forked from qinxuewu/docs
-
Notifications
You must be signed in to change notification settings - Fork 0
/
MySQL实战45讲笔记.md
708 lines (587 loc) · 70.9 KB
/
MySQL实战45讲笔记.md
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
368
369
370
371
372
373
374
375
376
377
378
379
380
381
382
383
384
385
386
387
388
389
390
391
392
393
394
395
396
397
398
399
400
401
402
403
404
405
406
407
408
409
410
411
412
413
414
415
416
417
418
419
420
421
422
423
424
425
426
427
428
429
430
431
432
433
434
435
436
437
438
439
440
441
442
443
444
445
446
447
448
449
450
451
452
453
454
455
456
457
458
459
460
461
462
463
464
465
466
467
468
469
470
471
472
473
474
475
476
477
478
479
480
481
482
483
484
485
486
487
488
489
490
491
492
493
494
495
496
497
498
499
500
501
502
503
504
505
506
507
508
509
510
511
512
513
514
515
516
517
518
519
520
521
522
523
524
525
526
527
528
529
530
531
532
533
534
535
536
537
538
539
540
541
542
543
544
545
546
547
548
549
550
551
552
553
554
555
556
557
558
559
560
561
562
563
564
565
566
567
568
569
570
571
572
573
574
575
576
577
578
579
580
581
582
583
584
585
586
587
588
589
590
591
592
593
594
595
596
597
598
599
600
601
602
603
604
605
606
607
608
609
610
611
612
613
614
615
616
617
618
619
620
621
622
623
624
625
626
627
628
629
630
631
632
633
634
635
636
637
638
639
640
641
642
643
644
645
646
647
648
649
650
651
652
653
654
655
656
657
658
659
660
661
662
663
664
665
666
667
668
669
670
671
672
673
674
675
676
677
678
679
680
681
682
683
684
685
686
687
688
689
690
691
692
693
694
695
696
697
698
699
700
701
702
703
704
705
706
707
708
### 一条SQL查询语句是如何执行的
```sql
mysql> select * from T where ID=10;
```

>大体来说,MySQL可以分为`Server`层和`存储引擎`层两部分
* `Server`层包括连接器、查询缓存、分析器、优化器、执行器等,涵盖MySQL的大多数核心服务功能,以及所有的内置函数(如日期、时间、数学和加密函数等),所有跨存储引擎的功能都在这一层实现,比如存储过程、触发器、视图等。
* `存储引擎层`负责数据的存储和提取。其架构模式是插件式的,支持InnoDB、MyISAM、Memory等多个存储引擎。现在最常用的存储引擎是InnoDB,它从MySQL 5.5.5版本开始成为了默认存储引擎。
* 不同的存储引擎共用一个Server层,也就是从连接器到执行器的部分
*
**连接器**
* 第一步,你会先连接到这个数据库上,这时候接待你的就是连接器。连接器负责跟客户端建立连接、获取权限、维持和管理连接。连接完成后,如果你没有后续的动作,这个连接就处于空闲状态,你可以在`show processlist`命令中看到它。客户端如果太长时间没动静,连接器就会自动将它断开。这个时间是由参数`wait_timeout`控制的,默认值是`8`小时。数据库里面,长连接是指连接成功后,如果客户端持续有请求,则一直使用同一个连接。短连接则是指每次执行完很少的几次查询就断开连接,下次查询再重新建立一个。
**查询缓存**
* 连接建立完成后,你就可以执行select语句了。执行逻辑就会来到第二步:查询缓存。
* MySQL拿到一个查询请求后,会先到查询缓存看看,之前是不是执行过这条语句。之前执行过的语句及其结果可能会以key-value对的形式,被直接缓存在内存中。key是查询的语句,value是查询的结果。如果你的查询能够直接在这个缓存中找到key,那么这个value就会被直接返回给客户端。
* 如果语句不在查询缓存中,就会继续后面的执行阶段。执行完成后,执行结果会被存入查询缓存中。
>大多数情况下我会建议你不要使用查询缓存,为什么呢?因为查询缓存往往弊大于利。查询缓存的失效非常频繁,只要有对一个表的更新,这个表上所有的查询缓存都会被清空。
**分析器**
* 如果没有命中查询缓存,就要开始真正执行语句了。首先,MySQL需要知道你要做什么,因此需要对SQL语句做解析。分析器先会做`“词法分析”`,词法分析完后就要做`“语法分析”`。根据词法分析的结果,语法分析器会根据语法规则,判断你输入的这个SQL语句是否满足MySQL语法。如果你的语句不对,就会收到“You have an error in your SQL syntax”的错误提醒
**优化器**
* 经过了分析器,MySQL就知道你要做什么了。在开始执行之前,还要先经过优化器的处理。
* 优化器是在表里面有多个索引的时候,决定使用哪个索引;或者在一个语句有多表关联(join)的时候,决定各个表的连接顺序。
>比如你执行下面这样的语句,这个语句是执行两个表的join:
>`mysql> select * from t1 join t2 using(ID) where t1.c=10 and t2.d=20;`
>既可以先从表t1里面取出c=10的记录的ID值,再根据ID值关联到表t2,再判断t2里面d的值是否等于20。
>也可以先从表t2里面取出d=20的记录的ID值,再根据ID值关联到t1,再判断t1里面c的值是否等于10。
>这两种执行方法的逻辑结果是一样的,但是执行的效率会有不同,而优化器的作用就是决定选择使用哪一个方案。
**执行器**
* MySQL通过分析器知道了你要做什么,通过优化器知道了该怎么做,于是就进入了执行器阶段,开始执行语句。
* 开始执行的时候,要先判断一下你对这个表T有没有执行查询的权限,如果没有,就会返回没有权限的错误
* 如果有权限,就打开表继续执行。打开表的时候,执行器就会根据表的引擎定义,去使用这个引擎提供的接口。
>`mysql> select * from T where ID=10;`
>比如我们这个例子中的表T中,ID字段没有索引,那么执行器的执行流程是这样的:
>调用InnoDB引擎接口取这个表的第一行,判断ID值是不是10,如果不是则跳过,如果是则将这行存在结果集中;
>调用引擎接口取“下一行”,重复相同的判断逻辑,直到取到这个表的最后一行。
>执行器将上述遍历过程中所有满足条件的行组成的记录集作为结果集返回给客户端。
* 至此,这个整个语句就执行完成了。一条查询语句的执行过程一般是经过连接器、分析器、优化器、执行器等功能模块,最后到达存储引擎。
### 一条SQL更新语句是如何执行的
```sql
update T set c=c+1 where ID=2;
```
* 与查询流程不一样的是,更新流程还涉及两个重要的日志模块 `redo log`(重做日志)和 `binlog`(归档日志)
* 每一次的更新操作都需要写进磁盘,然后磁盘也要找到对应的那条记录,然后再更新,整个过程IO成本、查找成本都很高。为了解决这个问题,MySQL的设计者WAL技术,WAL的全称是Write-Ahead Logging,它的关键点就是`先写日志`,`再写磁盘`
* 当有一条记录需要更新的时候,InnoDB引擎就会先把记录写到redo log里面,并更新内存,这个时候更新就算完成了。
* 同时,`InnoDB`引擎会在适当的时候,将这个操作记录更新到磁盘里面,而这个更新往往是在系统比较空闲的时候做。但是`InnoDB`的`redo log`是固定大小的,比如可以配置为一组4个文件,每个文件的大小是1GB,总共就可以记录4GB的操作。从头开始写,写到末尾就又回到开头循环写。
* 在进行`redo log`写入时,有两个重要参数的write pos(当前记录的位置),`checkpoint`是当前要擦除的位置

* 一边写一边后移,写到第3号文件末尾后就回到0号文件开头,checkpoint也是往后推移并且循环的,擦除记录前要把记录更新到数据文件。write pos和checkpoint之间还空着的部分,可以用来记录新的操作。
* 如果`write pos`追上`checkpoin`,表示`redo log`满了,这时候不能再执行新的更新,得停下来先擦掉一些记录,把checkpoint推进一下。
* 有了redo log,InnoDB就可以保证即使数据库发生异常重启,之前提交的记录都不会丢失,这个能力称为crash-safe(崩溃安全()。
* redo log是InnoDB引擎特有的日志,而Server层也有自己的日志,称为binlog(归档日志)
* 最开始MySQL里并没有`InnoDB引擎`。MySQL自带的引擎是MyISAM,但是MyISAM没有crash-safe的能力,binlog日志只能用于归档。而InnoDB是另一个公司以插件形式引入MySQL的,既然只依靠binlog是没有crash-safe能力的,所以InnoDB使用另外一套日志系统——也就是redo log来实现crash-safe能力。
> `redo log是InnoDB引擎特有的`;binlog是MySQL的Server层实现的,所有引擎都可以使用。
> `redo log是物理日志`,记录的是“在某个数据页上做了什么修改”;`binlog是逻辑日志`,记录的是这个语句的原始逻辑,比如“给ID=2这一行的c字段加1 ”。
> r`edo log是循环写的`,`空间固定`会用完;`binlog是可以追加写入的`。“追加写”是指binlog文件写到一定大小后会切换到下一个,并不会覆盖以前的日志。
**执行器和InnoDB引擎在执行这个简单的update语句时的内部流程:**
* 执行器先找引擎取ID=2这一行。ID是主键,引擎直接用树搜索找到这一行。如果ID=2这一行所在的数据页本来就在内存中,就直接返回给执行器;否则,需要先从磁盘读入内存,然后再返回。
* 执行器拿到引擎给的行数据,把这个值加上1,比如原来是N,现在就是N+1,得到新的一行数据,再调用引擎接口写入这行新数据。
* 引擎将这行新数据更新到内存中,同时将这个更新操作记录到redo log里面,此时redo log处于prepare状态。然后告知执行器执行完成了,随时可以提交事务。
* 执行器生成这个操作的binlog,并把binlog写入磁盘。
* 执行器调用引擎的提交事务接口,引擎把刚刚写入的redo log改成提交(commit)状态,更新完成。
* redo log的写入拆成了两个步骤:prepare和commit,这就是`"两阶段提交"`。

> `1 prepare阶段 2 写binlog 3 commit` , 当在`2之前崩溃时`,重启恢复:后发现没有commit,回滚。备份恢复:没有binlog 。
> `当在3之前崩溃`,重启恢复:虽没有commit,但满足prepare和binlog完整,所以重启后会自动commit。备份:有binlog. 一致
#### 总结
* Redo log不是记录数据页“更新之后的状态”,而是记录这个页 “做了什么改动”。
* Binlog有两种模式,statement 格式的话是记sql语句, row格式会记录行的内容,记两条,更新前和更新后都有。
### 事务隔离:为什么你改了我还看不见
* 事务就是要保证一组数据库操作,要么全部成功,要么全部失败。在MySQL中,事务支持是在引擎层实现的。MySQL默认的`MyISAM`引擎就不支持事务,这也是`MyISAM`被`InnoDB`取代的重要原因之一。
* 事务的特性:`ACID`即原子性、一致性、隔离性、持久性。多个事务同时执行的时候,就可能出现`脏读`,`不可重复读`,`幻读`,为了解决这些问题,就有了“`隔离级别`”的概念。但是隔离得越严实,效率就会越低
* SQL标准的事务隔离级别包括:`读未提交`(read uncommitted)、`读提交`(read committed)、`可重复读`(repeatable read)和`串行化`(serializable )
> 读未提交是指,一个事务还没提交时,它做的变更就能被别的事务看到。
> 读提交是指,一个事务提交之后,它做的变更才会被其他事务看到。
> 可重复读是指,一个事务执行过程中看到的数据,总是跟这个事务在启动时看到的数据是一致的。未提交的更改对其他事务是不可见的
> 串行化:对应一个记录会加读写锁,出现冲突的时候,后访问的事务必须等前一个事务执行完成才能继续执行
* 在实现上,数据库里面会创建一个视图,访问的时候以视图的逻辑结果为准。在“`可重复读`”隔离级别下,这个视图是在事务启动时创建的,整个事务存在期间都用这个视图。在`“读提交”`隔离级别下,这个视图是在每个SQL语句开始执行的时候创建的。`“读未提交”`隔离级别下直接返回记录上的最新值,没有视图概念。`串行化`”隔离级别下直接用加锁的方式来避免并行访问
* 查看数据库的实物隔离级别:`show variables like '%isolation%';`
* 事务隔离的实现:在MySQL中,实际上每条记录在更新的时候都会同时记录一条回滚操作。记录上的最新值,通过回滚操作,都可以得到前一个状态的值。
假设一个值从1被按顺序改成了2、3、4,在回滚日志里面就会有类似下面的记录。不同时刻启动的事务会有不同的read-view,同一条记录在系统中可以存在多个版本,就是数据库的多版本并发控制(`MVCC`)

* 回滚日志总不能一直保留吧,什么时候删除呢?答案是,在不需要的时候才删除。系统会判断,当没有事务再需要用到这些回滚日志时,回滚日志会被删除。什么时候才不需要了呢?就是当系统里没有比这个回滚日志更早的read-view的时候。
* 为什么尽量不要使用长事务。长事务意味着系统里面会存在很老的事务视图,在这个事务提交之前,回滚记录都要保留,这会导致大量占用存储空间。除此之外,长事务还占用锁资源,可能会拖垮库。
* 事务启动方式:一、显式启动事务语句,`begin`或者`start transaction`,提交`commit`,回滚`rollback`;二、`set autocommit=0`,该命令会把这个线程的自动提交关掉。这样只要执行一个select语句,事务就启动,并不会自动提交,直到主动执行`commit`或`rollback`或断开连接。
* 建议使用方法一,如果考虑多一次交互问题,可以使用`commit work and chain`语法。在`autocommit=1`的情况下用`begin`显式启动事务,如果执行`commit`则提交事务。如果执行`commit work and chain`则提交事务并自动启动下一个事务
### 深入浅出索引(上)
**索引的常见模型**
* 索引的出现是为了提高查询效率,常见的三种索引模型分别是`哈希表`、`有序数组`和`搜索树`
* `哈希表`:一种以`key-value` 存储数据的结构,哈希的思路是把值放在数组里,用一个哈希函数把`key`换算成一个确定的位置,然后把`value`放在数组的这个位置。哈希冲突的处理办法是使用`链表`。哈希表适用只有`等值查询`的场景
* `有序数组`:按顺序存储。查询用二分法就可以快速查询,时间复杂度是:O(log(N))。查询效率高,更新效率低(涉及到移位)。在等值查询和范围查询场景中的性能就都非常优秀。有序数组索引只适用于静态存储引擎。
* 二叉搜索树:每个节点的左儿子小于父节点,右儿子大于父节点。查询时间复杂度O(log(N)),更新时间复杂度O(log(N))。数据库存储大多不适用二叉树,因为树高过高,会适用N叉树
**InnoDB 的索引模型**
* `InnoDB`使用了`B+树`索引模型,所以数据都是存储在B+树中的。每一个索引在`InnoDB`里面对应一棵B+树。
* 索引类型分为`主键索引`和`非主键索引`。主键索引的叶子节点存的是整行数据。在InnoDB里,主键索引也被称为`聚簇索引`。非主键索引的叶子节点内容是主键的值。在InnoDB里,非主键索引也被称为`二级索引`

**主键索引和普通索引的查询有什么区别?**
* 如果语句是`select * from T where ID=500`,即主键查询方式,则只需要搜索ID这棵B+树;
* 如果语句是`select * from T where k=5`,即普通索引查询方式,则需要先搜索k索引树,得到ID的值为500,再到ID索引树搜索一次。这个过程称为`回表`。
* 基于非主键索引的查询需要多扫描一棵索引树。因此,我们在应用中应该尽量使用主键查询
**索引维护**
* `B+树`为了维护索引有序性,在插入新值的时候需要做必要的维护。涉及到数据的移动和数据页的增加和删减
* 一个数据页满了,按照B+Tree算法,新增加一个数据页,叫做`页分裂`,会导致性能下降。空间利用率降低大概50%。当相邻的两个数据页利用率很低的时候会做`数据页合并`,合并的过程是分裂过程的`逆过程`。
#### 总结
* 索引可能因为删除,或者页分裂等原因,导致数据页有空洞,重建索引的过程会创建一个新的索引,把数据按顺序插入,这样页面的利用率最高,也就是索引更紧凑、更省空间。
> `alter table T drop index k`; alter table T add index(k);
> 要重建主键索引
> `alter table T drop primary key`; `alter table T add primary key(id)`;
> 重建索引k的做法是合理的,可以达到省空间的目的。但是,重建主键的过程不合理。不论是删除主键还是创建主键,都会将整个表重建。所以连着执行这两个语句的话,第一个语句就白做了。
> 可以用这个语句代替 : alter table T engine=InnoDB
### 深入浅出索引(下)
```sql
mysql> create table T (
ID int primary key,
k int NOT NULL DEFAULT 0,
s varchar(16) NOT NULL DEFAULT '',
index k(k))
engine=InnoDB;
insert into T values(100,1, 'aa'),(200,2,'bb'),(300,3,'cc'),(500,5,'ee'),(600,6,'ff'),(700,7,'gg');
```

如果我执行 `select * from T where k between 3 and 5`,需要执行几次树的搜索操作,会扫描多少行?
**SQL查询语句的执行流程:**
* 在k索引树上找到k=3的记录,取得 ID = 300;
* 再到ID索引树查到ID=300对应的R3;
* 在k索引树取下一个值k=5,取得ID=500;
* 再回到ID索引树查到ID=500对应的R4;
* 在k索引树取下一个值k=6,不满足条件,循环结束。
* 在这个过程中,回到主键索引树搜索的过程,我们称为回表。可以看到,这个查询过程读了k索引树的3条记录,回表了两次。在这个例子中,由于查询结果所需要的数据只在主键索引上有,所以不得不回表。
**优化方式**
* sql语句修改为`select ID from T where k between 3 and 5`,这时只需要查ID的值,而ID的值已经在k索引树上了,因此可以直接提供查询结果,不需要回表。也就是说,在这个查询里面,索引k已经“覆盖了”我们的查询需求,我们称为`覆盖索引`。
* 由于`覆盖索引`可以减少树的搜索次数,显著提升查询性能,所以使用覆盖索引是一个常用的性能优化手段。
#### 总结
* `覆盖索引`:如果查询条件使用的是普通索引(或是联合索引的最左原则字段),查询结果是联合索引的字段或是主键,不用回表操作,直接返回结果,减少IO磁盘读写读取正行数据
* `最左前缀`:联合索引的最左 N 个字段,也可以是字符串索引的最左 M 个字符
* `联合索引`:根据创建联合索引的顺序,以最左原则进行where检索,比如(age,name)以age=1 或 age= 1 and name=‘张三’可以使用索引,单以name=‘张三’ 不会使用索引,考虑到存储空间的问题,还请根据业务需求,将查找频繁的数据进行靠左创建索引。
* 索引下推:`like 'hello%’and age >10` 检索,MySQL5.6版本之前,会对匹配的数据进行回表查询。5.6版本后,会先过滤掉age<10的数据,再进行回表查询,减少回表率,提升检索速度
### 讲全局锁和表锁:给表加个字段怎么有这么多阻碍
>根据加锁的范围,MySQL里面的锁大致可以分成全局锁、表级锁和行锁三类
**全局锁**
* 对整个数据库实例加锁。MySQL提供加全局读锁的方法:`Flush tables with read lock(FTWRL)`。这个命令可以使整个库处于只读状态。使用该命令之后,数据更新语句、数据定义语句和更新类事务的提交语句等操作都会被阻塞。使用场景:`全库逻辑备份`。
* 风险是如果在主库备份,在备份期间不能更新,业务停摆。如果在从库备份,备份期间不能执行主库同步的binlog,导致主从延迟。官方自带的逻辑备份工具`mysqldump`,当mysqldump使用参数`--single-transaction`的时候,会启动一个事务,确保拿到一致性视图。而由于`MVCC`的支持,这个过程中数据是可以正常更新的。
* 一致性读是好,但是前提是引擎要支持这个隔离级别。如果要全库只读,为什么不使用`set global readonly=true`的方式?在有些系统中,`readonly`的值会被用来做其他逻辑,比如判断主备库。所以修改global变量的方式影响太大。
* 在异常处理机制上有差异。如果执行`FTWRL`命令之后由于客户端发生异常断开,那么MySQL会自动释放这个全局锁,整个库回到可以正常更新的状态。而将整个库设置为`readonly`之后,如果客户端发生异常,则数据库就会一直保持`readonly`状态,这样会导致整个库长时间处于不可写状态,风险较高。
**表级锁**
* MySQL里面表级锁有两种,一种是表锁,一种是元数据所(meta data lock,MDL)。表锁的语法是:l`ock tables ... read/write`
* 可以用`unlock tables`主动释放锁,也可以在客户端断开的时候自动释放。`lock tables`语法除了会限制别的线程的读写外,也限定了本线程接下来的操作对象。
* 对于`InnoDB`这种支持`行锁`的引擎,一般不使用`lock tables`命令来控制并发,毕竟锁住整个表的影响面还是太大。
* 另一类表级的锁是`MDL`(metadata lock)。`MDL不需要显式使用`,在访问一个表的时候会被`自动加上`。MDL的作用是,`保证读写的正确性`。当对一个表做增删改查操作的时候,加`MDL读锁`;当要对表做结构变更操作的时候,加`MDL写锁`。`读锁之间不互斥`,因此你可以有多个线程同时对一张表增删改查。`读写锁之间、写锁之间是互斥的`,用来保证变更表结构操作的安全性。因此,如果有两个线程要同时给一个表加字段,其中一个要等另一个执行完才能开始执行。
* `MDL` 会直到事务提交才会释放,在做表结构变更的时候,一定要小心不要导致锁住线上查询和更新。
**如何安全地给表加字段**
* 给一个表加字段,或者修改字段,或者加索引,需要扫描全表的数据。首先我们要解决长事务,事务不提交,就会一直占着MDL锁。在MySQL的`information_schema` 库的 `innodb_trx` 表中,你可以查到当前执行中的事务。如果你要做`DDL`变更的表刚好有`长事务`在执行,要考虑先暂停DDL,或者`kill`掉这个长事务。
* 如果你要变更的表是一个`热点表`,虽然数据量不大,但是上面的请求很频繁,这时候kill可能未必管用,因为新的请求马上就来了。比较理想的机制是,在`alter table`语句里面设定等待时间,如果在这个指定的等待时间里面能够拿到`MDL写锁`最好,拿不到也不要阻塞后面的业务语句,先放弃。之后开发人员或者DBA再通过重试命令重复这个过程。
### 讲行锁功过:怎么减少行锁对性能的影响
* MySQL的`行锁`是在引擎层由各个`引擎自己实现`的。但并不是所有的引擎都支持行锁,比`如MyISAM引擎就不支持行锁`。不支持行锁意味着并发控制只能使用表锁,对于这种引擎的表,同一张表上任何时刻只能有一个更新在执行,这就会影响到业务并发度。`InnoDB是支持行锁`的,这也是`MyISAM`被`InnoDB`替代的重要原因之一。
* `两阶段锁协议`:在`InnoDB`事务中,行锁是在需要的时候才加上的,但并不是不需要了就立刻释放,而是要等到事务结束时才释放。如果你的事务中需要锁多个行,要把最可能造成锁冲突、最可能影响并发度的锁尽量往后放。
* `死锁`:当并发系统中不同线程出现循环资源依赖,涉及的线程都在等待别的线程释放资源时,就会导致这几个线程都进入无限等待的状态,称为死锁

* `事务A`在等待`事务B`释放id=2的行锁,而`事务B在等待事务A`释放id=1的行锁。 事务A和事务B在互相等待对方的资源释放,就是进入了`死锁状态`
**出现死锁以后,有两种策略:**
* 一种策略是,`直接进入等待,直到超时`。这个超时时间可以通过参数`innodb_lock_wait_timeout`来设置。在InnoDB中,默认值是`50s`
* 另一种策略是,`发起死锁检测`,发现死锁后,主动回滚死锁链条中的某一个事务,让其他事务得以继续执行。将参数`innodb_deadlock_detect设置为on`,表示开启这个逻辑。默认值本身就是on
* 正常情况下选择第二种策略,但是它也是有额外负担的,如果瞬间有大量线程请求会消耗消耗大量的CPU资源,但是每秒却执行不了几个事务,因为每次都要检测。
**怎么解决由这种热点行更新导致的性能问题?**
* 问题的症结在于,死锁检测要耗费大量的CPU资源
* 如果你能确保这个业务一定不会出现死锁,可以临时把死锁检测关掉。 一般不建议采用
* 控制并发度,对应相同行的更新,在进入引擎之前排队。这样在InnoDB内部就不会有大量的死锁检测工作了。
* 将热更新的行数据拆分成逻辑上的多行来减少锁冲突,但是业务复杂度可能会大大提高。
* `innodb行级锁是通过锁索引记录实现的,如果更新的列没建索引是会锁住整个表的。`
#### 小结
如果你要删除一个表里面的前10000行数据,有以下三种方法可以做到:
* 第一种,直接执行 `delete from T limit 10000;`
* 第二种,在一个连接中循环执行20次 `delete from T limit 500;`
* 第三种,在20个连接中同时执行 `delete from T limit 500`
**三种方案分析**
* 方案一,事务相对较长,则占用锁的时间较长,会导致其他客户端等待资源时间较长。
* 方案二,串行化执行,将相对长的事务分成多次相对短的事务,则每次事务占用锁的时间相对较短,其他客户端在等待相应资源的时间也较短。这样的操作,同时也意味着将资源分片使用(每次执行使用不同片段的资源),可以提高并发性。
* 方案三,人为自己制造锁竞争,加剧并发量。
### 事务到底是隔离的还是不隔离的
* `innodb`支持`RC(读提交)`和`RR(可重复读)`隔离级别实现是用的一致性视图(consistent read view)
* .事务在启动时会拍一个快照,这个快照是基于整个库的。基于整个库的意思就是说一个事务内,整个库的修改对于该事务都是不可见的(对于快照读的情况)。如果在事务内`select t`表,另外的事务执行了`DDL t`表,根据发生时间,`要吗锁住要嘛报错`
**事务是如何实现的MVCC呢?**
* 每个事务都有一个事务ID,叫做`transaction id`(严格递增)
* 事务在启动时,找到已提交的最大事务ID记为up_limit_id。
* 事务在更新一条语句时,比如id=1改为了id=2.会把id=1和该行之前的`row trx_id`写到`undo log`里。并且在数据页上把id的值改为2,并且把修改这条语句的`transaction id`记在该行行头。
* 再定一个规矩,一个事务要查看一条数据时,必须先用该事务的`up_limit_id`与该行的`transaction id`做比对
* 如果`up_limit_id>=transaction id`,那么可以看.如果`up_limit_id<transaction id`,则只能去`undo log`里去取。去undo log查找数据的时候,也需要做比对,必须`up_limit_id>transaction id`,才返回数据
**什么是当前读,**
* 由于当前读都是先读后写,只能读当前的值,所以认为当前读.会更新事务内的up_limit_id为该事务的transaction id
**为什么`RR`能实现可重复读而`RC`不能,分两种情况**
* 快照读的情况下,rr(可重复读)不能更新事务内的up_limit_id,而`rc(读提交)`每次会把`up_limit_id`更新为快照读之前最新已提交事务的`transaction id`,则`rc(读提交)`不能可重复读
* 当前读的情况下,`rr(可重复读)`是利用`record lock+gap lock`来实现的,而`rc(读提交)`没有gap,所以rc不能可重复读
### MySQL为什么有时候会选错索引
* 在MySQL中一张表其实是可以支持多个索引的。但是,你写SQL语句的时候,并没有主动指定使用哪个索引。也就是说,使用哪个索引是由MySQL来确定的。所以有时候由于MySQL选错了索引,而导致执行速度变得很慢
测试代码
```sql
CREATE TABLE `t` (
`id` int(11) NOT NULL,
`a` int(11) DEFAULT NULL,
`b` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `a` (`a`),
KEY `b` (`b`)
) ENGINE=InnoDB;
```
然后,我们往表t中插入10万行记录,取值按整数递增,即:(1,1,1),(2,2,2),(3,3,3) 直到(100000,100000,100000)。
分析一条SQL语句:
```sql
mysql> select * from t where a between 10000 and 20000;
```
正常情况下,a上有索引,肯定是要使用索引a的。

但是特许情况下如果同时有两个以下下操作执行:
* 如果一个A请求首先开启了事物,随后,B请求把数据都删除后,又插入了10万行数据。
* 这时候, B操作的查询语句`select * from t where a between 10000 and 20000`就不会再选择索引a了,会执行全表扫描,执行时间会比之前慢很多。`为什么会出现这样情况?`因为选择索引是优化器的工作,而优化器选择索引的目的,是找到一个最优的执行方案,并用最小的代价去执行语句。
* MySQL在真正开始执行语句之前,并不能精确地知道满足这个条件的记录有多少条,而只能根据统计信息来估算记录数。这个统计信息就是索引的“`区分度`”。一个索引上不同的值越多,这个索引的区分度就越好。而一个索引上不同的值的个数,我们称之为`“基数”`(cardinality)。也就是说,这个基数越大,索引的区分度越好。
* 可以使用`show index table`方法,看到一个索引的基数
* MySQL是怎样得到索引的基数的呢?MySQL通过采样统计的方法得到基数
* 如果使用索引a,每次从索引a上拿到一个值,都要回到主键索引上查出整行数据,这个代价优化器也要算进去的。而如果选择扫描10万行,是直接在主键索引上扫描的,没有额外的代价。优化器会估算这两个选择的代价,从结果看来,优化器认为直接扫描主键索引更快。当然,从执行时间看来,这个选择并不是最优的。
* `analyze table t` 命令可以用来重新统计索引信息
* 采用`force index`强行选择一个索引。如果force index指定的索引在候选索引列表中,就直接选择这个索引,不再评估其他索引的执行代价。

```sql
set long_query_time=0;
select * from t where a between 10000 and 20000; /*Q1*/
select * from t force index(a) where a between 10000 and 20000;/*Q2*/
第一句,是将慢查询日志的阈值设置为0,表示这个线程接下来的语句都会被记录入慢查询日志中;
第二句,Q1是session B原来的查询;
第三句,Q2是加了force index(a)来和session B原来的查询语句执行情况对比。
```
* delete 语句删掉了所有的数据,然后再通过call idata()插入了10万行数据,看上去是覆盖了原来的10万行。
* 但是,session A开启了事务并没有提交,所以之前插入的10万行数据是不能删除的。这样,之前的数据每一行数据都有两个版本,旧版本是delete之前的数据,新版本是标记为deleted的数据。这样,索引a上的数据其实就有两份
### 怎么给字符串字段加索引
* 假设,你现在维护一个支持邮箱登录的系统,用户表是这么定义的:
```sql
mysql> create table SUser(
ID bigint unsigned primary key,
email varchar(64),
...
)engine=innodb;
```
由于要使用邮箱登录,所以业务代码中一定会出现类似于这样的语句:
```sql
mysql> select f1, f2 from SUser where email='xxx';
```
* 如果email这个字段上没有索引,那么这个语句就只能做全表扫描。同时,MySQL是支持前缀索引的,也就是说,你可以定义字符串的一部分作为索引。默认地,如果你创建索引的语句不指定前缀长度,那么索引就会包含整个字符串。
比如,这两个在email字段上创建索引的语句:
```sql
mysql> alter table SUser add index index1(email);
或
mysql> alter table SUser add index index2(email(6));
```


* 第一个语句创建的index1索引里面,包含了每个记录的整个字符串;
* 第二个语句创建的index2索引里面,对于每个记录都是只取前6个字节。由于email(6)这个索引结构中每个邮箱字段都只取前6个字节,所以占用的空间会更小,这就是使用前缀索引的优势。但是 可能会增加额外的记录扫描次数。
**使用的是index1的执行流程**
* 从`index1`索引树找到满足索引值是’[email protected]’的这条记录,取得ID2的值;
* 到主键上查到主键值是ID2的行,判断email的值是正确的,将这行记录加入结果集;
* 取index1索引树上刚刚查到的位置的下一条记录,发现已经不满足email='[email protected]’的条件了,循环结束
* 这个过程中,只需要回主键索引取一次数据,所以系统认为只扫描了一行。
**使用的是index2的执行流程**
* 从`index2`索引树找到满足索引值是’zhangs’的记录,找到的第一个是ID1;
* 到主键上查到主键值是ID1的行,判断出email的值不是’[email protected]’,这行记录丢弃;
* 取index2上刚刚查到的位置的下一条记录,发现仍然是’zhangs’,取出ID2,再到ID索引上取整行然后判断,这次值对了,将这行记录加入结果集;
* 重复上一步,直到在idxe2上取到的值不是’zhangs’时,循环结束。
* 在这个过程中,要回主键索引取4次数据,也就是扫描了4行。
* 但是 对于这个查询语句来说,如果你定义的`index2`不是email(6)而是email(7),也就是说取email字段的前7个字节来构建索引的话,即满足前缀’zhangss’的记录只有一个,也能够直接查到ID2,只扫描一行就结束了。
* 也就是说`使用前缀索引,定义好长度,就可以做到既节省空间,又不用额外增加太多的查询成本`。
**前缀索引对覆盖索引的影响**
* 使用前缀索引可能会增加扫描行数,这会影响到性能。其实,前缀索引的影响不止如此
```sql
#查询1
select id,email from SUser where email='[email protected]';
# 查询2
select id,name,email from SUser where email='[email protected]';
```
* 如果使用index1(即email整个字符串的索引结构)的话,可以利用覆盖索引,从index1查到结果后直接就返回了,不需要回到ID索引再去查一次。而如果使用index2(即email(6)索引结构)的话,就不得不回到ID索引再去判断email字段的值。
* 即使你将index2的定义修改为email(18)的前缀索引,这时候虽然index2已经包含了所有的信息,但InnoDB还是要回到id索引再查一下,因为系统并不确定前缀索引的定义是否截断了完整信息。
* 使用前缀索引就用不上覆盖索引对查询性能的优化了
#### 小结
对于类似于邮箱这样的字段来说,使用前缀索引的效果可能还不错。但是,遇到前缀的区分度不够好的情况时。比如,我们国家的身份证号,一共18位,其中前6位是地址码,所以同一个县的人的身份证号前6位一般会是相同的。
假设你维护的数据库是一个市的公民信息系统,这时候如果对身份证号做长度为6的前缀索引的话,这个索引的区分度就非常低了。可能你需要创建长度为12以上的前缀索引,才能够满足区分度要求。但是,`索引选取的越长,占用的磁盘空间就越大,相同的数据页能放下的索引值就越少,搜索的效率也就会越低`。
那么,如果我们能够确定业务需求里面只有按照身份证进行等值查询的需求,还有没有别的处理方法呢?这种方法,既可以占用更小的空间,也能达到相同的查询效率。
第一种方式是使用`倒序存储`。如果你存储身份证号的时候把它倒过来存,每次查询的时候,你可以这么写:
```sql
mysql> select field_list from t where id_card = reverse('input_id_card_string');
```
由于身份证号的最后6位没有地址码这样的重复逻辑,所以最后这6位很可能就提供了足够的区分度。
第二种方式是`使用hash字段`。你可以在表上再创建一个整数字段,来保存身份证的校验码,同时在这个字段上创建索引。
```sql
mysql> alter table t add id_card_crc int unsigned, add index(id_card_crc);
```
然后每次插入新记录的时候,都同时用crc32()这个函数得到校验码填到这个新字段。由于校验码可能存在冲突,也就是说两个不同的身份证号通过crc32()函数得到的结果可能是相同的,所以你的查询语句where部分要判断id_card的值是否精确相同。
```sql
mysql> select field_list from t where id_card_crc=crc32('input_id_card_string') and id_card='input_id_card_string'
```
这样,索引的长度变成了4个字节,比原来小了很多。
**使用倒序存储和使用hash字段这两种方法的异同点**
* 首先,它们的相同点是,都不支持范围查询。
* `从占用的额外空间来看`,倒序存储方式在主键索引上,不会消耗额外的存储空间,而hash字段方法需要增加一个字段
* `在CPU消耗方面`,倒序方式每次写和读的时候,都需要额外调用一次reverse函数,而hash字段的方式需要额外调用一次crc32()函数
* `从查询效率上看`,使用hash字段方式的查询性能相对更稳定一些。因为crc32算出来的值虽然有冲突的概率,但是概率非常小,可以认为每次查询的平均扫描行数接近1。而倒序存储方式毕竟还是用的前缀索引的方式,也就是说还是会增加扫描行数。
**字符串字段创建索引的场景你可以使用的方式有:**
* 直接创建完整索引,这样可能比较占用空间;
* 创建前缀索引,节省空间,但会增加查询扫描次数,并且不能使用覆盖索引;
* 倒序存储,再创建前缀索引,用于绕过字符串本身前缀的区分度不够的问题;
* 创建hash字段索引,查询性能稳定,有额外的存储和计算消耗,跟第三种方式一样,都不支持范围扫描。
**利用学号作为登录名索引设计问题?**
> 如果你在维护一个学校的学生信息数据库,学生登录名的统一格式是”学号@gmail.com", 而学号的规则是:十五位的数字,其中前三位是所在城市编号、第四到第六位是学校编号、第七位到第十位是入学年份、最后五位是顺序编号。
系统登录的时候都需要学生输入登录名和密码,验证正确后才能继续使用系统。就只考虑登录验证这个行为的话,你会怎么设计这个登录名的索引呢?
**`设计思路:`**
* 由于这个学号的规则,无论是正向还是反向的前缀索引,重复度都比较高。因为维护的只是一个学校的,因此前面6位(其中,前三位是所在城市编号、第四到第六位是学校编号)其实是固定的,邮箱后缀都是@gamil.com,因此可以只存入学年份加顺序编号,它们的长度是9位。
* 而其实在此基础上,可以用数字类型来存这9位数字。比如201100001,这样只需要占4个字节。其实这个就是一种hash,只是它用了最简单的转换规则:字符串转数字的规则,而刚好我们设定的这个背景,可以保证这个转换后结果的唯一性。
### 为什么我的MySQL会“抖”一下
* 一条SQL语句,正常执行的时候特别快,但是有时也不知道怎么回事,它就会变得特别慢,并且这样的场景很难复现,它不只随机,而且持续时间还很短。看上去,这就像是数据库“抖”了一下
* 在MySQL里,如果每一次的更新操作都需要写进磁盘,然后磁盘也要找到对应的那条记录,然后再更新,整个过程IO成本、查找成本都很高。为了解决这个问题,MySQL的设计者使用了`WAL技术`,WAL的全称是Write-Ahead Logging,它的关键点就是`先写日志,再写磁盘`。
* 利用WAL技术,数据库将随机写转换成了顺序写,大大提升了数据库的性能。但是,由此也带来了内存脏页的问题。脏页会被后台线程自动flush,也会由于数据页淘汰而触发flush,而刷脏页的过程由于会占用资源,可能会让你的更新和查询语句的响应时间长一些
* 当内存数据页跟磁盘数据页内容不一致的时候,我们称这个内存页为“脏页”。内存数据写入到磁盘后,内存和磁盘上的数据页的内容就一致了,称为“干净页”。
* 平时执行很快的更新操作,其实就是在写内存和日志,而MySQL偶尔“抖”一下的那个瞬间,可能就是在刷脏页(`flush`)。
**什么情况会引发数据库的flush过程呢?**
* `InnoDB`在处理更新语句的时候,只做了写日志这一个磁盘操作。这个日志叫作redo log(重做日志)。在更新内存写完`redo log`后,就返回给客户端,本次更新成功。
* `InnoDB`的`redo log`(重做日志)写满了。这时候系统会停止所有更新操作,把`checkpoint(检查点)`往前推进,`redo log`留出空间可以继续写
* 第二种场景是:对应的就是系统内存不足。当需要新的内存页,而内存不够用的时候,就要淘汰一些数据页,空出内存给别的数据页使用。如果淘汰的是“脏页”,就要先将脏页写到磁盘。
* 第三种场景就是`MySQL`认为系统`“空闲”`的时候。也要见缝插针地找时间,只要有机会就刷一点`“脏页”`
* 第四种场景就是`MySQL正常关闭的情况`。这时候,MySQL会把内存的脏页都flush到磁盘上,这样下次MySQL启动的时候,就可以直接从磁盘上读数据,启动速度会很快。
**分析一下上面四种场景对性能的影响**
* `第一种是“redo log写满了,要flush脏页”`,这种情况是InnoDB要尽量避免的。因为出现这种情况的时候,整个系统就不能再接受更新了,所有的更新都必须堵住。如果你从监控上看,这时候更新数会跌为0。
* `第二种是“内存不够用了,要先将脏页写到磁盘”`,这种情况其实是常态。InnoDB用缓冲池(buffer pool)管理内存,缓冲池中的内存页有三种状态:第一种是,还没有使用的;第二种是,使用了并且是干净页;第三种是,使用了并且是脏页。InnoDB的策略是尽量使用内存,因此对于一个长时间运行的库来说,未被使用的页面很少。
* 而当要读入的数据页没有在内存的时候,就必须到缓冲池中申请一个数据页。这时候只能把最久不使用的数据页从内存中淘汰掉:如果要淘汰的是一个干净页,就直接释放出来复用;但如果是脏页呢,就必须将脏页先刷到磁盘,变成干净页后才能复用。
* 所以,刷脏页虽然是常态,但是出现以下这两种情况,都是会明显影响性能的:一个查询要淘汰的脏页个数太多,会导致查询的响应时间明显变长;日志写满,更新全部堵住,写性能跌为0,这种情况对敏感业务来说,是不能接受的。
**InnoDB刷脏页的控制策略**
* 首先,你要正确地告诉`InnoDB`所在主机的`IO能力`,这样`InnoDB`才能知道需要全力刷脏页的时候,可以刷多快。这就要用到`innodb_io_capacity`这个参数了,它会告诉`InnoDB`你的磁盘能力。这个值我建议你设置成`磁盘的IOPS`。
* 假设有这样一个场景:`MySQL的写入速度很慢,TPS很低`,但是数据库主机的`IO压力并不大`。主机磁盘用的是SSD,但是`innodb_io_capacity`的值设置的是`300`。于是,InnoDB认为这个系统的能力就这么差,所以刷脏页刷得特别慢,甚至比脏页生成的速度还慢,这样就造成了脏页累积,影响了查询和更新性能。
* `InnoDB`的刷盘速度就是要参考这两个因素:一个是`脏页比例`,一个是`redo log写盘速度`。
* 参数`innodb_max_dirty_pages_pct`是`脏页比例上限`,默认值是`75%`。InnoDB会根据当前的脏页比例(假设为M),算出一个范围在0到100之间的数字。`InnoDB`每次写入的日志`都有一个序号`,当前写入的序号跟`checkpoint`对应的序号之间的差值。我们假设为N。InnoDB会根据这个N算出一个范围在0到100之间的数字,这个计算公式可以记为F2(N)。F2(N)算法比较复杂,你只要知道N越大,算出来的值越大就好了。
* 然后,根据上述算得的F1(M)和F2(N)两个值,取其中较大的值记为R,之后引擎就可以按照`innodb_io_capacity`定义的能力乘以`R%`来控制刷脏页的速度。

* InnoDB会在后台刷脏页,而刷脏页的过程是要将内存页写入磁盘。所以,无论是你的查询语句在需要内存的时候可能要求淘汰一个脏页,还是由于刷脏页的逻辑会占用IO资源并可能影响到了你的更新语句,都可能是造成你从业务端感知到MySQL“抖”了一下的原因。
* 要尽量避免这种情况,你就要合理地设置`innodb_io_capacity的值`,并且平时要多关注脏页比例,不要让它经常接近`75%`。
>脏页比例是通过Innodb_buffer_pool_pages_dirty/Innodb_buffer_pool_pages_total得到的
```sql
mysql> select VARIABLE_VALUE into @a from global_status where VARIABLE_NAME = 'Innodb_buffer_pool_pages_dirty';
select VARIABLE_VALUE into @b from global_status where VARIABLE_NAME = 'Innodb_buffer_pool_pages_total';
select @a/@b;
```
* 一旦一个查询请求需要在执行过程中先flush掉一个脏页时,这个查询就可能要比平时慢了。而MySQL中的一个机制,可能让你的查询会更慢:在准备刷一个脏页的时候,如果这个数据页旁边的数据页刚好是脏页,就会把这个“邻居”也带着一起刷掉;而且这个把“邻居”拖下水的逻辑还可以继续蔓延,也就是对于每个邻居数据页,如果跟它相邻的数据页也还是脏页的话,也会被放到一起刷。
* 在InnoDB中,`innodb_flush_neighbors` 参数就是用来控制这个行为的,`值为1`的时候会有上述的`“连坐”机制`,`值为0时`表示不找邻居,自己刷自己的。
* 找`“邻居”`这个优化在`机械硬盘时代是很有意义`的,可以`减少很多随机IO`。机械硬盘的随机`IOPS`一般只有几百,相同的逻辑操作减少随机IO就意味着系统性能的大幅度提升。
* 而如果使用的是`SSD这类IOPS比较高的设备`的话,我就建议你把`innodb_flush_neighbors`的值设置成0。因为这时候`IOPS`往往不是瓶颈,而`“只刷自己”`,就能更快地执行完必要的刷脏页操作,减少SQL语句响应时间。
* 在MySQL 8.0中`,innodb_flush_neighbors参数的默认值已经是0`了。
### 为什么表数据删掉一半,表文件大小不变
* 一个InnoDB表包含两部分,即:表结构定义和数据。在MySQL 8.0版本以前,表结构是存在以.frm为后缀的文件里。
* 表数据既可以存在共享表空间里,也可以是单独的文件。这个行为是由参数`innodb_file_per_table`控制的,设置为`OFF`表示的是,表的数据放在`系统共享表空间`,也就是跟数据字典放在一起;设置为`ON`表示的是,每个InnoDB表数据存储在一个以 `.ibd`为后缀的文件中。从`MySQL 5.6.6`版本开始,它的`默认值就是ON`了
* 建议你不论使用MySQL的哪个版本,都将这个值设置为ON。因为,一个表单独存储为一个文件更容易管理,而且在你不需要这个表的时候,通过`drop table`命令,系统就会直接删除这个文件。而如果是放在共享表空间中,即使表删掉了,空间也是不会回收的。
* 我们在删除整个表的时候,可以使用drop table命令回收表空间。但是,我们遇到的更多的删除数据的场景是删除某些行,表中的数据被删除了,但是表空间却没有被回收。
**数据删除流程**

* 假设,我们要删掉R4这个记录,InnoDB引擎只会把R4这个记录标记为删除。如果之后要再插入一个ID在300和600之间的记录时,可能会复用这个位置。但是,磁盘文件的大小并不会缩小。
* InnoDB的数据是按页存储的,那么如果我们删掉了一个数据页上的所有记录,整个数据页就可以被复用了。
* 但是,数据页的复用跟记录的复用是不同的。记录的复用,只限于符合范围条件的数据,比如R4这条记录被删除后,如果插入一个ID是400的行,可以直接复用这个空间。但如果插入的是一个ID是800的行,就不能复用这个位置了。
* 而当整个页从B+树里面摘掉以后,可以复用到任何位置。如果相邻的两个数据页利用率都很小,系统就会把这两个页上的数据合到其中一个页上,另外一个数据页就被标记为可复用。
* 所以如果我们用delete命令把整个表的数据删除,结果就是,所有的数据页都会被标记为可复用。但是磁盘上,文件不会变小。也就是说,通过delete命令是不能回收表空间的。这些可以复用,而没有被使用的空间,看起来就像是`“空洞”`。
* 实际上,不止是删除数据会造成空洞,插入数据也会。如果数据是按照索引递增顺序插入的,那么索引是紧凑的。但如果数据是随机插入的,就可能造成索引的数据页分裂。另外,更新索引上的值,可以理解为删除一个旧的值,再插入一个新值。不难理解,这也是会造成空洞的。
**重建表**
* 重建表就是新建一个与表A结构相同的表B,然后按照主键ID递增的顺序,把数据一行一行地从表A里读出来再插入到表B中。由于表B是新建的表,所以表A主键索引上的空洞,在表B中就都不存在了。
* 可以使用`alter table A engine=InnoDB`命令来重建表。MySQL 5.5之后会自动完成转存数据、交换表名、删除旧表的操作。
* 重建表的过程中,如果中途有新的数据要写入,就会造成数据丢失。所以在整个`DDL`过程中,表A中不能有更新。也就是说,这个DDL不是`Online`的。在MySQL 5.6版本开始引入的`Online DDL`,对这个操作流程做了优化。
* 对于很大的表来说,这个操作是很消耗IO和CPU资源的。想要比较安全的操作的话,推荐使用`GitHub`开源的[gh-ost](https://github.com/github/gh-ost)来做。
**MySQL执行DDL()原理**
* `DML`:它们是SELECT、UPDATE、INSERT、DELETE,就象它的名字一样,这4条命令是用来对数据库里的数据进行操作的语言
* `DDL`:DDL比DML要多,主要的命令有CREATE、ALTER、DROP等,DDL主要是用在定义或改变表(TABLE)的结构,数据类型,表之间的链接和约束等初始化工作上,他们大多在建立表时使用
* `DCL`:是数据库控制功能。是用来设置或更改数据库用户或角色权限的语句
* MySQL各版本,对于DDL的处理方式是不同的,主要有三种:
* `Copy Table`方式:这是InnoDB最早支持的方式。通过临时表拷贝的方式实现的。新建一个带有新结构的临时表,将原表数据全部拷贝到临时表,然后Rename,完成创建操作。这个方式过程中,`原表是可读的,不可写`。但是`会消耗一倍的存储空间`。
* `Inplace`方式:这是原生MySQL 5.5,以及`innodb_plugin`中提供的方式。所谓Inplace,也就是在`原表上直接进行,不会拷贝临时表`。相对于Copy Table方式,这比较高效率。`原表同样可读的,但是不可写`。
* `Online方式`:MySQL 5.6以上版本中提供的方式,无论是Copy Table方式,还是Inplace方式,`原表只能允许读取,不可写`。对应用有较大的限制,因此MySQL最新版本中,InnoDB支持了所谓的`Online方式DDL`。与以上两种方式相比,`online方式支持DDL时不仅可以读,还可以写`
### count(*)语句到底是怎样实现的
* 在不同的MySQL引擎中,count(*)有不同的实现方式。
* `MyISAM引擎`把一个表的总行数存在了磁盘上,因此执行`count(*)`的时候会直接返回这个数,效率很高。这里讨论的是没有过滤条件的count(*),如果加了where 条件的话,MyISAM表也是不能返回得这么快的。
* `InnoDB引擎`就麻烦了,它执行count(*)的时候,需要把数据一行一行地从引擎里面读出来,然后累积计数。
**为什么InnoDB不跟MyISAM一样,也把数字存起来呢?**
* 这是因为即使是在同一个时刻的多个查询,由于`多版本并发控制`(MVCC)的原因,InnoDB表“应该返回多少行”也是不确定的。
* 这和InnoDB的事务设计有关系,`可重复读是它默认的隔离级别`,在代码上就是通过多版本并发控制,也就是MVCC来实现的。每一行记录都要判断自己是否对这个会话可见,因此对于count(*)请求来说,InnoDB只好把数据一行一行地读出依次判断,可见的行才能够用于计算“基于这个查询”的表的总行数。
* `InnoDB是索引组织表`,`主键索引树的叶子节点是数据`,而`普通索引树的叶子节点是主键值`。所以,普通索引树比主键索引树小很多。对于count(*)这样的操作,遍历哪个索引树得到的结果逻辑上都是一样的。因此,MySQL优化器会找到最小的那棵树来遍历。在保证逻辑正确的前提下,尽量减少扫描的数据量,是数据库系统设计的通用法则之一。
* MyISAM表虽然count(*)很快,但是不支持事务;show table status命令虽然返回很快,但是不准确;InnoDB表直接count(*)会遍历全表,虽然结果准确,但会导致性能问题。
### 不同的count用法
`select count(?) from t`这样的查询语句里面,`count(*)、count(主键id)、count(字段)和count(1)`等不同用法的性能,有哪些差别。
* count()是一个聚合函数,对于返回的结果集,一行行地判断,如果count函数的参数不是NULL,累计值就加1,否则不加。最后返回累计值。
* 所以,count(*)、count(主键id)和count(1) 都表示返回满足条件的结果集的总行数;而count(字段),则表示返回满足条件的数据行里面,参数“字段”不为NULL的总个数。
* `对于count(主键id)来说`,InnoDB引擎会遍历整张表,把每一行的id值都取出来,返回给server层。server层拿到id后,判断是不可能为空的,就按行累加。
* `对于count(1)来说`,InnoDB引擎遍历整张表,但不取值。server层对于返回的每一行,放一个数字“1”进去,判断是不可能为空的,按行累加。
* `对于count(字段)来说`:如果这个“字段”是定义为not null的话,一行行地从记录里面读出这个字段,判断不能为null,按行累加;如果这个“字段”定义允许为null,那么执行的时候,判断到有可能是null,还要把值取出来再判断一下,不是null才累加。
* count(*)是例外:并不会把全部字段取出来,而是专门做了优化,不取值。count(*)肯定不是null,按行累加。
* 所以结论是:按照效率排序的话,count(字段)<count(主键id)<count(1)≈count(*),所以我建议你,尽量使用count(*)。
### order by是怎么工作的
首先创建一个测试表 `t_city`
```sql
CREATE TABLE `t_city` (
`id` int(11) NOT NULL,
`city` varchar(16) NOT NULL,
`name` varchar(16) NOT NULL,
`age` int(11) NOT NULL,
`addr` varchar(128) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `city` (`city`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
```
使用存储过程 添加10W条测试数据
```sql
delimiter ;;
create procedure idata2()
begin
declare i int;
set i=1;
while(i<=10000)do
insert into t_city values(i,'广州', i,i,i);
set i=i+1;
end while;
end;;
delimiter ;
call idata2();
```
比如有如下sql语句,为避免全表扫描,已经在city字段加上索引
```sql
select city,name,age from t_city where city='广州' order by name limit 1000;
```
这个语句看上去逻辑很清晰, 那吗数据库内部到底是怎样执行的了?
首先先用`explain`看看执行计划
```sql
explain select city,name,age from t_city where city='广州' order by name limit 1000;
```

**先看下个执行计划各参数的含义:**
* `select_type`:显 示查询中每个select子句的类型
* `table`: 显示这一行的数据是关于哪张表的,有时不是真实的表名字
* `type`:在表中找到所需行的方式,又称“访问类型”。常用的类型有: ALL, index, range, ref, eq_ref, const, system, NULL(从左到右,性能从差到好)
* `possible_keys`:指出MySQL能使用哪个索引在表中找到记录,查询涉及到的字段上若存在索引,则该索引将被列出,但不一定被查询使用
* `Key`:key列显示MySQL实际决定使用的键(索引)
* `key_len`:表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度,key_len显示的值为索引字段的最大可能长度,并非实际使用长度,不损失精确性的情况下,长度越短越好
* `ref`:表示上述表的连接匹配条件,即哪些列或常量被用于查找索引列上的值
* `rows`: 表示MySQL根据表统计信息及索引选用情况,估算的找到所需的记录所需要读取的行数
* `Extra`:该列包含MySQL解决查询的详细信息。Extra这个字段中的`“Using filesort”表示的就是需要排序`,MySQL会给每个线程分配一块内存用于排序,称为`sort_buffer`。

* 按name排序”这个动作,可能在内存中完成,也可能需要使用外部排序,这取决于排序所需的内存和参数`sort_buffer_size`。
* `sort_buffer_size`就是MySQL为排序开辟的内存(`sort_buffer`)的大小。如果要排序的数据量小于sort_buffer_size,排序就在内存中完成。但如果排序数据量太大,内存放不下,则不得不利用磁盘临时文件辅助排序。
>确定一个排序语句是否使用了临时文件
```sql
/* 打开optimizer_trace,只对本线程有效 */
SET optimizer_trace='enabled=on';
/* @a保存Innodb_rows_read的初始值 */
select VARIABLE_VALUE into @a from performance_schema.session_status where variable_name = 'Innodb_rows_read';
/* 执行语句 */
select city, name,age from t where city='杭州' order by name limit 1000;
/* 查看 OPTIMIZER_TRACE 输出 */
SELECT * FROM `information_schema`.`OPTIMIZER_TRACE`
/* @b保存Innodb_rows_read的当前值 */
select VARIABLE_VALUE into @b from performance_schema.session_status where variable_name = 'Innodb_rows_read';
/* 计算Innodb_rows_read差值 */
select @b-@a;
```
这个方法是通过查看 OPTIMIZER_TRACE 的结果来确认的,你可以从 number_of_tmp_files中看到是否使用了临时文件。
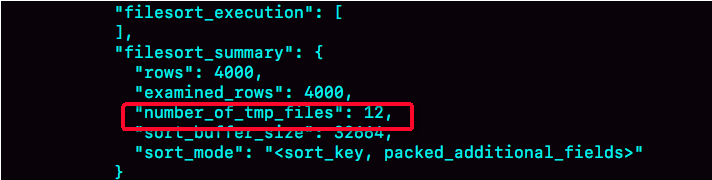
* `number_of_tmp_files`表示的是,排序过程中使用的临时文件数。内存放不下时,就需要使用外部排序,外部排序一般使用归并排序算法。,MySQL将需要排序的数据分成12份,每一份单独排序后存在这些临时文件中。然后把这12个有序文件再合并成一个有序的大文件。
* 如果`sort_buffer_size`超过了需要排序的数据量的大小,`number_of_tmp_files`就是0,表示排序可以直接在内存中完成。否则就需要放在临时文件中排序。
* `sort_buffer_size`越小,需要分成的份数越多,`number_of_tmp_files`的值就越大。
* `sort_mode` 里面的`packed_additional_fields`的意思是,排序过程对字符串做了`“紧凑”`处理。即使name字段的定义是varchar(16),在排序过程中还是要按照实际长度来分配空间的。
* 同时,最后一个查询语句select @b-@a 的返回结果是4000,表示整个执行过程只扫描了4000行。
* 这里需要注意的是,为了避免对结论造成干扰,我把internal_tmp_disk_storage_engine设置成MyISAM。否则,select @b-@a的结果会大于4000
* 在上面这个算法过程里面,只对原表的数据读了一遍,剩下的操作都是在sort_buffer和临时文件中执行的。但这个算法有一个问题,就是如果查询要返回的字段很多的话,那么sort_buffer里面要放的字段数太多,这样内存里能够同时放下的行数很少,要分成很多个临时文件,排序的性能会很差。
**如果MySQL认为排序的单行长度太大会怎么做呢?**
* `max_length_for_sort_data`,是MySQL中专门控制用于排序的行数据的长度的一个参数。它的意思是,如果单行的长度超过这个值,MySQL就认为单行太大,要换一个算法。
### 如何正确地显示随机消息
从一个单词表中随机选出三个单词
创建测试表
```sql
CREATE TABLE `words` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`word` varchar(64) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB;
```
添加测试数据
```sql
delimiter ;;
create procedure idata3()
begin
declare i int;
set i=0;
while i<10000 do
insert into words(word) values(concat(char(97+(i div 1000)), char(97+(i % 1000 div 100)), char(97+(i % 100 div 10)), char(97+(i % 10))));
set i=i+1;
end while;
end;;
delimiter ;
call idata3();
```
**首先,会想到用order by rand()来实现这个逻辑**
```sql
EXPLAIN select word from words order by rand() limit 3;
```

* Extra字段显示`Using temporary`,表示的是需要使用临时表;`Using filesort`,表示的是需要执行排序操作。因此这个Extra的意思就是,需要临时表,并且需要在临时表上排序
* order by rand()使用了内存临时表,内存临时表排序的时候使用了rowid排序方法。
* tmp_table_size这个配置限制了内存临时表的大小,默认值是16M。如果临时表大小超过了tmp_table_size,那么内存临时表就会转成磁盘临时表。
* 磁盘临时表使用的引擎默认是InnoDB,是由参数internal_tmp_disk_storage_engine控制的。当使用磁盘临时表的时候,对应的就是一个没有显式索引的InnoDB表的排序过程。
### 幻读是什么,幻读有什么问题
* 幻读指的是一个事务在前后两次查询同一个范围的时候,后一次查询看到了前一次查询没有看到的行。
* 在可重复读隔离级别下,普通的查询是快照读,是不会看到别的事务插入的数据的。因此,幻读在“当前读”下才会出现。
**创建测试数据**
```sqll
CREATE TABLE `t` (
`id` int(11) NOT NULL,
`c` int(11) DEFAULT NULL,
`d` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `c` (`c`)
) ENGINE=InnoDB;
insert into t values(0,0,0),(5,5,5),
(10,10,10),(15,15,15),(20,20,20),(25,25,25);
```
**下面的语句序列,是怎么加锁的,加的锁又是什么时候释放的呢?**
```sql
begin;
select * from t where d=5 for update;
commit;
```
* 这个语句会命中d=5的这一行,对应的主键id=5,因此在select 语句执行完成后,id=5这一行会加一个写锁,而且由于两阶段锁协议,这个写锁会在执行commit语句的时候释放。
* 由于字段d上没有索引,因此这条查询语句会做全表扫描。那么,其他被扫描到的,但是不满足条件的5行记录上,会不会被加锁呢?

* 可以看到,session A里执行了三次查询,分别是Q1、Q2和Q3。它们的SQL语句相同,都是select * from t where d=5 for update。这个语句的意思你应该很清楚了,查所有d=5的行,而且使用的是当前读,并且加上写锁
**图中SQL执行流程**
* Q1只返回id=5这一行;
* 在T2时刻,session B把id=0这一行的d值改成了5,因此T3时刻Q2查出来的是id=0和id=5这两行;
* 在T4时刻,session C又插入一行(1,1,5),因此T5时刻Q3查出来的是id=0、id=1和id=5的这三行。
* 其中,Q3读到id=1这一行的现象,被称为`“幻读”`。
* 在`可重复读`(InnoDB的默认)隔离级别下,普通的查询是快照读,是不会看到别的事务插入的数据的。因此,`幻读在“当前读”下才会出现。`
* 上面session B的修改结果,被session A之后的select语句用“当前读”看到,不能称为幻读。幻读仅专指“新插入的行”
从事务可见性规则来分析的话,上面这三条SQL语句的返回结果都没有问题。因为这三个查询都是加了for update,都是当前读。而当前读的规则,就是要能读到所有已经提交的记录的最新值。并且,session B和sessionC的两条语句,执行后就会提交,所以Q2和Q3就是应该看到这两个事务的操作效果,而且也看到了,这跟事务的可见性规则并不矛盾。但是,这是不是真的没问题呢?
**幻读有什么问题?**
* 首先是语义上的。session A在T1时刻就声明了,“我要把所有d=5的行锁住,不准别的事务进行读写操作”。而实际上,这个语义被破坏了。
**其次,是数据一致性的问题。**
* 我们知道,锁的设计是为了保证数据的一致性。而这个一致性,不止是数据库内部数据状态在此刻的一致性,还包含了数据和日志在逻辑上的一致性
* 为了说明这个问题,我给session A在T1时刻再加一个更新语句,即:update t set d=100 where d=5。

**上面的执行流程**
* 经过T1时刻,id=5这一行变成 (5,5,100),当然这个结果最终是在T6时刻正式提交的;
* 经过T2时刻,id=0这一行变成(0,5,5);
* 经过T4时刻,表里面多了一行(1,5,5);
这样看,这些数据也没啥问题,但是我们再来看看这时候binlog里面的内容。
* T2时刻,session B事务提交,写入了两条语句;
* T4时刻,session C事务提交,写入了两条语句;
* T6时刻,session A事务提交,写入了update t set d=100 where d=5 这条语句。
放到一起的话,就是这样的:
```sql
update t set d=5 where id=0; /*(0,0,5)*/
update t set c=5 where id=0; /*(0,5,5)*/
insert into t values(1,1,5); /*(1,1,5)*/
update t set c=5 where id=1; /*(1,5,5)*/
update t set d=100 where d=5;/*所有d=5的行,d改成100*/
```
>这个语句序列,不论是拿到备库去执行,还是以后用binlog来克隆一个库,这三行的结果,都变成了 (0,5,100)、(1,5,100)和(5,5,100)。也就是说,id=0和id=1这两行,发生了数据不一致。这个问题很严重,是不行的。
**如何解决幻读?**
* 产生幻读的原因是,行锁只能锁住行,但是新插入记录这个动作,要更新的是记录之间的“间隙”。因此,为了解决幻读问题,InnoDB只好引入新的锁,也就是间隙锁(Gap Lock)。
* 间隙锁,锁的就是两个值之间的空隙。比如文章开头的表t,初始化插入了6个记录,这就产生了7个间隙。
* 这样,当你执行 select * from t where d=5 for update的时候,就不止是给数据库中已有的6个记录加上了行锁,还同时加了7个间隙锁。这样就确保了无法再插入新的记录。
* 也就是说这时候,在一行行扫描的过程中,不仅将给行加上了行锁,还给行两边的空隙,也加上了间隙锁。
* 间隙锁存在冲突关系的,是“往这个间隙中插入一个记录”这个操作。间隙锁之间都不存在冲突关系。
* 间隙锁和next-key lock的引入,帮我们解决了幻读的问题,但同时也带来了一些“困扰”
>比如现在有这样一个场景 业务逻辑这样的:任意锁住一行,如果这一行不存在的话就插入,如果存在这一行就更新它的数据,代码如下:
```sql
begin;
select * from t where id=N for update;
/*如果行不存在*/
insert into t values(N,N,N);
/*如果行存在*/
update t set d=N set id=N;
commit;
```
> 可能你会说,这个不是`insert ... on duplicate key update` 就能解决吗?但其实在有多个唯一键的时候,这个方法是不能满足要求的。这个逻辑一旦有并发,就会碰到死锁。你一定也觉得奇怪,这个逻辑每次操作前用for update锁起来,已经是最严格的模式了,怎么还会有死锁呢?

你看到了,其实都不需要用到后面的update语句,就已经形成死锁了。我们按语句执行顺序来分析一下:
* session A 执行select ... for update语句,由于id=9这一行并不存在,因此会加上间隙锁(5,10);
* session B 执行select ... for update语句,同样会加上间隙锁(5,10),间隙锁之间不会冲突,因此这个语句可以执行成功;
* session B 试图插入一行(9,9,9),被session A的间隙锁挡住了,只好进入等待;
* session A试图插入一行(9,9,9),被session B的间隙锁挡住了。
* 至此,两个session进入互相等待状态,形成死锁。当然,InnoDB的死锁检测马上就发现了这对死锁关系,让session A的insert语句报错返回了。
> `间隙锁是在可重复读隔离级别下才会生效的`。所以,你如果把隔离级别设置为读提交的话,就没有间隙锁了。但同时,你要解决可能出现的数据和日志不一致问题,需要把`binlog`格式设置为row。这,也是现在不少公司使用的配置组合。