Actors and their Ties (Tutorial)
Goal: We retrace the network of the IPCC author’s institutions through hyperlinks
Date: 2018-06-18
The Intergovernmental Panel on Climate Change (IPCC) is “a scientific and intergovernmental body under the auspices of the United Nations, set up at the request of member governments, dedicated to the task of providing the world with an objective, scientific view of climate change and its political and economic impacts” (Wikipedia). It produces the reports that establish the consensus in the international academic community, and famously won the 2007 Nobel Peace Prize (shared in equal parts with Al Gore).
Tommaso Venturini provided a CSV file containing the URLs of the 170 institutions indicated as the main affiliation by 10 or more authors of the IPCC reports (until “AR5” the fifth assessment report), manually completed during the MEDEA project.
Source file: Institutions with 10+ IPCC authors.csv
We just need to create a new corpus. We are going to crawl a list of 170 web entities, and we have already seen how to crawl in tutorials 1 and 2. However crawling a large number of web entities has minor differences that we will address here.
We have a CSV file containing the URLs that we want to crawl. We can copy-paste the list of URLs or we can open the file itself from the IMPORT page. Hyphe can read a CSV and we just have to specify the column containing the URLs. Actually in our situation, Hyphe just guessed (because the column was named “URL” in the file).
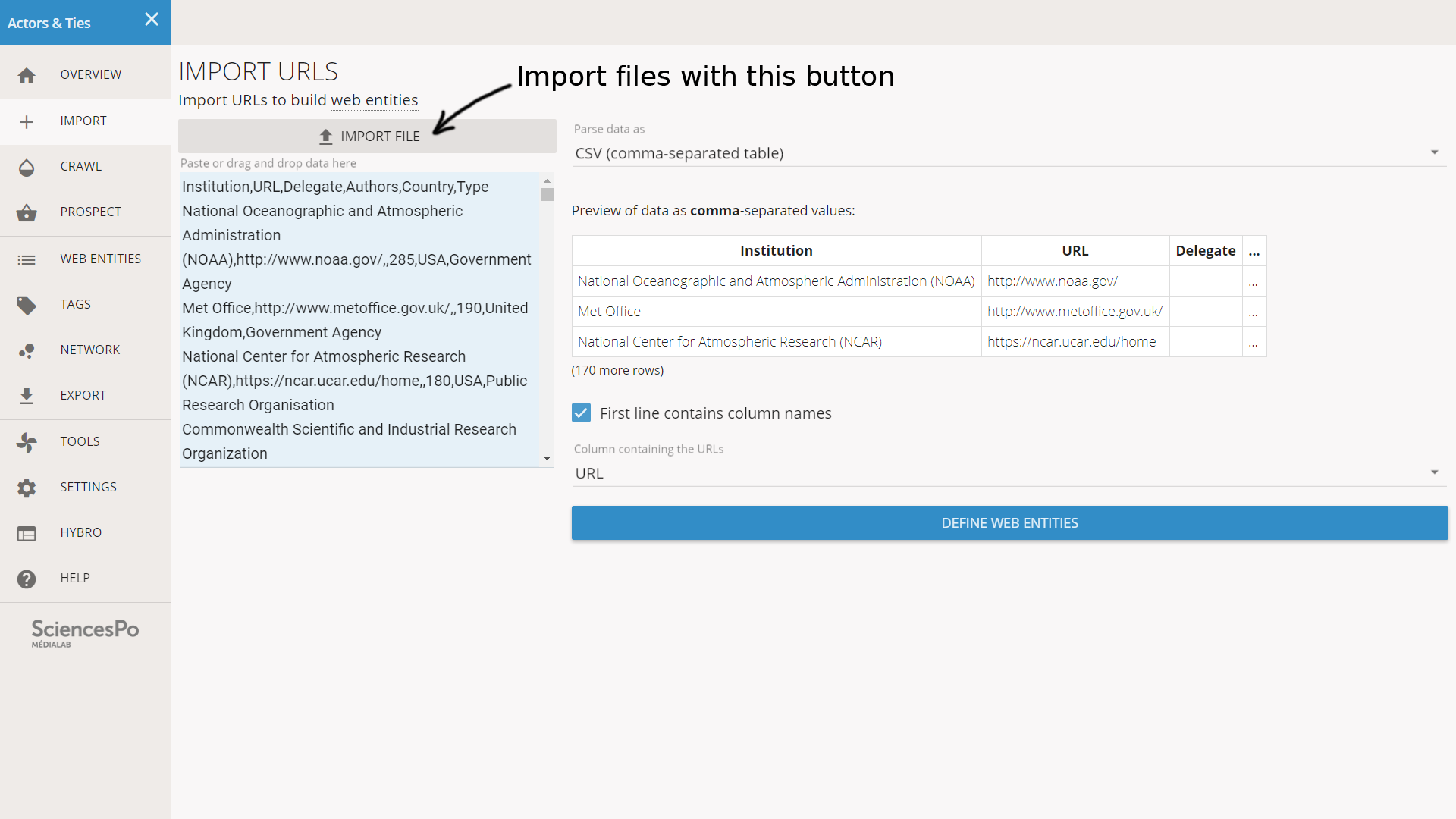
After we click on DEFINE WEB ENTITIES, we reach a screen containing the long list of URLs found in the file. Each must be checked so that the web entity is properly delimited. We can easily put all the sliders to the right or to the left with the buttons on top, but we will still need to check each case.
Reminder: the parts of a URL are reordered here from generic to specific. So https://www.nasa.gov/topics/earth/ will be reordered as:
https | .gov | nasa | www. | /topics | /earth
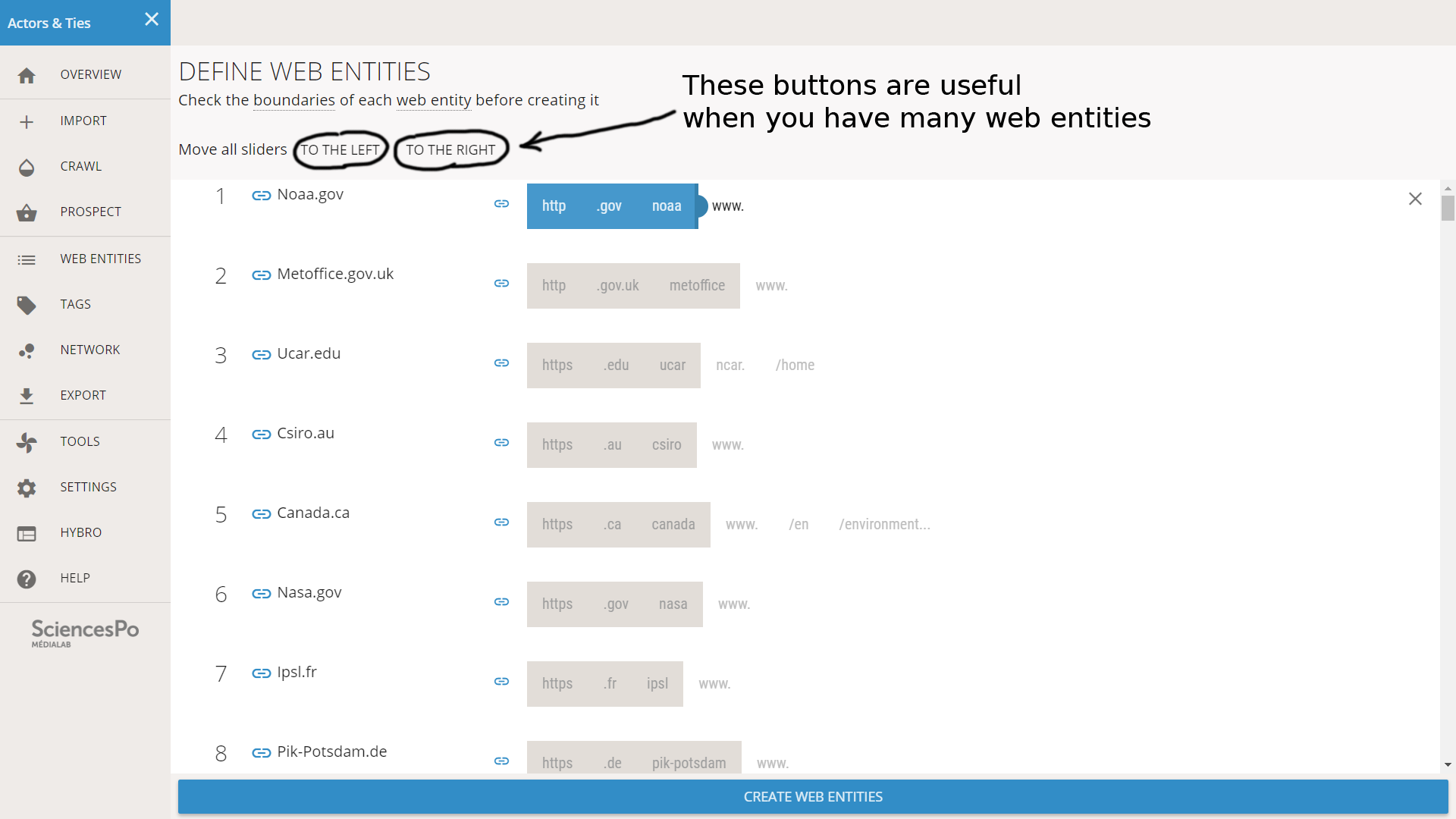
In our file we meet different situations. Most of the time the URL is a domain. In such a situation, our only option is to take the “www.” or not, and it does not even matter: Hyphe will take the two cases in account when creating the web entity. We need to do nothing, so we just leave the slider as it is.

This URL is a domain
Some websites have a specific URL for the home page. It is often called “home” or “index”. In this situation we must not put the slider to the right, or we would only crawl the home page itself. The relevant position is just before the part that specifies the home page.

This URL is of a home page
However sometimes the URL is of a page that is not the home page. In the example below, it is a page about environment on the website of Canada. In this situation we want to only crawl the page, because the domain is too generic.

This URL is of a specific page
It is not always trivial to make a choice. As a rule of thumb, we try to find the level that is specific to our topic (climate change).
Different errors may happen during the creation of web entities. In this case we can ignore them or retry.
In our situation, two URLs ended up creating the same web entity. Hyphe detected the conflict and notifies us. Since the entity 165 was defined earlier, we can just ignore it and crawl the rest.
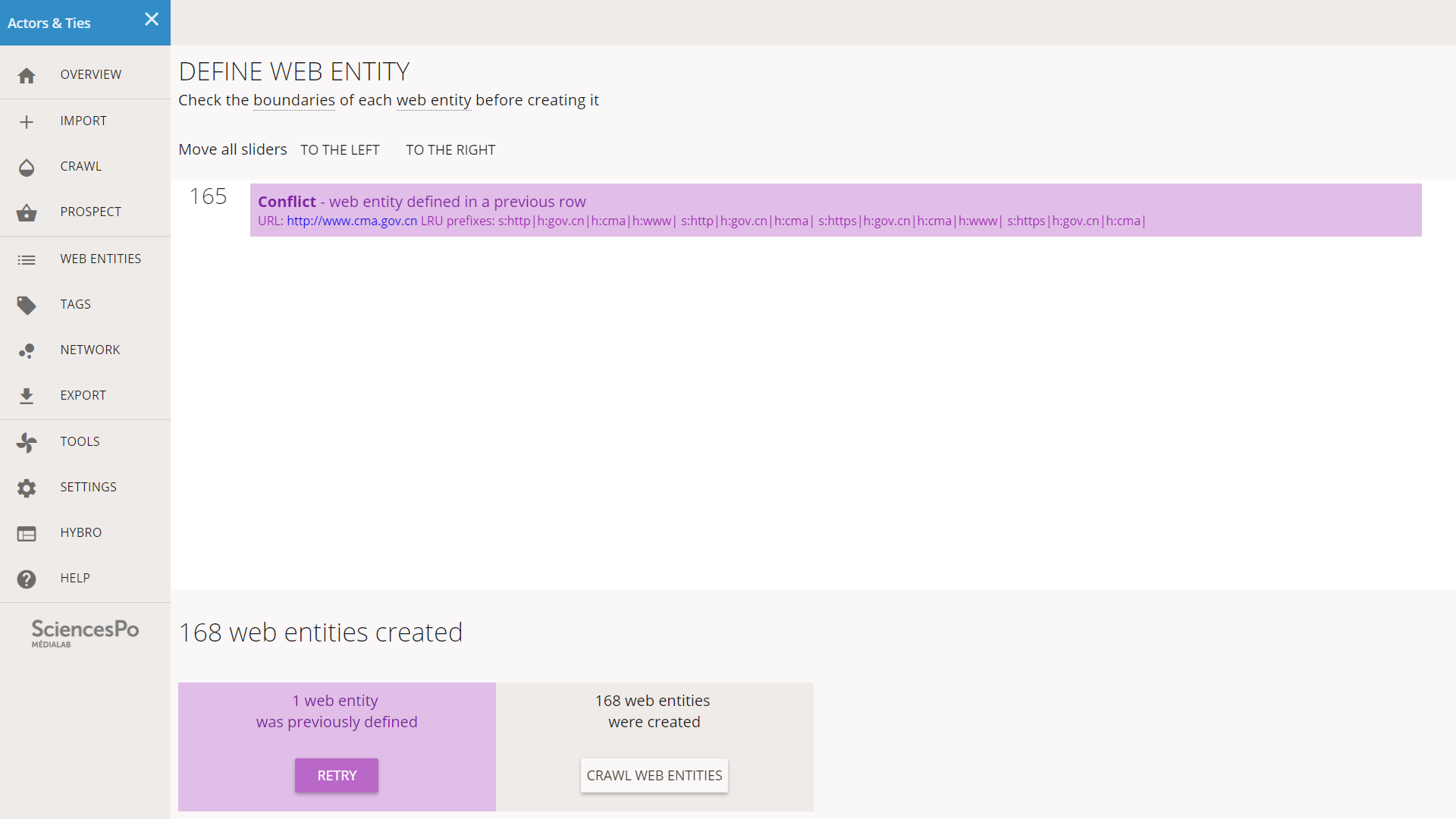
When the list of entities is long, it is important to wait until it is fully loaded before jumping to the next step.
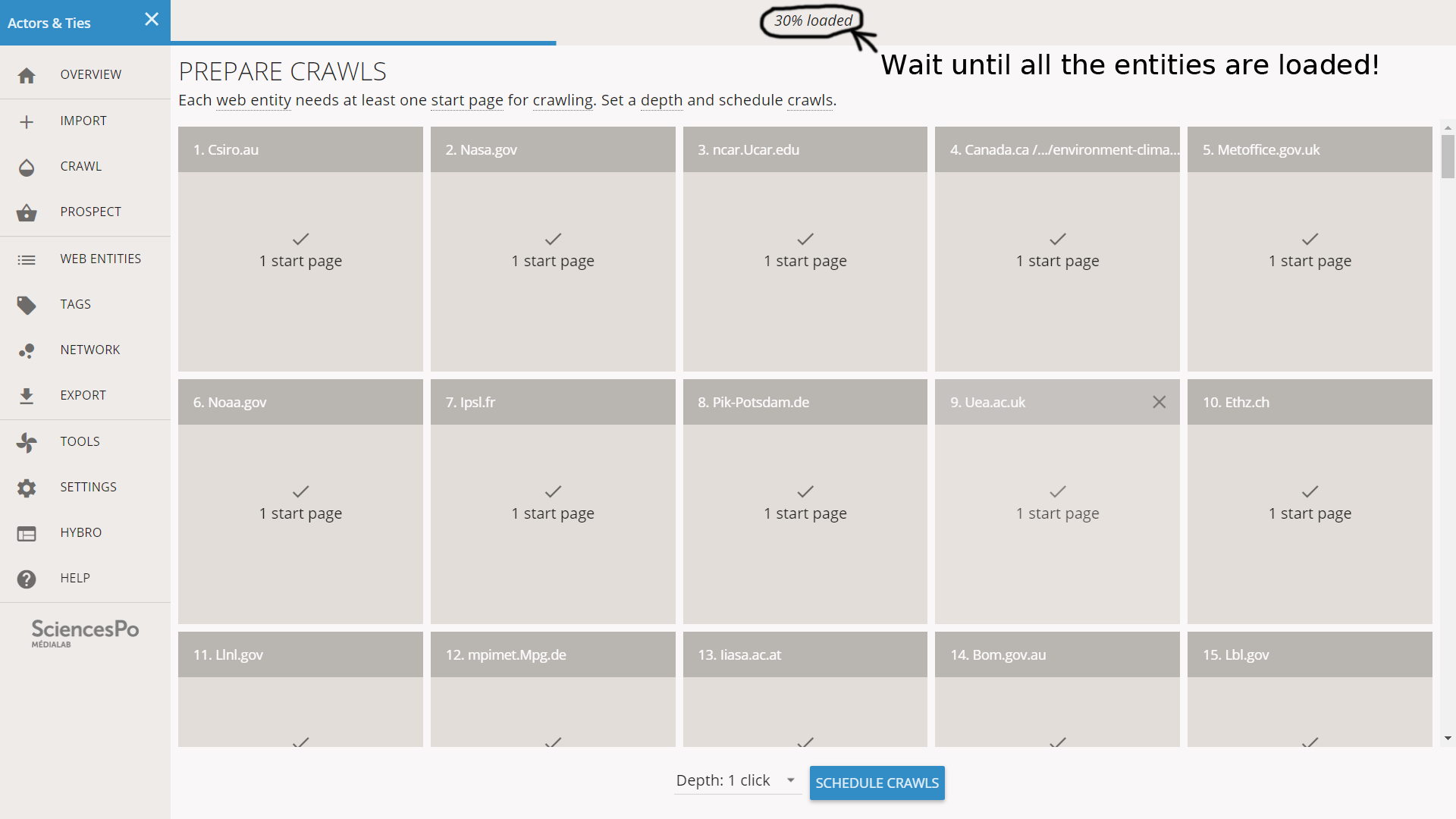
A crawl needs a valid start page, or it will be unable to start and will just fail. Hyphe takes a look at the start pages and tells us if there is something wrong. In our situation, the start pages are just the URLs from the file. Most of them are valid but a few have issues.

Web entity 46 has a start page issue
If we click on a web entity, we open a panel with additional details.
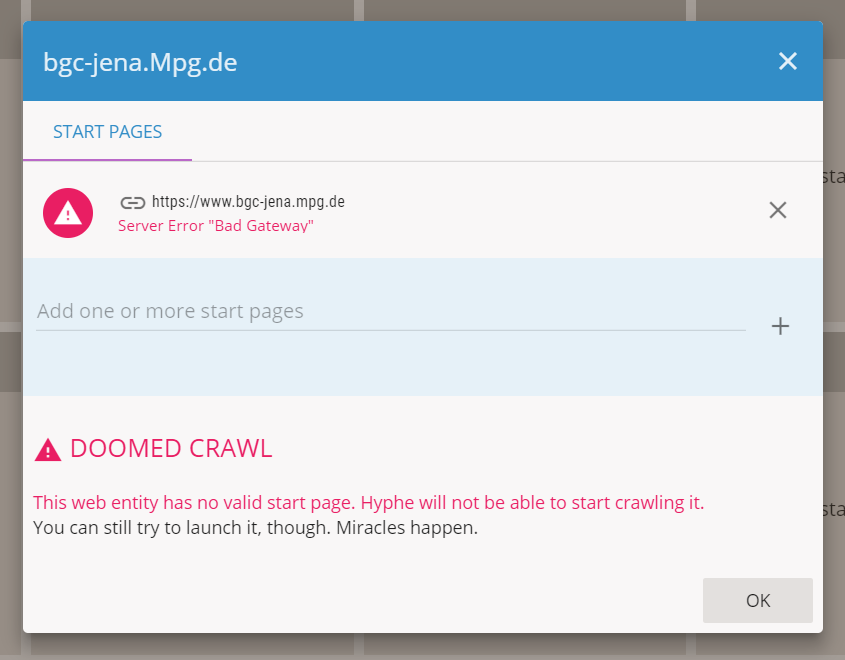
Most of the time we will just ignore these issues and launch the crawls. We always have the opportunity to retry the failed crawls later and try to fix it. The reason why we can ignore these issues is because the multiple cases mostly fall in two categories: issues that Hyphe can solve without our help, and issues that Hyphe cannot overcome anyway. The only notable exception is the redirection to a different web entity, which is best handled manually.
Most common issues with start pages:
- Redirection. If the target of the redirection falls in the same web entity, Hyphe is able to follow it. If it is out of the boundaries, the crawl job will be unsuccessful. In both scenarios we can try to fix it by opening the link in ourbrowser. We will be redirected to a different page, and we can then copy-paste the resulting URL in Hyphe to add a new start page. If it is in a different web entity, Hyphe will propose us to merge it. This is a common situation when a website has changed its domain name.
- Page does not exist anymore. It can be a 404 error status, or the page can be completely offline. In this situation we have to figure out if we have the wrong page or if the whole domain is now offline.
- The website refuses to be crawled. Not all web entities allow the crawl. In addition, some websites send incoherent HTTP statuses, for instance pretending that the pages are not available but still allowing us to download them. It is possible that Hyphe detects an issue but can still crawl the entity. It is also possible that we can browse the page in a browser but that Hyphe cannot crawl it. It is not always possible to find a solution.
Anyway in our situation we just set the crawl depth to 1 click and we launch the crawl jobs without trying to fix any start pages. We will care later if some of the crawls fail.
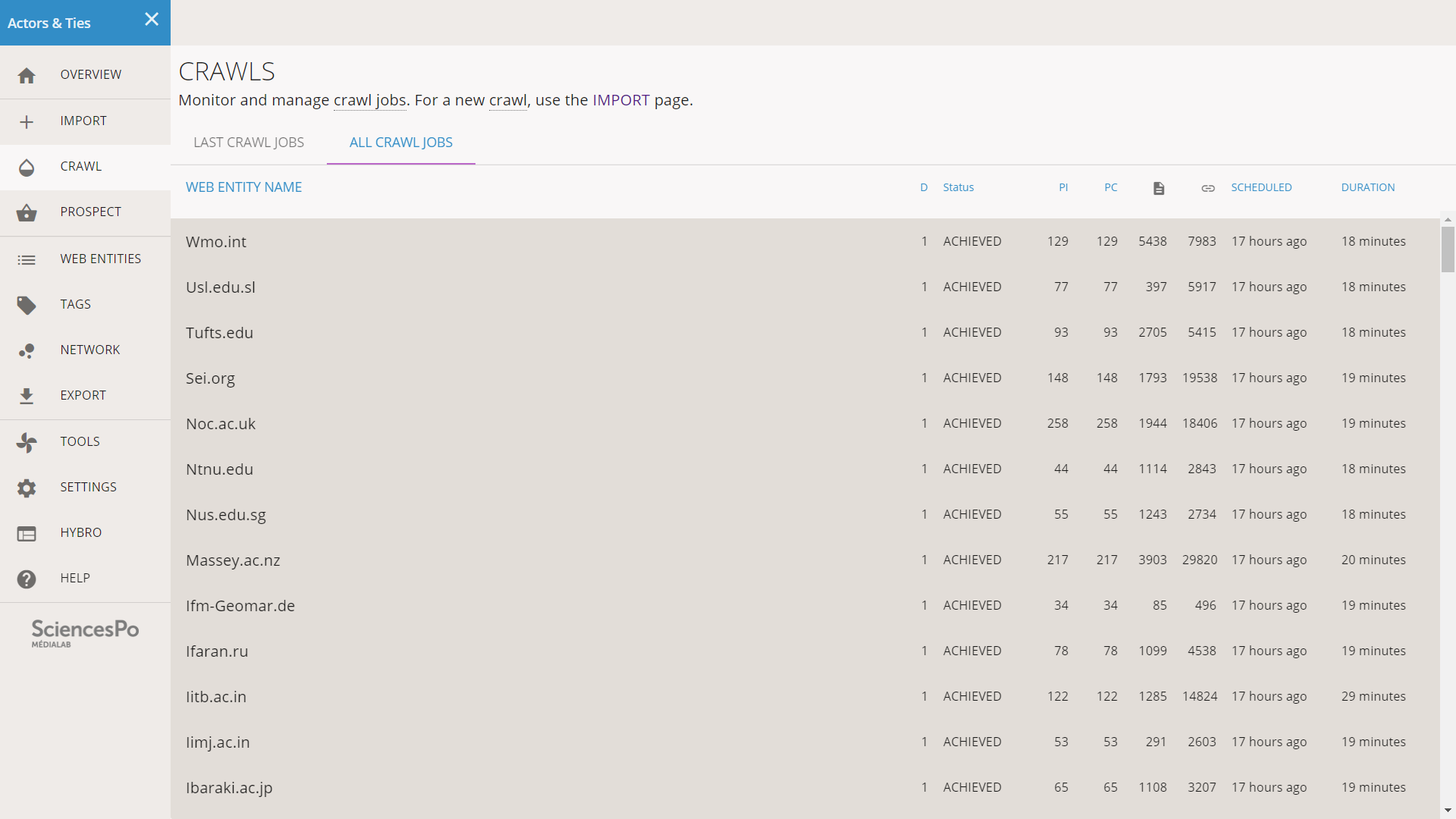
Once the crawl jobs are done, we check if there were any problems. We click on CRAWL in the left menu and then on the ALL CRAWL JOBS tab on top. This list contains all of them, as opposed to the LAST CRAWL JOBS view that only contains the last 50. We scroll the list to check if there are some anomalies.
If a crawl job is still ongoing, it will appear in blue. If it was cancelled or went wrong, it will appear in pink/red. The successful crawl jobs appear in grey and their status is “ACHIEVED”. In our situation, all the crawl are like that: despite the warnings at the moment of start pages, Hyphe was able to crawl all of the web entities.
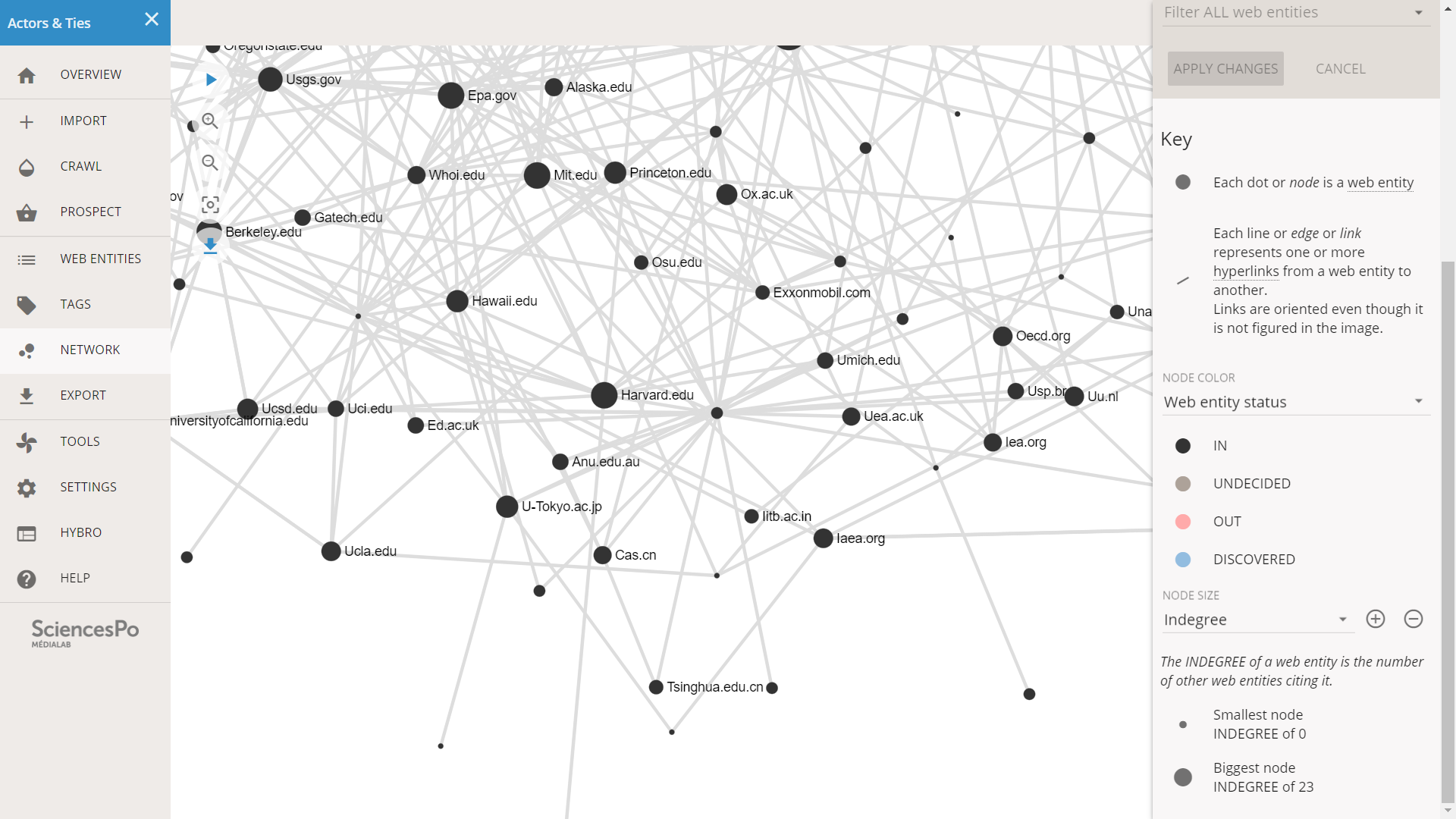
We click on NETWORK in the left menu, we stop the layout when it is stabilized, and we adjust the size of the nodes in the right side bar. The network is pretty dense and everyone seems to be connected to everyone.

Not all networks have clusters, but some networks have hidden clusters that we need to render visible. Different strategies are possible:
- Exporting to Gephi and using a clustering algorithm
- Exporting to Gephi and removing the most connected nodes
- Tagging the web entities in Hyphe
In such a dense network, it is possible that some nodes end up close because they belong to a connected subgroup, a subcluster. The network might be more structured than it looks like at first glance, and a clustered structure might just be hidden by overconnected nodes like Nasa.gov, Noaa.gov etc (in our case).
We investigate for potential subclusters by looking at the names of web entities that are close in the layout. We might be able to spot share traits, points in common for web entities located in the same area. Of course the more knowledge we have on these actors, the more efficient we are at this exercise, but even by just looking at the TLD (.com, .org...) or the domain names, we might get some useful informations.
After zooming and panning in the network, we realize that:
- There are many “.gov” entities in the middle, and they seem well connected. Are US governmental agencies bridging the other actors together?
- There are many “.edu” in the bottom of the network. Is this a cluster of universities?
- On top of the network, there are a number of “.fr” and “.de”. Is this a European cluster?
- Some actors seem to gather on the top-right around IPCC.ch and WMO.int: what do they have in common?
It looks like there are many “.edu” website is this part of the network
We already have a number of hypotheses about the structure of the network, and it would be useful to encode them into tags so that we can investigate this network further.
We will tag the web entities after their TLD. We will first show how to do it, knowing that it may raise a number of questions about how the tagging works in Hyphe. We will explain in details just after we show the steps to do it.
We click on TAGS on the left menu, and we reach a screen dedicated to monitoring and editing the tags or our corpus. It contains the 168 web entities of status IN (in the logic of Hyphe we never tag the DISCOVERED, OUT or UNDECIDED entities). We do not have any tags yet.
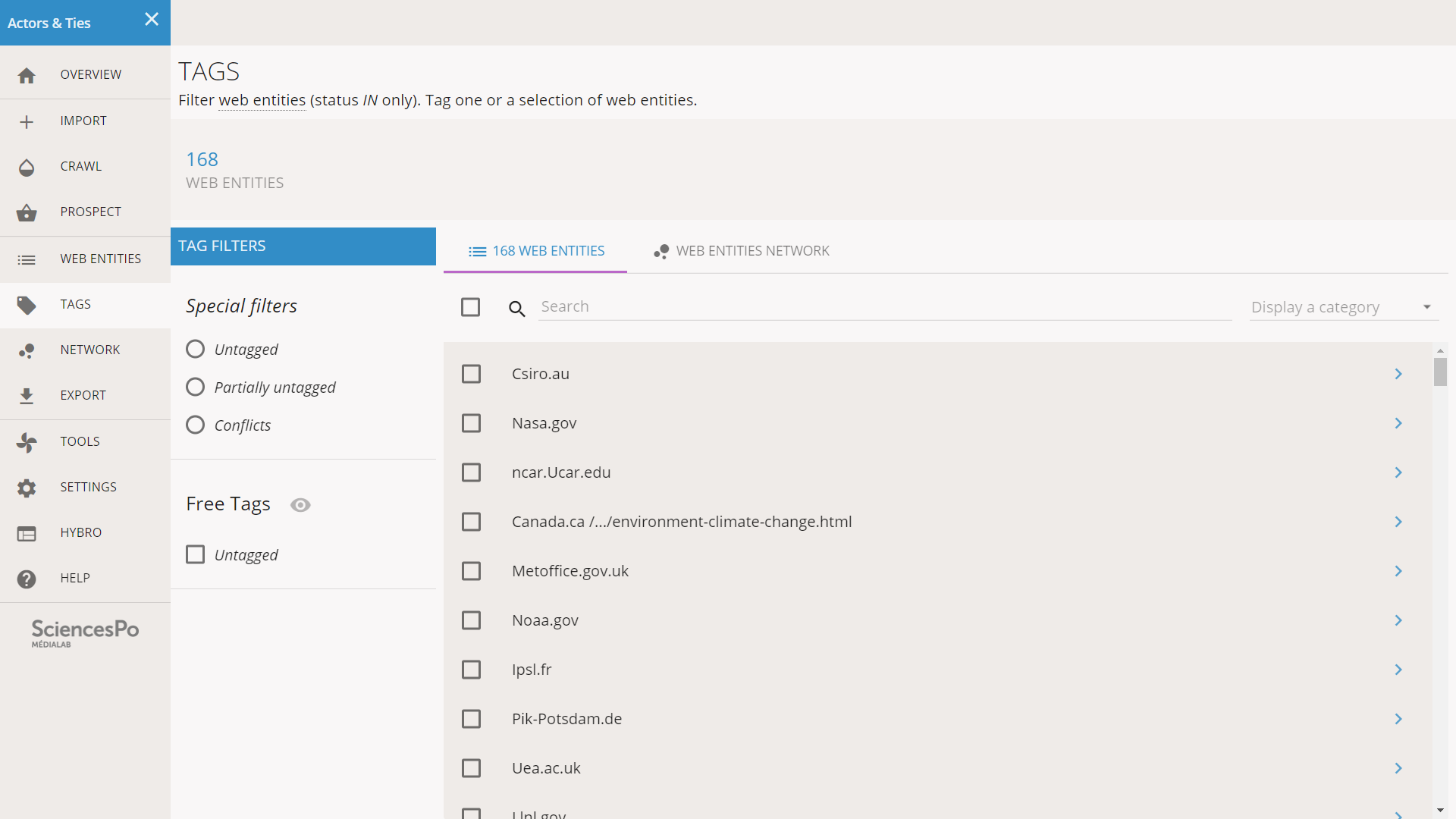
Our first task will be to use tags to describe the TLDs of the web entities. It might not be very subtle, it has the benefit of being objective. Hyphe is not able to do it automatically, notably because web entities are not necessary domains. We have such exceptions in our corpus. Nevertheless since most web entities are defined at the domain level, it might still provide useful insights. We will not define all the TLDs but only the most common.
In the Search field on top of the list of web entities, we enter “.edu”.
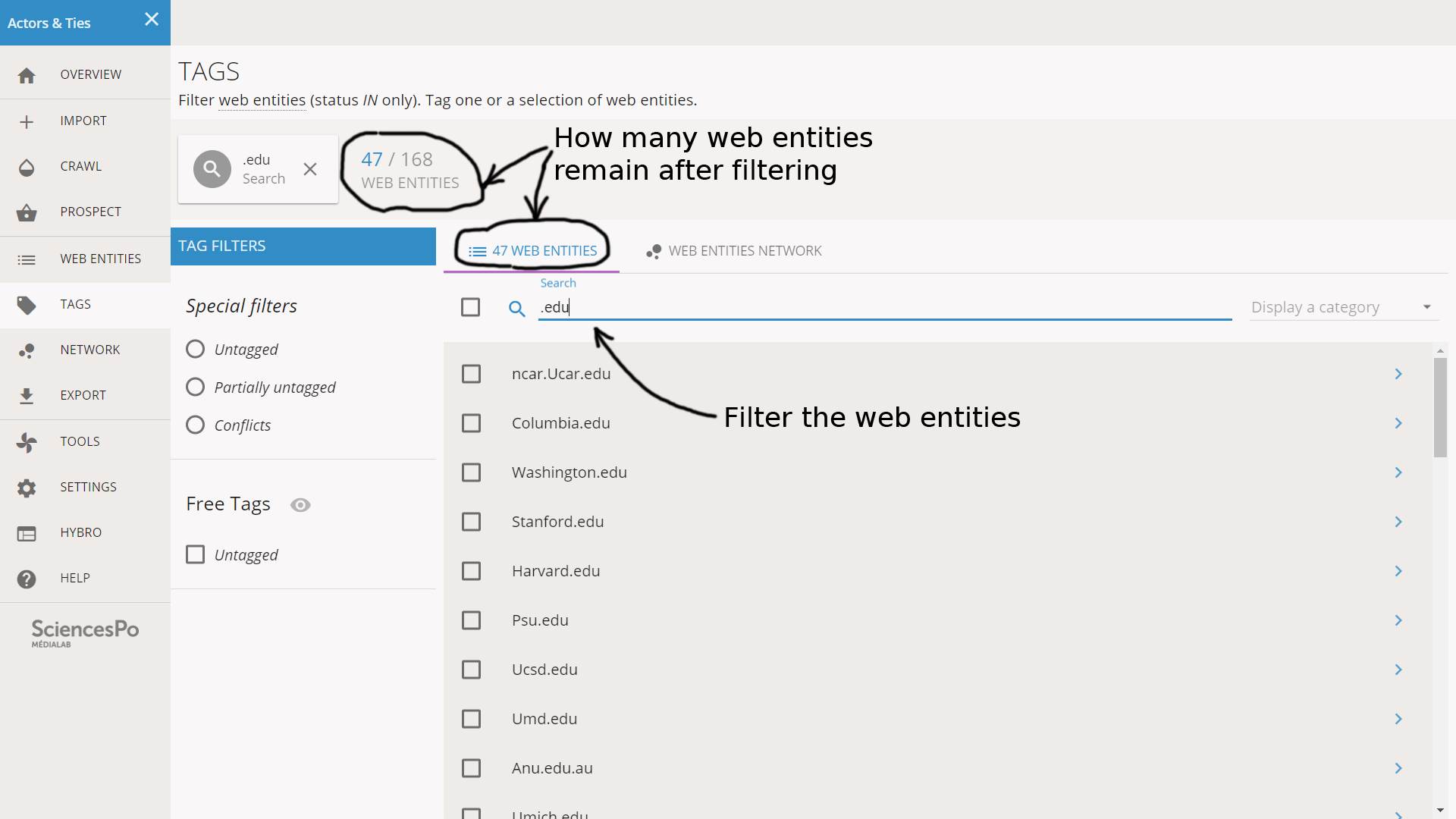
47 web entities match this query. We scroll the list to check that these entities are filtered for the right reason: it might be something else than the “.edu” TLD, for instance “example.education.com” which also contains “.edu”. Here we see no anomaly. We select all the entities by clicking on the check box situated in the menu, left to the Search field.
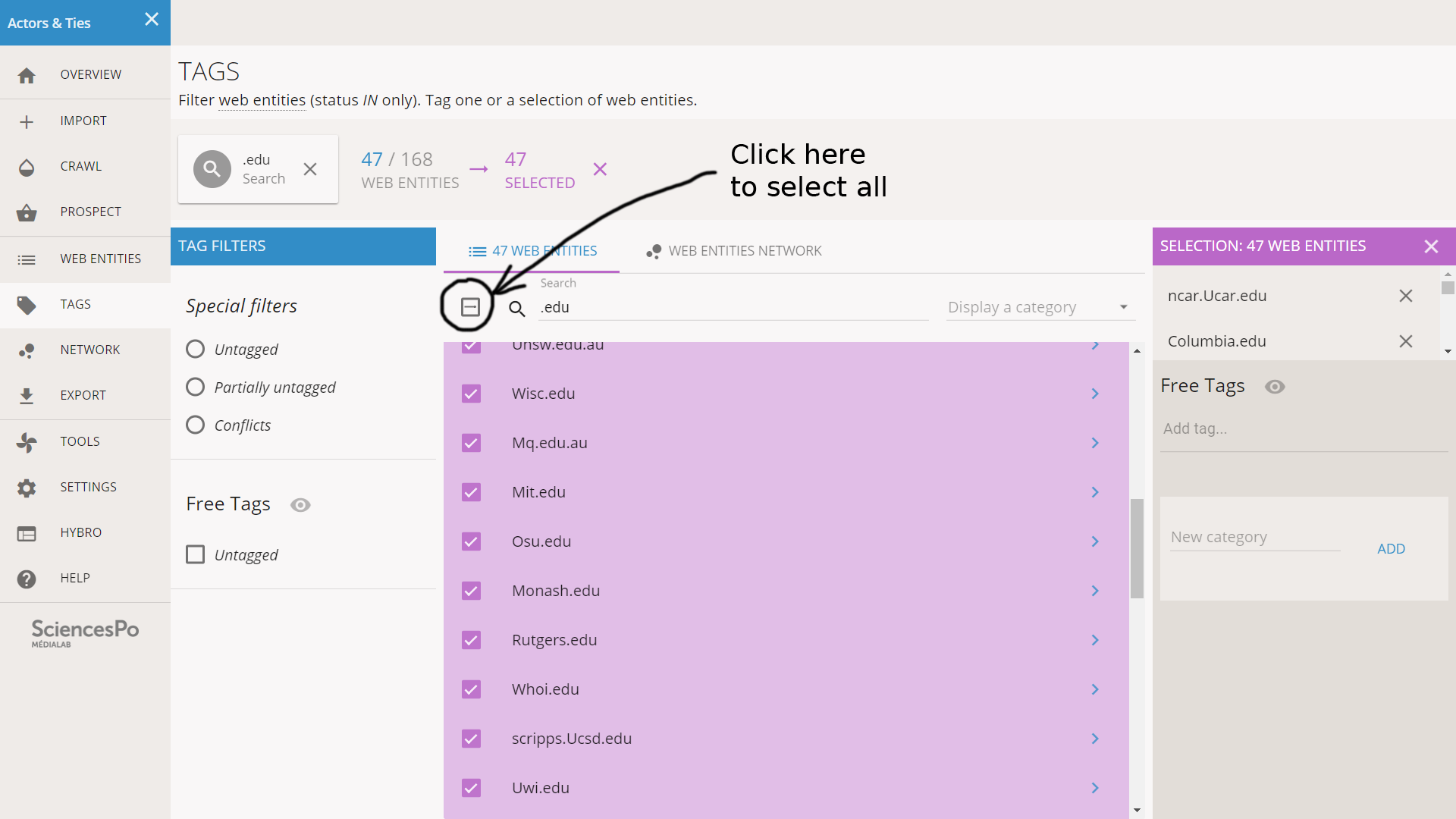
All the selected web entities appear in purple. A side bar on the right recaps the tags of the selection, and allows to edit them.
We create a new category dedicated to the TLDs. In the right sidebar, in the “New category” field, we enter “TLD” and we click on ADD. The category is now created, and we can add the tag “edu” to the 47 web entities: we type it in the new TLD field and we hit enter.
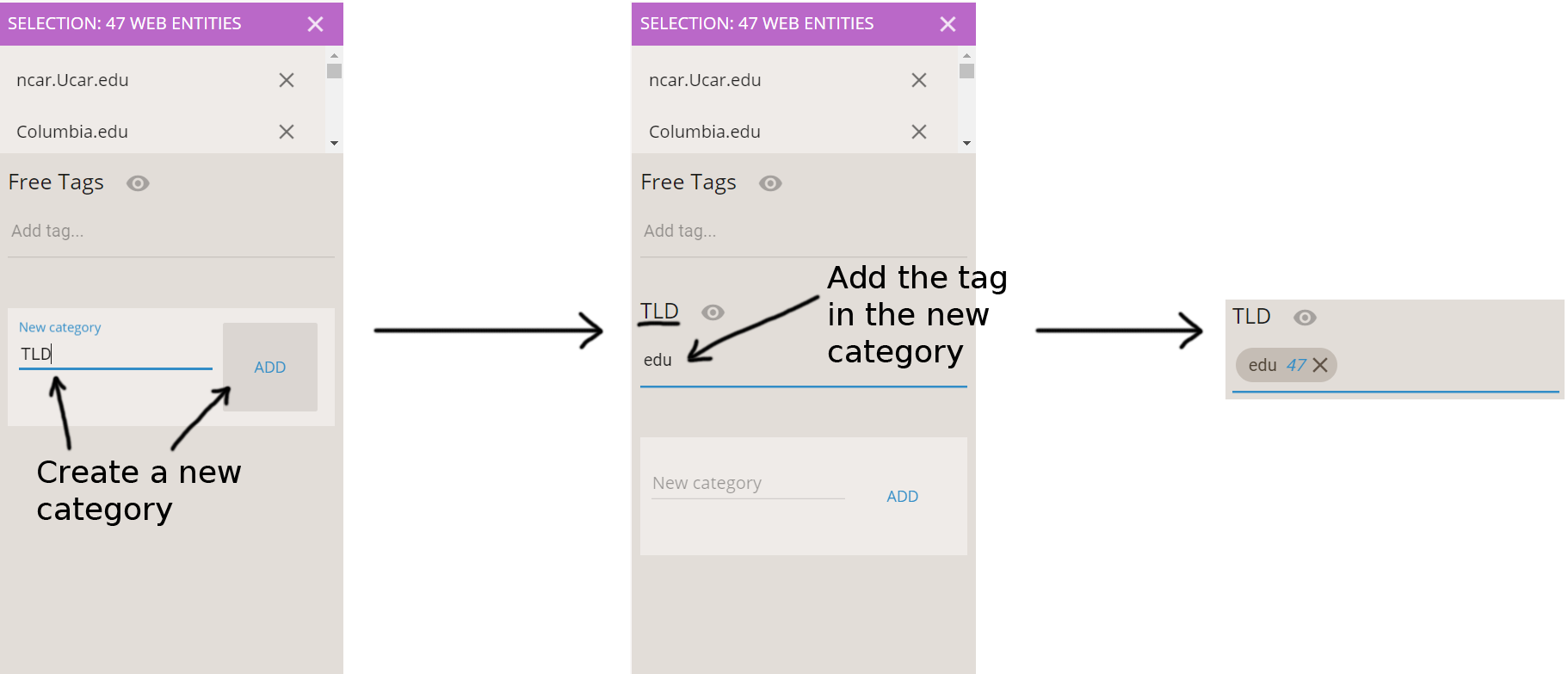
The “edu” TLD tag is now added to these 47 web entities. We deselect them by clicking on the X button (see below).
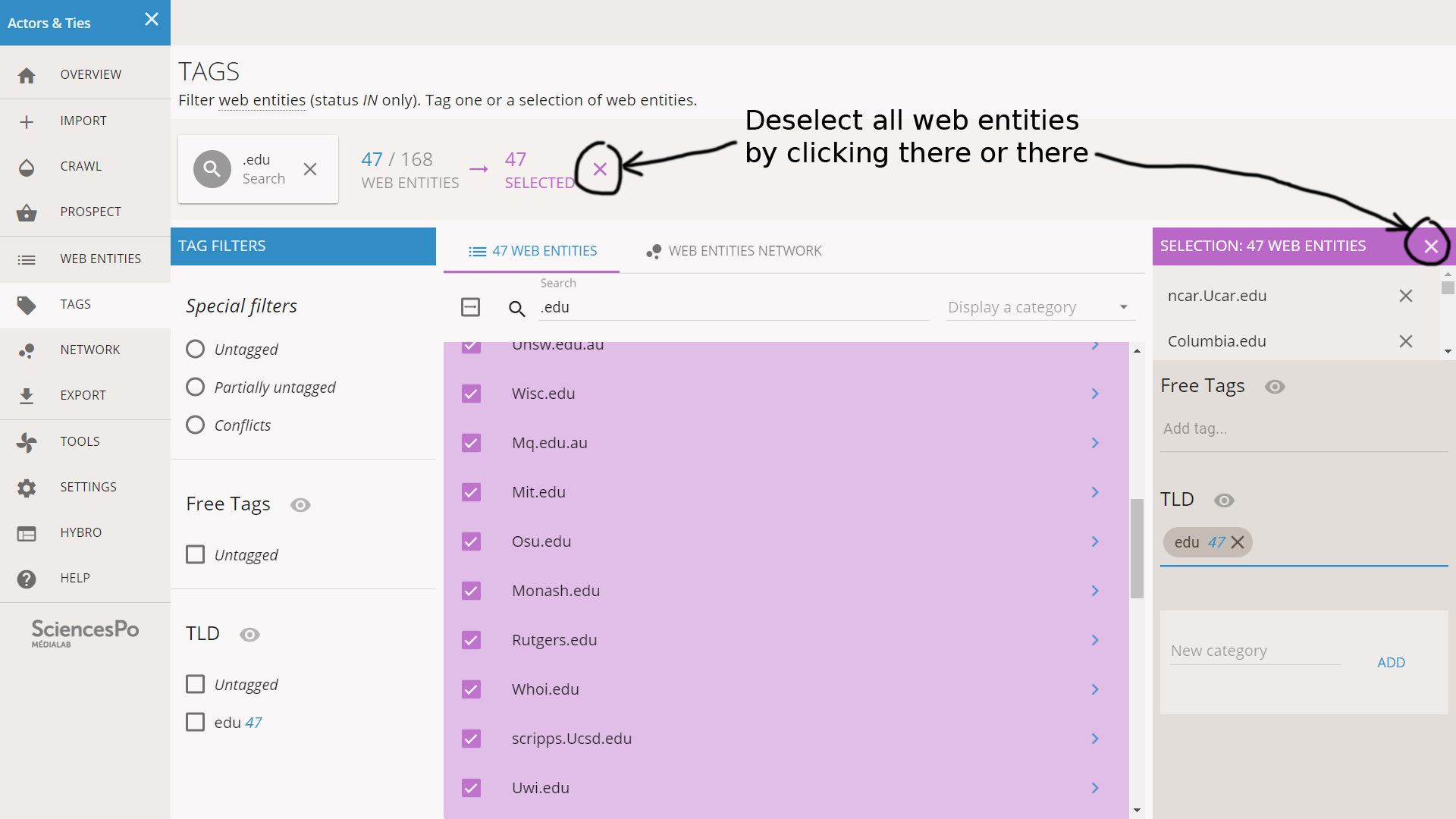
We also clear the search field on top of the list. We are now back to our initial situation except that 47 entities have now been tagged. We want to look at other common TLDs to tag.
In the left part of the screen, under TAG FILTERS, we have different buttons that activate different filters. Under TLD, we have a check box labelled “Untagged”. We check it so that the list of web entities only displays those that were not yet tagged for the TLD category.
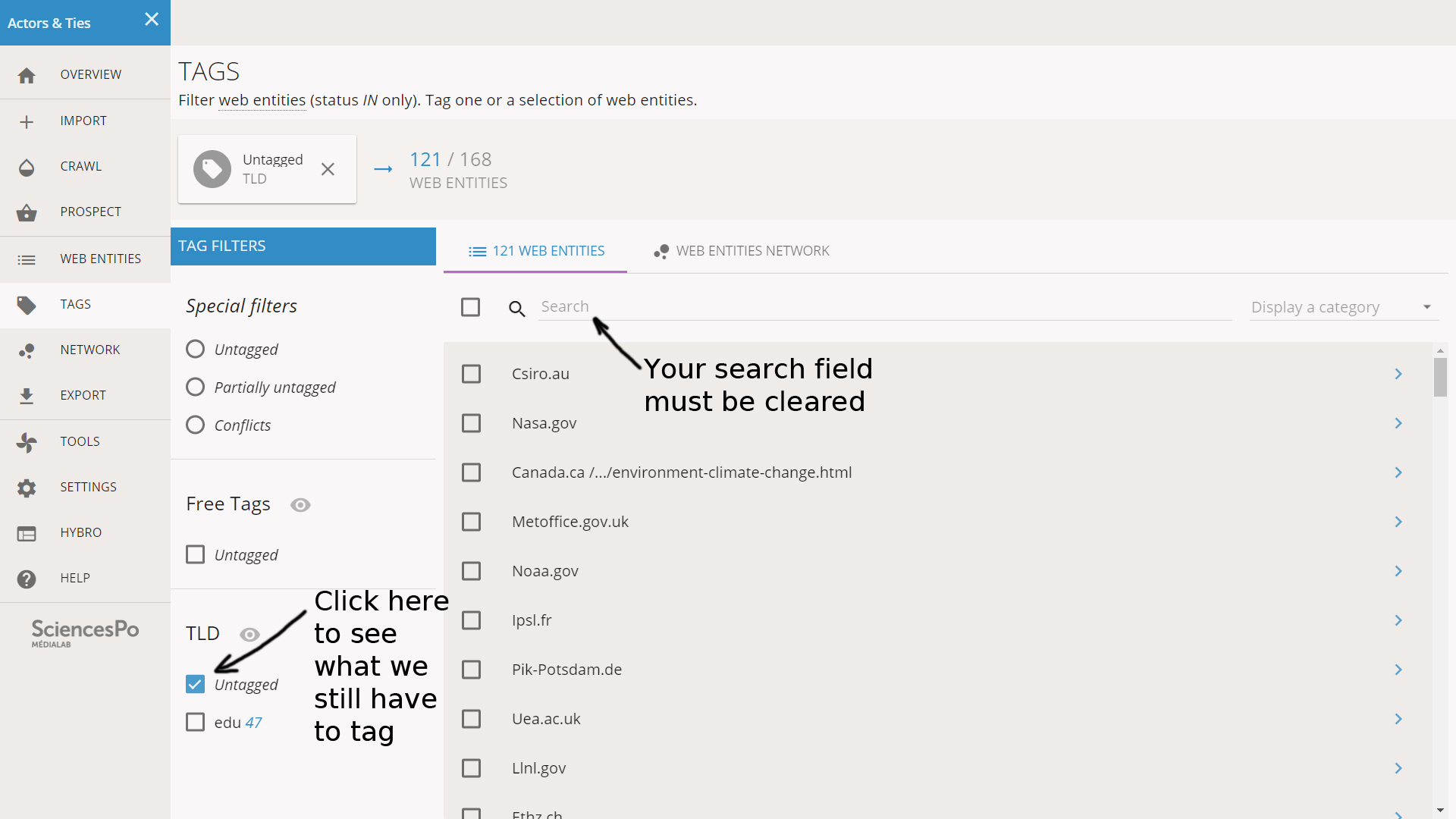
Note that the number of web entities displayed is 121: this is equal to the 168 that we have in total, minus the 47 that we tagged as “edu”. If your list of entities is empty, this is probably because you forgot to clear the Search field on top of the list of web entities.
At this point we used the concept of tag categories without explaining it, so it might not be completely clear. We will explain how it works in the next section. As long as we have only one category (TLD) it does not matter.
It looks like there are many “.gov” entities and we have seen that some of them are in the central position of the network. Like before we enter “.gov” in the search field, which displays 13 web entities. We look for anomalies and we see that some of the entities have a composite TLD like “Bom.gov.au”. We chose to not tag these the same way, so we pay attention to not check them.
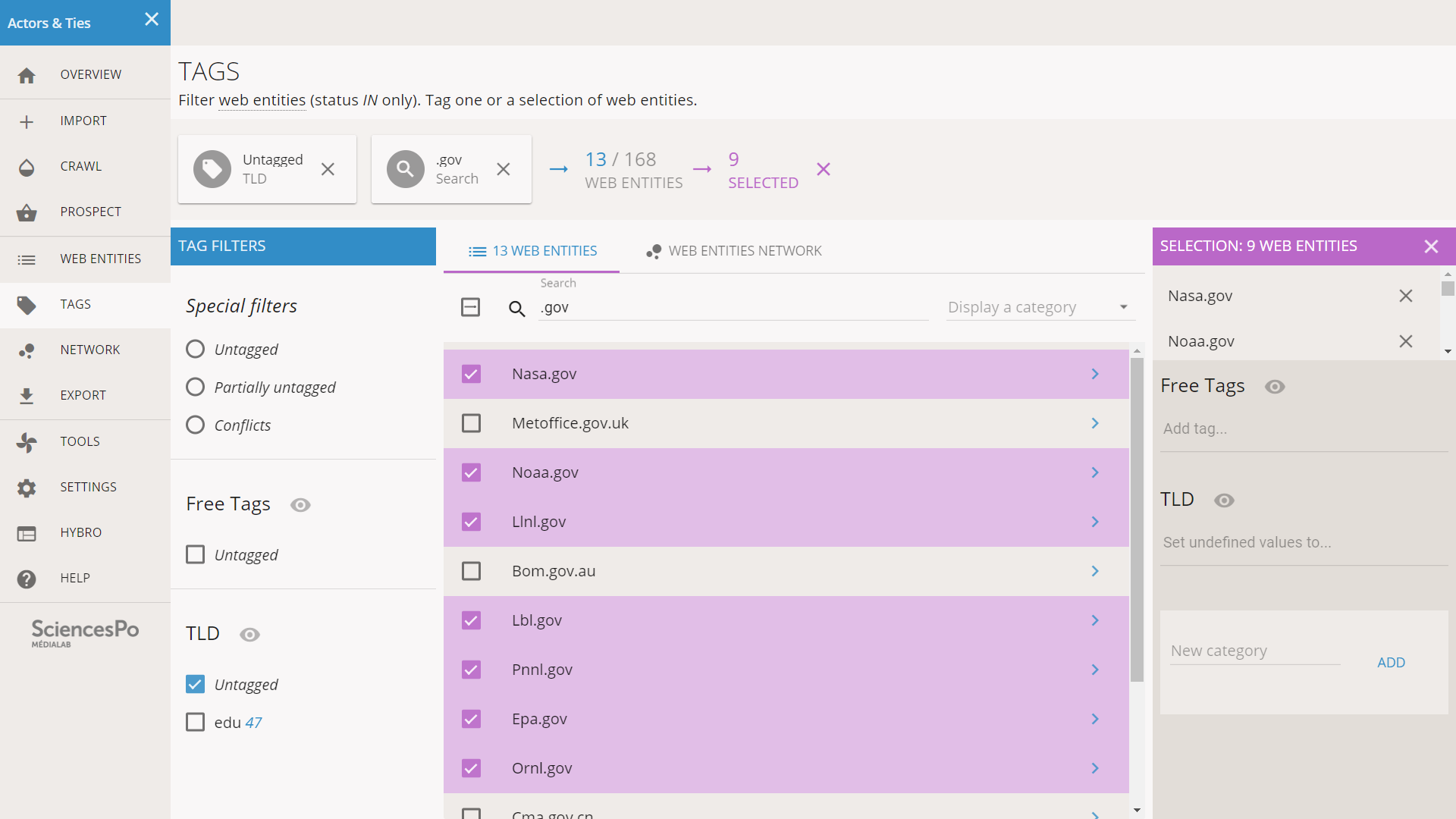
The situation is now quite complicated and deserves a clarification. We have some filtered entities and we have some selected entities. The top bar of the screen recaps the situation by showing the chain of filters that we used: first we filtered only the untagged of the TLD category, then we filtered by search (“.gov”), then we selected only 9 of the 13 filtered entities.
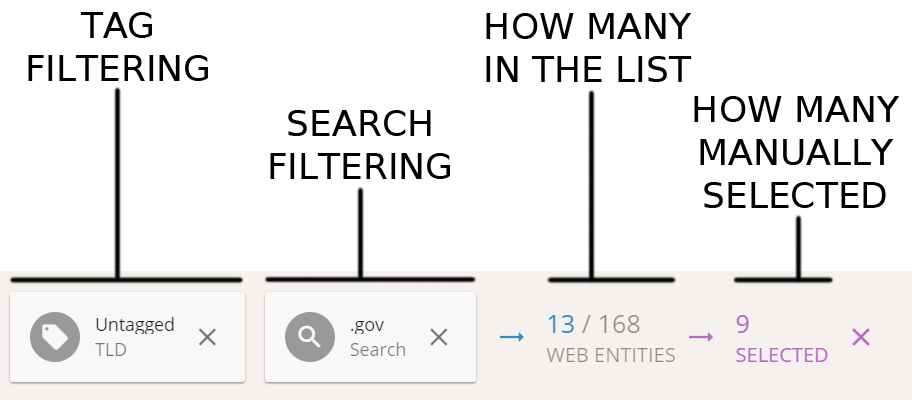
The TLD category is already created, so we just enter the “gov” tag in the right part of the screen, under TLD.
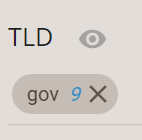
Still 112 web entities to tag! As often with such data, there are diminishing returns. If we filter the list to see other TLDs, we do not find high numbers. For instance “.de” (Germany) has 9 and “.fr” (France) has 5. If we group them however, they might make a relevant category. We are incentivized to do so because we remarked earlier that they appeared in the same area in the network. Let’s try to aggregate the western European TLDs as a single category.
Let us open a short parenthesis to focus on how tags work. Two different systems coexist: the free tags, and the tag categories. Free tags work like a bag of tags, while tag categories organize the tags like columns in a table.
Imagine that we use a spreadsheet to tag our book collection, using the same system. We have a table where each row is a book. Then free tags would be a single column, and in each cell we have as many tags as necessary, for instance separated by a comma. On the contrary the tag categories would be as many column as necessary to describe traits of the books: genre, author… Each cell of these columns would only contain 1 tag (or 0).
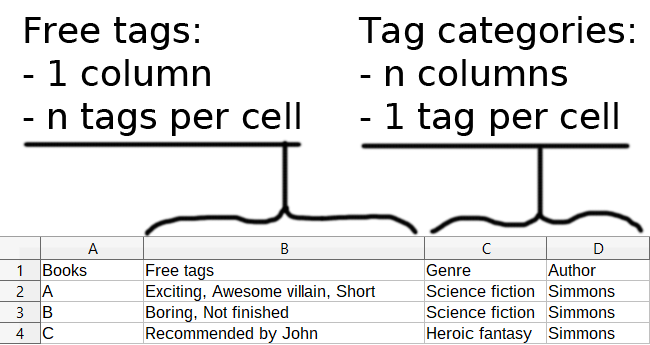
If we had to tag books à la Hyphe
Free tags are useful early in the tagging process, when we do not know yet how to organize tagging. They offer more freedom but also tend to be messier. Because they are not organized as a system, they are also more difficult to leverage in a data science setting.
Tag categories require more work but have more applications. Their biggest issue is to misunderstand them as groups of tags, while what they really are is layers of description. The difference is more obvious when we see the data as a table, since each category, as a layer, is a column. We can stack as many layers as we want, but we must have only one tag per web entity per layer. This constraint is beneficial to many applications. We can see each layer as a partition of our nodes in separate groups: each node belongs to one, and only one, group. Coloring the nodes in a network visualization also benefits from this, since each node requires one, and only one, color.
Free tags can be used as a way to take notes about the web entities before a categorization is stabilized. The description of web entities should be progressively transferred to categories. Refining a description of the corpus requires a number of iterations anyway, notably because the web often proposes unexpected types of web entities.
We filter by untagged TLD and “.fr” the same way we have done before, we select all the relevant entities and we tag them as “Western Europe”.
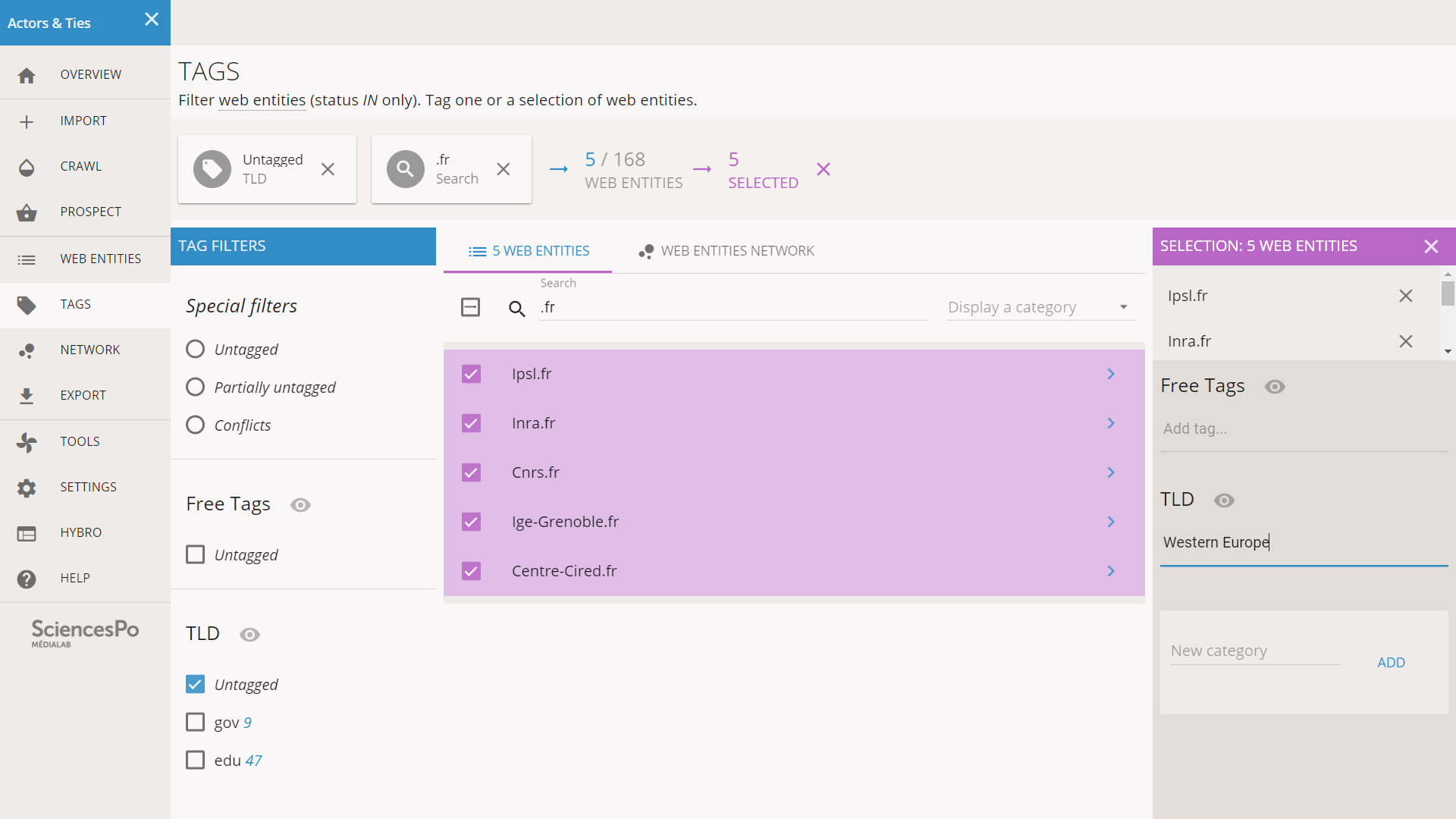
Note: as soon as we have hit enter to validate the tagging, we see an empty list while we still have 5 web entities selected (see below). This deserves a quick explanation.
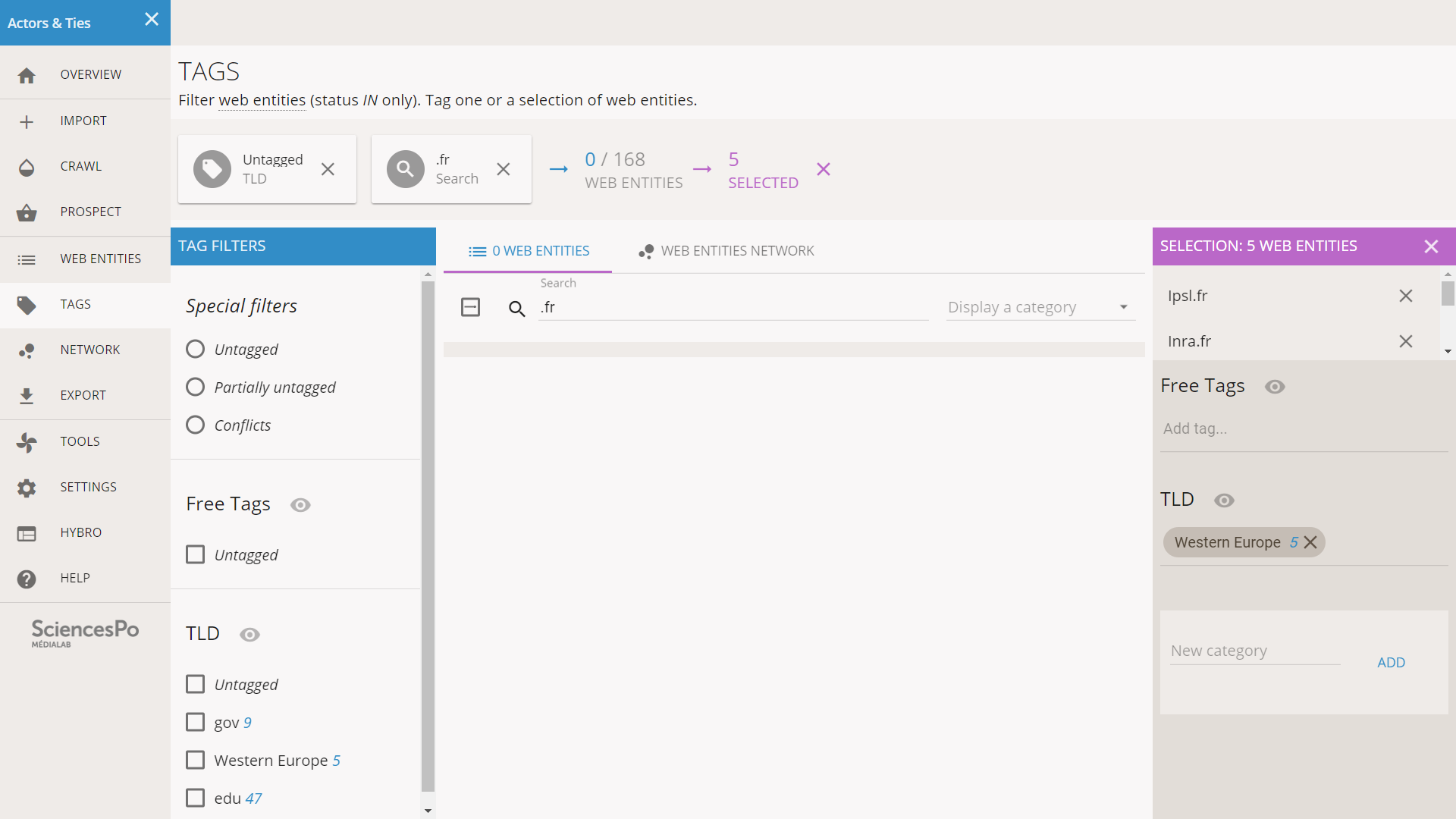
It is normal to have an empty list with a nonempty selection
What happened? When we tagged the list of entities, they were ruled out of the “Untagged” filter, and since we still have the “.fr” Search filter, nothing remains in the list. However this did not change the selection.
In Hyphe’s tagging interface, the selection is independent from the displayed list. This feature is useful in many situations where you need complex filters. We may search for A and check everything, then search for B and uncheck entities so that we get A minus B. This system is powerful but as a drawback, in some situations where it would make sense to have the selection automatically discarded, it is not. Do not forget to clear your selection after tagging!
So here we clear the selection, even though it is not mandatory since we will use the same tag again.
We now select the “.de” web entities, there are 10 of them. Without tagging it, we clear the Search field to look for other western European TLDs. We see .nl, .ch, .be, .fi, .se. There is also .uk but we don’t know if they will share the same space so we leave it out of this tag for now. We tag the rest, which gives us 27 web entities for “Western Europe”.
There are 16 “.uk”, enough for a separate tag.
There are 14 “.org” which is also enough.
There are 4 “.ru”, 6 “.jp”, 2 “.cn”, 4 “.int”... all of which are two small but also do not assemble in obvious groups. We just leave 55 untagged web entities for now.
We click on NETWORK in the left menu and in the right side bar we set the NODE COLOR to TLD.
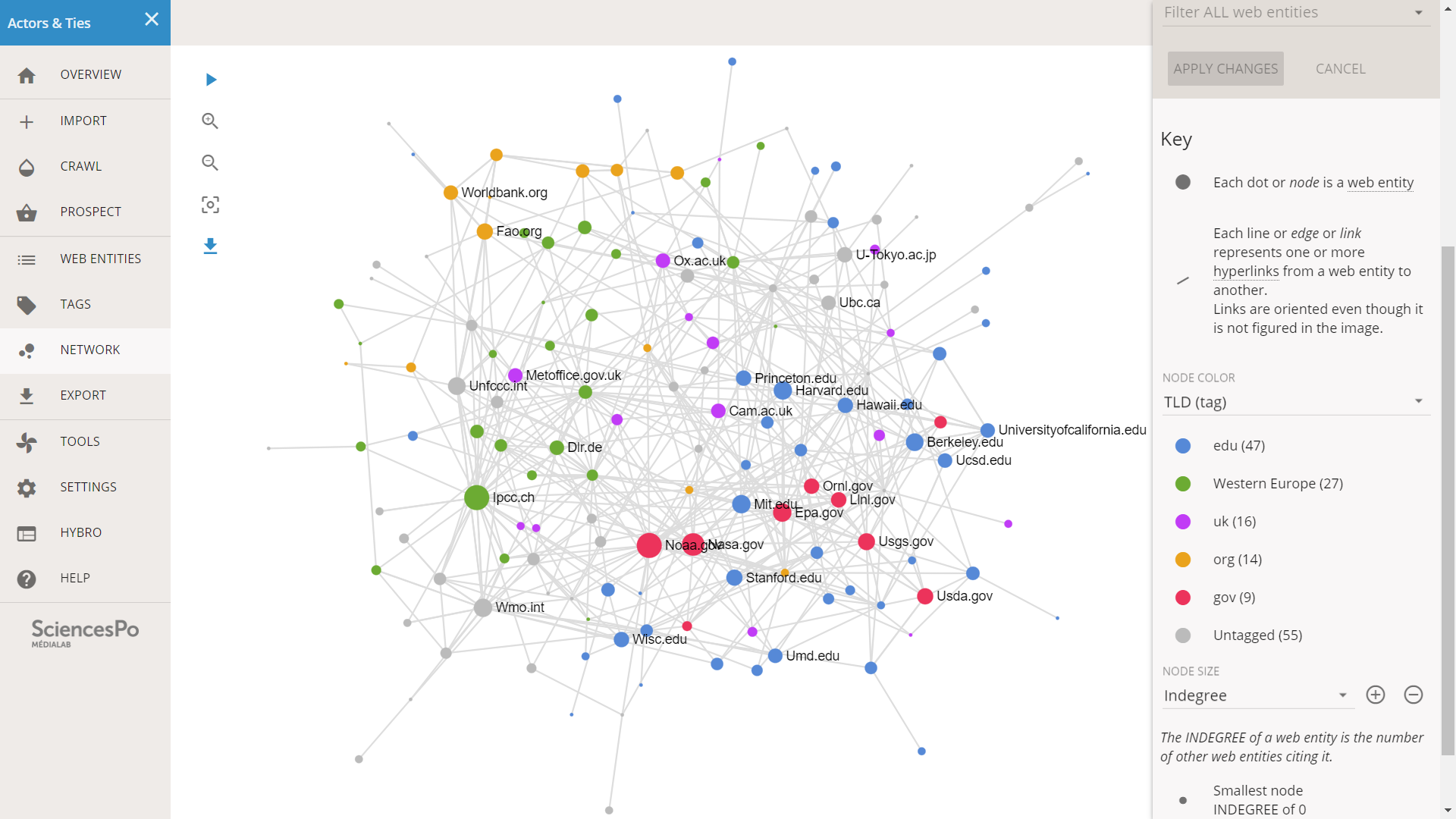
Before analysing the network, note that the layout is not exactly the same as before. The algorithm used here is non-deterministic: a part of randomness produces different results each time. Of course there are invariants that allow us to read the image: centralities, clusters… You can learn more on that topic in this article. In our situation, it suffices to remark that this network is a rotated version of the one we have seen earlier.
When visualizing a network in Hyphe, we should not invest too much energy in its specific shape: not only the layout is not deterministic, but the corpus and the tagging may also evolve. Hyphe’s network is mostly a preview for monitoring our activity. Once the crawl and the tagging are stabilized, we should export it to Gephi, rerun the layout with better settings, and only then stabilize a description of the topology based on the image.
In this tutorial we have no other choice than describing the screenshots, but every time we will come back to this screen, the image will be different even if the topology is not.
On the bottom-right part of the network, we see the blue and red nodes blending. This seems to be a cluster where educational institutions and governmental agencies form a cohesive subcluster.
On the other half of the network (top-left) there seems to be a blend of the Western Europe and UK institutions. It does not seem that the UK actors are more linked to the USA than to the rest of western Europe: these two categories could be merged together.
The “.org” web entities seem to form a small group at the periphery, in yellow, around FAO and the World Bank. It seems relevant.
Considering our observation and by spending more time with the network, we decide to modify the tagging. Our goal is to build a description that can support different hypotheses. We do not use the tags to reflect the inner truth of actors, but to give us the elements we need for an analysis. Tags encode our knowledge about the actors in a methodologically relevant way.
Should we merge the EDU and GOV actors? We hypothesize that they belong to the same structure but also that the GOV in at the center of the EDU. If we merge them, we will lose the elements that allow to analyse the centrality. Conversely if we do not merge them, we will lose the ability to compare the main subclusters of the network. Our solution is to create two different layers. A general tag category is dedicated to the main clusters, while a separate category provides more details view of the elements of the network.
For the same reason, we decided to merge UK in “Western Europe” in the general category and to keep it separated in the detailed version.
We changed the naming convention: in the general layer we used generic names such as “Western Europe” while in the detailed version we used the list of TLDs to reflect more precisely the criteria we used (a less readable but more explicit naming). We also created a tag named “Other” for the otherwise untagged entities.
By spending more time with the data we also realized that we could group TLDs of countries in Asia and the Pacific area, which also seem relatively connected. We also decided to have a way to identify minor groups of actors like Africa, Russia and non-US America, but only in the detailed layer and not the general layer.
Ultimately we get the following categories:
“TLD” (the detailed version)
- EDU
- AT+BE+CH+DE+DK+FI+FR+NL+NO+SE
- AU+CN+IN+NZ+JP
- UK
- ORG
- GOV
- AR+BR+MX+VE
- CA
- KE+ZA
- RU
- Other
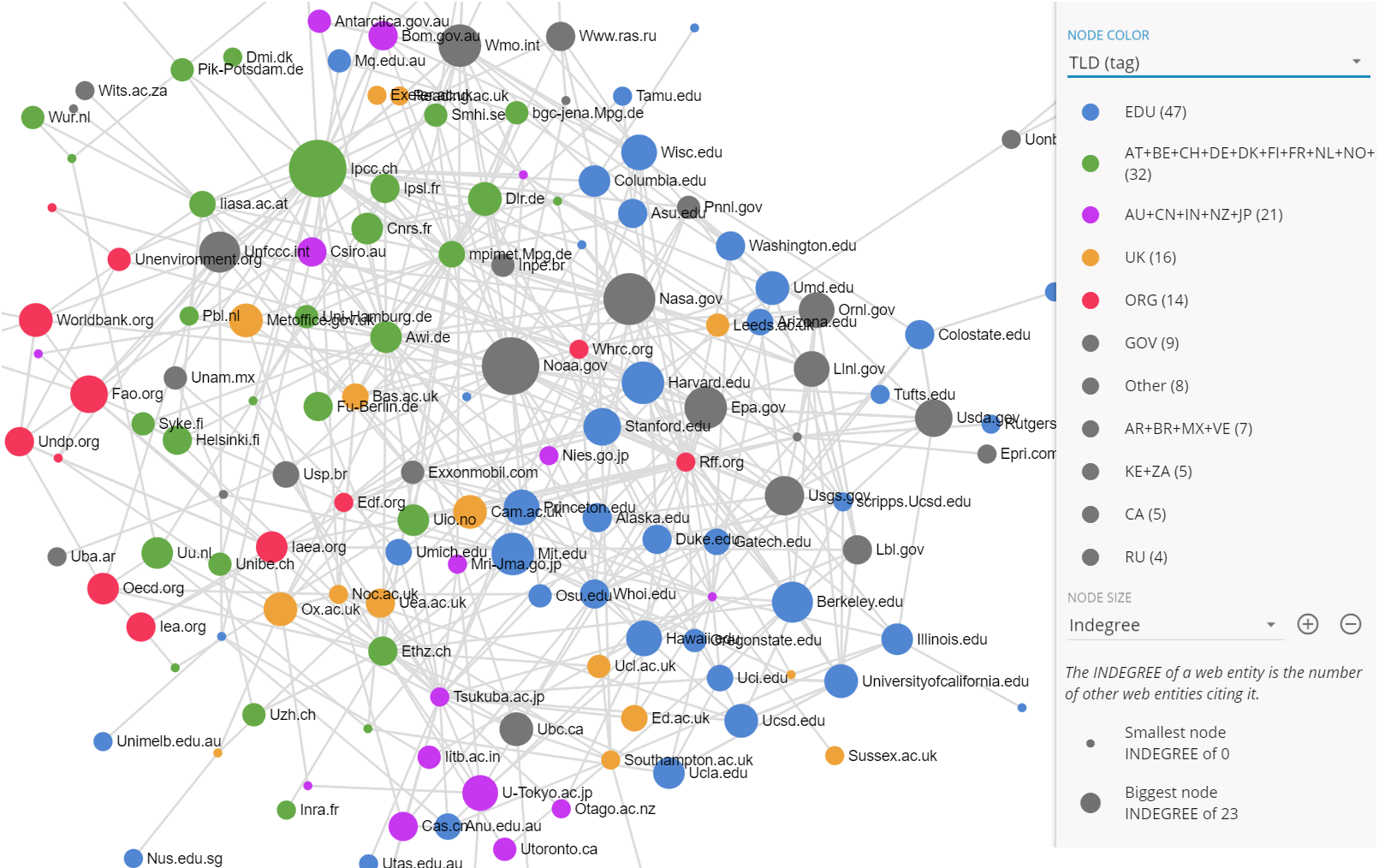
Detailed version
“General Group (TLD)”
- EDU+GOV
- Western Europe
- Asia Pacific
- ORG
- Other
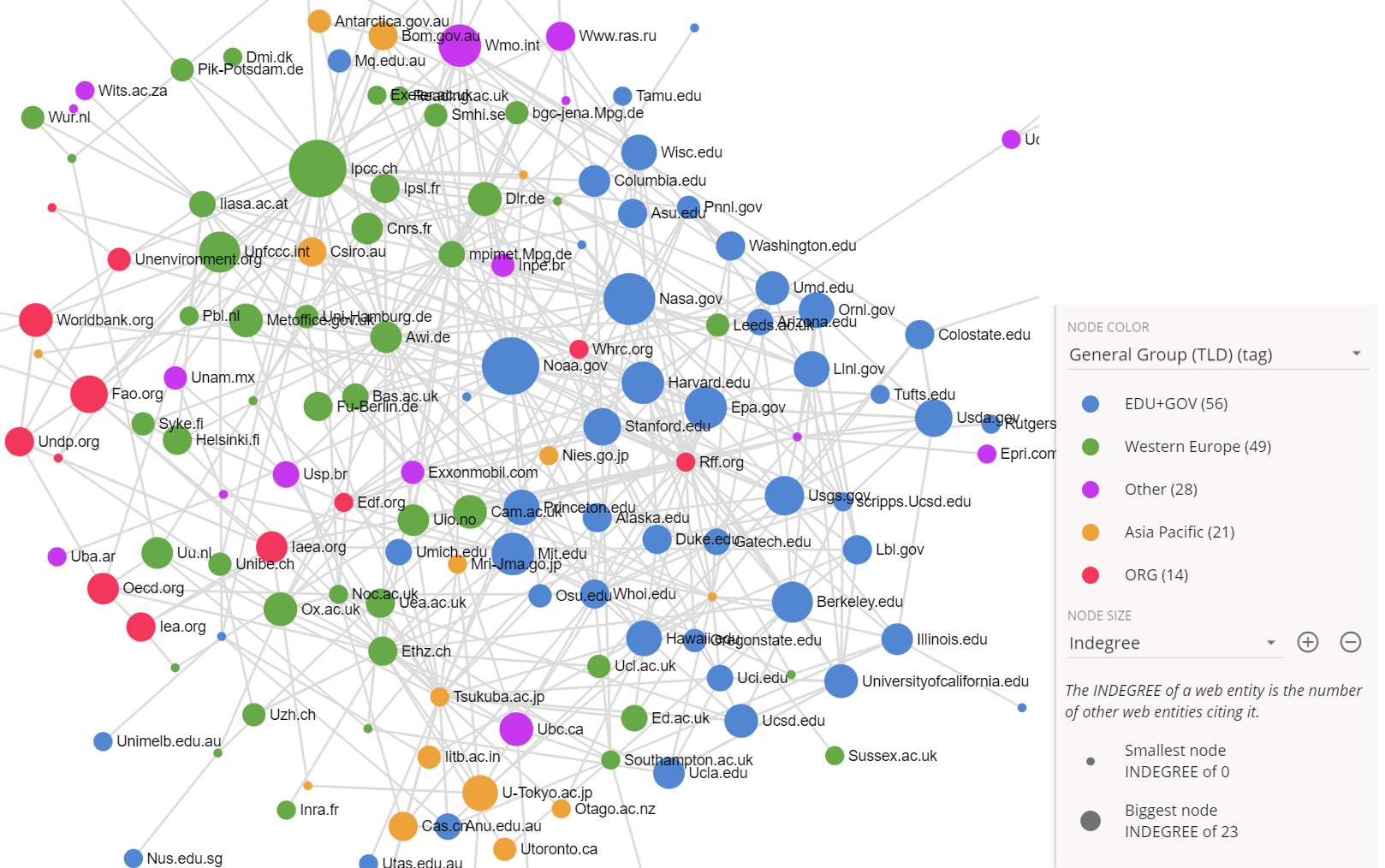
Reduced version
Hyphe offers a statistical tool that analyzes the direction of links in groups of entities having the same tag in a given layer. This is very useful as a complement to the network view, which does not visualize well the orientation of hyperlinks. Using this tool is a major motivation for tagging web entities in Hyphe.
We click on TOOLS on the left menu and then on TAGS AND TOPOLOGY STATISTICS. A tag category is selected by default (here it is “TLD”) but we can change it in the select menu on top. The interface is basically a scrollable page with statistical charts with explanations.
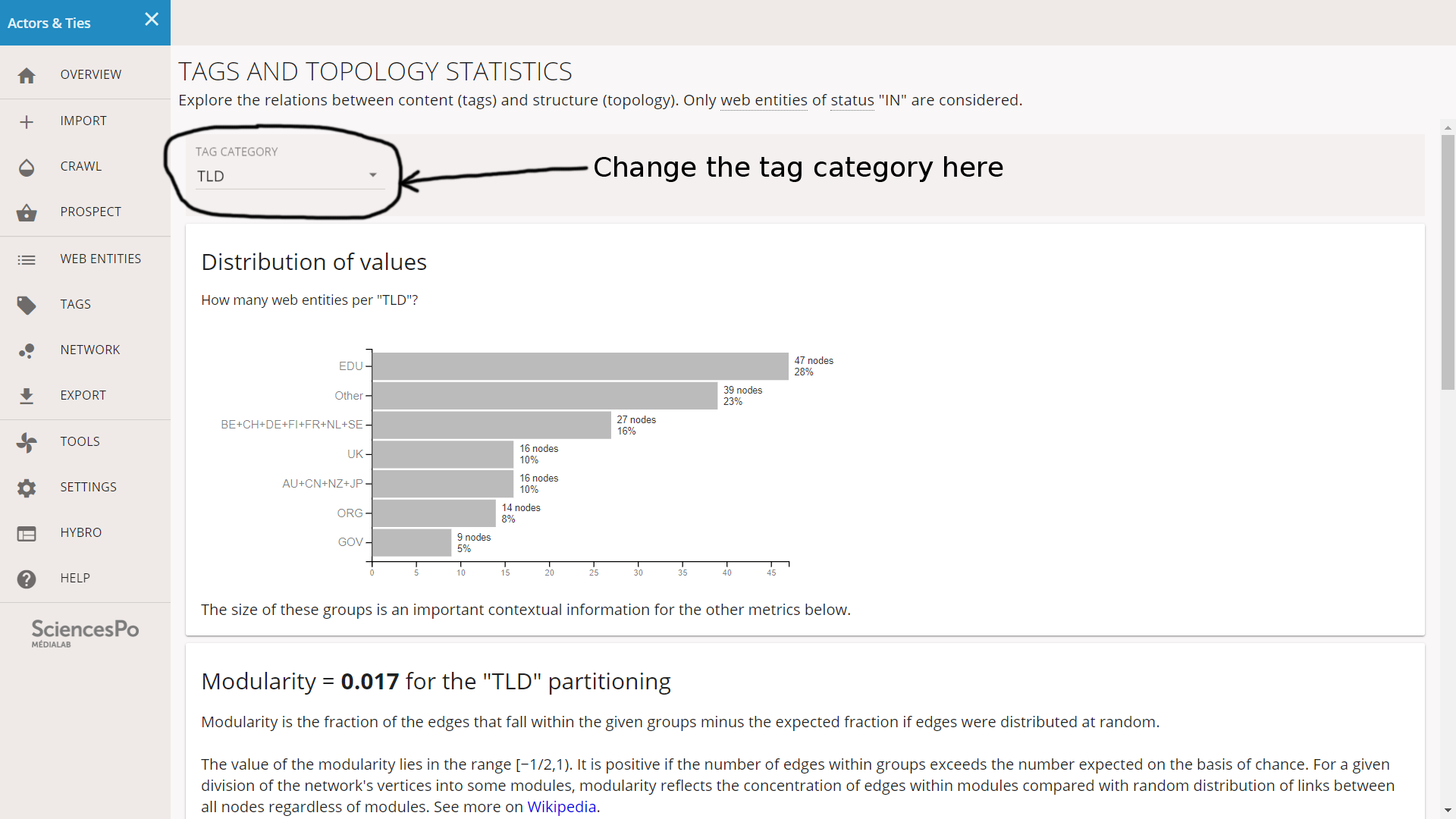
We will not explain the specifics of these charts because they are already argumented in the interface. In the next section, we will use them to interpret our groups of nodes. We just need to mind that a selector at the end of the page allows to get informations about one specific modality group.
We crawled the websites of the 170 institutions hosting 10 or more authors of the IPCC reports. We crawled them with a depth of 1 click, which means that the harvested hyperlinks cover most of the institutional linking (present in headers, footers and menus) as well as a part of the general linking (present in documents), but we did not collect all the content of these websites.
We identified 5 general groups of actors, after the top level domain (TLD) they use:
- “EDU+GOV” is mainly composed of US educational and governmental agencies
- “Western Europe” gathers the actors whose TLD is of a country of western Europe (Germany, France…)
- “Asia Pacific” gathers the actors whose TLD is of a country of Asia or Pacific ocean (Japan, China, Australia…)
- “ORG” gathers actors using the “.org” TLD, mainly NGOs and fundations
- “Other” is formed of all the other cases
We first notice that 33% of the corpus is formed of the “EDU+GOV” group, followed by 29% as “Western Europe”. “Asia Pacific” only counts for 13% and the other cases (Russia, Africa, South America…) all together do not exceed 17%. The top institutions of IPCC authors are dominated by developed countries and in particular the USA.
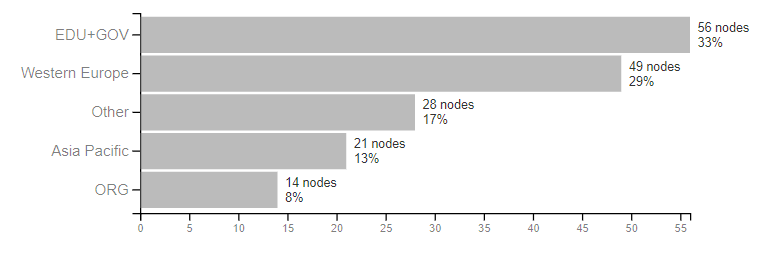
Distribution of actors by General Group
We must note that two factors have to be distinguished here: (1) the western world might have more contributing authors, and/or (2) it might have a higher concentration of authors per institution. Since we only considered institutions with 10 authors or more, it is possible that countries where authors are divided among many institutions are put at a disadvantage here. We also note that each institution being represented as a single node (web entity), they are not all on an equal foot, since some have much more authors than others.
List of the 170 institutions to which have been indicated as the main affiliation by more than 10 the IPCC: https://docs.google.com/spreadsheets/d/1cfRQFVzWGQr8Smfj2lgmokvBw8q7C7fOYkt2Ky-8VXo/edit#gid=0
To download a file, use right-click => Save as... (or similar)