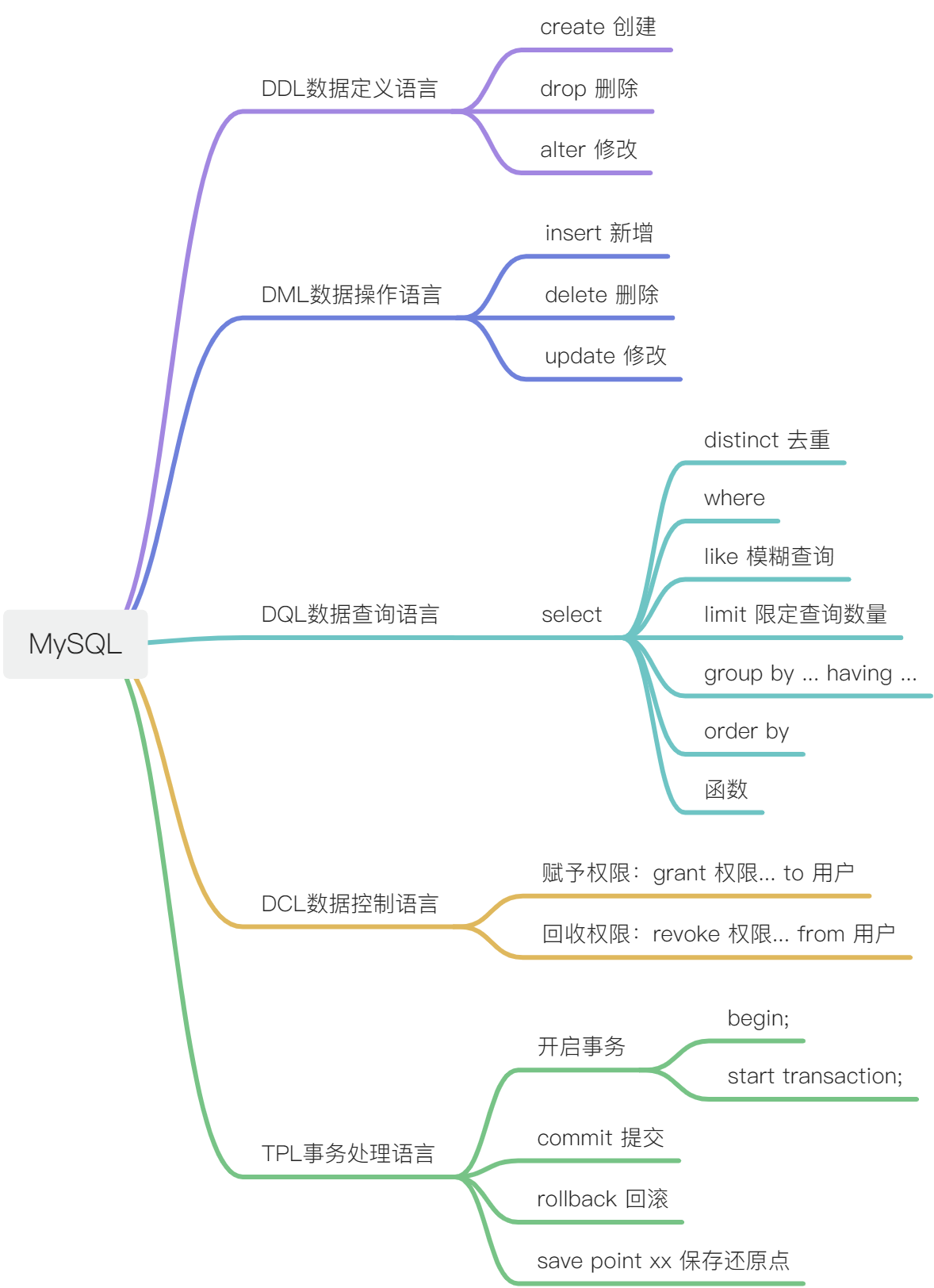
针对数据库对象进行操作,如数据库、表、视图等对象
create database 数据库名 [default charset utf8] ;
数据库名要求:不区分大小写,英文,见名知义
数据库默认字符集:latin1
create table 表名(
列名 数据类型(长度),
......
列名 数据类型(长度)
) [character set utf8 collate utf8_general_ci] ;3.1 修改表名:
alter table 原表名 rename [to] 新表名;
3.2 修改表中的列:(列名、列类型、列长度)
alter table 表名 change 原列名 新列名 新类型(新长度);
3.3 新增一个列:
alter table 表名 add 新列名 新类型(新长度);
3.4 删除一个列:
alter table 表名 drop 原列名;
删除table:drop table 表名;
删除数据库:drop database 数据库名;
操作的是表中的数据信息
主要分为写数据(新增、删除、修改)、读数据(查询)
insert into 表名 (列名, ......, 列名) values (值, ......, 值);
注意:
a. 如果新增全部列,可以省略表名后的括号及内容,此时values后的值的个数、类型、顺序要与表中列保持一致。
b. 若想要一条insert语句新增多个记录,每个 (值, ......, 值) 之间用逗号隔开。
delete from 表名 [where ....] ;
没有where条件会删除表中所有数据
update 表名 set 列=值, ... , 列=值 [where ...] ;
没有where条件会将对应的列的数据全部都修改
select 列名, ... , 列名 from 表名 [where ...] ;
需要起别名使用as关键字 列名 as 别名
去重使用关键字**distinct**** **
根据列去重复,如果有一样的列信息,将一样的信息合并,行数可能会减少。
distinct 列1,列2 两个列以上的,会当作一个整体,整体一样的才去重,否则全部显示。
用来筛选符合条件的记录行,并不是控制显示的列。
按照某个列或某些条件进行筛选
使用where关键字,其后可以跟:
1、比较运算符:>、 >=、 <、 <=、 !=、 =
2、算术运算符:+、-、****、*/**
3、逻辑运算符:and、or、not(如果and和or同时出现,and优先级更高)
4、[not] between ... and ...
5、[not] in (... , ...)
6、[not] like %xxx_(% 匹配0~n个字符,_ 仅匹配一个字符)
order by 列名 asc/desc(连接在查询语句后,先筛选再排序)
asc 升序 (默认)
desc 降序
联合排序:order by 列名1, 列名2
按书写顺序依次排序,不同的列可以有不同的排序规则
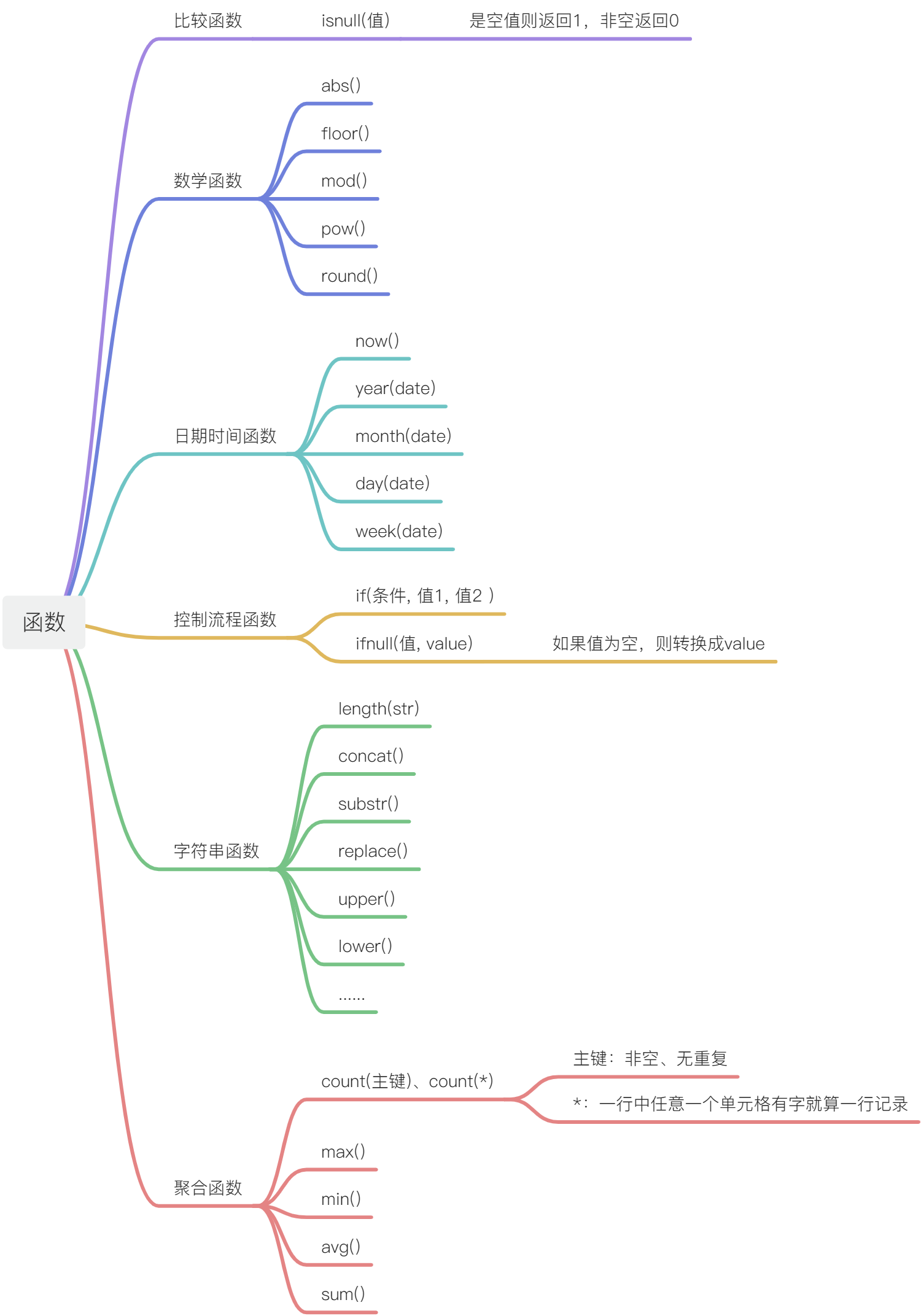
1、MySQL的函数都有返回值,但不一定都有参数列表。
2、函数直接放置在SQL语句中相当于调用,可以放置在:
a. 查询中用来显示的部分select 函数(列) from 表名;
b. 条件筛选where的后面
group by 列
一旦搭配了分组条件,select能展示的信息就只有两种:
1、分组条件(按什么分组就可显示什么)
2、聚合函数(结果就剩一个值)
查询时分组了,查询的行数会减少。
比如按班级分组统计每个班的人数,那么原来可能有多个班级数据,一个班级可能又有多条学生数据,但现在查询出来就一个班级一条数据,统计着每个班级的人数。
先分组?还是先筛选条件?
1、先筛选后分组:where + group by
2、先分组再筛选:group by + having
3、先筛选一部分后分组,分完组再筛选符合条件的:where + group by + having
优先级:where > group by > having > order by
一个完整的SQL语句中嵌套了另一个完整的SQL语句(用括号括起来优先级更高)
1、嵌套可以将一个查询的结果当作另一个查询的条件来使用(同一张表格)
2、可以将查询的结果当作一张表格,在这个表格的基础上再次查询
- 注意:在将结果当作表格时,需要给这个表格起别名才能用(表别名不需要as关键字,空格即可)
3、嵌套将一个查询结果当作条件时,使用的表格可以不是同一张,将另外一张表格查询的信息,当作当前表格的查询条件。(即:与第1点不同在于是可以不同表格)
使用like关键字
% :表示任意 0 个或多个字符。
_: 表示任意单个字符。
语法:select * from xxx limit a,b;
a:想要显示的起始行索引,偏移量从0开始(包括此行)。
b:想要显示的行数(多少条记录)。
in() 括号内是待查询的子集,满足下面一个即可:
1、常量固定值
2、另一条SQL语句查询出来的结果
默认以=进行比较
以下三个关键字使用与in相似,查询是否满足子集中的条件,区别在于不允许写固定值,只允许写SQL语句,通过嵌套来获取子集。
满足查询子集中的某一个即可
与any一样
满足查询子集中的全部才可以
用union连接两条查询语句,将两个查询结果进行合并(是那种上下拼合的效果)
1、要求前后两个查询子集的列数一致
2、对应的类型没有要求
3、拼接后显示的列名是前一个查询子集默认的列名
union和union all的区别:
union 合并后做去重复的处理,性能比较慢,如果有重复元素,记录的是第一次出现的那一行。
union all 将两个查询到的子集直接合并,不做任何处理,性能比较快。
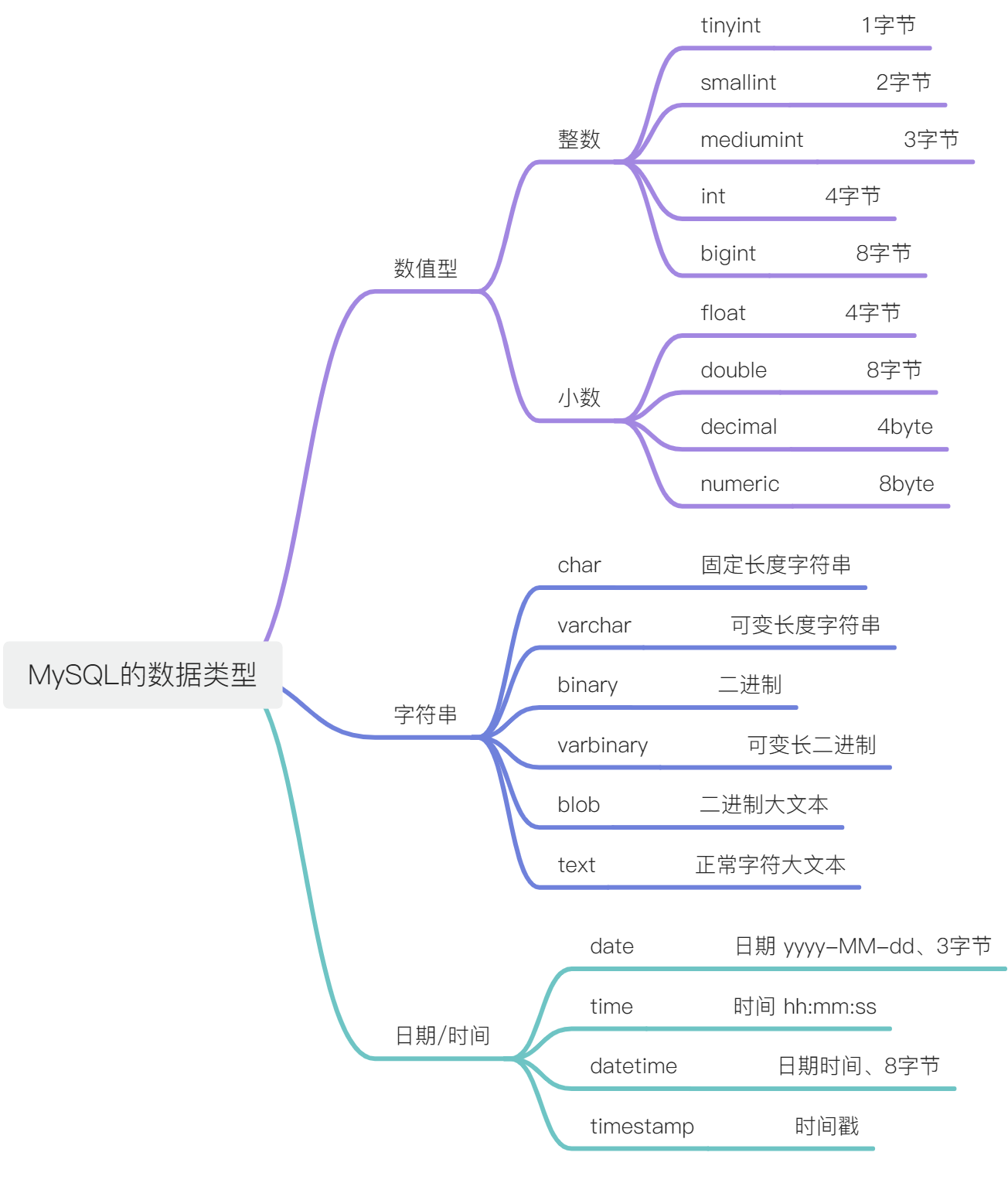
表格中列的约束全部都是在创建表格之后做的表格列结构的修改。
需要用到DDL语句进行操作(alter、drop)
- 每一个表格内只能有一个列被设置为主键约束
- 主键约束通常是用来标记表格中数据的唯一存在
- 主键约束要求当前的列 不能为null值
- 主键约束要求当前的列 值是唯一存在的 不能重复
添加主键约束:
语法:alter table 表名 add constraint 约束名字 约束类型 (列);
例:alter table myclass add constraint pk_myclass primary key (classid);
简写:alter table 表名 add primary key (列);
主键自增:
语法1:alter table 表名 modify 列名 字段类型 auto_increment;
例:alter table myclass modify classid int(4) auto_increment;
语法2:alter table 表名 change 列名 字段类型 auto_increment;
例:alter table myclass change classid int(4) auto_increment;
没有做起始值的说明,主键列的值会从1开始。
设置自增起始值:alter table 表名 auto_increment = 起始值;
删除主键约束:
alter table 表名 drop primary key;
注意:删除主键约束以后,不重复的特性取消了,但非空特性还在。
需要手动取消非空:alter table 表名 modify 字段名 字段类型 null;
- 可以为表格中的某一个列添加唯一约束,唯一约束在表格中可以存在多个列
- 唯一约束表示的是列的值不能重复,但可以为空
添加唯一约束:
语法:alter table 表名 add constraint 约束名 约束类型 (列);
例:alter table myclass add constraint uk_myclass unique [key] (loc);
简写:alter table 表名 add unique key(字段); 约束名为默认的列名
删除唯一约束: alter table 表名 drop index 约束名;
- 在表格中的某一个列上添加非空约束
- 当前列的值不能为null
添加非空约束:
语法1:
alter table 表名 modify 原列名 原类型 原长度 [not] null default xxx;
语法2:
alter table 表名 change 原列名 原列名 原类型 原长度 [not] null default xxx;
删除非空约束:
alter table 表名字 modify 列 类型 长度 null;
alter table 表名字 change 列 列 类型 长度 null;
列在存值的时候做一个细致的检查
例如:范围是否合理
alter table student add constraint ck_sage check( sage>15 and sage<30);
- 约束自己表格内的信息不能随意填写
- 受到另外一个表格某一个列的影响,当前列的值要去另外一张表格内寻找(另外一张表格的列是唯一的【主键、唯一】)
- 表格中可以有多个列被设置为外键约束
- 当前列的值可以为空,可以重复
添加外键约束:
alter table 表名字 add constraint fk_当前表_关联表 foreign key(列) references 另一个表(列);
简写:
alter table student add foreign key(列) references 另一个表(列);
注意: 如果是简写的形式添加外键,外键的名字不是默认列名
查看外键约束:
【通过show keys from 表; 或 desc 表;或 show create table 表名;】
PRI UNI MUL---->multiple(多样 并联)
删除外键约束:
alter table 表名字 drop foreign key 约束名字;
注意:通过上述语句其实已经将外键约束删掉了
但会自动在当前表格内添加一个新的key
需要再次手动将这个生成的key删掉,外键约束才真的删除干净
alter table 表名字 drop key 约束名字;
将两张表格或多张表格,进行无条件的拼接。(即使两张表格没有关系也可以进行拼接)
语法:select * from A , B
列的个数 :A和B表之和,A数据在左边显示,B数据在右边显示(按上述语法)
行的个数 :A和B表乘积
语法:select * from A , B where 条件
在拼接后的一张大表格的基础上进行了where的筛选 -> 等值连接
在笛卡尔积的基础上进行了where条件筛选,只不过筛选条件都是按照值相等来进行的。
拼接后相当于在一张大的表格中挑选有用的记录,性能比较慢。
外连接分为左外连接和右外连接。
语法:select * from A left/right [outer] join B on 条件
可省略outer关键字
1)两张表格A和B ,谁的数据在左边显示?
A和B表格出现的顺序决定了 谁在左边 谁在右边
A表格先出现,A左边显示
B表格后出现,B右边显示
2)left和right来决定以哪一个表格的数据作为基准
作为基准的表格数据必须全部显示出来
非基准的表格按照on条件与之拼接,若找到则正常显示,若找不到满足条件的则显示 null。
因此,外连接查询结果有可能比等值连接的最终结果多一部分数据。
语法:select * from A inner join B on 条件
特点:
1)查询出的结果与等值连接的结果一致。
2)内连接不分左右,不能省略inner关键字。
3)A和B是可以不同的两张表格。
4)A和B也可以是相同的一张表格,但必须给表格起别名,可能还需要当前的表格有一定的设计。
数据控制语言Data Control Language:控制用户的权限
语法:create user '用户名'@'IP' identified by '密码';
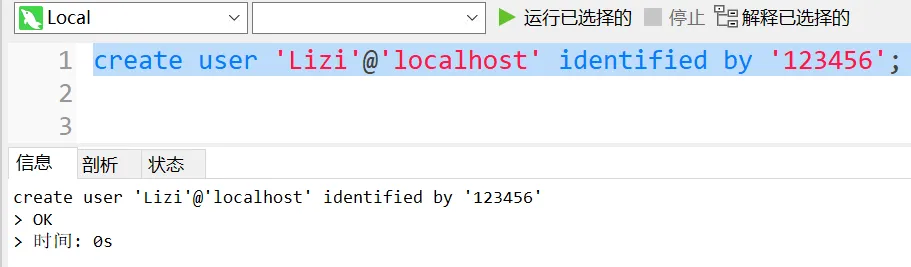
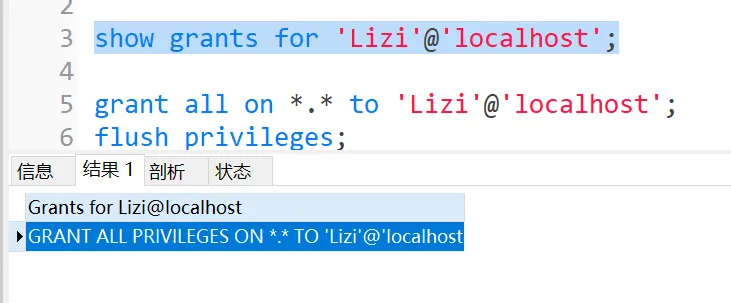
语法:show grants for '用户名'@'IP';
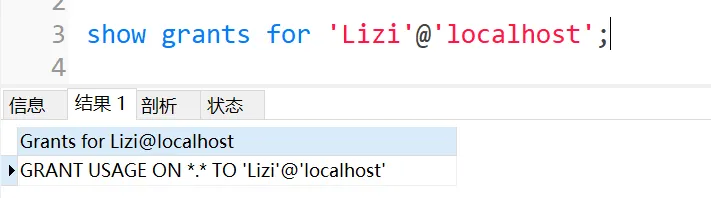
用户被创建成功 (只有一个默认的权限 Usage 只允许登录 不允许做其他事情)
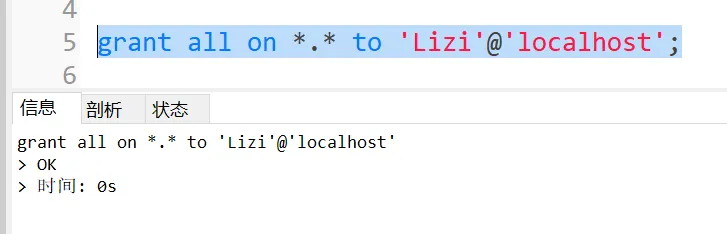
语法:grant 权限 on 数据库名.表名 to '用户'@'IP';
赋予权限之后最好做一个刷新flush privileges;
语法:revoke 权限 on 数据库名.表名 from '用户名'@'IP';
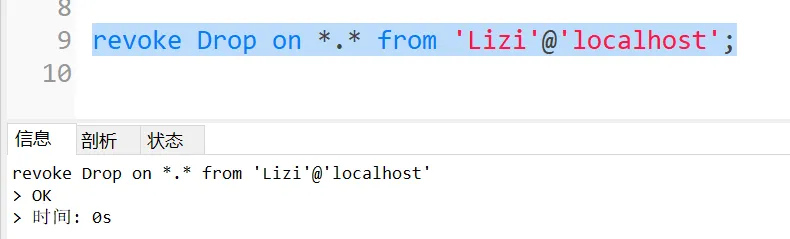

上述回收了用户删除数据表或数据库的权限。
1、数据库/数据表/数据列权限:
Create: 建立新的数据库或数据表
Alter : 修改已存在的数据表(例如增加/删除列)
Drop : 删除数据表或数据库
Insert: 增加表的记录
Delete: 删除表的记录
Update: 修改表中已存在的记录
Select: 显示/搜索表的记录
References: 允许创建外键
Index : 建立或删除索引
Create View: 允许创建视图
Create Routine: 允许创建存储过程和包
Execute: 允许执行存储过程和包
Trigger: 允许操作触发器
Create User: 允许更改、创建、删除、重命名用户和收回所有权限
2、全局管理MySQL用户权限:
Grant Option: 允许向其他用户授予或移除权限
Show View: 允许执行SHOW CREATE VIEW语句
Show Databases: 允许账户执行SHOW DATABASE语句来查看数据库
Lock Table: 允许执行LOCK TABLES语句来锁定表
File: 在MySQL服务器上读写文件
Process: 显示或杀死属于其它用户的服务线程
Reload: 重载访问控制表,刷新日志等
ShutDown: 关闭MySQL服务
3、特别的权限:
All: 允许做任何事(和root一样)
Usage: 只允许登录,其它什么也不允许做
1)查看用户密码
select u.User, u.Host,u.authentication_string from mysql.user u where u.User = 'Lizi';

2)修改用户密码
update mysql.user set authentication_string = password('新密码') where user = '用户名';
刷新:flush privileges;


语法:drop user '用户名'@'IP';

SQL语句是我们给数据库发送指令,让数据库帮我们做事情。
事务:可以理解为是让数据库做的事情,可能存在多个 SQL 操作。
所有的操作应该是统一的,要么都成功,要么都失败。
事务的本质可以理解成:多线程并发操作同一张表格可能带来的安全问题。
1、Atomicity 原子性
一个事务中的所有操作是一个整体,不可再分。事务中的所有操作要么都成功,要么都失败。
2、Consistency 一致性
一个用户操作了数据,提交以后,另一个用户看到的数据效果是一致。
3、Isolation 隔离性
多个用户并发访问数据库时,一个用户操作数据库,另一个用户不能有所干扰。
多个用户之间的数据事务操作要互相隔离。
4、Durability 持久性
一个用户操作数据的事务一旦被提交(缓存-->文件),对数据库底层真实的改变是永久性的。
1、开启一个事务
每一次执行的一条sql语句之前,mysql数据库都会默认的开启
begin;`或 `start transaction;
2、执行操作(执行SQL)
3、事务处理
mysql数据库会默认的执行提交事务
提交 commit
回滚 rollback
保存还原点 save point xx
事务的隔离性可能会产生多线程并发操作同一个数据库表格的问题,会带来数据的安全隐患。
1.脏读:一个人读到了另外一个人还没有提交的数据。
A、B在操作同一张表格
A修改了数据,还没有提交,B读取到了
A不提交了,回滚回来,B刚刚读取到的那些数据就是无用的----脏数据
2、不可重复读
A、B在操作同一个表格
A先读取了一些数据,读完之后B此时将数据做了修改/删除
A再按照之前的条件重新读一遍,与第一次读取的不一致
3、幻读(虚读)
A、B在操作同一个表格
A先读取了一些数据,读完之后B此时将数据做了新增
A再按照之前的条件重新读一遍,与第一次读取的不一致
隔离级别
1、Serializable 级别最高,可以避免所有出现的问题,性能很慢
2、Repeatable Read 可重复读 (避免脏读、不可重复读)
3、Read Committed 读已提交 (避免脏读)
4、Read UnCommitted 读未提交 (所有效果均无法保证)
MySQL数据库提供默认隔离级别 Repeatable Read
Oracle数据库提供默认隔离级别 Read Committed
查看数据库隔离级别:select @@tx_isolation;

修改隔离级别:set session transaction isolation level xxx;
一般情况下不需要改动。
# 显示有哪些database
show databases;
#使用哪个数据库
use database名字;
# 显示当前数据库有哪些table
show tables;
# 查询数据库的字符集
select schema_name, default_character_set_name from information_schema.schemata where schema_name = `查询的数据库名`;
# 查询表格信息
show table status from 数据库名 like `表名`;
#查看表有什么约束
desc 表名;
show keys from 表名;
show create table 表名;