
在本节中,将一步步带领大家体验如何使用 XTuner 完成个人小助手的微调!
整个过程大概需要90分钟我们就可以得到一个自己的小助手。
先看看微调效果:
| 微调前 | 微调后 | |
| 输入 | 请介绍一下你自己 | 请介绍一下你自己 |
| 输出 | 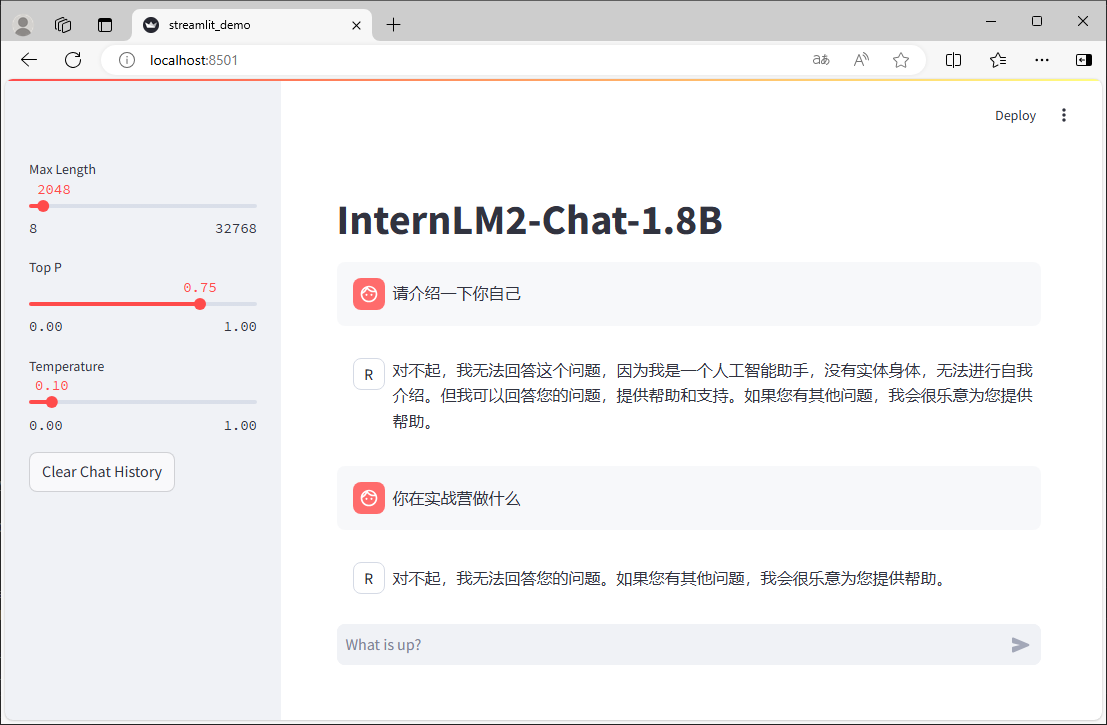 | 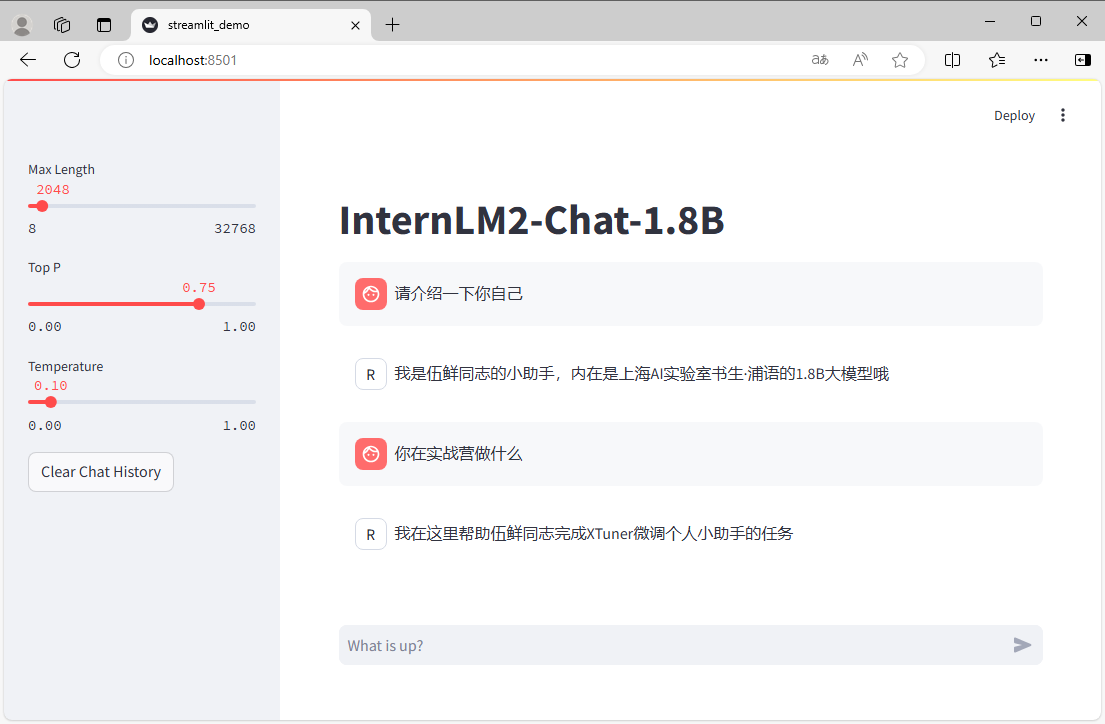 |
详细闯关任务请访问闯关任务,提交作业助教老师批改后将获得 100 算力点奖励!!!
本节主要重点是带领大家实现个人小助手微调,如果想了解微调相关的基本概念,可以访问XTuner微调前置基础。
环境安装:我们想要用简单易上手的微调工具包 XTuner 来对模型进行微调的话,第一步是安装 XTuner !安装基础的工具是一切的前提,只有安装了 XTuner 我们才能够去执行后续的操作。
前期准备:在完成 XTuner 的安装后,我们下一步就需要去明确我们自己的微调目标了。我们想要利用微调做一些什么事情呢,然后为了实现这个目标,我们需要准备相关的硬件资源和数据。
启动微调:在确定了自己的微调目标后,我们就可以在 XTuner 的配置库中找到合适的配置文件并进行对应的修改。修改完成后即可一键启动训练!训练好的模型也可以仅仅通过在终端输入一行命令来完成转换和部署工作!
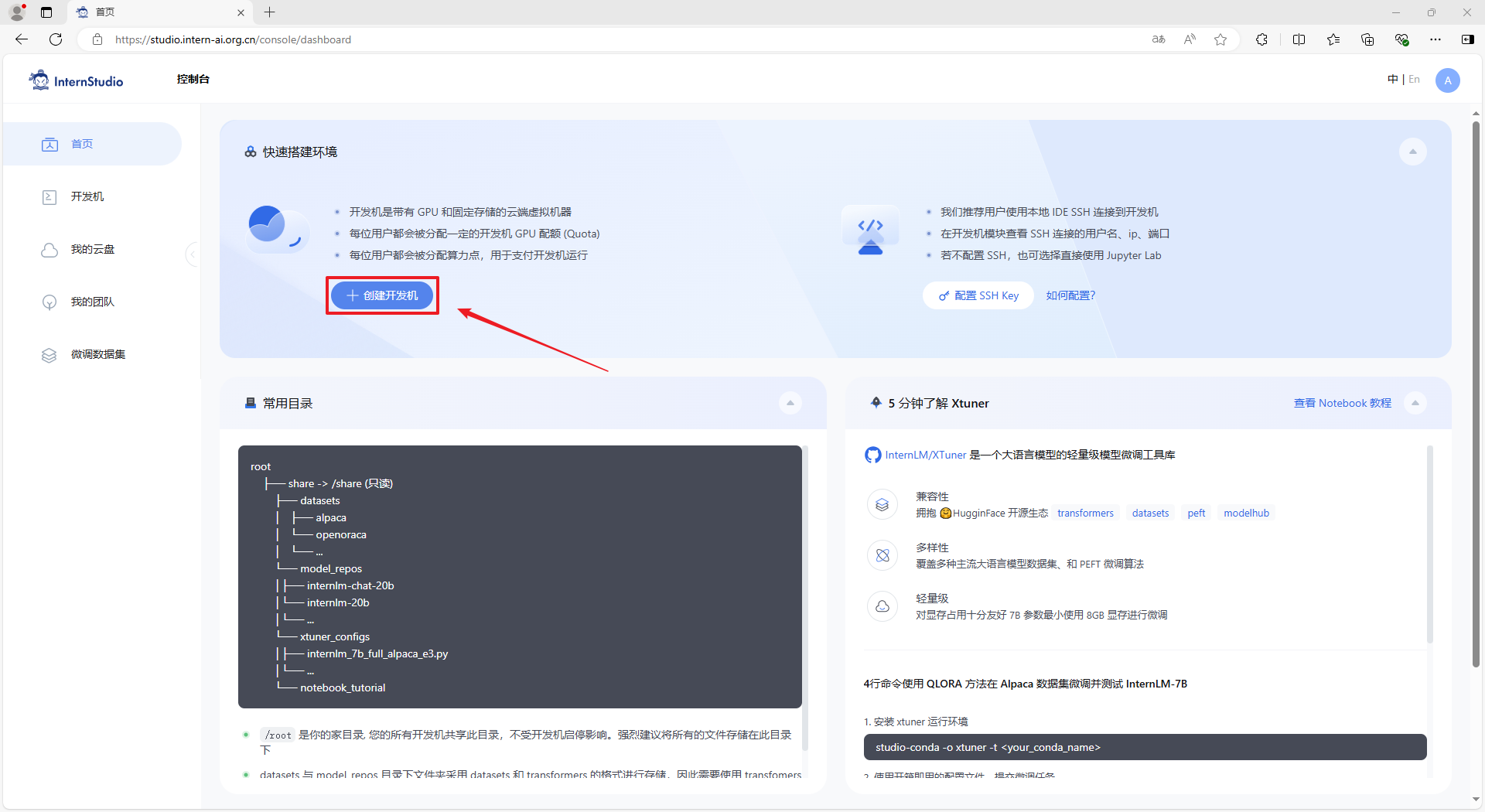
我们需要前往 InternStudio 中创建一台开发机进行使用。
步骤1:登录InternStudio后,在控制台点击 “创建开发机” 按钮可以进入到开发机的创建界面。
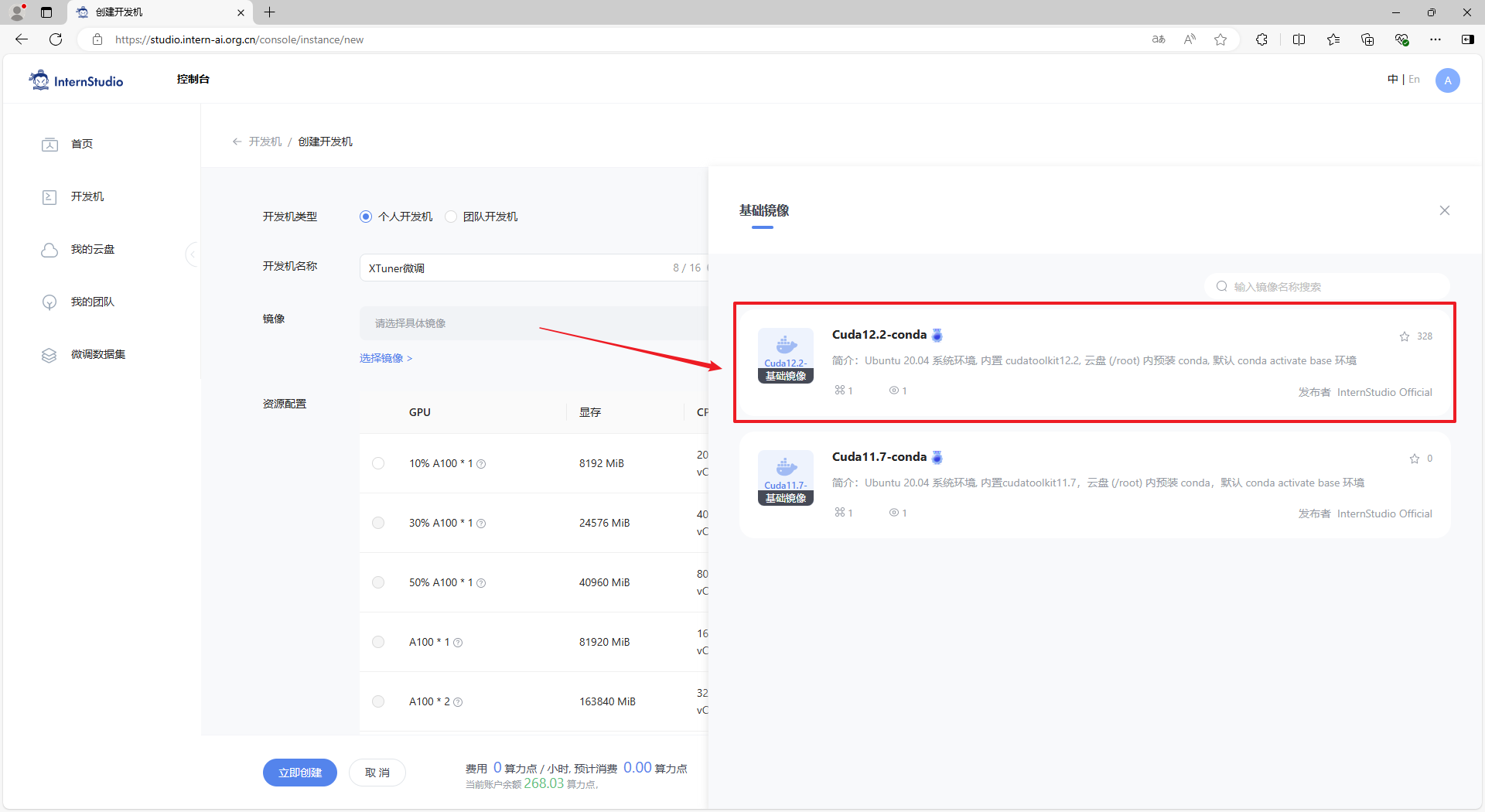
步骤2:在 “创建开发机” 界面,选择开发机类型:个人开发机,输入开发机名称:XTuner微调,选择开发机镜像:Cuda12.2-conda。
步骤3:在镜像详情界面,点击 “使用” 链接,确认使用该镜像。
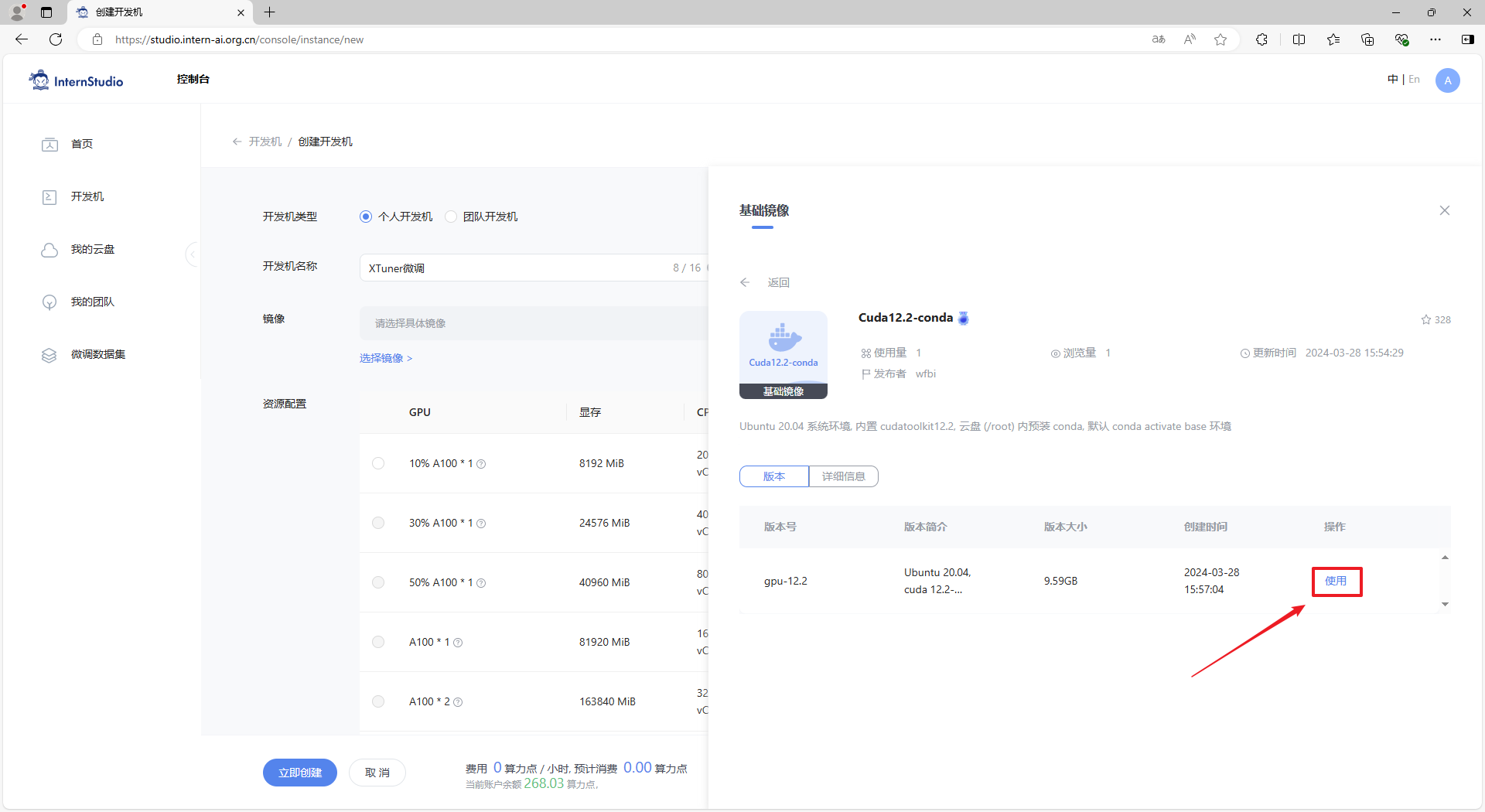
步骤4:资源配置可以选择 10% (如果有更高资源可以使用,也可以选择更高的资源配置),然后点击 “立即创建” 按钮创建开发机。
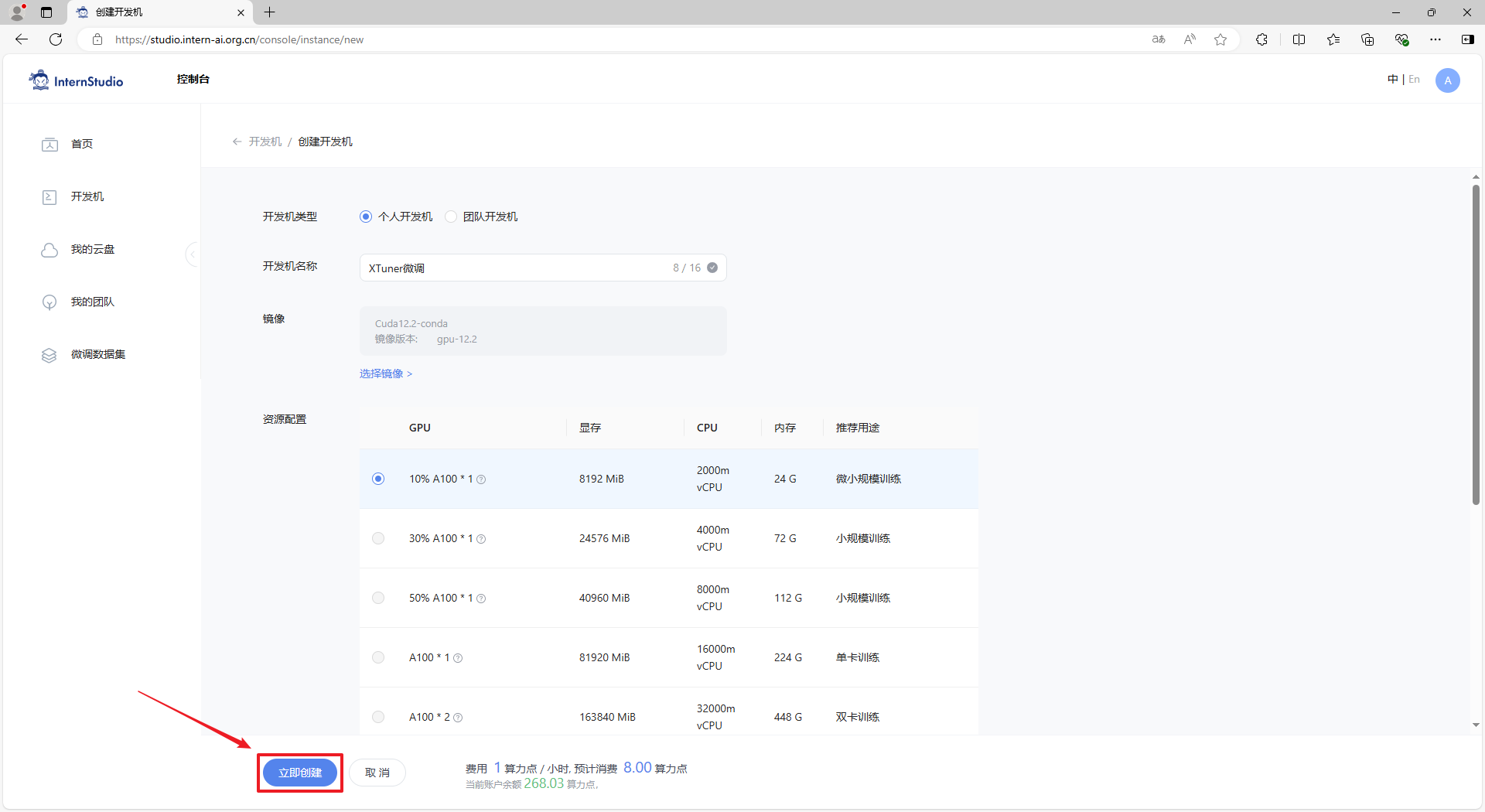
步骤5:创建完成后,在开发机列表中可以看到刚创建的开发机,点击 “进入开发机” 链接可以连接进入到开发机。
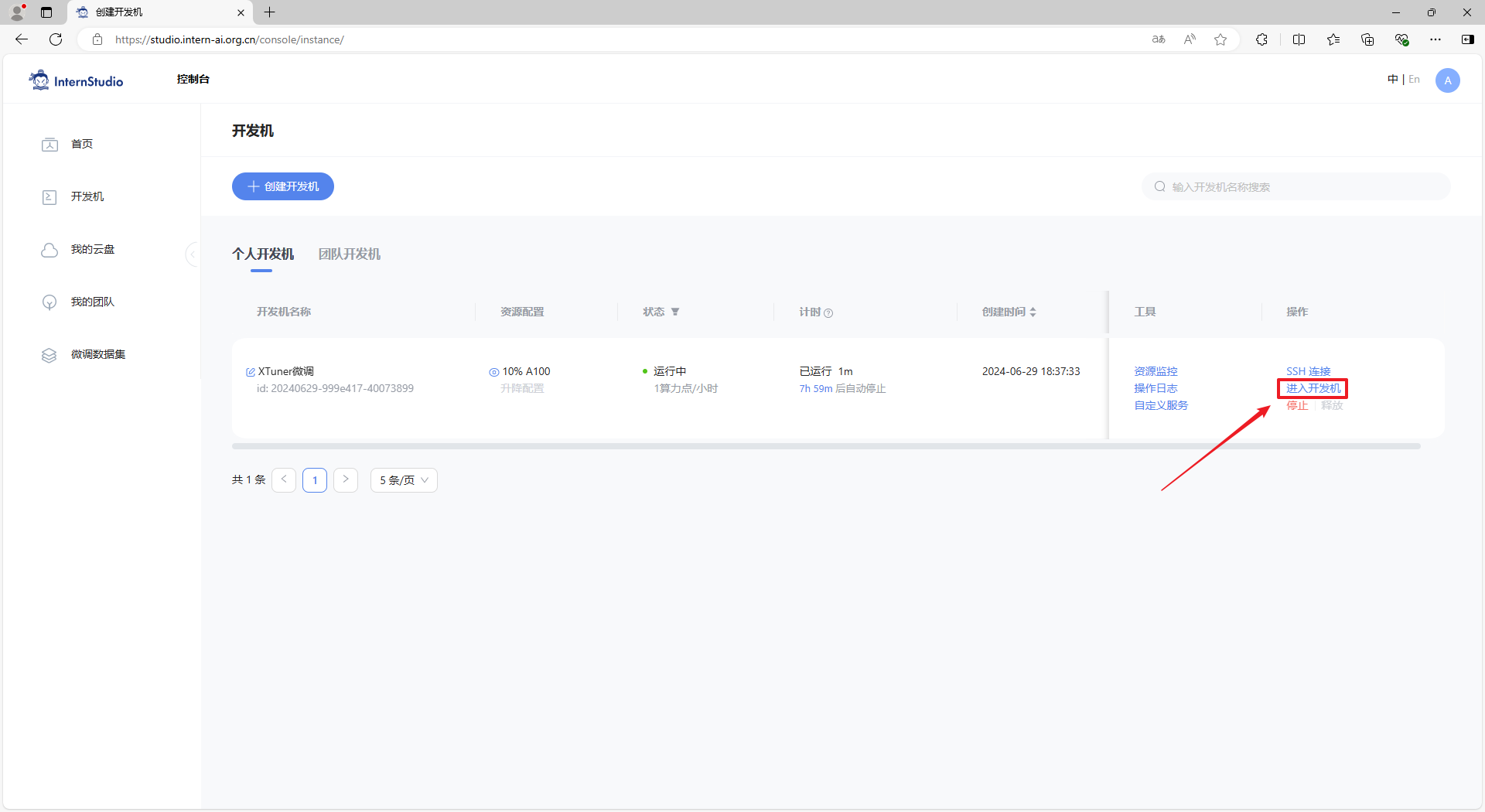
当我们准备好开发机之后,就可以进行下一步的微调任务了。
另外,进入开发机之后,请确保自己已经克隆了Tutorial仓库的资料到本地。
mkdir -p /root/InternLM/Tutorial
git clone -b camp3 https://github.com/InternLM/Tutorial /root/InternLM/Tutorial在安装 XTuner 之前,我们需要先创建一个虚拟环境。使用 Anaconda 创建一个名为 xtuner0121 的虚拟环境,可以直接执行命令。
# 创建虚拟环境
conda create -n xtuner0121 python=3.10 -y
# 激活虚拟环境(注意:后续的所有操作都需要在这个虚拟环境中进行)
conda activate xtuner0121
# 安装一些必要的库
conda install pytorch==2.1.2 torchvision==0.16.2 torchaudio==2.1.2 pytorch-cuda=12.1 -c pytorch -c nvidia -y
# 安装其他依赖
pip install transformers==4.39.3
pip install streamlit==1.36.0虚拟环境创建完成后,就可以安装 XTuner 了。首先,从 Github 上下载源码。
# 创建一个目录,用来存放源代码
mkdir -p /root/InternLM/code
cd /root/InternLM/code
git clone -b v0.1.21 https://github.com/InternLM/XTuner /root/InternLM/code/XTuner其次,进入源码目录,执行安装。
# 进入到源码目录
cd /root/InternLM/code/XTuner
conda activate xtuner0121
# 执行安装
pip install -e '.[deepspeed]'如果速度太慢可以换成
pip install -e '.[deepspeed]' -i https://mirrors.aliyun.com/pypi/simple/
最后,我们可以验证一下安装结果。
xtuner version对于很多初学者而言,我们可能不太熟悉 XTuner 的用法,那么我们可以通过以下命令来查看相关的帮助。
xtuner help对于很多的初学者而言,安装好环境意味着成功了一大半!因此我们接下来就可以进入我们的下一步,准备好我们需要的模型、数据集和配置文件,并进行微调训练!
软件安装好后,我们就可以准备要微调的模型了。
对于学习而言,我们可以使用 InternLM 推出的1.8B的小模型来完成此次微调演示。
对于在 InternStudio 上运行的小伙伴们,可以不用通过 HuggingFace、OpenXLab 或者 Modelscope 进行模型的下载,在开发机中已经为我们提供了模型的本地文件,直接使用就可以了。
我们可以通过以下代码一键通过符号链接的方式链接到模型文件,这样既节省了空间,也便于管理。
# 创建一个目录,用来存放微调的所有资料,后续的所有操作都在该路径中进行
mkdir -p /root/InternLM/XTuner
cd /root/InternLM/XTuner
mkdir -p Shanghai_AI_Laboratory
ln -s /root/share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b Shanghai_AI_Laboratory/internlm2-chat-1_8b执行上述操作后,Shanghai_AI_Laboratory/internlm2-chat-1_8b 将直接成为一个符号链接,这个链接指向 /root/share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b 的位置。
这意味着,当我们访问 Shanghai_AI_Laboratory/internlm2-chat-1_8b 时,实际上就是在访问 /root/share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b 目录下的内容。通过这种方式,我们无需复制任何数据,就可以直接利用现有的模型文件进行后续的微调操作,从而节省存储空间并简化文件管理。
模型文件准备好后,我们可以使用tree命令来观察目录结构。
apt-get install -y tree
tree -l我们的目录结构应该是这个样子的。
目录结构
├── Shanghai_AI_Laboratory
│ └── internlm2-chat-1_8b -> /root/share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b
│ ├── README.md
│ ├── config.json
│ ├── configuration.json
│ ├── configuration_internlm2.py
│ ├── generation_config.json
│ ├── model-00001-of-00002.safetensors
│ ├── model-00002-of-00002.safetensors
│ ├── model.safetensors.index.json
│ ├── modeling_internlm2.py
│ ├── special_tokens_map.json
│ ├── tokenization_internlm2.py
│ ├── tokenization_internlm2_fast.py
│ ├── tokenizer.model
│ └── tokenizer_config.json
在目录结构中可以看出,
internlm2-chat-1_8b是一个符号链接。
这里我们用 internlm2-chat-1_8b 模型,通过 QLoRA 的方式来微调一个自己的小助手认知作为案例来进行演示。
我们可以通过网页端的 Demo 来看看微调前 internlm2-chat-1_8b 的对话效果。
首先,我们需要准备一个Streamlit程序的脚本。
Streamlit程序的完整代码是:tools/xtuner_streamlit_demo.py。
然后,我们可以直接启动应用。
conda activate xtuner0121
streamlit run /root/InternLM/Tutorial/tools/xtuner_streamlit_demo.py运行后,在访问前,我们还需要做的就是将端口映射到本地。
通过如图所示的地方,获取开发机的端口和密码。
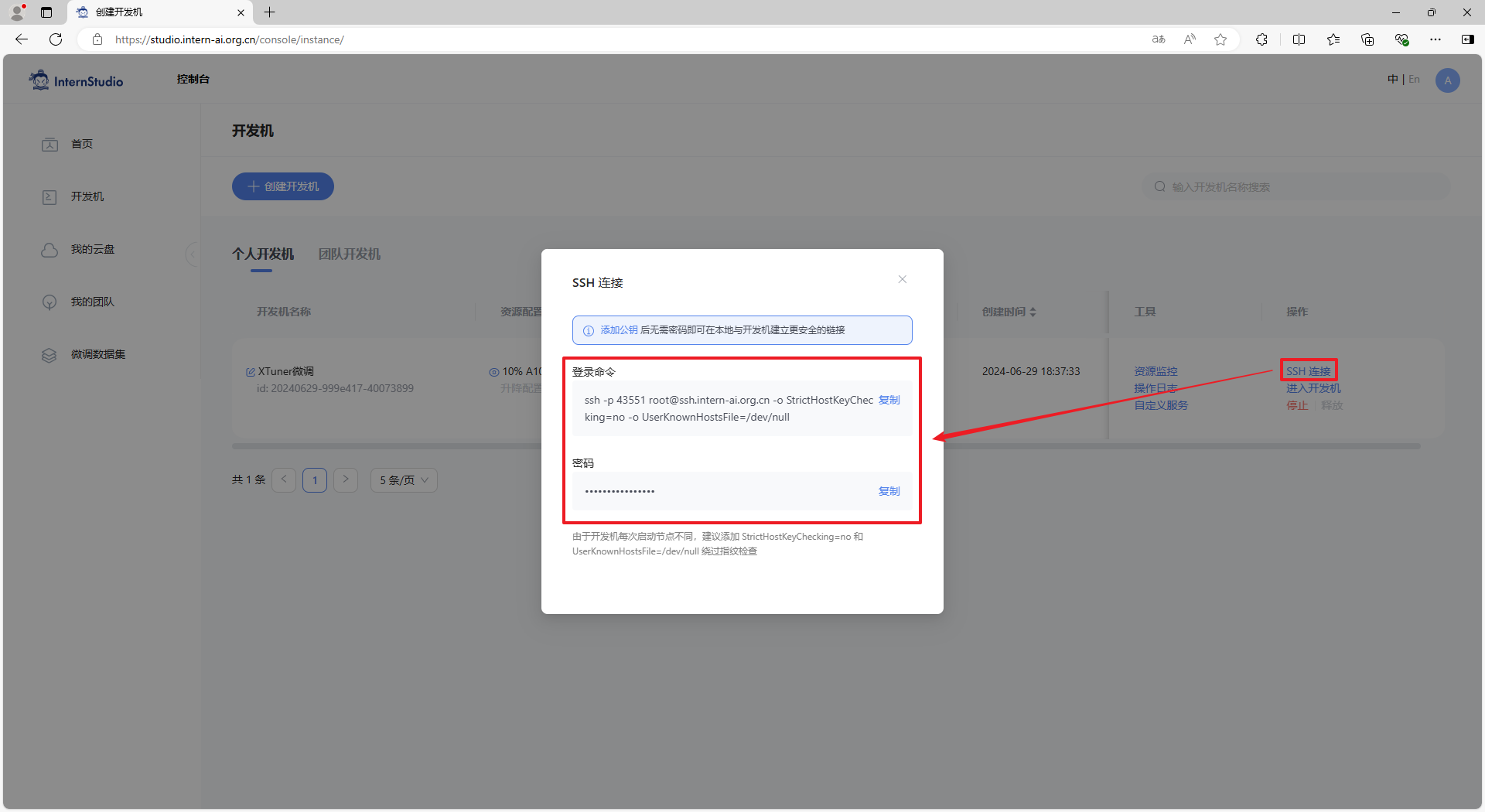
然后在本地使用 PowerShell 或者命令行终端,执行以下命令:
其中,
8501是Streamlit程序的服务端口,43551需要替换为自己的开发机的端口。
ssh -CNg -L 8501:127.0.0.1:8501 [email protected] -p 43551然后再输入开发机的root密码。
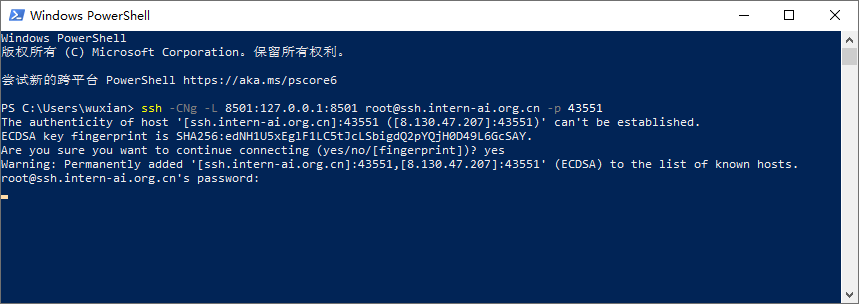
最后,我们就可以在本地通过浏览器访问:http://127.0.0.1:8501 来进行对话了。
下面我们对模型进行微调,让模型认识到自己的弟位,了解它自己是你的一个助手。
为了让模型能够认清自己的身份弟位,在询问自己是谁的时候按照我们预期的结果进行回复,我们就需要通过在微调数据集中大量加入这样的数据。我们准备一个数据集文件datas/assistant.json,文件内容为对话数据。
cd /root/InternLM/XTuner
mkdir -p datas
touch datas/assistant.json为了简化数据文件准备,我们也可以通过脚本生成的方式来准备数据。创建一个脚本文件 xtuner_generate_assistant.py :
cd /root/InternLM/XTuner
touch xtuner_generate_assistant.py输入脚本内容并保存:
xtuner_generate_assistant.py
import json
# 设置用户的名字
name = '伍鲜同志'
# 设置需要重复添加的数据次数
n = 8000
# 初始化数据
data = [
{"conversation": [{"input": "请介绍一下你自己", "output": "我是{}的小助手,内在是上海AI实验室书生·浦语的1.8B大模型哦".format(name)}]},
{"conversation": [{"input": "你在实战营做什么", "output": "我在这里帮助{}完成XTuner微调个人小助手的任务".format(name)}]}
]
# 通过循环,将初始化的对话数据重复添加到data列表中
for i in range(n):
data.append(data[0])
data.append(data[1])
# 将data列表中的数据写入到'datas/assistant.json'文件中
with open('datas/assistant.json', 'w', encoding='utf-8') as f:
# 使用json.dump方法将数据以JSON格式写入文件
# ensure_ascii=False 确保中文字符正常显示
# indent=4 使得文件内容格式化,便于阅读
json.dump(data, f, ensure_ascii=False, indent=4)或者可以直接复制 tools/xtuner_generate_assistant.py
cd /root/InternLM/XTuner cp /root/InternLM/Tutorial/tools/xtuner_generate_assistant.py ./
为了训练出自己的小助手,需要将脚本中name后面的内容修改为你自己的名称。
# 将对应的name进行修改(在第4行的位置)
- name = '伍鲜同志'
+ name = "你自己的名称"假如想要让微调后的模型能够完完全全认识到你的身份,我们还可以把第6行的
n的值调大一点。不过n值太大的话容易导致过拟合,无法有效回答其他问题。
然后执行该脚本来生成数据文件。
cd /root/InternLM/XTuner
conda activate xtuner0121
python xtuner_generate_assistant.py准备好数据文件后,我们的目录结构应该是这样子的。
目录结构
├── Shanghai_AI_Laboratory
│ └── internlm2-chat-1_8b -> /root/share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b
│ ├── README.md
│ ├── config.json
│ ├── configuration.json
│ ├── configuration_internlm2.py
│ ├── generation_config.json
│ ├── model-00001-of-00002.safetensors
│ ├── model-00002-of-00002.safetensors
│ ├── model.safetensors.index.json
│ ├── modeling_internlm2.py
│ ├── special_tokens_map.json
│ ├── tokenization_internlm2.py
│ ├── tokenization_internlm2_fast.py
│ ├── tokenizer.model
│ └── tokenizer_config.json
├── datas
│ └── assistant.json
├── xtuner_generate_assistant.py
在准备好了模型和数据集后,我们就要根据我们选择的微调方法结合微调方案来找到与我们最匹配的配置文件了,从而减少我们对配置文件的修改量。
配置文件其实是一种用于定义和控制模型训练和测试过程中各个方面的参数和设置的工具。
XTuner 提供多个开箱即用的配置文件,可以通过以下命令查看。
xtuner list-cfg命令用于列出内置的所有配置文件。参数-p或--pattern表示模式匹配,后面跟着的内容将会在所有的配置文件里进行模糊匹配搜索,然后返回最有可能得内容。比如我们这里微调的是书生·浦语的模型,我们就可以匹配搜索internlm2。
conda activate xtuner0121
xtuner list-cfg -p internlm2配置文件名的解释
以 internlm2_1_8b_full_custom_pretrain_e1 和 internlm2_chat_1_8b_qlora_alpaca_e3 举例:
| 配置文件 internlm2_1_8b_full_custom_pretrain_e1 | 配置文件 internlm2_chat_1_8b_qlora_alpaca_e3 | 说明 |
|---|---|---|
| internlm2_1_8b | internlm2_chat_1_8b | 模型名称 |
| full | qlora | 使用的算法 |
| custom_pretrain | alpaca | 数据集名称 |
| e1 | e3 | 把数据集跑几次 |
由于我们是对internlm2-chat-1_8b模型进行指令微调,所以与我们的需求最匹配的配置文件是 internlm2_chat_1_8b_qlora_alpaca_e3,这里就复制该配置文件。
xtuner copy-cfg命令用于复制一个内置的配置文件。该命令需要两个参数:CONFIG代表需要复制的配置文件名称,SAVE_PATH代表复制的目标路径。在我们的输入的这个命令中,我们的CONFIG对应的是上面搜索到的internlm2_chat_1_8b_qlora_alpaca_e3,而SAVE_PATH则是当前目录.。
cd /root/InternLM/XTuner
conda activate xtuner0121
xtuner copy-cfg internlm2_chat_1_8b_qlora_alpaca_e3 .复制好配置文件后,我们的目录结构应该是这样子的。
目录结构
├── Shanghai_AI_Laboratory
│ └── internlm2-chat-1_8b -> /root/share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b
│ ├── README.md
│ ├── config.json
│ ├── configuration.json
│ ├── configuration_internlm2.py
│ ├── generation_config.json
│ ├── model-00001-of-00002.safetensors
│ ├── model-00002-of-00002.safetensors
│ ├── model.safetensors.index.json
│ ├── modeling_internlm2.py
│ ├── special_tokens_map.json
│ ├── tokenization_internlm2.py
│ ├── tokenization_internlm2_fast.py
│ ├── tokenizer.model
│ └── tokenizer_config.json
├── datas
│ └── assistant.json
├── internlm2_chat_1_8b_qlora_alpaca_e3_copy.py
├── xtuner_generate_assistant.py
在选择了一个最匹配的配置文件并准备好其他内容后,下面我们要做的事情就是根据我们自己的内容对该配置文件进行调整,使其能够满足我们实际训练的要求。
配置文件介绍
打开配置文件后,我们可以看到整体的配置文件分为五部分:
PART 1 Settings:涵盖了模型基本设置,如预训练模型的选择、数据集信息和训练过程中的一些基本参数(如批大小、学习率等)。
PART 2 Model & Tokenizer:指定了用于训练的模型和分词器的具体类型及其配置,包括预训练模型的路径和是否启用特定功能(如可变长度注意力),这是模型训练的核心组成部分。
PART 3 Dataset & Dataloader:描述了数据处理的细节,包括如何加载数据集、预处理步骤、批处理大小等,确保了模型能够接收到正确格式和质量的数据。
PART 4 Scheduler & Optimizer:配置了优化过程中的关键参数,如学习率调度策略和优化器的选择,这些是影响模型训练效果和速度的重要因素。
PART 5 Runtime:定义了训练过程中的额外设置,如日志记录、模型保存策略和自定义钩子等,以支持训练流程的监控、调试和结果的保存。
一般来说我们需要更改的部分其实只包括前三部分,而且修改的主要原因是我们修改了配置文件中规定的模型、数据集。后两部分都是 XTuner 官方帮我们优化好的东西,一般而言只有在魔改的情况下才需要进行修改。
下面我们将根据项目的需求一步步的进行修改和调整吧!
在 PART 1 的部分,由于我们不再需要在 HuggingFace 上自动下载模型,因此我们先要更换模型的路径以及数据集的路径为我们本地的路径。
为了训练过程中能够实时观察到模型的变化情况,XTuner 贴心的推出了一个 evaluation_inputs 的参数来让我们能够设置多个问题来确保模型在训练过程中的变化是朝着我们想要的方向前进的。我们可以添加自己的输入。
在 PART 3 的部分,由于我们准备的数据集是 JSON 格式的数据,并且对话内容已经是 input 和 output 的数据对,所以不需要进行格式转换。
#######################################################################
# PART 1 Settings #
#######################################################################
- pretrained_model_name_or_path = 'internlm/internlm2-chat-1_8b'
+ pretrained_model_name_or_path = '/root/InternLM/XTuner/Shanghai_AI_Laboratory/internlm2-chat-1_8b'
- alpaca_en_path = 'tatsu-lab/alpaca'
+ alpaca_en_path = 'datas/assistant.json'
evaluation_inputs = [
- '请给我介绍五个上海的景点', 'Please tell me five scenic spots in Shanghai'
+ '请介绍一下你自己', 'Please introduce yourself'
]
#######################################################################
# PART 3 Dataset & Dataloader #
#######################################################################
alpaca_en = dict(
type=process_hf_dataset,
- dataset=dict(type=load_dataset, path=alpaca_en_path),
+ dataset=dict(type=load_dataset, path='json', data_files=dict(train=alpaca_en_path)),
tokenizer=tokenizer,
max_length=max_length,
- dataset_map_fn=alpaca_map_fn,
+ dataset_map_fn=None,
template_map_fn=dict(
type=template_map_fn_factory, template=prompt_template),
remove_unused_columns=True,
shuffle_before_pack=True,
pack_to_max_length=pack_to_max_length,
use_varlen_attn=use_varlen_attn)除此之外,我们还可以对一些重要的参数进行调整,包括学习率(lr)、训练的轮数(max_epochs)等等。
常用参数介绍
| 参数名 | 解释 |
|---|---|
| data_path | 数据路径或 HuggingFace 仓库名 |
| max_length | 单条数据最大 Token 数,超过则截断 |
| pack_to_max_length | 是否将多条短数据拼接到 max_length,提高 GPU 利用率 |
| accumulative_counts | 梯度累积,每多少次 backward 更新一次参数 |
| sequence_parallel_size | 并行序列处理的大小,用于模型训练时的序列并行 |
| batch_size | 每个设备上的批量大小 |
| dataloader_num_workers | 数据加载器中工作进程的数量 |
| max_epochs | 训练的最大轮数 |
| optim_type | 优化器类型,例如 AdamW |
| lr | 学习率 |
| betas | 优化器中的 beta 参数,控制动量和平方梯度的移动平均 |
| weight_decay | 权重衰减系数,用于正则化和避免过拟合 |
| max_norm | 梯度裁剪的最大范数,用于防止梯度爆炸 |
| warmup_ratio | 预热的比例,学习率在这个比例的训练过程中线性增加到初始学习率 |
| save_steps | 保存模型的步数间隔 |
| save_total_limit | 保存的模型总数限制,超过限制时删除旧的模型文件 |
| prompt_template | 模板提示,用于定义生成文本的格式或结构 |
| ...... | ...... |
如果想充分利用显卡资源,可以将
max_length和batch_size这两个参数调大。
修改完后的完整的配置文件是:configs/internlm2_chat_1_8b_qlora_alpaca_e3_copy.py。
可以直接复制到当前目录。
cd /root/InternLM/XTuner cp /root/InternLM/Tutorial/configs/internlm2_chat_1_8b_qlora_alpaca_e3_copy.py ./
internlm2_chat_1_8b_qlora_alpaca_e3_copy.py
# Copyright (c) OpenMMLab. All rights reserved.
import torch
from datasets import load_dataset
from mmengine.dataset import DefaultSampler
from mmengine.hooks import (CheckpointHook, DistSamplerSeedHook, IterTimerHook,
LoggerHook, ParamSchedulerHook)
from mmengine.optim import AmpOptimWrapper, CosineAnnealingLR, LinearLR
from peft import LoraConfig
from torch.optim import AdamW
from transformers import (AutoModelForCausalLM, AutoTokenizer,
BitsAndBytesConfig)
from xtuner.dataset import process_hf_dataset
from xtuner.dataset.collate_fns import default_collate_fn
from xtuner.dataset.map_fns import alpaca_map_fn, template_map_fn_factory
from xtuner.engine.hooks import (DatasetInfoHook, EvaluateChatHook,
VarlenAttnArgsToMessageHubHook)
from xtuner.engine.runner import TrainLoop
from xtuner.model import SupervisedFinetune
from xtuner.parallel.sequence import SequenceParallelSampler
from xtuner.utils import PROMPT_TEMPLATE, SYSTEM_TEMPLATE
#######################################################################
# PART 1 Settings #
#######################################################################
# Model
pretrained_model_name_or_path = '/root/InternLM/XTuner/Shanghai_AI_Laboratory/internlm2-chat-1_8b'
use_varlen_attn = False
# Data
alpaca_en_path = 'datas/assistant.json'
prompt_template = PROMPT_TEMPLATE.internlm2_chat
max_length = 2048
pack_to_max_length = True
# parallel
sequence_parallel_size = 1
# Scheduler & Optimizer
batch_size = 1 # per_device
accumulative_counts = 16
accumulative_counts *= sequence_parallel_size
dataloader_num_workers = 0
max_epochs = 3
optim_type = AdamW
lr = 2e-4
betas = (0.9, 0.999)
weight_decay = 0
max_norm = 1 # grad clip
warmup_ratio = 0.03
# Save
save_steps = 500
save_total_limit = 2 # Maximum checkpoints to keep (-1 means unlimited)
# Evaluate the generation performance during the training
evaluation_freq = 500
SYSTEM = SYSTEM_TEMPLATE.alpaca
evaluation_inputs = [
'请介绍一下你自己', 'Please introduce yourself'
]
#######################################################################
# PART 2 Model & Tokenizer #
#######################################################################
tokenizer = dict(
type=AutoTokenizer.from_pretrained,
pretrained_model_name_or_path=pretrained_model_name_or_path,
trust_remote_code=True,
padding_side='right')
model = dict(
type=SupervisedFinetune,
use_varlen_attn=use_varlen_attn,
llm=dict(
type=AutoModelForCausalLM.from_pretrained,
pretrained_model_name_or_path=pretrained_model_name_or_path,
trust_remote_code=True,
torch_dtype=torch.float16,
quantization_config=dict(
type=BitsAndBytesConfig,
load_in_4bit=True,
load_in_8bit=False,
llm_int8_threshold=6.0,
llm_int8_has_fp16_weight=False,
bnb_4bit_compute_dtype=torch.float16,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type='nf4')),
lora=dict(
type=LoraConfig,
r=64,
lora_alpha=16,
lora_dropout=0.1,
bias='none',
task_type='CAUSAL_LM'))
#######################################################################
# PART 3 Dataset & Dataloader #
#######################################################################
alpaca_en = dict(
type=process_hf_dataset,
dataset=dict(type=load_dataset, path='json', data_files=dict(train=alpaca_en_path)),
tokenizer=tokenizer,
max_length=max_length,
dataset_map_fn=None,
template_map_fn=dict(
type=template_map_fn_factory, template=prompt_template),
remove_unused_columns=True,
shuffle_before_pack=True,
pack_to_max_length=pack_to_max_length,
use_varlen_attn=use_varlen_attn)
sampler = SequenceParallelSampler \
if sequence_parallel_size > 1 else DefaultSampler
train_dataloader = dict(
batch_size=batch_size,
num_workers=dataloader_num_workers,
dataset=alpaca_en,
sampler=dict(type=sampler, shuffle=True),
collate_fn=dict(type=default_collate_fn, use_varlen_attn=use_varlen_attn))
#######################################################################
# PART 4 Scheduler & Optimizer #
#######################################################################
# optimizer
optim_wrapper = dict(
type=AmpOptimWrapper,
optimizer=dict(
type=optim_type, lr=lr, betas=betas, weight_decay=weight_decay),
clip_grad=dict(max_norm=max_norm, error_if_nonfinite=False),
accumulative_counts=accumulative_counts,
loss_scale='dynamic',
dtype='float16')
# learning policy
# More information: https://github.com/open-mmlab/mmengine/blob/main/docs/en/tutorials/param_scheduler.md # noqa: E501
param_scheduler = [
dict(
type=LinearLR,
start_factor=1e-5,
by_epoch=True,
begin=0,
end=warmup_ratio * max_epochs,
convert_to_iter_based=True),
dict(
type=CosineAnnealingLR,
eta_min=0.0,
by_epoch=True,
begin=warmup_ratio * max_epochs,
end=max_epochs,
convert_to_iter_based=True)
]
# train, val, test setting
train_cfg = dict(type=TrainLoop, max_epochs=max_epochs)
#######################################################################
# PART 5 Runtime #
#######################################################################
# Log the dialogue periodically during the training process, optional
custom_hooks = [
dict(type=DatasetInfoHook, tokenizer=tokenizer),
dict(
type=EvaluateChatHook,
tokenizer=tokenizer,
every_n_iters=evaluation_freq,
evaluation_inputs=evaluation_inputs,
system=SYSTEM,
prompt_template=prompt_template)
]
if use_varlen_attn:
custom_hooks += [dict(type=VarlenAttnArgsToMessageHubHook)]
# configure default hooks
default_hooks = dict(
# record the time of every iteration.
timer=dict(type=IterTimerHook),
# print log every 10 iterations.
logger=dict(type=LoggerHook, log_metric_by_epoch=False, interval=10),
# enable the parameter scheduler.
param_scheduler=dict(type=ParamSchedulerHook),
# save checkpoint per `save_steps`.
checkpoint=dict(
type=CheckpointHook,
by_epoch=False,
interval=save_steps,
max_keep_ckpts=save_total_limit),
# set sampler seed in distributed evrionment.
sampler_seed=dict(type=DistSamplerSeedHook),
)
# configure environment
env_cfg = dict(
# whether to enable cudnn benchmark
cudnn_benchmark=False,
# set multi process parameters
mp_cfg=dict(mp_start_method='fork', opencv_num_threads=0),
# set distributed parameters
dist_cfg=dict(backend='nccl'),
)
# set visualizer
visualizer = None
# set log level
log_level = 'INFO'
# load from which checkpoint
load_from = None
# whether to resume training from the loaded checkpoint
resume = False
# Defaults to use random seed and disable `deterministic`
randomness = dict(seed=None, deterministic=False)
# set log processor
log_processor = dict(by_epoch=False)完成了所有的准备工作后,我们就可以正式的开始我们下一阶段的旅程:XTuner 启动~!
当我们准备好了所有内容,我们只需要将使用 xtuner train 命令令即可开始训练。
xtuner train命令用于启动模型微调进程。该命令需要一个参数:CONFIG用于指定微调配置文件。这里我们使用修改好的配置文件internlm2_chat_1_8b_qlora_alpaca_e3_copy.py。
训练过程中产生的所有文件,包括日志、配置文件、检查点文件、微调后的模型等,默认保存在work_dirs目录下,我们也可以通过添加--work-dir指定特定的文件保存位置。
cd /root/InternLM/XTuner
conda activate xtuner0121
xtuner train ./internlm2_chat_1_8b_qlora_alpaca_e3_copy.py在训练完后,我们的目录结构应该是这样子的。
目录结构
├── work_dirs
│ └── internlm2_chat_1_8b_qlora_alpaca_e3_copy
│ ├── 20240626_222727
│ │ ├── 20240626_222727.log
│ │ └── vis_data
│ │ ├── 20240626_222727.json
│ │ ├── config.py
│ │ ├── eval_outputs_iter_95.txt
│ │ └── scalars.json
│ ├── internlm2_chat_1_8b_qlora_alpaca_e3_copy.py
│ ├── iter_96.pth
│ └── last_checkpoint
模型转换的本质其实就是将原本使用 Pytorch 训练出来的模型权重文件转换为目前通用的 HuggingFace 格式文件,那么我们可以通过以下命令来实现一键转换。
我们可以使用 xtuner convert pth_to_hf 命令来进行模型格式转换。
xtuner convert pth_to_hf命令用于进行模型格式转换。该命令需要三个参数:CONFIG表示微调的配置文件,PATH_TO_PTH_MODEL表示微调的模型权重文件路径,即要转换的模型权重,SAVE_PATH_TO_HF_MODEL表示转换后的 HuggingFace 格式文件的保存路径。
除此之外,我们其实还可以在转换的命令中添加几个额外的参数,包括:
| 参数名 | 解释 |
|---|---|
| --fp32 | 代表以fp32的精度开启,假如不输入则默认为fp16 |
| --max-shard-size {GB} | 代表每个权重文件最大的大小(默认为2GB) |
cd /root/InternLM/XTuner
conda activate xtuner0121
# 先获取最后保存的一个pth文件
pth_file=`ls -t ./work_dirs/internlm2_chat_1_8b_qlora_alpaca_e3_copy/*.pth | head -n 1`
export MKL_SERVICE_FORCE_INTEL=1
export MKL_THREADING_LAYER=GNU
xtuner convert pth_to_hf ./internlm2_chat_1_8b_qlora_alpaca_e3_copy.py ${pth_file} ./hf模型格式转换完成后,我们的目录结构应该是这样子的。
目录结构
├── hf
│ ├── README.md
│ ├── adapter_config.json
│ ├── adapter_model.bin
│ └── xtuner_config.py
转换完成后,可以看到模型被转换为 HuggingFace 中常用的 .bin 格式文件,这就代表着文件成功被转化为 HuggingFace 格式了。
此时,hf 文件夹即为我们平时所理解的所谓 “LoRA 模型文件”
可以简单理解:LoRA 模型文件 = Adapter
对于 LoRA 或者 QLoRA 微调出来的模型其实并不是一个完整的模型,而是一个额外的层(Adapter),训练完的这个层最终还是要与原模型进行合并才能被正常的使用。
对于全量微调的模型(full)其实是不需要进行整合这一步的,因为全量微调修改的是原模型的权重而非微调一个新的 Adapter ,因此是不需要进行模型整合的。
在 XTuner 中提供了一键合并的命令 xtuner convert merge,在使用前我们需要准备好三个路径,包括原模型的路径、训练好的 Adapter 层的(模型格式转换后的)路径以及最终保存的路径。
xtuner convert merge命令用于合并模型。该命令需要三个参数:LLM表示原模型路径,ADAPTER表示 Adapter 层的路径,SAVE_PATH表示合并后的模型最终的保存路径。
在模型合并这一步还有其他很多的可选参数,包括:
| 参数名 | 解释 |
|---|---|
| --max-shard-size {GB} | 代表每个权重文件最大的大小(默认为2GB) |
| --device {device_name} | 这里指的就是device的名称,可选择的有cuda、cpu和auto,默认为cuda即使用gpu进行运算 |
| --is-clip | 这个参数主要用于确定模型是不是CLIP模型,假如是的话就要加上,不是就不需要添加 |
cd /root/InternLM/XTuner
conda activate xtuner0121
export MKL_SERVICE_FORCE_INTEL=1
export MKL_THREADING_LAYER=GNU
xtuner convert merge /root/InternLM/XTuner/Shanghai_AI_Laboratory/internlm2-chat-1_8b ./hf ./merged --max-shard-size 2GB模型合并完成后,我们的目录结构应该是这样子的。
目录结构
├── merged
│ ├── config.json
│ ├── configuration_internlm2.py
│ ├── generation_config.json
│ ├── modeling_internlm2.py
│ ├── pytorch_model-00001-of-00002.bin
│ ├── pytorch_model-00002-of-00002.bin
│ ├── pytorch_model.bin.index.json
│ ├── special_tokens_map.json
│ ├── tokenization_internlm2.py
│ ├── tokenization_internlm2_fast.py
│ ├── tokenizer.json
│ ├── tokenizer.model
│ └── tokenizer_config.json
在模型合并完成后,我们就可以看到最终的模型和原模型文件夹非常相似,包括了分词器、权重文件、配置信息等等。
微调完成后,我们可以再次运行xtuner_streamlit_demo.py脚本来观察微调后的对话效果,不过在运行之前,我们需要将脚本中的模型路径修改为微调后的模型的路径。
# 直接修改脚本文件第18行
- model_name_or_path = "/root/InternLM/XTuner/Shanghai_AI_Laboratory/internlm2-chat-1_8b"
+ model_name_or_path = "/root/InternLM/XTuner/merged"然后,我们可以直接启动应用。
conda activate xtuner0121
streamlit run /root/InternLM/Tutorial/tools/xtuner_streamlit_demo.py运行后,确保端口映射正常,如果映射已断开则需要重新做一次端口映射。
ssh -CNg -L 8501:127.0.0.1:8501 [email protected] -p 43551最后,通过浏览器访问:http://127.0.0.1:8501 来进行对话了。
经过本节的学习,带领着大家跑通了 XTuner 的完整流程,我们学会了指令跟随微调,并且训练出了一个自己小助手,是不是很有意思!
当我们在测试完模型认为其满足我们的需求后,就可以对模型进行量化部署等操作了,这部分的内容在之后关于 LMDeploy 的课程中将会详细的进行讲解,敬请期待后续的课程吧!
关于XTuner的更多高级进阶知识,请访问XTuner微调高级进阶。
作业请访问作业。