本文讲解原生态spring boot jdbc操作数据库的方式,现在大家开发项目的时候,一般都会使用orm持久化框架在操作数据库,但是对于其底层jdbc技术,我们也是需要了解掌握的,可以扩展大家的技术面帮助我们系统的学习spring boot开发知识, 在开发中更加灵活地操作数据库。
本文讲解原生态spring boot jdbc操作数据库的方式,现在大家开发项目的时候,一般都会使用orm持久化框架在操作数据库,但是对于其底层jdbc技术,我们也是需要了解掌握的,可以扩展大家的技术面帮助我们系统的学习spring boot开发知识, 在开发中更加灵活地操作数据库。如果有兴趣的话,不妨读一读下文~
JDBC(Java DataBase Connectivity)是一种用于执行SQL语句的Java API,可以为多种关系数据库提供统一访问,它由一组用Java语言编写的类和接口组成。JDBC提供了一种基准,据此可以构建更高级的工具和接口,使数据库开发人员能够编写数据库应用程序。
什么是持久层:在后面的章节我会经常用到持久层这个词,持久层就是指对数据进行持久化操作的代码,比如将数据保存到数据库、文件、磁盘等操作都是持久层操作。所谓持久就是保存起来的意思。对于web应用最常用的持久层框架就是JDBC、Mybatis、JPA。
需要7步:
- 加载数据库驱动
- 建立数据库连接
- 创建数据库操作对象
- 定义操作SQL语句
- 执行数据库操作
- 获取并操作结果集
- 关闭对象,回收资源
try {
// 1、加载数据库驱动
Class.forName(driver);
// 2、获取数据库连接
conn = DriverManager.getConnection(url, username, password);
// 3、获取数据库操作对象
stmt = conn.createStatement();
// 4、定义操作的 SQL 语句
String sql = "select * from user where id = 6";
// 5、执行数据库操作
rs = stmt.executeQuery(sql);
// 6、获取并操作结果集
while (rs.next()) {
// 解析结果集
}
} catch (Exception e) {
// 日志信息
} finally {
// 7、关闭资源
}通过上面的示例可以看出直接使用 JDBC 来操作数据库比较复杂。为此,Spring Boot 针对 JDBC 的使用提供了对应的 Starter 包:spring-boot-starter-jdbc,它其实就是在 Spring JDBC 上做了进一步的封装,方便在 Spring Boot 生态中更好的使用 JDBC
不论是JDBC,还是封装之后的Spring JDBC,直接操作数据库都比较麻烦。如果企业有成熟的ORM知识积累,并且无特殊需求,不建议直接使用JDBC操作数据库。
- 引入依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>- 修改yml配置文件,增加数据库连接、用户名密码等信息
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/test_db?useSSL=false&useUnicode=true&characterEncoding=UTF-8&serverTimezone=GMT%2B8
username: root
password: 123456- 首先我们新建一张测试表article并且定义好对应的实体类。
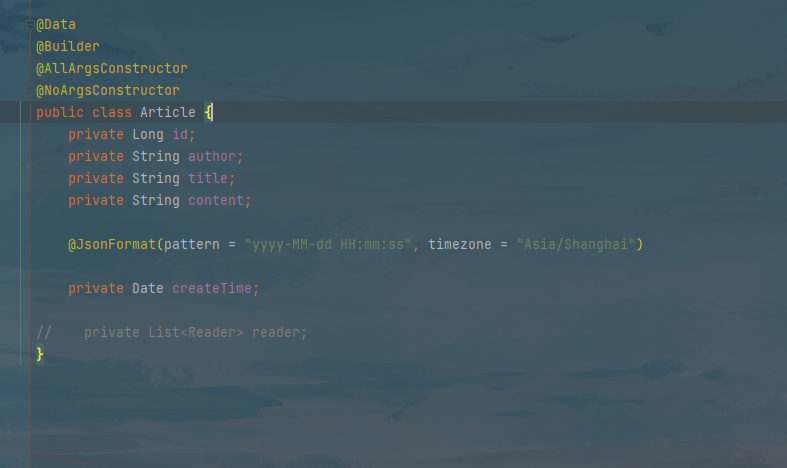
CREATE TABLE `article` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`author` VARCHAR(32) NOT NULL,
`title` VARCHAR(32) NOT NULL,
`content` VARCHAR(512) NOT NULL,
`create_time` DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
)
COMMENT='文章'
ENGINE=InnoDB;- DAO层代码:
- jdbcTemplate.update适合于insert 、update和delete操作;
- jdbcTemplate.queryForObject用于查询单条记录返回结果
- jdbcTemplate.query用于查询结果列表
- BeanPropertyRowMapper可以将数据库字段的值向Article对象映射,满足驼峰标识也可以自动映射。如:数据库create_time字段映射到createTime属性。
@Repository //持久层依赖注入注解
public class ArticleJDBCDAO {
@Resource
private JdbcTemplate jdbcTemplate;
//保存文章
public void save(Article article) {
//jdbcTemplate.update适合于insert 、update和delete操作;
jdbcTemplate.update("INSERT INTO article(author, title,content,create_time) values(?, ?, ?, ?)",
article.getAuthor(),
article.getTitle(),
article.getContent(),
article.getCreateTime());
}
//删除文章
public void deleteById(Long id) {
//jdbcTemplate.update适合于insert 、update和delete操作;
jdbcTemplate.update("DELETE FROM article WHERE id = ?",id);
}
//更新文章
public void updateById(Article article) {
//jdbcTemplate.update适合于insert 、update和delete操作;
jdbcTemplate.update("UPDATE article SET author = ?, title = ? ,content = ?,create_time = ? WHERE id = ?",
article.getAuthor(),
article.getTitle(),
article.getContent(),
article.getCreateTime(),
article.getId());
}
//根据id查找文章
public Article findById(Long id) {
//queryForObject用于查询单条记录返回结果
return (Article) jdbcTemplate.queryForObject("SELECT * FROM article WHERE id=?",
new Object[]{id},new BeanPropertyRowMapper<>(Article.class));
}
//查询所有
public List<Article> findAll(){
//query用于查询结果列表
return (List<Article>) jdbcTemplate.query("SELECT * FROM article ", new BeanPropertyRowMapper<>(Article.class));
}
}- service层操作JDBC持久层
@Slf4j
@Service //服务层依赖注入注解
public class ArticlleJDBCService implements ArticleService {
@Resource
private
ArticleJDBCDAO articleJDBCDAO;
@Transactional
public void saveArticle( Article article) {
articleJDBCDAO.save(article);
//int a = 2/0; //人为制造一个异常,用于测试事务
}
public void deleteArticle(Long id){
articleJDBCDAO.deleteById(id);
}
public void updateArticle(Article article){
articleJDBCDAO.updateById(article);
}
public Article getArticle(Long id){
return articleJDBCDAO.findById(id);
}
public List<Article> getAll(){
return articleJDBCDAO.findAll();
}
}- 在Controller层调用service接口的方法即可。
spring jdbc可以自动实现数据库下划线命名法转成实体类的驼峰命名:注意在sql语句里的字段名一定是数据库的字段名即可。
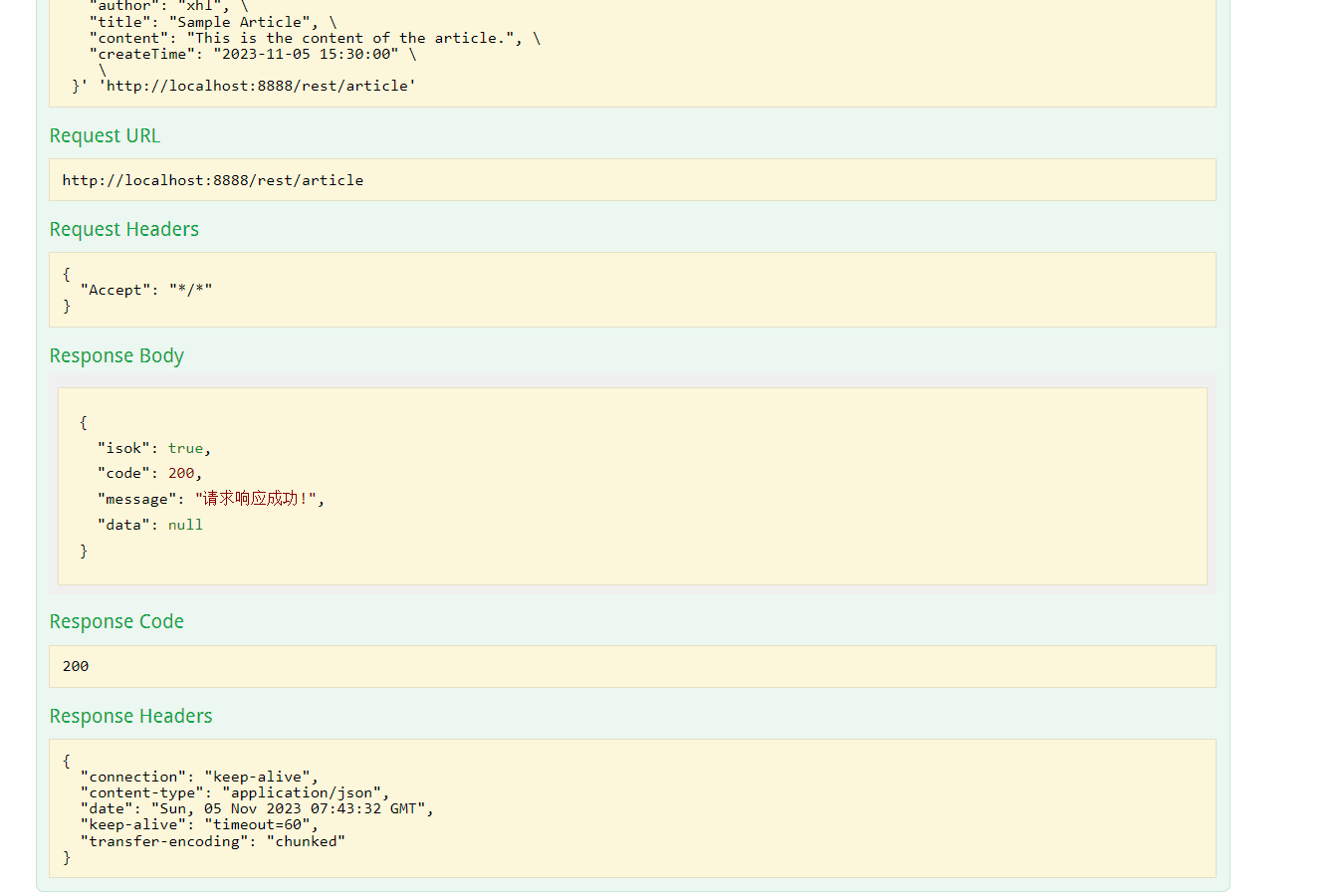
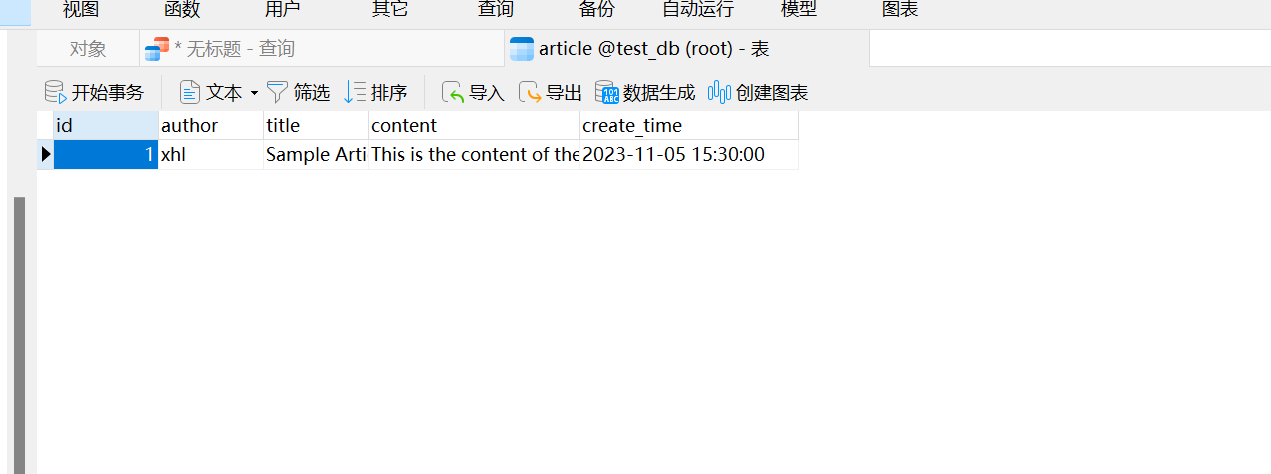
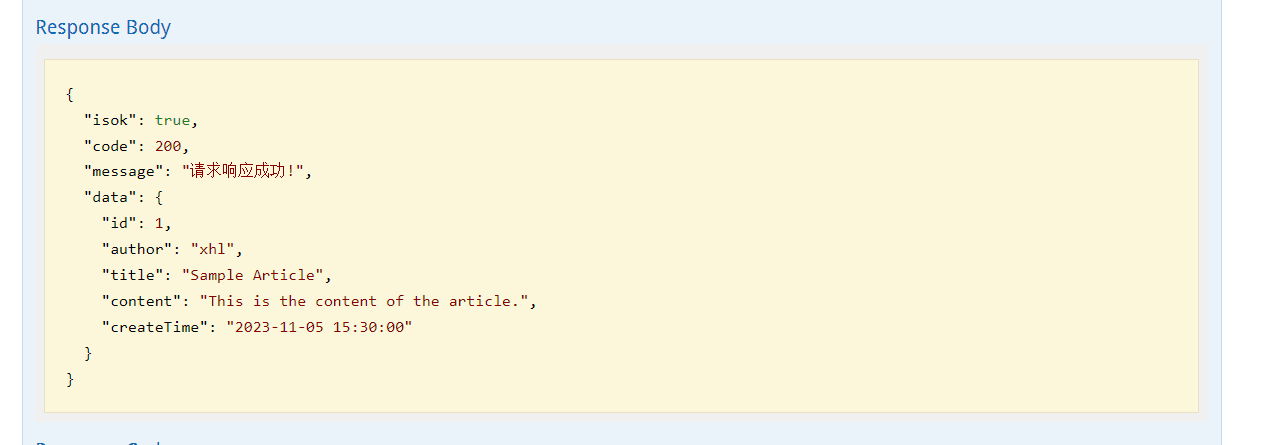
测试数据:
{
"author": "xhl",
"title": "Sample Article",
"content": "This is the content of the article.",
"createTime": "2023-11-05 15:30:00"
}
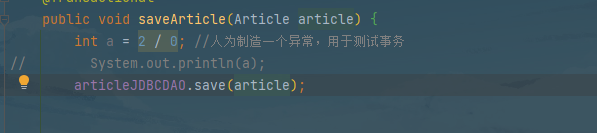
- 重点测试一下事务的回滚,人为制造一个被除数为0的异常。
- 在saveArticle方法上使用了@Trasactional注解,该注解基本功能为事务管理,保证saveArticle方法一旦有异常,所有的数据库操作就回滚。
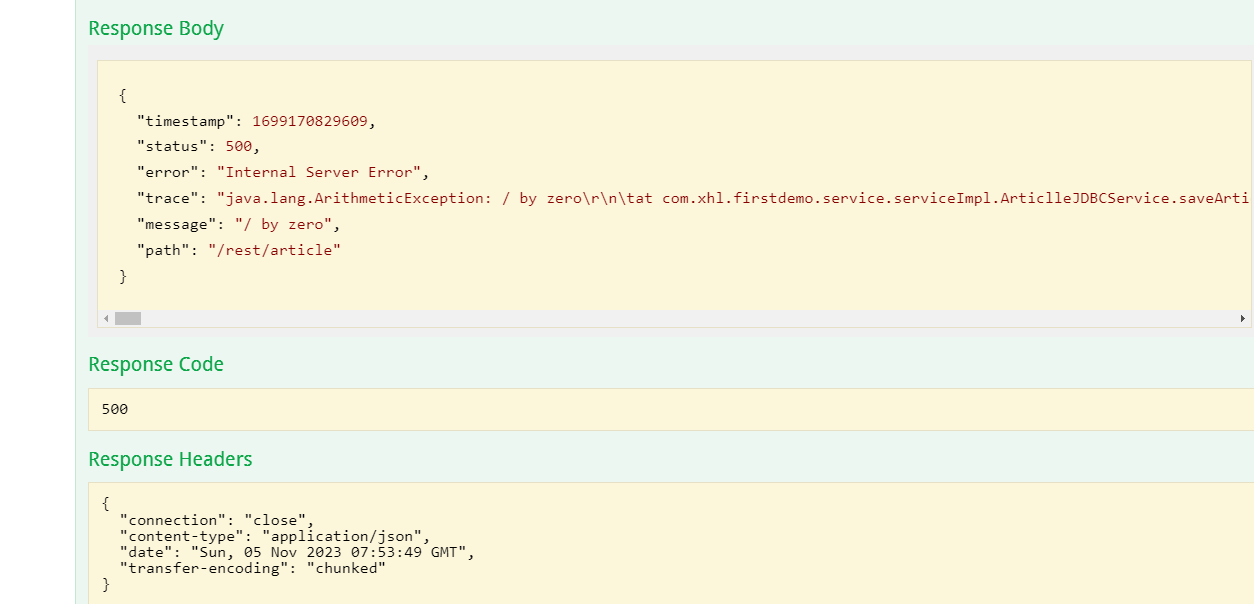
使用事务注解测试一下:测试成功

随着应用的数据量增多,很可能会采用数据分库存储的方案,所以说对于我们的持久层代码可能面临在一个服务函数中操作多个数据库的场景。
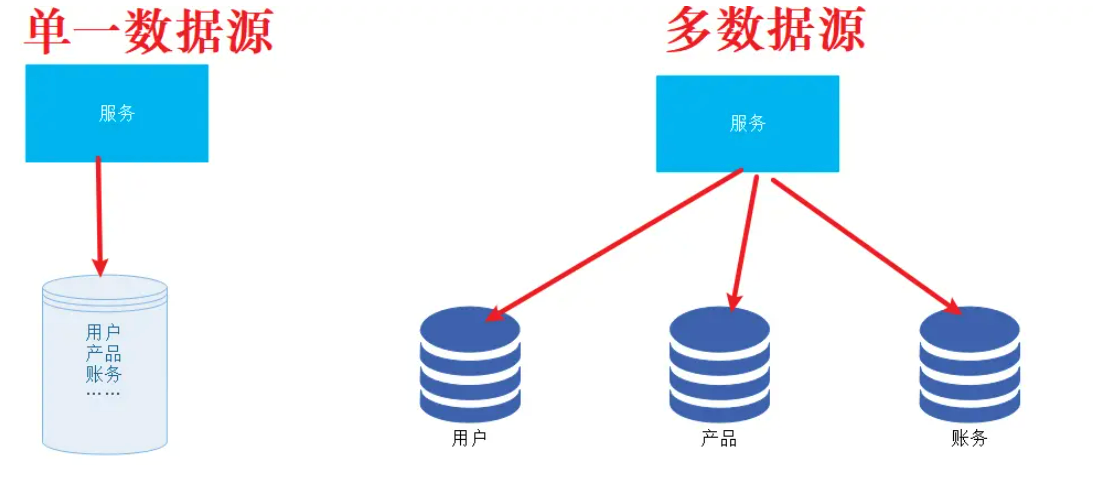
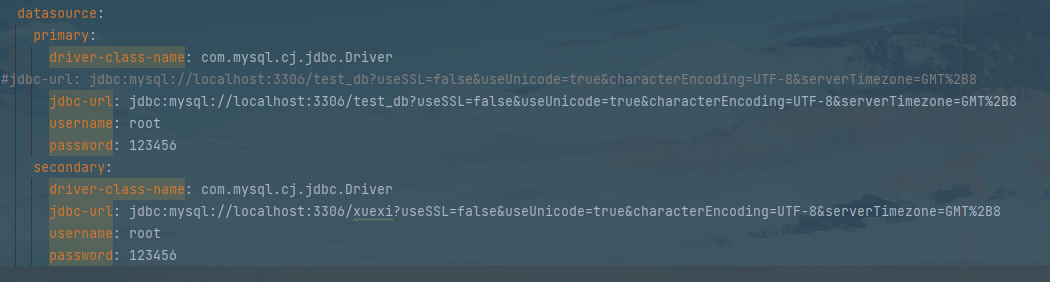
application.yml配置2个数据源,第一个叫做primary,第二个叫做secondary。注意两个数据源连接的是不同的库
datasource:
primary:
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://localhost:3306/test_db?useSSL=false&useUnicode=true&characterEncoding=UTF-8&serverTimezone=GMT%2B8
username: root
password: 123456
secondary:
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://localhost:3306/xuexi?useSSL=false&useUnicode=true&characterEncoding=UTF-8&serverTimezone=GMT%2B8
username: root
password: 123456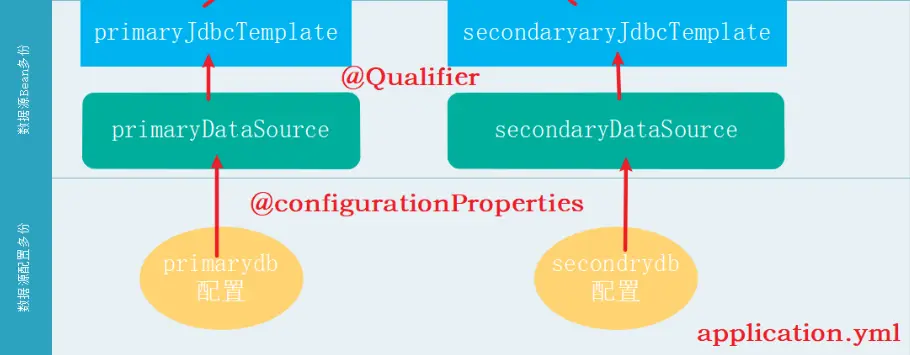
- primaryJdbcTemplate使用primaryDataSource数据源操作数据库test_db。
- secondaryJdbcTemplate使用secondaryDataSource数据源操作数据库xuexi。
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.boot.jdbc.DataSourceBuilder;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Primary;
import org.springframework.jdbc.core.JdbcTemplate;
import javax.sql.DataSource;
@Configuration
public class DataSourceConfig {
@Primary
@Bean(name = "primaryDataSource")
@ConfigurationProperties(prefix="spring.datasource.primary") //test_db
public DataSource primaryDataSource() {
return DataSourceBuilder.create().build();
}
@Bean(name = "secondaryDataSource")
@ConfigurationProperties(prefix="spring.datasource.secondary") //xuexi
public DataSource secondaryDataSource() {
return DataSourceBuilder.create().build();
}
@Bean(name="primaryJdbcTemplate")
public JdbcTemplate primaryJdbcTemplate (@Qualifier("primaryDataSource") DataSource dataSource ) {
return new JdbcTemplate(dataSource);
}
@Bean(name="secondaryJdbcTemplate")
public JdbcTemplate secondaryJdbcTemplate(@Qualifier("secondaryDataSource") DataSource dataSource) {
return new JdbcTemplate(dataSource);
}
}- primaryDataSource和secondaryDataSource都是DataSource接口的实例化对象(Bean)
- @Primary注解的作用是当一个接口有多个实现类的时候,我们在主实现类对象的上面加上这个注解。表示当Spring如果只能选一个实现进行依赖注入的时候,就选@Primary标识的这个Bean。(如果这个项目只使用一个数据源,那就是primaryDataSource)
- @Qualifier明确通过编码的形式说明,当一个接口有多个实现类对象Bean的时候,我要使用哪一个Bean。
这个配置类定义了两个数据源(DataSource)和对应的两个JdbcTemplate实例,分别用于操作两个不同的数据库。
首先,使用@Configuration注解将该类标记为配置类,告诉Spring容器这是一个用于配置Bean的类。
接下来,使用@Primary注解标记primaryDataSource()方法,表示该方法返回的数据源是主要的数据源。在Spring中,如果存在多个同类型的Bean时,通过@Primary注解可以指定默认使用的Bean。
primaryDataSource()方法使用了@Bean注解将返回的数据源Bean注册到Spring容器中,并使用@ConfigurationProperties注解指定了数据源的配置前缀。这意味着Spring将根据配置文件中以spring.datasource.primary开头的属性来自动装配数据源的配置。
类似地,secondaryDataSource()方法定义了返回次要数据源的Bean,并使用了@ConfigurationProperties注解指定了配置前缀。
接下来,定义了两个JdbcTemplate实例的Bean。primaryJdbcTemplate()方法使用了@Qualifier注解,并指定了其中一个数据源Bean的名称primaryDataSource,表示使用名为primaryDataSource的数据源创建JdbcTemplate实例。同样,secondaryJdbcTemplate()方法使用了@Qualifier注解,并指定了另一个数据源Bean的名称secondaryDataSource。
通过这样的配置,当需要使用primaryJdbcTemplate时,Spring会自动从容器中获取名为primaryDataSource的数据源,并使用该数据源创建一个JdbcTemplate实例。同样,获取secondaryJdbcTemplate时会自动获取名为secondaryDataSource的数据源。
在测试类中,通过@Resource注解将primaryJdbcTemplate和secondaryJdbcTemplate注入到articleJDBCDAO中。这样,articleJDBCDAO就可以使用这两个JdbcTemplate实例来操作不同的数据库,并通过调用save()方法将数据保存到相应的数据库中。
- 注入primaryJdbcTemplate作为默认的数据库操作对象。
- 将jdbcTemplate作为参数传入ArticleJDBCDAO的方法,不同的template操作不同的库。
@Resource
// private JdbcTemplate jdbcTemplate;
private JdbcTemplate primaryJdbcTemplate;
//保存文章
//以保存文章为例,新增一个参数:jdbcTemplate ,其他的方法照做
public void save(Article article, JdbcTemplate jdbcTemplate) {
if (jdbcTemplate == null) {//判断新增参数不能为空,如果为空使用primaryJdbcTemplate
jdbcTemplate = primaryJdbcTemplate;
}
jdbcTemplate.update(
"insert into article(author,title,content,create_time) values(?,?,?,?)",
article.getAuthor(),
article.getTitle(),
article.getContent(),
article.getCreateTime()
);
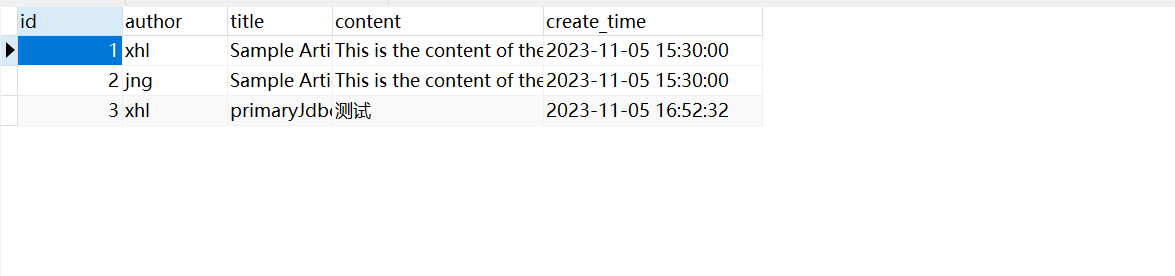
}加入如下单元测试类,并进行测试。正常情况下,在test_db和xuexi数据库的article表,将分别插入一条数据,表示多数据源测试成功。
注意在注入jdbctemplate的时候需要对应好配置类写的名字
@SpringBootTest
public class SpringJdbcTest {
@Resource
private ArticleJDBCDAO articleJDBCDAO;
@Resource
private JdbcTemplate primaryJdbcTemplate;
@Resource
private JdbcTemplate secondaryJdbcTemplate;
@Test
public void testJdbc() {
articleJDBCDAO.save(
Article.builder()
.author("xhl").title("primaryJdbcTemplate").content("测试").createTime(new Date())
.build(),
primaryJdbcTemplate);
articleJDBCDAO.save(
Article.builder()
.author("xhl").title("secondaryJdbcTemplate").content("测试").createTime(new Date())
.build(),
secondaryJdbcTemplate);
}jdbcUrl is required with driverClassName.”
https://blog.csdn.net/weixin_40085570/article/details/80968099
解决:springboot 升级到2.0之后发现配置多数据源的时候报错,把配置url改成jdbc-url即可
保存成功:

总结
至此,大家已经掌握了如何在spring boot中使用spring-jdbc操作数据以及配置多数据源,像多个数据库插入数据,为后续分库分表的操作打下基础。多实践,多敲代码,会越来越好~⚛️