diff --git a/chapters/fr/chapter3/2.mdx b/chapters/fr/chapter3/2.mdx
index 70b529f7b..0aa69be72 100644
--- a/chapters/fr/chapter3/2.mdx
+++ b/chapters/fr/chapter3/2.mdx
@@ -246,7 +246,7 @@ tokenized_dataset = tokenizer(
Cela fonctionne bien, mais a l'inconvénient de retourner un dictionnaire (avec nos clés, `input_ids`, `attention_mask`, et `token_type_ids`, et des valeurs qui sont des listes de listes). Cela ne fonctionnera également que si vous avez assez de RAM pour stocker l'ensemble de votre jeu de données pendant la tokenisation (alors que les jeux de données de la bibliothèque 🤗 *Datasets* sont des fichiers [Apache Arrow](https://arrow.apache.org/) stockés sur le disque, vous ne gardez donc en mémoire que les échantillons que vous demandez).
-Pour conserver les données sous forme de jeu de données, nous utiliserons la méthode [`Dataset.map()`](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.map). Cela nous permet également une certaine flexibilité, si nous avons besoin d'un prétraitement plus poussé que la simple tokenisation. La méthode `map()` fonctionne en appliquant une fonction sur chaque élément de l'ensemble de données, donc définissons une fonction qui tokenise nos entrées :
+Pour conserver les données sous forme de jeu de données, nous utiliserons la méthode [`Dataset.map()`](https://huggingface.co/docs/datasets/package_reference/main_classes#datasets.Dataset.map). Cela nous permet également une certaine flexibilité, si nous avons besoin d'un prétraitement plus poussé que la simple tokenisation. La méthode `map()` fonctionne en appliquant une fonction sur chaque élément de l'ensemble de données, donc définissons une fonction qui tokenise nos entrées :
```py
def tokenize_function(example):
diff --git a/chapters/fr/chapter5/2.mdx b/chapters/fr/chapter5/2.mdx
index 86a218a7c..58640da8b 100644
--- a/chapters/fr/chapter5/2.mdx
+++ b/chapters/fr/chapter5/2.mdx
@@ -132,7 +132,7 @@ C'est exactement ce que nous voulions. Désormais, nous pouvons appliquer divers
-L'argument `data_files` de la fonction `load_dataset()` est assez flexible et peut être soit un chemin de fichier unique, une liste de chemins de fichiers, ou un dictionnaire qui fait correspondre les noms des échantillons aux chemins de fichiers. Vous pouvez également regrouper les fichiers correspondant à un motif spécifié selon les règles utilisées par le shell Unix. Par exemple, vous pouvez regrouper tous les fichiers JSON d'un répertoire en une seule division en définissant `data_files="*.json"`. Voir la [documentation](https://huggingface.co/docs/datasets/loading.html#local-and-remote-files) de 🤗 *Datasets* pour plus de détails.
+L'argument `data_files` de la fonction `load_dataset()` est assez flexible et peut être soit un chemin de fichier unique, une liste de chemins de fichiers, ou un dictionnaire qui fait correspondre les noms des échantillons aux chemins de fichiers. Vous pouvez également regrouper les fichiers correspondant à un motif spécifié selon les règles utilisées par le shell Unix. Par exemple, vous pouvez regrouper tous les fichiers JSON d'un répertoire en une seule division en définissant `data_files="*.json"`. Voir la [documentation](https://huggingface.co/docs/datasets/loading#local-and-remote-files) de 🤗 *Datasets* pour plus de détails.
@@ -164,6 +164,6 @@ Cela renvoie le même objet `DatasetDict` obtenu ci-dessus mais nous évite de t
-✏️ **Essayez !** Choisissez un autre jeu de données hébergé sur GitHub ou dans le [*UCI Machine Learning Repository*](https://archive.ics.uci.edu/ml/index.php) et essayez de le charger localement et à distance en utilisant les techniques présentées ci-dessus. Pour obtenir des points bonus, essayez de charger un jeu de données stocké au format CSV ou texte (voir la [documentation](https://huggingface.co/docs/datasets/loading.html#local-and-remote-files) pour plus d'informations sur ces formats).
+✏️ **Essayez !** Choisissez un autre jeu de données hébergé sur GitHub ou dans le [*UCI Machine Learning Repository*](https://archive.ics.uci.edu/ml/index.php) et essayez de le charger localement et à distance en utilisant les techniques présentées ci-dessus. Pour obtenir des points bonus, essayez de charger un jeu de données stocké au format CSV ou texte (voir la [documentation](https://huggingface.co/docs/datasets/loading#local-and-remote-files) pour plus d'informations sur ces formats).
diff --git a/chapters/fr/chapter5/3.mdx b/chapters/fr/chapter5/3.mdx
index 271396fcb..1c38a5fff 100644
--- a/chapters/fr/chapter5/3.mdx
+++ b/chapters/fr/chapter5/3.mdx
@@ -249,7 +249,7 @@ Comme vous pouvez le constater, cela a supprimé environ 15 % des avis de nos je
-✏️ **Essayez !** Utilisez la fonction `Dataset.sort()` pour inspecter les avis avec le plus grand nombre de mots. Consultez la [documentation](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.sort) pour voir quel argument vous devez utiliser pour trier les avis par longueur dans l'ordre décroissant.
+✏️ **Essayez !** Utilisez la fonction `Dataset.sort()` pour inspecter les avis avec le plus grand nombre de mots. Consultez la [documentation](https://huggingface.co/docs/datasets/package_reference/main_classes#datasets.Dataset.sort) pour voir quel argument vous devez utiliser pour trier les avis par longueur dans l'ordre décroissant.
@@ -396,7 +396,7 @@ tokenized_dataset = drug_dataset.map(tokenize_and_split, batched=True)
ArrowInvalid: Column 1 named condition expected length 1463 but got length 1000
```
-Oh non ! Cela n'a pas fonctionné ! Pourquoi ? L'examen du message d'erreur nous donne un indice : il y a une incompatibilité dans les longueurs de l'une des colonnes. L'une étant de longueur 1 463 et l'autre de longueur 1 000. Si vous avez consulté la [documentation](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.map) de `Dataset.map()`, vous vous souvenez peut-être qu'il s'agit du nombre d'échantillons passés à la fonction que nous mappons. Ici, ces 1 000 exemples ont donné 1 463 nouvelles caractéristiques, entraînant une erreur de forme.
+Oh non ! Cela n'a pas fonctionné ! Pourquoi ? L'examen du message d'erreur nous donne un indice : il y a une incompatibilité dans les longueurs de l'une des colonnes. L'une étant de longueur 1 463 et l'autre de longueur 1 000. Si vous avez consulté la [documentation](https://huggingface.co/docs/datasets/package_reference/main_classes#datasets.Dataset.map) de `Dataset.map()`, vous vous souvenez peut-être qu'il s'agit du nombre d'échantillons passés à la fonction que nous mappons. Ici, ces 1 000 exemples ont donné 1 463 nouvelles caractéristiques, entraînant une erreur de forme.
Le problème est que nous essayons de mélanger deux jeux de données différents de tailles différentes : les colonnes `drug_dataset` auront un certain nombre d'exemples (les 1 000 dans notre erreur), mais le `tokenized_dataset` que nous construisons en aura plus (le 1 463 dans le message d'erreur). Cela ne fonctionne pas pour un `Dataset`, nous devons donc soit supprimer les colonnes de l'ancien jeu de données, soit leur donner la même taille que dans le nouveau jeu de données. Nous pouvons faire la première option avec l'argument `remove_columns` :
diff --git a/chapters/fr/chapter5/4.mdx b/chapters/fr/chapter5/4.mdx
index 1fdc67418..2d3d62ba6 100644
--- a/chapters/fr/chapter5/4.mdx
+++ b/chapters/fr/chapter5/4.mdx
@@ -48,7 +48,7 @@ Nous pouvons voir qu'il y a 15 518 009 lignes et 2 colonnes dans notre jeu de do
-✎ Par défaut, 🤗 *Datasets* décompresse les fichiers nécessaires pour charger un jeu de données. Si vous souhaitez conserver de l'espace sur le disque dur, vous pouvez passer `DownloadConfig(delete_extracted=True)` à l'argument `download_config` de `load_dataset()`. Voir la [documentation](https://huggingface.co/docs/datasets/package_reference/builder_classes.html?#datasets.utils.DownloadConfig) pour plus de détails.
+✎ Par défaut, 🤗 *Datasets* décompresse les fichiers nécessaires pour charger un jeu de données. Si vous souhaitez conserver de l'espace sur le disque dur, vous pouvez passer `DownloadConfig(delete_extracted=True)` à l'argument `download_config` de `load_dataset()`. Voir la [documentation](https://huggingface.co/docs/datasets/package_reference/builder_classes#datasets.DownloadConfig) pour plus de détails.
diff --git a/chapters/fr/chapter5/5.mdx b/chapters/fr/chapter5/5.mdx
index af48c82b3..63a14bf36 100644
--- a/chapters/fr/chapter5/5.mdx
+++ b/chapters/fr/chapter5/5.mdx
@@ -431,7 +431,7 @@ Cool, nous avons poussé notre jeu de données vers le *Hub* et il est disponibl
-💡 Vous pouvez également télécharger un jeu de données sur le *Hub* directement depuis le terminal en utilisant `huggingface-cli` et un peu de magie Git. Consultez le [guide de 🤗 *Datasets*](https://huggingface.co/docs/datasets/share.html#add-a-community-dataset) pour savoir comment procéder.
+💡 Vous pouvez également télécharger un jeu de données sur le *Hub* directement depuis le terminal en utilisant `huggingface-cli` et un peu de magie Git. Consultez le [guide de 🤗 *Datasets*](https://huggingface.co/docs/datasets/share#share-a-dataset-using-the-cli) pour savoir comment procéder.
diff --git a/chapters/fr/chapter5/6.mdx b/chapters/fr/chapter5/6.mdx
index 610af1078..19d2e1f5d 100644
--- a/chapters/fr/chapter5/6.mdx
+++ b/chapters/fr/chapter5/6.mdx
@@ -193,7 +193,7 @@ D'accord, cela nous a donné quelques milliers de commentaires avec lesquels tra
-✏️ **Essayez !** Voyez si vous pouvez utiliser `Dataset.map()` pour exploser la colonne `comments` de `issues_dataset` _sans_ recourir à l'utilisation de Pandas. C'est un peu délicat. La section [« Batch mapping »](https://huggingface.co/docs/datasets/v1.12.1/about_map_batch.html?batch-mapping#batch-mapping) de la documentation 🤗 *Datasets* peut être utile pour cette tâche.
+✏️ **Essayez !** Voyez si vous pouvez utiliser `Dataset.map()` pour exploser la colonne `comments` de `issues_dataset` _sans_ recourir à l'utilisation de Pandas. C'est un peu délicat. La section [« Batch mapping »](https://huggingface.co/docs/datasets/about_map_batch#batch-mapping) de la documentation 🤗 *Datasets* peut être utile pour cette tâche.
diff --git a/chapters/fr/chapter6/8.mdx b/chapters/fr/chapter6/8.mdx
index f8a740502..5bed366b9 100644
--- a/chapters/fr/chapter6/8.mdx
+++ b/chapters/fr/chapter6/8.mdx
@@ -30,14 +30,14 @@ La bibliothèque 🤗 *Tokenizers* a été construite pour fournir plusieurs opt
Plus précisément, la bibliothèque est construite autour d'une classe centrale `Tokenizer` avec les blocs de construction regroupés en sous-modules :
-- `normalizers` contient tous les types de `Normalizer` que vous pouvez utiliser (liste complète [ici](https://huggingface.co/docs/tokenizers/python/latest/api/reference.html#module-tokenizers.normalizers)),
-- `pre_tokenizers` contient tous les types de `PreTokenizer` que vous pouvez utiliser (liste complète [ici](https://huggingface.co/docs/tokenizers/python/latest/api/reference.html#module-tokenizers.pre_tokenizers)),
-- `models` contient les différents types de `Model` que vous pouvez utiliser, comme `BPE`, `WordPiece`, et `Unigram` (liste complète [ici](https://huggingface.co/docs/tokenizers/python/latest/api/reference.html#module-tokenizers.models)),
-- `trainers` contient tous les différents types de `Trainer` que vous pouvez utiliser pour entraîner votre modèle sur un corpus (un par type de modèle ; liste complète [ici](https://huggingface.co/docs/tokenizers/python/latest/api/reference.html#module-tokenizers.trainers)),
-- `post_processors` contient les différents types de `PostProcessor` que vous pouvez utiliser (liste complète [ici](https://huggingface.co/docs/tokenizers/python/latest/api/reference.html#module-tokenizers.processors)),
-- `decoders` contient les différents types de `Decoder` que vous pouvez utiliser pour décoder les sorties de tokenization (liste complète [ici](https://huggingface.co/docs/tokenizers/python/latest/components.html#decoders)).
-
-Vous pouvez trouver la liste complète des blocs de construction [ici](https://huggingface.co/docs/tokenizers/python/latest/components.html).
+- `normalizers` contient tous les types de `Normalizer` que vous pouvez utiliser (liste complète [ici](https://huggingface.co/docs/tokenizers/api/normalizers)),
+- `pre_tokenizers` contient tous les types de `PreTokenizer` que vous pouvez utiliser (liste complète [ici](https://huggingface.co/docs/tokenizers/api/pre-tokenizers)),
+- `models` contient les différents types de `Model` que vous pouvez utiliser, comme `BPE`, `WordPiece`, et `Unigram` (liste complète [ici](https://huggingface.co/docs/tokenizers/api/models)),
+- `trainers` contient tous les différents types de `Trainer` que vous pouvez utiliser pour entraîner votre modèle sur un corpus (un par type de modèle ; liste complète [ici](https://huggingface.co/docs/tokenizers/api/trainers)),
+- `post_processors` contient les différents types de `PostProcessor` que vous pouvez utiliser (liste complète [ici](https://huggingface.co/docs/tokenizers/api/post-processors)),
+- `decoders` contient les différents types de `Decoder` que vous pouvez utiliser pour décoder les sorties de tokenization (liste complète [ici](https://huggingface.co/docs/tokenizers/components#decoders)).
+
+Vous pouvez trouver la liste complète des blocs de construction [ici](https://huggingface.co/docs/tokenizers/components).
## Acquisition d'un corpus
diff --git a/chapters/fr/chapter9/4.mdx b/chapters/fr/chapter9/4.mdx
index ea9509a02..937ac66d0 100644
--- a/chapters/fr/chapter9/4.mdx
+++ b/chapters/fr/chapter9/4.mdx
@@ -48,7 +48,7 @@ gr.Interface(
title=title,
description=description,
article=article,
- examples=[["What are you doing?"], ["Where should we time travel to?"]]
+ examples=[["What are you doing?"], ["Where should we time travel to?"]],
# ["Que faites-vous ?"], ["Où devrions-nous voyager dans le temps ?"]
).launch()
```
diff --git a/chapters/hi/chapter3/2.mdx b/chapters/hi/chapter3/2.mdx
index 481fc824f..066bfddfc 100644
--- a/chapters/hi/chapter3/2.mdx
+++ b/chapters/hi/chapter3/2.mdx
@@ -235,7 +235,7 @@ tokenized_dataset = tokenizer(
यह अच्छी तरह से काम करता है, लेकिन इसमें एक शब्दकोश (साथ में हमारी कुंजी, `input_ids`, `attention_mask`, और `token_type_ids`, और मान जो सूचियों की सूचियां हैं) के लौटने का नुकसान है। यह केवल तभी काम करेगा जब आपके पास पर्याप्त RAM हो अपने पूरे डेटासेट को टोकननाइजेशन के दौरान स्टोर करने के लिए (जबकि 🤗 डेटासेट लाइब्रेरी के डेटासेट [अपाचे एरो](https://arrow.apache.org/) फाइलें हैं जो डिस्क पर संग्रहीत है, तो आप केवल उन सैम्पल्स को रखते हैं जिन्हें आप मेमोरी मे लोड करना चाहतें है)।
-डेटा को डेटासेट के रूप में रखने के लिए, हम [`Dataset.map()`](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.map) पद्धति का उपयोग करेंगे। अगर हमें सिर्फ टोकननाइजेशन की तुलना में अधिक पूर्व प्रसंस्करण की आवश्यकता होती है, तो यह हमें कुछ अधिक लचीलेपन की भी अनुमति देता है। `map()` विधि डेटासेट के प्रत्येक तत्व पर एक फ़ंक्शन लागू करके काम करती है, तो चलिए एक फ़ंक्शन को परिभाषित करते हैं जो हमारे इनपुट को टोकननाइज़ करेगा :
+डेटा को डेटासेट के रूप में रखने के लिए, हम [`Dataset.map()`](https://huggingface.co/docs/datasets/package_reference/main_classes#datasets.Dataset.map) पद्धति का उपयोग करेंगे। अगर हमें सिर्फ टोकननाइजेशन की तुलना में अधिक पूर्व प्रसंस्करण की आवश्यकता होती है, तो यह हमें कुछ अधिक लचीलेपन की भी अनुमति देता है। `map()` विधि डेटासेट के प्रत्येक तत्व पर एक फ़ंक्शन लागू करके काम करती है, तो चलिए एक फ़ंक्शन को परिभाषित करते हैं जो हमारे इनपुट को टोकननाइज़ करेगा :
```py
def tokenize_function(example):
diff --git a/chapters/it/chapter3/2.mdx b/chapters/it/chapter3/2.mdx
index 5ebea52a6..0b428d08d 100644
--- a/chapters/it/chapter3/2.mdx
+++ b/chapters/it/chapter3/2.mdx
@@ -236,7 +236,7 @@ tokenized_dataset = tokenizer(
Questo metodo funziona, ma ha lo svantaggio di restituire un dizionario (avente `input_ids`, `attention_mask`, e `token_type_ids` come chiavi, e delle liste di liste come valori). Oltretutto, questo metodo funziona solo se si ha a disposizione RAM sufficiente per contenere l'intero dataset durante la tokenizzazione (mentre i dataset dalla libreria 🤗 Datasets sono file [Apache Arrow](https://arrow.apache.org/) archiviati su disco, perciò in memoria vengono caricati solo i campioni richiesti).
-Per tenere i dati come dataset, utilizzare il metodo [`Dataset.map()`](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.map). Ciò permette anche della flessibilità extra, qualora fosse necessario del preprocessing aggiuntivo oltre alla tokenizzazione. Il metodo `map()` applica una funziona ad ogni elemento del dataset, perciò bisogna definire una funzione che tokenizzi gli input:
+Per tenere i dati come dataset, utilizzare il metodo [`Dataset.map()`](https://huggingface.co/docs/datasets/package_reference/main_classes#datasets.Dataset.map). Ciò permette anche della flessibilità extra, qualora fosse necessario del preprocessing aggiuntivo oltre alla tokenizzazione. Il metodo `map()` applica una funziona ad ogni elemento del dataset, perciò bisogna definire una funzione che tokenizzi gli input:
```py
def tokenize_function(example):
diff --git a/chapters/it/chapter5/2.mdx b/chapters/it/chapter5/2.mdx
index 738710236..c3ead7ad6 100644
--- a/chapters/it/chapter5/2.mdx
+++ b/chapters/it/chapter5/2.mdx
@@ -128,7 +128,7 @@ Questo è proprio ciò che volevamo. Ora possiamo applicare diverse tecniche di
-L'argomento `data_files` della funzione `load_dataset()` è molto flessibile, e può essere usato con un percorso file singolo, con una lista di percorsi file, o un dizionario che mappa i nomi delle sezioni ai percorsi file. È anche possibile usare comandi glob per recuperare tutti i file che soddisfano uno specifico pattern secondo le regole dello shell di Unix (ad esempio, è possibile recuperare tutti i file JSON presenti in una cartella usando il pattern `data_files="*.json"`). Consulta la [documentazione](https://huggingface.co/docs/datasets/loading.html#local-and-remote-files) 🤗 Datasets per maggiori informazioni.
+L'argomento `data_files` della funzione `load_dataset()` è molto flessibile, e può essere usato con un percorso file singolo, con una lista di percorsi file, o un dizionario che mappa i nomi delle sezioni ai percorsi file. È anche possibile usare comandi glob per recuperare tutti i file che soddisfano uno specifico pattern secondo le regole dello shell di Unix (ad esempio, è possibile recuperare tutti i file JSON presenti in una cartella usando il pattern `data_files="*.json"`). Consulta la [documentazione](https://huggingface.co/docs/datasets/loading#local-and-remote-files) 🤗 Datasets per maggiori informazioni.
@@ -160,7 +160,7 @@ Questo codice restituisce lo stesso oggetto `DatasetDict` visto in precedenza, m
-✏️ **Prova tu!** Scegli un altro dataset presente su GitHub o sulla [Repository di Machine Learning UCI](https://archive.ics.uci.edu/ml/index.php) e cerca di caricare sia in locale che in remoto usando le tecniche introdotte in precedenza. Per punti extra, prova a caricare un dataset archiviato in formato CSV o testuale (vedi la [documentazione](https://huggingface.co/docs/datasets/loading.html#local-and-remote-files) per ulteriori informazioni su questi formati).
+✏️ **Prova tu!** Scegli un altro dataset presente su GitHub o sulla [Repository di Machine Learning UCI](https://archive.ics.uci.edu/ml/index.php) e cerca di caricare sia in locale che in remoto usando le tecniche introdotte in precedenza. Per punti extra, prova a caricare un dataset archiviato in formato CSV o testuale (vedi la [documentazione](https://huggingface.co/docs/datasets/loading#local-and-remote-files) per ulteriori informazioni su questi formati).
diff --git a/chapters/it/chapter5/3.mdx b/chapters/it/chapter5/3.mdx
index 6b8bc7f8f..3eafa185e 100644
--- a/chapters/it/chapter5/3.mdx
+++ b/chapters/it/chapter5/3.mdx
@@ -241,7 +241,7 @@ Come puoi vedere, questo ha rimosso circa il 15% delle recensioni nelle sezioni
-✏️ **Prova tu!** Usa la funzione `Dataset.sort()` per analizzare le revisioni con il maggior numero di parole. Controlla la [documentazione](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.sort) per vedere quali argomenti bisogna usare per ordinare le recensioni in ordine decrescente di lunghezza.
+✏️ **Prova tu!** Usa la funzione `Dataset.sort()` per analizzare le revisioni con il maggior numero di parole. Controlla la [documentazione](https://huggingface.co/docs/datasets/package_reference/main_classes#datasets.Dataset.sort) per vedere quali argomenti bisogna usare per ordinare le recensioni in ordine decrescente di lunghezza.
@@ -386,7 +386,7 @@ tokenized_dataset = drug_dataset.map(tokenize_and_split, batched=True)
ArrowInvalid: Column 1 named condition expected length 1463 but got length 1000
```
-Oh no! Non ha funzionato! Perché? Il messaggio di errore ci dà un indizio: c'è una discordanza tra la lungheza di una delle colonne (una è lunga 1.463 e l'altra 1.000). Se hai guardato la [documentazione](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.map) di `Dataset.map()`, ricorderai che quello è il numero di campioni passati alla funzione map; qui quei 1.000 esempi danno 1.463 nuove feature, che risulta in un errore di shape.
+Oh no! Non ha funzionato! Perché? Il messaggio di errore ci dà un indizio: c'è una discordanza tra la lungheza di una delle colonne (una è lunga 1.463 e l'altra 1.000). Se hai guardato la [documentazione](https://huggingface.co/docs/datasets/package_reference/main_classes#datasets.Dataset.map) di `Dataset.map()`, ricorderai che quello è il numero di campioni passati alla funzione map; qui quei 1.000 esempi danno 1.463 nuove feature, che risulta in un errore di shape.
Il problema è che stiamo cercando di mescolare due dataset diversi di grandezze diverse: le colonne del `drug_dataset` avranno un certo numero di esempi (il 1.000 del nostro errore), ma il `tokenized_dataset` che stiamo costruendo ne avrà di più (il 1.463 nel nostro messaggio di errore). Non va bene per un `Dataset`, per cui abbiamo bisogno o di rimuovere le colonne dal dataset vecchio, o renderle della stessa dimensione del nuovo dataset. La prima opzione può essere effettuata utilizzando l'argomento `remove_columns`:
diff --git a/chapters/it/chapter5/4.mdx b/chapters/it/chapter5/4.mdx
index 57f15060c..ad2f6e191 100644
--- a/chapters/it/chapter5/4.mdx
+++ b/chapters/it/chapter5/4.mdx
@@ -47,7 +47,7 @@ Possiamo vedere che ci sono 15.518.009 righe e 2 colonne nel nostro dataset -- u
-✎ Di base, 🤗 Datasets decomprimerà i file necessari a caricare un dataset. Se vuoi risparmiare sullo spazio dell'hard disk, puoi passare `DownloadConfig(delete_extracted_True)` all'argomento `download_config` di `load_dataset()`. Per maggiori dettagli leggi la [documentazione](https://huggingface.co/docs/datasets/package_reference/builder_classes.html?#datasets.utils.DownloadConfig).
+✎ Di base, 🤗 Datasets decomprimerà i file necessari a caricare un dataset. Se vuoi risparmiare sullo spazio dell'hard disk, puoi passare `DownloadConfig(delete_extracted_True)` all'argomento `download_config` di `load_dataset()`. Per maggiori dettagli leggi la [documentazione](https://huggingface.co/docs/datasets/package_reference/builder_classes#datasets.DownloadConfig).
diff --git a/chapters/it/chapter5/5.mdx b/chapters/it/chapter5/5.mdx
index 3a9c0f19f..a9246a463 100644
--- a/chapters/it/chapter5/5.mdx
+++ b/chapters/it/chapter5/5.mdx
@@ -430,7 +430,7 @@ Bene, abbiamo caricato il nostro dataset sull'Hub, e può essere utilizzato da t
-💡 Puoi caricare un dataset nell'Hub di Hugging Face anche direttamente dal terminale usando `huggingface-cli` e un po' di magia Git. La [guida a 🤗 Datasets](https://huggingface.co/docs/datasets/share.html#add-a-community-dataset) spiega come farlo.
+💡 Puoi caricare un dataset nell'Hub di Hugging Face anche direttamente dal terminale usando `huggingface-cli` e un po' di magia Git. La [guida a 🤗 Datasets](https://huggingface.co/docs/datasets/share#share-a-dataset-using-the-cli) spiega come farlo.
diff --git a/chapters/it/chapter5/6.mdx b/chapters/it/chapter5/6.mdx
index b1296144f..1bd0dca34 100644
--- a/chapters/it/chapter5/6.mdx
+++ b/chapters/it/chapter5/6.mdx
@@ -190,7 +190,7 @@ Perfetto, ora abbiamo qualche migliaio di commenti con cui lavorare!
-✏️ **Prova tu!** Prova ad utilizzare `Dataset.map()` per far esplodere la colonna `commenti` di `issues_dataset` _senza_ utilizzare Pandas. È un po' difficile: potrebbe tornarti utile la sezione ["Batch mapping"](https://huggingface.co/docs/datasets/v1.12.1/about_map_batch.html?batch-mapping#batch-mapping) della documentazione di 🤗 Datasets.
+✏️ **Prova tu!** Prova ad utilizzare `Dataset.map()` per far esplodere la colonna `commenti` di `issues_dataset` _senza_ utilizzare Pandas. È un po' difficile: potrebbe tornarti utile la sezione ["Batch mapping"](https://huggingface.co/docs/datasets/about_map_batch#batch-mapping) della documentazione di 🤗 Datasets.
diff --git a/chapters/ko/chapter5/2.mdx b/chapters/ko/chapter5/2.mdx
index 9f8c463f1..67ccff72a 100644
--- a/chapters/ko/chapter5/2.mdx
+++ b/chapters/ko/chapter5/2.mdx
@@ -128,7 +128,7 @@ DatasetDict({
-`load_dataset()` 함수의 `data_files` 인수는 매우 유연하여 하나의 파일 경로 (str), 파일 경로들의 리스트 (list) 또는 스플릿 이름을 각 파일 경로에 매핑하는 dictionary를 값으로 받을 수 있습니다. 또한 Unix 쉘에서 사용하는 규칙에 따라 지정된 패턴과 일치하는 파일들을 glob할 수도 있습니다. (예를 들어, `data_files="*.json"`와 같이 설정하면 한 폴더에 있는 모든 JSON 파일들을 하나의 스플릿으로 glob할 수 있습니다.) 자세한 내용은 🤗 Datasets [documentation](https://huggingface.co/docs/datasets/loading.html#local-and-remote-files)에서 확인할 수 있습니다.
+`load_dataset()` 함수의 `data_files` 인수는 매우 유연하여 하나의 파일 경로 (str), 파일 경로들의 리스트 (list) 또는 스플릿 이름을 각 파일 경로에 매핑하는 dictionary를 값으로 받을 수 있습니다. 또한 Unix 쉘에서 사용하는 규칙에 따라 지정된 패턴과 일치하는 파일들을 glob할 수도 있습니다. (예를 들어, `data_files="*.json"`와 같이 설정하면 한 폴더에 있는 모든 JSON 파일들을 하나의 스플릿으로 glob할 수 있습니다.) 자세한 내용은 🤗 Datasets [documentation](https://huggingface.co/docs/datasets/loading#local-and-remote-files)에서 확인할 수 있습니다.
diff --git a/chapters/pt/chapter5/2.mdx b/chapters/pt/chapter5/2.mdx
index 053e35ae9..2d12ad4e0 100644
--- a/chapters/pt/chapter5/2.mdx
+++ b/chapters/pt/chapter5/2.mdx
@@ -130,7 +130,7 @@ Isto é exatamente o que queríamos. Agora, podemos aplicar várias técnicas de
-O argumento `data_files` da função `load_dataset()` é bastante flexível e pode ser um único caminho de arquivo ou uma lista de caminhos de arquivo, ou um dicionário que mapeia nomes divididos para caminhos de arquivo. Você também pode incluir arquivos que correspondam a um padrão especificado de acordo com as regras utilizadas pela Unix shell (por exemplo, você pode adicionar todos os arquivos JSON em um diretório como uma única divisão, definindo `data_files="*.json"`). Consulte a [documentação](https://huggingface.co/docs/datasets/loading.html#local-and-remote-files) do 🤗 Datasets para obter mais detalhes.
+O argumento `data_files` da função `load_dataset()` é bastante flexível e pode ser um único caminho de arquivo ou uma lista de caminhos de arquivo, ou um dicionário que mapeia nomes divididos para caminhos de arquivo. Você também pode incluir arquivos que correspondam a um padrão especificado de acordo com as regras utilizadas pela Unix shell (por exemplo, você pode adicionar todos os arquivos JSON em um diretório como uma única divisão, definindo `data_files="*.json"`). Consulte a [documentação](https://huggingface.co/docs/datasets/loading#local-and-remote-files) do 🤗 Datasets para obter mais detalhes.
@@ -161,7 +161,7 @@ squad_it_dataset = load_dataset("json", data_files=data_files, field="data")
Isto retorna o mesmo objeto `DatasetDict` obtido anteriormente, mas nos poupa o passo de baixar e descomprimir manualmente os arquivos _SQuAD_it-*.json.gz_. Isto envolve nas várias formas de carregar conjuntos de dados que não estão hospedados no Hugging Face Hub. Agora que temos um conjunto de dados para brincar, vamos sujar as mãos com várias técnicas de manipulação de dados!
-✏️ **Tente fazer isso!** Escolha outro conjunto de dados hospedado no GitHub ou no [UCI Machine Learning Repository](https://archive.ics.uci.edu/ml/index.php) e tente carregá-lo tanto local como remotamente usando as técnicas introduzidas acima. Para pontos bônus, tente carregar um conjunto de dados que esteja armazenado em formato CSV ou texto (veja a [documentação](https://huggingface.co/docs/datasets/loading.html#local-and-remote-files) para mais informações sobre estes formatos).
+✏️ **Tente fazer isso!** Escolha outro conjunto de dados hospedado no GitHub ou no [UCI Machine Learning Repository](https://archive.ics.uci.edu/ml/index.php) e tente carregá-lo tanto local como remotamente usando as técnicas introduzidas acima. Para pontos bônus, tente carregar um conjunto de dados que esteja armazenado em formato CSV ou texto (veja a [documentação](https://huggingface.co/docs/datasets/loading#local-and-remote-files) para mais informações sobre estes formatos).
diff --git a/chapters/pt/chapter5/3.mdx b/chapters/pt/chapter5/3.mdx
index 7d48c6149..ba734d249 100644
--- a/chapters/pt/chapter5/3.mdx
+++ b/chapters/pt/chapter5/3.mdx
@@ -238,7 +238,7 @@ Como você pode ver, isso removeu cerca de 15% das avaliações de nossos conjun
-✏️ **Experimente!** Use a função `Dataset.sort()` para inspecionar as resenhas com o maior número de palavras. Consulte a [documentação](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.sort) para ver qual argumento você precisa usar para classificar as avaliações por tamanho em ordem decrescente.
+✏️ **Experimente!** Use a função `Dataset.sort()` para inspecionar as resenhas com o maior número de palavras. Consulte a [documentação](https://huggingface.co/docs/datasets/package_reference/main_classes#datasets.Dataset.sort) para ver qual argumento você precisa usar para classificar as avaliações por tamanho em ordem decrescente.
@@ -384,7 +384,7 @@ tokenized_dataset = drug_dataset.map(tokenize_and_split, batched=True)
ArrowInvalid: Column 1 named condition expected length 1463 but got length 1000
```
-Oh não! Isso não funcionou! Por que não? Observar a mensagem de erro nos dará uma pista: há uma incompatibilidade nos comprimentos de uma das colunas, sendo uma de comprimento 1.463 e a outra de comprimento 1.000. Se você consultou a [documentação] do `Dataset.map()` (https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.map), você deve se lembrar de que é o número de amostras passadas para a função que estamos mapeando; aqui, esses 1.000 exemplos forneceram 1.463 novos recursos, resultando em um erro de forma.
+Oh não! Isso não funcionou! Por que não? Observar a mensagem de erro nos dará uma pista: há uma incompatibilidade nos comprimentos de uma das colunas, sendo uma de comprimento 1.463 e a outra de comprimento 1.000. Se você consultou a [documentação] do `Dataset.map()` (https://huggingface.co/docs/datasets/package_reference/main_classes#datasets.Dataset.map), você deve se lembrar de que é o número de amostras passadas para a função que estamos mapeando; aqui, esses 1.000 exemplos forneceram 1.463 novos recursos, resultando em um erro de forma.
O problema é que estamos tentando misturar dois conjuntos de dados diferentes de tamanhos diferentes: as colunas `drug_dataset` terão um certo número de exemplos (os 1.000 em nosso erro), mas o `tokenized_dataset` que estamos construindo terá mais (o 1.463 na mensagem de erro). Isso não funciona para um `Dataset`, portanto, precisamos remover as colunas do conjunto de dados antigo ou torná-las do mesmo tamanho do novo conjunto de dados. Podemos fazer o primeiro com o argumento `remove_columns`:
diff --git a/chapters/pt/chapter5/4.mdx b/chapters/pt/chapter5/4.mdx
index 0018334e6..2a64e2471 100644
--- a/chapters/pt/chapter5/4.mdx
+++ b/chapters/pt/chapter5/4.mdx
@@ -46,7 +46,7 @@ Podemos ver que há 15.518.009 linhas e 2 colunas em nosso conjunto de dados - i
-✎ Por padrão, 🤗 Datasets descompactará os arquivos necessários para carregar um dataset. Se você quiser preservar espaço no disco rígido, você pode passar `DownloadConfig(delete_extracted=True)` para o argumento `download_config` de `load_dataset()`. Consulte a [documentação](https://huggingface.co/docs/datasets/package_reference/builder_classes.html?#datasets.utils.DownloadConfig) para obter mais detalhes.
+✎ Por padrão, 🤗 Datasets descompactará os arquivos necessários para carregar um dataset. Se você quiser preservar espaço no disco rígido, você pode passar `DownloadConfig(delete_extracted=True)` para o argumento `download_config` de `load_dataset()`. Consulte a [documentação](https://huggingface.co/docs/datasets/package_reference/builder_classes#datasets.DownloadConfig) para obter mais detalhes.
diff --git a/chapters/pt/chapter5/5.mdx b/chapters/pt/chapter5/5.mdx
index 9207fa010..23e3831dc 100644
--- a/chapters/pt/chapter5/5.mdx
+++ b/chapters/pt/chapter5/5.mdx
@@ -430,7 +430,7 @@ Legal, nós enviamos nosso conjunto de dados para o Hub e está disponível para
-💡 Você também pode enviar um conjunto de dados para o Hugging Face Hub diretamente do terminal usando `huggingface-cli` e um pouco de magia Git. Consulte o [guia do 🤗 Datasets](https://huggingface.co/docs/datasets/share.html#add-a-community-dataset) para obter detalhes sobre como fazer isso.
+💡 Você também pode enviar um conjunto de dados para o Hugging Face Hub diretamente do terminal usando `huggingface-cli` e um pouco de magia Git. Consulte o [guia do 🤗 Datasets](https://huggingface.co/docs/datasets/share#share-a-dataset-using-the-cli) para obter detalhes sobre como fazer isso.
diff --git a/chapters/pt/chapter5/6.mdx b/chapters/pt/chapter5/6.mdx
index c77091eef..f0a868c57 100644
--- a/chapters/pt/chapter5/6.mdx
+++ b/chapters/pt/chapter5/6.mdx
@@ -188,7 +188,7 @@ Ok, isso nos deu alguns milhares de comentários para trabalhar!
-✏️ **Experimente!** Veja se você pode usar `Dataset.map()` para explodir a coluna `comments` de `issues_dataset` _sem_ recorrer ao uso de Pandas. Isso é um pouco complicado; você pode achar útil para esta tarefa a seção ["Mapeamento em lote"](https://huggingface.co/docs/datasets/v1.12.1/about_map_batch.html?batch-mapping#batch-mapping) da documentação do 🤗 Dataset.
+✏️ **Experimente!** Veja se você pode usar `Dataset.map()` para explodir a coluna `comments` de `issues_dataset` _sem_ recorrer ao uso de Pandas. Isso é um pouco complicado; você pode achar útil para esta tarefa a seção ["Mapeamento em lote"](https://huggingface.co/docs/datasets/v1.12.1/about_map_batch#batch-mapping) da documentação do 🤗 Dataset.
diff --git a/chapters/ru/_toctree.yml b/chapters/ru/_toctree.yml
index 597730c46..0ec4ac451 100644
--- a/chapters/ru/_toctree.yml
+++ b/chapters/ru/_toctree.yml
@@ -113,6 +113,28 @@
title: Тест в конце главы
quiz: 6
+- title: 7. Основные задачи NLP
+ sections:
+ - local: chapter7/1
+ title: Введение
+ - local: chapter7/2
+ title: Классификация токенов
+ - local: chapter7/3
+ title: Дообучение модели маскированного языкового моделирования
+ - local: chapter7/4
+ title: Перевод
+ - local: chapter7/5
+ title: Суммаризация
+ - local: chapter7/6
+ title: Обучение каузальной языковой модели с нуля
+ - local: chapter7/7
+ title: Ответы на вопросы
+ - local: chapter7/8
+ title: Освоение NLP
+ - local: chapter7/9
+ title: Тест в конце главы
+ quiz: 7
+
- title: Глоссарий
sections:
- local: glossary/1
diff --git a/chapters/ru/chapter0/1.mdx b/chapters/ru/chapter0/1.mdx
index 6e42a9fc7..72fce3460 100644
--- a/chapters/ru/chapter0/1.mdx
+++ b/chapters/ru/chapter0/1.mdx
@@ -1,6 +1,6 @@
# Введение
-Добро пожаловать на курс от Hugging Face! Это введение поможет настроить рабочее окружение. Если вы только начинаете курс, мы рекомендуем сначала заглянуть в [Главу 1](/course/ru/chapter1), затем вернуться и настроить среду, чтобы попробовать запустить код самостоятельно.
+Добро пожаловать на курс от Hugging Face! Это введение поможет настроить рабочее окружение. Если вы только начинаете курс, мы рекомендуем сначала заглянуть в [Главу 1](../chapter1/1), затем вернуться и настроить среду, чтобы попробовать запустить код самостоятельно.
Все библиотеки, которые мы будем использовать в этом курсе, доступны в качестве Python-пакетов. В этом уроке мы покажем, как установить окружение и необходимые библиотеки.
diff --git a/chapters/ru/chapter2/1.mdx b/chapters/ru/chapter2/1.mdx
index 47421460e..ce2dbae74 100644
--- a/chapters/ru/chapter2/1.mdx
+++ b/chapters/ru/chapter2/1.mdx
@@ -5,7 +5,7 @@
classNames="absolute z-10 right-0 top-0"
/>
-Как вы могли заметить в [Главе 1](/course/chapter1), модели трансформеров обычно бывают очень большие. Обучение и развертывание таких моделей с миллионами и даже десятками *миллиардов* параметров является сложной задачей. Кроме того, новые модели выпускаются почти ежедневно, и каждая из них имеет собственную реализацию, опробовать их все — непростая задача.
+Как вы могли заметить в [Главе 1](../chapter1/1), модели трансформеров обычно бывают очень большие. Обучение и развертывание таких моделей с миллионами и даже десятками *миллиардов* параметров является сложной задачей. Кроме того, новые модели выпускаются почти ежедневно, и каждая из них имеет собственную реализацию, опробовать их все — непростая задача.
Библиотека 🤗 Transformers была создана для решения этой проблемы. Её цель — предоставить единый API, с помощью которого можно загружать, обучать и сохранять любую модель трансформера. Основными функциями библиотеки являются:
@@ -15,7 +15,7 @@
Последняя особенность сильно отличает библиотеку 🤗 Transformers от других библиотек машинного обучения. Модели не строятся на модулях, которые являются общими для всех файлов; вместо этого каждая модель имеет свои собственные слои. Это не только делает модели более доступными и понятными, но и позволяет легко экспериментировать с одной моделью, не затрагивая другие.
-Эта глава начнается со сквозного примера, в котором мы используем модель и токенизатор вместе, чтобы воспроизвести функцию `pipeline()` представленную в [Главе 1](/course/chapter1). Далее мы обсудим API модели: углубимся в классы модели и конфигурации и покажем, как загружать модель и как она обрабатывает числовые входные данные для получения прогнозов.
+Эта глава начнается со сквозного примера, в котором мы используем модель и токенизатор вместе, чтобы воспроизвести функцию `pipeline()` представленную в [Главе 1](../chapter1/1). Далее мы обсудим API модели: углубимся в классы модели и конфигурации и покажем, как загружать модель и как она обрабатывает числовые входные данные для получения прогнозов.
Затем мы рассмотрим API токенизатора, который является другим основным компонентом функции `pipeline()`. Токенизаторы берут на себя первый и последний этапы обработки, обрабатывая преобразование текста в числовые входные данные для нейронной сети и обратное преобразование в текст, когда это необходимо. Наконец, мы покажем вам, как обработывается передача нескольких предложений в модель с помощью подготовленных пакетов, а затем завершим все это более детальным рассмотрением высокоуровневой функции `tokenizer()`.
diff --git a/chapters/ru/chapter2/2.mdx b/chapters/ru/chapter2/2.mdx
index ff5c6a630..3960afe39 100644
--- a/chapters/ru/chapter2/2.mdx
+++ b/chapters/ru/chapter2/2.mdx
@@ -32,7 +32,7 @@
{/if}
-Давайте начнем с готового примера, взглянув на то, что происходило за кулисами, когда мы выполняли следующий код в [Главе 1](/course/chapter1):
+Давайте начнем с готового примера, взглянув на то, что происходило за кулисами, когда мы выполняли следующий код в [Главе 1](../chapter1/1):
```python
from transformers import pipeline
@@ -53,7 +53,7 @@ classifier(
{'label': 'NEGATIVE', 'score': 0.9994558095932007}]
```
-Как мы уже увидели в [Главе 1](/course/chapter1), данный конвейер включает в себя три шага: предварительная обработка, передача входных данных через модель и постобработка:
+Как мы уже увидели в [Главе 1](../chapter1/1), данный конвейер включает в себя три шага: предварительная обработка, передача входных данных через модель и постобработка:

@@ -176,7 +176,7 @@ model = TFAutoModel.from_pretrained(checkpoint)
Если вы пока не понимаете в чем смысл, не беспокойтесь об этом. Мы объясним все это позже.
-Хотя эти скрытые состояния могут быть полезны сами по себе, они обычно являются входными данными для другой части модели, известной как слой *head*. В [Главе 1](/course/chapter1) разные задачи могли бы выполняться с одной и той же архитектурой, но с каждой из этих задач будет связан отдельный слой "head".
+Хотя эти скрытые состояния могут быть полезны сами по себе, они обычно являются входными данными для другой части модели, известной как слой *head*. В [Главе 1](../chapter1/1) разные задачи могли бы выполняться с одной и той же архитектурой, но с каждой из этих задач будет связан отдельный слой "head".
### Многомерный вектор, что это?
diff --git a/chapters/ru/chapter2/3.mdx b/chapters/ru/chapter2/3.mdx
index 41d226813..b7e941ac4 100644
--- a/chapters/ru/chapter2/3.mdx
+++ b/chapters/ru/chapter2/3.mdx
@@ -112,7 +112,7 @@ model = TFBertModel(config)
```
{/if}
-Модель можно использовать в этом состоянии, но она будет выводить тарабарщину; сначала ее нужно обучить. Мы могли бы обучить модель с нуля для решения поставленной задачи, но, как вы видели в [Главе 1](/course/chapter1), это потребовало бы много времени и большого количества данных, а также имело бы значительное воздействие на окружающую среду. Чтобы избежать ненужных и дублирующих усилий, крайне важно иметь возможность делиться и повторно использовать модели, которые уже были обучены.
+Модель можно использовать в этом состоянии, но она будет выводить тарабарщину; сначала ее нужно обучить. Мы могли бы обучить модель с нуля для решения поставленной задачи, но, как вы видели в [Главе 1](../chapter1/1), это потребовало бы много времени и большого количества данных, а также имело бы значительное воздействие на окружающую среду. Чтобы избежать ненужных и дублирующих усилий, крайне важно иметь возможность делиться и повторно использовать модели, которые уже были обучены.
Загрузить уже обученную модель Transformer очень просто — мы можем сделать это с помощью метода `from_pretrained()`:
diff --git a/chapters/ru/chapter3/1.mdx b/chapters/ru/chapter3/1.mdx
index 476152eb3..953a2bd45 100644
--- a/chapters/ru/chapter3/1.mdx
+++ b/chapters/ru/chapter3/1.mdx
@@ -7,7 +7,7 @@
classNames="absolute z-10 right-0 top-0"
/>
-В [главе 2](/course/ru/chapter2) мы увидели, как можно использовать токенизаторы и предобученные модели для построения предсказаний. Но что если мы хотим дообучить предобученную модель на собственном датасете? Это и есть тема данной главы! Мы изучим:
+В [главе 2](../chapter2/1) мы увидели, как можно использовать токенизаторы и предобученные модели для построения предсказаний. Но что если мы хотим дообучить предобученную модель на собственном датасете? Это и есть тема данной главы! Мы изучим:
{#if fw === 'pt'}
* Как подготовить большой датасет из Model Hub
diff --git a/chapters/ru/chapter3/2.mdx b/chapters/ru/chapter3/2.mdx
index dc8c83f24..0eada491c 100644
--- a/chapters/ru/chapter3/2.mdx
+++ b/chapters/ru/chapter3/2.mdx
@@ -23,7 +23,7 @@
{/if}
{#if fw === 'pt'}
-Продолжим с примером из [предыдущей главы](/course/ru/chapter2), вот как мы будем обучать классификатор последовательности на одном батче с помощью PyTorch:
+Продолжим с примером из [предыдущей главы](../chapter2/1), вот как мы будем обучать классификатор последовательности на одном батче с помощью PyTorch:
```python
import torch
@@ -48,7 +48,7 @@ loss.backward()
optimizer.step()
```
{:else}
-Continuing with the example from the [previous chapter](/course/ru/chapter2), вот как мы будем обучать классификатор последовательности на одном батче с помощью TensorFlow:
+Continuing with the example from the [previous chapter](../chapter2/1), вот как мы будем обучать классификатор последовательности на одном батче с помощью TensorFlow:
```python
import tensorflow as tf
@@ -159,7 +159,7 @@ raw_train_dataset.features
{/if}
-Чтобы предобработать датасет, нам необходимо конвертировать текст в числа, которые может обработать модель. Как вы видели в [предыдущей главе](/course/ru/chapter2), это делается с помощью токенайзера. Мы можем подать на вход токенайзеру одно или список предложений, т.е. можно токенизировать предложения попарно таким образом:
+Чтобы предобработать датасет, нам необходимо конвертировать текст в числа, которые может обработать модель. Как вы видели в [предыдущей главе](../chapter2/1), это делается с помощью токенайзера. Мы можем подать на вход токенайзеру одно или список предложений, т.е. можно токенизировать предложения попарно таким образом:
```py
from transformers import AutoTokenizer
@@ -185,7 +185,7 @@ inputs
}
```
-Мы уже обсуждали ключи `input_ids` и `attention_mask` в [главе 2](/course/ru/chapter2), но не упоминали о `token_type_ids`. В этом примере мы указываем модели какая часть входных данных является первым предложением, а какая вторым.
+Мы уже обсуждали ключи `input_ids` и `attention_mask` в [главе 2](../chapter2/1), но не упоминали о `token_type_ids`. В этом примере мы указываем модели какая часть входных данных является первым предложением, а какая вторым.
@@ -216,13 +216,13 @@ tokenizer.convert_ids_to_tokens(inputs["input_ids"])
Обратите внимание, что если вы выберете другой чекпоинт, `token_type_ids` необязательно будут присутствовать в ваших токенизированных входных данных (например, они не возвращаются, если вы используете модель DistilBERT). Они возвращаются только тогда, когда модель будет знать, что с ними делать, потому что она видела их во время предобучения.
-В данном случае BERT был обучен с информацией о идентификаторах типов токенов, и помимо задачи маскированной языковой модели, о которой мы говорили в [главе 1](/course/ru/chapter1), он может решать еще одну задачу: предсказание следующего предложения (_next sentence prediction_). Суть этой задачи - смоделировать связь между предложениями.
+В данном случае BERT был обучен с информацией о идентификаторах типов токенов, и помимо задачи маскированной языковой модели, о которой мы говорили в [главе 1](../chapter1/1), он может решать еще одну задачу: предсказание следующего предложения (_next sentence prediction_). Суть этой задачи - смоделировать связь между предложениями.
В этой задаче модели на вход подаются пары предложений (со случайно замаскированными токенами), от модели требуется предсказать, является ли следующее предложение продолжением текущего. Чтобы задача не была слишком тривиальной, половина времени модель обучается на соседних предложениях из одного документа, другую половину на парах предложений, взятых из разных источников.
В общем случае вам не нужно беспокоиться о наличии `token_type_ids` в ваших токенизированных данных: пока вы используете одинаковый чекпоинт и для токенизатора, и для модели – токенизатор будет знать, как нужно обработать данные.
-Теперь мы знаем, что токенизатор может подготовить сразу пару предложений, а значит мы можем использовать его для целого датасета: так же как и в [предыдущей главе](/course/ru/chapter2) можно подать на вход токенизатору список первых предложений и список вторых предложений. Это также сработает и для механизмов дополнения (padding) и усечения до максимальной длины (truncation) - об этом мы говорили в [главе 2](/course/chapter2). Итак, один из способов предобработать обучающий датасет такой:
+Теперь мы знаем, что токенизатор может подготовить сразу пару предложений, а значит мы можем использовать его для целого датасета: так же как и в [предыдущей главе](../chapter2/1) можно подать на вход токенизатору список первых предложений и список вторых предложений. Это также сработает и для механизмов дополнения (padding) и усечения до максимальной длины (truncation) - об этом мы говорили в [главе 2](../chapter2). Итак, один из способов предобработать обучающий датасет такой:
```py
tokenized_dataset = tokenizer(
@@ -235,7 +235,7 @@ tokenized_dataset = tokenizer(
Это хорошо работает, однако есть недостаток, который формирует токенизатор (с ключами, `input_ids`, `attention_mask`, и `token_type_ids`, и значениями в формате списка списков). Это будет работать только если у нас достаточно оперативной памяти (RAM) для хранения целого датасета во время токенизации (в то время как датасеты из библиотеки 🤗 Datasets являются [Apache Arrow](https://arrow.apache.org/) файлами, хранящимися на диске; они будут загружены только в тот момент, когда вы их будете запрашивать).
-Чтобы хранить данные в формате датасета, мы будем использовать методы [`Dataset.map()`](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.map). Это позволит нам сохранить высокую гибкость даже если нам нужно что-то большее, чем просто токенизация. Метод `map()` работает так: применяет некоторую функцию к каждому элементу датасета, давайте определим функцию, которая токенизирует наши входные данные:
+Чтобы хранить данные в формате датасета, мы будем использовать методы [`Dataset.map()`](https://huggingface.co/docs/datasets/package_reference/main_classes#datasets.Dataset.map). Это позволит нам сохранить высокую гибкость даже если нам нужно что-то большее, чем просто токенизация. Метод `map()` работает так: применяет некоторую функцию к каждому элементу датасета, давайте определим функцию, которая токенизирует наши входные данные:
```py
def tokenize_function(example):
diff --git a/chapters/ru/chapter3/3.mdx b/chapters/ru/chapter3/3.mdx
index 8da9c30d1..4f00a73b3 100644
--- a/chapters/ru/chapter3/3.mdx
+++ b/chapters/ru/chapter3/3.mdx
@@ -45,11 +45,11 @@ training_args = TrainingArguments("test-trainer")
-💡 Если вы хотите автоматически загружать модель на Hub во время обучения, передайте аргумент `push_to_hub=True` в `TrainingArguments`. Мы больше узнаем об этом в главе [Chapter 4](/course/chapter4/3).
+💡 Если вы хотите автоматически загружать модель на Hub во время обучения, передайте аргумент `push_to_hub=True` в `TrainingArguments`. Мы больше узнаем об этом в [главе 4](../chapter4/3).
-Второй шаг – задание модели. Так же, как и в [предыдущей главе](/course/chapter2), мы будем использовать класс `AutoModelForSequenceClassification` с двумя лейблами:
+Второй шаг – задание модели. Так же, как и в [предыдущей главе](../chapter2/1), мы будем использовать класс `AutoModelForSequenceClassification` с двумя лейблами:
```py
from transformers import AutoModelForSequenceClassification
@@ -57,7 +57,7 @@ from transformers import AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
```
-После создания экземпляра предобученной модели будет распечатано предупреждение (в [главе 2](/course/chapter2) мы с таким не сталкивались). Это происходит потому, что BERT не был предобучен для задачи классификации пар предложений, его последний слой не будет использован, вместо него будет добавлен слой, позволяющий работать с такой задачей. Предупреждения сообщают, что некоторые веса не будут использованы (как раз тех слоев, которые не будут использоваться) и для новых будут инициализированы случайные веса. В заключении предлагается обучить модель, что мы и сделаем прямо сейчас.
+После создания экземпляра предобученной модели будет распечатано предупреждение (в [главе 2](../chapter2/1) мы с таким не сталкивались). Это происходит потому, что BERT не был предобучен для задачи классификации пар предложений, его последний слой не будет использован, вместо него будет добавлен слой, позволяющий работать с такой задачей. Предупреждения сообщают, что некоторые веса не будут использованы (как раз тех слоев, которые не будут использоваться) и для новых будут инициализированы случайные веса. В заключении предлагается обучить модель, что мы и сделаем прямо сейчас.
После того, как мы загрузили модель, мы можем определить `Trainer` и передать туда нужные объекты: `model`, `training_args`, обучающую и валидационную выборки, `data_collator` и `tokenizer`
@@ -105,7 +105,7 @@ print(predictions.predictions.shape, predictions.label_ids.shape)
Результат функции `predict()` - другой именованный кортеж с полями `predictions`, `label_ids` и `metrics`. Поле `metrics` будет содержать значение лосса на нашем датасете и значения метрик. После реализации функции `compute_metrics()` и передачи ее в `Trainer` поле `metrics` также будет содержать результат функции `compute_metrics()`.
-Как можно заметить, `predictions` - массив 408 х 2 (408 - число элементов в датасете, который мы использовали). Это логиты для каждого элемента нашего датасета, переданного в `predict()` (как вы видели в [предыдущей главе](/course/chapter2) все модели Трансформеров возвращают логиты). Чтобы превратить их в предсказания и сравнить с нашими лейблами, нам необходимо узнать индекс максимального элемента второй оси:
+Как можно заметить, `predictions` - массив 408 х 2 (408 - число элементов в датасете, который мы использовали). Это логиты для каждого элемента нашего датасета, переданного в `predict()` (как вы видели в [предыдущей главе](../chapter2/1) все модели Трансформеров возвращают логиты). Чтобы превратить их в предсказания и сравнить с нашими лейблами, нам необходимо узнать индекс максимального элемента второй оси:
```py
import numpy as np
diff --git a/chapters/ru/chapter3/3_tf.mdx b/chapters/ru/chapter3/3_tf.mdx
index 92b68b191..bbe24dee5 100644
--- a/chapters/ru/chapter3/3_tf.mdx
+++ b/chapters/ru/chapter3/3_tf.mdx
@@ -58,7 +58,7 @@ tf_validation_dataset = tokenized_datasets["validation"].to_tf_dataset(
-Как и в [предыдущей главе](/course/ru/chapter2), мы будем использовать класс `TFAutoModelForSequenceClassification` с двумя метками:
+Как и в [предыдущей главе](../chapter2/1), мы будем использовать класс `TFAutoModelForSequenceClassification` с двумя метками:
```py
from transformers import TFAutoModelForSequenceClassification
@@ -66,7 +66,7 @@ from transformers import TFAutoModelForSequenceClassification
model = TFAutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
```
-Вы заметите, что в отличие от [Главы 2](/course/ru/chapter2), вы получаете предупреждение после создания экземпляра этой предварительно обученной модели. Это связано с тем, что BERT не был предварительно обучен классификации пар предложений, поэтому последний слой предварительно обученной модели был отброшен, а вместо него был вставлен новый слой, подходящий для классификации последовательностей. Предупреждения указывают на то, что некоторые веса не использовались (те, которые соответствуют удаленным слоям), а некоторые другие были инициализированы случайным образом (те, что для новых слоев). В заключение предлагается обучить модель, что мы и собираемся сделать сейчас.
+Вы заметите, что в отличие от [Главы 2](../chapter2/1), вы получаете предупреждение после создания экземпляра этой предварительно обученной модели. Это связано с тем, что BERT не был предварительно обучен классификации пар предложений, поэтому последний слой предварительно обученной модели был отброшен, а вместо него был вставлен новый слой, подходящий для классификации последовательностей. Предупреждения указывают на то, что некоторые веса не использовались (те, которые соответствуют удаленным слоям), а некоторые другие были инициализированы случайным образом (те, что для новых слоев). В заключение предлагается обучить модель, что мы и собираемся сделать сейчас.
Чтобы точно настроить модель в нашем наборе данных, нам просто нужно вызвать `compile()` у нашей модели, а затем передать наши данные в метод `fit()`. Это запустит процесс fine tuning (который должен занять пару минут на графическом процессоре) и сообщит о значениях функции потерь при обучении, а также о значениях функции потерь на валидации.
@@ -147,7 +147,7 @@ model.fit(tf_train_dataset, validation_data=tf_validation_dataset, epochs=3)
-💡 Если вы хотите автоматически загружать свою модель на Hub во время обучения, вы можете передать `PushToHubCallback` в метод `model.fit()`. Мы узнаем об этом больше в [Chapter 4](/course/chapter4/3).
+💡 Если вы хотите автоматически загружать свою модель на Hub во время обучения, вы можете передать `PushToHubCallback` в метод `model.fit()`. Мы узнаем об этом больше в [Главе 4](../chapter4/3).
@@ -188,4 +188,4 @@ metric.compute(predictions=class_preds, references=raw_datasets["validation"]["l
Точные результаты, которые вы получите, могут отличаться, так как случайная инициализация параметров выходных слоев модели может изменить показатели. Здесь мы видим, что наша модель имеет точность 85,78% на валидационном наборе и оценку F1 89,97. Это две метрики, используемые для оценки результатов датасета MRPC для теста GLUE. В таблице в [документации BERT] (https://arxiv.org/pdf/1810.04805.pdf) сообщается о балле F1 88,97% для базовой модели. Это была модель, которая не чувствительна к регистру текста, в то время как сейчас мы используем модель, учитывающую регистр, что и объясняет лучший результат.
-На этом введение в fine tuning с помощью Keras API завершено. Пример выполнения этого для наиболее распространенных задач NLP будет дан в [Главе 7](/course/ru/chapter7). Если вы хотите отточить свои навыки работы с Keras API, попробуйте точно настроить модель в наборе данных GLUE SST-2, используя обработку данных, которую вы выполнили в разделе 2.
+На этом введение в fine tuning с помощью Keras API завершено. Пример выполнения этого для наиболее распространенных задач NLP будет дан в [Главе 7](../chapter7). Если вы хотите отточить свои навыки работы с Keras API, попробуйте точно настроить модель в наборе данных GLUE SST-2, используя обработку данных, которую вы выполнили в разделе 2.
diff --git a/chapters/ru/chapter4/3.mdx b/chapters/ru/chapter4/3.mdx
index d737fd07a..3a7fbf507 100644
--- a/chapters/ru/chapter4/3.mdx
+++ b/chapters/ru/chapter4/3.mdx
@@ -50,7 +50,7 @@
Простейший путь загрузки файлов на Hub – `push_to_hub` API.
-Перед тем, как пойдем дальше, необходимо сгенерировать токен аутентификации. Это необходимо сделать для того, чтобы `huggingface_hub` API «узнал» вас и предоставил вам необходимые права на запись. Убедитесь, что вы находитесь в окружении, в котором установлена библиотека `transformers` (см. [Установка](/course/ru/chapter0)). Если вы работаете в Jupyter'е, вы можете использовать следующую функцию для авторизации:
+Перед тем, как пойдем дальше, необходимо сгенерировать токен аутентификации. Это необходимо сделать для того, чтобы `huggingface_hub` API «узнал» вас и предоставил вам необходимые права на запись. Убедитесь, что вы находитесь в окружении, в котором установлена библиотека `transformers` (см. [Установка](../chapter0)). Если вы работаете в Jupyter'е, вы можете использовать следующую функцию для авторизации:
```python
from huggingface_hub import notebook_login
diff --git a/chapters/ru/chapter5/1.mdx b/chapters/ru/chapter5/1.mdx
index ff8429d6a..911a94fa8 100644
--- a/chapters/ru/chapter5/1.mdx
+++ b/chapters/ru/chapter5/1.mdx
@@ -1,6 +1,6 @@
# Введение
-В [главе 3](/course/ru/chapter3) вы поверхностно ознакомились с библиотекой 🤗 Datasets и увидели три главных шага для использования ее в процессе fine-tuning:
+В [главе 3](../chapter3/1) вы поверхностно ознакомились с библиотекой 🤗 Datasets и увидели три главных шага для использования ее в процессе fine-tuning:
1. Загрузить датасет из Hugging Face Hub.
2. Произвести препроцессинг с помощью `Dataset.map()`.
@@ -14,4 +14,4 @@
* Что, черт возьми, такое «отображение памяти» (memory mapping) и Apache Arrow?
* Как вы можете создать свой собственный датасет и отправить его в Hub?
-Принципы, которые вы изучите в этой главе, подготовят вас к более глубокому использованию токенизации и fine-tuning'а моделей в [главе 6](/course/ru/chapter6) и [главе 7](/course/ru/chapter7) – заваривайте кофе и мы начинаем!
\ No newline at end of file
+Принципы, которые вы изучите в этой главе, подготовят вас к более глубокому использованию токенизации и fine-tuning'а моделей в [главе 6](../chapter6) и [главе 7](../chapter7) – заваривайте кофе и мы начинаем!
\ No newline at end of file
diff --git a/chapters/ru/chapter5/2.mdx b/chapters/ru/chapter5/2.mdx
index ee50ef207..b4a9c9ab5 100644
--- a/chapters/ru/chapter5/2.mdx
+++ b/chapters/ru/chapter5/2.mdx
@@ -123,7 +123,7 @@ DatasetDict({
-Аргумент `data_files` функции `load_dataset()` очень гибкий и может являться путем к файлу, списком путей файлов или словарем, в котором указаны названия сплитов (обучающего и тестового) и пути к соответствующим файлам. Вы также можете найти все подходящие файлы в директории с использованием маски по правилам Unix-консоли (т.е. указать путь к директории и указать `data_files="*.json"` для конкретного сплита). Более подробно это изложено в [документации](https://huggingface.co/docs/datasets/loading.html#local-and-remote-files) 🤗 Datasets.
+Аргумент `data_files` функции `load_dataset()` очень гибкий и может являться путем к файлу, списком путей файлов или словарем, в котором указаны названия сплитов (обучающего и тестового) и пути к соответствующим файлам. Вы также можете найти все подходящие файлы в директории с использованием маски по правилам Unix-консоли (т.е. указать путь к директории и указать `data_files="*.json"` для конкретного сплита). Более подробно это изложено в [документации](https://huggingface.co/docs/datasets/loading#local-and-remote-files) 🤗 Datasets.
@@ -156,7 +156,7 @@ squad_it_dataset = load_dataset("json", data_files=data_files, field="data")
-✏️ **Попробуйте!** Выберите другой датасет, расположенный на GitHub или в архиве [UCI Machine Learning Repository](https://archive.ics.uci.edu/ml/index.php) и попробуйте загрузить его с локальной машины и с удаленного сервера. В качестве бонуса попробуйте загрузить датасет в формате CSV или обычного тектового файла (см. детали по поддерживаемым форматам в [документации](https://huggingface.co/docs/datasets/loading.html#local-and-remote-files)).
+✏️ **Попробуйте!** Выберите другой датасет, расположенный на GitHub или в архиве [UCI Machine Learning Repository](https://archive.ics.uci.edu/ml/index.php) и попробуйте загрузить его с локальной машины и с удаленного сервера. В качестве бонуса попробуйте загрузить датасет в формате CSV или обычного тектового файла (см. детали по поддерживаемым форматам в [документации](https://huggingface.co/docs/datasets/loading#local-and-remote-files)).
diff --git a/chapters/ru/chapter5/3.mdx b/chapters/ru/chapter5/3.mdx
index 378b05e24..d5c232d63 100644
--- a/chapters/ru/chapter5/3.mdx
+++ b/chapters/ru/chapter5/3.mdx
@@ -13,7 +13,7 @@
## Управление данными
-Как и в Pandas, 🤗 Datasets предоставляет несколько функция для управления содержимым объектов `Dataset` и `DatasetDict`. Мы уже познакомились с методом `Dataset.map()` в [главе 3](/course/ru/chapter3), а далее мы посмотрим на другие функции, имеющиеся в нашем распоряжении.
+Как и в Pandas, 🤗 Datasets предоставляет несколько функция для управления содержимым объектов `Dataset` и `DatasetDict`. Мы уже познакомились с методом `Dataset.map()` в [главе 3](../chapter3/1), а далее мы посмотрим на другие функции, имеющиеся в нашем распоряжении.
Для этого примера мы будем использовать датасет [Drug Review Dataset](https://archive.ics.uci.edu/ml/datasets/Drug+Review+Dataset+%28Drugs.com%29), расположенный на сервере [UC Irvine Machine Learning Repository](https://archive.ics.uci.edu/ml/index.php) и содержащий отзывы пациентов на различные лекарства, сведения о состоянии пациентов и рейтинг удовлетворенности, выраженный в 10-балльной шкале.
@@ -95,7 +95,7 @@ DatasetDict({
-Далее нормализуем все лейблы столбца `condition` с применением `Dataset.map()`. Так же, как мы делали токенизацию в [главе 3](/course/ru/chapter3), мы можем определить простую функцию, которая будет применения для всех строк каждого сплита в `drug_dataset`:
+Далее нормализуем все лейблы столбца `condition` с применением `Dataset.map()`. Так же, как мы делали токенизацию в [главе 3](../chapter3/1), мы можем определить простую функцию, которая будет применения для всех строк каждого сплита в `drug_dataset`:
```py
def lowercase_condition(example):
@@ -122,7 +122,7 @@ def filter_nones(x):
lambda
:
```
-где `lambda` - одно из [ключевых](https://docs.python.org/3/reference/lexical_analysis.html#keywords) слов Python, а `` - список или множество разделенных запятой значений, которые пойдут на вход функции, и `` задает операции, которые вы хотите применить к аргументам. Например, мы можем задать простую лямбда-функцию, которая возводит в квадрат числа:
+где `lambda` - одно из [ключевых](https://docs.python.org/3/reference/lexical_analysis#keywords) слов Python, а `` - список или множество разделенных запятой значений, которые пойдут на вход функции, и `` задает операции, которые вы хотите применить к аргументам. Например, мы можем задать простую лямбда-функцию, которая возводит в квадрат числа:
```
lambda x : x * x
@@ -238,7 +238,7 @@ print(drug_dataset.num_rows)
-✏️ **Попробуйте!** Используйте функцию `Dataset.sort()` для проверки наиболее длинных отзывов. Изучите [документацию](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.sort) чтобы понять, какой аргумент нужно передать в функцию, чтобы сортировка произошла в убывающем порядке.
+✏️ **Попробуйте!** Используйте функцию `Dataset.sort()` для проверки наиболее длинных отзывов. Изучите [документацию](https://huggingface.co/docs/datasets/package_reference/main_classes#datasets.Dataset.sort) чтобы понять, какой аргумент нужно передать в функцию, чтобы сортировка произошла в убывающем порядке.
@@ -277,7 +277,7 @@ new_drug_dataset = drug_dataset.map(
Если вы запустите этот код в блокноте, вы увидите, что эта команда выполняется намного быстрее, чем предыдущая. И это не потому, что наши отзывы уже были HTML-экранированными — если вы повторно выполните инструкцию из предыдущего раздела (без `batched=True`), это займет столько же времени, сколько и раньше. Это связано с тем, что обработка списков обычно выполняется быстрее, чем выполнение того же кода в цикле `for`, мы также повышаем производительность за счет одновременного доступа к множеству элементов, а не по одному.
-Использование `Dataset.map()` с `batched=True` – хороший способ «разблокировать» скоростные ограничения "быстрых" токенизаторов, с которыми мы познакомимся в [главе 6](/course/chapter6), которые могут быстро токенизировать большие списки текста. Например, чтобы токенизировать все отзывы на лекарства с помощью быстрого токенизатора, мы можем использовать функцию, подобную этой:
+Использование `Dataset.map()` с `batched=True` – хороший способ «разблокировать» скоростные ограничения "быстрых" токенизаторов, с которыми мы познакомимся в [главе 6](../chapter6), которые могут быстро токенизировать большие списки текста. Например, чтобы токенизировать все отзывы на лекарства с помощью быстрого токенизатора, мы можем использовать функцию, подобную этой:
```python
from transformers import AutoTokenizer
@@ -289,7 +289,7 @@ def tokenize_function(examples):
return tokenizer(examples["review"], truncation=True)
```
-Как вы видели в [главе 3](/course/ru/chapter3), мы можем передать один или несколько элементов в токенизатор, так что мы можем использовать эту функцию без параметра `batched=True`. Давайте воспользуемся этой возможностью и сравним производительность. В ноутбуке можно замерить время выполнения функции путем добавления `%time` перед строкой кода, время исполнения которой вы хотите измерить:
+Как вы видели в [главе 3](../chapter3/1), мы можем передать один или несколько элементов в токенизатор, так что мы можем использовать эту функцию без параметра `batched=True`. Давайте воспользуемся этой возможностью и сравним производительность. В ноутбуке можно замерить время выполнения функции путем добавления `%time` перед строкой кода, время исполнения которой вы хотите измерить:
```python no-format
%time tokenized_dataset = drug_dataset.map(tokenize_function, batched=True)
@@ -344,7 +344,7 @@ Options | Fast tokenizer | Slow tokenizer
-Объединение всей этой функциональности во всего лишь один метод само по себе прекрасно, но это еще не все! Используя `Dataset.map()` и `batched=True` вы можете поменять число элементов в датасете. Это очень полезно во множестве ситуаций, например, когда вы хотите создать несколько обучающих признаков из одного экземпляра текста. Мы воспользуеся этой возможностью на этапе препроцессинга для нескольких NLP-задач, которые рассмотрим в [главе 7](/course/ru/chapter7)
+Объединение всей этой функциональности во всего лишь один метод само по себе прекрасно, но это еще не все! Используя `Dataset.map()` и `batched=True` вы можете поменять число элементов в датасете. Это очень полезно во множестве ситуаций, например, когда вы хотите создать несколько обучающих признаков из одного экземпляра текста. Мы воспользуеся этой возможностью на этапе препроцессинга для нескольких NLP-задач, которые рассмотрим в [главе 7](../chapter7)
@@ -385,9 +385,9 @@ tokenized_dataset = drug_dataset.map(tokenize_and_split, batched=True)
ArrowInvalid: Column 1 named condition expected length 1463 but got length 1000
```
-О, нет! Не сработало! Почему? Посмотрим на ошибку: несовпадение в длинах, один из которых длиной 1463, а другой – 1000. Если вы обратитесь в [документацию](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.map) `Dataset.map()`, вы можете увидеть, что одно из этих чисел – число объектов, поданных на вход функции, а другое –
+О, нет! Не сработало! Почему? Посмотрим на ошибку: несовпадение в длинах, один из которых длиной 1463, а другой – 1000. Если вы обратитесь в [документацию](https://huggingface.co/docs/datasets/package_reference/main_classes#datasets.Dataset.map) `Dataset.map()`, вы можете увидеть, что одно из этих чисел – число объектов, поданных на вход функции, а другое –
-Oh no! That didn't work! Why not? Looking at the error message will give us a clue: there is a mismatch in the lengths of one of the columns, one being of length 1,463 and the other of length 1,000. If you've looked at the [documentation](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.map), you may recall that it's the number of samples passed to the function that we are mapping; here those 1,000 examples gave 1,463 new features, resulting in a shape error.
+Oh no! That didn't work! Why not? Looking at the error message will give us a clue: there is a mismatch in the lengths of one of the columns, one being of length 1,463 and the other of length 1,000. If you've looked at the [documentation](https://huggingface.co/docs/datasets/package_reference/main_classes#datasets.Dataset.map), you may recall that it's the number of samples passed to the function that we are mapping; here those 1,000 examples gave 1,463 new features, resulting in a shape error.
Проблема заключается в том, что мы пытаемся смешать два разных датасета разной размерности: число колонок датасета `drug_dataset` равняется 1000, а нужный нам `tokenized_dataset` имеет 1463 колонки. Чтобы избежать этой ошибки, необходимо удалить несколько столбцов из старого датасета и сделать оба датасета одинакового размера. Мы можем достичь этого с помощью аргумента `remove_columns`:
@@ -641,7 +641,7 @@ DatasetDict({
})
```
-Отлично, теперь мы подготовили датасет, на котором можно обучить некоторые модели. В [разделе 5](/course/ru/chapter5/5) мы покажем, как загрузить датасеты на Hugging Face Hub, а пока закончим наш обзор и посмотрим несколько способов сохранения датасетов на локальный компьютер.
+Отлично, теперь мы подготовили датасет, на котором можно обучить некоторые модели. В [разделе 5](../chapter5/5) мы покажем, как загрузить датасеты на Hugging Face Hub, а пока закончим наш обзор и посмотрим несколько способов сохранения датасетов на локальный компьютер.
## Сохранение датасетов
@@ -727,7 +727,7 @@ for split, dataset in drug_dataset_clean.items():
{"patient_id":141780,"drugName":"Escitalopram","condition":"depression","review":"\"I seemed to experience the regular side effects of LEXAPRO, insomnia, low sex drive, sleepiness during the day. I am taking it at night because my doctor said if it made me tired to take it at night. I assumed it would and started out taking it at night. Strange dreams, some pleasant. I was diagnosed with fibromyalgia. Seems to be helping with the pain. Have had anxiety and depression in my family, and have tried quite a few other medications that haven't worked. Only have been on it for two weeks but feel more positive in my mind, want to accomplish more in my life. Hopefully the side effects will dwindle away, worth it to stick with it from hearing others responses. Great medication.\"","rating":9.0,"date":"May 29, 2011","usefulCount":10,"review_length":125}
```
-Мы можем использовать приёмы из [раздела 2](/course/ru/chapter5/2) для загрузки JSON-файлов:
+Мы можем использовать приёмы из [раздела 2](../chapter5/2) для загрузки JSON-файлов:
```py
data_files = {
@@ -740,8 +740,8 @@ drug_dataset_reloaded = load_dataset("json", data_files=data_files)
Вот и все, что нужно для нашего экскурса при работе с 🤗 Datasets! Мы очистили датасет для обучения модели, вот некоторые идеи, которые вы могли бы реализовать самостоятельно:
-1. Примените знания из [раздела 3](/course/ru/chapter3) для обучения классификатора, который может предсказывать состояние пациента по отзыву на лекарство.
-2. Используйте pipeline `summarization` из [раздела 1](/course/ru/chapter1)для генерации саммари отзывов.
+1. Примените знания из [раздела 3](../chapter3/1) для обучения классификатора, который может предсказывать состояние пациента по отзыву на лекарство.
+2. Используйте pipeline `summarization` из [раздела 1](../chapter1/1)для генерации саммари отзывов.
Далее мы посмотрим, как 🤗 Datasets могут помочь вам в работе с громадными датасетами, которые _невозможно_ обработать на вашем ноутбуке!
diff --git a/chapters/ru/chapter5/4.mdx b/chapters/ru/chapter5/4.mdx
index d96ca1b35..c62459ec4 100644
--- a/chapters/ru/chapter5/4.mdx
+++ b/chapters/ru/chapter5/4.mdx
@@ -23,7 +23,7 @@ The Pile — это корпус текстов на английском язы
!pip install zstandard
```
-Затем мы можем загрузить набор данных, используя метод для подгрузки файлов, который мы изучили в [разделе 2](/course/ru/chapter5/2):
+Затем мы можем загрузить набор данных, используя метод для подгрузки файлов, который мы изучили в [разделе 2](../chapter5/2):
```py
from datasets import load_dataset
@@ -45,7 +45,7 @@ Dataset({
-✎ По умолчанию 🤗 Datasets распаковывает файлы, необходимые для загрузки набора данных. Если вы хотите сохранить место на жестком диске, вы можете передать `DownloadConfig(delete_extracted=True)` в аргумент `download_config` функции `load_dataset()`. Дополнительные сведения см. в [документации](https://huggingface.co/docs/datasets/package_reference/builder_classes.html?#datasets.utils.DownloadConfig).
+✎ По умолчанию 🤗 Datasets распаковывает файлы, необходимые для загрузки набора данных. Если вы хотите сохранить место на жестком диске, вы можете передать `DownloadConfig(delete_extracted=True)` в аргумент `download_config` функции `load_dataset()`. Дополнительные сведения см. в [документации](https://huggingface.co/docs/datasets/package_reference/builder_classes#datasets.DownloadConfig).
@@ -157,7 +157,7 @@ next(iter(pubmed_dataset_streamed))
'text': 'Epidemiology of hypoxaemia in children with acute lower respiratory infection.\nTo determine the prevalence of hypoxaemia in children aged under 5 years suffering acute lower respiratory infections (ALRI), the risk factors for hypoxaemia in children under 5 years of age with ALRI, and the association of hypoxaemia with an increased risk of dying in children of the same age ...'}
```
-Элементы из потокового набора данных можно обрабатывать на лету с помощью `IterableDataset.map()`, что полезно во время обучения, если вам нужно токенизировать входные данные. Процесс точно такой же, как тот, который мы использовали для токенизации нашего набора данных в [Главе 3] (/course/ru/chapter3), с той лишь разницей, что выходные данные возвращаются один за другим:
+Элементы из потокового набора данных можно обрабатывать на лету с помощью `IterableDataset.map()`, что полезно во время обучения, если вам нужно токенизировать входные данные. Процесс точно такой же, как тот, который мы использовали для токенизации нашего набора данных в [Главе 3](../chapter3/1), с той лишь разницей, что выходные данные возвращаются один за другим:
```py
from transformers import AutoTokenizer
diff --git a/chapters/ru/chapter5/6.mdx b/chapters/ru/chapter5/6.mdx
index b238ba8a9..117b06c60 100644
--- a/chapters/ru/chapter5/6.mdx
+++ b/chapters/ru/chapter5/6.mdx
@@ -22,13 +22,13 @@
{/if}
-В [разделе 5](/course/ru/chapter5/5) мы создали набор данных о issues и комментариях GitHub из репозитория 🤗 Datasets. В этом разделе мы будем использовать эту информацию для создания поисковой системы, которая поможет нам найти ответы на самые насущные вопросы о библиотеке!
+В [разделе 5](../chapter5/5) мы создали набор данных о issues и комментариях GitHub из репозитория 🤗 Datasets. В этом разделе мы будем использовать эту информацию для создания поисковой системы, которая поможет нам найти ответы на самые насущные вопросы о библиотеке!
## Использование эмбеддингов для семанического поиска
-Как мы видели в [Главе 1](/course/ru/chapter1), языковые модели на основе Transformer представляют каждую лексему в текстовом фрагменте как _эмбеддинг-вектор_. Оказывается, можно «объединить» отдельные вложения, чтобы создать векторное представление для целых предложений, абзацев или (в некоторых случаях) документов. Затем эти вложения можно использовать для поиска похожих документов в корпусе путем вычисления скалярного произведения (или какой-либо другой метрики сходства) между каждым вложением и возврата документов с наибольшим перекрытием.
+Как мы видели в [Главе 1](../chapter1/1), языковые модели на основе Transformer представляют каждую лексему в текстовом фрагменте как _эмбеддинг-вектор_. Оказывается, можно «объединить» отдельные вложения, чтобы создать векторное представление для целых предложений, абзацев или (в некоторых случаях) документов. Затем эти вложения можно использовать для поиска похожих документов в корпусе путем вычисления скалярного произведения (или какой-либо другой метрики сходства) между каждым вложением и возврата документов с наибольшим перекрытием.
В этом разделе мы будем использовать вложения для разработки семантической поисковой системы. Эти поисковые системы предлагают несколько преимуществ по сравнению с традиционными подходами, основанными на сопоставлении ключевых слов в запросе с документами.
@@ -51,7 +51,7 @@ data_files = hf_hub_url(
)
```
-С URL-адресом, сохраненным в `data_files`, мы можем загрузить удаленный набор данных, используя метод, представленный в [раздел 2](/course/ru/chapter5/2):
+С URL-адресом, сохраненным в `data_files`, мы можем загрузить удаленный набор данных, используя метод, представленный в [раздел 2](../chapter5/2):
```py
from datasets import load_dataset
@@ -190,7 +190,7 @@ Dataset({
-✏️ **Попробуйте!** Посмотрите, сможете ли вы использовать `Dataset.map()`, чтобы развернуть столбец `comments` столбца `issues_dataset` _без_ использования Pandas. Это немного сложно; вы можете найти раздел ["Batch mapping"](https://huggingface.co/docs/datasets/v1.12.1/about_map_batch.html?batch-mapping#batch-mapping) документации 🤗 Datasets, полезным для этой задачи.
+✏️ **Попробуйте!** Посмотрите, сможете ли вы использовать `Dataset.map()`, чтобы развернуть столбец `comments` столбца `issues_dataset` _без_ использования Pandas. Это немного сложно; вы можете найти раздел ["Batch mapping"](https://huggingface.co/docs/datasets/about_map_batch#batch-mapping) документации 🤗 Datasets, полезным для этой задачи.
@@ -236,7 +236,7 @@ comments_dataset = comments_dataset.map(concatenate_text)
## Создание текстовых эмбединнгов
-В [Главе 2](/course/ru/chapter2) мы видели, что можно получить эмбеддингов токенов с помощью класса AutoModel. Все, что нам нужно сделать, это выбрать подходящую контрольную точку для загрузки модели. К счастью, есть библиотека под названием `sentence-transformers`, предназначенная для создания эмбеддингов. Как описано в [документации](https://www.sbert.net/examples/applications/semantic-search/README.html#симметричный-vs-асимметричный-semantic-search) библиотеки, наш вариант использования является примером _асимметричного семантического поиска_ потому что у нас есть короткий запрос, ответ на который мы хотели бы найти в более длинном документе, например, в комментарии к проблеме. В удобной [таблице обзора модели](https://www.sbert.net/docs/pretrained_models.html#model-overview) в документации указано, что контрольная точка `multi-qa-mpnet-base-dot-v1` имеет лучшую производительность для семантического поиска, поэтому мы будем использовать её для нашего приложения. Мы также загрузим токенизатор, используя ту же контрольную точку:
+В [Главе 2](../chapter2/1) мы видели, что можно получить эмбеддингов токенов с помощью класса AutoModel. Все, что нам нужно сделать, это выбрать подходящую контрольную точку для загрузки модели. К счастью, есть библиотека под названием `sentence-transformers`, предназначенная для создания эмбеддингов. Как описано в [документации](https://www.sbert.net/examples/applications/semantic-search/README.html#симметричный-vs-асимметричный-semantic-search) библиотеки, наш вариант использования является примером _асимметричного семантического поиска_ потому что у нас есть короткий запрос, ответ на который мы хотели бы найти в более длинном документе, например, в комментарии к проблеме. В удобной [таблице обзора модели](https://www.sbert.net/docs/pretrained_models.html#model-overview) в документации указано, что контрольная точка `multi-qa-mpnet-base-dot-v1` имеет лучшую производительность для семантического поиска, поэтому мы будем использовать её для нашего приложения. Мы также загрузим токенизатор, используя ту же контрольную точку:
{#if fw === 'pt'}
diff --git a/chapters/ru/chapter5/7.mdx b/chapters/ru/chapter5/7.mdx
index d40c7f871..687891774 100644
--- a/chapters/ru/chapter5/7.mdx
+++ b/chapters/ru/chapter5/7.mdx
@@ -13,4 +13,4 @@
- Создавать свой собственный набор данных и отправлять его в Hugging Face Hub.
- Строить свои эмбеддинги документов с помощью модели Transformer и создавать семантический поисковик с помощью FAISS.
-В [Главе 7](/course/ru/chapter7) мы будем использовать все это с пользой, поскольку мы углубимся в основные задачи NLP, для которых отлично подходят модели Transformer. Однако, прежде чем идти вперед, проверьте свои знания о 🤗 Datasets с помощью быстрого теста!
+В [Главе 7](../chapter7) мы будем использовать все это с пользой, поскольку мы углубимся в основные задачи NLP, для которых отлично подходят модели Transformer. Однако, прежде чем идти вперед, проверьте свои знания о 🤗 Datasets с помощью быстрого теста!
diff --git a/chapters/ru/chapter6/1.mdx b/chapters/ru/chapter6/1.mdx
index 93525db9d..3aaeb428a 100644
--- a/chapters/ru/chapter6/1.mdx
+++ b/chapters/ru/chapter6/1.mdx
@@ -5,7 +5,7 @@
classNames="absolute z-10 right-0 top-0"
/>
-В [Главе 3](/course/chapter3) мы рассмотрели, как дообучить модель для конкретной задачи. При этом мы используем тот же токенизатор, на котором была предварительно обучена модель, но что делать, когда мы хотим обучить модель с нуля? В таких случаях использование токенизатора, который был предварительно обучен на корпусе из другой области или языка, как правило, является неоптимальным. Например, токенизатор, обученный на корпусе английских текстов, будет плохо работать на корпусе японских текстов, поскольку использование пробелов и знаков препинания в этих двух языках сильно отличается.
+В [Главе 3](../chapter3/1) мы рассмотрели, как дообучить модель для конкретной задачи. При этом мы используем тот же токенизатор, на котором была предварительно обучена модель, но что делать, когда мы хотим обучить модель с нуля? В таких случаях использование токенизатора, который был предварительно обучен на корпусе из другой области или языка, как правило, является неоптимальным. Например, токенизатор, обученный на корпусе английских текстов, будет плохо работать на корпусе японских текстов, поскольку использование пробелов и знаков препинания в этих двух языках сильно отличается.
В этой главе вы узнаете, как обучить совершенно новый токенизатор на корпусе текстов, чтобы затем использовать его для предварительного обучения языковой модели. Все это будет сделано с помощью библиотеки [🤗 Tokenizers](https://github.com/huggingface/tokenizers), которая предоставляет "быстрые" токенизаторы в библиотеке [🤗 Transformers](https://github.com/huggingface/transformers). Мы подробно рассмотрим возможности, которые предоставляет эта библиотека, и выясним, чем быстрые токенизаторы отличаются от "медленных" версий.
@@ -16,4 +16,4 @@
* Различия между тремя основными алгоритмами токенизации по подсловам, используемыми в NLP сегодня
* Как создать токенизатор с нуля с помощью библиотеки 🤗 Tokenizers и обучить его на некоторых данных
-Техники, представленные в этой главе, подготовят вас к разделу в [Главе 7](/course/chapter7/6), где мы рассмотрим создание языковой модели по исходному коду Python. Для начала давайте разберемся, что значит "обучить" токенизатор.
\ No newline at end of file
+Техники, представленные в этой главе, подготовят вас к разделу в [Главе 7](../chapter7/6), где мы рассмотрим создание языковой модели по исходному коду Python. Для начала давайте разберемся, что значит "обучить" токенизатор.
\ No newline at end of file
diff --git a/chapters/ru/chapter6/2.mdx b/chapters/ru/chapter6/2.mdx
index 4dfd465bb..089e23962 100644
--- a/chapters/ru/chapter6/2.mdx
+++ b/chapters/ru/chapter6/2.mdx
@@ -7,7 +7,7 @@
{label: "Aws Studio", value: "https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/master/course/en/chapter6/section2.ipynb"},
]} />
-Если языковая модель не доступна на интересующем вас языке или ваш корпус сильно отличается от того, на котором обучалась языковая модель, вам, скорее всего, придется заново обучать модель с нуля, используя токенизатор, адаптированный к вашим данным. Для этого потребуется обучить новый токенизатор на вашем наборе данных. Но что именно это значит? Когда мы впервые рассматривали токенизаторы в [Главе 2](/course/chapter2), мы увидели, что большинство моделей трансформеров используют _алгоритм токенизации по подсловам_. Чтобы определить, какие подслова представляют интерес и наиболее часто встречаются в корпусе, токенизатор должен внимательно изучить все тексты в корпусе - этот процесс мы называем *обучением*. Точные правила обучения зависят от типа используемого токенизатора, далее в этой главе мы рассмотрим три основных алгоритма.
+Если языковая модель не доступна на интересующем вас языке или ваш корпус сильно отличается от того, на котором обучалась языковая модель, вам, скорее всего, придется заново обучать модель с нуля, используя токенизатор, адаптированный к вашим данным. Для этого потребуется обучить новый токенизатор на вашем наборе данных. Но что именно это значит? Когда мы впервые рассматривали токенизаторы в [Главе 2](../chapter2/1), мы увидели, что большинство моделей трансформеров используют _алгоритм токенизации по подсловам_. Чтобы определить, какие подслова представляют интерес и наиболее часто встречаются в корпусе, токенизатор должен внимательно изучить все тексты в корпусе - этот процесс мы называем *обучением*. Точные правила обучения зависят от типа используемого токенизатора, далее в этой главе мы рассмотрим три основных алгоритма.
@@ -169,7 +169,7 @@ tokenizer = old_tokenizer.train_new_from_iterator(training_corpus, 52000)
Обратите внимание, что `AutoTokenizer.train_new_from_iterator()` работает только в том случае, если используемый вами токенизатор является "быстрым" токенизатором. Как вы увидите в следующем разделе, библиотека 🤗 Transformers содержит два типа токенизаторов: одни написаны исключительно на Python, а другие (быстрые) опираются на библиотеку 🤗 Tokenizers, которая написана на языке программирования [Rust](https://www.rust-lang.org). Python - это язык, который чаще всего используется для приложений data science и deep learning, но когда что-то нужно распараллелить для быстроты, это приходится писать на другом языке. Например, матричные умножения, которые лежат в основе вычислений модели, написаны на CUDA, оптимизированной библиотеке языка C для GPU.
-Обучение совершенно нового токенизатора на чистом Python было бы мучительно медленным, поэтому мы разработали библиотеку 🤗 Tokenizers. Обратите внимание, что так же как вам не нужно было изучать язык CUDA, чтобы выполнить свою модель на батче входных данных на GPU, вам не понадобится изучать Rust, чтобы использовать быстрый токенизатор. Библиотека 🤗 Tokenizers предоставляет привязки к Python для многих методов, которые внутренне вызывают некоторые части кода на Rust; например, для распараллеливания обучения вашего нового токенизатора или, как мы видели в [Главе 3](/course/chapter3), токенизации батча входных данных.
+Обучение совершенно нового токенизатора на чистом Python было бы мучительно медленным, поэтому мы разработали библиотеку 🤗 Tokenizers. Обратите внимание, что так же как вам не нужно было изучать язык CUDA, чтобы выполнить свою модель на батче входных данных на GPU, вам не понадобится изучать Rust, чтобы использовать быстрый токенизатор. Библиотека 🤗 Tokenizers предоставляет привязки к Python для многих методов, которые внутренне вызывают некоторые части кода на Rust; например, для распараллеливания обучения вашего нового токенизатора или, как мы видели в [Главе 3](../chapter3/1), токенизации батча входных данных.
В большинстве моделей Transformer доступен быстрый токенизатор (есть некоторые исключения, о которых вы можете узнать [здесь](https://huggingface.co/transformers/#supported-frameworks)), а API `AutoTokenizer` всегда выбирает быстрый токенизатор, если он доступен. В следующем разделе мы рассмотрим некоторые другие особенности быстрых токенизаторов, которые будут очень полезны для таких задач, как классификация токенов и ответы на вопросы. Однако прежде чем погрузиться в эту тему, давайте попробуем наш новый токенизатор на предыдущем примере:
@@ -254,4 +254,4 @@ tokenizer.push_to_hub("code-search-net-tokenizer")
tokenizer = AutoTokenizer.from_pretrained("huggingface-course/code-search-net-tokenizer")
```
-Теперь вы готовы обучить языковую модель с нуля и дообучить ее в соответствии с поставленной задачей! Мы займемся этим в [Главе 7](/course/chapter7), но сначала в этой главе мы рассмотрим быстрые токенизаторы и подробно изучим, что происходит при вызове метода `train_new_from_iterator()`.
+Теперь вы готовы обучить языковую модель с нуля и дообучить ее в соответствии с поставленной задачей! Мы займемся этим в [Главе 7](../chapter7), но сначала в этой главе мы рассмотрим быстрые токенизаторы и подробно изучим, что происходит при вызове метода `train_new_from_iterator()`.
diff --git a/chapters/ru/chapter6/3.mdx b/chapters/ru/chapter6/3.mdx
index 25aa85b22..214e2ba13 100644
--- a/chapters/ru/chapter6/3.mdx
+++ b/chapters/ru/chapter6/3.mdx
@@ -22,11 +22,11 @@
{/if}
-В этом разделе мы подробно рассмотрим возможности токенизаторов в 🤗 Transformers. До сих пор мы использовали их только для токенизации входных данных или декодирования идентификаторов обратно в текст, но токенизаторы -- особенно те, которые поддерживаются библиотекой 🤗 Tokenizers - могут делать гораздо больше. Чтобы проиллюстрировать эти дополнительные возможности, мы рассмотрим, как воспроизвести результаты конвейеров `token-classification` (которые мы назвали `ner`) и `question-answering`, с которыми мы впервые столкнулись в [Главе 1] (/course/chapter1).
+В этом разделе мы подробно рассмотрим возможности токенизаторов в 🤗 Transformers. До сих пор мы использовали их только для токенизации входных данных или декодирования идентификаторов обратно в текст, но токенизаторы -- особенно те, которые поддерживаются библиотекой 🤗 Tokenizers - могут делать гораздо больше. Чтобы проиллюстрировать эти дополнительные возможности, мы рассмотрим, как воспроизвести результаты конвейеров `token-classification` (которые мы назвали `ner`) и `question-answering`, с которыми мы впервые столкнулись в [Главе 1](../chapter1/1).
-В дальнейшем обсуждении мы будем часто проводить различие между "медленными" и "быстрыми" токенизаторами. Медленные токенизаторы - это те, что написаны на Python в библиотеке 🤗 Transformers, а быстрые версии - это те, что предоставляются в 🤗 Tokenizers, которые написаны на Rust. Если вы помните таблицу из [Главы 5](/course/chapter5/3), в которой приводилось, сколько времени потребовалось быстрому и медленному токенизаторам для токенизации датасета Drug Review Dataset, вы должны иметь представление о том, почему мы называем их быстрыми и медленными:
+В дальнейшем обсуждении мы будем часто проводить различие между "медленными" и "быстрыми" токенизаторами. Медленные токенизаторы - это те, что написаны на Python в библиотеке 🤗 Transformers, а быстрые версии - это те, что предоставляются в 🤗 Tokenizers, которые написаны на Rust. Если вы помните таблицу из [Главы 5](../chapter5/3), в которой приводилось, сколько времени потребовалось быстрому и медленному токенизаторам для токенизации датасета Drug Review Dataset, вы должны иметь представление о том, почему мы называем их быстрыми и медленными:
| | Быстрый токенизатор | Медленный токенизатор
:--------------:|:----------------------:|:----------------------:
@@ -139,7 +139,7 @@ Sylvain
## Внутри конвейера `token-classification`[[inside-the-token-classification-pipeline]]
-В [Главе 1](/course/chapter1) мы впервые попробовали применить NER - когда задача состоит в том, чтобы определить, какие части текста соответствуют сущностям, таким как люди, места или организации - с помощью функции 🤗 Transformers `pipeline()`. Затем, в [Главе 2](/course/chapter2), мы увидели, как конвейер объединяет три этапа, необходимые для получения прогнозов из необработанного текста: токенизацию, прохождение входных данных через модель и постобработку. Первые два шага в конвейере `token-classification` такие же, как и в любом другом конвейере, но постобработка немного сложнее - давайте посмотрим, как это сделать!
+В [Главе 1](../chapter1/1) мы впервые попробовали применить NER - когда задача состоит в том, чтобы определить, какие части текста соответствуют сущностям, таким как люди, места или организации - с помощью функции 🤗 Transformers `pipeline()`. Затем, в [Главе 2](../chapter2/1), мы увидели, как конвейер объединяет три этапа, необходимые для получения прогнозов из необработанного текста: токенизацию, прохождение входных данных через модель и постобработку. Первые два шага в конвейере `token-classification` такие же, как и в любом другом конвейере, но постобработка немного сложнее - давайте посмотрим, как это сделать!
{#if fw === 'pt'}
@@ -200,7 +200,7 @@ token_classifier("My name is Sylvain and I work at Hugging Face in Brooklyn.")
{#if fw === 'pt'}
-Сначала нам нужно токенизировать наш ввод и пропустить его через модель. Это делается точно так же, как в [Главе 2](/course/chapter2); мы инстанцируем токенизатор и модель с помощью классов `AutoXxx`, а затем используем их в нашем примере:
+Сначала нам нужно токенизировать наш ввод и пропустить его через модель. Это делается точно так же, как в [Главе 2](../chapter2/1); мы инстанцируем токенизатор и модель с помощью классов `AutoXxx`, а затем используем их в нашем примере:
```py
from transformers import AutoTokenizer, AutoModelForTokenClassification
@@ -228,7 +228,7 @@ torch.Size([1, 19, 9])
{:else}
-Сначала нам нужно токенизировать наши входные данные и пропустить их через модель. Это делается точно так же, как в [Главе 2](/course/chapter2); мы инстанцируем токенизатор и модель с помощью классов `TFAutoXxx`, а затем используем их в нашем примере:
+Сначала нам нужно токенизировать наши входные данные и пропустить их через модель. Это делается точно так же, как в [Главе 2](../chapter2/1); мы инстанцируем токенизатор и модель с помощью классов `TFAutoXxx`, а затем используем их в нашем примере:
```py
from transformers import AutoTokenizer, TFAutoModelForTokenClassification
diff --git a/chapters/ru/chapter6/3b.mdx b/chapters/ru/chapter6/3b.mdx
index 7902ec2ff..6ad4b6ed0 100644
--- a/chapters/ru/chapter6/3b.mdx
+++ b/chapters/ru/chapter6/3b.mdx
@@ -36,7 +36,7 @@
## Использование конвейера `question-answering`[[using-the-question-answering-pipeline]]
-Как мы видели в [Главе 1](/course/chapter1), для получения ответа на вопрос мы можем использовать конвейер `question-answering` следующим образом:
+Как мы видели в [Главе 1](../chapter1/1), для получения ответа на вопрос мы можем использовать конвейер `question-answering` следующим образом:
```py
from transformers import pipeline
@@ -111,7 +111,7 @@ question_answerer(question=question, context=long_context)
## Использование модели для ответа на вопросы[[using-a-model-for-question-answering]]
-Как и в любом другом конвейере, мы начинаем с токенизации входных данных, а затем отправляем их через модель. По умолчанию для конвейера `question-answering` используется контрольная точка [`distilbert-base-cased-distilled-squad`](https://huggingface.co/distilbert-base-cased-distilled-squad) (слово "squad" в названии происходит от набора данных, на котором дообучили модель; подробнее о наборе данных SQuAD мы поговорим в [главе 7](/course/chapter7/7)):
+Как и в любом другом конвейере, мы начинаем с токенизации входных данных, а затем отправляем их через модель. По умолчанию для конвейера `question-answering` используется контрольная точка [`distilbert-base-cased-distilled-squad`](https://huggingface.co/distilbert-base-cased-distilled-squad) (слово "squad" в названии происходит от набора данных, на котором дообучили модель; подробнее о наборе данных SQuAD мы поговорим в [главе 7](../chapter7/7)):
{#if fw === 'pt'}
diff --git a/chapters/ru/chapter6/4.mdx b/chapters/ru/chapter6/4.mdx
index e3c04d37a..fc5eaecf0 100644
--- a/chapters/ru/chapter6/4.mdx
+++ b/chapters/ru/chapter6/4.mdx
@@ -57,7 +57,7 @@ print(tokenizer.backend_tokenizer.normalizer.normalize_str("Héllò hôw are ü?
-Как мы увидим в следующих разделах, токенизатор не может быть обучен только на сыром тексте. Сначала необходимо разбить текст на небольшие части, например, на слова. Именно в этом и заключается этап предварительной токенизации. Как мы видели в [Главе 2](/course/chapter2), токенизатор на основе слов (word-based tokenizer) может просто разбить необработанный текст на слова по пробелам и знакам пунктуации. Эти слова станут границами подтокенов, которые токенизатор сможет выучить в процессе обучения.
+Как мы увидим в следующих разделах, токенизатор не может быть обучен только на сыром тексте. Сначала необходимо разбить текст на небольшие части, например, на слова. Именно в этом и заключается этап предварительной токенизации. Как мы видели в [Главе 2](../chapter2/1), токенизатор на основе слов (word-based tokenizer) может просто разбить необработанный текст на слова по пробелам и знакам пунктуации. Эти слова станут границами подтокенов, которые токенизатор сможет выучить в процессе обучения.
Чтобы увидеть, как быстрый токенизатор выполняет предварительную токенизацию, мы можем воспользоваться методом `pre_tokenize_str()` атрибута `pre_tokenizer` объекта `tokenizer`:
@@ -104,7 +104,7 @@ tokenizer.backend_tokenizer.pre_tokenizer.pre_tokenize_str("Hello, how are you?
## SentencePiece[[sentencepiece]]
-[SentencePiece](https://github.com/google/sentencepiece) - это алгоритм токенизации для предварительной обработки текста, который можно использовать с любой из моделей, которые мы рассмотрим в следующих трех разделах. Он рассматривает текст как последовательность символов Unicode и заменяет пробелы специальным символом `▁`. При использовании в сочетании с алгоритмом Unigram (см. [раздел 7](/course/chapter7/7)) он даже не требует шага предварительной токенизации, что очень полезно для языков, где символ пробела не используется (например, китайского или японского).
+[SentencePiece](https://github.com/google/sentencepiece) - это алгоритм токенизации для предварительной обработки текста, который можно использовать с любой из моделей, которые мы рассмотрим в следующих трех разделах. Он рассматривает текст как последовательность символов Unicode и заменяет пробелы специальным символом `▁`. При использовании в сочетании с алгоритмом Unigram (см. [раздел 7](../chapter7/7)) он даже не требует шага предварительной токенизации, что очень полезно для языков, где символ пробела не используется (например, китайского или японского).
Другой главной особенностью SentencePiece является *обратимая токенизация*: поскольку в нем нет специальной обработки пробелов, декодирование токенов осуществляется просто путем их конкатенации и замены `_` на пробелы - в результате получается нормализованный текст. Как мы видели ранее, токенизатор BERT удаляет повторяющиеся пробелы, поэтому его токенизация не является обратимой.
diff --git a/chapters/ru/chapter6/8.mdx b/chapters/ru/chapter6/8.mdx
index 191e1d2f4..36b260a6b 100644
--- a/chapters/ru/chapter6/8.mdx
+++ b/chapters/ru/chapter6/8.mdx
@@ -21,24 +21,24 @@

-Библиотека 🤗 Tokenizers была создана для того, чтобы предоставить несколько вариантов каждого из этих шагов, которые вы можете смешивать и сочетать между собой. В этом разделе мы рассмотрим, как можно создать токенизатор с нуля, а не обучать новый токенизатор на основе старого, как мы делали в [разделе 2](/course/chapter6/2). После этого вы сможете создать любой токенизатор, который только сможете придумать!
+Библиотека 🤗 Tokenizers была создана для того, чтобы предоставить несколько вариантов каждого из этих шагов, которые вы можете смешивать и сочетать между собой. В этом разделе мы рассмотрим, как можно создать токенизатор с нуля, а не обучать новый токенизатор на основе старого, как мы делали в [разделе 2](../chapter6/2). После этого вы сможете создать любой токенизатор, который только сможете придумать!
Точнее, библиотека построена вокруг центрального класса `Tokenizer`, а строительные блоки сгруппированы в подмодули:
-- `normalizers` содержит все возможные типы нормализаторов текста `Normalizer`, которые вы можете использовать (полный список [здесь](https://huggingface.co/docs/tokenizers/python/latest/api/reference.html#module-tokenizers.normalizers)).
-- `pre_tokenizers` содержит все возможные типы предварительных токенизаторов `PreTokenizer`, которые вы можете использовать (полный список [здесь](https://huggingface.co/docs/tokenizers/python/latest/api/reference.html#module-tokenizers.pre_tokenizers)).
-- `models` содержит различные типы моделей `Model`, которые вы можете использовать, такие как `BPE`, `WordPiece` и `Unigram` (полный список [здесь](https://huggingface.co/docs/tokenizers/python/latest/api/reference.html#module-tokenizers.models)).
-- `trainers` содержит все различные типы `Trainer`, которые вы можете использовать для обучения модели на корпусе (по одному на каждый тип модели; полный список [здесь](https://huggingface.co/docs/tokenizers/python/latest/api/reference.html#module-tokenizers.trainers)).
-- `post_processors` содержит различные типы постпроцессоров `PostProcessor`, которые вы можете использовать (полный список [здесь](https://huggingface.co/docs/tokenizers/python/latest/api/reference.html#module-tokenizers.processors)).
-- `decoders` содержит различные типы декодеров `Decoder`, которые вы можете использовать для декодирования результатов токенизации (полный список [здесь](https://huggingface.co/docs/tokenizers/python/latest/components.html#decoders)).
+- `normalizers` содержит все возможные типы нормализаторов текста `Normalizer`, которые вы можете использовать (полный список [здесь](https://huggingface.co/docs/tokenizers/api/normalizers)).
+- `pre_tokenizers` содержит все возможные типы предварительных токенизаторов `PreTokenizer`, которые вы можете использовать (полный список [здесь](https://huggingface.co/docs/tokenizers/api/pre-tokenizers)).
+- `models` содержит различные типы моделей `Model`, которые вы можете использовать, такие как `BPE`, `WordPiece` и `Unigram` (полный список [здесь](https://huggingface.co/docs/tokenizers/api/models)).
+- `trainers` содержит все различные типы `Trainer`, которые вы можете использовать для обучения модели на корпусе (по одному на каждый тип модели; полный список [здесь](https://huggingface.co/docs/tokenizers/api/trainers)).
+- `post_processors` содержит различные типы постпроцессоров `PostProcessor`, которые вы можете использовать (полный список [здесь](https://huggingface.co/docs/tokenizers/api/post-processors)).
+- `decoders` содержит различные типы декодеров `Decoder`, которые вы можете использовать для декодирования результатов токенизации (полный список [здесь](https://huggingface.co/docs/tokenizers/components#decoders)).
-Весь список блоков вы можете найти [здесь](https://huggingface.co/docs/tokenizers/python/latest/components.html).
+Весь список блоков вы можете найти [здесь](https://huggingface.co/docs/tokenizers/components).
## Получение корпуса текста[[acquiring-a-corpus]]
-Для обучения нашего нового токенизатора мы будем использовать небольшой корпус текстов (чтобы примеры выполнялись быстро). Шаги по сбору корпуса аналогичны тем, что мы делали в [начале этой главы](/course/chapter6/2), но на этот раз мы будем использовать набор данных [WikiText-2](https://huggingface.co/datasets/wikitext):
+Для обучения нашего нового токенизатора мы будем использовать небольшой корпус текстов (чтобы примеры выполнялись быстро). Шаги по сбору корпуса аналогичны тем, что мы делали в [начале этой главы](../chapter6/2), но на этот раз мы будем использовать набор данных [WikiText-2](https://huggingface.co/datasets/wikitext):
```python
from datasets import load_dataset
diff --git a/chapters/ru/chapter7/1.mdx b/chapters/ru/chapter7/1.mdx
new file mode 100644
index 000000000..47cf244b5
--- /dev/null
+++ b/chapters/ru/chapter7/1.mdx
@@ -0,0 +1,38 @@
+
+
+# Введение[[introduction]]
+
+
+
+В [Главе 3](../chapter3/1) вы узнали, как дообучить модель для классификации текстов. В этой главе мы рассмотрим следующие общие задачи NLP:
+
+- Классификация токенов (Token classification)
+- Маскированное языковое моделирование (Masked language modeling, например, BERT)
+- Резюмирование текста (Summarization)
+- Перевод (Translation)
+- Предварительное обучение каузального языкового моделирования (Causal language modeling, например, GPT-2)
+- Ответы на вопросы (Question answering)
+
+{#if fw === 'pt'}
+
+Для этого вам понадобится использовать все, что вы узнали об API `Trainer` и библиотеке 🤗 Accelerate в [Главе 3](../chapter3/1), библиотеке 🤗 Datasets в [Главе 5](../chapter5/1) и библиотеке 🤗 Tokenizers в [Главе 6](../chapter6/1). Мы также загрузим наши результаты в хаб моделей, как мы делали это в [Главе 4](../chapter4/1), так что это действительно глава,в которой все собирается воедино!
+
+Каждый раздел можно читать независимо друг от друга, и в нем вы узнаете, как обучить модель с помощью API `Trainer` или с помощью собственного цикла обучения, используя 🤗 Accelerate. Вы можете пропустить любую часть и сосредоточиться на той, которая вас больше всего интересует: API `Trainer` отлично подходит для того, чтобы дообучить или обучить вашу модель, не беспокоясь о том, что происходит за кулисами, а цикл обучения с `Accelerate` позволит вам легче настроить любую часть, которую вы хотите.
+
+{:else}
+
+Для этого вам понадобится использовать все, что вы узнали об обучении моделей с помощью Keras API в [Главе 3](../chapter3/1), библиотеке 🤗 Datasets в [Главе 5](../chapter5/1) и библиотеке 🤗 Tokenizers в [Главе 6](../chapter6/1). Мы также загрузим наши результаты в хаб моделей, как мы делали это в [Главе 4](../chapter4/1), так что это действительно глава, в которой все собирается воедино!
+
+Каждый раздел можно читать самостоятельно.
+
+{/if}
+
+
+
+
+Если вы будете читать разделы по порядку, то заметите, что в них довольно много общего в коде и тексте. Повторение сделано намеренно, чтобы вы могли погрузиться (или вернуться позже) в любую интересующую вас задачу и найти полный рабочий пример.
+
+
diff --git a/chapters/ru/chapter7/2.mdx b/chapters/ru/chapter7/2.mdx
new file mode 100644
index 000000000..edc843490
--- /dev/null
+++ b/chapters/ru/chapter7/2.mdx
@@ -0,0 +1,981 @@
+
+
+# Классификация токенов[[token-classification]]
+
+{#if fw === 'pt'}
+
+
+
+{:else}
+
+
+
+{/if}
+
+Первое приложение, которое мы рассмотрим, - это классификация токенов. Эта общая задача охватывает любую проблему, которую можно сформулировать как "присвоение метки каждому токену в предложении", например:
+
+- **Распознавание именованных сущностей (Named entity recognition - NER)**: Поиск сущностей (например, лиц, мест или организаций) в предложении. Это можно сформулировать как приписывание метки каждому токену, имея один класс для сущности и один класс для "нет сущности".
+- **Морфологическая разметка (Part-of-speech tagging - POS)**: Пометить каждое слово в предложении как соответствующее определенной части речи (например, существительное, глагол, прилагательное и т. д.).
+- **Выделение токенов (Chunking)**: Поиск токенов, принадлежащих одной и той же сущности. Эта задача (которая может быть объединена с POS или NER) может быть сформулирована как присвоение одной метки (обычно `B-`) всем токенам, которые находятся в начале фрагмента текста, другой метки (обычно `I-`) - токенам, которые находятся внутри фрагмента текста, и третьей метки (обычно `O`) - токенам, которые не принадлежат ни к одному фрагменту.
+
+
+
+Конечно, существует множество других типов задач классификации токенов; это лишь несколько показательных примеров. В этом разделе мы дообучим модель (BERT) для задачи NER, которая затем сможет вычислять прогнозы, подобные этому:
+
+
+
+
+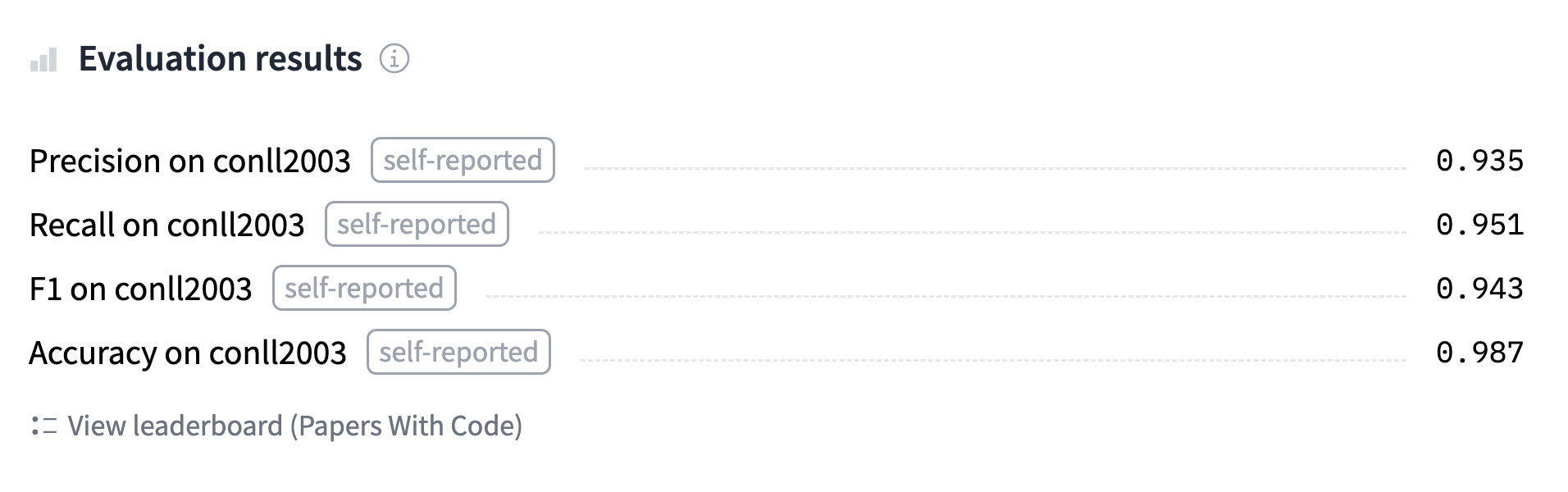 +
+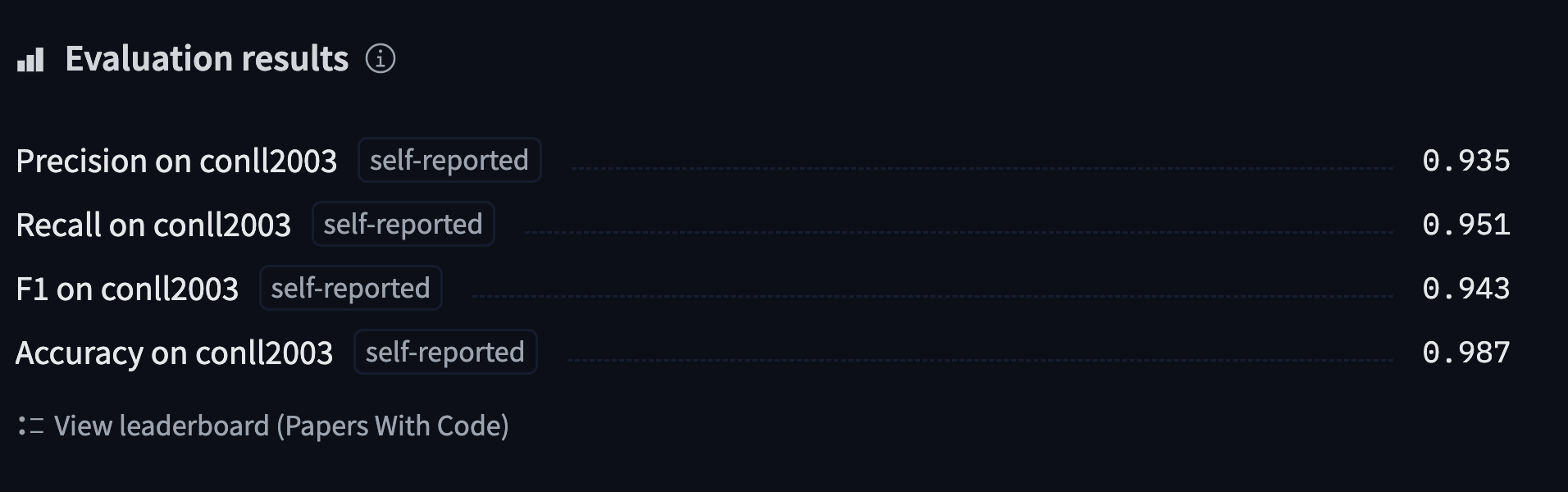 +
+
+
+Вы можете найти модель, которую мы обучим и загрузим на хаб, и перепроверить ее предсказания [здесь](https://huggingface.co/huggingface-course/bert-finetuned-ner?text=My+name+is+Sylvain+and+I+work+at+Hugging+Face+in+Brooklyn).
+
+## Подготовка данных[[preparing-the-data]]
+
+Прежде всего, нам нужен набор данных, подходящий для классификации токенов. В этом разделе мы будем использовать [набор данных CoNLL-2003](https://huggingface.co/datasets/conll2003), который содержит новости от Reuters.
+
+
+
+💡 Если ваш набор данных состоит из текстов, часть которых состоит из слов с соответствующими метками, вы сможете адаптировать описанные здесь процедуры обработки данных к своему набору данных. Обратитесь к [Главе 5](../chapter5/1), если вам нужно освежить в памяти то, как загружать собственные данные в `Dataset`.
+
+
+
+### Датасет CoNLL-2003[[the-conll-2003-dataset]]
+
+Для загрузки датасета CoNLL-2003 мы используем метод `load_dataset()` из библиотеки 🤗 Datasets:
+
+```py
+from datasets import load_dataset
+
+raw_datasets = load_dataset("conll2003")
+```
+
+Это позволит загрузить и кэшировать датасет, как мы видели в [Главе 3](../chapter3/1) для датасета GLUE MRPC. Изучение этого объекта показывает нам присутствующие столбцы и части тренировочного, проверочного и тестового наборов:
+
+```py
+raw_datasets
+```
+
+```python out
+DatasetDict({
+ train: Dataset({
+ features: ['chunk_tags', 'id', 'ner_tags', 'pos_tags', 'tokens'],
+ num_rows: 14041
+ })
+ validation: Dataset({
+ features: ['chunk_tags', 'id', 'ner_tags', 'pos_tags', 'tokens'],
+ num_rows: 3250
+ })
+ test: Dataset({
+ features: ['chunk_tags', 'id', 'ner_tags', 'pos_tags', 'tokens'],
+ num_rows: 3453
+ })
+})
+```
+
+В частности, мы видим, что датасет содержит метки для трех задач, о которых мы говорили ранее: NER, POS и chunking. Существенным отличием от других датасетов является то, что входные тексты представлены не как предложения или документы, а как списки слов (последний столбец называется `tokens`, но он содержит слова в том смысле, что это предварительно токинизированные входные данные, которые еще должны пройти через токенизатор для токенизации по подсловам).
+
+Давайте посмотрим на первый элемент обучающего набора:
+
+```py
+raw_datasets["train"][0]["tokens"]
+```
+
+```python out
+['EU', 'rejects', 'German', 'call', 'to', 'boycott', 'British', 'lamb', '.']
+```
+
+Поскольку мы хотим выполнить распознавание именованных сущностей, мы изучим теги NER:
+
+```py
+raw_datasets["train"][0]["ner_tags"]
+```
+
+```python out
+[3, 0, 7, 0, 0, 0, 7, 0, 0]
+```
+
+Это метки в виде целых чисел, готовые для обучения, но они не всегда полезны, когда мы хотим проанализировать данные. Как и в случае с классификацией текста, мы можем получить доступ к соответствию между этими целыми числами и названиями меток, посмотрев на атрибут `features` нашего датасета:
+
+```py
+ner_feature = raw_datasets["train"].features["ner_tags"]
+ner_feature
+```
+
+```python out
+Sequence(feature=ClassLabel(num_classes=9, names=['O', 'B-PER', 'I-PER', 'B-ORG', 'I-ORG', 'B-LOC', 'I-LOC', 'B-MISC', 'I-MISC'], names_file=None, id=None), length=-1, id=None)
+```
+
+Таким образом, этот столбец содержит элементы, которые являются последовательностями `ClassLabel`. Тип элементов последовательности указан в атрибуте `feature` этого `ner_feature`, и мы можем получить доступ к списку имен, посмотрев на атрибут `names` этого `feature`:
+
+```py
+label_names = ner_feature.feature.names
+label_names
+```
+
+```python out
+['O', 'B-PER', 'I-PER', 'B-ORG', 'I-ORG', 'B-LOC', 'I-LOC', 'B-MISC', 'I-MISC']
+```
+
+Мы уже видели эти метки при изучении конвейера `token-classification` в [Главе 6](../chapter6/3), но для краткости напомним:
+
+- `O` означает, что слово не соответствует какой-либо сущности.
+- `B-PER`/`I-PER` означает, что слово соответствует началу/находится внутри сущности персоны *person*.
+- `B-ORG`/`I-ORG` означает, что слово соответствует началу/находится внутри сущности *organization*.
+- `B-LOC`/`I-LOC` означает, что слово соответствует началу/находится внутри сущности *location*.
+- `B-MISC`/`I-MISC` означает, что слово соответствует началу/находится внутри сущности *miscellaneous*.
+
+Теперь декодирование меток, которые мы видели ранее, дает нам следующее:
+
+```python
+words = raw_datasets["train"][0]["tokens"]
+labels = raw_datasets["train"][0]["ner_tags"]
+line1 = ""
+line2 = ""
+for word, label in zip(words, labels):
+ full_label = label_names[label]
+ max_length = max(len(word), len(full_label))
+ line1 += word + " " * (max_length - len(word) + 1)
+ line2 += full_label + " " * (max_length - len(full_label) + 1)
+
+print(line1)
+print(line2)
+```
+
+```python out
+'EU rejects German call to boycott British lamb .'
+'B-ORG O B-MISC O O O B-MISC O O'
+```
+
+В качестве примера смешивания меток `B-` и `I-`, вот что дает тот же код для элемента обучающего множества с индексом 4:
+
+```python out
+'Germany \'s representative to the European Union \'s veterinary committee Werner Zwingmann said on Wednesday consumers should buy sheepmeat from countries other than Britain until the scientific advice was clearer .'
+'B-LOC O O O O B-ORG I-ORG O O O B-PER I-PER O O O O O O O O O O O B-LOC O O O O O O O'
+```
+
+Как мы видим, сущностям, состоящим из двух слов, например "European Union" и "Werner Zwingmann", присваивается метка `B-` для первого слова и метка `I-` для второго.
+
+
+
+✏️ **Попробуйте!** Выведите те же два предложения с метками POS или chunking.
+
+
+
+### Обработка данных[[processing-the-data]]
+
+
+
+Как обычно, наши тексты должны быть преобразованы в идентификаторы токенов, прежде чем модель сможет понять их смысл. Как мы видели в [Главе 6](../chapter6/), существенным отличием задачи классификации токенов является то, что у нас есть предварительно токенизированные входные данные. К счастью, API токенизатора справляется с этим довольно легко; нам просто нужно предупредить `tokenizer` специальным флагом.
+
+Для начала давайте создадим объект `tokenizer`. Как мы уже говорили, мы будем использовать предварительно обученную модель BERT, поэтому начнем с загрузки и кэширования соответствующего токенизатора:
+
+```python
+from transformers import AutoTokenizer
+
+model_checkpoint = "bert-base-cased"
+tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
+```
+
+Вы можете заменить `model_checkpoint` на любую другую модель из [Hub](https://huggingface.co/models) или на локальную папку, в которой вы сохранили предварительно обученную модель и токенизатор. Единственное ограничение - токенизатор должен быть создан с помощью библиотеки 🤗 Tokenizers, поэтому существует "быстрая" версия. Вы можете увидеть все архитектуры, которые поставляются с быстрой версией в [этой большой таблице](https://huggingface.co/transformers/#supported-frameworks), а чтобы проверить, что используемый вами объект `tokenizer` действительно поддерживается 🤗 Tokenizers, вы можете посмотреть на его атрибут `is_fast`:
+
+```py
+tokenizer.is_fast
+```
+
+```python out
+True
+```
+
+Для токенизации предварительно токинизированного ввода мы можем использовать наш `tokenizer`, как обычно, просто добавив `is_split_into_words=True`:
+
+```py
+inputs = tokenizer(raw_datasets["train"][0]["tokens"], is_split_into_words=True)
+inputs.tokens()
+```
+
+```python out
+['[CLS]', 'EU', 'rejects', 'German', 'call', 'to', 'boycott', 'British', 'la', '##mb', '.', '[SEP]']
+```
+
+Как мы видим, токенизатор добавил специальные токены, используемые моделью (`[CLS]` в начале и `[SEP]` в конце), и оставил большинство слов нетронутыми. Слово `lamb`, однако, было токенизировано на два подслова, `la` и `##mb`. Это вносит несоответствие между нашими входными данными и метками: список меток состоит всего из 9 элементов, в то время как наши входные данные теперь содержат 12 токенов. Учесть специальные токены легко (мы знаем, что они находятся в начале и в конце), но нам также нужно убедиться, что мы выровняли все метки с соответствующими словами.
+
+К счастью, поскольку мы используем быстрый токенизатор, у нас есть доступ к суперспособностям 🤗 Tokenizers, что означает, что мы можем легко сопоставить каждый токен с соответствующим словом (как показано в [Глава 6](../chapter6/3)):
+
+```py
+inputs.word_ids()
+```
+
+```python out
+[None, 0, 1, 2, 3, 4, 5, 6, 7, 7, 8, None]
+```
+
+Немного поработав, мы сможем расширить список меток, чтобы он соответствовал токенам. Первое правило, которое мы применим, заключается в том, что специальные токены получают метку `-100`. Это связано с тем, что по умолчанию `-100` - это индекс, который игнорируется в функции потерь, которую мы будем использовать (кросс-энтропия). Затем каждый токен получает ту же метку, что и токен, с которого началось слово, в котором он находится, поскольку они являются частью одной и той же сущности. Для токенов, находящихся внутри слова, но не в его начале, мы заменяем `B-` на `I-` (поскольку такие токены не являются началом сущности):
+
+```python
+def align_labels_with_tokens(labels, word_ids):
+ new_labels = []
+ current_word = None
+ for word_id in word_ids:
+ if word_id != current_word:
+ # Начало нового слова!
+ current_word = word_id
+ label = -100 if word_id is None else labels[word_id]
+ new_labels.append(label)
+ elif word_id is None:
+ # Специальный токен
+ new_labels.append(-100)
+ else:
+ # То же слово, что и предыдущий токен
+ label = labels[word_id]
+ # Если метка B-XXX, заменяем ее на I-XXX
+ if label % 2 == 1:
+ label += 1
+ new_labels.append(label)
+
+ return new_labels
+```
+
+Давайте опробуем это на нашем первом предложении:
+
+```py
+labels = raw_datasets["train"][0]["ner_tags"]
+word_ids = inputs.word_ids()
+print(labels)
+print(align_labels_with_tokens(labels, word_ids))
+```
+
+```python out
+[3, 0, 7, 0, 0, 0, 7, 0, 0]
+[-100, 3, 0, 7, 0, 0, 0, 7, 0, 0, 0, -100]
+```
+
+Как мы видим, наша функция добавила `-100` для двух специальных токенов в начале и в конце и новый `0` для нашего слова, которое было разбито на две части.
+
+
+
+✏️ **Попробуйте!** Некоторые исследователи предпочитают назначать только одну метку на слово и присваивать `-100` другим подтокенам в данном слове. Это делается для того, чтобы длинные слова, часть которых состоит из множества субтокенов, не вносили значительный вклад в потери.
+
+
+
+Чтобы предварительно обработать весь наш датасет, нам нужно провести токенизацию всех входных данных и применить `align_labels_with_tokens()` ко всем меткам. Чтобы воспользоваться преимуществами скорости нашего быстрого токенизатора, лучше всего токенизировать много текстов одновременно, поэтому мы напишем функцию, которая обрабатывает список примеров и использует метод `Dataset.map()` с параметром `batched=True`. Единственное отличие от нашего предыдущего примера заключается в том, что функция `word_ids()` должна получить индекс примера, идентификаторы слов которого нам нужны, с учётом того что входными данными для токенизатора являются списки текстов (или, в нашем случае, списки слов), поэтому мы добавляем и это:
+
+```py
+def tokenize_and_align_labels(examples):
+ tokenized_inputs = tokenizer(
+ examples["tokens"], truncation=True, is_split_into_words=True
+ )
+ all_labels = examples["ner_tags"]
+ new_labels = []
+ for i, labels in enumerate(all_labels):
+ word_ids = tokenized_inputs.word_ids(i)
+ new_labels.append(align_labels_with_tokens(labels, word_ids))
+
+ tokenized_inputs["labels"] = new_labels
+ return tokenized_inputs
+```
+
+Обратите внимание, что мы еще не добавляли во входные данные дополняющие токены; мы сделаем это позже, при создании батчей с помощью коллатора данных.
+
+Теперь мы можем применить всю эту предварительную обработку к другим частям нашего датасета:
+
+```py
+tokenized_datasets = raw_datasets.map(
+ tokenize_and_align_labels,
+ batched=True,
+ remove_columns=raw_datasets["train"].column_names,
+)
+```
+
+Мы сделали самую сложную часть! Теперь, когда данные прошли предварительную обработку, само обучение будет выглядеть примерно так, как мы делали это в [Главе 3](../chapter3/1).
+
+{#if fw === 'pt'}
+
+## Дообучение модели с помощью API `Trainer`[[fine-tuning-the-model-with-the-trainer-api]]
+
+Фактический код, использующий `Trainer`, будет таким же, как и раньше; единственные изменения - это способ объединения данных в батч и функция вычисления метрики.
+
+{:else}
+
+## Дообучение модели с помощью Keras[[fine-tuning-the-model-with-keras]]
+
+Фактический код, использующий Keras, будет очень похож на предыдущий; единственные изменения - это способ объединения данных в батч и функция вычисления метрики.
+
+{/if}
+
+
+### Сопоставление данных[[data-collation]]
+
+Мы не можем просто использовать `DataCollatorWithPadding`, как в [Главе 3](../chapter3/1), потому что в этом случае дополняются только входные данные (идентификаторы входов, маска внимания и идентификаторы типов токенов). Здесь наши метки должны быть дополнены точно так же, как и входы, чтобы они оставались одного размера, используя `-100` в качестве значения, чтобы соответствующие прогнозы игнорировались при вычислении потерь.
+
+Все это делает [`DataCollatorForTokenClassification`](https://huggingface.co/transformers/main_classes/data_collator.html#datacollatorfortokenclassification). Как и `DataCollatorWithPadding`, он принимает `токенизатор`, используемый для предварительной обработки входных данных:
+
+{#if fw === 'pt'}
+
+```py
+from transformers import DataCollatorForTokenClassification
+
+data_collator = DataCollatorForTokenClassification(tokenizer=tokenizer)
+```
+
+{:else}
+
+```py
+from transformers import DataCollatorForTokenClassification
+
+data_collator = DataCollatorForTokenClassification(
+ tokenizer=tokenizer, return_tensors="tf"
+)
+```
+
+{/if}
+
+Чтобы проверить его на нескольких примерах, мы можем просто вызвать его на списке примеров из нашего токенизированного обучающего набора:
+
+```py
+batch = data_collator([tokenized_datasets["train"][i] for i in range(2)])
+batch["labels"]
+```
+
+```python out
+tensor([[-100, 3, 0, 7, 0, 0, 0, 7, 0, 0, 0, -100],
+ [-100, 1, 2, -100, -100, -100, -100, -100, -100, -100, -100, -100]])
+```
+
+Давайте сравним это с метками для первого и второго элементов в нашем датасете:
+
+```py
+for i in range(2):
+ print(tokenized_datasets["train"][i]["labels"])
+```
+
+```python out
+[-100, 3, 0, 7, 0, 0, 0, 7, 0, 0, 0, -100]
+[-100, 1, 2, -100]
+```
+
+{#if fw === 'pt'}
+
+Как мы видим, второй набор меток был дополнен до длины первого с помощью значения `-100`.
+
+{:else}
+
+Наш коллатор данных готов к работе! Теперь давайте используем его для создания датасета `tf.data.Dataset` с помощью метода `to_tf_dataset()`. Вы также можете использовать `model.prepare_tf_dataset()`, чтобы сделать это с меньшим количеством кода - вы увидите это в некоторых других разделах этой главы.
+
+```py
+tf_train_dataset = tokenized_datasets["train"].to_tf_dataset(
+ columns=["attention_mask", "input_ids", "labels", "token_type_ids"],
+ collate_fn=data_collator,
+ shuffle=True,
+ batch_size=16,
+)
+
+tf_eval_dataset = tokenized_datasets["validation"].to_tf_dataset(
+ columns=["attention_mask", "input_ids", "labels", "token_type_ids"],
+ collate_fn=data_collator,
+ shuffle=False,
+ batch_size=16,
+)
+```
+
+
+ Следующая остановка: сама модель.
+
+{/if}
+
+{#if fw === 'tf'}
+
+### Определение модели[[defining-the-model]]
+
+Поскольку мы работаем над проблемой классификации токенов, мы будем использовать класс `TFAutoModelForTokenClassification`. Главное, что нужно помнить при определении этой модели, - это передать информацию о количестве имеющихся у нас меток. Проще всего передать это число с помощью аргумента `num_labels`, но если мы хотим получить красивый виджет инференса, подобный тому, что мы видели в начале этого раздела, то лучше задать правильные соответствия меток.
+
+Они должны быть заданы двумя словарями, `id2label` и `label2id`, которые содержат отображение идентификатора в метку и наоборот:
+
+```py
+id2label = {i: label for i, label in enumerate(label_names)}
+label2id = {v: k for k, v in id2label.items()}
+```
+
+Теперь мы можем просто передать их в метод `TFAutoModelForTokenClassification.from_pretrained()`, и они будут заданы в конфигурации модели, затем правильно сохранены и загружены в Hub:
+
+```py
+from transformers import TFAutoModelForTokenClassification
+
+model = TFAutoModelForTokenClassification.from_pretrained(
+ model_checkpoint,
+ id2label=id2label,
+ label2id=label2id,
+)
+```
+
+Как и при определении `TFAutoModelForSequenceClassification` в [Главе 3](../chapter3/1), при создании модели выдается предупреждение о том, что некоторые веса не были использованы (веса из предварительно обученной головы), а другие веса инициализированы случайно (веса из новой головы классификации токенов), и что эту модель нужно обучить. Мы сделаем это через минуту, но сначала давайте перепроверим, что наша модель имеет правильное количество меток:
+
+```python
+model.config.num_labels
+```
+
+```python out
+9
+```
+
+
+
+⚠️ Если у вас есть модель с неправильным количеством меток, то при последующем вызове `model.fit()` вы получите непонятную ошибку. Это может вызвать раздражение при отладке, поэтому обязательно выполните эту проверку, чтобы убедиться, что у вас есть ожидаемое количество меток.
+
+
+
+### Дообучение модели[[fine-tuning-the-model]]
+
+Теперь мы готовы к обучению нашей модели! Однако сначала нам нужно сделать еще немного работы: войти в Hugging Face и определить гиперпараметры обучения. Если вы работаете в блокноте, есть удобная функция, которая поможет вам в этом:
+
+```python
+from huggingface_hub import notebook_login
+
+notebook_login()
+```
+
+Появится виджет, в котором вы можете ввести свои учетные данные для входа в Hugging Face.
+
+Если вы работаете не в блокноте, просто введите следующую строку в терминале:
+
+```bash
+huggingface-cli login
+```
+
+После входа в аккаунт мы можем подготовить все необходимое для компиляции нашей модели. 🤗 Transformers предоставляет удобную функцию `create_optimizer()`, которая создаст вам оптимизатор `AdamW` с соответствующими настройками затухания весов и затухания скорости обучения, что позволит улучшить качество вашей модели по сравнению со встроенным оптимизатором `Adam`:
+
+```python
+from transformers import create_optimizer
+import tensorflow as tf
+
+# Обучение со смешанной точностью float16
+# Закомментируйте эту строку, если вы используете GPU, которому это не принесет никаких преимуществ
+tf.keras.mixed_precision.set_global_policy("mixed_float16")
+
+# Количество шагов обучения - это количество примеров в датасете, разделенное на размер батча, затем умноженное
+# на общее количество эпох. Обратите внимание, что tf_train_dataset здесь - это разбитое на батчи tf.data.Dataset,
+# а не оригинальный датасет Hugging Face, поэтому его len() уже равен num_samples // batch_size.
+num_epochs = 3
+num_train_steps = len(tf_train_dataset) * num_epochs
+
+optimizer, schedule = create_optimizer(
+ init_lr=2e-5,
+ num_warmup_steps=0,
+ num_train_steps=num_train_steps,
+ weight_decay_rate=0.01,
+)
+model.compile(optimizer=optimizer)
+```
+
+Обратите внимание, что мы не указываем аргумент `loss` в `compile()`. Это связано с тем, что модели могут вычислять потери внутри себя - если вы компилируете без потерь и предоставляете свои метки во входном словаре (как мы делаем в наших датасетах), то модель будет обучаться, используя эти внутренние потери, которые будут соответствовать задаче и типу выбранной вами модели.
+
+Далее мы определяем `PushToHubCallback` для загрузки нашей модели в Hub во время обучения модели с помощью этого обратного вызова:
+
+```python
+from transformers.keras_callbacks import PushToHubCallback
+
+callback = PushToHubCallback(output_dir="bert-finetuned-ner", tokenizer=tokenizer)
+
+model.fit(
+ tf_train_dataset,
+ validation_data=tf_eval_dataset,
+ callbacks=[callback],
+ epochs=num_epochs,
+)
+```
+
+С помощью аргумента `hub_model_id` можно указать полное имя репозитория, в который вы хотите передать модель (в частности, этот аргумент нужно использовать, чтобы передать модель в организацию). Например, когда мы отправили модель в [организацию `huggingface-course`](https://huggingface.co/huggingface-course), мы добавили `hub_model_id="huggingface-course/bert-finetuned-ner"`. По умолчанию используемое хранилище будет находиться в вашем пространстве имен и называться в соответствии с заданной вами выходной директорией, например `"cool_huggingface_user/bert-finetuned-ner"`.
+
+
+
+💡 Если выходной каталог, который вы используете, уже существует, он должен быть локальным клоном репозитория, в который вы хотите выполнить push. Если это не так, вы получите ошибку при вызове `model.fit()` и должны будете задать новое имя.
+
+
+
+Обратите внимание, что во время обучения каждый раз, когда модель сохраняется (здесь - каждую эпоху), она загружается на хаб в фоновом режиме. Таким образом, при необходимости вы сможете возобновить обучение на другой машине.
+
+На этом этапе вы можете использовать виджет инференса на Model Hub, чтобы протестировать свою модель и поделиться ею с друзьями. Вы успешно дообучили модель для задачи классификации токенов - поздравляем! Но насколько хороша наша модель на самом деле? Чтобы выяснить это, нам следует оценить некоторые метрики.
+
+{/if}
+
+
+### Метрики[[metrics]]
+
+{#if fw === 'pt'}
+
+Чтобы `Trainer` вычислял метрику каждую эпоху, нам нужно определить функцию `compute_metrics()`, которая принимает массивы прогнозов и меток и возвращает словарь с именами и значениями метрик.
+
+Традиционно для оценки прогнозирования классификации токенов используется библиотека [*seqeval*](https://github.com/chakki-works/seqeval). Чтобы использовать эту метрику, сначала нужно установить библиотеку *seqeval*:
+
+```py
+!pip install seqeval
+```
+
+Мы можем загрузить ее с помощью функции `evaluate.load()`, как мы это делали в [Главе 3](../chapter3/1):
+
+{:else}
+
+Традиционно для оценки прогнозирования классификации токенов используется библиотека [*seqeval*](https://github.com/chakki-works/seqeval). Чтобы использовать эту метрику, сначала нужно установить библиотеку *seqeval*:
+
+```py
+!pip install seqeval
+```
+
+Мы можем загрузить ее с помощью функции `evaluate.load()`, как мы это делали в [Главе 3](../chapter3/1):
+
+{/if}
+
+```py
+import evaluate
+
+metric = evaluate.load("seqeval")
+```
+
+Эта метрика ведет себя не так, как стандартная accuracy: на самом деле она принимает списки меток как строки, а не как целые числа, поэтому нам нужно полностью декодировать прогноз и метки перед передачей их в метрику. Давайте посмотрим, как это работает. Сначала мы получим метки для нашего первого обучающего примера:
+
+```py
+labels = raw_datasets["train"][0]["ner_tags"]
+labels = [label_names[i] for i in labels]
+labels
+```
+
+```python out
+['B-ORG', 'O', 'B-MISC', 'O', 'O', 'O', 'B-MISC', 'O', 'O']
+```
+
+Затем мы можем создать фальшивые прогнозы для них, просто изменив значение в индексе 2:
+
+```py
+predictions = labels.copy()
+predictions[2] = "O"
+metric.compute(predictions=[predictions], references=[labels])
+```
+
+Обратите внимание, что метрика принимает список прогнозов (не только один) и список меток. Вот результат:
+
+```python out
+{'MISC': {'precision': 1.0, 'recall': 0.5, 'f1': 0.67, 'number': 2},
+ 'ORG': {'precision': 1.0, 'recall': 1.0, 'f1': 1.0, 'number': 1},
+ 'overall_precision': 1.0,
+ 'overall_recall': 0.67,
+ 'overall_f1': 0.8,
+ 'overall_accuracy': 0.89}
+```
+
+{#if fw === 'pt'}
+
+Она возвращает огромное количество информации! Мы получаем оценки precision, recall и F1 для каждой отдельной сущности, а также в целом. Для расчета метрик мы сохраним только общую оценку, но вы можете настроить функцию `compute_metrics()` так, чтобы она возвращала все метрики, которые вы хотите получить.
+
+Эта функция `compute_metrics()` сначала берет argmax логитов, чтобы преобразовать их в прогнозы (как обычно, логиты и вероятности расположены в том же порядке, поэтому нам не нужно применять softmax). Затем нам нужно преобразовать метки и прогнозы из целых чисел в строки. Мы удаляем все значения, для которых метка равна `-100`, а затем передаем результаты в метод `metric.compute()`:
+
+```py
+import numpy as np
+
+
+def compute_metrics(eval_preds):
+ logits, labels = eval_preds
+ predictions = np.argmax(logits, axis=-1)
+
+ # Удаляем игнорируемый индекс (специальные токены) и преобразуем в метки
+ true_labels = [[label_names[l] for l in label if l != -100] for label in labels]
+ true_predictions = [
+ [label_names[p] for (p, l) in zip(prediction, label) if l != -100]
+ for prediction, label in zip(predictions, labels)
+ ]
+ all_metrics = metric.compute(predictions=true_predictions, references=true_labels)
+ return {
+ "precision": all_metrics["overall_precision"],
+ "recall": all_metrics["overall_recall"],
+ "f1": all_metrics["overall_f1"],
+ "accuracy": all_metrics["overall_accuracy"],
+ }
+```
+
+Теперь, когда это сделано, мы почти готовы к определению нашего `Trainer`. Нам просто нужна `model`, чтобы дообучить ее!
+
+{:else}
+
+Она возвращает огромное количество информации! Мы получаем оценки precision, recall и F1 для каждой отдельной сущности, а также в целом. Теперь давайте посмотрим, что произойдет, если мы попробуем использовать реальные прогнозы модели для вычисления реальных оценок.
+
+TensorFlow не любит конкатенировать наши прогнозы, поскольку они имеют переменную длину последовательности. Это означает, что мы не можем просто использовать `model.predict()` - но это нас не остановит. Мы будем получать прогнозы по батчу за раз и конкатенировать их в один большой длинный список по мере продвижения, отбрасывая токены `-100`, которые указывают на маскирование/дополнение, а затем вычислять метрики для списка в конце:
+
+```py
+import numpy as np
+
+all_predictions = []
+all_labels = []
+for batch in tf_eval_dataset:
+ logits = model.predict_on_batch(batch)["logits"]
+ labels = batch["labels"]
+ predictions = np.argmax(logits, axis=-1)
+ for prediction, label in zip(predictions, labels):
+ for predicted_idx, label_idx in zip(prediction, label):
+ if label_idx == -100:
+ continue
+ all_predictions.append(label_names[predicted_idx])
+ all_labels.append(label_names[label_idx])
+metric.compute(predictions=[all_predictions], references=[all_labels])
+```
+
+
+```python out
+{'LOC': {'precision': 0.91, 'recall': 0.92, 'f1': 0.91, 'number': 1668},
+ 'MISC': {'precision': 0.70, 'recall': 0.79, 'f1': 0.74, 'number': 702},
+ 'ORG': {'precision': 0.85, 'recall': 0.90, 'f1': 0.88, 'number': 1661},
+ 'PER': {'precision': 0.95, 'recall': 0.95, 'f1': 0.95, 'number': 1617},
+ 'overall_precision': 0.87,
+ 'overall_recall': 0.91,
+ 'overall_f1': 0.89,
+ 'overall_accuracy': 0.97}
+```
+
+Как ваша модель показала себя по сравнению с нашей? Если вы получили похожие цифры, значит, ваше обучение прошло успешно!
+
+{/if}
+
+{#if fw === 'pt'}
+
+### Определение модели[[defining-the-model]]
+
+Поскольку мы работаем над проблемой классификации токенов, мы будем использовать класс `AutoModelForTokenClassification`. Главное, что нужно помнить при определении этой модели, - это передать информацию о количестве имеющихся у нас меток. Проще всего передать это число с помощью аргумента `num_labels`, но если мы хотим получить красивый виджет инференса, подобный тому, что мы видели в начале этого раздела, то лучше задать правильное сопоставление меток.
+
+Оно должно задаваться двумя словарями, `id2label` и `label2id`, которые содержат соответствие между идентификатором и меткой и наоборот:
+
+```py
+id2label = {i: label for i, label in enumerate(label_names)}
+label2id = {v: k for k, v in id2label.items()}
+```
+
+Теперь мы можем просто передать их в метод `AutoModelForTokenClassification.from_pretrained()`, и они будут заданы в конфигурации модели, а затем правильно сохранены и загружены в Hub:
+
+```py
+from transformers import AutoModelForTokenClassification
+
+model = AutoModelForTokenClassification.from_pretrained(
+ model_checkpoint,
+ id2label=id2label,
+ label2id=label2id,
+)
+```
+
+Как и в случае определения `AutoModelForSequenceClassification` в [Главе 3](../chapter3/1), при создании модели выдается предупреждение о том, что некоторые веса не были использованы (те, что были получены из предварительно обученной головы), а другие инициализированы случайно (те, что были получены из новой головы классификации токенов), и что эту модель необходимо обучить. Мы сделаем это через минуту, но сначала давайте перепроверим, что наша модель имеет правильное количество меток:
+
+```python
+model.config.num_labels
+```
+
+```python out
+9
+```
+
+
+
+⚠️ Если у вас есть модель с неправильным количеством меток, то при последующем вызове метода `Trainer.train()` вы получите непонятную ошибку (что-то вроде "CUDA error: device-side assert triggered"). Это главная причина ошибок, о которых сообщают пользователи, поэтому обязательно выполните эту проверку, чтобы убедиться, что у вас есть ожидаемое количество меток.
+
+
+
+### Дообучение модели[[fine-tuning-the-model]]
+
+Теперь мы готовы к обучению нашей модели! Нам осталось сделать две последние вещи, прежде чем мы определим наш `Trainer`: войти в Hugging Face и определить наши аргументы для обучения. Если вы работаете в блокноте, есть удобная функция, которая поможет вам в этом:
+
+```python
+from huggingface_hub import notebook_login
+
+notebook_login()
+```
+
+Появится виджет, в котором вы можете ввести свои учетные данные для входа в Hugging Face.
+
+Если вы работаете не в ноутбуке, просто введите следующую строку в терминале:
+
+```bash
+huggingface-cli login
+```
+
+Как только это будет сделано, мы сможем определить наши `TrainingArguments`:
+
+```python
+from transformers import TrainingArguments
+
+args = TrainingArguments(
+ "bert-finetuned-ner",
+ evaluation_strategy="epoch",
+ save_strategy="epoch",
+ learning_rate=2e-5,
+ num_train_epochs=3,
+ weight_decay=0.01,
+ push_to_hub=True,
+)
+```
+
+Большинство из них вы уже видели: мы задаем некоторые гиперпараметры (например, скорость обучения, количество эпох для обучения и затухание весов) и указываем `push_to_hub=True`, чтобы указать, что мы хотим сохранить модель и оценить ее в конце каждой эпохи, а также что мы хотим загрузить наши результаты в Model Hub. Обратите внимание, что с помощью аргумента `hub_model_id` можно указать имя репозитория, в который вы хотите передать модель (в частности, этот аргумент нужно использовать, чтобы передать модель в организацию). Например, когда мы передавали модель в [организацию `huggingface-course`](https://huggingface.co/huggingface-course), мы добавили `hub_model_id="huggingface-course/bert-finetuned-ner"` в `TrainingArguments`. По умолчанию используемый репозиторий будет находиться в вашем пространстве имен и называться в соответствии с заданным вами выходным каталогом, так что в нашем случае это будет `"sgugger/bert-finetuned-ner"`.
+
+
+
+💡 Если выходной каталог, который вы используете, уже существует, он должен быть локальным клоном репозитория, в который вы хотите передать модель. Если это не так, вы получите ошибку при определении вашего `Trainer` и должны будете задать новое имя.
+
+
+
+Наконец, мы просто передаем все в `Trainer` и запускаем обучение:
+
+```python
+from transformers import Trainer
+
+trainer = Trainer(
+ model=model,
+ args=args,
+ train_dataset=tokenized_datasets["train"],
+ eval_dataset=tokenized_datasets["validation"],
+ data_collator=data_collator,
+ compute_metrics=compute_metrics,
+ tokenizer=tokenizer,
+)
+trainer.train()
+```
+
+Обратите внимание, что во время обучения каждый раз, когда модель сохраняется (здесь - каждую эпоху), она загружается в Hub в фоновом режиме. Таким образом, при необходимости вы сможете возобновить обучение на другой машине.
+
+После завершения обучения мы используем метод `push_to_hub()`, чтобы убедиться, что загружена самая последняя версия модели:
+
+```py
+trainer.push_to_hub(commit_message="Training complete")
+```
+
+Эта команда возвращает URL только что выполненного commit, если вы хотите его проверить:
+
+```python out
+'https://huggingface.co/sgugger/bert-finetuned-ner/commit/26ab21e5b1568f9afeccdaed2d8715f571d786ed'
+```
+
+ `Trainer` также создает черновик карточки модели со всеми результатами оценки и загружает его. На этом этапе вы можете использовать виджет инференса на Model Hub, чтобы протестировать свою модель и поделиться ею с друзьями. Вы успешно дообучили модель для задачи классификации токенов - поздравляем!
+
+ Если вы хотите более глубоко погрузиться в цикл обучения, мы покажем вам, как сделать то же самое с помощью 🤗 Accelerate.
+
+## Индивидуальный цикл обучения[[a-custom-training-loop]]
+
+Теперь давайте рассмотрим полный цикл обучения, чтобы вы могли легко настроить нужные вам части. Он будет очень похож на тот, что мы делали в [Главе 3](../chapter3/4), с некоторыми изменениями для оценки.
+
+### Подготовка всего к обучению[[preparing-everything-for-training]]
+
+Сначала нам нужно создать `DataLoader` для наших датасетов. Мы используем наш `data_collator` в качестве `collate_fn` и перемешиваем обучающий набор, но не валидационный:
+
+```py
+from torch.utils.data import DataLoader
+
+train_dataloader = DataLoader(
+ tokenized_datasets["train"],
+ shuffle=True,
+ collate_fn=data_collator,
+ batch_size=8,
+)
+eval_dataloader = DataLoader(
+ tokenized_datasets["validation"], collate_fn=data_collator, batch_size=8
+)
+```
+
+Затем мы повторно инстанцируем нашу модель, чтобы убедиться, что мы не продолжаем дообучать модель, а снова начинаем с предварительно обученной модели BERT:
+
+```py
+model = AutoModelForTokenClassification.from_pretrained(
+ model_checkpoint,
+ id2label=id2label,
+ label2id=label2id,
+)
+```
+
+Тогда нам понадобится оптимизатор. Мы будем использовать классический `AdamW`, который похож на `Adam`, но с исправлениями в способе применения затухания весов:
+
+```py
+from torch.optim import AdamW
+
+optimizer = AdamW(model.parameters(), lr=2e-5)
+```
+
+Когда у нас есть все эти объекты, мы можем отправить их в метод `accelerator.prepare()`:
+
+```py
+from accelerate import Accelerator
+
+accelerator = Accelerator()
+model, optimizer, train_dataloader, eval_dataloader = accelerator.prepare(
+ model, optimizer, train_dataloader, eval_dataloader
+)
+```
+
+
+
+🚨 Если вы обучаетесь на TPU, вам нужно будет перенести весь код, начиная с ячейки выше, в специальную функцию обучения. Подробнее смотрите [Главу 3](../chapter3/1).
+
+
+
+Теперь, когда мы отправили наш `train_dataloader` в `accelerator.prepare()`, мы можем использовать его длину для вычисления количества шагов обучения. Помните, что это всегда нужно делать после подготовки загрузчика данных, так как этот метод изменит его длину. Мы используем классический линейный планировшик скорости обучения до 0:
+
+```py
+from transformers import get_scheduler
+
+num_train_epochs = 3
+num_update_steps_per_epoch = len(train_dataloader)
+num_training_steps = num_train_epochs * num_update_steps_per_epoch
+
+lr_scheduler = get_scheduler(
+ "linear",
+ optimizer=optimizer,
+ num_warmup_steps=0,
+ num_training_steps=num_training_steps,
+)
+```
+
+Наконец, чтобы передать нашу модель в Hub, нам нужно создать объект `Repository` в рабочей папке. Сначала авторизуйтесь в Hugging Face, если вы еще не авторизованы. Мы определим имя репозитория по идентификатору модели, который мы хотим присвоить нашей модели (не стесняйтесь заменить `repo_name` на свой собственный выбор; он просто должен содержать ваше имя пользователя, что и делает функция `get_full_repo_name()`):
+
+```py
+from huggingface_hub import Repository, get_full_repo_name
+
+model_name = "bert-finetuned-ner-accelerate"
+repo_name = get_full_repo_name(model_name)
+repo_name
+```
+
+```python out
+'sgugger/bert-finetuned-ner-accelerate'
+```
+
+Затем мы можем клонировать этот репозиторий в локальную папку. Если она уже существует, эта локальная папка должна быть существующим клоном репозитория, с которым мы работаем:
+
+```py
+output_dir = "bert-finetuned-ner-accelerate"
+repo = Repository(output_dir, clone_from=repo_name)
+```
+
+Теперь мы можем загрузить все, что сохранили в `output_dir`, вызвав метод `repo.push_to_hub()`. Это поможет нам загружать промежуточные модели в конце каждой эпохи.
+
+### Цикл обучения[[training-loop]]
+
+Теперь мы готовы написать полный цикл обучения. Чтобы упростить его оценочную часть, мы определяем функцию `postprocess()`, которая принимает прогнозы и метки и преобразует их в списки строк, как того ожидает наш объект `metric`:
+
+```py
+def postprocess(predictions, labels):
+ predictions = predictions.detach().cpu().clone().numpy()
+ labels = labels.detach().cpu().clone().numpy()
+
+ # Удаляем игнорируемый индекс (специальные токены) и преобразуем в метки
+ true_labels = [[label_names[l] for l in label if l != -100] for label in labels]
+ true_predictions = [
+ [label_names[p] for (p, l) in zip(prediction, label) if l != -100]
+ for prediction, label in zip(predictions, labels)
+ ]
+ return true_labels, true_predictions
+```
+
+Затем мы можем написать цикл обучения. После определения прогресс-бара, чтобы следить за ходом обучения, цикл состоит из трех частей:
+
+- Само обучение представляет собой классическую итерацию по `train_dataloader`, прямой проход по модели, затем обратный проход и шаг оптимизатора.
+- Оценка, в которой есть новшество после получения выходов нашей модели на батче: поскольку два процесса могли дополнять входы и метки до разных форм, нам нужно использовать `accelerator.pad_across_processes()`, чтобы сделать прогнозы и метки одинаковой формы перед вызовом метода `gather()`. Если мы этого не сделаем, оценка либо завершится с ошибкой, либо зависнет навсегда. Затем мы отправляем результаты в `metric.add_batch()` и вызываем `metric.compute()` после завершения цикла оценки.
+- Сохранение и загрузка, где мы сначала сохраняем модель и токенизатор, а затем вызываем `repo.push_to_hub()`. Обратите внимание, что мы используем аргумент `blocking=False`, чтобы указать библиотеке 🤗 Hub на выполнение push в асинхронном процессе. Таким образом, обучение продолжается нормально, а эта (длинная) инструкция выполняется в фоновом режиме.
+
+Вот полный код цикла обучения:
+
+```py
+from tqdm.auto import tqdm
+import torch
+
+progress_bar = tqdm(range(num_training_steps))
+
+for epoch in range(num_train_epochs):
+ # Обучение
+ model.train()
+ for batch in train_dataloader:
+ outputs = model(**batch)
+ loss = outputs.loss
+ accelerator.backward(loss)
+
+ optimizer.step()
+ lr_scheduler.step()
+ optimizer.zero_grad()
+ progress_bar.update(1)
+
+ # Оценка
+ model.eval()
+ for batch in eval_dataloader:
+ with torch.no_grad():
+ outputs = model(**batch)
+
+ predictions = outputs.logits.argmax(dim=-1)
+ labels = batch["labels"]
+
+ # Необходимо добавить предсказания и метки для gather
+ predictions = accelerator.pad_across_processes(predictions, dim=1, pad_index=-100)
+ labels = accelerator.pad_across_processes(labels, dim=1, pad_index=-100)
+
+ predictions_gathered = accelerator.gather(predictions)
+ labels_gathered = accelerator.gather(labels)
+
+ true_predictions, true_labels = postprocess(predictions_gathered, labels_gathered)
+ metric.add_batch(predictions=true_predictions, references=true_labels)
+
+ results = metric.compute()
+ print(
+ f"epoch {epoch}:",
+ {
+ key: results[f"overall_{key}"]
+ for key in ["precision", "recall", "f1", "accuracy"]
+ },
+ )
+
+ # Сохранение и загрузка
+ accelerator.wait_for_everyone()
+ unwrapped_model = accelerator.unwrap_model(model)
+ unwrapped_model.save_pretrained(output_dir, save_function=accelerator.save)
+ if accelerator.is_main_process:
+ tokenizer.save_pretrained(output_dir)
+ repo.push_to_hub(
+ commit_message=f"Training in progress epoch {epoch}", blocking=False
+ )
+```
+
+Если вы впервые видите модель, сохраненную с помощью 🤗 Accelerate, давайте посмотрим на три строки кода, которые идут вместе с ним:
+
+```py
+accelerator.wait_for_everyone()
+unwrapped_model = accelerator.unwrap_model(model)
+unwrapped_model.save_pretrained(output_dir, save_function=accelerator.save)
+```
+
+Первая строка не требует пояснений: она указывает всем процессам подождать, пока все не окажутся на этой стадии, прежде чем продолжить работу. Это нужно для того, чтобы убедиться, что у нас одна и та же модель в каждом процессе перед сохранением. Затем мы берем `unwrapped_model`, которая является базовой моделью, которую мы определили. Метод `accelerator.prepare()` изменяет модель для работы в распределенном обучении, поэтому у нее больше не будет метода `save_pretrained()`; метод `accelerator.unwrap_model()` отменяет этот шаг. Наконец, мы вызываем `save_pretrained()`, но указываем этому методу использовать `accelerator.save()` вместо `torch.save()`.
+
+После того как это будет сделано, у вас должна получиться модель, выдающая результаты, очень похожие на те, что были обучены с помощью `Trainer`. Вы можете посмотреть модель, которую мы обучили с помощью этого кода, на [*huggingface-course/bert-finetuned-ner-accelerate*](https://huggingface.co/huggingface-course/bert-finetuned-ner-accelerate). А если вы хотите протестировать какие-либо изменения в цикле обучения, вы можете напрямую реализовать их, отредактировав код, показанный выше!
+
+{/if}
+
+## Использование дообученной модели[[using-the-fine-tuned-model]]
+
+Мы уже показали вам, как можно использовать модель, которую мы дообучили на Model Hub, с помощью виджета инференса. Чтобы использовать ее локально в `pipeline`, нужно просто указать соответствующий идентификатор модели:
+
+```py
+from transformers import pipeline
+
+# Замените это на свою собственную контрольную точку
+model_checkpoint = "huggingface-course/bert-finetuned-ner"
+token_classifier = pipeline(
+ "token-classification", model=model_checkpoint, aggregation_strategy="simple"
+)
+token_classifier("My name is Sylvain and I work at Hugging Face in Brooklyn.")
+```
+
+```python out
+[{'entity_group': 'PER', 'score': 0.9988506, 'word': 'Sylvain', 'start': 11, 'end': 18},
+ {'entity_group': 'ORG', 'score': 0.9647625, 'word': 'Hugging Face', 'start': 33, 'end': 45},
+ {'entity_group': 'LOC', 'score': 0.9986118, 'word': 'Brooklyn', 'start': 49, 'end': 57}]
+```
+
+Отлично! Наша модель работает так же хорошо, как и модель по умолчанию для этого конвейера!
diff --git a/chapters/ru/chapter7/3.mdx b/chapters/ru/chapter7/3.mdx
new file mode 100644
index 000000000..da62408eb
--- /dev/null
+++ b/chapters/ru/chapter7/3.mdx
@@ -0,0 +1,1044 @@
+
+
+# Дообучение модели маскированного языкового моделирования[[fine-tuning-a-masked-language-model]]
+
+{#if fw === 'pt'}
+
+
+
+{:else}
+
+
+
+{/if}
+
+Для многих приложений NLP, в которых используются модели-трансформеры, можно просто взять предварительно обученную модель из Hugging Face Hub и дообучить ее непосредственно на ваших данных для решения поставленной задачи. При условии, что корпус, использованный для предварительного обучения, не слишком отличается от корпуса, используемого для дообучения, трансферное обучение обычно дает хорошие результаты.
+
+Однако есть несколько случаев, когда перед обучением специфичной для конкретной задачи головы необходимо дообучить языковые модели на ваших данных. Например, если ваш датасет содержит юридические контракты или научные статьи, ванильная модель трансформер, такая как BERT, обычно рассматривает специфические для области слова в вашем корпусе как редкие токены, и результирующее качество может быть менее чем удовлетворительным. Дообучив языковую модель на данных из домена, вы сможете повысить качество работы во многих последующих задачах, а это значит, что обычно этот шаг нужно выполнить только один раз!
+
+Этот процесс дообучить предварительно обученную языковую модель на данных из домена обычно называют _доменной адаптацией (domain adaptation)_. Он был популяризирован в 2018 году благодаря [ULMFiT](https://arxiv.org/abs/1801.06146), которая стала одной из первых нейронных архитектур (основанных на LSTM), заставивших трансферное обучение действительно работать в NLP. Пример доменной адаптации с помощью ULMFiT показан на изображении ниже; в этом разделе мы сделаем нечто подобное, но с трансформером вместо LSTM!
+
+
+

+

+
+
+К концу этого раздела у вас будет [модель маскированного языкового моделирования](https://huggingface.co/huggingface-course/distilbert-base-uncased-finetuned-imdb?text=This+is+a+great+%5BMASK%5D.) на Hub, которая позволяет автоматически дописывать предложения, как показано ниже:
+
+
+
+Давайте погрузимся в работу!
+
+
+
+
+
+🙋 Если термины "маскированное моделирование языка (masked language modeling)" и "предварительно обученная модель (pretrained model)" кажутся вам незнакомыми, загляните в [Главу 1](../chapter1/1), где мы объясняем все эти основные понятия, сопровождая их видеороликами!
+
+
+
+## Выбор предварительно обученной модели для маскированного моделирования языка[[picking-a-pretrained-model-for-masked-language-modeling]]
+
+Для начала давайте выберем подходящую предварительно обученную модель для маскированного языкового моделирования. Как показано на следующем скриншоте, вы можете найти список кандидатов, применив фильтр "Fill-Mask" на [Hugging Face Hub](https://huggingface.co/models?pipeline_tag=fill-mask&sort=downloads):
+
+
+
+
+
+Хотя модели семейства BERT и RoBERTa являются наиболее загружаемыми, мы будем использовать модель под названием [DistilBERT](https://huggingface.co/distilbert-base-uncased)
+которая может быть обучена гораздо быстрее и практически без потерь в качестве. Эта модель была обучена с помощью специальной техники, называемой [_дистилляцией знаний (knowledge distillation)_](https://en.wikipedia.org/wiki/Knowledge_distillation), когда большая "модель-учитель", такая как BERT, используется для обучения "модели-ученика", имеющей гораздо меньше параметров. Объяснение деталей дистилляции знаний завело бы нас слишком далеко в этом разделе, но если вам интересно, вы можете прочитать об этом в [_Natural Language Processing with Transformers_](https://www.oreilly.com/library/view/natural-language-processing/9781098136789/) (в просторечии известном как учебник по Трансформерам).
+
+{#if fw === 'pt'}
+
+Давайте перейдем к загрузке DistilBERT с помощью класса `AutoModelForMaskedLM`:
+
+```python
+from transformers import AutoModelForMaskedLM
+
+model_checkpoint = "distilbert-base-uncased"
+model = AutoModelForMaskedLM.from_pretrained(model_checkpoint)
+```
+
+Мы можем узнать, сколько параметров имеет эта модель, вызвав метод `num_parameters()`:
+
+```python
+distilbert_num_parameters = model.num_parameters() / 1_000_000
+print(f"'>>> DistilBERT number of parameters: {round(distilbert_num_parameters)}M'")
+print(f"'>>> BERT number of parameters: 110M'")
+```
+
+```python out
+'>>> DistilBERT number of parameters: 67M'
+'>>> BERT number of parameters: 110M'
+```
+
+{:else}
+
+Давайте загрузим DistilBERT, используя класс `AutoModelForMaskedLM`:
+
+```python
+from transformers import TFAutoModelForMaskedLM
+
+model_checkpoint = "distilbert-base-uncased"
+model = TFAutoModelForMaskedLM.from_pretrained(model_checkpoint)
+```
+
+Мы можем узнать, сколько параметров имеет эта модель, вызвав метод `summary()`:
+
+```python
+model.summary()
+```
+
+```python out
+Model: "tf_distil_bert_for_masked_lm"
+_________________________________________________________________
+Layer (type) Output Shape Param #
+=================================================================
+distilbert (TFDistilBertMain multiple 66362880
+_________________________________________________________________
+vocab_transform (Dense) multiple 590592
+_________________________________________________________________
+vocab_layer_norm (LayerNorma multiple 1536
+_________________________________________________________________
+vocab_projector (TFDistilBer multiple 23866170
+=================================================================
+Total params: 66,985,530
+Trainable params: 66,985,530
+Non-trainable params: 0
+_________________________________________________________________
+```
+
+{/if}
+
+Имея около 67 миллионов параметров, DistilBERT примерно в два раза меньше, чем базовая модель BERT, что примерно соответствует двукратному ускорению обучения - неплохо! Теперь посмотрим, какие виды токенов эта модель предсказывает как наиболее вероятные завершения небольшого образца текста:
+
+```python
+text = "This is a great [MASK]."
+```
+
+Как люди, мы можем представить множество вариантов использования токена `[MASK]`, например "day (день)", "ride (поездка)" или "painting (картина)". Для предварительно обученных моделей прогнозы зависят от корпуса, на котором обучалась модель, поскольку она учится улавливать статистические закономерности, присутствующие в данных. Как и BERT, DistilBERT был предварительно обучен на датасетах [English Wikipedia](https://huggingface.co/datasets/wikipedia) и [BookCorpus](https://huggingface.co/datasets/bookcorpus), поэтому мы ожидаем, что прогнозы для `[MASK]` будут отражать эти домены. Для прогнозирования маски нам нужен токенизатор DistilBERT для создания входных данных для модели, поэтому давайте загрузим и его с хаба:
+
+```python
+from transformers import AutoTokenizer
+
+tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
+```
+
+Теперь, имея токенизатор и модель, мы можем передать наш текстовый пример в модель, извлечь логиты и вывести 5 лучших кандидатов:
+
+{#if fw === 'pt'}
+
+```python
+import torch
+
+inputs = tokenizer(text, return_tensors="pt")
+token_logits = model(**inputs).logits
+# Определеним местоположения [MASK] и извлечем его логиты
+mask_token_index = torch.where(inputs["input_ids"] == tokenizer.mask_token_id)[1]
+mask_token_logits = token_logits[0, mask_token_index, :]
+# Выберем кандидатов [MASK] с наибольшими логитами
+top_5_tokens = torch.topk(mask_token_logits, 5, dim=1).indices[0].tolist()
+
+for token in top_5_tokens:
+ print(f"'>>> {text.replace(tokenizer.mask_token, tokenizer.decode([token]))}'")
+```
+
+{:else}
+
+```python
+import numpy as np
+import tensorflow as tf
+
+inputs = tokenizer(text, return_tensors="np")
+token_logits = model(**inputs).logits
+# Определеним местоположения [MASK] и извлечем его логиты
+mask_token_index = np.argwhere(inputs["input_ids"] == tokenizer.mask_token_id)[0, 1]
+mask_token_logits = token_logits[0, mask_token_index, :]
+# Выберем кандидатов [MASK] с наибольшими логитами
+# Мы выполняем отрицание массива перед argsort, чтобы получить самые большие, а не самые маленькие логиты
+top_5_tokens = np.argsort(-mask_token_logits)[:5].tolist()
+
+for token in top_5_tokens:
+ print(f">>> {text.replace(tokenizer.mask_token, tokenizer.decode([token]))}")
+```
+
+{/if}
+
+```python out
+'>>> This is a great deal.'
+'>>> This is a great success.'
+'>>> This is a great adventure.'
+'>>> This is a great idea.'
+'>>> This is a great feat.'
+```
+
+Из результатов видно, что предсказания модели относятся к повседневным терминам, что, пожалуй, неудивительно, учитывая основу английской Википедии. Давайте посмотрим, как мы можем изменить эту область на что-то более нишевое - сильно поляризованные обзоры фильмов!
+
+
+## Датасет[[the-dataset]]
+
+Для демонстрации адаптации к домену мы используем знаменитый [Large Movie Review Dataset](https://huggingface.co/datasets/imdb) (или сокращенно IMDb) - корпус кинорецензий, который часто используется для тестирования моделей анализа настроения. Дообучив DistilBERT на этом корпусе, мы ожидаем, что языковая модель адаптирует свой словарный запас от фактических данных Википедии, на которых она была предварительно обучена, к более субъективным элементам кинорецензий. Мы можем получить данные из Hugging Face Hub с помощью функции `load_dataset()` из 🤗 Datasets:
+
+```python
+from datasets import load_dataset
+
+imdb_dataset = load_dataset("imdb")
+imdb_dataset
+```
+
+```python out
+DatasetDict({
+ train: Dataset({
+ features: ['text', 'label'],
+ num_rows: 25000
+ })
+ test: Dataset({
+ features: ['text', 'label'],
+ num_rows: 25000
+ })
+ unsupervised: Dataset({
+ features: ['text', 'label'],
+ num_rows: 50000
+ })
+})
+```
+
+Мы видим, что части `train` и `test` состоят из 25 000 отзывов каждая, а часть без меток, называемая `unsupervised`, содержит 50 000 отзывов. Давайте посмотрим на несколько примеров, чтобы получить представление о том, с каким текстом мы имеем дело. Как мы уже делали в предыдущих главах курса, мы используем функции `Dataset.shuffle()` и `Dataset.select()` для создания случайной выборки:
+
+```python
+sample = imdb_dataset["train"].shuffle(seed=42).select(range(3))
+
+for row in sample:
+ print(f"\n'>>> Review: {row['text']}'")
+ print(f"'>>> Label: {row['label']}'")
+```
+
+```python out
+
+'>>> Review: This is your typical Priyadarshan movie--a bunch of loony characters out on some silly mission. His signature climax has the entire cast of the film coming together and fighting each other in some crazy moshpit over hidden money. Whether it is a winning lottery ticket in Malamaal Weekly, black money in Hera Pheri, "kodokoo" in Phir Hera Pheri, etc., etc., the director is becoming ridiculously predictable. Don\'t get me wrong; as clichéd and preposterous his movies may be, I usually end up enjoying the comedy. However, in most his previous movies there has actually been some good humor, (Hungama and Hera Pheri being noteworthy ones). Now, the hilarity of his films is fading as he is using the same formula over and over again.
Songs are good. Tanushree Datta looks awesome. Rajpal Yadav is irritating, and Tusshar is not a whole lot better. Kunal Khemu is OK, and Sharman Joshi is the best.'
+'>>> Label: 0'
+
+'>>> Review: Okay, the story makes no sense, the characters lack any dimensionally, the best dialogue is ad-libs about the low quality of movie, the cinematography is dismal, and only editing saves a bit of the muddle, but Sam" Peckinpah directed the film. Somehow, his direction is not enough. For those who appreciate Peckinpah and his great work, this movie is a disappointment. Even a great cast cannot redeem the time the viewer wastes with this minimal effort.
The proper response to the movie is the contempt that the director San Peckinpah, James Caan, Robert Duvall, Burt Young, Bo Hopkins, Arthur Hill, and even Gig Young bring to their work. Watch the great Peckinpah films. Skip this mess.'
+'>>> Label: 0'
+
+'>>> Review: I saw this movie at the theaters when I was about 6 or 7 years old. I loved it then, and have recently come to own a VHS version.
My 4 and 6 year old children love this movie and have been asking again and again to watch it.
I have enjoyed watching it again too. Though I have to admit it is not as good on a little TV.
I do not have older children so I do not know what they would think of it.
The songs are very cute. My daughter keeps singing them over and over.
Hope this helps.'
+'>>> Label: 1'
+```
+
+Да, это точно рецензии на фильмы, и если вы родились до 1990х, вам будет лучше понятен комментарий в последней рецензии о VHS-версии. 😜! Хотя нам не понадобятся эти метки для языкового моделирования, мы уже видим, что `0` обозначает отрицательный отзыв, а `1` - положительный.
+
+
+
+✏️ **Попробуйте!** Создайте случайную выборку из части `unsupervised` и проверьте, что метки не являются ни `0`, ни `1`. В процессе работы вы также можете проверить, что метки в частях `train` и `test` действительно равны `0` или `1` - это полезная проверка здравомыслия, которую каждый практикующий NLP должен выполнять в начале нового проекта!
+
+
+
+Теперь, когда мы вкратце ознакомились с данными, давайте перейдем к их подготовке к моделированию языка по маске. Как мы увидим, есть несколько дополнительных шагов, которые необходимо сделать по сравнению с задачами классификации последовательностей, которые мы рассматривали в [Главе 3](../chapter3/1). Поехали!
+
+## Предварительная обработка данных[[preprocessing-the-data]]
+
+
+
+Как для авторегрессивного, так и для масочного моделирования языка общим шагом предварительной обработки является объединение всех примеров, а затем разбиение всего корпуса на части одинакового размера. Это сильно отличается от нашего обычного подхода, когда мы просто проводим токенизацию отдельных примеров. Зачем конкатенируем все вместе? Причина в том, что отдельные примеры могут быть обрезаны, если они слишком длинные, и это приведет к потере информации, которая может быть полезна для задачи языкового моделирования!
+
+Итак, для начала мы проведем обычную токенизацию нашего корпуса, но _без_ задания параметра `truncation=True` в нашем токенизаторе. Мы также возьмем идентификаторы слов, если они доступны (а они будут доступны, если мы используем быстрый токенизатор, как описано в [Главе 6](../chapter6/3)), поскольку они понадобятся нам позже для маскирования целых слов. Мы обернем это в простую функцию, а пока удалим столбцы `text` и `label`, поскольку они нам больше не нужны:
+
+```python
+def tokenize_function(examples):
+ result = tokenizer(examples["text"])
+ if tokenizer.is_fast:
+ result["word_ids"] = [result.word_ids(i) for i in range(len(result["input_ids"]))]
+ return result
+
+
+# Используйте batched=True для активации быстрой многопоточности!
+tokenized_datasets = imdb_dataset.map(
+ tokenize_function, batched=True, remove_columns=["text", "label"]
+)
+tokenized_datasets
+```
+
+```python out
+DatasetDict({
+ train: Dataset({
+ features: ['attention_mask', 'input_ids', 'word_ids'],
+ num_rows: 25000
+ })
+ test: Dataset({
+ features: ['attention_mask', 'input_ids', 'word_ids'],
+ num_rows: 25000
+ })
+ unsupervised: Dataset({
+ features: ['attention_mask', 'input_ids', 'word_ids'],
+ num_rows: 50000
+ })
+})
+```
+
+Поскольку DistilBERT - это BERT-подобная модель, мы видим, что закодированные тексты состоят из `input_ids` и `attention_mask`, которые мы уже видели в других главах, а также из `word_ids`, которые мы добавили.
+
+Теперь, когда мы провели токенизацию рецензий на фильмы, следующий шаг - сгруппировать их вместе и разбить результат на части. Но какого размера должны быть эти части? В конечном итоге это будет зависеть от объема доступной памяти GPU, но хорошей отправной точкой будет узнать, каков максимальный размер контекста модели. Это можно сделать путем проверки атрибута `model_max_length` токенизатора:
+
+```python
+tokenizer.model_max_length
+```
+
+```python out
+512
+```
+
+Это значение берется из файла *tokenizer_config.json*, связанного с контрольной точкой; в данном случае мы видим, что размер контекста составляет 512 токенов, как и в случае с BERT.
+
+
+
+✏️ **Попробуйте!** Некоторые модели трансформеров, например [BigBird](https://huggingface.co/google/bigbird-roberta-base) и [Longformer](hf.co/allenai/longformer-base-4096), имеют гораздо большую длину контекста, чем BERT и другие ранние модели трансформеров. Инстанцируйте токенизатор для одной из этих контрольных точек и проверьте, что `model_max_length` согласуется с тем, что указано в описании модели.
+
+
+
+Поэтому для проведения экспериментов на GPU, подобных тем, что стоят в Google Colab, мы выберем что-нибудь поменьше, что может поместиться в памяти:
+
+```python
+chunk_size = 128
+```
+
+
+
+Обратите внимание, что использование небольшого размера фрагмента может быть вредным в реальных сценариях, поэтому следует использовать размер, соответствующий сценарию использования, к которому вы будете применять вашу модель.
+
+
+
+Теперь наступает самое интересное. Чтобы показать, как работает конкатенация, давайте возьмем несколько отзывов из нашего обучающего набора с токенизацией и выведем количество токенов в отзыве:
+
+```python
+# С помощью среза получаем список списков для каждого признака
+tokenized_samples = tokenized_datasets["train"][:3]
+
+for idx, sample in enumerate(tokenized_samples["input_ids"]):
+ print(f"'>>> Review {idx} length: {len(sample)}'")
+```
+
+```python out
+'>>> Review 0 length: 200'
+'>>> Review 1 length: 559'
+'>>> Review 2 length: 192'
+```
+
+Затем мы можем объединить все эти примеры с помощью простого dictionary comprehension, как показано ниже:
+
+```python
+concatenated_examples = {
+ k: sum(tokenized_samples[k], []) for k in tokenized_samples.keys()
+}
+total_length = len(concatenated_examples["input_ids"])
+print(f"'>>> Concatenated reviews length: {total_length}'")
+```
+
+```python out
+'>>> Concatenated reviews length: 951'
+```
+
+Отлично, общая длина подтвердилась - теперь давайте разобьем конкатенированные обзоры на части размером `chunk_size`. Для этого мы перебираем признаки в `concatenated_examples` и используем list comprehension для создания срезов каждого признака. В результате мы получаем словарь фрагментов для каждого признака:
+
+```python
+chunks = {
+ k: [t[i : i + chunk_size] for i in range(0, total_length, chunk_size)]
+ for k, t in concatenated_examples.items()
+}
+
+for chunk in chunks["input_ids"]:
+ print(f"'>>> Chunk length: {len(chunk)}'")
+```
+
+```python out
+'>>> Chunk length: 128'
+'>>> Chunk length: 128'
+'>>> Chunk length: 128'
+'>>> Chunk length: 128'
+'>>> Chunk length: 128'
+'>>> Chunk length: 128'
+'>>> Chunk length: 128'
+'>>> Chunk length: 55'
+```
+
+Как видно из этого примера, последний фрагмент, как правило, будет меньше максимального размера фрагмента. Существует две основные стратегии решения этой проблемы:
+
+* Отбросить последний фрагмент, если он меньше `chunk_size`.
+* Дополнить последний фрагмент до длины, равной `chunk_size`.
+
+Мы воспользуемся первым подходом, поэтому обернем всю описанную выше логику в одну функцию, которую можно применить к нашим токенизированным датасетам:
+
+```python
+def group_texts(examples):
+ # Конкатенируем все тексты
+ concatenated_examples = {k: sum(examples[k], []) for k in examples.keys()}
+ # Вычисляем длину конкатенированных текстов
+ total_length = len(concatenated_examples[list(examples.keys())[0]])
+ # Отбрасываем последний фрагмент, если он меньше chunk_size
+ total_length = (total_length // chunk_size) * chunk_size
+ # Разбиваем на фрагменты длиной max_len
+ result = {
+ k: [t[i : i + chunk_size] for i in range(0, total_length, chunk_size)]
+ for k, t in concatenated_examples.items()
+ }
+ # Создаем новый столбец меток
+ result["labels"] = result["input_ids"].copy()
+ return result
+```
+
+Обратите внимание, что на последнем шаге `group_texts()` мы создаем новый столбец `labels`, который является копией столбца `input_ids`. Как мы вскоре увидим, это связано с тем, что при моделировании языка по маске цель состоит в прогнозировании случайно замаскированных токенов во входном батче, и, создавая столбец `labels`, мы предоставляем базовую истину для нашей языковой модели, на которой она будет учиться.
+
+Теперь давайте применим `group_texts()` к нашим токенизированным датасетам, используя нашу надежную функцию `Dataset.map()`:
+
+```python
+lm_datasets = tokenized_datasets.map(group_texts, batched=True)
+lm_datasets
+```
+
+```python out
+DatasetDict({
+ train: Dataset({
+ features: ['attention_mask', 'input_ids', 'labels', 'word_ids'],
+ num_rows: 61289
+ })
+ test: Dataset({
+ features: ['attention_mask', 'input_ids', 'labels', 'word_ids'],
+ num_rows: 59905
+ })
+ unsupervised: Dataset({
+ features: ['attention_mask', 'input_ids', 'labels', 'word_ids'],
+ num_rows: 122963
+ })
+})
+```
+
+Вы можете видеть, что группировка и последующее разбиение текстов на фрагменты позволили получить гораздо больше примеров, чем наши первоначальные 25 000 примеров для частей `train` и `test`. Это потому, что теперь у нас есть примеры с _непрерывными токенами (contiguous tokens)_, которые охватывают несколько примеров из исходного корпуса. В этом можно убедиться, поискав специальные токены `[SEP]` и `[CLS]` в одном из фрагментов:
+
+```python
+tokenizer.decode(lm_datasets["train"][1]["input_ids"])
+```
+
+```python out
+".... at.......... high. a classic line : inspector : i'm here to sack one of your teachers. student : welcome to bromwell high. i expect that many adults of my age think that bromwell high is far fetched. what a pity that it isn't! [SEP] [CLS] homelessness ( or houselessness as george carlin stated ) has been an issue for years but never a plan to help those on the street that were once considered human who did everything from going to school, work, or vote for the matter. most people think of the homeless"
+```
+
+В этом примере вы можете увидеть два перекрывающихся обзора фильмов: один - о старшей школе, другой - о бездомности. Давайте также посмотрим, как выглядят метки при моделировании языка по маске:
+
+```python out
+tokenizer.decode(lm_datasets["train"][1]["labels"])
+```
+
+```python out
+".... at.......... high. a classic line : inspector : i'm here to sack one of your teachers. student : welcome to bromwell high. i expect that many adults of my age think that bromwell high is far fetched. what a pity that it isn't! [SEP] [CLS] homelessness ( or houselessness as george carlin stated ) has been an issue for years but never a plan to help those on the street that were once considered human who did everything from going to school, work, or vote for the matter. most people think of the homeless"
+```
+
+Как и ожидалось от нашей функции `group_texts()` выше, это выглядит идентично декодированным `input_ids` - но как тогда наша модель может чему-то научиться? Нам не хватает ключевого шага: вставки токенов `[MASK]` в случайные позиции во входных данных! Давайте посмотрим, как это можно сделать на лету во время дообучения с помощью специального коллатора данных.
+
+## Дообучение DistilBERT с помощью API `Trainer`[[fine-tuning-distilbert-with-the-trainer-api]]
+
+Дообучить модель моделирования языка по маске почти то же самое, что и дообучить модель классификации последовательностей, как мы делали в [Главе 3](../chapter3/1). Единственное отличие заключается в том, что нам нужен специальный коллатор данных, который может случайным образом маскировать некоторые токены в каждом батче текстов. К счастью, 🤗 Transformers поставляется со специальным `DataCollatorForLanguageModeling`, предназначенным именно для этой задачи. Нам нужно только передать ему токенизатор и аргумент `mlm_probability`, который указывает, какую долю токенов нужно маскировать. Мы выберем 15 % - это количество используется для BERT и является распространенным выбором в литературе:
+
+```python
+from transformers import DataCollatorForLanguageModeling
+
+data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm_probability=0.15)
+```
+
+Чтобы увидеть, как работает случайное маскирование, давайте отправим несколько примеров в коллатор данных. Поскольку он ожидает список `dict`, где каждый `dict` представляет собой один фрагмент непрерывного текста, мы сначала выполняем итерацию над датасетом, прежде чем отправить батч коллатору. Мы удаляем ключ `"word_ids"` для этого коллатора данных, поскольку он его не ожидает:
+
+```python
+samples = [lm_datasets["train"][i] for i in range(2)]
+for sample in samples:
+ _ = sample.pop("word_ids")
+
+for chunk in data_collator(samples)["input_ids"]:
+ print(f"\n'>>> {tokenizer.decode(chunk)}'")
+```
+
+```python output
+'>>> [CLS] bromwell [MASK] is a cartoon comedy. it ran at the same [MASK] as some other [MASK] about school life, [MASK] as " teachers ". [MASK] [MASK] [MASK] in the teaching [MASK] lead [MASK] to believe that bromwell high\'[MASK] satire is much closer to reality than is " teachers ". the scramble [MASK] [MASK] financially, the [MASK]ful students whogn [MASK] right through [MASK] pathetic teachers\'pomp, the pettiness of the whole situation, distinction remind me of the schools i knew and their students. when i saw [MASK] episode in [MASK] a student repeatedly tried to burn down the school, [MASK] immediately recalled. [MASK]...'
+
+'>>> .... at.. [MASK]... [MASK]... high. a classic line plucked inspector : i\'[MASK] here to [MASK] one of your [MASK]. student : welcome to bromwell [MASK]. i expect that many adults of my age think that [MASK]mwell [MASK] is [MASK] fetched. what a pity that it isn\'t! [SEP] [CLS] [MASK]ness ( or [MASK]lessness as george 宇in stated )公 been an issue for years but never [MASK] plan to help those on the street that were once considered human [MASK] did everything from going to school, [MASK], [MASK] vote for the matter. most people think [MASK] the homeless'
+```
+
+Отлично, сработало! Мы видим, что токен `[MASK]` был случайным образом вставлен в различные места нашего текста. Это будут токены, которые наша модель должна будет предсказать в процессе обучения - и прелесть коллатора данных в том, что он будет случайным образом вставлять `[MASK]` в каждом батче!
+
+
+
+✏️ **Попробуйте!** Запустите приведенный выше фрагмент кода несколько раз, чтобы увидеть, как случайное маскирование происходит на ваших глазах! Также замените метод `tokenizer.decode()` на `tokenizer.convert_ids_to_tokens()`, чтобы увидеть, что иногда маскируется один токен из данного слова, а не все остальные.
+
+
+
+{#if fw === 'pt'}
+
+Одним из побочных эффектов случайного маскирования является то, что наши метрики оценки не будут детерминированными при использовании `Trainer`, поскольку мы используем один и тот же коллатор данных для обучающего и тестового наборов. Позже, когда мы рассмотрим дообучение с помощью 🤗 Accelerate, мы увидим, как можно использовать гибкость пользовательского цикла оценки, чтобы заморозить случайность.
+
+{/if}
+
+При обучении моделей для моделирования языка с маской можно использовать один из методов - маскировать целые слова, а не только отдельные токены. Такой подход называется _маскированием целых слов (whole word masking)_. Если мы хотим использовать маскирование целых слов, нам нужно будет самостоятельно создать коллатор данных. Коллатор данных - это просто функция, которая берет список примеров и преобразует их в батч, так что давайте сделаем это прямо сейчас! Мы будем использовать идентификаторы слов, вычисленные ранее, для создания карты между индексами слов и соответствующими токенами, затем случайным образом определим, какие слова нужно маскировать, и применим эту маску к входным данным. Обратите внимание, что все метки - `-100`, кроме тех, что соответствуют словам-маскам.
+
+{#if fw === 'pt'}
+
+```py
+import collections
+import numpy as np
+
+from transformers import default_data_collator
+
+wwm_probability = 0.2
+
+
+def whole_word_masking_data_collator(features):
+ for feature in features:
+ word_ids = feature.pop("word_ids")
+
+ # Создаем отображение между словами и соответствующими индексами токенов
+ mapping = collections.defaultdict(list)
+ current_word_index = -1
+ current_word = None
+ for idx, word_id in enumerate(word_ids):
+ if word_id is not None:
+ if word_id != current_word:
+ current_word = word_id
+ current_word_index += 1
+ mapping[current_word_index].append(idx)
+
+ # Случайно маскируем слова
+ mask = np.random.binomial(1, wwm_probability, (len(mapping),))
+ input_ids = feature["input_ids"]
+ labels = feature["labels"]
+ new_labels = [-100] * len(labels)
+ for word_id in np.where(mask)[0]:
+ word_id = word_id.item()
+ for idx in mapping[word_id]:
+ new_labels[idx] = labels[idx]
+ input_ids[idx] = tokenizer.mask_token_id
+ feature["labels"] = new_labels
+
+ return default_data_collator(features)
+```
+
+{:else}
+
+```py
+import collections
+import numpy as np
+
+from transformers.data.data_collator import tf_default_data_collator
+
+wwm_probability = 0.2
+
+
+def whole_word_masking_data_collator(features):
+ for feature in features:
+ word_ids = feature.pop("word_ids")
+
+ # Создаем отображение между словами и соответствующими индексами токенов
+ mapping = collections.defaultdict(list)
+ current_word_index = -1
+ current_word = None
+ for idx, word_id in enumerate(word_ids):
+ if word_id is not None:
+ if word_id != current_word:
+ current_word = word_id
+ current_word_index += 1
+ mapping[current_word_index].append(idx)
+
+ # Случайно маскируем слова
+ mask = np.random.binomial(1, wwm_probability, (len(mapping),))
+ input_ids = feature["input_ids"]
+ labels = feature["labels"]
+ new_labels = [-100] * len(labels)
+ for word_id in np.where(mask)[0]:
+ word_id = word_id.item()
+ for idx in mapping[word_id]:
+ new_labels[idx] = labels[idx]
+ input_ids[idx] = tokenizer.mask_token_id
+ feature["labels"] = new_labels
+
+ return tf_default_data_collator(features)
+```
+
+{/if}
+
+Далее мы можем опробовать ее на тех же примерах, что и раньше:
+
+```py
+samples = [lm_datasets["train"][i] for i in range(2)]
+batch = whole_word_masking_data_collator(samples)
+
+for chunk in batch["input_ids"]:
+ print(f"\n'>>> {tokenizer.decode(chunk)}'")
+```
+
+```python out
+'>>> [CLS] bromwell high is a cartoon comedy [MASK] it ran at the same time as some other programs about school life, such as " teachers ". my 35 years in the teaching profession lead me to believe that bromwell high\'s satire is much closer to reality than is " teachers ". the scramble to survive financially, the insightful students who can see right through their pathetic teachers\'pomp, the pettiness of the whole situation, all remind me of the schools i knew and their students. when i saw the episode in which a student repeatedly tried to burn down the school, i immediately recalled.....'
+
+'>>> .... [MASK] [MASK] [MASK] [MASK]....... high. a classic line : inspector : i\'m here to sack one of your teachers. student : welcome to bromwell high. i expect that many adults of my age think that bromwell high is far fetched. what a pity that it isn\'t! [SEP] [CLS] homelessness ( or houselessness as george carlin stated ) has been an issue for years but never a plan to help those on the street that were once considered human who did everything from going to school, work, or vote for the matter. most people think of the homeless'
+```
+
+
+
+✏️ **Попробуйте!** Запустите приведенный выше фрагмент кода несколько раз, чтобы увидеть, как случайное маскирование происходит на ваших глазах! Также замените метод `tokenizer.decode()` на `tokenizer.convert_ids_to_tokens()`, чтобы увидеть, что токены из данного слова всегда маскируются вместе.
+
+
+
+Теперь, когда у нас есть два колатора данных, остальные шаги по дообучению стандартны. Обучение может занять много времени в Google Colab, если вам не посчастливилось получить мифический GPU P100 😭, поэтому мы сначала уменьшим размер обучающего набора до нескольких тысяч примеров. Не волнуйтесь, мы все равно получим довольно приличную языковую модель! Быстрый способ уменьшить размер датасета в 🤗 Datasets - это функция `Dataset.train_test_split()`, которую мы рассматривали в [Главе 5](../chapter5/1):
+
+```python
+train_size = 10_000
+test_size = int(0.1 * train_size)
+
+downsampled_dataset = lm_datasets["train"].train_test_split(
+ train_size=train_size, test_size=test_size, seed=42
+)
+downsampled_dataset
+```
+
+```python out
+DatasetDict({
+ train: Dataset({
+ features: ['attention_mask', 'input_ids', 'labels', 'word_ids'],
+ num_rows: 10000
+ })
+ test: Dataset({
+ features: ['attention_mask', 'input_ids', 'labels', 'word_ids'],
+ num_rows: 1000
+ })
+})
+```
+
+Это автоматически создаст новые части `train` и `test`, с размером обучающего набора в 10 000 примеров и валидацией в 10 % от этого количества - не стесняйтесь увеличить это значение, если у вас мощный GPU! Следующее, что нам нужно сделать, это авторизоваться на Hugging Face Hub. Если вы выполняете этот код в блокноте, вы можете сделать это с помощью следующей служебной функции:
+
+```python
+from huggingface_hub import notebook_login
+
+notebook_login()
+```
+
+которая отобразит виджет, где вы можете ввести свои учетные данные. В качестве альтернативы можно выполнить команду:
+
+```
+huggingface-cli login
+```
+
+в вашем любимом терминале и авторизуйтесь там.
+
+{#if fw === 'tf'}
+
+После того как мы авторизовались, мы можем создавать наши датасеты `tf.data`. Для этого мы воспользуемся методом `prepare_tf_dataset()`, который использует нашу модель для автоматического инференса того, какие столбцы должны войти в датасет. Если вы хотите контролировать, какие именно столбцы будут использоваться, вы можете использовать метод `Dataset.to_tf_dataset()` вместо этого. Для простоты мы будем использовать стандартный коллатор данных, но вы также можете попробовать коллатор для маскировки слов целиком и сравнить результаты в качестве упражнения:
+
+```python
+tf_train_dataset = model.prepare_tf_dataset(
+ downsampled_dataset["train"],
+ collate_fn=data_collator,
+ shuffle=True,
+ batch_size=32,
+)
+
+tf_eval_dataset = model.prepare_tf_dataset(
+ downsampled_dataset["test"],
+ collate_fn=data_collator,
+ shuffle=False,
+ batch_size=32,
+)
+```
+
+Далее мы задаем гиперпараметры обучения и компилируем нашу модель. Мы используем функцию `create_optimizer()` из библиотеки 🤗 Transformers, которая возвращает нам оптимизатор `AdamW` с линейным затуханием скорости обучения. Мы также используем встроенные потери модели, которые используются по умолчанию, если в качестве аргумента `compile()` не указаны потери, и устанавливаем точность обучения на `"mixed_float16"`. Обратите внимание, что если вы используете Colab GPU или другой GPU, который не имеет поддержки ускорения float16, вам, вероятно, следует закомментировать эту строку.
+
+Кроме того, мы настроили `PushToHubCallback`, который будет сохранять модель в Hub после каждой эпохи. Вы можете указать имя репозитория, в который хотите отправить модель, с помощью аргумента `hub_model_id` (в частности, этот аргумент нужно использовать, чтобы отправить модель в организацию). Например, чтобы отправить модель в организацию [`huggingface-course`](https://huggingface.co/huggingface-course), мы добавили `hub_model_id="huggingface-course/distilbert-finetuned-imdb"`. По умолчанию используемый репозиторий будет находиться в вашем пространстве имен и называться в соответствии с заданным вами выходным каталогом, так что в нашем случае это будет `"lewtun/distilbert-finetuned-imdb"`.
+
+```python
+from transformers import create_optimizer
+from transformers.keras_callbacks import PushToHubCallback
+import tensorflow as tf
+
+num_train_steps = len(tf_train_dataset)
+optimizer, schedule = create_optimizer(
+ init_lr=2e-5,
+ num_warmup_steps=1_000,
+ num_train_steps=num_train_steps,
+ weight_decay_rate=0.01,
+)
+model.compile(optimizer=optimizer)
+
+# Обучение со смешанной точностью float16
+tf.keras.mixed_precision.set_global_policy("mixed_float16")
+
+model_name = model_checkpoint.split("/")[-1]
+callback = PushToHubCallback(
+ output_dir=f"{model_name}-finetuned-imdb", tokenizer=tokenizer
+)
+```
+
+Теперь мы готовы запустить `model.fit()`, но перед этим давайте вкратце рассмотрим _перплексию (perplexity)_, которая является общей метрикой для оценки качества работы языковых моделей.
+
+{:else}
+
+После того как мы авторизовались, мы можем указать аргументы для `Trainer`:
+
+```python
+from transformers import TrainingArguments
+
+batch_size = 64
+# Показываем потери при обучении для каждой эпохи
+logging_steps = len(downsampled_dataset["train"]) // batch_size
+model_name = model_checkpoint.split("/")[-1]
+
+training_args = TrainingArguments(
+ output_dir=f"{model_name}-finetuned-imdb",
+ overwrite_output_dir=True,
+ evaluation_strategy="epoch",
+ learning_rate=2e-5,
+ weight_decay=0.01,
+ per_device_train_batch_size=batch_size,
+ per_device_eval_batch_size=batch_size,
+ push_to_hub=True,
+ fp16=True,
+ logging_steps=logging_steps,
+)
+```
+
+Здесь мы изменили несколько параметров по умолчанию, включая `logging_steps`, чтобы обеспечить отслеживание потерь при обучении в каждой эпохе. Мы также использовали `fp16=True`, чтобы включить обучение со смешанной точностью, что дает нам еще большее улучшение скорости. По умолчанию `Trainer` удаляет все столбцы, которые не являются частью метода `forward()` модели. Это означает, что если вы используете коллатор для маскировки слов целиком, вам также нужно установить `remove_unused_columns=False`, чтобы не потерять колонку `word_ids` во время обучения.
+
+Обратите внимание, что с помощью аргумента `hub_model_id` можно указать имя репозитория, в который вы хотите отправить модель (в частности, этот аргумент нужно использовать, чтобы отправить модель в ырепозиторий организации). Например, когда мы отправили модель в репозиторий организации [`huggingface-course`](https://huggingface.co/huggingface-course), мы добавили `hub_model_id="huggingface-course/distilbert-finetuned-imdb"` в `TrainingArguments`. По умолчанию используемый репозиторий будет находиться в вашем пространстве имен и называться в соответствии с заданной вами выходной директорией, так что в нашем случае это будет `"lewtun/distilbert-finetuned-imdb"`.
+
+Теперь у нас есть все компоненты для создания `Trainer`. Здесь мы просто используем стандартный `data_collator`, но вы можете попробовать коллатор для маскирования слов целиком и сравнить результаты в качестве упражнения:
+
+```python
+from transformers import Trainer
+
+trainer = Trainer(
+ model=model,
+ args=training_args,
+ train_dataset=downsampled_dataset["train"],
+ eval_dataset=downsampled_dataset["test"],
+ data_collator=data_collator,
+ tokenizer=tokenizer,
+)
+```
+
+Теперь мы готовы запустить `trainer.train()`, но перед этим давайте вкратце рассмотрим _перплексию (perplexity), которая является общей метрикой для оценки качества языковых моделей.
+
+{/if}
+
+### Перплексия языковых моделей[[perplexity-for-language-models]]
+
+
+
+В отличие от других задач, таких как классификация текстов или ответов на вопросы, где для обучения нам дается помеченный корпус, при языковом моделировании у нас нет никаких явных меток. Как же определить, какая языковая модель является хорошей? Как и в случае с функцией автокоррекции в вашем телефоне, хорошая языковая модель - это та, которая присваивает высокую вероятность грамматически правильным предложениям и низкую вероятность бессмысленным предложениям. Чтобы лучше представить себе, как это выглядит, вы можете найти в Интернете целые подборки "неудач автокоррекции", где модель в телефоне человека выдает довольно забавные (и часто неуместные) завершения!
+
+{#if fw === 'pt'}
+
+Если предположить, что наш тестовый набор состоит в основном из грамматически правильных предложений, то одним из способов измерения качества нашей языковой модели является подсчет вероятностей, которые она присваивает следующему слову во всех предложениях тестового набора. Высокие вероятности указывают на то, что модель не "удивлена" и не "перплексирована" не виденными ранее примерами, и предполагают, что она усвоила основные грамматические закономерности языка. Существуют различные математические определения перплексии, но то, которое мы будем использовать, определяет ее как экспоненту потери перекрестной энтропии. Таким образом, мы можем вычислить перплексию нашей предварительно обученной модели, используя функцию `Trainer.evaluate()` для вычисления потерь кросс-энтропии на тестовом наборе, а затем взяв экспоненту результата:
+
+```python
+import math
+
+eval_results = trainer.evaluate()
+print(f">>> Perplexity: {math.exp(eval_results['eval_loss']):.2f}")
+```
+
+{:else}
+
+Если предположить, что наш тестовый набор состоит в основном из грамматически правильных предложений, то одним из способов измерения качества нашей языковой модели является подсчет вероятностей, которые она присваивает следующему слову во всех предложениях тестового набора. Высокие вероятности указывают на то, что модель не "удивлена" или не "перплексирована" не виденными ранее примерами, и предполагают, что она выучила основные грамматические закономерности языка. Существуют различные математические определения перплексии, но то, которое мы будем использовать, определяет ее как экспоненту потери перекрестной энтропии. Таким образом, мы можем вычислить перплексию нашей предварительно обученной модели, используя метод `model.evaluate()` для вычисления потери кросс-энтропии на тестовом наборе, а затем взяв экспоненту результата:
+
+```python
+import math
+
+eval_loss = model.evaluate(tf_eval_dataset)
+print(f"Perplexity: {math.exp(eval_loss):.2f}")
+```
+
+{/if}
+
+```python out
+>>> Perplexity: 21.75
+```
+
+Более низкий показатель перплексии означает лучшую языковую модель, и мы видим, что наша начальная модель имеет несколько большое значение. Давайте посмотрим, сможем ли мы снизить его, дообучив модель! Для этого сначала запустим цикл обучения:
+
+{#if fw === 'pt'}
+
+```python
+trainer.train()
+```
+
+{:else}
+
+```python
+model.fit(tf_train_dataset, validation_data=tf_eval_dataset, callbacks=[callback])
+```
+
+{/if}
+
+и затем вычислить результирующую перплексию на тестовом наборе, как и раньше:
+
+{#if fw === 'pt'}
+
+```python
+eval_results = trainer.evaluate()
+print(f">>> Perplexity: {math.exp(eval_results['eval_loss']):.2f}")
+```
+
+{:else}
+
+```python
+eval_loss = model.evaluate(tf_eval_dataset)
+print(f"Perplexity: {math.exp(eval_loss):.2f}")
+```
+
+{/if}
+
+```python out
+>>> Perplexity: 11.32
+```
+
+Неплохо - это довольно значительное уменьшение перплексии, что говорит о том, что модель узнала что-то новое об области рецензий на фильмы!
+
+{#if fw === 'pt'}
+
+После завершения обучения мы можем отправить карточку модели с информацией об обучении в Hub (контрольные точки сохраняются во время самого обучения):
+
+```python
+trainer.push_to_hub()
+```
+
+{/if}
+
+
+
+✏️ **Попробуйте!** Запустите обучение, описанное выше, после замены коллатора данных на коллатор маскирующий все слово. Получили ли вы лучшие результаты?
+
+
+
+{#if fw === 'pt'}
+
+В нашем случае нам не нужно было делать ничего особенного с циклом обучения, но в некоторых случаях вам может понадобиться реализовать некоторую пользовательскую логику. Для таких случаев вы можете использовать 🤗 Accelerate - давайте посмотрим!
+
+## Дообучение DistilBERT с помощью 🤗 Accelerate[[fine-tuning-distilbert-with-accelerate]]
+
+Как мы видели на примере `Trainer`, дообучение модели маскированного языкового моделирования очень похоже на пример классификации текста из [Главы 3](../chapter3/1). Фактически, единственной особенностью является использование специального коллатора данных, о котором мы уже рассказывали ранее в этом разделе!
+
+Однако мы видели, что `DataCollatorForLanguageModeling` также применяет случайное маскирование при каждой оценке, поэтому мы увидим некоторые колебания в наших оценках перплексии при каждом цикле обучения. Один из способов устранить этот источник случайности - применить маскирование _один раз_ ко всему тестовому набору, а затем использовать стандартный коллатор данных в 🤗 Transformers для сбора батчей во время оценки. Чтобы увидеть, как это работает, давайте реализуем простую функцию, которая применяет маскирование к батчу, подобно нашей первой работе с `DataCollatorForLanguageModeling`:
+
+```python
+def insert_random_mask(batch):
+ features = [dict(zip(batch, t)) for t in zip(*batch.values())]
+ masked_inputs = data_collator(features)
+ # Создаем новый "маскированный" столбец для каждого столбца в датасете
+ return {"masked_" + k: v.numpy() for k, v in masked_inputs.items()}
+```
+
+Далее мы применим эту функцию к нашему тестовому набору и удалим столбцы без маскирования, чтобы заменить их столбцами с маскированием. Вы можете использовать маскирование целых слов, заменив `data_collator` выше на соответствующий, в этом случае вам следует удалить первую строку здесь:
+
+```py
+downsampled_dataset = downsampled_dataset.remove_columns(["word_ids"])
+eval_dataset = downsampled_dataset["test"].map(
+ insert_random_mask,
+ batched=True,
+ remove_columns=downsampled_dataset["test"].column_names,
+)
+eval_dataset = eval_dataset.rename_columns(
+ {
+ "masked_input_ids": "input_ids",
+ "masked_attention_mask": "attention_mask",
+ "masked_labels": "labels",
+ }
+)
+```
+
+Затем мы можем настроить загрузчики данных как обычно, но для оценочного набора мы будем использовать `default_data_collator` из 🤗 Transformers:
+
+```python
+from torch.utils.data import DataLoader
+from transformers import default_data_collator
+
+batch_size = 64
+train_dataloader = DataLoader(
+ downsampled_dataset["train"],
+ shuffle=True,
+ batch_size=batch_size,
+ collate_fn=data_collator,
+)
+eval_dataloader = DataLoader(
+ eval_dataset, batch_size=batch_size, collate_fn=default_data_collator
+)
+```
+
+Здесь мы следуем стандартным шагам 🤗 Accelerate. Первым делом загружаем свежую версию предварительно обученной модели:
+
+```
+model = AutoModelForMaskedLM.from_pretrained(model_checkpoint)
+```
+
+Затем нужно указать оптимизатор; мы будем использовать стандартный `AdamW`:
+
+```python
+from torch.optim import AdamW
+
+optimizer = AdamW(model.parameters(), lr=5e-5)
+```
+
+Теперь, имея эти объекты, мы можем подготовить все для обучения с помощью объекта `Accelerator`:
+
+```python
+from accelerate import Accelerator
+
+accelerator = Accelerator()
+model, optimizer, train_dataloader, eval_dataloader = accelerator.prepare(
+ model, optimizer, train_dataloader, eval_dataloader
+)
+```
+
+Теперь, когда наша модель, оптимизатор и загрузчики данных настроены, мы можем задать планировщик скорости обучения следующим образом:
+
+```python
+from transformers import get_scheduler
+
+num_train_epochs = 3
+num_update_steps_per_epoch = len(train_dataloader)
+num_training_steps = num_train_epochs * num_update_steps_per_epoch
+
+lr_scheduler = get_scheduler(
+ "linear",
+ optimizer=optimizer,
+ num_warmup_steps=0,
+ num_training_steps=num_training_steps,
+)
+```
+
+Осталось сделать еще одну последнюю вещь перед обучением: создать репозиторий модели на Hugging Face Hub! Мы можем использовать библиотеку 🤗 Hub, чтобы сначала сгенерировать полное имя нашего репозитория:
+
+```python
+from huggingface_hub import get_full_repo_name
+
+model_name = "distilbert-base-uncased-finetuned-imdb-accelerate"
+repo_name = get_full_repo_name(model_name)
+repo_name
+```
+
+```python out
+'lewtun/distilbert-base-uncased-finetuned-imdb-accelerate'
+```
+
+затем создадим и клонируем репозиторий, используя класс `Repository` из 🤗 Hub:
+
+```python
+from huggingface_hub import Repository
+
+output_dir = model_name
+repo = Repository(output_dir, clone_from=repo_name)
+```
+
+После этого остается только написать полный цикл обучения и оценки:
+
+```python
+from tqdm.auto import tqdm
+import torch
+import math
+
+progress_bar = tqdm(range(num_training_steps))
+
+for epoch in range(num_train_epochs):
+ # Обучение
+ model.train()
+ for batch in train_dataloader:
+ outputs = model(**batch)
+ loss = outputs.loss
+ accelerator.backward(loss)
+
+ optimizer.step()
+ lr_scheduler.step()
+ optimizer.zero_grad()
+ progress_bar.update(1)
+
+ # Оценка
+ model.eval()
+ losses = []
+ for step, batch in enumerate(eval_dataloader):
+ with torch.no_grad():
+ outputs = model(**batch)
+
+ loss = outputs.loss
+ losses.append(accelerator.gather(loss.repeat(batch_size)))
+
+ losses = torch.cat(losses)
+ losses = losses[: len(eval_dataset)]
+ try:
+ perplexity = math.exp(torch.mean(losses))
+ except OverflowError:
+ perplexity = float("inf")
+
+ print(f">>> Epoch {epoch}: Perplexity: {perplexity}")
+
+ # Сохранение и загрузка
+ accelerator.wait_for_everyone()
+ unwrapped_model = accelerator.unwrap_model(model)
+ unwrapped_model.save_pretrained(output_dir, save_function=accelerator.save)
+ if accelerator.is_main_process:
+ tokenizer.save_pretrained(output_dir)
+ repo.push_to_hub(
+ commit_message=f"Training in progress epoch {epoch}", blocking=False
+ )
+```
+
+```python out
+>>> Epoch 0: Perplexity: 11.397545307900472
+>>> Epoch 1: Perplexity: 10.904909330983092
+>>> Epoch 2: Perplexity: 10.729503505340409
+```
+
+Круто, мы смогли оценить перплексию для каждой эпохи и обеспечить воспроизводимость нескольких циклов обучения!
+
+{/if}
+
+## Использование нашей дообученной модели[[using-our-fine-tuned-model]]
+
+Вы можете взаимодействовать с дообученной моделью либо с помощью ее виджета на Hub, либо локально с помощью `pipeline` из 🤗 Transformers. Давайте воспользуемся последним вариантом, чтобы загрузить нашу модель с помощью конвейера `fill-mask`:
+
+```python
+from transformers import pipeline
+
+mask_filler = pipeline(
+ "fill-mask", model="huggingface-course/distilbert-base-uncased-finetuned-imdb"
+)
+```
+
+Затем мы можем передать конвейеру наш пример текста " This is a great [MASK]" и посмотреть, каковы 5 лучших прогнозов:
+
+```python
+preds = mask_filler(text)
+
+for pred in preds:
+ print(f">>> {pred['sequence']}")
+```
+
+```python out
+'>>> this is a great movie.'
+'>>> this is a great film.'
+'>>> this is a great story.'
+'>>> this is a great movies.'
+'>>> this is a great character.'
+```
+
+Отлично - наша модель явно адаптировала свои веса, чтобы прогнозировать слова, которые сильнее ассоциируются с фильмами!
+
+
+
+На этом мы завершаем наш первый эксперимент по обучению языковой модели. В [разделе 6](../chapter7/6) вы узнаете, как обучить авторегрессионную модель типа GPT-2 с нуля; загляните туда, если хотите посмотреть, как можно предварительно обучить свою собственную модель трансформера!
+
+
+
+✏️ **Попробуйте!** Чтобы оценить преимущества адаптации к домену, дообучите классификатор на метках IMDb как для предварительно обученных, так и для дообученных контрольных точек DistilBERT. Если вам нужно освежить в памяти классификацию текстов, ознакомьтесь с [Главой 3](../chapter3/1).
+
+
diff --git a/chapters/ru/chapter7/4.mdx b/chapters/ru/chapter7/4.mdx
new file mode 100644
index 000000000..53d1155ef
--- /dev/null
+++ b/chapters/ru/chapter7/4.mdx
@@ -0,0 +1,1002 @@
+
+
+# Перевод[[translation]]
+
+{#if fw === 'pt'}
+
+
+
+{:else}
+
+
+
+{/if}
+
+Теперь давайте погрузимся в перевод. Это еще одна [задача преобразования последовательности в последовательность (sequence-to-sequence)](../chapter1/7), что означает, что это проблема, которую можно сформулировать как переход от одной последовательности к другой. В этом смысле задача очень близка к [резюмированию (summarization)](../chapter7/6), и вы можете приспособить то, что мы здесь рассмотрим, к другим задачам преобразования последовательности в последовательность, таким как:
+
+- **Перенос стиля (Style transfer)**: Создание модели, которая *переводит* тексты, написанные в определенном стиле, в другой (например, из формального в повседневный или из шекспировского английского в современный).
+- **Генеративные ответы на вопросы (Generative question answering)**: Создание модели, которая генерирует ответы на вопросы, учитывая контекст
+
+
+
+Если у вас есть достаточно большой корпус текстов на двух (или более) языках, вы можете обучить новую модель перевода с нуля, как мы это сделаем в разделе по [казуальному языковому моделированию (causal language modeling)](../chapter7/6). Однако быстрее будет дообучить существующую модель перевода, будь то многоязычная модель типа mT5 или mBART, которую нужно дообучить для конкретной пары языков, или даже модель, специализированная для перевода с одного языка на другой, которую нужно дообучить для конкретного корпуса.
+
+В этом разделе мы дообучим модель Marian, предварительно обученную переводу с английского на французский (поскольку многие сотрудники Hugging Face говорят на обоих этих языках), на датасете [KDE4](https://huggingface.co/datasets/kde4), который представляет собой набор локализованных файлов для приложений [KDE](https://apps.kde.org/). Модель, которую мы будем использовать, была предварительно обучена на большом корпусе французских и английских текстов, взятых из [Opus dataset](https://opus.nlpl.eu/), который фактически содержит датасет KDE4. Но даже если модель, которую мы используем, видела эти данные во время предварительного обучения, мы увидим, что после дообучения мы сможем получить ее лучшую версию.
+
+Когда мы закончим, у нас будет модель, способная делать прогнозы, подобные этому:
+
+
+
+
+ +
+ +
+
+
+Как и в предыдущих разделах, вы можете найти актуальную модель, которую мы обучим и загрузим на Hub, используя приведенный ниже код, и перепроверить ее предсказания [здесь](https://huggingface.co/huggingface-course/marian-finetuned-kde4-en-to-fr?text=This+plugin+allows+you+to+automatically+translate+web+pages+between+several+languages.).
+
+## Подготовка данных[[preparing-the-data]]
+
+Чтобы дообучить или обучить модель перевода с нуля, нам понадобится датасет, подходящий для этой задачи. Как уже упоминалось, мы будем использовать [датасет KDE4](https://huggingface.co/datasets/kde4) , но вы можете легко адаптировать код для использования своих собственных данных, если у вас есть пары предложений на двух языках, с которых вы хотите переводить и на которые хотите переводить. Обратитесь к [Главе 5](../chapter5/1) если вам нужно вспомнить, как загружать пользовательские данные в `Dataset`.
+
+### Датасет KDE4[[the-kde4-dataset]]
+
+Как обычно, мы загружаем наш датасет с помощью функции `load_dataset()`:
+
+```py
+from datasets import load_dataset
+
+raw_datasets = load_dataset("kde4", lang1="en", lang2="fr")
+```
+
+Если вы хотите работать с другой парой языков, вы можете указать их по кодам. Всего для этого датасета доступно 92 языка; вы можете увидеть их все, развернув языковые теги в его [карточке датасета](https://huggingface.co/datasets/kde4).
+
+

+
+Давайте посмотрим на датасет:
+
+```py
+raw_datasets
+```
+
+```python out
+DatasetDict({
+ train: Dataset({
+ features: ['id', 'translation'],
+ num_rows: 210173
+ })
+})
+```
+
+У нас есть 210 173 пары предложений, но в одной части, поэтому нам нужно создать собственный проверочный набор. Как мы видели в [Главе 5](../chapter5/1), у `Dataset` есть метод `train_test_split()`, который может нам помочь. Мы зададим seed для воспроизводимости:
+
+```py
+split_datasets = raw_datasets["train"].train_test_split(train_size=0.9, seed=20)
+split_datasets
+```
+
+```python out
+DatasetDict({
+ train: Dataset({
+ features: ['id', 'translation'],
+ num_rows: 189155
+ })
+ test: Dataset({
+ features: ['id', 'translation'],
+ num_rows: 21018
+ })
+})
+```
+
+Мы можем переименовать ключ `"test"` в `"validation"` следующим образом:
+
+```py
+split_datasets["validation"] = split_datasets.pop("test")
+```
+
+Теперь давайте рассмотрим один элемент датасета:
+
+```py
+split_datasets["train"][1]["translation"]
+```
+
+```python out
+{'en': 'Default to expanded threads',
+ 'fr': 'Par défaut, développer les fils de discussion'}
+```
+
+Мы получаем словарь с двумя предложениями на запрошенной паре языков. Одна из особенностей этого датасета, наполненного техническими терминами в области компьютерных наук, заключается в том, что все они полностью переведены на французский язык. Однако французские инженеры при разговоре оставляют большинство специфических для компьютерных наук слов на английском. Например, слово "threads" вполне может встретиться во французском предложении, особенно в техническом разговоре; но в данном датасете оно переведено как более правильное "fils de discussion". Используемая нами модель, предварительно обученная на большем корпусе французских и английских предложений, выбирает более простой вариант - оставить слово как есть:
+
+```py
+from transformers import pipeline
+
+model_checkpoint = "Helsinki-NLP/opus-mt-en-fr"
+translator = pipeline("translation", model=model_checkpoint)
+translator("Default to expanded threads")
+```
+
+```python out
+[{'translation_text': 'Par défaut pour les threads élargis'}]
+```
+
+Другой пример такого поведения можно увидеть на примере слова "plugin", которое официально не является французским словом, но большинство носителей языка поймут его и не станут переводить.
+В датасете KDE4 это слово было переведено на французский как более официальное "module d'extension":
+
+```py
+split_datasets["train"][172]["translation"]
+```
+
+```python out
+{'en': 'Unable to import %1 using the OFX importer plugin. This file is not the correct format.',
+ 'fr': "Impossible d'importer %1 en utilisant le module d'extension d'importation OFX. Ce fichier n'a pas un format correct."}
+```
+
+Однако наша предварительно обученная модель придерживается компактного и знакомого английского слова:
+
+```py
+translator(
+ "Unable to import %1 using the OFX importer plugin. This file is not the correct format."
+)
+```
+
+```python out
+[{'translation_text': "Impossible d'importer %1 en utilisant le plugin d'importateur OFX. Ce fichier n'est pas le bon format."}]
+```
+
+Будет интересно посмотреть, сможет ли наша дообученная модель уловить эти особенности датасета (спойлер: сможет).
+
+
+
+
+
+✏️ **Попробуйте!** Еще одно английское слово, которое часто используется во французском языке, - "email". Найдите в обучающем датасете первый образец, в котором используется это слово. Как оно переводится? Как предварительно обученная модель переводит то же английское предложение?
+
+
+
+### Предварительная обработка данных[[processing-the-data]]
+
+
+
+Вы уже должны знать, как это делается: все тексты нужно преобразовать в наборы идентификаторов токенов, чтобы модель могла понять их смысл. Для этой задачи нам понадобится токенизация как входных данных, так и целевых. Наша первая задача - создать объект `tokenizer`. Как отмечалось ранее, мы будем использовать предварительно обученную модель Marian English to French. Если вы будете пробовать этот код с другой парой языков, обязательно адаптируйте контрольную точку модели. Организация [Helsinki-NLP](https://huggingface.co/Helsinki-NLP) предоставляет более тысячи моделей на разных языках.
+
+```python
+from transformers import AutoTokenizer
+
+model_checkpoint = "Helsinki-NLP/opus-mt-en-fr"
+tokenizer = AutoTokenizer.from_pretrained(model_checkpoint, return_tensors="pt")
+```
+
+Вы также можете заменить `model_checkpoint` на любую другую модель из [Hub](https://huggingface.co/models) или локальной папки, в которой вы сохранили предварительно обученную модель и токенизатор.
+
+
+
+💡 Если вы используете многоязыковой токенизатор, такой как mBART, mBART-50 или M2M100, вам нужно задать языковые коды ваших входных и целевых данных в токенизаторе, задав правильные значения параметрам `tokenizer.src_lang` и `tokenizer.tgt_lang`.
+
+
+
+Подготовка наших данных довольно проста. Нужно помнить только об одном: необходимо убедиться, что токенизатор обрабатывает целевые значения на выходном языке (здесь - французском). Вы можете сделать это, передав целевые данные в аргумент `text_targets` метода `__call__` токенизатора.
+
+Чтобы увидеть, как это работает, давайте обработаем по одному примеру каждого языка из обучающего набора:
+
+```python
+en_sentence = split_datasets["train"][1]["translation"]["en"]
+fr_sentence = split_datasets["train"][1]["translation"]["fr"]
+
+inputs = tokenizer(en_sentence, text_target=fr_sentence)
+inputs
+```
+
+```python out
+{'input_ids': [47591, 12, 9842, 19634, 9, 0], 'attention_mask': [1, 1, 1, 1, 1, 1], 'labels': [577, 5891, 2, 3184, 16, 2542, 5, 1710, 0]}
+```
+
+Как мы видим, в выходных данных содержатся входные идентификаторы, связанные с английским предложением, а идентификаторы, связанные с французским, хранятся в поле `labels`. Если вы забудете указать, что выполняете токенизацию меток, они будут токенизированы входным токенизатором, что в случае с моделью Marian не приведет ни к чему хорошему:
+
+```python
+wrong_targets = tokenizer(fr_sentence)
+print(tokenizer.convert_ids_to_tokens(wrong_targets["input_ids"]))
+print(tokenizer.convert_ids_to_tokens(inputs["labels"]))
+```
+
+```python out
+['▁Par', '▁dé', 'f', 'aut', ',', '▁dé', 've', 'lop', 'per', '▁les', '▁fil', 's', '▁de', '▁discussion', '']
+['▁Par', '▁défaut', ',', '▁développer', '▁les', '▁fils', '▁de', '▁discussion', '']
+```
+
+Как мы видим, при использовании английского токенизатора для предварительной обработки французского предложения получается гораздо больше токенов, поскольку токенизатор не знает ни одного французского слова (кроме тех, которые также встречаются в английском языке, например "discussion").
+
+Поскольку `inputs` - это словарь с нашими обычными ключами (идентификаторы входных данных, маска внимания и т. д.), последним шагом будет определение функции предварительной обработки, которую мы будем применять к датасетам:
+
+```python
+max_length = 128
+
+
+def preprocess_function(examples):
+ inputs = [ex["en"] for ex in examples["translation"]]
+ targets = [ex["fr"] for ex in examples["translation"]]
+ model_inputs = tokenizer(
+ inputs, text_target=targets, max_length=max_length, truncation=True
+ )
+ return model_inputs
+```
+
+Обратите внимание, что мы установили одинаковую максимальную длину для наших входов и выходов. Поскольку тексты, с которыми мы имеем дело, довольно короткие, мы используем 128.
+
+
+
+💡 Если вы используете модель T5 (точнее, одну из контрольных точек `t5-xxx`), модель будет ожидать, что текстовые данные будут иметь префикс, указывающий на поставленную задачу, например `translate: English to French:`.
+
+
+
+
+
+⚠️ Мы не обращаем внимания на маску внимания целевых значений, так как модель не будет этого ожидать. Вместо этого метки, соответствующие токенам дополнения, должны быть заданы как `-100`, чтобы они игнорировались при вычислении потерь. Это будет сделано нашим коллатором данных позже, так как мы применяем динамическое дополнение (dynamic padding), но если вы используете дополнение (padding) здесь, вы должны адаптировать функцию предварительной обработки данных, чтобы установить все метки, соответствующие токену дополнения, в `-100`.
+
+
+
+Теперь мы можем применить эту функцию предварительной обработки ко всем частям нашего датасета за один раз:
+
+```py
+tokenized_datasets = split_datasets.map(
+ preprocess_function,
+ batched=True,
+ remove_columns=split_datasets["train"].column_names,
+)
+```
+
+Теперь, когда данные прошли предварительную обработку, мы готовы дообучить нашу предварительно обученную модель!
+
+{#if fw === 'pt'}
+
+## Дообучение модели с помощью API `Trainer`[[fine-tuning-the-model-with-the-trainer-api]]
+
+Фактический код, использующий `Trainer`, будет таким же, как и раньше, с одним лишь небольшим изменением: мы используем [`Seq2SeqTrainer`](https://huggingface.co/transformers/main_classes/trainer.html#seq2seqtrainer), который является подклассом `Trainer`, что позволит нам правильно работать с оценкой, используя метод `generate()` для предсказания выходов на основе входов. Мы рассмотрим это более подробно, когда будем говорить о вычислении метрик.
+
+Прежде всего, нам нужна реальная модель, которую нужно дообучить. Мы воспользуемся обычным API `AutoModel`:
+
+```py
+from transformers import AutoModelForSeq2SeqLM
+
+model = AutoModelForSeq2SeqLM.from_pretrained(model_checkpoint)
+```
+
+{:else}
+
+## Дообучение модели с Keras[[fine-tuning-the-model-with-keras]]
+
+Прежде всего, нам нужна актуальная модель, которую нужно дообучить. Мы воспользуемся обычным API `AutoModel`:
+
+```py
+from transformers import TFAutoModelForSeq2SeqLM
+
+model = TFAutoModelForSeq2SeqLM.from_pretrained(model_checkpoint, from_pt=True)
+```
+
+
+
+💡 Контрольная точка `Helsinki-NLP/opus-mt-en-fr` имеет только веса PyTorch, поэтому
+вы получите ошибку, если попытаетесь загрузить модель без использования аргумента
+`from_pt=True` в методе `from_pretrained()`. Когда вы указываете
+`from_pt=True`, библиотека автоматически загрузит и преобразует
+веса из PyTorch для вас. Как видите, очень просто переключаться между
+фреймворками в 🤗 Transformers!
+
+
+
+{/if}
+
+Обратите внимание, что в этот раз мы используем модель, которая была обучена на задаче перевода и фактически уже может быть использована, поэтому нет предупреждения о пропущенных или новых инициализированных весах.
+
+### Сопоставление данных[[data-collation]]
+
+Для динамического батча нам понадобится коллатор данных для работы с дополнением (padding). Мы не можем просто использовать `DataCollatorWithPadding`, как в [Главе 3](../chapter3/1), потому что в этом случае будут заполнены только входы (идентификаторы входов, маска внимания и идентификаторы типов токенов). Наши метки также должны быть дополнены до максимальной длины, встречающейся в метках. И, как уже говорилось, добовляемое значение, используемое для дополнения меток, должно быть `-100`, а не добавочный токен токенизатора, чтобы эти добавочные значения игнорировались при вычислении потерь.
+
+Все это делает [`DataCollatorForSeq2Seq`](https://huggingface.co/transformers/main_classes/data_collator.html#datacollatorforseq2seq). Как и `DataCollatorWithPadding`, он принимает `tokenizer`, используемый для препроцессирования входных данных, а также `model`. Это связано с тем, что данный коллатор данных также будет отвечать за подготовку входных идентификаторов декодера, которые представляют собой сдвинутые версии меток со специальным токеном в начале. Поскольку для разных архитектур этот сдвиг выполняется по-разному, `DataCollatorForSeq2Seq` должен знать объект `model`:
+
+{#if fw === 'pt'}
+
+```py
+from transformers import DataCollatorForSeq2Seq
+
+data_collator = DataCollatorForSeq2Seq(tokenizer, model=model)
+```
+
+{:else}
+
+```py
+from transformers import DataCollatorForSeq2Seq
+
+data_collator = DataCollatorForSeq2Seq(tokenizer, model=model, return_tensors="tf")
+```
+
+{/if}
+
+Чтобы протестировать его на нескольких примерах, мы просто вызываем его на списке примеров из нашего токинезированного обучающего набора:
+
+```py
+batch = data_collator([tokenized_datasets["train"][i] for i in range(1, 3)])
+batch.keys()
+```
+
+```python out
+dict_keys(['attention_mask', 'input_ids', 'labels', 'decoder_input_ids'])
+```
+
+Мы можем проверить, что наши метки были дополнены до максимальной длины батча, с использованием `-100`:
+
+```py
+batch["labels"]
+```
+
+```python out
+tensor([[ 577, 5891, 2, 3184, 16, 2542, 5, 1710, 0, -100,
+ -100, -100, -100, -100, -100, -100],
+ [ 1211, 3, 49, 9409, 1211, 3, 29140, 817, 3124, 817,
+ 550, 7032, 5821, 7907, 12649, 0]])
+```
+
+Также мы можем взглянуть на идентификаторы входов декодера и убедиться, что они являются сдвинутыми версиями меток:
+
+```py
+batch["decoder_input_ids"]
+```
+
+```python out
+tensor([[59513, 577, 5891, 2, 3184, 16, 2542, 5, 1710, 0,
+ 59513, 59513, 59513, 59513, 59513, 59513],
+ [59513, 1211, 3, 49, 9409, 1211, 3, 29140, 817, 3124,
+ 817, 550, 7032, 5821, 7907, 12649]])
+```
+
+Вот метки для первого и второго элементов в нашем датасете:
+
+```py
+for i in range(1, 3):
+ print(tokenized_datasets["train"][i]["labels"])
+```
+
+```python out
+[577, 5891, 2, 3184, 16, 2542, 5, 1710, 0]
+[1211, 3, 49, 9409, 1211, 3, 29140, 817, 3124, 817, 550, 7032, 5821, 7907, 12649, 0]
+```
+
+{#if fw === 'pt'}
+
+Мы передадим этот `data_collator` в `Seq2SeqTrainer`. Далее давайте рассмотрим метрику.
+
+{:else}
+
+Теперь мы можем использовать этот `data_collator` для преобразования каждого из наших датасетов в `tf.data.Dataset`, готовый к обучению:
+
+```python
+tf_train_dataset = model.prepare_tf_dataset(
+ tokenized_datasets["train"],
+ collate_fn=data_collator,
+ shuffle=True,
+ batch_size=32,
+)
+tf_eval_dataset = model.prepare_tf_dataset(
+ tokenized_datasets["validation"],
+ collate_fn=data_collator,
+ shuffle=False,
+ batch_size=16,
+)
+```
+
+{/if}
+
+
+### Метрики[[metrics]]
+
+
+
+{#if fw === 'pt'}
+
+Свойство, которое `Seq2SeqTrainer` добавляет к своему суперклассу `Trainer`, - это возможность использовать метод `generate()` во время оценки или предсказания. Во время обучения модель будет использовать `decoder_input_ids` с маской внимания, гарантирующей, что она не будет использовать токены после токена, который пытается предсказать, чтобы ускорить обучение. Во время инференса мы не сможем использовать эти данные, так как у нас не будет меток, поэтому было бы неплохо оценить нашу модель с аналогичной настройкой.
+
+Как мы видели в [Главе 1](../chapter1/6), декодер выполняет инференс, предсказывая токены один за другим - то, что за кулисами реализовано в 🤗 Transformers методом `generate()`. Тренер `Seq2SeqTrainer` позволит нам использовать этот метод для оценки, если мы установим `predict_with_generate=True`.
+
+{/if}
+
+Традиционной метрикой, используемой для перевода, является [BLEU score](https://en.wikipedia.org/wiki/BLEU), представленная в [статье 2002 года](https://aclanthology.org/P02-1040.pdf) Кишором Папинени и др. BLEU score оценивает, насколько близки переводы к своим меткам. Он не измеряет разборчивость или грамматическую правильность сгенерированных моделью результатов, но использует статистические правила, чтобы гарантировать, что все слова в сгенерированных результатах также встречаются в целевых. Кроме того, существуют правила, наказывающие повторы одних и тех же слов, если они не повторяются в целевых словах (чтобы модель не выводила предложения типа `"the the the the the the the"), и вывод предложений, которые короче, чем целевые (чтобы модель не выводила предложения типа `"the"`).
+
+Один из недостатков BLEU заключается в том, что она предполагает, что текст уже прошел токенизацию, что затрудняет сравнение оценок между моделями, использующими различные токенизаторы. Поэтому сегодня для сравнения моделей перевода чаще всего используется метрика [SacreBLEU](https://github.com/mjpost/sacrebleu), которая устраняет этот недостаток (и другие) путем стандартизации этапа токенизации. Чтобы использовать эту метрику, сначала нужно установить библиотеку SacreBLEU:
+
+```py
+!pip install sacrebleu
+```
+
+Затем мы можем загрузить ее с помощью `evaluate.load()`, как мы это делали в [Главе 3](../chapter3/1):
+
+```py
+import evaluate
+
+metric = evaluate.load("sacrebleu")
+```
+
+Эта метрика принимает тексты в качестве входных и целевых данных. Она рассчитана на использование нескольких приемлемых целей, так как часто существует несколько приемлемых переводов одного и того же предложения - в используемом нами датасете есть только один, но в NLP нередко встречаются датасеты, дающие несколько предложений в качестве меток. Таким образом, прогнозы должны представлять собой список предложений, а ссылки - список списков предложений.
+
+Попробуем рассмотреть пример:
+
+```py
+predictions = [
+ "This plugin lets you translate web pages between several languages automatically."
+]
+references = [
+ [
+ "This plugin allows you to automatically translate web pages between several languages."
+ ]
+]
+metric.compute(predictions=predictions, references=references)
+```
+
+```python out
+{'score': 46.750469682990165,
+ 'counts': [11, 6, 4, 3],
+ 'totals': [12, 11, 10, 9],
+ 'precisions': [91.67, 54.54, 40.0, 33.33],
+ 'bp': 0.9200444146293233,
+ 'sys_len': 12,
+ 'ref_len': 13}
+```
+
+Это дает оценку BLEU 46,75, что довольно хорошо - для сравнения, оригинальная модель Transformer в статье ["Attention Is All You Need" paper](https://arxiv.org/pdf/1706.03762.pdf) достигла оценки BLEU 41,8 на аналогичной задаче перевода с английского на французский! (Более подробную информацию об отдельных метриках, таких как `counts` и `bp`, можно найти в репозитории [SacreBLEU](https://github.com/mjpost/sacrebleu/blob/078c440168c6adc89ba75fe6d63f0d922d42bcfe/sacrebleu/metrics/bleu.py#L74)). С другой стороны, если мы попробуем использовать два плохих типа предсказаний (много повторов или слишком короткие), которые часто получаются в моделях перевода, мы получим довольно плохие оценки BLEU:
+
+```py
+predictions = ["This This This This"]
+references = [
+ [
+ "This plugin allows you to automatically translate web pages between several languages."
+ ]
+]
+metric.compute(predictions=predictions, references=references)
+```
+
+```python out
+{'score': 1.683602693167689,
+ 'counts': [1, 0, 0, 0],
+ 'totals': [4, 3, 2, 1],
+ 'precisions': [25.0, 16.67, 12.5, 12.5],
+ 'bp': 0.10539922456186433,
+ 'sys_len': 4,
+ 'ref_len': 13}
+```
+
+```py
+predictions = ["This plugin"]
+references = [
+ [
+ "This plugin allows you to automatically translate web pages between several languages."
+ ]
+]
+metric.compute(predictions=predictions, references=references)
+```
+
+```python out
+{'score': 0.0,
+ 'counts': [2, 1, 0, 0],
+ 'totals': [2, 1, 0, 0],
+ 'precisions': [100.0, 100.0, 0.0, 0.0],
+ 'bp': 0.004086771438464067,
+ 'sys_len': 2,
+ 'ref_len': 13}
+```
+
+Оценка может варьироваться от 0 до 100, причем чем больше, тем лучше.
+
+{#if fw === 'tf'}
+
+Чтобы получить из результатов модели тексты, которые может использовать метрика, мы воспользуемся методом `tokenizer.batch_decode()`. Нам нужно только очистить все знаки `-100` в метках; токенизатор автоматически сделает то же самое для дополняющего токена. Определим функцию, которая берет нашу модель и датасет и вычисляет на нем метрики. Мы также используем трюк, который значительно повышает производительность, - компиляцию нашего кода генерации с помощью [XLA](https://www.tensorflow.org/xla), ускоренного компилятора линейной алгебры TensorFlow. XLA применяет различные оптимизации к графу вычислений модели, что приводит к значительному увеличению скорости и использования памяти. Как описано в блоге Hugging Face [blog](https://huggingface.co/blog/tf-xla-generate), XLA лучше всего работает, когда наши входные формы не слишком сильно варьируются. Чтобы справиться с этим, мы разделим наши входные данные на части, кратные 128, и создадим новый датасет с коллатором с дополнением, а затем применим декоратор `@tf.function(jit_compile=True)` к нашей функции генерации, который обозначит всю функцию для компиляции с помощью XLA.
+
+```py
+import numpy as np
+import tensorflow as tf
+from tqdm import tqdm
+
+generation_data_collator = DataCollatorForSeq2Seq(
+ tokenizer, model=model, return_tensors="tf", pad_to_multiple_of=128
+)
+
+tf_generate_dataset = model.prepare_tf_dataset(
+ tokenized_datasets["validation"],
+ collate_fn=generation_data_collator,
+ shuffle=False,
+ batch_size=8,
+)
+
+
+@tf.function(jit_compile=True)
+def generate_with_xla(batch):
+ return model.generate(
+ input_ids=batch["input_ids"],
+ attention_mask=batch["attention_mask"],
+ max_new_tokens=128,
+ )
+
+
+def compute_metrics():
+ all_preds = []
+ all_labels = []
+
+ for batch, labels in tqdm(tf_generate_dataset):
+ predictions = generate_with_xla(batch)
+ decoded_preds = tokenizer.batch_decode(predictions, skip_special_tokens=True)
+ labels = labels.numpy()
+ labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
+ decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
+ decoded_preds = [pred.strip() for pred in decoded_preds]
+ decoded_labels = [[label.strip()] for label in decoded_labels]
+ all_preds.extend(decoded_preds)
+ all_labels.extend(decoded_labels)
+
+ result = metric.compute(predictions=all_preds, references=all_labels)
+ return {"bleu": result["score"]}
+```
+
+{:else}
+
+Чтобы получить из результатов модели тексты, которые может использовать метрика, мы воспользуемся методом `tokenizer.batch_decode()`. Нам просто нужно очистить все значения `-100` в метках (токенизатор автоматически сделает то же самое для дополняющего токена):
+
+```py
+import numpy as np
+
+
+def compute_metrics(eval_preds):
+ preds, labels = eval_preds
+ # В случае, если модель возвращает больше, чем предсказанные логиты
+ if isinstance(preds, tuple):
+ preds = preds[0]
+
+ decoded_preds = tokenizer.batch_decode(preds, skip_special_tokens=True)
+
+ # Заменяем -100 в метках, так как мы не можем их декодировать
+ labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
+ decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
+
+ # Немного простой постобработки
+ decoded_preds = [pred.strip() for pred in decoded_preds]
+ decoded_labels = [[label.strip()] for label in decoded_labels]
+
+ result = metric.compute(predictions=decoded_preds, references=decoded_labels)
+ return {"bleu": result["score"]}
+```
+
+{/if}
+
+Теперь, когда все готово, мы готовы дообучить нашу модель!
+
+
+### Дообучение модели[[fine-tuning-the-model]]
+
+Первый шаг - войти в Hugging Face, чтобы загрузить результаты в Model Hub. В блокноте есть удобная функция, которая поможет вам в этом:
+
+```python
+from huggingface_hub import notebook_login
+
+notebook_login()
+```
+
+Появится виджет, в котором вы можете ввести свои учетные данные для входа в Hugging Face.
+
+Если вы работаете не в блокноте, просто введите следующую строку в терминале:
+
+```bash
+huggingface-cli login
+```
+
+{#if fw === 'tf'}
+
+Прежде чем начать, давайте посмотрим, какие результаты мы получим от нашей модели без какого-либо обучения:
+
+```py
+print(compute_metrics())
+```
+
+```
+{'bleu': 33.26983701454733}
+```
+
+Как только это будет сделано, мы сможем подготовить все необходимое для компиляции и обучения нашей модели. Обратите внимание на использование `tf.keras.mixed_precision.set_global_policy("mixed_float16")` - это укажет Keras обучать с использованием float16, что может дать значительное ускорение на GPU, поддерживающих эту функцию (Nvidia 20xx/V100 или новее).
+
+```python
+from transformers import create_optimizer
+from transformers.keras_callbacks import PushToHubCallback
+import tensorflow as tf
+
+# Количество шагов обучения - это количество примеров в датасете, разделенное на размер батча, затем умноженное
+# на общее количество эпох. Обратите внимание, что tf_train_dataset здесь - это батч tf.data.Dataset,
+# а не оригинальный датасет Hugging Face, поэтому его len() уже равен num_samples // batch_size.
+num_epochs = 3
+num_train_steps = len(tf_train_dataset) * num_epochs
+
+optimizer, schedule = create_optimizer(
+ init_lr=5e-5,
+ num_warmup_steps=0,
+ num_train_steps=num_train_steps,
+ weight_decay_rate=0.01,
+)
+model.compile(optimizer=optimizer)
+
+# Обучение со смешанной точностью float16
+tf.keras.mixed_precision.set_global_policy("mixed_float16")
+```
+
+Далее мы определяем обратный вызов `PushToHubCallback` для загрузки нашей модели в Hub во время обучения, как мы видели в [разделе 2](../chapter7/2), а затем мы просто подгоняем модель с помощью этого обратного вызова:
+
+```python
+from transformers.keras_callbacks import PushToHubCallback
+
+callback = PushToHubCallback(
+ output_dir="marian-finetuned-kde4-en-to-fr", tokenizer=tokenizer
+)
+
+model.fit(
+ tf_train_dataset,
+ validation_data=tf_eval_dataset,
+ callbacks=[callback],
+ epochs=num_epochs,
+)
+```
+
+Обратите внимание, что с помощью аргумента `hub_model_id` можно указать имя репозитория, в который вы хотите отправить модель (в частности, этот аргумент нужно использовать, чтобы отправить модель в организацию). Например, когда мы отправили модель в организацию [`huggingface-course`](https://huggingface.co/huggingface-course), мы добавили `hub_model_id="huggingface-course/marian-finetuned-kde4-en-to-fr"` в `Seq2SeqTrainingArguments`. По умолчанию используемый репозиторий будет находиться в вашем пространстве имен и называться в соответствии с заданным вами выходным каталогом, поэтому здесь это будет `"sgugger/marian-finetuned-kde4-en-to-fr"` (это модель, на которую мы ссылались в начале этого раздела).
+
+
+
+💡 Если выходной каталог, который вы используете, уже существует, он должен быть локальным клоном репозитория, в который вы хотите выполнить push. Если это не так, вы получите ошибку при вызове `model.fit()` и должны будете задать новое имя.
+
+
+
+Наконец, давайте посмотрим, как выглядят наши метрики после завершения обучения:
+
+```py
+print(compute_metrics())
+```
+
+```
+{'bleu': 57.334066271545865}
+```
+
+На этом этапе вы можете использовать виджет инференса на Model Hub, чтобы протестировать свою модель и поделиться ею с друзьями. Вы успешно дообучили модель для задачи перевода - поздравляем!
+
+{:else}
+
+Когда это сделано, мы можем определить наши `Seq2SeqTrainingArguments`. Как и в случае с `Trainer`, мы используем подкласс `TrainingArguments`, который содержит еще несколько дополнительных полей:
+
+```python
+from transformers import Seq2SeqTrainingArguments
+
+args = Seq2SeqTrainingArguments(
+ f"marian-finetuned-kde4-en-to-fr",
+ evaluation_strategy="no",
+ save_strategy="epoch",
+ learning_rate=2e-5,
+ per_device_train_batch_size=32,
+ per_device_eval_batch_size=64,
+ weight_decay=0.01,
+ save_total_limit=3,
+ num_train_epochs=3,
+ predict_with_generate=True,
+ fp16=True,
+ push_to_hub=True,
+)
+```
+
+Помимо обычных гиперпараметров (таких как скорость обучения, количество эпох, размер батча и некоторое затухание веса), здесь есть несколько отличий по сравнению с тем, что мы видели в предыдущих разделах:
+
+- Мы не задаем никаких регулярных оценок, так как оценка занимает много времени; мы просто оценим нашу модель один раз до обучения и после.
+- Мы установили `fp16=True`, что ускоряет обучение на современных GPU.
+- Мы устанавливаем `predict_with_generate=True`, как обсуждалось выше.
+- Мы используем `push_to_hub=True` для загрузки модели в Hub в конце каждой эпохи.
+
+Обратите внимание, что в аргументе `hub_model_id` можно указать полное имя розитория, в который вы хотите отправить модель (в частности, этот аргумент нужно использовать, чтобы отправить модель в организацию). Например, когда мы отправили модель в организацию [`huggingface-course`](https://huggingface.co/huggingface-course), мы добавили `hub_model_id="huggingface-course/marian-finetuned-kde4-en-to-fr"` в `Seq2SeqTrainingArguments`. По умолчанию используемый розиторий будет находиться в вашем пространстве имен и называться в соответствии с заданным вами выходным каталогом, поэтому в нашем случае это будет `"sgugger/marian-finetuned-kde4-en-to-fr"` (это модель, на которую мы ссылались в начале этого раздела).
+
+
+
+💡 Если выходной каталог, который вы используете, уже существует, он должен быть локальным клоном того розитория, в который вы хотите выполнить push. Если это не так, вы получите ошибку при определении вашего `Seq2SeqTrainer` и должны будете задать новое имя.
+
+
+
+
+Наконец, мы просто передаем все в `Seq2SeqTrainer`:
+
+```python
+from transformers import Seq2SeqTrainer
+
+trainer = Seq2SeqTrainer(
+ model,
+ args,
+ train_dataset=tokenized_datasets["train"],
+ eval_dataset=tokenized_datasets["validation"],
+ data_collator=data_collator,
+ tokenizer=tokenizer,
+ compute_metrics=compute_metrics,
+)
+```
+
+Перед обучением мы сначала посмотрим, какую оценку получила наша модель, чтобы проверить, не ухудшаем ли мы результаты, дообучив ее. Выполнение этой команды займет некоторое время, поэтому во время ее выполнения можно выпить кофе:
+
+```python
+trainer.evaluate(max_length=max_length)
+```
+
+```python out
+{'eval_loss': 1.6964408159255981,
+ 'eval_bleu': 39.26865061007616,
+ 'eval_runtime': 965.8884,
+ 'eval_samples_per_second': 21.76,
+ 'eval_steps_per_second': 0.341}
+```
+
+Оценка BLEU в 39 баллов не так уж плохо, что говорит о том, что наша модель уже хорошо справляется с переводом английских предложений на французский.
+
+Далее следует обучение, которое также займет некоторое время:
+
+```python
+trainer.train()
+```
+
+Обратите внимание, что во время обучения каждый раз, когда модель сохраняется (здесь - каждую эпоху), она загружается на Hub в фоновом режиме. Таким образом, при необходимости вы сможете возобновить обучение на другой машине.
+
+После завершения обучения мы снова оцениваем нашу модель - надеемся, мы увидим некоторое улучшение в показателе BLEU!
+
+```py
+trainer.evaluate(max_length=max_length)
+```
+
+```python out
+{'eval_loss': 0.8558505773544312,
+ 'eval_bleu': 52.94161337775576,
+ 'eval_runtime': 714.2576,
+ 'eval_samples_per_second': 29.426,
+ 'eval_steps_per_second': 0.461,
+ 'epoch': 3.0}
+```
+
+Это улучшение почти на 14 пунктов, что очень хорошо.
+
+Наконец, мы используем метод `push_to_hub()`, чтобы убедиться, что загружена последняя версия модели. Тренер также создает карту модели со всеми результатами оценки и загружает ее. Эта карта модели содержит метаданные, которые помогают хабу моделей выбрать виджет для демонстрации инференса. Обычно ничего не нужно указывать, так как он сам определяет нужный виджет по классу модели, но в данном случае один и тот же класс модели может быть использован для всех видов задач, связанных с последовательностями, поэтому мы указываем, что это модель перевода:
+
+```py
+trainer.push_to_hub(tags="translation", commit_message="Training complete")
+```
+
+Эта команда возвращает URL-адрес только что выполненного коммита, если вы хотите его просмотреть:
+
+```python out
+'https://huggingface.co/sgugger/marian-finetuned-kde4-en-to-fr/commit/3601d621e3baae2bc63d3311452535f8f58f6ef3'
+```
+
+На этом этапе вы можете использовать виджет инференса на Model Hub, чтобы протестировать свою модель и поделиться ею с друзьями. Вы успешно дообучили модель для задачи перевода - поздравляем!
+
+Если вы хотите более глубоко погрузиться в цикл обучения, мы покажем вам, как сделать то же самое с помощью 🤗 Accelerate.
+
+{/if}
+
+{#if fw === 'pt'}
+
+## Индивидуальный цикл обучения[[a-custom-training-loop]]
+
+Теперь давайте рассмотрим полный цикл обучения, чтобы вы могли легко настроить нужные вам части. Он будет выглядеть примерно так же, как мы делали это в [Главе 2](../chapter7/2) и [Главе 3](../chapter3/4).
+
+### Подготовка всего к обучению[[preparing-everything-for-training]]
+
+Вы уже видели все это несколько раз, поэтому мы пройдемся по коду довольно быстро. Сначала мы создадим `DataLoader` из наших датасетов, после чего установим для датасетов формат `"torch"`, чтобы получить тензоры PyTorch:
+
+```py
+from torch.utils.data import DataLoader
+
+tokenized_datasets.set_format("torch")
+train_dataloader = DataLoader(
+ tokenized_datasets["train"],
+ shuffle=True,
+ collate_fn=data_collator,
+ batch_size=8,
+)
+eval_dataloader = DataLoader(
+ tokenized_datasets["validation"], collate_fn=data_collator, batch_size=8
+)
+```
+
+Затем мы повторно инстанцируем нашу модель, чтобы убедиться, что мы не продолжаем дообучение предыдущей модели, а начинаем с предварительно обученной модели:
+
+```py
+model = AutoModelForSeq2SeqLM.from_pretrained(model_checkpoint)
+```
+
+Тогда нам понадобится оптимизатор:
+
+```py
+from transformers import AdamW
+
+optimizer = AdamW(model.parameters(), lr=2e-5)
+```
+
+Когда у нас есть все эти объекты, мы можем отправить их в метод `accelerator.prepare()`. Помните, что если вы хотите обучаться на TPU в блокноте Colab, вам нужно будет перенести весь этот код в функцию обучения, которая не должна выполнять ни одной ячейки, инстанцирующей `Accelerator`.
+
+```py
+from accelerate import Accelerator
+
+accelerator = Accelerator()
+model, optimizer, train_dataloader, eval_dataloader = accelerator.prepare(
+ model, optimizer, train_dataloader, eval_dataloader
+)
+```
+
+Теперь, когда мы отправили наш `train_dataloader` в `accelerator.prepare()`, мы можем использовать его длину для вычисления количества шагов обучения. Помните, что это всегда нужно делать после подготовки загрузчика данных, так как этот метод изменит длину `DataLoader`. Мы используем классический линейный планировшик скорости обучения до 0:
+
+```py
+from transformers import get_scheduler
+
+num_train_epochs = 3
+num_update_steps_per_epoch = len(train_dataloader)
+num_training_steps = num_train_epochs * num_update_steps_per_epoch
+
+lr_scheduler = get_scheduler(
+ "linear",
+ optimizer=optimizer,
+ num_warmup_steps=0,
+ num_training_steps=num_training_steps,
+)
+```
+
+Наконец, чтобы отправить нашу модель в Hub, нам нужно создать объект `Repository` в рабочей папке. Сначала войдите в Hub Hugging Face, если вы еще не авторизованы. Мы определим имя розитория по идентификатору модели, который мы хотим присвоить нашей модели (не стесняйтесь заменить `repo_name` на свой собственный выбор; оно просто должно содержать ваше имя пользователя, что и делает функция `get_full_repo_name()`):
+
+```py
+from huggingface_hub import Repository, get_full_repo_name
+
+model_name = "marian-finetuned-kde4-en-to-fr-accelerate"
+repo_name = get_full_repo_name(model_name)
+repo_name
+```
+
+```python out
+'sgugger/marian-finetuned-kde4-en-to-fr-accelerate'
+```
+
+Затем мы можем клонировать этот розиторий в локальную папку. Если она уже существует, эта локальная папка должна быть клоном того розитория, с которым мы работаем:
+
+```py
+output_dir = "marian-finetuned-kde4-en-to-fr-accelerate"
+repo = Repository(output_dir, clone_from=repo_name)
+```
+
+Теперь мы можем загрузить все, что сохранили в `output_dir`, вызвав метод `repo.push_to_hub()`. Это поможет нам загружать промежуточные модели в конце каждой эпохи.
+
+### Цикл обучения[[training-loop]]
+
+Теперь мы готовы написать полный цикл обучения. Чтобы упростить его оценочную часть, мы определяем эту функцию `postprocess()`, которая принимает прогнозы и метки и преобразует их в списки строк, которые будет ожидать наш объект `metric`:
+
+```py
+def postprocess(predictions, labels):
+ predictions = predictions.cpu().numpy()
+ labels = labels.cpu().numpy()
+
+ decoded_preds = tokenizer.batch_decode(predictions, skip_special_tokens=True)
+
+ # Заменим -100 в метках, так как мы не можем их декодировать.
+ labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
+ decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
+
+ # Немного простой постобработки
+ decoded_preds = [pred.strip() for pred in decoded_preds]
+ decoded_labels = [[label.strip()] for label in decoded_labels]
+ return decoded_preds, decoded_labels
+```
+
+Цикл обучения очень похож на циклы в [разделе 2](../chapter7/2) и [главе 3](../chapter3/1), с некоторыми отличиями в части оценки - так что давайте сосредоточимся на этом!
+
+Первое, что следует отметить, это то, что мы используем метод `generate()` для вычисления прогнозов, но это метод нашей базовой модели, а не обернутой модели 🤗 Accelerate, созданной в методе `prepare()`. Поэтому мы сначала развернем модель, а затем вызовем этот метод.
+
+Второй момент заключается в том, что, как и в случае с [классификацией токенов](../chapter7/2), два процесса могут дополнить входы и метки до разных форм, поэтому мы используем `accelerator.pad_across_processes()`, чтобы сделать прогнозы и метки одинаковыми по форме перед вызовом метода `gather()`. Если мы этого не сделаем, оценка либо выдаст ошибку, либо зависнет навсегда.
+
+```py
+from tqdm.auto import tqdm
+import torch
+
+progress_bar = tqdm(range(num_training_steps))
+
+for epoch in range(num_train_epochs):
+ # Обучение
+ model.train()
+ for batch in train_dataloader:
+ outputs = model(**batch)
+ loss = outputs.loss
+ accelerator.backward(loss)
+
+ optimizer.step()
+ lr_scheduler.step()
+ optimizer.zero_grad()
+ progress_bar.update(1)
+
+ # Оценка
+ model.eval()
+ for batch in tqdm(eval_dataloader):
+ with torch.no_grad():
+ generated_tokens = accelerator.unwrap_model(model).generate(
+ batch["input_ids"],
+ attention_mask=batch["attention_mask"],
+ max_length=128,
+ )
+ labels = batch["labels"]
+
+ ## Необходимо дополнить прогнозы и метки
+ generated_tokens = accelerator.pad_across_processes(
+ generated_tokens, dim=1, pad_index=tokenizer.pad_token_id
+ )
+ labels = accelerator.pad_across_processes(labels, dim=1, pad_index=-100)
+
+ predictions_gathered = accelerator.gather(generated_tokens)
+ labels_gathered = accelerator.gather(labels)
+
+ decoded_preds, decoded_labels = postprocess(predictions_gathered, labels_gathered)
+ metric.add_batch(predictions=decoded_preds, references=decoded_labels)
+
+ results = metric.compute()
+ print(f"epoch {epoch}, BLEU score: {results['score']:.2f}")
+
+ # Сохранение и загрузка
+ accelerator.wait_for_everyone()
+ unwrapped_model = accelerator.unwrap_model(model)
+ unwrapped_model.save_pretrained(output_dir, save_function=accelerator.save)
+ if accelerator.is_main_process:
+ tokenizer.save_pretrained(output_dir)
+ repo.push_to_hub(
+ commit_message=f"Training in progress epoch {epoch}", blocking=False
+ )
+```
+
+```python out
+epoch 0, BLEU score: 53.47
+epoch 1, BLEU score: 54.24
+epoch 2, BLEU score: 54.44
+```
+
+После этого у вас должна получиться модель, результаты которой будут очень похожи на модель, обученную с помощью `Seq2SeqTrainer`. Вы можете проверить модель, которую мы обучили с помощью этого кода, на [*huggingface-course/marian-finetuned-kde4-en-to-fr-accelerate*](https://huggingface.co/huggingface-course/marian-finetuned-kde4-en-to-fr-accelerate). А если вы хотите протестировать какие-либо изменения в цикле обучения, вы можете реализовать их напрямую, отредактировав код, показанный выше!
+
+{/if}
+
+## Использование дообученной модели[[using-the-fine-tuned-model]]
+
+Мы уже показали вам, как можно использовать модель, которую мы дообучили на Model Hub, с помощью виджета инференса. Чтобы использовать ее локально в `pipeline`, нам просто нужно указать соответствующий идентификатор модели:
+
+```py
+from transformers import pipeline
+
+# Замените это на свою собственную контрольную точку
+model_checkpoint = "huggingface-course/marian-finetuned-kde4-en-to-fr"
+translator = pipeline("translation", model=model_checkpoint)
+translator("Default to expanded threads")
+```
+
+```python out
+[{'translation_text': 'Par défaut, développer les fils de discussion'}]
+```
+
+Как и ожидалось, наша предварительно обученная модель адаптировала свои знания к корпусу, на котором мы ее дообучили, и вместо того, чтобы оставить английское слово "threads" в покое, она теперь переводит его на официальный французский вариант. То же самое относится и к слову " plugin ":
+
+```py
+translator(
+ "Unable to import %1 using the OFX importer plugin. This file is not the correct format."
+)
+```
+
+```python out
+[{'translation_text': "Impossible d'importer %1 en utilisant le module externe d'importation OFX. Ce fichier n'est pas le bon format."}]
+```
+
+Еще один отличный пример доменной адаптации!
+
+
+
+✏️ **Попробуйте!** Что возвращает модель для примера со словом "email", который вы определили ранее?
+
+
diff --git a/chapters/ru/chapter7/5.mdx b/chapters/ru/chapter7/5.mdx
new file mode 100644
index 000000000..9c14bb75a
--- /dev/null
+++ b/chapters/ru/chapter7/5.mdx
@@ -0,0 +1,1072 @@
+
+
+# Суммаризация[[summarization]]
+
+{#if fw === 'pt'}
+
+
+
+{:else}
+
+
+
+{/if}
+
+
+В этом разделе мы рассмотрим, как модели Transformer могут быть использованы для сжатия длинных документов в краткое изложение - задача, известная как _суммаризация текста (text summarization)_. Это одна из самых сложных задач NLP, поскольку она требует целого ряда способностей, таких как понимание длинных отрывков и генерация связного текста, отражающего основные темы документа. Однако при правильном подходе суммаризация текста - это мощный инструмент, который может ускорить различные бизнес-процессы, избавив экспертов домена от необходимости детального прочтения длинных документов.
+
+
+
+Хотя на [Hugging Face Hub](https://huggingface.co/models?pipeline_tag=summarization&sort=downloads) уже существуют различные дообученные модели для суммаризации, почти все они подходят только для англоязычных документов. Поэтому, чтобы добавить изюминку в этот раздел, мы обучим двухязыковую модель для английского и испанского языков. К концу этого раздела у вас будет [модель](https://huggingface.co/huggingface-course/mt5-small-finetuned-amazon-en-es), способная к суммаризации отзывов покупателей, как показано здесь:
+
+
+
+Как мы увидим, эти резюме кратки, поскольку они составляются на основе названий, которые покупатели указывают в своих отзывах о товаре. Для начала давайте соберем подходящий двуязыковой корпус для этой задачи.
+
+## Подготовка многоязыкового корпуса[[preparing-a-multilingual-corpus]]
+
+Для создания нашей двуязыковой суммаризации мы будем использовать [Multilingual Amazon Reviews Corpus](https://huggingface.co/datasets/amazon_reviews_multi). Этот корпус состоит из отзывов о товарах Amazon на шести языках и обычно используется для тестирования многоязыковых классификаторов. Однако, поскольку каждый отзыв сопровождается коротким заголовком, мы можем использовать заголовки в качестве целевых резюме для обучения нашей модели! Чтобы начать работу, давайте загрузим английские и испанские подмножества из Hugging Face Hub:
+
+```python
+from datasets import load_dataset
+
+spanish_dataset = load_dataset("amazon_reviews_multi", "es")
+english_dataset = load_dataset("amazon_reviews_multi", "en")
+english_dataset
+```
+
+```python out
+DatasetDict({
+ train: Dataset({
+ features: ['review_id', 'product_id', 'reviewer_id', 'stars', 'review_body', 'review_title', 'language', 'product_category'],
+ num_rows: 200000
+ })
+ validation: Dataset({
+ features: ['review_id', 'product_id', 'reviewer_id', 'stars', 'review_body', 'review_title', 'language', 'product_category'],
+ num_rows: 5000
+ })
+ test: Dataset({
+ features: ['review_id', 'product_id', 'reviewer_id', 'stars', 'review_body', 'review_title', 'language', 'product_category'],
+ num_rows: 5000
+ })
+})
+```
+
+Как видите, для каждого языка есть 200 000 отзывов в части `train` и по 5 000 отзывов в частях `validation` и `test`. Интересующая нас информация о рецензиях содержится в столбцах `review_body` и `review_title`. Давайте рассмотрим несколько примеров, создав простую функцию, которая берет случайную выборку из обучающего множества с помощью методов, изученных в [Главе 5](../chapter5/1):
+
+```python
+def show_samples(dataset, num_samples=3, seed=42):
+ sample = dataset["train"].shuffle(seed=seed).select(range(num_samples))
+ for example in sample:
+ print(f"\n'>> Title: {example['review_title']}'")
+ print(f"'>> Review: {example['review_body']}'")
+
+
+show_samples(english_dataset)
+```
+
+```python out
+'>> Title: Worked in front position, not rear'
+'>> Review: 3 stars because these are not rear brakes as stated in the item description. At least the mount adapter only worked on the front fork of the bike that I got it for.'
+
+'>> Title: meh'
+'>> Review: Does it’s job and it’s gorgeous but mine is falling apart, I had to basically put it together again with hot glue'
+
+'>> Title: Can\'t beat these for the money'
+'>> Review: Bought this for handling miscellaneous aircraft parts and hanger "stuff" that I needed to organize; it really fit the bill. The unit arrived quickly, was well packaged and arrived intact (always a good sign). There are five wall mounts-- three on the top and two on the bottom. I wanted to mount it on the wall, so all I had to do was to remove the top two layers of plastic drawers, as well as the bottom corner drawers, place it when I wanted and mark it; I then used some of the new plastic screw in wall anchors (the 50 pound variety) and it easily mounted to the wall. Some have remarked that they wanted dividers for the drawers, and that they made those. Good idea. My application was that I needed something that I can see the contents at about eye level, so I wanted the fuller-sized drawers. I also like that these are the new plastic that doesn\'t get brittle and split like my older plastic drawers did. I like the all-plastic construction. It\'s heavy duty enough to hold metal parts, but being made of plastic it\'s not as heavy as a metal frame, so you can easily mount it to the wall and still load it up with heavy stuff, or light stuff. No problem there. For the money, you can\'t beat it. Best one of these I\'ve bought to date-- and I\'ve been using some version of these for over forty years.'
+```
+
+
+
+✏️ **Попробуйте!** Измените random seed в команде `Dataset.shuffle()`, чтобы изучить другие отзывы в корпусе. Если вы владеете испанским языком, посмотрите на некоторые отзывы в `spanish_dataset`, чтобы понять, похожи ли их названия на разумные резюме.
+
+
+
+Эта выборка демонстрирует разнообразие отзывов, которые обычно можно найти в сети, - от положительных до отрицательных (и все, что между ними!). Хотя пример с названием "meh" не очень информативен, остальные названия выглядят как достойные резюме самих отзывов. Обучение модели суммаризации всех 400 000 отзывов заняло бы слишком много времени на одном GPU, поэтому вместо этого мы сосредоточимся на создании резюме для одного домена продуктов. Чтобы получить представление о том, какие домены мы можем выбрать, давайте преобразуем `english_dataset` в `pandas.DataFrame` и вычислим количество отзывов по каждой категории товаров:
+
+```python
+english_dataset.set_format("pandas")
+english_df = english_dataset["train"][:]
+# Show counts for top 20 products
+english_df["product_category"].value_counts()[:20]
+```
+
+```python out
+home 17679
+apparel 15951
+wireless 15717
+other 13418
+beauty 12091
+drugstore 11730
+kitchen 10382
+toy 8745
+sports 8277
+automotive 7506
+lawn_and_garden 7327
+home_improvement 7136
+pet_products 7082
+digital_ebook_purchase 6749
+pc 6401
+electronics 6186
+office_product 5521
+shoes 5197
+grocery 4730
+book 3756
+Name: product_category, dtype: int64
+```
+
+Самые популярные товары в английском датасете - это бытовые товары, одежда и беспроводная электроника. Однако, чтобы поддержать тему Amazon, давайте сосредоточимся на суммаризации отзывов о книгах - в конце концов, именно для этого компания и была основана! Мы видим две категории товаров, которые подходят для этой цели (`book` и `digital_ebook_purchase`), поэтому давайте отфильтруем датасеты на обоих языках только для этих товаров. Как мы видели в [Главе 5](../chapter5/1), функция `Dataset.filter()` позволяет нам очень эффективно разделять датасет на части, поэтому мы можем определить простую функцию для этого:
+
+```python
+def filter_books(example):
+ return (
+ example["product_category"] == "book"
+ or example["product_category"] == "digital_ebook_purchase"
+ )
+```
+
+Теперь, когда мы применим эту функцию к `english_dataset` и `spanish_dataset`, результат будет содержать только те строки, в которых присутствуют категории книг. Прежде чем применить фильтр, давайте изменим формат `english_dataset` с `"pandas"` обратно на `"arrow"`:
+
+```python
+english_dataset.reset_format()
+```
+
+Затем мы можем применить функцию фильтрации, и в качестве проверки работоспособности давайте посмотрим на выборку отзывов, чтобы убедиться, что они действительно посвящены книгам:
+
+```python
+spanish_books = spanish_dataset.filter(filter_books)
+english_books = english_dataset.filter(filter_books)
+show_samples(english_books)
+```
+
+```python out
+'>> Title: I\'m dissapointed.'
+'>> Review: I guess I had higher expectations for this book from the reviews. I really thought I\'d at least like it. The plot idea was great. I loved Ash but, it just didnt go anywhere. Most of the book was about their radio show and talking to callers. I wanted the author to dig deeper so we could really get to know the characters. All we know about Grace is that she is attractive looking, Latino and is kind of a brat. I\'m dissapointed.'
+
+'>> Title: Good art, good price, poor design'
+'>> Review: I had gotten the DC Vintage calendar the past two years, but it was on backorder forever this year and I saw they had shrunk the dimensions for no good reason. This one has good art choices but the design has the fold going through the picture, so it\'s less aesthetically pleasing, especially if you want to keep a picture to hang. For the price, a good calendar'
+
+'>> Title: Helpful'
+'>> Review: Nearly all the tips useful and. I consider myself an intermediate to advanced user of OneNote. I would highly recommend.'
+```
+
+Хорошо, мы видим, что отзывы не совсем о книгах и могут относиться к таким вещам, как календари и электронные приложения, например OneNote. Тем не менее, домен кажется подходящим для обучения модели суммаризации. Прежде чем мы рассмотрим различные модели, подходящие для этой задачи, нам осталось подготовить данные: объединить английские и испанские отзывы в один объект `DatasetDict`. 🤗Datasets предоставляет удобную функцию `concatenate_datasets()`, которая (как следует из названия) стекирует два объекта `Dataset` друг на друга. Таким образом, чтобы создать двуязыковой датасет, мы пройдемся по каждой части, объединим датасеты для этой части и перемешаем результат, чтобы наша модель не была слишком переобучена для одного языка:
+
+```python
+from datasets import concatenate_datasets, DatasetDict
+
+books_dataset = DatasetDict()
+
+for split in english_books.keys():
+ books_dataset[split] = concatenate_datasets(
+ [english_books[split], spanish_books[split]]
+ )
+ books_dataset[split] = books_dataset[split].shuffle(seed=42)
+
+# Посмотрим на несколько примеров
+show_samples(books_dataset)
+```
+
+```python out
+'>> Title: Easy to follow!!!!'
+'>> Review: I loved The dash diet weight loss Solution. Never hungry. I would recommend this diet. Also the menus are well rounded. Try it. Has lots of the information need thanks.'
+
+'>> Title: PARCIALMENTE DAÑADO'
+'>> Review: Me llegó el día que tocaba, junto a otros libros que pedí, pero la caja llegó en mal estado lo cual dañó las esquinas de los libros porque venían sin protección (forro).'
+
+'>> Title: no lo he podido descargar'
+'>> Review: igual que el anterior'
+```
+
+Это определенно похоже на смесь английских и испанских обзоров! Теперь, когда у нас есть тренировочный корпус, осталось проверить распределение слов в рецензиях и их заголовках. Это особенно важно для задач суммаризации, где короткие эталонные резюме в данных могут склонять модель в сторону вывода только одного или двух слов в сгенерированных резюме. На графиках ниже показаны распределения слов, и мы видим, что названия сильно перекошены в сторону 1-2 слов:
+
+
+

+

+
+
+Чтобы справиться с этой проблемой, мы отфильтруем примеры с очень короткими заголовками, чтобы наша модель могла создавать более интересные резюме. Поскольку мы имеем дело с английскими и испанскими текстами, мы можем использовать грубую эвристику для разделения названий по символам пробела, а затем использовать наш надежный метод `Dataset.filter()` следующим образом:
+
+```python
+books_dataset = books_dataset.filter(lambda x: len(x["review_title"].split()) > 2)
+```
+
+Теперь, когда мы подготовили корпус, давайте рассмотрим несколько возможных моделей Transformer, которые можно было бы дообучить на его основе!
+
+## Модели для суммаризации текста[[models-for-text-summarization]]
+
+Если задуматься, то суммаризация текста - это задача, похожая на машинный перевод: у нас есть текст, например рецензия, который мы хотели бы "перевести" в более короткую версию, передающую основные особенности исходного текста. Соответственно, большинство моделей Transformer для суммаризации используют архитектуру кодер-декодер, с которой мы впервые столкнулись в [Глава 1](../chapter1/1), хотя есть и исключения, например семейство моделей GPT, которые также могут использоваться для суммаризации в условиях few-shot настроек. В следующей таблице перечислены некоторые популярные предварительно обученные модели, которые можно дообучить для суммаризации.
+
+| Модель Transformer | Описание | Многоязычная? |
+| :---------: | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | :-----------: |
+| [GPT-2](https://huggingface.co/gpt2-xl) | Хотя GPT-2 обучен как авторегрессивная языковая модель, вы можете заставить его генерировать резюме, добавляя "TL;DR" в конце входного текста. | ❌ |
+| [PEGASUS](https://huggingface.co/google/pegasus-large) | Использует цель предварительного обучения для предсказания замаскированных предложений в текстах с несколькими предложениями. Эта задача предварительного обучения ближе к суммаризации, чем к классическому языковому моделированию демонстрирует высокие результаты в популярных бенчмарках.| ❌ |
+| [T5](https://huggingface.co/t5-base) | Универсальная трансформерная архитектура, которая формулирует все задачи в рамках преобразования текста в текст; например, входной формат модели для суммаризации документа - `summarize: ARTICLE`. | ❌ |
+| [mT5](https://huggingface.co/google/mt5-base) | Многоязыковая версия T5, предварительно обученная на многоязыковом корпусе Common Crawl (mC4), охватывающем 101 язык. | ✅ |
+| [BART](https://huggingface.co/facebook/bart-base) | Новая архитектура Transformer с кодером и стеком декодеров, обученных восстанавливать поврежденный входной сигнал, сочетает в себе схемы предварительного обучения BERT и GPT-2. | ❌ |
+| [mBART-50](https://huggingface.co/facebook/mbart-large-50) | Многоязыковая версия BART, предварительно обученная на 50 языках. | ✅ |
+
+Как видно из этой таблицы, большинство моделей Transformer для суммаризации (и вообще для большинства задач NLP) являются монолингвистическими. Это хорошо, если ваша задача на "высокоресурсном" языке, таком как английский или немецкий, но не очень хорошо для тысяч других языков, используемых по всему миру. К счастью, существует класс многоязыковых моделей Transformer, таких как mT5 и mBART, которые приходят на помощь. Эти модели предварительно обучаются с помощью языкового моделирования, но с изюминкой: вместо обучения на корпусе одного языка они обучаются совместно на текстах более чем на 50 языках одновременно!
+
+Мы сосредоточимся на mT5, интересной архитектуре, основанной на T5, которая была предварительно обучена на фреймворке "текс-в-текст" (text-to-text). В T5 каждая задача NLP формулируется в терминах префикса подсказки, например `summarize:`, который определяет, что модель должна адаптировать сгенерированный текст к подсказке. Как показано на рисунке ниже, это делает T5 чрезвычайно универсальным, поскольку вы можете решать множество задач с помощью одной модели!
+
+
+

+

+
+
+В mT5 не используются префиксы, но она обладает многими универсальными возможностями T5 и имеет многоязыковое преимущество. Теперь, когда мы выбрали модель, давайте посмотрим, как подготовить данные для обучения.
+
+
+
+
+✏️ **Попробуйте!** После того как вы проработаете этот раздел, посмотрите, насколько хорошо mT5 сравнится с mBART, дообучив его тем же методам. Чтобы получить бонусные очки, вы также можете попробовать дообучить T5 только на английских рецензиях. Поскольку в T5 есть специальный префикс запроса, вам нужно будет добавить `summarize:` к входным примерам на следующих шагах предварительной обработки.
+
+
+
+## Предварительная обработка данных[[preprocessing-the-data]]
+
+
+
+Наша следующая задача - токенизация и кодирование отзывов и их заголовков. Как обычно, мы начинаем с загрузки токенизатора, связанного с контрольной точкой предварительно обученной модели. В качестве контрольной точки мы будем использовать `mt5-small`, чтобы можно было дообучить модель за разумное время:
+
+```python
+from transformers import AutoTokenizer
+
+model_checkpoint = "google/mt5-small"
+tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
+```
+
+
+
+💡 На ранних стадиях ваших NLP-проектов хорошей практикой является обучение класса "маленьких" моделей на небольшой выборке данных. Это позволит вам быстрее отлаживать и итерировать модели, чтобы создать сквозной рабочий процесс. Когда вы будете уверены в результатах, вы всегда сможете увеличить масштаб модели, просто изменив контрольную точку модели!
+
+
+
+Давайте протестируем токенизатор mT5 на небольшом примере:
+
+```python
+inputs = tokenizer("I loved reading the Hunger Games!")
+inputs
+```
+
+```python out
+{'input_ids': [336, 259, 28387, 11807, 287, 62893, 295, 12507, 1], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1]}
+```
+
+Здесь мы видим знакомые нам `input_ids` и `attention_mask`, с которыми мы столкнулись в наших первых экспериментах по дообучению еще в [Главе 3](../chapter3/1). Давайте декодируем эти входные идентификаторы с помощью функции токенизатора `convert_ids_to_tokens()`, чтобы понять, с каким токенизатором мы имеем дело:
+
+```python
+tokenizer.convert_ids_to_tokens(inputs.input_ids)
+```
+
+```python out
+['▁I', '▁', 'loved', '▁reading', '▁the', '▁Hung', 'er', '▁Games', '']
+```
+
+Специальный символ Юникода `▁` и токен конца последовательности `` указывают на то, что мы имеем дело с токенизатором SentencePiece, который основан на алгоритме сегментации Unigram, рассмотренном в [Главе 6](../chapter6/1). Unigram особенно полезен для многоязычных корпусов, поскольку он позволяет SentencePiece не зависеть от ударений, пунктуации и того факта, что во многих языках, например в японском, нет пробельных символов.
+
+Для токенизации нашего корпуса нам придется столкнуться с одной тонкостью, связанной с сумризацией: поскольку наши метки также являются текстом, возможно, что они превышают максимальный размер контекста модели. Это означает, что нам нужно применять усечение как к обзорам, так и к их заголовкам, чтобы не передавать в модель слишком длинные данные. Токенизаторы в 🤗 Transformers предоставляют интересный аргумент `text_target`, который позволяет вам токенизировать метки параллельно с входными данными. Вот пример того, как обрабатываются входные и целевые данные для mT5:
+
+```python
+max_input_length = 512
+max_target_length = 30
+
+
+def preprocess_function(examples):
+ model_inputs = tokenizer(
+ examples["review_body"],
+ max_length=max_input_length,
+ truncation=True,
+ )
+ labels = tokenizer(
+ examples["review_title"], max_length=max_target_length, truncation=True
+ )
+ model_inputs["labels"] = labels["input_ids"]
+ return model_inputs
+```
+
+Давайте пройдемся по этому коду, чтобы понять, что происходит. Первое, что мы сделали, это определили значения `max_input_length` и `max_target_length`, которые устанавливают верхние границы длины наших обзоров и заголовков. Поскольку тело обзора обычно намного больше заголовка, мы соответственно изменили эти значения.
+
+С помощью `preprocess_function()` можно провести токенизацию всего корпуса с помощью удобной функции `Dataset.map()`, которую мы часто использовали на протяжении всего курса:
+
+```python
+tokenized_datasets = books_dataset.map(preprocess_function, batched=True)
+```
+
+Теперь, когда корпус был предварительно обработан, давайте посмотрим на некоторые метрики, которые обычно используются для суммаризации. Как мы увидим, не существует серебряной пули, когда дело доходит до измерения качества сгенерированного машиной текста.
+
+
+
+💡 Возможно, вы заметили, что выше в функции `Dataset.map()` мы использовали `batched=True`. Это кодирует примеры в батчах по 1 000 (по умолчанию) и позволяет использовать возможности многопоточности быстрых токенизаторов в 🤗 Transformers. По возможности, попробуйте использовать `batched=True`, чтобы получить максимальную отдачу от препроцессинга!
+
+
+
+
+## Метрики для суммаризации текста[[metrics-for-text-summarization]]
+
+
+
+По сравнению с большинством других задач, которые мы рассматривали в этом курсе, измерение качества работы задач по созданию текста, таких как суммаризация или перевод, не так просто. Например, для рецензии типа "I loved reading the Hunger Games" существует множество правильных резюме, таких как "I loved the Hunger Games" или "Hunger Games is a great read". Очевидно, что применение какого-то точного соответствия между сгенерированным резюме и меткой не является хорошим решением - даже люди не справятся с такой метрикой, потому что у каждого из нас свой стиль написания.
+
+Для суммаризации одной из наиболее часто используемых метрик является [оценка ROUGE](https://en.wikipedia.org/wiki/ROUGE_(metric)) (сокращение от Recall-Oriented Understudy for Gisting Evaluation). Основная идея этой метрики заключается в сравнении сгенерированного резюме с набором эталонных резюме, которые обычно создаются людьми. Чтобы сделать ее более точной, предположим, что мы хотим сравнить следующие два резюме:
+
+```python
+generated_summary = "I absolutely loved reading the Hunger Games"
+reference_summary = "I loved reading the Hunger Games"
+```
+
+Одним из способов их сравнения может быть подсчет количества перекрывающихся слов, которых в данном случае будет 6. Однако это несколько грубовато, поэтому вместо этого ROUGE основывается на вычислении оценок _precision_ и _recall_ для перекрытия.
+
+
+
+🙋 Не волнуйтесь, если вы впервые слышите о precision и recall - мы вместе разберем несколько наглядных примеров, чтобы все стало понятно. Эти метрики обычно встречаются в задачах классификации, поэтому, если вы хотите понять, как определяются precision и recall в этом контексте, мы рекомендуем ознакомиться с `scikit-learn` [руководством](https://scikit-learn.org/stable/auto_examples/model_selection/plot_precision_recall.html).
+
+
+
+Для ROUGE recall измеряет, насколько эталонное резюме соответствует сгенерированному. Если мы просто сравниваем слова, recall можно рассчитать по следующей формуле:
+
+$$ \mathrm{Recall} = \frac{\mathrm{Number\,of\,overlapping\, words}}{\mathrm{Total\, number\, of\, words\, in\, reference\, summary}} $$
+
+Для нашего простого примера выше эта формула дает идеальный recall 6/6 = 1; то есть все слова в эталонном резюме были получены моделью. Это может показаться замечательным, но представьте, если бы сгенерированное нами резюме было "I really really loved reading the Hunger Games all night". Это тоже дало бы идеальный recall, но, возможно, было бы хуже, поскольку было бы многословным. Чтобы справиться с этими сценариями, мы также вычисляем precision, которая в контексте ROUGE измеряет, насколько сгенерированное резюме было релевантным:
+
+$$ \mathrm{Precision} = \frac{\mathrm{Number\,of\,overlapping\, words}}{\mathrm{Total\, number\, of\, words\, in\, generated\, summary}} $$
+
+Если применить это к нашему подробному резюме, то precision составит 6/10 = 0,6, что значительно хуже, чем precision 6/7 = 0,86, полученная при использовании более короткого резюме. На практике обычно вычисляют и precision, и recall, а затем F1-score (среднее гармоническое из precision и recall). Мы можем легко это сделать с помощью 🤗 Datasets, предварительно установив пакет `rouge_score`:
+
+```py
+!pip install rouge_score
+```
+
+а затем загрузить метрику ROUGE следующим образом:
+
+```python
+import evaluate
+
+rouge_score = evaluate.load("rouge")
+```
+
+Затем мы можем использовать функцию `rouge_score.compute()`, чтобы рассчитать все метрики сразу:
+
+```python
+scores = rouge_score.compute(
+ predictions=[generated_summary], references=[reference_summary]
+)
+scores
+```
+
+```python out
+{'rouge1': AggregateScore(low=Score(precision=0.86, recall=1.0, fmeasure=0.92), mid=Score(precision=0.86, recall=1.0, fmeasure=0.92), high=Score(precision=0.86, recall=1.0, fmeasure=0.92)),
+ 'rouge2': AggregateScore(low=Score(precision=0.67, recall=0.8, fmeasure=0.73), mid=Score(precision=0.67, recall=0.8, fmeasure=0.73), high=Score(precision=0.67, recall=0.8, fmeasure=0.73)),
+ 'rougeL': AggregateScore(low=Score(precision=0.86, recall=1.0, fmeasure=0.92), mid=Score(precision=0.86, recall=1.0, fmeasure=0.92), high=Score(precision=0.86, recall=1.0, fmeasure=0.92)),
+ 'rougeLsum': AggregateScore(low=Score(precision=0.86, recall=1.0, fmeasure=0.92), mid=Score(precision=0.86, recall=1.0, fmeasure=0.92), high=Score(precision=0.86, recall=1.0, fmeasure=0.92))}
+```
+
+Ого, в этом выводе много информации - что же она означает? Во-первых, 🤗 Datasets действительно вычисляет доверительные интервалы для precision, recall и F1-score; это `low`, `mid`, и `high` атрибуты, которые вы можете здесь увидеть. Кроме того, 🤗 Dataset вычисляет различные оценки ROUGE, которые основаны на различных типах детализации текста при сравнении сгенерированных и эталонных резюме. Вариант `rouge1` представляет собой перекрытие униграмм - это просто модный способ сказать о перекрытии слов, и это именно та метрика, которую мы обсуждали выше. Чтобы убедиться в этом, давайте извлечем `среднее` значение наших оценок:
+
+```python
+scores["rouge1"].mid
+```
+
+```python out
+Score(precision=0.86, recall=1.0, fmeasure=0.92)
+```
+
+Отлично, показатели precision и recall совпадают! А как насчет других показателей ROUGE? `rouge2` измеряет перекрытие биграмм (считайте, что это перекрытие пар слов), а `rougeL` и `rougeLsum` измеряют самые длинные совпадающие последовательности слов, ища самые длинные общие подстроки в сгенерированных и эталонных резюме. Слово "sum" в `rougeLsum` означает, что эта метрика вычисляется для всего резюме, в то время как `rougeL` вычисляется как среднее по отдельным предложениям.
+
+
+
+✏️ **Попробуйте!** Создайте свой собственный пример сгенерированного и эталонного резюме и посмотрите, согласуются ли полученные оценки ROUGE с ручным расчетом по формулам precision и recall. Для получения бонусных очков разбейте текст на биграммы и сравните precision и recall для метрики `rouge2`.
+
+
+
+Мы будем использовать эту оценку ROUGE для отслеживания эффективности нашей модели, но перед этим давайте сделаем то, что должен сделать каждый хороший NLP-практик: создадим сильную, но простую базовую модель!
+
+### Создание сильного базового уровня[[creating-a-strong-baseline]]
+
+Для суммаризации текста обычно берут первые три предложения статьи, что часто называют базвым уровнем _lead-3_. Мы могли бы использовать символы полной остановки для отслеживания границ предложений, но это не поможет при использовании таких аббревиатур, как " U.S." или "U.N.". -- поэтому вместо этого мы воспользуемся библиотекой `nltk`, которая включает в себя лучший алгоритм для таких случаев. Вы можете установить пакет с помощью `pip` следующим образом:
+
+```python
+!pip install nltk
+```
+
+а затем скачайте правила пунктуации:
+
+```python
+import nltk
+
+nltk.download("punkt")
+```
+
+Далее мы импортируем токенизатор предложений из `nltk` и создадим простую функцию для извлечения первых трех предложений в обзоре. При суммаризации текста принято отделять каждое предложение новой строкой, поэтому давайте включим эту функцию и протестируем ее на обучающем примере:
+
+```python
+from nltk.tokenize import sent_tokenize
+
+
+def three_sentence_summary(text):
+ return "\n".join(sent_tokenize(text)[:3])
+
+
+print(three_sentence_summary(books_dataset["train"][1]["review_body"]))
+```
+
+```python out
+'I grew up reading Koontz, and years ago, I stopped,convinced i had "outgrown" him.'
+'Still,when a friend was looking for something suspenseful too read, I suggested Koontz.'
+'She found Strangers.'
+```
+
+Похоже, что это работает, так что теперь давайте реализуем функцию, которая извлекает эти "резюме" из датасета и вычисляет оценку ROUGE для базового уровня:
+
+```python
+def evaluate_baseline(dataset, metric):
+ summaries = [three_sentence_summary(text) for text in dataset["review_body"]]
+ return metric.compute(predictions=summaries, references=dataset["review_title"])
+```
+
+Затем мы можем использовать эту функцию для вычисления оценок ROUGE на валидационном множестве и немного приукрасить их с помощью Pandas:
+
+```python
+import pandas as pd
+
+score = evaluate_baseline(books_dataset["validation"], rouge_score)
+rouge_names = ["rouge1", "rouge2", "rougeL", "rougeLsum"]
+rouge_dict = dict((rn, round(score[rn].mid.fmeasure * 100, 2)) for rn in rouge_names)
+rouge_dict
+```
+
+```python out
+{'rouge1': 16.74, 'rouge2': 8.83, 'rougeL': 15.6, 'rougeLsum': 15.96}
+```
+
+Мы видим, что оценка `rouge2` значительно ниже, чем у остальных; скорее всего, это отражает тот факт, что заголовки рецензий обычно лаконичны, и поэтому базовый уровень lead-3 слишком многословен. Теперь, когда у нас есть хороший базовый уровень для работы, давайте дообучим mT5!
+
+{#if fw === 'pt'}
+
+## Дообучение mT5 с API `Trainer`[[fine-tuning-mt5-with-the-trainer-api]]
+
+Дообучение модели суммаризации очень похоже на другие задачи, которые мы рассмотрели в этой главе. Первое, что нам нужно сделать, это загрузить предварительно обученную модель из контрольной точки `mt5-small`. Поскольку суммаризация - это задача преобразования последовательности в последовательность, мы можем загрузить модель с помощью класса `AutoModelForSeq2SeqLM`, который автоматически загрузит и кэширует веса:
+
+```python
+from transformers import AutoModelForSeq2SeqLM
+
+model = AutoModelForSeq2SeqLM.from_pretrained(model_checkpoint)
+```
+
+{:else}
+
+## Дообучение mT5 с Keras[[fine-tuning-mt5-with-keras]]
+
+Дообучение модели суммаризации очень похоже на другие задачи, которые мы рассмотрели в этой главе. Первое, что нам нужно сделать, это загрузить предварительно обученную модель из контрольной точки `mt5-small`. Поскольку суммаризация - это задача преобразования последовательности в последовательность, мы можем загрузить модель с помощью класса `TFAutoModelForSeq2SeqLM`, который автоматически загрузит и кэширует веса:
+
+```python
+from transformers import TFAutoModelForSeq2SeqLM
+
+model = TFAutoModelForSeq2SeqLM.from_pretrained(model_checkpoint)
+```
+
+{/if}
+
+
+
+💡 Если вы задаетесь вопросом, почему вы не видите предупреждений о необходимости дообучить модель для последующей задачи, то это потому, что для задач "последовательность-в-последовательность" мы сохраняем все веса сети. Сравните это с нашей моделью классификации текста из [Главы 3](../chapter3/1), где голова предварительно обученной модели была заменена на случайно инициализированную сеть.
+
+
+
+Следующее, что нам нужно сделать, это войти в Hugging Face Hub. Если вы выполняете этот код в ноутбуке, вы можете сделать это с помощью следующей полезной функции:
+
+```python
+from huggingface_hub import notebook_login
+
+notebook_login()
+```
+
+которая отобразит виджет, где вы можете ввести свои учетные данные. Также вы можете запустить эту команду в терминале и войти в систему там:
+
+```
+huggingface-cli login
+```
+
+{#if fw === 'pt'}
+
+Для вычисления оценки ROUGE в процессе обучения нам понадобится генерировать резюме. К счастью, 🤗 Transformers предоставляет специальные классы `Seq2SeqTrainingArguments` и `Seq2SeqTrainer`, которые могут сделать это за нас автоматически! Чтобы увидеть, как это работает, давайте сначала определим гиперпараметры и другие аргументы для наших экспериментов:
+
+```python
+from transformers import Seq2SeqTrainingArguments
+
+batch_size = 8
+num_train_epochs = 8
+# Выводим потери при обучении по каждой эпохе
+logging_steps = len(tokenized_datasets["train"]) // batch_size
+model_name = model_checkpoint.split("/")[-1]
+
+args = Seq2SeqTrainingArguments(
+ output_dir=f"{model_name}-finetuned-amazon-en-es",
+ evaluation_strategy="epoch",
+ learning_rate=5.6e-5,
+ per_device_train_batch_size=batch_size,
+ per_device_eval_batch_size=batch_size,
+ weight_decay=0.01,
+ save_total_limit=3,
+ num_train_epochs=num_train_epochs,
+ predict_with_generate=True,
+ logging_steps=logging_steps,
+ push_to_hub=True,
+)
+```
+
+Здесь аргумент `predict_with_generate` был задан, чтобы указать, что мы должны генерировать резюме во время оценки, чтобы мы могли вычислить баллы ROUGE для каждой эпохи. Как обсуждалось в [Главе 1](../chapter1/1), декодер выполняет инференс, предсказывая токены по одному, и это реализуется методом модели `generate()`. Задание `predict_with_generate=True` указывает `Seq2SeqTrainer` на использование этого метода для оценки. Мы также скорректировали некоторые гиперпараметры по умолчанию, такие как скорость обучения, количество эпох и затухание весов, и задали параметр `save_total_limit`, чтобы сохранять только 3 контрольные точки во время обучения - это сделано потому, что даже "маленькая" версия mT5 использует около Гигабайта места на жестком диске, и мы можем сэкономить немного места, ограничив количество копий, которые мы сохраняем.
+
+Аргумент `push_to_hub=True` позволит нам отправить модель в Hub после обучения; вы найдете розиторий под своим профилем пользователя в месте, определенном `output_dir`. Обратите внимание, что вы можете указать имя розитория, в который хотите отправить модель, с помощью аргумента `hub_model_id` (в частности, вам нужно использовать этот аргумент, чтобы отправить модель в организацию). Например, когда мы отправили модель в организацию [`huggingface-course`](https://huggingface.co/huggingface-course), мы добавили `hub_model_id="huggingface-course/mt5-finetuned-amazon-en-es"` в `Seq2SeqTrainingArguments`.
+
+Следующее, что нам нужно сделать, это предоставить тренеру функцию `compute_metrics()`, чтобы мы могли оценить нашу модель во время обучения. Для суммаризации это немного сложнее, чем просто вызвать `rouge_score.compute()` для прогнозов модели, поскольку нам нужно _декодировать_ выводы и метки в текст, прежде чем мы сможем вычислить оценку ROUGE. Следующая функция делает именно это, а также использует функцию `sent_tokenize()` из `nltk` для разделения предложений резюме символом новой строки:
+
+```python
+import numpy as np
+
+
+def compute_metrics(eval_pred):
+ predictions, labels = eval_pred
+ # Декодируем сгенерированные резюме в текст
+ decoded_preds = tokenizer.batch_decode(predictions, skip_special_tokens=True)
+ # Заменяем -100 в метках, поскольку мы не можем их декодировать
+ labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
+ # Декодируем эталонные резюме в текст
+ decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
+ # ROUGE ожидает символ новой строки после каждого предложения
+ decoded_preds = ["\n".join(sent_tokenize(pred.strip())) for pred in decoded_preds]
+ decoded_labels = ["\n".join(sent_tokenize(label.strip())) for label in decoded_labels]
+ # Вычисляем оценки ROUGE
+ result = rouge_score.compute(
+ predictions=decoded_preds, references=decoded_labels, use_stemmer=True
+ )
+ # Извлекаем медианные оценки
+ result = {key: value.mid.fmeasure * 100 for key, value in result.items()}
+ return {k: round(v, 4) for k, v in result.items()}
+```
+
+{/if}
+
+Далее нам нужно определить коллатор данных для нашей задачи преобразования последовательности в последовательность. Поскольку mT5 является моделью трансформера кодер-декодер, одна из тонкостей подготовки наших батчей заключается в том, что во время декодирования нам нужно сдвинуть метки вправо на единицу. Это необходимо для того, чтобы декодер видел только предыдущие метки, а не текущие или будущие, которые модели было бы легко запомнить. Это похоже на то, как маскированное самовнимание применяется к входным данным в задаче типа [каузального языкового моделирования](../chapter7/6).
+
+К счастью, 🤗 Transformers предоставляет коллатор `DataCollatorForSeq2Seq`, который будет динамически дополнять входные данные и метки за нас. Чтобы инстанцировать этот коллатор, нам просто нужно предоставить `tokenizer` и `model`:
+
+{#if fw === 'pt'}
+
+```python
+from transformers import DataCollatorForSeq2Seq
+
+data_collator = DataCollatorForSeq2Seq(tokenizer, model=model)
+```
+
+{:else}
+
+```python
+from transformers import DataCollatorForSeq2Seq
+
+data_collator = DataCollatorForSeq2Seq(tokenizer, model=model, return_tensors="tf")
+```
+
+{/if}
+
+Давайте посмотрим, что выдает этот коллатор, когда ему передается небольшой батч примеров. Во-первых, нам нужно удалить столбцы со строками, потому что коллатор не будет знать, как вставлять эти элементы:
+
+```python
+tokenized_datasets = tokenized_datasets.remove_columns(
+ books_dataset["train"].column_names
+)
+```
+
+Поскольку коллатор ожидает список словарей `dict`, где каждый словарь `dict` представляет один пример в датасете, нам также необходимо привести данные к ожидаемому формату, прежде чем передавать их коллатору:
+
+```python
+features = [tokenized_datasets["train"][i] for i in range(2)]
+data_collator(features)
+```
+
+```python out
+{'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
+ 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0],
+ [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
+ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]), 'input_ids': tensor([[ 1494, 259, 8622, 390, 259, 262, 2316, 3435, 955,
+ 772, 281, 772, 1617, 263, 305, 14701, 260, 1385,
+ 3031, 259, 24146, 332, 1037, 259, 43906, 305, 336,
+ 260, 1, 0, 0, 0, 0, 0, 0],
+ [ 259, 27531, 13483, 259, 7505, 260, 112240, 15192, 305,
+ 53198, 276, 259, 74060, 263, 260, 459, 25640, 776,
+ 2119, 336, 259, 2220, 259, 18896, 288, 4906, 288,
+ 1037, 3931, 260, 7083, 101476, 1143, 260, 1]]), 'labels': tensor([[ 7483, 259, 2364, 15695, 1, -100],
+ [ 259, 27531, 13483, 259, 7505, 1]]), 'decoder_input_ids': tensor([[ 0, 7483, 259, 2364, 15695, 1],
+ [ 0, 259, 27531, 13483, 259, 7505]])}
+```
+
+Главное, что здесь нужно заметить, - это то, что первый пример длиннее второго, поэтому `input_ids` и `attention_mask` второго примера были дополнены справа токеном `[PAD]` (чей идентификатор равен `0`). Аналогично, мы видим, что `labels` были дополнены значением `-100`, чтобы функция потерь игнорировала токены дополнения. И наконец, мы видим новый `decoder_input_ids`, в котором метки сдвинуты вправо за счет вставки токена `[PAD]` в первую запись.
+
+{#if fw === 'pt'}
+
+Наконец-то у нас есть все необходимые ингредиенты для обучения! Теперь нам нужно просто создать тренер со стандартными аргументами:
+
+```python
+from transformers import Seq2SeqTrainer
+
+trainer = Seq2SeqTrainer(
+ model,
+ args,
+ train_dataset=tokenized_datasets["train"],
+ eval_dataset=tokenized_datasets["validation"],
+ data_collator=data_collator,
+ tokenizer=tokenizer,
+ compute_metrics=compute_metrics,
+)
+```
+
+и запустить наш цикл обучения:
+
+```python
+trainer.train()
+```
+
+Во время обучения вы должны видеть, как потери при обучении уменьшаются, а оценка ROUGE увеличивается с каждой эпохой. После завершения обучения вы можете увидеть итоговую оценку ROUGE, выполнив команду `Trainer.evaluate()`:
+
+```python
+trainer.evaluate()
+```
+
+```python out
+{'eval_loss': 3.028524398803711,
+ 'eval_rouge1': 16.9728,
+ 'eval_rouge2': 8.2969,
+ 'eval_rougeL': 16.8366,
+ 'eval_rougeLsum': 16.851,
+ 'eval_gen_len': 10.1597,
+ 'eval_runtime': 6.1054,
+ 'eval_samples_per_second': 38.982,
+ 'eval_steps_per_second': 4.914}
+```
+
+Из оценок видно, что наша модель значительно превзошла базовый уровень lead-3 - отлично! Осталось отправить веса модели в Hub, как показано ниже:
+
+```
+trainer.push_to_hub(commit_message="Training complete", tags="summarization")
+```
+
+```python out
+'https://huggingface.co/huggingface-course/mt5-finetuned-amazon-en-es/commit/aa0536b829b28e73e1e4b94b8a5aacec420d40e0'
+```
+
+Это позволит сохранить контрольную точку и файлы конфигурации в `output_dir`, а затем загрузить все файлы на Хаб. Указав аргумент `tags`, мы также гарантируем, что виджет на хабе будет предназначен для конвейера суммаризации, а не для конвейера генерации текста по умолчанию, связанного с архитектурой mT5 (более подробную информацию о тегах моделей можно найти в [🤗 документации по Hub](https://huggingface.co/docs/hub/main#how-is-a-models-type-of-inference-api-and-widget-determined)). Вывод `trainer.push_to_hub()` - это URL на хэш Git-коммита, так что вы можете легко увидеть изменения, которые были сделаны в розитории модели!
+
+В завершение этого раздела рассмотрим, как можно дообучить mT5 с помощью низкоуровневых функций, предоставляемых 🤗 Accelerate.
+
+{:else}
+
+Мы почти готовы к обучению! Нам нужно только преобразовать наши датасеты в `tf.data.Dataset` с помощью коллатора данных, который мы определили выше, а затем выолнить `compile()` и `fit()` модели. Сначала датасеты:
+
+```python
+tf_train_dataset = model.prepare_tf_dataset(
+ tokenized_datasets["train"],
+ collate_fn=data_collator,
+ shuffle=True,
+ batch_size=8,
+)
+tf_eval_dataset = model.prepare_tf_dataset(
+ tokenized_datasets["validation"],
+ collate_fn=data_collator,
+ shuffle=False,
+ batch_size=8,
+)
+```
+
+Теперь определяем гиперпараметры обучения и компилируем:
+
+```python
+from transformers import create_optimizer
+import tensorflow as tf
+
+# Количество шагов обучения - это количество примеров в датасете, разделенное на размер батча, затем умноженное
+# на общее количество эпох. Обратите внимание, что tf_train_dataset здесь - это батч tf.data.Dataset,
+# а не оригинальный датасет Hugging Face, поэтому его len() уже равен num_samples // batch_size.
+num_train_epochs = 8
+num_train_steps = len(tf_train_dataset) * num_train_epochs
+model_name = model_checkpoint.split("/")[-1]
+
+optimizer, schedule = create_optimizer(
+ init_lr=5.6e-5,
+ num_warmup_steps=0,
+ num_train_steps=num_train_steps,
+ weight_decay_rate=0.01,
+)
+
+model.compile(optimizer=optimizer)
+
+# Обучение со смешанной точностью float16
+tf.keras.mixed_precision.set_global_policy("mixed_float16")
+```
+
+И наконец, мы подгоняем модель. Мы используем `PushToHubCallback` для сохранения модели на Hub после каждой эпохи, что позволит нам использовать ее позже для инференса:
+
+```python
+from transformers.keras_callbacks import PushToHubCallback
+
+callback = PushToHubCallback(
+ output_dir=f"{model_name}-finetuned-amazon-en-es", tokenizer=tokenizer
+)
+
+model.fit(
+ tf_train_dataset, validation_data=tf_eval_dataset, callbacks=[callback], epochs=8
+)
+```
+
+Мы получили некоторые значения потерь во время обучения, но на самом деле нам хотелось бы увидеть метрику ROUGE, которую мы вычисляли ранее. Чтобы получить эти метрики, нам нужно сгенерировать выходные данные модели и преобразовать их в строки. Давайте создадим несколько списков меток и прогнозов для сравнения с метрикой ROUGE (обратите внимание, что если вы получаете ошибки импорта в этом разделе, вам может понадобиться команда `!pip install tqdm`). Мы также используем трюк, который значительно повышает производительность, - компиляцию генерируемого кода с помощью [XLA](https://www.tensorflow.org/xla), ускоренного компилятора линейной алгебры TensorFlow. XLA применяет различные оптимизации к графу вычислений модели, что приводит к значительному увеличению скорости и использования памяти. Как описано в Hugging Face [блоге](https://huggingface.co/blog/tf-xla-generate), XLA работает лучше всего, когда формы наших входных данных не слишком сильно различаются. Чтобы справиться с этим, мы дополним наши входные данные до кратных 128 и создадим новый датасет с помощью дополняющего коллатора, а затем применим декоратор `@tf.function(jit_compile=True)` к нашей функции генерации, который помечает всю функцию для компиляции с помощью XLA.
+
+```python
+from tqdm import tqdm
+import numpy as np
+
+generation_data_collator = DataCollatorForSeq2Seq(
+ tokenizer, model=model, return_tensors="tf", pad_to_multiple_of=320
+)
+
+tf_generate_dataset = model.prepare_tf_dataset(
+ tokenized_datasets["validation"],
+ collate_fn=generation_data_collator,
+ shuffle=False,
+ batch_size=8,
+ drop_remainder=True,
+)
+
+
+@tf.function(jit_compile=True)
+def generate_with_xla(batch):
+ return model.generate(
+ input_ids=batch["input_ids"],
+ attention_mask=batch["attention_mask"],
+ max_new_tokens=32,
+ )
+
+
+all_preds = []
+all_labels = []
+for batch, labels in tqdm(tf_generate_dataset):
+ predictions = generate_with_xla(batch)
+ decoded_preds = tokenizer.batch_decode(predictions, skip_special_tokens=True)
+ labels = labels.numpy()
+ labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
+ decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
+ decoded_preds = ["\n".join(sent_tokenize(pred.strip())) for pred in decoded_preds]
+ decoded_labels = ["\n".join(sent_tokenize(label.strip())) for label in decoded_labels]
+ all_preds.extend(decoded_preds)
+ all_labels.extend(decoded_labels)
+```
+
+Когда у нас есть списки строк меток и прогнозов, вычислить оценку ROUGE очень просто:
+
+```python
+result = rouge_score.compute(
+ predictions=decoded_preds, references=decoded_labels, use_stemmer=True
+)
+result = {key: value.mid.fmeasure * 100 for key, value in result.items()}
+{k: round(v, 4) for k, v in result.items()}
+```
+
+```
+{'rouge1': 31.4815, 'rouge2': 25.4386, 'rougeL': 31.4815, 'rougeLsum': 31.4815}
+```
+
+
+{/if}
+
+{#if fw === 'pt'}
+
+## Дообучение mT5 с 🤗 Accelerate[[fine-tuning-mt5-with-accelerate]]
+
+Дообучение нашей модели с помощью 🤗 Accelerate очень похоже на пример с классификацией текста, который мы рассматривали в [Главе 3](../chapter3/1). Основные отличия заключаются в необходимости явной генерации резюме во время обучения и определении способа вычисления оценок ROUGE (напомним, что `Seq2SeqTrainer` позаботился о генерации за нас). Давайте посмотрим, как мы можем реализовать эти два требования в 🤗 Accelerate!
+
+### Подготовка всего к обучению[[preparing-everything-for-training]]
+
+Первое, что нам нужно сделать, это создать `DataLoader` для каждой из наших частей. Поскольку загрузчики данных PyTorch ожидают батч тензоров, нам нужно задать формат `"torch"` в наших датасетах:
+
+```python
+tokenized_datasets.set_format("torch")
+```
+
+Теперь, когда у нас есть датасеты, состоящие только из тензоров, следующее, что нужно сделать, - это снова инстанцировать `DataCollatorForSeq2Seq`. Для этого нам нужно предоставить свежую версию модели, поэтому давайте снова загрузим ее из нашего кэша:
+
+```python
+model = AutoModelForSeq2SeqLM.from_pretrained(model_checkpoint)
+```
+
+Затем мы можем инстанцировать коллатор данных и использовать его для определения наших загрузчиков данных:
+
+```python
+from torch.utils.data import DataLoader
+
+batch_size = 8
+train_dataloader = DataLoader(
+ tokenized_datasets["train"],
+ shuffle=True,
+ collate_fn=data_collator,
+ batch_size=batch_size,
+)
+eval_dataloader = DataLoader(
+ tokenized_datasets["validation"], collate_fn=data_collator, batch_size=batch_size
+)
+```
+
+Следующее, что нужно сделать, это определить оптимизатор, который мы хотим использовать. Как и в других наших примерах, мы будем использовать `AdamW`, который хорошо работает для большинства задач:
+
+```python
+from torch.optim import AdamW
+
+optimizer = AdamW(model.parameters(), lr=2e-5)
+```
+
+Наконец, мы передаем нашу модель, оптимизатор и загрузчики данных в метод `accelerator.prepare()`:
+
+```python
+from accelerate import Accelerator
+
+accelerator = Accelerator()
+model, optimizer, train_dataloader, eval_dataloader = accelerator.prepare(
+ model, optimizer, train_dataloader, eval_dataloader
+)
+```
+
+
+
+🚨 Если вы обучаете на TPU, вам нужно будет перенести весь приведенный выше код в специальную функцию обучения. Подробнее смотрите в [Главе 3](../chapter3/1).
+
+
+
+Теперь, когда мы подготовили наши объекты, осталось сделать три вещи:
+
+* Определить график скорости обучения.
+* Реализовать функцию для постобработки резюме для оценки.
+* Создать розиторий на Hub, в который мы можем отправить нашу модель.
+
+В качестве графика скорости обучения мы будем использовать стандартный линейный график из предыдущих разделов:
+
+```python
+from transformers import get_scheduler
+
+num_train_epochs = 10
+num_update_steps_per_epoch = len(train_dataloader)
+num_training_steps = num_train_epochs * num_update_steps_per_epoch
+
+lr_scheduler = get_scheduler(
+ "linear",
+ optimizer=optimizer,
+ num_warmup_steps=0,
+ num_training_steps=num_training_steps,
+)
+```
+
+Для постобработки нам нужна функция, которая разбивает сгенерированные резюме на предложения, разделенные символами новой строки. Именно такой формат ожидает метрика ROUGE, и мы можем достичь этого с помощью следующего фрагмента кода:
+
+```python
+def postprocess_text(preds, labels):
+ preds = [pred.strip() for pred in preds]
+ labels = [label.strip() for label in labels]
+
+ # ROUGE ожидает символ новой строки после каждого предложения
+ preds = ["\n".join(nltk.sent_tokenize(pred)) for pred in preds]
+ labels = ["\n".join(nltk.sent_tokenize(label)) for label in labels]
+
+ return preds, labels
+```
+
+Это должно показаться вам знакомым, если вы помните, как мы определяли функцию `compute_metrics()` для `Seq2SeqTrainer`.
+
+Наконец, нам нужно создать розиторий модели на Hugging Face Hub. Для этого мы можем использовать библиотеку 🤗Hub с соответствующим заголовком. Нам нужно только задать имя нашего розитория, а в библиотеке есть служебная функция для объединения идентификатора розитория с профилем пользователя:
+
+```python
+from huggingface_hub import get_full_repo_name
+
+model_name = "test-bert-finetuned-squad-accelerate"
+repo_name = get_full_repo_name(model_name)
+repo_name
+```
+
+```python out
+'lewtun/mt5-finetuned-amazon-en-es-accelerate'
+```
+
+Теперь мы можем использовать имя этого розитория для клонирования локальной версии в каталог результатов, в котором будут храниться результаты обучения:
+
+```python
+from huggingface_hub import Repository
+
+output_dir = "results-mt5-finetuned-squad-accelerate"
+repo = Repository(output_dir, clone_from=repo_name)
+```
+
+Это позволит нам отправить результаты в Hub, вызвав метод `repo.push_to_hub()` во время обучения! Теперь давайте завершим наш анализ, написав цикл обучения.
+
+### Цикл обучения[[training-loop]]
+
+Цикл обучения суммаризации очень похож на другие примеры 🤗 Accelerate, с которыми мы сталкивались, и состоит из четырех основных этапов:
+
+1. Обучение модели путем итерации по всем примерам в `train_dataloader` на каждой эпохе.
+2. Генерация резюме моделью в конце каждой эпохи, сначала генерируются токены, а затем они (и эталонные резюме) декодируются в текст.
+3. Вычисление оценок ROUGE с помощью тех же приемов, которые мы рассмотрели ранее.
+4. Сохранение контрольных точек и отправка всего в Hub. Здесь мы полагаемся на полезный аргумент `blocking=False` объекта `Repository`, чтобы мы могли отправить контрольные точки на каждой эпохе _асинхронно_. Это позволяет нам продолжать обучение, не дожидаясь медленной загрузки, связанной с моделью размером в гигабайт!
+
+Эти шаги можно увидеть в следующем блоке кода:
+
+```python
+from tqdm.auto import tqdm
+import torch
+import numpy as np
+
+progress_bar = tqdm(range(num_training_steps))
+
+for epoch in range(num_train_epochs):
+ # Обучение
+ model.train()
+ for step, batch in enumerate(train_dataloader):
+ outputs = model(**batch)
+ loss = outputs.loss
+ accelerator.backward(loss)
+
+ optimizer.step()
+ lr_scheduler.step()
+ optimizer.zero_grad()
+ progress_bar.update(1)
+
+ # Оценка
+ model.eval()
+ for step, batch in enumerate(eval_dataloader):
+ with torch.no_grad():
+ generated_tokens = accelerator.unwrap_model(model).generate(
+ batch["input_ids"],
+ attention_mask=batch["attention_mask"],
+ )
+
+ generated_tokens = accelerator.pad_across_processes(
+ generated_tokens, dim=1, pad_index=tokenizer.pad_token_id
+ )
+ labels = batch["labels"]
+
+ # Если мы не дополнили до максимальной длины, нам нужно дополнить и метки
+ labels = accelerator.pad_across_processes(
+ batch["labels"], dim=1, pad_index=tokenizer.pad_token_id
+ )
+
+ generated_tokens = accelerator.gather(generated_tokens).cpu().numpy()
+ labels = accelerator.gather(labels).cpu().numpy()
+
+ # Заменяем -100 в метках, поскольку мы не можем их декодировать
+ labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
+ if isinstance(generated_tokens, tuple):
+ generated_tokens = generated_tokens[0]
+ decoded_preds = tokenizer.batch_decode(
+ generated_tokens, skip_special_tokens=True
+ )
+ decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
+
+ decoded_preds, decoded_labels = postprocess_text(
+ decoded_preds, decoded_labels
+ )
+
+ rouge_score.add_batch(predictions=decoded_preds, references=decoded_labels)
+
+ # Вычисляем метрики
+ result = rouge_score.compute()
+ # Извлекаем медианные оценки ROUGE
+ result = {key: value.mid.fmeasure * 100 for key, value in result.items()}
+ result = {k: round(v, 4) for k, v in result.items()}
+ print(f"Epoch {epoch}:", result)
+
+ # Сохранение и загрузка
+ accelerator.wait_for_everyone()
+ unwrapped_model = accelerator.unwrap_model(model)
+ unwrapped_model.save_pretrained(output_dir, save_function=accelerator.save)
+ if accelerator.is_main_process:
+ tokenizer.save_pretrained(output_dir)
+ repo.push_to_hub(
+ commit_message=f"Training in progress epoch {epoch}", blocking=False
+ )
+```
+
+```python out
+Epoch 0: {'rouge1': 5.6351, 'rouge2': 1.1625, 'rougeL': 5.4866, 'rougeLsum': 5.5005}
+Epoch 1: {'rouge1': 9.8646, 'rouge2': 3.4106, 'rougeL': 9.9439, 'rougeLsum': 9.9306}
+Epoch 2: {'rouge1': 11.0872, 'rouge2': 3.3273, 'rougeL': 11.0508, 'rougeLsum': 10.9468}
+Epoch 3: {'rouge1': 11.8587, 'rouge2': 4.8167, 'rougeL': 11.7986, 'rougeLsum': 11.7518}
+Epoch 4: {'rouge1': 12.9842, 'rouge2': 5.5887, 'rougeL': 12.7546, 'rougeLsum': 12.7029}
+Epoch 5: {'rouge1': 13.4628, 'rouge2': 6.4598, 'rougeL': 13.312, 'rougeLsum': 13.2913}
+Epoch 6: {'rouge1': 12.9131, 'rouge2': 5.8914, 'rougeL': 12.6896, 'rougeLsum': 12.5701}
+Epoch 7: {'rouge1': 13.3079, 'rouge2': 6.2994, 'rougeL': 13.1536, 'rougeLsum': 13.1194}
+Epoch 8: {'rouge1': 13.96, 'rouge2': 6.5998, 'rougeL': 13.9123, 'rougeLsum': 13.7744}
+Epoch 9: {'rouge1': 14.1192, 'rouge2': 7.0059, 'rougeL': 14.1172, 'rougeLsum': 13.9509}
+```
+
+Вот и все! После запуска у вас будет модель и результаты, очень похожие на те, что мы получили с помощью `Trainer`.
+
+{/if}
+
+## Использование дообученной вами модели[[using-your-fine-tuned-model]]
+
+После того как вы отправили модель в Hub, вы можете работать с ней либо с помощью виджета инференса, либо с помощью объекта `pipeline`, как показано ниже:
+
+```python
+from transformers import pipeline
+
+hub_model_id = "huggingface-course/mt5-small-finetuned-amazon-en-es"
+summarizer = pipeline("summarization", model=hub_model_id)
+```
+
+Мы можем передать в наш конвейер несколько примеров из тестового набора (которые модель не видела), чтобы получить представление о качестве резюме. Для начала давайте реализуем простую функцию, которая будет показывать обзор, заголовок и сгенерированное резюме вместе:
+
+```python
+def print_summary(idx):
+ review = books_dataset["test"][idx]["review_body"]
+ title = books_dataset["test"][idx]["review_title"]
+ summary = summarizer(books_dataset["test"][idx]["review_body"])[0]["summary_text"]
+ print(f"'>>> Review: {review}'")
+ print(f"\n'>>> Title: {title}'")
+ print(f"\n'>>> Summary: {summary}'")
+```
+
+Давайте посмотрим на один из английских примеров, которые мы получаем:
+
+```python
+print_summary(100)
+```
+
+```python out
+'>>> Review: Nothing special at all about this product... the book is too small and stiff and hard to write in. The huge sticker on the back doesn’t come off and looks super tacky. I would not purchase this again. I could have just bought a journal from the dollar store and it would be basically the same thing. It’s also really expensive for what it is.'
+
+'>>> Title: Not impressed at all... buy something else'
+
+'>>> Summary: Nothing special at all about this product'
+```
+
+Это не так уж плохо! Мы видим, что наша модель действительно способна выполнять _абстрактную_ суммуризацию, дополняя части обзора новыми словами. И, пожалуй, самый интересный аспект нашей модели - это то, что она билингвистическая, так что мы можем генерировать резюме и для испанских рецензий:
+
+```python
+print_summary(0)
+```
+
+```python out
+'>>> Review: Es una trilogia que se hace muy facil de leer. Me ha gustado, no me esperaba el final para nada'
+
+'>>> Title: Buena literatura para adolescentes'
+
+'>>> Summary: Muy facil de leer'
+```
+
+Резюме переводится как "Very easy to read" на английском языке, что, как мы видим, в данном случае было непосредственно взято из обзора. Тем не менее, это демонстрирует универсальность модели mT5 и дает вам представление о том, каково это - работать с многоязычным корпусом!
+
+Далее мы обратимся к несколько более сложной задаче: обучению языковой модели с нуля.
diff --git a/chapters/ru/chapter7/6.mdx b/chapters/ru/chapter7/6.mdx
new file mode 100644
index 000000000..6ade23c1c
--- /dev/null
+++ b/chapters/ru/chapter7/6.mdx
@@ -0,0 +1,914 @@
+
+
+# Обучение каузальной языковой модели с нуля[[training-a-causal-language-model-from-scratch]]
+
+{#if fw === 'pt'}
+
+
+
+{:else}
+
+
+
+{/if}
+
+До сих пор мы в основном использовали предварительно обученные модели и осуществляли их дообучение для новых случаев использования, повторно используя веса, полученные в ходе предварительного обучения. Как мы видели в [Главе 1](../chapter1/1), это принято называть _трансферным обучением_, и это очень успешная стратегия применения моделей Transformer для большинства реальных случаев использования, когда размеченных данных недостаточно. В этой главе мы применим другой подход и обучим совершенно новую модель с нуля. Это хороший подход, если у вас много данных, и они сильно отличаются от данных предварительного обучения, используемых для имеющихся моделей. Однако предварительное обучение языковой модели требует значительно больше вычислительных ресурсов, чем дообучение существующей. Примеры, когда имеет смысл обучать новую модель, включают датасеты, состоящие из музыкальных нот, молекулярных последовательностей, таких как ДНК, или языков программирования. Последние в недавнее время получили широкое распространение благодаря таким инструментам, как TabNine и GitHub's Copilot, работающим на основе модели Codex от OpenAI, которые могут генерировать длинные последовательности кода. Для решения этой задачи генерации текста лучше всего подходят авторегрессионные или каузальные языковые модели, такие как GPT-2.
+
+В этом разделе мы построим уменьшенную версию модели генерации кода: мы сосредоточимся на однострочных завершениях вместо полных функций или классов, используя подмножество кода Python. Работая с данными на Python, вы часто сталкиваетесь со стеком Data Science на Python, состоящем из библиотек `matplotlib`, `seaborn`, `pandas` и `scikit-learn`. При использовании этих фреймворков часто возникает необходимость поиска определенных команд, поэтому было бы неплохо, если бы мы могли использовать модель выполненяющую эти вызововы за нас.
+
+
+
+В [Главе 6](../chapter6/1) мы создали эффективный токенизатор для обработки исходного кода Python, но нам все еще нужен крупный датасет для предварительного обучения модели. Здесь мы применим наш токенизатор к корпусу кода Python, полученному из розиториев GitHub. Затем мы воспользуемся API `Trainer` и 🤗 Accelerate для обучения модели. Приступим!
+
+
+
+На самом деле это демонстрация модели, которая была обучена и загружена в Hub с помощью кода, приведенного в этом разделе. Вы можете найти ее [здесь](https://huggingface.co/huggingface-course/codeparrot-ds?text=plt.imshow%28). Обратите внимание, что поскольку при генерации текста происходит некоторая рандомизация, вы, вероятно, получите немного другой результат.
+
+## Сбор данных[[gathering-the-data]]
+
+Код на Python в изобилии доступен в таких репозиториях кода, как GitHub, и мы можем использовать его для создания датасета путем поиска каждого розитория Python. Именно такой подход был использован в книге [Transformers textbook](https://learning.oreilly.com/library/view/natural-language-processing/9781098136789/) для предварительного обучения большой модели GPT-2. Используя дамп GitHub объемом около 180 ГБ, содержащий примерно 20 миллионов файлов Python под названием `codeparrot`, авторы создали датасет, которым затем поделились на [Hugging Face Hub](https://huggingface.co/datasets/transformersbook/codeparrot).
+
+Однако обучение на полном корпусе требует много времени и вычислений, а нам нужно только подмножество датасетов, связанных со стеком data science на Python. Итак, давайте начнем с фильтрации датасета `codeparrot` по всем файлам, включающим любую из библиотек из этого стека. Из-за большого размера датасета мы хотим избежать его загрузки; вместо этого мы будем использовать функцию потоковой передачи (streaming), чтобы фильтровать его на лету. Чтобы помочь нам отфильтровать примеры кода с использованием библиотек, о которых мы говорили ранее, мы воспользуемся следующей функцией:
+
+```py
+def any_keyword_in_string(string, keywords):
+ for keyword in keywords:
+ if keyword in string:
+ return True
+ return False
+```
+
+Давайте протестируем ее на двух примерах:
+
+```py
+filters = ["pandas", "sklearn", "matplotlib", "seaborn"]
+example_1 = "import numpy as np"
+example_2 = "import pandas as pd"
+
+print(
+ any_keyword_in_string(example_1, filters), any_keyword_in_string(example_2, filters)
+)
+```
+
+```python out
+False True
+```
+
+Мы можем использовать ее для создания функции, которая будет передавать датасет и отфильтровывать нужные нам элементы:
+
+```py
+from collections import defaultdict
+from tqdm import tqdm
+from datasets import Dataset
+
+
+def filter_streaming_dataset(dataset, filters):
+ filtered_dict = defaultdict(list)
+ total = 0
+ for sample in tqdm(iter(dataset)):
+ total += 1
+ if any_keyword_in_string(sample["content"], filters):
+ for k, v in sample.items():
+ filtered_dict[k].append(v)
+ print(f"{len(filtered_dict['content'])/total:.2%} of data after filtering.")
+ return Dataset.from_dict(filtered_dict)
+```
+
+Затем мы можем просто применить эту функцию к потоковому датасету:
+
+```py
+# Выполнение этой ячейки займет очень много времени, поэтому ее следует пропустить и перейти к
+# следующей!
+from datasets import load_dataset
+
+split = "train" # "valid"
+filters = ["pandas", "sklearn", "matplotlib", "seaborn"]
+
+data = load_dataset(f"transformersbook/codeparrot-{split}", split=split, streaming=True)
+filtered_data = filter_streaming_dataset(data, filters)
+```
+
+```python out
+3.26% of data after filtering.
+```
+
+Таким образом, у нас остается около 3% от исходного датасета, что все равно довольно много - результирующий датасет занимает 6 ГБ и состоит из 600 000 Python-скриптов!
+
+Фильтрация полного датасета может занять 2-3 часа в зависимости от вашей машины и пропускной способности сети. Если вы не хотите выполнять этот длительный процесс самостоятельно, мы предоставляем отфильтрованный датасет на Hub для загрузки:
+
+```py
+from datasets import load_dataset, DatasetDict
+
+ds_train = load_dataset("huggingface-course/codeparrot-ds-train", split="train")
+ds_valid = load_dataset("huggingface-course/codeparrot-ds-valid", split="validation")
+
+raw_datasets = DatasetDict(
+ {
+ "train": ds_train, # .shuffle().select(range(50000)),
+ "valid": ds_valid, # .shuffle().select(range(500))
+ }
+)
+
+raw_datasets
+```
+
+```python out
+DatasetDict({
+ train: Dataset({
+ features: ['repo_name', 'path', 'copies', 'size', 'content', 'license'],
+ num_rows: 606720
+ })
+ valid: Dataset({
+ features: ['repo_name', 'path', 'copies', 'size', 'content', 'license'],
+ num_rows: 3322
+ })
+})
+```
+
+
+
+Предварительное обучение языковой модели займет некоторое время. Мы рекомендуем сначала запустить цикл обучения на выборке данных, раскомментировав две частичные строки выше, и убедиться, что обучение успешно завершено и модели сохранены. Нет ничего обиднее, чем неудачное обучение на последнем этапе из-за того, что вы забыли создать папку или из-за опечатки в конце цикла обучения!
+
+
+
+Давайте рассмотрим пример из датасета. Мы покажем только первые 200 символов каждого поля:
+
+```py
+for key in raw_datasets["train"][0]:
+ print(f"{key.upper()}: {raw_datasets['train'][0][key][:200]}")
+```
+
+```python out
+'REPO_NAME: kmike/scikit-learn'
+'PATH: sklearn/utils/__init__.py'
+'COPIES: 3'
+'SIZE: 10094'
+'''CONTENT: """
+The :mod:`sklearn.utils` module includes various utilites.
+"""
+
+from collections import Sequence
+
+import numpy as np
+from scipy.sparse import issparse
+import warnings
+
+from .murmurhash import murm
+LICENSE: bsd-3-clause'''
+```
+
+Мы видим, что поле `content` содержит код, на котором мы хотим обучить нашу модель. Теперь, когда у нас есть датасет, нам нужно подготовить тексты, чтобы они были в формате, подходящем для предварительного обучения.
+
+## Подготовка датасета[[preparing-the-dataset]]
+
+
+
+Первым шагом будет токенизация данных, чтобы мы могли использовать их для обучения. Поскольку наша цель - автозаполнение коротких вызовов функций, мы можем оставить размер контекста относительно небольшим. Благодаря этому мы сможем обучать модель гораздо быстрее, и она будет занимать значительно меньше памяти. Если для вашего приложения важно, чтобы контекст был больше (например, если вы хотите, чтобы модель писала юнит-тесты на основе файла с определением функции), обязательно увеличьте это число, но не забывайте, что это приведет к увеличению объема памяти GPU. Пока что давайте зафиксируем размер контекста на 128 токенов, в отличие от 1 024 или 2 048, используемых в GPT-2 или GPT-3 соответственно.
+
+Большинство документов содержит гораздо больше 128 токенов, поэтому простое обрезание входных данных до максимальной длины приведет к тому, что большая часть нашего датасета будет удалена. Вместо этого мы используем параметр `return_overflowing_tokens` для токенизации всего ввода и разбиения его на части, как мы делали в [Главе 6](../chapter6/4). Мы также будем использовать параметр `return_length`, чтобы автоматически возвращать длину каждого созданного фрагмента. Часто последний фрагмент будет меньше размера контекста, и мы избавимся от этих фрагментов, чтобы избежать проблем с дополнением; на самом деле они нам не нужны, поскольку у нас и так много данных.
+
+
+

+

+
+
+Давайте посмотрим, как это работает, на первых двух примерах:
+
+```py
+from transformers import AutoTokenizer
+
+context_length = 128
+tokenizer = AutoTokenizer.from_pretrained("huggingface-course/code-search-net-tokenizer")
+
+outputs = tokenizer(
+ raw_datasets["train"][:2]["content"],
+ truncation=True,
+ max_length=context_length,
+ return_overflowing_tokens=True,
+ return_length=True,
+)
+
+print(f"Input IDs length: {len(outputs['input_ids'])}")
+print(f"Input chunk lengths: {(outputs['length'])}")
+print(f"Chunk mapping: {outputs['overflow_to_sample_mapping']}")
+```
+
+```python out
+Input IDs length: 34
+Input chunk lengths: [128, 128, 128, 128, 128, 128, 128, 128, 128, 128, 128, 128, 128, 128, 128, 128, 128, 128, 128, 117, 128, 128, 128, 128, 128, 128, 128, 128, 128, 128, 128, 128, 128, 41]
+Chunk mapping: [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
+```
+
+Из этих двух примеров видно, что в общей сложности мы получили 34 сегмента. Взглянув на длину фрагментов, мы видим, что фрагменты в конце обоих документов содержат менее 128 токенов (117 и 41, соответственно). Это лишь малая часть всех имеющихся у нас фрагментов, поэтому мы можем смело отбросить их. С помощью поля `overflow_to_sample_mapping` мы также можем восстановить, какие фрагменты принадлежали каким входным примерам.
+
+В этой операции мы используем удобную особенность функции `Dataset.map()` из 🤗 Datasets, которая заключается в том, что она не требует отображения один к одному; как мы видели в [разделе 3](../chapter7/3), мы можем создавать батч с большим или меньшим количеством элементов, чем входной батч. Это полезно при выполнении таких операций, как аугментация или фильтрация данных, которые изменяют количество элементов. В нашем случае при токенизации каждого элемента на фрагменты заданного размера контекста мы создаем много примеров из каждого документа. Нам просто нужно убедиться, что мы удалили существующие столбцы, поскольку они имеют противоречивый размер. Если бы мы хотели их сохранить, то могли бы повторить их соответствующим образом и вернуть в рамках вызова `Dataset.map()`:
+
+```py
+def tokenize(element):
+ outputs = tokenizer(
+ element["content"],
+ truncation=True,
+ max_length=context_length,
+ return_overflowing_tokens=True,
+ return_length=True,
+ )
+ input_batch = []
+ for length, input_ids in zip(outputs["length"], outputs["input_ids"]):
+ if length == context_length:
+ input_batch.append(input_ids)
+ return {"input_ids": input_batch}
+
+
+tokenized_datasets = raw_datasets.map(
+ tokenize, batched=True, remove_columns=raw_datasets["train"].column_names
+)
+tokenized_datasets
+```
+
+```python out
+DatasetDict({
+ train: Dataset({
+ features: ['input_ids'],
+ num_rows: 16702061
+ })
+ valid: Dataset({
+ features: ['input_ids'],
+ num_rows: 93164
+ })
+})
+```
+
+Теперь у нас есть 16,7 миллиона примеров со 128 токенами в каждом, что соответствует примерно 2,1 миллиарда токенов в общей сложности. Для сравнения, модели OpenAI GPT-3 и Codex обучены на 300 и 100 миллиардах токенов соответственно, причем модели Codex инициализируются из контрольных точек GPT-3. Наша цель в этом разделе - не конкурировать с этими моделями, которые могут генерировать длинные, связные тексты, а создать уменьшенную версию, обеспечивающую быструю функцию автозаполнения для специалистов по обработке данных.
+
+Теперь, когда у нас есть готовый датасет, давайте создадим модель!
+
+
+
+✏️ **Попробуйте!** Избавление от всех фрагментов, размер которых меньше размера контекста, не является большой проблемой, поскольку мы используем небольшие контекстные окна. При увеличении размера контекста (или если у вас корпус коротких документов) доля отбрасываемых фрагментов также будет расти. Более эффективный способ подготовки данных - объединить все токенизированные примеры в батч с маркером `eos_token_id` между ними, а затем выполнить фрагментацию на конкатенированных последовательностях. В качестве упражнения измените функцию `tokenize()`, чтобы использовать этот подход. Обратите внимание, что вам нужно установить `truncation=False` и удалить другие аргументы из токенизатора, чтобы получить полную последовательность идентификаторов токенов.
+
+
+
+
+## Инициализация новой модели[[initializing-a-new-model]]
+
+Наш первый шаг - инициализация свежей модели GPT-2. Мы будем использовать ту же конфигурацию для нашей модели, что и для маленькой модели GPT-2, поэтому загрузим предварительно обученную конфигурацию, убедимся, что размер токенизатора соответствует размеру словарного запаса модели, и передадим идентификаторы токенов `bos` и `eos` (начало и конец последовательности):
+
+{#if fw === 'pt'}
+
+```py
+from transformers import AutoTokenizer, GPT2LMHeadModel, AutoConfig
+
+config = AutoConfig.from_pretrained(
+ "gpt2",
+ vocab_size=len(tokenizer),
+ n_ctx=context_length,
+ bos_token_id=tokenizer.bos_token_id,
+ eos_token_id=tokenizer.eos_token_id,
+)
+```
+
+С этой конфигурацией мы можем загрузить новую модель. Обратите внимание, что впервые мы не используем функцию `from_pretrained()`, поскольку фактически инициализируем модель самостоятельно:
+
+```py
+model = GPT2LMHeadModel(config)
+model_size = sum(t.numel() for t in model.parameters())
+print(f"GPT-2 size: {model_size/1000**2:.1f}M parameters")
+```
+
+```python out
+GPT-2 size: 124.2M parameters
+```
+
+{:else}
+
+```py
+from transformers import AutoTokenizer, TFGPT2LMHeadModel, AutoConfig
+
+config = AutoConfig.from_pretrained(
+ "gpt2",
+ vocab_size=len(tokenizer),
+ n_ctx=context_length,
+ bos_token_id=tokenizer.bos_token_id,
+ eos_token_id=tokenizer.eos_token_id,
+)
+```
+
+С этой конфигурацией мы можем загрузить новую модель. Обратите внимание, что впервые мы не используем функцию `from_pretrained()`, поскольку фактически инициализируем модель самостоятельно:
+
+```py
+model = TFGPT2LMHeadModel(config)
+model(model.dummy_inputs) # Создание модели
+model.summary()
+```
+
+```python out
+_________________________________________________________________
+Layer (type) Output Shape Param #
+=================================================================
+transformer (TFGPT2MainLayer multiple 124242432
+=================================================================
+Total params: 124,242,432
+Trainable params: 124,242,432
+Non-trainable params: 0
+_________________________________________________________________
+```
+
+{/if}
+
+Наша модель имеет 124 миллиона параметров, которые нам предстоит дообучить. Прежде чем начать обучение, нам нужно настроить коллатор данных, который займется созданием батчей. Мы можем использовать коллатор `DataCollatorForLanguageModeling`, который разработан специально для языкового моделирования (о чем недвусмысленно говорит его название). Помимо стекирования и дополнения батчей, он также заботится о создании меток языковой модели - в каузальном языковом моделировании входы тоже служат метками (просто сдвинутыми на один элемент), и этот коллатор данных создает их на лету во время обучения, так что нам не нужно дублировать `input_ids`.
+
+Обратите внимание, что `DataCollatorForLanguageModeling` поддерживает как маскированное языковое моделирование (masked language modeling - MLM), так и каузальное языковое моделирование (causal language modeling - CLM). По умолчанию он подготавливает данные для MLM, но мы можем переключиться на CLM, задав аргумент `mlm=False`:
+
+{#if fw === 'pt'}
+
+```py
+from transformers import DataCollatorForLanguageModeling
+
+tokenizer.pad_token = tokenizer.eos_token
+data_collator = DataCollatorForLanguageModeling(tokenizer, mlm=False)
+```
+
+{:else}
+
+```py
+from transformers import DataCollatorForLanguageModeling
+
+tokenizer.pad_token = tokenizer.eos_token
+data_collator = DataCollatorForLanguageModeling(tokenizer, mlm=False, return_tensors="tf")
+```
+
+{/if}
+
+Давайте посмотрим на пример:
+
+```py
+out = data_collator([tokenized_datasets["train"][i] for i in range(5)])
+for key in out:
+ print(f"{key} shape: {out[key].shape}")
+```
+
+{#if fw === 'pt'}
+
+```python out
+input_ids shape: torch.Size([5, 128])
+attention_mask shape: torch.Size([5, 128])
+labels shape: torch.Size([5, 128])
+```
+
+{:else}
+
+```python out
+input_ids shape: (5, 128)
+attention_mask shape: (5, 128)
+labels shape: (5, 128)
+```
+
+{/if}
+
+Мы видим, что примеры были стекированы, и все тензоры имеют одинаковую форму.
+
+{#if fw === 'tf'}
+
+Теперь мы можем использовать метод `prepare_tf_dataset()` для преобразования наших датасетов в датасеты TensorFlow с помощью коллатора данных, который мы создали выше:
+
+```python
+tf_train_dataset = model.prepare_tf_dataset(
+ tokenized_dataset["train"],
+ collate_fn=data_collator,
+ shuffle=True,
+ batch_size=32,
+)
+tf_eval_dataset = model.prepare_tf_dataset(
+ tokenized_dataset["valid"],
+ collate_fn=data_collator,
+ shuffle=False,
+ batch_size=32,
+)
+```
+
+{/if}
+
+
+
+⚠️ Сдвиг входов и меток для их выравнивания происходит внутри модели, поэтому коллатор данных просто копирует входы для создания меток.
+
+
+
+
+Теперь у нас есть все необходимое для обучения нашей модели - в конце концов, это было не так уж и сложно! Прежде чем приступить к обучению, мы должны войти в Hugging Face. Если вы работаете в блокноте, вы можете сделать это с помощью следующей служебной функции:
+
+```python
+from huggingface_hub import notebook_login
+
+notebook_login()
+```
+
+Появится виджет, в котором вы можете ввести свои учетные данные для входа в Hugging Face.
+
+Если вы работаете не в блокноте, просто введите следующую строку в терминале:
+
+```bash
+huggingface-cli login
+```
+
+{#if fw === 'pt'}
+
+Осталось только настроить аргументы обучения и запустить `Trainer`. Мы будем использовать косинусный график скорости обучения с некоторым разогревом (warmup) и эффективным размером батча в 256 (`per_device_train_batch_size` * `gradient_accumulation_steps`). Аккумулирование градиента используется, когда один батч не помещается в память, и инкрементально накапливает градиент за несколько проходов вперед/назад. Мы увидим это в действии, когда создадим цикл обучения с использованием 🤗 Accelerate.
+
+```py
+from transformers import Trainer, TrainingArguments
+
+args = TrainingArguments(
+ output_dir="codeparrot-ds",
+ per_device_train_batch_size=32,
+ per_device_eval_batch_size=32,
+ evaluation_strategy="steps",
+ eval_steps=5_000,
+ logging_steps=5_000,
+ gradient_accumulation_steps=8,
+ num_train_epochs=1,
+ weight_decay=0.1,
+ warmup_steps=1_000,
+ lr_scheduler_type="cosine",
+ learning_rate=5e-4,
+ save_steps=5_000,
+ fp16=True,
+ push_to_hub=True,
+)
+
+trainer = Trainer(
+ model=model,
+ tokenizer=tokenizer,
+ args=args,
+ data_collator=data_collator,
+ train_dataset=tokenized_datasets["train"],
+ eval_dataset=tokenized_datasets["valid"],
+)
+```
+
+Теперь мы можем просто запустить `Trainer` и дождаться окончания обучения. В зависимости от того, запустите ли вы его на полном или на подмножестве обучающего набора, это займет 20 или 2 часа соответственно, так что захватите несколько чашек кофе и хорошую книгу для чтения!
+
+```py
+trainer.train()
+```
+
+После завершения обучения мы можем отправить модель и токенизатор в Hub:
+
+```py
+trainer.push_to_hub()
+```
+
+{:else}
+
+Осталось только настроить гиперпараметры обучения и вызвать `compile()` и `fit()`. Мы будем использовать график скорости обучения с некоторым разогревом, чтобы повысить стабильность обучения:
+
+```py
+from transformers import create_optimizer
+import tensorflow as tf
+
+num_train_steps = len(tf_train_dataset)
+optimizer, schedule = create_optimizer(
+ init_lr=5e-5,
+ num_warmup_steps=1_000,
+ num_train_steps=num_train_steps,
+ weight_decay_rate=0.01,
+)
+model.compile(optimizer=optimizer)
+
+# Обучение со смешанной точностью float16
+tf.keras.mixed_precision.set_global_policy("mixed_float16")
+```
+
+Теперь мы можем просто вызвать `model.fit()` и дождаться окончания обучения. В зависимости от того, запустите ли вы его на полном или на подмножестве обучающего набора, это займет 20 или 2 часа соответственно, так что захватите несколько чашек кофе и хорошую книгу для чтения! После завершения обучения мы можем отправить модель и токенизатор в Hub:
+
+```py
+from transformers.keras_callbacks import PushToHubCallback
+
+callback = PushToHubCallback(output_dir="codeparrot-ds", tokenizer=tokenizer)
+
+model.fit(tf_train_dataset, validation_data=tf_eval_dataset, callbacks=[callback])
+```
+
+{/if}
+
+
+
+✏️ **Попробуйте!** Всего около 30 строк кода в дополнение к `TrainingArguments` понадобилось нам, чтобы перейти от сырых текстов к обучению GPT-2. Попробуйте это на своем датасете и посмотрите, сможете ли вы получить хорошие результаты!
+
+
+
+
+
+{#if fw === 'pt'}
+
+💡 Если у вас есть доступ к компьютеру с несколькими GPU, попробуйте запустить код на нем. `Trainer` автоматически управляет несколькими компьютерами, и это может значительно ускорить обучение.
+
+{:else}
+
+💡 Если у вас есть доступ к компьютеру с несколькими GPU, вы можете попробовать использовать контекст `MirroredStrategy` для существенного ускорения обучения. Вам нужно будет создать объект `tf.distribute.MirroredStrategy` и убедиться, что все методы `to_tf_dataset()` или `prepare_tf_dataset()`, а также создание модели и вызов `fit()` выполняются в его контексте `scope()`. Документацию на эту тему можно посмотреть [здесь](https://www.tensorflow.org/guide/distributed_training#use_tfdistributestrategy_with_keras_modelfit).
+
+{/if}
+
+
+
+## Генерация кода с помощью конвейера[[code-generation-with-a-pipeline]]
+
+Настал момент истины: давайте посмотрим, насколько хорошо работает обученная модель! В логах мы видим, что потери постоянно снижаются, но чтобы проверить модель на практике, давайте посмотрим, насколько хорошо она работает на некоторых подсказках. Для этого мы обернем модель в `pipeline` для генерации текста и поместим ее на GPU для быстрой генерации, если таковой доступен:
+
+{#if fw === 'pt'}
+
+```py
+import torch
+from transformers import pipeline
+
+device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
+pipe = pipeline(
+ "text-generation", model="huggingface-course/codeparrot-ds", device=device
+)
+```
+
+{:else}
+
+```py
+from transformers import pipeline
+
+course_model = TFGPT2LMHeadModel.from_pretrained("huggingface-course/codeparrot-ds")
+course_tokenizer = AutoTokenizer.from_pretrained("huggingface-course/codeparrot-ds")
+pipe = pipeline(
+ "text-generation", model=course_model, tokenizer=course_tokenizer, device=0
+)
+```
+
+{/if}
+
+Давайте начнем с простой задачи - создания диаграммы рассеивания (scatter plot):
+
+```py
+txt = """\
+# create some data
+x = np.random.randn(100)
+y = np.random.randn(100)
+
+# create scatter plot with x, y
+"""
+print(pipe(txt, num_return_sequences=1)[0]["generated_text"])
+```
+
+```python out
+# create some data
+x = np.random.randn(100)
+y = np.random.randn(100)
+
+# create scatter plot with x, y
+plt.scatter(x, y)
+
+# create scatter
+```
+
+Результат выглядит корректно. Работает ли это также для `pandas` операции? Давайте посмотрим, сможем ли мы создать `DataFrame` из двух массивов:
+
+```py
+txt = """\
+# create some data
+x = np.random.randn(100)
+y = np.random.randn(100)
+
+# create dataframe from x and y
+"""
+print(pipe(txt, num_return_sequences=1)[0]["generated_text"])
+```
+
+```python out
+# create some data
+x = np.random.randn(100)
+y = np.random.randn(100)
+
+# create dataframe from x and y
+df = pd.DataFrame({'x': x, 'y': y})
+df.insert(0,'x', x)
+for
+```
+
+Отлично, это правильный ответ -- хотя затем он снова вставляет столбец `x`. Поскольку количество генерируемых токенов ограничено, следующий цикл `for` обрывается. Давайте посмотрим, сможем ли мы сделать что-то более сложное, и чтобы модель помогла нам использовать операцию `groupby`:
+
+```py
+txt = """\
+# dataframe with profession, income and name
+df = pd.DataFrame({'profession': x, 'income':y, 'name': z})
+
+# calculate the mean income per profession
+"""
+print(pipe(txt, num_return_sequences=1)[0]["generated_text"])
+```
+
+```python out
+# dataframe with profession, income and name
+df = pd.DataFrame({'profession': x, 'income':y, 'name': z})
+
+# calculate the mean income per profession
+profession = df.groupby(['profession']).mean()
+
+# compute the
+```
+
+Неплохо; это правильный способ сделать это. Наконец, давайте посмотрим, сможем ли мы также использовать его для `scikit-learn` и создать модель Random Forest:
+
+```py
+txt = """
+# import random forest regressor from scikit-learn
+from sklearn.ensemble import RandomForestRegressor
+
+# fit random forest model with 300 estimators on X, y:
+"""
+print(pipe(txt, num_return_sequences=1)[0]["generated_text"])
+```
+
+```python out
+# import random forest regressor from scikit-learn
+from sklearn.ensemble import RandomForestRegressor
+
+# fit random forest model with 300 estimators on X, y:
+rf = RandomForestRegressor(n_estimators=300, random_state=random_state, max_depth=3)
+rf.fit(X, y)
+rf
+```
+
+{#if fw === 'tf'}
+
+Глядя на эти несколько примеров, кажется, что модель усвоила часть синтаксиса стека Python Data Science. Конечно, нам нужно будет более тщательно оценить модель, прежде чем внедрять ее в реальный мир, но все же это впечатляющий прототип.
+
+{:else}
+
+Глядя на эти несколько примеров, кажется, что модель усвоила часть синтаксиса стека Python Data Science (конечно, нам нужно будет оценить это более тщательно, прежде чем разворачивать модель в реальном мире). Однако иногда требуется более тщательная настройка обучения модели, чтобы добиться необходимого качества работы для конкретного случая использования. Например, если мы хотим динамически обновлять размер батча или иметь условный цикл обучения, который пропускает плохие примеры на лету? Одним из вариантов может быть подкласс `Trainer` и добавление необходимых изменений, но иногда проще написать цикл обучения с нуля. Вот тут-то и приходит на помощь 🤗 Accelerate.
+
+{/if}
+
+{#if fw === 'pt'}
+
+## Обучение с 🤗 Accelerate[[training-with-accelerate]]
+
+Мы уже видели, как обучать модель с помощью `Trainer`, который позволяет сделать некоторые настройки. Однако иногда нам нужен полный контроль над циклом обучения, или мы хотим внести некоторые экзотические изменения. В этом случае 🤗 Accelerate - отличный выбор, и в этом разделе мы рассмотрим шаги по его использованию для обучения нашей модели. Чтобы сделать все более интересным, мы также добавим изюминку в цикл обучения.
+
+
+
+Поскольку нас в основном интересует разумное автодополнение для библиотек data science, имеет смысл придать больший вес обучающим примерам, в которых чаще используются эти библиотеки. Мы можем легко определить эти примеры по использованию таких ключевых слов, как `plt`, `pd`, `sk`, `fit` и `predict`, которые являются наиболее частыми именами для импорта `matplotlib.pyplot`, `pandas` и `sklearn`, а также шаблонам fit/predict для последней. Если каждый из них представлен в виде одного токена, мы можем легко проверить, встречаются ли они во входной последовательности. Токены могут иметь пробельный префикс, поэтому мы также проверим наличие таких версий в словаре токенизатора. Чтобы убедиться, что все работает, мы добавим один тестовый токен, который должен быть разбит на несколько токенов:
+
+```py
+keytoken_ids = []
+for keyword in [
+ "plt",
+ "pd",
+ "sk",
+ "fit",
+ "predict",
+ " plt",
+ " pd",
+ " sk",
+ " fit",
+ " predict",
+ "testtest",
+]:
+ ids = tokenizer([keyword]).input_ids[0]
+ if len(ids) == 1:
+ keytoken_ids.append(ids[0])
+ else:
+ print(f"Keyword has not single token: {keyword}")
+```
+
+```python out
+'Keyword has not single token: testtest'
+```
+
+Отлично, похоже, это прекрасно работает! Теперь мы можем написать пользовательскую функцию потерь, которая принимает входную последовательность, логиты и ключевые токены, которые мы только что выбрали в качестве входных данных. Сначала нам нужно выровнять логиты и входные данные: входная последовательность, сдвинутая на единицу вправо, формирует метки, поскольку следующий токен является меткой для текущего токена. Мы можем добиться этого, начиная метки со второго токена входной последовательности, поскольку модель все равно не делает предсказания для первого токена. Затем мы отсекаем последний логит, поскольку у нас нет метки для токена, который следует за всей входной последовательностью. Таким образом, мы можем вычислить потери для каждого примера и подсчитать количество вхождений всех ключевых слов в каждом примере. Наконец, мы вычисляем средневзвешенное значение по всем примерам, используя вхождения в качестве весов. Поскольку мы не хотим отбрасывать все выборки, в которых нет ключевых слов, мы добавляем 1 к весам:
+
+```py
+from torch.nn import CrossEntropyLoss
+import torch
+
+
+def keytoken_weighted_loss(inputs, logits, keytoken_ids, alpha=1.0):
+ # Сдвигаем так, чтобы токены < n предсказывали n
+ shift_labels = inputs[..., 1:].contiguous()
+ shift_logits = logits[..., :-1, :].contiguous()
+ # Вычисляем потери на каждый токен
+ loss_fct = CrossEntropyLoss(reduce=False)
+ loss = loss_fct(shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1))
+ # Изменение размера и средние потери на каждый пример
+ loss_per_sample = loss.view(shift_logits.size(0), shift_logits.size(1)).mean(axis=1)
+ # Расчет и масштабирование весов
+ weights = torch.stack([(inputs == kt).float() for kt in keytoken_ids]).sum(
+ axis=[0, 2]
+ )
+ weights = alpha * (1.0 + weights)
+ # Расчет взвешенного среднего
+ weighted_loss = (loss_per_sample * weights).mean()
+ return weighted_loss
+```
+
+Прежде чем приступить к обучению с этой потрясающей новой функцией потерь, нам нужно подготовить несколько вещей:
+
+- Нам нужны загрузчики данных, чтобы загружать данные батчами.
+- Нам нужно настроить параметры затухания веса (weight decay).
+- Время от времени мы хотим проводить оценку, поэтому имеет смысл обернуть код оценки в функцию.
+
+Давайте начнем с загрузчиков данных. Нам нужно только задать для датасета формат `"torch"`, а затем мы можем передать его в PyTorch `DataLoader` с соответствующим размером батча:
+
+```py
+from torch.utils.data.dataloader import DataLoader
+
+tokenized_dataset.set_format("torch")
+train_dataloader = DataLoader(tokenized_dataset["train"], batch_size=32, shuffle=True)
+eval_dataloader = DataLoader(tokenized_dataset["valid"], batch_size=32)
+```
+
+Далее мы группируем параметры, чтобы оптимизатор знал, какие из них получат дополнительное затухание веса. Обычно все смещения (bias) и весовые коэффициенты LayerNorm (LayerNorm weights) исключаются из этого правила; вот как мы можем это реализовать:
+
+```py
+weight_decay = 0.1
+
+
+def get_grouped_params(model, no_decay=["bias", "LayerNorm.weight"]):
+ params_with_wd, params_without_wd = [], []
+ for n, p in model.named_parameters():
+ if any(nd in n for nd in no_decay):
+ params_without_wd.append(p)
+ else:
+ params_with_wd.append(p)
+ return [
+ {"params": params_with_wd, "weight_decay": weight_decay},
+ {"params": params_without_wd, "weight_decay": 0.0},
+ ]
+```
+
+Поскольку мы хотим регулярно оценивать модель на валидационном множестве во время обучения, давайте напишем функцию и для этого. Она просто запускается через загрузчик оценочных данных и собирает все потери:
+
+```py
+def evaluate():
+ model.eval()
+ losses = []
+ for step, batch in enumerate(eval_dataloader):
+ with torch.no_grad():
+ outputs = model(batch["input_ids"], labels=batch["input_ids"])
+
+ losses.append(accelerator.gather(outputs.loss))
+ loss = torch.mean(torch.cat(losses))
+ try:
+ perplexity = torch.exp(loss)
+ except OverflowError:
+ perplexity = float("inf")
+ return loss.item(), perplexity.item()
+```
+
+С помощью функции `evaluate()` мы можем сообщать о потерях и [перплексии](../chapter7/3) через регулярные промежутки времени. Далее мы переопределим нашу модель, чтобы убедиться, что мы снова обучаемся с нуля:
+
+```py
+model = GPT2LMHeadModel(config)
+```
+
+Затем мы можем определить наш оптимизатор, используя предыдущую функцию для части параметров для затухания веса:
+
+```py
+from torch.optim import AdamW
+
+optimizer = AdamW(get_grouped_params(model), lr=5e-4)
+```
+
+Теперь давайте подготовим модель, оптимизатор и загрузчики данных, чтобы начать обучение:
+
+```py
+from accelerate import Accelerator
+
+accelerator = Accelerator(fp16=True)
+
+model, optimizer, train_dataloader, eval_dataloader = accelerator.prepare(
+ model, optimizer, train_dataloader, eval_dataloader
+)
+```
+
+
+
+🚨 Если вы проводите обучение на TPU, вам нужно будет перенести весь код, начиная с ячейки выше, в выделенную функцию обучения. Подробнее смотрите [Главу 3](../chapter3/1).
+
+
+
+Теперь, когда мы отправили наш `train_dataloader` в `accelerator.prepare()`, мы можем использовать его длину для вычисления количества шагов обучения. Помните, что это всегда нужно делать после подготовки загрузчика данных, так как этот метод изменит его длину. Мы используем классический линейный график скорости обучения до 0:
+
+```py
+from transformers import get_scheduler
+
+num_train_epochs = 1
+num_update_steps_per_epoch = len(train_dataloader)
+num_training_steps = num_train_epochs * num_update_steps_per_epoch
+
+lr_scheduler = get_scheduler(
+ name="linear",
+ optimizer=optimizer,
+ num_warmup_steps=1_000,
+ num_training_steps=num_training_steps,
+)
+```
+
+Наконец, чтобы отправить нашу модель в Hub, нам нужно создать объект `Repository` в рабочей папке. Сначала войдите в Hub Hugging Face, если вы еще не вошли в него. Мы определим имя розитория по идентификатору модели, который мы хотим присвоить нашей модели (не стесняйтесь заменить `repo_name` на свой собственный вариант; он просто должен содержать ваше имя пользователя, что и делает функция `get_full_repo_name()`):
+
+```py
+from huggingface_hub import Repository, get_full_repo_name
+
+model_name = "codeparrot-ds-accelerate"
+repo_name = get_full_repo_name(model_name)
+repo_name
+```
+
+```python out
+'sgugger/codeparrot-ds-accelerate'
+```
+
+Затем мы можем клонировать этот розиторий в локальную папку. Если она уже существует, эта локальная папка должна быть существующим клоном розитория, с которым мы работаем:
+
+```py
+output_dir = "codeparrot-ds-accelerate"
+repo = Repository(output_dir, clone_from=repo_name)
+```
+
+Теперь мы можем загрузить все, что сохранили в `output_dir`, вызвав метод `repo.push_to_hub()`. Это поможет нам загружать промежуточные модели в конце каждой эпохи.
+
+Перед обучением давайте проведем быстрый тест, чтобы проверить, правильно ли работает функция оценки:
+
+```py
+evaluate()
+```
+
+```python out
+(10.934126853942871, 56057.14453125)
+```
+
+Это очень высокие значения для потерь и перплексии, но это неудивительно, ведь мы еще не обучили модель. Итак, у нас все готово для написания основной части скрипта обучения: цикла обучения. В цикле обучения мы выполняем итерации по загрузчику данных и передаем батчи в модель. С помощью логитов мы можем оценить нашу пользовательскую функцию потерь. Мы масштабируем потери по количеству шагов накопления градиента, чтобы не создавать больших потерь при агрегировании большего количества шагов. Перед оптимизацией мы также обрезаем градиенты для лучшей сходимости. Наконец, каждые несколько шагов мы оцениваем модель на оценочном наборе с помощью нашей новой функции `evaluate()`:
+
+```py
+from tqdm.notebook import tqdm
+
+gradient_accumulation_steps = 8
+eval_steps = 5_000
+
+model.train()
+completed_steps = 0
+for epoch in range(num_train_epochs):
+ for step, batch in tqdm(
+ enumerate(train_dataloader, start=1), total=num_training_steps
+ ):
+ logits = model(batch["input_ids"]).logits
+ loss = keytoken_weighted_loss(batch["input_ids"], logits, keytoken_ids)
+ if step % 100 == 0:
+ accelerator.print(
+ {
+ "samples": step * samples_per_step,
+ "steps": completed_steps,
+ "loss/train": loss.item() * gradient_accumulation_steps,
+ }
+ )
+ loss = loss / gradient_accumulation_steps
+ accelerator.backward(loss)
+ if step % gradient_accumulation_steps == 0:
+ accelerator.clip_grad_norm_(model.parameters(), 1.0)
+ optimizer.step()
+ lr_scheduler.step()
+ optimizer.zero_grad()
+ completed_steps += 1
+ if (step % (eval_steps * gradient_accumulation_steps)) == 0:
+ eval_loss, perplexity = evaluate()
+ accelerator.print({"loss/eval": eval_loss, "perplexity": perplexity})
+ model.train()
+ accelerator.wait_for_everyone()
+ unwrapped_model = accelerator.unwrap_model(model)
+ unwrapped_model.save_pretrained(output_dir, save_function=accelerator.save)
+ if accelerator.is_main_process:
+ tokenizer.save_pretrained(output_dir)
+ repo.push_to_hub(
+ commit_message=f"Training in progress step {step}", blocking=False
+ )
+```
+
+Вот и все -- теперь у вас есть свой собственный цикл обучения для каузальных языковых моделей, таких как GPT-2, который вы можете дополнительно настроить под свои нужды.
+
+
+
+✏️ **Попробуйте!** Либо создайте свою собственную функцию потерь, подходящую для вашего случая, либо добавьте еще один пользовательский шаг в цикл обучения.
+
+
+
+
+
+✏️ **Попробуйте!** При проведении длительных экспериментов по обучению полезно регистрировать важные метрики с помощью таких инструментов, как TensorBoard или Weights & Biases. Добавьте соответствующее логирование в цикл обучения, чтобы вы всегда могли проверить, как проходит обучение.
+
+
+
+{/if}
diff --git a/chapters/ru/chapter7/7.mdx b/chapters/ru/chapter7/7.mdx
new file mode 100644
index 000000000..c3c6764c1
--- /dev/null
+++ b/chapters/ru/chapter7/7.mdx
@@ -0,0 +1,1203 @@
+
+
+# Ответы на вопросы[[question-answering]]
+
+{#if fw === 'pt'}
+
+
+
+{:else}
+
+
+
+{/if}
+
+Пришло время взглянуть на ответы на вопросы! Эта задача имеет множество разновидностей, но та, на которой мы сосредоточимся в этом разделе, называется *экстрактивным* ответом на вопросы. Она включает в себя постановку вопросов о документе и определение ответов в виде _участков текста_ в самом документе.
+
+
+
+Мы проведем дообучение BERT-модели на датасете [SQuAD](https://rajpurkar.github.io/SQuAD-explorer/), состоящем из вопросов, заданных краудворкерами по набору статей Википедии. В результате мы получим модель, способную вычислять прогнозы, подобные этому:
+
+
+
+На самом деле это демонстрация модели, которая была обучена и загружена на Hub с помощью кода, показанного в этом разделе. Вы можете найти ее и перепроверить прогнозы [здесь](https://huggingface.co/huggingface-course/bert-finetuned-squad?context=%F0%9F%A4%97+Transformers+is+backed+by+the+three+most+popular+deep+learning+libraries+%E2%80%94+Jax%2C+PyTorch+and+TensorFlow+%E2%80%94+with+a+seamless+integration+between+them.+It%27s+straightforward+to+train+your+models+with+one+before+loading+them+for+inference+with+the+other.&question=Which+deep+learning+libraries+back+%F0%9F%A4%97+Transformers%3F).
+
+
+
+💡 Модели, основанные только на энкодере, такие как BERT, как правило, отлично справляются с извлечением ответов на фактоидные вопросы типа "Кто изобрел архитектуру трансформера?", но плохо справляются с открытыми вопросами типа "Почему небо голубое?". В таких сложных случаях для синтеза информации обычно используются модели энкодеров-декодеров, такие как T5 и BART, что очень похоже на [сумризацию текста](/course/chapter7/5). Если вам интересен этот тип *генеративных* ответов на вопросы, рекомендуем ознакомиться с нашим [демо](https://yjernite.github.io/lfqa.html) основанным на [датасете ELI5](https://huggingface.co/datasets/eli5).
+
+
+
+## Подготовка данных[[preparing-the-data]]
+
+В качестве академического бенчмарка для экстрактивных ответов на вопросы чаще всего используется датасет [SQuAD](https://rajpurkar.github.io/SQuAD-explorer/), поэтому мы будем использовать именно его. Существует также более сложный датасет [SQuAD v2](https://huggingface.co/datasets/squad_v2), который включает вопросы, не имеющие ответа. Если ваш собственный датасет содержит столбец контекстов, столбец вопросов и столбец ответов, вы сможете адаптировать описанные ниже шаги.
+
+### Датасет SQuAD[[the-squad-dataset]]
+
+Как обычно, мы можем загрузить и кэшировать датасет всего за один шаг благодаря функции `load_dataset()`:
+
+```py
+from datasets import load_dataset
+
+raw_datasets = load_dataset("squad")
+```
+
+Мы можем взглянуть на этот объект, чтобы узнать больше о датасете SQuAD:
+
+```py
+raw_datasets
+```
+
+```python out
+DatasetDict({
+ train: Dataset({
+ features: ['id', 'title', 'context', 'question', 'answers'],
+ num_rows: 87599
+ })
+ validation: Dataset({
+ features: ['id', 'title', 'context', 'question', 'answers'],
+ num_rows: 10570
+ })
+})
+```
+
+Похоже, у нас есть все необходимое в полях `context`, `question` и `answers`, так что давайте выведем их для первого элемента нашего обучающего набора:
+
+```py
+print("Context: ", raw_datasets["train"][0]["context"])
+print("Question: ", raw_datasets["train"][0]["question"])
+print("Answer: ", raw_datasets["train"][0]["answers"])
+```
+
+```python out
+Context: 'Architecturally, the school has a Catholic character. Atop the Main Building\'s gold dome is a golden statue of the Virgin Mary. Immediately in front of the Main Building and facing it, is a copper statue of Christ with arms upraised with the legend "Venite Ad Me Omnes". Next to the Main Building is the Basilica of the Sacred Heart. Immediately behind the basilica is the Grotto, a Marian place of prayer and reflection. It is a replica of the grotto at Lourdes, France where the Virgin Mary reputedly appeared to Saint Bernadette Soubirous in 1858. At the end of the main drive (and in a direct line that connects through 3 statues and the Gold Dome), is a simple, modern stone statue of Mary.'
+Question: 'To whom did the Virgin Mary allegedly appear in 1858 in Lourdes France?'
+Answer: {'text': ['Saint Bernadette Soubirous'], 'answer_start': [515]}
+```
+
+Поля `context` и `question` очень просты в использовании. С полем `answers` немного сложнее, поскольку оно представляет собой словарь с двумя полями, которые оба являются списками. Именно такой формат будет ожидать метрика `squad` при оценке; если вы используете свои собственные данные, вам не обязательно беспокоиться о том, чтобы привести ответы к такому же формату. Поле `text` довольно очевидно, а поле `answer_start` содержит индекс начального символа каждого ответа в контексте.
+
+Во время обучения существует только один возможный ответ. Мы можем перепроверить это с помощью метода `Dataset.filter()`:
+
+```py
+raw_datasets["train"].filter(lambda x: len(x["answers"]["text"]) != 1)
+```
+
+```python out
+Dataset({
+ features: ['id', 'title', 'context', 'question', 'answers'],
+ num_rows: 0
+})
+```
+
+Для оценки, однако, существует несколько возможных ответов для каждого примера, которые могут быть одинаковыми или разными:
+
+```py
+print(raw_datasets["validation"][0]["answers"])
+print(raw_datasets["validation"][2]["answers"])
+```
+
+```python out
+{'text': ['Denver Broncos', 'Denver Broncos', 'Denver Broncos'], 'answer_start': [177, 177, 177]}
+{'text': ['Santa Clara, California', "Levi's Stadium", "Levi's Stadium in the San Francisco Bay Area at Santa Clara, California."], 'answer_start': [403, 355, 355]}
+```
+
+Мы не будем углубляться в сценарий оценки, поскольку все это будет завернуто в метрику 🤗 Datasets для нас, но кратко суть в том, что некоторые вопросы имеют несколько возможных ответов, и этот сценарий будет сравнивать спрогнозированный ответ со всеми допустимыми ответами и выбирать лучший результат. Если мы посмотрим, например, на выборку с индексом 2:
+
+```py
+print(raw_datasets["validation"][2]["context"])
+print(raw_datasets["validation"][2]["question"])
+```
+
+```python out
+'Super Bowl 50 was an American football game to determine the champion of the National Football League (NFL) for the 2015 season. The American Football Conference (AFC) champion Denver Broncos defeated the National Football Conference (NFC) champion Carolina Panthers 24–10 to earn their third Super Bowl title. The game was played on February 7, 2016, at Levi\'s Stadium in the San Francisco Bay Area at Santa Clara, California. As this was the 50th Super Bowl, the league emphasized the "golden anniversary" with various gold-themed initiatives, as well as temporarily suspending the tradition of naming each Super Bowl game with Roman numerals (under which the game would have been known as "Super Bowl L"), so that the logo could prominently feature the Arabic numerals 50.'
+'Where did Super Bowl 50 take place?'
+```
+
+мы можем увидеть, что ответ действительно может быть одним из трех возможных вариантов, которые мы видели ранее.
+
+### Подготовка обучающих данных[[processing-the-training-data]]
+
+
+
+Начнем с предварительной подготовки обучающих данных. Самое сложное - сгенерировать метки для ответа на вопрос, которые будут представлять собой начальную и конечную позиции токенов, соответствующих ответу в контексте.
+
+Но не будем забегать вперед. Сначала нам нужно преобразовать текст во входных данных в идентификаторы, которые модель сможет понять, используя токенизатор:
+
+```py
+from transformers import AutoTokenizer
+
+model_checkpoint = "bert-base-cased"
+tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
+```
+
+Как упоминалось ранее, мы будем проводить дообучение модели BERT, но вы можете использовать любой другой тип модели, если в ней реализован быстрый токенизатор. Вы можете увидеть все архитектуры с быстрой версией в [этой большой таблице](https://huggingface.co/transformers/#supported-frameworks), а чтобы проверить, что используемый вами объект `tokenizer` действительно поддерживается 🤗 Tokenizers, вы можете посмотреть на его атрибут `is_fast`:
+
+```py
+tokenizer.is_fast
+```
+
+```python out
+True
+```
+
+Мы можем передать нашему токенизатору вопрос и контекст вместе, и он правильно вставит специальные токены, чтобы сформировать предложение, подобное этому:
+
+```
+[CLS] question [SEP] context [SEP]
+```
+
+Давайте перепроверим:
+
+```py
+context = raw_datasets["train"][0]["context"]
+question = raw_datasets["train"][0]["question"]
+
+inputs = tokenizer(question, context)
+tokenizer.decode(inputs["input_ids"])
+```
+
+```python out
+'[CLS] To whom did the Virgin Mary allegedly appear in 1858 in Lourdes France? [SEP] Architecturally, '
+'the school has a Catholic character. Atop the Main Building\'s gold dome is a golden statue of the Virgin '
+'Mary. Immediately in front of the Main Building and facing it, is a copper statue of Christ with arms '
+'upraised with the legend " Venite Ad Me Omnes ". Next to the Main Building is the Basilica of the Sacred '
+'Heart. Immediately behind the basilica is the Grotto, a Marian place of prayer and reflection. It is a '
+'replica of the grotto at Lourdes, France where the Virgin Mary reputedly appeared to Saint Bernadette '
+'Soubirous in 1858. At the end of the main drive ( and in a direct line that connects through 3 statues '
+'and the Gold Dome ), is a simple, modern stone statue of Mary. [SEP]'
+```
+
+В качестве меток будут использоваться индексы токенов, начинающих и заканчивающих ответ, а задача модели - предсказать один начальный и конечный логит для каждого токена на входе, при этом теоретические метки будут выглядеть следующим образом:
+
+
+

+

+
+
+В данном случае контекст не слишком длинный, но некоторые примеры в датасете имеют очень длинные контексты, которые превысят установленную нами максимальную длину (которая в данном случае равна 384). Как мы видели в [Главе 6](../chapter6/4), когда изучали внутреннее устройство конвейера `question-answering`, мы будем работать с длинными контекстами, создавая несколько обучающих признаков из одной выборки нашего датасета, со скользящим окном между ними.
+
+Чтобы увидеть, как это работает на текущем примере, мы можем ограничить длину до 100 и использовать скользящее окно из 50 токенов. В качестве напоминания мы используем:
+
+- `max_length` для установки максимальной длины (здесь 100)
+- `truncation="only_second"` для усечения контекста (который находится во второй позиции), когда вопрос с его контекстом слишком длинный
+- `stride` для задания количества перекрывающихся токенов между двумя последовательными фрагментами (здесь 50)
+- `return_overflowing_tokens=True`, чтобы сообщить токенизатору, что нам нужны переполненные токены (overflowing tokens)
+
+```py
+inputs = tokenizer(
+ question,
+ context,
+ max_length=100,
+ truncation="only_second",
+ stride=50,
+ return_overflowing_tokens=True,
+)
+
+for ids in inputs["input_ids"]:
+ print(tokenizer.decode(ids))
+```
+
+```python out
+'[CLS] To whom did the Virgin Mary allegedly appear in 1858 in Lourdes France? [SEP] Architecturally, the school has a Catholic character. Atop the Main Building\'s gold dome is a golden statue of the Virgin Mary. Immediately in front of the Main Building and facing it, is a copper statue of Christ with arms upraised with the legend " Venite Ad Me Omnes ". Next to the Main Building is the Basilica of the Sacred Heart. Immediately behind the basi [SEP]'
+'[CLS] To whom did the Virgin Mary allegedly appear in 1858 in Lourdes France? [SEP] the Main Building and facing it, is a copper statue of Christ with arms upraised with the legend " Venite Ad Me Omnes ". Next to the Main Building is the Basilica of the Sacred Heart. Immediately behind the basilica is the Grotto, a Marian place of prayer and reflection. It is a replica of the grotto at Lourdes, France where the Virgin [SEP]'
+'[CLS] To whom did the Virgin Mary allegedly appear in 1858 in Lourdes France? [SEP] Next to the Main Building is the Basilica of the Sacred Heart. Immediately behind the basilica is the Grotto, a Marian place of prayer and reflection. It is a replica of the grotto at Lourdes, France where the Virgin Mary reputedly appeared to Saint Bernadette Soubirous in 1858. At the end of the main drive ( and in a direct line that connects through 3 [SEP]'
+'[CLS] To whom did the Virgin Mary allegedly appear in 1858 in Lourdes France? [SEP]. It is a replica of the grotto at Lourdes, France where the Virgin Mary reputedly appeared to Saint Bernadette Soubirous in 1858. At the end of the main drive ( and in a direct line that connects through 3 statues and the Gold Dome ), is a simple, modern stone statue of Mary. [SEP]'
+```
+
+Как мы можем видеть, наш пример был разбит на четыре входа, каждый из которых содержит вопрос и часть контекста. Обратите внимание, что ответ на вопрос ("Bernadette Soubirous") появляется только в третьем и последнем входе, поэтому, работая с длинными контекстами таким образом, мы создадим несколько обучающих примеров, в которых ответ не будет включен в контекст. Для этих примеров метками будут `start_position = end_position = 0` (таким образом мы предсказываем токен `[CLS]`). Мы также зададим эти метки в неудачном случае, когда ответ был усечен, так что у нас есть только его начало (или конец). Для примеров, где ответ полностью находится в контексте, метками будут индекс токена, с которого начинается ответ, и индекс токена, на котором ответ заканчивается.
+
+Датасет предоставляет нам начальный символ ответа в контексте, а прибавив к нему длину ответа, мы можем найти конечный символ в контексте. Чтобы сопоставить их с индексами токенов, нам нужно использовать сопоставление смещений, которое мы изучали в [Главе 6](../chapter6/4). Мы можем настроить наш токенизатор на их возврат, передав `return_offsets_mapping=True`:
+
+```py
+inputs = tokenizer(
+ question,
+ context,
+ max_length=100,
+ truncation="only_second",
+ stride=50,
+ return_overflowing_tokens=True,
+ return_offsets_mapping=True,
+)
+inputs.keys()
+```
+
+```python out
+dict_keys(['input_ids', 'token_type_ids', 'attention_mask', 'offset_mapping', 'overflow_to_sample_mapping'])
+```
+
+Как мы видим, нам возвращаются обычные идентификаторы входа, идентификаторы типов токенов и маска внимания, а также необходимое нам сопоставление смещений и дополнительный ключ `overflow_to_sample_mapping`. Соответствующее значение мы будем использовать при токенизации нескольких текстов одновременно (что мы и должны делать, чтобы извлечь выгоду из того, что наш токенизатор основан на Rust). Поскольку один образец может давать несколько признаков, он сопоставляет каждый признак с примером, из которого он произошел. Поскольку здесь мы токенизировали только один пример, мы получим список `0`:
+
+```py
+inputs["overflow_to_sample_mapping"]
+```
+
+```python out
+[0, 0, 0, 0]
+```
+
+Но если мы проведем токенизацию большего количества примеров, это станет более полезным:
+
+```py
+inputs = tokenizer(
+ raw_datasets["train"][2:6]["question"],
+ raw_datasets["train"][2:6]["context"],
+ max_length=100,
+ truncation="only_second",
+ stride=50,
+ return_overflowing_tokens=True,
+ return_offsets_mapping=True,
+)
+
+print(f"The 4 examples gave {len(inputs['input_ids'])} features.")
+print(f"Here is where each comes from: {inputs['overflow_to_sample_mapping']}.")
+```
+
+```python out
+'The 4 examples gave 19 features.'
+'Here is where each comes from: [0, 0, 0, 0, 1, 1, 1, 1, 2, 2, 2, 2, 3, 3, 3, 3, 3, 3, 3].'
+```
+
+Как мы видим, первые три примера (с индексами 2, 3 и 4 в обучающем наборе) дали по четыре признака, а последний пример (с индексом 5 в обучающем наборе) - 7 признаков.
+
+Эта информация будет полезна для сопоставления каждого полученного признака с соответствующей меткой. Как уже упоминалось ранее, этими метками являются:
+
+- `(0, 0)`, если ответ не находится в соответствующей области контекста
+- `(start_position, end_position)`, если ответ находится в соответствующей области контекста, причем `start_position` - это индекс токена (во входных идентификаторах) в начале ответа, а `end_position` - индекс токена (во входных идентификаторах) в конце ответа
+
+Чтобы определить, какой из этих случаев имеет место, и, если нужно, позиции токенов, мы сначала находим индексы, с которых начинается и заканчивается контекст во входных идентификаторах. Для этого мы могли бы использовать идентификаторы типов токенов, но поскольку они не обязательно существуют для всех моделей (например, DistilBERT их не требует), вместо этого мы воспользуемся методом `sequence_ids()` из `BatchEncoding`, который возвращает наш токенизатор.
+
+Получив индексы токенов, мы смотрим на соответствующие смещения, которые представляют собой кортежи из двух целых чисел, обозначающих промежуток символов внутри исходного контекста. Таким образом, мы можем определить, начинается ли фрагмент контекста в этом признаке после ответа или заканчивается до начала ответа (в этом случае метка будет `(0, 0)`). Если это не так, мы зацикливаемся, чтобы найти первый и последний токен ответа:
+
+```py
+answers = raw_datasets["train"][2:6]["answers"]
+start_positions = []
+end_positions = []
+
+for i, offset in enumerate(inputs["offset_mapping"]):
+ sample_idx = inputs["overflow_to_sample_mapping"][i]
+ answer = answers[sample_idx]
+ start_char = answer["answer_start"][0]
+ end_char = answer["answer_start"][0] + len(answer["text"][0])
+ sequence_ids = inputs.sequence_ids(i)
+
+ # Найдём начало и конец контекста
+ idx = 0
+ while sequence_ids[idx] != 1:
+ idx += 1
+ context_start = idx
+ while sequence_ids[idx] == 1:
+ idx += 1
+ context_end = idx - 1
+
+ # Если ответ не полностью находится внутри контекста, меткой будет (0, 0)
+ if offset[context_start][0] > start_char or offset[context_end][1] < end_char:
+ start_positions.append(0)
+ end_positions.append(0)
+ else:
+ # В противном случае это начальная и конечная позиции токенов
+ idx = context_start
+ while idx <= context_end and offset[idx][0] <= start_char:
+ idx += 1
+ start_positions.append(idx - 1)
+
+ idx = context_end
+ while idx >= context_start and offset[idx][1] >= end_char:
+ idx -= 1
+ end_positions.append(idx + 1)
+
+start_positions, end_positions
+```
+
+```python out
+([83, 51, 19, 0, 0, 64, 27, 0, 34, 0, 0, 0, 67, 34, 0, 0, 0, 0, 0],
+ [85, 53, 21, 0, 0, 70, 33, 0, 40, 0, 0, 0, 68, 35, 0, 0, 0, 0, 0])
+```
+
+Давайте посмотрим на несколько результатов, чтобы убедиться в правильности нашего подхода. Для первого признака мы находим `(83, 85)` в качестве меток, поэтому давайте сравним теоретический ответ с декодированным диапазоном лексем с 83 по 85 (включительно):
+
+```py
+idx = 0
+sample_idx = inputs["overflow_to_sample_mapping"][idx]
+answer = answers[sample_idx]["text"][0]
+
+start = start_positions[idx]
+end = end_positions[idx]
+labeled_answer = tokenizer.decode(inputs["input_ids"][idx][start : end + 1])
+
+print(f"Theoretical answer: {answer}, labels give: {labeled_answer}")
+```
+
+```python out
+'Theoretical answer: the Main Building, labels give: the Main Building'
+```
+
+Итак, это совпадение! Теперь проверим индекс 4, где мы установили метки на `(0, 0)`, что означает, что ответ не находится в фрагменте контекста этого признака:
+
+```py
+idx = 4
+sample_idx = inputs["overflow_to_sample_mapping"][idx]
+answer = answers[sample_idx]["text"][0]
+
+decoded_example = tokenizer.decode(inputs["input_ids"][idx])
+print(f"Theoretical answer: {answer}, decoded example: {decoded_example}")
+```
+
+```python out
+'Theoretical answer: a Marian place of prayer and reflection, decoded example: [CLS] What is the Grotto at Notre Dame? [SEP] Architecturally, the school has a Catholic character. Atop the Main Building\'s gold dome is a golden statue of the Virgin Mary. Immediately in front of the Main Building and facing it, is a copper statue of Christ with arms upraised with the legend " Venite Ad Me Omnes ". Next to the Main Building is the Basilica of the Sacred Heart. Immediately behind the basilica is the Grot [SEP]'
+```
+
+Действительно, мы не видим ответа в контексте.
+
+
+
+✏️ **Ваша очередь!** При использовании архитектуры XLNet дополнение применяется слева, а вопрос и контекст меняются местами. Адаптируйте весь код, который мы только что рассмотрели, к архитектуре XLNet (и добавьте `padding=True`). Имейте в виду, что токен `[CLS]` может не находиться в позиции 0 при использовании дополнения.
+
+
+
+Теперь, когда мы шаг за шагом разобрались с предварительной обработкой обучающих данных, мы можем сгруппировать их в функцию, которую будем применять ко всему датасету. Мы дополним каждый признак до максимальной длины, которую мы задали, поскольку большинство контекстов будут длинными (и соответствующие образцы будут разбиты на несколько признаков), поэтому применение динамического дополнения здесь не имеет реальной пользы:
+
+```py
+max_length = 384
+stride = 128
+
+
+def preprocess_training_examples(examples):
+ questions = [q.strip() for q in examples["question"]]
+ inputs = tokenizer(
+ questions,
+ examples["context"],
+ max_length=max_length,
+ truncation="only_second",
+ stride=stride,
+ return_overflowing_tokens=True,
+ return_offsets_mapping=True,
+ padding="max_length",
+ )
+
+ offset_mapping = inputs.pop("offset_mapping")
+ sample_map = inputs.pop("overflow_to_sample_mapping")
+ answers = examples["answers"]
+ start_positions = []
+ end_positions = []
+
+ for i, offset in enumerate(offset_mapping):
+ sample_idx = sample_map[i]
+ answer = answers[sample_idx]
+ start_char = answer["answer_start"][0]
+ end_char = answer["answer_start"][0] + len(answer["text"][0])
+ sequence_ids = inputs.sequence_ids(i)
+
+ # Найдём начало и конец контекста
+ idx = 0
+ while sequence_ids[idx] != 1:
+ idx += 1
+ context_start = idx
+ while sequence_ids[idx] == 1:
+ idx += 1
+ context_end = idx - 1
+
+ # Если ответ не полностью находится внутри контекста, меткой будет (0, 0)
+ if offset[context_start][0] > start_char or offset[context_end][1] < end_char:
+ start_positions.append(0)
+ end_positions.append(0)
+ else:
+ # В противном случае это начальная и конечная позиции токенов
+ idx = context_start
+ while idx <= context_end and offset[idx][0] <= start_char:
+ idx += 1
+ start_positions.append(idx - 1)
+
+ idx = context_end
+ while idx >= context_start and offset[idx][1] >= end_char:
+ idx -= 1
+ end_positions.append(idx + 1)
+
+ inputs["start_positions"] = start_positions
+ inputs["end_positions"] = end_positions
+ return inputs
+```
+
+Обратите внимание, что мы определили две константы для определения максимальной длины и длины скользящего окна, а также добавили немного очистки перед токенизацией: некоторые вопросы в датасете SQuAD имеют лишние пробелы в начале и конце, которые ничего не добавляют (и занимают место при токенизации, если вы используете модель вроде RoBERTa), поэтому мы удалили эти лишние пробелы.
+
+Чтобы применить эту функцию ко всему обучающему набору, мы используем метод `Dataset.map()` с флагом `batched=True`. Это необходимо, так как мы изменяем длину датасета (поскольку один пример может давать несколько обучающих признаков):
+
+```py
+train_dataset = raw_datasets["train"].map(
+ preprocess_training_examples,
+ batched=True,
+ remove_columns=raw_datasets["train"].column_names,
+)
+len(raw_datasets["train"]), len(train_dataset)
+```
+
+```python out
+(87599, 88729)
+```
+
+Как мы видим, предварительная обработка добавила около 1 000 признаков. Теперь наш обучающий набор готов к использованию - давайте займемся предварительной обработкой валидационного набора!
+
+### Подготовка валидационных данных[[processing-the-validation-data]]
+
+Предварительная обработка валидационных данных будет немного проще, поскольку нам не нужно генерировать метки (если только мы не хотим вычислять потери на валидации, но это число не поможет нам понять, насколько хороша модель). Настоящей радостью будет интерпретация прогнозов модели в диапазонах исходного контекста. Для этого нам нужно хранить как сопоставления смещений, так и способ сопоставления каждого созданного признака с оригинальным примером, из которого он взят. Поскольку в исходном датасете есть столбец ID, мы будем использовать этот ID.
+
+Единственное, что мы добавим сюда, - это немного почистим сопоставления смещений. Они будут содержать смещения для вопроса и контекста, но на этапе постобработки у нас не будет возможности узнать, какая часть входных идентификаторов соответствует контексту, а какая - вопросу (метод `sequence_ids()`, который мы использовали, доступен только для выхода токенизатора). Поэтому мы установим смещения, соответствующие вопросу, в `None`:
+
+```py
+def preprocess_validation_examples(examples):
+ questions = [q.strip() for q in examples["question"]]
+ inputs = tokenizer(
+ questions,
+ examples["context"],
+ max_length=max_length,
+ truncation="only_second",
+ stride=stride,
+ return_overflowing_tokens=True,
+ return_offsets_mapping=True,
+ padding="max_length",
+ )
+
+ sample_map = inputs.pop("overflow_to_sample_mapping")
+ example_ids = []
+
+ for i in range(len(inputs["input_ids"])):
+ sample_idx = sample_map[i]
+ example_ids.append(examples["id"][sample_idx])
+
+ sequence_ids = inputs.sequence_ids(i)
+ offset = inputs["offset_mapping"][i]
+ inputs["offset_mapping"][i] = [
+ o if sequence_ids[k] == 1 else None for k, o in enumerate(offset)
+ ]
+
+ inputs["example_id"] = example_ids
+ return inputs
+```
+
+Мы можем применить эту функцию ко всему валидационому датасету, как и раньше:
+
+```py
+validation_dataset = raw_datasets["validation"].map(
+ preprocess_validation_examples,
+ batched=True,
+ remove_columns=raw_datasets["validation"].column_names,
+)
+len(raw_datasets["validation"]), len(validation_dataset)
+```
+
+```python out
+(10570, 10822)
+```
+
+В данном случае мы добавили всего пару сотен примеров, поэтому контексты в валидационном датасете немного короче.
+
+Теперь, когда мы предварительно обработали все данные, можно приступать к обучению.
+
+{#if fw === 'pt'}
+
+## Дообучение модели с API `Trainer`[[fine-tuning-the-model-with-the-trainer-api]]
+
+Код обучения для этого примера будет очень похож на код из предыдущих разделов -- самым сложным будет написание функции `compute_metrics()`. Поскольку мы дополнили все примеры до максимальной длины, которую мы задали, нет никакого коллатора данных, поэтому вычисление метрики - это единственное, о чем нам нужно беспокоиться. Самым сложным будет постобработка прогнозов модели в отрезки текста оригинальных примеров; как только мы это сделаем, метрика из библиотеки 🤗 Datasets сделает за нас большую часть работы.
+
+{:else}
+
+## Дообучение модели с Keras[[fine-tuning-the-model-with-keras]]
+
+Код обучения для этого примера будет очень похож на код в предыдущих разделах, но вычисление метрик будет уникальным. Поскольку мы дополнили все примеры до максимальной длины, которую мы задали, нет коллатора данных, который нужно определить, поэтому вычисление метрики - это единственное, о чем нам нужно беспокоиться. Самое сложное - это постобработка прогнозов модели в отрезки текста в исходных примерах; как только мы это сделаем, метрика из библиотеки 🤗 Datasets сделает за нас большую часть работы.
+
+{/if}
+
+### Постобработка[[post-processing]]
+
+{#if fw === 'pt'}
+
+
+
+{:else}
+
+
+
+{/if}
+
+Модель выведет логиты для начальной и конечной позиций ответа во входных идентификаторах, как мы видели при изучении [конвейера `question-answering`](../chapter6/3b). Шаг постобработки будет аналогичен тому, что мы делали там, так что вот краткое напоминание о том, что мы делали:
+
+- Мы маскировали начальные и конечные логиты, соответствующие токенам вне контекста.
+- Затем мы преобразовали начальные и конечные логиты в вероятности с помощью softmax.
+- Каждой паре `(start_token, end_token)` мы присваивали оценку, взяв произведение двух соответствующих вероятностей.
+- Мы искали пару с максимальной оценкой, которая давала правильный ответ (например, `start_token` меньше `end_token`).
+
+В данном случае мы немного изменим этот процесс, поскольку нам не нужно вычислять фактические оценки (только спрогнозированный ответ). Это означает, что мы можем пропустить шаг softmax. Чтобы ускорить процесс, мы также не будем оценивать все возможные пары `(start_token, end_token)`, а только те, которые соответствуют наибольшим `n_best` логитам (при `n_best=20`). Так как мы пропустим softmax, эти оценки будут оценками логитов, и будут получены путем взятия суммы начального и конечного логитов (вместо произведения, по правилу \\(\log(ab) = \log(a) + \log(b)\\)).
+
+Чтобы продемонстрировать все это, нам понадобятся некоторые прогнозы. Поскольку мы еще не обучили нашу модель, мы будем использовать модель по умолчанию для конвейера QA, чтобы сгенерировать несколько прогнозов на небольшой части набора для валидации. Мы можем использовать ту же функцию обработки, что и раньше; поскольку она опирается на глобальную константу `tokenizer`, нам просто нужно изменить этот объект на токенизатор модели, которую мы хотим временно использовать:
+
+```python
+small_eval_set = raw_datasets["validation"].select(range(100))
+trained_checkpoint = "distilbert-base-cased-distilled-squad"
+
+tokenizer = AutoTokenizer.from_pretrained(trained_checkpoint)
+eval_set = small_eval_set.map(
+ preprocess_validation_examples,
+ batched=True,
+ remove_columns=raw_datasets["validation"].column_names,
+)
+```
+
+Теперь, когда препроцессинг завершен, мы меняем токенизатор обратно на тот, который был выбран изначально:
+
+```python
+tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
+```
+
+Затем мы удаляем из нашего `eval_set` столбцы, которые не ожидает модель, создаем батч со всей этой небольшой валидацией и пропускаем его через модель. Если доступен GPU, мы используем его для ускорения работы:
+
+{#if fw === 'pt'}
+
+```python
+import torch
+from transformers import AutoModelForQuestionAnswering
+
+eval_set_for_model = eval_set.remove_columns(["example_id", "offset_mapping"])
+eval_set_for_model.set_format("torch")
+
+device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
+batch = {k: eval_set_for_model[k].to(device) for k in eval_set_for_model.column_names}
+trained_model = AutoModelForQuestionAnswering.from_pretrained(trained_checkpoint).to(
+ device
+)
+
+with torch.no_grad():
+ outputs = trained_model(**batch)
+```
+
+Поскольку `Trainer` будет возвращать нам прогнозы в виде массивов NumPy, мы берем начальный и конечный логиты и конвертируем их в этот формат:
+
+```python
+start_logits = outputs.start_logits.cpu().numpy()
+end_logits = outputs.end_logits.cpu().numpy()
+```
+
+{:else}
+
+```python
+import tensorflow as tf
+from transformers import TFAutoModelForQuestionAnswering
+
+eval_set_for_model = eval_set.remove_columns(["example_id", "offset_mapping"])
+eval_set_for_model.set_format("numpy")
+
+batch = {k: eval_set_for_model[k] for k in eval_set_for_model.column_names}
+trained_model = TFAutoModelForQuestionAnswering.from_pretrained(trained_checkpoint)
+
+outputs = trained_model(**batch)
+```
+
+Для облегчения экспериментов преобразуем выходные данные в массивы NumPy:
+
+```python
+start_logits = outputs.start_logits.numpy()
+end_logits = outputs.end_logits.numpy()
+```
+
+{/if}
+
+Теперь нам нужно найти спрогнозированный ответ для каждого примера в `small_eval_set`. Один пример может быть разбит на несколько признаков в `eval_set`, поэтому первым шагом будет сопоставление каждого примера в `small_eval_set` с соответствующими признаками в `eval_set`:
+
+```python
+import collections
+
+example_to_features = collections.defaultdict(list)
+for idx, feature in enumerate(eval_set):
+ example_to_features[feature["example_id"]].append(idx)
+```
+
+Имея это на руках, мы можем приступить к работе, итерируясь по всем примерам и, для каждого примера, по всем ассоциированным с ним признакам. Как мы уже говорили, мы рассмотрим оценки логитов для `n_best` начальных логитов и конечных логитов, исключая позиции, которые дают:
+
+- Ответ, который не вписывается в контекст
+- Ответ с отрицательной длиной
+- Слишком длинный ответ (мы ограничиваем возможности по `max_answer_length=30`).
+
+После того как мы получили все возможные ответы для одного примера, мы просто выбираем тот, который имеет лучшую оценку логита:
+
+```python
+import numpy as np
+
+n_best = 20
+max_answer_length = 30
+predicted_answers = []
+
+for example in small_eval_set:
+ example_id = example["id"]
+ context = example["context"]
+ answers = []
+
+ for feature_index in example_to_features[example_id]:
+ start_logit = start_logits[feature_index]
+ end_logit = end_logits[feature_index]
+ offsets = eval_set["offset_mapping"][feature_index]
+
+ start_indexes = np.argsort(start_logit)[-1 : -n_best - 1 : -1].tolist()
+ end_indexes = np.argsort(end_logit)[-1 : -n_best - 1 : -1].tolist()
+ for start_index in start_indexes:
+ for end_index in end_indexes:
+ # Пропускаем ответы, которые не полностью соответствуют контексту
+ if offsets[start_index] is None or offsets[end_index] is None:
+ continue
+ # Пропускайте ответы, длина которых либо < 0, либо > max_answer_length.
+ if (
+ end_index < start_index
+ or end_index - start_index + 1 > max_answer_length
+ ):
+ continue
+
+ answers.append(
+ {
+ "text": context[offsets[start_index][0] : offsets[end_index][1]],
+ "logit_score": start_logit[start_index] + end_logit[end_index],
+ }
+ )
+
+ best_answer = max(answers, key=lambda x: x["logit_score"])
+ predicted_answers.append({"id": example_id, "prediction_text": best_answer["text"]})
+```
+
+Окончательный формат спрогнозированных ответов - это тот, который ожидает метрика, которую мы будем использовать. Как обычно, мы можем загрузить ее с помощью библиотеки 🤗 Evaluate:
+
+```python
+import evaluate
+
+metric = evaluate.load("squad")
+```
+
+Эта метрика ожидает прогнозируемые ответы в формате, который мы видели выше (список словарей с одним ключом для идентификатора примера и одним ключом для прогнозируемого текста), и теоретические ответы в формате ниже (список словарей с одним ключом для идентификатора примера и одним ключом для возможных ответов):
+
+```python
+theoretical_answers = [
+ {"id": ex["id"], "answers": ex["answers"]} for ex in small_eval_set
+]
+```
+
+Теперь мы можем убедиться, что получаем разумные результаты, посмотрев на первый элемент обоих списков:
+
+```python
+print(predicted_answers[0])
+print(theoretical_answers[0])
+```
+
+```python out
+{'id': '56be4db0acb8001400a502ec', 'prediction_text': 'Denver Broncos'}
+{'id': '56be4db0acb8001400a502ec', 'answers': {'text': ['Denver Broncos', 'Denver Broncos', 'Denver Broncos'], 'answer_start': [177, 177, 177]}}
+```
+
+Не так уж плохо! Теперь давайте посмотрим на оценку, которую дает нам метрика:
+
+```python
+metric.compute(predictions=predicted_answers, references=theoretical_answers)
+```
+
+```python out
+{'exact_match': 83.0, 'f1': 88.25}
+```
+
+Опять же, это довольно хорошо, если учесть, что согласно [его статье](https://arxiv.org/abs/1910.01108v2) DistilBERT с дообучением на SQuAD получает 79,1 и 86,9 для этих оценок на всем датасете.
+
+{#if fw === 'pt'}
+
+Теперь давайте поместим все, что мы только что сделали, в функцию `compute_metrics()`, которую мы будем использовать в `Trainer`. Обычно функция `compute_metrics()` получает только кортеж `eval_preds` с логитами и метками. Здесь нам понадобится немного больше, так как мы должны искать в датасете признаков смещения и в датасете примеров исходные контексты, поэтому мы не сможем использовать эту функцию для получения обычных результатов оценки во время обучения. Мы будем использовать ее только в конце обучения для проверки результатов.
+
+Функция `compute_metrics()` группирует те же шаги, что и до этого, только добавляется небольшая проверка на случай, если мы не найдем ни одного правильного ответа (в этом случае мы прогнозируем пустую строку).
+
+{:else}
+
+Теперь давайте поместим все, что мы только что сделали, в функцию `compute_metrics()`, которую мы будем использовать после обучения нашей модели. Нам нужно будет передать несколько больше, чем просто выходные логиты, поскольку мы должны искать в датасете признаков смещение, а в датасете примеров - исходные контексты:
+
+{/if}
+
+```python
+from tqdm.auto import tqdm
+
+
+def compute_metrics(start_logits, end_logits, features, examples):
+ example_to_features = collections.defaultdict(list)
+ for idx, feature in enumerate(features):
+ example_to_features[feature["example_id"]].append(idx)
+
+ predicted_answers = []
+ for example in tqdm(examples):
+ example_id = example["id"]
+ context = example["context"]
+ answers = []
+
+ # Итерируемся по всем признакам, ассоциированным с этим примером
+ for feature_index in example_to_features[example_id]:
+ start_logit = start_logits[feature_index]
+ end_logit = end_logits[feature_index]
+ offsets = features[feature_index]["offset_mapping"]
+
+ start_indexes = np.argsort(start_logit)[-1 : -n_best - 1 : -1].tolist()
+ end_indexes = np.argsort(end_logit)[-1 : -n_best - 1 : -1].tolist()
+ for start_index in start_indexes:
+ for end_index in end_indexes:
+ # Пропускаем ответы, которые не полностью соответствуют контексту
+ if offsets[start_index] is None or offsets[end_index] is None:
+ continue
+ # Пропускайте ответы, длина которых либо < 0, либо > max_answer_length
+ if (
+ end_index < start_index
+ or end_index - start_index + 1 > max_answer_length
+ ):
+ continue
+
+ answer = {
+ "text": context[offsets[start_index][0] : offsets[end_index][1]],
+ "logit_score": start_logit[start_index] + end_logit[end_index],
+ }
+ answers.append(answer)
+
+ # Выбираем ответ с лучшей оценкой
+ if len(answers) > 0:
+ best_answer = max(answers, key=lambda x: x["logit_score"])
+ predicted_answers.append(
+ {"id": example_id, "prediction_text": best_answer["text"]}
+ )
+ else:
+ predicted_answers.append({"id": example_id, "prediction_text": ""})
+
+ theoretical_answers = [{"id": ex["id"], "answers": ex["answers"]} for ex in examples]
+ return metric.compute(predictions=predicted_answers, references=theoretical_answers)
+```
+
+Мы можем проверить ее работу на наших прогнозах:
+
+```python
+compute_metrics(start_logits, end_logits, eval_set, small_eval_set)
+```
+
+```python out
+{'exact_match': 83.0, 'f1': 88.25}
+```
+
+Выглядит отлично! Теперь давайте используем это для дообучения нашей модели.
+
+### Дообучение модели[[fine-tuning-the-model]]
+
+{#if fw === 'pt'}
+
+Теперь мы готовы к обучению нашей модели. Давайте сначала создадим ее, используя класс `AutoModelForQuestionAnswering`, как и раньше:
+
+```python
+model = AutoModelForQuestionAnswering.from_pretrained(model_checkpoint)
+```
+
+{:else}
+
+Теперь мы готовы к обучению нашей модели. Давайте сначала создадим ее, используя класс `TFAutoModelForQuestionAnswering`, как и раньше:
+
+```python
+model = TFAutoModelForQuestionAnswering.from_pretrained(model_checkpoint)
+```
+
+{/if}
+
+Как обычно, мы получаем предупреждение о том, что некоторые веса не используются (веса головы предварительного обучения), а другие инициализируются случайным образом (веса головы ответов на вопросы). Вы уже должны были привыкнуть к этому, но это означает, что модель еще не готова к использованию и нуждается в дообучении - хорошо, что мы сейчас этим займемся!
+
+Чтобы отправить нашу модель на Hub, нам нужно войти в Hugging Face. Если вы выполняете этот код в блокноте, вы можете сделать это с помощью следующей служебной функции, которая отображает виджет, где вы можете ввести свои учетные данные:
+
+```python
+from huggingface_hub import notebook_login
+
+notebook_login()
+```
+
+Если вы работаете не в блокноте, просто введите следующую строку в терминале:
+
+```bash
+huggingface-cli login
+```
+
+{#if fw === 'pt'}
+
+Когда это сделано, мы можем определить наши `TrainingArguments`. Как мы уже говорили, когда определяли нашу функцию для вычисления метрики, мы не сможем сделать обычный цикл оценки из-за сигнатуры функции `compute_metrics()`. Мы могли бы написать собственный подкласс `Trainer` для этого (такой подход можно найти в [примере скрипта ответа на вопросы](https://github.com/huggingface/transformers/blob/master/examples/pytorch/question-answering/trainer_qa.py)), но это слишком длинно для данного раздела. Вместо этого мы будем оценивать модель только в конце обучения, а как проводить регулярную оценку, покажем ниже в разделе "Пользовательский цикл обучения".
+
+Именно здесь API `Trainer` показывает свои ограничения, а библиотека 🤗 Accelerate блистает: настройка класса под конкретный случай использования может быть болезненной, но настройка полностью открытого цикла обучения - это просто.
+
+Let's take a look at our `TrainingArguments`:
+
+```python
+from transformers import TrainingArguments
+
+args = TrainingArguments(
+ "bert-finetuned-squad",
+ evaluation_strategy="no",
+ save_strategy="epoch",
+ learning_rate=2e-5,
+ num_train_epochs=3,
+ weight_decay=0.01,
+ fp16=True,
+ push_to_hub=True,
+)
+```
+
+Большинство из них мы уже видели: мы задаем некоторые гиперпараметры (например, скорость обучения, количество эпох обучения и затухание веса) и указываем, что хотим сохранять модель в конце каждой эпохи, пропускать оценку и загружать результаты в Model Hub. Мы также включаем обучение со смешанной точностью с `fp16=True`, так как это может значительно ускорить обучение на современных GPU.
+
+{:else}
+
+Теперь все готово, и мы можем создать наш TF датасет. На этот раз мы можем использовать простой коллатор данных по умолчанию:
+
+```python
+from transformers import DefaultDataCollator
+
+data_collator = DefaultDataCollator(return_tensors="tf")
+```
+
+А теперь создадим датасет, как обычно.
+
+```python
+tf_train_dataset = model.prepare_tf_dataset(
+ train_dataset,
+ collate_fn=data_collator,
+ shuffle=True,
+ batch_size=16,
+)
+tf_eval_dataset = model.prepare_tf_dataset(
+ validation_dataset,
+ collate_fn=data_collator,
+ shuffle=False,
+ batch_size=16,
+)
+```
+
+Далее мы задаем гиперпараметры обучения и компилируем нашу модель:
+
+```python
+from transformers import create_optimizer
+from transformers.keras_callbacks import PushToHubCallback
+import tensorflow as tf
+
+# Количество шагов обучения - это количество примеров в датасете, разделенное на размер батча, затем умноженное
+# by the total number of epochs. Note that the tf_train_dataset here is a batched tf.data.Dataset,
+# а не оригинальный датасет Hugging Face, поэтому его len() уже равен num_samples // batch_size.
+num_train_epochs = 3
+num_train_steps = len(tf_train_dataset) * num_train_epochs
+optimizer, schedule = create_optimizer(
+ init_lr=2e-5,
+ num_warmup_steps=0,
+ num_train_steps=num_train_steps,
+ weight_decay_rate=0.01,
+)
+model.compile(optimizer=optimizer)
+
+# Обучение со смешанной точностью float16
+tf.keras.mixed_precision.set_global_policy("mixed_float16")
+```
+
+Наконец, мы готовы к обучению с помощью `model.fit()`. Мы используем `PushToHubCallback` для загрузки модели в Hub после каждой эпохи.
+
+{/if}
+
+По умолчанию используемый розиторий будет находиться в вашем пространстве имен и называться в соответствии с заданным выходным каталогом, так что в нашем случае он будет находиться в `"sgugger/bert-finetuned-squad"`. Мы можем переопределить это, передав `hub_model_id`; например, чтобы отправить модель в организацию `huggingface_course`, мы использовали `hub_model_id="huggingface_course/bert-finetuned-squad"` (это модель, на которую мы ссылались в начале этого раздела).
+
+{#if fw === 'pt'}
+
+
+
+💡 Если используемый вами выходной каталог существует, он должен быть локальным клоном того розитория, в который вы хотите отправлять данные (поэтому задайте новое имя, если вы получите ошибку при определении `Trainer`).
+
+
+
+Наконец, мы просто передаем все в класс `Trainer` и запускаем обучение:
+
+```python
+from transformers import Trainer
+
+trainer = Trainer(
+ model=model,
+ args=args,
+ train_dataset=train_dataset,
+ eval_dataset=validation_dataset,
+ tokenizer=tokenizer,
+)
+trainer.train()
+```
+
+{:else}
+
+```python
+from transformers.keras_callbacks import PushToHubCallback
+
+callback = PushToHubCallback(output_dir="bert-finetuned-squad", tokenizer=tokenizer)
+
+# Мы собираемся провести валидацию после обучения, поэтому не нужно проводить валидацию в середине обучения
+model.fit(tf_train_dataset, callbacks=[callback], epochs=num_train_epochs)
+```
+
+{/if}
+
+Обратите внимание, что во время обучения каждый раз, когда модель сохраняется (здесь - каждую эпоху), она загружается на Hub в фоновом режиме. Таким образом, при необходимости вы сможете возобновить обучение на другой машине. Все обучение занимает некоторое время (чуть больше часа на Titan RTX), поэтому во время его проведения вы можете выпить кофе или перечитать те части курса, которые показались вам более сложными. Также обратите внимание, что как только закончится первая эпоха, вы увидите, что некоторые веса загружены в Hub, и сможете начать играть с вашей моделью на ее странице.
+
+{#if fw === 'pt'}
+
+Когда обучение завершено, мы можем наконец оценить нашу модель (и помолиться, что не потратили все это время вычислений впустую). Метод `predict()` функции `Trainer` вернет кортеж, где первыми элементами будут предсказания модели (здесь пара с начальным и конечным логитами). Мы отправляем его в нашу функцию `compute_metrics()`:
+
+```python
+predictions, _, _ = trainer.predict(validation_dataset)
+start_logits, end_logits = predictions
+compute_metrics(start_logits, end_logits, validation_dataset, raw_datasets["validation"])
+```
+
+{:else}
+
+Когда обучение завершено, мы можем наконец оценить нашу модель (и помолиться, что не потратили все это время вычислений впустую). Метод `predict()` функции `Trainer` вернет кортеж, где первыми элементами будут предсказания модели (здесь пара с начальным и конечным логитами). Мы отправляем его в нашу функцию `compute_metrics()`:
+
+```python
+predictions = model.predict(tf_eval_dataset)
+compute_metrics(
+ predictions["start_logits"],
+ predictions["end_logits"],
+ validation_dataset,
+ raw_datasets["validation"],
+)
+```
+
+{/if}
+
+```python out
+{'exact_match': 81.18259224219489, 'f1': 88.67381321905516}
+```
+
+Отлично! Для сравнения, базовые показатели, указанные в статье BERT для этой модели, составляют 80,8 и 88,5, так что мы как раз там, где должны быть.
+
+{#if fw === 'pt'}
+
+Наконец, мы используем метод `push_to_hub()`, чтобы убедиться, что мы загрузили последнюю версию модели:
+
+```py
+trainer.push_to_hub(commit_message="Training complete")
+```
+
+Это возвращает URL только что выполненного коммита, если вы хотите его просмотреть:
+
+```python out
+'https://huggingface.co/sgugger/bert-finetuned-squad/commit/9dcee1fbc25946a6ed4bb32efb1bd71d5fa90b68'
+```
+
+`Trainer` также создает черновик карточки модели со всеми результатами оценки и загружает ее.
+
+{/if}
+
+На этом этапе вы можете использовать виджет инференса на Model Hub, чтобы протестировать модель и поделиться ею с друзьями, семьей и любимыми питомцами. Вы успешно провели дообучение модели для задачи ответа на вопрос - поздравляем!
+
+
+
+✏️ **Ваша очередь!** Попробуйте другую архитектуру модели, чтобы узнать, лучше ли она справляется с этой задачей!
+
+
+
+{#if fw === 'pt'}
+
+Если вы хотите более глубоко погрузиться в тренировочный цикл, мы покажем вам, как сделать то же самое с помощью 🤗 Accelerate.
+
+## Пользовательский цикл обучения[[a-custom-training-loop]]
+
+Теперь давайте посмотрим на полный цикл обучения, чтобы вы могли легко настроить нужные вам части. Он будет очень похож на цикл обучения в [Главе 3](../chapter3/4), за исключением цикла оценки. Мы сможем регулярно оценивать модель, поскольку больше не ограничены классом `Trainer`.
+
+### Подготовим все для обучения[[preparing-everything-for-training]]
+
+Сначала нам нужно создать `DataLoader`ы из наших датасетов. Мы установим формат этих датасетов в `"torch"` и удалим столбцы в наборе валидации, которые не используются моделью. Затем мы можем использовать `default_data_collator`, предоставляемый Transformers, в качестве `collate_fn` и перемешаем обучающий набор, но не набор для валидации:
+
+```py
+from torch.utils.data import DataLoader
+from transformers import default_data_collator
+
+train_dataset.set_format("torch")
+validation_set = validation_dataset.remove_columns(["example_id", "offset_mapping"])
+validation_set.set_format("torch")
+
+train_dataloader = DataLoader(
+ train_dataset,
+ shuffle=True,
+ collate_fn=default_data_collator,
+ batch_size=8,
+)
+eval_dataloader = DataLoader(
+ validation_set, collate_fn=default_data_collator, batch_size=8
+)
+```
+
+Затем мы реинстанцируем нашу модель, чтобы убедиться, что мы не продолжаем дообучение, а снова начинаем с предварительно обученной модели BERT:
+
+```py
+model = AutoModelForQuestionAnswering.from_pretrained(model_checkpoint)
+```
+
+Тогда нам понадобится оптимизатор. Как обычно, мы используем классический `AdamW`, который похож на Adam, но с исправлением в способе применения затухания веса:
+
+```py
+from torch.optim import AdamW
+
+optimizer = AdamW(model.parameters(), lr=2e-5)
+```
+
+Когда у нас есть все эти объекты, мы можем отправить их в метод `accelerator.prepare()`. Помните, что если вы хотите обучать на TPU в блокноте Colab, вам нужно будет перенести весь этот код в функцию обучения, которая не должна выполнять ни одну ячейку, инстанцирующую `Accelerator`. Мы можем принудительно обучать со смешанной точностью, передав `fp16=True` в `Accelerator` (или, если вы выполняете код в виде скрипта, просто убедитесь, что заполнили 🤗 Accelerate `config` соответствующим образом).
+
+```py
+from accelerate import Accelerator
+
+accelerator = Accelerator(fp16=True)
+model, optimizer, train_dataloader, eval_dataloader = accelerator.prepare(
+ model, optimizer, train_dataloader, eval_dataloader
+)
+```
+
+Как вы уже поняли из предыдущих разделов, мы можем использовать длину `train_dataloader` для вычисления количества шагов обучения только после того, как она пройдет через метод `accelerator.prepare()`. Мы используем тот же линейный график, что и в предыдущих разделах:
+
+```py
+from transformers import get_scheduler
+
+num_train_epochs = 3
+num_update_steps_per_epoch = len(train_dataloader)
+num_training_steps = num_train_epochs * num_update_steps_per_epoch
+
+lr_scheduler = get_scheduler(
+ "linear",
+ optimizer=optimizer,
+ num_warmup_steps=0,
+ num_training_steps=num_training_steps,
+)
+```
+
+Чтобы отправить нашу модель на Hub, нам нужно создать объект `Repository` в рабочей папке. Сначала войдите в Hub Hugging Face, если вы еще не вошли в него. Мы определим имя розитория по идентификатору модели, который мы хотим присвоить нашей модели (не стесняйтесь заменить `repo_name` на свое усмотрение; оно просто должно содержать ваше имя пользователя, что и делает функция `get_full_repo_name()`):
+
+```py
+from huggingface_hub import Repository, get_full_repo_name
+
+model_name = "bert-finetuned-squad-accelerate"
+repo_name = get_full_repo_name(model_name)
+repo_name
+```
+
+```python out
+'sgugger/bert-finetuned-squad-accelerate'
+```
+
+Затем мы можем клонировать этот розиторий в локальную папку. Если она уже существует, эта локальная папка должна быть клоном того розитория, с которым мы работаем:
+
+```py
+output_dir = "bert-finetuned-squad-accelerate"
+repo = Repository(output_dir, clone_from=repo_name)
+```
+
+Теперь мы можем загрузить все, что сохранили в `output_dir`, вызвав метод `repo.push_to_hub()`. Это поможет нам загружать промежуточные модели в конце каждой эпохи.
+
+### Цикл обучения[[training-loop]]
+
+Теперь мы готовы написать полный цикл обучения. После определения прогресс-бара, чтобы следить за ходом обучения, цикл состоит из трех частей:
+
+- Собственно обучение, которое представляет собой классическую итерацию по `train_dataloader`, прямой проход по модели, затем обратный проход и шаг оптимизатора.
+- Оценка, в которой мы собираем все значения для `start_logits` и `end_logits` перед преобразованием их в массивы NumPy. После завершения цикла оценки мы объединяем все результаты. Обратите внимание, что нам нужно произвести усечение, потому что `Accelerator` может добавить несколько примеров в конце, чтобы убедиться, что у нас одинаковое количество примеров в каждом процессе.
+- Сохранение и загрузка, где мы сначала сохраняем модель и токенизатор, а затем вызываем `repo.push_to_hub()`. Как и раньше, мы используем аргумент `blocking=False`, чтобы указать библиотеке 🤗 Hub на асинхронный процесс push. Таким образом, обучение продолжается нормально, а эта (длинная) инструкция выполняется в фоновом режиме.
+
+Вот полный код цикла обучения:
+
+```py
+from tqdm.auto import tqdm
+import torch
+
+progress_bar = tqdm(range(num_training_steps))
+
+for epoch in range(num_train_epochs):
+ # Обучение
+ model.train()
+ for step, batch in enumerate(train_dataloader):
+ outputs = model(**batch)
+ loss = outputs.loss
+ accelerator.backward(loss)
+
+ optimizer.step()
+ lr_scheduler.step()
+ optimizer.zero_grad()
+ progress_bar.update(1)
+
+ # Оценка
+ model.eval()
+ start_logits = []
+ end_logits = []
+ accelerator.print("Evaluation!")
+ for batch in tqdm(eval_dataloader):
+ with torch.no_grad():
+ outputs = model(**batch)
+
+ start_logits.append(accelerator.gather(outputs.start_logits).cpu().numpy())
+ end_logits.append(accelerator.gather(outputs.end_logits).cpu().numpy())
+
+ start_logits = np.concatenate(start_logits)
+ end_logits = np.concatenate(end_logits)
+ start_logits = start_logits[: len(validation_dataset)]
+ end_logits = end_logits[: len(validation_dataset)]
+
+ metrics = compute_metrics(
+ start_logits, end_logits, validation_dataset, raw_datasets["validation"]
+ )
+ print(f"epoch {epoch}:", metrics)
+
+ # Сохранение и загрузка
+ accelerator.wait_for_everyone()
+ unwrapped_model = accelerator.unwrap_model(model)
+ unwrapped_model.save_pretrained(output_dir, save_function=accelerator.save)
+ if accelerator.is_main_process:
+ tokenizer.save_pretrained(output_dir)
+ repo.push_to_hub(
+ commit_message=f"Training in progress epoch {epoch}", blocking=False
+ )
+```
+
+Если вы впервые видите модель, сохраненную с помощью 🤗 Accelerate, давайте посмотрим на три строки кода, которые с этим связаны:
+
+```py
+accelerator.wait_for_everyone()
+unwrapped_model = accelerator.unwrap_model(model)
+unwrapped_model.save_pretrained(output_dir, save_function=accelerator.save)
+```
+
+Первая строка не требует пояснений: она предписывает всем процессам подождать, пока все не окажутся на этой стадии, прежде чем продолжить работу. Это нужно для того, чтобы убедиться, что у нас одна и та же модель в каждом процессе перед сохранением. Затем мы захватываем `unwrapped_model`, которая является базовой моделью, которую мы определили. Метод `accelerator.prepare()` изменяет модель для работы в распределенном обучении, поэтому у нее больше не будет метода `save_pretrained()`; метод `accelerator.unwrap_model()` отменяет этот шаг. Наконец, мы вызываем `save_pretrained()`, но указываем этому методу использовать `accelerator.save()` вместо `torch.save()`.
+
+После этого у вас должна получиться модель, которая дает результаты, очень похожие на модель, обученную с помощью `Trainer`. Вы можете проверить модель, которую мы обучили с помощью этого кода, на [*huggingface-course/bert-finetuned-squad-accelerate*](https://huggingface.co/huggingface-course/bert-finetuned-squad-accelerate). А если вы хотите протестировать какие-либо изменения в цикле обучения, вы можете напрямую реализовать их, отредактировав код, показанный выше!
+
+{/if}
+
+## Использование дообученной модели[[using-the-fine-tuned-model]]
+
+Мы уже показали вам, как можно использовать модель, дообучение которой мы проводили на Model Hub, с помощью виджета инференса. Чтобы использовать ее локально в `pipeline`, нужно просто указать идентификатор модели:
+
+```py
+from transformers import pipeline
+
+# Замените здесь на выбранную вами контрольную точку
+model_checkpoint = "huggingface-course/bert-finetuned-squad"
+question_answerer = pipeline("question-answering", model=model_checkpoint)
+
+context = """
+🤗 Transformers is backed by the three most popular deep learning libraries — Jax, PyTorch and TensorFlow — with a seamless integration
+between them. It's straightforward to train your models with one before loading them for inference with the other.
+"""
+question = "Which deep learning libraries back 🤗 Transformers?"
+question_answerer(question=question, context=context)
+```
+
+```python out
+{'score': 0.9979003071784973,
+ 'start': 78,
+ 'end': 105,
+ 'answer': 'Jax, PyTorch and TensorFlow'}
+```
+
+Отлично! Наша модель работает так же хорошо, как и модель по умолчанию для этого конвейера!
diff --git a/chapters/ru/chapter7/8.mdx b/chapters/ru/chapter7/8.mdx
new file mode 100644
index 000000000..2ef75562c
--- /dev/null
+++ b/chapters/ru/chapter7/8.mdx
@@ -0,0 +1,22 @@
+# Освоение NLP[[mastering-nlp]]
+
+
+
+Если вы дошли до конца курса, поздравляем - теперь у вас есть все знания и инструменты, необходимые для решения (почти) любой задачи NLP с помощью 🤗 Transformers и экосистемы Hugging Face!
+
+Мы видели много разных коллаторов данных, поэтому сделали это небольшое видео, чтобы помочь вам определить, какой из них лучше использовать для каждой задачи:
+
+
+
+Пройдя этот молниеносный тур по основным задачам NLP, вы должны:
+
+* Знать, какие архитектуры (кодер, декодер или кодер-декодер) лучше всего подходят для конкретной задачи
+* Понимать разницу между предварительным обучением и дообучением языковой модели
+* Знать, как обучать модели Transformer, используя либо API `Trainer` и возможности распределенного обучения в 🤗 Accelerate, либо TensorFlow и Keras, в зависимости от того, какой путь вы выбрали
+* Понимать значение и ограничения таких метрик, как ROUGE и BLEU, для задач генерации текста
+* Знать, как взаимодействовать с вашими дообученными моделями, как на Hub, так и с помощью `pipeline` из 🤗 Transformers
+
+Несмотря на все эти знания, настанет момент, когда вы столкнетесь с трудной ошибкой в своем коде или у вас возникнет вопрос о том, как решить ту или иную задачу NLP. К счастью, сообщество Hugging Face готово помочь вам! В заключительной главе этой части курса мы рассмотрим, как можно отлаживать свои модели Transformer и эффективно обращаться за помощью.
\ No newline at end of file
diff --git a/chapters/ru/chapter7/9.mdx b/chapters/ru/chapter7/9.mdx
new file mode 100644
index 000000000..3a99a72eb
--- /dev/null
+++ b/chapters/ru/chapter7/9.mdx
@@ -0,0 +1,329 @@
+
+
+
+
+# Тест в конце главы[[end-of-chapter-quiz]]
+
+
+
+Давайте проверим, чему вы научились в этой главе!
+
+### 1. Какую из следующих задач можно сформулировать как проблему классификации токенов?
+
+
+
+### 2. Какая часть предварительной обработки для классификации токенов отличается от других конвейеров предварительной обработки?
+
+
-100 для обозначения специальных токенов.",
+ explain: "Это не относится к классификации токенов - мы всегда используем -100 в качестве метки для токенов, которые мы хотим игнорировать в потерях."
+ },
+ {
+ text: "При применении усечения/дополнения нам нужно убедиться, что метки имеют тот же размер, что и входные данные.",
+ explain: "Действительно! Но это не единственное отличие.",
+ correct: true
+ }
+ ]}
+/>
+
+### 3. Какая проблема возникает при токенизации слов в проблеме классификации токенов и при необходимости их маркировки?
+
+
+
+### 4. Что означает "доменная адаптация"?
+
+
+
+### 5. Что такое метки в проблеме маскированного языкового моделирования?
+
+
+
+### 6. Какую из этих задач можно рассматривать как проблему преобразования последовательности-в-последовательность (sequence-to-sequence problem)?
+
+
+
+### 7. Каков правильный способ предварительной обработки данных для проблемы преобразования последовательности-в-последовательность?
+
+inputs=... и targets=....",
+ explain: "Возможно, в будущем мы добавим такой API, но сейчас это невозможно."
+ },
+ {
+ text: "Входные данные и цели должны быть предварительно обработаны в двух раздельных вызовах токенизатора.",
+ explain: "Это правда, но неполная. Вам нужно кое-что сделать, чтобы убедиться, что токенизатор правильно обрабатывает оба варианта."
+ },
+ {
+ text: "Как обычно, нам просто нужно выполнить токенизацию входных данных.",
+ explain: "Не в проблеме классификации последовательностей; цели - это тексты, которые мы должны преобразовать в числа!"
+ },
+ {
+ text: "Входные данные должны быть переданы токенизатору, и цели тоже, но под управлением специального контекстного менеджера.",
+ explain: "Верно, токенизатор должен быть переведен в target режим этим менеджером контекста.",
+ correct: true
+ }
+ ]}
+/>
+
+{#if fw === 'pt'}
+
+### 8. Почему существует специальный подкласс `Trainer` для проблем преобразования " последовательности-в-последовательность"?
+
+-100.",
+ explain: "Это вовсе не определенные пользователем потери, а то, как потери всегда вычисляются."
+ },
+ {
+ text: "Поскольку проблемы преобразования последовательности-в-последовательность требуют специального цикла оценки",
+ explain: "Это верно. Предсказания моделей преобразующих последовательность-в-последовательность часто выполняются с помощью метода generate().",
+ correct: true
+ },
+ {
+ text: "Поскольку целью являются тексты в проблемах преобразования последовательности-в-последовательность",
+ explain: "Trainer не особо заботится об этом, поскольку они уже были предварительно обработаны."
+ },
+ {
+ text: "Поскольку в проблемах преобразования последовательности-в-последовательность мы используем две модели",
+ explain: "В некотором смысле мы используем две модели, энкодер и декодер, но они сгруппированы в одну модель."
+ }
+ ]}
+/>
+
+{:else}
+
+### 9. Почему при вызове `compile()` для модели трансформера часто нет необходимости определять потери?
+
+
+
+{/if}
+
+### 10. Когда следует проводить предварительное обучение новой модели?
+
+
+
+### 11. Почему легко провести предварительное обучение языковой модели на большом количестве текстов?
+
+
+
+### 12. Какие основные проблемы возникают при предварительной обработке данных для задачи ответа на вопрос (question answering)?
+
+
+
+### 13. Как обычно выполняется постобработка в задаче ответов на вопросы?
+
+
diff --git a/chapters/th/chapter3/2.mdx b/chapters/th/chapter3/2.mdx
index 73f8ec8cf..7e33dd154 100644
--- a/chapters/th/chapter3/2.mdx
+++ b/chapters/th/chapter3/2.mdx
@@ -235,7 +235,7 @@ tokenized_dataset = tokenizer(
ซึ่งการเขียนคำสั่งแบบนี้ก็ได้ผลลัพธ์ที่ถูกต้อง แต่จะมีจุดด้อยคือการทำแบบนี้จะได้ผลลัพธ์ออกมาเป็น dictionary (โดยมี keys ต่าง ๆ คือ `input_ids`, `attention_mask` และ `token_type_ids` และมี values เป็น lists ของ lists) วิธีการนี้จะใช้การได้ก็ต่อเมื่อคอมพิวเตอร์ของคุณมี RAM เพียงพอที่จะเก็บข้อมูลของทั้งชุดข้อมูลในตอนที่ทำการ tokenize ชุดข้อมูลทั้งหมด (ในขณะที่ dataset ที่ได้จากไลบรารี่ 🤗 Datasets จะเป็นไฟล์ [Apache Arrow](https://arrow.apache.org/) ซึ่งจะเก็บข้อมูลไว้ใน disk คุณจึงสามารถโหลดเฉพาะข้อมูลที่ต้องการมาเก็บไว้ใน memory ได้)
-เพื่อให้ข้อมูลของเรายังเป็นข้อมูลชนิด dataset เราจะใช้เมธอด [`Dataset.map()`](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.map) ซึ่งจะช่วยให้เราเลือกได้ว่าเราจะทำการประมวลผลอื่น ๆ นอกเหนือจากการ tokenize หรือไม่ โดยเมธอด `map()` ทำงานโดยการเรียกใช้ฟังก์ชั่นกับแต่ละ element ของชุดข้อมูล เรามาสร้างฟังก์ชั่นสำหรับ tokenize ข้อมูลของเรากันก่อน:
+เพื่อให้ข้อมูลของเรายังเป็นข้อมูลชนิด dataset เราจะใช้เมธอด [`Dataset.map()`](https://huggingface.co/docs/datasets/package_reference/main_classes#datasets.Dataset.map) ซึ่งจะช่วยให้เราเลือกได้ว่าเราจะทำการประมวลผลอื่น ๆ นอกเหนือจากการ tokenize หรือไม่ โดยเมธอด `map()` ทำงานโดยการเรียกใช้ฟังก์ชั่นกับแต่ละ element ของชุดข้อมูล เรามาสร้างฟังก์ชั่นสำหรับ tokenize ข้อมูลของเรากันก่อน:
```py
def tokenize_function(example):
diff --git a/chapters/th/chapter6/8.mdx b/chapters/th/chapter6/8.mdx
index 30369b8b3..5d7e90c33 100644
--- a/chapters/th/chapter6/8.mdx
+++ b/chapters/th/chapter6/8.mdx
@@ -29,14 +29,14 @@
library นี้ ประกอบด้วยส่วนหลักคือ `Tokenizer` class ที่มีส่วนประกอบย่อยสำคัญอื่นๆ แบ่งเป็นหลาย submodules
-- `normalizers` ประกอบไปด้วย `Normalizer` หลายประเภทที่คุณสามารถใช้ได้ (รายชื่อทั้งหมดดูได้[ที่นี่](https://huggingface.co/docs/tokenizers/python/latest/api/reference.html#module-tokenizers.normalizers)).
-- `pre_tokenizers` ประกอบไปด้วย `PreTokenizer` หลายประเภทที่คุณสามารถใช้ได้ (รายชื่อทั้งหมดดูได้[ที่นี่](https://huggingface.co/docs/tokenizers/python/latest/api/reference.html#module-tokenizers.pre_tokenizers)).
-- `models` ประกอบไปด้วย `Model` หลายประเภทที่คุณสามารถใช้ได้ เช่น `BPE`, `WordPiece`, และ `Unigram` (รายชื่อทั้งหมดดูได้[ที่นี่](https://huggingface.co/docs/tokenizers/python/latest/api/reference.html#module-tokenizers.models)).
-- `trainers` ประกอบไปด้วย `Trainer` หลายประเภทที่คุณสามารถใช้เพื่อเทรนโมเดลด้วย corpus ที่มีได้ (แต่ละโมเดลจะมีเทรนเนอร์อย่างละตัว; รายชื่อทั้งหมดดูได้[ที่นี่](https://huggingface.co/docs/tokenizers/python/latest/api/reference.html#module-tokenizers.trainers)).
-- `post_processors` ประกอบไปด้วย `PostProcessor` หลายประเภทที่คุณสามารถใช้ได้ (รายชื่อทั้งหมดดูได้[ที่นี่](https://huggingface.co/docs/tokenizers/python/latest/api/reference.html#module-tokenizers.processors))
-- `decoders` ประกอบไปด้วย `Decoder` หลายประเภทที่ใช้เพื่อ decode ผลลัพธ์จากการ tokenization (รายชื่อทั้งหมดดูได้[ที่นี่](https://huggingface.co/docs/tokenizers/python/latest/components.html#decoders))
-
-คุณสามารถดูรายชื่อของส่วนประกอบสำคัญๆต่างๆได้[ที่นี่](https://huggingface.co/docs/tokenizers/python/latest/components.html)
+- `normalizers` ประกอบไปด้วย `Normalizer` หลายประเภทที่คุณสามารถใช้ได้ (รายชื่อทั้งหมดดูได้[ที่นี่](https://huggingface.co/docs/tokenizers/api/normalizers)).
+- `pre_tokenizers` ประกอบไปด้วย `PreTokenizer` หลายประเภทที่คุณสามารถใช้ได้ (รายชื่อทั้งหมดดูได้[ที่นี่](https://huggingface.co/docs/tokenizers/api/pre-tokenizers)).
+- `models` ประกอบไปด้วย `Model` หลายประเภทที่คุณสามารถใช้ได้ เช่น `BPE`, `WordPiece`, และ `Unigram` (รายชื่อทั้งหมดดูได้[ที่นี่](https://huggingface.co/docs/tokenizers/api/models)).
+- `trainers` ประกอบไปด้วย `Trainer` หลายประเภทที่คุณสามารถใช้เพื่อเทรนโมเดลด้วย corpus ที่มีได้ (แต่ละโมเดลจะมีเทรนเนอร์อย่างละตัว; รายชื่อทั้งหมดดูได้[ที่นี่](https://huggingface.co/docs/tokenizers/api/trainers)).
+- `post_processors` ประกอบไปด้วย `PostProcessor` หลายประเภทที่คุณสามารถใช้ได้ (รายชื่อทั้งหมดดูได้[ที่นี่](https://huggingface.co/docs/tokenizers/api/post-processors))
+- `decoders` ประกอบไปด้วย `Decoder` หลายประเภทที่ใช้เพื่อ decode ผลลัพธ์จากการ tokenization (รายชื่อทั้งหมดดูได้[ที่นี่](https://huggingface.co/docs/tokenizers/components#decoders))
+
+คุณสามารถดูรายชื่อของส่วนประกอบสำคัญๆต่างๆได้[ที่นี่](https://huggingface.co/docs/tokenizers/components)
## การโหลด corpus
diff --git a/chapters/vi/chapter3/2.mdx b/chapters/vi/chapter3/2.mdx
index e04c61e6d..3d2b3af2d 100644
--- a/chapters/vi/chapter3/2.mdx
+++ b/chapters/vi/chapter3/2.mdx
@@ -235,7 +235,7 @@ tokenized_dataset = tokenizer(
Điều này hoạt động tốt, nhưng nó có nhược điểm là trả về từ điển (với các khóa của chúng tôi, `input_ids`, `attention_mask` và `token_type_ids`, và các giá trị là danh sách các danh sách). Nó cũng sẽ chỉ hoạt động nếu bạn có đủ RAM để lưu trữ toàn bộ tập dữ liệu của mình trong quá trình tokenize (trong khi các tập dữ liệu từ thư viện 🤗 Datasets là các tệp [Apache Arrow](https://arrow.apache.org/) được lưu trữ trên đĩa, vì vậy bạn chỉ giữ các mẫu bạn yêu cầu đã tải trong bộ nhớ).
-Để giữ dữ liệu dưới dạng tập dữ liệu, chúng ta sẽ sử dụng phương thức [`Dataset.map()`](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.map). Điều này cũng cho phép chúng ta linh hoạt hơn, nếu chúng ta cần thực hiện nhiều tiền xử lý hơn là chỉ tokenize. Phương thức `map()` hoạt động bằng cách áp dụng một hàm trên mỗi phần tử của tập dữ liệu, vì vậy hãy xác định một hàm tokenize các đầu vào của chúng ta:
+Để giữ dữ liệu dưới dạng tập dữ liệu, chúng ta sẽ sử dụng phương thức [`Dataset.map()`](https://huggingface.co/docs/datasets/package_reference/main_classes#datasets.Dataset.map). Điều này cũng cho phép chúng ta linh hoạt hơn, nếu chúng ta cần thực hiện nhiều tiền xử lý hơn là chỉ tokenize. Phương thức `map()` hoạt động bằng cách áp dụng một hàm trên mỗi phần tử của tập dữ liệu, vì vậy hãy xác định một hàm tokenize các đầu vào của chúng ta:
```py
def tokenize_function(example):
diff --git a/chapters/vi/chapter5/2.mdx b/chapters/vi/chapter5/2.mdx
index 25f910110..660739c0a 100644
--- a/chapters/vi/chapter5/2.mdx
+++ b/chapters/vi/chapter5/2.mdx
@@ -128,7 +128,7 @@ DatasetDict({
-Tham số `data_files` của hàm `load_dataset()` khá linh hoạt và có thể là một đường dẫn tệp duy nhất, danh sách các đường dẫn tệp hoặc từ điển ánh xạ các tên tách thành đường dẫn tệp. Bạn cũng có thể tập hợp các tệp phù hợp với một mẫu được chỉ định theo các quy tắc được sử dụng bởi Unix shell (ví dụ: bạn có thể tổng hợp tất cả các tệp JSON trong một thư mục dưới dạng một lần tách duy nhất bằng cách đặt `data_files="*.json"`). Xem [tài liệu](https://huggingface.co/docs/datasets/loading.html#local-and-remote-files) 🤗 Datasets để biết thêm chi tiết.
+Tham số `data_files` của hàm `load_dataset()` khá linh hoạt và có thể là một đường dẫn tệp duy nhất, danh sách các đường dẫn tệp hoặc từ điển ánh xạ các tên tách thành đường dẫn tệp. Bạn cũng có thể tập hợp các tệp phù hợp với một mẫu được chỉ định theo các quy tắc được sử dụng bởi Unix shell (ví dụ: bạn có thể tổng hợp tất cả các tệp JSON trong một thư mục dưới dạng một lần tách duy nhất bằng cách đặt `data_files="*.json"`). Xem [tài liệu](https://huggingface.co/docs/datasets/loading#local-and-remote-files) 🤗 Datasets để biết thêm chi tiết.
@@ -160,6 +160,6 @@ squad_it_dataset = load_dataset("json", data_files=data_files, field="data")
-✏️ **Thử nghiệm thôi!** Chọn một tập dữ liệu khác được lưu trữ trên GitHub hoặc [Kho lưu trữ Học Máy UCI](https://archive.ics.uci.edu/ml/index.php) và thử tải nó cả cục bộ và từ xa bằng cách sử dụng các kỹ thuật đã giới thiệu ở trên. Để có điểm thưởng, hãy thử tải tập dữ liệu được lưu trữ ở định dạng CSV hoặc dạng văn bản (xem [tài liệu](https://huggingface.co/docs/datasets/loading.html#local-and-remote-files) để biết thêm thông tin trên các định dạng này).
+✏️ **Thử nghiệm thôi!** Chọn một tập dữ liệu khác được lưu trữ trên GitHub hoặc [Kho lưu trữ Học Máy UCI](https://archive.ics.uci.edu/ml/index.php) và thử tải nó cả cục bộ và từ xa bằng cách sử dụng các kỹ thuật đã giới thiệu ở trên. Để có điểm thưởng, hãy thử tải tập dữ liệu được lưu trữ ở định dạng CSV hoặc dạng văn bản (xem [tài liệu](https://huggingface.co/docs/datasets/loading#local-and-remote-files) để biết thêm thông tin trên các định dạng này).
diff --git a/chapters/vi/chapter5/3.mdx b/chapters/vi/chapter5/3.mdx
index 70eb79d19..1c0035536 100644
--- a/chapters/vi/chapter5/3.mdx
+++ b/chapters/vi/chapter5/3.mdx
@@ -237,7 +237,7 @@ Như bạn có thể thấy, điều này đã loại bỏ khoảng 15% bài đ
-✏️ **Thử nghiệm thôi!** Sử dụng hàm `Dataset.sort()` để kiểm tra các bài đánh giá có số lượng từ lớn nhất. Tham khảo [tài liệu](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.sort) để biết bạn cần sử dụng tham số nào để sắp xếp các bài đánh giá theo thứ tự giảm dần.
+✏️ **Thử nghiệm thôi!** Sử dụng hàm `Dataset.sort()` để kiểm tra các bài đánh giá có số lượng từ lớn nhất. Tham khảo [tài liệu](https://huggingface.co/docs/datasets/package_reference/main_classes#datasets.Dataset.sort) để biết bạn cần sử dụng tham số nào để sắp xếp các bài đánh giá theo thứ tự giảm dần.
@@ -384,7 +384,7 @@ tokenized_dataset = drug_dataset.map(tokenize_and_split, batched=True)
ArrowInvalid: Column 1 named condition expected length 1463 but got length 1000
```
-Ôi không! Nó đã không hoạt động! Tại sao không? Nhìn vào thông báo lỗi sẽ cho chúng ta manh mối: có sự không khớp về độ dài của một trong các cột, một cột có độ dài 1,463 và cột còn lại có độ dài 1,000. Nếu bạn đã xem [tài liệu](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.map) về `Dataset.map()`, bạn có thể nhớ rằng đó là số các mẫu được truyền vào hàm mà chúng ta đang ánh xạ; ở đây 1,000 mẫu đó đã cung cấp 1,463 đặc trưng mới, dẫn đến lỗi hình dạng.
+Ôi không! Nó đã không hoạt động! Tại sao không? Nhìn vào thông báo lỗi sẽ cho chúng ta manh mối: có sự không khớp về độ dài của một trong các cột, một cột có độ dài 1,463 và cột còn lại có độ dài 1,000. Nếu bạn đã xem [tài liệu](https://huggingface.co/docs/datasets/package_reference/main_classes#datasets.Dataset.map) về `Dataset.map()`, bạn có thể nhớ rằng đó là số các mẫu được truyền vào hàm mà chúng ta đang ánh xạ; ở đây 1,000 mẫu đó đã cung cấp 1,463 đặc trưng mới, dẫn đến lỗi hình dạng.
Vấn đề là chúng ta đang cố gắng kết hợp hai tập dữ liệu khác nhau với các kích thước khác nhau: cột `drug_dataset` sẽ có một số mẫu nhất định (lỗi phía chúng ta là 1,000), nhưng `tokenized_dataset` mà chúng ta đang xây dựng sẽ có nhiều hơn (1,463 trong thông báo lỗi). Điều này không hoạt động đối với `Dataset`, vì vậy chúng ta cần xóa các cột khỏi tập dữ liệu cũ hoặc làm cho chúng có cùng kích thước với chúng trong tập dữ liệu mới. Chúng ta có thể thực hiện điều đầu thông qua tham số `remove_columns`:
diff --git a/chapters/vi/chapter5/4.mdx b/chapters/vi/chapter5/4.mdx
index 381224111..c105b0b28 100644
--- a/chapters/vi/chapter5/4.mdx
+++ b/chapters/vi/chapter5/4.mdx
@@ -54,7 +54,7 @@ Chúng ta có thể thấy rằng có 15,518,009 hàng và 2 cột trong tập d
-✎ Theo mặc định, 🤗 Datasets sẽ giải nén các tệp cần thiết để tải tập dữ liệu. Nếu bạn muốn bảo toàn dung lượng ổ cứng, bạn có thể truyền `DownloadConfig(delete_extracted=True)` vào tham số `download_config` của `load_dataset()`. Xem [tài liệu](https://huggingface.co/docs/datasets/package_reference/builder_classes.html?#datasets.utils.DownloadConfig) để biết thêm chi tiết.
+✎ Theo mặc định, 🤗 Datasets sẽ giải nén các tệp cần thiết để tải tập dữ liệu. Nếu bạn muốn bảo toàn dung lượng ổ cứng, bạn có thể truyền `DownloadConfig(delete_extracted=True)` vào tham số `download_config` của `load_dataset()`. Xem [tài liệu](https://huggingface.co/docs/datasets/package_reference/builder_classes#datasets.DownloadConfig) để biết thêm chi tiết.
diff --git a/chapters/vi/chapter5/5.mdx b/chapters/vi/chapter5/5.mdx
index d8faafb4f..9b05d75d6 100644
--- a/chapters/vi/chapter5/5.mdx
+++ b/chapters/vi/chapter5/5.mdx
@@ -435,7 +435,7 @@ Tuyệt vời, chúng ta đã đưa tập dữ liệu của mình vào Hub và n
-💡 Bạn cũng có thể tải tập dữ liệu lên Hugging Face Hub trực tiếp từ thiết bị đầu cuối bằng cách sử dụng `huggingface-cli` và một chút phép thuật từ Git. Tham khảo [hướng dẫn 🤗 Datasets](https://huggingface.co/docs/datasets/share.html#add-a-community-dataset) để biết chi tiết về cách thực hiện việc này.
+💡 Bạn cũng có thể tải tập dữ liệu lên Hugging Face Hub trực tiếp từ thiết bị đầu cuối bằng cách sử dụng `huggingface-cli` và một chút phép thuật từ Git. Tham khảo [hướng dẫn 🤗 Datasets](https://huggingface.co/docs/datasets/share#share-a-dataset-using-the-cli) để biết chi tiết về cách thực hiện việc này.
diff --git a/chapters/vi/chapter5/6.mdx b/chapters/vi/chapter5/6.mdx
index cfaca863b..6c29fff33 100644
--- a/chapters/vi/chapter5/6.mdx
+++ b/chapters/vi/chapter5/6.mdx
@@ -190,7 +190,7 @@ Dataset({
-✏️ **Thử nghiệm thôi!** Cùng xem liệu bạn có thể sử dụng `Dataset.map()` để khám phá cột `comments` của `issues_dataset` _mà không cần_ sử dụng Pandas hay không. Nó sẽ hơi khó khăn một chút; bạn có thể xem phần ["Batch mapping"](https://huggingface.co/docs/datasets/v1.12.1/about_map_batch.html?batch-mapping#batch-mapping) của tài liệu 🤗 Datasets, một tài liệu hữu ích cho tác vụ này.
+✏️ **Thử nghiệm thôi!** Cùng xem liệu bạn có thể sử dụng `Dataset.map()` để khám phá cột `comments` của `issues_dataset` _mà không cần_ sử dụng Pandas hay không. Nó sẽ hơi khó khăn một chút; bạn có thể xem phần ["Batch mapping"](https://huggingface.co/docs/datasets/about_map_batch#batch-mapping) của tài liệu 🤗 Datasets, một tài liệu hữu ích cho tác vụ này.
diff --git a/chapters/vi/chapter6/8.mdx b/chapters/vi/chapter6/8.mdx
index 7ce6fd78e..aa93a0fed 100644
--- a/chapters/vi/chapter6/8.mdx
+++ b/chapters/vi/chapter6/8.mdx
@@ -25,14 +25,14 @@ Thư viện 🤗 Tokenizers đã được xây dựng để cung cấp nhiều s
Chính xác hơn, thư viện được xây dựng tập trung vào lớp `Tokenizer` với các khối được tập hợp lại trong các mô-đun con:
-- `normalizers` chứa tất cả các kiểu `Normalizer` bạn có thể sử dụng (hoàn thiện danh sách tại [đây](https://huggingface.co/docs/tokenizers/python/latest/api/reference.html#module-tokenizers.normalizers)).
-- `pre_tokenizers` chứa tất cả các kiểu `PreTokenizer` bạn có thể sử dụng (hoàn thiện danh sách tại [đây](https://huggingface.co/docs/tokenizers/python/latest/api/reference.html#module-tokenizers.pre_tokenizers)).
-- `models` chứa tất cả các kiểu `Model` bạn có thể sử dụng, như `BPE`, `WordPiece`, and `Unigram` (hoàn thiện danh sách tại [đây](https://huggingface.co/docs/tokenizers/python/latest/api/reference.html#module-tokenizers.models)).
-- `trainers` chứa tất cả các kiểu `Trainer` khác nhau bạn có thể sử dụng để huấn luyện mô hình của bạn trên kho ngữ liệu (một cho mỗi loại mô hình; hoàn thiện danh sách tại [đây](https://huggingface.co/docs/tokenizers/python/latest/api/reference.html#module-tokenizers.trainers)).
-- `post_processors` chứa tất cả các kiểu `PostProcessor` bạn có thể sử dụng (hoàn thiện danh sách tại [đây](https://huggingface.co/docs/tokenizers/python/latest/api/reference.html#module-tokenizers.processors)).
-- `decoders` chứa tất cả các kiểu `Decoder` đa dạng bạn có thể sử dụng để giải mã đầu ra của tokenize (hoàn thiện danh sách tại [đây](https://huggingface.co/docs/tokenizers/python/latest/components.html#decoders)).
-
-Bạn có thể tìm được toàn bộ danh sách các khối tại [đây](https://huggingface.co/docs/tokenizers/python/latest/components.html).
+- `normalizers` chứa tất cả các kiểu `Normalizer` bạn có thể sử dụng (hoàn thiện danh sách tại [đây](https://huggingface.co/docs/tokenizers/api/normalizers)).
+- `pre_tokenizers` chứa tất cả các kiểu `PreTokenizer` bạn có thể sử dụng (hoàn thiện danh sách tại [đây](https://huggingface.co/docs/tokenizers/api/pre-tokenizers)).
+- `models` chứa tất cả các kiểu `Model` bạn có thể sử dụng, như `BPE`, `WordPiece`, and `Unigram` (hoàn thiện danh sách tại [đây](https://huggingface.co/docs/tokenizers/api/models)).
+- `trainers` chứa tất cả các kiểu `Trainer` khác nhau bạn có thể sử dụng để huấn luyện mô hình của bạn trên kho ngữ liệu (một cho mỗi loại mô hình; hoàn thiện danh sách tại [đây](https://huggingface.co/docs/tokenizers/api/trainers)).
+- `post_processors` chứa tất cả các kiểu `PostProcessor` bạn có thể sử dụng (hoàn thiện danh sách tại [đây](https://huggingface.co/docs/tokenizers/api/post-processors)).
+- `decoders` chứa tất cả các kiểu `Decoder` đa dạng bạn có thể sử dụng để giải mã đầu ra của tokenize (hoàn thiện danh sách tại [đây](https://huggingface.co/docs/tokenizers/components#decoders)).
+
+Bạn có thể tìm được toàn bộ danh sách các khối tại [đây](https://huggingface.co/docs/tokenizers/components).
## Thu thập một kho ngữ liệu
diff --git a/chapters/zh-CN/chapter3/2.mdx b/chapters/zh-CN/chapter3/2.mdx
index 57e649e65..fbe6d00d3 100644
--- a/chapters/zh-CN/chapter3/2.mdx
+++ b/chapters/zh-CN/chapter3/2.mdx
@@ -235,7 +235,7 @@ tokenized_dataset = tokenizer(
这很有效,但它的缺点是返回字典(字典的键是**输入词id(input_ids)** , **注意力遮罩(attention_mask)** 和 **类型标记ID(token_type_ids)**,字典的值是键所对应值的列表)。而且只有当您在转换过程中有足够的内存来存储整个数据集时才不会出错(而🤗数据集库中的数据集是以[Apache Arrow](https://arrow.apache.org/)文件存储在磁盘上,因此您只需将接下来要用的数据加载在内存中,因此会对内存容量的需求要低一些)。
-为了将数据保存为数据集,我们将使用[Dataset.map()](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.map)方法,如果我们需要做更多的预处理而不仅仅是标记化,那么这也给了我们一些额外的自定义的方法。这个方法的工作原理是在数据集的每个元素上应用一个函数,因此让我们定义一个标记输入的函数:
+为了将数据保存为数据集,我们将使用[Dataset.map()](https://huggingface.co/docs/datasets/package_reference/main_classes#datasets.Dataset.map)方法,如果我们需要做更多的预处理而不仅仅是标记化,那么这也给了我们一些额外的自定义的方法。这个方法的工作原理是在数据集的每个元素上应用一个函数,因此让我们定义一个标记输入的函数:
```py
def tokenize_function(example):
diff --git a/chapters/zh-CN/chapter5/2.mdx b/chapters/zh-CN/chapter5/2.mdx
index 95b8691b1..555e35f70 100644
--- a/chapters/zh-CN/chapter5/2.mdx
+++ b/chapters/zh-CN/chapter5/2.mdx
@@ -160,7 +160,7 @@ squad_it_dataset = load_dataset("json", data_files=data_files, field="data")
-✏️ **试试看!** 选择托管在GitHub或[UCI Machine Learning Repository](https://archive.ics.uci.edu/ml/index.php)上的另一个数据集并尝试使用上述技术在本地和远程加载它。另外,可以尝试加载CSV或者文本格式存储的数据集(有关这些格式的更多信息,请参阅[文档](https://huggingface.co/docs/datasets/loading.html#local-and-remote-files))。
+✏️ **试试看!** 选择托管在GitHub或[UCI Machine Learning Repository](https://archive.ics.uci.edu/ml/index.php)上的另一个数据集并尝试使用上述技术在本地和远程加载它。另外,可以尝试加载CSV或者文本格式存储的数据集(有关这些格式的更多信息,请参阅[文档](https://huggingface.co/docs/datasets/loading#local-and-remote-files))。
diff --git a/chapters/zh-CN/chapter5/4.mdx b/chapters/zh-CN/chapter5/4.mdx
index 70ef713ca..bf34117ff 100644
--- a/chapters/zh-CN/chapter5/4.mdx
+++ b/chapters/zh-CN/chapter5/4.mdx
@@ -46,7 +46,7 @@ Dataset({
-✎ 默认情况下, 🤗 Datasets 会自动解压加载数据集所需的文件。 如果你想保留硬盘空间, 你可以传递 `DownloadConfig(delete_extracted=True)` 到 `download_config` 的 `load_dataset()`参数. 有关更多详细信息, 请参阅文档](https://huggingface.co/docs/datasets/package_reference/builder_classes.html?#datasets.utils.DownloadConfig)。
+✎ 默认情况下, 🤗 Datasets 会自动解压加载数据集所需的文件。 如果你想保留硬盘空间, 你可以传递 `DownloadConfig(delete_extracted=True)` 到 `download_config` 的 `load_dataset()`参数. 有关更多详细信息, 请参阅文档](https://huggingface.co/docs/datasets/package_reference/builder_classes#datasets.DownloadConfig)。
diff --git a/chapters/zh-CN/chapter5/5.mdx b/chapters/zh-CN/chapter5/5.mdx
index a18ee94f4..f6454f914 100644
--- a/chapters/zh-CN/chapter5/5.mdx
+++ b/chapters/zh-CN/chapter5/5.mdx
@@ -360,7 +360,7 @@ Dataset({
-💡 您还可以使用一些 Git 魔法直接从终端将数据集上传到 Hugging Face Hub。有关如何执行此操作的详细信息,请参阅 [🤗 Datasets guide](https://huggingface.co/docs/datasets/share.html#add-a-community-dataset) 指南。
+💡 您还可以使用一些 Git 魔法直接从终端将数据集上传到 Hugging Face Hub。有关如何执行此操作的详细信息,请参阅 [🤗 Datasets guide](https://huggingface.co/docs/datasets/share#share-a-dataset-using-the-cli) 指南。
diff --git a/chapters/zh-CN/chapter5/6.mdx b/chapters/zh-CN/chapter5/6.mdx
index 8de5fb335..f3a1044e9 100644
--- a/chapters/zh-CN/chapter5/6.mdx
+++ b/chapters/zh-CN/chapter5/6.mdx
@@ -177,7 +177,7 @@ Dataset({
-✏️ **Try it out!** 看看能不能不用pandas就可以完成列的扩充; 这有点棘手; 你可能会发现 🤗 Datasets 文档的 ["Batch mapping"](https://huggingface.co/docs/datasets/v1.12.1/about_map_batch.html?batch-mapping#batch-mapping) 对这个任务很有用。
+✏️ **Try it out!** 看看能不能不用pandas就可以完成列的扩充; 这有点棘手; 你可能会发现 🤗 Datasets 文档的 ["Batch mapping"](https://huggingface.co/docs/datasets/about_map_batch#batch-mapping) 对这个任务很有用。
diff --git a/chapters/zh-CN/chapter6/8.mdx b/chapters/zh-CN/chapter6/8.mdx
index 7e6802bdc..73e07c7fa 100644
--- a/chapters/zh-CN/chapter6/8.mdx
+++ b/chapters/zh-CN/chapter6/8.mdx
@@ -27,14 +27,14 @@
更准确地说,该库是围绕一个中央“Tokenizer”类构建的,构建这个类的每一部分可以在子模块的列表中重新组合:
-- `normalizers` 包含你可以使用的所有可能的Normalizer类型(完整列表[在这里](https://huggingface.co/docs/tokenizers/python/latest/api/reference.html#module-tokenizers.normalizers))。
-- `pre_tokenizesr` 包含您可以使用的所有可能的PreTokenizer类型(完整列表[在这里](https://huggingface.co/docs/tokenizers/python/latest/api/reference.html#module-tokenizers.pre_tokenizers))。
-- `models` 包含您可以使用的各种类型的Model,如BPE、WordPiece和Unigram(完整列表[在这里](https://huggingface.co/docs/tokenizers/python/latest/api/reference.html#module-tokenizers.models))。
-- `trainers` 包含所有不同类型的 trainer,你可以使用一个语料库训练你的模型(每种模型一个;完整列表[在这里](https://huggingface.co/docs/tokenizers/python/latest/api/reference.html#module-tokenizers.trainers))。
-- `post_processors` 包含你可以使用的各种类型的PostProcessor(完整列表[在这里](https://huggingface.co/docs/tokenizers/python/latest/api/reference.html#module-tokenizers.processors))。
-- `decoders` 包含各种类型的Decoder,可以用来解码标记化的输出(完整列表[在这里](https://huggingface.co/docs/tokenizers/python/latest/components.html#decoders))。
-
-您可以[在这里](https://huggingface.co/docs/tokenizers/python/latest/components.html)找到完整的模块列表。
+- `normalizers` 包含你可以使用的所有可能的Normalizer类型(完整列表[在这里](https://huggingface.co/docs/tokenizers/api/normalizers))。
+- `pre_tokenizesr` 包含您可以使用的所有可能的PreTokenizer类型(完整列表[在这里](https://huggingface.co/docs/tokenizers/api/pre-tokenizers))。
+- `models` 包含您可以使用的各种类型的Model,如BPE、WordPiece和Unigram(完整列表[在这里](https://huggingface.co/docs/tokenizers/api/models))。
+- `trainers` 包含所有不同类型的 trainer,你可以使用一个语料库训练你的模型(每种模型一个;完整列表[在这里](https://huggingface.co/docs/tokenizers/api/trainers))。
+- `post_processors` 包含你可以使用的各种类型的PostProcessor(完整列表[在这里](https://huggingface.co/docs/tokenizers/api/post-processors))。
+- `decoders` 包含各种类型的Decoder,可以用来解码标记化的输出(完整列表[在这里](https://huggingface.co/docs/tokenizers/components#decoders))。
+
+您可以[在这里](https://huggingface.co/docs/tokenizers/components)找到完整的模块列表。
## 获取语料库 [[获取语料库]]
diff --git a/chapters/zh-TW/chapter3/2.mdx b/chapters/zh-TW/chapter3/2.mdx
index 4970fb9eb..5dd10b0a0 100644
--- a/chapters/zh-TW/chapter3/2.mdx
+++ b/chapters/zh-TW/chapter3/2.mdx
@@ -235,7 +235,7 @@ tokenized_dataset = tokenizer(
這很有效,但它的缺點是返回字典(字典的鍵是**輸入詞id(input_ids)** , **注意力遮罩(attention_mask)** 和 **類型標記ID(token_type_ids)**,字典的值是鍵所對應值的列表)。而且只有當您在轉換過程中有足夠的內存來存儲整個數據集時才不會出錯(而🤗數據集庫中的數據集是以[Apache Arrow](https://arrow.apache.org/)文件存儲在磁盤上,因此您只需將接下來要用的數據加載在內存中,因此會對內存容量的需求要低一些)。
-為了將數據保存為數據集,我們將使用[Dataset.map()](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.map)方法,如果我們需要做更多的預處理而不僅僅是標記化,那麼這也給了我們一些額外的自定義的方法。這個方法的工作原理是在數據集的每個元素上應用一個函數,因此讓我們定義一個標記輸入的函數:
+為了將數據保存為數據集,我們將使用[Dataset.map()](https://huggingface.co/docs/datasets/package_reference/main_classes#datasets.Dataset.map)方法,如果我們需要做更多的預處理而不僅僅是標記化,那麼這也給了我們一些額外的自定義的方法。這個方法的工作原理是在數據集的每個元素上應用一個函數,因此讓我們定義一個標記輸入的函數:
```py
def tokenize_function(example):
diff --git a/chapters/zh-TW/chapter5/2.mdx b/chapters/zh-TW/chapter5/2.mdx
index f47239575..90cbfdc43 100644
--- a/chapters/zh-TW/chapter5/2.mdx
+++ b/chapters/zh-TW/chapter5/2.mdx
@@ -160,7 +160,7 @@ squad_it_dataset = load_dataset("json", data_files=data_files, field="data")
-✏️ **試試看!** 選擇託管在GitHub或[UCI Machine Learning Repository](https://archive.ics.uci.edu/ml/index.php)上的另一個數據集並嘗試使用上述技術在本地和遠程加載它。另外,可以嘗試加載CSV或者文本格式存儲的數據集(有關這些格式的更多信息,請參閱[文檔](https://huggingface.co/docs/datasets/loading.html#local-and-remote-files))。
+✏️ **試試看!** 選擇託管在GitHub或[UCI Machine Learning Repository](https://archive.ics.uci.edu/ml/index.php)上的另一個數據集並嘗試使用上述技術在本地和遠程加載它。另外,可以嘗試加載CSV或者文本格式存儲的數據集(有關這些格式的更多信息,請參閱[文檔](https://huggingface.co/docs/datasets/loading#local-and-remote-files))。
diff --git a/chapters/zh-TW/chapter5/4.mdx b/chapters/zh-TW/chapter5/4.mdx
index 4cd7ae730..96e11bb8c 100644
--- a/chapters/zh-TW/chapter5/4.mdx
+++ b/chapters/zh-TW/chapter5/4.mdx
@@ -46,7 +46,7 @@ Dataset({
-✎ 默認情況下, 🤗 Datasets 會自動解壓加載數據集所需的文件。 如果你想保留硬盤空間, 你可以傳遞 `DownloadConfig(delete_extracted=True)` 到 `download_config` 的 `load_dataset()`參數. 有關更多詳細信息, 請參閱文檔](https://huggingface.co/docs/datasets/package_reference/builder_classes.html?#datasets.utils.DownloadConfig)。
+✎ 默認情況下, 🤗 Datasets 會自動解壓加載數據集所需的文件。 如果你想保留硬盤空間, 你可以傳遞 `DownloadConfig(delete_extracted=True)` 到 `download_config` 的 `load_dataset()`參數. 有關更多詳細信息, 請參閱文檔](https://huggingface.co/docs/datasets/package_reference/builder_classes#datasets.DownloadConfig)。
diff --git a/chapters/zh-TW/chapter5/5.mdx b/chapters/zh-TW/chapter5/5.mdx
index f65b1c0e2..6f9953910 100644
--- a/chapters/zh-TW/chapter5/5.mdx
+++ b/chapters/zh-TW/chapter5/5.mdx
@@ -423,7 +423,7 @@ Dataset({
-💡 您還可以使用一些 Git 魔法直接從終端將數據集上傳到 Hugging Face Hub。有關如何執行此操作的詳細信息,請參閱 [🤗 Datasets guide](https://huggingface.co/docs/datasets/share.html#add-a-community-dataset) 指南。
+💡 您還可以使用一些 Git 魔法直接從終端將數據集上傳到 Hugging Face Hub。有關如何執行此操作的詳細信息,請參閱 [🤗 Datasets guide](https://huggingface.co/docs/datasets/share#share-a-dataset-using-the-cli) 指南。
diff --git a/chapters/zh-TW/chapter5/6.mdx b/chapters/zh-TW/chapter5/6.mdx
index b5646f739..24bb8e9dd 100644
--- a/chapters/zh-TW/chapter5/6.mdx
+++ b/chapters/zh-TW/chapter5/6.mdx
@@ -188,7 +188,7 @@ Dataset({
-✏️ **Try it out!** 看看能不能不用pandas就可以完成列的擴充; 這有點棘手; 你可能會發現 🤗 Datasets 文檔的 ["Batch mapping"](https://huggingface.co/docs/datasets/v1.12.1/about_map_batch.html?batch-mapping#batch-mapping) 對這個任務很有用。
+✏️ **Try it out!** 看看能不能不用pandas就可以完成列的擴充; 這有點棘手; 你可能會發現 🤗 Datasets 文檔的 ["Batch mapping"](https://huggingface.co/docs/datasets/about_map_batch#batch-mapping) 對這個任務很有用。
diff --git a/chapters/zh-TW/chapter6/8.mdx b/chapters/zh-TW/chapter6/8.mdx
index 9a31a2bf1..c61e14d7f 100644
--- a/chapters/zh-TW/chapter6/8.mdx
+++ b/chapters/zh-TW/chapter6/8.mdx
@@ -27,14 +27,14 @@
更準確地說,該庫是圍繞一個中央「Tokenizer」類構建的,構建這個類的每一部分可以在子模塊的列表中重新組合:
-- `normalizers` 包含你可以使用的所有可能的Normalizer類型(完整列表[在這裡](https://huggingface.co/docs/tokenizers/python/latest/api/reference.html#module-tokenizers.normalizers))。
-- `pre_tokenizesr` 包含您可以使用的所有可能的PreTokenizer類型(完整列表[在這裡](https://huggingface.co/docs/tokenizers/python/latest/api/reference.html#module-tokenizers.pre_tokenizers))。
-- `models` 包含您可以使用的各種類型的Model,如BPE、WordPiece和Unigram(完整列表[在這裡](https://huggingface.co/docs/tokenizers/python/latest/api/reference.html#module-tokenizers.models))。
-- `trainers` 包含所有不同類型的 trainer,你可以使用一個語料庫訓練你的模型(每種模型一個;完整列表[在這裡](https://huggingface.co/docs/tokenizers/python/latest/api/reference.html#module-tokenizers.trainers))。
-- `post_processors` 包含你可以使用的各種類型的PostProcessor(完整列表[在這裡](https://huggingface.co/docs/tokenizers/python/latest/api/reference.html#module-tokenizers.processors))。
-- `decoders` 包含各種類型的Decoder,可以用來解碼標記化的輸出(完整列表[在這裡](https://huggingface.co/docs/tokenizers/python/latest/components.html#decoders))。
-
-您可以[在這裡](https://huggingface.co/docs/tokenizers/python/latest/components.html)找到完整的模塊列表。
+- `normalizers` 包含你可以使用的所有可能的Normalizer類型(完整列表[在這裡](https://huggingface.co/docs/tokenizers/api/normalizers))。
+- `pre_tokenizesr` 包含您可以使用的所有可能的PreTokenizer類型(完整列表[在這裡](https://huggingface.co/docs/tokenizers/api/pre-tokenizers))。
+- `models` 包含您可以使用的各種類型的Model,如BPE、WordPiece和Unigram(完整列表[在這裡](https://huggingface.co/docs/tokenizers/api/models))。
+- `trainers` 包含所有不同類型的 trainer,你可以使用一個語料庫訓練你的模型(每種模型一個;完整列表[在這裡](https://huggingface.co/docs/tokenizers/api/trainers))。
+- `post_processors` 包含你可以使用的各種類型的PostProcessor(完整列表[在這裡](https://huggingface.co/docs/tokenizers/api/post-processors))。
+- `decoders` 包含各種類型的Decoder,可以用來解碼標記化的輸出(完整列表[在這裡](https://huggingface.co/docs/tokenizers/components#decoders))。
+
+您可以[在這裡](https://huggingface.co/docs/tokenizers/components)找到完整的模塊列表。
## 獲取語料庫