| + | patient_id | +drugName | +condition | +review | +rating | +date | +usefulCount | +review_length | +
|---|---|---|---|---|---|---|---|---|
| 0 | +95260 | +Guanfacine | +adhd | +"My son is halfway through his fourth week of Intuniv..." | +8.0 | +April 27, 2010 | +192 | +141 | +
| 1 | +92703 | +Lybrel | +birth control | +"I used to take another oral contraceptive, which had 21 pill cycle, and was very happy- very light periods, max 5 days, no other side effects..." | +5.0 | +December 14, 2009 | +17 | +134 | +
| 2 | +138000 | +Ortho Evra | +birth control | +"This is my first time using any form of birth control..." | +8.0 | +November 3, 2015 | +10 | +89 | +
| + | condition | +frequency | +
|---|---|---|
| 0 | +birth control | +27655 | +
| 1 | +depression | +8023 | +
| 2 | +acne | +5209 | +
| 3 | +anxiety | +4991 | +
| 4 | +pain | +4744 | +
+ +
+
+
+Se clicchi su una di questi issue vedrai che contiene un titolo, una descrizione, e un set di etichette che caratterizzano l'issue. Un esempio è mostrato nello screenshot successivo.
+
+
+
+ +
+
+
+Per scaricare gli issue della repository, useremo la [REST API di GitHub](https://docs.github.com/en/rest) per interrogare l'[endpoint `Issues`](https://docs.github.com/en/rest/reference/issues#list-repository-issues). Questo endpoint restituisce una lista di oggetti JSON, e ogni oggetto contiene un gran numero di campi, tra cui il titolo e la descrizione, così come dei metadati circo lo status dell'issue e altro ancora.
+
+Una maniera conveniente di scaricare gli issue è attraverso la libreria `requests`, che rappresenta il metodo standard di fare richieste HTTP su Python. Puoi installa la libreria attraverso il codice:
+
+```python
+!pip install requests
+```
+
+Una volta che la libreria è stata installata, puoi effettuare una richiesta GET all'endpoint `Issues` utilizzando la funzione `requests.get()`. Ad esempio, puoi eseguire il comando mostrato di seguito per recuperare il primo issue nella prima pagina:
+
+```py
+import requests
+
+url = "https://api.github.com/repos/huggingface/datasets/issues?page=1&per_page=1"
+response = requests.get(url)
+```
+
+L'oggetto `response` contiene un sacco di informazioni utili sulla richiesta, compreso il codice di stato HTTP:
+
+```py
+response.status_code
+```
+
+```python out
+200
+```
+
+Lo status `200` indica che la richiesta ha avuto buon fine (puoi trovare una lista di codici di stato HTTTP [qui](https://it.wikipedia.org/wiki/Codici_di_stato_HTTP)). Ma ciò che ci interessa davvero è il _payload_, a cui è possibile accedere utilizzando diversi formati come byte, stringh, o JSON. Visto che sappiamo che i nostri issue sono in formato JSON, diamo un'occhiata al payload come segue:
+
+```py
+response.json()
+```
+
+```python out
+[{'url': 'https://api.github.com/repos/huggingface/datasets/issues/2792',
+ 'repository_url': 'https://api.github.com/repos/huggingface/datasets',
+ 'labels_url': 'https://api.github.com/repos/huggingface/datasets/issues/2792/labels{/name}',
+ 'comments_url': 'https://api.github.com/repos/huggingface/datasets/issues/2792/comments',
+ 'events_url': 'https://api.github.com/repos/huggingface/datasets/issues/2792/events',
+ 'html_url': 'https://github.com/huggingface/datasets/pull/2792',
+ 'id': 968650274,
+ 'node_id': 'MDExOlB1bGxSZXF1ZXN0NzEwNzUyMjc0',
+ 'number': 2792,
+ 'title': 'Update GooAQ',
+ 'user': {'login': 'bhavitvyamalik',
+ 'id': 19718818,
+ 'node_id': 'MDQ6VXNlcjE5NzE4ODE4',
+ 'avatar_url': 'https://avatars.githubusercontent.com/u/19718818?v=4',
+ 'gravatar_id': '',
+ 'url': 'https://api.github.com/users/bhavitvyamalik',
+ 'html_url': 'https://github.com/bhavitvyamalik',
+ 'followers_url': 'https://api.github.com/users/bhavitvyamalik/followers',
+ 'following_url': 'https://api.github.com/users/bhavitvyamalik/following{/other_user}',
+ 'gists_url': 'https://api.github.com/users/bhavitvyamalik/gists{/gist_id}',
+ 'starred_url': 'https://api.github.com/users/bhavitvyamalik/starred{/owner}{/repo}',
+ 'subscriptions_url': 'https://api.github.com/users/bhavitvyamalik/subscriptions',
+ 'organizations_url': 'https://api.github.com/users/bhavitvyamalik/orgs',
+ 'repos_url': 'https://api.github.com/users/bhavitvyamalik/repos',
+ 'events_url': 'https://api.github.com/users/bhavitvyamalik/events{/privacy}',
+ 'received_events_url': 'https://api.github.com/users/bhavitvyamalik/received_events',
+ 'type': 'User',
+ 'site_admin': False},
+ 'labels': [],
+ 'state': 'open',
+ 'locked': False,
+ 'assignee': None,
+ 'assignees': [],
+ 'milestone': None,
+ 'comments': 1,
+ 'created_at': '2021-08-12T11:40:18Z',
+ 'updated_at': '2021-08-12T12:31:17Z',
+ 'closed_at': None,
+ 'author_association': 'CONTRIBUTOR',
+ 'active_lock_reason': None,
+ 'pull_request': {'url': 'https://api.github.com/repos/huggingface/datasets/pulls/2792',
+ 'html_url': 'https://github.com/huggingface/datasets/pull/2792',
+ 'diff_url': 'https://github.com/huggingface/datasets/pull/2792.diff',
+ 'patch_url': 'https://github.com/huggingface/datasets/pull/2792.patch'},
+ 'body': '[GooAQ](https://github.com/allenai/gooaq) dataset was recently updated after splits were added for the same. This PR contains new updated GooAQ with train/val/test splits and updated README as well.',
+ 'performed_via_github_app': None}]
+```
+
+Wow, quante informazioni! Possiamo vedere alcuni campi utili come `title`, `body` e `number` che descrivono l'issue, così come informazioni sull'utente che l'ha aperto.
+
+
+
+ +
+
+
+La REST API di GitHub offre un [endpoint `Comments`](https://docs.github.com/en/rest/reference/issues#list-issue-comments) che restituisce tutti i commenti associati con un numero di issue. Testiamo quest'endpoint per vedere cosa restituisce:
+
+```py
+issue_number = 2792
+url = f"https://api.github.com/repos/huggingface/datasets/issues/{issue_number}/comments"
+response = requests.get(url, headers=headers)
+response.json()
+```
+
+```python out
+[{'url': 'https://api.github.com/repos/huggingface/datasets/issues/comments/897594128',
+ 'html_url': 'https://github.com/huggingface/datasets/pull/2792#issuecomment-897594128',
+ 'issue_url': 'https://api.github.com/repos/huggingface/datasets/issues/2792',
+ 'id': 897594128,
+ 'node_id': 'IC_kwDODunzps41gDMQ',
+ 'user': {'login': 'bhavitvyamalik',
+ 'id': 19718818,
+ 'node_id': 'MDQ6VXNlcjE5NzE4ODE4',
+ 'avatar_url': 'https://avatars.githubusercontent.com/u/19718818?v=4',
+ 'gravatar_id': '',
+ 'url': 'https://api.github.com/users/bhavitvyamalik',
+ 'html_url': 'https://github.com/bhavitvyamalik',
+ 'followers_url': 'https://api.github.com/users/bhavitvyamalik/followers',
+ 'following_url': 'https://api.github.com/users/bhavitvyamalik/following{/other_user}',
+ 'gists_url': 'https://api.github.com/users/bhavitvyamalik/gists{/gist_id}',
+ 'starred_url': 'https://api.github.com/users/bhavitvyamalik/starred{/owner}{/repo}',
+ 'subscriptions_url': 'https://api.github.com/users/bhavitvyamalik/subscriptions',
+ 'organizations_url': 'https://api.github.com/users/bhavitvyamalik/orgs',
+ 'repos_url': 'https://api.github.com/users/bhavitvyamalik/repos',
+ 'events_url': 'https://api.github.com/users/bhavitvyamalik/events{/privacy}',
+ 'received_events_url': 'https://api.github.com/users/bhavitvyamalik/received_events',
+ 'type': 'User',
+ 'site_admin': False},
+ 'created_at': '2021-08-12T12:21:52Z',
+ 'updated_at': '2021-08-12T12:31:17Z',
+ 'author_association': 'CONTRIBUTOR',
+ 'body': "@albertvillanova my tests are failing here:\r\n```\r\ndataset_name = 'gooaq'\r\n\r\n def test_load_dataset(self, dataset_name):\r\n configs = self.dataset_tester.load_all_configs(dataset_name, is_local=True)[:1]\r\n> self.dataset_tester.check_load_dataset(dataset_name, configs, is_local=True, use_local_dummy_data=True)\r\n\r\ntests/test_dataset_common.py:234: \r\n_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ \r\ntests/test_dataset_common.py:187: in check_load_dataset\r\n self.parent.assertTrue(len(dataset[split]) > 0)\r\nE AssertionError: False is not true\r\n```\r\nWhen I try loading dataset on local machine it works fine. Any suggestions on how can I avoid this error?",
+ 'performed_via_github_app': None}]
+```
+
+Possiamo vedere che il commento è archiviato nel campo `body`, quindi possiamo scvrivere una semplice funzione che restituisce tutti i commenti associati con un issue estraendo i contenuti di `body` per ogni elemento in `response.json()`:
+
+```py
+def get_comments(issue_number):
+ url = f"https://api.github.com/repos/huggingface/datasets/issues/{issue_number}/comments"
+ response = requests.get(url, headers=headers)
+ return [r["body"] for r in response.json()]
+
+
+# Testiamo la nostra funzione
+get_comments(2792)
+```
+
+```python out
+["@albertvillanova my tests are failing here:\r\n```\r\ndataset_name = 'gooaq'\r\n\r\n def test_load_dataset(self, dataset_name):\r\n configs = self.dataset_tester.load_all_configs(dataset_name, is_local=True)[:1]\r\n> self.dataset_tester.check_load_dataset(dataset_name, configs, is_local=True, use_local_dummy_data=True)\r\n\r\ntests/test_dataset_common.py:234: \r\n_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ \r\ntests/test_dataset_common.py:187: in check_load_dataset\r\n self.parent.assertTrue(len(dataset[split]) > 0)\r\nE AssertionError: False is not true\r\n```\r\nWhen I try loading dataset on local machine it works fine. Any suggestions on how can I avoid this error?"]
+```
+
+Sembra andar bene, quindi possiamo usare `Dataset.map()` per aggiungere una nuova colonna `comments` a ogni usse nel nostro dataset:
+
+```py
+# A seconda della tua connessione, potrebbe volerci qualche secondo...
+issues_with_comments_dataset = issues_dataset.map(
+ lambda x: {"comments": get_comments(x["number"])}
+)
+```
+
+Come passaggio finale, salviamo il dataset esteso assieme ai nostri dati non processati, così da poter caricare entrambi sull'Hub:
+
+```py
+issues_with_comments_dataset.to_json("issues-datasets-with-comments.jsonl")
+```
+
+## Caricare il dataset sull'Hub Hugging Face
+
+
+
+ +
+
+
+Da qui, chiunque può scaricare il dataset semplicemente inserendo l'ID della repository come argomento `path` di `load_dataset()`:
+
+```py
+remote_dataset = load_dataset("lewtun/github-issues", split="train")
+remote_dataset
+```
+
+```python out
+Dataset({
+ features: ['url', 'repository_url', 'labels_url', 'comments_url', 'events_url', 'html_url', 'id', 'node_id', 'number', 'title', 'user', 'labels', 'state', 'locked', 'assignee', 'assignees', 'milestone', 'comments', 'created_at', 'updated_at', 'closed_at', 'author_association', 'active_lock_reason', 'pull_request', 'body', 'performed_via_github_app', 'is_pull_request'],
+ num_rows: 2855
+})
+```
+
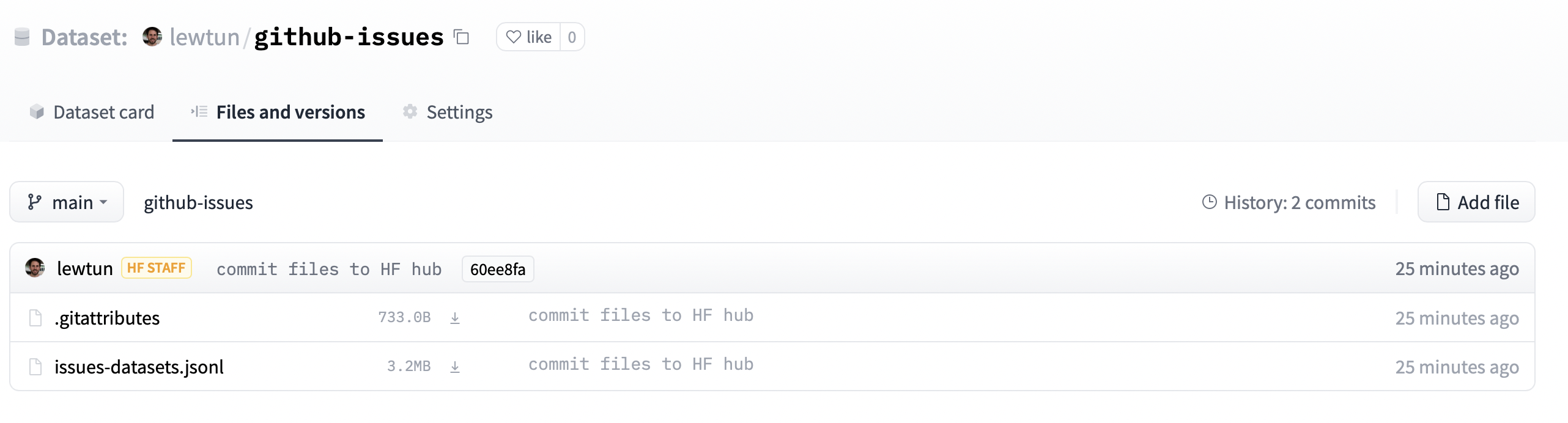
+Bene, abbiamo caricato il nostro dataset sull'Hub, e può essere utilizzato da tutti! C'è un'altra cosa importante che dobbiamo fare: aggiungere una _dataset card_ che spiega come è stato creato il corpus, e offre altre informazioni utili per la community.
+
+
+
+ +
+
+
+2. Leggi la [guida 🤗 Datasets](https://github.com/huggingface/datasets/blob/master/templates/README_guide.md) sulla creazione di dataset card informative, e usala come template.
+
+Puoi creare il file *README.md* direttamente sull'Hub, e puoi trovare un modello per una dataset card nella repository `lewtun/github-issues`. Di seguito è mostrato uno screenshot di una dataset card già compilata.
+
+
+
+ +
+
+
+
+
+ +
+ +
+
+
+## Caricare e preparare il dataset
+
+La prima cosa che dobbiamo fare è scaricare il nostro dataset di issue, quindi utilizziamo la libreria 🤗 Hub per scaricare i file usando l'URL dell'Hub Hugging Face:
+
+```py
+from huggingface_hub import hf_hub_url
+
+data_files = hf_hub_url(
+ repo_id="lewtun/github-issues",
+ filename="datasets-issues-with-comments.jsonl",
+ repo_type="dataset",
+)
+```
+
+Se conseriamo l'URL iin `data_files`, possiamo caricare il dataset utilizzando il metodo introdotto nella [sezione 2](/course/chapter5/2):
+
+```py
+from datasets import load_dataset
+
+issues_dataset = load_dataset("json", data_files=data_files, split="train")
+issues_dataset
+```
+
+```python out
+Dataset({
+ features: ['url', 'repository_url', 'labels_url', 'comments_url', 'events_url', 'html_url', 'id', 'node_id', 'number', 'title', 'user', 'labels', 'state', 'locked', 'assignee', 'assignees', 'milestone', 'comments', 'created_at', 'updated_at', 'closed_at', 'author_association', 'active_lock_reason', 'pull_request', 'body', 'performed_via_github_app', 'is_pull_request'],
+ num_rows: 2855
+})
+```
+
+Qui abbiamo specificato la sezione di defaul `train` in `load_dataset()`, così che questa funzione resituisce un `Dataset` invece di un `DatasetDict`. La prima cosa da fare è filtrare le richieste di pull, poichè queste tendono a essere usate raramente come risposta alle domande degli utenti, e introdurrebbero rumore nel nostro motore di ricerca. Come dovrebbe esser enoto, possiamo usare la funzione `Dataset.filter()` per escludere questi dati dal nostro dataset. Già che ci siamo, eliminiamo anche le righe senza commenti, poiché queste non presentano nessuna risposta alle domande degli utenti:
+
+```py
+issues_dataset = issues_dataset.filter(
+ lambda x: (x["is_pull_request"] == False and len(x["comments"]) > 0)
+)
+issues_dataset
+```
+
+```python out
+Dataset({
+ features: ['url', 'repository_url', 'labels_url', 'comments_url', 'events_url', 'html_url', 'id', 'node_id', 'number', 'title', 'user', 'labels', 'state', 'locked', 'assignee', 'assignees', 'milestone', 'comments', 'created_at', 'updated_at', 'closed_at', 'author_association', 'active_lock_reason', 'pull_request', 'body', 'performed_via_github_app', 'is_pull_request'],
+ num_rows: 771
+})
+```
+
+Possiamo vedere che ci sono molte colonne nel nostro dataset, molte delle quali non servono alla costruzione del nostro motore di ricerca. Da una prospettiva di ricerca, le colonne maggiormente informative sono `title`, `body`, e `comments`, mentre `html_url` ci fornisce un link all'issue originale. Usiamo la funzione `Dataset.remove_columns()` per eliminare le colonne rimanenti:
+
+```py
+columns = issues_dataset.column_names
+columns_to_keep = ["title", "body", "html_url", "comments"]
+columns_to_remove = set(columns_to_keep).symmetric_difference(columns)
+issues_dataset = issues_dataset.remove_columns(columns_to_remove)
+issues_dataset
+```
+
+```python out
+Dataset({
+ features: ['html_url', 'title', 'comments', 'body'],
+ num_rows: 771
+})
+```
+
+Per crare i nostri embedding arricchiremo ognu commento con il titolo e il corpo dell'issue, visto che questi campi spesso includono informazioni utili sul contesto. Poiché la nostra colonna `comment` è al momento una lista di commenti per ogni issue, dobbiamo "farla esplodere" così che ogni riga consista in una tupla `(html_url, title, body, comment)`. In panda è possibile farlo utilizzando la [funzione `Dataframe.explode()`](https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.explode.html), che crea una nuova riga per ogni elemento in una colonna in formato di lista, ripetendo i valori di tutte le altre colonne. Per vederlo in azione, prima di tutto passiamo al formato `DataFrame`:
+
+```py
+issues_dataset.set_format("pandas")
+df = issues_dataset[:]
+```
+
+Se diamo un'occhiata alla prima riga di questo `DataFrame`, possiamo vedere che ci sono quattro commenti associati con quest'issue:
+
+```py
+df["comments"][0].tolist()
+```
+
+```python out
+['the bug code locate in :\r\n if data_args.task_name is not None:\r\n # Downloading and loading a dataset from the hub.\r\n datasets = load_dataset("glue", data_args.task_name, cache_dir=model_args.cache_dir)',
+ 'Hi @jinec,\r\n\r\nFrom time to time we get this kind of `ConnectionError` coming from the github.com website: https://raw.githubusercontent.com\r\n\r\nNormally, it should work if you wait a little and then retry.\r\n\r\nCould you please confirm if the problem persists?',
+ 'cannot connect,even by Web browser,please check that there is some problems。',
+ 'I can access https://raw.githubusercontent.com/huggingface/datasets/1.7.0/datasets/glue/glue.py without problem...']
+```
+
+Quando "esplodiamo" `df`, ci aspettiamo di avere una riga per ognuno di questi commenti. Controlliamo se è così:
+
+```py
+comments_df = df.explode("comments", ignore_index=True)
+comments_df.head(4)
+```
+
+
+
+| + | html_url | +title | +comments | +body | +
|---|---|---|---|---|
| 0 | +https://github.com/huggingface/datasets/issues/2787 | +ConnectionError: Couldn't reach https://raw.githubusercontent.com | +the bug code locate in :\r\n if data_args.task_name is not None... | +Hello,\r\nI am trying to run run_glue.py and it gives me this error... | +
| 1 | +https://github.com/huggingface/datasets/issues/2787 | +ConnectionError: Couldn't reach https://raw.githubusercontent.com | +Hi @jinec,\r\n\r\nFrom time to time we get this kind of `ConnectionError` coming from the github.com website: https://raw.githubusercontent.com... | +Hello,\r\nI am trying to run run_glue.py and it gives me this error... | +
| 2 | +https://github.com/huggingface/datasets/issues/2787 | +ConnectionError: Couldn't reach https://raw.githubusercontent.com | +cannot connect,even by Web browser,please check that there is some problems。 | +Hello,\r\nI am trying to run run_glue.py and it gives me this error... | +
| 3 | +https://github.com/huggingface/datasets/issues/2787 | +ConnectionError: Couldn't reach https://raw.githubusercontent.com | +I can access https://raw.githubusercontent.com/huggingface/datasets/1.7.0/datasets/glue/glue.py without problem... | +Hello,\r\nI am trying to run run_glue.py and it gives me this error... | +
load_dataset() per caricare dataset locali.",
+ correct: true
+ },
+ {
+ text: "L'Hub Hugging Face.",
+ explain: "Corretto! Puoi caricare i dataset presenti sull'Hub fornendo l'ID del dataset, ad esempio load_dataset('emotion').",
+ correct: true
+ },
+ {
+ text: "Un server remoto",
+ explain: "Corretto! Puoi passare un URL nell'argomento data_files di load_dataset() per caricare file in remoto.",
+ correct: true
+ },
+ ]}
+/>
+
+### 2. Immagina di caricare uno dei task GLUE come segue:
+
+```py
+from datasets import load_dataset
+
+dataset = load_dataset("glue", "mrpc", split="train")
+```
+
+Quale dei comandi seguenti produce un campione di 50 elementi casuali da `dataset`?
+
+Dataset.sample()."
+ },
+ {
+ text: "dataset.shuffle().select(range(50))",
+ explain: "Corretto! Come hai visto in questo capitolo, puoi mescolare il dataset e selezionarne i campioni.",
+ correct: true
+ },
+ {
+ text: "dataset.select(range(50)).shuffle()",
+ explain: "Questa risposta è sbagliata -- anche se il codice verrebbe eseguito, mescolerebbe solo i primi 50 elementi del dataset"
+ }
+ ]}
+/>
+
+### 3. Immagina di avere un dataset sugli animali domestici, chiamto `pets_dataset`, che ha una colonna `name` che denota il nome di ogni animale. Quale degli approcci ci permetterebbe di filtrare il dataset e lasciare solo gli animali il cui nome inizia con la lettera "L"?
+pets_dataset.filter(lambda x['name'].startswith('L'))",
+ explain: "Questa risposta è sbagliata: una funzione lambda ha la forma generica lambda *argomenti* : *espressione*, per cui devi esplicitare gli argomenti in questo caso."
+ },
+ {
+ text: "Creare una funzione come def filter_names(x): return x['name'].startswith('L') ed eseguire pets_dataset.filter(filter_names).",
+ explain: "Corretto! Proprio come Dataset.map(), puoi passare delle funzioni esplicite a Dataset.filter(). Quest'opzione è utile quando hai un'espressione complessa che non è adatta a una funzione lambda. Quale altra soluzione potrebbe funzionare?",
+ correct: true
+ }
+ ]}
+/>
+
+### 4. Cos'è il memory mapping?
+
+IterableDataset è un generatore e non un contenitore, per cui puoi accedere ai suoi elementi solo usando next(iter(dataset)).",
+ correct: true
+ },
+ {
+ text: "Il dataset allocine non ha una sezione train.",
+ explain: "Questa risposta è sbagliata -- controlla le [informazioni sul dataset allocine](https://huggingface.co/datasets/allocine) sull'Hub per vedere quali sezioni contiente."
+ }
+ ]}
+/>
+
+### 7. Quali dei seguenti sono i vantaggi principali di creare una dataset card?
+
+