[TOC]
注意力主要分为三种类型:空间注意力、通道注意力、Self-Attention。论文阅读注重以下几点:
- motivation
- method
- result
可能的思路:
- 搜索attention block,固定插入到人工设计的网络中。
- 同时搜索attention block和网络结构。
可能的目标:
- 更高的准确率
- 更少的计算量
- 内存更加友好
- 解决某个痛点
- 针对特定任务
可能的方案:
- spatial -> spp
- se -> 2nd pool
- 搜索空间变小,需要领域启发知识。
链接:https://arxiv.org/abs/1709.01507
Squeeze and Excitation Network是在CV领域中应用Attention机制的鼻祖,且拿到了ImageNet17分类比赛冠军。
核心思想:自学习channel之间相关性,筛选针对通道的注意力。
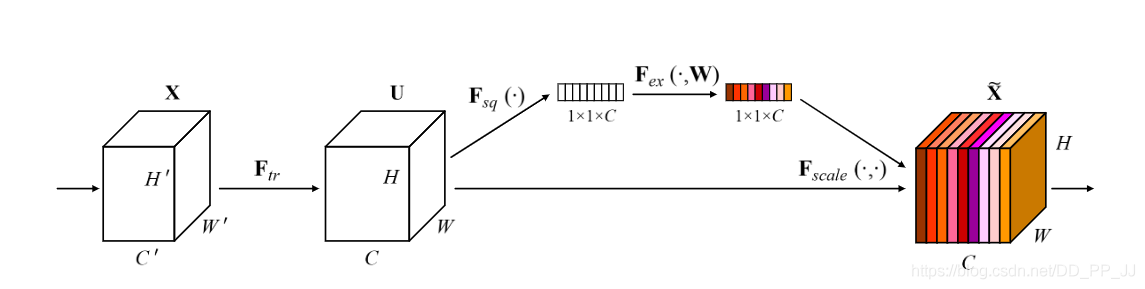
看一下SE-ResNet Module具体实现:

详细解释:
- Sequeeze: 使用global average pooling, 得到具有全局感受野的1x1特征图。
- Excitation: 使用全连接神经网络,做非线性变换。
- 特征重标定:将Excitation得到的重要性权重赋给原来的输入特征得到新的特征。
人工调整:
需要人工参与的部分有:
-
reduction 参数的选取
-
squeeze方式:global average pooling 还是max pooling
-
excitation方式:ReLU、Tanh、Sigmoid等激活
-
stage: 将SE模块添加到网络不同的深度
链接:https://arxiv.org/pdf/1903.06586.pdf
Selective Kernel Network想法是提出一个动态选择机制让CNN每个神经元可以自适应的调整其感受野大小。初步引入了空间注意力机制。

上下两个分支和SENet一致,分支之间区别在于选择的kernel大小不同。SKNet方法非常类似于merge-and-run mapping(https://arxiv.org/pdf/1611.07718.pdf)的思想,该文中还提到了三个基础模块:

(a)类似ResNet的结构,添加残差链接。
(b)类似Inception结构,加了一个分支卷积。
(c)merge-and-run mapping结构,两个分支将残差结果处理(可以是add、multi、或者就是SKNet中这种带有Attention的方法),然后再合并到原先分支。
人工调整:
需要人工参与的部分有:
- kernel size的选取
- SK分支个数
- 组卷积分组个数
- SKNet中卷积的channel参数
- 激活方法,这里默认用的是softmax
- Reduction参数设置
- 卷积中的dilation参数设置
CBAM链接:https://arxiv.org/pdf/1807.06521.pdf
BAM链接:https://arxiv.org/pdf/1807.06514.pdf
scSE链接:http://arxiv.org/pdf/1803.02579v2.pdf
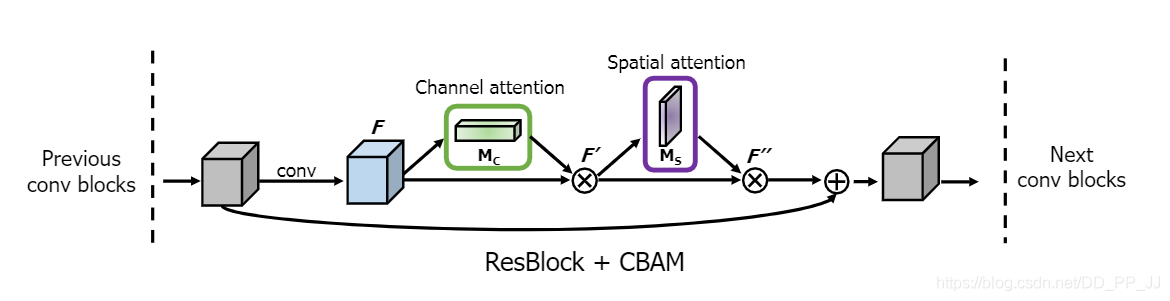
Convolutional Block Attention Module和BottleNeck Attention Module两篇文章都是一个团队在同一个时期发表的文章,CBAM被ECCV18接收,BAM被BMVC18接收。
核心思想:通道注意力机制和空间注意力机制的串联(CBAM)或者并联(BAM)。
CBAM(串联)
通道注意力机制:与SENet不同,这里使用了MaxPool和AvgPool来增加更多的信息。

空间注意力机制:

CBAM将两者顺序串联,这个顺序也是通过实验决定得到的。

ResNet中这样调用CBAM模块,如下图所示:
然后简单看一下并联版本的BAM,通道注意力和SENet一致。

和BAM类似,scSE也是相似的思路,应用在U-Net中,能够让分割边缘变得更加精细。

人工调整:
需要人工调整的地方有:
- 空间注意力和通道注意力位置/串联或者并联
- 空间注意力
- kernel size
- 激活函数
- concate or add
- dilation rate
- 通道注意力
- reduction
- avgpool maxpool or softpool
- 融合方式的选择add multi
链接:https://arxiv.org/abs/1711.07971
Non-Local是CVPR2018上的一篇文章,提出了自注意力模型。灵感来自于Non Local means非局部均值去噪滤波,所以称为Non-Local Network。
Non-local的通用公式表示:
- x是输入信号,cv中使用的一般是feature map
- i 代表的是输出位置,如空间、时间或者时空的索引,他的响应应该对j进行枚举然后计算得到的
- f 函数式计算i和j的相似度
- g 函数计算feature map在j位置的表示
- 最终的y是通过响应因子C(x) 进行标准化处理以后得到的
简单来说,就是i位置的代表当前位置,j遍历全体位置计算响应值,通过加权得到非局部的响应值。其核心原理就是通过计算任意两个位置之间的交互,捕捉远程依赖,不用局限于相邻点,从而可以得到更多的信息,扩展了网络的感受野。
具体实现如下图:

感觉和Transformer结构有点点相似,也是key, value, query的模式,只不过实现上有一定的差距,这里使用的是卷积操作而NLP中一般都是矩阵乘操作。这个方法大概能带来1个百分点的收益。缺点是计算量比较大,随后的GCNet、CCNet等进行了改进。
人工调整:
- 降维倍数reduction
- 通道设置
- 特征融合方式add multi
链接: https://arxiv.org/abs/1904.11492
GCNet: Non-local Networks Meet Squeeze-Excitation Networks and Beyond 这篇文章是清华大学提出来的一个注意力模型,结合了SENet和Non-Local Network,进行了改进。
GCNet发现对于不同的query查询点,对attention map进行了可视化,发现他们几乎是一致的,这说明Non-Local Network学习到的是独立于查询的依赖,即全局上下文不受位置依赖。基于这个发现,进行一下改进:

简化版本中将query分支去掉了,减少了计算量,并且也去掉了最后的1x1卷积。简化后版本的Simplified NLNet想要通过计算一个全局注意力即可,可以表达为: $$ z_i=x_i+W_v\sum^{N_p}{j=1}\frac{exp(W_kx_j)}{\sum^{N_p}{m=1}exp(W_kx_m)}x_j $$ 这里的$W_v、W_q、W_k$都是$1\times1$卷积,具体实现可以参考上图。
经过以上修改以后,可以做到让计算量下降,但是准确率并没有上升。所以参考SENet结合了其中的模块化设计,得到最终版本的GCNet。

(a)图展示了全局上下文的架构,Context Modeling是上下文建模,计算当前value和其他位置的相似度;Transform表示转换,用于捕获通道间依赖关系;Fusion将全局上下文特征融合到原有特征中。
可以看出(d)中的GCBlock结合了(b)的Context Modeling和(c)的Transform,从而得到GCNet基础模块GC block。
人工调整:
GCNet中将Non-Local中的设计范式总结出来,以此为基础可以设计更多更好的模块。
- 特征融合方式: add or mul
- 池化方式:avgpool, spatial pool
- 激活方法
- 上下文提取方法选择
- Transform部分选择
链接:https://arxiv.org/abs/1811.11721
CCNet: Criss-Cross Attention for Semantic Segmentation也是再Non-local Network基础上改进的,CCNet设定的上下文信息为该像素得水平和竖直两条路径

(a)图展示的是Non local Block所处理的上下文信息。(b)图展示的是CC Attention Block处理得上下文信息,只有周围的十字型区域像素与其有关,并认为通过两次堆叠可以覆盖全部的点,可以达到超过Non-Local Network的效果。
CCNet认为这种处理方式对GPU训练更加友好,计算效率更高,效果也达到了当时的SOTA。
CCNet应用于语义分割领域,将CC Attention Block加到CNN之后来获取丰富得语义信息,下图展示的是设置循环R=2的情况下的结果,即将CC Attention Module循环两次,然后和处理之前的特征进行concate到一起,得到分割结果。

具体实现细节如下:

Affinity操作就是CCNet核心,得到Attention map。CVPR2020有一篇Strip Pooling的文章和CCNet非常相似,也是分横向和竖向两个方向进行学习,然后融合。
链接:https://arxiv.org/pdf/2102.00240.pdf
Shuffle Attention也是结合了空间注意力机制和通道注意力机制。同时为了减少计算量引入了组,首先将input tensor划分为多个组,每个组内部使用类似SENet的通道注意力机制和使用了GroupNorm的空间注意力机制,最终得到优化后的tensor。

链接:https://arxiv.org/pdf/1910.03151.pdf
ECANet是CVPR2020接受的文章,在SENet上进行了改进,是单纯的通道注意力,比SENet能高出一个点。
核心思想:避免降维对学习通道注意力很重要,适当跨通道的交互可以降低模型复杂度同时保持性能。核心就是不降维,使用自适应选择一维卷积核大小的方法,来确定局部跨通道交互覆盖率。

链接:https://arxiv.org/pdf/1905.09646.pdf
Spatial Group-wise Enhance: Improving Semantic Feature Learning in Convolutional Networks 目前没有发表,NIPS2019没中。核心是提出了一种parameter free的注意力机制。

一开始分成多个组,每个组内部使用SENet+Normalization操作,然后合并得到最终结果。和shuffleAttention非常相似。
Global Second-order Pooling Convolutional Networks发表于CVPR 2019,将高阶和注意力机制在网络中部地方结合起来。

2nd-order pool 最初是在Semantic segmentation with second-order pooling文章中提出的,采用对称矩阵形式捕获的二阶信息。
Second-order pooling:在CNN中普通的池化一般都用的是mean pooling max pooling等,这都属于一阶pooling,直接对feature map进行一阶操作。二阶pooling就是对feature map的二阶进行操作,也就是feature map每个向量和自身转置求外积来实现的。
如果特征 x 和特征 y来自两个特征提取器,则被称为多模双线性池化(MBP,Multimodal Bilinear Pooling);如果特征 x =特征 y,则被称为同源双线性池化(HBP,Homogeneous Bilinear Pooling)或者二阶池化(Second-order Pooling)
https://zhuanlan.zhihu.com/p/62532887
Low-Rank Bilinear Pooling for Fine grained classification
Compact bilinear model LRBP等等都是这方面工作
二阶池化和Non-Local实际操作是一致的
GSoP Block对协方差矩阵计算,然后进行线性卷积和非线性激活两个运算得到输出的权重再对输入进行通道赋值。属于一个二阶统计的通道注意力机制。高阶也是一个研究的方向。
链接: https://arxiv.org/pdf/2012.11879.pdf
FcaNet: Frequency Channel Attention Networks

在SENet基础上引入DCT频域信息进行处理。
链接: https://cs.jhu.edu/~alanlab/Pubs20/li2020neural.pdf Non Local计算代价比较大并且计算资源有限,如何对NL寻找一个最优的配置也是一个开放问题。AutoNL提出就是为了解决以上两个问题,提出了轻量级Non-Local模型,LightNL。
主要有三个贡献:
- 为移动端设备设计了一个轻量级NL Block
- 提出了高效的神经网络搜索算法来自动化找到最优的LightNL block配置方案
- 在ImageNet任务上达到了SOTA(轻量级网络MobileNetV2基础上的改进)

LightNL如上图所示,矩阵乘法运算量更少,同时使用了深度可分离卷积来进行计算,实现了LightNL模块。该模块进行了削减,减少了原来的3个1x1卷积并用深度可分离卷积替换掉Transform部分的1x1卷积,实现了计算量的极小化。
具体搜索方法结合了Single-path NAS和MNasNet,同时对网络架构和Light NL Block参数进行搜索。AutoNL对NL Block的插入位置、降采样方案和模型的计算复杂度进行了搜索和限制。
链接:https://arxiv.org/pdf/2004.08955.pdf
SK+SE+ResNeXt的合体,虽刷了很多榜,但是并没有发表成功,还在投稿中。这篇文章工程性很强,作者做了非常多的实验来证明其有效性,将Attention做到了Group Level。
ResNeSt Block的设计如下:

相当于ResNeXt在根据参数K设置为模型基数,分成K个并行分支,然后每个分支内部再进行分割为r个子分支,经过卷积处理后,一个cardinal内部使用Split Attention进行信息聚合,具体实现如下图。

Split-Attention内部先将所有子分支加和,然后使用类似SENet操作,得到一个channel Attention,然后再和SKNet类似,得到每个子分支对应的attention,进行激活,最后将每个分支结果进行加和。
论文名称为:A2-Net,其中的核心模块叫double attention mechanism,具体实现分为两步:
- 第一步:使用二阶池化将整个空间的特征汇集到一个紧凑的集合中。
- 第二步:使用另外一个attention来自适应选择和将特征分散到每个location。
第一个Feature Gathering使用的是Bilinear Pooling, 红色部分对应softmax操作的是spatial维度。
第二个Feature Distribution使用的是矩阵乘,将上一步得到的全局描述符施加到Attention Vector上,红色部分softmax操作的是channel维度。

总体来说是将NL应用在Spatial和Channel维度。
链接:http://vladlen.info/papers/self-attention.pdf
Exploring Self-attention for Image Recognition发表在CVPR20中提出了两个self-attention, pairwise self-attention和patchwise self-attention,用了一些数学公式和抽象的语言来描述,但实际上个人理解是,pairwise self-attention类似channel attention;patchwise self-attention类似spatial attention。(术语比较多,看起来不是很清晰)
-
pairwise self-attention相当或者优于卷积网络,开销低。
- 普通卷积网络各层执行两个功能:1. 特征聚合,将kernel所有问题特征组合在一起。2. 特征变换,通过连续的线性映射和非线性函数来完成,通过连续的映射和非线性操作产生复杂的分段映射。
- 这部分提出了特征聚合和特征转换可以解耦。特征转换可以通过感知机层来执行,处理对象是像素级别的对象,是一个点态操作。
-
patchwise self-attention大大优于卷积。
- 这部分的注意力是在一个局部patch内进行计算的,可以理解成spatial部分区域。
自注意力网络在鲁棒性和泛化方面可能更具优势。

看一下SA block设计,其中的aggregation的实现就是hadamard product, 要求两个张量维度必须一致;左侧路径先通过linear层,channel数变为C/r1,
总体来说,理论性很强,如果写文章的话,需要在精读几遍,学一下语言描述。
链接:https://arxiv.org/pdf/1908.07678.pdf
针对Non Local Network计算量过大、GPU内存占用高的问题(主要解决分割的问题),提出了两个模块:Asymmetric Pyramid Non-local Block (APNB) 和Asymmetric Fusion Non-local Block (AFNB)。
- APNB在Non-Local 基础上使用了金字塔采样模块来减低计算量和内存占用,与此同时并没有牺牲模型的表现。
- AFNB用于处理不同层的特征,从而可以充分考虑远距离依赖同时提升了模型表现。

具体结构一句话描述就是Non-Local + SPP。实验部分主要和其他分割模型进行了对比,没有对比类似的attention模型。
(未发表)官方解读:https://cmsflash.github.io/ai/2019/12/02/efficient-attention.html
目标依然是降低模型计算量:

通过线性代数运算的顺序确定,减小了attenion mask的维度,降低计算量,可能创新性不够。
链接: https://arxiv.org/pdf/1909.11065.pdf
ECCV20发表的Object-Contextual Representations for Semantic Segmentation也是针对分割问题所提出来的一个模块。使用HRNet+OCR+SegFix组合在ECCV2020的Cityscapes赛道拿到了第一位。

首先,在GT的监督下学习目标的区域,如上图粉色框显示的模块所示。
然后,通过汇集在目标区域的像素点表征来计算目标区域表征,如上图紫色框所示。
最后,计算每个每个像素点和每个目标区域的关系,并且使用OCR模块增强每个像素点的表征,如上图黄色框所示。
内部实现非常复杂,有和Self-Attention类似的ObjectAttentionBlock,具体实现分析可以看https://blog.csdn.net/Alvarez/article/details/113744646
链接:https://arxiv.org/pdf/2009.01035.pdf
本文认为现有的基于CNN的方法没能充分利用时空信息,所以提出了Interaction-Aggregation-Update(IAU)模块。
- Spatial-Temporal IAU(STIAU) 模块被引入,该模块同时协调两种上下文交互信息。
- Spatial interaction可以计算单帧图片中不同身体区域的上下文依赖关系。
- Temporal Interaction可以被用来捕捉不同帧之间同一个目标的上下文依赖关系。

先将T帧图片分割成四个part,然后分成两个分支分别处理空间关系和时序关系,融合两者信息得到时空信息,然后对每个part进行分别更新。
在此基础上,还提出了一个channel IAU 模块来建模通道间的语义信息交互来强化特征表达,感觉计算量会很大。

链接: http://mftp.mmcheng.net/Papers/20cvprSCNet.pdf
南开程明明团队发表于CVPR20的文章,引入了自校准卷积模块,和attention机制没啥区别。

先沿通道分成两个部分x1和x2,第一个分支使用残差下采样,F代表2D卷积,先经过平均池化,然后经过3x3卷积操作,再进行双线性插值。然后经过一个残差操作,经过Sigmoid激活得到Attention。
第一个分支第二部分使用一个3x3的空洞卷积进行特征求,然后和上一个分支结果通过相乘融合起来,最后经过一个3x3空洞卷积进行变换。
第二个分支就是使用了3x3卷积,然后将两个分支结果融合到一起得到最终结果。这部分操作和PRN非常相似。
链接:https://papers.nips.cc/paper/2018/file/dc363817786ff182b7bc59565d864523-Paper.pdf
Gather-Excite: Exploiting Feature Context in Convolutional Neural Networks是SENet作者的续作,从空间角度得到的attention,没有SENet影响力大。

- gather: 聚合较大空间范围的特征响应。
- excite: 激发这些信息,将聚合得到的信息重新分配到局部特征。
具体实现方式是,将SENet中的Global Pooling替换为深度可分离卷积,完成上下文信息提取,然后就和SE一致,先及性能上采样,得到与输入tensor相同的大小,经过sigmoid激活函数得到attention,完成激活过程。
链接:https://arxiv.org/pdf/2010.03045.pdf
WACV2021的印度小哥的文章,让不同维度之间的信息互相交互起来,三个维度CHW,让它们两两进行交互。其中的Z-Pool其实就是maxpool和avgpool进行concate以后的结果。

链接:https://arxiv.org/pdf/1809.02983.pdf
中科院发表在CVPR19上的论文,提出Dual Attention来解决捕捉长距离依赖问题。类似self-attention, 上边的position attention module对spatial level信息进行建模,是一种空间注意力机制,实现方式是self-attention。
下边的channel attention module对channel level信息进行建模,也是用的self-attention机制,最后通过加和的方式进行特征融合。

链接:https://arxiv.org/pdf/1904.02998v1.pdf
微软提出的用于行人REID领域的模块,初步看上去,和Dual Attention非常类似,一个是spatial level的self-attention,一个是channel level 的self-attention。对比的对象也是大部分18年发表的顶会,少部分是19年发布的,通过加入该模块,baseline可以提高几个点。

链接:https://arxiv.org/pdf/2009.14082.pdf
Attentional Feature Fusion注意力特征融合机制AFF,可以用于分割、分类、检测等任务。目标是融合语义和尺度不一致特征,并且还提出了多尺度通道注意力模块。
Multi-Scale Channel Attention Modul(MS-CAM)核心思想是通过改变空间池化大小,将局部上下文信息添加到全局上下文中,并且使用逐点卷积作为上下文融合器。

左侧分支是类似SENet的通道注意力,右侧对应的是空间注意力机制,两者融合得到混合域注意力机制,这个和普通的注意力模块是一样的,可以对单个tensor进行优化。
特征融合模块AFF和iAFF如下图所示,这样融合的计算量真的很大。iAFF的提出是为了解决初始融合输入特征,直观方法是再使用一个attention来融合输入特征,得到了Iterative Attentional Feature Fusion。
