diff --git a/README.md b/README.md
index 6ffc91ebc7..0b73beda53 100644
--- a/README.md
+++ b/README.md
@@ -118,6 +118,7 @@ Supported methods:
- [x] [STDC (CVPR'2021)](configs/stdc)
- [x] [SETR (CVPR'2021)](configs/setr)
- [x] [DPT (ArXiv'2021)](configs/dpt)
+- [x] [Segmenter (ICCV'2021)](configs/segmenter)
- [x] [SegFormer (NeurIPS'2021)](configs/segformer)
Supported datasets:
diff --git a/README_zh-CN.md b/README_zh-CN.md
index 0b0503f984..ebcdd45047 100644
--- a/README_zh-CN.md
+++ b/README_zh-CN.md
@@ -117,6 +117,7 @@ MMSegmentation 是一个基于 PyTorch 的语义分割开源工具箱。它是 O
- [x] [STDC (CVPR'2021)](configs/stdc)
- [x] [SETR (CVPR'2021)](configs/setr)
- [x] [DPT (ArXiv'2021)](configs/dpt)
+- [x] [Segmenter (ICCV'2021)](configs/segmenter)
- [x] [SegFormer (NeurIPS'2021)](configs/segformer)
已支持的数据集:
diff --git a/configs/_base_/models/segmenter_vit-b16_mask.py b/configs/_base_/models/segmenter_vit-b16_mask.py
new file mode 100644
index 0000000000..967a65c200
--- /dev/null
+++ b/configs/_base_/models/segmenter_vit-b16_mask.py
@@ -0,0 +1,35 @@
+# model settings
+backbone_norm_cfg = dict(type='LN', eps=1e-6, requires_grad=True)
+model = dict(
+ type='EncoderDecoder',
+ pretrained='pretrain/vit_base_p16_384.pth',
+ backbone=dict(
+ type='VisionTransformer',
+ img_size=(512, 512),
+ patch_size=16,
+ in_channels=3,
+ embed_dims=768,
+ num_layers=12,
+ num_heads=12,
+ drop_path_rate=0.1,
+ attn_drop_rate=0.0,
+ drop_rate=0.0,
+ final_norm=True,
+ norm_cfg=backbone_norm_cfg,
+ with_cls_token=True,
+ interpolate_mode='bicubic',
+ ),
+ decode_head=dict(
+ type='SegmenterMaskTransformerHead',
+ in_channels=768,
+ channels=768,
+ num_classes=150,
+ num_layers=2,
+ num_heads=12,
+ embed_dims=768,
+ dropout_ratio=0.0,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0),
+ ),
+ test_cfg=dict(mode='slide', crop_size=(512, 512), stride=(480, 480)),
+)
diff --git a/configs/segmenter/README.md b/configs/segmenter/README.md
new file mode 100644
index 0000000000..b073e88ceb
--- /dev/null
+++ b/configs/segmenter/README.md
@@ -0,0 +1,73 @@
+# Segmenter
+
+[Segmenter: Transformer for Semantic Segmentation](https://arxiv.org/abs/2105.05633)
+
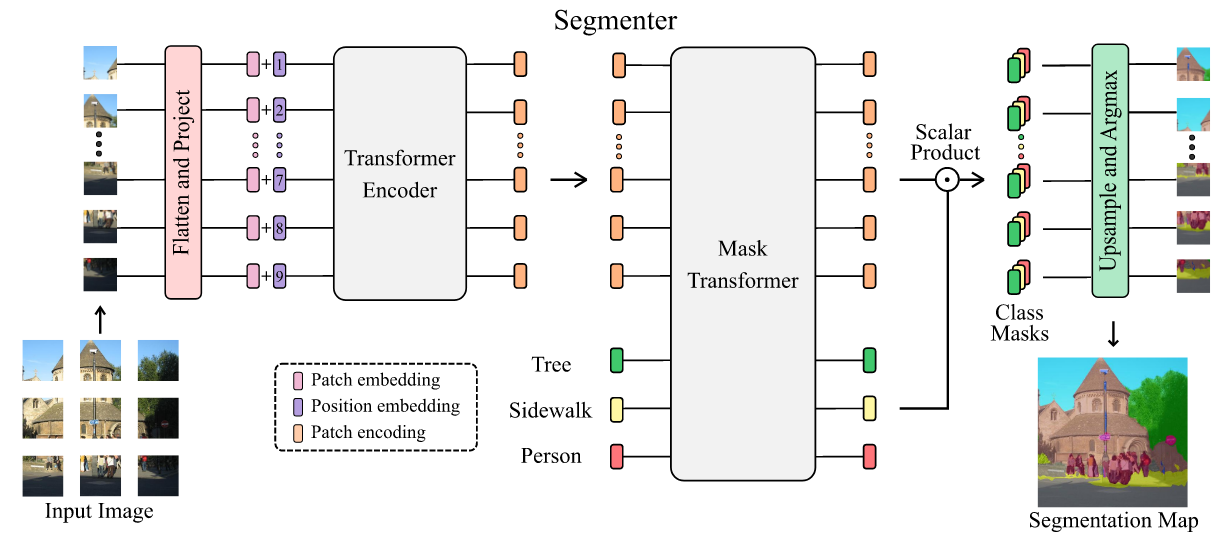
+## Introduction
+
+
+
+Official Repo
+
+Code Snippet
+
+## Abstract
+
+
+
+Image segmentation is often ambiguous at the level of individual image patches and requires contextual information to reach label consensus. In this paper we introduce Segmenter, a transformer model for semantic segmentation. In contrast to convolution-based methods, our approach allows to model global context already at the first layer and throughout the network. We build on the recent Vision Transformer (ViT) and extend it to semantic segmentation. To do so, we rely on the output embeddings corresponding to image patches and obtain class labels from these embeddings with a point-wise linear decoder or a mask transformer decoder. We leverage models pre-trained for image classification and show that we can fine-tune them on moderate sized datasets available for semantic segmentation. The linear decoder allows to obtain excellent results already, but the performance can be further improved by a mask transformer generating class masks. We conduct an extensive ablation study to show the impact of the different parameters, in particular the performance is better for large models and small patch sizes. Segmenter attains excellent results for semantic segmentation. It outperforms the state of the art on both ADE20K and Pascal Context datasets and is competitive on Cityscapes.
+
+
+
+
+