diff --git a/.github/actions/gmt-pytest/action.yml b/.github/actions/gmt-pytest/action.yml
index da151b8ca..102f1d1f6 100644
--- a/.github/actions/gmt-pytest/action.yml
+++ b/.github/actions/gmt-pytest/action.yml
@@ -9,10 +9,6 @@ inputs:
description: 'The root directory of the gmt repository'
required: false
default: '.'
- tests-directory:
- description: 'The directory where to run the tests from'
- required: false
- default: './test'
tests-command:
description: 'The command to run the tests'
required: false
@@ -24,26 +20,33 @@ inputs:
runs:
using: 'composite'
steps:
- - name: setup python
+ - name: setup_python
uses: actions/setup-python@v4
with:
python-version: '3.10'
- cache: 'pip'
-
- - name: pip install
- working-directory: ${{ inputs.gmt-directory }}
+
+ - id: python_cache
+ uses: actions/cache@v3
+ with:
+ path: venv
+ key: pip-${{ steps.setup_python.outputs.python-version }}-${{ hashFiles('requirements.txt') }}-${{ hashFiles('requirements-dev.txt') }}-${{ hashFiles('metric_providers/psu/energy/ac/xgboost/machine/model/requirements.txt') }}
+
+ - name: install script and packages
shell: bash
+ working-directory: ${{ inputs.gmt-directory }}
run: |
- pip install -r requirements-dev.txt
- pip install -r metric_providers/psu/energy/ac/xgboost/machine/model/requirements.txt
-
- - name: Run Install / Setup scripts
+ ./install_linux.sh -p testpw -a http://api.green-coding.internal:9142 -m http://metrics.green-coding.internal:9142 -n -t
+ source venv/bin/activate
+ python3 -m pip install -r requirements-dev.txt
+ python3 -m pip install -r metric_providers/psu/energy/ac/xgboost/machine/model/requirements.txt
+
+ - name: disable unneeded metric providers and run test setup script
shell: bash
working-directory: ${{ inputs.gmt-directory }}
run: |
- ./install_linux.sh -p testpw -a http://api.green-coding.internal:9142 -m http://metrics.green-coding.internal:9142 -n -t -w
+ source venv/bin/activate
python3 disable_metric_providers.py ${{ inputs.metrics-to-turn-off }}
- cd test && python3 setup-test-env.py --no-docker-build
+ cd tests && python3 setup-test-env.py --no-docker-build
- name: Set up Docker Buildx
id: buildx
@@ -63,30 +66,33 @@ runs:
- name: Start Test container
shell: bash
- working-directory: ${{ inputs.gmt-directory }}/test
+ working-directory: ${{ inputs.gmt-directory }}/tests
run: |
- ./start-test-containers.sh -d
+ source ../venv/bin/activate && ./start-test-containers.sh -d
- name: Sleep for 10 seconds
run: sleep 10s
shell: bash
-
+
+ # - name: Setup upterm session
+ # uses: lhotari/action-upterm@v1
+
- name: Run Tests
shell: bash
- working-directory: ${{ inputs.tests-directory }}
+ working-directory: ${{ inputs.gmt-directory }}/tests
run: |
- ${{ inputs.tests-command }} -rA | tee /tmp/test-results.txt
+ source ../venv/bin/activate
+ python3 -m ${{ inputs.tests-command }} -rA | tee /tmp/test-results.txt
- name: Display Results
shell: bash
if: always()
- working-directory: ${{ inputs.tests-directory }}
run: |
cat /tmp/test-results.txt | grep -oPz '(=*) short test summary(.*\n)*' >> $GITHUB_STEP_SUMMARY
- name: Stop Containers
shell: bash
if: always()
- working-directory: ${{ inputs.gmt-directory }}/test
+ working-directory: ${{ inputs.gmt-directory }}/tests
run: |
./stop-test-containers.sh
diff --git a/.github/dependabot.yml b/.github/dependabot.yml
index b25c4c4a3..b07b40b7c 100644
--- a/.github/dependabot.yml
+++ b/.github/dependabot.yml
@@ -11,7 +11,12 @@ updates:
schedule:
interval: "daily"
- package-ecosystem: "docker"
- directory: "/"
+ directory: "/docker/"
+ target-branch: "main"
+ schedule:
+ interval: "weekly"
+ - package-ecosystem: "docker"
+ directory: "/docker/auxiliary-containers/gcb_playwright/"
target-branch: "main"
schedule:
interval: "weekly"
diff --git a/.github/workflows/build-and-push-containers.yml b/.github/workflows/build-and-push-containers.yml
new file mode 100644
index 000000000..4911859ff
--- /dev/null
+++ b/.github/workflows/build-and-push-containers.yml
@@ -0,0 +1,36 @@
+name: Build and Push Containers
+on:
+ pull_request:
+ types:
+ - closed
+ paths:
+ - 'docker/auxiliary-containers/**/Dockerfile'
+
+ workflow_dispatch:
+
+jobs:
+ build-and-push-containers:
+ if: github.event.pull_request.merged == true
+ runs-on: ubuntu-latest
+ permissions:
+ packages: write
+ contents: read
+ steps:
+ - name: Checkout repository
+ uses: actions/checkout@v4
+
+ ## This is needed for multi-architecture builds
+ - name: Set up QEMU
+ uses: docker/setup-qemu-action@v3
+
+ - name: Set up Docker Buildx
+ uses: docker/setup-buildx-action@v3
+
+ - name: Login to Docker Registry
+ uses: docker/login-action@v3
+ with:
+ username: ${{ secrets.DOCKERHUB_USERNAME }}
+ password: ${{ secrets.DOCKERHUB_TOKEN }}
+
+ - name: Build and Push Containers
+ run: bash ./docker/auxiliary-containers/build-containers.sh
\ No newline at end of file
diff --git a/.github/workflows/tests-bare-metal-main.yml b/.github/workflows/tests-bare-metal-main.yml
index 7a72cfb2c..0fbaa43a7 100644
--- a/.github/workflows/tests-bare-metal-main.yml
+++ b/.github/workflows/tests-bare-metal-main.yml
@@ -22,7 +22,7 @@ jobs:
# - if: ${{ github.event_name == 'workflow_dispatch' || steps.check-date.outputs.should_run == 'true'}}
- name: 'Checkout repository'
- uses: actions/checkout@v3
+ uses: actions/checkout@v4
with:
ref: 'main'
submodules: 'true'
diff --git a/.github/workflows/tests-eco-ci-energy-estimation.yaml b/.github/workflows/tests-eco-ci-energy-estimation.yaml
index e1a184d1c..fecf400f8 100644
--- a/.github/workflows/tests-eco-ci-energy-estimation.yaml
+++ b/.github/workflows/tests-eco-ci-energy-estimation.yaml
@@ -11,7 +11,7 @@ jobs:
contents: read
steps:
- name: 'Checkout repository'
- uses: actions/checkout@v3
+ uses: actions/checkout@v4
with:
ref: 'main'
submodules: 'true'
@@ -30,7 +30,7 @@ jobs:
name: 'Setup, Run, and Teardown Tests'
uses: ./.github/actions/gmt-pytest
with:
- metrics-to-turn-off: '--categories RAPL Machine Sensors Debug CGroupV2 MacOS --providers CpuFrequencySysfsCoreProvider'
+ metrics-to-turn-off: '--categories RAPL Machine Sensors Debug CGroupV2 MacOS'
github-token: ${{ secrets.GITHUB_TOKEN }}
- name: Eco CI Energy Estimation - Get Measurement
diff --git a/.github/workflows/tests-vm-main.yml b/.github/workflows/tests-vm-main.yml
index bc46f217f..b1698912e 100644
--- a/.github/workflows/tests-vm-main.yml
+++ b/.github/workflows/tests-vm-main.yml
@@ -20,13 +20,13 @@ jobs:
- if: ${{ github.event_name == 'workflow_dispatch' || steps.check-date.outputs.should_run == 'true'}}
name: 'Checkout repository'
- uses: actions/checkout@v3
+ uses: actions/checkout@v4
with:
ref: 'main'
submodules: 'true'
- name: Eco CI Energy Estimation - Initialize
- uses: green-coding-berlin/eco-ci-energy-estimation@701b5f2f4ba601be587823cd0786f07cb6ae2ee6
+ uses: green-coding-berlin/eco-ci-energy-estimation@v2
with:
task: start-measurement
@@ -34,17 +34,17 @@ jobs:
name: 'Setup, Run, and Teardown Tests'
uses: ./.github/actions/gmt-pytest
with:
- metrics-to-turn-off: '--categories RAPL Machine Sensors Debug CGroupV2 MacOS --providers CpuFrequencySysfsCoreProvider'
+ metrics-to-turn-off: '--categories RAPL Machine Sensors Debug CGroupV2 MacOS'
github-token: ${{ secrets.GITHUB_TOKEN }}
- name: Eco CI Energy Estimation - Get Measurement
- uses: green-coding-berlin/eco-ci-energy-estimation@701b5f2f4ba601be587823cd0786f07cb6ae2ee6
+ uses: green-coding-berlin/eco-ci-energy-estimation@v2
with:
task: get-measurement
branch: main
- name: Eco CI Energy Estimation - End Measurement
- uses: green-coding-berlin/eco-ci-energy-estimation@701b5f2f4ba601be587823cd0786f07cb6ae2ee6
+ uses: green-coding-berlin/eco-ci-energy-estimation@v2
with:
task: display-results
branch: main
diff --git a/.github/workflows/tests-vm-pr.yml b/.github/workflows/tests-vm-pr.yml
index f16f01261..ab79032d7 100644
--- a/.github/workflows/tests-vm-pr.yml
+++ b/.github/workflows/tests-vm-pr.yml
@@ -12,7 +12,7 @@ jobs:
pull-requests: write
steps:
- name: 'Checkout repository'
- uses: actions/checkout@v3
+ uses: actions/checkout@v4
with:
ref: ${{ github.event.pull_request.head.ref }}
submodules: 'true'
@@ -25,7 +25,7 @@ jobs:
- name: 'Setup, Run, and Teardown Tests'
uses: ./.github/actions/gmt-pytest
with:
- metrics-to-turn-off: '--categories RAPL Machine Sensors Debug CGroupV2 MacOS --providers CpuFrequencySysfsCoreProvider'
+ metrics-to-turn-off: '--categories RAPL Machine Sensors Debug CGroupV2 MacOS'
github-token: ${{ secrets.GITHUB_TOKEN }}
- name: Eco CI Energy Estimation - Get Measurement
diff --git a/.gitignore b/.gitignore
index c43ed7604..86615b0fe 100644
--- a/.gitignore
+++ b/.gitignore
@@ -14,6 +14,6 @@ static-binary
.pytest_cache
test-compose.yml
test-config.yml
-test/structure.sql
+tests/structure.sql
tools/sgx_enable
venv/
diff --git a/.pylintrc b/.pylintrc
index 686de9f34..772c57041 100644
--- a/.pylintrc
+++ b/.pylintrc
@@ -25,9 +25,15 @@ disable=missing-function-docstring,
too-many-branches,
too-many-statements,
too-many-arguments,
+ too-many-return-statements,
+ too-many-instance-attributes,
+ invalid-name,
+ wrong-import-position,
+ wrong-import-order,
+ ungrouped-imports,
+ fixme
-# import-error
[MASTER]
ignore=env
diff --git a/README.md b/README.md
index 811f18779..f2e018e61 100644
--- a/README.md
+++ b/README.md
@@ -7,6 +7,8 @@
The Green Metrics Tool is a developer tool is indented for measuring the energy consumption of software and doing life-cycle-analysis.
+One of it's key features is the detailed statistical dashboard and the measurement cluster for making reproducible measurements.
+
It is designed to re-use existing infrastructure and testing files as much as possible to be easily integrateable into every software repository and create transparency around software energy consumption.
It can orchestrate Docker containers according to a given specificaion in a `usage_scenario.yml` file.
@@ -27,15 +29,18 @@ as well as a web interface to view the measured metrics in some nice charts.
# Frontend
To see the frontend in action and get an idea of what kind of metrics the tool can collect and display go to out [Green Metrics Frontend](https://metrics.green-coding.berlin)
-
# Documentation
To see the the documentation and how to install and use the tool please go to [Green Metrics Tool Documentation](https://docs.green-coding.berlin)
-# Screenshots
+# Screenshots of Single Run View
-
-> Web Flow Demo with CPU measurement provider
+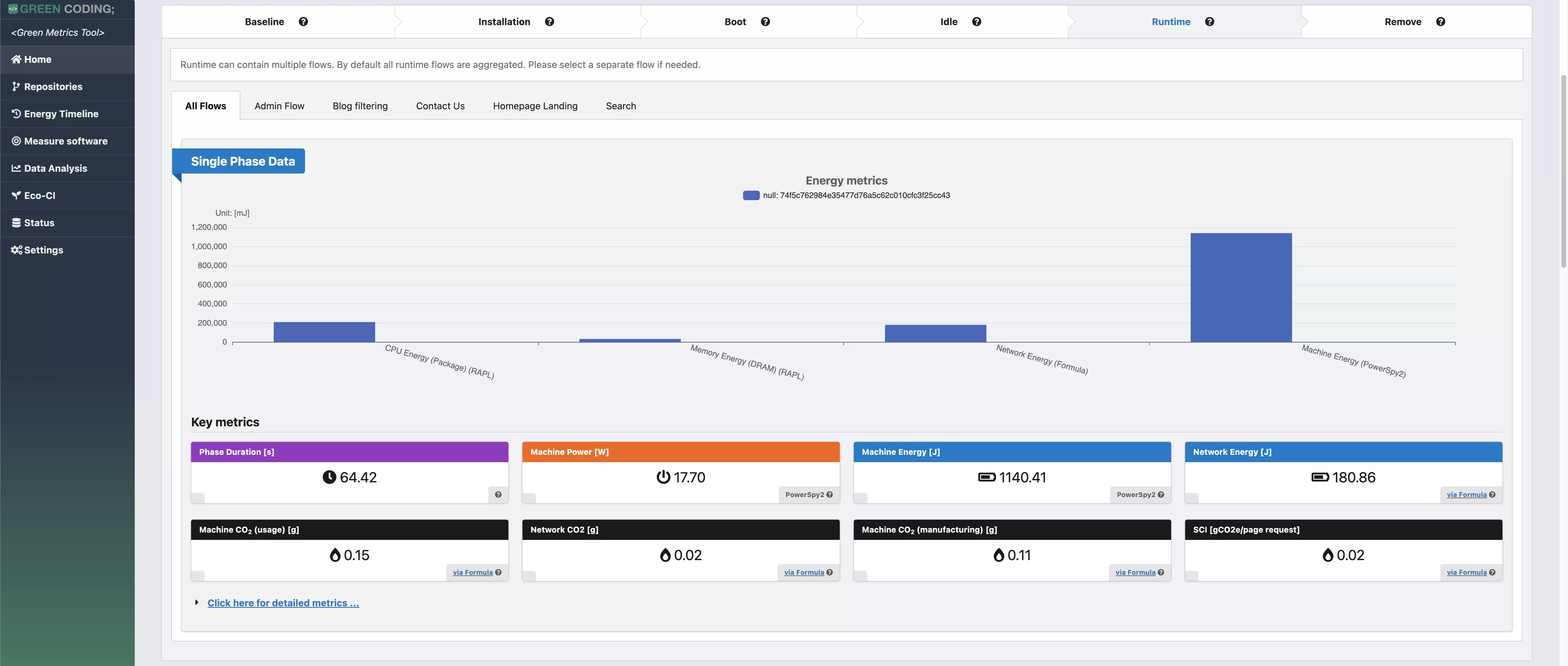
+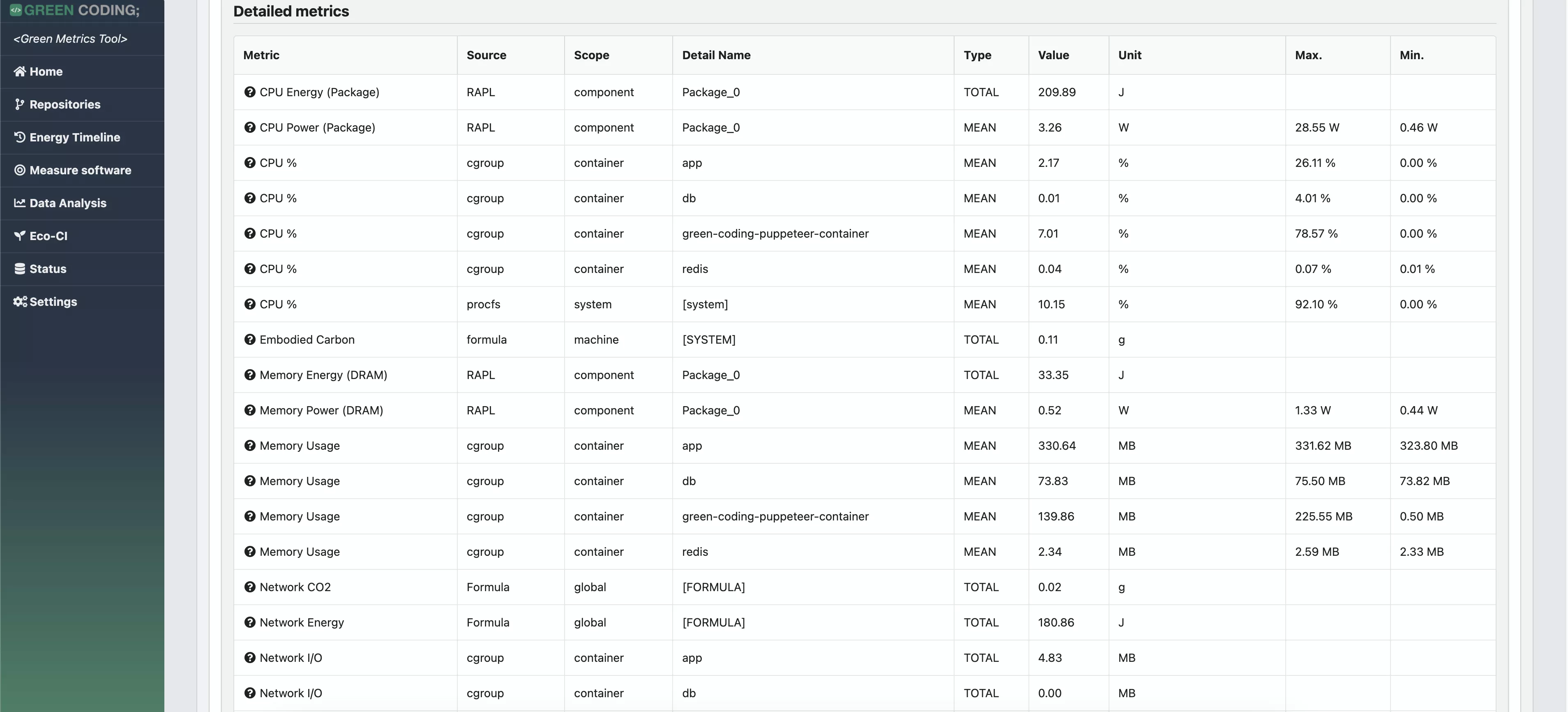
+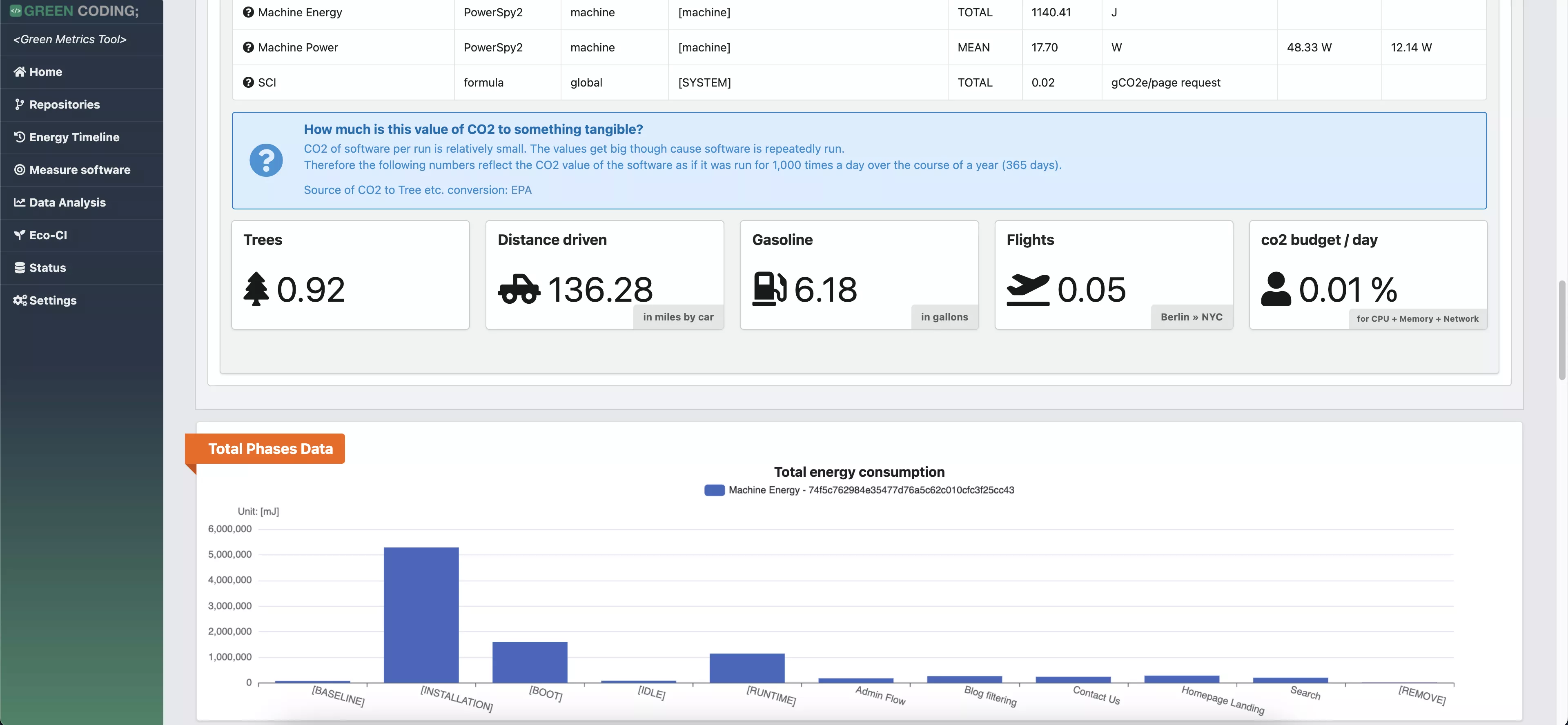
+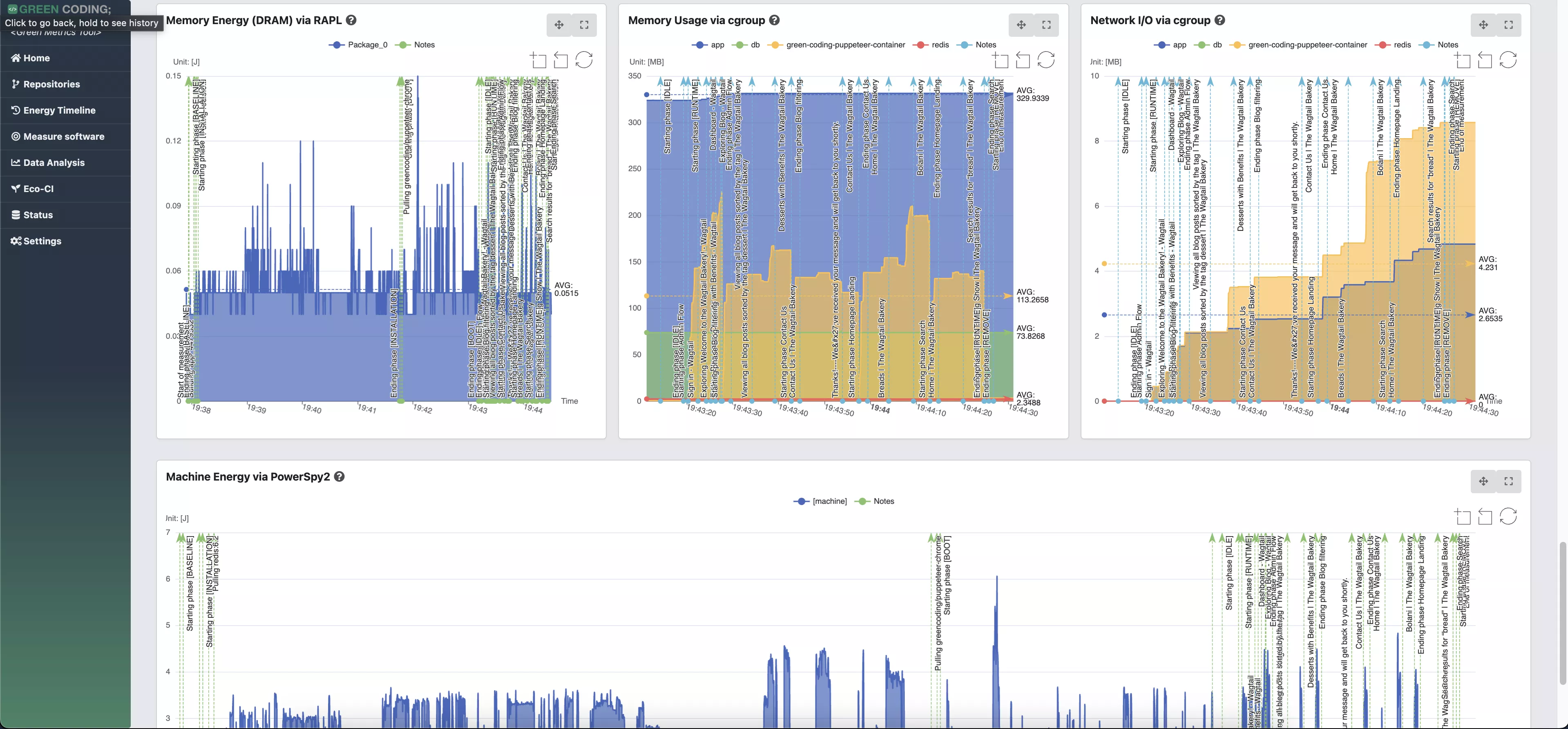
-
-> Web Flow Demo with energy measurement provider
+
+# Screenshots of Comparison View
+
+
diff --git a/api/api.py b/api/api.py
deleted file mode 100644
index 105c03b2f..000000000
--- a/api/api.py
+++ /dev/null
@@ -1,596 +0,0 @@
-
-# pylint: disable=import-error
-# pylint: disable=no-name-in-module
-# pylint: disable=wrong-import-position
-
-import faulthandler
-import sys
-import os
-
-from xml.sax.saxutils import escape as xml_escape
-from fastapi import FastAPI, Request, Response, status
-from fastapi.responses import ORJSONResponse
-from fastapi.encoders import jsonable_encoder
-from fastapi.exceptions import RequestValidationError
-from fastapi.middleware.cors import CORSMiddleware
-
-from starlette.responses import RedirectResponse
-from pydantic import BaseModel
-
-sys.path.append(os.path.dirname(os.path.abspath(__file__)) + '/../lib')
-sys.path.append(os.path.dirname(os.path.abspath(__file__)) + '/../tools')
-
-from global_config import GlobalConfig
-from db import DB
-import jobs
-import email_helpers
-import error_helpers
-import anybadge
-from api_helpers import (add_phase_stats_statistics, determine_comparison_case,
- html_escape_multi, get_phase_stats, get_phase_stats_object,
- is_valid_uuid, rescale_energy_value, get_timeline_query,
- get_project_info, get_machine_list)
-
-# It seems like FastAPI already enables faulthandler as it shows stacktrace on SEGFAULT
-# Is the redundant call problematic
-faulthandler.enable() # will catch segfaults and write to STDERR
-
-app = FastAPI()
-
-async def log_exception(request: Request, body, exc):
- error_message = f"""
- Error in API call
-
- URL: {request.url}
-
- Query-Params: {request.query_params}
-
- Client: {request.client}
-
- Headers: {str(request.headers)}
-
- Body: {body}
-
- Exception: {exc}
- """
- error_helpers.log_error(error_message)
- email_helpers.send_error_email(
- GlobalConfig().config['admin']['email'],
- error_helpers.format_error(error_message),
- project_id=None,
- )
-
-@app.exception_handler(RequestValidationError)
-async def validation_exception_handler(request: Request, exc: RequestValidationError):
- await log_exception(request, exc.body, exc)
- return ORJSONResponse(
- status_code=status.HTTP_422_UNPROCESSABLE_ENTITY,
- content=jsonable_encoder({"detail": exc.errors(), "body": exc.body}),
- )
-
-async def catch_exceptions_middleware(request: Request, call_next):
- #pylint: disable=broad-except
- try:
- return await call_next(request)
- except Exception as exc:
- # body = await request.body() # This blocks the application. Unclear atm how to handle it properly
- # seems like a bug: https://github.com/tiangolo/fastapi/issues/394
- # Although the issue is closed the "solution" still behaves with same failure
- await log_exception(request, None, exc)
- return ORJSONResponse(
- content={
- 'success': False,
- 'err': 'Technical error with getting data from the API - Please contact us: info@green-coding.berlin',
- },
- status_code=500,
- )
-
-
-# Binding the Exception middleware must confusingly come BEFORE the CORS middleware.
-# Otherwise CORS will not be sent in response
-app.middleware('http')(catch_exceptions_middleware)
-
-origins = [
- GlobalConfig().config['cluster']['metrics_url'],
- GlobalConfig().config['cluster']['api_url'],
-]
-
-app.add_middleware(
- CORSMiddleware,
- allow_origins=origins,
- allow_credentials=True,
- allow_methods=['*'],
- allow_headers=['*'],
-)
-
-
-@app.get('/')
-async def home():
- return RedirectResponse(url='/docs')
-
-
-# A route to return all of the available entries in our catalog.
-@app.get('/v1/notes/{project_id}')
-async def get_notes(project_id):
- if project_id is None or not is_valid_uuid(project_id):
- return ORJSONResponse({'success': False, 'err': 'Project ID is not a valid UUID or empty'}, status_code=400)
-
- query = """
- SELECT project_id, detail_name, note, time
- FROM notes
- WHERE project_id = %s
- ORDER BY created_at DESC -- important to order here, the charting library in JS cannot do that automatically!
- """
- data = DB().fetch_all(query, (project_id,))
- if data is None or data == []:
- return Response(status_code=204) # No-Content
-
- escaped_data = [html_escape_multi(note) for note in data]
- return ORJSONResponse({'success': True, 'data': escaped_data})
-
-# return a list of all possible registered machines
-@app.get('/v1/machines/')
-async def get_machines():
-
- data = get_machine_list()
- if data is None or data == []:
- return Response(status_code=204) # No-Content
-
- return ORJSONResponse({'success': True, 'data': data})
-
-
-# A route to return all of the available entries in our catalog.
-@app.get('/v1/projects')
-async def get_projects(repo: str, filename: str):
- query = """
- SELECT a.id, a.name, a.uri, COALESCE(a.branch, 'main / master'), a.end_measurement, a.last_run, a.invalid_project, a.filename, b.description, a.commit_hash
- FROM projects as a
- LEFT JOIN machines as b on a.machine_id = b.id
- WHERE 1=1
- """
- params = []
-
- filename = filename.strip()
- if filename not in ('', 'null'):
- query = f"{query} AND a.filename LIKE %s \n"
- params.append(f"%{filename}%")
-
- repo = repo.strip()
- if repo not in ('', 'null'):
- query = f"{query} AND a.uri LIKE %s \n"
- params.append(f"%{repo}%")
-
- query = f"{query} ORDER BY a.created_at DESC -- important to order here, the charting library in JS cannot do that automatically!"
-
- data = DB().fetch_all(query, params=tuple(params))
- if data is None or data == []:
- return Response(status_code=204) # No-Content
-
- escaped_data = [html_escape_multi(project) for project in data]
-
- return ORJSONResponse({'success': True, 'data': escaped_data})
-
-
-# Just copy and paste if we want to deprecate URLs
-# @app.get('/v1/measurements/uri', deprecated=True) # Here you can see, that URL is nevertheless accessible as variable
-# later if supplied. Also deprecation shall be used once we move to v2 for all v1 routesthrough
-
-@app.get('/v1/compare')
-async def compare_in_repo(ids: str):
- if ids is None or not ids.strip():
- return ORJSONResponse({'success': False, 'err': 'Project_id is empty'}, status_code=400)
- ids = ids.split(',')
- if not all(is_valid_uuid(id) for id in ids):
- return ORJSONResponse({'success': False, 'err': 'One of Project IDs is not a valid UUID or empty'}, status_code=400)
-
- try:
- case = determine_comparison_case(ids)
- except RuntimeError as err:
- return ORJSONResponse({'success': False, 'err': str(err)}, status_code=400)
- try:
- phase_stats = get_phase_stats(ids)
- except RuntimeError:
- return Response(status_code=204) # No-Content
- try:
- phase_stats_object = get_phase_stats_object(phase_stats, case)
- phase_stats_object = add_phase_stats_statistics(phase_stats_object)
- phase_stats_object['common_info'] = {}
-
- project_info = get_project_info(ids[0])
-
- machine_list = get_machine_list()
- machines = {machine[0]: machine[1] for machine in machine_list}
-
- machine = machines[project_info['machine_id']]
- uri = project_info['uri']
- usage_scenario = project_info['usage_scenario']['name']
- branch = project_info['branch'] if project_info['branch'] is not None else 'main / master'
- commit = project_info['commit_hash']
- filename = project_info['filename']
-
- match case:
- case 'Repeated Run':
- # same repo, same usage scenarios, same machines, same branches, same commit hashes
- phase_stats_object['common_info']['Repository'] = uri
- phase_stats_object['common_info']['Filename'] = filename
- phase_stats_object['common_info']['Usage Scenario'] = usage_scenario
- phase_stats_object['common_info']['Machine'] = machine
- phase_stats_object['common_info']['Branch'] = branch
- phase_stats_object['common_info']['Commit'] = commit
- case 'Usage Scenario':
- # same repo, diff usage scenarios, same machines, same branches, same commit hashes
- phase_stats_object['common_info']['Repository'] = uri
- phase_stats_object['common_info']['Machine'] = machine
- phase_stats_object['common_info']['Branch'] = branch
- phase_stats_object['common_info']['Commit'] = commit
- case 'Machine':
- # same repo, same usage scenarios, diff machines, same branches, same commit hashes
- phase_stats_object['common_info']['Repository'] = uri
- phase_stats_object['common_info']['Filename'] = filename
- phase_stats_object['common_info']['Usage Scenario'] = usage_scenario
- phase_stats_object['common_info']['Branch'] = branch
- phase_stats_object['common_info']['Commit'] = commit
- case 'Commit':
- # same repo, same usage scenarios, same machines, diff commit hashes
- phase_stats_object['common_info']['Repository'] = uri
- phase_stats_object['common_info']['Filename'] = filename
- phase_stats_object['common_info']['Usage Scenario'] = usage_scenario
- phase_stats_object['common_info']['Machine'] = machine
- case 'Repository':
- # diff repo, diff usage scenarios, same machine, same branches, diff/same commits_hashes
- phase_stats_object['common_info']['Machine'] = machine
- phase_stats_object['common_info']['Branch'] = branch
- case 'Branch':
- # same repo, same usage scenarios, same machines, diff branch
- phase_stats_object['common_info']['Repository'] = uri
- phase_stats_object['common_info']['Filename'] = filename
- phase_stats_object['common_info']['Usage Scenario'] = usage_scenario
- phase_stats_object['common_info']['Machine'] = machine
-
- except RuntimeError as err:
- return ORJSONResponse({'success': False, 'err': str(err)}, status_code=500)
-
- return ORJSONResponse({'success': True, 'data': phase_stats_object})
-
-
-@app.get('/v1/phase_stats/single/{project_id}')
-async def get_phase_stats_single(project_id: str):
- if project_id is None or not is_valid_uuid(project_id):
- return ORJSONResponse({'success': False, 'err': 'Project ID is not a valid UUID or empty'}, status_code=400)
-
- try:
- phase_stats = get_phase_stats([project_id])
- phase_stats_object = get_phase_stats_object(phase_stats, None)
- phase_stats_object = add_phase_stats_statistics(phase_stats_object)
-
- except RuntimeError:
- return Response(status_code=204) # No-Content
-
- return ORJSONResponse({'success': True, 'data': phase_stats_object})
-
-
-# This route gets the measurements to be displayed in a timeline chart
-@app.get('/v1/measurements/single/{project_id}')
-async def get_measurements_single(project_id: str):
- if project_id is None or not is_valid_uuid(project_id):
- return ORJSONResponse({'success': False, 'err': 'Project ID is not a valid UUID or empty'}, status_code=400)
-
- query = """
- SELECT measurements.detail_name, measurements.time, measurements.metric,
- measurements.value, measurements.unit
- FROM measurements
- WHERE measurements.project_id = %s
- """
-
- # extremely important to order here, cause the charting library in JS cannot do that automatically!
-
- query = f" {query} ORDER BY measurements.metric ASC, measurements.detail_name ASC, measurements.time ASC"
-
- params = params = (project_id, )
-
- data = DB().fetch_all(query, params=params)
-
- if data is None or data == []:
- return Response(status_code=204) # No-Content
-
- return ORJSONResponse({'success': True, 'data': data})
-
-@app.get('/v1/timeline')
-async def get_timeline_stats(uri: str, machine_id: int, branch: str | None = None, filename: str | None = None, start_date: str | None = None, end_date: str | None = None, metrics: str | None = None, phase: str | None = None, sorting: str | None = None,):
- if uri is None or uri.strip() == '':
- return ORJSONResponse({'success': False, 'err': 'URI is empty'}, status_code=400)
-
- query, params = get_timeline_query(uri,filename,machine_id, branch, metrics, phase, start_date=start_date, end_date=end_date, sorting=sorting)
-
- data = DB().fetch_all(query, params=params)
-
- if data is None or data == []:
- return Response(status_code=204) # No-Content
-
- return ORJSONResponse({'success': True, 'data': data})
-
-@app.get('/v1/badge/timeline')
-async def get_timeline_badge(detail_name: str, uri: str, machine_id: int, branch: str | None = None, filename: str | None = None, metrics: str | None = None, phase: str | None = None):
- if uri is None or uri.strip() == '':
- return ORJSONResponse({'success': False, 'err': 'URI is empty'}, status_code=400)
-
- if detail_name is None or detail_name.strip() == '':
- return ORJSONResponse({'success': False, 'err': 'Detail Name is mandatory'}, status_code=400)
-
- query, params = get_timeline_query(uri,filename,machine_id, branch, metrics, phase, detail_name=detail_name, limit_365=True)
-
- query = f"""
- WITH trend_data AS (
- {query}
- ) SELECT
- MAX(row_num::float),
- regr_slope(value, row_num::float) AS trend_slope,
- regr_intercept(value, row_num::float) AS trend_intercept,
- MAX(unit)
- FROM trend_data;
- """
-
- data = DB().fetch_one(query, params=params)
-
- if data is None or data == [] or data[1] is None: # special check for data[1] as this is aggregate query which always returns result
- return Response(status_code=204) # No-Content
-
- cost = data[1]/data[0]
- cost = f"+{round(float(cost), 2)}" if abs(cost) == cost else f"{round(float(cost), 2)}"
-
- badge = anybadge.Badge(
- label=xml_escape('Project Trend'),
- value=xml_escape(f"{cost} {data[3]} per day"),
- num_value_padding_chars=1,
- default_color='orange')
- return Response(content=str(badge), media_type="image/svg+xml")
-
-
-# A route to return all of the available entries in our catalog.
-@app.get('/v1/badge/single/{project_id}')
-async def get_badge_single(project_id: str, metric: str = 'ml-estimated'):
-
- if project_id is None or not is_valid_uuid(project_id):
- return ORJSONResponse({'success': False, 'err': 'Project ID is not a valid UUID or empty'}, status_code=400)
-
- query = '''
- SELECT
- SUM(value), MAX(unit)
- FROM
- phase_stats
- WHERE
- project_id = %s
- AND metric LIKE %s
- AND phase LIKE '%%_[RUNTIME]'
- '''
-
- value = None
- label = 'Energy Cost'
- via = ''
- if metric == 'ml-estimated':
- value = 'psu_energy_ac_xgboost_machine'
- via = 'via XGBoost ML'
- elif metric == 'RAPL':
- value = '%_energy_rapl_%'
- via = 'via RAPL'
- elif metric == 'AC':
- value = 'psu_energy_ac_%'
- via = 'via PSU (AC)'
- elif metric == 'SCI':
- label = 'SCI'
- value = 'software_carbon_intensity_global'
- else:
- return ORJSONResponse({'success': False, 'err': f"Unknown metric '{metric}' submitted"}, status_code=400)
-
- params = (project_id, value)
- data = DB().fetch_one(query, params=params)
-
- if data is None or data == [] or data[1] is None: # special check for data[1] as this is aggregate query which always returns result
- badge_value = 'No energy data yet'
- else:
- [energy_value, energy_unit] = rescale_energy_value(data[0], data[1])
- badge_value= f"{energy_value:.2f} {energy_unit} {via}"
-
- badge = anybadge.Badge(
- label=xml_escape(label),
- value=xml_escape(badge_value),
- num_value_padding_chars=1,
- default_color='cornflowerblue')
- return Response(content=str(badge), media_type="image/svg+xml")
-
-
-class Project(BaseModel):
- name: str
- url: str
- email: str
- filename: str
- branch: str
- machine_id: int
-
-@app.post('/v1/project/add')
-async def post_project_add(project: Project):
- if project.url is None or project.url.strip() == '':
- return ORJSONResponse({'success': False, 'err': 'URL is empty'}, status_code=400)
-
- if project.name is None or project.name.strip() == '':
- return ORJSONResponse({'success': False, 'err': 'Name is empty'}, status_code=400)
-
- if project.email is None or project.email.strip() == '':
- return ORJSONResponse({'success': False, 'err': 'E-mail is empty'}, status_code=400)
-
- if project.branch.strip() == '':
- project.branch = None
-
- if project.filename.strip() == '':
- project.filename = 'usage_scenario.yml'
-
- if project.machine_id == 0:
- project.machine_id = None
- project = html_escape_multi(project)
-
- # Note that we use uri here as the general identifier, however when adding through web interface we only allow urls
- query = """
- INSERT INTO projects (uri,name,email,branch,filename)
- VALUES (%s, %s, %s, %s, %s)
- RETURNING id
- """
- params = (project.url, project.name, project.email, project.branch, project.filename)
- project_id = DB().fetch_one(query, params=params)[0]
-
- # This order as selected on purpose. If the admin mail fails, we currently do
- # not want the job to be queued, as we want to monitor every project execution manually
- config = GlobalConfig().config
- if (config['admin']['notify_admin_for_own_project_add'] or config['admin']['email'] != project.email):
- email_helpers.send_admin_email(
- f"New project added from Web Interface: {project.name}", project
- ) # notify admin of new project
-
- jobs.insert_job('project', project_id, project.machine_id)
-
- return ORJSONResponse({'success': True}, status_code=202)
-
-
-@app.get('/v1/project/{project_id}')
-async def get_project(project_id: str):
- if project_id is None or not is_valid_uuid(project_id):
- return ORJSONResponse({'success': False, 'err': 'Project ID is not a valid UUID or empty'}, status_code=400)
-
- data = get_project_info(project_id)
-
- if data is None or data == []:
- return Response(status_code=204) # No-Content
-
- data = html_escape_multi(data)
-
- return ORJSONResponse({'success': True, 'data': data})
-
-@app.get('/robots.txt')
-async def robots_txt():
- data = "User-agent: *\n"
- data += "Disallow: /"
-
- return Response(content=data, media_type='text/plain')
-
-# pylint: disable=invalid-name
-class CI_Measurement(BaseModel):
- energy_value: int
- energy_unit: str
- repo: str
- branch: str
- cpu: str
- cpu_util_avg: float
- commit_hash: str
- workflow: str
- run_id: str
- project_id: str
- source: str
- label: str
- duration: int
-
-@app.post('/v1/ci/measurement/add')
-async def post_ci_measurement_add(measurement: CI_Measurement):
- for key, value in measurement.model_dump().items():
- match key:
- case 'project_id':
- if value is None or value.strip() == '':
- measurement.project_id = None
- continue
- if not is_valid_uuid(value.strip()):
- return ORJSONResponse({'success': False, 'err': f"project_id '{value}' is not a valid uuid"}, status_code=400)
- continue
-
- case 'unit':
- if value is None or value.strip() == '':
- return ORJSONResponse({'success': False, 'err': f"{key} is empty"}, status_code=400)
- if value != 'mJ':
- return ORJSONResponse({'success': False, 'err': "Unit is unsupported - only mJ currently accepted"}, status_code=400)
- continue
-
- case 'label': # Optional fields
- continue
-
- case _:
- if value is None:
- return ORJSONResponse({'success': False, 'err': f"{key} is empty"}, status_code=400)
- if isinstance(value, str):
- if value.strip() == '':
- return ORJSONResponse({'success': False, 'err': f"{key} is empty"}, status_code=400)
-
- measurement = html_escape_multi(measurement)
-
- query = """
- INSERT INTO
- ci_measurements (energy_value, energy_unit, repo, branch, workflow, run_id, project_id, label, source, cpu, commit_hash, duration, cpu_util_avg)
- VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)
- """
- params = (measurement.energy_value, measurement.energy_unit, measurement.repo, measurement.branch,
- measurement.workflow, measurement.run_id, measurement.project_id,
- measurement.label, measurement.source, measurement.cpu, measurement.commit_hash,
- measurement.duration, measurement.cpu_util_avg)
-
- DB().query(query=query, params=params)
- return ORJSONResponse({'success': True}, status_code=201)
-
-@app.get('/v1/ci/measurements')
-async def get_ci_measurements(repo: str, branch: str, workflow: str):
- query = """
- SELECT energy_value, energy_unit, run_id, created_at, label, cpu, commit_hash, duration, source, cpu_util_avg
- FROM ci_measurements
- WHERE repo = %s AND branch = %s AND workflow = %s
- ORDER BY run_id ASC, created_at ASC
- """
- params = (repo, branch, workflow)
- data = DB().fetch_all(query, params=params)
- if data is None or data == []:
- return Response(status_code=204) # No-Content
-
- return ORJSONResponse({'success': True, 'data': data})
-
-@app.get('/v1/ci/projects')
-async def get_ci_projects():
- query = """
- SELECT repo, branch, workflow, source, MAX(created_at)
- FROM ci_measurements
- GROUP BY repo, branch, workflow, source
- ORDER BY repo ASC
- """
-
- data = DB().fetch_all(query)
- if data is None or data == []:
- return Response(status_code=204) # No-Content
-
- return ORJSONResponse({'success': True, 'data': data})
-
-@app.get('/v1/ci/badge/get')
-async def get_ci_badge_get(repo: str, branch: str, workflow:str):
- query = """
- SELECT SUM(energy_value), MAX(energy_unit), MAX(run_id)
- FROM ci_measurements
- WHERE repo = %s AND branch = %s AND workflow = %s
- GROUP BY run_id
- ORDER BY MAX(created_at) DESC
- LIMIT 1
- """
-
- params = (repo, branch, workflow)
- data = DB().fetch_one(query, params=params)
-
- if data is None or data == [] or data[1] is None: # special check for data[1] as this is aggregate query which always returns result
- return Response(status_code=204) # No-Content
-
- energy_value = data[0]
- energy_unit = data[1]
-
- [energy_value, energy_unit] = rescale_energy_value(energy_value, energy_unit)
- badge_value= f"{energy_value:.2f} {energy_unit}"
-
- badge = anybadge.Badge(
- label='Energy Used',
- value=xml_escape(badge_value),
- num_value_padding_chars=1,
- default_color='green')
- return Response(content=str(badge), media_type="image/svg+xml")
-
-
-if __name__ == '__main__':
- app.run()
diff --git a/api/api_helpers.py b/api/api_helpers.py
index 4284e921f..4a64d4ce4 100644
--- a/api/api_helpers.py
+++ b/api/api_helpers.py
@@ -1,23 +1,17 @@
-#pylint: disable=fixme, import-error, wrong-import-position
-
-import sys
-import os
import uuid
import faulthandler
from functools import cache
from html import escape as html_escape
-import psycopg
import numpy as np
import scipy.stats
-# pylint: disable=no-name-in-module
+
+from psycopg.rows import dict_row as psycopg_rows_dict_row
+
from pydantic import BaseModel
faulthandler.enable() # will catch segfaults and write to STDERR
-sys.path.append(os.path.dirname(os.path.abspath(__file__)) + '/../lib')
-sys.path.append(os.path.dirname(os.path.abspath(__file__)) + '/../tools')
-
-from db import DB
+from lib.db import DB
def rescale_energy_value(value, unit):
# We only expect values to be mJ for energy!
@@ -30,7 +24,6 @@ def rescale_energy_value(value, unit):
value = value / (10**3)
unit = f"m{unit_type}"
- # pylint: disable=multiple-statements
if value > 1_000_000_000: return [value/(10**12), f"G{unit_type}"]
if value > 1_000_000_000: return [value/(10**9), f"M{unit_type}"]
if value > 1_000_000: return [value/(10**6), f"k{unit_type}"]
@@ -94,20 +87,20 @@ def get_machine_list():
"""
return DB().fetch_all(query)
-def get_project_info(project_id):
+def get_run_info(run_id):
query = """
SELECT
id, name, uri, branch, commit_hash,
- (SELECT STRING_AGG(t.name, ', ' ) FROM unnest(projects.categories) as elements
+ (SELECT STRING_AGG(t.name, ', ' ) FROM unnest(runs.categories) as elements
LEFT JOIN categories as t on t.id = elements) as categories,
filename, start_measurement, end_measurement,
measurement_config, machine_specs, machine_id, usage_scenario,
- last_run, created_at, invalid_project, phases, logs
- FROM projects
+ created_at, invalid_run, phases, logs
+ FROM runs
WHERE id = %s
"""
- params = (project_id,)
- return DB().fetch_one(query, params=params, row_factory=psycopg.rows.dict_row)
+ params = (run_id,)
+ return DB().fetch_one(query, params=params, row_factory=psycopg_rows_dict_row)
def get_timeline_query(uri,filename,machine_id, branch, metrics, phase, start_date=None, end_date=None, detail_name=None, limit_365=False, sorting='run'):
@@ -115,84 +108,76 @@ def get_timeline_query(uri,filename,machine_id, branch, metrics, phase, start_da
if filename is None or filename.strip() == '':
filename = 'usage_scenario.yml'
- params = [uri, filename, machine_id]
+ params = [uri, filename, machine_id, f"%{phase}"]
- branch_condition = ''
+ branch_condition = 'AND r.branch IS NULL'
if branch is not None and branch.strip() != '':
- branch_condition = 'AND projects.branch = %s'
+ branch_condition = 'AND r.branch = %s'
params.append(branch)
metrics_condition = ''
if metrics is None or metrics.strip() == '' or metrics.strip() == 'key':
- metrics_condition = "AND (metric LIKE '%%_energy_%%' OR metric = 'software_carbon_intensity_global')"
+ metrics_condition = "AND (p.metric LIKE '%%_energy_%%' OR metric = 'software_carbon_intensity_global')"
elif metrics.strip() != 'all':
- metrics_condition = "AND metric = %s"
+ metrics_condition = "AND p.metric = %s"
params.append(metrics)
- phase_condition = ''
- if phase is not None and phase.strip() != '':
- phase_condition = "AND (phase LIKE %s)"
- params.append(f"%{phase}")
-
start_date_condition = ''
if start_date is not None and start_date.strip() != '':
- start_date_condition = "AND DATE(projects.last_run) >= TO_DATE(%s, 'YYYY-MM-DD')"
+ start_date_condition = "AND DATE(r.created_at) >= TO_DATE(%s, 'YYYY-MM-DD')"
params.append(start_date)
end_date_condition = ''
if end_date is not None and end_date.strip() != '':
- end_date_condition = "AND DATE(projects.last_run) <= TO_DATE(%s, 'YYYY-MM-DD')"
+ end_date_condition = "AND DATE(r.created_at) <= TO_DATE(%s, 'YYYY-MM-DD')"
params.append(end_date)
detail_name_condition = ''
if detail_name is not None and detail_name.strip() != '':
- detail_name_condition = "AND phase_stats.detail_name = %s"
+ detail_name_condition = "AND p.detail_name = %s"
params.append(detail_name)
limit_365_condition = ''
if limit_365:
- limit_365_condition = "AND projects.last_run >= CURRENT_DATE - INTERVAL '365 days'"
+ limit_365_condition = "AND r.created_at >= CURRENT_DATE - INTERVAL '365 days'"
- sorting_condition = 'projects.commit_timestamp ASC, projects.last_run ASC'
+ sorting_condition = 'r.commit_timestamp ASC, r.created_at ASC'
if sorting is not None and sorting.strip() == 'run':
- sorting_condition = 'projects.last_run ASC, projects.commit_timestamp ASC'
-
+ sorting_condition = 'r.created_at ASC, r.commit_timestamp ASC'
query = f"""
SELECT
- projects.id, projects.name, projects.last_run, phase_stats.metric, phase_stats.detail_name, phase_stats.phase,
- phase_stats.value, phase_stats.unit, projects.commit_hash, projects.commit_timestamp,
+ r.id, r.name, r.created_at, p.metric, p.detail_name, p.phase,
+ p.value, p.unit, r.commit_hash, r.commit_timestamp,
row_number() OVER () AS row_num
- FROM projects
- LEFT JOIN phase_stats ON
- projects.id = phase_stats.project_id
+ FROM runs as r
+ LEFT JOIN phase_stats as p ON
+ r.id = p.run_id
WHERE
- projects.uri = %s
- AND projects.filename = %s
- AND projects.end_measurement IS NOT NULL
- AND projects.last_run IS NOT NULL
- AND machine_id = %s
- {metrics_condition}
+ r.uri = %s
+ AND r.filename = %s
+ AND r.end_measurement IS NOT NULL
+ AND r.machine_id = %s
+ AND p.phase LIKE %s
{branch_condition}
- {phase_condition}
+ {metrics_condition}
{start_date_condition}
{end_date_condition}
{detail_name_condition}
{limit_365_condition}
- AND projects.commit_timestamp IS NOT NULL
+ AND r.commit_timestamp IS NOT NULL
ORDER BY
- phase_stats.metric ASC, phase_stats.detail_name ASC,
- phase_stats.phase ASC, {sorting_condition}
+ p.metric ASC, p.detail_name ASC,
+ p.phase ASC, {sorting_condition}
"""
- print(query)
return (query, params)
def determine_comparison_case(ids):
query = '''
WITH uniques as (
- SELECT uri, filename, machine_id, commit_hash, COALESCE(branch, 'main / master') as branch FROM projects
+ SELECT uri, filename, machine_id, commit_hash, COALESCE(branch, 'main / master') as branch FROM runs
WHERE id = ANY(%s::uuid[])
GROUP BY uri, filename, machine_id, commit_hash, branch
)
@@ -209,7 +194,7 @@ def determine_comparison_case(ids):
[repos, usage_scenarios, machine_ids, commit_hashes, branches] = data
# If we have one or more measurement in a phase_stat it will currently just be averaged
- # however, when we allow comparing projects we will get same phase_stats but with different repo etc.
+ # however, when we allow comparing runs we will get same phase_stats but with different repo etc.
# these cannot be just averaged. But they have to be split and then compared via t-test
# For the moment I think it makes sense to restrict to two repositories. Comparing three is too much to handle I believe if we do not want to drill down to one specific metric
@@ -282,7 +267,6 @@ def determine_comparison_case(ids):
raise RuntimeError('Less than 1 or more than 2 Usage scenarios per repo not supported.')
else:
- # TODO: Metric drilldown has to be implemented at some point ...
# The functionality I imagine here is, because comparing more than two repos is very complex with
# multiple t-tests / ANOVA etc. and hard to grasp, only a focus on one metric shall be provided.
raise RuntimeError('Less than 1 or more than 2 repos not supported for overview. Please apply metric filter.')
@@ -295,11 +279,11 @@ def get_phase_stats(ids):
a.phase, a.metric, a.detail_name, a.value, a.type, a.max_value, a.min_value, a.unit,
b.uri, c.description, b.filename, b.commit_hash, COALESCE(b.branch, 'main / master') as branch
FROM phase_stats as a
- LEFT JOIN projects as b on b.id = a.project_id
+ LEFT JOIN runs as b on b.id = a.run_id
LEFT JOIN machines as c on c.id = b.machine_id
WHERE
- a.project_id = ANY(%s::uuid[])
+ a.run_id = ANY(%s::uuid[])
ORDER BY
a.phase ASC,
a.metric ASC,
@@ -316,7 +300,6 @@ def get_phase_stats(ids):
raise RuntimeError('Data is empty')
return data
-# TODO: This method needs proper database caching
# Would be interesting to know if in an application server like gunicor @cache
# Will also work for subsequent requests ...?
''' Object structure
@@ -347,8 +330,8 @@ def get_phase_stats(ids):
// although we can have 2 commits on 2 repos, we do not keep
// track of the multiple commits here as key
- // currently the system is limited to compare only two projects until we have
- // figured out how big our StdDev is and how many projects we can run per day
+ // currently the system is limited to compare only two runs until we have
+ // figured out how big our StdDev is and how many runs we can run per day
// at all (and how many repetitions are needed and possbile time-wise)
repo/usage_scenarios/machine/commit/:
mean: // mean per commit/repo etc.
@@ -361,10 +344,10 @@ def get_phase_stats(ids):
data: dict -> key: repo/usage_scenarios/machine/commit/branch
- project_1: dict
- project_2: dict
+ run_1: dict
+ run_2: dict
...
- project_x : dict -> key: phase_name
+ run_x : dict -> key: phase_name
[BASELINE]: dict
[INSTALLATION]: dict
....
diff --git a/api/main.py b/api/main.py
new file mode 100644
index 000000000..02a3f0b27
--- /dev/null
+++ b/api/main.py
@@ -0,0 +1,1144 @@
+import faulthandler
+
+# It seems like FastAPI already enables faulthandler as it shows stacktrace on SEGFAULT
+# Is the redundant call problematic
+faulthandler.enable() # will catch segfaults and write to STDERR
+
+import zlib
+import base64
+import json
+from typing import List
+from xml.sax.saxutils import escape as xml_escape
+import math
+from fastapi import FastAPI, Request, Response
+from fastapi.responses import ORJSONResponse
+from fastapi.encoders import jsonable_encoder
+from fastapi.exceptions import RequestValidationError
+from fastapi.middleware.cors import CORSMiddleware
+
+from starlette.responses import RedirectResponse
+from starlette.exceptions import HTTPException as StarletteHTTPException
+
+from pydantic import BaseModel
+
+import anybadge
+
+from api.object_specifications import Measurement
+from api.api_helpers import (add_phase_stats_statistics, determine_comparison_case,
+ html_escape_multi, get_phase_stats, get_phase_stats_object,
+ is_valid_uuid, rescale_energy_value, get_timeline_query,
+ get_run_info, get_machine_list)
+
+from lib.global_config import GlobalConfig
+from lib.db import DB
+from lib import email_helpers
+from lib import error_helpers
+from tools.jobs import Job
+from tools.timeline_projects import TimelineProject
+
+
+app = FastAPI()
+
+async def log_exception(request: Request, exc, body=None, details=None):
+ error_message = f"""
+ Error in API call
+
+ URL: {request.url}
+
+ Query-Params: {request.query_params}
+
+ Client: {request.client}
+
+ Headers: {str(request.headers)}
+
+ Body: {body}
+
+ Optional details: {details}
+
+ Exception: {exc}
+ """
+ error_helpers.log_error(error_message)
+
+ # This saves us from crawler requests to the IP directly, or to our DNS reverse PTR etc.
+ # which would create email noise
+ request_url = str(request.url).replace('https://', '').replace('http://', '')
+ api_url = GlobalConfig().config['cluster']['api_url'].replace('https://', '').replace('http://', '')
+
+ if not request_url.startswith(api_url):
+ return
+
+ if GlobalConfig().config['admin']['no_emails'] is False:
+ email_helpers.send_error_email(
+ GlobalConfig().config['admin']['email'],
+ error_helpers.format_error(error_message),
+ run_id=None,
+ )
+
+@app.exception_handler(RequestValidationError)
+async def validation_exception_handler(request: Request, exc: RequestValidationError):
+ await log_exception(request, exc, body=exc.body, details=exc.errors())
+ return ORJSONResponse(
+ status_code=422, # HTTP_422_UNPROCESSABLE_ENTITY
+ content=jsonable_encoder({'success': False, 'err': exc.errors(), 'body': exc.body}),
+ )
+
+@app.exception_handler(StarletteHTTPException)
+async def http_exception_handler(request, exc):
+ await log_exception(request, exc, body='StarletteHTTPException handler cannot read body atm. Waiting for FastAPI upgrade.', details=exc.detail)
+ return ORJSONResponse(
+ status_code=exc.status_code,
+ content=jsonable_encoder({'success': False, 'err': exc.detail}),
+ )
+
+async def catch_exceptions_middleware(request: Request, call_next):
+ #pylint: disable=broad-except
+ try:
+ return await call_next(request)
+ except Exception as exc:
+ # body = await request.body() # This blocks the application. Unclear atm how to handle it properly
+ # seems like a bug: https://github.com/tiangolo/fastapi/issues/394
+ # Although the issue is closed the "solution" still behaves with same failure
+ # Actually Starlette, the underlying library to FastAPI has already introduced this functionality:
+ # https://github.com/encode/starlette/pull/1692
+ # However FastAPI does not support the new Starlette 0.31.1
+ # The PR relevant here is: https://github.com/tiangolo/fastapi/pull/9939
+ await log_exception(request, exc, body='Middleware cannot read body atm. Waiting for FastAPI upgrade')
+ return ORJSONResponse(
+ content={
+ 'success': False,
+ 'err': 'Technical error with getting data from the API - Please contact us: info@green-coding.berlin',
+ },
+ status_code=500,
+ )
+
+
+# Binding the Exception middleware must confusingly come BEFORE the CORS middleware.
+# Otherwise CORS will not be sent in response
+app.middleware('http')(catch_exceptions_middleware)
+
+origins = [
+ GlobalConfig().config['cluster']['metrics_url'],
+ GlobalConfig().config['cluster']['api_url'],
+]
+
+app.add_middleware(
+ CORSMiddleware,
+ allow_origins=origins,
+ allow_credentials=True,
+ allow_methods=['*'],
+ allow_headers=['*'],
+)
+
+
+@app.get('/')
+async def home():
+ return RedirectResponse(url='/docs')
+
+
+# A route to return all of the available entries in our catalog.
+@app.get('/v1/notes/{run_id}')
+async def get_notes(run_id):
+ if run_id is None or not is_valid_uuid(run_id):
+ raise RequestValidationError('Run ID is not a valid UUID or empty')
+
+ query = """
+ SELECT run_id, detail_name, note, time
+ FROM notes
+ WHERE run_id = %s
+ ORDER BY created_at DESC -- important to order here, the charting library in JS cannot do that automatically!
+ """
+ data = DB().fetch_all(query, (run_id,))
+ if data is None or data == []:
+ return Response(status_code=204) # No-Content
+
+ escaped_data = [html_escape_multi(note) for note in data]
+ return ORJSONResponse({'success': True, 'data': escaped_data})
+
+@app.get('/v1/network/{run_id}')
+async def get_network(run_id):
+ if run_id is None or not is_valid_uuid(run_id):
+ raise RequestValidationError('Run ID is not a valid UUID or empty')
+
+ query = """
+ SELECT *
+ FROM network_intercepts
+ WHERE run_id = %s
+ ORDER BY time
+ """
+ data = DB().fetch_all(query, (run_id,))
+
+ escaped_data = html_escape_multi(data)
+ return ORJSONResponse({'success': True, 'data': escaped_data})
+
+
+# return a list of all possible registered machines
+@app.get('/v1/machines/')
+async def get_machines():
+
+ data = get_machine_list()
+ if data is None or data == []:
+ return Response(status_code=204) # No-Content
+
+ return ORJSONResponse({'success': True, 'data': data})
+
+@app.get('/v1/repositories')
+async def get_repositories(uri: str | None = None, branch: str | None = None, machine_id: int | None = None, machine: str | None = None, filename: str | None = None, ):
+ query = """
+ SELECT DISTINCT(r.uri)
+ FROM runs as r
+ LEFT JOIN machines as m on r.machine_id = m.id
+ WHERE 1=1
+ """
+ params = []
+
+ if uri:
+ query = f"{query} AND r.uri LIKE %s \n"
+ params.append(f"%{uri}%")
+
+ if branch:
+ query = f"{query} AND r.branch LIKE %s \n"
+ params.append(f"%{branch}%")
+
+ if filename:
+ query = f"{query} AND r.filename LIKE %s \n"
+ params.append(f"%{filename}%")
+
+ if machine_id:
+ query = f"{query} AND m.id = %s \n"
+ params.append(machine_id)
+
+ if machine:
+ query = f"{query} AND m.description LIKE %s \n"
+ params.append(f"%{machine}%")
+
+
+ query = f"{query} ORDER BY r.uri ASC"
+
+ data = DB().fetch_all(query, params=tuple(params))
+ if data is None or data == []:
+ return Response(status_code=204) # No-Content
+
+ escaped_data = [html_escape_multi(run) for run in data]
+
+ return ORJSONResponse({'success': True, 'data': escaped_data})
+
+# A route to return all of the available entries in our catalog.
+@app.get('/v1/runs')
+async def get_runs(uri: str | None = None, branch: str | None = None, machine_id: int | None = None, machine: str | None = None, filename: str | None = None, limit: int | None = None):
+
+ query = """
+ SELECT r.id, r.name, r.uri, COALESCE(r.branch, 'main / master'), r.created_at, r.invalid_run, r.filename, m.description, r.commit_hash, r.end_measurement
+ FROM runs as r
+ LEFT JOIN machines as m on r.machine_id = m.id
+ WHERE 1=1
+ """
+ params = []
+
+ if uri:
+ query = f"{query} AND r.uri LIKE %s \n"
+ params.append(f"%{uri}%")
+
+ if branch:
+ query = f"{query} AND r.branch LIKE %s \n"
+ params.append(f"%{branch}%")
+
+ if filename:
+ query = f"{query} AND r.filename LIKE %s \n"
+ params.append(f"%{filename}%")
+
+ if machine_id:
+ query = f"{query} AND m.id = %s \n"
+ params.append(machine_id)
+
+ if machine:
+ query = f"{query} AND m.description LIKE %s \n"
+ params.append(f"%{machine}%")
+
+ query = f"{query} ORDER BY r.created_at DESC"
+
+ if limit:
+ query = f"{query} LIMIT %s"
+ params.append(limit)
+
+
+ data = DB().fetch_all(query, params=tuple(params))
+ if data is None or data == []:
+ return Response(status_code=204) # No-Content
+
+ escaped_data = [html_escape_multi(run) for run in data]
+
+ return ORJSONResponse({'success': True, 'data': escaped_data})
+
+
+# Just copy and paste if we want to deprecate URLs
+# @app.get('/v1/measurements/uri', deprecated=True) # Here you can see, that URL is nevertheless accessible as variable
+# later if supplied. Also deprecation shall be used once we move to v2 for all v1 routesthrough
+
+@app.get('/v1/compare')
+async def compare_in_repo(ids: str):
+ if ids is None or not ids.strip():
+ raise RequestValidationError('run_id is empty')
+ ids = ids.split(',')
+ if not all(is_valid_uuid(id) for id in ids):
+ raise RequestValidationError('One of Run IDs is not a valid UUID or empty')
+
+ try:
+ case = determine_comparison_case(ids)
+ except RuntimeError as err:
+ raise RequestValidationError(str(err)) from err
+ try:
+ phase_stats = get_phase_stats(ids)
+ except RuntimeError:
+ return Response(status_code=204) # No-Content
+ try:
+ phase_stats_object = get_phase_stats_object(phase_stats, case)
+ phase_stats_object = add_phase_stats_statistics(phase_stats_object)
+ phase_stats_object['common_info'] = {}
+
+ run_info = get_run_info(ids[0])
+
+ machine_list = get_machine_list()
+ machines = {machine[0]: machine[1] for machine in machine_list}
+
+ machine = machines[run_info['machine_id']]
+ uri = run_info['uri']
+ usage_scenario = run_info['usage_scenario']['name']
+ branch = run_info['branch'] if run_info['branch'] is not None else 'main / master'
+ commit = run_info['commit_hash']
+ filename = run_info['filename']
+
+ match case:
+ case 'Repeated Run':
+ # same repo, same usage scenarios, same machines, same branches, same commit hashes
+ phase_stats_object['common_info']['Repository'] = uri
+ phase_stats_object['common_info']['Filename'] = filename
+ phase_stats_object['common_info']['Usage Scenario'] = usage_scenario
+ phase_stats_object['common_info']['Machine'] = machine
+ phase_stats_object['common_info']['Branch'] = branch
+ phase_stats_object['common_info']['Commit'] = commit
+ case 'Usage Scenario':
+ # same repo, diff usage scenarios, same machines, same branches, same commit hashes
+ phase_stats_object['common_info']['Repository'] = uri
+ phase_stats_object['common_info']['Machine'] = machine
+ phase_stats_object['common_info']['Branch'] = branch
+ phase_stats_object['common_info']['Commit'] = commit
+ case 'Machine':
+ # same repo, same usage scenarios, diff machines, same branches, same commit hashes
+ phase_stats_object['common_info']['Repository'] = uri
+ phase_stats_object['common_info']['Filename'] = filename
+ phase_stats_object['common_info']['Usage Scenario'] = usage_scenario
+ phase_stats_object['common_info']['Branch'] = branch
+ phase_stats_object['common_info']['Commit'] = commit
+ case 'Commit':
+ # same repo, same usage scenarios, same machines, diff commit hashes
+ phase_stats_object['common_info']['Repository'] = uri
+ phase_stats_object['common_info']['Filename'] = filename
+ phase_stats_object['common_info']['Usage Scenario'] = usage_scenario
+ phase_stats_object['common_info']['Machine'] = machine
+ case 'Repository':
+ # diff repo, diff usage scenarios, same machine, same branches, diff/same commits_hashes
+ phase_stats_object['common_info']['Machine'] = machine
+ phase_stats_object['common_info']['Branch'] = branch
+ case 'Branch':
+ # same repo, same usage scenarios, same machines, diff branch
+ phase_stats_object['common_info']['Repository'] = uri
+ phase_stats_object['common_info']['Filename'] = filename
+ phase_stats_object['common_info']['Usage Scenario'] = usage_scenario
+ phase_stats_object['common_info']['Machine'] = machine
+
+ except RuntimeError as err:
+ raise RequestValidationError(str(err)) from err
+
+ return ORJSONResponse({'success': True, 'data': phase_stats_object})
+
+
+@app.get('/v1/phase_stats/single/{run_id}')
+async def get_phase_stats_single(run_id: str):
+ if run_id is None or not is_valid_uuid(run_id):
+ raise RequestValidationError('Run ID is not a valid UUID or empty')
+
+ try:
+ phase_stats = get_phase_stats([run_id])
+ phase_stats_object = get_phase_stats_object(phase_stats, None)
+ phase_stats_object = add_phase_stats_statistics(phase_stats_object)
+
+ except RuntimeError:
+ return Response(status_code=204) # No-Content
+
+ return ORJSONResponse({'success': True, 'data': phase_stats_object})
+
+
+# This route gets the measurements to be displayed in a timeline chart
+@app.get('/v1/measurements/single/{run_id}')
+async def get_measurements_single(run_id: str):
+ if run_id is None or not is_valid_uuid(run_id):
+ raise RequestValidationError('Run ID is not a valid UUID or empty')
+
+ query = """
+ SELECT measurements.detail_name, measurements.time, measurements.metric,
+ measurements.value, measurements.unit
+ FROM measurements
+ WHERE measurements.run_id = %s
+ """
+
+ # extremely important to order here, cause the charting library in JS cannot do that automatically!
+
+ query = f" {query} ORDER BY measurements.metric ASC, measurements.detail_name ASC, measurements.time ASC"
+
+ params = params = (run_id, )
+
+ data = DB().fetch_all(query, params=params)
+
+ if data is None or data == []:
+ return Response(status_code=204) # No-Content
+
+ return ORJSONResponse({'success': True, 'data': data})
+
+@app.get('/v1/timeline')
+async def get_timeline_stats(uri: str, machine_id: int, branch: str | None = None, filename: str | None = None, start_date: str | None = None, end_date: str | None = None, metrics: str | None = None, phase: str | None = None, sorting: str | None = None,):
+ if uri is None or uri.strip() == '':
+ raise RequestValidationError('URI is empty')
+
+ if phase is None or phase.strip() == '':
+ raise RequestValidationError('Phase is empty')
+
+ query, params = get_timeline_query(uri,filename,machine_id, branch, metrics, phase, start_date=start_date, end_date=end_date, sorting=sorting)
+
+ data = DB().fetch_all(query, params=params)
+
+ if data is None or data == []:
+ return Response(status_code=204) # No-Content
+
+ return ORJSONResponse({'success': True, 'data': data})
+
+@app.get('/v1/badge/timeline')
+async def get_timeline_badge(detail_name: str, uri: str, machine_id: int, branch: str | None = None, filename: str | None = None, metrics: str | None = None):
+ if uri is None or uri.strip() == '':
+ raise RequestValidationError('URI is empty')
+
+ if detail_name is None or detail_name.strip() == '':
+ raise RequestValidationError('Detail Name is mandatory')
+
+ query, params = get_timeline_query(uri,filename,machine_id, branch, metrics, '[RUNTIME]', detail_name=detail_name, limit_365=True)
+
+ query = f"""
+ WITH trend_data AS (
+ {query}
+ ) SELECT
+ MAX(row_num::float),
+ regr_slope(value, row_num::float) AS trend_slope,
+ regr_intercept(value, row_num::float) AS trend_intercept,
+ MAX(unit)
+ FROM trend_data;
+ """
+
+ data = DB().fetch_one(query, params=params)
+
+ if data is None or data == [] or data[1] is None: # special check for data[1] as this is aggregate query which always returns result
+ return Response(status_code=204) # No-Content
+
+ cost = data[1]/data[0]
+ cost = f"+{round(float(cost), 2)}" if abs(cost) == cost else f"{round(float(cost), 2)}"
+
+ badge = anybadge.Badge(
+ label=xml_escape('Run Trend'),
+ value=xml_escape(f"{cost} {data[3]} per day"),
+ num_value_padding_chars=1,
+ default_color='orange')
+ return Response(content=str(badge), media_type="image/svg+xml")
+
+
+# A route to return all of the available entries in our catalog.
+@app.get('/v1/badge/single/{run_id}')
+async def get_badge_single(run_id: str, metric: str = 'ml-estimated'):
+
+ if run_id is None or not is_valid_uuid(run_id):
+ raise RequestValidationError('Run ID is not a valid UUID or empty')
+
+ query = '''
+ SELECT
+ SUM(value), MAX(unit)
+ FROM
+ phase_stats
+ WHERE
+ run_id = %s
+ AND metric LIKE %s
+ AND phase LIKE '%%_[RUNTIME]'
+ '''
+
+ value = None
+ label = 'Energy Cost'
+ via = ''
+ if metric == 'ml-estimated':
+ value = 'psu_energy_ac_xgboost_machine'
+ via = 'via XGBoost ML'
+ elif metric == 'RAPL':
+ value = '%_energy_rapl_%'
+ via = 'via RAPL'
+ elif metric == 'AC':
+ value = 'psu_energy_ac_%'
+ via = 'via PSU (AC)'
+ elif metric == 'SCI':
+ label = 'SCI'
+ value = 'software_carbon_intensity_global'
+ else:
+ raise RequestValidationError(f"Unknown metric '{metric}' submitted")
+
+ params = (run_id, value)
+ data = DB().fetch_one(query, params=params)
+
+ if data is None or data == [] or data[1] is None: # special check for data[1] as this is aggregate query which always returns result
+ badge_value = 'No energy data yet'
+ else:
+ [energy_value, energy_unit] = rescale_energy_value(data[0], data[1])
+ badge_value= f"{energy_value:.2f} {energy_unit} {via}"
+
+ badge = anybadge.Badge(
+ label=xml_escape(label),
+ value=xml_escape(badge_value),
+ num_value_padding_chars=1,
+ default_color='cornflowerblue')
+ return Response(content=str(badge), media_type="image/svg+xml")
+
+
+@app.get('/v1/timeline-projects')
+async def get_timeline_projects():
+ # Do not get the email jobs as they do not need to be display in the frontend atm
+ # Also do not get the email field for privacy
+ query = """
+ SELECT
+ p.id, p.name, p.url,
+ (
+ SELECT STRING_AGG(t.name, ', ' )
+ FROM unnest(p.categories) as elements
+ LEFT JOIN categories as t on t.id = elements
+ ) as categories,
+ p.branch, p.filename, p.machine_id, m.description, p.schedule_mode, p.last_scheduled, p.created_at, p.updated_at,
+ (
+ SELECT created_at
+ FROM runs as r
+ WHERE
+ p.url = r.uri
+ AND COALESCE(p.branch, 'main / master') = COALESCE(r.branch, 'main / master')
+ AND COALESCE(p.filename, 'usage_scenario.yml') = COALESCE(r.filename, 'usage_scenario.yml')
+ AND p.machine_id = r.machine_id
+ ORDER BY r.created_at DESC
+ LIMIT 1
+ ) as "last_run"
+ FROM timeline_projects as p
+ LEFT JOIN machines as m ON m.id = p.machine_id
+ ORDER BY p.url ASC;
+ """
+ data = DB().fetch_all(query)
+ if data is None or data == []:
+ return Response(status_code=204) # No-Content
+
+ return ORJSONResponse({'success': True, 'data': data})
+
+
+@app.get('/v1/jobs')
+async def get_jobs():
+ # Do not get the email jobs as they do not need to be display in the frontend atm
+ query = """
+ SELECT j.id, j.name, j.url, j.filename, j.branch, m.description, j.state, j.updated_at, j.created_at
+ FROM jobs as j
+ LEFT JOIN machines as m on m.id = j.machine_id
+ ORDER BY j.updated_at DESC, j.created_at ASC
+ """
+ data = DB().fetch_all(query)
+ if data is None or data == []:
+ return Response(status_code=204) # No-Content
+
+ return ORJSONResponse({'success': True, 'data': data})
+
+####
+
+class HogMeasurement(BaseModel):
+ time: int
+ data: str
+ settings: str
+ machine_uuid: str
+
+def replace_nan_with_zero(obj):
+ if isinstance(obj, dict):
+ for k, v in obj.items():
+ if isinstance(v, (dict, list)):
+ replace_nan_with_zero(v)
+ elif isinstance(v, float) and math.isnan(v):
+ obj[k] = 0
+ elif isinstance(obj, list):
+ for i, item in enumerate(obj):
+ if isinstance(item, (dict, list)):
+ replace_nan_with_zero(item)
+ elif isinstance(item, float) and math.isnan(item):
+ obj[i] = 0
+ return obj
+
+
+
+@app.post('/v1/hog/add')
+async def hog_add(measurements: List[HogMeasurement]):
+
+ for measurement in measurements:
+ decoded_data = base64.b64decode(measurement.data)
+ decompressed_data = zlib.decompress(decoded_data)
+ measurement_data = json.loads(decompressed_data.decode())
+
+ # For some reason we sometimes get NaN in the data.
+ measurement_data = replace_nan_with_zero(measurement_data)
+
+ #Check if the data is valid, if not this will throw an exception and converted into a request by the middleware
+ try:
+ _ = Measurement(**measurement_data)
+ except RequestValidationError as exc:
+ print(f"Caught Exception {exc}")
+ print(f"Errors are: {exc.errors()}")
+ raise exc
+
+ coalitions = []
+ for coalition in measurement_data['coalitions']:
+ if coalition['name'] == 'com.googlecode.iterm2' or \
+ coalition['name'] == 'com.apple.Terminal' or \
+ coalition['name'] == 'com.vix.cron' or \
+ coalition['name'].strip() == '':
+ tmp = coalition['tasks']
+ for tmp_el in tmp:
+ tmp_el['tasks'] = []
+ coalitions.extend(tmp)
+ else:
+ coalitions.append(coalition)
+
+ # We remove the coalitions as we don't want to save all the data in hog_measurements
+ del measurement_data['coalitions']
+ del measurement.data
+
+ cpu_energy_data = {}
+ energy_impact = round(measurement_data['all_tasks'].get('energy_impact_per_s') * measurement_data['elapsed_ns'] / 1_000_000_000)
+ if 'ane_energy' in measurement_data['processor']:
+ cpu_energy_data = {
+ 'combined_energy': round(measurement_data['processor'].get('combined_power', 0) * measurement_data['elapsed_ns'] / 1_000_000_000.0),
+ 'cpu_energy': round(measurement_data['processor'].get('cpu_energy', 0)),
+ 'gpu_energy': round(measurement_data['processor'].get('gpu_energy', 0)),
+ 'ane_energy': round(measurement_data['processor'].get('ane_energy', 0)),
+ 'energy_impact': energy_impact,
+ }
+ elif 'package_joules' in measurement_data['processor']:
+ # Intel processors report in joules/ watts and not mJ
+ cpu_energy_data = {
+ 'combined_energy': round(measurement_data['processor'].get('package_joules', 0) * 1_000),
+ 'cpu_energy': round(measurement_data['processor'].get('cpu_joules', 0) * 1_000),
+ 'gpu_energy': round(measurement_data['processor'].get('igpu_watts', 0) * measurement_data['elapsed_ns'] / 1_000_000_000.0 * 1_000),
+ 'ane_energy': 0,
+ 'energy_impact': energy_impact,
+ }
+ else:
+ raise RequestValidationError("input not valid")
+
+ query = """
+ INSERT INTO
+ hog_measurements (
+ time,
+ machine_uuid,
+ elapsed_ns,
+ combined_energy,
+ cpu_energy,
+ gpu_energy,
+ ane_energy,
+ energy_impact,
+ thermal_pressure,
+ settings,
+ data)
+ VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)
+ RETURNING id
+ """
+ params = (
+ measurement.time,
+ measurement.machine_uuid,
+ measurement_data['elapsed_ns'],
+ cpu_energy_data['combined_energy'],
+ cpu_energy_data['cpu_energy'],
+ cpu_energy_data['gpu_energy'],
+ cpu_energy_data['ane_energy'],
+ cpu_energy_data['energy_impact'],
+ measurement_data['thermal_pressure'],
+ measurement.settings,
+ json.dumps(measurement_data),
+ )
+
+ measurement_db_id = DB().fetch_one(query=query, params=params)[0]
+
+
+ # Save hog_measurements
+ for coalition in coalitions:
+
+ if coalition['energy_impact'] < 1.0:
+ # If the energy_impact is too small we just skip the coalition.
+ continue
+
+ c_tasks = coalition['tasks'].copy()
+ del coalition['tasks']
+
+ c_energy_impact = round((coalition['energy_impact_per_s'] / 1_000_000_000) * measurement_data['elapsed_ns'])
+ c_cputime_ns = ((coalition['cputime_ms_per_s'] * 1_000_000) / 1_000_000_000) * measurement_data['elapsed_ns']
+
+ query = """
+ INSERT INTO
+ hog_coalitions (
+ measurement,
+ name,
+ cputime_ns,
+ cputime_per,
+ energy_impact,
+ diskio_bytesread,
+ diskio_byteswritten,
+ intr_wakeups,
+ idle_wakeups,
+ data)
+ VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s)
+ RETURNING id
+ """
+ params = (
+ measurement_db_id,
+ coalition['name'],
+ c_cputime_ns,
+ int(c_cputime_ns / measurement_data['elapsed_ns'] * 100),
+ c_energy_impact,
+ coalition['diskio_bytesread'],
+ coalition['diskio_byteswritten'],
+ coalition['intr_wakeups'],
+ coalition['idle_wakeups'],
+ json.dumps(coalition)
+ )
+
+ coaltion_db_id = DB().fetch_one(query=query, params=params)[0]
+
+ for task in c_tasks:
+ t_energy_impact = round((task['energy_impact_per_s'] / 1_000_000_000) * measurement_data['elapsed_ns'])
+ t_cputime_ns = ((task['cputime_ms_per_s'] * 1_000_000) / 1_000_000_000) * measurement_data['elapsed_ns']
+
+ query = """
+ INSERT INTO
+ hog_tasks (
+ coalition,
+ name,
+ cputime_ns,
+ cputime_per,
+ energy_impact,
+ bytes_received,
+ bytes_sent,
+ diskio_bytesread,
+ diskio_byteswritten,
+ intr_wakeups,
+ idle_wakeups,
+ data)
+ VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)
+ RETURNING id
+ """
+ params = (
+ coaltion_db_id,
+ task['name'],
+ t_cputime_ns,
+ int(t_cputime_ns / measurement_data['elapsed_ns'] * 100),
+ t_energy_impact,
+ task.get('bytes_received', 0),
+ task.get('bytes_sent', 0),
+ task.get('diskio_bytesread', 0),
+ task.get('diskio_byteswritten', 0),
+ task.get('intr_wakeups', 0),
+ task.get('idle_wakeups', 0),
+ json.dumps(task)
+
+ )
+ DB().fetch_one(query=query, params=params)
+
+ return Response(status_code=204) # No-Content
+
+
+@app.get('/v1/hog/top_processes')
+async def hog_get_top_processes():
+ query = """
+ SELECT
+ name,
+ (SUM(energy_impact)::bigint) AS total_energy_impact
+ FROM
+ hog_coalitions
+ GROUP BY
+ name
+ ORDER BY
+ total_energy_impact DESC
+ LIMIT 100;
+ """
+ data = DB().fetch_all(query)
+
+ if data is None:
+ data = []
+
+ query = """
+ SELECT COUNT(DISTINCT machine_uuid) FROM hog_measurements;
+ """
+
+ machine_count = DB().fetch_one(query)[0]
+
+ return ORJSONResponse({'success': True, 'process_data': data, 'machine_count': machine_count})
+
+
+@app.get('/v1/hog/machine_details/{machine_uuid}')
+async def hog_get_machine_details(machine_uuid: str):
+
+ if machine_uuid is None or not is_valid_uuid(machine_uuid):
+ return ORJSONResponse({'success': False, 'err': 'machine_uuid is empty or malformed'}, status_code=400)
+
+ query = """
+ SELECT
+ time,
+ combined_energy,
+ cpu_energy,
+ gpu_energy,
+ ane_energy,
+ energy_impact::bigint,
+ id
+ FROM
+ hog_measurements
+ WHERE
+ machine_uuid = %s
+ ORDER BY
+ time
+ """
+
+ data = DB().fetch_all(query, (machine_uuid,))
+
+ return ORJSONResponse({'success': True, 'data': data})
+
+
+@app.get('/v1/hog/coalitions_tasks/{machine_uuid}/{measurements_id_start}/{measurements_id_end}')
+async def hog_get_coalitions_tasks(machine_uuid: str, measurements_id_start: int, measurements_id_end: int):
+
+ if machine_uuid is None or not is_valid_uuid(machine_uuid):
+ return ORJSONResponse({'success': False, 'err': 'machine_uuid is empty'}, status_code=400)
+
+ if measurements_id_start is None:
+ return ORJSONResponse({'success': False, 'err': 'measurements_id_start is empty'}, status_code=400)
+
+ if measurements_id_end is None:
+ return ORJSONResponse({'success': False, 'err': 'measurements_id_end is empty'}, status_code=400)
+
+
+ coalitions_query = """
+ SELECT
+ name,
+ (SUM(hc.energy_impact)::bigint) AS total_energy_impact,
+ (SUM(hc.diskio_bytesread)::bigint) AS total_diskio_bytesread,
+ (SUM(hc.diskio_byteswritten)::bigint) AS total_diskio_byteswritten,
+ (SUM(hc.intr_wakeups)::bigint) AS total_intr_wakeups,
+ (SUM(hc.idle_wakeups)::bigint) AS total_idle_wakeups,
+ (AVG(hc.cputime_per)::integer) AS avg_cpu_per
+ FROM
+ hog_coalitions AS hc
+ JOIN
+ hog_measurements AS hm ON hc.measurement = hm.id
+ WHERE
+ hc.measurement BETWEEN %s AND %s
+ AND hm.machine_uuid = %s
+ GROUP BY
+ name
+ ORDER BY
+ total_energy_impact DESC
+ LIMIT 100;
+ """
+
+ measurements_query = """
+ SELECT
+ (SUM(combined_energy)::bigint) AS total_combined_energy,
+ (SUM(cpu_energy)::bigint) AS total_cpu_energy,
+ (SUM(gpu_energy)::bigint) AS total_gpu_energy,
+ (SUM(ane_energy)::bigint) AS total_ane_energy,
+ (SUM(energy_impact)::bigint) AS total_energy_impact
+ FROM
+ hog_measurements
+ WHERE
+ id BETWEEN %s AND %s
+ AND machine_uuid = %s
+
+ """
+
+ coalitions_data = DB().fetch_all(coalitions_query, (measurements_id_start, measurements_id_end, machine_uuid))
+
+ energy_data = DB().fetch_one(measurements_query, (measurements_id_start, measurements_id_end, machine_uuid))
+
+ return ORJSONResponse({'success': True, 'data': coalitions_data, 'energy_data': energy_data})
+
+@app.get('/v1/hog/tasks_details/{machine_uuid}/{measurements_id_start}/{measurements_id_end}/{coalition_name}')
+async def hog_get_task_details(machine_uuid: str, measurements_id_start: int, measurements_id_end: int, coalition_name: str):
+
+ if machine_uuid is None or not is_valid_uuid(machine_uuid):
+ return ORJSONResponse({'success': False, 'err': 'machine_uuid is empty'}, status_code=400)
+
+ if measurements_id_start is None:
+ return ORJSONResponse({'success': False, 'err': 'measurements_id_start is empty'}, status_code=400)
+
+ if measurements_id_end is None:
+ return ORJSONResponse({'success': False, 'err': 'measurements_id_end is empty'}, status_code=400)
+
+ if coalition_name is None or not coalition_name.strip():
+ return ORJSONResponse({'success': False, 'err': 'coalition_name is empty'}, status_code=400)
+
+ tasks_query = """
+ SELECT
+ t.name,
+ COUNT(t.id) AS number_of_tasks,
+ (SUM(t.energy_impact)::bigint) AS total_energy_impact,
+ SUM(t.cputime_ns) AS total_cputime_ns,
+ SUM(t.bytes_received) AS total_bytes_received,
+ SUM(t.bytes_sent) AS total_bytes_sent,
+ SUM(t.diskio_bytesread) AS total_diskio_bytesread,
+ SUM(t.diskio_byteswritten) AS total_diskio_byteswritten,
+ SUM(t.intr_wakeups) AS total_intr_wakeups,
+ SUM(t.idle_wakeups) AS total_idle_wakeups
+ FROM
+ hog_tasks t
+ JOIN hog_coalitions c ON t.coalition = c.id
+ JOIN hog_measurements m ON c.measurement = m.id
+ WHERE
+ c.name = %s
+ AND c.measurement BETWEEN %s AND %s
+ AND m.machine_uuid = %s
+ GROUP BY
+ t.name
+ ORDER BY
+ total_energy_impact DESC;
+ """
+
+ coalitions_query = """
+ SELECT
+ c.name,
+ (SUM(c.energy_impact)::bigint) AS total_energy_impact,
+ (SUM(c.diskio_bytesread)::bigint) AS total_diskio_bytesread,
+ (SUM(c.diskio_byteswritten)::bigint) AS total_diskio_byteswritten,
+ (SUM(c.intr_wakeups)::bigint) AS total_intr_wakeups,
+ (SUM(c.idle_wakeups)::bigint) AS total_idle_wakeups
+ FROM
+ hog_coalitions c
+ JOIN hog_measurements m ON c.measurement = m.id
+ WHERE
+ c.name = %s
+ AND c.measurement BETWEEN %s AND %s
+ AND m.machine_uuid = %s
+ GROUP BY
+ c.name
+ ORDER BY
+ total_energy_impact DESC
+ LIMIT 100;
+ """
+
+ tasks_data = DB().fetch_all(tasks_query, (coalition_name, measurements_id_start,measurements_id_end, machine_uuid))
+ coalitions_data = DB().fetch_one(coalitions_query, (coalition_name, measurements_id_start, measurements_id_end, machine_uuid))
+
+ return ORJSONResponse({'success': True, 'tasks_data': tasks_data, 'coalitions_data': coalitions_data})
+
+
+
+####
+
+class Software(BaseModel):
+ name: str
+ url: str
+ email: str
+ filename: str
+ branch: str
+ machine_id: int
+ schedule_mode: str
+
+@app.post('/v1/software/add')
+async def software_add(software: Software):
+
+ software = html_escape_multi(software)
+
+ if software.name is None or software.name.strip() == '':
+ raise RequestValidationError('Name is empty')
+
+ # Note that we use uri as the general identifier, however when adding through web interface we only allow urls
+ if software.url is None or software.url.strip() == '':
+ raise RequestValidationError('URL is empty')
+
+ if software.name is None or software.name.strip() == '':
+ raise RequestValidationError('Name is empty')
+
+ if software.email is None or software.email.strip() == '':
+ raise RequestValidationError('E-mail is empty')
+
+ if not DB().fetch_one('SELECT id FROM machines WHERE id=%s AND available=TRUE', params=(software.machine_id,)):
+ raise RequestValidationError('Machine does not exist')
+
+
+ if software.branch.strip() == '':
+ software.branch = None
+
+ if software.filename.strip() == '':
+ software.filename = 'usage_scenario.yml'
+
+ if software.schedule_mode not in ['one-off', 'time', 'commit', 'variance']:
+ raise RequestValidationError(f"Please select a valid measurement interval. ({software.schedule_mode}) is unknown.")
+
+ # notify admin of new add
+ if GlobalConfig().config['admin']['no_emails'] is False:
+ email_helpers.send_admin_email(f"New run added from Web Interface: {software.name}", software)
+
+ if software.schedule_mode == 'one-off':
+ Job.insert(software.name, software.url, software.email, software.branch, software.filename, software.machine_id)
+ elif software.schedule_mode == 'variance':
+ for _ in range(0,3):
+ Job.insert(software.name, software.url, software.email, software.branch, software.filename, software.machine_id)
+ else:
+ TimelineProject.insert(software.name, software.url, software.branch, software.filename, software.machine_id, software.schedule_mode)
+
+ return ORJSONResponse({'success': True}, status_code=202)
+
+
+@app.get('/v1/run/{run_id}')
+async def get_run(run_id: str):
+ if run_id is None or not is_valid_uuid(run_id):
+ raise RequestValidationError('Run ID is not a valid UUID or empty')
+
+ data = get_run_info(run_id)
+
+ if data is None or data == []:
+ return Response(status_code=204) # No-Content
+
+ data = html_escape_multi(data)
+
+ return ORJSONResponse({'success': True, 'data': data})
+
+@app.get('/robots.txt')
+async def robots_txt():
+ data = "User-agent: *\n"
+ data += "Disallow: /"
+
+ return Response(content=data, media_type='text/plain')
+
+# pylint: disable=invalid-name
+class CI_Measurement(BaseModel):
+ energy_value: int
+ energy_unit: str
+ repo: str
+ branch: str
+ cpu: str
+ cpu_util_avg: float
+ commit_hash: str
+ workflow: str # workflow_id, change when we make API change of workflow_name being mandatory
+ run_id: str
+ source: str
+ label: str
+ duration: int
+ workflow_name: str = None
+
+@app.post('/v1/ci/measurement/add')
+async def post_ci_measurement_add(measurement: CI_Measurement):
+ for key, value in measurement.model_dump().items():
+ match key:
+ case 'unit':
+ if value is None or value.strip() == '':
+ raise RequestValidationError(f"{key} is empty")
+ if value != 'mJ':
+ raise RequestValidationError("Unit is unsupported - only mJ currently accepted")
+ continue
+
+ case 'label' | 'workflow_name': # Optional fields
+ continue
+
+ case _:
+ if value is None:
+ raise RequestValidationError(f"{key} is empty")
+ if isinstance(value, str):
+ if value.strip() == '':
+ raise RequestValidationError(f"{key} is empty")
+
+ measurement = html_escape_multi(measurement)
+
+ query = """
+ INSERT INTO
+ ci_measurements (energy_value, energy_unit, repo, branch, workflow_id, run_id, label, source, cpu, commit_hash, duration, cpu_util_avg, workflow_name)
+ VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)
+ """
+ params = (measurement.energy_value, measurement.energy_unit, measurement.repo, measurement.branch,
+ measurement.workflow, measurement.run_id, measurement.label, measurement.source, measurement.cpu,
+ measurement.commit_hash, measurement.duration, measurement.cpu_util_avg, measurement.workflow_name)
+
+ DB().query(query=query, params=params)
+ return ORJSONResponse({'success': True}, status_code=201)
+
+@app.get('/v1/ci/measurements')
+async def get_ci_measurements(repo: str, branch: str, workflow: str):
+ query = """
+ SELECT energy_value, energy_unit, run_id, created_at, label, cpu, commit_hash, duration, source, cpu_util_avg,
+ (SELECT workflow_name FROM ci_measurements AS latest_workflow
+ WHERE latest_workflow.repo = ci_measurements.repo
+ AND latest_workflow.branch = ci_measurements.branch
+ AND latest_workflow.workflow_id = ci_measurements.workflow_id
+ ORDER BY latest_workflow.created_at DESC
+ LIMIT 1) AS workflow_name
+ FROM ci_measurements
+ WHERE repo = %s AND branch = %s AND workflow_id = %s
+ ORDER BY run_id ASC, created_at ASC
+ """
+ params = (repo, branch, workflow)
+ data = DB().fetch_all(query, params=params)
+
+ if data is None or data == []:
+ return Response(status_code=204) # No-Content
+
+ return ORJSONResponse({'success': True, 'data': data})
+
+@app.get('/v1/ci/projects')
+async def get_ci_projects():
+ query = """
+ SELECT repo, branch, workflow_id, source, MAX(created_at),
+ (SELECT workflow_name FROM ci_measurements AS latest_workflow
+ WHERE latest_workflow.repo = ci_measurements.repo
+ AND latest_workflow.branch = ci_measurements.branch
+ AND latest_workflow.workflow_id = ci_measurements.workflow_id
+ ORDER BY latest_workflow.created_at DESC
+ LIMIT 1) AS workflow_name
+ FROM ci_measurements
+ GROUP BY repo, branch, workflow_id, source
+ ORDER BY repo ASC
+ """
+
+ data = DB().fetch_all(query)
+ if data is None or data == []:
+ return Response(status_code=204) # No-Content
+
+ return ORJSONResponse({'success': True, 'data': data})
+
+@app.get('/v1/ci/badge/get')
+async def get_ci_badge_get(repo: str, branch: str, workflow:str):
+ query = """
+ SELECT SUM(energy_value), MAX(energy_unit), MAX(run_id)
+ FROM ci_measurements
+ WHERE repo = %s AND branch = %s AND workflow_id = %s
+ GROUP BY run_id
+ ORDER BY MAX(created_at) DESC
+ LIMIT 1
+ """
+
+ params = (repo, branch, workflow)
+ data = DB().fetch_one(query, params=params)
+
+ if data is None or data == [] or data[1] is None: # special check for data[1] as this is aggregate query which always returns result
+ return Response(status_code=204) # No-Content
+
+ energy_value = data[0]
+ energy_unit = data[1]
+
+ [energy_value, energy_unit] = rescale_energy_value(energy_value, energy_unit)
+ badge_value= f"{energy_value:.2f} {energy_unit}"
+
+ badge = anybadge.Badge(
+ label='Energy Used',
+ value=xml_escape(badge_value),
+ num_value_padding_chars=1,
+ default_color='green')
+ return Response(content=str(badge), media_type="image/svg+xml")
+
+
+if __name__ == '__main__':
+ app.run()
diff --git a/api/object_specifications.py b/api/object_specifications.py
new file mode 100644
index 000000000..4f57826fd
--- /dev/null
+++ b/api/object_specifications.py
@@ -0,0 +1,56 @@
+from typing import List, Dict, Optional
+from pydantic import BaseModel
+
+class Task(BaseModel):
+ # We need to set the optional to a value as otherwise the key is required in the input
+ # https://docs.pydantic.dev/latest/migration/#required-optional-and-nullable-fields
+ name: str
+ cputime_ns: int
+ timer_wakeups: List
+ diskio_bytesread: Optional[int] = 0
+ diskio_byteswritten: Optional[int] = 0
+ packets_received: int
+ packets_sent: int
+ bytes_received: int
+ bytes_sent: int
+ energy_impact: float
+
+class Coalition(BaseModel):
+ name: str
+ cputime_ns: int
+ diskio_bytesread: int = 0
+ diskio_byteswritten: int = 0
+ energy_impact: float
+ tasks: List[Task]
+
+class Processor(BaseModel):
+ # https://docs.pydantic.dev/latest/migration/#required-optional-and-nullable-fields
+ clusters: Optional[List] = None
+ cpu_power_zones_engaged: Optional[float] = None
+ cpu_energy: Optional[int] = None
+ cpu_power: Optional[float] = None
+ gpu_energy: Optional[int] = None
+ gpu_power: Optional[float] = None
+ ane_energy: Optional[int] = None
+ ane_power: Optional[float] = None
+ combined_power: Optional[float] = None
+ package_joules: Optional[float] = None
+ cpu_joules: Optional[float] = None
+ igpu_watts: Optional[float] = None
+
+class GPU(BaseModel):
+ gpu_energy: Optional[int] = None
+
+class Measurement(BaseModel):
+ is_delta: bool
+ elapsed_ns: int
+ timestamp: int
+ coalitions: List[Coalition]
+ all_tasks: Dict
+ network: Optional[Dict] = None # network is optional when system is in flight mode / network turned off
+ disk: Dict
+ interrupts: List
+ processor: Processor
+ thermal_pressure: str
+ sfi: Dict
+ gpu: Optional[GPU] = None
diff --git a/api_test.py b/api_test.py
index 31a3530ed..5c73fbfd3 100644
--- a/api_test.py
+++ b/api_test.py
@@ -1,17 +1,10 @@
-import sys, os
import json
-CURRENT_DIR = os.path.dirname(os.path.abspath(__file__))
-sys.path.append(f"{CURRENT_DIR}/lib")
-from db import DB
-from global_config import GlobalConfig
-
-from api.api_helpers import *
+from api import api_helpers
if __name__ == '__main__':
import argparse
- from pathlib import Path
parser = argparse.ArgumentParser()
@@ -21,9 +14,9 @@
ids = args.ids.split(',')
- case = determine_comparison_case(ids)
- phase_stats = get_phase_stats(ids)
- phase_stats_object = get_phase_stats_object(phase_stats, case)
- phase_stats_object = add_phase_stats_statistics(phase_stats_object)
+ case = api_helpers.determine_comparison_case(ids)
+ phase_stats = api_helpers.get_phase_stats(ids)
+ phase_stats_object = api_helpers.get_phase_stats_object(phase_stats, case)
+ phase_stats_object = api_helpers.add_phase_stats_statistics(phase_stats_object)
print(json.dumps(phase_stats_object, indent=4))
diff --git a/config.yml.example b/config.yml.example
index 5e61bd773..38ae881f0 100644
--- a/config.yml.example
+++ b/config.yml.example
@@ -16,34 +16,33 @@ smtp:
user: SMTP_AUTH_USER
admin:
- # This address will get an email, when a new project was added through the frontend
+ # This address will get an email, for any error or new project added etc.
email: myemail@dev.local
+ # This email will always get a copy of every email sent, even for user-only mails like the "Your report is ready" mail. Put an empty string if you do not want that: ""
+ bcc_email: ""
# no_emails: True will suppress all emails. Helpful in development servers
no_emails: True
- # notifiy_admin_for_own_project_*: False will suppress an email if a project is added / ready with the
- # same email address as the admin.
- # If no_emails is set to True, this will have no effect
- notify_admin_for_own_project_add: False
- notify_admin_for_own_project_ready: False
-
cluster:
api_url: __API_URL__
metrics_url: __METRICS_URL__
+
client:
- sleep_time: 300
+ sleep_time_no_job: 300
+ sleep_time_after_job: 300
machine:
id: 1
description: "Development machine for testing"
# Takes a file path to log all the errors to it. This is disabled if False
error_log_file: False
+ jobs_processing: random
measurement:
idle-time-start: 10
idle-time-end: 5
- flow-process-runtime: 1800
+ flow-process-runtime: 3800
phase-transition-time: 1
metric-providers:
@@ -58,8 +57,6 @@ measurement:
#--- Always-On - We recommend these providers to be always enabled
cpu.utilization.procfs.system.provider.CpuUtilizationProcfsSystemProvider:
resolution: 100
- cpu.frequency.sysfs.core.provider.CpuFrequencySysfsCoreProvider:
- resolution: 100
#--- CGroupV2 - Turn these on if you have CGroupsV2 working on your machine
cpu.utilization.cgroup.container.provider.CpuUtilizationCgroupContainerProvider:
resolution: 100
@@ -81,7 +78,7 @@ measurement:
# resolution: 100
# psu.energy.ac.ipmi.machine.provider.PsuEnergyAcIpmiMachineProvider:
# resolution: 100
- #--- Sensors
+ #--- Sensors - these providers need the lm-sensors package installed
# lm_sensors.temperature.component.provider.LmSensorsTemperatureComponentProvider:
# resolution: 100
# Please change these values according to the names in '$ sensors'
@@ -92,7 +89,9 @@ measurement:
# Please change these values according to the names in '$ sensors'
# chips: ['thinkpad-isa-0000']
# features: ['fan1', 'fan2']
- #--- Debug - These providers are just for development of the tool itself
+ #--- Debug - These providers should only be needed for debugging and introspection purposes
+# cpu.frequency.sysfs.core.provider.CpuFrequencySysfsCoreProvider:
+# resolution: 100
# cpu.time.cgroup.container.provider.CpuTimeCgroupContainerProvider:
# resolution: 100
# cpu.time.cgroup.system.provider.CpuTimeCgroupSystemProvider:
@@ -101,12 +100,14 @@ measurement:
# resolution: 100
#--- Architecture - MacOS
macos:
- #--- MacOS: On Mac you only need this provider. Please delete all others!
+ #--- MacOS: On Mac you only need this provider. Please remove all others!
powermetrics.provider.PowermetricsProvider:
resolution: 100
#--- Architecture - Common
common:
- #--- Model based
+# network.connections.proxy.container.provider.NetworkConnectionsProxyContainerProvider:
+## host_ip: 192.168.1.2 # This only needs to be enabled if automatic detection fails
+ #--- Model based - These providers estimate rather than measure. Helpful where measuring is not possible, like in VMs
# psu.energy.ac.sdia.machine.provider.PsuEnergyAcSdiaMachineProvider:
# resolution: 100
#-- This is a default configuration. Please change this to your system!
diff --git a/docker/Dockerfile-gunicorn b/docker/Dockerfile-gunicorn
index 2f77559c4..94a85f6cd 100644
--- a/docker/Dockerfile-gunicorn
+++ b/docker/Dockerfile-gunicorn
@@ -1,8 +1,15 @@
# syntax=docker/dockerfile:1
-FROM python:3.11.4-slim-bookworm
+FROM python:3.11.5-slim-bookworm
ENV DEBIAN_FRONTEND=noninteractive
+WORKDIR /var/www/startup/
COPY requirements.txt requirements.txt
-RUN pip3 install -r requirements.txt
+RUN python -m venv venv
+RUN venv/bin/pip install --upgrade pip
+RUN venv/bin/pip install -r requirements.txt
+RUN find venv -type d -name "site-packages" -exec sh -c 'echo /var/www/green-metrics-tool > "$0/gmt-lib.pth"' {} \;
-ENTRYPOINT ["/usr/local/bin/gunicorn", "--workers=2", "--access-logfile=-", "--error-logfile=-", "--worker-tmp-dir=/dev/shm", "--threads=4", "--worker-class=gthread", "--bind", "unix:/tmp/green-coding-api.sock", "-m", "007", "--user", "www-data", "--chdir", "/var/www/green-metrics-tool/api", "-k", "uvicorn.workers.UvicornWorker", "api:app"]
\ No newline at end of file
+
+COPY startup_gunicorn.sh /var/www/startup/startup_gunicorn.sh
+
+ENTRYPOINT ["/bin/bash", "/var/www/startup/startup_gunicorn.sh"]
diff --git a/docker/auxiliary-containers/build-containers.sh b/docker/auxiliary-containers/build-containers.sh
new file mode 100644
index 000000000..d819e9ef8
--- /dev/null
+++ b/docker/auxiliary-containers/build-containers.sh
@@ -0,0 +1,18 @@
+#!/bin/bash
+
+set -euo pipefail
+
+# The names of the folders within "auxiliary-containers" must match the repository name in dockerhub!
+
+# Get the list of subdirectories within "auxiliary-containers" directory containing a Dockerfile
+subdirs=($(find ./docker/auxiliary-containers -type f -name 'Dockerfile' -exec dirname {} \;))
+
+# Loop through each subdirectory, build and push the Docker image
+for subdir in "${subdirs[@]}"; do
+ folder=$(basename "${subdir}")
+ docker buildx build \
+ --push \
+ --tag "greencoding/${folder}:latest" \
+ --platform linux/amd64,linux/arm64 \
+ "${subdir}"
+done
\ No newline at end of file
diff --git a/docker/auxiliary-containers/gcb_playwright/Dockerfile b/docker/auxiliary-containers/gcb_playwright/Dockerfile
new file mode 100644
index 000000000..475da385e
--- /dev/null
+++ b/docker/auxiliary-containers/gcb_playwright/Dockerfile
@@ -0,0 +1,13 @@
+FROM mcr.microsoft.com/playwright/python:v1.35.0-jammy
+
+# Install dependencies
+RUN apt-get update && apt-get install -y curl wget gnupg && rm -rf /var/lib/apt/lists/*
+
+# Install Playwright
+RUN pip install playwright==1.35.0
+
+# Set up Playwright dependencies for Chromium, Firefox and Webkit
+RUN playwright install
+RUN playwright install-deps
+
+CMD ["/bin/bash"]
\ No newline at end of file
diff --git a/docker/compose.yml.example b/docker/compose.yml.example
index e76e90f04..9f65d6da5 100644
--- a/docker/compose.yml.example
+++ b/docker/compose.yml.example
@@ -1,5 +1,8 @@
services:
green-coding-postgres:
+ # No need to fix version anymore than major version here
+ # for measurement accuracy the db container is not relevant as it
+ # should not run on the measurement node anyway
image: postgres:15
shm_size: 256MB
container_name: green-coding-postgres-container
@@ -24,6 +27,9 @@ services:
-p 9573
# This option can potentially speed up big queries: https://www.twilio.com/blog/sqlite-postgresql-complicated
green-coding-nginx:
+ # No need to fix the version here, as we just waant to use latest, never have experienced
+ # incompatibilities and for measurement accuracy the web container is not relevant as it
+ # should not run on the measurement node anyway
image: nginx
container_name: green-coding-nginx-container
depends_on:
diff --git a/docker/requirements.txt b/docker/requirements.txt
index a81d7769c..f6815fecd 100644
--- a/docker/requirements.txt
+++ b/docker/requirements.txt
@@ -1,10 +1,10 @@
gunicorn==21.2.0
-psycopg[binary]==3.1.10
-fastapi==0.101.1
+psycopg[binary]==3.1.12
+fastapi==0.104.0
uvicorn[standard]==0.23.2
-pandas==2.0.3
+pandas==2.1.1
PyYAML==6.0.1
anybadge==1.14.0
-scipy==1.11.1
-orjson==3.9.4
+orjson==3.9.9
+scipy==1.11.3
schema==0.7.5
diff --git a/docker/startup_gunicorn.sh b/docker/startup_gunicorn.sh
new file mode 100644
index 000000000..99dd3ab8b
--- /dev/null
+++ b/docker/startup_gunicorn.sh
@@ -0,0 +1,16 @@
+#!/bin/sh
+source /var/www/startup/venv/bin/activate
+
+/var/www/startup/venv/bin/gunicorn \
+--workers=2 \
+--access-logfile=- \
+--error-logfile=- \
+--worker-tmp-dir=/dev/shm \
+--threads=4 \
+--worker-class=gthread \
+--bind unix:/tmp/green-coding-api.sock \
+-m 007 \
+--user www-data \
+--chdir /var/www/green-metrics-tool/api \
+-k uvicorn.workers.UvicornWorker \
+main:app
\ No newline at end of file
diff --git a/docker/structure.sql b/docker/structure.sql
index 504874fcf..483d1a588 100644
--- a/docker/structure.sql
+++ b/docker/structure.sql
@@ -2,9 +2,41 @@ CREATE DATABASE "green-coding";
\c green-coding;
CREATE EXTENSION "uuid-ossp";
+CREATE EXTENSION "moddatetime";
-CREATE TABLE projects (
+CREATE TABLE machines (
+ id SERIAL PRIMARY KEY,
+ description text,
+ available boolean DEFAULT false,
+ created_at timestamp with time zone DEFAULT now(),
+ updated_at timestamp with time zone
+);
+CREATE TRIGGER machines_moddatetime
+ BEFORE UPDATE ON machines
+ FOR EACH ROW
+ EXECUTE PROCEDURE moddatetime (updated_at);
+
+CREATE TABLE jobs (
+ id SERIAL PRIMARY KEY,
+ state text,
+ name text,
+ email text,
+ url text,
+ branch text,
+ filename text,
+ categories int[],
+ machine_id int REFERENCES machines(id) ON DELETE SET NULL ON UPDATE CASCADE,
+ created_at timestamp with time zone DEFAULT now(),
+ updated_at timestamp with time zone
+);
+CREATE TRIGGER jobs_moddatetime
+ BEFORE UPDATE ON jobs
+ FOR EACH ROW
+ EXECUTE PROCEDURE moddatetime (updated_at);
+
+CREATE TABLE runs (
id uuid DEFAULT uuid_generate_v4() PRIMARY KEY,
+ job_id integer REFERENCES jobs(id) ON DELETE SET NULL ON UPDATE CASCADE UNIQUE,
name text,
uri text,
branch text,
@@ -15,85 +47,109 @@ CREATE TABLE projects (
usage_scenario json,
filename text,
machine_specs jsonb,
- machine_id int DEFAULT 1,
+ runner_arguments json,
+ machine_id int REFERENCES machines(id) ON DELETE SET NULL ON UPDATE CASCADE,
gmt_hash text,
measurement_config jsonb,
start_measurement bigint,
end_measurement bigint,
- phases JSON DEFAULT null,
- logs text DEFAULT null,
- invalid_project text,
- last_run timestamp with time zone,
- created_at timestamp with time zone DEFAULT now()
+ phases JSON,
+ logs text,
+ invalid_run text,
+ created_at timestamp with time zone DEFAULT now(),
+ updated_at timestamp with time zone
);
+CREATE TRIGGER runs_moddatetime
+ BEFORE UPDATE ON runs
+ FOR EACH ROW
+ EXECUTE PROCEDURE moddatetime (updated_at);
+
CREATE TABLE measurements (
id SERIAL PRIMARY KEY,
- project_id uuid NOT NULL REFERENCES projects(id) ON DELETE CASCADE ON UPDATE CASCADE ,
+ run_id uuid NOT NULL REFERENCES runs(id) ON DELETE CASCADE ON UPDATE CASCADE ,
detail_name text NOT NULL,
metric text NOT NULL,
value bigint NOT NULL,
unit text NOT NULL,
time bigint NOT NULL,
- created_at timestamp with time zone DEFAULT now()
+ created_at timestamp with time zone DEFAULT now(),
+ updated_at timestamp with time zone
);
-
-CREATE UNIQUE INDEX measurements_get ON measurements(project_id ,metric ,detail_name ,time );
-CREATE INDEX measurements_build_and_store_phase_stats ON measurements(project_id, metric, unit, detail_name);
+CREATE UNIQUE INDEX measurements_get ON measurements(run_id ,metric ,detail_name ,time );
+CREATE INDEX measurements_build_and_store_phase_stats ON measurements(run_id, metric, unit, detail_name);
CREATE INDEX measurements_build_phases ON measurements(metric, unit, detail_name);
+CREATE TRIGGER measurements_moddatetime
+ BEFORE UPDATE ON measurements
+ FOR EACH ROW
+ EXECUTE PROCEDURE moddatetime (updated_at);
-CREATE TABLE categories (
+CREATE TABLE network_intercepts (
id SERIAL PRIMARY KEY,
- name text,
- parent_id int REFERENCES categories(id) ON DELETE CASCADE ON UPDATE CASCADE,
- created_at timestamp with time zone DEFAULT now()
+ run_id uuid NOT NULL REFERENCES runs(id) ON DELETE CASCADE ON UPDATE CASCADE ,
+ time bigint NOT NULL,
+ connection_type text NOT NULL,
+ protocol text NOT NULL,
+ created_at timestamp with time zone DEFAULT now(),
+ updated_at timestamp with time zone
);
+CREATE TRIGGER network_intercepts_moddatetime
+ BEFORE UPDATE ON network_intercepts
+ FOR EACH ROW
+ EXECUTE PROCEDURE moddatetime (updated_at);
-CREATE TABLE machines (
+
+CREATE TABLE categories (
id SERIAL PRIMARY KEY,
- description text,
- available boolean DEFAULT false,
+ name text,
+ parent_id int REFERENCES categories(id) ON DELETE CASCADE ON UPDATE CASCADE,
created_at timestamp with time zone DEFAULT now(),
- updated_at timestamp with time zone DEFAULT NULL
+ updated_at timestamp with time zone
);
+CREATE TRIGGER categories_moddatetime
+ BEFORE UPDATE ON categories
+ FOR EACH ROW
+ EXECUTE PROCEDURE moddatetime (updated_at);
+
CREATE TABLE phase_stats (
id SERIAL PRIMARY KEY,
- project_id uuid NOT NULL REFERENCES projects(id) ON DELETE CASCADE ON UPDATE CASCADE,
+ run_id uuid NOT NULL REFERENCES runs(id) ON DELETE CASCADE ON UPDATE CASCADE,
metric text NOT NULL,
detail_name text NOT NULL,
phase text NOT NULL,
value bigint NOT NULL,
type text NOT NULL,
- max_value bigint DEFAULT NULL,
- min_value bigint DEFAULT NULL,
+ max_value bigint,
+ min_value bigint,
unit text NOT NULL,
- created_at timestamp with time zone DEFAULT now()
+ created_at timestamp with time zone DEFAULT now(),
+ updated_at timestamp with time zone
);
-CREATE INDEX "phase_stats_project_id" ON "phase_stats" USING HASH ("project_id");
+CREATE INDEX "phase_stats_run_id" ON "phase_stats" USING HASH ("run_id");
+CREATE TRIGGER phase_stats_moddatetime
+ BEFORE UPDATE ON phase_stats
+ FOR EACH ROW
+ EXECUTE PROCEDURE moddatetime (updated_at);
+
-CREATE TABLE jobs (
- id SERIAL PRIMARY KEY,
- project_id uuid REFERENCES projects(id) ON DELETE CASCADE ON UPDATE CASCADE DEFAULT null,
- type text,
- machine_id int REFERENCES machines(id) ON DELETE SET NULL ON UPDATE CASCADE DEFAULT null,
- failed boolean DEFAULT false,
- running boolean DEFAULT false,
- last_run timestamp with time zone,
- created_at timestamp with time zone DEFAULT now()
-);
CREATE TABLE notes (
id SERIAL PRIMARY KEY,
- project_id uuid REFERENCES projects(id) ON DELETE CASCADE ON UPDATE CASCADE,
+ run_id uuid REFERENCES runs(id) ON DELETE CASCADE ON UPDATE CASCADE,
detail_name text,
note text,
time bigint,
- created_at timestamp with time zone DEFAULT now()
+ created_at timestamp with time zone DEFAULT now(),
+ updated_at timestamp with time zone
);
-CREATE INDEX "notes_project_id" ON "notes" USING HASH ("project_id");
+CREATE INDEX "notes_run_id" ON "notes" USING HASH ("run_id");
+CREATE TRIGGER notes_moddatetime
+ BEFORE UPDATE ON notes
+ FOR EACH ROW
+ EXECUTE PROCEDURE moddatetime (updated_at);
CREATE TABLE ci_measurements (
@@ -102,24 +158,126 @@ CREATE TABLE ci_measurements (
energy_unit text,
repo text,
branch text,
- workflow text,
+ workflow_id text,
+ workflow_name text,
run_id text,
- cpu text DEFAULT NULL,
+ cpu text,
cpu_util_avg int,
- commit_hash text DEFAULT NULL,
+ commit_hash text,
label text,
duration bigint,
source text,
- project_id uuid REFERENCES projects(id) ON DELETE SET NULL ON UPDATE CASCADE DEFAULT null,
- created_at timestamp with time zone DEFAULT now()
+ created_at timestamp with time zone DEFAULT now(),
+ updated_at timestamp with time zone
);
-CREATE INDEX "ci_measurements_get" ON ci_measurements(repo, branch, workflow, run_id, created_at);
+CREATE INDEX "ci_measurements_get" ON ci_measurements(repo, branch, workflow_id, run_id, created_at);
+CREATE TRIGGER ci_measurements_moddatetime
+ BEFORE UPDATE ON ci_measurements
+ FOR EACH ROW
+ EXECUTE PROCEDURE moddatetime (updated_at);
+
CREATE TABLE client_status (
id SERIAL PRIMARY KEY,
status_code TEXT NOT NULL,
- machine_id int REFERENCES machines(id) ON DELETE SET NULL ON UPDATE CASCADE DEFAULT null,
+ machine_id int REFERENCES machines(id) ON DELETE SET NULL ON UPDATE CASCADE,
"data" TEXT,
- project_id uuid REFERENCES projects(id) ON DELETE CASCADE ON UPDATE CASCADE,
- created_at timestamp with time zone DEFAULT now()
-);
\ No newline at end of file
+ run_id uuid REFERENCES runs(id) ON DELETE CASCADE ON UPDATE CASCADE,
+ created_at timestamp with time zone DEFAULT now(),
+ updated_at timestamp with time zone
+);
+CREATE TRIGGER client_status_moddatetime
+ BEFORE UPDATE ON client_status
+ FOR EACH ROW
+ EXECUTE PROCEDURE moddatetime (updated_at);
+
+CREATE TABLE timeline_projects (
+ id SERIAL PRIMARY KEY,
+ name text,
+ url text,
+ categories integer[],
+ branch text DEFAULT 'NULL'::text,
+ filename text,
+ machine_id integer REFERENCES machines(id) ON DELETE RESTRICT ON UPDATE CASCADE NOT NULL,
+ schedule_mode text NOT NULL,
+ last_scheduled timestamp with time zone,
+ created_at timestamp with time zone DEFAULT now(),
+ updated_at timestamp with time zone
+);
+CREATE TRIGGER timeline_projects_moddatetime
+ BEFORE UPDATE ON timeline_projects
+ FOR EACH ROW
+ EXECUTE PROCEDURE moddatetime (updated_at);
+
+CREATE TABLE hog_measurements (
+ id SERIAL PRIMARY KEY,
+ time bigint NOT NULL,
+ machine_uuid uuid NOT NULL,
+ elapsed_ns bigint NOT NULL,
+ combined_energy int,
+ cpu_energy int,
+ gpu_energy int,
+ ane_energy int,
+ energy_impact int,
+ thermal_pressure text,
+ settings jsonb,
+ data jsonb,
+ created_at timestamp with time zone DEFAULT now(),
+ updated_at timestamp with time zone
+);
+CREATE TRIGGER hog_measurements_moddatetime
+ BEFORE UPDATE ON hog_measurements
+ FOR EACH ROW
+ EXECUTE PROCEDURE moddatetime (updated_at);
+
+CREATE INDEX idx_hog_measurements_machine_uuid ON hog_measurements USING hash (machine_uuid);
+CREATE INDEX idx_hog_measurements_time ON hog_measurements (time);
+
+
+CREATE TABLE hog_coalitions (
+ id SERIAL PRIMARY KEY,
+ measurement integer REFERENCES hog_measurements(id) ON DELETE RESTRICT ON UPDATE CASCADE NOT NULL,
+ name text NOT NULL,
+ cputime_ns bigint,
+ cputime_per int,
+ energy_impact int,
+ diskio_bytesread bigint,
+ diskio_byteswritten bigint,
+ intr_wakeups bigint,
+ idle_wakeups bigint,
+ data jsonb,
+ created_at timestamp with time zone DEFAULT now(),
+ updated_at timestamp with time zone
+);
+CREATE TRIGGER hog_coalitions_moddatetime
+ BEFORE UPDATE ON hog_coalitions
+ FOR EACH ROW
+ EXECUTE PROCEDURE moddatetime (updated_at);
+
+CREATE INDEX idx_coalition_energy_impact ON hog_coalitions(energy_impact);
+CREATE INDEX idx_coalition_name ON hog_coalitions(name);
+
+CREATE TABLE hog_tasks (
+ id SERIAL PRIMARY KEY,
+ coalition integer REFERENCES hog_coalitions(id) ON DELETE RESTRICT ON UPDATE CASCADE NOT NULL,
+ name text NOT NULL,
+ cputime_ns bigint,
+ cputime_per int,
+ energy_impact int,
+ bytes_received bigint,
+ bytes_sent bigint,
+ diskio_bytesread bigint,
+ diskio_byteswritten bigint,
+ intr_wakeups bigint,
+ idle_wakeups bigint,
+
+ data jsonb,
+ created_at timestamp with time zone DEFAULT now(),
+ updated_at timestamp with time zone
+);
+CREATE TRIGGER hog_tasks_moddatetime
+ BEFORE UPDATE ON hog_tasks
+ FOR EACH ROW
+ EXECUTE PROCEDURE moddatetime (updated_at);
+
+CREATE INDEX idx_task_coalition ON hog_tasks(coalition);
diff --git a/frontend/ci-index.html b/frontend/ci-index.html
index 6ed613ea1..90cfd0cdf 100644
--- a/frontend/ci-index.html
+++ b/frontend/ci-index.html
@@ -40,11 +40,10 @@
+
- | Repositories ( / ) |
- Branch |
+ Repository ( / ) |
diff --git a/frontend/ci.html b/frontend/ci.html
index de275557a..3041c960f 100644
--- a/frontend/ci.html
+++ b/frontend/ci.html
@@ -18,6 +18,7 @@
+
@@ -104,7 +105,7 @@ Run Stats
Label |
Energy |
Time |
- Avg. CPU Util. |
+ Avg. CPU Util. |
Total |
@@ -137,7 +138,7 @@ Avg. CPU Util.
| Duration |
Commit Hash |
diff --git a/frontend/compare.html b/frontend/compare.html
index d887a17a8..0fa00d9a4 100644
--- a/frontend/compare.html
+++ b/frontend/compare.html
@@ -38,10 +38,10 @@