【GiantPandaCV导读】Single Path One Shot(SPOS)是旷视和清华、港科大联合的工作。与之前的工作不同,SPOS可以直接在大型数据集ImageNet上搜索,并且文章还提出了一种缓和权重共享的NAS的解耦策略,让模型能有更好的排序一致性。

代码:https://github.com/megvii-model/SinglePathOneShot
论文:https://arxiv.org/abs/1904.00420
之前的One-Shot NAS训练难度很大,并且在大型数据集比如ImageNet上非常低效。SPOS就是来解决训练过程中的挑战,其核心思想构建一个简化的超网,每个结构都是单路径的,每次训练是一个单路径的子网络,通过这种方式可以缓解权重耦合的问题。训练过程中使用的是均匀路径采样,这样所有的子网的权重才能被充分且公平地得到训练。
SPOS训练方式简单并且搜索非常迅速,支持多重搜索空间比如block-wise, channel-wise,混合精度量化和资源受限情况下的搜索等,并且在ImageNet上实现了SOTA。
目前的神经网络搜索方法可以分成以下几种:
- 使用嵌套优化的方式处理权重优化和网络架构优化的问题。
- 使用权重共享策略来降低计算量,加速搜索过程。
- 使用基于梯度的方法,将离散空间松弛到连续空间。
- 使用嵌套联合优化方法。
在基于梯度的方法中,存在一些问题:
- 超网中的权重是紧密耦合的,尚不清楚子网的权重继承为何是有效的。
- 使用同时优化的方式也给网络架构参数和超网参数引入了耦合。
基于梯度的方法在优化过程中可能会引入bias,从而误导网络的搜索,出现马太效应,算子被训练的次数越多,权重会越大,强者越强。
本文主要贡献:
- 对现有的NAS算法进行详尽的分析,并指出了现有的使用嵌套优化方法存在的缺点。
- 提出了均匀采样的single path one-shot方法,可以克服现有one-shot方法的缺点。其简单的形式允许更大的搜索空间,包括通道搜索、比特宽度搜索等。采用进化算法来进行搜索,可以满足低延迟等约束。
早期的NAS方法采用嵌套优化的方式来实现,第一步优化是优化子网络的权重,优化目标是降低在训练集上的loss;第二步优化是网络架构优化,所有子网中验证集上准确率最高的那个网络。这种方式最大的缺点是训练代价太大,很多工作只能在Cifar10这样的小数据集或者小的搜索空间中完成。
近来的NAS方法通常会采用权重共享的训练策略,在这种策略中,所有子网会继承超网的权重,这样就可以不从头开始训练,降低搜索代价。这样的策略可以在ImageNet这类大型数据集上进行快速搜索。
大多数权重共享方法将离散的搜索空间转化为连续的搜索空间,这样就可以使用梯度优化的方式来建模神经网络搜索问题。权重和架构参数是同时优化的,或者使用两级优化方法来处理。
基于权重共享方法的NAS有两个缺点:
- 超网中各个子网耦合度高,尚不清楚为何从超网继承权重的方式是有效的。
- 同时优化网络权重参数W和架构参数θ会不可避免对架构引入某些偏好,这样在优化过程中会偏向于训练某些权重,造成不公平训练。
架构参数和权重的耦合是基于权重共享的NAS方法不得不面对的问题,这是由于同时对两者进行优化导致的。为了缓解耦合问题,很自然的想法就是将超网的训练和网络搜索解耦合。
one-shot方法分为两步,具体描述如下:
第一步,超网优化方式为:
第二步,网络架构搜索为: $$ a^{*}=\underset{a \in \mathcal{A}}{\operatorname{argmax}} \mathrm{ACC}{\text {val }}\left(\mathcal{N}\left(a, W{\mathcal{A}}(a)\right)\right) $$ a代表被采样的子网架构,它会继承超网的权重$W_{\mathcal{A}}(a)$, 然后在这个过程中挑选验证集上准确率最高的子网结构。
耦合问题的缓解方法
耦合缓解的方法有Path dropout 策略, 超网的每个边会被随机drop。通过这种方式可以降低节点之间的耦合程度,但是网络对其中的超参数dropout rate非常敏感,让训练过程变得更加困难。
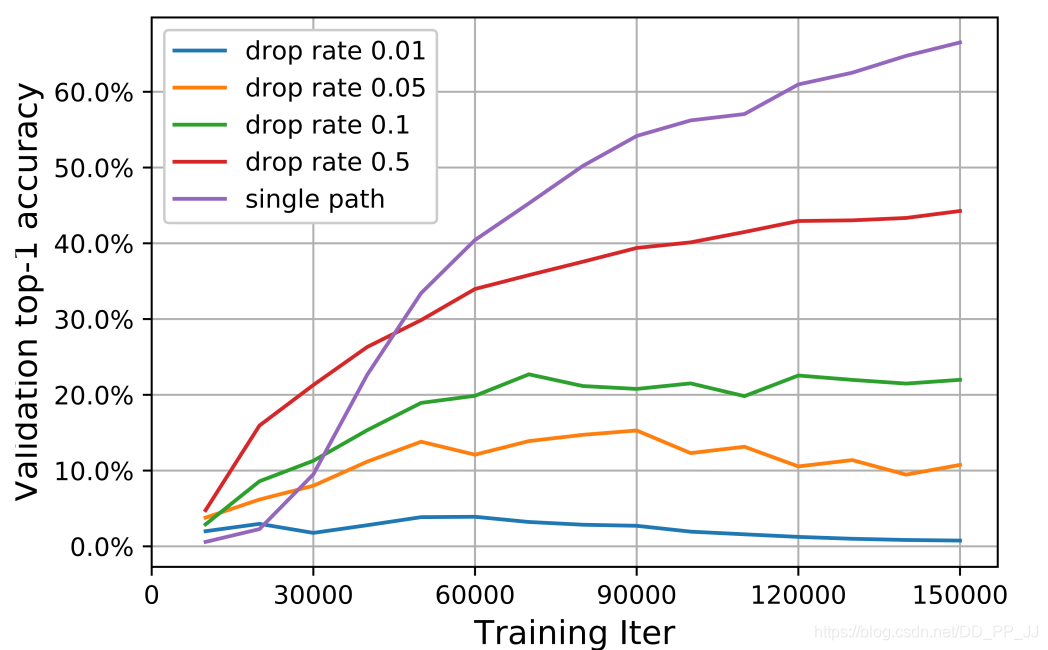
基于均匀采样的单路径方法缓解耦合问题
权重共享的神经网络搜索方法背后有一个基础原则:即继承权重后的子网络在验证集上的表现能够反映出该子网络充分训练以后的结果。在NAS中,这被称为一致性问题,继承权重训练的子网得到的验证集精度(supernet performance)高,是否能代表子网从头训练的验证集精度(evaluation performance)同样高呢?实际上,很多基于权重共享的神经网络搜索方法的排序一致性都没有很理想。
SPOS处理方法是:提出了一个单路径的超网结构,如下图所示:
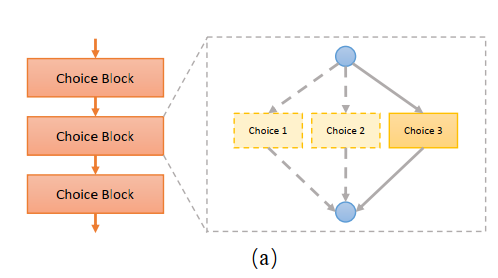
为了减少权重之间的耦合度,在每个Choice Block选择的时候必定会选择其中的一个choice,不存在恒等映射。在训练阶段随机选择子网,并验证其在验证集上的准确率。
此外,为了保证每个选项都有均匀的训练机会,采用了均匀采样策略。同时为了满足一定的资源约束,比如FLOPS大小,会通过均匀采样策略采样一批网络,只训练满足资源约束的子网络。
不同类型的搜索方式
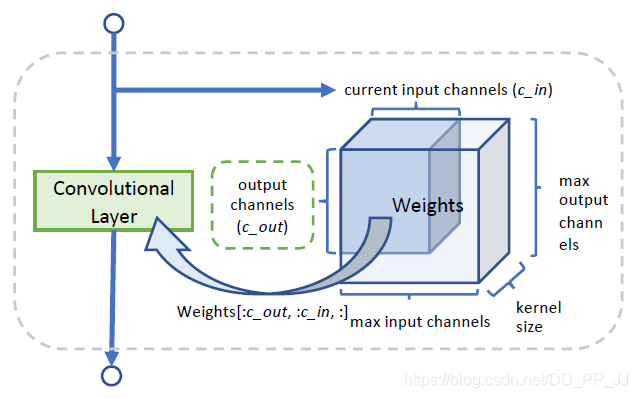
- 通道数搜索: 提出了一个基于权重共享的choice block, 其核心思想是预先分配一个最大通道个数的,然后随机选择通道个数,切分出对应的权重进行训练。通过权重共享策略,发现超网可以快速收敛。
- 混合精度量化搜索:在超网的训练过程中,每个选择block的 Feature Bit Width和Weight Bit Width会被随机采样,这个过程会在进化算法过程中决定。

- 进化神经网络架构搜索:之前的one-shot工作使用的是随机搜索策略,对于较大的搜索空间来说不够高效。与其他工作不同,SPOS不需要将每个架构都从头进行搜索,而是每个架构只进行推理,来决定该架构是否有效。

重要细节:在进行子网推理之前,网络中所有的Batch Normalization的需要在训练集的子集上重新计算。这是因为supernet中由BN计算的数值往往不能应用于候选网络中。这部分操作被称为BN校正。
代码实现:
def bn_calibration_init(m):
""" calculating post-statistics of batch normalization """
cumulative_bn_stats = True
if getattr(m, 'track_running_stats', False):
# reset all values for post-statistics
m.reset_running_stats()
# set bn in training mode to update post-statistics
m.training = True
# if use cumulative moving average
# if getattr(FLAGS, 'cumulative_bn_stats', False):
if cumulative_bn_stats:
m.momentum = None使用了BN校正技术以后,需要在训练集上再次训练。
数据集: 在ImageNet上完成,将原先的训练集切分成50000张作为验证集,剩下的作为训练集,原先的验证集作为测试集。
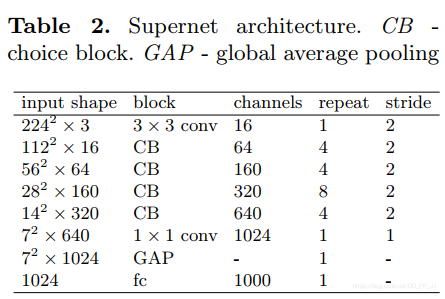
搜索空间:block 基于ShuffleNetv2设计的搜索空间,具体采用的架构如下,总共有20个CB(choice block),每个choice block 可以选择四个block,分别是kernel=3、5、7的shufflenet Units和一个Xception的block组成。
初步baseline:
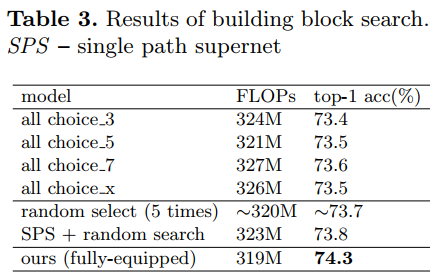
其baseline是所有的choice block中都选择相同的选择,比如3x3的shufflenet Units,得到的top1准确率都差不太多;从搜索空间中随机采样一些候选网络,得到的结果虽然一样,但是作者认为这是由于随机搜索方法太过简单,以至于不能从大型的搜索空间找到好的候选网络;使用进化算法进行搜索,得到的结果是74.3,比所有的的baeline模型都高。
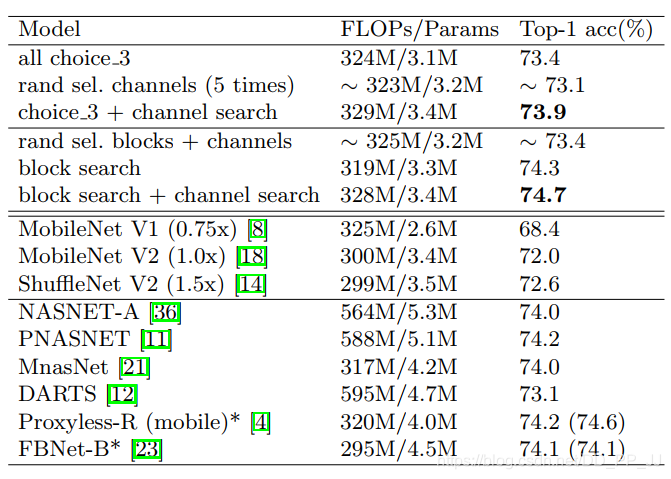
可以看出,同时搜索block和channel的结果性能更高,超过了其他同类型方法。
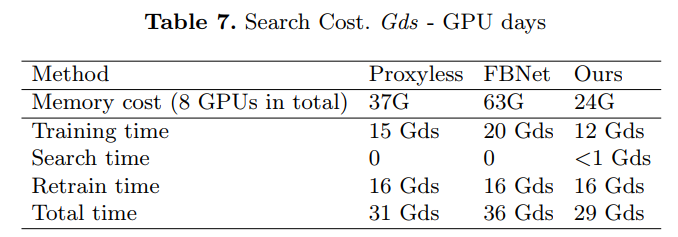
一致性分析: 基于超网模型的表现和独立训练模型的表现之间的相关性越强代表NAS算法有效性更强。SPOS对相关性进行了分析来测试SPOS的有效性,使用NAS-Bench-201这个benchmark来分析SPOS的有效性。NASBench201是cell-based搜索空间,搜索空间中包含5个可选操作zero, skip connection,1x1卷积,3x3卷积,3x3 average pooling。基于这个进一步设计了一些缩小的搜索空间,Reduce-1代表删除了1x1卷积、Reduce-2代表删除了3x3 average pooling, Reduce-3代表删除了以上两者。使用的是kendell Tau来计算相关性。
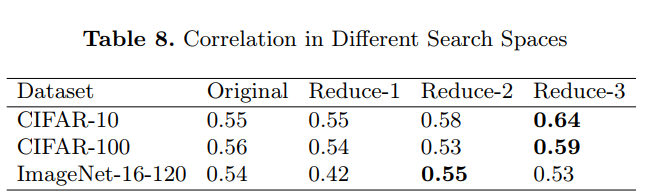
通过以上实验可以看出,SPOS有一定的局限性:SPOS的超网是部分相关的,无法实现完美的真实排序。搜索空间越小,其相关性越强。
Sinlge Path One Shot分析了以往的基于权重共享的NAS方法中存在的权重耦合问题,并提出了单路径训练策略来缓解耦合问题。本文还分析了SPOS的搜索代价和排序一致性问题,还指出了算法的局限在于超网的排序一致性是部分关联的,并不能完美的符合真实排序。搜索空间越小,排序一致性越强。