本文转自互联网,侵删
本系列文章将整理到我在GitHub上的《Java面试指南》仓库,更多精彩内容请到我的仓库里查看
喜欢的话麻烦点下Star哈
文章将同步到我的个人博客:
本文是微信公众号【Java技术江湖】的《深入理解JVM虚拟机》其中一篇,本文部分内容来源于网络,为了把本文主题讲得清晰透彻,也整合了很多我认为不错的技术博客内容,引用其中了一些比较好的博客文章,如有侵权,请联系作者。
该系列博文会告诉你如何从入门到进阶,一步步地学习JVM基础知识,并上手进行JVM调优实战,JVM是每一个Java工程师必须要学习和理解的知识点,你必须要掌握其实现原理,才能更完整地了解整个Java技术体系,形成自己的知识框架。
为了更好地总结和检验你的学习成果,本系列文章也会提供每个知识点对应的面试题以及参考答案。
如果对本系列文章有什么建议,或者是有什么疑问的话,也可以关注公众号【Java技术江湖】联系作者,欢迎你参与本系列博文的创作和修订。
java语言的编译期其实是一段不确定的操作过程,因为它可以分为三类编译过程: 1.前端编译:把_.java文件转变为_.class文件 2.后端编译:把字节码转变为机器码 3.静态提前编译:直接把*.java文件编译成本地机器代码 从JDK1.3开始,虚拟机设计团队就把对性能的优化集中到了后端的即时编译中,这样可以让那些不是由Javac产生的Class文件(如JRuby、Groovy等语言的Class文件)也能享受到编译期优化所带来的好处 Java中即时编译在运行期的优化过程对于程序运行来说更重要,而前端编译期在编译期的优化过程对于程序编码来说关系更加密切
早期编译过程主要分为3个部分:1.解析与填充符号表过程:词法、语法分析;填充符号表 2.插入式注解处理器的注解处理过程 3.语义分析与字节码生成过程:标注检查、数据与控制流分析、解语法糖、字节码生成
Java语言中的泛型只在程序源码中存在,在编译后的字节码文件中,就已经替换成原来的原生类型了,并且在相应的地方插入了强制转型代码
泛型擦除前的例子
public static void main( String[] args )
{
Map<String,String> map = new HashMap<String, String>();
map.put("hello","你好");
System.out.println(map.get("hello"));
}
泛型擦除后的例子
public static void main( String[] args )
{
Map map = new HashMap();
map.put("hello","你好");
System.out.println((String)map.get("hello"));
}
自动装箱、拆箱在编译之后会被转化成对应的包装和还原方法,如Integer.valueOf()与Integer.intValue(),而遍历循环则把代码还原成了迭代器的实现,变长参数会变成数组类型的参数。 然而包装类的“==”运算在不遇到算术运算的情况下不会自动拆箱,以及它们的equals()方法不处理数据转型的关系。
Java语言也可以进行条件编译,方法就是使用条件为常量的if语句,它在编译阶段就会被“运行”:
public static void main(String[] args) {
if(true){
System.out.println("block 1");
}
else{
System.out.println("block 2");
}
}
编译后Class文件的反编译结果:
public static void main(String[] args) {
System.out.println("block 1");
}
只能是条件为常量的if语句,这也是Java语言的语法糖,根据布尔常量值的真假,编译器会把分支中不成立的代码块消除掉
Java程序最初是通过解释器进行解释执行的,当程序需要迅速启动和执行时,解释器可以首先发挥作用,省去编译时间,立即执行;当程序运行后,随着时间的推移,编译期逐渐发挥作用,把越来越多的代码编译成本地代码,获得更高的执行效率。**解释执行节约内存,编译执行提升效率。**同时,解释器可以作为编译器激进优化时的一个“逃生门”,让编译器根据概率选择一些大多数时候都能提升运行速度的优化手段,当激进优化的假设不成立,则通过逆优化退回到解释状态继续执行。
HotSpot虚拟机中内置了两个即时编译器,分别称为Client Compiler(C1编译器)和Server Compiler(C2编译器),默认采用解释器与其中一个编译器直接配合的方式工作,使用哪个编译器取决于虚拟机运行的模式,也可以自己去指定。若强制虚拟机运行与“解释模式”,编译器完全不介入工作,若强制虚拟机运行于“编译模式”,则优先采用编译方式执行程序,解释器仍然要在编译无法进行的情况下介入执行过程。
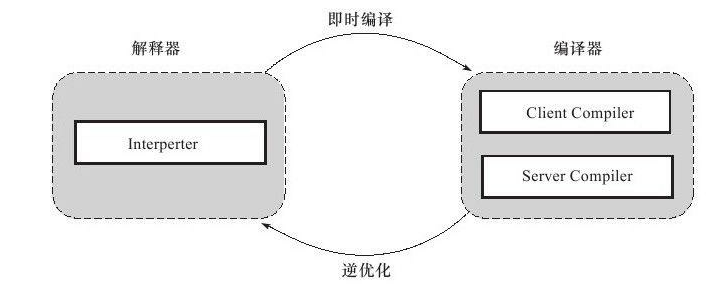
分层编译策略作为默认编译策略在JDK1.7的Server模式虚拟机中被开启,其中包括:
第0层:程序解释执行,解释器不开启性能监控功能,可触发第1层编译;
第1层:C1编译,将字节码编译成本地代码,进行简单可靠的优化,如有必要将加入性能监控的逻辑;
第2层:C2编译,也是将字节码编译成本地代码,但是会启动一些编译耗时较长的优化,甚至会根据性能监控信息进行一些不可靠的激进优化。
实施分层编译后,C1和C2将会同时工作,C1获取更高的编译速度,C2获取更好的编译质量,在解释执行的时候也无须再承担性能监控信息的任务。
在运行过程中会被即时编译器编译的“热点代码”有两类:
1.被多次调用的方法:由方法调用触发的编译,属于JIT编译方式
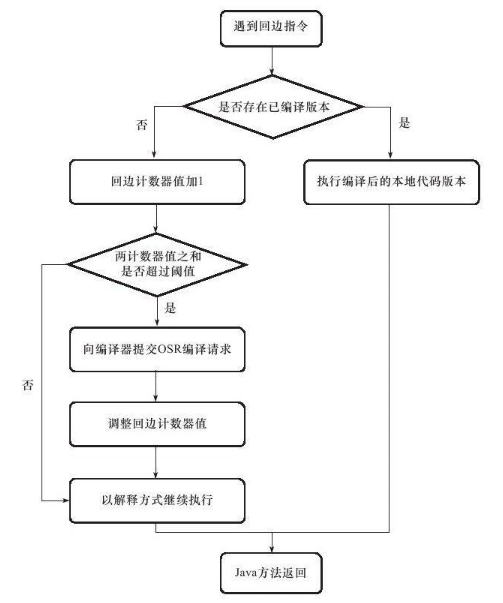
2.被多次执行的循环体:也以整个方法作为编译对象,因为编译发生在方法执行过程中,因此成为栈上替换(OSR编译)
热点探测判定方式有两种:
1.基于采样的热点探测:虚拟机周期性的检查各个线程的栈顶,如果某个方法经常出现在栈顶,则判定为“热点方法”。(简单高效,可以获取方法的调用关系,但容易受线程阻塞或别的外界因素影响扰乱热点探测)
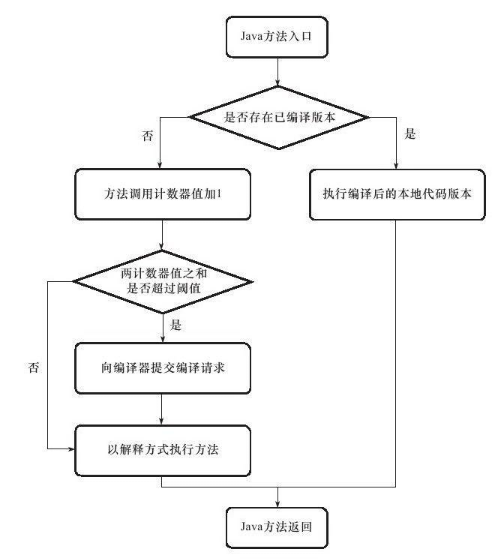
2.基于计数的热点探测:虚拟机为每个方法建立一个计数器,统计方法的执行次数,超过一定阈值就是“热点方法”。(需要为每个方法维护计数器,不能直接获取方法的调用关系,但是统计结果精确严谨)
HotSpot虚拟机使用的是第二种,它为每个方法准备了两类计数器:方法调用计数器和回边计数器,下图表示方法调用计数器触发即时编译:
下图表示回边计数器触发即时编译:
虚拟机设计团队几乎把对代码的所有优化措施都集中在了即时编译器之中,那么在编译器编译的过程中,到底做了些什么事情呢?下面将介绍几种最有代表性的优化技术: 公共子表达式消除 如果一个表达式E已经计算过了,并且先前的计算到现在E中所有变量的值都没有发生变化,那么E的这次出现就成为了公共表达式,可以直接用之前的结果替换。 例:int d = (c * b) * 12 + a + (a + b * c) => int d = E * 12 + a + (a + E)
数组边界检查消除 Java语言中访问数组元素都要进行上下界的范围检查,每次读写都有一次条件判定操作,这无疑是一种负担。编译器只要通过数据流分析就可以判定循环变量的取值范围永远在数组长度以内,那么整个循环中就可以把上下界检查消除,这样可以省很多次的条件判断操作。
另一种方法叫做隐式异常处理,Java中空指针的判断和算术运算中除数为0的检查都采用了这个思路:
if(foo != null){
return foo.value;
}else{
throw new NullPointException();
}
使用隐式异常优化以后:
try{
return foo.value;
}catch(segment_fault){
uncommon_trap();
}
当foo极少为空时,隐式异常优化是值得的,但是foo经常为空,这样的优化反而会让程序变慢,而HotSpot虚拟机会根据运行期收集到的Profile信息自动选择最优方案。
方法内联 方法内联能去除方法调用的成本,同时也为其他优化建立了良好的基础,因此各种编译器一般会把内联优化放在优化序列的最靠前位置,然而由于Java对象的方法默认都是虚方法,因此方法调用都需要在运行时进行多态选择,为了解决虚方法的内联问题,首先引入了“类型继承关系分析(CHA)”的技术。
1.在内联时,若是非虚方法,则可以直接内联
2.遇到虚方法,首先根据CHA判断此方法是否有多个目标版本,若只有一个,可以直接内联,但是需要预留一个“逃生门”,称为守护内联,若在程序的后续执行过程中,加载了导致继承关系发生变化的新类,就需要抛弃已经编译的代码,退回到解释状态执行,或者重新编译。
3.若CHA判断此方法有多个目标版本,则编译器会使用“内联缓存”,第一次调用缓存记录下方法接收者的版本信息,并且每次调用都比较版本,若一致则可以一直使用,若不一致则取消内联,查找虚方法表进行方法分派。
逃逸分析 逃逸分析的基本行为就是分析对象动态作用域,当一个对象被外部方法所引用,称为方法逃逸;当被外部线程访问,称为线程逃逸。若能证明一个对象不会被外部方法或进程引用,则可以为这个变量进行一些优化:
1.栈上分配:如果确定一个对象不会逃逸,则可以让它分配在栈上,对象所占用的内存空间就可以随栈帧出栈而销毁。这样可以减小垃圾收集系统的压力。
2.同步消除:线程同步相对耗时,如果确定一个变量不会逃逸出线程,那这个变量的读写不会有竞争,则对这个变量实施的同步措施也就可以消除掉。
3.标量替换:如果逃逸分析证明一个对象不会被外部访问,并且这个对象可以被拆散的话,那么程序真正执行的时候可以不创建这个对象,改为直接创建它的成员变量,这样就可以在栈上分配。
可是目前还不能保证逃逸分析的性能收益必定高于它的消耗,所以这项技术还不是很成熟。
Java虚拟机的即时编译器与C/C++的静态编译器相比,可能会由于下面的原因导致输出的本地代码有一些劣势:
1.即时编译器运行占用的是用户程序的运行时间,具有很大的时间压力,因此不敢随便引入大规模的优化技术;
2.Java语言是动态的类型安全语言,虚拟器需要频繁的进行动态检查,如空指针,上下界范围,继承关系等;
3.Java中使用虚方法频率远高于C++,则需要进行多态选择的频率远高于C++;
4.Java是可以动态扩展的语言,运行时加载新的类可能改变原有的继承关系,许多全局的优化措施只能以激进优化的方式来完成;
5.Java语言的对象内存都在堆上分配,垃圾回收的压力比C++大
然而,Java语言这些性能上的劣势换取了开发效率上的优势,并且由于C++编译器所有优化都是在编译期完成的,以运行期性能监控为基础的优化措施都无法进行,这也是Java编译器独有的优势。
https://segmentfault.com/a/1190000009707894
https://www.cnblogs.com/hysum/p/7100874.html