Custom recipes can improve performance. Domain knowledge and intuition are essential for achieving optimal results.
See the examples in this repository. Examples include:
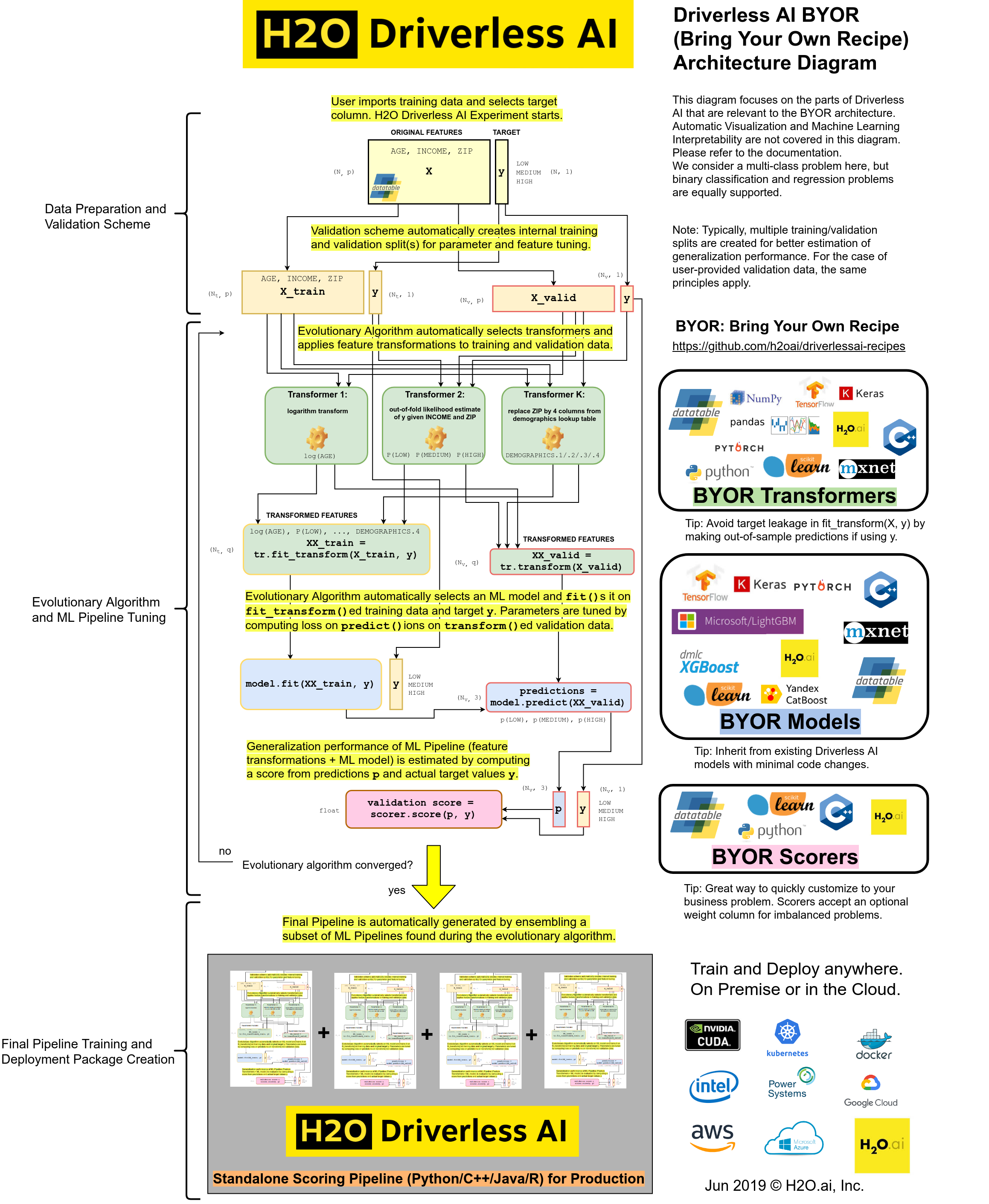
-
Transformer:
- Split string columns into multiple numeric columns (e.g.,
"A:B:10:5"becomes[0,1,10,5]). - PyTorch deep learning model for text similarity analysis.
- ARIMA model for time-series forecasting.
- Data augmentation, like replacing zip codes with demographic info or using a national holiday flag.
- Split string columns into multiple numeric columns (e.g.,
-
Model:
- H2O-3 algorithms, including H2O AutoML.
- Yandex CatBoost gradient boosting.
- Custom loss functions for LightGBM or XGBoost.
-
Scorer:
- Optimize for the top decile in regression tasks.
- Improve the false discovery rate for binary classification.
-
Explainer:
- Create custom recipes for model interpretability, fairness, robustness, and explanations.
- Generate custom plots, charts, markdown reports, and more.
H2O Driverless AI continues to improve with each version, so you may not need custom recipes. However, adding your own recipes can optimize performance for specific use cases.
Writing recipes improves your data science skills and helps achieve better results. It is one of the best ways to enhance your expertise.
Anyone with the necessary expertise can contribute. Data scientists and developers typically write recipes, though even simple recipes can have a significant impact.
A text editor and knowledge of Python. Recipes are written as .py files with the source code.
- Review the API specifications and architecture diagrams.
- Review the examples in this repository.
- Upload your recipe in the Expert Settings section during the experiment setup.
H2O Driverless AI uses Python 3.11. Ensure your recipes are compatible with this version.
H2O Driverless AI will notify you whether your recipe passes the acceptance tests. If it fails, feedback will guide you on how to fix it.
Upload your recipe to the Expert Settings and use the experiment log for debugging. Alternatively, make minimal changes as shown in this debugging example and debug with a Python debugger, like PyCharm.
Review the error message, which usually includes a stack trace and hints for fixing the issue. If you need help, ask questions in the H2O Driverless AI community Slack channel. You can also send your experiment logs zip file, which will contain the recipe source files.
Features created by your transformer might not have the strongest signal, but they can still improve the overall model performance.
H2O Driverless AI will use the best-performing recipes. Check the experiment logs for errors related to your recipe. You can also disable recipe failures in Expert Settings.
You can use any language as long as you can interface it with Python. Many recipes rely on Java and C++ backends.
Custom recipes are treated the same as built-in recipes. There is no performance penalty or calling overhead.
The transformer API allows flexibility. For example, transformers can process specific input columns while leaving others unchanged, resulting in improved accuracy.
Recipes can be disabled by setting enable_custom_recipes=false in the config.toml file or using the DRIVERLESS_AI_ENABLE_CUSTOM_RECIPES=0 environment variable. To disable uploading new recipes, set enable_custom_recipes_upload=false or DRIVERLESS_AI_ENABLE_CUSTOM_RECIPES_UPLOAD=0.
When you upload a new version of a recipe, it becomes the default. Older experiments will continue using the previous version.
Anyone with access to the H2O Driverless AI instance can run any uploaded recipe, but recipes are shared only within the instance.
To delete all recipes, remove the contrib folder from the data directory (usually tmp) and restart H2O Driverless AI. This will prevent old experiments from making predictions unless related experiments are also deleted.
In most cases, MOJOs are not available for custom recipes. Contact [email protected] for more details.
Contribute to this repository by making a pull request. If your recipe works, it can help others optimize their experiments.
- sklearn API
- Implement
fit_transform(X, y)for batch transformation of the training data - Implement
transform(X)for row-by-row transformation of validation and test data
- Implement
- Custom Transformer Recipe SDK/API Reference
- Using datatable
- sklearn API
- Implement
fit(X, y)for batch training on the training data - Implement
predict(X)for row-by-row predictions on validation and test data
- Implement
- Custom Model Recipe SDK/API Reference
- sklearn API
- Implement
score(actual, predicted, sample_weight, labels)for computing scores and metrics from predictions and actual values
- Implement
- Custom Scorer Recipe SDK/API Reference

{kind=link}
Webinar: Extending the H2O Driverless AI Platform with Your Recipes Website: H2O Driverless AI Recipes