网络上的"喷子"现象导致新闻文章评论区充斥着大量谩骂言辞。为了提升平台品质和用户体验,急需解决如何自动拦截这些谩骂评论的问题。本文旨在通过构建卷积神经网络模型,实现对谩骂评论的自动识别,以机器方式对抗这些网络喷子。
在新闻文章评论中,经常可见包括对新闻人物的辱骂、对编辑的恶语以及评论回复中对楼主的攻击等谩骂言辞,这不仅损害了平台的声誉和品质,更直接影响了用户的使用体验。因此,减少谩骂评论的出现成为迫切需要解决的问题。鉴于评论数量庞大,仅依赖人工审核显然是不切实际的。我们的目标是建立一种自动识别算法,通过模型拦截这些脏话脏语,从而有效净化评论区。
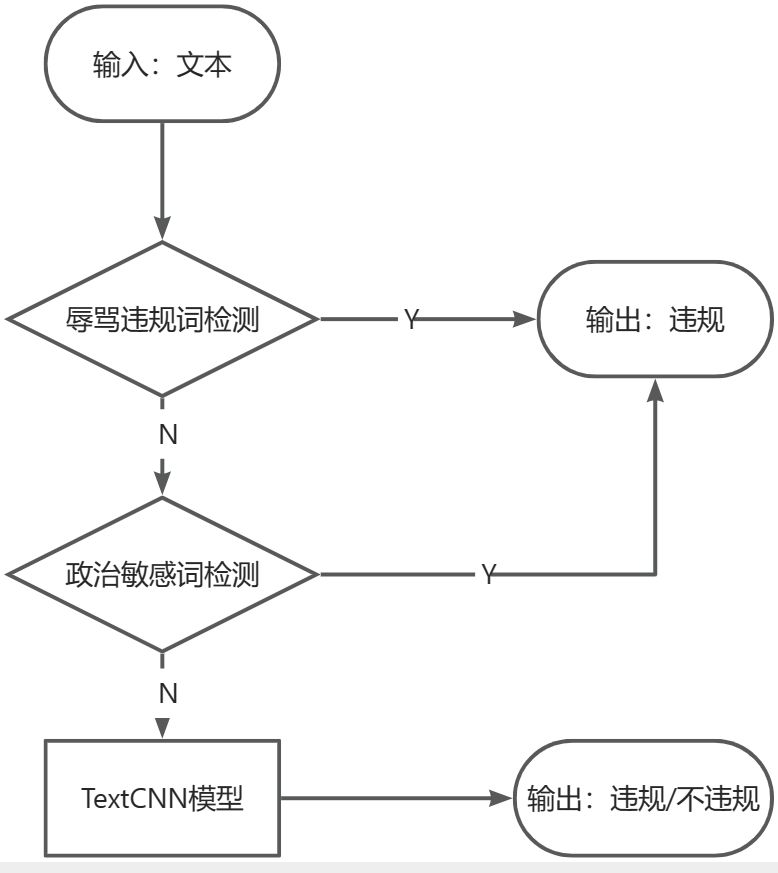
- 预处理阶段:
-
- 文本清洗:去除无关字符、标点符号,统一大小写等,以规范输入文本。
- 分词处理:将文本划分为词汇,有助于更精准地进行后续检测。
- 辱骂违规词检测:
-
- 建立违规词库:维护一个包含辱骂和不当言辞的词汇库,定期更新以适应新的网络用语。
- 多层次匹配:采用多层次的匹配策略,包括精确匹配、模糊匹配和同义词匹配,提高检测的准确性。
- 动态过滤:考虑引入动态过滤机制,即根据用户行为和社交网络动态,调整违规词库,使其更符合实际使用情境。
- 政治敏感词检测:
-
- 建立敏感词库:创建一个包含政治敏感词汇的库,以便检测涉及政治敏感话题的评论。
- 关联性分析:考虑评论中词汇的关联性,以防止误判。某些词汇可能在特定上下文中并非政治敏感,因此需要综合考虑。
- TextCNN模型:
-
- 模型架构:确保TextCNN模型具有合适的深度和广度,以捕捉评论中的语义和上下文信息。
- 多通道卷积:考虑使用多个卷积核和多通道的卷积层,以捕获不同尺度的特征。
- 输出和审核结果:
-
- 综合判断:融合辱骂违规词检测、政治敏感词检测和TextCNN模型的输出,形成最终的审核决策。
- 可解释性:为了提高模型的可解释性,记录各个阶段的判断结果,以便后续调整和分析。
总结逻辑设计的好处:
- 多层次策略:通过多层次的违规词检测和模型判断,提高了对违规评论的综合判断能力。
- 实时适应性:动态过滤机制和动态更新词库能够使模型更好地适应不断变化的网络用语和社交动态。
- 综合性能:综合利用违规词检测和深度学习模型,既考虑了明显的违规用语,也能够处理语义和上下文信息。
- 可解释性:记录各个阶段的判断结果,有助于理解模型的决策过程,方便进一步优化和维护。
通过这样细致和综合的设计,可以提高评论审核模型的准确性和鲁棒性,更好地满足实际需求。
- 参考文章:https://cloud.tencent.com/developer/article/1068648
- 数据来源:https://github.com/wjx-git/IllegalTextDetection
以下是TextCNN模型的结构图,结构简单,即使在CPU也能训练:
Input: 文本序列 (batch, sentence_length)
|
V
Embedding层: (batch, sentence_length, embed_dim)
| \
V V
Conv2D + ReLU + MaxPool: (batch, kernel_num) (conv11)
|
V
Conv2D + ReLU + MaxPool: (batch, kernel_num) (conv12)
|
V
Conv2D + ReLU + MaxPool: (batch, kernel_num) (conv13)
|
V
| | |
V V V
Concatenate: (batch, 3 * kernel_num)
|
V
Dropout层: (batch, 3 * kernel_num)
|
V
全连接层: 输出 (batch, class_num)- Embedding层:
-
- 作用:将输入的文本序列中的每个词汇映射为对应的词向量,提供词汇的语义信息。
- Conv2D + ReLU + MaxPool(conv11、conv12、conv13,三个相同结构的层):
-
- 作用:这三个层组成了多个不同尺寸的卷积核,用于捕捉输入文本中不同尺度的语义特征。
- Conv2D:卷积操作用于检测输入文本中的局部模式。
- ReLU:激活函数引入非线性,增强模型表达能力。
- MaxPool:最大池化操作用于降维,保留最显著的特征。
- Concatenate:
-
- 作用:将三个卷积核得到的不同尺度的特征连接在一起,使模型能够同时考虑多个尺度的语义信息。
- Dropout层:
-
- 作用:在训练过程中随机丢弃部分神经元,减少过拟合的风险。
- 全连接层:
-
- 作用:将连接后的特征映射到最终的输出类别空间,用于文本分类任务。
这个textCNN模型通过嵌入层、卷积层、全连接层等组件,能够有效地捕捉输入文本的语义信息,并用于文本分类。
当我们使用嵌入层时,我们将每个单词的索引映射为一个词向量。让我们假设我们有一个词汇表,其中包含5个单词:['I', 'love', 'natural', 'language', 'processing'],并且我们选择一个嵌入维度 embed_dim 为 4。
如果我们的输入文本是 "I love language",我们可以将它表示为索引序列 [0, 1, 3],其中 "I" 的索引是 0,"love" 的索引是 1,"language" 的索引是 3。
通过嵌入层,我们可以将这些索引映射为词向量。假设我们的嵌入层参数是随机初始化的,那么可能的映射如下:
Embedding Matrix:
[[ 0.1, 0.2, 0.3, 0.4], # 对应 "I"
[ 0.5, 0.6, 0.7, 0.8], # 对应 "love"
[ 0.9, 1.0, 1.1, 1.2], # 对应 "natural"
[ 1.3, 1.4, 1.5, 1.6], # 对应 "language"
[ 1.7, 1.8, 1.9, 2.0]] # 对应 "processing"
输入序列 [0, 1, 3] 对应的词向量:
[[ 0.1, 0.2, 0.3, 0.4], # 对应 "I"
[ 0.5, 0.6, 0.7, 0.8], # 对应 "love"
[ 1.3, 1.4, 1.5, 1.6]] # 对应 "language"
这就是嵌入层的作用:将文本中的单词索引映射为对应的词向量。这些词向量将成为模型的输入,帮助模型理解文本中的语义信息。在训练的过程中,这些嵌入矩阵的权重会被学习,以更好地适应具体的任务。
在文本处理中,原始的单词索引是一维的,通过嵌入操作,我们将这一维的离散索引映射为连续的词向量,从而引入了更多的语义信息。嵌入操作将原始的离散表示转换成密集的连续表示,这样模型可以更好地理解词汇之间的语义关系。
嵌入的维度(embed_dim)通常是一个超参数,可以根据任务和数据集的性质进行调整。较大的嵌入维度能够提供更丰富的语义信息,但也需要更多的计算资源和数据来进行训练。
本文的数据处理过程涵盖以下主要步骤:
- 通过对原始数据集
train.txt进行处理,生成词表word_list.txt。为了提升词表的容量,我们并未设定单词阈值,而是完全将所有单词纳入词表中。
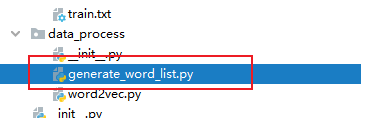
- 利用生成的词表
word_list.txt,将train.txt、dev.txt和test.txt转换为相应的单词索引向量。


采用Python3.9,conda环境,
可手动安装以下依赖(不写版本号默认最新版)其余依赖应该会自动装好,如果没有,按需安装即可:
- pytorch(从官方下载自己设备适配的版本即可)
- jieba
- nltk
- pandas
- re(Python自带)
- tqdm
- numpy
- flask
- flask_cors
- gunicorn(处理高并发的服务器,云部署时用)
所有依赖包信息如下:
Package Version
anyio 3.6.2
argon2-cffi 21.3.0
argon2-cffi-bindings 21.2.0
asttokens 2.2.1
attrs 22.2.0
backcall 0.2.0
beautifulsoup4 4.11.1
bleach 6.0.0
blinker 1.7.0
bs4 0.0.1
certifi 2022.12.7
cffi 1.15.1
chardet 4.0.0
charset-normalizer 3.0.1
click 8.1.7
cloudpickle 2.2.1
colorama 0.4.6
comm 0.1.2
contourpy 1.0.5
cycler 0.11.0
d2l 0.17.6
debugpy 1.6.6
decorator 5.1.1
defusedxml 0.7.1
et-xmlfile 1.1.0
executing 1.2.0
filelock 3.13.1
Flask 3.0.0
Flask-Cors 4.0.0
fonttools 4.37.4
fsspec 2023.12.2
idna 2.10
imageio 2.26.0
importlib-metadata 6.0.0
ipykernel 6.20.2
ipython 8.8.0
ipython-genutils 0.2.0
ipywidgets 8.0.4
itsdangerous 2.1.2
jdcal 1.4.1
jedi 0.18.2
jieba 0.42.1
Jinja2 3.1.2
joblib 1.3.2
jsonschema 4.17.3
jupyter 1.0.0
jupyter_client 8.0.1
jupyter-console 6.4.4
jupyter_core 5.1.5
jupyter-events 0.6.3
jupyter_server 2.1.0
jupyter_server_terminals 0.4.4
jupyterlab-pygments 0.2.2
jupyterlab-widgets 3.0.5
kiwisolver 1.4.4
lazy_loader 0.1
MarkupSafe 2.1.2
matplotlib 3.5.1
matplotlib-inline 0.1.6
mistune 2.0.4
mpmath 1.3.0
nbclassic 0.5.1
nbclient 0.7.2
nbconvert 7.2.9
nbformat 5.7.3
nest-asyncio 1.5.6
networkx 3.2.1
nltk 3.8.1
notebook 6.5.2
notebook_shim 0.2.2
numpy 1.26.2
openpyxl 3.2.0b1
packaging 21.3
pandas 2.1.4
pandocfilters 1.5.0
parso 0.8.3
pickleshare 0.7.5
Pillow 9.2.0
pip 23.3.1
platformdirs 2.6.2
prometheus-client 0.16.0
prompt-toolkit 3.0.36
psutil 5.9.4
psycopg2 2.9.6
pure-eval 0.2.2
pycparser 2.21
pygad 2.19.2
Pygments 2.14.0
pyparsing 3.0.9
pyrsistent 0.19.3
python-dateutil 2.8.2
python-json-logger 2.0.4
pytz 2022.4
PyWavelets 1.4.1
pywin32 305
pywinpty 2.0.10
pyzmq 25.0.0
qtconsole 5.4.0
QtPy 2.3.0
regex 2023.10.3
requests 2.25.1
rfc3339-validator 0.1.4
rfc3986-validator 0.1.1
Send2Trash 1.8.0
sentencepiece 0.1.99
setuptools 68.2.2
six 1.16.0
sklearn 0.0.post1
sniffio 1.3.0
soupsieve 2.3.2.post1
stack-data 0.6.2
sympy 1.12
terminado 0.17.1
tifffile 2023.2.28
tinycss2 1.2.1
torch 2.1.2
torchaudio 2.1.2
torchdata 0.7.1
torchtext 0.6.0
torchvision 0.16.2
tornado 6.2
tqdm 4.66.1
traitlets 5.8.1
typing_extensions 4.4.0
tzdata 2023.3
urllib3 1.26.14
wcwidth 0.2.6
webencodings 0.5.1
websocket-client 1.5.0
Werkzeug 3.0.1
wheel 0.41.2
widgetsnbextension 4.0.5
xlrd 2.0.1
zipp 3.11.0
这段模型训练文件的相关信息总结如下:
- textCNN模型:
-
- 输入:文本序列
- 嵌入层:词表大小为
vocab_size,嵌入维度为embed_dim - 三个卷积核(kernel_num=16):分别大小为 3、4、5
- Dropout层:丢弃率为 0.5
- 全连接层:输出类别数量为
class_num(这里为2)
- 通过
word2vec模块加载词表映射,得到word2ind和ind2word。 - 数据集参数
dataLoader_param: -
batch_size: 128shuffle: True
- 优化器:Adam,学习率为 0.01
- 损失函数:负对数似然损失(NLLLoss)
- 模型参数初始化:
-
- 如果已存在保存的权重文件
textCNN.pkl,则加载权重 - 否则,使用
init_weight方法初始化权重
- 如果已存在保存的权重文件
- 日志记录:每个epoch记录每个batch的训练损失,保存在日志文件
log_YYMMDDHH.txt中。 - 训练时遍历数据集,进行前向传播、计算损失、反向传播更新参数。
- 每50个batch输出一次当前epoch的训练损失。
- 每个epoch结束后输出该epoch的平均训练损失。
- 训练总共进行了100个epoch。
- 训练完成后,保存模型权重到文件
textCNN.pkl。

最后,经过100轮训练,可将验证损失控制在0.01,效果良好。
经过类似的步骤,执行test.py文件即可得到测试结果,并将结果保存至日志文件log_test中
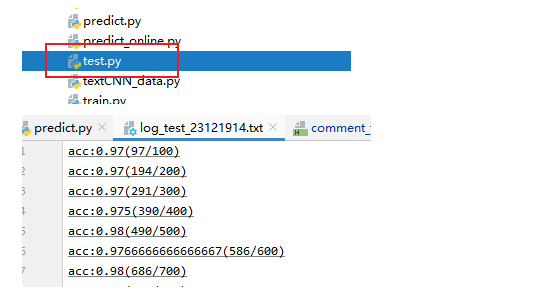
可以看到,测试准确率也维持在97%以上,模型可用。
主要利用Flask进行本地网络api部署,操作简单易行,同时提供了html页面进行简单测试,也可使用接口测试工具如apifox、postman进行测试。

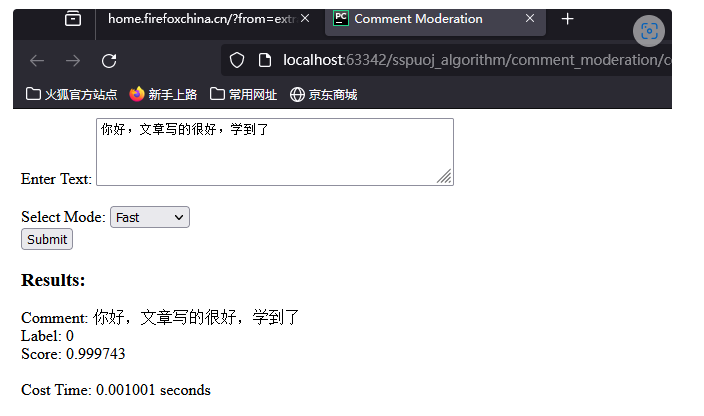
这里以apifox为例:

- 阿里云轻量应用服务器,系统为centos7
- conda环境:如未安装,可参考此博客:https://blog.csdn.net/wyf2017/article/details/118676765
- 使用前根据本文5.2安装依赖即可
- 记得将本地文件上传至服务器
在生产环境中,Flask自带的开发服务器通常不适用于处理高负载和并发请求。Flask的开发服务器是单线程的,并不是为了处理大量并发请求而设计的。它更适合在开发环境中使用,用于调试和测试。
以下是使用 Flask开发服务器的一些主要限制:
- 单线程处理请求: Flask的开发服务器是单线程的,意味着它一次只能处理一个请求。在高并发情况下,这可能导致性能瓶颈。
- 不适合生产环境: Flask的开发服务器没有被设计为在生产环境中处理大规模负载的工具。它缺乏许多生产服务器所具有的优化和安全功能。
- 有安全风险: Flask的开发服务器没有像生产级服务器那样经过严格的安全审查和配置。在生产环境中使用它可能会增加安全风险。
为了解决这些问题,通常建议在生产环境中使用专业的Web服务器,如Gunicorn、uWSGI等。这些服务器可以处理更多的并发请求,提供更好的性能和安全性,并具有适用于生产环境的配置选项。
Gunicorn就是在生产环境中使用专业的Web服务器。
在使用 Gunicorn 启动 Flask 应用时,可以使用 Gunicorn 的 --workers 选项指定工作进程的数量,以实现并发处理请求。每个工作进程都是一个独立的进程,可以独立运行应用代码。
以下是一些示例命令,演示如何在 Gunicorn 中启动 Flask 应用并设置多个工作进程:
gunicorn -w 4 -b 0.0.0.0:9102 predict_online:app在这个例子中:
-w 4指定了使用 4 个工作进程。-b 0.0.0.0:9102指定了绑定的地址和端口。predict_online:app指定了要运行的 Flask 应用。
请注意,predict_online 应该是你文件中定义 Flask 应用的地方。
此外,你可以考虑使用 Gunicorn 的其他配置选项,例如 --preload,这将在每个工作进程启动时加载应用代码,而不是在每个请求中加载。这样可以减少工作进程的启动时间,提高性能。
gunicorn -w 4 -b 0.0.0.0:9102 --preload predict_online:app确保在生产环境中使用专业的 Web 服务器(如 Gunicorn)来运行 Flask 应用,以确保应用能够正确处理并发请求并保持稳定性。
当使用 Gunicorn 的 --preload 选项时,应用代码会在每个工作进程启动时加载,而不是在每个请求中动态加载。这个过程称为应用的“预加载”。
动态加载(非预加载):
在动态加载模式下,每当接收到一个请求时,Gunicorn 会动态地加载应用代码并初始化应用。这意味着在每个请求处理之前,都会执行一次应用的初始化过程。这种方式的好处是在运行时可以动态更新应用代码,但也可能导致每个请求都需要花费额外的时间来加载和初始化应用。
预加载:
在预加载模式下,应用代码会在工作进程启动时加载和初始化。这意味着在工作进程启动时,应用的所有代码都被加载到内存中,并且在处理请求时无需再次加载。这样一来,每个请求的处理过程更加高效,因为不需要在请求级别进行初始化操作。然而,这也意味着在更新应用代码时,你需要重新启动工作进程,以便使新的代码生效。
假设你有一个 Flask 应用,其中包含一些全局变量或初始化操作。在动态加载模式下,这些初始化操作会在每个请求中执行。在预加载模式下,这些初始化操作会在工作进程启动时执行,而不会在每个请求中重复执行。
在动态加载模式下,some_global_variable 的初始化操作将在每个请求中执行。在预加载模式下,初始化操作只会在工作进程启动时执行一次,而后续的请求将直接使用已初始化的变量,而不需要重新执行初始化。
在 Gunicorn 中,worker 是处理请求的工作单元,而 master 则是管理这些 worker 的主进程。在 Gunicorn 的工作模型中,master 进程负责监听端口、接收请求,并将请求分配给不同的 worker 进程进行处理。
Gunicorn 支持多种 worker 类型,包括 sync(同步)、eventlet、gevent、tornado 等。这些 worker 的主要区别在于它们处理请求的方式。下面是关于 Gunicorn worker 的一些关键概念:
- Master 进程:
-
- 主进程,负责启动和管理所有 worker 进程。
- 监听端口,接收客户端的连接请求。
- 当有请求到达时,负责将请求分配给可用的 worker 进程。
- Worker 进程:
-
- 工作进程,实际处理客户端请求的单元。
- 一个 Gunicorn 实例可以有多个 worker 进程,每个 worker 处理一个请求。
- Worker 之间是独立的,它们可以并发处理多个请求。
- Worker 类型:
-
- Gunicorn 支持多种 worker 类型,包括 sync(同步)、eventlet、gevent、tornado 等。
- 同步 worker 在每个进程中处理一个请求,而异步 worker 可以处理多个请求。
- 并发性:
-
- Worker 的数量和并发连接数之间有关系。更多的 worker 可以处理更多的并发请求。
- 例如,使用
-w参数可以指定启动的 worker 数量,如gunicorn -w 4 myapp:app表示启动 4 个 worker 进程。
- 负载均衡:
-
- Master 进程通过简单的轮询或其他算法将请求分配给不同的 worker 进程,实现简单的负载均衡。
- Gunicorn 还支持其他负载均衡算法,如预先分配请求到不同的 worker。
总体而言,master 进程和多个 worker 进程之间的关系是一种主从关系。Master 进程负责管理和分配任务,而 worker 进程负责实际的请求处理。这种结构使得 Gunicorn 能够更好地利用多核处理器,并提供高性能的 Web 服务。
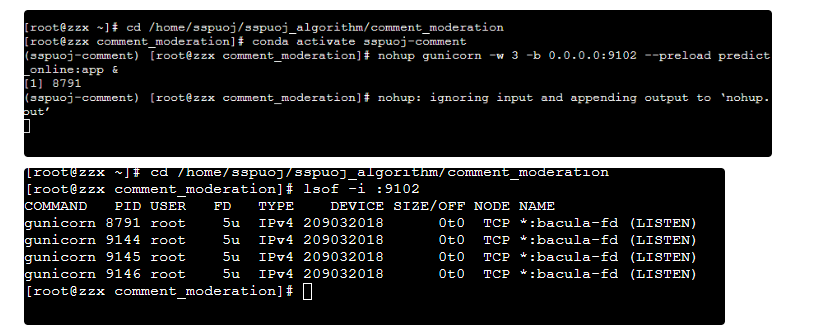
由此,我们可以使用以下命令,实现最终的部署:
nohup gunicorn -w 3 -b 0.0.0.0:9102 --preload predict_online:app &执行结果:
后台运行日志文件:
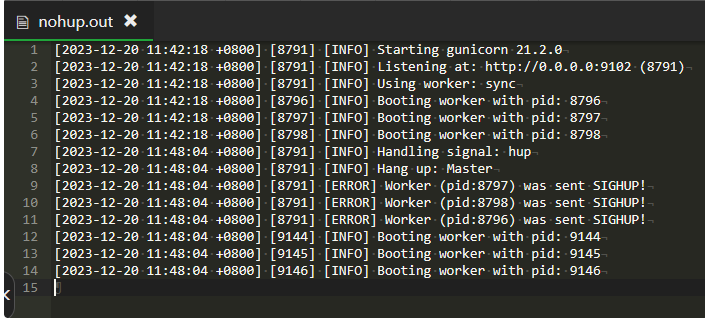
可见,已成功启动。
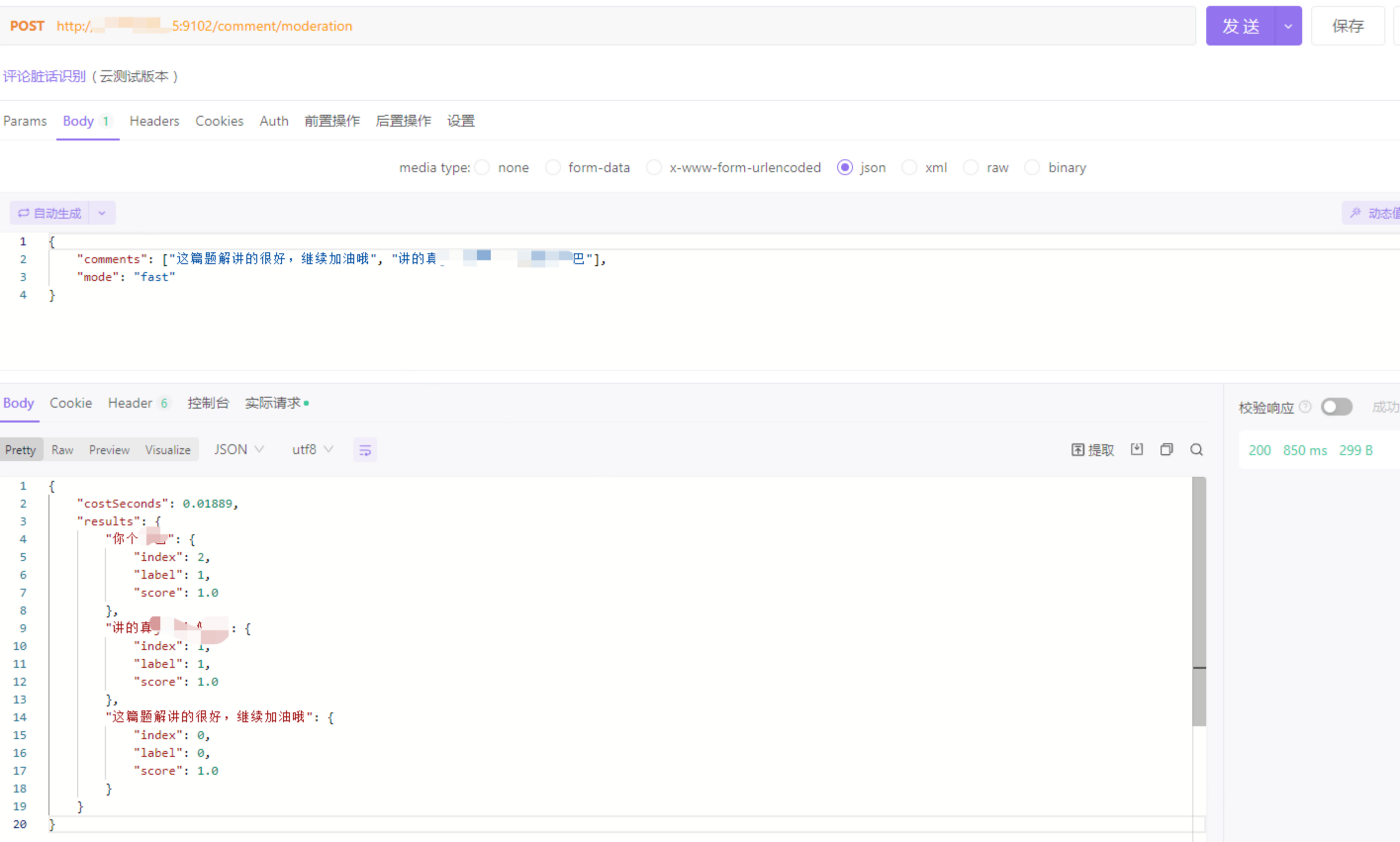
使用apifox测试:
- Gitee开源地址:https://gitee.com/crzzx/comment_moderation
- 项目代码结构和说明:
E:.
│ .gitignore
│ comment_test_demo.html # 前端测试代码
│ example.log
│ LICENSE
│ model.py # 模型文件
│ predict.py # 预测代码
│ predict_online.py # 预测代码上线版
│ README.en.md
│ README.md # 说明文档
│ test.py # 模型测试代码
│ textCNN_data.py # 数据集生成代码
│ train.py # 模型训练代码(cpu版本)
│ train_gpu.py # 模型训练代码(gpu版本)
│ __init__.py
│
├─data
│ │ dev.txt # 验证数据集
│ │ stop_word.txt # 停词表
│ │ test.txt # 测试数据集
│ │ train.txt # 验证数据集
│ │
│ ├─logs
│ ├─result
│ │ log_23121911.txt # 训练日志
│ │ log_test_23121914.txt # 测试日志
│ │ test_vec.txt # 测试集词向量
│ │ textCNN.pkl # 训练好的模型文件
│ │ train_vec.txt # 训练集词向量
│ │ valid_vec.txt # 验证集词向量
│ │ word_list.txt # 词表
│ │
│ └─suspect
│ illegal.txt # 政治敏感词
│ illegal_char_split.txt
│ suspected_illegal.txt # 辱骂词
│
├─data_process
│ │ generate_word_list.py # 词表生成代码
│ │ word2vec.py # 词向量生成代码
│ │ __init__.py
│ │
│ └─__pycache__
│ word2vec.cpython-39.pyc
│ __init__.cpython-39.pyc
│
└─__pycache__
model.cpython-39.pyc
textCNN_data.cpython-39.pyc
__init__.cpython-39.pyc本文介绍了基于TextCNN文本分类模型的实现和部署,主要解决了新闻文章评论区存在的谩骂言辞问题。以下是文章的主要内容和步骤:
文章提到新闻文章评论区经常充斥着辱骂言辞,损害了平台声誉和用户体验。为了解决这个问题,需要建立一个自动识别算法,通过模型拦截谩骂评论,提升评论区的品质。
文章详细描述了解决问题的算法结构和设计思路,包括:
- 预处理阶段:文本清洗和分词处理。
- 辱骂违规词检测:建立违规词库,采用多层次匹配策略和动态过滤机制。
- 政治敏感词检测:建立敏感词库,进行关联性分析。
- TextCNN模型:使用卷积神经网络结构,包括嵌入层、卷积层、全连接层等。
- 输出和审核结果:综合判断辱骂违规词检测、政治敏感词检测和TextCNN模型的输出。
文章引用了一个参考文章和一个数据来源链接,其中数据来源包括了违规词和政治敏感词。
文章选择了TextCNN模型,并提供了模型的结构图和关于嵌入层的详细解释。描述了数据处理、训练和验证的过程,以及模型的保存和测试效果。
使用Flask进行本地网络API部署,提供了HTML页面进行简单测试,同时使用Gunicorn处理高并发的服务器。
介绍了在阿里云轻量应用服务器上的部署环境和配置,并通过Gunicorn进行服务启动。详细说明了Gunicorn的工作原理、worker和负载均衡的概念,以及如何使用Gunicorn进行生产环境部署。
提供了项目的Gitee开源地址、代码结构和各个文件的功能说明。