data displaying using OceanDataLab Syntool #71
Comments
|
Sorry for the very late reply, the beginning of the year has been quite busy... Here is a simplified diagram showing how software components interacted when we ingested OMB data in Syntool during the January campaign at sea: As you can see it relies on many 3rd party software and on the custom scheduling system that we use for automating our processing tasks, which makes it unsuitable for a local deployment. Yet, with some effort it should be possible to replace the 3rd party software by less scalable but simpler/more user-friendly implementations, and to remove the ODL-specific parts of the processing scripts to create a Python package that is easy to install:
So it would turn the previous diagram into this: Not saying that we will have time to handle this in the near future, but this is how I would proceed to create a standalone version that users can run on their own computer. |
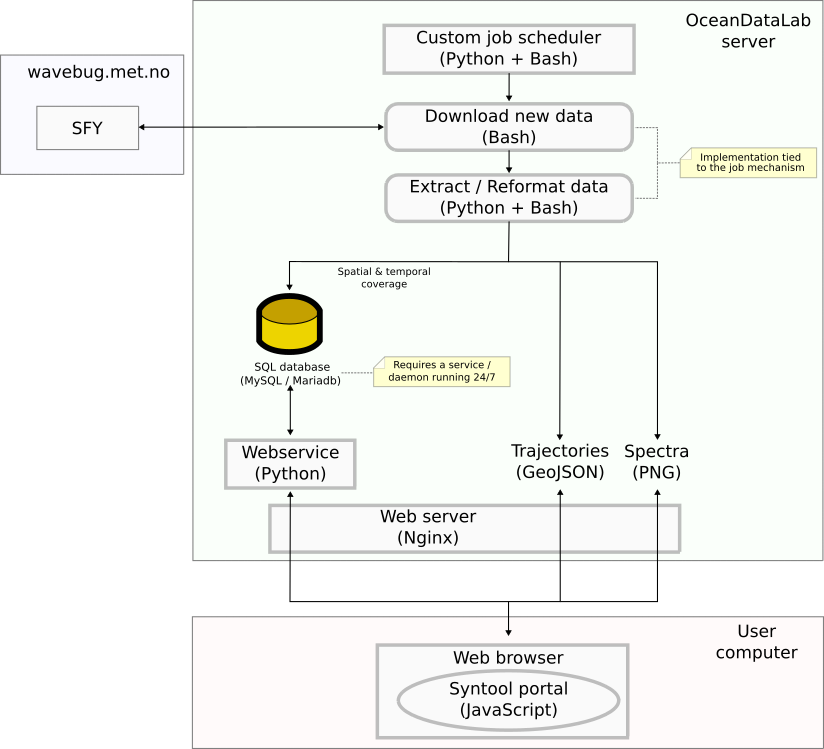
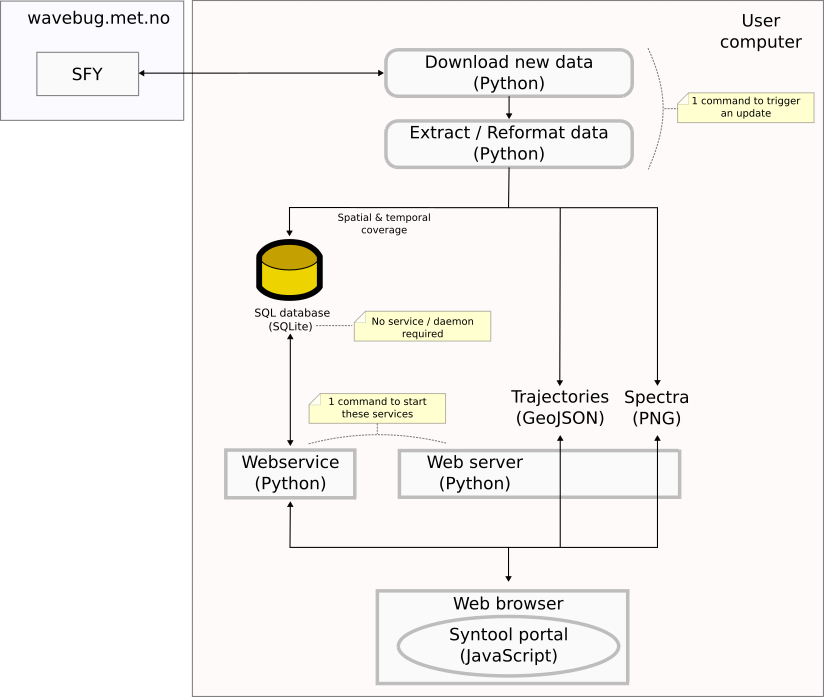
|
Many thanks for the explanation! Agree this looks like quite a lot of work, we can keep this in mind and see if there is a growing user group at some point in the future asking for something in this kind come back to this discussion :) . |
@gauteh @oceandatalab feel free to edit if anything in the "statements" is inaccurate, and / or further discuss what you think is best for the discussion part :) .
If I understand well, the current workflow is:
sfy-data collects data from Rock7 and hosts / organize them in a database and server, accessible through a web API for further use of the data: https://github.com/gauteh/sfy/tree/main/sfy-data (note: may move to a separate repo at some point). An instance of it is now run at MetNo by @gauteh, but could be run by any user locally.
sfy-dashboard provides a simple visualization of the data, that uses the data from sfy-data; sfy-dashboard is available at: https://github.com/gauteh/sfy/tree/main/sfy-dashboard . An instance is now run at MetNo by @gauteh , showing the data from the MetNo sfy-data server, but could be run by any user locally against their own sfy-data server.
syntool provides a more advanced visualization of the data, that uses the data from a sfy-data server(s) and renders them in OceanDataLab Syntool. It is now run at OceanDataLab by @oceandatalab , visible for a small set of buoys at: https://ovl.oceandatalab.com/?date=1672680846000×pan=1d&extent=3429882.2211749_-3083087.4238932_3872299.7408279_-2888784.4980194¢er=3651090.9810014_-2985935.9609563&zoom=10&products=3857_OpenMetBuoys&opacity=100&stackLevel=80.07&selection=1 .
A possible question is, how to make this further available to more users if they want, can this be automated, and / or can we provide a standard workflow that users can follow to see their data displayed online somewhere?
I guess the steps would be:
get a sfy-data server to collect and further serve their data; @gauteh , how would you like this to be organized? Do you think it may be possible to offer 2 solutions to users, ie either i) for MetNo to get the users Rock7 details and IDs to track and the MetNo server then collects the users data, or ii) making a simple recipe for helping users run their own sfy-data (a script or container or similar that non expert users could just run?)? I think i) may be easier on users, so if possible that would be great :) . Note: i) may request at some point having data access granularity and different user accounts with access to different subset of the data?
once a sfy-data server collects the user data, Syntool can be used to display them. Same point here, @oceandatalab do you think it would be possible / how to provide this as a service to the users? If it would be possible for users to provide for example the sfy-data server url and access credentials, and the list of IDs, could you add their data to your tool? And / or a simple recipe for running things locally, ideally a single script or container to run. Note: to keep things organized, it may be useful to be able to search for buoys using both i) category "openmetbuoy", ii) username or sfy-data server url / ID, iii) buoy individual name, iv) a combination of these, as if several users start using this for different campaigns, things may get a bit complicated otherwise.
Do you think / how do you think we should proceed further on that? :)
Key points from the email, copying here to keep them easy to find:
The text was updated successfully, but these errors were encountered: