| title | date | categories | tags | permalink | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
HBase 数据模型 |
2023-03-16 08:58:10 -0700 |
|
|
/pages/c8cfeb/ |
HBase 是一个面向 列 的数据库管理系统,这里更为确切的而说,HBase 是一个面向 列族 的数据库管理系统。表 schema 仅定义列族,表具有多个列族,每个列族可以包含任意数量的列,列由多个单元格(cell)组成,单元格可以存储多个版本的数据,多个版本数据以时间戳进行区分。
Table:Table 由 Row 和 Column 组成。Row:Row 是列族(Column Family)的集合。Row Key:Row Key是用来检索记录的主键。Row Key是未解释的字节数组,所以理论上,任何数据都可以通过序列化表示成字符串或二进制,从而存为 HBase 的键值。- 表中的行,是按照
Row Key的字典序进行排序。这里需要注意以下两点:- 因为字典序对 Int 排序的结果是 1,10,100,11,12,13,14,15,16,17,18,19,2,20,21,…,9,91,92,93,94,95,96,97,98,99。如果你使用整型的字符串作为行键,那么为了保持整型的自然序,行键必须用 0 作左填充。
- 行的一次读写操作是原子性的 (不论一次读写多少列)。
- 所有对表的访问都要通过 Row Key,有以下三种方式:
- 通过指定的
Row Key进行访问; - 通过
Row Key的 range 进行访问,即访问指定范围内的行; - 进行全表扫描。
- 通过指定的
Column Family:即列族。HBase 表中的每个列,都归属于某个列族。列族是表的 Schema 的一部分,所以列族需要在创建表时进行定义。- 一个表的列族必须作为表模式定义的一部分预先给出,但是新的列族成员可以随后按需加入。
- 同一个列族的所有成员具有相同的前缀,例如
info:format,info:geo都属于info这个列族。
Column Qualifier:列限定符。可以理解为是具体的列名,例如info:format,info:geo都属于info这个列族,它们的列限定符分别是format和geo。列族和列限定符之间始终以冒号分隔。需要注意的是列限定符不是表 Schema 的一部分,你可以在插入数据的过程中动态创建列。Column:HBase 中的列由列族和列限定符组成,由:(冒号) 进行分隔,即一个完整的列名应该表述为列族名 :列限定符。Cell:Cell是行,列族和列限定符的组合,并包含值和时间戳。HBase 中通过row key和column确定的为一个存储单元称为Cell,你可以等价理解为关系型数据库中由指定行和指定列确定的一个单元格,但不同的是 HBase 中的一个单元格是由多个版本的数据组成的,每个版本的数据用时间戳进行区分。Cell由行和列的坐标交叉决定,是有版本的。默认情况下,版本号是自动分配的,为 HBase 插入Cell时的时间戳。Cell的内容是未解释的字节数组。
Timestamp:Cell的版本通过时间戳来索引,时间戳的类型是 64 位整型,时间戳可以由 HBase 在数据写入时自动赋值,也可以由客户显式指定。每个Cell中,不同版本的数据按照时间戳倒序排列,即最新的数据排在最前面。
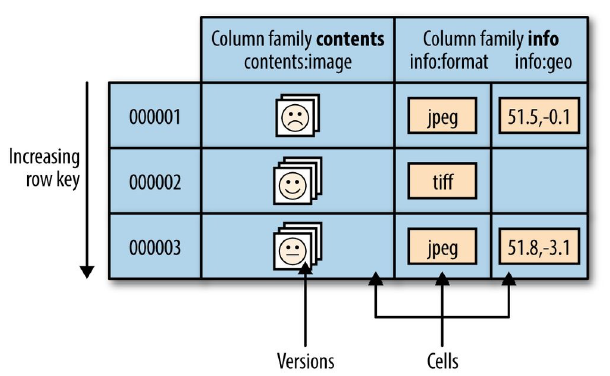
HBase 自动将表水平划分成区域(Region)。每个 Region 由表中 Row 的子集构成。每个 Region 由它所属的表的起始范围来表示(包含的第一行和最后一行)。初始时,一个表只有一个 Region,随着 Region 膨胀,当超过一定阈值时,会在某行的边界上分裂成两个大小基本相同的新 Region。在第一次划分之前,所有加载的数据都放在原始 Region 所在的那台服务器上。随着表变大,Region 个数也会逐渐增加。Region 是在 HBase 集群上分布数据的最小单位。
下图为 HBase 中一张表的:
- RowKey 为行的唯一标识,所有行按照 RowKey 的字典序进行排序;
- 该表具有两个列族,分别是 personal 和 office;
- 其中列族 personal 拥有 name、city、phone 三个列,列族 office 拥有 tel、addres 两个列。
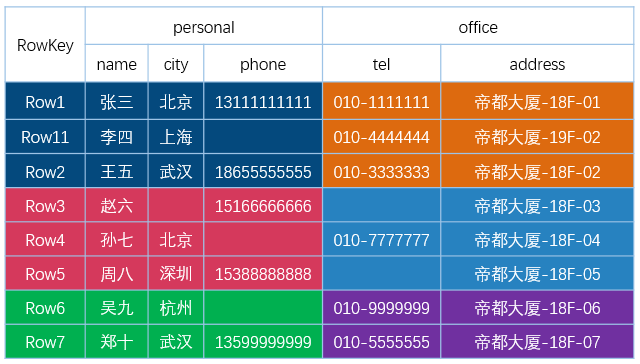
图片引用自 : HBase 是列式存储数据库吗 https://www.iteblog.com/archives/2498.html
Hbase 的表具有以下特点:
- 容量大:一个表可以有数十亿行,上百万列;
- 面向列:数据是按照列存储,每一列都单独存放,数据即索引,在查询时可以只访问指定列的数据,有效地降低了系统的 I/O 负担;
- 稀疏性:空 (null) 列并不占用存储空间,表可以设计的非常稀疏 ;
- 数据多版本:每个单元中的数据可以有多个版本,按照时间戳排序,新的数据在最上面;
- 存储类型:所有数据的底层存储格式都是字节数组 (byte[])。