[中文|English]
Using the Naive Bayes idea to extend the context handling length of LLM.
Now, any LLM can utilize NBCE to become a model capable of processing context of any length (as long as there is enough computing power)!
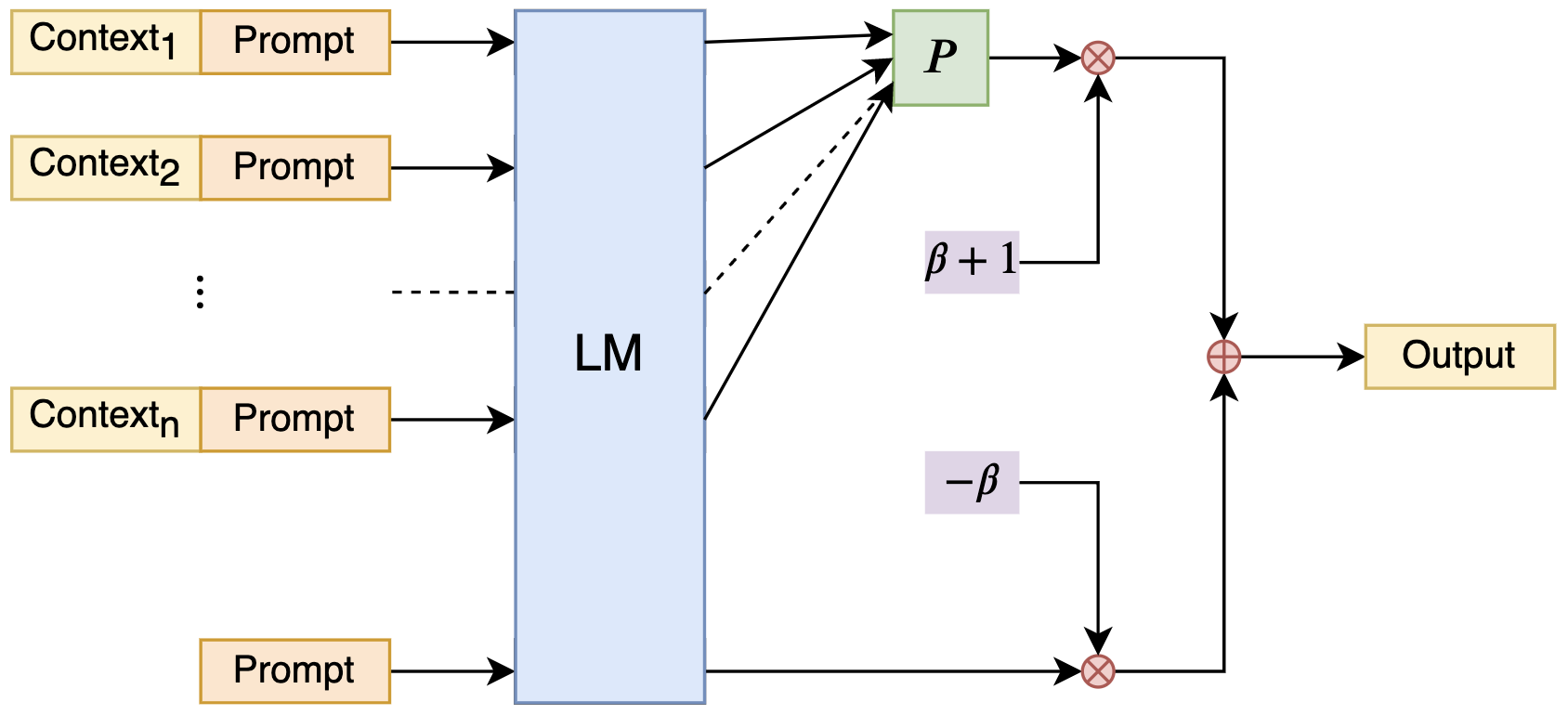
Inspired by the Naive Bayes formula:
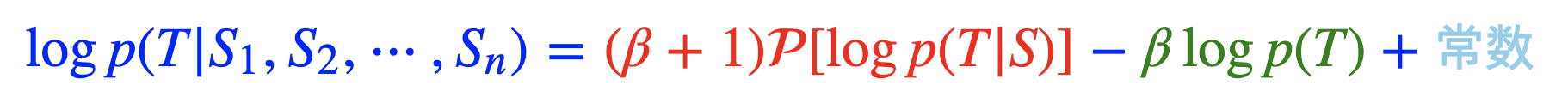
For details, please refer to the blog: https://kexue.fm/archives/9617
The given demo includes 12 different contexts, with a total length of more than 9,000 words, along with 8 questions inputted into the model all at once (the model's training length is 2048, with 7 billion parameters, and can be downloaded from OpenBuddy). The model is able to answer these 8 questions correctly one by one, based on the given contexts. It is worth noting that the total word count of all contexts, questions, and answers combined exceeds 10,000 words! Additionally, some friends have tried simple resume matching and essay scoring applications with acceptable results. It is highly recommended for everyone to personally test and experiment with it.
Latest test results: Under 8*A800, the 7B model can handle 50k context and perform reading comprehension accurately. (Not all GPUs are used up, about 160G video memory is consumed)
- Plug and play
- Model-Agnostic
- No fine-tuning required
- Linear efficiency
- Simple implementation
- Decent performance
- Interpretability
@inproceedings{nbce_naacl,
author = {Jianlin Su and
Murtadha Ahmed and
Bo Wen and
Luo Ao and
Mingren Zhu and
Yunfeng Liu},
editor = {Kevin Duh and
Helena G{\'{o}}mez{-}Adorno and
Steven Bethard},
title = {Naive Bayes-based Context Extension for Large Language Models},
booktitle = {Proceedings of the 2024 Conference of the North American Chapter of
the Association for Computational Linguistics: Human Language Technologies
(Volume 1: Long Papers), {NAACL} 2024, Mexico City, Mexico, June 16-21,
2024},
pages = {7791--7807},
publisher = {Association for Computational Linguistics},
year = {2024},
url = {https://doi.org/10.18653/v1/2024.naacl-long.431},
doi = {10.18653/V1/2024.NAACL-LONG.431},
timestamp = {Thu, 29 Aug 2024 17:13:57 +0200},
}
QQ discussion group: 808623966, for WeChat group, please add the robot WeChat ID spaces_ac_cn