pip install 'ms-swift[llm]' -U
pip install attrdict模型链接:
- deepseek-vl-1_3b-chat: https://www.modelscope.cn/models/deepseek-ai/deepseek-vl-1.3b-chat/summary
- deepseek-vl-7b-chat: https://www.modelscope.cn/models/deepseek-ai/deepseek-vl-7b-chat/summary
推理deepseek-vl-7b-chat:
# Experimental environment: A100
# 30GB GPU memory
CUDA_VISIBLE_DEVICES=0 swift infer --model_type deepseek-vl-7b-chat
# 如果你想在3090上运行, 可以推理1.3b模型
CUDA_VISIBLE_DEVICES=0 swift infer --model_type deepseek-vl-1_3b-chat7b模型效果展示: (支持传入本地路径或URL)
"""
<<< 你是谁?
我是一个人工智能助手,专门设计来帮助用户解答问题和提供信息。我可以帮助你了解各种主题,从语言学习到视觉识别技术。有什么我可以帮助你的吗?
--------------------------------------------------
<<< <img>http://modelscope-open.oss-cn-hangzhou.aliyuncs.com/images/animal.png</img><img>http://modelscope-open.oss-cn-hangzhou.aliyuncs.com/images/cat.png</img>这两张图片有什么区别
这两张图片的主要区别在于它们描绘的动物和场景。
第一张图片展示了一只小猫,它有着醒目的蓝色眼睛和灰白色的毛皮。小猫坐在一个模糊的背景前,看起来像是一张白色的床单或毯子。小猫的目光直直地对着相机,给人一种好奇和警觉的印象。
第二张图片展示了一群羊站在一个绿色的田野中。羊的毛皮是白色和棕色的,它们站在一片绿色的草地上,背景中可以看到山脉。羊群看起来很平静,没有特别指向相机,这表明它们可能正在吃草或仅仅是享受田野。
两张图片的背景都是模糊的,这有助于将焦点集中在动物上。然而,第一张图片中的背景更简单,只有一张白色的床单,而第二张图片中的背景更复杂,包括了绿色的田野和远处的山脉。
总的来说,这两张图片捕捉了两种不同的场景:一只小猫在室内环境中,而一群羊在户外环境中。
--------------------------------------------------
<<< <img>http://modelscope-open.oss-cn-hangzhou.aliyuncs.com/images/animal.png</img>图中有几只羊
图中有四只羊。
--------------------------------------------------
<<< <img>http://modelscope-open.oss-cn-hangzhou.aliyuncs.com/images/math.png</img>计算结果是多少
将1452和45304相加的结果是1452 + 45304 = 46756。
--------------------------------------------------
<<< <img>http://modelscope-open.oss-cn-hangzhou.aliyuncs.com/images/poem.png</img>根据图片中的内容写首诗
星辉洒落湖面静,
独舟轻摇夜色中。
灯火摇曳伴星辰,
波光粼粼映山影。
轻风拂过水面涟,
舟儿前行不自知。
夜深人静思绪远,
孤舟独行心悠然。
--------------------------------------------------
<<< clear
<<< <img>https://modelscope-open.oss-cn-hangzhou.aliyuncs.com/images/ocr.png</img>对图片进行OCR
The image contains Chinese text and appears to be a screenshot of a document or webpage. The text is divided into several paragraphs, and there are several instances of URLs and Chinese characters. The text is not entirely clear due to the resolution, but some of the visible words and phrases include "SWIFT", "250+", "LLM35+", "MLM", "PEFT", "adapters", "GPT", "XNLI", "Tune", "LORA", "LAMA-PRO", "Gradio", "web.ui", "AnimateDiff", "HuggingFace", "space", "ModelScope", and "SWIFT web".
The text seems to be discussing topics related to machine learning, specifically mentioning models like SWIFT, GPT, and LAMA-PRO, as well as tools and frameworks like HuggingFace and ModelScope. The URLs suggest that the text might be referencing online resources or repositories related to these topics.
The text is not fully legible due to the low resolution and the angle at which the image was taken, which makes it difficult to provide a precise transcription. However, the presence of technical terms and URLs indicates that the content is likely from a technical or academic context, possibly a research paper, a technical report, or an article discussing advancements in machine learning and related technologies.
"""示例图片如下:
cat:

animal:

math:
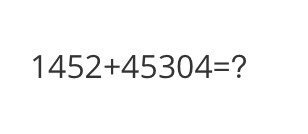
poem:

ocr:

单样本推理
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
from swift.llm import (
get_model_tokenizer, get_template, inference, ModelType,
get_default_template_type, inference_stream
)
from swift.utils import seed_everything
import torch
model_type = ModelType.deepseek_vl_7b_chat
template_type = get_default_template_type(model_type)
print(f'template_type: {template_type}')
model, tokenizer = get_model_tokenizer(model_type, torch.float16,
model_kwargs={'device_map': 'auto'})
model.generation_config.max_new_tokens = 256
template = get_template(template_type, tokenizer)
seed_everything(42)
query = '<img>http://modelscope-open.oss-cn-hangzhou.aliyuncs.com/images/road.png</img>距离各城市多远?'
response, history = inference(model, template, query)
print(f'query: {query}')
print(f'response: {response}')
# 流式
query = '距离最远的城市是哪?'
gen = inference_stream(model, template, query, history)
print_idx = 0
print(f'query: {query}\nresponse: ', end='')
for response, history in gen:
delta = response[print_idx:]
print(delta, end='', flush=True)
print_idx = len(response)
print()
print(f'history: {history}')
"""
query: <img>http://modelscope-open.oss-cn-hangzhou.aliyuncs.com/images/road.png</img>距离各城市多远?
response: 这个标志显示了从当前位置到以下城市的距离:
- 马塔(Mata):14公里
- 阳江(Yangjiang):62公里
- 广州(Guangzhou):293公里
这些信息是根据图片中的标志提供的。
query: 距离最远的城市是哪?
response: 根据图片中的标志,距离最远的城市是广州,距离为293公里。
history: [['<img>http://modelscope-open.oss-cn-hangzhou.aliyuncs.com/images/road.png</img>距离各城市多远?', '这个标志显示了从当前位置到以下城市的距离:\n\n- 马塔(Mata):14公里\n- 阳江(Yangjiang):62公里\n- 广州(Guangzhou):293公里\n\n这些信息是根据图片中的标志提供的。'], ['距离最远的城市是哪?', '根据图片中的标志,距离最远的城市是广州,距离为293公里。']]
"""示例图片如下:
road:

多模态大模型微调通常使用自定义数据集进行微调. 这里展示可直接运行的demo:
LoRA微调:
# Experimental environment: A10, 3090, V100
# 20GB GPU memory
CUDA_VISIBLE_DEVICES=0 swift sft \
--model_type deepseek-vl-7b-chat \
--dataset coco-en-mini \全参数微调:
# Experimental environment: 4 * A100
# 4 * 70GB GPU memory
NPROC_PER_NODE=4 CUDA_VISIBLE_DEVICES=0,1,2,3 swift sft \
--model_type deepseek-vl-7b-chat \
--dataset coco-en-mini \
--sft_type full \
--use_flash_attn true \
--deepspeed default-zero2自定义数据集支持json, jsonl样式, 以下是自定义数据集的例子:
(支持多轮对话, 支持每轮对话含多张图片或不含图片, 支持传入本地路径或URL)
[
{"conversations": [
{"from": "user", "value": "<img>img_path</img>11111"},
{"from": "assistant", "value": "22222"}
]},
{"conversations": [
{"from": "user", "value": "<img>img_path</img><img>img_path2</img><img>img_path3</img>aaaaa"},
{"from": "assistant", "value": "bbbbb"},
{"from": "user", "value": "<img>img_path</img>ccccc"},
{"from": "assistant", "value": "ddddd"}
]},
{"conversations": [
{"from": "user", "value": "AAAAA"},
{"from": "assistant", "value": "BBBBB"},
{"from": "user", "value": "CCCCC"},
{"from": "assistant", "value": "DDDDD"}
]}
]直接推理:
CUDA_VISIBLE_DEVICES=0 swift infer \
--ckpt_dir output/deepseek-vl-7b-chat/vx-xxx/checkpoint-xxx \
--load_dataset_config true \merge-lora并推理:
CUDA_VISIBLE_DEVICES=0 swift export \
--ckpt_dir output/deepseek-vl-7b-chat/vx-xxx/checkpoint-xxx \
--merge_lora true
CUDA_VISIBLE_DEVICES=0 swift infer \
--ckpt_dir output/deepseek-vl-7b-chat/vx-xxx/checkpoint-xxx-merged \
--load_dataset_config true