- RocksDB + Cloud storage (e.g., Amazon S3)
- Rockset의 distributed converged index의 building block
- Cloud-native DB의 주요 디자인 원칙 중 하나는 compute와 storage 분리 ⇒ Rockset도 마찬가지
- RocksDB-Cloud의 경우, 데이터를 local SSD 또는 HDD에 저장
- Write path: in-memory memtable ⇒ SST file in the storage
- LSM 스토리지 엔진 특성상, bg thread의 compaction은 필수적
- Compaction: 중복된 키 값을 갖거나 삭제된 키를 갖는 여러 SST 파일을 병합해 새로운 SST 파일을 생성하는 과정 ⇒ Compute-intensive; 많은 컴퓨팅 리소스 필요
- Write rate가 높을수록, compaction을 위한 더 많은 컴퓨팅 리소스가 필요
- Compaction 속도가 write 속도를 따라가야 system이 stable 함
- 전형적인 RocksDB 기반 시스템에서 compaction은 local (CPU와 storage가 붙어 있는 서버)에서 발생 ⇒ performance 상 이점
- Write rate가 높아지는데 전체 DB 크기를 유지하고 싶다면, 더 많은 서버를 provisioning 해서 데이터를 여러 서버에 spread 해야함 ⇒ compaction load 줄이기 위해
- Cloud 환경에서 위의 방법은 2가지 문제가 있음:
- 많은 양의 데이터를 카피해야 하기 때문에 여러 대의 서버에 데이터를 spreading 하는 게 동시에 이루어지지 않음 ⇒ 빠르게 변하는 워크로드에 대해서 제때 대응 불가
- 여러 대에 데이터를 나눠서 저장하기 때문에 각 서버의 스토리지 용량 사용률이 매우 낮아짐 ⇒ price-to-performance 측면에서 손해
- B-Tree 기반 DB와 달리, RocksDB-Cloud는 LSM 기반
- LSM 기반이기 때문에, SST 파일은 일단 생성되고 나면 그 후엔 업데이트 되지 않음 ⇒ Read-only
- 소량의 active한 memtable의 데이터는 논외
- 즉, S3와 같은 cloud storage object store에 저장된 모든 SST 파일은 read-only이기 때문에 모든 서버에서 안전하게 접근 가능
- 위의 backgound 내용을 활용해, storage와 compaction compute 분리; 자세한 동작 과정은 아래와 같음:
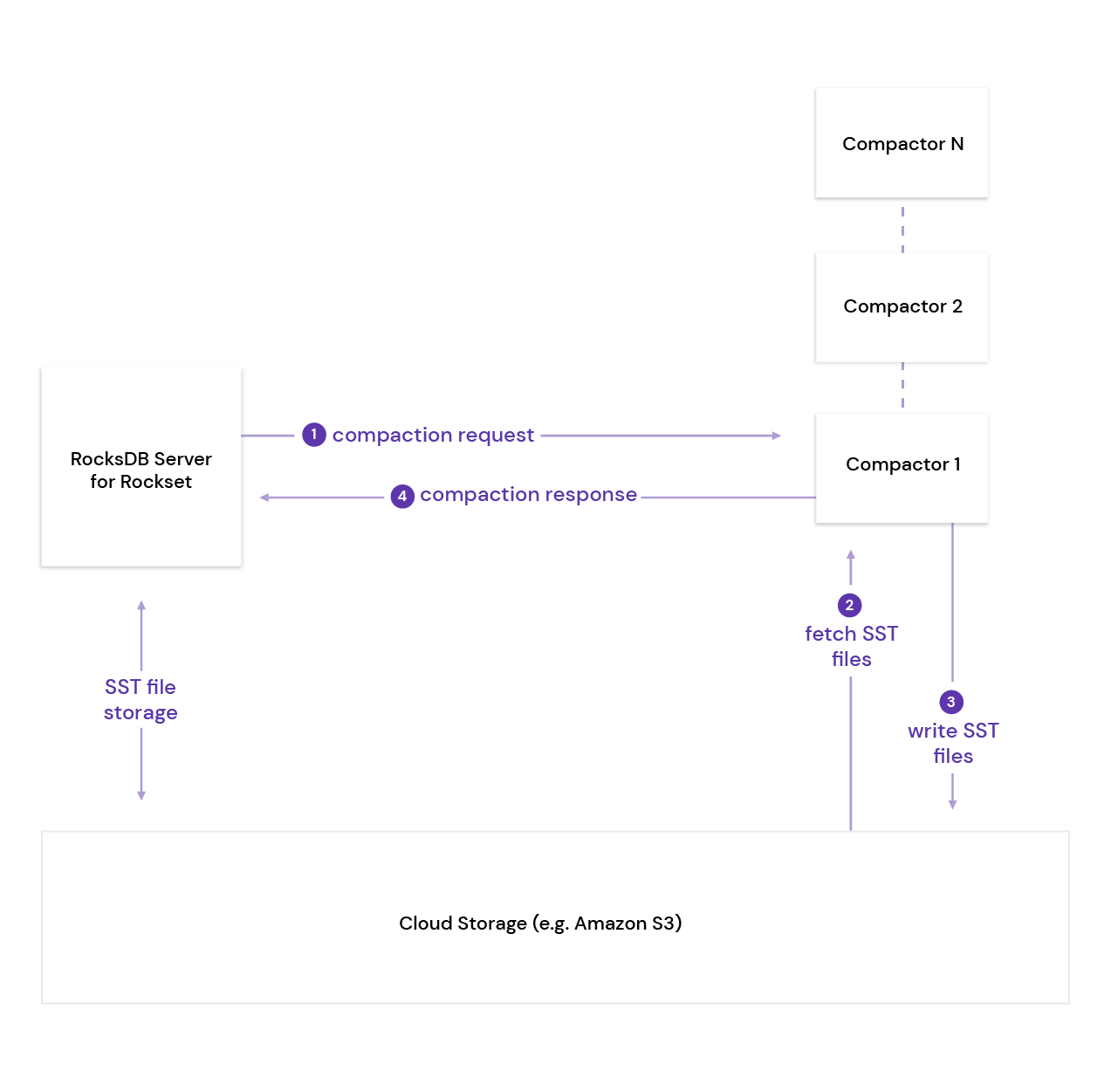
서버 A ⇒ Storage
서버 B ⇒ Compaction compute- RocksDB-Cloud 서버 A가 compaction job을 encapsulation ⇒ Remote stateless 서버인 B에게 compaction request 전송
- 서버 B는 cloud store에서 compaction 대상이 되는 object를 fetch ⇒ compaction 수행
- 새로운 SST 파일 생성 ⇒ cloud object store에 write
- 서버 A에게 compaction이 완료됐다는 response 전송
- RocksDB의 compaction 엔진을 externally pluggable 하게 만들기 위해 기존 RocksDB API에 2개의 method 추가해 확장
Status RegisterPluggableCompactionService(std::unique_ptr<PluggableCompactionService>);- Compaction 서비스 등록하는 API 추가
PluggableCompactionService플러그인에 위 두 단계 API 추가:
Status Run(const PluggableCompactionParam& job, PluggableCompactionResult* result)
std::vector<Status> InstallFiles(
const std::vector<std::string>& remote_paths,
const std::vector<std::string>& local_paths,
const EnvOptions& env_options, Env* local_env)- Remote compaction은 크게 두 단계로 이루어짐:
- Run
- Remote compaction tier에게 RPC 전송
- Compaction 결과 (새롭게 생성된 SST 파일 리스트) 응답 받음
- InstallFiles
- 새로 생성된 SST 파일을 cloud (
remote_paths)에서 local database (local_paths)로 install
- 새로 생성된 SST 파일을 cloud (
- Run
- Compaction 정보 (e.g., input SST 파일 이름, compression 정보)를 RPC를 통해 remote compaction tier에게 전송
- Compaction job을 수행하는 host = compactor
- Compaction 요청을 받은 compactor는 ghost 모드로 RocksDB-Cloud 인스턴스를 open
- Ghost 모드: cloud storage의 모든 SST 파일을 fetch하지 않고, 필요한 메타데이터만을 사용해 local database를 open
- Compactor는 compacton job 수행; 이때, 필요한 SST 파일을 fetch
- Compaction 후, 새로 생성된 SST 파일을 cloud의 temporaty storage에 업로드
# Options to open RocksDB-Cloud in the compactor
rocksdb::CloudOptions cloud_options;
cloud_options.ephemeral_resync_on_open = false;
cloud_options.constant_sst_file_size_in_sst_file_manager = 1024;
cloud_options.skip_cloud_files_in_getchildren = true;
rocksdb::Options rocksdb_options;
rocksdb_options.max_open_files = 0;
rocksdb_options.disable_auto_compactions = true;
rocksdb_options.skip_stats_update_on_db_open = true;
rocksdb_options.paranoid_checks = false;
rocksdb_options.compaction_readahead_size = 10 * 1024 * 1024;- RocksDB 인스턴스를 open 하는 동안 성능 저하를 일으키는 요소:
- SST 파일 리스트 가져오기
- 각 SST 파일의 크기 가져오기
- 모든 SST 파일이 local storage에 존재하는 경우, SST 파일 크기를 얻어오는 작업의 latency는 짧음
- 문제점:
- RocksDB-Cloud의 경우 cloud storage에 remote request를 보내야하기 때문에 get-file-size의 total latency가 높음
- 수천 개의 SST 파일을 갖는 RocksDB-Cloud 인스턴스의 경우, S3에 수천 개의 get-file-size 요청을 보내야 하기 때문에 opening 하는 데에 최대 1분까지 소요
- 해결책:
- Opening 과정 중 RPC를 disable할 수 있는 다양한 opening 옵션 제공
- 이를 활용하면, 평균 opening time = 700ms ~ 7s
- Opening 과정 중 RPC를 disable할 수 있는 다양한 opening 옵션 제공
- Remote compaction의 tradeoff: 단일 compaction의 속도 ↔ 여러 compaction을 parallel하게 수행
- 각 remote compaction job은 cloud를 통해 data를 전송해야하기 때문에, local로 실행된 compaction보다 느림
- RocksDB-Cloud는 parallel하게 compaction을 수행할 수 없음
- But, compaction 과정의 병목을 최소화하고 싶음
- L0 파일들은 키 범위가 겹치기 때문에 L0 → L1 compaction은 parallel 하게 수행될 수 없음
- L0 → L1 compaction이 발생할 때, compaction target이 되는 L0 파일의 개수를 줄이고 L0 file limit으로 인한 write stall을 방지하기 위해 L0 → L0 compaction을 수행할 수 있음
- Tradeoff: L0 파일 개수 감소 ↔ 각 L0 파일의 크기 증가
- 경험상, 이 옵션은 이득보다 손해가 더 큼
- L0 파일의 크기가 커지면 L0 → L1 compaction에 걸리는 시간도 증가 ⇒ Bottleneck
- 따라서, RocksDB-Cloud는 L0 → L0 compaction DISABLE
- 드물게 발생하는 write stall 감수
- 실험상, 이렇게 했을 때 RocksDB-Cloud compaction은 incoming write를 잘 따라잡음