", "We", "sure", "do."]
+```
+
+This is a sensible first step, but if we look at the tokens `"Transformers?"` and `"do."`, we notice that the
+punctuation is attached to the words `"Transformer"` and `"do"`, which is suboptimal. We should take the
+punctuation into account so that a model does not have to learn a different representation of a word and every possible
+punctuation symbol that could follow it, which would explode the number of representations the model has to learn.
+Taking punctuation into account, tokenizing our exemplary text would give:
+
+```
+["Don", "'", "t", "you", "love", "🤗", "Transformers", "?", "We", "sure", "do", "."]
+```
+
+Better. However, it is disadvantageous, how the tokenization dealt with the word `"Don't"`. `"Don't"` stands for
+`"do not"`, so it would be better tokenized as `["Do", "n't"]`. This is where things start getting complicated, and
+part of the reason each model has its own tokenizer type. Depending on the rules we apply for tokenizing a text, a
+different tokenized output is generated for the same text. A pretrained model only performs properly if you feed it an
+input that was tokenized with the same rules that were used to tokenize its training data.
+
+[spaCy](https://spacy.io/) and [Moses](http://www.statmt.org/moses/?n=Development.GetStarted) are two popular
+rule-based tokenizers. Applying them on our example, *spaCy* and *Moses* would output something like:
+
+```
+["Do", "n't", "you", "love", "🤗", "Transformers", "?", "We", "sure", "do", "."]
+```
+
+As can be seen space and punctuation tokenization, as well as rule-based tokenization, is used here. Space and
+punctuation tokenization and rule-based tokenization are both examples of word tokenization, which is loosely defined
+as splitting sentences into words. While it's the most intuitive way to split texts into smaller chunks, this
+tokenization method can lead to problems for massive text corpora. In this case, space and punctuation tokenization
+usually generates a very big vocabulary (the set of all unique words and tokens used). *E.g.*, [Transformer XL](model_doc/transformerxl) uses space and punctuation tokenization, resulting in a vocabulary size of 267,735!
+
+Such a big vocabulary size forces the model to have an enormous embedding matrix as the input and output layer, which
+causes both an increased memory and time complexity. In general, transformers models rarely have a vocabulary size
+greater than 50,000, especially if they are pretrained only on a single language.
+
+So if simple space and punctuation tokenization is unsatisfactory, why not simply tokenize on characters?
+
+
+
+While character tokenization is very simple and would greatly reduce memory and time complexity it makes it much harder
+for the model to learn meaningful input representations. *E.g.* learning a meaningful context-independent
+representation for the letter `"t"` is much harder than learning a context-independent representation for the word
+`"today"`. Therefore, character tokenization is often accompanied by a loss of performance. So to get the best of
+both worlds, transformers models use a hybrid between word-level and character-level tokenization called **subword**
+tokenization.
+
+### Subword tokenization
+
+
+
+Subword tokenization algorithms rely on the principle that frequently used words should not be split into smaller
+subwords, but rare words should be decomposed into meaningful subwords. For instance `"annoyingly"` might be
+considered a rare word and could be decomposed into `"annoying"` and `"ly"`. Both `"annoying"` and `"ly"` as
+stand-alone subwords would appear more frequently while at the same time the meaning of `"annoyingly"` is kept by the
+composite meaning of `"annoying"` and `"ly"`. This is especially useful in agglutinative languages such as Turkish,
+where you can form (almost) arbitrarily long complex words by stringing together subwords.
+
+Subword tokenization allows the model to have a reasonable vocabulary size while being able to learn meaningful
+context-independent representations. In addition, subword tokenization enables the model to process words it has never
+seen before, by decomposing them into known subwords. For instance, the [`~transformers.BertTokenizer`] tokenizes
+`"I have a new GPU!"` as follows:
+
+```py
+>>> from transformers import BertTokenizer
+
+>>> tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
+>>> tokenizer.tokenize("I have a new GPU!")
+["i", "have", "a", "new", "gp", "##u", "!"]
+```
+
+Because we are considering the uncased model, the sentence was lowercased first. We can see that the words `["i", "have", "a", "new"]` are present in the tokenizer's vocabulary, but the word `"gpu"` is not. Consequently, the
+tokenizer splits `"gpu"` into known subwords: `["gp" and "##u"]`. `"##"` means that the rest of the token should
+be attached to the previous one, without space (for decoding or reversal of the tokenization).
+
+As another example, [`~transformers.XLNetTokenizer`] tokenizes our previously exemplary text as follows:
+
+```py
+>>> from transformers import XLNetTokenizer
+
+>>> tokenizer = XLNetTokenizer.from_pretrained("xlnet-base-cased")
+>>> tokenizer.tokenize("Don't you love 🤗 Transformers? We sure do.")
+["▁Don", "'", "t", "▁you", "▁love", "▁", "🤗", "▁", "Transform", "ers", "?", "▁We", "▁sure", "▁do", "."]
+```
+
+We'll get back to the meaning of those `"▁"` when we look at [SentencePiece](#sentencepiece). As one can see,
+the rare word `"Transformers"` has been split into the more frequent subwords `"Transform"` and `"ers"`.
+
+Let's now look at how the different subword tokenization algorithms work. Note that all of those tokenization
+algorithms rely on some form of training which is usually done on the corpus the corresponding model will be trained
+on.
+
+
+
+## Byte-Pair Encoding (BPE)
+
+Byte-Pair Encoding (BPE) was introduced in [Neural Machine Translation of Rare Words with Subword Units (Sennrich et
+al., 2015)](https://arxiv.org/abs/1508.07909). BPE relies on a pre-tokenizer that splits the training data into
+words. Pretokenization can be as simple as space tokenization, e.g. [GPT-2](model_doc/gpt2), [Roberta](model_doc/roberta). More advanced pre-tokenization include rule-based tokenization, e.g. [XLM](model_doc/xlm),
+[FlauBERT](model_doc/flaubert) which uses Moses for most languages, or [GPT](model_doc/gpt) which uses
+Spacy and ftfy, to count the frequency of each word in the training corpus.
+
+After pre-tokenization, a set of unique words has been created and the frequency of each word it occurred in the
+training data has been determined. Next, BPE creates a base vocabulary consisting of all symbols that occur in the set
+of unique words and learns merge rules to form a new symbol from two symbols of the base vocabulary. It does so until
+the vocabulary has attained the desired vocabulary size. Note that the desired vocabulary size is a hyperparameter to
+define before training the tokenizer.
+
+As an example, let's assume that after pre-tokenization, the following set of words including their frequency has been
+determined:
+
+```
+("hug", 10), ("pug", 5), ("pun", 12), ("bun", 4), ("hugs", 5)
+```
+
+Consequently, the base vocabulary is `["b", "g", "h", "n", "p", "s", "u"]`. Splitting all words into symbols of the
+base vocabulary, we obtain:
+
+```
+("h" "u" "g", 10), ("p" "u" "g", 5), ("p" "u" "n", 12), ("b" "u" "n", 4), ("h" "u" "g" "s", 5)
+```
+
+BPE then counts the frequency of each possible symbol pair and picks the symbol pair that occurs most frequently. In
+the example above `"h"` followed by `"u"` is present _10 + 5 = 15_ times (10 times in the 10 occurrences of
+`"hug"`, 5 times in the 5 occurrences of `"hugs"`). However, the most frequent symbol pair is `"u"` followed by
+`"g"`, occurring _10 + 5 + 5 = 20_ times in total. Thus, the first merge rule the tokenizer learns is to group all
+`"u"` symbols followed by a `"g"` symbol together. Next, `"ug"` is added to the vocabulary. The set of words then
+becomes
+
+```
+("h" "ug", 10), ("p" "ug", 5), ("p" "u" "n", 12), ("b" "u" "n", 4), ("h" "ug" "s", 5)
+```
+
+BPE then identifies the next most common symbol pair. It's `"u"` followed by `"n"`, which occurs 16 times. `"u"`,
+`"n"` is merged to `"un"` and added to the vocabulary. The next most frequent symbol pair is `"h"` followed by
+`"ug"`, occurring 15 times. Again the pair is merged and `"hug"` can be added to the vocabulary.
+
+At this stage, the vocabulary is `["b", "g", "h", "n", "p", "s", "u", "ug", "un", "hug"]` and our set of unique words
+is represented as
+
+```
+("hug", 10), ("p" "ug", 5), ("p" "un", 12), ("b" "un", 4), ("hug" "s", 5)
+```
+
+Assuming, that the Byte-Pair Encoding training would stop at this point, the learned merge rules would then be applied
+to new words (as long as those new words do not include symbols that were not in the base vocabulary). For instance,
+the word `"bug"` would be tokenized to `["b", "ug"]` but `"mug"` would be tokenized as `["", "ug"]` since
+the symbol `"m"` is not in the base vocabulary. In general, single letters such as `"m"` are not replaced by the
+`""` symbol because the training data usually includes at least one occurrence of each letter, but it is likely
+to happen for very special characters like emojis.
+
+As mentioned earlier, the vocabulary size, *i.e.* the base vocabulary size + the number of merges, is a hyperparameter
+to choose. For instance [GPT](model_doc/gpt) has a vocabulary size of 40,478 since they have 478 base characters
+and chose to stop training after 40,000 merges.
+
+### Byte-level BPE
+
+A base vocabulary that includes all possible base characters can be quite large if *e.g.* all unicode characters are
+considered as base characters. To have a better base vocabulary, [GPT-2](https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf) uses bytes
+as the base vocabulary, which is a clever trick to force the base vocabulary to be of size 256 while ensuring that
+every base character is included in the vocabulary. With some additional rules to deal with punctuation, the GPT2's
+tokenizer can tokenize every text without the need for the symbol. [GPT-2](model_doc/gpt) has a vocabulary
+size of 50,257, which corresponds to the 256 bytes base tokens, a special end-of-text token and the symbols learned
+with 50,000 merges.
+
+
+
+#### WordPiece
+
+WordPiece is the subword tokenization algorithm used for [BERT](model_doc/bert), [DistilBERT](model_doc/distilbert), and [Electra](model_doc/electra). The algorithm was outlined in [Japanese and Korean
+Voice Search (Schuster et al., 2012)](https://static.googleusercontent.com/media/research.google.com/ja//pubs/archive/37842.pdf) and is very similar to
+BPE. WordPiece first initializes the vocabulary to include every character present in the training data and
+progressively learns a given number of merge rules. In contrast to BPE, WordPiece does not choose the most frequent
+symbol pair, but the one that maximizes the likelihood of the training data once added to the vocabulary.
+
+So what does this mean exactly? Referring to the previous example, maximizing the likelihood of the training data is
+equivalent to finding the symbol pair, whose probability divided by the probabilities of its first symbol followed by
+its second symbol is the greatest among all symbol pairs. *E.g.* `"u"`, followed by `"g"` would have only been
+merged if the probability of `"ug"` divided by `"u"`, `"g"` would have been greater than for any other symbol
+pair. Intuitively, WordPiece is slightly different to BPE in that it evaluates what it _loses_ by merging two symbols
+to ensure it's _worth it_.
+
+
+
+#### Unigram
+
+Unigram is a subword tokenization algorithm introduced in [Subword Regularization: Improving Neural Network Translation
+Models with Multiple Subword Candidates (Kudo, 2018)](https://arxiv.org/pdf/1804.10959.pdf). In contrast to BPE or
+WordPiece, Unigram initializes its base vocabulary to a large number of symbols and progressively trims down each
+symbol to obtain a smaller vocabulary. The base vocabulary could for instance correspond to all pre-tokenized words and
+the most common substrings. Unigram is not used directly for any of the models in the transformers, but it's used in
+conjunction with [SentencePiece](#sentencepiece).
+
+At each training step, the Unigram algorithm defines a loss (often defined as the log-likelihood) over the training
+data given the current vocabulary and a unigram language model. Then, for each symbol in the vocabulary, the algorithm
+computes how much the overall loss would increase if the symbol was to be removed from the vocabulary. Unigram then
+removes p (with p usually being 10% or 20%) percent of the symbols whose loss increase is the lowest, *i.e.* those
+symbols that least affect the overall loss over the training data. This process is repeated until the vocabulary has
+reached the desired size. The Unigram algorithm always keeps the base characters so that any word can be tokenized.
+
+Because Unigram is not based on merge rules (in contrast to BPE and WordPiece), the algorithm has several ways of
+tokenizing new text after training. As an example, if a trained Unigram tokenizer exhibits the vocabulary:
+
+```
+["b", "g", "h", "n", "p", "s", "u", "ug", "un", "hug"],
+```
+
+`"hugs"` could be tokenized both as `["hug", "s"]`, `["h", "ug", "s"]` or `["h", "u", "g", "s"]`. So which one
+to choose? Unigram saves the probability of each token in the training corpus on top of saving the vocabulary so that
+the probability of each possible tokenization can be computed after training. The algorithm simply picks the most
+likely tokenization in practice, but also offers the possibility to sample a possible tokenization according to their
+probabilities.
+
+Those probabilities are defined by the loss the tokenizer is trained on. Assuming that the training data consists of
+the words \\(x_{1}, \dots, x_{N}\\) and that the set of all possible tokenizations for a word \\(x_{i}\\) is
+defined as \\(S(x_{i})\\), then the overall loss is defined as
+
+$$\mathcal{L} = -\sum_{i=1}^{N} \log \left ( \sum_{x \in S(x_{i})} p(x) \right )$$
+
+
+
+#### SentencePiece
+
+All tokenization algorithms described so far have the same problem: It is assumed that the input text uses spaces to
+separate words. However, not all languages use spaces to separate words. One possible solution is to use language
+specific pre-tokenizers, *e.g.* [XLM](model_doc/xlm) uses a specific Chinese, Japanese, and Thai pre-tokenizer).
+To solve this problem more generally, [SentencePiece: A simple and language independent subword tokenizer and
+detokenizer for Neural Text Processing (Kudo et al., 2018)](https://arxiv.org/pdf/1808.06226.pdf) treats the input
+as a raw input stream, thus including the space in the set of characters to use. It then uses the BPE or unigram
+algorithm to construct the appropriate vocabulary.
+
+The [`XLNetTokenizer`] uses SentencePiece for example, which is also why in the example earlier the
+`"▁"` character was included in the vocabulary. Decoding with SentencePiece is very easy since all tokens can just be
+concatenated and `"▁"` is replaced by a space.
+
+All transformers models in the library that use SentencePiece use it in combination with unigram. Examples of models
+using SentencePiece are [ALBERT](model_doc/albert), [XLNet](model_doc/xlnet), [Marian](model_doc/marian), and [T5](model_doc/t5).
diff --git a/docs/source/en/training.mdx b/docs/source/en/training.mdx
new file mode 100644
index 00000000000000..0d3648a9255145
--- /dev/null
+++ b/docs/source/en/training.mdx
@@ -0,0 +1,374 @@
+
+
+# Fine-tune a pretrained model
+
+[[open-in-colab]]
+
+There are significant benefits to using a pretrained model. It reduces computation costs, your carbon footprint, and allows you to use state-of-the-art models without having to train one from scratch. 🤗 Transformers provides access to thousands of pretrained models for a wide range of tasks. When you use a pretrained model, you train it on a dataset specific to your task. This is known as fine-tuning, an incredibly powerful training technique. In this tutorial, you will fine-tune a pretrained model with a deep learning framework of your choice:
+
+* Fine-tune a pretrained model with 🤗 Transformers [`Trainer`].
+* Fine-tune a pretrained model in TensorFlow with Keras.
+* Fine-tune a pretrained model in native PyTorch.
+
+
+
+## Prepare a dataset
+
+
+
+Before you can fine-tune a pretrained model, download a dataset and prepare it for training. The previous tutorial showed you how to process data for training, and now you get an opportunity to put those skills to the test!
+
+Begin by loading the [Yelp Reviews](https://huggingface.co/datasets/yelp_review_full) dataset:
+
+```py
+>>> from datasets import load_dataset
+
+>>> dataset = load_dataset("yelp_review_full")
+>>> dataset["train"][100]
+{'label': 0,
+ 'text': 'My expectations for McDonalds are t rarely high. But for one to still fail so spectacularly...that takes something special!\\nThe cashier took my friends\'s order, then promptly ignored me. I had to force myself in front of a cashier who opened his register to wait on the person BEHIND me. I waited over five minutes for a gigantic order that included precisely one kid\'s meal. After watching two people who ordered after me be handed their food, I asked where mine was. The manager started yelling at the cashiers for \\"serving off their orders\\" when they didn\'t have their food. But neither cashier was anywhere near those controls, and the manager was the one serving food to customers and clearing the boards.\\nThe manager was rude when giving me my order. She didn\'t make sure that I had everything ON MY RECEIPT, and never even had the decency to apologize that I felt I was getting poor service.\\nI\'ve eaten at various McDonalds restaurants for over 30 years. I\'ve worked at more than one location. I expect bad days, bad moods, and the occasional mistake. But I have yet to have a decent experience at this store. It will remain a place I avoid unless someone in my party needs to avoid illness from low blood sugar. Perhaps I should go back to the racially biased service of Steak n Shake instead!'}
+```
+
+As you now know, you need a tokenizer to process the text and include a padding and truncation strategy to handle any variable sequence lengths. To process your dataset in one step, use 🤗 Datasets [`map`](https://huggingface.co/docs/datasets/process.html#map) method to apply a preprocessing function over the entire dataset:
+
+```py
+>>> from transformers import AutoTokenizer
+
+>>> tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
+
+
+>>> def tokenize_function(examples):
+... return tokenizer(examples["text"], padding="max_length", truncation=True)
+
+
+>>> tokenized_datasets = dataset.map(tokenize_function, batched=True)
+```
+
+If you like, you can create a smaller subset of the full dataset to fine-tune on to reduce the time it takes:
+
+```py
+>>> small_train_dataset = tokenized_datasets["train"].shuffle(seed=42).select(range(1000))
+>>> small_eval_dataset = tokenized_datasets["test"].shuffle(seed=42).select(range(1000))
+```
+
+
+
+## Train
+
+
+
+
+
+🤗 Transformers provides a [`Trainer`] class optimized for training 🤗 Transformers models, making it easier to start training without manually writing your own training loop. The [`Trainer`] API supports a wide range of training options and features such as logging, gradient accumulation, and mixed precision.
+
+Start by loading your model and specify the number of expected labels. From the Yelp Review [dataset card](https://huggingface.co/datasets/yelp_review_full#data-fields), you know there are five labels:
+
+```py
+>>> from transformers import AutoModelForSequenceClassification
+
+>>> model = AutoModelForSequenceClassification.from_pretrained("bert-base-cased", num_labels=5)
+```
+
+
+
+You will see a warning about some of the pretrained weights not being used and some weights being randomly
+initialized. Don't worry, this is completely normal! The pretrained head of the BERT model is discarded, and replaced with a randomly initialized classification head. You will fine-tune this new model head on your sequence classification task, transferring the knowledge of the pretrained model to it.
+
+
+
+### Training hyperparameters
+
+Next, create a [`TrainingArguments`] class which contains all the hyperparameters you can tune as well as flags for activating different training options. For this tutorial you can start with the default training [hyperparameters](https://huggingface.co/docs/transformers/main_classes/trainer#transformers.TrainingArguments), but feel free to experiment with these to find your optimal settings.
+
+Specify where to save the checkpoints from your training:
+
+```py
+>>> from transformers import TrainingArguments
+
+>>> training_args = TrainingArguments(output_dir="test_trainer")
+```
+
+### Metrics
+
+[`Trainer`] does not automatically evaluate model performance during training. You will need to pass [`Trainer`] a function to compute and report metrics. The 🤗 Datasets library provides a simple [`accuracy`](https://huggingface.co/metrics/accuracy) function you can load with the `load_metric` (see this [tutorial](https://huggingface.co/docs/datasets/metrics.html) for more information) function:
+
+```py
+>>> import numpy as np
+>>> from datasets import load_metric
+
+>>> metric = load_metric("accuracy")
+```
+
+Call `compute` on `metric` to calculate the accuracy of your predictions. Before passing your predictions to `compute`, you need to convert the predictions to logits (remember all 🤗 Transformers models return logits):
+
+```py
+>>> def compute_metrics(eval_pred):
+... logits, labels = eval_pred
+... predictions = np.argmax(logits, axis=-1)
+... return metric.compute(predictions=predictions, references=labels)
+```
+
+If you'd like to monitor your evaluation metrics during fine-tuning, specify the `evaluation_strategy` parameter in your training arguments to report the evaluation metric at the end of each epoch:
+
+```py
+>>> from transformers import TrainingArguments, Trainer
+
+>>> training_args = TrainingArguments(output_dir="test_trainer", evaluation_strategy="epoch")
+```
+
+### Trainer
+
+Create a [`Trainer`] object with your model, training arguments, training and test datasets, and evaluation function:
+
+```py
+>>> trainer = Trainer(
+... model=model,
+... args=training_args,
+... train_dataset=small_train_dataset,
+... eval_dataset=small_eval_dataset,
+... compute_metrics=compute_metrics,
+... )
+```
+
+Then fine-tune your model by calling [`~transformers.Trainer.train`]:
+
+```py
+>>> trainer.train()
+```
+
+
+
+
+
+
+🤗 Transformers models also supports training in TensorFlow with the Keras API.
+
+### Convert dataset to TensorFlow format
+
+The [`DefaultDataCollator`] assembles tensors into a batch for the model to train on. Make sure you specify `return_tensors` to return TensorFlow tensors:
+
+```py
+>>> from transformers import DefaultDataCollator
+
+>>> data_collator = DefaultDataCollator(return_tensors="tf")
+```
+
+
+
+[`Trainer`] uses [`DataCollatorWithPadding`] by default so you don't need to explicitly specify a data collator.
+
+
+
+Next, convert the tokenized datasets to TensorFlow datasets with the [`to_tf_dataset`](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.to_tf_dataset) method. Specify your inputs in `columns`, and your label in `label_cols`:
+
+```py
+>>> tf_train_dataset = small_train_dataset.to_tf_dataset(
+... columns=["attention_mask", "input_ids", "token_type_ids"],
+... label_cols=["labels"],
+... shuffle=True,
+... collate_fn=data_collator,
+... batch_size=8,
+... )
+
+>>> tf_validation_dataset = small_eval_dataset.to_tf_dataset(
+... columns=["attention_mask", "input_ids", "token_type_ids"],
+... label_cols=["labels"],
+... shuffle=False,
+... collate_fn=data_collator,
+... batch_size=8,
+... )
+```
+
+### Compile and fit
+
+Load a TensorFlow model with the expected number of labels:
+
+```py
+>>> import tensorflow as tf
+>>> from transformers import TFAutoModelForSequenceClassification
+
+>>> model = TFAutoModelForSequenceClassification.from_pretrained("bert-base-cased", num_labels=5)
+```
+
+Then compile and fine-tune your model with [`fit`](https://keras.io/api/models/model_training_apis/) as you would with any other Keras model:
+
+```py
+>>> model.compile(
+... optimizer=tf.keras.optimizers.Adam(learning_rate=5e-5),
+... loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
+... metrics=tf.metrics.SparseCategoricalAccuracy(),
+... )
+
+>>> model.fit(tf_train_dataset, validation_data=tf_validation_dataset, epochs=3)
+```
+
+
+
+
+
+## Train in native PyTorch
+
+
+
+
+
+[`Trainer`] takes care of the training loop and allows you to fine-tune a model in a single line of code. For users who prefer to write their own training loop, you can also fine-tune a 🤗 Transformers model in native PyTorch.
+
+At this point, you may need to restart your notebook or execute the following code to free some memory:
+
+```py
+del model
+del pytorch_model
+del trainer
+torch.cuda.empty_cache()
+```
+
+Next, manually postprocess `tokenized_dataset` to prepare it for training.
+
+1. Remove the `text` column because the model does not accept raw text as an input:
+
+ ```py
+ >>> tokenized_datasets = tokenized_datasets.remove_columns(["text"])
+ ```
+
+2. Rename the `label` column to `labels` because the model expects the argument to be named `labels`:
+
+ ```py
+ >>> tokenized_datasets = tokenized_datasets.rename_column("label", "labels")
+ ```
+
+3. Set the format of the dataset to return PyTorch tensors instead of lists:
+
+ ```py
+ >>> tokenized_datasets.set_format("torch")
+ ```
+
+Then create a smaller subset of the dataset as previously shown to speed up the fine-tuning:
+
+```py
+>>> small_train_dataset = tokenized_datasets["train"].shuffle(seed=42).select(range(1000))
+>>> small_eval_dataset = tokenized_datasets["test"].shuffle(seed=42).select(range(1000))
+```
+
+### DataLoader
+
+Create a `DataLoader` for your training and test datasets so you can iterate over batches of data:
+
+```py
+>>> from torch.utils.data import DataLoader
+
+>>> train_dataloader = DataLoader(small_train_dataset, shuffle=True, batch_size=8)
+>>> eval_dataloader = DataLoader(small_eval_dataset, batch_size=8)
+```
+
+Load your model with the number of expected labels:
+
+```py
+>>> from transformers import AutoModelForSequenceClassification
+
+>>> model = AutoModelForSequenceClassification.from_pretrained("bert-base-cased", num_labels=5)
+```
+
+### Optimizer and learning rate scheduler
+
+Create an optimizer and learning rate scheduler to fine-tune the model. Let's use the [`AdamW`](https://pytorch.org/docs/stable/generated/torch.optim.AdamW.html) optimizer from PyTorch:
+
+```py
+>>> from torch.optim import AdamW
+
+>>> optimizer = AdamW(model.parameters(), lr=5e-5)
+```
+
+Create the default learning rate scheduler from [`Trainer`]:
+
+```py
+>>> from transformers import get_scheduler
+
+>>> num_epochs = 3
+>>> num_training_steps = num_epochs * len(train_dataloader)
+>>> lr_scheduler = get_scheduler(
+... name="linear", optimizer=optimizer, num_warmup_steps=0, num_training_steps=num_training_steps
+... )
+```
+
+Lastly, specify `device` to use a GPU if you have access to one. Otherwise, training on a CPU may take several hours instead of a couple of minutes.
+
+```py
+>>> import torch
+
+>>> device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
+>>> model.to(device)
+```
+
+
+
+Get free access to a cloud GPU if you don't have one with a hosted notebook like [Colaboratory](https://colab.research.google.com/) or [SageMaker StudioLab](https://studiolab.sagemaker.aws/).
+
+
+
+Great, now you are ready to train! 🥳
+
+### Training loop
+
+To keep track of your training progress, use the [tqdm](https://tqdm.github.io/) library to add a progress bar over the number of training steps:
+
+```py
+>>> from tqdm.auto import tqdm
+
+>>> progress_bar = tqdm(range(num_training_steps))
+
+>>> model.train()
+>>> for epoch in range(num_epochs):
+... for batch in train_dataloader:
+... batch = {k: v.to(device) for k, v in batch.items()}
+... outputs = model(**batch)
+... loss = outputs.loss
+... loss.backward()
+
+... optimizer.step()
+... lr_scheduler.step()
+... optimizer.zero_grad()
+... progress_bar.update(1)
+```
+
+### Metrics
+
+Just like how you need to add an evaluation function to [`Trainer`], you need to do the same when you write your own training loop. But instead of calculating and reporting the metric at the end of each epoch, this time you will accumulate all the batches with [`add_batch`](https://huggingface.co/docs/datasets/package_reference/main_classes.html?highlight=add_batch#datasets.Metric.add_batch) and calculate the metric at the very end.
+
+```py
+>>> metric = load_metric("accuracy")
+>>> model.eval()
+>>> for batch in eval_dataloader:
+... batch = {k: v.to(device) for k, v in batch.items()}
+... with torch.no_grad():
+... outputs = model(**batch)
+
+... logits = outputs.logits
+... predictions = torch.argmax(logits, dim=-1)
+... metric.add_batch(predictions=predictions, references=batch["labels"])
+
+>>> metric.compute()
+```
+
+
+
+
+
+## Additional resources
+
+For more fine-tuning examples, refer to:
+
+- [🤗 Transformers Examples](https://github.com/huggingface/transformers/tree/main/examples) includes scripts
+ to train common NLP tasks in PyTorch and TensorFlow.
+
+- [🤗 Transformers Notebooks](notebooks) contains various notebooks on how to fine-tune a model for specific tasks in PyTorch and TensorFlow.
diff --git a/docs/source/en/troubleshooting.mdx b/docs/source/en/troubleshooting.mdx
new file mode 100644
index 00000000000000..ea0724cd4e2af7
--- /dev/null
+++ b/docs/source/en/troubleshooting.mdx
@@ -0,0 +1,176 @@
+
+
+# Troubleshoot
+
+Sometimes errors occur, but we are here to help! This guide covers some of the most common issues we've seen and how you can resolve them. However, this guide isn't meant to be a comprehensive collection of every 🤗 Transformers issue. For more help with troubleshooting your issue, try:
+
+
+
+1. Asking for help on the [forums](https://discuss.huggingface.co/). There are specific categories you can post your question to, like [Beginners](https://discuss.huggingface.co/c/beginners/5) or [🤗 Transformers](https://discuss.huggingface.co/c/transformers/9). Make sure you write a good descriptive forum post with some reproducible code to maximize the likelihood that your problem is solved!
+
+
+
+2. Create an [Issue](https://github.com/huggingface/transformers/issues/new/choose) on the 🤗 Transformers repository if it is a bug related to the library. Try to include as much information describing the bug as possible to help us better figure out what's wrong and how we can fix it.
+
+3. Check the [Migration](migration) guide if you use an older version of 🤗 Transformers since some important changes have been introduced between versions.
+
+For more details about troubleshooting and getting help, take a look at [Chapter 8](https://huggingface.co/course/chapter8/1?fw=pt) of the Hugging Face course.
+
+
+## Firewalled environments
+
+Some GPU instances on cloud and intranet setups are firewalled to external connections, resulting in a connection error. When your script attempts to download model weights or datasets, the download will hang and then timeout with the following message:
+
+```
+ValueError: Connection error, and we cannot find the requested files in the cached path.
+Please try again or make sure your Internet connection is on.
+```
+
+In this case, you should try to run 🤗 Transformers on [offline mode](installation#offline-mode) to avoid the connection error.
+
+## CUDA out of memory
+
+Training large models with millions of parameters can be challenging without the appropriate hardware. A common error you may encounter when the GPU runs out of memory is:
+
+```
+CUDA out of memory. Tried to allocate 256.00 MiB (GPU 0; 11.17 GiB total capacity; 9.70 GiB already allocated; 179.81 MiB free; 9.85 GiB reserved in total by PyTorch)
+```
+
+Here are some potential solutions you can try to lessen memory use:
+
+- Reduce the [`per_device_train_batch_size`](main_classes/trainer#transformers.TrainingArguments.per_device_train_batch_size) value in [`TrainingArguments`].
+- Try using [`gradient_accumulation_steps`](main_classes/trainer#transformers.TrainingArguments.gradient_accumulation_steps) in [`TrainingArguments`] to effectively increase overall batch size.
+
+
+
+Refer to the Performance [guide](performance) for more details about memory-saving techniques.
+
+
+
+## Unable to load a saved TensorFlow model
+
+TensorFlow's [model.save](https://www.tensorflow.org/tutorials/keras/save_and_load#save_the_entire_model) method will save the entire model - architecture, weights, training configuration - in a single file. However, when you load the model file again, you may run into an error because 🤗 Transformers may not load all the TensorFlow-related objects in the model file. To avoid issues with saving and loading TensorFlow models, we recommend you:
+
+- Save the model weights as a `h5` file extension with [`model.save_weights`](https://www.tensorflow.org/tutorials/keras/save_and_load#save_the_entire_model) and then reload the model with [`~TFPreTrainedModel.from_pretrained`]:
+
+```py
+>>> from transformers import TFPreTrainedModel
+>>> from tensorflow import keras
+
+>>> model.save_weights("some_folder/tf_model.h5")
+>>> model = TFPreTrainedModel.from_pretrained("some_folder")
+```
+
+- Save the model with [`~TFPretrainedModel.save_pretrained`] and load it again with [`~TFPreTrainedModel.from_pretrained`]:
+
+```py
+>>> from transformers import TFPreTrainedModel
+
+>>> model.save_pretrained("path_to/model")
+>>> model = TFPreTrainedModel.from_pretrained("path_to/model")
+```
+
+## ImportError
+
+Another common error you may encounter, especially if it is a newly released model, is `ImportError`:
+
+```
+ImportError: cannot import name 'ImageGPTFeatureExtractor' from 'transformers' (unknown location)
+```
+
+For these error types, check to make sure you have the latest version of 🤗 Transformers installed to access the most recent models:
+
+```bash
+pip install transformers --upgrade
+```
+
+## CUDA error: device-side assert triggered
+
+Sometimes you may run into a generic CUDA error about an error in the device code.
+
+```
+RuntimeError: CUDA error: device-side assert triggered
+```
+
+You should try to run the code on a CPU first to get a more descriptive error message. Add the following environment variable to the beginning of your code to switch to a CPU:
+
+```py
+>>> import os
+
+>>> os.environ["CUDA_VISIBLE_DEVICES"] = ""
+```
+
+Another option is to get a better traceback from the GPU. Add the following environment variable to the beginning of your code to get the traceback to point to the source of the error:
+
+```py
+>>> import os
+
+>>> os.environ["CUDA_LAUNCH_BLOCKING"] = "1"
+```
+
+## Incorrect output when padding tokens aren't masked
+
+In some cases, the output `hidden_state` may be incorrect if the `input_ids` include padding tokens. To demonstrate, load a model and tokenizer. You can access a model's `pad_token_id` to see its value. The `pad_token_id` may be `None` for some models, but you can always manually set it.
+
+```py
+>>> from transformers import AutoModelForSequenceClassification
+>>> import torch
+
+>>> model = AutoModelForSequenceClassification.from_pretrained("bert-base-uncased")
+>>> model.config.pad_token_id
+0
+```
+
+The following example shows the output without masking the padding tokens:
+
+```py
+>>> input_ids = torch.tensor([[7592, 2057, 2097, 2393, 9611, 2115], [7592, 0, 0, 0, 0, 0]])
+>>> output = model(input_ids)
+>>> print(output.logits)
+tensor([[ 0.0082, -0.2307],
+ [ 0.1317, -0.1683]], grad_fn=)
+```
+
+Here is the actual output of the second sequence:
+
+```py
+>>> input_ids = torch.tensor([[7592]])
+>>> output = model(input_ids)
+>>> print(output.logits)
+tensor([[-0.1008, -0.4061]], grad_fn=)
+```
+
+Most of the time, you should provide an `attention_mask` to your model to ignore the padding tokens to avoid this silent error. Now the output of the second sequence matches its actual output:
+
+
+
+By default, the tokenizer creates an `attention_mask` for you based on your specific tokenizer's defaults.
+
+
+
+```py
+>>> attention_mask = torch.tensor([[1, 1, 1, 1, 1, 1], [1, 0, 0, 0, 0, 0]])
+>>> output = model(input_ids, attention_mask=attention_mask)
+>>> print(output.logits)
+tensor([[ 0.0082, -0.2307],
+ [-0.1008, -0.4061]], grad_fn=)
+```
+
+🤗 Transformers doesn't automatically create an `attention_mask` to mask a padding token if it is provided because:
+
+- Some models don't have a padding token.
+- For some use-cases, users want a model to attend to a padding token.
\ No newline at end of file
diff --git a/docs/source/es/_config.py b/docs/source/es/_config.py
new file mode 100644
index 00000000000000..cd76263e9a5cb2
--- /dev/null
+++ b/docs/source/es/_config.py
@@ -0,0 +1,14 @@
+# docstyle-ignore
+INSTALL_CONTENT = """
+# Transformers installation
+! pip install transformers datasets
+# To install from source instead of the last release, comment the command above and uncomment the following one.
+# ! pip install git+https://github.com/huggingface/transformers.git
+"""
+
+notebook_first_cells = [{"type": "code", "content": INSTALL_CONTENT}]
+black_avoid_patterns = {
+ "{processor_class}": "FakeProcessorClass",
+ "{model_class}": "FakeModelClass",
+ "{object_class}": "FakeObjectClass",
+}
diff --git a/docs/source/es/_toctree.yml b/docs/source/es/_toctree.yml
new file mode 100644
index 00000000000000..f5f44df54fd942
--- /dev/null
+++ b/docs/source/es/_toctree.yml
@@ -0,0 +1,19 @@
+- sections:
+ - local: quicktour
+ title: Quick tour
+ - local: installation
+ title: Instalación
+ title: Get started
+- sections:
+ - local: pipeline_tutorial
+ title: Pipelines para inferencia
+ - local: autoclass_tutorial
+ title: Carga instancias preentrenadas con un AutoClass
+ - local: training
+ title: Fine-tuning a un modelo pre-entrenado
+ - local: accelerate
+ title: Entrenamiento distribuido con 🤗 Accelerate
+ title: Tutorials
+- sections:
+ - local: multilingual
+ title: Modelos multilingües para inferencia
\ No newline at end of file
diff --git a/docs/source/es/accelerate.mdx b/docs/source/es/accelerate.mdx
new file mode 100644
index 00000000000000..59825cd8171839
--- /dev/null
+++ b/docs/source/es/accelerate.mdx
@@ -0,0 +1,132 @@
+
+
+# Entrenamiento distribuido con 🤗 Accelerate
+
+El paralelismo ha emergido como una estrategia para entrenar modelos grandes en hardware limitado e incrementar la velocidad de entrenamiento en varios órdenes de magnitud. En Hugging Face creamos la biblioteca [🤗 Accelerate](https://huggingface.co/docs/accelerate/index.html) para ayudar a los usuarios a entrenar modelos 🤗 Transformers en cualquier tipo de configuración distribuida, ya sea en una máquina con múltiples GPUs o en múltiples GPUs distribuidas entre muchas máquinas. En este tutorial aprenderás cómo personalizar tu bucle de entrenamiento de PyTorch nativo para poder entrenar en entornos distribuidos.
+
+## Configuración
+
+Empecemos por instalar 🤗 Accelerate:
+
+```bash
+pip install accelerate
+```
+
+Luego, importamos y creamos un objeto [`Accelerator`](https://huggingface.co/docs/accelerate/accelerator.html#accelerate.Accelerator). `Accelerator` detectará automáticamente el tipo de configuración distribuida que tengas disponible e inicializará todos los componentes necesarios para el entrenamiento. No necesitas especificar el dispositivo en donde se debe colocar tu modelo.
+
+```py
+>>> from accelerate import Accelerator
+
+>>> accelerator = Accelerator()
+```
+
+## Prepárate para acelerar
+
+Pasa todos los objetos relevantes para el entrenamiento al método [`prepare`](https://huggingface.co/docs/accelerate/accelerator.html#accelerate.Accelerator.prepare). Esto incluye los DataLoaders de entrenamiento y evaluación, un modelo y un optimizador:
+
+```py
+>>> train_dataloader, eval_dataloader, model, optimizer = accelerator.prepare(
+... train_dataloader, eval_dataloader, model, optimizer
+... )
+```
+
+## Backward
+
+Por último, reemplaza el típico `loss.backward()` en tu bucle de entrenamiento con el método [`backward`](https://huggingface.co/docs/accelerate/accelerator.html#accelerate.Accelerator.backward) de 🤗 Accelerate:
+
+```py
+>>> for epoch in range(num_epochs):
+... for batch in train_dataloader:
+... outputs = model(**batch)
+... loss = outputs.loss
+... accelerator.backward(loss)
+
+... optimizer.step()
+... lr_scheduler.step()
+... optimizer.zero_grad()
+... progress_bar.update(1)
+```
+
+Como se puede ver en el siguiente código, ¡solo necesitas adicionar cuatro líneas de código a tu bucle de entrenamiento para habilitar el entrenamiento distribuido!
+
+```diff
++ from accelerate import Accelerator
+ from transformers import AdamW, AutoModelForSequenceClassification, get_scheduler
+
++ accelerator = Accelerator()
+
+ model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
+ optimizer = AdamW(model.parameters(), lr=3e-5)
+
+- device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
+- model.to(device)
+
++ train_dataloader, eval_dataloader, model, optimizer = accelerator.prepare(
++ train_dataloader, eval_dataloader, model, optimizer
++ )
+
+ num_epochs = 3
+ num_training_steps = num_epochs * len(train_dataloader)
+ lr_scheduler = get_scheduler(
+ "linear",
+ optimizer=optimizer,
+ num_warmup_steps=0,
+ num_training_steps=num_training_steps
+ )
+
+ progress_bar = tqdm(range(num_training_steps))
+
+ model.train()
+ for epoch in range(num_epochs):
+ for batch in train_dataloader:
+- batch = {k: v.to(device) for k, v in batch.items()}
+ outputs = model(**batch)
+ loss = outputs.loss
+- loss.backward()
++ accelerator.backward(loss)
+
+ optimizer.step()
+ lr_scheduler.step()
+ optimizer.zero_grad()
+ progress_bar.update(1)
+```
+
+## Entrenamiento
+
+Una vez que hayas añadido las líneas de código relevantes, inicia el entrenamiento desde un script o notebook como Colaboratory.
+
+### Entrenar con un script
+
+Si estas corriendo tu entrenamiento desde un script ejecuta el siguiente comando para crear y guardar un archivo de configuración:
+
+```bash
+accelerate config
+```
+
+Comienza el entrenamiento con:
+
+```bash
+accelerate launch train.py
+```
+
+### Entrenar con un notebook
+
+🤗 Accelerate puede correr en un notebook si, por ejemplo, estás planeando utilizar las TPUs de Colaboratory. Encierra el código responsable del entrenamiento en una función y pásalo a `notebook_launcher`:
+
+```py
+>>> from accelerate import notebook_launcher
+
+>>> notebook_launcher(training_function)
+```
+
+Para obtener más información sobre 🤗 Accelerate y sus numerosas funciones, consulta la [documentación](https://huggingface.co/docs/accelerate/index.html).
diff --git a/docs/source/es/autoclass_tutorial.mdx b/docs/source/es/autoclass_tutorial.mdx
new file mode 100644
index 00000000000000..1b24c6afbd99f1
--- /dev/null
+++ b/docs/source/es/autoclass_tutorial.mdx
@@ -0,0 +1,119 @@
+
+
+# Carga instancias preentrenadas con un AutoClass
+
+Con tantas arquitecturas diferentes de Transformer puede ser retador crear una para tu checkpoint. Como parte de la filosofía central de 🤗 Transformers para hacer que la biblioteca sea fácil, simple y flexible de usar; una `AutoClass` automáticamente infiere y carga la arquitectura correcta desde un checkpoint dado. El método `from_pretrained` te permite cargar rápidamente un modelo preentrenado para cualquier arquitectura, por lo que no tendrás que dedicar tiempo y recursos para entrenar uno desde cero. Producir este tipo de código con checkpoint implica que si funciona con uno, funcionará también con otro (siempre que haya sido entrenado para una tarea similar) incluso si la arquitectura es distinta.
+
+
+
+Recuerda, la arquitectura se refiere al esqueleto del modelo y los checkpoints son los pesos para una arquitectura dada. Por ejemplo, [BERT](https://huggingface.co/bert-base-uncased) es una arquitectura, mientras que `bert-base-uncased` es un checkpoint. Modelo es un término general que puede significar una arquitectura o un checkpoint.
+
+
+
+En este tutorial, aprende a:
+
+* Cargar un tokenizador preentrenado.
+* Cargar un extractor de características (feature extractor) preentrenado.
+* Cargar un procesador preentrenado.
+* Cargar un modelo preentrenado.
+
+## AutoTokenizer
+
+Casi cualquier tarea de Natural Language Processing comienza con un tokenizador. Un tokenizador convierte tu input a un formato que puede ser procesado por el modelo.
+
+Carga un tokenizador con [`AutoTokenizer.from_pretrained`]:
+
+```py
+>>> from transformers import AutoTokenizer
+
+>>> tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
+```
+
+Luego tokeniza tu input como lo mostrado a continuación:
+
+```py
+>>> sequence = "In a hole in the ground there lived a hobbit."
+>>> print(tokenizer(sequence))
+{'input_ids': [101, 1999, 1037, 4920, 1999, 1996, 2598, 2045, 2973, 1037, 7570, 10322, 4183, 1012, 102],
+ 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
+ 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
+```
+
+## AutoFeatureExtractor
+
+Para tareas de audio y visión, un extractor de características procesa la señal de audio o imagen al formato de input correcto.
+
+Carga un extractor de características con [`AutoFeatureExtractor.from_pretrained`]:
+
+```py
+>>> from transformers import AutoFeatureExtractor
+
+>>> feature_extractor = AutoFeatureExtractor.from_pretrained(
+... "ehcalabres/wav2vec2-lg-xlsr-en-speech-emotion-recognition"
+... )
+```
+
+## AutoProcessor
+
+Las tareas multimodales requieren un procesador que combine dos tipos de herramientas de preprocesamiento. Por ejemplo, el modelo [LayoutLMV2](model_doc/layoutlmv2) requiere que un extractor de características maneje las imágenes y que un tokenizador maneje el texto; un procesador combina ambas.
+
+Carga un procesador con [`AutoProcessor.from_pretrained`]:
+
+```py
+>>> from transformers import AutoProcessor
+
+>>> processor = AutoProcessor.from_pretrained("microsoft/layoutlmv2-base-uncased")
+```
+
+## AutoModel
+
+
+
+Finalmente, las clases `AutoModelFor` te permiten cargar un modelo preentrenado para una tarea dada (revisa [aquí](model_doc/auto) para conocer la lista completa de tareas disponibles). Por ejemplo, cargue un modelo para clasificación de secuencias con [`AutoModelForSequenceClassification.from_pretrained`]:
+
+```py
+>>> from transformers import AutoModelForSequenceClassification
+
+>>> model = AutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased")
+```
+
+Reutilice fácilmente el mismo checkpoint para cargar una aquitectura para alguna tarea diferente:
+
+```py
+>>> from transformers import AutoModelForTokenClassification
+
+>>> model = AutoModelForTokenClassification.from_pretrained("distilbert-base-uncased")
+```
+
+Generalmente recomendamos utilizar las clases `AutoTokenizer` y `AutoModelFor` para cargar instancias preentrenadas de modelos. Ésto asegurará que cargues la arquitectura correcta en cada ocasión. En el siguiente [tutorial](preprocessing), aprende a usar tu tokenizador recién cargado, el extractor de características y el procesador para preprocesar un dataset para fine-tuning.
+
+
+Finalmente, la clase `TFAutoModelFor` te permite cargar tu modelo preentrenado para una tarea dada (revisa [aquí](model_doc/auto) para conocer la lista completa de tareas disponibles). Por ejemplo, carga un modelo para clasificación de secuencias con [`TFAutoModelForSequenceClassification.from_pretrained`]:
+
+```py
+>>> from transformers import TFAutoModelForSequenceClassification
+
+>>> model = TFAutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased")
+```
+
+Reutilice fácilmente el mismo checkpoint para cargar una aquitectura para alguna tarea diferente:
+
+```py
+>>> from transformers import TFAutoModelForTokenClassification
+
+>>> model = TFAutoModelForTokenClassification.from_pretrained("distilbert-base-uncased")
+```
+
+Generalmente recomendamos utilizar las clases `AutoTokenizer` y `TFAutoModelFor` para cargar instancias de modelos preentrenados. Ésto asegurará que cargues la arquitectura correcta cada vez. En el siguiente [tutorial](preprocessing), aprende a usar tu tokenizador recién cargado, el extractor de características y el procesador para preprocesar un dataset para fine-tuning.
+
+
diff --git a/docs/source/es/installation.mdx b/docs/source/es/installation.mdx
new file mode 100644
index 00000000000000..cc7601c117cd2a
--- /dev/null
+++ b/docs/source/es/installation.mdx
@@ -0,0 +1,238 @@
+
+
+# Guía de instalación
+
+En esta guía puedes encontrar información para instalar 🤗 Transformers para cualquier biblioteca de Machine Learning con la que estés trabajando. Además, encontrarás información sobre cómo establecer el caché y cómo configurar 🤗 Transformers para correrlo de manera offline (opcional).
+
+🤗 Transformers ha sido probada en Python 3.6+, PyTorch 1.1.0+, TensorFlow 2.0+, y Flax. Para instalar la biblioteca de deep learning con la que desees trabajar, sigue las instrucciones correspondientes listadas a continuación:
+
+* [PyTorch](https://pytorch.org/get-started/locally/)
+* [TensorFlow 2.0](https://www.tensorflow.org/install/pip)
+* [Flax](https://flax.readthedocs.io/en/latest/)
+
+## Instalación con pip
+
+Es necesario instalar 🤗 Transformers en un [entorno virtual](https://docs.python.org/3/library/venv.html). Si necesitas más información sobre entornos virtuales de Python, consulta esta [guía](https://packaging.python.org/guides/installing-using-pip-and-virtual-environments/
+). Un entorno virtual facilita el manejo de proyectos y evita problemas de compatibilidad entre dependencias.
+
+Comienza por crear un entorno virtual en el directorio de tu proyecto:
+
+```bash
+python -m venv .env
+```
+
+Activa el entorno virtual:
+
+```bash
+source .env/bin/activate
+```
+
+Ahora puedes instalar 🤗 Transformers con el siguiente comando:
+
+```bash
+pip install transformers
+```
+
+Solo para CPU, puedes instalar 🤗 Transformers y una biblioteca de deep learning con un comando de una sola línea.
+
+Por ejemplo, instala 🤗 Transformers y Pytorch:
+
+```bash
+pip install transformers[torch]
+```
+
+🤗 Transformers y TensorFlow 2.0:
+
+```bash
+pip install transformers[tf-cpu]
+```
+
+🤗 Transformers y Flax:
+
+```bash
+pip install transformers[flax]
+```
+
+Por último, revisa si 🤗 Transformers ha sido instalada exitosamente con el siguiente comando que descarga un modelo pre-entrenado:
+
+```bash
+python -c "from transformers import pipeline; print(pipeline('sentiment-analysis')('we love you'))"
+```
+Después imprime la etiqueta y el puntaje:
+
+```bash
+[{'label': 'POSITIVE', 'score': 0.9998704791069031}]
+```
+
+## Instalación desde la fuente
+
+Instala 🤗 Transformers desde la fuente con el siguiente comando:
+
+```bash
+pip install git+https://github.com/huggingface/transformers
+```
+
+El comando de arriba instala la versión `master` más actual en vez de la última versión estable. La versión `master` es útil para obtener los últimos avances de 🤗 Transformers. Por ejemplo, se puede dar el caso de que un error fue corregido después de la última versión estable pero aún no se ha liberado un nuevo lanzamiento. Sin embargo, existe la posibilidad de que la versión `master` no sea estable. El equipo trata de mantener la versión `master` operacional y la mayoría de los errores son resueltos en unas cuantas horas o un día. Si encuentras algún problema, por favor abre un [Issue](https://github.com/huggingface/transformers/issues) para que pueda ser corregido más rápido.
+
+Verifica si 🤗 Transformers está instalada apropiadamente con el siguiente comando:
+
+```bash
+python -c "from transformers import pipeline; print(pipeline('sentiment-analysis')('I love you'))"
+```
+
+## Instalación editable
+
+Necesitarás una instalación editable si deseas:
+* Usar la versión `master` del código fuente.
+* Contribuir a 🤗 Transformers y necesitas probar cambios en el código.
+
+Clona el repositorio e instala 🤗 Transformers con los siguientes comandos:
+
+```bash
+git clone https://github.com/huggingface/transformers.git
+cd transformers
+pip install -e .
+```
+
+Éstos comandos van a ligar el directorio desde donde clonamos el repositorio al path de las bibliotecas de Python. Python ahora buscará dentro de la carpeta que clonaste además de los paths normales de la biblioteca. Por ejemplo, si los paquetes de Python se encuentran instalados en `~/anaconda3/envs/main/lib/python3.7/site-packages/`, Python también buscará en el directorio desde donde clonamos el repositorio `~/transformers/`.
+
+
+
+Debes mantener el directorio `transformers` si deseas seguir usando la biblioteca.
+
+
+
+Puedes actualizar tu copia local a la última versión de 🤗 Transformers con el siguiente comando:
+
+```bash
+cd ~/transformers/
+git pull
+```
+
+El entorno de Python que creaste para la instalación de 🤗 Transformers encontrará la versión `master` en la siguiente ejecución.
+
+## Instalación con conda
+
+Puedes instalar 🤗 Transformers desde el canal de conda `huggingface` con el siguiente comando:
+
+```bash
+conda install -c huggingface transformers
+```
+
+## Configuración de Caché
+
+Los modelos preentrenados se descargan y almacenan en caché localmente en: `~/.cache/huggingface/transformers/`. Este es el directorio predeterminado proporcionado por la variable de entorno de shell `TRANSFORMERS_CACHE`. En Windows, el directorio predeterminado es dado por `C:\Users\username\.cache\huggingface\transformers`. Puedes cambiar las variables de entorno de shell que se muestran a continuación, en orden de prioridad, para especificar un directorio de caché diferente:
+
+1. Variable de entorno del shell (por defecto): `TRANSFORMERS_CACHE`.
+2. Variable de entorno del shell:`HF_HOME` + `transformers/`.
+3. Variable de entorno del shell: `XDG_CACHE_HOME` + `/huggingface/transformers`.
+
+
+
+🤗 Transformers usará las variables de entorno de shell `PYTORCH_TRANSFORMERS_CACHE` o `PYTORCH_PRETRAINED_BERT_CACHE` si viene de una iteración anterior de la biblioteca y ha configurado esas variables de entorno, a menos que especifiques la variable de entorno de shell `TRANSFORMERS_CACHE`.
+
+
+
+
+## Modo Offline
+
+🤗 Transformers puede ejecutarse en un entorno con firewall o fuera de línea (offline) usando solo archivos locales. Configura la variable de entorno `TRANSFORMERS_OFFLINE=1` para habilitar este comportamiento.
+
+
+
+Puedes añadir [🤗 Datasets](https://huggingface.co/docs/datasets/) al flujo de entrenamiento offline declarando la variable de entorno `HF_DATASETS_OFFLINE=1`.
+
+
+
+Por ejemplo, normalmente ejecutarías un programa en una red normal con firewall para instancias externas con el siguiente comando:
+
+```bash
+python examples/pytorch/translation/run_translation.py --model_name_or_path t5-small --dataset_name wmt16 --dataset_config ro-en ...
+```
+
+Ejecuta este mismo programa en una instancia offline con el siguiente comando:
+
+```bash
+HF_DATASETS_OFFLINE=1 TRANSFORMERS_OFFLINE=1 \
+python examples/pytorch/translation/run_translation.py --model_name_or_path t5-small --dataset_name wmt16 --dataset_config ro-en ...
+```
+
+El script ahora debería ejecutarse sin bloquearse ni esperar a que se agote el tiempo de espera porque sabe que solo debe buscar archivos locales.
+
+### Obtener modelos y tokenizers para uso offline
+
+Otra opción para usar 🤗 Transformers offline es descargando previamente los archivos y después apuntar al path local donde se encuentren. Hay tres maneras de hacer esto:
+
+* Descarga un archivo mediante la interfaz de usuario del [Model Hub](https://huggingface.co/models) haciendo click en el ícono ↓.
+
+ 
+
+
+* Utiliza el flujo de [`PreTrainedModel.from_pretrained`] y [`PreTrainedModel.save_pretrained`]:
+ 1. Descarga previamente los archivos con [`PreTrainedModel.from_pretrained`]:
+
+ ```py
+ >>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
+
+ >>> tokenizer = AutoTokenizer.from_pretrained("bigscience/T0_3B")
+ >>> model = AutoModelForSeq2SeqLM.from_pretrained("bigscience/T0_3B")
+ ```
+
+
+ 2. Guarda los archivos en un directorio específico con [`PreTrainedModel.save_pretrained`]:
+
+ ```py
+ >>> tokenizer.save_pretrained("./your/path/bigscience_t0")
+ >>> model.save_pretrained("./your/path/bigscience_t0")
+ ```
+
+ 3. Cuando te encuentres offline, recarga los archivos con [`PreTrainedModel.from_pretrained`] desde el directorio especificado:
+
+ ```py
+ >>> tokenizer = AutoTokenizer.from_pretrained("./your/path/bigscience_t0")
+ >>> model = AutoModel.from_pretrained("./your/path/bigscience_t0")
+ ```
+
+* Descarga de manera programática los archivos con la biblioteca [huggingface_hub](https://github.com/huggingface/huggingface_hub/tree/main/src/huggingface_hub):
+
+ 1. Instala la biblioteca [huggingface_hub](https://github.com/huggingface/huggingface_hub/tree/main/src/huggingface_hub) en tu entorno virtual:
+
+ ```bash
+ python -m pip install huggingface_hub
+ ```
+
+ 2. Utiliza la función [`hf_hub_download`](https://huggingface.co/docs/hub/adding-a-library#download-files-from-the-hub) para descargar un archivo a un path específico. Por ejemplo, el siguiente comando descarga el archivo `config.json` del modelo [T0](https://huggingface.co/bigscience/T0_3B) al path deseado:
+
+ ```py
+ >>> from huggingface_hub import hf_hub_download
+
+ >>> hf_hub_download(repo_id="bigscience/T0_3B", filename="config.json", cache_dir="./your/path/bigscience_t0")
+ ```
+
+Una vez que el archivo se descargue y se almacene en caché localmente, especifica tu ruta local para cargarlo y usarlo:
+
+```py
+>>> from transformers import AutoConfig
+
+>>> config = AutoConfig.from_pretrained("./your/path/bigscience_t0/config.json")
+```
+
+
+
+Para más detalles sobre cómo descargar archivos almacenados en el Hub consulta la sección [How to download files from the Hub](https://huggingface.co/docs/hub/how-to-downstream).
+
+
diff --git a/docs/source/es/multilingual.mdx b/docs/source/es/multilingual.mdx
new file mode 100644
index 00000000000000..4849416a44db85
--- /dev/null
+++ b/docs/source/es/multilingual.mdx
@@ -0,0 +1,175 @@
+
+
+# Modelos multilingües para inferencia
+
+[[open-in-colab]]
+
+Existen varios modelos multilingües en 🤗 Transformers y su uso para inferencia difiere de los modelos monolingües. Sin embargo, no *todos* los usos de los modelos multilingües son diferentes. Algunos modelos, como [bert-base-multilingual-uncased](https://huggingface.co/bert-base-multilingual-uncased), pueden utilizarse igual que un modelo monolingüe. Esta guía te enseñará cómo utilizar modelos multilingües cuyo uso difiere en la inferencia.
+
+## XLM
+
+XLM tiene diez checkpoints diferentes de los cuales solo uno es monolingüe. Los nueve checkpoints restantes del modelo pueden dividirse en dos categorías: los checkpoints que utilizan language embeddings y los que no.
+
+### XLM con language embeddings
+
+Los siguientes modelos XLM usan language embeddings para especificar el lenguaje utilizado en la inferencia:
+
+- `xlm-mlm-ende-1024` (Masked language modeling, English-German)
+- `xlm-mlm-enfr-1024` (Masked language modeling, English-French)
+- `xlm-mlm-enro-1024` (Masked language modeling, English-Romanian)
+- `xlm-mlm-xnli15-1024` (Masked language modeling, XNLI languages)
+- `xlm-mlm-tlm-xnli15-1024` (Masked language modeling + translation, XNLI languages)
+- `xlm-clm-enfr-1024` (Causal language modeling, English-French)
+- `xlm-clm-ende-1024` (Causal language modeling, English-German)
+
+Los language embeddings son representados como un tensor de la mismas dimensiones que los `input_ids` pasados al modelo. Los valores de estos tensores dependen del idioma utilizado y se identifican mediante los atributos `lang2id` y `id2lang` del tokenizador.
+
+En este ejemplo, carga el checkpoint `xlm-clm-enfr-1024` (Causal language modeling, English-French):
+
+```py
+>>> import torch
+>>> from transformers import XLMTokenizer, XLMWithLMHeadModel
+
+>>> tokenizer = XLMTokenizer.from_pretrained("xlm-clm-enfr-1024")
+>>> model = XLMWithLMHeadModel.from_pretrained("xlm-clm-enfr-1024")
+```
+
+El atributo `lang2id` del tokenizador muestra los idiomas de este modelo y sus ids:
+
+```py
+>>> print(tokenizer.lang2id)
+{'en': 0, 'fr': 1}
+```
+
+A continuación, crea un input de ejemplo:
+
+```py
+>>> input_ids = torch.tensor([tokenizer.encode("Wikipedia was used to")]) # batch size of 1
+```
+
+Establece el id del idioma, por ejemplo `"en"`, y utilízalo para definir el language embedding. El language embedding es un tensor lleno de `0` ya que es el id del idioma para inglés. Este tensor debe ser del mismo tamaño que `input_ids`.
+
+```py
+>>> language_id = tokenizer.lang2id["en"] # 0
+>>> langs = torch.tensor([language_id] * input_ids.shape[1]) # torch.tensor([0, 0, 0, ..., 0])
+
+>>> # We reshape it to be of size (batch_size, sequence_length)
+>>> langs = langs.view(1, -1) # is now of shape [1, sequence_length] (we have a batch size of 1)
+```
+
+Ahora puedes pasar los `input_ids` y el language embedding al modelo:
+
+```py
+>>> outputs = model(input_ids, langs=langs)
+```
+
+El script [run_generation.py](https://github.com/huggingface/transformers/tree/master/examples/pytorch/text-generation/run_generation.py) puede generar texto con language embeddings utilizando los checkpoints `xlm-clm`.
+
+### XLM sin language embeddings
+
+Los siguientes modelos XLM no requieren language embeddings durante la inferencia:
+
+- `xlm-mlm-17-1280` (modelado de lenguaje enmascarado, 17 idiomas)
+- `xlm-mlm-100-1280` (modelado de lenguaje enmascarado, 100 idiomas)
+
+Estos modelos se utilizan para representaciones genéricas de frases a diferencia de los anteriores checkpoints XLM.
+
+## BERT
+
+Los siguientes modelos de BERT pueden utilizarse para tareas multilingües:
+
+- `bert-base-multilingual-uncased` (modelado de lenguaje enmascarado + predicción de la siguiente oración, 102 idiomas)
+- `bert-base-multilingual-cased` (modelado de lenguaje enmascarado + predicción de la siguiente oración, 104 idiomas)
+
+Estos modelos no requieren language embeddings durante la inferencia. Deben identificar la lengua a partir del
+contexto e inferir en consecuencia.
+
+## XLM-RoBERTa
+
+Los siguientes modelos de XLM-RoBERTa pueden utilizarse para tareas multilingües:
+
+- `xlm-roberta-base` (modelado de lenguaje enmascarado, 100 idiomas)
+- `xlm-roberta-large` (Modelado de lenguaje enmascarado, 100 idiomas)
+
+XLM-RoBERTa se entrenó con 2,5 TB de datos CommonCrawl recién creados y depurados en 100 idiomas. Proporciona fuertes ventajas sobre los modelos multilingües publicados anteriormente como mBERT o XLM en tareas posteriores como la clasificación, el etiquetado de secuencias y la respuesta a preguntas.
+
+## M2M100
+
+Los siguientes modelos de M2M100 pueden utilizarse para traducción multilingüe:
+
+- `facebook/m2m100_418M` (traducción)
+- `facebook/m2m100_1.2B` (traducción)
+
+En este ejemplo, carga el checkpoint `facebook/m2m100_418M` para traducir del chino al inglés. Puedes establecer el idioma de origen en el tokenizador:
+
+```py
+>>> from transformers import M2M100ForConditionalGeneration, M2M100Tokenizer
+
+>>> en_text = "Do not meddle in the affairs of wizards, for they are subtle and quick to anger."
+>>> chinese_text = "不要插手巫師的事務, 因為他們是微妙的, 很快就會發怒."
+
+>>> tokenizer = M2M100Tokenizer.from_pretrained("facebook/m2m100_418M", src_lang="zh")
+>>> model = M2M100ForConditionalGeneration.from_pretrained("facebook/m2m100_418M")
+```
+
+Tokeniza el texto:
+
+```py
+>>> encoded_zh = tokenizer(chinese_text, return_tensors="pt")
+```
+
+M2M100 fuerza el id del idioma de destino como el primer token generado para traducir al idioma de destino.. Establece el `forced_bos_token_id` a `en` en el método `generate` para traducir al inglés:
+
+```py
+>>> generated_tokens = model.generate(**encoded_zh, forced_bos_token_id=tokenizer.get_lang_id("en"))
+>>> tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
+'Do not interfere with the matters of the witches, because they are delicate and will soon be angry.'
+```
+
+## MBart
+
+Los siguientes modelos de MBart pueden utilizarse para traducción multilingüe:
+
+- `facebook/mbart-large-50-one-to-many-mmt` (traducción automática multilingüe de uno a muchos, 50 idiomas)
+- `facebook/mbart-large-50-many-to-many-mmt` (traducción automática multilingüe de muchos a muchos, 50 idiomas)
+- `facebook/mbart-large-50-many-to-one-mmt` (traducción automática multilingüe muchos a uno, 50 idiomas)
+- `facebook/mbart-large-50` (traducción multilingüe, 50 idiomas)
+- `facebook/mbart-large-cc25`
+
+En este ejemplo, carga el checkpoint `facebook/mbart-large-50-many-to-many-mmt` para traducir del finlandés al inglés. Puedes establecer el idioma de origen en el tokenizador:
+
+```py
+>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
+
+>>> en_text = "Do not meddle in the affairs of wizards, for they are subtle and quick to anger."
+>>> fi_text = "Älä sekaannu velhojen asioihin, sillä ne ovat hienovaraisia ja nopeasti vihaisia."
+
+>>> tokenizer = AutoTokenizer.from_pretrained("facebook/mbart-large-50-many-to-many-mmt", src_lang="fi_FI")
+>>> model = AutoModelForSeq2SeqLM.from_pretrained("facebook/mbart-large-50-many-to-many-mmt")
+```
+
+Tokeniza el texto:
+
+```py
+>>> encoded_en = tokenizer(en_text, return_tensors="pt")
+```
+
+MBart fuerza el id del idioma de destino como el primer token generado para traducirlo. Establece el `forced_bos_token_id` a `en` en el método `generate` para traducir al inglés:
+
+```py
+>>> generated_tokens = model.generate(**encoded_en, forced_bos_token_id=tokenizer.lang_code_to_id("en_XX"))
+>>> tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
+"Don't interfere with the wizard's affairs, because they are subtle, will soon get angry."
+```
+
+Si estás usando el checkpoint `facebook/mbart-large-50-many-to-one-mmt` no necesitas forzar el id del idioma de destino como el primer token generado, de lo contrario el uso es el mismo.
diff --git a/docs/source/es/pipeline_tutorial.mdx b/docs/source/es/pipeline_tutorial.mdx
new file mode 100644
index 00000000000000..c4f1778b8506b2
--- /dev/null
+++ b/docs/source/es/pipeline_tutorial.mdx
@@ -0,0 +1,139 @@
+
+
+# Pipelines para inferencia
+
+Un [pipeline] simplifica el uso de cualquier modelo del [Model Hub](https://huggingface.co/models) para la inferencia en una variedad de tareas como la generación de texto, la segmentación de imágenes y la clasificación de audio. Incluso si no tienes experiencia con una modalidad específica o no comprendes el código que alimenta los modelos, ¡aún puedes usarlos con el [pipeline]! Este tutorial te enseñará a:
+
+* Utilizar un [`pipeline`] para inferencia.
+* Utilizar un tokenizador o modelo específico.
+* Utilizar un [`pipeline`] para tareas de audio y visión.
+
+
+
+Echa un vistazo a la documentación de [`pipeline`] para obtener una lista completa de tareas admitidas.
+
+
+
+## Uso del pipeline
+
+Si bien cada tarea tiene un [`pipeline`] asociado, es más sencillo usar la abstracción general [`pipeline`] que contiene todos los pipelines de tareas específicas. El [`pipeline`] carga automáticamente un modelo predeterminado y un tokenizador con capacidad de inferencia para tu tarea.
+
+1. Comienza creando un [`pipeline`] y específica una tarea de inferencia:
+
+```py
+>>> from transformers import pipeline
+
+>>> generator = pipeline(task="text-generation")
+```
+
+2. Pasa tu texto de entrada al [`pipeline`]:
+
+```py
+>>> generator("Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone")
+[{'generated_text': 'Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone, Seven for the Iron-priests at the door to the east, and thirteen for the Lord Kings at the end of the mountain'}]
+```
+
+Si tienes más de una entrada, pásala como una lista:
+
+```py
+>>> generator(
+... [
+... "Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone",
+... "Nine for Mortal Men, doomed to die, One for the Dark Lord on his dark throne",
+... ]
+... )
+```
+
+Cualquier parámetro adicional para tu tarea también se puede incluir en el [`pipeline`]. La tarea `text-generation` tiene un método [`~generation_utils.GenerationMixin.generate`] con varios parámetros para controlar la salida. Por ejemplo, si deseas generar más de una salida, defínelo en el parámetro `num_return_sequences`:
+
+```py
+>>> generator(
+... "Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone",
+... num_return_sequences=2,
+... )
+```
+
+### Selecciona un modelo y un tokenizador
+
+El [`pipeline`] acepta cualquier modelo del [Model Hub](https://huggingface.co/models). Hay etiquetas en el Model Hub que te permiten filtrar por el modelo que te gustaría utilizar para tu tarea. Una vez que hayas elegido un modelo apropiado, cárgalo con la clase `AutoModelFor` y [`AutoTokenizer'] correspondientes. Por ejemplo, carga la clase [`AutoModelForCausalLM`] para una tarea de modelado de lenguaje causal:
+
+```py
+>>> from transformers import AutoTokenizer, AutoModelForCausalLM
+
+>>> tokenizer = AutoTokenizer.from_pretrained("distilgpt2")
+>>> model = AutoModelForCausalLM.from_pretrained("distilgpt2")
+```
+
+Crea un [`pipeline`] para tu tarea y específica el modelo y el tokenizador que cargaste:
+
+```py
+>>> from transformers import pipeline
+
+>>> generator = pipeline(task="text-generation", model=model, tokenizer=tokenizer)
+```
+
+Pasa tu texto de entrada a [`pipeline`] para generar algo de texto:
+
+```py
+>>> generator("Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone")
+[{'generated_text': 'Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone, Seven for the Dragon-lords (for them to rule in a world ruled by their rulers, and all who live within the realm'}]
+```
+
+## Pipeline de audio
+
+La flexibilidad de [`pipeline`] significa que también se puede extender a tareas de audio.
+
+Por ejemplo, clasifiquemos la emoción de un breve fragmento del famoso discurso de John F. Kennedy ["We choose to go to the Moon"](https://en.wikipedia.org/wiki/We_choose_to_go_to_the_Moon). Encuentra un modelo de [audio classification](https://huggingface.co/models?pipeline_tag=audio-classification) para reconocimiento de emociones en el Model Hub y cárgalo en el [`pipeline`]:
+
+```py
+>>> from transformers import pipeline
+
+>>> audio_classifier = pipeline(
+... task="audio-classification", model="ehcalabres/wav2vec2-lg-xlsr-en-speech-emotion-recognition"
+... )
+```
+
+Pasa el archivo de audio al [`pipeline`]:
+
+```py
+>>> audio_classifier("jfk_moon_speech.wav")
+[{'label': 'calm', 'score': 0.13856211304664612},
+ {'label': 'disgust', 'score': 0.13148026168346405},
+ {'label': 'happy', 'score': 0.12635163962841034},
+ {'label': 'angry', 'score': 0.12439591437578201},
+ {'label': 'fearful', 'score': 0.12404385954141617}]
+```
+
+## Pipeline de visión
+
+Finalmente, utilizar un [`pipeline`] para tareas de visión es prácticamente idéntico.
+
+Específica tu tarea de visión y pasa tu imagen al clasificador. La imagen puede ser un enlace o una ruta local a la imagen. Por ejemplo, ¿qué especie de gato se muestra a continuación?
+
+
+
+```py
+>>> from transformers import pipeline
+
+>>> vision_classifier = pipeline(task="image-classification")
+>>> vision_classifier(
+... images="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
+... )
+[{'label': 'lynx, catamount', 'score': 0.4403027892112732},
+ {'label': 'cougar, puma, catamount, mountain lion, painter, panther, Felis concolor',
+ 'score': 0.03433405980467796},
+ {'label': 'snow leopard, ounce, Panthera uncia',
+ 'score': 0.032148055732250214},
+ {'label': 'Egyptian cat', 'score': 0.02353910356760025},
+ {'label': 'tiger cat', 'score': 0.023034192621707916}]
+```
diff --git a/docs/source/es/quicktour.mdx b/docs/source/es/quicktour.mdx
new file mode 100644
index 00000000000000..e9fb764a90e610
--- /dev/null
+++ b/docs/source/es/quicktour.mdx
@@ -0,0 +1,397 @@
+
+
+# Quick tour
+
+[[open-in-colab]]
+
+¡Entra en marcha con los 🤗 Transformers! Comienza usando [`pipeline`] para una inferencia veloz, carga un modelo preentrenado y un tokenizador con una [AutoClass](./model_doc/auto) para resolver tu tarea de texto, visión o audio.
+
+
+
+Todos los ejemplos de código presentados en la documentación tienen un botón arriba a la izquierda para elegir entre Pytorch y TensorFlow.
+Si no fuese así, se espera que el código funcione para ambos backends sin ningún cambio.
+
+
+
+## Pipeline
+
+[`pipeline`] es la forma más fácil de usar un modelo preentrenado para una tarea dada.
+
+
+
+El [`pipeline`] soporta muchas tareas comunes listas para usar:
+
+**Texto**:
+* Análisis de Sentimientos: clasifica la polaridad de un texto dado.
+* Generación de texto (solo en inglés): genera texto a partir de un input dado.
+* Name entity recognition (NER): etiqueta cada palabra con la entidad que representa (persona, fecha, ubicación, etc.).
+* Responder preguntas: extrae la respuesta del contexto dado un contexto y una pregunta.
+* Fill-mask: rellena el espacio faltante dado un texto con palabras enmascaradas.
+* Summarization: genera un resumen de una secuencia larga de texto o un documento.
+* Traducción: traduce un texto a otro idioma.
+* Extracción de características: crea una representación tensorial del texto.
+
+**Imagen**:
+* Clasificación de imágenes: clasifica una imagen.
+* Segmentación de imágenes: clasifica cada pixel de una imagen.
+* Detección de objetos: detecta objetos dentro de una imagen.
+
+**Audio**:
+* Clasificación de audios: asigna una etiqueta a un segmento de audio.
+* Automatic speech recognition (ASR): transcribe datos de audio a un texto.
+
+
+
+Para más detalles acerca del [`pipeline`] y tareas asociadas, consulta la documentación [aquí](./main_classes/pipelines).
+
+
+
+### Uso del Pipeline
+
+En el siguiente ejemplo, usarás el [`pipeline`] para análisis de sentimiento.
+
+Instala las siguientes dependencias si aún no lo has hecho:
+
+
+
+```bash
+pip install torch
+```
+
+
+```bash
+pip install tensorflow
+```
+
+
+
+Importa [`pipeline`] y especifica la tarea que deseas completar:
+
+```py
+>>> from transformers import pipeline
+
+>>> classifier = pipeline("sentiment-analysis")
+```
+
+El pipeline descarga y almacena en caché un [modelo preentrenado](https://huggingface.co/distilbert-base-uncased-finetuned-sst-2-english) por defecto y tokeniza para análisis de sentimiento. Ahora puedes usar `classifier` en tu texto objetivo:
+
+```py
+>>> classifier("We are very happy to show you the 🤗 Transformers library.")
+[{'label': 'POSITIVE', 'score': 0.9998}]
+```
+
+Para más de un enunciado entrega una lista de frases al [`pipeline`] que devolverá una lista de diccionarios:
+
+```py
+>>> results = classifier(["We are very happy to show you the 🤗 Transformers library.", "We hope you don't hate it."])
+>>> for result in results:
+... print(f"label: {result['label']}, with score: {round(result['score'], 4)}")
+label: POSITIVE, with score: 0.9998
+label: NEGATIVE, with score: 0.5309
+```
+
+El [`pipeline`] también puede iterar sobre un dataset entero. Comienza instalando la biblioteca [🤗 Datasets](https://huggingface.co/docs/datasets/):
+
+```bash
+pip install datasets
+```
+
+Crea un [`pipeline`] con la tarea que deseas resolver y el modelo que quieres usar. Coloca el parámetro `device` a `0` para poner los tensores en un dispositivo CUDA:
+
+```py
+>>> import torch
+>>> from transformers import pipeline
+
+>>> speech_recognizer = pipeline("automatic-speech-recognition", model="facebook/wav2vec2-base-960h", device=0)
+```
+
+A continuación, carga el dataset (ve 🤗 Datasets [Quick Start](https://huggingface.co/docs/datasets/quickstart.html) para más detalles) sobre el que quisieras iterar. Por ejemplo, vamos a cargar el dataset [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14):
+
+```py
+>>> from datasets import load_dataset, Audio
+
+>>> dataset = load_dataset("PolyAI/minds14", name="en-US", split="train") # doctest: +IGNORE_RESULT
+```
+
+Debemos asegurarnos de que la frecuencia de muestreo del conjunto de datos coincide con la frecuencia de muestreo con la que se entrenó `facebook/wav2vec2-base-960h`.
+
+```py
+>>> dataset = dataset.cast_column("audio", Audio(sampling_rate=speech_recognizer.feature_extractor.sampling_rate))
+```
+
+Los archivos de audio se cargan y remuestrean automáticamente cuando se llama a la columna `"audio"`.
+Extraigamos las matrices de forma de onda cruda de las primeras 4 muestras y pasémosla como una lista al pipeline:
+
+```py
+>>> result = speech_recognizer(dataset[:4]["audio"])
+>>> print([d["text"] for d in result])
+['I WOULD LIKE TO SET UP A JOINT ACCOUNT WITH MY PARTNER HOW DO I PROCEED WITH DOING THAT', "FONDERING HOW I'D SET UP A JOIN TO HET WITH MY WIFE AND WHERE THE AP MIGHT BE", "I I'D LIKE TOY SET UP A JOINT ACCOUNT WITH MY PARTNER I'M NOT SEEING THE OPTION TO DO IT ON THE APSO I CALLED IN TO GET SOME HELP CAN I JUST DO IT OVER THE PHONE WITH YOU AND GIVE YOU THE INFORMATION OR SHOULD I DO IT IN THE AP AND I'M MISSING SOMETHING UQUETTE HAD PREFERRED TO JUST DO IT OVER THE PHONE OF POSSIBLE THINGS", 'HOW DO I TURN A JOIN A COUNT']
+```
+
+Para un dataset más grande, donde los inputs son de mayor tamaño (como en habla/audio o visión), querrás pasar un generador en lugar de una lista que carga todos los inputs en memoria. Ve la [documentación del pipeline](./main_classes/pipelines) para más información.
+
+### Use otro modelo y otro tokenizador en el pipeline
+
+El [`pipeline`] puede adaptarse a cualquier modelo del [Model Hub](https://huggingface.co/models) haciendo más fácil adaptar el [`pipeline`] para otros casos de uso. Por ejemplo, si quisieras un modelo capaz de manejar texto en francés, usa los tags en el Model Hub para filtrar entre los modelos apropiados. El resultado mejor filtrado devuelve un [modelo BERT](https://huggingface.co/nlptown/bert-base-multilingual-uncased-sentiment) multilingual fine-tuned para el análisis de sentimiento. Genial, ¡vamos a usar este modelo!
+
+```py
+>>> model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
+```
+
+
+
+Usa [`AutoModelForSequenceClassification`] y ['AutoTokenizer'] para cargar un modelo preentrenado y un tokenizador asociado (más en un `AutoClass` debajo):
+
+```py
+>>> from transformers import AutoTokenizer, AutoModelForSequenceClassification
+
+>>> model = AutoModelForSequenceClassification.from_pretrained(model_name)
+>>> tokenizer = AutoTokenizer.from_pretrained(model_name)
+```
+
+
+
+
+Usa [`TFAutoModelForSequenceClassification`] y ['AutoTokenizer'] para cargar un modelo preentrenado y un tokenizador asociado (más en un `TFAutoClass` debajo):
+
+```py
+>>> from transformers import AutoTokenizer, TFAutoModelForSequenceClassification
+
+>>> model = TFAutoModelForSequenceClassification.from_pretrained(model_name)
+>>> tokenizer = AutoTokenizer.from_pretrained(model_name)
+```
+
+
+
+
+Después puedes especificar el modelo y el tokenizador en el [`pipeline`], y aplicar el `classifier` en tu texto objetivo:
+
+```py
+>>> classifier = pipeline("sentiment-analysis", model=model, tokenizer=tokenizer)
+>>> classifier("Nous sommes très heureux de vous présenter la bibliothèque 🤗 Transformers.")
+[{'label': '5 stars', 'score': 0.7273}]
+```
+
+Si no pudieras encontrar el modelo para tu caso respectivo de uso necesitarás ajustar un modelo preentrenado a tus datos. Mira nuestro [tutorial de fine-tuning](./training) para aprender cómo. Finalmente, después de que has ajustado tu modelo preentrenado, ¡por favor considera compartirlo (ve el tutorial [aquí](./model_sharing)) con la comunidad en el Model Hub para democratizar el NLP! 🤗
+
+## AutoClass
+
+
+
+Debajo del capó, las clases [`AutoModelForSequenceClassification`] y [`AutoTokenizer`] trabajan juntas para dar poder al [`pipeline`]. Una [AutoClass](./model_doc/auto) es un atajo que automáticamente recupera la arquitectura de un modelo preentrenado con su nombre o el path. Sólo necesitarás seleccionar el `AutoClass` apropiado para tu tarea y tu tokenizador asociado con [`AutoTokenizer`].
+
+Regresemos a nuestro ejemplo y veamos cómo puedes usar el `AutoClass` para reproducir los resultados del [`pipeline`].
+
+### AutoTokenizer
+
+Un tokenizador es responsable de procesar el texto a un formato que sea entendible para el modelo. Primero, el tokenizador separará el texto en palabras llamadas *tokens*. Hay múltiples reglas que gobiernan el proceso de tokenización incluyendo el cómo separar una palabra y en qué nivel (aprende más sobre tokenización [aquí](./tokenizer_summary)). Lo más importante es recordar que necesitarás instanciar el tokenizador con el mismo nombre del modelo para asegurar que estás usando las mismas reglas de tokenización con las que el modelo fue preentrenado.
+
+Carga un tokenizador con [`AutoTokenizer`]:
+
+```py
+>>> from transformers import AutoTokenizer
+
+>>> model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
+>>> tokenizer = AutoTokenizer.from_pretrained(model_name)
+```
+
+Después, el tokenizador convierte los tokens a números para construir un tensor que servirá como input para el modelo. Esto es conocido como el *vocabulario* del modelo.
+
+Pasa tu texto al tokenizador:
+
+```py
+>>> encoding = tokenizer("We are very happy to show you the 🤗 Transformers library.")
+>>> print(encoding)
+{'input_ids': [101, 11312, 10320, 12495, 19308, 10114, 11391, 10855, 10103, 100, 58263, 13299, 119, 102],
+ 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
+ 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
+```
+
+El tokenizador devolverá un diccionario conteniendo:
+
+* [input_ids](./glossary#input-ids): representaciones numéricas de los tokens.
+* [atttention_mask](.glossary#attention-mask): indica cuáles tokens deben ser atendidos.
+
+Como con el [`pipeline`], el tokenizador aceptará una lista de inputs. Además, el tokenizador también puede rellenar (pad, en inglés) y truncar el texto para devolver un lote (batch, en inglés) de longitud uniforme:
+
+
+
+```py
+>>> pt_batch = tokenizer(
+... ["We are very happy to show you the 🤗 Transformers library.", "We hope you don't hate it."],
+... padding=True,
+... truncation=True,
+... max_length=512,
+... return_tensors="pt",
+... )
+```
+
+
+```py
+>>> tf_batch = tokenizer(
+... ["We are very happy to show you the 🤗 Transformers library.", "We hope you don't hate it."],
+... padding=True,
+... truncation=True,
+... max_length=512,
+... return_tensors="tf",
+... )
+```
+
+
+
+Lee el tutorial de [preprocessing](./preprocessing) para más detalles acerca de la tokenización.
+
+### AutoModel
+
+
+
+🤗 Transformers provee una forma simple y unificada de cargar tus instancias preentrenadas. Esto significa que puedes cargar un [`AutoModel`] como cargarías un [`AutoTokenizer`]. La única diferencia es seleccionar el [`AutoModel`] correcto para la tarea. Ya que estás clasificando texto, o secuencias, carga [`AutoModelForSequenceClassification`]:
+
+```py
+>>> from transformers import AutoModelForSequenceClassification
+
+>>> model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
+>>> pt_model = AutoModelForSequenceClassification.from_pretrained(model_name)
+```
+
+
+
+Ve el [task summary](./task_summary) para revisar qué clase del [`AutoModel`] deberías usar para cada tarea.
+
+
+
+Ahora puedes pasar tu lote (batch) preprocesado de inputs directamente al modelo. Solo tienes que desempacar el diccionario añadiendo `**`:
+
+```py
+>>> pt_outputs = pt_model(**pt_batch)
+```
+
+El modelo producirá las activaciones finales en el atributo `logits`. Aplica la función softmax a `logits` para obtener las probabilidades:
+
+```py
+>>> from torch import nn
+
+>>> pt_predictions = nn.functional.softmax(pt_outputs.logits, dim=-1)
+>>> print(pt_predictions)
+tensor([[0.0021, 0.0018, 0.0115, 0.2121, 0.7725],
+ [0.2084, 0.1826, 0.1969, 0.1755, 0.2365]], grad_fn=)
+```
+
+
+🤗 Transformers provee una forma simple y unificada de cargar tus instancias preentrenadas. Esto significa que puedes cargar un [`TFAutoModel`] como cargarías un [`AutoTokenizer`]. La única diferencia es seleccionar el [`TFAutoModel`] correcto para la tarea. Ya que estás clasificando texto, o secuencias, carga [`TFAutoModelForSequenceClassification`]:
+
+```py
+>>> from transformers import TFAutoModelForSequenceClassification
+
+>>> model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
+>>> tf_model = TFAutoModelForSequenceClassification.from_pretrained(model_name)
+```
+
+
+ Ve el [task summary](./task_summary) para revisar qué clase del [`AutoModel`]
+ deberías usar para cada tarea.
+
+
+Ahora puedes pasar tu lote preprocesado de inputs directamente al modelo pasando las llaves del diccionario directamente a los tensores:
+
+```py
+>>> tf_outputs = tf_model(tf_batch)
+```
+
+El modelo producirá las activaciones finales en el atributo `logits`. Aplica la función softmax a `logits` para obtener las probabilidades:
+
+```py
+>>> import tensorflow as tf
+
+>>> tf_predictions = tf.nn.softmax(tf_outputs.logits, axis=-1)
+>>> print(tf.math.round(tf_predictions * 10**4) / 10**4)
+tf.Tensor(
+[[0.0021 0.0018 0.0116 0.2121 0.7725]
+ [0.2084 0.1826 0.1969 0.1755 0.2365]], shape=(2, 5), dtype=float32)
+```
+
+
+
+
+
+Todos los modelos de 🤗 Transformers (PyTorch o TensorFlow) producirán los tensores *antes* de la función de activación
+final (como softmax) porque la función de activación final es comúnmente fusionada con la pérdida.
+
+
+
+Los modelos son [`torch.nn.Module`](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) o [`tf.keras.Model`](https://www.tensorflow.org/api_docs/python/tf/keras/Model) estándares así que podrás usarlos en tu training loop usual. Sin embargo, para facilitar las cosas, 🤗 Transformers provee una clase [`Trainer`] para PyTorch que añade funcionalidades para entrenamiento distribuido, precición mixta, y más. Para TensorFlow, puedes usar el método `fit` desde [Keras](https://keras.io/). Consulta el [tutorial de entrenamiento](./training) para más detalles.
+
+
+
+Los outputs del modelo de 🤗 Transformers son dataclasses especiales por lo que sus atributos pueden ser completados en un IDE.
+Los outputs del modelo también se comportan como tuplas o diccionarios (e.g., puedes indexar con un entero, un slice o una cadena) en cuyo caso los atributos que son `None` son ignorados.
+
+
+
+### Guarda un modelo
+
+
+
+Una vez que tu modelo esté fine-tuned puedes guardarlo con tu tokenizador usando [`PreTrainedModel.save_pretrained`]:
+
+```py
+>>> pt_save_directory = "./pt_save_pretrained"
+>>> tokenizer.save_pretrained(pt_save_directory) # doctest: +IGNORE_RESULT
+>>> pt_model.save_pretrained(pt_save_directory)
+```
+
+Cuando quieras usar el modelo otra vez cárgalo con [`PreTrainedModel.from_pretrained`]:
+
+```py
+>>> pt_model = AutoModelForSequenceClassification.from_pretrained("./pt_save_pretrained")
+```
+
+
+
+
+Una vez que tu modelo esté fine-tuned puedes guardarlo con tu tokenizador usando [`TFPreTrainedModel.save_pretrained`]:
+
+```py
+>>> tf_save_directory = "./tf_save_pretrained"
+>>> tokenizer.save_pretrained(tf_save_directory) # doctest: +IGNORE_RESULT
+>>> tf_model.save_pretrained(tf_save_directory)
+```
+
+Cuando quieras usar el modelo otra vez cárgalo con [`TFPreTrainedModel.from_pretrained`]:
+
+```py
+>>> tf_model = TFAutoModelForSequenceClassification.from_pretrained("./tf_save_pretrained")
+```
+
+
+
+Una característica particularmente cool de 🤗 Transformers es la habilidad de guardar el modelo y cargarlo como un modelo de PyTorch o TensorFlow. El parámetro `from_pt` o `from_tf` puede convertir el modelo de un framework al otro:
+
+
+
+```py
+>>> from transformers import AutoModel
+
+>>> tokenizer = AutoTokenizer.from_pretrained(tf_save_directory)
+>>> pt_model = AutoModelForSequenceClassification.from_pretrained(tf_save_directory, from_tf=True)
+```
+
+
+```py
+>>> from transformers import TFAutoModel
+
+>>> tokenizer = AutoTokenizer.from_pretrained(pt_save_directory)
+>>> tf_model = TFAutoModelForSequenceClassification.from_pretrained(pt_save_directory, from_pt=True)
+```
+
+
diff --git a/docs/source/es/training.mdx b/docs/source/es/training.mdx
new file mode 100644
index 00000000000000..653e9437ae2ebd
--- /dev/null
+++ b/docs/source/es/training.mdx
@@ -0,0 +1,367 @@
+
+
+# Fine-tuning a un modelo pre-entrenado
+
+[[open-in-colab]]
+
+El uso de un modelo pre-entrenado tiene importantes ventajas. Reduce los costos de computación, la huella de carbono, y te permite utilizar modelos de última generación sin tener que entrenar uno desde cero. 🤗 Transformers proporciona acceso a miles de modelos pre-entrenados en una amplia gama de tareas. Cuando utilizas un modelo pre-entrenado, lo entrenas con un dataset específico para tu tarea. Esto se conoce como fine-tuning, una técnica de entrenamiento increíblemente poderosa. En este tutorial haremos fine-tuning a un modelo pre-entrenado con un framework de Deep Learning de tu elección:
+
+* Fine-tuning a un modelo pre-entrenado con 🤗 Transformers [`Trainer`].
+* Fine-tuning a un modelo pre-entrenado en TensorFlow con Keras.
+* Fine-tuning a un modelo pre-entrenado en PyTorch nativo.
+
+
+
+## Prepara un dataset
+
+
+
+Antes de aplicar fine-tuning a un modelo pre-entrenado, descarga un dataset y prepáralo para el entrenamiento. El tutorial anterior nos enseñó cómo procesar los datos para el entrenamiento, y ahora es la oportunidad de poner a prueba estas habilidades.
+
+Comienza cargando el dataset de [Yelp Reviews](https://huggingface.co/datasets/yelp_review_full):
+
+```py
+>>> from datasets import load_dataset
+
+>>> dataset = load_dataset("yelp_review_full")
+>>> dataset[100]
+{'label': 0,
+ 'text': 'My expectations for McDonalds are t rarely high. But for one to still fail so spectacularly...that takes something special!\\nThe cashier took my friends\'s order, then promptly ignored me. I had to force myself in front of a cashier who opened his register to wait on the person BEHIND me. I waited over five minutes for a gigantic order that included precisely one kid\'s meal. After watching two people who ordered after me be handed their food, I asked where mine was. The manager started yelling at the cashiers for \\"serving off their orders\\" when they didn\'t have their food. But neither cashier was anywhere near those controls, and the manager was the one serving food to customers and clearing the boards.\\nThe manager was rude when giving me my order. She didn\'t make sure that I had everything ON MY RECEIPT, and never even had the decency to apologize that I felt I was getting poor service.\\nI\'ve eaten at various McDonalds restaurants for over 30 years. I\'ve worked at more than one location. I expect bad days, bad moods, and the occasional mistake. But I have yet to have a decent experience at this store. It will remain a place I avoid unless someone in my party needs to avoid illness from low blood sugar. Perhaps I should go back to the racially biased service of Steak n Shake instead!'}
+```
+
+Como ya sabes, necesitas un tokenizador para procesar el texto e incluir una estrategia para el padding y el truncamiento, para manejar cualquier longitud de secuencia variable. Para procesar tu dataset en un solo paso, utiliza el método de 🤗 Datasets [`map`](https://huggingface.co/docs/datasets/process.html#map) para aplicar una función de preprocesamiento sobre todo el dataset:
+
+```py
+>>> from transformers import AutoTokenizer
+
+>>> tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
+
+
+>>> def tokenize_function(examples):
+... return tokenizer(examples["text"], padding="max_length", truncation=True)
+
+
+>>> tokenized_datasets = dataset.map(tokenize_function, batched=True)
+```
+
+Si lo deseas, puedes crear un subconjunto más pequeño del dataset completo para aplicarle fine-tuning y así reducir el tiempo.
+
+```py
+>>> small_train_dataset = tokenized_datasets["train"].shuffle(seed=42).select(range(1000))
+>>> small_eval_dataset = tokenized_datasets["test"].shuffle(seed=42).select(range(1000))
+```
+
+
+
+## Fine-tuning con `Trainer`
+
+
+
+🤗 Transformers proporciona una clase [`Trainer`] optimizada para el entrenamiento de modelos de 🤗 Transformers, haciendo más fácil el inicio del entrenamiento sin necesidad de escribir manualmente tu propio ciclo. La API del [`Trainer`] soporta una amplia gama de opciones de entrenamiento y características como el logging, el gradient accumulation y el mixed precision.
+
+Comienza cargando tu modelo y especifica el número de labels previstas. A partir del [Card Dataset](https://huggingface.co/datasets/yelp_review_full#data-fields) de Yelp Review, que como ya sabemos tiene 5 labels:
+
+```py
+>>> from transformers import AutoModelForSequenceClassification
+
+>>> model = AutoModelForSequenceClassification.from_pretrained("bert-base-cased", num_labels=5)
+```
+
+
+
+Verás una advertencia acerca de que algunos de los pesos pre-entrenados que no están siendo utilizados y que algunos pesos están siendo inicializados al azar.
+No te preocupes, esto es completamente normal. El head/cabezal pre-entrenado del modelo BERT se descarta y se sustituye por un head de clasificación inicializado aleatoriamente. Puedes aplicar fine-tuning a este nuevo head del modelo en tu tarea de clasificación de secuencias haciendo transfer learning del modelo pre-entrenado.
+
+
+
+### Hiperparámetros de entrenamiento
+
+A continuación, crea una clase [`TrainingArguments`] que contenga todos los hiperparámetros que puedes ajustar así como los indicadores para activar las diferentes opciones de entrenamiento. Para este tutorial puedes empezar con los [hiperparámetros](https://huggingface.co/docs/transformers/main_classes/trainer#transformers.TrainingArguments) de entrenamiento por defecto, pero siéntete libre de experimentar con ellos para encontrar tu configuración óptima.
+
+Especifica dónde vas a guardar los checkpoints de tu entrenamiento:
+
+```py
+>>> from transformers import TrainingArguments
+
+>>> training_args = TrainingArguments(output_dir="test_trainer")
+```
+
+### Métricas
+
+El [`Trainer`] no evalúa automáticamente el rendimiento del modelo durante el entrenamiento. Tendrás que pasarle a [`Trainer`] una función para calcular y hacer un reporte de las métricas. La librería de 🤗 Datasets proporciona una función de [`accuracy`](https://huggingface.co/metrics/accuracy) simple que puedes cargar con la función `load_metric` (ver este [tutorial](https://huggingface.co/docs/datasets/metrics.html) para más información):
+
+```py
+>>> import numpy as np
+>>> from datasets import load_metric
+
+>>> metric = load_metric("accuracy")
+```
+
+Define la función `compute` en `metric` para calcular el accuracy de tus predicciones. Antes de pasar tus predicciones a `compute`, necesitas convertir las predicciones a logits (recuerda que todos los modelos de 🤗 Transformers devuelven logits).
+
+```py
+>>> def compute_metrics(eval_pred):
+... logits, labels = eval_pred
+... predictions = np.argmax(logits, axis=-1)
+... return metric.compute(predictions=predictions, references=labels)
+```
+
+Si quieres controlar tus métricas de evaluación durante el fine-tuning, especifica el parámetro `evaluation_strategy` en tus argumentos de entrenamiento para que el modelo tenga en cuenta la métrica de evaluación al final de cada época:
+
+```py
+>>> from transformers import TrainingArguments
+
+>>> training_args = TrainingArguments(output_dir="test_trainer", evaluation_strategy="epoch")
+```
+
+### Trainer
+
+Crea un objeto [`Trainer`] con tu modelo, argumentos de entrenamiento, conjuntos de datos de entrenamiento y de prueba, y tu función de evaluación:
+
+```py
+>>> trainer = Trainer(
+... model=model,
+... args=training_args,
+... train_dataset=small_train_dataset,
+... eval_dataset=small_eval_dataset,
+... compute_metrics=compute_metrics,
+... )
+```
+
+A continuación, aplica fine-tuning a tu modelo llamando [`~transformers.Trainer.train`]:
+
+```py
+>>> trainer.train()
+```
+
+
+
+## Fine-tuning con Keras
+
+
+
+Los modelos de 🤗 Transformers también permiten realizar el entrenamiento en TensorFlow con la API de Keras. Sólo es necesario hacer algunos cambios antes de hacer fine-tuning.
+
+### Convierte el dataset al formato de TensorFlow
+
+El [`DefaultDataCollator`] junta los tensores en un batch para que el modelo se entrene en él. Asegúrate de especificar `return_tensors` para devolver los tensores de TensorFlow:
+
+```py
+>>> from transformers import DefaultDataCollator
+
+>>> data_collator = DefaultDataCollator(return_tensors="tf")
+```
+
+
+
+[`Trainer`] utiliza [`DataCollatorWithPadding`] por defecto por lo que no es necesario especificar explícitamente un intercalador de datos (data collator, en inglés).
+
+
+
+A continuación, convierte los datasets tokenizados en datasets de TensorFlow con el método [`to_tf_dataset`](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.to_tf_dataset). Especifica tus entradas en `columns` y tu etiqueta en `label_cols`:
+
+```py
+>>> tf_train_dataset = small_train_dataset.to_tf_dataset(
+... columns=["attention_mask", "input_ids", "token_type_ids"],
+... label_cols=["labels"],
+... shuffle=True,
+... collate_fn=data_collator,
+... batch_size=8,
+... )
+
+>>> tf_validation_dataset = small_eval_dataset.to_tf_dataset(
+... columns=["attention_mask", "input_ids", "token_type_ids"],
+... label_cols=["labels"],
+... shuffle=False,
+... collate_fn=data_collator,
+... batch_size=8,
+... )
+```
+
+### Compila y ajusta
+
+Carguemos un modelo TensorFlow con el número esperado de labels:
+
+```py
+>>> import tensorflow as tf
+>>> from transformers import TFAutoModelForSequenceClassification
+
+>>> model = TFAutoModelForSequenceClassification.from_pretrained("bert-base-cased", num_labels=5)
+```
+
+A continuación, compila y aplica fine-tuning a tu modelo con [`fit`](https://keras.io/api/models/model_training_apis/) como lo harías con cualquier otro modelo de Keras:
+
+```py
+>>> model.compile(
+... optimizer=tf.keras.optimizers.Adam(learning_rate=5e-5),
+... loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
+... metrics=tf.metrics.SparseCategoricalAccuracy(),
+... )
+
+>>> model.fit(tf_train_dataset, validation_data=tf_validation_dataset, epochs=3)
+```
+
+
+
+## Fine-tune en PyTorch nativo
+
+
+
+El [`Trainer`] se encarga del ciclo de entrenamiento y permite aplicar fine-tuning a un modelo en una sola línea de código. Para los usuarios que prefieren escribir tu propio ciclo de entrenamiento, también puedes aplicar fine-tuning a un modelo de 🤗 Transformers en PyTorch nativo.
+
+En este punto, es posible que necesites reiniciar tu notebook o ejecutar el siguiente código para liberar algo de memoria:
+
+```py
+del model
+del pytorch_model
+del trainer
+torch.cuda.empty_cache()
+```
+
+A continuación, haremos un post-procesamiento manual al `tokenized_dataset` y así prepararlo para el entrenamiento.
+
+1. Elimina la columna de `text` porque el modelo no acepta texto en crudo como entrada:
+
+ ```py
+ >>> tokenized_datasets = tokenized_datasets.remove_columns(["text"])
+ ```
+
+2. Cambia el nombre de la columna de `label` a `labels` porque el modelo espera que el argumento se llame `labels`:
+
+ ```py
+ >>> tokenized_datasets = tokenized_datasets.rename_column("label", "labels")
+ ```
+
+3. Establece el formato del dataset para devolver tensores PyTorch en lugar de listas:
+
+ ```py
+ >>> tokenized_datasets.set_format("torch")
+ ```
+
+A continuación, crea un subconjunto más pequeño del dataset, como se ha mostrado anteriormente, para acelerar el fine-tuning:
+
+```py
+>>> small_train_dataset = tokenized_datasets["train"].shuffle(seed=42).select(range(1000))
+>>> small_eval_dataset = tokenized_datasets["test"].shuffle(seed=42).select(range(1000))
+```
+
+### DataLoader
+
+Crea un `DataLoader` para tus datasets de entrenamiento y de prueba para poder iterar sobre batches de datos:
+
+```py
+>>> from torch.utils.data import DataLoader
+
+>>> train_dataloader = DataLoader(small_train_dataset, shuffle=True, batch_size=8)
+>>> eval_dataloader = DataLoader(small_eval_dataset, batch_size=8)
+```
+
+Carga tu modelo con el número de labels previstas:
+
+```py
+>>> from transformers import AutoModelForSequenceClassification
+
+>>> model = AutoModelForSequenceClassification.from_pretrained("bert-base-cased", num_labels=5)
+```
+
+### Optimiza y progrma el learning rate
+
+Crea un optimizador y el learning rate para aplicar fine-tuning al modelo. Vamos a utilizar el optimizador [`AdamW`](https://pytorch.org/docs/stable/generated/torch.optim.AdamW.html) de PyTorch:
+
+```py
+>>> from torch.optim import AdamW
+
+>>> optimizer = AdamW(model.parameters(), lr=5e-5)
+```
+
+Crea el learning rate desde el [`Trainer`]:
+
+```py
+>>> from transformers import get_scheduler
+
+>>> num_epochs = 3
+>>> num_training_steps = num_epochs * len(train_dataloader)
+>>> lr_scheduler = get_scheduler(
+... name="linear", optimizer=optimizer, num_warmup_steps=0, num_training_steps=num_training_steps
+... )
+```
+
+Por último, especifica el `device` o entorno de ejecución para utilizar una GPU si tienes acceso a una. De lo contrario, el entrenamiento en una CPU puede llevarte varias horas en lugar de un par de minutos.
+
+```py
+>>> import torch
+
+>>> device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
+>>> model.to(device)
+```
+
+
+
+Consigue acceso gratuito a una GPU en la nube si es que no tienes este recurso de forma local con un notebook alojado en [Colaboratory](https://colab.research.google.com/) o [SageMaker StudioLab](https://studiolab.sagemaker.aws/).
+
+
+
+Genial, ¡ahora estamos listos entrenar! 🥳
+
+### Ciclo de entrenamiento
+
+Para hacer un seguimiento al progreso del entrenamiento, utiliza la librería [tqdm](https://tqdm.github.io/) para añadir una barra de progreso sobre el número de pasos de entrenamiento:
+
+```py
+>>> from tqdm.auto import tqdm
+
+>>> progress_bar = tqdm(range(num_training_steps))
+
+>>> model.train()
+>>> for epoch in range(num_epochs):
+... for batch in train_dataloader:
+... batch = {k: v.to(device) for k, v in batch.items()}
+... outputs = model(**batch)
+... loss = outputs.loss
+... loss.backward()
+
+... optimizer.step()
+... lr_scheduler.step()
+... optimizer.zero_grad()
+... progress_bar.update(1)
+```
+
+### Métricas
+
+De la misma manera que necesitas añadir una función de evaluación al [`Trainer`], necesitas hacer lo mismo cuando escribas tu propio ciclo de entrenamiento. Pero en lugar de calcular y reportar la métrica al final de cada época, esta vez acumularás todos los batches con [`add_batch`](https://huggingface.co/docs/datasets/package_reference/main_classes.html?highlight=add_batch#datasets.Metric.add_batch) y calcularás la métrica al final.
+
+```py
+>>> metric = load_metric("accuracy")
+>>> model.eval()
+>>> for batch in eval_dataloader:
+... batch = {k: v.to(device) for k, v in batch.items()}
+... with torch.no_grad():
+... outputs = model(**batch)
+
+... logits = outputs.logits
+... predictions = torch.argmax(logits, dim=-1)
+... metric.add_batch(predictions=predictions, references=batch["labels"])
+
+>>> metric.compute()
+```
+
+
+
+## Recursos adicionales
+
+Para más ejemplos de fine-tuning consulta:
+
+- [🤗 Transformers Examples](https://github.com/huggingface/transformers/tree/main/examples) incluye scripts
+ para entrenar tareas comunes de NLP en PyTorch y TensorFlow.
+
+- [🤗 Transformers Notebooks](notebooks) contiene varios notebooks sobre cómo aplicar fine-tuning a un modelo para tareas específicas en PyTorch y TensorFlow.
diff --git a/docs/source/examples.md b/docs/source/examples.md
deleted file mode 120000
index 6fa53604d90234..00000000000000
--- a/docs/source/examples.md
+++ /dev/null
@@ -1 +0,0 @@
-../../examples/README.md
\ No newline at end of file
diff --git a/docs/source/favicon.ico b/docs/source/favicon.ico
deleted file mode 100644
index 424101de717bf4..00000000000000
Binary files a/docs/source/favicon.ico and /dev/null differ
diff --git a/docs/source/glossary.rst b/docs/source/glossary.rst
deleted file mode 100644
index be7a4686946b68..00000000000000
--- a/docs/source/glossary.rst
+++ /dev/null
@@ -1,302 +0,0 @@
-..
- Copyright 2020 The HuggingFace Team. All rights reserved.
-
- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
- the License. You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
- Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
- an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
- specific language governing permissions and limitations under the License.
-
-Glossary
-^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
-
-General terms
------------------------------------------------------------------------------------------------------------------------
-
-- autoencoding models: see MLM
-- autoregressive models: see CLM
-- CLM: causal language modeling, a pretraining task where the model reads the texts in order and has to predict the
- next word. It's usually done by reading the whole sentence but using a mask inside the model to hide the future
- tokens at a certain timestep.
-- deep learning: machine learning algorithms which uses neural networks with several layers.
-- MLM: masked language modeling, a pretraining task where the model sees a corrupted version of the texts, usually done
- by masking some tokens randomly, and has to predict the original text.
-- multimodal: a task that combines texts with another kind of inputs (for instance images).
-- NLG: natural language generation, all tasks related to generating text (for instance talk with transformers,
- translation).
-- NLP: natural language processing, a generic way to say "deal with texts".
-- NLU: natural language understanding, all tasks related to understanding what is in a text (for instance classifying
- the whole text, individual words).
-- pretrained model: a model that has been pretrained on some data (for instance all of Wikipedia). Pretraining methods
- involve a self-supervised objective, which can be reading the text and trying to predict the next word (see CLM) or
- masking some words and trying to predict them (see MLM).
-- RNN: recurrent neural network, a type of model that uses a loop over a layer to process texts.
-- self-attention: each element of the input finds out which other elements of the input they should attend to.
-- seq2seq or sequence-to-sequence: models that generate a new sequence from an input, like translation models, or
- summarization models (such as :doc:`Bart ` or :doc:`T5 `).
-- token: a part of a sentence, usually a word, but can also be a subword (non-common words are often split in subwords)
- or a punctuation symbol.
-- transformer: self-attention based deep learning model architecture.
-
-Model inputs
------------------------------------------------------------------------------------------------------------------------
-
-Every model is different yet bears similarities with the others. Therefore most models use the same inputs, which are
-detailed here alongside usage examples.
-
-.. _input-ids:
-
-Input IDs
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-The input ids are often the only required parameters to be passed to the model as input. *They are token indices,
-numerical representations of tokens building the sequences that will be used as input by the model*.
-
-Each tokenizer works differently but the underlying mechanism remains the same. Here's an example using the BERT
-tokenizer, which is a `WordPiece `__ tokenizer:
-
-.. code-block::
-
- >>> from transformers import BertTokenizer
- >>> tokenizer = BertTokenizer.from_pretrained("bert-base-cased")
-
- >>> sequence = "A Titan RTX has 24GB of VRAM"
-
-The tokenizer takes care of splitting the sequence into tokens available in the tokenizer vocabulary.
-
-.. code-block::
-
- >>> tokenized_sequence = tokenizer.tokenize(sequence)
-
-The tokens are either words or subwords. Here for instance, "VRAM" wasn't in the model vocabulary, so it's been split
-in "V", "RA" and "M". To indicate those tokens are not separate words but parts of the same word, a double-hash prefix
-is added for "RA" and "M":
-
-.. code-block::
-
- >>> print(tokenized_sequence)
- ['A', 'Titan', 'R', '##T', '##X', 'has', '24', '##GB', 'of', 'V', '##RA', '##M']
-
-These tokens can then be converted into IDs which are understandable by the model. This can be done by directly feeding
-the sentence to the tokenizer, which leverages the Rust implementation of `huggingface/tokenizers
-`__ for peak performance.
-
-.. code-block::
-
- >>> inputs = tokenizer(sequence)
-
-The tokenizer returns a dictionary with all the arguments necessary for its corresponding model to work properly. The
-token indices are under the key "input_ids":
-
-.. code-block::
-
- >>> encoded_sequence = inputs["input_ids"]
- >>> print(encoded_sequence)
- [101, 138, 18696, 155, 1942, 3190, 1144, 1572, 13745, 1104, 159, 9664, 2107, 102]
-
-Note that the tokenizer automatically adds "special tokens" (if the associated model relies on them) which are special
-IDs the model sometimes uses.
-
-If we decode the previous sequence of ids,
-
-.. code-block::
-
- >>> decoded_sequence = tokenizer.decode(encoded_sequence)
-
-we will see
-
-.. code-block::
-
- >>> print(decoded_sequence)
- [CLS] A Titan RTX has 24GB of VRAM [SEP]
-
-because this is the way a :class:`~transformers.BertModel` is going to expect its inputs.
-
-.. _attention-mask:
-
-Attention mask
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-The attention mask is an optional argument used when batching sequences together. This argument indicates to the model
-which tokens should be attended to, and which should not.
-
-For example, consider these two sequences:
-
-.. code-block::
-
- >>> from transformers import BertTokenizer
- >>> tokenizer = BertTokenizer.from_pretrained("bert-base-cased")
-
- >>> sequence_a = "This is a short sequence."
- >>> sequence_b = "This is a rather long sequence. It is at least longer than the sequence A."
-
- >>> encoded_sequence_a = tokenizer(sequence_a)["input_ids"]
- >>> encoded_sequence_b = tokenizer(sequence_b)["input_ids"]
-
-The encoded versions have different lengths:
-
-.. code-block::
-
- >>> len(encoded_sequence_a), len(encoded_sequence_b)
- (8, 19)
-
-Therefore, we can't put them together in the same tensor as-is. The first sequence needs to be padded up to the length
-of the second one, or the second one needs to be truncated down to the length of the first one.
-
-In the first case, the list of IDs will be extended by the padding indices. We can pass a list to the tokenizer and ask
-it to pad like this:
-
-.. code-block::
-
- >>> padded_sequences = tokenizer([sequence_a, sequence_b], padding=True)
-
-We can see that 0s have been added on the right of the first sentence to make it the same length as the second one:
-
-.. code-block::
-
- >>> padded_sequences["input_ids"]
- [[101, 1188, 1110, 170, 1603, 4954, 119, 102, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [101, 1188, 1110, 170, 1897, 1263, 4954, 119, 1135, 1110, 1120, 1655, 2039, 1190, 1103, 4954, 138, 119, 102]]
-
-This can then be converted into a tensor in PyTorch or TensorFlow. The attention mask is a binary tensor indicating the
-position of the padded indices so that the model does not attend to them. For the :class:`~transformers.BertTokenizer`,
-:obj:`1` indicates a value that should be attended to, while :obj:`0` indicates a padded value. This attention mask is
-in the dictionary returned by the tokenizer under the key "attention_mask":
-
-.. code-block::
-
- >>> padded_sequences["attention_mask"]
- [[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]
-
-.. _token-type-ids:
-
-Token Type IDs
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-Some models' purpose is to do sequence classification or question answering. These require two different sequences to
-be joined in a single "input_ids" entry, which usually is performed with the help of special tokens, such as the
-classifier (``[CLS]``) and separator (``[SEP]``) tokens. For example, the BERT model builds its two sequence input as
-such:
-
-.. code-block::
-
- >>> # [CLS] SEQUENCE_A [SEP] SEQUENCE_B [SEP]
-
-We can use our tokenizer to automatically generate such a sentence by passing the two sequences to ``tokenizer`` as two
-arguments (and not a list, like before) like this:
-
-.. code-block::
-
- >>> from transformers import BertTokenizer
- >>> tokenizer = BertTokenizer.from_pretrained("bert-base-cased")
- >>> sequence_a = "HuggingFace is based in NYC"
- >>> sequence_b = "Where is HuggingFace based?"
-
- >>> encoded_dict = tokenizer(sequence_a, sequence_b)
- >>> decoded = tokenizer.decode(encoded_dict["input_ids"])
-
-which will return:
-
-.. code-block::
-
- >>> print(decoded)
- [CLS] HuggingFace is based in NYC [SEP] Where is HuggingFace based? [SEP]
-
-This is enough for some models to understand where one sequence ends and where another begins. However, other models,
-such as BERT, also deploy token type IDs (also called segment IDs). They are represented as a binary mask identifying
-the two types of sequence in the model.
-
-The tokenizer returns this mask as the "token_type_ids" entry:
-
-.. code-block::
-
- >>> encoded_dict['token_type_ids']
- [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1]
-
-The first sequence, the "context" used for the question, has all its tokens represented by a :obj:`0`, whereas the
-second sequence, corresponding to the "question", has all its tokens represented by a :obj:`1`.
-
-Some models, like :class:`~transformers.XLNetModel` use an additional token represented by a :obj:`2`.
-
-.. _position-ids:
-
-Position IDs
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-Contrary to RNNs that have the position of each token embedded within them, transformers are unaware of the position of
-each token. Therefore, the position IDs (``position_ids``) are used by the model to identify each token's position in
-the list of tokens.
-
-They are an optional parameter. If no ``position_ids`` are passed to the model, the IDs are automatically created as
-absolute positional embeddings.
-
-Absolute positional embeddings are selected in the range ``[0, config.max_position_embeddings - 1]``. Some models use
-other types of positional embeddings, such as sinusoidal position embeddings or relative position embeddings.
-
-.. _labels:
-
-Labels
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-The labels are an optional argument which can be passed in order for the model to compute the loss itself. These labels
-should be the expected prediction of the model: it will use the standard loss in order to compute the loss between its
-predictions and the expected value (the label).
-
-These labels are different according to the model head, for example:
-
-- For sequence classification models (e.g., :class:`~transformers.BertForSequenceClassification`), the model expects a
- tensor of dimension :obj:`(batch_size)` with each value of the batch corresponding to the expected label of the
- entire sequence.
-- For token classification models (e.g., :class:`~transformers.BertForTokenClassification`), the model expects a tensor
- of dimension :obj:`(batch_size, seq_length)` with each value corresponding to the expected label of each individual
- token.
-- For masked language modeling (e.g., :class:`~transformers.BertForMaskedLM`), the model expects a tensor of dimension
- :obj:`(batch_size, seq_length)` with each value corresponding to the expected label of each individual token: the
- labels being the token ID for the masked token, and values to be ignored for the rest (usually -100).
-- For sequence to sequence tasks,(e.g., :class:`~transformers.BartForConditionalGeneration`,
- :class:`~transformers.MBartForConditionalGeneration`), the model expects a tensor of dimension :obj:`(batch_size,
- tgt_seq_length)` with each value corresponding to the target sequences associated with each input sequence. During
- training, both `BART` and `T5` will make the appropriate `decoder_input_ids` and decoder attention masks internally.
- They usually do not need to be supplied. This does not apply to models leveraging the Encoder-Decoder framework. See
- the documentation of each model for more information on each specific model's labels.
-
-The base models (e.g., :class:`~transformers.BertModel`) do not accept labels, as these are the base transformer
-models, simply outputting features.
-
-.. _decoder-input-ids:
-
-Decoder input IDs
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-This input is specific to encoder-decoder models, and contains the input IDs that will be fed to the decoder. These
-inputs should be used for sequence to sequence tasks, such as translation or summarization, and are usually built in a
-way specific to each model.
-
-Most encoder-decoder models (BART, T5) create their :obj:`decoder_input_ids` on their own from the :obj:`labels`. In
-such models, passing the :obj:`labels` is the preferred way to handle training.
-
-Please check each model's docs to see how they handle these input IDs for sequence to sequence training.
-
-.. _feed-forward-chunking:
-
-Feed Forward Chunking
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-In each residual attention block in transformers the self-attention layer is usually followed by 2 feed forward layers.
-The intermediate embedding size of the feed forward layers is often bigger than the hidden size of the model (e.g., for
-``bert-base-uncased``).
-
-For an input of size ``[batch_size, sequence_length]``, the memory required to store the intermediate feed forward
-embeddings ``[batch_size, sequence_length, config.intermediate_size]`` can account for a large fraction of the memory
-use. The authors of `Reformer: The Efficient Transformer `_ noticed that since the
-computation is independent of the ``sequence_length`` dimension, it is mathematically equivalent to compute the output
-embeddings of both feed forward layers ``[batch_size, config.hidden_size]_0, ..., [batch_size, config.hidden_size]_n``
-individually and concat them afterward to ``[batch_size, sequence_length, config.hidden_size]`` with ``n =
-sequence_length``, which trades increased computation time against reduced memory use, but yields a mathematically
-**equivalent** result.
-
-For models employing the function :func:`~.transformers.apply_chunking_to_forward`, the ``chunk_size`` defines the
-number of output embeddings that are computed in parallel and thus defines the trade-off between memory and time
-complexity. If ``chunk_size`` is set to 0, no feed forward chunking is done.
diff --git a/docs/source/imgs/local_attention_mask.png b/docs/source/imgs/local_attention_mask.png
deleted file mode 100644
index 284e728820c8fb..00000000000000
Binary files a/docs/source/imgs/local_attention_mask.png and /dev/null differ
diff --git a/docs/source/imgs/ppl_chunked.gif b/docs/source/imgs/ppl_chunked.gif
deleted file mode 100644
index 2e3373693502c1..00000000000000
Binary files a/docs/source/imgs/ppl_chunked.gif and /dev/null differ
diff --git a/docs/source/imgs/ppl_full.gif b/docs/source/imgs/ppl_full.gif
deleted file mode 100644
index 2869208faa30cb..00000000000000
Binary files a/docs/source/imgs/ppl_full.gif and /dev/null differ
diff --git a/docs/source/imgs/ppl_sliding.gif b/docs/source/imgs/ppl_sliding.gif
deleted file mode 100644
index d2dc26f55b82bd..00000000000000
Binary files a/docs/source/imgs/ppl_sliding.gif and /dev/null differ
diff --git a/docs/source/imgs/transformers_logo_name.png b/docs/source/imgs/transformers_logo_name.png
deleted file mode 100644
index 5e4c2dcf575b7f..00000000000000
Binary files a/docs/source/imgs/transformers_logo_name.png and /dev/null differ
diff --git a/docs/source/imgs/transformers_overview.png b/docs/source/imgs/transformers_overview.png
deleted file mode 100644
index abb15b3dd7c2f7..00000000000000
Binary files a/docs/source/imgs/transformers_overview.png and /dev/null differ
diff --git a/docs/source/imgs/warmup_constant_schedule.png b/docs/source/imgs/warmup_constant_schedule.png
deleted file mode 100644
index e2448e9f2c7999..00000000000000
Binary files a/docs/source/imgs/warmup_constant_schedule.png and /dev/null differ
diff --git a/docs/source/imgs/warmup_cosine_hard_restarts_schedule.png b/docs/source/imgs/warmup_cosine_hard_restarts_schedule.png
deleted file mode 100644
index be73605b9c080c..00000000000000
Binary files a/docs/source/imgs/warmup_cosine_hard_restarts_schedule.png and /dev/null differ
diff --git a/docs/source/imgs/warmup_cosine_schedule.png b/docs/source/imgs/warmup_cosine_schedule.png
deleted file mode 100644
index 6d27926ab10e9d..00000000000000
Binary files a/docs/source/imgs/warmup_cosine_schedule.png and /dev/null differ
diff --git a/docs/source/imgs/warmup_cosine_warm_restarts_schedule.png b/docs/source/imgs/warmup_cosine_warm_restarts_schedule.png
deleted file mode 100644
index 71b39bffd3dacc..00000000000000
Binary files a/docs/source/imgs/warmup_cosine_warm_restarts_schedule.png and /dev/null differ
diff --git a/docs/source/imgs/warmup_linear_schedule.png b/docs/source/imgs/warmup_linear_schedule.png
deleted file mode 100644
index 4e1af31025fafb..00000000000000
Binary files a/docs/source/imgs/warmup_linear_schedule.png and /dev/null differ
diff --git a/docs/source/index.rst b/docs/source/index.rst
deleted file mode 100644
index e069b997e8140a..00000000000000
--- a/docs/source/index.rst
+++ /dev/null
@@ -1,467 +0,0 @@
-Transformers
-=======================================================================================================================
-
-State-of-the-art Natural Language Processing for Pytorch and TensorFlow 2.0.
-
-🤗 Transformers (formerly known as `pytorch-transformers` and `pytorch-pretrained-bert`) provides general-purpose
-architectures (BERT, GPT-2, RoBERTa, XLM, DistilBert, XLNet...) for Natural Language Understanding (NLU) and Natural
-Language Generation (NLG) with over 32+ pretrained models in 100+ languages and deep interoperability between
-TensorFlow 2.0 and PyTorch.
-
-This is the documentation of our repository `transformers `_.
-
-Features
------------------------------------------------------------------------------------------------------------------------
-
-- High performance on NLU and NLG tasks
-- Low barrier to entry for educators and practitioners
-
-State-of-the-art NLP for everyone:
-
-- Deep learning researchers
-- Hands-on practitioners
-- AI/ML/NLP teachers and educators
-
-..
- Copyright 2020 The HuggingFace Team. All rights reserved.
-
- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
- the License. You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
- Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
- an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
- specific language governing permissions and limitations under the License.
-
-Lower compute costs, smaller carbon footprint:
-
-- Researchers can share trained models instead of always retraining
-- Practitioners can reduce compute time and production costs
-- 8 architectures with over 30 pretrained models, some in more than 100 languages
-
-Choose the right framework for every part of a model's lifetime:
-
-- Train state-of-the-art models in 3 lines of code
-- Deep interoperability between TensorFlow 2.0 and PyTorch models
-- Move a single model between TF2.0/PyTorch frameworks at will
-- Seamlessly pick the right framework for training, evaluation, production
-
-Experimental support for Flax with a few models right now, expected to grow in the coming months.
-
-`All the model checkpoints `__ are seamlessly integrated from the huggingface.co `model
-hub `__ where they are uploaded directly by `users `__ and
-`organizations `__.
-
-Current number of checkpoints: |checkpoints|
-
-.. |checkpoints| image:: https://img.shields.io/endpoint?url=https://huggingface.co/api/shields/models&color=brightgreen
-
-Contents
------------------------------------------------------------------------------------------------------------------------
-
-The documentation is organized in five parts:
-
-- **GET STARTED** contains a quick tour, the installation instructions and some useful information about our philosophy
- and a glossary.
-- **USING 🤗 TRANSFORMERS** contains general tutorials on how to use the library.
-- **ADVANCED GUIDES** contains more advanced guides that are more specific to a given script or part of the library.
-- **RESEARCH** focuses on tutorials that have less to do with how to use the library but more about general research in
- transformers model
-- The three last section contain the documentation of each public class and function, grouped in:
-
- - **MAIN CLASSES** for the main classes exposing the important APIs of the library.
- - **MODELS** for the classes and functions related to each model implemented in the library.
- - **INTERNAL HELPERS** for the classes and functions we use internally.
-
-The library currently contains PyTorch, Tensorflow and Flax implementations, pretrained model weights, usage scripts
-and conversion utilities for the following models:
-
-..
- This list is updated automatically from the README with `make fix-copies`. Do not update manually!
-
-1. :doc:`ALBERT ` (from Google Research and the Toyota Technological Institute at Chicago) released
- with the paper `ALBERT: A Lite BERT for Self-supervised Learning of Language Representations
- `__, by Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush
- Sharma, Radu Soricut.
-2. :doc:`BART ` (from Facebook) released with the paper `BART: Denoising Sequence-to-Sequence
- Pre-training for Natural Language Generation, Translation, and Comprehension
- `__ by Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman
- Mohamed, Omer Levy, Ves Stoyanov and Luke Zettlemoyer.
-3. :doc:`BARThez ` (from École polytechnique) released with the paper `BARThez: a Skilled Pretrained
- French Sequence-to-Sequence Model `__ by Moussa Kamal Eddine, Antoine J.-P.
- Tixier, Michalis Vazirgiannis.
-4. :doc:`BERT ` (from Google) released with the paper `BERT: Pre-training of Deep Bidirectional
- Transformers for Language Understanding `__ by Jacob Devlin, Ming-Wei Chang,
- Kenton Lee and Kristina Toutanova.
-5. :doc:`BERT For Sequence Generation ` (from Google) released with the paper `Leveraging
- Pre-trained Checkpoints for Sequence Generation Tasks `__ by Sascha Rothe, Shashi
- Narayan, Aliaksei Severyn.
-6. :doc:`Blenderbot ` (from Facebook) released with the paper `Recipes for building an
- open-domain chatbot `__ by Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary
- Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston.
-7. :doc:`BlenderbotSmall ` (from Facebook) released with the paper `Recipes for building an
- open-domain chatbot `__ by Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary
- Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston.
-8. :doc:`BORT ` (from Alexa) released with the paper `Optimal Subarchitecture Extraction For BERT
- `__ by Adrian de Wynter and Daniel J. Perry.
-9. :doc:`CamemBERT ` (from Inria/Facebook/Sorbonne) released with the paper `CamemBERT: a Tasty
- French Language Model `__ by Louis Martin*, Benjamin Muller*, Pedro Javier Ortiz
- Suárez*, Yoann Dupont, Laurent Romary, Éric Villemonte de la Clergerie, Djamé Seddah and Benoît Sagot.
-10. :doc:`ConvBERT ` (from YituTech) released with the paper `ConvBERT: Improving BERT with
- Span-based Dynamic Convolution `__ by Zihang Jiang, Weihao Yu, Daquan Zhou,
- Yunpeng Chen, Jiashi Feng, Shuicheng Yan.
-11. :doc:`CTRL ` (from Salesforce) released with the paper `CTRL: A Conditional Transformer Language
- Model for Controllable Generation `__ by Nitish Shirish Keskar*, Bryan McCann*,
- Lav R. Varshney, Caiming Xiong and Richard Socher.
-12. :doc:`DeBERTa ` (from Microsoft) released with the paper `DeBERTa: Decoding-enhanced BERT with
- Disentangled Attention `__ by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu
- Chen.
-13. :doc:`DeBERTa-v2 ` (from Microsoft) released with the paper `DeBERTa: Decoding-enhanced BERT
- with Disentangled Attention `__ by Pengcheng He, Xiaodong Liu, Jianfeng Gao,
- Weizhu Chen.
-14. :doc:`DialoGPT ` (from Microsoft Research) released with the paper `DialoGPT: Large-Scale
- Generative Pre-training for Conversational Response Generation `__ by Yizhe
- Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao, Jianfeng Gao, Jingjing Liu, Bill Dolan.
-15. :doc:`DistilBERT ` (from HuggingFace), released together with the paper `DistilBERT, a
- distilled version of BERT: smaller, faster, cheaper and lighter `__ by Victor
- Sanh, Lysandre Debut and Thomas Wolf. The same method has been applied to compress GPT2 into `DistilGPT2
- `__, RoBERTa into `DistilRoBERTa
- `__, Multilingual BERT into
- `DistilmBERT `__ and a German
- version of DistilBERT.
-16. :doc:`DPR ` (from Facebook) released with the paper `Dense Passage Retrieval for Open-Domain
- Question Answering `__ by Vladimir Karpukhin, Barlas Oğuz, Sewon Min, Patrick
- Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih.
-17. :doc:`ELECTRA ` (from Google Research/Stanford University) released with the paper `ELECTRA:
- Pre-training text encoders as discriminators rather than generators `__ by Kevin
- Clark, Minh-Thang Luong, Quoc V. Le, Christopher D. Manning.
-18. :doc:`FlauBERT ` (from CNRS) released with the paper `FlauBERT: Unsupervised Language Model
- Pre-training for French `__ by Hang Le, Loïc Vial, Jibril Frej, Vincent Segonne,
- Maximin Coavoux, Benjamin Lecouteux, Alexandre Allauzen, Benoît Crabbé, Laurent Besacier, Didier Schwab.
-19. :doc:`Funnel Transformer ` (from CMU/Google Brain) released with the paper `Funnel-Transformer:
- Filtering out Sequential Redundancy for Efficient Language Processing `__ by
- Zihang Dai, Guokun Lai, Yiming Yang, Quoc V. Le.
-20. :doc:`GPT ` (from OpenAI) released with the paper `Improving Language Understanding by Generative
- Pre-Training `__ by Alec Radford, Karthik Narasimhan, Tim Salimans
- and Ilya Sutskever.
-21. :doc:`GPT-2 ` (from OpenAI) released with the paper `Language Models are Unsupervised Multitask
- Learners `__ by Alec Radford*, Jeffrey Wu*, Rewon Child, David
- Luan, Dario Amodei** and Ilya Sutskever**.
-22. :doc:`I-BERT ` (from Berkeley) released with the paper `I-BERT: Integer-only BERT Quantization
- `__ by Sehoon Kim, Amir Gholami, Zhewei Yao, Michael W. Mahoney, Kurt Keutzer
-23. :doc:`LayoutLM ` (from Microsoft Research Asia) released with the paper `LayoutLM: Pre-training
- of Text and Layout for Document Image Understanding `__ by Yiheng Xu, Minghao Li,
- Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou.
-24. :doc:`LED ` (from AllenAI) released with the paper `Longformer: The Long-Document Transformer
- `__ by Iz Beltagy, Matthew E. Peters, Arman Cohan.
-25. :doc:`Longformer ` (from AllenAI) released with the paper `Longformer: The Long-Document
- Transformer `__ by Iz Beltagy, Matthew E. Peters, Arman Cohan.
-26. :doc:`LXMERT ` (from UNC Chapel Hill) released with the paper `LXMERT: Learning Cross-Modality
- Encoder Representations from Transformers for Open-Domain Question Answering `__
- by Hao Tan and Mohit Bansal.
-27. :doc:`M2M100 ` (from Facebook) released with the paper `Beyond English-Centric Multilingual
- Machine Translation `__ by by Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi
- Ma, Ahmed El-Kishky, Siddharth Goyal, Mandeep Baines, Onur Celebi, Guillaume Wenzek, Vishrav Chaudhary, Naman
- Goyal, Tom Birch, Vitaliy Liptchinsky, Sergey Edunov, Edouard Grave, Michael Auli, Armand Joulin.
-28. :doc:`MarianMT ` Machine translation models trained using `OPUS `__ data by
- Jörg Tiedemann. The `Marian Framework `__ is being developed by the Microsoft
- Translator Team.
-29. :doc:`MBart ` (from Facebook) released with the paper `Multilingual Denoising Pre-training for
- Neural Machine Translation `__ by Yinhan Liu, Jiatao Gu, Naman Goyal, Xian Li,
- Sergey Edunov, Marjan Ghazvininejad, Mike Lewis, Luke Zettlemoyer.
-30. :doc:`MBart-50 ` (from Facebook) released with the paper `Multilingual Translation with Extensible
- Multilingual Pretraining and Finetuning `__ by Yuqing Tang, Chau Tran, Xian Li,
- Peng-Jen Chen, Naman Goyal, Vishrav Chaudhary, Jiatao Gu, Angela Fan.
-31. :doc:`MPNet ` (from Microsoft Research) released with the paper `MPNet: Masked and Permuted
- Pre-training for Language Understanding `__ by Kaitao Song, Xu Tan, Tao Qin,
- Jianfeng Lu, Tie-Yan Liu.
-32. :doc:`MT5 ` (from Google AI) released with the paper `mT5: A massively multilingual pre-trained
- text-to-text transformer `__ by Linting Xue, Noah Constant, Adam Roberts, Mihir
- Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, Colin Raffel.
-33. :doc:`Pegasus ` (from Google) released with the paper `PEGASUS: Pre-training with Extracted
- Gap-sentences for Abstractive Summarization `__> by Jingqing Zhang, Yao Zhao,
- Mohammad Saleh and Peter J. Liu.
-34. :doc:`ProphetNet ` (from Microsoft Research) released with the paper `ProphetNet: Predicting
- Future N-gram for Sequence-to-Sequence Pre-training `__ by Yu Yan, Weizhen Qi,
- Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou.
-35. :doc:`Reformer ` (from Google Research) released with the paper `Reformer: The Efficient
- Transformer `__ by Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya.
-36. :doc:`RoBERTa ` (from Facebook), released together with the paper a `Robustly Optimized BERT
- Pretraining Approach `__ by Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar
- Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov.
-37. :doc:`SpeechToTextTransformer ` (from Facebook), released together with the paper
- `fairseq S2T: Fast Speech-to-Text Modeling with fairseq `__ by Changhan Wang, Yun
- Tang, Xutai Ma, Anne Wu, Dmytro Okhonko, Juan Pino.
-38. :doc:`SqueezeBert ` released with the paper `SqueezeBERT: What can computer vision teach NLP
- about efficient neural networks? `__ by Forrest N. Iandola, Albert E. Shaw, Ravi
- Krishna, and Kurt W. Keutzer.
-39. :doc:`T5 ` (from Google AI) released with the paper `Exploring the Limits of Transfer Learning with a
- Unified Text-to-Text Transformer `__ by Colin Raffel and Noam Shazeer and Adam
- Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu.
-40. :doc:`TAPAS ` (from Google AI) released with the paper `TAPAS: Weakly Supervised Table Parsing via
- Pre-training `__ by Jonathan Herzig, Paweł Krzysztof Nowak, Thomas Müller,
- Francesco Piccinno and Julian Martin Eisenschlos.
-41. :doc:`Transformer-XL ` (from Google/CMU) released with the paper `Transformer-XL:
- Attentive Language Models Beyond a Fixed-Length Context `__ by Zihang Dai*,
- Zhilin Yang*, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan Salakhutdinov.
-42. :doc:`Wav2Vec2 ` (from Facebook AI) released with the paper `wav2vec 2.0: A Framework for
- Self-Supervised Learning of Speech Representations `__ by Alexei Baevski, Henry
- Zhou, Abdelrahman Mohamed, Michael Auli.
-43. :doc:`XLM ` (from Facebook) released together with the paper `Cross-lingual Language Model
- Pretraining `__ by Guillaume Lample and Alexis Conneau.
-44. :doc:`XLM-ProphetNet ` (from Microsoft Research) released with the paper `ProphetNet:
- Predicting Future N-gram for Sequence-to-Sequence Pre-training `__ by Yu Yan,
- Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou.
-45. :doc:`XLM-RoBERTa ` (from Facebook AI), released together with the paper `Unsupervised
- Cross-lingual Representation Learning at Scale `__ by Alexis Conneau*, Kartikay
- Khandelwal*, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzmán, Edouard Grave, Myle Ott, Luke
- Zettlemoyer and Veselin Stoyanov.
-46. :doc:`XLNet ` (from Google/CMU) released with the paper `XLNet: Generalized Autoregressive
- Pretraining for Language Understanding `__ by Zhilin Yang*, Zihang Dai*, Yiming
- Yang, Jaime Carbonell, Ruslan Salakhutdinov, Quoc V. Le.
-47. :doc:`XLSR-Wav2Vec2 ` (from Facebook AI) released with the paper `Unsupervised
- Cross-Lingual Representation Learning For Speech Recognition `__ by Alexis
- Conneau, Alexei Baevski, Ronan Collobert, Abdelrahman Mohamed, Michael Auli.
-
-
-.. _bigtable:
-
-The table below represents the current support in the library for each of those models, whether they have a Python
-tokenizer (called "slow"). A "fast" tokenizer backed by the 🤗 Tokenizers library, whether they have support in PyTorch,
-TensorFlow and/or Flax.
-
-..
- This table is updated automatically from the auto modules with `make fix-copies`. Do not update manually!
-
-.. rst-class:: center-aligned-table
-
-+-----------------------------+----------------+----------------+-----------------+--------------------+--------------+
-| Model | Tokenizer slow | Tokenizer fast | PyTorch support | TensorFlow support | Flax Support |
-+=============================+================+================+=================+====================+==============+
-| ALBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
-+-----------------------------+----------------+----------------+-----------------+--------------------+--------------+
-| BART | ✅ | ✅ | ✅ | ✅ | ❌ |
-+-----------------------------+----------------+----------------+-----------------+--------------------+--------------+
-| BERT | ✅ | ✅ | ✅ | ✅ | ✅ |
-+-----------------------------+----------------+----------------+-----------------+--------------------+--------------+
-| Bert Generation | ✅ | ❌ | ✅ | ❌ | ❌ |
-+-----------------------------+----------------+----------------+-----------------+--------------------+--------------+
-| Blenderbot | ✅ | ❌ | ✅ | ✅ | ❌ |
-+-----------------------------+----------------+----------------+-----------------+--------------------+--------------+
-| BlenderbotSmall | ✅ | ❌ | ✅ | ✅ | ❌ |
-+-----------------------------+----------------+----------------+-----------------+--------------------+--------------+
-| CTRL | ✅ | ❌ | ✅ | ✅ | ❌ |
-+-----------------------------+----------------+----------------+-----------------+--------------------+--------------+
-| CamemBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
-+-----------------------------+----------------+----------------+-----------------+--------------------+--------------+
-| ConvBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
-+-----------------------------+----------------+----------------+-----------------+--------------------+--------------+
-| DPR | ✅ | ✅ | ✅ | ✅ | ❌ |
-+-----------------------------+----------------+----------------+-----------------+--------------------+--------------+
-| DeBERTa | ✅ | ❌ | ✅ | ❌ | ❌ |
-+-----------------------------+----------------+----------------+-----------------+--------------------+--------------+
-| DeBERTa-v2 | ✅ | ❌ | ✅ | ❌ | ❌ |
-+-----------------------------+----------------+----------------+-----------------+--------------------+--------------+
-| DistilBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
-+-----------------------------+----------------+----------------+-----------------+--------------------+--------------+
-| ELECTRA | ✅ | ✅ | ✅ | ✅ | ❌ |
-+-----------------------------+----------------+----------------+-----------------+--------------------+--------------+
-| Encoder decoder | ❌ | ❌ | ✅ | ❌ | ❌ |
-+-----------------------------+----------------+----------------+-----------------+--------------------+--------------+
-| FairSeq Machine-Translation | ✅ | ❌ | ✅ | ❌ | ❌ |
-+-----------------------------+----------------+----------------+-----------------+--------------------+--------------+
-| FlauBERT | ✅ | ❌ | ✅ | ✅ | ❌ |
-+-----------------------------+----------------+----------------+-----------------+--------------------+--------------+
-| Funnel Transformer | ✅ | ✅ | ✅ | ✅ | ❌ |
-+-----------------------------+----------------+----------------+-----------------+--------------------+--------------+
-| I-BERT | ❌ | ❌ | ✅ | ❌ | ❌ |
-+-----------------------------+----------------+----------------+-----------------+--------------------+--------------+
-| LED | ✅ | ✅ | ✅ | ✅ | ❌ |
-+-----------------------------+----------------+----------------+-----------------+--------------------+--------------+
-| LXMERT | ✅ | ✅ | ✅ | ✅ | ❌ |
-+-----------------------------+----------------+----------------+-----------------+--------------------+--------------+
-| LayoutLM | ✅ | ✅ | ✅ | ❌ | ❌ |
-+-----------------------------+----------------+----------------+-----------------+--------------------+--------------+
-| Longformer | ✅ | ✅ | ✅ | ✅ | ❌ |
-+-----------------------------+----------------+----------------+-----------------+--------------------+--------------+
-| M2M100 | ✅ | ❌ | ✅ | ❌ | ❌ |
-+-----------------------------+----------------+----------------+-----------------+--------------------+--------------+
-| MPNet | ✅ | ✅ | ✅ | ✅ | ❌ |
-+-----------------------------+----------------+----------------+-----------------+--------------------+--------------+
-| Marian | ✅ | ❌ | ✅ | ✅ | ❌ |
-+-----------------------------+----------------+----------------+-----------------+--------------------+--------------+
-| MobileBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
-+-----------------------------+----------------+----------------+-----------------+--------------------+--------------+
-| OpenAI GPT | ✅ | ✅ | ✅ | ✅ | ❌ |
-+-----------------------------+----------------+----------------+-----------------+--------------------+--------------+
-| OpenAI GPT-2 | ✅ | ✅ | ✅ | ✅ | ❌ |
-+-----------------------------+----------------+----------------+-----------------+--------------------+--------------+
-| Pegasus | ✅ | ✅ | ✅ | ✅ | ❌ |
-+-----------------------------+----------------+----------------+-----------------+--------------------+--------------+
-| ProphetNet | ✅ | ❌ | ✅ | ❌ | ❌ |
-+-----------------------------+----------------+----------------+-----------------+--------------------+--------------+
-| RAG | ✅ | ❌ | ✅ | ✅ | ❌ |
-+-----------------------------+----------------+----------------+-----------------+--------------------+--------------+
-| Reformer | ✅ | ✅ | ✅ | ❌ | ❌ |
-+-----------------------------+----------------+----------------+-----------------+--------------------+--------------+
-| RetriBERT | ✅ | ✅ | ✅ | ❌ | ❌ |
-+-----------------------------+----------------+----------------+-----------------+--------------------+--------------+
-| RoBERTa | ✅ | ✅ | ✅ | ✅ | ✅ |
-+-----------------------------+----------------+----------------+-----------------+--------------------+--------------+
-| Speech2Text | ✅ | ❌ | ✅ | ❌ | ❌ |
-+-----------------------------+----------------+----------------+-----------------+--------------------+--------------+
-| SqueezeBERT | ✅ | ✅ | ✅ | ❌ | ❌ |
-+-----------------------------+----------------+----------------+-----------------+--------------------+--------------+
-| T5 | ✅ | ✅ | ✅ | ✅ | ❌ |
-+-----------------------------+----------------+----------------+-----------------+--------------------+--------------+
-| TAPAS | ✅ | ❌ | ✅ | ❌ | ❌ |
-+-----------------------------+----------------+----------------+-----------------+--------------------+--------------+
-| Transformer-XL | ✅ | ❌ | ✅ | ✅ | ❌ |
-+-----------------------------+----------------+----------------+-----------------+--------------------+--------------+
-| Wav2Vec2 | ✅ | ❌ | ✅ | ❌ | ❌ |
-+-----------------------------+----------------+----------------+-----------------+--------------------+--------------+
-| XLM | ✅ | ❌ | ✅ | ✅ | ❌ |
-+-----------------------------+----------------+----------------+-----------------+--------------------+--------------+
-| XLM-RoBERTa | ✅ | ✅ | ✅ | ✅ | ❌ |
-+-----------------------------+----------------+----------------+-----------------+--------------------+--------------+
-| XLMProphetNet | ✅ | ❌ | ✅ | ❌ | ❌ |
-+-----------------------------+----------------+----------------+-----------------+--------------------+--------------+
-| XLNet | ✅ | ✅ | ✅ | ✅ | ❌ |
-+-----------------------------+----------------+----------------+-----------------+--------------------+--------------+
-| mBART | ✅ | ✅ | ✅ | ✅ | ❌ |
-+-----------------------------+----------------+----------------+-----------------+--------------------+--------------+
-| mT5 | ✅ | ✅ | ✅ | ✅ | ❌ |
-+-----------------------------+----------------+----------------+-----------------+--------------------+--------------+
-
-.. toctree::
- :maxdepth: 2
- :caption: Get started
-
- quicktour
- installation
- philosophy
- glossary
-
-.. toctree::
- :maxdepth: 2
- :caption: Using 🤗 Transformers
-
- task_summary
- model_summary
- preprocessing
- training
- model_sharing
- tokenizer_summary
- multilingual
-
-.. toctree::
- :maxdepth: 2
- :caption: Advanced guides
-
- pretrained_models
- examples
- custom_datasets
- notebooks
- community
- converting_tensorflow_models
- migration
- contributing
- add_new_model
- testing
- serialization
-
-.. toctree::
- :maxdepth: 2
- :caption: Research
-
- bertology
- perplexity
- benchmarks
-
-.. toctree::
- :maxdepth: 2
- :caption: Main Classes
-
- main_classes/callback
- main_classes/configuration
- main_classes/logging
- main_classes/model
- main_classes/optimizer_schedules
- main_classes/output
- main_classes/pipelines
- main_classes/processors
- main_classes/tokenizer
- main_classes/trainer
- main_classes/feature_extractor
-
-.. toctree::
- :maxdepth: 2
- :caption: Models
-
- model_doc/albert
- model_doc/auto
- model_doc/bart
- model_doc/barthez
- model_doc/bert
- model_doc/bertweet
- model_doc/bertgeneration
- model_doc/blenderbot
- model_doc/blenderbot_small
- model_doc/bort
- model_doc/camembert
- model_doc/convbert
- model_doc/ctrl
- model_doc/deberta
- model_doc/deberta_v2
- model_doc/dialogpt
- model_doc/distilbert
- model_doc/dpr
- model_doc/electra
- model_doc/encoderdecoder
- model_doc/flaubert
- model_doc/fsmt
- model_doc/funnel
- model_doc/herbert
- model_doc/ibert
- model_doc/layoutlm
- model_doc/led
- model_doc/longformer
- model_doc/lxmert
- model_doc/marian
- model_doc/m2m_100
- model_doc/mbart
- model_doc/mobilebert
- model_doc/mpnet
- model_doc/mt5
- model_doc/gpt
- model_doc/gpt2
- model_doc/pegasus
- model_doc/phobert
- model_doc/prophetnet
- model_doc/rag
- model_doc/reformer
- model_doc/retribert
- model_doc/roberta
- model_doc/speech_to_text
- model_doc/squeezebert
- model_doc/t5
- model_doc/tapas
- model_doc/transformerxl
- model_doc/wav2vec2
- model_doc/xlm
- model_doc/xlmprophetnet
- model_doc/xlmroberta
- model_doc/xlnet
- model_doc/xlsr_wav2vec2
-
-.. toctree::
- :maxdepth: 2
- :caption: Internal Helpers
-
- internal/modeling_utils
- internal/pipelines_utils
- internal/tokenization_utils
- internal/trainer_utils
- internal/generation_utils
- internal/file_utils
diff --git a/docs/source/installation.md b/docs/source/installation.md
deleted file mode 100644
index f8e35b69eb1273..00000000000000
--- a/docs/source/installation.md
+++ /dev/null
@@ -1,192 +0,0 @@
-
-
-# Installation
-
-🤗 Transformers is tested on Python 3.6+, and PyTorch 1.1.0+ or TensorFlow 2.0+.
-
-You should install 🤗 Transformers in a [virtual environment](https://docs.python.org/3/library/venv.html). If you're
-unfamiliar with Python virtual environments, check out the [user guide](https://packaging.python.org/guides/installing-using-pip-and-virtual-environments/). Create a virtual environment with the version of Python you're going
-to use and activate it.
-
-Now, if you want to use 🤗 Transformers, you can install it with pip. If you'd like to play with the examples, you
-must install it from source.
-
-## Installation with pip
-
-First you need to install one of, or both, TensorFlow 2.0 and PyTorch.
-Please refer to [TensorFlow installation page](https://www.tensorflow.org/install/pip#tensorflow-2.0-rc-is-available),
-[PyTorch installation page](https://pytorch.org/get-started/locally/#start-locally) and/or
-[Flax installation page](https://github.com/google/flax#quick-install)
-regarding the specific install command for your platform.
-
-When TensorFlow 2.0 and/or PyTorch has been installed, 🤗 Transformers can be installed using pip as follows:
-
-```bash
-pip install transformers
-```
-
-Alternatively, for CPU-support only, you can install 🤗 Transformers and PyTorch in one line with:
-
-```bash
-pip install transformers[torch]
-```
-
-or 🤗 Transformers and TensorFlow 2.0 in one line with:
-
-```bash
-pip install transformers[tf-cpu]
-```
-
-or 🤗 Transformers and Flax in one line with:
-
-```bash
-pip install transformers[flax]
-```
-
-To check 🤗 Transformers is properly installed, run the following command:
-
-```bash
-python -c "from transformers import pipeline; print(pipeline('sentiment-analysis')('we love you'))"
-```
-
-It should download a pretrained model then print something like
-
-```bash
-[{'label': 'POSITIVE', 'score': 0.9998704791069031}]
-```
-
-(Note that TensorFlow will print additional stuff before that last statement.)
-
-## Installing from source
-
-Here is how to quickly install `transformers` from source:
-
-```bash
-pip install git+https://github.com/huggingface/transformers
-```
-
-Note that this will install not the latest released version, but the bleeding edge `master` version, which you may want to use in case a bug has been fixed since the last official release and a new release hasn't been yet rolled out.
-
-While we strive to keep `master` operational at all times, if you notice some issues, they usually get fixed within a few hours or a day and and you're more than welcome to help us detect any problems by opening an [Issue](https://github.com/huggingface/transformers/issues) and this way, things will get fixed even sooner.
-
-Again, you can run:
-
-```bash
-python -c "from transformers import pipeline; print(pipeline('sentiment-analysis')('I hate you'))"
-```
-
-to check 🤗 Transformers is properly installed.
-
-## Editable install
-
-If you want to constantly use the bleeding edge `master` version of the source code, or if you want to contribute to the library and need to test the changes in the code you're making, you will need an editable install. This is done by cloning the repository and installing with the following commands:
-
-``` bash
-git clone https://github.com/huggingface/transformers.git
-cd transformers
-pip install -e .
-```
-
-This command performs a magical link between the folder you cloned the repository to and your python library paths, and it'll look inside this folder in addition to the normal library-wide paths. So if normally your python packages get installed into:
-```
-~/anaconda3/envs/main/lib/python3.7/site-packages/
-```
-now this editable install will reside where you clone the folder to, e.g. `~/transformers/` and python will search it too.
-
-Do note that you have to keep that `transformers` folder around and not delete it to continue using the `transfomers` library.
-
-Now, let's get to the real benefit of this installation approach. Say, you saw some new feature has been just committed into `master`. If you have already performed all the steps above, to update your transformers to include all the latest commits, all you need to do is to `cd` into that cloned repository folder and update the clone to the latest version:
-
-```
-cd ~/transformers/
-git pull
-```
-
-There is nothing else to do. Your python environment will find the bleeding edge version of `transformers` on the next run.
-
-
-## With conda
-
-Since Transformers version v4.0.0, we now have a conda channel: `huggingface`.
-
-🤗 Transformers can be installed using conda as follows:
-
-```
-conda install -c huggingface transformers
-```
-
-Follow the installation pages of TensorFlow, PyTorch or Flax to see how to install them with conda.
-
-## Caching models
-
-This library provides pretrained models that will be downloaded and cached locally. Unless you specify a location with
-`cache_dir=...` when you use methods like `from_pretrained`, these models will automatically be downloaded in the
-folder given by the shell environment variable ``TRANSFORMERS_CACHE``. The default value for it will be the Hugging
-Face cache home followed by ``/transformers/``. This is (by order of priority):
-
- * shell environment variable ``HF_HOME``
- * shell environment variable ``XDG_CACHE_HOME`` + ``/huggingface/``
- * default: ``~/.cache/huggingface/``
-
-So if you don't have any specific environment variable set, the cache directory will be at
-``~/.cache/huggingface/transformers/``.
-
-**Note:** If you have set a shell environment variable for one of the predecessors of this library
-(``PYTORCH_TRANSFORMERS_CACHE`` or ``PYTORCH_PRETRAINED_BERT_CACHE``), those will be used if there is no shell
-environment variable for ``TRANSFORMERS_CACHE``.
-
-### Note on model downloads (Continuous Integration or large-scale deployments)
-
-If you expect to be downloading large volumes of models (more than 1,000) from our hosted bucket (for instance through
-your CI setup, or a large-scale production deployment), please cache the model files on your end. It will be way
-faster, and cheaper. Feel free to contact us privately if you need any help.
-
-### Offline mode
-
-It's possible to run 🤗 Transformers in a firewalled or a no-network environment.
-
-Setting environment variable `TRANSFORMERS_OFFLINE=1` will tell 🤗 Transformers to use local files only and will not try to look things up.
-
-Most likely you may want to couple this with `HF_DATASETS_OFFLINE=1` that performs the same for 🤗 Datasets if you're using the latter.
-
-Here is an example of how this can be used on a filesystem that is shared between a normally networked and a firewalled to the external world instances.
-
-On the instance with the normal network run your program which will download and cache models (and optionally datasets if you use 🤗 Datasets). For example:
-
-```
-python examples/seq2seq/run_translation.py --model_name_or_path t5-small --dataset_name wmt16 --dataset_config ro-en ...
-```
-
-and then with the same filesystem you can now run the same program on a firewalled instance:
-```
-HF_DATASETS_OFFLINE=1 TRANSFORMERS_OFFLINE=1 \
-python examples/seq2seq/run_translation.py --model_name_or_path t5-small --dataset_name wmt16 --dataset_config ro-en ...
-```
-and it should succeed without any hanging waiting to timeout.
-
-
-
-## Do you want to run a Transformer model on a mobile device?
-
-You should check out our [swift-coreml-transformers](https://github.com/huggingface/swift-coreml-transformers) repo.
-
-It contains a set of tools to convert PyTorch or TensorFlow 2.0 trained Transformer models (currently contains `GPT-2`,
-`DistilGPT-2`, `BERT`, and `DistilBERT`) to CoreML models that run on iOS devices.
-
-At some point in the future, you'll be able to seamlessly move from pretraining or fine-tuning models in PyTorch or
-TensorFlow 2.0 to productizing them in CoreML, or prototype a model or an app in CoreML then research its
-hyperparameters or architecture from PyTorch or TensorFlow 2.0. Super exciting!
diff --git a/docs/source/internal/file_utils.rst b/docs/source/internal/file_utils.rst
deleted file mode 100644
index 5122ed303bc091..00000000000000
--- a/docs/source/internal/file_utils.rst
+++ /dev/null
@@ -1,54 +0,0 @@
-..
- Copyright 2021 The HuggingFace Team. All rights reserved.
-
- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
- the License. You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
- Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
- an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
- specific language governing permissions and limitations under the License.
-
-General Utilities
------------------------------------------------------------------------------------------------------------------------
-
-This page lists all of Transformers general utility functions that are found in the file ``file_utils.py``.
-
-Most of those are only useful if you are studying the general code in the library.
-
-
-Enums and namedtuples
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.file_utils.ExplicitEnum
-
-.. autoclass:: transformers.file_utils.PaddingStrategy
-
-.. autoclass:: transformers.file_utils.TensorType
-
-
-Special Decorators
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autofunction:: transformers.file_utils.add_start_docstrings
-
-.. autofunction:: transformers.file_utils.add_start_docstrings_to_model_forward
-
-.. autofunction:: transformers.file_utils.add_end_docstrings
-
-.. autofunction:: transformers.file_utils.add_code_sample_docstrings
-
-.. autofunction:: transformers.file_utils.replace_return_docstrings
-
-
-Special Properties
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.file_utils.cached_property
-
-
-Other Utilities
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.file_utils._BaseLazyModule
diff --git a/docs/source/internal/generation_utils.rst b/docs/source/internal/generation_utils.rst
deleted file mode 100644
index 25fc82cbbeb37f..00000000000000
--- a/docs/source/internal/generation_utils.rst
+++ /dev/null
@@ -1,185 +0,0 @@
-..
- Copyright 2020 The HuggingFace Team. All rights reserved.
-
- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
- the License. You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
- Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
- an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
- specific language governing permissions and limitations under the License.
-
-Utilities for Generation
------------------------------------------------------------------------------------------------------------------------
-
-This page lists all the utility functions used by :meth:`~transformers.PreTrainedModel.generate`,
-:meth:`~transformers.PreTrainedModel.greedy_search`, :meth:`~transformers.PreTrainedModel.sample`,
-:meth:`~transformers.PreTrainedModel.beam_search`, :meth:`~transformers.PreTrainedModel.beam_sample`, and
-:meth:`~transformers.PreTrainedModel.group_beam_search`.
-
-Most of those are only useful if you are studying the code of the generate methods in the library.
-
-Generate Outputs
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-The output of :meth:`~transformers.PreTrainedModel.generate` is an instance of a subclass of
-:class:`~transformers.file_utils.ModelOutput`. This output is a data structure containing all the information returned
-by :meth:`~transformers.PreTrainedModel.generate`, but that can also be used as tuple or dictionary.
-
-Here's an example:
-
-.. code-block::
-
- from transformers import GPT2Tokenizer, GPT2LMHeadModel
-
- tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
- model = GPT2LMHeadModel.from_pretrained('gpt2')
-
- inputs = tokenizer("Hello, my dog is cute and ", return_tensors="pt")
- generation_output = model.generate(**inputs, return_dict_in_generate=True, output_scores=True)
-
-The ``generation_output`` object is a :class:`~transformers.generation_utils.GreedySearchDecoderOnlyOutput`, as we can
-see in the documentation of that class below, it means it has the following attributes:
-
-- ``sequences``: the generated sequences of tokens
-- ``scores`` (optional): the prediction scores of the language modelling head, for each generation step
-- ``hidden_states`` (optional): the hidden states of the model, for each generation step
-- ``attentions`` (optional): the attention weights of the model, for each generation step
-
-Here we have the ``scores`` since we passed along ``output_scores=True``, but we don't have ``hidden_states`` and
-``attentions`` because we didn't pass ``output_hidden_states=True`` or ``output_attentions=True``.
-
-You can access each attribute as you would usually do, and if that attribute has not been returned by the model, you
-will get ``None``. Here for instance ``generation_output.scores`` are all the generated prediction scores of the
-language modeling head, and ``generation_output.attentions`` is ``None``.
-
-When using our ``generation_output`` object as a tuple, it only keeps the attributes that don't have ``None`` values.
-Here, for instance, it has two elements, ``loss`` then ``logits``, so
-
-.. code-block::
-
- generation_output[:2]
-
-will return the tuple ``(generation_output.sequences, generation_output.scores)`` for instance.
-
-When using our ``generation_output`` object as a dictionary, it only keeps the attributes that don't have ``None``
-values. Here, for instance, it has two keys that are ``sequences`` and ``scores``.
-
-We document here all output types.
-
-
-GreedySearchOutput
-^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
-
-.. autoclass:: transformers.generation_utils.GreedySearchDecoderOnlyOutput
- :members:
-
-.. autoclass:: transformers.generation_utils.GreedySearchEncoderDecoderOutput
- :members:
-
-
-SampleOutput
-^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
-
-.. autoclass:: transformers.generation_utils.SampleDecoderOnlyOutput
- :members:
-
-.. autoclass:: transformers.generation_utils.SampleEncoderDecoderOutput
- :members:
-
-
-BeamSearchOutput
-^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
-
-.. autoclass:: transformers.generation_utils.BeamSearchDecoderOnlyOutput
- :members:
-
-.. autoclass:: transformers.generation_utils.BeamSearchEncoderDecoderOutput
- :members:
-
-
-BeamSampleOutput
-^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
-
-.. autoclass:: transformers.generation_utils.BeamSampleDecoderOnlyOutput
- :members:
-
-.. autoclass:: transformers.generation_utils.BeamSampleEncoderDecoderOutput
- :members:
-
-
-LogitsProcessor
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-A :class:`~transformers.LogitsProcessor` can be used to modify the prediction scores of a language model head for
-generation.
-
-.. autoclass:: transformers.LogitsProcessor
- :members: __call__
-
-.. autoclass:: transformers.LogitsProcessorList
- :members: __call__
-
-.. autoclass:: transformers.LogitsWarper
- :members: __call__
-
-.. autoclass:: transformers.MinLengthLogitsProcessor
- :members: __call__
-
-.. autoclass:: transformers.TemperatureLogitsWarper
- :members: __call__
-
-.. autoclass:: transformers.RepetitionPenaltyLogitsProcessor
- :members: __call__
-
-.. autoclass:: transformers.TopPLogitsWarper
- :members: __call__
-
-.. autoclass:: transformers.TopKLogitsWarper
- :members: __call__
-
-.. autoclass:: transformers.NoRepeatNGramLogitsProcessor
- :members: __call__
-
-.. autoclass:: transformers.NoBadWordsLogitsProcessor
- :members: __call__
-
-.. autoclass:: transformers.PrefixConstrainedLogitsProcessor
- :members: __call__
-
-.. autoclass:: transformers.HammingDiversityLogitsProcessor
- :members: __call__
-
-StoppingCriteria
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-A :class:`~transformers.StoppingCriteria` can be used to change when to stop generation (other than EOS token).
-
-.. autoclass:: transformers.StoppingCriteria
- :members: __call__
-
-.. autoclass:: transformers.StoppingCriteriaList
- :members: __call__
-
-.. autoclass:: transformers.MaxLengthCriteria
- :members: __call__
-
-.. autoclass:: transformers.MaxTimeCriteria
- :members: __call__
-
-BeamSearch
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.BeamScorer
- :members: process, finalize
-
-.. autoclass:: transformers.BeamSearchScorer
- :members: process, finalize
-
-Utilities
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autofunction:: transformers.top_k_top_p_filtering
-
-.. autofunction:: transformers.tf_top_k_top_p_filtering
diff --git a/docs/source/internal/modeling_utils.rst b/docs/source/internal/modeling_utils.rst
deleted file mode 100644
index 3d6d770dcdb8a0..00000000000000
--- a/docs/source/internal/modeling_utils.rst
+++ /dev/null
@@ -1,98 +0,0 @@
-..
- Copyright 2020 The HuggingFace Team. All rights reserved.
-
- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
- the License. You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
- Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
- an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
- specific language governing permissions and limitations under the License.
-
-Custom Layers and Utilities
------------------------------------------------------------------------------------------------------------------------
-
-This page lists all the custom layers used by the library, as well as the utility functions it provides for modeling.
-
-Most of those are only useful if you are studying the code of the models in the library.
-
-
-Pytorch custom modules
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.modeling_utils.Conv1D
-
-.. autoclass:: transformers.modeling_utils.PoolerStartLogits
- :members: forward
-
-.. autoclass:: transformers.modeling_utils.PoolerEndLogits
- :members: forward
-
-.. autoclass:: transformers.modeling_utils.PoolerAnswerClass
- :members: forward
-
-.. autoclass:: transformers.modeling_utils.SquadHeadOutput
-
-.. autoclass:: transformers.modeling_utils.SQuADHead
- :members: forward
-
-.. autoclass:: transformers.modeling_utils.SequenceSummary
- :members: forward
-
-
-PyTorch Helper Functions
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autofunction:: transformers.apply_chunking_to_forward
-
-.. autofunction:: transformers.modeling_utils.find_pruneable_heads_and_indices
-
-.. autofunction:: transformers.modeling_utils.prune_layer
-
-.. autofunction:: transformers.modeling_utils.prune_conv1d_layer
-
-.. autofunction:: transformers.modeling_utils.prune_linear_layer
-
-TensorFlow custom layers
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.modeling_tf_utils.TFConv1D
-
-.. autoclass:: transformers.modeling_tf_utils.TFSharedEmbeddings
- :members: call
-
-.. autoclass:: transformers.modeling_tf_utils.TFSequenceSummary
- :members: call
-
-
-TensorFlow loss functions
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.modeling_tf_utils.TFCausalLanguageModelingLoss
- :members:
-
-.. autoclass:: transformers.modeling_tf_utils.TFMaskedLanguageModelingLoss
- :members:
-
-.. autoclass:: transformers.modeling_tf_utils.TFMultipleChoiceLoss
- :members:
-
-.. autoclass:: transformers.modeling_tf_utils.TFQuestionAnsweringLoss
- :members:
-
-.. autoclass:: transformers.modeling_tf_utils.TFSequenceClassificationLoss
- :members:
-
-.. autoclass:: transformers.modeling_tf_utils.TFTokenClassificationLoss
- :members:
-
-
-TensorFlow Helper Functions
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autofunction:: transformers.modeling_tf_utils.get_initializer
-
-.. autofunction:: transformers.modeling_tf_utils.keras_serializable
-
-.. autofunction:: transformers.modeling_tf_utils.shape_list
diff --git a/docs/source/internal/pipelines_utils.rst b/docs/source/internal/pipelines_utils.rst
deleted file mode 100644
index 5d93defafd6b5a..00000000000000
--- a/docs/source/internal/pipelines_utils.rst
+++ /dev/null
@@ -1,52 +0,0 @@
-..
- Copyright 2020 The HuggingFace Team. All rights reserved.
-
- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
- the License. You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
- Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
- an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
- specific language governing permissions and limitations under the License.
-
-Utilities for pipelines
------------------------------------------------------------------------------------------------------------------------
-
-This page lists all the utility functions the library provides for pipelines.
-
-Most of those are only useful if you are studying the code of the models in the library.
-
-
-Argument handling
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.pipelines.ArgumentHandler
-
-.. autoclass:: transformers.pipelines.ZeroShotClassificationArgumentHandler
-
-.. autoclass:: transformers.pipelines.QuestionAnsweringArgumentHandler
-
-
-Data format
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.pipelines.PipelineDataFormat
- :members:
-
-.. autoclass:: transformers.pipelines.CsvPipelineDataFormat
- :members:
-
-.. autoclass:: transformers.pipelines.JsonPipelineDataFormat
- :members:
-
-.. autoclass:: transformers.pipelines.PipedPipelineDataFormat
- :members:
-
-
-Utilities
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autofunction:: transformers.pipelines.get_framework
-
-.. autoclass:: transformers.pipelines.PipelineException
diff --git a/docs/source/internal/tokenization_utils.rst b/docs/source/internal/tokenization_utils.rst
deleted file mode 100644
index 4198c552c8edee..00000000000000
--- a/docs/source/internal/tokenization_utils.rst
+++ /dev/null
@@ -1,45 +0,0 @@
-..
- Copyright 2020 The HuggingFace Team. All rights reserved.
-
- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
- the License. You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
- Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
- an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
- specific language governing permissions and limitations under the License.
-
-Utilities for Tokenizers
------------------------------------------------------------------------------------------------------------------------
-
-This page lists all the utility functions used by the tokenizers, mainly the class
-:class:`~transformers.tokenization_utils_base.PreTrainedTokenizerBase` that implements the common methods between
-:class:`~transformers.PreTrainedTokenizer` and :class:`~transformers.PreTrainedTokenizerFast` and the mixin
-:class:`~transformers.tokenization_utils_base.SpecialTokensMixin`.
-
-Most of those are only useful if you are studying the code of the tokenizers in the library.
-
-PreTrainedTokenizerBase
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.tokenization_utils_base.PreTrainedTokenizerBase
- :special-members: __call__
- :members:
-
-
-SpecialTokensMixin
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.tokenization_utils_base.SpecialTokensMixin
- :members:
-
-
-Enums and namedtuples
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.tokenization_utils_base.TruncationStrategy
-
-.. autoclass:: transformers.tokenization_utils_base.CharSpan
-
-.. autoclass:: transformers.tokenization_utils_base.TokenSpan
diff --git a/docs/source/internal/trainer_utils.rst b/docs/source/internal/trainer_utils.rst
deleted file mode 100644
index c649eb3ab4e4ff..00000000000000
--- a/docs/source/internal/trainer_utils.rst
+++ /dev/null
@@ -1,48 +0,0 @@
-..
- Copyright 2020 The HuggingFace Team. All rights reserved.
-
- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
- the License. You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
- Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
- an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
- specific language governing permissions and limitations under the License.
-
-Utilities for Trainer
------------------------------------------------------------------------------------------------------------------------
-
-This page lists all the utility functions used by :class:`~transformers.Trainer`.
-
-Most of those are only useful if you are studying the code of the Trainer in the library.
-
-Utilities
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.EvalPrediction
-
-.. autoclass:: transformers.IntervalStrategy
-
-.. autofunction:: transformers.set_seed
-
-.. autofunction:: transformers.torch_distributed_zero_first
-
-
-Callbacks internals
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.trainer_callback.CallbackHandler
-
-
-Distributed Evaluation
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.trainer_pt_utils.DistributedTensorGatherer
- :members:
-
-
-Distributed Evaluation
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.HfArgumentParser
diff --git a/docs/source/main_classes/callback.rst b/docs/source/main_classes/callback.rst
deleted file mode 100644
index 464c41ff828546..00000000000000
--- a/docs/source/main_classes/callback.rst
+++ /dev/null
@@ -1,89 +0,0 @@
-..
- Copyright 2020 The HuggingFace Team. All rights reserved.
-
- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
- the License. You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
- Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
- an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
- specific language governing permissions and limitations under the License.
-
-Callbacks
------------------------------------------------------------------------------------------------------------------------
-
-Callbacks are objects that can customize the behavior of the training loop in the PyTorch
-:class:`~transformers.Trainer` (this feature is not yet implemented in TensorFlow) that can inspect the training loop
-state (for progress reporting, logging on TensorBoard or other ML platforms...) and take decisions (like early
-stopping).
-
-Callbacks are "read only" pieces of code, apart from the :class:`~transformers.TrainerControl` object they return, they
-cannot change anything in the training loop. For customizations that require changes in the training loop, you should
-subclass :class:`~transformers.Trainer` and override the methods you need (see :doc:`trainer` for examples).
-
-By default a :class:`~transformers.Trainer` will use the following callbacks:
-
-- :class:`~transformers.DefaultFlowCallback` which handles the default behavior for logging, saving and evaluation.
-- :class:`~transformers.PrinterCallback` or :class:`~transformers.ProgressCallback` to display progress and print the
- logs (the first one is used if you deactivate tqdm through the :class:`~transformers.TrainingArguments`, otherwise
- it's the second one).
-- :class:`~transformers.integrations.TensorBoardCallback` if tensorboard is accessible (either through PyTorch >= 1.4
- or tensorboardX).
-- :class:`~transformers.integrations.WandbCallback` if `wandb `__ is installed.
-- :class:`~transformers.integrations.CometCallback` if `comet_ml `__ is installed.
-- :class:`~transformers.integrations.MLflowCallback` if `mlflow `__ is installed.
-- :class:`~transformers.integrations.AzureMLCallback` if `azureml-sdk `__ is
- installed.
-
-The main class that implements callbacks is :class:`~transformers.TrainerCallback`. It gets the
-:class:`~transformers.TrainingArguments` used to instantiate the :class:`~transformers.Trainer`, can access that
-Trainer's internal state via :class:`~transformers.TrainerState`, and can take some actions on the training loop via
-:class:`~transformers.TrainerControl`.
-
-
-Available Callbacks
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-Here is the list of the available :class:`~transformers.TrainerCallback` in the library:
-
-.. autoclass:: transformers.integrations.CometCallback
- :members: setup
-
-.. autoclass:: transformers.DefaultFlowCallback
-
-.. autoclass:: transformers.PrinterCallback
-
-.. autoclass:: transformers.ProgressCallback
-
-.. autoclass:: transformers.EarlyStoppingCallback
-
-.. autoclass:: transformers.integrations.TensorBoardCallback
-
-.. autoclass:: transformers.integrations.WandbCallback
- :members: setup
-
-.. autoclass:: transformers.integrations.MLflowCallback
- :members: setup
-
-.. autoclass:: transformers.integrations.AzureMLCallback
-
-TrainerCallback
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.TrainerCallback
- :members:
-
-
-TrainerState
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.TrainerState
- :members:
-
-
-TrainerControl
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.TrainerControl
- :members:
diff --git a/docs/source/main_classes/configuration.rst b/docs/source/main_classes/configuration.rst
deleted file mode 100644
index 1f39f771809570..00000000000000
--- a/docs/source/main_classes/configuration.rst
+++ /dev/null
@@ -1,25 +0,0 @@
-..
- Copyright 2020 The HuggingFace Team. All rights reserved.
-
- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
- the License. You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
- Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
- an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
- specific language governing permissions and limitations under the License.
-
-Configuration
------------------------------------------------------------------------------------------------------------------------
-
-The base class :class:`~transformers.PretrainedConfig` implements the common methods for loading/saving a configuration
-either from a local file or directory, or from a pretrained model configuration provided by the library (downloaded
-from HuggingFace's AWS S3 repository).
-
-
-PretrainedConfig
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.PretrainedConfig
- :members:
diff --git a/docs/source/main_classes/feature_extractor.rst b/docs/source/main_classes/feature_extractor.rst
deleted file mode 100644
index d8d95941538eb5..00000000000000
--- a/docs/source/main_classes/feature_extractor.rst
+++ /dev/null
@@ -1,41 +0,0 @@
-..
- Copyright 2021 The HuggingFace Team. All rights reserved.
-
- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
- the License. You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
- Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
- an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
- specific language governing permissions and limitations under the License.
-
-
-Feature Extractor
------------------------------------------------------------------------------------------------------------------------
-
-A feature extractor is in charge of preparing input features for a multi-modal model. This includes feature extraction
-from sequences, *e.g.*, pre-processing audio files to Log-Mel Spectrogram features, feature extraction from images
-*e.g.* cropping image image files, but also padding, normalization, and conversion to Numpy, PyTorch, and TensorFlow
-tensors.
-
-
-FeatureExtractionMixin
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.feature_extraction_utils.FeatureExtractionMixin
- :members: from_pretrained, save_pretrained
-
-
-SequenceFeatureExtractor
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.SequenceFeatureExtractor
- :members: pad
-
-
-BatchFeature
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.BatchFeature
- :members:
diff --git a/docs/source/main_classes/logging.rst b/docs/source/main_classes/logging.rst
deleted file mode 100644
index 6e2441a349dfd3..00000000000000
--- a/docs/source/main_classes/logging.rst
+++ /dev/null
@@ -1,74 +0,0 @@
-..
- Copyright 2020 The HuggingFace Team. All rights reserved.
-
- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
- the License. You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
- Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
- an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
- specific language governing permissions and limitations under the License.
-
-Logging
------------------------------------------------------------------------------------------------------------------------
-
-🤗 Transformers has a centralized logging system, so that you can setup the verbosity of the library easily.
-
-Currently the default verbosity of the library is ``WARNING``.
-
-To change the level of verbosity, just use one of the direct setters. For instance, here is how to change the verbosity
-to the INFO level.
-
-.. code-block:: python
-
- import transformers
- transformers.logging.set_verbosity_info()
-
-You can also use the environment variable ``TRANSFORMERS_VERBOSITY`` to override the default verbosity. You can set it
-to one of the following: ``debug``, ``info``, ``warning``, ``error``, ``critical``. For example:
-
-.. code-block:: bash
-
- TRANSFORMERS_VERBOSITY=error ./myprogram.py
-
-All the methods of this logging module are documented below, the main ones are
-:func:`transformers.logging.get_verbosity` to get the current level of verbosity in the logger and
-:func:`transformers.logging.set_verbosity` to set the verbosity to the level of your choice. In order (from the least
-verbose to the most verbose), those levels (with their corresponding int values in parenthesis) are:
-
-- :obj:`transformers.logging.CRITICAL` or :obj:`transformers.logging.FATAL` (int value, 50): only report the most
- critical errors.
-- :obj:`transformers.logging.ERROR` (int value, 40): only report errors.
-- :obj:`transformers.logging.WARNING` or :obj:`transformers.logging.WARN` (int value, 30): only reports error and
- warnings. This the default level used by the library.
-- :obj:`transformers.logging.INFO` (int value, 20): reports error, warnings and basic information.
-- :obj:`transformers.logging.DEBUG` (int value, 10): report all information.
-
-Base setters
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autofunction:: transformers.logging.set_verbosity_error
-
-.. autofunction:: transformers.logging.set_verbosity_warning
-
-.. autofunction:: transformers.logging.set_verbosity_info
-
-.. autofunction:: transformers.logging.set_verbosity_debug
-
-Other functions
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autofunction:: transformers.logging.get_verbosity
-
-.. autofunction:: transformers.logging.set_verbosity
-
-.. autofunction:: transformers.logging.get_logger
-
-.. autofunction:: transformers.logging.enable_default_handler
-
-.. autofunction:: transformers.logging.disable_default_handler
-
-.. autofunction:: transformers.logging.enable_explicit_format
-
-.. autofunction:: transformers.logging.reset_format
diff --git a/docs/source/main_classes/model.rst b/docs/source/main_classes/model.rst
deleted file mode 100644
index fef1426fa9a9f2..00000000000000
--- a/docs/source/main_classes/model.rst
+++ /dev/null
@@ -1,75 +0,0 @@
-..
- Copyright 2020 The HuggingFace Team. All rights reserved.
-
- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
- the License. You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
- Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
- an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
- specific language governing permissions and limitations under the License.
-
-Models
------------------------------------------------------------------------------------------------------------------------
-
-The base classes :class:`~transformers.PreTrainedModel`, :class:`~transformers.TFPreTrainedModel`, and
-:class:`~transformers.FlaxPreTrainedModel` implement the common methods for loading/saving a model either from a local
-file or directory, or from a pretrained model configuration provided by the library (downloaded from HuggingFace's AWS
-S3 repository).
-
-:class:`~transformers.PreTrainedModel` and :class:`~transformers.TFPreTrainedModel` also implement a few methods which
-are common among all the models to:
-
-- resize the input token embeddings when new tokens are added to the vocabulary
-- prune the attention heads of the model.
-
-The other methods that are common to each model are defined in :class:`~transformers.modeling_utils.ModuleUtilsMixin`
-(for the PyTorch models) and :class:`~transformers.modeling_tf_utils.TFModuleUtilsMixin` (for the TensorFlow models) or
-for text generation, :class:`~transformers.generation_utils.GenerationMixin` (for the PyTorch models) and
-:class:`~transformers.generation_tf_utils.TFGenerationMixin` (for the TensorFlow models)
-
-
-PreTrainedModel
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.PreTrainedModel
- :members:
-
-
-ModuleUtilsMixin
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.modeling_utils.ModuleUtilsMixin
- :members:
-
-
-TFPreTrainedModel
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.TFPreTrainedModel
- :members:
-
-
-TFModelUtilsMixin
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.modeling_tf_utils.TFModelUtilsMixin
- :members:
-
-
-FlaxPreTrainedModel
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.FlaxPreTrainedModel
- :members:
-
-
-Generation
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.generation_utils.GenerationMixin
- :members:
-
-.. autoclass:: transformers.generation_tf_utils.TFGenerationMixin
- :members:
diff --git a/docs/source/main_classes/optimizer_schedules.rst b/docs/source/main_classes/optimizer_schedules.rst
deleted file mode 100644
index 71cf19257427ed..00000000000000
--- a/docs/source/main_classes/optimizer_schedules.rst
+++ /dev/null
@@ -1,97 +0,0 @@
-..
- Copyright 2020 The HuggingFace Team. All rights reserved.
-
- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
- the License. You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
- Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
- an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
- specific language governing permissions and limitations under the License.
-
-Optimization
------------------------------------------------------------------------------------------------------------------------
-
-The ``.optimization`` module provides:
-
-- an optimizer with weight decay fixed that can be used to fine-tuned models, and
-- several schedules in the form of schedule objects that inherit from ``_LRSchedule``:
-- a gradient accumulation class to accumulate the gradients of multiple batches
-
-AdamW (PyTorch)
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.AdamW
- :members:
-
-AdaFactor (PyTorch)
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.Adafactor
-
-AdamWeightDecay (TensorFlow)
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.AdamWeightDecay
-
-.. autofunction:: transformers.create_optimizer
-
-Schedules
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-Learning Rate Schedules (Pytorch)
-^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
-
-.. autoclass:: transformers.SchedulerType
-
-.. autofunction:: transformers.get_scheduler
-
-.. autofunction:: transformers.get_constant_schedule
-
-
-.. autofunction:: transformers.get_constant_schedule_with_warmup
-
-.. image:: /imgs/warmup_constant_schedule.png
- :target: /imgs/warmup_constant_schedule.png
- :alt:
-
-
-.. autofunction:: transformers.get_cosine_schedule_with_warmup
-
-.. image:: /imgs/warmup_cosine_schedule.png
- :target: /imgs/warmup_cosine_schedule.png
- :alt:
-
-
-.. autofunction:: transformers.get_cosine_with_hard_restarts_schedule_with_warmup
-
-.. image:: /imgs/warmup_cosine_hard_restarts_schedule.png
- :target: /imgs/warmup_cosine_hard_restarts_schedule.png
- :alt:
-
-
-
-.. autofunction:: transformers.get_linear_schedule_with_warmup
-
-.. image:: /imgs/warmup_linear_schedule.png
- :target: /imgs/warmup_linear_schedule.png
- :alt:
-
-
-.. autofunction:: transformers.get_polynomial_decay_schedule_with_warmup
-
-
-Warmup (TensorFlow)
-^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
-
-.. autoclass:: transformers.WarmUp
- :members:
-
-Gradient Strategies
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-GradientAccumulator (TensorFlow)
-^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
-
-.. autoclass:: transformers.GradientAccumulator
diff --git a/docs/source/main_classes/output.rst b/docs/source/main_classes/output.rst
deleted file mode 100644
index 7b7c05568a4598..00000000000000
--- a/docs/source/main_classes/output.rst
+++ /dev/null
@@ -1,301 +0,0 @@
-..
- Copyright 2020 The HuggingFace Team. All rights reserved.
-
- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
- the License. You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
- Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
- an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
- specific language governing permissions and limitations under the License.
-
-Model outputs
------------------------------------------------------------------------------------------------------------------------
-
-PyTorch models have outputs that are instances of subclasses of :class:`~transformers.file_utils.ModelOutput`. Those
-are data structures containing all the information returned by the model, but that can also be used as tuples or
-dictionaries.
-
-Let's see of this looks on an example:
-
-.. code-block::
-
- from transformers import BertTokenizer, BertForSequenceClassification
- import torch
-
- tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
- model = BertForSequenceClassification.from_pretrained('bert-base-uncased')
-
- inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
- labels = torch.tensor([1]).unsqueeze(0) # Batch size 1
- outputs = model(**inputs, labels=labels)
-
-The ``outputs`` object is a :class:`~transformers.modeling_outputs.SequenceClassifierOutput`, as we can see in the
-documentation of that class below, it means it has an optional ``loss``, a ``logits`` an optional ``hidden_states`` and
-an optional ``attentions`` attribute. Here we have the ``loss`` since we passed along ``labels``, but we don't have
-``hidden_states`` and ``attentions`` because we didn't pass ``output_hidden_states=True`` or
-``output_attentions=True``.
-
-You can access each attribute as you would usually do, and if that attribute has not been returned by the model, you
-will get ``None``. Here for instance ``outputs.loss`` is the loss computed by the model, and ``outputs.attentions`` is
-``None``.
-
-When considering our ``outputs`` object as tuple, it only considers the attributes that don't have ``None`` values.
-Here for instance, it has two elements, ``loss`` then ``logits``, so
-
-.. code-block::
-
- outputs[:2]
-
-will return the tuple ``(outputs.loss, outputs.logits)`` for instance.
-
-When considering our ``outputs`` object as dictionary, it only considers the attributes that don't have ``None``
-values. Here for instance, it has two keys that are ``loss`` and ``logits``.
-
-We document here the generic model outputs that are used by more than one model type. Specific output types are
-documented on their corresponding model page.
-
-ModelOutput
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.file_utils.ModelOutput
- :members: to_tuple
-
-
-BaseModelOutput
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.modeling_outputs.BaseModelOutput
- :members:
-
-
-BaseModelOutputWithPooling
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.modeling_outputs.BaseModelOutputWithPooling
- :members:
-
-
-BaseModelOutputWithCrossAttentions
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.modeling_outputs.BaseModelOutputWithCrossAttentions
- :members:
-
-
-BaseModelOutputWithPoolingAndCrossAttentions
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.modeling_outputs.BaseModelOutputWithPoolingAndCrossAttentions
- :members:
-
-
-BaseModelOutputWithPast
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.modeling_outputs.BaseModelOutputWithPast
- :members:
-
-
-BaseModelOutputWithPastAndCrossAttentions
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.modeling_outputs.BaseModelOutputWithPastAndCrossAttentions
- :members:
-
-
-Seq2SeqModelOutput
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.modeling_outputs.Seq2SeqModelOutput
- :members:
-
-
-CausalLMOutput
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.modeling_outputs.CausalLMOutput
- :members:
-
-
-CausalLMOutputWithCrossAttentions
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.modeling_outputs.CausalLMOutputWithCrossAttentions
- :members:
-
-
-CausalLMOutputWithPast
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.modeling_outputs.CausalLMOutputWithPast
- :members:
-
-
-MaskedLMOutput
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.modeling_outputs.MaskedLMOutput
- :members:
-
-
-Seq2SeqLMOutput
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.modeling_outputs.Seq2SeqLMOutput
- :members:
-
-
-NextSentencePredictorOutput
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.modeling_outputs.NextSentencePredictorOutput
- :members:
-
-
-SequenceClassifierOutput
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.modeling_outputs.SequenceClassifierOutput
- :members:
-
-
-Seq2SeqSequenceClassifierOutput
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.modeling_outputs.Seq2SeqSequenceClassifierOutput
- :members:
-
-
-MultipleChoiceModelOutput
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.modeling_outputs.MultipleChoiceModelOutput
- :members:
-
-
-TokenClassifierOutput
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.modeling_outputs.TokenClassifierOutput
- :members:
-
-
-QuestionAnsweringModelOutput
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.modeling_outputs.QuestionAnsweringModelOutput
- :members:
-
-
-Seq2SeqQuestionAnsweringModelOutput
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.modeling_outputs.Seq2SeqQuestionAnsweringModelOutput
- :members:
-
-
-TFBaseModelOutput
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.modeling_tf_outputs.TFBaseModelOutput
- :members:
-
-
-TFBaseModelOutputWithPooling
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.modeling_tf_outputs.TFBaseModelOutputWithPooling
- :members:
-
-
-TFBaseModelOutputWithPast
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.modeling_tf_outputs.TFBaseModelOutputWithPast
- :members:
-
-
-TFSeq2SeqModelOutput
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.modeling_tf_outputs.TFSeq2SeqModelOutput
- :members:
-
-
-TFCausalLMOutput
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.modeling_tf_outputs.TFCausalLMOutput
- :members:
-
-
-TFCausalLMOutputWithPast
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.modeling_tf_outputs.TFCausalLMOutputWithPast
- :members:
-
-
-TFMaskedLMOutput
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.modeling_tf_outputs.TFMaskedLMOutput
- :members:
-
-
-TFSeq2SeqLMOutput
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.modeling_tf_outputs.TFSeq2SeqLMOutput
- :members:
-
-
-TFNextSentencePredictorOutput
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.modeling_tf_outputs.TFNextSentencePredictorOutput
- :members:
-
-
-TFSequenceClassifierOutput
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.modeling_tf_outputs.TFSequenceClassifierOutput
- :members:
-
-
-TFSeq2SeqSequenceClassifierOutput
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.modeling_tf_outputs.TFSeq2SeqSequenceClassifierOutput
- :members:
-
-
-TFMultipleChoiceModelOutput
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.modeling_tf_outputs.TFMultipleChoiceModelOutput
- :members:
-
-
-TFTokenClassifierOutput
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.modeling_tf_outputs.TFTokenClassifierOutput
- :members:
-
-
-TFQuestionAnsweringModelOutput
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.modeling_tf_outputs.TFQuestionAnsweringModelOutput
- :members:
-
-
-TFSeq2SeqQuestionAnsweringModelOutput
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.modeling_tf_outputs.TFSeq2SeqQuestionAnsweringModelOutput
- :members:
diff --git a/docs/source/main_classes/pipelines.rst b/docs/source/main_classes/pipelines.rst
deleted file mode 100644
index 04ec19c9a5b5c1..00000000000000
--- a/docs/source/main_classes/pipelines.rst
+++ /dev/null
@@ -1,148 +0,0 @@
-..
- Copyright 2020 The HuggingFace Team. All rights reserved.
-
- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
- the License. You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
- Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
- an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
- specific language governing permissions and limitations under the License.
-
-Pipelines
------------------------------------------------------------------------------------------------------------------------
-
-The pipelines are a great and easy way to use models for inference. These pipelines are objects that abstract most of
-the complex code from the library, offering a simple API dedicated to several tasks, including Named Entity
-Recognition, Masked Language Modeling, Sentiment Analysis, Feature Extraction and Question Answering. See the
-:doc:`task summary <../task_summary>` for examples of use.
-
-There are two categories of pipeline abstractions to be aware about:
-
-- The :func:`~transformers.pipeline` which is the most powerful object encapsulating all other pipelines.
-- The other task-specific pipelines:
-
- - :class:`~transformers.ConversationalPipeline`
- - :class:`~transformers.FeatureExtractionPipeline`
- - :class:`~transformers.FillMaskPipeline`
- - :class:`~transformers.QuestionAnsweringPipeline`
- - :class:`~transformers.SummarizationPipeline`
- - :class:`~transformers.TextClassificationPipeline`
- - :class:`~transformers.TextGenerationPipeline`
- - :class:`~transformers.TokenClassificationPipeline`
- - :class:`~transformers.TranslationPipeline`
- - :class:`~transformers.ZeroShotClassificationPipeline`
- - :class:`~transformers.Text2TextGenerationPipeline`
- - :class:`~transformers.TableQuestionAnsweringPipeline`
-
-The pipeline abstraction
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-The `pipeline` abstraction is a wrapper around all the other available pipelines. It is instantiated as any other
-pipeline but requires an additional argument which is the `task`.
-
-.. autofunction:: transformers.pipeline
-
-
-The task specific pipelines
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-ConversationalPipeline
-=======================================================================================================================
-
-.. autoclass:: transformers.Conversation
-
-.. autoclass:: transformers.ConversationalPipeline
- :special-members: __call__
- :members:
-
-FeatureExtractionPipeline
-=======================================================================================================================
-
-.. autoclass:: transformers.FeatureExtractionPipeline
- :special-members: __call__
- :members:
-
-FillMaskPipeline
-=======================================================================================================================
-
-.. autoclass:: transformers.FillMaskPipeline
- :special-members: __call__
- :members:
-
-NerPipeline
-=======================================================================================================================
-
-.. autoclass:: transformers.NerPipeline
-
-See :class:`~transformers.TokenClassificationPipeline` for all details.
-
-QuestionAnsweringPipeline
-=======================================================================================================================
-
-.. autoclass:: transformers.QuestionAnsweringPipeline
- :special-members: __call__
- :members:
-
-SummarizationPipeline
-=======================================================================================================================
-
-.. autoclass:: transformers.SummarizationPipeline
- :special-members: __call__
- :members:
-
-TableQuestionAnsweringPipeline
-=======================================================================================================================
-
-.. autoclass:: transformers.TableQuestionAnsweringPipeline
- :special-members: __call__
-
-
-TextClassificationPipeline
-=======================================================================================================================
-
-.. autoclass:: transformers.TextClassificationPipeline
- :special-members: __call__
- :members:
-
-TextGenerationPipeline
-=======================================================================================================================
-
-.. autoclass:: transformers.TextGenerationPipeline
- :special-members: __call__
- :members:
-
-Text2TextGenerationPipeline
-=======================================================================================================================
-
-.. autoclass:: transformers.Text2TextGenerationPipeline
- :special-members: __call__
- :members:
-
-TokenClassificationPipeline
-=======================================================================================================================
-
-.. autoclass:: transformers.TokenClassificationPipeline
- :special-members: __call__
- :members:
-
-TranslationPipeline
-=======================================================================================================================
-
-.. autoclass:: transformers.TranslationPipeline
- :special-members: __call__
- :members:
-
-ZeroShotClassificationPipeline
-=======================================================================================================================
-
-.. autoclass:: transformers.ZeroShotClassificationPipeline
- :special-members: __call__
- :members:
-
-Parent class: :obj:`Pipeline`
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.Pipeline
- :members:
diff --git a/docs/source/main_classes/processors.rst b/docs/source/main_classes/processors.rst
deleted file mode 100644
index 793ee1b1332d7d..00000000000000
--- a/docs/source/main_classes/processors.rst
+++ /dev/null
@@ -1,172 +0,0 @@
-..
- Copyright 2020 The HuggingFace Team. All rights reserved.
-
- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
- the License. You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
- Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
- an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
- specific language governing permissions and limitations under the License.
-
-Processors
------------------------------------------------------------------------------------------------------------------------
-
-This library includes processors for several traditional tasks. These processors can be used to process a dataset into
-examples that can be fed to a model.
-
-Processors
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-All processors follow the same architecture which is that of the
-:class:`~transformers.data.processors.utils.DataProcessor`. The processor returns a list of
-:class:`~transformers.data.processors.utils.InputExample`. These
-:class:`~transformers.data.processors.utils.InputExample` can be converted to
-:class:`~transformers.data.processors.utils.InputFeatures` in order to be fed to the model.
-
-.. autoclass:: transformers.data.processors.utils.DataProcessor
- :members:
-
-
-.. autoclass:: transformers.data.processors.utils.InputExample
- :members:
-
-
-.. autoclass:: transformers.data.processors.utils.InputFeatures
- :members:
-
-
-GLUE
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-`General Language Understanding Evaluation (GLUE) `__ is a benchmark that evaluates the
-performance of models across a diverse set of existing NLU tasks. It was released together with the paper `GLUE: A
-multi-task benchmark and analysis platform for natural language understanding
-`__
-
-This library hosts a total of 10 processors for the following tasks: MRPC, MNLI, MNLI (mismatched), CoLA, SST2, STSB,
-QQP, QNLI, RTE and WNLI.
-
-Those processors are:
-
- - :class:`~transformers.data.processors.utils.MrpcProcessor`
- - :class:`~transformers.data.processors.utils.MnliProcessor`
- - :class:`~transformers.data.processors.utils.MnliMismatchedProcessor`
- - :class:`~transformers.data.processors.utils.Sst2Processor`
- - :class:`~transformers.data.processors.utils.StsbProcessor`
- - :class:`~transformers.data.processors.utils.QqpProcessor`
- - :class:`~transformers.data.processors.utils.QnliProcessor`
- - :class:`~transformers.data.processors.utils.RteProcessor`
- - :class:`~transformers.data.processors.utils.WnliProcessor`
-
-Additionally, the following method can be used to load values from a data file and convert them to a list of
-:class:`~transformers.data.processors.utils.InputExample`.
-
-.. automethod:: transformers.data.processors.glue.glue_convert_examples_to_features
-
-Example usage
-^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
-
-An example using these processors is given in the `run_glue.py
-`__ script.
-
-
-XNLI
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-`The Cross-Lingual NLI Corpus (XNLI) `__ is a benchmark that evaluates the
-quality of cross-lingual text representations. XNLI is crowd-sourced dataset based on `MultiNLI
-`: pairs of text are labeled with textual entailment annotations for 15
-different languages (including both high-resource language such as English and low-resource languages such as Swahili).
-
-It was released together with the paper `XNLI: Evaluating Cross-lingual Sentence Representations
-`__
-
-This library hosts the processor to load the XNLI data:
-
- - :class:`~transformers.data.processors.utils.XnliProcessor`
-
-Please note that since the gold labels are available on the test set, evaluation is performed on the test set.
-
-An example using these processors is given in the `run_xnli.py
-`__ script.
-
-
-SQuAD
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-`The Stanford Question Answering Dataset (SQuAD) `__ is a benchmark that
-evaluates the performance of models on question answering. Two versions are available, v1.1 and v2.0. The first version
-(v1.1) was released together with the paper `SQuAD: 100,000+ Questions for Machine Comprehension of Text
-`__. The second version (v2.0) was released alongside the paper `Know What You Don't
-Know: Unanswerable Questions for SQuAD `__.
-
-This library hosts a processor for each of the two versions:
-
-Processors
-^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
-
-Those processors are:
-
- - :class:`~transformers.data.processors.utils.SquadV1Processor`
- - :class:`~transformers.data.processors.utils.SquadV2Processor`
-
-They both inherit from the abstract class :class:`~transformers.data.processors.utils.SquadProcessor`
-
-.. autoclass:: transformers.data.processors.squad.SquadProcessor
- :members:
-
-Additionally, the following method can be used to convert SQuAD examples into
-:class:`~transformers.data.processors.utils.SquadFeatures` that can be used as model inputs.
-
-.. automethod:: transformers.data.processors.squad.squad_convert_examples_to_features
-
-These processors as well as the aforementionned method can be used with files containing the data as well as with the
-`tensorflow_datasets` package. Examples are given below.
-
-
-Example usage
-^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
-
-Here is an example using the processors as well as the conversion method using data files:
-
-.. code-block::
-
- # Loading a V2 processor
- processor = SquadV2Processor()
- examples = processor.get_dev_examples(squad_v2_data_dir)
-
- # Loading a V1 processor
- processor = SquadV1Processor()
- examples = processor.get_dev_examples(squad_v1_data_dir)
-
- features = squad_convert_examples_to_features(
- examples=examples,
- tokenizer=tokenizer,
- max_seq_length=max_seq_length,
- doc_stride=args.doc_stride,
- max_query_length=max_query_length,
- is_training=not evaluate,
- )
-
-Using `tensorflow_datasets` is as easy as using a data file:
-
-.. code-block::
-
- # tensorflow_datasets only handle Squad V1.
- tfds_examples = tfds.load("squad")
- examples = SquadV1Processor().get_examples_from_dataset(tfds_examples, evaluate=evaluate)
-
- features = squad_convert_examples_to_features(
- examples=examples,
- tokenizer=tokenizer,
- max_seq_length=max_seq_length,
- doc_stride=args.doc_stride,
- max_query_length=max_query_length,
- is_training=not evaluate,
- )
-
-
-Another example using these processors is given in the :prefix_link:`run_squad.py
-` script.
diff --git a/docs/source/main_classes/tokenizer.rst b/docs/source/main_classes/tokenizer.rst
deleted file mode 100644
index 3bd9b3a9667e14..00000000000000
--- a/docs/source/main_classes/tokenizer.rst
+++ /dev/null
@@ -1,76 +0,0 @@
-..
- Copyright 2020 The HuggingFace Team. All rights reserved.
-
- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
- the License. You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
- Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
- an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
- specific language governing permissions and limitations under the License.
-
-Tokenizer
------------------------------------------------------------------------------------------------------------------------
-
-A tokenizer is in charge of preparing the inputs for a model. The library contains tokenizers for all the models. Most
-of the tokenizers are available in two flavors: a full python implementation and a "Fast" implementation based on the
-Rust library `tokenizers `__. The "Fast" implementations allows:
-
-1. a significant speed-up in particular when doing batched tokenization and
-2. additional methods to map between the original string (character and words) and the token space (e.g. getting the
- index of the token comprising a given character or the span of characters corresponding to a given token). Currently
- no "Fast" implementation is available for the SentencePiece-based tokenizers (for T5, ALBERT, CamemBERT, XLMRoBERTa
- and XLNet models).
-
-The base classes :class:`~transformers.PreTrainedTokenizer` and :class:`~transformers.PreTrainedTokenizerFast`
-implement the common methods for encoding string inputs in model inputs (see below) and instantiating/saving python and
-"Fast" tokenizers either from a local file or directory or from a pretrained tokenizer provided by the library
-(downloaded from HuggingFace's AWS S3 repository). They both rely on
-:class:`~transformers.tokenization_utils_base.PreTrainedTokenizerBase` that contains the common methods, and
-:class:`~transformers.tokenization_utils_base.SpecialTokensMixin`.
-
-:class:`~transformers.PreTrainedTokenizer` and :class:`~transformers.PreTrainedTokenizerFast` thus implement the main
-methods for using all the tokenizers:
-
-- Tokenizing (splitting strings in sub-word token strings), converting tokens strings to ids and back, and
- encoding/decoding (i.e., tokenizing and converting to integers).
-- Adding new tokens to the vocabulary in a way that is independent of the underlying structure (BPE, SentencePiece...).
-- Managing special tokens (like mask, beginning-of-sentence, etc.): adding them, assigning them to attributes in the
- tokenizer for easy access and making sure they are not split during tokenization.
-
-:class:`~transformers.BatchEncoding` holds the output of the tokenizer's encoding methods (``__call__``,
-``encode_plus`` and ``batch_encode_plus``) and is derived from a Python dictionary. When the tokenizer is a pure python
-tokenizer, this class behaves just like a standard python dictionary and holds the various model inputs computed by
-these methods (``input_ids``, ``attention_mask``...). When the tokenizer is a "Fast" tokenizer (i.e., backed by
-HuggingFace `tokenizers library `__), this class provides in addition
-several advanced alignment methods which can be used to map between the original string (character and words) and the
-token space (e.g., getting the index of the token comprising a given character or the span of characters corresponding
-to a given token).
-
-
-PreTrainedTokenizer
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.PreTrainedTokenizer
- :special-members: __call__
- :members: batch_decode, convert_ids_to_tokens, convert_tokens_to_ids, convert_tokens_to_string, decode, encode,
- get_added_vocab, get_special_tokens_mask, num_special_tokens_to_add, prepare_for_tokenization, tokenize,
- vocab_size
-
-
-PreTrainedTokenizerFast
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.PreTrainedTokenizerFast
- :special-members: __call__
- :members: batch_decode, convert_ids_to_tokens, convert_tokens_to_ids, convert_tokens_to_string, decode, encode,
- get_added_vocab, get_special_tokens_mask, num_special_tokens_to_add,
- set_truncation_and_padding,tokenize, vocab_size
-
-
-BatchEncoding
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.BatchEncoding
- :members:
diff --git a/docs/source/main_classes/trainer.rst b/docs/source/main_classes/trainer.rst
deleted file mode 100644
index d50a6664d3fc65..00000000000000
--- a/docs/source/main_classes/trainer.rst
+++ /dev/null
@@ -1,992 +0,0 @@
-..
- Copyright 2020 The HuggingFace Team. All rights reserved.
-
- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
- the License. You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
- Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
- an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
- specific language governing permissions and limitations under the License.
-
-Trainer
------------------------------------------------------------------------------------------------------------------------
-
-The :class:`~transformers.Trainer` and :class:`~transformers.TFTrainer` classes provide an API for feature-complete
-training in most standard use cases. It's used in most of the :doc:`example scripts <../examples>`.
-
-Before instantiating your :class:`~transformers.Trainer`/:class:`~transformers.TFTrainer`, create a
-:class:`~transformers.TrainingArguments`/:class:`~transformers.TFTrainingArguments` to access all the points of
-customization during training.
-
-The API supports distributed training on multiple GPUs/TPUs, mixed precision through `NVIDIA Apex
-`__ and Native AMP for PyTorch and :obj:`tf.keras.mixed_precision` for TensorFlow.
-
-Both :class:`~transformers.Trainer` and :class:`~transformers.TFTrainer` contain the basic training loop which supports
-the above features. To inject custom behavior you can subclass them and override the following methods:
-
-- **get_train_dataloader**/**get_train_tfdataset** -- Creates the training DataLoader (PyTorch) or TF Dataset.
-- **get_eval_dataloader**/**get_eval_tfdataset** -- Creates the evaluation DataLoader (PyTorch) or TF Dataset.
-- **get_test_dataloader**/**get_test_tfdataset** -- Creates the test DataLoader (PyTorch) or TF Dataset.
-- **log** -- Logs information on the various objects watching training.
-- **create_optimizer_and_scheduler** -- Sets up the optimizer and learning rate scheduler if they were not passed at
- init. Note, that you can also subclass or override the ``create_optimizer`` and ``create_scheduler`` methods
- separately.
-- **create_optimizer** -- Sets up the optimizer if it wasn't passed at init.
-- **create_scheduler** -- Sets up the learning rate scheduler if it wasn't passed at init.
-- **compute_loss** - Computes the loss on a batch of training inputs.
-- **training_step** -- Performs a training step.
-- **prediction_step** -- Performs an evaluation/test step.
-- **run_model** (TensorFlow only) -- Basic pass through the model.
-- **evaluate** -- Runs an evaluation loop and returns metrics.
-- **predict** -- Returns predictions (with metrics if labels are available) on a test set.
-
-.. warning::
-
- The :class:`~transformers.Trainer` class is optimized for 🤗 Transformers models and can have surprising behaviors
- when you use it on other models. When using it on your own model, make sure:
-
- - your model always return tuples or subclasses of :class:`~transformers.file_utils.ModelOutput`.
- - your model can compute the loss if a :obj:`labels` argument is provided and that loss is returned as the first
- element of the tuple (if your model returns tuples)
- - your model can accept multiple label arguments (use the :obj:`label_names` in your
- :class:`~transformers.TrainingArguments` to indicate their name to the :class:`~transformers.Trainer`) but none
- of them should be named :obj:`"label"`.
-
-Here is an example of how to customize :class:`~transformers.Trainer` using a custom loss function for multi-label
-classification:
-
-.. code-block:: python
-
- import torch
- from transformers import Trainer
-
- class MultilabelTrainer(Trainer):
- def compute_loss(self, model, inputs, return_outputs=False):
- labels = inputs.pop("labels")
- outputs = model(**inputs)
- logits = outputs.logits
- loss_fct = torch.nn.BCEWithLogitsLoss()
- loss = loss_fct(logits.view(-1, self.model.config.num_labels),
- labels.float().view(-1, self.model.config.num_labels))
- return (loss, outputs) if return_outputs else loss
-
-Another way to customize the training loop behavior for the PyTorch :class:`~transformers.Trainer` is to use
-:doc:`callbacks ` that can inspect the training loop state (for progress reporting, logging on TensorBoard or
-other ML platforms...) and take decisions (like early stopping).
-
-
-Trainer
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.Trainer
- :members:
-
-
-Seq2SeqTrainer
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.Seq2SeqTrainer
- :members: evaluate, predict
-
-
-TFTrainer
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.TFTrainer
- :members:
-
-
-TrainingArguments
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.TrainingArguments
- :members:
-
-
-Seq2SeqTrainingArguments
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.Seq2SeqTrainingArguments
- :members:
-
-
-TFTrainingArguments
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.TFTrainingArguments
- :members:
-
-
-Trainer Integrations
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-
-
-The :class:`~transformers.Trainer` has been extended to support libraries that may dramatically improve your training
-time and fit much bigger models.
-
-Currently it supports third party solutions, `DeepSpeed `__ and `FairScale
-`__, which implement parts of the paper `ZeRO: Memory Optimizations
-Toward Training Trillion Parameter Models, by Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, Yuxiong He
-`__.
-
-This provided support is new and experimental as of this writing.
-
-Installation Notes
-^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
-
-As of this writing, both FairScale and Deepspeed require compilation of CUDA C++ code, before they can be used.
-
-While all installation issues should be dealt with through the corresponding GitHub Issues of `FairScale
-`__ and `Deepspeed
-`__, there are a few common issues that one may encounter while building
-any PyTorch extension that needs to build CUDA extensions.
-
-Therefore, if you encounter a CUDA-related build issue while doing one of the following or both:
-
-.. code-block:: bash
-
- pip install fairscale
- pip install deepspeed
-
-please, read the following notes first.
-
-In these notes we give examples for what to do when ``pytorch`` has been built with CUDA ``10.2``. If your situation is
-different remember to adjust the version number to the one you are after.
-
-**Possible problem #1:**
-
-While, Pytorch comes with its own CUDA toolkit, to build these two projects you must have an identical version of CUDA
-installed system-wide.
-
-For example, if you installed ``pytorch`` with ``cudatoolkit==10.2`` in the Python environment, you also need to have
-CUDA ``10.2`` installed system-wide.
-
-The exact location may vary from system to system, but ``/usr/local/cuda-10.2`` is the most common location on many
-Unix systems. When CUDA is correctly set up and added to the ``PATH`` environment variable, one can find the
-installation location by doing:
-
-.. code-block:: bash
-
- which nvcc
-
-If you don't have CUDA installed system-wide, install it first. You will find the instructions by using your favorite
-search engine. For example, if you're on Ubuntu you may want to search for: `ubuntu cuda 10.2 install
-`__.
-
-**Possible problem #2:**
-
-Another possible common problem is that you may have more than one CUDA toolkit installed system-wide. For example you
-may have:
-
-.. code-block:: bash
-
- /usr/local/cuda-10.2
- /usr/local/cuda-11.0
-
-Now, in this situation you need to make sure that your ``PATH`` and ``LD_LIBRARY_PATH`` environment variables contain
-the correct paths to the desired CUDA version. Typically, package installers will set these to contain whatever the
-last version was installed. If you encounter the problem, where the package build fails because it can't find the right
-CUDA version despite you having it installed system-wide, it means that you need to adjust the 2 aforementioned
-environment variables.
-
-First, you may look at their contents:
-
-.. code-block:: bash
-
- echo $PATH
- echo $LD_LIBRARY_PATH
-
-so you get an idea of what is inside.
-
-It's possible that ``LD_LIBRARY_PATH`` is empty.
-
-``PATH`` lists the locations of where executables can be found and ``LD_LIBRARY_PATH`` is for where shared libraries
-are to looked for. In both cases, earlier entries have priority over the later ones. ``:`` is used to separate multiple
-entries.
-
-Now, to tell the build program where to find the specific CUDA toolkit, insert the desired paths to be listed first by
-doing:
-
-.. code-block:: bash
-
- export PATH=/usr/local/cuda-10.2/bin:$PATH
- export LD_LIBRARY_PATH=/usr/local/cuda-10.2/lib64:$LD_LIBRARY_PATH
-
-Note that we aren't overwriting the existing values, but prepending instead.
-
-Of course, adjust the version number, the full path if need be. Check that the directories you assign actually do
-exist. ``lib64`` sub-directory is where the various CUDA ``.so`` objects, like ``libcudart.so`` reside, it's unlikely
-that your system will have it named differently, but if it is adjust it to reflect your reality.
-
-
-**Possible problem #3:**
-
-Some older CUDA versions may refuse to build with newer compilers. For example, you my have ``gcc-9`` but it wants
-``gcc-7``.
-
-There are various ways to go about it.
-
-If you can install the latest CUDA toolkit it typically should support the newer compiler.
-
-Alternatively, you could install the lower version of the compiler in addition to the one you already have, or you may
-already have it but it's not the default one, so the build system can't see it. If you have ``gcc-7`` installed but the
-build system complains it can't find it, the following might do the trick:
-
-.. code-block:: bash
-
- sudo ln -s /usr/bin/gcc-7 /usr/local/cuda-10.2/bin/gcc
- sudo ln -s /usr/bin/g++-7 /usr/local/cuda-10.2/bin/g++
-
-
-Here, we are making a symlink to ``gcc-7`` from ``/usr/local/cuda-10.2/bin/gcc`` and since
-``/usr/local/cuda-10.2/bin/`` should be in the ``PATH`` environment variable (see the previous problem's solution), it
-should find ``gcc-7`` (and ``g++7``) and then the build will succeed.
-
-As always make sure to edit the paths in the example to match your situation.
-
-**If still unsuccessful:**
-
-If after addressing these you still encounter build issues, please, proceed with the GitHub Issue of `FairScale
-`__ and `Deepspeed
-`__, depending on the project you have the problem with.
-
-
-FairScale
-^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
-
-By integrating `FairScale `__ the :class:`~transformers.Trainer`
-provides support for the following features from `the ZeRO paper `__:
-
-1. Optimizer State Sharding
-2. Gradient Sharding
-3. Model Parameters Sharding (new and very experimental)
-4. CPU offload (new and very experimental)
-
-You will need at least two GPUs to use this feature.
-
-To deploy this feature:
-
-1. Install the library via pypi:
-
- .. code-block:: bash
-
- pip install fairscale
-
- or find more details on `the FairScale's GitHub page
- `__.
-
-2. To use the first version of Sharded data-parallelism, add ``--sharded_ddp simple`` to the command line arguments,
- and make sure you have added the distributed launcher ``-m torch.distributed.launch
- --nproc_per_node=NUMBER_OF_GPUS_YOU_HAVE`` if you haven't been using it already.
-
-For example here is how you could use it for ``run_translation.py`` with 2 GPUs:
-
-.. code-block:: bash
-
- python -m torch.distributed.launch --nproc_per_node=2 examples/seq2seq/run_translation.py \
- --model_name_or_path t5-small --per_device_train_batch_size 1 \
- --output_dir output_dir --overwrite_output_dir \
- --do_train --max_train_samples 500 --num_train_epochs 1 \
- --dataset_name wmt16 --dataset_config "ro-en" \
- --source_lang en --target_lang ro \
- --fp16 --sharded_ddp simple
-
-Notes:
-
-- This feature requires distributed training (so multiple GPUs).
-- It is not implemented for TPUs.
-- It works with ``--fp16`` too, to make things even faster.
-- One of the main benefits of enabling ``--sharded_ddp simple`` is that it uses a lot less GPU memory, so you should be
- able to use significantly larger batch sizes using the same hardware (e.g. 3x and even bigger) which should lead to
- significantly shorter training time.
-
-3. To use the second version of Sharded data-parallelism, add ``--sharded_ddp zero_dp_2`` or ``--sharded_ddp zero_dp_3`
- to the command line arguments, and make sure you have added the distributed launcher ``-m torch.distributed.launch
- --nproc_per_node=NUMBER_OF_GPUS_YOU_HAVE`` if you haven't been using it already.
-
-For example here is how you could use it for ``run_translation.py`` with 2 GPUs:
-
-.. code-block:: bash
-
- python -m torch.distributed.launch --nproc_per_node=2 examples/seq2seq/run_translation.py \
- --model_name_or_path t5-small --per_device_train_batch_size 1 \
- --output_dir output_dir --overwrite_output_dir \
- --do_train --max_train_samples 500 --num_train_epochs 1 \
- --dataset_name wmt16 --dataset_config "ro-en" \
- --source_lang en --target_lang ro \
- --fp16 --sharded_ddp zero_dp_2
-
-:obj:`zero_dp_2` is an optimized version of the simple wrapper, while :obj:`zero_dp_3` fully shards model weights,
-gradients and optimizer states.
-
-Both are compatible with adding :obj:`cpu_offload` to enable ZeRO-offload (activate it like this: :obj:`--sharded_ddp
-"zero_dp_2 cpu_offload"`).
-
-Notes:
-
-- This feature requires distributed training (so multiple GPUs).
-- It is not implemented for TPUs.
-- It works with ``--fp16`` too, to make things even faster.
-- The ``cpu_offload`` additional option requires ``--fp16``.
-- This is an area of active development, so make sure you have a source install of fairscale to use this feature as
- some bugs you encounter may have been fixed there already.
-
-Known caveats:
-
-- This feature is incompatible with :obj:`--predict_with_generate` in the `run_translation.py` script.
-- Using :obj:`--sharded_ddp zero_dp_3` requires wrapping each layer of the model in the special container
- :obj:`FullyShardedDataParallelism` of fairscale. It should be used with the option :obj:`auto_wrap` if you are not
- doing this yourself: :obj:`--sharded_ddp "zero_dp_3 auto_wrap"`.
-
-
-DeepSpeed
-^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
-
-`DeepSpeed `__ implements everything described in the `ZeRO paper
-`__, except ZeRO's stage 3. "Parameter Partitioning (Pos+g+p)". Currently it provides
-full support for:
-
-1. Optimizer State Partitioning (ZeRO stage 1)
-2. Add Gradient Partitioning (ZeRO stage 2)
-3. Custom fp16 handling
-4. A range of fast Cuda-extension-based Optimizers
-5. ZeRO-Offload
-
-ZeRO-Offload has its own dedicated paper: `ZeRO-Offload: Democratizing Billion-Scale Model Training
-`__.
-
-DeepSpeed is currently used only for training, as all the currently available features are of no use to inference.
-
-
-
-Installation
-=======================================================================================================================
-
-Install the library via pypi:
-
-.. code-block:: bash
-
- pip install deepspeed
-
-or find more details on `the DeepSpeed's GitHub page `__.
-
-Deployment with multiple GPUs
-=======================================================================================================================
-
-To deploy this feature with multiple GPUs adjust the :class:`~transformers.Trainer` command line arguments as
-following:
-
-1. replace ``python -m torch.distributed.launch`` with ``deepspeed``.
-2. add a new argument ``--deepspeed ds_config.json``, where ``ds_config.json`` is the DeepSpeed configuration file as
- documented `here `__. The file naming is up to you.
-
-Therefore, if your original command line looked as following:
-
-.. code-block:: bash
-
- python -m torch.distributed.launch --nproc_per_node=2 your_program.py
-
-Now it should be:
-
-.. code-block:: bash
-
- deepspeed --num_gpus=2 your_program.py --deepspeed ds_config.json
-
-Unlike, ``torch.distributed.launch`` where you have to specify how many GPUs to use with ``--nproc_per_node``, with the
-``deepspeed`` launcher you don't have to use the corresponding ``--num_gpus`` if you want all of your GPUs used. The
-full details on how to configure various nodes and GPUs can be found `here
-`__.
-
-In fact, you can continue using ``-m torch.distributed.launch`` with DeepSpeed as long as you don't need to use
-``deepspeed`` launcher-specific arguments. Typically if you don't need a multi-node setup you're not required to use
-the ``deepspeed`` launcher. But since in the DeepSpeed documentation it'll be used everywhere, for consistency we will
-use it here as well.
-
-Here is an example of running ``run_translation.py`` under DeepSpeed deploying all available GPUs:
-
-.. code-block:: bash
-
- deepspeed examples/seq2seq/run_translation.py \
- --deepspeed examples/tests/deepspeed/ds_config.json \
- --model_name_or_path t5-small --per_device_train_batch_size 1 \
- --output_dir output_dir --overwrite_output_dir --fp16 \
- --do_train --max_train_samples 500 --num_train_epochs 1 \
- --dataset_name wmt16 --dataset_config "ro-en" \
- --source_lang en --target_lang ro
-
-
-Note that in the DeepSpeed documentation you are likely to see ``--deepspeed --deepspeed_config ds_config.json`` - i.e.
-two DeepSpeed-related arguments, but for the sake of simplicity, and since there are already so many arguments to deal
-with, we combined the two into a single argument.
-
-For some practical usage examples, please, see this `post
-`__.
-
-
-
-Deployment with one GPU
-=======================================================================================================================
-
-To deploy DeepSpeed with one GPU adjust the :class:`~transformers.Trainer` command line arguments as following:
-
-.. code-block:: bash
-
- deepspeed --num_gpus=1 examples/seq2seq/run_translation.py \
- --deepspeed examples/tests/deepspeed/ds_config.json \
- --model_name_or_path t5-small --per_device_train_batch_size 1 \
- --output_dir output_dir --overwrite_output_dir --fp16 \
- --do_train --max_train_samples 500 --num_train_epochs 1 \
- --dataset_name wmt16 --dataset_config "ro-en" \
- --source_lang en --target_lang ro
-
-This is almost the same as with multiple-GPUs, but here we tell DeepSpeed explicitly to use just one GPU. By default,
-DeepSpeed deploys all GPUs it can see. If you have only 1 GPU to start with, then you don't need this argument. The
-following `documentation `__ discusses the
-launcher options.
-
-Why would you want to use DeepSpeed with just one GPU?
-
-1. It has a ZeRO-offload feature which can delegate some computations and memory to the host's CPU and RAM, and thus
- leave more GPU resources for model's needs - e.g. larger batch size, or enabling a fitting of a very big model which
- normally won't fit.
-2. It provides a smart GPU memory management system, that minimizes memory fragmentation, which again allows you to fit
- bigger models and data batches.
-
-While we are going to discuss the configuration in details next, the key to getting a huge improvement on a single GPU
-with DeepSpeed is to have at least the following configuration in the configuration file:
-
-.. code-block:: json
-
- {
- "zero_optimization": {
- "stage": 2,
- "allgather_partitions": true,
- "allgather_bucket_size": 2e8,
- "reduce_scatter": true,
- "reduce_bucket_size": 2e8,
- "overlap_comm": true,
- "contiguous_gradients": true,
- "cpu_offload": true
- },
- }
-
-which enables ``cpu_offload`` and some other important features. You may experiment with the buffer sizes, you will
-find more details in the discussion below.
-
-For a practical usage example of this type of deployment, please, see this `post
-`__.
-
-Notes:
-
-- if you need to run on a specific GPU, which is different from GPU 0, you can't use ``CUDA_VISIBLE_DEVICES`` to limit
- the visible scope of available GPUs. Instead, you have to use the following syntax:
-
- .. code-block:: bash
-
- deepspeed --include localhost:1 examples/seq2seq/run_translation.py ...
-
- In this example, we tell DeepSpeed to use GPU 1 (second gpu).
-
-
-
-Deployment in Notebooks
-=======================================================================================================================
-
-The problem with running notebook cells as a script is that there is no normal ``deepspeed`` launcher to rely on, so
-under certain setups we have to emulate it.
-
-Here is how you'd have to adjust your training code in the notebook to use DeepSpeed.
-
-.. code-block:: python
-
- # DeepSpeed requires a distributed environment even when only one process is used.
- # This emulates a launcher in the notebook
- import os
- os.environ['MASTER_ADDR'] = 'localhost'
- os.environ['MASTER_PORT'] = '9994' # modify if RuntimeError: Address already in use
- os.environ['RANK'] = "0"
- os.environ['LOCAL_RANK'] = "0"
- os.environ['WORLD_SIZE'] = "1"
-
- # Now proceed as normal, plus pass the deepspeed config file
- training_args = TrainingArguments(..., deepspeed="ds_config.json")
- trainer = Trainer(...)
- trainer.train()
-
-Note: `...` stands for the normal arguments that you'd pass to the functions.
-
-If you want to create the config file on the fly in the notebook in the current directory, you could have a dedicated
-cell with:
-
-.. code-block:: python
-
- %%bash
- cat <<'EOT' > ds_config.json
- {
- "fp16": {
- "enabled": true,
- "loss_scale": 0,
- "loss_scale_window": 1000,
- "hysteresis": 2,
- "min_loss_scale": 1
- },
-
- "zero_optimization": {
- "stage": 2,
- "allgather_partitions": true,
- "allgather_bucket_size": 2e8,
- "overlap_comm": true,
- "reduce_scatter": true,
- "reduce_bucket_size": 2e8,
- "contiguous_gradients": true,
- "cpu_offload": true
- },
-
- "optimizer": {
- "type": "AdamW",
- "params": {
- "lr": 3e-5,
- "betas": [0.8, 0.999],
- "eps": 1e-8,
- "weight_decay": 3e-7
- }
- },
-
- "scheduler": {
- "type": "WarmupLR",
- "params": {
- "warmup_min_lr": 0,
- "warmup_max_lr": 3e-5,
- "warmup_num_steps": 500
- }
- },
-
- "steps_per_print": 2000,
- "wall_clock_breakdown": false
- }
- EOT
-
-
-That's said if the script is not in the notebook cells, you can launch ``deepspeed`` normally via shell from a cell
-with:
-
-.. code-block::
-
- !deepspeed examples/seq2seq/run_translation.py ...
-
-or with bash magic, where you can write a multi-line code for the shell to run:
-
-.. code-block::
-
- %%bash
-
- cd /somewhere
- deepspeed examples/seq2seq/run_translation.py ...
-
-
-
-
-Configuration
-=======================================================================================================================
-
-For the complete guide to the DeepSpeed configuration options that can be used in its configuration file please refer
-to the `following documentation `__.
-
-You can find dozens of DeepSpeed configuration examples that address various practical needs in `the DeepSpeedExamples
-repo `__:
-
-.. code-block:: bash
-
- git clone https://github.com/microsoft/DeepSpeedExamples
- cd DeepSpeedExamples
- find . -name '*json'
-
-Continuing the code from above, let's say you're looking to configure the Lamb optimizer. So you can search through the
-example ``.json`` files with:
-
-.. code-block:: bash
-
- grep -i Lamb $(find . -name '*json')
-
-Some more examples are to be found in the `main repo `__ as well.
-
-When using DeepSpeed you always need to supply a DeepSpeed configuration file, yet some configuration parameters have
-to be configured via the command line. You will find the nuances in the rest of this guide.
-
-To get an idea of what DeepSpeed configuration file looks like, here is one that activates ZeRO stage 2 features,
-enables FP16, uses ``AdamW`` optimizer and ``WarmupLR`` scheduler:
-
-.. code-block:: json
-
- {
- "fp16": {
- "enabled": true,
- "loss_scale": 0,
- "loss_scale_window": 1000,
- "hysteresis": 2,
- "min_loss_scale": 1
- },
-
- "zero_optimization": {
- "stage": 2,
- "allgather_partitions": true,
- "allgather_bucket_size": 5e8,
- "overlap_comm": true,
- "reduce_scatter": true,
- "reduce_bucket_size": 5e8,
- "contiguous_gradients": true,
- "cpu_offload": true
- },
-
- "optimizer": {
- "type": "AdamW",
- "params": {
- "lr": 3e-5,
- "betas": [ 0.8, 0.999 ],
- "eps": 1e-8,
- "weight_decay": 3e-7
- }
- },
-
- "scheduler": {
- "type": "WarmupLR",
- "params": {
- "warmup_min_lr": 0,
- "warmup_max_lr": 3e-5,
- "warmup_num_steps": 500
- }
- }
- }
-
-When you execute the program, DeepSpeed will log the configuration it received from the :class:`~transformers.Trainer`
-to the console, so you can see exactly what was the final configuration passed to it.
-
-
-Passing Configuration
-=======================================================================================================================
-
-As discussed in this document normally the DeepSpeed configuration is passed as a path to a json file, but if you're
-not using the command line interface to configure the training, and instead instantiate the
-:class:`~transformers.Trainer` via :class:`~transformers.TrainingArguments` then for the ``deepspeed`` argument you can
-pass a nested ``dict``. This allows you to create the configuration on the fly and doesn't require you to write it to
-the file system before passing it to :class:`~transformers.TrainingArguments`.
-
-To summarize you can do:
-
-.. code-block:: python
-
- TrainingArguments(..., deespeed="/path/to/ds_config.json")
-
-or:
-
-.. code-block:: python
-
- ds_config_dict=dict(scheduler=scheduler_params, optimizer=optimizer_params)
- TrainingArguments(..., deespeed=ds_config_dict)
-
-
-
-Shared Configuration
-=======================================================================================================================
-
-Some configuration information is required by both the :class:`~transformers.Trainer` and DeepSpeed to function
-correctly, therefore, to prevent conflicting definitions, which could lead to hard to detect errors, we chose to
-configure those via the :class:`~transformers.Trainer` command line arguments.
-
-Therefore, the following DeepSpeed configuration params shouldn't be used with the :class:`~transformers.Trainer`:
-
-* ``train_batch_size``
-* ``train_micro_batch_size_per_gpu``
-* ``gradient_accumulation_steps``
-
-as these will be automatically derived from the run time environment and the following 2 command line arguments:
-
-.. code-block:: bash
-
- --per_device_train_batch_size 8 --gradient_accumulation_steps 2
-
-which are always required to be supplied.
-
-Of course, you will need to adjust the values in this example to your situation.
-
-
-
-ZeRO
-=======================================================================================================================
-
-The ``zero_optimization`` section of the configuration file is the most important part (`docs
-`__), since that is where you define
-which ZeRO stages you want to enable and how to configure them.
-
-.. code-block:: json
-
- {
- "zero_optimization": {
- "stage": 2,
- "allgather_partitions": true,
- "allgather_bucket_size": 5e8,
- "overlap_comm": true,
- "reduce_scatter": true,
- "reduce_bucket_size": 5e8,
- "contiguous_gradients": true,
- "cpu_offload": true
- }
- }
-
-Notes:
-
-- enabling ``cpu_offload`` should reduce GPU RAM usage (it requires ``"stage": 2``)
-- ``"overlap_comm": true`` trades off increased GPU RAM usage to lower all-reduce latency. ``overlap_comm`` uses 4.5x
- the ``allgather_bucket_size`` and ``reduce_bucket_size`` values. So if they are set to 5e8, this requires a 9GB
- footprint (``5e8 x 2Bytes x 2 x 4.5``). Therefore, if you have a GPU with 8GB or less RAM, to avoid getting
- OOM-errors you will need to reduce those parameters to about ``2e8``, which would require 3.6GB. You will want to do
- the same on larger capacity GPU as well, if you're starting to hit OOM.
-- when reducing these buffers you're trading communication speed to avail more GPU RAM. The smaller the buffer size,
- the slower the communication, and the more GPU RAM will be available to other tasks. So if a bigger batch size is
- important, getting a slightly slower training time could be a good trade.
-
-This section has to be configured exclusively via DeepSpeed configuration - the :class:`~transformers.Trainer` provides
-no equivalent command line arguments.
-
-
-
-Optimizer and Scheduler
-=======================================================================================================================
-
-As long as you don't enable ``cpu_offload`` you can mix and match DeepSpeed and HuggingFace schedulers and optimizers,
-with the exception of using the combination of HuggingFace scheduler and DeepSpeed optimizer:
-
-+--------------+--------------+--------------+
-| Combos | HF Scheduler | DS Scheduler |
-+--------------+--------------+--------------+
-| HF Optimizer | Yes | Yes |
-+--------------+--------------+--------------+
-| DS Optimizer | No | Yes |
-+--------------+--------------+--------------+
-
-If ``cpu_offload`` is enabled you must use both DeepSpeed scheduler and DeepSpeed optimizer.
-
-
-
-Optimizer
-"""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""
-
-
-DeepSpeed's main optimizers are Adam, AdamW, OneBitAdam, and Lamb. These have been thoroughly tested with ZeRO and are
-thus recommended to be used. It, however, can import other optimizers from ``torch``. The full documentation is `here
-`__.
-
-If you don't configure the ``optimizer`` entry in the configuration file, the :class:`~transformers.Trainer` will
-automatically set it to ``AdamW`` and will use the supplied values or the defaults for the following command line
-arguments: ``--learning_rate``, ``--adam_beta1``, ``--adam_beta2``, ``--adam_epsilon`` and ``--weight_decay``.
-
-Here is an example of the pre-configured ``optimizer`` entry for ``AdamW``:
-
-.. code-block:: json
-
- {
- "optimizer": {
- "type": "AdamW",
- "params": {
- "lr": 0.001,
- "betas": [0.8, 0.999],
- "eps": 1e-8,
- "weight_decay": 3e-7
- }
- }
- }
-
-Note that the command line arguments will override the values in the configuration file. This is so that there is one
-definitive source of the values and to avoid hard to find errors when for example, the learning rate is set to
-different values in different places. Command line rules. The values that get overridden are:
-
-- ``lr`` with the value of ``--learning_rate``
-- ``betas`` with the value of ``--adam_beta1 --adam_beta2``
-- ``eps`` with the value of ``--adam_epsilon``
-- ``weight_decay`` with the value of ``--weight_decay``
-
-Therefore please remember to tune the shared hyperparameters on the command line.
-
-If you want to use another optimizer which is not listed above, you will have to add ``"zero_allow_untested_optimizer":
-true`` to the top level configuration.
-
-If you want to use one of the officially supported optimizers, configure them explicitly in the configuration file, and
-make sure to adjust the values. e.g. if use Adam you will want ``weight_decay`` around ``0.01``.
-
-
-Scheduler
-"""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""""
-
-DeepSpeed supports LRRangeTest, OneCycle, WarmupLR and WarmupDecayLR LR schedulers. The full documentation is `here
-`__.
-
-
-Here is where the schedulers overlap between 🤗 Transformers and DeepSpeed:
-
-* ``WarmupLR`` via ``--lr_scheduler_type constant_with_warmup``
-* ``WarmupDecayLR`` via ``--lr_scheduler_type linear``. This is also the default value for ``--lr_scheduler_type``,
- therefore, if you don't configure the scheduler this is scheduler that will get configured by default.
-
-
-If you don't configure the ``scheduler`` entry in the configuration file, the :class:`~transformers.Trainer` will use
-the values of ``--lr_scheduler_type``, ``--learning_rate`` and ``--warmup_steps`` to configure a 🤗 Transformers version
-of it.
-
-Here is an example of the pre-configured ``scheduler`` entry for ``WarmupLR``:
-
-.. code-block:: json
-
- {
- "scheduler": {
- "type": "WarmupLR",
- "params": {
- "warmup_min_lr": 0,
- "warmup_max_lr": 0.001,
- "warmup_num_steps": 1000
- }
- }
- }
-
-Note that the command line arguments will override the values in the configuration file. This is so that there is one
-definitive source of the values and to avoid hard to find errors when for example, the learning rate is set to
-different values in different places. Command line rules. The values that get overridden are:
-
-- ``warmup_max_lr`` with the value of ``--learning_rate``
-- ``warmup_num_steps`` with the value of ``--warmup_steps``
-- ``total_num_steps`` with either the value of ``--max_steps`` or if it is not provided, derived automatically at run
- time based on the environment and the size of the dataset and other command line arguments (needed for
- ``WarmupDecayLR``).
-
-Therefore please remember to tune the shared hyperparameters on the command line.
-
-For example, for ``WarmupDecayLR``, you can use the following entry:
-
-.. code-block:: json
-
- {
- "scheduler": {
- "type": "WarmupDecayLR",
- "params": {
- "total_num_steps": 10,
- "last_batch_iteration": -1,
- "warmup_min_lr": 0,
- "warmup_max_lr": 0.001,
- "warmup_num_steps": 1000
- }
- }
- }
-
-and ``warmup_max_lr``, ``warmup_num_steps`` and ``total_num_steps`` will be corrected at loading time.
-
-
-
-Automatic Mixed Precision
-=======================================================================================================================
-
-You can work with FP16 in one of the following ways:
-
-1. Pytorch native amp, as documented `here `__.
-2. NVIDIA's apex, as documented `here
- `__.
-
-If you want to use an equivalent of the Pytorch native amp, you can either configure the ``fp16`` entry in the
-configuration file, or use the following command line arguments: ``--fp16 --fp16_backend amp``.
-
-Here is an example of the ``fp16`` configuration:
-
-.. code-block:: json
-
- {
- "fp16": {
- "enabled": true,
- "loss_scale": 0,
- "loss_scale_window": 1000,
- "hysteresis": 2,
- "min_loss_scale": 1
- },
- }
-
-If you want to use NVIDIA's apex instead, you can can either configure the ``amp`` entry in the configuration file, or
-use the following command line arguments: ``--fp16 --fp16_backend apex --fp16_opt_level 01``.
-
-Here is an example of the ``amp`` configuration:
-
-.. code-block:: json
-
- {
- "amp": {
- "enabled": true,
- "opt_level": "O1"
- }
- }
-
-
-Gradient Accumulation
-=======================================================================================================================
-
-While normally DeepSpeed gets gradient accumulation configured with:
-
-.. code-block:: json
-
- {
- "gradient_accumulation_steps": 3,
- }
-
-in this case, to enable gradient accumulation, pass the command line `--gradient_accumulation_steps` argument as normal
-and it will get injected into the DeepSpeed configuration.
-
-If you try to add it directly to the configuration file, you will receive an error from the Trainer - this is because
-this setting is needed by the Trainer too, and so this approach ensures that there is a single way of setting this
-value and thus avoid potential subtle errors.
-
-
-
-
-
-
-Gradient Clipping
-=======================================================================================================================
-
-If you don't configure the ``gradient_clipping`` entry in the configuration file, the :class:`~transformers.Trainer`
-will use the value of the ``--max_grad_norm`` command line argument to set it.
-
-Here is an example of the ``gradient_clipping`` configuration:
-
-.. code-block:: json
-
- {
- "gradient_clipping": 1.0,
- }
-
-
-
-Notes
-=======================================================================================================================
-
-* DeepSpeed works with the PyTorch :class:`~transformers.Trainer` but not TF :class:`~transformers.TFTrainer`.
-* While DeepSpeed has a pip installable PyPI package, it is highly recommended that it gets installed from `source
- `__ to best match your hardware and also if you need to enable
- certain features, like 1-bit Adam, which aren't available in the pypi distribution.
-* You don't have to use the :class:`~transformers.Trainer` to use DeepSpeed with 🤗 Transformers - you can use any model
- with your own trainer, and you will have to adapt the latter according to `the DeepSpeed integration instructions
- `__.
-
-Main DeepSpeed Resources
-=======================================================================================================================
-
-- `Project's github `__
-- `Usage docs `__
-- `API docs `__
-- `Blog posts `__
-
-Papers:
-
-- `ZeRO: Memory Optimizations Toward Training Trillion Parameter Models `__
-- `ZeRO-Offload: Democratizing Billion-Scale Model Training `__
-
-Finally, please, remember that, HuggingFace :class:`~transformers.Trainer` only integrates DeepSpeed, therefore if you
-have any problems or questions with regards to DeepSpeed usage, please, file an issue with `DeepSpeed GitHub
-`__.
diff --git a/docs/source/migration.md b/docs/source/migration.md
deleted file mode 100644
index e44af20c0f1e79..00000000000000
--- a/docs/source/migration.md
+++ /dev/null
@@ -1,303 +0,0 @@
-
-
-# Migrating from previous packages
-
-## Migrating from transformers `v3.x` to `v4.x`
-
-A couple of changes were introduced when the switch from version 3 to version 4 was done. Below is a summary of the
-expected changes:
-
-#### 1. AutoTokenizers and pipelines now use fast (rust) tokenizers by default.
-
-The python and rust tokenizers have roughly the same API, but the rust tokenizers have a more complete feature set.
-
-This introduces two breaking changes:
-- The handling of overflowing tokens between the python and rust tokenizers is different.
-- The rust tokenizers do not accept integers in the encoding methods.
-
-##### How to obtain the same behavior as v3.x in v4.x
-
-- The pipelines now contain additional features out of the box. See the [token-classification pipeline with the `grouped_entities` flag](https://huggingface.co/transformers/main_classes/pipelines.html?highlight=textclassification#tokenclassificationpipeline).
-- The auto-tokenizers now return rust tokenizers. In order to obtain the python tokenizers instead, the user may use the `use_fast` flag by setting it to `False`:
-
-In version `v3.x`:
-```py
-from transformers import AutoTokenizer
-
-tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
-```
-to obtain the same in version `v4.x`:
-```py
-from transformers import AutoTokenizer
-
-tokenizer = AutoTokenizer.from_pretrained("bert-base-cased", use_fast=False)
-```
-
-#### 2. SentencePiece is removed from the required dependencies
-
-The requirement on the SentencePiece dependency has been lifted from the `setup.py`. This is done so that we may have a channel on anaconda cloud without relying on `conda-forge`. This means that the tokenizers that depend on the SentencePiece library will not be available with a standard `transformers` installation.
-
-This includes the **slow** versions of:
-- `XLNetTokenizer`
-- `AlbertTokenizer`
-- `CamembertTokenizer`
-- `MBartTokenizer`
-- `PegasusTokenizer`
-- `T5Tokenizer`
-- `ReformerTokenizer`
-- `XLMRobertaTokenizer`
-
-##### How to obtain the same behavior as v3.x in v4.x
-
-In order to obtain the same behavior as version `v3.x`, you should install `sentencepiece` additionally:
-
-In version `v3.x`:
-```bash
-pip install transformers
-```
-to obtain the same in version `v4.x`:
-```bash
-pip install transformers[sentencepiece]
-```
-or
-```bash
-pip install transformers sentencepiece
-```
-#### 3. The architecture of the repo has been updated so that each model resides in its folder
-
-The past and foreseeable addition of new models means that the number of files in the directory `src/transformers` keeps growing and becomes harder to navigate and understand. We made the choice to put each model and the files accompanying it in their own sub-directories.
-
-This is a breaking change as importing intermediary layers using a model's module directly needs to be done via a different path.
-
-##### How to obtain the same behavior as v3.x in v4.x
-
-In order to obtain the same behavior as version `v3.x`, you should update the path used to access the layers.
-
-In version `v3.x`:
-```bash
-from transformers.modeling_bert import BertLayer
-```
-to obtain the same in version `v4.x`:
-```bash
-from transformers.models.bert.modeling_bert import BertLayer
-```
-
-#### 4. Switching the `return_dict` argument to `True` by default
-
-The [`return_dict` argument](https://huggingface.co/transformers/main_classes/output.html) enables the return of dict-like python objects containing the model outputs, instead of the standard tuples. This object is self-documented as keys can be used to retrieve values, while also behaving as a tuple as users may retrieve objects by index or by slice.
-
-This is a breaking change as the limitation of that tuple is that it cannot be unpacked: `value0, value1 = outputs` will not work.
-
-##### How to obtain the same behavior as v3.x in v4.x
-
-In order to obtain the same behavior as version `v3.x`, you should specify the `return_dict` argument to `False`, either in the model configuration or during the forward pass.
-
-In version `v3.x`:
-```bash
-model = BertModel.from_pretrained("bert-base-cased")
-outputs = model(**inputs)
-```
-to obtain the same in version `v4.x`:
-```bash
-model = BertModel.from_pretrained("bert-base-cased")
-outputs = model(**inputs, return_dict=False)
-```
-or
-```bash
-model = BertModel.from_pretrained("bert-base-cased", return_dict=False)
-outputs = model(**inputs)
-```
-
-#### 5. Removed some deprecated attributes
-
-Attributes that were deprecated have been removed if they had been deprecated for at least a month. The full list of deprecated attributes can be found in [#8604](https://github.com/huggingface/transformers/pull/8604).
-
-Here is a list of these attributes/methods/arguments and what their replacements should be:
-
-In several models, the labels become consistent with the other models:
-- `masked_lm_labels` becomes `labels` in `AlbertForMaskedLM` and `AlbertForPreTraining`.
-- `masked_lm_labels` becomes `labels` in `BertForMaskedLM` and `BertForPreTraining`.
-- `masked_lm_labels` becomes `labels` in `DistilBertForMaskedLM`.
-- `masked_lm_labels` becomes `labels` in `ElectraForMaskedLM`.
-- `masked_lm_labels` becomes `labels` in `LongformerForMaskedLM`.
-- `masked_lm_labels` becomes `labels` in `MobileBertForMaskedLM`.
-- `masked_lm_labels` becomes `labels` in `RobertaForMaskedLM`.
-- `lm_labels` becomes `labels` in `BartForConditionalGeneration`.
-- `lm_labels` becomes `labels` in `GPT2DoubleHeadsModel`.
-- `lm_labels` becomes `labels` in `OpenAIGPTDoubleHeadsModel`.
-- `lm_labels` becomes `labels` in `T5ForConditionalGeneration`.
-
-In several models, the caching mechanism becomes consistent with the other models:
-- `decoder_cached_states` becomes `past_key_values` in all BART-like, FSMT and T5 models.
-- `decoder_past_key_values` becomes `past_key_values` in all BART-like, FSMT and T5 models.
-- `past` becomes `past_key_values` in all CTRL models.
-- `past` becomes `past_key_values` in all GPT-2 models.
-
-Regarding the tokenizer classes:
-- The tokenizer attribute `max_len` becomes `model_max_length`.
-- The tokenizer attribute `return_lengths` becomes `return_length`.
-- The tokenizer encoding argument `is_pretokenized` becomes `is_split_into_words`.
-
-Regarding the `Trainer` class:
-- The `Trainer` argument `tb_writer` is removed in favor of the callback `TensorBoardCallback(tb_writer=...)`.
-- The `Trainer` argument `prediction_loss_only` is removed in favor of the class argument `args.prediction_loss_only`.
-- The `Trainer` attribute `data_collator` should be a callable.
-- The `Trainer` method `_log` is deprecated in favor of `log`.
-- The `Trainer` method `_training_step` is deprecated in favor of `training_step`.
-- The `Trainer` method `_prediction_loop` is deprecated in favor of `prediction_loop`.
-- The `Trainer` method `is_local_master` is deprecated in favor of `is_local_process_zero`.
-- The `Trainer` method `is_world_master` is deprecated in favor of `is_world_process_zero`.
-
-Regarding the `TFTrainer` class:
-- The `TFTrainer` argument `prediction_loss_only` is removed in favor of the class argument `args.prediction_loss_only`.
-- The `Trainer` method `_log` is deprecated in favor of `log`.
-- The `TFTrainer` method `_prediction_loop` is deprecated in favor of `prediction_loop`.
-- The `TFTrainer` method `_setup_wandb` is deprecated in favor of `setup_wandb`.
-- The `TFTrainer` method `_run_model` is deprecated in favor of `run_model`.
-
-Regarding the `TrainerArgument` class:
-- The `TrainerArgument` argument `evaluate_during_training` is deprecated in favor of `evaluation_strategy`.
-
-Regarding the Transfo-XL model:
-- The Transfo-XL configuration attribute `tie_weight` becomes `tie_words_embeddings`.
-- The Transfo-XL modeling method `reset_length` becomes `reset_memory_length`.
-
-Regarding pipelines:
-- The `FillMaskPipeline` argument `topk` becomes `top_k`.
-
-
-
-## Migrating from pytorch-transformers to 🤗 Transformers
-
-Here is a quick summary of what you should take care of when migrating from `pytorch-transformers` to 🤗 Transformers.
-
-### Positional order of some models' keywords inputs (`attention_mask`, `token_type_ids`...) changed
-
-To be able to use Torchscript (see #1010, #1204 and #1195) the specific order of some models **keywords inputs** (`attention_mask`, `token_type_ids`...) has been changed.
-
-If you used to call the models with keyword names for keyword arguments, e.g. `model(inputs_ids, attention_mask=attention_mask, token_type_ids=token_type_ids)`, this should not cause any change.
-
-If you used to call the models with positional inputs for keyword arguments, e.g. `model(inputs_ids, attention_mask, token_type_ids)`, you may have to double check the exact order of input arguments.
-
-## Migrating from pytorch-pretrained-bert
-
-Here is a quick summary of what you should take care of when migrating from `pytorch-pretrained-bert` to 🤗 Transformers
-
-### Models always output `tuples`
-
-The main breaking change when migrating from `pytorch-pretrained-bert` to 🤗 Transformers is that the models forward method always outputs a `tuple` with various elements depending on the model and the configuration parameters.
-
-The exact content of the tuples for each model are detailed in the models' docstrings and the [documentation](https://huggingface.co/transformers/).
-
-In pretty much every case, you will be fine by taking the first element of the output as the output you previously used in `pytorch-pretrained-bert`.
-
-Here is a `pytorch-pretrained-bert` to 🤗 Transformers conversion example for a `BertForSequenceClassification` classification model:
-
-```python
-# Let's load our model
-model = BertForSequenceClassification.from_pretrained('bert-base-uncased')
-
-# If you used to have this line in pytorch-pretrained-bert:
-loss = model(input_ids, labels=labels)
-
-# Now just use this line in 🤗 Transformers to extract the loss from the output tuple:
-outputs = model(input_ids, labels=labels)
-loss = outputs[0]
-
-# In 🤗 Transformers you can also have access to the logits:
-loss, logits = outputs[:2]
-
-# And even the attention weights if you configure the model to output them (and other outputs too, see the docstrings and documentation)
-model = BertForSequenceClassification.from_pretrained('bert-base-uncased', output_attentions=True)
-outputs = model(input_ids, labels=labels)
-loss, logits, attentions = outputs
-```
-
-### Serialization
-
-Breaking change in the `from_pretrained()`method:
-
-1. Models are now set in evaluation mode by default when instantiated with the `from_pretrained()` method. To train them don't forget to set them back in training mode (`model.train()`) to activate the dropout modules.
-
-2. The additional `*inputs` and `**kwargs` arguments supplied to the `from_pretrained()` method used to be directly passed to the underlying model's class `__init__()` method. They are now used to update the model configuration attribute first which can break derived model classes build based on the previous `BertForSequenceClassification` examples. More precisely, the positional arguments `*inputs` provided to `from_pretrained()` are directly forwarded the model `__init__()` method while the keyword arguments `**kwargs` (i) which match configuration class attributes are used to update said attributes (ii) which don't match any configuration class attributes are forwarded to the model `__init__()` method.
-
-Also, while not a breaking change, the serialization methods have been standardized and you probably should switch to the new method `save_pretrained(save_directory)` if you were using any other serialization method before.
-
-Here is an example:
-
-```python
-### Let's load a model and tokenizer
-model = BertForSequenceClassification.from_pretrained('bert-base-uncased')
-tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
-
-### Do some stuff to our model and tokenizer
-# Ex: add new tokens to the vocabulary and embeddings of our model
-tokenizer.add_tokens(['[SPECIAL_TOKEN_1]', '[SPECIAL_TOKEN_2]'])
-model.resize_token_embeddings(len(tokenizer))
-# Train our model
-train(model)
-
-### Now let's save our model and tokenizer to a directory
-model.save_pretrained('./my_saved_model_directory/')
-tokenizer.save_pretrained('./my_saved_model_directory/')
-
-### Reload the model and the tokenizer
-model = BertForSequenceClassification.from_pretrained('./my_saved_model_directory/')
-tokenizer = BertTokenizer.from_pretrained('./my_saved_model_directory/')
-```
-
-### Optimizers: BertAdam & OpenAIAdam are now AdamW, schedules are standard PyTorch schedules
-
-The two optimizers previously included, `BertAdam` and `OpenAIAdam`, have been replaced by a single `AdamW` optimizer which has a few differences:
-
-- it only implements weights decay correction,
-- schedules are now externals (see below),
-- gradient clipping is now also external (see below).
-
-The new optimizer `AdamW` matches PyTorch `Adam` optimizer API and let you use standard PyTorch or apex methods for the schedule and clipping.
-
-The schedules are now standard [PyTorch learning rate schedulers](https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate) and not part of the optimizer anymore.
-
-Here is a conversion examples from `BertAdam` with a linear warmup and decay schedule to `AdamW` and the same schedule:
-
-```python
-# Parameters:
-lr = 1e-3
-max_grad_norm = 1.0
-num_training_steps = 1000
-num_warmup_steps = 100
-warmup_proportion = float(num_warmup_steps) / float(num_training_steps) # 0.1
-
-### Previously BertAdam optimizer was instantiated like this:
-optimizer = BertAdam(model.parameters(), lr=lr, schedule='warmup_linear', warmup=warmup_proportion, num_training_steps=num_training_steps)
-### and used like this:
-for batch in train_data:
- loss = model(batch)
- loss.backward()
- optimizer.step()
-
-### In 🤗 Transformers, optimizer and schedules are split and instantiated like this:
-optimizer = AdamW(model.parameters(), lr=lr, correct_bias=False) # To reproduce BertAdam specific behavior set correct_bias=False
-scheduler = get_linear_schedule_with_warmup(optimizer, num_warmup_steps=num_warmup_steps, num_training_steps=num_training_steps) # PyTorch scheduler
-### and used like this:
-for batch in train_data:
- loss = model(batch)
- loss.backward()
- torch.nn.utils.clip_grad_norm_(model.parameters(), max_grad_norm) # Gradient clipping is not in AdamW anymore (so you can use amp without issue)
- optimizer.step()
- scheduler.step()
-```
diff --git a/docs/source/model_doc/albert.rst b/docs/source/model_doc/albert.rst
deleted file mode 100644
index 256695df9b96e1..00000000000000
--- a/docs/source/model_doc/albert.rst
+++ /dev/null
@@ -1,175 +0,0 @@
-..
- Copyright 2020 The HuggingFace Team. All rights reserved.
-
- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
- the License. You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
- Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
- an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
- specific language governing permissions and limitations under the License.
-
-ALBERT
------------------------------------------------------------------------------------------------------------------------
-
-Overview
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-The ALBERT model was proposed in `ALBERT: A Lite BERT for Self-supervised Learning of Language Representations
-`__ by Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma,
-Radu Soricut. It presents two parameter-reduction techniques to lower memory consumption and increase the training
-speed of BERT:
-
-- Splitting the embedding matrix into two smaller matrices.
-- Using repeating layers split among groups.
-
-The abstract from the paper is the following:
-
-*Increasing model size when pretraining natural language representations often results in improved performance on
-downstream tasks. However, at some point further model increases become harder due to GPU/TPU memory limitations,
-longer training times, and unexpected model degradation. To address these problems, we present two parameter-reduction
-techniques to lower memory consumption and increase the training speed of BERT. Comprehensive empirical evidence shows
-that our proposed methods lead to models that scale much better compared to the original BERT. We also use a
-self-supervised loss that focuses on modeling inter-sentence coherence, and show it consistently helps downstream tasks
-with multi-sentence inputs. As a result, our best model establishes new state-of-the-art results on the GLUE, RACE, and
-SQuAD benchmarks while having fewer parameters compared to BERT-large.*
-
-Tips:
-
-- ALBERT is a model with absolute position embeddings so it's usually advised to pad the inputs on the right rather
- than the left.
-- ALBERT uses repeating layers which results in a small memory footprint, however the computational cost remains
- similar to a BERT-like architecture with the same number of hidden layers as it has to iterate through the same
- number of (repeating) layers.
-
-The original code can be found `here `__.
-
-AlbertConfig
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.AlbertConfig
- :members:
-
-
-AlbertTokenizer
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.AlbertTokenizer
- :members: build_inputs_with_special_tokens, get_special_tokens_mask,
- create_token_type_ids_from_sequences, save_vocabulary
-
-
-AlbertTokenizerFast
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.AlbertTokenizerFast
- :members:
-
-
-Albert specific outputs
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.models.albert.modeling_albert.AlbertForPreTrainingOutput
- :members:
-
-.. autoclass:: transformers.models.albert.modeling_tf_albert.TFAlbertForPreTrainingOutput
- :members:
-
-
-AlbertModel
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.AlbertModel
- :members: forward
-
-
-AlbertForPreTraining
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.AlbertForPreTraining
- :members: forward
-
-
-AlbertForMaskedLM
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.AlbertForMaskedLM
- :members: forward
-
-
-AlbertForSequenceClassification
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.AlbertForSequenceClassification
- :members: forward
-
-
-AlbertForMultipleChoice
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.AlbertForMultipleChoice
- :members:
-
-
-AlbertForTokenClassification
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.AlbertForTokenClassification
- :members: forward
-
-
-AlbertForQuestionAnswering
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.AlbertForQuestionAnswering
- :members: forward
-
-
-TFAlbertModel
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.TFAlbertModel
- :members: call
-
-
-TFAlbertForPreTraining
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.TFAlbertForPreTraining
- :members: call
-
-
-TFAlbertForMaskedLM
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.TFAlbertForMaskedLM
- :members: call
-
-
-TFAlbertForSequenceClassification
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.TFAlbertForSequenceClassification
- :members: call
-
-
-TFAlbertForMultipleChoice
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.TFAlbertForMultipleChoice
- :members: call
-
-
-TFAlbertForTokenClassification
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.TFAlbertForTokenClassification
- :members: call
-
-
-TFAlbertForQuestionAnswering
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.TFAlbertForQuestionAnswering
- :members: call
diff --git a/docs/source/model_doc/auto.rst b/docs/source/model_doc/auto.rst
deleted file mode 100644
index 5945a150be0cca..00000000000000
--- a/docs/source/model_doc/auto.rst
+++ /dev/null
@@ -1,191 +0,0 @@
-..
- Copyright 2020 The HuggingFace Team. All rights reserved.
-
- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
- the License. You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
- Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
- an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
- specific language governing permissions and limitations under the License.
-
-Auto Classes
------------------------------------------------------------------------------------------------------------------------
-
-In many cases, the architecture you want to use can be guessed from the name or the path of the pretrained model you
-are supplying to the :obj:`from_pretrained()` method. AutoClasses are here to do this job for you so that you
-automatically retrieve the relevant model given the name/path to the pretrained weights/config/vocabulary.
-
-Instantiating one of :class:`~transformers.AutoConfig`, :class:`~transformers.AutoModel`, and
-:class:`~transformers.AutoTokenizer` will directly create a class of the relevant architecture. For instance
-
-
-.. code-block:: python
-
- model = AutoModel.from_pretrained('bert-base-cased')
-
-will create a model that is an instance of :class:`~transformers.BertModel`.
-
-There is one class of :obj:`AutoModel` for each task, and for each backend (PyTorch or TensorFlow).
-
-
-AutoConfig
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.AutoConfig
- :members:
-
-
-AutoTokenizer
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.AutoTokenizer
- :members:
-
-
-AutoModel
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.AutoModel
- :members:
-
-
-AutoModelForPreTraining
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.AutoModelForPreTraining
- :members:
-
-
-AutoModelForCausalLM
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.AutoModelForCausalLM
- :members:
-
-
-AutoModelForMaskedLM
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.AutoModelForMaskedLM
- :members:
-
-
-AutoModelForSeq2SeqLM
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.AutoModelForSeq2SeqLM
- :members:
-
-
-AutoModelForSequenceClassification
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.AutoModelForSequenceClassification
- :members:
-
-
-AutoModelForMultipleChoice
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.AutoModelForMultipleChoice
- :members:
-
-
-AutoModelForNextSentencePrediction
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.AutoModelForNextSentencePrediction
- :members:
-
-
-AutoModelForTokenClassification
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.AutoModelForTokenClassification
- :members:
-
-
-AutoModelForQuestionAnswering
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.AutoModelForQuestionAnswering
- :members:
-
-
-AutoModelForTableQuestionAnswering
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.AutoModelForTableQuestionAnswering
- :members:
-
-
-TFAutoModel
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.TFAutoModel
- :members:
-
-
-TFAutoModelForPreTraining
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.TFAutoModelForPreTraining
- :members:
-
-
-TFAutoModelForCausalLM
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.TFAutoModelForCausalLM
- :members:
-
-
-TFAutoModelForMaskedLM
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.TFAutoModelForMaskedLM
- :members:
-
-
-TFAutoModelForSeq2SeqLM
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.TFAutoModelForSeq2SeqLM
- :members:
-
-
-TFAutoModelForSequenceClassification
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.TFAutoModelForSequenceClassification
- :members:
-
-
-TFAutoModelForMultipleChoice
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.TFAutoModelForMultipleChoice
- :members:
-
-
-TFAutoModelForTokenClassification
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.TFAutoModelForTokenClassification
- :members:
-
-
-TFAutoModelForQuestionAnswering
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.TFAutoModelForQuestionAnswering
- :members:
-
-
-FlaxAutoModel
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.FlaxAutoModel
- :members:
diff --git a/docs/source/model_doc/bart.rst b/docs/source/model_doc/bart.rst
deleted file mode 100644
index 3e754f67c72f69..00000000000000
--- a/docs/source/model_doc/bart.rst
+++ /dev/null
@@ -1,152 +0,0 @@
-..
- Copyright 2020 The HuggingFace Team. All rights reserved.
-
- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
- the License. You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
- Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
- an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
- specific language governing permissions and limitations under the License.
-
-BART
------------------------------------------------------------------------------------------------------------------------
-
-**DISCLAIMER:** If you see something strange, file a `Github Issue
-`__ and assign
-@patrickvonplaten
-
-Overview
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-The Bart model was proposed in `BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation,
-Translation, and Comprehension `__ by Mike Lewis, Yinhan Liu, Naman Goyal, Marjan
-Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov and Luke Zettlemoyer on 29 Oct, 2019.
-
-According to the abstract,
-
-- Bart uses a standard seq2seq/machine translation architecture with a bidirectional encoder (like BERT) and a
- left-to-right decoder (like GPT).
-- The pretraining task involves randomly shuffling the order of the original sentences and a novel in-filling scheme,
- where spans of text are replaced with a single mask token.
-- BART is particularly effective when fine tuned for text generation but also works well for comprehension tasks. It
- matches the performance of RoBERTa with comparable training resources on GLUE and SQuAD, achieves new
- state-of-the-art results on a range of abstractive dialogue, question answering, and summarization tasks, with gains
- of up to 6 ROUGE.
-
-The Authors' code can be found `here `__.
-
-
-Examples
-_______________________________________________________________________________________________________________________
-
-- Examples and scripts for fine-tuning BART and other models for sequence to sequence tasks can be found in
- :prefix_link:`examples/seq2seq/ `.
-- An example of how to train :class:`~transformers.BartForConditionalGeneration` with a Hugging Face :obj:`datasets`
- object can be found in this `forum discussion
- `__.
-- `Distilled checkpoints `__ are described in this `paper
- `__.
-
-
-Implementation Notes
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-- Bart doesn't use :obj:`token_type_ids` for sequence classification. Use :class:`~transformers.BartTokenizer` or
- :meth:`~transformers.BartTokenizer.encode` to get the proper splitting.
-- The forward pass of :class:`~transformers.BartModel` will create the ``decoder_input_ids`` if they are not passed.
- This is different than some other modeling APIs. A typical use case of this feature is mask filling.
-- Model predictions are intended to be identical to the original implementation when
- :obj:`force_bos_token_to_be_generated=True`. This only works, however, if the string you pass to
- :func:`fairseq.encode` starts with a space.
-- :meth:`~transformers.BartForConditionalGeneration.generate` should be used for conditional generation tasks like
- summarization, see the example in that docstrings.
-- Models that load the `facebook/bart-large-cnn` weights will not have a :obj:`mask_token_id`, or be able to perform
- mask-filling tasks.
-
-Mask Filling
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-The :obj:`facebook/bart-base` and :obj:`facebook/bart-large` checkpoints can be used to fill multi-token masks.
-
-.. code-block::
-
- from transformers import BartForConditionalGeneration, BartTokenizer
- model = BartForConditionalGeneration.from_pretrained("facebook/bart-large", force_bos_token_to_be_generated=True)
- tok = BartTokenizer.from_pretrained("facebook/bart-large")
- example_english_phrase = "UN Chief Says There Is No in Syria"
- batch = tok(example_english_phrase, return_tensors='pt')
- generated_ids = model.generate(batch['input_ids'])
- assert tok.batch_decode(generated_ids, skip_special_tokens=True) == ['UN Chief Says There Is No Plan to Stop Chemical Weapons in Syria']
-
-
-
-BartConfig
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.BartConfig
- :members:
-
-
-BartTokenizer
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.BartTokenizer
- :members:
-
-
-BartTokenizerFast
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.BartTokenizerFast
- :members:
-
-
-BartModel
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.BartModel
- :members: forward
-
-
-BartForConditionalGeneration
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.BartForConditionalGeneration
- :members: forward
-
-
-BartForSequenceClassification
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.BartForSequenceClassification
- :members: forward
-
-
-BartForQuestionAnswering
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.BartForQuestionAnswering
- :members: forward
-
-BartForCausalLM
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.BartForCausalLM
- :members: forward
-
-
-
-TFBartModel
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.TFBartModel
- :members: call
-
-
-TFBartForConditionalGeneration
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.TFBartForConditionalGeneration
- :members: call
diff --git a/docs/source/model_doc/barthez.rst b/docs/source/model_doc/barthez.rst
deleted file mode 100644
index 3b360e30f6e05f..00000000000000
--- a/docs/source/model_doc/barthez.rst
+++ /dev/null
@@ -1,59 +0,0 @@
-..
- Copyright 2020 The HuggingFace Team. All rights reserved.
-
- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
- the License. You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
- Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
- an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
- specific language governing permissions and limitations under the License.
-
-BARThez
------------------------------------------------------------------------------------------------------------------------
-
-Overview
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-The BARThez model was proposed in `BARThez: a Skilled Pretrained French Sequence-to-Sequence Model`
-`__ by Moussa Kamal Eddine, Antoine J.-P. Tixier, Michalis Vazirgiannis on 23 Oct,
-2020.
-
-The abstract of the paper:
-
-
-*Inductive transfer learning, enabled by self-supervised learning, have taken the entire Natural Language Processing
-(NLP) field by storm, with models such as BERT and BART setting new state of the art on countless natural language
-understanding tasks. While there are some notable exceptions, most of the available models and research have been
-conducted for the English language. In this work, we introduce BARThez, the first BART model for the French language
-(to the best of our knowledge). BARThez was pretrained on a very large monolingual French corpus from past research
-that we adapted to suit BART's perturbation schemes. Unlike already existing BERT-based French language models such as
-CamemBERT and FlauBERT, BARThez is particularly well-suited for generative tasks, since not only its encoder but also
-its decoder is pretrained. In addition to discriminative tasks from the FLUE benchmark, we evaluate BARThez on a novel
-summarization dataset, OrangeSum, that we release with this paper. We also continue the pretraining of an already
-pretrained multilingual BART on BARThez's corpus, and we show that the resulting model, which we call mBARTHez,
-provides a significant boost over vanilla BARThez, and is on par with or outperforms CamemBERT and FlauBERT.*
-
-The Authors' code can be found `here `__.
-
-
-Examples
-_______________________________________________________________________________________________________________________
-
-- BARThez can be fine-tuned on sequence-to-sequence tasks in a similar way as BART, check:
- :prefix_link:`examples/seq2seq/ `.
-
-
-BarthezTokenizer
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.BarthezTokenizer
- :members:
-
-
-BarthezTokenizerFast
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.BarthezTokenizerFast
- :members:
diff --git a/docs/source/model_doc/bert.rst b/docs/source/model_doc/bert.rst
deleted file mode 100644
index 0ed892783c1158..00000000000000
--- a/docs/source/model_doc/bert.rst
+++ /dev/null
@@ -1,216 +0,0 @@
-..
- Copyright 2020 The HuggingFace Team. All rights reserved.
-
- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
- the License. You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
- Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
- an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
- specific language governing permissions and limitations under the License.
-
-BERT
------------------------------------------------------------------------------------------------------------------------
-
-Overview
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-The BERT model was proposed in `BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
-`__ by Jacob Devlin, Ming-Wei Chang, Kenton Lee and Kristina Toutanova. It's a
-bidirectional transformer pretrained using a combination of masked language modeling objective and next sentence
-prediction on a large corpus comprising the Toronto Book Corpus and Wikipedia.
-
-The abstract from the paper is the following:
-
-*We introduce a new language representation model called BERT, which stands for Bidirectional Encoder Representations
-from Transformers. Unlike recent language representation models, BERT is designed to pre-train deep bidirectional
-representations from unlabeled text by jointly conditioning on both left and right context in all layers. As a result,
-the pre-trained BERT model can be fine-tuned with just one additional output layer to create state-of-the-art models
-for a wide range of tasks, such as question answering and language inference, without substantial task-specific
-architecture modifications.*
-
-*BERT is conceptually simple and empirically powerful. It obtains new state-of-the-art results on eleven natural
-language processing tasks, including pushing the GLUE score to 80.5% (7.7% point absolute improvement), MultiNLI
-accuracy to 86.7% (4.6% absolute improvement), SQuAD v1.1 question answering Test F1 to 93.2 (1.5 point absolute
-improvement) and SQuAD v2.0 Test F1 to 83.1 (5.1 point absolute improvement).*
-
-Tips:
-
-- BERT is a model with absolute position embeddings so it's usually advised to pad the inputs on the right rather than
- the left.
-- BERT was trained with the masked language modeling (MLM) and next sentence prediction (NSP) objectives. It is
- efficient at predicting masked tokens and at NLU in general, but is not optimal for text generation.
-
-The original code can be found `here `__.
-
-BertConfig
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.BertConfig
- :members:
-
-
-BertTokenizer
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.BertTokenizer
- :members: build_inputs_with_special_tokens, get_special_tokens_mask,
- create_token_type_ids_from_sequences, save_vocabulary
-
-
-BertTokenizerFast
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.BertTokenizerFast
- :members:
-
-
-Bert specific outputs
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.models.bert.modeling_bert.BertForPreTrainingOutput
- :members:
-
-.. autoclass:: transformers.models.bert.modeling_tf_bert.TFBertForPreTrainingOutput
- :members:
-
-
-BertModel
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.BertModel
- :members: forward
-
-
-BertForPreTraining
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.BertForPreTraining
- :members: forward
-
-
-BertModelLMHeadModel
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.BertLMHeadModel
- :members: forward
-
-
-BertForMaskedLM
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.BertForMaskedLM
- :members: forward
-
-
-BertForNextSentencePrediction
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.BertForNextSentencePrediction
- :members: forward
-
-
-BertForSequenceClassification
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.BertForSequenceClassification
- :members: forward
-
-
-BertForMultipleChoice
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.BertForMultipleChoice
- :members: forward
-
-
-BertForTokenClassification
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.BertForTokenClassification
- :members: forward
-
-
-BertForQuestionAnswering
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.BertForQuestionAnswering
- :members: forward
-
-
-TFBertModel
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.TFBertModel
- :members: call
-
-
-TFBertForPreTraining
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.TFBertForPreTraining
- :members: call
-
-
-TFBertModelLMHeadModel
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.TFBertLMHeadModel
- :members: call
-
-
-TFBertForMaskedLM
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.TFBertForMaskedLM
- :members: call
-
-
-TFBertForNextSentencePrediction
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.TFBertForNextSentencePrediction
- :members: call
-
-
-TFBertForSequenceClassification
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.TFBertForSequenceClassification
- :members: call
-
-
-TFBertForMultipleChoice
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.TFBertForMultipleChoice
- :members: call
-
-
-TFBertForTokenClassification
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.TFBertForTokenClassification
- :members: call
-
-
-TFBertForQuestionAnswering
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.TFBertForQuestionAnswering
- :members: call
-
-
-FlaxBertModel
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.FlaxBertModel
- :members: __call__
-
-
-FlaxBertForMaskedLM
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.FlaxBertForMaskedLM
- :members: __call__
diff --git a/docs/source/model_doc/bertgeneration.rst b/docs/source/model_doc/bertgeneration.rst
deleted file mode 100644
index 6099385bea4cd3..00000000000000
--- a/docs/source/model_doc/bertgeneration.rst
+++ /dev/null
@@ -1,108 +0,0 @@
-..
- Copyright 2020 The HuggingFace Team. All rights reserved.
-
- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
- the License. You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
- Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
- an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
- specific language governing permissions and limitations under the License.
-
-BertGeneration
------------------------------------------------------------------------------------------------------------------------
-
-Overview
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-The BertGeneration model is a BERT model that can be leveraged for sequence-to-sequence tasks using
-:class:`~transformers.EncoderDecoderModel` as proposed in `Leveraging Pre-trained Checkpoints for Sequence Generation
-Tasks `__ by Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
-
-The abstract from the paper is the following:
-
-*Unsupervised pretraining of large neural models has recently revolutionized Natural Language Processing. By
-warm-starting from the publicly released checkpoints, NLP practitioners have pushed the state-of-the-art on multiple
-benchmarks while saving significant amounts of compute time. So far the focus has been mainly on the Natural Language
-Understanding tasks. In this paper, we demonstrate the efficacy of pre-trained checkpoints for Sequence Generation. We
-developed a Transformer-based sequence-to-sequence model that is compatible with publicly available pre-trained BERT,
-GPT-2 and RoBERTa checkpoints and conducted an extensive empirical study on the utility of initializing our model, both
-encoder and decoder, with these checkpoints. Our models result in new state-of-the-art results on Machine Translation,
-Text Summarization, Sentence Splitting, and Sentence Fusion.*
-
-Usage:
-
-- The model can be used in combination with the :class:`~transformers.EncoderDecoderModel` to leverage two pretrained
- BERT checkpoints for subsequent fine-tuning.
-
-.. code-block::
-
- # leverage checkpoints for Bert2Bert model...
- # use BERT's cls token as BOS token and sep token as EOS token
- encoder = BertGenerationEncoder.from_pretrained("bert-large-uncased", bos_token_id=101, eos_token_id=102)
- # add cross attention layers and use BERT's cls token as BOS token and sep token as EOS token
- decoder = BertGenerationDecoder.from_pretrained("bert-large-uncased", add_cross_attention=True, is_decoder=True, bos_token_id=101, eos_token_id=102)
- bert2bert = EncoderDecoderModel(encoder=encoder, decoder=decoder)
-
- # create tokenizer...
- tokenizer = BertTokenizer.from_pretrained("bert-large-uncased")
-
- input_ids = tokenizer('This is a long article to summarize', add_special_tokens=False, return_tensors="pt").input_ids
- labels = tokenizer('This is a short summary', return_tensors="pt").input_ids
-
- # train...
- loss = bert2bert(input_ids=input_ids, decoder_input_ids=labels, labels=labels).loss
- loss.backward()
-
-
-- Pretrained :class:`~transformers.EncoderDecoderModel` are also directly available in the model hub, e.g.,
-
-
-.. code-block::
-
- # instantiate sentence fusion model
- sentence_fuser = EncoderDecoderModel.from_pretrained("google/roberta2roberta_L-24_discofuse")
- tokenizer = AutoTokenizer.from_pretrained("google/roberta2roberta_L-24_discofuse")
-
- input_ids = tokenizer('This is the first sentence. This is the second sentence.', add_special_tokens=False, return_tensors="pt").input_ids
-
- outputs = sentence_fuser.generate(input_ids)
-
- print(tokenizer.decode(outputs[0]))
-
-
-Tips:
-
-- :class:`~transformers.BertGenerationEncoder` and :class:`~transformers.BertGenerationDecoder` should be used in
- combination with :class:`~transformers.EncoderDecoder`.
-- For summarization, sentence splitting, sentence fusion and translation, no special tokens are required for the input.
- Therefore, no EOS token should be added to the end of the input.
-
-The original code can be found `here `__.
-
-BertGenerationConfig
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.BertGenerationConfig
- :members:
-
-
-BertGenerationTokenizer
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.BertGenerationTokenizer
- :members: save_vocabulary
-
-BertGenerationEncoder
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.BertGenerationEncoder
- :members: forward
-
-
-BertGenerationDecoder
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.BertGenerationDecoder
- :members: forward
diff --git a/docs/source/model_doc/bertweet.rst b/docs/source/model_doc/bertweet.rst
deleted file mode 100644
index 4fe1470def8329..00000000000000
--- a/docs/source/model_doc/bertweet.rst
+++ /dev/null
@@ -1,64 +0,0 @@
-..
- Copyright 2020 The HuggingFace Team. All rights reserved.
-
- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
- the License. You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
- Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
- an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
- specific language governing permissions and limitations under the License.
-
-Bertweet
------------------------------------------------------------------------------------------------------------------------
-
-Overview
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-The BERTweet model was proposed in `BERTweet: A pre-trained language model for English Tweets
-`__ by Dat Quoc Nguyen, Thanh Vu, Anh Tuan Nguyen.
-
-The abstract from the paper is the following:
-
-*We present BERTweet, the first public large-scale pre-trained language model for English Tweets. Our BERTweet, having
-the same architecture as BERT-base (Devlin et al., 2019), is trained using the RoBERTa pre-training procedure (Liu et
-al., 2019). Experiments show that BERTweet outperforms strong baselines RoBERTa-base and XLM-R-base (Conneau et al.,
-2020), producing better performance results than the previous state-of-the-art models on three Tweet NLP tasks:
-Part-of-speech tagging, Named-entity recognition and text classification.*
-
-Example of use:
-
-.. code-block::
-
- import torch
- from transformers import AutoModel, AutoTokenizer
-
- bertweet = AutoModel.from_pretrained("vinai/bertweet-base")
-
- # For transformers v4.x+:
- tokenizer = AutoTokenizer.from_pretrained("vinai/bertweet-base", use_fast=False)
-
- # For transformers v3.x:
- # tokenizer = AutoTokenizer.from_pretrained("vinai/bertweet-base")
-
- # INPUT TWEET IS ALREADY NORMALIZED!
- line = "SC has first two presumptive cases of coronavirus , DHEC confirms HTTPURL via @USER :cry:"
-
- input_ids = torch.tensor([tokenizer.encode(line)])
-
- with torch.no_grad():
- features = bertweet(input_ids) # Models outputs are now tuples
-
- ## With TensorFlow 2.0+:
- # from transformers import TFAutoModel
- # bertweet = TFAutoModel.from_pretrained("vinai/bertweet-base")
-
-
-The original code can be found `here `__.
-
-BertweetTokenizer
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. autoclass:: transformers.BertweetTokenizer
- :members:
diff --git a/docs/source/model_doc/blenderbot.rst b/docs/source/model_doc/blenderbot.rst
deleted file mode 100644
index 4a13199d61bef2..00000000000000
--- a/docs/source/model_doc/blenderbot.rst
+++ /dev/null
@@ -1,119 +0,0 @@
-..
- Copyright 2020 The HuggingFace Team. All rights reserved.
-
- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
- the License. You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
- Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
- an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
- specific language governing permissions and limitations under the License.
-
-Blenderbot
------------------------------------------------------------------------------------------------------------------------
-
-**DISCLAIMER:** If you see something strange, file a `Github Issue
-`__ .
-
-Overview
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-The Blender chatbot model was proposed in `Recipes for building an open-domain chatbot
-