在这项工作中,我们展示了视频中的3D姿态可以被基于2D关节点的空洞时域的全卷积模型有效的预测,同时引进了反向映射back-projection, 一种可以利用为标记的视频数据的简单而有效的半监督训练方法。我们首先根据未标签的视频预测2D关节点,然后预测3D姿态,最后反向映射回2D关节点。在监督学习设置中,本方法超越了之前最好的结果(在Human3.6M的6mm平均关节点位置错误中mean per-joint position),将错误率减少了11%,模型在HumanEva-I中也有极大的提高。此外,反向映射实验表明,在标签数据稀少的情况下,它的效果也超越这方面之前最好的结果。
本项目聚焦于视频中的3D人体姿态的预测。我们建立在最先进方法(2D关节点检测,然后3D姿态预测)的基础上【34,44,30,42,8,33,47,29】,虽然分解问题可以减少任务的困难,但由于多个3D姿势可以映射到相同的2D关键点,因此它本质上是有歧义的。之前的工作在处理这种歧义性问题是通过RNN建模时序信息【14,24】。另一方面来说,CNN也可以处理时序信息,尽管传统上都是用RNN(例如神经机器翻译【9】、语言模型【6】)卷积模型能够并行处理多帧,这是循环神经网络所不具备的。
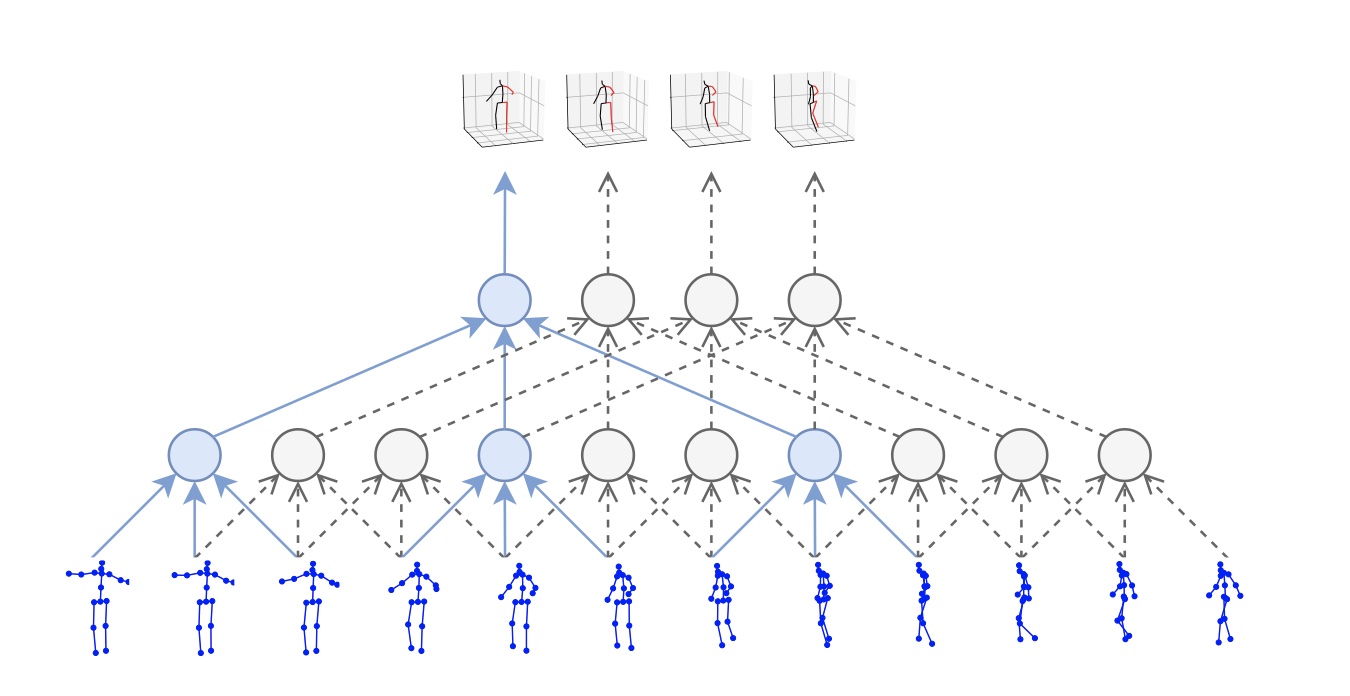
图一:我们的时域卷积模型使用2D关节点序列(底部)作为输入,然后产生3D姿态预测作为输出(顶部)。采用空洞时域卷积去捕捉长期信息
在本文中,如图一所示,我们呈现一种全卷积结构来对视频中的2D关节点执行时域卷积,得到精确的3D姿态预测。这种方法是与任何的2D关节点检测器都兼容,并可以通过时域卷积来处理大的上下文信息。相比于给予RNN的方法【14,24】,它具有更高的精度、简洁性和有效性,在计算复杂度和参数数量上都有优势。
具备了高精度和高效的结构,我们处理当标签训练集稀少的情况,引进了一种新的半监督训练策略去利用未标记的视频。对于需要大量标记的训练数据并收集用于3D人体姿势估计的标签的神经网络模型来说,低资源设定情况尤其具有挑战性,这需要昂贵的动作捕捉设置以及相当长的信息记录。本论文方法受到半监督训练学习机器翻译【23】(只用一种语言提供的句子翻译成另一种语言,然后再翻译成原始语言【38,7】的)启发。详细来说,先用现成的2D姿态检测器来预测未标记的视频,然后预测3D姿态,再映射回2D空间。
总之,本文提供了两个主要的贡献:1.呈现了一种基于2D关节点轨迹的空洞时域卷积方法,简单、有效的预测出视频中的3D人体姿态。此模型在相同精确度水平下比基于RNN的模型更加高效,不论是在计算复杂度方面还是模型参数方面。
在深度学习流行起来之前,对3D姿态预测一直是基于特征工程和骨架与关节的流动性方面进行的【48,16,18】。最初基于CNN的方法是专注于通过无需中间监督直接从RGB图像预测3D姿态的端到端的重建进行3D姿态预测【25,45,34,43】。
两步姿态预测。一种新的3D姿态预测家族,首先在图片空间中预测出2D关节点的位置(kepoints),接下来提升到3D空间【19,30,34,44,3,14】。因为他们利用了中间监督模式,因此这些方法是比端到端的方法效果更佳。最近的研究表明,对于真实的2D关键点,预测3D姿势相对简单,所以困难之处就在与难以预测准确的2D姿势【30】。 早期方法【19,3】简单地执行最近邻搜索在多组2D关键点上的预测的一组2D关键点,然后简单地输出相应的3D姿势。 一些方法利用图像特征和2D实际姿态【34,44】。 或者,可以通过简单地预测其深度来从一组给定的2D关键点预测3D姿势[49]。
视频姿态预测。 很多之前的方法是在单帧图片上进行3D姿态预测,但是最近有一些研究如何从视频中探究时域信息进而产生更稳定的预测,减少对噪声的敏感性。【45】是涉及基于空间时域卷的梯度直方图(HoG)特征。【21】双向LSTMs一直是用来精调从单帧图片上的3D姿态预测。然而最成功的方法是从2D关节点运动轨迹中学习,本文就是基于此种方法的。
最近,LSTM序列到序列的方法已经提出了编码视频中的2D姿态到固定大小的向量,然后解码到3D姿态序列【14】。然而,输入和输出序列都具有相同的长度,并且2D姿势的确定性变换是更自然的选择。我们实验了这种seq2seq模型,发现输出序列是趋向于冗长的序列,【14】处理这样的问题是以时间上的连续性为代价通过每5帧重新初始化编码器。这也被用于基于RNN的方法(考虑之前身体部位上的连接性)【24】。
半监督训练。一直用于多任务网络【2】,比如2D 关节点、3D姿态预测,还有使用Human3.6M【18】的2D/3D标注和MPII【1】2D标注的动作识别上。为标签的多角度录像用于3D姿态预测【37】上的预训练表示上。但是这些录像无法在非监督学习中被使用。在只有2D标注数据集可用的情况下GAN(对抗生成网络)可以从非时间的姿态中找出实际的姿态【47】,这提供了有用的正则化形式。【33】提出了一种弱监督学习方法,基于序数深度(ordinal depth),这利用2D标注的深度对比信息,如:左腿位置是在右腿之后。
我们的工作不同于以上的几种方法,比较与【33】【34】,我们没有使用heatmap, 而使用检测的关节点坐标来代表姿态。heatmap可以传递更多信息但是需要更大的2D卷积(如果考虑时间,就是3D卷积)计算量并且他们的准确率取决于heatmap的分辨率。我们的模型在只有较少参数的同时可以达到很高的准确率,能够快速的训练和运行。比较于基于单帧的两种方法:【30】和通过【14】的LSTM模型,我们通过一维的卷积操作探究了时域信息,并且提出了几种优化方法取得了更低的重建错误。不同于【14】,我们采用了确定性映射来代替seq2seq模型。最后比较于所有的2D姿态预测方法,我们发现MASK-RCNN和CPN(级联金字塔网络)检测器是对3D人体姿态预测来说,效果更具有鲁棒性。
我们的模型是一种带有残差连接的全卷积结构,采用一个密集2D姿态序列作为输入,并将时域卷积与线性投影层交替。卷积模型可以同时处理2D姿态信息和时间维度信息(RNN无法做到)。在卷积模型中,这个输入、输出的梯度路径有一个固定的长度,无论序列长度的大小,这相较于RNN减少了梯度消失和梯度爆炸的风险。此外,卷积结构对时间感受野有着精确的控制,这有利于3D姿态预测模型的时间依赖性。另外,我们采用扩张卷积[13]来建模长时间依赖性,同时保持效率。相似的空洞卷积结构在音频生成【46】、语意分割【48】和机器翻译上也有着杰出的效果。

图二:一个全卷积3D姿态预测模型结构的实例。这个输入包含了243帧(B = 4 块)的2D关节点感受野, 每帧有J=17的关节点。卷积层是绿色的,其中$2J, 3d1, 1024$ 分别代表2 x J 个输入通道、一个过滤器大小为3的空洞卷积和1024个输出通道。一帧的3D预测需要$(243, 34)$, 这代表243帧和34个通道。因为卷积的效果,我们需要在残差连接中间切割,去匹配这卷积生成的张量。
此结构把每帧关节点的x, y轴坐标作为输入,应用过滤器为$W$的卷积层来输出$C$个特征, 然后应用$B$个残差网络风格的残差块,来形成一个skip-connection【11】。每个残差块执行过滤器大小为$W$的空洞因子为$D=W^B$的1D卷积操作,然后是线性映射,接下来是组正则化【15】,线性修正单元【31】和dropout【41】。通过参数$W$每个残差块都指数级增大了感受野,尽管参数只有线性级的增加。过滤器超参数的设置$W and D$是使得对于任何输出帧的感受野形成一种树状,能够覆盖所有的输入帧(参考图一)。最后一个输出包含所有输入序列的一个3D姿态,同时考虑了过去和未来的时间信息.为了评估这个方法在实时场景的应用, 我们试验了因果卷积的方法(只对过去的信息进行卷积)。我们在附录$A.1$中展示了空洞卷积和因果卷积的结果。
卷积网络一般采用零填充来获得和输入大小一样的输出,然而在早期实验中发现这会导致边际效应,增加了损失值。所以,我们填充这个输入序列通过左右帧关节点的复制(看 附录
图2显示了我们的体系结构的实例化,其中接收字段大小为243帧,B = 4块。 对于卷积层,我们设置W = 3,C = 1024 输出特征,我们使用dropout丢失率p = 0.25。
因为获得实际的3D姿态预测的标注很困难,我们引进了一种半监督训练方法去提高在实际3D姿态标注有限情况下的姿态预测准确率。我们利用现有的2D姿态检测器和未标注的视频,将反向映射损失加入到监督损失函数中。去解决未标签数据的自动编码问题的关键思想是:将3D姿态预测作为编码器,把预测的姿态反向映射到2D姿态,基于此进行一个重建损失的计算。
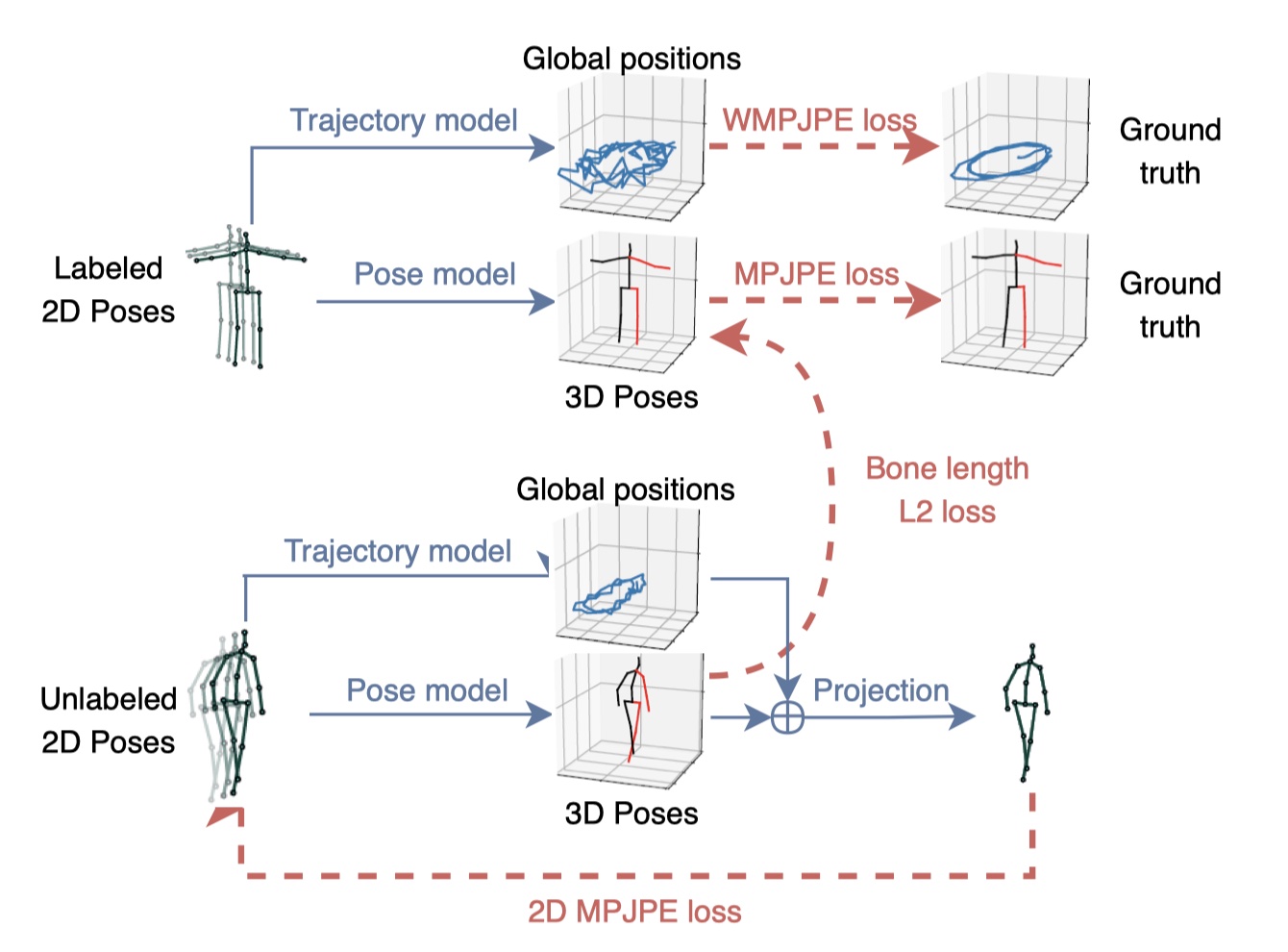
图3.带有3D姿态预测模型的半监督训练采用预测的2D关节点作为输入,我们回归人体的3D轨迹并添加一个软限制(soft-constraint) 将未标签预测的平均骨骼长度映射到标签的数据中。所有的都在一起联合训练。$WMPJPE$ 代表带有权重的
$MPJPE$
此方法的概括在图三中可见,我们有一个监督元件和一个,非监督元件(充当正则器)。这两个对象是联合优化的。有标签的数据占据一个批次的前半部分、无标签的数据占据一个批次的后半部分。对于有标签的数据我们采用实际的3D姿态作为目标,训练一个有监督的损失。这个未标签的数据被用于去执行一个自动编码器损失,即将预测的3D姿态反向映射到2D,然后检查它输入的连贯性。
Trajectory model. 由于透视投影,屏幕上的2D姿势取决于轨迹(即,在每个时间步长处空间中人体的相对位置)和3D姿势(人体的相对关节位置)。因此我们回归人体的3D轨迹,使得可以正确的反向传播到2D。为此, 我们优化第二个神经网络去回归相机空间的全局轨迹。后者在投影到2D姿态之前,添加到3D姿态中。这两个网络拥有同样的结构但不共享任何的权重,因为,就我们的观察,他们在多任务方法训练上会互相造成不好的效果。因为随着物体远离摄像头,回归精确的轨迹变的愈加困难,所以我们优化一种带权重的平均关节点位置错误(WMPJPE)损失函数:
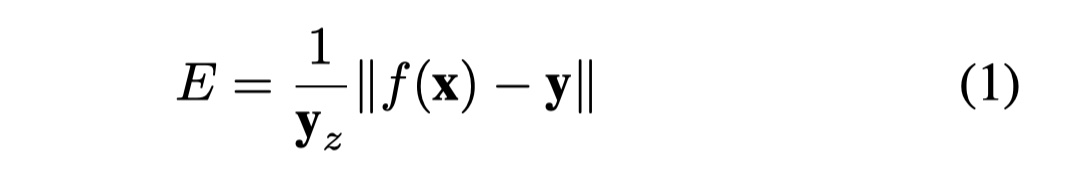
即,我们对每个样本给一个实际相机空间深度$y_z$的倒数作为权重。因为在远处物体中,相关的2D关节点都集中在一起,所以回归远处的物体也不是我们的目标。
Bone length L2 loss 我们希望去激励这个大概的3D姿态预测,而不仅仅是复制这个输入。为此,发现那是有效的去大概的匹配一个批次中以标签的数据集的平均骨长度到未标签数据的平均骨长度(“L2骨长损失” in 图3),这在自我监督中启到了巨大的作用。见在$6.2$
讨论。 我们的方法仅仅需要相机的内部参数(如:焦距、焦点、偏斜参数),在一般的商用相机中都可得到。此方法并没有特定的网络结构,可以适用于任何采用2D关节点作为输入的3D姿态预测器。在实验中,我们采用在$$3$ 中描述的结构去映射2D到3D。去映射3D到2D,我们采用简单的映射层(考虑线性参数:焦距、焦点;非线性失真系数:切向和径向)。观察到非线性项几乎没有什么大的影响,这增加了我们方法对输入视频要求的实用性。
我们在两个动作捕捉数据集上做评估测试:Human3.6M[18,17] 和 HumanEva-I【39】。Human3.6M 训练11个对象的360万帧的数据,其中7个对象是由3D姿态的标注。每个对象包含15个动作的视频,使用的是4个50赫兹的同步摄像头来记录的。根据之前的工作【34,44,30,42,8,33,47,29】,我们采用一个17帧的骨架,在5个对象(S1, S5, S6, S7, S8), 测试在(S9, S11)上。对于所有对象训练出单个模型。
HumanEva-I 是一个很小的数据集,包含3个对象视频记录,由60Hz的3个角度摄像头所拍摄。根据【30,14】,我们通过对每个动作训练一个不一样的模型(单行为SA)来分别测试三个动作(行走、慢跑、拳击), 如【34, 24】。采用15个关节点骨架和提供测试/训练分割。
本实验中,考虑到3个评估协议。协议一:毫米级的平均关节点位置错误(MPJPE),意味着预测的关节点和实际的关节点之间的欧几里得距离【26,45,50,30,43】。协议二:实际关节点刚性对齐(rigif alignment)之后的误差P-MPJPE【30,42,8,33,47,14】。协议三:仅仅在标量上对其实际和预测的姿态关节点:N-MPJPE. 根据【37】的半监督实现。
很多之前的工作【30,49,44】,在图片中提取实际的人体边框,然后应用栈式沙漏型检测器中预测2D关节点。本方法(图2 图3)不依赖于任何特殊的2D关节点检测器,因此可以探究了一些没有实际边框标注的视频。除了栈式沙漏检测器,我们研究了$Detectron$(ResNet-101-FPN backbone)和CPN(需要提供人体边框)
对于Mask R-CNN 和 CPN, 我们从coco上的预训练模型【28】上所开始的,然后在Human3.6M【18】的2D投影上做些(微调)fine-tune(COCO上的关节点与Human3.6M上有所不同)。在控制变量实验中,我们也直接将2D的COCO关节点作为输入去预测Human3.6M的3D关节点。
对于 Mask R-CNN, 我们采用ResNet-101后端,“stretched x1”策略【10】。在Human3.6M上做fine-tune时, 重新初始化最后一层关节点网络和反卷积层,即回归heatmap到一系列新的关节点。我们在4个GPU上训练,逐步的衰减学习率:6万步的1e-3, 10万步的1e-4, 1万步的1e-5的学习率。在interface(实施)层,我们对heatmap做softmax并提取期待的2D分布结果。这个结果比hard-argmax【29】更平滑、更准确。
对于CPN,我们采用带有384x288分辨率的ResNet50后端。去做fine-tune,重新初始化了$GlobalNet$ 和
参考之前的一系列工作【30,26,45,50,30,34】。我们在相机空间中训练和测试3D姿态,根据逆相机变换旋转和平移实际姿势,而不是使用全局轨迹(半监督设置除外,图4)。
选用Amsgrad【35】作为优化器训练80个epochs,对于Human3.6M,我们采用指数级衰减策略,$\eta$ = 0.001 (缩减因子为$\alpha$=0.95)应用到每个epoch。 所有的时域模型(感受野超过一的),在姿态序列中(图3),都对样本相关性很敏感,这导致批量标准化的偏差统计量(其假定独立样本)。在初步实验中,发现在训练过程中预测大量的相邻帧会导致结果比没有时域信息(在batch中随机样本)时更差,我们通过选择从不同视频中选择片段来减少训练样本的相关性。这个片段的大小是模型结构的感受野大小,这是为了预测单个3D姿态。我们在附录A.5中分析详情。
我们可以极大的优化单帧通过代替空洞卷积为步幅卷积(stride convolutions),其中步幅长度为空洞系数(见附录A.6)。这避免了计算从未使用的状态,我们仅在训练期间应用此优化。在interface中,我们可以处理整个序列,并重新使用其它3D帧的中间状态,去做更快的interface。这种可实施性是因为本模型没有在时间维度使用任何的池化操作(?),为了避免在valid conv中丢失帧,我们在序列的边界做pad.(见附录A.5, 图片9a).
实验发现,默认的批次标准化超参数会导致在测试误差和interface误差上的较大的波动(1 mm).为了避免这个,实现更稳定的运行,我们对批次标准化上定一个衰减策略:从$\beta$=0.1开始,到最后一个epoch,$\beta$=0.001结束。
最后在训练、测试中做一些横向的数据扩充,在附录A.4中显示他的效果。
对于 HumanEva, 我们使用N=128,
表一展示了在两个评估协议上(图5)感受野为243个输入帧、block=4 的卷积模型的结果。本模型在这两种协议上比任何其他的模型的平均误差都要低,且不依赖于其他的数据。在协议一上(表1a) 本模型是比之前最佳的结果【24】要平均好上6mm, 大约11%的误差减少率。更可观的是,【24】使用的是实际边框,本模型则没有用。
在协议一上,使用时域信息的模型比未使用(W设置为1)的要至少好上5mm.在快速运动的行为上(比如走路6.7mm, 一起走路 =8.8mm),其中的差距会更大。具有因果卷积的模型的性能大约是单帧基线和空洞卷积模型之间的一半。因果卷积可以实现在线预测3D姿态,即预测最右边的输入帧。
有趣的是在提供实际人体检测框和有Mask-RCNN预测的检测框之间的效果很相似,这表明我们的单一主题情景中的预测几乎是完美的。图表4显示了包含预测的2D关节点和3D姿态,在附属材料(附录A.7)和https://dariopavllo.github.io/VideoPose3D 有视频展示。
接下来,我们评估2D关键点检测器对最终结果的影响。 表3报告了我们的模型的准确性,具有实际2D姿势,[30]的沙漏网络预测(均在MPII上预先训练并在人类3.6M上进行了调整),Detectron和CPN(均在COCO上预先训练和 在Human3.6M上进行了调整)。 Mask R-CNN和CPN都比叠层沙漏网络具有更好的性能。 改善可能是由于热图heatmap较高的分辨率,更强的特征结合(Mask-RCNN的特征金字塔【27,36】和CPN的RefineNet),和我们预测的更多样的数据集,比如COCO【28】。当采用实际的2D关节点时,在协议一上 本模型比【30】错误降低了8.3mm. 【24】比它错误降低了1.2mm.因此,本模型的提升比仅仅在于使用了更好的2D检测器。
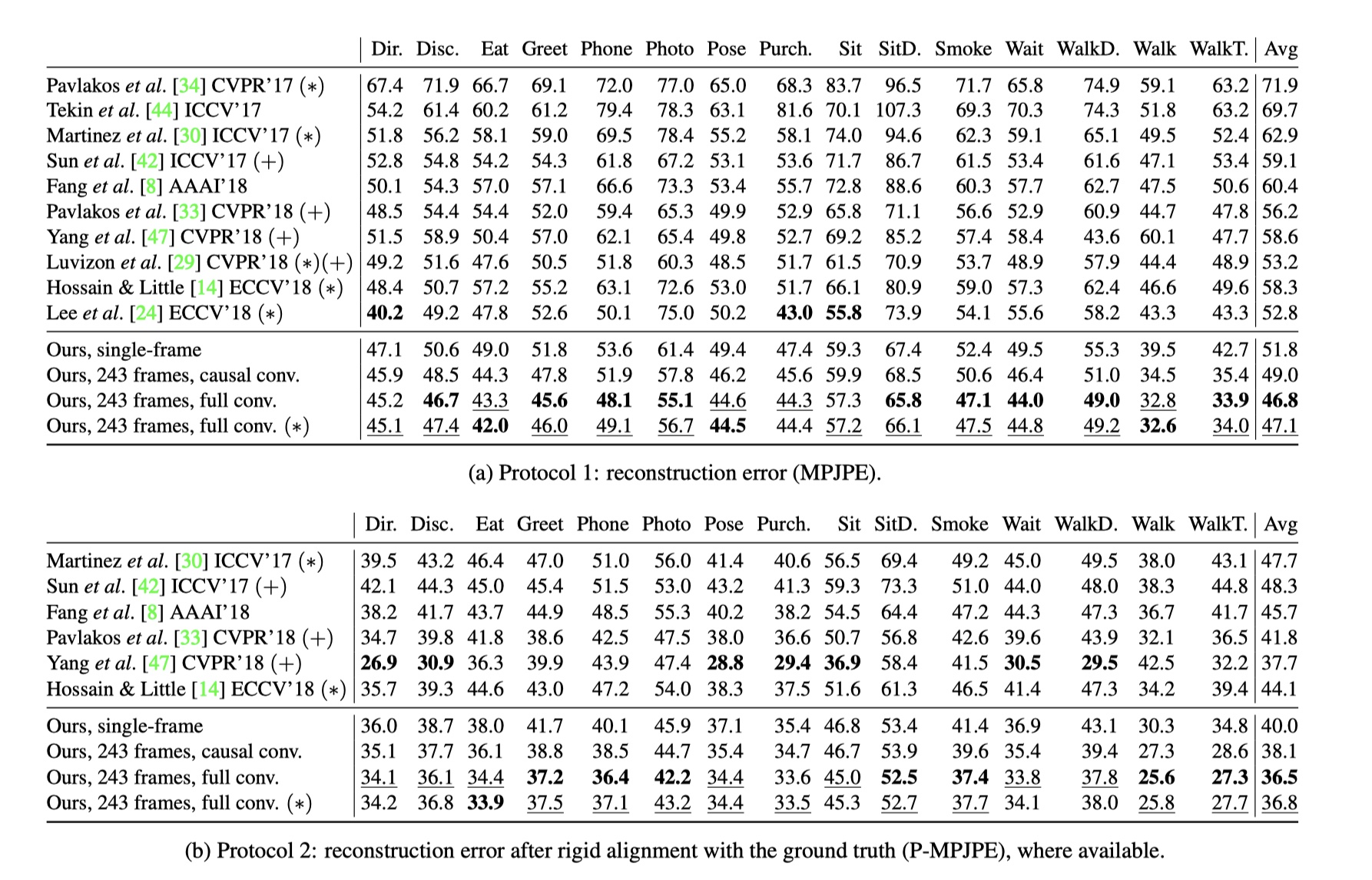
表一:在Human3.6上的重建错误,图例(*)实际的人体边框。(+)额外的数据-【42,33,47,29】使用了MPII数据集上的2D标注,【33】使用额外的Leeds sports Pose(LSP)数据集和序列标注,【42,29】评估在每64帧。【14】向我们提供了最初公布的结果的更正结果3。 较低的是更好的,最好的是粗体,最好的第二个下划线。
绝对位置误差不会测量预测的平滑性,这对于视频很重要。 为了评估这一点,我们测量联合速度误差(MPJVE),对应于3D姿势序列的第一导数的MPJPE。 表2显示我们的时间卷积模型将单帧基线的MPJVE平均降低了76%,从而使姿势更加平滑。
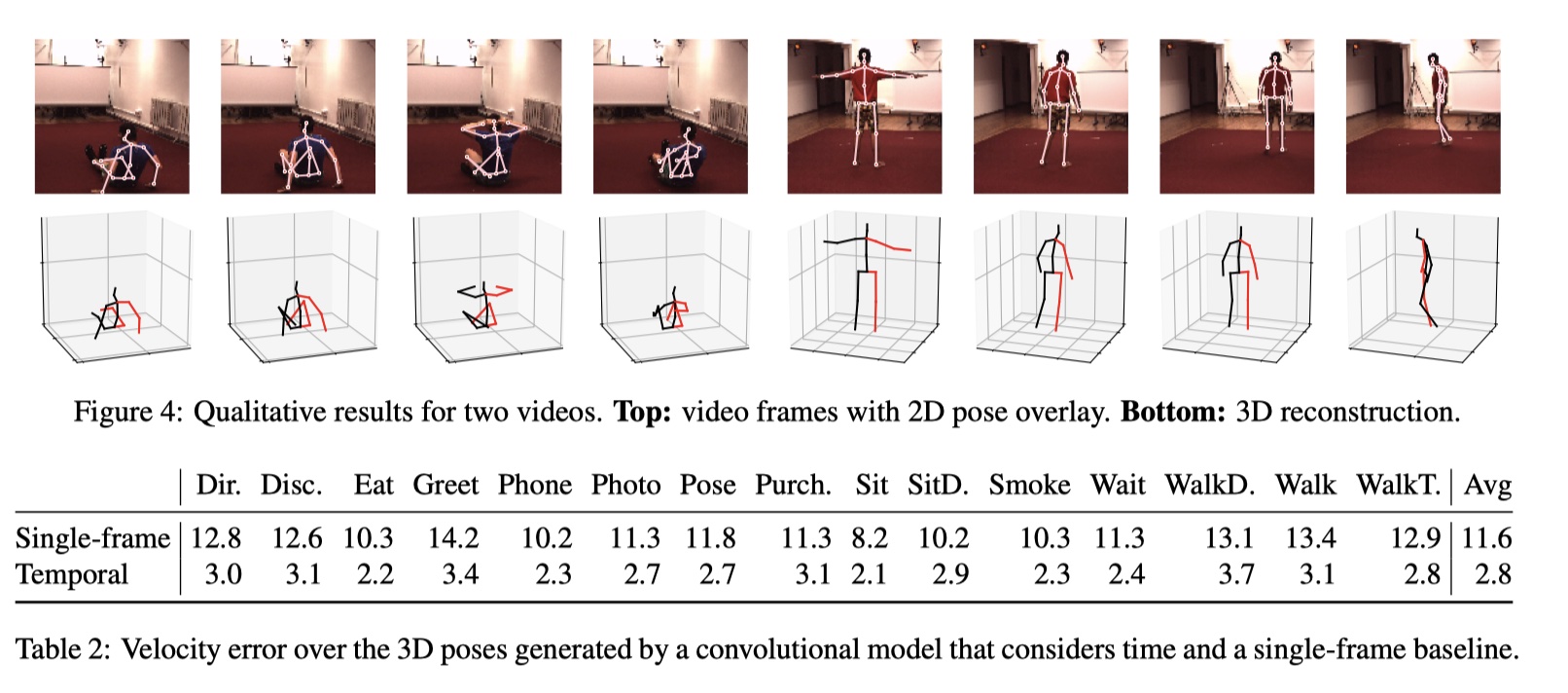
鉴于时间和单帧基线的由卷积模型产生的3D姿态的速度误差
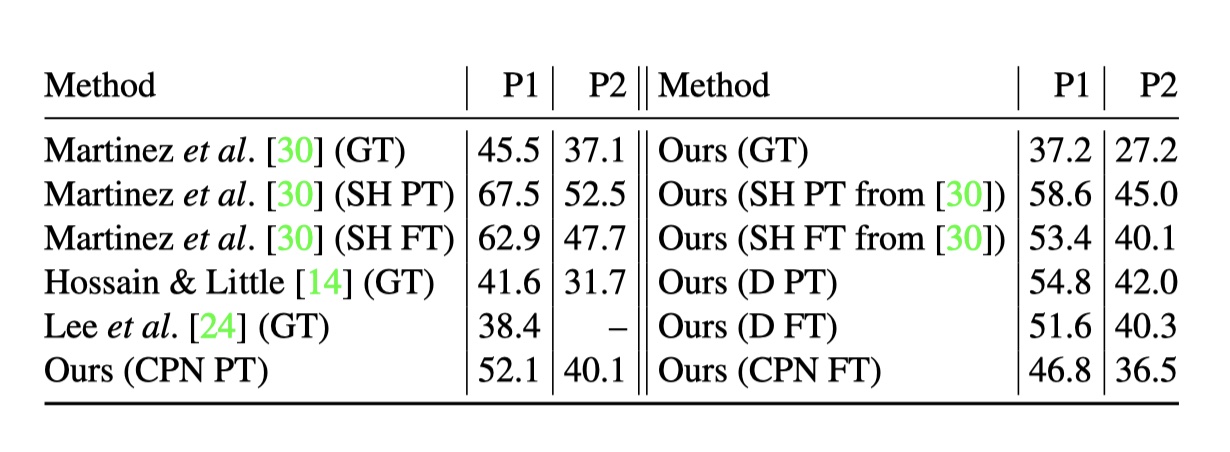
表3: 在协议一和协议二下的2D检测器结果下的影响。图表GT(实际)、SH(栈式沙漏)、D(detection)、PT(预训练)、FT(fine-tune)
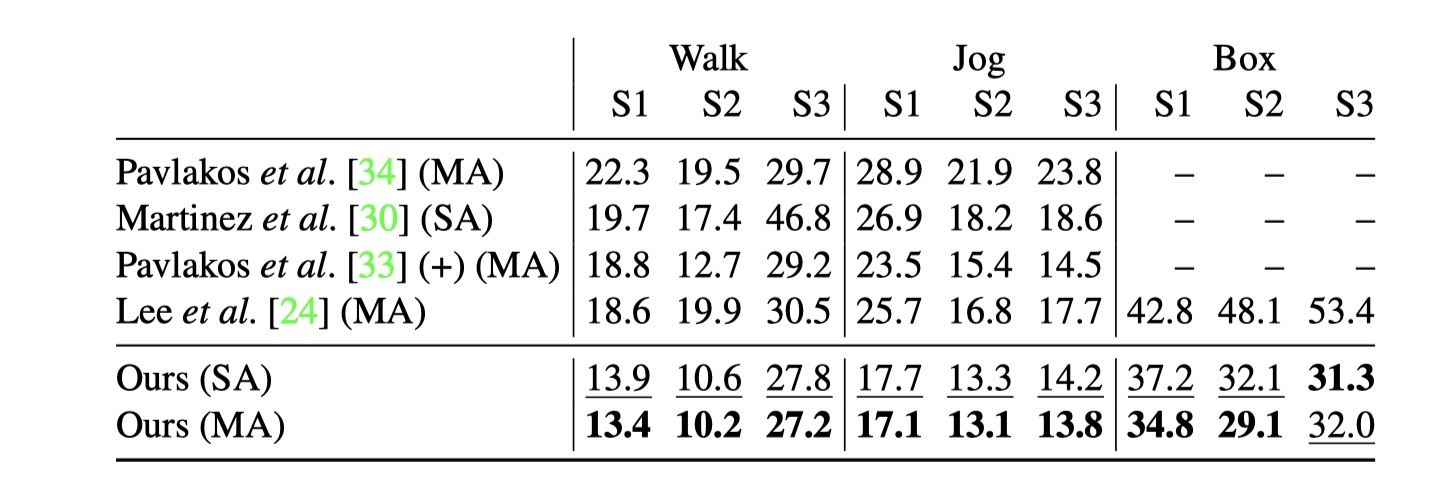
表四:在HumanEva-I数据集、协议2下的单动作(SA)和多动作(MA)模型。
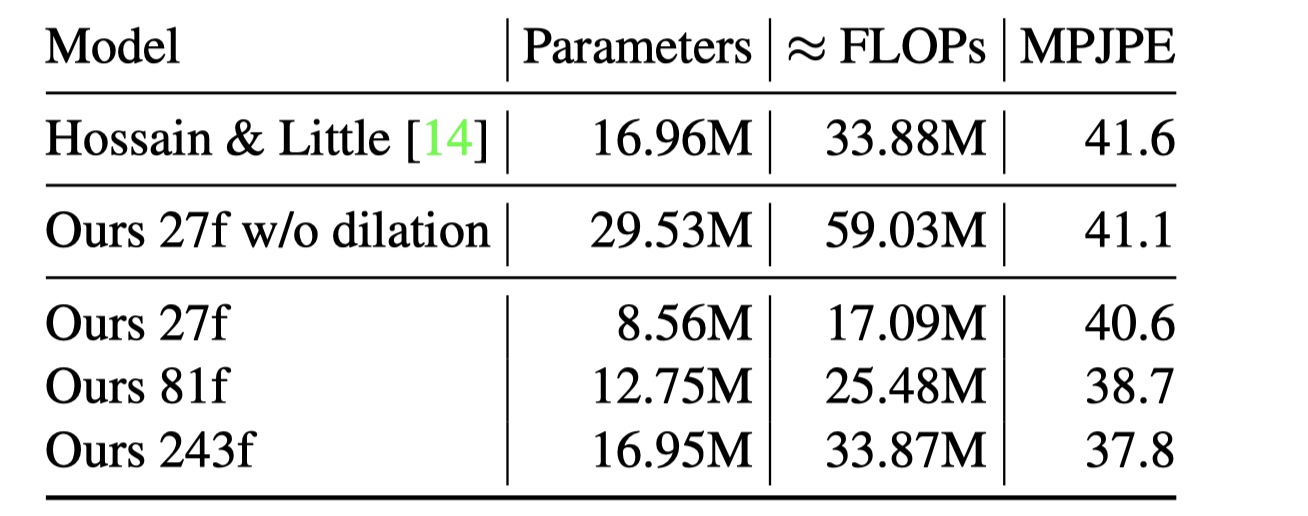
表5⃣️:训练在实际2D姿态下(没有测试阶段数据增强)的不同计算复杂度(感受野)下的协议一的误差。
最后表5⃣️在复杂度方面比较了与LSTM 模型【14】的差距。我们在一次interface时的测量了参数数量和浮点运算(FLOPs)详情可见附录A.2。本模型在计算量减半的情况下实现了更低的错误率。最大的模型(感受野为243帧)计算复杂度和【14】几乎相等,但误差减少了3.8mm。这个表也强调了空洞卷积的效果,它就感受野方面仅仅增加了对数级别的复杂度。
由于我们的模型是卷积的,因此可以在序列数量和时间维度上并行化。 这与RNN形成对比,RNN只能在不同的序列上进行并行化,因此对于小批量大小效率要低得多。 在interface过程中,我们在单个NVIDIA GP100 GPU上测量了大约150k FPS的单个长序列,即批量大小为1(假设2D姿势已经可用)。 但是,由于并行处理,速度在很大程度上与批量大小无关。
我们采用[37]的设置,他们将Human3.6M训练集的各种子集视为标记数据,其余样本用作未标记数据。他们的设置通常还将所有数据下采样到10 FPS(从50 FPS, 每五帧选一帧)。 通过首先减少subjects数量然后通过下采样subject 1来创有标记的子集。
由于数据集被下采样,我们使用9帧的感受野,这相当于45帧上采样。 对于非常小的子集,S1的1%和5%,我们使用3帧感受野,并且我们使用单帧模型用于0.1%的S1,其中仅有49帧可用。 我们仅对标记数据进行了CPN的fine-tuned,并通过仅针对几个时期的标记数据进行迭代来加热训练(对于较小的子集,1个epoch≥1S,20个epochs)。
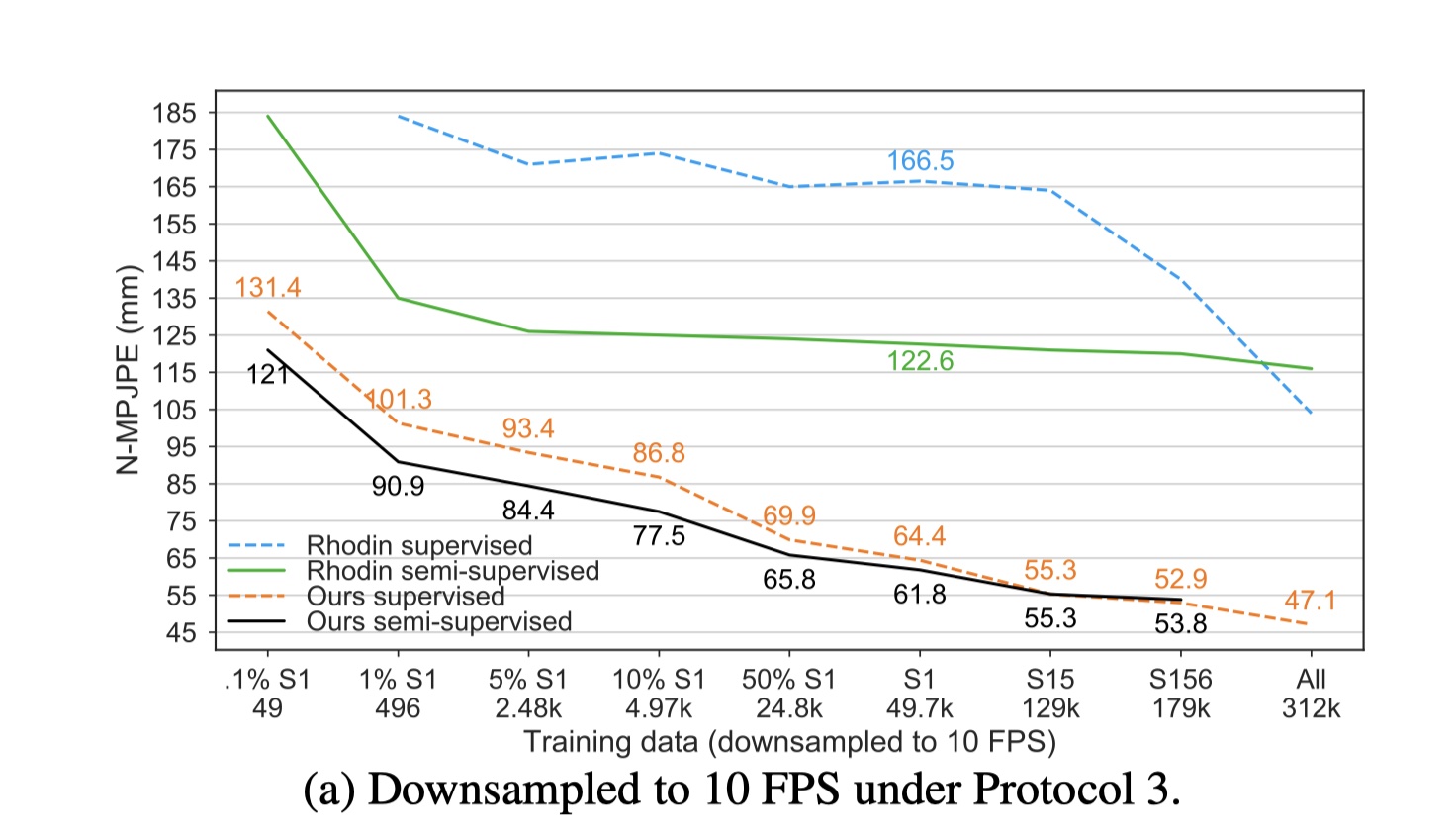
图5a显示,随着标记数据量的减少,我们的半监督方法变得更加有效。 对于标记帧数少于5K的设置,我们的方法在我们的监督基线上实现了约9-10.4 mm NMPJPE的改进。 我们的监督基线比[37]强得多,并且大大超过了他们的所有结果。
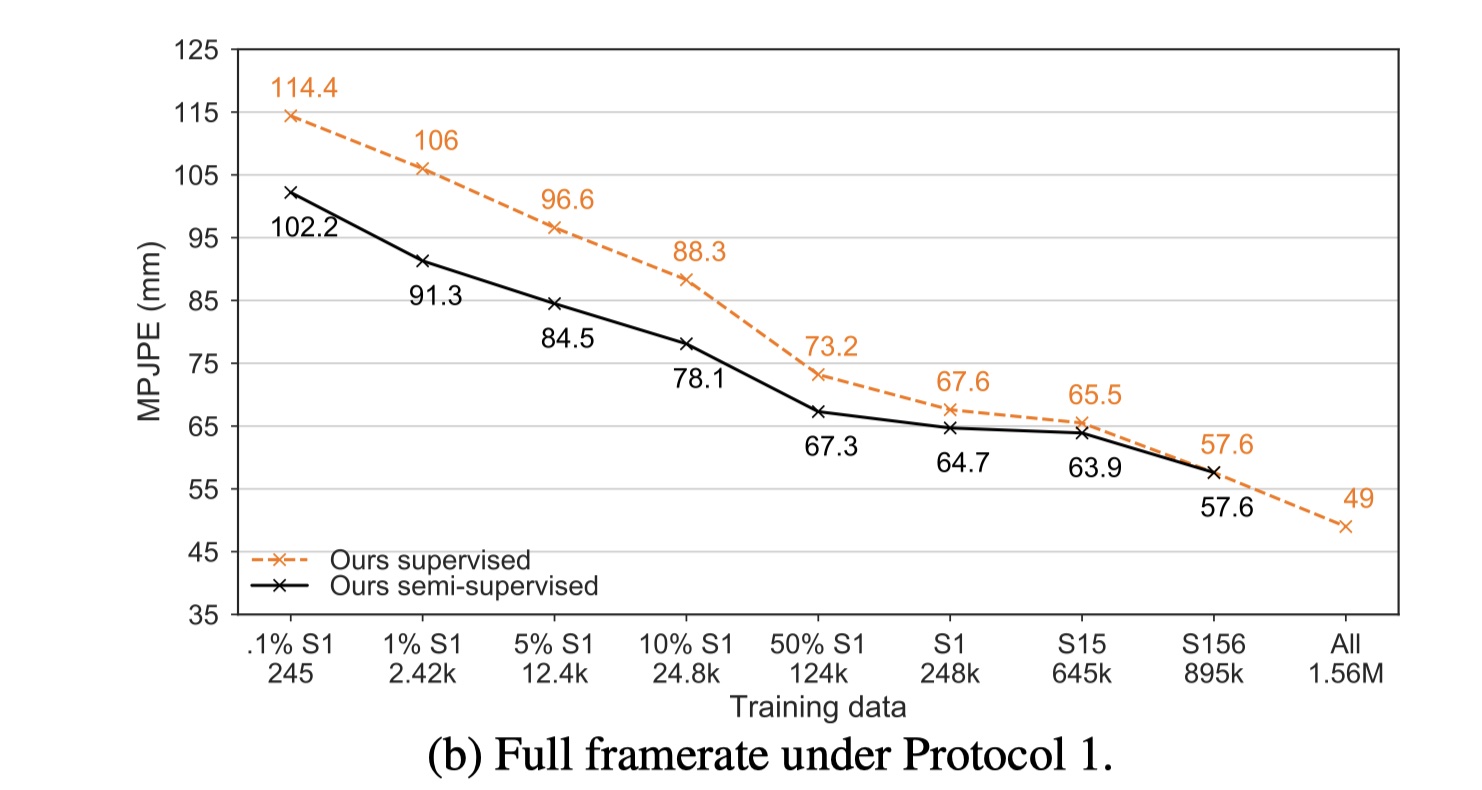
图5b显示了针对数据集的非下采样版本(50 FPS)的更常见的协议1下的我们的方法的结果。 此设置更适合我们的方法,因为它允许我们利用视频中的完整时态信息。 这里我们使用一个27帧的感受野,除了1%的S1,我们使用9帧,和0.1%的S1,我们使用一帧。 我们的半监督方法在监督基线上获得高达14.7 mm的MPJPE。
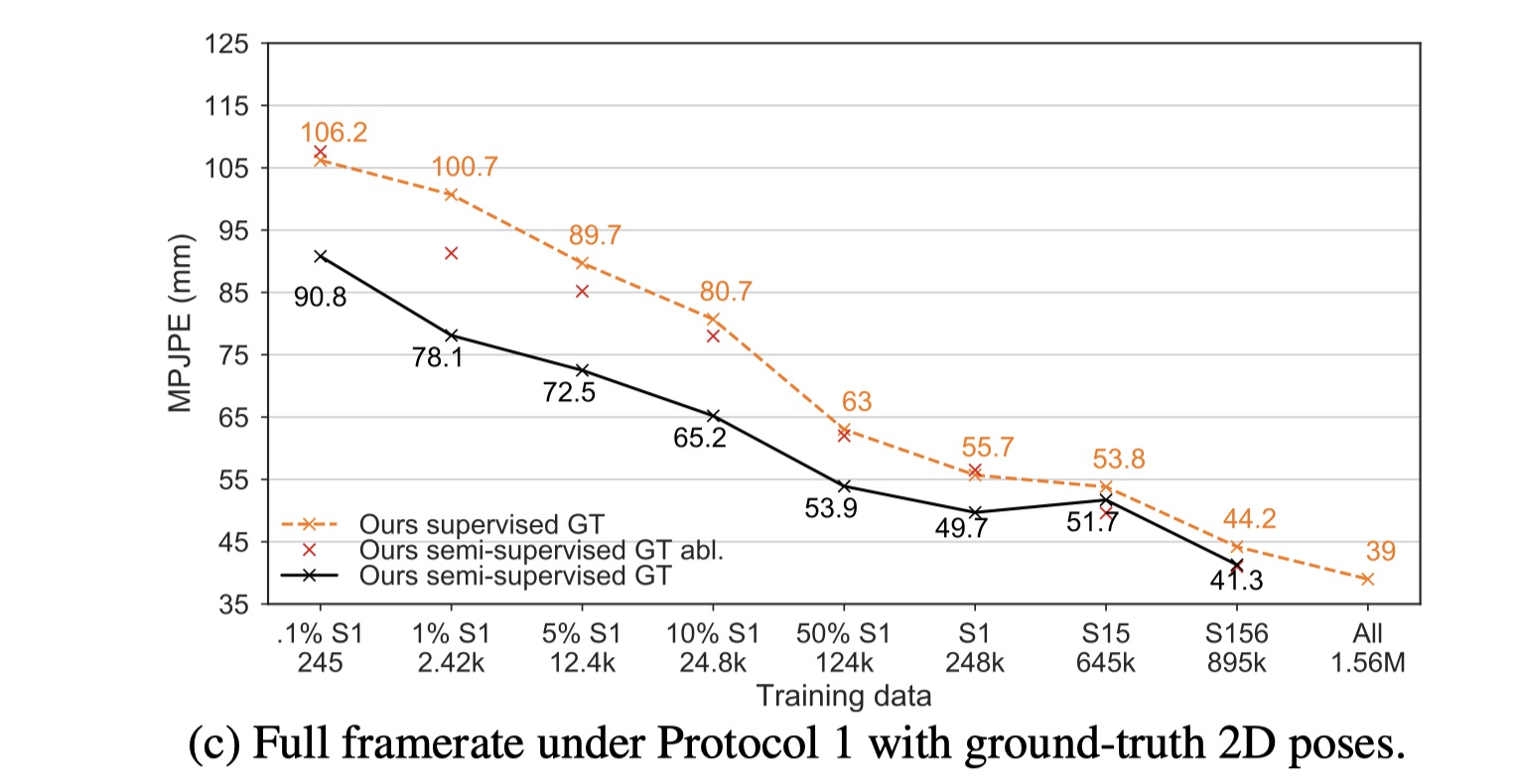
图5c切换用于实际 2D姿势为CPN 检测的2D关键点,以测量我们是否可以使用更好的2D关键点检测器更好地执行。 在这种情况下,改进可以达到22.6 mm MPJPE(S1的1%),这证明了更好的2D检测可以提高性能。 同一图表显示骨骼长度项对于预测有效姿势至关重要,因为它迫使模型遵守运动学约束(图表中的 “our semi-surprised GT abl)。 删除该项会大大降低半监督训练的有效性:对于1%的S1,误差从78.1 mm增加到91.3 mm,而监督训练误差则达到100.7 mm。
我们在视频中引入了一个简单的全卷积模型用于3D人体姿态估计。 我们的架构利用2D关键点轨迹上的空洞卷积来利用时间信息。 这项工作的第二个贡献是反向投影,这是一种半监督的训练方法,用于在标记数据稀缺时提高性能。 该方法适用于未标记的视频,只需要内置的摄像头参数。
我们的全卷积体系结构改善了Human3.6M数据集的先前最佳结果有6mm平均关节误差,相当于相对减少了11%,并且还显示了在HumanEva-I数据集上的大幅改进。 当5K或更少的注释帧可用时,反投影可以在强基线上提高约10mm N-MPJPE(15mm MPJPE)的3D姿态估计精度。
图表6中我们展示了了本模型中的信息流,也强调了对称卷积和因果(causal)卷积之间的差异
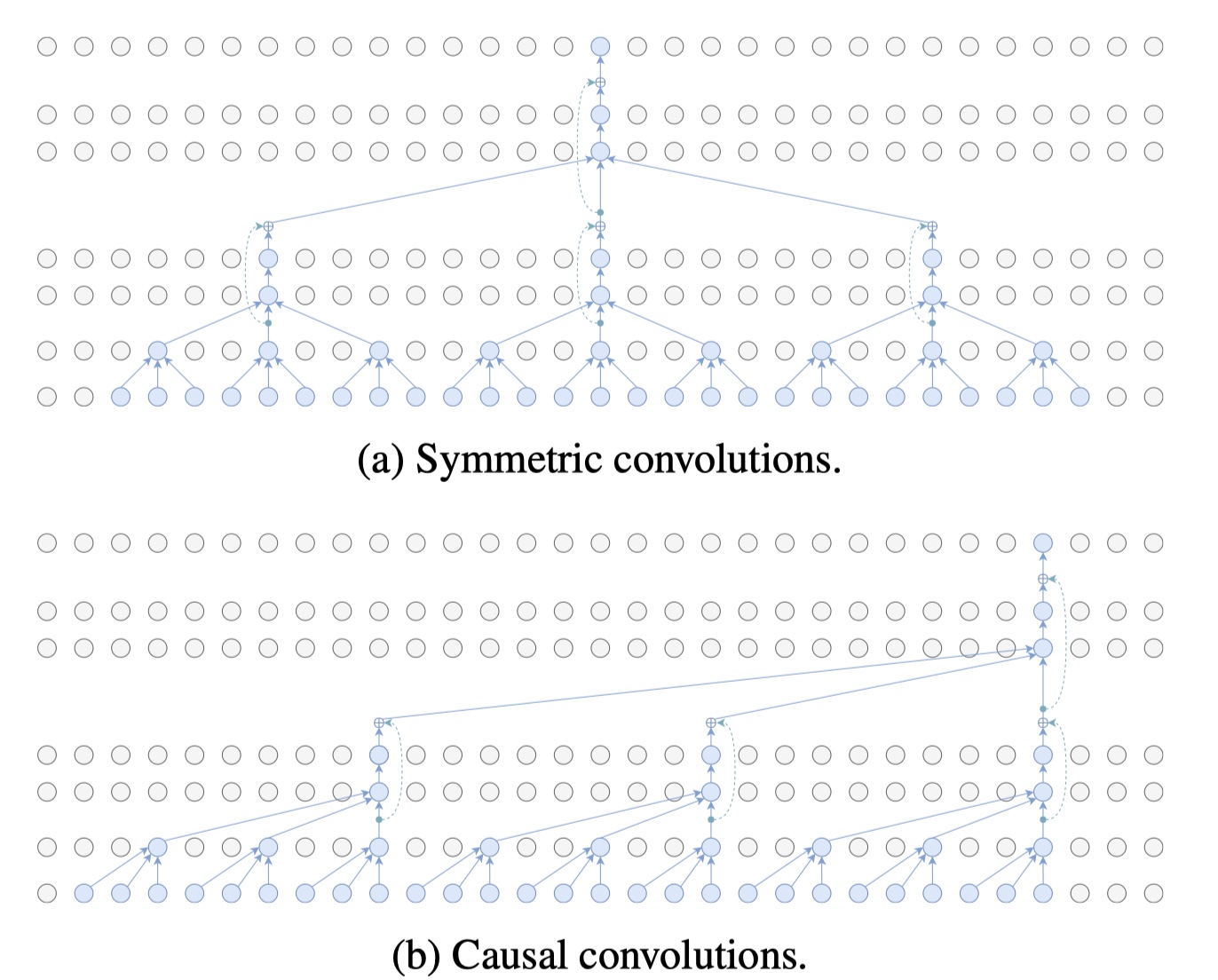
模型中从底(输入)到首(输出)的信息流, 虚线表示skip-connectiobs
在图8b中,我们总结了不感受野的测试误差,即1, 9, 27, 72和243帧。 为此,我们堆叠了不同数量的残差块,每个块将接收场乘以3. 在单帧场景中,我们使用2个残差块并将所有层的卷积宽度设置为1,从而获得功能等效的模型 [30]。 可以看出,随着感受野的增加,该模型似乎并未过拟合, 另一方面,误差趋于快速饱和,这表明3D人体姿态估计的任务不需要建模长期依赖性, 因此,我们通常采用243帧的接收场。 类似地,在图8a中,我们将通道大小在128和2048之间变化,具有相同的结果:模型不容易过度配置,但是误差在某个点之后饱和。 由于计算复杂度相对于信道大小呈二次方增加,因此我们采用C = 1024。
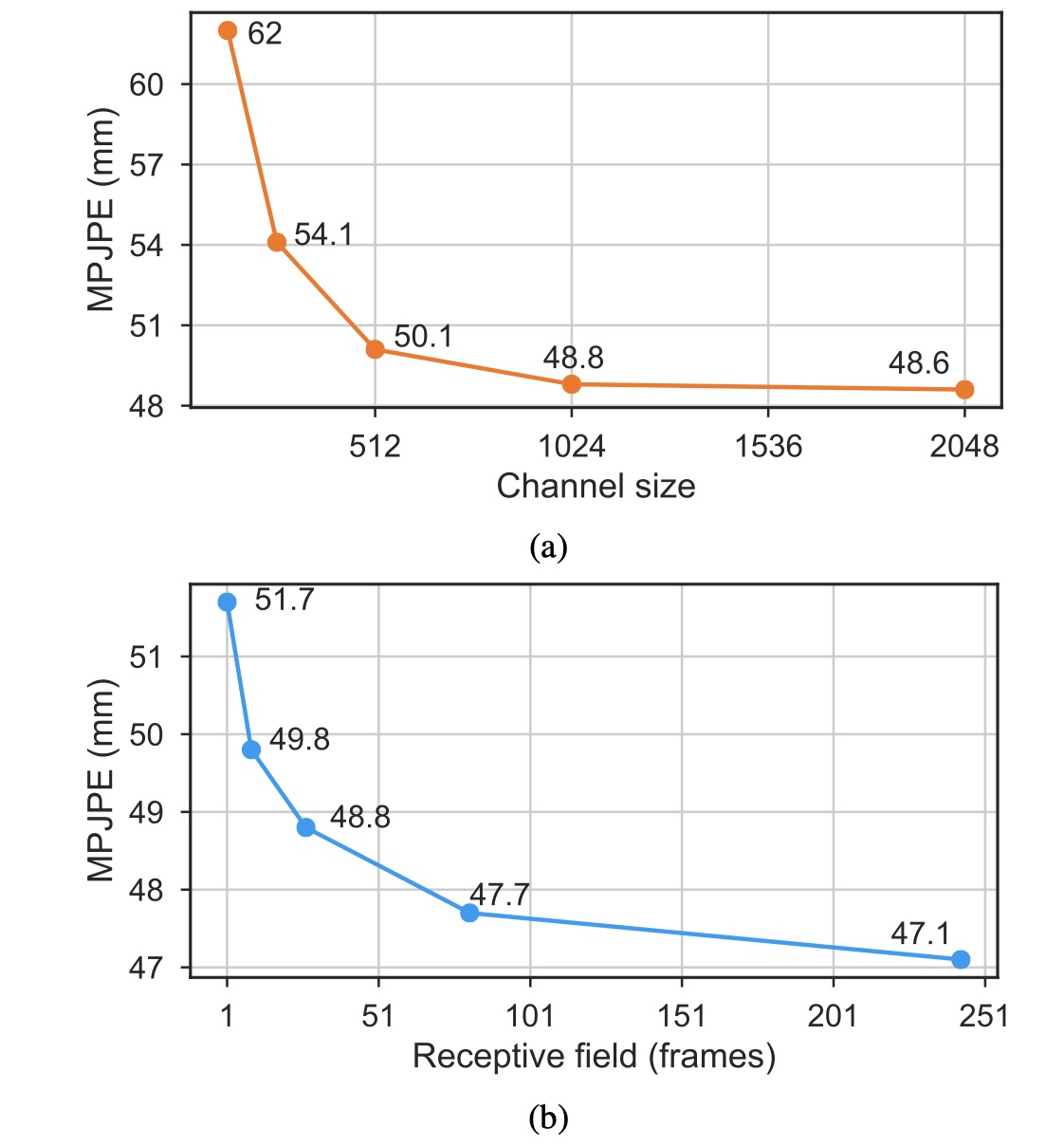
图表8, fine-tune 两个实验的CPN检测器
当我们删除测试阶段的数据增强时,在我们的最佳性能模型中,误差增加到47.7 mm(从46.8 mm)。 如果我们也取消了训练阶段的数据增强,则误差达到49.2 mm(另一个+1.5 mm)。
接下来,我们用常规的密集卷积代替空洞卷积。 在具有27帧的接收场和fine-tune的CPN检测的模型中,误差从48.8mm增加到50.4mm(+ 1.6mm),同时还将参数和计算的数量增加了≈3.5倍。 这突出表明,空洞卷积对于效率至关重要,并且它们抵消了过拟合。
我们认为重建误差在很大程度上取决于模型的训练方式,我们建议以预测一次只有一个输出帧的方式。 为了说明这一点,我们引入了一个新的超参数 - 块大小C(或步长),它指定了每个样本一次预测的帧数。 仅预测一帧,即C = 1,需要完整的接收场F作为输入。 预测两帧(C = 2)需要F + 1帧,依此类推。 很明显,预测多个帧在计算上更有效,因为中间卷积的结果可以在帧之间共享 - 事实上,我们在在interface阶段这样做的。 另一方面,实验显示在训练期间这样做是有害的。
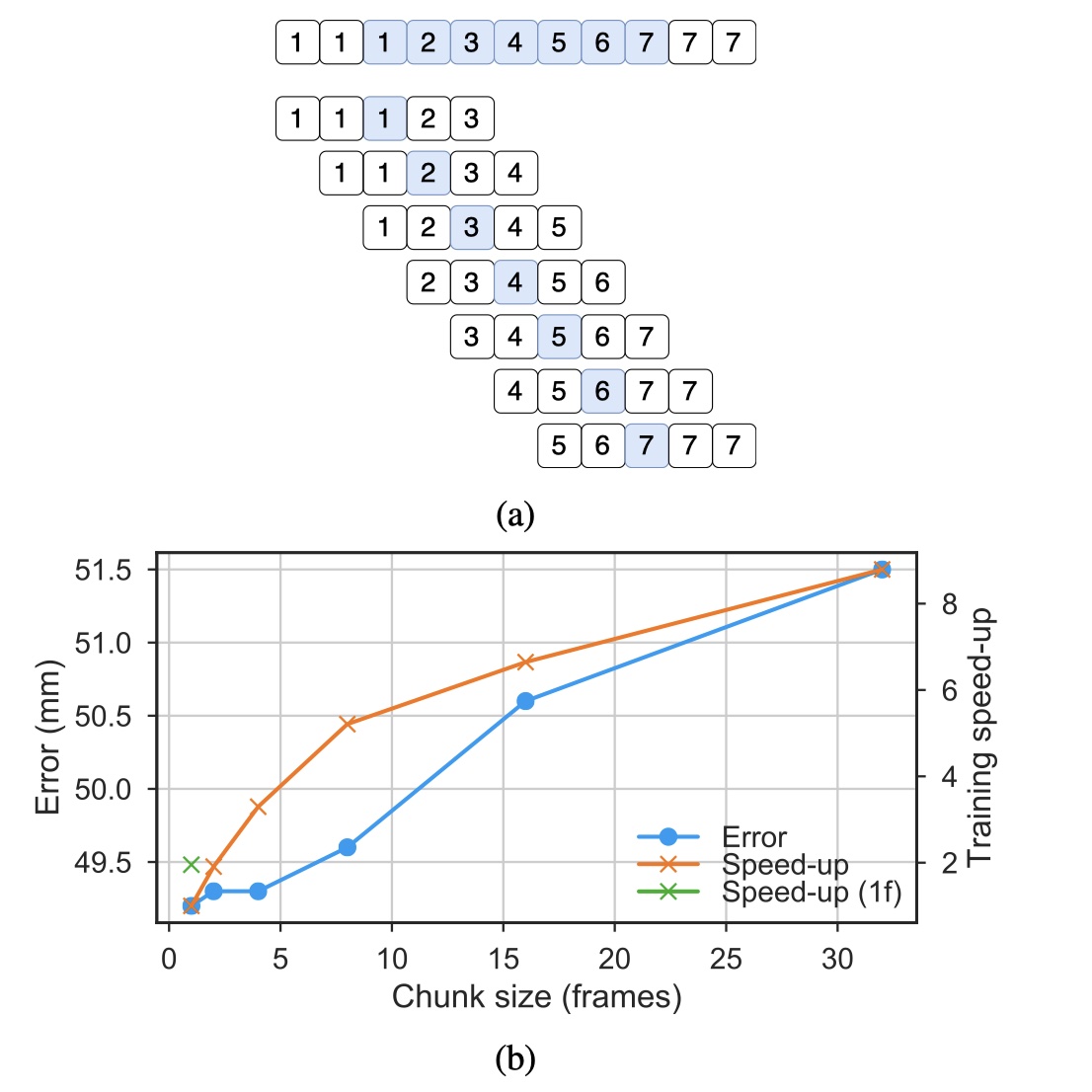
图表8, fine-tune 两个实验的CPN检测器
图9b示出了当训练具有不同步长的27帧模型(即1,2,4,8,16和32帧)时的重建误差(以及训练时间的相对加速)。 由于预测多个帧相当于增加批量大小 - 这不利于泛化结果[22] - 我们通过调整批量大小使结果具有可比性,以便模型始终预测1024帧。 因此,1帧实验采用1024个序列的批量大小,2帧为512,4帧为256,依此类推。 该方法还确保模型将以相同数量的重量更新进行训练。
结果表明,误差随步长的减小而减小,但代价是训练速度。 高步长训练模型的性能受损是由相关性批次统计引起的[12]。 我们针对单帧输出优化的实现了2倍的加速,但是对于具有较大接收场的模型(例如,≈4具有81帧),该增益甚至更高,并且使我们能够训练具有243帧的模型。
图10显示了为单帧预测定制的实施方案的重要性。 常规实现是逐层计算中间状态,这对于长序列非常有效,因为在层n中计算的状态可以由层n + 1重用,而无需重新计算它们。 但是,对于短序列,这种方法变得无效,因为不使用靠近边界的状态。 在单帧预测(我们用于训练)的极端情况下,浪费了许多中间计算,如图10a所示。 在这种情况下,我们用跨步卷积代替扩张的卷积,确保获得在功能上等同于原始的卷积模型(例如,通过也适应跳过连接)。 该策略确保不会丢弃任何中间状态。
如上所述,在推理中,我们使用常规的逐层实现,因为它更有效地进行多帧预测。
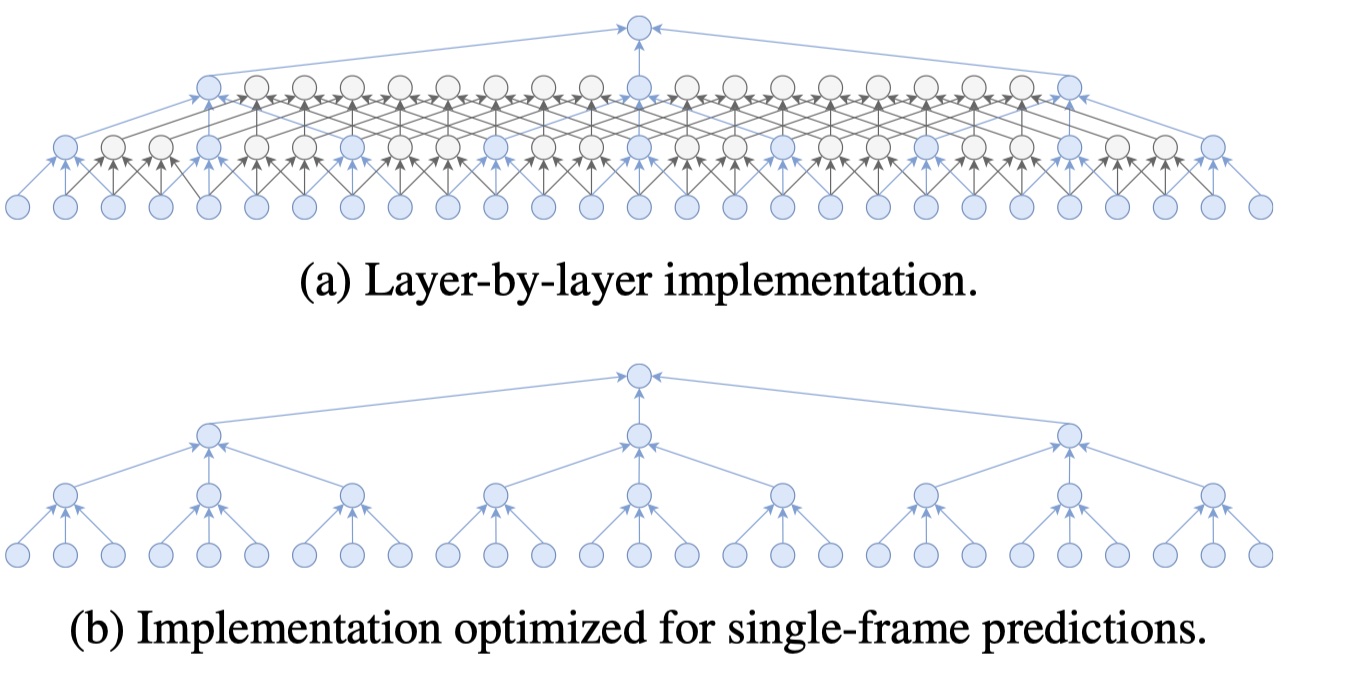
比较于感受野为243的两种实现,在层到层的实现中,多个中间状态被丢弃,只保留实现过程中所需要的状态。随着训练序列长度的增加,层到层的实现方式变的更加高效。
补充材料包含几个视频,突出显示我们的时间卷积模型与单帧基线相比的预测的平滑性。 具体而言,我们并排显示由单帧基线预测的3D姿势,来自时间卷积模型的3D姿势以及实际的3D姿势。 一些演示视频也可以在https://dariopavllo.githubIO/VideoPose3D上找到。
[1] M. Andriluka, L. Pishchulin, P. Gehler, and B. Schiele. 2d human pose estimation: New benchmark and state of the art analysis. In Conference on Computer Vision and Pattern Recognition (CVPR), pages 3686–3693, 2014. 2
[2] R. Caruana. Multitask learning. Machine learning, 28(1):41–75, 1997. 2
[3] C.-H. Chen and D. Ramanan. 3D human pose estimation = 2D pose estimation + matching. In Conference on Computer Vision and Pattern Recognition (CVPR), pages 5759–5767, 2017. 2
[4] Y. Chen, Z. Wang, Y. Peng, and Z. Zhang. Cascaded pyramid network for multi-person pose estimation. In Conference on Computer Vision and Pattern Recognition (CVPR), 2018. 2, 4
[5] R. Collobert, C. Puhrsch, and G. Synnaeve. Wav2letter: an end-to-end convnet-based speech recognition system. arXiv preprint arXiv:1609.03193, 2016. 1
[6] Y. N. Dauphin, A. Fan, M. Auli, and D. Grangier. Language modeling with gated convolutional networks. In International Conference on Machine Learning (ICML), 2017. 1
[7] S. Edunov, M. Ott, M. Auli, and D. Grangier. Understanding back-translation at scale. In Proc. of EMNLP, 2018. 1
[8] H. Fang, Y. Xu, W. Wang, X. Liu, and S.-C. Zhu. Learning pose grammar to encode human body configuration for 3d pose estimation. In AAAI, 2018. 1, 4, 6
[9] J. Gehring, M. Auli, D. Grangier, D. Yarats, and Y. N. Dauphin. Convolutional sequence to sequence learning. In International Conference on Machine Learning (ICML), 2017. 1
[10] K. He, G. Gkioxari, P. Doll´ar, and R. Girshick. Mask R-CNN. In International Conference on Computer Vision (ICCV), pages 2980–2988. IEEE, 2017. 2, 4, 5
[11] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In Conference on Computer Vision and Pattern Recognition (CVPR), pages 770–778, 2016. 3
[12] E. Hoffer, R. Banner, I. Golan, and D. Soudry. Norm matters: efficient and accurate normalization schemes in deep networks. arXiv preprint arXiv:1803.01814, 2018. 12
[13] M. Holschneider, R. Kronland-Martinet, J. Morlet, and
P. Tchamitchian. A real-time algorithm for signal analysis with the help of the wavelet transform. Wavelets, TimeFrequency Methods and Phase Space, -1:286, 01 1989. 3
[14] M. R. I. Hossain and J. J. Little. Exploiting temporal information for 3d pose estimation. In European Conference on Computer Vision (ECCV),2018. 1, 2, 4, 6, 7, 11
[15] S. Ioffe and C. Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In International Conference on Machine Learning (ICML), pages 448–456, 2015. 3, 5
[16] C. Ionescu, J. Carreira, and C. Sminchisescu. Iterated second-order label sensitive pooling for 3d human pose estimation. In Conference on Computer Vision and Pattern Recognition (CVPR), pages 1661–1668, 2014. 2
[17] C. Ionescu, F. Li, and C. Sminchisescu. Latent structured models for human pose estimation. In International Conference on Computer Vision (ICCV), 2011. 4
[18] C. Ionescu, D. Papava, V. Olaru, and C. Sminchisescu. Human3.6m: Large scale datasets and predictive methods for 3D human sensing in natural environments. Transaction on Pattern Analysis and Machine Intelligence (TPAMI), 2014. 2, 4, 5
[19] H. Jiang. 3d human pose reconstruction using millions of exemplars. In International Conference on Pattern Recognition (ICPR), pages 1674–1677. IEEE, 2010. 2
[20] N. Kalchbrenner, L. Espeholt, K. Simonyan, A. van den Oord, A. Graves, and K. Kavukcuoglu. Neural machine translation in linear time. arXiv, abs/1610.10099, 2016. 3
[21] I. Katircioglu, B. Tekin, M. Salzmann, V. Lepetit, and P. Fua. Learning latent representations of 3d human pose with deep neural networks. International Journal of Computer Vision (IJCV), pages 1–16, 2018. 2
[22] N. S. Keskar, D. Mudigere, J. Nocedal, M. Smelyanskiy, and
P. T. P. Tang. On large-batch training for deep learning: Generalization gap and sharp minima. In International Conference on Learning Representations (ICLR), 2017. 12
[23] G. Lample, A. Conneau, L. Denoyer, and M. Ranzato. Unsupervised machine translation using monolingual corpora only. In International Conference on Learning Representations (ICLR), 2018. 1
[24] K. Lee, I. Lee, and S. Lee. Propagating lstm: 3d pose estimation based on joint interdependency. In European Conference on Computer Vision (ECCV), pages 119–135, 2018. 1, 2, 4, 5, 6, 7
[25] S. Li and A. B. Chan. 3d human pose estimation from monocular images with deep convolutional neural network. In Asian Conference on Computer Vision (ACCV), pages 332–347. Springer, 2014. 2
[26] S. Li, W. Zhang, and A. B. Chan. Maximum-margin structured learning with deep networks for 3d human pose estimation. In International Conference on Computer Vision (ICCV), pages 2848–2856, 2015. 4, 5
[27] T.-Y. Lin, P. Doll´ar, R. B. Girshick, K. He, B. Hariharan, and
S. J. Belongie. Feature pyramid networks for object detection. In Conference on Computer Vision and Pattern Recognition (CVPR), pages 936–944, 2017. 4, 6
[28] T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Doll´ar, and C. L. Zitnick. Microsoft COCO: Common objects in context. In European conference on computer vision (ECCV), pages 740–755. Springer, 2014. 4, 6
[29] D. C. Luvizon, D. Picard, and H. Tabia. 2d/3d pose estimation and action recognition using multitask deep learning. In Conference on Computer Vision and Pattern Recognition (CVPR), volume 2, 2018. 1, 2, 4, 5, 6
[30] J. Martinez, R. Hossain, J. Romero, and J. J. Little. A simple yet effective baseline for 3d human pose estimation. In International Conference on Computer Vision (ICCV), pages 2659–2668, 2017. 1, 2, 4, 5, 6, 7, 11
[31] V. Nair and G. E. Hinton. Rectified linear units improve restricted boltzmann machines. In International Conference on Machine Learning (ICML), pages 807–814, 2010. 3
[32] A. Newell, K. Yang, and J. Deng. Stacked hourglass networks for human pose estimation. In European Conference on Computer Vision, pages 483–499. Springer, 2016. 2, 4
[33] G. Pavlakos, X. Zhou, and K. Daniilidis. Ordinal depth supervision for 3d human pose estimation. Conference onComputer Vision and Pattern Recognition (CVPR), 2018. 1, 2, 4, 6, 7
[34] G. Pavlakos, X. Zhou, K. G. Derpanis, and K. Daniilidis. Coarse-to-fine volumetric prediction for single-image 3d human pose. In Conference on Computer Vision and Pattern Recognition (CVPR), pages 1263–1272. IEEE, 2017. 1, 2, 4, 5, 6, 7
[35] S. J. Reddi, S. Kale, and S. Kumar. On the convergence of Adam and beyond. In International Conference on Learning Representations (ICLR), 2018. 5
[36] S. Ren, K. He, R. Girshick, and J. Sun. Faster R-CNN: Towards real-time object detection with region proposal networks. In Advances in Neural Information Processing Systems (NIPS), pages 91–99, 2015. 6
[37] H. Rhodin, M. Salzmann, and P. Fua. Unsupervised geometry-aware representation for 3D human pose estimation. In European Conference on Computer Vision (ECCV), 2018. 2, 4, 7, 8
[38] R. Sennrich, B. Haddow, and A. Birch. Neural machine translation of rare words with subword units. In Proc. of ACL, 2016. 1
[39] L. Sigal, A. O. Balan, and M. J. Black. HumanEva: Synchronized video and motion capture dataset and baseline algorithm for evaluation of articulated human motion. International Journal of Computer Vision (IJCV), 87(1-2):4, 2010. 4
[40] C. Sminchisescu. 3d human motion analysis in monocular video: techniques and challenges. In Human Motion, pages 185–211. Springer, 2008. 2
[41] N. Srivastava, G. Hinton, A. Krizhevsky, I. Sutskever, and
R. Salakhutdinov. Dropout: a simple way to prevent neural networks from overfitting. The Journal of Machine Learning Research, 15(1):1929–1958, 2014. 3
[42] X. Sun, J. Shang, S. Liang, and Y. Wei. Compositional human pose regression. In International Conference on Computer Vision (ICCV), pages 2621–2630, 2017. 1, 4, 6
[43] B. Tekin, I. Katircioglu, M. Salzmann, V. Lepetit, and P. Fua. Structured prediction of 3d human pose with deep neural networks. In British Machine Vision Conference (BMVC), 2016. 2
[44] B. Tekin, P. Marquez Neila, M. Salzmann, and P. Fua. Learning to fuse 2d and 3d image cues for monocular body pose estimation. In International Conference on Computer Vision (ICCV), 2017. 1, 2, 4, 6
[45] B. Tekin, A. Rozantsev, V. Lepetit, and P. Fua. Direct prediction of 3d body poses from motion compensated sequences. In Conference on Computer Vision and Pattern Recognition (CVPR), pages 991–1000, 2016. 2, 4, 5
[46] A. Van Den Oord, S. Dieleman, H. Zen, K. Simonyan,O. Vinyals, A. Graves, N. Kalchbrenner, A. Senior, and K. Kavukcuoglu. Wavenet: A generative model for raw audio. arXiv preprint arXiv:1609.03499, 2016. 1, 3
[47] W. Yang, W. Ouyang, X. Wang, J. Ren, H. Li, and X. Wang. 3d human pose estimation in the wild by adversarial learning. In Conference on Computer Vision and Pattern Recognition (CVPR), volume 1, 2018. 1, 2, 4, 6
[48] F. Yu and V. Koltun. Multi-scale context aggregation by dilated convolutions. In International Conference on Learning Representations (ICLR), 2016. 3
[49] X. Zhou, Q. Huang, X. Sun, X. Xue, and Y. Wei. Towards 3d human pose estimation in the wild: a weakly-supervised approach. In Conference on Computer Vision and Pattern Recognition (CVPR), 2017. 2, 4
[50] X. Zhou, M. Zhu, S. Leonardos, K. G. Derpanis, and
K. Daniilidis. Sparseness meets deepness: 3d human pose estimation from monocular video. In Conference on Computer Vision and Pattern Recognition (CVPR), pages 49664975, 2016. 4, 5