We are very open to community contributions and appreciate anything that improves haystack! This includes fixings typos, adding missing documentation, fixing bugs or adding new features.
To avoid unnecessary work on either side, please stick to the following process:
- Check if there is already a related issue.
- Open a new issue to start a quick discussion. Some features might be a nice idea, but don't fit in the scope of Haystack and we hate to close finished PRs!
- Create a pull request in an early draft version and ask for feedback. If this is your first pull request and you wonder how to actually create a pull request, checkout this manual.
- Verify that all tests in the CI pass (and add new ones if you implement anything new)
Please give a concise description in the first comment in the PR that includes:
- What is changing?
- Why?
- What are limitations?
- Breaking changes (Example of before vs. after)
- Link the issue that this relates to
Some actions in our CI (code style and documentation updates) will run on your code and occasionally commit back small changes after a push. To be able to do so, these actions are configured to run on your fork instead of on the base repository. To allow those actions to run, please don't forget to:
- Enable actions on your fork with read and write permissions:

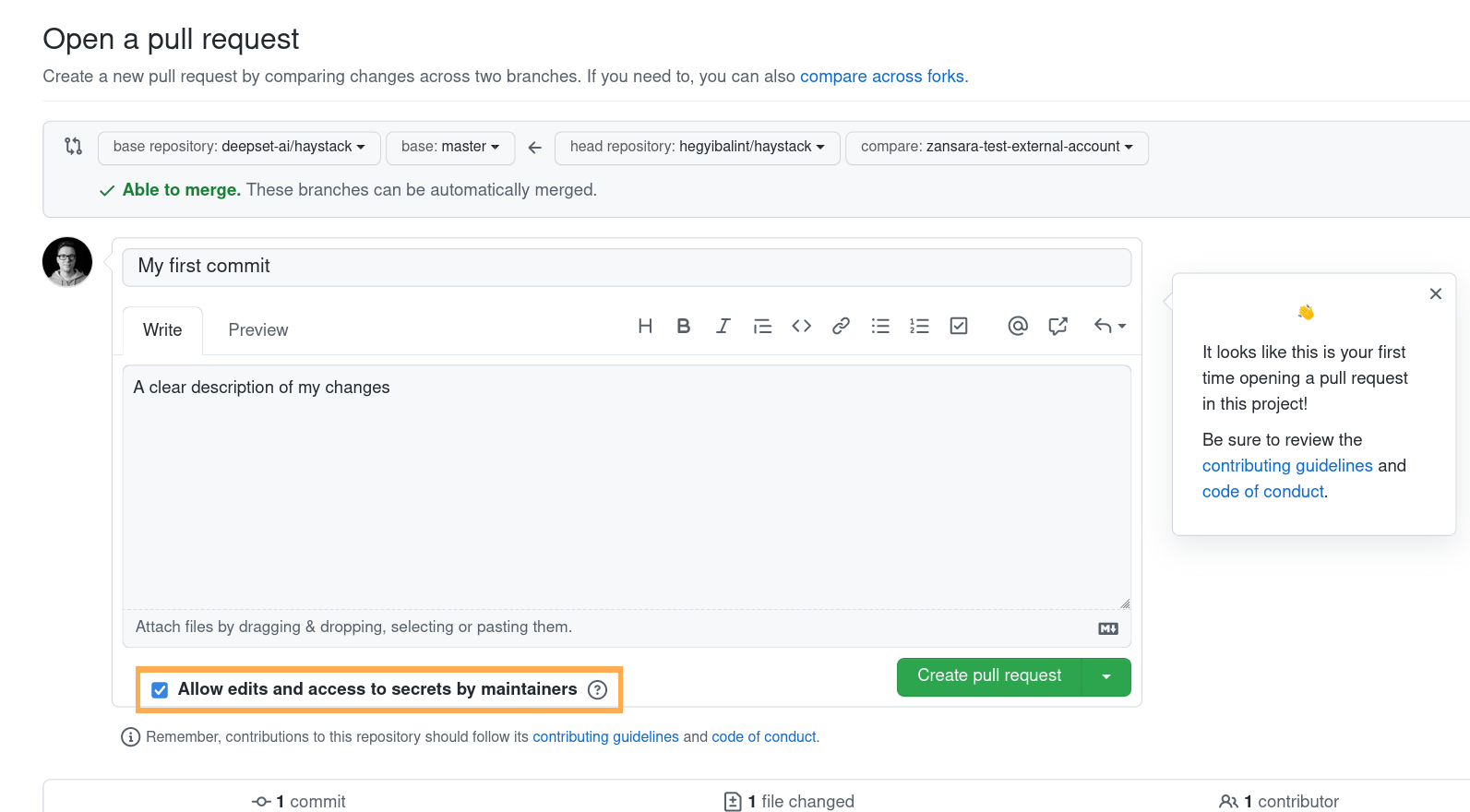
- Verify that "Allow edits and access to secrets by maintainers" on the PR preview page is checked (you can check it later on the PR's sidebar once it's created).
- Make sure the branch of your fork where you push your changes is not called
master. If it is, either change its name or remember to manually trigger theCode & Documentation Updatesaction after a push.
When working on Haystack, we recommend installing it in editable mode with pip install -e in a Python virtual
environment. From the root folder:
pip install -e '.[test]'
This will install all the dependencies you need to work on the codebase, which most of the times is a subset of all the dependencies needed to run Haystack.
Tests will automatically run in our CI for every commit you push to your PR on Github. This is usually the most convenient way and we encourage you to create early "draft pull requests" to leverage the CI at an early stage.
Tests can also be executed locally, by launching pytest from the /test folder (this is important because running from the
root folder would also execute the ui and rest API tests, that require specific dependencies).
You can control which tests to run using Pytest markers, let's see how.
In most cases you rather want to run a subset of tests locally that are related to your dev, and the most important
option to reduce the number of tests in a meaningful way, is to run tests only for a list of selected document stores.
This is possible by adding the --document_store_type arg to your pytest command (possible values are: "elasticsearch, faiss, memory, milvus, weaviate").
For example, calling pytest . --document_store_type="memory" will run all the document store tests using the
InMemoryDocumentStore only, skipping the others (the logs will show which ones). The InMemoryDocument store is a very
good starting point as it doesn't require any external resource:
pytest . --document_store_type="memory"
You can also run the tests using a combination of document stores, provided the corresponding services are up and running in your local environment. For example, Elasticsearch must be running before launching the following:
pytest . --document_store_type="memory,elasticsearch"
Note: we recommend using Docker containers to run document stores locally:
# Elasticsearch
docker run -d -p 9200:9200 -e "discovery.type=single-node" -e "ES_JAVA_OPTS=-Xms128m -Xmx128m" elasticsearch:7.9.2
# Milvus
wget https://github.com/milvus-io/milvus/releases/download/v2.0.0/milvus-standalone-docker-compose.yml -O docker-compose.yml
docker-compose up -d
# Weaviate
docker run -d -p 8080:8080 --name haystack_test_weaviate --env AUTHENTICATION_ANONYMOUS_ACCESS_ENABLED='true' --env PERSISTENCE_DATA_PATH='/var/lib/weaviate' semitechnologies/weaviate:1.11.0
# GraphDB
docker run -d -p 7200:7200 --name haystack_test_graphdb deepset/graphdb-free:9.4.1-adoptopenjdk11
# Tika
docker run -d -p 9998:9998 -e "TIKA_CHILD_JAVA_OPTS=-JXms128m" -e "TIKA_CHILD_JAVA_OPTS=-JXmx128m" apache/tika:1.24.1
Tests can be also run individually:
pytest -v test_retriever.py::test_dpr_embedding
Or you can select a logical subset of tests via markers and the optional "not" keyword:
pytest -m not elasticsearch
pytest -m elasticsearch
pytest -m generator
pytest -m tika
pytest -m not slow
...
Important: If you want to run all the tests locally, you'll need all document stores running in the background before you run the tests. Many of the tests will then be executed multiple times with different document stores.
To run all tests, from the /test folder just run:
pytest
If you are writing a test that depend on a document store, there are a few conventions to define on which document store type this test should/can run:
Option 1: The test should run on all document stores / those supplied in the CLI arg --document_store_type:
Use one of the fixtures document_store or document_store_with_docs or document_store_type.
Do not parameterize it yourself.
Example:
def test_write_with_duplicate_doc_ids(document_store):
...
document_store.write(docs)
....
Some tests you don't want to run on all possible document stores. Either because the test is specific to one/few doc store(s) or the test is not really document store related and it's enough to test it on one document store and speed up the execution time.
Example:
# Currently update_document_meta() is not implemented for InMemoryDocStore so it's not listed here as an option
@pytest.mark.parametrize("document_store", ["elasticsearch", "faiss"], indirect=True)
def test_update_meta(document_store):
....
Option 3: The test is not using a document_store/ fixture, but still has a hard requirement for a certain document store:
Example:
@pytest.mark.elasticsearch
def test_elasticsearch_custom_fields(elasticsearch_fixture):
client = Elasticsearch()
client.indices.delete(index='haystack_test_custom', ignore=[404])
document_store = ElasticsearchDocumentStore(index="haystack_test_custom", text_field="custom_text_field",
embedding_field="custom_embedding_field")
We use Black to ensure consistent code style, mypy for static type checking and pylint for linting and code quality.
All checks and autoformatting happen on the CI, so in general you don't need to worry about configuring them in your local environment. However, should you prefer to execute them locally, here are a few details about the setup.
Black runs with no other configuration than an increase line lenght to 120 characters. Its condiguration can be found in pyproject.toml.
You can run it with python -m black . from the root folder.
Mypy currently runs with limited configuration options that can be found at the bottom of setup.cfg.
You can run it with python -m mypy haystack/ rest_api/ ui/ from the root folder.
Pylint is still being integrated in Haystack. The current exclusion list is very long, and can be found in pyproject.toml.
You can run it with python -m pylint haystack/ rest_api/ ui/ -ry from the root folder.
Significant contributions to Haystack require a Contributor License Agreement (CLA). If the contribution requires a CLA, we will get in contact with you. CLAs are quite common among company backed open-source frameworks and our CLA’s wording is similar to other popular projects, like Rasa or Google's Tensorflow (retrieved 4th November 2021).
The agreement's main purpose is to protect the continued open use of Haystack. At the same time it also helps in protecting you as a contributor. Contributions under this agreement will ensure that your code will continue to be open to everyone in the future (“You hereby grant to Deepset and anyone [...]”) as well as removing liabilities on your end (“you provide your Contributions on an AS IS basis, without warranties or conditions of any kind [...]”). You can find the Contributor Licence Agreement here.
If you have further questions about the licensing feel free to reach out to [email protected].