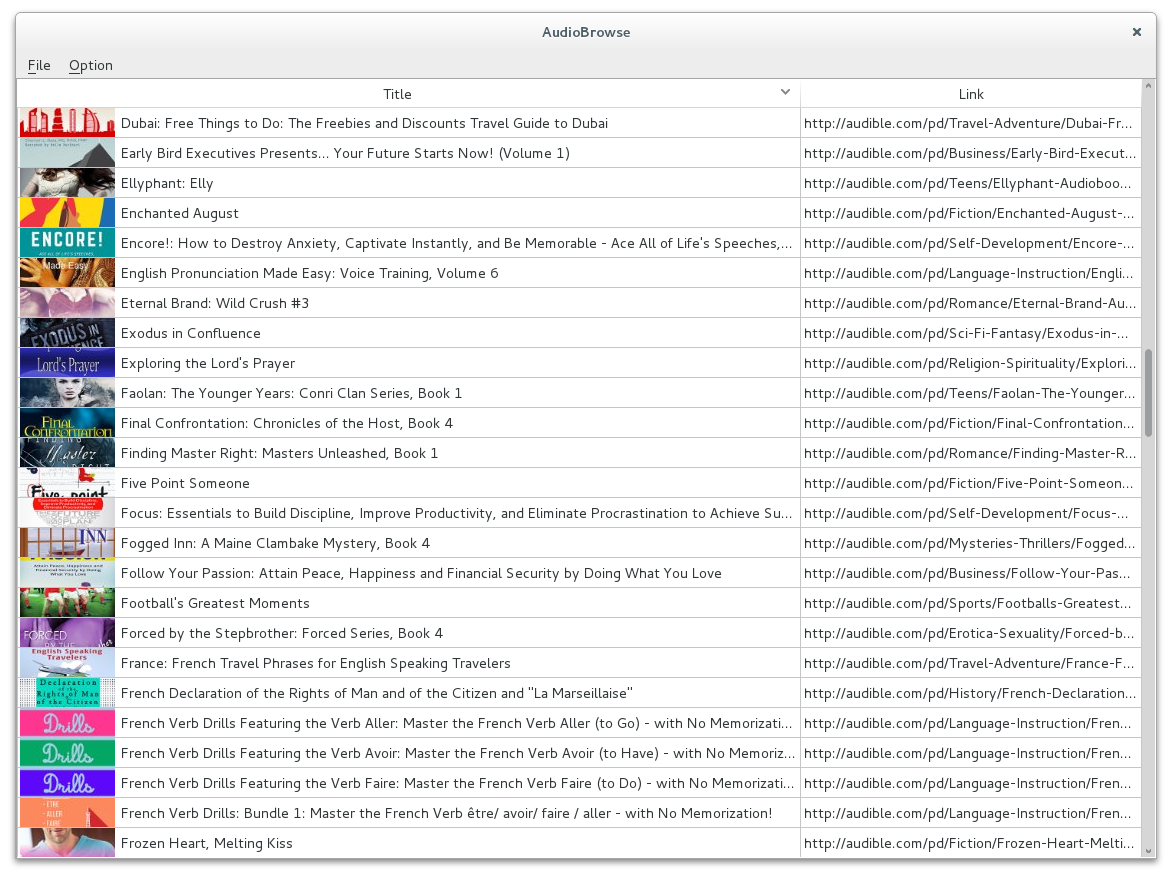
Simply run ./audiobrowse
The program will scrape the 10 first pages of http://audible.com/newreleases and show them in a table.
To get familiar with PyQt again. I've got an idea or two on how to turn this into a proper half meaningful project, but it still won't be anything that can't be achieved with a web client, and will most likely aggregate data from a different source.
Surprisingly it looks like they don't. Other platforms do (Goodreads and the like) and could have been used instead of Audible, but most Web APIs are not meant to be used on the client, requests are gonna be limited in frequency. Of course, setting up my own server to cache their (say Goodreads's) database seems way overkill for the task (and probably break their ToS in a dozen different ways). So I'll stay with scraping for the moment :)