”never_split“ not working on BertTokenizer #23459
Comments
|
The '[' or ']' in BertTokenizer is punctuation, it will be split at first. And the |

Thanks for replying. As stated before, I am using my own vocab, and ’[outline]‘ is in it, tokenizer = BertTokenizer.from_pretrained(my_vocab_path, never_split='[outline]')
|

|
Hey, reading the doc for the |
Your link is broken, it says '404 - page not found'? tokenizer = BertTokenizer.from_pretrained(my_vocab_path, never_split=['[outline]'], do_basic_tokenize=True) Correct me if I do anything wrong. |
|
Sorry, anyway the argument was set to |
|
( the doc mentions : never_split (`List[str]`, *optional*)
Kept for backward compatibility purposes. Now implemented directly at the base class level (see
[`PreTrainedTokenizer.tokenize`]) List of token not to split. |
|
The best solution is to add the token to the list of special tokens using the |
|
Yeah, add it as special_token does take care of the splitting problem. But in the latter process, I will decode with argument |
|
Then that means that the token that you want to add is not |
|
Without |
|
No it won't : tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased", use_fast=False)
tokenizer.add_tokens("[outline]")
tokenizer.added_tokens_encoder
>>> {'[outline]': 30522}
tokenizer.encode("[outline]")
>>> [101, 30522, 102]
tokenizer.decode(tokenizer.encode("[outline]"))
>>> '[CLS] [outline] [SEP]'
print(tokenizer.tokenize(". [outline]"))
>>> ['.', '[outline]']
tokenizer.decode(tokenizer.encode(". [outline]"), skip_special_tokens=True)
>>> '. [outline]' |
|
In your case, it won't. But I am using a different vocab.txt, it splits. |
|
Seems like |
|
I don't understand. You have a very specific usage, where you don't want to split tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased", use_fast=False, never_split= ["outline"])
tokenizer.add_tokens("[outline]")I am guessing that this should work |
|
Edit: I manually added "[outline]" to my vocab and it worked for both the solution I gave you |
|
Unfortunately, it still doesn't work on my vocab. I think it strictly related to the vocab. So far, only adding it to the special tokens works for me. |
|
vocab.txt |
|
I tried loading a tokenizer using your vocabulary and I cannot reproduce your issue. |
|
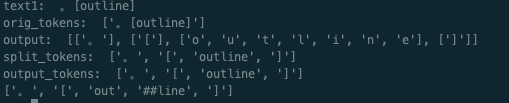
Why...... tokenizer = BertTokenizer.from_pretrained('../base_model/vocab.txt', never_split= ["[outline]"])
tokenizer.add_tokens("[outline]")
print(tokenizer.tokenize("。[outline]"))
# ['。', '[', 'out', '##line', ']'] |
|
Can you try |
|
Here is the Colab result: |

|
can you share a link to the colab, I'll try to reproduce and modify a copy 😉 |
|
Also you did not add the token using |
|
Another solution is to initialise the tokenizer using |
|
https://colab.research.google.com/drive/1EStD5K_lQM0-PgMUQ8z273TzAUcgY2IV?usp=sharing
|
|
Thanks a lot. tokenizer.added_tokens_encoder.update({"[outline]":85})
tokenizer.added_tokens_decoder.update({85:"[outline]"})
tokenizer.unique_no_split_tokens = sorted(set(tokenizer.unique_no_split_tokens).union({"[outline]"}))
tokenizer._create_trie(tokenizer.unique_no_split_tokens)Its is not really elegant indeed. Also adding a token means that whether or not it is in the vocab, we want it to be in the added tokens, so I think it makes sense to add it, even if it exists. WDYT @Narsil |
|
About never split, the last commit is 4 years old, it has never been touch, and I'd rather we find a way to work around your problem using new code rather than changing legacy code! |
|
Glad we are on the same page in the end. |
|
I am not entirely sure yet whether or not we will support this as the fast ones don't, and my few tests appear to show that it might not be optimal |
|
For now closing as
|
|
@lllyyyqqq @ArthurZucker so i don't want to split word into multiple token with Autotokenizer and Bertokenizer. can you please help me how can i do this?? |
|
you should add |
|
@ArthurZucker Is this supported in BertTokenizer ?? |
|
Actually yes!
but this is now possible 😉 see the following: >>> from transformers import BertTokenizer
>>> tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
>>> tokenizer.add_tokens("[outline]")
>>> print(tokenizer.tokenize("。[outline]"))
['。', '[outline]']I tested with both fast and slow and it worked as expected 🤗 |
System Info
transformers 4.28.1
python 3.8.13
Who can help?
No response
Information
Tasks
examplesfolder (such as GLUE/SQuAD, ...)Reproduction
tokenizer = BertTokenizer.from_pretrained(pretrained_path,never_split=['[outline]']) input = "。[outline]" print(tokenizer.tokenize(input)) # ['。', '[', 'out', '##line', ']']print(tokenizer.basic_tokenizer.tokenize(input)) #['。', '[', 'outline', ']']Expected behavior
When I do:
tokenizer.tokenize("。[outline]")Get the result as
['。', '[outline]'], the tokens in never_split don't be splited.The text was updated successfully, but these errors were encountered: