Quality Assessment using MRQy: An Example
This tutorial will describe how we used MRQy for quality assessment of a cohort of brain MRIs from the TCGA-GBM repository, both before and and after processing. A similar process was conducted to generate quality assessment measures for multiple TCIA cohorts, for which the results have been made publicly available.
TCGA-GBM is a publicly available cohort of brain MRI data from the Cancer Imaging Archive (TCIA) and comprises scans from n=259 subjects. This study was limited to subjects for whom a post-contrast T1-weighted images in the axial plane was available, resulting in a cohort of n=133 T1-POST MRI scans accrued from 7 different institutions. As these MRI scans were acquired under different environmental conditions and using different scanner equipment and imaging protocols, this cohort includes typical data variations and image artifacts that may be observed in a TCIA dataset. All 133 T1-POST studies were downloaded as DICOM files from TCIA.
The manifest file to access the specific studies and sequences in this tutorial is available from TCIA (bottom of page, "Detailed Description" tab, available for all TCIA cohorts). Detailed instructions for downloading a TCIA cohort using a manifest file are available, which we briefly summarize below:
- Download and install NBIA Data Retreiver.
- Download the TCGA-GBM manifest file for this cohort.
- This manifest file should open in the NBIA Data Retreiver tool, which should list all the studies used to be downloaded and allow you to specify the directory where the downloaded files should be stored.
Assuming you have downloaded or pulled MRQy from the repo, it can be run as explained earlier:
python QC.py output_folder_name "<directory of downloaded DICOM files>"
In our testing, analysis via MRQy took 93.5 minutes to process all 133 datasets in the original TCGA-GBM cohort (approximately 42 s/dataset). The output of this is a (results.tsv) that is stored within the UserInterface/Data folder under the <output_folder_name> specified above. This can be interrogated via a specialized front-end HTML interface (index.html) that is available within the UserInterface folder, which can be opened in any web browser of choice (shown in Figure 1(a) below).

Figure 1. (a) MRQy front-end interface for interrogating TCGA-GBM cohort. (b) Outlier dataset identified on PC chart for the CJV (coefficient of joint variation, see Table) measure is seen to exhibit a shading artifact on (c) representative images, especially when compared to (d) a different dataset. (e) Scatter plot revealing presence of institution-specific batch effects.
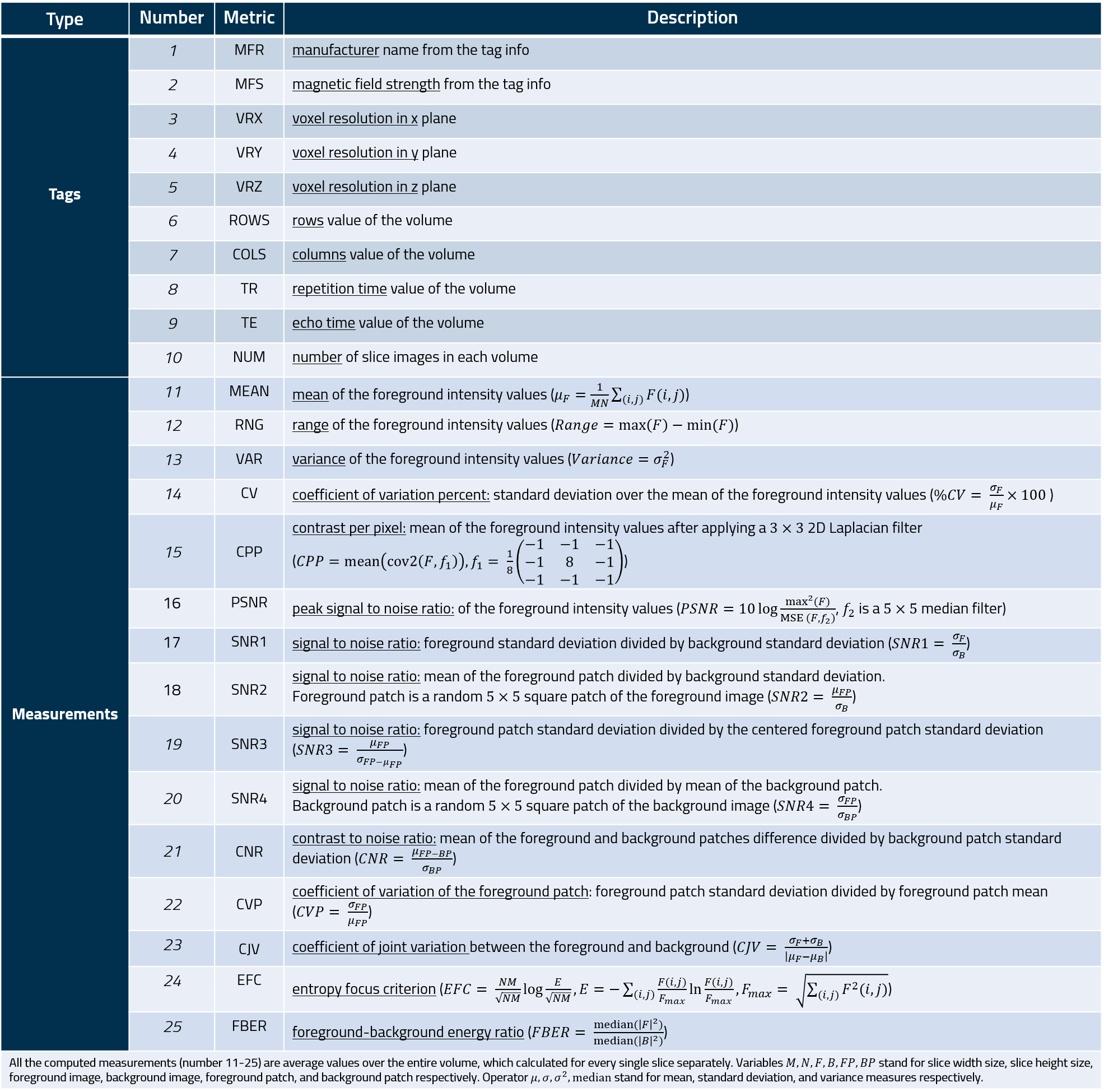{kind=link}
Examples of 2 quality issues in the original data (as downloaded from TCIA) that can be determined from this interface are as follows:
-
Imaging artifact detection (Figure 1(b)): The PC chart of the
measure is shown, where each line is a different subject from the TCGA-GBM cohort. A distinct outlier is highlighted in orange + orange arrow on the PC chart (
, compare to cohort mean
). Clicking on this outlier and visualizing the images for this subject depicts a distinct shading artifact being present in the MRI scan (Figure 1(c)). For comparison, we have shown images for a different dataset from the cohort (Figure 1(d), cyan arrow in the PC chart,
). Note that this is the specific type of image artifact that the
-
Batch effect detection (Figure 1(e)): The embedding calculated via t-SNE is visualized as a 2D scatter plot. To better illustrate the institution-specific batch effects observed, this plot has been overlaid with a different colored symbol per institution. Each of the 7 institutions appears as a distinct cluster, suggesting that there are institution-specific variations present in the cohort and need to be corrected prior to model development. The accuracy of identifying these batch effects was additionally validated via a clustering experiment (see paper for details).
MRQy can be used in an "active" fashion to understand how well the MRI data has been processed for artifacts or batch effects as well. MRI datasets can be processed via one or more "corrective" operations, after which the processed datasets can be re-run through MRQy to understand if any outliers or errors are still present.
We demonstrate this by comparing the MRQy output between pre-processed MRI datasets and the post-processed MRI datasets. Briefly, the processing steps included: (1) re-orientation to the left-posterior-superior coordinate system, (2) co-registration to the T1w anatomical template of SRI24 Multi-Channel Normal Adult Human Brain Atlas via affine registration, (3) resampling to voxel resolution, (4) skull-stripping, (5) de-noising using a low-level image processing smoothing filter in place of N4ITK-bias correction, (6) intensity standardization to correct for "intensity drift" between scanners and institutions. The processed images are available via Bakas et al (Set 1, Set 2) in the NII file format from TCIA.
MRQy was then re-run on the post-processed TCGA-GBM datasets in order to evaluate the impact of these steps in minimizing batch effects in the cohort (note MRQy natively supports NII files). For instance, if the batch effects in the cohort have been minimized, institution-specific clusters should no longer be present in the embedding plots generated in the MRQy interface. The figure below shows both t-SNE (top row) and UMAP (bottom row) plots from the MRQy interface, with results from the unprocessed cohort on the left and the processed cohort on the right. Note that for ease of visualization, datasets from different institutions are overlaid with different colored symbols.

Figure 2. 2D Scatter plots from the MRQy interface, based on t-SNE (top row) and UMAP (bottom row) embeddings of extracted IQMs. Note that different colored symbols are used to denote datasets from each institution in the cohort, as indicated in the legend.
Note that in Figure 2, both the t-SNE and UMAP plots of the unprocessed MRI dataset reveal institution-specific clusters (indicating batch effects and site differences). By comparison, t-SNE and UMAP plots corresponding to the processed MRI datasets reveal a largely merged cohort, with no clearly demarcated institution-specific clusters. In other words, MRQy suggests that the processing steps may have largely minimixed the impact of batch effects and site variations in the TCGA-GBM cohort.
A similar process can be undertaken to evaluate how well specific artifacts have been corrected in a cohort, including comparison of the PC and bar charts before and after processing to confirm that there are no outliers or errors remaining in the cohort.