Applying 3D pose estimation to a new dataset #2121
Assignees

Labels
question
Further information is requested
Comments
|
This is likely to be a performance issue. The pose lifting model trained on the Human3.6M dataset may not generalize well to other datasets, especially if there is a large scale or pose distribution gap. In the video pose lifting demo we try to alleviate this gap by normalizing the 2D pose at: https://github.com/open-mmlab/mmpose/blob/master/demo/body3d_two_stage_video_demo.py#L202-L208. You may consider adding these codes to your script. |
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
I am trying to read the images from the market dataset and get a 3D pose from them. The 2D pose works about right, but 3D goes horribly wrong.
2D pose:

3D pose:
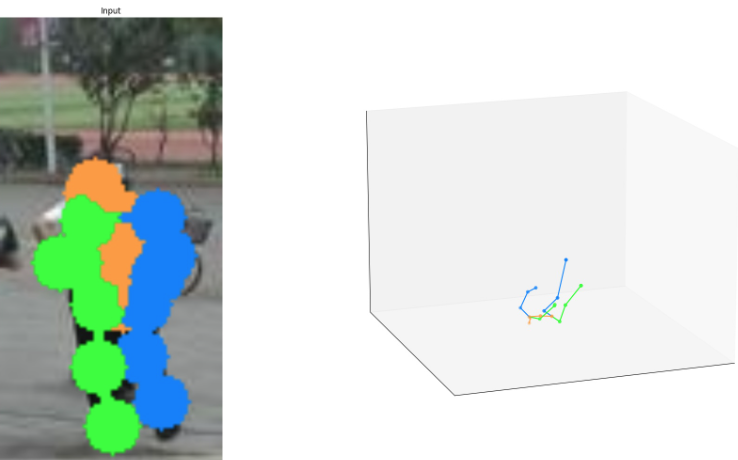
I did apply the transformation from Coco to the other format.
Terminal:
python top_down_img_demo_2ndAttempt.py \
--pose-lifter-config ../mmpose/configs/body/3d_kpt_sview_rgb_img/pose_lift/h36m/simplebaseline3d_h36m.py \
--pose-lifter-checkpoint https://download.openmmlab.com/mmpose/body3d/simple_baseline/simple3Dbaseline_h36m-f0ad73a4_20210419.pth \
--pose-detector-config ../mmpose/configs/body/2d_kpt_sview_rgb_img/topdown_heatmap/coco/hrnet_w48_coco_256x192.py \
--pose-detector-checkpoint https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w48_coco_256x192-b9e0b3ab_20200708.pth
Code:
from mmpose.apis import inference_top_down_pose_model, init_pose_model, vis_pose_result, vis_3d_pose_result,inference_pose_lifter_model
from mmdet.apis import inference_detector, init_detector
from mmcv import Config
import glob
import os
import os.path as osp
import warnings
from argparse import ArgumentParser
import mmcv
import numpy as np
from xtcocotools.coco import COCO
from mmpose.apis import (inference_pose_lifter_model, inference_top_down_pose_model, vis_3d_pose_result)
from mmpose.apis.inference import init_pose_model
from mmpose.core.bbox import bbox_xywh2xyxy
from mmpose.core.camera import SimpleCamera
from mmpose.datasets import DatasetInfo
import cv2
import numpy as np
parser = ArgumentParser()
parser.add_argument(
'--pose-lifter-config',
help='Config file for the 2nd stage pose lifter model')
parser.add_argument(
'--pose-lifter-checkpoint',
help='Checkpoint file for the 2nd stage pose lifter model')
parser.add_argument(
'--pose-detector-config',
type=str,
default=None,
help='Config file for the 1st stage 2D pose detector')
parser.add_argument(
'--pose-detector-checkpoint',
type=str,
default=None,
help='Checkpoint file for the 1st stage 2D pose detector')
parser.add_argument('--img-root', type=str, default='', help='Image root')
parser.add_argument(
'--json-file',
type=str,
default=None,
help='Json file containing image and bbox information. Optionally,'
'The Json file can also contain 2D pose information. See'
'"only-second-stage"')
parser.add_argument(
'--camera-param-file',
type=str,
default=None,
help='Camera parameter file for converting 3D pose predictions from '
' the camera space to the world space. If None, no conversion will be '
'applied.')
parser.add_argument(
'--only-second-stage',
action='store_true',
help='If true, load 2D pose detection result from the Json file and '
'skip the 1st stage. The pose detection model will be ignored.')
parser.add_argument(
'--rebase-keypoint-height',
action='store_true',
help='Rebase the predicted 3D pose so its lowest keypoint has a '
'height of 0 (landing on the ground). This is useful for '
'visualization when the model do not predict the global position '
'of the 3D pose.')
parser.add_argument(
'--show-ground-truth',
action='store_true',
help='If True, show ground truth if it is available. The ground truth '
'should be contained in the annotations in the Json file with the key '
'"keypoints_3d" for each instance.')
parser.add_argument(
'--show',
action='store_true',
default=False,
help='whether to show img')
parser.add_argument(
'--out-img-root',
type=str,
default=None,
help='Root of the output visualization images. '
'Default not saving the visualization images.')
parser.add_argument(
'--device', default='cuda:0', help='Device for inference')
parser.add_argument('--kpt-thr', type=float, default=0.3)
parser.add_argument(
'--radius',
type=int,
default=4,
help='Keypoint radius for visualization')
parser.add_argument(
'--thickness',
type=int,
default=1,
help='Link thickness for visualization')
args = parser.parse_args()
def keypoint_camera_to_world(keypoints,
camera_params,
image_name=None,
dataset='Body3DH36MDataset'):
"""Project 3D keypoints from the camera space to the world space.
Args:
keypoints (np.ndarray): 3D keypoints in shape [..., 3]
camera_params (dict): Parameters for all cameras.
image_name (str): The image name to specify the camera.
dataset (str): The dataset type, e.g. Body3DH36MDataset.
"""
cam_key = None
if dataset == 'Body3DH36MDataset':
subj, rest = osp.basename(image_name).split('', 1)
, rest = rest.split('.', 1)
camera, rest = rest.split('', 1)
cam_key = (subj, camera)
else:
raise NotImplementedError
pose_det_model = init_pose_model(
args.pose_detector_config,
args.pose_detector_checkpoint,
device=args.device.lower())
dataset_pose = pose_det_model.cfg.data['test']['type']
dataset_info_pose = pose_det_model.cfg.data['test'].get(
'dataset_info', None)
if dataset_info_pose is None:
warnings.warn(
'Please set
dataset_infoin the config.''Check #663 '
'for details.', DeprecationWarning)
else:
dataset_info_pose = DatasetInfo(dataset_info_pose)
pose_lift_model = init_pose_model(
args.pose_lifter_config,
args.pose_lifter_checkpoint,
device=args.device.lower())
dataset_lift = pose_lift_model.cfg.data['test']['type']
dataset_info_lift = pose_lift_model.cfg.data['test'].get('dataset_info', None)
dataset_info = DatasetInfo(dataset_info_lift)
camera_params = None
if args.camera_param_file is not None:
camera_params = mmcv.load(args.camera_param_file)
IMAGES=glob.glob("dataset/Market-1501-v15.09.15/*/*jpg")
for i,img_path in enumerate(IMAGES):
IMAGE=cv2.imread(img_path)
height, width, _ = IMAGE.shape
Output:
keypoints original [{'bbox': array([ 0, 0, 64, 128]), 'keypoints': array([[ 13.875004 , 13.375008 , 0.8679933 ],
[ 17.625004 , 9.625008 , 0.9091866 ],
[ 12.625004 , 9.625008 , 0.85018086],
[ 28.875004 , 8.375008 , 0.8347409 ],
[ 13.875004 , 12.125008 , 0.48255536],
[ 45.124996 , 23.375008 , 0.7653254 ],
[ 22.625004 , 27.125008 , 0.8329678 ],
[ 51.374996 , 39.625008 , 0.8024229 ],
[ 18.875004 , 43.375008 , 0.7981914 ],
[ 26.375004 , 49.625008 , 0.7004429 ],
[ 10.125004 , 52.125008 , 0.77925396],
[ 40.124996 , 65.87501 , 0.6822058 ],
[ 23.875004 , 65.87501 , 0.6890224 ],
[ 36.374996 , 89.62501 , 0.6135676 ],
[ 20.125004 , 93.37501 , 0.7035966 ],
[ 27.625004 , 119.62499 , 0.6539408 ],
[ 23.875004 , 118.37499 , 0.73575735]], dtype=float32), 'track_id': 'dataset/Market-1501-v15.09.15/bounding_box_test/0873_c1s4_049281_03.jpg'}]
keypoints modified [{'bbox': array([ 0, 0, 64, 128]), 'keypoints': array([[ 32. , 65.87500763, 0.68561411],
[ 23.87500381, 65.87500763, 0.68902242],
[ 20.12500381, 93.37500763, 0.70359659],
[ 23.87500381, 118.37499237, 0.73575735],
[ 40.12499619, 65.87500763, 0.6822058 ],
[ 36.37499619, 89.62500763, 0.61356759],
[ 27.62500381, 119.62499237, 0.6539408 ],
[ 32.9375 , 45.56250763, 0.74238038],
[ 33.875 , 25.25000763, 0.79914665],
[ 13.87500381, 13.37500763, 0.8679933 ],
[ 15.12500381, 9.62500763, 0.87968373],
[ 45.12499619, 23.37500763, 0.76532543],
[ 51.37499619, 39.62500763, 0.80242288],
[ 26.37500381, 49.62500763, 0.70044291],
[ 22.62500381, 27.12500763, 0.83296782],
[ 18.87500381, 43.37500763, 0.79819143],
[ 10.12500381, 52.12500763, 0.77925396]]), 'track_id': 'dataset/Market-1501-v15.09.15/bounding_box_test/0873_c1s4_049281_03.jpg'}]
keypoints3d original [{'track_id': 'dataset/Market-1501-v15.09.15/bounding_box_test/0873_c1s4_049281_03.jpg', 'keypoints': array([[[ 32. , 65.87501 , 0.6856141 ],
[ 23.875004 , 65.87501 , 0.6890224 ],
[ 20.125004 , 93.37501 , 0.7035966 ],
[ 23.875004 , 118.37499 , 0.73575735],
[ 40.124996 , 65.87501 , 0.6822058 ],
[ 36.374996 , 89.62501 , 0.6135676 ],
[ 27.625004 , 119.62499 , 0.6539408 ],
[ 32.9375 , 45.562508 , 0.7423804 ],
[ 33.875 , 25.250008 , 0.79914665],
[ 13.875004 , 13.375008 , 0.8679933 ],
[ 15.125004 , 9.625008 , 0.87968373],
[ 45.124996 , 23.375008 , 0.7653254 ],
[ 51.374996 , 39.625008 , 0.8024229 ],
[ 26.375004 , 49.625008 , 0.7004429 ],
[ 22.625004 , 27.125008 , 0.8329678 ],
[ 18.875004 , 43.375008 , 0.7981914 ],
[ 10.125004 , 52.125008 , 0.77925396]]], dtype=float32), 'keypoints_3d': array([[ 0. , 0. , 0. , 1. ],
[-0.02912175, -0.00983818, 0.04821105, 1. ],
[-0.07817433, 0.13621846, 0.15344839, 1. ],
[-0.120669 , 0.26412347, 0.49825853, 1. ],
[ 0.02912096, 0.00983802, -0.04821098, 1. ],
[ 0.0049951 , 0.10275619, 0.10495035, 1. ],
[-0.11571439, 0.2495088 , 0.2646287 , 1. ],
[ 0.03858054, -0.13171132, -0.0414178 , 1. ],
[ 0.06530353, -0.27890605, -0.13705736, 1. ],
[-0.00390939, -0.32655197, -0.21490136, 1. ],
[-0.00983662, -0.3704325 , -0.24948072, 1. ],
[ 0.11711289, -0.25695574, -0.16577992, 1. ],
[ 0.12720732, -0.12673481, -0.07381997, 1. ],
[-0.0021978 , -0.05077913, -0.09699042, 1. ],
[ 0.01618155, -0.27189797, -0.03421849, 1. ],
[-0.04616348, -0.14377919, 0.12970994, 1. ],
[-0.10080958, -0.08541844, 0.13969952, 1. ]],
dtype=float32)}]
keypoints3d modified [{'track_id': 'dataset/Market-1501-v15.09.15/bounding_box_test/0873_c1s4_049281_03.jpg', 'keypoints': array([[[ 32. , 65.87501 , 0.6856141 ],
[ 23.875004 , 65.87501 , 0.6890224 ],
[ 20.125004 , 93.37501 , 0.7035966 ],
[ 23.875004 , 118.37499 , 0.73575735],
[ 40.124996 , 65.87501 , 0.6822058 ],
[ 36.374996 , 89.62501 , 0.6135676 ],
[ 27.625004 , 119.62499 , 0.6539408 ],
[ 32.9375 , 45.562508 , 0.7423804 ],
[ 33.875 , 25.250008 , 0.79914665],
[ 13.875004 , 13.375008 , 0.8679933 ],
[ 15.125004 , 9.625008 , 0.87968373],
[ 45.124996 , 23.375008 , 0.7653254 ],
[ 51.374996 , 39.625008 , 0.8024229 ],
[ 26.375004 , 49.625008 , 0.7004429 ],
[ 22.625004 , 27.125008 , 0.8329678 ],
[ 18.875004 , 43.375008 , 0.7981914 ],
[ 10.125004 , 52.125008 , 0.77925396]]], dtype=float32), 'keypoints_3d': array([[ 0. , 0. , 0.24948072, 1. ],
[-0.02912175, -0.00983818, 0.29769176, 1. ],
[-0.07817433, 0.13621846, 0.40292913, 1. ],
[-0.120669 , 0.26412347, 0.74773926, 1. ],
[ 0.02912096, 0.00983802, 0.20126975, 1. ],
[ 0.0049951 , 0.10275619, 0.3544311 , 1. ],
[-0.11571439, 0.2495088 , 0.51410943, 1. ],
[ 0.03858054, -0.13171132, 0.20806292, 1. ],
[ 0.06530353, -0.27890605, 0.11242336, 1. ],
[-0.00390939, -0.32655197, 0.03457937, 1. ],
[-0.00983662, -0.3704325 , 0. , 1. ],
[ 0.11711289, -0.25695574, 0.08370081, 1. ],
[ 0.12720732, -0.12673481, 0.17566076, 1. ],
[-0.0021978 , -0.05077913, 0.1524903 , 1. ],
[ 0.01618155, -0.27189797, 0.21526223, 1. ],
[-0.04616348, -0.14377919, 0.37919068, 1. ],
[-0.10080958, -0.08541844, 0.38918024, 1. ]],
dtype=float32)}]
The text was updated successfully, but these errors were encountered: